mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
commit
e19ba90e8f
@ -0,0 +1,901 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (guevaraya)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10700-1.html)
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 11 Input02)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input02.html)
|
||||
[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
|
||||
|
||||
计算机实验室之树莓派:课程 11 输入02
|
||||
======
|
||||
|
||||
课程输入 02 是以课程输入 01 为基础讲解的,通过一个简单的命令行实现用户的命令输入和计算机的处理和显示。本文假设你已经具备 [课程11:输入01][1] 的操作系统代码基础。
|
||||
|
||||
### 1、终端
|
||||
|
||||
几乎所有的操作系统都是以字符终端显示启动的。经典的黑底白字,通过键盘输入计算机要执行的命令,然后会提示你拼写错误,或者恰好得到你想要的执行结果。这种方法有两个主要优点:键盘和显示器可以提供简易、健壮的计算机交互机制,几乎所有的计算机系统都采用这个机制,这个也广泛被系统管理员应用。
|
||||
|
||||
> 早期的计算一般是在一栋楼里的一个巨型计算机系统,它有很多可以输命令的'终端'。计算机依次执行不同来源的命令。
|
||||
|
||||
让我们分析下真正想要哪些信息:
|
||||
|
||||
1. 计算机打开后,显示欢迎信息
|
||||
2. 计算机启动后可以接受输入标志
|
||||
3. 用户从键盘输入带参数的命令
|
||||
4. 用户输入回车键或提交按钮
|
||||
5. 计算机解析命令后执行可用的命令
|
||||
6. 计算机显示命令的执行结果,过程信息
|
||||
7. 循环跳转到步骤 2
|
||||
|
||||
这样的终端被定义为标准的输入输出设备。用于(显示)输入的屏幕和打印输出内容的屏幕是同一个(LCTT 译注:最早期的输出打印真是“打印”到打印机/电传机的,而用于输入的终端只是键盘,除非做了回显,否则输出终端是不会显示输入的字符的)。也就是说终端是对字符显示的一个抽象。字符显示中,单个字符是最小的单元,而不是像素。屏幕被划分成固定数量不同颜色的字符。我们可以在现有的屏幕代码基础上,先存储字符和对应的颜色,然后再用方法 `DrawCharacter` 把其推送到屏幕上。一旦我们需要字符显示,就只需要在屏幕上画出一行字符串。
|
||||
|
||||
新建文件名为 `terminal.s`,如下:
|
||||
|
||||
```
|
||||
.section .data
|
||||
.align 4
|
||||
terminalStart:
|
||||
.int terminalBuffer
|
||||
terminalStop:
|
||||
.int terminalBuffer
|
||||
terminalView:
|
||||
.int terminalBuffer
|
||||
terminalColour:
|
||||
.byte 0xf
|
||||
.align 8
|
||||
terminalBuffer:
|
||||
.rept 128*128
|
||||
.byte 0x7f
|
||||
.byte 0x0
|
||||
.endr
|
||||
terminalScreen:
|
||||
.rept 1024/8 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 768/16
|
||||
.byte 0x7f
|
||||
.byte 0x0
|
||||
.endr
|
||||
```
|
||||
|
||||
这是文件终端的配置数据文件。我们有两个主要的存储变量:`terminalBuffer` 和 `terminalScreen`。`terminalBuffer` 保存所有显示过的字符。它保存 128 行字符文本(1 行包含 128 个字符)。每个字符有一个 ASCII 字符和颜色单元组成,初始值为 0x7f(ASCII 的删除字符)和 0(前景色和背景色为黑)。`terminalScreen` 保存当前屏幕显示的字符。它保存 128x48 个字符,与 `terminalBuffer` 初始化值一样。你可能会觉得我仅需要 `terminalScreen` 就够了,为什么还要`terminalBuffer`,其实有两个好处:
|
||||
|
||||
1. 我们可以很容易看到字符串的变化,只需画出有变化的字符。
|
||||
2. 我们可以回滚终端显示的历史字符,也就是缓冲的字符(有限制)
|
||||
|
||||
这种独特的技巧在低功耗系统里很常见。画屏是很耗时的操作,因此我们仅在不得已的时候才去执行这个操作。在这个系统里,我们可以任意改变 `terminalBuffer`,然后调用一个仅拷贝屏幕上字节变化的方法。也就是说我们不需要持续画出每个字符,这样可以节省一大段跨行文本的操作时间。
|
||||
|
||||
> 你总是需要尝试去设计一个高效的系统,如果在很少变化的情况下这个系统会运行的更快。
|
||||
|
||||
其他在 `.data` 段的值得含义如下:
|
||||
|
||||
* `terminalStart`
|
||||
写入到 `terminalBuffer` 的第一个字符
|
||||
* `terminalStop`
|
||||
写入到 `terminalBuffer` 的最后一个字符
|
||||
* `terminalView`
|
||||
表示当前屏幕的第一个字符,这样我们可以控制滚动屏幕
|
||||
* `temrinalColour`
|
||||
即将被描画的字符颜色
|
||||
|
||||
`terminalStart` 需要保存起来的原因是 `termainlBuffer` 是一个环状缓冲区。意思是当缓冲区变满时,末尾地方会回滚覆盖开始位置,这样最后一个字符变成了第一个字符。因此我们需要将 `terminalStart` 往前推进,这样我们知道我们已经占满它了。如何实现缓冲区检测:如果索引越界到缓冲区的末尾,就将索引指向缓冲区的开始位置。环状缓冲区是一个比较常见的存储大量数据的高明方法,往往这些数据的最近部分比较重要。它允许无限制的写入,只保证最近一些特定数据有效。这个常常用于信号处理和数据压缩算法。这样的情况,可以允许我们存储 128 行终端记录,超过128行也不会有问题。如果不是这样,当超过第 128 行时,我们需要把 127 行分别向前拷贝一次,这样很浪费时间。
|
||||
|
||||
![显示 Hellow world 插入到大小为5的循环缓冲区的示意图。][2]
|
||||
|
||||
> 环状缓冲区是**数据结构**一个例子。这是一个组织数据的思路,有时我们通过软件实现这种思路。
|
||||
|
||||
之前已经提到过 `terminalColour` 几次了。你可以根据你的想法实现终端颜色,但这个文本终端有 16 个前景色和 16 个背景色(这里相当于有 16^2 = 256 种组合)。[CGA][3]终端的颜色定义如下:
|
||||
|
||||
|
||||
表格 1.1 - CGA 颜色编码
|
||||
|
||||
| 序号 | 颜色 (R, G, B) |
|
||||
| ------ | ------------------------|
|
||||
| 0 | 黑 (0, 0, 0) |
|
||||
| 1 | 蓝 (0, 0, ⅔) |
|
||||
| 2 | 绿 (0, ⅔, 0) |
|
||||
| 3 | 青色 (0, ⅔, ⅔) |
|
||||
| 4 | 红色 (⅔, 0, 0) |
|
||||
| 5 | 品红 (⅔, 0, ⅔) |
|
||||
| 6 | 棕色 (⅔, ⅓, 0) |
|
||||
| 7 | 浅灰色 (⅔, ⅔, ⅔) |
|
||||
| 8 | 灰色 (⅓, ⅓, ⅓) |
|
||||
| 9 | 淡蓝色 (⅓, ⅓, 1) |
|
||||
| 10 | 淡绿色 (⅓, 1, ⅓) |
|
||||
| 11 | 淡青色 (⅓, 1, 1) |
|
||||
| 12 | 淡红色 (1, ⅓, ⅓) |
|
||||
| 13 | 浅品红 (1, ⅓, 1) |
|
||||
| 14 | 黄色 (1, 1, ⅓) |
|
||||
| 15 | 白色 (1, 1, 1) |
|
||||
|
||||
我们将前景色保存到颜色的低字节,背景色保存到颜色高字节。除了棕色,其他这些颜色遵循一种模式如二进制的高位比特代表增加 ⅓ 到每个组件,其他比特代表增加 ⅔ 到各自组件。这样很容易进行 RGB 颜色转换。
|
||||
|
||||
> 棕色作为替代色(黑黄色)既不吸引人也没有什么用处。
|
||||
|
||||
我们需要一个方法从 `TerminalColour` 读取颜色编码的四个比特,然后用 16 比特等效参数调用 `SetForeColour`。尝试你自己实现。如果你感觉麻烦或者还没有完成屏幕系列课程,我们的实现如下:
|
||||
|
||||
```
|
||||
.section .text
|
||||
TerminalColour:
|
||||
teq r0,#6
|
||||
ldreq r0,=0x02B5
|
||||
beq SetForeColour
|
||||
|
||||
tst r0,#0b1000
|
||||
ldrne r1,=0x52AA
|
||||
moveq r1,#0
|
||||
tst r0,#0b0100
|
||||
addne r1,#0x15
|
||||
tst r0,#0b0010
|
||||
addne r1,#0x540
|
||||
tst r0,#0b0001
|
||||
addne r1,#0xA800
|
||||
mov r0,r1
|
||||
b SetForeColour
|
||||
```
|
||||
|
||||
### 2、文本显示
|
||||
|
||||
我们的终端第一个真正需要的方法是 `TerminalDisplay`,它用来把当前的数据从 `terminalBuffer`拷贝到 `terminalScreen` 和实际的屏幕。如上所述,这个方法必须是最小开销的操作,因为我们需要频繁调用它。它主要比较 `terminalBuffer` 与 `terminalDisplay` 的文本,然后只拷贝有差异的字节。请记住 `terminalBuffer` 是以环状缓冲区运行的,这种情况,就是从 `terminalView` 到 `terminalStop`,或者 128*48 个字符,要看哪个来的最快。如果我们遇到 `terminalStop`,我们将会假定在这之后的所有字符是 7f<sub>16</sub> (ASCII 删除字符),颜色为 0(黑色前景色和背景色)。
|
||||
|
||||
让我们看看必须要做的事情:
|
||||
|
||||
1. 加载 `terminalView`、`terminalStop` 和 `terminalDisplay` 的地址。
|
||||
2. 对于每一行:
|
||||
1. 对于每一列:
|
||||
1. 如果 `terminalView` 不等于 `terminalStop`,根据 `terminalView` 加载当前字符和颜色
|
||||
2. 否则加载 0x7f 和颜色 0
|
||||
3. 从 `terminalDisplay` 加载当前的字符
|
||||
4. 如果字符和颜色相同,直接跳转到第 10 步
|
||||
5. 存储字符和颜色到 `terminalDisplay`
|
||||
6. 用 `r0` 作为背景色参数调用 `TerminalColour`
|
||||
7. 用 `r0 = 0x7f`(ASCII 删除字符,一个块)、 `r1 = x`、`r2 = y` 调用 `DrawCharacter`
|
||||
8. 用 `r0` 作为前景色参数调用 `TerminalColour`
|
||||
9. 用 `r0 = 字符`、`r1 = x`、`r2 = y` 调用 `DrawCharacter`
|
||||
10. 对位置参数 `terminalDisplay` 累加 2
|
||||
11. 如果 `terminalView` 不等于 `terminalStop`,`terminalView` 位置参数累加 2
|
||||
12. 如果 `terminalView` 位置已经是文件缓冲器的末尾,将它设置为缓冲区的开始位置
|
||||
13. x 坐标增加 8
|
||||
2. y 坐标增加 16
|
||||
|
||||
尝试去自己实现吧。如果你遇到问题,我们的方案下面给出来了:
|
||||
|
||||
1、我这里的变量有点乱。为了方便起见,我用 `taddr` 存储 `textBuffer` 的末尾位置。
|
||||
|
||||
```
|
||||
.globl TerminalDisplay
|
||||
TerminalDisplay:
|
||||
push {r4,r5,r6,r7,r8,r9,r10,r11,lr}
|
||||
x .req r4
|
||||
y .req r5
|
||||
char .req r6
|
||||
col .req r7
|
||||
screen .req r8
|
||||
taddr .req r9
|
||||
view .req r10
|
||||
stop .req r11
|
||||
|
||||
ldr taddr,=terminalStart
|
||||
ldr view,[taddr,#terminalView - terminalStart]
|
||||
ldr stop,[taddr,#terminalStop - terminalStart]
|
||||
add taddr,#terminalBuffer - terminalStart
|
||||
add taddr,#128*128*2
|
||||
mov screen,taddr
|
||||
```
|
||||
|
||||
2、从 `yLoop` 开始运行。
|
||||
|
||||
```
|
||||
mov y,#0
|
||||
yLoop$:
|
||||
```
|
||||
|
||||
2.1、
|
||||
|
||||
```
|
||||
mov x,#0
|
||||
xLoop$:
|
||||
```
|
||||
从 `xLoop` 开始运行。
|
||||
|
||||
|
||||
2.1.1、为了方便起见,我把字符和颜色同时加载到 `char` 变量了
|
||||
|
||||
```
|
||||
teq view,stop
|
||||
ldrneh char,[view]
|
||||
```
|
||||
|
||||
2.1.2、这行是对上面一行的补充说明:读取黑色的删除字符
|
||||
|
||||
|
||||
```
|
||||
moveq char,#0x7f
|
||||
```
|
||||
|
||||
2.1.3、为了简便我把字符和颜色同时加载到 `col` 里。
|
||||
|
||||
```
|
||||
ldrh col,[screen]
|
||||
```
|
||||
|
||||
2.1.4、 现在我用 `teq` 指令检查是否有数据变化
|
||||
|
||||
```
|
||||
teq col,char
|
||||
beq xLoopContinue$
|
||||
```
|
||||
|
||||
2.1.5、我可以容易的保存当前值
|
||||
|
||||
|
||||
```
|
||||
strh char,[screen]
|
||||
```
|
||||
|
||||
2.1.6、我用比特偏移指令 `lsr` 和 `and` 指令从切分 `char` 变量,将颜色放到 `col` 变量,字符放到 `char` 变量,然后再用比特偏移指令 `lsr` 获取背景色后调用 `TerminalColour` 。
|
||||
|
||||
```
|
||||
lsr col,char,#8
|
||||
and char,#0x7f
|
||||
lsr r0,col,#4
|
||||
bl TerminalColour
|
||||
```
|
||||
|
||||
2.1.7、写入一个彩色的删除字符
|
||||
|
||||
```
|
||||
mov r0,#0x7f
|
||||
mov r1,x
|
||||
mov r2,y
|
||||
bl DrawCharacter
|
||||
```
|
||||
|
||||
2.1.8、用 `and` 指令获取 `col` 变量的低半字节,然后调用 `TerminalColour`
|
||||
|
||||
```
|
||||
and r0,col,#0xf
|
||||
bl TerminalColour
|
||||
```
|
||||
|
||||
2.1.9、写入我们需要的字符
|
||||
|
||||
```
|
||||
mov r0,char
|
||||
mov r1,x
|
||||
mov r2,y
|
||||
bl DrawCharacter
|
||||
```
|
||||
|
||||
2.1.10、自增屏幕指针
|
||||
|
||||
```
|
||||
xLoopContinue$:
|
||||
add screen,#2
|
||||
```
|
||||
|
||||
2.1.11、如果可能自增 `view` 指针
|
||||
|
||||
```
|
||||
teq view,stop
|
||||
addne view,#2
|
||||
```
|
||||
|
||||
2.1.12、很容易检测 `view` 指针是否越界到缓冲区的末尾,因为缓冲区的地址保存在 `taddr` 变量里
|
||||
|
||||
```
|
||||
teq view,taddr
|
||||
subeq view,#128*128*2
|
||||
```
|
||||
|
||||
2.1.13、 如果还有字符需要显示,我们就需要自增 `x` 变量然后到 `xLoop` 循环执行
|
||||
|
||||
```
|
||||
add x,#8
|
||||
teq x,#1024
|
||||
bne xLoop$
|
||||
```
|
||||
|
||||
2.2、 如果还有更多的字符显示我们就需要自增 `y` 变量,然后到 `yLoop` 循环执行
|
||||
|
||||
```
|
||||
add y,#16
|
||||
teq y,#768
|
||||
bne yLoop$
|
||||
```
|
||||
|
||||
3、不要忘记最后清除变量
|
||||
|
||||
```
|
||||
pop {r4,r5,r6,r7,r8,r9,r10,r11,pc}
|
||||
.unreq x
|
||||
.unreq y
|
||||
.unreq char
|
||||
.unreq col
|
||||
.unreq screen
|
||||
.unreq taddr
|
||||
.unreq view
|
||||
.unreq stop
|
||||
```
|
||||
|
||||
### 3、行打印
|
||||
|
||||
现在我有了自己 `TerminalDisplay` 方法,它可以自动显示 `terminalBuffer` 内容到 `terminalScreen`,因此理论上我们可以画出文本。但是实际上我们没有任何基于字符显示的例程。 首先快速容易上手的方法便是 `TerminalClear`, 它可以彻底清除终端。这个方法不用循环也很容易实现。可以尝试分析下面的方法应该不难:
|
||||
|
||||
```
|
||||
.globl TerminalClear
|
||||
TerminalClear:
|
||||
ldr r0,=terminalStart
|
||||
add r1,r0,#terminalBuffer-terminalStart
|
||||
str r1,[r0]
|
||||
str r1,[r0,#terminalStop-terminalStart]
|
||||
str r1,[r0,#terminalView-terminalStart]
|
||||
mov pc,lr
|
||||
```
|
||||
|
||||
现在我们需要构造一个字符显示的基础方法:`Print` 函数。它将保存在 `r0` 的字符串和保存在 `r1` 的字符串长度简单的写到屏幕上。有一些特定字符需要特别的注意,这些特定的操作是确保 `terminalView` 是最新的。我们来分析一下需要做什么:
|
||||
|
||||
1. 检查字符串的长度是否为 0,如果是就直接返回
|
||||
2. 加载 `terminalStop` 和 `terminalView`
|
||||
3. 计算出 `terminalStop` 的 x 坐标
|
||||
4. 对每一个字符的操作:
|
||||
1. 检查字符是否为新起一行
|
||||
2. 如果是的话,自增 `bufferStop` 到行末,同时写入黑色删除字符
|
||||
3. 否则拷贝当前 `terminalColour` 的字符
|
||||
4. 检查是否在行末
|
||||
5. 如果是,检查从 `terminalView` 到 `terminalStop` 之间的字符数是否大于一屏
|
||||
6. 如果是,`terminalView` 自增一行
|
||||
7. 检查 `terminalView` 是否为缓冲区的末尾,如果是的话将其替换为缓冲区的起始位置
|
||||
8. 检查 `terminalStop` 是否为缓冲区的末尾,如果是的话将其替换为缓冲区的起始位置
|
||||
9. 检查 `terminalStop` 是否等于 `terminalStart`, 如果是的话 `terminalStart` 自增一行。
|
||||
10. 检查 `terminalStart` 是否为缓冲区的末尾,如果是的话将其替换为缓冲区的起始位置
|
||||
5. 存取 `terminalStop` 和 `terminalView`
|
||||
|
||||
试一下自己去实现。我们的方案提供如下:
|
||||
|
||||
1、这个是 `Print` 函数开始快速检查字符串为0的代码
|
||||
|
||||
```
|
||||
.globl Print
|
||||
Print:
|
||||
teq r1,#0
|
||||
moveq pc,lr
|
||||
```
|
||||
|
||||
2、这里我做了很多配置。 `bufferStart` 代表 `terminalStart`, `bufferStop` 代表`terminalStop`, `view` 代表 `terminalView`,`taddr` 代表 `terminalBuffer` 的末尾地址。
|
||||
|
||||
```
|
||||
push {r4,r5,r6,r7,r8,r9,r10,r11,lr}
|
||||
bufferStart .req r4
|
||||
taddr .req r5
|
||||
x .req r6
|
||||
string .req r7
|
||||
length .req r8
|
||||
char .req r9
|
||||
bufferStop .req r10
|
||||
view .req r11
|
||||
|
||||
mov string,r0
|
||||
mov length,r1
|
||||
|
||||
ldr taddr,=terminalStart
|
||||
ldr bufferStop,[taddr,#terminalStop-terminalStart]
|
||||
ldr view,[taddr,#terminalView-terminalStart]
|
||||
ldr bufferStart,[taddr]
|
||||
add taddr,#terminalBuffer-terminalStart
|
||||
add taddr,#128*128*2
|
||||
```
|
||||
|
||||
3、和通常一样,巧妙的对齐技巧让许多事情更容易。由于需要对齐 `terminalBuffer`,每个字符的 x 坐标需要 8 位要除以 2。
|
||||
|
||||
|
||||
```
|
||||
and x,bufferStop,#0xfe
|
||||
lsr x,#1
|
||||
```
|
||||
|
||||
4.1、我们需要检查新行
|
||||
|
||||
```
|
||||
charLoop$:
|
||||
ldrb char,[string]
|
||||
and char,#0x7f
|
||||
teq char,#'\n'
|
||||
bne charNormal$
|
||||
```
|
||||
|
||||
4.2、循环执行值到行末写入 0x7f;黑色删除字符
|
||||
|
||||
```
|
||||
mov r0,#0x7f
|
||||
clearLine$:
|
||||
strh r0,[bufferStop]
|
||||
add bufferStop,#2
|
||||
add x,#1
|
||||
teq x,#128 blt clearLine$
|
||||
|
||||
b charLoopContinue$
|
||||
```
|
||||
|
||||
4.3、存储字符串的当前字符和 `terminalBuffer` 末尾的 `terminalColour` 然后将它和 x 变量自增
|
||||
|
||||
```
|
||||
charNormal$:
|
||||
strb char,[bufferStop]
|
||||
ldr r0,=terminalColour
|
||||
ldrb r0,[r0]
|
||||
strb r0,[bufferStop,#1]
|
||||
add bufferStop,#2
|
||||
add x,#1
|
||||
```
|
||||
|
||||
4.4、检查 x 是否为行末;128
|
||||
|
||||
|
||||
```
|
||||
charLoopContinue$:
|
||||
cmp x,#128
|
||||
blt noScroll$
|
||||
```
|
||||
|
||||
4.5、设置 x 为 0 然后检查我们是否已经显示超过 1 屏。请记住,我们是用的循环缓冲区,因此如果 `bufferStop` 和 `view` 之前的差是负值,我们实际上是环绕了缓冲区。
|
||||
|
||||
```
|
||||
mov x,#0
|
||||
subs r0,bufferStop,view
|
||||
addlt r0,#128*128*2
|
||||
cmp r0,#128*(768/16)*2
|
||||
```
|
||||
|
||||
4.6、增加一行字节到 `view` 的地址
|
||||
|
||||
```
|
||||
addge view,#128*2
|
||||
```
|
||||
|
||||
4.7、 如果 `view` 地址是缓冲区的末尾,我们就从它上面减去缓冲区的长度,让其指向开始位置。我会在开始的时候设置 `taddr` 为缓冲区的末尾地址。
|
||||
|
||||
```
|
||||
teq view,taddr
|
||||
subeq view,taddr,#128*128*2
|
||||
```
|
||||
|
||||
4.8、如果 `stop` 的地址在缓冲区末尾,我们就从它上面减去缓冲区的长度,让其指向开始位置。我会在开始的时候设置 `taddr` 为缓冲区的末尾地址。
|
||||
|
||||
```
|
||||
noScroll$:
|
||||
teq bufferStop,taddr
|
||||
subeq bufferStop,taddr,#128*128*2
|
||||
```
|
||||
|
||||
4.9、检查 `bufferStop` 是否等于 `bufferStart`。 如果等于增加一行到 `bufferStart`。
|
||||
|
||||
```
|
||||
teq bufferStop,bufferStart
|
||||
addeq bufferStart,#128*2
|
||||
```
|
||||
|
||||
4.10、如果 `start` 的地址在缓冲区的末尾,我们就从它上面减去缓冲区的长度,让其指向开始位置。我会在开始的时候设置 `taddr` 为缓冲区的末尾地址。
|
||||
|
||||
```
|
||||
teq bufferStart,taddr
|
||||
subeq bufferStart,taddr,#128*128*2
|
||||
```
|
||||
循环执行知道字符串结束
|
||||
|
||||
```
|
||||
subs length,#1
|
||||
add string,#1
|
||||
bgt charLoop$
|
||||
```
|
||||
|
||||
5、保存变量然后返回
|
||||
|
||||
```
|
||||
charLoopBreak$:
|
||||
sub taddr,#128*128*2
|
||||
sub taddr,#terminalBuffer-terminalStart
|
||||
str bufferStop,[taddr,#terminalStop-terminalStart]
|
||||
str view,[taddr,#terminalView-terminalStart]
|
||||
str bufferStart,[taddr]
|
||||
|
||||
pop {r4,r5,r6,r7,r8,r9,r10,r11,pc}
|
||||
.unreq bufferStart
|
||||
.unreq taddr
|
||||
.unreq x
|
||||
.unreq string
|
||||
.unreq length
|
||||
.unreq char
|
||||
.unreq bufferStop
|
||||
.unreq view
|
||||
```
|
||||
|
||||
这个方法允许我们打印任意字符到屏幕。然而我们用了颜色变量,但实际上没有设置它。一般终端用特性的组合字符去行修改颜色。如 ASCII 转义(1b<sub>16</sub>)后面跟着一个 0 - f 的 16 进制的数,就可以设置前景色为 CGA 颜色号。如果你自己想尝试实现;在下载页面有一个我的详细的例子。
|
||||
|
||||
### 4、标志输入
|
||||
|
||||
现在我们有一个可以打印和显示文本的输出终端。这仅仅是说对了一半,我们需要输入。我们想实现一个方法:`ReadLine`,可以保存文件的一行文本,文本位置由 `r0` 给出,最大的长度由 `r1` 给出,返回 `r0` 里面的字符串长度。棘手的是用户输出字符的时候要回显功能,同时想要退格键的删除功能和命令回车执行功能。它们还需要一个闪烁的下划线代表计算机需要输入。这些完全合理的要求让构造这个方法更具有挑战性。有一个方法完成这些需求就是存储用户输入的文本和文件大小到内存的某个地方。然后当调用 `ReadLine` 的时候,移动 `terminalStop` 的地址到它开始的地方然后调用 `Print`。也就是说我们只需要确保在内存维护一个字符串,然后构造一个我们自己的打印函数。
|
||||
|
||||
> 按照惯例,许多编程语言中,任意程序可以访问 stdin 和 stdin,它们可以连接到终端的输入和输出流。在图形程序其实也可以进行同样操作,但实际几乎不用。
|
||||
|
||||
让我们看看 `ReadLine` 做了哪些事情:
|
||||
|
||||
1. 如果字符串可保存的最大长度为 0,直接返回
|
||||
2. 检索 `terminalStop` 和 `terminalStop` 的当前值
|
||||
3. 如果字符串的最大长度大约缓冲区的一半,就设置大小为缓冲区的一半
|
||||
4. 从最大长度里面减去 1 来确保输入的闪烁字符或结束符
|
||||
5. 向字符串写入一个下划线
|
||||
6. 写入一个 `terminalView` 和 `terminalStop` 的地址到内存
|
||||
7. 调用 `Print` 打印当前字符串
|
||||
8. 调用 `TerminalDisplay`
|
||||
9. 调用 `KeyboardUpdate`
|
||||
10. 调用 `KeyboardGetChar`
|
||||
11. 如果是一个新行直接跳转到第 16 步
|
||||
12. 如果是一个退格键,将字符串长度减 1(如果其大于 0)
|
||||
13. 如果是一个普通字符,将它写入字符串(字符串大小确保小于最大值)
|
||||
14. 如果字符串是以下划线结束,写入一个空格,否则写入下划线
|
||||
15. 跳转到第 6 步
|
||||
16. 字符串的末尾写入一个新行字符
|
||||
17. 调用 `Print` 和 `TerminalDisplay`
|
||||
18. 用结束符替换新行
|
||||
19. 返回字符串的长度
|
||||
|
||||
|
||||
为了方便读者理解,然后然后自己去实现,我们的实现提供如下:
|
||||
|
||||
1. 快速处理长度为 0 的情况
|
||||
|
||||
```
|
||||
.globl ReadLine
|
||||
ReadLine:
|
||||
teq r1,#0
|
||||
moveq r0,#0
|
||||
moveq pc,lr
|
||||
```
|
||||
|
||||
2、考虑到常见的场景,我们初期做了很多初始化动作。`input` 代表 `terminalStop` 的值,`view` 代表 `terminalView`。`Length` 默认为 `0`。
|
||||
|
||||
```
|
||||
string .req r4
|
||||
maxLength .req r5
|
||||
input .req r6
|
||||
taddr .req r7
|
||||
length .req r8
|
||||
view .req r9
|
||||
|
||||
push {r4,r5,r6,r7,r8,r9,lr}
|
||||
|
||||
mov string,r0
|
||||
mov maxLength,r1
|
||||
ldr taddr,=terminalStart
|
||||
ldr input,[taddr,#terminalStop-terminalStart]
|
||||
ldr view,[taddr,#terminalView-terminalStart]
|
||||
mov length,#0
|
||||
```
|
||||
|
||||
3、我们必须检查异常大的读操作,我们不能处理超过 `terminalBuffer` 大小的输入(理论上可行,但是 `terminalStart` 移动越过存储的 terminalStop`,会有很多问题)。
|
||||
|
||||
```
|
||||
cmp maxLength,#128*64
|
||||
movhi maxLength,#128*64
|
||||
```
|
||||
|
||||
4、由于用户需要一个闪烁的光标,我们需要一个备用字符在理想状况在这个字符串后面放一个结束符。
|
||||
|
||||
```
|
||||
sub maxLength,#1
|
||||
```
|
||||
|
||||
5、写入一个下划线让用户知道我们可以输入了。
|
||||
|
||||
```
|
||||
mov r0,#'_'
|
||||
strb r0,[string,length]
|
||||
```
|
||||
|
||||
6、保存 `terminalStop` 和 `terminalView`。这个对重置一个终端很重要,它会修改这些变量。严格讲也可以修改 `terminalStart`,但是不可逆。
|
||||
|
||||
```
|
||||
readLoop$:
|
||||
str input,[taddr,#terminalStop-terminalStart]
|
||||
str view,[taddr,#terminalView-terminalStart]
|
||||
```
|
||||
|
||||
7、写入当前的输入。由于下划线因此字符串长度加 1
|
||||
|
||||
```
|
||||
mov r0,string
|
||||
mov r1,length
|
||||
add r1,#1
|
||||
bl Print
|
||||
```
|
||||
|
||||
8、拷贝下一个文本到屏幕
|
||||
|
||||
```
|
||||
bl TerminalDisplay
|
||||
```
|
||||
|
||||
|
||||
9、获取最近一次键盘输入
|
||||
|
||||
```
|
||||
bl KeyboardUpdate
|
||||
```
|
||||
|
||||
10、检索键盘输入键值
|
||||
|
||||
```
|
||||
bl KeyboardGetChar
|
||||
```
|
||||
|
||||
11、如果我们有一个回车键,循环中断。如果有结束符和一个退格键也会同样跳出循环。
|
||||
|
||||
```
|
||||
teq r0,#'\n'
|
||||
beq readLoopBreak$
|
||||
teq r0,#0
|
||||
beq cursor$
|
||||
teq r0,#'\b'
|
||||
bne standard$
|
||||
```
|
||||
|
||||
12、从 `length` 里面删除一个字符
|
||||
|
||||
```
|
||||
delete$:
|
||||
cmp length,#0
|
||||
subgt length,#1
|
||||
b cursor$
|
||||
```
|
||||
|
||||
13、写回一个普通字符
|
||||
|
||||
```
|
||||
standard$:
|
||||
cmp length,maxLength
|
||||
bge cursor$
|
||||
strb r0,[string,length]
|
||||
add length,#1
|
||||
```
|
||||
|
||||
14、加载最近的一个字符,如果不是下划线则修改为下换线,如果是则修改为空格
|
||||
|
||||
```
|
||||
cursor$:
|
||||
ldrb r0,[string,length]
|
||||
teq r0,#'_'
|
||||
moveq r0,#' '
|
||||
movne r0,#'_'
|
||||
strb r0,[string,length]
|
||||
```
|
||||
|
||||
15、循环执行值到用户输入按下
|
||||
|
||||
```
|
||||
b readLoop$
|
||||
readLoopBreak$:
|
||||
```
|
||||
|
||||
16、在字符串的结尾处存入一个新行字符
|
||||
|
||||
```
|
||||
mov r0,#'\n'
|
||||
strb r0,[string,length]
|
||||
```
|
||||
|
||||
17、重置 `terminalView` 和 `terminalStop` 然后调用 `Print` 和 `TerminalDisplay` 显示最终的输入
|
||||
|
||||
```
|
||||
str input,[taddr,#terminalStop-terminalStart]
|
||||
str view,[taddr,#terminalView-terminalStart]
|
||||
mov r0,string
|
||||
mov r1,length
|
||||
add r1,#1
|
||||
bl Print
|
||||
bl TerminalDisplay
|
||||
```
|
||||
|
||||
18、写入一个结束符
|
||||
|
||||
```
|
||||
mov r0,#0
|
||||
strb r0,[string,length]
|
||||
```
|
||||
|
||||
19、返回长度
|
||||
|
||||
```
|
||||
mov r0,length
|
||||
pop {r4,r5,r6,r7,r8,r9,pc}
|
||||
.unreq string
|
||||
.unreq maxLength
|
||||
.unreq input
|
||||
.unreq taddr
|
||||
.unreq length
|
||||
.unreq view
|
||||
```
|
||||
|
||||
### 5、终端:机器进化
|
||||
|
||||
现在我们理论用终端和用户可以交互了。最显而易见的事情就是拿去测试了!删除 `main.s` 里 `bl UsbInitialise` 后面的代码后如下:
|
||||
|
||||
```
|
||||
reset$:
|
||||
mov sp,#0x8000
|
||||
bl TerminalClear
|
||||
|
||||
ldr r0,=welcome
|
||||
mov r1,#welcomeEnd-welcome
|
||||
bl Print
|
||||
|
||||
loop$:
|
||||
ldr r0,=prompt
|
||||
mov r1,#promptEnd-prompt
|
||||
bl Print
|
||||
|
||||
ldr r0,=command
|
||||
mov r1,#commandEnd-command
|
||||
bl ReadLine
|
||||
|
||||
teq r0,#0
|
||||
beq loopContinue$
|
||||
|
||||
mov r4,r0
|
||||
|
||||
ldr r5,=command
|
||||
ldr r6,=commandTable
|
||||
|
||||
ldr r7,[r6,#0]
|
||||
ldr r9,[r6,#4]
|
||||
commandLoop$:
|
||||
ldr r8,[r6,#8]
|
||||
sub r1,r8,r7
|
||||
|
||||
cmp r1,r4
|
||||
bgt commandLoopContinue$
|
||||
|
||||
mov r0,#0
|
||||
commandName$:
|
||||
ldrb r2,[r5,r0]
|
||||
ldrb r3,[r7,r0]
|
||||
teq r2,r3
|
||||
bne commandLoopContinue$
|
||||
add r0,#1
|
||||
teq r0,r1
|
||||
bne commandName$
|
||||
|
||||
ldrb r2,[r5,r0]
|
||||
teq r2,#0
|
||||
teqne r2,#' '
|
||||
bne commandLoopContinue$
|
||||
|
||||
mov r0,r5
|
||||
mov r1,r4
|
||||
mov lr,pc
|
||||
mov pc,r9
|
||||
b loopContinue$
|
||||
|
||||
commandLoopContinue$:
|
||||
add r6,#8
|
||||
mov r7,r8
|
||||
ldr r9,[r6,#4]
|
||||
teq r9,#0
|
||||
bne commandLoop$
|
||||
|
||||
ldr r0,=commandUnknown
|
||||
mov r1,#commandUnknownEnd-commandUnknown
|
||||
ldr r2,=formatBuffer
|
||||
ldr r3,=command
|
||||
bl FormatString
|
||||
|
||||
mov r1,r0
|
||||
ldr r0,=formatBuffer
|
||||
bl Print
|
||||
|
||||
loopContinue$:
|
||||
bl TerminalDisplay
|
||||
b loop$
|
||||
|
||||
echo:
|
||||
cmp r1,#5
|
||||
movle pc,lr
|
||||
|
||||
add r0,#5
|
||||
sub r1,#5
|
||||
b Print
|
||||
|
||||
ok:
|
||||
teq r1,#5
|
||||
beq okOn$
|
||||
teq r1,#6
|
||||
beq okOff$
|
||||
mov pc,lr
|
||||
|
||||
okOn$:
|
||||
ldrb r2,[r0,#3]
|
||||
teq r2,#'o'
|
||||
ldreqb r2,[r0,#4]
|
||||
teqeq r2,#'n'
|
||||
movne pc,lr
|
||||
mov r1,#0
|
||||
b okAct$
|
||||
|
||||
okOff$:
|
||||
ldrb r2,[r0,#3]
|
||||
teq r2,#'o'
|
||||
ldreqb r2,[r0,#4]
|
||||
teqeq r2,#'f'
|
||||
ldreqb r2,[r0,#5]
|
||||
teqeq r2,#'f'
|
||||
movne pc,lr
|
||||
mov r1,#1
|
||||
|
||||
okAct$:
|
||||
|
||||
mov r0,#16
|
||||
b SetGpio
|
||||
|
||||
.section .data
|
||||
.align 2
|
||||
welcome: .ascii "Welcome to Alex's OS - Everyone's favourite OS"
|
||||
welcomeEnd:
|
||||
.align 2
|
||||
prompt: .ascii "\n> "
|
||||
promptEnd:
|
||||
.align 2
|
||||
command:
|
||||
.rept 128
|
||||
.byte 0
|
||||
.endr
|
||||
commandEnd:
|
||||
.byte 0
|
||||
.align 2
|
||||
commandUnknown: .ascii "Command `%s' was not recognised.\n"
|
||||
commandUnknownEnd:
|
||||
.align 2
|
||||
formatBuffer:
|
||||
.rept 256
|
||||
.byte 0
|
||||
.endr
|
||||
formatEnd:
|
||||
|
||||
.align 2
|
||||
commandStringEcho: .ascii "echo"
|
||||
commandStringReset: .ascii "reset"
|
||||
commandStringOk: .ascii "ok"
|
||||
commandStringCls: .ascii "cls"
|
||||
commandStringEnd:
|
||||
|
||||
.align 2
|
||||
commandTable:
|
||||
.int commandStringEcho, echo
|
||||
.int commandStringReset, reset$
|
||||
.int commandStringOk, ok
|
||||
.int commandStringCls, TerminalClear
|
||||
.int commandStringEnd, 0
|
||||
```
|
||||
|
||||
这块代码集成了一个简易的命令行操作系统。支持命令:`echo`、`reset`、`ok` 和 `cls`。`echo` 拷贝任意文本到终端,`reset` 命令会在系统出现问题的是复位操作系统,`ok` 有两个功能:设置 OK 灯亮灭,最后 `cls` 调用 TerminalClear 清空终端。
|
||||
|
||||
试试树莓派的代码吧。如果遇到问题,请参照问题集锦页面吧。
|
||||
|
||||
如果运行正常,祝贺你完成了一个操作系统基本终端和输入系列的课程。很遗憾这个教程先讲到这里,但是我希望将来能制作更多教程。有问题请反馈至 awc32@cam.ac.uk。
|
||||
|
||||
你已经在建立了一个简易的终端操作系统。我们的代码在 commandTable 构造了一个可用的命令表格。每个表格的入口是一个整型数字,用来表示字符串的地址,和一个整型数字表格代码的执行入口。 最后一个入口是 为 0 的 `commandStringEnd`。尝试实现你自己的命令,可以参照已有的函数,建立一个新的。函数的参数 `r0` 是用户输入的命令地址,`r1` 是其长度。你可以用这个传递你输入值到你的命令。也许你有一个计算器程序,或许是一个绘图程序或国际象棋。不管你的什么点子,让它跑起来!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input02.html
|
||||
|
||||
作者:[Alex Chadwick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[guevaraya](https://github.com/guevaraya)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cl.cam.ac.uk
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-10676-1.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/circular_buffer.png
|
||||
[3]: https://en.wikipedia.org/wiki/Color_Graphics_Adapter
|
||||
351
published/20160301 How To Set Password Policies In Linux.md
Normal file
351
published/20160301 How To Set Password Policies In Linux.md
Normal file
@ -0,0 +1,351 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (liujing97)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10698-1.html)
|
||||
[#]: subject: (How To Set Password Policies In Linux)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-set-password-policies-in-linux/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
|
||||
如何设置 Linux 系统的密码策略
|
||||
======
|
||||
|
||||

|
||||
|
||||
虽然 Linux 的设计是安全的,但还是存在许多安全漏洞的风险,弱密码就是其中之一。作为系统管理员,你必须为用户提供一个强密码。因为大部分的系统漏洞就是由于弱密码而引发的。本教程描述了在基于 DEB 系统的 Linux,比如 Debian、Ubuntu、Linux Mint 等和基于 RPM 系统的 Linux,比如 RHEL、CentOS、Scientific Linux 等的系统下设置像**密码长度**、**密码复杂度**、**密码有效期**等密码策略。
|
||||
|
||||
### 在基于 DEB 的系统中设置密码长度
|
||||
|
||||
默认情况下,所有的 Linux 操作系统要求用户**密码长度最少 6 个字符**。我强烈建议不要低于这个限制。并且不要使用你的真实名称、父母、配偶、孩子的名字,或者你的生日作为密码。即便是一个黑客新手,也可以很快地破解这类密码。一个好的密码必须是至少 6 个字符,并且包含数字、大写字母和特殊符号。
|
||||
|
||||
通常地,在基于 DEB 的操作系统中,密码和身份认证相关的配置文件被存储在 `/etc/pam.d/` 目录中。
|
||||
|
||||
设置最小密码长度,编辑 `/etc/pam.d/common-password` 文件;
|
||||
|
||||
```
|
||||
$ sudo nano /etc/pam.d/common-password
|
||||
```
|
||||
|
||||
找到下面这行:
|
||||
|
||||
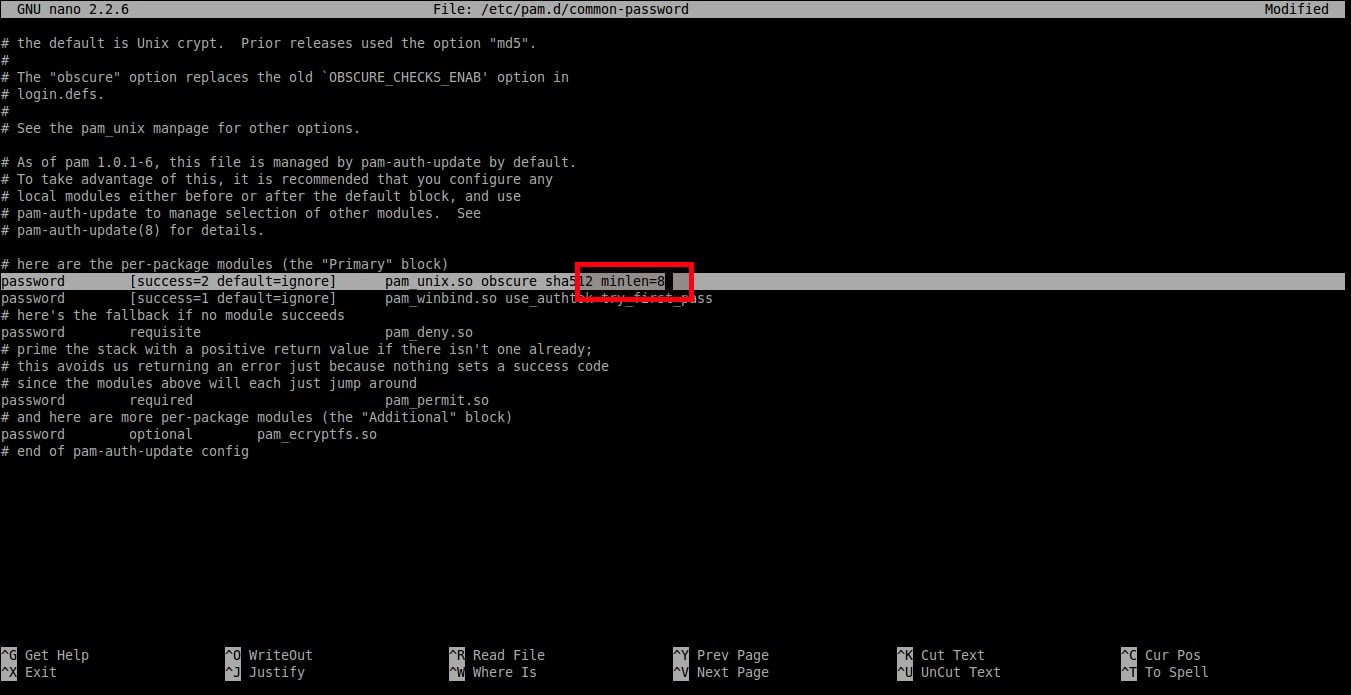
```
|
||||
password [success=2 default=ignore] pam_unix.so obscure sha512
|
||||
```
|
||||
|
||||
![][2]
|
||||
|
||||
在末尾添加额外的文字:`minlen=8`。在这里我设置的最小密码长度为 `8`。
|
||||
|
||||
```
|
||||
password [success=2 default=ignore] pam_unix.so obscure sha512 minlen=8
|
||||
```
|
||||
|
||||
|
||||
|
||||
保存并关闭该文件。这样一来,用户现在不能设置小于 8 个字符的密码。
|
||||
|
||||
### 在基于 RPM 的系统中设置密码长度
|
||||
|
||||
**在 RHEL、CentOS、Scientific Linux 7.x** 系统中, 以 root 身份执行下面的命令来设置密码长度。
|
||||
|
||||
```
|
||||
# authconfig --passminlen=8 --update
|
||||
```
|
||||
|
||||
查看最小密码长度,执行:
|
||||
|
||||
```
|
||||
# grep "^minlen" /etc/security/pwquality.conf
|
||||
```
|
||||
|
||||
**输出样例:**
|
||||
|
||||
```
|
||||
minlen = 8
|
||||
```
|
||||
|
||||
**在 RHEL、CentOS、Scientific Linux 6.x** 系统中,编辑 `/etc/pam.d/system-auth` 文件:
|
||||
|
||||
```
|
||||
# nano /etc/pam.d/system-auth
|
||||
```
|
||||
|
||||
找到下面这行并在该行末尾添加:
|
||||
|
||||
```
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 type= minlen=8
|
||||
```
|
||||
|
||||

|
||||
|
||||
如上设置中,最小密码长度是 `8` 个字符。
|
||||
|
||||
### 在基于 DEB 的系统中设置密码复杂度
|
||||
|
||||
此设置会强制要求密码中应该包含多少类型,比如大写字母、小写字母和其他字符。
|
||||
|
||||
首先,用下面命令安装密码质量检测库:
|
||||
|
||||
```
|
||||
$ sudo apt-get install libpam-pwquality
|
||||
```
|
||||
|
||||
之后,编辑 `/etc/pam.d/common-password` 文件:
|
||||
|
||||
```
|
||||
$ sudo nano /etc/pam.d/common-password
|
||||
```
|
||||
|
||||
为了设置密码中至少有一个**大写字母**,则在下面这行的末尾添加文字 `ucredit=-1`。
|
||||
|
||||
```
|
||||
password requisite pam_pwquality.so retry=3 ucredit=-1
|
||||
```
|
||||
|
||||
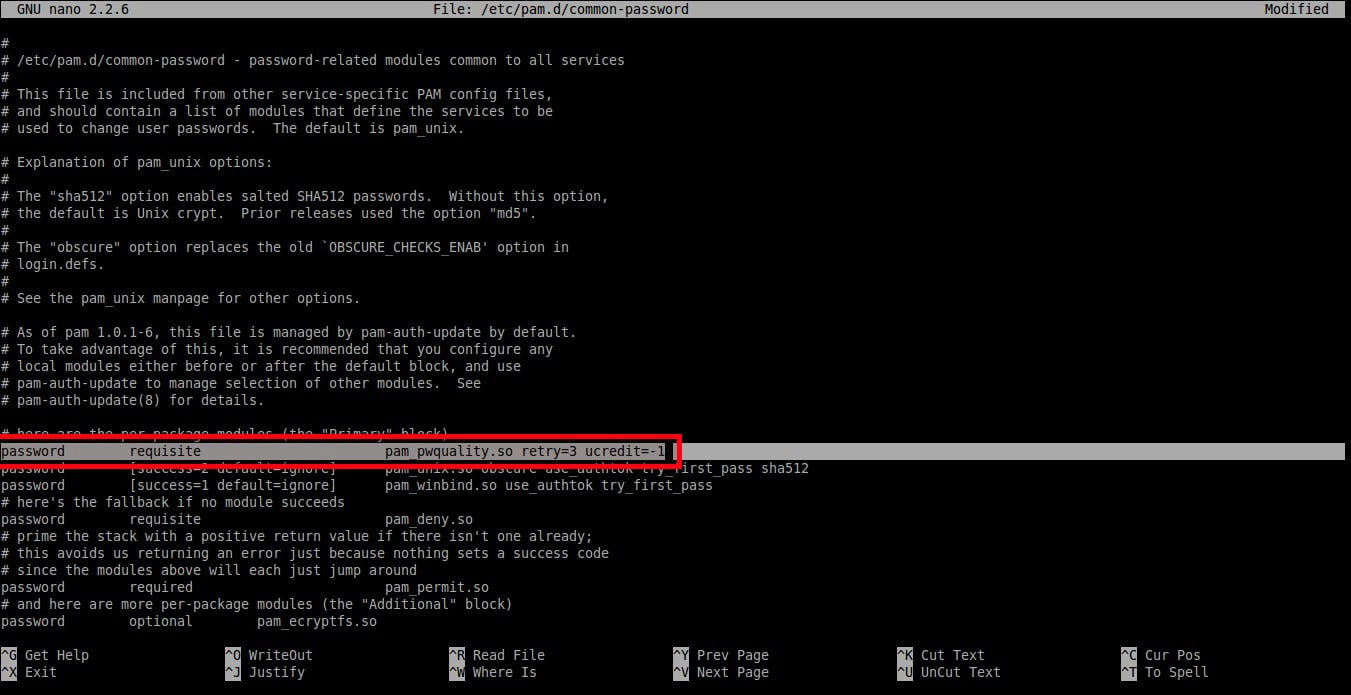
|
||||
|
||||
设置密码中至少有一个**小写字母**,如下所示。
|
||||
|
||||
```
|
||||
password requisite pam_pwquality.so retry=3 dcredit=-1
|
||||
```
|
||||
|
||||
设置密码中至少含有其他字符,如下所示。
|
||||
|
||||
```
|
||||
password requisite pam_pwquality.so retry=3 ocredit=-1
|
||||
```
|
||||
|
||||
正如你在上面样例中看到的一样,我们设置了密码中至少含有一个大写字母、一个小写字母和一个特殊字符。你可以设置被最大允许的任意数量的大写字母、小写字母和特殊字符。
|
||||
|
||||
你还可以设置密码中被允许的字符类的最大或最小数量。
|
||||
|
||||
下面的例子展示了设置一个新密码中被要求的字符类的最小数量:
|
||||
|
||||
```
|
||||
password requisite pam_pwquality.so retry=3 minclass=2
|
||||
```
|
||||
|
||||
### 在基于 RPM 的系统中设置密码复杂度
|
||||
|
||||
**在 RHEL 7.x / CentOS 7.x / Scientific Linux 7.x 中:**
|
||||
|
||||
设置密码中至少有一个小写字母,执行:
|
||||
|
||||
```
|
||||
# authconfig --enablereqlower --update
|
||||
```
|
||||
|
||||
查看该设置,执行:
|
||||
|
||||
```
|
||||
# grep "^lcredit" /etc/security/pwquality.conf
|
||||
```
|
||||
|
||||
**输出样例:**
|
||||
|
||||
```
|
||||
lcredit = -1
|
||||
```
|
||||
|
||||
类似地,使用以下命令去设置密码中至少有一个大写字母:
|
||||
|
||||
```
|
||||
# authconfig --enablerequpper --update
|
||||
```
|
||||
|
||||
查看该设置:
|
||||
|
||||
```
|
||||
# grep "^ucredit" /etc/security/pwquality.conf
|
||||
```
|
||||
|
||||
**输出样例:**
|
||||
|
||||
```
|
||||
ucredit = -1
|
||||
```
|
||||
|
||||
设置密码中至少有一个数字,执行:
|
||||
|
||||
```
|
||||
# authconfig --enablereqdigit --update
|
||||
```
|
||||
|
||||
查看该设置,执行:
|
||||
|
||||
```
|
||||
# grep "^dcredit" /etc/security/pwquality.conf
|
||||
```
|
||||
|
||||
**输出样例:**
|
||||
|
||||
```
|
||||
dcredit = -1
|
||||
```
|
||||
|
||||
设置密码中至少含有一个其他字符,执行:
|
||||
|
||||
```
|
||||
# authconfig --enablereqother --update
|
||||
```
|
||||
|
||||
查看该设置,执行:
|
||||
|
||||
```
|
||||
# grep "^ocredit" /etc/security/pwquality.conf
|
||||
```
|
||||
|
||||
**输出样例:**
|
||||
|
||||
```
|
||||
ocredit = -1
|
||||
```
|
||||
|
||||
在 **RHEL 6.x / CentOS 6.x / Scientific Linux 6.x systems** 中,以 root 身份编辑 `/etc/pam.d/system-auth` 文件:
|
||||
|
||||
```
|
||||
# nano /etc/pam.d/system-auth
|
||||
```
|
||||
|
||||
找到下面这行并且在该行末尾添加:
|
||||
|
||||
```
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 type= minlen=8 dcredit=-1 ucredit=-1 lcredit=-1 ocredit=-1
|
||||
```
|
||||
|
||||
如上设置中,密码必须要至少包含 `8` 个字符。另外,密码必须至少包含一个大写字母、一个小写字母、一个数字和一个其他字符。
|
||||
|
||||
### 在基于 DEB 的系统中设置密码有效期
|
||||
|
||||
现在,我们将要设置下面的策略。
|
||||
|
||||
1. 密码被使用的最长天数。
|
||||
2. 密码更改允许的最小间隔天数。
|
||||
3. 密码到期之前发出警告的天数。
|
||||
|
||||
设置这些策略,编辑:
|
||||
|
||||
```
|
||||
$ sudo nano /etc/login.defs
|
||||
```
|
||||
|
||||
在你的每个需求后设置值。
|
||||
|
||||
```
|
||||
PASS_MAX_DAYS 100
|
||||
PASS_MIN_DAYS 0
|
||||
PASS_WARN_AGE 7
|
||||
```
|
||||
|
||||
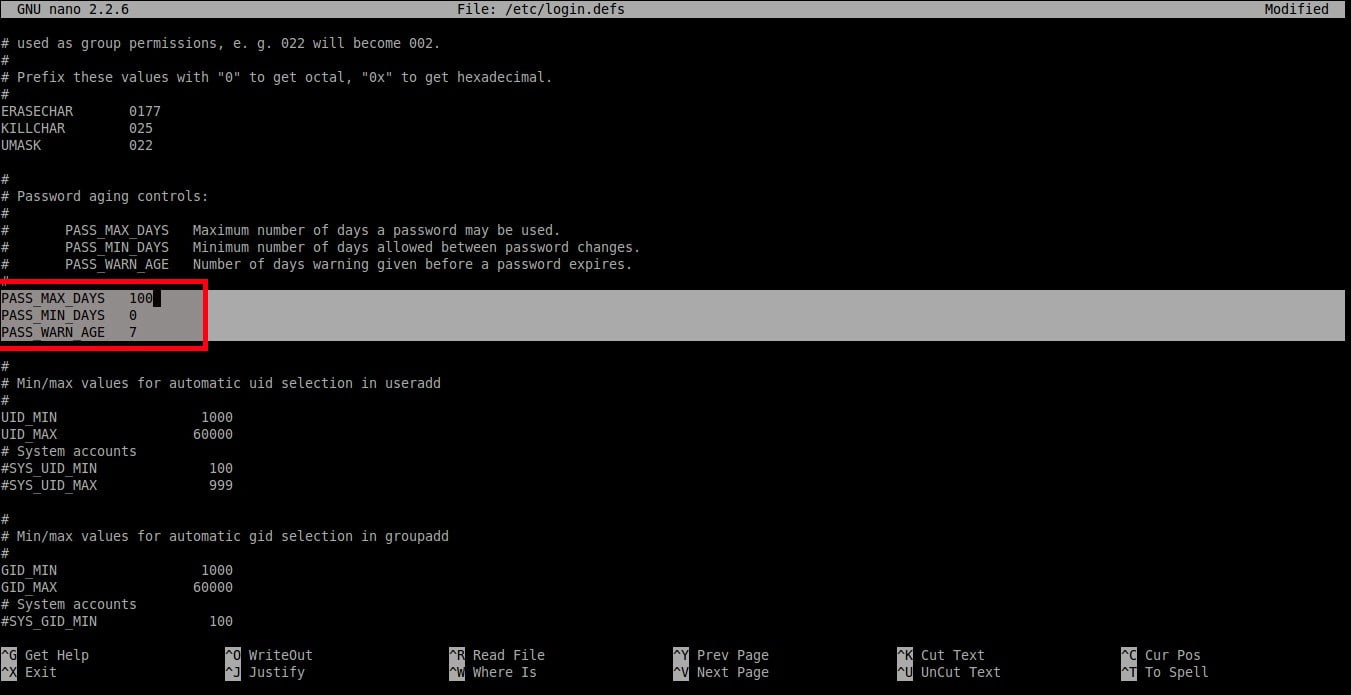
|
||||
|
||||
正如你在上面样例中看到的一样,用户应该每 `100` 天修改一次密码,并且密码到期之前的 `7` 天开始出现警告信息。
|
||||
|
||||
请注意,这些设置将会在新创建的用户中有效。
|
||||
|
||||
为已存在的用户设置修改密码的最大间隔天数,你必须要运行下面的命令:
|
||||
|
||||
```
|
||||
$ sudo chage -M <days> <username>
|
||||
```
|
||||
|
||||
设置修改密码的最小间隔天数,执行:
|
||||
|
||||
```
|
||||
$ sudo chage -m <days> <username>
|
||||
```
|
||||
|
||||
设置密码到期之前的警告,执行:
|
||||
|
||||
```
|
||||
$ sudo chage -W <days> <username>
|
||||
```
|
||||
|
||||
显示已存在用户的密码,执行:
|
||||
|
||||
```
|
||||
$ sudo chage -l sk
|
||||
```
|
||||
|
||||
这里,**sk** 是我的用户名。
|
||||
|
||||
**输出样例:**
|
||||
|
||||
```
|
||||
Last password change : Feb 24, 2017
|
||||
Password expires : never
|
||||
Password inactive : never
|
||||
Account expires : never
|
||||
Minimum number of days between password change : 0
|
||||
Maximum number of days between password change : 99999
|
||||
Number of days of warning before password expires : 7
|
||||
```
|
||||
|
||||
正如你在上面看到的输出一样,该密码是无限期的。
|
||||
|
||||
修改已存在用户的密码有效期,
|
||||
|
||||
```
|
||||
$ sudo chage -E 24/06/2018 -m 5 -M 90 -I 10 -W 10 sk
|
||||
```
|
||||
|
||||
上面的命令将会设置用户 `sk` 的密码期限是 `24/06/2018`。并且修改密码的最小间隔时间为 `5` 天,最大间隔时间为 `90` 天。用户账号将会在 `10` 天后被自动锁定,而且在到期之前的 `10` 天前显示警告信息。
|
||||
|
||||
### 在基于 RPM 的系统中设置密码效期
|
||||
|
||||
这点和基于 DEB 的系统是相同的。
|
||||
|
||||
### 在基于 DEB 的系统中禁止使用近期使用过的密码
|
||||
|
||||
你可以限制用户去设置一个已经使用过的密码。通俗的讲,就是说用户不能再次使用相同的密码。
|
||||
|
||||
为设置这一点,编辑 `/etc/pam.d/common-password` 文件:
|
||||
|
||||
```
|
||||
$ sudo nano /etc/pam.d/common-password
|
||||
```
|
||||
|
||||
找到下面这行并且在末尾添加文字 `remember=5`:
|
||||
|
||||
```
|
||||
password [success=2 default=ignore] pam_unix.so obscure use_authtok try_first_pass sha512 remember=5
|
||||
```
|
||||
|
||||
上面的策略将会阻止用户去使用最近使用过的 5 个密码。
|
||||
|
||||
### 在基于 RPM 的系统中禁止使用近期使用过的密码
|
||||
|
||||
这点对于 RHEL 6.x 和 RHEL 7.x 和它们的衍生系统 CentOS、Scientific Linux 是相同的。
|
||||
|
||||
以 root 身份编辑 `/etc/pam.d/system-auth` 文件,
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
```
|
||||
|
||||
找到下面这行,并且在末尾添加文字 `remember=5`。
|
||||
|
||||
```
|
||||
password sufficient pam_unix.so sha512 shadow nullok try_first_pass use_authtok remember=5
|
||||
```
|
||||
|
||||
现在你了解了 Linux 中的密码策略,以及如何在基于 DEB 和 RPM 的系统中设置不同的密码策略。
|
||||
|
||||
就这样,我很快会在这里发表另外一天有趣而且有用的文章。在此之前请保持关注。如果您觉得本教程对你有帮助,请在您的社交,专业网络上分享并支持我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-set-password-policies-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[liujing97](https://github.com/liujing97)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: http://www.ostechnix.com/wp-content/uploads/2016/03/sk@sk-_003-2-1.jpg
|
||||
@ -0,0 +1,173 @@
|
||||
12 个最佳 GNOME(GTK)主题
|
||||
======
|
||||
|
||||
> 让我们来看一些漂亮的 GTK 主题,你不仅可以用在 Ubuntu 上,也可以用在其它使用 GNOME 的 Linux 发行版上。
|
||||
|
||||
对于我们这些使用 Ubuntu 的人来说,默认的桌面环境从 Unity 变成了 Gnome 使得主题和定制变得前所未有的简单。Gnome 有个相当大的定制用户社区,其中不乏可供用户选择的漂亮的 GTK 主题。最近几个月,我不断找到了一些喜欢的主题。我相信这些是你所能找到的最好的主题之一了。
|
||||
|
||||
### Ubuntu 和其它 Linux 发行版的最佳主题
|
||||
|
||||
这不是一个详细清单,可能不包括一些你已经使用和喜欢的主题,但希望你能至少找到一个能让你喜爱的没见过的主题。所有这里提及的主题都可以工作在 Gnome 3 上,不管是 Ubuntu 还是其它 Linux 发行版。有一些主题的屏幕截屏我没有,所以我从官方网站上找到了它们的图片。
|
||||
|
||||
在这里列出的主题没有特别的次序。
|
||||
|
||||
但是,在你看这些最好的 GNOME 主题前,你应该学习一下 [如何在 Ubuntu GNOME 中安装主题][1]。
|
||||
|
||||
#### 1、Arc-Ambiance
|
||||
|
||||
![][2]
|
||||
|
||||
Arc 和 Arc 变体主题已经出现了相当长的时间,普遍认为它们是最好的主题之一。在这个示例中,我选择了 Arc-Ambiance ,因为它是 Ubuntu 中的默认 Ambiance 主题。
|
||||
|
||||
我是 Arc 主题和默认 Ambiance 主题的粉丝,所以不用说,当我遇到一个融合了两者优点的主题,我不禁长吸了一口气。如果你是 Arc 主题的粉丝,但不是这个特定主题的粉丝,Gnome 的外观上当然还有适合你口味的大量的选择。
|
||||
|
||||
- [下载 Arc-Ambiance 主题][3]
|
||||
|
||||
#### 2、Adapta Colorpack
|
||||
|
||||
![][4]
|
||||
|
||||
Adapta 主题是我所见过的最喜欢的扁平主题之一。像 Arc 一样,Adapata 被很多 Linux 用户广泛采用。我选择这个配色包,是因为一次下载你就有数个可选择的配色方案。事实上,有 19 个配色方案可以选择,是的,你没看错,19 个呢!
|
||||
|
||||
所以,如果你是如今常见的扁平风格/<ruby>材料设计风格<rt>Material Design Language</rt></ruby>的粉丝,那么,在这个主题包中很可能至少有一个能满足你喜好的变体。
|
||||
|
||||
- [下载 Adapta Colorpack 主题][5]
|
||||
|
||||
#### 3、Numix Collection
|
||||
|
||||
![][6]
|
||||
|
||||
啊,Numix! 让我想起了我们一起度过的那些年!对于那些在过去几年装点过桌面环境的人来说,你肯定在某个时间点上遇到过 Numix 主题或图标包。Numix 可能是我爱上的第一个 Linux 现代主题,现在我仍然爱它。虽然经过这些年,但它仍然魅力不失。
|
||||
|
||||
灰色色调贯穿主题,尤其是默认的粉红色高亮,带来了真正干净而完整的体验。你可能很难找到一个像 Numix 一样精美的主题包。而且在这个主题包中,你还有很多可供选择的余地,简直不要太棒了!
|
||||
|
||||
- [下载 Numix Collection 主题][7]
|
||||
|
||||
#### 4、Hooli
|
||||
|
||||
![][8]
|
||||
|
||||
Hooli 是一个已经出现了一段时间的主题,但是我最近才偶然发现它。我是很多扁平主题的粉丝,但是通常不太喜欢材料设计风格的主题。Hooli 像 Adapta 一样吸取了那些设计风格,但是我认为它和其它的那些有所不同。绿色高亮是我对这个主题最喜欢的部分之一,并且,它在不冲击整个主题方面做的很好。
|
||||
|
||||
- [下载 Hooli 主题][9]
|
||||
|
||||
#### 5、Arrongin/Telinkrin
|
||||
|
||||
![][10]
|
||||
|
||||
福利:二合一主题!它们是在主题领域中的相对新的竞争者。它们都吸取了 Ubuntu 接近完成的 “[communitheme][11]” 的思路,并带它到了你的桌面。这两个主题我能找到的唯一真正的区别就是颜色。Arrongin 以 Ubuntu 家族的橙色颜色为中心,而 Telinkrin 则更偏向于 KDE Breeze 系的蓝色,我个人更喜欢蓝色,但是两者都是极好的选择!
|
||||
|
||||
- [下载 Arrongin/Telinkrin 主题][12]
|
||||
|
||||
#### 6、Gnome-osx
|
||||
|
||||
![][13]
|
||||
|
||||
我不得不承认,通常,当我看到一个主题有 “osx” 或者在标题中有类似的内容时我就不会不期望太多。大多数受 Apple 启发的主题看起来都比较雷同,我真不能找到使用它们的原因。但我想这两个主题能够打破这种思维定式:这就是 Arc-osc 主题和 Gnome-osx 主题。
|
||||
|
||||
我喜欢 Gnome-osx 主题的原因是它在 Gnome 桌面上看起来确实很像 OSX。它在融入桌面环境而不至于变的太扁平方面做得很好。所以,对于那些喜欢稍微扁平的主题的人来说,如果你喜欢红黄绿按钮样式(用于关闭、最小化和最大化),这个主题非常适合你。
|
||||
|
||||
- [下载 Gnome-osx 主题][14]
|
||||
|
||||
#### 7、Ultimate Maia
|
||||
|
||||
![][15]
|
||||
|
||||
曾经有一段时间我使用 Manjaro Gnome。尽管那以后我又回到了 Ubuntu,但是,我希望我能打包带走的一个东西是 Manjaro 主题。如果你对 Manjaro 主题和我一样感受相同,那么你是幸运的,因为你可以带它到你想运行 Gnome 的任何 Linux 发行版!
|
||||
|
||||
丰富的绿色颜色,Breeze 式的关闭、最小化、最大化按钮,以及全面雕琢过的主题使它成为一个不可抗拒的选择。如果你不喜欢绿色,它甚至为你提供一些其它颜色的变体。但是说实话……谁会不喜欢 Manjaro 的绿色呢?
|
||||
|
||||
- [下载 Ultimate Maia 主题][16]
|
||||
|
||||
#### 8、Vimix
|
||||
|
||||
![][17]
|
||||
|
||||
这是一个让我激动的主题。它是现代风格的,吸取了 macOS 的红黄绿按钮的风格,但并不是直接复制了它们,并且减少了多变的主题颜色,使之成为了大多数主题的独特替代品。它带来三个深色的变体和几个彩色配色,我们中大多数人都可以从中找到我们喜欢的。
|
||||
|
||||
- [下载 Vimix 主题][18]
|
||||
|
||||
#### 9、Ant
|
||||
|
||||
![][19]
|
||||
|
||||
像 Vimix 一样,Ant 从 macOS 的按钮颜色中吸取了灵感,但不是直接复制了样式。在 Vimix 减少了颜色花哨的地方,Ant 却增加了丰富的颜色,在我的 System 76 Galago Pro 屏幕看起来绚丽极了。三个主题变体的变化差异大相径庭,虽然它可能不见得符合每个人的口味,它无疑是最适合我的。
|
||||
|
||||
- [下载 Ant 主题][20]
|
||||
|
||||
#### 10、Flat Remix
|
||||
|
||||
![][21]
|
||||
|
||||
如果你还没有注意到这点,对于一些关注关闭、最小化、最大化按钮的人来说我就是一个傻瓜。Flat Remix 使用的颜色主题是我从未在其它地方看到过的,它采用红色、蓝色和橙色方式。把这些添加到一个几乎看起来像是一个混合了 Arc 和 Adapta 的主题的上面,就有了 Flat Remix。
|
||||
|
||||
我本人喜欢它的深色主题,但是换成亮色的也是非常好的。因此,如果你喜欢稍稍透明、风格一致的深色主题,以及偶尔的一点点颜色,那 Flat Remix 就适合你。
|
||||
|
||||
- [下载 Flat Remix 主题][22]
|
||||
|
||||
#### 11、Paper
|
||||
|
||||
![][23]
|
||||
|
||||
[Paper][24] 已经出现一段时间。我记得第一次使用它是在 2014 年。可以说,Paper 的图标包比其 GTK 主题更出名,但是这并不意味着它自身的主题不是一个极好的选择。即使我从一开始就倾心于 Paper 图标,我不能说当我第一次尝试它的时候我就是一个 Paper 主题忠实粉丝。
|
||||
|
||||
我觉得鲜亮的色彩和有趣的方式被放到一个主题里是一种“不成熟”的体验。现在,几年后,Paper 在我心目中已经长大,至少可以这样说,这个主题采取的轻快方式是我非常欣赏的一个。
|
||||
|
||||
- [下载 Paper 主题][25]
|
||||
|
||||
#### 12、Pop
|
||||
|
||||
![][26]
|
||||
|
||||
Pop 在这个列表上是一个较新的主题,是由 [System 76][27] 的人们创造的,Pop GTK 主题是前面列出的 Adapta 主题的一个分支,并带有一个匹配的图标包,图标包是先前提到的 Paper 图标包的一个分支。
|
||||
|
||||
该主题是在 System 76 发布了 [他们自己的发行版][28] Pop!_OS 之后不久发布的。你可以阅读我的 [Pop!_OS 点评][29] 来了解更多信息。不用说,我认为 Pop 是一个极好的主题,带有华丽的装饰,并为 Gnome 桌面带来了一股清新之风。
|
||||
|
||||
- [下载 Pop 主题][30]
|
||||
|
||||
#### 结束语
|
||||
|
||||
很明显,我们有比文中所描述的主题更多的选择,但是这些大多是我在最近几月所使用的最完整、最精良的主题。如果你认为我们错过一些你确实喜欢的主题,或你确实不喜欢我在上面描述的主题,那么在下面的评论区让我们知道,并分享你喜欢的主题更好的原因!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-gtk-themes/
|
||||
|
||||
作者:[Phillip Prado][a]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/phillip/
|
||||
[1]:https://itsfoss.com/install-themes-ubuntu/
|
||||
[2]:https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/03/arcambaince.png
|
||||
[3]:https://www.gnome-look.org/p/1193861/
|
||||
[4]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/03/adapta.jpg
|
||||
[5]:https://www.gnome-look.org/p/1190851/
|
||||
[6]:https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/03/numix.png
|
||||
[7]:https://www.gnome-look.org/p/1170667/
|
||||
[8]:https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/03/hooli2.jpg
|
||||
[9]:https://www.gnome-look.org/p/1102901/
|
||||
[10]:https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/03/AT.jpg
|
||||
[11]:https://itsfoss.com/ubuntu-community-theme/
|
||||
[12]:https://www.gnome-look.org/p/1215199/
|
||||
[13]:https://itsfoss.com/wp-content/uploads/2018/03/gosx-800x473.jpg
|
||||
[14]:https://www.opendesktop.org/s/Gnome/p/1171688/
|
||||
[15]:https://itsfoss.com/wp-content/uploads/2018/03/ultimatemaia-800x450.jpg
|
||||
[16]:https://www.opendesktop.org/s/Gnome/p/1193879/
|
||||
[17]:https://itsfoss.com/wp-content/uploads/2018/03/vimix-800x450.jpg
|
||||
[18]:https://www.gnome-look.org/p/1013698/
|
||||
[19]:https://itsfoss.com/wp-content/uploads/2018/03/ant-800x533.png
|
||||
[20]:https://www.opendesktop.org/p/1099856/
|
||||
[21]:https://itsfoss.com/wp-content/uploads/2018/03/flatremix-800x450.png
|
||||
[22]:https://www.opendesktop.org/p/1214931/
|
||||
[23]:https://itsfoss.com/wp-content/uploads/2018/04/paper-800x450.jpg
|
||||
[24]:https://itsfoss.com/install-paper-theme-linux/
|
||||
[25]:https://snwh.org/paper/download
|
||||
[26]:https://itsfoss.com/wp-content/uploads/2018/04/pop-800x449.jpg
|
||||
[27]:https://system76.com/
|
||||
[28]:https://itsfoss.com/system76-popos-linux/
|
||||
[29]:https://itsfoss.com/pop-os-linux-review/
|
||||
[30]:https://github.com/pop-os/gtk-theme/blob/master/README.md
|
||||
@ -1,48 +1,48 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: " "
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: translator: "Auk7F7"
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: subject: "Arch-Wiki-Man – A Tool to Browse The Arch Wiki Pages As Linux Man Page from Offline"
|
||||
[#]: via: "https://www.2daygeek.com/arch-wiki-man-a-tool-to-browse-the-arch-wiki-pages-as-linux-man-page-from-offline/"
|
||||
[#]: author: "[Prakash Subramanian](https://www.2daygeek.com/author/prakash/)"
|
||||
[#]: url: " "
|
||||
[#]: author: "Prakash Subramanian https://www.2daygeek.com/author/prakash/"
|
||||
[#]: url: "https://linux.cn/article-10694-1.html"
|
||||
|
||||
Arch-Wiki-Man – 一个以 Linux Man 手册样式离线浏览 Arch Wiki 的工具
|
||||
Arch-Wiki-Man:一个以 Linux Man 手册样式离线浏览 Arch Wiki 的工具
|
||||
======
|
||||
|
||||
现在上网已经很方便了,但技术上会有限制。
|
||||
现在上网已经很方便了,但技术上会有限制。看到技术的发展,我很惊讶,但与此同时,各种地方也都会出现衰退。
|
||||
|
||||
看到技术的发展,我很惊讶,但与此同时,各个地方都会出现衰退。
|
||||
|
||||
当你搜索有关其他 Linux 发型版本的某些东西时,大多数时候你会首先得到一个第三方的链接,但是对于 Arch Linux 来说,每次你都会得到 Arch Wiki 页面的结果。
|
||||
当你搜索有关其他 Linux 发行版的某些东西时,大多数时候你会得到的是一个第三方的链接,但是对于 Arch Linux 来说,每次你都会得到 Arch Wiki 页面的结果。
|
||||
|
||||
因为 Arch Wiki 提供了除第三方网站以外的大多数解决方案。
|
||||
|
||||
到目前为止,你也许可以使用 Web 浏览器为你的 Arch Linux 系统找到一个解决方案,但现在你可以不用这么做了。
|
||||
|
||||
一个名为 arch-wiki-man 的工具t提供了一个在命令行中更快地执行这个操作的方案。如果你是一个 Arch Linux 爱好者,我建议你阅读 **[Arch Linux 安装后指南][1]** ,它可以帮助你调整你的系统以供日常使用。
|
||||
一个名为 arch-wiki-man 的工具提供了一个在命令行中更快地执行这个操作的方案。如果你是一个 Arch Linux 爱好者,我建议你阅读 [Arch Linux 安装后指南][1],它可以帮助你调整你的系统以供日常使用。
|
||||
|
||||
### arch-wiki-man 是什么?
|
||||
|
||||
[arch-wiki-man][2] 工具允许用户在离线的时候从命令行(CLI)中搜索 Arch Wiki 页面。它允许用户以 Linux Man 手册样式访问和搜索整个 Wiki 页面。
|
||||
[arch-wiki-man][2] 工具允许用户从命令行(CLI)中离线搜索 Arch Wiki 页面。它允许用户以 Linux Man 手册样式访问和搜索整个 Wiki 页面。
|
||||
|
||||
而且,你无需切换到GUI。更新将每两天自动推送一次,因此,你的 Arch Wiki 本地副本页面将是最新的。这个工具的名字是`awman`, `awman` 是 Arch Wiki Man 的缩写。
|
||||
而且,你无需切换到 GUI。更新将每两天自动推送一次,因此,你的 Arch Wiki 本地副本页面将是最新的。这个工具的名字是 `awman`, `awman` 是 “Arch Wiki Man” 的缩写。
|
||||
|
||||
我们已经写出了名为 **[Arch Wiki 命令行实用程序][3]** (arch-wiki-cli)的类似工具。它允许用户从互联网上搜索 Arch Wiki。但确保你因该在线使用这个实用程序。
|
||||
我们之前写过一篇类似工具 [Arch Wiki 命令行实用程序][3](arch-wiki-cli)的文章。这个工具允许用户从互联网上搜索 Arch Wiki。但你需要在线使用这个实用程序。
|
||||
|
||||
### 如何安装 arch-wiki-man 工具?
|
||||
|
||||
arch-wiki-man 工具可以在 AUR 仓库(LCTT译者注:AUR 即 Arch 用户软件仓库(Archx User Repository))中获得,因此,我们需要使用 AUR 工具来安装它。有许多 AUR 工具可用,而且我们曾写了一篇有关非常著名的 AUR 工具: **[Yaourt AUR helper][4]** 和 **[Packer AUR helper][5]** 的文章,
|
||||
arch-wiki-man 工具可以在 AUR 仓库(LCTT 译注:AUR 即<ruby>Arch 用户软件仓库<rt>Arch User Repository</rt></ruby>)中获得,因此,我们需要使用 AUR 工具来安装它。有许多 AUR 工具可用,而且我们曾写了一篇关于流行的 AUR 辅助工具: [Yaourt AUR helper][4] 和 [Packer AUR helper][5] 的文章。
|
||||
|
||||
```
|
||||
$ yaourt -S arch-wiki-man
|
||||
```
|
||||
|
||||
or
|
||||
或
|
||||
|
||||
```
|
||||
$ packer -S arch-wiki-man
|
||||
```
|
||||
|
||||
或者,我们可以使用 npm 包管理器来安装它,确保你已经在你的系统上安装了 **[NodeJS][6]** 。然后运行以下命令来安装它。
|
||||
或者,我们可以使用 npm 包管理器来安装它,确保你已经在你的系统上安装了 [NodeJS][6]。然后运行以下命令来安装它。
|
||||
|
||||
```
|
||||
$ npm install -g arch-wiki-man
|
||||
@ -61,13 +61,15 @@ $ sudo awman-update
|
||||
arch-wiki-md-repo has been successfully updated or reinstalled.
|
||||
```
|
||||
|
||||
awman-update 是一种更快更方便的更新方法。但是,你也可以通过运行以下命令重新安装arch-wiki-man 来获取更新。
|
||||
`awman-update` 是一种更快、更方便的更新方法。但是,你也可以通过运行以下命令重新安装 arch-wiki-man 来获取更新。
|
||||
|
||||
```
|
||||
$ yaourt -S arch-wiki-man
|
||||
```
|
||||
|
||||
or
|
||||
或
|
||||
|
||||
```
|
||||
$ packer -S arch-wiki-man
|
||||
```
|
||||
|
||||
@ -81,7 +83,7 @@ $ awman Search-Term
|
||||
|
||||
### 如何搜索多个匹配项?
|
||||
|
||||
如果希望列出包含`installation`字符串的所有结果的标题,运行以下格式的命令,如果输出有多个结果,那么你将会获得一个选择菜单来浏览每个项目。
|
||||
如果希望列出包含 “installation” 字符串的所有结果的标题,运行以下格式的命令,如果输出有多个结果,那么你将会获得一个选择菜单来浏览每个项目。
|
||||
|
||||
```
|
||||
$ awman installation
|
||||
@ -89,35 +91,39 @@ $ awman installation
|
||||
|
||||
![][8]
|
||||
|
||||
详细页面的截屏
|
||||
详细页面的截屏:
|
||||
|
||||
![][9]
|
||||
|
||||
### 在标题和描述中搜索给定的字符串
|
||||
|
||||
`-d` 或 `--desc-search` 选项允许用户在标题和描述中搜索给定的字符串。
|
||||
`-d` 或 `--desc-search` 选项允许用户在标题和描述中搜索给定的字符串。
|
||||
|
||||
```
|
||||
$ awman -d mirrors
|
||||
```
|
||||
|
||||
or
|
||||
或
|
||||
|
||||
```
|
||||
$ awman --desc-search mirrors
|
||||
? Select an article: (Use arrow keys)
|
||||
❯ [1/3] Mirrors: Related articles
|
||||
[2/3] DeveloperWiki-NewMirrors: Contents
|
||||
[3/3] Powerpill: Powerpill is a pac
|
||||
[2/3] DeveloperWiki-NewMirrors: Contents
|
||||
[3/3] Powerpill: Powerpill is a pac
|
||||
```
|
||||
|
||||
### 在内容中搜索给定的字符串
|
||||
|
||||
`-k` 或 `--apropos` 选项也允许用户在内容中搜索给定的字符串。但须注意,此选项会显著降低搜索速度,因为此选项会扫描整个 Wiki 页面的内容。
|
||||
`-k` 或 `--apropos` 选项也允许用户在内容中搜索给定的字符串。但须注意,此选项会显著降低搜索速度,因为此选项会扫描整个 Wiki 页面的内容。
|
||||
|
||||
```
|
||||
$ awman -k openjdk
|
||||
```
|
||||
|
||||
or
|
||||
或
|
||||
|
||||
```
|
||||
$ awman --apropos openjdk
|
||||
? Select an article: (Use arrow keys)
|
||||
❯ [1/26] Hadoop: Related articles
|
||||
@ -132,13 +138,15 @@ $ awman --apropos openjdk
|
||||
|
||||
### 在浏览器中打开搜索结果
|
||||
|
||||
`-w` 或 `--web` 选项允许用户在 Web 浏览器中打开搜索结果。
|
||||
`-w` 或 `--web` 选项允许用户在 Web 浏览器中打开搜索结果。
|
||||
|
||||
```
|
||||
$ awman -w AUR helper
|
||||
```
|
||||
|
||||
or
|
||||
或
|
||||
|
||||
```
|
||||
$ awman --web AUR helper
|
||||
```
|
||||
|
||||
@ -146,7 +154,7 @@ $ awman --web AUR helper
|
||||
|
||||
### 以其他语言搜索
|
||||
|
||||
`-w` 或 `--web` 选项允许用户在 Web 浏览器中打开搜索结果。想要查看支持的语言列表,请运行以下命令。
|
||||
想要查看支持的语言列表,请运行以下命令。
|
||||
|
||||
```
|
||||
$ awman --list-languages
|
||||
@ -196,7 +204,7 @@ via: https://www.2daygeek.com/arch-wiki-man-a-tool-to-browse-the-arch-wiki-pages
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Auk7F7](https://github.com/Auk7F7)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,95 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10709-1.html)
|
||||
[#]: subject: (Take to the virtual skies with FlightGear)
|
||||
[#]: via: (https://opensource.com/article/19/1/flightgear)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
使用 FlightGear 翱翔天空
|
||||
======
|
||||
|
||||
> 你梦想驾驶飞机么?试试开源飞行模拟器 FlightGear 吧。
|
||||
|
||||

|
||||
|
||||
如果你曾梦想驾驶飞机,你会喜欢 [FlightGear][1] 的。它是一个功能齐全的[开源][2]飞行模拟器,可在 Linux、MacOS 和 Windows 中运行。
|
||||
|
||||
FlightGear 项目始于 1996 年,原因是对商业飞行模拟程序的不满,因为这些程序无法扩展。它的目标是创建一个复杂、强大、可扩展、开放的飞行模拟器框架,来用于学术界和飞行员培训,以及任何想要玩飞行模拟场景的人。
|
||||
|
||||
### 入门
|
||||
|
||||
FlightGear 的硬件要求适中,包括支持 OpenGL 以实现平滑帧速的加速 3D 显卡。它在我的配备 i5 处理器和仅 4GB 的内存的 Linux 笔记本上运行良好。它的文档包括[在线手册][3]、一个面向[用户][5]和[开发者][6]的 [wiki][4] 门户网站,还有大量的教程(例如它的默认飞机 [Cessna 172p][7])教你如何操作它。
|
||||
|
||||
在 [Fedora][8] 和 [Ubuntu][9] Linux 中很容易安装。Fedora 用户可以参考 [Fedora 安装页面][10]来运行 FlightGear。
|
||||
|
||||
在 Ubuntu 18.04 中,我需要安装一个仓库:
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:saiarcot895/flightgear
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install flightgear
|
||||
```
|
||||
|
||||
安装完成后,我从 GUI 启动它,但你也可以通过输入以下命令从终端启动应用:
|
||||
|
||||
```
|
||||
$ fgfs
|
||||
```
|
||||
|
||||
### 配置 FlightGear
|
||||
|
||||
应用窗口左侧的菜单提供配置选项。
|
||||
|
||||
|
||||
|
||||
“Summary” 返回应用的主页面。
|
||||
|
||||
“Aircraft” 显示你已安装的飞机,并提供了 FlightGear 的默认“机库”中安装多达 539 种其他飞机的选项。我安装了 Cessna 150L、Piper J-3 Cub 和 Bombardier CRJ-700。一些飞机(包括 CRJ-700)有教你如何驾驶商用喷气式飞机的教程。我发现这些教程内容翔实且准确。
|
||||
|
||||
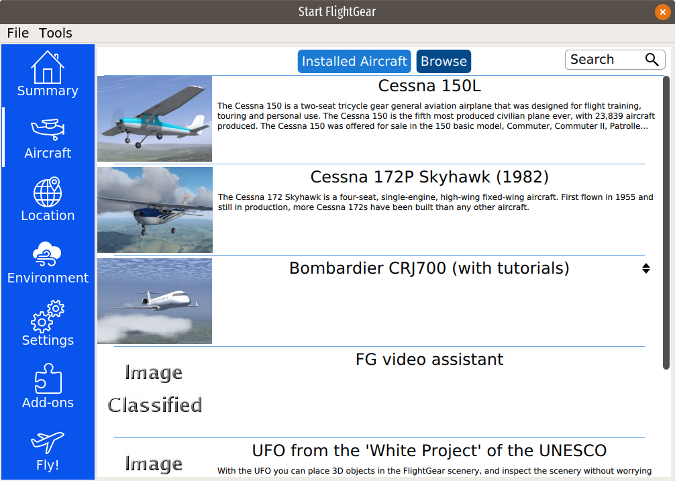
|
||||
|
||||
要选择驾驶的飞机,请将其高亮显示,然后单击菜单底部的 “Fly!”。我选择了默认的 Cessna 172p 并发现驾驶舱的刻画非常准确。
|
||||
|
||||
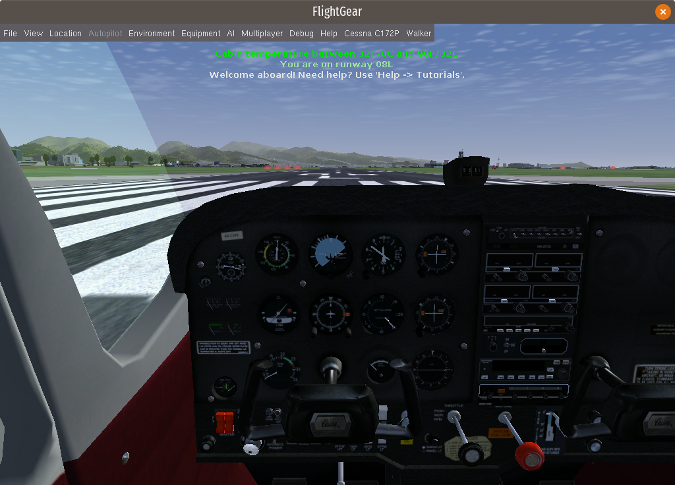
|
||||
|
||||
默认机场是檀香山,但你在 “Location” 菜单中提供你最喜欢机场的 [ICAO 机场代码] [11]进行修改。我找到了一些小型的本地无塔机场,如 Olean 和 Dunkirk,纽约,以及包括 Buffalo,O'Hare 和 Raleigh 在内的大型机场,甚至可以选择特定的跑道。
|
||||
|
||||
在 “Environment” 下,你可以调整一天中的时间、季节和天气。模拟包括高级天气建模和从 [NOAA][12] 下载当前天气的能力。
|
||||
|
||||
“Settings” 提供在暂停模式中开始模拟的选项。同样在设置中,你可以选择多人模式,这样你就可以与 FlightGear 支持者的全球服务器网络上的其他玩家一起“飞行”。你必须有比较快速的互联网连接来支持此功能。
|
||||
|
||||
“Add-ons” 菜单允许你下载飞机和其他场景。
|
||||
|
||||
### 开始飞行
|
||||
|
||||
为了“起飞”我的 Cessna,我使用了罗技操纵杆,它用起来不错。你可以使用顶部 “File” 菜单中的选项校准操纵杆。
|
||||
|
||||
总的来说,我发现模拟非常准确,图形界面也很棒。你自己试下 FlightGear —— 我想你会发现它是一个非常有趣和完整的模拟软件。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/flightgear
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://home.flightgear.org/
|
||||
[2]: http://wiki.flightgear.org/GNU_General_Public_License
|
||||
[3]: http://flightgear.sourceforge.net/getstart-en/getstart-en.html
|
||||
[4]: http://wiki.flightgear.org/FlightGear_Wiki
|
||||
[5]: http://wiki.flightgear.org/Portal:User
|
||||
[6]: http://wiki.flightgear.org/Portal:Developer
|
||||
[7]: http://wiki.flightgear.org/Cessna_172P
|
||||
[8]: http://rpmfind.net/linux/rpm2html/search.php?query=flightgear
|
||||
[9]: https://launchpad.net/~saiarcot895/+archive/ubuntu/flightgear
|
||||
[10]: https://apps.fedoraproject.org/packages/FlightGear/
|
||||
[11]: https://en.wikipedia.org/wiki/ICAO_airport_code
|
||||
[12]: https://www.noaa.gov/
|
||||
@ -0,0 +1,348 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (liujing97)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10716-1.html)
|
||||
[#]: subject: (How To Understand And Identify File types in Linux)
|
||||
[#]: via: (https://www.2daygeek.com/how-to-understand-and-identify-file-types-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
怎样理解和识别 Linux 中的文件类型
|
||||
======
|
||||
|
||||
众所周知,在 Linux 中一切皆为文件,包括硬盘和显卡等。在 Linux 中导航时,大部分的文件都是普通文件和目录文件。但是也有其他的类型,对应于 5 类不同的作用。因此,理解 Linux 中的文件类型在许多方面都是非常重要的。
|
||||
|
||||
如果你不相信,那只需要浏览全文,就会发现它有多重要。如果你不能理解文件类型,就不能够毫无畏惧的做任意的修改。
|
||||
|
||||
如果你做了一些错误的修改,会毁坏你的文件系统,那么当你操作的时候请小心一点。在 Linux 系统中文件是非常重要的,因为所有的设备和守护进程都被存储为文件。
|
||||
|
||||
### 在 Linux 中有多少种可用类型?
|
||||
|
||||
据我所知,在 Linux 中总共有 7 种类型的文件,分为 3 大类。具体如下。
|
||||
|
||||
* 普通文件
|
||||
* 目录文件
|
||||
* 特殊文件(该类有 5 个文件类型)
|
||||
* 链接文件
|
||||
* 字符设备文件
|
||||
* Socket 文件
|
||||
* 命名管道文件
|
||||
* 块文件
|
||||
|
||||
参考下面的表可以更好地理解 Linux 中的文件类型。
|
||||
|
||||
| 符号 | 意义 |
|
||||
| ------- | --------------------------------- |
|
||||
| `–` | 普通文件。长列表中以下划线 `_` 开头。 |
|
||||
| `d` | 目录文件。长列表中以英文字母 `d` 开头。 |
|
||||
| `l` | 链接文件。长列表中以英文字母 `l` 开头。 |
|
||||
| `c` | 字符设备文件。长列表中以英文字母 `c` 开头。 |
|
||||
| `s` | Socket 文件。长列表中以英文字母 `s` 开头。 |
|
||||
| `p` | 命名管道文件。长列表中以英文字母 `p` 开头。 |
|
||||
| `b` | 块文件。长列表中以英文字母 `b` 开头。 |
|
||||
|
||||
|
||||
### 方法1:手动识别 Linux 中的文件类型
|
||||
|
||||
如果你很了解 Linux,那么你可以借助上表很容易地识别文件类型。
|
||||
|
||||
#### 在 Linux 中如何查看普通文件?
|
||||
|
||||
在 Linux 中使用下面的命令去查看普通文件。在 Linux 文件系统中普通文件可以出现在任何地方。
|
||||
普通文件的颜色是“白色”。
|
||||
|
||||
```
|
||||
# ls -la | grep ^-
|
||||
-rw-------. 1 mageshm mageshm 1394 Jan 18 15:59 .bash_history
|
||||
-rw-r--r--. 1 mageshm mageshm 18 May 11 2012 .bash_logout
|
||||
-rw-r--r--. 1 mageshm mageshm 176 May 11 2012 .bash_profile
|
||||
-rw-r--r--. 1 mageshm mageshm 124 May 11 2012 .bashrc
|
||||
-rw-r--r--. 1 root root 26 Dec 27 17:55 liks
|
||||
-rw-r--r--. 1 root root 104857600 Jan 31 2006 test100.dat
|
||||
-rw-r--r--. 1 root root 104874307 Dec 30 2012 test100.zip
|
||||
-rw-r--r--. 1 root root 11536384 Dec 30 2012 test10.zip
|
||||
-rw-r--r--. 1 root root 61 Dec 27 19:05 test2-bzip2.txt
|
||||
-rw-r--r--. 1 root root 61 Dec 31 14:24 test3-bzip2.txt
|
||||
-rw-r--r--. 1 root root 60 Dec 27 19:01 test-bzip2.txt
|
||||
```
|
||||
|
||||
#### 在 Linux 中如何查看目录文件?
|
||||
|
||||
在 Linux 中使用下面的命令去查看目录文件。在 Linux 文件系统中目录文件可以出现在任何地方。目录文件的颜色是“蓝色”。
|
||||
|
||||
```
|
||||
# ls -la | grep ^d
|
||||
drwxr-xr-x. 3 mageshm mageshm 4096 Dec 31 14:24 links/
|
||||
drwxrwxr-x. 2 mageshm mageshm 4096 Nov 16 15:44 perl5/
|
||||
drwxr-xr-x. 2 mageshm mageshm 4096 Nov 16 15:37 public_ftp/
|
||||
drwxr-xr-x. 3 mageshm mageshm 4096 Nov 16 15:37 public_html/
|
||||
```
|
||||
|
||||
#### 在 Linux 中如何查看链接文件?
|
||||
|
||||
在 Linux 中使用下面的命令去查看链接文件。在 Linux 文件系统中链接文件可以出现在任何地方。
|
||||
链接文件有两种可用类型,软连接和硬链接。链接文件的颜色是“浅绿宝石色”。
|
||||
|
||||
```
|
||||
# ls -la | grep ^l
|
||||
lrwxrwxrwx. 1 root root 31 Dec 7 15:11 s-link-file -> /links/soft-link/test-soft-link
|
||||
lrwxrwxrwx. 1 root root 38 Dec 7 15:12 s-link-folder -> /links/soft-link/test-soft-link-folder
|
||||
```
|
||||
|
||||
#### 在 Linux 中如何查看字符设备文件?
|
||||
|
||||
在 Linux 中使用下面的命令查看字符设备文件。字符设备文件仅出现在特定位置。它出现在目录 `/dev` 下。字符设备文件的颜色是“黄色”。
|
||||
|
||||
```
|
||||
# ls -la | grep ^c
|
||||
# ls -la | grep ^c
|
||||
crw-------. 1 root root 5, 1 Jan 28 14:05 console
|
||||
crw-rw----. 1 root root 10, 61 Jan 28 14:05 cpu_dma_latency
|
||||
crw-rw----. 1 root root 10, 62 Jan 28 14:05 crash
|
||||
crw-rw----. 1 root root 29, 0 Jan 28 14:05 fb0
|
||||
crw-rw-rw-. 1 root root 1, 7 Jan 28 14:05 full
|
||||
crw-rw-rw-. 1 root root 10, 229 Jan 28 14:05 fuse
|
||||
```
|
||||
|
||||
#### 在 Linux 中如何查看块文件?
|
||||
|
||||
在 Linux 中使用下面的命令查看块文件。块文件仅出现在特定位置。它出现在目录 `/dev` 下。块文件的颜色是“黄色”。
|
||||
|
||||
```
|
||||
# ls -la | grep ^b
|
||||
brw-rw----. 1 root disk 7, 0 Jan 28 14:05 loop0
|
||||
brw-rw----. 1 root disk 7, 1 Jan 28 14:05 loop1
|
||||
brw-rw----. 1 root disk 7, 2 Jan 28 14:05 loop2
|
||||
brw-rw----. 1 root disk 7, 3 Jan 28 14:05 loop3
|
||||
brw-rw----. 1 root disk 7, 4 Jan 28 14:05 loop4
|
||||
```
|
||||
|
||||
#### 在 Linux 中如何查看 Socket 文件?
|
||||
|
||||
在 Linux 中使用下面的命令查看 Socket 文件。Socket 文件可以出现在任何地方。Scoket 文件的颜色是“粉色”。(LCTT 译注:此处及下面关于 Socket 文件、命名管道文件可出现的位置原文描述有误,已修改。)
|
||||
|
||||
```
|
||||
# ls -la | grep ^s
|
||||
srw-rw-rw- 1 root root 0 Jan 5 16:36 system_bus_socket
|
||||
```
|
||||
|
||||
#### 在 Linux 中如何查看命名管道文件?
|
||||
|
||||
在 Linux 中使用下面的命令查看命名管道文件。命名管道文件可以出现在任何地方。命名管道文件的颜色是“黄色”。
|
||||
|
||||
```
|
||||
# ls -la | grep ^p
|
||||
prw-------. 1 root root 0 Jan 28 14:06 replication-notify-fifo|
|
||||
prw-------. 1 root root 0 Jan 28 14:06 stats-mail|
|
||||
```
|
||||
|
||||
### 方法2:在 Linux 中如何使用 file 命令识别文件类型
|
||||
|
||||
在 Linux 中 `file` 命令允许我们去确定不同的文件类型。这里有三个测试集,按此顺序进行三组测试:文件系统测试、魔术字节测试和用于识别文件类型的语言测试。
|
||||
|
||||
#### 在 Linux 中如何使用 file 命令查看普通文件
|
||||
|
||||
在你的终端简单地输入 `file` 命令跟着普通文件。`file` 命令将会读取提供的文件内容并且准确地显示文件的类型。
|
||||
|
||||
这就是我们看到对于每个普通文件有不同结果的原因。参考下面普通文件的不同结果。
|
||||
|
||||
```
|
||||
# file 2daygeek_access.log
|
||||
2daygeek_access.log: ASCII text, with very long lines
|
||||
|
||||
# file powertop.html
|
||||
powertop.html: HTML document, ASCII text, with very long lines
|
||||
|
||||
# file 2g-test
|
||||
2g-test: JSON data
|
||||
|
||||
# file powertop.txt
|
||||
powertop.txt: HTML document, UTF-8 Unicode text, with very long lines
|
||||
|
||||
# file 2g-test-05-01-2019.tar.gz
|
||||
2g-test-05-01-2019.tar.gz: gzip compressed data, last modified: Sat Jan 5 18:22:20 2019, from Unix, original size 450560
|
||||
```
|
||||
|
||||
#### 在 Linux 中如何使用 file 命令查看目录文件?
|
||||
|
||||
在你的终端简单地输入 `file` 命令跟着目录。参阅下面的结果。
|
||||
|
||||
```
|
||||
# file Pictures/
|
||||
Pictures/: directory
|
||||
```
|
||||
|
||||
#### 在 Linux 中如何使用 file 命令查看链接文件?
|
||||
|
||||
在你的终端简单地输入 `file` 命令跟着链接文件。参阅下面的结果。
|
||||
|
||||
```
|
||||
# file log
|
||||
log: symbolic link to /run/systemd/journal/dev-log
|
||||
```
|
||||
|
||||
#### 在 Linux 中如何使用 file 命令查看字符设备文件?
|
||||
|
||||
在你的终端简单地输入 `file` 命令跟着字符设备文件。参阅下面的结果。
|
||||
|
||||
```
|
||||
# file vcsu
|
||||
vcsu: character special (7/64)
|
||||
```
|
||||
|
||||
#### 在 Linux 中如何使用 file 命令查看块文件?
|
||||
|
||||
在你的终端简单地输入 `file` 命令跟着块文件。参阅下面的结果。
|
||||
|
||||
```
|
||||
# file sda1
|
||||
sda1: block special (8/1)
|
||||
```
|
||||
|
||||
#### 在 Linux 中如何使用 file 命令查看 Socket 文件?
|
||||
|
||||
在你的终端简单地输入 `file` 命令跟着 Socket 文件。参阅下面的结果。
|
||||
|
||||
```
|
||||
# file system_bus_socket
|
||||
system_bus_socket: socket
|
||||
```
|
||||
|
||||
#### 在 Linux 中如何使用 file 命令查看命名管道文件?
|
||||
|
||||
在你的终端简单地输入 `file` 命令跟着命名管道文件。参阅下面的结果。
|
||||
|
||||
```
|
||||
# file pipe-test
|
||||
pipe-test: fifo (named pipe)
|
||||
```
|
||||
|
||||
### 方法 3:在 Linux 中如何使用 stat 命令识别文件类型?
|
||||
|
||||
`stat` 命令允许我们去查看文件类型或文件系统状态。该实用程序比 `file` 命令提供更多的信息。它显示文件的大量信息,例如大小、块大小、IO 块大小、Inode 值、链接、文件权限、UID、GID、文件的访问/更新和修改的时间等详细信息。
|
||||
|
||||
#### 在 Linux 中如何使用 stat 命令查看普通文件?
|
||||
|
||||
在你的终端简单地输入 `stat` 命令跟着普通文件。参阅下面的结果。
|
||||
|
||||
```
|
||||
# stat 2daygeek_access.log
|
||||
File: 2daygeek_access.log
|
||||
Size: 14406929 Blocks: 28144 IO Block: 4096 regular file
|
||||
Device: 10301h/66305d Inode: 1727555 Links: 1
|
||||
Access: (0644/-rw-r--r--) Uid: ( 1000/ daygeek) Gid: ( 1000/ daygeek)
|
||||
Access: 2019-01-03 14:05:26.430328867 +0530
|
||||
Modify: 2019-01-03 14:05:26.460328868 +0530
|
||||
Change: 2019-01-03 14:05:26.460328868 +0530
|
||||
Birth: -
|
||||
```
|
||||
|
||||
#### 在 Linux 中如何使用 stat 命令查看目录文件?
|
||||
|
||||
在你的终端简单地输入 `stat` 命令跟着目录文件。参阅下面的结果。
|
||||
|
||||
```
|
||||
# stat Pictures/
|
||||
File: Pictures/
|
||||
Size: 4096 Blocks: 8 IO Block: 4096 directory
|
||||
Device: 10301h/66305d Inode: 1703982 Links: 3
|
||||
Access: (0755/drwxr-xr-x) Uid: ( 1000/ daygeek) Gid: ( 1000/ daygeek)
|
||||
Access: 2018-11-24 03:22:11.090000828 +0530
|
||||
Modify: 2019-01-05 18:27:01.546958817 +0530
|
||||
Change: 2019-01-05 18:27:01.546958817 +0530
|
||||
Birth: -
|
||||
```
|
||||
|
||||
#### 在 Linux 中如何使用 stat 命令查看链接文件?
|
||||
|
||||
在你的终端简单地输入 `stat` 命令跟着链接文件。参阅下面的结果。
|
||||
|
||||
```
|
||||
# stat /dev/log
|
||||
File: /dev/log -> /run/systemd/journal/dev-log
|
||||
Size: 28 Blocks: 0 IO Block: 4096 symbolic link
|
||||
Device: 6h/6d Inode: 278 Links: 1
|
||||
Access: (0777/lrwxrwxrwx) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
Access: 2019-01-05 16:36:31.033333447 +0530
|
||||
Modify: 2019-01-05 16:36:30.766666768 +0530
|
||||
Change: 2019-01-05 16:36:30.766666768 +0530
|
||||
Birth: -
|
||||
```
|
||||
|
||||
#### 在 Linux 中如何使用 stat 命令查看字符设备文件?
|
||||
|
||||
在你的终端简单地输入 `stat` 命令跟着字符设备文件。参阅下面的结果。
|
||||
|
||||
```
|
||||
# stat /dev/vcsu
|
||||
File: /dev/vcsu
|
||||
Size: 0 Blocks: 0 IO Block: 4096 character special file
|
||||
Device: 6h/6d Inode: 16 Links: 1 Device type: 7,40
|
||||
Access: (0660/crw-rw----) Uid: ( 0/ root) Gid: ( 5/ tty)
|
||||
Access: 2019-01-05 16:36:31.056666781 +0530
|
||||
Modify: 2019-01-05 16:36:31.056666781 +0530
|
||||
Change: 2019-01-05 16:36:31.056666781 +0530
|
||||
Birth: -
|
||||
```
|
||||
|
||||
#### 在 Linux 中如何使用 stat 命令查看块文件?
|
||||
|
||||
在你的终端简单地输入 `stat` 命令跟着块文件。参阅下面的结果。
|
||||
|
||||
```
|
||||
# stat /dev/sda1
|
||||
File: /dev/sda1
|
||||
Size: 0 Blocks: 0 IO Block: 4096 block special file
|
||||
Device: 6h/6d Inode: 250 Links: 1 Device type: 8,1
|
||||
Access: (0660/brw-rw----) Uid: ( 0/ root) Gid: ( 994/ disk)
|
||||
Access: 2019-01-05 16:36:31.596666806 +0530
|
||||
Modify: 2019-01-05 16:36:31.596666806 +0530
|
||||
Change: 2019-01-05 16:36:31.596666806 +0530
|
||||
Birth: -
|
||||
```
|
||||
|
||||
#### 在 Linux 中如何使用 stat 命令查看 Socket 文件?
|
||||
|
||||
在你的终端简单地输入 `stat` 命令跟着 Socket 文件。参阅下面的结果。
|
||||
|
||||
```
|
||||
# stat /var/run/dbus/system_bus_socket
|
||||
File: /var/run/dbus/system_bus_socket
|
||||
Size: 0 Blocks: 0 IO Block: 4096 socket
|
||||
Device: 15h/21d Inode: 576 Links: 1
|
||||
Access: (0666/srw-rw-rw-) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
Access: 2019-01-05 16:36:31.823333482 +0530
|
||||
Modify: 2019-01-05 16:36:31.810000149 +0530
|
||||
Change: 2019-01-05 16:36:31.810000149 +0530
|
||||
Birth: -
|
||||
```
|
||||
|
||||
#### 在 Linux 中如何使用 stat 命令查看命名管道文件?
|
||||
|
||||
在你的终端简单地输入 `stat` 命令跟着命名管道文件。参阅下面的结果。
|
||||
|
||||
```
|
||||
# stat pipe-test
|
||||
File: pipe-test
|
||||
Size: 0 Blocks: 0 IO Block: 4096 fifo
|
||||
Device: 10301h/66305d Inode: 1705583 Links: 1
|
||||
Access: (0644/prw-r--r--) Uid: ( 1000/ daygeek) Gid: ( 1000/ daygeek)
|
||||
Access: 2019-01-06 02:00:03.040394731 +0530
|
||||
Modify: 2019-01-06 02:00:03.040394731 +0530
|
||||
Change: 2019-01-06 02:00:03.040394731 +0530
|
||||
Birth: -
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-understand-and-identify-file-types-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[liujing97](https://github.com/liujing97)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -0,0 +1,74 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10723-1.html)
|
||||
[#]: subject: (Ubuntu 14.04 is Reaching the End of Life. Here are Your Options)
|
||||
[#]: via: (https://itsfoss.com/ubuntu-14-04-end-of-life/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Ubuntu 14.04 即将结束支持,你该怎么办?
|
||||
======
|
||||
|
||||
Ubuntu 14.04 即将于 2019 年 4 月 30 日结束支持。这意味着在此日期之后 Ubuntu 14.04 用户将无法获得安全和维护更新。
|
||||
|
||||
你甚至不会获得已安装应用的更新,并且不手动修改 `sources.list` 则无法使用 `apt` 命令或软件中心安装新应用。
|
||||
|
||||
Ubuntu 14.04 大约在五年前发布。这是 Ubuntu 长期支持版本(LTS)。
|
||||
|
||||
[检查 Ubuntu 版本][1]并查看你是否仍在使用 Ubuntu 14.04。如果是桌面或服务器版,你可能想知道在这种情况下你应该怎么做。
|
||||
|
||||
我来帮助你。告诉你在这种情况下你有些什么选择。
|
||||
|
||||
![][2]
|
||||
|
||||
### 升级到 Ubuntu 16.04 LTS(最简单的方式)
|
||||
|
||||
如果你可以连接互联网,你可以从 Ubuntu 14.04 升级到 Ubuntu 16.04 LTS。
|
||||
|
||||
Ubuntu 16.04 也是一个长期支持版本,它将支持到 2021 年 4 月。这意味着下次升级前你还有两年的时间。
|
||||
|
||||
我建议阅读这个[升级 Ubuntu 版本][3]的教程。它最初是为了将 Ubuntu 16.04 升级到 Ubuntu 18.04 而编写的,但这些步骤也适用于你的情况。
|
||||
|
||||
### 做好备份,全新安装 Ubuntu 18.04 LTS(非常适合桌面用户)
|
||||
|
||||
另一个选择是备份你的文档、音乐、图片、下载和其他任何你不想丢失数据的文件夹。
|
||||
|
||||
我说的备份指的是将这些文件夹复制到外部 USB 盘。换句话说,你应该有办法将数据复制回计算机,因为你将格式化你的系统。
|
||||
|
||||
我建议桌面用户使用此选项。Ubuntu 18.04 是目前的长期支持版本,它将至少在 2023 年 4 月之前得到支持。在你被迫进行下次升级之前,你将有四年的时间。
|
||||
|
||||
### 支付扩展安全维护费用并继续使用 Ubuntu 14.04
|
||||
|
||||
这适用于企业客户。Canonical 是 Ubuntu 的母公司,它提供 Ubuntu Advantage 计划,客户可以支付电话电子邮件支持和其他益处。
|
||||
|
||||
Ubuntu Advantage 计划用户还有[扩展安全维护][4](ESM)功能。即使给定版本的生命周期结束后,此计划也会提供安全更新。
|
||||
|
||||
这需要付出金钱。服务器用户每个物理节点每年花费 225 美元。对于桌面用户,价格为每年 150 美元。你可以在[此处][5]了解 Ubuntu Advantage 计划的详细定价。
|
||||
|
||||
### 还在使用 Ubuntu 14.04 吗?
|
||||
|
||||
如果你还在使用 Ubuntu 14.04,那么你应该开始了解这些选择,因为你还有不到一个月的时间。
|
||||
|
||||
在任何情况下,你都不能在 2019 年 4 月 30 日之后使用 Ubuntu 14.04,因为你的系统由于缺乏安全更新而容易受到攻击。无法安装新应用将是一个额外的痛苦。
|
||||
|
||||
那么,你会做什么选择?升级到 Ubuntu 16.04 或 18.04 或付费 ESM?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-14-04-end-of-life/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/ubuntu-14-04-end-of-life-featured.png?resize=800%2C450&ssl=1
|
||||
[3]: https://itsfoss.com/upgrade-ubuntu-version/
|
||||
[4]: https://www.ubuntu.com/esm
|
||||
[5]: https://www.ubuntu.com/support/plans-and-pricing
|
||||
@ -1,41 +1,42 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10707-1.html)
|
||||
[#]: subject: (7 resources for learning to use your Raspberry Pi)
|
||||
[#]: via: (https://opensource.com/article/19/3/resources-raspberry-pi)
|
||||
[#]: author: (Manuel Dewald https://opensource.com/users/ntlx)
|
||||
|
||||
学习使用树莓派的 7 个资源
|
||||
======
|
||||
缩短树莓派学习曲线的书籍、课程和网站。
|
||||
|
||||
> 一些缩短树莓派学习曲线的书籍、课程和网站。
|
||||
|
||||

|
||||
|
||||
[树莓派][1]是一款小型单板计算机,最初用于教学和学习编程和计算机科学。但如今它有更多用处。它是一种经济、低功耗计算机,人们将它用于各种各样的事情 - 从家庭娱乐到服务器应用,再到物联网 (IoT) 项目。
|
||||
[树莓派][1]是一款小型单板计算机,最初用于教学和学习编程和计算机科学。但如今它有更多用处。它是一种经济的低功耗计算机,人们将它用于各种各样的事情 —— 从家庭娱乐到服务器应用,再到物联网(IoT) 项目。
|
||||
|
||||
关于这个主题有很多资源,你可以做很多不同的项目,很难知道从哪里开始。以下是一些资源,可以帮助你开始使用树莓派。愉快地浏览,但不要停留在这里。到处看下,深入下去你就会发现树莓派的新世界。
|
||||
关于这个主题有很多资源,你可以做很多不同的项目,却很难知道从哪里开始。以下是一些资源,可以帮助你开始使用树莓派。看看这篇文章,但不要满足于此。到处看下,深入下去你就会发现树莓派的新世界。
|
||||
|
||||
### 书籍
|
||||
|
||||
关于树莓派有很多不同语言的书籍。这两本将帮助你开始了解,然后深入了解树莓派。
|
||||
关于树莓派有很多不同语言的书籍。这两本书将帮助你开始了解,然后深入了解树莓派。
|
||||
|
||||
#### 由 Simon Monk 编写的 Raspberry Pi Cookbook:软件和硬件问题及解决方案
|
||||
#### 由 Simon Monk 编写的《树莓派手边书:软件和硬件问题及解决方案》
|
||||
|
||||
Simon Monk 是一名软件工程师,并且多年来一直是手工业余爱好者。他最初被 Arduino 这块易于使用的开发板所吸引,后来出版了一本关于它的[书][2]。后来,他开始使用树莓派并写了 [Raspberry Pi Cookbook:软件和硬件问题和解决方案][3]这本书。在本书中,你可以找到大量树莓派项目的最佳时间,以及你可能面对的各种挑战的解决方案。
|
||||
Simon Monk 是一名软件工程师,并且多年来一直是业余手工爱好者。他最初被 Arduino 这块易于使用的开发板所吸引,后来出版了一本关于它的[书][2]。后来,他开始使用树莓派并写了《[树莓派手边书:软件和硬件问题和解决方案][3]》这本书。在本书中,你可以找到大量树莓派项目的最佳时间,以及你可能面对的各种挑战的解决方案。
|
||||
|
||||
####由 Simon Monk 编写的树莓派编程:从 Python 入门
|
||||
#### 由 Simon Monk 编写的《树莓派编程:从 Python 入门》
|
||||
|
||||
Python 已经发展成为开始树莓派项目的首选编程语言,因为它易于学习和使用,即使你没有任何编程经验。此外,它的许多库可以帮助你专注于使你的项目变得特别,而不是实现协议反复地与传感器不断通信。Monk 在 Raspberry Pi Cookbook 中写了两章关于 Python 编程,但[树莓派编程:从 Python 入门][4]是一个更全面的快速入门。它向你介绍了 Python,并向你展示了可以在树莓派上使用它创建的一些项目。
|
||||
Python 已经发展成为开始一个树莓派项目的首选编程语言,因为它易于学习和使用,即使你没有任何编程经验。此外,它的许多库可以帮助你专注于使你的项目变得特别,而不是实现协议以与传感器反复通信。Monk 在《树莓派手边书》中写了两章关于 Python 编程,但《[树莓派编程:从 Python 入门][4]》是一个更全面的快速入门。它向你介绍了 Python,并向你展示了可以在树莓派上使用它创建的一些项目。
|
||||
|
||||
### 在线课程
|
||||
|
||||
新的树莓派用户可以选择许多在线课程和教程,包括这个入门课程。
|
||||
|
||||
#### Raspberry Pi Class
|
||||
|
||||
Instructables 的免费 [Raspberry Pi Class][5] 在线课程提供了对树莓派的全面介绍。它从树莓派和 Linux 操作基础开始,然后进入 Python 编程和 GPIO 通信。如果你是这方面的新手,并希望快速入门,这使它成为一个很好的从上到下的树莓派指南。
|
||||
#### 树莓派课程
|
||||
|
||||
Instructables 免费的在线[树莓派课程][5]提供了对树莓派的全面介绍。它从树莓派和 Linux 操作基础开始,然后进入 Python 编程和 GPIO 通信。如果你是这方面的新手,并希望快速入门,这使它成为一个很好的自上而下的树莓派指南。
|
||||
|
||||
### 网站
|
||||
|
||||
@ -43,7 +44,7 @@ Instructables 的免费 [Raspberry Pi Class][5] 在线课程提供了对树莓
|
||||
|
||||
#### RaspberryPi.org
|
||||
|
||||
官方的[树莓派][6]网站是最好的入门之一。许多关于特定项目的文章有链接到基础知识的链接,如将 Raspbian 安装到树莓派上。 (这是我倾向的,而不是在每个操作中重复说明。)你还可以找到学生技术[教育][8]方面的[示例项目][7]和课程。
|
||||
官方的[树莓派][6]网站是最好的入门之一。有许多关于特定项目的文章会链接到这里的基础知识,如将 Raspbian 安装到树莓派上。(这是我倾向的做法,而不是在每篇文章中重复说明。)你还可以找到学生技术[教育][8]方面的[示例项目][7]和课程。
|
||||
|
||||
#### Opensource.com
|
||||
|
||||
@ -51,7 +52,7 @@ Instructables 的免费 [Raspberry Pi Class][5] 在线课程提供了对树莓
|
||||
|
||||
#### Instructables 和 Hackaday
|
||||
|
||||
你想造自己的复古街机么?或者在镜子上显示当天的天气信息、时间和第一事务?你是否想要为派对创建一个文字时钟或者相簿?你可以在 [Instructables][10] 和 [Hackaday][11] 这样的网站上找到如何使用树莓派完成所有这些(以及更多!)的说明。如果你不确定是否要买树莓派,请浏览这些网站,你会发现有很多理由可以购买。
|
||||
你想造自己的复古街机么?或者在镜子上显示当天的天气信息、时间和第一事务?你是否想要为派对创建一个文字时钟或者相簿?你可以在 [Instructables][10] 和 [Hackaday][11] 这样的网站上找到如何使用树莓派完成所有这些(以及更多!)的说明。如果你不确定是否要买树莓派,请浏览这些网站,你会发现有很多理由值得购买。
|
||||
|
||||
你最喜欢的树莓派资源是什么?请在评论中分享!
|
||||
|
||||
@ -62,7 +63,7 @@ via: https://opensource.com/article/19/3/resources-raspberry-pi
|
||||
作者:[Manuel Dewald][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,19 +1,20 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10711-1.html)
|
||||
[#]: subject: (Do advanced math with Mathematica on the Raspberry Pi)
|
||||
[#]: via: (https://opensource.com/article/19/3/do-math-raspberry-pi)
|
||||
[#]: author: (Anderson Silva https://opensource.com/users/ansilva)
|
||||
|
||||
在树莓派上使用 Mathematica 进行高级数学运算
|
||||
树莓派使用入门:在树莓派上使用 Mathematica 进行高级数学运算
|
||||
======
|
||||
Wolfram 将一个版本 Mathematica 捆绑到了 Raspbian 中。在我们关于树莓派入门系列的第 12 篇文章中学习如何使用它。
|
||||
|
||||
> Wolfram 在 Raspbian 中捆绑了一个版本的 Mathematica。在我们的树莓派入门系列的第 12 篇文章中将学习如何使用它。
|
||||
|
||||

|
||||
|
||||
在 90 年代中期,我进入了大学数学专业,即使我以计算机科学学位毕业,第二专业数学我已经上了足够的课程,但还有两门小课没有上。当时,我被介绍了 [Wolfram][2] 中一个名为[Mathematica][1] 的应用,我们可以将黑板上的许多代数和微分方程输入计算机。我每月花几个小时在实验室学习 Wolfram 语言并在 Mathematica 上解决积分等问题。
|
||||
在 90 年代中期,我进入了大学数学专业,虽然我是以计算机科学学位毕业的,但是我就差两门课程就拿到了双学位,包括数学专业的学位。当时,我接触到了 [Wolfram][2] 的一个名为 [Mathematica][1] 的应用,我们可以将黑板上的许多代数和微分方程输入计算机。我每月花几个小时在实验室学习 Wolfram 语言,并在 Mathematica 上解决积分等问题。
|
||||
|
||||
对于大学生来说 Mathematica 是闭源而且昂贵的,因此在差不多 20 年后,看到 Wolfram 将一个版本的 Mathematica 与 Raspbian 和 Raspberry Pi 捆绑在一起是一个惊喜。如果你决定使用另一个基于 Debian 的发行版,你可以从这里[下载][3]。请注意,此版本仅供非商业用途免费使用。
|
||||
|
||||
@ -23,7 +24,7 @@ Wolfram 将一个版本 Mathematica 捆绑到了 Raspbian 中。在我们关于
|
||||
|
||||
要深入了解 Mathematica,请查看 [Wolfram 语言文档][5]。如果你只是想解决一些基本的微积分问题,请[查看它的函数][6]部分。如果你想[绘制一些 2D 和 3D 图形][7],请阅读链接的教程。
|
||||
|
||||
或者,如果你想在做数学运算时坚持使用开源工具,请查看命令行工具 **expr**、**factor** 和 **bc**。(记住使用 [**man** 命令][8] 阅读使用帮助)如果想画图,[Gnuplot][9] 是个不错的选择。
|
||||
或者,如果你想在做数学运算时坚持使用开源工具,请查看命令行工具 `expr`、`factor` 和 `bc`。(记住使用 [man 命令][8] 阅读使用帮助)如果想画图,[Gnuplot][9] 是个不错的选择。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -32,7 +33,7 @@ via: https://opensource.com/article/19/3/do-math-raspberry-pi
|
||||
作者:[Anderson Silva][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -46,4 +47,4 @@ via: https://opensource.com/article/19/3/do-math-raspberry-pi
|
||||
[6]: https://reference.wolfram.com/language/guide/Calculus.html
|
||||
[7]: https://reference.wolfram.com/language/howto/PlotAGraph.html
|
||||
[8]: https://opensource.com/article/19/3/learn-linux-raspberry-pi
|
||||
[9]: http://gnuplot.info/
|
||||
[9]: http://gnuplot.info/
|
||||
118
published/20190314 A Look Back at the History of Firefox.md
Normal file
118
published/20190314 A Look Back at the History of Firefox.md
Normal file
@ -0,0 +1,118 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Moelf)
|
||||
[#]: reviewer: (acyanbird, wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10714-1.html)
|
||||
[#]: subject: (A Look Back at the History of Firefox)
|
||||
[#]: via: (https://itsfoss.com/history-of-firefox)
|
||||
[#]: author: (John Paul https://itsfoss.com/author/john/)
|
||||
|
||||
回顾 Firefox 历史
|
||||
======
|
||||
|
||||
从很久之前开始,火狐浏览器就一直是开源社区的一根顶梁柱。这些年来它几乎是所有 Linux 发行版的默认浏览器,并且曾是阻挡微软彻底争霸浏览器界的最后一块磐石。这款浏览器的起源可以一直回溯到互联网创生的时代。本周(LCTT 译注:此文发布于 2019.3.14)是互联网成立 30 周年的纪念日,趁这个机会回顾一下我们熟悉并爱戴的火狐浏览器实在是再好不过了。
|
||||
|
||||
### 发源
|
||||
|
||||
在上世纪 90 年代早期,一个叫 [Marc Andreessen][1] 的年轻人正在伊利诺伊大学攻读计算机科学学士学位。在那里,他开始为[国家超算应用中心(NCSA)][2]工作。就在这段时间内,<ruby>[蒂姆·伯纳斯·李][3]<rt>Tim Berners-Lee</rt></ruby> 爵士发布了今天已经为我们所熟知的 Web 的早期标准。Marc 在那时候[了解][4]到了一款叫 [ViolaWWW][5] 的化石级浏览器。Marc 和 Eric Bina 看到了这种技术的潜力,他们开发了一个易于安装的基于 Unix 平台的浏览器,并取名 [NCSA Mosaic][6]。第一个 alpha 版本发布于 1993 年 6 月。到 9 月的时候,浏览器已经有 Windows 和 Macintosh 移植版本了。因为比当时其他任何浏览器软件都易于使用,Mosaic 很快变得相当流行。
|
||||
|
||||
1994 年,Marc 毕业并移居到加州。一个叫 Jim Clark 的人结识了他,Clark 那时候通过卖电脑软硬件赚了点钱。Clark 也用过 Mosaic 浏览器并且看到了互联网的经济前景。Clark 创立了一家公司并且雇了 Marc 和 Eric 专做互联网软件。公司一开始叫 “Mosaic 通讯”,但是伊利诺伊大学并不喜欢他们用 [Mosaic 这个名字][7]。所以公司转而改名为 “<ruby>网景<rt>Netscape</rt></ruby>通讯”。
|
||||
|
||||
该公司的第一个项目是给任天堂 64 开发在线对战网络,然而不怎么成功。他们第一个以公司名义发布的产品是一款叫做 Mosaic Netscape 0.9 的浏览器,很快这款浏览器被改名叫 Netscape Navigator。在内部,浏览器的开发代号就是 mozilla,意即 “Mosaic 杀手”。一位员工还创作了一幅[哥斯拉风格的][8]卡通画。他们当时想在竞争中彻底胜出。
|
||||
|
||||
![Early Firefox Mascot][9]
|
||||
|
||||
*早期 Mozilla 在 Netscape 的吉祥物*
|
||||
|
||||
他们取得了辉煌的胜利。那时,Netscape 最大的优势是他们的浏览器在各种操作系统上体验极为一致。Netscape 将其宣传为给所有人平等的互联网体验。
|
||||
|
||||
随着越来越多的人使用 Netscape Navigator,NCSA Mosaic 的市场份额逐步下降。到了 1995 年,Netscape 公开上市了。[上市首日][10],股价从开盘的 $28,直窜到 $78,收盘于 $58。Netscape 那时所向披靡。
|
||||
|
||||
但好景不长。在 1994 年的夏天,微软发布了 Internet Explorer 1.0,这款浏览器基于 Spyglass Mosaic,而后者又直接基于 NCSA Mosaic。[浏览器战争][11] 就此展开。
|
||||
|
||||
在接下来的几年里,Netscape 和微软就浏览器霸主地位展开斗争。他们各自加入了很多新特性以取得优势。不幸的是,IE 有和 Windows 操作系统捆绑的巨大优势。更甚于此,微软也有更多的程序员和资本可以调动。在 1997 年年底,Netscape 公司开始遇到财务问题。
|
||||
|
||||
### 迈向开源
|
||||
|
||||
![Mozilla Firefox][12]
|
||||
|
||||
1998 年 1 月,Netscape 开源了 Netscape Communicator 4.0 软件套装的代码。[旨在][13] “集合互联网成千上万的程序员的才智,把最好的功能加入 Netscape 的软件。这一策略旨在加速开发,并且让 Netscape 在未来能向个人和商业用户免费提供高质量的 Netscape Communicator 版本”。
|
||||
|
||||
这个项目由新创立的 Mozilla 机构管理。然而,Netscape Communicator 4.0 的代码由于大小和复杂程度而很难开发。雪上加霜的是,浏览器的一些组件由于第三方的许可证问题而不能被开源。到头来,他们决定用新兴的 [Gecko][14] 渲染引擎重新开发浏览器。
|
||||
|
||||
到了 1998 年的 11 月,Netscape 被美国在线(AOL)以[价值 42 亿美元的股权][15]收购。
|
||||
|
||||
从头来过是一项艰巨的任务。Mozilla Firefox(最初名为 Phoenix)直到 2002 年 6 月才面世,它同样可以运行在多种操作系统上:Linux、Mac OS、Windows 和 Solaris。
|
||||
|
||||
1999 年,AOL 宣布他们将停止浏览器开发。随后创建了 Mozilla 基金会,用于管理 Mozilla 的商标和项目相关的融资事宜。最早 Mozilla 基金会从 AOL、IBM、Sun Microsystems 和红帽(Red Hat)收到了总计 200 万美金的捐赠。
|
||||
|
||||
到了 2003 年 3 月,因为套件越来越臃肿,Mozilla [宣布][16] 计划把该套件分割成单独的应用。这个单独的浏览器一开始起名 Phoenix。但是由于和 BIOS 制造企业凤凰科技的商标官司,浏览器改名 Firebird(火鸟) —— 结果和火鸟数据库的开发者又起了冲突。浏览器只能再次被重命名,才有了现在家喻户晓的 Firefox(火狐)。
|
||||
|
||||
那时,[Mozilla 说][17],”我们在过去一年里学到了很多关于起名的技巧(不是因为我们愿意才学的)。我们现在很小心地研究了名字,确保不会再有什么夭蛾子了。我们已经开始向美国专利商标局注册我们新商标”。
|
||||
|
||||
![Mozilla Firefox 1.0][18]
|
||||
|
||||
*Firefox 1.0 : [图片致谢][19]*
|
||||
|
||||
第一个正式的 Firefox 版本是 [0.8][20],发布于 2004 年 2 月 8 日。紧接着 11 月 9 日他们发布了 1.0 版本。2.0 和 3.0 版本分别在 06 年 10 月 和 08 年 6 月问世。每个大版本更新都带来了很多新的特性和提升。从很多角度上讲,Firefox 都领先 IE 不少,无论是功能还是技术先进性,即便如此 IE 还是有更多用户。
|
||||
|
||||
一切都在 Google 发布 Chrome 浏览器的时候改变了。在 Chrome 发布(2008 年 9 月)的前几个月,Firefox 占有 30% 的[浏览器份额][21] 而 IE 有超过 60%。而在 StatCounter 的 [2019 年 1 月][22]报告里,Firefox 有不到 10% 的份额,而 Chrome 有超过 70%。
|
||||
|
||||
> 趣味知识点
|
||||
|
||||
> 和大家以为的不一样,火狐的 logo 其实没有狐狸。那其实是个 <ruby>[小熊猫][23]<rt>Red Panda</rt></ruby>。在中文里,“火狐狸”是小熊猫的另一个名字。
|
||||
|
||||
### 展望未来
|
||||
|
||||
如上文所说的一样,Firefox 正在经历很长一段以来的份额低谷。曾经有那么一段时间,有很多浏览器都基于 Firefox 开发,比如早期的 [Flock 浏览器][24]。而现在大多数浏览器都基于谷歌的技术了,比如 Opera 和 Vivaldi。甚至连微软都放弃开发自己的浏览器而转而[加入 Chromium 帮派][25]。
|
||||
|
||||
这也许看起来和 Netscape 当年的辉煌形成鲜明的对比。但让我们不要忘记 Firefox 已经有的许多成就。一群来自世界各地的程序员,就这么开发出了这个星球上第二大份额的浏览器。他们在微软垄断如日中天的时候还占据这 30% 的份额,他们可以再次做到这一点。无论如何,他们都有我们。开源社区坚定地站在他们身后。
|
||||
|
||||
抗争垄断是我使用 Firefox [的众多原因之一][26]。随着 Mozilla 在改头换面的 [Firefox Quantum][27] 上赢回了一些份额,我相信它将一路向上攀爬。
|
||||
|
||||
你还想了解 Linux 和开源历史上的什么其他事件?欢迎在评论区告诉我们。
|
||||
|
||||
如果你觉得这篇文章不错,请在社交媒体上分享!比如 Hacker News 或者 [Reddit][28]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/history-of-firefox
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Moelf](https://github.com/Moelf)
|
||||
校对:[acyanbird](https://github.com/acyanbird), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Marc_Andreessen
|
||||
[2]: https://en.wikipedia.org/wiki/National_Center_for_Supercomputing_Applications
|
||||
[3]: https://en.wikipedia.org/wiki/Tim_Berners-Lee
|
||||
[4]: https://www.w3.org/DesignIssues/TimBook-old/History.html
|
||||
[5]: http://viola.org/
|
||||
[6]: https://en.wikipedia.org/wiki/Mosaic_(web_browser
|
||||
[7]: http://www.computinghistory.org.uk/det/1789/Marc-Andreessen/
|
||||
[8]: http://www.davetitus.com/mozilla/
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/Mozilla_boxing.jpg?ssl=1
|
||||
[10]: https://www.marketwatch.com/story/netscape-ipo-ignited-the-boom-taught-some-hard-lessons-20058518550
|
||||
[11]: https://en.wikipedia.org/wiki/Browser_wars
|
||||
[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/mozilla-firefox.jpg?resize=800%2C450&ssl=1
|
||||
[13]: https://web.archive.org/web/20021001071727/wp.netscape.com/newsref/pr/newsrelease558.html
|
||||
[14]: https://en.wikipedia.org/wiki/Gecko_(software)
|
||||
[15]: http://news.cnet.com/2100-1023-218360.html
|
||||
[16]: https://web.archive.org/web/20050618000315/http://www.mozilla.org/roadmap/roadmap-02-Apr-2003.html
|
||||
[17]: https://www-archive.mozilla.org/projects/firefox/firefox-name-faq.html
|
||||
[18]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/firefox-1.jpg?ssl=1
|
||||
[19]: https://www.iceni.com/blog/firefox-1-0-introduced-2004/
|
||||
[20]: https://en.wikipedia.org/wiki/Firefox_version_history
|
||||
[21]: https://en.wikipedia.org/wiki/Usage_share_of_web_browsers
|
||||
[22]: http://gs.statcounter.com/browser-market-share/desktop/worldwide/#monthly-201901-201901-bar
|
||||
[23]: https://en.wikipedia.org/wiki/Red_panda
|
||||
[24]: https://en.wikipedia.org/wiki/Flock_(web_browser
|
||||
[25]: https://www.windowscentral.com/microsoft-building-chromium-powered-web-browser-windows-10
|
||||
[26]: https://itsfoss.com/why-firefox/
|
||||
[27]: https://itsfoss.com/firefox-quantum-ubuntu/
|
||||
[28]: http://reddit.com/r/linuxusersgroup
|
||||
[29]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/mozilla-firefox.jpg?fit=800%2C450&ssl=1
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10695-1.html)
|
||||
[#]: subject: (Quickly Go Back To A Specific Parent Directory Using bd Command In Linux)
|
||||
[#]: via: (https://www.2daygeek.com/bd-quickly-go-back-to-a-specific-parent-directory-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
@ -10,45 +10,43 @@
|
||||
在 Linux 中使用 bd 命令快速返回到特定的父目录
|
||||
======
|
||||
|
||||
<to 校正:我在 ubuntu 上似乎没有按照这个教程成功使用 bd 命令,难道我的姿势不对?>
|
||||
|
||||
两天前我们写了一篇关于 `autocd` 的文章,它是一个内置的 `shell` 变量,可以帮助我们在**[没有 `cd` 命令的情况下导航到目录中][1]**.
|
||||
两天前我们写了一篇关于 `autocd` 的文章,它是一个内置的 shell 变量,可以帮助我们在[没有 cd 命令的情况下导航到目录中][1]。
|
||||
|
||||
如果你想回到上一级目录,那么你需要输入 `cd ..`。
|
||||
|
||||
如果你想回到上两级目录,那么你需要输入 `cd ../..`。
|
||||
|
||||
这在 Linux 中是正常的,但如果你想从第九个目录回到第三个目录,那么使用 cd 命令是很糟糕的。
|
||||
这在 Linux 中是正常的,但如果你想从第九级目录回到第三级目录,那么使用 `cd` 命令是很糟糕的。
|
||||
|
||||
有什么解决方案呢?
|
||||
|
||||
是的,在 Linux 中有一个解决方案。我们可以使用 bd 命令来轻松应对这种情况。
|
||||
是的,在 Linux 中有一个解决方案。我们可以使用 `bd` 命令来轻松应对这种情况。
|
||||
|
||||
### 什么是 bd 命令?
|
||||
|
||||
bd 命令允许用户快速返回 Linux 中的父目录,而不是反复输入 `cd ../../..`。
|
||||
`bd` 命令允许用户快速返回 Linux 中的父目录,而不是反复输入 `cd ../../..`。
|
||||
|
||||
你可以列出给定目录的内容,而不用提供完整路径 `ls `bd Directory_Name``。它支持以下其它命令,如 ls、ln、echo、zip、tar 等。
|
||||
你可以列出给定目录的内容,而不用提供完整路径 ls `bd Directory_Name`。它支持以下其它命令,如 `ls`、`ln`、`echo`、`zip`、`tar` 等。
|
||||
|
||||
另外,它还允许我们执行 shell 文件而不用提供完整路径 `bd p`/shell_file.sh``。
|
||||
另外,它还允许我们执行 shell 文件而不用提供完整路径 bd p`/shell_file.sh`。
|
||||
|
||||
### 如何在 Linux 中安装 bd 命令?
|
||||
|
||||
除了 Debian/Ubuntu 之外,bd 没有官方发行包。因此,我们需要手动执行方法。
|
||||
除了 Debian/Ubuntu 之外,`bd` 没有官方发行包。因此,我们需要手动执行方法。
|
||||
|
||||
对于 **`Debian/Ubuntu`** 系统,使用 **[APT-GET 命令][2]**或**[APT 命令][3]**来安装 bd。
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][2]或[APT 命令][3]来安装 `bd`。
|
||||
|
||||
```
|
||||
$ sudo apt install bd
|
||||
```
|
||||
|
||||
对于其它 Linux 发行版,使用 **[wget 命令][4]**下载 bd 可执行二进制文件。
|
||||
对于其它 Linux 发行版,使用 [wget 命令][4]下载 `bd` 可执行二进制文件。
|
||||
|
||||
```
|
||||
$ sudo wget --no-check-certificate -O /usr/local/bin/bd https://raw.github.com/vigneshwaranr/bd/master/bd
|
||||
```
|
||||
|
||||
设置 bd 二进制文件的可执行权限。
|
||||
设置 `bd` 二进制文件的可执行权限。
|
||||
|
||||
```
|
||||
$ sudo chmod +rx /usr/local/bin/bd
|
||||
@ -61,17 +59,19 @@ $ echo 'alias bd=". bd -si"' >> ~/.bashrc
|
||||
```
|
||||
|
||||
运行以下命令以使更改生效。
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
要启用自动完成,执行以下两个步骤。
|
||||
|
||||
```
|
||||
$ sudo wget -O /etc/bash_completion.d/bd https://raw.github.com/vigneshwaranr/bd/master/bash_completion.d/bd
|
||||
$ sudo source /etc/bash_completion.d/bd
|
||||
```
|
||||
|
||||
我们已经在系统上成功安装并配置了 bd 实用程序,现在是时候测试一下了。
|
||||
我们已经在系统上成功安装并配置了 `bd` 实用程序,现在是时候测试一下了。
|
||||
|
||||
我将使用下面的目录路径进行测试。
|
||||
|
||||
@ -79,7 +79,7 @@ $ sudo source /etc/bash_completion.d/bd
|
||||
|
||||
```
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ pwd
|
||||
或者
|
||||
或
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ dirs
|
||||
|
||||
/usr/share/icons/Adwaita/256x256/apps
|
||||
@ -94,19 +94,20 @@ daygeek@Ubuntu18:/usr/share/icons$
|
||||
```
|
||||
|
||||
甚至,你不需要输入完整的目录名称,也可以输入几个字母。
|
||||
|
||||
```
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ bd i
|
||||
/usr/share/icons/
|
||||
daygeek@Ubuntu18:/usr/share/icons$
|
||||
```
|
||||
|
||||
`注意:` 如果层次结构中有多个同名的目录,bd 会将你带到最近的目录。(不考虑直接的父目录)
|
||||
注意:如果层次结构中有多个同名的目录,`bd` 会将你带到最近的目录。(不考虑直接的父目录)
|
||||
|
||||
如果要列出给定的目录内容,使用以下格式。它会打印出 `/usr/share/icons/` 的内容。
|
||||
|
||||
```
|
||||
$ ls -lh `bd icons`
|
||||
or
|
||||
或
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ ls -lh `bd i`
|
||||
total 64K
|
||||
drwxr-xr-x 12 root root 4.0K Jul 25 2018 Adwaita
|
||||
@ -132,7 +133,7 @@ drwxr-xr-x 3 root root 4.0K Jul 25 2018 whiteglass
|
||||
|
||||
```
|
||||
$ `bd i`/users-list.sh
|
||||
or
|
||||
或
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ `bd icon`/users-list.sh
|
||||
daygeek
|
||||
thanu
|
||||
@ -151,7 +152,7 @@ user3
|
||||
|
||||
```
|
||||
$ cd `bd i`/gnome
|
||||
or
|
||||
或
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ cd `bd icon`/gnome
|
||||
daygeek@Ubuntu18:/usr/share/icons/gnome$
|
||||
```
|
||||
@ -167,7 +168,7 @@ drwxr-xr-x 2 root root 4096 Mar 16 05:44 /usr/share/icons//2g
|
||||
|
||||
本教程允许你快速返回到特定的父目录,但没有快速前进的选项。
|
||||
|
||||
我们有另一个解决方案,很快就会提出新的解决方案,请跟我们保持联系。
|
||||
我们有另一个解决方案,很快就会提出,请保持关注。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -176,7 +177,7 @@ via: https://www.2daygeek.com/bd-quickly-go-back-to-a-specific-parent-directory-
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
144
published/20190326 Using Square Brackets in Bash- Part 1.md
Normal file
144
published/20190326 Using Square Brackets in Bash- Part 1.md
Normal file
@ -0,0 +1,144 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10717-1.html)
|
||||
[#]: subject: (Using Square Brackets in Bash: Part 1)
|
||||
[#]: via: (https://www.linux.com/blog/2019/3/using-square-brackets-bash-part-1)
|
||||
[#]: author: (Paul Brown https://www.linux.com/users/bro66)
|
||||
|
||||
在 Bash 中使用[方括号] (一)
|
||||
======
|
||||
|
||||
![square brackets][1]
|
||||
|
||||
> 这篇文章将要介绍方括号及其在命令行中的不同用法。
|
||||
|
||||
看完[花括号在命令行中的用法][3]之后,现在我们继续来看方括号(`[]`)在上下文中是如何发挥作用的。
|
||||
|
||||
### 通配
|
||||
|
||||
方括号最简单的用法就是通配。你可能在知道“<ruby><rt>Globbing</rt></ruby>”这个概念之前就已经通过通配来匹配内容了,列出具有相同特征的多个文件就是一个很常见的场景,例如列出所有 JPEG 文件:
|
||||
|
||||
```
|
||||
ls *.jpg
|
||||
```
|
||||
|
||||
使用<ruby>通配符<rt>wildcard</rt></ruby>来得到符合某个模式的所有内容,这个过程就叫通配。
|
||||
|
||||
在上面的例子当中,星号(`*`)就代表“0 个或多个字符”。除此以外,还有代表“有且仅有一个字符”的问号(`?`)。因此
|
||||
|
||||
```
|
||||
ls d*k*
|
||||
```
|
||||
|
||||
可以列出 `darkly` 和 `ducky`,而且 `dark` 和 `duck` 也是可以被列出的,因为 `*` 可以匹配 0 个字符。而
|
||||
|
||||
```
|
||||
ls d*k?
|
||||
```
|
||||
|
||||
则只能列出 `ducky`,不会列出 `darkly`、`dark` 和 `duck`。
|
||||
|
||||
方括号也可以用于通配。为了便于演示,可以创建一个用于测试的目录,并在这个目录下创建文件:
|
||||
|
||||
```
|
||||
touch file0{0..9}{0..9}
|
||||
```
|
||||
|
||||
(如果你还不清楚上面这个命令的原理,可以看一下[另一篇介绍花括号的文章][3])
|
||||
|
||||
执行上面这个命令之后,就会创建 `file000`、`file001`、……、`file099` 这 100 个文件。
|
||||
|
||||
如果要列出这些文件当中第二位数字是 7 或 8 的文件,可以执行:
|
||||
|
||||
```
|
||||
ls file0[78]?
|
||||
```
|
||||
|
||||
如果要列出 `file022`、`file027`、`file028`、`file052`、`file057`、`file058`、`file092`、`file097`、`file098`,可以执行:
|
||||
|
||||
```
|
||||
ls file0[259][278]
|
||||
```
|
||||
|
||||
当然,不仅仅是 `ls`,很多其它的命令行工具都可以使用方括号来进行通配操作。但在删除文件、移动文件、复制文件的过程中使用通配,你需要有一点横向思维。
|
||||
|
||||
例如将 `file010` 到 `file029` 这 30 个文件复制成 `archive010` 到 `archive029` 这 30 个副本,不可以这样执行:
|
||||
|
||||
```
|
||||
cp file0[12]? archive0[12]?
|
||||
```
|
||||
|
||||
因为通配只能针对已有的文件,而 `archive` 开头的文件并不存在,不能进行通配。
|
||||
|
||||
而这条命令
|
||||
|
||||
```
|
||||
cp file0[12]? archive0[1..2][0..9]
|
||||
```
|
||||
|
||||
也同样不行,因为 `cp` 并不允许将多个文件复制到多个文件。在复制多个文件的情况下,只能将多个文件复制到一个指定的目录下:
|
||||
|
||||
```
|
||||
mkdir archive
|
||||
cp file0[12]? archive
|
||||
```
|
||||
|
||||
这条命令是可以正常运行的,但它只会把这 30 个文件以同样的名称复制到 `archive/` 目录下,而这并不是我们想要的效果。
|
||||
|
||||
如果你阅读过我[关于花括号的文章][3],你大概会记得可以使用 `%` 来截掉字符串的末尾部分,而使用 `#` 则可以截掉字符串的开头部分。
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
myvar="Hello World"
|
||||
echo Goodbye Cruel ${myvar#Hello}
|
||||
```
|
||||
|
||||
就会输出 `Goodbye Cruel World`,因为 `#Hello` 将 `myvar` 变量中开头的 `Hello` 去掉了。
|
||||
|
||||
在通配的过程中,也可以使用这一个技巧。
|
||||
|
||||
```
|
||||
for i in file0[12]?;\
|
||||
do\
|
||||
cp $i archive${i#file};\
|
||||
done
|
||||
```
|
||||
|
||||
上面的第一行命令告诉 Bash 需要对所有 `file01` 开头或者 `file02` 开头,且后面只跟一个任意字符的文件进行操作,第二行的 `do` 和第四行的 `done` 代表需要对这些文件都执行这一块中的命令。
|
||||
|
||||
第三行就是实际的复制操作了,这里使用了两次 `$i` 变量:第一次在 `cp` 命令中直接作为源文件的文件名使用,第二次则是截掉文件名开头的 `file` 部分,然后在开头补上一个 `archive`,也就是这样:
|
||||
|
||||
```
|
||||
"archive" + "file019" - "file" = "archive019"
|
||||
```
|
||||
|
||||
最终整个 `cp` 命令展开为:
|
||||
|
||||
```
|
||||
cp file019 archive019
|
||||
```
|
||||
|
||||
最后,顺带说明一下反斜杠 `\` 的作用是将一条长命令拆分成多行,这样可以方便阅读。
|
||||
|
||||
在下一节,我们会了解方括号的更多用法,敬请关注。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2019/3/using-square-brackets-bash-part-1
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/square-gabriele-diwald-475007-unsplash.jpg?itok=cKmysLfd "square brackets"
|
||||
[2]: https://www.linux.com/LICENSES/CATEGORY/CREATIVE-COMMONS-ZERO
|
||||
[3]: https://linux.cn/article-10624-1.html
|
||||
|
||||
@ -0,0 +1,71 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10715-1.html)
|
||||
[#]: subject: (Setting kernel command line arguments with Fedora 30)
|
||||
[#]: via: (https://fedoramagazine.org/setting-kernel-command-line-arguments-with-fedora-30/)
|
||||
[#]: author: (Laura Abbott https://fedoramagazine.org/makes-fedora-kernel/)
|
||||
|
||||
如何在 Fedora 30 中设置内核命令行参数
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
在调试或试验内核时,向内核命令行添加选项是一项常见任务。即将发布的 Fedora 30 版本改为使用 Bootloader 规范([BLS][2])。根据你修改内核命令行选项的方式,你的工作流可能会更改。继续阅读获取更多信息。
|
||||
|
||||
要确定你的系统是使用 BLS 还是旧的规范,请查看文件:
|
||||
|
||||
```
|
||||
/etc/default/grub
|
||||
```
|
||||
|
||||
如果你看到:
|
||||
|
||||
```
|
||||
GRUB_ENABLE_BLSCFG=true
|
||||
```
|
||||
|
||||
看到这个,你运行的是 BLS,你可能需要更改设置内核命令行参数的方式。
|
||||
|
||||
如果你只想修改单个内核条目(例如,暂时解决显示问题),可以使用 `grubby` 命令:
|
||||
|
||||
```
|
||||
$ grubby --update-kernel /boot/vmlinuz-5.0.1-300.fc30.x86_64 --args="amdgpu.dc=0"
|
||||
```
|
||||
|
||||
要删除内核参数,可以传递 `--remove-args` 参数给 `grubby`:
|
||||
|
||||
```
|
||||
$ grubby --update-kernel /boot/vmlinuz-5.0.1-300.fc30.x86_64 --remove-args="amdgpu.dc=0"
|
||||
```
|
||||
|
||||
如果有应该添加到每个内核命令行的选项(例如,你希望禁用 `rdrand` 指令生成随机数),则可以运行 `grubby` 命令:
|
||||
|
||||
```
|
||||
$ grubby --update-kernel=ALL --args="nordrand"
|
||||
```
|
||||
|
||||
这将更新所有内核条目的命令行,并保存作为将来条目的命令行选项。
|
||||
|
||||
如果你想要从所有内核中删除该选项,则可以再次使用 `--remove-args` 和 `--update-kernel=ALL`:
|
||||
|
||||
```
|
||||
$ grubby --update-kernel=ALL --remove-args="nordrand"
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/setting-kernel-command-line-arguments-with-fedora-30/
|
||||
|
||||
作者:[Laura Abbott][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/makes-fedora-kernel/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/03/f30-kernel-1-816x345.jpg
|
||||
[2]: https://fedoraproject.org/wiki/Changes/BootLoaderSpecByDefault
|
||||
70
published/20190401 3 cool text-based email clients.md
Normal file
70
published/20190401 3 cool text-based email clients.md
Normal file
@ -0,0 +1,70 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10722-1.html)
|
||||
[#]: subject: (3 cool text-based email clients)
|
||||
[#]: via: (https://fedoramagazine.org/3-cool-text-based-email-clients/)
|
||||
[#]: author: (Clément Verna https://fedoramagazine.org/author/cverna/)
|
||||
|
||||
3 个很酷的基于文本的邮件客户端
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
编写和接收电子邮件是每个人日常工作的重要组成部分,选择电子邮件客户端通常是一个重要决定。Fedora 系统提供了大量的电子邮件客户端可供选择,其中包括基于文本的电子邮件应用。
|
||||
|
||||
### Mutt
|
||||
|
||||
Mutt 可能是最受欢迎的基于文本的电子邮件客户端之一。它有人们期望的所有常用功能。Mutt 支持颜色代码、邮件会话、POP3 和 IMAP。但它最好的功能之一是它具有高度可配置性。实际上,用户可以轻松地更改键绑定,并创建宏以使工具适应特定的工作流程。
|
||||
|
||||
要尝试 Mutt,请[使用 sudo][2] 和 `dnf` 安装它:
|
||||
|
||||
```
|
||||
$ sudo dnf install mutt
|
||||
```
|
||||
|
||||
为了帮助新手入门,Mutt 有一个非常全面的充满了宏示例和配置技巧的 [wiki][3]。
|
||||
|
||||
### Alpine
|
||||
|
||||
Alpine 也是最受欢迎的基于文本的电子邮件客户端。它比 Mutt 更适合初学者,你可以通过应用本身配置大部分功能而无需编辑配置文件。Alpine 的一个强大功能是能够对电子邮件进行评分。这对那些订阅含有大量邮件的邮件列表如 Fedora 的[开发列表][4]的用户来说尤其有趣。通过使用分数,Alpine 可以根据用户的兴趣对电子邮件进行排序,首先显示高分的电子邮件。
|
||||
|
||||
也可以使用 `dnf` 从 Fedora 的仓库安装 Alpine。
|
||||
|
||||
```
|
||||
$ sudo dnf install alpine
|
||||
```
|
||||
|
||||
使用 Alpine 时,你可以按 `Ctrl+G` 组合键轻松访问文档。
|
||||
|
||||
### nmh
|
||||
|
||||
nmh(new Mail Handling)遵循 UNIX 工具哲学。它提供了一组用于发送、接收、保存、检索和操作电子邮件的单一用途程序。这使你可以将 `nmh` 命令与其他程序交换,或利用 `nmh` 编写脚本来创建更多自定义工具。例如,你可以将 Mutt 与 `nmh` 一起使用。
|
||||
|
||||
使用 `dnf` 可以轻松安装 `nmh`。
|
||||
|
||||
```
|
||||
$ sudo dnf install nmh
|
||||
```
|
||||
|
||||
要了解有关 `nmh` 和邮件处理的更多信息,你可以阅读这本 GPL 许可的[书][5]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/3-cool-text-based-email-clients/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/cverna/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2018/07/email-clients-816x345.png
|
||||
[2]: https://fedoramagazine.org/howto-use-sudo/
|
||||
[3]: https://gitlab.com/muttmua/mutt/wikis/home
|
||||
[4]: https://lists.fedoraproject.org/archives/list/devel@lists.fedoraproject.org/
|
||||
[5]: https://rand-mh.sourceforge.io/book/
|
||||
@ -1,27 +1,28 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: translator: (liujing97)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10705-1.html)
|
||||
[#]: subject: (How to create a filesystem on a Linux partition or logical volume)
|
||||
[#]: via: (https://opensource.com/article/19/4/create-filesystem-linux-partition)
|
||||
[#]: author: (Kedar Vijay Kulkarni (Red Hat) https://opensource.com/users/kkulkarn)
|
||||
[#]: 作者: (Kedar Vijay Kulkarni (Red Hat) https://opensource.com/users/kkulkarn)
|
||||
|
||||
How to create a filesystem on a Linux partition or logical volume
|
||||
如何在 Linux 分区或逻辑卷中创建文件系统
|
||||
======
|
||||
Learn to create a filesystem and mount it persistently or
|
||||
non-persistently in your system.
|
||||
|
||||
> 学习在你的系统中创建一个文件系统,并且长期或者非长期地挂载它。
|
||||
|
||||
![Filing papers and documents][1]
|
||||
|
||||
In computing, a filesystem controls how data is stored and retrieved and helps organize the files on the storage media. Without a filesystem, information in storage would be one large block of data, and you couldn't tell where one piece of information stopped and the next began. A filesystem helps manage all of this by providing names to files that store data and maintaining a table of files and directories—along with their start/end location, total size, etc.—on disks within the filesystem.
|
||||
在计算技术中,文件系统控制如何存储和检索数据,并且帮助组织存储媒介中的文件。如果没有文件系统,信息将被存储为一个大数据块,而且你无法知道一条信息在哪结束,下一条信息在哪开始。文件系统通过为存储数据的文件提供名称,并且在文件系统中的磁盘上维护文件和目录表以及它们的开始和结束位置、总的大小等来帮助管理所有的这些信息。
|
||||
|
||||
In Linux, when you create a hard disk partition or a logical volume, the next step is usually to create a filesystem by formatting the partition or logical volume. This how-to assumes you know how to create a partition or a logical volume, and you just want to format it to contain a filesystem and mount it.
|
||||
在 Linux 中,当你创建一个硬盘分区或者逻辑卷之后,接下来通常是通过格式化这个分区或逻辑卷来创建文件系统。这个操作方法假设你已经知道如何创建分区或逻辑卷,并且你希望将它格式化为包含有文件系统,并且挂载它。
|
||||
|
||||
### Create a filesystem
|
||||
### 创建文件系统
|
||||
|
||||
Imagine you just added a new disk to your system and created a partition named **/dev/sda1** on it.
|
||||
假设你为你的系统添加了一块新的硬盘并且在它上面创建了一个叫 `/dev/sda1` 的分区。
|
||||
|
||||
1. To verify that the Linux kernel can see the partition, you can **cat** out **/proc/partitions** like this:
|
||||
1、为了验证 Linux 内核已经发现这个分区,你可以 `cat` 出 `/proc/partitions` 的内容,就像这样:
|
||||
|
||||
```
|
||||
[root@localhost ~]# cat /proc/partitions
|
||||
@ -40,7 +41,7 @@ major minor #blocks name
|
||||
```
|
||||
|
||||
|
||||
2. Decide what kind of filesystem you want to create, such as ext4, XFS, or anything else. Here are a few options:
|
||||
2、决定你想要去创建的文件系统种类,比如 ext4、XFS,或者其他的一些。这里是一些可选项:
|
||||
|
||||
```
|
||||
[root@localhost ~]# mkfs.<tab><tab>
|
||||
@ -48,7 +49,7 @@ mkfs.btrfs mkfs.cramfs mkfs.ext2 mkfs.ext3 mkfs.ext4 mkfs.minix mkfs.xfs
|
||||
```
|
||||
|
||||
|
||||
3. For the purposes of this exercise, choose ext4. (I like ext4 because it allows you to shrink the filesystem if you need to, a thing that isn't as straightforward with XFS.) Here's how it can be done (the output may differ based on device name/sizes):
|
||||
3、为了这次练习的目的,选择 ext4。(我喜欢 ext4,因为如果你需要的话,它可以允许你去压缩文件系统,这对于 XFS 并不简单。)这里是完成它的方法(输出可能会因设备名称或者大小而不同):
|
||||
|
||||
```
|
||||
[root@localhost ~]# mkfs.ext4 /dev/sda1
|
||||
@ -74,18 +75,16 @@ Creating journal (16384 blocks): done
|
||||
Writing superblocks and filesystem accounting information: done
|
||||
```
|
||||
|
||||
4. In the previous step, if you want to create a different kind of filesystem, use a different **mkfs** command variation.
|
||||
4、在上一步中,如果你想去创建不同的文件系统,请使用不同变种的 `mkfs` 命令。
|
||||
|
||||
### 挂载文件系统
|
||||
|
||||
当你创建好文件系统后,你可以在你的操作系统中挂载它。
|
||||
|
||||
### Mount a filesystem
|
||||
|
||||
After you create your filesystem, you can mount it in your operating system.
|
||||
|
||||
1. First, identify the UUID of your new filesystem. Issue the **blkid** command to list all known block storage devices and look for **sda1** in the output:
|
||||
1、首先,识别出新文件系统的 UUID 编码。使用 `blkid` 命令列出所有可识别的块存储设备并且在输出信息中查找 `sda1`:
|
||||
|
||||
```
|
||||
[root@localhost ~]# blkid
|
||||
[root@localhost ~]# blkid
|
||||
/dev/vda1: UUID="716e713d-4e91-4186-81fd-c6cfa1b0974d" TYPE="xfs"
|
||||
/dev/sr1: UUID="2019-03-08-16-17-02-00" LABEL="config-2" TYPE="iso9660"
|
||||
/dev/sda1: UUID="wow9N8-dX2d-ETN4-zK09-Gr1k-qCVF-eCerbF" TYPE="LVM2_member"
|
||||
@ -94,11 +93,10 @@ After you create your filesystem, you can mount it in your operating system.
|
||||
[root@localhost ~]#
|
||||
```
|
||||
|
||||
|
||||
2. Run the following command to mount the **/dev/sd1** device :
|
||||
2、运行下面的命令挂载 `/dev/sd1` 设备:
|
||||
|
||||
```
|
||||
[root@localhost ~]# mkdir /mnt/mount_point_for_dev_sda1
|
||||
[root@localhost ~]# mkdir /mnt/mount_point_for_dev_sda1
|
||||
[root@localhost ~]# ls /mnt/
|
||||
mount_point_for_dev_sda1
|
||||
[root@localhost ~]# mount -t ext4 /dev/sda1 /mnt/mount_point_for_dev_sda1/
|
||||
@ -113,19 +111,16 @@ tmpfs 93M 0 93M 0% /run/user/0
|
||||
/dev/sda1 2.9G 9.0M 2.7G 1% /mnt/mount_point_for_dev_sda1
|
||||
[root@localhost ~]#
|
||||
```
|
||||
The **df -h** command shows which filesystem is mounted on which mount point. Look for **/dev/sd1**. The mount command above used the device name **/dev/sda1**. Substitute it with the UUID identified in the **blkid** command. Also, note that a new directory was created to mount **/dev/sda1** under **/mnt**.
|
||||
|
||||
命令 `df -h` 显示了每个文件系统被挂载的挂载点。查找 `/dev/sd1`。上面的挂载命令使用的设备名称是 `/dev/sda1`。用 `blkid` 命令中的 UUID 编码替换它。注意,在 `/mnt` 下一个被新创建的目录挂载了 `/dev/sda1`。
|
||||
|
||||
|
||||
3. A problem with using the mount command directly on the command line (as in the previous step) is that the mount won't persist across reboots. To mount the filesystem persistently, edit the **/etc/fstab** file to include your mount information:
|
||||
3、直接在命令行下使用挂载命令(就像上一步一样)会有一个问题,那就是挂载不会在设备重启后存在。为使永久性地挂载文件系统,编辑 `/etc/fstab` 文件去包含你的挂载信息:
|
||||
|
||||
```
|
||||
UUID=ac96b366-0cdd-4e4c-9493-bb93531be644 /mnt/mount_point_for_dev_sda1/ ext4 defaults 0 0
|
||||
```
|
||||
|
||||
|
||||
|
||||
4. After you edit **/etc/fstab** , you can **umount /mnt/mount_point_for_dev_sda1** and run the command **mount -a** to mount everything listed in **/etc/fstab**. If everything went right, you can still list **df -h** and see your filesystem mounted:
|
||||
4、编辑完 `/etc/fstab` 文件后,你可以 `umount /mnt/mount_point_for_fev_sda1` 并且运行 `mount -a` 命令去挂载被列在 `/etc/fstab` 文件中的所有设备文件。如果一切顺利的话,你可以使用 `df -h` 列出并且查看你挂载的文件系统:
|
||||
|
||||
```
|
||||
root@localhost ~]# umount /mnt/mount_point_for_dev_sda1/
|
||||
@ -141,25 +136,23 @@ tmpfs 93M 0 93M 0% /run/user/0
|
||||
/dev/sda1 2.9G 9.0M 2.7G 1% /mnt/mount_point_for_dev_sda1
|
||||
```
|
||||
|
||||
5. You can also check whether the filesystem was mounted:
|
||||
5、你也可以检测文件系统是否被挂载:
|
||||
|
||||
```
|
||||
[root@localhost ~]# mount | grep ^/dev/sd
|
||||
/dev/sda1 on /mnt/mount_point_for_dev_sda1 type ext4 (rw,relatime,seclabel,stripe=8191,data=ordered)
|
||||
```
|
||||
|
||||
|
||||
|
||||
Now you know how to create a filesystem and mount it persistently or non-persistently within your system.
|
||||
现在你已经知道如何去创建文件系统并且长期或者非长期的挂载在你的系统中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/create-filesystem-linux-partition
|
||||
|
||||
作者:[Kedar Vijay Kulkarni (Red Hat)][a]
|
||||
作者:[Kedar Vijay Kulkarni][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[liujing97](https://github.com/liujing97)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,74 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (zhs852)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10702-1.html)
|
||||
[#]: subject: (Happy 14th anniversary Git: What do you love about Git?)
|
||||
[#]: via: (https://opensource.com/article/19/4/what-do-you-love-about-git)
|
||||
[#]: author: (Jen Wike Huger https://opensource.com/users/jen-wike/users/seth)
|
||||
|
||||
Git 十四周年:你喜欢 Git 的哪一点?
|
||||
======
|
||||
|
||||
> Git 为软件开发所带来的巨大影响是其它工具难以企及的。
|
||||
|
||||
![arrows cycle symbol for failing faster][1]
|
||||
|
||||
在 Linus Torvalds 开发 Git 后的十四年间,它为软件开发所带来的影响是其它工具难以企及的:在 [StackOverflow 的 2018 年开发者调查][2] 中,87% 的受访者都表示他们使用 Git 来作为他们项目的版本控制工具。显然,没有其它工具能撼动 Git 版本控制管理工具(SCM)之王的地位。
|
||||
|
||||
为了在 4 月 7 日 Git 的十四周年这一天向 Git 表示敬意,我问了一些爱好者他们最喜欢 Git 的哪一点。以下便是他们所告诉我的:
|
||||
|
||||
*(为了便于理解,部分回答已经进行了小幅修改)*
|
||||
|
||||
“我无法忍受 Git。无论是难以理解的术语还是它的分布式。使用 Gerrit 这样的插件才能使它像 Subversion 或 Perforce 这样的集中式仓库管理器使用的工具的一半好用。不过既然这次的问题是‘你喜欢 Git 的什么?’,我还是希望回答:Git 使得对复杂的源代码树操作成为可能,并且它的回滚功能使得实现一个要 20 次修改才能更正的问题变得简单起来。” — _[Sweet Tea Dorminy][3]_
|
||||
|
||||
“我喜欢 Git 是因为它不会强制我执行特定的工作流程,并且开发团队可以自由地以适合自己的方式来进行团队开发,无论是拉取请求、以电子邮件递送差异文件或是给予所有人推送的权限。” — _[Andy Price][4]_
|
||||
|
||||
“我从 2006、2007 年的样子就开始使用 Git 了。我喜欢 Git 是因为,它既适用于那种从未离开过我电脑的小项目,也适用于大型的团队合作的分布式项目。Git 使你可以从(几乎)所有的错误提交中回滚到先前版本,这个功能显著地减轻了我在软件版本管理方面的压力。” — _[Jonathan S. Katz][5]_
|
||||
|
||||
“我很欣赏 Git 那种 [底层命令和高层命令][6] 的理念。用户可以使用 Git 有效率地分享任何形式的信息,而不需要知道其内部工作原理。而好奇的人可以透过其表层的命令,而发现其为许多代码分享平台提供了支持的可以定位内容的文件系统。” — _[Matthew Broberg][7]_
|
||||
|
||||
“我喜欢 Git 是因为浏览、开发、构建、测试和向我的 Git 仓库中提交代码的工作几乎都能用它来完成。它经常会调动起我参与开源项目的积极性。” — _[Daniel Oh][8]_
|
||||
|
||||
“Git 是我用过的首个版本控制工具。数年间,它从一个可怕的工具变成了一个友好的工具。我喜欢它使你在修改代码的时候更加自信,因为它能保证你主分支的安全(除非你强制提交了一段考虑不周的代码到主分支)。你可以检出先前的提交来撤销更改,这一点也是很棒的。” — _[Kedar Vijay Kulkarni][9]_
|
||||
|
||||
“我之所以喜欢 Git 是因为它淘汰了一些其它的版本控制工具。没人使用 VSS,而 Subversion 可以和 git-svn 一起使用(如果必要),BitKeeper 则和 Monotone 一样只为老一辈所知。当然,我们还有 Mercurial,不过在我几年之前用它来为 Firefox 添加 AArch64 支持时,我觉得它仍是那种还未完善的工具。部分人可能还会提到 Perforce、SourceSafe 或是其它企业级的解决方案,我只想说它们在开源世界里并不流行。” — _[Marcin Juszkiewicz][10]_
|
||||
|
||||
“我喜欢内置的 SHA1 化对象模型(commit → tree → blob)的简易性。我也喜欢它的高层命令。同时我也将它作为对 JBoss/Red Hat Fuse 的补丁机制。并且这种机制确实有效。我还喜欢 Git 的 [三棵树的故事][11]。” — _[Grzegorz Grzybek][12]_
|
||||
|
||||
“我喜欢 [自动生成的 Git 说明页][13](这个页面虽然听起来是有关 Git 的,但是事实上这是一个没有实际意义的页面,不过它总是会给人一种像是真的 Git 页面的感觉…),这使得我对 Git 的敬意油然而生。” — _[Marko Myllynen][14]_
|
||||
|
||||
“Git 改变了我作为开发者的生活。它使得 SCM 问题从世界上消失得无影无踪。”— _[Joel Takvorian][15]_
|
||||
|
||||
* * *
|
||||
|
||||
看完这十个爱好者的回答之后,就轮到你了:你最欣赏 Git 的什么?请在评论区分享你的看法!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/what-do-you-love-about-git
|
||||
|
||||
作者:[Jen Wike Huger][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[zhs852](https://github.com/zhs852)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jen-wike/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/fail_progress_cycle_momentum_arrow.png?itok=q-ZFa_Eh (arrows cycle symbol for failing faster)
|
||||
[2]: https://insights.stackoverflow.com/survey/2018/#work-_-version-control
|
||||
[3]: https://github.com/sweettea
|
||||
[4]: https://www.linkedin.com/in/andrew-price-8771796/
|
||||
[5]: https://opensource.com/users/jkatz05
|
||||
[6]: https://git-scm.com/book/en/v2/Git-Internals-Plumbing-and-Porcelain
|
||||
[7]: https://opensource.com/users/mbbroberg
|
||||
[8]: https://opensource.com/users/daniel-oh
|
||||
[9]: https://opensource.com/users/kkulkarn
|
||||
[10]: https://github.com/hrw
|
||||
[11]: https://speakerdeck.com/schacon/a-tale-of-three-trees
|
||||
[12]: https://github.com/grgrzybek
|
||||
[13]: https://git-man-page-generator.lokaltog.net/
|
||||
[14]: https://github.com/myllynen
|
||||
[15]: https://github.com/jotak
|
||||
@ -1,115 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (A Look Back at the History of Firefox)
|
||||
[#]: via: (https://itsfoss.com/history-of-firefox)
|
||||
[#]: author: (John Paul https://itsfoss.com/author/john/)
|
||||
|
||||
A Look Back at the History of Firefox
|
||||
======
|
||||
|
||||
The Firefox browser has been a mainstay of the open-source community for a long time. For many years it was the default web browser on (almost) all Linux distros and the lone obstacle to Microsoft’s total dominance of the internet. This browser has roots that go back all the way to the very early days of the internet. Since this week marks the 30th anniversary of the internet, there is no better time to talk about how Firefox became the browser we all know and love.
|
||||
|
||||
### Early Roots
|
||||
|
||||
In the early 1990s, a young man named [Marc Andreessen][1] was working on his bachelor’s degree in computer science at the University of Illinois. While there, he started working for the [National Center for Supercomputing Applications][2]. During that time [Sir Tim Berners-Lee][3] released an early form of the web standards that we know today. Marc [was introduced][4] to a very primitive web browser named [ViolaWWW][5]. Seeing that the technology had potential, Marc and Eric Bina created an easy to install browser for Unix named [NCSA Mosaic][6]). The first alpha was released in June 1993. By September, there were ports to Windows and Macintosh. Mosaic became very popular because it was easier to use than other browsing software.
|
||||
|
||||
In 1994, Marc graduated and moved to California. He was approached by Jim Clark, who had made his money selling computer hardware and software. Clark had used Mosaic and saw the financial possibilities of the internet. Clark recruited Marc and Eric to start an internet software company. The company was originally named Mosaic Communications Corporation, however, the University of Illinois did not like [their use of the name Mosaic][7]. As a result, the company name was changed to Netscape Communications Corporation.
|
||||
|
||||
The company’s first project was an online gaming network for the Nintendo 64, but that fell through. The first product they released was a web browser named Mosaic Netscape 0.9, subsequently renamed Netscape Navigator. Internally, the browser project was codenamed mozilla, which stood for “Mosaic killer”. An employee created a cartoon of a [Godzilla like creature][8]. They wanted to take out the competition.
|
||||
|
||||
![Early Firefox Mascot][9]Early Mozilla mascot at Netscape
|
||||
|
||||
They succeed mightily. At the time, one of the biggest advantages that Netscape had was the fact that its browser looked and functioned the same on every operating system. Netscape described this as giving everyone a level playing field.
|
||||
|
||||
As usage of Netscape Navigator increase, the market share of NCSA Mosaic cratered. In 1995, Netscape went public. [On the first day][10], the stock started at $28, jumped to $75 and ended the day at $58. Netscape was without any rivals.
|
||||
|
||||
But that didn’t last for long. In the summer of 1994, Microsoft released Internet Explorer 1.0, which was based on Spyglass Mosaic which was based on NCSA Mosaic. The [browser wars][11] had begun.
|
||||
|
||||
Over the next few years, Netscape and Microsoft competed for dominance of the internet. Each added features to compete with the other. Unfortunately, Internet Explorer had an advantage because it came bundled with Windows. On top of that, Microsoft had more programmers and money to throw at the problem. Toward the end of 1997, Netscape started to run into financial problems.
|
||||
|
||||
### Going Open Source
|
||||
|
||||
![Mozilla Firefox][12]
|
||||
|
||||
In January 1998, Netscape open-sourced the code of the Netscape Communicator 4.0 suite. The [goal][13] was to “harness the creative power of thousands of programmers on the Internet by incorporating their best enhancements into future versions of Netscape’s software. This strategy is designed to accelerate development and free distribution by Netscape of future high-quality versions of Netscape Communicator to business customers and individuals.”
|
||||
|
||||
The project was to be shepherded by the newly created Mozilla Organization. However, the code from Netscape Communicator 4.0 proved to be very difficult to work with due to its size and complexity. On top of that, several parts could not be open sourced because of licensing agreements with third parties. In the end, it was decided to rewrite the browser from scratch using the new [Gecko][14]) rendering engine.
|
||||
|
||||
In November 1998, Netscape was acquired by AOL for [stock swap valued at $4.2 billion][15].
|
||||
|
||||
Starting from scratch was a major undertaking. Mozilla Firefox (initially nicknamed Phoenix) was created in June 2002 and it worked on multiple operating systems, such as Linux, Mac OS, Microsoft Windows, and Solaris.
|
||||
|
||||
The following year, AOL announced that they would be shutting down browser development. The Mozilla Foundation was subsequently created to handle the Mozilla trademarks and handle the financing of the project. Initially, the Mozilla Foundation received $2 million in donations from AOL, IBM, Sun Microsystems, and Red Hat.
|
||||
|
||||
In March 2003, Mozilla [announced pl][16][a][16][ns][16] to separate the suite into stand-alone applications because of creeping software bloat. The stand-alone browser was initially named Phoenix. However, the name was changed due to a trademark dispute with the BIOS manufacturer Phoenix Technologies, which had a BIOS-based browser named trademark dispute with the BIOS manufacturer Phoenix Technologies. Phoenix was renamed Firebird only to run afoul of the Firebird database server people. The browser was once more renamed to the Firefox that we all know.
|
||||
|
||||
At the time, [Mozilla said][17], “We’ve learned a lot about choosing names in the past year (more than we would have liked to). We have been very careful in researching the name to ensure that we will not have any problems down the road. We have begun the process of registering our new trademark with the US Patent and Trademark office.”
|
||||
|
||||
![Mozilla Firefox 1.0][18]Firefox 1.0 : [Picture Credit][19]
|
||||
|
||||
The first official release of Firefox was [0.8][20] on February 8, 2004. 1.0 followed on November 9, 2004. Version 2.0 and 3.0 followed in October 2006 and June 2008 respectively. Each major release brought with it many new features and improvements. In many respects, Firefox pulled ahead of Internet Explorer in terms of features and technology, but IE still had more users.
|
||||
|
||||
That changed with the release of Google’s Chrome browser. In the months before the release of Chrome in September 2008, Firefox accounted for 30% of all [browser usage][21] and IE had over 60%. According to StatCounter’s [January 2019 report][22], Firefox accounts for less than 10% of all browser usage, while Chrome has over 70%.
|
||||
|
||||
Fun Fact
|
||||
|
||||
Contrary to popular belief, the logo of Firefox doesn’t feature a fox. It’s actually a [Red Panda][23]. In Chinese, “fire fox” is another name for the red panda.
|
||||
|
||||
### The Future
|
||||
|
||||
As noted above, Firefox currently has the lowest market share in its recent history. There was a time when a bunch of browsers were based on Firefox, such as the early version of the [Flock browser][24]). Now most browsers are based on Google technology, such as Opera and Vivaldi. Even Microsoft is giving up on browser development and [joining the Chromium band wagon][25].
|
||||
|
||||
This might seem like quite a downer after the heights of the early Netscape years. But don’t forget what Firefox has accomplished. A group of developers from around the world have created the second most used browser in the world. They clawed 30% market share away from Microsoft’s monopoly, they can do it again. After all, they have us, the open source community, behind them.
|
||||
|
||||
The fight against the monopoly is one of the several reasons [why I use Firefox][26]. Mozilla regained some of its lost market-share with the revamped release of [Firefox Quantum][27] and I believe that it will continue the upward path.
|
||||
|
||||
What event from Linux and open source history would you like us to write about next? Please let us know in the comments below.
|
||||
|
||||
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][28].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/history-of-firefox
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Marc_Andreessen
|
||||
[2]: https://en.wikipedia.org/wiki/National_Center_for_Supercomputing_Applications
|
||||
[3]: https://en.wikipedia.org/wiki/Tim_Berners-Lee
|
||||
[4]: https://www.w3.org/DesignIssues/TimBook-old/History.html
|
||||
[5]: http://viola.org/
|
||||
[6]: https://en.wikipedia.org/wiki/Mosaic_(web_browser
|
||||
[7]: http://www.computinghistory.org.uk/det/1789/Marc-Andreessen/
|
||||
[8]: http://www.davetitus.com/mozilla/
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/Mozilla_boxing.jpg?ssl=1
|
||||
[10]: https://www.marketwatch.com/story/netscape-ipo-ignited-the-boom-taught-some-hard-lessons-20058518550
|
||||
[11]: https://en.wikipedia.org/wiki/Browser_wars
|
||||
[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/mozilla-firefox.jpg?resize=800%2C450&ssl=1
|
||||
[13]: https://web.archive.org/web/20021001071727/wp.netscape.com/newsref/pr/newsrelease558.html
|
||||
[14]: https://en.wikipedia.org/wiki/Gecko_(software)
|
||||
[15]: http://news.cnet.com/2100-1023-218360.html
|
||||
[16]: https://web.archive.org/web/20050618000315/http://www.mozilla.org/roadmap/roadmap-02-Apr-2003.html
|
||||
[17]: https://www-archive.mozilla.org/projects/firefox/firefox-name-faq.html
|
||||
[18]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/firefox-1.jpg?ssl=1
|
||||
[19]: https://www.iceni.com/blog/firefox-1-0-introduced-2004/
|
||||
[20]: https://en.wikipedia.org/wiki/Firefox_version_history
|
||||
[21]: https://en.wikipedia.org/wiki/Usage_share_of_web_browsers
|
||||
[22]: http://gs.statcounter.com/browser-market-share/desktop/worldwide/#monthly-201901-201901-bar
|
||||
[23]: https://en.wikipedia.org/wiki/Red_panda
|
||||
[24]: https://en.wikipedia.org/wiki/Flock_(web_browser
|
||||
[25]: https://www.windowscentral.com/microsoft-building-chromium-powered-web-browser-windows-10
|
||||
[26]: https://itsfoss.com/why-firefox/
|
||||
[27]: https://itsfoss.com/firefox-quantum-ubuntu/
|
||||
[28]: http://reddit.com/r/linuxusersgroup
|
||||
[29]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/mozilla-firefox.jpg?fit=800%2C450&ssl=1
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (zgj1024 )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -0,0 +1,69 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Anti-lasers could give us perfect antennas, greater data capacity)
|
||||
[#]: via: (https://www.networkworld.com/article/3386879/anti-lasers-could-give-us-perfect-antennas-greater-data-capacity.html#tk.rss_all)
|
||||
[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
|
||||
|
||||
Anti-lasers could give us perfect antennas, greater data capacity
|
||||
======
|
||||
Anti-lasers get close to providing a 100% efficient signal channel for data, say engineers.
|
||||
![Guirong Hao / Valery Brozhinsky / Getty Images][1]
|
||||
|
||||
Playing laser light backwards could adjust data transmission signals so that they perfectly match receiving antennas. The fine-tuning of signals like this, not achieved with such detail before, could create more capacity for ever-increasing data demand.
|
||||
|
||||
"Imagine, for example, that you could adjust a cell phone signal exactly the right way, so that it is perfectly absorbed by the antenna in your phone," says Stefan Rotter of the Institute for Theoretical Physics of Technische Universität Wien (TU Wien) in a [press release][2].
|
||||
|
||||
Rotter is talking about “Random Anti-Laser,” a project he has been a part of. The idea behind it is that if one could time-reverse a laser, then the laser (right now considered the best light source ever built) becomes the best available light absorber. Perfect absorption of a signal wave would mean that all of the data-carrying energy is absorbed by the receiving device, thus it becomes 100% efficient.
|
||||
|
||||
**[ Related:[What is 5G wireless? How it will change networking as we know it?][3] ]**
|
||||
|
||||
“The easiest way to think about this process is in terms of a movie showing a conventional laser sending out laser light, which is played backwards,” the TU Wein article says. The anti-laser is the exact opposite of the laser — instead of sending specific colors perfectly when energy is applied, it receives specific colors perfectly.
|
||||
|
||||
Perfect absorption of a signal wave would mean that all of the data-carrying energy is absorbed by the receiving device, thus it becomes 100% efficient.
|
||||
|
||||
Counter-intuitively, it’s the random scattering of light in all directions that’s behind the engineering. However, the Vienna, Austria, university group performs precise calculations on those scattering, splitting signals. That lets the researchers harness the light.
|
||||
|
||||
### How the anti-laser technology works
|
||||
|
||||
The microwave-based, experimental device the researchers have built in the lab to prove the idea doesn’t just potentially apply to cell phones; wireless internet of things (IoT) devices would also get more data throughput. How it works: The device consists of an antenna-containing chamber encompassed by cylinders, all arranged haphazardly, the researchers explain. The cylinders distribute an elaborate, arbitrary wave pattern “similar to [throwing] stones in a puddle of water, at which water waves are deflected.”
|
||||
|
||||
Measurements then take place to identify exactly how the signals return. The team involved, which also includes collaborators from the University of Nice, France, then “characterize the random structure and calculate the wave front that is completely swallowed by the central antenna at the right absorption strength.” Ninety-nine point eight percent is absorbed, making it remarkably and virtually perfect. Data throughput, range, and other variables thus improve.
|
||||
|
||||
**[[Take this mobile device management course from PluralSight and learn how to secure devices in your company without degrading the user experience.][4] ]**
|
||||
|
||||
Achieving perfect antennas has been pretty much only theoretically possible for engineers to date. Reflected energy (RF back into the transmitter from antenna inefficiencies) has always been an issue in general. Reflections from surfaces, too, have been always been a problem.
|
||||
|
||||
“Think about a mobile phone signal that is reflected several times before it reaches your cell phone,” Rotter says. It’s not easy to get the tuning right — as the antennas’ physical locations move, reflected surfaces become different.
|
||||
|
||||
### Scattering lasers
|
||||
|
||||
Scattering, similar to that used in this project, is becoming more important in communications overall. “Waves that are being scattered in a complex way are really all around us,” the group says.
|
||||
|
||||
An example is random-lasers (which the group’s anti-laser is based on) that unlike traditional lasers, do not use reflective surfaces but trap scattered light and then “emit a very complicated, system-specific laser field when supplied with energy.” The anti-random-laser developed by Rotter and his group simply reverses that in time:
|
||||
|
||||
“Instead of a light source that emits a specific wave depending on its random inner structure, it is also possible to build the perfect absorber.” The anti-random-laser.
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3386879/anti-lasers-could-give-us-perfect-antennas-greater-data-capacity.html#tk.rss_all
|
||||
|
||||
作者:[Patrick Nelson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Patrick-Nelson/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/03/data_cubes_transformation_conversion_by_guirong_hao_gettyimages-1062387214_plus_abstract_binary_by_valerybrozhinsky_gettyimages-865457032_3x2_2400x1600-100790211-large.jpg
|
||||
[2]: https://www.tuwien.ac.at/en/news/news_detail/article/126574/
|
||||
[3]: https://www.networkworld.com/article/3203489/lan-wan/what-is-5g-wireless-networking-benefits-standards-availability-versus-lte.html
|
||||
[4]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fmobile-device-management-big-picture
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,60 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Google partners with Intel, HPE and Lenovo for hybrid cloud)
|
||||
[#]: via: (https://www.networkworld.com/article/3388062/google-partners-with-intel-hpe-and-lenovo-for-hybrid-cloud.html#tk.rss_all)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Google partners with Intel, HPE and Lenovo for hybrid cloud
|
||||
======
|
||||
Google boosted its on-premises and cloud connections with Kubernetes and serverless computing.
|
||||
![Ilze Lucero \(CC0\)][1]
|
||||
|
||||
Still struggling to get its Google Cloud business out of single-digit marketshare, Google this week introduced new partnerships with Lenovo and Intel to help bolster its hybrid cloud offerings, both built on Google’s Kubernetes container technology.
|
||||
|
||||
At Google’s Next ’19 show this week, Intel and Google said they will collaborate on Google's Anthos, a new reference design based on the second-Generation Xeon Scalable processor introduced last week and an optimized Kubernetes software stack designed to deliver increased workload portability between public and private cloud environments.
|
||||
|
||||
**[ Read also:[What hybrid cloud means in practice][2] | Get regularly scheduled insights: [Sign up for Network World newsletters][3] ]**
|
||||
|
||||
As part the Anthos announcement, Hewlett Packard Enterprise (HPE) said it has validated Anthos on its ProLiant servers, while Lenovo has done the same for its ThinkAgile platform. This solution will enable customers to get a consistent Kubernetes experience between Google Cloud and their on-premises HPE or Lenovo servers. No official word from Dell yet, but they can’t be far behind.
|
||||
|
||||
Users will be able to manage their Kubernetes clusters and enforce policy consistently across environments – either in the public cloud or on-premises. In addition, Anthos delivers a fully integrated stack of hardened components, including OS and container runtimes that are tested and validated by Google, so customers can upgrade their clusters with confidence and minimize downtime.
|
||||
|
||||
### What is Google Anthos?
|
||||
|
||||
Google formally introduced [Anthos][4] at this year’s show. Anthos, formerly Cloud Services Platform, is meant to allow users to run their containerized applications without spending time on building, managing, and operating Kubernetes clusters. It runs both on Google Cloud Platform (GCP) with Google Kubernetes Engine (GKE) and in your data center with GKE On-Prem. Anthos will also let you manage workloads running on third-party clouds such as Amazon Web Services (AWS) and Microsoft Azure.
|
||||
|
||||
Google also announced the beta release of Anthos Migrate, which auto-migrates virtual machines (VM) from on-premises or other clouds directly into containers in GKE with minimal effort. This allows enterprises to migrate their infrastructure in one streamlined motion, without upfront modifications to the original VMs or applications.
|
||||
|
||||
Intel said it will publish the production design as an Intel Select Solution, as well as a developer platform, making it available to anyone who wants it.
|
||||
|
||||
### Serverless environments
|
||||
|
||||
Google isn’t stopping with Kubernetes containers, it’s also pushing ahead with serverless environments. [Cloud Run][5] is Google’s implementation of serverless computing, which is something of a misnomer. You still run your apps on servers; you just aren’t using a dedicated physical server. It is stateless, so resources are not allocated until you actually run or use the application.
|
||||
|
||||
Cloud Run is a fully serverless offering that takes care of all infrastructure management, including the provisioning, configuring, scaling, and managing of servers. It automatically scales up or down within seconds, even down to zero depending on traffic, ensuring you pay only for the resources you actually use. Cloud Run can be used on GKE, offering the option to run side by side with other workloads deployed in the same cluster.
|
||||
|
||||
Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3388062/google-partners-with-intel-hpe-and-lenovo-for-hybrid-cloud.html#tk.rss_all
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/03/cubes_blocks_squares_containers_ilze_lucero_cc0_via_unsplash_1200x800-100752172-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3249495/what-hybrid-cloud-mean-practice
|
||||
[3]: https://www.networkworld.com/newsletters/signup.html
|
||||
[4]: https://cloud.google.com/blog/topics/hybrid-cloud/new-platform-for-managing-applications-in-todays-multi-cloud-world
|
||||
[5]: https://cloud.google.com/blog/products/serverless/announcing-cloud-run-the-newest-member-of-our-serverless-compute-stack
|
||||
[6]: https://www.facebook.com/NetworkWorld/
|
||||
[7]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,60 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (HPE and Nutanix partner for hyperconverged private cloud systems)
|
||||
[#]: via: (https://www.networkworld.com/article/3388297/hpe-and-nutanix-partner-for-hyperconverged-private-cloud-systems.html#tk.rss_all)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
HPE and Nutanix partner for hyperconverged private cloud systems
|
||||
======
|
||||
Both companies will sell HP ProLiant appliances with Nutanix software but to different markets.
|
||||
![Hewlett Packard Enterprise][1]
|
||||
|
||||
Hewlett Packard Enterprise (HPE) has partnered with Nutanix to offer Nutanix’s hyperconverged infrastructure (HCI) software available as a managed private cloud service and on HPE-branded appliances.
|
||||
|
||||
As part of the deal, the two companies will be competing against each other in hardware sales, sort of. If you want the consumption model you get through HPE’s GreenLake, where your usage is metered and you pay for only the time you use it (similar to the cloud), then you would get the ProLiant hardware from HPE.
|
||||
|
||||
If you want an appliance model where you buy the hardware outright, like in the traditional sense of server sales, you would get the same ProLiant through Nutanix.
|
||||
|
||||
**[ Read also:[What is hybrid cloud computing?][2] and [Multicloud mania: what to know][3] ]**
|
||||
|
||||
As it is, HPE GreenLake offers multiple cloud offerings to customers, including virtualization courtesy of VMware and Microsoft. With the Nutanix partnership, HPE is adding Nutanix’s free Acropolis hypervisor to its offerings.
|
||||
|
||||
“Customers get to choose an alternative to VMware with this,” said Pradeep Kumar, senior vice president and general manager of HPE’s Pointnext consultancy. “They like the Acropolis license model, since it’s license-free. Then they have choice points so pricing is competitive. Some like VMware, and I think it’s our job to offer them both and they can pick and choose.”
|
||||
|
||||
Kumar added that the whole Nutanix stack is 15 to 18% less with Acropolis than a VMware-powered system, since they save on the hypervisor.
|
||||
|
||||
The HPE-Nutanix partnership offers a fully managed hybrid cloud infrastructure delivered as a service and deployed in customers’ data centers or co-location facility. The managed private cloud service gives enterprises a hyperconverged environment in-house without having to manage the infrastructure themselves and, more importantly, without the burden of ownership. GreenLake operates more like a lease than ownership.
|
||||
|
||||
### HPE GreenLake's private cloud services promise to significantly reduce costs
|
||||
|
||||
HPE is pushing hard on GreenLake, which basically mimics cloud platform pricing models of paying for what you use rather than outright ownership. Kumar said HPE projects the consumption model will account for 30% of HPE’s business in the next few years.
|
||||
|
||||
GreenLake makes some hefty promises. According to Nutanix-commissioned IDC research, customers will achieve a 60% reduction in the five-year cost of operations, while a HPE-commissioned Forrester report found customers benefit from a 30% Capex savings due to eliminated need for overprovisioning and a 90% reduction in support and professional services costs.
|
||||
|
||||
By shifting to an IT as a Service model, HPE claims to provide a 40% increase in productivity by reducing the support load on IT operations staff and to shorten the time to deploy IT projects by 65%.
|
||||
|
||||
The two new offerings from the partnership – HPE GreenLake’s private cloud service running Nutanix software and the HPE-branded appliances integrated with Nutanix software – are expected to be available during the 2019 third quarter, the companies said.
|
||||
|
||||
Join the Network World communities on [Facebook][4] and [LinkedIn][5] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3388297/hpe-and-nutanix-partner-for-hyperconverged-private-cloud-systems.html#tk.rss_all
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.techhive.com/images/article/2015/11/hpe_building-100625424-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3233132/cloud-computing/what-is-hybrid-cloud-computing.html
|
||||
[3]: https://www.networkworld.com/article/3252775/hybrid-cloud/multicloud-mania-what-to-know.html
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
@ -1,356 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Set Password Policies In Linux)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-set-password-policies-in-linux/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
|
||||
How To Set Password Policies In Linux
|
||||
======
|
||||

|
||||
|
||||
Even though Linux is secure by design, there are many chances for the security breach. One of them is weak passwords. As a System administrator, you must provide a strong password for the users. Because, mostly system breaches are happening due to weak passwords. This tutorial describes how to set password policies such as **password length** , **password complexity** , **password** **expiration period** etc., in DEB based systems like Debian, Ubuntu, Linux Mint, and RPM based systems like RHEL, CentOS, Scientific Linux.
|
||||
|
||||
### Set password length in DEB based systems
|
||||
|
||||
By default, all Linux operating systems requires **password length of minimum 6 characters** for the users. I strongly advice you not to go below this limit. Also, don’t use your real name, parents/spouse/kids name, or your date of birth as a password. Even a novice hacker can easily break such kind of passwords in minutes. The good password must always contains more than 6 characters including a number, a capital letter, and a special character.
|
||||
|
||||
Usually, the password and authentication-related configuration files will be stored in **/etc/pam.d/** location in DEB based operating systems.
|
||||
|
||||
To set minimum password length, edit**/etc/pam.d/common-password** file;
|
||||
|
||||
```
|
||||
$ sudo nano /etc/pam.d/common-password
|
||||
```
|
||||
|
||||
Find the following line:
|
||||
|
||||
```
|
||||
password [success=2 default=ignore] pam_unix.so obscure sha512
|
||||
```
|
||||
|
||||
![][2]
|
||||
|
||||
And add an extra word: **minlen=8** at the end. Here I set the minimum password length as **8**.
|
||||
|
||||
```
|
||||
password [success=2 default=ignore] pam_unix.so obscure sha512 minlen=8
|
||||
```
|
||||
|
||||

|
||||
|
||||
Save and close the file. So, now the users can’t use less than 8 characters for their password.
|
||||
|
||||
### Set password length in RPM based systems
|
||||
|
||||
**In RHEL, CentOS, Scientific Linux 7.x** systems, run the following command as root user to set password length.
|
||||
|
||||
```
|
||||
# authconfig --passminlen=8 --update
|
||||
```
|
||||
|
||||
To view the minimum password length, run:
|
||||
|
||||
```
|
||||
# grep "^minlen" /etc/security/pwquality.conf
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||
```
|
||||
minlen = 8
|
||||
```
|
||||
|
||||
**In RHEL, CentOS, Scientific Linux 6.x** systems, edit **/etc/pam.d/system-auth** file:
|
||||
|
||||
```
|
||||
# nano /etc/pam.d/system-auth
|
||||
```
|
||||
|
||||
Find the following line and add the following at the end of the line:
|
||||
|
||||
```
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 type= minlen=8
|
||||
```
|
||||
|
||||

|
||||
|
||||
As per the above setting, the minimum password length is **8** characters.
|
||||
|
||||
### Set password complexity in DEB based systems
|
||||
|
||||
This setting enforces how many classes, i.e upper-case, lower-case, and other characters, should be in a password.
|
||||
|
||||
First install password quality checking library using command:
|
||||
|
||||
```
|
||||
$ sudo apt-get install libpam-pwquality
|
||||
```
|
||||
|
||||
Then, edit **/etc/pam.d/common-password** file:
|
||||
|
||||
```
|
||||
$ sudo nano /etc/pam.d/common-password
|
||||
```
|
||||
|
||||
To set at least one **upper-case** letters in the password, add a word **‘ucredit=-1’** at the end of the following line.
|
||||
|
||||
```
|
||||
password requisite pam_pwquality.so retry=3 ucredit=-1
|
||||
```
|
||||
|
||||

|
||||
|
||||
Set at least one **lower-case** letters in the password as shown below.
|
||||
|
||||
```
|
||||
password requisite pam_pwquality.so retry=3 dcredit=-1
|
||||
```
|
||||
|
||||
Set at least **other** letters in the password as shown below.
|
||||
|
||||
```
|
||||
password requisite pam_pwquality.so retry=3 ocredit=-1
|
||||
```
|
||||
|
||||
As you see in the above examples, we have set at least (minimum) one upper-case, lower-case, and a special character in the password. You can set any number of maximum allowed upper-case, lower-case, and other letters in your password.
|
||||
|
||||
You can also set the minimum/maximum number of allowed classes in the password.
|
||||
|
||||
The following example shows the minimum number of required classes of characters for the new password:
|
||||
|
||||
```
|
||||
password requisite pam_pwquality.so retry=3 minclass=2
|
||||
```
|
||||
|
||||
### Set password complexity in RPM based systems
|
||||
|
||||
**In RHEL 7.x / CentOS 7.x / Scientific Linux 7.x:**
|
||||
|
||||
To set at least one lower-case letter in the password, run:
|
||||
|
||||
```
|
||||
# authconfig --enablereqlower --update
|
||||
```
|
||||
|
||||
To view the settings, run:
|
||||
|
||||
```
|
||||
# grep "^lcredit" /etc/security/pwquality.conf
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||
```
|
||||
lcredit = -1
|
||||
```
|
||||
|
||||
Similarly, set at least one upper-case letter in the password using command:
|
||||
|
||||
```
|
||||
# authconfig --enablerequpper --update
|
||||
```
|
||||
|
||||
To view the settings:
|
||||
|
||||
```
|
||||
# grep "^ucredit" /etc/security/pwquality.conf
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||
```
|
||||
ucredit = -1
|
||||
```
|
||||
|
||||
To set at least one digit in the password, run:
|
||||
|
||||
```
|
||||
# authconfig --enablereqdigit --update
|
||||
```
|
||||
|
||||
To view the setting, run:
|
||||
|
||||
```
|
||||
# grep "^dcredit" /etc/security/pwquality.conf
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||
```
|
||||
dcredit = -1
|
||||
```
|
||||
|
||||
To set at least one other character in the password, run:
|
||||
|
||||
```
|
||||
# authconfig --enablereqother --update
|
||||
```
|
||||
|
||||
To view the setting, run:
|
||||
|
||||
```
|
||||
# grep "^ocredit" /etc/security/pwquality.conf
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||
```
|
||||
ocredit = -1
|
||||
```
|
||||
|
||||
In **RHEL 6.x / CentOS 6.x / Scientific Linux 6.x systems** , edit **/etc/pam.d/system-auth** file as root user:
|
||||
|
||||
```
|
||||
# nano /etc/pam.d/system-auth
|
||||
```
|
||||
|
||||
Find the following line and add the following at the end of the line:
|
||||
|
||||
```
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 type= minlen=8 dcredit=-1 ucredit=-1 lcredit=-1 ocredit=-1
|
||||
```
|
||||
|
||||
As per the above setting, the password must have at least 8 characters. In addtion, the password should also have at least one upper-case letter, one lower-case letter, one digit, and one other characters.
|
||||
|
||||
### Set password expiration period in DEB based systems
|
||||
|
||||
Now, We are going to set the following policies.
|
||||
|
||||
1. Maximum number of days a password may be used.
|
||||
2. Minimum number of days allowed between password changes.
|
||||
3. Number of days warning given before a password expires.
|
||||
|
||||
|
||||
|
||||
To set this policy, edit:
|
||||
|
||||
```
|
||||
$ sudo nano /etc/login.defs
|
||||
```
|
||||
|
||||
Set the values as per your requirement.
|
||||
|
||||
```
|
||||
PASS_MAX_DAYS 100
|
||||
PASS_MIN_DAYS 0
|
||||
PASS_WARN_AGE 7
|
||||
```
|
||||
|
||||

|
||||
|
||||
As you see in the above example, the user should change the password once in every **100** days and the warning message will appear **7** days before password expiration.
|
||||
|
||||
Be mindful that these settings will impact the newly created users.
|
||||
|
||||
To set maximum number of days between password change to existing users, you must run the following command:
|
||||
|
||||
```
|
||||
$ sudo chage -M <days> <username>
|
||||
```
|
||||
|
||||
To set minimum number of days between password change, run:
|
||||
|
||||
```
|
||||
$ sudo chage -m <days> <username>
|
||||
```
|
||||
|
||||
To set warning before password expires, run:
|
||||
|
||||
```
|
||||
$ sudo chage -W <days> <username>
|
||||
```
|
||||
|
||||
To display the password for the existing users, run:
|
||||
|
||||
```
|
||||
$ sudo chage -l sk
|
||||
```
|
||||
|
||||
Here, **sk** is my username.
|
||||
|
||||
**Sample output:**
|
||||
|
||||
```
|
||||
Last password change : Feb 24, 2017
|
||||
Password expires : never
|
||||
Password inactive : never
|
||||
Account expires : never
|
||||
Minimum number of days between password change : 0
|
||||
Maximum number of days between password change : 99999
|
||||
Number of days of warning before password expires : 7
|
||||
```
|
||||
|
||||
As you see in the above output, the password never expires.
|
||||
|
||||
To change the password expiration period of an existing user,
|
||||
|
||||
```
|
||||
$ sudo chage -E 24/06/2018 -m 5 -M 90 -I 10 -W 10 sk
|
||||
```
|
||||
|
||||
The above command will set password of the user **‘sk’** to expire on **24/06/2018**. Also the the minimum number days between password change is set 5 days and the maximum number of days between password changes is set to **90** days. The user account will be locked automatically after **10 days** and It will display a warning message for **10 days** before password expiration.
|
||||
|
||||
### Set password expiration period in RPM based systems
|
||||
|
||||
This is same as DEB based systems.
|
||||
|
||||
### Forbid previously used passwords in DEB based systems
|
||||
|
||||
You can limit the users to set a password which is already used in the past. To put this in layman terms, the users can’t use the same password again.
|
||||
|
||||
To do so, edit**/etc/pam.d/common-password** file:
|
||||
|
||||
```
|
||||
$ sudo nano /etc/pam.d/common-password
|
||||
```
|
||||
|
||||
Find the following line and add the word **‘remember=5’** at the end:
|
||||
|
||||
```
|
||||
password [success=2 default=ignore] pam_unix.so obscure use_authtok try_first_pass sha512 remember=5
|
||||
```
|
||||
|
||||
The above policy will prevent the users to use the last 5 used passwords.
|
||||
|
||||
### Forbid previously used passwords in RPM based systems
|
||||
|
||||
This is same for both RHEL 6.x and RHEL 7.x and it’s clone systems like CentOS, Scientific Linux.
|
||||
|
||||
Edit **/etc/pam.d/system-auth** file as root user,
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
```
|
||||
|
||||
Find the following line, and add **remember=5** at the end.
|
||||
|
||||
```
|
||||
password sufficient pam_unix.so sha512 shadow nullok try_first_pass use_authtok remember=5
|
||||
```
|
||||
|
||||
You know now what is password policies in Linux, and how to set different password policies in DEB and RPM based systems.
|
||||
|
||||
That’s all for now. I will be here soon with another interesting and useful article. Until then stay tuned with OSTechNix. If you find this tutorial helpful, share it on your social, professional networks and support us.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-set-password-policies-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: http://www.ostechnix.com/wp-content/uploads/2016/03/sk@sk-_003-2-1.jpg
|
||||
@ -1,290 +0,0 @@
|
||||
Moelf translating
|
||||
Myths about /dev/urandom
|
||||
======
|
||||
|
||||
There are a few things about /dev/urandom and /dev/random that are repeated again and again. Still they are false.
|
||||
|
||||
I'm mostly talking about reasonably recent Linux systems, not other UNIX-like systems.
|
||||
|
||||
### /dev/urandom is insecure. Always use /dev/random for cryptographic purposes.
|
||||
|
||||
Fact: /dev/urandom is the preferred source of cryptographic randomness on UNIX-like systems.
|
||||
|
||||
### /dev/urandom is a pseudo random number generator, a PRNG, while /dev/random is a “true” random number generator.
|
||||
|
||||
Fact: Both /dev/urandom and /dev/random are using the exact same CSPRNG (a cryptographically secure pseudorandom number generator). They only differ in very few ways that have nothing to do with “true” randomness.
|
||||
|
||||
### /dev/random is unambiguously the better choice for cryptography. Even if /dev/urandom were comparably secure, there's no reason to choose the latter.
|
||||
|
||||
Fact: /dev/random has a very nasty problem: it blocks.
|
||||
|
||||
### But that's good! /dev/random gives out exactly as much randomness as it has entropy in its pool. /dev/urandom will give you insecure random numbers, even though it has long run out of entropy.
|
||||
|
||||
Fact: No. Even disregarding issues like availability and subsequent manipulation by users, the issue of entropy “running low” is a straw man. About 256 bits of entropy are enough to get computationally secure numbers for a long, long time.
|
||||
|
||||
And the fun only starts here: how does /dev/random know how much entropy there is available to give out? Stay tuned!
|
||||
|
||||
### But cryptographers always talk about constant re-seeding. Doesn't that contradict your last point?
|
||||
|
||||
Fact: You got me! Kind of. It is true, the random number generator is constantly re-seeded using whatever entropy the system can lay its hands on. But that has (partly) other reasons.
|
||||
|
||||
Look, I don't claim that injecting entropy is bad. It's good. I just claim that it's bad to block when the entropy estimate is low.
|
||||
|
||||
### That's all good and nice, but even the man page for /dev/(u)random contradicts you! Does anyone who knows about this stuff actually agree with you?
|
||||
|
||||
Fact: No, it really doesn't. It seems to imply that /dev/urandom is insecure for cryptographic use, unless you really understand all that cryptographic jargon.
|
||||
|
||||
The man page does recommend the use of /dev/random in some cases (it doesn't hurt, in my opinion, but is not strictly necessary), but it also recommends /dev/urandom as the device to use for “normal” cryptographic use.
|
||||
|
||||
And while appeal to authority is usually nothing to be proud of, in cryptographic issues you're generally right to be careful and try to get the opinion of a domain expert.
|
||||
|
||||
And yes, quite a few experts share my view that /dev/urandom is the go-to solution for your random number needs in a cryptography context on UNIX-like systems. Obviously, their opinions influenced mine, not the other way around.
|
||||
|
||||
Hard to believe, right? I must certainly be wrong! Well, read on and let me try to convince you.
|
||||
|
||||
I tried to keep it out, but I fear there are two preliminaries to be taken care of, before we can really tackle all those points.
|
||||
|
||||
Namely, what is randomness, or better: what kind of randomness am I talking about here?
|
||||
|
||||
And, even more important, I'm really not being condescending. I have written this document to have a thing to point to, when this discussion comes up again. More than 140 characters. Without repeating myself again and again. Being able to hone the writing and the arguments itself, benefitting many discussions in many venues.
|
||||
|
||||
And I'm certainly willing to hear differing opinions. I'm just saying that it won't be enough to state that /dev/urandom is bad. You need to identify the points you're disagreeing with and engage them.
|
||||
|
||||
### You're saying I'm stupid!
|
||||
|
||||
Emphatically no!
|
||||
|
||||
Actually, I used to believe that /dev/urandom was insecure myself, a few years ago. And it's something you and me almost had to believe, because all those highly respected people on Usenet, in web forums and today on Twitter told us. Even the man page seems to say so. Who were we to dismiss their convincing argument about “entropy running low”?
|
||||
|
||||
This misconception isn't so rampant because people are stupid, it is because with a little knowledge about cryptography (namely some vague idea what entropy is) it's very easy to be convinced of it. Intuition almost forces us there. Unfortunately intuition is often wrong in cryptography. So it is here.
|
||||
|
||||
### True randomness
|
||||
|
||||
What does it mean for random numbers to be “truly random”?
|
||||
|
||||
I don't want to dive into that issue too deep, because it quickly gets philosophical. Discussions have been known to unravel fast, because everyone can wax about their favorite model of randomness, without paying attention to anyone else. Or even making himself understood.
|
||||
|
||||
I believe that the “gold standard” for “true randomness” are quantum effects. Observe a photon pass through a semi-transparent mirror. Or not. Observe some radioactive material emit alpha particles. It's the best idea we have when it comes to randomness in the world. Other people might reasonably believe that those effects aren't truly random. Or even that there is no randomness in the world at all. Let a million flowers bloom.
|
||||
|
||||
Cryptographers often circumvent this philosophical debate by disregarding what it means for randomness to be “true”. They care about unpredictability. As long as nobody can get any information about the next random number, we're fine. And when you're talking about random numbers as a prerequisite in using cryptography, that's what you should aim for, in my opinion.
|
||||
|
||||
Anyway, I don't care much about those “philosophically secure” random numbers, as I like to think of your “true” random numbers.
|
||||
|
||||
### Two kinds of security, one that matters
|
||||
|
||||
But let's assume you've obtained those “true” random numbers. What are you going to do with them?
|
||||
|
||||
You print them out, frame them and hang them on your living-room wall, to revel in the beauty of a quantum universe? That's great, and I certainly understand.
|
||||
|
||||
Wait, what? You're using them? For cryptographic purposes? Well, that spoils everything, because now things get a bit ugly.
|
||||
|
||||
You see, your truly-random, quantum effect blessed random numbers are put into some less respectable, real-world tarnished algorithms.
|
||||
|
||||
Because almost all of the cryptographic algorithms we use do not hold up to ### information-theoretic security**. They can “only” offer **computational security. The two exceptions that come to my mind are Shamir's Secret Sharing and the One-time pad. And while the first one may be a valid counterpoint (if you actually intend to use it), the latter is utterly impractical.
|
||||
|
||||
But all those algorithms you know about, AES, RSA, Diffie-Hellman, Elliptic curves, and all those crypto packages you're using, OpenSSL, GnuTLS, Keyczar, your operating system's crypto API, these are only computationally secure.
|
||||
|
||||
What's the difference? While information-theoretically secure algorithms are secure, period, those other algorithms cannot guarantee security against an adversary with unlimited computational power who's trying all possibilities for keys. We still use them because it would take all the computers in the world taken together longer than the universe has existed, so far. That's the level of “insecurity” we're talking about here.
|
||||
|
||||
Unless some clever guy breaks the algorithm itself, using much less computational power. Even computational power achievable today. That's the big prize every cryptanalyst dreams about: breaking AES itself, breaking RSA itself and so on.
|
||||
|
||||
So now we're at the point where you don't trust the inner building blocks of the random number generator, insisting on “true randomness” instead of “pseudo randomness”. But then you're using those “true” random numbers in algorithms that you so despise that you didn't want them near your random number generator in the first place!
|
||||
|
||||
Truth is, when state-of-the-art hash algorithms are broken, or when state-of-the-art block ciphers are broken, it doesn't matter that you get “philosophically insecure” random numbers because of them. You've got nothing left to securely use them for anyway.
|
||||
|
||||
So just use those computationally-secure random numbers for your computationally-secure algorithms. In other words: use /dev/urandom.
|
||||
|
||||
### Structure of Linux's random number generator
|
||||
|
||||
#### An incorrect view
|
||||
|
||||
Chances are, your idea of the kernel's random number generator is something similar to this:
|
||||
|
||||
![image: mythical structure of the kernel's random number generator][1]
|
||||
|
||||
“True randomness”, albeit possibly skewed and biased, enters the system and its entropy is precisely counted and immediately added to an internal entropy counter. After de-biasing and whitening it's entering the kernel's entropy pool, where both /dev/random and /dev/urandom get their random numbers from.
|
||||
|
||||
The “true” random number generator, /dev/random, takes those random numbers straight out of the pool, if the entropy count is sufficient for the number of requested numbers, decreasing the entropy counter, of course. If not, it blocks until new entropy has entered the system.
|
||||
|
||||
The important thing in this narrative is that /dev/random basically yields the numbers that have been input by those randomness sources outside, after only the necessary whitening. Nothing more, just pure randomness.
|
||||
|
||||
/dev/urandom, so the story goes, is doing the same thing. Except when there isn't sufficient entropy in the system. In contrast to /dev/random, it does not block, but gets “low quality random” numbers from a pseudorandom number generator (conceded, a cryptographically secure one) that is running alongside the rest of the random number machinery. This CSPRNG is just seeded once (or maybe every now and then, it doesn't matter) with “true randomness” from the randomness pool, but you can't really trust it.
|
||||
|
||||
In this view, that seems to be in a lot of people's minds when they're talking about random numbers on Linux, avoiding /dev/urandom is plausible.
|
||||
|
||||
Because either there is enough entropy left, then you get the same you'd have gotten from /dev/random. Or there isn't, then you get those low-quality random numbers from a CSPRNG that almost never saw high-entropy input.
|
||||
|
||||
Devilish, right? Unfortunately, also utterly wrong. In reality, the internal structure of the random number generator looks like this.
|
||||
|
||||
#### A better simplification
|
||||
|
||||
##### Before Linux 4.8
|
||||
|
||||
![image: actual structure of the kernel's random number generator before Linux 4.8][2] This is a pretty rough simplification. In fact, there isn't just one, but three pools filled with entropy. One primary pool, and one for /dev/random and /dev/urandom each, feeding off the primary pool. Those three pools all have their own entropy counts, but the counts of the secondary pools (for /dev/random and /dev/urandom) are mostly close to zero, and “fresh” entropy flows from the primary pool when needed, decreasing its entropy count. Also there is a lot of mixing and re-injecting outputs back into the system going on. All of this is far more detail than is necessary for this document.
|
||||
|
||||
See the big difference? The CSPRNG is not running alongside the random number generator, filling in for those times when /dev/urandom wants to output something, but has nothing good to output. The CSPRNG is an integral part of the random number generation process. There is no /dev/random handing out “good and pure” random numbers straight from the whitener. Every randomness source's input is thoroughly mixed and hashed inside the CSPRNG, before it emerges as random numbers, either via /dev/urandom or /dev/random.
|
||||
|
||||
Another important difference is that there is no entropy counting going on here, but estimation. The amount of entropy some source is giving you isn't something obvious that you just get, along with the data. It has to be estimated. Please note that when your estimate is too optimistic, the dearly held property of /dev/random, that it's only giving out as many random numbers as available entropy allows, is gone. Unfortunately, it's hard to estimate the amount of entropy.
|
||||
|
||||
The Linux kernel uses only the arrival times of events to estimate their entropy. It does that by interpolating polynomials of those arrival times, to calculate “how surprising” the actual arrival time was, according to the model. Whether this polynomial interpolation model is the best way to estimate entropy is an interesting question. There is also the problem that internal hardware restrictions might influence those arrival times. The sampling rates of all kinds of hardware components may also play a role, because it directly influences the values and the granularity of those event arrival times.
|
||||
|
||||
In the end, to the best of our knowledge, the kernel's entropy estimate is pretty good. Which means it's conservative. People argue about how good it really is, but that issue is far above my head. Still, if you insist on never handing out random numbers that are not “backed” by sufficient entropy, you might be nervous here. I'm sleeping sound because I don't care about the entropy estimate.
|
||||
|
||||
So to make one thing crystal clear: both /dev/random and /dev/urandom are fed by the same CSPRNG. Only the behavior when their respective pool runs out of entropy, according to some estimate, differs: /dev/random blocks, while /dev/urandom does not.
|
||||
|
||||
##### From Linux 4.8 onward
|
||||
|
||||
In Linux 4.8 the equivalency between /dev/urandom and /dev/random was given up. Now /dev/urandom output does not come from an entropy pool, but directly from a CSPRNG.
|
||||
|
||||
![image: actual structure of the kernel's random number generator from Linux 4.8 onward][3]
|
||||
|
||||
We will see shortly why that is not a security problem.
|
||||
|
||||
### What's wrong with blocking?
|
||||
|
||||
Have you ever waited for /dev/random to give you more random numbers? Generating a PGP key inside a virtual machine maybe? Connecting to a web server that's waiting for more random numbers to create an ephemeral session key?
|
||||
|
||||
That's the problem. It inherently runs counter to availability. So your system is not working. It's not doing what you built it to do. Obviously, that's bad. You wouldn't have built it if you didn't need it.
|
||||
|
||||
I'm working on safety-related systems in factory automation. Can you guess what the main reason for failures of safety systems is? Manipulation. Simple as that. Something about the safety measure bugged the worker. It took too much time, was too inconvenient, whatever. People are very resourceful when it comes to finding “inofficial solutions”.
|
||||
|
||||
But the problem runs even deeper: people don't like to be stopped in their ways. They will devise workarounds, concoct bizarre machinations to just get it running. People who don't know anything about cryptography. Normal people.
|
||||
|
||||
Why not patching out the call to `random()`? Why not having some guy in a web forum tell you how to use some strange ioctl to increase the entropy counter? Why not switch off SSL altogether?
|
||||
|
||||
In the end you just educate your users to do foolish things that compromise your system's security without you ever knowing about it.
|
||||
|
||||
It's easy to disregard availability, usability or other nice properties. Security trumps everything, right? So better be inconvenient, unavailable or unusable than feign security.
|
||||
|
||||
But that's a false dichotomy. Blocking is not necessary for security. As we saw, /dev/urandom gives you the same kind of random numbers as /dev/random, straight out of a CSPRNG. Use it!
|
||||
|
||||
### The CSPRNGs are alright
|
||||
|
||||
But now everything sounds really bleak. If even the high-quality random numbers from /dev/random are coming out of a CSPRNG, how can we use them for high-security purposes?
|
||||
|
||||
It turns out, that “looking random” is the basic requirement for a lot of our cryptographic building blocks. If you take the output of a cryptographic hash, it has to be indistinguishable from a random string so that cryptographers will accept it. If you take a block cipher, its output (without knowing the key) must also be indistinguishable from random data.
|
||||
|
||||
If anyone could gain an advantage over brute force breaking of cryptographic building blocks, using some perceived weakness of those CSPRNGs over “true” randomness, then it's the same old story: you don't have anything left. Block ciphers, hashes, everything is based on the same mathematical fundament as CSPRNGs. So don't be afraid.
|
||||
|
||||
### What about entropy running low?
|
||||
|
||||
It doesn't matter.
|
||||
|
||||
The underlying cryptographic building blocks are designed such that an attacker cannot predict the outcome, as long as there was enough randomness (a.k.a. entropy) in the beginning. A usual lower limit for “enough” may be 256 bits. No more.
|
||||
|
||||
Considering that we were pretty hand-wavey about the term “entropy” in the first place, it feels right. As we saw, the kernel's random number generator cannot even precisely know the amount of entropy entering the system. Only an estimate. And whether the model that's the basis for the estimate is good enough is pretty unclear, too.
|
||||
|
||||
### Re-seeding
|
||||
|
||||
But if entropy is so unimportant, why is fresh entropy constantly being injected into the random number generator?
|
||||
|
||||
djb [remarked][4] that more entropy actually can hurt.
|
||||
|
||||
First, it cannot hurt. If you've got more randomness just lying around, by all means use it!
|
||||
|
||||
There is another reason why re-seeding the random number generator every now and then is important:
|
||||
|
||||
Imagine an attacker knows everything about your random number generator's internal state. That's the most severe security compromise you can imagine, the attacker has full access to the system.
|
||||
|
||||
You've totally lost now, because the attacker can compute all future outputs from this point on.
|
||||
|
||||
But over time, with more and more fresh entropy being mixed into it, the internal state gets more and more random again. So that such a random number generator's design is kind of self-healing.
|
||||
|
||||
But this is injecting entropy into the generator's internal state, it has nothing to do with blocking its output.
|
||||
|
||||
### The random and urandom man page
|
||||
|
||||
The man page for /dev/random and /dev/urandom is pretty effective when it comes to instilling fear into the gullible programmer's mind:
|
||||
|
||||
> A read from the /dev/urandom device will not block waiting for more entropy. As a result, if there is not sufficient entropy in the entropy pool, the returned values are theoretically vulnerable to a cryptographic attack on the algorithms used by the driver. Knowledge of how to do this is not available in the current unclassified literature, but it is theoretically possible that such an attack may exist. If this is a concern in your application, use /dev/random instead.
|
||||
|
||||
Such an attack is not known in “unclassified literature”, but the NSA certainly has one in store, right? And if you're really concerned about this (you should!), please use /dev/random, and all your problems are solved.
|
||||
|
||||
The truth is, while there may be such an attack available to secret services, evil hackers or the Bogeyman, it's just not rational to just take it as a given.
|
||||
|
||||
And even if you need that peace of mind, let me tell you a secret: no practical attacks on AES, SHA-3 or other solid ciphers and hashes are known in the “unclassified” literature, either. Are you going to stop using those, as well? Of course not!
|
||||
|
||||
Now the fun part: “use /dev/random instead”. While /dev/urandom does not block, its random number output comes from the very same CSPRNG as /dev/random's.
|
||||
|
||||
If you really need information-theoretically secure random numbers (you don't!), and that's about the only reason why the entropy of the CSPRNGs input matters, you can't use /dev/random, either!
|
||||
|
||||
The man page is silly, that's all. At least it tries to redeem itself with this:
|
||||
|
||||
> If you are unsure about whether you should use /dev/random or /dev/urandom, then probably you want to use the latter. As a general rule, /dev/urandom should be used for everything except long-lived GPG/SSL/SSH keys.
|
||||
|
||||
Fine. I think it's unnecessary, but if you want to use /dev/random for your “long-lived keys”, by all means, do so! You'll be waiting a few seconds typing stuff on your keyboard, that's no problem.
|
||||
|
||||
But please don't make connections to a mail server hang forever, just because you “wanted to be safe”.
|
||||
|
||||
### Orthodoxy
|
||||
|
||||
The view espoused here is certainly a tiny minority's opinions on the Internet. But ask a real cryptographer, you'll be hard pressed to find someone who sympathizes much with that blocking /dev/random.
|
||||
|
||||
Let's take [Daniel Bernstein][5], better known as djb:
|
||||
|
||||
> Cryptographers are certainly not responsible for this superstitious nonsense. Think about this for a moment: whoever wrote the /dev/random manual page seems to simultaneously believe that
|
||||
>
|
||||
> * (1) we can't figure out how to deterministically expand one 256-bit /dev/random output into an endless stream of unpredictable keys (this is what we need from urandom), but
|
||||
>
|
||||
> * (2) we _can_ figure out how to use a single key to safely encrypt many messages (this is what we need from SSL, PGP, etc.).
|
||||
>
|
||||
>
|
||||
|
||||
>
|
||||
> For a cryptographer this doesn't even pass the laugh test.
|
||||
|
||||
Or [Thomas Pornin][6], who is probably one of the most helpful persons I've ever encountered on the Stackexchange sites:
|
||||
|
||||
> The short answer is yes. The long answer is also yes. /dev/urandom yields data which is indistinguishable from true randomness, given existing technology. Getting "better" randomness than what /dev/urandom provides is meaningless, unless you are using one of the few "information theoretic" cryptographic algorithm, which is not your case (you would know it).
|
||||
>
|
||||
> The man page for urandom is somewhat misleading, arguably downright wrong, when it suggests that /dev/urandom may "run out of entropy" and /dev/random should be preferred;
|
||||
|
||||
Or maybe [Thomas Ptacek][7], who is not a real cryptographer in the sense of designing cryptographic algorithms or building cryptographic systems, but still the founder of a well-reputed security consultancy that's doing a lot of penetration testing and breaking bad cryptography:
|
||||
|
||||
> Use urandom. Use urandom. Use urandom. Use urandom. Use urandom. Use urandom.
|
||||
|
||||
### Not everything is perfect
|
||||
|
||||
/dev/urandom isn't perfect. The problems are twofold:
|
||||
|
||||
On Linux, unlike FreeBSD, /dev/urandom never blocks. Remember that the whole security rested on some starting randomness, a seed?
|
||||
|
||||
Linux's /dev/urandom happily gives you not-so-random numbers before the kernel even had the chance to gather entropy. When is that? At system start, booting the computer.
|
||||
|
||||
FreeBSD does the right thing: they don't have the distinction between /dev/random and /dev/urandom, both are the same device. At startup /dev/random blocks once until enough starting entropy has been gathered. Then it won't block ever again.
|
||||
|
||||
In the meantime, Linux has implemented a new syscall, originally introduced by OpenBSD as getentropy(2): getrandom(2). This syscall does the right thing: blocking until it has gathered enough initial entropy, and never blocking after that point. Of course, it is a syscall, not a character device, so it isn't as easily accessible from shell or script languages. It is available from Linux 3.17 onward.
|
||||
|
||||
On Linux it isn't too bad, because Linux distributions save some random numbers when booting up the system (but after they have gathered some entropy, since the startup script doesn't run immediately after switching on the machine) into a seed file that is read next time the machine is booting. So you carry over the randomness from the last running of the machine.
|
||||
|
||||
Obviously that isn't as good as if you let the shutdown scripts write out the seed, because in that case there would have been much more time to gather entropy. The advantage is obviously that this does not depend on a proper shutdown with execution of the shutdown scripts (in case the computer crashes, for example).
|
||||
|
||||
And it doesn't help you the very first time a machine is running, but the Linux distributions usually do the same saving into a seed file when running the installer. So that's mostly okay.
|
||||
|
||||
Virtual machines are the other problem. Because people like to clone them, or rewind them to a previously saved check point, this seed file doesn't help you.
|
||||
|
||||
But the solution still isn't using /dev/random everywhere, but properly seeding each and every virtual machine after cloning, restoring a checkpoint, whatever.
|
||||
|
||||
### tldr;
|
||||
|
||||
Just use /dev/urandom!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2uo.de/myths-about-urandom/
|
||||
|
||||
作者:[Thomas Hühn][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2uo.de/
|
||||
[1]:https://www.2uo.de/myths-about-urandom/structure-no.png
|
||||
[2]:https://www.2uo.de/myths-about-urandom/structure-yes.png
|
||||
[3]:https://www.2uo.de/myths-about-urandom/structure-new.png
|
||||
[4]:http://blog.cr.yp.to/20140205-entropy.html
|
||||
[5]:http://www.mail-archive.com/cryptography@randombit.net/msg04763.html
|
||||
[6]:http://security.stackexchange.com/questions/3936/is-a-rand-from-dev-urandom-secure-for-a-login-key/3939#3939
|
||||
[7]:http://sockpuppet.org/blog/2014/02/25/safely-generate-random-numbers/
|
||||
@ -1,6 +1,3 @@
|
||||
ezio is translating
|
||||
|
||||
|
||||
In Device We Trust: Measure Twice, Compute Once with Xen, Linux, TPM 2.0 and TXT
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,174 +0,0 @@
|
||||
translating by robsean
|
||||
|
||||
12 Best GTK Themes for Ubuntu and other Linux Distributions
|
||||
======
|
||||
**Brief: Let’s have a look at some of the beautiful GTK themes that you can use not only in Ubuntu but other Linux distributions that use GNOME.**
|
||||
|
||||
For those of us that use Ubuntu proper, the move from Unity to Gnome as the default desktop environment has made theming and customizing easier than ever. Gnome has a fairly large tweaking community, and there is no shortage of fantastic GTK themes for users to choose from. With that in mind, I went ahead and found some of my favorite themes that I have come across in recent months. These are what I believe offer some of the best experiences that you can find.
|
||||
|
||||
### Best themes for Ubuntu and other Linux distributions
|
||||
|
||||
This is not an exhaustive list and may exclude some of the themes you already use and love, but hopefully, you find at least one theme that you enjoy that you did not already know about. All themes present should work on any Gnome 3 setup, Ubuntu or not. I lost some screenshots so I have taken images from the official websites.
|
||||
|
||||
The themes listed here are in no particular order.
|
||||
|
||||
But before you see the best GNOME themes, you should learn [how to install themes in Ubuntu GNOME][1].
|
||||
|
||||
#### 1\. Arc-Ambiance
|
||||
|
||||
![][2]
|
||||
|
||||
Arc and Arc variant themes have been around for quite some time now, and are widely regarded as some of the best themes you can find. In this example, I have selected Arc-Ambiance because of its modern take on the default Ambiance theme in Ubuntu.
|
||||
|
||||
I am a fan of both the Arc theme and the default Ambiance theme, so needless to say, I was pumped when I came across a theme that merged the best of both worlds. If you are a fan of the arc themes but not a fan of this one in particular, Gnome look has plenty of other options that will most certainly suit your taste.
|
||||
|
||||
[Arc-Ambiance Theme][3]
|
||||
|
||||
#### 2\. Adapta Colorpack
|
||||
|
||||
![][4]
|
||||
|
||||
The Adapta theme has been one of my favorite flat themes I have ever found. Like Arc, Adapata is widely adopted by many-a-linux user. I have selected this color pack because in one download you have several options to choose from. In fact, there are 19 to choose from. Yep. You read that correctly. 19!
|
||||
|
||||
So, if you are a fan of the flat/material design language that we see a lot of today, then there is most likely a variant in this theme pack that will satisfy you.
|
||||
|
||||
[Adapta Colorpack Theme][5]
|
||||
|
||||
#### 3\. Numix Collection
|
||||
|
||||
![][6]
|
||||
|
||||
Ah, Numix! Oh, the years we have spent together! For those of us that have been theming our DE for the last couple of years, you must have come across the Numix themes or icon packs at some point in time. Numix was probably the first modern theme for Linux that I fell in love with, and I am still in love with it today. And after all these years, it still hasn’t lost its charm.
|
||||
|
||||
The gray tone throughout the theme, especially with the default pinkish-red highlight color, makes for a genuinely clean and complete experience. You would be hard pressed to find a theme pack as polished as Numix. And in this offering, you have plenty of options to choose from, so go crazy!
|
||||
|
||||
[Numix Collection Theme][7]
|
||||
|
||||
#### 4\. Hooli
|
||||
|
||||
![][8]
|
||||
|
||||
Hooli is a theme that has been out for some time now, but only recently came across my radar. I am a fan of most flat themes but have usually strayed away from themes that come to close to the material design language. Hooli, like Adapta, takes notes from that design language, but does it in a way that I think sets it apart from the rest. The green highlight color is one of my favorite parts about the theme, and it does a good job at not overpowering the entire theme.
|
||||
|
||||
[Hooli Theme][9]
|
||||
|
||||
#### 5\. Arrongin/Telinkrin
|
||||
|
||||
![][10]
|
||||
|
||||
Bonus: Two themes in one! And they are relatively new contenders in the theming realm. They both take notes from Ubuntu’s soon to be finished “[communitheme][11]” and bring it to your desktop today. The only real difference I can find between the offerings are the colors. Arrongin is centered around an Ubuntu-esq orange color, while Telinkrin uses a slightly more KDE Breeze-esq blue. I personally prefer the blue, but both are great options!
|
||||
|
||||
[Arrongin/Telinkrin Themes][12]
|
||||
|
||||
#### 6\. Gnome-osx
|
||||
|
||||
![][13]
|
||||
|
||||
I have to admit, usually, when I see that a theme has “osx” or something similar in the title, I don’t expect much. Most Apple inspired themes seem to have so much in common that I can’t really find a reason to use them. There are two themes I can think of that break this mold: the Arc-osc them and the Gnome-osx theme that we have here.
|
||||
|
||||
The reason I like the Gnome-osx theme is because it truly does look at home on the Gnome desktop. It does a great job at blending into the DE without being too flat. So for those of you that enjoy a slightly less flat theme, and you like the red, yellow, and green button scheme for the close, minimize, and maximize buttons, than this theme is perfect for you.
|
||||
|
||||
[Gnome-osx Theme][14]
|
||||
|
||||
#### 7\. Ultimate Maia
|
||||
|
||||
![][15]
|
||||
|
||||
There was a time when I used Manjaro Gnome. Since then I have reverted back to Ubuntu, but one thing I wish I could have brought with me was the Manjaro theme. If you feel the same about the Manjaro theme as I do, then you are in luck because you can bring it to ANY distro you want that is running Gnome!
|
||||
|
||||
The rich green color, the Breeze-esq close, minimize, maximize buttons, and the over-all polish of the theme makes for one compelling option. It even offers some other color variants of you are not a fan of the green. But let’s be honest…who isn’t a fan of that Manjaro green color?
|
||||
|
||||
[Ultimate Maia Theme][16]
|
||||
|
||||
#### 8\. Vimix
|
||||
|
||||
![][17]
|
||||
|
||||
This was a theme I easily got excited about. It is modern, pulls from the macOS red, yellow, green buttons without directly copying them, and tones down the vibrancy of the theme, making for one unique alternative to most other themes. It comes with three dark variants and several colors to choose from so most of us will find something we like.
|
||||
|
||||
[Vimix Theme][18]
|
||||
|
||||
#### 9\. Ant
|
||||
|
||||
![][19]
|
||||
|
||||
Like Vimix, Ant pulls inspiration from macOS for the button colors without directly copying the style. Where Vimix tones down the color options, Ant adds a richness to the colors that looks fantastic on my System 76 Galago Pro screen. The variation between the three theme options is pretty dramatic, and though it may not be to everyone’s taste, it is most certainly to mine.
|
||||
|
||||
[Ant Theme][20]
|
||||
|
||||
#### 10\. Flat Remix
|
||||
|
||||
![][21]
|
||||
|
||||
If you haven’t noticed by this point, I am a sucker for someone who pays attention to the details in the close, minimize, maximize buttons. The color theme that Flat Remix uses is one I have not seen anywhere else, with a red, blue, and orange color way. Add that on top of a theme that looks almost like a mix between Arc and Adapta, and you have Flat Remix.
|
||||
|
||||
I am personally a fan of the dark option, but the light alternative is very nice as well. So if you like subtle transparencies, a cohesive dark theme, and a touch of color here and there, Flat Remix is for you.
|
||||
|
||||
[Flat Remix Theme][22]
|
||||
|
||||
#### 11\. Paper
|
||||
|
||||
![][23]
|
||||
|
||||
[Paper][24] has been around for some time now. I remember using it for the first back in 2014. I would say, at this point, Paper is more known for its icon pack than for its GTK theme, but that doesn’t mean that the theme isn’t a wonderful option in and of its self. Even though I adored the Paper icons from the beginning, I can’t say that I was a huge fan of the Paper theme when I first tried it out.
|
||||
|
||||
I felt like the bright colors and fun approach to a theme made for an “immature” experience. Now, years later, Paper has grown on me, to say the least, and the light hearted approach that the theme takes is one I greatly appreciate.
|
||||
|
||||
[Paper Theme][25]
|
||||
|
||||
#### 12\. Pop
|
||||
|
||||
![][26]
|
||||
|
||||
Pop is one of the newer offerings on this list. Created by the folks over at [System 76][27], the Pop GTK theme is a fork of the Adapta theme listed earlier and comes with a matching icon pack, which is a fork of the previously mentioned Paper icon pack.
|
||||
|
||||
The theme was released soon after System 76 announced that they were releasing [their own distribution,][28] Pop!_OS. You can read my [Pop!_OS review][29] to know more about it. Needless to say, I think Pop is a fantastic theme with a superb amount of polish and offers a fresh feel to any Gnome desktop.
|
||||
|
||||
[Pop Theme][30]
|
||||
|
||||
#### Conclusion
|
||||
|
||||
Obviously, there way more themes to choose from than we could feature in one article, but these are some of the most complete and polished themes I have used in recent months. If you think we missed any that you really like or you just really dislike one that I featured above, then feel free to let me know in the comment section below and share why you think your favorite themes are better!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-gtk-themes/
|
||||
|
||||
作者:[Phillip Prado][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/phillip/
|
||||
[1]:https://itsfoss.com/install-themes-ubuntu/
|
||||
[2]:https://itsfoss.com/wp-content/uploads/2018/03/arcambaince-300x225.png
|
||||
[3]:https://www.gnome-look.org/p/1193861/
|
||||
[4]:https://itsfoss.com/wp-content/uploads/2018/03/adapta-300x169.jpg
|
||||
[5]:https://www.gnome-look.org/p/1190851/
|
||||
[6]:https://itsfoss.com/wp-content/uploads/2018/03/numix-300x169.png
|
||||
[7]:https://www.gnome-look.org/p/1170667/
|
||||
[8]:https://itsfoss.com/wp-content/uploads/2018/03/hooli2-800x500.jpg
|
||||
[9]:https://www.gnome-look.org/p/1102901/
|
||||
[10]:https://itsfoss.com/wp-content/uploads/2018/03/AT-800x590.jpg
|
||||
[11]:https://itsfoss.com/ubuntu-community-theme/
|
||||
[12]:https://www.gnome-look.org/p/1215199/
|
||||
[13]:https://itsfoss.com/wp-content/uploads/2018/03/gosx-800x473.jpg
|
||||
[14]:https://www.opendesktop.org/s/Gnome/p/1171688/
|
||||
[15]:https://itsfoss.com/wp-content/uploads/2018/03/ultimatemaia-800x450.jpg
|
||||
[16]:https://www.opendesktop.org/s/Gnome/p/1193879/
|
||||
[17]:https://itsfoss.com/wp-content/uploads/2018/03/vimix-800x450.jpg
|
||||
[18]:https://www.gnome-look.org/p/1013698/
|
||||
[19]:https://itsfoss.com/wp-content/uploads/2018/03/ant-800x533.png
|
||||
[20]:https://www.opendesktop.org/p/1099856/
|
||||
[21]:https://itsfoss.com/wp-content/uploads/2018/03/flatremix-800x450.png
|
||||
[22]:https://www.opendesktop.org/p/1214931/
|
||||
[23]:https://itsfoss.com/wp-content/uploads/2018/04/paper-800x450.jpg
|
||||
[24]:https://itsfoss.com/install-paper-theme-linux/
|
||||
[25]:https://snwh.org/paper/download
|
||||
[26]:https://itsfoss.com/wp-content/uploads/2018/04/pop-800x449.jpg
|
||||
[27]:https://system76.com/
|
||||
[28]:https://itsfoss.com/system76-popos-linux/
|
||||
[29]:https://itsfoss.com/pop-os-linux-review/
|
||||
[30]:https://github.com/pop-os/gtk-theme/blob/master/README.md
|
||||
@ -1,3 +1,5 @@
|
||||
translating by MjSeven
|
||||
|
||||
Getting started with Sensu monitoring
|
||||
======
|
||||

|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
liujing97 is translating
|
||||
Working with data streams on the Linux command line
|
||||
======
|
||||
Learn to connect data streams from one utility to another using STDIO.
|
||||
|
||||
@ -1,93 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Take to the virtual skies with FlightGear)
|
||||
[#]: via: (https://opensource.com/article/19/1/flightgear)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
Take to the virtual skies with FlightGear
|
||||
======
|
||||
Dreaming of piloting a plane? Try open source flight simulator FlightGear.
|
||||

|
||||
|
||||
If you've ever dreamed of piloting a plane, you'll love [FlightGear][1]. It's a full-featured, [open source][2] flight simulator that runs on Linux, MacOS, and Windows.
|
||||
|
||||
The FlightGear project began in 1996 due to dissatisfaction with commercial flight simulation programs, which were not scalable. Its goal was to create a sophisticated, robust, extensible, and open flight simulator framework for use in academia and pilot training or by anyone who wants to play with a flight simulation scenario.
|
||||
|
||||
### Getting started
|
||||
|
||||
FlightGear's hardware requirements are fairly modest, including an accelerated 3D video card that supports OpenGL for smooth framerates. It runs well on my Linux laptop with an i5 processor and only 4GB of RAM. Its documentation includes an [online manual][3]; a [wiki][4] with portals for [users][5] and [developers][6]; and extensive tutorials (such as one for its default aircraft, the [Cessna 172p][7]) to teach you how to operate it.
|
||||
|
||||
It's easy to install on both [Fedora][8] and [Ubuntu][9] Linux. Fedora users can consult the [Fedora installation page][10] to get FlightGear running.
|
||||
|
||||
On Ubuntu 18.04, I had to install a repository:
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:saiarcot895/flightgear
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install flightgear
|
||||
```
|
||||
|
||||
Once the installation finished, I launched it from the GUI, but you can also launch the application from a terminal by entering:
|
||||
|
||||
```
|
||||
$ fgfs
|
||||
```
|
||||
|
||||
### Configuring FlightGear
|
||||
|
||||
The menu on the left side of the application window provides configuration options.
|
||||
|
||||

|
||||
|
||||
**Summary** returns you to the application's home screen.
|
||||
|
||||
**Aircraft** shows the aircraft you have installed and offers the option to install up to 539 other aircraft available in FlightGear's default "hangar." I installed a Cessna 150L, a Piper J-3 Cub, and a Bombardier CRJ-700. Some of the aircraft (including the CRJ-700) have tutorials to teach you how to fly a commercial jet; I found the tutorials informative and accurate.
|
||||
|
||||

|
||||
|
||||
To select an aircraft to pilot, highlight it and click on **Fly!** at the bottom of the menu. I chose the default Cessna 172p and found the cockpit depiction extremely accurate.
|
||||
|
||||

|
||||
|
||||
The default airport is Honolulu, but you can change it in the **Location** menu by providing your favorite airport's [ICAO airport code][11] identifier. I found some small, local, non-towered airports like Olean and Dunkirk, New York, as well as larger airports including Buffalo, O'Hare, and Raleigh—and could even choose a specific runway.
|
||||
|
||||
Under **Environment** , you can adjust the time of day, the season, and the weather. The simulation includes advance weather modeling and the ability to download current weather from [NOAA][12].
|
||||
|
||||
**Settings** provides an option to start the simulation in Paused mode by default. Also in Settings, you can select multi-player mode, which allows you to "fly" with other players on FlightGear supporters' global network of servers that allow for multiple users. You must have a moderately fast internet connection to support this functionality.
|
||||
|
||||
The **Add-ons** menu allows you to download aircraft and additional scenery.
|
||||
|
||||
### Take flight
|
||||
|
||||
To "fly" my Cessna, I used a Logitech joystick that worked well. You can calibrate your joystick using an option in the **File** menu at the top.
|
||||
|
||||
Overall, I found the simulation very accurate and think the graphics are great. Try FlightGear yourself — I think you will find it a very fun and complete simulation package.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/flightgear
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://home.flightgear.org/
|
||||
[2]: http://wiki.flightgear.org/GNU_General_Public_License
|
||||
[3]: http://flightgear.sourceforge.net/getstart-en/getstart-en.html
|
||||
[4]: http://wiki.flightgear.org/FlightGear_Wiki
|
||||
[5]: http://wiki.flightgear.org/Portal:User
|
||||
[6]: http://wiki.flightgear.org/Portal:Developer
|
||||
[7]: http://wiki.flightgear.org/Cessna_172P
|
||||
[8]: http://rpmfind.net/linux/rpm2html/search.php?query=flightgear
|
||||
[9]: https://launchpad.net/~saiarcot895/+archive/ubuntu/flightgear
|
||||
[10]: https://apps.fedoraproject.org/packages/FlightGear/
|
||||
[11]: https://en.wikipedia.org/wiki/ICAO_airport_code
|
||||
[12]: https://www.noaa.gov/
|
||||
@ -1,359 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Understand And Identify File types in Linux)
|
||||
[#]: via: (https://www.2daygeek.com/how-to-understand-and-identify-file-types-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
How To Understand And Identify File types in Linux
|
||||
======
|
||||
|
||||
We all are knows, that everything is a file in Linux which includes Hard Disk, Graphics Card, etc.
|
||||
|
||||
When you are navigating the Linux filesystem most of the files are fall under regular files and directories.
|
||||
|
||||
But it has other file types as well for different purpose which fall in five categories.
|
||||
|
||||
So, it’s very important to understand the file types in Linux that helps you in many ways.
|
||||
|
||||
If you can’t believe this, you just gone through the complete article then you come to know how important is.
|
||||
|
||||
If you don’t understand the file types you can’t make any changes on that without fear.
|
||||
|
||||
If you made the changes wrongly that damage your system very badly so be careful when you are doing that.
|
||||
|
||||
Files are very important in Linux because all the devices and daemon’s were stored as a file in Linux system.
|
||||
|
||||
### How Many Types of File is Available in Linux?
|
||||
|
||||
As per my knowledge, totally 7 types of files are available in Linux with 3 Major categories. The details are below.
|
||||
|
||||
* Regular File
|
||||
* Directory File
|
||||
* Special Files (This category having five type of files)
|
||||
* Link File
|
||||
* Character Device File
|
||||
* Socket File
|
||||
* Named Pipe File
|
||||
* Block File
|
||||
|
||||
|
||||
|
||||
Refer the below table for better understanding of file types in Linux.
|
||||
| Symbol | Meaning |
|
||||
| – | Regular File. It starts with underscore “_”. |
|
||||
| d | Directory File. It starts with English alphabet letter “d”. |
|
||||
| l | Link File. It starts with English alphabet letter “l”. |
|
||||
| c | Character Device File. It starts with English alphabet letter “c”. |
|
||||
| s | Socket File. It starts with English alphabet letter “s”. |
|
||||
| p | Named Pipe File. It starts with English alphabet letter “p”. |
|
||||
| b | Block File. It starts with English alphabet letter “b”. |
|
||||
|
||||
### Method-1: Manual Way to Identify File types in Linux
|
||||
|
||||
If you are having good knowledge in Linux then you can easily identify the files type with help of above table.
|
||||
|
||||
#### How to view the Regular files in Linux?
|
||||
|
||||
Use the below command to view the Regular files in Linux. Regular files are available everywhere in Linux filesystem.
|
||||
The Regular files color is `WHITE`
|
||||
|
||||
```
|
||||
# ls -la | grep ^-
|
||||
-rw-------. 1 mageshm mageshm 1394 Jan 18 15:59 .bash_history
|
||||
-rw-r--r--. 1 mageshm mageshm 18 May 11 2012 .bash_logout
|
||||
-rw-r--r--. 1 mageshm mageshm 176 May 11 2012 .bash_profile
|
||||
-rw-r--r--. 1 mageshm mageshm 124 May 11 2012 .bashrc
|
||||
-rw-r--r--. 1 root root 26 Dec 27 17:55 liks
|
||||
-rw-r--r--. 1 root root 104857600 Jan 31 2006 test100.dat
|
||||
-rw-r--r--. 1 root root 104874307 Dec 30 2012 test100.zip
|
||||
-rw-r--r--. 1 root root 11536384 Dec 30 2012 test10.zip
|
||||
-rw-r--r--. 1 root root 61 Dec 27 19:05 test2-bzip2.txt
|
||||
-rw-r--r--. 1 root root 61 Dec 31 14:24 test3-bzip2.txt
|
||||
-rw-r--r--. 1 root root 60 Dec 27 19:01 test-bzip2.txt
|
||||
```
|
||||
|
||||
#### How to view the Directory files in Linux?
|
||||
|
||||
Use the below command to view the Directory files in Linux. Directory files are available everywhere in Linux filesystem. The Directory files colour is `BLUE`
|
||||
|
||||
```
|
||||
# ls -la | grep ^d
|
||||
drwxr-xr-x. 3 mageshm mageshm 4096 Dec 31 14:24 links/
|
||||
drwxrwxr-x. 2 mageshm mageshm 4096 Nov 16 15:44 perl5/
|
||||
drwxr-xr-x. 2 mageshm mageshm 4096 Nov 16 15:37 public_ftp/
|
||||
drwxr-xr-x. 3 mageshm mageshm 4096 Nov 16 15:37 public_html/
|
||||
```
|
||||
|
||||
#### How to view the Link files in Linux?
|
||||
|
||||
Use the below command to view the Link files in Linux. Link files are available everywhere in Linux filesystem.
|
||||
Two type of link files are available, it’s Soft link and Hard link. The Link files color is `LIGHT TURQUOISE`
|
||||
|
||||
```
|
||||
# ls -la | grep ^l
|
||||
lrwxrwxrwx. 1 root root 31 Dec 7 15:11 s-link-file -> /links/soft-link/test-soft-link
|
||||
lrwxrwxrwx. 1 root root 38 Dec 7 15:12 s-link-folder -> /links/soft-link/test-soft-link-folder
|
||||
```
|
||||
|
||||
#### How to view the Character Device files in Linux?
|
||||
|
||||
Use the below command to view the Character Device files in Linux. Character Device files are available only in specific location.
|
||||
|
||||
It’s available under `/dev` directory. The Character Device files color is `YELLOW`
|
||||
|
||||
```
|
||||
# ls -la | grep ^c
|
||||
crw-------. 1 root root 5, 1 Jan 28 14:05 console
|
||||
crw-rw----. 1 root root 10, 61 Jan 28 14:05 cpu_dma_latency
|
||||
crw-rw----. 1 root root 10, 62 Jan 28 14:05 crash
|
||||
crw-rw----. 1 root root 29, 0 Jan 28 14:05 fb0
|
||||
crw-rw-rw-. 1 root root 1, 7 Jan 28 14:05 full
|
||||
crw-rw-rw-. 1 root root 10, 229 Jan 28 14:05 fuse
|
||||
```
|
||||
|
||||
#### How to view the Block files in Linux?
|
||||
|
||||
Use the below command to view the Block files in Linux. The Block files are available only in specific location.
|
||||
It’s available under `/dev` directory. The Block files color is `YELLOW`
|
||||
|
||||
```
|
||||
# ls -la | grep ^b
|
||||
brw-rw----. 1 root disk 7, 0 Jan 28 14:05 loop0
|
||||
brw-rw----. 1 root disk 7, 1 Jan 28 14:05 loop1
|
||||
brw-rw----. 1 root disk 7, 2 Jan 28 14:05 loop2
|
||||
brw-rw----. 1 root disk 7, 3 Jan 28 14:05 loop3
|
||||
brw-rw----. 1 root disk 7, 4 Jan 28 14:05 loop4
|
||||
```
|
||||
|
||||
#### How to view the Socket files in Linux?
|
||||
|
||||
Use the below command to view the Socket files in Linux. The Socket files are available only in specific location.
|
||||
The Socket files color is `PINK`
|
||||
|
||||
```
|
||||
# ls -la | grep ^s
|
||||
srw-rw-rw- 1 root root 0 Jan 5 16:36 system_bus_socket
|
||||
```
|
||||
|
||||
#### How to view the Named Pipe files in Linux?
|
||||
|
||||
Use the below command to view the Named Pipe files in Linux. The Named Pipe files are available only in specific location. The Named Pipe files color is `YELLOW`
|
||||
|
||||
```
|
||||
# ls -la | grep ^p
|
||||
prw-------. 1 root root 0 Jan 28 14:06 replication-notify-fifo|
|
||||
prw-------. 1 root root 0 Jan 28 14:06 stats-mail|
|
||||
```
|
||||
|
||||
### Method-2: How to Identify File types in Linux Using file Command?
|
||||
|
||||
The file command allow us to determine various file types in Linux. There are three sets of tests, performed in this order: filesystem tests, magic tests, and language tests to identify file types.
|
||||
|
||||
#### How to view the Regular files in Linux Using file Command?
|
||||
|
||||
Simple enter the file command on your terminal and followed by Regular file. The file command will read the given file contents and display exactly what kind of file it is.
|
||||
|
||||
That’s why we are seeing different results for each Regular files. See the below various results for Regular files.
|
||||
|
||||
```
|
||||
# file 2daygeek_access.log
|
||||
2daygeek_access.log: ASCII text, with very long lines
|
||||
|
||||
# file powertop.html
|
||||
powertop.html: HTML document, ASCII text, with very long lines
|
||||
|
||||
# file 2g-test
|
||||
2g-test: JSON data
|
||||
|
||||
# file powertop.txt
|
||||
powertop.txt: HTML document, UTF-8 Unicode text, with very long lines
|
||||
|
||||
# file 2g-test-05-01-2019.tar.gz
|
||||
2g-test-05-01-2019.tar.gz: gzip compressed data, last modified: Sat Jan 5 18:22:20 2019, from Unix, original size 450560
|
||||
```
|
||||
|
||||
#### How to view the Directory files in Linux Using file Command?
|
||||
|
||||
Simple enter the file command on your terminal and followed by Directory file. See the results below.
|
||||
|
||||
```
|
||||
# file Pictures/
|
||||
Pictures/: directory
|
||||
```
|
||||
|
||||
#### How to view the Link files in Linux Using file Command?
|
||||
|
||||
Simple enter the file command on your terminal and followed by Link file. See the results below.
|
||||
|
||||
```
|
||||
# file log
|
||||
log: symbolic link to /run/systemd/journal/dev-log
|
||||
```
|
||||
|
||||
#### How to view the Character Device files in Linux Using file Command?
|
||||
|
||||
Simple enter the file command on your terminal and followed by Character Device file. See the results below.
|
||||
|
||||
```
|
||||
# file vcsu
|
||||
vcsu: character special (7/64)
|
||||
```
|
||||
|
||||
#### How to view the Block files in Linux Using file Command?
|
||||
|
||||
Simple enter the file command on your terminal and followed by Block file. See the results below.
|
||||
|
||||
```
|
||||
# file sda1
|
||||
sda1: block special (8/1)
|
||||
```
|
||||
|
||||
#### How to view the Socket files in Linux Using file Command?
|
||||
|
||||
Simple enter the file command on your terminal and followed by Socket file. See the results below.
|
||||
|
||||
```
|
||||
# file system_bus_socket
|
||||
system_bus_socket: socket
|
||||
```
|
||||
|
||||
#### How to view the Named Pipe files in Linux Using file Command?
|
||||
|
||||
Simple enter the file command on your terminal and followed by Named Pipe file. See the results below.
|
||||
|
||||
```
|
||||
# file pipe-test
|
||||
pipe-test: fifo (named pipe)
|
||||
```
|
||||
|
||||
### Method-3: How to Identify File types in Linux Using stat Command?
|
||||
|
||||
The stat command allow us to check file types or file system status. This utility giving more information than file command. It shows lot of information about the given file such as Size, Block Size, IO Block Size, Inode Value, Links, File permission, UID, GID, File Access, Modify and Change time details.
|
||||
|
||||
#### How to view the Regular files in Linux Using stat Command?
|
||||
|
||||
Simple enter the stat command on your terminal and followed by Regular file.
|
||||
|
||||
```
|
||||
# stat 2daygeek_access.log
|
||||
File: 2daygeek_access.log
|
||||
Size: 14406929 Blocks: 28144 IO Block: 4096 regular file
|
||||
Device: 10301h/66305d Inode: 1727555 Links: 1
|
||||
Access: (0644/-rw-r--r--) Uid: ( 1000/ daygeek) Gid: ( 1000/ daygeek)
|
||||
Access: 2019-01-03 14:05:26.430328867 +0530
|
||||
Modify: 2019-01-03 14:05:26.460328868 +0530
|
||||
Change: 2019-01-03 14:05:26.460328868 +0530
|
||||
Birth: -
|
||||
```
|
||||
|
||||
#### How to view the Directory files in Linux Using stat Command?
|
||||
|
||||
Simple enter the stat command on your terminal and followed by Directory file. See the results below.
|
||||
|
||||
```
|
||||
# stat Pictures/
|
||||
File: Pictures/
|
||||
Size: 4096 Blocks: 8 IO Block: 4096 directory
|
||||
Device: 10301h/66305d Inode: 1703982 Links: 3
|
||||
Access: (0755/drwxr-xr-x) Uid: ( 1000/ daygeek) Gid: ( 1000/ daygeek)
|
||||
Access: 2018-11-24 03:22:11.090000828 +0530
|
||||
Modify: 2019-01-05 18:27:01.546958817 +0530
|
||||
Change: 2019-01-05 18:27:01.546958817 +0530
|
||||
Birth: -
|
||||
```
|
||||
|
||||
#### How to view the Link files in Linux Using stat Command?
|
||||
|
||||
Simple enter the stat command on your terminal and followed by Link file. See the results below.
|
||||
|
||||
```
|
||||
# stat /dev/log
|
||||
File: /dev/log -> /run/systemd/journal/dev-log
|
||||
Size: 28 Blocks: 0 IO Block: 4096 symbolic link
|
||||
Device: 6h/6d Inode: 278 Links: 1
|
||||
Access: (0777/lrwxrwxrwx) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
Access: 2019-01-05 16:36:31.033333447 +0530
|
||||
Modify: 2019-01-05 16:36:30.766666768 +0530
|
||||
Change: 2019-01-05 16:36:30.766666768 +0530
|
||||
Birth: -
|
||||
```
|
||||
|
||||
#### How to view the Character Device files in Linux Using stat Command?
|
||||
|
||||
Simple enter the stat command on your terminal and followed by Character Device file. See the results below.
|
||||
|
||||
```
|
||||
# stat /dev/vcsu
|
||||
File: /dev/vcsu
|
||||
Size: 0 Blocks: 0 IO Block: 4096 character special file
|
||||
Device: 6h/6d Inode: 16 Links: 1 Device type: 7,40
|
||||
Access: (0660/crw-rw----) Uid: ( 0/ root) Gid: ( 5/ tty)
|
||||
Access: 2019-01-05 16:36:31.056666781 +0530
|
||||
Modify: 2019-01-05 16:36:31.056666781 +0530
|
||||
Change: 2019-01-05 16:36:31.056666781 +0530
|
||||
Birth: -
|
||||
```
|
||||
|
||||
#### How to view the Block files in Linux Using stat Command?
|
||||
|
||||
Simple enter the stat command on your terminal and followed by Block file. See the results below.
|
||||
|
||||
```
|
||||
# stat /dev/sda1
|
||||
File: /dev/sda1
|
||||
Size: 0 Blocks: 0 IO Block: 4096 block special file
|
||||
Device: 6h/6d Inode: 250 Links: 1 Device type: 8,1
|
||||
Access: (0660/brw-rw----) Uid: ( 0/ root) Gid: ( 994/ disk)
|
||||
Access: 2019-01-05 16:36:31.596666806 +0530
|
||||
Modify: 2019-01-05 16:36:31.596666806 +0530
|
||||
Change: 2019-01-05 16:36:31.596666806 +0530
|
||||
Birth: -
|
||||
```
|
||||
|
||||
#### How to view the Socket files in Linux Using stat Command?
|
||||
|
||||
Simple enter the stat command on your terminal and followed by Socket file. See the results below.
|
||||
|
||||
```
|
||||
# stat /var/run/dbus/system_bus_socket
|
||||
File: /var/run/dbus/system_bus_socket
|
||||
Size: 0 Blocks: 0 IO Block: 4096 socket
|
||||
Device: 15h/21d Inode: 576 Links: 1
|
||||
Access: (0666/srw-rw-rw-) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
Access: 2019-01-05 16:36:31.823333482 +0530
|
||||
Modify: 2019-01-05 16:36:31.810000149 +0530
|
||||
Change: 2019-01-05 16:36:31.810000149 +0530
|
||||
Birth: -
|
||||
```
|
||||
|
||||
#### How to view the Named Pipe files in Linux Using stat Command?
|
||||
|
||||
Simple enter the stat command on your terminal and followed by Named Pipe file. See the results below.
|
||||
|
||||
```
|
||||
# stat pipe-test
|
||||
File: pipe-test
|
||||
Size: 0 Blocks: 0 IO Block: 4096 fifo
|
||||
Device: 10301h/66305d Inode: 1705583 Links: 1
|
||||
Access: (0644/prw-r--r--) Uid: ( 1000/ daygeek) Gid: ( 1000/ daygeek)
|
||||
Access: 2019-01-06 02:00:03.040394731 +0530
|
||||
Modify: 2019-01-06 02:00:03.040394731 +0530
|
||||
Change: 2019-01-06 02:00:03.040394731 +0530
|
||||
Birth: -
|
||||
```
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-understand-and-identify-file-types-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -1,159 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (7 Methods To Identify Disk Partition/FileSystem UUID On Linux)
|
||||
[#]: via: (https://www.2daygeek.com/check-partitions-uuid-filesystem-uuid-universally-unique-identifier-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
7 Methods To Identify Disk Partition/FileSystem UUID On Linux
|
||||
======
|
||||
|
||||
As a Linux administrator you should aware of that how do you check partition UUID or filesystem UUID.
|
||||
|
||||
Because most of the Linux systems are mount the partitions with UUID. The same has been verified in the `/etc/fstab` file.
|
||||
|
||||
There are many utilities are available to check UUID. In this article we will show you how to check UUID in many ways and you can choose the one which is suitable for you.
|
||||
|
||||
### What Is UUID?
|
||||
|
||||
UUID stands for Universally Unique Identifier which helps Linux system to identify a hard drives partition instead of block device file.
|
||||
|
||||
libuuid is part of the util-linux-ng package since kernel version 2.15.1 and it’s installed by default in Linux system.
|
||||
|
||||
The UUIDs generated by this library can be reasonably expected to be unique within a system, and unique across all systems.
|
||||
|
||||
It’s a 128 bit number used to identify information in computer systems. UUIDs were originally used in the Apollo Network Computing System (NCS) and later UUIDs are standardized by the Open Software Foundation (OSF) as part of the Distributed Computing Environment (DCE).
|
||||
|
||||
UUIDs are represented as 32 hexadecimal (base 16) digits, displayed in five groups separated by hyphens, in the form 8-4-4-4-12 for a total of 36 characters (32 alphanumeric characters and four hyphens).
|
||||
|
||||
For example: d92fa769-e00f-4fd7-b6ed-ecf7224af7fa
|
||||
|
||||
Sample of my /etc/fstab file.
|
||||
|
||||
```
|
||||
# cat /etc/fstab
|
||||
|
||||
# /etc/fstab: static file system information.
|
||||
#
|
||||
# Use 'blkid' to print the universally unique identifier for a device; this may
|
||||
# be used with UUID= as a more robust way to name devices that works even if
|
||||
# disks are added and removed. See fstab(5).
|
||||
#
|
||||
#
|
||||
UUID=69d9dd18-36be-4631-9ebb-78f05fe3217f / ext4 defaults,noatime 0 1
|
||||
UUID=a2092b92-af29-4760-8e68-7a201922573b swap swap defaults,noatime 0 2
|
||||
```
|
||||
|
||||
We can check this using the following seven commands.
|
||||
|
||||
* **`blkid Command:`** locate/print block device attributes.
|
||||
* **`lsblk Command:`** lsblk lists information about all available or the specified block devices.
|
||||
* **`hwinfo Command:`** hwinfo stands for hardware information tool is another great utility that used to probe for the hardware present in the system.
|
||||
* **`udevadm Command:`** udev management tool.
|
||||
* **`tune2fs Command:`** adjust tunable filesystem parameters on ext2/ext3/ext4 filesystems.
|
||||
* **`dumpe2fs Command:`** dump ext2/ext3/ext4 filesystem information.
|
||||
* **`Using by-uuid Path:`** The directory contains UUID and real block device files, UUIDs were symlink with real block device files.
|
||||
|
||||
|
||||
|
||||
### How To Check Disk Partition/FileSystem UUID In Linux Uusing blkid Command?
|
||||
|
||||
blkid is a command-line utility to locate/print block device attributes. It uses libblkid library to get disk partition UUID in Linux system.
|
||||
|
||||
```
|
||||
# blkid
|
||||
/dev/sda1: UUID="d92fa769-e00f-4fd7-b6ed-ecf7224af7fa" TYPE="ext4" PARTUUID="eab59449-01"
|
||||
/dev/sdc1: UUID="d17e3c31-e2c9-4f11-809c-94a549bc43b7" TYPE="ext2" PARTUUID="8cc8f9e5-01"
|
||||
/dev/sdc3: UUID="ca307aa4-0866-49b1-8184-004025789e63" TYPE="ext4" PARTUUID="8cc8f9e5-03"
|
||||
/dev/sdc5: PARTUUID="8cc8f9e5-05"
|
||||
```
|
||||
|
||||
### How To Check Disk Partition/FileSystem UUID In Linux Uusing lsblk Command?
|
||||
|
||||
lsblk lists information about all available or the specified block devices. The lsblk command reads the sysfs filesystem and udev db to gather information.
|
||||
|
||||
If the udev db is not available or lsblk is compiled without udev support than it tries to read LABELs, UUIDs and filesystem types from the block device. In this case root permissions are necessary. The command prints all block devices (except RAM disks) in a tree-like format by default.
|
||||
|
||||
```
|
||||
# lsblk -o name,mountpoint,size,uuid
|
||||
NAME MOUNTPOINT SIZE UUID
|
||||
sda 30G
|
||||
└─sda1 / 20G d92fa769-e00f-4fd7-b6ed-ecf7224af7fa
|
||||
sdb 10G
|
||||
sdc 10G
|
||||
├─sdc1 1G d17e3c31-e2c9-4f11-809c-94a549bc43b7
|
||||
├─sdc3 1G ca307aa4-0866-49b1-8184-004025789e63
|
||||
├─sdc4 1K
|
||||
└─sdc5 1G
|
||||
sdd 10G
|
||||
sde 10G
|
||||
sr0 1024M
|
||||
```
|
||||
|
||||
### How To Check Disk Partition/FileSystem UUID In Linux Uusing by-uuid path?
|
||||
|
||||
The directory contains UUID and real block device files, UUIDs were symlink with real block device files.
|
||||
|
||||
```
|
||||
# ls -lh /dev/disk/by-uuid/
|
||||
total 0
|
||||
lrwxrwxrwx 1 root root 10 Jan 29 08:34 ca307aa4-0866-49b1-8184-004025789e63 -> ../../sdc3
|
||||
lrwxrwxrwx 1 root root 10 Jan 29 08:34 d17e3c31-e2c9-4f11-809c-94a549bc43b7 -> ../../sdc1
|
||||
lrwxrwxrwx 1 root root 10 Jan 29 08:34 d92fa769-e00f-4fd7-b6ed-ecf7224af7fa -> ../../sda1
|
||||
```
|
||||
|
||||
### How To Check Disk Partition/FileSystem UUID In Linux Uusing hwinfo Command?
|
||||
|
||||
**[hwinfo][1]** stands for hardware information tool is another great utility that used to probe for the hardware present in the system and display detailed information about varies hardware components in human readable format.
|
||||
|
||||
```
|
||||
# hwinfo --block | grep by-uuid | awk '{print $3,$7}'
|
||||
/dev/sdc1, /dev/disk/by-uuid/d17e3c31-e2c9-4f11-809c-94a549bc43b7
|
||||
/dev/sdc3, /dev/disk/by-uuid/ca307aa4-0866-49b1-8184-004025789e63
|
||||
/dev/sda1, /dev/disk/by-uuid/d92fa769-e00f-4fd7-b6ed-ecf7224af7fa
|
||||
```
|
||||
|
||||
### How To Check Disk Partition/FileSystem UUID In Linux Uusing udevadm Command?
|
||||
|
||||
udevadm expects a command and command specific options. It controls the runtime behavior of systemd-udevd, requests kernel events, manages the event queue, and provides simple debugging mechanisms.
|
||||
|
||||
```
|
||||
udevadm info -q all -n /dev/sdc1 | grep -i by-uuid | head -1
|
||||
S: disk/by-uuid/d17e3c31-e2c9-4f11-809c-94a549bc43b7
|
||||
```
|
||||
|
||||
### How To Check Disk Partition/FileSystem UUID In Linux Uusing tune2fs Command?
|
||||
|
||||
tune2fs allows the system administrator to adjust various tunable filesystem parameters on Linux ext2, ext3, or ext4 filesystems. The current values of these options can be displayed by using the -l option.
|
||||
|
||||
```
|
||||
# tune2fs -l /dev/sdc1 | grep UUID
|
||||
Filesystem UUID: d17e3c31-e2c9-4f11-809c-94a549bc43b7
|
||||
```
|
||||
|
||||
### How To Check Disk Partition/FileSystem UUID In Linux Uusing dumpe2fs Command?
|
||||
|
||||
dumpe2fs prints the super block and blocks group information for the filesystem present on device.
|
||||
|
||||
```
|
||||
# dumpe2fs /dev/sdc1 | grep UUID
|
||||
dumpe2fs 1.43.5 (04-Aug-2017)
|
||||
Filesystem UUID: d17e3c31-e2c9-4f11-809c-94a549bc43b7
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/check-partitions-uuid-filesystem-uuid-universally-unique-identifier-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/hwinfo-check-display-detect-system-hardware-information-linux/
|
||||
@ -0,0 +1,147 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (VA Linux: The Linux Company That Once Ruled NASDAQ)
|
||||
[#]: via: (https://itsfoss.com/story-of-va-linux/)
|
||||
[#]: author: (Avimanyu Bandyopadhyay https://itsfoss.com/author/avimanyu/)
|
||||
|
||||
VA Linux: The Linux Company That Once Ruled NASDAQ
|
||||
======
|
||||
|
||||
This is our first article in the Linux and open source history series. We will be covering more trivia, anecdotes and other nostalgic events from the past.
|
||||
|
||||
At its time, _VA Linux_ was indeed a crusade to free the world from Microsoft’s domination.
|
||||
|
||||
On a historical incident in December 1999, the shares of a private firm skyrocketed from just $30 to a whopping $239 within just a day of its [IPO][1]! It was a record-breaking development that day.
|
||||
|
||||
The company was _VA Linux_ , a firm with only 200 employees that was based on the idea of deploying Intel Hardware with Linux and FOSS, had begun a fantastic journey [on the likes of Sun and Dell][2].
|
||||
|
||||
It traded with a symbol LNUX and gained around 700 percent on its first day of trading. But hardly one year later, the [LNUX stocks were selling below $9 per share][3].
|
||||
|
||||
How come a successful Linux based company become a subsidiary of [Gamestop][4], a gaming company?
|
||||
|
||||
Let us look back into the highs and lows of this record-breaking Linux corporation by knowing their history in brief.
|
||||
|
||||
### How did it all actually begin?
|
||||
|
||||
In the year 1993, a graduate student at Stanford University wanted to own a powerful workstation but could not afford to buy expensive [Sun][5] Workstations, which used to be sold at extremely high prices of $7,000 per system at that time.
|
||||
|
||||
So, he decided to do build one on his own ([DIY][6] [FTW][7]!). Using an Intel 486-chip running at just 33 megahertz, he installed Linux and finally had a machine that was twice as fast as Sun’s but at a much lower price tag: $2,000.
|
||||
|
||||
That student was none other than _VA Research_ founder [Larry Augustin][8], whose idea was loved by many at that exciting time in the Stanford campus. People started buying machines with similar configurations from him and his friend and co-founder, James Vera. This is how _VA Research_ was formed.
|
||||
|
||||
![VA Linux founder, Larry Augustin][9]
|
||||
|
||||
> Once software goes into the GPL, you can’t take it back. People can stop contributing, but the code that exists, people can continue to develop on it.
|
||||
>
|
||||
> Without a doubt, a futuristic quote from VA Linux founder, Larry Augustin, 10 years ago | Read the whole interview [here][10]
|
||||
|
||||
#### Some screenshots of their web domains from the early days
|
||||
|
||||
![Linux Powered Machines on sale on varesearch.com | July 15, 1997][11]
|
||||
|
||||
![varesearch.com reveals emerging growth | February 16, 1998][12]
|
||||
|
||||
![On June 26, 2001, they transitioned from hardware to software | valinux.com as on June 22, 2001][13]
|
||||
|
||||
### The spectacular rise and the devastating fall of VA Linux
|
||||
|
||||
VA Research had a big year in 1999 and perhaps it was the biggest for them as they acquired many growing companies and competitors at that time, along with starting many innovative initiatives. The next year in 2000, they created a subsidiary in Japan named _VA Linux Systems Japan K.K._ They were at their peak that year.
|
||||
|
||||
After they transitioned completely from hardware to software, stock prices started to fall drastically since 2002. It all happened because of slower-than-expected sales growth from new customers in the dot-com sector. In the later years they sold off a few brands and top employees also resigned in 2010.
|
||||
|
||||
Gamestop finally [acquired][14] Geeknet Inc. (the new name of VA Linux) for $140 million on June 2, 2015.
|
||||
|
||||
In case you’re curious for a detailed chronicle, I have separately created this [timeline][15], highlighting events year-wise.
|
||||
|
||||
![Image Credit: Wikipedia][16]
|
||||
|
||||
### What happened to VA Linux afterward?
|
||||
|
||||
Geeknet owned by Gamestop is now an online retailer for the global geek community as [ThinkGeek][17].
|
||||
|
||||
SourceForge and Slashdot were what still kept them linked with Linux and Open Source until _Dice Holdings_ acquired Slashdot, SourceForge, and Freecode.
|
||||
|
||||
An [article][18] from 2016 sadly quotes in its final paragraph:
|
||||
|
||||
> “Being acquired by a company that caters to gamers and does not have anything in particular to do with open source software may be a lackluster ending for what was once a spectacularly valuable Linux business.”
|
||||
|
||||
Did we note Linux and Gamers? Does Linux really not have anything to do with Gaming? Are these two terms really so far apart? What about [Gaming on Linux][19]? What about [Open Source Games][20]?
|
||||
|
||||
How could have the stalwarts from _VA Linux_ with years and years of experience in the Linux arena contributed to the Linux Gaming community? What could have happened had [Valve][21] (who are currently so [dedicated][22] towards Linux Gaming) acquired _VA Linux_ instead of Gamestop? Can we ponder?
|
||||
|
||||
The seeds of ideas that were planted by _VA Research_ will continue to inspire the Linux and FOSS community because of its significant contributions in the world of Open Source. At _It’s FOSS,_ our heartfelt salute goes out to those noble ideas!
|
||||
|
||||
Want to feel the nostalgia? Use the [timeline][15] dates with the [Way Back Machine][23] to check out previously owned _VA_ domains like _valinux.com_ or _varesearch.com_ in the past three decades! You can even check _linux.com_ that was once owned by _VA Linux Systems_.
|
||||
|
||||
But wait, are we really done here? What happened to the subsidiary named _VA Linux Systems Japan K.K._? Well, it’s [a different story there][24] and still going strong with the original ideologies of _VA Linux_!
|
||||
|
||||
![VA Linux booth circa 2000 | Image Credit: Storem][25]
|
||||
|
||||
#### _VA Linux_ Subsidiary Still Operational in Japan!
|
||||
|
||||
VA Linux is still operational through its [Japanese subsidiary][26]. It provides the following services:
|
||||
|
||||
* Failure Analysis and Support Services: [_VA Quest_][27]
|
||||
* Entrusted Development Service
|
||||
* Consulting Service
|
||||
|
||||
|
||||
|
||||
_VA_ _Quest_ , in particular, continues its services as a failure-analysis solution for tracking down and dealing with kernel bugs which might be getting in its customers’ way since 2005. [Tetsuro Yogo][28] took over as the New President and CEO on April 3, 2017. Check out their timeline [here][29]! They are also [on GitHub][30]!
|
||||
|
||||
You can also read about a recent development reported on August 2 last year, on this [translated][31] version of a Japanese IT news page. It’s an update about _VA Linux_ providing technical support service of “[Kubernetes][32]” container management software in Japan.
|
||||
|
||||
Its good to know that their 18-year-old subsidiary is still doing well in Japan and the name of _VA Linux_ continues to flourish there even today!
|
||||
|
||||
What are your views? Do you want to share anything on _VA Linux_? Please let us know in the comments section below.
|
||||
|
||||
I hope you liked this first article in the Linux history series. If you know such interesting facts from the past that you would like us to cover here, please let us know.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/story-of-va-linux/
|
||||
|
||||
作者:[Avimanyu Bandyopadhyay][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/avimanyu/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Initial_public_offering
|
||||
[2]: https://www.forbes.com/1999/05/03/feat.html
|
||||
[3]: https://www.channelfutures.com/open-source/open-source-history-the-spectacular-rise-and-fall-of-va-linux
|
||||
[4]: https://www.gamestop.com/
|
||||
[5]: http://www.sun.com/
|
||||
[6]: https://en.wikipedia.org/wiki/Do_it_yourself
|
||||
[7]: https://www.urbandictionary.com/define.php?term=FTW
|
||||
[8]: https://www.linkedin.com/in/larryaugustin/
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/09/VA-Linux-Founder-Larry-Augustin.jpg?ssl=1
|
||||
[10]: https://www.linuxinsider.com/story/SourceForges-Larry-Augustin-A-Better-Way-to-Build-Web-Apps-62155.html
|
||||
[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/09/VA-Research-com-Snapshot-July-15-1997.jpg?ssl=1
|
||||
[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/09/VA-Research-com-Snapshot-Feb-16-1998.jpg?ssl=1
|
||||
[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/09/VA-Linux-com-Snapshot-June-22-2001.jpg?ssl=1
|
||||
[14]: http://geekgirlpenpals.com/geeknet-parent-company-to-thinkgeek-entered-agreement-with-gamestop/
|
||||
[15]: https://medium.com/@avimanyu786/a-timeline-of-va-linux-through-the-years-6813e2bd4b13
|
||||
[16]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/LNUX-stock-fall.png?ssl=1
|
||||
[17]: https://www.thinkgeek.com/
|
||||
[18]: https://www.channelfutures.com/open-source/open-source-history-spectacular-rise-and-fall-va-linux
|
||||
[19]: https://itsfoss.com/linux-gaming-distributions/
|
||||
[20]: https://en.wikipedia.org/wiki/Open-source_video_game
|
||||
[21]: https://www.valvesoftware.com/
|
||||
[22]: https://itsfoss.com/steam-play-proton/
|
||||
[23]: https://archive.org/web/web.php
|
||||
[24]: https://translate.google.com/translate?sl=auto&tl=en&js=y&prev=_t&hl=en&ie=UTF-8&u=https%3A%2F%2Fwww.valinux.co.jp%2Fcorp%2Fstatement%2F&edit-text=
|
||||
[25]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/va-linux-team-booth.jpg?resize=800%2C600&ssl=1
|
||||
[26]: https://www.valinux.co.jp/english/
|
||||
[27]: https://www.linux.com/news/va-linux-announces-linux-failure-analysis-service
|
||||
[28]: https://www.linkedin.com/in/yogo45/
|
||||
[29]: https://www.valinux.co.jp/english/about/timeline/
|
||||
[30]: https://github.com/vaj
|
||||
[31]: https://translate.google.com/translate?sl=auto&tl=en&js=y&prev=_t&hl=en&ie=UTF-8&u=https%3A%2F%2Fit.impressbm.co.jp%2Farticles%2F-%2F16499
|
||||
[32]: https://en.wikipedia.org/wiki/Kubernetes
|
||||
@ -0,0 +1,98 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (CrossCode is an Awesome 16-bit Sci-Fi RPG Game)
|
||||
[#]: via: (https://itsfoss.com/crosscode-game/)
|
||||
[#]: author: (Phillip Prado https://itsfoss.com/author/phillip/)
|
||||
|
||||
CrossCode is an Awesome 16-bit Sci-Fi RPG Game
|
||||
======
|
||||
|
||||
What starts off as an obvious sci-fi 16-bit 2D action RPG quickly turns into a JRPG inspired pseudo-MMO open-world puzzle platformer. Though at first glance this sounds like a jumbled mess, [CrossCode][1] manages to bundle all of its influences into a seamless gaming experience that feels nothing shy of excellent.
|
||||
|
||||
Note: CrossCode is not open source software. We have covered it because it is Linux specific.
|
||||
|
||||
![][2]
|
||||
|
||||
### Story
|
||||
|
||||
You play as Lea, a girl who has forgotten her identity, where she comes from, and how to speak. As you walk through the early parts of the story, you come to find that you are a character in a digital world — a video game. But not just any video game — an MMO. And you, Lea, must venture into the digital world known as CrossWorlds in order to unravel the secrets of your past.
|
||||
|
||||
As you progress through the game, you unveil more and more about yourself, learning how you got to this point in the first place. This doesn’t sound too crazy of a story, but the gameplay implementation and appropriately paced storyline make for quite a captivating experience.
|
||||
|
||||
The story unfolds at a satisfying speed and the character’s development is genuinely gratifying — both fictionally and mechanically. The only critique I had was that it felt like the introductory segment took a little too long — dragging the tutorial into the gameplay for quite some time, and keeping the player from getting into the real meat of the game.
|
||||
|
||||
All-in-all, CrossCode’s story did not leave me wanting, not even in the slightest. It’s deep, fun, heartwarming, intelligent, and all while never sacrificing great character development. Without spoiling anything, I will say that if you are someone that enjoys a good story, you will need to give CrossCode a look.
|
||||
|
||||
![][3]
|
||||
|
||||
### Gameplay
|
||||
|
||||
Yes, the story is great and all, but if there is one place that CrossCode truly shines, it has to be its gameplay. The game’s mechanics are fast-paced, challenging, intuitive, and downright fun!
|
||||
|
||||
You start off with a dodge, block, melee, and ranged attack, each slowly developing overtime as the character tree is unlocked. This all-too-familiar mix of combat elements balances skill and hack-n-slash mechanics in a way that doesn’t conflict with one another.
|
||||
|
||||
The game utilizes this mix of skills to create some amazing puzzle solving and combat that helps CrossCode’s gameplay truly stand out. Whether you are making your way through one of the four main dungeons, or you are taking a boss head on, you can’t help but periodically stop and think “wow, this game is great!”
|
||||
|
||||
Though this has to be the game’s strongest feature, it can also be the game’s biggest downfall. Part of the reason that the story and character progression is so satisfying is because the combat and puzzle mechanics can be incredibly challenging, and that’s putting it lightly.
|
||||
|
||||
There are times in which CrossCode’s gameplay feels downright impossible. Bosses take an expert amount of focus, and dungeons require all of the patience you can muster up just to simply finish them.
|
||||
|
||||
![][4]
|
||||
|
||||
The game requires a type of dexterity I have not quite had to master yet. I mean, sure there are more challenging puzzle games out there, yes there are more difficult platformers, and of course there are more grueling RPGs, but adding all of these elements into one game while spurring the player along with an alluring story requires a level of mechanical balance that I haven’t found in many other games.
|
||||
|
||||
And though there were times I felt the gameplay was flat out punishing, I was constantly reminded that this is simply not the case. Death doesn’t cause serious character regression, you can take a break from dungeons when you feel overwhelmed, and there is a plethora of checkpoints throughout the game’s most difficult parts to help the player along.
|
||||
|
||||
Where other games fall short by giving the player nothing to lose, this reality redeems CrossCode amid its rigorous gameplay. CrossCode may be one of the only games I know that takes two common flaws in games and holds the tension between them so well that it becomes one of the game’s best strengths.
|
||||
|
||||
![][5]
|
||||
|
||||
### Design
|
||||
|
||||
One of the things that surprised me most about CrossCode was how well it’s world and sound design come together. Right off the bat, from the moment you boot the game up, it is clear the developers meant business when designing CrossCode.
|
||||
|
||||
Being in a fictional MMO world, the game’s character ensemble is vibrant and distinctive, each having its own tone and personality. The games sound and motion graphics are tactile and responsive, giving the player a healthy amount of feedback during gameplay. And the soundtrack behind the game is simply beautiful, ebbing and flowing between intense moments of combat to blissful moments of exploration.
|
||||
|
||||
If I had to fault CrossCode in this category it would have to be in the size of the map. Yes, the dungeons are long, and yes, the CrossWorlds map looks gigantic, but I still wanted more to explore outside crippling dungeons. The game is beautiful and fluid, but akin to RPG games of yore — aka. Zelda games pre-Breath of the Wild — I wish there was just a little more for me to freely explore.
|
||||
|
||||
It is obvious that the developers really cared about this aspect of the game, and you can tell they spent an incredible amount of time developing its design. CrossCode set itself up for success here in its plot and content, and the developers capitalize on the opportunity, knocking another category out of the park.
|
||||
|
||||
![][6]
|
||||
|
||||
### Conclusion
|
||||
|
||||
In the end, it is obvious how I feel about this game. And just in case you haven’t caught on yet…I love it. It holds a near perfect balance between being difficult and rewarding, simple and complex, linear and open, making CrossCode one of [the best Linux games][7] out there.
|
||||
|
||||
Developed by [Radical Fish Games][8], CrossCode was officially released for Linux on September 21, 2018, seven years after development began. You can pick up the game over on [Steam][9], [GOG][10], or [Humble Bundle][11].
|
||||
|
||||
If you play games regularly, you may want to [subscribe to Humble Monthly][12] ([affiliate][13] link). For $12 per month, you’ll get games worth over $100 (not all for Linux). Over 450,000 gamers worldwide use Humble Monthly.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/crosscode-game/
|
||||
|
||||
作者:[Phillip Prado][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/phillip/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://www.cross-code.com/en/home
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/CrossCode-Level-up.png?fit=800%2C451&ssl=1
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/CrossCode-Equpiment.png?fit=800%2C451&ssl=1
|
||||
[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/CrossCode-character-development.png?fit=800%2C451&ssl=1
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/CrossCode-Environment.png?fit=800%2C451&ssl=1
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/CrossCode-dungeon.png?fit=800%2C451&ssl=1
|
||||
[7]: https://itsfoss.com/free-linux-games/
|
||||
[8]: http://www.radicalfishgames.com/
|
||||
[9]: https://store.steampowered.com/app/368340/CrossCode/
|
||||
[10]: https://www.gog.com/game/crosscode
|
||||
[11]: https://www.humblebundle.com/store/crosscode
|
||||
[12]: https://www.humblebundle.com/monthly?partner=itsfoss
|
||||
[13]: https://itsfoss.com/affiliate-policy/
|
||||
@ -0,0 +1,91 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Enjoy Netflix? You Should Thank FreeBSD)
|
||||
[#]: via: (https://itsfoss.com/netflix-freebsd-cdn/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Enjoy Netflix? You Should Thank FreeBSD
|
||||
======
|
||||
|
||||
Netflix is one of the most popular streaming services in the world.
|
||||
|
||||
But you already know that. Don’t you?
|
||||
|
||||
What you probably did not know is that Netflix uses [FreeBSD][1] to deliver its content to you.
|
||||
|
||||
Yes, that’s right. Netflix relies on FreeBSD to build its in-house content delivery network (CDN).
|
||||
|
||||
A [CDN][2] is a group of servers located in various part of the world. It is mainly used to deliver ‘heavy content’ like images and videos to the end-user faster than a centralized server.
|
||||
|
||||
Instead of opting for a commercial CDN service, Netflix has built its own in-house CDN called [Open Connect][3].
|
||||
|
||||
Open Connect utilizes [custom hardware][4], Open Connect Appliance. You can see it in the image below. It can handle 40Gb/s data and has a storage capacity of 248TB.
|
||||
|
||||
![Netflix’s Open Connect Appliance runs FreeBSD][5]
|
||||
|
||||
Netflix provides Open Connect Appliance to qualifying Internet Service Providers (ISP) for free. This way, substantial Netflix traffic gets localized and the ISPs deliver the Netflix content more efficiently.
|
||||
|
||||
This Open Connect Appliance runs on FreeBSD operating system and [almost exclusively runs open source software][6].
|
||||
|
||||
### Open Connect uses FreeBSD “Head”
|
||||
|
||||
![][7]
|
||||
|
||||
You would expect Netflix to use a stable release of FreeBSD for such a critical infrastructure but Netflix tracks the [FreeBSD head/current version][8]. Netflix says that tracking “head” lets them “stay forward-looking and focused on innovation”.
|
||||
|
||||
Here are the benefits Netflix sees of tracking FreeBSD:
|
||||
|
||||
* Quicker feature iteration
|
||||
* Quicker access to new FreeBSD features
|
||||
* Quicker bug fixes
|
||||
* Enables collaboration
|
||||
* Minimizes merge conflicts
|
||||
* Amortizes merge “cost”
|
||||
|
||||
|
||||
|
||||
> Running FreeBSD “head” lets us deliver large amounts of data to our users very efficiently, while maintaining a high velocity of feature development.
|
||||
>
|
||||
> Netflix
|
||||
|
||||
Remember, even [Google uses Debian][9] testing instead of Debian stable. Perhaps these enterprises prefer the cutting edge features more than anything else.
|
||||
|
||||
Like Google, Netflix also plans to upstream any code they can. This should help FreeBSD and other BSD distributions based on FreeBSD.
|
||||
|
||||
So what does Netflix achieves with FreeBSD? Here are some quick stats:
|
||||
|
||||
> Using FreeBSD and commodity parts, we achieve 90 Gb/s serving TLS-encrypted connections with ~55% CPU on a 16-core 2.6-GHz CPU.
|
||||
>
|
||||
> Netflix
|
||||
|
||||
If you want to know more about Netflix and FreeBSD, you can refer to [this presentation from FOSDEM][10]. You can also watch the video of the presentation [here][11].
|
||||
|
||||
These days big enterprises rely mostly on Linux for their server infrastructure but Netflix has put their trust in BSD. This is a good thing for BSD community because if an industry leader like Netflix throws its weight behind BSD, others could follow the lead. What do you think?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/netflix-freebsd-cdn/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.freebsd.org/
|
||||
[2]: https://www.cloudflare.com/learning/cdn/what-is-a-cdn/
|
||||
[3]: https://openconnect.netflix.com/en/
|
||||
[4]: https://openconnect.netflix.com/en/hardware/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/netflix-open-connect-appliance.jpeg?fit=800%2C533&ssl=1
|
||||
[6]: https://openconnect.netflix.com/en/software/
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/netflix-freebsd.png?resize=800%2C450&ssl=1
|
||||
[8]: https://www.bsdnow.tv/tutorials/stable-current
|
||||
[9]: https://itsfoss.com/goobuntu-glinux-google/
|
||||
[10]: https://fosdem.org/2019/schedule/event/netflix_freebsd/attachments/slides/3103/export/events/attachments/netflix_freebsd/slides/3103/FOSDEM_2019_Netflix_and_FreeBSD.pdf
|
||||
[11]: http://mirror.onet.pl/pub/mirrors/video.fosdem.org/2019/Janson/netflix_freebsd.webm
|
||||
@ -0,0 +1,146 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Installing Kali Linux on VirtualBox: Quickest & Safest Way)
|
||||
[#]: via: (https://itsfoss.com/install-kali-linux-virtualbox/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Installing Kali Linux on VirtualBox: Quickest & Safest Way
|
||||
======
|
||||
|
||||
_**This tutorial shows you how to install Kali Linux on Virtual Box in Windows and Linux in the quickest way possible.**_
|
||||
|
||||
[Kali Linux][1] is one of the [best Linux distributions for hacking][2] and security enthusiasts.
|
||||
|
||||
Since it deals with a sensitive topic like hacking, it’s like a double-edged sword. We have discussed it in the detailed Kali Linux review in the past so I am not going to bore you with the same stuff again.
|
||||
|
||||
While you can install Kali Linux by replacing the existing operating system, using it via a virtual machine would be a better and safer option.
|
||||
|
||||
With Virtual Box, you can use Kali Linux as a regular application in your Windows/Linux system. It’s almost the same as running VLC or a game in your system.
|
||||
|
||||
Using Kali Linux in a virtual machine is also safe. Whatever you do inside Kali Linux will NOT impact your ‘host system’ (i.e. your original Windows or Linux operating system). Your actual operating system will be untouched and your data in the host system will be safe.
|
||||
|
||||
![][3]
|
||||
|
||||
### How to install Kali Linux on VirtualBox
|
||||
|
||||
I’ll be using [VirtualBox][4] here. It is a wonderful open source virtualization solution for just about anyone (professional or personal use). It’s available free of cost.
|
||||
|
||||
In this tutorial, we will talk about Kali Linux in particular but you can install almost any other OS whose ISO file exists or a pre-built virtual machine save file is available.
|
||||
|
||||
**Note:** _The same steps apply for Windows/Linux running VirtualBox._
|
||||
|
||||
As I already mentioned, you can have either Windows or Linux installed as your host. But, in this case, I have Windows 10 installed (don’t hate me!) where I try to install Kali Linux in VirtualBox step by step.
|
||||
|
||||
And, the best part is – even if you happen to use a Linux distro as your primary OS, the same steps will be applicable!
|
||||
|
||||
Wondering, how? Let’s see…
|
||||
|
||||
[Subscribe to Our YouTube Channel for More Linux Videos][5]
|
||||
|
||||
### Step by Step Guide to install Kali Linux on VirtualBox
|
||||
|
||||
_We are going to use a custom Kali Linux image made for VirtualBox specifically. You can also download the ISO file for Kali Linux and create a new virtual machine – but why do that when you have an easy alternative?_
|
||||
|
||||
#### 1\. Download and install VirtualBox
|
||||
|
||||
The first thing you need to do is to download and install VirtualBox from Oracle’s official website.
|
||||
|
||||
[Download VirtualBox][6]
|
||||
|
||||
Once you download the installer, just double click on it to install VirtualBox. It’s the same for [installing VirtualBox on Ubuntu][7]/Fedora Linux as well.
|
||||
|
||||
#### 2\. Download ready-to-use virtual image of Kali Linux
|
||||
|
||||
After installing it successfully, head to [Offensive Security’s download page][8] to download the VM image for VirtualBox. If you change your mind to utilize [VMware][9], that is available too.
|
||||
|
||||
![][10]
|
||||
|
||||
As you can see the file size is well over 3 GB, you should either use the torrent option or download it using a [download manager][11].
|
||||
|
||||
[Kali Linux Virtual Image][8]
|
||||
|
||||
#### 3\. Install Kali Linux on Virtual Box
|
||||
|
||||
Once you have installed VirtualBox and downloaded the Kali Linux image, you just need to import it to VirtualBox in order to make it work.
|
||||
|
||||
Here’s how to import the VirtualBox image for Kali Linux:
|
||||
|
||||
**Step 1** : Launch VirtualBox. You will notice an **Import** button – click on it
|
||||
|
||||
![Click on Import button][12]
|
||||
|
||||
**Step 2:** Next, browse the file you just downloaded and choose it to be imported (as you can see in the image below). The file name should start with ‘kali linux‘ and end with . **ova** extension.
|
||||
|
||||
![Importing Kali Linux image][13]
|
||||
|
||||
**S** Once selected, proceed by clicking on **Next**.
|
||||
|
||||
**Step 3** : Now, you will be shown the settings for the virtual machine you are about to import. So, you can customize them or not – that is your choice. It is okay if you go with the default settings.
|
||||
|
||||
You need to select a path where you have sufficient storage available. I would never recommend the **C:** drive on Windows.
|
||||
|
||||
![Import hard drives as VDI][14]
|
||||
|
||||
Here, the hard drives as VDI refer to virtually mount the hard drives by allocating the storage space set.
|
||||
|
||||
After you are done with the settings, hit **Import** and wait for a while.
|
||||
|
||||
**Step 4:** You will now see it listed. So, just hit **Start** to launch it.
|
||||
|
||||
You might get an error at first for USB port 2.0 controller support, you can disable it to resolve it or just follow the on-screen instruction of installing an additional package to fix it. And, you are done!
|
||||
|
||||
![Kali Linux running in VirtualBox][15]
|
||||
|
||||
The default username in Kali Linux is root and the default password is toor. You should be able to login to the system with it.
|
||||
|
||||
Do note that you should [update Kali Linux][16] before trying to install a new applications or trying to hack your neighbor’s WiFi.
|
||||
|
||||
I hope this guide helps you easily install Kali Linux on Virtual Box. Of course, Kali Linux has a lot of useful tools in it for penetration testing – good luck with that!
|
||||
|
||||
**Tip** : Both Kali Linux and Ubuntu are Debian-based. If you face any issues or error with Kali Linux, you may follow the tutorials intended for Ubuntu or Debian on the internet.
|
||||
|
||||
### Bonus: Free Kali Linux Guide Book
|
||||
|
||||
If you are just starting with Kali Linux, it will be a good idea to know how to use Kali Linux.
|
||||
|
||||
Offensive Security, the company behind Kali Linux, has created a guide book that explains the basics of Linux, basics of Kali Linux, configuration, setups. It also has a few chapters on penetration testing and security tools.
|
||||
|
||||
Basically, it has everything you need to get started with Kali Linux. And the best thing is that the book is available to download for free.
|
||||
|
||||
[Download Kali Linux Revealed for FREE][17]
|
||||
|
||||
Let us know in the comments below if you face an issue or simply share your experience with Kali Linux on VirtualBox.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-kali-linux-virtualbox/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.kali.org/
|
||||
[2]: https://itsfoss.com/linux-hacking-penetration-testing/
|
||||
[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/kali-linux-virtual-box.png?resize=800%2C450&ssl=1
|
||||
[4]: https://www.virtualbox.org/
|
||||
[5]: https://www.youtube.com/c/itsfoss?sub_confirmation=1
|
||||
[6]: https://www.virtualbox.org/wiki/Downloads
|
||||
[7]: https://itsfoss.com/install-virtualbox-ubuntu/
|
||||
[8]: https://www.offensive-security.com/kali-linux-vm-vmware-virtualbox-image-download/
|
||||
[9]: https://itsfoss.com/install-vmware-player-ubuntu-1310/
|
||||
[10]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/kali-linux-virtual-box-image.jpg?resize=800%2C347&ssl=1
|
||||
[11]: https://itsfoss.com/4-best-download-managers-for-linux/
|
||||
[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmbox-import-kali-linux.jpg?ssl=1
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmbox-linux-next.jpg?ssl=1
|
||||
[14]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmbox-kali-linux-settings.jpg?ssl=1
|
||||
[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/kali-linux-on-windows-virtualbox.jpg?resize=800%2C429&ssl=1
|
||||
[16]: https://linuxhandbook.com/update-kali-linux/
|
||||
[17]: https://kali.training/downloads/Kali-Linux-Revealed-1st-edition.pdf
|
||||
@ -0,0 +1,96 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Flowblade 2.0 is Here with New Video Editing Tools and a Refreshed UI)
|
||||
[#]: via: (https://itsfoss.com/flowblade-video-editor-release/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Flowblade 2.0 is Here with New Video Editing Tools and a Refreshed UI
|
||||
======
|
||||
|
||||
[Flowblade][1] is one of the rare [video editors that are only available for Linux][2]. It is not the feature set – but the simplicity, flexibility, and being an open source project that counts.
|
||||
|
||||
However, with Flowblade 2.0 – released recently – it is now more powerful and useful. A lot of new tools along with a complete overhaul in the workflow can be seen.
|
||||
|
||||
In this article, we shall take a look at what’s new with Flowblade 2.0.
|
||||
|
||||
### New Features in Flowblade 2.0
|
||||
|
||||
Here are some of the major new changes in the latest release of Flowblade.
|
||||
|
||||
#### GUI Updates
|
||||
|
||||
![Flowblade 2.0][3]
|
||||
|
||||
This was a much needed change. I’m always looking for open source solutions that works as expected along with a great GUI.
|
||||
|
||||
So, in this update, you will observe a new custom theme set as the default – which looks good though.
|
||||
|
||||
Overall, the panel design, the toolbox and stuff has been taken care of to make it look modern. The overhaul considers small changes like the cursor icon upon tool selection and so on.
|
||||
|
||||
#### Workflow Overhaul
|
||||
|
||||
No matter what features you get to utilize, the workflow matters to people who regularly edit videos. So, it has to be intuitive.
|
||||
|
||||
With the recent release, they have made sure that you can configure and set the workflow as per your preference. Well, that is definitely flexible because not everyone has the same requirement.
|
||||
|
||||
#### New Tools
|
||||
|
||||
![Flowblade Video Editor Interface][4]
|
||||
|
||||
**Keyframe tool** : This enables editing and adjusting the Volume and Brightness [keyframes][5] on timeline.
|
||||
|
||||
**Multitrim** : A combination of trill, roll, and slip tool.
|
||||
|
||||
**Cut:** Available now as a tool in addition to the traditional cut at the playhead.
|
||||
|
||||
**Ripple trim:** It is a mode of Trim tool – not often used by many – now available as a separate tool.
|
||||
|
||||
#### More changes?
|
||||
|
||||
In addition to these major changes listed above, they have added some keyframe editing updates and compositors ( _AlphaXOR, Alpha Out, and Alpha_ ) to utilize alpha channel data to combine images.
|
||||
|
||||
A lot of more tiny little changes have taken place as well – you can check those out in the official [changelog][6] on GitHub.
|
||||
|
||||
### Installing Flowblade 2.0
|
||||
|
||||
If you use Debian or Ubuntu based Linux distributions, there are .deb binaries available for easily installing Flowblade 2.0.
|
||||
|
||||
For the rest, you’ll have to [install it using the source code][7].
|
||||
|
||||
All the files are available on it’s GitHub page. You can download it from the page below.
|
||||
|
||||
[Download Flowblade 2.0][8]
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
If you are interested in video editing, perhaps you would like to follow the development of [Olive][9], a new open source video editor in development.
|
||||
|
||||
Now that you know about the latest changes and additions. What do you think about Flowblade 2.0 as a video editor? Is it good enough for you?
|
||||
|
||||
Let us know your thoughts in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/flowblade-video-editor-release/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/jliljebl/flowblade
|
||||
[2]: https://itsfoss.com/best-video-editing-software-linux/
|
||||
[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/flowblade-2.jpg?ssl=1
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/flowblade-2-1.jpg?resize=800%2C450&ssl=1
|
||||
[5]: https://en.wikipedia.org/wiki/Key_frame
|
||||
[6]: https://github.com/jliljebl/flowblade/blob/master/flowblade-trunk/docs/RELEASE_NOTES.md
|
||||
[7]: https://itsfoss.com/install-software-from-source-code/
|
||||
[8]: https://github.com/jliljebl/flowblade/releases/tag/v2.0
|
||||
[9]: https://itsfoss.com/olive-video-editor/
|
||||
@ -0,0 +1,133 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Review of Debian System Administrator’s Handbook)
|
||||
[#]: via: (https://itsfoss.com/debian-administrators-handbook/)
|
||||
[#]: author: (Shirish https://itsfoss.com/author/shirish/)
|
||||
|
||||
Review of Debian System Administrator’s Handbook
|
||||
======
|
||||
|
||||
_**Debian System Administrator’s Handbook is a free-to-download book that covers all the essential part of Debian that a sysadmin might need.**_
|
||||
|
||||
This has been on my to-do review list for quite some time. The book was started by two French Debian Developers Raphael Hertzog and Roland Mas to increase awareness about the Debian project in France. The book was a huge hit among francophone Linux users. The English translation followed soon after that.
|
||||
|
||||
### Debian Administrator’s Handbook
|
||||
|
||||
![][1]
|
||||
|
||||
[Debian Administrator’s Handbook][2] is targeted from a newbie who may be looking to understand what the [Debian project][3] is all about to somebody who might be running a Debian in a production server.
|
||||
|
||||
The latest version of the book covers Debian 8 while the current stable version is Debian 9. But it doesn’t mean that book is outdated and is of no use to Debian 9 users. Most of the part of the book is valid for all Debian and Linux users.
|
||||
|
||||
Let me give you a quick summary of what this book covers.
|
||||
|
||||
#### Section 1 – Debian Project
|
||||
|
||||
The first section sets the tone of the book where it gives a solid foundation to somebody who might be looking into Debian as to what it actually means. Some of it will probably be updated to match the current scenario.
|
||||
|
||||
#### Section 2 – Using fictional case studies for different needs
|
||||
|
||||
The second section deals with the various case-scenarios as to where Debian could be used. The idea being how Debian can be used in various hierarchical or functional scenarios. One aspect which I felt that should have stressed upon is the culture mindshift and openness which at least should have been mentioned.
|
||||
|
||||
#### Section 3 & 4- Setups and Installation
|
||||
|
||||
The third section goes into looking in existing setups. I do think it should have stressed more into documenting existing setups, migrating partial services and users before making a full-fledged transition. While all of the above seem minor points, I have seen many of them come and bit me on the back during a transition.
|
||||
|
||||
Section Four covers the various ways you could install, how the installation process flows and things to keep in mind before installing a Debian System. Unfortunately, UEFI was not present at that point so it was not talked about.
|
||||
|
||||
#### Section 5 & 6 – Packaging System and Updates
|
||||
|
||||
Section Five starts on how a binary package is structured and then goes on to tell how a source package is structured as well. It does mention several gotchas or tricky ways in which a sys-admin can be caught.
|
||||
|
||||
Section Six is perhaps where most of the sysadmins spend most of the time apart from troubleshooting which is another chapter altogether. While it starts from many of the most often used sysadmin commands, the interesting point which I liked was on page 156 which is on better solver algorithims.
|
||||
|
||||
#### Section 7 – Solving Problems and finding Relevant Solutions
|
||||
|
||||
Section Seven, on the other hand, speaks of the various problem scenarios and various ways when you find yourself with a problem. In Debian and most GNU/Linux distributions, the keyword is ‘patience’. If you are patient then many problems in Debian are resolved or can be resolved after a good night’s sleep.
|
||||
|
||||
#### Section 8 – Basic Configuration, Network, Accounts, Printing
|
||||
|
||||
Section Eight introduces you to the basics of networking and having single or multiple user accounts on the workstation. It goes a bit into user and group configuration and practices then gives a brief introduction to the bash shell and gets a brief overview of the [CUPS][4] printing daemon. There is much to explore here.
|
||||
|
||||
#### Section 9 – Unix Service
|
||||
|
||||
Section 9 starts with the introduction to specific Unix services. While it starts with the much controversial, hated and reviled in many quarters [systemd][5], they also shared System V which is still used by many a sysadmin.
|
||||
|
||||
#### Section 10, 11 & 12 – Networking and Adminstration
|
||||
|
||||
Section 10 makes you dive into network infrastructure where it goes into the basics of Virtual Private Networks (OpenVPN), OpenSSH, the PKI credentials and some basics of information security. It also gets into basics of DNS, DHCP and IPv6 and ends with some tools which could help in troubleshooting network issues.
|
||||
|
||||
Section 11 starts with basic configuration and workflow of mail server and postfix. It tries to a bit into depth as there is much to play with. It then goes into the popular web server Apache, FTP File server, NFS and CIFS with Windows shares via Samba. Again, much to explore therein.
|
||||
|
||||
Section 12 starts with Advanced Administration topics such as RAID, LVM, when one is better than the other. Then gets into Virtualization, Xen and give brief about lxc. Again, there is much more to explore than shared herein.
|
||||
|
||||
![Author Raphael Hertzog at a Debian booth circa 2013 | Image Credit][6]
|
||||
|
||||
#### Section 13 – Workstation
|
||||
|
||||
Section 13 shares about having schemas for xserver, display managers, window managers, menu management, the different desktops i.e. GNOME, KDE, XFCE and others. It does mention about lxde in the others. The one omission I felt which probably will be updated in a new release would be [Wayland][7] and [Xwayland][8]. Again much to explore in this section as well. This is rectified in the conclusion
|
||||
|
||||
#### Section 14 – Security
|
||||
|
||||
Section 14 is somewhat comprehensive on what constitues security and bits of threats analysis but stops short as it shares in the introduction of the chapter itself that it’s a vast topic.
|
||||
|
||||
#### Section 15 – Creating a Debian package
|
||||
|
||||
Section 15 explains the tools and processes to ‘ _debianize_ ‘ an application so it becomes part of the Debian archive and available for distribution on the 10 odd hardware architectures that Debian supports.
|
||||
|
||||
### Pros and Cons
|
||||
|
||||
Where Raphael and Roland have excelled is at breaking the visual monotony of the book by using a different style and structure wherever possible from the rest of the reading material. This compels the reader to refresh her eyes while at the same time focus on the important matter at the hand. The different visual style also indicates that this is somewhat more important from the author’s point of view.
|
||||
|
||||
One of the drawbacks, if I may call it that, is the absolute absence of humor in the book.
|
||||
|
||||
### Final Thoughts
|
||||
|
||||
I have been [using Debian][9] for a decade so lots of it was a refresher for myself. Some of it is outdated if I look it from a buster perspective but is invaluable as a historical artifact.
|
||||
|
||||
If you are looking to familiarize yourself with Debian or looking to run Debian 8 or 9 as a production server for your business wouldn’t be able to recommend a better book than this.
|
||||
|
||||
### Download Debian Administrator’s Handbook
|
||||
|
||||
The Debian Handbook has been available in every Debian release after 2012. The [liberation][10] of the Debian Handbook was done in 2012 using [ulule][11].
|
||||
|
||||
You can download an electronic version of the Debian Administrator’s Handbook in PDF, ePub or Mobi format from the link below:
|
||||
|
||||
[Download Debian Administrator’s Handbook][12]
|
||||
|
||||
You can also buy the book paperback edition of the book if you want to support the amazing work of the authors.
|
||||
|
||||
[Buy the paperback edition][13]
|
||||
|
||||
Lastly, if you want to motivate Raphael, you can reward by donating to his PayPal [account][14].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/debian-administrators-handbook/
|
||||
|
||||
作者:[Shirish][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/shirish/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/Debian-Administrators-Handbook-review.png?resize=800%2C450&ssl=1
|
||||
[2]: https://debian-handbook.info/
|
||||
[3]: https://www.debian.org/
|
||||
[4]: https://www.cups.org
|
||||
[5]: https://itsfoss.com/systemd-features/
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/stand-debian-Raphael.jpg?resize=800%2C600&ssl=1
|
||||
[7]: https://wayland.freedesktop.org/
|
||||
[8]: https://en.wikipedia.org/wiki/X.Org_Server#XWayland
|
||||
[9]: https://itsfoss.com/reasons-why-i-love-debian/
|
||||
[10]: https://debian-handbook.info/liberation/
|
||||
[11]: https://www.ulule.com/debian-handbook/
|
||||
[12]: https://debian-handbook.info/get/now/
|
||||
[13]: https://debian-handbook.info/get/
|
||||
[14]: https://raphaelhertzog.com/
|
||||
@ -0,0 +1,114 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (LibreOffice 6.2 is Here: This is the Last Release with 32-bit Binaries)
|
||||
[#]: via: (https://itsfoss.com/libreoffice-drops-32-bit-support/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
LibreOffice 6.2 is Here: This is the Last Release with 32-bit Binaries
|
||||
======
|
||||
|
||||
LibreOffice is my favorite office suite as a free and powerful [alternative to Microsoft Office tools on Linux][1]. Even when I use my Windows machine – I prefer to have LibreOffice installed instead of Microsoft Office tools any day.
|
||||
|
||||
Now, with the recent [LibreOffice][2] 6.2 update, there’s a lot of good stuff to talk about along with a bad news.
|
||||
|
||||
### What’s New in LibreOffice 6.2?
|
||||
|
||||
Let’s have a quick look at the major new features in the [latest release of LibreOffice][3].
|
||||
|
||||
If you like Linux videos, don’t forget to [subscribe to our YouTube channel][4] as well.
|
||||
|
||||
#### The new NotebookBar
|
||||
|
||||
![][5]
|
||||
|
||||
A new addition to the interface that is optional and not enabled by default. In order to enable it, go to **View - > User Interface -> Tabbed**.
|
||||
|
||||
You can either set it as a tabbed layout or a grouped compact layout.
|
||||
|
||||
While it is not something that is mind blowing – but it still counts as a significant user interface update considering a variety of user preferences.
|
||||
|
||||
#### Icon Theme
|
||||
|
||||
![][6]
|
||||
|
||||
A new set of icons is now available to choose from. I will definitely utilize the new set of icons – they look good!
|
||||
|
||||
#### Platform Compatibility
|
||||
|
||||
With the new update, the compatibility has been improved across all the platforms (Mac, Windows, and Linux).
|
||||
|
||||
#### Performance Improvements
|
||||
|
||||
This shouldn’t concern you if you didn’t have any issues. But, still, the better they work on this – it is a win-win for all.
|
||||
|
||||
They have removed unnecessary animations, worked on latency reduction, avoided repeated re-layout, and more such things to improve the performance.
|
||||
|
||||
#### More fixes and improvements
|
||||
|
||||
A lot of bugs have been fixed in this new update along with little tweaks here and there for all the tools (Writer, Calc, Draw, Impress).
|
||||
|
||||
To get to know all the technical details, you should check out their [release notes.
|
||||
][7]
|
||||
|
||||
### The Sad News: Dropping the support for 32-bit binaries
|
||||
|
||||
Of course, this is not a feature. But, this was bound to happen – because it was anticipated a few months ago. LibreOffice will no more provide 32-bit binary releases.
|
||||
|
||||
This is inevitable. [Ubuntu has dropped 32-bit support][8]. Many other Linux distributions have also stopped supporting 32-bit processors. The number of [Linux distributions still supporting a 32-bit architecture][9] is fast dwindling.
|
||||
|
||||
For the future versions of LibreOffice on 32-bit systems, you’ll have to rely on your distribution to provide it to you. You cannot download the binaries anymore.
|
||||
|
||||
### Installing LibreOffice 6.2
|
||||
|
||||
![][10]
|
||||
|
||||
Your Linux distribution should be providing this update sooner or later.
|
||||
|
||||
Arch-based Linux users should be getting it already while Ubuntu and Debian users would have to wait a bit longer.
|
||||
|
||||
If you cannot wait, you should download it and [install it from the deb file][11]. Do remove the existing LibreOffice install before using the DEB file.
|
||||
|
||||
[Download LibreOffice 6.2][12]
|
||||
|
||||
If you don’t want to use the deb file, you may use the official PPA should provide you LibreOffice 6.2 before Ubuntu (it doesn’t have 6.2 release at the moment). It will update your existing LibreOffice install.
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:libreoffice/ppa
|
||||
sudo apt update
|
||||
sudo apt install libreoffice
|
||||
```
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
LibreOffice 6.2 is definitely a major step up to keep it as a better alternative to Microsoft Office for Linux users.
|
||||
|
||||
Do you happen to use LibreOffice? Do these updates matter to you? Let us know in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/libreoffice-drops-32-bit-support/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/
|
||||
[2]: https://www.libreoffice.org/
|
||||
[3]: https://itsfoss.com/libreoffice-6-0-released/
|
||||
[4]: https://www.youtube.com/c/itsfoss?sub_confirmation=1
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/libreoffice-tabbed.png?resize=800%2C434&ssl=1
|
||||
[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/Libreoffice-style-elementary.png?ssl=1
|
||||
[7]: https://wiki.documentfoundation.org/ReleaseNotes/6.2
|
||||
[8]: https://itsfoss.com/ubuntu-drops-32-bit-desktop/
|
||||
[9]: https://itsfoss.com/32-bit-os-list/
|
||||
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/libre-office-6-2-release.png?resize=800%2C450&ssl=1
|
||||
[11]: https://itsfoss.com/install-deb-files-ubuntu/
|
||||
[12]: https://www.libreoffice.org/download/download/
|
||||
@ -0,0 +1,103 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (The Earliest Linux Distros: Before Mainstream Distros Became So Popular)
|
||||
[#]: via: (https://itsfoss.com/earliest-linux-distros/)
|
||||
[#]: author: (Avimanyu Bandyopadhyay https://itsfoss.com/author/avimanyu/)
|
||||
|
||||
The Earliest Linux Distros: Before Mainstream Distros Became So Popular
|
||||
======
|
||||
|
||||
In this throwback history article, we’ve tried to look back into how some of the earliest Linux distributions evolved and came into being as we know them today.
|
||||
|
||||
![][1]
|
||||
|
||||
In here we have tried to explore how the idea of popular distros such as Red Hat, Debian, Slackware, SUSE, Ubuntu and many others came into being after the first Linux kernel became available.
|
||||
|
||||
As Linux was initially released in the form of a kernel in 1991, the distros we know today was made possible with the help of numerous collaborators throughout the world with the creation of shells, libraries, compilers and related packages to make it a complete Operating System.
|
||||
|
||||
### 1\. The first known “distro” by HJ Lu
|
||||
|
||||
The way we know Linux distributions today goes back to 1992, when the first known distro-like tools to get access to Linux were released by HJ Lu. It consisted of two 5.25” floppy diskettes:
|
||||
|
||||
![Linux 0.12 Boot and Root Disks | Photo Credit][2]
|
||||
|
||||
* **LINUX 0.12 BOOT DISK** : The “boot” disk was used to boot the system first.
|
||||
* **LINUX 0.12 ROOT DISK** : The second “root” disk for getting a command prompt for access to the Linux file system after booting.
|
||||
|
||||
|
||||
|
||||
To install 0.12 on a hard drive, one had to use a hex editor to edit its master boot record (MBR) and that was quite a complex process, especially during that era.
|
||||
|
||||
Feeling too nostalgic?
|
||||
|
||||
You can [install cool-retro-term application][3] that gives you a Linux terminal in the vintage looks of the 90’s computers.
|
||||
|
||||
### 2\. MCC Interim Linux
|
||||
|
||||
![MCC Linux 0.99.14, 1993 | Image Credit][4]
|
||||
|
||||
Initially released in the same year as “LINUX 0.12” by Owen Le Blanc of Manchester Computing Centre in England, MCC Interim Linux was the first Linux distribution for novice users with a menu driven installer and end user/programming tools. Also in the form of a collection of diskettes, it could be installed on a system to provide a basic text-based environment.
|
||||
|
||||
MCC Interim Linux was much more user-friendly than 0.12 and the installation process on a hard drive was much easier and similar to modern ways. It did not require using a hex editor to edit the MBR.
|
||||
|
||||
Though it was first released in February 1992, it was also available for download through FTP since November that year.
|
||||
|
||||
### 3\. TAMU Linux
|
||||
|
||||
![TAMU Linux | Image Credit][5]
|
||||
|
||||
TAMU Linux was developed by Aggies at Texas A&M with the Texas A&M Unix & Linux Users Group in May 1992 and was called TAMU 1.0A. It was the first Linux distribution to offer the X Window System instead of just a text based operating system.
|
||||
|
||||
### 4\. Softlanding Linux System (SLS)
|
||||
|
||||
![SLS Linux 1.05, 1994 | Image Credit][6]
|
||||
|
||||
“Gentle Touchdowns for DOS Bailouts” was their slogan! SLS was released by Peter McDonald in May 1992. SLS was quite widely used and popular during its time and greatly promoted the idea of Linux. But due to a decision by the developers to change the executable format in the distro, users stopped using it.
|
||||
|
||||
Many of the popular distros the present community is most familiar with, evolved via SLS. Two of them are:
|
||||
|
||||
* **Slackware** : One of the earliest Linux distros, Slackware was created by Patrick Volkerding in 1993. Slackware is based on SLS and was one of the very first Linux distributions.
|
||||
* **Debian** : An initiative by Ian Murdock, Debian was also released in 1993 after moving on from the SLS model. The very popular Ubuntu distro we know today is based on Debian.
|
||||
|
||||
|
||||
|
||||
### 5\. Yggdrasil
|
||||
|
||||
![LGX Yggdrasil Fall 1993 | Image Credit][7]
|
||||
|
||||
Released on December 1992, Yggdrasil was the first distro to give birth to the idea of Live Linux CDs. It was developed by Yggdrasil Computing, Inc., founded by Adam J. Richter in Berkeley, California. It could automatically configure itself on system hardware as “Plug-and-Play”, which is a very regular and known feature in today’s time. The later versions of Yggdrasil included a hack for running any proprietary MS-DOS CD-ROM driver within Linux.
|
||||
|
||||
![Yggdrasil’s Plug-and-Play Promo | Image Credit][8]
|
||||
|
||||
Their motto was “Free Software For The Rest of Us”.
|
||||
|
||||
In the late 90s, one very popular distro was [Mandriva][9], first released in 1998, by unifying the French _Mandrake Linux_ distribution with the Brazilian _Conectiva Linux_ distribution. It had a release lifetime of 18 months for updates related to Linux and system software and desktop based updates were released every year. It also had server versions with 5 years of support. Now we have [Open Mandriva][10].
|
||||
|
||||
If you have more nostalgic distros to share from the earliest days of Linux release, please share with us in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/earliest-linux-distros/
|
||||
|
||||
作者:[Avimanyu Bandyopadhyay][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/avimanyu/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/earliest-linux-distros.png?resize=800%2C450&ssl=1
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/Linux-0.12-Floppies.jpg?ssl=1
|
||||
[3]: https://itsfoss.com/cool-retro-term/
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/MCC-Interim-Linux-0.99.14-1993.jpg?fit=800%2C600&ssl=1
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/TAMU-Linux.jpg?ssl=1
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/SLS-1.05-1994.jpg?ssl=1
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/LGX_Yggdrasil_CD_Fall_1993.jpg?fit=781%2C800&ssl=1
|
||||
[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/Yggdrasil-Linux-Summer-1994.jpg?ssl=1
|
||||
[9]: https://en.wikipedia.org/wiki/Mandriva_Linux
|
||||
[10]: https://www.openmandriva.org/
|
||||
@ -0,0 +1,99 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Decentralized Slack Alternative Riot Releases its First Stable Version)
|
||||
[#]: via: (https://itsfoss.com/riot-stable-release/)
|
||||
[#]: author: (Shirish https://itsfoss.com/author/shirish/)
|
||||
|
||||
Decentralized Slack Alternative Riot Releases its First Stable Version
|
||||
======
|
||||
|
||||
Remember [Riot messenger][1]? It’s a decentralized, encrypted open source messaging software based on the [Matrix protocol][2].
|
||||
|
||||
I wrote a [detailed tutorial on using Riot on Linux desktop][3]. The software was in beta back then. The first stable version, Riot 1.0 has been released a few days ago. Wonder what’s new?
|
||||
|
||||
![][4]
|
||||
|
||||
### New Features in Riot 1.0
|
||||
|
||||
Let’s look at some of the changes which were introduced in the move to Riot 1.0.
|
||||
|
||||
#### New Looks and Branding
|
||||
|
||||
![][5]
|
||||
|
||||
The first thing that you see is the welcome screen which has a nice background and also a refreshed sky and dark blue logo which is cleaner and clearer than the previous logo.
|
||||
|
||||
The welcome screen gives you the option to sign into an existing riot account on either matrix.org or any other homeserver or create an account. There is also the option to talk with the Riot Bot and have a room directory listing.
|
||||
|
||||
#### Changing Homeservers and Making your own homeserver
|
||||
|
||||
![Make your own homeserver][6]
|
||||
|
||||
As you can see, here you can change the homeserver. The idea of riot as was shared before is to have [de-centralized][7] chat services, without foregoing the simplicity that centralized services offer. For those who want to run their own homeservers, you need the new [matrix-syanpse 0.99.1.1 reference homeserver][8].
|
||||
|
||||
You can find an unofficial list of matrix homeservers listed [here][9] although it’s far from complete.
|
||||
|
||||
#### Internationalization and Languages.
|
||||
|
||||
One of the more interesting things are that the UI and everything is now il8n-aware and has been translated to catala, dansk, duetsch, Spanish along with English (US) which is/was the default when I installed. We can hope to see some more improvements in language support going ahead.
|
||||
|
||||
#### Favoriting a channel
|
||||
|
||||
![Favoriting a channel in Riot][10]
|
||||
|
||||
One of the things that has changed from last time is how you favorite a channel. Now as you can see, you select the channel, click on the three vertical dots in it and then either favorite or do whatever you want with it.
|
||||
|
||||
#### Making changes to your profile and Settings
|
||||
|
||||
![Riot Different settings you can do. ][11]
|
||||
|
||||
Just clicking the drop-down box beside your Avatar you get the settings box. You click on the box and it gives a wide variety of settings you can change.
|
||||
|
||||
As you can see there are lot more choices and the language is easier than before.
|
||||
|
||||
#### Encryption and E2E
|
||||
|
||||
![Riot encryption screen][12]
|
||||
|
||||
One of the big things which riot has been talked about is Encryption and end-to-end encryption. This is still a work in progress.
|
||||
|
||||
The new release brings the focus on two enhancements in encryption: key backup and emoji device verification (still in progress).
|
||||
|
||||
With Riot 1.0, you can automatically backup your keys on your server. This key itself will be encrypted with a password so that it is stored securely. With this, you’ll never lose your encrypted message because you won’t lose your encryption key.
|
||||
|
||||
You will soon be able to verify your device with emoji now which is easier than matching long strings, isn’t it?
|
||||
|
||||
**In the end**
|
||||
|
||||
Using Riot requires a bit of patience. Once you get the hang of it, there is nothing like it. This decentralized messaging app becomes an important tool in the arsenal of privacy cautious people.
|
||||
|
||||
Riot is an important tool in the continuous effort to keep our data secure and privacy intact. The new major release makes it even more awesome. What do you think?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/riot-stable-release/
|
||||
|
||||
作者:[Shirish][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/shirish/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://about.riot.im/
|
||||
[2]: https://matrix.org/blog/home/
|
||||
[3]: https://itsfoss.com/riot-desktop/
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/riot-messenger.jpg?ssl=1
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/riot-im-web-1.0-welcome-screen.jpg?ssl=1
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/riot-web-1.0-change-homeservers.jpg?resize=800%2C420&ssl=1
|
||||
[7]: https://medium.com/s/story/why-decentralization-matters-5e3f79f7638e
|
||||
[8]: https://github.com/matrix-org/synapse/releases/tag/v0.99.1.1
|
||||
[9]: https://www.hello-matrix.net/public_servers.php
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/riot-web-1.0-channel-preferences.jpg?resize=800%2C420&ssl=1
|
||||
[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/riot-web-1.0-settings-1-e1550427251686.png?ssl=1
|
||||
[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/riot-web-1.0-encryption.jpg?fit=800%2C572&ssl=1
|
||||
@ -0,0 +1,104 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (DevOps for Network Engineers: Linux Foundation’s New Training Course)
|
||||
[#]: via: (https://itsfoss.com/devops-for-network-engineers/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
DevOps for Network Engineers: Linux Foundation’s New Training Course
|
||||
======
|
||||
|
||||
_**Linux Foundation has launched a[DevOps course for sysadmins][1] and network engineers. They are also offering a limited time 40% discount on the launch.**_
|
||||
|
||||
DevOps is no longer a buzzword. It has become the necessity for any IT company.
|
||||
|
||||
The role and responsibility of a sysadmin and a network engineer have changed as well. They are required to have knowledge of the DevOps tools popular in the IT industry.
|
||||
|
||||
If you are a sysadmin or a network engineer, you can no longer laugh off DevOps anymore. It’s time to learn new skills to stay relevant in today’s rapidly changing IT industry otherwise the ‘automation’ trend might cost you your job.
|
||||
|
||||
And who knows it better than Linux Foundation, the official organization behind Linux project and the employer of Linux-creator Linus Torvalds?
|
||||
|
||||
[Linux Foundation has a number of courses on Linux and related technologies][2] that help you in getting a job or improving your existing skills at work.
|
||||
|
||||
The [latest course offering][1] from Linux Foundation specifically focuses on sysadmins who would like to familiarize with DevOps tools.
|
||||
|
||||
### DevOps for Network Engineers Course
|
||||
|
||||
![][3]
|
||||
|
||||
[This course][1] is intended for existing sysadmins and network engineers. So you need to have some knowledge of Linux system administration, shell scripting and Python.
|
||||
|
||||
The course will help you with:
|
||||
|
||||
* Integrating into a DevOps/Agile environment
|
||||
* Familiarizing with commonly used DevOps tools
|
||||
* Collaborating on projects as DevOps
|
||||
* Confidently working with software and configuration files in version control
|
||||
* Recognizing the roles of SCRUM team members
|
||||
* Confidently applying Agile principles in an organization
|
||||
|
||||
|
||||
|
||||
This is the course outline:
|
||||
|
||||
* Chapter 1. Course Introduction
|
||||
* Chapter 2. Modern Project Management
|
||||
* Chapter 3. The DevOps Process: A Network Engineer’s Perspective
|
||||
* Chapter 4. Network Simulation and Testing with [Mininet][4]
|
||||
* Chapter 5. [OpenFlow][5] and [ONOS][6]
|
||||
* Chapter 6. Infrastructure as Code ([Ansible][7] Basics)
|
||||
* Chapter 7. Version Control ([Git][8])
|
||||
* Chapter 8. Continuous Integration and Continuous Delivery ([Jenkins][9])
|
||||
* Chapter 9. Using [Gerrit][10] in DevOps
|
||||
* Chapter 10. Jenkins, Gerrit and Code Review for DevOps
|
||||
* Chapter 11. The DevOps Process and Tools (Review)
|
||||
|
||||
|
||||
|
||||
Altogether, you get 25-30 hours of course material. The online course is self-paced and you can access the material for one year from the date of purchase.
|
||||
|
||||
_**Unlike most other courses on Linux Foundation, this is NOT a video course.**_
|
||||
|
||||
There is no certification for this course because it is more focused on learning and improving skills.
|
||||
|
||||
#### Get the course at a 40% discount (limited time)
|
||||
|
||||
The course costs $299 but since it’s just launched, they are offering 40% discount till March 1st, 2019. You can get the discount by using the **DEVOPSNET** coupon code at checkout.
|
||||
|
||||
[DevOps for Network Engineers][1]
|
||||
|
||||
By the way, if you are interested in Open Source development, you can benefit from the “[Introduction to Open Source Development, Git, and Linux][11]” video course. You can get a limited time 50% discount using **OSDEV50** code at the checkout.
|
||||
|
||||
Staying relevant is absolutely necessary in any industry, not just IT industry. Learning new skills that are in-demand in your industry is perhaps the best way in this regard.
|
||||
|
||||
What do you think? What are your views on the current automation trend? How would you go about it?
|
||||
|
||||
_Disclaimer: This post contains affiliate links. Please read our_ [_affiliate policy_][12] _for more details._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/devops-for-network-engineers/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://shrsl.com/1glcb
|
||||
[2]: https://shareasale.com/r.cfm?b=1074561&u=747593&m=59485&urllink=&afftrack=
|
||||
[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/DevOps-for-Network-Engineers-800x450.png?resize=800%2C450&ssl=1
|
||||
[4]: http://mininet.org/
|
||||
[5]: https://en.wikipedia.org/wiki/OpenFlow
|
||||
[6]: https://onosproject.org/
|
||||
[7]: https://www.ansible.com/
|
||||
[8]: https://itsfoss.com/basic-git-commands-cheat-sheet/
|
||||
[9]: https://jenkins.io/
|
||||
[10]: https://www.gerritcodereview.com/
|
||||
[11]: https://shareasale.com/r.cfm?b=1193750&u=747593&m=59485&urllink=&afftrack=
|
||||
[12]: https://itsfoss.com/affiliate-policy/
|
||||
@ -0,0 +1,54 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to contribute to the Raspberry Pi community)
|
||||
[#]: via: (https://opensource.com/article/19/3/contribute-raspberry-pi-community)
|
||||
[#]: author: (Anderson Silva (Red Hat) https://opensource.com/users/ansilva/users/kepler22b/users/ansilva)
|
||||
|
||||
How to contribute to the Raspberry Pi community
|
||||
======
|
||||
Find ways to get involved in the Raspberry Pi community in the 13th
|
||||
article in our getting-started series.
|
||||
![][1]
|
||||
|
||||
Things are starting to wind down in this series, and as much fun as I've had writing it, mostly I hope it has helped someone out there use start using a Raspberry Pi for education or entertainment. Maybe the articles convinced you to buy your first Raspberry Pi or perhaps helped you rediscover the device that was collecting dust in a drawer. If any of that is true, I'll consider the series a success.
|
||||
|
||||
If you now want to pay it forward and help spread the word on how versatile this little green digital board is, here are a few ways you can get connected to the Raspberry Pi community:
|
||||
|
||||
* Contribute to improving the [official documentation][2]
|
||||
* Contribute code to [projects][3] the Raspberry Pi depends on
|
||||
* File [bugs][4] with Raspbian
|
||||
* File bugs with the different ARM architecture platform distributions
|
||||
* Help kids learn to code by taking a look at the Raspberry Pi Foundation's [Code Club][5] in the UK or [Code Club International][6] outside the UK
|
||||
* Help with [translation][7]
|
||||
* Volunteer on a [Raspberry Jam][8]
|
||||
|
||||
|
||||
|
||||
These are just a few of the ways you can contribute to the Raspberry Pi community. Last but not least, you can join me and [contribute articles][9] to your favorite open source website, [Opensource.com][10]. :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/contribute-raspberry-pi-community
|
||||
|
||||
作者:[Anderson Silva (Red Hat)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ansilva/users/kepler22b/users/ansilva
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/raspberry_pi_community.jpg?itok=dcKwb5et
|
||||
[2]: https://www.raspberrypi.org/documentation/CONTRIBUTING.md
|
||||
[3]: https://www.raspberrypi.org/github/
|
||||
[4]: https://www.raspbian.org/RaspbianBugs
|
||||
[5]: https://www.codeclub.org.uk/
|
||||
[6]: https://www.codeclubworld.org/
|
||||
[7]: https://www.raspberrypi.org/translate/
|
||||
[8]: https://www.raspberrypi.org/jam/
|
||||
[9]: https://opensource.com/participate
|
||||
[10]: http://Opensource.com
|
||||
@ -0,0 +1,56 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Open Source is Eating the Startup Ecosystem: A Guide for Assessing the Value Creation of Startups)
|
||||
[#]: via: (https://www.linux.com/BLOG/2019/3/OPEN-SOURCE-EATING-STARTUP-ECOSYSTEM-GUIDE-ASSESSING-VALUE-CREATION-STARTUPS)
|
||||
[#]: author: (Ibrahim Haddad https://www.linux.com/USERS/IBRAHIM)
|
||||
|
||||
Open Source is Eating the Startup Ecosystem: A Guide for Assessing the Value Creation of Startups
|
||||
======
|
||||
|
||||
![Open Source][1]
|
||||
|
||||
If you want a deeper understanding of defining, implementing, and improving open source compliance programs within your organizations—this ebook is a must read. Download now.
|
||||
|
||||
[Creative Commons Zero][2]
|
||||
|
||||
Unsplash
|
||||
|
||||
In the last few years, we have witnessed the unprecedented growth of open source in all industries—from the increased adoption of open source software in products and services, to the extensive growth in open source contributions and the releasing of proprietary technologies under an open source license. It has been an incredible experience to be a part of.
|
||||
|
||||
![Open Source][3]
|
||||
|
||||
[The Linux Foundation][4]
|
||||
|
||||
As many have stated, Open Source is the New Normal, Open Source is Eating the World, Open Source is Eating Software, etc. all of which are true statements. To that extent, I’d like to add one more maxim: Open Source is Eating the Startup Ecosystem. It is almost impossible to find a technology startup today that does not rely in one shape or form on open source software to boot up its operation and develop its product offering. As a result, we are operating in a space where open source due diligence is now a mandatory exercise in every M&A transaction. These exercises evaluate the open source practices of an organization and scope out all open source software used in product(s)/service(s) and how it interacts with proprietary components—all of which is necessary to assess the value creation of the company in relation to open source software.
|
||||
|
||||
Being intimately involved in this space has allowed me to observe, learn, and apply many open source best practices. I decided to chronicle these learnings in an ebook as a contribution to the [OpenChain project][5]: [Assessment of Open Source Practices as part of Due Diligence in Merger and Acquisition Transactions][6]. This ebook addresses the basic question of: How does one evaluate open source practices in a given organization that is an acquisition target? We address this question by offering a path to evaluate these practices along with appropriate checklists for reference. Essentially, it explains how the acquirer and the target company can prepare for this due diligence, offers an explanation of the audit process, and provides general recommended practices for ensuring open source compliance.
|
||||
|
||||
If is important to note that not every organization will see a need to implement every practice we recommend. Some organizations will find alternative practices or implementation approaches to achieve the same results. Appropriately, an organization will adapt its open source approach based upon the nature and amount of the open source it uses, the licenses that apply to open source it uses, the kinds of products it distributes or services it offers, and the design of the products or services themselves
|
||||
|
||||
If you are involved in assessing the open source and compliance practices of organizations, or involved in an M&A transaction focusing on open source due diligence, or simply want to have a deeper level of understanding of defining, implementing, and improving open source compliance programs within your organizations—this ebook is a must read. [Download the Brief][6].
|
||||
|
||||
This article originally appeared at the [Linux Foundation.][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/BLOG/2019/3/OPEN-SOURCE-EATING-STARTUP-ECOSYSTEM-GUIDE-ASSESSING-VALUE-CREATION-STARTUPS
|
||||
|
||||
作者:[Ibrahim Haddad][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/USERS/IBRAHIM
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/open-alexandre-godreau-510220-unsplash.jpg?itok=2udo1XKo (Open Source)
|
||||
[2]: /LICENSES/CATEGORY/CREATIVE-COMMONS-ZERO
|
||||
[3]: https://www.linux.com/sites/lcom/files/styles/floated_images/public/assessmentofopensourcepractices_ebook_mockup-768x994.png?itok=qpLKAVGR (Open Source)
|
||||
[4]: /LICENSES/CATEGORY/LINUX-FOUNDATION
|
||||
[5]: https://www.openchainproject.org/
|
||||
[6]: https://www.linuxfoundation.org/open-source-management/2019/03/assessment-open-source-practices/
|
||||
[7]: https://www.linuxfoundation.org/blog/2019/03/open-source-is-eating-the-startup-ecosystem-a-guide-for-assessing-the-value-creation-of-startups/
|
||||
@ -0,0 +1,125 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Mageia Linux Is a Modern Throwback to the Underdog Days)
|
||||
[#]: via: (https://www.linux.com/BLOG/LEARN/2019/3/MAGEIA-LINUX-MODERN-THROWBACK-UNDERDOG-DAYS)
|
||||
[#]: author: (Jack Wallen https://www.linux.com/users/jlwallen)
|
||||
|
||||
Mageia Linux Is a Modern Throwback to the Underdog Days
|
||||
======
|
||||
|
||||
![Welcome to Mageia][1]
|
||||
|
||||
The Mageia Welcome App is a boon for new Linux users.
|
||||
|
||||
[Used with permission][2]
|
||||
|
||||
I’ve been using Linux long enough to remember Linux Mandrake. I recall, at one of my first-ever Linux conventions, hanging out with the MandrakeSoft crew and being starstruck to think that they were creating a Linux distribution that was sure to bring about world domination for the open source platform.
|
||||
|
||||
Well, that didn’t happen. In fact, Linux Mandrake didn’t even stand the test of time. It was renamed Mandriva and rebranded. Mandriva retained popularity but eventually came to a halt in 2011. The company disbanded, sending all those star developers to other projects. Of course, rising from the ashes of Mandrake Linux came the likes of [OpenMandriva][3], as well as another distribution called [Mageia Linux][4].
|
||||
|
||||
Like OpenMandriva, Mageia Linux is a fork of Mandriva. It was created (by a group of former Mandriva employees) in 2010 and first released in 2011, so there was next to no downtime between the end of Mandriva and the release of Mageia. Since then, Mageia has existed in the shadows of bigger, more popular flavors of Linux (e.g., Ubuntu, Mint, Fedora, Elementary OS, etc.), but it’s never faltered. As of this writing, Mageia is listed as number 26 on the [Distrowatch][5] Page Hit Ranking chart and is enjoying release number 6.1.
|
||||
|
||||
### What Sets Mageia Apart?
|
||||
|
||||
This question has become quite important when looking at Linux distributions, considering just how many distros there are—many of which are hard to tell apart. If you’ve seen one KDE, GNOME, or Xfce distribution, you’ve seen them all, right? Anyone who's used Linux enough knows this statement is not even remotely true. For many distributions, though, the differences lie in the subtleties. It’s not about what you do with the desktop; it’s how you put everything together to improve the user experience.
|
||||
|
||||
Mageia Linux defaults to the KDE desktop and does as good a job as any other distribution at presenting KDE to users. But before you start using KDE, you should note some differences between Mageia and other distributions. To start, the installation is quite simple, but it’s slightly askew from what might expect. In similar fashion to most modern distributions, you boot up the live instance and click on the Install icon (Figure 1).
|
||||
|
||||
![Installing Mageia][6]
|
||||
|
||||
Figure 1: Installing Mageia from the Live instance.
|
||||
|
||||
[Used with permission][2]
|
||||
|
||||
Once you’ve launched the installation app, it’s fairly straightforward, although not quite as simple as some other versions of Linux. New users might hesitate when they are presented with the partition choice between Use free space or Custom disk partition (Remember, I’m talking about new users here). This type of user might prefer a bit simpler verbiage. Consider this: What if you were presented (at the partition section) by two choices:
|
||||
|
||||
* Basic Install
|
||||
|
||||
* Custom Install
|
||||
|
||||
|
||||
|
||||
|
||||
The Basic install path would choose a fairly standard set of options (e.g., using the whole disk for installation and placing the bootloader in the proper/logical place). In contrast, the Custom install would allow the user to install in a non-default fashion (for dual boot, etc.) and choose where the bootloader would go and what options to apply.
|
||||
|
||||
The next possible confusing step (again, for new users) is the bootloader (Figure 2). For those who have installed Linux before, this option is a no-brainer. For new users, even understanding what a bootloader does can be a bit of an obstacle.
|
||||
|
||||
![bootloader][7]
|
||||
|
||||
Figure 2: Configuring the Mageia bootloader.
|
||||
|
||||
[Used with permission][2]
|
||||
|
||||
The bootloader configuration screen also allows you to password protect GRUB2. Because of the layout of this screen, it could be confused as the root user password. It’s not. If you don’t want to password protect GRUB2, leave this blank. In the final installation screen (Figure 3), you can set any bootloader options you might want. Once again, we find a window that could cause confusion with new users.
|
||||
|
||||
![bootloader options][8]
|
||||
|
||||
Figure 3: Advanced bootloader options can be configured here.
|
||||
|
||||
[Used with permission][2]
|
||||
|
||||
Click Finish and the installation will complete. You might have noticed the absence of user configuration or root user password options. With the first stage of the installation complete, you reboot the machine, remove the installer media, and (when the machine reboots) you’ll then be prompted to configure both the root user password and a standard user account (Figure 4).
|
||||
|
||||
![Configuring your users][9]
|
||||
|
||||
Figure 4: Configuring your users.
|
||||
|
||||
[Used with permission][2]
|
||||
|
||||
And that’s all there is to the Mageia installation.
|
||||
|
||||
### Welcome to Mageia
|
||||
|
||||
Once you log into Mageia, you’ll be greeted by something every Linux distribution should use—a welcome app (Figure 5).
|
||||
|
||||
![welcome app][10]
|
||||
|
||||
Figure 5: The Mageia welcome app is a new user’s best friend.
|
||||
|
||||
[Used with permission][2]
|
||||
|
||||
From this welcome app, you can get information about the distribution, get help, and join communities. The importance of having such an approach to greet users at login cannot be overstated. When new users log into Linux for the first time, they want to know that help is available, should they need it. Mageia Linux has done an outstanding job with this feature. Granted, all this app does is serve as a means to point users to various websites, but it’s important information for users to have at the ready.
|
||||
|
||||
Beyond the welcome app, the Mageia Control Center (Figure 6) also helps Mageia stand out. This one-stop-shop is where users can take care of installing/updating software, configuring media sources for installation, configure update frequency, manage/configure hardware, configure network devices (e.g., VPNs, proxies, and more), configure system services, view logs, open an administrator console, create network shares, and so much more. This is as close to the openSUSE YaST tool as you’ll find (without using either SUSE or openSUSE).
|
||||
|
||||
![Control Center][11]
|
||||
|
||||
Figure 6: The Mageia Control Center is an outstanding system management tool.
|
||||
|
||||
[Used with permission][2]
|
||||
|
||||
Beyond those two tools, you’ll find everything else you need to work. Mageia Linux comes with the likes of LibreOffice, Firefox, KMail, GIMP, Clementine, VLC, and more. Out of the box, you’d be hard pressed to find another tool you need to install to get your work done. It’s that complete a distribution.
|
||||
|
||||
### Target Audience
|
||||
|
||||
Figuring out the Mageia Linux target audience is a tough question to answer. If new users can get past the somewhat confusing installation (which isn’t really that challenging, just slightly misleading), using Mageia Linux is a dream.
|
||||
|
||||
The slick, barely modified KDE desktop, combined with the welcome app and control center make for a desktop Linux that will let users of all skill levels feel perfectly at home. If the developers could tighten up the verbiage on the installation, Mageia Linux could be one of the greatest new user Linux experiences available. Until then, new users should make sure they understand what they’re getting into with the installation portion of this take on the Linux platform.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/BLOG/LEARN/2019/3/MAGEIA-LINUX-MODERN-THROWBACK-UNDERDOG-DAYS
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/jlwallen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/mageia-main.jpg?itok=ZmkbMxfM (Welcome to Mageia)
|
||||
[2]: /LICENSES/CATEGORY/USED-PERMISSION
|
||||
[3]: https://www.openmandriva.org/
|
||||
[4]: https://www.mageia.org/en/
|
||||
[5]: https://distrowatch.com/
|
||||
[6]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/mageia_1.jpg?itok=RYXPU70j (Installing Mageia)
|
||||
[7]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/mageia_2.jpg?itok=m2IPxgA4 (bootloader)
|
||||
[8]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/mageia_3.jpg?itok=Bs2PPrMF (bootloader options)
|
||||
[9]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/mageia_4.jpg?itok=YZBIZ0Ua (Configuring your users)
|
||||
[10]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/mageia_5.jpg?itok=gYcTfUKv (welcome app)
|
||||
[11]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/mageia_6.jpg?itok=eSl2qpPp (Control Center)
|
||||
@ -1,73 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Sweet Home 3D: An open source tool to help you decide on your dream home)
|
||||
[#]: via: (https://opensource.com/article/19/3/tool-find-home)
|
||||
[#]: author: (Jeff Macharyas (Community Moderator) )
|
||||
|
||||
Sweet Home 3D: An open source tool to help you decide on your dream home
|
||||
======
|
||||
|
||||
Interior design application makes it easy to render your favorite house—real or imaginary.
|
||||
|
||||
![Houses in a row][1]
|
||||
|
||||
I recently accepted a new job in Virginia. Since my wife was working and watching our house in New York until it sold, it was my responsibility to go out and find a new house for us and our cat. A house that she would not see until we moved into it!
|
||||
|
||||
I contracted with a real estate agent and looked at a few houses, taking many pictures and writing down illegible notes. At night, I would upload the photos into a Google Drive folder, and my wife and I would review them simultaneously over the phone while I tried to remember whether the room was on the right or the left, whether it had a fan, etc.
|
||||
|
||||
Since this was a rather tedious and not very accurate way to present my findings, I went in search of an open source solution to better illustrate what our future dream house would look like that wouldn't hinge on my fuzzy memory and blurry photos.
|
||||
|
||||
[Sweet Home 3D][2] did exactly what I wanted it to do. Sweet Home 3D is available on Sourceforge and released under the GNU General Public License. The [website][3] is very informative, and I was able to get it up and running in no time. Sweet Home 3D was developed by Paris-based Emmanuel Puybaret of eTeks.
|
||||
|
||||
### Hanging the drywall
|
||||
|
||||
I downloaded Sweet Home 3D onto my MacBook Pro and added a PNG version of a flat floorplan of a house to use as a background base map.
|
||||
|
||||
From there, it was a simple matter of using the Rooms palette to trace the pattern and set the "real life" dimensions. After I mapped the rooms, I added the walls, which I could customize by color, thickness, height, etc.
|
||||
|
||||
![Sweet Home 3D floorplan][5]
|
||||
|
||||
Now that I had the "drywall" built, I downloaded various pieces of "furniture" from a large array that includes actual furniture as well as doors, windows, shelves, and more. Each item downloads as a ZIP file, so I created a folder of all my uncompressed pieces. I could customize each piece of furniture, and repetitive items, such as doors, were easy to copy-and-paste into place.
|
||||
|
||||
Once I had all my walls and doors and windows in place, I used the application's 3D view to navigate through the house. Drawing upon my photos and memory, I made adjustments to all the objects until I had a close representation of the house. I could have spent more time modifying the house by adding textures, additional furniture, and objects, but I got it to the point I needed.
|
||||
|
||||
![Sweet Home 3D floorplan][7]
|
||||
|
||||
After I finished, I exported the plan as an OBJ file, which can be opened in a variety of programs, such as [Blender][8] and Preview on the Mac, to spin the house around and examine it from various angles. The Video function was most useful, as I could create a starting point, draw a path through the house, and record the "journey." I exported the video as a MOV file, which I opened and viewed on the Mac using QuickTime.
|
||||
|
||||
My wife was able to see (almost) exactly what I saw, and we could even start arranging furniture ahead of the move, too. Now, all I have to do is load up the moving truck and head south.
|
||||
|
||||
Sweet Home 3D will also prove useful at my new job. I was looking for a way to improve the map of the college's buildings and was planning to just re-draw it in [Inkscape][9] or Illustrator or something. However, since I have the flat map, I can use Sweet Home 3D to create a 3D version of the floorplan and upload it to our website to make finding the bathrooms so much easier!
|
||||
|
||||
### An open source crime scene?
|
||||
|
||||
An interesting aside: according to the [Sweet Home 3D blog][10], "the French Forensic Police Office (Scientific Police) recently chose Sweet Home 3D as a tool to design plans [to represent roads and crime scenes]. This is a concrete application of the recommendation of the French government to give the preference to free open source solutions."
|
||||
|
||||
This is one more bit of evidence of how open source solutions are being used by citizens and governments to create personal projects, solve crimes, and build worlds.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/tool-find-home
|
||||
|
||||
作者:[Jeff Macharyas (Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/house_home_colors_live_building.jpg?itok=HLpsIfIL (Houses in a row)
|
||||
[2]: https://sourceforge.net/projects/sweethome3d/
|
||||
[3]: http://www.sweethome3d.com/
|
||||
[4]: /file/426441
|
||||
[5]: https://opensource.com/sites/default/files/uploads/virginia-house-create-screenshot.png (Sweet Home 3D floorplan)
|
||||
[6]: /file/426451
|
||||
[7]: https://opensource.com/sites/default/files/uploads/virginia-house-3d-screenshot.png (Sweet Home 3D floorplan)
|
||||
[8]: https://opensource.com/article/18/5/blender-hotkey-cheat-sheet
|
||||
[9]: https://opensource.com/article/19/1/inkscape-cheat-sheet
|
||||
[10]: http://www.sweethome3d.com/blog/2018/12/10/customization_for_the_forensic_police.html
|
||||
@ -1,301 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Configure sudo Access In Linux?)
|
||||
[#]: via: (https://www.2daygeek.com/how-to-configure-sudo-access-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
How To Configure sudo Access In Linux?
|
||||
======
|
||||
|
||||
The root user has all the controls in Linux system.
|
||||
|
||||
root user is the most powerful user in the Linux system and can perform any action in the system.
|
||||
|
||||
If any users wants to perform some actions, don’t provide the root access to anybody because if he/she done anything wrong there is no option/way to rectify it.
|
||||
|
||||
To fix this, what will be the solution?
|
||||
|
||||
We can grant sudo permission to the corresponding user to overcome this situation.
|
||||
|
||||
The sudo command offers a mechanism for providing trusted users with administrative access to a system without sharing the password of the root user.
|
||||
|
||||
They can perform most of the administrative operations but not all operations like root.
|
||||
|
||||
### What Is sudo?
|
||||
|
||||
sudo is a program, which can be used by a normal users to execute a command as the super user or another user, as specified by the security policy.
|
||||
|
||||
sudo users access is controlled by `/etc/sudoers` file.
|
||||
|
||||
### What Is An Advantage Of sudo Users?
|
||||
|
||||
sudo is a safe way to run a command in Linux system if you are not familiar on it.
|
||||
|
||||
* The Linux system keeps a logs into the `/var/log/secure` and `/var/log/auth.log` file where you can verify what actions was made by the sudo user.
|
||||
* Every time, it will prompt a password to perform the current action. So, you will be getting a time to verify the action, which you are going to perform. If you feel it’s not a correct action then you can safely exit there itself without perform the current action.
|
||||
|
||||
|
||||
|
||||
It’s different for RHEL based systems such as Redhat (RHEL), CentOS and Oracle Enterprise Linux (OEL) and Debian based systems such as Debian, Ubuntu and LinuxMint.
|
||||
|
||||
We will tech you, how to perform this on both the distributions in this article.
|
||||
|
||||
It can be done in three ways in both the distributions.
|
||||
|
||||
* Add a user into corresponding groups. For RHEL based system, we need to add a user into `wheel` group. For Debian based system, we need to add a user into `sudo` or `admin` groups.
|
||||
* Add a user into `/etc/group` file manually.
|
||||
* Add a user into `/etc/sudoers` file using visudo.
|
||||
|
||||
|
||||
|
||||
### How To Configure sudo Access In RHEL/CentOS/OEL Systems?
|
||||
|
||||
It can be done on RHEL based systems such as Redhat (RHEL), CentOS and Oracle Enterprise Linux (OEL) using following three methods.
|
||||
|
||||
### Method-1: How To Grant The Super User Access To A Normal User In Linux Using wheel Group?
|
||||
|
||||
Wheel is a special group in the RHEL based systems that provides additional privileges that empower a user to execute restricted commands as the super user.
|
||||
|
||||
Make a note that the `wheel` group should be enabled in the `/etc/sudoers` file to gain this access.
|
||||
|
||||
```
|
||||
# grep -i wheel /etc/sudoers
|
||||
|
||||
## Allows people in group wheel to run all commands
|
||||
%wheel ALL=(ALL) ALL
|
||||
# %wheel ALL=(ALL) NOPASSWD: ALL
|
||||
```
|
||||
|
||||
I assume that we had already created an user account to perform this. In my case, I’m going to use `daygeek` user account.
|
||||
|
||||
Run the following command to add an user into wheel group.
|
||||
|
||||
```
|
||||
# usermod -aG wheel daygeek
|
||||
```
|
||||
|
||||
We can doube confirm this by running the following command.
|
||||
|
||||
```
|
||||
# getent group wheel
|
||||
wheel:x:10:daygeek
|
||||
```
|
||||
|
||||
I’m going to check whether `daygeek` user can access a file which is owned by the root user.
|
||||
|
||||
```
|
||||
$ tail -5 /var/log/secure
|
||||
tail: cannot open _/var/log/secure_ for reading: Permission denied
|
||||
```
|
||||
|
||||
I was getting an error when i try to access the `/var/log/secure` file as a normal user. I’m going to access the same file with sudo, let’s see the magic.
|
||||
|
||||
```
|
||||
$ sudo tail -5 /var/log/secure
|
||||
[sudo] password for daygeek:
|
||||
Mar 17 07:01:56 CentOS7 sudo: daygeek : TTY=pts/0 ; PWD=/home/daygeek ; USER=root ; COMMAND=/bin/tail -5 /var/log/secure
|
||||
Mar 17 07:01:56 CentOS7 sudo: pam_unix(sudo:session): session opened for user root by daygeek(uid=0)
|
||||
Mar 17 07:01:56 CentOS7 sudo: pam_unix(sudo:session): session closed for user root
|
||||
Mar 17 07:05:10 CentOS7 sudo: daygeek : TTY=pts/0 ; PWD=/home/daygeek ; USER=root ; COMMAND=/bin/tail -5 /var/log/secure
|
||||
Mar 17 07:05:10 CentOS7 sudo: pam_unix(sudo:session): session opened for user root by daygeek(uid=0)
|
||||
```
|
||||
|
||||
### Method-2: How To Grant The Super User Access To A Normal User In RHEL/CentOS/OEL using /etc/group file?
|
||||
|
||||
We can manually add an user into the wheel group by editing the `/etc/group` file.
|
||||
|
||||
Just open the file then append the corresponding user in the appropriate group to achieve this.
|
||||
|
||||
```
|
||||
$ grep -i wheel /etc/group
|
||||
wheel:x:10:daygeek,user1
|
||||
```
|
||||
|
||||
In this example, I’m going to use `user1` user account.
|
||||
|
||||
I’m going to check whether `user1` user has sudo access or not by restarting the `Apache` service in the system. let’s see the magic.
|
||||
|
||||
```
|
||||
$ sudo systemctl restart httpd
|
||||
[sudo] password for user1:
|
||||
|
||||
$ sudo grep -i user1 /var/log/secure
|
||||
[sudo] password for user1:
|
||||
Mar 17 07:09:47 CentOS7 sudo: user1 : TTY=pts/0 ; PWD=/home/user1 ; USER=root ; COMMAND=/bin/systemctl restart httpd
|
||||
Mar 17 07:10:40 CentOS7 sudo: user1 : TTY=pts/0 ; PWD=/home/user1 ; USER=root ; COMMAND=/bin/systemctl restart httpd
|
||||
Mar 17 07:12:35 CentOS7 sudo: user1 : TTY=pts/0 ; PWD=/home/user1 ; USER=root ; COMMAND=/bin/grep -i httpd /var/log/secure
|
||||
```
|
||||
|
||||
### Method-3: How To Grant The Super User Access To A Normal User In Linux Using /etc/sudoers file?
|
||||
|
||||
sudo users access is controlled by `/etc/sudoers` file. So, simply add an user into the sudoers file under wheel group.
|
||||
|
||||
Just append the desired user into /etc/suoders file by using visudo command.
|
||||
|
||||
```
|
||||
# grep -i user2 /etc/sudoers
|
||||
user2 ALL=(ALL) ALL
|
||||
```
|
||||
|
||||
In this example, I’m going to use `user2` user account.
|
||||
|
||||
I’m going to check whether `user2` user has sudo access or not by restarting the `MariaDB` service in the system. let’s see the magic.
|
||||
|
||||
```
|
||||
$ sudo systemctl restart mariadb
|
||||
[sudo] password for user2:
|
||||
|
||||
$ sudo grep -i mariadb /var/log/secure
|
||||
[sudo] password for user2:
|
||||
Mar 17 07:23:10 CentOS7 sudo: user2 : TTY=pts/0 ; PWD=/home/user2 ; USER=root ; COMMAND=/bin/systemctl restart mariadb
|
||||
Mar 17 07:26:52 CentOS7 sudo: user2 : TTY=pts/0 ; PWD=/home/user2 ; USER=root ; COMMAND=/bin/grep -i mariadb /var/log/secure
|
||||
```
|
||||
|
||||
### How To Configure sudo Access In Debian/Ubuntu Systems?
|
||||
|
||||
It can be done on Debian based systems such as Debian based systems such as Debian, Ubuntu and LinuxMint using following three methods.
|
||||
|
||||
### Method-1: How To Grant The Super User Access To A Normal User In Linux Using sudo or admin Groups?
|
||||
|
||||
sudo or admin is a special group in the Debian based systems that provides additional privileges that empower a user to execute restricted commands as the super user.
|
||||
|
||||
Make a note that the `sudo` or `admin` group should be enabled in the `/etc/sudoers` file to gain this access.
|
||||
|
||||
```
|
||||
# grep -i 'sudo\|admin' /etc/sudoers
|
||||
|
||||
# Members of the admin group may gain root privileges
|
||||
%admin ALL=(ALL) ALL
|
||||
|
||||
# Allow members of group sudo to execute any command
|
||||
%sudo ALL=(ALL:ALL) ALL
|
||||
```
|
||||
|
||||
I assume that we had already created an user account to perform this. In my case, I’m going to use `2gadmin` user account.
|
||||
|
||||
Run the following command to add an user into sudo group.
|
||||
|
||||
```
|
||||
# usermod -aG sudo 2gadmin
|
||||
```
|
||||
|
||||
We can doube confirm this by running the following command.
|
||||
|
||||
```
|
||||
# getent group sudo
|
||||
sudo:x:27:2gadmin
|
||||
```
|
||||
|
||||
I’m going to check whether `2gadmin` user can access a file which is owned by the root user.
|
||||
|
||||
```
|
||||
$ less /var/log/auth.log
|
||||
/var/log/auth.log: Permission denied
|
||||
```
|
||||
|
||||
I was getting an error when i try to access the `/var/log/auth.log` file as a normal user. I’m going to access the same file with sudo, let’s see the magic.
|
||||
|
||||
```
|
||||
$ sudo tail -5 /var/log/auth.log
|
||||
[sudo] password for 2gadmin:
|
||||
Mar 17 20:39:47 Ubuntu18 sudo: 2gadmin : TTY=pts/0 ; PWD=/home/2gadmin ; USER=root ; COMMAND=/bin/bash
|
||||
Mar 17 20:39:47 Ubuntu18 sudo: pam_unix(sudo:session): session opened for user root by 2gadmin(uid=0)
|
||||
Mar 17 20:40:23 Ubuntu18 sudo: pam_unix(sudo:session): session closed for user root
|
||||
Mar 17 20:40:48 Ubuntu18 sudo: 2gadmin : TTY=pts/0 ; PWD=/home/2gadmin ; USER=root ; COMMAND=/usr/bin/tail -5 /var/log/auth.log
|
||||
Mar 17 20:40:48 Ubuntu18 sudo: pam_unix(sudo:session): session opened for user root by 2gadmin(uid=0)
|
||||
```
|
||||
|
||||
Alternatively we can perform the same by adding an user to `admin` group.
|
||||
|
||||
Run the following command to add an user into sudo group.
|
||||
|
||||
```
|
||||
# usermod -aG admin user1
|
||||
```
|
||||
|
||||
We can doube confirm this by running the following command.
|
||||
|
||||
```
|
||||
# getent group admin
|
||||
admin:x:1011:user1
|
||||
```
|
||||
|
||||
Let’s see the output.
|
||||
|
||||
```
|
||||
$ sudo tail -2 /var/log/auth.log
|
||||
[sudo] password for user1:
|
||||
Mar 17 20:53:36 Ubuntu18 sudo: user1 : TTY=pts/0 ; PWD=/home/user1 ; USER=root ; COMMAND=/usr/bin/tail -2 /var/log/auth.log
|
||||
Mar 17 20:53:36 Ubuntu18 sudo: pam_unix(sudo:session): session opened for user root by user1(uid=0)
|
||||
```
|
||||
|
||||
### Method-2: How To Grant The Super User Access To A Normal User In Debian/Ubuntu using /etc/group file?
|
||||
|
||||
We can manually add an user into the sudo or admin group by editing the `/etc/group` file.
|
||||
|
||||
Just open the file then append the corresponding user in the appropriate group to achieve this.
|
||||
|
||||
```
|
||||
$ grep -i sudo /etc/group
|
||||
sudo:x:27:2gadmin,user2
|
||||
```
|
||||
|
||||
In this example, I’m going to use `user2` user account.
|
||||
|
||||
I’m going to check whether `user2` user has sudo access or not by restarting the `Apache` service in the system. let’s see the magic.
|
||||
|
||||
```
|
||||
$ sudo systemctl restart apache2
|
||||
[sudo] password for user2:
|
||||
|
||||
$ sudo tail -f /var/log/auth.log
|
||||
[sudo] password for user2:
|
||||
Mar 17 21:01:04 Ubuntu18 systemd-logind[559]: New session 22 of user user2.
|
||||
Mar 17 21:01:04 Ubuntu18 systemd: pam_unix(systemd-user:session): session opened for user user2 by (uid=0)
|
||||
Mar 17 21:01:33 Ubuntu18 sudo: user2 : TTY=pts/0 ; PWD=/home/user2 ; USER=root ; COMMAND=/bin/systemctl restart apache2
|
||||
```
|
||||
|
||||
### Method-3: How To Grant The Super User Access To A Normal User In Linux Using /etc/sudoers file?
|
||||
|
||||
sudo users access is controlled by `/etc/sudoers` file. So, simply add an user into the sudoers file under sudo or admin group.
|
||||
|
||||
Just append the desired user into /etc/suoders file by using visudo command.
|
||||
|
||||
```
|
||||
# grep -i user3 /etc/sudoers
|
||||
user3 ALL=(ALL:ALL) ALL
|
||||
```
|
||||
|
||||
In this example, I’m going to use `user3` user account.
|
||||
|
||||
I’m going to check whether `user3` user has sudo access or not by restarting the `MariaDB` service in the system. let’s see the magic.
|
||||
|
||||
```
|
||||
$ sudo systemctl restart mariadb
|
||||
[sudo] password for user3:
|
||||
|
||||
$ sudo tail -f /var/log/auth.log
|
||||
[sudo] password for user3:
|
||||
Mar 17 21:12:32 Ubuntu18 systemd-logind[559]: New session 24 of user user3.
|
||||
Mar 17 21:12:49 Ubuntu18 sudo: user3 : TTY=pts/0 ; PWD=/home/user3 ; USER=root ; COMMAND=/bin/systemctl restart mariadb
|
||||
Mar 17 21:12:49 Ubuntu18 sudo: pam_unix(sudo:session): session opened for user root by user3(uid=0)
|
||||
Mar 17 21:12:53 Ubuntu18 sudo: pam_unix(sudo:session): session closed for user root
|
||||
Mar 17 21:13:08 Ubuntu18 sudo: user3 : TTY=pts/0 ; PWD=/home/user3 ; USER=root ; COMMAND=/usr/bin/tail -f /var/log/auth.log
|
||||
Mar 17 21:13:08 Ubuntu18 sudo: pam_unix(sudo:session): session opened for user root by user3(uid=0)
|
||||
```
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-configure-sudo-access-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
150
sources/tech/20190318 Let-s try dwm - dynamic window manager.md
Normal file
150
sources/tech/20190318 Let-s try dwm - dynamic window manager.md
Normal file
@ -0,0 +1,150 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Let’s try dwm — dynamic window manager)
|
||||
[#]: via: (https://fedoramagazine.org/lets-try-dwm-dynamic-window-manger/)
|
||||
[#]: author: (Adam Šamalík https://fedoramagazine.org/author/asamalik/)
|
||||
|
||||
Let’s try dwm — dynamic window manager
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
If you like efficiency and minimalism, and are looking for a new window manager for your Linux desktop, you should try _dwm_ — dynamic window manager. Written in under 2000 standard lines of code, dwm is extremely fast yet powerful and highly customizable window manager.
|
||||
|
||||
You can dynamically choose between tiling, monocle and floating layouts, organize your windows into multiple workspaces using tags, and quickly navigate through using keyboard shortcuts. This article helps you get started using dwm.
|
||||
|
||||
## **Installation**
|
||||
|
||||
To install dwm on Fedora, run:
|
||||
|
||||
```
|
||||
$ sudo dnf install dwm dwm-user
|
||||
```
|
||||
|
||||
The _dwm_ package installs the window manager itself, and the _dwm-user_ package significantly simplifies configuration which will be explained later in this article.
|
||||
|
||||
Additionally, to be able to lock the screen when needed, we’ll also install _slock_ — a simple X display locker.
|
||||
|
||||
```
|
||||
$ sudo dnf install slock
|
||||
```
|
||||
|
||||
However, you can use a different one based on your personal preference.
|
||||
|
||||
## **Quick start**
|
||||
|
||||
To start dwm, choose the _dwm-user_ option on the login screen.
|
||||
|
||||
![][2]
|
||||
|
||||
After you log in, you’ll see a very simple desktop. In fact, the only thing there will be a bar at the top listing our nine tags that represent workspaces and a _[]=_ symbol that represents the layout of your windows.
|
||||
|
||||
### Launching applications
|
||||
|
||||
Before looking into the layouts, first launch some applications so you can play with the layouts as you go. Apps can be started by pressing _Alt+p_ and typing the name of the app followed by _Enter_. There’s also a shortcut _Alt+Shift+Enter_ for opening a terminal.
|
||||
|
||||
Now that some apps are running, have a look at the layouts.
|
||||
|
||||
### Layouts
|
||||
|
||||
There are three layouts available by default: the tiling layout, the monocle layout, and the floating layout.
|
||||
|
||||
The tiling layout, represented by _[]=_ on the bar, organizes windows into two main areas: master on the left, and stack on the right. You can activate the tiling layout by pressing _Alt+t._
|
||||
|
||||
![][3]
|
||||
|
||||
The idea behind the tiling layout is that you have your primary window in the master area while still seeing the other ones in the stack. You can quickly switch between them as needed.
|
||||
|
||||
To swap windows between the two areas, hover your mouse over one in the stack area and press _Alt+Enter_ to swap it with the one in the master area.
|
||||
|
||||
![][4]
|
||||
|
||||
The monocle layout, represented by _[N]_ on the top bar, makes your primary window take the whole screen. You can switch to it by pressing _Alt+m_.
|
||||
|
||||
Finally, the floating layout lets you move and resize your windows freely. The shortcut for it is _Alt+f_ and the symbol on the top bar is _> <>_.
|
||||
|
||||
### Workspaces and tags
|
||||
|
||||
Each window is assigned to a tag (1-9) listed at the top bar. To view a specific tag, either click on its number using your mouse or press _Alt+1..9._ You can even view multiple tags at once by clicking on their number using the secondary mouse button.
|
||||
|
||||
Windows can be moved between different tags by highlighting them using your mouse, and pressing _Alt+Shift+1..9._
|
||||
|
||||
## **Configuration**
|
||||
|
||||
To make dwm as minimalistic as possible, it doesn’t use typical configuration files. Instead, you modify a C header file representing the configuration, and recompile it. But don’t worry, in Fedora it’s as simple as just editing one file in your home directory and everything else happens in the background thanks to the _dwm-user_ package provided by the maintainer in Fedora.
|
||||
|
||||
First, you need to copy the file into your home directory using a command similar to the following:
|
||||
|
||||
```
|
||||
$ mkdir ~/.dwm
|
||||
$ cp /usr/src/dwm-VERSION-RELEASE/config.def.h ~/.dwm/config.h
|
||||
```
|
||||
|
||||
You can get the exact path by running _man dwm-start._
|
||||
|
||||
Second, just edit the _~/.dwm/config.h_ file. As an example, let’s configure a new shortcut to lock the screen by pressing _Alt+Shift+L_.
|
||||
|
||||
Considering we’ve installed the _slock_ package mentioned earlier in this post, we need to add the following two lines into the file to make it work:
|
||||
|
||||
Under the _/* commands */_ comment, add:
|
||||
|
||||
```
|
||||
static const char *slockcmd[] = { "slock", NULL };
|
||||
```
|
||||
|
||||
And the following line into _static Key keys[]_ :
|
||||
|
||||
```
|
||||
{ MODKEY|ShiftMask, XK_l, spawn, {.v = slockcmd } },
|
||||
```
|
||||
|
||||
In the end, it should look like as follows: (added lines are highlighted)
|
||||
|
||||
```
|
||||
...
|
||||
/* commands */
|
||||
static char dmenumon[2] = "0"; /* component of dmenucmd, manipulated in spawn() */
|
||||
static const char *dmenucmd[] = { "dmenu_run", "-m", dmenumon, "-fn", dmenufont, "-nb", normbgcolor, "-nf", normfgcolor, "-sb", selbgcolor, "-sf", selfgcolor, NULL };
|
||||
static const char *termcmd[] = { "st", NULL };
|
||||
static const char *slockcmd[] = { "slock", NULL };
|
||||
|
||||
static Key keys[] = {
|
||||
/* modifier key function argument */
|
||||
{ MODKEY|ShiftMask, XK_l, spawn, {.v = slockcmd } },
|
||||
{ MODKEY, XK_p, spawn, {.v = dmenucmd } },
|
||||
{ MODKEY|ShiftMask, XK_Return, spawn, {.v = termcmd } },
|
||||
...
|
||||
```
|
||||
|
||||
Save the file.
|
||||
|
||||
Finally, just log out by pressing _Alt+Shift+q_ and log in again. The scripts provided by the _dwm-user_ package will recognize that you have changed the _config.h_ file in your home directory and recompile dwm on login. And becuse dwm is so tiny, it’s fast enough you won’t even notice it.
|
||||
|
||||
You can try locking your screen now by pressing _Alt+Shift+L_ , and then logging back in again by typing your password and pressing enter.
|
||||
|
||||
## **Conclusion**
|
||||
|
||||
If you like minimalism and want a very fast yet powerful window manager, dwm might be just what you’ve been looking for. However, it probably isn’t for beginners. There might be a lot of additional configuration you’ll need to do in order to make it just as you like it.
|
||||
|
||||
To learn more about dwm, see the project’s homepage at <https://dwm.suckless.org/>.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/lets-try-dwm-dynamic-window-manger/
|
||||
|
||||
作者:[Adam Šamalík][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/asamalik/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/03/dwm-magazine-image-816x345.png
|
||||
[2]: https://fedoramagazine.org/wp-content/uploads/2019/03/choosing-dwm-1024x469.png
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2019/03/dwm-desktop-1024x593.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/03/Screenshot-2019-03-15-at-11.12.32-1024x592.png
|
||||
@ -1,188 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Check If A Port Is Open On Multiple Remote Linux System Using Shell Script With nc Command?)
|
||||
[#]: via: (https://www.2daygeek.com/check-a-open-port-on-multiple-remote-linux-server-using-nc-command/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
How To Check If A Port Is Open On Multiple Remote Linux System Using Shell Script With nc Command?
|
||||
======
|
||||
|
||||
We had recently written an article to check if a port is open on the remote Linux server. It will help you to check for single server.
|
||||
|
||||
If you want to check for five servers then no issues, you can use any of the one following command such as nc (netcat), nmap and telnet.
|
||||
|
||||
If you would like to check for 50+ servers then what will be the solution?
|
||||
|
||||
It’s not easy to check all servers, if you do the same then there is no point and you will be wasting a lots of time unnecessarily.
|
||||
|
||||
To overcome this situation, i had coded a small shell script using nc command that will allow us to scan any number of servers with given port.
|
||||
|
||||
If you are looking for a single server scan then you have multiple options, to know more about it. Simply navigate to the following URL to **[Check Whether A Port Is Open On The Remote Linux System?][1]**
|
||||
|
||||
There are two scripts available in this tutorial and both the scripts are useful.
|
||||
|
||||
Both scripts are used for different purpose, which you can easily understand by reading a head line.
|
||||
|
||||
I will ask you few questions before you are reading this article, just answer yourself if you know or you can get it by reading this article.
|
||||
|
||||
How to check, if a port is open on the remote Linux server?
|
||||
|
||||
How to check, if a port is open on the multiple remote Linux server?
|
||||
|
||||
How to check, if multiple ports are open on the multiple remote Linux server?
|
||||
|
||||
### What Is nc (netcat) Command?
|
||||
|
||||
nc stands for netcat. Netcat is a simple Unix utility which reads and writes data across network connections, using TCP or UDP protocol.
|
||||
|
||||
It is designed to be a reliable “back-end” tool that can be used directly or easily driven by other programs and scripts.
|
||||
|
||||
At the same time, it is a feature-rich network debugging and exploration tool, since it can create almost any kind of connection you would need and has several interesting built-in capabilities.
|
||||
|
||||
Netcat has three main modes of functionality. These are the connect mode, the listen mode, and the tunnel mode.
|
||||
|
||||
**Common Syntax for nc (netcat):**
|
||||
|
||||
```
|
||||
$ nc [-options] [HostName or IP] [PortNumber]
|
||||
```
|
||||
|
||||
### How To Check If A Port Is Open On Multiple Remote Linux Server?
|
||||
|
||||
Use the following shell script if you would like to check the given port is open on multiple remote Linux servers or not.
|
||||
|
||||
In my case, we are going to check whether the port 22 is open in the following remote servers or not? Make sure you have to update your servers list in the file instead of us.
|
||||
|
||||
Make sure you have to update the servers list into `server-list.txt file`. Each server should be in separate line.
|
||||
|
||||
```
|
||||
# cat server-list.txt
|
||||
192.168.1.2
|
||||
192.168.1.3
|
||||
192.168.1.4
|
||||
192.168.1.5
|
||||
192.168.1.6
|
||||
192.168.1.7
|
||||
```
|
||||
|
||||
Use the following script to achieve this.
|
||||
|
||||
```
|
||||
# vi port_scan.sh
|
||||
|
||||
#!/bin/sh
|
||||
for server in `more server-list.txt`
|
||||
do
|
||||
#echo $i
|
||||
nc -zvw3 $server 22
|
||||
done
|
||||
```
|
||||
|
||||
Set an executable permission to `port_scan.sh` file.
|
||||
|
||||
```
|
||||
$ chmod +x port_scan.sh
|
||||
```
|
||||
|
||||
Finally run the script to achieve this.
|
||||
|
||||
```
|
||||
# sh port_scan.sh
|
||||
|
||||
Connection to 192.168.1.2 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.3 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.4 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.5 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.6 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.7 22 port [tcp/ssh] succeeded!
|
||||
```
|
||||
|
||||
### How To Check If Multiple Ports Are Open On Multiple Remote Linux Server?
|
||||
|
||||
Use the following script if you want to check the multiple ports in multiple servers.
|
||||
|
||||
In my case, we are going to check whether the port 22 and 80 is open or not in the given servers. Make sure you have to replace your required ports and servers name instead of us.
|
||||
|
||||
Make sure you have to update the port lists into `port-list.txt` file. Each port should be in a separate line.
|
||||
|
||||
```
|
||||
# cat port-list.txt
|
||||
22
|
||||
80
|
||||
```
|
||||
|
||||
Make sure you have to update the servers list into `server-list.txt` file. Each server should be in separate line.
|
||||
|
||||
```
|
||||
# cat server-list.txt
|
||||
192.168.1.2
|
||||
192.168.1.3
|
||||
192.168.1.4
|
||||
192.168.1.5
|
||||
192.168.1.6
|
||||
192.168.1.7
|
||||
```
|
||||
|
||||
Use the following script to achieve this.
|
||||
|
||||
```
|
||||
# vi multiple_port_scan.sh
|
||||
|
||||
#!/bin/sh
|
||||
for server in `more server-list.txt`
|
||||
do
|
||||
for port in `more port-list.txt`
|
||||
do
|
||||
#echo $server
|
||||
nc -zvw3 $server $port
|
||||
echo ""
|
||||
done
|
||||
done
|
||||
```
|
||||
|
||||
Set an executable permission to `multiple_port_scan.sh` file.
|
||||
|
||||
```
|
||||
$ chmod +x multiple_port_scan.sh
|
||||
```
|
||||
|
||||
Finally run the script to achieve this.
|
||||
|
||||
```
|
||||
# sh multiple_port_scan.sh
|
||||
Connection to 192.168.1.2 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.2 80 port [tcp/http] succeeded!
|
||||
|
||||
Connection to 192.168.1.3 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.3 80 port [tcp/http] succeeded!
|
||||
|
||||
Connection to 192.168.1.4 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.4 80 port [tcp/http] succeeded!
|
||||
|
||||
Connection to 192.168.1.5 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.5 80 port [tcp/http] succeeded!
|
||||
|
||||
Connection to 192.168.1.6 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.6 80 port [tcp/http] succeeded!
|
||||
|
||||
Connection to 192.168.1.7 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.7 80 port [tcp/http] succeeded!
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/check-a-open-port-on-multiple-remote-linux-server-using-nc-command/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/how-to-check-whether-a-port-is-open-on-the-remote-linux-system-server/
|
||||
@ -0,0 +1,98 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (NVIDIA Jetson Nano is a $99 Raspberry Pi Rival for AI Development)
|
||||
[#]: via: (https://itsfoss.com/nvidia-jetson-nano/)
|
||||
[#]: author: (Atharva Lele https://itsfoss.com/author/atharva/)
|
||||
|
||||
NVIDIA Jetson Nano is a $99 Raspberry Pi Rival for AI Development
|
||||
======
|
||||
|
||||
At the [GPU Technology Conference][1] NVIDIA announced the [Jetson Nano Module][2] and the [Jetson Nano Developer Kit][3]. Compared to other Jetson boards which cost between $299 and $1099, the Jetson Nano bears a low cost of $99. This puts it within the reach of many developers, educators, and researchers who could not spend hundreds of dollars to get such a product.
|
||||
|
||||
![The Jetson Nano Development Kit \(left\) and the Jetson Nano Module \(right\)][4]
|
||||
|
||||
### Bringing back AI development from ‘cloud’
|
||||
|
||||
In the last few years, we have seen a lot of [advances in AI research][5]. Traditionally AI computing was always done in the cloud, where there was plenty of processing power available.
|
||||
|
||||
Recently, there’s been a trend in shifting this computation away from the cloud and do it locally. This is called [Edge Computing][6]. Now at the embedded level, products which could do such complex calculations required for AI and Machine Learning were sparse, but we’re seeing a great explosion these days in this product segment.
|
||||
|
||||
Products like the [SparkFun Edge][7] and [OpenMV Board][8] are good examples. The Jetson Nano, is NVIDIA’s latest offering in this market. When connected to your system, it will be able to supply the processing power needed for Machine Learning and AI tasks without having to rely on the cloud.
|
||||
|
||||
This is great for privacy as well as saving on internet bandwidth. It is also more secure since your data always stays on the device itself.
|
||||
|
||||
### Jetson Nano focuses on smaller AI projects
|
||||
|
||||
![Jetson Nano powered JetBot][9]
|
||||
|
||||
Previously released Jetson Boards like the [TX2][10] and [AGX Xavier][11] were used in products like drones and cars, the Jetson Nano is targeting smaller projects, projects where you need to have the processing power which boards like the [Raspberry Pi][12] cannot provide.
|
||||
|
||||
Did you know?
|
||||
|
||||
NVIDIA’s JetPack SDK provides a ‘complete desktop Linux environment based on Ubuntu 18.04 LTS’. In other words, the Jetson Nano is powered by Ubuntu Linux.
|
||||
|
||||
### NVIDIA Jetson Nano Specifications
|
||||
|
||||
For $99, you get 472 GFLOPS of processing power due to 128 NVIDIA Maxwell Architecture CUDA Cores, a quad-core ARM A57 processor, 4GB of LP-DDR4 RAM, 16GB of on-board storage, and 4k video encode/decode capabilities. The port selection is also pretty decent with the Nano having Gigabit Ethernet, MIPI Camera, Display outputs, and a couple of USB ports (1×3.0, 3×2.0). Full range of specifications can be found [here][13].
|
||||
|
||||
CPU | Quad-core ARM® Cortex®-A57 MPCore processor
|
||||
---|---
|
||||
GPU | NVIDIA Maxwell™ architecture with 128 NVIDIA CUDA® cores
|
||||
RAM | 4 GB 64-bit LPDDR4
|
||||
Storage | 16 GB eMMC 5.1 Flash
|
||||
Camera | 12 lanes (3×4 or 4×2) MIPI CSI-2 DPHY 1.1 (1.5 Gbps)
|
||||
Connectivity | Gigabit Ethernet
|
||||
Display Ports | HDMI 2.0 and DP 1.2
|
||||
USB Ports | 1 USB 3.0 and 3 USB 2.0
|
||||
Other | 1 x1/2/4 PCIE, 1x SDIO / 2x SPI / 6x I2C / 2x I2S / GPIOs
|
||||
Size | 69.6 mm x 45 mm
|
||||
|
||||
Along with good hardware, you get support for the majority of popular AI frameworks like TensorFlow, PyTorch, Keras, etc. It also has support for NVIDIA’s [JetPack][14] and [DeepStream][15] SDKs, same as the more expensive TX2 and AGX Boards.
|
||||
|
||||
“Jetson Nano makes AI more accessible to everyone — and is supported by the same underlying architecture and software that powers our nation’s supercomputer. Bringing AI to the maker movement opens up a whole new world of innovation, inspiring people to create the next big thing.” said Deepu Talla, VP and GM of Autonomous Machines at NVIDIA.
|
||||
|
||||
[Subscribe to It’s FOSS YouTube Channel][16]
|
||||
|
||||
**What do you think of Jetson Nano?**
|
||||
|
||||
The availability of Jetson Nano differs from country to country.
|
||||
|
||||
The [Intel Neural Stick][17], is also one such accelerator which is competitively prices at $79. It’s good to see competition stirring up at these lower price points from the big manufacturers.
|
||||
|
||||
I’m looking forward to getting my hands on the product if possible.
|
||||
|
||||
What do you guys think about a product like this? Let us know in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/nvidia-jetson-nano/
|
||||
|
||||
作者:[Atharva Lele][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/atharva/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.nvidia.com/en-us/gtc/
|
||||
[2]: https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-nano/
|
||||
[3]: https://developer.nvidia.com/embedded/buy/jetson-nano-devkit
|
||||
[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/jetson-nano-family-press-image-hd.jpg?ssl=1
|
||||
[5]: https://itsfoss.com/nanotechnology-open-science-ai/
|
||||
[6]: https://en.wikipedia.org/wiki/Edge_computing
|
||||
[7]: https://www.sparkfun.com/news/2886
|
||||
[8]: https://openmv.io/
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/nvidia_jetson_bot.jpg?ssl=1
|
||||
[10]: https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-tx2/
|
||||
[11]: https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-agx-xavier/
|
||||
[12]: https://itsfoss.com/things-you-need-to-get-your-raspberry-pi-working/
|
||||
[13]: https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-nano/#specifications
|
||||
[14]: https://developer.nvidia.com/embedded/jetpack
|
||||
[15]: https://developer.nvidia.com/deepstream-sdk
|
||||
[16]: https://www.youtube.com/c/itsfoss?sub_confirmation=1
|
||||
[17]: https://software.intel.com/en-us/movidius-ncs-get-started
|
||||
101
sources/tech/20190321 Top 10 New Linux SBCs to Watch in 2019.md
Normal file
101
sources/tech/20190321 Top 10 New Linux SBCs to Watch in 2019.md
Normal file
@ -0,0 +1,101 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Top 10 New Linux SBCs to Watch in 2019)
|
||||
[#]: via: (https://www.linux.com/blog/2019/3/top-10-new-linux-sbcs-watch-2019)
|
||||
[#]: author: (Eric Brown https://www.linux.com/users/ericstephenbrown)
|
||||
|
||||
Top 10 New Linux SBCs to Watch in 2019
|
||||
======
|
||||
|
||||
![UP Xtreme][1]
|
||||
|
||||
Aaeon's Linux-ready UP Xtreme SBC.
|
||||
|
||||
[Used with permission][2]
|
||||
|
||||
A recent [Global Market Insights report][3] projects the single board computer market will grow from $600 million in 2018 to $1 billion by 2025. Yet, you don’t need to read a market research report to realize the SBC market is booming. Driven by the trends toward IoT and AI-enabled edge computing, new boards keep rolling off the assembly lines, many of them [tailored for highly specific applications][4].
|
||||
|
||||
Much of the action has been in Linux-compatible boards, including the insanely popular Raspberry Pi. The number of different vendors and models has exploded thanks in part to the rise of [community-backed, open-spec SBCs][5].
|
||||
|
||||
Here we examine 10 of the most intriguing, Linux-driven SBCs among the many products announced in the last four weeks that bookended the recent [Embedded World show][6] in Nuremberg. (There was also some [interesting Linux software news][7] at the show.) Two of the SBCs—the Intel Whiskey Lake based UP Xtreme and Nvidia Jetson Nano driven Jetson Nano Dev Kit—were announced only this week.
|
||||
|
||||
Our mostly open source list also includes a few commercial boards. Processors range from the modest, Cortex-A7 driven STM32MP1 to the high-powered Whiskey Lake and Snapdragon 845. Mid-range models include Google’s i.MX8M powered Coral Dev Board and a similarly AI-enhanced, TI AM5729 based BeagleBone AI. Deep learning acceleration chips—and standard RPi 40-pin or 96Boards expansion connectors—are common themes among most of these boards.
|
||||
|
||||
The SBCs are listed in reverse chronological order according to their announcement dates. The links in the product names go to recent LinuxGizmos reports, which link to vendor product pages.
|
||||
|
||||
**[UP Xtreme][8]** —The latest in Aaeon’s line of community-backed SBCs taps Intel’s 8th Gen Whiskey Lake-U CPUs, which maintain a modest 15W TDP while boosting performance with up to quad-core, dual threaded configurations. Depending on when it ships, this Linux-ready model will likely be the most powerful community-backed SBC around -- and possibly the most expensive.
|
||||
|
||||
The SBC supports up to 16GB DDR4 and 128GB eMMC and offers 4K displays via HDMI, DisplayPort, and eDP. Other features include SATA, 2x GbE, 4x USB 3.0, and 40-pin “HAT” and 100-pin GPIO add-on board connectors. You also get mini-PCIe and dual M.2 slots that support wireless modems and more SATA options. The slots also support Aaeon’s new AI Core X modules, which offer Intel’s latest Movidius Myriad X VPUs for 1TOPS neural processing acceleration.
|
||||
|
||||
**[Jetson Nano Dev Kit][9]** —Nvidia just announced a low-end Jetson Nano compute module that’s sort of like a smaller (70 x 45mm) version of the old Jetson TX1. It offers the same 4x Cortex-A57 cores but has an even lower-end 128-core Maxwell GPU. The module has half the RAM and flash (4GB/16GB) of the TX1 and TX2, and no WiFi/Bluetooth radios. Like the hexa-core Jetson TX2, however, it supports 4K video and the GPU offers similar CUDA-X deep learning libraries.
|
||||
|
||||
Although Nvidia has backed all its Linux-driven Jetson modules with development kits, the Jetson Nano Dev Kit is its first community-backed, maker-oriented kit. It does not appear to offer open specifications, but it costs only $99 and there’s a forum and other community resources. Many of the specs match or surpass the Raspberry Pi 3B+, including the addition of a 40-pin GPIO. Highlights include an M.2 slot, GbE with Power-over-Ethernet, HDMI 2.0 and eDP links, and 4x USB 3.0 ports.
|
||||
|
||||
**[Coral Dev Board][10]** —Google’s very first Linux maker board arrived earlier this month featuring an NXP i.MX8M and Google’s Edge TPU AI chip—a stripped-down version of Google’s TPU Unit is designed to run TensorFlow Lite ML models. The $150, Raspberry Pi-like Coral Dev Board was joined by a similarly Edge TPU-enabled Coral USB Accelerator USB stick. These will be followed by an Edge TPU based Coral PCIe Accelerator and a Coral SOM compute module. All these devices are backed with schematics, community resources, and other open-spec resources.
|
||||
|
||||
The Coral Dev Board combines the Edge TPU chip with NXP’s quad-core, 1.5GHz Cortex-A53 i.MX8M with a 3D Vivante GPU/VPU and a Cortex-M4 MCU. The SBC is even more like the Raspberry Pi 3B+ than Nvidia’s Dev Kit, mimicking the size and much of the layout and I/O, including the 40-pin GPIO connector. Highlights include 4K-ready GbE, HDMI 2.0a, 4-lane MIPI-DSI and CSI, and USB 3.0 host and Type-C ports.
|
||||
|
||||
**[SBC-C43][11]** —Seco’s commercial, industrial temperature SBC-C43 board is the first SBC based on NXP’s high-end, up to hexa-core i.MX8. The 3.5-inch SBC supports the i.MX8 QuadMax with 2x Cortex-A72 cores and 4x Cortex-A53 cores, the QuadPlus with a single Cortex-A72 and 4x -A53, and the Quad with no -A72 cores and 4x -A53. There are also 2x Cortex-M4F real-time cores and 2x Vivante GPU/VPU cores. Yocto Project, Wind River Linux, and Android are available.
|
||||
|
||||
The feature-rich SBC-C43 supports up to 8GB DDR4 and 32GB eMMC, both soldered for greater reliability. Highlights include dual GbE, HDMI 2.0a in and out ports, WiFi/Bluetooth, and a variety of industrial interfaces. Dual M.2 slots support SATA, wireless, and more.
|
||||
|
||||
**[Nitrogen8M_Mini][12]** —This Boundary Devices cousin to the earlier, i.MX8M based Nitrogen8M is available for $135, with shipments due this Spring. The open-spec Nitrogen8M_Mini is the first SBC to feature NXP’s new i.MX8M Mini SoC. The Mini uses a more advanced 14LPC FinFET process than the i.MX8M, resulting in lower power consumption and higher clock rates for both the 4x Cortex-A53 (1.5GHz to 2GHz) and Cortex-M4 (400MHz) cores. The drawback is that you’re limited to HD video resolution.
|
||||
|
||||
Supported with Linux and Android, the Nitrogen8M_Mini ships with 2GB to 4GB LPDDR4 RAM and 8GB to 128GB eMMC. MIPI-DSI and -CSI interfaces support optional touchscreens and cameras, respectively. A GbE port is standard and PoE and WiFi/BT are optional. Other features include 3x USB ports, one or two PCIe slots, and optional -40 to 85°C support. A Nitrogen8M_Mini SOM module with similar specs is also in the works.
|
||||
|
||||
**[Pine H64 Model B][13]** —Pine64’s latest hacker board was teased in late January as part of an [ambitious roll-out][14] of open source products, including a laptop, tablet, and phone. The Raspberry Pi semi-clone, which recently went on sale for $39 (2GB) or $49 (3GB), showcases the high-end, but low-cost Allwinner H64. The quad -A53 SoC is notable for its 4K video with HDR support.
|
||||
|
||||
The Pine H64 Model B offers up to 128GB eMMC storage, WiFi/BT, and a GbE port. I/O includes 2x USB 2.0 and single USB 3.0 and HDMI 2.0a ports plus SPDIF audio and an RPi-like 40-pin connector. Images include Android 7.0 and an “in progress” Armbian Debian Stretch.
|
||||
|
||||
**[AI-ML Board][15]** —Arrow unveiled this i.MX8X based SBC early this month along with a similarly 96Boards CE Extended format, i.MX8M based Thor96 SBC. While there are plenty of i.MX8M boards these days, we’re more intrigued with the lowest-end i.MX8X member of the i.MX8 family. The AI-ML Board is the first SBC we’ve seen to feature the low-power i.MX8X, which offers up to 4x 64-bit, 1.2GHz Cortex-A35 cores, a 4-shader, 4K-ready Vivante GPU/VPU, a Cortex-M4F chip, and a Tensilica HiFi 4 DSP.
|
||||
|
||||
The open-spec, Yocto Linux driven AI-ML Board is targeted at low-power, camera-equipped applications such as drones. The board has 2GB LPDDR4, Ethernet, WiFi/BT, and a pair each of MIPI-DSI and USB 3.0 ports. Cameras are controlled via the 96Boards 60-pin, high-power GPIO connector, which is joined by the usual 40-pin low-power link. The launch is expected June 1.
|
||||
|
||||
**[BeagleBone AI][16]** —The long-awaited successor to the Cortex-A8 AM3358 based BeagleBone family of boards advances to TIs dual-core Cortex-A15 AM5729, with similar PowerVR GPU and MCU-like PRU cores. The real story, however, is the AI firepower enabled by the SoC’s dual TI C66x DSPs and four embedded-vision-engine (EVE) neural processing cores. BeagleBoard.org claims that calculations for computer-vision models using EVE run at 8x times the performance per watt compared to the similar, but EVE-less, AM5728. The EVE and DSP chips are supported through a TIDL machine learning OpenCL API and pre-installed tools.
|
||||
|
||||
Due to go on sale in April for about $100, the Linux-powered BeagleBone AI is based closely on the BeagleBone Black and offers backward header, mechanical, and software compatibility. It doubles the RAM to 1GB and quadruples the eMMC storage to 16GB. You now get GbE and high-speed WiFi, as well as a USB Type-C port.
|
||||
|
||||
**[Robotics RB3 Platform (DragonBoard 845c)][17]** —Qualcomm and Thundercomm are initially launching their 96Boards CE form factor, Snapdragon 845-based upgrade to the Snapdragon 820-based [DragonBoard 820c][18] SBC as part of a Qualcomm Robotics RB3 Platform. Yet, 96Boards.org has already posted a [DragonBoard 845c product page][17], and we imagine the board will be available in the coming months without all the robotics bells and whistles. A compute module version is also said to be in the works.
|
||||
|
||||
The 10nm, octa-core, “Kryo” based Snapdragon 845 is one of the most powerful Arm SoCs around. It features an advanced Adreno 630 GPU with “eXtended Reality” (XR) VR technology and a Hexagon 685 DSP with a third-gen Neural Processing Engine (NPE) for AI applications. On the RB3 kit, the board’s expansion connectors are pre-stocked with Qualcomm cellular and robotics camera mezzanines. The $449 and up kit also includes standard 4K video and tracking cameras, and there are optional Time-of-Flight (ToF) and stereo SLM camera depth cameras. The SBC runs Linux with ROS (Robot Operating System).
|
||||
|
||||
**[Avenger96][19]** —Like Arrow’s AI-ML Board, the Avenger96 is a 96Boards CE Extended SBC aimed at low-power IoT applications. Yet, the SBC features an even more power-efficient (and slower) SoC: ST’s recently announced [STM32MP153][20]. The Avenger96 runs Linux on the high-end STM32MP157 model, which has dual, 650MHz Cortex-A7 cores, a Cortex-M4, and a Vivante 3D GPU.
|
||||
|
||||
This sandwich-style board features an Avenger96 module with the STM32MP157 SoC, 1GB of DDR3L, 2MB SPI flash, and a power management IC. It’s unclear if the 8GB eMMC and WiFi-ac/Bluetooth 4.2 module are on the module or carrier board. The Avenger96 SBC is further equipped with GbE, HDMI, micro-USB OTG, and dual USB 2.0 host ports. There’s also a microSD slot and the usual 40- and 60-pin GPIO connectors. The board is expected to go on sale in April.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2019/3/top-10-new-linux-sbcs-watch-2019
|
||||
|
||||
作者:[Eric Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/ericstephenbrown
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/aaeon_upxtreme.jpg?itok=QnwAt3mp (UP Xtreme)
|
||||
[2]: /LICENSES/CATEGORY/USED-PERMISSION
|
||||
[3]: https://www.globenewswire.com/news-release/2019/02/13/1724445/0/en/Single-Board-Computer-Market-to-surpass-1bn-by-2025-Global-Market-Insights-Inc.html
|
||||
[4]: https://www.linux.com/blog/2019/1/linux-hacker-board-trends-2018-and-beyond
|
||||
[5]: http://linuxgizmos.com/catalog-of-122-open-spec-linux-hacker-boards/
|
||||
[6]: https://www.embedded-world.de/en
|
||||
[7]: https://www.linux.com/news/2019/2/embedded-linux-software-highlights-embedded-world
|
||||
[8]: http://linuxgizmos.com/latest-up-board-combines-whiskey-lake-with-ai-core-x-modules/
|
||||
[9]: http://linuxgizmos.com/trimmed-down-jetson-nano-modules-ships-on-99-linux-dev-kit/
|
||||
[10]: http://linuxgizmos.com/google-launches-i-mx8m-dev-board-with-edge-tpu-ai-chip/
|
||||
[11]: http://linuxgizmos.com/first-i-mx8-quadmax-sbc-breaks-cover/
|
||||
[12]: http://linuxgizmos.com/open-spec-nitrogen8m_mini-sbc-ships-along-with-new-mini-based-som/
|
||||
[13]: http://linuxgizmos.com/revised-allwiner-h64-based-pine-h64-sbc-has-rpi-size-and-gpio/
|
||||
[14]: https://www.linux.com/blog/2019/2/pine64-launch-open-source-phone-laptop-tablet-and-camera
|
||||
[15]: http://linuxgizmos.com/arrows-latest-96boards-sbcs-tap-i-mx8x-and-i-mx8m/
|
||||
[16]: http://linuxgizmos.com/beaglebone-ai-sbc-features-dual-a15-soc-with-eve-ai-cores/
|
||||
[17]: http://linuxgizmos.com/robotics-kit-runs-linux-on-new-dragonboard-845c-96boards-sbc/
|
||||
[18]: http://linuxgizmos.com/debian-driven-dragonboard-expands-to-96boards-extended-spec/
|
||||
[19]: http://linuxgizmos.com/sandwich-style-96boards-sbc-runs-linux-on-sts-new-cortex-a7-m4-soc/
|
||||
[20]: https://www.linux.com/news/2019/2/st-spins-its-first-linux-powered-cortex-soc
|
||||
@ -0,0 +1,100 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to set up Fedora Silverblue as a gaming station)
|
||||
[#]: via: (https://fedoramagazine.org/set-up-fedora-silverblue-gaming-station/)
|
||||
[#]: author: (Michal Konečný https://fedoramagazine.org/author/zlopez/)
|
||||
|
||||
How to set up Fedora Silverblue as a gaming station
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
This article gives you a step by step guide to turn your Fedora Silverblue into an awesome gaming station with the help of Flatpak and Steam.
|
||||
|
||||
Note: Do you need the NVIDIA proprietary driver on Fedora 29 Silverblue for a complete experience? Check out [this blog post][2] for pointers.
|
||||
|
||||
### Add the Flathub repository
|
||||
|
||||
This process starts with a clean Fedora 29 Silverblue installation with a user already created for you.
|
||||
|
||||
First, go to <https://flathub.org/home> and enable the Flathub repository on your system. To do this, click the _Quick setup_ button on the main page.
|
||||
|
||||
![Quick setup button on flathub.org/home][3]
|
||||
|
||||
This redirects you to <https://flatpak.org/setup/> where you should click on the Fedora icon.
|
||||
|
||||
![Fedora icon on flatpak.org/setup][4]
|
||||
|
||||
Now you just need to click on _Flathub repository file._ Open the downloaded file with the _Software Install_ application.
|
||||
|
||||
![Flathub repository file button on flatpak.org/setup/Fedora][5]
|
||||
|
||||
The GNOME Software application opens. Next, click on the _Install_ button. This action needs _sudo_ permissions, because it installs the Flathub repository for use by the whole system.
|
||||
|
||||
![Install button in GNOME Software][6]
|
||||
|
||||
### Install the Steam flatpak
|
||||
|
||||
You can now search for the S _team_ flatpak in _GNOME Software_. If you can’t find it, try rebooting — or logout and login — in case _GNOME Software_ didn’t read the metadata. That happens automatically when you next login.
|
||||
|
||||
![Searching for Steam][7]
|
||||
|
||||
Click on the _Steam_ row and the _Steam_ page opens in _GNOME Software._ Next, click on _Install_.
|
||||
|
||||
![Steam page in GNOME Software][8]
|
||||
|
||||
And now you have installed _Steam_ flatpak on your system.
|
||||
|
||||
### Enable Steam Play in Steam
|
||||
|
||||
Now that you have _Steam_ installed, launch it and log in. To play Windows games too, you need to enable _Steam Play_ in _Steam._ To enable it, choose _Steam > Settings_ from the menu in the main window.
|
||||
|
||||
![Settings button in Steam][9]
|
||||
|
||||
Navigate to the _Steam Play_ section. You should see the option _Enable Steam Play for supported titles_ is already ticked, but it’s recommended you also tick the _Enable Steam Play_ option for all other titles. There are plenty of games that are actually playable, but not whitelisted yet on _Steam._ To see which games are playable, visit [ProtonDB][10] and search for your favorite game. Or just look for the games with the most platinum reports.
|
||||
|
||||
![Steam Play settings menu on Steam][11]
|
||||
|
||||
If you want to know more about Steam Play, you can read the [article][12] about it here on Fedora Magazine:
|
||||
|
||||
> [Play Windows games on Fedora with Steam Play and Proton][12]
|
||||
|
||||
### Appendix
|
||||
|
||||
You’re now ready to play plenty of games on Linux. Please remember to share your experience with others using the _Contribute_ button on [ProtonDB][10] and report bugs you find on [GitHub][13], because sharing is nice. 🙂
|
||||
|
||||
* * *
|
||||
|
||||
_Photo by _[ _Hardik Sharma_][14]_ on _[_Unsplash_][15]_._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/set-up-fedora-silverblue-gaming-station/
|
||||
|
||||
作者:[Michal Konečný][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/zlopez/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/03/silverblue-gaming-816x345.jpg
|
||||
[2]: https://blogs.gnome.org/alexl/2019/03/06/nvidia-drivers-in-fedora-silverblue/
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2019/03/Screenshot-from-2019-03-15-12-29-00.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/03/Screenshot-from-2019-03-15-12-36-35-1024x713.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2019/03/Screenshot-from-2019-03-15-12-45-12.png
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2019/03/Screenshot-from-2019-03-15-12-57-37.png
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2019/03/Screenshot-from-2019-03-15-13-08-21.png
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2019/03/Screenshot-from-2019-03-15-13-13-59-1024x769.png
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2019/03/Screenshot-from-2019-03-15-13-30-20.png
|
||||
[10]: https://www.protondb.com/
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2019/03/Screenshot-from-2019-03-15-13-41-53.png
|
||||
[12]: https://fedoramagazine.org/play-windows-games-steam-play-proton/
|
||||
[13]: https://github.com/ValveSoftware/Proton
|
||||
[14]: https://unsplash.com/photos/I7rXyzBNVQM?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[15]: https://unsplash.com/search/photos/video-game-laptop?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -0,0 +1,50 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Contribute at the Fedora Test Day for Fedora Modularity)
|
||||
[#]: via: (https://fedoramagazine.org/contribute-at-the-fedora-test-day-for-fedora-modularity/)
|
||||
[#]: author: (Sumantro Mukherjee https://fedoramagazine.org/author/sumantrom/)
|
||||
|
||||
Contribute at the Fedora Test Day for Fedora Modularity
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Modularity lets you keep the right version of an application, language runtime, or other software on your Fedora system even as the operating system is updated. You can read more about Modularity in general on the [Fedora documentation site][2].
|
||||
|
||||
The Modularity folks have been working on Modules for everyone. As a result, the Fedora Modularity and QA teams have organized a test day for **Tuesday, March 26, 2019**. Refer to the [wiki page][3] for links to the test images you’ll need to participate. Read on for more information on the test day.
|
||||
|
||||
### How do test days work?
|
||||
|
||||
A test day is an event where anyone can help make sure changes in Fedora work well in an upcoming release. Fedora community members often participate, and the public is welcome at these events. If you’ve never contributed before, this is a perfect way to get started.
|
||||
|
||||
To contribute, you only need to be able to do the following things:
|
||||
|
||||
* Download test materials, which include some large files
|
||||
* Read and follow directions step by step
|
||||
|
||||
|
||||
|
||||
The [wiki page][3] for the modularity test day has a lot of good information on what and how to test. After you’ve done some testing, you can log your results in the test day [web application][4]. If you’re available on or around the day of the event, please do some testing and report your results.
|
||||
|
||||
Happy testing, and we hope to see you on test day.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/contribute-at-the-fedora-test-day-for-fedora-modularity/
|
||||
|
||||
作者:[Sumantro Mukherjee][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/sumantrom/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2015/03/test-days-945x400.png
|
||||
[2]: https://docs.fedoraproject.org/en-US/modularity/
|
||||
[3]: https://fedoraproject.org/wiki/Test_Day:2019-03-26_Modularity_Test_Day
|
||||
[4]: http://testdays.fedorainfracloud.org/events/61
|
||||
@ -0,0 +1,77 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How Open Source Is Accelerating NFV Transformation)
|
||||
[#]: via: (https://www.linux.com/blog/2019/3/how-open-source-accelerating-nfv-transformation)
|
||||
[#]: author: (Pam Baker https://www.linux.com/users/pambaker)
|
||||
|
||||
How Open Source Is Accelerating NFV Transformation
|
||||
======
|
||||
|
||||
![NFV][1]
|
||||
|
||||
In anticipation of the upcoming Open Networking Summit, we talked with Thomas Nadeau, Technical Director NFV at Red Hat, about the role of open source in innovation for telecommunications service providers.
|
||||
|
||||
[Creative Commons Zero][2]
|
||||
|
||||
Red Hat is noted for making open source a culture and business model, not just a way of developing software, and its message of [open source as the path to innovation][3] resonates on many levels.
|
||||
|
||||
In anticipation of the upcoming [Open Networking Summit][4], we talked with [Thomas Nadeau][5], Technical Director NFV at Red Hat, who gave a [keynote address][6] at last year’s event, to hear his thoughts regarding the role of open source in innovation for telecommunications service providers.
|
||||
|
||||
One reason for open source’s broad acceptance in this industry, he said, was that some very successful projects have grown too large for any one company to manage, or single-handedly push their boundaries toward additional innovative breakthroughs.
|
||||
|
||||
“There are projects now, like Kubernetes, that are too big for any one company to do. There's technology that we as an industry need to work on, because no one company can push it far enough alone,” said Nadeau. “Going forward, to solve these really hard problems, we need open source and the open source software development model.”
|
||||
|
||||
Here are more insights he shared on how and where open source is making an innovative impact on telecommunications companies.
|
||||
|
||||
**Linux.com: Why is open source central to innovation in general for telecommunications service providers?**
|
||||
|
||||
**Nadeau:** The first reason is that the service providers can be in more control of their own destiny. There are some service providers that are more aggressive and involved in this than others. Second, open source frees service providers from having to wait for long periods for the features they need to be developed.
|
||||
|
||||
And third, open source frees service providers from having to struggle with using and managing monolith systems when all they really wanted was a handful of features. Fortunately, network equipment providers are responding to this overkill problem. They're becoming much more flexible, more modular, and open source is the best means to achieve that.
|
||||
|
||||
**Linux.com: In your ONS keynote presentation, you said open source levels the playing field for traditional carriers in competing with cloud-scale companies in creating digital services and revenue streams. Please explain how open source helps.**
|
||||
|
||||
**Nadeau:** Kubernetes again. OpenStack is another one. These are tools that these businesses really need, not to just expand, but to exist in today's marketplace. Without open source in that virtualization space, you’re stuck with proprietary monoliths, no control over your future, and incredibly long waits to get the capabilities you need to compete.
|
||||
|
||||
There are two parts in the NFV equation: the infrastructure and the applications. NFV is not just the underlying platforms, but this constant push and pull between the platforms and the applications that use the platforms.
|
||||
|
||||
NFV is really virtualization of functions. It started off with monolithic virtual machines (VMs). Then came "disaggregated VMs" where individual functions, for a variety of reasons, were run in a more distributed way. To do so meant separating them, and this is where SDN came in, with the separation of the control plane from the data plane. Those concepts were driving changes in the underlying platforms too, which drove up the overhead substantially. That in turn drove interest in container environments as a potential solution, but it's still NFV.
|
||||
|
||||
You can think of it as the latest iteration of SOA with composite applications. Kubernetes is the kind of SOA model that they had at Google, which dropped the worry about the complicated networking and storage underneath and simply allowed users to fire up applications that just worked. And for the enterprise application model, this works great.
|
||||
|
||||
But not in the NFV case. In the NFV case, in the previous iteration of the platform at OpenStack, everybody enjoyed near one-for-one network performance. But when we move it over here to OpenShift, we're back to square one where you lose 80% of the performance because of the latest SOA model that they've implemented. And so now evolving the underlying platform rises in importance, and so the pendulum swing goes, but it's still NFV. Open source allows you to adapt to these changes and influences effectively and quickly. Thus innovations happen rapidly and logically, and so do their iterations.
|
||||
|
||||
**Linux.com: Tell us about the underlying Linux in NFV, and why that combo is so powerful.**
|
||||
|
||||
**Nadeau:** Linux is open source and it always has been in some of the purest senses of open source. The other reason is that it's the predominant choice for the underlying operating system. The reality is that all major networks and all of the top networking companies run Linux as the base operating system on all their high-performance platforms. Now it's all in a very flexible form factor. You can lay it on a Raspberry Pi, or you can lay it on a gigantic million-dollar router. It's secure, it's flexible, and scalable, so operators can really use it as a tool now.
|
||||
|
||||
**Linux.com: Carriers are always working to redefine themselves. Indeed, many are actively seeking ways to move out of strictly defensive plays against disruptors, and onto offense where they ARE the disruptor. How can network function virtualization (NFV) help in either or both strategies?**
|
||||
|
||||
**Nadeau:** Telstra and Bell Canada are good examples. They are using open source code in concert with the ecosystem of partners they have around that code which allows them to do things differently than they have in the past. There are two main things they do differently today. One is they design their own network. They design their own things in a lot of ways, whereas before they would possibly need to use a turnkey solution from a vendor that looked a lot, if not identical, to their competitors’ businesses.
|
||||
|
||||
These telcos are taking a real “in-depth, roll up your sleeves” approach. ow that they understand what they're using at a much more intimate level, they can collaborate with the downstream distro providers or vendors. This goes back to the point that the ecosystem, which is analogous to partner programs that we have at Red Hat, is the glue that fills in gaps and rounds out the network solution that the telco envisions.
|
||||
|
||||
_Learn more at[Open Networking Summit][4], happening April 3-5 at the San Jose McEnery Convention Center._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2019/3/how-open-source-accelerating-nfv-transformation
|
||||
|
||||
作者:[Pam Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/pambaker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/nfv-443852_1920.jpg?itok=uFbzmEPY (NFV)
|
||||
[2]: /LICENSES/CATEGORY/CREATIVE-COMMONS-ZERO
|
||||
[3]: https://www.linuxfoundation.org/blog/2018/02/open-source-standards-team-red-hat-measures-open-source-success/
|
||||
[4]: https://events.linuxfoundation.org/events/open-networking-summit-north-america-2019/
|
||||
[5]: https://www.linkedin.com/in/tom-nadeau/
|
||||
[6]: https://onseu18.sched.com/event/Fmpr
|
||||
@ -0,0 +1,74 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (An inside look at an IIoT-powered smart factory)
|
||||
[#]: via: (https://www.networkworld.com/article/3384378/an-inside-look-at-tempo-automations-iiot-powered-smart-factory.html#tk.rss_all)
|
||||
[#]: author: (Fredric Paul https://www.networkworld.com/author/Fredric-Paul/)
|
||||
|
||||
An inside look at an IIoT-powered smart factory
|
||||
======
|
||||
|
||||
### Despite housing some 50 robots and 50 people, Tempo Automation’s gleaming connected factory relies on industrial IoT and looks more like a high-tech startup office than a manufacturing plant.
|
||||
|
||||
![Tempo Automation][1]
|
||||
|
||||
As someone who’s spent his whole career working in offices, not factories, I had very little idea what a modern “smart factory” powered by the industrial Internet of Things (IIoT) might look like. That’s why I was so interested in [Tempo Automation][2]’s new 42,000-square-foot facility in San Francisco’s trendy Design District.
|
||||
|
||||
Frankly, I pictured the company’s facility, which uses IIoT to automatically configure, operate, and monitor the prototyping and low-volume production of printed circuit board assemblies (PCBAs), as a cacophony of robots and conveyor belts attended to by a grizzled band of grease-stained technicians. You know, a 21stcentury update of Charlie Chaplin’s 1936 classic *Modern Times *making equipment for customers in the aerospace, medtech, industrial automation, consumer electronics, and automotive industries. (The company just inked a [new contract with Lockheed Martin][3].)
|
||||
|
||||
**[ Learn more about the[industrial Internet of Things][4]. | Get regularly scheduled insights by [signing up for Network World newsletters][5]. ]**
|
||||
|
||||
Not exactly. As you can see from the below pictures, despite housing some 50 robots and 50 people, this gleaming “connected factory” looks more like a high-tech startup office, with just as many computers and few more hard-to-identify machines, including Solder Jet and Stencil Printers, zone reflow ovens, 3D X-ray devices and many more.
|
||||
|
||||
![Tempo Automation office space][6]
|
||||
|
||||
![Tempo Automation factory floor][7]
|
||||
|
||||
## How Tempo Automation's 'smart factory' works
|
||||
|
||||
On the front end, Tempo’s customers upload CAD files with their board designs and Bills of Materials (BOM) listing the required parts to be used. After performing feature extraction on the design and developing a virtual model of the finished product, the Tempo system, the platform (called Tempocom) creates a manufacturing plan and automatically programs the factory’s machines. Tempocom also creates work plans for the factory employees, uploading them to the networked IIoT mobile devicesthey all carry. Updated in real time based on design and process changes, this“digital traveler” tells workers where to go and what to work on next.
|
||||
|
||||
While Tempocom is planning and organizing the internal work of production, the system is also connected to supplier databases, seeking and ordering the parts that will be used in assembly, optimizing for speed of delivery to the Tempo factory.
|
||||
|
||||
## Connecting the digital thread
|
||||
|
||||
“There could be up to 20 robots, 400 unique parts, and 25 people working on the factory floor to produce one order start to finish in a matter of hours,” explained [Shashank Samala][8], Tempo’s co-founder and vice president of product in an email. Tempo “employs IIoT to automatically configure, operate, and monitor” the entire process, coordinated by a “connected manufacturing system” that creates an “unbroken digital thread from design intent of the engineer captured on the website, to suppliers distributed across the country, to robots and people on the factory floor.”
|
||||
|
||||
Rather than the machines on the floor functioning as “isolated islands of technology,” Samala added, Tempo Automation uses [Amazon Web Services (AWS) GovCloud][9] to network everything in a bi-directional feedback loop.
|
||||
|
||||
“After customers upload their design to the Tempo platform, our software extracts the design features and then streams relevant data down to all the devices, processes, and robots on the factory floor,” he said. “This loop then works the other way: As the robots build the products, they collect data and feedback about the design during production. This data is then streamed back through the Tempo secure cloud architecture to the customer as a ‘Production Forensics’ report.”
|
||||
|
||||
Samala claimed the system has “streamlined operations, improved collaboration, and simplified remote management and control.”
|
||||
|
||||
## Traditional IoT, too
|
||||
|
||||
Of course, the Tempo factory isn’t all fancy, cutting-edge IIoT implementations. According to Ryan Saul, vice president of manufacturing,the plant also includes an array of IoT sensors that track temperature, humidity, equipment status, job progress, reported defects, and so on to help engineers and executives understand how the facility is operating.
|
||||
|
||||
Join the Network World communities on [Facebook][10] and [LinkedIn][11] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3384378/an-inside-look-at-tempo-automations-iiot-powered-smart-factory.html#tk.rss_all
|
||||
|
||||
作者:[Fredric Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Fredric-Paul/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/03/tempo-automation-iiot-factory-floor-100791923-large.jpg
|
||||
[2]: http://www.tempoautomation.com/
|
||||
[3]: https://www.businesswire.com/news/home/20190325005097/en/Tempo-Automation-Announces-Contract-Lockheed-Martin
|
||||
[4]: https://www.networkworld.com/article/3243928/internet-of-things/what-is-the-industrial-iot-and-why-the-stakes-are-so-high.html#nww-fsb
|
||||
[5]: https://www.networkworld.com/newsletters/signup.html#nww-fsb
|
||||
[6]: https://images.idgesg.net/images/article/2019/03/tempo-automation-iiot-factory-2-100791921-large.jpg
|
||||
[7]: https://images.idgesg.net/images/article/2019/03/tempo-automation-iiot-factory-100791922-large.jpg
|
||||
[8]: https://www.linkedin.com/in/shashanksamala/
|
||||
[9]: https://aws.amazon.com/govcloud-us/
|
||||
[10]: https://www.facebook.com/NetworkWorld/
|
||||
[11]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,65 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Changes in SD-WAN Purchase Drivers Show Maturity of the Technology)
|
||||
[#]: via: (https://www.networkworld.com/article/3384103/changes-in-sd-wan-purchase-drivers-show-maturity-of-the-technology.html#tk.rss_all)
|
||||
[#]: author: (Cliff Grossner https://www.networkworld.com/author/Cliff-Grossner/)
|
||||
|
||||
Changes in SD-WAN Purchase Drivers Show Maturity of the Technology
|
||||
======
|
||||
|
||||
![istock][1]
|
||||
|
||||
[SD-WANs][2] have been available now for the past five years, but adoption has been light compared to that of the overall WAN market. This should be no surprise, as the technology was immature, and customers were dipping their toes in the water first as a test. Recently, however, there are signs that the market is maturing, which also happens to coincide with an acceleration of the market.
|
||||
|
||||
Evidence of the maturation of SD-WANs can be seen in the most recent IHS Markit _Campus LAN and WAN SDN Strategies and Leadership North American Enterprise Survey_. Exhibit 1 shows that the top drivers of SD-WAN deployments are the simplification of WAN provisioning, automation capabilities. and direct cloud connectivity—all of which require an architectural change.
|
||||
|
||||
This is in stark contrast to the approach of early adopters looking for a reduction in opex and capex savings, doing so in the past by shifting to cheap broadband and low-cost branch hardware. The survey data finds that opex savings now ranks tied in fifth place among the purchase drivers of SD-WAN; and that reduced capex is last, indicating that cost savings no longer possess the same level of importance as with early adopters.
|
||||
|
||||
The shift in purchase drivers indicates companies are looking for SD-WAN to provide more value than legacy WAN.
|
||||
|
||||
With [SD-WAN][3], the “software defined” indicates that the control plane has been separated from the data plane, enabling the control plane to be abstracted away from the hardware and allowing centralized, distributed, and hybrid control architectures, working alongside the centralized management of those architectures. This provides many benefits, the biggest of which is to make WAN provisioning easier.
|
||||
|
||||
![Exhibit 1: Simplification and automation are top drivers for SD-WAN.][4]
|
||||
|
||||
With SD-WAN, most mainstream buyers now demand Zero Touch Provisioning, where the SD-WAN appliance automatically calls home when it attaches to the network and pulls its configuration down from a centralized location. Also, changes can be made through a centralized console and then immediately pushed out to every device. This can automate many of the mundane and repetitive tasks associated with running a network.
|
||||
|
||||
Such a setup carries many benefits—the most important being that highly skilled network engineers can dedicate more time to innovation and less time to working on tasks associated with “keeping the lights on.”
|
||||
|
||||
At present, most resources—time and money—associated with running the WAN are allocated to maintaining the status quo. In the cloud era, however, business leaders embracing digital transformation are looking to their IT organization to help drive innovation and leapfrog the competition. SD-WANs can modernize the network, and the technology will tip the IT resource scale back in favor of innovation.
|
||||
|
||||
### Mainstream buyers set new expectations for SD-WAN
|
||||
|
||||
With early adopters, technology innovation is key because adopters are generally tech-savvy buyers and are always looking to use the latest and greatest to gain an edge. With mainstream buyers, other concerns arise. Exhibit 2 from the IHS Markit survey shows that technological innovation now ranks tied in fourth place in what buyers look for from an SD-WAN provider. While innovation is still important, factors such as security, financial stability, and product service and reliability rank higher. And although businesses need a strong technical solution, it cannot be achieved at the expense of security, vendor stability, or quality without putting operations at risk.
|
||||
|
||||
It’s not surprising, then, that security turned out to be the overwhelming top evaluation criterion, as SD-WANs enable businesses to implement local internet breakout and cloud on-ramp features. Overall, SD-WANs help make applications perform better, especially as enterprises deploy workloads in off-premises, cloud-service-provider-operated data centers as they build their hybrid and multi-clouds.
|
||||
|
||||
Another security capability of SD-WANs is their ability to easily implement segmentation, which enables businesses to establish centrally defined and globally consistent security policies that isolate traffic. For example, a retailer could isolate point-of-sale systems from its guest Wi-Fi network. [SD-WAN vendors][5] can also establish partnerships with well-known security vendors that enable the SD-WAN software to be service chained into application traffic flows, in the process allowing mainstream buyers their choice of security technology.
|
||||
|
||||
![Exhibit 2: SD-WAN buyers now want security and financially viable vendors.][6]
|
||||
|
||||
### The bottom line
|
||||
|
||||
The SD-WAN market is maturing, and the shift from early adopters to mainstream businesses will create a “rising tide” that will benefit all SD-WAN buyers in the WAN ecosystem. As a result, vendors will work to meet calls emphasizing greater simplicity and risk reduction, as well as bring about features that provide an integrated connectivity fabric for enterprise edge, hybrid, and multi-clouds.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3384103/changes-in-sd-wan-purchase-drivers-show-maturity-of-the-technology.html#tk.rss_all
|
||||
|
||||
作者:[Cliff Grossner][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Cliff-Grossner/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/03/istock-998475736-100791932-large.jpg
|
||||
[2]: https://www.silver-peak.com/sd-wan
|
||||
[3]: https://www.silver-peak.com/sd-wan/sd-wan-explained
|
||||
[4]: https://images.idgesg.net/images/article/2019/03/chart-1_post-10-100791930-large.jpg
|
||||
[5]: https://www.silver-peak.com/sd-wan/choosing-an-sd-wan-vendor
|
||||
[6]: https://images.idgesg.net/images/article/2019/03/chart-2_post-10-100791931-large.jpg
|
||||
@ -0,0 +1,52 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Today’s Retailer is Turning to the Edge for CX)
|
||||
[#]: via: (https://www.networkworld.com/article/3384202/today-s-retailer-is-turning-to-the-edge-for-cx.html#tk.rss_all)
|
||||
[#]: author: (Cindy Waxer https://www.networkworld.com/author/Cindy-Waxer/)
|
||||
|
||||
Today’s Retailer is Turning to the Edge for CX
|
||||
======
|
||||
|
||||
### Despite the increasing popularity and convenience of ecommerce, 92% of purchases continue to be made off-line, according to the U.S. Census.
|
||||
|
||||
![iStock][1]
|
||||
|
||||
Despite the increasing popularity and convenience of ecommerce, 92% of purchases continue to be made off-line, according to the [U.S. Census][2]. That’s putting enormous pressure on retailers to meet new consumer expectations around real-time access to merchandise and order information. In fact, 85.3% of shoppers expect retailers to provide associates with handheld or fixed devices to check inventory and price within a store, a nearly 51% increase over 2017, according to a [survey from SOTI][3].
|
||||
|
||||
With an eye on transforming the customer experience of spending time in a store, retailers are investing aggressively in compute power located closer to the buyer, also known as [edge computing][4].
|
||||
|
||||
So what new and innovative technologies are edge environments supporting? Here’s where retail is headed with customer service and how edge computing will help them get there.
|
||||
|
||||
**Face forward** : Facial recognition technology is on the rise in retail as brands search for new ways to engage customers. Take, CaliBurger, for example. The restaurant chain recently tested out self-ordering kiosks that use AI and facial-recognition technology to identify registered customers and pull up their loyalty accounts and order preferences. By automatically displaying a customer’s most popular purchases, the system aims to help patrons complete their orders in seconds flat for greater speed and convenience.
|
||||
|
||||
**Customer experience on display** : Forget about traditional counter displays. Savvy retailers are experimenting with high-tech, in-store digital signage solutions to attract consumers and gather valuable data. For instance, Glass Media’s projection-based, end-to-end digital retail signage combines display technology, a cloud-based IoT platform, and data analytic capabilities. Through projection, the solution can influence customers at the point-of-decision.
|
||||
|
||||
**Backroom access** : Tracking inventory manually requires substantial human resources. IoT-powered backroom technologies such as RFID, real-time point of sale (POS), and smart shelving systems promise to change that by improving the accuracy of inventory tracking throughout the supply chain. These automated solutions can track and reorder items automatically, eliminating the need for humans to take inventory and reducing the risk of product shortages.
|
||||
|
||||
**Robots to the rescue** : Hoping to transform the branch experience, HSBC recently unveiled Pepper, a concierge robot whose job is to help customers with simple tasks, from answering commonly asked questions to directing them to available tellers. Pepper also acts as an online banking station where customers can log into their mobile banking account or access information about products. By putting Pepper on the payroll, HSBC hopes to reduce customer wait times and free up its “human” bankers.
|
||||
|
||||
These innovative technologies provide retailers with unique opportunities to enhance customer experience, develop new revenue streams, and boost customer loyalty. But many of them require edge computing to work properly. Bandwidth-intensive content and vast volumes of data can lead to latency issues, outages, and other IT headaches. Fortunately, by placing computing power and storage capabilities directly on the edge of the network, edge computing can help retailers deliver the best customer experience possible.
|
||||
|
||||
To find out more about how edge computing is transforming the customer experience in retail, visit [APC.com][5].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3384202/today-s-retailer-is-turning-to-the-edge-for-cx.html#tk.rss_all
|
||||
|
||||
作者:[Cindy Waxer][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Cindy-Waxer/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/03/istock-508154656-100791924-large.jpg
|
||||
[2]: https://ycharts.com/indicators/ecommerce_sales_as_percent_retail_sales
|
||||
[3]: https://www.soti.net/resources/newsroom/2019/annual-connected-retailer-survey-new-soti-survey-reveals-us-consumers-prefer-speed-and-convenience-when-shopping-with-limited-human-interaction/
|
||||
[4]: https://www.hpe.com/us/en/servers/edgeline-iot-systems.html?pp=false&jumpid=ps_83cqske5um_aid-510380402&gclid=CjwKCAjw6djYBRB8EiwAoAF6oWwk-M6LWcfCbbZ331fXhEHShXGbLWoSwTIzue6mxQg4gDvYx59XZxoC_4oQAvD_BwE&gclsrc=aw.ds
|
||||
[5]: https://www.apc.com/us/en/solutions/business-solutions/edge-computing.jsp
|
||||
@ -1,154 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Using Square Brackets in Bash: Part 1)
|
||||
[#]: via: (https://www.linux.com/blog/2019/3/using-square-brackets-bash-part-1)
|
||||
[#]: author: (Paul Brown https://www.linux.com/users/bro66)
|
||||
|
||||
Using Square Brackets in Bash: Part 1
|
||||
======
|
||||
|
||||
![square brackets][1]
|
||||
|
||||
This tutorial tackle square brackets and how they are used in different contexts at the command line.
|
||||
|
||||
[Creative Commons Zero][2]
|
||||
|
||||
After taking a look at [how curly braces (`{}`) work on the command line][3], now it’s time to tackle brackets (`[]`) and see how they are used in different contexts.
|
||||
|
||||
### Globbing
|
||||
|
||||
The first and easiest use of square brackets is in _globbing_. You have probably used globbing before without knowing it. Think of all the times you have listed files of a certain type, say, you wanted to list JPEGs, but not PNGs:
|
||||
|
||||
```
|
||||
ls *.jpg
|
||||
```
|
||||
|
||||
Using wildcards to get all the results that fit a certain pattern is precisely what we call globbing.
|
||||
|
||||
In the example above, the asterisk means " _zero or more characters_ ". There is another globbing wildcard, `?`, which means " _exactly one character_ ", so, while
|
||||
|
||||
```
|
||||
ls d*k*
|
||||
```
|
||||
|
||||
will list files called _darkly_ and _ducky_ (and _dark_ and _duck_ \-- remember `*` can also be zero characters),
|
||||
|
||||
```
|
||||
ls d*k?
|
||||
```
|
||||
|
||||
will not list _darkly_ (or _dark_ or _duck_ ), but it will list _ducky_.
|
||||
|
||||
Square brackets are used in globbing for sets of characters. To see what this means, make directory in which to carry out tests, `cd` into it and create a bunch of files like this:
|
||||
|
||||
```
|
||||
touch file0{0..9}{0..9}
|
||||
```
|
||||
|
||||
(If you don't know why that works, [take a look at the last installment that explains curly braces `{}`][3]).
|
||||
|
||||
This will create files _file000_ , _file001_ , _file002_ , etc., through _file097_ , _file098_ and _file099_.
|
||||
|
||||
Then, to list the files in the 70s and 80s, you can do this:
|
||||
|
||||
```
|
||||
ls file0[78]?
|
||||
```
|
||||
|
||||
To list _file022_ , _file027_ , _file028_ , _file052_ , _file057_ , _file058_ , _file092_ , _file097_ , and _file98_ you can do this:
|
||||
|
||||
```
|
||||
ls file0[259][278]
|
||||
```
|
||||
|
||||
Of course, you can use globbing (and square brackets for sets) for more than just `ls`. You can use globbing with any other tool for listing, removing, moving, or copying files, although the last two may require a bit of lateral thinking.
|
||||
|
||||
Let's say you want to create duplicates of files _file010_ through _file029_ and call the copies _archive010_ , _archive011_ , _archive012_ , etc..
|
||||
|
||||
You can't do:
|
||||
|
||||
```
|
||||
cp file0[12]? archive0[12]?
|
||||
```
|
||||
|
||||
Because globbing is for matching against existing files and directories and the _archive..._ files don't exist yet.
|
||||
|
||||
Doing this:
|
||||
|
||||
```
|
||||
cp file0[12]? archive0[1..2][0..9]
|
||||
```
|
||||
|
||||
won't work either, because `cp` doesn't let you copy many files to other many new files. Copying many files only works if you are copying them to a directory, so this:
|
||||
|
||||
```
|
||||
mkdir archive
|
||||
|
||||
cp file0[12]? archive
|
||||
```
|
||||
|
||||
would work, but it would copy the files, using their same names, into a directory called _archive/_. This is not what you set out to do.
|
||||
|
||||
However, if you look back at [the article on curly braces (`{}`)][3], you will remember how you can use `%` to lop off the end of a string contained in a variable.
|
||||
|
||||
Of course, there is a way you can also lop of the beginning of string contained in a variable. Instead of `%`, you use `#`.
|
||||
|
||||
For practice, you can try this:
|
||||
|
||||
```
|
||||
myvar="Hello World"
|
||||
|
||||
echo Goodbye Cruel ${myvar#Hello}
|
||||
```
|
||||
|
||||
It prints " _Goodbye Cruel World_ " because `#Hello` gets rid of the _Hello_ part at the beginning of the string stored in `myvar`.
|
||||
|
||||
You can use this feature alongside your globbing tools to make your _archive_ duplicates:
|
||||
|
||||
```
|
||||
for i in file0[12]?;\
|
||||
|
||||
do\
|
||||
|
||||
cp $i archive${i#file};\
|
||||
|
||||
done
|
||||
```
|
||||
|
||||
The first line tells the Bash interpreter that you want to loop through all the files that contain the string _file0_ followed by the digits _1_ or _2_ , and then one other character, which can be anything. The second line `do` indicates that what follows is the instruction or list of instructions you want the interpreter to loop through.
|
||||
|
||||
Line 3 is where the actually copying happens, and you use the contents of the loop variable _`i`_ **twice: First, straight out, as the first parameter of the `cp` command, and then you add _archive_ to its contents, while at the same time cutting of _file_. So, if _`i`_ contains, say, _file019_...
|
||||
|
||||
```
|
||||
"archive" + "file019" - "file" = "archive019"
|
||||
```
|
||||
|
||||
the `cp` line is expanded to this:
|
||||
|
||||
```
|
||||
cp file019 archive019
|
||||
```
|
||||
|
||||
Finally, notice how you can use the backslash `\` to split a chain of commands over several lines for clarity.
|
||||
|
||||
In part two, we’ll look at more ways to use square brackets. Stay tuned.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2019/3/using-square-brackets-bash-part-1
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/square-gabriele-diwald-475007-unsplash.jpg?itok=cKmysLfd (square brackets)
|
||||
[2]: https://www.linux.com/LICENSES/CATEGORY/CREATIVE-COMMONS-ZERO
|
||||
[3]: https://www.linux.com/blog/learn/2019/2/all-about-curly-braces-bash
|
||||
@ -0,0 +1,66 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Cisco forms VC firm looking to weaponize fledgling technology companies)
|
||||
[#]: via: (https://www.networkworld.com/article/3385039/cisco-forms-vc-firm-looking-to-weaponize-fledgling-technology-companies.html#tk.rss_all)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
Cisco forms VC firm looking to weaponize fledgling technology companies
|
||||
======
|
||||
|
||||
### Decibel, an investment firm focused on early stage funding for enterprise-product startups, will back technologies related to Cisco's core interests.
|
||||
|
||||
![BrianaJackson / Getty][1]
|
||||
|
||||
Cisco this week stepped deeper into the venture capital world by announcing Decibel, an early-stage investment firm that will focus on bringing enterprise-oriented startups to market.
|
||||
|
||||
Veteran VC groundbreaker and former general partner at New Enterprise Associates [Jon Sakoda][2] will lead Decibel. Sakoda had been with NEA since 2006 and focused on startup investments in software and Internet companies.
|
||||
|
||||
**[ Now see[7 free network tools you must have][3]. ]**
|
||||
|
||||
Of Decibel Sakoda said: “We want to invest in companies that are helping our customers use innovation as a weapon in the game to transform their respective industries.”
|
||||
|
||||
“Decibel combines the speed, agility, and independent risk-taking traditionally found in the best VC firms, while offering differentiated access to the scale, entrepreneurial talent, and deep customer relationships found in one of the largest tech companies in the world,” [Sakoda said][4]. “This approach is an industry first and provides a unique way for entrepreneurs to get access to unparalleled resources at a time and stage when they need it most.”
|
||||
|
||||
“As one of the most prolific strategic venture capitalists in the world, Cisco already has a view into future technologies shaping our markets through our rich portfolio of companies,” wrote Rob Salvagno, vice president of Corporate Development and Cisco Investments in a [blog about Decibel][5]. “But we realized we could do even more by engaging with the startup community earlier in its lifecycle.”
|
||||
|
||||
Indeed Cisco already has an investment arm, Cisco Investments, that focuses on later stage startups, the company says. Cisco said this arm invests $200 to $300 million annually, and it will continue its charter of investing and partnering with best-in-class companies in core and adjacent markets.
|
||||
|
||||
Cisco didn’t talk about how much money would be involved in Decibel, but according to a [CNBC report][6], Cisco is setting up Decibel as an independent firm with a separate pool of cash, an unusual model for corporate investors. The fund hasn’t closed yet, but a [Securities and Exchange Commission filing][7] from October indicated that Sakoda was setting out to [raise $500 million][8], CNBC wrote.
|
||||
|
||||
**[[Become a Microsoft Office 365 administrator in record time with this quick start course from PluralSight.][9] ]**
|
||||
|
||||
Decibel does plan to invest anywhere from $5M – 15M in each start up in their portfolio, Cisco says.
|
||||
|
||||
“Cisco has a culture of leveraging both internal and external innovation – accelerating our rich internal development capabilities by our ability to also partner, invest and acquire, Salvagno said.
|
||||
|
||||
He said the company recognizes that significant innovation happens outside of the walls of Cisco. Cisco has acquired more than 200 companies, accounting for more than one in eight Cisco employees have joined as a result. "We have a deep bench of acquired founders, many of which play leadership roles within the company today, which continues to reinforce this entrepreneurial spirit," Salvagno said.
|
||||
|
||||
Join the Network World communities on [Facebook][10] and [LinkedIn][11] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3385039/cisco-forms-vc-firm-looking-to-weaponize-fledgling-technology-companies.html#tk.rss_all
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/02/money_salary_magnet_flying-money_money-magnet-by-brianajackson-getty-100787974-large.jpg
|
||||
[2]: https://twitter.com/jonsakoda
|
||||
[3]: https://www.networkworld.com/article/2825879/7-free-open-source-network-monitoring-tools.html
|
||||
[4]: https://www.decibel.vc/the-blast/announcingdecibel
|
||||
[5]: https://blogs.cisco.com/news/cisco-fuels-innovation-engine-with-investment-in-new-early-stage-vc-fund
|
||||
[6]: https://www.cnbc.com/2019/03/26/cisco-introduces-decibel-an-early-stage-venture-firm-with-jon-sakoda.html
|
||||
[7]: https://www.sec.gov/Archives/edgar/data/1754260/000175426018000002/xslFormDX01/primary_doc.xml
|
||||
[8]: https://www.cnbc.com/2018/10/08/cisco-lead-investor-jon-sakoda-catalyst-labs-500-million.html
|
||||
[9]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fadministering-office-365-quick-start
|
||||
[10]: https://www.facebook.com/NetworkWorld/
|
||||
[11]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,59 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (HPE introduces hybrid cloud consulting business)
|
||||
[#]: via: (https://www.networkworld.com/article/3384919/hpe-introduces-hybrid-cloud-consulting-business.html#tk.rss_all)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
HPE introduces hybrid cloud consulting business
|
||||
======
|
||||
|
||||
### HPE's Right Mix Advisor is designed to find a balance between on-premises and cloud systems.
|
||||
|
||||
![Hewlett Packard Enterprise][1]
|
||||
|
||||
Hybrid cloud is pretty much the de facto way to go, with only a few firms adopting a pure cloud play to replace their data center and only suicidal firms refusing to go to the cloud. But picking the right balance between on-premises and the cloud is tricky, and a mistake can be costly.
|
||||
|
||||
Enter Right Mix Advisor from Hewlett Packard Enterprise, a combination of consulting from HPE's Pointnext division and software tools. It draws on quite a bit of recent acquisitions. Another part of Right Mix Advisor is a British cloud consultancy RedPixie, Amazon Web Services (AWS) specialists Cloud Technology Partners, and automated discovery capabilities from an Irish startup iQuate.
|
||||
|
||||
Right Mix Advisor gathers data points from the company’s entire enterprise, ranging from configuration management database systems (CMDBs), such as ServiceNow, to external sources, such as cloud providers. HPE says that in a recent customer engagement it scanned 9 million IP addresses across six data centers.
|
||||
|
||||
**[ Read also:[What is hybrid cloud computing][2]. | Learn [what you need to know about multi-cloud][3]. | Get regularly scheduled insights by [signing up for Network World newsletters][4]. ]**
|
||||
|
||||
HPE Pointnext consultants then work with the client’s IT teams to analyze the data to determine the optimal configuration for workload placement. Pointnext has become HPE’s main consulting outfit following its divestiture of EDS, which it acquired in 2008 but spun off in a merger with CSC to form DXC Consulting. Pointnext now has 25,000 consultants in 88 countries.
|
||||
|
||||
In a typical engagement, HPE claims it can deliver a concrete action plan within weeks, whereas previously businesses may have needed months to come to a conclusion using a manual processes. HPE has found migrating the right workloads to the right mix of hybrid cloud can typically result in 40 percent total cost of ownership savings*. *
|
||||
|
||||
Although HPE has thrown its weight behind AWS, that doesn’t mean it doesn’t support competitors. Erik Vogel, vice president of hybrid IT for HPE Pointnext, notes in the blog post announcing Right Mix Advisor that target environments could be Microsoft Azure or Azure Stack, AWS, Google or Ali Cloud.
|
||||
|
||||
“New service providers are popping up every day, and we see the big public cloud providers constantly producing new services and pricing models. As a result, the calculus for determining your right mix is constantly changing. If Azure, for example, offers a new service capability or a 10 percent pricing discount and it makes sense to leverage it, you want to be able to move an application seamlessly into that new environment,” he wrote.
|
||||
|
||||
Key to Right Mix Advisor is app migration, and Pointnext follows the 50/30/20 rule: About 50 percent of apps are suitable for migration to the cloud, and for about 30 percent, migration is not a good choice for migration to be worth the effort. The remaining 20 percent should be retired.
|
||||
|
||||
“With HPE Right Mix Advisor, you can identify that 50 percent,” he wrote. “Rather than hand you a laundry list of 10,000 apps to start migrating, HPE Right Mix Advisor hones in on what’s most impactful right now to meet your business goals – the 10 things you can do on Monday morning that you can be confident will really help your business.”
|
||||
|
||||
HPE has already done some pilot projects with the Right Mix service and expects to expand it to include channel partners.
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3384919/hpe-introduces-hybrid-cloud-consulting-business.html#tk.rss_all
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.techhive.com/images/article/2015/11/hpe_building-100625424-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3233132/cloud-computing/what-is-hybrid-cloud-computing.html
|
||||
[3]: https://www.networkworld.com/article/3252775/hybrid-cloud/multicloud-mania-what-to-know.html
|
||||
[4]: https://www.networkworld.com/newsletters/signup.html
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,126 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Identifying exceptional user experience (UX) in IoT platforms)
|
||||
[#]: via: (https://www.networkworld.com/article/3384738/identifying-exceptional-user-experience-ux-in-iot-platforms.html#tk.rss_all)
|
||||
[#]: author: (Steven Hilton https://www.networkworld.com/author/Steven-Hilton/)
|
||||
|
||||
Identifying exceptional user experience (UX) in IoT platforms
|
||||
======
|
||||
|
||||
### Examples of excellent IoT platform UX from the perspectives of 5 typical IoT platform personas.
|
||||
|
||||
![Leo Wolfert / Getty Images][1]
|
||||
|
||||
Enterprises are inundated with information about IoT platforms’ features and capabilities. But to find a long-lived IoT platform that minimizes ongoing development costs, enterprises must focus on exceptional user experience (UX) for 5 types of IoT platform users.
|
||||
|
||||
Marketing and sales literature from IoT platform vendors is filled with information about IoT platform features. And no doubt, enterprises choosing to buy IoT platform services need to understand the actual capabilities of IoT platforms – preferably by [testing a variety of IoT platforms][2] – before making a purchase decision.
|
||||
|
||||
However, it is a lot harder to gauge the quality of an IoT platform UX than itemizing an IoT platform’s features. Having excellent UX leads to lower platform deployment and management costs and higher customer satisfaction and retention. So enterprises should make UX one of their top criteria when selecting an IoT platform.
|
||||
|
||||
[RELATED: Storage tank operator turns to IoT for energy savings][3]
|
||||
|
||||
One of the ways to determine excellent IoT platform UX is to simulate the tasks conducted by typical IoT platform users. By completing these tasks, it becomes readily apparent when an IoT platform is exceptional or annoyingly bad.
|
||||
|
||||
In this blog, I describe excellent IoT platform UX from the perspectives of five typical IoT platform users or personas.
|
||||
|
||||
## Persona 1: platform administrator
|
||||
|
||||
A platform administrator’s primary role is to configure, monitor, and maintain the functionality of an IoT platform. A platform administrator is typically an IT employee responsible for maintaining and configuring the various data management, device management, access control, external integration, and monitoring services that comprise an IoT platform.
|
||||
|
||||
Typical platform administrator tasks include
|
||||
|
||||
* configuration of the on-platform data visualization and data aggregation tools
|
||||
* configuration of available device management functionality or execution of in-bulk device management tasks
|
||||
* configuration and creation of on-platform complex event processing (CEP) workflows
|
||||
* management and configuration of platform service orchestration
|
||||
|
||||
|
||||
|
||||
Enterprises should pick IoT platforms with superlative access to on-platform configuration functionality with an emphasis on declarative interfaces for configuration management. Although many platform administrators are capable of working with RESTful API endpoints, good UX design should not require that platform administrators use third-party tools to automate basic functionality or execute bulk tasks. Some programmatic interfaces, such as SQL syntax for limiting monitoring views or dashboards for setting event processing trigger criteria, are acceptable and expected, although a fully declarative solution that maintains similar functionality is preferred.
|
||||
|
||||
## Persona 2: platform operator
|
||||
|
||||
A platform operator’s primary role is to leverage an IoT platform to execute common day-to-day business-centric operations and services. While the responsibilities of a platform operator will vary based on enterprise vertical and use case, all platform operators conduct business rather than IoT domain tasks.
|
||||
|
||||
Typical platform operator tasks include
|
||||
|
||||
* visualizing and aggregating on-platform data to view key business KPIs
|
||||
* using device management functionality on a per-device basis
|
||||
* creating, managing, and monitoring per-device and per-location event processing rules
|
||||
* executing self-service administrative tasks, such as enrolling downstream operators
|
||||
|
||||
|
||||
|
||||
Enterprises should pick IoT platforms centered on excellent ease-of-use for a business user. In general, the UX should be focused on providing information immediately required for the execution of day-to-day operational tasks while removing more complex functionality. These platforms should have easy access to well-defined and well-constrained operational functions or data visualization. An effective UX should enable easy creation and modification of data views, graphs, dashboards, and other visualizations by allowing operators to select devices using a declarative rather than SQL or other programmatic interfaces.
|
||||
|
||||
## Persona 3: hardware and systems developer
|
||||
|
||||
A hardware and systems developer’s primary role is the integration and configuration of IoT assets into an IoT platform. The hardware and systems developer possesses very specific, detailed knowledge about IoT hardware (e.g., specific multipoint control units, embedded platforms, or PLC/SCADA control systems), and leverages this knowledge to enable protocol and asset compatibility with northbound platform services.
|
||||
|
||||
Typical hardware and systems developer tasks include
|
||||
|
||||
* designing and implementing firmware for IoT assets based on either standardized IoT SDKs or platform-specific SDKs
|
||||
* updating firmware or software packages over deployment lifecycles
|
||||
* integrating manufacturer-specific protocols adapters into either IoT assets or the northbound platform
|
||||
|
||||
|
||||
|
||||
Enterprises should pick IoT platforms that allow hardware and systems developers to most efficiently design and implement low-level device and protocol functionality. An effective developer experience provides well-documented and fully-featured SDKs supporting a variety of languages and device architectures to enable integration with various types of IoT hardware.
|
||||
|
||||
## Persona 4: platform and backend developer
|
||||
|
||||
A platform and backend developer’s primary role is to execute customer-specific application logic and integrations within an IoT deployment. Customer-specific logic may include on-platform or on-edge custom applications, such as those used for analytics, data aggregation and normalization, or any type of event processing workflow. In addition, a platform and backend developer is responsible for integrating the IoT platform with external databases, analytic solutions, or business systems such as MES, ERP, or CRM applications.
|
||||
|
||||
Typical platform and backend developer tasks include
|
||||
|
||||
* integrating streaming data from the IoT platform into external systems and applications
|
||||
* configuring inbound and outbound platform actions and interactions with external systems
|
||||
* configuring complex code-based event processing capabilities beyond the scope of a platform administrator’s knowledge or ability
|
||||
* debugging low-level platform functionalities that require coding to detect or resolve
|
||||
|
||||
|
||||
|
||||
Enterprises should pick excellent IoT platforms that provide access to well-documented and well-featured platform-level SDKs for application or service development. A best-in-class platform UX should provide real-time logging tools, debugging tools, and indexed and searchable access to all platform logs. Finally, a platform and backend developer is particularly dependent upon high-quality, platform-level documentation, especially for platform APIs.
|
||||
|
||||
## Persona 5: user interface and experience (UI/UX) developer
|
||||
|
||||
A UI/UX developer’s primary role is to design the various operator interfaces and monitoring views for an IoT platform. In more complex IoT deployments, various operator audiences will need to be addressed, including solution domain experts such as a factory manager; role-specific experts such as an equipment operator or factory technician; and business experts such as a supply-chain analyst or company executive.
|
||||
|
||||
Typical UI/UX developer tasks include
|
||||
|
||||
* building and maintaining customer-specific dashboards and monitoring views on either the IoT platform or edge devices
|
||||
* designing, implementing, and maintaining various operator consoles for a variety of operator audiences and customer-specific use cases
|
||||
* ensuring good user experience for customers over the lifetime of an IoT implementation
|
||||
|
||||
|
||||
|
||||
Enterprises should pick IoT platforms that provide an exceptional variety and quality of UI/UX tools, such as dashboarding frameworks for on-platform monitoring solutions that are declaratively or programmatically customizable, as well as various widget and display blocks to help the developer rapidly implement customer-specific views. An IoT platform must also provide a UI/UX developer with appropriate debugging and logging tools for monitoring and operator console frameworks and platform APIs. Finally, a best-in-class platform should provide a sample dashboard, operator console, and on-edge monitoring implementation in order to enable the UI/UX developer to quickly become accustomed with platform paradigms and best practices.
|
||||
|
||||
Enterprises should make UX one of their top criteria when selecting an IoT platform. Having excellent UX allows enterprises to minimize platform deployment and management costs. At the same time, excellent UX allows enterprises to more readily launch new solutions to the market thereby increasing customer satisfaction and retention.
|
||||
|
||||
**This article is published as part of the IDG Contributor Network.[Want to Join?][4]**
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3384738/identifying-exceptional-user-experience-ux-in-iot-platforms.html#tk.rss_all
|
||||
|
||||
作者:[Steven Hilton][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Steven-Hilton/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/02/industry_4-0_industrial_iot_smart_factory_by_leowolfert_gettyimages-689799380_2400x1600-100788464-large.jpg
|
||||
[2]: https://www.machnation.com/2018/09/25/announcing-mit-e-2-0-hands-on-benchmarking-for-iot-cloud-edge-and-analytics-platforms/
|
||||
[3]: https://www.networkworld.com/article/3169384/internet-of-things/storage-tank-operator-turns-to-iot-for-energy-savings.html#tk.nww-fsb
|
||||
[4]: /contributor-network/signup.html
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,71 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (IoT roundup: Keeping an eye on energy use and Volkswagen teams with AWS)
|
||||
[#]: via: (https://www.networkworld.com/article/3384697/iot-roundup-keeping-an-eye-on-energy-use-and-volkswagen-teams-with-aws.html#tk.rss_all)
|
||||
[#]: author: (Jon Gold https://www.networkworld.com/author/Jon-Gold/)
|
||||
|
||||
IoT roundup: Keeping an eye on energy use and Volkswagen teams with AWS
|
||||
======
|
||||
|
||||
### This week's roundup features new tech from MIT, big news in the automotive sector and a handy new level of centralization from a smaller IoT-focused company.
|
||||
|
||||
![Getty Images][1]
|
||||
|
||||
Much of what’s exciting about IoT technology has to do with getting data from a huge variety of sources into one place so it can be mined for insight, but sensors used to gather that data are frequently legacy devices from the early days of industrial automation or cheap, lightweight, SoC-based gadgets without a lot of sophistication of their own.
|
||||
|
||||
Researchers at MIT have devised a system that can gather a certain slice of data from unsophisticated devices that are grouped on the same electrical circuit without adding sensors to each device.
|
||||
|
||||
**[ Check out our[corporate guide to addressing IoT security][2]. ]**
|
||||
|
||||
The technology’s called non-intrusive load monitoring, and sits directly on a given building's, vehicle's or other piece of infrastructure’s electrical circuits, identifies devices based on their power usage, and sends alerts when there are irregularities.
|
||||
|
||||
It seems likely to make IIoT-related waves once it’s out of testing and onto the market.
|
||||
|
||||
NLIM was recently tested, said MIT’s news service, on a U.S. Coast Guard cutter based in Boston, where it was attached to the outside of an electrical wire “at a single point, without requiring any cutting or splicing of wires.”
|
||||
|
||||
Two such connections allowed the scientists to monitor roughly 20 separate devices on an electrical circuit, and the system was able to detect an anomalous amount of energy use from a component of the ship’s diesel engines known as a jacket water heater.
|
||||
|
||||
“[C]rewmembers were skeptical about the reading but went to check it anyway. The heaters are hidden under protective metal covers, but as soon as the cover was removed from the suspect device, smoke came pouring out, and severe corrosion and broken insulation were clearly revealed,” the MIT report stated. Two other important but slightly less critical faults were also detected by the system.
|
||||
|
||||
It’s easy to see why NLIM could easily prove to be an attractive technology for IIoT use in the future. It sounds as though it’s very simple to install, can operate without any kind of Internet connection (though most implementers will probably want to connect it to a wider monitoring setup for a more holistic picture of their systems) and does all of its computational work locally. It can even be used for general energy audits. What, in short, is not to like?
|
||||
|
||||
**Volkswagen teams up with Amazon**
|
||||
|
||||
AWS has got a new flagship client for its growing IoT services in the form of the Volkswagen Group, which [announced][3] that AWS is going to design and build the Volkswagen Industrial Cloud, a floor-to-ceiling industrial IoT implementation aimed at improving uptime, flexibility, productivity and vehicle quality.
|
||||
|
||||
Real-time data from all 122 of VW’s manufacturing plants around the world will be available to the system, everything from part tracking to comparative analysis of efficiency to even deeper forms of analytics will take place in the company’s “data lake,” as the announcement calls it. Oh, and machine learning is part of it, too.
|
||||
|
||||
The German carmaker clearly believes that AWS’s technology can provide a lot of help to its operations across the board, [even in the wake of a partnership with Microsoft for Azure-based cloud services announced last year.][4]
|
||||
|
||||
**IoT-in-a-box**
|
||||
|
||||
IoT can be very complicated. While individual components of any given implementation are often quite simple, each implementation usually contains a host of technologies that have to work in close concert. That means a lot of orchestration work has to go into making this stuff work.
|
||||
|
||||
Enter Digi International, which rolled out an IoT-in-a-box package called Digi Foundations earlier this month. The idea is to take a lot of the logistical legwork out of IoT implementations by integrating cloud-connection software and edge-computing capabilities into the company’s core industrial router business. Foundations, which is packaged as a software subscription that adds these capabilities and more to the company’s devices, also includes a built-in management layer, allowing for simplified configuration and monitoring.
|
||||
|
||||
OK, so it’s not quite all-in-one, but it’s still an impressive level of integration, particularly from a company that many might not have heard of before. It’s also a potential bellwether for other smaller firms upping their technical sophistication in the IoT sector.
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3384697/iot-roundup-keeping-an-eye-on-energy-use-and-volkswagen-teams-with-aws.html#tk.rss_all
|
||||
|
||||
作者:[Jon Gold][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Jon-Gold/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/08/nw_iot-news_internet-of-things_smart-city_smart-home7-100768495-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3269165/internet-of-things/a-corporate-guide-to-addressing-iot-security-concerns.html
|
||||
[3]: https://www.volkswagen-newsroom.com/en/press-releases/volkswagen-and-amazon-web-services-to-develop-industrial-cloud-4780
|
||||
[4]: https://www.volkswagenag.com/en/news/2018/09/volkswagen-and-microsoft-announce-strategic-partnership.html
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -1,85 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Setting kernel command line arguments with Fedora 30)
|
||||
[#]: via: (https://fedoramagazine.org/setting-kernel-command-line-arguments-with-fedora-30/)
|
||||
[#]: author: (Laura Abbott https://fedoramagazine.org/makes-fedora-kernel/)
|
||||
|
||||
Setting kernel command line arguments with Fedora 30
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Adding options to the kernel command line is a common task when debugging or experimenting with the kernel. The upcoming Fedora 30 release made a change to use Bootloader Spec ([BLS][2]). Depending on how you are used to modifying kernel command line options, your workflow may now change. Read on for more information.
|
||||
|
||||
To determine if your system is running with BLS or the older layout, look in the file
|
||||
|
||||
```
|
||||
/etc/default/grub
|
||||
```
|
||||
|
||||
If you see
|
||||
|
||||
```
|
||||
GRUB_ENABLE_BLSCFG=true
|
||||
```
|
||||
|
||||
in there, you are running with the BLS setup and you may need to change how you set kernel command line arguments.
|
||||
|
||||
If you only want to modify a single kernel entry (for example, to temporarily work around a display problem) you can use a grubby command
|
||||
|
||||
```
|
||||
$ grubby --update-kernel /boot/vmlinuz-5.0.1-300.fc30.x86_64 --args="amdgpu.dc=0"
|
||||
```
|
||||
|
||||
To remove a kernel argument, you can use the
|
||||
|
||||
```
|
||||
--remove-args
|
||||
```
|
||||
argument to grubby
|
||||
|
||||
```
|
||||
$ grubby --update-kernel /boot/vmlinuz-5.0.1-300.fc30.x86_64 --remove-args="amdgpu.dc=0"
|
||||
```
|
||||
|
||||
If there is an option that should be added to every kernel command line (for example, you always want to disable the use of the rdrand instruction for random number generation) you can run a grubby command:
|
||||
|
||||
```
|
||||
$ grubby --update-kernel=ALL --args="nordrand"
|
||||
```
|
||||
|
||||
This will update the command line of all kernel entries and save the option to the saved kernel command line for future entries.
|
||||
|
||||
If you later want to remove the option from all kernels, you can again use
|
||||
|
||||
```
|
||||
--remove-args
|
||||
```
|
||||
with
|
||||
|
||||
```
|
||||
--update-kernel=ALL
|
||||
```
|
||||
|
||||
```
|
||||
$ grubby --update-kernel=ALL --remove-args="nordrand"
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/setting-kernel-command-line-arguments-with-fedora-30/
|
||||
|
||||
作者:[Laura Abbott][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/makes-fedora-kernel/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/03/f30-kernel-1-816x345.jpg
|
||||
[2]: https://fedoraproject.org/wiki/Changes/BootLoaderSpecByDefault
|
||||
@ -0,0 +1,85 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (As memory prices plummet, PCIe is poised to overtake SATA for SSDs)
|
||||
[#]: via: (https://www.networkworld.com/article/3384700/as-memory-prices-plummet-pcie-is-poised-to-overtake-sata-for-ssds.html#tk.rss_all)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
As memory prices plummet, PCIe is poised to overtake SATA for SSDs
|
||||
======
|
||||
|
||||
### Taiwan vendors believe PCIe and SATA will achieve price and market share parity by years' end.
|
||||
|
||||
![Intel SSD DC P6400 Series][1]
|
||||
|
||||
A collapse in price for NAND flash memory and a shrinking gap between the prices of PCI Express-based and SATA-based [solid-state drives][2] (SSDs) means the shift to PCI Express SSDs will accelerate in 2019, with the newer, faster format replacing the old by years' end.
|
||||
|
||||
According to the Taiwanese tech publication DigiTimes (the stories are now archived and unavailable without a subscription), falling NAND flash prices continue to drag down SSD prices, which will drive the adoption of SSDs in enterprise and data-center applications. This, in turn, will further drive the adoption of PCIe drives, which are a superior format to SATA.
|
||||
|
||||
**[ Read also:[Backup vs. archive: Why it’s important to know the difference][3] ]**
|
||||
|
||||
## SATA vs. PCI Express
|
||||
|
||||
SATA was introduced in 2001 as a replacement for the IDE interface, which had a much larger cable and slower interface. But SATA is a legacy HDD connection and not fast enough for NAND flash memory.
|
||||
|
||||
I used to review SSDs, and it was always the same when it came to benchmarking, with the drives scoring within a few milliseconds of each other despite the memory used. The SATA interface was the bottleneck. A SATA SSD is like a one-lane highway with no speed limit.
|
||||
|
||||
PCIe is several times faster and has much more parallelism, so throughput is more suited to the NAND format. It comes in two physical formats: an [add-in card][4] that plugs into a PCIe slot and M.2, which is about the size of a [stick of gum][5] and sits on the motherboard. PCIe is most widely used in servers, while M.2 is in consumer devices.
|
||||
|
||||
There used to be a significant price difference between PCIe and SATA drives with the same capacity, but they have come into parity thanks to Moore’s Law, said Jim Handy, principal analyst with Objective Analysis, who follows the memory market.
|
||||
|
||||
“The controller used to be a big part of the price of an SSD. But complexity has not grown with transistor count. It can have a lot of transistors, and it doesn’t cost more. SATA got more complicated, but PCIe has not. PCIe is very close to the same price as SATA, and [the controller] was the only thing that justified the price diff between the two,” he said.
|
||||
|
||||
**[[Get certified as an Apple Technical Coordinator with this seven-part online course from PluralSight.][6] ]**
|
||||
|
||||
DigiTimes estimates that the price drop for NAND flash chips will cause global shipments of SSDs to surge 20 to 25 percent in 2019, and PCIe SSDs are expected to emerge as a new mainstream offering by the end of 2019 with a market share of 50 percent, matching SATA SSDs.
|
||||
|
||||
## SSD and NAND memory prices already falling
|
||||
|
||||
Market sources to DigiTimes said that unit price for 512GB PCIe SSD has fallen by 11 percent sequentially in the first quarter of 2019, while SATA SSDs have dropped 9 percent. They added that the current average unit price for 512GB SSDs is now equal to that of 256GB SSDs from one year ago, with prices continuing to drop.
|
||||
|
||||
According to DRAMeXchange, NAND flash contract prices will continue falling but at a slower rate in the second quarter of 2019. Memory makers are cutting production to avoid losing any more profits.
|
||||
|
||||
“We’re in a price collapse. For over a year I’ve been saying the destination for NAND is 8 cents per gigabyte, and some spot markets are 6 cents. It was 30 cents a year ago. Contract pricing is around 15 cents now, it had been 25 to 27 cents last year,” said Handy.
|
||||
|
||||
A contract price is what it sounds like. A memory maker like Samsung or Micron signs a contract with a SSD maker like Toshiba or Kingston for X amount for Y cents per gigabyte. Spot prices are prices that take place at the end of a quarter (like now) where a vendor anxious to unload excessive inventory has a fire sale to a drive maker that needs it on short supply.
|
||||
|
||||
DigiTimes’s contacts aren’t the only ones who foresee this. Handy was at an analyst event by Samsung a few months back where they presented their projection that PCIe SSD would outsell SATA by the end of this year, and not just in the enterprise but everywhere.
|
||||
|
||||
**More about backup and recovery:**
|
||||
|
||||
* [Backup vs. archive: Why it’s important to know the difference][3]
|
||||
* [How to pick an off-site data-backup method][7]
|
||||
* [Tape vs. disk storage: Why isn’t tape dead yet?][8]
|
||||
* [The correct levels of backup save time, bandwidth, space][9]
|
||||
|
||||
|
||||
|
||||
Join the Network World communities on [Facebook][10] and [LinkedIn][11] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3384700/as-memory-prices-plummet-pcie-is-poised-to-overtake-sata-for-ssds.html#tk.rss_all
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/12/intel-ssd-p4600-series1-100782098-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3326058/what-is-an-ssd.html
|
||||
[3]: https://www.networkworld.com/article/3285652/storage/backup-vs-archive-why-its-important-to-know-the-difference.html
|
||||
[4]: https://www.newegg.com/Product/Product.aspx?Item=N82E16820249107
|
||||
[5]: https://www.newegg.com/Product/Product.aspx?Item=20-156-199&cm_sp=SearchSuccess-_-INFOCARD-_-m.2+-_-20-156-199-_-2&Description=m.2+
|
||||
[6]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fapple-certified-technical-trainer-10-11
|
||||
[7]: https://www.networkworld.com/article/3328488/backup-systems-and-services/how-to-pick-an-off-site-data-backup-method.html
|
||||
[8]: https://www.networkworld.com/article/3315156/storage/tape-vs-disk-storage-why-isnt-tape-dead-yet.html
|
||||
[9]: https://www.networkworld.com/article/3302804/storage/the-correct-levels-of-backup-save-time-bandwidth-space.html
|
||||
[10]: https://www.facebook.com/NetworkWorld/
|
||||
[11]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,133 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Can Better Task Stealing Make Linux Faster?)
|
||||
[#]: via: (https://www.linux.com/blog/can-better-task-stealing-make-linux-faster)
|
||||
[#]: author: (Oracle )
|
||||
|
||||
Can Better Task Stealing Make Linux Faster?
|
||||
======
|
||||
|
||||
_Oracle Linux kernel developer Steve Sistare contributes this discussion on kernel scheduler improvements._
|
||||
|
||||
### Load balancing via scalable task stealing
|
||||
|
||||
The Linux task scheduler balances load across a system by pushing waking tasks to idle CPUs, and by pulling tasks from busy CPUs when a CPU becomes idle. Efficient scaling is a challenge on both the push and pull sides on large systems. For pulls, the scheduler searches all CPUs in successively larger domains until an overloaded CPU is found, and pulls a task from the busiest group. This is very expensive, costing 10's to 100's of microseconds on large systems, so search time is limited by the average idle time, and some domains are not searched. Balance is not always achieved, and idle CPUs go unused.
|
||||
|
||||
I have implemented an alternate mechanism that is invoked after the existing search in idle_balance() limits itself and finds nothing. I maintain a bitmap of overloaded CPUs, where a CPU sets its bit when its runnable CFS task count exceeds 1. The bitmap is sparse, with a limited number of significant bits per cacheline. This reduces cache contention when many threads concurrently set, clear, and visit elements. There is a bitmap per last-level cache. When a CPU becomes idle, it searches the bitmap to find the first overloaded CPU with a migratable task, and steals it. This simple stealing yields a higher CPU utilization than idle_balance() alone, because the search is cheap, costing 1 to 2 microseconds, so it may be called every time the CPU is about to go idle. Stealing does not offload the globally busiest queue, but it is much better than running nothing at all.
|
||||
|
||||
### Results
|
||||
|
||||
Stealing improves utilization with only a modest CPU overhead in scheduler code. In the following experiment, hackbench is run with varying numbers of groups (40 tasks per group), and the delta in /proc/schedstat is shown for each run, averaged per CPU, augmented with these non-standard stats:
|
||||
|
||||
* %find - percent of time spent in old and new functions that search for idle CPUs and tasks to steal and set the overloaded CPUs bitmap.
|
||||
* steal - number of times a task is stolen from another CPU. Elapsed time improves by 8 to 36%, costing at most 0.4% more find time.
|
||||
|
||||
|
||||
|
||||
![load balancing][1]
|
||||
|
||||
[Used with permission][2]
|
||||
|
||||
CPU busy utilization is close to 100% for the new kernel, as shown by the green curve in the following graph, versus the orange curve for the baseline kernel:
|
||||
|
||||
![][3]
|
||||
|
||||
Stealing improves Oracle database OLTP performance by up to 9% depending on load, and we have seen some nice improvements for mysql, pgsql, gcc, java, and networking. In general, stealing is most helpful for workloads with a high context switch rate.
|
||||
|
||||
### The code
|
||||
|
||||
As of this writing, this work is not yet upstream, but the latest patch series is at [https://lkml.org/lkml/2018/12/6/1253. ][4]If your kernel is built with CONFIG_SCHED_DEBUG=y, you can verify that it contains the stealing optimization using
|
||||
|
||||
```
|
||||
# grep -q STEAL /sys/kernel/debug/sched_features && echo Yes
|
||||
Yes
|
||||
```
|
||||
|
||||
If you try it, note that stealing is disabled for systems with more than 2 NUMA nodes, because hackbench regresses on such systems, as I explain in [https://lkml.org/lkml/2018/12/6/1250 .][5]However, I suspect this effect is specific to hackbench and that stealing will help other workloads on many-node systems. To try it, reboot with kernel parameter sched_steal_node_limit = 8 (or larger).
|
||||
|
||||
### Future work
|
||||
|
||||
After the basic stealing algorithm is pushed upstream, I am considering the following enhancements:
|
||||
|
||||
* If stealing within the last-level cache does not find a candidate, steal across LLC's and NUMA nodes.
|
||||
* Maintain a sparse bitmap to identify stealing candidates in the RT scheduling class. Currently pull_rt_task() searches all run queues.
|
||||
* Remove the core and socket levels from idle_balance(), as stealing handles those levels. Remove idle_balance() entirely when stealing across LLC is supported.
|
||||
* Maintain a bitmap to identify idle cores and idle CPUs, for push balancing.
|
||||
|
||||
|
||||
|
||||
_This article originally appeared at[Oracle Developers Blog][6]._
|
||||
|
||||
_Oracle Linux kernel developer Steve Sistare contributes this discussion on kernel scheduler improvements._
|
||||
|
||||
### Load balancing via scalable task stealing
|
||||
|
||||
The Linux task scheduler balances load across a system by pushing waking tasks to idle CPUs, and by pulling tasks from busy CPUs when a CPU becomes idle. Efficient scaling is a challenge on both the push and pull sides on large systems. For pulls, the scheduler searches all CPUs in successively larger domains until an overloaded CPU is found, and pulls a task from the busiest group. This is very expensive, costing 10's to 100's of microseconds on large systems, so search time is limited by the average idle time, and some domains are not searched. Balance is not always achieved, and idle CPUs go unused.
|
||||
|
||||
I have implemented an alternate mechanism that is invoked after the existing search in idle_balance() limits itself and finds nothing. I maintain a bitmap of overloaded CPUs, where a CPU sets its bit when its runnable CFS task count exceeds 1. The bitmap is sparse, with a limited number of significant bits per cacheline. This reduces cache contention when many threads concurrently set, clear, and visit elements. There is a bitmap per last-level cache. When a CPU becomes idle, it searches the bitmap to find the first overloaded CPU with a migratable task, and steals it. This simple stealing yields a higher CPU utilization than idle_balance() alone, because the search is cheap, costing 1 to 2 microseconds, so it may be called every time the CPU is about to go idle. Stealing does not offload the globally busiest queue, but it is much better than running nothing at all.
|
||||
|
||||
### Results
|
||||
|
||||
Stealing improves utilization with only a modest CPU overhead in scheduler code. In the following experiment, hackbench is run with varying numbers of groups (40 tasks per group), and the delta in /proc/schedstat is shown for each run, averaged per CPU, augmented with these non-standard stats:
|
||||
|
||||
* %find - percent of time spent in old and new functions that search for idle CPUs and tasks to steal and set the overloaded CPUs bitmap.
|
||||
* steal - number of times a task is stolen from another CPU. Elapsed time improves by 8 to 36%, costing at most 0.4% more find time.
|
||||
|
||||
|
||||
|
||||
![load balancing][1]
|
||||
|
||||
[Used with permission][2]
|
||||
|
||||
CPU busy utilization is close to 100% for the new kernel, as shown by the green curve in the following graph, versus the orange curve for the baseline kernel:
|
||||
|
||||
![][3]
|
||||
|
||||
Stealing improves Oracle database OLTP performance by up to 9% depending on load, and we have seen some nice improvements for mysql, pgsql, gcc, java, and networking. In general, stealing is most helpful for workloads with a high context switch rate.
|
||||
|
||||
### The code
|
||||
|
||||
As of this writing, this work is not yet upstream, but the latest patch series is at [https://lkml.org/lkml/2018/12/6/1253. ][4]If your kernel is built with CONFIG_SCHED_DEBUG=y, you can verify that it contains the stealing optimization using
|
||||
|
||||
```
|
||||
# grep -q STEAL /sys/kernel/debug/sched_features && echo Yes
|
||||
Yes
|
||||
```
|
||||
|
||||
If you try it, note that stealing is disabled for systems with more than 2 NUMA nodes, because hackbench regresses on such systems, as I explain in [https://lkml.org/lkml/2018/12/6/1250 .][5]However, I suspect this effect is specific to hackbench and that stealing will help other workloads on many-node systems. To try it, reboot with kernel parameter sched_steal_node_limit = 8 (or larger).
|
||||
|
||||
### Future work
|
||||
|
||||
After the basic stealing algorithm is pushed upstream, I am considering the following enhancements:
|
||||
|
||||
* If stealing within the last-level cache does not find a candidate, steal across LLC's and NUMA nodes.
|
||||
* Maintain a sparse bitmap to identify stealing candidates in the RT scheduling class. Currently pull_rt_task() searches all run queues.
|
||||
* Remove the core and socket levels from idle_balance(), as stealing handles those levels. Remove idle_balance() entirely when stealing across LLC is supported.
|
||||
* Maintain a bitmap to identify idle cores and idle CPUs, for push balancing.
|
||||
|
||||
|
||||
|
||||
_This article originally appeared at[Oracle Developers Blog][6]._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/can-better-task-stealing-make-linux-faster
|
||||
|
||||
作者:[Oracle][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/linux-load-balancing.png?itok=2Uk1yALt (load balancing)
|
||||
[2]: /LICENSES/CATEGORY/USED-PERMISSION
|
||||
[3]: https://cdn.app.compendium.com/uploads/user/e7c690e8-6ff9-102a-ac6d-e4aebca50425/b7a700fe-edc3-4ea0-876a-c91e1850b59b/Image/00c074f4282bcbaf0c10dd153c5dfa76/steal_graph.png
|
||||
[4]: https://lkml.org/lkml/2018/12/6/1253
|
||||
[5]: https://lkml.org/lkml/2018/12/6/1250
|
||||
[6]: https://blogs.oracle.com/linux/can-better-task-stealing-make-linux-faster
|
||||
@ -0,0 +1,72 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Cisco warns of two security patches that don’t work, issues 17 new ones for IOS flaws)
|
||||
[#]: via: (https://www.networkworld.com/article/3384742/cisco-warns-of-two-security-patches-that-dont-work-issues-17-new-ones-for-ios-flaws.html#tk.rss_all)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
Cisco warns of two security patches that don’t work, issues 17 new ones for IOS flaws
|
||||
======
|
||||
|
||||
### Cisco is issuing 17 new fixes for security problems with IOS and IOS/XE software that runs most of its routers and switches, while it has no patch yet to replace flawed patches to RV320 and RV 325 routers.
|
||||
|
||||
![Marisa9 / Getty][1]
|
||||
|
||||
Cisco has dropped [17 Security advisories describing 19 vulnerabilities][2] in the software that runs most of its routers and switches, IOS and IOS/XE.
|
||||
|
||||
The company also announced that two previously issued patches for its RV320 and RV325 Dual Gigabit WAN VPN Routers were “incomplete” and would need to be redone and reissued.
|
||||
|
||||
**[ Also see[What to consider when deploying a next generation firewall][3]. | Get regularly scheduled insights by [signing up for Network World newsletters][4]. ]**
|
||||
|
||||
Cisco rates both those router vulnerabilities as “High” and describes the problems like this:
|
||||
|
||||
* [One vulnerability][5] is due to improper validation of user-supplied input. An attacker could exploit this vulnerability by sending malicious HTTP POST requests to the web-based management interface of an affected device. A successful exploit could allow the attacker to execute arbitrary commands on the underlying Linux shell as _root_.
|
||||
* The [second exposure][6] is due to improper access controls for URLs. An attacker could exploit this vulnerability by connecting to an affected device via HTTP or HTTPS and requesting specific URLs. A successful exploit could allow the attacker to download the router configuration or detailed diagnostic information.
|
||||
|
||||
|
||||
|
||||
Cisco said firmware updates that address these vulnerabilities are not available and no workarounds exist, but is working on a complete fix for both.
|
||||
|
||||
On the IOS front, the company said six of the vulnerabilities affect both Cisco IOS Software and Cisco IOS XE Software, one of the vulnerabilities affects just Cisco IOS software and ten of the vulnerabilities affect just Cisco IOS XE software. Some of the security bugs, which are all rated as “High”, include:
|
||||
|
||||
* [A vulnerability][7] in the web UI of Cisco IOS XE Software could let an unauthenticated, remote attacker access sensitive configuration information.
|
||||
* [A vulnerability][8] in Cisco IOS XE Software could let an authenticated, local attacker inject arbitrary commands that are executed with elevated privileges. The vulnerability is due to insufficient input validation of commands supplied by the user. An attacker could exploit this vulnerability by authenticating to a device and submitting crafted input to the affected commands.
|
||||
* [A weakness][9] in the ingress traffic validation of Cisco IOS XE Software for Cisco Aggregation Services Router (ASR) 900 Route Switch Processor 3 could let an unauthenticated, adjacent attacker trigger a reload of an affected device, resulting in a denial of service (DoS) condition, Cisco said. The vulnerability exists because the software insufficiently validates ingress traffic on the ASIC used on the RSP3 platform. An attacker could exploit this vulnerability by sending a malformed OSPF version 2 message to an affected device.
|
||||
* A problem in the [authorization subsystem][10] of Cisco IOS XE Software could allow an authenticated but unprivileged (level 1), remote attacker to run privileged Cisco IOS commands by using the web UI. The vulnerability is due to improper validation of user privileges of web UI users. An attacker could exploit this vulnerability by submitting a malicious payload to a specific endpoint in the web UI, Cisco said.
|
||||
* A vulnerability in the [Cluster Management Protocol][11] (CMP) processing code in Cisco IOS Software and Cisco IOS XE Software could allow an unauthenticated, adjacent attacker to trigger a DoS condition on an affected device. The vulnerability is due to insufficient input validation when processing CMP management packets, Cisco said.
|
||||
|
||||
|
||||
|
||||
Cisco has released free software updates that address the vulnerabilities described in these advisories and [directs users to their software agreements][12] to find out how they can download the fixes.
|
||||
|
||||
Join the Network World communities on [Facebook][13] and [LinkedIn][14] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3384742/cisco-warns-of-two-security-patches-that-dont-work-issues-17-new-ones-for-ios-flaws.html#tk.rss_all
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/02/woman-with-hands-over-face_mistake_oops_embarrassed_shy-by-marisa9-getty-100787990-large.jpg
|
||||
[2]: https://tools.cisco.com/security/center/viewErp.x?alertId=ERP-71135
|
||||
[3]: https://www.networkworld.com/article/3236448/lan-wan/what-to-consider-when-deploying-a-next-generation-firewall.html
|
||||
[4]: https://www.networkworld.com/newsletters/signup.html
|
||||
[5]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190123-rv-inject
|
||||
[6]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190123-rv-info
|
||||
[7]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190327-xeid
|
||||
[8]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190327-xecmd
|
||||
[9]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190327-rsp3-ospf
|
||||
[10]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190327-iosxe-privesc
|
||||
[11]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190327-cmp-dos
|
||||
[12]: https://www.cisco.com/c/en/us/about/legal/cloud-and-software/end_user_license_agreement.html
|
||||
[13]: https://www.facebook.com/NetworkWorld/
|
||||
[14]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,65 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Elizabeth Warren's right-to-repair plan fails to consider data from IoT equipment)
|
||||
[#]: via: (https://www.networkworld.com/article/3385122/elizabeth-warrens-right-to-repair-plan-fails-to-consider-data-from-iot-equipment.html#tk.rss_all)
|
||||
[#]: author: (Fredric Paul https://www.networkworld.com/author/Fredric-Paul/)
|
||||
|
||||
Elizabeth Warren's right-to-repair plan fails to consider data from IoT equipment
|
||||
======
|
||||
|
||||
### Senator and presidential candidate Elizabeth Warren suggests national legislation focused on farm equipment. But that’s only a first step. The data collected by that equipment must also be considered.
|
||||
|
||||
![Thinkstock][1]
|
||||
|
||||
There’s a surprising battle being fought on America’s farms, between farmers and the companies that sell them tractors, combines, and other farm equipment. Surprisingly, the outcome of that war could have far-reaching implications for the internet of things (IoT) — and now Massachusetts senator and Democratic presidential candidate Elizabeth Warren has weighed in with a proposal that could shift the balance of power in this largely under-the-radar struggle.
|
||||
|
||||
## Right to repair farm equipment
|
||||
|
||||
Here’s the story: As part of a new plan to support family farms, Warren came out in support of a national right-to-repair law for farm equipment. That might not sound like a big deal, but it raises the stakes in a long-simmering fight between farmers and equipment makers over who really controls access to the equipment — and to the increasingly critical data gathered by the IoT capabilities built into it.
|
||||
|
||||
**[ Also read:[Right-to-repair smartphone ruling loosens restrictions on industrial, farm IoT][2] | Get regularly scheduled insights: [Sign up for Network World newsletters][3] ]**
|
||||
|
||||
[Warren’s proposal reportedly][4] calls for making all diagnostics tools and manuals freely available to the equipment owners, as well as independent repair shops — not just vendors and their authorized agents — and focuses solely on farm equipment.
|
||||
|
||||
That’s a great start, and kudos to Warren for being by far the most prominent politician to weigh in on the issue.
|
||||
|
||||
## Part of a much bigger IoT data issue
|
||||
|
||||
But Warren's proposal merely scratches the surface of the much larger issue of who actually controls the equipment and devices that consumers and businesses buy. Even more important, it doesn’t address the critical data gathered by IoT sensors in everything ranging from smartphones, wearables, and smart-home devices to private and commercial vehicles and aircraft to industrial equipment.
|
||||
|
||||
And as many farmers can tell you, this isn’t some academic argument. That data has real value — not to mention privacy implications. For farmers, it’s GPS-equipped smart sensors tracking everything — from temperature to moisture to soil acidity — that can determine the most efficient times to plant and harvest crops. For consumers, it might be data that affects their home or auto insurance rates, or even divorce cases. For manufacturers, it might cover everything from which equipment needs maintenance to potential issues with raw materials or finished products.
|
||||
|
||||
The solution is simple: IoT users need consistent regulations that ensure free access to what is really their own data, and give them the option to share that data with the equipment vendors — if they so choose and on their own terms.
|
||||
|
||||
At the very least, users need clear statements of the rules, so they know exactly what they’re getting — and not getting — when they buy IoT-enhanced devices and equipment. And if they’re being honest, most equipment vendors would likely admit that clear rules would benefit them as well by creating a level playing field, reducing potential liabilities and helping to avoid making customers unhappy.
|
||||
|
||||
Sen. Warren made headlines earlier this month by proposing to ["break up" tech giants][5] such as Amazon, Apple, and Facebook. If she really wants to help technology buyers, prioritizing the right-to-repair and the associated right to own your own data seems like a more effective approach.
|
||||
|
||||
**[ Now read this:[Big trouble down on the IoT farm][6] ]**
|
||||
|
||||
Join the Network World communities on [Facebook][7] and [LinkedIn][8] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3385122/elizabeth-warrens-right-to-repair-plan-fails-to-consider-data-from-iot-equipment.html#tk.rss_all
|
||||
|
||||
作者:[Fredric Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Fredric-Paul/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.techhive.com/images/article/2017/03/ai_agriculture_primary-100715481-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3317696/the-recent-right-to-repair-smartphone-ruling-will-also-affect-farm-and-industrial-equipment.html
|
||||
[3]: https://www.networkworld.com/newsletters/signup.html
|
||||
[4]: https://appleinsider.com/articles/19/03/27/presidential-candidate-elizabeth-warren-focusing-right-to-repair-on-farmers-not-tech
|
||||
[5]: https://www.nytimes.com/2019/03/08/us/politics/elizabeth-warren-amazon.html
|
||||
[6]: https://www.networkworld.com/article/3262631/big-trouble-down-on-the-iot-farm.html
|
||||
[7]: https://www.facebook.com/NetworkWorld/
|
||||
[8]: https://www.linkedin.com/company/network-world
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (arrowfeng)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -0,0 +1,63 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Microsoft introduces Azure Stack for HCI)
|
||||
[#]: via: (https://www.networkworld.com/article/3385078/microsoft-introduces-azure-stack-for-hci.html#tk.rss_all)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Microsoft introduces Azure Stack for HCI
|
||||
======
|
||||
|
||||
### Azure Stack is great for your existing hardware, so Microsoft is covering the bases with a turnkey solution.
|
||||
|
||||
![Thinkstock/Microsoft][1]
|
||||
|
||||
Microsoft has introduced Azure Stack HCI Solutions, a new implementation of its on-premises Azure product specifically for [Hyper Converged Infrastructure][2] (HCI) hardware.
|
||||
|
||||
[Azure Stack][3] is an on-premises version of its Azure cloud service. It gives companies a chance to migrate to an Azure environment within the confines of their own enterprise rather than onto Microsoft’s data centers. Once you have migrated your apps and infrastructure to Azure Stack, moving between your systems and Microsoft’s cloud service is easy.
|
||||
|
||||
HCI is the latest trend in server hardware. It uses scale-out hardware systems and a full software-defined platform to handle [virtualization][4] and management. It’s designed to reduce the complexity of a deployment and on-going management, since everything ships fully integrated, hardware and software.
|
||||
|
||||
**[ Read also:[12 most powerful hyperconverged infrasctructure vendors][5] | Get regularly scheduled insights: [Sign up for Network World newsletters][6] ]**
|
||||
|
||||
It makes sense for Microsoft to take this step. Azure Stack was ideal for an existing enterprise. Now you can deploy a whole new hardware configuration setup to run Azure in-house, complete with Hyper-V-based software-defined compute, storage, and networking.
|
||||
|
||||
The Windows Admin Center is the main management tool for Azure Stack HCI. It connects to other Azure tools, such as Azure Monitor, Azure Security Center, Azure Update Management, Azure Network Adapter, and Azure Site Recovery.
|
||||
|
||||
“We are bringing our existing HCI technology into the Azure Stack family for customers to run virtualized applications on-premises with direct access to Azure management services such as backup and disaster recovery,” wrote Julia White, corporate vice president of Microsoft Azure, in a [blog post announcing Azure Stack HCI][7].
|
||||
|
||||
It’s not so much a new product launch as a rebranding. When Microsoft launched Server 2016, it introduced a version called Windows Server Software-Defined Data Center (SDDC), which was built on the Hyper-V hypervisor, and says so in a [FAQ][8] as part of the announcement.
|
||||
|
||||
"Azure Stack HCI is the evolution of Windows Server Software-Defined (WSSD) solutions previously available from our hardware partners. We brought it into the Azure Stack family because we have started to offer new options to connect seamlessly with Azure for infrastructure management services,” the company said.
|
||||
|
||||
Microsoft introduced Azure Stack in 2017, but it was not the first to offer an on-premises cloud option. That distinction goes to [OpenStack][9], a joint project between Rackspace and NASA built on open-source code. Amazon followed with its own product, called [Outposts][10].
|
||||
|
||||
Join the Network World communities on [Facebook][11] and [LinkedIn][12] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3385078/microsoft-introduces-azure-stack-for-hci.html#tk.rss_all
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2017/08/5_microsoft-azure-100733132-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3207567/what-is-hyperconvergence.html
|
||||
[3]: https://www.networkworld.com/article/3207748/microsoft-introduces-azure-stack-its-answer-to-openstack.html
|
||||
[4]: https://www.networkworld.com/article/3234795/what-is-virtualization-definition-virtual-machine-hypervisor.html
|
||||
[5]: https://www.networkworld.com/article/3112622/hardware/12-most-powerful-hyperconverged-infrastructure-vendors.htmll
|
||||
[6]: https://www.networkworld.com/newsletters/signup.html
|
||||
[7]: https://azure.microsoft.com/en-us/blog/enabling-customers-hybrid-strategy-with-new-microsoft-innovation/
|
||||
[8]: https://azure.microsoft.com/en-us/blog/announcing-azure-stack-hci-a-new-member-of-the-azure-stack-family/
|
||||
[9]: https://www.openstack.org/
|
||||
[10]: https://www.networkworld.com/article/3324043/aws-does-hybrid-cloud-with-on-prem-hardware-vmware-help.html
|
||||
[11]: https://www.facebook.com/NetworkWorld/
|
||||
[12]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,68 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Motorola taps freed-up wireless spectrum for enterprise LTE networks)
|
||||
[#]: via: (https://www.networkworld.com/article/3385117/motorola-taps-cbrs-spectrum-to-create-private-broadband-lmr-system.html#tk.rss_all)
|
||||
[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
|
||||
|
||||
Motorola taps freed-up wireless spectrum for enterprise LTE networks
|
||||
======
|
||||
|
||||
### Citizens Broadband Radio Service (CBRS) is developing. Out of the gate, Motorola is creating a land mobile radio (LMR) system that includes enterprise-level, voice handheld devices and fast, private data networks.
|
||||
|
||||
![Jiraroj Praditcharoenkul / Getty Images][1]
|
||||
|
||||
In a move that could upend how workers access data in the enterprise, Motorola has announced a broadband product that it says will deliver data at double the capacity and four-times the range of Wi-Fi for end users. The handheld, walkie-talkie-like device, called Mototrbo Nitro, will, importantly, also include a voice channel. “Business-critical voice with private broadband data,” as [Motorola describes it on its website][2].
|
||||
|
||||
The company sees the product being implemented in traditional, moving-around, voice communications environments, such as factories and warehouses, that increasingly need data supplementation, too. A shop floor that has an electronically delivered repair manual, with included video demonstration, could be one example. Video could be two-way, even.
|
||||
|
||||
**[ Also read:[Wi-Fi 6 is coming to a router near you][3] | Get regularly scheduled insights: [Sign up for Network World newsletters][4] ]**
|
||||
|
||||
The product takes advantage of upcoming Citizens Broadband Radio Service (CBRS) spectrum. That’s a swath of radio bandwidth that’s being released by the Federal Communications Commission (FCC) in the 3.5GHz band. It’s a frequency chunk that is also expected to be used heavily for 5G. In this case, though, Motorola is creating a private LTE network for the enterprise.
|
||||
|
||||
The CBRS band is the first time publicly available broadband spectrum has been available, [Motorola explains in a white paper][5] (pdf) — organizations don’t have to buy licenses, yet they can get access to useful spectrum: [A tiered sharing system, where auction winners will get priority access licenses, but others will have some access too is proposed][6] by the FCC. The non-prioritized open access could be used by any enterprise for whatever — internet of things (IoT) or private networks.
|
||||
|
||||
## Motorola's pitch for using a private broadband network
|
||||
|
||||
Why a private broadband network and not simply cell phones? One giveaway line is in Motorola’s promotional video: “Without sacrificing control,” it says. What it means is that the firm thinks there’s a market for companies who want to run entire business communications systems — data and voice — without involvement from possibly nosy Mobile Network Operator phone companies. [I’ve written before about how control over security is prompting large industrials to explore private networks][7] more. Motorola manages the network in this case, though, for the enterprise.
|
||||
|
||||
Motorola also refers to potentially limited or intermittent onsite coverage and congestion for public, commercial, single-platform voice and data networks. That’s particularly the case in factories, [Motorola says in an ebook][8]. Heavy machinery containing radio-unfriendly metal can hinder Wi-Fi and cellular, it claims. Or that traditional Land Mobile Radios (LMRs), such as walkie-talkies and vehicle-mounted mobile radios, don’t handle data natively. In particular, it says that if you want to get into artificial intelligence (AI) and analytics, say, you need a more evolving voice and fast data communications setup.
|
||||
|
||||
## Industrial IoT uses for Motorola's Nitro network
|
||||
|
||||
Industrial IoT will be another beneficiary, Motorola says. It says its CBRS Nitro network could include instant notifications of equipment failures that traditional products can’t provide. It also suggests merging fixed security cameras with “photos and videos of broken machines and sending real-time video to an expert.”
|
||||
|
||||
**[[Take this mobile device management course from PluralSight and learn how to secure devices in your company without degrading the user experience.][9] ]**
|
||||
|
||||
Motorola also suggests that by separating consumer Wi-Fi (as is offered in hospitality and transport verticals, for example) from business-critical systems, one reduces traffic congestion risks.
|
||||
|
||||
The highly complicated CBRS band-sharing system is still not through its government testing. “However, we could deploy customer systems under an experimental license,” a Motorola representative told me.
|
||||
|
||||
Join the Network World communities on [Facebook][10] and [LinkedIn][11] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3385117/motorola-taps-cbrs-spectrum-to-create-private-broadband-lmr-system.html#tk.rss_all
|
||||
|
||||
作者:[Patrick Nelson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Patrick-Nelson/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/02/industry_4-0_industrial_iot_smart_factory_automation_robotic_arm_gear_engineer_tablet_by_jiraroj_praditcharoenkul_gettyimages-1091790364_2400x1600-100788459-large.jpg
|
||||
[2]: https://www.motorolasolutions.com/en_us/products/two-way-radios/mototrbo/nitro.html
|
||||
[3]: https://www.networkworld.com/article/3311921/mobile-wireless/wi-fi-6-is-coming-to-a-router-near-you.html
|
||||
[4]: https://www.networkworld.com/newsletters/signup.html
|
||||
[5]: https://www.motorolasolutions.com/content/dam/msi/docs/products/mototrbo/nitro/cbrs-white-paper.pdf
|
||||
[6]: https://www.networkworld.com/article/3300339/private-lte-using-new-spectrum-approaching-market-readiness.html
|
||||
[7]: https://www.networkworld.com/article/3319176/private-5g-networks-are-coming.html
|
||||
[8]: https://img04.en25.com/Web/MotorolaSolutionsInc/%7B293ce809-fde0-4619-8507-2b42076215c3%7D_radio_evolution_eBook_Nitro_03.13.19_MS_V3.pdf?elqTrackId=850d56c6d53f4013afa2290a66d6251f&elqaid=2025&elqat=2
|
||||
[9]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fmobile-device-management-big-picture
|
||||
[10]: https://www.facebook.com/NetworkWorld/
|
||||
[11]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,48 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Robots in Retail are Real… and so is Edge Computing)
|
||||
[#]: via: (https://www.networkworld.com/article/3385046/robots-in-retail-are-real-and-so-is-edge-computing.html#tk.rss_all)
|
||||
[#]: author: (Wendy Torell https://www.networkworld.com/author/Wendy-Torell/)
|
||||
|
||||
Robots in Retail are Real… and so is Edge Computing
|
||||
======
|
||||
|
||||
### I’ve seen plenty of articles touting the promise of edge computing technologies like AI and robotics in retail brick & mortar, but it wasn’t until this past weekend that I had my first encounter with an actual robot in a retail store.
|
||||
|
||||
![Getty][1]
|
||||
|
||||
I’ve seen plenty of articles touting the promise of [edge computing][2] technologies like AI and robotics in retail brick & mortar, but it wasn’t until this past weekend that I had my first encounter with an actual robot in a retail store. I was doing my usual weekly grocery shopping at my local Stop & Shop, and who comes strolling down the aisle, but…. Marty… the autonomous robot. He was friendly looking with his big googly eyes and was wearing a sign that explained he was there for safety, and that he was monitoring the aisles to report spills, debris, and other hazards to employees to improve my shopping experience. He caught the attention of most of the shoppers.
|
||||
|
||||
At the National Retail Federation conference in NY that I attended in January, this was a topic of one of the [panel sessions][3]. It all makes sense… a positive customer experience is critical to retail success. But employee-to-customer (human to human) interaction has also been proven important. That’s where Marty comes in… to free up resources spent on tedious, time consuming tasks so that personnel can spend more time directly helping customers.
|
||||
|
||||
**Use cases for robots in stores**
|
||||
|
||||
Robotics have been utilized by retailers in manufacturing floors, and in distribution warehouses to improve productivity and optimize business processes along the supply chain. But it is only more recently that we’re seeing them make their way into the retail store front, where they are in contact with the customers. Alerting to hazards in the aisles is just one of many use-cases for the robots. They can also be used to scan and re-stock shelves, or as general information sources and greeters upon entering the store to guide your shopping experience. But how does a retailer justify the investment in this type of technology? Determining your ROI isn’t as cut and dry as in a warehouse environment, for example, where costs are directly tied to number of staff, time to complete tasks, etc… I guess time will tell for the retailers that are giving it a go.
|
||||
|
||||
**What does it mean for the IT equipment on-premise ([micro data center][4])**
|
||||
|
||||
Robotics are one of the many ways retail stores are being digitized. Video analytics is another big one, being used to analyze facial expressions for customer satisfaction, obtain customer demographics as input to product development, or ensure queue lines don’t get too long. My colleague, Patrick Donovan, wrote a detailed [blog post][5] about our trip to NRF and the impact on the physical infrastructure in the stores. In a nutshell, the equipment on-premise is becoming more mission critical, more integrated to business applications in the cloud, more tied to positive customer-experiences… and with that comes the need for more secure, more available, more manageable edge. But this is easier said than done in an environment that generally has no IT staff on-premise, and with hundreds or potentially thousands of stores spread out geographically. So how do we address this?
|
||||
|
||||
We answer this question in a white paper that Patrick and I are currently writing titled “An Integrated Ecosystem to Solve Edge Computing Infrastructure Challenges”. Here’s a hint, (1) an integrated ecosystem of partners, and (2) an integrated micro data center that emerges from the ecosystem. I’ll be sure to comment on this blog with the link when the white paper becomes publicly available! In the meantime, explore our [edge computing][2] landing page to learn more.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3385046/robots-in-retail-are-real-and-so-is-edge-computing.html#tk.rss_all
|
||||
|
||||
作者:[Wendy Torell][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Wendy-Torell/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/03/gettyimages-828488368-1060x445-100792228-large.jpg
|
||||
[2]: https://www.apc.com/us/en/solutions/business-solutions/edge-computing.jsp
|
||||
[3]: https://stores.org/2019/01/15/why-is-there-a-robot-in-my-store/
|
||||
[4]: https://www.apc.com/us/en/solutions/business-solutions/micro-data-centers.jsp
|
||||
[5]: https://blog.apc.com/2019/02/06/4-thoughts-edge-computing-infrastructure-retail-sector/
|
||||
177
sources/tech/20190329 How to manage your Linux environment.md
Normal file
177
sources/tech/20190329 How to manage your Linux environment.md
Normal file
@ -0,0 +1,177 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to manage your Linux environment)
|
||||
[#]: via: (https://www.networkworld.com/article/3385516/how-to-manage-your-linux-environment.html#tk.rss_all)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
How to manage your Linux environment
|
||||
======
|
||||
|
||||
### Linux user environments help you find the command you need and get a lot done without needing details about how the system is configured. Where the settings come from and how they can be modified is another matter.
|
||||
|
||||
![IIP Photo Archive \(CC BY 2.0\)][1]
|
||||
|
||||
The configuration of your user account on a Linux system simplifies your use of the system in a multitude of ways. You can run commands without knowing where they're located. You can reuse previously run commands without worrying how the system is keeping track of them. You can look at your email, view man pages, and get back to your home directory easily no matter where you might have wandered off to in the file system. And, when needed, you can tweak your account settings so that it works even more to your liking.
|
||||
|
||||
Linux environment settings come from a series of files — some are system-wide (meaning they affect all user accounts) and some are configured in files that are sitting in your home directory. The system-wide settings take effect when you log in and local ones take effect right afterwards, so the changes that you make in your account will override system-wide settings. For bash users, these files include these system files:
|
||||
|
||||
```
|
||||
/etc/environment
|
||||
/etc/bash.bashrc
|
||||
/etc/profile
|
||||
```
|
||||
|
||||
And some of these local files:
|
||||
|
||||
```
|
||||
~/.bashrc
|
||||
~/.profile -- not read if ~/.bash_profile or ~/.bash_login
|
||||
~/.bash_profile
|
||||
~/.bash_login
|
||||
```
|
||||
|
||||
You can modify any of the local four that exist, since they sit in your home directory and belong to you.
|
||||
|
||||
**[ Two-Minute Linux Tips:[Learn how to master a host of Linux commands in these 2-minute video tutorials][2] ]**
|
||||
|
||||
### Viewing your Linux environment settings
|
||||
|
||||
To view your environment settings, use the **env** command. Your output will likely look similar to this:
|
||||
|
||||
```
|
||||
$ env
|
||||
LS_COLORS=rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;
|
||||
01:or=40;31;01:mi=00:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:
|
||||
*.tar=01;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01;31:*.lz4=01;31:
|
||||
*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=01;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:
|
||||
*.z=01;31:*.Z=01;31:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.xz=01;
|
||||
31:*.zst=01;31:*.tzst=01;31:*.bz2=01;31:*.bz=01;31:*.tbz=01;31:*.tbz2=01;31:*.tz=01;31:
|
||||
*.deb=01;31:*.rpm=01;31:*.jar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:
|
||||
*.alz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.rz=01;31:*.cab=01;31:
|
||||
*.wim=01;31:*.swm=01;31:*.dwm=01;31:*.esd=01;31:*.jpg=01;35:*.jpeg=01;35:*.mjpg=01;35:
|
||||
*.mjpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:*.ppm=01;35:*.tga=01;35:
|
||||
*.xbm=01;35:*.xpm=01;35:*.tif=01;35:*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:
|
||||
*.mng=01;35:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;35:*.mkv=01;35:
|
||||
*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:
|
||||
*.nuv=01;35:*.wmv=01;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01;35:
|
||||
*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;35:*.xwd=01;35:*.yuv=01;35:
|
||||
*.cgm=01;35:*.emf=01;35:*.ogv=01;35:*.ogx=01;35:*.aac=00;36:*.au=00;36:*.flac=00;36:
|
||||
*.m4a=00;36:*.mid=00;36:*.midi=00;36:*.mka=00;36:*.mp3=00;36:*.mpc=00;36:*.ogg=00;36:
|
||||
*.ra=00;36:*.wav=00;36:*.oga=00;36:*.opus=00;36:*.spx=00;36:*.spf=00;36:
|
||||
SSH_CONNECTION=192.168.0.21 34975 192.168.0.11 22
|
||||
LESSCLOSE=/usr/bin/lesspipe %s %s
|
||||
LANG=en_US.UTF-8
|
||||
OLDPWD=/home/shs
|
||||
XDG_SESSION_ID=2253
|
||||
USER=shs
|
||||
PWD=/home/shs
|
||||
HOME=/home/shs
|
||||
SSH_CLIENT=192.168.0.21 34975 22
|
||||
XDG_DATA_DIRS=/usr/local/share:/usr/share:/var/lib/snapd/desktop
|
||||
SSH_TTY=/dev/pts/0
|
||||
MAIL=/var/mail/shs
|
||||
TERM=xterm
|
||||
SHELL=/bin/bash
|
||||
SHLVL=1
|
||||
LOGNAME=shs
|
||||
DBUS_SESSION_BUS_ADDRESS=unix:path=/run/user/1000/bus
|
||||
XDG_RUNTIME_DIR=/run/user/1000
|
||||
PATH=/home/shs/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
|
||||
LESSOPEN=| /usr/bin/lesspipe %s
|
||||
_=/usr/bin/env
|
||||
```
|
||||
|
||||
While you're likely to get a _lot_ of output, the first big section shown above deals with the colors that are used on the command line to identify various file types. When you see something like ***.tar=01;31:** , this tells you that tar files will be displayed in a file listing in red, while ***.jpg=01;35:** tells you that jpg files will show up in purple. These colors are meant to make it easy to pick out certain files from a file listing. You can learn more about these colors are defined and how to customize them at [Customizing your colors on the Linux command line][3].
|
||||
|
||||
One easy way to turn colors off when you prefer a simpler display is to use a command such as this one:
|
||||
|
||||
```
|
||||
$ ls -l --color=never
|
||||
```
|
||||
|
||||
That command could easily be turned into an alias:
|
||||
|
||||
```
|
||||
$ alias ll2='ls -l --color=never'
|
||||
```
|
||||
|
||||
You can also display individual settings using the **echo** command. In this command, we display the number of commands that will be remembered in our history buffer:
|
||||
|
||||
```
|
||||
$ echo $HISTSIZE
|
||||
1000
|
||||
```
|
||||
|
||||
Your last location in the file system will be remembered if you've moved.
|
||||
|
||||
```
|
||||
PWD=/home/shs
|
||||
OLDPWD=/tmp
|
||||
```
|
||||
|
||||
### Making changes
|
||||
|
||||
You can make changes to environment settings with a command like this, but add a line lsuch as "HISTSIZE=1234" in your ~/.bashrc file if you want to retain this setting.
|
||||
|
||||
```
|
||||
$ export HISTSIZE=1234
|
||||
```
|
||||
|
||||
### What it means to "export" a variable
|
||||
|
||||
Exporting a variable makes the setting available to your shell and possible subshells. By default, user-defined variables are local and are not exported to new processes such as subshells and scripts. The export command makes variables available to functions to child processes.
|
||||
|
||||
### Adding and removing variables
|
||||
|
||||
You can create new variables and make them available to you on the command line and subshells quite easily. However, these variables will not survive your logging out and then back in again unless you also add them to ~/.bashrc or a similar file.
|
||||
|
||||
```
|
||||
$ export MSG="Hello, World!"
|
||||
```
|
||||
|
||||
You can unset a variable if you need by using the **unset** command:
|
||||
|
||||
```
|
||||
$ unset MSG
|
||||
```
|
||||
|
||||
If the variable is defined locally, you can easily set it back up by sourcing your startup file(s). For example:
|
||||
|
||||
```
|
||||
$ echo $MSG
|
||||
Hello, World!
|
||||
$ unset $MSG
|
||||
$ echo $MSG
|
||||
|
||||
$ . ~/.bashrc
|
||||
$ echo $MSG
|
||||
Hello, World!
|
||||
```
|
||||
|
||||
### Wrap-up
|
||||
|
||||
User accounts are set up with an appropriate set of startup files for creating a userful user environment, but both individual users and sysadmins can change the default settings by editing their personal setup files (users) or the files from which many of the settings originate (sysadmins).
|
||||
|
||||
Join the Network World communities on [Facebook][4] and [LinkedIn][5] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3385516/how-to-manage-your-linux-environment.html#tk.rss_all
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/03/environment-rocks-leaves-100792229-large.jpg
|
||||
[2]: https://www.youtube.com/playlist?list=PL7D2RMSmRO9J8OTpjFECi8DJiTQdd4hua
|
||||
[3]: https://www.networkworld.com/article/3269587/customizing-your-text-colors-on-the-linux-command-line.html
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,102 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to submit a bug report with Bugzilla)
|
||||
[#]: via: (https://opensource.com/article/19/3/bug-reporting)
|
||||
[#]: author: (David Both (Community Moderator) https://opensource.com/users/dboth)
|
||||
|
||||
How to submit a bug report with Bugzilla
|
||||
======
|
||||
|
||||
Submitting bug reports is an easy way to give back and it helps everyone.
|
||||
|
||||
![][1]
|
||||
|
||||
I spend a lot of time doing research for my books and [Opensource.com][2] articles. Sometimes this leads me to discover bugs in the software I use, including Fedora and the Linux kernel. As a long-time Linux user and sysadmin, I have benefited greatly from GNU/Linux, and I like to give back. I am not a C language programmer, so I don't create fixes and submit them with bug reports, as some people do. But a way I can return some value to the Linux community is by reporting bugs.
|
||||
|
||||
Product maintainers use a lot of tools to let their users search for existing bugs and report new ones. Bugzilla is a popular tool, and I use the Red Hat [Bugzilla][3] website to report Fedora-related bugs because I primarily use Fedora on the systems I'm responsible for. It's an easy process, but it may seem daunting if you have never done it before. So let's start with the basics.
|
||||
|
||||
### Start with a search
|
||||
|
||||
Even though it's tempting, never assume that seemingly anomalous behavior is the result of a bug. I always start with a search of relevant websites, such as the [Fedora wiki][4], the [CentOS wiki][5], and the documentation for the distro I'm using. I also try to check the various distro listservs.
|
||||
|
||||
If it appears that no one has encountered this problem before (or if they have, they haven't reported it as a bug), I go to the Red Hat Bugzilla site and begin searching for a bug report that might come close to matching the symptoms I encountered.
|
||||
|
||||
You can search the Red Hat Bugzilla site without an account. Go to the Bugzilla site and click on the [Advanced Search tab][6].
|
||||
|
||||
![Searching for a bug][7]
|
||||
|
||||
For example, if you want to search for bug reports related to Fedora's Rescue mode kernel, enter the following data in the Advanced Search form.
|
||||
|
||||
Field | Logic | Data or Selection
|
||||
---|---|---
|
||||
Summary | Contains the string | Rescue mode kernel
|
||||
Classification | | Fedora
|
||||
Product | | Fedora
|
||||
Component | | grub2
|
||||
Status | | New + Assigned
|
||||
|
||||
Then press **Search**. This returns a list of one bug with the ID 1654337 (which happens to be a bug I reported).
|
||||
|
||||
![Bug report list][8]
|
||||
|
||||
Click on the ID to view my bug report details. I entered as much relevant data as possible in the top section of the report. In the comments, I described the problem and included supporting files, other relevant comments (such as the fact that the problem occurred on multiple motherboards), and the steps to reproduce the problem.
|
||||
|
||||
![Bug report details][9]
|
||||
|
||||
The more information you can provide here that pertains to the bug, such as symptoms, the hardware and software environments (if they are applicable), other software that was running at the time, kernel and distro release levels, and so on, the easier it will be to determine where to assign your bug. In this case, I originally chose the kernel component, but it was quickly changed to the GRUB2 component because the problem occurred before the kernel loaded.
|
||||
|
||||
### How to submit a bug report
|
||||
|
||||
The Red Hat [Bugzilla][3] website requires an account to submit new bugs or comment on old ones. It is easy to sign up. On Bugzilla's main page, click **Open a New Account** and fill in the requested information. After you verify your email address, you can fill in the rest of the information to create your account.
|
||||
|
||||
_**Advisory:**_ _Bugzilla is a working website that people count on for support. I strongly suggest not creating an account unless you intend to submit bug reports or comment on existing bugs._
|
||||
|
||||
To demonstrate how to submit a bug report, I'll use a fictional example of creating a bug against the Xfce4-terminal emulator in Fedora. _Please do not do this unless you have a real bug to report._
|
||||
|
||||
Log into your account and click on **New** in the menu bar or the **File a Bug** button. You'll need to select a classification for the bug to continue the process. This will narrow down some of the choices on the next page.
|
||||
|
||||
The following image shows how I filled out the required fields (and a couple of others that are not required).
|
||||
|
||||
![Reporting a bug][10]
|
||||
|
||||
When you type a short problem description in the **Summary** field, Bugzilla displays a list of other bugs that might match yours. If one matches, click **Add Me to the CC List** to receive emails when changes are made to the bug.
|
||||
|
||||
If none match, fill in the information requested in the **Description** field. Add as much information as you can, including error messages and screen captures that illustrate the problem. Be sure to describe the exact steps needed to reproduce the problem and how reproducible it is: does it fail every time, every second, third, fourth, random time, or whatever. If it happened only once, it's very unlikely anyone will be able to reproduce the problem you observed.
|
||||
|
||||
When you finish adding as much information as you can, press **Submit Bug**.
|
||||
|
||||
### Be kind
|
||||
|
||||
Bug reporting websites are not for asking questions—they are for searching and reporting bugs. That means you must have performed some work on your own to conclude that there really is a bug. There are many wikis, listservs, and Q&A websites that are appropriate for asking questions. Use sites like Bugzilla to search for existing bug reports on the problem you have found.
|
||||
|
||||
Be sure you submit your bugs on the correct bug reporting website. For example, only submit bugs about Red Hat products on the Red Hat Bugzilla, and submit bugs about LibreOffice by following [LibreOffice's instructions][11].
|
||||
|
||||
Reporting bugs is not difficult, and it is an important way to participate.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/bug-reporting
|
||||
|
||||
作者:[David Both (Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/bug-insect-butterfly-diversity-inclusion-2.png?itok=TcC9eews
|
||||
[2]: http://Opensource.com
|
||||
[3]: https://bugzilla.redhat.com/
|
||||
[4]: https://fedoraproject.org/wiki/
|
||||
[5]: https://wiki.centos.org/
|
||||
[6]: https://bugzilla.redhat.com/query.cgi?format=advanced
|
||||
[7]: https://opensource.com/sites/default/files/uploads/bugreporting-1.png (Searching for a bug)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/bugreporting-2.png (Bug report list)
|
||||
[9]: https://opensource.com/sites/default/files/uploads/bugreporting-4.png (Bug report details)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/bugreporting-3.png (Reporting a bug)
|
||||
[11]: https://wiki.documentfoundation.org/QA/BugReport
|
||||
@ -0,0 +1,77 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Russia demands access to VPN providers’ servers)
|
||||
[#]: via: (https://www.networkworld.com/article/3385050/russia-demands-access-to-vpn-providers-servers.html#tk.rss_all)
|
||||
[#]: author: (Tim Greene https://www.networkworld.com/author/Tim-Greene/)
|
||||
|
||||
Russia demands access to VPN providers’ servers
|
||||
======
|
||||
|
||||
### 10 VPN service providers have been ordered to link their servers in Russia to the state censorship agency by April 26
|
||||
|
||||
![Getty Images][1]
|
||||
|
||||
The Russian censorship agency Roskomnadzor has ordered 10 [VPN][2] service providers to link their servers in Russia to its network in order to stop users within the country from reaching banned sites.
|
||||
|
||||
If they fail to comply, their services will be blocked, according to a machine translation of the order.
|
||||
|
||||
[RELATED: Best VPN routers for small business][3]
|
||||
|
||||
The 10 VPN providers are ExpressVPN, HideMyAss!, Hola VPN, IPVanish, Kaspersky Secure Connection, KeepSolid, NordVPN, OpenVPN, TorGuard, and VyprVPN.
|
||||
|
||||
In response at least five of the 10 – Express VPN, IPVanish, KeepSolid, NordVPN, TorGuard and – say they are tearing down their servers in Russia but continuing to offer their services to Russian customers if they can reach the providers’ servers located outside of Russia. A sixth provider, Kaspersky Labs, which is based in Moscow, says it will comply with the order. The other four could not be reached for this article.
|
||||
|
||||
IPVanish characterized the order as another phase of “Russia’s censorship agenda” dating back to 2017 when the government enacted a law forbidding the use of VPNs to access blocked Web sites.
|
||||
|
||||
“Up until recently, however, they had done little to enforce such rules,” IPVanish [says in its blog][4]. “These new demands mark a significant escalation.”
|
||||
|
||||
The reactions of those not complying are similar. TorGuard says it has taken steps to remove all its physical servers from Russia. It is also cutting off its business with data centers in the region
|
||||
|
||||
**[[Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][5] ]**
|
||||
|
||||
“We would like to be clear that this removal of servers was a voluntary decision by TorGuard management and no equipment seizure occurred,” [TorGuard says in its blog][6]. “We do not store any logs so even if servers were compromised it would be impossible for customer’s data to be exposed.”
|
||||
|
||||
TorGuard says it is deploying more servers in adjacent countries to protect fast download speeds for customers in the region.
|
||||
|
||||
IPVanish says it has faced similar demands from Russia before and responded similarly. In 2016, a new Russian law required online service providers to store customers’ private data for a year. “In response, [we removed all physical server presence in Russia][7], while still offering Russians encrypted connections via servers outside of Russian borders,” the company says. “That decision was made in accordance with our strict zero-logs policy.”
|
||||
|
||||
KeepSolid says it had no servers in Russia, but it will not comply with the order to link with Roskomnadzor's network. KeepSolid says it will [draw on its experience dealing with the Great Firewall of China][8] to fight the Russian censorship attempt. "Our team developed a special [KeepSolid Wise protocol][9] which is designed for use in countries where the use of VPN is blocked," a spokesperson for the company said in an email statement.
|
||||
|
||||
NordVPN says it’s shutting down all its Russian servers, and all of them will be shredded as of April 1. [The company says in a blog][10] that some of its customers who connected to its Russian servers without use of the NordVPN application will have to reconfigure their devices to insure their security. Those customers using the app won’t have to do anything differently because the option to connect to Russia via the app has been removed.
|
||||
|
||||
ExpressVPN is also not complying with the order. "As a matter of principle, ExpressVPN will never cooperate with efforts to censor the internet by any country," said the company's vice presidentn Harold Li in an email, but he said that blocking traffic will be ineffective. "We epect that Russian internet users will still be able to find means of accessing the sites and services they want, albeit perhaps with some additional effort."
|
||||
|
||||
Kaspersky Labs says it will comply with the Russian order and responded to emailed questions about its reaction with this written response:
|
||||
|
||||
“Kaspersky Lab is aware of the new requirements from Russian regulators for VPN providers operating in the country. These requirements oblige VPN providers to restrict access to a number of websites that were listed and prohibited by the Russian Government in the country’s territory. As a responsible company, Kaspersky Lab complies with the laws of all the countries where it operates, including Russia. At the same time, the new requirements don’t affect the main purpose of Kaspersky Secure Connection which protects user privacy and ensures confidentiality and protection against data interception, for example, when using open Wi-Fi networks, making online payments at cafes, airports or hotels. Additionally, the new requirements are relevant to VPN use only in Russian territory and do not concern users in other countries.”
|
||||
|
||||
Join the Network World communities on [Facebook][11] and [LinkedIn][12] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3385050/russia-demands-access-to-vpn-providers-servers.html#tk.rss_all
|
||||
|
||||
作者:[Tim Greene][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Tim-Greene/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/10/ipsecurity-protocols-network-security-vpn-100775457-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3268744/understanding-virtual-private-networks-and-why-vpns-are-important-to-sd-wan.html
|
||||
[3]: http://www.networkworld.com/article/3002228/router/best-vpn-routers-for-small-business.html#tk.nww-fsb
|
||||
[4]: https://nordvpn.com/blog/nordvpn-servers-roskomnadzor-russia/
|
||||
[5]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
|
||||
[6]: https://torguard.net/blog/why-torguard-has-removed-all-russian-servers/
|
||||
[7]: https://blog.ipvanish.com/ipvanish-removes-russian-vpn-servers-from-moscow/
|
||||
[8]: https://www.vpnunlimitedapp.com/blog/what-roskomnadzor-demands-from-vpns/
|
||||
[9]: https://www.vpnunlimitedapp.com/blog/keepsolid-wise-a-smart-solution-to-get-total-online-freedom/
|
||||
[10]: /cms/article/blog%20https:/nordvpn.com/blog/nordvpn-servers-roskomnadzor-russia/
|
||||
[11]: https://www.facebook.com/NetworkWorld/
|
||||
[12]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,126 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to build a mobile particulate matter sensor with a Raspberry Pi)
|
||||
[#]: via: (https://opensource.com/article/19/3/mobile-particulate-matter-sensor)
|
||||
[#]: author: (Stephan Tetzel https://opensource.com/users/stephan)
|
||||
|
||||
How to build a mobile particulate matter sensor with a Raspberry Pi
|
||||
======
|
||||
|
||||
Monitor your air quality with a Raspberry Pi, a cheap sensor, and an inexpensive display.
|
||||
|
||||
![Team communication, chat][1]
|
||||
|
||||
About a year ago, I wrote about [measuring air quality][2] using a Raspberry Pi and a cheap sensor. We've been using this project in our school and privately for a few years now. However, it has one disadvantage: It is not portable because it depends on a WLAN network or a wired network connection to work. You can't even access the sensor's measurements if the Raspberry Pi and the smartphone or computer are not on the same network.
|
||||
|
||||
To overcome this limitation, we added a small screen to the Raspberry Pi so we can read the values directly from the device. Here's how we set up and configured a screen for our mobile fine particulate matter sensor.
|
||||
|
||||
### Setting up the screen for the Raspberry Pi
|
||||
|
||||
There is a wide range of Raspberry Pi displays available from [Amazon][3], AliExpress, and other sources. They range from ePaper screens to LCDs with touch function. We chose an inexpensive [3.5″ LCD][4] with touch and a resolution of 320×480 pixels that can be plugged directly into the Raspberry Pi's GPIO pins. It's also nice that a 3.5″ display is about the same size as a Raspberry Pi.
|
||||
|
||||
The first time you turn on the screen and start the Raspberry Pi, the screen will remain white because the driver is missing. You have to install [the appropriate drivers][5] for the display first. Log in with SSH and execute the following commands:
|
||||
|
||||
```
|
||||
$ rm -rf LCD-show
|
||||
$ git clone <https://github.com/goodtft/LCD-show.git>
|
||||
$ chmod -R 755 LCD-show
|
||||
$ cd LCD-show/
|
||||
```
|
||||
|
||||
Execute the appropriate command for your screen to install the drivers. For example, this is the command for our model MPI3501 screen:
|
||||
|
||||
```
|
||||
$ sudo ./LCD35-show
|
||||
```
|
||||
|
||||
This command installs the appropriate drivers and restarts the Raspberry Pi.
|
||||
|
||||
### Installing PIXEL desktop and setting up autostart
|
||||
|
||||
Here is what we want our project to do: If the Raspberry Pi boots up, we want to display a small website with our air quality measurements.
|
||||
|
||||
First, install the Raspberry Pi's [PIXEL desktop environment][6]:
|
||||
|
||||
```
|
||||
$ sudo apt install raspberrypi-ui-mods
|
||||
```
|
||||
|
||||
Then install the Chromium browser to display the website:
|
||||
|
||||
```
|
||||
$ sudo apt install chromium-browser
|
||||
```
|
||||
|
||||
Autologin is required for the measured values to be displayed directly after startup; otherwise, you will just see the login screen. However, autologin is not configured for the "pi" user by default. You can configure autologin with the **raspi-config** tool:
|
||||
|
||||
```
|
||||
$ sudo raspi-config
|
||||
```
|
||||
|
||||
In the menu, select: **3 Boot Options → B1 Desktop / CLI → B4 Desktop Autologin**.
|
||||
|
||||
There is a step missing to start Chromium with our website right after boot. Create the folder **/home/pi/.config/lxsession/LXDE-pi/** :
|
||||
|
||||
```
|
||||
$ mkdir -p /home/pi/config/lxsession/LXDE-pi/
|
||||
```
|
||||
|
||||
Then create the **autostart** file in this folder:
|
||||
|
||||
```
|
||||
$ nano /home/pi/.config/lxsession/LXDE-pi/autostart
|
||||
```
|
||||
|
||||
and paste the following code:
|
||||
|
||||
```
|
||||
#@unclutter
|
||||
@xset s off
|
||||
@xset -dpms
|
||||
@xset s noblank
|
||||
|
||||
# Open Chromium in Full Screen Mode
|
||||
@chromium-browser --incognito --kiosk <http://localhost>
|
||||
```
|
||||
|
||||
If you want to hide the mouse pointer, you have to install the package **unclutter** and remove the comment character at the beginning of the **autostart** file:
|
||||
|
||||
```
|
||||
$ sudo apt install unclutter
|
||||
```
|
||||
|
||||
![Mobile particulate matter sensor][7]
|
||||
|
||||
I've made a few small changes to the code in the last year. So, if you set up the air quality project before, make sure to re-download the script and files for the AQI website using the instructions in the [original article][2].
|
||||
|
||||
By adding the touch screen, you now have a mobile particulate matter sensor! We use it at our school to check the quality of the air in the classrooms or to do comparative measurements. With this setup, you are no longer dependent on a network connection or WLAN. You can use the small measuring station everywhere—you can even use it with a power bank to be independent of the power grid.
|
||||
|
||||
* * *
|
||||
|
||||
_This article originally appeared on[Open School Solutions][8] and is republished with permission._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/mobile-particulate-matter-sensor
|
||||
|
||||
作者:[Stephan Tetzel][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/stephan
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/talk_chat_team_mobile_desktop.png?itok=d7sRtKfQ (Team communication, chat)
|
||||
[2]: https://opensource.com/article/18/3/how-measure-particulate-matter-raspberry-pi
|
||||
[3]: https://www.amazon.com/gp/search/ref=as_li_qf_sp_sr_tl?ie=UTF8&tag=openschoolsol-20&keywords=lcd%20raspberry&index=aps&camp=1789&creative=9325&linkCode=ur2&linkId=51d6d7676e10d6c7db203c4a8b3b529a
|
||||
[4]: https://amzn.to/2CcvgpC
|
||||
[5]: https://github.com/goodtft/LCD-show
|
||||
[6]: https://opensource.com/article/17/1/try-raspberry-pis-pixel-os-your-pc
|
||||
[7]: https://opensource.com/sites/default/files/uploads/mobile-aqi-sensor.jpg (Mobile particulate matter sensor)
|
||||
[8]: https://openschoolsolutions.org/mobile-particulate-matter-sensor/
|
||||
@ -0,0 +1,87 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Meta Networks builds user security into its Network-as-a-Service)
|
||||
[#]: via: (https://www.networkworld.com/article/3385531/meta-networks-builds-user-security-into-its-network-as-a-service.html#tk.rss_all)
|
||||
[#]: author: (Linda Musthaler https://www.networkworld.com/author/Linda-Musthaler/)
|
||||
|
||||
Meta Networks builds user security into its Network-as-a-Service
|
||||
======
|
||||
|
||||
### Meta Networks has a unique approach to the security of its Network-as-a-Service. A tight security perimeter is built around every user and the specific resources each person needs to access.
|
||||
|
||||
![MF3d / Getty Images][1]
|
||||
|
||||
Network-as-a-Service (NaaS) is growing in popularity and availability for those organizations that don’t want to host their own LAN or WAN, or that want to complement or replace their traditional network with something far easier to manage.
|
||||
|
||||
With NaaS, a service provider creates a multi-tenant wide area network comprised of geographically dispersed points of presence (PoPs) connected via high-speed Tier 1 carrier links that create the network backbone. The PoPs peer with cloud services to facilitate customer access to cloud applications such as SaaS offerings, as well as to infrastructure services from the likes of Amazon, Google and Microsoft. User organizations connect to the network from whatever facilities they have — data centers, branch offices, or even individual client devices — typically via SD-WAN appliances and/or VPNs.
|
||||
|
||||
Numerous service providers now offer Network-as-a-Service. As the network backbone and the PoPs become more of a commodity, the providers are distinguishing themselves on other value-added services, such as integrated security or WAN optimization.
|
||||
|
||||
**[ Also read:[What to consider when deploying a next generation firewall][2] | Get regularly scheduled insights: [Sign up for Network World newsletters][3]. ]**
|
||||
|
||||
Ever since its launch about a year ago, [Meta Networks][4] has staked security as its primary value-add. What’s different about the Meta NaaS is the philosophy that the network is built around users, not around specific sites or offices. Meta Networks does this by building a software-defined perimeter (SDP) for each user, giving workers micro-segmented access to only the applications and network resources they need. The vendor was a little ahead of its time with SDP, but the market is starting to catch up. Companies are beginning to show interest in SDP as a VPN replacement or VPN alternative.
|
||||
|
||||
Meta NaaS has a zero-trust architecture where each user is bound by an SDP. Each user has a unique, fixed identity no matter from where they connect to this network. The SDP security framework allows one-to-one network connections that are dynamically created on demand between the user and the specific resources they need to access. Everything else on the NaaS is invisible to the user. No access is possible unless it is explicitly granted, and it’s continuously verified at the packet level. This model effectively provides dynamically provisioned secure network segmentation.
|
||||
|
||||
## SDP tightly controls access to specific resources
|
||||
|
||||
This approach works very well when a company wants to securely connect employees, contractors, and external partners to specific resources on the network. For example, one of Meta Networks’ customers is Via Transportation, a New York-based company that has a ride-sharing platform. The company operates its own ride-sharing services in various cities in North America and Europe, and it licenses its technology to other transit systems around the world.
|
||||
|
||||
Via’s operations are completely cloud-native, and so it has no legacy-style site-based WAN to connect its 400-plus employees and contractors to their cloud-based applications. Via’s partners, primarily transportation operators in different cities and countries, also need controlled access to specific portions of Via’s software platform to manage rideshares. Giving each group of users access to the applications they need — and _only_ to the ones they specifically need – was a challenge using a VPN. Using the Meta NaaS instead gives Via more granular control over who has what access.
|
||||
|
||||
**[[Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][5] ]**
|
||||
|
||||
Via’s employees with managed devices connect to the Meta NaaS using client software on the device, and they are authenticated using Okta and a certificate. Contractors and customers with unmanaged devices use a browser-based access solution from Meta that doesn’t require installation or setup. New users can be on-boarded quickly and assigned granular access policies based on their role. Integration with Okta provides information that facilitates identity-based access policies. Once users connect to the network, they can see only the applications and network resources that their policy allows; everything else is invisible to them under the SDP architecture.
|
||||
|
||||
For Via, there are several benefits to the Meta NaaS approach. First and foremost, the company doesn’t have to own or operate its own WAN infrastructure. Everything is a managed service located in the cloud — the same business model that Via itself espouses. Next, this solution scales easily to support the company’s growth. Meta’s security integrates with Via’s existing identity management system, so identities and access policies can be centrally managed. And finally, the software-defined perimeter hides resources from unauthorized users, creating security by obscurity.
|
||||
|
||||
## Tightening security even further
|
||||
|
||||
Meta Networks further tightens the security around the user by doing device posture checks — “NAC lite,” if you will. A customer can define the criteria that devices have to meet before they are allowed to connect to the NaaS. For example, the check could be whether a security certificate is installed, if a registry key is set to a specific value, or if anti-virus software is installed and running. It’s one more way to enforce company policies on network access.
|
||||
|
||||
When end users use the browser-based method to connect to the Meta NaaS, all activity is recorded in a rich log so that everything can be audited, but also to set alerts and look for anomalies. This data can be exported to a SIEM if desired, but Meta has its own notification and alert system for security incidents.
|
||||
|
||||
Meta Networks recently implemented some new features around management, including smart groups and support for the System for Cross-Domain Identity Management (SCIM) protocol. The smart groups feature provides the means to add an extra notation or tag to elements such as devices, services, network subnets or segments, and basically everything that’s in the system. These tags can then be applied to policy. For example, a customer could label some of their services as a production, staging, or development environment. Then a policy could be implemented to say that only sales people can access the production environment. Smart groups are just one more way to get even more granular about policy.
|
||||
|
||||
The SCIM support makes on-boarding new users simple. SCIM is a protocol that is used to synchronize and provision users and identities from a third-party identity provider such as Okta, Azure AD, or OneLogin. A customer can use SCIM to provision all the users from the IdP into the Meta system, synchronize in real time the groups and attributes, and then use that information to build the access policies inside Meta NaaS.
|
||||
|
||||
These and other security features fit into Meta Networks’ vision that the security perimeter goes with you no matter where you are, and the perimeter includes everything that was formerly delivered through the data center. It is delivered through the cloud to your client device with always-on security. It’s a broad approach to SDP and a unique approach to NaaS.
|
||||
|
||||
**Reviews: 4 free, open-source network monitoring tools**
|
||||
|
||||
* [Icinga: Enterprise-grade, open-source network-monitoring that scales][6]
|
||||
* [Nagios Core: Network-monitoring software with lots of plugins, steep learning curve][7]
|
||||
* [Observium open-source network monitoring tool: Won’t run on Windows but has a great user interface][8]
|
||||
* [Zabbix delivers effective no-frills network monitoring][9]
|
||||
|
||||
|
||||
|
||||
Join the Network World communities on [Facebook][10] and [LinkedIn][11] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3385531/meta-networks-builds-user-security-into-its-network-as-a-service.html#tk.rss_all
|
||||
|
||||
作者:[Linda Musthaler][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Linda-Musthaler/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/10/firewall_network-security_lock_padlock_cyber-security-100776989-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3236448/lan-wan/what-to-consider-when-deploying-a-next-generation-firewall.html
|
||||
[3]: https://www.networkworld.com/newsletters/signup.html
|
||||
[4]: https://www.metanetworks.com/
|
||||
[5]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
|
||||
[6]: https://www.networkworld.com/article/3273439/review-icinga-enterprise-grade-open-source-network-monitoring-that-scales.html?nsdr=true#nww-fsb
|
||||
[7]: https://www.networkworld.com/article/3304307/nagios-core-monitoring-software-lots-of-plugins-steep-learning-curve.html
|
||||
[8]: https://www.networkworld.com/article/3269279/review-observium-open-source-network-monitoring-won-t-run-on-windows-but-has-a-great-user-interface.html?nsdr=true#nww-fsb
|
||||
[9]: https://www.networkworld.com/article/3304253/zabbix-delivers-effective-no-frills-network-monitoring.html
|
||||
[10]: https://www.facebook.com/NetworkWorld/
|
||||
[11]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,103 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Top Ten Reasons to Think Outside the Router #2: Simplify and Consolidate the WAN Edge)
|
||||
[#]: via: (https://www.networkworld.com/article/3384928/top-ten-reasons-to-think-outside-the-router-2-simplify-and-consolidate-the-wan-edge.html#tk.rss_all)
|
||||
[#]: author: (Rami Rammaha https://www.networkworld.com/author/Rami-Rammaha/)
|
||||
|
||||
Top Ten Reasons to Think Outside the Router #2: Simplify and Consolidate the WAN Edge
|
||||
======
|
||||
|
||||
![istock][1]
|
||||
|
||||
We’re now near reaching the end of our homage to the iconic David Letterman Top Ten List segment from his former Late Show, as [Silver Peak][2] counts down the *Top Ten Reasons to Think Outside the Router. *Click for the [#3][3], [#4][4], [#5][5], [#6][6], [#7][7], [#8][8], [#9][9] and [#10][10] reasons to retire traditional branch routers.
|
||||
|
||||
_The #2 reason it’s time to retire branch routers: conventional router-centric WAN architectures are rigid and complex to manage!_
|
||||
|
||||
### **Challenges of conventional WAN edge architecture**
|
||||
|
||||
A conventional WAN edge architecture consists of a disparate array of devices, including routers, firewalls, WAN optimization appliances, wireless controllers and so on. This architecture was born in the era when applications were hosted exclusively in the data center. With this model, deploying new applications or provisioning new policies or making policy changes has become an arduous and time-consuming task. Configuration, deployment and management requires specialized on-premise IT expertise to manually program and configure each device with its own management interface, often using an arcane CLI. This process has hit the wall in the cloud era proving too slow, complex, error-prone, costly and inefficient.
|
||||
|
||||
As cloud-first enterprises increasingly migrate applications and infrastructure to the cloud, the traditional WAN architecture is no longer efficient. IT is now faced with a new set of challenges when it comes to connecting users securely and directly to the applications that run their businesses:
|
||||
|
||||
* How do you manage and consistently apply QoS and security policies across the distributed enterprise?
|
||||
* How do you intelligently automate traffic steering across multiple WAN transport services based on application type and unique requirements?
|
||||
* How do you deliver the highest quality of experiences to users when running applications over broadband, especially voice and video?
|
||||
* How do you quickly respond to continuously changing business requirements?
|
||||
|
||||
|
||||
|
||||
These are just some of the new challenges facing IT teams in the cloud era. To be successful, enterprises will need to shift toward a business-first networking model where top-down business intent drives how the network behaves. And they would be well served to deploy a business-driven unified [SD-WAN][11] edge platform to transform their networks from a business constraint to a business accelerant.
|
||||
|
||||
### **Shifting toward a business-driven WAN edge platform**
|
||||
|
||||
A business-driven WAN edge platform is designed to enable enterprises to realize the full transformation promise of the cloud. It is a model where top-down business intent is the driver, not bottoms-up technology constraints. It’s outcome oriented, utilizing automation, artificial intelligence (AI) and machine learning to get smarter every day. Through this continuous adaptation, and the ability to improve the performance of underlying transport and applications, it delivers the highest quality of experience to end users. This is in stark contrast to the router-centric model where application policies must be shoe-horned to fit within the constraints of the network. A business-driven, top-down approach continuously stays in compliance with business intent and centrally defined security policies.
|
||||
|
||||
### **A unified platform for simplifying and consolidating the WAN Edge**
|
||||
|
||||
Achieving a business-driven architecture requires a unified platform, designed from the ground up as one system, uniting [SD-WAN][12], [firewall][13], [segmentation][14], [routing][15], [WAN optimization][16], application visibility and control in a single-platform. Furthermore, it requires [centralized orchestration][17] with complete observability of the entire wide area network through a single pane of glass.
|
||||
|
||||
The use case “[Simplifying WAN Architecture][18]” describes in detail key capabilities of the Silver Peak [Unity EdgeConnect™][19] SD-WAN edge platform. It illustrates how EdgeConnect enables enterprises to simplify branch office WAN edge infrastructure and streamline deployment, configuration and ongoing management.
|
||||
|
||||
![][20]
|
||||
|
||||
### **Business and IT outcomes of a business-driven SD-WAN**
|
||||
|
||||
* Accelerates deployment, leveraging consistent hardware, software, cloud delivery models
|
||||
* Saves up to 40 percent on hardware, software, installation, management and maintenance costs when replacing traditional routers
|
||||
* Protects existing investment in security through simplified service chaining with our broadest ecosystem partners: [Check Point][21], [Forcepoint][22], [McAfee][23], [OPAQ][24], [Palo Alto Networks][25], [Symantec][26] and [Zscaler][27].
|
||||
* Reduces foot print by 75 percent as it unifies network functions into a single platform
|
||||
* Saves more than 50 percent on WAN optimization costs by selectively applying it when and where is needed on an application-by-application basis
|
||||
* Accelerates time-to-resolution of application or network performance bottlenecks from days to minutes with simple, visual application and WAN analytics
|
||||
|
||||
|
||||
|
||||
Calculate your [ROI][28] today and learn why the time is now to [think outside the router][29] and deploy the business-driven Silver Peak EdgeConnect SD-WAN edge platform!
|
||||
|
||||
![][30]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3384928/top-ten-reasons-to-think-outside-the-router-2-simplify-and-consolidate-the-wan-edge.html#tk.rss_all
|
||||
|
||||
作者:[Rami Rammaha][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Rami-Rammaha/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/04/silverpeak_main-100792490-large.jpg
|
||||
[2]: https://www.silver-peak.com/why-silver-peak
|
||||
[3]: http://blog.silver-peak.com/think-outside-the-router-reason-3-mpls-contract-renewal
|
||||
[4]: http://blog.silver-peak.com/top-ten-reasons-to-think-outside-the-router-4-broadband-is-used-only-for-failover
|
||||
[5]: http://blog.silver-peak.com/think-outside-the-router-reason-5-manual-cli-based-configuration-and-management
|
||||
[6]: http://blog.silver-peak.com/https-blog-silver-peak-com-think-outside-the-router-reason-6
|
||||
[7]: http://blog.silver-peak.com/think-outside-the-router-reason-7-exorbitant-router-support-and-maintenance-costs
|
||||
[8]: http://blog.silver-peak.com/think-outside-the-router-reason-8-garbled-voip-pixelated-video
|
||||
[9]: http://blog.silver-peak.com/think-outside-router-reason-9-sub-par-saas-performance
|
||||
[10]: http://blog.silver-peak.com/think-outside-router-reason-10-its-getting-cloudy
|
||||
[11]: https://www.silver-peak.com/sd-wan/sd-wan-explained
|
||||
[12]: https://www.silver-peak.com/sd-wan
|
||||
[13]: https://www.silver-peak.com/products/unity-edge-connect/orchestrated-security-policies
|
||||
[14]: https://www.silver-peak.com/resource-center/centrally-orchestrated-end-end-segmentation
|
||||
[15]: https://www.silver-peak.com/products/unity-edge-connect/bgp-routing
|
||||
[16]: https://www.silver-peak.com/products/unity-boost
|
||||
[17]: https://www.silver-peak.com/products/unity-orchestrator
|
||||
[18]: https://www.silver-peak.com/use-cases/simplifying-wan-architecture
|
||||
[19]: https://www.silver-peak.com/products/unity-edge-connect
|
||||
[20]: https://images.idgesg.net/images/article/2019/04/sp_linkthrough-copy-100792505-large.jpg
|
||||
[21]: https://www.silver-peak.com/resource-center/check-point-silver-peak-securing-internet-sd-wan
|
||||
[22]: https://www.silver-peak.com/company/tech-partners/forcepoint
|
||||
[23]: https://www.silver-peak.com/company/tech-partners/mcafee
|
||||
[24]: https://www.silver-peak.com/company/tech-partners/opaq-networks
|
||||
[25]: https://www.silver-peak.com/resource-center/palo-alto-networks-and-silver-peak
|
||||
[26]: https://www.silver-peak.com/company/tech-partners/symantec
|
||||
[27]: https://www.silver-peak.com/resource-center/zscaler-and-silver-peak-solution-brief
|
||||
[28]: https://www.silver-peak.com/sd-wan-interactive-roi-calculator
|
||||
[29]: https://www.silver-peak.com/think-outside-router
|
||||
[30]: https://images.idgesg.net/images/article/2019/04/roi-100792506-large.jpg
|
||||
171
sources/tech/20190401 What is 5G- How is it better than 4G.md
Normal file
171
sources/tech/20190401 What is 5G- How is it better than 4G.md
Normal file
@ -0,0 +1,171 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What is 5G? How is it better than 4G?)
|
||||
[#]: via: (https://www.networkworld.com/article/3203489/what-is-5g-how-is-it-better-than-4g.html#tk.rss_all)
|
||||
[#]: author: (Josh Fruhlinger https://www.networkworld.com/author/Josh-Fruhlinger/)
|
||||
|
||||
What is 5G? How is it better than 4G?
|
||||
======
|
||||
|
||||
### 5G networks will boost wireless throughput by a factor of 10 and may replace wired broadband. But when will they be available, and why are 5G and IoT so linked together?
|
||||
|
||||
![Thinkstock][1]
|
||||
|
||||
[5G wireless][2] is an umbrella term to describe a set of standards and technologies for a radically faster wireless internet that ideally is up to 20 times faster with 120 times less latency than 4G, setting the stage for IoT networking advances and support for new high-bandwidth applications.
|
||||
|
||||
## What is 5G? Technology or buzzword?
|
||||
|
||||
It will be years before the technology reaches its full potential worldwide, but meanwhile some 5G network services are being rolled out today. 5G is as much a marketing buzzword as a technical term, and not all services marketed as 5G are standard.
|
||||
|
||||
**[From Mobile World Congress:[The time of 5G is almost here][3].]**
|
||||
|
||||
## 5G speed vs 4G
|
||||
|
||||
With every new generation of wireless technology, the biggest appeal is increased speed. 5G networks have potential peak download speeds of [20 Gbps, with 10 Gbps being seen as typical][4]. That's not just faster than current 4G networks, which currently top out at around 1 Gbps, but also faster than cable internet connections that deliver broadband to many people's homes. 5G offers network speeds that rival optical-fiber connections.
|
||||
|
||||
Throughput alone isn't 5G's only important speed improvement; it also features a huge reduction in network latency*.* That's an important distinction: throughput measures how long it would take to download a large file, while latency is determined by network bottlenecks and delays that slow down responses in back-and-forth communication.
|
||||
|
||||
Latency can be difficult to quantify because it varies based on myriad network conditions, but 5G networks are capable of latency rates that are less than a millisecond in ideal conditions. Overall, 5G latency will be lower than 4G's by a factor of 60 to 120. That will make possible a number of applications such as virtual reality that delay makes impractical today.
|
||||
|
||||
## 5G technology
|
||||
|
||||
The technology underpinnings of 5G are defined by a series of standards that have been in the works for the better part of a decade. One of the most important of these is 5G New Radio, or 5G NR*,* formalized by the 3rd Generation Partnership Project, a standards organization that develops protocols for mobile telephony. 5G NR will dictate many of the ways in which consumer 5G devices will operate, and was [finalized in June of 2018][5].
|
||||
|
||||
**[[Take this mobile device management course from PluralSight and learn how to secure devices in your company without degrading the user experience.][6] ]**
|
||||
|
||||
A number of individual technologies have come together to make the speed and latency improvements of 5G possible, and below are some of the most important.
|
||||
|
||||
## Millimeter waves
|
||||
|
||||
5G networks will for the most part use frequencies in the 30 to 300 GHz range. (Wavelengths at these frequencies are between 1 and 10 millimeters, thus the name.) This high-frequency band can [carry much more information per unit of time than the lower-frequency signals][7] currently used by 4G LTE, which is generally below 1 GHz, or Wi-Fi, which tops out at 6 GHz.
|
||||
|
||||
Millimeter-wave technology has traditionally been expensive and difficult to deploy. Technical advances have overcome those difficulties, which is part of what's made 5G possible today.
|
||||
|
||||
## Small cells
|
||||
|
||||
One drawback of millimeter wave transmission is that it's more prone to interference than Wi-Fi or 4G signals as they pass through physical objects.
|
||||
|
||||
To overcome this, the model for 5G infrastructure will be different from 4G's. Instead of the large cellular-antenna masts we've come to accept as part of the landscape, 5G networks will be powered by [much smaller base stations spread throughout cities about 250 meters apart][8], creating cells of service that are also smaller.
|
||||
|
||||
These 5G base stations have lower power requirements than those for 4G and can be attached to buildings and utility poles more easily.
|
||||
|
||||
## Massive MIMO
|
||||
|
||||
Despite 5G base stations being much smaller than their 4G counterparts, they pack in many more antennas. These antennas are [multiple-input multiple-output (MIMO)][9], meaning that they can handle multiple two-way conversations over the same data signal simultaneously. 5G networks can handle more than [20 times more conversations in this way than 4G networks][10].
|
||||
|
||||
Massive MIMO promises to [radically improve on base station capacity limits][11], allowing individual base stations to have conversations with many more devices. This in particular is why 5G may drive wider adoption of IoT. In theory, a lot more internet-connected wireless gadgets will be able to be deployed in the same space without overwhelming the network.
|
||||
|
||||
## Beamforming
|
||||
|
||||
Making sure all these conversations go back and forth to the right places is tricky, especially with the aforementioned problems millimeter-wave signals have with interference. To overcome those issues, 5G stations deploy advanced beamforming techniques, which use constructive and destructive radio interference to make signals directional rather than broadcast. That effectively boosts signal strength and range in a particular direction.
|
||||
|
||||
## 5G availability
|
||||
|
||||
The first commercial 5G network was [rolled out in Qatar in May 2018][12]. Since then, networks have been popping up across the world, from Argentina to Vietnam. [Lifewire has a good, frequently updated list][13].
|
||||
|
||||
One thing to keep in mind, though, is that not all 5G networks deliver on all the technology's promises yet. Some early 5G offerings piggyback on existing 4G infrastructure, which reduces the potential speed gains; other services dubbed 5G for marketing purposes don't even comply with the standard. A closer look at offerings from U.S. wireless carriers will demonstrate some of the pitfalls.
|
||||
|
||||
## Wireless carriers and 5G
|
||||
|
||||
Technically, 5G is available in the U.S. today. But the caveats involved in that statement vary from carrier to carrier, demonstrating the long road that still lies ahead before 5G becomes omnipresent.
|
||||
|
||||
Verizon is making probably the biggest early 5G push. It announced [5G Home][14] in parts of four cities in October of 2018, a service that requires using a special 5G hotspot to connect to the network and feed it to your other devices via Wi-Fi.
|
||||
|
||||
Verizon planned an April rollout of a [mobile service in Minneapolis and Chicago][15], which will spread to other cities over the course of the year. Accessing the 5G network will cost customers an extra monthly fee plus what they’ll have to spend on a phone that can actually connect to it (more on that in a moment). As an added wrinkle, Verizon is deploying what it calls [5G TF][16], which doesn't match up with the 5G NR standard.
|
||||
|
||||
AT&T [announced the availability of 5G in 12 U.S. cities in December 2018][17], with nine more coming by the end of 2019, but even in those cities, availability is limited to the downtown areas. To use the network requires a special Netgear hotspot that connects to the service, then provides a Wi-Fi signal to phones and other devices.
|
||||
|
||||
Meanwhile, AT&T is also rolling out speed boosts to its 4G network, which it's dubbed 5GE even though these improvements aren't related to 5G networking. ([This is causing backlash][18].)
|
||||
|
||||
Sprint will have 5G service in parts of four cities by May of 2019, and five more by the end of the year. But while Sprint's 5G offering makes use of massive MIMO cells, they [aren't using millimeter-wave signals][19], meaning that Sprint users won't see as much of a speed boost as customers of other carriers.
|
||||
|
||||
T-Mobile is pursuing a similar model,and it [won't roll out its service until the end of 2019][20] because there won't be any phones to connect to it.
|
||||
|
||||
One kink that might stop a rapid spread of 5G is the need to spread out all those small-cell base stations. Their small size and low power requirements make them easier to deploy than current 4G tech in a technical sense, but that doesn't mean it's simple to convince governments and property owners to install dozens of them everywhere. Verizon actually set up a [website that you can use to petition your local elected officials][21] to speed up 5G base station deployment.
|
||||
|
||||
## **5G phones: When available? When to buy?**
|
||||
|
||||
The first major 5G phone to be announced is the Samsung Galaxy S10 5G, which should be available by the end of the summer of 2019. You can also order a "[Moto Mod][22]" from Verizon, which [transforms Moto Z3 phones into 5G-compatible device][23]s.
|
||||
|
||||
But unless you can't resist the lure of being an early adopter, you may wish to hold off for a bit; some of the quirks and looming questions about carrier rollout may mean that you end up with a phone that [isn't compatible with your carrier's entire 5G network][24].
|
||||
|
||||
One laggard that may surprise you is Apple: analysts believe that there won't be a [5G-compatible iPhone until 2020 at the earliest][25]. But this isn't out of character for the company; Apple [also lagged behind Samsung in releasing 4G-compatible phones][26] in back in 2012.
|
||||
|
||||
Still, the 5G flood is coming. 5G-compatible devices [dominated Barcelona's Mobile World Congress in 2019][3], so expect to have a lot more choice on the horizon.
|
||||
|
||||
## Why are people talking about 6G already?
|
||||
|
||||
Some experts say [5G won’t be able to meet the latency and reliability targets][27] it is shooting for. These skeptics are already looking ahead to 6G, which they say will try to address these projected shortcomings.
|
||||
|
||||
There is [a group that is researching new technologies that can be rolled into 6G][28] that calls itself
|
||||
|
||||
The Center for Converged TeraHertz Communications and Sensing (ComSenTer). Part of the spec they’re working on calls for 100Gbps speed for every device.
|
||||
|
||||
In addition to adding reliability, overcoming reliability and boosting speed, 6G is also trying to enable thousands of simultaneous connections. If successful, this feature could help to network IoT devices, which can be deployed in the thousands as sensors in a variety of industrial settings.
|
||||
|
||||
Even in its embryonic form, 6G may already be facing security concerns due to the emergence of newly discovered [potential for man-in-the-middle attacks in tera-hertz based networks][29]. The good news is that there’s plenty of time to find solutions to the problem. 6G networks aren’t expected to start rolling out until 2030.
|
||||
|
||||
**More about 5g networks:**
|
||||
|
||||
* [How enterprises can prep for 5G networks][30]
|
||||
* [5G vs 4G: How speed, latency and apps support differ][31]
|
||||
* [Private 5G networks are coming][32]
|
||||
* [5G and 6G wireless have security issues][33]
|
||||
* [How millimeter-wave wireless could help support 5G and IoT][34]
|
||||
|
||||
|
||||
|
||||
Join the Network World communities on [Facebook][35] and [LinkedIn][36] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3203489/what-is-5g-how-is-it-better-than-4g.html#tk.rss_all
|
||||
|
||||
作者:[Josh Fruhlinger][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Josh-Fruhlinger/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.techhive.com/images/article/2017/04/5g-100718139-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3203489/what-is-5g-wireless-networking-benefits-standards-availability-versus-lte.html
|
||||
[3]: https://www.networkworld.com/article/3354477/mobile-world-congress-the-time-of-5g-is-almost-here.html
|
||||
[4]: https://www.networkworld.com/article/3330603/5g-versus-4g-how-speed-latency-and-application-support-differ.html
|
||||
[5]: https://www.theverge.com/2018/6/15/17467734/5g-nr-standard-3gpp-standalone-finished
|
||||
[6]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fmobile-device-management-big-picture
|
||||
[7]: https://www.networkworld.com/article/3291323/millimeter-wave-wireless-could-help-support-5g-and-iot.html
|
||||
[8]: https://spectrum.ieee.org/video/telecom/wireless/5g-bytes-small-cells-explained
|
||||
[9]: https://www.networkworld.com/article/3250268/what-is-mu-mimo-and-why-you-need-it-in-your-wireless-routers.html
|
||||
[10]: https://spectrum.ieee.org/tech-talk/telecom/wireless/5g-researchers-achieve-new-spectrum-efficiency-record
|
||||
[11]: https://www.networkworld.com/article/3262991/future-wireless-networks-will-have-no-capacity-limits.html
|
||||
[12]: https://venturebeat.com/2018/05/14/worlds-first-commercial-5g-network-launches-in-qatar/
|
||||
[13]: https://www.lifewire.com/5g-availability-world-4156244
|
||||
[14]: https://www.digitaltrends.com/computing/verizon-5g-home-promises-up-to-gigabit-internet-speeds-for-50/
|
||||
[15]: https://lifehacker.com/heres-your-cheat-sheet-for-verizons-new-5g-data-plans-1833278817
|
||||
[16]: https://www.theverge.com/2018/10/2/17927712/verizon-5g-home-internet-real-speed-meaning
|
||||
[17]: https://www.cnn.com/2018/12/18/tech/5g-mobile-att/index.html
|
||||
[18]: https://www.networkworld.com/article/3339720/like-4g-before-it-5g-is-being-hyped.html?nsdr=true
|
||||
[19]: https://www.digitaltrends.com/mobile/sprint-5g-rollout/
|
||||
[20]: https://www.cnet.com/news/t-mobile-delays-full-600-mhz-5g-launch-until-second-half/
|
||||
[21]: https://lets5g.com/
|
||||
[22]: https://www.verizonwireless.com/support/5g-moto-mod-faqs/?AID=11365093&SID=100098X1555750Xbc2e857934b22ebca1a0570d5ba93b7c&vendorid=CJM&PUBID=7105813&cjevent=2e2150cb478c11e98183013b0a1c0e0c
|
||||
[23]: https://www.digitaltrends.com/cell-phone-reviews/moto-z3-review/
|
||||
[24]: https://www.businessinsider.com/samsung-galaxy-s10-5g-which-us-cities-have-5g-networks-2019-2
|
||||
[25]: https://www.cnet.com/news/why-apples-in-no-rush-to-sell-you-a-5g-iphone/
|
||||
[26]: https://mashable.com/2012/09/09/iphone-5-4g-lte/#hYyQUelYo8qq
|
||||
[27]: https://www.networkworld.com/article/3305359/6g-will-achieve-terabits-per-second-speeds.html
|
||||
[28]: https://www.networkworld.com/article/3285112/get-ready-for-upcoming-6g-wireless-too.html
|
||||
[29]: https://www.networkworld.com/article/3315626/5g-and-6g-wireless-technologies-have-security-issues.html
|
||||
[30]: https://%20https//www.networkworld.com/article/3306720/mobile-wireless/how-enterprises-can-prep-for-5g.html
|
||||
[31]: https://%20https//www.networkworld.com/article/3330603/mobile-wireless/5g-versus-4g-how-speed-latency-and-application-support-differ.html
|
||||
[32]: https://%20https//www.networkworld.com/article/3319176/mobile-wireless/private-5g-networks-are-coming.html
|
||||
[33]: https://www.networkworld.com/article/3315626/network-security/5g-and-6g-wireless-technologies-have-security-issues.html
|
||||
[34]: https://www.networkworld.com/article/3291323/mobile-wireless/millimeter-wave-wireless-could-help-support-5g-and-iot.html
|
||||
[35]: https://www.facebook.com/NetworkWorld/
|
||||
[36]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,83 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (3 Essentials for Achieving Resiliency at the Edge)
|
||||
[#]: via: (https://www.networkworld.com/article/3386438/3-essentials-for-achieving-resiliency-at-the-edge.html#tk.rss_all)
|
||||
[#]: author: (Anne Taylor https://www.networkworld.com/author/Anne-Taylor/)
|
||||
|
||||
3 Essentials for Achieving Resiliency at the Edge
|
||||
======
|
||||
|
||||
### Edge computing requires different thinking and management to ensure the always-on availability that users have come to demand.
|
||||
|
||||
![iStock][1]
|
||||
|
||||
> “The IT industry has done a good job of making robust data centers that are highly manageable, highly secure, with redundant systems,” [says Kevin Brown][2], SVP Innovation and CTO for Schneider Electric’s Secure Power Division.
|
||||
|
||||
However, he continues, companies then connect these data centers to messy edge closets and server rooms, which over time have become “micro mission-critical data centers” in their own right — making system availability vital. If not designed and managed correctly, the situation can be disastrous if users cannot connect to business-critical applications.
|
||||
|
||||
To avoid unacceptable downtime, companies should incorporate three essential ingredients into their edge computing deployments: remote management, physical security, and rapid deployments.
|
||||
|
||||
**Remote management**
|
||||
|
||||
Depending on the company’s size, staff could be managing several — or many multiple — edge sites. Not only is this time consuming and costly, it’s also complex, especially if protocols differ from site to site.
|
||||
|
||||
While some organizations might deploy traditional remote monitoring technology to manage these sites, it’s important to note these tools: don’t provide real-time status updates; are largely reactionary rather than proactive; and are sometimes limited in terms of data output.
|
||||
|
||||
Coupled with the need to overcome these limitations, the economics for managing edge sites necessitate that organizations consider a digital, or cloud-based, solution. In addition to cost savings, these platforms provide:
|
||||
|
||||
* Simplification in monitoring across edge sites
|
||||
* Real-time visibility, right down to any device on the network
|
||||
* Predictive analytics, including data-driven intelligence and recommendations to ensure proactive service delivery
|
||||
|
||||
|
||||
|
||||
**Physical security**
|
||||
|
||||
Small, local edge computing sites are often situated within larger corporate or wide-open spaces, sometimes in highly accessible, shared offices and public areas. And sometimes they’re set up on-the-fly for a time-sensitive project.
|
||||
|
||||
However, when there is no dedicated location and open racks are unsecured, the risks of malicious and accidental incidents escalate.
|
||||
|
||||
To prevent unauthorized access to IT equipment at edge computing sites, proper physical security is critical and requires:
|
||||
|
||||
* Physical space monitoring, with environmental sensors for temperature and humidity
|
||||
* Access control, with biometric sensors as an option
|
||||
* Audio and video surveillance and monitoring with recording
|
||||
* If possible, install IT equipment within a secure enclosure
|
||||
|
||||
|
||||
|
||||
**Rapid deployments**
|
||||
|
||||
The [benefits of edge computing][3] are significant, especially the ability to bring bandwidth-intensive computing closer to the user, which leads to faster speed to market and greater productivity.
|
||||
|
||||
Create a holistic plan that will enable the company to quickly deploy edge sites, while ensuring resiliency and reliability. That means having a standardized, repeatable process including:
|
||||
|
||||
* Pre-configured, integrated equipment that combines server, storage, networking, and software in a single enclosure — a prefabricated micro data center, if you will
|
||||
* Designs that specify supporting racks, UPSs, PDUs, cable management, airflow practices, and cooling systems
|
||||
|
||||
|
||||
|
||||
These best practices as well as a balanced, systematic approach to edge computing deployments will ensure the always-on availability that today’s employees and users have come to expect.
|
||||
|
||||
Learn how to enable resiliency within your edge computing deployment at [APC.com][4].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3386438/3-essentials-for-achieving-resiliency-at-the-edge.html#tk.rss_all
|
||||
|
||||
作者:[Anne Taylor][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Anne-Taylor/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/04/istock-900882382-100792635-large.jpg
|
||||
[2]: https://www.youtube.com/watch?v=IfsCTFSH6Jc
|
||||
[3]: https://www.networkworld.com/article/3342455/how-edge-computing-will-bring-business-to-the-next-level.html
|
||||
[4]: https://www.apc.com/us/en/solutions/business-solutions/edge-computing.jsp
|
||||
@ -0,0 +1,70 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5G: A deep dive into fast, new wireless)
|
||||
[#]: via: (https://www.networkworld.com/article/3385030/5g-a-deep-dive-into-fast-new-wireless.html#tk.rss_all)
|
||||
[#]: author: (Craig Mathias https://www.networkworld.com/author/Craig-Mathias/)
|
||||
|
||||
5G: A deep dive into fast, new wireless
|
||||
======
|
||||
|
||||
### 5G wireless networks are just about ready for prime time, overcoming backhaul and backward-compatibility issues, and promising the possibility of all-mobile networking through enhanced throughput.
|
||||
|
||||
The next step in the evolution of wireless WAN communications - [5G networks][1] \- is about to hit the front pages, and for good reason: it will complete the evolution of cellular from wireline augmentation to wireline replacement, and strategically from mobile-first to mobile-only.
|
||||
|
||||
So it’s not too early to start least basic planning to understanding how 5G will fit into and benefit IT plans across organizations of all sizes, industries and missions.
|
||||
|
||||
**[ From Mobile World Congress:[The time of 5G is almost here][2] ]**
|
||||
|
||||
5G will of course provide end-users with the additional throughput, capacity, and other elements to address the continuing and dramatic growth in geographic availability, user base, range of subscriber devices, demand for capacity, and application requirements, but will also enable service providers to benefit from new opportunities in overall strategy, service offerings and broadened marketplace presence.
|
||||
|
||||
A look at the key features you can expect in 5G wireless. (Click for larger image.)
|
||||
|
||||
![A look at the key features you can expect in 5G wireless.][3]
|
||||
|
||||
This article explores the technologies and market drivers behind 5G, with an emphasis on what 5G means to enterprise and organizational IT.
|
||||
|
||||
While 5G remains an imprecise term today, key objectives for the development of the advances required have become clear. These are as follows:
|
||||
|
||||
## 5G speeds
|
||||
|
||||
As is the case with Wi-Fi, major advances in cellular are first and foremost defined by new upper-bound _throughput_ numbers. The magic number here for 5G is in fact a _floor_ of 1 Gbps, with numbers as high as 10 Gbps mentioned by some. However, and again as is the case with Wi-Fi, it’s important to think more in terms of overall individual-cell and system-wide _capacity_. We believe, then, that per-user throughput of 50 Mbps is a more reasonable – but clearly still remarkable – working assumption, with up to 300 Mbps peak throughput realized in some deployments over the next five years. The possibility of reaching higher throughput than that exceeds our planning horizon, but such is, well, possible.
|
||||
|
||||
## Reduced latency
|
||||
|
||||
Perhaps even more important than throughput, though, is a reduction in the round-trip time for each packet. Reducing latency is important for voice, which will most certainly be all-IP in 5G implementations, video, and, again, in improving overall capacity. The over-the-air latency goal for 5G is less than 10ms, with 1ms possible in some defined classes of service.
|
||||
|
||||
## 5G network management and OSS
|
||||
|
||||
Operators are always seeking to reduce overhead and operating expense, so enhancements to both system management and operational support systems (OSS) yielding improvements in reliability, availability, serviceability, resilience, consistency, analytics capabilities, and operational efficiency, are all expected. The benefits of these will, in most cases, however, be transparent to end-users.
|
||||
|
||||
## Mobility and 5G technology
|
||||
|
||||
Very-high-speed user mobility, to as much as hundreds of kilometers per hour, will be supported, thus serving users on all modes of transportation. Regulatory and situation-dependent restrictions – most notably, on aircraft – however, will still apply.
|
||||
|
||||
To continue reading this article register now
|
||||
|
||||
[Get Free Access][4]
|
||||
|
||||
[Learn More][5] Existing Users [Sign In][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3385030/5g-a-deep-dive-into-fast-new-wireless.html#tk.rss_all
|
||||
|
||||
作者:[Craig Mathias][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Craig-Mathias/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3203489/what-is-5g-how-is-it-better-than-4g.html
|
||||
[2]: https://www.networkworld.com/article/3354477/mobile-world-congress-the-time-of-5g-is-almost-here.html
|
||||
[3]: https://images.idgesg.net/images/article/2017/06/2017_nw_5g_wireless_key_features-100727485-large.jpg
|
||||
[4]: javascript://
|
||||
[5]: /learn-about-insider/
|
||||
@ -0,0 +1,90 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Announcing the release of Fedora 30 Beta)
|
||||
[#]: via: (https://fedoramagazine.org/announcing-the-release-of-fedora-30-beta/)
|
||||
[#]: author: (Ben Cotton https://fedoramagazine.org/author/bcotton/)
|
||||
|
||||
Announcing the release of Fedora 30 Beta
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
The Fedora Project is pleased to announce the immediate availability of Fedora 30 Beta, the next big step on our journey to the exciting Fedora 30 release.
|
||||
|
||||
Download the prerelease from our Get Fedora site:
|
||||
|
||||
* [Get Fedora 30 Beta Workstation][2]
|
||||
* [Get Fedora 30 Beta Server][3]
|
||||
* [Get Fedora 30 Beta Silverblue][4]
|
||||
|
||||
|
||||
|
||||
Or, check out one of our popular variants, including KDE Plasma, Xfce, and other desktop environments, as well as images for ARM devices like the Raspberry Pi 2 and 3:
|
||||
|
||||
* [Get Fedora 30 Beta Spins][5]
|
||||
* [Get Fedora 30 Beta Labs][6]
|
||||
* [Get Fedora 30 Beta ARM][7]
|
||||
|
||||
|
||||
|
||||
### Beta Release Highlights
|
||||
|
||||
#### New desktop environment options
|
||||
|
||||
Fedora 30 Beta includes two new options for desktop environment. [DeepinDE][8] and [Pantheon Desktop][9] join GNOME, KDE Plasma, Xfce, and others as options for users to customize their Fedora experience.
|
||||
|
||||
#### DNF performance improvements
|
||||
|
||||
All dnf repository metadata for Fedora 30 Beta is compressed with the zchunk format in addition to xz or gzip. zchunk is a new compression format designed to allow for highly efficient deltas. When Fedora’s metadata is compressed using zchunk, dnf will download only the differences between any earlier copies of the metadata and the current version.
|
||||
|
||||
#### GNOME 3.32
|
||||
|
||||
Fedora 30 Workstation Beta includes GNOME 3.32, the latest version of the popular desktop environment. GNOME 3.32 features updated visual style, including the user interface, the icons, and the desktop itself. For a full list of GNOME 3.32 highlights, see the [release notes][10].
|
||||
|
||||
#### Other updates
|
||||
|
||||
Fedora 30 Beta also includes updated versions of many popular packages like Golang, the Bash shell, the GNU C Library, Python, and Perl. For a full list, see the [Change set][11] on the Fedora Wiki. In addition, many Python 2 packages are removed in preparation for Python 2 end-of-life on 2020-01-01.
|
||||
|
||||
#### Testing needed
|
||||
|
||||
Since this is a Beta release, we expect that you may encounter bugs or missing features. To report issues encountered during testing, contact the Fedora QA team via the mailing list or in #fedora-qa on Freenode. As testing progresses, common issues are tracked on the [Common F30 Bugs page][12].
|
||||
|
||||
For tips on reporting a bug effectively, read [how to file a bug][13].
|
||||
|
||||
#### What is the Beta Release?
|
||||
|
||||
A Beta release is code-complete and bears a very strong resemblance to the final release. If you take the time to download and try out the Beta, you can check and make sure the things that are important to you are working. Every bug you find and report doesn’t just help you, it improves the experience of millions of Fedora users worldwide! Together, we can make Fedora rock-solid. We have a culture of coordinating new features and pushing fixes upstream as much as we can. Your feedback improves not only Fedora, but Linux and free software as a whole.
|
||||
|
||||
#### More information
|
||||
|
||||
For more detailed information about what’s new on Fedora 30 Beta release, you can consult the [Fedora 30 Change set][11]. It contains more technical information about the new packages and improvements shipped with this release.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/announcing-the-release-of-fedora-30-beta/
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/bcotton/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/03/f30-beta-816x345.jpg
|
||||
[2]: https://getfedora.org/workstation/prerelease/
|
||||
[3]: https://getfedora.org/server/prerelease/
|
||||
[4]: https://silverblue.fedoraproject.org/download
|
||||
[5]: https://spins.fedoraproject.org/prerelease
|
||||
[6]: https://labs.fedoraproject.org/prerelease
|
||||
[7]: https://arm.fedoraproject.org/prerelease
|
||||
[8]: https://www.deepin.org/en/dde/
|
||||
[9]: https://www.fosslinux.com/4652/pantheon-everything-you-need-to-know-about-the-elementary-os-desktop.htm
|
||||
[10]: https://help.gnome.org/misc/release-notes/3.32/
|
||||
[11]: https://fedoraproject.org/wiki/Releases/30/ChangeSet
|
||||
[12]: https://fedoraproject.org/wiki/Common_F30_bugs
|
||||
[13]: https://docs.fedoraproject.org/en-US/quick-docs/howto-file-a-bug/
|
||||
@ -0,0 +1,103 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Intel's Agilex FPGA family targets data-intensive workloads)
|
||||
[#]: via: (https://www.networkworld.com/article/3386158/intels-agilex-fpga-family-targets-data-intensive-workloads.html#tk.rss_all)
|
||||
[#]: author: (Marc Ferranti https://www.networkworld.com)
|
||||
|
||||
Intel's Agilex FPGA family targets data-intensive workloads
|
||||
======
|
||||
Agilex processors are the first Intel FPGAs to use 10nm manufacturing, achieving a performance boost for AI, financial and IoT workloads
|
||||
![Intel][1]
|
||||
|
||||
After teasing out details about the technology for a year and half under the code name Falcon Mesa, Intel has unveiled the Agilex family of FPGAs, aimed at data-center and network applications that are processing increasing amounts of data for AI, financial, database and IoT workloads.
|
||||
|
||||
The Agilex family, expected to start appearing in devices in the third quarter, is part of a new wave of more easily programmable FPGAs that is beginning to take an increasingly central place in computing as data centers are called on to handle an explosion of data.
|
||||
|
||||
**Learn about edge networking**
|
||||
|
||||
* [How edge networking and IoT will reshape data centers][2]
|
||||
* [Edge computing best practices][3]
|
||||
* [How edge computing can help secure the IoT][4]
|
||||
|
||||
|
||||
|
||||
FPGAs, or field programmable gate arrays, are built around around a matrix of configurable logic blocks (CLBs) linked via programmable interconnects that can be programmed after manufacturing – and even reprogrammed after being deployed in devices – to run algorithms written for specific workloads. They can thus be more efficient on a performance-per-watt basis than general-purpose CPUs, even while driving higher performance.
|
||||
|
||||
### Accelerated computing takes center stage
|
||||
|
||||
CPUs can be packaged with FPGAs, offloading specific tasks to them and enhancing overall data-center and network efficiency. The concept, known as accelerated computing, is increasingly viewed by data-center and network managers as a cost-efficient way to handle increasing data and network traffic.
|
||||
|
||||
"This data is creating what I call an innovation race across from the edge to the network to the cloud," said Dan McNamara, general manager of the Programmable Solutions Group (PSG) at Intel. "We believe that we’re in the largest adoption phase for FPGAs in our history."
|
||||
|
||||
The Agilex family is the first line of FPGAs developed from the ground up in the wake of [Intel’s $16.7 billion 2015 acquisition of Altera.][5] It's the first FPGA line to be made with Intel's 10nm manufacturing process, which adds billions of transistors to the FPGAs compared to earlier generations. Along with Intel's second-generation HyperFlex architecture, it helps give Agilex 40 percent higher performance than the company's current high-end FPGA family, the Stratix 10 line, Intel says.
|
||||
|
||||
HyperFlex architecture includes additional registers – places on a processor that temporarily hold data – called Hyper-Registers, located everywhere throughout the core fabric to enhance bandwidth as well as area and power efficiency.
|
||||
|
||||
**[[Take this mobile device management course from PluralSight and learn how to secure devices in your company without degrading the user experience.][6] ]**
|
||||
|
||||
### Memory coherency is key
|
||||
|
||||
Agilex FPGAs are also the first processors to support [Compute Express Link (CXL), a high-speed interconnect][7] designed to maintain memory coherency among CPUs like Intel's second-generation Xeon Scalable processors and purpose-built accelerators like FPGAs and GPUs. It ensures that different processors don't clash when trying to write to the same memory space, essentially allowing CPUs and accelerators to share memory.
|
||||
|
||||
"By having this CXL bus you can actually write applications that will use all the real memory so what that does is it simplifies the programming model in large memory workloads," said Patrick Moorhead, founder and principal at Moor Insights & Strategy.
|
||||
|
||||
The ability to integrate FPGAs, other accelerators and CPUs is key to Intel's accelerated computing strategy for the data center. Intel calls it "any to any" integration.
|
||||
|
||||
### 'Any-to-any' integration is crucial for the data center
|
||||
|
||||
The Agilex family uses embedded multi-die interconnect bridge (EMIB) packaging technology to integrate, for example, Xeon Scalable CPUs or ASICs – special-function processors that are not reprogammable – alongside FPGA fabric. Intel last year bought eASIC, a maker of structured ASICs, which the company describes as an intermediary technology between FPGAs and ASICs. The idea is to deliver products that offer a mix of functionality to achieve optimal cost and performance efficiency for data-intensive workloads.
|
||||
|
||||
Intel underscored the importance of processor integration for the data center by unveiling Agilex on Tuesday at its Data Centric Innovation Day in San Francisco, when it also discussed plans for its second generation Xeon Scalable line.
|
||||
|
||||
Traditionally, FPGAs were mainly used in embedded devices, communications equipment and in hyperscale data centers, and not sold directly to enterprises. But several products based on Intel Stratix 10 and Arria 10 FPGAs are now being sold to enterprises, including in Dell EMC and Fujitsu off-the-shelf servers.
|
||||
|
||||
Making FPGAs easier to program is key to making them more mainstream. "What's really, really important is the software story," said Intel's McNamara. "None of this really matters if we can't generate more users and make it easier to program FPGA's."
|
||||
|
||||
Intel's Quartus Prime design tool will be available for Agilex hardware developers but the real breakthrough for FPGA software development will be Intel's OneAPI concept, announced in December.
|
||||
|
||||
"OneAPI is is an effort by Intel to be able to have programmers write to OneAPI and OneAPI determines the best piece of silicon to run it on," Moorhead said. "I lovingly refer to it as the magic API; this is the big play I always thought Intel was gonna be working on ever since it bought Altera. The first thing I expect to happen are the big enterprise developers like SAP and Oracle to write to Agilex, then smaller ISVs, then custom enterprise applications."
|
||||
|
||||
![][8]
|
||||
|
||||
Intel plans three different product lines in the Agilex family – from low to high end, the F-, I- and M-series – aimed at different applications and processing requirements. The Agilex family, depending on the series, supports PCIe (peripheral component interconnect express) Gen 5, and different types of memory including DDR5 RAM, HBM (high-bandwidth memory) and Optane DC persistent memory. It will offer up to 112G bps transceiver data rates and a greater mix of arithmetic precision for AI, including bfloat16 number format.
|
||||
|
||||
In addition to accelerating server-based workloads like AI, genomics, financial and database applications, FPGAs play an important part in networking. Their cost-per-watt efficiency makes them suitable for edge networks, IoT devices as well as deep packet inspection. In addition, they can be used in 5G base stations; as 5G standards evolve, they can be reprogrammed. Once 5G standards are hardened, the "any to any" integration will allow processing to be offloaded to special-purpose ASICs for ultimate cost efficiency.
|
||||
|
||||
### Agilex will compete with Xylinx's ACAPs
|
||||
|
||||
Agilex will likely vie with Xylinx's upcoming [Versal product family][9], due out in devices in the second half of the year. Xylinx competed for years with Altera in the FPGA market, and with Versal has introduced what it says is [a new product category, the Adaptive Compute Acceleration Platform (ACAP)][10]. Versal ACAPs will be made using TSMC's 7nm manufacturing process technology, though because Intel achieves high transistor density, the number of transistors offered by Agilex and Versal chips will likely be equivalent, noted Moorhead.
|
||||
|
||||
Though Agilex and Versal differ in details, the essential pitch is similar: the programmable processors offer a wider variety of programming options than prior generations of FPGA, work with CPUs to accelerate data-intensive workloads, and offer memory coherence. Rather than CXL, though, the Versal family uses the cache coherent interconnect for accelerators (CCIX) interconnect fabric.
|
||||
|
||||
Neither Intel or Xylinx for the moment have announced OEM support for Agilex or Versal products that will be sold to the enterprise, but that should change as the year progresses.
|
||||
|
||||
Join the Network World communities on [Facebook][11] and [LinkedIn][12] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3386158/intels-agilex-fpga-family-targets-data-intensive-workloads.html#tk.rss_all
|
||||
|
||||
作者:[Marc Ferranti][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/04/agilex-100792596-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3291790/data-center/how-edge-networking-and-iot-will-reshape-data-centers.html
|
||||
[3]: https://www.networkworld.com/article/3331978/lan-wan/edge-computing-best-practices.html
|
||||
[4]: https://www.networkworld.com/article/3331905/internet-of-things/how-edge-computing-can-help-secure-the-iot.html
|
||||
[5]: https://www.networkworld.com/article/2903454/intel-could-strengthen-its-server-product-stack-with-altera.html
|
||||
[6]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fmobile-device-management-big-picture
|
||||
[7]: https://www.networkworld.com/article/3359254/data-center-giants-announce-new-high-speed-interconnect.html
|
||||
[8]: https://images.idgesg.net/images/article/2019/04/agilex-family-100792597-large.jpg
|
||||
[9]: https://www.xilinx.com/news/press/2018/xilinx-unveils-versal-the-first-in-a-new-category-of-platforms-delivering-rapid-innovation-with-software-programmability-and-scalable-ai-inference.html
|
||||
[10]: https://www.networkworld.com/article/3263436/fpga-maker-xilinx-aims-range-of-software-programmable-chips-at-data-centers.html
|
||||
[11]: https://www.facebook.com/NetworkWorld/
|
||||
[12]: https://www.linkedin.com/company/network-world
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
168
sources/tech/20190402 Using Square Brackets in Bash- Part 2.md
Normal file
168
sources/tech/20190402 Using Square Brackets in Bash- Part 2.md
Normal file
@ -0,0 +1,168 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Using Square Brackets in Bash: Part 2)
|
||||
[#]: via: (https://www.linux.com/blog/learn/2019/4/using-square-brackets-bash-part-2)
|
||||
[#]: author: (Paul Brown https://www.linux.com/users/bro66)
|
||||
|
||||
Using Square Brackets in Bash: Part 2
|
||||
======
|
||||
|
||||
![square brackets][1]
|
||||
|
||||
We continue our tour of square brackets in Bash with a look at how they can act as a command.
|
||||
|
||||
[Creative Commons Zero][2]
|
||||
|
||||
Welcome back to our mini-series on square brackets. In the [previous article][3], we looked at various ways square brackets are used at the command line, including globbing. If you've not read that article, you might want to start there.
|
||||
|
||||
Square brackets can also be used as a command. Yep, for example, in:
|
||||
|
||||
```
|
||||
[ "a" = "a" ]
|
||||
```
|
||||
|
||||
which is, by the way, a valid command that you can execute, `[ ... ]` is a command. Notice that there are spaces between the opening bracket `[` and the parameters `"a" = "a"`, and then between the parameters and the closing bracket `]`. That is precisely because the brackets here act as a command, and you are separating the command from its parameters.
|
||||
|
||||
You would read the above line as " _test whether the string "a" is the same as string "a"_ ". If the premise is true, the `[ ... ]` command finishes with an exit status of 0. If not, the exit status is 1. [We talked about exit statuses in a previous article][4], and there you saw that you could access the value by checking the `$?` variable.
|
||||
|
||||
Try it out:
|
||||
|
||||
```
|
||||
[ "a" = "a" ]
|
||||
echo $?
|
||||
```
|
||||
|
||||
And now try:
|
||||
|
||||
```
|
||||
[ "a" = "b" ]
|
||||
echo $?
|
||||
```
|
||||
|
||||
In the first case, you will get a 0 (the premise is true), and running the second will give you a 1 (the premise is false). Remember that, in Bash, an exit status from a command that is 0 means it exited normally with no errors, and that makes it `true`. If there were any errors, the exit value would be a non-zero value (`false`). The `[ ... ]` command follows the same rules so that it is consistent with the rest of the other commands.
|
||||
|
||||
The `[ ... ]` command comes in handy in `if ... then` constructs and also in loops that require a certain condition to be met (or not) before exiting, like the `while` and `until` loops.
|
||||
|
||||
The logical operators for testing stuff are pretty straightforward:
|
||||
|
||||
```
|
||||
[ STRING1 = STRING2 ] => checks to see if the strings are equal
|
||||
[ STRING1 != STRING2 ] => checks to see if the strings are not equal
|
||||
[ INTEGER1 -eq INTEGER2 ] => checks to see if INTEGER1 is equal to INTEGER2
|
||||
[ INTEGER1 -ge INTEGER2 ] => checks to see if INTEGER1 is greater than or equal to INTEGER2
|
||||
[ INTEGER1 -gt INTEGER2 ] => checks to see if INTEGER1 is greater than INTEGER2
|
||||
[ INTEGER1 -le INTEGER2 ] => checks to see if INTEGER1 is less than or equal to INTEGER2
|
||||
[ INTEGER1 -lt INTEGER2 ] => checks to see if INTEGER1 is less than INTEGER2
|
||||
[ INTEGER1 -ne INTEGER2 ] => checks to see if INTEGER1 is not equal to INTEGER2
|
||||
etc...
|
||||
```
|
||||
|
||||
You can also test for some very shell-specific things. The `-f` option, for example, tests whether a file exists or not:
|
||||
|
||||
```
|
||||
for i in {000..099}; \
|
||||
do \
|
||||
if [ -f file$i ]; \
|
||||
then \
|
||||
echo file$i exists; \
|
||||
else \
|
||||
touch file$i; \
|
||||
echo I made file$i; \
|
||||
fi; \
|
||||
done
|
||||
```
|
||||
|
||||
If you run this in your test directory, line 3 will test to whether a file is in your long list of files. If it does exist, it will just print a message; but if it doesn't exist, it will create it, to make sure the whole set is complete.
|
||||
|
||||
You could write the loop more compactly like this:
|
||||
|
||||
```
|
||||
for i in {000..099};\
|
||||
do\
|
||||
if [ ! -f file$i ];\
|
||||
then\
|
||||
touch file$i;\
|
||||
echo I made file$i;\
|
||||
fi;\
|
||||
done
|
||||
```
|
||||
|
||||
The `!` modifier in the condition inverts the premise, thus line 3 would translate to " _if the file`file$i` does not exist_ ".
|
||||
|
||||
Try it: delete some random files from the bunch you have in your test directory. Then run the loop shown above and watch how it rebuilds the list.
|
||||
|
||||
There are plenty of other tests you can try, including `-d` tests to see if the name belongs to a directory and `-h` tests to see if it is a symbolic link. You can also test whether a files belongs to a certain group of users (`-G`), whether one file is older than another (`-ot`), or even whether a file contains something or is, on the other hand, empty.
|
||||
|
||||
Try the following for example. Add some content to some of your files:
|
||||
|
||||
```
|
||||
echo "Hello World" >> file023
|
||||
echo "This is a message" >> file065
|
||||
echo "To humanity" >> file010
|
||||
```
|
||||
|
||||
and then run this:
|
||||
|
||||
```
|
||||
for i in {000..099};\
|
||||
do\
|
||||
if [ ! -s file$i ];\
|
||||
then\
|
||||
rm file$i;\
|
||||
echo I removed file$i;\
|
||||
fi;\
|
||||
done
|
||||
```
|
||||
|
||||
And you'll remove all the files that are empty, leaving only the ones you added content to.
|
||||
|
||||
To find out more, check the manual page for the `test` command (a synonym for `[ ... ]`) with `man test`.
|
||||
|
||||
You may also see double brackets (`[[ ... ]]`) sometimes used in a similar way to single brackets. The reason for this is because double brackets give you a wider range of comparison operators. You can use `==`, for example, to compare a string to a pattern instead of just another string; or < and `>` to test whether a string would come before or after another in a dictionary.
|
||||
|
||||
To find out more about extended operators [check out this full list of Bash expressions][5].
|
||||
|
||||
### Next Time
|
||||
|
||||
In an upcoming article, we'll continue our tour and take a look at the role of parentheses `()` in Linux command lines. See you then!
|
||||
|
||||
_Read more:_
|
||||
|
||||
1. [The Meaning of Dot (`.`)][6]
|
||||
2. [Understanding Angle Brackets in Bash (`<...>`)][7]
|
||||
3. [More About Angle Brackets in Bash(`<` and `>`)][8]
|
||||
4. [And, Ampersand, and & in Linux (`&`)][9]
|
||||
5. [Ampersands and File Descriptors in Bash (`&`)][10]
|
||||
6. [Logical & in Bash (`&`)][4]
|
||||
7. [All about {Curly Braces} in Bash (`{}`)][11]
|
||||
8. [Using Square Brackets in Bash: Part 1][3]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2019/4/using-square-brackets-bash-part-2
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/square-brackets-3734552_1920.jpg?itok=hv9D6TBy (square brackets)
|
||||
[2]: /LICENSES/CATEGORY/CREATIVE-COMMONS-ZERO
|
||||
[3]: https://www.linux.com/blog/2019/3/using-square-brackets-bash-part-1
|
||||
[4]: https://www.linux.com/blog/learn/2019/2/logical-ampersand-bash
|
||||
[5]: https://www.gnu.org/software/bash/manual/bashref.html#Bash-Conditional-Expressions
|
||||
[6]: https://www.linux.com/blog/learn/2019/1/linux-tools-meaning-dot
|
||||
[7]: https://www.linux.com/blog/learn/2019/1/understanding-angle-brackets-bash
|
||||
[8]: https://www.linux.com/blog/learn/2019/1/more-about-angle-brackets-bash
|
||||
[9]: https://www.linux.com/blog/learn/2019/2/and-ampersand-and-linux
|
||||
[10]: https://www.linux.com/blog/learn/2019/2/ampersands-and-file-descriptors-bash
|
||||
[11]: https://www.linux.com/blog/learn/2019/2/all-about-curly-braces-bash
|
||||
@ -0,0 +1,90 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (When Wi-Fi is mission-critical, a mixed-channel architecture is the best option)
|
||||
[#]: via: (https://www.networkworld.com/article/3386376/when-wi-fi-is-mission-critical-a-mixed-channel-architecture-is-the-best-option.html#tk.rss_all)
|
||||
[#]: author: (Zeus Kerravala https://www.networkworld.com/author/Zeus-Kerravala/)
|
||||
|
||||
When Wi-Fi is mission-critical, a mixed-channel architecture is the best option
|
||||
======
|
||||
|
||||
### Multi-channel is the norm for Wi-Fi today, but it’s not always the best choice. Single-channel and hybrid APs offer compelling alternatives when reliable Wi-Fi is a must.
|
||||
|
||||
![Getty Images][1]
|
||||
|
||||
I’ve worked with a number of companies that have implemented digital projects only to see them fail. The ideation was correct, the implementation was sound, and the market opportunity was there. The weak link? The Wi-Fi network.
|
||||
|
||||
For example, a large hospital wanted to improve clinician response times to patient alarms by having telemetry information sent to mobile devices. Without the system, the only way a nurse would know about a patient alarm is from an audible alert. And with all the background noise, it’s often tough to discern where noises are coming from. The problem was the Wi-Fi network in the hospital had not been upgraded in years and caused messages to be significantly delayed in their delivery, often taking four to five minutes to deliver. The long delivery times caused a lack of confidence in the system, so many clinicians stopped using it and went back to manual alerting. As a result, the project was considered a failure.
|
||||
|
||||
I’ve seen similar examples in manufacturing, K-12 education, entertainment, and other industries. Businesses are competing on the basis of customer experience, and that’s driven from the ever-expanding, ubiquitous wireless edge. Great Wi-Fi doesn’t necessarily mean market leadership, but bad Wi-Fi will have a negative impact on customers and employees. And in today’s competitive climate, that’s a recipe for disaster.
|
||||
|
||||
**[ Read also:[Wi-Fi site-survey tips: How to avoid interference, dead spots][2] ]**
|
||||
|
||||
## Wi-Fi performance historically inconsistent
|
||||
|
||||
The problem with Wi-Fi is that it’s inherently flaky. I’m sure everyone reading this has experienced the typical flaws with failed downloads, dropped connections, inconsistent performance, and lengthy wait times to connect to public hot spots.
|
||||
|
||||
Picture sitting in a conference prior to a keynote address and being able to tweet, send email, browse the web, and do other things with no problem. Then the keynote speaker comes on stage and the entire audiences start snapping pics, uploading those pictures, and streaming things – and the Wi-Fi stops working. I find this to be the norm more than the exception, underscoring the need for [no-compromise Wi-Fi][3].
|
||||
|
||||
The question for network professionals is how to get to a place where the Wi-Fi is rock solid 100% of the time. Some say that just beefing up the existing network will do that, and it might, but in some cases, the type of Wi-Fi might not be appropriate.
|
||||
|
||||
The most commonly deployed type of Wi-Fi is multi-channel, also known as micro-cell, where each client connects to the access point (AP) using a radio channel. A high-quality experience is based on two things: good signal strength and minimal interference. Several things can cause interference, such as APs being too close, layout issues, or interference from other equipment. To minimize interference, businesses invest a significant amount of time and money in [site surveys to plan the optimal channel map][2], but even with that’s done well, Wi-Fi glitches can still happen.
|
||||
|
||||
**[[Take this mobile device management course from PluralSight and learn how to secure devices in your company without degrading the user experience.][4] ]**
|
||||
|
||||
## Multi-channel Wi-Fi not always the best choice
|
||||
|
||||
For many carpeted offices, multi-channel Wi-Fi is likely to be solid, but there are some environments where external circumstances will impact performance. A good example of this is a multi-tenant building in which there are multiple Wi-Fi networks transmitting on the same channel and interfering with one another. Another example is a hospital where there are many campus workers moving between APs. The client will also try to connect to the best AP, causing the client to continually disconnect and reconnect resulting in dropped sessions. Then there are environments such as schools, airports, and conference facilities where there is a high number of transient devices and multi-channel can struggle to keep up.
|
||||
|
||||
## Single channel Wi-Fi offers better reliability but with a performance hit
|
||||
|
||||
What’s a network manager to do? Is inconsistent Wi-Fi just a fait accompli? Multi-channel is the norm, but it isn’t designed for dynamic physical environments or those where reliable connectivity is a must.
|
||||
|
||||
Several years ago an alternative architecture was proposed that would solve these problems. As the name suggests, “single channel” Wi-Fi uses a single radio channel for all APs in the network. Think of this as being a single Wi-Fi fabric that operates on one channel. With this architecture, the placement of APs is irrelevant because they all utilize the same channel, so they won’t interfere with one another. This has an obvious simplicity advantage, such as if coverage is poor, there’s no reason to do another expensive site survey. Instead, just drop in APs where they are needed.
|
||||
|
||||
One of the disadvantages of single-channel is that aggregate network throughput was lower than multi-channel because only one channel can be used. This might be fine in environments where reliability trumps performance, but many organizations want both.
|
||||
|
||||
## Hybrid APs offer the best of both worlds
|
||||
|
||||
There has been recent innovation from the manufacturers of single-channel systems that mix channel architectures, creating a “best of both worlds” deployment that offers the throughput of multi-channel with the reliability of single-channel. For example, Allied Telesis offers Hybrid APs that can operate in multi-channel and single-channel mode simultaneously. That means some web clients can be assigned to the multi-channel to have maximum throughput, while others can use single-channel for seamless roaming experience.
|
||||
|
||||
A practical use-case of such a mix might be a logistics facility where the office staff uses multi-channel, but the fork-lift operators use single-channel for continuous connectivity as they move throughout the warehouse.
|
||||
|
||||
Wi-Fi was once a network of convenience, but now it is perhaps the most mission-critical of all networks. A traditional multi-channel system might work, but due diligence should be done to see how it functions under a heavy load. IT leaders need to understand how important Wi-Fi is to digital transformation initiatives and do the proper testing to ensure it’s not the weak link in the infrastructure chain and choose the best technology for today’s environment.
|
||||
|
||||
**Reviews: 4 free, open-source network monitoring tools:**
|
||||
|
||||
* [Icinga: Enterprise-grade, open-source network-monitoring that scales][5]
|
||||
* [Nagios Core: Network-monitoring software with lots of plugins, steep learning curve][6]
|
||||
* [Observium open-source network monitoring tool: Won’t run on Windows but has a great user interface][7]
|
||||
* [Zabbix delivers effective no-frills network monitoring][8]
|
||||
|
||||
|
||||
|
||||
Join the Network World communities on [Facebook][9] and [LinkedIn][10] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3386376/when-wi-fi-is-mission-critical-a-mixed-channel-architecture-is-the-best-option.html#tk.rss_all
|
||||
|
||||
作者:[Zeus Kerravala][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Zeus-Kerravala/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/09/tablet_graph_wifi_analytics-100771638-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3315269/wi-fi-site-survey-tips-how-to-avoid-interference-dead-spots.html
|
||||
[3]: https://www.alliedtelesis.com/blog/no-compromise-wi-fi
|
||||
[4]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fmobile-device-management-big-picture
|
||||
[5]: https://www.networkworld.com/article/3273439/review-icinga-enterprise-grade-open-source-network-monitoring-that-scales.html?nsdr=true#nww-fsb
|
||||
[6]: https://www.networkworld.com/article/3304307/nagios-core-monitoring-software-lots-of-plugins-steep-learning-curve.html
|
||||
[7]: https://www.networkworld.com/article/3269279/review-observium-open-source-network-monitoring-won-t-run-on-windows-but-has-a-great-user-interface.html?nsdr=true#nww-fsb
|
||||
[8]: https://www.networkworld.com/article/3304253/zabbix-delivers-effective-no-frills-network-monitoring.html
|
||||
[9]: https://www.facebook.com/NetworkWorld/
|
||||
[10]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,137 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Zero-trust: microsegmentation networking)
|
||||
[#]: via: (https://www.networkworld.com/article/3384748/zero-trust-microsegmentation-networking.html#tk.rss_all)
|
||||
[#]: author: (Matt Conran https://www.networkworld.com/author/Matt-Conran/)
|
||||
|
||||
Zero-trust: microsegmentation networking
|
||||
======
|
||||
|
||||
### Microsegmentation gives administrators the control to set granular policies in order to protect the application environment.
|
||||
|
||||
![Aaron Burson \(CC0\)][1]
|
||||
|
||||
The transformation to the digital age has introduced significant changes to the cloud and data center environments. This has compelled the organizations to innovate more quickly than ever before. This, however, brings with it both – the advantages and disadvantages.
|
||||
|
||||
The network and security need to keep up with this rapid pace of change. If you cannot match with the speed of the [digital age,][2] then ultimately bad actors will become a hazard. Therefore, the organizations must move to a [zero-trust environment][3]: default deny, with least privilege access. In today’s evolving digital world this is the primary key to success.
|
||||
|
||||
Ideally, a comprehensive solution must provide protection across all platforms including legacy servers, VMs, services in public clouds, on-premise, off-premise, hosted, managed or self-managed. We are going to stay hybrid for a long time, therefore we need to equip our architecture with [zero-trust][4].
|
||||
|
||||
**[ Don’t miss[customer reviews of top remote access tools][5] and see [the most powerful IoT companies][6] . | Get daily insights by [signing up for Network World newsletters][7]. ]**
|
||||
|
||||
We need to have the ability to support all of these hybrid environments that can analyze at a process, flow data, and infrastructure level. As a matter of fact, there is never just one element to analyze within a network in order to create an effective security posture.
|
||||
|
||||
To adequately secure such an environment requires a solution with key components: such as appropriate visibility, microsegmentation, and breach detection. Let's learn more about one of these primary elements: zero-trust microsegmentation networking.
|
||||
|
||||
There are a variety of microsegmentation vendors, all with competing platforms. We have, for example, SDN-based, container-centric, network-based appliance be it physical or virtual, and container-centric to name just a few.
|
||||
|
||||
## What is microsegmentation?
|
||||
|
||||
Microsegmentation is the ability to put a wrapper around the access control for each component of an application. The traditional days are gone where we can just impose a block on source/destination/port numbers or higher up in the stack with protocols, such as HTTP or HTTPS.
|
||||
|
||||
As the communication patterns become more complex, thereby isolating the communication flows between entities, hence following the microsegmentation principles has become a necessity.
|
||||
|
||||
## Why is microsegmentation important?
|
||||
|
||||
Microsegmentation gives administrators the control to set granular policies in order to protect the application environment. It defines the rules and policies as to how an application can communicate within its tier. The policies are granular (a lot more granular than what we had before), which restrict the communication to hosts that are only allowed to communicate.
|
||||
|
||||
Eventually, this reduces the available attack surface and completely locks down the ability for the bad actors to move laterally within the application infrastructure. Why? Because it governs the application’s activity at a granular level, thereby improving the entire security posture. The traditional zone-based networking no longer cuts it in today’s [digital world][8].
|
||||
|
||||
## General networking
|
||||
|
||||
Let's start with the basics. We all know that with security, you are only as strong as your weakest link. As a result, enterprises have begun to further segment networks into microsegments. Some call them nanosegments.
|
||||
|
||||
But first, let’s recap on what we actually started within the initial stage- nothing! We had IP addresses that were used for connectivity but unfortunately, they have no built-in authentication mechanism. Why? Because it wasn't a requirement back then.
|
||||
|
||||
Network connectivity based on network routing protocols was primarily used for sharing resources. A printer, 30 years ago, could cost the same as a house, so connectivity and the sharing of resources were important. The authentication of the communication endpoints was not considered significant.
|
||||
|
||||
## Broadcast domains
|
||||
|
||||
As networks grew in size, virtual LANs (VLANs) were introduced to divide the broadcast domains and improve network performance. A broadcast domain is a logical division of a computer network. All nodes can reach each other by sending a broadcast at the data link layer. When the broadcast domain swells, the network performance takes a hit.
|
||||
|
||||
Over time the role of the VLAN grew to be used as a security tool but it was never meant to be in that space. VLANs were used to improve performance, not to isolate the resources. The problem with VLANs is that there is no intra VLAN filtering. They have a very broad level of access and trust. If bad actors gain access to one segment in the zone, they should not be allowed to try and compromise another device within that zone, but with VLANs, this is a strong possibility.
|
||||
|
||||
Hence, VLAN offers the bad actor a pretty large attack surface to play with and move across laterally without inspection. Lateral movements are really hard to detect with traditional architectures.
|
||||
|
||||
Therefore, enterprises were forced to switch to microsegmentation. Microsegmentation further segments networks within the zone. On the contrary, the whole area of virtualization complicates the segmentation process. A virtualized server may only have a single physical network port but it supports numerous logical networks where services and applications reside across multiple security zones.
|
||||
|
||||
Thus, microsegmentation needs to work at both; the physical network layer as well as within the virtualized networking layer. As you are aware, there has been a change in the traffic pattern. The good thing about microsegmentation is that it controls both; the “north & south” and also the “east & west” movement of traffic, further isolating the size of broadcast domains.
|
||||
|
||||
## Microsegmentation – a multi-stage process
|
||||
|
||||
Implementing microsegmentation is a multi-stage process. There are certain prerequisites that must be followed before the implementation. Firstly, you need to fully understand the communication patterns, map the flows and all the application dependencies.
|
||||
|
||||
Once this is done, it's only then you can enable microsegmentation in a platform-agnostic manner across all the environments. Segmenting your network appropriately creates a dark network until the administrator turns on the lights. Authentication is performed first and then access is granted to the communicating entities operating with zero-trust with least privilege access.
|
||||
|
||||
Once you are connecting the entities, they need to run through a number of technologies in order to be fully connected. There is not a once-off check with microsegmentation. It’s rather a continuous process to make sure that both entities are doing what they are supposed to do.
|
||||
|
||||
This ensures that everyone is doing what they are entitled to do. You want to reduce the unnecessary cross-talk to an absolute minimum and only allow communication that is a complete necessity.
|
||||
|
||||
## How do you implement microsegmentation?
|
||||
|
||||
Firstly, you need strong visibility not just at the traffic flow level but also at the process and data contextual level. Without granular application visibility, it's impossible to map and fully understand what is normal traffic flow and irregular application communication patterns.
|
||||
|
||||
Visibility cannot be mapped out manually, as there could be hundreds of workloads. Therefore, an automatic approach must be taken. Manual mapping is more prone to errors and is inefficient. The visibility also needs to be in real-time. A static snapshot of the application architecture, even if it's down to a process level, will not tell you anything about the behaviors that are sanctioned or unsanctioned.
|
||||
|
||||
You also need to make sure that you, not under-segmenting, similar to what we had in the old days. Primarily, microsegmentation must manage communication workflows all the way up to Layer 7 of the Open Systems Interconnection (OSI) layer. Layer 4 microsegmentation only focuses on the Transport layer. If you are only segmenting the network at Layer 4 then you are widening your attack surface, thereby opening the network to be compromised.
|
||||
|
||||
Segmenting right up to the application layer means you are locking down the lateral movements, open ports, and protocols. It enables you to restrict access to the source and destination process rather than source and destination port numbers.
|
||||
|
||||
## Security issues with hybrid cloud
|
||||
|
||||
Since the [network perimeter][9] has been removed, therefore, it has become difficult to bolt the traditional security tools. Traditionally, we could position a static perimeter around the network infrastructure. However, this is not an available option today as we have a mixture of containerized applications, for example, a legacy database server. We have legacy communicating to the containerized land.
|
||||
|
||||
Hybrid enables organizations to use different types of cloud architects to include the on-premise and new technologies, such as containers. We are going to have a hybrid cloud in coming times which will change the way we think about networking. Hybrid forces the organizations to rethink about the network architectures.
|
||||
|
||||
When you attach the microsegment policies around the workload itself, then the policies will go with the workload. Then it would not matter if the entity moves to the on-premise or to the cloud. If the workload auto scales up and down or horizontally, the policy needs to go with the workload. Even if you go deeper than the workload, into the process level, you can set even more granular controls for microsegmentation.
|
||||
|
||||
## Identity
|
||||
|
||||
However, this is the point where identity becomes a challenge. If things are scaling and becoming dynamic, you can’t tie policies to the IP addresses. Rather than using IP addresses as the base for microsegmentation, policies are based on the logical (not physical) attributes.
|
||||
|
||||
With microsegmentation, the workload identity is based on logical attributes, such as the multi-factor authentication (MFA), transport layer security (TLS) certificate, the application service, or the use of a logical label associated with the workload.
|
||||
|
||||
These are what are known as logical attributes. Ultimately the policies map to the IP addresses but these are set by using the logical attributes, not the physical ones. As we progress in this technological era, the IP address is less relevant now. Named data networking is one of the perfect examples.
|
||||
|
||||
Other identity methods for microsegmentation are TLS certificates. If the traffic is encrypted with a different TLS certificate or from an invalid source, it automatically gets dropped, even if it comes from the right location. It will get blocked as it does not have the right identity.
|
||||
|
||||
You can even extend that further and look inside the actual payload. If an entity is trying to do a hypertext transfer protocol (HTTP) post to a record and if it tries to perform any other operation, it will get blocked.
|
||||
|
||||
## Policy enforcement
|
||||
|
||||
Practically, all of these policies can be implemented and enforced in different places throughout the network. However, if you enforce in only one place, that point in the network can become compromised and become an entry door to the bad actor. You can, for example, enforce in 10 different network points, even if you subvert in 2 of them the other 8 will still protect you.
|
||||
|
||||
Zero-trust microsegmentation ensures that you can enforce in different points throughout the network and also with different mechanics.
|
||||
|
||||
**This article is published as part of the IDG Contributor Network.[Want to Join?][10]**
|
||||
|
||||
Join the Network World communities on [Facebook][11] and [LinkedIn][12] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3384748/zero-trust-microsegmentation-networking.html#tk.rss_all
|
||||
|
||||
作者:[Matt Conran][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Matt-Conran/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/07/hive-structured_windows_architecture_connections_connectivity_network_lincoln_park_pavilion_chicago_by_aaron_burson_cc0_via_unsplash_1200x800-100765880-large.jpg
|
||||
[2]: https://youtu.be/AnMQH_noNDo
|
||||
[3]: https://network-insight.net/2018/10/zero-trust-networking-ztn-want-ghosted/
|
||||
[4]: https://network-insight.net/2018/09/embrace-zero-trust-networking/
|
||||
[5]: https://www.networkworld.com/article/3262145/lan-wan/customer-reviews-top-remote-access-tools.html#nww-fsb
|
||||
[6]: https://www.networkworld.com/article/2287045/internet-of-things/wireless-153629-10-most-powerful-internet-of-things-companies.html#nww-fsb
|
||||
[7]: https://www.networkworld.com/newsletters/signup.html#nww-fsb
|
||||
[8]: https://network-insight.net/2017/10/internet-things-iot-dissolving-cloud/
|
||||
[9]: https://network-insight.net/2018/09/software-defined-perimeter-zero-trust/
|
||||
[10]: /contributor-network/signup.html
|
||||
[11]: https://www.facebook.com/NetworkWorld/
|
||||
[12]: https://www.linkedin.com/company/network-world
|
||||
@ -1,124 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 useful open source log analysis tools)
|
||||
[#]: via: (https://opensource.com/article/19/4/log-analysis-tools)
|
||||
[#]: author: (Sam Bocetta https://opensource.com/users/sambocetta)
|
||||
|
||||
5 useful open source log analysis tools
|
||||
======
|
||||
Monitoring network activity is as important as it is tedious. These
|
||||
tools can make it easier.
|
||||
![People work on a computer server][1]
|
||||
|
||||
Monitoring network activity can be a tedious job, but there are good reasons to do it. For one, it allows you to find and investigate suspicious logins on workstations, devices connected to networks, and servers while identifying sources of administrator abuse. You can also trace software installations and data transfers to identify potential issues in real time rather than after the damage is done.
|
||||
|
||||
Those logs also go a long way towards keeping your company in compliance with the [General Data Protection Regulation][2] (GDPR) that applies to any entity operating within the European Union. If you have a website that is viewable in the EU, you qualify.
|
||||
|
||||
Logging—both tracking and analysis—should be a fundamental process in any monitoring infrastructure. A transaction log file is necessary to recover a SQL server database from disaster. Further, by tracking log files, DevOps teams and database administrators (DBAs) can maintain optimum database performance or find evidence of unauthorized activity in the case of a cyber attack. For this reason, it's important to regularly monitor and analyze system logs. It's a reliable way to re-create the chain of events that led up to whatever problem has arisen.
|
||||
|
||||
There are quite a few open source log trackers and analysis tools available today, making choosing the right resources for activity logs easier than you think. The free and open source software community offers log designs that work with all sorts of sites and just about any operating system. Here are five of the best I've used, in no particular order.
|
||||
|
||||
### Graylog
|
||||
|
||||
[Graylog][3] started in Germany in 2011 and is now offered as either an open source tool or a commercial solution. It is designed to be a centralized log management system that receives data streams from various servers or endpoints and allows you to browse or analyze that information quickly.
|
||||
|
||||
![Graylog screenshot][4]
|
||||
|
||||
Graylog has built a positive reputation among system administrators because of its ease in scalability. Most web projects start small but can grow exponentially. Graylog can balance loads across a network of backend servers and handle several terabytes of log data each day.
|
||||
|
||||
IT administrators will find Graylog's frontend interface to be easy to use and robust in its functionality. Graylog is built around the concept of dashboards, which allows you to choose which metrics or data sources you find most valuable and quickly see trends over time.
|
||||
|
||||
When a security or performance incident occurs, IT administrators want to be able to trace the symptoms to a root cause as fast as possible. Search functionality in Graylog makes this easy. It has built-in fault tolerance that can run multi-threaded searches so you can analyze several potential threats together.
|
||||
|
||||
### Nagios
|
||||
|
||||
[Nagios][5] started with a single developer back in 1999 and has since evolved into one of the most reliable open source tools for managing log data. The current version of Nagios can integrate with servers running Microsoft Windows, Linux, or Unix.
|
||||
|
||||
![Nagios Core][6]
|
||||
|
||||
Its primary product is a log server, which aims to simplify data collection and make information more accessible to system administrators. The Nagios log server engine will capture data in real-time and feed it into a powerful search tool. Integrating with a new endpoint or application is easy thanks to the built-in setup wizard.
|
||||
|
||||
Nagios is most often used in organizations that need to monitor the security of their local network. It can audit a range of network-related events and help automate the distribution of alerts. Nagios can even be configured to run predefined scripts if a certain condition is met, allowing you to resolve issues before a human has to get involved.
|
||||
|
||||
As part of network auditing, Nagios will filter log data based on the geographic location where it originates. That means you can build comprehensive dashboards with mapping technology to understand how your web traffic is flowing.
|
||||
|
||||
### Elastic Stack (the "ELK Stack")
|
||||
|
||||
[Elastic Stack][7], often called the ELK Stack, is one of the most popular open source tools among organizations that need to sift through large sets of data and make sense of their system logs (and it's a personal favorite, too).
|
||||
|
||||
![ELK Stack][8]
|
||||
|
||||
Its primary offering is made up of three separate products: Elasticsearch, Kibana, and Logstash:
|
||||
|
||||
* As its name suggests, _**Elasticsearch**_ is designed to help users find matches within datasets using a wide range of query languages and types. Speed is this tool's number one advantage. It can be expanded into clusters of hundreds of server nodes to handle petabytes of data with ease.
|
||||
|
||||
* _**Kibana**_ is a visualization tool that runs alongside Elasticsearch to allow users to analyze their data and build powerful reports. When you first install the Kibana engine on your server cluster, you will gain access to an interface that shows statistics, graphs, and even animations of your data.
|
||||
|
||||
* The final piece of ELK Stack is _**Logstash**_ , which acts as a purely server-side pipeline into the Elasticsearch database. You can integrate Logstash with a variety of coding languages and APIs so that information from your websites and mobile applications will be fed directly into your powerful Elastic Stalk search engine.
|
||||
|
||||
|
||||
|
||||
|
||||
A unique feature of ELK Stack is that it allows you to monitor applications built on open source installations of WordPress. In contrast to most out-of-the-box security audit log tools that [track admin and PHP logs][9] but little else, ELK Stack can sift through web server and database logs.
|
||||
|
||||
Poor log tracking and database management are one of the [most common causes of poor website performance][10]. Failure to regularly check, optimize, and empty database logs can not only slow down a site but could lead to a complete crash as well. Thus, the ELK Stack is an excellent tool for every WordPress developer's toolkit.
|
||||
|
||||
### LOGalyze
|
||||
|
||||
[LOGalyze][11] is an organization based in Hungary that builds open source tools for system administrators and security experts to help them manage server logs and turn them into useful data points. Its primary product is available as a free download for either personal or commercial use.
|
||||
|
||||
![LOGalyze][12]
|
||||
|
||||
LOGalyze is designed to work as a massive pipeline in which multiple servers, applications, and network devices can feed information using the Simple Object Access Protocol (SOAP) method. It provides a frontend interface where administrators can log in to monitor the collection of data and start analyzing it.
|
||||
|
||||
From within the LOGalyze web interface, you can run dynamic reports and export them into Excel files, PDFs, or other formats. These reports can be based on multi-dimensional statistics managed by the LOGalyze backend. It can even combine data fields across servers or applications to help you spot trends in performance.
|
||||
|
||||
LOGalyze is designed to be installed and configured in less than an hour. It has prebuilt functionality that allows it to gather audit data in formats required by regulatory acts. For example, LOGalyze can easily run different HIPAA reports to ensure your organization is adhering to health regulations and remaining compliant.
|
||||
|
||||
### Fluentd
|
||||
|
||||
If your organization has data sources living in many different locations and environments, your goal should be to centralize them as much as possible. Otherwise, you will struggle to monitor performance and protect against security threats.
|
||||
|
||||
[Fluentd][13] is a robust solution for data collection and is entirely open source. It does not offer a full frontend interface but instead acts as a collection layer to help organize different pipelines. Fluentd is used by some of the largest companies worldwide but can be implemented in smaller organizations as well.
|
||||
|
||||
![Fluentd architecture][14]
|
||||
|
||||
The biggest benefit of Fluentd is its compatibility with the most common technology tools available today. For example, you can use Fluentd to gather data from web servers like Apache, sensors from smart devices, and dynamic records from MongoDB. What you do with that data is entirely up to you.
|
||||
|
||||
Fluentd is based around the JSON data format and can be used in conjunction with [more than 500 plugins][15] created by reputable developers. This allows you to extend your logging data into other applications and drive better analysis from it with minimal manual effort.
|
||||
|
||||
### The bottom line
|
||||
|
||||
If you aren't already using activity logs for security reasons, governmental compliance, and measuring productivity, commit to changing that. There are plenty of plugins on the market that are designed to work with multiple environments and platforms, even on your internal network. Don't wait for a serious incident to justify taking a proactive approach to logs maintenance and oversight.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/log-analysis-tools
|
||||
|
||||
作者:[Sam Bocetta][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/sambocetta
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_linux11x_cc.png?itok=XMDOouJR (People work on a computer server)
|
||||
[2]: https://opensource.com/article/18/4/gdpr-impact
|
||||
[3]: https://www.graylog.org/products/open-source
|
||||
[4]: https://opensource.com/sites/default/files/uploads/graylog-data.png (Graylog screenshot)
|
||||
[5]: https://www.nagios.org/downloads/
|
||||
[6]: https://opensource.com/sites/default/files/uploads/nagios_core_4.0.8.png (Nagios Core)
|
||||
[7]: https://www.elastic.co/products
|
||||
[8]: https://opensource.com/sites/default/files/uploads/elk-stack.png (ELK Stack)
|
||||
[9]: https://www.wpsecurityauditlog.com/benefits-wordpress-activity-log/
|
||||
[10]: https://websitesetup.org/how-to-speed-up-wordpress/
|
||||
[11]: http://www.logalyze.com/
|
||||
[12]: https://opensource.com/sites/default/files/uploads/logalyze.jpg (LOGalyze)
|
||||
[13]: https://www.fluentd.org/
|
||||
[14]: https://opensource.com/sites/default/files/uploads/fluentd-architecture.png (Fluentd architecture)
|
||||
[15]: https://opensource.com/article/18/9/open-source-log-aggregation-tools
|
||||
@ -0,0 +1,70 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to rebase to Fedora 30 Beta on Silverblue)
|
||||
[#]: via: (https://fedoramagazine.org/how-to-rebase-to-fedora-30-beta-on-silverblue/)
|
||||
[#]: author: (Michal Konečný https://fedoramagazine.org/author/zlopez/)
|
||||
|
||||
How to rebase to Fedora 30 Beta on Silverblue
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Silverblue is [an operating system for your desktop built on Fedora][2]. It’s excellent for daily use, development, and container-based workflows. It offers [numerous advantages][3] such as being able to roll back in case of any problems. If you want to test Fedora 30 on your Silverblue system, this article tells you how. It not only shows you what to do, but also how to revert back if anything unforeseen happens.
|
||||
|
||||
### Switching to Fedora 30 branch
|
||||
|
||||
Switching to Fedora 30 on Silverblue is easy. First, check if the _30_ branch is available, which should be true now:
|
||||
|
||||
```
|
||||
ostree remote refs fedora-workstation
|
||||
```
|
||||
|
||||
You should see the following in the output:
|
||||
|
||||
```
|
||||
fedora-workstation:fedora/30/x86_64/silverblue
|
||||
```
|
||||
|
||||
Next, import the GPG key for the Fedora 30 branch. Without this step, you won’t be able to rebase.
|
||||
|
||||
```
|
||||
sudo ostree remote gpg-import fedora-workstation -k /etc/pki/rpm-gpg/RPM-GPG-KEY-fedora-30-primary
|
||||
```
|
||||
|
||||
Next, rebase your system to the Fedora 30 branch.
|
||||
|
||||
```
|
||||
rpm-ostree rebase fedora-workstation:fedora/30/x86_64/silverblue
|
||||
```
|
||||
|
||||
Finally, the last thing to do is restart your computer and boot to Fedora 30.
|
||||
|
||||
### How to revert things back
|
||||
|
||||
Remember that Fedora 30’s still in beta testing phase, so there could still be some issues. If anything bad happens — for instance, if you can’t boot to Fedora 30 at all — it’s easy to go back. Just pick the previous entry in GRUB, and your system will start in its previous state before switching to Fedora 30. To make this change permanent, use the following command:
|
||||
|
||||
```
|
||||
rpm-ostree rollback
|
||||
```
|
||||
|
||||
That’s it. Now you know how to rebase to Fedora 30 and back. So why not test it today? 🙂
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/how-to-rebase-to-fedora-30-beta-on-silverblue/
|
||||
|
||||
作者:[Michal Konečný][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/zlopez/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/03/silverblue-f30beta-816x345.jpg
|
||||
[2]: https://docs.fedoraproject.org/en-US/fedora-silverblue/
|
||||
[3]: https://fedoramagazine.org/give-fedora-silverblue-a-test-drive/
|
||||
@ -0,0 +1,78 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Intel unveils an epic response to AMD’s server push)
|
||||
[#]: via: (https://www.networkworld.com/article/3386142/intel-unveils-an-epic-response-to-amds-server-push.html#tk.rss_all)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Intel unveils an epic response to AMD’s server push
|
||||
======
|
||||
|
||||
### Intel introduced more than 50 new Xeon Scalable Processors for servers that cover a variety of workloads.
|
||||
|
||||
![Intel][1]
|
||||
|
||||
Intel on Tuesday introduced its second-generation Xeon Scalable Processors for servers, developed under the codename Cascade Lake, and it’s clear AMD has lit a fire under a once complacent company.
|
||||
|
||||
These new Xeon SP processors max out at 28 cores and 56 threads, a bit shy of AMD’s Epyc server processors with 32 cores and 64 threads, but independent benchmarks are still to come, which may show Intel having a lead at single core performance.
|
||||
|
||||
And for absolute overkill, there is the Xeon SP Platinum 9200 Series, which sports 56 cores and 112 threads. It will also require up to 400W of power, more than twice what the high-end Xeons usually consume.
|
||||
|
||||
**[ Now read:[What is quantum computing (and why enterprises should care)][2] ]**
|
||||
|
||||
The new processors were unveiled at a big event at Intel’s headquarters in Santa Clara, California, and live-streamed on the web. [Newly minted CEO][3] Bob Swan kicked off the event, saying the new processors were the “first truly data-centric portfolio for our customers.”
|
||||
|
||||
“For the last several years, we have embarked on a journey to transform from a PC-centric company to a data-centric computing company and build the silicon processors with our partners to help our customers prosper and grow in an increasingly data-centric world,” he added.
|
||||
|
||||
He also said the move to a data-centric world isn’t just CPUs, but a suite of accelerant technologies, including the [Agilex FPGA processors][4], Optane memory, and more.
|
||||
|
||||
This launch is the largest Xeon launch in the company’s history, with more than 50 processor designs across the Xeon 8200 and 9200 lines. While something like that can lead to confusion, many of these are specific to certain workloads instead of general-purpose processors.
|
||||
|
||||
**[[Get certified as an Apple Technical Coordinator with this seven-part online course from PluralSight.][5] ]**
|
||||
|
||||
Cascade Lake chips are the replacement for the previous Skylake platform, and the mainstream Cascade Lake chips have the same architecture as the Purley motherboard used by Skylake. Like the current Xeon Scalable processors, they have up to 28 cores with up to 38.5 MB of L3 cache, but speeds and feeds have been bumped up.
|
||||
|
||||
The Cascade Lake generation supports the new UPI (Ultra Path Interface) high-speed interconnect, up to six memory channels, AVX-512 support, and up to 48 PCIe lanes. Memory capacity has been doubled, from 768GB to 1.5TB of memory per socket. They work in the same socket as Purley motherboards and are built on a 14nm manufacturing process.
|
||||
|
||||
Some of the new Xeons, however, can access up to 4.5TB of memory per processor: 1.5TB of memory and 3TB of Optane memory, the new persistent memory that sits between DRAM and NAND flash memory and acts as a massive cache for both.
|
||||
|
||||
## Built-in fixes for Meltdown and Spectre vulnerabilities
|
||||
|
||||
Most important, though, is that these new Xeons have built-in fixes for the Meltdown and Spectre vulnerabilities. There are existing fixes for the exploits, but they have the effect of reducing performance, which varies based on workload. Intel showed a slide at the event that shows the company is using a combination of firmware and software mitigation.
|
||||
|
||||
New features also include Intel Deep Learning Boost (DL Boost), a technology developed to accelerate vector computing that Intel said makes this the first CPU with built-in inference acceleration for AI workloads. It works with the AVX-512 extension, which should make it ideal for machine learning scenarios.
|
||||
|
||||
Most of the new Xeons are available now, except for the 9200 Platinum, which is coming in the next few months. Many Intel partners – Dell, Cray, Cisco, Supermicro – all have new products, with Supermicro launching more than 100 new products built around Cascade Lake.
|
||||
|
||||
## Intel also rolls out Xeon D-1600 series processors
|
||||
|
||||
In addition to its hot rod Xeons, Intel also rolled out the Xeon D-1600 series processors, a low power variant based on a completely different architecture. Xeon D-1600 series processors are designed for space and/or power constrained environments, such as edge network devices and base stations.
|
||||
|
||||
Along with the new Xeons and FPGA chips, Intel also announced the Intel Ethernet 800 series adapter, which supports 25, 50 and 100 Gigabit transfer speeds.
|
||||
|
||||
Thank you, AMD. This is what competition looks like.
|
||||
|
||||
Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3386142/intel-unveils-an-epic-response-to-amds-server-push.html#tk.rss_all
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/04/intel-xeon-family-1-100792811-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3275367/what-s-quantum-computing-and-why-enterprises-need-to-care.html
|
||||
[3]: https://www.networkworld.com/article/3336921/intel-promotes-swan-to-ceo-bumps-off-itanium-and-eyes-mellanox.html
|
||||
[4]: https://www.networkworld.com/article/3386158/intels-agilex-fpga-family-targets-data-intensive-workloads.html
|
||||
[5]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fapple-certified-technical-trainer-10-11
|
||||
[6]: https://www.facebook.com/NetworkWorld/
|
||||
[7]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,101 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Top Ten Reasons to Think Outside the Router #1: It’s Time for a Router Refresh)
|
||||
[#]: via: (https://www.networkworld.com/article/3386116/top-ten-reasons-to-think-outside-the-router-1-it-s-time-for-a-router-refresh.html#tk.rss_all)
|
||||
[#]: author: (Rami Rammaha https://www.networkworld.com/author/Rami-Rammaha/)
|
||||
|
||||
Top Ten Reasons to Think Outside the Router #1: It’s Time for a Router Refresh
|
||||
======
|
||||
|
||||
![istock][1]
|
||||
|
||||
We’re now at the end of our homage to the iconic David Letterman Top Ten List segment from his former Late Show, as [Silver Peak][2] counts down the _Top Ten Reasons to Think Outside the Router._ Click for the [#2][3], [#3][4], [#4][5], [#5][6], [#6][7], [#7][8], [#8][9], [#9][10] and [#10][11] reasons to retire traditional branch routers.
|
||||
|
||||
_**The #1 reason it’s time to retire conventional routers at the branch: your branch routers are coming due for a refresh – the perfect time to evaluate new options.**_
|
||||
|
||||
Your WAN architecture is due for a branch router refresh! You’re under immense pressure to advance your organization’s digital transformation initiatives and deliver a high quality of experience to your users and customers. Your applications – at least SaaS apps – are all cloud-based. You know you need to move more quickly to keep pace with changing business requirements to realize the transformational promise of the cloud. And, you’re dealing with shifting traffic patterns and an insatiable appetite for more bandwidth at branch sites to support your users and applications. Finally, you know your IT budget for networking isn’t going to increase.
|
||||
|
||||
_So, what’s next?_ You really only have three options when it comes to refreshing your WAN. You can continue to try and stretch your conventional router-centric model. You can choose a basic [SD-WAN][12] model that may or may not be good enough. Or you can take a new approach and deploy a business-driven SD-WAN edge platform.
|
||||
|
||||
### **The pitfalls of a router-centric model**
|
||||
|
||||
![][13]
|
||||
|
||||
The router-centric approach worked well when enterprise applications were hosted in the data center; before the advent of the cloud. All traffic was routed directly from branch offices to the data center. With the emergence of the cloud, businesses were forced to conform to the constraints of the network when deploying new applications or making network changes. This is a bottoms-up device centric approach in which the network becomes a bottleneck to the business.
|
||||
|
||||
A router-centric approach requires manual device-by-device configuration that results in endless hours of manual programming, making it extremely difficult for network administrators to scale without experiencing major challenges in configuration, outages and troubleshooting. Any changes that arise when deploying a new application or changing a QoS or security policy, once again requires manually programming every router at every branch across the network. Re-programming is time consuming and requires utilizing a complex, cumbersome CLI, further adding to the inefficiencies of the model. In short, the router-centric WAN has hit the wall.
|
||||
|
||||
### **Basic SD-WAN, a step in the right direction**
|
||||
|
||||
![][14]
|
||||
|
||||
In this model, businesses realize the benefit of foundational features, but this model falls short of the goal of a fully automated, business-driven network. A basic SD-WAN approach is unable to provide what the business really needs, including the ability to deliver the best Quality of Experience for users.
|
||||
|
||||
Some of the basic SD-WAN features include the ability to use multiple forms of transport, path selection, centralized management, zero-touch provisioning and encrypted VPN overlays. However, a basic SD-WAN lacks in many areas:
|
||||
|
||||
* Limited end-to-end orchestration of WAN edge network functions
|
||||
* Rudimentary path selection with traffic steering limited to pre-defined rules
|
||||
* Long fail-over times in response to WAN transport outages
|
||||
* Inability to use links when they experience brownouts due to link congestion or packet loss
|
||||
* Fixed application definitions and manually scripted ACLs to control traffic steering across the internet
|
||||
|
||||
|
||||
|
||||
### **The solution: shift to a business-first networking model**
|
||||
|
||||
![][15]
|
||||
|
||||
In this model, the network enables the business. The WAN is transformed into a business accelerant that is fully automated and continuous, giving every application the resources it truly needs while delivering 10x the bandwidth for the same budget – ultimately achieving the highest quality of experience to users and IT alike. With a business-first networking model, the network functions (SD-WAN, firewall, segmentation, routing, WAN optimization and application visibility and control) are unified in a single platform and are centrally orchestrated and managed. Top-down business intent is the driver, enabling businesses to unlock the full transformational promise of the cloud.
|
||||
|
||||
The business-driven [Silver Peak® EdgeConnect™ SD-WAN][16] edge platform was built for the cloud, enabling enterprises to liberate their applications from the constraints of existing WAN approaches. EdgeConnect offers the following advanced capabilities:
|
||||
|
||||
1\. Automates traffic steering and security policy enforcement based on business intent instead of TCP/IP addresses, delivering the highest Quality of Experience for users
|
||||
|
||||
2\. Actively embraces broadband to increase application performance and availability while lowering costs
|
||||
|
||||
3\. Securely and directly connect branch users to SaaS and IaaS cloud services
|
||||
|
||||
4\. Increases operational efficiency while increasing business agility and time-to-market via centralized orchestration
|
||||
|
||||
Silver Peak has more than 1,000 enterprise customer deployments across a range of vertical industries. Bentley Systems, [Nuffield Health][17] and [Solis Mammography][18] have all realized tangible business outcomes from their EdgeConnect deployments.
|
||||
|
||||
![][19]
|
||||
|
||||
Learn why the time is now to [think outside the router][20]!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3386116/top-ten-reasons-to-think-outside-the-router-1-it-s-time-for-a-router-refresh.html#tk.rss_all
|
||||
|
||||
作者:[Rami Rammaha][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Rami-Rammaha/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/04/istock-478729482-100792542-large.jpg
|
||||
[2]: https://www.silver-peak.com/why-silver-peak
|
||||
[3]: http://blog.silver-peak.com/think-outside-the-router-reason-2-simplify-and-consolidate-the-wan-edge
|
||||
[4]: http://blog.silver-peak.com/think-outside-the-router-reason-3-mpls-contract-renewal
|
||||
[5]: http://blog.silver-peak.com/top-ten-reasons-to-think-outside-the-router-4-broadband-is-used-only-for-failover
|
||||
[6]: http://blog.silver-peak.com/think-outside-the-router-reason-5-manual-cli-based-configuration-and-management
|
||||
[7]: http://blog.silver-peak.com/https-blog-silver-peak-com-think-outside-the-router-reason-6
|
||||
[8]: http://blog.silver-peak.com/think-outside-the-router-reason-7-exorbitant-router-support-and-maintenance-costs
|
||||
[9]: http://blog.silver-peak.com/think-outside-the-router-reason-8-garbled-voip-pixelated-video
|
||||
[10]: http://blog.silver-peak.com/think-outside-router-reason-9-sub-par-saas-performance
|
||||
[11]: http://blog.silver-peak.com/think-outside-router-reason-10-its-getting-cloudy
|
||||
[12]: https://www.silver-peak.com/sd-wan/sd-wan-explained
|
||||
[13]: https://images.idgesg.net/images/article/2019/04/1_router-centric-vs-business-first-100792538-medium.jpg
|
||||
[14]: https://images.idgesg.net/images/article/2019/04/2_basic-sd-wan-vs-business-first-100792539-medium.jpg
|
||||
[15]: https://images.idgesg.net/images/article/2019/04/3_bus-first-networking-model-100792540-large.jpg
|
||||
[16]: https://www.silver-peak.com/products/unity-edge-connect
|
||||
[17]: https://www.silver-peak.com/resource-center/nuffield-health-deploys-uk-wide-sd-wan-silver-peak
|
||||
[18]: https://www.silver-peak.com/resource-center/national-leader-mammography-services-accelerates-access-life-critical-scans
|
||||
[19]: https://images.idgesg.net/images/article/2019/04/4_real-world-business-outcomes-100792541-large.jpg
|
||||
[20]: https://www.silver-peak.com/think-outside-router
|
||||
@ -0,0 +1,158 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (9 features developers should know about Selenium IDE)
|
||||
[#]: via: (https://opensource.com/article/19/4/features-selenium-ide)
|
||||
[#]: author: (Al Sargent https://opensource.com/users/alsargent)
|
||||
|
||||
9 features developers should know about Selenium IDE
|
||||
======
|
||||
The new Selenium IDE brings the benefits of functional test automation
|
||||
to many IT professionals—and to frontend developers specifically.
|
||||
![magnifying glass on computer screen][1]
|
||||
|
||||
There has long been a stigma associated with using record-and-playback tools for testing rather than scripted QA automation tools like [Selenium Webdriver][2], [Cypress][3], and [WebdriverIO][4].
|
||||
|
||||
Record-and-playbook tools are perceived to suffer from many issues, including a lack of cross-browser support, no way to run scripts in parallel or from CI build scripts, poor support for responsive web apps, and no way to quickly diagnose frontend bugs.
|
||||
|
||||
Needless to say, it's been somewhat of a rough road for these tools, and after Selenium IDE [went end-of-life][5] in 2017, many thought the road for record and playback would end altogether.
|
||||
|
||||
Well, it turns out this perception was wrong. Not long after the Selenium IDE project was discontinued, my colleagues at [Applitools approached the Selenium open source community][6] to see how they could help.
|
||||
|
||||
Since then, much of Selenium IDE's code has been revamped. The code is now freely available on GitHub under an Apache 2.0 license, managed by the Selenium community, and supported by [two full-time engineers][7], one of whom literally wrote the book on [Selenium testing][8].
|
||||
|
||||
![Selenium IDE's GitHub repository][9]
|
||||
|
||||
The new Selenium IDE brings the benefits of functional test automation to many IT professionals—and to frontend developers specifically. Here are nine things developers should know about the new Selenium IDE.
|
||||
|
||||
### 1\. Selenium IDE is now cross-browser
|
||||
|
||||
When the record-and-playback tool first came out in 2006, Firefox was the shiny new browser it hitched its wagon to, and it remained that way for a decade. No more! Selenium IDE is now available as a [Google Chrome Extension][10] and [Firefox Add-on][11].
|
||||
|
||||
Even better, Selenium IDE can run its tests on Selenium WebDriver servers by using Selenium IDE's new command-line test runner, [SIDE Runner][12]. SIDE Runner blends elements of Selenium IDE and Selenium Webdriver. It takes a Selenium IDE script, saved as a [**.side** file][13], and runs it using browser drivers such as [ChromeDriver][14], [EdgeDriver][15], Firefox's [Geckodriver][16], [IEDriver][17], and [SafariDriver][18].
|
||||
|
||||
SIDE Runner and the other drivers above are available as [straightforward npm installs][12]. Here's what it looks like in action.
|
||||
|
||||
![SIDE Runner][19]
|
||||
|
||||
### 2\. No more brittle functional tests
|
||||
|
||||
For years, brittle tests have been an issue for functional tests—whether you record them or code them by hand. Now that developers are releasing new features more frequently, their user interface (UI) code is constantly changing as well. When a UI changes, object locators often change, too.
|
||||
|
||||
Selenium IDE fixes that by capturing multiple object locators when you record your script. During playback, if Selenium IDE can't find one locator, it tries each of the other locators until it finds one that works. Your test will fail only if none of the locators work. This doesn't guarantee scripts will always play back, but it does insulate scripts against numerous changes. As you can see below, Selenium IDE captures linkText, an xPath expression, and CSS-based locators.
|
||||
|
||||
![Selenium IDE captures linkText, an xPath expression, and CSS-based locators][20]
|
||||
|
||||
### 3\. Conditional logic to handle UI features
|
||||
|
||||
When testing web apps, scripts have to handle intermittent UI elements that can randomly appear in your app. These come in the form of cookie notices, popups for special offers, quote requests, newsletter subscriptions, paywall notifications, adblocker requests, and more.
|
||||
|
||||
Conditional logic is a great way to handle these intermittent UI features. Developers can easily insert conditional logic—also called control flow—into Selenium IDE scripts. [Here are details][21] and how it looks.
|
||||
|
||||
![Selenium IDE's Conditional logic][22]
|
||||
|
||||
### 4\. Support for embedded code
|
||||
|
||||
As broad as the new [Selenium IDE API][23] is, it doesn't do everything. For this reason, Selenium IDE has **[**execute** **script**][24]** and **[execute async script][25]** commands that let your script call a JavaScript snippet.
|
||||
|
||||
This provides developers with a tremendous amount of flexibility to take advantage of JavaScript's flexibility and wide range of libraries. To use it, click on the test step where you want JavaScript to run, choose **Insert New Command** , and enter **execute script** or **execute async script** in the command field, as shown below.
|
||||
|
||||
![Selenium IDE's command line][26]
|
||||
|
||||
### 5\. Selenium IDE runs from CI build scripts
|
||||
|
||||
Because SIDE Runner is called from the command line, you can easily fit it into CI build scripts, so long as the CI server can call **selenium-ide-runner** and upload the **.side** file (the test script) as a build artifact. For example, here's how to upload an input file in [Jenkins][27], [Travis][28], and [CircleCI][29].
|
||||
|
||||
This means Selenium IDE can be better integrated into the software development technology stack. In addition, the scripts created by less-technical QA team members—including business analysts—can run with every build. This helps better align QA with the developer so fewer bugs escape into production.
|
||||
|
||||
### 6\. Support for third-party plugins
|
||||
|
||||
Imagine companies building plugins to have Selenium IDE do all kinds of things, like uploading scripts to a functional testing cloud, a load testing cloud, or a production application monitoring service.
|
||||
|
||||
Plenty of companies have integrated Selenium Webdriver into their offerings, and I bet the same will happen with Selenium IDE. You can also [build your own Selenium IDE plugin][30].
|
||||
|
||||
### 7\. Visual UI testing
|
||||
|
||||
Speaking of new plugins, Applitools introduced a new Selenium IDE plugin to add artificial intelligence-powered visual validations to the equation. Available through the [Chrome][31] and [Firefox][32] stores via a three-second install, just plug in the Applitools API key and go.
|
||||
|
||||
Visual checkpoints are a great way to ensure a UI renders correctly. Rather than a bunch of assert statements on all the UI elements—which would be a pain to maintain—one visual checkpoint checks all your page elements.
|
||||
|
||||
Best of all, visual AI looks at a web app the same way a human does, ignoring minor differences. This means fewer fake bugs to frustrate a development team.
|
||||
|
||||
### 8\. Visually test responsive web apps
|
||||
|
||||
When testing the visual layout of [responsive web apps][33], it's best to do it on a wide range of screen sizes (also called viewports) to ensure nothing appears out of whack. It's all too easy for responsive web bugs to creep in, and when they do, the problems can range from merely cosmetic to business stopping.
|
||||
|
||||
When you use visual UI testing for Selenium IDE, you can visually test your webpages on the Applitools [Visual Grid][34], which has more than 100 combinations of browsers, emulated devices, and viewport sizes.
|
||||
|
||||
Once tests run on the Visual Grid, developers can easily check the test results on all the various combinations.
|
||||
|
||||
![Selenium IDE's Visual Grid][35]
|
||||
|
||||
### 9\. Responsive web bugs have nowhere to hide
|
||||
|
||||
Selenium IDE can help pinpoint the cause of frontend bugs. Every Selenium IDE script that's run with the Visual Grid can be analyzed with Applitools' [Root Cause Analysis][36]. It's no longer enough to find a bug—developers also need to fix it.
|
||||
|
||||
When a visual bug is discovered, it can be clicked on and just the relevant (not all) Document Object Model (DOM) and CSS differences will be displayed.
|
||||
|
||||
![Finding visual bugs][37]
|
||||
|
||||
In summary, much like many emerging technologies in software development, Selenium IDE is part of a larger trend of making life easier and simpler for technical professionals and enabling them to spend more time and effort on creating code for even faster feedback.
|
||||
|
||||
* * *
|
||||
|
||||
_This article is based on[16 reasons why to use Selenium IDE in 2019 (and 2 why not)][38] originally published on the Applitools blog._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/features-selenium-ide
|
||||
|
||||
作者:[Al Sargent][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/alsargent
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/search_find_code_issue_bug_programming.png?itok=XPrh7fa0 (magnifying glass on computer screen)
|
||||
[2]: https://www.seleniumhq.org/projects/webdriver/
|
||||
[3]: https://www.cypress.io/
|
||||
[4]: https://webdriver.io/
|
||||
[5]: https://seleniumhq.wordpress.com/2017/08/09/firefox-55-and-selenium-ide/
|
||||
[6]: https://seleniumhq.wordpress.com/2018/08/06/selenium-ide-tng/
|
||||
[7]: https://github.com/SeleniumHQ/selenium-ide/graphs/contributors
|
||||
[8]: http://davehaeffner.com/
|
||||
[9]: https://opensource.com/sites/default/files/uploads/selenium_ide_github_graphic_1.png (Selenium IDE's GitHub repository)
|
||||
[10]: https://chrome.google.com/webstore/detail/selenium-ide/mooikfkahbdckldjjndioackbalphokd
|
||||
[11]: https://addons.mozilla.org/en-US/firefox/addon/selenium-ide/
|
||||
[12]: https://www.seleniumhq.org/selenium-ide/docs/en/introduction/command-line-runner/
|
||||
[13]: https://www.seleniumhq.org/selenium-ide/docs/en/introduction/command-line-runner/#launching-the-runner
|
||||
[14]: http://chromedriver.chromium.org/
|
||||
[15]: https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
|
||||
[16]: https://github.com/mozilla/geckodriver
|
||||
[17]: https://github.com/SeleniumHQ/selenium/wiki/InternetExplorerDriver
|
||||
[18]: https://developer.apple.com/documentation/webkit/testing_with_webdriver_in_safari
|
||||
[19]: https://opensource.com/sites/default/files/uploads/selenium_ide_side_runner_2.png (SIDE Runner)
|
||||
[20]: https://opensource.com/sites/default/files/uploads/selenium_ide_linktext_3.png (Selenium IDE captures linkText, an xPath expression, and CSS-based locators)
|
||||
[21]: https://www.seleniumhq.org/selenium-ide/docs/en/introduction/control-flow/
|
||||
[22]: https://opensource.com/sites/default/files/uploads/selenium_ide_conditional_logic_4.png (Selenium IDE's Conditional logic)
|
||||
[23]: https://www.seleniumhq.org/selenium-ide/docs/en/api/commands/
|
||||
[24]: https://www.seleniumhq.org/selenium-ide/docs/en/api/commands/#execute-script
|
||||
[25]: https://www.seleniumhq.org/selenium-ide/docs/en/api/commands/#execute-async-script
|
||||
[26]: https://opensource.com/sites/default/files/uploads/selenium_ide_command_line_5.png (Selenium IDE's command line)
|
||||
[27]: https://stackoverflow.com/questions/27491789/how-to-upload-a-generic-file-into-a-jenkins-job
|
||||
[28]: https://docs.travis-ci.com/user/uploading-artifacts/
|
||||
[29]: https://circleci.com/docs/2.0/artifacts/
|
||||
[30]: https://www.seleniumhq.org/selenium-ide/docs/en/plugins/plugins-getting-started/
|
||||
[31]: https://chrome.google.com/webstore/detail/applitools-for-selenium-i/fbnkflkahhlmhdgkddaafgnnokifobik
|
||||
[32]: https://addons.mozilla.org/en-GB/firefox/addon/applitools-for-selenium-ide/
|
||||
[33]: https://en.wikipedia.org/wiki/Responsive_web_design
|
||||
[34]: https://applitools.com/visualgrid
|
||||
[35]: https://opensource.com/sites/default/files/uploads/selenium_ide_visual_grid_6.png (Selenium IDE's Visual Grid)
|
||||
[36]: https://applitools.com/root-cause-analysis
|
||||
[37]: https://opensource.com/sites/default/files/uploads/seleniumice_rootcauseanalysis_7.png (Finding visual bugs)
|
||||
[38]: https://applitools.com/blog/why-selenium-ide-2019
|
||||
@ -0,0 +1,72 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Edge Computing is Key to Meeting Digital Transformation Demands – and Partnerships Can Help Deliver Them)
|
||||
[#]: via: (https://www.networkworld.com/article/3387140/edge-computing-is-key-to-meeting-digital-transformation-demands-and-partnerships-can-help-deliver-t.html#tk.rss_all)
|
||||
[#]: author: (Rob McKernan https://www.networkworld.com/author/Rob-McKernan/)
|
||||
|
||||
Edge Computing is Key to Meeting Digital Transformation Demands – and Partnerships Can Help Deliver Them
|
||||
======
|
||||
|
||||
### Organizations in virtually every vertical industry are undergoing a digital transformation in an attempt to take advantage of edge computing technology
|
||||
|
||||
![Getty Images][1]
|
||||
|
||||
Organizations in virtually every vertical industry are undergoing a digital transformation in an attempt to take advantage of [edge computing][2] technology to make their businesses more efficient, innovative and profitable. In the process, they’re coming face to face with challenges ranging from time to market to reliability of IT infrastructure.
|
||||
|
||||
It’s a complex problem, especially when you consider the scope of what digital transformation entails. “Digital transformation is not simply a list of IT projects, it involves completely rethinking how an organization uses technology to pursue new revenue streams, products, services, and business models,” as the [research firm IDC says][3].
|
||||
|
||||
Companies will be spending more than $650 billion per year on digital transformation efforts by 2024, a CAGR of more than 18.5% from 2018, according to the research firm [Market Research Engine][4].
|
||||
|
||||
The drivers behind all that spending include Internet of Things (IoT) technology, which involves collecting data from machines and sensors covering every aspect of the organization. That is contributing to Big Data – the treasure trove of data that companies mine to find the keys to efficiency, opportunity and more. Artificial intelligence and machine learning are crucial to that effort, helping companies make sense of the mountains of data they’re creating and consuming, and to find opportunities.
|
||||
|
||||
**Requirements for Edge Computing**
|
||||
|
||||
All of these trends are creating the need for more and more compute power and data storage. And much of it needs to be close to the source of the data, and to those employees who are working with it. In other words, it’s driving the need for companies to build edge data centers or edge computing sites.
|
||||
|
||||
Physically, these edge computing sites bear little resemblance to large, centralized data centers, but they have many of the same requirements in terms of performance, reliability, efficiency and security. Given they are typically in locations with few if any IT personnel, the data centers must have a high degree of automation and remote management capabilities. And to meet business requirements, they must be built quickly.
|
||||
|
||||
**Answering the Call at the Edge**
|
||||
|
||||
These are complex requirements, but if companies are to meet time-to-market goals and deal with the lack of IT personnel at the edge, they demand simple solutions.
|
||||
|
||||
One solution is integration. We’re seeing this already in the IT space, with vendors delivering hyper-converged infrastructure that combines servers, storage, networking and software that is tightly integrated and delivered in a single enclosure. This saves IT groups valuable time in terms of procuring and configuring equipment and makes it far easier to manage over the long term.
|
||||
|
||||
Now we’re seeing the same strategy applied to edge data centers. Prefabricated, modular data centers are an ideal solution for delivering edge data center capacity quickly and reliably. All the required infrastructure – power, cooling, racks, UPSs – can be configured and installed in a factory and delivered as a single, modular unit to the data center site (or multiple modules, depending on requirements).
|
||||
|
||||
Given they’re built in a factory under controlled conditions, modular data centers are more reliable over the long haul. They can be configured with management software built-in, enabling remote management capabilities and a high degree of automation. And they can be delivered in weeks or months, not years – and in whatever size is required, including small “micro” data centers.
|
||||
|
||||
Few companies, however, have all the components required to deliver a complete, functional data center, not to mention the expertise required to install and configure it. So, it takes effective partnerships to deliver complete edge data center solutions.
|
||||
|
||||
**Tech Data Partnership Delivers at the Edge **
|
||||
|
||||
APC by Schneider Electric has a long history of partnering to deliver complete solutions that address customer needs. Of the thousands of partnerships it has established over the years, the [25-year partnership][5] with [Tech Data][6] is particularly relevant for the digital transformation era.
|
||||
|
||||
Tech Data is a $36.8 billion, Fortune 100 company that has established itself as the world’s leading end-to-end IT distributor. Power and physical infrastructure specialists from Tech Data team up with their counterparts from APC to deliver innovative solutions, including modular and [micro data centers][7]. Many of these solutions are pre-certified by major alliance partners, including IBM, HPE, Cisco, Nutanix, Dell EMC and others.
|
||||
|
||||
To learn more, [access the full story][8] that explains how the Tech Data and APC partnership helps deliver [Certainty in a Connected World][9] and effective edge computing solutions that meet today’s time to market requirements.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3387140/edge-computing-is-key-to-meeting-digital-transformation-demands-and-partnerships-can-help-deliver-t.html#tk.rss_all
|
||||
|
||||
作者:[Rob McKernan][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Rob-McKernan/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/04/gettyimages-494323751-942x445-100792905-large.jpg
|
||||
[2]: https://www.apc.com/us/en/solutions/business-solutions/edge-computing.jsp
|
||||
[3]: https://www.idc.com/getdoc.jsp?containerId=US43985717
|
||||
[4]: https://www.marketresearchengine.com/digital-transformation-market
|
||||
[5]: https://www.apc.com/us/en/partners-alliances/partners/tech-data-and-apc-partnership-drives-edge-computing-success/full-resource.jsp
|
||||
[6]: https://www.techdata.com/
|
||||
[7]: https://www.apc.com/us/en/solutions/business-solutions/micro-data-centers.jsp
|
||||
[8]: https://www.apc.com/us/en/partners-alliances/partners/tech-data-and-apc-partnership-drives-edge-computing-success/index.jsp
|
||||
[9]: https://www.apc.com/us/en/who-we-are/certainty-in-a-connected-world.jsp
|
||||
@ -0,0 +1,73 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Intel formally launches Optane for data center memory caching)
|
||||
[#]: via: (https://www.networkworld.com/article/3387117/intel-formally-launches-optane-for-data-center-memory-caching.html#tk.rss_all)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Intel formally launches Optane for data center memory caching
|
||||
======
|
||||
|
||||
### Intel formally launched the Optane persistent memory product line, which includes 3D Xpoint memory technology. The Intel-only solution is meant to sit between DRAM and NAND and to speed up performance.
|
||||
|
||||
![Intel][1]
|
||||
|
||||
As part of its [massive data center event][2] on Tuesday, Intel formally launched the Optane persistent memory product line. It had been out for a while, but the current generation of Xeon server processors could not fully utilize it. The new Xeon 8200 and 9200 lines take full advantage of it.
|
||||
|
||||
And since Optane is an Intel product (co-developed with Micron), that means AMD and Arm server processors are out of luck.
|
||||
|
||||
As I have [stated in the past][3], Optane DC Persistent Memory uses 3D Xpoint memory technology that Intel developed with Micron Technology. 3D Xpoint is a non-volatile memory type that is much faster than solid-state drives (SSD), almost at the speed of DRAM, but it has the persistence of NAND flash.
|
||||
|
||||
**[ Read also:[Why NVMe? Users weigh benefits of NVMe-accelerated flash storage][4] and [IDC’s top 10 data center predictions][5] | Get regularly scheduled insights [Sign up for Network World newsletters][6] ]**
|
||||
|
||||
The first 3D Xpoint products were SSDs called Intel’s ["ruler,"][7] because they were designed in a long, thin format similar to the shape of a ruler. They were designed that way to fit in 1u server carriages. As part of Tuesday’s announcement, Intel introduced the new Intel SSD D5-P4326 'Ruler' SSD, using four-cell or QLC 3D NAND memory, with up to 1PB of storage in a 1U design.
|
||||
|
||||
Optane DC Persistent Memory will be available in DIMM capacities of 128GB on up to 512GB initially. That’s two to four times what you can get with DRAM, said Navin Shenoy, executive vice president and general manager of Intel’s Data Center Group, who keynoted the event.
|
||||
|
||||
“We expect system capacity in a server system to scale to 4.5 terabytes per socket or 36 TB in an 8-socket system. That’s three times larger than what we were able to do with the first-generation of Xeon Scalable,” he said.
|
||||
|
||||
## Intel Optane memory uses and speed
|
||||
|
||||
Optane runs in two different modes: Memory Mode and App Direct Mode. Memory mode is what I have been describing to you, where Optane memory exists “above” the DRAM and acts as a cache. In App Direct mode, the DRAM and Optane DC Persistent Memory are pooled together to maximize the total capacity. Not every workload is ideal for this kind of configuration, so it should be used in applications that are not latency-sensitive. The primary use case for Optane, as Intel is promoting it, is Memory Mode.
|
||||
|
||||
**[[Get certified as an Apple Technical Coordinator with this seven-part online course from PluralSight.][8] ]**
|
||||
|
||||
When 3D Xpoint was initially announced a few years back, Intel claimed it was 1,000 times faster than NAND, with 1000 times the endurance, and 10 times the density potential of DRAM. Well that was a little exaggerated, but it does have some intriguing elements.
|
||||
|
||||
Optane memory, when used in 256B contiguous 4 cacheline, can achieve read speeds of 8.3GB/sec and write speeds of 3.0GB/sec. Compare that with the read/write speed of 500 or so MB/sec for a SATA SSD, and you can see the performance gain. Optane, remember, is feeding memory, so it caches frequently accessed SSD content.
|
||||
|
||||
This is the key takeaware of Optane DC. It will keep very large data sets very close to memory, and hence the CPU, with low latency while at the same time minimizing the need to access the slower storage subsystem, whether it’s SSD or HDD. It now offers the possibility of putting multiple terabytes of data very close to the CPU for much faster access.
|
||||
|
||||
## One challenge with Optane memory
|
||||
|
||||
The only real challenge is that Optane goes into DIMM slots, which is where memory goes. Now some motherboards come with as many as 16 DIMM slots per CPU socket, but that’s still board real estate that the customer and OEM provider will need to balance out: Optane vs. memory. There are some Optane drives in PCI Express format, which alleviate the memory crowding on the motherboard.
|
||||
|
||||
3D Xpoint also offers higher endurance than traditional NAND flash memory due to the way it writes data. Intel promises a five-year warranty with its Optane, while a lot of SSDs offer only three years.
|
||||
|
||||
Join the Network World communities on [Facebook][9] and [LinkedIn][10] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3387117/intel-formally-launches-optane-for-data-center-memory-caching.html#tk.rss_all
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/06/intel-optane-persistent-memory-100760427-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3386142/intel-unveils-an-epic-response-to-amds-server-push.html
|
||||
[3]: https://www.networkworld.com/article/3279271/intel-launches-optane-the-go-between-for-memory-and-storage.html
|
||||
[4]: https://www.networkworld.com/article/3290421/why-nvme-users-weigh-benefits-of-nvme-accelerated-flash-storage.html
|
||||
[5]: https://www.networkworld.com/article/3242807/data-center/top-10-data-center-predictions-idc.html#nww-fsb
|
||||
[6]: https://www.networkworld.com/newsletters/signup.html#nww-fsb
|
||||
[7]: https://www.theregister.co.uk/2018/02/02/ruler_and_miniruler_ssd_formats_look_to_banish_diskstyle_drives/
|
||||
[8]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fapple-certified-technical-trainer-10-11
|
||||
[9]: https://www.facebook.com/NetworkWorld/
|
||||
[10]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,68 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Running LEDs in reverse could cool computers)
|
||||
[#]: via: (https://www.networkworld.com/article/3386876/running-leds-in-reverse-could-cool-computers.html#tk.rss_all)
|
||||
[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
|
||||
|
||||
Running LEDs in reverse could cool computers
|
||||
======
|
||||
|
||||
### The miniaturization of electronics is reaching its limits in part because of heat management. Many are now aggressively trying to solve the problem. A kind of reverse-running LED is one avenue being explored.
|
||||
|
||||
![monsitj / Getty Images][1]
|
||||
|
||||
The quest to find more efficient methods for cooling computers is almost as high on scientists’ agendas as the desire to discover better battery chemistries.
|
||||
|
||||
More cooling is crucial for reducing costs. It would also allow for more powerful processing to take place in smaller spaces, where limited processing should be crunching numbers instead of making wasteful heat. It would stop heat-caused breakdowns, thereby creating longevity in components, and it would promote eco-friendly data centers — less heat means less impact on the environment.
|
||||
|
||||
Removing heat from microprocessors is one angle scientists have been exploring, and they think they have come up with a simple, but unusual and counter-intuitive solution. They say that running a variant of a Light Emitting Diode (LED) with its electrodes reversed forces the component to act as if it were at an unusually low temperature. Placing it next to warmer electronics, then, with a nanoscale gap introduced, causes the LED to suck out the heat.
|
||||
|
||||
**[ Read also:[IDC’s top 10 data center predictions][2] | Get regularly scheduled insights: [Sign up for Network World newsletters][3] ]**
|
||||
|
||||
“Once the LED is reverse biased, it began acting as a very low temperature object, absorbing photons,” says Edgar Meyhofer, professor of mechanical engineering at University of Michigan, in a [press release][4] announcing the breakthrough. “At the same time, the gap prevents heat from traveling back, resulting in a cooling effect.”
|
||||
|
||||
The researchers say the LED and the adjacent electrical device (in this case a calorimeter, usually used for measuring heat energy) have to be extremely close. They say they’ve been able to demonstrate cooling of six watts per meter-squared. That’s about the power of sunshine on the earth’s surface, they explain.
|
||||
|
||||
Internet of things (IoT) devices and smartphones could be among those electronics that would ultimately benefit from the LED modification. Both kinds of devices require increasing computing power to be squashed into smaller spaces.
|
||||
|
||||
“Removing the heat from the microprocessor is beginning to limit how much power can be squeezed into a given space,” the University of Michigan announcement says.
|
||||
|
||||
### Materials Science and cooling computers
|
||||
|
||||
[I’ve written before about new forms of computer cooling][5]. Exotic materials, derived from Materials Science, are among ideas being explored. Sodium bismuthide (Na3Bi) could be used in transistor design, the U.S. Department of Energy’s Lawrence Berkeley National Laboratory says. The new substance carries a charge and is importantly tunable; however, it doesn’t need to be chilled as superconductors currently do.
|
||||
|
||||
In fact, that’s a problem with superconductors. They unfortunately need more cooling than most electronics — electrical resistance with the technology is expelled through extreme cooling.
|
||||
|
||||
Separately, [researchers in Germany at the University of Konstanz][6] say they soon will have superconductor-driven computers without waste heat. They plan to use electron spin — a new physical dimension in electrons that could create efficiency gains. The method “significantly reduces the energy consumption of computing centers,” the university said in a press release last year.
|
||||
|
||||
Another way to reduce heat could be [to replace traditional heatsinks with spirals and mazes][7] embedded on microprocessors. Miniscule channels printed on the chip itself could provide paths for coolant to travel, again separately, scientists from Binghamton University say.
|
||||
|
||||
“The miniaturization of the semiconductor technology is approaching its physical limits,” the University of Konstanz says. Heat management is very much on scientists’ agenda now. It’s “one of the big challenges in miniaturization."
|
||||
|
||||
Join the Network World communities on [Facebook][8] and [LinkedIn][9] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3386876/running-leds-in-reverse-could-cool-computers.html#tk.rss_all
|
||||
|
||||
作者:[Patrick Nelson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Patrick-Nelson/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/02/big_data_center_server_racks_storage_binary_analytics_by_monsitj_gettyimages-944444446_3x2-100787357-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3242807/data-center/top-10-data-center-predictions-idc.html#nww-fsb
|
||||
[3]: https://www.networkworld.com/newsletters/signup.html#nww-fsb
|
||||
[4]: https://news.umich.edu/running-an-led-in-reverse-could-cool-future-computers/
|
||||
[5]: https://www.networkworld.com/article/3326831/computers-could-soon-run-cold-no-heat-generated.html
|
||||
[6]: https://www.uni-konstanz.de/en/university/news-and-media/current-announcements/news/news-in-detail/Supercomputer-ohne-Abwaerme/
|
||||
[7]: https://www.networkworld.com/article/3322956/chip-cooling-breakthrough-will-reduce-data-center-power-costs.html
|
||||
[8]: https://www.facebook.com/NetworkWorld/
|
||||
[9]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,79 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why blockchain (might be) coming to an IoT implementation near you)
|
||||
[#]: via: (https://www.networkworld.com/article/3386881/why-blockchain-might-be-coming-to-an-iot-implementation-near-you.html#tk.rss_all)
|
||||
[#]: author: (Jon Gold https://www.networkworld.com/author/Jon-Gold/)
|
||||
|
||||
Why blockchain (might be) coming to an IoT implementation near you
|
||||
======
|
||||
|
||||
![MF3D / Getty Images][1]
|
||||
|
||||
Companies have found that IoT partners well with a host of other popular enterprise computing technologies of late, and blockchain – the innovative system of distributed trust most famous for underpinning cryptocurrencies – is no exception. Yet while the two phenomena can be complementary in certain circumstances, those expecting an explosion of blockchain-enabled IoT technologies probably shouldn’t hold their breath.
|
||||
|
||||
Blockchain technology can be counter-intuitive to understand at a basic level, but it’s probably best thought of as a sort of distributed ledger keeping track of various transactions. Every “block” on the chain contains transactional records or other data to be secured against tampering, and is linked to the previous one by a cryptographic hash, which means that any tampering with the block will invalidate that connection. The nodes – which can be largely anything with a CPU in it – communicate via a decentralized, peer-to-peer network to share data and ensure the validity of the data in the chain.
|
||||
|
||||
**[ Also see[What is edge computing?][2] and [How edge networking and IoT will reshape data centers][3].]**
|
||||
|
||||
The system works because all the blocks have to agree with each other on the specifics of the data that they’re safeguarding, according to Nir Kshetri, a professor of management at the University of North Carolina – Greensboro. If someone attempts to alter a previous transaction on a given node, the rest of the data on the network pushes back. “The old record of the data is still there,” said Kshetri.
|
||||
|
||||
That’s a powerful security technique – absent a bad actor successfully controlling all of the nodes on a given blockchain (the [famous “51% attack][4]”), the data protected by that blockchain can’t be falsified or otherwise fiddled with. So it should be no surprise that the use of blockchain is an attractive option to companies in some corners of the IoT world.
|
||||
|
||||
Part of the reason for that, over and above the bare fact of blockchain’s ability to securely distribute trusted information across a network, is its place in the technology stack, according to Jay Fallah, CTO and co-founder of NXMLabs, an IoT security startup.
|
||||
|
||||
“Blockchain stands at a very interesting intersection. Computing has accelerated in the last 15 years [in terms of] storage, CPU, etc, but networking hasn’t changed that much until recently,” he said. “[Blockchain]’s not a network technology, it’s not a data technology, it’s both.”
|
||||
|
||||
### Blockchain and IoT**
|
||||
|
||||
**
|
||||
|
||||
Where blockchain makes sense as a part of the IoT world depends on who you speak to and what they are selling, but the closest thing to a general summation may have come from Allison Clift-Jenning, CEO of enterprise blockchain vendor Filament.
|
||||
|
||||
“Anywhere where you've got people who are kind of wanting to trust each other, and have very archaic ways of doing it, that is usually a good place to start with use cases,” she said.
|
||||
|
||||
One example, culled directly from Filament’s own customer base, is used car sales. Filament’s working with “a major Detroit automaker” to create a trusted-vehicle history platform, based on a device that plugs into the diagnostic port of a used car, pulls information from there, and writes that data to a blockchain. Just like that, there’s an immutable record of a used car’s history, including whether its airbags have ever been deployed, whether it’s been flooded, and so on. No unscrupulous used car lot or duplicitous former owner could change the data, and even unplugging the device would mean that there’s a suspicious blank period in the records.
|
||||
|
||||
Most of present-day blockchain IoT implementation is about trust and the validation of data, according to Elvira Wallis, senior vice president and global head of IoT at SAP.
|
||||
|
||||
“Most of the use cases that we have come across are in the realm of tracking and tracing items,” she said, giving the example of a farm-to-fork tracking system for high-end foodstuffs, using blockchain nodes mounted on crates and trucks, allowing for the creation of an un-fudgeable record of an item’s passage through transport infrastructure. (e.g., how long has this steak been refrigerated at such-and-such a temperature, how far has it traveled today, and so on.)
|
||||
|
||||
### **Is using blockchain with IoT a good idea?**
|
||||
|
||||
Different vendors sell different blockchain-based products for different use cases, which use different implementations of blockchain technology, some of which don’t bear much resemblance to the classic, linear, mined-transaction blockchain used in cryptocurrency.
|
||||
|
||||
That means it’s a capability that you’d buy from a vendor for a specific use case, at this point. Few client organizations have the in-house expertise to implement a blockchain security system, according to 451 Research senior analyst Csilla Zsigri.
|
||||
|
||||
The idea with any intelligent application of blockchain technology is to play to its strengths, she said, creating a trusted platform for critical information.
|
||||
|
||||
“That’s where I see it really adding value, just in adding a layer of trust and validation,” said Zsigri.
|
||||
|
||||
Yet while the basic idea of blockchain-enabled IoT applications is fairly well understood, it’s not applicable to every IoT use case, experts agree. Applying blockchain to non-transactional systems – although there are exceptions, including NXM Labs’ blockchain-based configuration product for IoT devices – isn’t usually the right move.
|
||||
|
||||
If there isn’t a need to share data between two different parties – as opposed to simply moving data from sensor to back-end – blockchain doesn’t generally make sense, since it doesn’t really do anything for the key value-add present in most IoT implementations today: data analysis.
|
||||
|
||||
“We’re still in kind of the early dial-up era of blockchain today,” said Clift-Jennings. “It’s slower than a typical database, it often isn't even readable, it often doesn't have a query engine tied to it. You don't really get privacy, by nature of it.”
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3386881/why-blockchain-might-be-coming-to-an-iot-implementation-near-you.html#tk.rss_all
|
||||
|
||||
作者:[Jon Gold][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Jon-Gold/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/02/chains_binary_data_blockchain_security_by_mf3d_gettyimages-941175690_2400x1600-100788434-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3224893/internet-of-things/what-is-edge-computing-and-how-it-s-changing-the-network.html
|
||||
[3]: https://www.networkworld.com/article/3291790/data-center/how-edge-networking-and-iot-will-reshape-data-centers.html
|
||||
[4]: https://bitcoinist.com/51-percent-attack-hackers-steals-18-million-bitcoin-gold-btg-tokens/
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,97 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 open source tools for teaching young children to read)
|
||||
[#]: via: (https://opensource.com/article/19/4/early-literacy-tools)
|
||||
[#]: author: (Laura B. Janusek https://opensource.com/users/lbjanusek)
|
||||
|
||||
5 open source tools for teaching young children to read
|
||||
======
|
||||
Early literacy apps give kids a foundation in letter recognition,
|
||||
alphabet sequencing, word finding, and more.
|
||||
![][1]
|
||||
|
||||
Anyone who sees a child using a tablet or smartphone observes their seemingly innate ability to scroll through apps and swipe through screens, flexing those "digital native" muscles. According to [Common Sense Media][2], the percentage of US households in which 0- to 8-year-olds have access to a smartphone has grown from 52% in 2011 to 98% in 2017. While the debates around age guidelines and screen time surge, it's hard to deny that children are developing familiarity and skills with technology at an unprecedented rate.
|
||||
|
||||
This rise in early technical literacy may be astonishing, but what about _traditional_ literacy, the good old-fashioned ability to read? What does the intersection of early literacy development and early tech use look like? Let's explore some open source tools for early learners that may help develop both of these critical skill sets.
|
||||
|
||||
### Balancing risks and rewards
|
||||
|
||||
But first, a disclaimer: Guidelines for technology use, especially for young children, are [constantly changing][3]. Organizations like the American Academy of Pediatrics, Common Sense Media, Zero to Three, and PBS Kids are continually conducting research and publishing recommendations. One position that all of these and other organizations can agree on is that plopping a child in front of a screen with unmonitored content for an unlimited set of time is highly inadvisable.
|
||||
|
||||
Even setting kids up with educational content or tools for extended periods of time may have risks. And on the flip side, research on the benefits of education technologies is often limited or unavailable. In short, there are many cases in which we don't know for certain if educational technology use at a young age is beneficial, detrimental, or simply neutral.
|
||||
|
||||
But if screen time is available to your child or student, it's logical to infer that educational resources would be preferable over simpler pop-the-bubble or slice-the-fruit games or platforms that could house inappropriate content or online predators. While we may not be able to prove that education apps will make a child's test scores soar, we can at least take comfort in their generally being safer and more age-appropriate than the internet at large.
|
||||
|
||||
That said, if you're open to exploring early-education technologies, there are many reasons to look to open source options. Open source technologies are not only free but open to collaborative improvement. In many cases, they are created by developers who are educators or parents themselves, and they're a great way to avoid in-app purchases, advertisements, and paid upgrades. Open source programs can often be downloaded and installed on your device and accessed without an internet connection. Plus, the idea of [open source in education][4] is a growing trend, and there are countless resources to [learn more][5] about the concept.
|
||||
|
||||
But for now, let's check out some open source tools for early literacy in action!
|
||||
|
||||
### Childsplay
|
||||
|
||||
![Childsplay screenshot][6]
|
||||
|
||||
Let's start simple. [Childsplay][7], licensed under the GPLv2, is the most basic of the resources on this list. It's a compilation of just over a dozen educational games for young learners, four of which are specific to letter recognition, including memory games and an activity where the learner identifies a spoken letter.
|
||||
|
||||
### eduActiv8
|
||||
|
||||
![eduActiv8 screenshot][8]
|
||||
|
||||
[eduActiv8][9] started in 2011 as a personal project for the developer's son, "whose thirst for learning and knowledge inspired the creation of this educational program." It includes activities for building basic math and early literacy skills, including a variety of spelling, matching, and listening activities. Games include filling in missing letters in the alphabet, unscrambling letters to form a word, matching words to images, and completing mazes by connecting letters in the correct order. eduActiv8 was written in [Python][10] and is available under the GPLv3.
|
||||
|
||||
### GCompris
|
||||
|
||||
![GCompris screenshot][11]
|
||||
|
||||
[GCompris][12] is an open source behemoth (licensed under the GPLv3) of early educational activities. A French software engineer started it in 2000, and it now includes over 130 educational games in nearly 20 languages. Tailored for learners under age 10, it includes activities for letter recognition and drawing, alphabet sequencing, vocabulary building, and games like hangman to identify missing letters in words, plus activities for learning braille. It also includes games in math and music, plus classics from tic-tac-toe to chess.
|
||||
|
||||
### Feed the Monster
|
||||
|
||||
![Feed the Monster screenshot][13]
|
||||
|
||||
The quality of the playful "monster" graphics in [Feed the Monster][14] definitely sets it apart from the others on this list, plus it supports nearly 40 languages! The app includes activities for sorting letters to form words, memory games to match words to images, and letter-tracing writing activities. The app is developed by Curious Learning, which states: "We create, localize, distribute, and optimize open source mobile software so every child can learn to read." While Feed the Monster's offerings are geared toward early readers, Curious Mind's roadmap suggests it's headed towards a more robust personalized literacy platform growing on a foundation of research with MIT, Tufts, and Georgia State University.
|
||||
|
||||
### Syntax Untangler
|
||||
|
||||
![Syntax Untangler screenshot][15]
|
||||
|
||||
[Syntax Untangler][16] is the outlier of this group. Developed by a technologist at the University of Wisconsin–Madison under the GPLv2, the application is "particularly designed for training language learners to recognize and parse linguistic features." Examples show the software being used for foreign language learning, but anyone can use it to create language identification games, including games for early literacy activities like letter recognition. It could also be applied to later literacy skills, like identifying parts of speech in complex sentences or literary techniques in poetry or fiction.
|
||||
|
||||
### Wrapping up
|
||||
|
||||
Access to [literary environments][17] has been shown to impact literacy and attitudes towards reading. Why not strive to create a digital literary environment for our kids by filling our devices with educational technologies, just like our shelves are filled with books?
|
||||
|
||||
Now it's your turn! What open source literacy tools have you used? Comment below to share.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/early-literacy-tools
|
||||
|
||||
作者:[Laura B. Janusek][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/lbjanusek
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/idea_innovation_kid_education.png?itok=3lRp6gFa
|
||||
[2]: https://www.commonsensemedia.org/research/the-common-sense-census-media-use-by-kids-age-zero-to-eight-2017?action
|
||||
[3]: https://www.businessinsider.com/smartphone-use-young-kids-toddlers-limits-science-2018-3
|
||||
[4]: /article/18/1/best-open-education
|
||||
[5]: https://opensource.com/resources/open-source-education
|
||||
[6]: https://opensource.com/sites/default/files/uploads/cp_flashcards.gif (Childsplay screenshot)
|
||||
[7]: http://www.childsplay.mobi/
|
||||
[8]: https://opensource.com/sites/default/files/uploads/eduactiv8.jpg (eduActiv8 screenshot)
|
||||
[9]: https://www.eduactiv8.org/
|
||||
[10]: /article/17/11/5-approaches-learning-python
|
||||
[11]: https://opensource.com/sites/default/files/uploads/gcompris2.png (GCompris screenshot)
|
||||
[12]: https://gcompris.net/index-en.html
|
||||
[13]: https://opensource.com/sites/default/files/uploads/feedthemonster.png (Feed the Monster screenshot)
|
||||
[14]: https://www.curiouslearning.org/
|
||||
[15]: https://opensource.com/sites/default/files/uploads/syntaxuntangler.png (Syntax Untangler screenshot)
|
||||
[16]: https://courses.dcs.wisc.edu/untangler/
|
||||
[17]: http://www.jstor.org/stable/41386459
|
||||
@ -0,0 +1,91 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Command line quick tips: Cutting content out of files)
|
||||
[#]: via: (https://fedoramagazine.org/command-line-quick-tips-cutting-content-out-of-files/)
|
||||
[#]: author: (Stephen Snow https://fedoramagazine.org/author/jakfrost/)
|
||||
|
||||
Command line quick tips: Cutting content out of files
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
The Fedora distribution is a full featured operating system with an excellent graphical desktop environment. A user can point and click their way through just about any typical task easily. All of this wonderful ease of use masks the details of a powerful command line under the hood. This article is part of a series that shows you some common command line utilities. So let’s drop into the shell, and have a look at **cut**.
|
||||
|
||||
Often when you work in the command line, you are working with text files. Sometimes these files may be quite long. Reading them in their entirety, while feasible, can be time consuming and prone to errors. In this installment you’ll learn how to extract content from text files, and get the information you want from them.
|
||||
|
||||
It’s important to recognize that there are many ways to accomplish similar command line tasks in Fedora. The Fedora repositories include entire language systems for parsing and working with text, as an example. Also, there are multiple command line utilities available for just about any purpose conceivable in the shell. This article will only focus on using a few of those utility choices, to extract some information from a file and present it in a readable format.
|
||||
|
||||
### Making the cut
|
||||
|
||||
To illustrate this example use a standard sizable file on the system like _/etc/passwd_. As seen in a prior article in this series, you can execute the _cat_ command to view an entire file:
|
||||
|
||||
```
|
||||
$ cat /etc/passwd
|
||||
root:x:0:0:root:/root:/bin/bash
|
||||
bin:x:1:1:bin:/bin:/sbin/nologin
|
||||
daemon:x:2:2:daemon:/sbin:/sbin/nologin
|
||||
adm:x:3:4:adm:/var/adm:/sbin/nologin
|
||||
...
|
||||
```
|
||||
|
||||
This file contains information on all accounts present on the system. It has a specific format:
|
||||
|
||||
```
|
||||
name:password:user-id:group-id:comment:home-directory:shell
|
||||
```
|
||||
|
||||
Imagine that you want to simply have a list of all the account names on the system. If you could only cut out the _name_ value from each line. This is where the _cut_ command comes in handy! This command treats any input one line at a time, and extracts a specific part of the line.
|
||||
|
||||
The _cut_ command provides options for selecting parts of a line differently, and in this example two of them are needed, _-d_ which is an option to specify a delimiter type to use, and _-f_ which is an option to specify which field of the line to cut. The _-d_ option lets you declare the _delimiter_ that separates values in a line. In this case a colon (:) is used to separate values. The _-f_ option lets you choose which field value or values to extract. So for this example the command entered would be:
|
||||
|
||||
```
|
||||
$ cut -d: -f1 /etc/passwd
|
||||
root
|
||||
bin
|
||||
daemon
|
||||
adm
|
||||
...
|
||||
```
|
||||
|
||||
That’s great, it worked! But you get the printout to the standard output, which in a terminal session at least means the screen. What if you needed the information for another task to be done later? It would be really nice if there was a way to put the output of the _cut_ command into a text file to save it. There is an easy builtin shell function for such a task, the redirect function ( _>_ ).
|
||||
|
||||
```
|
||||
$ cut -d: -f1 /etc/passwd > names.txt
|
||||
```
|
||||
|
||||
This will place the output of cut into a file called _names.txt_ and you can check the contents with _cat:_
|
||||
|
||||
```
|
||||
$ cat names.txt
|
||||
root
|
||||
bin
|
||||
daemon
|
||||
adm
|
||||
...
|
||||
```
|
||||
|
||||
With two commands and one shell function, it was easy to identify using _cat_ , extract using _cut_ , and redirect the extracted information from one file, saving it to another file for later use.
|
||||
|
||||
* * *
|
||||
|
||||
_Photo by _[ _Joel Mbugua_][2]_ on _[_Unsplash_][3]_._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/command-line-quick-tips-cutting-content-out-of-files/
|
||||
|
||||
作者:[Stephen Snow][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/jakfrost/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/04/commandline-cutting-816x345.jpg
|
||||
[2]: https://unsplash.com/photos/tA5eSY_hay8?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[3]: https://unsplash.com/search/photos/command-line?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
234
sources/tech/20190405 File sharing with Git.md
Normal file
234
sources/tech/20190405 File sharing with Git.md
Normal file
@ -0,0 +1,234 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (File sharing with Git)
|
||||
[#]: via: (https://opensource.com/article/19/4/file-sharing-git)
|
||||
[#]: author: (Seth Kenlon (Red Hat, Community Moderator) https://opensource.com/users/seth)
|
||||
|
||||
File sharing with Git
|
||||
======
|
||||
SparkleShare is an open source, Git-based, Dropbox-style file sharing
|
||||
application. Learn more in our series about little-known uses of Git.
|
||||
![][1]
|
||||
|
||||
[Git][2] is one of those rare applications that has managed to encapsulate so much of modern computing into one program that it ends up serving as the computational engine for many other applications. While it's best-known for tracking source code changes in software development, it has many other uses that can make your life easier and more organized. In this series leading up to Git's 14th anniversary on April 7, we'll share seven little-known ways to use Git. Today, we'll look at SparkleShare, which uses Git as the backbone for file sharing.
|
||||
|
||||
### Git for file sharing
|
||||
|
||||
One of the nice things about Git is that it's inherently distributed. It's built to share. Even if you're sharing a repository just with other computers on your own network, Git brings transparency to the act of getting files from a shared location.
|
||||
|
||||
As interfaces go, Git is pretty simple. It varies from user to user, but the common incantation when sitting down to get some work done is just **git pull** or maybe the slightly more complex **git pull && git checkout -b my-branch**. Still, for some people, the idea of _entering a command_ into their computer at all is confusing or bothersome. Computers are meant to make life easy, and computers are good at repetitious tasks, and so there are easier ways to share files with Git.
|
||||
|
||||
### SparkleShare
|
||||
|
||||
The [SparkleShare][3] project is a cross-platform, open source, Dropbox-style file sharing application based on Git. It automates all Git commands, triggering the add, commit, push, and pull processes with the simple act of dragging-and-dropping a file into a specially designated SparkleShare directory. Because it is based on Git, you get fast, diff-based pushes and pulls, and you inherit all the benefits of Git version control and backend infrastructure (like Git hooks). It can be entirely self-hosted, or you can use it with Git hosting services like [GitLab][4], GitHub, Bitbucket, and others. Furthermore, because it's basically just a frontend to Git, you can access your SparkleShare files on devices that may not have a SparkleShare client but do have Git clients.
|
||||
|
||||
Just as you get all the benefits of Git, you also get all the usual Git restrictions: It's impractical to use SparkleShare to store hundreds of photos and music and videos because Git is designed and optimized for text. Git certainly has the capability to store large files of binary data but it is designed to track history, so once a file is added to it, it's nearly impossible to completely remove it. This somewhat limits the usefulness of SparkleShare for some people, but it makes it ideal for many workflows, including [calendaring][5].
|
||||
|
||||
#### Installing SparkleShare
|
||||
|
||||
SparkleShare is cross-platform, with installers for Windows and Mac available from its [website][6]. For Linux, there's a [Flatpak][7] in your software installer, or you can run these commands in a terminal:
|
||||
|
||||
|
||||
```
|
||||
$ sudo flatpak remote-add flathub <https://flathub.org/repo/flathub.flatpakrepo>
|
||||
$ sudo flatpak install flathub org.sparkleshare.SparkleShare
|
||||
```
|
||||
|
||||
### Creating a Git repository
|
||||
|
||||
SparkleShare isn't software-as-a-service (SaaS). You run SparkleShare on your computer to communicate with a Git repository—SparkleShare doesn't store your data. If you don't have a Git repository to sync a folder with yet, you must create one before launching SparkleShare. You have three options: hosted Git, self-hosted Git, or self-hosted SparkleShare.
|
||||
|
||||
#### Git hosting
|
||||
|
||||
SparkleShare can use any Git repository you can access for storage, so if you have or create an account with GitLab or any other hosting service, it can become the backend for your SparkleShare. For example, the open source [Notabug.org][8] service is a Git hosting service like GitHub and GitLab, but unique enough to prove SparkleShare's flexibility. Creating a new repository differs from host to host depending on the user interface, but all of the major ones follow the same general model.
|
||||
|
||||
First, locate the button in your hosting service to create a new project or repository and click on it to begin. Then step through the repository creation process, providing a name for your repository, privacy level (repositories often default to being public), and whether or not to initialize the repository with a README file. Whether you need a README or not, enable an initial README file. Starting a repository with a file isn't strictly necessary, but it forces the Git host to instantiate a **master** branch in the repository, which helps ensure that frontend applications like SparkleShare have a branch to commit and push to. It's also useful for you to see a file, even if it's an almost empty README file, to confirm that you have connected.
|
||||
|
||||
![Creating a Git repository][9]
|
||||
|
||||
Once you've created a repository, obtain the URL it uses for SSH clones. You can get this URL the same way anyone gets any URL for a Git project: navigate to the page of the repository and look for the **Clone** button or field.
|
||||
|
||||
![Cloning a URL on GitHub][10]
|
||||
|
||||
Cloning a GitHub URL.
|
||||
|
||||
![Cloning a URL on GitLab][11]
|
||||
|
||||
Cloning a GitLab URL.
|
||||
|
||||
This is the address SparkleShare uses to reach your data, so make note of it. Your Git repository is now configured.
|
||||
|
||||
#### Self-hosted Git
|
||||
|
||||
You can use SparkleShare to access a Git repository on any computer you have access to. No special setup is required, aside from a bare Git repository. However, if you want to give access to your Git repository to anyone else, then you should run a Git manager like [Gitolite][12] or SparkleShare's own Dazzle server to help you manage SSH keys and accounts. At the very least, create a user specific to Git so that users with access to your Git repository don't also automatically gain access to the rest of your server.
|
||||
|
||||
Log into your server as the Git user (or yourself, if you're very good at managing user and group permissions) and create a repository:
|
||||
|
||||
|
||||
```
|
||||
$ mkdir ~/sparkly.git
|
||||
$ cd ~/sparkly.git
|
||||
$ git init --bare .
|
||||
```
|
||||
|
||||
Your Git repository is now configured.
|
||||
|
||||
#### Dazzle
|
||||
|
||||
SparkleShare's developers provide a Git management system called [Dazzle][13] to help you self-host Git repositories.
|
||||
|
||||
On your server, download the Dazzle application to some location in your path:
|
||||
|
||||
|
||||
```
|
||||
$ curl <https://raw.githubusercontent.com/hbons/Dazzle/master/dazzle.sh> \
|
||||
\--output ~/bin/dazzle
|
||||
$ chmod +x ~/bin/dazzle
|
||||
```
|
||||
|
||||
Dazzle sets up a user specific to Git and SparkleShare and also implements access rights based on keys generated by the SparkleShare application. For now, just set up a project:
|
||||
|
||||
|
||||
```
|
||||
`$ dazzle create sparkly`
|
||||
```
|
||||
|
||||
Your server is now configured as a SparkleShare host.
|
||||
|
||||
### Configuring SparkleShare
|
||||
|
||||
When you launch SparkleShare for the first time, you are prompted to configure what server you want SparkleShare to use for storage. This process may feel like a first-run setup wizard, but it's actually the usual process for setting up a new shared location within SparkleShare. Unlike many shared drive applications, with SparkleShare you can have several locations configured at once. The first shared location you configure isn't any more significant than any shared location you may set up later, and you're not signing up with SparkleShare or any other service. You're just pointing SparkleShare at a Git repository so that it knows what to keep your first SparkleShare folder in sync with.
|
||||
|
||||
On the first screen, identify yourself by whatever means you want on record in the Git commits that SparkleShare makes on your behalf. You can use anything, even fake information that resolves to nothing. It's purely for the commit messages, which you may never even see if you have no interest in reviewing the Git backend processes.
|
||||
|
||||
The next screen prompts you to choose your hosting type. If you are using GitLab, GitHub, Planio, or Bitbucket, then select the appropriate one. For anything else, select **Own server**.
|
||||
|
||||
![Choosing a Sparkleshare host][14]
|
||||
|
||||
At the bottom of this screen, you must enter the SSH clone URL. If you're self-hosting, the address is something like **<ssh://username@example.com>** and the remote path is the absolute path to the Git repository you created for this purpose.
|
||||
|
||||
Based on my self-hosted examples above, the address to my imaginary server is **<ssh://git@example.com:22122>** (the **:22122** indicates a nonstandard SSH port) and the remote path is **/home/git/sparkly.git**.
|
||||
|
||||
If I use my Notabug.org account instead, the address from the example above is **[git@notabug.org][15]** and the path is **seth/sparkly.git**.
|
||||
|
||||
SparkleShare will fail the first time it attempts to connect to the host because you have not yet copied the SparkleShare client ID (an SSH key specific to the SparkleShare application) to the Git host. This is expected, so don't cancel the process. Leave the SparkleShare setup window open and obtain the client ID from the SparkleShare icon in your system tray. Then copy the client ID to your clipboard so you can add it to your Git host.
|
||||
|
||||
![Getting the client ID from Sparkleshare][16]
|
||||
|
||||
#### Adding your client ID to a hosted Git account
|
||||
|
||||
Minor UI differences aside, adding an SSH key (which is all the client ID is) is basically the same process on any hosting service. In your Git host's web dashboard, navigate to your user settings and find the **SSH Keys** category. Click the **Add New Key** button (or similar) and paste the contents of your SparkleShare client ID.
|
||||
|
||||
![Adding an SSH key][17]
|
||||
|
||||
Save the key. If you want someone else, such as collaborators or family members, to be able to access this same repository, they must provide you with their SparkleShare client ID so you can add it to your account.
|
||||
|
||||
#### Adding your client ID to a self-hosted Git account
|
||||
|
||||
A SparkleShare client ID is just an SSH key, so copy and paste it into your Git user's **~/.ssh/authorized_keys** file.
|
||||
|
||||
#### Adding your client ID with Dazzle
|
||||
|
||||
If you are using Dazzle to manage your SparkleShare projects, add a client ID with this command:
|
||||
|
||||
|
||||
```
|
||||
`$ dazzle link`
|
||||
```
|
||||
|
||||
When Dazzle prompts you for the ID, paste in the client ID found in the SparkleShare menu.
|
||||
|
||||
### Using SparkleShare
|
||||
|
||||
Once you've added your client ID to your Git host, click the **Retry** button in the SparkleShare window to finish setup. When it's finished cloning your repository, you can close the SparkleShare setup window, and you'll find a new **SparkleShare** folder in your home directory. If you set up a Git repository with a hosting service and chose to include a README or license file, you can see them in your SparkleShare directory.
|
||||
|
||||
![Sparkleshare file manager][18]
|
||||
|
||||
Otherwise, there are some hidden directories, which you can see by revealing hidden directories in your file manager.
|
||||
|
||||
![Showing hidden files in GNOME][19]
|
||||
|
||||
You use SparkleShare the same way you use any directory on your computer: you put files into it. Anytime a file or directory is placed into a SparkleShare folder, it's copied in the background to your Git repository.
|
||||
|
||||
#### Excluding certain files
|
||||
|
||||
Since Git is designed to remember _everything_ , you may want to exclude specific file types from ever being recorded. There are a few reasons to manage excluded files. By defining files that are off limits for SparkleShare, you can avoid accidental copying of large files. You can also design a scheme for yourself that enables you to store files that logically belong together (MIDI files with their **.flac** exports, for instance) in one directory, but manually back up the large files yourself while letting SparkleShare back up the text-based files.
|
||||
|
||||
If you can't see hidden files in your system's file manager, then reveal them. Navigate to your SparkleShare folder, then to the directory representing your repository, locate a file called **.gitignore** , and open it in a text editor. You can enter file extensions or file names, one per line, into **.gitignore** , and any file matching what you list will be (as the file name suggests) ignored.
|
||||
|
||||
|
||||
```
|
||||
Thumbs.db
|
||||
$RECYCLE.BIN/
|
||||
.DS_Store
|
||||
._*
|
||||
.fseventsd
|
||||
.Spotlight-V100
|
||||
.Trashes
|
||||
.directory
|
||||
.Trash-*
|
||||
*.wav
|
||||
*.ogg
|
||||
*.flac
|
||||
*.mp3
|
||||
*.m4a
|
||||
*.opus
|
||||
*.jpg
|
||||
*.png
|
||||
*.mp4
|
||||
*.mov
|
||||
*.mkv
|
||||
*.avi
|
||||
*.pdf
|
||||
*.djvu
|
||||
*.epub
|
||||
*.od{s,t}
|
||||
*.cbz
|
||||
```
|
||||
|
||||
You know the types of files you encounter most often, so concentrate on the ones most likely to sneak their way into your SparkleShare directory. If you want to exercise a little overkill, you can find good collections of **.gitignore** files on Notabug.org and also on the internet at large.
|
||||
|
||||
With those entries in your **.gitignore** file, you can place large files that you don't want sent to your Git host in your SparkleShare directory, and SparkleShare will ignore them entirely. Of course, that means it's up to you to make sure they get onto a backup or distributed to your SparkleShare collaborators through some other means.
|
||||
|
||||
### Automation
|
||||
|
||||
[Automation][20] is part of the silent agreement we have with computers: they do the repetitious, boring stuff that we humans either aren't very good at doing or aren't very good at remembering. SparkleShare is a nice, simple way to automate the routine distribution of data. It isn't right for every Git repository, by any means. It doesn't have an interface for advanced Git functions; it doesn't have a pause button or a manual override. And that's OK because its scope is intentionally limited. SparkleShare does what SparkleShare sets out to do, it does it well, and it's one Git repository you won't have to think about.
|
||||
|
||||
If you have a use for that kind of steady, invisible automation, give SparkleShare a try.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/file-sharing-git
|
||||
|
||||
作者:[Seth Kenlon (Red Hat, Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_cloud21x_cc.png?itok=5UwC92dO
|
||||
[2]: https://git-scm.com/
|
||||
[3]: http://www.sparkleshare.org/
|
||||
[4]: http://gitlab.com
|
||||
[5]: https://opensource.com/article/19/4/calendar-git
|
||||
[6]: http://sparkleshare.org
|
||||
[7]: /business/16/8/flatpak
|
||||
[8]: http://notabug.org
|
||||
[9]: https://opensource.com/sites/default/files/uploads/git-new-repo.jpg (Creating a Git repository)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/github-clone-url.jpg (Cloning a URL on GitHub)
|
||||
[11]: https://opensource.com/sites/default/files/uploads/gitlab-clone-url.jpg (Cloning a URL on GitLab)
|
||||
[12]: http://gitolite.org
|
||||
[13]: https://github.com/hbons/Dazzle
|
||||
[14]: https://opensource.com/sites/default/files/uploads/sparkleshare-host.jpg (Choosing a Sparkleshare host)
|
||||
[15]: mailto:git@notabug.org
|
||||
[16]: https://opensource.com/sites/default/files/uploads/sparkleshare-clientid.jpg (Getting the client ID from Sparkleshare)
|
||||
[17]: https://opensource.com/sites/default/files/uploads/git-ssh-key.jpg (Adding an SSH key)
|
||||
[18]: https://opensource.com/sites/default/files/uploads/sparkleshare-file-manager.jpg (Sparkleshare file manager)
|
||||
[19]: https://opensource.com/sites/default/files/uploads/gnome-show-hidden-files.jpg (Showing hidden files in GNOME)
|
||||
[20]: /downloads/ansible-quickstart
|
||||
@ -0,0 +1,190 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Authenticate a Linux Desktop to Your OpenLDAP Server)
|
||||
[#]: via: (https://www.linux.com/blog/how-authenticate-linux-desktop-your-openldap-server)
|
||||
[#]: author: (Jack Wallen https://www.linux.com/users/jlwallen)
|
||||
|
||||
How to Authenticate a Linux Desktop to Your OpenLDAP Server
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
[Creative Commons Zero][2]
|
||||
|
||||
In this final part of our three-part series, we reach the conclusion everyone has been waiting for. The ultimate goal of using LDAP (in many cases) is enabling desktop authentication. With this setup, admins are better able to manage and control user accounts and logins. After all, Active Directory admins shouldn’t have all the fun, right?
|
||||
|
||||
WIth OpenLDAP, you can manage your users on a centralized directory server and connect the authentication of every Linux desktop on your network to that server. And since you already have [OpenLDAP][3] and the [LDAP Authentication Manager][4] setup and running, the hard work is out of the way. At this point, there is just a few quick steps to enabling those Linux desktops to authentication with that server.
|
||||
|
||||
I’m going to walk you through this process, using the Ubuntu Desktop 18.04 to demonstrate. If your desktop distribution is different, you’ll only have to modify the installation steps, as the configurations should be similar.
|
||||
|
||||
**What You’ll Need**
|
||||
|
||||
Obviously you’ll need the OpenLDAP server up and running. You’ll also need user accounts created on the LDAP directory tree, and a user account on the client machines with sudo privileges. With those pieces out of the way, let’s get those desktops authenticating.
|
||||
|
||||
**Installation**
|
||||
|
||||
The first thing we must do is install the necessary client software. This will be done on all the desktop machines that require authentication with the LDAP server. Open a terminal window on one of the desktop machines and issue the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install libnss-ldap libpam-ldap ldap-utils nscd -y
|
||||
```
|
||||
|
||||
During the installation, you will be asked to enter the LDAP server URI ( **Figure 1** ).
|
||||
|
||||
![][5]
|
||||
|
||||
Figure 1: Configuring the LDAP server URI for the client.
|
||||
|
||||
[Used with permission][6]
|
||||
|
||||
The LDAP URI is the address of the OpenLDAP server, in the form ldap://SERVER_IP (Where SERVER_IP is the IP address of the OpenLDAP server). Type that address, tab to OK, and press Enter on your keyboard.
|
||||
|
||||
In the next window ( **Figure 2)** , you are required to enter the Distinguished Name of the OpenLDAP server. This will be in the form dc=example,dc=com.
|
||||
|
||||
![][7]
|
||||
|
||||
Figure 2: Configuring the DN of your OpenLDAP server.
|
||||
|
||||
[Used with permission][6]
|
||||
|
||||
If you’re unsure of what your OpenLDAP DN is, log into the LDAP Account Manager, click Tree View, and you’ll see the DN listed in the left pane ( **Figure 3** ).
|
||||
|
||||
![][8]
|
||||
|
||||
Figure 3: Locating your OpenLDAP DN with LAM.
|
||||
|
||||
[Used with permission][6]
|
||||
|
||||
The next few configuration windows, will require the following information:
|
||||
|
||||
* Specify LDAP version (select 3)
|
||||
|
||||
* Make local root Database admin (select Yes)
|
||||
|
||||
* Does the LDAP database require login (select No)
|
||||
|
||||
* Specify LDAP admin account suffice (this will be in the form cn=admin,dc=example,dc=com)
|
||||
|
||||
* Specify password for LDAP admin account (this will be the password for the LDAP admin user)
|
||||
|
||||
|
||||
|
||||
|
||||
Once you’ve answered the above questions, the installation of the necessary bits is complete.
|
||||
|
||||
**Configuring the LDAP Client**
|
||||
|
||||
Now it’s time to configure the client to authenticate against the OpenLDAP server. This is not nearly as hard as you might think.
|
||||
|
||||
First, we must configure nsswitch. Open the configuration file with the command:
|
||||
|
||||
```
|
||||
sudo nano /etc/nsswitch.conf
|
||||
```
|
||||
|
||||
In that file, add ldap at the end of the following line:
|
||||
|
||||
```
|
||||
passwd: compat systemd
|
||||
|
||||
group: compat systemd
|
||||
|
||||
shadow: files
|
||||
```
|
||||
|
||||
These configuration entries should now look like:
|
||||
|
||||
```
|
||||
passwd: compat systemd ldap
|
||||
group: compat systemd ldap
|
||||
shadow: files ldap
|
||||
```
|
||||
|
||||
At the end of this section, add the following line:
|
||||
|
||||
```
|
||||
gshadow files
|
||||
```
|
||||
|
||||
The entire section should now look like:
|
||||
|
||||
```
|
||||
passwd: compat systemd ldap
|
||||
|
||||
group: compat systemd ldap
|
||||
|
||||
shadow: files ldap
|
||||
|
||||
gshadow files
|
||||
```
|
||||
|
||||
Save and close that file.
|
||||
|
||||
Now we need to configure PAM for LDAP authentication. Issue the command:
|
||||
|
||||
```
|
||||
sudo nano /etc/pam.d/common-password
|
||||
```
|
||||
|
||||
Remove use_authtok from the following line:
|
||||
|
||||
```
|
||||
password [success=1 user_unknown=ignore default=die] pam_ldap.so use_authtok try_first_pass
|
||||
```
|
||||
|
||||
Save and close that file.
|
||||
|
||||
There’s one more PAM configuration to take care of. Issue the command:
|
||||
|
||||
```
|
||||
sudo nano /etc/pam.d/common-session
|
||||
```
|
||||
|
||||
At the end of that file, add the following:
|
||||
|
||||
```
|
||||
session optional pam_mkhomedir.so skel=/etc/skel umask=077
|
||||
```
|
||||
|
||||
The above line will create the default home directory (upon first login), on the Linux desktop, for any LDAP user that doesn’t have a local account on the machine. Save and close that file.
|
||||
|
||||
**Logging In**
|
||||
|
||||
Reboot the client machine. When the login is presented, attempt to log in with a user on your OpenLDAP server. The user account should authenticate and present you with a desktop. You are good to go.
|
||||
|
||||
Make sure to configure every single Linux desktop on your network in the same fashion, so they too can authenticate against the OpenLDAP directory tree. By doing this, any user in the tree will be able to log into any configured Linux desktop machine on your network.
|
||||
|
||||
You now have an OpenLDAP server running, with the LDAP Account Manager installed for easy account management, and your Linux clients authenticating against that LDAP server.
|
||||
|
||||
And that, my friends, is all there is to it.
|
||||
|
||||
We’re done.
|
||||
|
||||
Keep using Linux.
|
||||
|
||||
It’s been an honor.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/how-authenticate-linux-desktop-your-openldap-server
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/jlwallen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/cyber-3400789_1280_0.jpg?itok=YiinDnTw
|
||||
[2]: /LICENSES/CATEGORY/CREATIVE-COMMONS-ZERO
|
||||
[3]: https://www.linux.com/blog/2019/3/how-install-openldap-ubuntu-server-1804
|
||||
[4]: https://www.linux.com/blog/learn/2019/3/how-install-ldap-account-manager-ubuntu-server-1804
|
||||
[5]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/ldapauth_1.jpg?itok=DgYT8iY1
|
||||
[6]: /LICENSES/CATEGORY/USED-PERMISSION
|
||||
[7]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/ldapauth_2.jpg?itok=CXITs7_J
|
||||
[8]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/ldapauth_3.jpg?itok=HmhiYj7J
|
||||
240
sources/tech/20190406 Run a server with Git.md
Normal file
240
sources/tech/20190406 Run a server with Git.md
Normal file
@ -0,0 +1,240 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Run a server with Git)
|
||||
[#]: via: (https://opensource.com/article/19/4/server-administration-git)
|
||||
[#]: author: (Seth Kenlon (Red Hat, Community Moderator) https://opensource.com/users/seth/users/seth)
|
||||
|
||||
Run a server with Git
|
||||
======
|
||||
Thanks to Gitolite, you can manage a Git server with Git. Learn how in
|
||||
our series about little-known Git uses.
|
||||
![computer servers processing data][1]
|
||||
|
||||
As I've tried to demonstrate in this series leading up to Git's 14th anniversary on April 7, [Git][2] can do a wide range of things beyond tracking source code. Believe it or not, Git can even manage your Git server, so you can, more or less, run a Git server with Git itself.
|
||||
|
||||
Of course, this involves a lot of components beyond everyday Git, not the least of which is [Gitolite][3], the backend application managing the fiddly bits that you configure using Git. The great thing about Gitolite is that, because it uses Git as its frontend interface, it's easy to integrate Git server administration within the rest of your Git-based workflow. Gitolite provides precise control over who can access specific repositories on your server and what permissions they have. You can manage that sort of thing yourself with the usual Linux system tools, but it takes a lot of work if you have more than just one or two repos across a half-dozen users.
|
||||
|
||||
Gitolite's developers have done the hard work to make it easy for you to provide many users with access to your Git server without giving them access to your entire environment—and you can do it all with Git.
|
||||
|
||||
What Gitolite is _not_ is a GUI admin and user panel. That sort of experience is available with the excellent [Gitea][4] project, but this article focuses on the simple elegance and comforting familiarity of Gitolite.
|
||||
|
||||
### Install Gitolite
|
||||
|
||||
Assuming your Git server runs Linux, you can install Gitolite with your package manager ( **yum** on CentOS and RHEL, **apt** on Debian and Ubuntu, **zypper** on OpenSUSE, and so on). For example, on RHEL:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo yum install gitolite3`
|
||||
```
|
||||
|
||||
Many repositories still have older versions of Gitolite for legacy support, but the current version is version 3.
|
||||
|
||||
You must have passwordless SSH access to your server. You can use a password to log in if you prefer, but Gitolite relies on SSH keys, so you must configure the option to log in with keys. If you don't know how to configure a server for passwordless SSH access, go learn how to do that first (the [Setting up SSH key authentication][5] section of Steve Ovens's Ansible article explains it well). It's an essential part of secure server administration—as well as of running Gitolite.
|
||||
|
||||
### Configure a Git user
|
||||
|
||||
Without Gitolite, if a person requests access to a Git repository you host on a server, you have to provide that person with a user account. Git provides a special shell, the **git-shell** , which is an ultra-specific shell that performs only Git tasks. This lets you have users who can access your server only through the filter of a very limited shell environment.
|
||||
|
||||
That solution works, but it usually means a user gains access to all repositories on your server unless you have a very good schema for group permissions and maintain those permissions strictly whenever a new repository is created. It also requires a lot of manual configuration at the system level, an area usually reserved for a specific tier of sysadmins and not necessarily the person usually in charge of Git repositories.
|
||||
|
||||
Gitolite sidesteps this issue entirely by designating one username for every person who needs access to any repository. By default, the username is **git** , and because Gitolite's documentation assumes that's what is used, it's a good default to keep when you're learning the tool. It's also a well-known convention for anyone who's ever used GitLab or GitHub or any other Git hosting service.
|
||||
|
||||
Gitolite calls this user the _hosting user_. Create an account on your server to act as the hosting user (I'll stick with **git** because that's the convention):
|
||||
|
||||
|
||||
```
|
||||
` $ sudo adduser --create-home git`
|
||||
```
|
||||
|
||||
For you to control the **git** user account, it must have a valid public SSH key that belongs to you. You should already have this set up, so **cp** your public key ( _not your private key_ ) to the **git** user's home directory:
|
||||
|
||||
|
||||
```
|
||||
$ sudo cp ~/.ssh/id_ed25519.pub /home/git/
|
||||
$ sudo chown git:git /home/git/id_ed25519.pub
|
||||
```
|
||||
|
||||
If your public key doesn't end with the extension **.pub** , Gitolite will not use it, so rename the file accordingly. Change to that user account to run Gitolite's setup:
|
||||
|
||||
|
||||
```
|
||||
$ sudo su - git
|
||||
$ gitolite setup --pubkey id_ed25519.pub
|
||||
```
|
||||
|
||||
After the setup script runs, the **git** home's user directory will have a **repositories** directory, which (for now) contains the files **git-admin.git** and **testing.git**. That's all the setup the server requires, so log out.
|
||||
|
||||
### Use Gitolite
|
||||
|
||||
Managing Gitolite is a matter of editing text files in a Git repository, specifically **gitolite-admin.git**. You won't SSH into your server for Git administration, and Gitolite encourages you not to try. The repositories you and your users store on the Gitolite server are _bare_ repositories, so it's best to stay out of them.
|
||||
|
||||
|
||||
```
|
||||
$ git clone [git@example.com][6]:gitolite-admin.git gitolite-admin.git
|
||||
$ cd gitolite-admin.git
|
||||
$ ls -1
|
||||
conf
|
||||
keydir
|
||||
```
|
||||
|
||||
The **conf** directory in this repository contains a file called **gitolite.conf**. Open it in a text editor or use **cat** to view its contents:
|
||||
|
||||
|
||||
```
|
||||
repo gitolite-admin
|
||||
RW+ = id_ed22519
|
||||
|
||||
repo testing
|
||||
RW+ = @all
|
||||
```
|
||||
|
||||
You may have an idea of what this configuration file does: **gitolite-admin** represents this repository, and the owner of the **id_ed25519** key has read, write, and Git administrative privileges. In other words, rather than mapping users to normal local Unix users (because all your users log in using the **git** hosting user identity), Gitolite maps users to SSH keys listed in the **keydir** directory.
|
||||
|
||||
The **testing.git** repository gives full permissions to everyone with access to the server using special group notation.
|
||||
|
||||
#### Add users
|
||||
|
||||
If you want to add a user called **alice** to your Git server, the person Alice must send you her public SSH key. Gitolite uses whatever is to the left of the **.pub** extension as the identifier for your Git users. Rather than using the default key name values, give keys a name indicative of the key owner. If a user has more than one key (e.g., one for her laptop, one for her desktop), you can use subdirectories to avoid file name collisions. For instance, the key Alice uses from her laptop might come to you as the default **id_rsa.pub** , so rename it **alice.pub** or similar (or let the users name the key according to their local user accounts on their computers), and place it into the **gitolite-admin.git/keydir/work/laptop/** directory. If she sends you another key from her desktop, name it **alice.pub** (the same as the previous one) and add it to **keydir/work/desktop/**. Another key might go into **keydir/home/desktop/** , and so on. Gitolite recursively searches **keydir** for a **.pub** file matching a repository "user" and treats any match as the same identity.
|
||||
|
||||
When you add keys to the **keydir** directory, you must commit them back to your server. This is such an easy thing to forget that there's a real argument here for using an automated Git application like [**Sparkleshare**][7] so any change is committed back to your Gitolite admin immediately. The first time you forget to commit and push—and waste three hours of your time and your user's time troubleshooting—you'll see that Gitolite is the perfect justification for using Sparkleshare.
|
||||
|
||||
|
||||
```
|
||||
$ git add keydir
|
||||
$ git commit -m 'added alice-laptop-0.pub'
|
||||
$ git push origin HEAD
|
||||
```
|
||||
|
||||
Alice, by default, gains access to the **testing.git** directory so she can test connectivity and functionality with that.
|
||||
|
||||
#### Set permissions
|
||||
|
||||
As with users, directory permissions and groups are abstracted away from the normal Unix tools you might be used to (or find information about online). Permissions to projects are granted in the **gitolite.conf** file in **gitolite-admin.git/conf** directory. There are four levels of permissions:
|
||||
|
||||
* **R** allows read-only. A user with **R** permissions on a repository may clone it, and that's all.
|
||||
* **RW** allows a user to perform a fast-forward push of a branch, create new branches, and create new tags. More or less, this one feels like a "normal" Git repository to most users.
|
||||
* **RW+** allows Git actions that are potentially destructive. A user can perform normal fast-forward pushes, as well as rewind pushes, do rebases, and delete branches and tags. This may or may not be something you want to grant to all contributors on a project.
|
||||
* **-** explicitly denies access to a repository. This is essentially the same as a user not being listed in the repository's configuration.
|
||||
|
||||
|
||||
|
||||
Create a new repository or modify an existing repository's permissions by adjusting **gitolite.conf**. For instance, to give Alice permissions to administrate a new repository called **widgets.git** :
|
||||
|
||||
|
||||
```
|
||||
repo gitolite-admin
|
||||
RW+ = id_ed22519
|
||||
|
||||
repo testing
|
||||
RW+ = @all
|
||||
|
||||
repo widgets
|
||||
RW+ = alice
|
||||
```
|
||||
|
||||
Now Alice—and Alice alone—can clone the repo:
|
||||
|
||||
|
||||
```
|
||||
[alice]$ git clone [git@example.com][6]:widgets.git
|
||||
Cloning into 'widgets'...
|
||||
warning: You appear to have cloned an empty repository.
|
||||
```
|
||||
|
||||
On her initial push, Alice must use the **-u** option to send her branch to the empty repository (as she would have to do with any Git host).
|
||||
|
||||
To make user management easier, you can define groups of repositories:
|
||||
|
||||
|
||||
```
|
||||
@qtrepo = widgets
|
||||
@qtrepo = games
|
||||
|
||||
repo gitolite-admin
|
||||
RW+ = id_ed22519
|
||||
|
||||
repo testing
|
||||
RW+ = @all
|
||||
|
||||
repo @qtrepo
|
||||
RW+ = alice
|
||||
```
|
||||
|
||||
Just as you can create group repositories, you can group users. One user group exists by default: **@all**. As you might expect, it includes all users, without exception. You can create your own:
|
||||
|
||||
|
||||
```
|
||||
@qtrepo = widgets
|
||||
@qtrepo = games
|
||||
|
||||
@developers = alice bob
|
||||
|
||||
repo gitolite-admin
|
||||
RW+ = id_ed22519
|
||||
|
||||
repo testing
|
||||
RW+ = @all
|
||||
|
||||
repo @qtrepo
|
||||
RW+ = @developers
|
||||
```
|
||||
|
||||
As with adding or modifying key files, any change to the **gitolite.conf** file must be committed and pushed to take effect.
|
||||
|
||||
### Create a repository
|
||||
|
||||
By default, Gitolite assumes repository creation happens from the top down. For instance, a project manager with access to the Git server creates a project repository and, through the Gitolite administration repo, adds developers.
|
||||
|
||||
In practice, you might prefer to grant users permission to create repositories. Gitolite calls these "wild repos" (I'm not sure whether that's commentary on how the repos come into being or a reference to the wildcard characters required by the configuration file to let it happen). Here's an example:
|
||||
|
||||
|
||||
```
|
||||
@managers = alice bob
|
||||
|
||||
repo foo/CREATOR/[a-z]..*
|
||||
C = @managers
|
||||
RW+ = CREATOR
|
||||
RW = WRITERS
|
||||
R = READERS
|
||||
```
|
||||
|
||||
The first line defines a group of users: the group is called **@managers** and contains users **alice** and **bob**. The next line sets up a wildcard allowing repositories that do not yet exist to be created in a directory called **foo** followed by a subdirectory named for the user creating the repo. For example:
|
||||
|
||||
|
||||
```
|
||||
[alice]$ git clone [git@example.com][6]:foo/alice/cool-app.git
|
||||
Cloning into cool-app'...
|
||||
Initialized empty Git repository in /home/git/repositories/foo/alice/cool-app.git
|
||||
warning: You appear to have cloned an empty repository.
|
||||
```
|
||||
|
||||
There are some mechanisms for the creator of a wild repo to define who can read and write to their repository, but they're limited in scope. For the most part, Gitolite assumes that a specific set of users governs project permission. One solution is to grant all users access to **gitolite-admin** using a Git hook to require manager approval to merge changes into the master branch.
|
||||
|
||||
### Learn more
|
||||
|
||||
Gitolite has many more features than what this introductory article covers, so try it out. The [documentation][8] is excellent, and once you read through it, you can customize your Gitolite server to provide your users whatever level of control you are comfortable with. Gitolite is a low-maintenance, simple system that you can install, set up, and then more or less forget about.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/server-administration-git
|
||||
|
||||
作者:[Seth Kenlon (Red Hat, Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/server_data_system_admin.png?itok=q6HCfNQ8 (computer servers processing data)
|
||||
[2]: https://git-scm.com/
|
||||
[3]: http://gitolite.com
|
||||
[4]: http://gitea.io
|
||||
[5]: Setting%20up%20SSH%20key%20authentication
|
||||
[6]: mailto:git@example.com
|
||||
[7]: https://opensource.com/article/19/4/file-sharing-git
|
||||
[8]: http://gitolite.com/gitolite/quick_install.html
|
||||
247
sources/tech/20190407 Manage multimedia files with Git.md
Normal file
247
sources/tech/20190407 Manage multimedia files with Git.md
Normal file
@ -0,0 +1,247 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Manage multimedia files with Git)
|
||||
[#]: via: (https://opensource.com/article/19/4/manage-multimedia-files-git)
|
||||
[#]: author: (Seth Kenlon (Red Hat, Community Moderator) https://opensource.com/users/seth)
|
||||
|
||||
Manage multimedia files with Git
|
||||
======
|
||||
Learn how to use Git to track large multimedia files in your projects in
|
||||
the final article in our series on little-known uses of Git.
|
||||
![video editing dashboard][1]
|
||||
|
||||
Git is very specifically designed for source code version control, so it's rarely embraced by projects and industries that don't primarily work in plaintext. However, the advantages of an asynchronous workflow are appealing, especially in the ever-growing number of industries that combine serious computing with seriously artistic ventures, including web design, visual effects, video games, publishing, currency design (yes, that's a real industry), education… the list goes on and on.
|
||||
|
||||
In this series leading up to Git's 14th anniversary, we've shared six little-known ways to use Git. In this final article, we'll look at software that brings the advantages of Git to managing multimedia files.
|
||||
|
||||
### The problem with managing multimedia files with Git
|
||||
|
||||
It seems to be common knowledge that Git doesn't work well with non-text files, but it never hurts to challenge assumptions. Here's an example of copying a photo file using Git:
|
||||
|
||||
|
||||
```
|
||||
$ du -hs
|
||||
108K .
|
||||
$ cp ~/photos/dandelion.tif .
|
||||
$ git add dandelion.tif
|
||||
$ git commit -m 'added a photo'
|
||||
[master (root-commit) fa6caa7] two photos
|
||||
1 file changed, 0 insertions(+), 0 deletions(-)
|
||||
create mode 100644 dandelion.tif
|
||||
$ du -hs
|
||||
1.8M .
|
||||
```
|
||||
|
||||
Nothing unusual so far; adding a 1.8MB photo to a directory results in a directory 1.8MB in size. So, let's try removing the file:
|
||||
|
||||
|
||||
```
|
||||
$ git rm dandelion.tif
|
||||
$ git commit -m 'deleted a photo'
|
||||
$ du -hs
|
||||
828K .
|
||||
```
|
||||
|
||||
You can see the problem here: Removing a large file after it's been committed increases a repository's size roughly eight times its original, barren state (from 108K to 828K). You can perform tests to get a better average, but this simple demonstration is consistent with my experience. The cost of committing files that aren't text-based is minimal at first, but the longer a project stays active, the more changes people make to static content, and the more those fractions start to add up. When a Git repository becomes very large, the major cost is usually speed. The time to perform pulls and pushes goes from being how long it takes to take a sip of coffee to how long it takes to wonder if your computer got kicked off the network.
|
||||
|
||||
The reason static content causes Git to grow in size is that formats based on text allow Git to pull out just the parts that have changed. Raster images and music files make as much sense to Git as they would to you if you looked at the binary data contained in a .png or .wav file. So Git just takes all the data and makes a new copy of it, even if only one pixel changes from one photo to the next.
|
||||
|
||||
### Git-portal
|
||||
|
||||
In practice, many multimedia projects don't need or want to track the media's history. The media part of a project tends to have a different lifecycle than the text or code part of a project. Media assets generally progress in one direction: a picture starts as a pencil sketch, proceeds toward its destination as a digital painting, and, even if the text is rolled back to an earlier version, the art continues its forward progress. It's rare for media to be bound to a specific version of a project. The exceptions are usually graphics that reflect datasets—usually tables or graphs or charts—that can be done in text-based formats such as SVG.
|
||||
|
||||
So, on many projects that involve both media and text (whether it's narrative prose or code), Git is an acceptable solution to file management, as long as there's a playground outside the version control cycle for artists to play in.
|
||||
|
||||
![Graphic showing relationship between art assets and Git][2]
|
||||
|
||||
A simple way to enable that is [Git-portal][3], a Bash script armed with Git hooks that moves your asset files to a directory outside Git's purview and replaces them with symlinks. Git commits the symlinks (sometimes called aliases or shortcuts), which are trivially small, so all you commit are your text files and whatever symlinks represent your media assets. Because the replacement files are symlinks, your project continues to function as expected because your local machine follows the symlinks to their "real" counterparts. Git-portal maintains a project's directory structure when it swaps out a file with a symlink, so it's easy to reverse the process, should you decide that Git-portal isn't right for your project or you need to build a version of your project without symlinks (for distribution, for instance).
|
||||
|
||||
Git-portal also allows remote synchronization of assets over rsync, so you can set up a remote storage location as a centralized source of authority.
|
||||
|
||||
Git-portal is ideal for multimedia projects, including video game and tabletop game design, virtual reality projects with big 3D model renders and textures, [books][4] with graphics and .odt exports, collaborative [blog websites][5], music projects, and much more. It's not uncommon for an artist to perform versioning in their application—in the form of layers (in the graphics world) and tracks (in the music world)—so Git adds nothing to multimedia project files themselves. The power of Git is leveraged for other parts of artistic projects (prose and narrative, project management, subtitle files, credits, marketing copy, documentation, and so on), and the power of structured remote backups is leveraged by the artists.
|
||||
|
||||
#### Install Git-portal
|
||||
|
||||
There are RPM packages for Git-portal located at <https://klaatu.fedorapeople.org/git-portal>, which you can download and install.
|
||||
|
||||
Alternately, you can install Git-portal manually from its home on GitLab. It's just a Bash script and some Git hooks (which are also Bash scripts), but it requires a quick build process so that it knows where to install itself:
|
||||
|
||||
|
||||
```
|
||||
$ git clone <https://gitlab.com/slackermedia/git-portal.git> git-portal.clone
|
||||
$ cd git-portal.clone
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
#### Use Git-portal
|
||||
|
||||
Git-portal is used alongside Git. This means, as with all large-file extensions to Git, there are some added steps to remember. But you only need Git-portal when dealing with your media assets, so it's pretty easy to remember unless you've acclimated yourself to treating large files the same as text files (which is rare for Git users). There's one setup step you must do to use Git-portal in a project:
|
||||
|
||||
|
||||
```
|
||||
$ mkdir bigproject.git
|
||||
$ cd !$
|
||||
$ git init
|
||||
$ git-portal init
|
||||
```
|
||||
|
||||
Git-portal's **init** function creates a **_portal** directory in your Git repository and adds it to your .gitignore file.
|
||||
|
||||
Using Git-portal in a daily routine integrates smoothly with Git. A good example is a MIDI-based music project: the project files produced by the music workstation are text-based, but the MIDI files are binary data:
|
||||
|
||||
|
||||
```
|
||||
$ ls -1
|
||||
_portal
|
||||
song.1.qtr
|
||||
song.qtr
|
||||
song-Track_1-1.mid
|
||||
song-Track_1-3.mid
|
||||
song-Track_2-1.mid
|
||||
$ git add song*qtr
|
||||
$ git-portal song-Track*mid
|
||||
$ git add song-Track*mid
|
||||
```
|
||||
|
||||
If you look into the **_portal** directory, you'll find the original MIDI files. The files in their place are symlinks to **_portal** , which keeps the music workstation working as expected:
|
||||
|
||||
|
||||
```
|
||||
$ ls -lG
|
||||
[...] _portal/
|
||||
[...] song.1.qtr
|
||||
[...] song.qtr
|
||||
[...] song-Track_1-1.mid -> _portal/song-Track_1-1.mid*
|
||||
[...] song-Track_1-3.mid -> _portal/song-Track_1-3.mid*
|
||||
[...] song-Track_2-1.mid -> _portal/song-Track_2-1.mid*
|
||||
```
|
||||
|
||||
As with Git, you can also add a directory of files:
|
||||
|
||||
|
||||
```
|
||||
$ cp -r ~/synth-presets/yoshimi .
|
||||
$ git-portal add yoshimi
|
||||
Directories cannot go through the portal. Sending files instead.
|
||||
$ ls -lG _portal/yoshimi
|
||||
[...] yoshimi.stat -> ../_portal/yoshimi/yoshimi.stat*
|
||||
```
|
||||
|
||||
Removal works as expected, but when removing something in **_portal** , you should use **git-portal rm** instead of **git rm**. Using Git-portal ensures that the file is removed from **_portal** :
|
||||
|
||||
|
||||
```
|
||||
$ ls
|
||||
_portal/ song.qtr song-Track_1-3.mid@ yoshimi/
|
||||
song.1.qtr song-Track_1-1.mid@ song-Track_2-1.mid@
|
||||
$ git-portal rm song-Track_1-3.mid
|
||||
rm 'song-Track_1-3.mid'
|
||||
$ ls _portal/
|
||||
song-Track_1-1.mid* song-Track_2-1.mid* yoshimi/
|
||||
```
|
||||
|
||||
If you forget to use Git-portal, then you have to remove the portal file manually:
|
||||
|
||||
|
||||
```
|
||||
$ git-portal rm song-Track_1-1.mid
|
||||
rm 'song-Track_1-1.mid'
|
||||
$ ls _portal/
|
||||
song-Track_1-1.mid* song-Track_2-1.mid* yoshimi/
|
||||
$ trash _portal/song-Track_1-1.mid
|
||||
```
|
||||
|
||||
Git-portal's only other function is to list all current symlinks and find any that may have become broken, which can sometimes happen if files move around in a project directory:
|
||||
|
||||
|
||||
```
|
||||
$ mkdir foo
|
||||
$ mv yoshimi foo
|
||||
$ git-portal status
|
||||
bigproject.git/song-Track_2-1.mid: symbolic link to _portal/song-Track_2-1.mid
|
||||
bigproject.git/foo/yoshimi/yoshimi.stat: broken symbolic link to ../_portal/yoshimi/yoshimi.stat
|
||||
```
|
||||
|
||||
If you're using Git-portal for a personal project and maintaining your own backups, this is technically all you need to know about Git-portal. If you want to add in collaborators or you want Git-portal to manage backups the way (more or less) Git does, you can a remote.
|
||||
|
||||
#### Add Git-portal remotes
|
||||
|
||||
Adding a remote location for Git-portal is done through Git's existing remote function. Git-portal implements Git hooks, scripts hidden in your repository's .git directory, to look at your remotes for any that begin with **_portal**. If it finds one, it attempts to **rsync** to the remote location and synchronize files. Git-portal performs this action anytime you do a Git push or a Git merge (or pull, which is really just a fetch and an automatic merge).
|
||||
|
||||
If you've only cloned Git repositories, then you may never have added a remote yourself. It's a standard Git procedure:
|
||||
|
||||
|
||||
```
|
||||
$ git remote add origin [git@gitdawg.com][6]:seth/bigproject.git
|
||||
$ git remote -v
|
||||
origin [git@gitdawg.com][6]:seth/bigproject.git (fetch)
|
||||
origin [git@gitdawg.com][6]:seth/bigproject.git (push)
|
||||
```
|
||||
|
||||
The name **origin** is a popular convention for your main Git repository, so it makes sense to use it for your Git data. Your Git-portal data, however, is stored separately, so you must create a second remote to tell Git-portal where to push to and pull from. Depending on your Git host, you may need a separate server because gigabytes of media assets are unlikely to be accepted by a Git host with limited space. Or maybe you're on a server that permits you to access only your Git repository and not external storage directories:
|
||||
|
||||
|
||||
```
|
||||
$ git remote add _portal [seth@example.com][7]:/home/seth/git/bigproject_portal
|
||||
$ git remote -v
|
||||
origin [git@gitdawg.com][6]:seth/bigproject.git (fetch)
|
||||
origin [git@gitdawg.com][6]:seth/bigproject.git (push)
|
||||
_portal [seth@example.com][7]:/home/seth/git/bigproject_portal (fetch)
|
||||
_portal [seth@example.com][7]:/home/seth/git/bigproject_portal (push)
|
||||
```
|
||||
|
||||
You may not want to give all of your users individual accounts on your server, and you don't have to. To provide access to the server hosting a repository's large file assets, you can run a Git frontend like **[Gitolite][8]** , or you can use **rrsync** (i.e., restricted rsync).
|
||||
|
||||
Now you can push your Git data to your remote Git repository and your Git-portal data to your remote portal:
|
||||
|
||||
|
||||
```
|
||||
$ git push origin HEAD
|
||||
master destination detected
|
||||
Syncing _portal content...
|
||||
sending incremental file list
|
||||
sent 9,305 bytes received 18 bytes 1,695.09 bytes/sec
|
||||
total size is 60,358,015 speedup is 6,474.10
|
||||
Syncing _portal content to example.com:/home/seth/git/bigproject_portal
|
||||
```
|
||||
|
||||
If you have Git-portal installed and a **_portal** remote configured, your **_portal** directory will be synchronized, getting new content from the server and sending fresh content with every push. While you don't have to do a Git commit and push to sync with the server (a user could just use rsync directly), I find it useful to require commits for artistic changes. It integrates artists and their digital assets into the rest of the workflow, and it provides useful metadata about project progress and velocity.
|
||||
|
||||
### Other options
|
||||
|
||||
If Git-portal is too simple for you, there are other options for managing large files with Git. [Git Large File Storage][9] (LFS) is a fork of a defunct project called git-media and is maintained and supported by GitHub. It requires special commands (like **git lfs track** to protect large files from being tracked by Git) and requires the user to manage a .gitattributes file to update which files in the repository are tracked by LFS. It supports _only_ HTTP and HTTPS remotes for large files, so your LFS server must be configured so users can authenticate over HTTP rather than SSH or rsync.
|
||||
|
||||
A more flexible option than LFS is [git-annex][10], which you can learn more about in my article about [managing binary blobs in Git][11] (ignore the parts about the deprecated git-media, as its former flexibility doesn't apply to its successor, Git LFS). Git-annex is a flexible and elegant solution with a detailed system for adding, removing, and moving large files within a repository. Because it's flexible and powerful, there are lots of new commands and rules to learn, so take a look at its [documentation][12].
|
||||
|
||||
If, however, your needs are simple and you like a solution that utilizes existing technology to do simple and obvious tasks, Git-portal might be the tool for the job.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/manage-multimedia-files-git
|
||||
|
||||
作者:[Seth Kenlon (Red Hat, Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/video_editing_folder_music_wave_play.png?itok=-J9rs-My (video editing dashboard)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/git-velocity.jpg (Graphic showing relationship between art assets and Git)
|
||||
[3]: http://gitlab.com/slackermedia/git-portal.git
|
||||
[4]: https://www.apress.com/gp/book/9781484241691
|
||||
[5]: http://mixedsignals.ml
|
||||
[6]: mailto:git@gitdawg.com
|
||||
[7]: mailto:seth@example.com
|
||||
[8]: https://opensource.com/article/19/4/file-sharing-git
|
||||
[9]: https://git-lfs.github.com/
|
||||
[10]: https://git-annex.branchable.com/
|
||||
[11]: https://opensource.com/life/16/8/how-manage-binary-blobs-git-part-7
|
||||
[12]: https://git-annex.branchable.com/walkthrough/
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user