mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-22 23:00:57 +08:00
commit
e18da6de6d
@ -0,0 +1,55 @@
|
||||
用 Apache Calcite 构建强大的实时流式应用
|
||||
==============
|
||||
|
||||

|
||||
|
||||
Calcite 是一个数据框架,它允许你创建自定义数据库功能,微软开发者 Atri Sharma 在 Apache 2016 年 11 月 14-16 日在西班牙塞维利亚举行的 Big Data Europe 中对此进行了讲演。
|
||||
|
||||
[Creative Commons Zero][2] Wikimedia Commons: Parent Géry
|
||||
|
||||
[Apache Calcite][7] 数据管理框架包含了典型的数据库管理系统的许多部分,但省略了如数据的存储和处理数据的算法等其他部分。 Microsoft 的 Azure Data Lake 的软件工程师 Atri Sharma 在西班牙塞维利亚的 [Apache:Big Data][6] 会议上的演讲中讨论了使用 [Apache Calcite][5] 的高级查询规划能力。我们与 Sharma 讨论了解有关 Calcite 的更多信息,以及现有程序如何利用其功能。
|
||||
|
||||

|
||||
|
||||
*Atri Sharma,微软 Azure Data Lake 的软件工程师,已经[授权使用][1]*
|
||||
|
||||
**Linux.com:你能提供一些关于 Apache Calcite 的背景吗? 它有什么作用?
|
||||
|
||||
Atri Sharma:Calcite 是一个框架,它是许多数据库内核的基础。Calcite 允许你构建自定义的数据库功能来使用 Calcite 所需的资源。例如,Hive 使用 Calcite 进行基于成本的查询优化、Drill 和 Kylin 使用 Calcite 进行 SQL 解析和优化、Apex 使用 Calcite 进行流式 SQL。
|
||||
|
||||
**Linux.com:有哪些是使得 Apache Calcite 与其他框架不同的特性?
|
||||
|
||||
Atri:Calcite 是独一无二的,它允许你建立自己的数据平台。 Calcite 不直接管理你的数据,而是允许你使用 Calcite 的库来定义你自己的组件。 例如,它允许使用 Calcite 中可用的 Planner 定义你的自定义查询优化器,而不是提供通用查询优化器。
|
||||
|
||||
**Linux.com:Apache Calcite 本身不会存储或处理数据。 它如何影响程序开发?
|
||||
|
||||
Atri:Calcite 是数据库内核中的依赖项。它针对的是希望扩展其功能,而无需从头开始编写大量功能的的数据管理平台。
|
||||
|
||||
** Linux.com:谁应该使用它? 你能举几个例子吗?**
|
||||
|
||||
Atri:任何旨在扩展其功能的数据管理平台都应使用 Calcite。 我们是你下一个高性能数据库的基础!
|
||||
|
||||
具体来说,我认为最大的例子是 Hive 使用 Calcite 用于查询优化、Flink 解析和流 SQL 处理。 Hive 和 Flink 是成熟的数据管理引擎,并将 Calcite 用于相当专业的用途。这是对 Calcite 应用进一步加强数据管理平台核心的一个好的案例研究。
|
||||
|
||||
**Linux.com:你有哪些期待的新功能?
|
||||
|
||||
Atri:流式 SQL 增强是令我非常兴奋的事情。这些功能令人兴奋,因为它们将使 Calcite 的用户能够更快地开发实时流式应用程序,并且这些程序的强大和功能将是多方面的。流式应用程序是新的事实,并且在流式 SQL 中具有查询优化的优点对于大部分人将是非常有用的。此外,关于暂存表的讨论还在进行,所以请继续关注!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/build-strong-real-time-streaming-apps-apache-calcite
|
||||
|
||||
作者:[AMBER ANKERHOLZ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/aankerholz
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[3]:https://www.linux.com/files/images/atri-sharmajpg
|
||||
[4]:https://www.linux.com/files/images/calcitejpg
|
||||
[5]:https://calcite.apache.org/
|
||||
[6]:http://events.linuxfoundation.org/events/apache-big-data-europe
|
||||
[7]:https://calcite.apache.org/
|
||||
@ -6,16 +6,17 @@
|
||||
|
||||
在软件设计中,“简单”并不意味着功能低级、有待改进。你如果喜欢花哨工具比较少的文本编辑器和笔记程序,那么在 Min 浏览器中会有同样舒适的感觉。
|
||||
|
||||
我经常在台式机和笔记本电脑上使用 Google Chrome、Chromium和 Firefox。我研究了它们的很多附加功能,所以我在长期的研究和工作中可以享用它们的特色服务。
|
||||
我经常在台式机和笔记本电脑上使用 Google Chrome、Chromium 和 Firefox。我研究了它们的很多附加功能,所以我在长期的研究和工作中可以享用它们的特色服务。
|
||||
|
||||
然而,有时我希望有个快速、整洁的替代品来上网。随着多个项目的进行,我需要很快打开一大批选项卡甚至是独立窗口的强大浏览器。
|
||||
然而,有时我希望有个快速、整洁的替代品来上网。随着多个项目的进行,我需要一个可以很快打开一大批选项卡甚至是独立窗口的强大浏览器。
|
||||
|
||||
我试过其他浏览器但很少能令我满意。替代品通常有一套独特的花哨的附件和功能,它们会让我开小差。
|
||||
|
||||
Min 浏览器就不这样。它是一个易于使用,并在 GitHub 开源的 web 浏览器,不会使我分心。
|
||||
|
||||
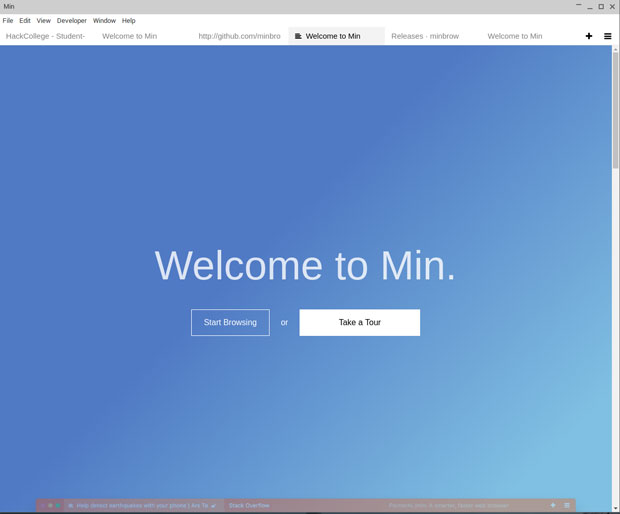
|
||||
Min 浏览器是精简的浏览器,提供了简单的功能以及快速的响应。只是不要指望马上上手。
|
||||
|
||||
*Min 浏览器是精简的浏览器,提供了简单的功能以及快速的响应。只是不要指望马上能上手。*
|
||||
|
||||
### 它做些什么
|
||||
|
||||
@ -25,7 +26,7 @@ Min 浏览器提供了 Debian Linux、Windows 和 Mac 机器的版本。它不
|
||||
|
||||
其中一个主要原因是其内置的广告拦截功能。开箱即用的 Min 浏览器不需要配置或寻找兼容的第三方应用程序来拦截广告。
|
||||
|
||||
在 Edit/Preferences 中,你可以通过三个选项来设置阻止的内容。它很容易修改屏蔽策略来满足你的喜好。阻止跟踪器和广告选项使用 EasyList 和 EasyPrivacy。 如果没有其他原因,请保持此选项选中。
|
||||
在 Edit/Preferences 菜单中,你可以通过三个选项来设置阻止的内容。它很容易修改屏蔽策略来满足你的喜好。阻止跟踪器和广告选项使用 EasyList 和 EasyPrivacy。 如果没有其他原因,请保持此选项选中。
|
||||
|
||||
你还可以阻止脚本和图像。这样做可以最大限度地提高网站加载速度,并能有效防御恶意代码。
|
||||
|
||||
@ -37,12 +38,13 @@ Min 浏览器提供了 Debian Linux、Windows 和 Mac 机器的版本。它不
|
||||
|
||||
这种方法很节省时间,因为你不必先进入搜索引擎窗口。 还有一个好处是可以搜索你的书签。
|
||||
|
||||
在 Edit/Preferences 菜单中,选择默认的搜索引擎。该列表包括 DuckDuckGo、Google、Bing、Yahoo、Baidu、Wikipedia 和 Yandex。
|
||||
在 Edit/Preferences 菜单中,可以选择默认的搜索引擎。该列表包括 DuckDuckGo、Google、Bing、Yahoo、Baidu、Wikipedia 和 Yandex。
|
||||
|
||||
尝试将 DuckDuckGo 作为默认搜索引擎。 Min 默认使用这个引擎,但你也能更换。
|
||||
|
||||
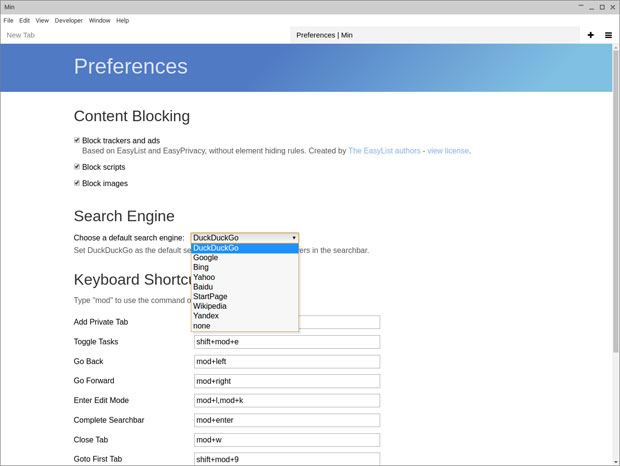
|
||||
Min 浏览器的搜索功能是 URL 栏的一部分。Min 利用搜索引擎 DuckDuckGo 和维基百科的内容。你可以直接在 web 地址栏中输入要搜索的东西。
|
||||
|
||||
*Min 浏览器的搜索功能是 URL 栏的一部分。Min 会使用搜索引擎 DuckDuckGo 和维基百科的内容。你可以直接在 web 地址栏中输入要搜索的东西。*
|
||||
|
||||
搜索栏会非常快速地显示问题的答案。它会使用 DuckDuckGo 的信息,包括维基百科条目、计算器和其它的内容。
|
||||
|
||||
@ -54,10 +56,9 @@ Min 允许你使用模糊搜索快速跳转到任何网站。它能立即向你
|
||||
|
||||
我喜欢在当前标签旁边打开标签的方式。你不必设置此选项。它在默认情况下没有其他选择,但这也有道理。
|
||||
|
||||
[
|
||||
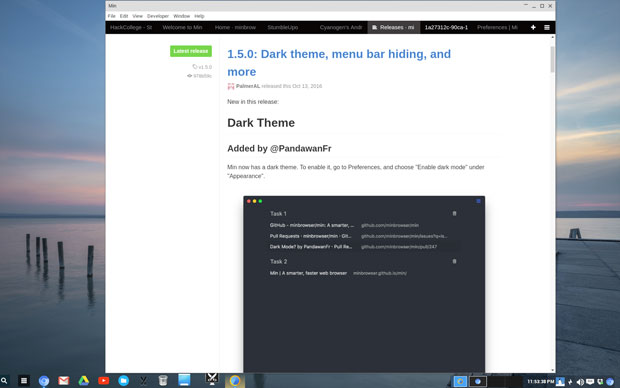
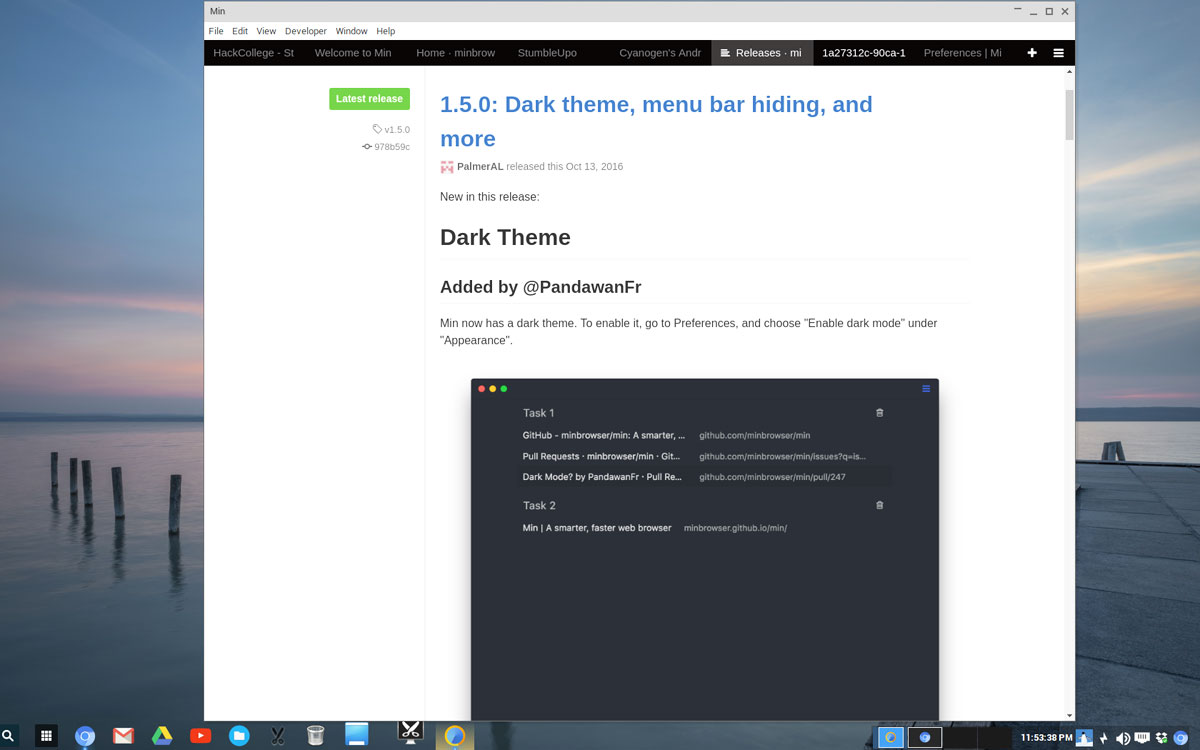
|
||||
][2]
|
||||
Min 的一个很酷的功能是将标签整理到任务栏中,这样你随时都可以搜索。(点击图片放大)
|
||||
|
||||
|
||||
*Min 的一个很酷的功能是将标签整理到任务栏中,这样你随时都可以搜索。*
|
||||
|
||||
不点击标签,过一会儿它就会消失。这使你可以专注于当前的任务,而不会分心。
|
||||
|
||||
@ -67,11 +68,11 @@ Min 不需要附加工具来控制多个标签。浏览器会显示标签列表
|
||||
|
||||
Min 在“视图”菜单中有一个可选的“聚焦模式”。启用后,除了你打开的选项卡外,它会隐藏其它所有选项卡。 你必须返回到菜单,关闭“聚焦模式”,才能打开新选项卡。
|
||||
|
||||
任务功能还可以帮助你保持专注。你可以在“文件(File)”菜单或使用 Ctrl+Shift+N 创建任务。如果要打开新选项卡,可以在“文件”菜单中选择该选项,或使用 Control+T。
|
||||
任务功能还可以帮助你保持专注。你可以在 File 菜单或使用 `Ctrl+Shift+N` 创建任务。如果要打开新选项卡,可以在 File 菜单中选择该选项,或使用 `Control+T`。
|
||||
|
||||
按照你的风格打开新任务。我喜欢按组来管理和显示标签,这组标签与工作项目或研究的某些部分相关。我可以在任何时间重新打开整个列表,从而轻松快速的方式找到我的浏览记录。
|
||||
|
||||
另一个好用的功能是可以在 tab 区域找到段落对齐按钮。单击它启用阅读模式。此模式会保存文章以供将来参考,并删除页面上的一切,以便你可以专注于阅读任务。
|
||||
另一个好用的功能是可以在选项卡区域找到段落对齐按钮。单击它启用阅读模式。此模式会保存文章以供将来参考,并删除页面上的一切,以便你可以专注于阅读任务。
|
||||
|
||||
### 并不完美
|
||||
|
||||
@ -91,7 +92,7 @@ Min 并不是一个功能完善、丰富的 web 浏览器。你在功能完善
|
||||
|
||||
我越使用 Min 浏览器,我越觉得它高效 - 但是当你第一次使用它时要小心。
|
||||
|
||||
Min 并不复杂,也不难操作 - 它只是有点古怪。你必须要玩弄一下才能明白它如何使用。
|
||||
Min 并不复杂,也不难操作 - 它只是有点古怪。你必须要体验一下才能明白它如何使用。
|
||||
|
||||
### 想要提建议么?
|
||||
|
||||
@ -105,11 +106,11 @@ Min 并不复杂,也不难操作 - 它只是有点古怪。你必须要玩弄一
|
||||
|
||||
作者简介:
|
||||
|
||||
Jack M. Germain 从苹果 II 和 PC 的早期起就一直在写关于计算机技术。他仍然有他原来的 IBM PC-Jr 和一些其他遗留的 DOS 和 Windows 盒子。他为 Linux 桌面的开源世界留下过共享软件。他运行几个版本的 Windows 和 Linux 操作系统,还通常不能决定是否用他的平板电脑、上网本或 Android 智能手机,还是用他的台式机或笔记本电脑。你可以在 Google+ 上与他联系。
|
||||
Jack M. Germain 从苹果 II 和 PC 的早期起就一直在写关于计算机技术。他仍然有他原来的 IBM PC-Jr 和一些其他遗留的 DOS 和 Windows 机器。他为 Linux 桌面的开源世界留下过共享软件。他运行几个版本的 Windows 和 Linux 操作系统,还通常不能决定是否用他的平板电脑、上网本或 Android 智能手机,还是用他的台式机或笔记本电脑。你可以在 Google+ 上与他联系。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/84212.html?rss=1
|
||||
via: http://www.linuxinsider.com/story/84212.html
|
||||
|
||||
作者:[Jack M. Germain][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
@ -1,33 +1,33 @@
|
||||
如何在 Vim 中使用标志和文本选择操作
|
||||
如何在 Vim 中进行文本选择操作和使用标志
|
||||
============================================================
|
||||
|
||||
基于图形界面的文本或源代码编辑器,提供了一些诸如文本选择的功能。我是想说,可能大多数人不觉得这是一个功能。不过像 Vim 这种基于命令行的编辑器就不是这样。当你仅使用键盘操作 Vim 的时候,就需要学习特定的命令来选择你想要的文本。在这个教程中,我们将详细讨论文本选择这一功能以及 Vim 中的标志功能。
|
||||
|
||||
在此之前需要说明的是,本教程中所提到的例子、命令和指令都是在 Ubuntu 16.04 的环境下测试的。Vim 的版本是 7.4。
|
||||
|
||||
# Vim 的文本选择功能
|
||||
### Vim 的文本选择功能
|
||||
|
||||
我们假设你已经具备了 Vim 编辑器的基本知识(如果没有,可以先阅读[这篇文章][2])。你应该知道,'d' 命令能够剪切/删除一行内容。如果你想要剪切 3 行的话,可以重复命令 3 次。不过,如果需要剪切 15 行呢?重复 ‘d’ 命令 15 次是个实用的解决方法吗?
|
||||
我们假设你已经具备了 Vim 编辑器的基本知识(如果没有,可以先阅读[这篇文章][2])。你应该知道,`d` 命令能够剪切/删除一行内容。如果你想要剪切 3 行的话,可以重复命令 3 次。不过,如果需要剪切 15 行呢?重复 `d` 命令 15 次是个实用的解决方法吗?
|
||||
|
||||
显然不是。这种情况下的最佳方法是,选中你想要剪切/删除的行,再运行 ‘d’ 命令。举个例子:
|
||||
显然不是。这种情况下的最佳方法是,选中你想要剪切/删除的行,再运行 `d` 命令。举个例子:
|
||||
|
||||
假如我想要剪切/删除下面截图中 INTRODUCTION 小节的第一段:
|
||||
|
||||
[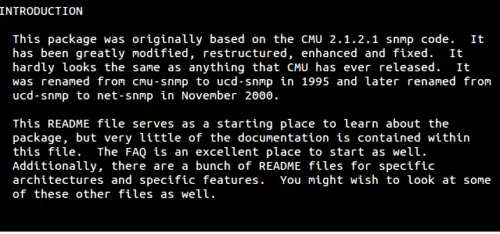][3]
|
||||
|
||||
那么我的做法是:将光标放在第一行的开始,(确保退出了 Insert 模式)按下 'V'(Shift+v)命令。这时 Vim 会开启视图模式,并选中第一行。
|
||||
那么我的做法是:将光标放在第一行的开始,(确保退出了 Insert 模式)按下 `V`(即 `Shift+v`)命令。这时 Vim 会开启视图模式,并选中第一行。
|
||||
|
||||
[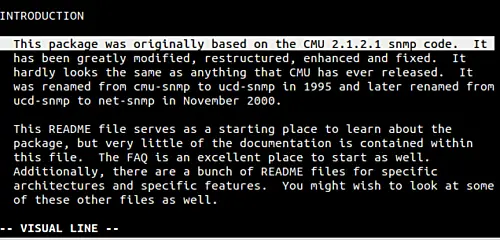][4]
|
||||
|
||||
现在,我可以使用方向键'下',来选中整个段落。
|
||||
现在,我可以使用方向键“下”,来选中整个段落。
|
||||
|
||||
[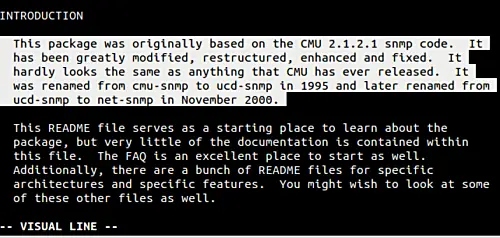][5]
|
||||
|
||||
这就是我们想要的,对吧!现在只需按 'd'键,就可以剪切/删除选中的段落了。当然,除了剪切/删除,你可以对选中的文本做任何操作。
|
||||
这就是我们想要的,对吧!现在只需按 `d` 键,就可以剪切/删除选中的段落了。当然,除了剪切/删除,你可以对选中的文本做任何操作。
|
||||
|
||||
这给我们带来了另一个重要的问题:当我们不需要删除整行的时候,该怎么做呢?也就是说,我们刚才讨论的解决方法,仅适用于想要对整行做操作的情况。那么如果我们只想删除段落的前三句话呢?
|
||||
|
||||
其实也有相应的命令 - 只需用 'v' 来代替 'V'(不包括单引号)即可。在下面的例子中,我使用 'v' 来选中段落的前三句话:
|
||||
其实也有相应的命令 - 只需用小写 `v` 来代替大写 `V` 即可。在下面的例子中,我使用 `v` 来选中段落的前三句话:
|
||||
|
||||
[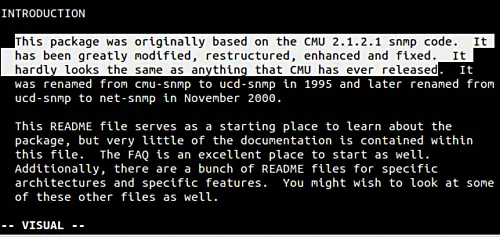][6]
|
||||
|
||||
@ -35,25 +35,25 @@
|
||||
|
||||
[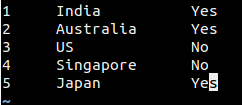][7]
|
||||
|
||||
假设我们只需选择文本的第二列,即国家的名字。这种情况下,你可以将光标放在这一列的第一个字母上,按 Ctrl+v 一次。然后,按方向键'下',选中每个国家名字的第一个字母:
|
||||
假设我们只需选择文本的第二列,即国家的名字。这种情况下,你可以将光标放在这一列的第一个字母上,按 `Ctrl+v` 一次。然后,按方向键“下”,选中每个国家名字的第一个字母:
|
||||
|
||||
[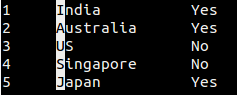][8]
|
||||
|
||||
然后按方向键'右',选中这一列。
|
||||
然后按方向键“右”,选中这一列。
|
||||
|
||||
[][9]
|
||||
|
||||
**小窍门**:如果你之前选中了某个文本块,现在想重新选中那个文本块,只需在命令模式下按 'gv' 即可。
|
||||
**小窍门**:如果你之前选中了某个文本块,现在想重新选中那个文本块,只需在命令模式下按 `gv` 即可。
|
||||
|
||||
# 使用标志
|
||||
### 使用标志
|
||||
|
||||
有时候,你在处理一个很大的文件(例如源代码文件或者一个 shell 脚本),可能想要切换到一个特定的位置,然后再回到刚才所在的行。如果这两行的位置不远,或者你并不常做这类操作,那么这不是什么问题。
|
||||
|
||||
但是,如果你需要频繁地在当前位置和一些较远的行之间切换,那么最好的方法就是使用标志。你只需标记当前的位置,然后就能够通过标志名,从文件的任意位置回到当前的位置。
|
||||
|
||||
在 Vim 中,我们使用 m 命令紧跟一个字母来标记一行(字母表示标志名,可用小写的 a-z)。例如 ma。然后你可以使用命令 'a (包括左单引号)回到标志为 a 的行。
|
||||
在 Vim 中,我们使用 `m` 命令紧跟一个字母来标记一行(字母表示标志名,可用小写的 `a` - `z`)。例如 `ma`。然后你可以使用命令 `'a` (包括左侧的单引号)回到标志为 `a` 的行。
|
||||
|
||||
**小窍门**:你可以使用单引号来跳转到标志行的第一个字符,或使用反引号来跳转到标志行的特定列。
|
||||
**小窍门**:你可以使用“单引号” `'` 来跳转到标志行的第一个字符,或使用“反引号” ` 来跳转到标志行的特定列。
|
||||
|
||||
Vim 的标志功能还有很多其他的用法。例如,你可以先标记一行,然后将光标移到其他行,运行下面的命令:
|
||||
|
||||
@ -65,43 +65,37 @@ d'[标志名]
|
||||
|
||||
在 Vim 官方文档中,有一个重要的内容:
|
||||
|
||||
```
|
||||
每个文件有一些由小写字母(a-z)定义的标志。此外,还存在一些由大写字母(A-Z)定义的全局标志,它们定义了一个特定文件的某个位置。例如,你可能在同时编辑十个文件,每个文件都可以有标志 a,但是只有一个文件能够有标志 A。
|
||||
```
|
||||
> 每个文件有一些由小写字母(`a`-`z`)定义的标志。此外,还存在一些由大写字母(`A`-`Z`)定义的全局标志,它们定义了一个特定文件的某个位置。例如,你可能在同时编辑十个文件,每个文件都可以有标志 `a`,但是只有一个文件能够有标志 `A`。
|
||||
|
||||
我们已经讨论了使用小写字母作为 Vim 标志的基本用法,以及它们的便捷之处。下面的这段摘录讲解的足够清晰:
|
||||
|
||||
```
|
||||
由于种种局限性,大写字母标志可能乍一看不如小写字母标志好用,但它可以用作一种快速的文件书签。例如,打开 .vimrc 文件,按下 mV,然后退出。下次再想要编辑 .vimrc 文件的时候,按下 'V 就能够打开它。
|
||||
```
|
||||
> 由于种种局限性,大写字母标志可能乍一看不如小写字母标志好用,但它可以用作一种快速的文件书签。例如,打开 `.vimrc` 文件,按下 `mV`,然后退出。下次再想要编辑 `.vimrc` 文件的时候,按下 `'V` 就能够打开它。
|
||||
|
||||
最后,我们使用 'delmarks' 命令来删除标志。例如:
|
||||
最后,我们使用 `delmarks` 命令来删除标志。例如:
|
||||
|
||||
```
|
||||
:delmarks a
|
||||
```
|
||||
|
||||
这一命令将从文件中删除一个标志。当然,你也可以删除标志行,这样标志将被自动删除。你可以在 [Vim 文档][11] 中找到关于标志的更多信息。
|
||||
这一命令将从文件中删除一个标志。当然,你也可以删除标志所在的行,这样标志将被自动删除。你可以在 [Vim 文档][11] 中找到关于标志的更多信息。
|
||||
|
||||
# 总结
|
||||
### 总结
|
||||
|
||||
当你开始使用 Vim 作为首选编辑器的时候,类似于这篇教程中提到的功能将会是非常有用的工具,能够节省大量的时间。你得承认,这里介绍的文本选择和标志功能几乎不怎么需要学习,所需要的只是一点练习。
|
||||
|
||||
你可以在 [HowtoForge][1] 上找到更多有关 Vim 的文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-use-markers-and-perform-text-selection-in-vim/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[Cathon](https://github.com/Cathon)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-use-markers-and-perform-text-selection-in-vim/
|
||||
[1]:https://www.howtoforge.com/tutorials/shell/
|
||||
[2]:https://www.howtoforge.com/vim-basics
|
||||
[2]:https://linux.cn/article-8143-1.html
|
||||
[3]:https://www.howtoforge.com/images/how-to-use-markers-and-perform-text-selection-in-vim/big/vim-select-example.png
|
||||
[4]:https://www.howtoforge.com/images/how-to-use-markers-and-perform-text-selection-in-vim/big/vim-select-initiated.png
|
||||
[5]:https://www.howtoforge.com/images/how-to-use-markers-and-perform-text-selection-in-vim/big/vim-select-working.png
|
||||
94
published/20170327 Using vi-mode in your shell.md
Normal file
94
published/20170327 Using vi-mode in your shell.md
Normal file
@ -0,0 +1,94 @@
|
||||
在 shell 中使用 vi 模式
|
||||
============================================================
|
||||
|
||||
> 介绍在命令行编辑中使用 vi 模式。
|
||||
|
||||

|
||||
|
||||
>图片提供: opensource.com
|
||||
|
||||
作为一名大型开源社区的参与者,更确切地说,作为 [Fedora 项目][2]的成员,我有机会与许多人会面并讨论各种有趣的技术主题。我最喜欢的主题是“命令行”或者说 [shell][3],因为了解人们如何熟练使用 shell 可以让你深入地了解他们的想法,他们喜欢什么样的工作流程,以及某种程度上是什么激发了他们的灵感。许多开发和运维人员在互联网上公开分享他们的“ dot 文件”(他们的 shell 配置文件的常见俚语),这将是一个有趣的协作机会,让每个人都能从对命令行有丰富经验的人中学习提示和技巧并分享快捷方式以及有效率的技巧。
|
||||
|
||||
今天我在这里会为你介绍 shell 中的 vi 模式。
|
||||
|
||||
在计算和操作系统的庞大生态系统中有[很多 shell][4]。然而,在 Linux 世界中,[bash][5] 已经成为事实上的标准,并在在撰写本文时,它是所有主要 Linux 发行版上的默认 shell。因此,它就是我所说的 shell。需要注意的是,bash 在其他类 UNIX 操作系统上也是一个相当受欢迎的选项,所以它可能跟你用的差别不大(对于 Windows 用户,可以用 [cygwin][6])。
|
||||
|
||||
在探索 shell 时,首先要做的是在其中输入命令并得到输出,如下所示:
|
||||
|
||||
```
|
||||
$ echo "Hello World!"
|
||||
Hello World!
|
||||
```
|
||||
|
||||
这是常见的练习,可能每个人都做过。没接触过的人和新手可能没有意识到 [bash][7] shell 的默认输入模式是 [Emacs][8] 模式,也就是说命令行中所用的行编辑功能都将使用 [Emacs 风格的“键盘快捷键”][9]。(行编辑功能实际上是由 [GNU Readline][10] 进行的。)
|
||||
|
||||
例如,如果你输入了 `echo "Hello Wrld!"`,并意识到你想要快速跳回一个单词(空格分隔)来修改打字错误,而无需按住左箭头键,那么你可以同时按下 `Alt+b`,光标会将向后跳到 `W`。
|
||||
|
||||
```
|
||||
$ echo "Hello Wrld!"
|
||||
^
|
||||
Cursor is here.
|
||||
```
|
||||
|
||||
这只是使用提供给 shell 用户的诸多 Emacs 快捷键组合之一完成的。还有其他更多东西,如复制文本、粘贴文本、删除文本以及使用快捷方式来编辑文本。使用复杂的快捷键组合并记住可能看起来很愚蠢,但是在使用较长的命令或从 shell 历史记录中调用一个命令并想再次编辑执行时,它们可能会非常强大。
|
||||
|
||||
尽管 Emacs 的键盘绑定都不错,如果你对 Emacs 编辑器熟悉或者发现它们很容易使用也不错,但是仍有一些人觉得 “vi 风格”的键盘绑定更舒服,因为他们经常使用 vi 编辑器(通常是 [vim][11] 或 [nvim][12])。bash shell(再说一次,通过 GNU Readline)可以为我们提供这个功能。要启用它,需要执行命令 `$ set -o vi`。
|
||||
|
||||
就像魔术一样,你现在处于 vi 模式了,现在可以使用 vi 风格的键绑定来轻松地进行编辑,以便复制文本、删除文本、并跳转到文本行中的不同位置。这与 Emacs 模式在功能方面没有太大的不同,但是它在你_如何_与 shell 进行交互执行操作上有一些差别,根据你的喜好这是一个强大的选择。
|
||||
|
||||
我们来看看先前的例子,但是在这种情况下一旦你在 shell 中进入 vi 模式,你就处于 INSERT 模式中,这意味着你可以和以前一样输入命令,现在点击 **Esc** 键,你将处于 NORMAL 模式,你可以自由浏览并进行文字修改。
|
||||
|
||||
看看先前的例子,如果你输入了 `echo "Hello Wrld!"`,并意识到你想跳回一个单词(再说一次,用空格分隔的单词)来修复那个打字错误,那么你可以点击 `Esc` 从 INSERT 模式变为 NORMAL 模式。然后,您可以输入 `B`(即 `Shift+b`),光标就能像以前那样回到前面了。(有关 vi 模式的更多信息,请参阅[这里][13]。):
|
||||
|
||||
```
|
||||
$ echo "Hello Wrld!"
|
||||
^
|
||||
Cursor is here.
|
||||
```
|
||||
|
||||
现在,对于 vi/vim/nvim 用户来说,你会惊喜地发现你可以一直使用相同的快捷键,而不仅仅是在编辑器中编写代码或文档的时候。如果你从未了解过这些,并且想要了解更多,那么我可能会建议你看看这个[交互式 vim 教程][14],看看 vi 风格的编辑是否有你所不知道的。
|
||||
|
||||
如果你喜欢在此风格下与 shell 交互,那么你可以在主目录中的 `~/.bashrc` 文件底部添加下面的行来持久设置它。
|
||||
|
||||
```
|
||||
set -o vi
|
||||
```
|
||||
|
||||
对于 emacs 模式的用户,希望这可以让你快速并愉快地看到 shell 的“另一面”。在结束之前,我认为每个人都应该使用任意一个让他们更有效率的编辑器和 shell 行编辑模式,如果你使用 vi 模式并且这篇文章给你展开了新的一页,那么恭喜你!现在就变得更有效率吧。
|
||||
|
||||
玩得愉快!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Adam Miller 是 Fedora 工程团队成员,专注于 Fedora 发布工程。他的工作包括下一代构建系统、自动化、RPM 包维护和基础架构部署。Adam 在山姆休斯顿州立大学完成了计算机科学学士学位与信息保障与安全科学硕士学位。他是一名红帽认证工程师(Cert#110-008-810),也是开源社区的活跃成员,并对 Fedora 项目(FAS 帐户名称:maxamillion)贡献有着悠久的历史。
|
||||
|
||||
|
||||
------------------------
|
||||
via: https://opensource.com/article/17/3/fun-vi-mode-your-shell
|
||||
|
||||
作者:[Adam Miller][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/maxamillion
|
||||
[1]:https://opensource.com/article/17/3/fun-vi-mode-your-shell?rate=5_eAB9UtByHOiZMysPcewU4Zz6hOrLwdcgIpu2Ub4vo
|
||||
[2]:https://getfedora.org/
|
||||
[3]:https://opensource.com/business/16/3/top-linux-shells
|
||||
[4]:https://opensource.com/business/16/3/top-linux-shells
|
||||
[5]:https://tiswww.case.edu/php/chet/bash/bashtop.html
|
||||
[6]:http://cygwin.org/
|
||||
[7]:https://tiswww.case.edu/php/chet/bash/bashtop.html
|
||||
[8]:https://www.gnu.org/software/emacs/
|
||||
[9]:https://en.wikipedia.org/wiki/GNU_Readline#Emacs_keyboard_shortcuts
|
||||
[10]:http://cnswww.cns.cwru.edu/php/chet/readline/rltop.html
|
||||
[11]:http://www.vim.org/
|
||||
[12]:https://neovim.io/
|
||||
[13]:https://en.wikibooks.org/wiki/Learning_the_vi_Editor/Vim/Modes
|
||||
[14]:http://www.openvim.com/tutorial.html
|
||||
[15]:https://opensource.com/user/10726/feed
|
||||
[16]:https://opensource.com/article/17/3/fun-vi-mode-your-shell#comments
|
||||
[17]:https://opensource.com/users/maxamillion
|
||||
155
sources/talk/20170320 Education of a Programmer.md
Normal file
155
sources/talk/20170320 Education of a Programmer.md
Normal file
@ -0,0 +1,155 @@
|
||||
Education of a Programmer
|
||||
============================================================
|
||||
|
||||
_When I left Microsoft in October 2016 after almost 21 years there and almost 35 years in the industry, I took some time to reflect on what I had learned over all those years. This is a lightly edited version of that post. Pardon the length!_
|
||||
|
||||
There are an amazing number of things you need to know to be a proficient programmer — details of languages, APIs, algorithms, data structures, systems and tools. These things change all the time — new languages and programming environments spring up and there always seems to be some hot new tool or language that “everyone” is using. It is important to stay current and proficient. A carpenter needs to know how to pick the right hammer and nail for the job and needs to be competent at driving the nail straight and true.
|
||||
|
||||
At the same time, I’ve found that there are some concepts and strategies that are applicable over a wide range of scenarios and across decades. We have seen multiple orders of magnitude change in the performance and capability of our underlying devices and yet certain ways of thinking about the design of systems still say relevant. These are more fundamental than any specific implementation. Understanding these recurring themes is hugely helpful in both the analysis and design of the complex systems we build.
|
||||
|
||||
Humility and Ego
|
||||
|
||||
This is not limited to programming, but in an area like computing which exhibits so much constant change, one needs a healthy balance of humility and ego. There is always more to learn and there is always someone who can help you learn it — if you are willing and open to that learning. One needs both the humility to recognize and acknowledge what you don’t know and the ego that gives you confidence to master a new area and apply what you already know. The biggest challenges I have seen are when someone works in a single deep area for a long time and “forgets” how good they are at learning new things. The best learning comes from actually getting hands dirty and building something, even if it is just a prototype or hack. The best programmers I know have had both a broad understanding of technology while at the same time have taken the time to go deep into some technology and become the expert. The deepest learning happens when you struggle with truly hard problems.
|
||||
|
||||
End to End Argument
|
||||
|
||||
Back in 1981, Jerry Saltzer, Dave Reed and Dave Clark were doing early work on the Internet and distributed systems and wrote up their [classic description][4] of the end to end argument. There is much misinformation out there on the Internet so it can be useful to go back and read the original paper. They were humble in not claiming invention — from their perspective this was a common engineering strategy that applies in many areas, not just in communications. They were simply writing it down and gathering examples. A minor paraphrasing is:
|
||||
|
||||
When implementing some function in a system, it can be implemented correctly and completely only with the knowledge and participation of the endpoints of the system. In some cases, a partial implementation in some internal component of the system may be important for performance reasons.
|
||||
|
||||
The SRC paper calls this an “argument”, although it has been elevated to a “principle” on Wikipedia and in other places. In fact, it is better to think of it as an argument — as they detail, one of the hardest problem for a system designer is to determine how to divide responsibilities between components of a system. This ends up being a discussion that involves weighing the pros and cons as you divide up functionality, isolate complexity and try to design a reliable, performant system that will be flexible to evolving requirements. There is no simple set of rules to follow.
|
||||
|
||||
Much of the discussion on the Internet focuses on communications systems, but the end-to-end argument applies in a much wider set of circumstances. One example in distributed systems is the idea of “eventual consistency”. An eventually consistent system can optimize and simplify by letting elements of the system get into a temporarily inconsistent state, knowing that there is a larger end-to-end process that can resolve these inconsistencies. I like the example of a scaled-out ordering system (e.g. as used by Amazon) that doesn’t require every request go through a central inventory control choke point. This lack of a central control point might allow two endpoints to sell the same last book copy, but the overall system needs some type of resolution system in any case, e.g. by notifying the customer that the book has been backordered. That last book might end up getting run over by a forklift in the warehouse before the order is fulfilled anyway. Once you realize an end-to-end resolution system is required and is in place, the internal design of the system can be optimized to take advantage of it.
|
||||
|
||||
In fact, it is this design flexibility in the service of either ongoing performance optimization or delivering other system features that makes this end-to-end approach so powerful. End-to-end thinking often allows internal performance flexibility which makes the overall system more robust and adaptable to changes in the characteristics of each of the components. This makes an end-to-end approach “anti-fragile” and resilient to change over time.
|
||||
|
||||
An implication of the end-to-end approach is that you want to be extremely careful about adding layers and functionality that eliminates overall performance flexibility. (Or other flexibility, but performance, especially latency, tends to be special.) If you expose the raw performance of the layers you are built on, end-to-end approaches can take advantage of that performance to optimize for their specific requirements. If you chew up that performance, even in the service of providing significant value-add functionality, you eliminate design flexibility.
|
||||
|
||||
The end-to-end argument intersects with organizational design when you have a system that is large and complex enough to assign whole teams to internal components. The natural tendency of those teams is to extend the functionality of those components, often in ways that start to eliminate design flexibility for applications trying to deliver end-to-end functionality built on top of them.
|
||||
|
||||
One of the challenges in applying the end-to-end approach is determining where the end is. “Little fleas have lesser fleas… and so on ad infinitum.”
|
||||
|
||||
Concentrating Complexity
|
||||
|
||||
Coding is an incredibly precise art, with each line of execution required for correct operation of the program. But this is misleading. Programs are not uniform in the overall complexity of their components or the complexity of how those components interact. The most robust programs isolate complexity in a way that lets significant parts of the system appear simple and straightforward and interact in simple ways with other components in the system. Complexity hiding can be isomorphic with other design approaches like information hiding and data abstraction but I find there is a different design sensibility if you really focus on identifying where the complexity lies and how you are isolating it.
|
||||
|
||||
The example I’ve returned to over and over again in my [writing][5] is the screen repaint algorithm that was used by early character video terminal editors like VI and EMACS. The early video terminals implemented control sequences for the core action of painting characters as well as additional display functions to optimize redisplay like scrolling the current lines up or down or inserting new lines or moving characters within a line. Each of those commands had different costs and those costs varied across different manufacturer’s devices. (See [TERMCAP][6] for links to code and a fuller history.) A full-screen application like a text editor wanted to update the screen as quickly as possible and therefore needed to optimize its use of these control sequences to transition the screen from one state to another.
|
||||
|
||||
These applications were designed so this underlying complexity was hidden. The parts of the system that modify the text buffer (where most innovation in functionality happens) completely ignore how these changes are converted into screen update commands. This is possible because the performance cost of computing the optimal set of updates for _any_ change in the content is swamped by the performance cost of actually executing the update commands on the terminal itself. It is a common pattern in systems design that performance analysis plays a key part in determining how and where to hide complexity. The screen update process can be asynchronous to the changes in the underlying text buffer and can be independent of the actual historical sequence of changes to the buffer. It is not important _how_ the buffer changed, but only _what_ changed. This combination of asynchronous coupling, elimination of the combinatorics of historical path dependence in the interaction between components and having a natural way for interactions to efficiently batch together are common characteristics used to hide coupling complexity.
|
||||
|
||||
Success in hiding complexity is determined not by the component doing the hiding but by the consumers of that component. This is one reason why it is often so critical for a component provider to actually be responsible for at least some piece of the end-to-end use of that component. They need to have clear optics into how the rest of the system interacts with their component and how (and whether) complexity leaks out. This often shows up as feedback like “this component is hard to use” — which typically means that it is not effectively hiding the internal complexity or did not pick a functional boundary that was amenable to hiding that complexity.
|
||||
|
||||
Layering and Componentization
|
||||
|
||||
It is the fundamental role of a system designer to determine how to break down a system into components and layers; to make decisions about what to build and what to pick up from elsewhere. Open Source may keep money from changing hands in this “build vs. buy” decision but the dynamics are the same. An important element in large scale engineering is understanding how these decisions will play out over time. Change fundamentally underlies everything we do as programmers, so these design choices are not only evaluated in the moment, but are evaluated in the years to come as the product continues to evolve.
|
||||
|
||||
Here are a few things about system decomposition that end up having a large element of time in them and therefore tend to take longer to learn and appreciate.
|
||||
|
||||
* Layers are leaky. Layers (or abstractions) are [fundamentally leaky][1]. These leaks have consequences immediately but also have consequences over time, in two ways. One consequence is that the characteristics of the layer leak through and permeate more of the system than you realize. These might be assumptions about specific performance characteristics or behavior ordering that is not an explicit part of the layer contract. This means that you generally are more _vulnerable_ to changes in the internal behavior of the component that you understood. A second consequence is it also means you are more _dependent_ on that internal behavior than is obvious, so if you consider changing that layer the consequences and challenges are probably larger than you thought.
|
||||
* Layers are too functional. It is almost a truism that a component you adopt will have more functionality than you actually require. In some cases, the decision to use it is based on leveraging that functionality for future uses. You adopt specifically because you want to “get on the train” and leverage the ongoing work that will go into that component. There are a few consequences of building on this highly functional layer. 1) The component will often make trade-offs that are biased by functionality that you do not actually require. 2) The component will embed complexity and constraints because of functionality you do not require and those constraints will impede future evolution of that component. 3) There will be more surface area to leak into your application. Some of that leakage will be due to true “leaky abstractions” and some will be explicit (but generally poorly controlled) increased dependence on the full capabilities of the component. Office is big enough that we found that for any layer we built on, we eventually fully explored its functionality in some part of the system. While that might appear to be positive (we are more completely leveraging the component), all uses are not equally valuable. So we end up having a massive cost to move from one layer to another based on this long-tail of often lower value and poorly recognized use cases. 4) The additional functionality creates complexity and opportunities for misuse. An XML validation API we used would optionally dynamically download the schema definition if it was specified as part of the XML tree. This was mistakenly turned on in our basic file parsing code which resulted in both a massive performance degradation as well as an (unintentional) distributed denial of service attack on a w3c.org web server. (These are colloquially known as “land mine” APIs.)
|
||||
* Layers get replaced. Requirements evolve, systems evolve, components are abandoned. You eventually need to replace that layer or component. This is true for external component dependencies as well as internal ones. This means that the issues above will end up becoming important.
|
||||
* Your build vs. buy decision will change. This is partly a corollary of above. This does not mean the decision to build or buy was wrong at the time. Often there was no appropriate component when you started and it only becomes available later. Or alternatively, you use a component but eventually find that it does not match your evolving requirements and your requirements are narrow enough, well-understood or so core to your value proposition that it makes sense to own it yourself. It does mean that you need to be just as concerned about leaky layers permeating more of the system for layers you build as well as for layers you adopt.
|
||||
* Layers get thick. As soon as you have defined a layer, it starts to accrete functionality. The layer is the natural throttle point to optimize for your usage patterns. The difficulty with a thick layer is that it tends to reduce your ability to leverage ongoing innovation in underlying layers. In some sense this is why OS companies hate thick layers built on top of their core evolving functionality — the pace at which innovation can be adopted is inherently slowed. One disciplined approach to avoid this is to disallow any additional state storage in an adaptor layer. Microsoft Foundation Classes took this general approach in building on top of Win32\. It is inevitably cheaper in the short term to just accrete functionality on to an existing layer (leading to all the eventual problems above) rather than refactoring and recomponentizing. A system designer who understands this looks for opportunities to break apart and simplify components rather than accrete more and more functionality within them.
|
||||
|
||||
Einsteinian Universe
|
||||
|
||||
I had been designing asynchronous distributed systems for decades but was struck by this quote from Pat Helland, a SQL architect, at an internal Microsoft talk. “We live in an Einsteinian universe — there is no such thing as simultaneity. “ When building distributed systems — and virtually everything we build is a distributed system — you cannot hide the distributed nature of the system. It’s just physics. This is one of the reasons I’ve always felt Remote Procedure Call, and especially “transparent” RPC that explicitly tries to hide the distributed nature of the interaction, is fundamentally wrong-headed. You need to embrace the distributed nature of the system since the implications almost always need to be plumbed completely through the system design and into the user experience.
|
||||
|
||||
Embracing the distributed nature of the system leads to a number of things:
|
||||
|
||||
* You think through the implications to the user experience from the start rather than trying to patch on error handling, cancellation and status reporting as an afterthought.
|
||||
* You use asynchronous techniques to couple components. Synchronous coupling is _impossible._ If something appears synchronous, it’s because some internal layer has tried to hide the asynchrony and in doing so has obscured (but definitely not hidden) a fundamental characteristic of the runtime behavior of the system.
|
||||
* You recognize and explicitly design for interacting state machines and that these states represent robust long-lived internal system states (rather than ad-hoc, ephemeral and undiscoverable state encoded by the value of variables in a deep call stack).
|
||||
* You recognize that failure is expected. The only guaranteed way to detect failure in a distributed system is to simply decide you have waited “too long”. This naturally means that [cancellation is first-class][2]. Some layer of the system (perhaps plumbed through to the user) will need to decide it has waited too long and cancel the interaction. Cancelling is only about reestablishing local state and reclaiming local resources — there is no way to reliably propagate that cancellation through the system. It can sometimes be useful to have a low-cost, unreliable way to attempt to propagate cancellation as a performance optimization.
|
||||
* You recognize that cancellation is not rollback since it is just reclaiming local resources and state. If rollback is necessary, it needs to be an end-to-end feature.
|
||||
* You accept that you can never really know the state of a distributed component. As soon as you discover the state, it may have changed. When you send an operation, it may be lost in transit, it might be processed but the response is lost, or it may take some significant amount of time to process so the remote state ultimately transitions at some arbitrary time in the future. This leads to approaches like idempotent operations and the ability to robustly and efficiently rediscover remote state rather than expecting that distributed components can reliably track state in parallel. The concept of “[eventual consistency][3]” succinctly captures many of these ideas.
|
||||
|
||||
I like to say you should “revel in the asynchrony”. Rather than trying to hide it, you accept it and design for it. When you see a technique like idempotency or immutability, you recognize them as ways of embracing the fundamental nature of the universe, not just one more design tool in your toolbox.
|
||||
|
||||
Performance
|
||||
|
||||
I am sure Don Knuth is horrified by how misunderstood his partial quote “Premature optimization is the root of all evil” has been. In fact, performance, and the incredible exponential improvements in performance that have continued for over 6 decades (or more than 10 decades depending on how willing you are to project these trends through discrete transistors, vacuum tubes and electromechanical relays), underlie all of the amazing innovation we have seen in our industry and all the change rippling through the economy as “software eats the world”.
|
||||
|
||||
A key thing to recognize about this exponential change is that while all components of the system are experiencing exponential change, these exponentials are divergent. So the rate of increase in capacity of a hard disk changes at a different rate from the capacity of memory or the speed of the CPU or the latency between memory and CPU. Even when trends are driven by the same underlying technology, exponentials diverge. [Latency improvements fundamentally trail bandwidth improvements][7]. Exponential change tends to look linear when you are close to it or over short periods but the effects over time can be overwhelming. This overwhelming change in the relationship between the performance of components of the system forces reevaluation of design decisions on a regular basis.
|
||||
|
||||
A consequence of this is that design decisions that made sense at one point no longer make sense after a few years. Or in some cases an approach that made sense two decades ago starts to look like a good trade-off again. Modern memory mapping has characteristics that look more like process swapping of the early time-sharing days than it does like demand paging. (This does sometimes result in old codgers like myself claiming that “that’s just the same approach we used back in ‘75” — ignoring the fact that it didn’t make sense for 40 years and now does again because some balance between two components — maybe flash and NAND rather than disk and core memory — has come to resemble a previous relationship).
|
||||
|
||||
Important transitions happen when these exponentials cross human constraints. So you move from a limit of two to the sixteenth characters (which a single user can type in a few hours) to two to the thirty-second (which is beyond what a single person can type). So you can capture a digital image with higher resolution than the human eye can perceive. Or you can store an entire music collection on a hard disk small enough to fit in your pocket. Or you can store a digitized video recording on a hard disk. And then later the ability to stream that recording in real time makes it possible to “record” it by storing it once centrally rather than repeatedly on thousands of local hard disks.
|
||||
|
||||
The things that stay as a fundamental constraint are three dimensions and the speed of light. We’re back to that Einsteinian universe. We will always have memory hierarchies — they are fundamental to the laws of physics. You will always have stable storage and IO, memory, computation and communications. The relative capacity, latency and bandwidth of these elements will change, but the system is always about how these elements fit together and the balance and tradeoffs between them. Jim Gray was the master of this analysis.
|
||||
|
||||
Another consequence of the fundamentals of 3D and the speed of light is that much of performance analysis is about three things: locality, locality, locality. Whether it is packing data on disk, managing processor cache hierarchies, or coalescing data into a communications packet, how data is packed together, the patterns for how you touch that data with locality over time and the patterns of how you transfer that data between components is fundamental to performance. Focusing on less code operating on less data with more locality over space and time is a good way to cut through the noise.
|
||||
|
||||
Jon Devaan used to say “design the data, not the code”. This also generally means when looking at the structure of a system, I’m less interested in seeing how the code interacts — I want to see how the data interacts and flows. If someone tries to explain a system by describing the code structure and does not understand the rate and volume of data flow, they do not understand the system.
|
||||
|
||||
A memory hierarchy also implies we will always have caches — even if some system layer is trying to hide it. Caches are fundamental but also dangerous. Caches are trying to leverage the runtime behavior of the code to change the pattern of interaction between different components in the system. They inherently need to model that behavior, even if that model is implicit in how they fill and invalidate the cache and test for a cache hit. If the model is poor _or becomes_ poor as the behavior changes, the cache will not operate as expected. A simple guideline is that caches _must_ be instrumented — their behavior will degrade over time because of changing behavior of the application and the changing nature and balance of the performance characteristics of the components you are modeling. Every long-time programmer has cache horror stories.
|
||||
|
||||
I was lucky that my early career was spent at BBN, one of the birthplaces of the Internet. It was very natural to think about communications between asynchronous components as the natural way systems connect. Flow control and queueing theory are fundamental to communications systems and more generally the way that any asynchronous system operates. Flow control is inherently resource management (managing the capacity of a channel) but resource management is the more fundamental concern. Flow control also is inherently an end-to-end responsibility, so thinking about asynchronous systems in an end-to-end way comes very naturally. The story of [buffer bloat][8]is well worth understanding in this context because it demonstrates how lack of understanding the dynamics of end-to-end behavior coupled with technology “improvements” (larger buffers in routers) resulted in very long-running problems in the overall network infrastructure.
|
||||
|
||||
The concept of “light speed” is one that I’ve found useful in analyzing any system. A light speed analysis doesn’t start with the current performance, it asks “what is the best theoretical performance I could achieve with this design?” What is the real information content being transferred and at what rate of change? What is the underlying latency and bandwidth between components? A light speed analysis forces a designer to have a deeper appreciation for whether their approach could ever achieve the performance goals or whether they need to rethink their basic approach. It also forces a deeper understanding of where performance is being consumed and whether this is inherent or potentially due to some misbehavior. From a constructive point of view, it forces a system designer to understand what are the true performance characteristics of their building blocks rather than focusing on the other functional characteristics.
|
||||
|
||||
I spent much of my career building graphical applications. A user sitting at one end of the system defines a key constant and constraint in any such system. The human visual and nervous system is not experiencing exponential change. The system is inherently constrained, which means a system designer can leverage ( _must_ leverage) those constraints, e.g. by virtualization (limiting how much of the underlying data model needs to be mapped into view data structures) or by limiting the rate of screen update to the perception limits of the human visual system.
|
||||
|
||||
The Nature of Complexity
|
||||
|
||||
I have struggled with complexity my entire career. Why do systems and apps get complex? Why doesn’t development within an application domain get easier over time as the infrastructure gets more powerful rather than getting harder and more constrained? In fact, one of our key approaches for managing complexity is to “walk away” and start fresh. Often new tools or languages force us to start from scratch which means that developers end up conflating the benefits of the tool with the benefits of the clean start. The clean start is what is fundamental. This is not to say that some new tool, platform or language might not be a great thing, but I can guarantee it will not solve the problem of complexity growth. The simplest way of controlling complexity growth is to build a smaller system with fewer developers.
|
||||
|
||||
Of course, in many cases “walking away” is not an alternative — the Office business is built on hugely valuable and complex assets. With OneNote, Office “walked away” from the complexity of Word in order to innovate along a different dimension. Sway is another example where Office decided that we needed to free ourselves from constraints in order to really leverage key environmental changes and the opportunity to take fundamentally different design approaches. With the Word, Excel and PowerPoint web apps, we decided that the linkage with our immensely valuable data formats was too fundamental to walk away from and that has served as a significant and ongoing constraint on development.
|
||||
|
||||
I was influenced by Fred Brook’s “[No Silver Bullet][9]” essay about accident and essence in software development. There is much irreducible complexity embedded in the essence of what the software is trying to model. I just recently re-read that essay and found it surprising on re-reading that two of the trends he imbued with the most power to impact future developer productivity were increasing emphasis on “buy” in the “build vs. buy” decision — foreshadowing the change that open-source and cloud infrastructure has had. The other trend was the move to more “organic” or “biological” incremental approaches over more purely constructivist approaches. A modern reader sees that as the shift to agile and continuous development processes. This in 1986!
|
||||
|
||||
I have been much taken with the work of Stuart Kauffman on the fundamental nature of complexity. Kauffman builds up from a simple model of Boolean networks (“[NK models][10]”) and then explores the application of this fundamentally mathematical construct to things like systems of interacting molecules, genetic networks, ecosystems, economic systems and (in a limited way) computer systems to understand the mathematical underpinning to emergent ordered behavior and its relationship to chaotic behavior. In a highly connected system, you inherently have a system of conflicting constraints that makes it (mathematically) hard to evolve that system forward (viewed as an optimization problem over a rugged landscape). A fundamental way of controlling this complexity is to batch the system into independent elements and limit the interconnections between elements (essentially reducing both “N” and “K” in the NK model). Of course this feels natural to a system designer applying techniques of complexity hiding, information hiding and data abstraction and using loose asynchronous coupling to limit interactions between components.
|
||||
|
||||
A challenge we always face is that many of the ways we want to evolve our systems cut across all dimensions. Real-time co-authoring has been a very concrete (and complex) recent example for the Office apps.
|
||||
|
||||
Complexity in our data models often equates with “power”. An inherent challenge in designing user experiences is that we need to map a limited set of gestures into a transition in the underlying data model state space. Increasing the dimensions of the state space inevitably creates ambiguity in the user gesture. This is “[just math][11]” which means that often times the most fundamental way to ensure that a system stays “easy to use” is to constrain the underlying data model.
|
||||
|
||||
Management
|
||||
|
||||
I started taking leadership roles in high school (student council president!) and always found it natural to take on larger responsibilities. At the same time, I was always proud that I continued to be a full-time programmer through every management stage. VP of development for Office finally pushed me over the edge and away from day-to-day programming. I’ve enjoyed returning to programming as I stepped away from that job over the last year — it is an incredibly creative and fulfilling activity (and maybe a little frustrating at times as you chase down that “last” bug).
|
||||
|
||||
Despite having been a “manager” for over a decade by the time I arrived at Microsoft, I really learned about management after my arrival in 1996\. Microsoft reinforced that “engineering leadership is technical leadership”. This aligned with my perspective and helped me both accept and grow into larger management responsibilities.
|
||||
|
||||
The thing that most resonated with me on my arrival was the fundamental culture of transparency in Office. The manager’s job was to design and use transparent processes to drive the project. Transparency is not simple, automatic, or a matter of good intentions — it needs to be designed into the system. The best transparency comes by being able to track progress as the granular output of individual engineers in their day-to-day activity (work items completed, bugs opened and fixed, scenarios complete). Beware subjective red/green/yellow, thumbs-up/thumbs-down dashboards!
|
||||
|
||||
I used to say my job was to design feedback loops. Transparent processes provide a way for every participant in the process — from individual engineer to manager to exec to use the data being tracked to drive the process and result and understand the role they are playing in the overall project goals. Ultimately transparency ends up being a great tool for empowerment — the manager can invest more and more local control in those closest to the problem because of confidence they have visibility to the progress being made. Coordination emerges naturally.
|
||||
|
||||
Key to this is that the goal has actually been properly framed (including key resource constraints like ship schedule). Decision-making that needs to constantly flow up and down the management chain usually reflects poor framing of goals and constraints by management.
|
||||
|
||||
I was at Beyond Software when I really internalized the importance of having a singular leader over a project. The engineering manager departed (later to hire me away for FrontPage) and all four of the leads were hesitant to step into the role — not least because we did not know how long we were going to stick around. We were all very technically sharp and got along well so we decided to work as peers to lead the project. It was a mess. The one obvious problem is that we had no strategy for allocating resources between the pre-existing groups — one of the top responsibilities of management! The deep accountability one feels when you know you are personally in charge was missing. We had no leader really accountable for unifying goals and defining constraints.
|
||||
|
||||
I have a visceral memory of the first time I fully appreciated the importance of _listening_ for a leader. I had just taken on the role of Group Development Manager for Word, OneNote, Publisher and Text Services. There was a significant controversy about how we were organizing the text services team and I went around to each of the key participants, heard what they had to say and then integrated and wrote up all I had heard. When I showed the write-up to one of the key participants, his reaction was “wow, you really heard what I had to say”! All of the largest issues I drove as a manager (e.g. cross-platform and the shift to continuous engineering) involved carefully listening to all the players. Listening is an active process that involves trying to understand the perspectives and then writing up what I learned and testing it to validate my understanding. When a key hard decision needed to happen, by the time the call was made everyone knew they had been heard and understood (whether they agreed with the decision or not).
|
||||
|
||||
It was the previous job, as FrontPage development manager, where I internalized the “operational dilemma” inherent in decision making with partial information. The longer you wait, the more information you will have to make a decision. But the longer you wait, the less flexibility you will have to actually implement it. At some point you just need to make a call.
|
||||
|
||||
Designing an organization involves a similar tension. You want to increase the resource domain so that a consistent prioritization framework can be applied across a larger set of resources. But the larger the resource domain, the harder it is to actually have all the information you need to make good decisions. An organizational design is about balancing these two factors. Software complicates this because characteristics of the software can cut across the design in an arbitrary dimensionality. Office has used [shared teams][12] to address both these issues (prioritization and resources) by having cross-cutting teams that can share work (add resources) with the teams they are building for.
|
||||
|
||||
One dirty little secret you learn as you move up the management ladder is that you and your new peers aren’t suddenly smarter because you now have more responsibility. This reinforces that the organization as a whole better be smarter than the leader at the top. Empowering every level to own their decisions within a consistent framing is the key approach to making this true. Listening and making yourself accountable to the organization for articulating and explaining the reasoning behind your decisions is another key strategy. Surprisingly, fear of making a dumb decision can be a useful motivator for ensuring you articulate your reasoning clearly and make sure you listen to all inputs.
|
||||
|
||||
Conclusion
|
||||
|
||||
At the end of my interview round for my first job out of college, the recruiter asked if I was more interested in working on “systems” or “apps”. I didn’t really understand the question. Hard, interesting problems arise at every level of the software stack and I’ve had fun plumbing all of them. Keep learning.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/education-of-a-programmer-aaecf2d35312
|
||||
|
||||
作者:[ Terry Crowley][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@terrycrowley
|
||||
[1]:https://medium.com/@terrycrowley/leaky-by-design-7b423142ece0#.x67udeg0a
|
||||
[2]:https://medium.com/@terrycrowley/how-to-think-about-cancellation-3516fc342ae#.3pfjc5b54
|
||||
[3]:http://queue.acm.org/detail.cfm?id=2462076
|
||||
[4]:http://web.mit.edu/Saltzer/www/publications/endtoend/endtoend.pdf
|
||||
[5]:https://medium.com/@terrycrowley/model-view-controller-and-loose-coupling-6370f76e9cde#.o4gnupqzq
|
||||
[6]:https://en.wikipedia.org/wiki/Termcap
|
||||
[7]:http://www.ll.mit.edu/HPEC/agendas/proc04/invited/patterson_keynote.pdf
|
||||
[8]:https://en.wikipedia.org/wiki/Bufferbloat
|
||||
[9]:http://worrydream.com/refs/Brooks-NoSilverBullet.pdf
|
||||
[10]:https://en.wikipedia.org/wiki/NK_model
|
||||
[11]:https://medium.com/@terrycrowley/the-math-of-easy-to-use-14645f819201#.untmk9eq7
|
||||
[12]:https://medium.com/@terrycrowley/breaking-conways-law-a0fdf8500413#.gqaqf1c5k
|
||||
@ -0,0 +1,53 @@
|
||||
Why do developers who could work anywhere flock to the world’s most expensive cities?
|
||||
============================================================
|
||||

|
||||
|
||||
Politicians and economists [lament][10] that certain alpha regions — SF, LA, NYC, Boston, Toronto, London, Paris — attract all the best jobs while becoming repellently expensive, reducing economic mobility and contributing to further bifurcation between haves and have-nots. But why don’t the best jobs move elsewhere?
|
||||
|
||||
Of course, many of them can’t. The average financier in NYC or London (until Brexit annihilates London’s banking industry, of course…) would be laughed out of the office, and not invited back, if they told their boss they wanted to henceforth work from Chiang Mai.
|
||||
|
||||
But this isn’t true of (much of) the software field. The average web/app developer might have such a request declined; but they would not be laughed at, or fired. The demand for good developers greatly outstrips supply, and in this era of Skype and Slack, there’s nothing about software development that requires meatspace interactions.
|
||||
|
||||
(This is even more true of writers, of course; I did in fact post this piece from Pohnpei. But writers don’t have anything like the leverage of software developers.)
|
||||
|
||||
Some people will tell you that remote teams are inherently less effective and productive than localized ones, or that “serendipitous collisions” are so important that every employee must be forced to the same physical location every day so that these collisions can be manufactured. These people are wrong, as long as the team in question is small — on the order of handfuls, dozens or scores, rather than hundreds or thousands — and flexible.
|
||||
|
||||
I should know: at [HappyFunCorp][11], we work extensively with remote teams, and actively recruit remote developers, and it works out fantastically well. A day in which I interact and collaborate with developers in Stockholm, São Paulo, Shanghai, Brooklyn and New Delhi, from my own home base in San Francisco, is not at all unusual.
|
||||
|
||||
At this point, whether it’s a good idea is almost irrelevant, though. Supply and demand is such that any sufficiently skilled developer could become a so-called digital nomad if they really wanted to. But many who could, do not. I recently spent some time in Reykjavik at a house Airbnb-ed for the month by an ever-shifting crew of temporary remote workers, keeping East Coast time to keep up with their jobs, while spending mornings and weekends exploring Iceland — but almost all of us then returned to live in the Bay Area.
|
||||
|
||||
Economically, of course, this is insane. Moving to and working from Southeast Asia would save us thousands of dollars a month in rent alone. So why do people who could live in Costa Rica on a San Francisco salary, or in Berlin while charging NYC rates, choose not to do so? Why are allegedly hardheaded engineers so financially irrational?
|
||||
|
||||
Of course there are social and cultural reasons. Chiang Mai is very nice, but doesn’t have the Met, or steampunk masquerade parties or 50 foodie restaurants within a 15-minute walk. Berlin is lovely, but doesn’t offer kite surfing, or Sierra hiking or California weather. Neither promises an effectively limitless population of people with whom you share values and a first language.
|
||||
|
||||
And yet I think there’s much more to it than this. I believe there’s a more fundamental economic divide opening than the one between haves and have-nots. I think we are witnessing a growing rift between the world’s Extremistan cities, in which truly extraordinary things can be achieved, and its Mediocristan towns, in which you can work and make money and be happy but never achieve greatness. (Labels stolen from the great Nassim Taleb.)
|
||||
|
||||
The arts have long had Extremistan cities. That’s why aspiring writers move to New York City, and even directors and actors who found international success are still drawn to L.A. like moths to a klieg light. Now it is true of tech, too. Even if you don’t even want to try to (help) build something extraordinary — and the startup myth is so powerful today that it’s a very rare engineer indeed who hasn’t at least dreamed about it — the prospect of being _where great things happen_ is intoxicatingly enticing.
|
||||
|
||||
But the interesting thing about this is that it could, in theory, change; because — as of quite recently — distributed, decentralized teams can, in fact, achieve extraordinary things. The cards are arguably stacked against them, because VCs tend to be quite myopic. But no law dictates that unicorns may only be born in California and a handful of other secondary territories; and it seems likely that, for better or worse, Extremistan is spreading. It would be pleasantly paradoxical if that expansion ultimately leads to _lower_ rents in the Mission.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/
|
||||
|
||||
作者:[ Jon Evans ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://techcrunch.com/author/jon-evans/
|
||||
[1]:https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/#comments
|
||||
[2]:https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/#
|
||||
[3]:http://twitter.com/share?via=techcrunch&url=http://tcrn.ch/2owXJ0C&text=Why%20do%20developers%20who%20could%20work%20anywhere%20flock%20to%20the%20world%E2%80%99s%20most%20expensive%C2%A0cities%3F&hashtags=
|
||||
[4]:https://www.linkedin.com/shareArticle?mini=true&url=https%3A%2F%2Ftechcrunch.com%2F2017%2F04%2F02%2Fwhy-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities%2F&title=Why%20do%20developers%20who%20could%20work%20anywhere%20flock%20to%20the%20world%E2%80%99s%20most%20expensive%C2%A0cities%3F
|
||||
[5]:https://plus.google.com/share?url=https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/
|
||||
[6]:http://www.reddit.com/submit?url=https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/&title=Why%20do%20developers%20who%20could%20work%20anywhere%20flock%20to%20the%20world%E2%80%99s%20most%20expensive%C2%A0cities%3F
|
||||
[7]:http://www.stumbleupon.com/badge/?url=https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/
|
||||
[8]:mailto:?subject=Why%20do%20developers%20who%20could%20work%20anywhere%20flock%20to%20the%20world%E2%80%99s%20most%20expensive%C2%A0cities?&body=Article:%20https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/
|
||||
[9]:https://share.flipboard.com/bookmarklet/popout?v=2&title=Why%20do%20developers%20who%20could%20work%20anywhere%20flock%20to%20the%20world%E2%80%99s%20most%20expensive%C2%A0cities%3F&url=https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/
|
||||
[10]:https://mobile.twitter.com/Noahpinion/status/846054187288866
|
||||
[11]:http://happyfuncorp.com/
|
||||
[12]:https://twitter.com/rezendi
|
||||
[13]:https://techcrunch.com/author/jon-evans/
|
||||
[14]:https://techcrunch.com/2017/04/01/discussing-the-limits-of-artificial-intelligence/
|
||||
@ -1,142 +0,0 @@
|
||||
[Data-Oriented Hash Table][1]
|
||||
============================================================
|
||||
|
||||
In recent years, there’s been a lot of discussion and interest in “data-oriented design”—a programming style that emphasizes thinking about how your data is laid out in memory, how you access it and how many cache misses it’s going to incur. With memory reads taking orders of magnitude longer for cache misses than hits, the number of misses is often the key metric to optimize. It’s not just about performance-sensitive code—data structures designed without sufficient attention to memory effects may be a big contributor to the general slowness and bloatiness of software.
|
||||
|
||||
The central tenet of cache-efficient data structures is to keep things flat and linear. For example, under most circumstances, to store a sequence of items you should prefer a flat array over a linked list—every pointer you have to chase to find your data adds a likely cache miss, while flat arrays can be prefetched and enable the memory system to operate at peak efficiency.
|
||||
|
||||
This is pretty obvious if you know a little about how the memory hierarchy works—but it’s still a good idea to test things sometimes, even if they’re “obvious”! [Baptiste Wicht tested `std::vector` vs `std::list` vs `std::deque`][4] (the latter of which is commonly implemented as a chunked array, i.e. an array of arrays) a couple of years ago. The results are mostly in line with what you’d expect, but there are a few counterintuitive findings. For instance, inserting or removing values in the middle of the sequence—something lists are supposed to be good at—is actually faster with an array, if the elements are a POD type and no bigger than 64 bytes (i.e. one cache line) or so! It turns out to actually be faster to shift around the array elements on insertion/removal than to first traverse the list to find the right position and then patch a few pointers to insert/remove one element. That’s because of the many cache misses in the list traversal, compared to relatively few for the array shift. (For larger element sizes, non-POD types, or if you already have a pointer into the list, the list wins, as you’d expect.)
|
||||
|
||||
Thanks to data like Baptiste’s, we know a good deal about how memory layout affects sequence containers. But what about associative containers, i.e. hash tables? There have been some expert recommendations: [Chandler Carruth tells us to use open addressing with local probing][5] so that we don’t have to chase pointers, and [Mike Acton suggests segregating keys from values][6] in memory so that we get more keys per cache line, improving locality when we have to look at multiple keys. These ideas make good sense, but again, it’s a good idea to test things, and I couldn’t find any data. So I had to collect some of my own!
|
||||
|
||||
### [][7]The Tests
|
||||
|
||||
I tested four different quick-and-dirty hash table implementations, as well as `std::unordered_map`. All five used the same hash function, Bob Jenkins’ [SpookyHash][8] with 64-bit hash values. (I didn’t test different hash functions, as that wasn’t the point here; I’m also not looking at total memory consumption in my analysis.) The implementations are identified by short codes in the results tables:
|
||||
|
||||
* **UM**: `std::unordered_map`. In both VS2012 and libstdc++-v3 (used by both gcc and clang), UM is implemented as a linked list containing all the elements, and an array of buckets that store iterators into the list. In VS2012, it’s a doubly-linked list and each bucket stores both begin and end iterators; in libstdc++, it’s a singly-linked list and each bucket stores just a begin iterator. In both cases, the list nodes are individually allocated and freed. Max load factor is 1.
|
||||
* **Ch**: separate chaining—each bucket points to a singly-linked list of element nodes. The element nodes are stored in a flat array pool, to avoid allocating each node individually. Unused nodes are kept on a free list. Max load factor is 1.
|
||||
* **OL**: open addressing with linear probing—each bucket stores a 62-bit hash, a 2-bit state (empty, filled, or removed), key, and value. Max load factor is 2/3.
|
||||
* **DO1**: “data-oriented 1”—like OL, but the hashes and states are segregated from the keys and values, in two separate flat arrays.
|
||||
* **DO2**: “data-oriented 2”—like OL, but the hashes/states, keys, and values are segregated in three separate flat arrays.
|
||||
|
||||
All my implementations, as well as VS2012’s UM, use power-of-2 sizes by default, growing by 2x upon exceeding their max load factor. In libstdc++, UM uses prime-number sizes by default and grows to the next prime upon exceeding its max load factor. However, I don’t think these details are very important for performance. The prime-number thing is a hedge against poor hash functions that don’t have enough entropy in their lower bits, but we’re using a good hash function.
|
||||
|
||||
The OL, DO1 and DO2 implementations will collectively be referred to as OA (open addressing), since we’ll find later that their performance characteristics are often pretty similar.
|
||||
|
||||
For each of these implementations, I timed several different operations, at element counts from 100K to 1M and for payload sizes (i.e. total key+value size) from 8 to 4K bytes. For my purposes, keys and values were always POD types and keys were always 8 bytes (except for the 8-byte payload, in which key and value were 4 bytes each). I kept the keys to a consistent size because my purpose here was to test memory effects, not hash function performance. Each test was repeated 5 times and the minimum timing was taken.
|
||||
|
||||
The operations tested were:
|
||||
|
||||
* **Fill**: insert a randomly shuffled sequence of unique keys into the table.
|
||||
* **Presized fill**: like Fill, but first reserve enough memory for all the keys we’ll insert, to prevent rehashing and reallocing during the fill process.
|
||||
* **Lookup**: perform 100K lookups of random keys, all of which are in the table.
|
||||
* **Failed lookup**: perform 100K lookups of random keys, none of which are in the table.
|
||||
* **Remove**: remove a randomly chosen half of the elements from a table.
|
||||
* **Destruct**: destroy a table and free its memory.
|
||||
|
||||
You can [download my test code here][9]. It builds for Windows or Linux, in 64-bit only. There are some flags near the top of `main()` that you can toggle to turn on or off different tests—with all of them on, it will likely take an hour or two to run. The results I gathered are also included, in an Excel spreadsheet in that archive. (Beware that the Windows and Linux results are run on different CPUs, so timings aren’t directly comparable.) The code also runs unit tests to verify that all the hash table implementations are behaving correctly.
|
||||
|
||||
Incidentally, I also tried two additional implementations: separate chaining with the first node stored in the bucket instead of the pool, and open addressing with quadratic probing. Neither of these was good enough to include in the final data, but the code for them is still there.
|
||||
|
||||
### [][10]The Results
|
||||
|
||||
There’s a ton of data here. In this section I’ll discuss the results in some detail, but if your eyes are glazing over in this part, feel free to skip down to the conclusions in the next section.
|
||||
|
||||
### [][11]Windows
|
||||
|
||||
Here are the graphed results of all the tests, compiled with Visual Studio 2012, and run on Windows 8.1 on a Core i7-4710HQ machine. (Click to zoom.)
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
From left to right are different payload sizes, from top to bottom are the various operations, and each graph plots time in milliseconds versus hash table element count for each of the five implementations. (Note that not all the Y-axes have the same scale!) I’ll summarize the main trends for each operation.
|
||||
|
||||
**Fill**: Among my hash tables, chaining is a bit better than any of the OA variants, with the gap widening at larger payloads and table sizes. I guess this is because chaining only has to pull an element off the free list and stick it on the front of its bucket, while OA may have to search a few buckets to find an empty one. The OA variants perform very similarly to each other, but DO1 appears to have a slight advantage.
|
||||
|
||||
All of my hash tables beat UM by quite a bit at small payloads, where UM pays a heavy price for doing a memory allocation on every insert. But they’re about equal at 128 bytes, and UM wins by quite a bit at large payloads: there, all of my implementations are hamstrung by the need to resize their element pool and spend a lot of time moving the large elements into the new pool, while UM never needs to move elements once they’re allocated. Notice the extreme “steppy” look of the graphs for my implementations at large payloads, which confirms that the problem comes when resizing. In contrast, UM is quite linear—it only has to resize its bucket array, which is cheap enough not to make much of a bump.
|
||||
|
||||
**Presized fill**: Generally similar to Fill, but the graphs are more linear, not steppy (since there’s no rehashing), and there’s less difference between all the implementations. UM is still slightly faster than chaining at large payloads, but only slightly—again confirming that the problem with Fill was the resizing. Chaining is still consistently faster than the OA variants, but DO1 has a slight advantage over the other OAs.
|
||||
|
||||
**Lookup**: All the implementations are closely clustered, with UM and DO2 the front-runners, except at the smallest payload, where it seems like DO1 and OL may be faster. It’s impressive how well UM is doing here, actually; it’s holding its own against the data-oriented variants despite needing to traverse a linked list.
|
||||
|
||||
Incidentally, it’s interesting to see that the lookup time weakly depends on table size. Hash table lookup is expected constant-time, so from the asymptotic view it shouldn’t depend on table size at all. But that’s ignoring cache effects! When we do 100K lookups on a 10K-entry table, for instance, we’ll get a speedup because most of the table will be in L3 after the first 10K–20K lookups.
|
||||
|
||||
**Failed lookup**: There’s a bit more spread here than the successful lookups. DO1 and DO2 are the front-runners, with UM not far behind, and OL a good deal worse than the rest. My guess is this is probably a case of OL having longer searches on average, especially in the case of a failed lookup; with the hash values spaced out in memory between keys and values, that hurts. DO1 and DO2 have equally-long searches, but they have all the hash values packed together in memory, and that turns things around.
|
||||
|
||||
**Remove**: DO2 is the clear winner, with DO1 not far behind, chaining further behind, and UM in a distant last place due to the need to free memory on every remove; the gap widens at larger payloads. The remove operation is the only one that doesn’t touch the value data, only the hashes and keys, which explains why DO1 and DO2 are differentiated from each other here but pretty much equal in all the other tests. (If your value type was non-POD and needed to run a destructor, that difference would presumably disappear.)
|
||||
|
||||
**Destruct**: Chaining is the fastest except at the smallest payload, where it’s about equal to the OA variants. All the OA variants are essentially equal. Note that for my hash tables, all they’re doing on destruction is freeing a handful of memory buffers, but [on Windows, freeing memory has a cost proportional to the amount allocated][13]. (And it’s a significant cost—an allocation of ~1 GB is taking ~100 ms to free!)
|
||||
|
||||
UM is the slowest to destruct—by an order of magnitude at small payloads, and only slightly slower at large payloads. The need to free each individual element instead of just freeing a couple of arrays really hurts here.
|
||||
|
||||
### [][14]Linux
|
||||
|
||||
I also ran tests with gcc 4.8 and clang 3.5, on Linux Mint 17.1 on a Core i5-4570S machine. The gcc and clang results were very similar, so I’ll only show the gcc ones; the full set of results are in the code download archive, linked above. (Click to zoom.)
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
Most of the results are quite similar to those in Windows, so I’ll just highlight a few interesting differences.
|
||||
|
||||
**Lookup**: Here, DO1 is the front-runner, where DO2 was a bit faster on Windows. Also, UM and chaining are way behind all the other implementations, which is actually what I expected to see in Windows as well, given that they have to do a lot of pointer chasing while the OA variants just stride linearly through memory. It’s not clear to me why the Windows and Linux results are so different here. UM is also a good deal slower than chaining, especially at large payloads, which is odd; I’d expect the two of them to be about equal.
|
||||
|
||||
**Failed lookup**: Again, UM is way behind all the others, even slower than OL. Again, it’s puzzling to me why this is so much slower than chaining, and why the results differ so much between Linux and Windows.
|
||||
|
||||
**Destruct**: For my implementations, the destruct cost was too small to measure at small payloads; at large payloads, it grows quite linearly with table size—perhaps proportional to the number of virtual memory pages touched, rather than the number allocated? It’s also orders of magnitude faster than the destruct cost on Windows. However, this isn’t anything to do with hash tables, really; we’re seeing the behavior of the respective OSes’ and runtimes’ memory systems here. It seems that Linux frees large blocks memory a lot faster than Windows (or it hides the cost better, perhaps deferring work to process exit, or pushing things off to another thread or process).
|
||||
|
||||
UM with its per-element frees is now orders of magnitude slower than all the others, across all payload sizes. In fact, I cut it from the graphs because it was screwing up the Y-axis scale for all the others.
|
||||
|
||||
### [][16]Conclusions
|
||||
|
||||
Well, after staring at all that data and the conflicting results for all the different cases, what can we conclude? I’d love to be able to tell you unequivocally that one of these hash table variants beats out the others, but of course it’s not that simple. Still, there is some wisdom we can take away.
|
||||
|
||||
First, in many cases it’s _easy_ to do better than `std::unordered_map`. All of the implementations I built for these tests (and they’re not sophisticated; it only took me a couple hours to write all of them) either matched or improved upon `unordered_map`, except for insertion performance at large payload sizes (over 128 bytes), where `unordered_map`‘s separately-allocated per-node storage becomes advantageous. (Though I didn’t test it, I also expect `unordered_map` to win with non-POD payloads that are expensive to move.) The moral here is that if you care about performance at all, don’t assume the data structures in your standard library are highly optimized. They may be optimized for C++ standard conformance, not performance. :P
|
||||
|
||||
Second, you could do a lot worse than to just use DO1 (open addressing, linear probing, with the hashes/states segregated from keys/values in separate flat arrays) whenever you have small, inexpensive payloads. It’s not the fastest for insertion, but it’s not bad either (still way better than `unordered_map`), and it’s very fast for lookup, removal, and destruction. What do you know—“data-oriented design” works!
|
||||
|
||||
Note that my test code for these hash tables is far from production-ready—they only support POD types, don’t have copy constructors and such, don’t check for duplicate keys, etc. I’ll probably build some more realistic hash tables for my utility library soon, though. To cover the bases, I think I’ll want two variants: one based on DO1, for small, cheap-to-move payloads, and another that uses chaining and avoids ever reallocating and moving elements (like `unordered_map`) for large or expensive-to-move payloads. That should give me the best of both worlds.
|
||||
|
||||
In the meantime, I hope this has been illuminating. And remember, if Chandler Carruth and Mike Acton give you advice about data structures, listen to them. 😉
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
I’m a graphics programmer, currently freelancing in Seattle. Previously I worked at NVIDIA on the DevTech software team, and at Sucker Punch Productions developing rendering technology for the Infamous series of games for PS3 and PS4.
|
||||
|
||||
I’ve been interested in graphics since about 2002 and have worked on a variety of assignments, including fog, atmospheric haze, volumetric lighting, water, visual effects, particle systems, skin and hair shading, postprocessing, specular models, linear-space rendering, and GPU performance measurement and optimization.
|
||||
|
||||
You can read about what I’m up to on my blog. In addition to graphics, I’m interested in theoretical physics, and in programming language design.
|
||||
|
||||
You can contact me at nathaniel dot reed at gmail dot com, or follow me on Twitter (@Reedbeta) or Google+. I can also often be found answering questions at Computer Graphics StackExchange.
|
||||
|
||||
--------------
|
||||
|
||||
via: http://reedbeta.com/blog/data-oriented-hash-table/
|
||||
|
||||
作者:[Nathan Reed][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://reedbeta.com/about/
|
||||
[1]:http://reedbeta.com/blog/data-oriented-hash-table/
|
||||
[2]:http://reedbeta.com/blog/category/coding/
|
||||
[3]:http://reedbeta.com/blog/data-oriented-hash-table/#comments
|
||||
[4]:http://baptiste-wicht.com/posts/2012/12/cpp-benchmark-vector-list-deque.html
|
||||
[5]:https://www.youtube.com/watch?v=fHNmRkzxHWs
|
||||
[6]:https://www.youtube.com/watch?v=rX0ItVEVjHc
|
||||
[7]:http://reedbeta.com/blog/data-oriented-hash-table/#the-tests
|
||||
[8]:http://burtleburtle.net/bob/hash/spooky.html
|
||||
[9]:http://reedbeta.com/blog/data-oriented-hash-table/hash-table-tests.zip
|
||||
[10]:http://reedbeta.com/blog/data-oriented-hash-table/#the-results
|
||||
[11]:http://reedbeta.com/blog/data-oriented-hash-table/#windows
|
||||
[12]:http://reedbeta.com/blog/data-oriented-hash-table/results-vs2012.png
|
||||
[13]:https://randomascii.wordpress.com/2014/12/10/hidden-costs-of-memory-allocation/
|
||||
[14]:http://reedbeta.com/blog/data-oriented-hash-table/#linux
|
||||
[15]:http://reedbeta.com/blog/data-oriented-hash-table/results-g++4.8.png
|
||||
[16]:http://reedbeta.com/blog/data-oriented-hash-table/#conclusions
|
||||
@ -0,0 +1,122 @@
|
||||
First 5 Commands When I Connect on a Linux Server
|
||||
============================================================
|
||||
|
||||

|
||||
[Creative Commons Attribution][1][Sylvain Kalache][2][First 5 shell commands I type when I connect to a linux server][3]
|
||||
|
||||
After half a decade working as a system administrator/SRE, I know where to start when I am connecting to a Linux server. There is a set of information that you must know about the server in order to properly, well most of the time, debug it.
|
||||
|
||||
### First 60 seconds on a Linux server
|
||||
|
||||
These commands are well known for experienced software engineers but I realized that for a beginner who is getting started with Linux systems, such as my students at [Holberton School][5], it is not obvious. That’s why I decided to share the list of the first 5 commands I type when I connect on a Linux server.
|
||||
|
||||
```
|
||||
w
|
||||
history
|
||||
top
|
||||
df
|
||||
netstat
|
||||
```
|
||||
|
||||
These 5 commands are shipped with any Linux distribution so you can use them everywhere without extra installation needed.
|
||||
|
||||
### w:
|
||||
|
||||
```
|
||||
[ubuntu@ip-172-31-48-251 ~]$ w
|
||||
23:40:25 up 273 days, 20:52, 2 users, load average: 0.33, 0.14, 0.12
|
||||
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
|
||||
ubuntu pts/0 104-7-14-91.ligh 23:39 0.00s 0.02s 0.00s w
|
||||
root pts/1 104-7-14-91.ligh 23:40 5.00s 0.01s 0.03s sshd: root [priv]
|
||||
[ubuntu@ip-172-31-48-251 ~]$
|
||||
```
|
||||
|
||||
A lot of great information in there. First, you can see the server [uptime][6] which is the time during which the server has been continuously running. You can then see what users are connected on the server, quite useful when you want to make sure that you are not impacting a colleague’s work. Finally the [load average][7] will give you a good sense of the server health.
|
||||
|
||||
### history:
|
||||
|
||||
```
|
||||
[ubuntu@ip-172-31-48-251 ~]$ history
|
||||
1 cd /var/app/current/log/
|
||||
2 ls -al
|
||||
3 tail -n 3000 production.log
|
||||
4 service apache2 status
|
||||
5 cat ../../app/services/discourse_service.rb
|
||||
```
|
||||
|
||||
`History` will tell you what was previously run by the user you are currently connected to. You will learn a lot about what type work was previously performed on the machine, what could have gone wrong with it, and where you might want to start your debugging work.
|
||||
|
||||
### top:
|
||||
|
||||
```
|
||||
top - 23:47:54 up 273 days, 21:00, 2 users, load average: 0.02, 0.07, 0.10
|
||||
Tasks: 79 total, 2 running, 77 sleeping, 0 stopped, 0 zombie
|
||||
Cpu(s): 1.0%us, 0.0%sy, 0.0%ni, 98.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.3%st
|
||||
Mem: 3842624k total, 3128036k used, 714588k free, 148860k buffers
|
||||
Swap: 0k total, 0k used, 0k free, 1052320k cached
|
||||
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
21095 root 20 0 513m 21m 4980 S 1.0 0.6 1237:05 python
|
||||
1380 healthd 20 0 669m 36m 5712 S 0.3 1.0 265:43.82 ruby
|
||||
19703 dd-agent 20 0 142m 25m 4912 S 0.3 0.7 11:32.32 python
|
||||
1 root 20 0 19596 1628 1284 S 0.0 0.0 0:10.64 init
|
||||
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
|
||||
3 root 20 0 0 0 0 S 0.0 0.0 27:31.42 ksoftirqd/0
|
||||
4 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0
|
||||
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
|
||||
7 root 20 0 0 0 0 S 0.0 0.0 42:51.60 rcu_sched
|
||||
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
|
||||
```
|
||||
|
||||
The next information you want to know: what is currently running on this server. With `top` you can see all running processes, then order them by CPU, memory utilization and catch the ones that are resource intensive.
|
||||
|
||||
### df:
|
||||
|
||||
```
|
||||
[ubuntu@ip-172-31-48-251 ~]$ df -h
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/xvda1 7.8G 4.5G 3.3G 58% /
|
||||
devtmpfs 1.9G 12K 1.9G 1% /dev
|
||||
tmpfs 1.9G 0 1.9G 0% /dev/shm
|
||||
```
|
||||
|
||||
The next important resource that your server needs to have to be working properly is disk space. Running out of it is a very classic issue.
|
||||
|
||||
### netstat:
|
||||
|
||||
```
|
||||
[ubuntu@ip-172-31-48-251 ec2-user]# netstat -lp
|
||||
Active Internet connections (only servers)
|
||||
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
|
||||
tcp 0 0 *:http *:* LISTEN 1637/nginx
|
||||
tcp 0 0 *:ssh *:* LISTEN 1209/sshd
|
||||
tcp 0 0 localhost:smtp *:* LISTEN 1241/sendmail
|
||||
tcp 0 0 localhost:17123 *:* LISTEN 19703/python
|
||||
tcp 0 0 localhost:22221 *:* LISTEN 1380/puma 2.11.1 (t
|
||||
tcp 0 0 *:4242 *:* LISTEN 18904/jsvc.exec
|
||||
tcp 0 0 *:ssh *:* LISTEN 1209/sshd
|
||||
```
|
||||
|
||||
Computers are a big part of our world now because they have the ability to communicate between each other via sockets. It is critical for you to know on what port and IP your server is listening on and what processes are using those.
|
||||
|
||||
Obviously this list might change depending on your goal and the amount of existing information you have. For example, when you want to debug specifically for performance, [Netflix came up with a customized list][8]. Do you have a useful command that is not in my top 5? Please share it in the comments section!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/first-5-commands-when-i-connect-linux-server
|
||||
|
||||
作者:[SYLVAIN KALACHE ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sylvainkalache
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-attribution
|
||||
[2]:https://twitter.com/sylvainkalache
|
||||
[3]:https://www.flickr.com/photos/sylvainkalache/29587668230/in/dateposted/
|
||||
[4]:https://www.linux.com/files/images/first-5-commandsjpg-0
|
||||
[5]:https://www.holbertonschool.com/
|
||||
[6]:http://whatis.techtarget.com/definition/uptime-and-downtime
|
||||
[7]:http://blog.scoutapp.com/articles/2009/07/31/understanding-load-averages
|
||||
[8]:http://techblog.netflix.com/2015/11/linux-performance-analysis-in-60s.html
|
||||
@ -1,89 +1,90 @@
|
||||
++翻译中
|
||||
+
|
||||
+
|
||||
### Configuring WINE with Winetricks
|
||||
用Winetricks配置WINE
|
||||
|
||||
Contents
|
||||
目录
|
||||
|
||||
* * [1. Introduction][1]
|
||||
* [2. Installing][2]
|
||||
* [3. Fonts][3]
|
||||
* [4. .dlls and Components][4]
|
||||
* [5. Registry][5]
|
||||
* [6. Closing][6]
|
||||
* [7. Table of Contents][7]
|
||||
|
||||
### Introduction
|
||||
[1简介][1]
|
||||
[2安装][2]
|
||||
[3字体][3]
|
||||
[4.dulls 和其他组件][4]
|
||||
[5注册][5]
|
||||
[6关闭][6]
|
||||
[7内容表][7]
|
||||
|
||||
If `winecfg` is a screwdriver, `winetricks` is a power drill. They both have their place, but `winetricks` is just a much more powerful tool. Actually, it even has the ability to launch `winecfg`.
|
||||
|
||||
While `winecfg` gives you the ability to change the settings of WINE itself, `winetricks` gives you the ability to modify the actual Windows layer. It allows you to install important components like `.dlls` and system fonts as well as giving you the capability to edit the Windows registry. It also has a task manager, an uninstall utility, and file browser.
|
||||
简介
|
||||
|
||||
Even though `winetricks` can do all of this, the majority of the time, you're going to be using it to manage `dlls` and Windows components.
|
||||
如果 winecfg (WINE的配置文件) 是一把螺丝刀,那么 winetricks 就是一个钻床.它们各有特长.但是 winetricks 真的是一个强大的工具.实际上,它完全有能力配置 winecfg,充当配置文件的配置文件
|
||||
|
||||
### Installing
|
||||
winecfg 让你可以改变 WINE 本身的设置,而winetricks 则可以让你改造 Windows 层,它可以让你安装 Windows重要的系统组件,比如 .dulls 文件,还可以允许你修改 Windows注册表的信息.它还有任务管理器,卸载工具和文件浏览器.
|
||||
|
||||
Unlike `winecfg`, `winetricks` doesn't come with WINE. That's fine, though, since it's actually just a script, so it's very easy to download and use on any distribution. Now, many distributions do package `winetricks`. You can definitely use the packaged version if you'd like. Sometimes, those packages fall out-of-date, so this guide is going to use the script, since it's both current and universal. By default, the graphical window is fairly ugly, so if you'd prefer a stylized window, install `zenity` through your distribution's package manager.
|
||||
尽管 winetricks 可以功能强大,但是大部分时间我们用到的功能也就是管理 dll 文件和 Windows 组件
|
||||
|
||||
|
||||
安装
|
||||
|
||||
和 winecfg 不同,winetricks 不是集成在 WINE 中的.这样也没什么问题,毕竟它实际上只是个脚本文件.所以你可以很轻松随意地下载到各种 winetricks 的发行版.现在,许多发行版把 winetricks 打包.只要你喜欢,你完全可以下载打包过的文件.不过有些包可能会过期,所以最好是使用引导脚本,毕竟引导脚本有着通用性.一般情况下,图形界面都比较丑,所以你要是想个性化界面,你最好通过发行版的包管理器安装一个 zenity
|
||||
|
||||
现在假定你想在你的家目录(~)下配置 winetricks. cd 到此,然后 wget(Linux下强大的下载命令) 这个脚本
|
||||
|
||||
Assuming that you want `winetricks` in your `/home` directory, `cd` there and `wget` the script.
|
||||
```
|
||||
$ cd ~
|
||||
$ wget https://raw.githubusercontent.com/Winetricks/winetricks/master/src/winetricks
|
||||
```
|
||||
Then, make the script executable.
|
||||
然后,给这个脚本可执行权限即可
|
||||
|
||||
```
|
||||
$ chmod+x winetricks
|
||||
```
|
||||
`winetricks` can be run in the command line, specifying what needs to be installed at the end of the command, but in most cases, you won't know the exact names of the `.dlls` or fonts that you're trying to install. For that reason, the graphical utility is best. Launching it really isn't any different. Just don't specify anything on the end.
|
||||
winetricks 可以通过命令行运行,在行末指定要安装的东西即可.但是大部分情况下,你都不知道 .dlls 或者是你想安装字体的名字,那么,这时候最好利用图形界面的程序.使用这个程序真的很简单,和其他程序没什么不同,就是别在末尾什么都别输入就行了
|
||||
```
|
||||
$ ~/winetricks
|
||||
```
|
||||
|
||||

|
||||
|
||||
|
||||
When the window first opens, it will display a menu with options including "View help" and "Install an application." By default, "Select the default wineprefix" will be selected. That's the primary option that you will use. The others may work, but aren't really recommended. To proceed, click "OK," and you will be brought to the menu for that WINE prefix.Everything that you will need to do through `winetricks` can be done through this prefix menu.
|
||||
当窗口第一次打开时候,将会给你一个有 View help 和 Install an application 选项的菜单.一般情况下,我们都选择 Select the default wineprefix,这将是你主要使用的选项.其他的也能用,但是我们不推荐.接下来,单击 OK,你就会进入到 WINE 的配置菜单,你可以在这完成所有的你要使用 winetricks 完成的事情
|
||||
|
||||

|
||||
|
||||
|
||||
### Fonts
|
||||
字体
|
||||
|
||||

|
||||
|
||||
字体一直很重要,一些应用程序没有字体没法正常的加载.winetricks 可以轻松地安装许多常用 Windows 字体.在配置菜单中,选中 Install a font 单选按钮,然后点击 OK 即可.
|
||||
|
||||
Fonts are surprisingly important. Some applications won't load or won't load properly without them.`winetricks` makes installing many common Windows fonts very easy. From the prefix menu, select the "Install a font" radio button and press "OK."
|
||||
然后你就会得到一列字体清单,它们都有着相对应的确认框.你很难确切地知道你到底要安装什么字体,毕竟它们都是在应用程序的配置中预先被设定的,那么我们可以先安装一款插件 corefonts,它包含了大多数 Windows 系统中应用程序被设定的字体.安装它也十分简单,所以可以试试.
|
||||
|
||||
You will be presented with a new list of fonts and corresponding checkboxes. It's hard to say exactly which fonts you will need, so most of this should be decided on a per-application basis, but it's usually a good idea to install `corefonts`. It contains the major Windows system fonts that many applications would be expecting to be present on a Windows machine. Installing them can't really hurt anything, so just having them is usually best.
|
||||
要安装 corefonts ,请选择相应的确认框,然后点击 OK ,你就会看到大概和在 Windows 下差不多的提示,字体就会被安装了.完成了这个插件的安装,你就会回到先前的菜单界面.接下来就是安装你需要的别的插件,步骤相同.
|
||||
|
||||
To install `corefonts`, check the corresponding checkbox and press "OK." You will be given roughly the same install prompts as you would on Windows, and the fonts will be installed. When it's done, you will be taken back to the prefix menu. Follow that same process for each additional font that you need.
|
||||
|
||||
### .dlls and Components
|
||||
.dlls和组件
|
||||
|
||||

|
||||
|
||||
winetricks 安装 Windows 下的 .dll 文件和别的组件也十分简单.如果你需要安装的话,在菜单页选择 Install a Windows DLL or component,然后点击 OK
|
||||
|
||||
`winetricks` tries to make installing Windows `.dll` files and other components as simple as possible. If you need to install them, select "Install a Windows DLL or component" on the prefix menu and click "OK."
|
||||
窗口就会进入到另一个菜单界面,其中包含可用的 dlls 和其他 Windows 组件.选择相应的确认框,点击 OK,winetricks 就会下载你选择的组件,接着通过 Windows 一般安装进程进行安装.跟着提示,它很像 Windows 界面下的那种提示,忽略掉报错信息.很多时候,Windows 安装程序会报错,但是你会发现 winetricks 已经将它安装到工作区.这很正常.由于组件之间的相互依赖关系,你可能会也可能不会看到成功安装的信息.只要安装完成时候,确定在菜单页中你的选项仍旧处于被选中状态就行了
|
||||
|
||||
The window will switch over to a menu of available `dlls` and other Windows components. Using the corresponding checkboxes, check off any that you need, and click "OK." The script will download each selected component and begin installing them via the usual Windows install process. Follow the prompts like you would on a Windows machine. Expect error messages. Many times, the Windows installers will present errors, but you will then receive windows from `winetricks` stating that it is following a workaround. That is perfectly normal. Depending on the component, you may or may not receive a success message. Just ensure that the box is still checked in the menu when the install is complete.
|
||||
|
||||
### Registry
|
||||
注册表
|
||||
|
||||

|
||||
|
||||
在WINE中你不需要常常编辑注册表对应的值,但是对于有些程序确实需要.技术层面来讲,winetricks 不向用户提供注册表编辑器,但是要获取编辑器也很容易.在菜单页选中 Run regedit,点击 OK,你就可以打开一个简单的注册表编辑器.讲真,写入注册表的值有点超出本篇引导文章的范围了,但是我还要多说一句,如果你已经知道你在干什么,增加一个注册表条目不是很难.注册表有点像电子表格,你可以将正确的值填入右面的格子中.这个有点过于简单,但是就是这样做的.你可以在以下地址精准地找到你需要在 WINE Appdp所要填入的东西.
|
||||
|
||||
It's not all that often that you have to edit registry values in WINE, but with some programs, you may. Technically, `winetricks` doesn't provide the registry editor, but it makes accessing it easier. Select "Run regedit" from the prefix menu and press "OK." A basic Windows registry editor will open up. Actually creating registry values is a bit out of the scope of this guide, but adding entries isn't too hard if you already know what you're entering. The registry acts sort of like a spreadsheet, so you can just plug in the right values into the right cells. That's somewhat of an oversimplification, but it works. You can usually find exactly what needs to be added or edited on the WINE Appdb `https://appdb.winehq.org`.
|
||||
|
||||
### Closing
|
||||
关闭
|
||||
|
||||
There's obviously much more that can be done with `winetricks`, but the purpose of this guide is to give you the basic knowledge that you'll need to use this powerful tool to get your programs up and running through WINE. The WINE Appdb is a wealth of knowledge on a per-program basis, and will be an invaluable resource going forward.
|
||||
很明显 winetricks 还有许多许多强大的功能远,远不止此,但是本篇引导的目的只是给你一点基础的知识,在你通过 WINE 运行程序一般都会用到.WINE Appdp 提供了强大的各种程序库,是一笔宝贵的知识财富,以后,它会变得更加无价.好好利用它吧.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/configuring-wine-with-winetricks
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[Taylor1024](https://github.com/Taylor1024)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,207 @@
|
||||
ictlyh translating
|
||||
|
||||
How to Install a DHCP Server in CentOS, RHEL and Fedora
|
||||
============================================================
|
||||
|
||||
|
||||
DHCP (Dynamic Host Configuration Protocol) is a network protocol that enables a server to automatically assign an IP address and provide other related network configuration parameters to a client on a network, from a pre-defined IP pool.
|
||||
|
||||
This means that each time a client (connected to the network) boots up, it gets a “dynamic” IP address, as opposed to “static” IP address that never changes. The IP address assigned by a DHCP server to DHCP client is on a “lease”, the lease time can vary depending on how long a client is likely to require the connection or DHCP configuration.
|
||||
|
||||
In this tutorial, we will cover how to install and configure a DHCP server in CentOS/RHEL and Fedora distributions.
|
||||
|
||||
#### Testing Environment Setup
|
||||
|
||||
We are going to use following testing environment for this setup.
|
||||
|
||||
```
|
||||
DHCP Server - CentOS 7
|
||||
DHCP Clients - Fedora 25 and Ubuntu 16.04
|
||||
```
|
||||
|
||||
#### How Does DHCP Work?
|
||||
|
||||
Before we move any further, let’s briefly explain how DHCP works:
|
||||
|
||||
* When a client computer (configured to use DHCP) and connected to a network is powered on, it forwards a DHCPDISCOVER message to the DHCP server.
|
||||
* And after the DHCP server receives the DHCPDISCOVER request message, it replies with a DHCPOFFER message.
|
||||
* Then the client receives the DHCPOFFER message, and it sends a DHCPREQUEST message to the server indicating, it is prepared to get the network configuration offered in the DHCPOFFERmessage.
|
||||
* Last but not least, the DHCP server receives the DHCPREQUEST message from the client, and sends the DHCPACK message showing that the client is now permitted to use the IP address assigned to it.
|
||||
|
||||
### Step 1: Installing DHCP Server in CentOS
|
||||
|
||||
1. Installing DCHP is quite straight forward, simply run the command below.
|
||||
|
||||
```
|
||||
# yum -y install dhcp
|
||||
```
|
||||
|
||||
Important: Assuming there is more than one network interface attached to the system, but you want the DHCP server to only be started on one of the interfaces, set the DHCP server to start only on that interface as follows.
|
||||
|
||||
2. Open the file /etc/sysconfig/dhcpd, add the name of the specific interface to the list of DHCPDARGS, for example if the interface is `eth0`, then add:
|
||||
|
||||
```
|
||||
DHCPDARGS=eth0
|
||||
```
|
||||
|
||||
Save the file and exit.
|
||||
|
||||
### Step 2: Configuring DHCP Server in CentOS
|
||||
|
||||
3. For starters, to setup a DHCP server, the first step is to create the `dhcpd.conf` configuration file, and the main DHCP configuration file is normally /etc/dhcp/dhcpd.conf (which is empty by default), it keeps all network information sent to clients.
|
||||
|
||||
However, there is a sample configuration file /usr/share/doc/dhcp*/dhcpd.conf.sample, which is a good starting point for configuring a DHCP server.
|
||||
|
||||
And, there are two types of statements defined in the DHCP configuration file, these are:
|
||||
|
||||
* parameters – state how to carry out a task, whether to perform a task, or what network configuration options to send to the DHCP client.
|
||||
* declarations – specify the network topology, define the clients, offer addresses for the clients, or apply a group of parameters to a group of declarations.
|
||||
|
||||
Therefore, start by copying the sample configuration file as the main configuration file like so:
|
||||
|
||||
```
|
||||
# cp /usr/share/doc/dhcp-4.2.5/dhcpd.conf.example /etc/dhcp/dhcpd.conf
|
||||
```
|
||||
|
||||
4. Now, open the main configuration file and define your DHCP server options:
|
||||
|
||||
```
|
||||
# vi /etc/dhcp/dhcpd.conf
|
||||
```
|
||||
|
||||
Start by setting the following global parameters which will apply to all the subnetworks (do specify values that apply to your scenario) at the top of the file:
|
||||
|
||||
```
|
||||
option domain-name "tecmint.lan";
|
||||
option domain-name-servers ns1.tecmint.lan, ns2.tecmint.lan;
|
||||
default-lease-time 3600;
|
||||
max-lease-time 7200;
|
||||
authoritative;
|
||||
```
|
||||
|
||||
5. Now, define a subnetwork; in this example, we will configure DHCP for 192.168.56.0/24 LAN network (remember to use parameters that apply to your scenario):
|
||||
|
||||
```
|
||||
subnet 192.168.56.0 netmask 255.255.255.0 {
|
||||
option routers 192.168.56.1;
|
||||
option subnet-mask 255.255.255.0;
|
||||
option domain-search "tecmint.lan";
|
||||
option domain-name-servers 192.168.56.1;
|
||||
range 192.168.56.10 192.168.56.100;
|
||||
range 192.168.56.120 192.168.56.200;
|
||||
}
|
||||
```
|
||||
|
||||
### Step 3: Assign Static IP to DHCP Client
|
||||
|
||||
You can assign a static IP address to a specific client computer on the network, simply define the section below in /etc/dhcp/dhcpd.conf file, where you must explicitly specify it’s MAC addresses and the fixed IP to be assigned:
|
||||
|
||||
```
|
||||
host ubuntu-node {
|
||||
hardware ethernet 00:f0:m4:6y:89:0g;
|
||||
fixed-address 192.168.56.105;
|
||||
}
|
||||
host fedora-node {
|
||||
hardware ethernet 00:4g:8h:13:8h:3a;
|
||||
fixed-address 192.168.56.110;
|
||||
}
|
||||
```
|
||||
|
||||
Save the file and close it.
|
||||
|
||||
Note: You can find out or display the Linux MAC address using following command.
|
||||
|
||||
```
|
||||
# ifconfig -a eth0 | grep HWaddr
|
||||
```
|
||||
|
||||
6. Now start the DHCP service for the mean time and enable it to start automatically from the next system boot, using following commands:
|
||||
|
||||
```
|
||||
---------- On CentOS/RHEL 7 ----------
|
||||
# systemctl start dhcpd
|
||||
# systemctl enable dhcpd
|
||||
---------- On CentOS/RHEL 6 ----------
|
||||
# service dhcpd start
|
||||
# chkconfig dhcpd on
|
||||
```
|
||||
|
||||
7. Next, do not forget to permit DHCP service (DHCPD daemon listens on port 67/UDP) as below:
|
||||
|
||||
```
|
||||
---------- On CentOS/RHEL 7 ----------
|
||||
# firewall-cmd --add-service=dhcp --permanent
|
||||
# firewall-cmd --reload
|
||||
---------- On CentOS/RHEL 6 ----------
|
||||
# iptables -A INPUT -p tcp -m state --state NEW --dport 67 -j ACCEPT
|
||||
# service iptables save
|
||||
```
|
||||
|
||||
### Step 4: Configuring DHCP Clients
|
||||
|
||||
8. Now, you can configure your clients on the network to automatically receive IP addresses from the DHCP server. Login to the client machine and modify the Ethernet interface configuration file as follows (take not of the interface name/number):
|
||||
|
||||
```
|
||||
# vi /etc/sysconfig/network-scripts/ifcfg-eth0
|
||||
```
|
||||
|
||||
Add the options below:
|
||||
|
||||
```
|
||||
DEVICE=eth0
|
||||
BOOTPROTO=dhcp
|
||||
TYPE=Ethernet
|
||||
ONBOOT=yes
|
||||
```
|
||||
|
||||
Save the file and exit.
|
||||
|
||||
9. You can also perform the settings using the GUI on a desktop computer, set the Method to Automatic (DHCP) as shown in the screenshot below (Ubuntu 16.04 desktop).
|
||||
|
||||
[
|
||||
|
||||
][3]
|
||||
|
||||
Set DHCP in Client Network
|
||||
|
||||
10. Then restart network services as follows (you can possibly reboot the system):
|
||||
|
||||
```
|
||||
---------- On CentOS/RHEL 7 ----------
|
||||
# systemctl restart network
|
||||
---------- On CentOS/RHEL 6 ----------
|
||||
# service network restart
|
||||
```
|
||||
|
||||
At this point, if all settings were correct, your clients should be receiving IP addresses automatically from the DHCP server.
|
||||
|
||||
You may also read:
|
||||
|
||||
1. [How to Install and Configure Multihomed ISC DHCP Server on Debian Linux][1]
|
||||
2. [10 Useful “IP” Commands to Configure Network Interfaces][2]
|
||||
|
||||
In this tutorial, we showed you how to setup a DHCP server in RHEL/CentOS. Use the comment form below to write back top us. In an upcoming article, we will show you how to setup a DHCP server in Debian/Ubuntu. Until then, always stay connected to TecMint.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-dhcp-server-in-centos-rhel-fedora/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/install-and-configure-multihomed-isc-dhcp-server-on-debian-linux/
|
||||
[2]:http://www.tecmint.com/ip-command-examples/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Set-DHCP-in-Client-Network.png
|
||||
[4]:http://www.tecmint.com/author/aaronkili/
|
||||
[5]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[6]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,100 @@
|
||||
# [Discovering my inner curmudgeon: A Linux laptop review][1]
|
||||
|
||||
Quick refresher: I'm a life-long Mac user, but I was [disappointed by Apple's latest MacBook Pro release][2]. I researched [a set of alternative computers][3] to consider. And, as a surprise even to myself, I decided to leave the Mac platform.
|
||||
|
||||
I chose the HP Spectre x360 13" laptop that was released after CES 2017, the new version with a 4K display. I bought the machine [from BestBuy][4] (not an affiliate link) because that was the only retailer selling this configuration. My goal was to run Ubuntu Linux instead of Windows.
|
||||
|
||||
Here are my impressions from using this computer over the past month, followed by some realizations about myself.
|
||||
|
||||
Ubuntu
|
||||
|
||||
Installing Ubuntu was easy. The machine came with Windows 10 preinstalled. I used Windows' built-in Disk Management app to [shrink the main partition][5] and free up space for Linux. I [loaded the Ubuntu image on a USB drive][6], which conveniently fit in the machine's USB-A port (missing on new Macs). Then I followed [Ubuntu's simple install instructions][7], which required some BIOS changes to [enable booting from USB][8].
|
||||
|
||||
Screen
|
||||
|
||||
The 4K screen on the Spectre x360 is gorgeous. The latest Ubuntu handles High DPI screens well, which surprised me. With a combination of the built-in settings app and additional packages like [gnome-tweak-tool][9], you can get UI controls rendering on the 4K display at 2x native size, so they look right. You can also boost the default font size to make it proportional. There are even settings to adjust icon sizes in the window titlebar and task manager. It's fiddly, but I got everything set up relatively quickly.
|
||||
|
||||
Trackpad
|
||||
|
||||
The trackpad hardware rattles a little, but it follows your fingers well and supports multi-touch input in Ubuntu by default. However, you immediately realize that something is wrong when you try to type and the mouse starts jumping around. The default Synaptics driver for Linux doesn't properly ignore palm presses on this machine. The solution is to switch to the [new libinput system][10]. By adjusting the [xinput settings][11] you can get it to work decently well.
|
||||
|
||||
But the gestures I'm used to, like two finger swipe to go back in Chrome, or four-finger swipe to switch workspaces, don't work by default in Ubuntu. You have to use a tool like [libinput-gestures][12] to enable them. Even then, the gestures are only recognized about 50% of the time, which is frustrating. The "clickpad" functionality is also problematic: When you press your thumb on the dual-purpose trackpad/button surface in order to click, the system will often think you meant to move the mouse or you're trying to multi-touch resize. Again: It's frustrating.
|
||||
|
||||
Keyboard
|
||||
|
||||
Physically the keyboard is good. The keys have a lot of travel and I can type fast. The left control key is in the far bottom left so it's usable (unlike Macs that put the function key there). The arrow keys work well. One peculiarity is the keyboard has an extra column of keys on the right side, which includes Delete, Home, Page Up, Page Down, and End. This caused my muscle memory for switching from arrow keys to home row keys to be off by one column. This also puts your hands off center while typing, which can make you feel like you're slightly reaching on your right side.
|
||||
|
||||
At first I thought that the extra column of keys (Home, Page Up, etc) was superfluous. But after struggling to use Sublime Text while writing some code, I realized that the text input controls on Linux and Windows rely on these keys. It makes sense that HP decided to include them. As a Mac user I'm used to Command-Right going to the end of line, where a Windows or Linux user would reach for the End key. Remapping every key to match the Mac setup is possible, but hard to make consistent across all programs. The right thing to do is to relearn how to do text input with these new keys. I spent some time trying to retrain my muscle memory, but it was frustrating, like that summer when I tried [Dvorak][13].
|
||||
|
||||
Sound
|
||||
|
||||
The machine comes with four speakers: two fancy Bang & Olufsen speakers on top, and two normal ones on the bottom. The top speakers don't work on Linux and there's a [kernel bug open][14] to figure it out. The bottom speakers do work, but they're too quiet. The headphone jack worked correctly, and it would even mute the speakers automatically when you plugged in headphones. I believe this only happened because I had upgraded my kernel to the bleeding edge [4.10 version][15] in my attempts to make other hardware functional. I figure the community will eventually resolve the kernel bug, so the top speaker issue is likely temporary. But this situation emphasizes why HP needs to ship their own custom distribution of Windows with a bunch of extra magical drivers.
|
||||
|
||||
Battery & power
|
||||
|
||||
Initially the battery life was terrible. The 4K screen burns a lot of power. I also noticed that the CPU fan would turn on frequently and blow warm air out the left side of the machine. It's hot enough that it's very uncomfortable if it's on your lap. I figured out that this was mostly the result of a lack of power management in Ubuntu's default configuration. You can enable a variety of powersaving tools, including [powertop][16] and [pm-powersave][17]. Intel also provides [Linux firmware support][18] to make the GPU idle properly. With all of these changes applied, my battery life got up to nearly 5 hours: a disappointment compared to the 9+ hours advertised. On a positive note, the USB-C charger works great and fills the battery quickly. It was also nice to be able to charge my Nexus X phone with the same plug.
|
||||
|
||||
Two-in-one
|
||||
|
||||
The Spectre x360 gets its name from the fact that its special hinges let the laptop's screen rotate completely around, turning it into a tablet. Without any special configuration, touching the screen in Ubuntu works properly for clicking, scrolling, and zooming. Touch even works for forward/back gestures that don't work on the trackpad. The keyboard and trackpad also automatically disable themselves when you rotate into tablet mode. You can set up [Onboard][19], Gnome's on-screen keyboard, and it's decent. Screen auto-rotation doesn't work, but I was able to cobble something together using [iio-sensor-proxy][20] and [this one-off script][21]. Once I did this, though, I realized that the 16:9 aspect ratio of the screen is too much: It hurts my eyeballs to scan down so far vertically in tablet mode.
|
||||
|
||||
Window manager and programs
|
||||
|
||||
I haven't used Linux regularly on a desktop machine since RedHat 5.0 in 1998\. It's come a long way. Ubuntu boots very quickly. The default UI uses their Unity window manager, a Gnome variant, and it's decent. I tried plain Gnome and it felt clunky in comparison. I ended up liking KDE the most, and would choose the KDE [Kubuntu variant][22] if I were to start again. Overall the KDE window manager felt nice and did everything I needed.
|
||||
|
||||
On this journey back into Linux I realized that most of the time I only use eight programs: a web browser (Chrome), a terminal (no preference), a text editor (Sublime Text 3), a settings configurator, a GUI file manager, an automatic backup process (Arq), a Flux-like screen dimmer, and an image editor (the Gimp). My requirements beyond that are also simple. I rely on four widgets: clock, wifi status, battery level, and volume level. I need a task manager (like the Dock) and virtual work spaces (like Mission Control / Expose). I don't use desktop icons, notifications, recent apps, search, or an applications menu. I was able to accommodate all of these preferences on Linux.
|
||||
|
||||
Conclusion
|
||||
|
||||
If you're in the market for a new laptop, by all means check this one out. However, I'll be selling my Spectre x360 and going back to my mid-2012 MacBook Air. It's not HP's fault or because of the Linux desktop. The problem is how I value my time.
|
||||
|
||||
I'm so accustomed to the UX of a Mac that it's extremely difficult for me to use anything else as efficiently. My brain is tuned to a Mac's trackpad, its keyboard layout, its behaviors of text editing, etc. Using the HP machine and Linux slows me down so much that it feels like I'm starting over. When I'm using my computer I want to spend my time improving my (programming, writing, etc) skills. I want to invest all of my "retraining" energy into understanding unfamiliar topics, like [new functional languages][23] and [homomorphic encryption][24]. I don't want to waste my time relearning the fundamentals.
|
||||
|
||||
In contrast, I've spent the past two years learning how to play the piano. It's required rote memorization and repeated physical exercises. By spending time practicing piano, I've opened myself up to ideas that I couldn't appreciate before. I've learned things about music that I couldn't comprehend in the past. My retraining efforts have expanded my horizons. I'm skeptical that adopting HP hardware and the Linux desktop could have a similar effect on me.
|
||||
|
||||
I'm stubborn. There will come a time when I need to master a new way of working to stay relevant, much like how telegraph operators had to switch from Morse code to [teletypes][25]. I hope that I will have the patience and foresight to make such a transition smoothly in the future. Choosing to retrain only when it would create new possibilities seems like a good litmus test for achieving that goal. In the meantime, I'll keep using a Mac.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I'm the author of the book Effective Python. I'm a software engineer and I've worked at Google for the past 11 years. My current focus is survey statistics. I formerly worked on Cloud infrastructure and open protocols.
|
||||
|
||||
Follow @haxor if you'd like to read posts from me in the future. You can also email me here if you have questions, or leave a comment below. If you enjoyed this post, look here for some of my other favorites.
|
||||
|
||||
-----------------
|
||||
|
||||
via: http://www.onebigfluke.com/2017/04/discovering-my-inner-curmudgeon-linux.html
|
||||
|
||||
作者:[Brett Slatkin ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.onebigfluke.com/
|
||||
[1]:http://www.onebigfluke.com/2017/04/discovering-my-inner-curmudgeon-linux.html
|
||||
[2]:http://www.onebigfluke.com/2016/10/lamenting-progress.html
|
||||
[3]:http://www.onebigfluke.com/2016/10/alternatives-to-apple-computers.html
|
||||
[4]:http://www.bestbuy.com/site/hp-spectre-x360-2-in-1-13-3-4k-ultra-hd-touch-screen-laptop-intel-core-i7-16gb-memory-512gb-solid-state-drive-dark-ash-silver/5713178.p?skuId=5713178
|
||||
[5]:https://www.howtogeek.com/101862/how-to-manage-partitions-on-windows-without-downloading-any-other-software/
|
||||
[6]:https://www.ubuntu.com/download/desktop/create-a-usb-stick-on-windows
|
||||
[7]:https://www.ubuntu.com/download/desktop/install-ubuntu-desktop
|
||||
[8]:http://support.hp.com/us-en/document/c00364979
|
||||
[9]:https://launchpad.net/gnome-tweak-tool
|
||||
[10]:https://launchpad.net/xserver-xorg-input-libinput
|
||||
[11]:https://wiki.archlinux.org/index.php/Libinput#Configuration
|
||||
[12]:https://github.com/bulletmark/libinput-gestures
|
||||
[13]:https://en.wikipedia.org/wiki/Dvorak_Simplified_Keyboard
|
||||
[14]:https://bugzilla.kernel.org/show_bug.cgi?id=189331
|
||||
[15]:http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.10/
|
||||
[16]:https://blog.sleeplessbeastie.eu/2015/08/10/how-to-set-all-tunable-powertop-options-at-system-boot/
|
||||
[17]:http://askubuntu.com/questions/765840/does-pm-powersave-start-automatically-when-running-on-battery
|
||||
[18]:https://01.org/linuxgraphics/downloads/firmware
|
||||
[19]:https://launchpad.net/onboard
|
||||
[20]:https://github.com/hadess/iio-sensor-proxy
|
||||
[21]:http://askubuntu.com/questions/634151/auto-rotate-screen-on-dell-13-7000-with-15-04-gnome/889591#889591
|
||||
[22]:https://www.kubuntu.org/
|
||||
[23]:http://docs.idris-lang.org/en/latest/tutorial/index.html#tutorial-index
|
||||
[24]:https://arxiv.org/abs/1702.07588
|
||||
[25]:https://en.wikipedia.org/wiki/Teleprinter
|
||||
@ -0,0 +1,209 @@
|
||||
Introducing Flashback, an Internet mocking tool
|
||||
============================================================
|
||||
|
||||
> Flashback is designed to mock HTTP and HTTPS resources, like web services and REST APIs, for testing purposes.
|
||||
|
||||

|
||||
>Image by : Opensource.com
|
||||
|
||||
At LinkedIn, we often develop web applications that need to interact with third-party websites. We also employ automatic testing to ensure the quality of our software before it is shipped to production. However, a test is only as useful as it is reliable.
|
||||
|
||||
With that in mind, it can be highly problematic for a test to have external dependencies, such as on a third-party website, for instance. These external sites may change without notice, suffer from downtime, or otherwise become temporarily inaccessible, as the Internet is not 100% reliable.
|
||||
|
||||
If one of our tests relies on being able to communicate with a third-party website, the cause of any failures is hard to pinpoint. A failure could be due to an internal change at LinkedIn, an external change made by the maintainers of the third-party website, or an issue with the network infrastructure. As you can imagine, there are many reasons why interactions with a third-party website may fail, so you may wonder, how will I deal with this problem?
|
||||
|
||||
The good news is that there are many Internet mocking tools that can help. One such tool is [Betamax][4]. It works by intercepting HTTP connections initiated by a web application and then later replaying them. For a test, Betamax can be used to replace any interaction over HTTP with previously recorded responses, which can be served very reliably.
|
||||
|
||||
Initially, we chose to use Betamax in our test automation at LinkedIn. It worked quite well, but we ran into a few problems:
|
||||
|
||||
* For security reasons, our test environment does not have Internet access; however, as with most proxies, Betamax requires an Internet connection to function properly.
|
||||
* We have many use cases that require using authentication protocols, such as OAuth and OpenId. Some of these protocols require complex interactions over HTTP. In order to mock them, we needed a sophisticated model for capturing and replaying the requests.
|
||||
|
||||
To address these challenges, we decided to build upon ideas established by Betamax and create our own Internet mocking tool, called Flashback. We are also proud to announce that Flashback is now open source.
|
||||
|
||||
### What is Flashback?
|
||||
|
||||
Flashback is designed to mock HTTP and HTTPS resources, like web services and [REST][5] APIs, for testing purposes. It records HTTP/HTTPS requests and plays back a previously recorded HTTP transaction—which we call a "scene"—so that no external connection to the Internet is required in order to complete testing.
|
||||
|
||||
Flashback can also replay scenes based on the partial matching of requests. It does so using "match rules." A match rule associates an incoming request with a previously recorded request, which is then used to generate a response. For example, the following code snippet implements a basic match rule, where the test method "matches" an incoming request via [this URL][6].
|
||||
|
||||
HTTP requests generally contain a URL, method, headers, and body. Flashback allows match rules to be defined for any combination of these components. Flashback also allows users to add whitelist or blacklist labels to URL query parameters, headers, and the body.
|
||||
|
||||
For instance, in an OAuth authorization flow, the request query parameters may look like the following:
|
||||
|
||||
```
|
||||
oauth_consumer_key="jskdjfljsdklfjlsjdfs",
|
||||
oauth_nonce="ajskldfjalksjdflkajsdlfjasldfja;lsdkj",
|
||||
oauth_signature="asdfjaklsdjflasjdflkajsdklf",
|
||||
oauth_signature_method="HMAC-SHA1",
|
||||
oauth_timestamp="1318622958",
|
||||
oauth_token="asdjfkasjdlfajsdklfjalsdjfalksdjflajsdlfa",
|
||||
oauth_version="1.0"
|
||||
```
|
||||
|
||||
Many of these values will change with every request because OAuth requires clients to generate a new value for **oauth_nonce** every time. In our testing, we need to verify values of **oauth_consumer_key, oauth_signature_method**, and **oauth_version** while also making sure that **oauth_nonce**, **oauth_signature**, **oauth_timestamp**, and **oauth_token** exist in the request. Flashback gives us the ability to create our own match rules to achieve this goal. This feature lets us test requests with time-varying data, signatures, tokens, etc. without any changes on the client side.
|
||||
|
||||
This flexible matching and the ability to function without connecting to the Internet are the attributes that separate Flashback from other mocking solutions. Some other notable features include:
|
||||
|
||||
* Flashback is a cross-platform and cross-language solution, with the ability to test both JVM (Java Virtual Machine) and non-JVM (C++, Python, etc.) apps.
|
||||
* Flashback can generate SSL/TLS certificates on the fly to emulate secured channels for HTTPS requests.
|
||||
|
||||
### How to record an HTTP transaction
|
||||
|
||||
Recording an HTTP transaction for later playback using Flashback is a relatively straightforward process. Before we dive into the procedure, let us first lay out some terminology:
|
||||
|
||||
* A** Scene** stores previously recorded HTTP transactions (in JSON format) that can be replayed later. For example, here is one sample [Flashback scene][1].
|
||||
* The **Root Path** is the file path of the directory that contains the Flashback scene data.
|
||||
* A **Scene Name** is the name of a given scene.
|
||||
* A **Scene Mode** is the mode in which the scene is being used—either "record" or "playback."
|
||||
* A **Match Rule** is a rule that determines if the incoming client request matches the contents of a given scene.
|
||||
* **Flashback Proxy** is an HTTP proxy with two modes of operation, record and playback.
|
||||
* **Host** and **port** are the proxy host and port.
|
||||
|
||||
In order to record a scene, you must make a real, external request to the destination, and the HTTPS request and response will then be stored in the scene with the match rule that you have specified. When recording, Flashback behaves exactly like a typical MITM (Man in the Middle) proxy—it is only in playback mode that the connection flow and data flow are restricted to just between the client and the proxy.
|
||||
|
||||
To see Flashback in action, let us create a scene that captures an interaction with example.org by doing the following:
|
||||
|
||||
1\. Check out the Flashback source code:
|
||||
|
||||
```
|
||||
git clone https://github.com/linkedin/flashback.git
|
||||
```
|
||||
|
||||
2\. Start the Flashback admin server:
|
||||
|
||||
```
|
||||
./startAdminServer.sh -port 1234
|
||||
```
|
||||
|
||||
3\. Start the [Flashback Proxy][7]. Note the Flashback above will be started in record mode on localhost, port 5555\. The match rule requires an exact match (match HTTP body, headers, and URL). The scene will be stored under **/tmp/test1**.
|
||||
|
||||
4\. Flashback is now ready to record, so use it to proxy a request to example.org:
|
||||
|
||||
```
|
||||
curl http://www.example.org -x localhost:5555 -X GET
|
||||
```
|
||||
|
||||
5\. Flashback can (optionally) record multiple requests in a single. To finish recording, [shut down Flashback][8].
|
||||
|
||||
6\. To verify what has been recorded, we can view the contents of the scene in the output directory (**/tmp/test1**). It should [contain the following][9].
|
||||
|
||||
It's also easy to [use Flashback in your Java code][10].
|
||||
|
||||
### How to replay an HTTP transaction
|
||||
|
||||
To replay a previously stored scene, use the same basic setup as is used when recording; the only difference is that you [set the "Scene Mode" to "playback" in Step 3 above][11].
|
||||
|
||||
One way to verify that the response is from the scene, and not the external source, is to disable your Internet connectivity temporarily when you go through Steps 1 through 6\. Another way is to modify your scene file and see if the response is the same as what you have in the file.
|
||||
|
||||
Here is [an example in Java][12].
|
||||
|
||||
### How to record and replay an HTTPS transaction
|
||||
|
||||
The process for recording and replaying an HTTPS transaction with Flashback is very similar to that used for HTTP transactions. However, special care needs to be given to the security certificates used for the SSL component of HTTPS. In order for Flashback to act as a MITM proxy, creating a Certificate Authority (CA) certificate is necessary. This certificate will be used during the creation of the secure channel between the client and Flashback, and will allow Flashback to inspect the data in HTTPS requests it proxies. This certificate should then be stored as a trusted source so that the client will be able to authenticate Flashback when making calls to it. For instructions on how to create a certificate, there are many resources [like this one][13] that can be quite helpful. Most companies have their own internal policies for administering and securing certificates—be sure to follow yours.
|
||||
|
||||
It is worth noting here that Flashback is intended to be used for testing purposes only. Feel free to integrate Flashback with your service whenever you need it, but note that the record feature of Flashback will need to store everything from the wire, then use it during the replay mode. We recommend that you pay extra attention to ensure that no sensitive member data is being recorded or stored inadvertently. Anything that may violate your company's data protection or privacy policy is your responsibility.
|
||||
|
||||
Once the security certificate is accounted for, the only difference between HTTP and HTTPS in terms of setup for recording is the addition of a few further parameters.
|
||||
|
||||
* **RootCertificateInputStream**: This can be either a stream or file path that indicates the CA certificate's filename.
|
||||
* **RootCertificatePassphrase**: This is the passphrase created for the CA certificate.
|
||||
* **CertificateAuthority**: These are the CA certificate's properties.
|
||||
|
||||
[View the code used to record an HTTPS transaction][14] with Flashback, including the above terms.
|
||||
|
||||
Replaying an HTTPS transaction with Flashback uses the same process as recording. The only difference is that the scene mode is set to "playback." This is demonstrated in [this code][15].
|
||||
|
||||
### Supporting dynamic changes
|
||||
|
||||
In order to allow for flexibility in testing, Flashback lets you dynamically change scenes and match rules. Changing scenes dynamically allows for testing the same requests with different responses, such as success, **time_out**, **rate_limit**, etc. [Scene changes][16] only apply to scenarios where we have POSTed data to update the external resource. See the following diagram as an example.
|
||||
|
||||

|
||||
|
||||
Being able to [change the match rule][17] dynamically allows us to test complicated scenarios. For example, we have a use case that requires us to test HTTP calls to both public and private resources of Twitter. For public resources, the HTTP requests are constant, so we can use the "MatchAll" rule. However, for private resources, we need to sign requests with an OAuth consumer secret and an OAuth access token. These requests contain a lot of parameters that have unpredictable values, so the static MatchAll rule wouldn't work.
|
||||
|
||||
### Use cases
|
||||
|
||||
At LinkedIn, Flashback is mainly used for mocking different Internet providers in integration tests, as illustrated in the diagrams below. The first diagram shows an internal service inside a LinkedIn production data center interacting with Internet providers (such as Google) via a proxy layer. We want to test this internal service in a testing environment.
|
||||
|
||||

|
||||
|
||||
The second and third diagrams show how we can record and playback scenes in different environments. Recording happens in our dev environment, where the user starts Flashback on the same port as the proxy started. All external requests from the internal service to providers will go through Flashback instead of our proxy layer. After the necessary scenes get recorded, we can deploy them to our test environment.
|
||||
|
||||

|
||||
|
||||
In the test environment (which is isolated and has no Internet access), Flashback is started on the same port as in the dev environment. All HTTP requests are still coming from the internal service, but the responses will come from Flashback instead of the Internet providers.
|
||||
|
||||

|
||||
|
||||
### Future directions
|
||||
|
||||
We'd like to see if we can support non-HTTP protocols, such as FTP or JDBC, in the future, and maybe even give users the flexibility to inject their own customized protocol using the MITM proxy framework. We will continue improving the Flashback setup API to make supporting non-Java languages easier.
|
||||
|
||||
### Now available as an open source project
|
||||
|
||||
We were fortunate enough to present Flashback at GTAC 2015\. At the show, several members of the audience asked if we would be releasing Flashback as an open source project so they could use it for their own testing efforts.
|
||||
|
||||
### Google TechTalks: GATC 2015—Mock the Internet
|
||||
|
||||
<iframe allowfullscreen="" frameborder="0" height="315" src="https://www.youtube.com/embed/6gPNrujpmn0?origin=https://opensource.com&enablejsapi=1" width="560" id="6gPNrujpmn0" data-sdi="true"></iframe>
|
||||
|
||||
We're happy to announce that Flashback is now open source and is available under a BSD (Berkeley Software Distribution) two-clause license. To get started, visit the [Flashback GitHub repo][18].
|
||||
|
||||
_Originally posted on the [LinkedIn Engineering blog][2]. Reposted with permission._
|
||||
|
||||
### Acknowledgements
|
||||
|
||||
Flashback was created by [Shangshang Feng][19], [Yabin Kang][20], and [Dan Vinegrad][21], and inspired by [Betamax][22]. Special thanks to [Hwansoo Lee][23], [Eran Leshem][24], [Kunal Kandekar][25], [Keith Dsouza][26], and [Kang Wang][27] for help with code reviews. We would also thank our management—[Byron Ma][28], [Yaz Shimizu][29], [Yuliya Averbukh][30], [Christopher Hazlett][31], and [Brandon Duncan][32]—for their support in the development and open sourcing of Flashback.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Shangshang Feng - Shangshang is senior software engineer in LinkedIn's NYC office. He spent the last three and half years working on a gateway platform at LinkedIn. Before LinkedIn, he worked on infrastructure teams at Thomson Reuters and ViewTrade securities.
|
||||
|
||||
---------
|
||||
|
||||
via: https://opensource.com/article/17/4/flashback-internet-mocking-tool
|
||||
|
||||
作者:[ Shangshang Feng][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/shangshangfeng
|
||||
[1]:https://gist.github.com/anonymous/17d226050d8a9b79746a78eda9292382
|
||||
[2]:https://engineering.linkedin.com/blog/2017/03/flashback-mocking-tool
|
||||
[3]:https://opensource.com/article/17/4/flashback-internet-mocking-tool?rate=Jwt7-vq6jP9kS7gOT6f6vgwVlZupbyzWsVXX41ikmGk
|
||||
[4]:https://github.com/betamaxteam/betamax
|
||||
[5]:https://en.wikipedia.org/wiki/Representational_state_transfer
|
||||
[6]:https://gist.github.com/anonymous/91637854364287b38897c0970aad7451
|
||||
[7]:https://gist.github.com/anonymous/2f5271191edca93cd2e03ce34d1c2b62
|
||||
[8]:https://gist.github.com/anonymous/f899ebe7c4246904bc764b4e1b93c783
|
||||
[9]:https://gist.github.com/sf1152/c91d6d62518fe62cc87157c9ce0e60cf
|
||||
[10]:https://gist.github.com/anonymous/fdd972f1dfc7363f4f683a825879ce19
|
||||
[11]:https://gist.github.com/anonymous/ae1c519a974c3bc7de2a925254b6550e
|
||||
[12]:https://gist.github.com/anonymous/edcc1d60847d51b159c8fd8a8d0a5f8b
|
||||
[13]:https://jamielinux.com/docs/openssl-certificate-authority/introduction.html
|
||||
[14]:https://gist.github.com/anonymous/091d13179377c765f63d7bf4275acc11
|
||||
[15]:https://gist.github.com/anonymous/ec6a0fd07aab63b7369bf8fde69c1f16
|
||||
[16]:https://gist.github.com/anonymous/1f1660280acb41277fbe2c257bab2217
|
||||
[17]:https://gist.github.com/anonymous/0683c43f31bd916b76aff348ff87f51b
|
||||
[18]:https://github.com/linkedin/flashback
|
||||
[19]:https://www.linkedin.com/in/shangshangfeng
|
||||
[20]:https://www.linkedin.com/in/benykang
|
||||
[21]:https://www.linkedin.com/in/danvinegrad/
|
||||
[22]:https://github.com/betamaxteam/betamax
|
||||
[23]:https://www.linkedin.com/in/hwansoo/
|
||||
[24]:https://www.linkedin.com/in/eranl/
|
||||
[25]:https://www.linkedin.com/in/kunalkandekar/
|
||||
[26]:https://www.linkedin.com/in/dsouzakeith/
|
||||
[27]:https://www.linkedin.com/in/kang-wang-44960b4/
|
||||
[28]:https://www.linkedin.com/in/byronma/
|
||||
[29]:https://www.linkedin.com/in/yazshimizu/
|
||||
[30]:https://www.linkedin.com/in/yuliya-averbukh-818a41/
|
||||
[31]:https://www.linkedin.com/in/chazlett/
|
||||
[32]:https://www.linkedin.com/in/dudcat/
|
||||
[33]:https://opensource.com/user/125361/feed
|
||||
[34]:https://opensource.com/users/shangshangfeng
|
||||
253
sources/tech/20170403 Introduction to functional programming.md
Normal file
253
sources/tech/20170403 Introduction to functional programming.md
Normal file
@ -0,0 +1,253 @@
|
||||
trnhoe translating~
|
||||
Introduction to functional programming
|
||||
============================================================
|
||||
|
||||
> We explain what functional programming is, explore its benefits, and look at resources for learning functional programming.
|
||||
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
Depending on whom you ask, _functional programming_ (FP) is either an enlightened approach to programming that should be spread far and wide, or an overly academic approach to programming with few real-world benefits. In this article, I will explain what functional programming is, explore its benefits, and recommend resources for learning functional programming.
|
||||
|
||||
### Syntax primer
|
||||
|
||||
Code examples in this article are in the [Haskell][40] programming language. All that you need to understand for this article is the basic function syntax:
|
||||
|
||||
```
|
||||
even :: Int -> Bool
|
||||
even = ... -- implementation goes here
|
||||
```
|
||||
|
||||
This defines a one-argument function named **even**. The first line is the _type declaration_ , which says that **even** takes an **Int** and returns a **Bool**. The implementation follows and consists of one or more _equations_ . We'll ignore the implementation (the name and type tell us enough):
|
||||
|
||||
```
|
||||
map :: (a -> b) -> [a] -> [b]
|
||||
map = ...
|
||||
```
|
||||
|
||||
In this example, **map** is a function that takes two arguments:
|
||||
|
||||
1. **(a -> b)**: a functions that turns an **a** into a **b**
|
||||
2. **[a]**: a list of **a**
|
||||
|
||||
and returns a list of **b**. Again, we don't care about the definition—the type is more interesting! **a** and **b** are _type variables_ that could stand for any type. In the expression below, **a** is **Int** and **b** is **Bool**:
|
||||
|
||||
```
|
||||
map even [1,2,3]
|
||||
```
|
||||
|
||||
It evaluates to a **[Bool]**:
|
||||
|
||||
```
|
||||
[False,True,False]
|
||||
```
|
||||
|
||||
If you see other syntax that you do not understand, don't panic; full comprehension of the syntax is not essential.
|
||||
|
||||
### Myths about functional programming
|
||||
|
||||
Programming and development
|
||||
|
||||
* [Our latest JavaScript articles][1]
|
||||
* [Recent Perl posts][2]
|
||||
* [New Python content][3]
|
||||
* [Red Hat Developers Blog][4]
|
||||
* [Tools for Red Hat Developers][5]
|
||||
|
||||
Let's begin by dispelling common misconceptions:
|
||||
|
||||
* Functional programming is not the rival or antithesis of imperative or object-oriented programming. This is a false dichotomy.
|
||||
* Functional programming is not just the domain of academics. It is true that the history of functional programming is steeped in academia, and languages such as like Haskell and OCaml are popular research languages. But today many companies use functional programming for large-scale systems, small specialized programs, and everything in between. There's even an annual conference for [Commercial Users of Functional Programming][33]; past programs give an insight into how functional programming is being used in industry, and by whom.
|
||||
* Functional programming has nothing to do with [monads][34], nor any other particular abstraction. For all the hand-wringing around this topic, monad is just an abstraction with laws. Some things are monads, others are not.
|
||||
* Functional programming is not especially hard to learn. Some languages may have different syntax or evaluation semantics from those you already know, but these differences are superficial. There are dense concepts in functional programming, but this is also true of other approaches.
|
||||
|
||||
### What is functional programming?
|
||||
|
||||
At its core, functional programming is just programming with functions— _pure_ mathematical functions. The result of a function depends only on the arguments, and there are no side effects, such as I/O or mutation of state. Programs are built by combining functions together. One way of combining functions is _function composition_ :
|
||||
|
||||
```
|
||||
(.) :: (b -> c) -> (a -> b) -> (a -> c)
|
||||
(g . f) x = g (f x)
|
||||
```
|
||||
|
||||
This _infix_ function combines two functions into one, applying **g** to the output of **f**. We'll see it used in an upcoming example. For comparison, the same function in Python looks like:
|
||||
|
||||
```
|
||||
def compose(g, f):
|
||||
return lambda x: g(f(x))
|
||||
```
|
||||
|
||||
The beauty of functional programming is that because functions are deterministic and have no side effects, you can always replace a function application with the result of the application. This substitution of equals for equals enables _equational reasoning_ . Every programmer has to reason about their code and others', and equational reasoning is a great tool for doing that. Let's look at an example. You encounter the expression:
|
||||
|
||||
```
|
||||
map even . map (+1)
|
||||
```
|
||||
|
||||
What does this program do? Can it be simplified? Equational reasoning lets you analyze the code through a series of substitutions:
|
||||
|
||||
```
|
||||
map even . map (+1)
|
||||
map (even . (+1)) -- from definition of 'map'
|
||||
map (\x -> even (x + 1)) -- lambda abstraction
|
||||
map odd -- from definition of 'even'
|
||||
```
|
||||
|
||||
We can use equational reasoning to understand programs and optimize for readability. The Haskell compiler uses equational reasoning to perform many kinds of program optimizations. Without pure functions, equational reasoning either isn't possible, or requires an inordinate effort from the programmer.
|
||||
|
||||
### Functional programming languages
|
||||
|
||||
What do you need from a programming language to be able to do functional programming?
|
||||
|
||||
Doing functional programming meaningfully in a language without _higher-order functions_ (the ability to pass functions as arguments and return functions), _lambdas_ (anonymous functions), and _generics_ is difficult. Most modern languages have these, but there are differences in _how well_ different languages support functional programming. The languages with the best support are called _functional programming languages_ . These include _Haskell_ , _OCaml_ , _F#_ , and _Scala_ , which are statically typed, and the dynamically typed _Erlang_ and _Clojure_ .
|
||||
|
||||
Even among functional languages there are big differences in how far you can exploit functional programming. Having a type system helps a lot, especially if it supports _type inference_ (so you don't always have to type the types). There isn't room in this article to go into detail, but suffice it to say, not all type systems are created equal.
|
||||
|
||||
As with all languages, different functional languages emphasize different concepts, techniques, or use cases. When choosing a language, considering how well it supports functional programming and whether it fits your use case is important. If you're stuck using some non-FP language, you will still benefit from applying functional programming to the extent the language supports it.
|
||||
|
||||
### Don't open that trap door!
|
||||
|
||||
Recall that the result of a function depends only on its inputs. Alas, almost all programming languages have "features" that break this assumption. Null values, type case (**instanceof**), type casting, exceptions, side-effects, and the possibility of infinite recursion are trap doors that break equational reasoning and impair a programmer's ability to reason about the behavior or correctness of a program. ( _Total languages_ , which do not have any trap doors, include Agda, Idris, and Coq.)
|
||||
|
||||
Fortunately, as programmers, we can choose to avoid these traps, and if we are disciplined, we can pretend that the trap doors do not exist. This idea is called _fast and loose reasoning_ . It costs nothing—almost any program can be written without using the trap doors—and by avoiding them you win back equational reasoning, composability and reuse.
|
||||
|
||||
Let's discuss exceptions in detail. This trap door breaks equational reasoning because the possibility of abnormal termination is not reflected in the type. (Count yourself lucky if the documentation even mentions the exceptions that could be thrown.) But there is no reason why we can't have a return type that encompasses all the failure modes.
|
||||
|
||||
Avoiding trap doors is an area in which language features can make a big difference. For avoiding exceptions, _algebraic data types_ can be used to model error conditions, like so:
|
||||
|
||||
```
|
||||
-- new data type for results of computations that can fail
|
||||
--
|
||||
data Result e a = Error e | Success a
|
||||
|
||||
-- new data type for three kinds of arithmetic errors
|
||||
--
|
||||
data ArithError = DivByZero | Overflow | Underflow
|
||||
|
||||
-- integer division, accounting for divide-by-zero
|
||||
--
|
||||
safeDiv :: Int -> Int -> Result ArithError Int
|
||||
safeDiv x y =
|
||||
if y == 0
|
||||
then Error DivByZero
|
||||
else Success (div x y)
|
||||
```
|
||||
|
||||
The trade-off in this example is that you must now work with values of type **Result ArithError Int** instead of plain old **Int**, but there are abstractions for dealing with this. You no longer need to handle exceptions and can use fast and loose reasoning, so overall it's a win.
|
||||
|
||||
### Theorems for free
|
||||
|
||||
Most modern statically typed languages have _generics_ (also called _parametric polymorphism_ ), where functions are defined over one or more abstract types. For example, consider a function over lists:
|
||||
|
||||
```
|
||||
f :: [a] -> [a]
|
||||
f = ...
|
||||
```
|
||||
|
||||
The same function in Java looks like:
|
||||
|
||||
```
|
||||
static <A> List<A> f(List<A> xs) { ... }
|
||||
```
|
||||
|
||||
The compiled program is a proof that this function will work with _any_ choice for the type **a**. With that in mind, and employing fast and loose reasoning, can you work out what the function does? Does knowing the type help?
|
||||
|
||||
In this case, the type doesn't tell us exactly what the function does (it could reverse the list, drop the first element, or many other things), but it does tell us a lot. Just from the type, we can derive theorems about the function:
|
||||
|
||||
* **Theorem 1**: Every element in the output appears in the input; it couldn't possibly add an **a** to the list because it has no knowledge of what **a** is or how to construct one.
|
||||
* **Theorem 2**: If you map any function over the list then apply **f**, the result is the same as applying **f** then mapping.
|
||||
|
||||
Theorem 1 helps us understand what the code is doing, and Theorem 2 is useful for program optimization. We learned all this just from the type! This result—the ability to derive useful theorems from types—is called _parametricity_ . It follows that a type is a partial (sometimes complete) specification of a function's behavior, and a kind of machine-checked documentation.
|
||||
|
||||
Now it's your turn to exploit parametricity. What can you conclude from the types of **map** and **(.)**, or the following functions?
|
||||
|
||||
* **foo :: a -> (a, a)**
|
||||
* **bar :: a -> a -> a**
|
||||
* **baz :: b -> a -> a**
|
||||
|
||||
### Resources for learning functional programming
|
||||
|
||||
Perhaps you have been convinced that functional programming is a better way to write software, and you are wondering how to get started? There are several approaches to learning functional programming; here are some I recommend (with, I admit, a strong bias toward Haskell):
|
||||
|
||||
* UPenn's [CIS 194: Introduction to Haskell][35] is a solid introduction to functional programming concepts and real-world Haskell development. The course material is available, but the lectures are not (you could view Brisbane Functional Programming Group's [series of talks covering CIS 194][36] from a few years ago instead).
|
||||
* Good introductory books include _[Functional Programming in Scala][30]_ , _[Thinking Functionally with Haskell][31]_ , and _[Haskell Programming from first principles][32]_ .
|
||||
* The [Data61 FP course][37] (f.k.a., _NICTA_ course) teaches foundational abstractions and data structures through _type-driven development_ . The payoff is huge, but it is _difficult by design_ , having its origins in training workshops, so only attempt it if you know a functional programmer who is willing to mentor you.
|
||||
* Start practicing functional programming in whatever code you're working on. Write pure functions (avoid non-determinism and mutation), use higher-order functions and recursion instead of loops, exploit parametricity for improved readability and reuse. Many people start out in functional programming by experimenting and experiencing the benefits in all kinds of languages.
|
||||
* Join a functional programming user group or study group in your area—or start one—and look out for functional programming conferences (new ones are popping up all the time).
|
||||
|
||||
### Conclusion
|
||||
|
||||
In this article, I discussed what functional programming is and is not, and looked at advantages of functional programming, including equational reasoning and parametricity. We learned that you can do _some_ functional programming in most programming languages, but the choice of language affects how much you can benefit, with _functional programming languages_ , such as Haskell, having the most to offer. I also recommended resources for learning functional programming.
|
||||
|
||||
Functional programming is a rich field and there are many deeper (and denser) topics awaiting exploration. I would be remiss not to mention a few that have practical implications, such as:
|
||||
|
||||
* lenses and prisms (first-class, composable getters and setters; great for working with nested data);
|
||||
* theorem proving (why test your code when you could _prove it correct_ instead?);
|
||||
* lazy evaluation (lets you work with potentially infinite data structures);
|
||||
* and category theory (the origin of many beautiful and practical abstractions in functional programming).
|
||||
|
||||
I hope that you have enjoyed this introduction to functional programming and are inspired to dive into this fun and practical approach to software development.
|
||||
|
||||
_This article is published under the [CC BY 4.0][38] license._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Software Engineer at Red Hat. Interested in functional programming, category theory and other intersections of math and programming. Crazy about jalapeños.
|
||||
|
||||
----------------------
|
||||
|
||||
via: https://opensource.com/article/17/4/introduction-functional-programming
|
||||
|
||||
作者:[Fraser Tweedale ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/frasertweedale
|
||||
[1]:https://opensource.com/tags/javascript?src=programming_resource_menu
|
||||
[2]:https://opensource.com/tags/perl?src=programming_resource_menu
|
||||
[3]:https://opensource.com/tags/python?src=programming_resource_menu
|
||||
[4]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ&src=programming_resource_menu
|
||||
[5]:https://developers.redhat.com/products/#developer_tools?intcmp=7016000000127cYAAQ&src=programming_resource_menu
|
||||
[6]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#t:Int
|
||||
[7]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#t:Int
|
||||
[8]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#t:Int
|
||||
[9]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#v:div
|
||||
[10]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#v:even
|
||||
[11]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#t:Int
|
||||
[12]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#t:Bool
|
||||
[13]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#v:even
|
||||
[14]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#v:map
|
||||
[15]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#v:map
|
||||
[16]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#v:map
|
||||
[17]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#v:even
|
||||
[18]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#v:map
|
||||
[19]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#v:even
|
||||
[20]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#v:map
|
||||
[21]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#v:map
|
||||
[22]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#v:even
|
||||
[23]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#v:map
|
||||
[24]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#v:map
|
||||
[25]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#v:even
|
||||
[26]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#v:map
|
||||
[27]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#v:even
|
||||
[28]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#v:map
|
||||
[29]:http://haskell.org/ghc/docs/latest/html/libraries/base/Prelude.html#v:odd
|
||||
[30]:https://www.manning.com/books/functional-programming-in-scala
|
||||
[31]:http://www.cambridge.org/gb/academic/subjects/computer-science/programming-languages-and-applied-logic/thinking-functionally-haskell
|
||||
[32]:http://haskellbook.com/
|
||||
[33]:http://cufp.org/
|
||||
[34]:https://www.haskell.org/tutorial/monads.html
|
||||
[35]:https://www.cis.upenn.edu/~cis194/fall16/
|
||||
[36]:https://github.com/bfpg/cis194-yorgey-lectures
|
||||
[37]:https://github.com/data61/fp-course
|
||||
[38]:https://creativecommons.org/licenses/by/4.0/
|
||||
[39]:https://opensource.com/article/17/4/introduction-functional-programming?rate=_tO5hNzT4hRKNMJtWwQM-K3Jmxm10iPeqoy3bbS12MQ
|
||||
[40]:https://wiki.haskell.org/Introduction
|
||||
[41]:https://opensource.com/user/123116/feed
|
||||
[42]:https://opensource.com/users/frasertweedale
|
||||
@ -0,0 +1,199 @@
|
||||
Remmina – A Feature Rich Remote Desktop Sharing Tool for Linux
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
Remmina is a is free and open-source, feature-rich and powerful remote desktop client for Linux and other Unix-like systems, written in GTK+3\. It’s intended for system administrators and travelers, who need to remotely access and work with many computers.
|
||||
|
||||
It supports several network protocols in a simple, unified, homogeneous and easy-to-use user interface.
|
||||
|
||||
#### Remmina Features
|
||||
|
||||
* Supports RDP, VNC, NX, XDMCP and SSH.
|
||||
* Enables users to maintain a list of connection profiles, organized by groups.
|
||||
* Supports quick connections by users directly putting in the server address.
|
||||
* Remote desktops with higher resolutions are scrollable/scalable in both window and fullscreen mode.
|
||||
* Supports viewport fullscreen mode; here the remote desktop automatically scrolls when the mouse moves over the screen edge.
|
||||
* Also supports floating toolbar in fullscreen mode; enables you to switch between modes, toggle keyboard grabbing, minimize and beyond.
|
||||
* Offers tabbed interface, optionally managed by groups.
|
||||
* Also offers tray icon, allows you to quickly access configured connection profiles.
|
||||
|
||||
In this article, we will show you how to install and use Remmina with a few supported protocols in Linux for desktop sharing.
|
||||
|
||||
#### Prerequisites
|
||||
|
||||
* Allow desktop sharing in remote machines (enable remote machines to permit remote connections).
|
||||
* Setup SSH services on the remote machines.
|
||||
|
||||
### How to Install Remmina Desktop Sharing Tool in Linux
|
||||
|
||||
Remmina and its plugin packages are already provided in the official repositories of the all if not most of the mainstream Linux distributions. Run the commands below to install it with all supported plugins:
|
||||
|
||||
```
|
||||
------------ On Debian/Ubuntu ------------
|
||||
$ sudo apt-get install remmina remmina-plugin-*
|
||||
```
|
||||
|
||||
```
|
||||
------------ On CentOS/RHEL ------------
|
||||
# yum install remmina remmina-plugin-*
|
||||
```
|
||||
|
||||
```
|
||||
------------ On Fedora 22+ ------------
|
||||
$ sudo dnf copr enable hubbitus/remmina-next
|
||||
$ sudo dnf upgrade --refresh 'remmina*' 'freerdp*'
|
||||
```
|
||||
|
||||
Once you have installed it, search for remmina in the Ubuntu Dash or Linux Mint Menu, then launch it:
|
||||
|
||||
[
|
||||
|
||||
][1]
|
||||
|
||||
Remmina Desktop Sharing Client
|
||||
|
||||
You can perform any configurations via the graphical interface or by editing the files under `$HOME/.remmina` or `$HOME/.config/remmina`.
|
||||
|
||||
To setup a new connection to a remote server press `[Ctrl+N]` or go to Connection -> New, configure the remote connection profile as shown in the screenshot below. This is the basic settings interface.
|
||||
|
||||
[
|
||||
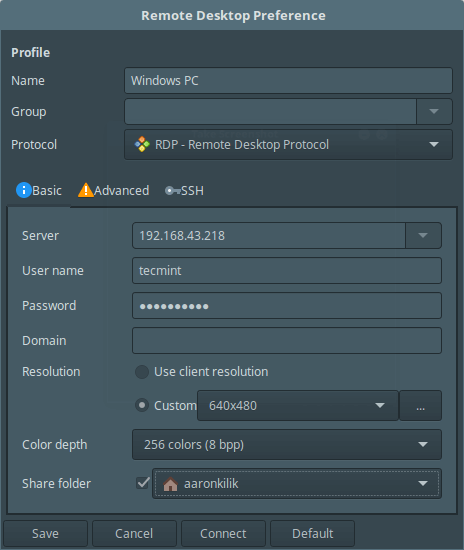
|
||||
][2]
|
||||
|
||||
Remmina Basic Desktop Preferences
|
||||
|
||||
Click on Advanced from the interface above to configure advanced connection settings.
|
||||
|
||||
[
|
||||
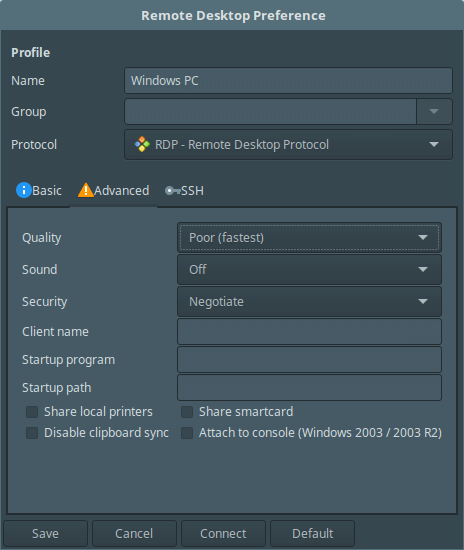
|
||||
][3]
|
||||
|
||||
Remmina Advance Desktop Settings
|
||||
|
||||
To configure SSH settings, click on the SSH from the profile interface above.
|
||||
|
||||
[
|
||||
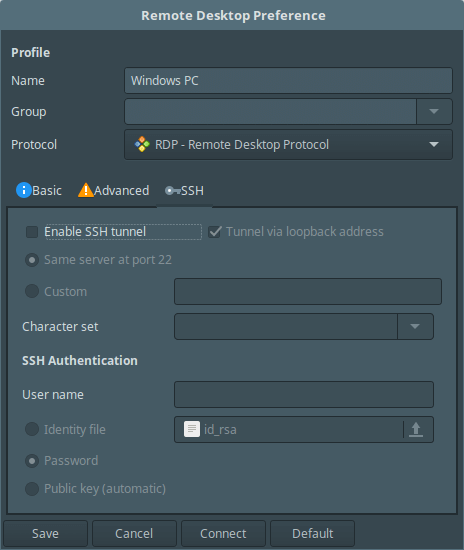
|
||||
][4]
|
||||
|
||||
Remmina SSH Settings
|
||||
|
||||
Once you have configured all the necessary settings, save the settings by clicking on Save button and from the main interface, you’ll be able to view all your configured remote connection profiles as shown below.
|
||||
|
||||
[
|
||||
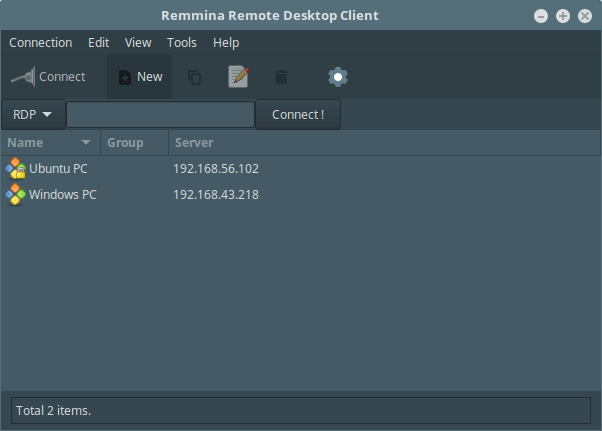
|
||||
][5]
|
||||
|
||||
Remmina Configured Servers
|
||||
|
||||
#### Connecting to Remote Machine Using sFTP
|
||||
|
||||
Choose the connection profile and edit the settings, choose SFTP – Secure File Transfer from the Protocols down menu. Then set a startup path (optional) and specify the SSH authentication details. Lastly, click Connect.
|
||||
|
||||
[
|
||||
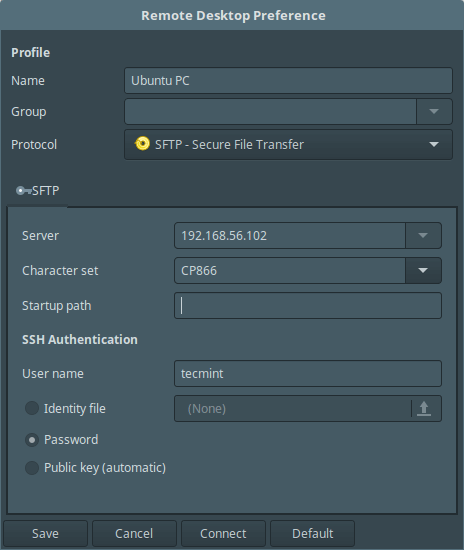
|
||||
][6]
|
||||
|
||||
Remmina sftp Connection
|
||||
|
||||
Enter your SSH user password here.
|
||||
|
||||
[
|
||||
|
||||
][7]
|
||||
|
||||
Enter SSH Password
|
||||
|
||||
If you see the interface below, then the SFTP connection is successful, you can now [transfer files between your machines][8].
|
||||
|
||||
[
|
||||
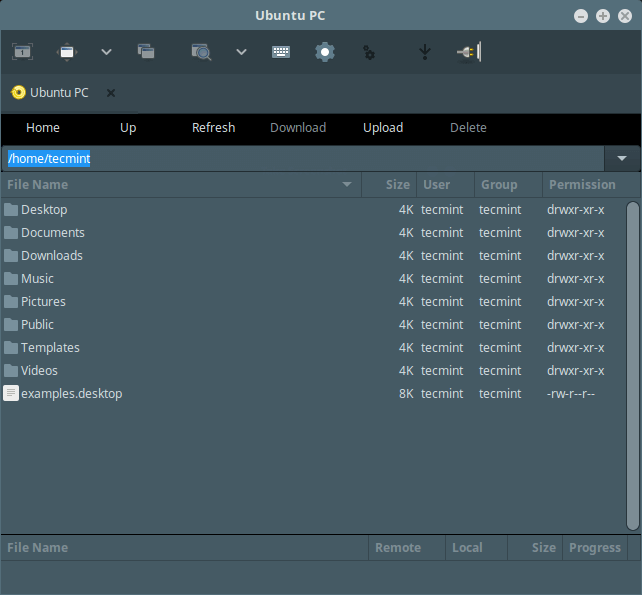
|
||||
][9]
|
||||
|
||||
Remmina Remote sFTP Filesystem
|
||||
|
||||
#### Connect to Remote Machine Using SSH
|
||||
|
||||
Select the connection profile and edit the settings, then choose SSH – Secure Shell from the Protocolsdown menu and optionally set a startup program and SSH authentication details. Lastly, click Connect, and enter the user SSH password.
|
||||
|
||||
[
|
||||
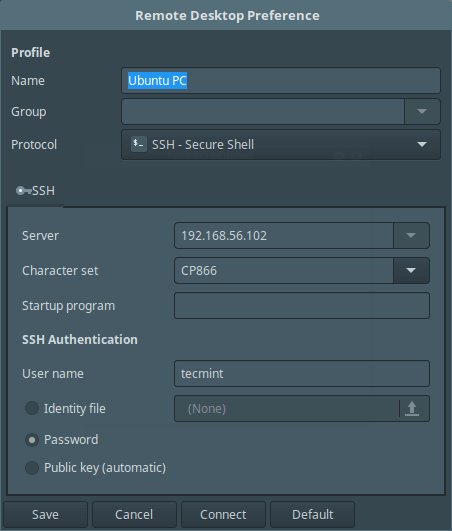
|
||||
][10]
|
||||
|
||||
Remmina SSH Connection
|
||||
|
||||
When you see the interface below, it means your connection is successful, you can now control the remote machine using SSH.
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
Remmina Remote SSH Connection
|
||||
|
||||
#### Connect to Remote Machine Using VNC
|
||||
|
||||
Choose the connection profile from the list and edit the settings, then select VNC – Virtual Network Computing from the Protocols down menu. Configure basic, advanced and ssh settings for the connection and click Connect, then enter the user SSH password.
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
Remmina VNC Connection
|
||||
|
||||
Once you see the following interface, it implies that you have successfully connected to the remote machine using VNC protocol.
|
||||
|
||||
Enter the user login password from the desktop login interface as shown in the screenshot below.
|
||||
|
||||
[
|
||||
|
||||
][13]
|
||||
|
||||
Remmina Remote Desktop Login
|
||||
|
||||
[
|
||||
|
||||
][14]
|
||||
|
||||
Remmina Remote Desktop Sharing
|
||||
|
||||
Simply follow the steps above to use the other remaining protocols to access remote machines, it’s that simple.
|
||||
|
||||
Remmina Homepage: [https://www.remmina.org/wp/][15]
|
||||
|
||||
That’s all! In this article, we showed you how to install and use Remmina remote connection client with a few supported protocols in Linux. You can share any thoughts in the comments via the feedback form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/remmina-remote-desktop-sharing-and-ssh-client/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Desktop-Sharing-Client.png
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Basic-Desktop-Preferences.png
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Advance-Desktop-Settings.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/ssh-remote-desktop-preferences.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Configured-Servers.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-sftp-connection.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/enter-userpasswd.png
|
||||
[8]:http://www.tecmint.com/sftp-upload-download-directory-in-linux/
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Remote-sFTP-Filesystem.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-SSH-Connection.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Remote-SSH-Connection.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-VNC-Connection.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Remote-Desktop-Login.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Remote-Desktop-Sharing.png
|
||||
[15]:https://www.remmina.org/wp/
|
||||
[16]:http://www.tecmint.com/author/aaronkili/
|
||||
[17]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[18]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
196
sources/tech/20170403 Yes Python is Slow and I Dont Care.md
Normal file
196
sources/tech/20170403 Yes Python is Slow and I Dont Care.md
Normal file
@ -0,0 +1,196 @@
|
||||
translated by zhousiyu325
|
||||
|
||||
Yes, Python is Slow, and I Don’t Care
|
||||
============================================================
|
||||
|
||||
### A rant on sacrificing performance for productivity.
|
||||
|
||||
|
||||

|
||||
|
||||
I’m taking a break from my discussion on asyncio in Python to talk about something that has been on my mind recently: the speed of Python. For those who don’t know, I am somewhat of a Python fanboy, and I aggressively use Python everywhere I can. One of the biggest complaints people have against Python is that it’s slow. Some people almost refuse to even try python because its slower than X. Here are my thoughts as to why you should try python, despite it being slow.
|
||||
|
||||
### Speed No Longer Matters
|
||||
|
||||
It used to be the case that programs took a really long time to run. CPU’s were expensive, memory was expensive. Running time of a program used to be an important metric. Computers were very expensive, and so was the electricity to run them. Optimization of these resources was done because of an eternal business law:
|
||||
|
||||
> Optimize your most expensive resource.
|
||||
|
||||
Historically, the most expensive resource was computer run time. This is what lead to the study of computer science which focuses on efficiency of different algorithms. However, this is no longer true, as silicon is now cheap. Like really cheap. Run time is no longer your most expensive resource. A company’s most expensive resource is now its employee’s time. Or in other words, you. It’s more important to get stuff done than to make it go fast. In fact this is so important, I am going to put it again right here as if it was a quote (for those who are just browsing):
|
||||
|
||||
> It’s more important to get stuff done than to make it go fast.
|
||||
|
||||
You might be saying, “My company cares about speed, I build a web application and all responses have to be faster than x milliseconds.” Or, “We have had customers cancel because they think our app is too slow.” I am not trying to say that speed doesn’t matter at all, I am simply trying to say that its no longer the most important thing; it’s not your most expensive resource.
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
### Speed Is The Only Thing That Matters
|
||||
|
||||
When you say _speed_ in the context of programming, you typically mean performance, aka CPU cycles. When your CEO say’s _speed_ in the context of programming he means business speed. The most important metric is time-to-market. Ultimately, it doesn’t matter how fast your product/web app is. It doesn’t matter what language its written in. It doesn't even matter how much money it takes to run. At the end of the day, the one thing that will make your company survive or die is time-to-market. I’m not just talking about the startup idea of how long it takes till you make money, but more so the time frame of “from idea, to customers hands.” The only way to survive in business is to innovate faster than your competitors. It doesn’t matter how many good ideas you come up with if your competitors “ship” before you do. You have to be the first to market, or at least keep up. Once you slow down, you are done.
|
||||
|
||||
> The only way to survive in business is to innovate faster than your competitors.
|
||||
|
||||
#### A Case of Microservices
|
||||
|
||||
Companies like Amazon, Google, and Netflix understand the importance of moving fast. They have created a business system where they can move fast and innovate quickly. Microservices are the solution to their problem. This article has nothing to do with whether or not you should be using microservices, but at least accept that Amazon and Google think they should be using them.
|
||||
|
||||

|
||||
|
||||
Microservices are inherently slow. The very concept of a microservice is to break up a boundary by a network call. This means you are taking what was a function call (a couple cpu cycles) and turning it into a network call. There isn’t much you could do that is worse in terms of performance. Network calls are really slow compared to the CPU. But these big companies still choose to use microservices. There really isn’t an architecture slower than microservices that I know of. Microservices’ biggest con is performance, but greatest pro is time-to-market. By building teams around smaller projects and code bases, a company is able to iterate and innovate at a much faster pace. This just goes to show that very large companies also care about time-to-market, not just startups.
|
||||
|
||||
#### CPU is Not your Bottleneck
|
||||
|
||||
|
||||

|
||||
|
||||
If you write a network application, such as a web server, chances are, CPU time is not the bottleneck of your application. When your web server handles a request, it probably makes a couple network calls, such as to your database, or perhaps a cache server like Redis. While these services themselves may be fast, the network call to them is slow. [There is a really great blog article on the speed differences of certain operations.][1] In the article, the author scales CPU cycle times into more understandable human times. If a single CPU cycle was the equivalent of 1 second, then a network call from California to New York, would be the equivalent of 4 years. That is how much slower network is. For some rough estimates, let’s say a normal network call inside the same data center takes about 3 ms. That would be the equivalent of 3 months in our “human scale”. Now imagine your program is very CPU intensive, it takes 100,000 cycles to respond to a single call. That would be the equivalent of just over 1 day. Now let’s say you use a language that is 5 times as slow, now it takes about 5 days. Well, compare that to our 3 month network call, and the 4 day difference doesn’t really matter much at all. If someone has to wait at least 3 months for a package, I don't think an extra 4 days will really matter all that much to them.
|
||||
|
||||
What this ultimately means is that, even if python is slow, it doesn’t matter. The speed of the language (or CPU time) is almost never the issue. Google actually did a study on this very concept, and [they wrote a paper on it][2]. The paper talks about designing a high throughput system. In the conclusion, they say:
|
||||
|
||||
> It may seem paradoxical to use an interpreted language in a high-throughput environment, but we have found that the CPU time is rarely the limiting factor; the expressibility of the language means that most programs are small and spend most of their time in I/O and native run-time code. Moreover, the flexibility of an interpreted implementation has been helpful, both in ease of experimentation at the linguistic level and in allowing us to explore ways to distribute the calculation across many machines.
|
||||
|
||||
or, to emphasise:
|
||||
|
||||
> the CPU time is rarely the limiting factor
|
||||
|
||||
#### What if CPU time is an issue?
|
||||
|
||||
You might be saying, “That’s great and all, but we have had issues where CPU was our bottleneck and caused much slowdown for our web app”, or “Language _x _ requires much less hardware to run than language _y_ on the server.” This all might be true. The wonderful thing about web servers is that you can load balance them almost infinitely. In other words, throw more hardware at it. Sure, Python might require better hardware than other languages, such as C. Just throw hardware at your CPU problem. Hardware is very cheap compared to your time. If you save a couple weeks worth of time in productivity in a year, that will more than pay for the added hardware cost.
|
||||
|
||||
|
||||
* * *
|
||||
|
||||

|
||||
|
||||
### So, is Python faster?
|
||||
|
||||
This whole time I have been talking about how the most important thing is development time. So the question remains: Is Python faster than language X when it comes to development time? Anecdotally, I, [google][3], [and][4] [several][5][others][6], can tell you how much more [productive][7] Python is. It abstracts so many things for you, helping you focus on what you’re really trying to code, without getting stuck in the weeds of the small things such as whether you should use a vector or an array. But you might not like to take others’ word for it, so let’s look at some more empirical data.
|
||||
|
||||
For the most part, this debate on whether python is more productive or not really comes down to scripting (or dynamic languages) vs statically typed languages. I think it is commonly excepted that statically typed languages are less productive, but [here is a good paper][8] that explains why. In terms of Python specifically, [here is a good summary][9] from a study that looked at how long it took to write code for strings processing in various languages.
|
||||
|
||||
|
||||
|
||||
|
||||
How long it takes to write a string processing application in various languages. (Prechelt and Garret)
|
||||
|
||||
Python is more than 2x as productive as Java in the above study. There are some other studies that show the same thing as well. Rosetta Code did a [fairly in-depth study][10] of the difference of programming languages. In the paper, they compare python to other scripting/interpreted languages and say:
|
||||
|
||||
> Python tends to be the most concise, even against functional languages (1.2–1.6 times shorter on average)
|
||||
|
||||
The common trend seems to be that “lines of code” is always less in Python. Lines of code might sound like a terrible metric, but [multiple studies][11], including the two already mentioned show that time spent per line of code is about the same in every language. Therefore, limiting the number of lines of code, increases productivity. Even the codinghorror himself (a C# programmer) [wrote an article on how Python is more productive][12].
|
||||
|
||||
I think it is fair to say that Python is more productive than many other languages. This is mainly due to the fact that python comes with “batteries included” and has many 3rd party libraries. [Here is a simple article talking about the differences between Python and X.][13] If you don’t know why Python is so “small” and productive, I invite you to take this opportunity to learn some python and see for yourself. Here is your first program:
|
||||
|
||||
_import __hello___
|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
### But what if speed really does matter?
|
||||
|
||||
|
||||

|
||||
|
||||
The tone of the points above might make it sound like optimization and speed don't matter at all. But the truth is, there are many times when runtime performance really does matter. One example is, you have a web application, and there is a specific endpoint that is taking a really long time to respond. You know how fast it needs to be, and how much it needs to be improved.
|
||||
|
||||
In our example, a couple things happened:
|
||||
|
||||
1. We noticed a single endpoint that was performing slowly
|
||||
2. We recognize it as slow because we have a metric of what is considered _fast enough_ , and it’s failing that metric.
|
||||
|
||||
We don’t have to micro-optimize everything in an application. Everything only needs to be “fast enough”. Your users might notice if an endpoint takes a couple seconds to respond, but they won’t notice you improved the response time of a 35 ms call to 25 ms. “Good enough”, really is all you need to achieve. _Disclaimer_ : _I should probably state that there are _ _some _ _applications, such as real-time bidding applications, that _ _do _ _need micro optimizations, and every millisecond does matter. But that is the exception, not the rule._
|
||||
|
||||
In order to figure out how to optimize the endpoint your first step would be to profile the code and try to figure out where you bottleneck is. After all:
|
||||
|
||||
> Any improvements made anywhere besides the bottleneck are an illusion. — Gene Kim
|
||||
|
||||
If your optimizations aren’t touching the bottleneck, you’re wasting your time and not fixing the real issue. You wont get any serious improvements until you optimize the bottleneck. If you try to optimize before you know what the bottleneck is, you’ll just end up playing whack-a-mole with parts of your code. Optimizing code before you measure and determine where the bottleneck is, is known as “premature optimization”. Donald Knuth is often attributed for the following quote, but he claims he stole the quote from someone else:
|
||||
|
||||
> _Premature optimization is the root of all evil._
|
||||
|
||||
In talking about maintaining code bases, the more full quote from Donald Knuth is:
|
||||
|
||||
> We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%.
|
||||
|
||||
In other words, he is saying that most of the time, you need to forget about optimizing your code. Its almost always good enough. In the cases when it isn’t good enough, we typically only need to touch three percent of the code path. You don’t win any prizes by making your endpoint a couple nanoseconds faster because you used an if statement instead of a function for example. Optimize only after you measure.
|
||||
|
||||
Premature optimization includes calling certain _faster_ methods, or even using a specific data structure because it’s generally faster. Computer Science argues that if a method or algorithm has the same asymptotic growth (or Big-O) as another, then they are equivalent, even if one is 2x as slow in practice. Computers are so fast, that the computational growth of an algorithm as data/usage increases matters much more than the actual speed itself. In other words, if you have two _O(log n)_ functions, but one is twice as slow, it doesn’t really matter. As the size of data increases, they both “slow down” at the same rate. This is why premature optimization is the root of all evil; It wastes our time, and almost never actually helps our general performance anyways.
|
||||
|
||||
In terms of Big-O, you could argue that all languages are _O(n) _ for your program where n is lines of code, or instructions. They all grow at the same rate for the same instructions. It doesn’t matter how slow a language/runtime is, in terms of asymptotic growth, all languages are created equal. Under this logic, you could say that choosing a language for your application simply because its “fast” is the ultimate form of premature optimization. Your choosing something supposedly fast without measuring, without understanding where the bottleneck is going to be.
|
||||
|
||||
> Choosing a language for you application simply because its “fast” is the ultimate form of premature optimization.
|
||||
|
||||
|
||||
* * *
|
||||
|
||||

|
||||
|
||||
### Optimizing Python
|
||||
|
||||
One of my favorite things about Python is that it lets you optimize code a little bit at a time. Lets say you have a method in Python that you find to be your bottleneck. You have optimized it several times, possibly following some guidance from [here][14] and [there][15], and now you are at the point where you are pretty sure Python itself is the bottleneck. Python has the ability to call into C code, which means that you can rewrite this one method in C to reduce the performance issue. You can do this one method at a time. This process allows you to write well optimized bottleneck methods in any language that compiles to C compatible assembler. This allows you to stay in Python most of the time, and only go into the lower level things when you really need it.
|
||||
|
||||
There is a language called Cython that is a super-set of Python. It is almost a merge of Python and C, and is a progressively typed language. Any Python code is valid Cython code, and Cython compiles to C code. With Cython, you can write a module or method, and slowly progress to more and more C-Types and performance. You can intermingle C types and Python’s duck types together. Using Cython you get the perfect mix of optimizing only at the bottleneck, and the beauty of Python everywhere else.
|
||||
|
||||
|
||||

|
||||
|
||||
A screenshot of Eve online: A space MMO written in Python
|
||||
|
||||
When you do eventually run into a Python wall of performance woes, you don't need to move your whole code base to a different language. You can almost always get the performance you need by just re-writing a couple methods in Cython. This is the strategy [Eve Online][16] takes. Eve is a Massive Multiplayer Computer Game, that uses Python and Cython for the entire stack. They achieve game level performance by optimizing the bottlenecks in C/Cython. If it works for them, it should work for most anyone. Alternatively, there are also other ways to optimize your python. For example, [PyPy][17] is a JIT implementation of Python that could give you significant runtime improvements for long running applications (such as a web server) simply by swapping out CPython (the default implementation) with PyPy.
|
||||
|
||||
|
||||

|
||||
|
||||
Lets review some of the main points:
|
||||
|
||||
* Optimize for your most expensive resource. That’s YOU, not the computer.
|
||||
* Choose a language/framework/architecture that helps you develop quickly (such as Python). Do not choose technologies simply because they are fast.
|
||||
* When you do have performance issues: find your bottleneck
|
||||
* Your bottleneck is most likely not CPU or Python itself.
|
||||
* If Python is your bottleneck (you’ve already optimized algorithms/etc.), then move the hot-spot to Cython/C
|
||||
* Go back to enjoying getting things done quickly
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
I hope you enjoyed reading this article as much as I enjoyed writing it. If you’d like to say thank you, just hit the heart button. Also, if you’d like to talk to me about Python sometime, you can hit me up on twitter (@nhumrich) or I can be found on the [Python slack channel][18].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I drink the KoolAid of Continuous Delivery and write tools to help us all get there. Python hacker, Technology fanatic. Currently a devops engineer @canopytax
|
||||
|
||||
--------------
|
||||
|
||||
via: https://hackernoon.com/yes-python-is-slow-and-i-dont-care-13763980b5a1
|
||||
|
||||
作者:[Nick Humrich ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@nhumrich
|
||||
[1]:https://blog.codinghorror.com/the-infinite-space-between-words/
|
||||
[2]:https://static.googleusercontent.com/media/research.google.com/en//archive/sawzall-sciprog.pdf
|
||||
[3]:https://www.codefellows.org/blog/5-reasons-why-python-is-powerful-enough-for-google/
|
||||
[4]:https://www.lynda.com/Python-tutorials/Python-Programming-Efficiently/534425-2.html
|
||||
[5]:https://www.linuxjournal.com/article/3882
|
||||
[6]:https://www.codeschool.com/blog/2016/01/27/why-python/
|
||||
[7]:http://pythoncard.sourceforge.net/what_is_python.html
|
||||
[8]:http://www.tcl.tk/doc/scripting.html
|
||||
[9]:http://www.connellybarnes.com/documents/language_productivity.pdf
|
||||
[10]:https://arxiv.org/pdf/1409.0252.pdf
|
||||
[11]:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.113.1831&rep=rep1&type=pdf
|
||||
[12]:https://blog.codinghorror.com/are-all-programming-languages-the-same/
|
||||
[13]:https://www.python.org/doc/essays/comparisons/
|
||||
[14]:https://wiki.python.org/moin/PythonSpeed
|
||||
[15]:https://wiki.python.org/moin/PythonSpeed/PerformanceTips
|
||||
[16]:https://www.eveonline.com/
|
||||
[17]:http://pypy.org/
|
||||
[18]:http://pythondevelopers.herokuapp.com/
|
||||
@ -1,56 +0,0 @@
|
||||
# 用 Apache Calcite 构建强大的实时流应用
|
||||
|
||||

|
||||
|
||||
Calcite 是一个数据框架,它允许你创建自定义数据库功能,微软开发者 Atri Sharma 在 Apache 即将到来的 11 月 14-16 日在西班牙塞维利亚举行的 Big Data Europe 中解释。[Creative Commons Zero][2]
|
||||
|
||||
Wikimedia Commons: Parent Géry
|
||||
|
||||
[Apache Calcite][7] 数据管理框架包含许多典型的数据库管理系统,但省略了其他部分,如存储数据和算法来处理数据。 Microsoft 在 Azure Data Lake 的软件工程师 Atri Sharma 在西班牙塞维利亚的即将到来的 [Apache:Big Data][6] 会议上的演讲中将讨论使用 [Apache Calcite][5]的高级查询规划能力。我们与 Sharma 讨论了解有关 Calcite 的更多信息,以及现有程序如何利用其功能。
|
||||
|
||||

|
||||
|
||||
Atri Sharma,微软 Azure Data Lake 的软件工程师,已经[授权使用][1]
|
||||
|
||||
**Linux.com:你能提供一些关于 Apache Calcite 的背景吗? 它有什么作用?
|
||||
|
||||
Atri Sharma:Calcite是一个框架,它是许多数据库内核的基础。Calcite 允许你构建自定义数据库功能并使用 Calcite 所需的资源。例如,Hive 使用 Calcite 进行基于成本的查询优化、Drill 和 Kylin 使用 Calcite 进行 SQL 解析和优化、Apex 使用 Calcite 进行流式 SQL。
|
||||
|
||||
**Linux.com:有哪些是使得 Apache Calcite 与其他框架不同的特性?
|
||||
|
||||
Atri:Calcite 是独一无二的,它允许你建立自己的数据平台。 Calcite 不直接管理你的数据,而是允许你使用 Calcite 的库来定义你自己的组件。 例如,它允许使用 Calcite 中可用的 Planner 定义自定义查询优化器,而不是提供通用查询优化器。
|
||||
|
||||
**Linux.com:Apache Calcite 本身不会存储或处理数据。 它如何影响程序开发?
|
||||
|
||||
Atri:Calcite 是数据库内核中的依赖项。它面向希望扩展其功能的数据管理平台,而无需从头开始编写大量功能。
|
||||
|
||||
** Linux.com:谁应该使用它? 你能举几个例子吗?**
|
||||
|
||||
Atri:任何旨在扩展其功能的数据管理平台都应使用 Calcite。 我们是你下一个高性能数据库的基础!
|
||||
|
||||
具体来说,我认为最大的例子是 Hive 使用 Calcite 用于查询优化、Flink 解析和流 SQL 处理。 Hive 和 Flink 是成熟的数据管理引擎,并使用 Calcite 高度专业目的。这是对 Calcite 应用进一步加强数据管理平台核心的一个好的案例研究。
|
||||
|
||||
**Linux.com:你有哪些期待的新功能?
|
||||
|
||||
Atri:流 SQL 增强是令我非常兴奋的事情。这些功能令人兴奋,因为它们将使 Calcite 的用户能够更快地开发实时流式应用程序,并且这些程序的强大和功能将是多方面的。流程序是新的事实,并且在流 SQL 中具有查询优化的优点对于大部分人将是非常有用的。此外,关于暂存表的讨论还在进行,所以请继续关注!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/build-strong-real-time-streaming-apps-apache-calcite
|
||||
|
||||
作者:[AMBER ANKERHOLZ][a]
|
||||
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/aankerholz
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[3]:https://www.linux.com/files/images/atri-sharmajpg
|
||||
[4]:https://www.linux.com/files/images/calcitejpg
|
||||
[5]:https://calcite.apache.org/
|
||||
[6]:http://events.linuxfoundation.org/events/apache-big-data-europe
|
||||
[7]:https://calcite.apache.org/
|
||||
@ -1,91 +0,0 @@
|
||||
在 shell 中使用 vi 模式
|
||||
============================================================
|
||||
|
||||
> 介绍在命令行编辑中使用 vi 模式。
|
||||
|
||||

|
||||
>图片提供: opensource.com
|
||||
|
||||
作为一名更大的开源社区的参与者,更确切地说,作为[ Fedora 项目][2]的成员,我有机会与许多人会面并讨论各种有趣的技术主题。我最喜欢的主题是“命令行”或者 [shell][3],因为了解人们如何熟练使用 shell 可以让你深入地了解他们的想法,他们喜欢什么样的工作流程,以及某种程度上什么激发了他们的灵感。许多开发人员和运维在互联网上公开分享他们的“ dot 文件”(他们的 shell 配置文件的常见俚语),这将是一个有趣的协作机会,让每个人都能从对命令行有丰富经验的人中学习提示和技巧并分享快捷方式以及有效率的技巧。
|
||||
|
||||
我在这里会为你介绍 shell 中的 vi 模式。
|
||||
|
||||
在计算和操作系统的庞大生态系统中有[很多 shell][4]。然而,在 Linux 世界中,[bash][5] 已经成为事实上标准,并在在撰写本文时,它是所有主要 Linux 发行版上的默认 shell。因此,它就是我所说的 shell。需要注意的是,bash 在其他类 UNIX 操作系统上也是一个相当受欢迎的选项,所以它可能跟你用的差别不大(对于 Windows 用户,可以用 [cygwin][6])。
|
||||
|
||||
在探索 shell 时,首先要做的是在其中输入命令并得到输出,如下所示:
|
||||
|
||||
```
|
||||
$ echo "Hello World!"
|
||||
Hello World!
|
||||
```
|
||||
|
||||
这是常见的练习,可能每个人都做过。没接触过的人和新手可能没有意识到 [bash][7] shell 的默认输入模式是 [Emacs][8],这意味着命令行中所用的行编辑功能都将使用[ Emacs 风格的“键盘组合][9]。(对这个感兴趣的人,行编辑功能实际上是由[GNU Readline][10]进行的。)
|
||||
|
||||
例如,如果你输入了 **echo "Hello Wrld!"**,并意识到你想要快速跳回一个单词(空格分隔)来修改打字错误,而无需按住左箭头键,那么你可以同时按下 **Alt+b**,光标会将向后跳到 **W**。
|
||||
|
||||
```
|
||||
$ echo "Hello Wrld!"
|
||||
^
|
||||
Cursor is here.
|
||||
```
|
||||
|
||||
这只是使用提供给 shell 用户的许多 Emacs 组合键之一完成的。还有其他更多东西,如复制文本、粘贴文本、删除文本以及使用快捷方式来编辑文本。使用复杂的组合键并记住可能看起来很愚蠢,但是在使用较长的命令或从 shell 历史记录中调用一个命令并想再次编辑执行时,它们可能会非常强大。
|
||||
|
||||
尽管 Emacs 的键盘绑定都不错,如果你对 Emacs 编辑器熟悉或者发现它们很容易使用也不错,但是仍有一些人对“ vi 风格”的键盘绑定更舒服,因为他们经常使用 vi 编辑器(通常是 [vim][11] 或 [nvim][12])。bash shell(再说一次,通过 GNU Readline)可以为我们提供这个功能。要启用它,需要执行命令 **$ ****set**** -o vi**。
|
||||
|
||||
就像魔术一样,你现在处于 vi 模式了,现在可以使用 vi 风格的键绑定轻松地进行编辑,以便复制文本、删除文本、并跳转到文本行中的不同位置。这与 Emacs 模式在功能方面没有太大的不同,但是它在你_如何_与 shell 进行交互执行操作上有一些差别,根据你的喜好这是一个强大的选择。
|
||||
|
||||
我们来看看先前的例子,但是在上下文中一旦你在 shell 中进入 vi 模式,你就处于 INSERT 模式中,这意味着你可以和以前一样输入命令,但是现在点击 **Esc** 键,你将处于 NORMAL 模式,你可以自由浏览并进行文字修改。
|
||||
|
||||
看看先前的例子,如果你输入了 **echo "Hello Wrld!"**,并意识到你想跳回一个单词(再说一次用空格分隔)来修复那个打字错误,那么你可以点击 **Esc** 从 INSERT 变为 NORMAL 模式。然后,您可以输入 **B**(**Shift+b**),光标就能像以前那样回到前面了。(有关 vi 模式的更多信息,请参阅[这里][13]。):
|
||||
|
||||
```
|
||||
$ echo "Hello Wrld!"
|
||||
^
|
||||
Cursor is here.
|
||||
```
|
||||
|
||||
现在,对于 vi/vim/nvim 用户来说,当你发现你一直可以使用相同的快捷键,而不仅仅是在编辑器中编写代码或文档的时候我希望这是一个惊喜时刻。如果这对你是全新的,并且你想要了解更多,那么我可能会建议你参加这个[交互式 vim 教程][14],看看 vi 风格的编辑是否还有有用的。
|
||||
|
||||
如果你喜欢在此风格下与 shell 交互,那么你可以在主目录中的 **~/.bashrc** 文件底部添加下面的行来持久设置它。
|
||||
|
||||
**set -o vi**
|
||||
|
||||
对于 emacs 模式的用户,希望这可以让你快速并愉快地看到 shell 的“另一面”。在结束之前,我认为每个人都应该使用任意一个让他们更有效率的编辑器和 shell 行编辑模式,如果你使用 vi 模式并且这篇对你是新的,那么恭喜你!现在就变得更有效率吧。
|
||||
|
||||
玩得愉快!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Adam Miller 是 Fedora 工程团队成员,专注于 Fedora 发布工程。他的工作包括下一代构建系统、自动化、RPM 包维护和基础架构部署。Adam 在山姆休斯顿州立大学完成了计算机科学学士学位与信息保障与安全科学硕士学位。他是一名红帽认证工程师(Cert#110-008-810),也是开源社区的活跃成员,并对 Fedora 项目(FAS 帐户名称:maxamillion)贡献有着悠久的历史。
|
||||
|
||||
|
||||
------------------------
|
||||
via: https://opensource.com/article/17/3/fun-vi-mode-your-shell
|
||||
|
||||
作者:[Adam Miller ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/maxamillion
|
||||
[1]:https://opensource.com/article/17/3/fun-vi-mode-your-shell?rate=5_eAB9UtByHOiZMysPcewU4Zz6hOrLwdcgIpu2Ub4vo
|
||||
[2]:https://getfedora.org/
|
||||
[3]:https://opensource.com/business/16/3/top-linux-shells
|
||||
[4]:https://opensource.com/business/16/3/top-linux-shells
|
||||
[5]:https://tiswww.case.edu/php/chet/bash/bashtop.html
|
||||
[6]:http://cygwin.org/
|
||||
[7]:https://tiswww.case.edu/php/chet/bash/bashtop.html
|
||||
[8]:https://www.gnu.org/software/emacs/
|
||||
[9]:https://en.wikipedia.org/wiki/GNU_Readline#Emacs_keyboard_shortcuts
|
||||
[10]:http://cnswww.cns.cwru.edu/php/chet/readline/rltop.html
|
||||
[11]:http://www.vim.org/
|
||||
[12]:https://neovim.io/
|
||||
[13]:https://en.wikibooks.org/wiki/Learning_the_vi_Editor/Vim/Modes
|
||||
[14]:http://www.openvim.com/tutorial.html
|
||||
[15]:https://opensource.com/user/10726/feed
|
||||
[16]:https://opensource.com/article/17/3/fun-vi-mode-your-shell#comments
|
||||
[17]:https://opensource.com/users/maxamillion
|
||||
@ -0,0 +1,108 @@
|
||||
如何在 Linux 中列出通过 RPM 或者 DEB 包安装的文件
|
||||
============================================================
|
||||
|
||||
你是否想要了解安装包中各个文件在 Linux 系统中安装(位于)的位置?我们将在本文介绍如何列出文件的来源,或存在于某个特定包或者一组软件包中的文件。
|
||||
|
||||
这篇文章可以帮你轻松地找到重要的软件包文件,如配置文件、帮助文档等。我们来看看找出文件在哪个包中或者从哪个包中安装的几个方法:
|
||||
|
||||
### 如何列出 Linux 中全部已安装软件包的文件
|
||||
|
||||
你可以使用[ repoquery 命令][6],它是 [yum-utils][7] 的一部分,用来列出给定的软件包在 CentOS/RHEL 系统上安装的文件。
|
||||
|
||||
要安装并使用 yum-utils, 运行下面的命令:
|
||||
|
||||
```
|
||||
# yum update
|
||||
# yum install yum-utils
|
||||
```
|
||||
|
||||
现在你可以列出一个已安装包的文件了,比如 httpd 服务器 (注意包名是大小写敏感的)。`--installed` 表示安装的包名,`-l` 列出所有的文件:
|
||||
|
||||
```
|
||||
# repoquery --installed -l httpd
|
||||
# dnf repoquery --installed -l httpd [On Fedora 22+ versions]
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
>repoquery 列出 httpd 安装的文件
|
||||
|
||||
重要:在 Fedora 22 以上的版本中,`repoquery` 命令在基于 RPM 的发行版中已经与 [dnf 包管理器][9]整合,可以用上面的方法列出所有文件。
|
||||
|
||||
除此之外,你也可以使用下面的 [rpm 命令][10]列出 `.rpm` 包中或已经安装的 `.rpm` 包的文件,下面的 `-q` 和 `-l` 表示列出包中的文件:
|
||||
|
||||
```
|
||||
# rpm -ql httpd
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
>rpm 查询已安装程序的安装包
|
||||
|
||||
另外一个有用的建议是使用 `-p` 在安装之前列出 `.rpm` 中的文件。
|
||||
|
||||
```
|
||||
# rpm -qlp telnet-server-1.2-137.1.i586.rpm
|
||||
```
|
||||
|
||||
在 Debian/Ubuntu 发行版中,你可以使用 [dpkg 命令][12]带上 `-L` 标志在 Debian 系统或其衍生版本中列出给定 `.deb` 包的安装的文件。
|
||||
|
||||
在这个例子中,我们会列出 apache2 服务器安装的文件:
|
||||
|
||||
```
|
||||
$ dpkg -L apache2
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
>dpkg 列出安装的包
|
||||
|
||||
不要忘记查看其它有关在 Linux 中软件包管理的文章。
|
||||
|
||||
1. [20 个有用的 “yum” 包管理命令][1]
|
||||
2. [20 个有用的 rpm 包管理命令] [2]
|
||||
3. [15 个 Ubuntu 中有用的 apt 包管理命令] [3]
|
||||
4. [15 个 Ubuntu 中有用的 dpkg命令][4]
|
||||
5. [5 个最佳的对 Linux 新手的包管理器][5]
|
||||
|
||||
就是这样了!在本文中,我们向你展示了如何在 Linux 中列出/找到给定的软件包或软件包组安装的所有文件。在下面的评论栏中分享你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是 Linux 和 F.O.S.S 的爱好者,目前任 TecMint 的作者,志向是一名 Linux 系统管理员、web 开发者。他喜欢用电脑工作,并热衷于分享知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/list-files-installed-from-rpm-deb-package-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[ezio](https://github.com/oska874)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/20-practical-examples-of-rpm-commands-in-linux/
|
||||
[3]:http://www.tecmint.com/apt-advanced-package-command-examples-in-ubuntu/
|
||||
[4]:http://www.tecmint.com/dpkg-command-examples/
|
||||
[5]:http://www.tecmint.com/linux-package-managers/
|
||||
[6]:http://www.tecmint.com/list-installed-packages-in-rhel-centos-fedora/
|
||||
[7]:http://www.tecmint.com/linux-yum-package-management-with-yum-utils/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/Repoquery-List-Installed-Files-of-Httpd.png
|
||||
[9]:http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
[10]:http://www.tecmint.com/20-practical-examples-of-rpm-commands-in-linux/
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/rpm-ql-httpd.png
|
||||
[12]:http://www.tecmint.com/dpkg-command-examples/
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2017/03/dpkg-List-Installed-Packages.png
|
||||
[14]:http://www.tecmint.com/author/aaronkili/
|
||||
[15]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[16]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,380 @@
|
||||
Translating by sanfusu
|
||||
<!--[Data-Oriented Hash Table][1]-->
|
||||
[面向数据的哈希表][1]
|
||||
============================================================
|
||||
|
||||
<!--In recent years, there’s been a lot of discussion and interest in “data-oriented design”—a programming style that emphasizes thinking about how your data is laid out in memory, how you access it and how many cache misses it’s going to incur. -->
|
||||
最近几年中,面向数据的设计已经受到了很多的关注 —— 一种强调内存中数据布局的编程风格,包括如何访问以及将会引发多少的 cache 缺失。
|
||||
<!--With memory reads taking orders of magnitude longer for cache misses than hits, the number of misses is often the key metric to optimize.-->
|
||||
由于在内存读取操作中缺失所占的数量级要大于命中的数量级,所以缺失的数量通常是优化的关键标准。
|
||||
<!--It’s not just about performance-sensitive code—data structures designed without sufficient attention to memory effects may be a big contributor to the general slowness and bloatiness of software.
|
||||
-->
|
||||
这不仅仅关乎那些对性能有要求的 code-data 结构设计的软件,由于缺乏对内存效益的重视而成为软件运行缓慢、膨胀的一个很大因素。
|
||||
|
||||
<!--The central tenet of cache-efficient data structures is to keep things flat and linear. For example, under most circumstances, to store a sequence of items you should prefer a flat array over a linked list—every pointer you have to chase to find your data adds a likely cache miss, while flat arrays can be prefetched and enable the memory system to operate at peak efficiency.
|
||||
-->
|
||||
|
||||
高效缓存数据结构的中心原则是将事情变得平滑和线性。
|
||||
比如,在大部分情况下,存储一个序列元素更倾向于使用平滑的数组而不是链表 —— 每一次通过指针来查找数据都会为 cache 缺失增加一份风险;而平滑的数组可以预先获取,并使得内存系统以最大的效率运行
|
||||
|
||||
<!--This is pretty obvious if you know a little about how the memory hierarchy works—but it’s still a good idea to test things sometimes, even if they’re “obvious”! [Baptiste Wicht tested `std::vector` vs `std::list` vs `std::deque`][4] (the latter of which is commonly implemented as a chunked array, i.e. an array of arrays) a couple of years ago. The results are mostly in line with what you’d expect, but there are a few counterintuitive findings. For instance, inserting or removing values in the middle of the sequence—something lists are supposed to be good at—is actually faster with an array, if the elements are a POD type and no bigger than 64 bytes (i.e. one cache line) or so! It turns out to actually be faster to shift around the array elements on insertion/removal than to first traverse the list to find the right position and then patch a few pointers to insert/remove one element. That’s because of the many cache misses in the list traversal, compared to relatively few for the array shift. (For larger element sizes, non-POD types, or if you already have a pointer into the list, the list wins, as you’d expect.)
|
||||
-->
|
||||
|
||||
如果你知道一点内存层级如何运作的知识,下面的内容会是想当然的结果——但是有时候即便他们相当明显,测试一下任不失为一个好主意。
|
||||
[Baptiste Wicht 测试过了 `std::vector` vs `std::list` vs `std::deque`][4]
|
||||
(几年前,后者通常使用分块数组来实现,比如:一个数组的数组)
|
||||
结果大部分会和你预期的保持一致,但是会存在一些违反直觉的东西。
|
||||
作为实例:在序列链表的中间位置做插入或者移除操作被认为会比数组快
|
||||
但如果该元素是一个 POD 类型,并且不大于 64 字节或者在 64 字节左右(在一个 cache 流水线内),
|
||||
通过对要操作的元素周围的数组元素进行移位操作要比从头遍历链表来的快。
|
||||
这是由于在遍历链表以及通过指针插入/删除元素的时候可能会导致不少的 cache 缺失,相对而言,数组移位则很少会发生。
|
||||
(对于更大的元素,非 POD 类型,或者你你已经有了指向链表元素的指针,此时和预期的一样,链表胜出)
|
||||
|
||||
|
||||
|
||||
<!--Thanks to data like Baptiste’s, we know a good deal about how memory layout affects sequence containers.-->
|
||||
多亏了 Baptiste 的数据,我们知道了内存布局如何影响序列容器。
|
||||
<!--But what about associative containers, i.e. hash tables?-->
|
||||
但是关联容器,比如 hash 表会怎么样呢?
|
||||
<!--There have been some expert recommendations: -->
|
||||
已经有了些权威推荐:
|
||||
<!--[Chandler Carruth tells us to use open addressing with local probing][5] -->
|
||||
[Chandler Carruth 推荐的带局部探测的开放寻址][5]
|
||||
<!--so that we don’t have to chase pointers,-->
|
||||
(此时,我们没必要追踪指针)
|
||||
<!--and [Mike Acton suggests segregating keys from values][6]
|
||||
in memory so that we get more keys per cache line,
|
||||
improving locality when we have to look at multiple keys. -->
|
||||
以及[Mike Acton 推荐的在内存中将 value 和 key 隔离][6](这种情况下,我们可以在每一个 cache 流水线中得到更多的 key), 这可以在我们不得查找多个 key 时提高局部性能。
|
||||
<!-- These ideas make good sense, but again, it’s a good idea to test things, -->
|
||||
<!-- and I couldn’t find any data. So I had to collect some of my own! -->
|
||||
这些想法很有意义,但再一次的说明:测试永远是好习惯,但由于我找不到任何数据,所以只好自己收集了。
|
||||
|
||||
<!--### [][7]The Tests-->
|
||||
### [][7]测试
|
||||
|
||||
<!--
|
||||
I tested four different quick-and-dirty hash table implementations, as well as `std::unordered_map`. All five used the same hash function, Bob Jenkins’ [SpookyHash][8] with 64-bit hash values. (I didn’t test different hash functions, as that wasn’t the point here; I’m also not looking at total memory consumption in my analysis.) The implementations are identified by short codes in the results tables:
|
||||
-->
|
||||
我测试了四个不同的 quick-and-dirty 哈希表实现,另外还包括 `std::unordered_map` 。
|
||||
这五个哈希表都使用了同一个哈希函数 —— Bob Jenkins' [SpookyHash][8](64 位哈希值)。
|
||||
(由于哈希函数在这里不是重点,所以我没有测试不同的哈希函数;我同样也没有检测我的分析中的总内存消耗。)
|
||||
实现会通过短代码在测试结果表中标注出来。
|
||||
|
||||
* **UM**: `std::unordered_map` 。<!--In both VS2012 and libstdc++-v3 (used by both gcc and clang), UM is implemented as a linked list containing all the elements, and an array of buckets that store iterators into the list. In VS2012, it’s a doubly-linked list and each bucket stores both begin and end iterators; in libstdc++, it’s a singly-linked list and each bucket stores just a begin iterator. In both cases, the list nodes are individually allocated and freed. Max load factor is 1.-->
|
||||
在 VS2012 和 libstdc++-v3 (libstdc++-v3: gcc 和 clang 都会用到这东西)中,
|
||||
UM 是以链接表的形式实现,所有的元素都在链表中,buckets 数组中存储了链表的迭代器。
|
||||
VS2012 中,则是一个双链表,每一个 bucket 存储了起始迭代器和结束迭代器;
|
||||
libstdc++ 中,是一个单链表,每一个 bucket 只存储了一个起始迭代器。
|
||||
这两种情况里,链表节点是独立申请和释放的。最大负载因子是 1 。
|
||||
|
||||
* **Ch**: <!--separate chaining—each bucket points to a singly-linked list of element nodes. The element nodes are stored in a flat array pool, to avoid allocating each node individually. Unused nodes are kept on a free list. Max load factor is 1.-->
|
||||
分离的、链状 buket 指向一个元素节点的单链表。
|
||||
为了避免分开申请每一个节点,元素节点存储在平滑的数组池中。
|
||||
未使用的节点保存在一个空闲链表中。
|
||||
最大负载因子是 1。
|
||||
|
||||
* **OL**:<!--open addressing with linear probing—each bucket stores a 62-bit hash,
|
||||
a 2-bit state (empty, filled, or removed), key, and value. Max load factor is 2/3.-->
|
||||
开地址线性探测 —— 每一个 bucket 存储一个 62 bit 的 hash 值,一个 2 bit 的状态值(包括 empty,filled,removed 三个状态),key 和 vale 。最大负载因子是 2/3。
|
||||
* **DO1**:<!--“data-oriented 1”—like OL, but the hashes and states are segregated from the keys and values, in two separate flat arrays.-->
|
||||
data-oriented 1 —— 和 OL 相似,但是哈希值、状态值和 key、values 分离在两个隔离的平滑数组中。
|
||||
|
||||
* **DO2**:<!--“data-oriented 2”—like OL, but the hashes/states, keys, and values are segregated in three separate flat arrays.-->
|
||||
"data-oriented 2" —— 与 OL 类似,但是哈希/状态,keys 和 values 被分离在 3 个相隔离的平滑数组中。
|
||||
|
||||
<!--All my implementations, as well as VS2012’s UM, use power-of-2 sizes by default, growing by 2x upon exceeding their max load factor. -->
|
||||
在我的所有实现中,包括 VS2012 的 UM 实现,默认使用尺寸为 2 的 n 次方。如果超出了最大负载因子,则扩展两倍。
|
||||
<!--In libstdc++, UM uses prime-number sizes by default and grows to the next prime upon exceeding its max load factor.-->
|
||||
在 libstdc++ 中,UM 默认尺寸是一个素数。如果超出了最大负载因子,则扩展为下一个素数大小。
|
||||
<!--However, I don’t think these details are very important for performance.-->
|
||||
但是我不认为这些细节对性能很重要。
|
||||
<!--The prime-number thing is a hedge against poor hash functions that don’t have enough entropy in their lower bits, but we’re using a good hash function.-->
|
||||
素数是一种对低 bit 位上没有足够熵的低劣 hash 函数的挽救手段,但是我们正在用的是一个很好的 hash 函数。
|
||||
|
||||
<!--The OL, DO1 and DO2 implementations will collectively be referred to as OA (open addressing), since we’ll find later that their performance characteristics are often pretty similar.-->
|
||||
OL,DO1 和 DO2 的实现将共同的被称为 OA(open addressing)——稍后我们将发现他们在性能特性上非常相似。
|
||||
<!--For each of these implementations, I timed several different operations, at element counts from 100K to 1M and for payload sizes (i.e. total key+value size) from 8 to 4K bytes.-->
|
||||
在每一个实现中,单元数从 100 K 到 1 M,有效负载(比如:总的 key + value 大小)从 8 到 4 k 字节
|
||||
我为几个不同的操作记了时间。
|
||||
<!--For my purposes, keys and values were always POD types and keys were always 8 bytes (except for the 8-byte payload, in which key and value were 4 bytes each).-->
|
||||
keys 和 values 永远是 POD 类型,keys 永远是 8 个字节(除了 8 字节的有效负载,此时 key 和 value 都是 4 字节)
|
||||
<!-- I kept the keys to a consistent size because my purpose here was to test memory effects, not hash function performance. Each test was repeated 5 times and the minimum timing was taken. -->
|
||||
因为我的目的是为了测试内存影响而不是哈希函数性能,所以我将 key 放在连续的尺寸空间中。
|
||||
每一个测试都会重复 5 遍,然后记录最小的耗时。
|
||||
|
||||
<!-- The operations tested were: -->
|
||||
测试的操作在这里:
|
||||
|
||||
* **Fill**:<!-- insert a randomly shuffled sequence of unique keys into the table. -->
|
||||
将一个随机的 key 序列插入到表中(key 在序列中是唯一的)。
|
||||
* **Presized fill**:<!-- like Fill, but first reserve enough memory for all the keys we’ll insert, to prevent rehashing and reallocing during the fill process. -->
|
||||
和 Fill 相似,但是在插入之间我们先为所有的 key 保留足够的内存空间,以防止在 fill 过程中 rehash 或者重申请。
|
||||
* **Lookup**: <!-- perform 100K lookups of random keys, all of which are in the table. -->
|
||||
执行 100 k 随机 key 查找,所有的 key 都在 table 中。
|
||||
* **Failed lookup**: <!-- perform 100K lookups of random keys, none of which are in the table. -->
|
||||
执行 100 k 随机 key 查找,所有的 key 都不在 table 中。
|
||||
* **Remove**:<!-- remove a randomly chosen half of the elements from a table. -->
|
||||
从 table 中移除随机选择的半数元素。
|
||||
* **Destruct**:<!-- destroy a table and free its memory. -->
|
||||
销毁 table 并释放内存.
|
||||
|
||||
<!-- You can [download my test code here][9]. -->
|
||||
你可以[在这里下载我的测试代码][9]。
|
||||
<!-- It builds for Windows or Linux, in 64-bit only. -->
|
||||
这些代码只能在 64 机器上编译(包括Windows和Linux)。
|
||||
<!-- There are some flags near the top of `main()` that you can toggle to turn on or off different tests—with all of them on, it will likely take an hour or two to run. -->
|
||||
在 `main()` 函数附件有一些标记,你可把他们打开或者关掉——如果全开,可能会需要一两个小时才能结束运行。
|
||||
<!-- The results I gathered are also included, in an Excel spreadsheet in that archive. -->
|
||||
我搜集的结果也放在了那个打包文件里的 Excel 表中。
|
||||
<!-- (Beware that the Windows and Linux results are run on different CPUs, so timings aren’t directly comparable.) -->
|
||||
(注意: Windows 和 Linux 在不同的 CPU 上跑的,所以时间不具备可比较性)
|
||||
<!-- The code also runs unit tests to verify that all the hash table implementations are behaving correctly. -->
|
||||
代码也跑了一些单元测试,用来验证所有的 hash 表实现都能运行正确。
|
||||
|
||||
<!-- Incidentally, I also tried two additional implementations: -->
|
||||
我还顺带尝试了附加的两个实现:
|
||||
<!-- separate chaining with the first node stored in the bucket instead of the pool, and open addressing with quadratic probing. -->
|
||||
Ch 中第一个节点存放在 bucket 中而不是 pool 里,二次探测的开放寻址。
|
||||
<!-- Neither of these was good enough to include in the final data, but the code for them is still there. -->
|
||||
这两个都不足以好到可以放在最终的数据里,但是他们的代码仍放在了打包文件里面。
|
||||
<!-- ### [][10]The Results -->
|
||||
### [][10]结果
|
||||
|
||||
<!-- There’s a ton of data here. -->
|
||||
这里有成吨的数据!!
|
||||
<!-- In this section I’ll discuss the results in some detail, but if your eyes are glazing over in this part, feel free to skip down to the conclusions in the next section. -->
|
||||
这一节我将详细的讨论一下结果,但是如果你对此不感兴趣,可以直接跳到下一节的总结。
|
||||
|
||||
### [][11]Windows
|
||||
|
||||
<!-- Here are the graphed results of all the tests, compiled with Visual Studio 2012, and run on Windows 8.1 on a Core i7-4710HQ machine. (Click to zoom.) -->
|
||||
这是所有的测试的图表结果,使用 Visual Studio 2012 编译,运行于 Windows8.1 和 Core i7-4710HQ 机器上。(点击可以放大。)
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
<!-- From left to right are different payload sizes, from top to bottom are the various operations, and each graph plots time in milliseconds versus hash table element count for each of the five implementations. -->
|
||||
从左至右是不同的有效负载大小,从上往下是不同的操作
|
||||
<!-- (Note that not all the Y-axes have the same scale!) I’ll summarize the main trends for each operation. -->
|
||||
(注意:不是所有的Y轴都是相同的比例!)我将为每一个操作总结一下主要趋向。
|
||||
|
||||
**Fill**:
|
||||
<!-- Among my hash tables, chaining is a bit better than any of the OA variants, with the gap widening at larger payloads and table sizes. -->
|
||||
在我的 hash 表中,Ch 稍比任何的 OA 变种要好。随着哈希表大小和有效负载的加大,差距也随之变大。
|
||||
<!-- I guess this is because chaining only has to pull an element off the free list and stick it on the front of its bucket, while OA may have to search a few buckets to find an empty one. -->
|
||||
我猜测这是由于 Ch 只需要从一个空闲链表中拉取一个元素,然后把他放在 bucket 前面,而 OA 不得不搜索一部分 buckets 来找到一个空位置。
|
||||
<!-- The OA variants perform very similarly to each other, but DO1 appears to have a slight advantage. -->
|
||||
所有的 OA 变种的性能表现基本都很相似,当然 DO1 稍微有点优势。
|
||||
|
||||
<!-- All of my hash tables beat UM by quite a bit at small payloads, where UM pays a heavy price for doing a memory allocation on every insert. -->
|
||||
在小负载的情况,UM 几乎是所有 hash 表中表现最差的 —— 因为 UM 为每一次的插入申请(内存)付出了沉重的代价。
|
||||
<!-- But they’re about equal at 128 bytes, and UM wins by quite a bit at large payloads: -->
|
||||
但是在 128 字节的时候,这些 hash 表基本相当,大负载的时候 UM 还赢了点。
|
||||
<!-- there, all of my implementations are hamstrung by the need to resize their element pool and spend a lot of time moving the large elements into the new pool, while UM never needs to move elements once they’re allocated. -->
|
||||
因为,我所有的实现都需要重新调整元素池的大小,并需要移动大量的元素到新池里面,这一点我几乎无能为力;而 UM 一旦为元素申请了内存后便不需要移动了。
|
||||
<!-- Notice the extreme “steppy” look of the graphs for my implementations at large payloads, -->
|
||||
注意大负载中图表上夸张的跳步!
|
||||
<!-- which confirms that the problem comes when resizing. -->
|
||||
这更确认了重新调整大小带来的问题。
|
||||
<!-- In contrast, UM is quite linear—it only has to resize its bucket array, which is cheap enough not to make much of a bump. -->
|
||||
相反,UM 只是线性上升 —— 只需要重新调整 bucket 数组大小。由于没有太多隆起的地方,所以相对有效率。
|
||||
|
||||
**Presized fill**:
|
||||
<!-- Generally similar to Fill, but the graphs are more linear, not steppy (since there’s no rehashing), and there’s less difference between all the implementations. -->
|
||||
大致和 Fill 相似,但是图示结果更加的线性光滑,没有太大的跳步(因为不需要 rehash ),所有的实现差距在这一测试中要缩小了些。
|
||||
<!-- UM is still slightly faster than chaining at large payloads, but only slightly—again confirming that the problem with Fill was the resizing. -->
|
||||
大负载时 UM 依然稍快于 Ch,问题还是在于重新调整大小上。
|
||||
<!-- Chaining is still consistently faster than the OA variants, but DO1 has a slight advantage over the other OAs. -->
|
||||
Ch 仍是稳步少快于 OA 变种,但是 DO1 比其他的 OA 稍有优势。
|
||||
|
||||
**Lookup**:
|
||||
<!-- All the implementations are closely clustered, with UM and DO2 the front-runners, except at the smallest payload, where it seems like DO1 and OL may be faster. -->
|
||||
所有的实现都相当的集中。除了最小负载时,DO1 和 OL 稍快,其余情况下 UM 和 DO2 都跑在了前面。<!--Note: 你确定?-->
|
||||
<!-- It’s impressive how well UM is doing here, actually; -->
|
||||
真的,我无法描述 UM 在这一步做的多么好。
|
||||
<!-- it’s holding its own against the data-oriented variants despite needing to traverse a linked list. -->
|
||||
尽管需要遍历链表,但是 UM 还是坚守了面向数据的本性。
|
||||
|
||||
<!-- Incidentally, it’s interesting to see that the lookup time weakly depends on table size. -->
|
||||
顺带一提,查找时间和 hash 表的大小有着很弱的关联,这真的很有意思。
|
||||
<!-- Hash table lookup is expected constant-time, so from the asymptotic view it shouldn’t depend on table size at all. But that’s ignoring cache effects! -->
|
||||
哈希表查找时间期望上是一个常量时间,所以在的渐进视图中,性能不应该依赖于表的大小。但是那是在忽视了 cache 影响的情况下!
|
||||
<!-- When we do 100K lookups on a 10K-entry table, for instance, we’ll get a speedup because most of the table will be in L3 after the first 10K–20K lookups. -->
|
||||
作为具体的例子,当我们在具有 10 k 条目的表中做 100 k 查找时,速度会便变快,因为在第一次 10 k - 20 k 查找后,大部分的表会处在 L3 中。
|
||||
|
||||
**Failed lookup**:
|
||||
<!-- There’s a bit more spread here than the successful lookups. -->
|
||||
相对于成功查找,这里就有点更分散一些。
|
||||
<!-- DO1 and DO2 are the front-runners, with UM not far behind, and OL a good deal worse than the rest. -->
|
||||
DO1 和 DO2 跑在了前面,但 UM 并没有落下,OL 则是捉襟见肘啊。
|
||||
<!-- My guess is this is probably a case of OL having longer searches on average, especially in the case of a failed lookup; -->
|
||||
我猜测,这可能是因为 OL 整体上具有更长的搜索路径,尤其是在失败查询时;
|
||||
<!-- with the hash values spaced out in memory between keys and values, that hurts. -->
|
||||
内存中,hash 值在 key 和 value 之飘来荡去的找不着出路,我也很受伤啊。
|
||||
<!-- DO1 and DO2 have equally-long searches, but they have all the hash values packed together in memory, and that turns things around. -->
|
||||
DO1 和 DO2 具有相同的搜索长度,但是他们将所有的 hash 值打包在内存中,这使得问题有所缓解。
|
||||
|
||||
**Remove**:
|
||||
<!-- DO2 is the clear winner, with DO1 not far behind, chaining further behind, and UM in a distant last place due to the need to free memory on every remove; -->
|
||||
DO2 很显然是赢家,但 DO1 也未落下。Ch 则落后,UM 则是差的不是一丁半点(主要是因为每次移除都要释放内存);
|
||||
<!-- the gap widens at larger payloads. -->
|
||||
差距随着负载的增加而拉大。
|
||||
<!-- The remove operation is the only one that doesn’t touch the value data, only the hashes and keys, which explains why DO1 and DO2 are differentiated from each other here but pretty much equal in all the other tests. -->
|
||||
移除操作是唯一不需要接触数据的操作,只需要 hash 值和 key 的帮助,这也是为什么 DO1 和 DO2 在移除操作中的表现大相径庭,而其他测试中却保持一致。
|
||||
<!-- (If your value type was non-POD and needed to run a destructor, that difference would presumably disappear.) -->
|
||||
(如果你的值不是 POD 类型的,并需要析构,这种差异应该是会消失的。)
|
||||
|
||||
**Destruct**:
|
||||
<!-- Chaining is the fastest except at the smallest payload, where it’s about equal to the OA variants. -->
|
||||
Ch 除了最小负载,其他的情况都是最快的(最小负载时,约等于 OA 变种)。
|
||||
<!-- All the OA variants are essentially equal. -->
|
||||
所有的 OA 变种基本都是相等的。
|
||||
<!-- Note that for my hash tables, all they’re doing on destruction is freeing a handful of memory buffers, -->
|
||||
注意,在我的 hash 表中所做的所有析构操作都是释放少量的内存 buffer 。
|
||||
<!-- but [on Windows, freeing memory has a cost proportional to the amount allocated][13]. -->
|
||||
但是 [在Windows中,释放内存的消耗和大小成比例关系][13]。
|
||||
<!-- (And it’s a significant cost—an allocation of ~1 GB is taking ~100 ms to free!) -->
|
||||
(而且,这是一个很显著的开支 —— 申请 ~1 GB 的内存需要 ~100 ms 的时间去释放!)
|
||||
|
||||
<!-- UM is the slowest to destruct—by an order of magnitude at small payloads, and only slightly slower at large payloads. -->
|
||||
UM 在析构时是最慢的一个(小负载时,慢的程度可以用数量级来衡量),大负载时依旧是稍慢些。
|
||||
<!-- The need to free each individual element instead of just freeing a couple of arrays really hurts here. -->
|
||||
对于 UM 来讲,释放每一个元素而不是释放一组数组真的是一个硬伤。
|
||||
|
||||
### [][14]Linux
|
||||
|
||||
<!-- I also ran tests with gcc 4.8 and clang 3.5, on Linux Mint 17.1 on a Core i5-4570S machine. The gcc and clang results were very similar, so I’ll only show the gcc ones; the full set of results are in the code download archive, linked above. (Click to zoom.) -->
|
||||
我还在装有 Linux Mint 17.1 的 Core i5-4570S 机器上使用 gcc 4.8 和 clang 3.5 来运行了测试。gcc 和 clang 的结果很相像,因此我只展示了 gcc 的;完整的结果集合包含在了代码下载打包文件中,链接在上面。(点击来缩放)
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
<!-- Most of the results are quite similar to those in Windows, so I’ll just highlight a few interesting differences. -->
|
||||
大部分结果和 Windows 很相似,因此我只高亮了一些有趣的不同点。
|
||||
|
||||
**Lookup**:
|
||||
<!-- Here, DO1 is the front-runner, where DO2 was a bit faster on Windows. -->
|
||||
这里 DO1 跑在前头,而在 Windows 中 DO2 更快些。
|
||||
<!-- Also, UM and chaining are way behind all the other implementations, which is actually what I expected to see in Windows as well, given that they have to do a lot of pointer chasing while the OA variants just stride linearly through memory. --><!-- @error这里原文写错了吧-->
|
||||
同样,UM 和 Ch 落后于其他所有的实现——过多的指针追踪,然而 OA 只需要在内存中线性的移动即可。
|
||||
<!-- It’s not clear to me why the Windows and Linux results are so different here. UM is also a good deal slower than chaining, especially at large payloads, which is odd; I’d expect the two of them to be about equal. -->
|
||||
至于 Windows 和 Linux 结果为何不同,则不是很清楚。UM 同样比 Ch 慢了不少,特别是大负载时,这很奇怪;我期望的是他们可以基本相同。
|
||||
|
||||
**Failed lookup**:
|
||||
<!-- Again, UM is way behind all the others, even slower than OL. -->
|
||||
UM 再一次落后于其他实现,甚至比 OL 还要慢。
|
||||
<!-- Again, it’s puzzling to me why this is so much slower than chaining, and why the results differ so much between Linux and Windows. -->
|
||||
我再一次无法理解为何 UM 比 Ch 慢这么多,Linux 和 Windows 的结果为何有着如此大的差距。
|
||||
|
||||
|
||||
**Destruct**:
|
||||
<!-- For my implementations, the destruct cost was too small to measure at small payloads; -->
|
||||
在我的实现中,小负载的时候,析构的消耗太少了,以至于无法测量;
|
||||
<!-- at large payloads, it grows quite linearly with table size—perhaps proportional to the number of virtual memory pages touched, rather than the number allocated? -->
|
||||
在大负载中,线性增加的比例和创建的虚拟内存页数量相关,而不是申请到的数量?
|
||||
<!-- It’s also orders of magnitude faster than the destruct cost on Windows. -->
|
||||
同样,要比 Windows 中的析构快上几个数量级。
|
||||
<!-- However, this isn’t anything to do with hash tables, really; -->
|
||||
但是并不是所有的都和 hash 表有关;
|
||||
<!-- we’re seeing the behavior of the respective OSes’ and runtimes’ memory systems here. -->
|
||||
我们在这里可以看出不同系统和运行时内存系统的表现。
|
||||
<!-- It seems that Linux frees large blocks memory a lot faster than Windows (or it hides the cost better, perhaps deferring work to process exit, or pushing things off to another thread or process). -->
|
||||
貌似,Linux 释放大内存块是要比 Windows 快上不少(或者 Linux 很好的隐藏了开支,或许将释放工作推迟到了进程退出,又或者将工作推给了其他线程或者进程)。
|
||||
|
||||
<!-- UM with its per-element frees is now orders of magnitude slower than all the others, across all payload sizes. -->
|
||||
UM 由于要释放每一个元素,所以在所有的负载中都比其他慢上几个数量级。
|
||||
<!-- In fact, I cut it from the graphs because it was screwing up the Y-axis scale for all the others. -->
|
||||
事实上,我将图片做了剪裁,因为 UM 太慢了,以至于破坏了 Y 轴的比例。
|
||||
|
||||
<!-- ### [][16]Conclusions -->
|
||||
### [][16]总结
|
||||
|
||||
<!-- Well, after staring at all that data and the conflicting results for all the different cases, what can we conclude? -->
|
||||
好,当我们凝视各种情况下的数据和矛盾的结果时,我们可以得出什么结果呢?
|
||||
<!-- I’d love to be able to tell you unequivocally that one of these hash table variants beats out the others, but of course it’s not that simple. -->
|
||||
我想直接了当的告诉你这些 hash 表变种中有一个打败了其他所有的 hash 表,但是这显然不那么简单。
|
||||
<!-- Still, there is some wisdom we can take away. -->
|
||||
不过我们仍然可以学到一些东西。
|
||||
|
||||
<!-- First, in many cases it’s _easy_ to do better than `std::unordered_map`. -->
|
||||
首先,在大多数情况下我们“很容易”做的比 `std::unordered_map` 还要好。
|
||||
<!-- All of the implementations I built for these tests (and they’re not sophisticated; it only took me a couple hours to write all of them) either matched or improved upon `unordered_map`, -->
|
||||
我为这些测试所写的所有实现(他们并不复杂;我只花了一两个小时就写完了)要么是符合 `unordered_map` 要么是在其基础上做的提高,
|
||||
<!-- except for insertion performance at large payload sizes (over 128 bytes), where `unordered_map`‘s separately-allocated per-node storage becomes advantageous. -->
|
||||
除了大负载(超过128字节)中的插入性能, `unordered_map` 为每一个节点独立申请存储占了优势。
|
||||
<!-- (Though I didn’t test it, I also expect `unordered_map` to win with non-POD payloads that are expensive to move.) -->
|
||||
(尽管我没有测试,我同样期望 `unordered_map` 能在非 POD 类型的负载上取得胜利。)
|
||||
<!-- The moral here is that if you care about performance at all, don’t assume the data structures in your standard library are highly optimized. -->
|
||||
具有指导意义的是,如果你非常关心性能,不要假设你的标准库中的数据结构是高度优化的。
|
||||
<!-- They may be optimized for C++ standard conformance, not performance. :P -->
|
||||
他们可能只是在 C++ 标准的一致性上做了优化,但不是性能。:P
|
||||
|
||||
<!-- Second, you could do a lot worse than to just use DO1 (open addressing, linear probing, with the hashes/states segregated from keys/values in separate flat arrays) whenever you have small, inexpensive payloads. -->
|
||||
其次,如果不管在小负载还是超负载中,若都只用 DO1 (开放寻址,线性探测,hashes/states 和 key/vaules分别处在隔离的平滑数组中),那可能不会有啥好表现。
|
||||
<!-- It’s not the fastest for insertion, but it’s not bad either (still way better than `unordered_map`), and it’s very fast for lookup, removal, and destruction. -->
|
||||
这不是最快的插入,但也不坏(还比 `unordered_map` 快),并且在查找,移除,析构中也很快。
|
||||
<!-- What do you know—“data-oriented design” works! -->
|
||||
你所知道的 —— “面向数据设计”完成了!
|
||||
|
||||
<!-- Note that my test code for these hash tables is far from production-ready—they only support POD types, -->
|
||||
注意,我的为这些哈希表做的测试代码远未能用于生产环境——他们只支持 POD 类型,
|
||||
<!-- don’t have copy constructors and such, don’t check for duplicate keys, etc. -->
|
||||
没有拷贝构造函数以及类似的东西,也未检测重复的 key,等等。
|
||||
<!-- I’ll probably build some more realistic hash tables for my utility library soon, though. -->
|
||||
我将可能尽快的构建一些实际的 hash 表,用于我的实用库中。
|
||||
<!-- To cover the bases, I think I’ll want two variants: one based on DO1, for small, cheap-to-move payloads, and another that uses chaining and avoids ever reallocating and moving elements (like `unordered_map`) for large or expensive-to-move payloads. -->
|
||||
为了覆盖基础部分,我想我将有两个变种:一个基于 DO1,用于小的,移动时不需要太大开支的负载;另一个用于链接并且避免重新申请和移动元素(就像 `unordered_map` ),用于大负载或者移动起来需要大开支的负载情况。
|
||||
<!-- That should give me the best of both worlds. -->
|
||||
这应该会给我带来最好的两个世界。
|
||||
|
||||
<!-- In the meantime, I hope this has been illuminating. -->
|
||||
与此同时,我希望你们会有所启迪。
|
||||
<!-- And remember, if Chandler Carruth and Mike Acton give you advice about data structures, listen to them. 😉 -->
|
||||
最后记住,如果 Chandler Carruth 和 Mike Acton 在数据结构上给你提出些建议,你一定要听 😉
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
<!-- I’m a graphics programmer, currently freelancing in Seattle. Previously I worked at NVIDIA on the DevTech software team, and at Sucker Punch Productions developing rendering technology for the Infamous series of games for PS3 and PS4. -->
|
||||
我是一名图形程序员,目前在西雅图做自由职业者。之前我在 NVIDIA 的 DevTech 软件团队中工作,并在美少女特工队工作室中为 PS3 和 PS4 的 Infamous 系列游戏开发渲染技术。
|
||||
|
||||
<!-- I’ve been interested in graphics since about 2002 and have worked on a variety of assignments, including fog, atmospheric haze, volumetric lighting, water, visual effects, particle systems, skin and hair shading, postprocessing, specular models, linear-space rendering, and GPU performance measurement and optimization. -->
|
||||
自 2002 年起,我对图形非常感兴趣,并且已经完成了一系列的工作,包括:雾、大气雾霾、体积照明、水、视觉效果、粒子系统、皮肤和头发阴影、后处理、镜面模型、线性空间渲染、和 GPU 性能测量和优化。
|
||||
|
||||
<!-- You can read about what I’m up to on my blog. In addition to graphics, I’m interested in theoretical physics, and in programming language design. -->
|
||||
你可以在我的博客了解更多和我有关的事,处理图形,我还对理论物理和程序设计感兴趣。
|
||||
|
||||
<!-- You can contact me at nathaniel dot reed at gmail dot com, or follow me on Twitter (@Reedbeta) or Google+. I can also often be found answering questions at Computer Graphics StackExchange. -->
|
||||
你可以在 nathaniel.reed@gmail.com 或者在 Twitter(@Reedbeta)/Google+ 上关注我。我也会经常在 StackExchange 上回答计算机图形的问题。
|
||||
|
||||
--------------
|
||||
|
||||
via: http://reedbeta.com/blog/data-oriented-hash-table/
|
||||
|
||||
作者:[Nathan Reed][a]
|
||||
译者:[sanfusu](https://github.com/sanfusu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://reedbeta.com/about/
|
||||
[1]:http://reedbeta.com/blog/data-oriented-hash-table/
|
||||
[2]:http://reedbeta.com/blog/category/coding/
|
||||
[3]:http://reedbeta.com/blog/data-oriented-hash-table/#comments
|
||||
[4]:http://baptiste-wicht.com/posts/2012/12/cpp-benchmark-vector-list-deque.html
|
||||
[5]:https://www.youtube.com/watch?v=fHNmRkzxHWs
|
||||
[6]:https://www.youtube.com/watch?v=rX0ItVEVjHc
|
||||
[7]:http://reedbeta.com/blog/data-oriented-hash-table/#the-tests
|
||||
[8]:http://burtleburtle.net/bob/hash/spooky.html
|
||||
[9]:http://reedbeta.com/blog/data-oriented-hash-table/hash-table-tests.zip
|
||||
[10]:http://reedbeta.com/blog/data-oriented-hash-table/#the-results
|
||||
[11]:http://reedbeta.com/blog/data-oriented-hash-table/#windows
|
||||
[12]:http://reedbeta.com/blog/data-oriented-hash-table/results-vs2012.png
|
||||
[13]:https://randomascii.wordpress.com/2014/12/10/hidden-costs-of-memory-allocation/
|
||||
[14]:http://reedbeta.com/blog/data-oriented-hash-table/#linux
|
||||
[15]:http://reedbeta.com/blog/data-oriented-hash-table/results-g++4.8.png
|
||||
[16]:http://reedbeta.com/blog/data-oriented-hash-table/#conclusions
|
||||
Loading…
Reference in New Issue
Block a user