mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
commit
e16909c329
@ -2,13 +2,13 @@ Ubuntu中跟踪多个时区的简捷方法
|
||||
================================================================================
|
||||

|
||||
|
||||
**我是否要确保在我醒来时或者安排与*山姆陈*,Ohso的半个开发商,进行Skype通话时,澳大利亚一个关于Chromebook销售的推特已经售罄,我大脑同时在多个时区下工作。**
|
||||
**无论我是要在醒来时发个关于澳大利亚的 Chromebook 销售已经售罄的推特,还是要记着和Ohso的半个开发商山姆陈进行Skype通话,我大脑都需要同时工作在多个时区下。**
|
||||
|
||||
那里头有个问题,如果你认识我,你会知道我的脑容量也就那么丁点,跟金鱼差不多,里头却塞着像Windows Vista这样一个臃肿货(也就是,不是很好)。我几乎记不得昨天之前的事情,更记不得我的门和金门大桥脚之间的时间差!
|
||||
|
||||
作为臂助,我使用一些小部件和菜单项来让我保持同步。在我常规工作日的空间里,我在多个操作系统间游弋,涵盖移动系统和桌面系统,但只有一个让我最快速便捷地设置“世界时钟”。
|
||||
作为臂助,我使用一些小部件和菜单项来让我保持同步。在我常规工作日的空间里,我在多个操作系统间游弋,涵盖移动系统和桌面系统,但只有一个可以让我最快速便捷地设置“世界时钟”。
|
||||
|
||||
**而它刚好是那个名字放在门上方的东西。**
|
||||
**它的名字就是我们标题上提到的那个。**
|
||||
|
||||

|
||||
|
||||
@ -16,10 +16,10 @@ Ubuntu中跟踪多个时区的简捷方法
|
||||
|
||||
Unity中默认的日期-时间指示器提供了添加并查看多个时区的支持,不需要附加组件,不需要额外的包。
|
||||
|
||||
1. 点击时钟小应用,然后uxuanze‘**时间和日期设置**’条目
|
||||
1. 点击时钟小应用,然后选择‘**时间和日期设置**’条目
|
||||
1. 在‘**时钟**’标签中,选中‘**其它位置的时间**’选框
|
||||
1. 点击‘**选择位置**’按钮
|
||||
1. 点击‘**+**’,然后输入位置名称那个
|
||||
1. 点击‘**+**’,然后输入位置名称
|
||||
|
||||
#### 其它桌面环境 ####
|
||||
|
||||
@ -34,13 +34,13 @@ Unity中默认的日期-时间指示器提供了添加并查看多个时区的
|
||||
|
||||

|
||||
|
||||
Cinnamon 2.4中的世界时钟日历
|
||||
*Cinnamon 2.4中的世界时钟日历*
|
||||
|
||||
**XFCE**和**LXDE**就不那么慷慨了,除了自带的“工作区”作为**多个时钟**添加到面板外,每个都需要手动配置以指定位置。两个都支持‘指示器小部件’,所以,如果你没有依赖于Unity,你可以安装/添加单独的日期/时间指示器。
|
||||
**XFCE**和**LXDE**就不那么慷慨了,除了自带的“工作区”作为**多个时钟**添加到面板外,每个都需要手动配置以指定位置。两个都支持‘指示器小部件’,所以,如果你不用Unity的话,你可以安装/添加单独的日期/时间指示器。
|
||||
|
||||
**Budgie**还刚初出茅庐,不足以胜任角落里的需求,因为Pantheon我还没试过——希望你们通过评论来让我知道得更多。
|
||||
**Budgie**还刚初出茅庐,不足以胜任这种角落里的需求,因为Pantheon我还没试过——希望你们通过评论来让我知道得更多。
|
||||
|
||||
#### Desktop Apps, Widgets & Conky Themes桌面应用、不见和Conky主题 ####
|
||||
#### 桌面应用、部件和Conky主题 ####
|
||||
|
||||
当然,面板小部件只是收纳其它国家多个时区的一种方式。如果你不满意通过面板去访问,那里还有各种各样的**桌面应用**可供使用,其中许多都可以跨版本,甚至跨平台使用。
|
||||
|
||||
@ -54,7 +54,7 @@ via: http://www.omgubuntu.co.uk/2014/12/add-time-zones-world-clock-ubuntu
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
CentOS上配置rsyslog客户端用以远程记录日志
|
||||
================================================================================
|
||||
**rsyslog**是一个开源工具,被广泛用于Linux系统以通过TCP/UDP协议转发或接收日志消息。rsyslog守护进程可以被配置称两种环境,一种是配置成日志收集服务器,rsyslog进程可以从网络中收集所有其它主机上的日志数据,这些主机已经将日志配置为发送到服务器。rsyslog的另外一个角色,就是可以配置为客户端,用来过滤和发送内部日志消息到本地文件夹(如/var/log)或一台可以路由到的远程rsyslog服务器上。
|
||||
**rsyslog**是一个开源工具,被广泛用于Linux系统以通过TCP/UDP协议转发或接收日志消息。rsyslog守护进程可以被配置成两种环境,一种是配置成日志收集服务器,rsyslog进程可以从网络中收集其它主机上的日志数据,这些主机会将日志配置为发送到另外的远程服务器。rsyslog的另外一个用法,就是可以配置为客户端,用来过滤和发送内部日志消息到本地文件夹(如/var/log)或一台可以路由到的远程rsyslog服务器上。
|
||||
|
||||
假定你的网络中已经有一台rsyslog服务器[已经起来并且处于运行中][1],本指南将为你展示如何来设置CentOS系统将其内部日志消息路由到一台远程rsyslog服务器上。这将大大改善你的系统磁盘空间的使用,尤其是你还没有一个独立的用于/var目录的大分区。
|
||||
假定你的网络中已经有一台[已经配置好并启动的][1]rsyslog服务器,本指南将为你展示如何来设置CentOS系统将其内部日志消息路由到一台远程rsyslog服务器上。这将大大改善你的系统磁盘空间的使用,尤其是当你还没有一个用于/var目录的独立的大分区。
|
||||
|
||||
### 步骤一: 安装Rsyslog守护进程 ###
|
||||
|
||||
@ -35,9 +35,9 @@ CentOS上配置rsyslog客户端用以远程记录日志
|
||||
|
||||
*.* @@192.168.1.25:514
|
||||
|
||||
注意,你也可以将rsyslog服务器的IP地址替换成它的DNS名称(FQDN)。
|
||||
注意,你也可以将rsyslog服务器的IP地址替换成它的主机名(FQDN)。
|
||||
|
||||
如果你只想要转发指定设备的日志消息,比如说内核设备,那么你可以在rsyslog配置文件中使用以下声明。
|
||||
如果你只想要转发服务器上的指定设备的日志消息,比如说内核设备,那么你可以在rsyslog配置文件中使用以下声明。
|
||||
|
||||
kern.* @192.168.1.25:514
|
||||
|
||||
@ -51,9 +51,11 @@ CentOS上配置rsyslog客户端用以远程记录日志
|
||||
|
||||
# service rsyslog restart
|
||||
|
||||
在另外一种环境中,让我们假定你已经在机器上安装了一个名为“foobar”的应用程序,它会在/var/log下生成foobar.log日志文件。现在,你只想要将它的日志定向到rsyslog服务器,这可以通过像下面这样在rsyslog配置文件中加载imfile模块来实现。
|
||||
####非 syslog 日志的转发
|
||||
|
||||
首先,加载imfile模块,这必须只做一次。
|
||||
在另外一种环境中,让我们假定你已经在机器上安装了一个名为“foobar”的应用程序,它会在/var/log下生成foobar.log日志文件。现在,你想要将它的日志定向到rsyslog服务器,这可以通过像下面这样在rsyslog配置文件中加载imfile模块来实现。
|
||||
|
||||
首先,加载imfile模块,这只需做一次。
|
||||
|
||||
module(load="imfile" PollingInterval="5")
|
||||
|
||||
@ -73,8 +75,7 @@ CentOS上配置rsyslog客户端用以远程记录日志
|
||||
|
||||
### 步骤三: 让Rsyslog进程自动启动 ###
|
||||
|
||||
To automatically start rsyslog client after every system reboot, run the following command to enable it system-wide:
|
||||
要让rsyslog客户端在每次系统重启后自动启动,请运行以下命令来在系统范围启用:
|
||||
要让rsyslog客户端在每次系统重启后自动启动,请运行以下命令:
|
||||
|
||||
**CentOS 7:**
|
||||
|
||||
@ -86,7 +87,7 @@ To automatically start rsyslog client after every system reboot, run the followi
|
||||
|
||||
### 小结 ###
|
||||
|
||||
在本教程中,我演示了如何将CentOS系统转变成rsyslog客户端以强制它发送日志消息到远程rsyslog服务器。这里我假定rsyslog客户端和服务器之间的连接是安全的(如,在有防火墙保护的公司网络中)。不管在任何情况下,都不要配置rsyslog客户端将日志消息通过不安全的网络转发,或者,特别是通过互联网转发,因为syslog协议是一个明文协议。要进行安全传输,可以考虑使用[TLS/SSL][2]来加密日志消息。
|
||||
在本教程中,我演示了如何将CentOS系统转变成rsyslog客户端以强制它发送日志消息到远程rsyslog服务器。这里我假定rsyslog客户端和服务器之间的连接是安全的(如,在有防火墙保护的公司网络中)。不管在任何情况下,都不要配置rsyslog客户端将日志消息通过不安全的网络转发,或者,特别是通过互联网转发,因为syslog协议是一个明文协议。要进行安全传输,可以考虑使用[TLS/SSL][2]来加密日志消息的传输。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -94,7 +95,7 @@ via: http://xmodulo.com/configure-rsyslog-client-centos.html
|
||||
|
||||
作者:[Caezsar M][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,143 @@
|
||||
20条Linux命令面试问答
|
||||
================================================================================
|
||||
**问:1 如何查看当前的Linux服务器的运行级别?**
|
||||
|
||||
答: ‘who -r’ 和 ‘runlevel’ 命令可以用来查看当前的Linux服务器的运行级别。
|
||||
|
||||
**问:2 如何查看Linux的默认网关?**
|
||||
|
||||
答: 用 “route -n” 和 “netstat -nr” 命令,我们可以查看默认网关。除了默认的网关信息,这两个命令还可以显示当前的路由表。
|
||||
|
||||
**问:3 如何在Linux上重建初始化内存盘镜像文件?**
|
||||
|
||||
答: 在CentOS 5.X / RHEL 5.X中,可以用mkinitrd命令来创建初始化内存盘文件,举例如下:
|
||||
|
||||
# mkinitrd -f -v /boot/initrd-$(uname -r).img $(uname -r)
|
||||
|
||||
如果你想要给特定的内核版本创建初始化内存盘,你就用所需的内核名替换掉 ‘uname -r’ 。
|
||||
|
||||
在CentOS 6.X / RHEL 6.X中,则用dracut命令来创建初始化内存盘文件,举例如下:
|
||||
|
||||
# dracut -f
|
||||
|
||||
以上命令能给当前的系统版本创建初始化内存盘,给特定的内核版本重建初始化内存盘文件则使用以下命令:
|
||||
|
||||
# dracut -f initramfs-2.x.xx-xx.el6.x86_64.img 2.x.xx-xx.el6.x86_64
|
||||
|
||||
**问:4 cpio命令是什么?**
|
||||
|
||||
答: cpio就是复制入和复制出的意思。cpio可以向一个归档文件(或单个文件)复制文件、列表,还可以从中提取文件。
|
||||
|
||||
**问:5 patch命令是什么?如何使用?**
|
||||
|
||||
答: 顾名思义,patch命令就是用来将修改(或补丁)写进文本文件里。patch命令通常是接收diff的输出并把文件的旧版本转换为新版本。举个例子,Linux内核源代码由百万行代码文件构成,所以无论何时,任何代码贡献者贡献出代码,只需发送改动的部分而不是整个源代码,然后接收者用patch命令将改动写进原始的源代码里。
|
||||
|
||||
创建一个diff文件给patch使用,
|
||||
|
||||
# diff -Naur old_file new_file > diff_file
|
||||
|
||||
旧文件和新文件要么都是单个的文件要么都是包含文件的目录,-r参数支持目录树递归。
|
||||
|
||||
一旦diff文件创建好,我们就能在旧的文件上打上补丁,把它变成新文件:
|
||||
|
||||
# patch < diff_file
|
||||
|
||||
**问:6 aspell有什么用 ?**
|
||||
|
||||
答: 顾名思义,aspell就是Linux操作系统上的一款交互式拼写检查器。aspell命令继任了更早的一个名为ispell的程序,并且作为一款免费替代品 ,最重要的是它非常好用。当aspell程序主要被其它一些需要拼写检查能力的程序所使用的时候,在命令行中作为一个独立运行的工具的它也能十分有效。
|
||||
|
||||
**问:7 如何从命令行查看域SPF记录?**
|
||||
|
||||
答: 我们可以用dig命令来查看域SPF记录。举例如下:
|
||||
|
||||
linuxtechi@localhost:~$ dig -t TXT google.com
|
||||
|
||||
**问:8 如何识别Linux系统中指定文件(/etc/fstab)的关联包?**
|
||||
|
||||
答: # rpm -qf /etc/fstab
|
||||
|
||||
以上命令能列出提供“/etc/fstab”这个文件的包。
|
||||
|
||||
**问:9 哪条命令用来查看bond0的状态?**
|
||||
|
||||
答: cat /proc/net/bonding/bond0
|
||||
|
||||
**问:10 Linux系统中的/proc文件系统有什么用?**
|
||||
|
||||
答: /proc文件系统是一个基于内存的文件系统,其维护着关于当前正在运行的内核状态信息,其中包括CPU、内存、分区划分、I/O地址、直接内存访问通道和正在运行的进程。这个文件系统所代表的并不是各种实际存储信息的文件,它们指向的是内存里的信息。/proc文件系统是由系统自动维护的。
|
||||
|
||||
**问:11 如何在/usr目录下找出大小超过10MB的文件?**
|
||||
|
||||
答: # find /usr -size +10M
|
||||
|
||||
**问:12 如何在/home目录下找出120天之前被修改过的文件?**
|
||||
|
||||
答: # find /home -mtime +120
|
||||
|
||||
**问:13 如何在/var目录下找出90天之内未被访问过的文件?**
|
||||
|
||||
答: # find /var \\! -atime -90
|
||||
|
||||
**问:14 在整个目录树下查找文件“core”,如发现则无需提示直接删除它们。**
|
||||
|
||||
答: # find / -name core -exec rm {} \;
|
||||
|
||||
**问:15 strings命令有什么作用?**
|
||||
|
||||
答: strings命令用来提取和显示非文本文件中的文本字符串。(LCTT 译注:当用来分析你系统上莫名其妙出现的二进制程序时,可以从中找到可疑的文件访问,对于追查入侵有用处)
|
||||
|
||||
**问:16 tee 过滤器有什么作用 ?**
|
||||
|
||||
答: tee 过滤器用来向多个目标发送输出内容。如果用于管道的话,它可以将输出复制一份到一个文件,并复制另外一份到屏幕上(或一些其它程序)。
|
||||
|
||||
linuxtechi@localhost:~$ ll /etc | nl | tee /tmp/ll.out
|
||||
|
||||
在以上例子中,从ll输出可以捕获到 /tmp/ll.out 文件中,并且同样在屏幕上显示了出来。
|
||||
|
||||
**问:17 export PS1 = ”$LOGNAME@`hostname`:\$PWD: 这条命令是在做什么?**
|
||||
|
||||
答: 这条export命令会更改登录提示符来显示用户名、本机名和当前工作目录。
|
||||
|
||||
**问:18 ll | awk ‘{print $3,”owns”,$9}’ 这条命令是在做什么?**
|
||||
|
||||
答: 这条ll命令会显示这些文件的文件名和它们的拥有者。
|
||||
|
||||
**问:19 :Linux中的at命令有什么用?**
|
||||
|
||||
答: at命令用来安排一个程序在未来的做一次一次性执行。所有提交的任务都被放在 /var/spool/at 目录下并且到了执行时间的时候通过atd守护进程来执行。
|
||||
|
||||
**问:20 linux中lspci命令的作用是什么?**
|
||||
|
||||
答: lspci命令用来显示你的系统上PCI总线和附加设备的信息。指定-v,-vv或-vvv来获取越来越详细的输出,加上-r参数的话,命令的输出则会更具有易读性。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/20-linux-commands-interview-questions-answers/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
[1]:
|
||||
[2]:
|
||||
[3]:
|
||||
[4]:
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
@ -1,13 +1,11 @@
|
||||
Linux有问必答 - linux如何安装WPS
|
||||
Linux有问必答 - 如何在linux上安装WPS
|
||||
================================================================================
|
||||
> **问题**: 我听说一个好东西Kingsoft Office(译注:就是WPS),所以我想在我的Linux上试试。我怎样才能安装Kingsoft Office呢?
|
||||
|
||||
Kingsoft Office 一套办公套件,支持多个平台,包括Windows, Linux, iOS 和 Android。它包含三个组件:Writer(WPS文字)用来文字处理,Presentation(WPS演示)支持幻灯片,Spereadsheets(WPS表格)为电子表格。使用免费增值模式,其中基础版本是免费使用。比较其他的linux办公套件,如LibreOffice、 OpenOffice,最大优势在于,Kingsoft Office能最好的兼容微软的Office(译注:版权问题?了解下wps和Office的历史问题,可以得到一些结论)。因此如果你需要在windowns和linux平台间交互,Kingsoft office是一个很好的选择。
|
||||
|
||||
Kingsoft Office 是一套办公套件,支持多个平台,包括Windows, Linux, iOS 和 Android。它包含三个组件:Writer(WPS文字)用来文字处理,Presentation(WPS演示)支持幻灯片,Spereadsheets(WPS表格)是电子表格。其使用免费增值模式,其中基础版本是免费使用。比较其他的linux办公套件,如LibreOffice、 OpenOffice,其最大优势在于,Kingsoft Office能最好的兼容微软的Office(译注:版权问题?了解下wps和Office的历史问题,可以得到一些结论)。因此如果你需要在windows和linux平台间交互,Kingsoft office是一个很好的选择。
|
||||
|
||||
### CentOS, Fedora 或 RHEL中安装Kingsoft Office ###
|
||||
|
||||
|
||||
在[官方页面][1]下载RPM文件.官方RPM包只支持32位版本linux,但是你可以在64位中安装。
|
||||
|
||||
需要使用yum命令并用"localinstall"选项来本地安装这个RPM包
|
||||
@ -39,7 +37,7 @@ DEB包同样遇到一堆依赖。因此使用[gdebi][3]命令来代替dpkg来自
|
||||
|
||||
### 启动 Kingsoft Office ###
|
||||
|
||||
安装完成后,你就可以在桌面管理器轻松启动Witer(WPS文字), Presentation(WPS演示), and Spreadsheets(WPS表格),如下图
|
||||
安装完成后,你就可以在桌面管理器轻松启动Witer(WPS文字), Presentation(WPS演示), and Spreadsheets(WPS表格),如下图。
|
||||
|
||||
Ubuntu Unity中:
|
||||
|
||||
@ -49,7 +47,7 @@ GNOME桌面中:
|
||||
|
||||
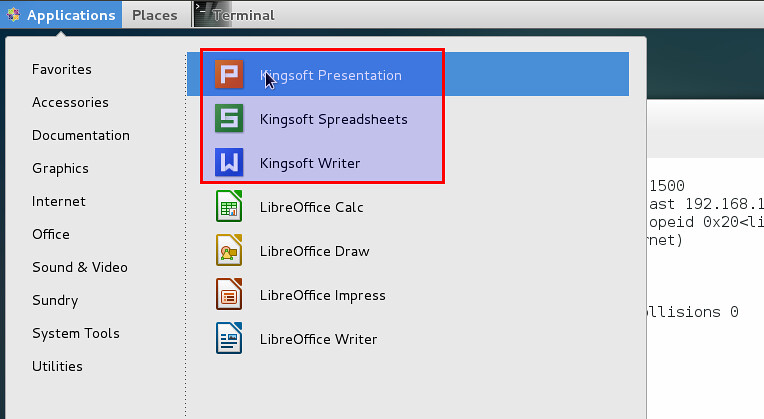
|
||||
|
||||
不但如此,你也可以在命令行中启动Kingsoft Office
|
||||
不但如此,你也可以在命令行中启动Kingsoft Office。
|
||||
|
||||
启动Wirter(WPS文字),使用这个命令:
|
||||
|
||||
@ -74,7 +72,7 @@ GNOME桌面中:
|
||||
via: http://ask.xmodulo.com/install-kingsoft-office-linux.html
|
||||
|
||||
译者:[Vic020/VicYu](http://www.vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -2,9 +2,9 @@
|
||||
================================================================================
|
||||

|
||||
|
||||
当你想重装Ubuntu或者仅仅是想安装它的一个新版本的时候,寻到一个便捷的方法去重新安装之前的应用并且重置其设置是很有用的。此时 *Aptik* 粉墨登场,它可以帮助你轻松实现。
|
||||
当你想重装Ubuntu或者仅仅是想安装它的一个新版本的时候,如果有个便捷的方法来重新安装之前的应用并且重置其设置会很方便的。此时 *Aptik* 粉墨登场,它可以帮助你轻松实现。
|
||||
|
||||
Aptik(自动包备份和回复)是一个可以用在Ubuntu,Linux Mint, 和其他基于Debian以及Ubuntu的Linux发行版上的应用,它允许你将已经安装过的包括软件库、下载包、安装的应用及其主题和设置在内的PPAs(个人软件包存档)备份到外部的U盘、网络存储或者类似于Dropbox的云服务上。
|
||||
Aptik(自动包备份和恢复)是一个可以用在Ubuntu,Linux Mint 和其他基于Debian以及Ubuntu的Linux发行版上的应用,它允许你将已经安装过的包括软件库、下载包、安装的应用和主题、用户设置在内的PPAs(个人软件包存档)备份到外部的U盘、网络存储或者类似于Dropbox的云服务上。
|
||||
|
||||
注意:当我们在此文章中说到输入某些东西的时候,如果被输入的内容被引号包裹,请不要将引号一起输入进去,除非我们有特殊说明。
|
||||
|
||||
@ -16,7 +16,7 @@ Aptik(自动包备份和回复)是一个可以用在Ubuntu,Linux Mint, 和
|
||||
|
||||

|
||||
|
||||
输入下边的命令到提示符旁边,来确保资源库已经是最新版本。
|
||||
在命令行提示符输入下边的命令,来确保资源库已经是最新版本。
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
@ -86,11 +86,11 @@ Aptik的主窗口显示出来了。从“Backup Directory”下拉列表中选
|
||||
|
||||
接下来,“Downloaded Packages (APT Cache)”的项目只对重装同样版本的Ubuntu有用处。它会备份下你系统缓存(/var/cache/apt/archives)中的包。如果你是升级系统的话,可以跳过这个条目,因为针对新系统的包会比现有系统缓存中的包更加新一些。
|
||||
|
||||
备份和回复下载过的包,这可以在重装Ubuntu,并且重装包的时候节省时间和网络带宽。因为一旦你把这些包恢复到系统缓存中之后,他们可以重新被利用起来,这样下载过程就免了,包的安装会更加快捷。
|
||||
备份和恢复下载过的包,这可以在重装Ubuntu,并且重装包的时候节省时间和网络带宽。因为一旦你把这些包恢复到系统缓存中之后,他们可以重新被利用起来,这样下载过程就免了,包的安装会更加快捷。
|
||||
|
||||
如果你是重装相同版本的Ubuntu系统的话,点击 “Downloaded Packages (APT Cache)” 右侧的 “Backup” 按钮来备份系统缓存中的包。
|
||||
|
||||
注意:当你备份下载过的包的时候是没有二级对话框出现。你系统缓存 (/var/cache/apt/archives) 中的包会被拷贝到备份目录下一个名叫 “archives” 的文件夹中,当整个过程完成后会出现一个对话框来告诉你备份已经完成。
|
||||
注意:当你备份下载过的包的时候是没有二级对话框出现的。你系统缓存 (/var/cache/apt/archives) 中的包会被拷贝到备份目录下一个名叫 “archives” 的文件夹中,当整个过程完成后会出现一个对话框来告诉你备份已经完成。
|
||||
|
||||

|
||||
|
||||
@ -104,7 +104,7 @@ Aptik的主窗口显示出来了。从“Backup Directory”下拉列表中选
|
||||
|
||||

|
||||
|
||||
名为 “packages.list” and “packages-installed.list” 的两个文件出现在了备份目录中,并且一个用来通知你备份完成的对话框出现。点击 ”OK“关闭它。
|
||||
备份目录中出现了两个名为 “packages.list” 和“packages-installed.list” 的文件,并且会弹出一个通知你备份完成的对话框。点击 ”OK“关闭它。
|
||||
|
||||
注意:“packages-installed.list”文件包含了所有的包,而 “packages.list” 在包含了所有包的前提下还指出了那些包被选择上了。
|
||||
|
||||
@ -120,27 +120,27 @@ Aptik的主窗口显示出来了。从“Backup Directory”下拉列表中选
|
||||
|
||||

|
||||
|
||||
当打包完成后,打包后的文件被拷贝到备份目录下,另外一个备份成功的对话框出现。点击”OK“,关掉。
|
||||
当打包完成后,打包后的文件被拷贝到备份目录下,另外一个备份成功的对话框出现。点击“OK”关掉。
|
||||
|
||||

|
||||
|
||||
来自 “/usr/share/themes” 目录的主题和来自 “/usr/share/icons” 目录的图标也可以备份。点击 “Themes and Icons” 右侧的 “Backup” 来进行此操作。“Backup Themes” 对话框默认选择了所有的主题和图标。你可以安装需要取消到一些然后点击 “Backup” 进行备份。
|
||||
放在 “/usr/share/themes” 目录的主题和放在 “/usr/share/icons” 目录的图标也可以备份。点击 “Themes and Icons” 右侧的 “Backup” 来进行此操作。“Backup Themes” 对话框默认选择了所有的主题和图标。你可以安装需要的、取消一些不要的,然后点击 “Backup” 进行备份。
|
||||
|
||||

|
||||
|
||||
主题被打包拷贝到备份目录下的 “themes” 文件夹中,图标被打包拷贝到备份目录下的 “icons” 文件夹中。然后成功提示对话框出现,点击”OK“关闭它。
|
||||
主题被打包拷贝到备份目录下的 “themes” 文件夹中,图标被打包拷贝到备份目录下的 “icons” 文件夹中。然后成功提示对话框出现,点击“OK”关闭它。
|
||||
|
||||

|
||||
|
||||
一旦你完成了需要的备份,点击主界面左上角的”X“关闭 Aptik 。
|
||||
一旦你完成了需要的备份,点击主界面左上角的“X”关闭 Aptik 。
|
||||
|
||||

|
||||
|
||||
备份过的文件已存在于你选择的备份目录中,可以随时取阅。
|
||||
备份过的文件已存在于你选择的备份目录中,可以随时查看。
|
||||
|
||||

|
||||
|
||||
当你重装Ubuntu或者安装新版本的Ubuntu后,在新的系统中安装 Aptik 并且将备份好的文件置于新系统中让其可被使用。运行 Aptik,并使用每个条目的 “Restore” 按钮来恢复你的软件源、应用、包、设置、主题以及图标。
|
||||
当你重装Ubuntu或者安装新版本的Ubuntu后,在新的系统中安装 Aptik 并且将备份好的文件置于新系统中使用。运行 Aptik,并使用每个条目的 “Restore” 按钮来恢复你的软件源、应用、包、设置、主题以及图标。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -148,7 +148,7 @@ via: http://www.howtogeek.com/206454/how-to-backup-and-restore-your-apps-and-ppa
|
||||
|
||||
作者:Lori Kaufman
|
||||
译者:[Ping](https://github.com/mr-ping)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,18 +1,17 @@
|
||||
如何在 Linux 上使用 HAProxy 配置 HTTP 负载均衡器
|
||||
使用 HAProxy 配置 HTTP 负载均衡器
|
||||
================================================================================
|
||||
随着基于 Web 的应用和服务的增多,IT 系统管理员肩上的责任也越来越重。当遇到不可预期的事件如流量达到高峰,流量增大或者内部的挑战比如硬件的损坏或紧急维修,无论如何,你的 Web 应用都必须要保持可用性。甚至现在流行的 devops 和持续交付也可能威胁到你的 Web 服务的可靠性和性能的一致性。
|
||||
随着基于 Web 的应用和服务的增多,IT 系统管理员肩上的责任也越来越重。当遇到不可预期的事件如流量达到高峰,流量增大或者内部的挑战比如硬件的损坏或紧急维修,无论如何,你的 Web 应用都必须要保持可用性。甚至现在流行的 devops 和持续交付(CD)也可能威胁到你的 Web 服务的可靠性和性能的一致性。
|
||||
|
||||
不可预测,不一直的性能表现是你无法接受的。但是我们怎样消除这些缺点呢?大多数情况下一个合适的负载均衡解决方案可以解决这个问题。今天我会给你们介绍如何使用 [HAProxy][1] 配置 HTTP 负载均衡器。
|
||||
不可预测,不一致的性能表现是你无法接受的。但是我们怎样消除这些缺点呢?大多数情况下一个合适的负载均衡解决方案可以解决这个问题。今天我会给你们介绍如何使用 [HAProxy][1] 配置 HTTP 负载均衡器。
|
||||
|
||||
###什么是 HTTP 负载均衡? ###
|
||||
|
||||
HTTP 负载均衡是一个网络解决方案,它将发入的 HTTP 或 HTTPs 请求分配至一组提供相同的 Web 应用内容的服务器用于响应。通过将请求在这样的多个服务器间进行均衡,负载均衡器可以防止服务器出现单点故障,可以提升整体的可用性和响应速度。它还可以让你能够简单的通过添加或者移除服务器来进行横向扩展或收缩,对工作负载进行调整。
|
||||
HTTP 负载均衡是一个网络解决方案,它将进入的 HTTP 或 HTTPs 请求分配至一组提供相同的 Web 应用内容的服务器用于响应。通过将请求在这样的多个服务器间进行均衡,负载均衡器可以防止服务器出现单点故障,可以提升整体的可用性和响应速度。它还可以让你能够简单的通过添加或者移除服务器来进行横向扩展或收缩,对工作负载进行调整。
|
||||
|
||||
### 什么时候,什么情况下需要使用负载均衡? ###
|
||||
|
||||
负载均衡可以提升服务器的使用性能和最大可用性,当你的服务器开始出现高负载时就可以使用负载均衡。或者你在为一个大型项目设计架构时,在前端使用负载均衡是一个很好的习惯。当你的环境需要扩展的时候它会很有用。
|
||||
|
||||
|
||||
### 什么是 HAProxy? ###
|
||||
|
||||
HAProxy 是一个流行的开源的 GNU/Linux 平台下的 TCP/HTTP 服务器的负载均衡和代理软件。HAProxy 是单线程,事件驱动架构,可以轻松的处理 [10 Gbps 速率][2] 的流量,在生产环境中被广泛的使用。它的功能包括自动健康状态检查,自定义负载均衡算法,HTTPS/SSL 支持,会话速率限制等等。
|
||||
@ -24,13 +23,13 @@ HAProxy 是一个流行的开源的 GNU/Linux 平台下的 TCP/HTTP 服务器的
|
||||
### 准备条件 ###
|
||||
|
||||
你至少要有一台,或者最好是两台 Web 服务器来验证你的负载均衡的功能。我们假设后端的 HTTP Web 服务器已经配置好并[可以运行][3]。
|
||||
You will need at least one, or preferably two web servers to verify functionality of your load balancer. We assume that backend HTTP web servers are already [up and running][3].
|
||||
|
||||
|
||||
### 在 Linux 中安装 HAProxy ###
|
||||
## 在 Linux 中安装 HAProxy ##
|
||||
|
||||
对于大多数的发行版,我们可以使用发行版的包管理器来安装 HAProxy。
|
||||
|
||||
#### 在 Debian 中安装 HAProxy ####
|
||||
### 在 Debian 中安装 HAProxy ###
|
||||
|
||||
在 Debian Wheezy 中我们需要添加源,在 /etc/apt/sources.list.d 下创建一个文件 "backports.list" ,写入下面的内容
|
||||
|
||||
@ -41,25 +40,25 @@ You will need at least one, or preferably two web servers to verify functionalit
|
||||
# apt get update
|
||||
# apt get install haproxy
|
||||
|
||||
#### 在 Ubuntu 中安装 HAProxy ####
|
||||
### 在 Ubuntu 中安装 HAProxy ###
|
||||
|
||||
# apt get install haproxy
|
||||
|
||||
#### 在 CentOS 和 RHEL 中安装 HAProxy ####
|
||||
### 在 CentOS 和 RHEL 中安装 HAProxy ###
|
||||
|
||||
# yum install haproxy
|
||||
|
||||
### 配置 HAProxy ###
|
||||
## 配置 HAProxy ##
|
||||
|
||||
本教程假设有两台运行的 HTTP Web 服务器,它们的 IP 地址是 192.168.100.2 和 192.168.100.3。我们将负载均衡配置在 192.168.100.4 的这台服务器上。
|
||||
|
||||
为了让 HAProxy 工作正常,你需要修改 /etc/haproxy/haproxy.cfg 中的一些选项。我们会在这一节中解释这些修改。一些配置可能因 GNU/Linux 发行版的不同而变化,这些会被标注出来。
|
||||
|
||||
#### 1. 配置日志功能 ####
|
||||
### 1. 配置日志功能 ###
|
||||
|
||||
你要做的第一件事是为 HAProxy 配置日志功能,在排错时日志将很有用。日志配置可以在 /etc/haproxy/haproxy.cfg 的 global 段中找到他们。下面是针对不同的 Linux 发型版的 HAProxy 日志配置。
|
||||
|
||||
**CentOS 或 RHEL:**
|
||||
#### CentOS 或 RHEL:####
|
||||
|
||||
在 CentOS/RHEL中启用日志,将下面的:
|
||||
|
||||
@ -82,7 +81,7 @@ You will need at least one, or preferably two web servers to verify functionalit
|
||||
|
||||
# service rsyslog restart
|
||||
|
||||
**Debian 或 Ubuntu:**
|
||||
####Debian 或 Ubuntu:####
|
||||
|
||||
在 Debian 或 Ubuntu 中启用日志,将下面的内容
|
||||
|
||||
@ -106,7 +105,7 @@ You will need at least one, or preferably two web servers to verify functionalit
|
||||
|
||||
# service rsyslog restart
|
||||
|
||||
#### 2. 设置默认选项 ####
|
||||
### 2. 设置默认选项 ###
|
||||
|
||||
下一步是设置 HAProxy 的默认选项。在 /etc/haproxy/haproxy.cfg 的 default 段中,替换为下面的配置:
|
||||
|
||||
@ -124,7 +123,7 @@ You will need at least one, or preferably two web servers to verify functionalit
|
||||
|
||||
上面的配置是当 HAProxy 为 HTTP 负载均衡时建议使用的,但是并不一定是你的环境的最优方案。你可以自己研究 HAProxy 的手册并配置它。
|
||||
|
||||
#### 3. Web 集群配置 ####
|
||||
### 3. Web 集群配置 ###
|
||||
|
||||
Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡中的大多数设置都在这里。现在我们会创建一些基本配置,定义我们的节点。将配置文件中从 frontend 段开始的内容全部替换为下面的:
|
||||
|
||||
@ -141,14 +140,14 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
server web01 192.168.100.2:80 cookie node1 check
|
||||
server web02 192.168.100.3:80 cookie node2 check
|
||||
|
||||
"listen webfarm *:80" 定义了负载均衡器监听的地址和端口。为了教程的需要,我设置为 "\*" 表示监听在所有接口上。在真实的场景汇总,这样设置可能不太合适,应该替换为可以从 internet 访问的那个网卡接口。
|
||||
"listen webfarm \*:80" 定义了负载均衡器监听的地址和端口。为了教程的需要,我设置为 "*" 表示监听在所有接口上。在真实的场景汇总,这样设置可能不太合适,应该替换为可以从 internet 访问的那个网卡接口。
|
||||
|
||||
stats enable
|
||||
stats uri /haproxy?stats
|
||||
stats realm Haproxy\ Statistics
|
||||
stats auth haproxy:stats
|
||||
|
||||
上面的设置定义了,负载均衡器的状态统计信息可以通过 http://<load-balancer-IP>/haproxy?stats 访问。访问需要简单的 HTTP 认证,用户名为 "haproxy" 密码为 "stats"。这些设置可以替换为你自己的认证方式。如果你不需要状态统计信息,可以完全禁用掉。
|
||||
上面的设置定义了,负载均衡器的状态统计信息可以通过 http://\<load-balancer-IP>/haproxy?stats 访问。访问需要简单的 HTTP 认证,用户名为 "haproxy" 密码为 "stats"。这些设置可以替换为你自己的认证方式。如果你不需要状态统计信息,可以完全禁用掉。
|
||||
|
||||
下面是一个 HAProxy 统计信息的例子
|
||||
|
||||
@ -160,7 +159,7 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
- **source**:对请求的客户端 IP 地址进行哈希计算,根据哈希值和服务器的权重将请求调度至后端服务器。
|
||||
- **uri**:对 URI 的左半部分(问号之前的部分)进行哈希,根据哈希结果和服务器的权重对请求进行调度
|
||||
- **url_param**:根据每个 HTTP GET 请求的 URL 查询参数进行调度,使用固定的请求参数将会被调度至指定的服务器上
|
||||
- **hdr(name**):根据 HTTP 首部中的 <name> 字段来进行调度
|
||||
- **hdr(name**):根据 HTTP 首部中的 \<name> 字段来进行调度
|
||||
|
||||
"cookie LBN insert indirect nocache" 这一行表示我们的负载均衡器会存储 cookie 信息,可以将后端服务器池中的节点与某个特定会话绑定。节点的 cookie 存储为一个自定义的名字。这里,我们使用的是 "LBN",你可以指定其他的名称。后端节点会保存这个 cookie 的会话。
|
||||
|
||||
@ -169,25 +168,25 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
|
||||
上面是我们的 Web 服务器节点的定义。服务器有由内部名称(如web01,web02),IP 地址和唯一的 cookie 字符串表示。cookie 字符串可以自定义,我这里使用的是简单的 node1,node2 ... node(n)
|
||||
|
||||
### 启动 HAProxy ###
|
||||
## 启动 HAProxy ##
|
||||
|
||||
如果你完成了配置,现在启动 HAProxy 并验证是否运行正常。
|
||||
|
||||
#### 在 Centos/RHEL 中启动 HAProxy ####
|
||||
### 在 Centos/RHEL 中启动 HAProxy ###
|
||||
|
||||
让 HAProxy 开机自启,使用下面的命令
|
||||
|
||||
# chkconfig haproxy on
|
||||
# service haproxy start
|
||||
|
||||
当然,防火墙需要开放 80 端口,想下面这样
|
||||
当然,防火墙需要开放 80 端口,像下面这样
|
||||
|
||||
**CentOS/RHEL 7 的防火墙**
|
||||
####CentOS/RHEL 7 的防火墙####
|
||||
|
||||
# firewallcmd permanent zone=public addport=80/tcp
|
||||
# firewallcmd reload
|
||||
|
||||
**CentOS/RHEL 6 的防火墙**
|
||||
####CentOS/RHEL 6 的防火墙####
|
||||
|
||||
把下面内容加至 /etc/sysconfig/iptables 中的 ":OUTPUT ACCEPT" 段中
|
||||
|
||||
@ -197,9 +196,9 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
|
||||
# service iptables restart
|
||||
|
||||
#### 在 Debian 中启动 HAProxy ####
|
||||
### 在 Debian 中启动 HAProxy ###
|
||||
|
||||
#### 启动 HAProxy ####
|
||||
启动 HAProxy
|
||||
|
||||
# service haproxy start
|
||||
|
||||
@ -207,7 +206,7 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
|
||||
A INPUT p tcp dport 80 j ACCEPT
|
||||
|
||||
#### 在 Ubuntu 中启动HAProxy ####
|
||||
### 在 Ubuntu 中启动HAProxy ###
|
||||
|
||||
让 HAProxy 开机自动启动在 /etc/default/haproxy 中配置
|
||||
|
||||
@ -221,7 +220,7 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
|
||||
# ufw allow 80
|
||||
|
||||
### 测试 HAProxy ###
|
||||
## 测试 HAProxy ##
|
||||
|
||||
检查 HAProxy 是否工作正常,我们可以这样做
|
||||
|
||||
@ -239,7 +238,7 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
|
||||
$ curl http://192.168.100.4/test.php
|
||||
|
||||
我们多次使用这个命令此时,会发现交替的输出下面的内容(因为使用了轮询算法):
|
||||
我们多次运行这个命令此时,会发现交替的输出下面的内容(因为使用了轮询算法):
|
||||
|
||||
Server IP: 192.168.100.2
|
||||
X-Forwarded-for: 192.168.100.4
|
||||
@ -251,13 +250,13 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
|
||||
如果我们停掉一台后端 Web 服务,curl 命令仍然正常工作,请求被分发至另一台可用的 Web 服务器。
|
||||
|
||||
### 总结 ###
|
||||
## 总结 ##
|
||||
|
||||
现在你有了一个完全可用的负载均衡器,以轮询的模式对你的 Web 节点进行负载均衡。还可以去实验其他的配置选项以适应你的环境。希望这个教程可以帮会组你们的 Web 项目有更好的可用性。
|
||||
现在你有了一个完全可用的负载均衡器,以轮询的模式对你的 Web 节点进行负载均衡。还可以去实验其他的配置选项以适应你的环境。希望这个教程可以帮助你们的 Web 项目有更好的可用性。
|
||||
|
||||
你可能已经发现了,这个教程只包含单台负载均衡的设置。这意味着我们仍然有单点故障的问题。在真实场景中,你应该至少部署 2 台或者 3 台负载均衡以防止意外发生,但这不是本教程的范围。
|
||||
|
||||
如果 你有任何问题或建议,请在评论中提出,我会尽我的努力回答。
|
||||
如果你有任何问题或建议,请在评论中提出,我会尽我的努力回答。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -265,11 +264,11 @@ via: http://xmodulo.com/haproxy-http-load-balancer-linux.html
|
||||
|
||||
作者:[Jaroslav Štěpánek][a]
|
||||
译者:[Liao](https://github.com/liaoishere)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/jaroslav
|
||||
[1]:http://www.haproxy.org/
|
||||
[2]:http://www.haproxy.org/10g.html
|
||||
[3]:http://xmodulo.com/how-to-install-lamp-server-on-ubuntu.html
|
||||
[3]:http://linux.cn/article-1567-1.html
|
||||
@ -0,0 +1,195 @@
|
||||
使用 nice、cpulimit 和 cgroups 限制 cpu 占用率
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
Linux内核是一名了不起的马戏表演者,它在进程和系统资源间小心地玩着杂耍,并保持系统的能够正常运转。 同时,内核也很公正:它将资源公平地分配给各个进程。
|
||||
|
||||
但是,如果你需要给一个重要进程提高优先级时,该怎么做呢? 或者是,如何降低一个进程的优先级? 又或者,如何限制一组进程所使用的资源呢?
|
||||
|
||||
**答案是需要由用户来为内核指定进程的优先级**
|
||||
|
||||
大部分进程启动时的优先级是相同的,因此Linux内核会公平地进行调度。 如果想让一个CPU密集型的进程运行在较低优先级,那么你就得事先配置好调度器。
|
||||
|
||||
下面介绍3种控制进程运行时间的方法:
|
||||
|
||||
- 使用 nice 命令手动降低任务的优先级。
|
||||
- 使用 cpulimit 命令不断的暂停进程,以控制进程所占用处理能力不超过特定限制。
|
||||
- 使用linux内建的**control groups(控制组)**功能,它提供了限制进程资源消耗的机制。
|
||||
|
||||
我们来看一下这3个工具的工作原理和各自的优缺点。
|
||||
|
||||
### 模拟高cpu占用率 ###
|
||||
|
||||
在分析这3种技术前,我们要先安装一个工具来模拟高CPU占用率的场景。我们会用到CentOS作为测试系统,并使用[Mathomatic toolkit][1]中的质数生成器来模拟CPU负载。
|
||||
|
||||
很不幸,在CentOS上这个工具没有预编译好的版本,所以必须要从源码进行安装。先从 http://mathomatic.orgserve.de/mathomatic-16.0.5.tar.bz2 这个链接下载源码包并解压。然后进入 **mathomatic-16.0.5/primes** 文件夹,运行 **make** 和 **sudo make install** 进行编译和安装。这样,就把 **matho-primes** 程序安装到了 **/usr/local/bin** 目录中。
|
||||
|
||||
接下来,通过命令行运行:
|
||||
|
||||
/usr/local/bin/matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||
程序运行后,将输出从0到9999999999之间的质数。因为我们并不需要这些输出结果,直接将输出重定向到/dev/null就好。
|
||||
|
||||
现在,使用top命令就可以看到matho-primes进程榨干了你所有的cpu资源。
|
||||
|
||||

|
||||
|
||||
好了,接下来(按q键)退出 top 并杀掉 matho-primes 进程(使用 fg 命令将进程切换到前台,再按 CTRL+C)
|
||||
|
||||
### nice命令 ###
|
||||
|
||||
下来介绍一下nice命令的使用方法,nice命令可以修改进程的优先级,这样就可以让进程运行得不那么频繁。 **这个功能在运行cpu密集型的后台进程或批处理作业时尤为有用。** nice值的取值范围是[-20,19],-20表示最高优先级,而19表示最低优先级。 Linux进程的默认nice值为0。使用nice命令(不带任何参数时)可以将进程的nice值设置为10。这样调度器就会将此进程视为较低优先级的进程,从而减少cpu资源的分配。
|
||||
|
||||
下面来看一个例子,我们同时运行两个 **matho-primes** 进程,一个使用nice命令来启动运行,而另一个正常启动运行:
|
||||
|
||||
nice matho-primes 0 9999999999 > /dev/null &
|
||||
matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||
再运行top命令。
|
||||
|
||||
|
||||

|
||||
|
||||
看到没,正常运行的进程(nice值为0)获得了更多的cpu运行时间,相反的,用nice命令运行的进程占用的cpu时间会较少(nice值为10)。
|
||||
|
||||
在实际使用中,如果你要运行一个CPU密集型的程序,那么最好用nice命令来启动它,这样就可以保证其他进程获得更高的优先级。 也就是说,即使你的服务器或者台式机在重载的情况下,也可以快速响应。
|
||||
|
||||
nice 还有一个关联命令叫做 renice,它可以在运行时调整进程的 nice 值。使用 renice 命令时,要先找出进程的 PID。下面是一个例子:
|
||||
|
||||
renice +10 1234
|
||||
|
||||
其中,1234是进程的 PID。
|
||||
|
||||
测试完 **nice** 和 **renice** 命令后,记得要将 **matho-primes** 进程全部杀掉。
|
||||
|
||||
### cpulimit命令 ###
|
||||
|
||||
接下来介绍 **cpulimit** 命令的用法。 **cpulimit** 命令的工作原理是为进程预设一个 cpu 占用率门限,并实时监控进程是否超出此门限,若超出则让该进程暂停运行一段时间。cpulimit 使用 SIGSTOP 和 SIGCONT 这两个信号来控制进程。它不会修改进程的 nice 值,而是通过监控进程的 cpu 占用率来做出动态调整。
|
||||
|
||||
cpulimit 的优势是可以控制进程的cpu使用率的上限值。但与 nice 相比也有缺点,那就是即使 cpu 是空闲的,进程也不能完全使用整个 cpu 资源。
|
||||
|
||||
在 CentOS 上,可以用下面的方法来安装它:
|
||||
|
||||
wget -O cpulimit.zip https://github.com/opsengine/cpulimit/archive/master.zip
|
||||
unzip cpulimit.zip
|
||||
cd cpulimit-master
|
||||
make
|
||||
sudo cp src/cpulimit /usr/bin
|
||||
|
||||
上面的命令行,会先从从 GitHub 上将源码下载到本地,然后再解压、编译、并安装到 /usr/bin 目录下。
|
||||
|
||||
cpulimit 的使用方式和 nice 命令类似,但是需要用户使用 **-l** 选项显式地定义进程的 cpu 使用率上限值。举例说明:
|
||||
|
||||
cpulimit -l 50 matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||

|
||||
|
||||
从上面的例子可以看出 matho-primes 只使用了50%的 cpu 资源,剩余的 cpu 时间都在 idle。
|
||||
|
||||
cpulimit 还可以在运行时对进程进行动态限制,使用 **-p** 选项来指定进程的 PID,下面是一个实例:
|
||||
|
||||
cpulimit -l 50 -p 1234
|
||||
|
||||
其中,1234是进程的 PID。
|
||||
|
||||
### cgroups 命令集 ###
|
||||
|
||||
最后介绍,功能最为强大的控制组(cgroups)的用法。cgroups 是 Linux 内核提供的一种机制,利用它可以指定一组进程的资源分配。 具体来说,使用 cgroups,用户能够限定一组进程的 cpu 占用率、系统内存消耗、网络带宽,以及这几种资源的组合。
|
||||
|
||||
对比nice和cpulimit,**cgroups 的优势**在于它可以控制一组进程,不像前者仅能控制单进程。同时,nice 和 cpulimit 只能限制 cpu 使用率,而 cgroups 则可以限制其他进程资源的使用。
|
||||
|
||||
对 cgroups 善加利用就可以控制好整个子系统的资源消耗。就拿 CoreOS 作为例子,这是一个专为大规模服务器部署而设计的最简化的 Linux 发行版本,它的 upgrade 进程就是使用 cgroups 来管控。这样,系统在下载和安装升级版本时也不会影响到系统的性能。
|
||||
|
||||
下面做一下演示,我们将创建两个控制组(cgroups),并对其分配不同的 cpu 资源。这两个控制组分别命名为“cpulimited”和“lesscpulimited”。
|
||||
|
||||
使用 cgcreate 命令来创建控制组,如下所示:
|
||||
|
||||
sudo cgcreate -g cpu:/cpulimited
|
||||
sudo cgcreate -g cpu:/lesscpulimited
|
||||
|
||||
其中“-g cpu”选项用于设定 cpu 的使用上限。除 cpu 外,cgroups 还提供 cpuset、memory、blkio 等控制器。cpuset 控制器与 cpu 控制器的不同在于,cpu 控制器只能限制一个 cpu 核的使用率,而 cpuset 可以控制多个 cpu 核。
|
||||
|
||||
cpu 控制器中的 cpu.shares 属性用于控制 cpu 使用率。它的默认值是 1024,我们将 lesscpulimited 控制组的 cpu.shares 设为1024(默认值),而 cpulimited 设为512,配置后内核就会按照2:1的比例为这两个控制组分配资源。
|
||||
|
||||
要设置cpulimited 组的 cpu.shares 为 512,输入以下命令:
|
||||
|
||||
sudo cgset -r cpu.shares=512 cpulimited
|
||||
|
||||
使用 cgexec 命令来启动控制组的运行,为了测试这两个控制组,我们先用cpulimited 控制组来启动 matho-primes 进程,命令行如下:
|
||||
|
||||
sudo cgexec -g cpu:cpulimited /usr/local/bin/matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||
打开 top 可以看到,matho-primes 进程占用了所有的 cpu 资源。
|
||||
|
||||

|
||||
|
||||
因为只有一个进程在系统中运行,不管将其放到哪个控制组中启动,它都会尽可能多的使用cpu资源。cpu 资源限制只有在两个进程争夺cpu资源时才会生效。
|
||||
|
||||
那么,现在我们就启动第二个 matho-primes 进程,这一次我们在 lesscpulimited 控制组中来启动它:
|
||||
|
||||
sudo cgexec -g cpu:lesscpulimited /usr/local/bin/matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||
再打开 top 就可以看到,cpu.shares 值大的控制组会得到更多的 cpu 运行时间。
|
||||
|
||||

|
||||
|
||||
现在,我们再在 cpulimited 控制组中增加一个 matho-primes 进程:
|
||||
|
||||
sudo cgexec -g cpu:cpulimited /usr/local/bin/matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||

|
||||
|
||||
看到没,两个控制组的 cpu 的占用率比例仍然为2:1。其中,cpulimited 控制组中的两个 matho-primes 进程获得的cpu 时间基本相当,而另一组中的 matho-primes 进程显然获得了更多的运行时间。
|
||||
|
||||
更多的使用方法,可以在 Red Hat 上查看详细的 cgroups 使用[说明][2]。(当然CentOS 7也有)
|
||||
|
||||
### 使用Scout来监控cpu占用率 ###
|
||||
|
||||
监控cpu占用率最为简单的方法是什么?[Scout][3] 工具能够监控能够自动监控进程的cpu使用率和内存使用情况。
|
||||
|
||||

|
||||
|
||||
[Scout][3]的触发器(trigger)功能还可以设定 cpu 和内存的使用门限,超出门限时会自动产生报警。
|
||||
|
||||
从这里可以获取 [Scout][4] 的试用版。
|
||||
|
||||
### 总结 ###
|
||||
|
||||

|
||||
|
||||
计算机的系统资源是非常宝贵的。上面介绍的这3个工具能够帮助大家有效地管理系统资源,特别是cpu资源:
|
||||
|
||||
- **nice**可以一次性调整进程的优先级。
|
||||
- **cpulimit**在运行cpu密集型任务且要保持系统的响应性时会很有用。
|
||||
- **cgroups**是资源管理的瑞士军刀,同时在使用上也很灵活。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.scoutapp.com/articles/2014/11/04/restricting-process-cpu-usage-using-nice-cpulimit-and-cgroups
|
||||
|
||||
译者:[coloka](https://github.com/coloka)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.mathomatic.org/
|
||||
[2]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Resource_Management_and_Linux_Containers_Guide/chap-Introduction_to_Control_Groups.html
|
||||
[3]:https://scoutapp.com/
|
||||
[4]:https://scoutapp.com/
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
@ -0,0 +1,186 @@
|
||||
10个重要的Linux ps命令实战
|
||||
================================================================================
|
||||
Linux作为Unix的衍生操作系统,Linux内建有查看当前进程的工具。这个工具能在命令行中使用。
|
||||
|
||||
### PS 命令是什么 ###
|
||||
|
||||
查看它的man手册可以看到,ps命令能够给出当前系统中进程的快照。它能捕获系统在某一事件的进程状态。如果你想不断更新查看的这个状态,可以使用top命令。
|
||||
|
||||
ps命令支持三种使用的语法格式
|
||||
|
||||
1. UNIX 风格,选项可以组合在一起,并且选项前必须有“-”连字符
|
||||
2. BSD 风格,选项可以组合在一起,但是选项前不能有“-”连字符
|
||||
3. GNU 风格的长选项,选项前有两个“-”连字符
|
||||
|
||||
我们能够混用这几种风格,但是可能会发生冲突。本文使用 UNIX 风格的ps命令。这里有在日常生活中使用较多的ps命令的例子。
|
||||
|
||||
### 1. 不加参数执行ps命令 ###
|
||||
|
||||
这是一个基本的 **ps** 使用。在控制台中执行这个命令并查看结果。
|
||||
|
||||

|
||||
|
||||
结果默认会显示4列信息。
|
||||
|
||||
- PID: 运行着的命令(CMD)的进程编号
|
||||
- TTY: 命令所运行的位置(终端)
|
||||
- TIME: 运行着的该命令所占用的CPU处理时间
|
||||
- CMD: 该进程所运行的命令
|
||||
|
||||
这些信息在显示时未排序。
|
||||
|
||||
### 2. 显示所有当前进程 ###
|
||||
|
||||
使用 **-a** 参数。**-a 代表 all**。同时加上x参数会显示没有控制终端的进程。
|
||||
|
||||
$ ps -ax
|
||||
|
||||
这个命令的结果或许会很长。为了便于查看,可以结合less命令和管道来使用。
|
||||
|
||||
$ ps -ax | less
|
||||
|
||||

|
||||
|
||||
### 3. 根据用户过滤进程 ###
|
||||
|
||||
在需要查看特定用户进程的情况下,我们可以使用 **-u** 参数。比如我们要查看用户'pungki'的进程,可以通过下面的命令:
|
||||
|
||||
$ ps -u pungki
|
||||
|
||||

|
||||
|
||||
### 4. 通过cpu和内存使用来过滤进程 ###
|
||||
|
||||
也许你希望把结果按照 CPU 或者内存用量来筛选,这样你就找到哪个进程占用了你的资源。要做到这一点,我们可以使用 **aux 参数**,来显示全面的信息:
|
||||
|
||||
$ ps -aux | less
|
||||
|
||||

|
||||
|
||||
当结果很长时,我们可以使用管道和less命令来筛选。
|
||||
|
||||
默认的结果集是未排好序的。可以通过 **--sort**命令来排序。
|
||||
|
||||
根据 **CPU 使用**来升序排序
|
||||
|
||||
$ ps -aux --sort -pcpu | less
|
||||
|
||||

|
||||
|
||||
根据 **内存使用** 来升序排序
|
||||
|
||||
$ ps -aux --sort -pmem | less
|
||||
|
||||

|
||||
|
||||
我们也可以将它们合并到一个命令,并通过管道显示前10个结果:
|
||||
|
||||
$ ps -aux --sort -pcpu,+pmem | head -n 10
|
||||
|
||||
### 5. 通过进程名和PID过滤 ###
|
||||
|
||||
使用 **-C 参数**,后面跟你要找的进程的名字。比如想显示一个名为getty的进程的信息,就可以使用下面的命令:
|
||||
|
||||
$ ps -C getty
|
||||
|
||||

|
||||
|
||||
如果想要看到更多的细节,我们可以使用-f参数来查看格式化的信息列表:
|
||||
|
||||
$ ps -f -C getty
|
||||
|
||||

|
||||
|
||||
### 6. 根据线程来过滤进程 ###
|
||||
|
||||
如果我们想知道特定进程的线程,可以使用**-L 参数**,后面加上特定的PID。
|
||||
|
||||
$ ps -L 1213
|
||||
|
||||

|
||||
|
||||
### 7. 树形显示进程 ###
|
||||
|
||||
有时候我们希望以树形结构显示进程,可以使用 **-axjf** 参数。
|
||||
|
||||
$ps -axjf
|
||||
|
||||

|
||||
|
||||
或者可以使用另一个命令。
|
||||
|
||||
$ pstree
|
||||
|
||||

|
||||
|
||||
### 8. 显示安全信息 ###
|
||||
|
||||
如果想要查看现在有谁登入了你的服务器。可以使用ps命令加上相关参数:
|
||||
|
||||
$ ps -eo pid,user,args
|
||||
|
||||
**参数 -e** 显示所有进程信息,**-o 参数**控制输出。**Pid**,**User 和 Args**参数显示**PID,运行应用的用户**和**该应用**。
|
||||
|
||||

|
||||
|
||||
能够与**-e 参数** 一起使用的关键字是**args, cmd, comm, command, fname, ucmd, ucomm, lstart, bsdstart 和 start**。
|
||||
|
||||
### 9. 格式化输出root用户(真实的或有效的UID)创建的进程 ###
|
||||
|
||||
系统管理员想要查看由root用户运行的进程和这个进程的其他相关信息时,可以通过下面的命令:
|
||||
|
||||
$ ps -U root -u root u
|
||||
|
||||
**-U 参数**按真实用户ID(RUID)筛选进程,它会从用户列表中选择真实用户名或 ID。真实用户即实际创建该进程的用户。
|
||||
|
||||
**-u** 参数用来筛选有效用户ID(EUID)。
|
||||
|
||||
最后的**u**参数用来决定以针对用户的格式输出,由**User, PID, %CPU, %MEM, VSZ, RSS, TTY, STAT, START, TIME 和 COMMAND**这几列组成。
|
||||
|
||||
这里有上面的命令的输出结果:
|
||||
|
||||

|
||||
|
||||
### 10. 使用PS实时监控进程状态 ###
|
||||
|
||||
ps 命令会显示你系统当前的进程状态,但是这个结果是静态的。
|
||||
|
||||
当有一种情况,我们需要像上面第四点中提到的通过CPU和内存的使用率来筛选进程,并且我们希望结果能够每秒刷新一次。为此,我们可以**将ps命令和watch命令结合起来**。
|
||||
|
||||
$ watch -n 1 ‘ps -aux --sort -pmem, -pcpu’
|
||||
|
||||

|
||||
|
||||
如果输出太长,我们也可以限制它,比如前20条,我们可以使用**head**命令来做到。
|
||||
|
||||
$ watch -n 1 ‘ps -aux --sort -pmem, -pcpu | head 20’
|
||||
|
||||

|
||||
|
||||
这里的动态查看并不像top或者htop命令一样。**但是使用ps的好处是**你能够定义显示的字段,你能够选择你想查看的字段。
|
||||
|
||||
举个例子,**如果你只需要看名为'pungki'用户的信息**,你可以使用下面的命令:
|
||||
|
||||
$ watch -n 1 ‘ps -aux -U pungki u --sort -pmem, -pcpu | head 20’
|
||||
|
||||

|
||||
|
||||
### 结论 ###
|
||||
|
||||
你也许每天都会使用ps命令来监控你的Linux系统。但是事实上,你可以通过ps命令的参数来生成各种你需要的报表。
|
||||
|
||||
ps命令的另一个优势是ps是各种 Linux系统都默认安装的,因此你只要用就行了。
|
||||
|
||||
不要忘了通过 man ps来查看更多的参数。(LCTT 译注:由于 ps 命令古老而重要,所以它在不同的 UNIX、BSD、Linux 等系统中的参数不尽相同,因此如果你用的不是 Linux 系统,请查阅你的文档了解具体可用的参数。)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/how-tos/linux-ps-command-examples/
|
||||
|
||||
作者:[Pungki Arianto][a]
|
||||
译者:[johnhoow](https://github.com/johnhoow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/pungki/
|
||||
158
published/201501/20141203 Docker--Present and Future.md
Normal file
158
published/201501/20141203 Docker--Present and Future.md
Normal file
@ -0,0 +1,158 @@
|
||||
Docker 的现状与未来
|
||||
================================================================================
|
||||
|
||||
### Docker - 迄今为止发生的那些事情 ###
|
||||
|
||||
Docker 是一个专为 Linux 容器而设计的工具集,用于‘构建、交付和运行’分布式应用。它最初是 DotCloud 的一个开源项目,于2013年3月发布。这个项目越来越受欢迎,以至于 DotCloud 公司都更名为 Docker 公司(并最终[出售了原有的 PaaS 业务][1])。[Docker 1.0][2]是在2014年6月发布的,而且延续了之前每月更新一个版本的传统。
|
||||
|
||||
Docker 1.0版本的发布标志着 Docker 公司认为该平台已经充分成熟,足以用于生产环境中(由该公司与合作伙伴提供付费支持选择)。每个月发布的更新表明该项目正在迅速发展,比如增添一些新特性、解决一些他们发现的问题。该项目已经成功地分离了‘运行’和‘交付’两件事,所以来自任何版本的 Docker 镜像源都可以与其它版本共同使用(具备向前和向后兼容的特性),这为 Docker 应对快速变化提供了稳定的保障。
|
||||
|
||||
Docker 之所以能够成为最受欢迎的开源项目之一可能会被很多人看做是炒作,但是也是由其坚实的基础所决定的。Docker 的影响力已经得到整个行业许多大企业的支持,包括亚马逊, Canonical 公司, CenturyLink, 谷歌, IBM, 微软, New Relic, Pivotal, 红帽和 VMware。这使得只要有 Linux 的地方,Docker 就可以无处不在。除了这些鼎鼎有名的大公司以外,许多初创公司也在围绕着 Docker 发展,或者改变他们的发展方向来与 Docker 更好地结合起来。这些合作伙伴们(无论大或小)都将帮助推动 Docker 核心项目及其周边生态环境的快速发展。
|
||||
|
||||
### Docker 技术简要综述 ###
|
||||
|
||||
Docker 利用 Linux 的一些内核机制例如 [cGroups][3]、命名空间和 [SElinux][4] 来实现容器之间的隔离。起初 Docker 只是 [LXC][5] 容器管理器子系统的前端,但是在 0.9 版本中引入了 [libcontainer][6],这是一个原生的 go 语言库,提供了用户空间和内核之间的接口。
|
||||
|
||||
容器是基于 [AUFS][7] 这样的联合文件系统的,它允许跨多个容器共享组件,如操作系统镜像和已安装的相关库。这种文件系统的分层方法也被 [Dockerfile][8] 的 DevOps 工具所利用,这些工具能够缓存成功完成的操作。这就省下了安装操作系统和相关应用程序依赖包的时间,极大地加速测试周期。另外,在容器之间的共享库也能够减少内存的占用。
|
||||
|
||||
一个容器是从一个镜像开始运行的,它可以来自本地创建,本地缓存,或者从一个注册库(registry)下载。Docker 公司运营的 [Docker Hub 公有注册库][9],为各种操作系统、中间件和数据库提供了官方仓库存储。各个组织和个人都可以在 docker Hub 上发布的镜像的公有库,也可以注册成私有仓库。由于上传的镜像可以包含几乎任何内容,所以 Docker 提供了一种自动构建工具(以往称为“可信构建”),镜像可以从一种称之为 Dockerfile 的镜像内容清单构建而成。
|
||||
|
||||
### 容器 vs. 虚拟机 ###
|
||||
|
||||
容器会比虚拟机更高效,因为它们能够分享一个内核和分享应用程序库。相比虚拟机系统,这也将使得 Docker 使用的内存更小,即便虚拟机利用了内存超量使用的技术。部署容器时共享底层的镜像层也可以减少存储占用。IBM 的 Boden Russel 已经做了一些[基准测试][10]来说明两者之间的不同。
|
||||
|
||||
相比虚拟机系统,容器具有较低系统开销的优势,所以在容器中,应用程序的运行效率将会等效于在同样的应用程序在虚拟机中运行,甚至效果更佳。IBM 的一个研究团队已经发表了一本名为[虚拟机与 Linux 容器的性能比较]的文章[11]。
|
||||
|
||||
容器只是在隔离特性上要比虚拟机逊色。虚拟机可以利用如 Intel 的 VT-d 和 VT-x 技术的 ring-1 [硬件隔离][12]技术。这种隔离可以防止虚拟机突破和彼此交互。而容器至今还没有任何形式的硬件隔离,这使它容易受到攻击。一个称为 [Shocker][13] 的概念攻击验证表明,在 Docker 1.0 之前的版本是存在这种脆弱性的。尽管 Docker 1.0 修复了许多由 Shocker 漏洞带来的较为严重的问题,Docker 的 CTO Solomon Hykes 仍然[说][14],“当我们可以放心宣称 Docker 的开箱即用是安全的,即便是不可信的 uid0 程序(超级用户权限程序),我们将会很明确地告诉大家。”Hykes 的声明承认,其漏洞及相关的风险依旧存在,所以在容器成为受信任的工具之前将有更多的工作要做。
|
||||
|
||||
对于许多用户案例而言,在容器和虚拟机之间二者选择其一是种错误的二分法。Docker 同样可以在虚拟机中工作的很好,这让它可以用在现有的虚拟基础措施、私有云或者公有云中。同样也可以在容器里跑虚拟机,这也类似于谷歌在其云平台的使用方式。像 IaaS 服务这样普遍可用的基础设施,能够即时提供所需的虚拟机,可以预期容器与虚拟机一起使用的情景将会在数年后出现。容器管理和虚拟机技术也有可能被集成到一起提供一个两全其美的方案;这样,一个硬件信任锚微虚拟化所支撑的 libcontainer 容器,可与前端 Docker 工具链和生态系统整合,而使用提供更好隔离性的不同后端。微虚拟化(例如 Bromium 的 [vSentry][15] 和 VMware 的 [Project Fargo][16])已经用于在桌面环境中以提供基于硬件的应用程序隔离,所以类似的方法也可以用于 libcontainer,作为 Linux内核中的容器机制的替代技术。
|
||||
|
||||
### ‘容器化’ 的应用程序 ###
|
||||
|
||||
几乎所有 Linux 应用程序都可以在 Docker 容器中运行,并没有编程语言或框架的限制。唯一的实际限制是以操作系统的角度来允许容器做什么。即使如此,也可以在特权模式下运行容器,从而大大减少了限制(与之对应的是容器中的应用程序的风险增加,可能导致损坏主机操作系统)。
|
||||
|
||||
容器都是从镜像开始运行的,而镜像也可以从运行中的容器获取。本质上说,有两种方法可以将应用程序放到容器中,分别是手动构建和 Dockerfile。
|
||||
|
||||
#### 手动构建 ####
|
||||
|
||||
手动构建从启动一个基础的操作系统镜像开始,然后在交互式终端中用你所选的 Linux 提供的包管理器安装应用程序及其依赖项。Zef Hemel 在‘[使用 Linux 容器来支持便携式应用程序部署][17]’的文章中讲述了他部署的过程。一旦应用程序被安装之后,容器就可以被推送至注册库(例如Docker Hub)或者导出为一个tar文件。
|
||||
|
||||
#### Dockerfile ####
|
||||
|
||||
Dockerfile 是一个用于构建 Docker 容器的脚本化系统。每一个 Dockerfile 定义了开始的基础镜像,以及一系列在容器中运行的命令或者一些被添加到容器中的文件。Dockerfile 也可以指定对外的端口和当前工作目录,以及容器启动时默认执行的命令。用 Dockerfile 构建的容器可以像手工构建的镜像一样推送或导出。Dockerfile 也可以用于 Docker Hub 的自动构建系统,即在 Docker 公司的控制下从头构建,并且该镜像的源代码是任何需要使用它的人可见的。
|
||||
|
||||
#### 单进程? ####
|
||||
|
||||
无论镜像是手动构建还是通过 Dockerfile 构建,有一个要考虑的关键因素是当容器启动时仅启动一个进程。对于一个单一用途的容器,例如运行一个应用服务器,运行一个单一的进程不是一个问题(有些关于容器应该只有一个单独的进程的争议)。对于一些容器需要启动多个进程的情况,必须先启动 [supervisor][18] 进程,才能生成其它内部所需的进程。由于容器内没有初始化系统,所以任何依赖于 systemd、upstart 或类似初始化系统的东西不修改是无法工作的。
|
||||
|
||||
### 容器和微服务 ###
|
||||
|
||||
全面介绍使用微服务结构体系的原理和好处已经超出了这篇文章的范畴(在 [InfoQ eMag: Microservices][19] 有全面阐述)。然而容器是绑定和部署微服务实例的捷径。
|
||||
|
||||
大规模微服务部署的多数案例都是部署在虚拟机上,容器只是用于较小规模的部署上。容器具有共享操作系统和公用库的的内存和硬盘存储的能力,这也意味着它可以非常有效的并行部署多个版本的服务。
|
||||
|
||||
### 连接容器 ###
|
||||
|
||||
一些小的应用程序适合放在单独的容器中,但在许多案例中应用程序需要分布在多个容器中。Docker 的成功包括催生了一连串新的应用程序组合工具、编制工具及平台作为服务(PaaS)的实现。在这些努力的背后,是希望简化从一组相互连接的容器来创建应用的过程。很多工具也在扩展、容错、性能管理以及对已部署资产进行版本控制方面提供了帮助。
|
||||
|
||||
#### 连通性 ####
|
||||
|
||||
Docker 的网络功能是相当原始的。在同一主机,容器内的服务可以互相访问,而且 Docker 也可以通过端口映射到主机操作系统,使服务可以通过网络访问。官方支持的提供连接能力的库叫做 [libchan][20],这是一个提供给 Go 语言的网络服务库,类似于[channels][21]。在 libchan 找到进入应用的方法之前,第三方应用仍然有很大空间可提供配套的网络服务。例如,[Flocker][22] 已经采取了基于代理的方法使服务实现跨主机(以及底层存储)的移植。
|
||||
|
||||
#### 合成 ####
|
||||
|
||||
Docker 本身拥有把容器连接在一起的机制,与元数据相关的依赖项可以被传递到相依赖的容器中,并用于环境变量和主机入口。如 [Fig][23] 和 [geard][24] 这样的应用合成工具可以在单一文件中展示出这种依赖关系图,这样多个容器就可以汇聚成一个连贯的系统。CenturyLink 公司的 [Panamax][25] 合成工具类似 Fig 和 geard 的底层实现方法,但新增了一些基于 web 的用户接口,并直接与 GitHub 相结合,以便于应用程序分享。
|
||||
|
||||
#### 编制 ####
|
||||
|
||||
像 [Decking][26]、New Relic 公司的 [Centurion][27] 和谷歌公司的 [Kubernetes][28] 这样的编制系统都是旨在协助容器的部署和管理其生命周期系统。也有许多 [Apache Mesos][30] (特别是 [Marathon(马拉松式)持续运行很久的框架])的案例(例如[Mesosphere][29])已经被用于配合 Docker 一起使用。通过为应用程序与底层基础架构之间(例如传递 CPU 核数和内存的需求)提供一个抽象的模型,编制工具提供了两者的解耦,简化了应用程序开发和数据中心操作。有很多各种各样的编制系统,因为许多来自内部系统的以前开发的用于大规模容器部署的工具浮现出来了;如 Kubernetes 是基于谷歌的 [Omega][32] 系统的,[Omega][32] 是用于管理遍布谷歌云环境中容器的系统。
|
||||
|
||||
虽然从某种程度上来说合成工具和编制工具的功能存在重叠,但这也是它们之间互补的一种方式。例如 Fig 可以被用于描述容器间如何实现功能交互,而 Kubernetes pods(容器组)可用于提供监控和扩展。
|
||||
|
||||
#### 平台(即服务)####
|
||||
|
||||
有一些 Docker 原生的 PaaS 服务实现,例如 [Deis][33] 和 [Flynn][34] 已经显现出 Linux 容器在开发上的的灵活性(而不是那些“自以为是”的给出一套语言和框架)。其它平台,例如 CloudFoundry、OpenShift 和 Apcera Continuum 都已经采取将 Docker 基础功能融入其现有的系统的技术路线,这样基于 Docker 镜像(或者基于 Dockerfile)的应用程序也可以与之前用支持的语言和框架的开发的应用一同部署和管理。
|
||||
|
||||
### 所有的云 ###
|
||||
|
||||
由于 Docker 能够运行在任何正常更新内核的 Linux 虚拟机中,它几乎可以用在所有提供 IaaS 服务的云上。大多数的主流云厂商已经宣布提供对 Docker 及其生态系统的支持。
|
||||
|
||||
亚马逊已经把 Docker 引入它们的 Elastic Beanstalk 系统(这是在底层 IaaS 上的一个编制系统)。谷歌使 Docker 成为了“可管理的 VM”,它提供了GAE PaaS 和GCE IaaS 之间的中转站。微软和 IBM 也都已经宣布了基于 Kubernetes 的服务,这样可以在它们的云上部署和管理多容器应用程序。
|
||||
|
||||
为了给现有种类繁多的后端提供可用的一致接口,Docker 团队已经引进 [libswarm][35], 它可以集成于众多的云和资源管理系统。Libswarm 所阐明的目标之一是“通过切换服务来源避免被特定供应商套牢”。这是通过呈现一组一致的服务(与API相关联的)来完成的,该服务会通过特定的后端服务所实现。例如 Docker 服务器将支持本地 Docker 命令行工具的 Docker 远程 API 调用,这样就可以管理一组服务供应商的容器了。
|
||||
|
||||
基于 Docker 的新服务类型仍在起步阶段。总部位于伦敦的 Orchard 实验室提供了 Docker 的托管服务,但是 Docker 公司表示,收购 Orchard 后,其相关服务不会置于优先位置。Docker 公司也出售了之前 DotCloud 的PaaS 业务给 cloudControl。基于更早的容器管理系统的服务例如 [OpenVZ][36] 已经司空见惯了,所以在一定程度上 Docker 需要向主机托管商们证明其价值。
|
||||
|
||||
### Docker 及其发行版 ###
|
||||
|
||||
Docker 已经成为大多数 Linux 发行版例如 Ubuntu、Red Hat 企业版(RHEL)和 CentOS 的一个标准功能。遗憾的是这些发行版的步调和 Docker 项目并不一致,所以在发布版中找到的版本总是远远落后于最新版本。例如 Ubuntu 14.04 版本中的版本是 Docker 0.9.1,而当 Ubuntu 升级至 14.04.1 时 Docker 版本并没有随之升级(此时 Docker 已经升至 1.1.2 版本)。在发行版的软件仓库中还有一个名字空间的冲突,因为 “Docker” 也是 KDE 系统托盘的名字;所以在 Ubuntu 14.04 版本中相关安装包的名字和命令行工具都是使用“Docker.io”的名字。
|
||||
|
||||
在企业级 Linux 的世界中,情况也并没有因此而不同。CentOS 7 中的 Docker 版本是 0.11.1,这是 Docker 公司宣布准备发行 Docker 1.0 产品版本之前的开发版。Linux 发行版用户如果希望使用最新版本以保障其稳定、性能和安全,那么最好地按照 Docker 的[安装说明][37]进行,使用 Docker 公司的所提供的软件库而不是采用发行版的。
|
||||
|
||||
Docker 的到来也催生了新的 Linux 发行版,如 [CoreOS][38] 和红帽的 [Project Atomic][39],它们被设计为能运行容器的最小环境。这些发布版相比传统的发行版,带着更新的内核及 Docker 版本,对内存的使用和硬盘占用率也更低。新发行版也配备了用于大型部署的新工具,例如 [fleet][40](一个分布式初始化系统)和[etcd][41](用于元数据管理)。这些发行版也有新的自我更新机制,以便可以使用最新的内核和 Docker。这也意味着使用 Docker 的影响之一是它抛开了对发行版和相关的包管理解决方案的关注,而对 Linux 内核(及使用它的 Docker 子系统)更加关注。
|
||||
|
||||
这些新发行版也许是运行 Docker 的最好方式,但是传统的发行版和它们的包管理器对容器来说仍然是非常重要的。Docker Hub 托管的官方镜像有 Debian、Ubuntu 和 CentOS,以及一个‘半官方’的 Fedora 镜像库。RHEL 镜像在Docker Hub 中不可用,因为它是 Red Hat 直接发布的。这意味着在 Docker Hub 的自动构建机制仅仅用于那些纯开源发行版下(并愿意信任那些源于 Docker 公司团队提供的基础镜像)。
|
||||
|
||||
Docker Hub 集成了如 Git Hub 和 Bitbucket 这样源代码控制系统来自动构建包管理器,用于管理构建过程中创建的构建规范(在Dockerfile中)和生成的镜像之间的复杂关系。构建过程的不确定结果并非是 Docker 的特定问题——而与软件包管理器如何工作有关。今天构建完成的是一个版本,明天构建的可能就是更新的版本,这就是为什么软件包管理器需要升级的原因。容器抽象(较少关注容器中的内容)以及容器扩展(因为轻量级资源利用率)有可能让这种不确定性成为 Docker 的痛点。
|
||||
|
||||
### Docker 的未来 ###
|
||||
|
||||
Docker 公司对核心功能(libcontainer),跨服务管理(libswarm) 和容器间的信息传递(libchan)的发展上提出了明确的路线。与此同时,该公司已经表明愿意收购 Orchard 实验室,将其纳入自身生态系统。然而 Docker 不仅仅是 Docker 公司的,这个项目的贡献者也来自许多大牌贡献者,其中不乏像谷歌、IBM 和 Red Hat 这样的大公司。在仁慈独裁者、CTO Solomon Hykes 掌舵的形势下,为公司和项目明确了技术领导关系。在前18个月的项目中通过成果输出展现了其快速行动的能力,而且这种趋势并没有减弱的迹象。
|
||||
|
||||
许多投资者正在寻找10年前 VMware 公司的 ESX/vSphere 平台的特征矩阵,并试图找出虚拟机的普及而带动的企业预期和当前 Docker 生态系统两者的距离(和机会)。目前 Docker 生态系统正缺乏类似网络、存储和(对于容器的内容的)细粒度版本管理,这些都为初创企业和创业者提供了机会。
|
||||
|
||||
随着时间的推移,在虚拟机和容器(Docker 的“运行”部分)之间的区别将变得没那么重要了,而关注点将会转移到“构建”和“交付”方面。这些变化将会使“Docker发生什么?”变得不如“Docker将会给IT产业带来什么?”那么重要了。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoq.com/articles/docker-future
|
||||
|
||||
作者:[Chris Swan][a]
|
||||
译者:[disylee](https://github.com/disylee)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoq.com/author/Chris-Swan
|
||||
[1]:http://blog.dotcloud.com/dotcloud-paas-joins-cloudcontrol
|
||||
[2]:http://www.infoq.com/news/2014/06/docker_1.0
|
||||
[3]:https://www.kernel.org/doc/Documentation/cgroups/cgroups.txt
|
||||
[4]:http://selinuxproject.org/page/Main_Page
|
||||
[5]:https://linuxcontainers.org/
|
||||
[6]:http://blog.docker.com/2014/03/docker-0-9-introducing-execution-drivers-and-libcontainer/
|
||||
[7]:http://aufs.sourceforge.net/aufs.html
|
||||
[8]:https://docs.docker.com/reference/builder/
|
||||
[9]:https://registry.hub.docker.com/
|
||||
[10]:http://bodenr.blogspot.co.uk/2014/05/kvm-and-docker-lxc-benchmarking-with.html?m=1
|
||||
[11]:http://domino.research.ibm.com/library/cyberdig.nsf/papers/0929052195DD819C85257D2300681E7B/$File/rc25482.pdf
|
||||
[12]:https://en.wikipedia.org/wiki/X86_virtualization#Hardware-assisted_virtualization
|
||||
[13]:http://stealth.openwall.net/xSports/shocker.c
|
||||
[14]:https://news.ycombinator.com/item?id=7910117
|
||||
[15]:http://www.bromium.com/products/vsentry.html
|
||||
[16]:http://cto.vmware.com/vmware-docker-better-together/
|
||||
[17]:http://www.infoq.com/articles/docker-containers
|
||||
[18]:http://docs.docker.com/articles/using_supervisord/
|
||||
[19]:http://www.infoq.com/minibooks/emag-microservices
|
||||
[20]:https://github.com/docker/libchan
|
||||
[21]:https://gobyexample.com/channels
|
||||
[22]:http://www.infoq.com/news/2014/08/clusterhq-launch-flocker
|
||||
[23]:http://www.fig.sh/
|
||||
[24]:http://openshift.github.io/geard/
|
||||
[25]:http://panamax.io/
|
||||
[26]:http://decking.io/
|
||||
[27]:https://github.com/newrelic/centurion
|
||||
[28]:https://github.com/GoogleCloudPlatform/kubernetes
|
||||
[29]:https://mesosphere.io/2013/09/26/docker-on-mesos/
|
||||
[30]:http://mesos.apache.org/
|
||||
[31]:https://github.com/mesosphere/marathon
|
||||
[32]:http://static.googleusercontent.com/media/research.google.com/en/us/pubs/archive/41684.pdf
|
||||
[33]:http://deis.io/
|
||||
[34]:https://flynn.io/
|
||||
[35]:https://github.com/docker/libswarm
|
||||
[36]:http://openvz.org/Main_Page
|
||||
[37]:https://docs.docker.com/installation/#installation
|
||||
[38]:https://coreos.com/
|
||||
[39]:http://www.projectatomic.io/
|
||||
[40]:https://github.com/coreos/fleet
|
||||
[41]:https://github.com/coreos/etcd
|
||||
@ -1,29 +1,29 @@
|
||||
如何从终端以后台模式运行Linux程序
|
||||
如何在终端下以后台模式运行Linux程序
|
||||
===
|
||||
|
||||

|
||||
|
||||
Linux终端窗口。
|
||||
*Linux终端窗口*
|
||||
|
||||
这是一个简短但是非常有用的教程:它向你展示从终端运行Linux应用程序的同时,如何保证终端仍然在控制之中。
|
||||
这是一个简短但是非常有用的教程:它向你展示从终端运行Linux应用程序的同时,如何保证终端仍然可以操作。
|
||||
|
||||
在Linux中有许多方式可以打开一个终端,这主要取决于你分类的选择和桌面环境。
|
||||
在Linux中有许多方式可以打开一个终端,这主要取决于你的发行版的选择和桌面环境。
|
||||
|
||||
使用Ubuntu,你可以使用CTRL + ALT + T组合键打开一个终端。你也可以点击超级键(Windows键)打开一个终端窗口。在键盘上,[打开Ubuntu Dash][1],然后搜索"TERM"。点击"Term"图标将会打开一个终端窗口。
|
||||
使用Ubuntu的话,你可以使用CTRL + ALT + T组合键打开一个终端。你也可以点击超级键(Windows键)打开一个终端窗口。在键盘上,[打开Ubuntu Dash][1],然后搜索"TERM"。点击"Term"图标将会打开一个终端窗口。
|
||||
|
||||
其他诸如XFCE, KDE, LXDE, Cinnamon和MATE的桌面环境,你将会在菜单中发现终端。还有一些分类会把终端图标放在入口处,或者在面板上放置终端启动器。
|
||||
其他诸如XFCE, KDE, LXDE, Cinnamon和MATE的桌面环境,你将会在菜单中发现“终端”这个应用。还有一些发行版会把终端图标放在菜单项,或者在面板上放置终端启动器。
|
||||
|
||||
你可以在终端输入一个程序的名字来启动一个应用。举例,你可以通过输入"firefox"启动火狐浏览器。
|
||||
你可以在终端里面输入一个程序的名字来启动一个应用。举例,你可以通过输入"firefox"启动火狐浏览器。
|
||||
|
||||
从终端运行程序的好处是一可以包含额外的选项。
|
||||
从终端运行程序的好处是可以使用额外的选项。
|
||||
|
||||
举个例子,如果你输入下面的命令,一个新的火狐浏览器将会打开,而且默认的搜索引擎将会搜索引用之间的术语:
|
||||
举个例子,如果你输入下面的命令,一个新的火狐浏览器将会打开,而且默认的搜索引擎将会搜索引号之间的词语:
|
||||
|
||||
firefox -search "Linux.About.Com"
|
||||
|
||||
你会发现,如果你运行火狐浏览器,应用程序将被打开,并且控制将会回到终端,这将意味着你可以继续在终端工作。
|
||||
你会发现,如果你运行火狐浏览器,应用程序打开后,控制权将会回到终端(重新出现了命令提示符),这将意味着你可以继续在终端工作。
|
||||
|
||||
通常情况下,如果你通过终端运行一个程序,程序将被打开,并且直到那个程序关闭结束,你将不会重新获得终端的控制权。这是因为你是在前台打开程序的。
|
||||
通常情况下,如果你通过终端运行一个程序,程序打开后,并且直到那个程序关闭结束,你都将不会获得终端的控制权。这是因为你是在前台打开程序的。
|
||||
|
||||
想要从终端运行一个程序,并且立即将终端的控制权返回给你,你需要以后台进程的方式打开程序。
|
||||
|
||||
@ -31,11 +31,11 @@ Linux终端窗口。
|
||||
|
||||
libreoffice &
|
||||
|
||||
在终端中仅仅提供程序的名字,应用程序可能运行不了。如果程序不存在于一个设置了路径变量的文件夹中,你需要指定完成的路径名来运行程序。
|
||||
在终端中仅仅提供程序的名字,应用程序可能运行不了。如果程序不存在于一个设置在PATH 环境变量的文件夹中,你需要指定完整的路径名来运行程序。
|
||||
|
||||
/path/to/yourprogram &
|
||||
|
||||
如果你并不确定一个程序是否存在于Linux文件结构,使用find或者locate命令来查询应用程序。
|
||||
如果你并不确定一个程序是否存在于Linux文件系统中,使用find或者locate命令来查找该应用程序。
|
||||
|
||||
找一个文件的语法如下:
|
||||
|
||||
@ -45,7 +45,7 @@ Linux终端窗口。
|
||||
|
||||
find / -name firefox
|
||||
|
||||
输出会很快掠过,所以你可以以管道的方式控制输出的多少:
|
||||
输出会很快滚动出很多,所以你可以以管道的方式控制输出的多少:
|
||||
|
||||
find / -name firefox | more
|
||||
|
||||
@ -57,26 +57,25 @@ find命令将会返回因权限拒绝而发生错误的文件夹数量,这些
|
||||
|
||||
sudo find / -name firefox | more
|
||||
|
||||
如果你知道你想寻找的文件在你的当前文件夹结构中,你可以一个点代替先前的斜线,如下:
|
||||
如果你知道你想寻找的文件在你的当前文件夹中,你可以一个点代替先前的斜线,如下:
|
||||
|
||||
sudo find . -name firefox | more
|
||||
|
||||
你可能不需要sudo来提升权限。如果你在home文件夹结构中寻找文件,sudo就不需要。
|
||||
你可能不需要sudo来提升权限。如果你在home文件夹中寻找文件,sudo就不需要。
|
||||
|
||||
一些应用程序需要提升用户权限来运行,你可能得到一个缺少权限的错误,除非你使用一个具有足够权限的用户,或者使用sudo提升你的权限。
|
||||
|
||||
下面是一个小花招。如果你运行一个程序,而且它需要提升权限来运行,输入下面命令:
|
||||
下面是一个小花招。如果你运行一个程序,而且它需要提升权限来运行,输入下面命令来提升权限重新执行:
|
||||
|
||||
sudo !!
|
||||
|
||||
---
|
||||
|
||||
via: http://linux.about.com/od/commands/fl/How-To-Run-Linux-Programs-From-T
|
||||
he-Terminal-In-Background-Mode.htm
|
||||
via: http://linux.about.com/od/commands/fl/How-To-Run-Linux-Programs-From-The-Terminal-In-Background-Mode.htm
|
||||
|
||||
作者:[Gary Newell][a]
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中>
|
||||
国](http://linux.cn/) 荣誉推出
|
||||
@ -1,24 +1,22 @@
|
||||
10个检测Linux内存使用情况的‘free’命令
|
||||
检测 Linux 内存使用情况的 free 命令的10个例子
|
||||
===
|
||||
|
||||
**Linux**是最有名的开源操作系统之一,它拥有着极其巨大的指令集。确定**物理内存**和**交换内存**所有可用空间的最重要,也是唯一的方法是使用“**free**”命令。
|
||||
**Linux**是最有名的开源操作系统之一,它拥有着极其巨大的命令集。确定**物理内存**和**交换内存**所有可用空间的最重要、也是唯一的方法是使用“**free**”命令。
|
||||
|
||||
Linux “**free**”命令通过给出**Linux/Unix**操作系统中内核已使用的**buffers**情况,来提供**物理内存**和**交换内存**的总使用量和可用量。
|
||||
Linux “**free**”命令可以给出类**Linux/Unix**操作系统中**物理内存**和**交换内存**的总使用量、可用量及内核使用的**缓冲区**情况。
|
||||
|
||||

|
||||
|
||||
这篇文章提供一些带有参数选项的“**free**”命令,这些命令对于你更好地利用你的内存会有帮助。
|
||||
这篇文章提供一些各种参数选项的“**free**”命令,这些命令对于你更好地利用你的内存会有帮助。
|
||||
|
||||
### 1. 显示你的系统内存 ###
|
||||
|
||||
free命令用于检测**物理内存**和**交换内存**已使用量和可用量(单位为**KB**)。下面演示命令的使用情况。
|
||||
free命令用于检测**物理内存**和**交换内存**已使用量和可用量(默认单位为**KB**)。下面演示命令的使用情况。
|
||||
|
||||
# free
|
||||
|
||||
total used free shared buffers cach
|
||||
ed
|
||||
Mem: 1021628 912548 109080 0 120368 6555
|
||||
48
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912548 109080 0 120368 655548
|
||||
-/+ buffers/cache: 136632 884996
|
||||
Swap: 4194296 0 4194296
|
||||
|
||||
@ -28,21 +26,18 @@ ed
|
||||
|
||||
# free -b
|
||||
|
||||
total used free shared buffers cach
|
||||
ed
|
||||
Mem: 1046147072 934420480 111726592 0 123256832 6712811
|
||||
52
|
||||
total used free shared buffers cached
|
||||
Mem: 1046147072 934420480 111726592 0 123256832 671281152
|
||||
-/+ buffers/cache: 139882496 906264576
|
||||
Swap: 4294959104 0 4294959104
|
||||
|
||||
### 3. 以千字节为单位显示内存 ###
|
||||
|
||||
加上**-k**参数的free命令,以(KB)**千字节**为单位显示内存大小。
|
||||
加上**-k**参数的free命令(默认单位,所以可以不用使用它),以(KB)**千字节**为单位显示内存大小。
|
||||
|
||||
# free -k
|
||||
|
||||
total used free shared buffers cach
|
||||
ed
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912520 109108 0 120368 655548
|
||||
-/+ buffers/cache: 136604 885024
|
||||
Swap: 4194296 0 4194296
|
||||
@ -53,10 +48,8 @@ ed
|
||||
|
||||
# free -m
|
||||
|
||||
total used free shared buffers cach
|
||||
ed
|
||||
Mem: 997 891 106 0 117 6
|
||||
40
|
||||
total used free shared buffers cached
|
||||
Mem: 997 891 106 0 117 640
|
||||
-/+ buffers/cache: 133 864
|
||||
Swap: 4095 0 4095
|
||||
|
||||
@ -66,8 +59,7 @@ ed
|
||||
|
||||
# free -g
|
||||
total used free shared buffers cached
|
||||
Mem: 0 0 0 0 0
|
||||
0
|
||||
Mem: 0 0 0 0 0 0
|
||||
-/+ buffers/cache: 0 0
|
||||
Swap: 3 0 3
|
||||
|
||||
@ -77,10 +69,8 @@ ed
|
||||
|
||||
# free -t
|
||||
|
||||
total used free shared buffers cache
|
||||
d
|
||||
Mem: 1021628 912520 109108 0 120368 6555
|
||||
48
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912520 109108 0 120368 655548
|
||||
-/+ buffers/cache: 136604 885024
|
||||
Swap: 4194296 0 4194296
|
||||
Total: 5215924 912520 4303404
|
||||
@ -91,10 +81,8 @@ d
|
||||
|
||||
# free -o
|
||||
|
||||
total used free shared buffers cache
|
||||
d
|
||||
Mem: 1021628 912520 109108 0 120368 6555
|
||||
48
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912520 109108 0 120368 655548
|
||||
Swap: 4194296 0 4194296
|
||||
|
||||
### 8. 定期时间间隔更新内存状态 ###
|
||||
@ -103,10 +91,8 @@ d
|
||||
|
||||
# free -s 5
|
||||
|
||||
total used free shared buffers cach
|
||||
ed
|
||||
Mem: 1021628 912368 109260 0 120368 6555
|
||||
48
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912368 109260 0 120368 655548
|
||||
-/+ buffers/cache: 136452 885176
|
||||
Swap: 4194296 0 4194296
|
||||
|
||||
@ -116,10 +102,8 @@ ed
|
||||
|
||||
# free -l
|
||||
|
||||
total used free shared buffers cach
|
||||
ed
|
||||
Mem: 1021628 912368 109260 0 120368 6555
|
||||
48
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912368 109260 0 120368 655548
|
||||
Low: 890036 789064 100972
|
||||
High: 131592 123304 8288
|
||||
-/+ buffers/cache: 136452 885176
|
||||
@ -139,7 +123,7 @@ via: http://www.tecmint.com/check-memory-usage-in-linux/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中>
|
||||
国](http://linux.cn/) 荣誉推出
|
||||
@ -1,10 +1,10 @@
|
||||
在Ubuntu上找出可用的网络适配器
|
||||
如何在Ubuntu上找出可用的网络适配器
|
||||
================================================================================
|
||||
想知道**在Linux中你正在使用的网卡是什么吗?** 在Linux中很容易就找出网卡的生产商。打开一个终端并输入下面的额命令:
|
||||
|
||||
sudo lshw -C network
|
||||
|
||||
如果上面的命令不能在sudo下使用,那就移除sudo。它的输出看上去有点奇怪但是很有用。
|
||||
如果上面的命令不能在sudo下使用,那就别用 sudo 的特权模式。它的输出看上去有点奇怪但是很有用。
|
||||
|
||||

|
||||
|
||||
@ -36,7 +36,7 @@
|
||||
>
|
||||
> resources: irq:18 memory:b0600000-b0607fff memory:b0400000-b05fffff
|
||||
|
||||
如你所见,我Macbook Air上的无线网卡是BCM4360,这是一款在Ubuntu下面经常无法检测无线网络的很容易出问题的网卡。
|
||||
如你所见,我Macbook Air上的无线网卡是BCM4360,这是一款在Ubuntu下面很容易出现无法检测无线网络问题的网卡。
|
||||
|
||||
[lshw][1] 命令实际上死用来列出硬件的,因此命令的名字是lshw。带上网络的选项后,就会只过滤出网络硬件了。
|
||||
|
||||
@ -82,7 +82,7 @@
|
||||
>
|
||||
> 04:00.0 SATA controller: Marvell Technology Group Ltd. 88SS9183 PCIe SSD Controller (rev 14)
|
||||
|
||||
这些命令会同时列出有线和无线的网卡。你应该注意到上面的输出中显示我的系统中没有有线网卡。因为我使用的是Macbook Air,他没有以太网端口
|
||||
这些命令会同时列出有线和无线的网卡。你应该注意到上面的输出中显示我的系统中没有有线网卡。因为我使用的是Macbook Air,它没有以太网端口
|
||||
|
||||
我希望这边文章可以帮助你找到你系统中的网卡。欢迎提出问题和建议。
|
||||
|
||||
@ -92,7 +92,7 @@ via: http://itsfoss.com/find-network-adapter-ubuntu-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -11,9 +11,9 @@ Jetty被广泛用于多种项目和产品,都可以在开发环境和生产环
|
||||
- 灵活和可扩展
|
||||
- 小足迹
|
||||
- 可嵌入
|
||||
- 异步
|
||||
- 异步支持
|
||||
- 企业弹性扩展
|
||||
- Apache和Eclipse双重许可
|
||||
- Apache和Eclipse双重许可证
|
||||
|
||||
### ubuntu 14.10 server上安装Jetty 9 ###
|
||||
|
||||
@ -71,10 +71,9 @@ Java将会安装到/usr/lib/jvm/java-8-openjdk-i386,同时在该目录下会
|
||||
|
||||
#### ** ERROR: JETTY_HOME not set, you need to set it or install in a standard location ####
|
||||
|
||||
你需要确保在/etc/default/jetty文件中设置了正确的Jetty家目录路径,
|
||||
你可以使用以下URL来测试jetty
|
||||
你需要确保在/etc/default/jetty文件中设置了正确的Jetty家目录路径,你可以使用以下URL来测试jetty。
|
||||
|
||||
Jetty现在应该运行在8085端口,打开浏览器并访问http://serverip:8085,你应该可以看到Jetty屏幕。
|
||||
Jetty现在应该运行在8085端口,打开浏览器并访问http://服务器IP:8085,你应该可以看到Jetty屏幕。
|
||||
|
||||
#### Jetty服务检查 ####
|
||||
|
||||
@ -96,7 +95,7 @@ via: http://www.ubuntugeek.com/install-jetty-9-java-servlet-engine-and-webserver
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,10 @@
|
||||
如何在Linux的命令行中使用Evernote
|
||||
================================================================================
|
||||
这周让我们继续什么学习如个使用Linux命令行管理和组织信息。在命令行中管理[你的个人花费][1]后,我建议你在命令行中管理你的笔记,特别地是,当你笔记放在Evernote中时。为防止你从来没有听说过,[Evernote][2]专门有一个用户有好的在线服务用来在不同的设备间同步笔记。除了提供花哨的基于Web的API,Evernote还发布了在Windows、Mac、[Android][3]和iOS上的客户端。然而至今还没有官方的Linux客户端可用。老实说在众多的非官方Linux程序中,一个程序一出现就吸引了所有的命令行爱好者:[Geeknote][4]
|
||||
这周让我们继续学习如何使用Linux命令行管理和组织信息。在命令行中管理[你的个人花费][1]后,我建议你在命令行中管理你的笔记,特别是当你用Evernote记录笔记时。要是你从来没有听说过它,[Evernote][2] 专门有一个用户友好的在线服务可以在不同的设备间同步笔记。除了提供花哨的基于Web的API,Evernote还发布了在Windows、Mac、[Android][3]和iOS上的客户端。然而至今还没有官方的Linux客户端可用。老实说在众多的非官方Linux客户端中,有一个程序一出现就吸引了所有的命令行爱好者,它就是[Geeknote][4]。
|
||||
|
||||
### Geeknote 的安装 ###
|
||||
|
||||
Geeknote使用Python开发的。因此,在开始之前请确保你已经安装了Python(最好是2.7的版本)和git。
|
||||
Geeknote是使用Python开发的。因此,在开始之前请确保你已经安装了Python(最好是2.7的版本)和git。
|
||||
|
||||
#### 在 Debian、 Ubuntu 和 Linux Mint 中 ####
|
||||
|
||||
@ -26,38 +26,38 @@ Geeknote使用Python开发的。因此,在开始之前请确保你已经安装
|
||||
|
||||
### Geeknote 的基本使用 ###
|
||||
|
||||
一旦你安装玩Geeknote后,你应该将Geeknote与你的Evernote账号关联:
|
||||
一旦你安装完Geeknote后,你应该将Geeknote与你的Evernote账号关联:
|
||||
|
||||
$ geeknote login
|
||||
|
||||
接着输入你的emial地址、密码、和你的二步验证码。如果你没有后者,忽略它并按下回车。
|
||||
接着输入你的email地址、密码和你的二步验证码。如果你没有后者的话,忽略它并按下回车。
|
||||
|
||||

|
||||
|
||||
很明显,你需要一个Evernote账号来完成这些,因此先去注册。
|
||||
显然你需要一个Evernote账号来完成这些,因此先去注册吧。
|
||||
|
||||
一旦完成这一切之后,你就可以开始了,创建新的笔记并编辑它们。
|
||||
完成这些之后,你就可以开始创建新的笔记并编辑它们了。
|
||||
|
||||
但是首先,你需要设置你最喜欢的文本编辑器:
|
||||
不过首先,你还需要设置你最喜欢的文本编辑器:
|
||||
|
||||
$ geeknote settings --editor vim
|
||||
|
||||
接着,常规创建一条新笔记的语法是:
|
||||
然后,一般创建一条新笔记的语法是:
|
||||
|
||||
$ geeknote create --title [title of the new note] (--content [content] --tags [comma-separated tags] --notebook [comma-separated notebooks])
|
||||
|
||||
上面的命令中,只有‘title’是必须的,它会与一条新笔记的标题相关联。其他的标注可以为笔记添加额外的元数据:添加标签来与你的笔记关联、指定放在那个笔记本里。同样,如果你的标题或者内容还有空格,不要忘记将它们放在引号中。
|
||||
上面的命令中,只有‘title’是必须的,它会与一条新笔记的标题相关联。其他的标注可以为笔记添加额外的元数据:添加标签来与你的笔记关联、指定放在那个笔记本里。同样,如果你的标题或者内容中有空格,不要忘记将它们放在引号中。
|
||||
|
||||
|
||||
比如:
|
||||
|
||||
$ geeknote create --title "My note" --content "This is a test note" --tags "finance, business, important" --notebook "Family"
|
||||
|
||||
通常上,下一步就是编辑你的笔记。语法很相似:
|
||||
然后,你可以编辑你的笔记。语法很相似:
|
||||
|
||||
$ geeknote edit --note [title of the note to edit] (--title [new title] --tags [new tags] --notebook [new notebooks])
|
||||
|
||||
注意可选的参数如标题、标签和笔记本,用来修改笔记的元数据。比如,你可以用下面的命令重命名笔记:
|
||||
注意可选的参数如新的标题、标签和笔记本,用来修改笔记的元数据。你也可以用下面的命令重命名笔记:
|
||||
|
||||
$ geeknote edit --note [old title] --title [new title]
|
||||
|
||||
@ -65,13 +65,13 @@ Geeknote使用Python开发的。因此,在开始之前请确保你已经安装
|
||||
|
||||
$ geeknote find --search [text-to-search] --tags [comma-separated tags] --notebook [comma-separated notebooks] --date [date-or-date-range] --content-search
|
||||
|
||||
默认上,上面的命令会通过标题搜索笔记。 用"--content-search"选项,就可以搜索它们的内容。
|
||||
默认地上面的命令会通过标题搜索笔记。 用"--content-search"选项,就可以按内容搜索。
|
||||
|
||||
比如:
|
||||
|
||||
$ geeknote find --search "*restaurant" --notebooks "Family" --date 31.03.2014-31.08.2014
|
||||
|
||||
显示制定标题的笔记:
|
||||
显示指定标题的笔记:
|
||||
|
||||
$ geeknote show [title]
|
||||
|
||||
@ -89,13 +89,13 @@ Geeknote使用Python开发的。因此,在开始之前请确保你已经安装
|
||||
|
||||
小心这是真正的删除。它会从云存储中删除这条笔记。
|
||||
|
||||
最后有很多的选项来管理标签和笔记本。我想最有用的是显示笔记本列表。
|
||||
最后有很多的选项来管理标签和笔记本。我想最有用的就是显示笔记本列表。
|
||||
|
||||
$ geeknote notebook-list
|
||||
|
||||
|
||||
|
||||
下面的非常相像。你可以猜到,可以用下面的命令列出所有的标签:
|
||||
下面的命令非常相像。你可以猜到,可以用下面的命令列出所有的标签:
|
||||
|
||||
$ geeknote tag-list
|
||||
|
||||
@ -107,27 +107,25 @@ Geeknote使用Python开发的。因此,在开始之前请确保你已经安装
|
||||
|
||||
$ geeknote tag-create --title [tag title]
|
||||
|
||||
一旦你了解了窍门,很明显语法是非常连贯且明确的。
|
||||
一旦你了解了窍门,很明显这些语法是非常自然明确的。
|
||||
|
||||
如果你想要了解更多,不要忘记查看[官方文档][6]。
|
||||
|
||||
### 福利 ###
|
||||
|
||||
As a bonus, Geeknote comes with the utility gnsync, which allows for file synchronization between your Evernote account and your local computer. However, I find its syntax a bit dry:
|
||||
福利的是,Geeknote自带的gnsync工具可以让你在Evernote和本地计算机之间同步。然而,我发现它的语法有点枯燥:
|
||||
作为福利,Geeknote自带的gnsync工具可以让你在Evernote和本地计算机之间同步。不过,我发现它的语法有点枯燥:
|
||||
|
||||
$ gnsync --path [where to sync] (--mask [what kind of file to sync] --format [in which format] --logpath [where to write the log] --notebook [which notebook to use])
|
||||
|
||||
下面是这些的意义。
|
||||
|
||||
下面是这些参数的意义。
|
||||
|
||||
- **--path /home/adrien/Documents/notes/**: 与Evernote同步笔记的位置。
|
||||
- **--mask "*.txt"**: 只同步纯文本文件。默认上,gnsync会尝试同步所有文件。
|
||||
- **--mask "*.txt"**: 只同步纯文本文件。默认gnsync会尝试同步所有文件。
|
||||
- **--format markdown**: 你希望它们是纯文本或者markdown格式(默认是纯文本)。
|
||||
- **--logpath /home/adrien/gnsync.log**: 同步日志的位置。为防出错,gnsync会在那里写入日志信息。
|
||||
- **--notebook "Family"**: 同步哪个笔记本中的笔记。如果你那里留空,程序会创建一个以你同步文件夹命令的笔记本。
|
||||
- **--notebook "Family"**: 同步哪个笔记本中的笔记。如果留空,程序会创建一个以你同步文件夹命令的笔记本。
|
||||
|
||||
总结来说,Geeknote是一款花哨的Evernote的命令行客户端。我个人不常使用Evernote,但它仍然很漂亮和有用。命令行一方面让它变得很极客且很容易与shell脚本结合。同样,还有Git上fork出来的Geeknote,在ArchLinux AUR上称为[geeknote-improved-git][7],貌似它有更多的特性和比其他分支更积极的开发。但在我看来,还很值得再看看。
|
||||
总的来说,Geeknote是一款漂亮的Evernote的命令行客户端。我个人不常使用Evernote,但它仍然很漂亮和有用。命令行一方面让它变得很极客且很容易与shell脚本结合。此外,在Git上还有Geeknote的一个分支项目,在ArchLinux AUR上称为[geeknote-improved-git][7],貌似它有更多的特性和比其他分支更积极的开发。我觉得值得去看看。
|
||||
|
||||
你认为Geeknote怎么样? 有什么你想用的么?或者你更喜欢使用传统的程序?在评论区中让我们知道。
|
||||
|
||||
@ -137,7 +135,7 @@ via: http://xmodulo.com/evernote-command-line-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,12 @@
|
||||
一个用%显示Linux命令进度预计完成时间的伟大工具
|
||||
一个可以显示Linux命令运行进度的伟大工具
|
||||
================================================================================
|
||||
Coreutils Viewer(**cv**)是一个简单的程序,它可以用于显示任何核心组件命令的进度。它使用文件描述信息来确定一个命令的进度,比如cp命令。**cv**之美在于,它能够和其它Linux命令一起使用,比如你所知道的watch以及I/O重定向命令。这样,你就可以在脚本中使用,或者你能想到的所有方式,别让你的想象力束缚住你。
|
||||
Coreutils Viewer(**cv**)是一个简单的程序,它可以用于显示任何核心组件命令(如:cp、mv、dd、tar、gzip、gunzip、cat、grep、fgrep、egrep、cut、sort、xz、exiting)的进度。它使用文件描述信息来确定一个命令的进度,比如cp命令。**cv**之美在于,它能够和其它Linux命令一起使用,比如你所知道的watch以及I/O重定向命令。这样,你就可以在脚本中使用,或者你能想到的所有方式,别让你的想象力束缚住你。
|
||||
|
||||
### 安装 ###
|
||||
|
||||
你可以从cv的[github仓库那儿][1]下载所需的源文件。把zip文件下载下来后,将它解压缩,然后进入到解压后的文件夹。
|
||||
|
||||
该程序依赖于**ncurses library**。如果你已经在你的Linux系统中安装了ncurses,那么cv的安装过程对你而言就是那么得轻松写意。
|
||||
该程序需要**ncurses library**。如果你已经在你的Linux系统中安装了ncurses,那么cv的安装过程对你而言就是那么的轻松写意。
|
||||
|
||||
通过以下两个简单步骤来进行编译和安装吧。
|
||||
|
||||
@ -23,20 +23,21 @@ Coreutils Viewer(**cv**)是一个简单的程序,它可以用于显示任
|
||||
|
||||
$ cv
|
||||
|
||||
如果没有核心组件命令在运行,那么cv程序会退出,并告诉你:No coreutils is running。
|
||||
如果没有核心组件命令在运行,那么cv程序会退出,并告诉你:没有核心组件命令在运行。
|
||||
|
||||

|
||||
|
||||
要有效使用该程序,请在你系统上运行某个核心组件程序。在本例中,我们将使用**cp**命令。
|
||||
|
||||
当拷贝一个打文件时,你就可以看到进度了,以百分比显示。
|
||||
当拷贝一个打文件时,你就可以看到当前进度了,以百分比显示。
|
||||
|
||||

|
||||
|
||||
### 添加选项到cv ###
|
||||
### 添加选项到 cv ###
|
||||
|
||||
你也可以添加几个选项到cv命令,就像其它命令一样。一个有用的选项是让你了解到拷贝或移动大文件时的预计剩余时间。
|
||||
添加**-w**选项,它会帮你做以上这些事。
|
||||
|
||||
添加**-w**选项,它就会帮你显示预计的剩余时间。
|
||||
|
||||
$ cv -w
|
||||
|
||||
@ -46,9 +47,9 @@ Coreutils Viewer(**cv**)是一个简单的程序,它可以用于显示任
|
||||
|
||||
$ cv -wq
|
||||
|
||||
### cv和watch命令 ###
|
||||
### cv 和 watch 命令 ###
|
||||
|
||||
watch是一个用于周期性运行程序并显示输出结果的程序。有时候,你可能想要看看命令运行期间的状况而不想存储数据到日志文件中。在这种情况下,watch就会派上用场了,它可以和cv一起使用。
|
||||
watch是一个用于周期性运行程序并显示输出结果的程序。有时候,你可能想要持续看看命令运行状况而不想将 cv 的结果存储到日志文件中。在这种情况下,watch就会派上用场了,它可以和cv一起使用。
|
||||
|
||||
$ watch cv -qw
|
||||
|
||||
@ -58,7 +59,7 @@ watch是一个用于周期性运行程序并显示输出结果的程序。有时
|
||||
|
||||
### 在日志文件中查看输出结果 ###
|
||||
|
||||
正如所承诺的那样,你可以使用cv来重定向它的输出结果到一个日志文件。这功能在命令运行太快而看不到任何有意义的内容时特别有用。
|
||||
正如其所承诺的那样,你可以使用cv来重定向它的输出结果到一个日志文件。这功能在命令运行太快而看不到任何有意义的内容时特别有用。
|
||||
|
||||
要在日志文件中查看进度,你仅仅需要重定向输出结果,就像下面这样。
|
||||
|
||||
@ -81,7 +82,7 @@ watch是一个用于周期性运行程序并显示输出结果的程序。有时
|
||||
|
||||
但是,要获取上述手册页,你必须执行make install来安装cv。
|
||||
|
||||
耶!现在,你的Linux工具箱中又多了个伟大的工具。
|
||||
耶!现在,你的Linux工具箱中又多了个伟大的工具。 你学会么?亲自去试试吧~
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -89,7 +90,7 @@ via: http://linoxide.com/linux-command/tool-show-command-progress/
|
||||
|
||||
作者:[Allan Mbugua][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
CentOS 7.x中正确设置时间与时钟服务器同步
|
||||
================================================================================
|
||||
**Chrony**是一个开源而自由的应用,它能帮助你保持系统时钟与时钟服务器同步,因此让你的时间保持精确。它由两个程序组成,分别是chronyd和chronyc。chronyd是一个后台运行的守护进程,用于调整内核中运行的系统时钟和时钟服务器同步。它确定计算机获取或丢失时间的比率,并对此进行补偿。chronyc提供了一个用户界面,用于监控性能并进行多样化的配置。它可以在chronyd实例控制的计算机上干这些事,也可以在一台不同的远程计算机上干这些事。
|
||||
**Chrony**是一个开源的自由软件,它能帮助你保持系统时钟与时钟服务器(NTP)同步,因此让你的时间保持精确。它由两个程序组成,分别是chronyd和chronyc。chronyd是一个后台运行的守护进程,用于调整内核中运行的系统时钟和时钟服务器同步。它确定计算机增减时间的比率,并对此进行补偿。chronyc提供了一个用户界面,用于监控性能并进行多样化的配置。它可以在chronyd实例控制的计算机上工作,也可以在一台不同的远程计算机上工作。
|
||||
|
||||
在像CentOS 7之类基于RHEL的操作系统上,已经默认安装有Chrony。
|
||||
|
||||
@ -10,19 +10,17 @@ CentOS 7.x中正确设置时间与时钟服务器同步
|
||||
|
||||
**server** - 该参数可以多次用于添加时钟服务器,必须以"server "格式使用。一般而言,你想添加多少服务器,就可以添加多少服务器。
|
||||
|
||||
Example:
|
||||
server 0.centos.pool.ntp.org
|
||||
server 3.europe.pool.ntp.org
|
||||
|
||||
**stratumweight** - stratumweight指令设置当chronyd从可用源中选择同步源时,每个层应该添加多少距离到同步距离。默认情况下,CentOS中设置为0,让chronyd在选择源时忽略层。
|
||||
**stratumweight** - stratumweight指令设置当chronyd从可用源中选择同步源时,每个层应该添加多少距离到同步距离。默认情况下,CentOS中设置为0,让chronyd在选择源时忽略源的层级。
|
||||
|
||||
**driftfile** - chronyd程序的主要行为之一,就是根据实际时间计算出计算机获取或丢失时间的比率,将它记录到一个文件中是最合理的,它会在重启后为系统时钟作出补偿,甚至它可能有机会从时钟服务器获得好的估值。
|
||||
**driftfile** - chronyd程序的主要行为之一,就是根据实际时间计算出计算机增减时间的比率,将它记录到一个文件中是最合理的,它会在重启后为系统时钟作出补偿,甚至可能的话,会从时钟服务器获得较好的估值。
|
||||
|
||||
**rtcsync** - rtcsync指令将启用一个内核模式,在该模式中,系统时间每11分钟会拷贝到实时时钟(RTC)。
|
||||
|
||||
**allow / deny** - 这里你可以指定一台主机、子网,或者网络以允许或拒绝NTP连接到扮演时钟服务器的机器。
|
||||
|
||||
Examples:
|
||||
allow 192.168.4.5
|
||||
deny 192.168/16
|
||||
|
||||
@ -30,11 +28,10 @@ CentOS 7.x中正确设置时间与时钟服务器同步
|
||||
|
||||
**bindcmdaddress** - 该指令允许你限制chronyd监听哪个网络接口的命令包(由chronyc执行)。该指令通过cmddeny机制提供了一个除上述限制以外可用的额外的访问控制等级。
|
||||
|
||||
Example:
|
||||
bindcmdaddress 127.0.0.1
|
||||
bindcmdaddress ::1
|
||||
|
||||
**makestep** - 通常,chronyd将根据需求通过减慢或加速时钟,使得系统逐步纠正所有时间偏差。在某些特定情况下,系统时钟可能会漂移过快,导致该回转过程消耗很长的时间来纠正系统时钟。该指令强制chronyd在调整期大于某个阀值时调停系统时钟,但只有在因为chronyd启动时间超过指定限制(可使用负值来禁用限制),没有更多时钟更新时才生效。
|
||||
**makestep** - 通常,chronyd将根据需求通过减慢或加速时钟,使得系统逐步纠正所有时间偏差。在某些特定情况下,系统时钟可能会漂移过快,导致该调整过程消耗很长的时间来纠正系统时钟。该指令强制chronyd在调整期大于某个阀值时步进调整系统时钟,但只有在因为chronyd启动时间超过指定限制(可使用负值来禁用限制),没有更多时钟更新时才生效。
|
||||
|
||||
### 使用chronyc ###
|
||||
|
||||
@ -66,7 +63,7 @@ via: http://linoxide.com/linux-command/chrony-time-sync/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,47 @@
|
||||
2015:开源已经完胜,但这并不是结束
|
||||
================================================================================
|
||||
> 在 2014 年的完胜后,接下来会如何?
|
||||
|
||||
新年伊始,习惯上都是回顾已经走过的一年。但只要一直关注我们,就会很容易获得过去一年的总结:开源已经全胜。让我们从头开始说起吧:
|
||||
|
||||
**超级计算机**: Linux 在超级计算机系统 500 强的名单上占据绝对的主导地位这本身就令其它操作系统很尴尬。[2014年11月的数据][1]显示前500系统中的485个系统都在运行着 Linux 的发布系统,而仅仅只有一台运行着 Windows 系统。如果您看看所用的处理器数量,这数据更是让人惊叹。截止到目前,运行 Linux 系统的处理器有 22,851,693 个之多,而 windows 系统仅仅只有 30,720。这意味着什么?Linux 不仅仅是占据主导地位,在大型系统中已经是绝对的霸主了。
|
||||
|
||||
**云计算**: 去年, Linux 基金会撰写了一个有趣的[报告][2],是关于大公司在云端使用 Linux 的情况的。它发现 75% 的大公司在使用 Linux 系统作为他们的主要平台,相对的使用 Windows 系统的只占 23%。因为需要考虑云端和非云端的因素,它们已经混淆在一起了,所以很难把这比例对应到真实的市场份额里。但是,鉴于当前云计算的流行度,可以很确定的说明 Linux 使用的高速增长。事实上,同样的调查发现,在云端的 Linux 部署率已经从 45% 增长到 79%,而对于 Windows 来说已经从 45% 下降到 36%。当然了,某些人可能认为 Linux 基金会在这块上并不是完全公正无私的,但即使是有私心或是因统计的不确定性而有失公允,事情也正朝着预料的正确方向迈进。
|
||||
|
||||
**Web 服务器**: 开源已经统治这个行业近20年 - 取得了一份很惊人的成绩。然而,最近在市场份额上出现了一些有趣的变动:一点就是,在 Web 服务器的总计数上,微软的 IIS 服务已经超越了 Apache 服务。但正如 Netcraft 公司其最近的[分析][3]解释所说的那样,这儿还有很多令人大饱眼福的地方呢:
|
||||
|
||||
> 这是网站总数持续大幅回落以来的第二个月,从一月份以来,本月达到了最低点。与十一月份情况一样,损失的仅仅只是集中在一小部分的主机提供商中,只占了5200万主机名数的十大点。这点损失相比于激活的站点和网站来说不是一个数据级的,所以造不成什么影响,但激活的这些站点大部分都是广告类的链接页面池,基本上没有原创的内容。大多数这些站点都是运行在微软的 IIS 服务器上的,所以在2014年7月份的调查中 IIS 的使用数就超过了 Apache。然而,近期跌势已导致其市场份额下降到 29.8%,现在已经低于Apache 10个百分点了。
|
||||
|
||||
这表明,微软的所谓“激增”更多的是表象,而事实并非如此,它的大多数增加都是基于没什么有用内容的链接页面池。事实上,Netcraft公司的关于活动网站的数据给我们描绘了一幅完全不同的图表:Apache 拥有 50.57% 的市场份额,nginx 的是 14.73% 位居第二;微软的 IIS 很无力,占到了相当微弱的 11.72%。这意味着在活跃 Web 服务器市场上开源大约有65%的份额 - 虽然没有超级计算机那么高的水平,但也还不错。
|
||||
|
||||
**移动设备系统**. 目前,开源的大军主要是 Andriod 为基础在不断高歌猛进。最新数据表明,在2014年第三季度的智能手机出货量中,Andriod 设备的市场份额从去年同期的 81.4% 上升到了 [83.6%][4]。苹果的从去年同期的 13.4% 下降到 12.3%。对于平板电脑来说,Android 平板遵循同样的轨迹:在2014年第二季度,Android 平板的占有率达到[全球平板电脑的销量的75%][5]左右,而苹果的只有25%。
|
||||
|
||||
**嵌入式系统**: 虽然很难量化 Linux 在的重要的嵌入式系统市场的市场份额,但来一个自 2013 年的研究数字表明,[按规划,大约一半的嵌入式系统][6]将会采用 Linux。
|
||||
|
||||
**物联网**: 在很多方面上可以把它们简单的认为是嵌入式系统的另外一个化身,不同之处在于它们被设计为一直在线的。虽然现在谈论它的市场份额还有点为时过早,但如我在[讨论栏目][7]里说的,AllSeen 的物联网开源框架正进行的如火如荼。他们所缺少的也最引入注目的事情只是还没有任何可信任的闭源项目对手。因此,很有可能物联网将会通过开源的方式来达到 Linux 在超级计算机中的占有率这样的水平。
|
||||
|
||||
当然了,这个阶段的成功也带来了一些问题:我们将何去何从?鉴于开源将会使很多成功的行业达到饱和点,想必唯一的办法就是下跌吗?要回答这个问题,我建议浏览下 Christopher Kelty 于2013年写的一篇供同行参阅、发人深省的文章,有个耐人寻味的标题“[天下没有免费的软件][8]”。下面是他的开头段:
|
||||
|
||||
> 自由软件并不存在。在我写了一整本书后,我莫名的忧伤。但这也是我写进文章的一个观点。自由软件和与它一体两面的开源正在不断的变化着。它并不是一直持续不变的,不稳定、不固定、不持久,这正是它的特色的一部分。
|
||||
|
||||
换句话说,无论2014年带给我们多少惊人的免费软件,我们也确信2015年会更多更丰富,因为进化是永无止境的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworlduk.com/blogs/open-enterprise/open-source-has-won-3592314/
|
||||
|
||||
作者:[lyn Moody][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworlduk.com/author/glyn-moody/
|
||||
[1]:http://www.top500.org/statistics/list/
|
||||
[2]:http://www.linuxfoundation.org/publications/linux-foundation/linux-end-user-trends-report-2014
|
||||
[3]:http://news.netcraft.com/archives/2014/12/18/december-2014-web-server-survey.html
|
||||
[4]:http://www.cnet.com/news/android-stays-unbeatable-in-smartphone-market-for-now/
|
||||
[5]:http://timesofindia.indiatimes.com/tech/tech-news/Android-tablet-market-share-hits-70-in-Q2-iPads-slip-to-25-Survey/articleshow/38966512.cms
|
||||
[6]:http://linuxgizmos.com/embedded-developers-prefer-linux-love-android/
|
||||
[7]:http://www.computerworlduk.com/blogs/open-enterprise/allseen-3591023/
|
||||
[8]:http://peerproduction.net/issues/issue-3-free-software-epistemics/debate/there-is-no-free-software/
|
||||
@ -1,30 +1,30 @@
|
||||
Linux 有问必答:如何在Ubuntu或者Debian中启动进入命令行
|
||||
Linux 有问必答:如何在Ubuntu或者Debian中启动后进入命令行
|
||||
================================================================================
|
||||
> **提问**:我运行的是Ubuntu桌面,但是我希望启动后临时进入命令行。有什么简便的方法可以启动进入终端?
|
||||
|
||||
Linux桌面自带了一个显示管理器(比如:GDM、KDM、LightDM),它们可以让计算机启动自动进入一个基于GUI的登录环境。然而,如果你要直接启动进入终端怎么办? 比如,你在排查桌面相关的问题或者想要运行一个不需要GUI的发行程序。
|
||||
Linux桌面自带了一个显示管理器(比如:GDM、KDM、LightDM),它们可以让计算机启动自动进入一个基于GUI的登录环境。然而,如果你要直接启动进入终端怎么办? 比如,你在排查桌面相关的问题或者想要运行一个不需要GUI的应用程序。
|
||||
|
||||
注意你可以通过按下Ctrl+Alt+F1到F6临时从桌面GUI切换到虚拟终端。然而,在本例中你的桌面GUI仍在后台运行,这不同于纯文本模式启动。
|
||||
注意虽然你可以通过按下Ctrl+Alt+F1到F6临时从桌面GUI切换到虚拟终端。然而,在这种情况下你的桌面GUI仍在后台运行,这不同于纯文本模式启动。
|
||||
|
||||
在Ubuntu或者Debian桌面中,你可以通过传递合适的内核参数在启动时启动文本模式。
|
||||
|
||||
### 启动临时进入命令行 ###
|
||||
|
||||
如果你想要禁止桌面GUI并只有一次进入文本模式,你可以使用GRUB菜单。
|
||||
如果你想要禁止桌面GUI并临时进入一次文本模式,你可以使用GRUB菜单。
|
||||
|
||||
首先,打开你的电脑。当你看到初始的GRUB菜单时,按下‘e’。
|
||||
|
||||
|
||||
|
||||
接着会进入下一屏,这里你可以修改内核启动选项。向下滚动到以“linux”开始的行,这里就是内核参数的列表。删除列表中的“quiet”和“splash”。在列表中添加“text”。
|
||||
接着会进入下一屏,这里你可以修改内核启动选项。向下滚动到以“linux”开始的行,这里就是内核参数的列表。删除参数列表中的“quiet”和“splash”。在参数列表中添加“text”。
|
||||
|
||||
|
||||
|
||||
升级的内核选项列表看上去像这样。按下Ctrl+x继续启动。这会一次性以详细模式启动控制台。
|
||||
升级的内核选项列表看上去像这样。按下Ctrl+x继续启动。这会以详细模式启动控制台一次(LCTT译注:由于没有保存修改,所以下次重启还会进入 GUI)。
|
||||
|
||||

|
||||
|
||||
永久启动进入命令行。
|
||||
### 永久启动进入命令行 ###
|
||||
|
||||
如果你想要永久启动进入命令行,你需要[更新定义了内核启动参数GRUB设置][1]。
|
||||
|
||||
@ -32,7 +32,7 @@ Linux桌面自带了一个显示管理器(比如:GDM、KDM、LightDM),
|
||||
|
||||
$ sudo vi /etc/default/grub
|
||||
|
||||
查找以GRUB_CMDLINE_LINUX_DEFAULT开头的行,并用“#”注释这行。这会禁止初始屏幕,而启动详细模式(也就是说显示详细的的启动过程)。
|
||||
查找以GRUB\_CMDLINE\_LINUX\_DEFAULT开头的行,并用“#”注释这行。这会禁止初始屏幕,而启动详细模式(也就是说显示详细的的启动过程)。
|
||||
|
||||
更改GRUB_CMDLINE_LINUX="" 成:
|
||||
|
||||
@ -48,7 +48,7 @@ Linux桌面自带了一个显示管理器(比如:GDM、KDM、LightDM),
|
||||
|
||||
$ sudo update-grub
|
||||
|
||||
这时,你的桌面应该从GUI启动切换到控制台启动了。可以通过重启验证。
|
||||
这时,你的桌面应该可以从GUI启动切换到控制台启动了。可以通过重启验证。
|
||||
|
||||

|
||||
|
||||
@ -57,7 +57,7 @@ Linux桌面自带了一个显示管理器(比如:GDM、KDM、LightDM),
|
||||
via: http://ask.xmodulo.com/boot-into-command-line-ubuntu-debian.html
|
||||
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,50 @@
|
||||
交友网站的2000万用户数据遭泄露
|
||||
----------
|
||||
*泄露数据包括Gmail、Hotmail以及Yahoo邮箱*
|
||||
|
||||

|
||||
|
||||
#一名黑客非法窃取了在线交友网站Topface一个包含2000万用户资料的数据库。
|
||||
|
||||
目前并不清楚这些数据是否已经公开,但是根据某些未公开页面的消息说,某个网名为“Mastermind”的人声称掌握着这些数据。
|
||||
|
||||
#泄露数据列表涵盖了全世界数百个域名
|
||||
|
||||
此人号称泄露数据的内容100%真实有效,而Easy Solutions的CTO,Daniel Ingevaldson 周日在一篇博客中说道,泄露数据包括Hotmail、Yahoo和Gmail等邮箱地址。
|
||||
|
||||
Easy Solutions是一家位于美国的公司,提供多个不同平台的网络检测与安全防护产品。
|
||||
|
||||
据Ingevaldson所说,泄露的数据中,700万来自于Hotmail,250万来自于Yahoo,220万来自于Gmail.com。
|
||||
|
||||
我们并不清楚这些数据是可以直接登录邮箱账户的用户名和密码,还是登录交友网站的账户。另外,也不清楚这些数据在数据库中是加密状态还是明文存在的。
|
||||
|
||||
邮箱地址常常被用于在线网站的登录用户名,用户可以凭借唯一密码进行登录。然而重复使用同一个密码是许多用户的常用作法,同一个密码可以登录许多在线账户。
|
||||
|
||||
[Ingevaldson 还说](1):“看起来,这些数据事实上涵盖了全世界数百个域名。除了原始被黑的网页,黑客和不法分子很可能利用窃取的帐密进行暴库、自动扫描、危害包括银行业、旅游业以及email提供商在内的多个网站。”
|
||||
|
||||
#预计将披露更多信息
|
||||
|
||||
据我们的多个消息源爆料,数据的泄露源就是Topface,一个包含9000万用户的在线交友网站。其总部位于俄罗斯圣彼得堡,超过50%的用户来自于俄罗斯以外的国家。
|
||||
|
||||
我们联系了Topface,向他们求证最近是否遭受了可能导致如此大量数据泄露的网络攻击;但目前我们仍未收到该公司的回复。
|
||||
|
||||
攻击者可能无需获得非法访问权限就窃取了这些数据,Easy Solutions 推测攻击者很可能针对网站客户端使用钓鱼邮件直接获取到了用户数据。
|
||||
|
||||
我们无法通过Easy Solutions的在线网站联系到他们,但我们已经尝试了其他交互通讯方式,目前正在等待更多信息的披露。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://news.softpedia.com/news/Data-of-20-Million-Users-Stolen-from-Dating-Website-471179.shtml
|
||||
|
||||
本文发布时间:26 Jan 2015, 10:20 GMT
|
||||
|
||||
作者:[Ionut Ilascu][a]
|
||||
|
||||
译者:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/ionut-ilascu
|
||||
[1]:http://newblog.easysol.net/dating-site-breached/
|
||||
@ -1,7 +1,7 @@
|
||||
Linux下如何过滤、分割以及合并 pcap 文件
|
||||
=============
|
||||
|
||||
如果你是个网络管理员,并且你的工作包括测试一个[入侵侦测系统][1]或一些网络访问控制策略,那么你通常需要抓取数据包并且在离线状态下分析这些文件。当需要保存捕获的数据包时,我们会想到 libpcap 的数据包格式被广泛使用于许多开源的嗅探工具以及捕包程序。如果 pcap 文件被用于入侵测试或离线分析的话,那么在将他们[注入][2]网络之前通常要先对 pcap 文件进行一些操作。
|
||||
如果你是一个测试[入侵侦测系统][1]或一些网络访问控制策略的网络管理员,那么你经常需要抓取数据包并在离线状态下分析这些文件。当需要保存捕获的数据包时,我们一般会存储为 libpcap 的数据包格式 pcap,这是一种被许多开源的嗅探工具以及捕包程序广泛使用的格式。如果 pcap 文件被用于入侵测试或离线分析的话,那么在将他们[注入][2]网络之前通常要先对 pcap 文件进行一些操作。
|
||||
|
||||
|
||||
|
||||
@ -9,9 +9,9 @@ Linux下如何过滤、分割以及合并 pcap 文件
|
||||
|
||||
### Editcap 与 Mergecap###
|
||||
|
||||
Wireshark,是最受欢迎的 GUI 嗅探工具,实际上它来源于一套非常有用的命令行工具集。其中包括 editcap 与 mergecap。editcap 是一个万能的 pcap 编辑器,它可以过滤并且能以多种方式来分割 pcap 文件。mergecap 可以将多个 pcap 文件合并为一个。 这篇文章就是基于这些 Wireshark 命令行工具。
|
||||
Wireshark,是最受欢迎的 GUI 嗅探工具,实际上它带了一套非常有用的命令行工具集。其中包括 editcap 与 mergecap。editcap 是一个万能的 pcap 编辑器,它可以过滤并且能以多种方式来分割 pcap 文件。mergecap 可以将多个 pcap 文件合并为一个。 这篇文章就是基于这些 Wireshark 命令行工具的。
|
||||
|
||||
如果你已经安装过Wireshark了,那么这些工具已经在你的系统中了。如果还没装的话,那么我们接下来就安装 Wireshark 命令行工具。 需要注意的是,在基于 Debian 的发行版上我们可以不用安装 Wireshark GUI 而仅安装 命令行工具,但是在 Red Hat 及 基于它的发行版中则需要安装整个 Wireshark 包。
|
||||
如果你已经安装过 Wireshark 了,那么这些工具已经在你的系统中了。如果还没装的话,那么我们接下来就安装 Wireshark 命令行工具。 需要注意的是,在基于 Debian 的发行版上我们可以不用安装 Wireshark GUI 而仅安装命令行工具,但是在 Red Hat 及 基于它的发行版中则需要安装整个 Wireshark 包。
|
||||
|
||||
**Debian, Ubuntu 或 Linux Mint**
|
||||
|
||||
@ -27,15 +27,15 @@ Wireshark,是最受欢迎的 GUI 嗅探工具,实际上它来源于一套非
|
||||
|
||||
通过 editcap, 我们能以很多不同的规则来过滤 pcap 文件中的内容,并且将过滤结果保存到新文件中。
|
||||
|
||||
首先,以“起止时间”来过滤 pcap 文件。 " - A < start-time > and " - B < end-time > 选项可以过滤出处在这个时间段到达的数据包(如,从 2:30 ~ 2:35)。时间的格式为 “ YYYY-MM-DD HH:MM:SS"。
|
||||
首先,以“起止时间”来过滤 pcap 文件。 " - A < start-time > 和 " - B < end-time > 选项可以过滤出在这个时间段到达的数据包(如,从 2:30 ~ 2:35)。时间的格式为 “ YYYY-MM-DD HH:MM:SS"。
|
||||
|
||||
$ editcap -A '2014-12-10 10:11:01' -B '2014-12-10 10:21:01' input.pcap output.pcap
|
||||
$ editcap -A '2014-12-10 10:11:01' -B '2014-12-10 10:21:01' input.pcap output.pcap
|
||||
|
||||
也可以从某个文件中提取指定的 N 个包。下面的命令行从 input.pcap 文件中提取100个包(从 401 到 500)并将它们保存到 output.pcap 中:
|
||||
|
||||
$ editcap input.pcap output.pcap 401-500
|
||||
|
||||
使用 "-D< dup-window >" (dup-window可以看成是对比的窗口大小,仅与此范围内的包进行对比)选项可以提取出重复包。每个包都依次与它之前的 < dup-window > -1 个包对比长度与MD5值,如果有匹配的则丢弃。
|
||||
使用 "-D < dup-window >" (dup-window可以看成是对比的窗口大小,仅与此范围内的包进行对比)选项可以提取出重复包。每个包都依次与它之前的 < dup-window > -1 个包对比长度与MD5值,如果有匹配的则丢弃。
|
||||
|
||||
$ editcap -D 10 input.pcap output.pcap
|
||||
|
||||
@ -71,13 +71,13 @@ Wireshark,是最受欢迎的 GUI 嗅探工具,实际上它来源于一套非
|
||||
|
||||
如果要忽略时间戳,仅仅想以命令行中的顺序来合并文件,那么使用 -a 选项即可。
|
||||
|
||||
例如,下列命令会将 input.pcap文件的内容写入到 output.pcap, 并且将 input2.pcap 的内容追加在后面。
|
||||
例如,下列命令会将 input.pcap 文件的内容写入到 output.pcap, 并且将 input2.pcap 的内容追加在后面。
|
||||
|
||||
$ mergecap -a -w output.pcap input.pcap input2.pcap
|
||||
|
||||
###总结###
|
||||
|
||||
在这篇指导中,我演示了多个 editcap、 mergecap 操作 pcap 文件的案例。除此之外,还有其它的相关工具,如 [reordercap][3]用于将数据包重新排序,[text2pcap][4] 用于将pcap 文件转换为 文本格式, [pcap-diff][5]用于比较 pcap 文件的异同,等等。当进行网络入侵测试及解决网络问题时,这些工具与[包注入工具][6]非常实用,所以最好了解他们。
|
||||
在这篇指导中,我演示了多个 editcap、 mergecap 操作 pcap 文件的例子。除此之外,还有其它的相关工具,如 [reordercap][3]用于将数据包重新排序,[text2pcap][4] 用于将 pcap 文件转换为文本格式, [pcap-diff][5]用于比较 pcap 文件的异同,等等。当进行网络入侵测试及解决网络问题时,这些工具与[包注入工具][6]非常实用,所以最好了解他们。
|
||||
|
||||
你是否使用过 pcap 工具? 如果用过的话,你用它来做过什么呢?
|
||||
|
||||
@ -86,8 +86,8 @@ Wireshark,是最受欢迎的 GUI 嗅探工具,实际上它来源于一套非
|
||||
via: http://xmodulo.com/filter-split-merge-pcap-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[SPccman](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[SPccman](https://github.com/SPccman)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,9 @@
|
||||
如何在Linux/类Unix系统中解压tar文件到不同的目录中
|
||||
如何解压 tar 文件到不同的目录中
|
||||
================================================================================
|
||||
我想要解压一个tar文件到一个指定的目录叫/tmp/data。我该如何在Linux或者类Unix的系统中使用tar命令解压一个tar文件到不同的目录中?
|
||||
|
||||
你不必使用cd名切换到其他的目录并解压。可以使用下面的语法解压一个文件:
|
||||
我想要解压一个tar文件到一个叫/tmp/data的指定目录。我该如何在Linux或者类Unix的系统中使用tar命令解压一个tar文件到不同的目录中?
|
||||
|
||||
你不必使用cd命令切换到其他的目录并解压。可以使用下面的语法解压一个文件:
|
||||
|
||||
### 语法 ###
|
||||
|
||||
@ -16,9 +17,9 @@ GNU/tar 语法:
|
||||
|
||||
tar xf file.tar --directory /path/to/directory
|
||||
|
||||
### 示例:解压文件到另一个文件夹中 ###
|
||||
### 示例:解压文件到另一个目录中 ###
|
||||
|
||||
在本例中。我解压$HOME/etc.backup.tar到文件夹/tmp/data中。首先,你需要手动创建这个目录,输入:
|
||||
在本例中。我解压$HOME/etc.backup.tar到/tmp/data目录中。首先,需要手动创建这个目录,输入:
|
||||
|
||||
mkdir /tmp/data
|
||||
|
||||
@ -34,7 +35,7 @@ GNU/tar 语法:
|
||||
|
||||

|
||||
|
||||
Gif 01: tar命令解压文件到不同的目录
|
||||
*Gif 01: tar命令解压文件到不同的目录*
|
||||
|
||||
你也可以指定解压的文件:
|
||||
|
||||
@ -56,8 +57,8 @@ via: http://www.cyberciti.biz/faq/howto-extract-tar-file-to-specific-directory-o
|
||||
|
||||
作者:[nixCraft][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.cyberciti.biz/tips/about-us
|
||||
[a]:http://www.cyberciti.biz/tips/about-us
|
||||
@ -0,0 +1,58 @@
|
||||
在 Ubuntu 14.04 中Apache从2.2迁移到2.4的问题
|
||||
================================================================================
|
||||
如果你将**Ubuntu**从12.04升级跨越到了14.04,那么这其中包括了一个重大的升级--**Apache**从2.2版本升级到2.4版本。**Apache**的这次升级带来了许多性能提升,**但是如果继续使用2.2的配置文件会导致很多错误**。
|
||||
|
||||
### 访问控制的改变 ###
|
||||
|
||||
从**Apache 2.4**起,所启用的授权机制比起2.2的只是针对单一数据存储的单一检查更加灵活。过去很难确定哪个 order 授权怎样被使用的,但是授权容器指令的引入解决了这些问题,现在,配置可以控制什么时候授权方法被调用,什么条件决定何时授权访问。
|
||||
|
||||
这就是为什么大多数的升级失败是由于配置错误的原因。2.2的访问控制是基于IP地址、主机名和其他角色,通过使用指令Order,来设置Allow, Deny或 Satisfy;但是2.4,这些一切都通过新的授权方式进行检查。
|
||||
|
||||
为了弄清楚这些,可以来看一些虚拟主机的例子,这些可以在/etc/apache2/sites-enabled/default 或者 /etc/apache2/sites-enabled/*你的网站名称* 中找到:
|
||||
|
||||
旧的2.2虚拟主机配置:
|
||||
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
|
||||
新的2.4虚拟主机配置:
|
||||
|
||||
Require all granted
|
||||
|
||||

|
||||
|
||||
(LCTT 译注:Order、Allow和deny 这些将在之后的版本废弃,请尽量避免使用,Require 指令已可以提供比其更强大和灵活的功能。)
|
||||
|
||||
### .htaccess 问题 ###
|
||||
|
||||
升级后如果一些设置不工作,或者你得到重定向错误,请检查是否这些设置是放在.htaccess文件中。如果Apache 2.4没有使用 .htaccess 文件中的设置,那是因为在2.4中AllowOverride指令的默认是 none,因此忽略了.htaccess文件。你只需要做的就是修改或者添加AllowOverride All命令到你的网站配置文件中。
|
||||
|
||||
上面截图中,可以看见AllowOverride All指令。
|
||||
|
||||
### 丢失配置文件或者模块 ###
|
||||
|
||||
根据我的经验,这次升级带来的另一个问题就是在2.4中,一些旧模块和配置文件不再需要或者不被支持了。你将会收到一条“Apache不能包含相应的文件”的明确警告,你需要做的是在配置文件中移除这些导致问题的配置行。之后你可以搜索和安装相似的模块来替代。
|
||||
|
||||
### 其他需要了解的小改变 ###
|
||||
|
||||
这里还有一些其他的改变需要考虑,虽然这些通常只会发生警告,而不是错误。
|
||||
|
||||
- MaxClients重命名为MaxRequestWorkers,使之有更准确的描述。而异步MPM,如event,客户端最大连接数不等于工作线程数。旧的配置名依然支持。
|
||||
- DefaultType命令无效,使用它已经没有任何效果了。如果使用除了 none 之外的其它配置值,你会得到一个警告。需要使用其他配置设定来替代它。
|
||||
- EnableSendfile默认关闭
|
||||
- FileETag 现在默认为"MTime Size"(没有INode)
|
||||
- KeepAlive 只接受“On”或“Off”值。之前的任何不是“Off”或者“0”的值都被认为是“On”
|
||||
- 单一的 Mutex 已经替代了 Directives AcceptMutex, LockFile, RewriteLock, SSLMutex, SSLStaplingMutex 和 WatchdogMutexPath 等指令。你需要做的是估计一下这些被替代的指令在2.2中的使用情况,来决定是否删除或者使用Mutex来替代。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/apache-migration-2-2-to-2-4-ubuntu-14-04/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[Vic020/VicYu](http://vicyu.net)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/adriand/
|
||||
[1]:http://httpd.apache.org/docs/2.4/
|
||||
@ -1,17 +1,16 @@
|
||||
translating by mtunique
|
||||
Linux FAQs with Answers--How to check disk space on Linux with df command
|
||||
在 Linux 下你所不知道的 df 命令的那些功能
|
||||
================================================================================
|
||||
> **Question**: I know I can use df command to check a file system's disk space usage on Linux. Can you show me practical examples of the df command so that I can make the most out of it?
|
||||
> **问题**: 我知道在Linux上我可以用df命令来查看磁盘使用空间。你能告诉我df命令的实际例子使我可以最大限度得利用它吗?
|
||||
|
||||
As far as disk storage is concerned, there are many command-line or GUI-based tools that can tell you about current disk space usage. These tools report on detailed disk utilization in various human-readable formats, such as easy-to-understand summary, detailed statistics, or [intuitive visualization][1]. If you simply want to know how much free disk space is available for different file systems, then df command is probably all you need.
|
||||
对于磁盘存储方面,有很多命令行或基于GUI的工具,它可以告诉你关于当前磁盘空间的使用情况。这些工具用各种人们可读的格式展示磁盘利用率的详细信息,比如易于理解的总结,详细的统计信息或直观的[可视化报告][1]。如果你只想知道不同文件系统有多少空闲的磁盘空间,那么df命令可能是你所需要的。
|
||||
|
||||
|
||||
|
||||
The df command can report on disk utilization of any "mounted" file system. There are different ways this command can be invoked. Here are some **useful** df **command examples**.
|
||||
df命令可以展示任何“mounted”文件系统的磁盘利用率。该命令可以用不同的方式调用。这里有一些**有用的** df **命令例子**.
|
||||
|
||||
### Display in Human-Readable Format ###
|
||||
### 用人们可读的方式展示 ###
|
||||
|
||||
By default, the df command reports disk space in 1K blocks, which is not easily interpretable. The "-h" parameter will make df print disk space in a more human-readable format (e.g., 100K, 200M, 3G).
|
||||
默认情况下,df命令用1K为块来展示磁盘空间,这看起来不是很直观。“-h”参数使df用更可读的方式打印磁盘空间(例如 100K,200M,3G)。
|
||||
|
||||
$ df -h
|
||||
|
||||
@ -27,9 +26,9 @@ By default, the df command reports disk space in 1K blocks, which is not easily
|
||||
none 100M 48K 100M 1% /run/user
|
||||
/dev/sda1 228M 98M 118M 46% /boot
|
||||
|
||||
### Display Inode Usage ###
|
||||
### 展示Inode使用情况 ###
|
||||
|
||||
When you monitor disk usage, you must watch out for not only disk space, but also "inode" usage. In Linux, inode is a data structure used to store metadata of a particular file, and when a file system is created, a pre-defined number of inodes are allocated. This means that a file system can run out of space not only because big files use up all available space, but also because many small files use up all available inodes. To display inode usage, use "-i" option.
|
||||
当你监视磁盘使用情况时,你必须注意的不仅仅是磁盘空间还有“inode”的使用情况。在Linux中,inode是用来存储特定文件的元数据的一种数据结构,在创建一个文件系统时,inode的预先定义数量将被分配。这意味着,**一个文件系统可能耗尽空间不只是因为大文件用完了所有可用空间,也可能是因为很多小文件用完了所有可能的inode**。用“-i”选项展示inode使用情况。
|
||||
|
||||
$ df -i
|
||||
|
||||
@ -45,9 +44,9 @@ When you monitor disk usage, you must watch out for not only disk space, but als
|
||||
none 1004417 28 1004389 1% /run/user
|
||||
/dev/sda1 124496 346 124150 1% /boot
|
||||
|
||||
### Display Disk Usage Grant Total ###
|
||||
### 展示磁盘总利用率 ###
|
||||
|
||||
By default, the df command shows disk utilization of individual file systems. If you want to know the total disk usage over all existing file systems, add "--total" option.
|
||||
默认情况下, df命令显示磁盘的单个文件系统的利用率。如果你想知道的所有文件系统的总磁盘使用量,增加“ --total ”选项(见最下面的汇总行)。
|
||||
|
||||
$ df -h --total
|
||||
|
||||
@ -64,9 +63,9 @@ By default, the df command shows disk utilization of individual file systems. If
|
||||
/dev/sda1 228M 98M 118M 46% /boot
|
||||
total 918G 565G 307G 65% -
|
||||
|
||||
### Display File System Types ###
|
||||
### 展示文件系统类型 ###
|
||||
|
||||
By default, the df command does not show file system type information. Use "-T" option to add file system types to the output.
|
||||
默认情况下,df命令不显示文件系统类型信息。用“-T”选项来添加文件系统信息到输出中。
|
||||
|
||||
$ df -T
|
||||
|
||||
@ -82,9 +81,9 @@ By default, the df command does not show file system type information. Use "-T"
|
||||
none tmpfs 102400 48 102352 1% /run/user
|
||||
/dev/sda1 ext2 233191 100025 120725 46% /boot
|
||||
|
||||
### Include or Exclude a Specific File System Type ###
|
||||
### 包含或排除特定的文件系统类型 ###
|
||||
|
||||
If you want to know free space of a specific file system type, use "-t <type>" option. You can use this option multiple times to include more than one file system types.
|
||||
如果你想知道特定文件系统类型的剩余空间,用“-t <type>”选项。你可以多次使用这个选项来包含更多的文件系统类型。
|
||||
|
||||
$ df -t ext2 -t ext4
|
||||
|
||||
@ -94,13 +93,13 @@ If you want to know free space of a specific file system type, use "-t <type>" o
|
||||
/dev/mapper/ubuntu-root 952893348 591583380 312882756 66% /
|
||||
/dev/sda1 233191 100025 120725 46% /boot
|
||||
|
||||
To exclude a specific file system type, use "-x <type>" option. You can use this option multiple times as well.
|
||||
排除特定的文件系统类型,用“-x <type>”选项。同样,你可以用这个选项多次来排除多种文件系统类型。
|
||||
|
||||
$ df -x tmpfs
|
||||
|
||||
### Display Disk Usage of a Specific Mount Point ###
|
||||
### 显示一个具体的挂载点磁盘使用情况 ###
|
||||
|
||||
If you specify a mount point with df, it will report disk usage of the file system mounted at that location. If you specify a regular file (or a directory) instead of a mount point, df will display disk utilization of the file system which contains the file (or the directory).
|
||||
如果你用df指定一个挂载点,它将报告挂载在那个地方的文件系统的磁盘使用情况。如果你指定一个普通文件(或一个目录)而不是一个挂载点,df将显示包含这个文件(或目录)的文件系统的磁盘利用率。
|
||||
|
||||
$ df /
|
||||
|
||||
@ -118,9 +117,9 @@ If you specify a mount point with df, it will report disk usage of the file syst
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
/dev/mapper/ubuntu-root 952893348 591583528 312882608 66% /
|
||||
|
||||
### Display Information about Dummy File Systems ###
|
||||
### 显示虚拟文件系统的信息 ###
|
||||
|
||||
If you want to display disk space information for all existing file systems including dummy file systems, use "-a" option. Here, dummy file systems refer to pseudo file systems which do not have corresponding physical devices, e.g., tmpfs, cgroup virtual file system or FUSE file systems. These dummy filesystems have size of 0, and are not reported by df without "-a" option.
|
||||
如果你想显示所有已经存在的文件系统(包括虚拟文件系统)的磁盘空间信息,用“-a”选项。这里,虚拟文件系统是指没有相对应的物理设备的假文件系统,例如,tmpfs,cgroup虚拟文件系统或FUSE文件安系统。这些虚拟文件系统大小为0,不用“-a”选项将不会被报告出来。
|
||||
|
||||
$ df -a
|
||||
|
||||
@ -150,8 +149,8 @@ If you want to display disk space information for all existing file systems incl
|
||||
|
||||
via: http://ask.xmodulo.com/check-disk-space-linux-df-command.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[mtunique](https://github.com/mtunique)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
Linux有问必答:如何检查Linux的内存使用状况
|
||||
================================================================================
|
||||
|
||||
>**问题**:我想要监测Linux系统的内存使用状况。有哪些可用的图形界面或者命令行工具来检查当前内存使用情况?
|
||||
|
||||
当涉及到Linux系统性能优化的时候,物理内存是一个最重要的因素。自然的,Linux提供了丰富的选择来监测珍贵的内存资源的使用情况。不同的工具,在监测粒度(例如:全系统范围,每个进程,每个用户),接口方式(例如:图形用户界面,命令行,ncurses)或者运行模式(交互模式,批量处理模式)上都不尽相同。
|
||||
|
||||
下面是一个可供选择的,但并不全面的图形或命令行工具列表,这些工具用来检查Linux平台中已用和可用的内存。
|
||||
|
||||
### 1. /proc/meminfo ###
|
||||
|
||||
一种最简单的方法是通过“/proc/meminfo”来检查内存使用状况。这个动态更新的虚拟文件事实上是诸如free,top和ps这些与内存相关的工具的信息来源。从可用/闲置物理内存数量到等待被写入缓存的数量或者已写回磁盘的数量,只要是你想要的关于内存使用的信息,“/proc/meminfo”应有尽有。特定进程的内存信息也可以通过“/proc/\<pid>/statm”和“/proc/\<pid>/status”来获取。
|
||||
|
||||
$ cat /proc/meminfo
|
||||
|
||||
|
||||
|
||||
### 2. atop ###
|
||||
|
||||
atop命令是用于终端环境的基于ncurses的交互式的系统和进程监测工具。它展示了动态更新的系统资源摘要(CPU, 内存, 网络, 输入/输出, 内核),并且用醒目的颜色把系统高负载的部分以警告信息标注出来。它同样提供了类似于top的线程(或用户)资源使用视图,因此系统管理员可以找到哪个进程或者用户导致的系统负载。内存统计报告包括了总计/闲置内存,缓存的/缓冲的内存和已提交的虚拟内存。
|
||||
|
||||
$ sudo atop
|
||||
|
||||
|
||||
|
||||
### 3. free ###
|
||||
|
||||
free命令是一个用来获得内存使用概况的快速简单的方法,这些信息从“/proc/meminfo”获取。它提供了一个快照,用于展示总计/闲置的物理内存和系统交换区,以及已使用/闲置的内核缓冲区。
|
||||
|
||||
$ free -h
|
||||
|
||||

|
||||
|
||||
### 4. GNOME System Monitor ###
|
||||
|
||||
GNOME System Monitor 是一个图形界面应用,它展示了包括CPU,内存,交换区和网络在内的系统资源使用率的较近历史信息。它同时也可以提供一个带有CPU和内存使用情况的进程视图。
|
||||
|
||||
$ gnome-system-monitor
|
||||
|
||||
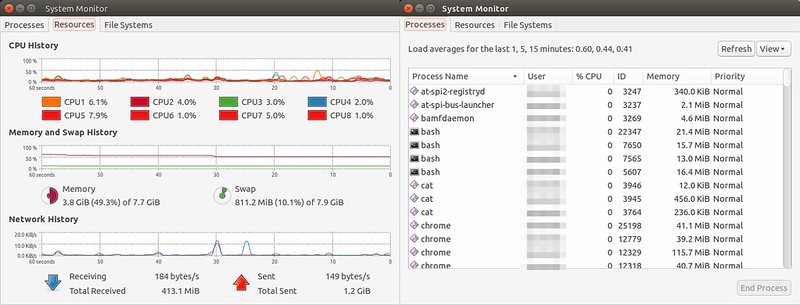
|
||||
|
||||
### 5. htop ###
|
||||
|
||||
htop命令是一个基于ncurses的交互式的进程视图,它实时展示了每个进程的内存使用情况。它可以报告所有运行中进程的常驻内存大小(RSS)、内存中程序的总大小、库大小、共享页面大小和脏页面大小。你可以横向或者纵向滚动进程列表进行查看。
|
||||
|
||||
$ htop
|
||||
|
||||
|
||||
|
||||
### 6. KDE System Monitor ###
|
||||
|
||||
就像GNOME桌面拥有GNOME System Monitor一样,KDE桌面也有它自己的对口应用:KDE System Monitor。这个工具的功能与GNOME版本极其相似,也就是说,它同样展示了一个关于系统资源使用情况,以及带有每个进程的CPU/内存消耗情况的实时历史记录。
|
||||
|
||||
$ ksysguard
|
||||
|
||||
|
||||
|
||||
### 7. memstat ###
|
||||
|
||||
memstat工具对于识别正在消耗虚拟内存的可执行部分、进程和共享库非常有用。给出一个进程识别号,memstat即可识别出与之相关联的可执行部分、数据和共享库究竟使用了多少虚拟内存。
|
||||
|
||||
$ memstat -p <PID>
|
||||
|
||||
|
||||
|
||||
### 8. nmon ###
|
||||
|
||||
nmon工具是一个基于ncurses系统基准测试工具,它能够以交互方式监测CPU、内存、磁盘I/O、内核、文件系统以及网络资源。对于内存使用状况而言,它能够展示像总计/闲置内存、交换区、缓冲的/缓存的内存,虚拟内存页面换入换出的统计,所有这些都是实时的。
|
||||
|
||||
$ nmon
|
||||
|
||||
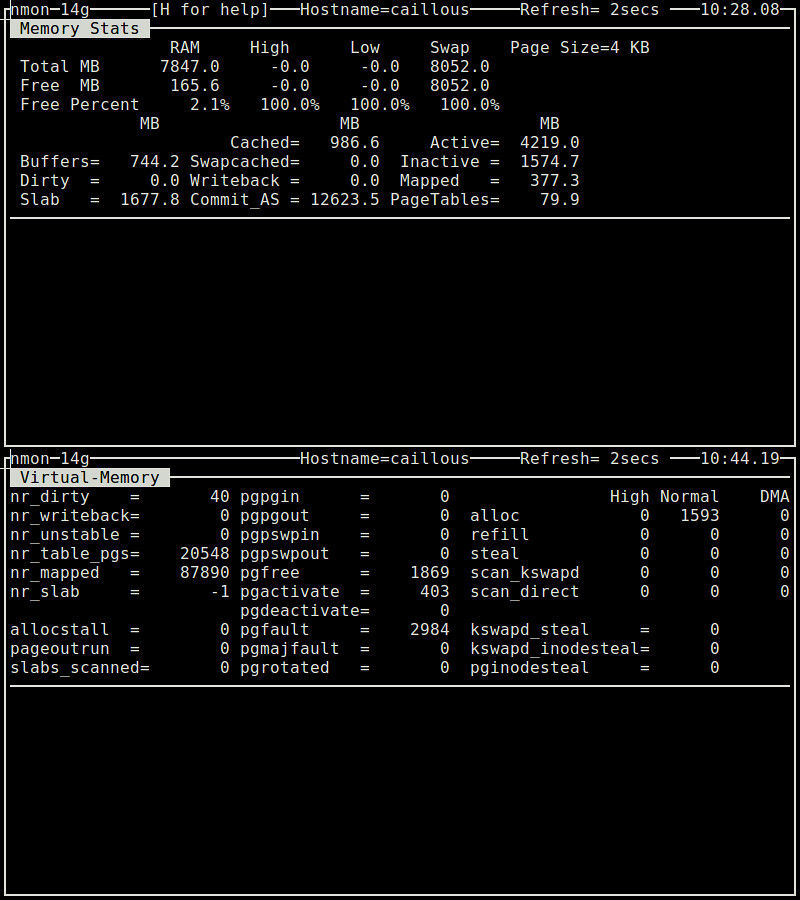
|
||||
|
||||
### 9. ps ###
|
||||
|
||||
ps命令能够实时展示每个进程的内存使用状况。内存使用报告里包括了 %MEM (物理内存使用百分比), VSZ (虚拟内存使用总量), 和 RSS (物理内存使用总量)。你可以使用“--sort”选项来对进程列表排序。例如,按照RSS降序排序:
|
||||
|
||||
$ ps aux --sort -rss
|
||||
|
||||
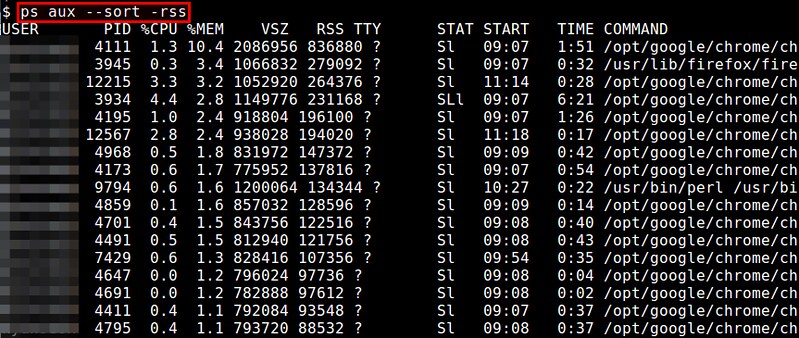
|
||||
|
||||
### 10. smem ###
|
||||
|
||||
[smem][1]命令允许你测定不同进程和用户的物理内存使用状况,这些信息来源于“/proc”目录。它利用“按比例分配大小(PSS)”指标来精确量化Linux进程的有效内存使用情况。内存使用分析结果能够输出为柱状图或者饼图类的图形化图表。
|
||||
|
||||
$ sudo smem --pie name -c "pss"
|
||||
|
||||
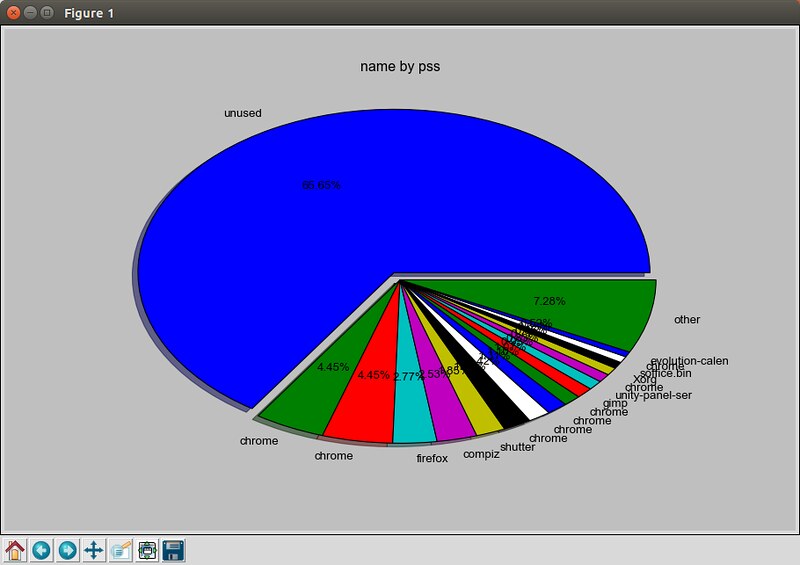
|
||||
|
||||
### 11. top ###
|
||||
|
||||
top命令提供了一个运行中进程的实时视图,以及特定进程的各种资源使用统计信息。与内存相关的信息包括 %MEM (内存使用率), VIRT (虚拟内存使用总量), SWAP (换出的虚拟内存使用量), CODE (分配给代码执行的物理内存数量), DATA (分配给非执行的数据的物理内存数量), RES (物理内存使用总量; CODE+DATA), 和 SHR (有可能与其他进程共享的内存数量)。你能够基于内存使用情况或者大小对进程列表进行排序。
|
||||
|
||||
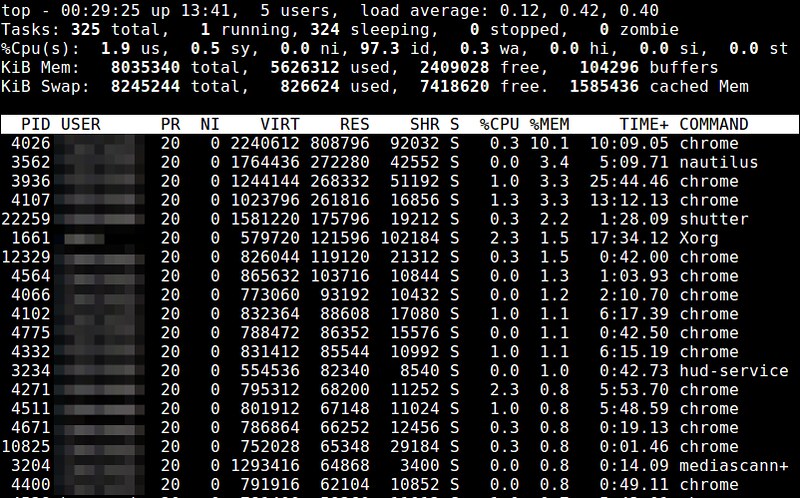
|
||||
|
||||
### 12. vmstat ###
|
||||
|
||||
vmstat命令行工具显示涵盖了CPU、内存、中断和磁盘I/O在内的各种系统活动的瞬时和平均统计数据。对于内存信息而言,命令不仅仅展示了物理内存使用情况(例如总计/已使用内存和缓冲的/缓存的内存),还同样展示了虚拟内存统计数据(例如,内存页的换入/换出,虚拟内存页的换入/换出)
|
||||
|
||||
$ vmstat -s
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/check-memory-usage-linux.html
|
||||
|
||||
译者:[Ping](https://github.com/mr-ping)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/visualize-memory-usage-linux.html
|
||||
@ -0,0 +1,87 @@
|
||||
4个最流行的Linux平台开源代码编辑器
|
||||
===
|
||||
|
||||

|
||||
|
||||
寻找**Linux平台最棒的代码编辑器**?如果你询问那些很早就玩Linux的人,他们会回答是Vi, Vim, Emacs, Nano等。但是,我今天不讨论那些。我将谈论一些新时代尖端、漂亮、时髦而且十分强大, 功能丰富的**最好的Linux平台开源代码编辑器**,它们将会提升你的编程经验。
|
||||
|
||||
### Linux平台最时髦的开源代码编辑器 ###
|
||||
|
||||
我使用Ubuntu作为我的主桌面,所以我提供的安装说明是基于Ubuntu的发行版。但是这并不意味着本文列表就是**Ubuntu最好的文本编辑器**,因为本列表是适用于任何Linux发行版。而且,列表的介绍顺序并没有特定的优先级别。
|
||||
|
||||
#### Brackets ####
|
||||
|
||||

|
||||
|
||||
[Brackets][1]是出自[Adobe][2]的一个开源代码编辑器。它专门关注web设计者的需求,内置支持HTML, CSS和Java Script。它轻量级,但却十分强大,提供在线编辑和实时预览。而且,为了你能更好地体验Brackets,你可以使用许多可用的插件。
|
||||
|
||||
为了[在Ubuntu][3],以及其它基于Ubuntu的发行版,诸如Linux Minit上安装Brackets,你可以使用这个非官方的PPA源:
|
||||
|
||||
sudo add-apt-repository ppa:webupd8team/brackets
|
||||
sudo apt-get update
|
||||
sudo apt-get install brackets
|
||||
|
||||
其他的Linux发行版本,你可以通过下载源代码或相应Linux, OS X和Windows的二进制文件,进行安装。
|
||||
|
||||
- [下载Brackets源码和二进制文件][5]
|
||||
|
||||
#### Atom ####
|
||||
|
||||

|
||||
|
||||
[Atom][5]是为程序员准备的另一个时尚开源代码编辑器。Atom由Github开发,被誉为“21世纪可破解的文本编辑器”。Atom的界面和Sublime Text编辑器十分相似。Sublime Text是一个十分流行但闭源的文本编辑器。
|
||||
|
||||
Atom最近已经发布了 .deb 和 .rpm包,所以在Debian和基于Fedora的Linux版本上安装很简单。当然,你也可以获取它的源代码。
|
||||
|
||||
- [下载Atom .deb][6]
|
||||
- [下载Atom .rpm][7]
|
||||
- [获取Atom源代码][8]
|
||||
|
||||
#### Lime Text ###
|
||||
|
||||

|
||||
|
||||
如果你喜欢Sublime Text,但是你对它的闭源十分反感。别担心,我们有一个[Sublime Text的开源克隆][9],叫做[Lime Text][10]。它基于Go, HTML和QT构造。说它是Sublime Text的克隆,背后原因是Sublime Text2仍有许多bug,而且Sublime Text3到目前为止仍处于测试版本。Sublime Text在开发过程中的bug是否修复,外界并不知情。
|
||||
|
||||
所以,开源爱好者们,你们可以很开心地通过下面的连接获得Lime Text的源码:
|
||||
|
||||
- [获取Lime Text源码][11]
|
||||
|
||||
#### Light Table ####
|
||||
|
||||

|
||||
|
||||
被誉为“下一代的代码编辑器”,[Light Table][12]是另一个时髦,功能丰富的开源编辑器,它更像是一个IDE,而非仅仅是一个文本编辑器。并且,有许多可以提高其性能的扩展方法。内联评价将是你会爱上它的原因。你一定要试用一下看,这样你才会体会它的实用之处。
|
||||
|
||||
- [获取Light Table的源码][13]
|
||||
|
||||
### 你的选择是什么? ###
|
||||
|
||||
在Linux平台,我们不能只局限于这四种代码编辑器。这份列表仅介绍了一些时髦的,可供程序员使用的编辑器。当然,你也有许多其他的选择,比如[Notepad++的替代品Notepadqq][14]或者[SciTE][15]等等。那么,文中这四个编辑器,你最喜欢哪个呢?
|
||||
|
||||
---
|
||||
|
||||
via: http://itsfoss.com/best-modern-open-source-code-editors-for-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://brackets.io/
|
||||
[2]:http://www.adobe.com/
|
||||
[3]:http://itsfoss.com/install-brackets-ubuntu/
|
||||
[4]:https://github.com/adobe/brackets/releases
|
||||
[5]:https://atom.io/
|
||||
[6]:https://atom.io/download/deb
|
||||
[7]:https://atom.io/download/rpm
|
||||
[8]:https://github.com/atom/atom/blob/master/docs/build-instructions/linux.md
|
||||
[9]:http://itsfoss.com/lime-text-open-source-alternative/
|
||||
[10]:http://limetext.org/
|
||||
[11]:https://github.com/limetext/lime
|
||||
[12]:http://lighttable.com/
|
||||
[13]:https://github.com/LightTable/LightTable
|
||||
[14]:http://itsfoss.com/notepadqq-notepad-for-linux/
|
||||
[15]:http://itsfoss.com/scite-the-notepad-for-linux/
|
||||
@ -0,0 +1,33 @@
|
||||
Ubuntu 15.04即将整合Linux内核3.19分支
|
||||
----
|
||||
*Ubuntu已经开始整合一个新的内核分支*
|
||||
|
||||
|
||||
|
||||
Linux内核是一个发行版中最重要的组成部分,Ubuntu用户很想知道哪个版本将用于预计几个月后就会发布的15.04分支的稳定版中。
|
||||
|
||||
Ubuntu和Linux内核开发周期并不同步,所以很难预测最终哪个版本将应用在Ubuntu 15.04中。目前,Ubuntu 15.04(长尾黑颚猴)使用的是Linux内核3.18,但是开发者们已经准备应用3.19分支了。
|
||||
|
||||
“我们的Vivid的内核仍然基于v3.18.2的上游稳定内核,但是我们很快将重新基于v3.18.3内核开发。我们也将把我们的非稳定版分支的基础变更到v3.19-rc5,然后上传到我们的团队PPA。”Canonical的Joseph Salisbury[说](1)。
|
||||
|
||||
Linux内核3.19仍然处于开发阶段,预计还要几个星期才会出稳定版本,但是有充足的时间将它加入到Ubuntu中并测试。但是不可能等到3.20分支了,举个例子,即使它能在4月23日前发布。
|
||||
|
||||
你现在就可以从Softpedia[下载Ubuntu 15.04](2),试用一下。这是一个每日构建版本,会包含发行版中目前已经做出的所有改善。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://linux.softpedia.com/blog/Ubuntu-15-04-to-Integrate-Linux-Kernel-3-19-Branch-Soon-471121.shtml
|
||||
|
||||
本文发布时间:25 Jan 2015, 20:39 GMT
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:https://lists.ubuntu.com/archives/ubuntu-devel/2015-January/038644.html
|
||||
[2]:http://linux.softpedia.com/get/Linux-Distributions/Ubuntu-Vivid-Vervet-103651.shtml
|
||||
@ -0,0 +1,47 @@
|
||||
Android 中的 Wi-Fi 直连方式的 Bug 会导致拒绝服务
|
||||
----
|
||||
|
||||
*Google标记这个问题为低严重性,并不急着修复*
|
||||
|
||||

|
||||
|
||||
Android处理Wi-Fi直连连接的方式中的一个漏洞可以导致在搜索连接节点的时候所连接的设备重启,这个节点可能是其他手机,摄像头,游戏设备,电脑或是打印机等任何设备。
|
||||
|
||||
Wi-Fi直连技术允许无线设备之间直接建立通信,而不用加入到本地网络中。
|
||||
|
||||
###安全公司致力于协调修复这个问题
|
||||
|
||||
这个漏洞允许攻击者发送一个特定的修改过的802.11侦测响应帧给设备,从而因为WiFi监控类中的一个未处理的异常导致设备重启。
|
||||
|
||||
Core Security通过自己的CoreLabs团队发现了这个瑕疵(CVE-2014-0997),早在2014年9月就汇报给了Google。Google确认了这个问题,却把它列为低严重性,并不提供修复时间表。
|
||||
|
||||
每次Core Security联系Android安全组要求提供修复时间表的时候都会收到同样的答复。最后一次答复是1月20日,意味着这么长的时间中都没有补丁。在星期一的时候,这家安全公司公布了他们的发现。
|
||||
|
||||
这家安全公司建立了一个[概念攻击][1]来展示他们研究结果的有效性。
|
||||
|
||||
根据这个漏洞的技术细节,一些Android设备在收到一个错误的wpa_supplicant事件后可能会进入拒绝服务状态,这些事件让无线驱动和Android平台框架之间的接口有效。
|
||||
|
||||
###Google并不着急解决这个问题
|
||||
|
||||
Android安全组对于这个问题的放松态度可能是基于这个原因:这种拒绝服务状态只发生在扫描节点这一小段时间。
|
||||
|
||||
不仅如此,实际上结果也并不严重,因为它会导致设备重启。不存在数据泄漏的风险或是能引起这个问题的攻击,不会吸引攻击者。但另一方面,不管怎样都应该提供一个补丁,以减轻任何未来的潜在风险。
|
||||
|
||||
Core Security声称在Android 5.0.1及以上版本中没有测试到这个问题,他们发现的受影响的设备有Android系统4.4.4的Nexus 5和4,运行Android 4.2.2的LG D806和Samsung SM-T310,以及4.1.2版本系统的Motorola RAZR HD。
|
||||
|
||||
目前,减轻影响的方式是尽量不用Wi-Fi直连,或者升级到没有漏洞的Android版本。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://news.softpedia.com/news/Bug-In-Wi-Fi-Direct-Android-Implementation-Causes-Denial-of-Service-471299.shtml
|
||||
|
||||
本文发布时间:27 Jan 2015, 09:11 GMT
|
||||
|
||||
作者:[Ionut Ilascu][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/ionut-ilascu
|
||||
[1]:http://www.coresecurity.com/advisories/android-wifi-direct-denial-service
|
||||
78
published/20150127 Install Jetty Web Server On CentOS 7.md
Normal file
78
published/20150127 Install Jetty Web Server On CentOS 7.md
Normal file
@ -0,0 +1,78 @@
|
||||
在CentOS 7中安装Jetty服务器
|
||||
================================================================================
|
||||
[Jetty][1] 是一款纯Java的HTTP **(Web) 服务器**和Java Servlet容器。 通常在更大的网络框架中,Jetty经常用于设备间的通信,而其他Web服务器通常给“人类”传递文件 :D。Jetty是一个Eclipse基金会的免费开源项目。这个Web服务器用于如Apache ActiveMQ、 Alfresco、 Apache Geronimo、 Apache Maven、 Apache Spark、Google App Engine、 Eclipse、 FUSE、 Twitter的 Streaming API 和 Zimbra中。
|
||||
|
||||
这篇文章会介绍‘如何在CentOS服务器中安装Jetty服务器’。
|
||||
|
||||
**首先我们要用下面的命令安装JDK:**
|
||||
|
||||
yum -y install java-1.7.0-openjdk wget
|
||||
|
||||
**JDK安装之后,我们就可以下载最新版本的Jetty了:**
|
||||
|
||||
wget http://download.eclipse.org/jetty/stable-9/dist/jetty-distribution-9.2.5.v20141112.tar.gz
|
||||
|
||||
**解压并移动下载的包到/opt:**
|
||||
|
||||
tar zxvf jetty-distribution-9.2.5.v20141112.tar.gz -C /opt/
|
||||
|
||||
**重命名文件夹名为jetty:**
|
||||
|
||||
mv /opt/jetty-distribution-9.2.5.v20141112/ /opt/jetty
|
||||
|
||||
**创建一个jetty用户:**
|
||||
|
||||
useradd -m jetty
|
||||
|
||||
**改变jetty文件夹的所属用户:**
|
||||
|
||||
chown -R jetty:jetty /opt/jetty/
|
||||
|
||||
**为jetty.sh创建一个软链接到 /etc/init.d directory 来创建一个启动脚本文件:**
|
||||
|
||||
ln -s /opt/jetty/bin/jetty.sh /etc/init.d/jetty
|
||||
|
||||
**添加脚本:**
|
||||
|
||||
chkconfig --add jetty
|
||||
|
||||
**是jetty在系统启动时启动:**
|
||||
|
||||
chkconfig --level 345 jetty on
|
||||
|
||||
**使用你最喜欢的文本编辑器打开 /etc/default/jetty 并修改端口和监听地址:**
|
||||
|
||||
vi /etc/default/jetty
|
||||
|
||||
----------
|
||||
|
||||
JETTY_HOME=/opt/jetty
|
||||
JETTY_USER=jetty
|
||||
JETTY_PORT=8080
|
||||
JETTY_HOST=50.116.24.78
|
||||
JETTY_LOGS=/opt/jetty/logs/
|
||||
|
||||
**我们完成了安装,现在可以启动jetty服务了 **
|
||||
|
||||
service jetty start
|
||||
|
||||
完成了!
|
||||
|
||||
现在你可以在 **http://\<你的 IP 地址>:8080** 中访问了
|
||||
|
||||
就是这样。
|
||||
|
||||
干杯!!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/install-jetty-web-server-centos-7/
|
||||
|
||||
作者:[Jijo][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/jijo/
|
||||
[1]:http://eclipse.org/jetty/
|
||||
@ -21,7 +21,7 @@ Developed in part by two ex-Rackspace engineers, [CoreOS][8] is a lightweight Li
|
||||
CoreOS was quickly adopted by many cloud providers, including Microsoft Azure, Amazon Web Services, DigitalOcean and Google Compute Engine.
|
||||
|
||||
Like CoreOS, Ubuntu Core offers an expedited process for updating components, reducing the amount of time that an administrator would need to manually manage them.
|
||||
|
||||
如同Coreos一样,Ubuntu内核提供了一个快速引擎来更新组件
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2860401/cloud-computing/google-cloud-offers-streamlined-ubuntu-for-docker-use.html
|
||||
@ -40,4 +40,4 @@ via: http://www.infoworld.com/article/2860401/cloud-computing/google-cloud-offer
|
||||
[5]:http://www.itworld.com/article/2695383/open-source-tools/docker-all-geared-up-for-the-enterprise.html
|
||||
[6]:http://www.itworld.com/article/2695501/cloud-computing/google-unleashes-docker-management-tools.html
|
||||
[7]:http://www.itworld.com/article/2696116/open-source-tools/coreos-linux-does-away-with-the-upgrade-cycle.html
|
||||
[8]:https://coreos.com/using-coreos/
|
||||
[8]:https://coreos.com/using-coreos/
|
||||
|
||||
@ -0,0 +1,38 @@
|
||||
LibreOffice 4.4 Released as the Most Beautiful LibreOffice Ever
|
||||
----
|
||||
*The developer has made a lot of UI improvements*
|
||||
|
||||

|
||||
|
||||
The Document Foundation has just announced that a new major update has been released for LibreOffice and it brings important UI improvements, enough for them to call this the most beautiful version ever.
|
||||
|
||||
The Document Foundation doesn't usually make the UI the main focus of an update, but now the developers are saying that this is the most beautiful release made so far and that says a lot. Fortunately, this version is not just about interface fixes and there are plenty of other major improvements that should really provide a very good reason to get LibreOffice 4.4.
|
||||
|
||||
LibreOffice has been gaining quite a lot of fans and users, and the past couple of years have been very successful. The office suite is implemented by default in most of the important Linux distributions out there and it was adopted by numerous administrations and companies across the world. LibreOffice is proving to be a difficult adversary for Microsoft's Office and each new version makes it even better.
|
||||
LibreOffice 4.4 brings a lot of new features
|
||||
|
||||
If we move aside all the improvements made to the interface, we're still left with a ton of fixes and changes. The Document Foundation takes its job very seriously and all upgrades really improve the users' experience tremendously.
|
||||
|
||||
"LibreOffice 4.4 has got a lot of UX and design love, and in my opinion is the most beautiful ever. We have completed the dialog conversion, redesigned menu bars, context menus, toolbars, status bars and rulers to make them much more useful. The Sifr monochrome icon theme is extended and now the default on OS X. We also developed a new Color Selector, improved the Sidebar to integrate more smoothly with menus, and reworked many user interface details to follow today’s UX trends," [says Jan "Kendy" Holesovsky](1), a member of the Membership Committee and the leader of the design team.
|
||||
|
||||
Some of the other improvements include much better support for OOXML file formats, the source code has been "groomed" and cleaned after a Coverity Scan analysis, digital signatures for exported PDF files, improved import filters for Microsoft Visio, Microsoft Publisher and AbiWord files, and Microsoft Works spreadsheets, and much more.
|
||||
|
||||
For now, the PPA doesn't have the latest version, but that should change soon. For the time being, you can download the [LibreOffice 4.4](2) source packages from Softpedia, if you want to compile them yourself.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://news.softpedia.com/news/LibreOffice-4-4-Releases-As-the-Most-Beautiful-LibreOffice-Ever-471575.shtml
|
||||
|
||||
本文发布时间:29 Jan 2015, 14:16 GMT
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:http://blog.documentfoundation.org/2015/01/29/libreoffice-4-4-the-most-beautiful-libreoffice-ever/
|
||||
[2]:http://linux.softpedia.com/get/Office/Office-Suites/LibreOffice-60713.shtml
|
||||
@ -0,0 +1,33 @@
|
||||
OpenJDK 7 Vulnerabilities Closed in Ubuntu 14.04 and Ubuntu 14.10
|
||||
----
|
||||
*Users have been advised to upgrade as soon as possible*
|
||||
|
||||
##Canonical published details about a new OpenJDK 7 version has been pushed to the Ubuntu 14.04 LTS and Ubuntu 14.10 repositories. This update fixes a number of problems and various vulnerabilities.
|
||||
|
||||
The Ubuntu maintainers have upgraded the OpenJDK packages in the repositories and numerous fixes have been implemented. This is an important update and it covers a few libraries.
|
||||
|
||||
"Several vulnerabilities were discovered in the OpenJDK JRE related to information disclosure, data integrity and availability. An attacker could
|
||||
exploit these to cause a denial of service or expose sensitive data over the network,” reads the security notice.
|
||||
|
||||
Also, "a vulnerability was discovered in the OpenJDK JRE related to information disclosure and integrity. An attacker could exploit this to
|
||||
expose sensitive data over the network."
|
||||
|
||||
These are just a couple of the vulnerabilities identified and corrected by the developer and implemented by the maintainers/., and for a more detailed description of the problems, you can see Canonical's security notification. Users have been advised to upgrade their systems as soon as possible.
|
||||
|
||||
The flaws can be fixed if you upgrade your system to the latest openjdk-7-related packages specific to each distribution. To apply the patch, users will have to run the Update Manager application. In general, a standard system update will make all the necessary changes. All Java-related applications will have to be restarted.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://linux.softpedia.com/blog/OpenJDK-7-Vulnerabilities-Closed-in-Ubuntu-14-04-and-Ubuntu-14-10-471605.shtml
|
||||
|
||||
本文发布时间:29 Jan 2015, 16:53 GMT
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
@ -0,0 +1,49 @@
|
||||
WordPress Can Be Used to Leverage Critical Ghost Flaw in Linux
|
||||
-----
|
||||
*Users are advised to apply available patches immediately*
|
||||
|
||||

|
||||
|
||||
**The vulnerability revealed this week by security researchers at Qualys, who dubbed it [Ghost](1), could be taken advantage of through WordPress or other PHP applications to compromise web servers.**
|
||||
|
||||
The glitch is a buffer overflow that can be triggered by an attacker to gain command execution privileges on a Linux machine. It is present in the glibc’s “__nss_hostname_digits_dots()” function that can be used by the “gethostbyname()” function.
|
||||
|
||||
##PHP applications can be used to exploit the glitch
|
||||
|
||||
Marc-Alexandre Montpas at Sucuri says that the problem is significant because these functions are used in plenty of software and server-level mechanism.
|
||||
|
||||
“An example of where this could be a big issue is within WordPress itself: it uses a function named wp_http_validate_url() to validate every pingback’s post URL,” which is carried out through the “gethostbyname()” function wrapper used by PHP applications, he writes in a blog post on Wednesday.
|
||||
|
||||
An attacker could use this method to introduce a malicious URL designed to trigger the vulnerability on the server side and thus obtain access to the machine.
|
||||
|
||||
In fact, security researchers at Trustwave created [proof-of-concept](2) code that would cause the buffer overflow using the pingback feature in WordPress.
|
||||
|
||||
##Multiple Linux distributions are affected
|
||||
|
||||
Ghost is present in glibc versions up to 2.17, which was made available in May 21, 2013. The latest version of glibc is 2.20, available since September 2014.
|
||||
|
||||
However, at that time it was not promoted as a security fix and was not included in many Linux distributions, those offering long-term support (LTS) in particular.
|
||||
|
||||
Among the impacted operating systems are Debian 7 (wheezy), Red Hat Enterprise Linux 6 and 7, CentOS 6 and 7, Ubuntu 12.04. Luckily, Linux vendors have started to distribute updates with the fix that mitigates the risk. Users are advised to waste no time downloading and applying them.
|
||||
|
||||
In order to demonstrate the flaw, Qualys has created an exploit that allowed them remote code execution through the Exim email server. The security company said that it would not release the exploit until the glitch reached its half-life, meaning that the number of the affected systems has been reduced by 50%.
|
||||
|
||||
Vulnerable application in Linux are clockdiff, ping and arping (under certain conditions), procmail, pppd, and Exim mail server.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://news.softpedia.com/news/WordPress-Can-Be-Used-to-Leverage-Critical-Ghost-Flaw-in-Linux-471730.shtml
|
||||
|
||||
本文发布时间:30 Jan 2015, 17:36 GMT
|
||||
|
||||
作者:[Ionut Ilascu][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/ionut-ilascu
|
||||
[1]:http://news.softpedia.com/news/Linux-Systems-Affected-by-14-year-old-Vulnerability-in-Core-Component-471428.shtml
|
||||
[2]:http://blog.spiderlabs.com/2015/01/ghost-gethostbyname-heap-overflow-in-glibc-cve-2015-0235.html
|
||||
38
sources/news/20150202 The Pirate Bay Is Now Back Online.md
Normal file
38
sources/news/20150202 The Pirate Bay Is Now Back Online.md
Normal file
@ -0,0 +1,38 @@
|
||||
The Pirate Bay Is Now Back Online
|
||||
------
|
||||
*The website was closed for about seven weeks*
|
||||

|
||||
##After being [raided](1) by the police almost two months ago, (in)famous torrent website The Pirate Bay is now back online. Those who thought the website will never return will be either disappointed or happy given that The Pirate Bay seems to live once again.
|
||||
|
||||
In order to celebrate its coming back, The Pirate Bay admins have posted a Phoenix bird on the front page, which signifies the fact that the website can't be killed only damaged.
|
||||
|
||||
About two weeks after The Pirate Bay was raided the domain miraculously came back to life. Soon after a countdown appeared on the temporary homepage of The Pirate Bay indicating that the website is almost ready for a comeback.
|
||||
|
||||
The countdown hinted to February 1, as the possible date for The Pirate Bay's comeback, but it looks like those who manage the website manage to pull it out one day earlier.
|
||||
|
||||
Beginning today, those who have accounts on The Pirate Bay can start downloading the torrents they want. Other than the Phoenix on the front page there are no other messages that might point to the resurrection The Pirate Bay except for the fact that it's now operational.
|
||||
|
||||
Admins of the website said a few weeks ago they will find ways to manage and optimize The Pirate Bay, so that there will be minimal chances for the website to be closed once again. Let's see how it lasts this time.
|
||||
|
||||
##Another version of The Pirate Bay may be launched soon
|
||||
|
||||
In related news, one of the members of the original staff was dissatisfied with the decisions made by the majority regarding some of the changes made in the way admins interact with the website.
|
||||
|
||||
He told [Torrentfreak](2) earlier this week that he, along with a few others, will open his version of The Pirate Bay, which they claim will be the "real" one.
|
||||
|
||||
------
|
||||
via:http://news.softpedia.com/news/The-Pirate-Bay-Is-Now-Back-Online-471802.shtml
|
||||
|
||||
本文发布时间:31 Jan 2015, 22:49 GMT
|
||||
|
||||
作者:[Cosmin Vasile][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/cosmin-vasile
|
||||
[1]:http://news.softpedia.com/news/The-Pirate-Bay-Is-Down-December-9-2014-466987.shtml
|
||||
[2]:http://torrentfreak.com/pirate-bay-back-online-150131/
|
||||
@ -0,0 +1,98 @@
|
||||
Debian Forked over systemd: Birth of Devuan GNU/Linux Distribution
|
||||
================================================================================
|
||||
Debian GNU/Linux distribution is one of the oldest Linux distribution that is currently in working state. init used to be the default central management and configuration platform for Linux operating system before systemd emerged. Systemd from the date of its release has been very much controversial.
|
||||
|
||||
Sooner or later it has replaced init on most of the Linux distribution. Debian remained no exception and Debian 8 codename JESSIE will be having systemd by default. The Debian adaptation of systemd in replacement of init caused polarization. This led to forking of Debian and hence Devuan GNU/Linux distribution born.
|
||||
|
||||
Devuan project started with the primary goal to put back nit and remove controversial systemd. A lot of Linux Distribution are based on Debian or a derivative of Debian and one does not simply fork Debian. Debian will always attract developers.
|
||||
|
||||
### What Devuan is all About? ###
|
||||
|
||||
Devuan in Italian (pronounced Devone in English) suggests “Don’t panic and keep forking Debian”, for Init-Freedom lovers. Developers see Devuan as the beginning of a process which aims at base distribution and is able to protect the freedom of developers and community.
|
||||
|
||||

|
||||
|
||||
Debian Forked over systemd: Birth of Devuan Linux
|
||||
|
||||
Devuan project priority includes – interoperability, diversity and backward compatibility. It will derive its own installer and repos from Debian and modify where ever required. If everything works smooth by the mid of 2015 users can switch to Devuan from Debian 7 and start using devuan repos.
|
||||
|
||||
The process of switching will fairly remain as simple as upgrading a Debian installation. The project will be as minimal as possible and completely in accordance of UNIX philosophy – “Doing one thing and doing it well”. The targeted users of Devuan will be System Admins, Developers and users having experience of Debian.
|
||||
|
||||
The project started by italian developers has raised a fund of 4.5k€ (EUR) in the year 2014. They have moved distro infrastructure from GitHub to GitLab, progress on Loginkit (systemd Logind replaced), discussing Logo and other important aspects useful in long run.
|
||||
|
||||
A few of the Logos are in discussion now are shown in the picture.
|
||||
|
||||

|
||||
|
||||
Devuan Logo Proposals
|
||||
|
||||
Have a look at them here at: [http://without-systemd.org/wiki/index.php/Category:Logo][1]
|
||||
|
||||
The unrest over systemd that gave birth to Devuan is good or bad? Lets have a look.
|
||||
|
||||
### Is Devuan fork a good thing? ###
|
||||
|
||||
Well! difficult to answer that forking such a huge distro is really going to be of any good. A (group of) developer(s) who initially were working with Debian got unsatisfied with systemd and forked it.
|
||||
|
||||
Now the actual number of developers working on Debian/Systemd decreased which is going to affect the productivity of both the projects. Now the same number of developers are working on two different projects.
|
||||
|
||||
What you think would be the fate of Devuan as well as Debian project? Won’t it hinder the progress of either distro and Linux in the long run?
|
||||
|
||||
Please give your [comments][2] about Devuan project.
|
||||
|
||||
注:如果可以在发布文章的时候发布一个调查,就把下面这段发成一个调查,如果不行,就直接嵌入js代码
|
||||
|
||||
<script type="text/javascript" charset="utf-8" src="http://static.polldaddy.com/p/8629256.js"></script>
|
||||
|
||||
Do you think systemd for Debian is
|
||||
|
||||
Good
|
||||
Bad
|
||||
Don't Know
|
||||
Don't Care
|
||||
Other:
|
||||
|
||||
VoteView ResultsPolldaddy.com
|
||||
|
||||
|
||||
**Do you really feel that Debian with systemd will have a bad fate as depicted below**
|
||||
|
||||

|
||||
|
||||
Strip SystmeD
|
||||
|
||||
Time to wait for Devuan 1.0 and lets see what it could contain.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
All the major Linux Distributions Like Fedora, RedHat, openSUSE, SUSE Enterprise, Arch, Megia have already switched to Systemd, Ubuntu and Debian are in the way to replace init with systemd. Only Gentoo and Slack till date have shown no interest in systemd but who knows someday even Gentoo and slack too started moving in the same direction.
|
||||
|
||||
The reputation of Debian as a Linux Distro is something very few have reached the mark. It is blessed by some hundreds of developers and millions of users. The actual question is what percentage of users and developers were not comfortable with systemd. If the percentage is really high then what led debian to switch to systemd. Had it moved against the wishes of its users and developers. If this is the case the chance of success of devuan is pretty fair. Well how many developers put long hours of code punching for the project.
|
||||
|
||||
Hope the fate of this project will not be something like those distros which once was started with high degree of passion and enthusiasm and later the developers got uninterested.
|
||||
|
||||
Post Script : Linus Torvalds do not mind systemd that much.
|
||||
|
||||
**If you need Devuan, then join and support it now!**
|
||||
|
||||
Development : [https://git.devuan.org][3]
|
||||
Donations : [https://devuan.org/donate.html][4]
|
||||
Discussions : [https://mailinglists.dyne.org/cgi-bin/mailman/listinfo/dng][5]
|
||||
Devuan Developers : onelove@devuan.org
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/debian-forked-over-systemd-birth-of-devuan-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://without-systemd.org/wiki/index.php/Category:Logo
|
||||
[2]:http://www.tecmint.com/debian-forked-over-systemd-birth-of-devuan-linux/#comments
|
||||
[3]:https://git.devuan.org/
|
||||
[4]:https://devuan.org/donate.html
|
||||
[5]:https://mailinglists.dyne.org/cgi-bin/mailman/listinfo/dng
|
||||
@ -0,0 +1,45 @@
|
||||
BQ and Canonical Officially Launch Aquaris E4.5 Ubuntu Edition, the First Ubuntu Phone
|
||||
------
|
||||
*Everything you need to know about Aquaris E4.5*
|
||||
|
||||
##BQ and Canonical have officially announced the new Aquaris E4.5 Ubuntu Edition and the fact that the phone will be available in the coming weeks through a series of flash sales.
|
||||
|
||||
Information about the imminent launch of BQ Ubuntu phone has been around for some time and now it the two companies seem to have decided to make it official. This is the first device powered by Ubuntu Touch and a lot of people will be paying very close attention to what is happening in the mobile world.
|
||||
|
||||
Ubuntu Touch is the latest operating system from Canonical and it's a brand new experience that aims to be very different from what users can find right now on the market, and that includes systems like Jola or Firefox OS. The OS has been in the works for more than two years and it's a system designed to work on all kind of devices, across the hardware spectrum.
|
||||
|
||||
##Who is BQ and why has Canonical chosen them?
|
||||
|
||||
When Mark Shuttleworth announced the two partners for the launch of Ubuntu Touch, BQ and Meizu, most of the people watching asked the same question. Who? BQ is not a very big company, but it's a young company and it has already started to penetrate the European market with some interesting devices. In many ways, they are doing the same thing companies like Meizu or Xiaomi are trying and succeeded in China: to offer devices that are interesting and different from what everyone else is doing.
|
||||
|
||||
Many Ubuntu fans have questioned Canonical’s decision of choosing small companies and not big ones, but they are trying to do the same thing as the just-mentioned hardware makers. They want to offer an operating system radically different from what everyone else is doing. It's easy to understand why the goals of Canonical and BQ are actually one and the same.
|
||||
|
||||
##What is Ubuntu Touch?
|
||||
|
||||
The new operating system developed by Canonical embraces the fact that people are now swiping a lot more than they are tapping. Smartphones are no longer something new and everyone can understand how to swipe and get things done on a phone. Ubuntu devs have taken this to a whole new level. The operating system has no buttons, with the exception of the regular power and volume buttons. Everything is done with swiped gestures, from all sides of the screen.
|
||||
|
||||
Also, Ubuntu Touch brings a new concept to the market, that of scopes. There is no longer a home screen, just scopes defined by the user to expand the experience. For example, you can have a Music scope that aggregates all your music sources on a single screen. It's a different way of looking at your smartphone, but this is built for people who crave a new experience. Don't worry, regular apps still exist, but they are differently integrated.
|
||||
|
||||

|
||||
|
||||
"As any kind of content can be presented via Scopes - they provide developers an easy path for their creations to be integral to the device experience. It is simple to create new Scopes via an easy to use UI toolkit with much lower development and maintenance costs than traditional apps. Canonical and BQ have worked with a host of partners to ensure that there is a wealth of interesting, relevant and dynamic content available at launch, with more content partners to follow," said Cristian Parrino, VP Mobile at Canonical.
|
||||
|
||||
##BQ’s Aquaris E4.5 Ubuntu Edition hardware specs
|
||||
|
||||
First of all, it's important to know that Aquaris E4.5 Ubuntu Edition is a dual-sim phone and it comes unlocked so that everyone can use it with their network. It boasts a MediaTek Quad-Core Cortex A7 processor running at up to 1.3 GHz, a 4.5-inch screen, 1GB RAM, rear camera with high-quality BSI sensors, Largan lens, and autofocus with dual flash(8MP), and front camera with 5MP.
|
||||
|
||||
It's also worth mentioning that several operators in Europe, including 3 Sweden, amena.com, giffgaff, and Portugal Telecom have decided to provide SIM bundles at purchase. The price is €169.90 ($191).
|
||||
|
||||
So, are you ready to buy the Aquaris E4.5 Ubuntu Edition?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/BQ-and-Canonical-Officially-Launch-Aquaris-E4-5-Ubuntu-Edition-472397.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
@ -1,66 +0,0 @@
|
||||
What is a good EPUB reader on Linux
|
||||
================================================================================
|
||||
If the habit on reading books on electronic tablets is still on its way, reading books on a computer is even rarer. It is hard enough to focus on the classics of the 16th century literature, so who needs the Facebook chat pop up sound in the background in addition? But if for some reasons you wish to open an electronic book in your computer, chances are that you will need specific software. Indeed, most editors agreed with using the EPUB format for electronic books (for "Electronic PUBlication"). Hopefully, Linux is not deprived of good programs capable of dealing with such format. In short, here is a non-exhaustive list of good EPUB readers on Linux.
|
||||
|
||||
### 1. Calibre ###
|
||||
|
||||
|
||||
|
||||
Let's dive in with maybe the biggest name of that list: [Calibre][1]. More than just an ebook reader, Calibre is a fully packaged e-library. It supports a plethora of formats (almost every I can think of), integrates a reader, a manager, a meta-data editor which can download covers from the Internet, an EPUB editor, a news reader, and a search engine to download additional books. To top it all, the interface is slick and has nothing to envy to other professional software. The only potential downside is that if you are looking for an EPUB reader, and are not interested in the whole library manager aspect, the program is too heavy for your needs.
|
||||
|
||||
### 2. FBReader ###
|
||||
|
||||
|
||||
|
||||
[FBReader][2] is also a library manager, but in a lighter way than Calibre. The interface is more sober, and is clearly cut in two: (1) the library aspect where you can add files, edit the meta-data, or download new books, and (2) the reader aspect. If you like simplicity, you might enjoy this program. I personally appreciate its straightforward tag and series system for classifying books.
|
||||
|
||||
### 3. Cool Reader ###
|
||||
|
||||

|
||||
|
||||
For all of you who are just looking for a way to visualize the content of an EPUB file, I recommend [Cool Reader][5]. In the spirit of Linux applications which do only one thing and do it well, Cool Reader is optimized to just open an EPUB file, and navigate through it via handy shortcuts. And since it is based on Qt, it also follows Qt's mentality by giving a ton of settings to mess around with.
|
||||
|
||||
### 4. Okular ###
|
||||
|
||||

|
||||
|
||||
Since we were talking about Qt applications, one of KDE's main document viewer, [Okular][3], also has the capacity to view EPUB files, once an EPUB library has been installed on the system. However, this is probably not a very good option if you are not a KDE user.
|
||||
|
||||
### 5. pPub ###
|
||||
|
||||

|
||||
|
||||
[pPub][4] is an old project that you can still find on Github. Its latest change seems to have been made two years ago. However, pPub is one of those programs that really deserve a second life. Written in Python and based on GTK3 and WebKit, pPub is lightweight and intuitive. The interface probably needs a little updating and is beyond sober, but the core is very good. It even supports JavaScript. So please, someone kick that up again.
|
||||
|
||||
### 6. epub ###
|
||||
|
||||
|
||||
|
||||
If all you need is a quick and easy way to check the content of an EPUB file, without caring about any fancy GUI, maybe an EPUB reader with command line interface might just do. [epub][6] is a minimalistic EPUB reader written in Python, which allows you to read an EPUB file in a terminal environment. You can switch between chapter/TOC views, up/down a page, and nothing more. This is as simple as any EPUB reader can possibly get.
|
||||
|
||||
### 7. Sigil ###
|
||||
|
||||
|
||||
|
||||
Finally, last of the list is not actually an EPUB reader, but more of a standalone editor. [Sigil][7] is able to extract the content of an EPUB file, and break it down for what it really is: xhtml text, images, styles, and sometimes audio. The interface is a lot more complex than the one for a basic reader, but remains clear and well thought, on par with the features it provides. I particularly appreciate the tab system. If you are familiar with editing web pages, you will be in know territory here.
|
||||
|
||||
To conclude, there are a lot of open source EPUB readers out there. Some do nothing more, while others go way beyond that. As usual, I recommend using the one that makes the most sense for you to use. If you know more good EPUB readers on Linux that you like, please let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/good-epub-reader-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://calibre-ebook.com/
|
||||
[2]:http://fbreader.org/
|
||||
[3]:http://okular.kde.org/
|
||||
[4]:https://github.com/sakisds/pPub
|
||||
[5]:http://crengine.sourceforge.net/
|
||||
[6]:https://github.com/rupa/epub
|
||||
[7]:https://github.com/user-none/Sigil
|
||||
@ -1,59 +0,0 @@
|
||||
This App Can Write a Single ISO to 20 USB Drives Simultaneously
|
||||
================================================================================
|
||||
**If I were to ask you to burn a single Linux ISO to 17 USB thumb drives how would you go about doing it?**
|
||||
|
||||
Code savvy folks would write a little bash script to automate the process, and a large number would use a GUI tool like the USB Startup Disk Creator to burn the ISO to each drive in turn, one by one. But the rest of us would fast conclude that neither method is ideal.
|
||||
|
||||
### Problem > Solution ###
|
||||
|
||||
|
||||
|
||||
GNOME MultiWriter in action
|
||||
|
||||
Richard Hughes, a GNOME developer, faced a similar dilemma. He wanted to create a number of USB drives pre-loaded with an OS, but wanted a tool simple enough for someone like his dad to use.
|
||||
|
||||
His response was to create a **brand new app** that combines both approaches into one easy to use tool.
|
||||
|
||||
It’s called “[GNOME MultiWriter][1]” and lets you write a single ISO or IMG to multiple USB drives at the same time.
|
||||
|
||||
It nixes the need to customize or create a command line script and relinquishes the need to waste an afternoon performing an identical set of actions on repeat.
|
||||
|
||||
All you need is this app, an ISO, some thumb-drives and lots of empty USB ports.
|
||||
|
||||
### Use Cases and Installing ###
|
||||
|
||||

|
||||
|
||||
The app can be installed on Ubuntu
|
||||
|
||||
The app has a pretty defined usage scenario, that being situations where USB sticks pre-loaded with an OS or live image are being distributed.
|
||||
|
||||
That being said, it should work just as well for anyone wanting to create a solitary bootable USB stick, too — and since I’ve never once successfully created a bootable image from Ubuntu’s built-in disk creator utility, working alternatives are welcome news to me!
|
||||
|
||||
Hughes, the developer, says it **supports up to 20 USB drives**, each being between 1GB and 32GB in size.
|
||||
|
||||
The drawback (for now) is that GNOME MultiWriter is not a finished, stable product. It works, but at this early blush there are no pre-built binaries to install or a PPA to add to your overstocked software sources.
|
||||
|
||||
If you know your way around the usual configure/make process you can get it up and running in no time. On Ubuntu 14.10 you may also need to install the following packages first:
|
||||
|
||||
sudo apt-get install gnome-common yelp-tools libcanberra-gtk3-dev libudisks2-dev gobject-introspection
|
||||
|
||||
If you get it up and running, give it a whirl and let us know what you think!
|
||||
|
||||
Bugs and pull requests can be longed on the GitHub page for the project, which is where you’ll also found tarball downloads for manual installation.
|
||||
|
||||
- [GNOME MultiWriter on Github][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/01/gnome-multiwriter-iso-usb-utility
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://github.com/hughsie/gnome-multi-writer/
|
||||
[2]:https://github.com/hughsie/gnome-multi-writer/
|
||||
@ -1,111 +0,0 @@
|
||||
Best GNOME Shell Themes For Ubuntu 14.04
|
||||
================================================================================
|
||||

|
||||
|
||||
Themes are the best way to customize your Linux desktop. If you [install GNOME on Ubuntu 14.04][1] or 14.10, you might want to change the default theme and give it a different look. To help you in this task, I have compiled here a **list of best GNOME shell themes for Ubuntu** or any other Linux OS that has GNOME shell installed on it. But before we see the list, let’s first see how to change install new themes in GNOME Shell.
|
||||
|
||||
### Install themes in GNOME Shell ###
|
||||
|
||||
To install new themes in GNOME with Ubuntu, you can use Gnome Tweak Tool which is available in software repository in Ubuntu. Open a terminal and use the following command:
|
||||
|
||||
sudo apt-get install gnome-tweak-tool
|
||||
|
||||
Alternatively, you can use themes by putting them in ~/.themes directory. I have written a detailed tutorial on [how to install and use themes in GNOME Shell][2], in case you need it.
|
||||
|
||||
### Best GNOME Shell themes ###
|
||||
|
||||
The themes listed here are tested on GNOME Shell 3.10.4 but it should work for all version of GNOME 3 and higher. For the sake of mentioning, the themes are not in any kind of priority order. Let’s have a look at the best GNOME themes:
|
||||
|
||||
#### Numix ####
|
||||
|
||||

|
||||
|
||||
No list can be completed without the mention of [Numix themes][3]. These themes got so popular that it encouraged [Numix team to work on a new Linux OS, Ozon][4]. Considering their design work with Numix theme, it won’t be exaggeration to call it one of the [most beautiful Linux OS][5] releasing in near future.
|
||||
|
||||
To install Numix theme in Ubuntu based distributions, use the following commands:
|
||||
|
||||
sudo apt-add-repository ppa:numix/ppa
|
||||
sudo apt-get update
|
||||
sudo apt-get install numix-icon-theme-circle
|
||||
|
||||
#### Elegance Colors ####
|
||||
|
||||

|
||||
|
||||
Another beautiful theme from Satyajit Sahoo, who is also a member of Numix team. [Elegance Colors][6] has its own PPA so that you can easily install it:
|
||||
|
||||
sudo add-apt-repository ppa:satyajit-happy/themes
|
||||
sudo apt-get update
|
||||
sudo apt-get install gnome-shell-theme-elegance-colors
|
||||
|
||||
#### Moka ####
|
||||
|
||||

|
||||
|
||||
[Moka][7] is another mesmerizing theme that is always included in the list of beautiful themes. Designed by the same developer who gave us Unity Tweak Tool, Moka is a must try:
|
||||
|
||||
sudo add-apt-repository ppa:moka/stable
|
||||
sudo apt-get update
|
||||
sudo apt-get install moka-gnome-shell-theme
|
||||
|
||||
#### Viva ####
|
||||
|
||||

|
||||
|
||||
Based on Gnome’s default Adwaita theme, Viva is a nice theme with shades of black and oranges. You can download Viva from the link below.
|
||||
|
||||
- [Download Viva GNOME Shell Theme][8]
|
||||
|
||||
#### Ciliora-Prima ####
|
||||
|
||||

|
||||
|
||||
Previously known as Zukitwo Dark, Ciliora-Prima has square icons theme. Theme is available in three versions that are slightly different from each other. You can download it from the link below.
|
||||
|
||||
- [Download Ciliora-Prima GNOME Shell Theme][9]
|
||||
|
||||
#### Faience ####
|
||||
|
||||

|
||||
|
||||
Faience has been a popular theme for quite some time and rightly so. You can install Faience using the PPA below for GNOME 3.10 and higher.
|
||||
|
||||
sudo add-apt-repository ppa:tiheum/equinox
|
||||
sudo apt-get update
|
||||
sudo apt-get install faience-theme
|
||||
|
||||
#### Paper [Incomplete] ####
|
||||
|
||||

|
||||
|
||||
Ever since Google talked about Material Design, people have been going gaga over it. Paper GTK theme, by Sam Hewitt (of Moka Project), is inspired by Google Material design and currently under development. Which means you will not have the best experience with Paper at the moment. But if your a bit experimental, like me, you can definitely give it a try.
|
||||
|
||||
sudo add-apt-repository ppa:snwh/pulp
|
||||
sudo apt-get update
|
||||
sudo apt-get install paper-gtk-theme
|
||||
|
||||
That concludes my list. If you are trying to give a different look to your Ubuntu, you should also try the list of [best icon themes for Ubuntu 14.04][10].
|
||||
|
||||
How do you find this list of **best GNOME Shell themes**? Which one is your favorite among the one listed here? And if it’s not listed here, do let us know which theme you think is the best GNOME Shell theme.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/gnome-shell-themes-ubuntu-1404/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://itsfoss.com/how-to-install-gnome-in-ubuntu-14-04/
|
||||
[2]:http://itsfoss.com/install-switch-themes-gnome-shell/
|
||||
[3]:https://numixproject.org/
|
||||
[4]:http://itsfoss.com/numix-linux-distribution/
|
||||
[5]:http://itsfoss.com/new-beautiful-linux-2015/
|
||||
[6]:http://satya164.deviantart.com/art/Gnome-Shell-Elegance-Colors-305966388
|
||||
[7]:http://mokaproject.com/
|
||||
[8]:https://github.com/vivaeltopo/gnome-shell-theme-viva
|
||||
[9]:http://zagortenay333.deviantart.com/art/Ciliora-Prima-Shell-451947568
|
||||
[10]:http://itsfoss.com/best-icon-themes-ubuntu-1404/
|
||||
128
sources/share/20150126 CD Audio Grabbers--Graphical Based.md
Normal file
128
sources/share/20150126 CD Audio Grabbers--Graphical Based.md
Normal file
@ -0,0 +1,128 @@
|
||||
CD Audio Grabbers - Graphical Based
|
||||
================================================================================
|
||||
CD audio grabbers are designed to extract ("rip") the raw digital audio (in a format commonly called CDDA) from a compact disc to a file or other output. This type of software enables a user to encode the digital audio into a variety of formats, and download and upload disc info from freedb, an internet compact disc database.
|
||||
|
||||
Is copying CDs legal? Under US copyright law, converting an original CD to digital files for personal use has been cited as qualifying as 'fair use'. However, US copyright law does not explicitly allow or forbid making copies of a personally-owned audio CD, and case law has not yet established what specific scenarios are permitted as fair use. The copyright position is much clearer in the UK. From 2014 it become legal for UK citizens to make copies of CDs, MP3s, DVD, Blu-rays and e-books. This only applies if the individual owns the physical media being ripped, and the copy is made only for their own private use. For other countries in the European Union, member nations can allow a private copy exception too.
|
||||
|
||||
If you are not sure what the position is for the country you live in, please check your local copyright law to make sure that you are on the right side of the law before using the software featured in this two page article.
|
||||
|
||||
To some extent, it may seem a bit of a chore to rip CDs. Streaming services like Spotify and Google Play Music offer access to a huge library of music in a convenient form, and without having to rip your CD collection. However, if you already have a large CD collection, it is still desirable to be able to convert your CDs to enjoy on mobile devices like smartphones, tablets, and portable MP3 players.
|
||||
|
||||
This two page article highlights my favorite audio CD grabbers. I pick the best four graphical audio grabbers, and the best four console audio grabbers. All of the utilities are released under an open source license.
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
fre:ac is an open source audio converter and CD ripper that supports a wide range of popular formats and encoders. The utility currently converts between MP3, MP4/M4A, WMA, Ogg Vorbis, FLAC, AAC, WAV and Bonk formats. It comes with several different presents for the LAME encoder.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
- Easy to learn and use
|
||||
- Converter for MP3, MP4/M4A, WMA, Ogg Vorbis, FLAC, AAC, WAV and Bonk formats
|
||||
- Integrated CD ripper with CDDB/freedb title database support
|
||||
- Multi-core optimized encoders to speed up conversions on modern PCs
|
||||
- Full Unicode support for tags and file names
|
||||
- Easy to learn and use, still offers expert options when you need them
|
||||
- Joblists
|
||||
- Can use Winamp 2 input plugins
|
||||
- Multilingual user interface available in 41 languages
|
||||
|
||||
- Website: [freac.org][1]
|
||||
- Developer: Robert Kausch
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 20141005
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Audex is an easy to use open source audio CD ripping application. Whilst it is in a fairly early stage of development, this KDE desktop tool is stable, slick and simple to use.
|
||||
|
||||
The assistant is able to create profiles for LAME, OGG Vorbis (oggenc), FLAC, FAAC (AAC/MP4) and RIFF WAVE. Beyond the assistant you can define your own profile, which means, that Audex works together with commmand line encoders in general.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
- Extract with CDDA Paranoia
|
||||
- Extract and encode run parallel
|
||||
- Filename editing with local and remote CDDB/FreeDB database
|
||||
- Submit new entries to CDDB/FreeDB database
|
||||
- Metadata correction tools like capitalize etc
|
||||
- Multi-profile extraction (with one commandline-encoder per profile)
|
||||
- Fetch covers from the internet and store them in the database
|
||||
- Create playlists, cover and template-based-info files in target directory
|
||||
- Create extraction and encoding protocols
|
||||
- Transfer files to a FTP-server
|
||||
- Internationalization support
|
||||
|
||||
- Website: [kde.maniatek.com/audex][2]
|
||||
- Developer: Marco Nelles
|
||||
- License: GNU GPL v3
|
||||
- Version Number: 0.79
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Sound Juicer is a lean CD ripper using GTK+ and GStreamer. It extracts audio from CDs and converts it into audio files. Sound Juicer can also play audio tracks directly from the CD, offering a preview before ripping.
|
||||
|
||||
It supports any audio codec supported by a GStreamer plugin, including MP3, Ogg Vorbis, FLAC, and uncompressed PCM formats.
|
||||
|
||||
It is an established part of the GNOME desktop environment.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
- Automatic track tagging via CDDB
|
||||
- Encoding to ogg / vorbis, FLAC and raw WAV
|
||||
- Easy to configure encoding path
|
||||
- Multiple genres
|
||||
- Internationalization support
|
||||
|
||||
- Website: [burtonini.com][3]
|
||||
- Developer: Ross Burton
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 3.14
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
ripperX is an open source graphical interface for ripping CD audio tracks and encoding them to Ogg, MP2, MP3, or FLAC formats. It's goal is to be easy to use, requiring only a few mouse clicks to convert an entire album. It supports CDDB lookups for album and track information.
|
||||
|
||||
It uses cdparanoia to convert (i.e. "rip") CD audio tracks to WAV files, and then calls the Vorbis/Ogg encoder oggenc to convert the WAV to an OGG file. It can also call flac to perform lossless compression on the WAV file, resulting in a FLAC file.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
- Very simple to use
|
||||
- Rip audio CD tracks into WAV, MP3, OGG, or FLAC files
|
||||
- Supports CDDB lookups
|
||||
- Supports ID3v2 tags
|
||||
- Pause the ripping process
|
||||
|
||||
- Website: [sourceforge.net/projects/ripperx][4]
|
||||
- Developer: Marc André Tanner
|
||||
- License: MIT/X Consortium License
|
||||
- Version Number: 2.8.0
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20150125043738417/AudioGrabbersGraphical.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.freac.org/
|
||||
[2]:http://kde.maniatek.com/audex/
|
||||
[3]:http://burtonini.com/blog/computers/sound-juicer
|
||||
[4]:http://sourceforge.net/projects/ripperx/
|
||||
@ -0,0 +1,60 @@
|
||||
Meet Vivaldi — A New Web Browser Built for Power Users
|
||||
================================================================================
|
||||
|
||||
|
||||
**A brand new web browser has arrived this week that aims to meet the needs of power users — and it’s already available for Linux.**
|
||||
|
||||
Vivaldi is the name of this new browser and it has been launched as a tech preview (read: a beta without the responsibility) for 64-bit Linux machines, Windows and Mac. It is built — shock — on the tried-and-tested open-source frameworks of Chromium, Blink and Google’s open-source V8 JavaScript engine (among other projects).
|
||||
|
||||
Does the world really want another browser? Vivaldi, the brain child of former Opera Software CEO Jon von Tetzchner, is less concerned about want and more about need.
|
||||
|
||||
Vivaldi is being built with the sort of features that keyboard preferring tab addicts need. It is not being pitched at users who find Firefox perplexing or whose sole criticism of Chrome is that it moved the bookmarks button.
|
||||
|
||||
That’s not tacky marketing spiel either. Despite the ‘technical preview’ badge it comes with, Vivaldi is already packed with features that demonstrate its power user slant.
|
||||
|
||||
Plenty of folks feel left behind and underserved by the simplified, paired back offerings other software companies are producing. Vivaldi, even at this early juncture, looks well placed to succeed in winning them over.
|
||||
|
||||
### Vivaldi Features ###
|
||||
|
||||
A few of Vivaldi’s key features already present include:
|
||||
|
||||

|
||||
|
||||
**Quick Commands** (Ctrl + Q) is an in-app HUD that lets you quickly filter through settings, options and features, be it opening a bookmark or hiding the status bar, using your keyboard. No clicks needed.
|
||||
|
||||
**Tab Stacks** let you clean up your workspace by grouping separate tabs into one, and then using a keyboard command or the tab preview picker to switch between them.
|
||||
|
||||

|
||||
|
||||
A collapsible **side panel** that houses extra features (just like old Opera) including a (not yet working) mail client, contacts, bookmarks browser and note taking section that lets you take and annotate screenshots.
|
||||
|
||||
A bunch of other features are on offer too, including customizable keyboard shortcuts, a tabs bar that can be set on any edge of the browser (or hidden entirely), privacy options and a speed dial with folders.
|
||||
|
||||
### Opera Mark II ###
|
||||
|
||||
|
||||
|
||||
It’s not a leap to see Vivaldi as the true successor to Opera post-Presto (Opera’s old, proprietary rendering engine). Opera (which also pushed out a minor new update today) has split out many of its “power user” features as it chases a lighter, more manageable set of features.
|
||||
|
||||
Vivaldi wants to pick up the baggage Opera has been so keen to offload. And while that might not help it grab marketshare it will see it grab the attention of power users, many of whom will no doubt already be using Linux.
|
||||
|
||||
### Download ###
|
||||
|
||||
Interested in taking it for a spin? You can. Vivaldi is available to download for Windows, Mac and 64-bit Linux distributions. On the latter you have a choice of Debian or RPM installer.
|
||||
|
||||
Bear in mind that it’s not finished and that more features (including extensions, sync and more) are planned for future builds.
|
||||
|
||||
- [Download Vivaldi Tech Preview for Linux][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/01/vivaldi-web-browser-linux-download-power-users
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://vivaldi.com/#Download
|
||||
@ -1,144 +0,0 @@
|
||||
Translating by ZTinoZ
|
||||
20 Linux Commands Interview Questions & Answers
|
||||
================================================================================
|
||||
**Q:1 How to check current run level of a linux server ?**
|
||||
|
||||
Ans: ‘who -r’ & ‘runlevel’ commands are used to check the current runlevel of a linux box.
|
||||
|
||||
**Q:2 How to check the default gatway in linux ?**
|
||||
|
||||
Ans: Using the commands “route -n” and “netstat -nr” , we can check default gateway. Apart from the default gateway info , these commands also display the current routing tables .
|
||||
|
||||
**Q:3 How to rebuild initrd image file on Linux ?**
|
||||
|
||||
Ans: In case of CentOS 5.X / RHEL 5.X , mkinitrd command is used to create initrd file , example is shown below :
|
||||
|
||||
# mkinitrd -f -v /boot/initrd-$(uname -r).img $(uname -r)
|
||||
|
||||
If you want to create initrd for a specific kernel version , then replace ‘uname -r’ with desired kernel
|
||||
|
||||
In Case of CentOS 6.X / RHEL 6.X , dracut command is used to create initrd file example is shown below :
|
||||
|
||||
# dracut -f
|
||||
|
||||
Above command will create the initrd file for the current version. To rebuild the initrd file for a specific kernel , use below command :
|
||||
|
||||
# dracut -f initramfs-2.x.xx-xx.el6.x86_64.img 2.x.xx-xx.el6.x86_64
|
||||
|
||||
**Q:4 What is cpio command ?**
|
||||
|
||||
Ans: cpio stands for Copy in and copy out. Cpio copies files, lists and extract files to and from a archive ( or a single file).
|
||||
|
||||
**Q:5 What is patch command and where to use it ?**
|
||||
|
||||
Ans: As the name suggest patch command is used to apply changes ( or patches) to the text file. Patch command generally accept output from the diff and convert older version of files into newer versions. For example Linux kernel source code consists of number of files with millions of lines , so whenever any contributor contribute the changes , then he/she will be send the only changes instead of sending the whole source code. Then the receiver will apply the changes with patch command to its original source code.
|
||||
|
||||
Create a diff file for use with patch,
|
||||
|
||||
# diff -Naur old_file new_file > diff_file
|
||||
|
||||
Where old_file and new_file are either single files or directories containing files. The r option supports recursion of a directory tree.
|
||||
|
||||
Once the diff file has been created, we can apply it to patch the old file into the new file:
|
||||
|
||||
# patch < diff_file
|
||||
|
||||
**Q:6 What is use of aspell ?**
|
||||
|
||||
Ans: As the name suggest aspell is an interactive spelling checker in linux operating system. The aspell command is the successor to an earlier program named ispell, and can be used, for the most part, as a drop-in replacement. While the aspell program is mostly used by other programs that require spell-checking capability, it can also be used very effectively as a stand-alone tool from the command line.
|
||||
|
||||
**Q:7 How to check the SPF record of domain from command line ?**
|
||||
|
||||
Ans: We can check SPF record of a domain using dig command. Example is shown below :
|
||||
|
||||
linuxtechi@localhost:~$ dig -t TXT google.com
|
||||
|
||||
**Q:8 How to identify which package the specified file (/etc/fstab) is associated with in linux ?**
|
||||
|
||||
Ans: # rpm -qf /etc/fstab
|
||||
|
||||
Above command will list the package which provides file “/etc/fstab”
|
||||
|
||||
**Q:9 Which command is used to check the status of bond0 ?**
|
||||
|
||||
Ans: cat /proc/net/bonding/bond0
|
||||
|
||||
**Q:10 What is the use of /proc file system in linux ?**
|
||||
|
||||
Ans: The /proc file system is a RAM based file system which maintains information about the current state of the running kernel including details on CPU, memory, partitioning, interrupts, I/O addresses, DMA channels, and running processes. This file system is represented by various files which do not actually store the information, they point to the information in the memory. The /proc file system is maintained automatically by the system.
|
||||
|
||||
**Q:11 How to find files larger than 10MB in size in /usr directory ?**
|
||||
|
||||
Ans: # find /usr -size +10M
|
||||
|
||||
**Q:12 How to find files in the /home directory that were modified more than 120 days ago ?**
|
||||
|
||||
Ans: # find /home -mtime +l20
|
||||
|
||||
**Q:13 How to find files in the /var directory that have not been accessed in the last 90 days ?**
|
||||
|
||||
Ans: # find /var -atime -90
|
||||
|
||||
**Q:14 Search for core files in the entire directory tree and delete them as found without prompting for confirmation**
|
||||
|
||||
Ans: # find / -name core -exec rm {} \;
|
||||
|
||||
**Q:15 What is the purpose of strings command ?**
|
||||
|
||||
Ans: The strings command is used to extract and display the legible contents of a non-text file.
|
||||
|
||||
**Q:16 What is the use tee filter ?**
|
||||
|
||||
Ans: The tee filter is used to send an output to more than one destination. It can send one copy of the output to a file and another to the screen (or some other program) if used with pipe.
|
||||
|
||||
linuxtechi@localhost:~$ ll /etc | nl | tee /tmp/ll.out
|
||||
|
||||
In the above example, the output from ll is numbered and captured in /tmp/ll.out file. The output is also displayed on the screen.
|
||||
|
||||
**Q:17 What would the command export PS1 = ”$LOGNAME@`hostname`:\$PWD: do ?**
|
||||
|
||||
Ans: The export command provided will change the login prompt to display username, hostname, and the current working directory.
|
||||
|
||||
**Q:18 What would the command ll | awk ‘{print $3,”owns”,$9}’ do ?**
|
||||
|
||||
Ans: The ll command provided will display file names and their owners.
|
||||
|
||||
**Q:19 What is the use of at command in linux ?**
|
||||
|
||||
Ans: The at command is used to schedule a one-time execution of a program in the future. All submitted jobs are spooled in the /var/spool/at directory and executed by the atd daemon when the scheduled time arrives.
|
||||
|
||||
**Q:20 What is the role of lspci command in linux ?**
|
||||
|
||||
Ans: The lspci command displays information about PCI buses and the devices attached to your system. Specify -v, -vv, or -vvv for detailed output. With the -m option, the command produces more legible output.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/20-linux-commands-interview-questions-answers/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
[1]:
|
||||
[2]:
|
||||
[3]:
|
||||
[4]:
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
@ -1,82 +0,0 @@
|
||||
[Translating by Stevearzh]
|
||||
Why Mac users don’t switch to Linux
|
||||
================================================================================
|
||||
Linux and Mac users share at least one common thing: they prefer not to use Windows. But after that the two groups part company and tend to go their separate ways. But why don’t more Mac users switch to Linux? Is there something that prevents Mac users from making the jump?
|
||||
|
||||
[Datamation took a look at these questions][1] and tried to answer them. Datamation’s conclusion was that it’s really about the applications and workflow, not the operating system:
|
||||
|
||||
> …there are some instances where replacing existing applications with new options isn’t terribly practical – both in workflow and in overall functionality. This is an area where, sadly, Apple has excelled in. So while it’s hardly “impossible” to get around these issues, they are definitely a large enough challenge that it will give the typical Mac enthusiast pause.
|
||||
>
|
||||
> But outside of Web developers, honestly, I don’t see Mac users “en masse,” seeking to disrupt their workflows for the mere idea of avoiding the upgrade to OS X Yosemite. Granted, having seen Yosemite up close – Mac users who are considered power users will absolutely find this change-up to be hideous. However, despite poor OS X UI changes, the core workflow for existing Mac users will remain largely unchanged and unchallenged.
|
||||
>
|
||||
> No, I believe Linux adoption will continue to be sporadic and random. Ever-growing, but not something that is easily measured or accurately calculated.
|
||||
|
||||
I agree to a certain extent with Datamation’s take on the importance of applications and workflows, both things are important and matter in the choice of a desktop operating system. But I think there’s something more going on with Mac users than just that. I believe that there’s a different mentality that exists between Linux and Mac users, and I think that’s the real reason why many Mac users don’t switch to Linux.
|
||||
|
||||

|
||||
|
||||
### It’s all about control for Linux users ###
|
||||
|
||||
Linux users tend to want control over their computing experience, they want to be able to change things to make them the way that they want them. One simply cannot do that in the same way with OS X or any other Apple products. With Apple you get what they give you for the most part.
|
||||
|
||||
For Mac (and iOS) users this is fine, they seem mostly content to stay within Apple’s walled garden and live according to whatever standards and options Apple gives them. But this is totally unacceptable to most Linux users. People who move to Linux usually come from Windows, and it’s there that they develop their loathing for someone else trying to define or control their computing experiences.
|
||||
|
||||
And once someone like that has tasted the freedom that Linux offers, it’s almost impossible for them to want to go back to living under the thumb of Apple, Microsoft or anyone else. You’d have to pry Linux from their cold, dead fingers before they’d accept the computing experience created for them Apple or Microsoft.
|
||||
|
||||
But you won’t find that same determination to have control among most Mac users. For them it’s mostly about getting the most out of whatever Apple has done with OS X in its latest update. They tend to adjust fairly quickly to new versions of OS X and even when unhappy with Apple’s changes they seem content to continue living within Apple’s walled garden.
|
||||
|
||||
So the need for control is a huge difference between Mac and Linux users. I don’t see it as a problem though since it just reflects the reality of two very different attitudes toward using computers.
|
||||
|
||||
### Mac users need Apple’s support mechanisms ###
|
||||
|
||||
Linux users are also different in the sense that they don’t mind getting their hands dirty by getting “under the hood” of their computers. Along with control comes the personal responsibility of making sure that their Linux systems work well and efficiently, and digging into the operating system is something that many Linux users have no problem doing.
|
||||
|
||||
When a Linux user needs to fix something, chances are they will attempt to do so immediately themselves. If that doesn’t work then they’ll seek additional information online from other Linux users and work through the problem until it has been resolved.
|
||||
|
||||
But Mac users are most likely not going to do that to the same extent. That is probably one of the reasons why Apple stores are so popular and why so many Mac users opt to buy Apple Care when they get a new Mac. A Mac user can simply take his or her computer to the Apple store and ask someone to fix it for them. There they can belly up to the Genius Bar and have their computer looked at by someone Apple has paid to fix it.
|
||||
|
||||
Most Linux users would blanche at the thought of doing such a thing. Who wants some guy you don’t even know to lay hands on your computer and start trying to fix it for you? Some Linux users would shudder at the very idea of such a thing happening.
|
||||
|
||||
So it would be hard for a Mac user to switch to Linux and suddenly be bereft of the support from Apple that he or she was used to getting in the past. Some Mac users might feel very vulnerable and uncertain if they were cut off from the Apple mothership in terms of support.
|
||||
|
||||
### Mac users love Apple’s hardware ###
|
||||
|
||||
The Datamation article focused on software, but I believe that hardware also matters to Mac users. Most Apple customers tend to love Apple’s hardware. When they buy a Mac, they aren’t just buying it for OS X. They are also buying Apple’s industrial design expertise and that can be an important differentiator for Mac users. Mac users are willing to pay more because they perceive that the overall value they are getting from Apple for a Mac is worth it.
|
||||
|
||||
Linux users, on the other hand, seem less concerned by such things. I think they tend to focus more on cost and less on the looks or design of their computer hardware. For them it’s probably about getting the most value from the hardware at the lowest cost. They aren’t in love with the way their computer hardware looks in the same way that some Mac users probably are, and so they don’t make buying decisions based on it.
|
||||
|
||||
I think both points of view on hardware are equally valid. It ultimately gets down to the needs of the individual user and what matters to them when they choose to buy or, in the case of some Linux users, build their computer. Value is the key for both groups, and each has its own perceptions of what constitutes real value in a computer.
|
||||
|
||||
Of course it is [possible to run Linux on a Mac][2], directly or indirectly via virtual machine. So a user that really liked Apple’s hardware does have the option of keeping their Mac but installing Linux on it.
|
||||
|
||||
### Too many Linux distros to choose from? ###
|
||||
|
||||
Another reason that might make it hard for a Mac user to move to Linux is the sheer number of distributions to choose from in the world of Linux. While most Linux users probably welcome the huge diversity of distros available, it could also be very confusing for a Mac user who hasn’t learned to navigate those choices.
|
||||
|
||||
Over time I think a Mac user would learn and adjust by figuring out which distribution worked best for him or her. But in the short term it might be a very daunting hurdle to overcome after being used to OS X for a long period of time. I don’t think it’s insurmountable, but it’s definitely something that is worth mentioning here.
|
||||
|
||||
Of course we do have helpful resources like [DistroWatch][3] and even my own [Desktop Linux Reviews][4] blog that can help people find the right Linux distribution. Plus there are many articles available about “the best Linux distro” and that sort of thing that Mac users can use as resources when trying to figure out the distribution they want to use.
|
||||
|
||||
But one of the reasons why Apple customers buy Macs is the simplicity and all-in-one solution that they offer in terms of the hardware and software being unified by Apple. So I am not sure how many Mac users would really want to spend the time trying to find the right Linux distribution. It might be something that puts them off really considering the switch to Linux.
|
||||
|
||||
### Mac users are apples and Linux users are oranges ###
|
||||
|
||||
I see nothing wrong with Mac and Linux users going their separate ways. I think we’re just talking about two very different groups of people, and it’s a good thing that both groups can find and use the operating system and software that they prefer. Let Mac users enjoy OS X and let Linux users enjoy Linux, and hopefully both groups will be happy and content with their computers.
|
||||
|
||||
Every once in a while a Mac user might stray over to Linux or vice versa, but for the most part I think the two groups live in different worlds and mostly prefer to stay separate and apart from one another. I generally don’t compare the two because when you get right down to it, it’s really just a case of apples and oranges.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://jimlynch.com/linux-articles/why-mac-users-dont-switch-to-linux/
|
||||
|
||||
作者:[Jim Lynch][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://jimlynch.com/author/Jim/
|
||||
[1]:http://www.datamation.com/open-source/why-linux-isnt-winning-over-mac-users-1.html
|
||||
[2]:http://www.howtogeek.com/187410/how-to-install-and-dual-boot-linux-on-a-mac/
|
||||
[3]:http://distrowatch.com/
|
||||
[4]:http://desktoplinuxreviews.com/
|
||||
@ -1,95 +0,0 @@
|
||||
If a 32-bit integer overflows, can we use a 40-bit structure instead of a 64-bit long one?
|
||||
---------
|
||||
|
||||
#Q:
|
||||
|
||||
If, say, a 32-bit integer is overflowing, instead of upgrading int to long, can we make use of some 40-bit type if we need a range only within 240, so that we save 24 (64-40) bits for every integer?
|
||||
|
||||
If so, how?
|
||||
|
||||
I have to deal with billions and space is a bigger constraint.
|
||||
|
||||
#A:
|
||||
|
||||
##Yes, but...
|
||||
|
||||
It is certainly possible, but it is usually nonsensical (for any program that doesn't use billions of these numbers):
|
||||
|
||||
```C
|
||||
#include <stdint.h> // don't want to rely on something like long long
|
||||
struct bad_idea
|
||||
{
|
||||
uint64_t var : 40;
|
||||
};
|
||||
```
|
||||
|
||||
Here, var will indeed have a width of 40 bits at the expense of much less efficient code generated (it turns out that "much" is very much wrong -- the measured overhead is a mere 1-2%, see timings below), and usually to no avail. Unless you have need for another 24-bit value (or an 8 and 16 bit value) which you wish to pack into the same structure, alignment will forfeit anything that you may gain.
|
||||
|
||||
In any case, unless you have billions of these, the effective difference in memory consumption will not be noticeable (but the extra code needed to manage the bit field will be noticeable!).
|
||||
|
||||
###Note:
|
||||
|
||||
The question has in the mean time been updated to reflect that indeed billions of numbers are needed, so this may be a viable thing to do, presumed that you take measures not to lose the gains due to structure alignment and padding, i.e. either by storing something else in the remaining 24 bits or by storing your 40-bit values in structures of 8 each or multiples thereof).
|
||||
Saving three bytes a billion times is worthwhile as it will require noticeably fewer memory pages and thus cause fewer cache and TLB misses, and above all page faults (a single page fault weighting tens of millions instructions).
|
||||
|
||||
While the above snippet does not make use of the remaining 24 bits (it merely demonstrates the "use 40 bits" part), something akin to the following will be necessary to really make the approach useful in a sense of preserving memory -- presumed that you indeed have other "useful" data to put in the holes:
|
||||
|
||||
```C
|
||||
struct using_gaps
|
||||
{
|
||||
uint64_t var : 40;
|
||||
uint64_t useful_uint16 : 16;
|
||||
uint64_t char_or_bool : 8;
|
||||
};
|
||||
```
|
||||
|
||||
Structure size and alignment will be equal to a 64 bit integer, so nothing is wasted if you make e.g. an array of a billion such structures (even without using compiler-specific extensions). If you don't have use for an 8-bit value, you could also use an 48-bit and a 16-bit value (giving a bigger overflow margin).
|
||||
Alternatively you could, at the expense of usability, put 8 40-bit values into a structure (least common multiple of 40 and 64 being 320 = 8*40). Of course then your code which accesses elements in the array of structures will become much more complicated (though one could probably implement an operator[] that restores the linear array functionality and hides the structure complexity).
|
||||
|
||||
Update:
|
||||
Wrote a quick test suite, just to see what overhead the bitfields (and operator overloading with bitfield refs) would have. Posted code (due to length) at gcc.godbolt.org, test output from my Win7-64 machine is:
|
||||
|
||||
```TXT
|
||||
Running test for array size = 1048576
|
||||
what alloc seq(w) seq(r) rand(w) rand(r) free
|
||||
-----------------------------------------------------------
|
||||
uint32_t 0 2 1 35 35 1
|
||||
uint64_t 0 3 3 35 35 1
|
||||
bad40_t 0 5 3 35 35 1
|
||||
packed40_t 0 7 4 48 49 1
|
||||
|
||||
|
||||
Running test for array size = 16777216
|
||||
what alloc seq(w) seq(r) rand(w) rand(r) free
|
||||
-----------------------------------------------------------
|
||||
uint32_t 0 38 14 560 555 8
|
||||
uint64_t 0 81 22 565 554 17
|
||||
bad40_t 0 85 25 565 561 16
|
||||
packed40_t 0 151 75 765 774 16
|
||||
|
||||
|
||||
Running test for array size = 134217728
|
||||
what alloc seq(w) seq(r) rand(w) rand(r) free
|
||||
-----------------------------------------------------------
|
||||
uint32_t 0 312 100 4480 4441 65
|
||||
uint64_t 0 648 172 4482 4490 130
|
||||
bad40_t 0 682 193 4573 4492 130
|
||||
packed40_t 0 1164 552 6181 6176 130
|
||||
```
|
||||
|
||||
What one can see is that the extra overhead of bitfields is neglegible, but the operator overloading with bitfield reference as a convenience thing is rather drastic (about 3x increase) when accessing data linearly in a cache-friendly manner. On the other hand, on random access it barely even matters.
|
||||
|
||||
These timings suggest that simply using 64-bit integers would be better since they are still faster overall than bitfields (despite touching more memory), but of course they do not take into account the cost of page faults with much bigger datasets. It might look very different once you run out of physical RAM (I didn't test that).
|
||||
|
||||
------
|
||||
|
||||
via:[stackoverflow](http://stackoverflow.com/questions/27705409/if-a-32-bit-integer-overflows-can-we-use-a-40-bit-structure-instead-of-a-64-bit/27705562#27705562)
|
||||
|
||||
作者:[Damon][a][Michael Kohne][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://stackoverflow.com/users/572743/damon
|
||||
[b]:http://stackoverflow.com/users/5801/michael-kohne
|
||||
@ -1,53 +0,0 @@
|
||||
How are C data types “supported directly by most computers”?
|
||||
---------
|
||||
|
||||
#Q:
|
||||
|
||||
I am reading K&R's *The C Programming Language*” and came across this statement [Introduction, p. 3]:
|
||||
|
||||
>Because the data types and control structures provided by C are supported directly by most computers, the run-time library required to implement self-contained programs is tiny.
|
||||
|
||||
What does the bolded statement mean? Is there an example of a data type or a control structure that isn't supported directly by a computer?
|
||||
|
||||
#A:
|
||||
|
||||
Yes, there are data types not directly supported.
|
||||
|
||||
On many embedded systems, there is no hardware floating point unit. So, when you write code like this:
|
||||
|
||||
```C
|
||||
float x = 1.0f, y = 2.0f;
|
||||
return x + y;
|
||||
```
|
||||
|
||||
It gets translated into something like this:
|
||||
|
||||
```C
|
||||
unsigned x = 0x3f800000, y = 0x40000000;
|
||||
return _float_add(x, y);
|
||||
```
|
||||
|
||||
Then the compiler or standard library has to supply an implementation of `_float_add()`, which takes up memory on your embedded system. If you're counting bytes on a really tiny system, this can add up.
|
||||
|
||||
Another common example is 64-bit integers (`long long` in the C standard since 1999), which are not directly supported by 32-bit systems. Old SPARC systems didn't support integer multiplication, so multiplication had to be supplied by the runtime. There are other examples.
|
||||
|
||||
##Other languages
|
||||
|
||||
By comparison, other languages have more complicated primitives.
|
||||
|
||||
For example, a Lisp symbol requires a lot of runtime support, just like tables in Lua, strings in Python, arrays in Fortran, et cetera. The equivalent types in C are usually either not part of the standard library at all (no standard symbols or tables) or they are much simpler and don't require much runtime support (arrays in C are basically just pointers, nul-terminated strings are almost as simple).
|
||||
|
||||
##Control structures
|
||||
|
||||
A notable control structure missing from C is exception handling. Nonlocal exit is limited to `setjmp()` and `longjmp()`, which just save and restore certain parts of processor state. By comparison, the C++ runtime has to walk the stack and call destructors and exception handlers.
|
||||
|
||||
----
|
||||
via:[stackoverflow](http://stackoverflow.com/questions/27977522/how-are-c-data-types-supported-directly-by-most-computers/27977605#27977605)
|
||||
|
||||
作者:[Dietrich Epp][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://stackoverflow.com/users/82294/dietrich-epp
|
||||
@ -0,0 +1,44 @@
|
||||
translating by KayGuoWhu
|
||||
Why does C++ promote an int to a float when a float cannot represent all int values?
|
||||
---------
|
||||
|
||||
#Q:
|
||||
|
||||
Say I have the following:
|
||||
|
||||
```C
|
||||
int i = 23;
|
||||
float f = 3.14;
|
||||
if (i == f) // do something
|
||||
```
|
||||
|
||||
The i will be promoted to a float and the two float numbers will be compared, but can a float represent all int values? Why not promote both the int and the float to a double?
|
||||
|
||||
#A:
|
||||
|
||||
When `int` is promoted to `unsigned` in the integral promotions, negative values are also lost (which leads to such fun as `0u < -1` being true).
|
||||
|
||||
Like most mechanisms in C (that are inherited in C++), the usual arithmetic conversions should be understood in terms of hardware operations. The makers of C were very familiar with the assembly language of the machines with which they worked, and they wrote C to make immediate sense to themselves and people like themselves when writing things that would until then have been written in assembly (such as the UNIX kernel).
|
||||
|
||||
Now, processors, as a rule, do not have mixed-type instructions (add float to double, compare int to float, etc.) because it would be a huge waste of real estate on the wafer -- you'd have to implement as many times more opcodes as you want to support different types. That you only have instructions for "add int to int," "compare float to float", "multiply unsigned with unsigned" etc. makes the usual arithmetic conversions necessary in the first place -- they are a mapping of two types to the instruction family that makes most sense to use with them.
|
||||
|
||||
From the point of view of someone who's used to writing low-level machine code, if you have mixed types, the assembler instructions you're most likely to consider in the general case are those that require the least conversions. This is particularly the case with floating points, where conversions are runtime-expensive, and particularly back in the early 1970s, when C was developed, computers were slow, and when floating point calculations were done in software. This shows in the usual arithmetic conversions -- only one operand is ever converted (with the single exception of `long/unsigned int`, where the `long` may be converted to `unsigned long`, which does not require anything to be done on most machines. Perhaps not on any where the exception applies).
|
||||
|
||||
So, the usual arithmetic conversions are written to do what an assembly coder would do most of the time: you have two types that don't fit, convert one to the other so that it does. This is what you'd do in assembler code unless you had a specific reason to do otherwise, and to people who are used to writing assembler code and do have a specific reason to force a different conversion, explicitly requesting that conversion is natural. After all, you can simply write
|
||||
|
||||
```C
|
||||
if((double) i < (double) f)
|
||||
```
|
||||
|
||||
It is interesting to note in this context, by the way, that `unsigned` is higher in the hierarchy than `int`, so that comparing `int` with `unsigned` will end in an unsigned comparison (hence the `0u < -1` bit from the beginning). I suspect this to be an indicator that people in olden times considered `unsigned` less as a restriction on `int` than as an extension of its value range: We don't need the sign right now, so let's use the extra bit for a larger value range. You'd use it if you had reason to expect that an `int` would overflow -- a much bigger worry in a world of 16-bit ints.
|
||||
|
||||
----
|
||||
via:[stackoverflow](http://stackoverflow.com/questions/28010565/why-does-c-promote-an-int-to-a-float-when-a-float-cannot-represent-all-int-val/28011249#28011249)
|
||||
|
||||
作者:[wintermute][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://stackoverflow.com/users/4301306/wintermute
|
||||
31
sources/talk/20150127 Windows 10 versus Linux.md
Normal file
31
sources/talk/20150127 Windows 10 versus Linux.md
Normal file
@ -0,0 +1,31 @@
|
||||
Windows 10 versus Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
Windows 10 seemed to dominate the headlines today, even in many Linux circles. Leading the pack is Brian Fagioli at betanews.com saying Windows 10 is ringing the death knell for Linux desktops. Microsoft announced today that Windows 10 will be free for loyal Windows users and Steven J. Vaughan-Nichols said it's the newest Open Source company. Then Matt Hartley compares Windows 10 to Ubuntu and Jesse Smith reviews Windows 10 from a Linux user's perspective.
|
||||
|
||||
**Windows 10** was the talk around water coolers today with Microsoft's [announcement][1] that it would be free for Windows 7 and up users. Here in Linuxland, that didn't go unnoticed. Brian Fagioli at betanews.com, a self-proclaimed Linux fan, said today, "Windows 10 closes the door entirely. The year of the Linux desktop will never happen. Rest in peace." [Fagioli explained][2] that Microsoft listened to user complaints and not only addressed them but improved way beyond that. He said Linux missed the boat by failing to capitalize on the Windows 8 unpopularity and ultimate failure. Then he concluded that we on the fringe must accept our "shattered dreams" thanks to Windows 10.
|
||||
|
||||
**H**owever, Jesse Smith, of Distrowatch.com fame, said Microsoft isn't making it easy to find the download, but it is possible and he did it. The installer was simple enough except for the partitioner, which was quite limited and almost scary. After finally getting into Windows 10, Smith said the layout was "sparce" without a lot of the distractions folks hated about 7. The menu is back and the start screen is gone. A new package manager looks a lot like Ubuntu's and Android's according to Smith, but requires an online Microsoft account to use. [Smith concludes][3] in part, "Windows 10 feels like a beta for an early version of Android, a consumer operating system that is designed to be on-line all the time. It does not feel like an operating system I would use to get work done."
|
||||
|
||||
**S**mith's [full article][4] compares Windows 10 to Linux quite a bit, but Matt Hartley today posted an actual Windows 10 vs Linux report. [He said][5] both installers were straightforward and easy Windows still doesn't dual boot easily and Windows provides encryption by default but Ubuntu offers it as an option. At the desktop Hartley said Windows 10 "is struggling to let go of its Windows 8 roots." He thought the Windows Store looks more polished than Ubuntu's but didn't really like the "tile everything" approach to newly installed apps. In conclusion, Hartley said, "The first issue is that it's going to be a free upgrade for a lot of Windows users. This means the barrier to entry and upgrade is largely removed. Second, it seems this time Microsoft has really buckled down on listening to what their users want."
|
||||
|
||||
**S**teven J. Vaughan-Nichols today said that Microsoft is the newest Open Source company; not because it's going to be releasing Windows 10 as a free upgrade but because Microsoft is changing itself from a software company to a software as a service company. And, according to Vaughan-Nichols, Microsoft needs Open Source to do it. They've been working on it for years beginning with Novell/SUSE. Not only that, they've been releasing software as Open Source as well (whatever the motives). [Vaughan-Nichols concluded][6], "Most people won't see it, but Microsoft -- yes Microsoft -- has become an open-source company."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ostatic.com/blog/windows-10-versus-linux
|
||||
|
||||
作者:[Susan Linton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ostatic.com/member/susan-linton
|
||||
[1]:https://news.google.com/news/section?q=microsoft+windows+10+free&ie=UTF-8&oe=UTF-8
|
||||
[2]:http://betanews.com/2015/01/25/windows-10-is-the-final-nail-in-the-coffin-for-the-linux-desktop/
|
||||
[3]:http://blowingupbits.com/2015/01/an-outsiders-perspective-on-windows-10-preview/
|
||||
[4]:http://blowingupbits.com/2015/01/an-outsiders-perspective-on-windows-10-preview/
|
||||
[5]:http://www.datamation.com/open-source/windows-vs-linux-the-2015-version-1.html
|
||||
[6]:http://www.zdnet.com/article/microsoft-the-open-source-company/
|
||||
@ -0,0 +1,86 @@
|
||||
7 communities driving open source development
|
||||
================================================================================
|
||||
Not so long ago, the open source model was the rebellious kid on the block, viewed with suspicion by established industry players. Today, open initiatives and foundations are flourishing with long lists of vendor committers who see the model as a key to innovation.
|
||||
|
||||

|
||||
|
||||
### Open Development of Tech Drives Innovation ###
|
||||
|
||||
Over the past two decades, open development of technology has come to be seen as a key to driving innovation. Even companies that once saw open source as a threat have come around — Microsoft, for example, is now active in a number of open source initiatives. To date, most open development has focused on software. But even that is changing as communities have begun to coalesce around open hardware initiatives. Here are seven organizations that are successfully promoting and developing open technologies, both hardware and software.
|
||||
|
||||
### OpenPOWER Foundation ###
|
||||
|
||||

|
||||
|
||||
The [OpenPOWER Foundation][2] was founded by IBM, Google, Mellanox, Tyan and NVIDIA in 2013 to drive open collaboration hardware development in the same spirit as the open source software development which has found fertile ground in the past two decades.
|
||||
|
||||
IBM seeded the foundation by opening up its Power-based hardware and software technologies, offering licenses to use Power IP in independent hardware products. More than 70 members now work together to create custom open servers, components and software for Linux-based data centers.
|
||||
|
||||
In April, OpenPOWER unveiled a technology roadmap based on new POWER8 process-based servers capable of analyzing data 50 times faster than the latest x86-based systems. In July, IBM and Google released a firmware stack. October saw the availability of NVIDIA GPU accelerated POWER8 systems and the first OpenPOWER reference server from Tyan.
|
||||
|
||||
### The Linux Foundation ###
|
||||
|
||||

|
||||
|
||||
Founded in 2000, [The Linux Foundation][2] is now the host for the largest open source, collaborative development effort in history, with more than 180 corporate members and many individual and student members. It sponsors the work of key Linux developers and promotes, protects and advances the Linux operating system and collaborative software development.
|
||||
|
||||
Some of its most successful collaborative projects include Code Aurora Forum (a consortium of companies with projects serving the mobile wireless industry), MeeGo (a project to build a Linux kernel-based operating system for mobile devices and IVI) and the Open Virtualization Alliance (which fosters the adoption of free and open source software virtualization solutions).
|
||||
|
||||
### Open Virtualization Alliance ###
|
||||
|
||||

|
||||
|
||||
The [Open Virtualization Alliance (OVA)][3] exists to foster the adoption of free and open source software virtualization solutions like Kernel-based Virtual Machine (KVM) through use cases and support for the development of interoperable common interfaces and APIs. KVM turns the Linux kernel into a hypervisor.
|
||||
|
||||
Today, KVM is the most commonly used hypervisor with OpenStack.
|
||||
|
||||
### The OpenStack Foundation ###
|
||||
|
||||

|
||||
|
||||
Originally launched as an Infrastructure-as-a-Service (IaaS) product by NASA and Rackspace hosting in 2010, the [OpenStack Foundation][4] has become the home for one of the biggest open source projects around. It boasts more than 200 member companies, including AT&T, AMD, Avaya, Canonical, Cisco, Dell and HP.
|
||||
|
||||
Organized around a six-month release cycle, the foundation's OpenStack projects are developed to control pools of processing, storage and networking resources through a data center — all managed or provisioned through a Web-based dashboard, command-line tools or a RESTful API. So far, the collaborative development supported by the foundation has resulted in the creation of OpenStack components including OpenStack Compute (a cloud computing fabric controller that is the main part of an IaaS system), OpenStack Networking (a system for managing networks and IP addresses) and OpenStack Object Storage (a scalable redundant storage system).
|
||||
|
||||
### OpenDaylight ###
|
||||
|
||||

|
||||
|
||||
Another collaborative project to come out of the Linux Foundation, [OpenDaylight][5] is a joint initiative of industry vendors, like Dell, HP, Oracle and Avaya founded in April 2013. Its mandate is the creation of a community-led, open, industry-supported framework consisting of code and blueprints for Software-Defined Networking (SDN). The idea is to provide a fully functional SDN platform that can be deployed directly, without requiring other components, though vendors can offer add-ons and enhancements.
|
||||
|
||||
### Apache Software Foundation ###
|
||||
|
||||

|
||||
|
||||
The [Apache Software Foundation (ASF)][7] is home to nearly 150 top level projects ranging from open source enterprise automation software to a whole ecosystem of distributed computing projects related to Apache Hadoop. These projects deliver enterprise-grade, freely available software products, while the Apache License is intended to make it easy for users, whether commercial or individual, to deploy Apache products.
|
||||
|
||||
ASF was incorporated in 1999 as a membership-based, not-for-profit corporation with meritocracy at its heart — to become a member you must first be actively contributing to one or more of the foundation's collaborative projects.
|
||||
|
||||
### Open Compute Project ###
|
||||
|
||||

|
||||
|
||||
An outgrowth of Facebook's redesign of its Oregon data center, the [Open Compute Project (OCP)][7] aims to develop open hardware solutions for data centers. The OCP is an initiative made up of cheap, vanity-free servers, modular I/O storage for Open Rack (a rack standard designed for data centers to integrate the rack into the data center infrastructure) and a relatively "green" data center design.
|
||||
|
||||
OCP board members include representatives from Facebook, Intel, Goldman Sachs, Rackspace and Microsoft.
|
||||
|
||||
OCP recently announced two options for licensing: an Apache 2.0-like license that allows for derivative works and a more prescriptive license that encourages changes to be rolled back into the original software.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.networkworld.com/article/2866074/opensource-subnet/7-communities-driving-open-source-development.html
|
||||
|
||||
作者:[Thor Olavsrud][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.networkworld.com/author/Thor-Olavsrud/
|
||||
[1]:http://openpowerfoundation.org/
|
||||
[2]:http://www.linuxfoundation.org/
|
||||
[3]:https://openvirtualizationalliance.org/
|
||||
[4]:http://www.openstack.org/foundation/
|
||||
[5]:http://www.opendaylight.org/
|
||||
[6]:http://www.apache.org/
|
||||
[7]:http://www.opencompute.org/
|
||||
153
sources/talk/20150128 The top 10 rookie open source projects.md
Normal file
153
sources/talk/20150128 The top 10 rookie open source projects.md
Normal file
@ -0,0 +1,153 @@
|
||||
The top 10 rookie open source projects
|
||||
================================================================================
|
||||
Black Duck presents its Open Source Rookies of the Year -- the 10 most exciting, active new projects germinated by the global open source community
|
||||
|
||||

|
||||
|
||||
### Open Source Rookies of the Year ###
|
||||
|
||||
Each year sees the start of thousands of new open source projects. Only a handful gets real traction. Some projects gain momentum by building on existing, well-known technologies; others truly break new ground. Many projects are created to solve a simple development problem, while others begin with loftier intentions shared by like-minded developers around the world.
|
||||
|
||||
Since 2009, the open source software logistics company Black Duck has identified the [Open Source Rookies of the Year][1], based on activity tracked by its [Open Hub][2] (formerly Ohloh) site. This year, we're delighted to present 10 winners and two honorable mentions for 2015, selected from thousands of open source projects. Using a weighted scoring system, points were awarded based on project activity, the pace of commits, and several other factors.
|
||||
|
||||
Open source has become the industry's engine of innovation. This year, for example, growth in projects related to Docker containerization trumped every other rookie area -- and not coincidentally reflected the most exciting area of enterprise technology overall. At the very least, the projects described here provide a window on what the global open source developer community is thinking, which is fast becoming a good indicator of where we're headed.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: DebOps ###
|
||||
|
||||

|
||||
|
||||
[DebOps][3] is a collection of [Ansible][4] playbooks and roles, scalable from one container to an entire data center. Founder Maciej Delmanowski open-sourced DebOps to ensure his work outlived his current work environment and could grow in strength and depth from outside contributors.
|
||||
|
||||
DebOps began at a small university in Poland that ran its own data center, where everything was configured by hand. Crashes sometimes led to days of downtime -- and Delmanowski realized that a configuration management system was needed. Starting with a Debian base, DebOps is a group of Ansible playbooks that configure an entire data infrastructure. The project has been implemented in many different working environments, and the founders plan to continue supporting and improving it as time goes on.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Code Combat ###
|
||||
|
||||

|
||||
|
||||
The traditional pen-and-paper way of learning falls short for technical subjects. Games, however, are all about engagement -- which is why the founders of [CodeCombat][5] went about creating a multiplayer programming game to teach people how to code.
|
||||
|
||||
At its inception, CodeCombat was an idea for a startup, but the founders decided to create an open source project instead. The idea blossomed within the community, and the project gained contributors at a steady rate. A mere two months after its launch, the game was accepted into Google’s Summer of Code. The game reaches a broad audience and is available in 45 languages. CodeCombat hopes to become the standard for people who want to learn to code and have fun at the same time.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Storj ###
|
||||
|
||||

|
||||
|
||||
[Storj][6] is a peer-to-peer cloud storage network that implements end-to-end encryption, enabling users to transfer and share data without reliance on a third party. Based on bitcoin blockchain technology and peer-to-peer protocols, Storj provides secure, private, and encrypted cloud storage.
|
||||
|
||||
Opponents of cloud-based data storage worry about cost efficiencies and vulnerability to attack. Intended to address both concerns, Storj is a private cloud storage marketplace where space is purchased and traded via Storjcoin X (SJCX). Files uploaded to Storj are shredded, encrypted, and stored across the community. File owners are the sole individuals who possess keys to the encrypted information.
|
||||
|
||||
The proof of concept for this decentralized cloud storage marketplace was first presented at the Texas Bitcoin Conference Hackathon in 2014. After winning first place in the hackathon, the project founders and leaders used open forums, Reddit, bitcoin forums, and social media to grow an active community, now an essential part of the Storj decision-making process.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Neovim ###
|
||||
|
||||

|
||||
|
||||
Since its inception in 1991, Vim has been a beloved text editor adopted by millions of software developers. [Neovim][6] is the next generation.
|
||||
|
||||
The software development ecosystem has experienced exponential growth and innovation over the past 23 years. Neovim founder Thiago de Arruda knew that Vim was lacking in modern-day features and development speed. Although determined to preserve the signature features of Vim, the community behind Neovim seeks to improve and evolve the technology of its favorite text editor. Crowdfunding initially enabled de Arruda to focus six uninterrupted months on launching this endeavor. He credits the Neovim community for supporting the project and for inspiring him to continue contributing.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: CockroachDB ###
|
||||
|
||||

|
||||
|
||||
Former Googlers are bringing a big-company data solution to open source in the form of [CockroachDB][8], a scalable, geo-replicated, transactional data store.
|
||||
|
||||
To maintain the terabytes of data transacted over its global online properties, Google developed Spanner. This powerful tool provides Google with scalability, survivability, and transactionality -- qualities that the team behind CockroachDB is serving up to the open source community. Like an actual cockroach, CockroachDB can survive without its head, tolerating the failure of any node. This open source project has a devoted community of experienced contributors, actively cultivated by the founders via social media, GitHub, networking, conferences, and meet-ups.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Kubernetes ###
|
||||
|
||||

|
||||
|
||||
In introducing containerized software development to the open source community, [Docker][9] has become the backbone of a strong, innovative set of tools and technologies. [Kubernetes][10], which Google introduced last June, is an open source container management tool used to accelerate development and simplify operations.
|
||||
|
||||
Google has been using containers for years in its internal operations. At the summer 2014 DockerCon, the Internet giant open-sourced Kubernetes, which was developed to meet the needs of the exponentially growing Docker ecosystem. Through collaborations with other organizations and projects, such as Red Hat and CoreOS, Kubernetes project managers have grown their project to be the No. 1 downloaded tool on the Docker Hub. The Kubernetes team hopes to expand the project and grow the community, so software developers can spend less time managing infrastructure and more time building the apps they want.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Open Bazaar ###
|
||||
|
||||

|
||||
|
||||
[OpenBazaar][11] is a decentralized marketplace for trading with anyone using bitcoin. The proof of concept for OpenBazaar was born at a hackathon, where its founders combined BitTorent, bitcoin, and traditional financial server methodologies to create a censorship-resistant trading platform. The OpenBazaar team sought new members, and before long they were able to expand the OpenBazaar community immensely. The table stakes of OpenBazaar -- transparency and a common goal to revolutionize trade and commerce -- are helping founders and contributors work toward a real-world, uncontrolled, and decentralized marketplace.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: IPFS ###
|
||||
|
||||

|
||||
|
||||
[IPFS (InterPlanetary File System)][12] is a global, versioned, peer-to-peer file system.It synthesizes many of the ideas behind Git, BitTorrent, and HTTP to bring a new data and data structure transport protocol to the open Web.
|
||||
|
||||
Open source is known for developing simple solutions to complex problems that result in many innovations, but these powerful projects represent only one slice of the open source community. IFPS belong to a more radical group whose proof of concept seems daring, outrageous, and even unattainable -- in this case, a peer-to-peer distributed file system that seeks to connect all computing devices. This possible HTTP replacement maintains a community through multiple mediums, including the Git community and an IRC channel that has more than 100 current contributors. This “crazy” idea will be available for alpha testing in 2015.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: cAdvisor ###
|
||||
|
||||

|
||||
|
||||
[cAdvisor (Container Advisor)][13] is a daemon that collects, aggregates, processes, and exports information about running containers, providing container users with an understanding of resource usage and performance characteristics. For each container, cAdvisor keeps resource isolation parameters, historical resource usage, histograms of complete historical resource usage, and network statistics. This data is exported by container and across machines.
|
||||
|
||||
cAdvisor can run on most Linux distros and supports many container types, including Docker. It has become the de facto monitoring agent for containers, has been integrated into many systems, and is one of the most downloaded images on the Docker Hub. The team hopes to grow cAdvisor to understand application performance more deeply and to integrate this information into clusterwide systems.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Terraform ###
|
||||
|
||||

|
||||
|
||||
[Terraform][14] provides a common configuration to launch infrastructure, from physical and virtual servers to email and DNS providers. The idea is to encompass everything from custom in-house solutions to services offered by public cloud platforms. Once launched, Terraform enables ops to change infrastructure safely and efficiently as the configuration evolves.
|
||||
|
||||
Working at a devops company, Terraform.io's founders identified a pain point in codifying the knowledge required to build a complete data center, from plugged-in servers to a fully networked and functional data center. Infrastructure is described using a high-level configuration syntax, which allows a blueprint of your data center to be versioned and treated as you would any other code. Sponsorship from the well-respected open source company HashiCorp helped launch the project.
|
||||
|
||||
### Honorable mention: Docker Fig ###
|
||||
|
||||

|
||||
|
||||
[Fig][15] provides fast, isolated development environments using [Docker][16]. It moves the configuration required to orchestrate Docker into a simple fig.yml file. It handles all the work of building and running containers and forwarding their ports, as well as sharing volumes and linking them.
|
||||
|
||||
Orchard formed Fig last year to create a new system of tools to make Docker work. It was developed as a way of setting up development environments with Docker, enabling users to define the exact environment for their apps, while also running databases and caches inside Docker. Fig solved a major pain point for developers. Docker fully supports this open source project and [recently purchased Orchard][17] to expand the reach of Fig.
|
||||
|
||||
### Honorable mention: Drone ###
|
||||
|
||||

|
||||
|
||||
[Drone][18] is a Continuous Integration platform built on Docker and [written in Go][19]. The Drone project grew out of frustration with existing available technologies and processes for setting up development environments.
|
||||
|
||||
Drone provides a simple approach to automated testing and continuous delivery: Simply pick a Docker image tailored to your needs, connect GitHub, and commit. Drone uses Docker containers to provision isolated testing environments, giving every project complete control over its stack without the burden of traditional server administration. The community behind Drone is 100 contributors strong and hopes to bring this project to the enterprise and to mobile app development.
|
||||
|
||||
### Open source rookies ###
|
||||
|
||||

|
||||
|
||||
- [Open Source Rookies of the 2014 Year][20]
|
||||
- [InfoWorld's 2015 Technology of the Year Award winners][21]
|
||||
- [Bossies: The Best of Open Source Software Awards][22]
|
||||
- [15 essential open source tools for Windows admins][23]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2875439/open-source-software/the-top-10-rookie-open-source-projects.html
|
||||
|
||||
作者:[Black Duck Software][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Black-Duck-Software/
|
||||
[1]:https://www.blackducksoftware.com/open-source-rookies
|
||||
[2]:https://www.openhub.net/
|
||||
[3]:https://github.com/debops/debops
|
||||
[4]:http://www.infoworld.com/article/2612397/data-center/review--ansible-orchestration-is-a-veteran-unix-admin-s-dream.html
|
||||
[5]:https://codecombat.com/
|
||||
[6]:http://storj.io/
|
||||
[7]:http://neovim.org/
|
||||
[8]:https://github.com/cockroachdb/cockroach
|
||||
[9]:http://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker
|
||||
[10]:http://kubernetes.io/
|
||||
[11]:https://openbazaar.org/
|
||||
[12]:http://ipfs.io/
|
||||
[13]:https://github.com/google/cadvisor
|
||||
[14]:https://www.terraform.io/
|
||||
[15]:http://www.fig.sh/
|
||||
[16]:http://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker
|
||||
[17]:http://www.infoworld.com/article/2608546/application-virtualization/docker-acquires-orchard-in-a-sign-of-rising-ambitions.html
|
||||
[18]:https://drone.io/
|
||||
[19]:http://www.infoworld.com/article/2683845/google-go/164121-Fast-guide-to-Go-programming.html
|
||||
[20]:https://www.blackducksoftware.com/open-source-rookies
|
||||
[21]:http://www.infoworld.com/article/2871935/application-development/infoworlds-2015-technology-of-the-year-award-winners.html
|
||||
[22]:http://www.infoworld.com/article/2688104/open-source-software/article.html
|
||||
[23]:http://www.infoworld.com/article/2854954/microsoft-windows/15-essential-open-source-tools-for-windows-admins.html
|
||||
@ -0,0 +1,82 @@
|
||||
9 Best IDEs and Code Editors for JavaScript Users
|
||||
================================================================================
|
||||
Web designing and developing is one of the trending sectors in the recent times, where more and more peoples started to search for their career opportunities. But, Getting the right opportunity as a web developer or graphic designer is not just a piece of cake for everyone, It certainly requires a strong mind presence as well as right skills to find the find the right job. There are a lot of websites available today which can help you to get the right job description according to your knowledge. But still if you want to achieve something in this sector you must have some excellent skills like working with different platforms, IDEs and various other tools too.
|
||||
|
||||
Talking about the different platforms and IDEs used for various languages for different purposes, gone is the time when we learn just one IDE and get the optimum solutions for our web design projects easily. Today we are living in the modern lifestyle where competition is getting more and more tough on every single day. Same is the case with the IDEs, IDE is basically a powerful client application for creating and deploying applications. Today we are going to share some best javascript IDE for web designers and developers.
|
||||
|
||||
Please visit this list of best code editors for javascript user and share your thought with us.
|
||||
|
||||
### 1) [Spket][1] ###
|
||||
|
||||
**Spket IDE** is powerful toolkit for JavaScript and XML development. The powerful editor for JavaScript, XUL/XBL and Yahoo! Widget development. The JavaScript editor provides features like code completion, syntax highlighting and content outline that helps developers productively create efficient JavaScript code.
|
||||
|
||||

|
||||
|
||||
### 2) [Ixedit][2] ###
|
||||
|
||||
IxEdit is a JavaScript-based interaction design tool for the web. With IxEdit, designers can practice DOM-scripting without coding to change, add, move, or transform elements dynamically on your web pages.
|
||||
|
||||

|
||||
|
||||
### 3) [Komodo Edit][3] ###
|
||||
|
||||
Komode is free and powerful code editor for Javascript and other programming languages.
|
||||
|
||||

|
||||
|
||||
### 4) [EpicEditor][4] ###
|
||||
|
||||
EpicEditor is an embeddable JavaScript Markdown editor with split fullscreen editing, live previewing, automatic draft saving, offline support, and more. For developers, it offers a robust API, can be easily themed, and allows you to swap out the bundled Markdown parser with anything you throw at it.
|
||||
|
||||

|
||||
|
||||
### 5) [codepress][5] ###
|
||||
|
||||
CodePress is web-based source code editor with syntax highlighting written in JavaScript that colors text in real time while it’s being typed in the browser.
|
||||
|
||||

|
||||
|
||||
### 6) [ACe][6] ###
|
||||
|
||||
Ace is an embeddable code editor written in JavaScript. It matches the features and performance of native editors such as Sublime, Vim and TextMate. It can be easily embedded in any web page and JavaScript application.
|
||||
|
||||

|
||||
|
||||
### 7) [scripted][7] ###
|
||||
|
||||
Scripted is a fast and lightweight code editor with an initial focus on JavaScript editing. Scripted is a browser based editor and the editor itself is served from a locally running Node.js server instance.
|
||||
|
||||

|
||||
|
||||
### 8) [Netbeans][8] ###
|
||||
|
||||
This is another more impressive and useful code editors for javascript and other programming languages.
|
||||
|
||||

|
||||
|
||||
### 9) [Webstorm][9] ###
|
||||
|
||||
This is the smartest ID for javascript. WebStorm is a lightweight yet powerful IDE, perfectly equipped for complex client-side development and server-side development with Node.js.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://devzum.com/2015/01/31/9-best-ides-and-code-editors-for-javascript-users/
|
||||
|
||||
作者:[vikas][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://devzum.com/author/vikas/
|
||||
[1]:http://spket.com/
|
||||
[2]:http://www.ixedit.com/
|
||||
[3]:http://komodoide.com/komodo-edit/
|
||||
[4]:http://oscargodson.github.io/EpicEditor/
|
||||
[5]:http://codepress.sourceforge.net/
|
||||
[6]:http://ace.c9.io/#nav=about
|
||||
[7]:https://github.com/scripted-editor/scripted
|
||||
[8]:https://netbeans.org/
|
||||
[9]:http://www.jetbrains.com/webstorm/
|
||||
@ -0,0 +1,34 @@
|
||||
GHOST: Another Security Bug Hits Linux, But is it That Bad?
|
||||
================================================================================
|
||||
> GHOST, a newly announced security vulnerability that affects Linux servers and other systems that use the open source glibc library, is not as dangerous to data privacy as the Shellshock or Heartbleed bugs.
|
||||
|
||||

|
||||
|
||||
Heartbleed is not even a year behind us, and the open source world has been hit with another major security vulnerability in the form of [GHOST][1], which involves holes in the Linux glibc library. This time, though, the actual danger may not live up to the hype.
|
||||
|
||||
The GHOST vulnerability, which was announced last week by security researchers at [Qualys][2], resides in the gethostbyname*() functions of the glibc library. glibc is one of the core building blocks of most Linux systems, and gethostbyname*(), which resolves domain names into IP addresses, is widely used in open source applications.
|
||||
|
||||
Attackers can exploit the GHOST security hole to create a buffer overflow, making it possible to execute any kind of code they want and do all sorts of nasty things.
|
||||
|
||||
All of the above suggests that GHOST is bad news indeed. Fortunately for the open source community, however, the actual risk appears small. As TrendMicro [points out][3], the bug that makes the exploit possible has been fixed in glibc since May 2013, meaning that any Linux servers or PCs running more recent versions of the software are safe from attack.
|
||||
|
||||
In addition, gethostbyname*() has been superseded by newer glibc functions that can better handle modern networking environments. Those include ones that use the IPv6 protocol, which gethostbyname*() doesn't support. As a result, newer applications often don't use the gethostbyname*() functions, and are not at risk.
|
||||
|
||||
And perhaps most importantly, there's currently no known way of executing GHOST attacks through the Web. That greatly reduces opportunities for using this vulnerability to steal the data of unsuspecting users or otherwise wreak havoc.
|
||||
|
||||
All in all, then, GHOST doesn't seem like a vulnerability that will prove as serious as Heartbleed or Shellshock, two other recent security problems that affected widely used open source software.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/020415/ghost-another-security-bug-hits-linux-it-bad
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:https://community.qualys.com/blogs/laws-of-vulnerabilities/2015/01/27/the-ghost-vulnerability
|
||||
[2]:http://qualys.com/
|
||||
[3]:http://blog.trendmicro.com/trendlabs-security-intelligence/not-so-spooky-linux-ghost-vulnerability/
|
||||
@ -0,0 +1,32 @@
|
||||
LinuxQuestions Survey Results Surface Top Open Source Projects
|
||||
================================================================================
|
||||

|
||||
|
||||
Many people in the Linux community look forward to the always highly detailed and reliable results of the annual surveys from LinuxQuestions.org. As [Susan covered in detail in this post][1], this year's [results][2], focused on what readers at the site deem to be the best open source projects, are now available. Most of the people at LinuxQuestions are expert-level users who are on the site to answer questions from newer Linux users.
|
||||
|
||||
In addition to the summary results that Susan provided in her post, below you'll find a graphical snapshot of what the experts took note of on the open source front.
|
||||
|
||||
You can get a very nice graphical summary of the findings from the LinuxQuestions survey [here][3]. Here is a snapshot of the site's determination of the best Linux distributions, where Mint and Slackware fare quite well:
|
||||
|
||||
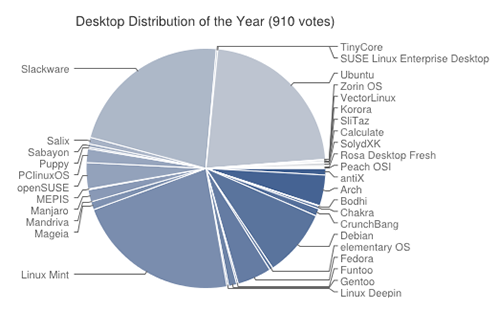
|
||||
|
||||
And below is a snapshot of the site's determination of the best cloud projects. Notably, the LinuxQuestions crowd gives very high praise to ownCloud. Definiitely check into the full results of the survey at the site, see [Susan's summary][4] of winners, and check out all the good graphics [here][5].
|
||||
|
||||
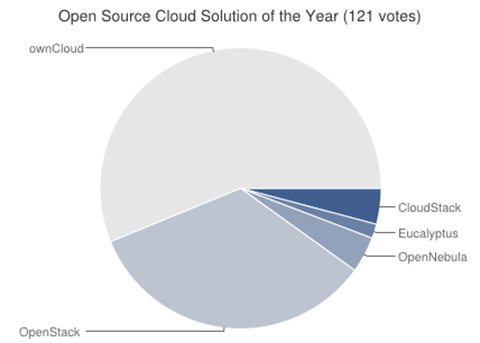
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ostatic.com/blog/linuxquestions-survey-results-surface-top-open-source-projects
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ostatic.com/member/samdean
|
||||
[1]:http://ostatic.com/blog/lq-members-choice-award-winners-announced
|
||||
[2]:http://www.linuxquestions.org/questions/linux-news-59/2014-linuxquestions-org-members-choice-award-winners-4175532948/
|
||||
[3]:http://www.linuxquestions.org/questions/2014mca.php
|
||||
[4]:http://ostatic.com/blog/lq-members-choice-award-winners-announced
|
||||
[5]:http://www.linuxquestions.org/questions/2014mca.php
|
||||
@ -1,100 +0,0 @@
|
||||
translating by alim0x
|
||||
|
||||
The history of Android
|
||||
================================================================================
|
||||
### Android 2.1—the discovery (and abuse) of animations ###
|
||||
|
||||
Android 2.1 came out with the launch of the Nexus One, which was only three months after the release of 2.0. The new OS wasn't a huge release, so it still kept the codename "Éclair." Android development was chugging along at an unheard-of pace, with Google averaging a new OS release every two-and-a-half months over the last 15 months.
|
||||
|
||||
Thanks mostly to the marketing efforts of Verizon and the "Droid" line of phones, Android was gaining in popularity. The OS was still considered ugly, though, and while the Android engineers at the time seemed to have almost no formal design training, in Android 2.1 they tried to spruce things up a bit by slathering on heavy-handed animation effects wherever they could. The result was an OS that seemed to be desperately trying to prove that it could do animation effects. Many of the new additions felt more like tech demos than user-experience improvements.
|
||||
|
||||

|
||||
The lock and home screens from Android 2.1 and 2.0.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Android 2.0's rotary dial lock screen was kicked to the curb after only one version and replaced with the same pull tabs the incoming call screen used. The lock screen clock was an attempt at a uniquely Android font, but as typefaces go, it was pretty hideous looking.
|
||||
|
||||
One of the biggest features in Android 2.1 was "Live Wallpapers"—interactive or moving images that could be set as the wallpaper. The default Live Wallpaper was a grid of squares with blue, red, yellow, and green lights continually streaking across it. Tapping on the screen would send lights firing out in all four directions from the center of your tap. While Live Wallpapers looked neat (and was a unique feature over the iPhone), the animated backgrounds sucked up battery power and CPU cycles. It seemed to make the whole phone run a little slower.
|
||||
|
||||
On the home screen, the default Google Search widget was given a lot more padding and now sits centered in its row. Page indicators now lived in the bottom left and right corners of the screen, and the number of home screen pages jumped from three to five. The app drawer tab at the bottom was replaced with an icon showing a grid of squares, a metaphor that Google still uses today.
|
||||
|
||||
|
||||
A picture showing the app drawer design and a composite image showing the app selection for Android 2.1 and 2.0.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
With the new app drawer icon came a totally new app drawer. Instead of a tabbed container that lifted up from the bottom of the screen, the app drawer displayed as a full-screen interface. The carbon fiber weave was removed, and the background switched to a plain black background—a decision that would stick around all the way up to KitKat.
|
||||
|
||||
Google decided to add a floating, semi-transparent home icon to the bottom of the app drawer to give people an easy way out of the full-screen tab interface. This could be seen as a precursor to the on-screen home button that was introduced in Android 4.0.
|
||||
|
||||
The app drawer was given a tacky graphics effect, too. While scrolling, the icons at the top and bottom of the list would bend inward and appear to move deeper into the phone, sort of like the opening scroll in Star Wars.
|
||||
|
||||
There were a few changes to the icons. "Amazon MP3" and "Alarm Clock" both lost their first names, along with their premium alphabetical real-estate at the top of the app drawer. Two new apps showed up: News and Weather, and Google Voice, which was Google's telecommunication service. Since the Nexus One was not a Verizon phone, Verizon's Visual Voicemail app was dumped.
|
||||
|
||||
|
||||
The revamped clock app.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Along with the name change, the clock app got a total revamp. Tapping on the clock shortcut no longer opened the alarms page; instead it went to a "desk clock" interface (left picture, above) with a background that matched the wallpaper. The clock used the same font from the lock screen, pulling in weather from the new News And Weather app.
|
||||
|
||||
The new alarm page cleaned up a lot of the weirder design decisions made in the old version. The analog clock and selectable clock designs were dead. The checkboxes were replaced with a green on/off light, which was much easier to parse than "gray check/green check." While it might be hard to see from the thumbnail (click for a bigger version), the old alarm design displayed AM and PM next to the time. The 2.1 design did away with that, only showing the relevant meridian. A digital clock was placed at the bottom, and the clock icon took you back to the desk clock interface.
|
||||
|
||||
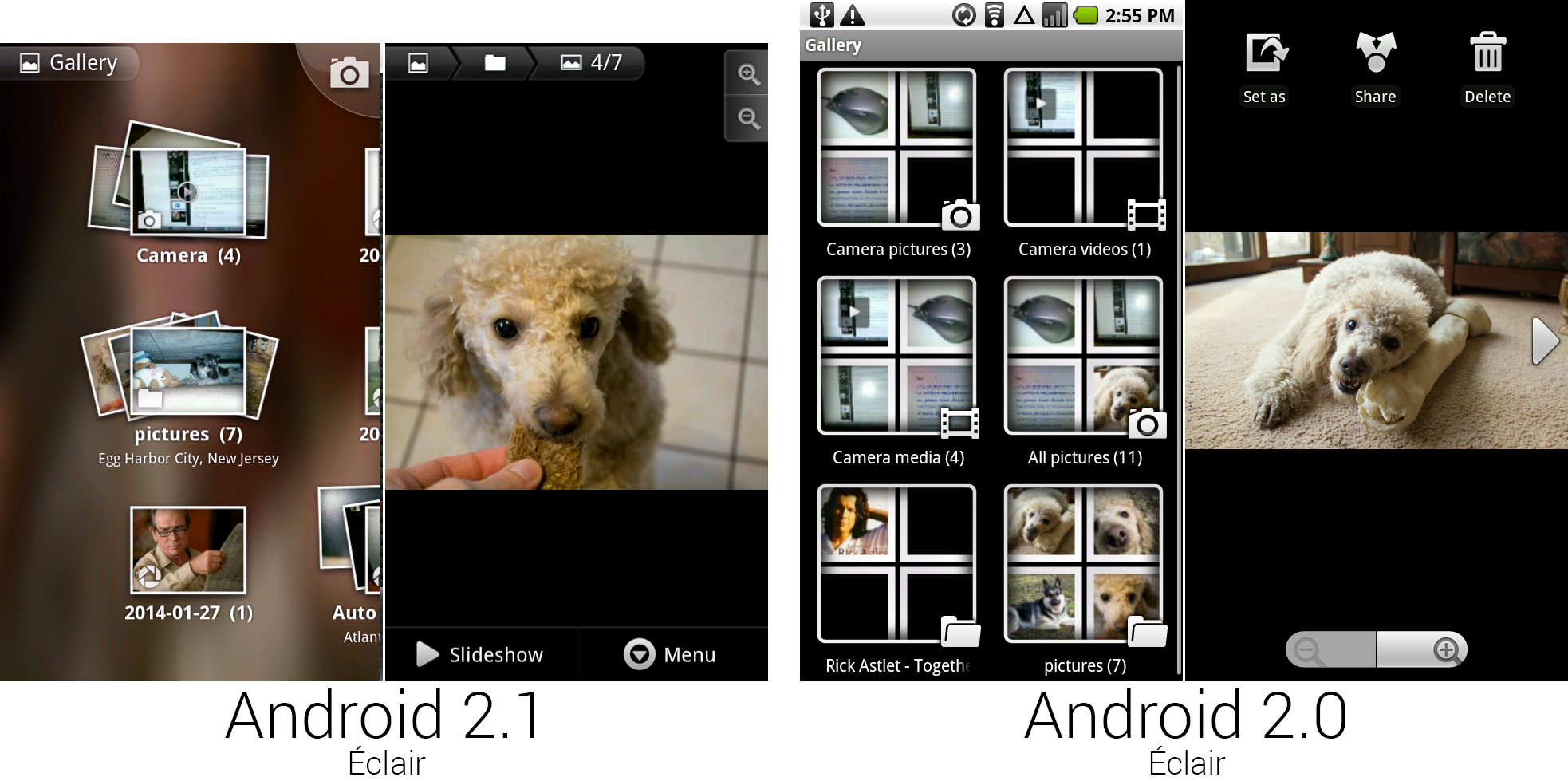
|
||||
The Gallery and individual image screens from 2.1 and 2.0.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Google's desire to improve the look of Android was most evident in the 2.1 Gallery, which was all about heavy-handed animation effects and transparencies. When the app opened, individual pictures flew in from the top of the screen and shuffled into little piles that made up an album. When opening an album, the picture stack separated, and the photos slid into a grid formation. Everything you touched would pop open, squish, and stretch like a spring-loaded piece of Jell-o.
|
||||
|
||||
There was no "normal" background for the Gallery. It would randomly pick a picture on the screen and heavily distort it for use as a background image. When that picture scrolled off-screen, it would pick a new background image, so the tone of the background always matched your pictures.
|
||||
|
||||
The top left of the screen housed a breadcrumbs bar. It displayed your current location and any folders between you and the main screen—it could be thought of as an early precursor to the "Up" button that would debut in Android 3.0. In the top right was a link to the camera app, which still sported the same faux-leather design that debuted in Android 1.6—the two designs could not be more different.
|
||||
|
||||
While the camera was another weird, one-off design, never was the wild UI disparity between Android apps more apparent than in the new Gallery. It didn't use Android buttons, menus, or any of the existing UI paradigms. It even hid the status bar in every screen—you could barely tell you were looking at Android.
|
||||
|
||||
In the individual photo view, you could finally swipe between images, which removed the need for chunky left and right arrows. For some reason, the color-matched background wasn't on this screen. It was the only part of the app where the background is black. Zoom controls were in the top-right (still no pinch zoom), and commands were held in a single strip along the bottom of the screen. Hitting the "menu" button (software or hardware) didn't bring up a 2×3 grid of options like every other app—the items in the bottom strip just changed from two options to three other options.
|
||||
|
||||
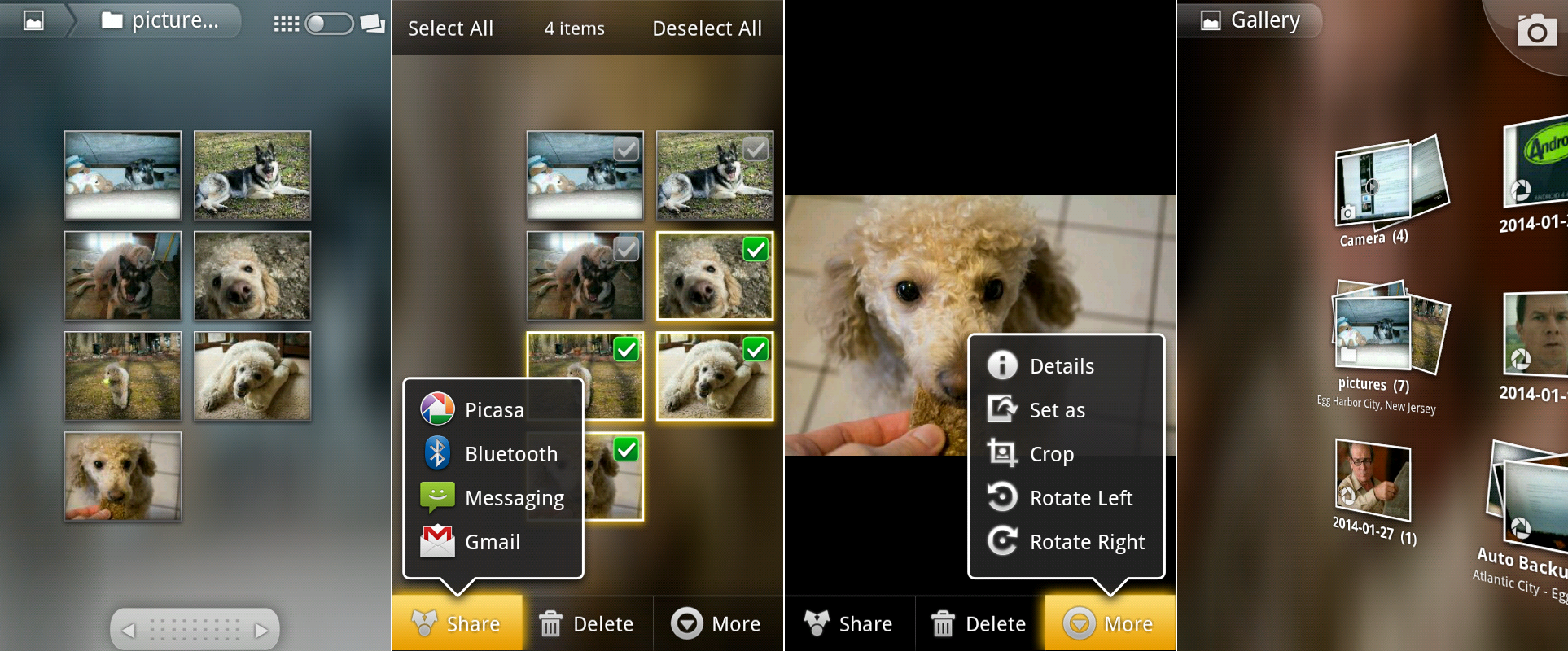
|
||||
The animation-filled Gallery app.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
The first picture, above, shows an album view. You could scroll horizontally through a large album or use the fast scroll bar at the bottom of the screen. Long pressing on a picture (or, bizarrely, pressing the hardware menu button) would bring up a "checkbox" interface, where you could tap on several pictures to select them. After you've selected pictures, you could then batch share, delete, or rotate them.
|
||||
|
||||
The menus on this screen and the next individual picture screen were semi-transparent speech bubbles that would spring out of their respective buttons when tapped on. Again, this was about as far away from the normal Android conventions as you could get. The Gallery was also one of the first apps to have an overscroll effect. When you hit the end of the photo wall, the entire surface would skew in the direction of the scrolling.
|
||||
|
||||
The 2.1 Gallery was the first photo client to show your cloud-stored Picasa photos along with local pictures. These were marked with a white camera shutter icon in the bottom left corner of a thumbnail. This would later become Google+ Photos.
|
||||
|
||||
No Android app before or since had looked like the gallery. There was good reason for that—it wasn’t made by Google! The app was farmed out to Cooliris, who didn't bother following a single existing Android UI paradigm. While the app was usable, all the animations and effects made it seem like a case of style over substance.
|
||||
|
||||

|
||||
The "News and Weather" app showing... the news and weather.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Compare the Gallery to the other new Android 2.1 app: News And Weather. While the Gallery was a transparency-filled animation fest, News And Weather was all about dark gradients and contrasting colors. This app powered the weather display on the desk clock app, and it even came with a home screen widget. The first screen just showed the weather and a six-day forecast for your current location. Along the top of the screens were tabs, next to the city name was a small "i" button that would bring up a temperature and precipitation graph. You could slide your finger along the graph to get exact temperatures and precipitation for any given minute.
|
||||
|
||||
The big innovation in this app was swipeable tabs, an idea that would eventually become a standard Android UI convention. After the weather were a bunch of user configurable news tabs, and besides tapping on the tabs to switch to them, you could just swipe horizontally across the screen and the tab would change. The news tabs all showed a list of news headlines that were almost always truncated to the point that you had no idea what the story was about. When opening a webpage from this app, it didn't load the browser. Instead, it opened the story within the app complete with a weird white border.
|
||||
|
||||
|
||||
Google Maps showing off some Labs features, the new widget designs, the only screen we can access in Google Voice, and the new tabbed music design.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Widgets in 2.1 were all redesigned, with almost everything receiving a black gradient, and made better use of the available space. The clock changed back to a circle, and the calendar got a blue top, which matched the app a little more closely. Google Voice will start up, but the sign-in is broken—this is as far as you can get.
|
||||
|
||||
The oft-neglected Music app got a minor update. The four-button home screen was removed completely, and tabs for each music display mode were added to the top of the screen. This meant when opening the app, you were immediately presented with a list of music, instead of a navigational page. Unlike the News and Weather app, these newly installed tabs here could not be swiped between.
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
|
||||
|
||||
[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -1,4 +1,4 @@
|
||||
The history of Android
|
||||
【translating】The history of Android
|
||||
================================================================================
|
||||
|
||||
|
||||
@ -101,4 +101,4 @@ via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-histor
|
||||
[3]:http://arstechnica.com/information-technology/2010/07/android-22-froyo/
|
||||
[4]:http://arstechnica.com/information-technology/2010/07/android-22-froyo/
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
alim0x translating
|
||||
|
||||
The history of Android
|
||||
================================================================================
|
||||
### Voice Actions—a supercomputer in your pocket ###
|
||||
@ -79,4 +81,4 @@ via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-histor
|
||||
[5]:http://arstechnica.com/gadgets/2013/12/google-robots-former-android-chief-will-lead-google-robotics-division/
|
||||
[6]:http://arstechnica.com/gadgets/2013/12/lg-g-flex-review-form-over-even-basic-function/
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
|
||||
@ -1,223 +0,0 @@
|
||||
How to create a software RAID-1 array with mdadm on Linux
|
||||
================================================================================
|
||||
Redundant Array of Independent Disks (RAID) is a storage technology that combines multiple hard disks into a single logical unit to provide fault-tolerance and/or improve disk I/O performance. Depending on how data is stored in an array of disks (e.g., with striping, mirroring, parity, or any combination thereof), different RAID levels are defined (e.g., RAID-0, RAID-1, RAID-5, etc). RAID can be implemented either in software or with a hardware RAID card. On modern Linux, basic software RAID functionality is available by default.
|
||||
|
||||
In this post, we'll discuss the software setup of a RAID-1 array (also known as a "mirroring" array), where identical data is written to the two devices that form the array. While it is possible to implement RAID-1 with partitions on a single physical hard drive (as with other RAID levels), it won't be of much use if that single hard drive fails. In fact, that's why most RAID levels normally use multiple physical drives to provide redundancy. In the event of any single drive failure, the virtual RAID block device should continue functioning without issues, and allow us to replace the faulty drive without significant production downtime and, more importantly, with no data loss. However, it does not replace the need to save periodic system backups in external storage.
|
||||
|
||||
Since the actual storage capacity (size) of a RAID-1 array is the size of the smallest drive, normally (if not always) you will find two identical physical drives in RAID-1 setup.
|
||||
|
||||
### Installing mdadm on Linux ###
|
||||
|
||||
The tool that we are going to use to create, assemble, manage, and monitor our software RAID-1 is called mdadm (short for **m**ultiple **d**isks **adm**in). On Linux distros such as Fedora, CentOS, RHEL or Arch Linux, mdadm is available by default. On Debian-based distros, mdadm can be installed with aptitude or apt-get.
|
||||
|
||||
#### Fedora, CentOS or RHEL ####
|
||||
|
||||
As mdadm comes pre-installed, all you have to do is to start RAID monitoring service, and configure it to auto-start upon boot:
|
||||
|
||||
# systemctl start mdmonitor
|
||||
# systemctl enable mdmonitor
|
||||
|
||||
For CentOS/RHEL 6, use these commands instead:
|
||||
|
||||
# service mdmonitor start
|
||||
# chkconfig mdmonitor on
|
||||
|
||||
#### Debian, Ubuntu or Linux Mint ####
|
||||
|
||||
On Debian and its derivatives, mdadm can be installed with **aptitude or apt-get**:
|
||||
|
||||
# aptitude install mdadm
|
||||
|
||||
On Ubuntu, you will be asked to configure postfix MTA for sending out email notifications (as part of RAID monitoring). You can skip it for now.
|
||||
|
||||
On Debian, the installation will start with the following explanatory message to help us decide whether or not we are going to install the root filesystem on a RAID array. What we need to enter on the next screen will depend on this decision. Read it carefully:
|
||||
|
||||
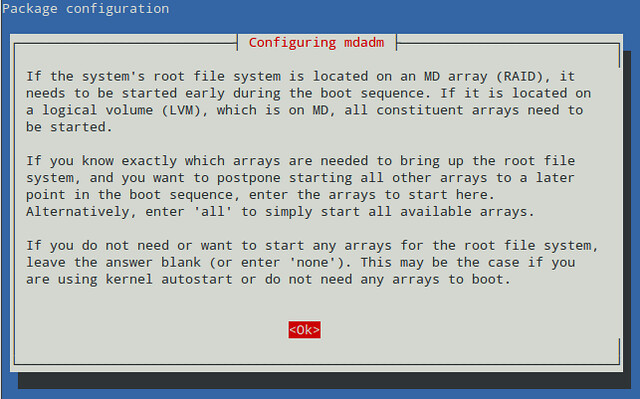
|
||||
|
||||
Since we will not use our RAID-1 for the root filesystem, we will leave the answer blank:
|
||||
|
||||
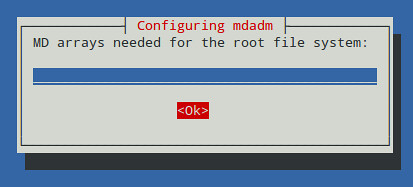
|
||||
|
||||
When asked whether we want to start (reassemble) our array automatically during each boot, choose "Yes". Note that we will need to add an entry to the /etc/fstab file later in order for the array to be properly mounted during the boot process as well.
|
||||
|
||||

|
||||
|
||||
### Partitioning Hard Drives ###
|
||||
|
||||
Now it's time to prepare the physical devices that will be used in our array. For this setup, I have plugged in two 8 GB USB drives that have been identified as /dev/sdb and /dev/sdc from dmesg output:
|
||||
|
||||
# dmesg | less
|
||||
|
||||
----------
|
||||
|
||||
[ 60.014863] sd 3:0:0:0: [sdb] 15826944 512-byte logical blocks: (8.10 GB/7.54 GiB)
|
||||
[ 75.066466] sd 4:0:0:0: [sdc] 15826944 512-byte logical blocks: (8.10 GB/7.54 GiB)
|
||||
|
||||
We will use fdisk to create a primary partition on each disk that will occupy its entire size. The following steps show how to perform this task on /dev/sdb, and assume that this drive hasn't been partitioned yet (otherwise, we can delete the existing partition(s) to start off with a clean disk):
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
Press 'p' to print the current partition table:
|
||||
|
||||

|
||||
|
||||
(if one or more partitions are found, they can be deleted with 'd' option. Then 'w' option is used to apply the changes).
|
||||
|
||||
Since no partitions are found, we will create a new primary partition ['n'] as a primary partition ['p'], assign the partition number = ['1'] to it, and then indicate its size. You can press Enter key to accept the proposed default values, or enter a value of your choosing, as shown in the image below.
|
||||
|
||||

|
||||
|
||||
Now repeat the same process for /dev/sdc.
|
||||
|
||||
If we have two drives of different sizes, say 750 GB and 1 TB for example, we should create a primary partition of 750 GB on each of them, and use the remaining space on the bigger drive for another purpose, independent of the RAID array.
|
||||
|
||||
### Create a RAID-1 Array ###
|
||||
|
||||
Once you are done with creating the primary partition on each drive, use the following command to create a RAID-1 array:
|
||||
|
||||
# mdadm -Cv /dev/md0 -l1 -n2 /dev/sdb1 /dev/sdc1
|
||||
|
||||
Where:
|
||||
|
||||
- **-Cv**: creates an array and produce verbose output.
|
||||
- **/dev/md0**: is the name of the array.
|
||||
- **-l1** (l as in "level"): indicates that this will be a RAID-1 array.
|
||||
- **-n2**: indicates that we will add two partitions to the array, namely /dev/sdb1 and /dev/sdc1.
|
||||
|
||||
The above command is equivalent to:
|
||||
|
||||
# mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sdb1 /dev/sdc1
|
||||
|
||||
If alternatively you want to add a spare device in order to replace a faulty disk in the future, you can add '--spare-devices=1 /dev/sdd1' to the above command.
|
||||
|
||||
Answer "y" when prompted if you want to continue creating an array, then press Enter:
|
||||
|
||||
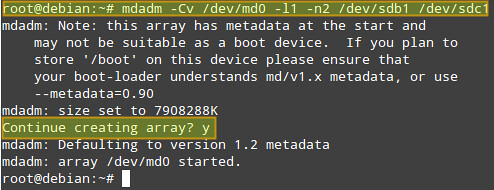
|
||||
|
||||
You can check the progress with the following command:
|
||||
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
Another way to obtain more information about a RAID array (both while it's being assembled and after the process is finished) is:
|
||||
|
||||
# mdadm --query /dev/md0
|
||||
# mdadm --detail /dev/md0 (or mdadm -D /dev/md0)
|
||||
|
||||
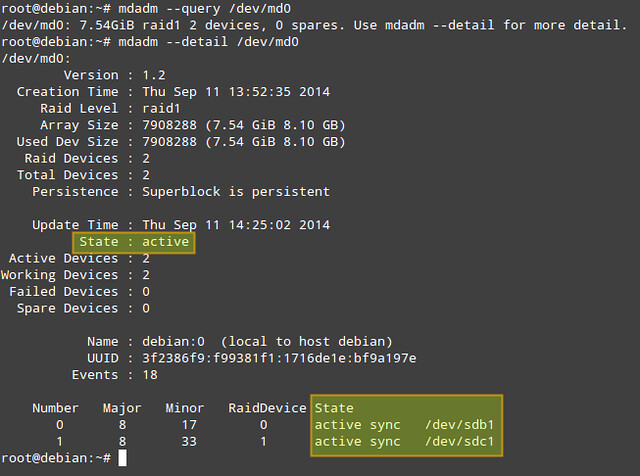
|
||||
|
||||
Of the information provided by 'mdadm -D', perhaps the most useful is that which shows the state of the array. The active state means that there is currently I/O activity happening. Other possible states are clean (all I/O activity has been completed), degraded (one of the devices is faulty or missing), resyncing (the system is recovering from an unclean shutdown such as a power outage), or recovering (a new drive has been added to the array, and data is being copied from the other drive onto it), to name the most common states.
|
||||
|
||||
### Formatting and Mounting a RAID Array ###
|
||||
|
||||
The next step is formatting (with ext4 in this example) the array:
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||
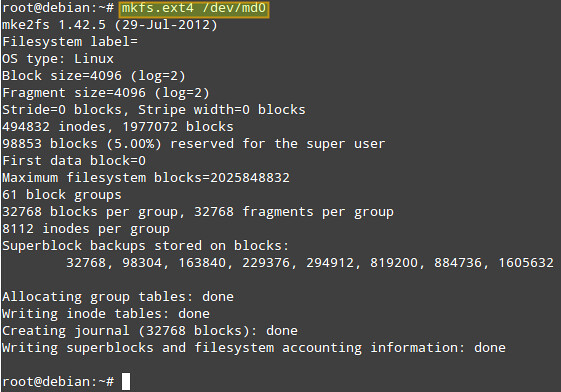
|
||||
|
||||
Now let's mount the array, and verify that it was mounted correctly:
|
||||
|
||||
# mount /dev/md0 /mnt
|
||||
# mount
|
||||
|
||||
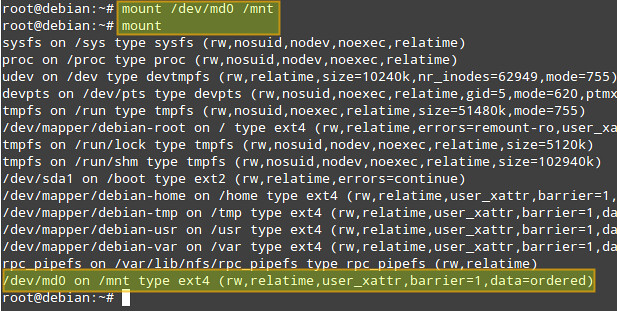
|
||||
|
||||
### Monitor a RAID Array ###
|
||||
|
||||
The mdadm tool comes with RAID monitoring capability built in. When mdadm is set to run as a daemon (which is the case with our RAID setup), it periodically polls existing RAID arrays, and reports on any detected events via email notification or syslog logging. Optionally, it can also be configured to invoke contingency commands (e.g., retrying or removing a disk) upon detecting any critical errors.
|
||||
|
||||
By default, mdadm scans all existing partitions and MD arrays, and logs any detected event to /var/log/syslog. Alternatively, you can specify devices and RAID arrays to scan in mdadm.conf located in /etc/mdadm/mdadm.conf (Debian-based) or /etc/mdadm.conf (Red Hat-based), in the following format. If mdadm.conf does not exist, create one.
|
||||
|
||||
DEVICE /dev/sd[bcde]1 /dev/sd[ab]1
|
||||
|
||||
ARRAY /dev/md0 devices=/dev/sdb1,/dev/sdc1
|
||||
ARRAY /dev/md1 devices=/dev/sdd1,/dev/sde1
|
||||
.....
|
||||
|
||||
# optional email address to notify events
|
||||
MAILADDR your@email.com
|
||||
|
||||
After modifying mdadm configuration, restart mdadm daemon:
|
||||
|
||||
On Debian, Ubuntu or Linux Mint:
|
||||
|
||||
# service mdadm restart
|
||||
|
||||
On Fedora, CentOS/RHEL 7:
|
||||
|
||||
# systemctl restart mdmonitor
|
||||
|
||||
On CentOS/RHEL 6:
|
||||
|
||||
# service mdmonitor restart
|
||||
|
||||
### Auto-mount a RAID Array ###
|
||||
|
||||
Now we will add an entry in the /etc/fstab to mount the array in /mnt automatically during boot (you can specify any other mount point):
|
||||
|
||||
# echo "/dev/md0 /mnt ext4 defaults 0 2" << /etc/fstab
|
||||
|
||||
To verify that mount works okay, we now unmount the array, restart mdadm, and remount. We can see that /dev/md0 has been mounted as per the entry we just added to /etc/fstab:
|
||||
|
||||
# umount /mnt
|
||||
# service mdadm restart (on Debian, Ubuntu or Linux Mint)
|
||||
or systemctl restart mdmonitor (on Fedora, CentOS/RHEL7)
|
||||
or service mdmonitor restart (on CentOS/RHEL6)
|
||||
# mount -a
|
||||
|
||||
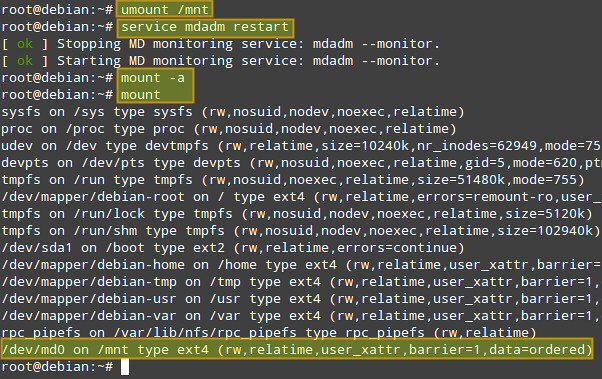
|
||||
|
||||
Now we are ready to access the RAID array via /mnt mount point. To test the array, we'll copy the /etc/passwd file (any other file will do) into /mnt:
|
||||
|
||||
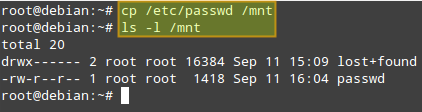
|
||||
|
||||
On Debian, we need to tell the mdadm daemon to automatically start the RAID array during boot by setting the AUTOSTART variable to true in the /etc/default/mdadm file:
|
||||
|
||||
AUTOSTART=true
|
||||
|
||||
### Simulating Drive Failures ###
|
||||
|
||||
We will simulate a faulty drive and remove it with the following commands. Note that in a real life scenario, it is not necessary to mark a device as faulty first, as it will already be in that state in case of a failure.
|
||||
|
||||
First, unmount the array:
|
||||
|
||||
# umount /mnt
|
||||
|
||||
Now, notice how the output of 'mdadm -D /dev/md0' indicates the changes after performing each command below.
|
||||
|
||||
# mdadm /dev/md0 --fail /dev/sdb1 #Marks /dev/sdb1 as faulty
|
||||
# mdadm --remove /dev/md0 /dev/sdb1 #Removes /dev/sdb1 from the array
|
||||
|
||||
Afterwards, when you have a new drive for replacement, re-add the drive again:
|
||||
|
||||
# mdadm /dev/md0 --add /dev/sdb1
|
||||
|
||||
The data is then immediately started to be rebuilt onto /dev/sdb1:
|
||||
|
||||

|
||||
|
||||
Note that the steps detailed above apply for systems with hot-swappable disks. If you do not have such technology, you will also have to stop a current array, and shutdown your system first in order to replace the part:
|
||||
|
||||
# mdadm --stop /dev/md0
|
||||
# shutdown -h now
|
||||
|
||||
Then add the new drive and re-assemble the array:
|
||||
|
||||
# mdadm /dev/md0 --add /dev/sdb1
|
||||
# mdadm --assemble /dev/md0 /dev/sdb1 /dev/sdc1
|
||||
|
||||
Hope this helps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/create-software-raid1-array-mdadm-linux.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
@ -1,75 +0,0 @@
|
||||
Test drive Linux with nothing but a flash drive
|
||||
================================================================================
|
||||

|
||||
Image by : Opensource.com
|
||||
|
||||
Maybe you’ve heard about Linux and are intrigued by it. So intrigued that you want to give it a try. But you might not know where to begin.
|
||||
|
||||
You’ve probably done a bit of research online and have run across terms like dual booting and virtualization. Those terms might mean nothing to you, and you’re definitely not ready to sacrifice the operating system that you’re currently using to give Linux a try. So what can you do?
|
||||
|
||||
If you have a USB flash drive lying around, you can test drive Linux by creating a live USB. It’s a USB flash drive that contains an operating system that can start from the flash drive. It doesn’t take much technical ability to create one. Let’s take a look at how to do that and how to run Linux using a live USB.
|
||||
|
||||
### What you’ll need ###
|
||||
|
||||
Aside from a desktop or laptop computer, you’ll need:
|
||||
|
||||
- A blank USB flash drive—preferably one that has a capacity of 4 GB or more.
|
||||
- An [ISO image][1] (an archive of the contents of a hard disk) of the Linux distribution that you want to try. More about this in a moment.
|
||||
- An application called [Unetbootin][2], an open source tool, cross platform tool that creates a live USB. You don’t need to be running Linux to use it. In the instructions that below, I’m running Unetbootin on a MacBook.
|
||||
|
||||
### Getting to work ###
|
||||
|
||||
Plug your flash drive into a USB port on your computer and then fire up Unetbootin. You’ll be asked for the password that you use to log into your computer.
|
||||
|
||||

|
||||
|
||||
Remember the ISO image that was mentioned a few moments ago? There are two ways you can get one: either by downloading it from the website of the Linux distribution that you want to try, or by having Unetbootin download it for you. To do that latter, click **Select Distribution** at the top of the window, choose the distribution that you want to download, and then click **Select Version** to select the version of the distribution that you want to try.
|
||||
|
||||

|
||||
|
||||
Or, you can download the distribution yourself. Usually, the Linux distributions that I want to try aren’t in the list. If you go the second route, click **Disk image** and then click the button to search for the .iso file that you downloaded.
|
||||
|
||||
Notice the **Space used to preserve files across reboots (Ubuntu only)** option? If you’re testing Ubuntu or one of its derivatives (like Lubuntu or Xubuntu), you can set aside a few megabytes of space on your flash drive to save files like web browser bookmarks or documents that you create. When you load Ubuntu from the flash drive again, you can reuse those files.
|
||||
|
||||

|
||||
|
||||
Once the ISO image is loaded, click **OK**. It takes anywhere from a couple of minutes to 10 minutes for Unetbootin to create the live USB.
|
||||
|
||||

|
||||
|
||||
### Testing out the live USB ###
|
||||
|
||||
This is the point where you have to embrace your inner geek a bit. Not too much, but you will be taking a peek into the innards of your computer by going into the [BIOS][3]. Your computer’s BIOS starts various bits of hardware and controls where the computer’s operating system starts, or boots, from.
|
||||
|
||||
The BIOS usually looks for the operating system in this order (or something like it): hard drive, then CD-ROM or DVD drive, and then an external drive. You’ll want to change that order so that the external drive (in this case, your live USB) is the one that the BIOS checks first.
|
||||
|
||||
To do that, restart your computer with the flash drive plugged into a USB port. When you see the message **Press F2 to enter setup**, do just that. On some computers, the key might be F10.
|
||||
|
||||
In the BIOS, use the right arrow key on your keyboard to navigate to the **Boot** menu. You’ll see a list of drives on your computer. Use the down arrow key on your keyboard to navigate to the item labeled **USB HDD** and then press **F6** to move that item to the top of the list.
|
||||
|
||||
Once you’ve done that, press **F10** to save the changes. You’ll be kicked out of the BIOS and your computer will start up. After a short amount of time, you’ll be presented with a menu listing the options for starting the Linux distribution you’re trying out. Select **Run without installing** (or the menu item closest to it).
|
||||
|
||||
Once the desktop loads, you can connect to a wireless or wired network, browse the web, and give the pre-installed software a whirl. You can also check to see if, for example, your printer or scanner works with the Linux distribution you’re testing. If you really, really want to you can also fiddle at the command line.
|
||||
|
||||
### What to expect ###
|
||||
|
||||
Depending on the Linux distribution you’re testing and the speed of the flash drive you’re using, the operating system might take longer to load and it might run a bit slower than it would if it was installed on your hard drive.
|
||||
|
||||
As well, you’ll only have the basic software that the Linux distribution packs out of the box. You generally get a web browser, a word processor, a text editor, a media player, an image viewer, and a set of utilities. That should be enough to give you a feel for what it’s like to use Linux.
|
||||
|
||||
If you decide that you like using Linux, you can install it from the flash drive by double clicking on the installer.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/14/10/test-drive-linux-nothing-flash-drive
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:http://en.wikipedia.org/wiki/ISO_image
|
||||
[2]:http://unetbootin.sourceforge.net/
|
||||
[3]:http://en.wikipedia.org/wiki/BIOS
|
||||
@ -1,91 +0,0 @@
|
||||
How To Use Emoji Anywhere With Twitter's Open Source Library
|
||||
================================================================================
|
||||
> Embed them in webpages and other projects via GitHub.
|
||||
|
||||

|
||||
|
||||
Emoji, tiny characters from Japan that convey emotions through images, have already conquered the world of cellphone text messaging.
|
||||
|
||||
Now, you can post them everywhere else in the virtual world, too. Twitter has just [open-sourced][1] its emoji library so you can use them for your own websites, apps, and projects.
|
||||
|
||||
This will require a little bit of heavy lifting. Unicode has recognized and even standardized the emoji alphabet, but emoji still [aren’t fully compliant with all Web browsers][2], meaning they'll show up as “tofu,” or blank boxes, most of the time. When Twitter wanted to make emoji available, the social network teamed up with a company called [Icon Factory][3] to render browser imitations of the text message symbols. As a result, Twitter says there’s been lots of demand for access to its emoji.
|
||||
|
||||
Now, you can clone Twitter’s entire library on [GitHub][4] to use in your development projects. Here’s how to do that, and how to make emoji easier to use after you do.
|
||||
|
||||
### Obtain Unicode Support For Emoji ###
|
||||
|
||||
Unicode is an international encoding standard that assigns a string of characters to any symbol, letter, or digit people want to use online. In other words, it’s the missing link between how you read text on a computer, and how the computer reads text. For example, while you are looking at an empty space between these words, the computer sees “&mbsp.”
|
||||
|
||||
Unicode even has its own [primitive emoji][5] that can be read in the browser without any effort on your part. For example while you see a ♥, your computer is decoding the string “2665.”
|
||||
|
||||
To use Twitter’s emoji library in most cases, you simply need to add a script inside the <head> section of your HTML page:
|
||||
|
||||
<script src="//twemoji.maxcdn.com/twemoji.min.js"></script>
|
||||
|
||||
This grants your project access to the JavaScript library that contains the hundreds of emoji that work on Twitter. However, creating a document with simply this script isn’t going to make emoji appear on your site. You also need to actually insert some emoji!
|
||||
|
||||
In the <body> section, paste a few of the emoji strings you can find in Twitter’s [preview.html source code][6]. I used 🎹 and 🏁 without really knowing how they'd appear in the browser window. Yeah, you’ll have to just paste and guess. You can already see the problem we're going to fix in section two.
|
||||
|
||||
However, through some trial and error, you can turn a raw HTML file that looks like this—
|
||||
|
||||

|
||||
|
||||
—into a webpage that looks something like this:
|
||||
|
||||

|
||||
|
||||
### Convert Emoji Into Readable Language ###
|
||||
|
||||
Twitter’s solution is all well and good for making a site or app emoji compliant. But if you want to be able to easily insert your favorite emoji at will via HTML, you’re going to need an easier solution than memorizing all those Unicode strings.
|
||||
|
||||
That’s where programmer Elle Kasai’s [Twemoji Awesome][7] styles come in.
|
||||
|
||||
By adding Elle’s open-source stylesheet to any webpage, you can use English words to understand which emoji you’re inserting. So if you want a heart emoji to show up, you can simply type this :
|
||||
|
||||
<i class="twa twa-heart"></i>
|
||||
|
||||
In order to do this, let’s download Elle’s project with the “Download ZIP” button on GitHub.
|
||||
|
||||
Next, let’s make a new folder on the desktop. Inside this folder, we’ll put emoji.html—the raw HTML file I showed you before, and also Elle’s [twemoji-awesome.css][8].
|
||||
|
||||
We’ll need the HTML file to acknowledge the CSS file, so in the <head> section of the html page you’ll want to add a link from the css file:
|
||||
|
||||
<link rel="stylesheet" href="twemoji-awesome.css">
|
||||
|
||||
Once you put this in, you can delete Twitter's script from before. Elle's styles each link to the Unicode string for the relevant emoji, so you no longer have to.
|
||||
|
||||
Now, go down to the body section and add a few emoji. I used <i class="twa twa-sparkling-heart"></i>, <i class="twa twa-exclamation"></i>, <i class="twa twa-lg twa-sparkles"></i> and <i class="twa twa-beer"></i>.
|
||||
|
||||
You'll end up with something like this:
|
||||
|
||||

|
||||
|
||||
Save and view your creation in the browser:
|
||||
|
||||

|
||||
|
||||
Ta-da! Not only have you gotten a basic webpage to support emoji in the browser, you’ve also made it easy to do. Feel free to check out this tutorial on [my GitHub][9] for actual files you can clone instead of screenshots.
|
||||
|
||||
Lead image via [Get Emoji][10]; screenshots by Lauren Orsini
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://readwrite.com/2014/11/12/how-to-use-emoji-in-the-browser-window
|
||||
|
||||
作者:[Lauren Orsini][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://readwrite.com/author/lauren-orsini
|
||||
[1]:https://blog.twitter.com/2014/open-sourcing-twitter-emoji-for-everyone
|
||||
[2]:http://www.unicode.org/reports/tr51/full-emoji-list.html
|
||||
[3]:https://twitter.com/iconfactory
|
||||
[4]:https://github.com/twitter/twemoji
|
||||
[5]:http://www.unicode.org/reports/tr51/full-emoji-list.html
|
||||
[6]:https://github.com/twitter/twemoji/blob/gh-pages/preview.html
|
||||
[7]:http://ellekasai.github.io/twemoji-awesome/
|
||||
[8]:https://github.com/ellekasai/twemoji-awesome/blob/gh-pages/twemoji-awesome.css
|
||||
[9]:https://github.com/laurenorsini/Emoji-Everywhere
|
||||
[10]:http://getemoji.com/
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user