` 标记。
### 三元表达式 vs &&
-正如您所看到的,三元表达式用于表达 if/else 条件式非常好。但是对于简单的 if 条件式怎么样呢?
+正如您所看到的,三元表达式用于表达 `if`/`else` 条件式非常好。但是对于简单的 `if` 条件式怎么样呢?
-让我们看另一个例子。如果 isPro(一个布尔值)为真,我们将显示一个奖杯表情符号。我们也要渲染星星的数量(如果不是0)。我们可以这样写。
+让我们看另一个例子。如果 `isPro`(一个布尔值)为真,我们将显示一个奖杯表情符号。我们也要渲染星星的数量(如果不是 0)。我们可以这样写。
```
const MyComponent = ({ name, isPro, stars}) => (
Hello {name}
- {isPro ? '🏆' : null}
+ {isPro ? '♨' : null}
{stars ? (
- Stars:{'⭐️'.repeat(stars)}
+ Stars:{'☆'.repeat(stars)}
) : null}
);
```
-请注意 “else” 条件返回 null 。 这是因为三元表达式要有"否则"条件。
+请注意 `else` 条件返回 `null` 。 这是因为三元表达式要有“否则”条件。
-对于简单的 “if” 条件式,我们可以使用更合适的东西:&& 运算符。这是使用 “&&” 编写的相同代码。
+对于简单的 `if` 条件式,我们可以使用更合适的东西:`&&` 运算符。这是使用 `&&` 编写的相同代码。
```
const MyComponent = ({ name, isPro, stars}) => (
Hello {name}
- {isPro && '🏆'}
+ {isPro && '♨'}
{stars && (
- Stars:{'⭐️'.repeat(stars)}
+ Stars:{'☆'.repeat(stars)}
)}
);
```
-没有太多区别,但是注意我们消除了每个三元表达式最后面的 `: null` (else 条件式)。一切都应该像以前一样渲染。
+没有太多区别,但是注意我们消除了每个三元表达式最后面的 `: null` (`else` 条件式)。一切都应该像以前一样渲染。
+嘿!约翰得到了什么?当什么都不应该渲染时,只有一个 `0`。这就是我上面提到的陷阱。这里有解释为什么:
-嘿!约翰得到了什么?当什么都不应该渲染时,只有一个0。这就是我上面提到的陷阱。这里有解释为什么。
-
-[根据 MDN][3],一个逻辑运算符“和”(也就是`&&`):
+[根据 MDN][3],一个逻辑运算符“和”(也就是 `&&`):
> `expr1 && expr2`
-> 如果 `expr1` 可以被转换成 `false` ,返回 `expr1`;否则返回 `expr2`。 如此,当与布尔值一起使用时,如果两个操作数都是 true,`&&` 返回 `true` ;否则,返回 `false`。
+> 如果 `expr1` 可以被转换成 `false` ,返回 `expr1`;否则返回 `expr2`。 如此,当与布尔值一起使用时,如果两个操作数都是 `true`,`&&` 返回 `true` ;否则,返回 `false`。
好的,在你开始拔头发之前,让我为你解释它。
-在我们这个例子里, `expr1` 是变量 `stars`,它的值是 `0`,因为0是 falsey 的值, `0` 会被返回和渲染。看,这还不算太坏。
+在我们这个例子里, `expr1` 是变量 `stars`,它的值是 `0`,因为 0 是假值,`0` 会被返回和渲染。看,这还不算太坏。
我会简单地这么写。
-> 如果 `expr1` 是 falsey,返回 `expr1` ,否则返回 `expr2`
+> 如果 `expr1` 是假值,返回 `expr1` ,否则返回 `expr2`。
-所以,当对非布尔值使用 “&&” 时,我们必须让 falsy 的值返回 React 无法渲染的东西,比如说,`false` 这个值。
+所以,当对非布尔值使用 `&&` 时,我们必须让这个假值返回 React 无法渲染的东西,比如说,`false` 这个值。
我们可以通过几种方式实现这一目标。让我们试试吧。
```
{!!stars && (
- {'⭐️'.repeat(stars)}
+ {'☆'.repeat(stars)}
)}
```
-注意 `stars` 前的双感叹操作符( `!!`)(呃,其实没有双感叹操作符。我们只是用了感叹操作符两次)。
+注意 `stars` 前的双感叹操作符(`!!`)(呃,其实没有双感叹操作符。我们只是用了感叹操作符两次)。
-第一个感叹操作符会强迫 `stars` 的值变成布尔值并且进行一次“非”操作。如果 `stars` 是 `0` ,那么 `!stars` 会 是 `true`。
+第一个感叹操作符会强迫 `stars` 的值变成布尔值并且进行一次“非”操作。如果 `stars` 是 `0` ,那么 `!stars` 会是 `true`。
-然后我们执行第二个`非`操作,所以如果 `stars` 是0,`!!stars` 会是 `false`。正好是我们想要的。
+然后我们执行第二个`非`操作,所以如果 `stars` 是 `0`,`!!stars` 会是 `false`。正好是我们想要的。
如果你不喜欢 `!!`,那么你也可以强制转换出一个布尔数比如这样(这种方式我觉得有点冗长)。
@@ -136,11 +134,11 @@ const MyComponent = ({ name, isPro, stars}) => (
#### 关于字符串
-空字符串与数字有一样的毛病。但是因为渲染后的空字符串是不可见的,所以这不是那种你很可能会去处理的难题,甚至可能不会注意到它。然而,如果你是完美主义者并且不希望DOM上有空字符串,你应采取我们上面对数字采取的预防措施。
+空字符串与数字有一样的毛病。但是因为渲染后的空字符串是不可见的,所以这不是那种你很可能会去处理的难题,甚至可能不会注意到它。然而,如果你是完美主义者并且不希望 DOM 上有空字符串,你应采取我们上面对数字采取的预防措施。
### 其它解决方案
-一种可能的将来可扩展到其他变量的解决方案,是创建一个单独的 `shouldRenderStars` 变量。然后你用“&&”处理布尔值。
+一种可能的将来可扩展到其他变量的解决方案,是创建一个单独的 `shouldRenderStars` 变量。然后你用 `&&` 处理布尔值。
```
const shouldRenderStars = stars > 0;
@@ -151,7 +149,7 @@ return (
{shouldRenderStars && (
- {'⭐️'.repeat(stars)}
+ {'☆'.repeat(stars)}
)}
@@ -170,7 +168,7 @@ return (
{shouldRenderStars && (
- {'⭐️'.repeat(stars)}
+ {'☆'.repeat(stars)}
)}
@@ -181,7 +179,7 @@ return (
我认为你应该充分利用这种语言。对于 JavaScript,这意味着为 `if/else` 条件式使用三元表达式,以及为 `if` 条件式使用 `&&` 操作符。
-我们可以回到每处都使用三元运算符的舒适区,但你现在消化了这些知识和力量,可以继续前进 && 取得成功了。
+我们可以回到每处都使用三元运算符的舒适区,但你现在消化了这些知识和力量,可以继续前进 `&&` 取得成功了。
--------------------------------------------------------------------------------
@@ -195,7 +193,7 @@ via: https://medium.freecodecamp.org/conditional-rendering-in-react-using-ternar
作者:[Donavon West][a]
译者:[GraveAccent](https://github.com/GraveAccent)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180522 Free Resources for Securing Your Open Source Code.md b/published/20180522 Free Resources for Securing Your Open Source Code.md
similarity index 53%
rename from translated/tech/20180522 Free Resources for Securing Your Open Source Code.md
rename to published/20180522 Free Resources for Securing Your Open Source Code.md
index 4e63a64e43..285a49c6a4 100644
--- a/translated/tech/20180522 Free Resources for Securing Your Open Source Code.md
+++ b/published/20180522 Free Resources for Securing Your Open Source Code.md
@@ -1,53 +1,43 @@
-一些提高你开源源码安全性的工具
+一些提高开源代码安全性的工具
======
+> 开源软件的迅速普及带来了对健全安全实践的需求。
+

-虽然目前开源依然发展势头较好,并被广大的厂商所采用,然而最近由 Black Duck 和 Synopsys 发布的[2018开源安全与风险评估报告][1]指出了一些存在的风险并重点阐述了对于健全安全措施的需求。这份报告的分析资料素材来自经过脱敏后的 1100 个商业代码库,这些代码所涉及:自动化、大数据、企业级软件、金融服务业、健康医疗、物联网、制造业等多个领域。
+虽然目前开源依然发展势头较好,并被广大的厂商所采用,然而最近由 Black Duck 和 Synopsys 发布的 [2018 开源安全与风险评估报告][1]指出了一些存在的风险,并重点阐述了对于健全安全措施的需求。这份报告的分析资料素材来自经过脱敏后的 1100 个商业代码库,这些代码所涉及:自动化、大数据、企业级软件、金融服务业、健康医疗、物联网、制造业等多个领域。
-这份报告强调开源软件正在被大量的使用,扫描结果中有 96% 的应用都使用了开源组件。然而,报告还指出许多其中存在很多漏洞。具体在 [这里][2]:
+这份报告强调开源软件正在被大量的使用,扫描结果中有 96% 的应用都使用了开源组件。然而,报告还指出许多其中存在很多漏洞。具体在 [这里][2]:
* 令人担心的是扫描的所有结果中,有 78% 的代码库存在至少一个开源的漏洞,平均每个代码库有 64 个漏洞。
-
* 在经过代码审计过后代码库中,发现超过 54% 的漏洞经验证是高危漏洞。
-
* 17% 的代码库包括一种已经早已公开的漏洞,包括:Heartbleed、Logjam、Freak、Drown、Poddle。
+Synopsys 旗下 Black Duck 的技术负责人 Tim Mackey 称,“这份报告清楚的阐述了:随着开源软件正在被企业广泛的使用,企业与组织也应当使用一些工具来检测可能出现在这些开源软件中的漏洞,以及管理其所使用的开源软件的方式是否符合相应的许可证规则。”
+确实,随着越来越具有影响力的安全威胁出现,历史上从未有过我们目前对安全工具和实践的需求。大多数的组织已经意识到网络与系统管理员需要具有相应的较强的安全技能和安全证书。[在一篇文章中][3],我们给出一些具有较大影响力的工具、认证和实践。
+Linux 基金会已经在安全方面提供了许多关于安全的信息与教育资源。比如,Linux 社区提供了许多针对特定平台的免费资源,其中 [Linux 工作站安全检查清单][4] 其中提到了很多有用的基础信息。线上的一些发表刊物也可以提升用户针对某些平台对于漏洞的保护,如:[Fedora 安全指南][5]、[Debian 安全手册][6]。
-Tim Mackey,Synopsys 旗下 Black Duck 的技术负责人称,"这份报告清楚的阐述了:随着开源软件正在被企业广泛的使用,企业与组织也应当使用一些工具来检测可能出现在这些开源软件中的漏洞,并且管理其所使用的开源软件的方式是否符合相应的许可证规则"
+目前被广泛使用的私有云平台 OpenStack 也加强了关于基于云的智能安全需求。根据 Linux 基金会发布的 [公有云指南][7]:“据 Gartner 的调研结果,尽管公有云的服务商在安全审查和提升透明度方面做的都还不错,安全问题仍然是企业考虑向公有云转移的最重要的考量之一。”
-确实,随着越来越具有影响力的安全威胁出现,历史上从未有过我们目前对安全工具和实践的需求。大多数的组织已经意识到网络与系统管理员需要具有相应的较强的安全技能和安全证书。[在这篇文章中,][3] 我们给出一些具有较大影响力的工具、认证和实践。
+无论是对于组织还是个人,千里之堤毁于蚁穴,这些“蚁穴”无论是来自路由器、防火墙、VPN 或虚拟机都可能导致灾难性的后果。以下是一些免费的工具可能对于检测这些漏洞提供帮助:
-Linux 基金会已经在安全方面提供了许多关于安全的信息与教育资源。比如,Linux 社区提供许多免费的用来针对一些平台的工具,其中[Linux 服务器安全检查表][4] 其中提到了很多有用的基础信息。线上的一些发表刊物也可以提升用户针对某些平台对于漏洞的保护,如:[Fedora 安全指南][5],[Debian 安全手册][6]。
+ * [Wireshark][8],流量包分析工具
+ * [KeePass Password Safe][9],自由开源的密码管理器
+ * [Malwarebytes][10],免费的反病毒和勒索软件工具
+ * [NMAP][11],安全扫描器
+ * [NIKTO][12],开源的 web 服务器扫描器
+ * [Ansible][13],自动化的配置运维工具,可以辅助做安全基线
+ * [Metasploit][14],渗透测试工具,可辅助理解攻击向量
-目前被广泛使用的私有云平台 OpenStack 也加强了关于基于云的智能安全需求。根据 Linux 基金会发布的 [公有云指南][7]:“据 Gartner 的调研结果,尽管公有云的服务商在安全和审查方面做的都还不错,安全问题是企业考虑向公有云转移的最重要的考量之一”
+这里有一些对上面工具讲解的视频。比如 [Metasploit 教学][15]、[Wireshark 教学][16]。还有一些传授安全技能的免费电子书,比如:由 Ibrahim Haddad 博士和 Linux 基金会共同出版的[并购过程中的开源审计][17],里面阐述了多条在技术平台合并过程中,因没有较好的进行开源审计,从而引发的安全问题。当然,书中也记录了如何在这一过程中进行代码合规检查、准备以及文档编写。
-无论是对于组织还是个人,千里之堤毁于蚁穴,这些“蚁穴”无论是来自路由器、防火墙、VPNs或虚拟机都可能导致灾难性的后果。以下是一些免费的工具可能对于检测这些漏洞提供帮助:
-
- * [Wireshark][8], 流量包分析工具
-
- * [KeePass Password Safe][9], 免费开源的密码管理器
-
- * [Malwarebytes][10], 免费的反病毒和勒索软件工具
-
- * [NMAP][11], 安全扫描器
-
- * [NIKTO][12], 开源 web 扫描器
-
- * [Ansible][13], 自动化的配置运维工具,可以辅助做安全基线
-
- * [Metasploit][14], 渗透测试工具,可辅助理解攻击向量
-
-
-
-这里有一些对上面工具讲解的视频。比如[Metasploit 教学][15]、[Wireshark 教学][16]。还有一些传授安全技能的免费电子书,比如:由 Ibrahim Haddad 博士和 Linux 基金会共同出版的[并购过程中的开源审计][17],里面阐述了多条在技术平台合并过程中,因没有较好的进行开源审计,从而引发的安全问题。当然,书中也记录了如何在这一过程中进行代码合规检查、准备以及文档编写。
-
-同时,我们 [之前提到的一个免费的电子书][18], 由来自[The New Stack][19] 编写的“Docker与容器中的网络、安全和存储”,里面也提到了关于加强容器网络安全的最新技术,以及Docker本身可提供的关于,提升其网络的安全与效率的最佳实践。这本电子书还记录了关于如何构建安全容器集群的最佳实践。
+同时,我们 [之前提到的一个免费的电子书][18], 由来自 [The New Stack][19] 编写的“Docker 与容器中的网络、安全和存储”,里面也提到了关于加强容器网络安全的最新技术,以及 Docker 本身可提供的关于提升其网络的安全与效率的最佳实践。这本电子书还记录了关于如何构建安全容器集群的最佳实践。
所有这些工具和资源,可以在很大的程度上预防安全问题,正如人们所说的未雨绸缪,考虑到一直存在的安全问题,现在就应该开始学习这些安全合规资料与工具。
-想要了解更多的安全、合规以及开源项目问题,点击[这里][20]
+
+想要了解更多的安全、合规以及开源项目问题,点击[这里][20]。
--------------------------------------------------------------------------------
@@ -55,8 +45,8 @@ via: https://www.linux.com/blog/2018/5/free-resources-securing-your-open-source-
作者:[Sam Dean][a]
选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/sd886393)
-校对:[校对者ID](https://github.com/校对者ID)
+译者:[sd886393](https://github.com/sd886393)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
@@ -64,7 +54,7 @@ via: https://www.linux.com/blog/2018/5/free-resources-securing-your-open-source-
[1]:https://www.blackducksoftware.com/open-source-security-risk-analysis-2018
[2]:https://www.prnewswire.com/news-releases/synopsys-report-finds-majority-of-software-plagued-by-known-vulnerabilities-and-license-conflicts-as-open-source-adoption-soars-300648367.html
[3]:https://www.linux.com/blog/sysadmin-ebook/2017/8/future-proof-your-sysadmin-career-locking-down-security
-[4]:http://go.linuxfoundation.org/ebook_workstation_security
+[4]:https://linux.cn/article-6753-1.html
[5]:https://docs.fedoraproject.org/en-US/Fedora/19/html/Security_Guide/index.html
[6]:https://www.debian.org/doc/manuals/securing-debian-howto/index.en.html
[7]:https://www.linux.com/publications/2016-guide-open-cloud
diff --git a/published/20180531 How to create shortcuts in vi.md b/published/20180531 How to create shortcuts in vi.md
new file mode 100644
index 0000000000..ec51ab53f7
--- /dev/null
+++ b/published/20180531 How to create shortcuts in vi.md
@@ -0,0 +1,114 @@
+如何在 vi 中创建快捷键
+======
+
+> 那些常见编辑任务的快捷键可以使 Vi 编辑器更容易使用,更有效率。
+
+
+
+学习使用 [vi 文本编辑器][1] 确实得花点功夫,不过 vi 的老手们都知道,经过一小会儿的锻炼,就可以将基本的 vi 操作融汇贯通。我们都知道“肌肉记忆”,那么学习 vi 的过程可以称之为“手指记忆”。
+
+当你抓住了基础的操作窍门之后,你就可以定制化地配置 vi 的快捷键,从而让其处理的功能更为强大、流畅。我希望下面描述的技术可以加速您的协作、编程和数据操作。
+
+在开始之前,我想先感谢下 Chris Hermansen(是他雇佣我写了这篇文章)仔细地检查了我的另一篇关于使用 vi 增强版本 [Vim][2] 的文章。当然还有他那些我未采纳的建议。
+
+首先,我们来说明下面几个惯例设定。我会使用符号 `
` 来代表按下回车,`` 代表按下空格键,`CTRL-x` 表示一起按下 `Control` 键和 `x` 键(`x` 可以是需要的某个键)。
+
+使用 `map` 命令来进行按键的映射。第一个例子是 `write` 命令,通常你之前保存使用这样的命令:
+
+```
+:w
+```
+
+虽然这里只有三个键,不过考虑到我用这个命令实在是太频繁了,我更想“一键”搞定它。在这里我选择逗号键,它不是标准的 vi 命令集的一部分。这样设置:
+
+```
+:map , :wCTRL-v
+```
+
+这里的 `CTRL-v` 事实上是对 `` 做了转义的操作,如果不加这个的话,默认 `` 会作为这条映射指令的结束信号,而非映射中的一个操作。 `CTRL-v` 后面所跟的操作会翻译为用户的实际操作,而非该按键平常的操作。
+
+在上面的映射中,右边的部分会在屏幕中显示为 `:w^M`,其中 `^` 字符就是指代 `control`,完整的意思就是 `CTRL-m`,表示就是系统中一行的结尾。
+
+目前来说,就很不错了。如果我编辑、创建了十二次文件,这个键位映射就可以省掉了 2*12 次按键。不过这里没有计算你建立这个键位映射所花费的 11 次按键(计算 `CTRL-v` 和 `:` 均为一次按键)。虽然这样已经省了很多次,但是每次打开 vi 都要重新建立这个映射也会觉得非常麻烦。
+
+幸运的是,这里可以将这些键位映射放到 vi 的启动配置文件中,让其在每次启动的时候自动读取:文件为 `.exrc`,对于 vim 是 `.vimrc`。只需要将这些文件放在你的用户根目录中即可,并在文件中每行写入一个键位映射,之后就会在每次启动 vi 生效直到你删除对应的配置。
+
+在继续说明 `map` 其他用法以及其他的缩写机制之前,这里在列举几个我常用提高文本处理效率的 map 设置:
+
+| 映射 | 显示为 |
+|------|-------|
+| `:map X :xCTRL-v` | `:x^M` |
+| `:map X ,:qCTRL-v` | `,:q^M` |
+
+上面的 `map` 指令的意思是写入并关闭当前的编辑文件。其中 `:x` 是 vi 原本的命令,而下面的版本说明之前的 `map` 配置可以继续用作第二个 `map` 键位映射。
+
+| 映射 | 显示为 |
+|------|-------|
+| `:map v :e` | `:e` |
+
+上面的指令意思是在 vi 编辑器内部切换文件,使用这个时候,只需要按 `v` 并跟着输入文件名,之后按 `` 键。
+
+| 映射 | 显示为 |
+|------|-------|
+| `:map CTRL-vCTRL-e :e#CTRL-v` | `:e #^M` |
+
+`#` 在这里是 vi 中标准的符号,意思是最后使用的文件名。所以切换当前与上一个文件的方法就使用上面的映射。
+
+| 映射 | 显示为 |
+|------|-------|
+| `map CTRL-vCTRL-r :!spell %>err &CTRL-v` | `:!spell %>err&^M` |
+
+(注意:在两个例子中出现的第一个 `CRTL-v` 在某些 vi 的版本中是不需要的)其中,`:!` 用来运行一个外部的(非 vi 内部的)命令。在这个拼写检查的例子中,`%` 是 vi 中的符号用来指代目前的文件, `>` 用来重定向拼写检查中的输出到 `err` 文件中,之后跟上 `&` 说明该命令是一个后台运行的任务,这样可以保证在拼写检查的同时还可以进行编辑文件的工作。这里我可以键入 `verr`(使用我之前定义的快捷键 `v` 跟上 `err`),进入 `spell` 输出结果的文件,之后再输入 `CTRL-e` 来回到刚才编辑的文件中。这样我就可以在拼写检查之后,使用 `CTRL-r` 来查看检查的错误,再通过 `CTRL-e` 返回刚才编辑的文件。
+
+还用很多字符串输入的缩写,也使用了各种 `map` 命令,比如:
+
+```
+:map! CTRL-o \fI
+:map! CTRL-k \fP
+```
+
+这个映射允许你使用 `CTRL-o` 作为 `groff` 命令的缩写,从而让让接下来书写的单词有斜体的效果,并使用 `CTRL-k` 进行恢复。
+
+还有两个类似的映射:
+
+```
+:map! rh rhinoceros
+:map! hi hippopotamus
+```
+
+上面的也可以使用 `ab` 命令来替换,就像下面这样(如果想这么用的话,需要首先按顺序运行: 1、 `unmap! rh`,2、`umap! hi`):
+
+```
+:ab rh rhinoceros
+:ab hi hippopotamus
+```
+
+在上面 `map!` 的命令中,缩写会马上的展开成原有的单词,而在 `ab` 命令中,单词展开的操作会在输入了空格和标点之后才展开(不过在 Vim 和我的 vi 中,展开的形式与 `map!` 类似)。
+
+想要取消刚才设定的按键映射,可以对应的输入 `:unmap`、 `unmap!` 或 `:unab`。
+
+在我使用的 vi 版本中,比较好用的候选映射按键包括 `g`、`K`、`q`、 `v`、 `V`、 `Z`,控制字符包括:`CTRL-a`、`CTRL-c`、 `CTRL-k`、`CTRL-n`、`CTRL-p`、`CTRL-x`;还有一些其他的字符如 `#`、 `*`,当然你也可以使用那些已经在 vi 中有过定义但不经常使用的字符,比如本文选择 `X` 和 `I`,其中 `X` 表示删除左边的字符,并立刻左移当前字符。
+
+最后,下面的命令
+
+```
+:map
+:map!
+:ab
+```
+
+将会显示,目前所有的缩写和键位映射。
+
+希望上面的技巧能够更好地更高效地帮助你使用 vi。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/5/shortcuts-vi-text-editor
+
+作者:[Dan Sonnenschein][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[sd886393](https://github.com/sd886393)
校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/dannyman
+[1]:http://ex-vi.sourceforge.net/
+[2]:https://www.vim.org/
diff --git a/translated/tech/20180709 How To Configure SSH Key-based Authentication In Linux.md b/published/20180709 How To Configure SSH Key-based Authentication In Linux.md
similarity index 53%
rename from translated/tech/20180709 How To Configure SSH Key-based Authentication In Linux.md
rename to published/20180709 How To Configure SSH Key-based Authentication In Linux.md
index 5c69d6a92b..8fb89b943d 100644
--- a/translated/tech/20180709 How To Configure SSH Key-based Authentication In Linux.md
+++ b/published/20180709 How To Configure SSH Key-based Authentication In Linux.md
@@ -1,33 +1,35 @@
-如何在 Linux 中配置基于密钥认证的 SSH
+如何在 Linux 中配置基于密钥认证的 SSH
======

-### 什么是基于 SSH密钥的认证?
+### 什么是基于 SSH 密钥的认证?
-众所周知,**Secure Shell**,又称 **SSH**,是允许你通过无安全网络(例如 Internet)和远程系统之间安全访问/通信的加密网络协议。无论何时使用 SSH 在无安全网络上发送数据,它都会在源系统上自动地被加密,并且在目的系统上解密。SSH 提供了四种加密方式,**基于密码认证**,**基于密钥认证**,**基于主机认证**和**键盘认证**。最常用的认证方式是基于密码认证和基于密钥认证。
+众所周知,**Secure Shell**,又称 **SSH**,是允许你通过无安全网络(例如 Internet)和远程系统之间安全访问/通信的加密网络协议。无论何时使用 SSH 在无安全网络上发送数据,它都会在源系统上自动地被加密,并且在目的系统上解密。SSH 提供了四种加密方式,**基于密码认证**,**基于密钥认证**,**基于主机认证**和**键盘认证**。最常用的认证方式是基于密码认证和基于密钥认证。
-在基于密码认证中,你需要的仅仅是远程系统上用户的密码。如果你知道远程用户的密码,你可以使用**“ssh[[email protected]][1]”**访问各自的系统。另一方面,在基于密钥认证中,为了通过 SSH 通信,你需要生成 SSH 密钥对,并且为远程系统上传 SSH 公钥。每个 SSH 密钥对由私钥与公钥组成。私钥应该保存在客户系统上,公钥应该上传给远程系统。你不应该将私钥透露给任何人。希望你已经对 SSH 和它的认证方式有了基本的概念。
+在基于密码认证中,你需要的仅仅是远程系统上用户的密码。如果你知道远程用户的密码,你可以使用 `ssh user@remote-system-name` 访问各自的系统。另一方面,在基于密钥认证中,为了通过 SSH 通信,你需要生成 SSH 密钥对,并且为远程系统上传 SSH 公钥。每个 SSH 密钥对由私钥与公钥组成。私钥应该保存在客户系统上,公钥应该上传给远程系统。你不应该将私钥透露给任何人。希望你已经对 SSH 和它的认证方式有了基本的概念。
-这篇教程,我们将讨论如何在 linux 上配置基于密钥认证的 SSH。
+这篇教程,我们将讨论如何在 Linux 上配置基于密钥认证的 SSH。
-### 在 Linux 上配置基于密钥认证的SSH
+### 在 Linux 上配置基于密钥认证的 SSH
-为本篇教程起见,我将使用 Arch Linux 为本地系统,Ubuntu 18.04 LTS 为远程系统。
+为方便演示,我将使用 Arch Linux 为本地系统,Ubuntu 18.04 LTS 为远程系统。
本地系统详情:
- * **OS** : Arch Linux Desktop
- * **IP address** : 192.168.225.37 /24
+
+* OS: Arch Linux Desktop
+* IP address: 192.168.225.37/24
远程系统详情:
- * **OS** : Ubuntu 18.04 LTS Server
- * **IP address** : 192.168.225.22/24
+
+* OS: Ubuntu 18.04 LTS Server
+* IP address: 192.168.225.22/24
### 本地系统配置
-就像我之前所说,在基于密钥认证的方法中,想要通过 SSH 访问远程系统,就应该将公钥上传给它。公钥通常会被保存在远程系统的一个文件**~/.ssh/authorized_keys** 中。
+就像我之前所说,在基于密钥认证的方法中,想要通过 SSH 访问远程系统,需要将公钥上传到远程系统。公钥通常会被保存在远程系统的一个 `~/.ssh/authorized_keys` 文件中。
-**注意事项:**不要使用**root** 用户生成密钥对,这样只有 root 用户才可以使用。使用普通用户创建密钥对。
+**注意事项**:不要使用 **root** 用户生成密钥对,这样只有 root 用户才可以使用。使用普通用户创建密钥对。
现在,让我们在本地系统上创建一个 SSH 密钥对。只需要在客户端系统上运行下面的命令。
@@ -35,9 +37,9 @@
$ ssh-keygen
```
-上面的命令将会创建一个 2048 位的 RSA 密钥对。输入两次密码。更重要的是,记住你的密码。后面将会用到它。
+上面的命令将会创建一个 2048 位的 RSA 密钥对。你需要输入两次密码。更重要的是,记住你的密码。后面将会用到它。
-**样例输出**
+**样例输出**:
```
Generating public/private rsa key pair.
@@ -62,22 +64,22 @@ The key's randomart image is:
+----[SHA256]-----+
```
-如果你已经创建了密钥对,你将看到以下信息。输入 ‘y’ 就会覆盖已存在的密钥。
+如果你已经创建了密钥对,你将看到以下信息。输入 `y` 就会覆盖已存在的密钥。
```
/home/username/.ssh/id_rsa already exists.
Overwrite (y/n)?
```
-请注意**密码是可选的**。如果你输入了密码,那么每次通过 SSH 访问远程系统时都要求输入密码,除非你使用了 SSH 代理保存了密码。如果你不想要密码(虽然不安全),简单地输入两次 ENTER。不过,我们建议你使用密码。从安全的角度来看,使用无密码的 ssh 密钥对大体上不是一个很好的主意。 这种方式应该限定在特殊的情况下使用,例如,没有用户介入的服务访问远程系统。(例如,用 rsync 远程备份...)
+请注意**密码是可选的**。如果你输入了密码,那么每次通过 SSH 访问远程系统时都要求输入密码,除非你使用了 SSH 代理保存了密码。如果你不想要密码(虽然不安全),简单地敲两次回车。不过,我建议你使用密码。从安全的角度来看,使用无密码的 ssh 密钥对不是什么好主意。这种方式应该限定在特殊的情况下使用,例如,没有用户介入的服务访问远程系统。(例如,用 `rsync` 远程备份……)
-如果你已经在个人文件 **~/.ssh/id_rsa** 中有了无密码的密钥对,但想要更新为带密码的密钥。使用下面的命令:
+如果你已经在个人文件 `~/.ssh/id_rsa` 中有了无密码的密钥,但想要更新为带密码的密钥。使用下面的命令:
```
$ ssh-keygen -p -f ~/.ssh/id_rsa
```
-样例输出:
+**样例输出**:
```
Enter new passphrase (empty for no passphrase):
@@ -91,40 +93,40 @@ Your identification has been saved with the new passphrase.
$ ssh-copy-id sk@192.168.225.22
```
-在这,我把本地(Arch Linux)系统上的公钥拷贝到了远程系统(Ubuntu 18.04 LTS)上。从技术上讲,上面的命令会把本地系统 **~/.ssh/id_rsa.pub key** 文件中的内容拷贝到远程系统**~/.ssh/authorized_keys** 中。明白了吗?非常棒。
+在这里,我把本地(Arch Linux)系统上的公钥拷贝到了远程系统(Ubuntu 18.04 LTS)上。从技术上讲,上面的命令会把本地系统 `~/.ssh/id_rsa.pub` 文件中的内容拷贝到远程系统 `~/.ssh/authorized_keys` 中。明白了吗?非常棒。
-输入 **yes** 来继续连接你的远程 SSH 服务端。接着,输入远程系统 root 用户的密码。
+输入 `yes` 来继续连接你的远程 SSH 服务端。接着,输入远程系统用户 `sk` 的密码。
```
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
-[email protected]2.168.225.22's password:
+sk@192.168.225.22's password:
Number of key(s) added: 1
-Now try logging into the machine, with: "ssh '[email protected]'"
+Now try logging into the machine, with: "ssh 'sk@192.168.225.22'"
and check to make sure that only the key(s) you wanted were added.
```
-如果你已经拷贝了密钥,但想要替换为新的密码,使用 **-f** 选项覆盖已有的密钥。
+如果你已经拷贝了密钥,但想要替换为新的密码,使用 `-f` 选项覆盖已有的密钥。
```
$ ssh-copy-id -f sk@192.168.225.22
```
-我们现在已经成功地将本地系统的 SSH 公钥添加进了远程系统。现在,让我们在远程系统上完全禁用掉基于密码认证的方式。因为,我们已经配置了密钥认证,因此我们不再需要密码认证了。
+我们现在已经成功地将本地系统的 SSH 公钥添加进了远程系统。现在,让我们在远程系统上完全禁用掉基于密码认证的方式。因为我们已经配置了密钥认证,因此不再需要密码认证了。
### 在远程系统上禁用基于密码认证的 SSH
-你需要在 root 或者 sudo 用户下执行下面的命令。
+你需要在 root 用户或者 `sudo` 执行下面的命令。
-为了禁用基于密码的认证,你需要在远程系统的控制台上编辑 **/etc/ssh/sshd_config** 配置文件:
+禁用基于密码的认证,你需要在远程系统的终端里编辑 `/etc/ssh/sshd_config` 配置文件:
```
$ sudo vi /etc/ssh/sshd_config
```
-找到下面这一行,去掉注释然后将值设为 **no**
+找到下面这一行,去掉注释然后将值设为 `no`:
```
PasswordAuthentication no
@@ -146,19 +148,19 @@ $ ssh sk@192.168.225.22
输入密码。
-**样例输出:**
+**样例输出**:
```
Enter passphrase for key '/home/sk/.ssh/id_rsa':
Last login: Mon Jul 9 09:59:51 2018 from 192.168.225.37
-[email protected]:~$
+sk@ubuntuserver:~$
```
-现在,你就能 SSH 你的远程系统了。如你所见,我们已经使用之前 **ssh-keygen** 创建的密码登录进了远程系统的账户,而不是使用账户实际的密码。
+现在,你就能 SSH 你的远程系统了。如你所见,我们已经使用之前 `ssh-keygen` 创建的密码登录进了远程系统的账户,而不是使用当前账户实际的密码。
-如果你试图从其他客户端系统 ssh (远程系统),你将会得到这条错误信息。比如,我试图通过命令从 CentOS SSH 访问 Ubuntu 系统:
+如果你试图从其它客户端系统 ssh(远程系统),你将会得到这条错误信息。比如,我试图通过命令从 CentOS SSH 访问 Ubuntu 系统:
-**样例输出:**
+**样例输出**:
```
The authenticity of host '192.168.225.22 (192.168.225.22)' can't be established.
@@ -168,7 +170,7 @@ Warning: Permanently added '192.168.225.22' (ECDSA) to the list of known hosts.
Permission denied (publickey).
```
-如你所见,除了 CentOS (译注:根据上文,这里应该是 Arch) 系统外,我不能通过其他任何系统 SSH 访问我的远程系统 Ubuntu 18.04。
+如你所见,除了 CentOS(LCTT 译注:根据上文,这里应该是 Arch)系统外,我不能通过其它任何系统 SSH 访问我的远程系统 Ubuntu 18.04。
### 为 SSH 服务端添加更多客户端系统的密钥
@@ -180,21 +182,21 @@ Permission denied (publickey).
$ ssh-keygen
```
-输入两次密码。现在, ssh 密钥对已经生成了。你需要手动把公钥(不是私钥)拷贝到远程服务端上。
+输入两次密码。现在,ssh 密钥对已经生成了。你需要手动把公钥(不是私钥)拷贝到远程服务端上。
-使用命令查看公钥:
+使用以下命令查看公钥:
```
$ cat ~/.ssh/id_rsa.pub
```
-应该会输出如下信息:
+应该会输出类似下面的信息:
```
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCt3a9tIeK5rPx9p74/KjEVXa6/OODyRp0QLS/sLp8W6iTxFL+UgALZlupVNgFjvRR5luJ9dLHWwc+d4umavAWz708e6Na9ftEPQtC28rTFsHwmyLKvLkzcGkC5+A0NdbiDZLaK3K3wgq1jzYYKT5k+IaNS6vtrx5LDObcPNPEBDt4vTixQ7GZHrDUUk5586IKeFfwMCWguHveTN7ykmo2EyL2rV7TmYq+eY2ZqqcsoK0fzXMK7iifGXVmuqTkAmZLGZK8a3bPb6VZd7KFum3Ezbu4BXZGp7FVhnOMgau2kYeOH/ItKPzpCAn+dg3NAAziCCxnII9b4nSSGz3mMY4Y7 ostechnix@centosserver
```
-拷贝所有内容(通过 USB 驱动器或者其它任何介质),然后去你的远程服务端的控制台。像下面那样,在 home 下创建文件夹叫做 **ssh**。你需要以 root 身份执行命令。
+拷贝所有内容(通过 USB 驱动器或者其它任何介质),然后去你的远程服务端的终端,像下面那样,在 `$HOME` 下创建文件夹叫做 `.ssh`。你需要以 root 身份执行命令(注:不一定需要 root)。
```
$ mkdir -p ~/.ssh
@@ -208,15 +210,16 @@ echo {Your_public_key_contents_here} >> ~/.ssh/authorized_keys
在远程系统上重启 ssh 服务。现在,你可以在新的客户端上 SSH 远程服务端了。
-如果觉得手动添加 ssh 公钥有些困难,在远程系统上暂时性启用密码认证,使用 “ssh-copy-id“ 命令从本地系统上拷贝密钥,最后关闭密码认证。
+如果觉得手动添加 ssh 公钥有些困难,在远程系统上暂时性启用密码认证,使用 `ssh-copy-id` 命令从本地系统上拷贝密钥,最后禁用密码认证。
**推荐阅读:**
-(译者注:在原文中此处有超链接)
+* [SSLH – Share A Same Port For HTTPS And SSH][1]
+* [ScanSSH – Fast SSH Server And Open Proxy Scanner][2]
好了,到此为止。基于密钥认证的 SSH 提供了一层防止暴力破解的额外保护。如你所见,配置密钥认证一点也不困难。这是一个非常好的方法让你的 Linux 服务端安全可靠。
-不久我就会带来另一篇有用的文章。到那时,继续关注 OSTechNix。
+不久我会带来另一篇有用的文章。请继续关注 OSTechNix。
干杯!
@@ -227,9 +230,10 @@ via: https://www.ostechnix.com/configure-ssh-key-based-authentication-linux/
作者:[SK][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[LuuMing](https://github.com/LuuMing)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[pityonline](https://github.com/pityonline)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-[a]:https://www.ostechnix.com/author/sk/
-[1]:https://www.ostechnix.com/cdn-cgi/l/email-protection
+[a]: https://www.ostechnix.com/author/sk/
+[1]: https://www.ostechnix.com/sslh-share-port-https-ssh/
+[2]: https://www.ostechnix.com/scanssh-fast-ssh-server-open-proxy-scanner/
diff --git a/translated/tech/20180813 5 of the Best Linux Educational Software and Games for Kids.md b/published/20180813 5 of the Best Linux Educational Software and Games for Kids.md
similarity index 79%
rename from translated/tech/20180813 5 of the Best Linux Educational Software and Games for Kids.md
rename to published/20180813 5 of the Best Linux Educational Software and Games for Kids.md
index 3a1981f0bc..029c70b675 100644
--- a/translated/tech/20180813 5 of the Best Linux Educational Software and Games for Kids.md
+++ b/published/20180813 5 of the Best Linux Educational Software and Games for Kids.md
@@ -1,4 +1,5 @@
-# 5 个给孩子的非常好的 Linux 教育软件和游戏
+5 个给孩子的非常好的 Linux 游戏和教育软件
+=================

@@ -8,39 +9,39 @@ Linux 是一个非常强大的操作系统,因此因特网上的大多数服
**相关阅读**:[使用一个 Linux 发行版的新手指南][1]
-### 1. GCompris
+### 1、GCompris
-如果你正在为你的孩子寻找一款最佳的教育软件,[GCompris][2] 将是你的最好的开端。这款软件专门为 2 到 10 岁的孩子所设计。作为所有的 Linux 教育软件套装的巅峰之作,GCompris 为孩子们提供了大约 100 项活动。它囊括了你期望你的孩子学习的所有内容,从阅读材料到科学、地理、绘画、代数、测验、等等。
+如果你正在为你的孩子寻找一款最佳的教育软件,[GCompris][2] 将是你的最好的开端。这款软件专门为 2 到 10 岁的孩子所设计。作为所有的 Linux 教育软件套装的巅峰之作,GCompris 为孩子们提供了大约 100 项活动。它囊括了你期望你的孩子学习的所有内容,从阅读材料到科学、地理、绘画、代数、测验等等。
![Linux educational software and games][3]
-GCompris 甚至有一项活动可以帮你的孩子学习计算机的相关知识。如果你的孩子还很小,你希望他去学习字母、颜色、和形状,GCompris 也有这方面的相关内容。更重要的是,它也为孩子们准备了一些益智类游戏,比如国际象棋、井字棋、好记性、以及猜词游戏。GCompris 并不是一个仅在 Linux 上可运行的游戏。它也可以运行在 Windows 和 Android 上。
+GCompris 甚至有一项活动可以帮你的孩子学习计算机的相关知识。如果你的孩子还很小,你希望他去学习字母、颜色和形状,GCompris 也有这方面的相关内容。更重要的是,它也为孩子们准备了一些益智类游戏,比如国际象棋、井字棋、好记性、以及猜词游戏。GCompris 并不是一个仅在 Linux 上可运行的游戏。它也可以运行在 Windows 和 Android 上。
-### 2. TuxMath
+### 2、TuxMath
-很多学生认为数学是们非常难的课程。你可以通过 Linux 教育软件如 [TuxMath][4] 来让你的孩子了解数学技能,从而来改变这种看法。TuxMath 是为孩子开发的顶级的数学教育辅助游戏。在这个游戏中,你的角色是在如雨点般下降的数学问题中帮助 Linux 企鹅 Tux 来保护它的星球。
+很多学生认为数学是门非常难的课程。你可以通过 Linux 教育软件如 [TuxMath][4] 来让你的孩子了解数学技能,从而来改变这种看法。TuxMath 是为孩子开发的顶级的数学教育辅助游戏。在这个游戏中,你的角色是在如雨点般下降的数学问题中帮助 Linux 企鹅 Tux 来保护它的星球。
![linux-educational-software-tuxmath-1][5]
在它们落下来毁坏 Tux 的星球之前,找到问题的答案,就可以使用你的激光去帮助 Tux 拯救它的星球。数字问题的难度每过一关就会提升一点。这个游戏非常适合孩子,因为它可以让孩子们去开动脑筋解决问题。而且还有助他们学好数学,以及帮助他们开发智力。
-### 3. Sugar on a Stick
+### 3、Sugar on a Stick
-[Sugar on a Stick][6] 是献给孩子们的学习程序 —— 一个广受好评的全新教学法。这个程序为你的孩子提供一个成熟的教学平台,在那里,他们可以收获创造、探索、发现和思考方面的技能。和 GCompris 一样,Sugar on a Stick 为孩子们带来了包括游戏和谜题在内的大量学习资源。
+[Sugar on a Stick][6] 是献给孩子们的学习程序 —— 一个广受好评的全新教学法。这个程序为你的孩子提供一个成熟的教学平台,在那里,他们可以收获创造、探索、发现和思考方面的技能。和 GCompris 一样,Sugar on a Stick 为孩子们带来了包括游戏和谜题在内的大量学习资源。
![linux-educational-software-sugar-on-a-stick][7]
关于 Sugar on a Stick 最大的一个好处是你可以将它配置在一个 U 盘上。你只要有一台 X86 的 PC,插入那个 U 盘,然后就可以从 U 盘引导这个发行版。Sugar on a Stick 是由 Sugar 实验室提供的一个项目 —— 这个实验室是一个由志愿者运作的非盈利组织。
-### 4. KDE Edu Suite
+### 4、KDE Edu Suite
-[KDE Edu Suite][8] 是一个用途与众不同的软件包。带来了大量不同领域的应用程序,KDE 社区已经证实,它不仅是一系列成年人授权的问题;它还关心年青一代如何适应他们周围的一切。它囊括了一系列孩子们使用的应用程序,从科学到数学、地理等等。
+[KDE Edu Suite][8] 是一个用途与众不同的软件包。带来了大量不同领域的应用程序,KDE 社区已经证实,它不仅可以给成年人授权;它还关心年青一代如何适应他们周围的一切。它囊括了一系列孩子们使用的应用程序,从科学到数学、地理等等。
![linux-educational-software-kde-1][9]
KDE Edu 套件根据长大后所必需的知识为基础,既能够用作学校的教学软件,也能够作为孩子们的学习 APP。它提供了大量的可免费下载的软件包。KDE Edu 套件在主流的 GNU/Linux 发行版都能安装。
-### 5. Tux Paint
+### 5、Tux Paint
![linux-educational-software-tux-paint-2][10]
@@ -61,20 +62,20 @@ via: https://www.maketecheasier.com/5-best-linux-software-packages-for-kids/
作者:[Kenneth Kimari][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[qhwdw](https://github.com/qhwdw)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
[a]: https://www.maketecheasier.com/author/kennkimari/
-[1]: https://www.maketecheasier.com/beginner-guide-to-using-linux-distro/ "The Beginner’s Guide to Using a Linux Distro"
+[1]: https://www.maketecheasier.com/beginner-guide-to-using-linux-distro/
[2]: http://www.gcompris.net/downloads-en.html
-[3]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-gcompris.jpg "Linux educational software and games"
+[3]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-gcompris.jpg
[4]: https://tuxmath.en.uptodown.com/ubuntu
-[5]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-tuxmath-1.jpg "linux-educational-software-tuxmath-1"
+[5]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-tuxmath-1.jpg
[6]: http://wiki.sugarlabs.org/go/Sugar_on_a_Stick/Downloads
-[7]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-sugar-on-a-stick.png "linux-educational-software-sugar-on-a-stick"
+[7]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-sugar-on-a-stick.png
[8]: https://edu.kde.org/
-[9]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-kde-1.jpg "linux-educational-software-kde-1"
-[10]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-tux-paint-2.jpg "linux-educational-software-tux-paint-2"
+[9]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-kde-1.jpg
+[10]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-tux-paint-2.jpg
[11]: http://www.tuxpaint.org/
-[12]: http://edubuntu.org/
\ No newline at end of file
+[12]: http://edubuntu.org/
diff --git a/published/20180815 How to Create M3U Playlists in Linux [Quick Tip].md b/published/20180815 How to Create M3U Playlists in Linux [Quick Tip].md
new file mode 100644
index 0000000000..1ce5ebde67
--- /dev/null
+++ b/published/20180815 How to Create M3U Playlists in Linux [Quick Tip].md
@@ -0,0 +1,84 @@
+Linux 下如何创建 M3U 播放列表
+======
+
+> 简介:关于如何在Linux终端中根据乱序文件创建M3U播放列表实现循序播放的小建议。
+
+![Create M3U playlists in Linux Terminal][1]
+
+我是外国电视连续剧的粉丝,这些连续剧不太容易从 DVD 或像 [Netflix][2] 这样的流媒体上获得。好在,您可以在 YouTube 上找到一些内容并[从 YouTube 下载][3]。
+
+现在出现了一个问题。你的文件可能不是按顺序存储的。在 GNU/Linux中,文件不是按数字顺序自然排序的,因此我必须创建 .m3u 播放列表,以便 [MPV 视频播放器][4]可以按顺序播放视频而不是乱顺进行播放。
+
+同样的,有时候表示第几集的数字是在文件名中间或结尾的,像这样 “My Web Series S01E01.mkv”。这里的剧集信息位于文件名的中间,“S01E01”告诉我们人类这是第一集,后面还有其它剧集。
+
+因此我要做的事情就是在视频墓中创建一个 .m3u 播放列表,并告诉 MPV 播放这个 .m3u 播放列表,MPV 自然会按顺序播放这些视频.
+
+### 什么是 M3U 文件?
+
+[M3U][5] 基本上就是个按特定顺序包含文件名的文本文件。当类似 MPV 或 VLC 这样的播放器打开 M3U 文件时,它会尝试按给定的顺序播放指定文件。
+
+### 创建 M3U 来按顺序播放音频/视频文件
+
+就我而言, 我使用了下面命令:
+
+```
+$/home/shirish/Videos/web-series-video/$ ls -1v |grep .mkv > /tmp/1.m3u && mv /tmp/1.m3u .
+```
+
+然我们拆分一下看看每个部分表示什么意思:
+
+`ls -1v` = 这就是用普通的 `ls` 来列出目录中的内容. 其中 `-1` 表示每行显示一个文件。而 `-v` 表示根据文本中的数字(版本)进行自然排序。
+
+`| grep .mkv` = 基本上就是告诉 `ls` 寻找那些以 `.mkv` 结尾的文件。它也可以是 `.mp4` 或其他任何你想要的媒体文件格式。
+
+通过在控制台上运行命令来进行试运行通常是个好主意:
+
+```
+ls -1v |grep .mkv
+My Web Series S01E01 [Episode 1 Name] Multi 480p WEBRip x264 - xRG.mkv
+My Web Series S01E02 [Episode 2 Name] Multi 480p WEBRip x264 - xRG.mkv
+My Web Series S01E03 [Episode 3 Name] Multi 480p WEBRip x264 - xRG.mkv
+My Web Series S01E04 [Episode 4 Name] Multi 480p WEBRip x264 - xRG.mkv
+My Web Series S01E05 [Episode 5 Name] Multi 480p WEBRip x264 - xRG.mkv
+My Web Series S01E06 [Episode 6 Name] Multi 480p WEBRip x264 - xRG.mkv
+My Web Series S01E07 [Episode 7 Name] Multi 480p WEBRip x264 - xRG.mkv
+My Web Series S01E08 [Episode 8 Name] Multi 480p WEBRip x264 - xRG.mkv
+```
+
+结果显示我要做的是正确的。现在下一步就是让输出以 `.m3u` 播放列表的格式输出。
+
+```
+ls -1v |grep .mkv > /tmp/web_playlist.m3u && mv /tmp/web_playlist.m3u .
+```
+
+这就在当前目录中创建了 .m3u 文件。这个 .m3u 播放列表只不过是一个 .txt 文件,其内容与上面相同,扩展名为 .m3u 而已。 你也可以手动编辑它,并按照想要的顺序添加确切的文件名。
+
+之后你只需要这样做:
+
+```
+mpv web_playlist.m3u
+```
+
+一般来说,MPV 和播放列表的好处在于你不需要一次性全部看完。 您可以一次看任意长时间,然后在下一次查看其余部分。
+
+我希望写一些有关 MPV 的文章,以及如何制作在媒体文件中嵌入字幕的 mkv 文件,但这是将来的事情了。
+
+注意: 这是开源软件,不鼓励盗版。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/create-m3u-playlist-linux/
+
+作者:[Shirsh][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://itsfoss.com/author/shirish/
+[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/Create-M3U-Playlists.jpeg
+[2]:https://itsfoss.com/netflix-open-source-ai/
+[3]:https://itsfoss.com/download-youtube-linux/
+[4]:https://itsfoss.com/mpv-video-player/
+[5]:https://en.wikipedia.org/wiki/M3U
diff --git a/published/20180823 How To Easily And Safely Manage Cron Jobs In Linux.md b/published/20180823 How To Easily And Safely Manage Cron Jobs In Linux.md
new file mode 100644
index 0000000000..84c37055bb
--- /dev/null
+++ b/published/20180823 How To Easily And Safely Manage Cron Jobs In Linux.md
@@ -0,0 +1,122 @@
+在 Linux 中安全且轻松地管理 Cron 定时任务
+======
+
+
+
+在 Linux 中遇到计划任务的时候,你首先会想到的大概就是 Cron 定时任务了。Cron 定时任务能帮助你在类 Unix 操作系统中计划性地执行命令或者任务。也可以参考一下我们之前的一篇《[关于 Cron 定时任务的新手指导][1]》。对于有一定 Linux 经验的人来说,设置 Cron 定时任务不是什么难事,但对于新手来说就不一定了,他们在编辑 crontab 文件的时候不知不觉中犯的一些小错误,也有可能把整个 Cron 定时任务搞挂了。如果你在处理 Cron 定时任务的时候为了以防万一,可以尝试使用 **Crontab UI**,它是一个可以在类 Unix 操作系统上安全轻松管理 Cron 定时任务的 Web 页面工具。
+
+Crontab UI 是使用 NodeJS 编写的自由开源软件。有了 Crontab UI,你在创建、删除和修改 Cron 定时任务的时候就不需要手工编辑 Crontab 文件了,只需要打开浏览器稍微操作一下,就能完成上面这些工作。你可以用 Crontab UI 轻松创建、编辑、暂停、删除、备份 Cron 定时任务,甚至还可以简单地做到导入、导出、部署其它机器上的 Cron 定时任务,它还支持错误日志、邮件发送和钩子。
+
+### 安装 Crontab UI
+
+只需要一条命令就可以安装好 Crontab UI,但前提是已经安装好 NPM。如果还没有安装 NPM,可以参考《[如何在 Linux 上安装 NodeJS][2]》这篇文章。
+
+执行这一条命令来安装 Crontab UI。
+
+```
+$ npm install -g crontab-ui
+```
+
+就是这么简单,下面继续来看看在 Crontab UI 上如何管理 Cron 定时任务。
+
+### 在 Linux 上安全轻松管理 Cron 定时任务
+
+执行这一条命令启动 Crontab UI:
+
+```
+$ crontab-ui
+```
+
+你会看到这样的输出:
+
+```
+Node version: 10.8.0
+Crontab UI is running at http://127.0.0.1:8000
+```
+
+首先在你的防火墙和路由器上放开 8000 端口,然后打开浏览器访问 ``。
+
+注意,默认只有在本地才能访问到 Crontab UI 的控制台页面。但如果你想让 Crontab UI 使用系统的 IP 地址和自定义端口,也就是想让其它机器也访问到本地的 Crontab UI,你需要使用以下这个命令:
+
+```
+$ HOST=0.0.0.0 PORT=9000 crontab-ui
+Node version: 10.8.0
+Crontab UI is running at http://0.0.0.0:9000
+```
+
+Crontab UI 就能够通过 `:9000` 这样的 URL 被远程机器访问到了。
+
+Crontab UI 的控制台页面长这样:
+
+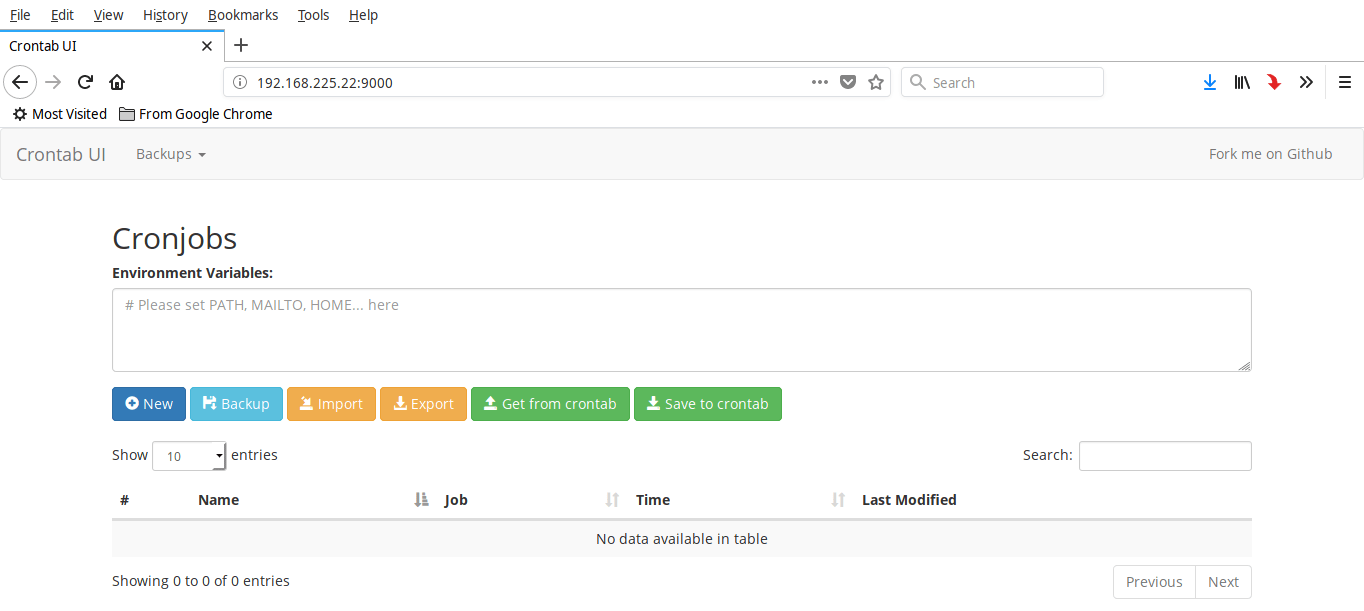
+
+从上面的截图就可以看到,Crontab UI 的界面非常简洁,所有选项的含义都能不言自明。
+
+在终端输入 `Ctrl + C` 就可以关闭 Crontab UI。
+
+#### 创建、编辑、运行、停止、删除 Cron 定时任务
+
+点击 “New”,输入 Cron 定时任务的信息并点击 “Save” 保存,就可以创建一个新的 Cron 定时任务了。
+
+ 1. 为 Cron 定时任务命名,这是可选的;
+ 2. 你想要执行的完整命令;
+ 3. 设定计划执行的时间。你可以按照启动、每时、每日、每周、每月、每年这些指标快速指定计划任务,也可以明确指定任务执行的具体时间。指定好计划时间后,“Jobs” 区域就会显示 Cron 定时任务的句式。
+ 4. 选择是否为某个 Cron 定时任务记录错误日志。
+
+这是我的一个 Cron 定时任务样例。
+
+
+
+如你所见,我设置了一个每月清理 `pacman` 缓存的 Cron 定时任务。你也可以设置多个 Cron 定时任务,都能在控制台页面看到。
+
+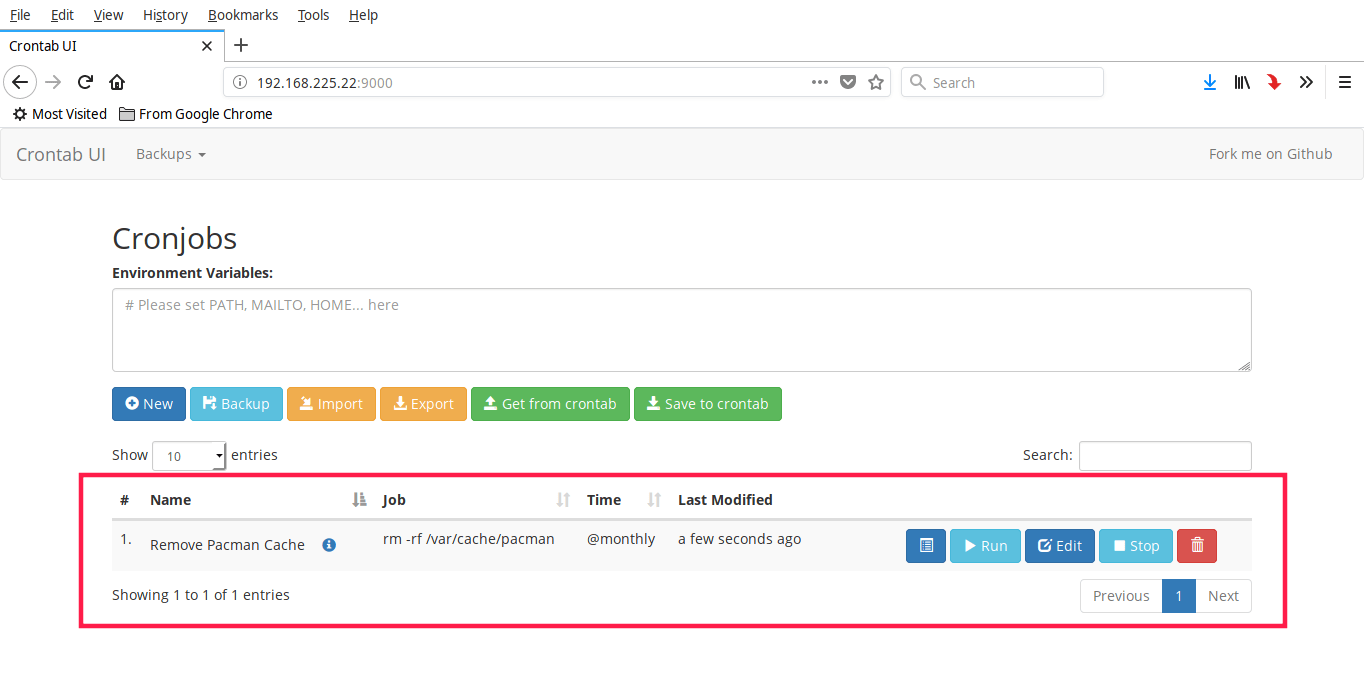
+
+如果你需要更改 Cron 定时任务中的某些参数,只需要点击 “Edit” 按钮并按照你的需求更改对应的参数。点击 “Run” 按钮可以立即执行 Cron 定时任务,点击 “Stop” 则可以立即停止 Cron 定时任务。如果想要查看某个 Cron 定时任务的详细日志,可以点击 “Log” 按钮。对于不再需要的 Cron 定时任务,就可以按 “Delete” 按钮删除。
+
+#### 备份 Cron 定时任务
+
+点击控制台页面的 “Backup” 按钮并确认,就可以备份所有 Cron 定时任务。
+
+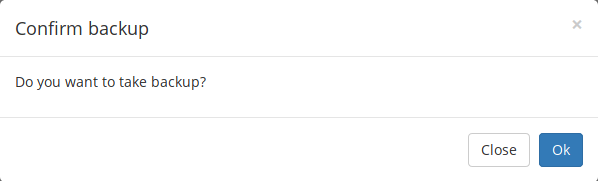
+
+备份之后,一旦 Crontab 文件出现了错误,就可以使用备份来恢复了。
+
+#### 导入/导出其它机器上的 Cron 定时任务
+
+Crontab UI 还有一个令人注目的功能,就是导入、导出、部署其它机器上的 Cron 定时任务。如果同一个网络里的多台机器都需要执行同样的 Cron 定时任务,只需要点击 “Export” 按钮并选择文件的保存路径,所有的 Cron 定时任务都会导出到 `crontab.db` 文件中。
+
+以下是 `crontab.db` 文件的内容:
+
+```
+$ cat Downloads/crontab.db
+{"name":"Remove Pacman Cache","command":"rm -rf /var/cache/pacman","schedule":"@monthly","stopped":false,"timestamp":"Thu Aug 23 2018 10:34:19 GMT+0000 (Coordinated Universal Time)","logging":"true","mailing":{},"created":1535020459093,"_id":"lcVc1nSdaceqS1ut"}
+```
+
+导出成文件以后,你就可以把这个 `crontab.db` 文件放置到其它机器上并导入成 Cron 定时任务,而不需要在每一台主机上手动设置 Cron 定时任务。总之,在一台机器上设置完,导出,再导入到其他机器,就完事了。
+
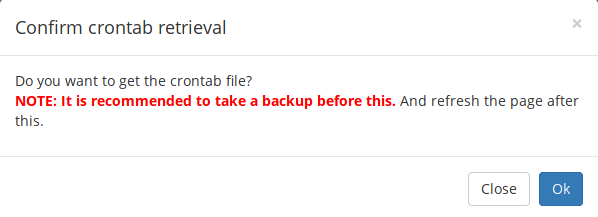
+#### 在 Crontab 文件获取/保存 Cron 定时任务
+
+你可能在使用 Crontab UI 之前就已经使用 `crontab` 命令创建过 Cron 定时任务。如果是这样,你可以点击控制台页面上的 “Get from crontab” 按钮来获取已有的 Cron 定时任务。
+
+
+
+同样地,你也可以使用 Crontab UI 来将新的 Cron 定时任务保存到 Crontab 文件中,只需要点击 “Save to crontab” 按钮就可以了。
+
+管理 Cron 定时任务并没有想象中那么难,即使是新手使用 Crontab UI 也能轻松管理 Cron 定时任务。赶快开始尝试并发表一下你的看法吧。
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-easily-and-safely-manage-cron-jobs-in-linux/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[HankChow](https://github.com/HankChow)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[1]:https://www.ostechnix.com/a-beginners-guide-to-cron-jobs/
+[2]:https://www.ostechnix.com/install-node-js-linux/
+
diff --git a/translated/tech/20180824 5 cool music player apps.md b/published/20180824 5 cool music player apps.md
similarity index 63%
rename from translated/tech/20180824 5 cool music player apps.md
rename to published/20180824 5 cool music player apps.md
index fb301ed4dd..76223f18ec 100644
--- a/translated/tech/20180824 5 cool music player apps.md
+++ b/published/20180824 5 cool music player apps.md
@@ -2,20 +2,21 @@
======

-你喜欢音乐吗?那么 Fedora 中可能有你正在寻找的东西。本文介绍在 Fedora 上运行的不同音乐播放器。无论你有大量的音乐库,还是小型音乐库,或者根本没有音乐库,你都会被覆盖到。这里有四个图形程序和一个基于终端的音乐播放器,可以让你挑选。
+
+你喜欢音乐吗?那么 Fedora 中可能有你正在寻找的东西。本文介绍在 Fedora 上运行的各种音乐播放器。无论你有庞大的音乐库,还是小一些的,抑或根本没有,你都可以用到音乐播放器。这里有四个图形程序和一个基于终端的音乐播放器,可以让你挑选。
### Quod Libet
-Quod Libet 是你的大型音频库的管理员。如果你有一个大量的音频库,你不想只听,但也要管理,Quod Libet 可能是一个很好的选择。
+Quod Libet 是一个完备的大型音频库管理器。如果你有一个庞大的音频库,你不想只是听,也想要管理,Quod Libet 可能是一个很好的选择。
![][1]
-Quod Libet 可以从磁盘上的多个位置导入音乐,并允许你编辑音频文件的标签 - 因此一切都在你的控制之下。额外地,它还有各种插件可用,从简单的均衡器到 [last.fm][2] 同步。你也可以直接从 [Soundcloud][3] 搜索和播放音乐。
+Quod Libet 可以从磁盘上的多个位置导入音乐,并允许你编辑音频文件的标签 —— 因此一切都在你的控制之下。此外,它还有各种插件可用,从简单的均衡器到 [last.fm][2] 同步。你也可以直接从 [Soundcloud][3] 搜索和播放音乐。
+
+Quod Libet 在 HiDPI 屏幕上工作得很好,它有 Fedora 的 RPM 包,如果你运行 [Silverblue][5],它在 [Flathub][4] 中也有。使用 Gnome Software 或命令行安装它:
-Quod Libet 在 HiDPI 屏幕上工作得很好,它有 Fedora 的 RPM 包,如果你运行[Silverblue][5],它在 [Flathub][4] 中也有。使用 Gnome Software 或命令行安装它:
```
$ sudo dnf install quodlibet
-
```
### Audacious
@@ -24,14 +25,14 @@ $ sudo dnf install quodlibet
![][6]
-Audacious 可能不会立即管理你的所有音乐,但你如果想将音乐组织为文件,它能做得很好。你还可以导出和导入播放列表,而无需重新组织音乐文件本身。
+Audacious 可能不直接管理你的所有音乐,但你如果想将音乐按文件组织起来,它能做得很好。你还可以导出和导入播放列表,而无需重新组织音乐文件本身。
-额外地,你可以让它看起来像 Winamp。要让它与上面的截图相同,请进入 “Settings/Appearance,”,选择顶部的 “Winamp Classic Interface”,然后选择右下方的 “Refugee” 皮肤。而鲍勃是你的叔叔!这就完成了。
+此外,你可以让它看起来像 Winamp。要让它与上面的截图相同,请进入 “Settings/Appearance”,选择顶部的 “Winamp Classic Interface”,然后选择右下方的 “Refugee” 皮肤。就这么简单。
Audacious 在 Fedora 中作为 RPM 提供,可以使用 Gnome Software 或在终端运行以下命令安装:
+
```
$ sudo dnf install audacious
-
```
### Lollypop
@@ -40,25 +41,25 @@ Lollypop 是一个音乐播放器,它与 GNOME 集成良好。如果你喜欢
![][7]
-除了与 GNOME Shell 的良好视觉集成之外,它还可以很好地用于 HiDPI 屏幕,并支持黑暗主题。
+除了与 GNOME Shell 的良好视觉集成之外,它还可以很好地用于 HiDPI 屏幕,并支持暗色主题。
额外地,Lollypop 有一个集成的封面下载器和一个所谓的派对模式(右上角的音符按钮),它可以自动选择和播放音乐。它还集成了 [last.fm][2] 或 [libre.fm][8] 等在线服务。
它有 Fedora 的 RPM 也有用于 [Silverblue][5] 工作站的 [Flathub][4],使用 Gnome Software 或终端进行安装:
+
```
$ sudo dnf install lollypop
-
```
### Gradio
-如果你没有任何音乐但仍喜欢听怎么办?或者你只是喜欢收音机?Gradio 就是为你准备的。
+如果你没有任何音乐但仍想听怎么办?或者你只是喜欢收音机?Gradio 就是为你准备的。
![][9]
Gradio 是一个简单的收音机,它允许你搜索和播放网络电台。你可以按国家、语言或直接搜索找到它们。额外地,它可视化地集成到了 GNOME Shell 中,可以与 HiDPI 屏幕配合使用,并且可以选择黑暗主题。
-可以在 [Flathub][4] 中找到 Gradio,它同时可以运行在 Fedora Workstation 和 [Silverblue][5] 中。使用 Gnome Software 安装它
+可以在 [Flathub][4] 中找到 Gradio,它同时可以运行在 Fedora Workstation 和 [Silverblue][5] 中。使用 Gnome Software 安装它。
### sox
@@ -67,19 +68,19 @@ Gradio 是一个简单的收音机,它允许你搜索和播放网络电台。
![][10]
sox 是一个非常简单的基于终端的音乐播放器。你需要做的就是运行如下命令:
+
```
$ play file.mp3
-
```
接着 sox 就会为你播放。除了单独的音频文件外,sox 还支持 m3u 格式的播放列表。
-额外地,因为 sox 是基于终端的程序,你可以在 ssh 中运行它。你有一个带扬声器的家用服务器吗?或者你想从另一台电脑上播放音乐吗?尝试将它与 [tmux][11] 一起使用,这样即使会话关闭也可以继续听。
+此外,因为 sox 是基于终端的程序,你可以通过 ssh 运行它。你有一个带扬声器的家用服务器吗?或者你想从另一台电脑上播放音乐吗?尝试将它与 [tmux][11] 一起使用,这样即使会话关闭也可以继续听。
sox 在 Fedora 中以 RPM 提供。运行下面的命令安装:
+
```
$ sudo dnf install sox
-
```
@@ -90,19 +91,19 @@ via: https://fedoramagazine.org/5-cool-music-player-apps/
作者:[Adam Šamalík][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
[a]:https://fedoramagazine.org/author/asamalik/
-[1]:https://fedoramagazine.org/wp-content/uploads/2018/08/qodlibet-300x217.png
+[1]:https://fedoramagazine.org/wp-content/uploads/2018/08/qodlibet-768x555.png
[2]:https://last.fm
[3]:https://soundcloud.com/
[4]:https://flathub.org/home
[5]:https://teamsilverblue.org/
-[6]:https://fedoramagazine.org/wp-content/uploads/2018/08/audacious-300x136.png
-[7]:https://fedoramagazine.org/wp-content/uploads/2018/08/lollypop-300x172.png
+[6]:https://fedoramagazine.org/wp-content/uploads/2018/08/audacious-768x348.png
+[7]:https://fedoramagazine.org/wp-content/uploads/2018/08/lollypop-768x439.png
[8]:https://libre.fm
-[9]:https://fedoramagazine.org/wp-content/uploads/2018/08/gradio.png
-[10]:https://fedoramagazine.org/wp-content/uploads/2018/08/sox-300x179.png
+[9]:https://fedoramagazine.org/wp-content/uploads/2018/08/gradio-768x499.png
+[10]:https://fedoramagazine.org/wp-content/uploads/2018/08/sox-768x457.png
[11]:https://fedoramagazine.org/use-tmux-more-powerful-terminal/
diff --git a/published/20180827 4 tips for better tmux sessions.md b/published/20180827 4 tips for better tmux sessions.md
new file mode 100644
index 0000000000..979568a171
--- /dev/null
+++ b/published/20180827 4 tips for better tmux sessions.md
@@ -0,0 +1,88 @@
+更好利用 tmux 会话的 4 个技巧
+======
+
+
+
+tmux 是一个终端多路复用工具,它可以让你系统上的终端支持多面板。你可以排列面板位置,在每个面板运行不同进程,这通常可以更好的地利用你的屏幕。我们在 [这篇早期的文章][1] 中向读者介绍过这一强力工具。如果你已经开始使用 tmux 了,那么这里有一些技巧可以帮你更好地使用它。
+
+本文假设你当前的前缀键是 `Ctrl+b`。如果你已重新映射该前缀,只需在相应位置替换为你定义的前缀即可。
+
+### 设置终端为自动使用 tmux
+
+使用 tmux 的一个最大好处就是可以随意的从会话中断开和重连。这使得远程登录会话功能更加强大。你有没有遇到过丢失了与远程系统的连接,然后好希望能够恢复在远程系统上做过的那些工作的情况?tmux 能够解决这一问题。
+
+然而,有时在远程系统上工作时,你可能会忘记开启会话。避免出现这一情况的一个方法就是每次通过交互式 shell 登录系统时都让 tmux 启动或附加上一个会话。
+
+在你远程系统上的 `~/.bash_profile` 文件中加入下面内容:
+
+```
+if [ -z "$TMUX" ]; then
+ tmux attach -t default || tmux new -s default
+fi
+```
+
+然后注销远程系统,并使用 SSH 重新登录。你会发现你处在一个名为 `default` 的 tmux 会话中了。如果退出该会话,则下次登录时还会重新生成此会话。但更重要的是,若您正常地从会话中分离,那么下次登录时你会发现之前工作并没有丢失 - 这在连接中断时非常有用。
+
+你当然也可以将这段配置加入本地系统中。需要注意的是,大多数 GUI 界面的终端并不会自动使用这个 `default` 会话,因此它们并不是登录 shell。虽然你可以修改这一行为,但它可能会导致终端嵌套执行附加到 tmux 会话这一动作,从而导致会话不太可用,因此当进行此操作时请一定小心。
+
+### 使用缩放功能使注意力专注于单个进程
+
+虽然 tmux 的目的就是在单个会话中提供多窗口、多面板和多进程的能力,但有时候你需要专注。如果你正在与一个进程进行交互并且需要更多空间,或需要专注于某个任务,则可以使用缩放命令。该命令会将当前面板扩展,占据整个当前窗口的空间。
+
+缩放在其他情况下也很有用。比如,想象你在图形桌面上运行一个终端窗口。面板会使得从 tmux 会话中拷贝和粘帖多行内容变得相对困难。但若你缩放了面板,就可以很容易地对多行数据进行拷贝/粘帖。
+
+要对当前面板进行缩放,按下 `Ctrl+b, z`。需要恢复的话,按下相同按键组合来恢复面板。
+
+### 绑定一些有用的命令
+
+tmux 默认有大量的命令可用。但将一些更常用的操作绑定到容易记忆的快捷键会很有用。下面一些例子可以让会话变得更好用,你可以添加到 `~/.tmux.conf` 文件中:
+
+```
+bind r source-file ~/.tmux.conf \; display "Reloaded config"
+```
+
+该命令重新读取你配置文件中的命令和键绑定。添加该条绑定后,退出任意一个 tmux 会话然后重启一个会话。现在你做了任何更改后,只需要简单的按下 `Ctrl+b, r` 就能将修改的内容应用到现有的会话中了。
+
+```
+bind V split-window -h
+bind H split-window
+```
+
+这些命令可以很方便地对窗口进行横向切分(按下 `Shift+V`)和纵向切分(`Shift+H`)。
+
+若你想查看所有绑定的快捷键,按下 `Ctrl+B, ?` 可以看到一个列表。你首先看到的应该是复制模式下的快捷键绑定,表示的是当你在 tmux 中进行复制粘帖时对应的快捷键。你添加的那两个键绑定会在前缀模式中看到。请随意把玩吧!
+
+### 使用 powerline 更清晰
+
+[如前文所示][2],powerline 工具是对 shell 的绝佳补充。而且它也兼容在 tmux 中使用。由于 tmux 接管了整个终端空间,powerline 窗口能提供的可不仅仅是更好的 shell 提示那么简单。
+
+[][3]
+
+如果你还没有这么做,按照 [这篇文章][4] 中的指示来安装该工具。然后[使用 sudo][5] 来安装附件:
+
+```
+sudo dnf install tmux-powerline
+```
+
+接着重启会话,就会在底部看到一个漂亮的新状态栏。根据终端的宽度,默认的状态栏会显示你当前会话 ID、打开的窗口、系统信息、日期和时间,以及主机名。若你进入了使用 git 进行版本控制的项目目录中还能看到分支名和用色彩标注的版本库状态。
+
+当然,这个状态栏具有很好的可配置性。享受你新增强的 tmux 会话吧,玩的开心点。
+
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/4-tips-better-tmux-sessions/
+
+作者:[Paul W. Frields][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://fedoramagazine.org/author/pfrields/
+[1]:https://fedoramagazine.org/use-tmux-more-powerful-terminal/
+[2]:https://fedoramagazine.org/add-power-terminal-powerline/
+[3]:https://fedoramagazine.org/wp-content/uploads/2018/08/Screenshot-from-2018-08-25-19-36-53.png
+[4]:https://fedoramagazine.org/add-power-terminal-powerline/
+[5]:https://fedoramagazine.org/howto-use-sudo/
diff --git a/published/20140805 How to Install Cinnamon Desktop on Ubuntu.md b/published/201809/20140805 How to Install Cinnamon Desktop on Ubuntu.md
similarity index 100%
rename from published/20140805 How to Install Cinnamon Desktop on Ubuntu.md
rename to published/201809/20140805 How to Install Cinnamon Desktop on Ubuntu.md
diff --git a/published/20160503 Cloud Commander - A Web File Manager With Console And Editor.md b/published/201809/20160503 Cloud Commander - A Web File Manager With Console And Editor.md
similarity index 100%
rename from published/20160503 Cloud Commander - A Web File Manager With Console And Editor.md
rename to published/201809/20160503 Cloud Commander - A Web File Manager With Console And Editor.md
diff --git a/published/20170706 Docker Guide Dockerizing Python Django Application.md b/published/201809/20170706 Docker Guide Dockerizing Python Django Application.md
similarity index 100%
rename from published/20170706 Docker Guide Dockerizing Python Django Application.md
rename to published/201809/20170706 Docker Guide Dockerizing Python Django Application.md
diff --git a/published/20170709 The Extensive Guide to Creating Streams in RxJS.md b/published/201809/20170709 The Extensive Guide to Creating Streams in RxJS.md
similarity index 100%
rename from published/20170709 The Extensive Guide to Creating Streams in RxJS.md
rename to published/201809/20170709 The Extensive Guide to Creating Streams in RxJS.md
diff --git a/published/20170829 How To Set Up PF Firewall on FreeBSD to Protect a Web Server.md b/published/201809/20170829 How To Set Up PF Firewall on FreeBSD to Protect a Web Server.md
similarity index 100%
rename from published/20170829 How To Set Up PF Firewall on FreeBSD to Protect a Web Server.md
rename to published/201809/20170829 How To Set Up PF Firewall on FreeBSD to Protect a Web Server.md
diff --git a/published/20171003 Trash-Cli - A Command Line Interface For Trashcan On Linux.md b/published/201809/20171003 Trash-Cli - A Command Line Interface For Trashcan On Linux.md
similarity index 100%
rename from published/20171003 Trash-Cli - A Command Line Interface For Trashcan On Linux.md
rename to published/201809/20171003 Trash-Cli - A Command Line Interface For Trashcan On Linux.md
diff --git a/published/20171010 Operating a Kubernetes network.md b/published/201809/20171010 Operating a Kubernetes network.md
similarity index 100%
rename from published/20171010 Operating a Kubernetes network.md
rename to published/201809/20171010 Operating a Kubernetes network.md
diff --git a/published/20171124 How do groups work on Linux.md b/published/201809/20171124 How do groups work on Linux.md
similarity index 100%
rename from published/20171124 How do groups work on Linux.md
rename to published/201809/20171124 How do groups work on Linux.md
diff --git a/published/20171202 Scrot Linux command-line screen grabs made simple.md b/published/201809/20171202 Scrot Linux command-line screen grabs made simple.md
similarity index 100%
rename from published/20171202 Scrot Linux command-line screen grabs made simple.md
rename to published/201809/20171202 Scrot Linux command-line screen grabs made simple.md
diff --git a/published/20180102 Top 7 open source project management tools for agile teams.md b/published/201809/20180102 Top 7 open source project management tools for agile teams.md
similarity index 100%
rename from published/20180102 Top 7 open source project management tools for agile teams.md
rename to published/201809/20180102 Top 7 open source project management tools for agile teams.md
diff --git a/published/20180131 What I Learned from Programming Interviews.md b/published/201809/20180131 What I Learned from Programming Interviews.md
similarity index 100%
rename from published/20180131 What I Learned from Programming Interviews.md
rename to published/201809/20180131 What I Learned from Programming Interviews.md
diff --git a/published/20180201 Here are some amazing advantages of Go that you dont hear much about.md b/published/201809/20180201 Here are some amazing advantages of Go that you dont hear much about.md
similarity index 100%
rename from published/20180201 Here are some amazing advantages of Go that you dont hear much about.md
rename to published/201809/20180201 Here are some amazing advantages of Go that you dont hear much about.md
diff --git a/published/20180203 API Star- Python 3 API Framework - Polyglot.Ninja().md b/published/201809/20180203 API Star- Python 3 API Framework - Polyglot.Ninja().md
similarity index 100%
rename from published/20180203 API Star- Python 3 API Framework - Polyglot.Ninja().md
rename to published/201809/20180203 API Star- Python 3 API Framework - Polyglot.Ninja().md
diff --git a/published/20180226 Linux Virtual Machines vs Linux Live Images.md b/published/201809/20180226 Linux Virtual Machines vs Linux Live Images.md
similarity index 100%
rename from published/20180226 Linux Virtual Machines vs Linux Live Images.md
rename to published/201809/20180226 Linux Virtual Machines vs Linux Live Images.md
diff --git a/published/20180308 What is open source programming.md b/published/201809/20180308 What is open source programming.md
similarity index 100%
rename from published/20180308 What is open source programming.md
rename to published/201809/20180308 What is open source programming.md
diff --git a/published/20180316 How to Encrypt Files From Within a File Manager.md b/published/201809/20180316 How to Encrypt Files From Within a File Manager.md
similarity index 100%
rename from published/20180316 How to Encrypt Files From Within a File Manager.md
rename to published/201809/20180316 How to Encrypt Files From Within a File Manager.md
diff --git a/published/20180324 How To Compress And Decompress Files In Linux.md b/published/201809/20180324 How To Compress And Decompress Files In Linux.md
similarity index 100%
rename from published/20180324 How To Compress And Decompress Files In Linux.md
rename to published/201809/20180324 How To Compress And Decompress Files In Linux.md
diff --git a/published/20180326 Start a blog in 30 minutes with Hugo, a static site generator written in Go.md b/published/201809/20180326 Start a blog in 30 minutes with Hugo, a static site generator written in Go.md
similarity index 100%
rename from published/20180326 Start a blog in 30 minutes with Hugo, a static site generator written in Go.md
rename to published/201809/20180326 Start a blog in 30 minutes with Hugo, a static site generator written in Go.md
diff --git a/published/20180402 Understanding Linux filesystems- ext4 and beyond.md b/published/201809/20180402 Understanding Linux filesystems- ext4 and beyond.md
similarity index 100%
rename from published/20180402 Understanding Linux filesystems- ext4 and beyond.md
rename to published/201809/20180402 Understanding Linux filesystems- ext4 and beyond.md
diff --git a/published/20180424 A gentle introduction to FreeDOS.md b/published/201809/20180424 A gentle introduction to FreeDOS.md
similarity index 100%
rename from published/20180424 A gentle introduction to FreeDOS.md
rename to published/201809/20180424 A gentle introduction to FreeDOS.md
diff --git a/published/20180425 Understanding metrics and monitoring with Python - Opensource.com.md b/published/201809/20180425 Understanding metrics and monitoring with Python - Opensource.com.md
similarity index 100%
rename from published/20180425 Understanding metrics and monitoring with Python - Opensource.com.md
rename to published/201809/20180425 Understanding metrics and monitoring with Python - Opensource.com.md
diff --git a/published/20180427 An Official Introduction to the Go Compiler.md b/published/201809/20180427 An Official Introduction to the Go Compiler.md
similarity index 100%
rename from published/20180427 An Official Introduction to the Go Compiler.md
rename to published/201809/20180427 An Official Introduction to the Go Compiler.md
diff --git a/published/20180516 How Graphics Cards Work.md b/published/201809/20180516 How Graphics Cards Work.md
similarity index 100%
rename from published/20180516 How Graphics Cards Work.md
rename to published/201809/20180516 How Graphics Cards Work.md
diff --git a/published/20180516 Manipulating Directories in Linux.md b/published/201809/20180516 Manipulating Directories in Linux.md
similarity index 100%
rename from published/20180516 Manipulating Directories in Linux.md
rename to published/201809/20180516 Manipulating Directories in Linux.md
diff --git a/published/20180518 Mastering CI-CD at OpenDev.md b/published/201809/20180518 Mastering CI-CD at OpenDev.md
similarity index 100%
rename from published/20180518 Mastering CI-CD at OpenDev.md
rename to published/201809/20180518 Mastering CI-CD at OpenDev.md
diff --git a/published/20180525 Getting started with the Python debugger.md b/published/201809/20180525 Getting started with the Python debugger.md
similarity index 100%
rename from published/20180525 Getting started with the Python debugger.md
rename to published/201809/20180525 Getting started with the Python debugger.md
diff --git a/published/20180529 How To Add Additional IP (Secondary IP) In Ubuntu System.md b/published/201809/20180529 How To Add Additional IP (Secondary IP) In Ubuntu System.md
similarity index 100%
rename from published/20180529 How To Add Additional IP (Secondary IP) In Ubuntu System.md
rename to published/201809/20180529 How To Add Additional IP (Secondary IP) In Ubuntu System.md
diff --git a/published/20180618 Twitter Sentiment Analysis using NodeJS.md b/published/201809/20180618 Twitter Sentiment Analysis using NodeJS.md
similarity index 100%
rename from published/20180618 Twitter Sentiment Analysis using NodeJS.md
rename to published/201809/20180618 Twitter Sentiment Analysis using NodeJS.md
diff --git a/published/20180626 How to build a professional network when you work in a bazaar.md b/published/201809/20180626 How to build a professional network when you work in a bazaar.md
similarity index 100%
rename from published/20180626 How to build a professional network when you work in a bazaar.md
rename to published/201809/20180626 How to build a professional network when you work in a bazaar.md
diff --git a/published/20180702 View The Contents Of An Archive Or Compressed File Without Extracting It.md b/published/201809/20180702 View The Contents Of An Archive Or Compressed File Without Extracting It.md
similarity index 100%
rename from published/20180702 View The Contents Of An Archive Or Compressed File Without Extracting It.md
rename to published/201809/20180702 View The Contents Of An Archive Or Compressed File Without Extracting It.md
diff --git a/published/20180703 Understanding Python Dataclasses — Part 1.md b/published/201809/20180703 Understanding Python Dataclasses — Part 1.md
similarity index 100%
rename from published/20180703 Understanding Python Dataclasses — Part 1.md
rename to published/201809/20180703 Understanding Python Dataclasses — Part 1.md
diff --git a/published/20180706 Anatomy of a Linux DNS Lookup - Part III.md b/published/201809/20180706 Anatomy of a Linux DNS Lookup - Part III.md
similarity index 100%
rename from published/20180706 Anatomy of a Linux DNS Lookup - Part III.md
rename to published/201809/20180706 Anatomy of a Linux DNS Lookup - Part III.md
diff --git a/published/20180710 How To View Detailed Information About A Package In Linux.md b/published/201809/20180710 How To View Detailed Information About A Package In Linux.md
similarity index 100%
rename from published/20180710 How To View Detailed Information About A Package In Linux.md
rename to published/201809/20180710 How To View Detailed Information About A Package In Linux.md
diff --git a/published/20180717 Getting started with Etcher.io.md b/published/201809/20180717 Getting started with Etcher.io.md
similarity index 100%
rename from published/20180717 Getting started with Etcher.io.md
rename to published/201809/20180717 Getting started with Etcher.io.md
diff --git a/published/20180720 An Introduction to Using Git.md b/published/201809/20180720 An Introduction to Using Git.md
similarity index 100%
rename from published/20180720 An Introduction to Using Git.md
rename to published/201809/20180720 An Introduction to Using Git.md
diff --git a/published/20180720 How to Install 2048 Game in Ubuntu and Other Linux Distributions.md b/published/201809/20180720 How to Install 2048 Game in Ubuntu and Other Linux Distributions.md
similarity index 100%
rename from published/20180720 How to Install 2048 Game in Ubuntu and Other Linux Distributions.md
rename to published/201809/20180720 How to Install 2048 Game in Ubuntu and Other Linux Distributions.md
diff --git a/published/20180720 How to build a URL shortener with Apache.md b/published/201809/20180720 How to build a URL shortener with Apache.md
similarity index 100%
rename from published/20180720 How to build a URL shortener with Apache.md
rename to published/201809/20180720 How to build a URL shortener with Apache.md
diff --git a/published/20180725 How do private keys work in PKI and cryptography.md b/published/201809/20180725 How do private keys work in PKI and cryptography.md
similarity index 100%
rename from published/20180725 How do private keys work in PKI and cryptography.md
rename to published/201809/20180725 How do private keys work in PKI and cryptography.md
diff --git a/published/20180730 7 Python libraries for more maintainable code.md b/published/201809/20180730 7 Python libraries for more maintainable code.md
similarity index 100%
rename from published/20180730 7 Python libraries for more maintainable code.md
rename to published/201809/20180730 7 Python libraries for more maintainable code.md
diff --git a/published/20180730 How to use VS Code for your Python projects.md b/published/201809/20180730 How to use VS Code for your Python projects.md
similarity index 100%
rename from published/20180730 How to use VS Code for your Python projects.md
rename to published/201809/20180730 How to use VS Code for your Python projects.md
diff --git a/published/20180802 Distrochooser Helps Linux Beginners To Choose A Suitable Linux Distribution.md b/published/201809/20180802 Distrochooser Helps Linux Beginners To Choose A Suitable Linux Distribution.md
similarity index 100%
rename from published/20180802 Distrochooser Helps Linux Beginners To Choose A Suitable Linux Distribution.md
rename to published/201809/20180802 Distrochooser Helps Linux Beginners To Choose A Suitable Linux Distribution.md
diff --git a/published/20180803 10 Popular Windows Apps That Are Also Available on Linux.md b/published/201809/20180803 10 Popular Windows Apps That Are Also Available on Linux.md
similarity index 100%
rename from published/20180803 10 Popular Windows Apps That Are Also Available on Linux.md
rename to published/201809/20180803 10 Popular Windows Apps That Are Also Available on Linux.md
diff --git a/published/20180804 Installing Andriod on VirtualBox.md b/published/201809/20180804 Installing Andriod on VirtualBox.md
similarity index 100%
rename from published/20180804 Installing Andriod on VirtualBox.md
rename to published/201809/20180804 Installing Andriod on VirtualBox.md
diff --git a/published/20180806 Anatomy of a Linux DNS Lookup - Part IV.md b/published/201809/20180806 Anatomy of a Linux DNS Lookup - Part IV.md
similarity index 100%
rename from published/20180806 Anatomy of a Linux DNS Lookup - Part IV.md
rename to published/201809/20180806 Anatomy of a Linux DNS Lookup - Part IV.md
diff --git a/published/20180806 Installing and using Git and GitHub on Ubuntu Linux- A beginner-s guide.md b/published/201809/20180806 Installing and using Git and GitHub on Ubuntu Linux- A beginner-s guide.md
similarity index 100%
rename from published/20180806 Installing and using Git and GitHub on Ubuntu Linux- A beginner-s guide.md
rename to published/201809/20180806 Installing and using Git and GitHub on Ubuntu Linux- A beginner-s guide.md
diff --git a/published/20180808 5 applications to manage your to-do list on Fedora.md b/published/201809/20180808 5 applications to manage your to-do list on Fedora.md
similarity index 100%
rename from published/20180808 5 applications to manage your to-do list on Fedora.md
rename to published/201809/20180808 5 applications to manage your to-do list on Fedora.md
diff --git a/published/20180808 5 open source role-playing games for Linux.md b/published/201809/20180808 5 open source role-playing games for Linux.md
similarity index 100%
rename from published/20180808 5 open source role-playing games for Linux.md
rename to published/201809/20180808 5 open source role-playing games for Linux.md
diff --git a/published/20180810 6 Reasons Why Linux Users Switch to BSD.md b/published/201809/20180810 6 Reasons Why Linux Users Switch to BSD.md
similarity index 100%
rename from published/20180810 6 Reasons Why Linux Users Switch to BSD.md
rename to published/201809/20180810 6 Reasons Why Linux Users Switch to BSD.md
diff --git a/published/20180810 Automatically Switch To Light - Dark Gtk Themes Based On Sunrise And Sunset Times With AutomaThemely.md b/published/201809/20180810 Automatically Switch To Light - Dark Gtk Themes Based On Sunrise And Sunset Times With AutomaThemely.md
similarity index 100%
rename from published/20180810 Automatically Switch To Light - Dark Gtk Themes Based On Sunrise And Sunset Times With AutomaThemely.md
rename to published/201809/20180810 Automatically Switch To Light - Dark Gtk Themes Based On Sunrise And Sunset Times With AutomaThemely.md
diff --git a/published/20180813 MPV Player- A Minimalist Video Player for Linux.md b/published/201809/20180813 MPV Player- A Minimalist Video Player for Linux.md
similarity index 100%
rename from published/20180813 MPV Player- A Minimalist Video Player for Linux.md
rename to published/201809/20180813 MPV Player- A Minimalist Video Player for Linux.md
diff --git a/published/20180815 How To Enable Hardware Accelerated Video Decoding In Chromium On Ubuntu Or Linux Mint.md b/published/201809/20180815 How To Enable Hardware Accelerated Video Decoding In Chromium On Ubuntu Or Linux Mint.md
similarity index 100%
rename from published/20180815 How To Enable Hardware Accelerated Video Decoding In Chromium On Ubuntu Or Linux Mint.md
rename to published/201809/20180815 How To Enable Hardware Accelerated Video Decoding In Chromium On Ubuntu Or Linux Mint.md
diff --git a/published/20180822 How To Switch Between TTYs Without Using Function Keys In Linux.md b/published/201809/20180822 How To Switch Between TTYs Without Using Function Keys In Linux.md
similarity index 100%
rename from published/20180822 How To Switch Between TTYs Without Using Function Keys In Linux.md
rename to published/201809/20180822 How To Switch Between TTYs Without Using Function Keys In Linux.md
diff --git a/published/20180822 What is a Makefile and how does it work.md b/published/201809/20180822 What is a Makefile and how does it work.md
similarity index 100%
rename from published/20180822 What is a Makefile and how does it work.md
rename to published/201809/20180822 What is a Makefile and how does it work.md
diff --git a/published/20180823 An introduction to pipes and named pipes in Linux.md b/published/201809/20180823 An introduction to pipes and named pipes in Linux.md
similarity index 100%
rename from published/20180823 An introduction to pipes and named pipes in Linux.md
rename to published/201809/20180823 An introduction to pipes and named pipes in Linux.md
diff --git a/published/20180823 How to publish a WordPress blog to a static GitLab Pages site.md b/published/201809/20180823 How to publish a WordPress blog to a static GitLab Pages site.md
similarity index 100%
rename from published/20180823 How to publish a WordPress blog to a static GitLab Pages site.md
rename to published/201809/20180823 How to publish a WordPress blog to a static GitLab Pages site.md
diff --git a/published/20180824 How to install software from the Linux command line.md b/published/201809/20180824 How to install software from the Linux command line.md
similarity index 100%
rename from published/20180824 How to install software from the Linux command line.md
rename to published/201809/20180824 How to install software from the Linux command line.md
diff --git a/published/20180824 Steam Makes it Easier to Play Windows Games on Linux.md b/published/201809/20180824 Steam Makes it Easier to Play Windows Games on Linux.md
similarity index 100%
rename from published/20180824 Steam Makes it Easier to Play Windows Games on Linux.md
rename to published/201809/20180824 Steam Makes it Easier to Play Windows Games on Linux.md
diff --git a/published/20180824 [Solved] -sub process usr bin dpkg returned an error code 1- Error in Ubuntu.md b/published/201809/20180824 [Solved] -sub process usr bin dpkg returned an error code 1- Error in Ubuntu.md
similarity index 100%
rename from published/20180824 [Solved] -sub process usr bin dpkg returned an error code 1- Error in Ubuntu.md
rename to published/201809/20180824 [Solved] -sub process usr bin dpkg returned an error code 1- Error in Ubuntu.md
diff --git a/published/20180826 How to capture and analyze packets with tcpdump command on Linux.md b/published/201809/20180826 How to capture and analyze packets with tcpdump command on Linux.md
similarity index 100%
rename from published/20180826 How to capture and analyze packets with tcpdump command on Linux.md
rename to published/201809/20180826 How to capture and analyze packets with tcpdump command on Linux.md
diff --git a/published/20180827 An introduction to diffs and patches.md b/published/201809/20180827 An introduction to diffs and patches.md
similarity index 100%
rename from published/20180827 An introduction to diffs and patches.md
rename to published/201809/20180827 An introduction to diffs and patches.md
diff --git a/published/20180828 15 command-line aliases to save you time.md b/published/201809/20180828 15 command-line aliases to save you time.md
similarity index 100%
rename from published/20180828 15 command-line aliases to save you time.md
rename to published/201809/20180828 15 command-line aliases to save you time.md
diff --git a/published/20180828 A Cat Clone With Syntax Highlighting And Git Integration.md b/published/201809/20180828 A Cat Clone With Syntax Highlighting And Git Integration.md
similarity index 100%
rename from published/20180828 A Cat Clone With Syntax Highlighting And Git Integration.md
rename to published/201809/20180828 A Cat Clone With Syntax Highlighting And Git Integration.md
diff --git a/published/20180828 How to Play Windows-only Games on Linux with Steam Play.md b/published/201809/20180828 How to Play Windows-only Games on Linux with Steam Play.md
similarity index 100%
rename from published/20180828 How to Play Windows-only Games on Linux with Steam Play.md
rename to published/201809/20180828 How to Play Windows-only Games on Linux with Steam Play.md
diff --git a/published/20180829 Add GUIs to your programs and scripts easily with PySimpleGUI.md b/published/201809/20180829 Add GUIs to your programs and scripts easily with PySimpleGUI.md
similarity index 100%
rename from published/20180829 Add GUIs to your programs and scripts easily with PySimpleGUI.md
rename to published/201809/20180829 Add GUIs to your programs and scripts easily with PySimpleGUI.md
diff --git a/published/20180830 How To Reset MySQL Or MariaDB Root Password.md b/published/201809/20180830 How To Reset MySQL Or MariaDB Root Password.md
similarity index 100%
rename from published/20180830 How To Reset MySQL Or MariaDB Root Password.md
rename to published/201809/20180830 How To Reset MySQL Or MariaDB Root Password.md
diff --git a/published/20180830 How to Update Firmware on Ubuntu 18.04.md b/published/201809/20180830 How to Update Firmware on Ubuntu 18.04.md
similarity index 100%
rename from published/20180830 How to Update Firmware on Ubuntu 18.04.md
rename to published/201809/20180830 How to Update Firmware on Ubuntu 18.04.md
diff --git a/published/20180831 6 open source tools for making your own VPN.md b/published/201809/20180831 6 open source tools for making your own VPN.md
similarity index 100%
rename from published/20180831 6 open source tools for making your own VPN.md
rename to published/201809/20180831 6 open source tools for making your own VPN.md
diff --git a/published/20180831 How to Create a Slideshow of Photos in Ubuntu 18.04 and other Linux Distributions.md b/published/201809/20180831 How to Create a Slideshow of Photos in Ubuntu 18.04 and other Linux Distributions.md
similarity index 100%
rename from published/20180831 How to Create a Slideshow of Photos in Ubuntu 18.04 and other Linux Distributions.md
rename to published/201809/20180831 How to Create a Slideshow of Photos in Ubuntu 18.04 and other Linux Distributions.md
diff --git a/published/20180903 Turn your vi editor into a productivity powerhouse.md b/published/201809/20180903 Turn your vi editor into a productivity powerhouse.md
similarity index 100%
rename from published/20180903 Turn your vi editor into a productivity powerhouse.md
rename to published/201809/20180903 Turn your vi editor into a productivity powerhouse.md
diff --git a/published/20180904 8 Linux commands for effective process management.md b/published/201809/20180904 8 Linux commands for effective process management.md
similarity index 100%
rename from published/20180904 8 Linux commands for effective process management.md
rename to published/201809/20180904 8 Linux commands for effective process management.md
diff --git a/published/20180904 Why I love Xonsh.md b/published/201809/20180904 Why I love Xonsh.md
similarity index 100%
rename from published/20180904 Why I love Xonsh.md
rename to published/201809/20180904 Why I love Xonsh.md
diff --git a/published/20180905 5 tips to improve productivity with zsh.md b/published/201809/20180905 5 tips to improve productivity with zsh.md
similarity index 100%
rename from published/20180905 5 tips to improve productivity with zsh.md
rename to published/201809/20180905 5 tips to improve productivity with zsh.md
diff --git a/published/20180905 8 great Python libraries for side projects.md b/published/201809/20180905 8 great Python libraries for side projects.md
similarity index 100%
rename from published/20180905 8 great Python libraries for side projects.md
rename to published/201809/20180905 8 great Python libraries for side projects.md
diff --git a/published/20180905 Find your systems easily on a LAN with mDNS.md b/published/201809/20180905 Find your systems easily on a LAN with mDNS.md
similarity index 100%
rename from published/20180905 Find your systems easily on a LAN with mDNS.md
rename to published/201809/20180905 Find your systems easily on a LAN with mDNS.md
diff --git a/published/20180906 3 top open source JavaScript chart libraries.md b/published/201809/20180906 3 top open source JavaScript chart libraries.md
similarity index 100%
rename from published/20180906 3 top open source JavaScript chart libraries.md
rename to published/201809/20180906 3 top open source JavaScript chart libraries.md
diff --git a/published/20180906 Two open source alternatives to Flash Player.md b/published/201809/20180906 Two open source alternatives to Flash Player.md
similarity index 100%
rename from published/20180906 Two open source alternatives to Flash Player.md
rename to published/201809/20180906 Two open source alternatives to Flash Player.md
diff --git a/published/20180907 Autotrash - A CLI Tool To Automatically Purge Old Trashed Files.md b/published/201809/20180907 Autotrash - A CLI Tool To Automatically Purge Old Trashed Files.md
similarity index 100%
rename from published/20180907 Autotrash - A CLI Tool To Automatically Purge Old Trashed Files.md
rename to published/201809/20180907 Autotrash - A CLI Tool To Automatically Purge Old Trashed Files.md
diff --git a/published/20180907 What do open source and cooking have in common.md b/published/201809/20180907 What do open source and cooking have in common.md
similarity index 100%
rename from published/20180907 What do open source and cooking have in common.md
rename to published/201809/20180907 What do open source and cooking have in common.md
diff --git a/published/20180909 What is ZFS- Why People Use ZFS- [Explained for Beginners].md b/published/201809/20180909 What is ZFS- Why People Use ZFS- [Explained for Beginners].md
similarity index 100%
rename from published/20180909 What is ZFS- Why People Use ZFS- [Explained for Beginners].md
rename to published/201809/20180909 What is ZFS- Why People Use ZFS- [Explained for Beginners].md
diff --git a/published/20180910 13 Keyboard Shortcut Every Ubuntu 18.04 User Should Know.md b/published/201809/20180910 13 Keyboard Shortcut Every Ubuntu 18.04 User Should Know.md
similarity index 100%
rename from published/20180910 13 Keyboard Shortcut Every Ubuntu 18.04 User Should Know.md
rename to published/201809/20180910 13 Keyboard Shortcut Every Ubuntu 18.04 User Should Know.md
diff --git a/published/20180910 3 open source log aggregation tools.md b/published/201809/20180910 3 open source log aggregation tools.md
similarity index 100%
rename from published/20180910 3 open source log aggregation tools.md
rename to published/201809/20180910 3 open source log aggregation tools.md
diff --git a/published/20180910 Randomize your MAC address using NetworkManager.md b/published/201809/20180910 Randomize your MAC address using NetworkManager.md
similarity index 100%
rename from published/20180910 Randomize your MAC address using NetworkManager.md
rename to published/201809/20180910 Randomize your MAC address using NetworkManager.md
diff --git a/published/20180911 Visualize Disk Usage On Your Linux System.md b/published/201809/20180911 Visualize Disk Usage On Your Linux System.md
similarity index 100%
rename from published/20180911 Visualize Disk Usage On Your Linux System.md
rename to published/201809/20180911 Visualize Disk Usage On Your Linux System.md
diff --git a/published/20180912 How To Configure Mouse Support For Linux Virtual Consoles.md b/published/201809/20180912 How To Configure Mouse Support For Linux Virtual Consoles.md
similarity index 100%
rename from published/20180912 How To Configure Mouse Support For Linux Virtual Consoles.md
rename to published/201809/20180912 How To Configure Mouse Support For Linux Virtual Consoles.md
diff --git a/published/20180917 Linux tricks that can save you time and trouble.md b/published/201809/20180917 Linux tricks that can save you time and trouble.md
similarity index 100%
rename from published/20180917 Linux tricks that can save you time and trouble.md
rename to published/201809/20180917 Linux tricks that can save you time and trouble.md
diff --git a/published/20180918 How To Force APT Package Manager To Use IPv4 In Ubuntu 16.04.md b/published/201809/20180918 How To Force APT Package Manager To Use IPv4 In Ubuntu 16.04.md
similarity index 100%
rename from published/20180918 How To Force APT Package Manager To Use IPv4 In Ubuntu 16.04.md
rename to published/201809/20180918 How To Force APT Package Manager To Use IPv4 In Ubuntu 16.04.md
diff --git a/published/20180919 Understand Fedora memory usage with top.md b/published/201809/20180919 Understand Fedora memory usage with top.md
similarity index 100%
rename from published/20180919 Understand Fedora memory usage with top.md
rename to published/201809/20180919 Understand Fedora memory usage with top.md
diff --git a/translated/tech/20180924 Make The Output Of Ping Command Prettier And Easier To Read.md b/published/201809/20180924 Make The Output Of Ping Command Prettier And Easier To Read.md
similarity index 70%
rename from translated/tech/20180924 Make The Output Of Ping Command Prettier And Easier To Read.md
rename to published/201809/20180924 Make The Output Of Ping Command Prettier And Easier To Read.md
index efca96da23..6267fad2e8 100644
--- a/translated/tech/20180924 Make The Output Of Ping Command Prettier And Easier To Read.md
+++ b/published/201809/20180924 Make The Output Of Ping Command Prettier And Easier To Read.md
@@ -3,21 +3,19 @@

-众所周知,`ping` 命令可以用来检查目标主机是否可达。使用 `ping` 命令的时候,会发送一个 ICMP Echo 请求,通过目标主机的响应与否来确定目标主机的状态。如果你经常使用 `ping` 命令,你可以尝试一下 `prettyping`。Prettyping 只是将一个标准的 ping 工具增加了一层封装,在运行标准 ping 命令的同时添加了颜色和 unicode 字符解析输出,所以它的输出更漂亮紧凑、清晰易读。它是用 `bash` 和 `awk` 编写的免费开源工具,支持大部分类 Unix 操作系统,包括 GNU/Linux、FreeBSD 和 Mac OS X。Prettyping 除了美化 ping 命令的输出,还有很多值得注意的功能。
+众所周知,`ping` 命令可以用来检查目标主机是否可达。使用 `ping` 命令的时候,会发送一个 ICMP Echo 请求,通过目标主机的响应与否来确定目标主机的状态。如果你经常使用 `ping` 命令,你可以尝试一下 `prettyping`。Prettyping 只是将一个标准的 ping 工具增加了一层封装,在运行标准 `ping` 命令的同时添加了颜色和 unicode 字符解析输出,所以它的输出更漂亮紧凑、清晰易读。它是用 `bash` 和 `awk` 编写的自由开源工具,支持大部分类 Unix 操作系统,包括 GNU/Linux、FreeBSD 和 Mac OS X。Prettyping 除了美化 `ping` 命令的输出,还有很多值得注意的功能。
* 检测丢失的数据包并在输出中标记出来。
- * 显示实时数据。每次收到响应后,都会更新统计数据,而对于普通 ping 命令,只会在执行结束后统计。
- * 能够在输出结果不混乱的前提下灵活处理“未知信息”(例如错误信息)。
+ * 显示实时数据。每次收到响应后,都会更新统计数据,而对于普通 `ping` 命令,只会在执行结束后统计。
+ * 可以灵活处理“未知信息”(例如错误信息),而不搞乱输出结果。
* 能够避免输出重复的信息。
- * 兼容常用的 ping 工具命令参数。
+ * 兼容常用的 `ping` 工具命令参数。
* 能够由普通用户执行。
* 可以将输出重定向到文件中。
* 不需要安装,只需要下载二进制文件,赋予可执行权限即可执行。
* 快速且轻巧。
* 输出结果清晰直观。
-
-
### 安装 Prettyping
如上所述,Prettyping 是一个绿色软件,不需要任何安装,只要使用以下命令下载 Prettyping 二进制文件:
@@ -52,9 +50,9 @@ $ prettyping ostechnix.com

-如果你不带任何参数执行 `prettyping`,它就会一直运行直到被 ctrl + c 中断。
+如果你不带任何参数执行 `prettyping`,它就会一直运行直到被 `ctrl + c` 中断。
-由于 Prettyping 只是一个对普通 ping 命令的封装,所以常用的 ping 参数也是有效的。例如使用 `-c 5` 来指定 ping 一台主机的 5 次:
+由于 Prettyping 只是一个对普通 `ping` 命令的封装,所以常用的 ping 参数也是有效的。例如使用 `-c 5` 来指定 ping 一台主机的 5 次:
```
$ prettyping -c 5 ostechnix.com
@@ -76,7 +74,7 @@ $ prettyping --nomulticolor ostechnix.com
-如果你的终端不支持 **UTF-8**,或者无法修复系统中的 unicode 字体,只需要加上 `--nounicode` 参数就能轻松解决。
+如果你的终端不支持 UTF-8,或者无法修复系统中的 unicode 字体,只需要加上 `--nounicode` 参数就能轻松解决。
Prettyping 支持将输出的内容重定向到文件中,例如执行以下这个命令会将 `prettyping ostechnix.com` 的输出重定向到 `ostechnix.txt` 中:
@@ -89,10 +87,9 @@ Prettyping 还有很多选项帮助你完成各种任务,例如:
* 启用/禁用延时图例(默认启用)
* 强制按照终端的格式输出(默认自动)
* 在统计数据中统计最后的 n 次 ping(默认 60 次)
- * 覆盖对终端尺寸的检测
- * 覆盖 awk 解释器(默认不覆盖)
- * 覆盖 ping 工具(默认不覆盖)
-
+ * 覆盖对终端尺寸的自动检测
+ * 指定 awk 解释器路径(默认:`awk`)
+ * 指定 ping 工具路径(默认:`ping`)
查看帮助文档可以了解更多:
@@ -101,18 +98,14 @@ Prettyping 还有很多选项帮助你完成各种任务,例如:
$ prettyping --help
```
-尽管 prettyping 没有添加任何额外功能,但我个人喜欢它的这些优点:
+尽管 Prettyping 没有添加任何额外功能,但我个人喜欢它的这些优点:
- * 实时统计 - 可以随时查看所有实时统计信息,标准 `ping` 命令只会在命令执行结束后才显示统计信息。
- * 紧凑的显示 - 可以在终端看到更长的时间跨度。
+ * 实时统计 —— 可以随时查看所有实时统计信息,标准 `ping` 命令只会在命令执行结束后才显示统计信息。
+ * 紧凑的显示 —— 可以在终端看到更长的时间跨度。
* 检测丢失的数据包并显示出来。
-
-
如果你一直在寻找可视化显示 `ping` 命令输出的工具,那么 Prettyping 肯定会有所帮助。尝试一下,你不会失望的。
-
-
--------------------------------------------------------------------------------
via: https://www.ostechnix.com/prettyping-make-the-output-of-ping-command-prettier-and-easier-to-read/
@@ -120,7 +113,7 @@ via: https://www.ostechnix.com/prettyping-make-the-output-of-ping-command-pretti
作者:[SK][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[HankChow](https://github.com/HankChow)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20180929 Getting started with the i3 window manager on Linux.md b/published/201809/20180929 Getting started with the i3 window manager on Linux.md
similarity index 100%
rename from published/20180929 Getting started with the i3 window manager on Linux.md
rename to published/201809/20180929 Getting started with the i3 window manager on Linux.md
diff --git a/translated/tech/20180901 5 Ways to Take Screenshot in Linux GUI and Terminal.md b/published/20180901 5 Ways to Take Screenshot in Linux GUI and Terminal.md
similarity index 68%
rename from translated/tech/20180901 5 Ways to Take Screenshot in Linux GUI and Terminal.md
rename to published/20180901 5 Ways to Take Screenshot in Linux GUI and Terminal.md
index b8872981fe..c6618b9a52 100644
--- a/translated/tech/20180901 5 Ways to Take Screenshot in Linux GUI and Terminal.md
+++ b/published/20180901 5 Ways to Take Screenshot in Linux GUI and Terminal.md
@@ -1,6 +1,7 @@
-5 种在 Linux 图形界面或命令行界面截图的方法
+在 Linux 下截屏并编辑的最佳工具
======
-下面介绍几种获取屏幕截图并对其编辑的方法,而且其中的屏幕截图工具在 Ubuntu 和其它主流 Linux 发行版中都能够使用。
+
+> 有几种获取屏幕截图并对其进行添加文字、箭头等编辑的方法,这里提及的的屏幕截图工具在 Ubuntu 和其它主流 Linux 发行版中都能够使用。
![在 Ubuntu Linux 中如何获取屏幕截图][1]
@@ -8,26 +9,26 @@
本文将会介绍在不适用第三方工具的情况下,如何通过系统自带的方法和工具获取屏幕截图,另外还会介绍一些可用于 Linux 的最佳截图工具。
-### 方法 1: 在 Linux 中截图的默认方式
+### 方法 1:在 Linux 中截图的默认方式
-你是否需要截取整个屏幕?屏幕中的某个区域?某个特定的窗口?
+你想要截取整个屏幕?屏幕中的某个区域?某个特定的窗口?
如果只需要获取一张屏幕截图,不对其进行编辑的话,那么键盘的默认快捷键就可以满足要求了。而且不仅仅是 Ubuntu ,绝大部分的 Linux 发行版和桌面环境都支持以下这些快捷键:
-**PrtSc** – 获取整个屏幕的截图并保存到 Pictures 目录。
-**Shift + PrtSc** – 获取屏幕的某个区域截图并保存到 Pictures 目录。
-**Alt + PrtSc** –获取当前窗口的截图并保存到 Pictures 目录。
-**Ctrl + PrtSc** – 获取整个屏幕的截图并存放到剪贴板。
-**Shift + Ctrl + PrtSc** – 获取屏幕的某个区域截图并存放到剪贴板。
-**Ctrl + Alt + PrtSc** – 获取当前窗口的 截图并存放到剪贴板。
+- `PrtSc` – 获取整个屏幕的截图并保存到 Pictures 目录。
+- `Shift + PrtSc` – 获取屏幕的某个区域截图并保存到 Pictures 目录。
+- `Alt + PrtSc` –获取当前窗口的截图并保存到 Pictures 目录。
+- `Ctrl + PrtSc` – 获取整个屏幕的截图并存放到剪贴板。
+- `Shift + Ctrl + PrtSc` – 获取屏幕的某个区域截图并存放到剪贴板。
+- `Ctrl + Alt + PrtSc` – 获取当前窗口的 截图并存放到剪贴板。
如上所述,在 Linux 中使用默认的快捷键获取屏幕截图是相当简单的。但如果要在不把屏幕截图导入到其它应用程序的情况下对屏幕截图进行编辑,还是使用屏幕截图工具比较方便。
-#### **方法 2: 在 Linux 中使用 Flameshot 获取屏幕截图并编辑**
+### 方法 2:在 Linux 中使用 Flameshot 获取屏幕截图并编辑
![flameshot][2]
-功能概述
+功能概述:
* 注释 (高亮、标示、添加文本、框选)
* 图片模糊
@@ -35,66 +36,63 @@
* 上传到 Imgur
* 用另一个应用打开截图
+Flameshot 在去年发布到 [GitHub][3],并成为一个引人注目的工具。
-
-Flameshot 在去年发布到 [GitHub][3],并成为一个引人注目的工具。如果你需要的是一个能够用于标注、模糊、上传到 imgur 的新式截图工具,那么 Flameshot 是一个好的选择。
+如果你需要的是一个能够用于标注、模糊、上传到 imgur 的新式截图工具,那么 Flameshot 是一个好的选择。
下面将会介绍如何安装 Flameshot 并根据你的偏好进行配置。
如果你用的是 Ubuntu,那么只需要在 Ubuntu 软件中心上搜索,就可以找到 Flameshot 进而完成安装了。要是你想使用终端来安装,可以执行以下命令:
+
```
sudo apt install flameshot
-
```
-如果你在安装过程中遇到问题,可以按照[官方的安装说明][4]进行操作。安装完成后,你还需要进行配置。尽管可以通过搜索来随时启动 Flameshot,但如果想使用 PrtSc 键触发启动,则需要指定对应的键盘快捷键。以下是相关配置步骤:
+如果你在安装过程中遇到问题,可以按照[官方的安装说明][4]进行操作。安装完成后,你还需要进行配置。尽管可以通过搜索来随时启动 Flameshot,但如果想使用 `PrtSc` 键触发启动,则需要指定对应的键盘快捷键。以下是相关配置步骤:
- * 进入系统设置中的键盘设置
- * 页面中会列出所有现有的键盘快捷键,拉到底部就会看见一个 **+** 按钮
+ * 进入系统设置中的“键盘设置”
+ * 页面中会列出所有现有的键盘快捷键,拉到底部就会看见一个 “+” 按钮
* 点击 “+” 按钮添加自定义快捷键并输入以下两个字段:
-**名称:** 任意名称均可
-**命令:** /usr/bin/flameshot gui
- * 最后将这个快捷操作绑定到 **PrtSc** 键上,可能会提示与系统的截图功能相冲突,但可以忽略掉这个警告。
-
-
+ * “名称”: 任意名称均可。
+ * “命令”: `/usr/bin/flameshot gui`
+ * 最后将这个快捷操作绑定到 `PrtSc` 键上,可能会提示与系统的截图功能相冲突,但可以忽略掉这个警告。
配置之后,你的自定义快捷键页面大概会是以下这样:
![][5]
-将键盘快捷键映射到 Flameshot
-### **方法 3: 在 Linux 中使用 Shutter 获取屏幕截图并编辑**
+*将键盘快捷键映射到 Flameshot*
+
+### 方法 3:在 Linux 中使用 Shutter 获取屏幕截图并编辑
![][6]
-功能概述:
+功能概述:
* 注释 (高亮、标示、添加文本、框选)
* 图片模糊
* 图片裁剪
* 上传到图片网站
-
-
[Shutter][7] 是一个对所有主流 Linux 发行版都适用的屏幕截图工具。尽管最近已经不太更新了,但仍然是操作屏幕截图的一个优秀工具。
-在使用过程中可能会遇到这个工具的一些缺陷。Shutter 在任何一款最新的 Linux 发行版上最常见的问题就是由于缺少了任务栏上的程序图标,导致默认禁用了编辑屏幕截图的功能。 对于这个缺陷,还是有解决方案的。下面介绍一下如何[在 Shutter 中重新打开这个功能并将程序图标在任务栏上显示出来][8]。问题修复后,就可以使用 Shutter 来快速编辑屏幕截图了。
+在使用过程中可能会遇到这个工具的一些缺陷。Shutter 在任何一款最新的 Linux 发行版上最常见的问题就是由于缺少了任务栏上的程序图标,导致默认禁用了编辑屏幕截图的功能。 对于这个缺陷,还是有解决方案的。你只需要跟随我们的教程[在 Shutter 中修复这个禁止编辑选项并将程序图标在任务栏上显示出来][8]。问题修复后,就可以使用 Shutter 来快速编辑屏幕截图了。
同样地,在软件中心搜索也可以找到进而安装 Shutter,也可以在基于 Ubuntu 的发行版中执行以下命令使用命令行安装:
+
```
sudo apt install shutter
-
```
-类似 Flameshot,你可以通过搜索 Shutter 手动启动它,也可以按照相似的方式设置自定义快捷方式以 **PrtSc** 键唤起 Shutter。
+类似 Flameshot,你可以通过搜索 Shutter 手动启动它,也可以按照相似的方式设置自定义快捷方式以 `PrtSc` 键唤起 Shutter。
如果要指定自定义键盘快捷键,只需要执行以下命令:
+
```
shutter -f
-
```
-### 方法 4: 在 Linux 中使用 GIMP 获取屏幕截图
+### 方法 4:在 Linux 中使用 GIMP 获取屏幕截图
![][9]
@@ -103,83 +101,79 @@ shutter -f
* 高级图像编辑功能(缩放、添加滤镜、颜色校正、添加图层、裁剪等)
* 截取某一区域的屏幕截图
-
-
如果需要对屏幕截图进行一些预先编辑,GIMP 是一个不错的选择。
通过软件中心可以安装 GIMP。如果在安装时遇到问题,可以参考其[官方网站的安装说明][10]。
-要使用 GIMP 获取屏幕截图,需要先启动程序,然后通过 **File-> Create-> Screenshot** 导航。
+要使用 GIMP 获取屏幕截图,需要先启动程序,然后通过 “File-> Create-> Screenshot” 导航。
-打开 Screenshot 选项后,会看到几个控制点来控制屏幕截图范围。点击 **Snap** 截取屏幕截图,图像将自动显示在 GIMP 中可供编辑。
+打开 Screenshot 选项后,会看到几个控制点来控制屏幕截图范围。点击 “Snap” 截取屏幕截图,图像将自动显示在 GIMP 中可供编辑。
-### 方法 5: 在 Linux 中使用命令行工具获取屏幕截图
+### 方法 5:在 Linux 中使用命令行工具获取屏幕截图
-这一节内容仅适用于终端爱好者。如果你也喜欢使用终端,可以使用 **GNOME 截图工具**或 **ImageMagick** 或 **Deepin Scrot**,大部分流行的 Linux 发行版中都自带这些工具。
+这一节内容仅适用于终端爱好者。如果你也喜欢使用终端,可以使用 “GNOME 截图工具”或 “ImageMagick” 或 “Deepin Scrot”,大部分流行的 Linux 发行版中都自带这些工具。
要立即获取屏幕截图,可以执行以下命令:
-#### GNOME Screenshot(可用于 GNOME 桌面)
+#### GNOME 截图工具(可用于 GNOME 桌面)
+
```
gnome-screenshot
-
```
-GNOME Screenshot 是使用 GNOME 桌面的 Linux 发行版中都自带的一个默认工具。如果需要延时获取屏幕截图,可以执行以下命令(这里的 **5** 是需要延迟的秒数):
+GNOME 截图工具是使用 GNOME 桌面的 Linux 发行版中都自带的一个默认工具。如果需要延时获取屏幕截图,可以执行以下命令(这里的 `5` 是需要延迟的秒数):
```
gnome-screenshot -d -5
-
```
#### ImageMagick
如果你的操作系统是 Ubuntu、Mint 或其它流行的 Linux 发行版,一般会自带 [ImageMagick][11] 这个工具。如果没有这个工具,也可以按照[官方安装说明][12]使用安装源来安装。你也可以在终端中执行这个命令:
+
```
sudo apt-get install imagemagick
-
```
安装完成后,执行下面的命令就可以获取到屏幕截图(截取整个屏幕):
```
import -window root image.png
-
```
-这里的“image.png”就是屏幕截图文件保存的名称。
+这里的 “image.png” 就是屏幕截图文件保存的名称。
要获取屏幕一个区域的截图,可以执行以下命令:
+
```
import image.png
-
```
#### Deepin Scrot
Deepin Scrot 是基于终端的一个较新的截图工具。和前面两个工具类似,一般自带于 Linux 发行版中。如果需要自行安装,可以执行以下命令:
+
```
sudo apt-get install scrot
-
```
安装完成后,使用下面这些命令可以获取屏幕截图。
获取整个屏幕的截图:
+
```
scrot myimage.png
-
```
获取屏幕某一区域的截图:
+
```
scrot -s myimage.png
-
```
### 总结
-以上是一些在 Linux 上的优秀截图工具。当然还有很多截图工具没有提及(例如 [Spectacle][13] for KDE-distros),但相比起来还是上面几个工具更为好用。
+以上是一些在 Linux 上的优秀截图工具。当然还有很多截图工具没有提及(例如用于 KDE 发行版的 [Spectacle][13]),但相比起来还是上面几个工具更为好用。
如果你有比文章中提到的更好的截图工具,欢迎讨论!
@@ -189,8 +183,8 @@ via: https://itsfoss.com/take-screenshot-linux/
作者:[Ankush Das][a]
选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
+译者:[HankChow](https://github.com/HankChow)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20180906 How To Limit Network Bandwidth In Linux Using Wondershaper.md b/published/20180906 How To Limit Network Bandwidth In Linux Using Wondershaper.md
new file mode 100644
index 0000000000..046777e1be
--- /dev/null
+++ b/published/20180906 How To Limit Network Bandwidth In Linux Using Wondershaper.md
@@ -0,0 +1,171 @@
+在 Linux 中使用 Wondershaper 限制网络带宽
+======
+
+
+
+以下内容将向你介绍如何轻松对网络带宽做出限制,并在类 Unix 操作系统中对网络流量进行优化。通过限制网络带宽,可以节省应用程序不必要的带宽消耗,包括软件包管理器(pacman、yum、apt)、web 浏览器、torrent 客户端、下载管理器等,并防止单个或多个用户滥用网络带宽。在本文当中,将会介绍 Wondershaper 这一个实用的命令行程序,这是我认为限制 Linux 系统 Internet 或本地网络带宽的最简单、最快捷的方式之一。
+
+请注意,Wondershaper 只能限制本地网络接口的传入和传出流量,而不能限制路由器或调制解调器的接口。换句话说,Wondershaper 只会限制本地系统本身的网络带宽,而不会限制网络中的其它系统。因此 Wondershaper 主要用于限制本地系统中一个或多个网卡的带宽。
+
+下面来看一下 Wondershaper 是如何优化网络流量的。
+
+### 在 Linux 中使用 Wondershaper 限制网络带宽
+
+`wondershaper` 是用于显示系统网卡网络带宽的简单脚本。它使用了 iproute 的 `tc` 命令,但大大简化了操作过程。
+
+#### 安装 Wondershaper
+
+使用 `git clone` 克隆 Wondershaper 的版本库就可以安装最新版本:
+
+```
+$ git clone https://github.com/magnific0/wondershaper.git
+```
+
+按照以下命令进入 `wondershaper` 目录并安装:
+
+```
+$ cd wondershaper
+$ sudo make install
+```
+
+然后执行以下命令,可以让 `wondershaper` 在每次系统启动时都自动开始服务:
+
+```
+$ sudo systemctl enable wondershaper.service
+$ sudo systemctl start wondershaper.service
+```
+
+如果你不强求安装最新版本,也可以使用软件包管理器(官方和非官方均可)来进行安装。
+
+`wondershaper` 在 [Arch 用户软件仓库][1](Arch User Repository,AUR)中可用,所以可以使用类似 [yay][2] 这些 AUR 辅助软件在基于 Arch 的系统中安装 `wondershaper` 。
+
+```
+$ yay -S wondershaper-git
+```
+
+对于 Debian、Ubuntu 和 Linux Mint 可以使用以下命令安装:
+
+```
+$ sudo apt-get install wondershaper
+```
+
+对于 Fedora 可以使用以下命令安装:
+
+```
+$ sudo dnf install wondershaper
+```
+
+对于 RHEL、CentOS,只需要启用 EPEL 仓库,就可以使用以下命令安装:
+
+```
+$ sudo yum install epel-release
+$ sudo yum install wondershaper
+```
+
+在每次系统启动时都自动启动 `wondershaper` 服务。
+
+```
+$ sudo systemctl enable wondershaper.service
+$ sudo systemctl start wondershaper.service
+```
+
+#### 用法
+
+首先需要找到网络接口的名称,通过以下几个命令都可以查询到网卡的详细信息:
+
+```
+$ ip addr
+$ route
+$ ifconfig
+```
+
+在确定网卡名称以后,就可以按照以下的命令限制网络带宽:
+
+```
+$ sudo wondershaper -a -d -u
+```
+
+例如,如果网卡名称是 `enp0s8`,并且需要把上行、下行速率分别限制为 1024 Kbps 和 512 Kbps,就可以执行以下命令:
+
+```
+$ sudo wondershaper -a enp0s8 -d 1024 -u 512
+```
+
+其中参数的含义是:
+
+ * `-a`:网卡名称
+ * `-d`:下行带宽
+ * `-u`:上行带宽
+
+如果要对网卡解除网络带宽的限制,只需要执行:
+
+```
+$ sudo wondershaper -c -a enp0s8
+```
+
+或者:
+
+```
+$ sudo wondershaper -c enp0s8
+```
+
+如果系统中有多个网卡,为确保稳妥,需要按照上面的方法手动设置每个网卡的上行、下行速率。
+
+如果你是通过 `git clone` 克隆 GitHub 版本库的方式安装 Wondershaper,那么在 `/etc/conf.d/` 目录中会存在一个名为 `wondershaper.conf` 的配置文件,修改这个配置文件中的相应值(包括网卡名称、上行速率、下行速率),也可以设置上行或下行速率。
+
+```
+$ sudo nano /etc/conf.d/wondershaper.conf
+
+[wondershaper]
+# Adapter
+#
+IFACE="eth0"
+
+# Download rate in Kbps
+#
+DSPEED="2048"
+
+# Upload rate in Kbps
+#
+USPEED="512"
+```
+
+Wondershaper 使用前:
+
+
+
+Wondershaper 使用后:
+
+
+
+可以看到,使用 Wondershaper 限制网络带宽之后,下行速率与限制之前相比已经大幅下降。
+
+执行以下命令可以查看更多相关信息。
+
+```
+$ wondershaper -h
+```
+
+也可以查看 Wondershaper 的用户手册:
+
+```
+$ man wondershaper
+```
+
+根据测试,Wondershaper 按照上面的方式可以有很好的效果。你可以试用一下,然后发表你的看法。
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-limit-network-bandwidth-in-linux-using-wondershaper/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[HankChow](https://github.com/HankChow)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[1]: https://aur.archlinux.org/packages/wondershaper-git/
+[2]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
+
diff --git a/translated/tech/20180913 ScreenCloud- The Screenshot-- App.md b/published/20180913 ScreenCloud- The Screenshot-- App.md
similarity index 63%
rename from translated/tech/20180913 ScreenCloud- The Screenshot-- App.md
rename to published/20180913 ScreenCloud- The Screenshot-- App.md
index a7002183c3..54a36dd377 100644
--- a/translated/tech/20180913 ScreenCloud- The Screenshot-- App.md
+++ b/published/20180913 ScreenCloud- The Screenshot-- App.md
@@ -1,43 +1,46 @@
-ScreenCloud:一个截屏程序
+ScreenCloud:一个增强的截屏程序
======
-[ScreenCloud][1]是一个很棒的小程序,你甚至不知道你需要它。桌面 Linux 的默认屏幕截图流程很好(Prt Scr 按钮),我们甚至有一些[强大的截图工具][2],如 [Shutter][3]。但是,ScreenCloud 有一个非常简单但非常方便的功能,让我爱上了它。在我们深入它之前,让我们先看一个背景故事。
-我截取了很多截图。远远超过平均水平。收据、注册详细信息、开发工作、文章中程序的截图等等。我接下来要做的就是打开浏览器,浏览我最喜欢的云存储并将重要的内容转储到那里,以便我可以在手机上以及 PC 上的多个操作系统上访问它们。这也让我可以轻松与我的团队分享我正在使用的程序的截图。
+[ScreenCloud][1]是一个很棒的小程序,你甚至不知道你需要它。桌面 Linux 的默认屏幕截图流程很好(`PrtScr` 按钮),我们甚至有一些[强大的截图工具][2],如 [Shutter][3]。但是,ScreenCloud 有一个非常简单但非常方便的功能,让我爱上了它。在我们深入它之前,让我们先看一个背景故事。
+
+我截取了很多截图,远超常人。收据、注册详细信息、开发工作、文章中程序的截图等等。我接下来要做的就是打开浏览器,浏览我最喜欢的云存储并将重要的内容转储到那里,以便我可以在手机上以及 PC 上的多个操作系统上访问它们。这也让我可以轻松与我的团队分享我正在使用的程序的截图。
我对这个标准的截图流程没有抱怨,打开浏览器并登录我的云,然后手动上传屏幕截图,直到我遇到 ScreenCloud。
### ScreenCloud
-ScreenCloud 是跨平台的程序,它提供简单的屏幕截图和灵活的[云备份选项][4]管理。这包括使用你自己的[ FTP 服务器][5]。
+ScreenCloud 是跨平台的程序,它提供轻松的屏幕截图功能和灵活的[云备份选项][4]管理。这包括使用你自己的 [FTP 服务器][5]。
![][6]
-ScreenCloud 很精简,投入了大量的注意力给小的东西。它为你提供了非常容易记住的热键来捕获全屏、活动窗口或捕获用鼠标选择的区域。
+ScreenCloud 很顺滑,在细节上投入了大量的精力。它为你提供了非常容易记住的热键来捕获全屏、活动窗口或鼠标选择区域。
-![][7]ScreenCloud 的默认键盘快捷键
+![][7]
+
+*ScreenCloud 的默认键盘快捷键*
截取屏幕截图后,你可以设置 ScreenCloud 如何处理图像或直接将其上传到你选择的云服务。它甚至支持 SFTP。截图上传后(通常在几秒钟内),图像链接就会被自动复制到剪贴板,这让你可以轻松共享。
![][8]
-你还可以使用 ScreenCloud 进行一些基本编辑。为此,你需要将 “Save to” 设置为 “Ask me”。此设置在下拉框中有并且通常是默认设置。当使用它时,当你截取屏幕截图时,你会看到编辑文件的选项。在这里,你可以在屏幕截图中添加箭头、文本和数字。
+你还可以使用 ScreenCloud 进行一些基本编辑。为此,你需要将 “Save to” 设置为 “Ask me”。此设置在应用图标菜单中有并且通常是默认设置。当使用它时,当你截取屏幕截图时,你会看到编辑文件的选项。在这里,你可以在屏幕截图中添加箭头、文本和数字。
-![Editing screenshots with ScreenCloud][9]Editing screenshots with ScreenCloud
+![Editing screenshots with ScreenCloud][9]
+
+*用 ScreenCloud 编辑截屏*
### 在 Linux 上安装 ScreenCloud
-ScreenCloud 可在[ Snap 商店][10]中找到。因此,你可以通过访问[ Snap 商店][12]或运行以下命令,轻松地将其安装在 Ubuntu 和其他[启用 Snap ][11]的发行版上。
+ScreenCloud 可在 [Snap 商店][10]中找到。因此,你可以通过访问 [Snap 商店][12]或运行以下命令,轻松地将其安装在 Ubuntu 和其他[启用 Snap][11] 的发行版上。
```
sudo snap install screencloud
-
```
对于无法通过 Snap 安装程序的 Linux 发行版,你可以[在这里][1]下载 AppImage。进入下载文件夹,右键单击并在那里打开终端。然后运行以下命令。
```
sudo chmod +x ScreenCloud-v1.4.0-x86_64.AppImage
-
```
然后,你可以通过双击下载的文件来启动程序。
@@ -57,7 +60,7 @@ via: https://itsfoss.com/screencloud-app/
作者:[Aquil Roshan][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180915 Backup Installed Packages And Restore Them On Freshly Installed Ubuntu.md b/published/20180915 Backup Installed Packages And Restore Them On Freshly Installed Ubuntu.md
similarity index 61%
rename from translated/tech/20180915 Backup Installed Packages And Restore Them On Freshly Installed Ubuntu.md
rename to published/20180915 Backup Installed Packages And Restore Them On Freshly Installed Ubuntu.md
index 1b21607ee9..b5a74c0ea9 100644
--- a/translated/tech/20180915 Backup Installed Packages And Restore Them On Freshly Installed Ubuntu.md
+++ b/published/20180915 Backup Installed Packages And Restore Them On Freshly Installed Ubuntu.md
@@ -1,23 +1,21 @@
-备份安装包并在全新安装的 Ubuntu 上恢复它们
+备份安装的包并在全新安装的 Ubuntu 上恢复它们
======

-在多个 Ubuntu 系统上安装同一组软件包是一项耗时且无聊的任务。你不会想花时间在多个系统上反复安装相同的软件包。在类似架构的 Ubuntu 系统上安装软件包时,有许多方法可以使这项任务更容易。你可以方便地通过 [**Aptik**][1] 并点击几次鼠标将以前的 Ubuntu 系统的应用程序、设置和数据迁移到新安装的系统中。或者,你可以使用软件包管理器(例如 APT)获取[**备份的已安装软件包的完整列表**][2],然后在新安装的系统上安装它们。今天,我了解到还有另一个专用工具可以完成这项工作。来看一下 **apt-clone**,这是一个简单的工具,可以让你为 Debian/Ubuntu 系统创建一个已安装的软件包列表,这些软件包可以在新安装的系统或容器上或目录中恢复。
+在多个 Ubuntu 系统上安装同一组软件包是一项耗时且无聊的任务。你不会想花时间在多个系统上反复安装相同的软件包。在类似架构的 Ubuntu 系统上安装软件包时,有许多方法可以使这项任务更容易。你可以方便地通过 [Aptik][1] 并点击几次鼠标将以前的 Ubuntu 系统的应用程序、设置和数据迁移到新安装的系统中。或者,你可以使用软件包管理器(例如 APT)获取[备份的已安装软件包的完整列表][2],然后在新安装的系统上安装它们。今天,我了解到还有另一个专用工具可以完成这项工作。来看一下 `apt-clone`,这是一个简单的工具,可以让你为 Debian/Ubuntu 系统创建一个已安装的软件包列表,这些软件包可以在新安装的系统或容器上或目录中恢复。
-Apt-clone 会帮助你处理你想要的情况,
+`apt-clone` 会帮助你处理你想要的情况,
- * 在运行类似 Ubuntu(及衍生版)的多个系统上安装一致的应用程序。
- * 经常在多个系统上安装相同的软件包。
- * 备份已安装的应用程序的完整列表,并在需要时随时随地恢复它们。
+* 在运行类似 Ubuntu(及衍生版)的多个系统上安装一致的应用程序。
+* 经常在多个系统上安装相同的软件包。
+* 备份已安装的应用程序的完整列表,并在需要时随时随地恢复它们。
-
-
-在本简要指南中,我们将讨论如何在基于 Debian 的系统上安装和使用 Apt-clone。我在 Ubuntu 18.04 LTS 上测试了这个程序,但它应该适用于所有基于 Debian 和 Ubuntu 的系统。
+在本简要指南中,我们将讨论如何在基于 Debian 的系统上安装和使用 `apt-clone`。我在 Ubuntu 18.04 LTS 上测试了这个程序,但它应该适用于所有基于 Debian 和 Ubuntu 的系统。
### 备份已安装的软件包并在新安装的 Ubuntu 上恢复它们
-Apt-clone 在默认仓库中有。要安装它,只需在终端输入以下命令:
+`apt-clone` 在默认仓库中有。要安装它,只需在终端输入以下命令:
```
$ sudo apt install apt-clone
@@ -27,11 +25,10 @@ $ sudo apt install apt-clone
```
$ mkdir ~/mypackages
-
$ sudo apt-clone clone ~/mypackages
```
-上面的命令将我的 Ubuntu 中所有已安装的软件包保存在 **~/mypackages** 目录下名为 **apt-clone-state-ubuntuserver.tar.gz** 的文件中。
+上面的命令将我的 Ubuntu 中所有已安装的软件包保存在 `~/mypackages` 目录下名为 `apt-clone-state-ubuntuserver.tar.gz` 的文件中。
要查看备份文件的详细信息,请运行:
@@ -53,7 +50,7 @@ Date: Sat Sep 15 10:23:05 2018
$ sudo apt-clone restore apt-clone-state-ubuntuserver.tar.gz
```
-请注意,此命令将覆盖你现有的 **/etc/apt/sources.list** 并将安装/删除软件包。警告过你了!此外,只需确保目标系统是相同的架构和操作系统。例如,如果源系统是 18.04 LTS 64位,那么目标系统必须也是相同的。
+请注意,此命令将覆盖你现有的 `/etc/apt/sources.list` 并将安装/删除软件包。警告过你了!此外,只需确保目标系统是相同的 CPU 架构和操作系统。例如,如果源系统是 18.04 LTS 64 位,那么目标系统必须也是相同的。
如果你不想在系统上恢复软件包,可以使用 `--destination /some/location` 选项将克隆复制到这个文件夹中。
@@ -61,7 +58,7 @@ $ sudo apt-clone restore apt-clone-state-ubuntuserver.tar.gz
$ sudo apt-clone restore apt-clone-state-ubuntuserver.tar.gz --destination ~/oldubuntu
```
-在此例中,上面的命令将软件包恢复到 **~/oldubuntu** 中。
+在此例中,上面的命令将软件包恢复到 `~/oldubuntu` 中。
有关详细信息,请参阅帮助部分:
@@ -75,7 +72,7 @@ $ apt-clone -h
$ man apt-clone
```
-**建议阅读:**
+建议阅读:
+ [Systemback - 将 Ubuntu 桌面版和服务器版恢复到以前的状态][3]
+ [Cronopete - Linux 下的苹果时间机器][4]
@@ -94,7 +91,7 @@ via: https://www.ostechnix.com/backup-installed-packages-and-restore-them-on-fre
作者:[SK][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20180917 4 scanning tools for the Linux desktop.md b/published/20180917 4 scanning tools for the Linux desktop.md
new file mode 100644
index 0000000000..b376fab108
--- /dev/null
+++ b/published/20180917 4 scanning tools for the Linux desktop.md
@@ -0,0 +1,73 @@
+用于 Linux 桌面的 4 个扫描工具
+======
+
+> 使用这些开源软件之一驱动你的扫描仪来实现无纸化办公。
+
+
+
+尽管无纸化世界还没有到来,但越来越多的人通过扫描文件和照片来摆脱纸张的束缚。不过,仅仅拥有一台扫描仪还不足够。你还需要软件来驱动扫描仪。
+
+然而问题是许多扫描仪制造商没有与他们的设备适配在一起的软件的 Linux 版本。不过在大多数情况下,即使没有也没多大关系。因为在 Linux 桌面上已经有很好的扫描软件了。它们能够与许多扫描仪配合很好的完成工作。
+
+现在就让我们看看四个简单又灵活的开源 Linux 扫描工具。我已经使用过了下面这些工具(甚至[早在 2014 年][1]写过关于其中三个工具的文章)并且觉得它们非常有用。希望你也会这样认为。
+
+### Simple Scan
+
+这是我最喜欢的一个软件之一,[Simple Scan][2] 小巧、快捷、高效且易用。如果你以前见过它,那是因为 Simple Scan 是 GNOME 桌面上的默认扫描应用程序,也是许多 Linux 发行版的默认扫描程序。
+
+你只需单击一下就能扫描文档或照片。扫描过某些内容后,你可以旋转或裁剪它并将其另存为图像(仅限 JPEG 或 PNG 格式)或 PDF 格式。也就是说 Simple Scan 可能会很慢,即使你用较低分辨率来扫描文档。最重要的是,Simple Scan 在扫描时会使用一组全局的默认值,例如 150dpi 用于文本,300dpi 用于照片。你需要进入 Simple Scan 的首选项才能更改这些设置。
+
+如果你扫描的内容超过了几页,还可以在保存之前重新排序页面。如果有必要的话 —— 假如你正在提交已签名的表格 —— 你可以使用 Simple Scan 来发送电子邮件。
+
+### Skanlite
+
+从很多方面来看,[Skanlite][3] 是 Simple Scan 在 KDE 世界中的表兄弟。虽然 Skanlite 功能很少,但它可以出色的完成工作。
+
+你可以自己配置这个软件的选项,包括自动保存扫描文件、设置扫描质量以及确定扫描保存位置。 Skanlite 可以保存为以下图像格式:JPEG、PNG、BMP、PPM、XBM 和 XPM。
+
+其中一个很棒的功能是 Skanlite 能够将你扫描的部分内容保存到单独的文件中。当你想要从照片中删除某人或某物时,这就派上用场了。
+
+### Gscan2pdf
+
+这是我另一个最爱的老软件,[gscan2pdf][4] 可能会显得很老旧了,但它仍然包含一些比这里提到的其他软件更好的功能。即便如此,gscan2pdf 仍然显得很轻便。
+
+除了以各种图像格式(JPEG、PNG 和 TIFF)保存扫描外,gscan2pdf 还可以将它们保存为 PDF 或 [DjVu][5] 文件。你可以在单击“扫描”按钮之前设置扫描的分辨率,无论是黑白、彩色还是纸张大小,每当你想要更改任何这些设置时,都可以进入 gscan2pdf 的首选项。你还可以旋转、裁剪和删除页面。
+
+虽然这些都不是真正的杀手级功能,但它们会给你带来更多的灵活性。
+
+### GIMP
+
+你大概会知道 [GIMP][6] 是一个图像编辑工具。但是你恐怕不知道可以用它来驱动你的扫描仪吧。
+
+你需要安装 [XSane][7] 扫描软件和 GIMP XSane 插件。这两个应该都可以从你的 Linux 发行版的包管理器中获得。在软件里,选择“文件>创建>扫描仪/相机”。单击“扫描仪”,然后单击“扫描”按钮即可进行扫描。
+
+如果这不是你想要的,或者它不起作用,你可以将 GIMP 和一个叫作 [QuiteInsane][8] 的插件结合起来。使用任一插件,都能使 GIMP 成为一个功能强大的扫描软件,它可以让你设置许多选项,如是否扫描彩色或黑白、扫描的分辨率,以及是否压缩结果等。你还可以使用 GIMP 的工具来修改或应用扫描后的效果。这使得它非常适合扫描照片和艺术品。
+
+### 它们真的能够工作吗?
+
+所有的这些软件在大多数时候都能够在各种硬件上运行良好。我将它们与我过去几年来拥有的多台多功能打印机一起使用 —— 无论是使用 USB 线连接还是通过无线连接。
+
+你可能已经注意到我在前一段中写过“大多数时候运行良好”。这是因为我确实遇到过一个例外:一个便宜的 canon 多功能打印机。我使用的软件都没有检测到它。最后我不得不下载并安装 canon 的 Linux 扫描仪软件才使它工作。
+
+你最喜欢的 Linux 开源扫描工具是什么?发表评论,分享你的选择。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/linux-scanner-tools
+
+作者:[Scott Nesbitt][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[way-ww](https://github.com/way-ww)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/scottnesbitt
+[1]: https://opensource.com/life/14/8/3-tools-scanners-linux-desktop
+[2]: https://gitlab.gnome.org/GNOME/simple-scan
+[3]: https://www.kde.org/applications/graphics/skanlite/
+[4]: http://gscan2pdf.sourceforge.net/
+[5]: http://en.wikipedia.org/wiki/DjVu
+[6]: http://www.gimp.org/
+[7]: https://en.wikipedia.org/wiki/Scanner_Access_Now_Easy#XSane
+[8]: http://sourceforge.net/projects/quiteinsane/
diff --git a/published/20180917 Getting started with openmediavault- A home NAS solution.md b/published/20180917 Getting started with openmediavault- A home NAS solution.md
new file mode 100644
index 0000000000..0d5d00ca74
--- /dev/null
+++ b/published/20180917 Getting started with openmediavault- A home NAS solution.md
@@ -0,0 +1,75 @@
+openmediavault 入门:一个家庭 NAS 解决方案
+======
+
+> 这个网络附属文件服务提供了一系列可靠的功能,�并且易于安装和配置。
+
+
+
+面对许多可供选择的云存储方案,一些人可能会质疑一个家庭 NAS(网络附属存储)服务器的价值。毕竟,当所有你的文件存储在云上,你就不需要为你自己云服务的维护、更新和安全担忧。
+
+但是,这不完全对,是不是?你有一个家庭网络,所以你已经要负责维护网络的健康和安全。假定你已经维护一个家庭网络,那么[一个家庭 NAS][1]并不会增加额外负担。反而你能从少量的工作中得到许多的好处。
+
+你可以为你家里所有的计算机进行备份(你也可以备份到其它地方)。构架一个存储电影、音乐和照片的媒体服务器,无需担心互联网连接是否连通。在家里的多台计算机上处理大型文件,不需要等待从互联网某个其它计算机传输这些文件过来。另外,可以让 NAS 与其他服务配合工作,如托管本地邮件或者家庭 Wiki。也许最重要的是,构架家庭 NAS,数据完全是你的,它始终处于在控制下,随时可访问。
+
+接下来的问题是如何选择 NAS 方案。当然,你可以购买预先搭建好的商品,并在一天内搞定,但是这会有什么乐趣呢?实际上,尽管拥有一个能为你搞定一切的设备很棒,但是有一个可以修复和升级的钻机平台更棒。这就我近期的需求,我选择安装和配置 [openmediavault][2]。
+
+### 为什么选择 openmediavault?
+
+市面上有不少开源的 NAS 解决方案,其中有些肯定比 openmediavault 流行。当我询问周遭,例如 [freeNAS][3] 这样的最常被推荐给我。那么为什么我不采纳他们的建议呢?毕竟,用它的人更多。[基于 FreeNAS 官网的一份对比数据][4],它包含了很多的功能,并且提供许多支持选项。这当然都对。但是 openmediavault 也不差。它实际上是基于 FreeNAS 早期版本的,虽然它在下载量和功能方面较少,但是对于我的需求而言,它已经相当足够了。
+
+另外一个因素是它让我感到很舒适。openmediavault 的底层操作系统是 [Debian][5],然而 FreeNAS 是 [FreeBSD][6]。由于我个人对 FreeBSD 不是很熟悉,因此如果我的 NAS 出现故障,必定难于在 FreeBSD 上修复故障。同样的,也会让我觉得难于优化或添加一些服务到这个机器上。当然,我可以学习 FreeBSD 以更熟悉它,但是我已经在家里构架了这个 NAS;我发现,如果完成它只需要较少的“学习机会”,那么构建 NAS 往往会更成功。
+
+当然,每个人情况都不同,所以你要自己调研,然后作出最适合自己方案的决定。FreeNAS 对于许多人似乎都是不错的解决方案。openmediavault 正是适合我的解决方案。
+
+### 安装与配置
+
+在 [openmediavault 文档][7]里详细记录了安装步骤,所以我不在这里重述了。如果你曾经安装过任何一个 Linux 发行版,大部分安装步骤都是很类似的(虽然是在相对丑陋的 [Ncurses][8] 界面,而不像你或许在现代发行版里见到的)。我按照 [专用的驱动器][9] 的说明来安装它。这些说明不但很好,而且相当精炼的。当你搞定这些步骤,就安装好了一个基本的系统,但是你还需要做更多才能真正构建好 NAS 来存储各种文件。例如,专用驱动器方式需要在硬盘驱动器上安装 openmediavault,但那是指你的操作系统的驱动器,而不是和网络上其他计算机共享的驱动器。你需要自己把这些建立起来并且配置好。
+
+你要做的第一件事是加载用来管理的网页界面,并修改默认密码。这个密码和之前你安装过程设置的 root 密码是不同的。这是网页界面的管理员账号,默认的账户和密码分别是 `admin` 和 `openmediavault`,当你登入后要马上修改。
+
+#### 设置你的驱动器
+
+一旦你安装好 openmediavault,你需要它为你做一些工作。逻辑上的第一个步骤是设置好你即将用来作为存储的驱动器。在这里,我假定你已经物理上安装好它们了,所以接下来你要做的就是让 openmediavault 识别和配置它们。第一步是确保这些磁盘是可见的。侧边栏菜单有很多选项,而且被精心的归类了。选择“Storage -> Disks”。一旦你点击该菜单,你应该能够看到所有你已经安装到该服务器的驱动,包括那个你已经用来安装 openmediavault 的驱动器。如果你没有在那里看到所有驱动器,点击“Scan”按钮去看是否能够挂载它们。通常,这不会是一个问题。
+
+你可以独立的挂载和设置这些驱动器用于文件共享,但是对于一个文件服务器,你会想要一些冗余。你想要能够把很多驱动器当作一个单一卷,并能够在某一个驱动器出现故障时恢复你的数据,或者空间不足时安装新驱动器。这意味你将需要一个 [RAID][10]。你想要的什么特定类型的 RAID 的这个主题是一个大坑,值得另写一篇文章专门来讲述它(而且已经有很多关于该主题的文章了),但是简而言之是你将需要不止一个驱动器,最好的情况下,你所有的驱动都存储一样的容量。
+
+openmediavault 支持所有标准的 RAID 级别,所以这里很简单。可以在“Storage -> RAID Management”里配置你的 RAID。配置是相当简单的:点击“Create”按钮,在你的 RAID 阵列里选择你想要的磁盘和你想要使用的 RAID 级别,并给这个阵列一个名字。openmediavault 为你处理剩下的工作。这里没有复杂的命令行,也不需要试图记住 `mdadm` 命令的一些选项参数。在我的例子,我有六个 2TB 驱动器,设置成了 RAID 10。
+
+当你的 RAID 构建好了,基本上你已经有一个地方可以存储东西了。你仅仅需要设置一个文件系统。正如你的桌面系统,一个硬盘驱动器在没有格式化的情况下是没什么用处的。所以下一个你要去的地方的是位于 openmediavault 控制面板里的“Storage -> File Systems”。和配置你的 RAID 一样,点击“Create”按钮,然后跟着提示操作。如果你在你的服务器上只有一个 RAID ,你应该可以看到一个像 `md0` 的东西。你也需要选择文件系统的类别。如果你不能确定,选择标准的 ext4 类型即可。
+
+#### 定义你的共享
+
+亲爱的!你有个地方可以存储文件了。现在你只需要让它在你的家庭网络中可见。可以从在 openmediavault 控制面板上的“Services”部分上配置。当谈到在网络上设置文件共享,主要有两个选择:NFS 或者 SMB/CIFS. 根据以往经验,如果你网络上的所有计算机都是 Linux 系统,那么你使用 NFS 会更好。然而,当你家庭网络是一个混合环境,是一个包含Linux、Windows、苹果系统和嵌入式设备的组合,那么 SMB/CIFS 可能会是你合适的选择。
+
+这些选项不是互斥的。实际上,你可以在服务器上运行这两个服务,同时拥有这些服务的好处。或者你可以混合起来,如果你有一个特定的设备做特定的任务。不管你的使用场景是怎样,配置这些服务是相当简单。点击你想要的服务,从它配置中激活它,和在网络中设定你想要的共享文件夹为可见。在基于 SMB/CIFS 共享的情况下,相对于 NFS 多了一些可用的配置,但是一般用默认配置就挺好的,接着可以在默认基础上修改配置。最酷的事情是它很容易配置,同时也很容易在需要的时候修改配置。
+
+#### 用户配置
+
+基本上已将完成了。你已经在 RAID 中配置了你的驱动器。你已经用一种文件系统格式化了 RAID,并且你已经在格式化的 RAID 上设定了共享文件夹。剩下来的一件事情是配置那些人可以访问这些共享和可以访问多少。这个可以在“Access Rights Management”配置里设置。使用“User”和“Group”选项来设定可以连接到你共享文件夹的用户,并设定这些共享文件的访问权限。
+
+一旦你完成用户配置,就几乎准备好了。你需要从不同客户端机器访问你的共享,但是这是另外一个可以单独写个文章的话题了。
+
+玩得开心!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/openmediavault
+
+作者:[Jason van Gumster][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[jamelouis](https://github.com/jamelouis)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mairin
+[1]: https://opensource.com/article/18/8/automate-backups-raspberry-pi
+[2]: https://openmediavault.org
+[3]: https://freenas.org
+[4]: http://www.freenas.org/freenas-vs-openmediavault/
+[5]: https://www.debian.org/
+[6]: https://www.freebsd.org/
+[7]: https://openmediavault.readthedocs.io/en/latest/installation/index.html
+[8]: https://invisible-island.net/ncurses/
+[9]: https://openmediavault.readthedocs.io/en/latest/installation/via_iso.html
+[10]: https://en.wikipedia.org/wiki/RAID
diff --git a/published/20180918 Linux firewalls- What you need to know about iptables and firewalld.md b/published/20180918 Linux firewalls- What you need to know about iptables and firewalld.md
new file mode 100644
index 0000000000..2e52cabba0
--- /dev/null
+++ b/published/20180918 Linux firewalls- What you need to know about iptables and firewalld.md
@@ -0,0 +1,170 @@
+Linux 防火墙:关于 iptables 和 firewalld 的那些事
+======
+
+> 以下是如何使用 iptables 和 firewalld 工具来管理 Linux 防火墙规则。
+
+
+
+这篇文章摘自我的书《[Linux in Action][1]》,尚未发布的第二个曼宁出版项目。
+
+### 防火墙
+
+防火墙是一组规则。当数据包进出受保护的网络区域时,进出内容(特别是关于其来源、目标和使用的协议等信息)会根据防火墙规则进行检测,以确定是否允许其通过。下面是一个简单的例子:
+
+![防火墙过滤请求] [3]
+
+*防火墙可以根据协议或基于目标的规则过滤请求。*
+
+一方面, [iptables][4] 是 Linux 机器上管理防火墙规则的工具。
+
+另一方面,[firewalld][5] 也是 Linux 机器上管理防火墙规则的工具。
+
+你有什么问题吗?如果我告诉你还有另外一种工具,叫做 [nftables][6],这会不会糟蹋你的美好一天呢?
+
+好吧,我承认整件事确实有点好笑,所以让我来解释一下。这一切都从 Netfilter 开始,它在 Linux 内核模块级别控制访问网络栈。几十年来,管理 Netfilter 钩子的主要命令行工具是 iptables 规则集。
+
+因为调用这些规则所需的语法看起来有点晦涩难懂,所以各种用户友好的实现方式,如 [ufw][7] 和 firewalld 被引入,作为更高级别的 Netfilter 解释器。然而,ufw 和 firewalld 主要是为解决单独的计算机所面临的各种问题而设计的。构建全方面的网络解决方案通常需要 iptables,或者从 2014 年起,它的替代品 nftables (nft 命令行工具)。
+
+iptables 没有消失,仍然被广泛使用着。事实上,在未来的许多年里,作为一名管理员,你应该会使用 iptables 来保护的网络。但是 nftables 通过操作经典的 Netfilter 工具集带来了一些重要的崭新的功能。
+
+从现在开始,我将通过示例展示 firewalld 和 iptables 如何解决简单的连接问题。
+
+### 使用 firewalld 配置 HTTP 访问
+
+正如你能从它的名字中猜到的,firewalld 是 [systemd][8] 家族的一部分。firewalld 可以安装在 Debian/Ubuntu 机器上,不过,它默认安装在 RedHat 和 CentOS 上。如果您的计算机上运行着像 Apache 这样的 web 服务器,您可以通过浏览服务器的 web 根目录来确认防火墙是否正在工作。如果网站不可访问,那么 firewalld 正在工作。
+
+你可以使用 `firewall-cmd` 工具从命令行管理 firewalld 设置。添加 `–state` 参数将返回当前防火墙的状态:
+
+```
+# firewall-cmd --state
+running
+```
+
+默认情况下,firewalld 处于运行状态,并拒绝所有传入流量,但有几个例外,如 SSH。这意味着你的网站不会有太多的访问者,这无疑会为你节省大量的数据传输成本。然而,这不是你对 web 服务器的要求,你希望打开 HTTP 和 HTTPS 端口,按照惯例,这两个端口分别被指定为 80 和 443。firewalld 提供了两种方法来实现这个功能。一个是通过 `–add-port` 参数,该参数直接引用端口号及其将使用的网络协议(在本例中为TCP)。 另外一个是通过 `–permanent` 参数,它告诉 firewalld 在每次服务器启动时加载此规则:
+
+```
+# firewall-cmd --permanent --add-port=80/tcp
+# firewall-cmd --permanent --add-port=443/tcp
+```
+
+`–reload` 参数将这些规则应用于当前会话:
+
+```
+# firewall-cmd --reload
+```
+
+查看当前防火墙上的设置,运行 `–list-services`:
+
+```
+# firewall-cmd --list-services
+dhcpv6-client http https ssh
+```
+
+假设您已经如前所述添加了浏览器访问,那么 HTTP、HTTPS 和 SSH 端口现在都应该是和 `dhcpv6-client` 一样开放的 —— 它允许 Linux 从本地 DHCP 服务器请求 IPv6 IP 地址。
+
+### 使用 iptables 配置锁定的客户信息亭
+
+我相信你已经看到了信息亭——它们是放在机场、图书馆和商务场所的盒子里的平板电脑、触摸屏和 ATM 类电脑,邀请顾客和路人浏览内容。大多数信息亭的问题是,你通常不希望用户像在自己家一样,把他们当成自己的设备。它们通常不是用来浏览、观看 YouTube 视频或对五角大楼发起拒绝服务攻击的。因此,为了确保它们没有被滥用,你需要锁定它们。
+
+一种方法是应用某种信息亭模式,无论是通过巧妙使用 Linux 显示管理器还是控制在浏览器级别。但是为了确保你已经堵塞了所有的漏洞,你可能还想通过防火墙添加一些硬性的网络控制。在下一节中,我将讲解如何使用iptables 来完成。
+
+关于使用 iptables,有两件重要的事情需要记住:你给出的规则的顺序非常关键;iptables 规则本身在重新启动后将无法保持。我会一次一个地在解释这些。
+
+### 信息亭项目
+
+为了说明这一切,让我们想象一下,我们为一家名为 BigMart 的大型连锁商店工作。它们已经存在了几十年;事实上,我们想象中的祖父母可能是在那里购物并长大的。但是如今,BigMart 公司总部的人可能只是在数着亚马逊将他们永远赶下去的时间。
+
+尽管如此,BigMart 的 IT 部门正在尽他们最大努力提供解决方案,他们向你发放了一些具有 WiFi 功能信息亭设备,你在整个商店的战略位置使用这些设备。其想法是,登录到 BigMart.com 产品页面,允许查找商品特征、过道位置和库存水平。信息亭还允许进入 bigmart-data.com,那里储存着许多图像和视频媒体信息。
+
+除此之外,您还需要允许下载软件包更新。最后,您还希望只允许从本地工作站访问 SSH,并阻止其他人登录。下图说明了它将如何工作:
+
+![信息亭流量IP表] [10]
+
+*信息亭业务流由 iptables 控制。 *
+
+### 脚本
+
+以下是 Bash 脚本内容:
+
+```
+#!/bin/bash
+iptables -A OUTPUT -p tcp -d bigmart.com -j ACCEPT
+iptables -A OUTPUT -p tcp -d bigmart-data.com -j ACCEPT
+iptables -A OUTPUT -p tcp -d ubuntu.com -j ACCEPT
+iptables -A OUTPUT -p tcp -d ca.archive.ubuntu.com -j ACCEPT
+iptables -A OUTPUT -p tcp --dport 80 -j DROP
+iptables -A OUTPUT -p tcp --dport 443 -j DROP
+iptables -A INPUT -p tcp -s 10.0.3.1 --dport 22 -j ACCEPT
+iptables -A INPUT -p tcp -s 0.0.0.0/0 --dport 22 -j DROP
+```
+
+我们从基本规则 `-A` 开始分析,它告诉 iptables 我们要添加规则。`OUTPUT` 意味着这条规则应该成为输出链的一部分。`-p` 表示该规则仅使用 TCP 协议的数据包,正如 `-d` 告诉我们的,目的地址是 [bigmart.com][11]。`-j` 参数的作用是当数据包符合规则时要采取的操作是 `ACCEPT`。第一条规则表示允许(或接受)请求。但,往下的规则你能看到丢弃(或拒绝)的请求。
+
+规则顺序是很重要的。因为 iptables 会对一个请求遍历每个规则,直到遇到匹配的规则。一个向外发出的浏览器请求,比如访问 bigmart.com 是会通过的,因为这个请求匹配第一条规则,但是当它到达 `dport 80` 或 `dport 443` 规则时——取决于是 HTTP 还是 HTTPS 请求——它将被丢弃。当遇到匹配时,iptables 不再继续往下检查了。(LCTT 译注:此处原文有误,径改。)
+
+另一方面,向 ubuntu.com 发出软件升级的系统请求,只要符合其适当的规则,就会通过。显然,我们在这里做的是,只允许向我们的 BigMart 或 Ubuntu 发送 HTTP 或 HTTPS 请求,而不允许向其他目的地发送。
+
+最后两条规则将处理 SSH 请求。因为它不使用端口 80 或 443 端口,而是使用 22 端口,所以之前的两个丢弃规则不会拒绝它。在这种情况下,来自我的工作站的登录请求将被接受,但是对其他任何地方的请求将被拒绝。这一点很重要:确保用于端口 22 规则的 IP 地址与您用来登录的机器的地址相匹配——如果不这样做,将立即被锁定。当然,这没什么大不了的,因为按照目前的配置方式,只需重启服务器,iptables 规则就会全部丢失。如果使用 LXC 容器作为服务器并从 LXC 主机登录,则使用主机 IP 地址连接容器,而不是其公共地址。
+
+如果机器的 IP 发生变化,请记住更新这个规则;否则,你会被拒绝访问。
+
+在家玩(是在某种一次性虚拟机上)?太好了。创建自己的脚本。现在我可以保存脚本,使用 `chmod` 使其可执行,并以 `sudo` 的形式运行它。不要担心“igmart-data.com 没找到”之类的错误 —— 当然没找到;它不存在。
+
+```
+chmod +X scriptname.sh
+sudo ./scriptname.sh
+```
+
+你可以使用 `cURL` 命令行测试防火墙。请求 ubuntu.com 奏效,但请求 [manning.com][13] 是失败的 。
+
+
+```
+curl ubuntu.com
+curl manning.com
+```
+
+### 配置 iptables 以在系统启动时加载
+
+现在,我如何让这些规则在每次信息亭启动时自动加载?第一步是将当前规则保存。使用 `iptables-save` 工具保存规则文件。这将在根目录中创建一个包含规则列表的文件。管道后面跟着 `tee` 命令,是将我的`sudo` 权限应用于字符串的第二部分:将文件实际保存到否则受限的根目录。
+
+然后我可以告诉系统每次启动时运行一个相关的工具,叫做 `iptables-restore` 。我们在上一章节(LCTT 译注:指作者的书)中看到的常规 cron 任务并不适用,因为它们在设定的时间运行,但是我们不知道什么时候我们的计算机可能会决定崩溃和重启。
+
+有许多方法来处理这个问题。这里有一个:
+
+在我的 Linux 机器上,我将安装一个名为 [anacron][14] 的程序,该程序将在 `/etc/` 目录中为我们提供一个名为 `anacrontab` 的文件。我将编辑该文件并添加这个 `iptables-restore` 命令,告诉它加载那个 .rule 文件的当前内容。当引导后,规则每天(必要时)01:01 时加载到 iptables 中(LCTT 译注:anacron 会补充执行由于机器没有运行而错过的 cron 任务,因此,即便 01:01 时机器没有启动,也会在机器启动会尽快执行该任务)。我会给该任务一个标识符(`iptables-restore`),然后添加命令本身。如果你在家和我一起这样,你应该通过重启系统来测试一下。
+
+```
+sudo iptables-save | sudo tee /root/my.active.firewall.rules
+sudo apt install anacron
+sudo nano /etc/anacrontab
+1 1 iptables-restore iptables-restore < /root/my.active.firewall.rules
+```
+
+我希望这些实际例子已经说明了如何使用 iptables 和 firewalld 来管理基于 Linux 的防火墙上的连接问题。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/linux-iptables-firewalld
+
+作者:[David Clinton][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[heguangzhi](https://github.com/heguangzhi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/remyd
+[1]: https://www.manning.com/books/linux-in-action?a_aid=bootstrap-it&a_bid=4ca15fc9&chan=opensource
+[2]: /file/409116
+[3]: https://opensource.com/sites/default/files/uploads/iptables1.jpg (firewall filtering request)
+[4]: https://en.wikipedia.org/wiki/Iptables
+[5]: https://firewalld.org/
+[6]: https://wiki.nftables.org/wiki-nftables/index.php/Main_Page
+[7]: https://en.wikipedia.org/wiki/Uncomplicated_Firewall
+[8]: https://en.wikipedia.org/wiki/Systemd
+[9]: /file/409121
+[10]: https://opensource.com/sites/default/files/uploads/iptables2.jpg (kiosk traffic flow ip tables)
+[11]: http://bigmart.com/
+[12]: http://youtube.com/
+[13]: http://manning.com/
+[14]: https://sourceforge.net/projects/anacron/
diff --git a/translated/tech/20180918 Top 3 Python libraries for data science.md b/published/20180918 Top 3 Python libraries for data science.md
similarity index 93%
rename from translated/tech/20180918 Top 3 Python libraries for data science.md
rename to published/20180918 Top 3 Python libraries for data science.md
index 4026b751d5..c6156e575a 100644
--- a/translated/tech/20180918 Top 3 Python libraries for data science.md
+++ b/published/20180918 Top 3 Python libraries for data science.md
@@ -1,7 +1,7 @@
3 个用于数据科学的顶级 Python 库
======
->使用这些库把 Python 变成一个科学数据分析和建模工具。
+> 使用这些库把 Python 变成一个科学数据分析和建模工具。
![][7]
@@ -49,7 +49,6 @@ matrix_two = np.arange(1,10).reshape(3,3)
matrix_two
```
-Here is the output:
输出如下:
```
@@ -62,9 +61,7 @@ array([[1, 2, 3],
```
matrix_multiply = np.dot(matrix_one, matrix_two)
-
matrix_multiply
-
```
相乘后的输出如下:
@@ -96,17 +93,15 @@ matrix_multiply
### Pandas
-[Pandas][3] 是另一个可以提高你的 Python 数据科学技能的优秀库。就和 NumPy 一样,它属于 SciPy 开源软件家族,可以在 BSD 免费许可证许可下使用。
+[Pandas][3] 是另一个可以提高你的 Python 数据科学技能的优秀库。就和 NumPy 一样,它属于 SciPy 开源软件家族,可以在 BSD 自由许可证许可下使用。
-Pandas 提供了多功能并且很强大的工具用于管理数据结构和执行大量数据分析。该库能够很好的处理不完整、非结构化和无序的真实世界数据,并且提供了用于整形、聚合、分析和可视化数据集的工具
+Pandas 提供了多能而强大的工具,用于管理数据结构和执行大量数据分析。该库能够很好的处理不完整、非结构化和无序的真实世界数据,并且提供了用于整形、聚合、分析和可视化数据集的工具
Pandas 中有三种类型的数据结构:
- * Series: 一维、相同数据类型的数组
- * DataFrame: 二维异型矩阵
- * Panel: 三维大小可变数组
-
-
+ * Series:一维、相同数据类型的数组
+ * DataFrame:二维异型矩阵
+ * Panel:三维大小可变数组
例如,我们来看一下如何使用 Panda 库(缩写成 `pd`)来执行一些描述性统计计算。
@@ -232,7 +227,7 @@ via: https://opensource.com/article/18/9/top-3-python-libraries-data-science
作者:[Dr.Michael J.Garbade][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[ucasFL](https://github.com/ucasFL)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180920 8 Python packages that will simplify your life with Django.md b/published/20180920 8 Python packages that will simplify your life with Django.md
similarity index 52%
rename from translated/tech/20180920 8 Python packages that will simplify your life with Django.md
rename to published/20180920 8 Python packages that will simplify your life with Django.md
index f242007433..8f914f87e0 100644
--- a/translated/tech/20180920 8 Python packages that will simplify your life with Django.md
+++ b/published/20180920 8 Python packages that will simplify your life with Django.md
@@ -1,7 +1,7 @@
简化 Django 开发的八个 Python 包
======
-这个月的 Python 专栏将介绍一些 Django 包,它们有益于你的工作,以及你的个人或业余项目。
+> 这个月的 Python 专栏将介绍一些 Django 包,它们有益于你的工作,以及你的个人或业余项目。

@@ -11,32 +11,31 @@ Django 开发者们,在这个月的 Python 专栏中,我们会介绍一些
### 有用又省时的工具集合:django-extensions
-[Django-extensions][4] 这个 Django 包非常受欢迎,全是有用的工具,比如下面这些管理命令:
+[django-extensions][4] 这个 Django 包非常受欢迎,全是有用的工具,比如下面这些管理命令:
- * **shell_plus** 打开 Django 的管理 shell,这个 shell 已经自动导入了所有的数据库模型。在测试复杂的数据关系时,就不需要再从几个不同的应用里做 import 的操作了。
- * **clean_pyc** 删除项目目录下所有位置的 .pyc 文件
- * **create_template_tags** 在指定的应用下,创建模板标签的目录结构。
- * **describe_form** 输出模型的表单定义,可以粘贴到 forms.py 文件中。(需要注意的是,这种方法创建的是普通 Django 表单,而不是模型表单。)
- * **notes** 输出你项目里所有带 TODO,FIXME 等标记的注释。
+ * `shell_plus` 打开 Django 的管理 shell,这个 shell 已经自动导入了所有的数据库模型。在测试复杂的数据关系时,就不需要再从几个不同的应用里做导入操作了。
+ * `clean_pyc` 删除项目目录下所有位置的 .pyc 文件
+ * `create_template_tags` 在指定的应用下,创建模板标签的目录结构。
+ * `describe_form` 输出模型的表单定义,可以粘贴到 `forms.py` 文件中。(需要注意的是,这种方法创建的是普通 Django 表单,而不是模型表单。)
+ * `notes` 输出你项目里所有带 TODO、FIXME 等标记的注释。
Django-extensions 还包括几个有用的抽象基类,在定义模型时,它们能满足常见的模式。当你需要以下模型时,可以继承这些基类:
+ * `TimeStampedModel`:这个模型的基类包含了 `created` 字段和 `modified` 字段,还有一个 `save()` 方法,在适当的场景下,该方法自动更新 `created` 和 `modified` 字段的值。
+ * `ActivatorModel`:如果你的模型需要像 `status`、`activate_date` 和 `deactivate_date` 这样的字段,可以使用这个基类。它还自带了一个启用 `.active()` 和 `.inactive()` 查询集的 manager。
+ * `TitleDescriptionModel` 和 `TitleSlugDescriptionModel`:这两个模型包括了 `title` 和 `description` 字段,其中 `description` 字段还包括 `slug`,它根据 `title` 字段自动产生。
- * **TimeStampedModel** : 这个模型的基类包含了 **created** 字段和 **modified** 字段,还有一个 **save()** 方法,在适当的场景下,该方法自动更新 created 和 modified 字段的值。
- * **ActivatorModel** : 如果你的模型需要像 **status**,**activate_date** 和 **deactivate_date** 这样的字段,可以使用这个基类。它还自带了一个启用 **.active()** 和 **.inactive()** 查询集的 manager。
- * **TitleDescriptionModel** 和 **TitleSlugDescriptionModel** : 这两个模型包括了 **title** 和 **description** 字段,其中 description 字段还包括 **slug**,它根据 **title** 字段自动产生。
-
-Django-extensions 还有其他更多的功能,也许对你的项目有帮助,所以,去浏览一下它的[文档][5]吧!
+django-extensions 还有其他更多的功能,也许对你的项目有帮助,所以,去浏览一下它的[文档][5]吧!
### 12 因子应用的配置:django-environ
-在 Django 项目的配置方面,[Django-environ][6] 提供了符合 [12 因子应用][7] 方法论的管理方法。它是其他一些库的集合,包括 [envparse][8] 和 [honcho][9] 等。安装了 django-environ 之后,在项目的根目录创建一个 .env 文件,用这个文件去定义那些随环境不同而不同的变量,或者需要保密的变量。(比如 API keys,是否启用 debug,数据库的 URLs 等)
+在 Django 项目的配置方面,[django-environ][6] 提供了符合 [12 因子应用][7] 方法论的管理方法。它是另外一些库的集合,包括 [envparse][8] 和 [honcho][9] 等。安装了 django-environ 之后,在项目的根目录创建一个 `.env` 文件,用这个文件去定义那些随环境不同而不同的变量,或者需要保密的变量。(比如 API 密钥,是否启用调试,数据库的 URL 等)
-然后,在项目的 settings.py 中引入 **environ**,并参考[官方文档的例子][10]设置好 **environ.PATH()** 和 **environ.Env()**。就可以通过 **env('VARIABLE_NAME')** 来获取 .env 文件中定义的变量值了。
+然后,在项目的 `settings.py` 中引入 `environ`,并参考[官方文档的例子][10]设置好 `environ.PATH()` 和 `environ.Env()`。就可以通过 `env('VARIABLE_NAME')` 来获取 `.env` 文件中定义的变量值了。
### 创建出色的管理命令:django-click
-[Django-click][11] 是基于 [Click][12] 的, ( 我们[之前推荐过][13]… [两次][14] Click),它对编写 Django 管理命令很有帮助。这个库没有很多文档,但是代码仓库中有个存放[测试命令][15]的目录,非常有参考价值。 Django-click 基本的 Hello World 命令是这样写的:
+[django-click][11] 是基于 [Click][12] 的,(我们[之前推荐过][13]… [两次][14] Click),它对编写 Django 管理命令很有帮助。这个库没有很多文档,但是代码仓库中有个存放[测试命令][15]的目录,非常有参考价值。 django-click 基本的 Hello World 命令是这样写的:
```
# app_name.management.commands.hello.py
@@ -57,31 +56,31 @@ Hello, Lacey
### 处理有限状态机:django-fsm
-[Django-fsm][16] 给 Django 的模型添加了有限状态机的支持。如果你管理一个新闻网站,想用类似于“写作中”,“编辑中”,“已发布”来流转文章的状态,django-fsm 能帮你定义这些状态,还能管理状态变化的规则与限制。
+[django-fsm][16] 给 Django 的模型添加了有限状态机的支持。如果你管理一个新闻网站,想用类似于“写作中”、“编辑中”、“已发布”来流转文章的状态,django-fsm 能帮你定义这些状态,还能管理状态变化的规则与限制。
-Django-fsm 为模型提供了 FSMField 字段,用来定义模型实例的状态。用 django-fsm 的 **@transition** 修饰符,可以定义状态变化的方法,并处理状态变化的任何副作用。
+Django-fsm 为模型提供了 FSMField 字段,用来定义模型实例的状态。用 django-fsm 的 `@transition` 修饰符,可以定义状态变化的方法,并处理状态变化的任何副作用。
-虽然 django-fsm 文档很轻量,不过 [Django 中的工作流(状态)][17] 这篇 GitHubGist 对有限状态机和 django-fsm 做了非常好的介绍。
+虽然 django-fsm 文档很轻量,不过 [Django 中的工作流(状态)][17] 这篇 GitHub Gist 对有限状态机和 django-fsm 做了非常好的介绍。
### 联系人表单:#django-contact-form
-联系人表单可以说是网站的标配。但是不要自己去写全部的样板代码,用 [django-contact-form][18] 在几分钟内就可以搞定。它带有一个可选的能过滤垃圾邮件的表单类(也有不过滤的普通表单类)和一个 **ContactFormView** 基类,基类的方法可以覆盖或自定义修改。而且它还能引导你完成模板的创建,好让表单正常工作。
+联系人表单可以说是网站的标配。但是不要自己去写全部的样板代码,用 [django-contact-form][18] 在几分钟内就可以搞定。它带有一个可选的能过滤垃圾邮件的表单类(也有不过滤的普通表单类)和一个 `ContactFormView` 基类,基类的方法可以覆盖或自定义修改。而且它还能引导你完成模板的创建,好让表单正常工作。
### 用户注册和认证:django-allauth
-[Django-allauth][19] 是一个 Django 应用,它为用户注册,登录注销,密码重置,还有第三方用户认证(比如 GitHub 或 Twitter)提供了视图,表单和 URLs,支持邮件地址作为用户名的认证方式,而且有大量的文档记录。第一次用的时候,它的配置可能会让人有点晕头转向;请仔细阅读[安装说明][20],在[自定义你的配置][21]时要专注,确保启用某个功能的所有配置都用对了。
+[django-allauth][19] 是一个 Django 应用,它为用户注册、登录/注销、密码重置,还有第三方用户认证(比如 GitHub 或 Twitter)提供了视图、表单和 URL,支持邮件地址作为用户名的认证方式,而且有大量的文档记录。第一次用的时候,它的配置可能会让人有点晕头转向;请仔细阅读[安装说明][20],在[自定义你的配置][21]时要专注,确保启用某个功能的所有配置都用对了。
### 处理 Django REST 框架的用户认证:django-rest-auth
-如果 Django 开发中涉及到对外提供 API,你很可能用到了 [Django REST Framework][22] (DRF)。如果你在用 DRF,那么你应该试试 django-rest-auth,它提供了用户注册,登录/注销,密码重置和社交媒体认证的 endpoints (是通过添加 django-allauth 的支持来实现的,这两个包协作得很好)。
+如果 Django 开发中涉及到对外提供 API,你很可能用到了 [Django REST Framework][22](DRF)。如果你在用 DRF,那么你应该试试 django-rest-auth,它提供了用户注册、登录/注销,密码重置和社交媒体认证的端点(是通过添加 django-allauth 的支持来实现的,这两个包协作得很好)。
### Django REST 框架的 API 可视化:django-rest-swagger
-[Django REST Swagger][24] 提供了一个功能丰富的用户界面,用来和 Django REST 框架的 API 交互。你只需要安装 Django REST Swagger,把它添加到 Django 项目的 installed apps 中,然后在 urls.py 中添加 Swagger 的视图和 URL 模式就可以了,剩下的事情交给 API 的 docstring 处理。
+[Django REST Swagger][24] 提供了一个功能丰富的用户界面,用来和 Django REST 框架的 API 交互。你只需要安装 Django REST Swagger,把它添加到 Django 项目的已安装应用中,然后在 `urls.py` 中添加 Swagger 的视图和 URL 模式就可以了,剩下的事情交给 API 的 docstring 处理。
-API 的用户界面按照 app 的维度展示了所有 endpoints 和可用方法,并列出了这些 endpoints 的可用操作,而且它提供了和 API 交互的功能(比如添加/删除/获取记录)。django-rest-swagger 从 API 视图中的 docstrings 生成每个 endpoint 的文档,通过这种方法,为你的项目创建了一份 API 文档,这对你,对前端开发人员和用户都很有用。
+API 的用户界面按照 app 的维度展示了所有端点和可用方法,并列出了这些端点的可用操作,而且它提供了和 API 交互的功能(比如添加/删除/获取记录)。django-rest-swagger 从 API 视图中的 docstrings 生成每个端点的文档,通过这种方法,为你的项目创建了一份 API 文档,这对你,对前端开发人员和用户都很有用。
--------------------------------------------------------------------------------
@@ -90,7 +89,7 @@ via: https://opensource.com/article/18/9/django-packages
作者:[Jeff Triplett][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[belitex](https://github.com/belitex)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
@@ -118,4 +117,4 @@ via: https://opensource.com/article/18/9/django-packages
[21]: https://django-allauth.readthedocs.io/en/latest/configuration.html
[22]: http://www.django-rest-framework.org/
[23]: https://django-rest-auth.readthedocs.io/
-[24]: https://django-rest-swagger.readthedocs.io/en/latest/
\ No newline at end of file
+[24]: https://django-rest-swagger.readthedocs.io/en/latest/
diff --git a/published/20180920 WinWorld - A Large Collection Of Defunct OSs, Software And Games.md b/published/20180920 WinWorld - A Large Collection Of Defunct OSs, Software And Games.md
new file mode 100644
index 0000000000..02bf0bdf9e
--- /dev/null
+++ b/published/20180920 WinWorld - A Large Collection Of Defunct OSs, Software And Games.md
@@ -0,0 +1,115 @@
+WinWorld:大型的废弃操作系统、软件、游戏的博物馆
+=====
+
+
+
+有一天,我正在测试 Dosbox -- 这是一个[在 Linux 平台上运行 MS-DOS 游戏与程序的软件][1]。当我在搜索一些常用的软件,例如 Turbo C++ 时,我意外留意到了一个叫做 [WinWorld][2] 的网站。我查看了这个网站上的某些内容,并且着实被惊艳到了。WinWorld 收集了非常多经典的,但已经被它们的开发者所抛弃许久的操作系统、软件、应用、开发工具、游戏以及各式各样的工具。它是一个以保存和分享古老的、已经被废弃的或者预发布版本程序为目的的线上博物馆,由社区成员和志愿者运营。
+
+WinWorld 于 2013 年开始运营。它的创始者声称是被 Yahoo birefcases 激发了灵感并以此构建了这个网站。这个网站原目标是保存并且分享老旧软件。多年来,许多志愿者以不同方式提供了帮助,WinWorld 收集的老旧软件增长迅速。整个 WinWorld 仓库都是自由开源的,所有人都可以使用。
+
+### WinWorld 保存了大量的废弃操作系统、软件、系统应用以及游戏
+
+就像我刚才说的那样, WinWorld 存储了大量的被抛弃并且不再被开发的软件。
+
+**Linux 与 Unix:**
+
+这里我给出了完整的 UNIX 和 LINUX 操作系统的列表,以及它们各自的简要介绍、首次发行的年代。
+
+* **A/UX** - 于 1988 年推出,移植到苹果的 68k Macintosh 平台的 Unix 系统。
+* **AIX** - 于 1986 年推出,IBM 移植的 Unix 系统。
+* **AT &T System V Unix** - 于 1983 年推出,最早的商业版 Unix 之一。
+* **Banyan VINES** - 于 1984 年推出,专为 Unix 设计的网络操作系统。
+* **Corel Linux** - 于 1999 年推出,商业 Linux 发行版。
+* **DEC OSF-1** - 于 1991 年推出,由 DEC 公司开发的 Unix 版本。
+* **Digital UNIX** - 由 DEC 于 1995 年推出,**OSF-1** 的重命名版本。
+* **FreeBSD 1.0** - 于 1993 年推出,FreeBSD 的首个发行版。这个系统是基于 4.3BSD 开发的。
+* **Gentus Linux** - 由 ABIT 于 2000 年推出,未遵守 GPL 协议的 Linux 发行版。
+* **HP-UX** - 于 1992 年推出,UNIX 的变种系统。
+* **IRIX** - 由硅谷图形公司(SGI)于 1988 年推出的操作系统。
+* **Lindows** - 于 2002 年推出,与 Corel Linux 类似的商业操作系统。
+* **Linux Kernel** - 0.01 版本于 90 年代早期推出,Linux 源代码的副本。
+* **Mandrake Linux** - 于 1999 年推出。基于 Red Hat Linux 的 Linux 发行版,稍后被重新命名为 Mandriva。
+* **NEWS-OS** - 由 Sony 于 1989 年推出,BSD 的变种。
+* **NeXTStep** - 由史蒂夫·乔布斯创立的 NeXT 公司于 1987 年推出,基于 Unix 的操作系统。
+* **PC/IX** - 于 1984 年推出,为 IBM 个人电脑服务的基于 Unix 的操作系统。
+* **Red Hat Linux 5.0** - 由 Red Hat 推出,商业 Linux 发行版。
+* **Sun Solaris** - 由 Sun Microsystem 于 1992 年推出,基于 Unix 的操作系统。
+* **SunOS** - 由 Sun Microsystem 于 1982 年推出,衍生自 BSD 基于 Unix 的操作系统。
+* **Tru64 UNIX** - 由 DEC 开发,旧称 OSF/1。
+* **Ubuntu 4.10** - 基于 Debian 的知名操作系统。这是早期的 beta 预发布版本,比第一个 Ubuntu 正式发行版更早推出。
+* **Ultrix** - 由 DEC 开发, UNIX 克隆。
+* **UnixWare** - 由 Novell 推出, UNIX 变种。
+* **Xandros Linux** - 首个版本于 2003 年推出。基于 Corel Linux 的专有 Linux 发行版。
+* **Xenix** - 最初由微软于 1984 推出,UNIX 变种操作系统。
+
+不仅仅是 Linux/Unix,你还能找到例如 DOS、Windows、Apple/Mac、OS 2、Novell netware 等其他的操作系统与 shell。
+
+**DOS & CP/M:**
+
+* 86-DOS
+* Concurrent CPM-86 & Concurrent DOS
+* CP/M 86 & CP/M-80
+* DOS Plus
+* DR-DOS
+* GEM
+* MP/M
+* MS-DOS
+* 多任务的 MS-DOS 4.00
+* 多用户 DOS
+* PC-DOS
+* PC-MOS
+* PTS-DOS
+* Real/32
+* Tandy Deskmate
+* Wendin DOS
+
+**Windows:**
+
+* BackOffice Server
+* Windows 1.0/2.x/3.0/3.1/95/98/2000/ME/NT 3.X/NT 4.0
+* Windows Whistler
+* WinFrame
+
+**Apple/Mac:**
+
+* Mac OS 7/8/9
+* Mac OS X
+* System Software (0-6)
+
+**OS/2:**
+
+* Citrix Multiuser
+* OS/2 1.x
+* OS/2 2.0
+* OS/2 3.x
+* OS/2 Warp 4
+
+于此同时,WinWorld 也收集了大量的旧软件、系统应用、开发工具和游戏。你也可以一起看看它们。
+
+说实话,这个网站列出的绝大部分东西,我甚至都不知道它们存在过。其中列出的某些工具发布于我出生之前。
+
+如果您需要或者打算去测试一个经典的程序(例如游戏、软件、操作系统),并且在其他地方找不到它们,那么来 WinWorld 资源库看看,下载它们然后开始你的探险吧。祝您好运!
+
+
+
+**免责声明:**
+
+OSTechNix 并非隶属于 WinWorld。我们 OSTechNix 并不确保 WinWorld 站点存储数据的真实性与可靠性。而且在你所在的地区,或许从第三方站点下载软件是违法行为。本篇文章作者和 OSTechNix 都不会承担任何责任,使用此服务意味着您将自行承担风险。(LCTT 译注:本站和译者亦同样申明。)
+
+本篇文章到此为止。希望这对您有用,更多的好文章即将发布,敬请期待!
+
+谢谢各位的阅读!
+
+--------------------------------------------------------------------------------
+via: https://www.ostechnix.com/winworld-a-large-collection-of-defunct-oss-software-and-games/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[thecyanbird](https://github.com/thecyanbird)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[1]: https://www.ostechnix.com/how-to-run-ms-dos-games-and-programs-in-linux/
+[2]: https://winworldpc.com/library/
diff --git a/translated/tech/20180924 How To Find Out Which Port Number A Process Is Using In Linux.md b/published/20180924 How To Find Out Which Port Number A Process Is Using In Linux.md
similarity index 87%
rename from translated/tech/20180924 How To Find Out Which Port Number A Process Is Using In Linux.md
rename to published/20180924 How To Find Out Which Port Number A Process Is Using In Linux.md
index ed3402e0fa..a77ee1ad62 100644
--- a/translated/tech/20180924 How To Find Out Which Port Number A Process Is Using In Linux.md
+++ b/published/20180924 How To Find Out Which Port Number A Process Is Using In Linux.md
@@ -1,22 +1,22 @@
如何在 Linux 中查看进程占用的端口号
======
+
对于 Linux 系统管理员来说,清楚某个服务是否正确地绑定或监听某个端口,是至关重要的。如果你需要处理端口相关的问题,这篇文章可能会对你有用。
端口是 Linux 系统上特定进程之间逻辑连接的标识,包括物理端口和软件端口。由于 Linux 操作系统是一个软件,因此本文只讨论软件端口。软件端口始终与主机的 IP 地址和相关的通信协议相关联,因此端口常用于区分应用程序。大部分涉及到网络的服务都必须打开一个套接字来监听传入的网络请求,而每个服务都使用一个独立的套接字。
**推荐阅读:**
-**(#)** [在 Linux 上查看进程 ID 的 4 种方法][1]
-**(#)** [在 Linux 上终止进程的 3 种方法][2]
-套接字是和 IP 地址,软件端口和协议结合起来使用的,而端口号对传输控制协议(Transmission Control Protocol, TCP)和 用户数据报协议(User Datagram Protocol, UDP)协议都适用,TCP 和 UDP 都可以使用0到65535之间的端口号进行通信。
+- [在 Linux 上查看进程 ID 的 4 种方法][1]
+- [在 Linux 上终止进程的 3 种方法][2]
+
+套接字是和 IP 地址、软件端口和协议结合起来使用的,而端口号对传输控制协议(TCP)和用户数据报协议(UDP)协议都适用,TCP 和 UDP 都可以使用 0 到 65535 之间的端口号进行通信。
以下是端口分配类别:
- * `0-1023:` 常用端口和系统端口
- * `1024-49151:` 软件的注册端口
- * `49152-65535:` 动态端口或私有端口
-
-
+ * 0 - 1023: 常用端口和系统端口
+ * 1024 - 49151: 软件的注册端口
+ * 49152 - 65535: 动态端口或私有端口
在 Linux 上的 `/etc/services` 文件可以查看到更多关于保留端口的信息。
@@ -74,29 +74,25 @@ telnet 23/udp
# 24 - private mail system
lmtp 24/tcp # LMTP Mail Delivery
lmtp 24/udp # LMTP Mail Delivery
-
```
可以使用以下六种方法查看端口信息。
- * `ss:` ss 可以用于转储套接字统计信息。
- * `netstat:` netstat 可以显示打开的套接字列表。
- * `lsof:` lsof 可以列出打开的文件。
- * `fuser:` fuser 可以列出那些打开了文件的进程的进程 ID。
- * `nmap:` nmap 是网络检测工具和端口扫描程序。
- * `systemctl:` systemctl 是 systemd 系统的控制管理器和服务管理器。
-
-
+ * `ss`:可以用于转储套接字统计信息。
+ * `netstat`:可以显示打开的套接字列表。
+ * `lsof`:可以列出打开的文件。
+ * `fuser`:可以列出那些打开了文件的进程的进程 ID。
+ * `nmap`:是网络检测工具和端口扫描程序。
+ * `systemctl`:是 systemd 系统的控制管理器和服务管理器。
以下我们将找出 `sshd` 守护进程所使用的端口号。
-### 方法1:使用 ss 命令
+### 方法 1:使用 ss 命令
`ss` 一般用于转储套接字统计信息。它能够输出类似于 `netstat` 输出的信息,但它可以比其它工具显示更多的 TCP 信息和状态信息。
它还可以显示所有类型的套接字统计信息,包括 PACKET、TCP、UDP、DCCP、RAW、Unix 域等。
-
```
# ss -tnlp | grep ssh
LISTEN 0 128 *:22 *:* users:(("sshd",pid=997,fd=3))
@@ -111,7 +107,7 @@ LISTEN 0 128 *:22 *:* users:(("sshd",pid=997,fd=3))
LISTEN 0 128 :::22 :::* users:(("sshd",pid=997,fd=4))
```
-### 方法2:使用 netstat 命令
+### 方法 2:使用 netstat 命令
`netstat` 能够显示网络连接、路由表、接口统计信息、伪装连接以及多播成员。
@@ -131,7 +127,7 @@ tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1208/sshd
tcp6 0 0 :::22 :::* LISTEN 1208/sshd
```
-### 方法3:使用 lsof 命令
+### 方法 3:使用 lsof 命令
`lsof` 能够列出打开的文件,并列出系统上被进程打开的文件的相关信息。
@@ -153,7 +149,7 @@ sshd 1208 root 4u IPv6 20921 0t0 TCP *:ssh (LISTEN)
sshd 11592 root 3u IPv4 27744 0t0 TCP vps.2daygeek.com:ssh->103.5.134.167:49902 (ESTABLISHED)
```
-### 方法4:使用 fuser 命令
+### 方法 4:使用 fuser 命令
`fuser` 工具会将本地系统上打开了文件的进程的进程 ID 显示在标准输出中。
@@ -165,7 +161,7 @@ sshd 11592 root 3u IPv4 27744 0t0 TCP vps.2daygeek.com:ssh->103.5.134.167:49902
root 49339 F.... sshd
```
-### 方法5:使用 nmap 命令
+### 方法 5:使用 nmap 命令
`nmap`(“Network Mapper”)是一款用于网络检测和安全审计的开源工具。它最初用于对大型网络进行快速扫描,但它对于单个主机的扫描也有很好的表现。
@@ -185,13 +181,14 @@ Service detection performed. Please report any incorrect results at http://nmap.
Nmap done: 1 IP address (1 host up) scanned in 0.44 seconds
```
-### 方法6:使用 systemctl 命令
+### 方法 6:使用 systemctl 命令
-`systemctl` 是 systemd 系统的控制管理器和服务管理器。它取代了旧的 SysV init 系统管理,目前大多数现代 Linux 操作系统都采用了 systemd。
+`systemctl` 是 systemd 系统的控制管理器和服务管理器。它取代了旧的 SysV 初始化系统管理,目前大多数现代 Linux 操作系统都采用了 systemd。
**推荐阅读:**
-**(#)** [chkservice – Linux 终端上的 systemd 单元管理工具][3]
-**(#)** [如何查看 Linux 系统上正在运行的服务][4]
+
+- [chkservice – Linux 终端上的 systemd 单元管理工具][3]
+- [如何查看 Linux 系统上正在运行的服务][4]
```
# systemctl status sshd
@@ -258,7 +255,7 @@ via: https://www.2daygeek.com/how-to-find-out-which-port-number-a-process-is-usi
作者:[Prakash Subramanian][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[HankChow](https://github.com/HankChow)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180927 How to Use RAR files in Ubuntu Linux.md b/published/20180927 How to Use RAR files in Ubuntu Linux.md
similarity index 75%
rename from translated/tech/20180927 How to Use RAR files in Ubuntu Linux.md
rename to published/20180927 How to Use RAR files in Ubuntu Linux.md
index 3521b21a8a..0a087de8be 100644
--- a/translated/tech/20180927 How to Use RAR files in Ubuntu Linux.md
+++ b/published/20180927 How to Use RAR files in Ubuntu Linux.md
@@ -1,40 +1,39 @@
如何在 Ubuntu Linux 中使用 RAR 文件
======
+
[RAR][1] 是一种非常好的归档文件格式。但相比之下 7-zip 能提供了更好的压缩率,并且默认情况下还可以在多个平台上轻松支持 Zip 文件。不过 RAR 仍然是最流行的归档格式之一。然而 [Ubuntu][2] 自带的归档管理器却不支持提取 RAR 文件,也不允许创建 RAR 文件。
-方法总比问题多。只要安装 `unrar` 这款由 [RARLAB][3] 提供的免费软件,就能在 Ubuntu 上支持提取RAR文件了。你也可以试安装 `rar` 来创建和管理 RAR 文件。
+办法总比问题多。只要安装 `unrar` 这款由 [RARLAB][3] 提供的免费软件,就能在 Ubuntu 上支持提取 RAR 文件了。你也可以安装 `rar` 试用版来创建和管理 RAR 文件。
![RAR files in Ubuntu Linux][4]
### 提取 RAR 文件
-在未安装 unrar 的情况下,提取 RAR 文件会报出“未能提取”错误,就像下面这样(以 [Ubuntu 18.04][5] 为例):
+在未安装 `unrar` 的情况下,提取 RAR 文件会报出“未能提取”错误,就像下面这样(以 [Ubuntu 18.04][5] 为例):
![Error in RAR extraction in Ubuntu][6]
-如果要解决这个错误并提取 RAR 文件,请按照以下步骤安装 unrar:
+如果要解决这个错误并提取 RAR 文件,请按照以下步骤安装 `unrar`:
打开终端并输入:
```
- sudo apt-get install unrar
-
+sudo apt-get install unrar
```
-安装 unrar 后,直接输入 `unrar` 就可以看到它的用法以及如何使用这个工具处理 RAR 文件。
+安装 `unrar` 后,直接输入 `unrar` 就可以看到它的用法以及如何使用这个工具处理 RAR 文件。
最常用到的功能是提取 RAR 文件。因此,可以**通过右键单击 RAR 文件并执行提取**,也可以借助此以下命令通过终端执行操作:
```
unrar x FileName.rar
-
```
结果类似以下这样:
![Using unrar in Ubuntu][7]
-如果家目录中不存在对应的文件,就必须使用 `cd` 命令移动到目标目录下。例如 RAR 文件如果在 `Music` 目录下,只需要使用 `cd Music` 就可以移动到相应的目录,然后提取 RAR 文件。
+如果压缩文件没放在家目录中,就必须使用 `cd` 命令移动到目标目录下。例如 RAR 文件如果在 `Music` 目录下,只需要使用 `cd Music` 就可以移动到相应的目录,然后提取 RAR 文件。
### 创建和管理 RAR 文件
@@ -42,18 +41,16 @@ unrar x FileName.rar
`unrar` 不允许创建 RAR 文件。因此还需要安装 `rar` 命令行工具才能创建 RAR 文件。
-要创建 RAR 文件,首先需要通过以下命令安装 rar:
+要创建 RAR 文件,首先需要通过以下命令安装 `rar`:
```
sudo apt-get install rar
-
```
按照下面的命令语法创建 RAR 文件:
```
rar a ArchiveName File_1 File_2 Dir_1 Dir_2
-
```
按照这个格式输入命令时,它会将目录中的每个文件添加到 RAR 文件中。如果需要某一个特定的文件,就要指定文件确切的名称或路径。
@@ -64,7 +61,6 @@ rar a ArchiveName File_1 File_2 Dir_1 Dir_2
```
rar u ArchiveName Filename
-
```
在终端输入 `rar` 就可以列出 RAR 工具的相关命令。
@@ -82,7 +78,7 @@ via: https://itsfoss.com/use-rar-ubuntu-linux/
作者:[Ankush Das][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[HankChow](https://github.com/HankChow)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20180928 How to Install Popcorn Time on Ubuntu 18.04 and Other Linux Distributions.md b/published/20180928 How to Install Popcorn Time on Ubuntu 18.04 and Other Linux Distributions.md
new file mode 100644
index 0000000000..72763c754b
--- /dev/null
+++ b/published/20180928 How to Install Popcorn Time on Ubuntu 18.04 and Other Linux Distributions.md
@@ -0,0 +1,228 @@
+如何在 Ubuntu 18.04 上安装 Popcorn Time
+======
+
+> 简要:这篇教程展示给你如何在 Ubuntu 和其他 Linux 发行版上安装 Popcorn Time,也会讨论一些 Popcorn Time 的便捷操作。
+
+[Popcorn Time][1] 是一个受 [Netflix][2] 启发的开源的 [torrent][3] 流媒体应用,可以在 Linux、Mac、Windows 上运行。
+
+传统的 torrent,在你看影片之前必须等待它下载完成。
+
+[Popcorn Time][4] 有所不同。它的使用基于 torrent,但是允许你(几乎)立即开始观看影片。它跟你在 Youtube 或者 Netflix 等流媒体网页上看影片一样,无需等待它下载完成。
+
+![Popcorn Time in Ubuntu Linux][5]
+
+*Popcorn Time*
+
+如果你不想在看在线电影时被突如其来的广告吓倒的话,Popcorn Time 是一个不错的选择。不过要记得,它的播放质量依赖于当前网络中可用的种子数。
+
+Popcorn Time 还提供了一个不错的用户界面,让你能够浏览可用的电影、电视剧和其他视频内容。如果你曾经[在 Linux 上使用过 Netflix][6],你会发现两者有一些相似之处。
+
+有些国家严格打击盗版,所以使用 torrent 下载电影是违法行为。在类似美国、英国和西欧等一些国家,你或许曾经收到过法律声明。也就是说,是否使用取决于你。已经警告过你了。
+
+Popcorn Time 一些主要的特点:
+
+ * 使用 Torrent 在线观看电影和电视剧
+ * 有一个时尚的用户界面让你浏览可用的电影和电视剧资源
+ * 调整流媒体的质量
+ * 标记为稍后观看
+ * 下载为离线观看
+ * 可以默认开启字幕,改变字母尺寸等
+ * 使用键盘快捷键浏览
+
+
+### 如何在 Ubuntu 和其它 Linux 发行版上安装 Popcorn Time
+
+这篇教程以 Ubuntu 18.04 为例,但是你可以使用类似的说明,在例如 Linux Mint、Debian、Manjaro、Deepin 等 Linux 发行版上安装。
+
+Popcorn Time 在 Deepin Linux 的软件中心中也可用。Manjaro 和 Arch 用户也可以轻松地使用 AUR 来安装 Popcorn Time。
+
+接下来我们看该如何在 Linux 上安装 Popcorn Time。事实上,这个过程非常简单。只需要按照说明操作复制粘贴我提到的这些命令即可。
+
+#### 第一步:下载 Popcorn Time
+
+你可以从它的官网上安装 Popcorn Time。下载链接在它的主页上。
+
+- [下载 Popcorn Time](https://popcorntime.sh/)
+
+#### 第二步:安装 Popcorn Time
+
+下载完成之后,就该使用它了。下载下来的是一个 tar 文件,在这些文件里面包含有一个可执行文件。你可以把 tar 文件提取在任何位置,[Linux 常把附加软件安装在][8] [/opt 目录][8]。
+
+在 `/opt` 下创建一个新的目录:
+
+```
+sudo mkdir /opt/popcorntime
+```
+
+现在进入你下载文件的文件夹中,比如我把 Popcorn Time 下载到了主目录的 Downloads 目录下。
+
+```
+cd ~/Downloads
+```
+
+提取下载好的 Popcorn Time 文件到新创建的 `/opt/popcorntime` 目录下:
+
+```
+sudo tar Jxf Popcorn-Time-* -C /opt/popcorntime
+```
+
+#### 第三步:让所有用户可以使用 Popcorn Time
+
+如果你想要系统中所有的用户无需经过 `sudo` 就可以运行 Popcorn Time。你需要在 `/usr/bin` 目录下创建一个[符号链接(软链接)][9]指向这个可执行文件。
+
+```
+ln -sf /opt/popcorntime/Popcorn-Time /usr/bin/Popcorn-Time
+```
+
+#### 第四步:为 Popcorn Time 创建桌面启动器
+
+到目前为止,一切顺利,但是你也许想要在应用菜单里看到 Popcorn Time,又或是想把它添加到最喜欢的应用列表里等。
+
+为此,你需要创建一个桌面入口。
+
+打开一个终端窗口,在 `/usr/share/applications` 目录下创建一个名为 `popcorntime.desktop` 的文件。
+
+你可以使用任何[基于命令行的文本编辑器][10]。Ubuntu 默认安装了 [Nano][11],所以你可以直接使用这个。
+
+```
+sudo nano /usr/share/applications/popcorntime.desktop
+```
+
+在里面插入以下内容:
+
+```
+[Desktop Entry]
+Version = 1.0
+Type = Application
+Terminal = false
+Name = Popcorn-Time
+Exec = /usr/bin/Popcorn-Time
+Icon = /opt/popcorntime/popcorn.png
+Categories = Application;
+```
+
+如果你使用的是 Nano 编辑器,使用 `Ctrl+X` 保存输入的内容,当询问是否保存时,输入 `Y`,然后按回车保存并退出。
+
+就快要完成了。最后一件事就是为 Popcorn Time 设置一个正确的图标。你可以下载一个 Popcorn Time 图标到 `/opt/popcorntime` 目录下,并命名为 `popcorn.png`。
+
+你可以使用以下命令:
+
+```
+sudo wget -O /opt/popcorntime/popcorn.png https://upload.wikimedia.org/wikipedia/commons/d/df/Pctlogo.png
+```
+
+这样就 OK 了。现在你可以搜索 Popcorn Time 然后点击启动它了。
+
+![Popcorn Time installed on Ubuntu][12]
+
+*在菜单里搜索 Popcorn Time*
+
+第一次启动时,你必须接受这些条款和条件。
+
+![Popcorn Time in Ubuntu][13]
+
+*接受这些服务条款*
+
+一旦你完成这些,你就可以享受你的电影和电视节目了。
+
+![Watch movies on Popcorn Time][14]
+
+好了,这就是所有你在 Ubuntu 或者其他 Linux 发行版上安装 Popcorn Time 所需要的了。你可以直接开始看你最喜欢的影视节目了。
+
+### 高效使用 Popcorn Time 的七个小贴士
+
+现在你已经安装好了 Popcorn Time 了,我接下来将要告诉你一些有用的 Popcorn Time 技巧。我保证它会增强你使用 Popcorn Time 的体验。
+
+#### 1、 使用高级设置
+
+始终启用高级设置。它给了你更多的选项去调整 Popcorn Time 点击右上角的齿轮标记。查看其中的高级设置。
+
+
+
+#### 2、 在 VLC 或者其他播放器里观看影片
+
+你知道你可以选择自己喜欢的播放器而不是 Popcorn Time 默认的播放器观看一个视频吗?当然,这个播放器必须已经安装在你的系统上了。
+
+现在你可能会问为什么要使用其他的播放器。我的回答是:其他播放器可以弥补 Popcorn Time 默认播放器上的一些不足。
+
+例如,如果一个文件的声音非常小,你可以使用 VLC 将音频声音增强 400%,你还可以[使用 VLC 同步不连贯的字幕][18]。你可以在播放文件之前在不同的媒体播放器之间进行切换。
+
+
+
+#### 3、 将影片标记为稍后观看
+
+只是浏览电影和电视节目,但是却没有时间和精力去看?这不是问题。你可以添加这些影片到书签里面,稍后可以在 Faveriate 标签里面访问这些影片。这可以让你创建一个你想要稍后观看的列表。
+
+
+
+#### 4、 检查 torrent 的信息和种子信息
+
+像我之前提到的,你在 Popcorn Time 的观看体验依赖于 torrent 的速度。好消息是 Popcorn Time 显示了 torrent 的信息,因此你可以知道流媒体的速度。
+
+你可以在文件上看到一个绿色/黄色/红色的点。绿色意味着有足够的种子,文件很容易播放。黄色意味着有中等数量的种子,应该可以播放。红色意味着只有非常少可用的种子,播放的速度会很慢甚至无法观看。
+
+
+
+#### 5、 添加自定义字幕
+
+如果你需要字幕而且它没有你想要的语言,你可以从外部网站下载自定义字幕。得到 .src 文件,然后就可以在 Popcorn Time 中使用它:
+
+
+
+你可以[用 VLC 自动下载字幕][19]。
+
+#### 6、 保存文件离线观看
+
+用 Popcorn Time 播放内容时,它会下载并暂时存储这些内容。当你关闭 APP 时,缓存会被清理干净。你可以更改这个操作,使得下载的文件可以保存下来供你未来使用。
+
+在高级设置里面,向下滚动一点。找到缓存目录,你可以把它更改到其他像是 Downloads 目录,这下你即便关闭了 Popcorn Time,这些文件依旧可以观看。
+
+
+
+#### 7、 拖放外部 torrent 文件立即播放
+
+我猜你不知道这个操作。如果你没有在 Popcorn Time 发现某些影片,从你最喜欢的 torrent 网站下载 torrent 文件,打开 Popcorn Time,然后拖放这个 torrent 文件到 Popcorn Time 里面。它将会立即播放文件,当然这个取决于种子。这次你不需要在观看前下载整个文件了。
+
+当你拖放文件到 Popcorn Time 后,它将会给你对应的选项,选择它应该播放的。如果里面有字幕,它会自动播放,否则你需要添加外部字幕。
+
+
+
+在 Popcorn Time 里面有很多的功能,但是我决定就此打住,剩下的就由你自己来探索吧。我希望你能发现更多 Popcorn Time 有用的功能和技巧。
+
+我再提醒一遍,使用 Torrents 在很多国家是违法的。
+
+-----------------------------------
+
+via: https://itsfoss.com/popcorn-time-ubuntu-linux/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[dianbanjiu](https://github.com/dianbanjiu)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[1]: https://popcorntime.sh/
+[2]: https://netflix.com/
+[3]: https://en.wikipedia.org/wiki/Torrent_file
+[4]: https://en.wikipedia.org/wiki/Popcorn_Time
+[5]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/popcorn-time-linux.jpeg
+[6]: https://itsfoss.com/netflix-firefox-linux/
+[7]: https://billing.ivacy.com/page/23628
+[8]: http://tldp.org/LDP/Linux-Filesystem-Hierarchy/html/opt.html
+[9]: https://en.wikipedia.org/wiki/Symbolic_link
+[10]: https://itsfoss.com/command-line-text-editors-linux/
+[11]: https://itsfoss.com/nano-3-release/
+[12]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/popcorn-time-ubuntu-menu.jpg
+[13]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/popcorn-time-ubuntu-license.jpeg
+[14]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/popcorn-time-watch-movies.jpeg
+[15]: https://ivacy.postaffiliatepro.com/accounts/default1/vdegzkxbw/7f82d531.png
+[16]: https://billing.ivacy.com/page/23628/7f82d531
+[17]: http://ivacy.postaffiliatepro.com/scripts/vdegzkxiw?aff=23628&a_bid=7f82d531
+[18]: https://itsfoss.com/how-to-synchronize-subtitles-with-movie-quick-tip/
+[19]: https://itsfoss.com/download-subtitles-automatically-vlc-media-player-ubuntu/
+[20]: https://protonvpn.net/?aid=chmod777
+[21]: https://itsfoss.com/protonmail/
+[22]: https://shop.itsfoss.com/search?utf8=%E2%9C%93&query=vpn
+[23]: https://itsfoss.com/affiliate-policy/
diff --git a/sources/talk/20180123 Moving to Linux from dated Windows machines.md b/sources/talk/20180123 Moving to Linux from dated Windows machines.md
deleted file mode 100644
index 6acd6e53f2..0000000000
--- a/sources/talk/20180123 Moving to Linux from dated Windows machines.md
+++ /dev/null
@@ -1,50 +0,0 @@
-Moving to Linux from dated Windows machines
-======
-
-
-
-Every day, while working in the marketing department at ONLYOFFICE, I see Linux users discussing our office productivity software on the internet. Our products are popular among Linux users, which made me curious about using Linux as an everyday work tool. My old Windows XP-powered computer was an obstacle to performance, so I started reading about Linux systems (particularly Ubuntu) and decided to try it out as an experiment. Two of my colleagues joined me.
-
-### Why Linux?
-
-We needed to make a change, first, because our old systems were not enough in terms of performance: we experienced regular crashes, an overload every time more than two apps were active, a 50% chance of freezing when a machine was shut down, and so forth. This was rather distracting to our work, which meant we were considerably less efficient than we could be.
-
-Upgrading to newer versions of Windows was an option, too, but that is an additional expense, plus our software competes against Microsoft's office suite. So that was an ideological question, too.
-
-Second, as I mentioned earlier, ONLYOFFICE products are rather popular within the Linux community. By reading about Linux users' experience with our software, we became interested in joining them.
-
-A week after we asked to change to Linux, we got our shiny new computer cases with [Kubuntu][1] inside. We chose version 16.04, which features KDE Plasma 5.5 and many KDE apps including Dolphin, as well as LibreOffice 5.1 and Firefox 45.
-
-### What we like about Linux
-
-Linux's biggest advantage, I believe, is its speed; for instance, it takes just seconds from pushing the machine's On button to starting your work. Everything seemed amazingly rapid from the very beginning: the overall responsiveness, the graphics, and even system updates.
-
-One other thing that surprised me compared to Windows is that Linux allows you to configure nearly everything, including the entire look of your desktop. In Settings, I found how to change the color and shape of bars, buttons, and fonts; relocate any desktop element; and build a composition of widgets, even including comics and Color Picker. I believe I've barely scratched the surface of the available options and have yet to explore most of the customization opportunities that this system is well known for.
-
-Linux distributions are generally a very safe environment. People rarely use antivirus apps in Linux, simply because there are so few viruses written for it. You save system speed, time, and, sure enough, money.
-
-In general, Linux has refreshed our everyday work lives, surprising us with a number of new options and opportunities. Even in the short time we've been using it, we'd characterize it as:
-
- * Fast and smooth to operate
- * Highly customizable
- * Relatively newcomer-friendly
- * Challenging with basic components, however very rewarding in return
- * Safe and secure
- * An exciting experience for everyone who seeks to refresh their workplace
-
-
-
-Have you switched from Windows or MacOS to Kubuntu or another Linux variant? Or are you considering making the change? Please share your reasons for wanting to adopt Linux, as well as your impressions of going open source, in the comments.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/1/move-to-linux-old-windows
-
-作者:[Michael Korotaev][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/michaelk
-[1]:https://kubuntu.org/
diff --git a/sources/talk/20180502 9 ways to improve collaboration between developers and designers.md b/sources/talk/20180502 9 ways to improve collaboration between developers and designers.md
index 293841714d..637a54ee91 100644
--- a/sources/talk/20180502 9 ways to improve collaboration between developers and designers.md
+++ b/sources/talk/20180502 9 ways to improve collaboration between developers and designers.md
@@ -1,3 +1,4 @@
+LuuMing translating
9 ways to improve collaboration between developers and designers
======
diff --git a/sources/talk/20180919 Linux Has a Code of Conduct and Not Everyone is Happy With it.md b/sources/talk/20180919 Linux Has a Code of Conduct and Not Everyone is Happy With it.md
index e161ec4eec..971a91f94f 100644
--- a/sources/talk/20180919 Linux Has a Code of Conduct and Not Everyone is Happy With it.md
+++ b/sources/talk/20180919 Linux Has a Code of Conduct and Not Everyone is Happy With it.md
@@ -1,3 +1,5 @@
+thecyanbird translating
+
Linux Has a Code of Conduct and Not Everyone is Happy With it
======
**Linux kernel has a new code of conduct (CoC). Linus Torvalds took a break from Linux kernel development just 30 minutes after signing this code of conduct. And since **the writer of this code of conduct has had a controversial past,** it has now become a point of heated discussion. With all the politics involved, not many people are happy with this new CoC.**
diff --git a/sources/talk/20180920 WinWorld - A Large Collection Of Defunct OSs, Software And Games.md b/sources/talk/20180920 WinWorld - A Large Collection Of Defunct OSs, Software And Games.md
deleted file mode 100644
index 93c84ae43c..0000000000
--- a/sources/talk/20180920 WinWorld - A Large Collection Of Defunct OSs, Software And Games.md
+++ /dev/null
@@ -1,126 +0,0 @@
-WinWorld – A Large Collection Of Defunct OSs, Software And Games
-======
-
-
-
-The other day, I was testing **Dosbox** which is used to [**run MS-DOS games and programs in Linux**][1]. While searching for some classic programs like Turbo C++, I stumbled upon a website named **WinWorld**. I went through a few links in this site and quite surprised. WinWorld has a plenty of good-old and classic OSs, software, applications, development tools, games and a lot of other miscellaneous utilities which are abandoned by the developers a long time ago. It is an online museum run by community members, volunteers and is dedicated to the preservation and sharing of vintage, abandoned, and pre-release software.
-
-WinWorld was started back in 2003 and its founder claims that the idea to start this site inspired by Yahoo briefcases. The primary purpose of this site is to preserve and share old software. Over the years, many people volunteered to improve this site in numerous ways and the collection of old software in WinWorld has grown exponentially. The entire WinWorld library is free, open and available to everyone.
-
-### WinWorld Hosts A Huge Collection Of Defunct OSs, Software, System Applications And Games
-
-Like I already said, WinWorld hosts a huge collection of abandonware which are no-longer in development.
-
-**Linux and Unix:**
-
-Here, I have given the complete list of UNIX and LINUX OSs with brief summary of the each OS and the release year of first version.
-
- * **A/UX** – An early port of Unix to Apple’s 68k based Macintosh platform, released in 1988.
- * **AIX** – A Unix port originally developed by IBM, released in 1986.
- * **AT &T System V Unix** – One of the first commercial versions of the Unix OS, released in 1983.
- * **Banyan VINES** – A network operating system originally designed for Unix, released in 1984.
- * **Corel Linux** – A commercial Linux distro, released in 1999.
- * **DEC OSF-1** – A version of UNIX developed by Digital Equipment Corporation (DEC), released in 1991.
- * **Digital UNIX** – A renamed version of **OSF-1** , released by DEC in 1995.**
-**
- * **FreeBSD** **1.0** – The first release of FreeBSD, released in 1993. It is based on 4.3BSD.
- * **Gentus Linux** – A distribution that failed to comply with GPL. Developed by ABIT and released in 2000.
- * **HP-UX** – A UNIX variant, released in 1992.
- * **IRIX** – An a operating system developed by Silicon Graphics Inc (SGI ) and it is released in 1988.
- * **Lindows** – Similar to Corel Linux. It is developed for commercial purpose and released in 2002.
- * **Linux Kernel** – A copy of the Linux Sourcecode, version 0.01. Released in the early 90’s.
- * **Mandrake Linux** – A Linux distribution based on Red Hat Linux. It was later renamed to Mandriva. Released in 1999.
- * **NEWS-OS** – A variant of BSD, developed by Sony and released in 1989.
- * **NeXTStep** – A Unix based OS from NeXT computers headed by **Steve Jobs**. It is released in 1987.
- * **PC/IX** – A UNIX variant created for IBM PCs. Released in 1984.
- * **Red Hat Linux 5.0** – A commercial Linux distribution by Red Hat.
- * **Sun Solaris** – A Unix based OS by Sun Microsystems. Released in 1992.
- * **SunOS** – A Unix-based OS derived from BSD by Sun Microsystems, released in 1982.
- * **Tru64 UNIX** – A formerly known OSF/1 by DEC.
- * **Ubuntu 4.10** – The well-known OS based on Debian.This was a beta pre-release, prior to the very first official Ubuntu release.
- * **Ultrix** – A UNIX clone developed by DEC.
- * **UnixWare** – A UNIX variant from Novell.
- * **Xandros Linux** – A proprietary variant of Linux. It is based on Corel Linux. The first version is released in 2003.
- * **Xenix** – A UNIX variant originally published by Microsoft released in 1984.
-
-
-
-Not just Linux/Unix, you can find other operating systems including DOS, Windows, Apple/Mac, OS 2, Novell netware and other OSs and shells.
-
-**DOS & CP/M:**
-
- * 86-DOS
- * Concurrent CPM-86 & Concurrent DOS
- * CP/M 86 & CP/M-80
- * DOS Plus
- * DR-DOS
- * GEM
- * MP/M
- * MS-DOS
- * Multitasking MS-DOS 4.00
- * Multiuser DOS
- * PC-DOS
- * PC-MOS
- * PTS-DOS
- * Real/32
- * Tandy Deskmate
- * Wendin DOS
-
-
-
-**Windows:**
-
- * BackOffice Server
- * Windows 1.0/2.x/3.0/3.1/95/98/2000/ME/NT 3.X/NT 4.0
- * Windows Whistler
- * WinFrame
-
-
-
-**Apple/Mac:**
-
- * Mac OS 7/8/9
- * Mac OS X
- * System Software (0-6)
-
-
-
-**OS/2:**
-
- * Citrix Multiuser
- * OS/2 1.x
- * OS/2 2.0
- * OS/2 3.x
- * OS/2 Warp 4
-
-
-
-Also, WinWorld hosts a huge collection of old software, system applications, development tools and games. Go and check them out as well.
-
-To be honest, I don’t even know the existence of most of the stuffs listed in this site. Some of the tools listed here were released years before I was born.
-
-Just in case, If you ever in need of or wanted to test a classic stuff (be it a game, software, OS), look nowhere, just head over to WinWorld library and download them that you want to explore. Good luck!
-
-**Disclaimer:**
-
-OSTechNix is not affiliated with WinWorld site in any way. We, at OSTechNix, don’t know the authenticity and integrity of the stuffs hosted in this site. Also, downloading software from third-party sites is not safe or may be illegal in your region. Neither the author nor OSTechNix is responsible for any kind of damage. Use this service at your own risk.
-
-And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/winworld-a-large-collection-of-defunct-oss-software-and-games/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.ostechnix.com/author/sk/
-[1]: https://www.ostechnix.com/how-to-run-ms-dos-games-and-programs-in-linux/
diff --git a/sources/tech/20140607 Five things that make Go fast.md b/sources/tech/20140607 Five things that make Go fast.md
deleted file mode 100644
index 88db93011c..0000000000
--- a/sources/tech/20140607 Five things that make Go fast.md
+++ /dev/null
@@ -1,493 +0,0 @@
-Five things that make Go fast
-============================================================
-
- _Anthony Starks has remixed my original Google Present based slides using his fantastic Deck presentation tool. You can check out his remix over on his blog,[mindchunk.blogspot.com.au/2014/06/remixing-with-deck][5]._
-
-* * *
-
-I was recently invited to give a talk at Gocon, a fantastic Go conference held semi-annually in Tokyo, Japan. [Gocon 2014][6] was an entirely community-run one day event combining training and an afternoon of presentations surrounding the theme of Go in production
.
-
-The following is the text of my presentation. The original text was structured to force me to speak slowly and clearly, so I have taken the liberty of editing it slightly to be more readable.
-
-I want to thank [Bill Kennedy][7], Minux Ma, and especially [Josh Bleecher Snyder][8], for their assistance in preparing this talk.
-
-* * *
-
-Good afternoon.
-
-My name is David.
-
-I am delighted to be here at Gocon today. I have wanted to come to this conference for two years and I am very grateful to the organisers for extending me the opportunity to present to you today.
-
- [][9]
-I want to begin my talk with a question.
-
-Why are people choosing to use Go ?
-
-When people talk about their decision to learn Go, or use it in their product, they have a variety of answers, but there always three that are at the top of their list
-
- [][10]
-These are the top three.
-
-The first, Concurrency.
-
-Go’s concurrency primitives are attractive to programmers who come from single threaded scripting languages like Nodejs, Ruby, or Python, or from languages like C++ or Java with their heavyweight threading model.
-
-Ease of deployment.
-
-We have heard today from experienced Gophers who appreciate the simplicity of deploying Go applications.
-
- [][11]
-
-This leaves Performance.
-
-I believe an important reason why people choose to use Go is because it is _fast_ .
-
- [][12]
-
-For my talk today I want to discuss five features that contribute to Go’s performance.
-
-I will also share with you the details of how Go implements these features.
-
- [][13]
-
-The first feature I want to talk about is Go’s efficient treatment and storage of values.
-
- [][14]
-
-This is an example of a value in Go. When compiled, `gocon` consumes exactly four bytes of memory.
-
-Let’s compare Go with some other languages
-
- [][15]
-
-Due to the overhead of the way Python represents variables, storing the same value using Python consumes six times more memory.
-
-This extra memory is used by Python to track type information, do reference counting, etc
-
-Let’s look at another example:
-
- [][16]
-
-Similar to Go, the Java `int` type consumes 4 bytes of memory to store this value.
-
-However, to use this value in a collection like a `List` or `Map`, the compiler must convert it into an `Integer` object.
-
- [][17]
-
-So an integer in Java frequently looks more like this and consumes between 16 and 24 bytes of memory.
-
-Why is this important ? Memory is cheap and plentiful, why should this overhead matter ?
-
- [][18]
-
-This is a graph showing CPU clock speed vs memory bus speed.
-
-Notice how the gap between CPU clock speed and memory bus speed continues to widen.
-
-The difference between the two is effectively how much time the CPU spends waiting for memory.
-
- [][19]
-
-Since the late 1960’s CPU designers have understood this problem.
-
-Their solution is a cache, an area of smaller, faster memory which is inserted between the CPU and main memory.
-
- [][20]
-
-This is a `Location` type which holds the location of some object in three dimensional space. It is written in Go, so each `Location` consumes exactly 24 bytes of storage.
-
-We can use this type to construct an array type of 1,000 `Location`s, which consumes exactly 24,000 bytes of memory.
-
-Inside the array, the `Location` structures are stored sequentially, rather than as pointers to 1,000 Location structures stored randomly.
-
-This is important because now all 1,000 `Location` structures are in the cache in sequence, packed tightly together.
-
- [][21]
-
-Go lets you create compact data structures, avoiding unnecessary indirection.
-
-Compact data structures utilise the cache better.
-
-Better cache utilisation leads to better performance.
-
- [][22]
-
-Function calls are not free.
-
- [][23]
-
-Three things happen when a function is called.
-
-A new stack frame is created, and the details of the caller recorded.
-
-Any registers which may be overwritten during the function call are saved to the stack.
-
-The processor computes the address of the function and executes a branch to that new address.
-
- [][24]
-
-Because function calls are very common operations, CPU designers have worked hard to optimise this procedure, but they cannot eliminate the overhead.
-
-Depending on what the function does, this overhead may be trivial or significant.
-
-A solution to reducing function call overhead is an optimisation technique called Inlining.
-
- [][25]
-
-The Go compiler inlines a function by treating the body of the function as if it were part of the caller.
-
-Inlining has a cost; it increases binary size.
-
-It only makes sense to inline when the overhead of calling a function is large relative to the work the function does, so only simple functions are candidates for inlining.
-
-Complicated functions are usually not dominated by the overhead of calling them and are therefore not inlined.
-
- [][26]
-
-This example shows the function `Double` calling `util.Max`.
-
-To reduce the overhead of the call to `util.Max`, the compiler can inline `util.Max` into `Double`, resulting in something like this
-
- [][27]
-
-After inlining there is no longer a call to `util.Max`, but the behaviour of `Double` is unchanged.
-
-Inlining isn’t exclusive to Go. Almost every compiled or JITed language performs this optimisation. But how does inlining in Go work?
-
-The Go implementation is very simple. When a package is compiled, any small function that is suitable for inlining is marked and then compiled as usual.
-
-Then both the source of the function and the compiled version are stored.
-
- [][28]
-
-This slide shows the contents of util.a. The source has been transformed a little to make it easier for the compiler to process quickly.
-
-When the compiler compiles Double it sees that `util.Max` is inlinable, and the source of `util.Max`is available.
-
-Rather than insert a call to the compiled version of `util.Max`, it can substitute the source of the original function.
-
-Having the source of the function enables other optimizations.
-
- [][29]
-
-In this example, although the function Test always returns false, Expensive cannot know that without executing it.
-
-When `Test` is inlined, we get something like this
-
- [][30]
-
-The compiler now knows that the expensive code is unreachable.
-
-Not only does this save the cost of calling Test, it saves compiling or running any of the expensive code that is now unreachable.
-
-The Go compiler can automatically inline functions across files and even across packages. This includes code that calls inlinable functions from the standard library.
-
- [][31]
-
-Mandatory garbage collection makes Go a simpler and safer language.
-
-This does not imply that garbage collection makes Go slow, or that garbage collection is the ultimate arbiter of the speed of your program.
-
-What it does mean is memory allocated on the heap comes at a cost. It is a debt that costs CPU time every time the GC runs until that memory is freed.
-
- [][32]
-
-There is however another place to allocate memory, and that is the stack.
-
-Unlike C, which forces you to choose if a value will be stored on the heap, via `malloc`, or on the stack, by declaring it inside the scope of the function, Go implements an optimisation called _escape analysis_ .
-
- [][33]
-
-Escape analysis determines whether any references to a value escape the function in which the value is declared.
-
-If no references escape, the value may be safely stored on the stack.
-
-Values stored on the stack do not need to be allocated or freed.
-
-Lets look at some examples
-
- [][34]
-
-`Sum` adds the numbers between 1 and 100 and returns the result. This is a rather unusual way to do this, but it illustrates how Escape Analysis works.
-
-Because the numbers slice is only referenced inside `Sum`, the compiler will arrange to store the 100 integers for that slice on the stack, rather than the heap.
-
-There is no need to garbage collect `numbers`, it is automatically freed when `Sum` returns.
-
- [][35]
-
-This second example is also a little contrived. In `CenterCursor` we create a new `Cursor` and store a pointer to it in c.
-
-Then we pass `c` to the `Center()` function which moves the `Cursor` to the center of the screen.
-
-Then finally we print the X and Y locations of that `Cursor`.
-
-Even though `c` was allocated with the `new` function, it will not be stored on the heap, because no reference `c` escapes the `CenterCursor` function.
-
- [][36]
-
-Go’s optimisations are always enabled by default. You can see the compiler’s escape analysis and inlining decisions with the `-gcflags=-m` switch.
-
-Because escape analysis is performed at compile time, not run time, stack allocation will always be faster than heap allocation, no matter how efficient your garbage collector is.
-
-I will talk more about the stack in the remaining sections of this talk.
-
- [][37]
-
-Go has goroutines. These are the foundations for concurrency in Go.
-
-I want to step back for a moment and explore the history that leads us to goroutines.
-
-In the beginning computers ran one process at a time. Then in the 60’s the idea of multiprocessing, or time sharing became popular.
-
-In a time-sharing system the operating systems must constantly switch the attention of the CPU between these processes by recording the state of the current process, then restoring the state of another.
-
-This is called _process switching_ .
-
- [][38]
-
-There are three main costs of a process switch.
-
-First is the kernel needs to store the contents of all the CPU registers for that process, then restore the values for another process.
-
-The kernel also needs to flush the CPU’s mappings from virtual memory to physical memory as these are only valid for the current process.
-
-Finally there is the cost of the operating system context switch, and the overhead of the scheduler function to choose the next process to occupy the CPU.
-
- [][39]
-
-There are a surprising number of registers in a modern processor. I have difficulty fitting them on one slide, which should give you a clue how much time it takes to save and restore them.
-
-Because a process switch can occur at any point in a process’ execution, the operating system needs to store the contents of all of these registers because it does not know which are currently in use.
-
- [][40]
-
-This lead to the development of threads, which are conceptually the same as processes, but share the same memory space.
-
-As threads share address space, they are lighter than processes so are faster to create and faster to switch between.
-
- [][41]
-
-Goroutines take the idea of threads a step further.
-
-Goroutines are cooperatively scheduled, rather than relying on the kernel to manage their time sharing.
-
-The switch between goroutines only happens at well defined points, when an explicit call is made to the Go runtime scheduler.
-
-The compiler knows the registers which are in use and saves them automatically.
-
- [][42]
-
-While goroutines are cooperatively scheduled, this scheduling is handled for you by the runtime.
-
-Places where Goroutines may yield to others are:
-
-* Channel send and receive operations, if those operations would block.
-
-* The Go statement, although there is no guarantee that new goroutine will be scheduled immediately.
-
-* Blocking syscalls like file and network operations.
-
-* After being stopped for a garbage collection cycle.
-
- [][43]
-
-This an example to illustrate some of the scheduling points described in the previous slide.
-
-The thread, depicted by the arrow, starts on the left in the `ReadFile` function. It encounters `os.Open`, which blocks the thread while waiting for the file operation to complete, so the scheduler switches the thread to the goroutine on the right hand side.
-
-Execution continues until the read from the `c` chan blocks, and by this time the `os.Open` call has completed so the scheduler switches the thread back the left hand side and continues to the `file.Read` function, which again blocks on file IO.
-
-The scheduler switches the thread back to the right hand side for another channel operation, which has unblocked during the time the left hand side was running, but it blocks again on the channel send.
-
-Finally the thread switches back to the left hand side as the `Read` operation has completed and data is available.
-
- [][44]
-
-This slide shows the low level `runtime.Syscall` function which is the base for all functions in the os package.
-
-Any time your code results in a call to the operating system, it will go through this function.
-
-The call to `entersyscall` informs the runtime that this thread is about to block.
-
-This allows the runtime to spin up a new thread which will service other goroutines while this current thread blocked.
-
-This results in relatively few operating system threads per Go process, with the Go runtime taking care of assigning a runnable Goroutine to a free operating system thread.
-
- [][45]
-
-In the previous section I discussed how goroutines reduce the overhead of managing many, sometimes hundreds of thousands of concurrent threads of execution.
-
-There is another side to the goroutine story, and that is stack management, which leads me to my final topic.
-
- [][46]
-
-This is a diagram of the memory layout of a process. The key thing we are interested is the location of the heap and the stack.
-
-Traditionally inside the address space of a process, the heap is at the bottom of memory, just above the program (text) and grows upwards.
-
-The stack is located at the top of the virtual address space, and grows downwards.
-
- [][47]
-
-Because the heap and stack overwriting each other would be catastrophic, the operating system usually arranges to place an area of unwritable memory between the stack and the heap to ensure that if they did collide, the program will abort.
-
-This is called a guard page, and effectively limits the stack size of a process, usually in the order of several megabytes.
-
- [][48]
-
-We’ve discussed that threads share the same address space, so for each thread, it must have its own stack.
-
-Because it is hard to predict the stack requirements of a particular thread, a large amount of memory is reserved for each thread’s stack along with a guard page.
-
-The hope is that this is more than will ever be needed and the guard page will never be hit.
-
-The downside is that as the number of threads in your program increases, the amount of available address space is reduced.
-
- [][49]
-
-We’ve seen that the Go runtime schedules a large number of goroutines onto a small number of threads, but what about the stack requirements of those goroutines ?
-
-Instead of using guard pages, the Go compiler inserts a check as part of every function call to check if there is sufficient stack for the function to run. If there is not, the runtime can allocate more stack space.
-
-Because of this check, a goroutines initial stack can be made much smaller, which in turn permits Go programmers to treat goroutines as cheap resources.
-
- [][50]
-
-This is a slide that shows how stacks are managed in Go 1.2.
-
-When `G` calls to `H` there is not enough space for `H` to run, so the runtime allocates a new stack frame from the heap, then runs `H` on that new stack segment. When `H` returns, the stack area is returned to the heap before returning to `G`.
-
- [][51]
-
-This method of managing the stack works well in general, but for certain types of code, usually recursive code, it can cause the inner loop of your program to straddle one of these stack boundaries.
-
-For example, in the inner loop of your program, function `G` may call `H` many times in a loop,
-
-Each time this will cause a stack split. This is known as the hot split problem.
-
- [][52]
-
-To solve hot splits, Go 1.3 has adopted a new stack management method.
-
-Instead of adding and removing additional stack segments, if the stack of a goroutine is too small, a new, larger, stack will be allocated.
-
-The old stack’s contents are copied to the new stack, then the goroutine continues with its new larger stack.
-
-After the first call to `H` the stack will be large enough that the check for available stack space will always succeed.
-
-This resolves the hot split problem.
-
- [][53]
-
-Values, Inlining, Escape Analysis, Goroutines, and segmented/copying stacks.
-
-These are the five features that I chose to speak about today, but they are by no means the only things that makes Go a fast programming language, just as there more that three reasons that people cite as their reason to learn Go.
-
-As powerful as these five features are individually, they do not exist in isolation.
-
-For example, the way the runtime multiplexes goroutines onto threads would not be nearly as efficient without growable stacks.
-
-Inlining reduces the cost of the stack size check by combining smaller functions into larger ones.
-
-Escape analysis reduces the pressure on the garbage collector by automatically moving allocations from the heap to the stack.
-
-Escape analysis is also provides better cache locality.
-
-Without growable stacks, escape analysis might place too much pressure on the stack.
-
- [][54]
-
-* Thank you to the Gocon organisers for permitting me to speak today
-* twitter / web / email details
-* thanks to @offbymany, @billkennedy_go, and Minux for their assistance in preparing this talk.
-
-### Related Posts:
-
-1. [Hear me speak about Go performance at OSCON][1]
-
-2. [Why is a Goroutine’s stack infinite ?][2]
-
-3. [A whirlwind tour of Go’s runtime environment variables][3]
-
-4. [Performance without the event loop][4]
-
---------------------------------------------------------------------------------
-
-作者简介:
-
-David is a programmer and author from Sydney Australia.
-
-Go contributor since February 2011, committer since April 2012.
-
-Contact information
-
-* dave@cheney.net
-* twitter: @davecheney
-
-----------------------
-
-via: https://dave.cheney.net/2014/06/07/five-things-that-make-go-fast
-
-作者:[Dave Cheney ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://dave.cheney.net/
-[1]:https://dave.cheney.net/2015/05/31/hear-me-speak-about-go-performance-at-oscon
-[2]:https://dave.cheney.net/2013/06/02/why-is-a-goroutines-stack-infinite
-[3]:https://dave.cheney.net/2015/11/29/a-whirlwind-tour-of-gos-runtime-environment-variables
-[4]:https://dave.cheney.net/2015/08/08/performance-without-the-event-loop
-[5]:http://mindchunk.blogspot.com.au/2014/06/remixing-with-deck.html
-[6]:http://ymotongpoo.hatenablog.com/entry/2014/06/01/124350
-[7]:http://www.goinggo.net/
-[8]:https://twitter.com/offbymany
-[9]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-1.jpg
-[10]:https://dave.cheney.net/2014/06/07/five-things-that-make-go-fast/gocon-2014-2
-[11]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-3.jpg
-[12]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-4.jpg
-[13]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-5.jpg
-[14]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-6.jpg
-[15]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-7.jpg
-[16]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-8.jpg
-[17]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-9.jpg
-[18]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-10.jpg
-[19]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-11.jpg
-[20]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-12.jpg
-[21]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-13.jpg
-[22]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-14.jpg
-[23]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-15.jpg
-[24]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-16.jpg
-[25]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-17.jpg
-[26]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-18.jpg
-[27]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-19.jpg
-[28]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-20.jpg
-[29]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-21.jpg
-[30]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-22.jpg
-[31]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-23.jpg
-[32]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-24.jpg
-[33]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-25.jpg
-[34]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-26.jpg
-[35]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-27.jpg
-[36]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-28.jpg
-[37]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-30.jpg
-[38]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-29.jpg
-[39]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-31.jpg
-[40]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-32.jpg
-[41]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-33.jpg
-[42]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-34.jpg
-[43]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-35.jpg
-[44]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-36.jpg
-[45]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-37.jpg
-[46]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-39.jpg
-[47]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-40.jpg
-[48]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-41.jpg
-[49]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-42.jpg
-[50]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-43.jpg
-[51]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-44.jpg
-[52]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-45.jpg
-[53]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-46.jpg
-[54]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-47.jpg
diff --git a/sources/tech/20170810 How we built our first full-stack JavaScript web app in three weeks.md b/sources/tech/20170810 How we built our first full-stack JavaScript web app in three weeks.md
deleted file mode 100644
index e423386d85..0000000000
--- a/sources/tech/20170810 How we built our first full-stack JavaScript web app in three weeks.md
+++ /dev/null
@@ -1,200 +0,0 @@
-The user’s home dashboard in our app, AlignHow we built our first full-stack JavaScript web app in three weeks
-============================================================
-
-
-
-### A simple step-by-step guide to go from idea to deployed app
-
-My three months of coding bootcamp at the Grace Hopper Program have come to a close, and the title of this article is actually not quite true — I’ve now built _three_ full-stack apps: [an e-commerce store from scratch][3], a [personal hackathon project][4] of my choice, and finally, a three-week capstone project. That capstone project was by far the most intensive— a three week journey with two teammates — and it is my proudest achievement from bootcamp. It is the first robust, complex app I have ever fully built and designed.
-
-As most developers know, even when you “know how to code”, it can be really overwhelming to embark on the creation of your first full-stack app. The JavaScript ecosystem is incredibly vast: with package managers, modules, build tools, transpilers, databases, libraries, and decisions to be made about all of them, it’s no wonder that so many budding coders never build anything beyond Codecademy tutorials. That’s why I want to walk you through a step-by-step guide of the decisions and steps my team took to create our live app, Align.
-
-* * *
-
-First, some context. Align is a web app that uses an intuitive timeline interface to help users set long-term goals and manage them over time.Our stack includes Firebase for back-end services and React on the front end. My teammates and I explain more in this short video:
-
-[video](https://youtu.be/YacM6uYP2Jo)
-
-Demoing Align @ Demo Day Live // July 10, 2017
-
-So how did we go from Day 1, when we were assigned our teams, to the final live app? Here’s a rundown of the steps we took:
-
-* * *
-
-### Step 1: Ideate
-
-The first step was to figure out what exactly we wanted to build. In my past life as a consultant at IBM, I led ideation workshops with corporate leaders. Pulling from that, I suggested to my group the classic post-it brainstorming strategy, in which we all scribble out as many ideas as we can — even ‘stupid ones’ — so that people’s brains keep moving and no one avoids voicing ideas out of fear.
-
-
-
-After generating a few dozen app ideas, we sorted them into categories to gain a better understanding of what themes we were collectively excited about. In our group, we saw a clear trend towards ideas surrounding self-improvement, goal-setting, nostalgia, and personal development. From that, we eventually honed in on a specific idea: a personal dashboard for setting and managing long-term goals, with elements of memory-keeping and data visualization over time.
-
-From there, we created a set of user stories — descriptions of features we wanted to have, from an end-user perspective — to elucidate what exactly we wanted our app to do.
-
-### Step 2: Wireframe UX/UI
-
-Next, on a white board, we drew out the basic views we envisioned in our app. We incorporated our set of user stories to understand how these views would work in a skeletal app framework.
-
-
-
-
-
-
-
-
-
-
-
-
-These sketches ensured we were all on the same page, and provided a visual blueprint going forward of what exactly we were all working towards.
-
-### Step 3: Choose a data structure and type of database
-
-It was now time to design our data structure. Based on our wireframes and user stories, we created a list in a Google doc of the models we would need and what attributes each should include. We knew we needed a ‘goal’ model, a ‘user’ model, a ‘milestone’ model, and a ‘checkin’ model, as well as eventually a ‘resource’ model, and an ‘upload’ model.
-
-
-
-Our initial sketch of our data models
-
-After informally sketching the models out, we needed to choose a _type _ of database: ‘relational’ vs. ‘non-relational’ (a.k.a. ‘SQL’ vs. ‘NoSQL’). Whereas SQL databases are table-based and need predefined schema, NoSQL databases are document-based and have dynamic schema for unstructured data.
-
-For our use case, it didn’t matter much whether we used a SQL or a No-SQL database, so we ultimately chose Google’s cloud NoSQL database Firebasefor other reasons:
-
-1. It could hold user image uploads in its cloud storage
-
-2. It included WebSocket integration for real-time updating
-
-3. It could handle our user authentication and offer easy OAuth integration
-
-Once we chose a database, it was time to understand the relations between our data models. Since Firebase is NoSQL, we couldn’t create join tables or set up formal relations like _“Checkins belongTo Goals”_ . Instead, we needed to figure out what the JSON tree would look like, and how the objects would be nested (or not). Ultimately, we structured our model like this:
-
- ** 此处有Canvas,请手动处理 **
-
-
-Our final Firebase data scheme for the Goal object. Note that Milestones & Checkins are nested under Goals.
-
- _(Note: Firebase prefers shallow, normalized data structures for efficiency, but for our use case, it made most sense to nest it, since we would never be pulling a Goal from the database without its child Milestones and Checkins.)_
-
-### Step 4: Set up Github and an agile workflow
-
-We knew from the start that staying organized and practicing agile development would serve us well. We set up a Github repo, on which weprevented merging to master to force ourselves to review each other’s code.
-
-
-
-
-We also created an agile board on [Waffle.io][5], which is free and has easy integration with Github. On the Waffle board, we listed our user stories as well as bugs we knew we needed to fix. Later, when we started coding, we would each create git branches for the user story we were currently working on, moving it from swim lane to swim lane as we made progress.
-
-
-
-
-We also began holding “stand-up” meetings each morning to discuss the previous day’s progress and any blockers each of us were encountering. This meeting often decided the day’s flow — who would be pair programming, and who would work on an issue solo.
-
-I highly recommend some sort of structured workflow like this, as it allowed us to clearly define our priorities and make efficient progress without any interpersonal conflict.
-
-### Step 5: Choose & download a boilerplate
-
-Because the JavaScript ecosystem is so complicated, we opted not to build our app from absolute ground zero. It felt unnecessary to spend valuable time wiring up our Webpack build scripts and loaders, and our symlink that pointed to our project directory. My team chose the [Firebones][6] skeleton because it fit our use case, but there are many open-source skeleton options available to choose from.
-
-### Step 6: Write back-end API routes (or Firebase listeners)
-
-If we weren’t using a cloud-based database, this would have been the time to start writing our back-end Express routes to make requests to our database. But since we were using Firebase, which is already in the cloud and has a different way of communicating with code, we just worked to set up our first successful database listener.
-
-To ensure our listener was working, we coded out a basic user form for creating a Goal, and saw that, indeed, when we filled out the form, our database was live-updating. We were connected!
-
-### Step 7: Build a “Proof Of Concept”
-
-Our next step was to create a “proof of concept” for our app, or a prototype of the most difficult fundamental features to implement, demonstrating that our app _could _ eventuallyexist. For us, this meant finding a front-end library to satisfactorily render timelines, and connecting it to Firebase successfully to display some seed data in our database.
-
-
-
-Basic Victory.JS timelines
-
-We found Victory.JS, a React library built on D3, and spent a day reading the documentation and putting together a very basic example of a _VictoryLine_ component and a _VictoryScatter_ component to visually display data from the database. Indeed, it worked! We were ready to build.
-
-### Step 8: Code out the features
-
-Finally, it was time to build out all the exciting functionality of our app. This is a giant step that will obviously vary widely depending on the app you’re personally building. We looked at our wireframes and started coding out the individual user stories in our Waffle. This often included touching both front-end and back-end code (for example, creating a front-end form and also connecting it to the database). Our features ranged from major to minor, and included things like:
-
-* ability to create new goals, milestones, and checkins
-
-* ability to delete goals, milestones, and checkins
-
-* ability to change a timeline’s name, color, and details
-
-* ability to zoom in on timelines
-
-* ability to add links to resources
-
-* ability to upload media
-
-* ability to bubble up resources and media from milestones and checkins to their associated goals
-
-* rich text editor integration
-
-* user signup / authentication / OAuth
-
-* popover to view timeline options
-
-* loading screens
-
-For obvious reasons, this step took up the bulk of our time — this phase is where most of the meaty code happened, and each time we finished a feature, there were always more to build out!
-
-### Step 9: Choose and code the design scheme
-
-Once we had an MVP of the functionality we desired in our app, it was time to clean it up and make it pretty. My team used Material-UI for components like form fields, menus, and login tabs, which ensured everything looked sleek, polished, and coherent without much in-depth design knowledge.
-
-
-
-This was one of my favorite features to code out. Its beauty is so satisfying!
-
-We spent a while choosing a color scheme and editing the CSS, which provided us a nice break from in-the-trenches coding. We also designed alogo and uploaded a favicon.
-
-### Step 10: Find and squash bugs
-
-While we should have been using test-driven development from the beginning, time constraints left us with precious little time for anything but features. This meant that we spent the final two days simulating every user flow we could think of and hunting our app for bugs.
-
-
-
-
-This process was not the most systematic, but we found plenty of bugs to keep us busy, including a bug in which the loading screen would last indefinitely in certain situations, and one in which the resource component had stopped working entirely. Fixing bugs can be annoying, but when it finally works, it’s extremely satisfying.
-
-### Step 11: Deploy the live app
-
-The final step was to deploy our app so it would be available live! Because we were using Firebase to store our data, we deployed to Firebase Hosting, which was intuitive and simple. If your back end uses a different database, you can use Heroku or DigitalOcean. Generally, deployment directions are readily available on the hosting site.
-
-We also bought a cheap domain name on Namecheap.com to make our app more polished and easy to find.
-
-
-
-* * *
-
-And that was it — we were suddenly the co-creators of a real live full-stack app that someone could use! If we had a longer runway, Step 12 would have been to run A/B testing on users, so we could better understand how actual users interact with our app and what they’d like to see in a V2.
-
-For now, however, we’re happy with the final product, and with the immeasurable knowledge and understanding we gained throughout this process. Check out Align [here][7]!
-
-
-
-Team Align: Sara Kladky (left), Melanie Mohn (center), and myself.
-
---------------------------------------------------------------------------------
-
-via: https://medium.com/ladies-storm-hackathons/how-we-built-our-first-full-stack-javascript-web-app-in-three-weeks-8a4668dbd67c?imm_mid=0f581a&cmp=em-web-na-na-newsltr_20170816
-
-作者:[Sophia Ciocca ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://medium.com/@sophiaciocca?source=post_header_lockup
-[1]:https://medium.com/@sophiaciocca?source=post_header_lockup
-[2]:https://medium.com/@sophiaciocca?source=post_header_lockup
-[3]:https://github.com/limitless-leggings/limitless-leggings
-[4]:https://www.youtube.com/watch?v=qyLoInHNjoc
-[5]:http://www.waffle.io/
-[6]:https://github.com/FullstackAcademy/firebones
-[7]:https://align.fun/
-[8]:https://github.com/align-capstone/align
-[9]:https://github.com/sophiaciocca
-[10]:https://github.com/Kladky
-[11]:https://github.com/melaniemohn
diff --git a/sources/tech/20170926 Managing users on Linux systems.md b/sources/tech/20170926 Managing users on Linux systems.md
deleted file mode 100644
index e47fc572df..0000000000
--- a/sources/tech/20170926 Managing users on Linux systems.md
+++ /dev/null
@@ -1,223 +0,0 @@
-Managing users on Linux systems
-======
-Your Linux users may not be raging bulls, but keeping them happy is always a challenge as it involves managing their accounts, monitoring their access rights, tracking down the solutions to problems they run into, and keeping them informed about important changes on the systems they use. Here are some of the tasks and tools that make the job a little easier.
-
-### Configuring accounts
-
-Adding and removing accounts is the easier part of managing users, but there are still a lot of options to consider. Whether you use a desktop tool or go with command line options, the process is largely automated. You can set up a new user with a command as simple as **adduser jdoe** and a number of things will happen. John 's account will be created using the next available UID and likely populated with a number of files that help to configure his account. When you run the adduser command with a single argument (the new username), it will prompt for some additional information and explain what it is doing.
-```
-$ sudo adduser jdoe
-Adding user `jdoe' ...
-Adding new group `jdoe' (1001) ...
-Adding new user `jdoe' (1001) with group `jdoe' ...
-Creating home directory `/home/jdoe' ...
-Copying files from `/etc/skel' …
-Enter new UNIX password:
-Retype new UNIX password:
-passwd: password updated successfully
-Changing the user information for jdoe
-Enter the new value, or press ENTER for the default
- Full Name []: John Doe
- Room Number []:
- Work Phone []:
- Home Phone []:
- Other []:
-Is the information correct? [Y/n] Y
-
-```
-
-As you can see, adduser adds the user's information (to the /etc/passwd and /etc/shadow files), creates the new home directory and populates it with some files from /etc/skel, prompts for you to assign the initial password and identifying information, and then verifies that it's got everything right. If you answer "n" for no at the final "Is the information correct?" prompt, it will run back through all of your previous answers, allowing you to change any that you might want to change.
-
-Once an account is set up, you might want to verify that it looks as you'd expect. However, a better strategy is to ensure that the choices being made "automagically" match what you want to see _before_ you add your first account. The defaults are defaults for good reason, but it 's useful to know where they're defined in case you want some to be different - for example, if you don't want home directories in /home, you don't want user UIDs to start with 1000, or you don't want the files in home directories to be readable by _everyone_ on the system.
-
-Some of the details of how the adduser command works are configured in the /etc/adduser.conf file. This file contains a lot of settings that determine how new accounts are configured and will look something like this. Note that the comments and blanks lines are omitted in the output below so that we can focus more easily on just the settings.
-```
-$ cat /etc/adduser.conf | grep -v "^#" | grep -v "^$"
-DSHELL=/bin/bash
-DHOME=/home
-GROUPHOMES=no
-LETTERHOMES=no
-SKEL=/etc/skel
-FIRST_SYSTEM_UID=100
-LAST_SYSTEM_UID=999
-FIRST_SYSTEM_GID=100
-LAST_SYSTEM_GID=999
-FIRST_UID=1000
-LAST_UID=29999
-FIRST_GID=1000
-LAST_GID=29999
-USERGROUPS=yes
-USERS_GID=100
-DIR_MODE=0755
-SETGID_HOME=no
-QUOTAUSER=""
-SKEL_IGNORE_REGEX="dpkg-(old|new|dist|save)"
-
-```
-
-As you can see, we've got a default shell (DSHELL), the starting value for UIDs (FIRST_UID), the location for home directories (DHOME) and the source location for startup files (SKEL) that will be added to each account as it is set up - along with a number of additional settings. This file also specifies the permissions to be assigned to home directories (DIR_MODE).
-
-One of the more important settings is DIR_MODE, which determines the permissions that are used for each user's home directory. Given this setting, the permissions assigned to a directory that the user creates will be 755. Given this setting, home directories will be set up with rwxr-xr-x permissions. Users will be able to read other users' files, but not modify or remove them. If you want to be more restrictive, you can change this setting to 750 (no access by anyone outside the user's group) or even 700 (no access but the user himself).
-
-Any user account settings can be manually changed after the accounts are set up. For example, you can edit the /etc/passwd file or chmod home directory, but configuring the /etc/adduser.conf file _before_ you start adding accounts on a new server will ensure some consistency and save you some time and trouble over the long run.
-
-Changes to the /etc/adduser.conf file will affect all accounts that are set up subsequent to those changes. If you want to set up some specific account differently, you've also got the option of providing account configuration options as arguments with the adduser command in addition to the username. Maybe you want to assign a different shell for some user, request a specific UID, or disable logins altogether. The man page for the adduser command will display some of your choices for configuring an individual account.
-```
-adduser [options] [--home DIR] [--shell SHELL] [--no-create-home]
-[--uid ID] [--firstuid ID] [--lastuid ID] [--ingroup GROUP | --gid ID]
-[--disabled-password] [--disabled-login] [--gecos GECOS]
-[--add_extra_groups] [--encrypt-home] user
-
-```
-
-These days probably every Linux system is, by default, going to put each user into his or her own group. As an admin, you might elect to do things differently. You might find that putting users in shared groups works better for your site, electing to use adduser's --gid option to select a specific group. Users can, of course, always be members of multiple groups, so you have some options on how to manage groups -- both primary and secondary.
-
-### Dealing with user passwords
-
-Since it's always a bad idea to know someone else's password, admins will generally use a temporary password when they set up an account and then run a command that will force the user to change his password on his first login. Here's an example:
-```
-$ sudo chage -d 0 jdoe
-
-```
-
-When the user logs in, he will see something like this:
-```
-WARNING: Your password has expired.
-You must change your password now and login again!
-Changing password for jdoe.
-(current) UNIX password:
-
-```
-
-### Adding users to secondary groups
-
-To add a user to a secondary group, you might use the usermod command as shown below -- to add the user to the group and then verify that the change was made.
-```
-$ sudo usermod -a -G sudo jdoe
-$ sudo grep sudo /etc/group
-sudo:x:27:shs,jdoe
-
-```
-
-Keep in mind that some groups -- like the sudo or wheel group -- imply certain privileges. More on this in a moment.
-
-### Removing accounts, adding groups, etc.
-
-Linux systems also provide commands to remove accounts, add new groups, remove groups, etc. The **deluser** command, for example, will remove the user login entries from the /etc/passwd and /etc/shadow files but leave her home directory intact unless you add the --remove-home or --remove-all-files option. The **addgroup** command adds a group, but will give it the next group id in the sequence (i.e., likely in the user group range) unless you use the --gid option.
-```
-$ sudo addgroup testgroup --gid=131
-Adding group `testgroup' (GID 131) ...
-Done.
-
-```
-
-### Managing privileged accounts
-
-Some Linux systems have a wheel group that gives members the ability to run commands as root. In this case, the /etc/sudoers file references this group. On Debian systems, this group is called sudo, but it works the same way and you'll see a reference like this in the /etc/sudoers file:
-```
-%sudo ALL=(ALL:ALL) ALL
-
-```
-
-This setting basically means that anyone in the wheel or sudo group can run all commands with the power of root once they preface them with the sudo command.
-
-You can also add more limited privileges to the sudoers file -- maybe to give particular users the ability to run one or two commands as root. If you do, you should also periodically review the /etc/sudoers file to gauge how much privilege users have and very that the privileges provided are still required.
-
-In the command shown below, we're looking at the active lines in the /etc/sudoers file. The most interesting lines in this file include the path set for commands that can be run using the sudo command and the two groups that are allowed to run commands via sudo. As was just mentioned, individuals can be given permissions by being directly included in the sudoers file, but it is generally better practice to define privileges through group memberships.
-```
-# cat /etc/sudoers | grep -v "^#" | grep -v "^$"
-Defaults env_reset
-Defaults mail_badpass
-Defaults secure_path="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin"
-root ALL=(ALL:ALL) ALL
-%admin ALL=(ALL) ALL <== admin group
-%sudo ALL=(ALL:ALL) ALL <== sudo group
-
-```
-
-### Checking on logins
-
-To see when a user last logged in, you can use a command like this one:
-```
-# last jdoe
-jdoe pts/18 192.168.0.11 Thu Sep 14 08:44 - 11:48 (00:04)
-jdoe pts/18 192.168.0.11 Thu Sep 14 13:43 - 18:44 (00:00)
-jdoe pts/18 192.168.0.11 Thu Sep 14 19:42 - 19:43 (00:00)
-
-```
-
-If you want to see when each of your users last logged in, you can run the last command through a loop like this one:
-```
-$ for user in `ls /home`; do last $user | head -1; done
-
-jdoe pts/18 192.168.0.11 Thu Sep 14 19:42 - 19:43 (00:03)
-
-rocket pts/18 192.168.0.11 Thu Sep 14 13:02 - 13:02 (00:00)
-shs pts/17 192.168.0.11 Thu Sep 14 12:45 still logged in
-
-
-```
-
-This command will only show you users who have logged on since the current wtmp file became active. The blank lines indicate that some users have never logged in since that time, but doesn't call them out. A better command would be this one that clear displays the users who have not logged in at all in this time period:
-```
-$ for user in `ls /home`; do echo -n "$user ";last $user | head -1 | awk '{print substr($0,40)}'; done
-dhayes
-jdoe pts/18 192.168.0.11 Thu Sep 14 19:42 - 19:43
-peanut pts/19 192.168.0.29 Mon Sep 11 09:15 - 17:11
-rocket pts/18 192.168.0.11 Thu Sep 14 13:02 - 13:02
-shs pts/17 192.168.0.11 Thu Sep 14 12:45 still logged
-tsmith
-
-```
-
-That command is a lot to type, but could be turned into a script to make it a lot easier to use.
-```
-#!/bin/bash
-
-for user in `ls /home`
-do
- echo -n "$user ";last $user | head -1 | awk '{print substr($0,40)}'
-done
-
-```
-
-Sometimes this kind of information can alert you to changes in users' roles that suggest they may no longer need the accounts in question.
-
-### Communicating with users
-
-Linux systems provide a number of ways to communicate with your users. You can add messages to the /etc/motd file that will be displayed when a user logs into a server using a terminal connection. You can also message users with commands such as write (message to single user) or wall (write to all logled in users.
-```
-$ wall System will go down in one hour
-
-Broadcast message from shs@stinkbug (pts/17) (Thu Sep 14 14:04:16 2017):
-
-System will go down in one hour
-
-```
-
-Important messages should probably be delivered through multiple channels as it's difficult to predict what users will actually notice. Together, message-of-the-day (motd), wall, and email notifications might stand of chance of getting most of your users' attention.
-
-### Paying attention to log files
-
-Paying attention to log files can also help you understand user activity. In particular, the /var/log/auth.log file will show you user login and logout activity, creation of new groups, etc. The /var/log/messages or /var/log/syslog files will tell you more about system activity.
-
-### Tracking problems and requests
-
-Whether or not you install a ticketing application on your Linux system, it's important to track the problems that your users run into and the requests that they make. Your users won't be happy if some portion of their requests fall through the proverbial cracks. Even a paper log could be helpful or, better yet, a spreadsheet that allows you to notice what issues are still outstanding and what the root cause of the problems turned out to be. Ensuring that problems and requests are addressed is important and logs can also help you remember what you had to do to address a problem that re-emerges many months or even years later.
-
-### Wrap-up
-
-Managing user accounts on a busy server depends in part on starting out with well configured defaults and in part on monitoring user activities and problems encountered. Users are likely to be happy if they feel you are responsive to their concerns and know what to expect when system upgrades are needed.
-
-
---------------------------------------------------------------------------------
-
-via: https://www.networkworld.com/article/3225109/linux/managing-users-on-linux-systems.html
-
-作者:[Sandra Henry-Stocker][a]
-译者:[runningwater](https://github.com/runningwater)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
diff --git a/sources/tech/20171116 How to use a here documents to write data to a file in bash script.md b/sources/tech/20171116 How to use a here documents to write data to a file in bash script.md
index 9c2a636b09..12d15af78f 100644
--- a/sources/tech/20171116 How to use a here documents to write data to a file in bash script.md
+++ b/sources/tech/20171116 How to use a here documents to write data to a file in bash script.md
@@ -1,4 +1,3 @@
-translating by ljgibbslf
How to use a here documents to write data to a file in bash script
======
diff --git a/sources/tech/20171130 Excellent Business Software Alternatives For Linux.md b/sources/tech/20171130 Excellent Business Software Alternatives For Linux.md
index 195b51423a..3469c62569 100644
--- a/sources/tech/20171130 Excellent Business Software Alternatives For Linux.md
+++ b/sources/tech/20171130 Excellent Business Software Alternatives For Linux.md
@@ -1,4 +1,3 @@
-Yoliver istranslating.
Excellent Business Software Alternatives For Linux
-------
diff --git a/sources/tech/20180105 The Best Linux Distributions for 2018.md b/sources/tech/20180105 The Best Linux Distributions for 2018.md
index 3be92638c5..cc60350641 100644
--- a/sources/tech/20180105 The Best Linux Distributions for 2018.md
+++ b/sources/tech/20180105 The Best Linux Distributions for 2018.md
@@ -1,4 +1,4 @@
-The Best Linux Distributions for 2018
+[translating by dianbanjiu] The Best Linux Distributions for 2018
============================================================

diff --git a/sources/tech/29180329 Python ChatOps libraries- Opsdroid and Errbot.md b/sources/tech/20180329 Python ChatOps libraries- Opsdroid and Errbot.md
similarity index 99%
rename from sources/tech/29180329 Python ChatOps libraries- Opsdroid and Errbot.md
rename to sources/tech/20180329 Python ChatOps libraries- Opsdroid and Errbot.md
index d7ef058106..5f409956f7 100644
--- a/sources/tech/29180329 Python ChatOps libraries- Opsdroid and Errbot.md
+++ b/sources/tech/20180329 Python ChatOps libraries- Opsdroid and Errbot.md
@@ -1,5 +1,3 @@
-Translating by shipsw
-
Python ChatOps libraries: Opsdroid and Errbot
======
diff --git a/sources/tech/20180522 How to Enable Click to Minimize On Ubuntu.md b/sources/tech/20180522 How to Enable Click to Minimize On Ubuntu.md
index 761138908d..50d68ad445 100644
--- a/sources/tech/20180522 How to Enable Click to Minimize On Ubuntu.md
+++ b/sources/tech/20180522 How to Enable Click to Minimize On Ubuntu.md
@@ -1,5 +1,3 @@
-translated by cyleft
-
How to Enable Click to Minimize On Ubuntu
============================================================
diff --git a/sources/tech/20180531 How to create shortcuts in vi.md b/sources/tech/20180531 How to create shortcuts in vi.md
deleted file mode 100644
index ba856e745a..0000000000
--- a/sources/tech/20180531 How to create shortcuts in vi.md
+++ /dev/null
@@ -1,131 +0,0 @@
-【sd886393认领翻译中】How to create shortcuts in vi
-======
-
-
-
-Learning the [vi text editor][1] takes some effort, but experienced vi users know that after a while, using basic commands becomes second nature. It's a form of what is known as muscle memory, which in this case might well be called finger memory.
-
-After you get a grasp of the main approach and basic commands, you can make editing with vi even more powerful and streamlined by using its customization options to create shortcuts. I hope that the techniques described below will facilitate your writing, programming, and data manipulation.
-
-Before proceeding, I'd like to thank Chris Hermansen (who recruited me to write this article) for checking my draft with [Vim][2], as I use another version of vi. I'm also grateful for Chris's helpful suggestions, which I incorporated here.
-
-First, let's review some conventions. I'll use to designate pressing the RETURN or ENTER key, and for the space bar. CTRL-x indicates simultaneously pressing the Control key and the x key (whatever x happens to be).
-
-Set up your own command abbreviations with the `map` command. My first example involves the `write` command, used to save the current state of the file you're working on:
-```
-:w
-
-```
-
-This is only three keystrokes, but since I do it so frequently, I'd rather use only one. The key I've chosen for this purpose is the comma, which is not part of the standard vi command set. The command to set this up is:
-```
-:map , :wCTRL-v
-
-```
-
-The CTRL-v is essential since without it the would signal the end of the map, and we want to include the as part of the mapped comma. In general, CTRL-v is used to enter the keystroke (or control character) that follows rather than being interpreted literally.
-
-In the above map, the part on the right will display on the screen as `:w^M`. The caret (`^`) indicates a control character, in this case CTRL-m, which is the system's form of .
-
-So far so good—sort of. If I write my current file about a dozen times while creating and/or editing it, this map could result in a savings of 2 x 12 keystrokes. But that doesn't account for the keystrokes needed to set up the map, which in the above example is 11 (counting CTRL-v and the shifted character `:` as one stroke each). Even with a net savings, it would be a bother to set up the map each time you start a vi session.
-
-Fortunately, there's a way to put maps and other abbreviations in a startup file that vi reads each time it is invoked: the `.exrc` file, or in Vim, the `.vimrc` file. Simply create this file in your home directory with a list of maps, one per line—without the colon—and the abbreviation is defined for all subsequent vi sessions until you delete or change it.
-
-Before going on to a variation of the `map` command and another type of abbreviation method, here are a few more examples of maps that I've found useful for streamlining my text editing:
-```
- Displays as
-
-
-
-:map X :xCTRL-v :x^M
-
-
-
-or
-
-
-
-:map X ,:qCTRL-v ,:q^M
-
-```
-
-The above equivalent maps write and quit (exit) the file. The `:x` is the standard vi command for this, and the second version illustrates that a previously defined map may be used in a subsequent map.
-```
-:map v :e :e
-
-```
-
-The above starts the command to move to another file while remaining within vi; when using this, just follow the "v" with a filename, followed by .
-```
-:map CTRL-vCTRL-e :e#CTRL-v :e #^M
-
-```
-
-The `#` here is the standard vi symbol for "the alternate file," which means the filename last used, so this shortcut is handy for switching back and forth between two files. Here's an example of how I use this:
-```
-map CTRL-vCTRL-r :!spell %>err &CTRL-v :!spell %>err&^M
-
-```
-
-(Note: The first CTRL-v in both examples above is not needed in some versions of vi.) The `:!` is a way to run an external (non-vi) command. In this case (`spell`), `%` is the vi symbol denoting the current file, the `>` redirects the output of the spell-check to a file called `err`, and the `&` says to run this in the background so I can continue editing while `spell` completes its task. I can then type `verr` (using my previous shortcut, `v`, followed by `err`) to go the file of potential errors flagged by the `spell` command, then back to the file I'm working on with CTRL-e. After running the spell-check the first time, I can use CTRL-r repeatedly and return to the `err` file with just CTRL-e.
-
-A variation of the `map` command may be used to abbreviate text strings while inputting. For example,
-```
-:map! CTRL-o \fI
-
-:map! CTRL-k \fP
-
-```
-
-This will allow you to use CTRL-o as a shortcut for entering the `groff` command to italicize the word that follows, and this will allow you to use CTRL-k for the `groff` command reverts to the previous font.
-
-Here are two other examples of this technique:
-```
-:map! rh rhinoceros
-
-:map! hi hippopotamus
-
-```
-
-The above may instead be accomplished using the `ab` command, as follows (if you're trying these out in order, first use `unmap! rh` and `umap! hi`):
-```
-:ab rh rhinoceros
-
-:ab hi hippopotamus
-
-```
-
-In the `map!` method above, the abbreviation immediately expands to the defined word when typed (in Vim), whereas with the `ab` method, the expansion occurs when the abbreviation is followed by a space or punctuation mark (in both Vim and my version of vi, where the expansion also works like this for the `map!` method).
-
-To reverse any `map`, `map!`, or `ab` within a vi session, use `:unmap`, `:unmap!`, or `:unab`.
-
-In my version of vi, undefined letters that are good candidates for mapping include g, K, q, v, V, and Z; undefined control characters are CTRL-a, CTRL-c, CTRL-k, CTRL-n, CTRL-o, CTRL-p, and CTRL-x; some other undefined characters are `#` and `*`. You can also redefine characters that have meaning in vi but that you consider obscure and of little use; for example, the X that I chose for two examples in this article is a built-in vi command to delete the character to the immediate left of the current character (easily accomplished by the two-key command `hx`).
-
-Finally, the commands
-```
-:map
-
-:map!
-
-:ab
-
-```
-
-will show all the currently defined mappings and abbreviations.
-
-I hope that all of these tips will help you customize vi and make it easier and more efficient to use.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/5/shortcuts-vi-text-editor
-
-作者:[Dan Sonnenschein][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/dannyman
-[1]:http://ex-vi.sourceforge.net/
-[2]:https://www.vim.org/
diff --git a/sources/tech/20180724 75 Most Used Essential Linux Applications of 2018.md b/sources/tech/20180724 75 Most Used Essential Linux Applications of 2018.md
deleted file mode 100644
index 919182ba1f..0000000000
--- a/sources/tech/20180724 75 Most Used Essential Linux Applications of 2018.md
+++ /dev/null
@@ -1,988 +0,0 @@
-75 Most Used Essential Linux Applications of 2018
-======
-
-**2018** has been an awesome year for a lot of applications, especially those that are both free and open source. And while various Linux distributions come with a number of default apps, users are free to take them out and use any of the free or paid alternatives of their choice.
-
-Today, we bring you a [list of Linux applications][3] that have been able to make it to users’ Linux installations almost all the time despite the butt-load of other alternatives.
-
-To simply put, any app on this list is among the most used in its category, and if you haven’t already tried it out you are probably missing out. Enjoy!
-
-### Backup Tools
-
-#### Rsync
-
-[Rsync][4] is an open source bandwidth-friendly utility tool for performing swift incremental file transfers and it is available for free.
-```
-$ rsync [OPTION...] SRC... [DEST]
-
-```
-
-To know more examples and usage, read our article “[10 Practical Examples of Rsync Command][5]” to learn more about it.
-
-#### Timeshift
-
-[Timeshift][6] provides users with the ability to protect their system by taking incremental snapshots which can be reverted to at a different date – similar to the function of Time Machine in Mac OS and System restore in Windows.
-
-
-
-### BitTorrent Client
-
-
-
-#### Deluge
-
-[Deluge][7] is a beautiful cross-platform BitTorrent client that aims to perfect the **μTorrent** experience and make it available to users for free.
-
-Install **Deluge** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:deluge-team/ppa
-$ sudo apt-get update
-$ sudo apt-get install deluge
-
-```
-
-#### qBittorent
-
-[qBittorent][8] is an open source BitTorrent protocol client that aims to provide a free alternative to torrent apps like μTorrent.
-
-Install **qBittorent** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:qbittorrent-team/qbittorrent-stable
-$ sudo apt-get update
-$ sudo apt-get install qbittorrent
-
-```
-
-#### Transmission
-
-[Transmission][9] is also a BitTorrent client with awesome functionalities and a major focus on speed and ease of use. It comes preinstalled with many Linux distros.
-
-Install **Transmission** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:transmissionbt/ppa
-$ sudo apt-get update
-$ sudo apt-get install transmission-gtk transmission-cli transmission-common transmission-daemon
-
-```
-
-### Cloud Storage
-
-
-
-#### Dropbox
-
-The [Dropbox][10] team rebranded their cloud service earlier this year to provide an even better performance and app integration for their clients. It starts with 2GB of storage for free.
-
-Install **Dropbox** on **Ubuntu** and **Debian** , using following commands.
-```
-$ cd ~ && wget -O - "https://www.dropbox.com/download?plat=lnx.x86" | tar xzf - [On 32-Bit]
-$ cd ~ && wget -O - "https://www.dropbox.com/download?plat=lnx.x86_64" | tar xzf - [On 64-Bit]
-$ ~/.dropbox-dist/dropboxd
-
-```
-
-#### Google Drive
-
-[Google Drive][11] is Google’s cloud service solution and my guess is that it needs no introduction. Just like with **Dropbox** , you can sync files across all your connected devices. It starts with 15GB of storage for free and this includes Gmail, Google photos, Maps, etc.
-
-Check out: [5 Google Drive Clients for Linux][12]
-
-#### Mega
-
-[Mega][13] stands out from the rest because apart from being extremely security-conscious, it gives free users 50GB to do as they wish! Its end-to-end encryption ensures that they can’t access your data, and if you forget your recovery key, you too wouldn’t be able to.
-
-[**Download MEGA Cloud Storage for Ubuntu][14]
-
-### Commandline Editors
-
-
-
-#### Vim
-
-[Vim][15] is an open source clone of vi text editor developed to be customizable and able to work with any type of text.
-
-Install **Vim** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:jonathonf/vim
-$ sudo apt update
-$ sudo apt install vim
-
-```
-
-#### Emacs
-
-[Emacs][16] refers to a set of highly configurable text editors. The most popular variant, GNU Emacs, is written in Lisp and C to be self-documenting, extensible, and customizable.
-
-Install **Emacs** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:kelleyk/emacs
-$ sudo apt update
-$ sudo apt install emacs25
-
-```
-
-#### Nano
-
-[Nano][17] is a feature-rich CLI text editor for power users and it has the ability to work with different terminals, among other functionalities.
-
-Install **Nano** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:n-muench/programs-ppa
-$ sudo apt-get update
-$ sudo apt-get install nano
-
-```
-
-### Download Manager
-
-
-
-#### Aria2
-
-[Aria2][18] is an open source lightweight multi-source and multi-protocol command line-based downloader with support for Metalinks, torrents, HTTP/HTTPS, SFTP, etc.
-
-Install **Aria2** on **Ubuntu** and **Debian** , using following command.
-```
-$ sudo apt-get install aria2
-
-```
-
-#### uGet
-
-[uGet][19] has earned its title as the **#1** open source download manager for Linux distros and it features the ability to handle any downloading task you can throw at it including using multiple connections, using queues, categories, etc.
-
-Install **uGet** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:plushuang-tw/uget-stable
-$ sudo apt update
-$ sudo apt install uget
-
-```
-
-#### XDM
-
-[XDM][20], **Xtreme Download Manager** is an open source downloader written in Java. Like any good download manager, it can work with queues, torrents, browsers, and it also includes a video grabber and a smart scheduler.
-
-Install **XDM** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:noobslab/apps
-$ sudo apt-get update
-$ sudo apt-get install xdman
-
-```
-
-### Email Clients
-
-
-
-#### Thunderbird
-
-[Thunderbird][21] is among the most popular email applications. It is free, open source, customizable, feature-rich, and above all, easy to install.
-
-Install **Thunderbird** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:ubuntu-mozilla-security/ppa
-$ sudo apt-get update
-$ sudo apt-get install thunderbird
-
-```
-
-#### Geary
-
-[Geary][22] is an open source email client based on WebKitGTK+. It is free, open-source, feature-rich, and adopted by the GNOME project.
-
-Install **Geary** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:geary-team/releases
-$ sudo apt-get update
-$ sudo apt-get install geary
-
-```
-
-#### Evolution
-
-[Evolution][23] is a free and open source email client for managing emails, meeting schedules, reminders, and contacts.
-
-Install **Evolution** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:gnome3-team/gnome3-staging
-$ sudo apt-get update
-$ sudo apt-get install evolution
-
-```
-
-### Finance Software
-
-
-
-#### GnuCash
-
-[GnuCash][24] is a free, cross-platform, and open source software for financial accounting tasks for personal and small to mid-size businesses.
-
-Install **GnuCash** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo sh -c 'echo "deb http://archive.getdeb.net/ubuntu $(lsb_release -sc)-getdeb apps" >> /etc/apt/sources.list.d/getdeb.list'
-$ sudo apt-get update
-$ sudo apt-get install gnucash
-
-```
-
-#### KMyMoney
-
-[KMyMoney][25] is a finance manager software that provides all important features found in the commercially-available, personal finance managers.
-
-Install **KMyMoney** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:claydoh/kmymoney2-kde4
-$ sudo apt-get update
-$ sudo apt-get install kmymoney
-
-```
-
-### IDE Editors
-
-
-
-#### Eclipse IDE
-
-[Eclipse][26] is the most widely used Java IDE containing a base workspace and an impossible-to-overemphasize configurable plug-in system for personalizing its coding environment.
-
-For installation, read our article “[How to Install Eclipse Oxygen IDE in Debian and Ubuntu][27]”
-
-#### Netbeans IDE
-
-A fan-favourite, [Netbeans][28] enables users to easily build applications for mobile, desktop, and web platforms using Java, PHP, HTML5, JavaScript, and C/C++, among other languages.
-
-For installation, read our article “[How to Install Netbeans Oxygen IDE in Debian and Ubuntu][29]”
-
-#### Brackets
-
-[Brackets][30] is an advanced text editor developed by Adobe to feature visual tools, preprocessor support, and a design-focused user flow for web development. In the hands of an expert, it can serve as an IDE in its own right.
-
-Install **Brackets** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:webupd8team/brackets
-$ sudo apt-get update
-$ sudo apt-get install brackets
-
-```
-
-#### Atom IDE
-
-[Atom IDE][31] is a more robust version of Atom text editor achieved by adding a number of extensions and libraries to boost its performance and functionalities. It is, in a sense, Atom on steroids.
-
-Install **Atom** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get install snapd
-$ sudo snap install atom --classic
-
-```
-
-#### Light Table
-
-[Light Table][32] is a self-proclaimed next-generation IDE developed to offer awesome features like data value flow stats and coding collaboration.
-
-Install **Light Table** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:dr-akulavich/lighttable
-$ sudo apt-get update
-$ sudo apt-get install lighttable-installer
-
-```
-
-#### Visual Studio Code
-
-[Visual Studio Code][33] is a source code editor created by Microsoft to offer users the best-advanced features in a text editor including syntax highlighting, code completion, debugging, performance statistics and graphs, etc.
-
-[**Download Visual Studio Code for Ubuntu][34]
-
-### Instant Messaging
-
-
-
-#### Pidgin
-
-[Pidgin][35] is an open source instant messaging app that supports virtually all chatting platforms and can have its abilities extended using extensions.
-
-Install **Pidgin** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:jonathonf/backports
-$ sudo apt-get update
-$ sudo apt-get install pidgin
-
-```
-
-#### Skype
-
-[Skype][36] needs no introduction and its awesomeness is available for any interested Linux user.
-
-Install **Skype** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt install snapd
-$ sudo snap install skype --classic
-
-```
-
-#### Empathy
-
-[Empathy][37] is a messaging app with support for voice, video chat, text, and file transfers over multiple several protocols. It also allows you to add other service accounts to it and interface with all of them through it.
-
-Install **Empathy** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get install empathy
-
-```
-
-### Linux Antivirus
-
-#### ClamAV/ClamTk
-
-[ClamAV][38] is an open source and cross-platform command line antivirus app for detecting Trojans, viruses, and other malicious codes. [ClamTk][39] is its GUI front-end.
-
-Install **ClamAV/ClamTk** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get install clamav
-$ sudo apt-get install clamtk
-
-```
-
-### Linux Desktop Environments
-
-#### Cinnamon
-
-[Cinnamon][40] is a free and open-source derivative of **GNOME3** and it follows the traditional desktop metaphor conventions.
-
-Install **Cinnamon** desktop on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:embrosyn/cinnamon
-$ sudo apt update
-$ sudo apt install cinnamon-desktop-environment lightdm
-
-```
-
-#### Mate
-
-The [Mate][41] Desktop Environment is a derivative and continuation of **GNOME2** developed to offer an attractive UI on Linux using traditional metaphors.
-
-Install **Mate** desktop on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt install tasksel
-$ sudo apt update
-$ sudo tasksel install ubuntu-mate-desktop
-
-```
-
-#### GNOME
-
-[GNOME][42] is a Desktop Environment comprised of several free and open-source applications and can run on any Linux distro and on most BSD derivatives.
-
-Install **Gnome** desktop on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt install tasksel
-$ sudo apt update
-$ sudo tasksel install ubuntu-desktop
-
-```
-
-#### KDE
-
-[KDE][43] is developed by the KDE community to provide users with a graphical solution to interfacing with their system and performing several computing tasks.
-
-Install **KDE** desktop on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt install tasksel
-$ sudo apt update
-$ sudo tasksel install kubuntu-desktop
-
-```
-
-### Linux Maintenance Tools
-
-#### GNOME Tweak Tool
-
-The [GNOME Tweak Tool][44] is the most popular tool for customizing and tweaking GNOME3 and GNOME Shell settings.
-
-Install **GNOME Tweak Tool** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt install gnome-tweak-tool
-
-```
-
-#### Stacer
-
-[Stacer][45] is a free, open-source app for monitoring and optimizing Linux systems.
-
-Install **Stacer** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:oguzhaninan/stacer
-$ sudo apt-get update
-$ sudo apt-get install stacer
-
-```
-
-#### BleachBit
-
-[BleachBit][46] is a free disk space cleaner that also works as a privacy manager and system optimizer.
-
-[**Download BleachBit for Ubuntu][47]
-
-### Linux Terminals
-
-#### GNOME Terminal
-
-[GNOME Terminal][48] is GNOME’s default terminal emulator.
-
-Install **Gnome Terminal** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get install gnome-terminal
-
-```
-
-#### Konsole
-
-[Konsole][49] is a terminal emulator for KDE.
-
-Install **Konsole** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get install konsole
-
-```
-
-#### Terminator
-
-[Terminator][50] is a feature-rich GNOME Terminal-based terminal app built with a focus on arranging terminals, among other functions.
-
-Install **Terminator** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get install terminator
-
-```
-
-#### Guake
-
-[Guake][51] is a lightweight drop-down terminal for the GNOME Desktop Environment.
-
-Install **Guake** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get install guake
-
-```
-
-### Multimedia Editors
-
-#### Ardour
-
-[Ardour][52] is a beautiful Digital Audio Workstation (DAW) for recording, editing, and mixing audio professionally.
-
-Install **Ardour** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:dobey/audiotools
-$ sudo apt-get update
-$ sudo apt-get install ardour
-
-```
-
-#### Audacity
-
-[Audacity][53] is an easy-to-use cross-platform and open source multi-track audio editor and recorder; arguably the most famous of them all.
-
-Install **Audacity** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:ubuntuhandbook1/audacity
-$ sudo apt-get update
-$ sudo apt-get install audacity
-
-```
-
-#### GIMP
-
-[GIMP][54] is the most popular open source Photoshop alternative and it is for a reason. It features various customization options, 3rd-party plugins, and a helpful user community.
-
-Install **Gimp** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:otto-kesselgulasch/gimp
-$ sudo apt update
-$ sudo apt install gimp
-
-```
-
-#### Krita
-
-[Krita][55] is an open source painting app that can also serve as an image manipulating tool and it features a beautiful UI with a reliable performance.
-
-Install **Krita** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:kritalime/ppa
-$ sudo apt update
-$ sudo apt install krita
-
-```
-
-#### Lightworks
-
-[Lightworks][56] is a powerful, flexible, and beautiful tool for editing videos professionally. It comes feature-packed with hundreds of amazing effects and presets that allow it to handle any editing task that you throw at it and it has 25 years of experience to back up its claims.
-
-[**Download Lightworks for Ubuntu][57]
-
-#### OpenShot
-
-[OpenShot][58] is an award-winning free and open source video editor known for its excellent performance and powerful capabilities.
-
-Install **Openshot** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:openshot.developers/ppa
-$ sudo apt update
-$ sudo apt install openshot-qt
-
-```
-
-#### PiTiV
-
-[Pitivi][59] is a beautiful video editor that features a beautiful code base, awesome community, is easy to use, and allows for hassle-free collaboration.
-
-Install **PiTiV** on **Ubuntu** and **Debian** , using following commands.
-```
-$ flatpak install --user https://flathub.org/repo/appstream/org.pitivi.Pitivi.flatpakref
-$ flatpak install --user http://flatpak.pitivi.org/pitivi.flatpakref
-$ flatpak run org.pitivi.Pitivi//stable
-
-```
-
-### Music Players
-
-#### Rhythmbox
-
-[Rhythmbox][60] posses the ability to perform all music tasks you throw at it and has so far proved to be a reliable music player that it ships with Ubuntu.
-
-Install **Rhythmbox** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:fossfreedom/rhythmbox
-$ sudo apt-get update
-$ sudo apt-get install rhythmbox
-
-```
-
-#### Lollypop
-
-[Lollypop][61] is a beautiful, relatively new, open source music player featuring a number of advanced options like online radio, scrubbing support and party mode. Yet, it manages to keep everything simple and easy to manage.
-
-Install **Lollypop** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:gnumdk/lollypop
-$ sudo apt-get update
-$ sudo apt-get install lollypop
-
-```
-
-#### Amarok
-
-[Amarok][62] is a robust music player with an intuitive UI and tons of advanced features bundled into a single unit. It also allows users to discover new music based on their genre preferences.
-
-Install **Amarok** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get update
-$ sudo apt-get install amarok
-
-```
-
-#### Clementine
-
-[Clementine][63] is an Amarok-inspired music player that also features a straight-forward UI, advanced control features, and the ability to let users search for and discover new music.
-
-Install **Clementine** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:me-davidsansome/clementine
-$ sudo apt-get update
-$ sudo apt-get install clementine
-
-```
-
-#### Cmus
-
-[Cmus][64] is arguably the most efficient CLI music player, Cmus is fast and reliable, and its functionality can be increased using extensions.
-
-Install **Cmus** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:jmuc/cmus
-$ sudo apt-get update
-$ sudo apt-get install cmus
-
-```
-
-### Office Suites
-
-#### Calligra Suite
-
-The [Calligra Suite][65] provides users with a set of 8 applications which cover working with office, management, and graphics tasks.
-
-Install **Calligra Suite** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get install calligra
-
-```
-
-#### LibreOffice
-
-[LibreOffice][66] the most actively developed office suite in the open source community, LibreOffice is known for its reliability and its functions can be increased using extensions.
-
-Install **LibreOffice** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:libreoffice/ppa
-$ sudo apt update
-$ sudo apt install libreoffice
-
-```
-
-#### WPS Office
-
-[WPS Office][67] is a beautiful office suite alternative with a more modern UI.
-
-[**Download WPS Office for Ubuntu][68]
-
-### Screenshot Tools
-
-#### Shutter
-
-[Shutter][69] allows users to take screenshots of their desktop and then edit them using filters and other effects coupled with the option to upload and share them online.
-
-Install **Shutter** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository -y ppa:shutter/ppa
-$ sudo apt update
-$ sudo apt install shutter
-
-```
-
-#### Kazam
-
-[Kazam][70] screencaster captures screen content to output a video and audio file supported by any video player with VP8/WebM and PulseAudio support.
-
-Install **Kazam** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:kazam-team/unstable-series
-$ sudo apt update
-$ sudo apt install kazam python3-cairo python3-xlib
-
-```
-
-#### Gnome Screenshot
-
-[Gnome Screenshot][71] was once bundled with Gnome utilities but is now a standalone app. It can be used to take screencasts in a format that is easily shareable.
-
-Install **Gnome Screenshot** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get update
-$ sudo apt-get install gnome-screenshot
-
-```
-
-### Screen Recorders
-
-#### SimpleScreenRecorder
-
-[SimpleScreenRecorder][72] was created to be better than the screen-recording apps available at the time of its creation and has now turned into one of the most efficient and easy-to-use screen recorders for Linux distros.
-
-Install **SimpleScreenRecorder** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:maarten-baert/simplescreenrecorder
-$ sudo apt-get update
-$ sudo apt-get install simplescreenrecorder
-
-```
-
-#### recordMyDesktop
-
-[recordMyDesktop][73] is an open source session recorder that is also capable of recording desktop session audio.
-
-Install **recordMyDesktop** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get update
-$ sudo apt-get install gtk-recordmydesktop
-
-```
-
-### Text Editors
-
-#### Atom
-
-[Atom][74] is a modern and customizable text editor created and maintained by GitHub. It is ready for use right out of the box and can have its functionality enhanced and its UI customized using extensions and themes.
-
-Install **Atom** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get install snapd
-$ sudo snap install atom --classic
-
-```
-
-#### Sublime Text
-
-[Sublime Text][75] is easily among the most awesome text editors to date. It is customizable, lightweight (even when bulldozed with a lot of data files and extensions), flexible, and remains free to use forever.
-
-Install **Sublime Text** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get install snapd
-$ sudo snap install sublime-text
-
-```
-
-#### Geany
-
-[Geany][76] is a memory-friendly text editor with basic IDE features designed to exhibit shot load times and extensible functions using libraries.
-
-Install **Geany** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get update
-$ sudo apt-get install geany
-
-```
-
-#### Gedit
-
-[Gedit][77] is famous for its simplicity and it comes preinstalled with many Linux distros because of its function as an excellent general purpose text editor.
-
-Install **Gedit** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get update
-$ sudo apt-get install gedit
-
-```
-
-### To-Do List Apps
-
-#### Evernote
-
-[Evernote][78] is a cloud-based note-taking productivity app designed to work perfectly with different types of notes including to-do lists and reminders.
-
-There is no any official evernote app for Linux, so check out other third party [6 Evernote Alternative Clients for Linux][79].
-
-#### Everdo
-
-[Everdo][78] is a beautiful, security-conscious, low-friction Getting-Things-Done app productivity app for handling to-dos and other note types. If Evernote comes off to you in an unpleasant way, Everdo is a perfect alternative.
-
-[**Download Everdo for Ubuntu][80]
-
-#### Taskwarrior
-
-[Taskwarrior][81] is an open source and cross-platform command line app for managing tasks. It is famous for its speed and distraction-free environment.
-
-Install **Taskwarrior** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get update
-$ sudo apt-get install taskwarrior
-
-```
-
-### Video Players
-
-#### Banshee
-
-[Banshee][82] is an open source multi-format-supporting media player that was first developed in 2005 and has only been getting better since.
-
-Install **Banshee** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:banshee-team/ppa
-$ sudo apt-get update
-$ sudo apt-get install banshee
-
-```
-
-#### VLC
-
-[VLC][83] is my favourite video player and it’s so awesome that it can play almost any audio and video format you throw at it. You can also use it to play internet radio, record desktop sessions, and stream movies online.
-
-Install **VLC** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:videolan/stable-daily
-$ sudo apt-get update
-$ sudo apt-get install vlc
-
-```
-
-#### Kodi
-
-[Kodi][84] is among the world’s most famous media players and it comes as a full-fledged media centre app for playing all things media whether locally or remotely.
-
-Install **Kodi** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get install software-properties-common
-$ sudo add-apt-repository ppa:team-xbmc/ppa
-$ sudo apt-get update
-$ sudo apt-get install kodi
-
-```
-
-#### SMPlayer
-
-[SMPlayer][85] is a GUI for the award-winning **MPlayer** and it is capable of handling all popular media formats; coupled with the ability to stream from YouTube, Chromcast, and download subtitles.
-
-Install **SMPlayer** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:rvm/smplayer
-$ sudo apt-get update
-$ sudo apt-get install smplayer
-
-```
-
-### Virtualization Tools
-
-#### VirtualBox
-
-[VirtualBox][86] is an open source app created for general-purpose OS virtualization and it can be run on servers, desktops, and embedded systems.
-
-Install **VirtualBox** on **Ubuntu** and **Debian** , using following commands.
-```
-$ wget -q https://www.virtualbox.org/download/oracle_vbox_2016.asc -O- | sudo apt-key add -
-$ wget -q https://www.virtualbox.org/download/oracle_vbox.asc -O- | sudo apt-key add -
-$ sudo apt-get update
-$ sudo apt-get install virtualbox-5.2
-$ virtualbox
-
-```
-
-#### VMWare
-
-[VMware][87] is a digital workspace that provides platform virtualization and cloud computing services to customers and is reportedly the first to successfully virtualize x86 architecture systems. One of its products, VMware workstations allows users to run multiple OSes in a virtual memory.
-
-For installation, read our article “[How to Install VMware Workstation Pro on Ubuntu][88]“.
-
-### Web Browsers
-
-#### Chrome
-
-[Google Chrome][89] is undoubtedly the most popular browser. Known for its speed, simplicity, security, and beauty following Google’s Material Design trend, Chrome is a browser that web developers cannot do without. It is also free to use and open source.
-
-Install **Google Chrome** on **Ubuntu** and **Debian** , using following commands.
-```
-$ wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | sudo apt-key add -
-$ sudo sh -c 'echo "deb http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list'
-$ sudo apt-get update
-$ sudo apt-get install google-chrome-stable
-
-```
-
-#### Firefox
-
-[Firefox Quantum][90] is a beautiful, speed, task-ready, and customizable browser capable of any browsing task that you throw at it. It is also free, open source, and packed with developer-friendly tools that are easy for even beginners to get up and running with.
-
-Install **Firefox Quantum** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:mozillateam/firefox-next
-$ sudo apt update && sudo apt upgrade
-$ sudo apt install firefox
-
-```
-
-#### Vivaldi
-
-[Vivaldi][91] is a free and open source Chrome-based project that aims to perfect Chrome’s features with a couple of more feature additions. It is known for its colourful panels, memory-friendly performance, and flexibility.
-
-[**Download Vivaldi for Ubuntu][91]
-
-That concludes our list for today. Did I skip a famous title? Tell me about it in the comments section below.
-
-Don’t forget to share this post and to subscribe to our newsletter to get the latest publications from FossMint.
-
-
---------------------------------------------------------------------------------
-
-via: https://www.fossmint.com/most-used-linux-applications/
-
-作者:[Martins D. Okoi][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.fossmint.com/author/dillivine/
-[1]:https://plus.google.com/share?url=https://www.fossmint.com/most-used-linux-applications/ (Share on Google+)
-[2]:https://www.linkedin.com/shareArticle?mini=true&url=https://www.fossmint.com/most-used-linux-applications/ (Share on LinkedIn)
-[3]:https://www.fossmint.com/awesome-linux-software/
-[4]:https://rsync.samba.org/
-[5]:https://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
-[6]:https://github.com/teejee2008/timeshift
-[7]:https://deluge-torrent.org/
-[8]:https://www.qbittorrent.org/
-[9]:https://transmissionbt.com/
-[10]:https://www.dropbox.com/
-[11]:https://www.google.com/drive/
-[12]:https://www.fossmint.com/best-google-drive-clients-for-linux/
-[13]:https://mega.nz/
-[14]:https://mega.nz/sync!linux
-[15]:https://www.vim.org/
-[16]:https://www.gnu.org/s/emacs/
-[17]:https://www.nano-editor.org/
-[18]:https://aria2.github.io/
-[19]:http://ugetdm.com/
-[20]:http://xdman.sourceforge.net/
-[21]:https://www.thunderbird.net/
-[22]:https://github.com/GNOME/geary
-[23]:https://github.com/GNOME/evolution
-[24]:https://www.gnucash.org/
-[25]:https://kmymoney.org/
-[26]:https://www.eclipse.org/ide/
-[27]:https://www.tecmint.com/install-eclipse-oxygen-ide-in-ubuntu-debian/
-[28]:https://netbeans.org/
-[29]:https://www.tecmint.com/install-netbeans-ide-in-ubuntu-debian-linux-mint/
-[30]:http://brackets.io/
-[31]:https://ide.atom.io/
-[32]:http://lighttable.com/
-[33]:https://code.visualstudio.com/
-[34]:https://code.visualstudio.com/download
-[35]:https://www.pidgin.im/
-[36]:https://www.skype.com/
-[37]:https://wiki.gnome.org/Apps/Empathy
-[38]:https://www.clamav.net/
-[39]:https://dave-theunsub.github.io/clamtk/
-[40]:https://github.com/linuxmint/cinnamon-desktop
-[41]:https://mate-desktop.org/
-[42]:https://www.gnome.org/
-[43]:https://www.kde.org/plasma-desktop
-[44]:https://github.com/nzjrs/gnome-tweak-tool
-[45]:https://github.com/oguzhaninan/Stacer
-[46]:https://www.bleachbit.org/
-[47]:https://www.bleachbit.org/download
-[48]:https://github.com/GNOME/gnome-terminal
-[49]:https://konsole.kde.org/
-[50]:https://gnometerminator.blogspot.com/p/introduction.html
-[51]:http://guake-project.org/
-[52]:https://ardour.org/
-[53]:https://www.audacityteam.org/
-[54]:https://www.gimp.org/
-[55]:https://krita.org/en/
-[56]:https://www.lwks.com/
-[57]:https://www.lwks.com/index.php?option=com_lwks&view=download&Itemid=206
-[58]:https://www.openshot.org/
-[59]:http://www.pitivi.org/
-[60]:https://wiki.gnome.org/Apps/Rhythmbox
-[61]:https://gnumdk.github.io/lollypop-web/
-[62]:https://amarok.kde.org/en
-[63]:https://www.clementine-player.org/
-[64]:https://cmus.github.io/
-[65]:https://www.calligra.org/tour/calligra-suite/
-[66]:https://www.libreoffice.org/
-[67]:https://www.wps.com/
-[68]:http://wps-community.org/downloads
-[69]:http://shutter-project.org/
-[70]:https://launchpad.net/kazam
-[71]:https://gitlab.gnome.org/GNOME/gnome-screenshot
-[72]:http://www.maartenbaert.be/simplescreenrecorder/
-[73]:http://recordmydesktop.sourceforge.net/about.php
-[74]:https://atom.io/
-[75]:https://www.sublimetext.com/
-[76]:https://www.geany.org/
-[77]:https://wiki.gnome.org/Apps/Gedit
-[78]:https://everdo.net/
-[79]:https://www.fossmint.com/evernote-alternatives-for-linux/
-[80]:https://everdo.net/linux/
-[81]:https://taskwarrior.org/
-[82]:http://banshee.fm/
-[83]:https://www.videolan.org/
-[84]:https://kodi.tv/
-[85]:https://www.smplayer.info/
-[86]:https://www.virtualbox.org/wiki/VirtualBox
-[87]:https://www.vmware.com/
-[88]:https://www.tecmint.com/install-vmware-workstation-in-linux/
-[89]:https://www.google.com/chrome/
-[90]:https://www.mozilla.org/en-US/firefox/
-[91]:https://vivaldi.com/
diff --git a/sources/tech/20180727 How to analyze your system with perf and Python.md b/sources/tech/20180727 How to analyze your system with perf and Python.md
index ccc66b04a7..c1be98cc0e 100644
--- a/sources/tech/20180727 How to analyze your system with perf and Python.md
+++ b/sources/tech/20180727 How to analyze your system with perf and Python.md
@@ -1,5 +1,3 @@
-pinewall translating
-
How to analyze your system with perf and Python
======
diff --git a/sources/tech/20180803 5 Essential Tools for Linux Development.md b/sources/tech/20180803 5 Essential Tools for Linux Development.md
deleted file mode 100644
index 006372ca82..0000000000
--- a/sources/tech/20180803 5 Essential Tools for Linux Development.md
+++ /dev/null
@@ -1,148 +0,0 @@
-5 Essential Tools for Linux Development
-======
-
-
-
-Linux has become a mainstay for many sectors of work, play, and personal life. We depend upon it. With Linux, technology is expanding and evolving faster than anyone could have imagined. That means Linux development is also happening at an exponential rate. Because of this, more and more developers will be hopping on board the open source and Linux dev train in the immediate, near, and far-off future. For that, people will need tools. Fortunately, there are a ton of dev tools available for Linux; so many, in fact, that it can be a bit intimidating to figure out precisely what you need (especially if you’re coming from another platform).
-
-To make that easier, I thought I’d help narrow down the selection a bit for you. But instead of saying you should use Tool X and Tool Y, I’m going to narrow it down to five categories and then offer up an example for each. Just remember, for most categories, there are several available options. And, with that said, let’s get started.
-
-### Containers
-
-Let’s face it, in this day and age you need to be working with containers. Not only are they incredibly easy to deploy, they make for great development environments. If you regularly develop for a specific platform, why not do so by creating a container image that includes all of the tools you need to make the process quick and easy. With that image available, you can then develop and roll out numerous instances of whatever software or service you need.
-
-Using containers for development couldn’t be easier than it is with [Docker][1]. The advantages of using containers (and Docker) are:
-
- * Consistent development environment.
-
- * You can trust it will “just work” upon deployment.
-
- * Makes it easy to build across platforms.
-
- * Docker images available for all types of development environments and languages.
-
- * Deploying single containers or container clusters is simple.
-
-
-
-
-Thanks to [Docker Hub][2], you’ll find images for nearly any platform, development environment, server, service… just about anything you need. Using images from Docker Hub means you can skip over the creation of the development environment and go straight to work on developing your app, server, API, or service.
-
-Docker is easily installable of most every Linux platform. For example: To install Docker on Ubuntu, you only have to open a terminal window and issue the command:
-```
-sudo apt-get install docker.io
-
-```
-
-With Docker installed, you’re ready to start pulling down specific images, developing, and deploying (Figure 1).
-
-![Docker images][4]
-
-Figure 1: Docker images ready to deploy.
-
-[Used with permission][5]
-
-### Version control system
-
-If you’re working on a large project or with a team on a project, you’re going to need a version control system. Why? Because you need to keep track of your code, where your code is, and have an easy means of making commits and merging code from others. Without such a tool, your projects would be nearly impossible to manage. For Linux users, you cannot beat the ease of use and widespread deployment of [Git][6] and [GitHub][7]. If you’re new to their worlds, Git is the version control system that you install on your local machine and GitHub is the remote repository you use to upload (and then manage) your projects. Git can be installed on most Linux distributions. For example, on a Debian-based system, the install is as simple as:
-```
-sudo apt-get install git
-
-```
-
-Once installed, you are ready to start your journey with version control (Figure 2).
-
-![Git installed][9]
-
-Figure 2: Git is installed and available for many important tasks.
-
-[Used with permission][5]
-
-Github requires you to create an account. You can use it for free for non-commercial projects, or you can pay for commercial project housing (for more information check out the price matrix [here][10]).
-
-### Text editor
-
-Let’s face it, developing on Linux would be a bit of a challenge without a text editor. Of course what a text editor is varies, depending upon who you ask. One person might say vim, emacs, or nano, whereas another might go full-on GUI with their editor. But since we’re talking development, we need a tool that can meet the needs of the modern day developer. And before I mention a couple of text editors, I will say this: Yes, I know that vim is a serious workhorse for serious developers and, if you know it well vim will meet and exceed all of your needs. However, getting up to speed enough that it won’t be in your way, can be a bit of a hurdle for some developers (especially those new to Linux). Considering my goal is to always help win over new users (and not just preach to an already devout choir), I’m taking the GUI route here.
-
-As far as text editors are concerned, you cannot go wrong with the likes of [Bluefish][11]. Bluefish can be found in most standard repositories and features project support, multi-threaded support for remote files, search and replace, open files recursively, snippets sidebar, integrates with make, lint, weblint, xmllint, unlimited undo/redo, in-line spell checker, auto-recovery, full screen editing, syntax highlighting (Figure 3), support for numerous languages, and much more.
-
-![Bluefish][13]
-
-Figure 3: Bluefish running on Ubuntu Linux 18.04.
-
-[Used with permission][5]
-
-### IDE
-
-Integrated Development Environment (IDE) is a piece of software that includes a comprehensive set of tools that enable a one-stop-shop environment for developing. IDEs not only enable you to code your software, but document and build them as well. There are a number of IDEs for Linux, but one in particular is not only included in the standard repositories it is also very user-friendly and powerful. That tool in question is [Geany][14]. Geany features syntax highlighting, code folding, symbol name auto-completion, construct completion/snippets, auto-closing of XML and HTML tags, call tips, many supported filetypes, symbol lists, code navigation, build system to compile and execute your code, simple project management, and a built-in plugin system.
-
-Geany can be easily installed on your system. For example, on a Debian-based distribution, issue the command:
-```
-sudo apt-get install geany
-
-```
-
-Once installed, you’re ready to start using this very powerful tool that includes a user-friendly interface (Figure 4) that has next to no learning curve.
-
-![Geany][16]
-
-Figure 4: Geany is ready to serve as your IDE.
-
-[Used with permission][5]
-
-### diff tool
-
-There will be times when you have to compare two files to find where they differ. This could be two different copies of what was the same file (only one compiles and the other doesn’t). When that happens, you don’t want to have to do that manually. Instead, you want to employ the power of tool like [Meld][17]. Meld is a visual diff and merge tool targeted at developers. With Meld you can make short shrift out of discovering the differences between two files. Although you can use a command line diff tool, when efficiency is the name of the game, you can’t beat Meld.
-
-Meld allows you to open a comparison between to files and it will highlight the differences between each. Meld also allows you to merge comparisons either from the right or the left (as the files are opened side by side - Figure 5).
-
-![Comparing two files][19]
-
-Figure 5: Comparing two files with a simple difference.
-
-[Used with permission][5]
-
-Meld can be installed from most standard repositories. On a Debian-based system, the installation command is:
-```
-sudo apt-get install meld
-
-```
-
-### Working with efficiency
-
-These five tools not only enable you to get your work done, they help to make it quite a bit more efficient. Although there are a ton of developer tools available for Linux, you’re going to want to make sure you have one for each of the above categories (maybe even starting with the suggestions I’ve made).
-
-Learn more about Linux through the free ["Introduction to Linux" ][20]course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2018/8/5-essential-tools-linux-development
-
-作者:[Jack Wallen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/jlwallen
-[1]:https://www.docker.com/
-[2]:https://hub.docker.com/
-[3]:/files/images/5devtools1jpg
-[4]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_1.jpg?itok=V1Bsbkg9 (Docker images)
-[5]:/licenses/category/used-permission
-[6]:https://git-scm.com/
-[7]:https://github.com/
-[8]:/files/images/5devtools2jpg
-[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_2.jpg?itok=YJjhe4O6 (Git installed)
-[10]:https://github.com/pricing
-[11]:http://bluefish.openoffice.nl/index.html
-[12]:/files/images/5devtools3jpg
-[13]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_3.jpg?itok=66A7Svme (Bluefish)
-[14]:https://www.geany.org/
-[15]:/files/images/5devtools4jpg
-[16]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_4.jpg?itok=jRcA-0ue (Geany)
-[17]:http://meldmerge.org/
-[18]:/files/images/5devtools5jpg
-[19]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_5.jpg?itok=eLkfM9oZ (Comparing two files)
-[20]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180815 How to Create M3U Playlists in Linux [Quick Tip].md b/sources/tech/20180815 How to Create M3U Playlists in Linux [Quick Tip].md
deleted file mode 100644
index 3c0b63d63b..0000000000
--- a/sources/tech/20180815 How to Create M3U Playlists in Linux [Quick Tip].md
+++ /dev/null
@@ -1,84 +0,0 @@
-translating by lujun9972
-How to Create M3U Playlists in Linux [Quick Tip]
-======
-**Brief: A quick tip on how to create M3U playlists in Linux terminal from unordered files to play them in a sequence.**
-
-![Create M3U playlists in Linux Terminal][1]
-
-I am a fan of foreign tv series and it’s not always easy to get them on DVD or on streaming services like [Netflix][2]. Thankfully, you can find some of them on YouTube and [download them from YouTube][3].
-
-Now there comes a problem. Your files might not be sorted in a particular order. In GNU/Linux files are not naturally sort ordered by number sequencing so I had to make a .m3u playlist so [MPV video player][4] would play the videos in sequence and not out of sequence.
-
-Also sometimes the numbers are in the middle or the end like ‘My Web Series S01E01.mkv’ as an example. The episode information here is in the middle of the filename, the ‘S01E01’ which tells us, humans, which is the first episode and which needs to come in next.
-
-So what I did was to generate an m3u playlist in the video directory and tell MPV to play the .m3u playlist and it would take care of playing them in the sequence.
-
-### What is an M3U file?
-
-[M3U][5] is basically a text file that contains filenames in a specific order. When a player like MPV or VLC opens an M3U file, it tries to play the specified files in the given sequence.
-
-### Creating M3U to play audio/video files in a sequence
-
-In my case, I used the following command:
-```
-$/home/shirish/Videos/web-series-video/$ ls -1v |grep .mkv > /tmp/1.m3u && mv /tmp/1.m3u .
-
-```
-
-Let’s break it down a bit and see each bit as to what it means –
-
-**ls -1v** = This is using the plain ls or listing entries in the directory. The -1 means list one file per line. while -v natural sort of (version) numbers within text
-
-**| grep .mkv** = It’s basically telling `ls` to look for files which are ending in .mkv . It could be .mp4 or any other media file format that you want.
-
-It’s usually a good idea to do a dry run by running the command on the console:
-```
-ls -1v |grep .mkv
-My Web Series S01E01 [Episode 1 Name] Multi 480p WEBRip x264 - xRG.mkv
-My Web Series S01E02 [Episode 2 Name] Multi 480p WEBRip x264 - xRG.mkv
-My Web Series S01E03 [Episode 3 Name] Multi 480p WEBRip x264 - xRG.mkv
-My Web Series S01E04 [Episode 4 Name] Multi 480p WEBRip x264 - xRG.mkv
-My Web Series S01E05 [Episode 5 Name] Multi 480p WEBRip x264 - xRG.mkv
-My Web Series S01E06 [Episode 6 Name] Multi 480p WEBRip x264 - xRG.mkv
-My Web Series S01E07 [Episode 7 Name] Multi 480p WEBRip x264 - xRG.mkv
-My Web Series S01E08 [Episode 8 Name] Multi 480p WEBRip x264 - xRG.mkv
-
-```
-
-This tells me that what I’m trying to do is correct. Now just have to make that the output is in the form of a .m3u playlist which is the next part.
-```
-ls -1v |grep .mkv > /tmp/web_playlist.m3u && mv /tmp/web_playlist.m3u .
-
-```
-
-This makes the .m3u generate in the current directory. The .m3u playlist is nothing but a .txt file with the same contents as above with the .m3u extension. You can edit it manually as well and add the exact filenames in an order you desire.
-
-After that you just have to do something like this:
-```
-mpv web_playlist.m3u
-
-```
-
-The great thing about MPV and the playlists, in general, is that you don’t have to binge-watch. You can see however much you want to do in one sitting and see the rest in the next session or the session after that.
-
-I hope to do articles featuring MPV as well as how to make mkv files embedding subtitles in a media file but that’s in the future.
-
-Note: It’s FOSS doesn’t encourage piracy.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/create-m3u-playlist-linux/
-
-作者:[Shirsh][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://itsfoss.com/author/shirish/
-[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/Create-M3U-Playlists.jpeg
-[2]:https://itsfoss.com/netflix-open-source-ai/
-[3]:https://itsfoss.com/download-youtube-linux/
-[4]:https://itsfoss.com/mpv-video-player/
-[5]:https://en.wikipedia.org/wiki/M3U
diff --git a/sources/tech/20180816 Add YouTube Player Controls To Your Linux Desktop With browser-mpris2 (Chrome Extension).md b/sources/tech/20180816 Add YouTube Player Controls To Your Linux Desktop With browser-mpris2 (Chrome Extension).md
deleted file mode 100644
index acc8f56e0c..0000000000
--- a/sources/tech/20180816 Add YouTube Player Controls To Your Linux Desktop With browser-mpris2 (Chrome Extension).md
+++ /dev/null
@@ -1,76 +0,0 @@
-translating---geekpi
-
-Add YouTube Player Controls To Your Linux Desktop With browser-mpris2 (Chrome Extension)
-======
-A Unity feature that I miss (it only actually worked for a short while though) is automatically getting player controls in the Ubuntu Sound Indicator when visiting a website like YouTube in a web browser, so you could pause or stop the video directly from the top bar, as well as see the video / song information and a preview.
-
-This Unity feature is long dead, but I was searching for something similar for Gnome Shell and I came across **[browser-mpris2][1], an extension that implements a MPRIS v2 interface for Google Chrome / Chromium, which currently only supports YouTube** , and I thought there might be some Linux Uprising readers who'll like this.
-
-**The extension also works with Chromium-based web browsers like Opera and Vivaldi.**
-**
-** **browser-mpris2 also supports Firefox but since loading extensions via about:debugging is temporary, and this is needed for browser-mpris2, this article doesn't include Firefox instructions. The developer[intends][2] to submit the extension to the Firefox addons website in the future.**
-
-**Using this Chrome extension you get YouTube media player controls (play, pause, stop and seeking) in MPRIS2-capable applets**. For example, if you use Gnome Shell, you get YouTube media player controls as a permanent notification or, you can use an extension like Media Player Indicator for this. In Cinnamon / Linux Mint with Cinnamon, it shows up in the Sound Applet.
-
-**It didn't work for me on Unity** , I'm not sure why. I didn't try this extension with other MPRIS2-capable applets available in various desktop environments (KDE, Xfce, MATE, etc.). If you give it a try, let us know if it works with your desktop environment / MPRIS2 enabled applet.
-
-Here is a screenshot with [Media Player Indicator][3] displaying information about the currently playing YouTube video, along with its controls (play/pause, stop and seeking), on Ubuntu 18.04 with Gnome Shell and Chromium browser:
-
-
-
-And in Linux Mint 19 Cinnamon with its default sound applet and Chromium browser:
-
-
-
-### How to install browser-mpris2 for Google Chrome / Chromium
-
-**1\. Install Git if you haven't already.**
-
-In Debian / Ubuntu / Linux Mint, use this command to install git:
-```
-sudo apt install git
-
-```
-
-**2\. Download and install the[browser-mpris2][1] required files.**
-
-The commands below clone the browser-mpris2 Git repository and install the chrome-mpris2 file to `/usr/local/bin/` (run the "git clone..." command in a folder where you can continue to keep the browser-mpris2 folder because you can't remove it, as it will be used by Chrome / Chromium):
-```
-git clone https://github.com/otommod/browser-mpris2
-sudo install browser-mpris2/native/chrome-mpris2 /usr/local/bin/
-
-```
-
-**3\. Load the extension in Chrome / Chromium-based web browsers.**
-
-
-
-Open Google Chrome, Chromium, Opera or Vivaldi web browsers, go to the Extensions page (enter `chrome://extensions` in the URL bar), enable `Developer mode` using the toggle available in the top right-hand side of the screen, then select `Load Unpacked` and select the chrome-mpris2 directory (make sure to not select a subfolder).
-
-Copy the extension ID and save it because you'll need it later (it's something like: `emngjajgcmeiligomkgpngljimglhhii` but it's different for you so make sure to use the ID from your computer!) .
-
-**4\. Run** `install-chrome.py` (from the `browser-mpris2/native` folder), specifying the extension id and chrome-mpris2 path.
-
-Use this command in a terminal (replace `REPLACE-THIS-WITH-EXTENSION-ID` with the browser-mpris2 extension ID displayed under `chrome://extensions` from the previous step) to install this extension:
-```
-browser-mpris2/native/install-chrome.py REPLACE-THIS-WITH-EXTENSION-ID /usr/local/bin/chrome-mpris2
-
-```
-
-You only need to run this command once, there's no need to add it to startup or anything like that. Any YouTube video you play in Google Chrome or Chromium browsers should show up in whatever MPRISv2 applet you're using. There's no need to restart the web browser.
-
---------------------------------------------------------------------------------
-
-via: https://www.linuxuprising.com/2018/08/add-youtube-player-controls-to-your.html
-
-作者:[Logix][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://plus.google.com/118280394805678839070
-[1]:https://github.com/otommod/browser-mpris2
-[2]:https://github.com/otommod/browser-mpris2/issues/11
-[3]:https://extensions.gnome.org/extension/55/media-player-indicator/
diff --git a/sources/tech/20180816 An introduction to the Django Python web app framework.md b/sources/tech/20180816 An introduction to the Django Python web app framework.md
deleted file mode 100644
index ab7dba9526..0000000000
--- a/sources/tech/20180816 An introduction to the Django Python web app framework.md
+++ /dev/null
@@ -1,1250 +0,0 @@
-Translating by MjSeven
-
-
-An introduction to the Django Python web app framework
-======
-
-
-
-In the first three articles of this four-part series comparing different Python web frameworks, we covered the [Pyramid][1], [Flask][2], and [Tornado][3] web frameworks. We've built the same app three times and have finally made our way to [Django][4]. Django is, by and large, the major web framework for Python developers these days and it's not too hard to see why. It excels in hiding a lot of the configuration logic and letting you focus on being able to build big, quickly.
-
-That said, when it comes to small projects, like our To-Do List app, Django can be a bit like bringing a firehose to a water gun fight. Let's see how it all comes together.
-
-### About Django
-
-Django styles itself as "a high-level Python web framework that encourages rapid development and clean, pragmatic design. Built by experienced developers, it takes care of much of the hassle of web development, so you can focus on writing your app without needing to reinvent the wheel." And they really mean it! This massive web framework comes with so many batteries included that oftentimes during development it can be a mystery as to how everything manages to work together.
-
-In addition to the framework itself being large, the Django community is absolutely massive. In fact, it's so big and active that there's [a whole website][5] devoted to the third-party packages people have designed to plug into Django to do a whole host of things. This includes everything from authentication and authorization, to full-on Django-powered content management systems, to e-commerce add-ons, to integrations with Stripe. Talk about not re-inventing the wheel; chances are if you want something done with Django, someone has already done it and you can just pull it into your project.
-
-For this purpose, we want to build a REST API with Django, so we'll leverage the always popular [Django REST framework][6]. Its job is to turn the Django framework, which was made to serve fully rendered HTML pages built with Django's own templating engine, into a system specifically geared toward effectively handling REST interactions. Let's get going with that.
-
-### Django startup and configuration
-```
-$ mkdir django_todo
-
-$ cd django_todo
-
-$ pipenv install --python 3.6
-
-$ pipenv shell
-
-(django-someHash) $ pipenv install django djangorestframework
-
-```
-
-For reference, we're working with `django-2.0.7` and `djangorestframework-3.8.2`.
-
-Unlike Flask, Tornado, and Pyramid, we don't need to write our own `setup.py` file. We're not making an installable Python distribution. As with many things, Django takes care of that for us in its own Django way. We'll still need a `requirements.txt` file to track all our necessary installs for deployment elsewhere. However, as far as targeting modules within our Django project goes, Django will let us list the subdirectories we want access to, then allow us to import from those directories as if they're installed packages.
-
-First, we have to create a Django project.
-
-When we installed Django, we also installed the command-line script `django-admin`. Its job is to manage all the various Django-related commands that help put our project together and maintain it as we continue to develop. Instead of having us build up the entire Django ecosystem from scratch, the `django-admin` will allow us to get started with all the absolutely necessary files (and more) we need for a standard Django project.
-
-The syntax for invoking `django-admin`'s start-project command is `django-admin startproject `. We want the files to exist in our current working directory, so:
-```
-(django-someHash) $ django-admin startproject django_todo .
-
-```
-
-Typing `ls` will show one new file and one new directory.
-```
-(django-someHash) $ ls
-
-manage.py django_todo
-
-```
-
-`manage.py` is a command-line-executable Python file that ends up just being a wrapper around `django-admin`. As such, its job is the same: to help us manage our project. Hence the name `manage.py`.
-
-The directory it created, the `django_todo` inside of `django_todo`, represents the configuration root for our project. Let's dig into that now.
-
-### Configuring Django
-
-By calling the `django_todo` directory the "configuration root," we mean this directory holds the files necessary for generally configuring our Django project. Pretty much everything outside this directory will be focused solely on the "business logic" associated with the project's models, views, routes, etc. All points that connect the project together will lead here.
-
-Calling `ls` within `django_todo` reveals four files:
-```
-(django-someHash) $ cd django_todo
-
-(django-someHash) $ ls
-
-__init__.py settings.py urls.py wsgi.py
-
-```
-
- * `__init__.py` is empty, solely existing to turn this directory into an importable Python package.
- * `settings.py` is where most configuration items will be set, like whether the project's in DEBUG mode, what databases are in use, where Django should look for files, etc. It is the "main configuration" part of the configuration root, and we'll dig into that momentarily.
- * `urls.py` is, as the name implies, where the URLs are set. While we don't have to explicitly write every URL for the project in this file, we **do** need to make this file aware of any other places where URLs have been declared. If this file doesn't point to other URLs, those URLs don't exist. **Period.**
- * `wsgi.py` is for serving the application in production. Just like how Pyramid, Tornado, and Flask exposed some "app" object that was the configured application to be served, Django must also expose one. That's done here. It can then be served with something like [Gunicorn][7], [Waitress][8], or [uWSGI][9].
-
-
-
-#### Setting the settings
-
-Taking a look inside `settings.py` will reveal its considerable size—and these are just the defaults! This doesn't even include hooks for the database, static files, media files, any cloud integration, or any of the other dozens of ways that a Django project can be configured. Let's see, top to bottom, what we've been given:
-
- * `BASE_DIR` sets the absolute path to the base directory, or the directory where `manage.py` is located. This is useful for locating files.
- * `SECRET_KEY` is a key used for cryptographic signing within the Django project. In practice, it's used for things like sessions, cookies, CSRF protection, and auth tokens. As soon as possible, preferably before the first commit, the value for `SECRET_KEY` should be changed and moved into an environment variable.
- * `DEBUG` tells Django whether to run the project in development mode or production mode. This is an extremely critical distinction.
- * In development mode, when an error pops up, Django will show the full stack trace that led to the error, as well as all the settings and configurations involved in running the project. This can be a massive security issue if `DEBUG` was set to `True` in a production environment.
- * In production, Django shows a plain error page when things go wrong. No information is given beyond an error code.
- * A simple way to safeguard our project is to set `DEBUG` to an environment variable, like `bool(os.environ.get('DEBUG', ''))`.
- * `ALLOWED_HOSTS` is the literal list of hostnames from which the application is being served. In development this can be empty, but in production our Django project will not run if the host that serves the project is not among the list of ALLOWED_HOSTS. Another thing for the box of environment variables.
- * `INSTALLED_APPS` is the list of Django "apps" (think of them as subdirectories; more on this later) that our Django project has access to. We're given a few by default to provide…
- * The built-in Django administrative website
- * Django's built-in authentication system
- * Django's one-size-fits-all manager for data models
- * Session management
- * Cookie and session-based messaging
- * Usage of static files inherent to the site, like `css` files, `js` files, any images that are a part of our site's design, etc.
- * `MIDDLEWARE` is as it sounds: the middleware that helps our Django project run. Much of it is for handling various types of security, although we can add others as we need them.
- * `ROOT_URLCONF` sets the import path of our base-level URL configuration file. That `urls.py` that we saw before? By default, Django points to that file to gather all our URLs. If we want Django to look elsewhere, we'll set the import path to that location here.
- * `TEMPLATES` is the list of template engines that Django would use for our site's frontend if we were relying on Django to build our HTML. Since we're not, it's irrelevant.
- * `WSGI_APPLICATION` sets the import path of our WSGI application—the thing that gets served when in production. By default, it points to an `application` object in `wsgi.py`. This rarely, if ever, needs to be modified.
- * `DATABASES` sets which databases our Django project will access. The `default` database must be set. We can set others by name, as long as we provide the `HOST`, `USER`, `PASSWORD`, `PORT`, database `NAME`, and appropriate `ENGINE`. As one might imagine, these are all sensitive pieces of information, so it's best to hide them away in environment variables. [Check the Django docs][10] for more details.
- * Note: If instead of providing individual pieces of a database's location, you'd rather provide the full database URL, check out [dj_database_url][11].
- * `AUTH_PASSWORD_VALIDATORS` is effectively a list of functions that run to check input passwords. We get a few by default, but if we had other, more complex validation needs—more than merely checking if the password matches a user's attribute, if it exceeds the minimum length, if it's one of the 1,000 most common passwords, or if the password is entirely numeric—we could list them here.
- * `LANGUAGE_CODE` will set the language for the site. By default it's US English, but we could switch it up to be other languages.
- * `TIME_ZONE` is the time zone for any autogenerated timestamps in our Django project. I cannot stress enough how important it is that we stick to UTC and perform any time zone-specific processing elsewhere instead of trying to reconfigure this setting. As [this article][12] states, UTC is the common denominator among all time zones because there are no offsets to worry about. If offsets are that important, we could calculate them as needed with an appropriate offset from UTC.
- * `USE_I18N` will let Django use its own translation services to translate strings for the front end. I18N = internationalization (18 characters between "i" and "n")
- * `USE_L10N` (L10N = localization [10 characters between "l" and "n"]) will use the common local formatting of data if set to `True`. A great example is dates: in the US it's MM-DD-YYYY. In Europe, dates tend to be written DD-MM-YYYY
- * `STATIC_URL` is part of a larger body of settings for serving static files. We'll be building a REST API, so we won't need to worry about static files. In general, this sets the root path after the domain name for every static file. So, if we had a logo image to serve, it'd be `http:////logo.gif`
-
-
-
-These settings are pretty much ready to go by default. One thing we'll have to change is the `DATABASES` setting. First, we create the database that we'll be using with:
-```
-(django-someHash) $ createdb django_todo
-
-```
-
-We want to use a PostgreSQL database like we did with Flask, Pyramid, and Tornado. That means we'll have to change the `DATABASES` setting to allow our server to access a PostgreSQL database. First: the engine. By default, the database engine is `django.db.backends.sqlite3`. We'll be changing that to `django.db.backends.postgresql`.
-
-For more information about Django's available engines, [check the docs][13]. Note that while it is technically possible to incorporate a NoSQL solution into a Django project, out of the box, Django is strongly biased toward SQL solutions.
-
-Next, we have to specify the key-value pairs for the different parts of the connection parameters.
-
- * `NAME` is the name of the database we just created.
- * `USER` is an individual's Postgres database username
- * `PASSWORD` is the password needed to access the database
- * `HOST` is the host for the database. `localhost` or `127.0.0.1` will work, as we're developing locally.
- * `PORT` is whatever PORT we have open for Postgres; it's typically `5432`.
-
-
-
-`settings.py` expects us to provide string values for each of these keys. However, this is highly sensitive information. That's not going to work for any responsible developer. There are several ways to address this problem, but we'll just set up environment variables.
-```
-DATABASES = {
-
- 'default': {
-
- 'ENGINE': 'django.db.backends.postgresql',
-
- 'NAME': os.environ.get('DB_NAME', ''),
-
- 'USER': os.environ.get('DB_USER', ''),
-
- 'PASSWORD': os.environ.get('DB_PASS', ''),
-
- 'HOST': os.environ.get('DB_HOST', ''),
-
- 'PORT': os.environ.get('DB_PORT', ''),
-
- }
-
-}
-
-```
-
-Before going forward, make sure to set the environment variables or Django will not work. Also, we need to install `psycopg2` into this environment so we can talk to our database.
-
-### Django routes and views
-
-Let's make something function inside this project. We'll be using Django REST Framework to construct our REST API, so we have to make sure we can use it by adding `rest_framework` to the end of `INSTALLED_APPS` in `settings.py`.
-```
-INSTALLED_APPS = [
-
- 'django.contrib.admin',
-
- 'django.contrib.auth',
-
- 'django.contrib.contenttypes',
-
- 'django.contrib.sessions',
-
- 'django.contrib.messages',
-
- 'django.contrib.staticfiles',
-
- 'rest_framework'
-
-]
-
-```
-
-While Django REST Framework doesn't exclusively require class-based views (like Tornado) to handle incoming requests, it is the preferred method for writing views. Let's define one.
-
-Let's create a file called `views.py` in `django_todo`. Within `views.py`, we'll create our "Hello, world!" view.
-```
-# in django_todo/views.py
-
-from rest_framework.response import JsonResponse
-
-from rest_framework.views import APIView
-
-
-
-class HelloWorld(APIView):
-
- def get(self, request, format=None):
-
- """Print 'Hello, world!' as the response body."""
-
- return JsonResponse("Hello, world!")
-
-```
-
-Every Django REST Framework class-based view inherits either directly or indirectly from `APIView`. `APIView` handles a ton of stuff, but for our purposes it does these specific things:
-
- * Sets up the methods needed to direct traffic based on the HTTP method (e.g. GET, POST, PUT, DELETE)
- * Populates the `request` object with all the data and attributes we'll need for parsing and processing any incoming request
- * Takes the `Response` or `JsonResponse` that every dispatch method (i.e., methods named `get`, `post`, `put`, `delete`) returns and constructs a properly formatted HTTP response.
-
-
-
-Yay, we have a view! On its own it does nothing. We need to connect it to a route.
-
-If we hop into `django_todo/urls.py`, we reach our default URL configuration file. As mentioned earlier: If a route in our Django project is not included here, it doesn't exist.
-
-We add desired URLs by adding them to the given `urlpatterns` list. By default, we get a whole set of URLs for Django's built-in site administration backend. We'll delete that completely.
-
-We also get some very helpful doc strings that tell us exactly how to add routes to our Django project. We'll need to provide a call to `path()` with three parameters:
-
- * The desired route, as a string (without the leading slash)
- * The view function (only ever a function!) that will handle that route
- * The name of the route in our Django project
-
-
-
-Let's import our `HelloWorld` view and attach it to the home route `"/"`. We can also remove the path to the `admin` from `urlpatterns`, as we won't be using it.
-```
-# django_todo/urls.py, after the big doc string
-
-from django.urls import path
-
-from django_todo.views import HelloWorld
-
-
-
-urlpatterns = [
-
- path('', HelloWorld.as_view(), name="hello"),
-
-]
-
-```
-
-Well, this is different. The route we specified is just a blank string. Why does that work? Django assumes that every path we declare begins with a leading slash. We're just specifying routes to resources after the initial domain name. If a route isn't going to a specific resource and is instead just the home page, the route is just `""`, or effectively "no resource."
-
-The `HelloWorld` view is imported from that `views.py` file we just created. In order to do this import, we need to update `settings.py` to include `django_todo` in the list of `INSTALLED_APPS`. Yeah, it's a bit weird. Here's one way to think about it.
-
-`INSTALLED_APPS` refers to the list of directories or packages that Django sees as importable. It's Django's way of treating individual components of a project like installed packages without going through a `setup.py`. We want the `django_todo` directory to be treated like an importable package, so we include that directory in `INSTALLED_APPS`. Now, any module within that directory is also importable. So we get our view.
-
-The `path` function will ONLY take a view function as that second argument, not just a class-based view on its own. Luckily, all valid Django class-based views include this `.as_view()` method. Its job is to roll up all the goodness of the class-based view into a view function and return that view function. So, we never have to worry about making that translation. Instead, we only have to think about the business logic, letting Django and Django REST Framework handle the rest.
-
-Let's crack this open in the browser!
-
-Django comes packaged with its own local development server, accessible through `manage.py`. Let's navigate to the directory containing `manage.py` and type:
-```
-(django-someHash) $ ./manage.py runserver
-
-Performing system checks...
-
-
-
-System check identified no issues (0 silenced).
-
-August 01, 2018 - 16:47:24
-
-Django version 2.0.7, using settings 'django_todo.settings'
-
-Starting development server at http://127.0.0.1:8000/
-
-Quit the server with CONTROL-C.
-
-```
-
-When `runserver` is executed, Django does a check to make sure the project is (more or less) wired together correctly. It's not fool-proof, but it does catch some glaring issues. It also notifies us if our database is out of sync with our code. Undoubtedly ours is because we haven't committed any of our application's stuff to our database, but that's fine for now. Let's visit `http://127.0.0.1:8000` to see the output of the `HelloWorld` view.
-
-Huh. That's not the plaintext data we saw in Pyramid, Flask, and Tornado. When Django REST Framework is used, the HTTP response (when viewed in the browser) is this sort of rendered HTML, showing our actual JSON response in red.
-
-But don't fret! If we do a quick `curl` looking at `http://127.0.0.1:8000` in the command line, we don't get any of that fancy HTML. Just the content.
-```
-# Note: try this in a different terminal window, outside of the virtual environment above
-
-$ curl http://127.0.0.1:8000
-
-"Hello, world!"
-
-```
-
-Bueno!
-
-Django REST Framework wants us to have a human-friendly interface when using the browser. This makes sense; if JSON is viewed in the browser, it's typically because a human wants to check that it looks right or get a sense of what the JSON response will look like as they design some consumer of an API. It's a lot like what you'd get from a service like [Postman][14].
-
-Either way, we know our view is working! Woo! Let's recap what we've done:
-
- 1. Started the project with `django-admin startproject `
- 2. Updated the `django_todo/settings.py` to use environment variables for `DEBUG`, `SECRET_KEY`, and values in the `DATABASES` dict
- 3. Installed `Django REST Framework` and added it to the list of `INSTALLED_APPS`
- 4. Created `django_todo/views.py` to include our first view class to say Hello to the World
- 5. Updated `django_todo/urls.py` with a path to our new home route
- 6. Updated `INSTALLED_APPS` in `django_todo/settings.py` to include the `django_todo` package
-
-
-
-### Creating models
-
-Let's create our data models now.
-
-A Django project's entire infrastructure is built around data models. It's written so each data model can have its own little universe with its own views, its own set of URLs that concern its resources, and even its own tests (if we are so inclined).
-
-If we wanted to build a simple Django project, we could circumvent this by just writing our own `models.py` file in the `django_todo` directory and importing it into our views. However, we're trying to write a Django project the "right" way, so we should divide up our models as best we can into their own little packages The Django Way™.
-
-The Django Way involves creating what are called Django "apps." Django "apps" aren't separate applications per se; they don't have their own settings and whatnot (although they can). They can, however, have just about everything else one might think of being in a standalone application:
-
- * Set of self-contained URLs
- * Set of self-contained HTML templates (if we want to serve HTML)
- * One or more data models
- * Set of self-contained views
- * Set of self-contained tests
-
-
-
-They are made to be independent so they can be easily shared like standalone applications. In fact, Django REST Framework is an example of a Django app. It comes packaged with its own views and HTML templates for serving up our JSON. We just leverage that Django app to turn our project into a full-on RESTful API with less hassle.
-
-To create the Django app for our To-Do List items, we'll want to use the `startapp` command with `manage.py`.
-```
-(django-someHash) $ ./manage.py startapp todo
-
-```
-
-The `startapp` command will succeed silently. We can check that it did what it should've done by using `ls`.
-```
-(django-someHash) $ ls
-
-Pipfile Pipfile.lock django_todo manage.py todo
-
-```
-
-Look at that: We've got a brand new `todo` directory. Let's look inside!
-```
-(django-someHash) $ ls todo
-
-__init__.py admin.py apps.py migrations models.py tests.py views.py
-
-```
-
-Here are the files that `manage.py startapp` created:
-
- * `__init__.py` is empty; it exists so this directory can be seen as a valid import path for models, views, etc.
- * `admin.py` is not quite empty; it's used for formatting this app's models in the Django admin, which we're not getting into in this article.
- * `apps.py` … not much work to do here either; it helps with formatting models for the Django admin.
- * `migrations` is a directory that'll contain snapshots of our data models; it's used for updating our database. This is one of the few frameworks that comes with database management built-in, and part of that is allowing us to update our database instead of having to tear it down and rebuild it to change the schema.
- * `models.py` is where the data models live.
- * `tests.py` is where tests would go—if we wrote any.
- * `views.py` is for the views we write that pertain to the models in this app. They don't have to be written here. We could, for example, write all our views in `django_todo/views.py`. It's here, however, so it's easier to separate our concerns. This becomes far more relevant with sprawling applications that cover many conceptual spaces.
-
-
-
-What hasn't been created for us is a `urls.py` file for this app. We can make that ourselves.
-```
-(django-someHash) $ touch todo/urls.py
-
-```
-
-Before moving forward we should do ourselves a favor and add this new Django app to our list of `INSTALLED_APPS` in `django_todo/settings.py`.
-```
-# in settings.py
-
-INSTALLED_APPS = [
-
- 'django.contrib.admin',
-
- 'django.contrib.auth',
-
- 'django.contrib.contenttypes',
-
- 'django.contrib.sessions',
-
- 'django.contrib.messages',
-
- 'django.contrib.staticfiles',
-
- 'rest_framework',
-
- 'django_todo',
-
- 'todo' # <--- the line was added
-
-]
-
-```
-
-Inspecting `todo/models.py` shows that `manage.py` already wrote a bit of code for us to get started. Diverging from how models were created in the Flask, Tornado, and Pyramid implementations, Django doesn't leverage a third party to manage database sessions or the construction of its object instances. It's all rolled into Django's `django.db.models` submodule.
-
-The way a model is built, however, is more or less the same. To create a model in Django, we'll need to build a `class` that inherits from `models.Model`. All the fields that will apply to instances of that model should appear as class attributes. Instead of importing columns and field types from SQLAlchemy like we have in the past, all of our fields will come directly from `django.db.models`.
-```
-# todo/models.py
-
-from django.db import models
-
-
-
-class Task(models.Model):
-
- """Tasks for the To Do list."""
-
- name = models.CharField(max_length=256)
-
- note = models.TextField(blank=True, null=True)
-
- creation_date = models.DateTimeField(auto_now_add=True)
-
- due_date = models.DateTimeField(blank=True, null=True)
-
- completed = models.BooleanField(default=False)
-
-```
-
-While there are some definite differences between what Django needs and what SQLAlchemy-based systems need, the overall contents and structure are more or less the same. Let's point out the differences.
-
-We no longer need to declare a separate field for an auto-incremented ID number for our object instances. Django builds one for us unless we specify a different field as the primary key.
-
-Instead of instantiating `Column` objects that are passed datatype objects, we just directly reference the datatypes as the columns themselves.
-
-The `Unicode` field became either `models.CharField` or `models.TextField`. `CharField` is for small text fields of a specific maximum length, whereas `TextField` is for any amount of text.
-
-The `TextField` should be able to be blank, and we specify this in TWO ways. `blank=True` says that when an instance of this model is constructed, and the data attached to this field is being validated, it's OK for that data to be empty. This is different from `null=True`, which says when the table for this model class is constructed, the column corresponding to `note` will allow for blank or `NULL` entries. So, to sum that all up, `blank=True` controls how data gets added to model instances while `null=True` controls how the database table holding that data is constructed in the first place.
-
-The `DateTime` field grew some muscle and became able to do some work for us instead of us having to modify the `__init__` method for the class. For the `creation_date` field, we specify `auto_now_add=True`. What this means in a practical sense is that when a new model instance is created Django will automatically record the date and time of now as that field's value. That's handy!
-
-When neither `auto_now_add` nor its close cousin `auto_now` are set to `True`, `DateTimeField` will expect data like any other field. It'll need to be fed with a proper `datetime` object to be valid. The `due_date` column has `blank` and `null` both set to `True` so that an item on the To-Do List can just be an item to be done at some point in the future, with no defined date or time.
-
-`BooleanField` just ends up being a field that can take one of two values: `True` or `False`. Here, the default value is set to be `False`.
-
-#### Managing the database
-
-As mentioned earlier, Django has its own way of doing database management. Instead of having to write… really any code at all regarding our database, we leverage the `manage.py` script that Django provided on construction. It'll manage not just the construction of the tables for our database, but also any updates we wish to make to those tables without necessarily having to blow the whole thing away!
-
-Because we've constructed a new model, we need to make our database aware of it. First, we need to put into code the schema that corresponds to this model. The `makemigrations` command of `manage.py` will take a snapshot of the model class we built and all its fields. It'll take that information and package it into a Python script that'll live in this particular Django app's `migrations` directory. There will never be a reason to run this migration script directly. It'll exist solely so that Django can use it as a basis to update our database table or to inherit information when we update our model class.
-```
-(django-someHash) $ ./manage.py makemigrations
-
-Migrations for 'todo':
-
- todo/migrations/0001_initial.py
-
- - Create model Task
-
-```
-
-This will look at every app listed in `INSTALLED_APPS` and check for models that exist in those apps. It'll then check the corresponding `migrations` directory for migration files and compare them to the models in each of those `INSTALLED_APPS` apps. If a model has been upgraded beyond what the latest migration says should exist, a new migration file will be created that inherits from the most recent one. It'll be automatically named and also be given a message that says what changed since the last migration.
-
-If it's been a while since you last worked on your Django project and can't remember if your models were in sync with your migrations, you have no need to fear. `makemigrations` is an idempotent operation; your `migrations` directory will have only one copy of the current model configuration whether you run `makemigrations` once or 20 times. Even better than that, when we run `./manage.py runserver`, Django will detect that our models are out of sync with our migrations, and it'll just flat out tell us in colored text so we can make the appropriate choice.
-
-This next point is something that trips everybody up at least once: Creating a migration file does not immediately affect our database. When we ran `makemigrations`, we prepared our Django project to define how a given table should be created and end up looking. It's still on us to apply those changes to our database. That's what the `migrate` command is for.
-```
-(django-someHash) $ ./manage.py migrate
-
-Operations to perform:
-
- Apply all migrations: admin, auth, contenttypes, sessions, todo
-
-Running migrations:
-
- Applying contenttypes.0001_initial... OK
-
- Applying auth.0001_initial... OK
-
- Applying admin.0001_initial... OK
-
- Applying admin.0002_logentry_remove_auto_add... OK
-
- Applying contenttypes.0002_remove_content_type_name... OK
-
- Applying auth.0002_alter_permission_name_max_length... OK
-
- Applying auth.0003_alter_user_email_max_length... OK
-
- Applying auth.0004_alter_user_username_opts... OK
-
- Applying auth.0005_alter_user_last_login_null... OK
-
- Applying auth.0006_require_contenttypes_0002... OK
-
- Applying auth.0007_alter_validators_add_error_messages... OK
-
- Applying auth.0008_alter_user_username_max_length... OK
-
- Applying auth.0009_alter_user_last_name_max_length... OK
-
- Applying sessions.0001_initial... OK
-
- Applying todo.0001_initial... OK
-
-```
-
-When we apply our migrations, Django first checks to see if the other `INSTALLED_APPS` have migrations to be applied. It checks them in roughly the order they're listed. We want our app to be listed last, because we want to make sure that, in case our model depends on any of Django's built-in models, the database updates we make don't suffer from dependency problems.
-
-We have another model to build: the User model. However, the game has changed a bit since we're using Django. So many applications require some sort of User model that Django's `django.contrib.auth` package built its own for us to use. If it weren't for the authentication token we require for our users, we could just move on and use it instead of reinventing the wheel.
-
-However, we need that token. There are a couple of ways we can handle this.
-
- * Inherit from Django's `User` object, making our own object that extends it by adding a `token` field
- * Create a new object that exists in a one-to-one relationship with Django's `User` object, whose only purpose is to hold a token
-
-
-
-I'm in the habit of building object relationships, so let's go with the second option. Let's call it an `Owner` as it basically has a similar connotation as a `User`, which is what we want.
-
-Out of sheer laziness, we could just include this new `Owner` object in `todo/models.py`, but let's refrain from that. `Owner` doesn't explicitly have to do with the creation or maintenance of items on the task list. Conceptually, the `Owner` is simply the owner of the task. There may even come a time where we want to expand this `Owner` to include other data that has absolutely nothing to do with tasks.
-
-Just to be safe, let's make an `owner` app whose job is to house and handle this `Owner` object.
-```
-(django-someHash) $ ./manage.py startapp owner
-
-```
-
-Don't forget to add it to the list of `INSTALLED_APPS` in `settings.py`.
-```
-INSTALLED_APPS = [
-
- 'django.contrib.admin',
-
- 'django.contrib.auth',
-
- 'django.contrib.contenttypes',
-
- 'django.contrib.sessions',
-
- 'django.contrib.messages',
-
- 'django.contrib.staticfiles',
-
- 'rest_framework',
-
- 'django_todo',
-
- 'todo',
-
- 'owner'
-
-]
-
-```
-
-If we look at the root of our Django project, we now have two Django apps:
-```
-(django-someHash) $ ls
-
-Pipfile Pipfile.lock django_todo manage.py owner todo
-
-```
-
-In `owner/models.py`, let's build this `Owner` model. As mentioned earlier, it'll have a one-to-one relationship with Django's built-in `User` object. We can enforce this relationship with Django's `models.OneToOneField`
-```
-# owner/models.py
-
-from django.db import models
-
-from django.contrib.auth.models import User
-
-import secrets
-
-
-
-class Owner(models.Model):
-
- """The object that owns tasks."""
-
- user = models.OneToOneField(User, on_delete=models.CASCADE)
-
- token = models.CharField(max_length=256)
-
-
-
- def __init__(self, *args, **kwargs):
-
- """On construction, set token."""
-
- self.token = secrets.token_urlsafe(64)
-
- super().__init__(*args, **kwargs)
-
-```
-
-This says the `Owner` object is linked to the `User` object, with one `owner` instance per `user` instance. `on_delete=models.CASCADE` dictates that if the corresponding `User` gets deleted, the `Owner` instance it's linked to will also get deleted. Let's run `makemigrations` and `migrate` to bake this new model into our database.
-```
-(django-someHash) $ ./manage.py makemigrations
-
-Migrations for 'owner':
-
- owner/migrations/0001_initial.py
-
- - Create model Owner
-
-(django-someHash) $ ./manage.py migrate
-
-Operations to perform:
-
- Apply all migrations: admin, auth, contenttypes, owner, sessions, todo
-
-Running migrations:
-
- Applying owner.0001_initial... OK
-
-```
-
-Now our `Owner` needs to own some `Task` objects. It'll be very similar to the `OneToOneField` seen above, except that we'll stick a `ForeignKey` field on the `Task` object pointing to an `Owner`.
-```
-# todo/models.py
-
-from django.db import models
-
-from owner.models import Owner
-
-
-
-class Task(models.Model):
-
- """Tasks for the To Do list."""
-
- name = models.CharField(max_length=256)
-
- note = models.TextField(blank=True, null=True)
-
- creation_date = models.DateTimeField(auto_now_add=True)
-
- due_date = models.DateTimeField(blank=True, null=True)
-
- completed = models.BooleanField(default=False)
-
- owner = models.ForeignKey(Owner, on_delete=models.CASCADE)
-
-```
-
-Every To-Do List task has exactly one owner who can own multiple tasks. When that owner is deleted, any task they own goes with them.
-
-Let's now run `makemigrations` to take a new snapshot of our data model setup, then `migrate` to apply those changes to our database.
-```
-(django-someHash) django $ ./manage.py makemigrations
-
-You are trying to add a non-nullable field 'owner' to task without a default; we can't do that (the database needs something to populate existing rows).
-
-Please select a fix:
-
- 1) Provide a one-off default now (will be set on all existing rows with a null value for this column)
-
- 2) Quit, and let me add a default in models.py
-
-```
-
-Oh no! We have a problem! What happened? Well, when we created the `Owner` object and added it as a `ForeignKey` to `Task`, we basically required that every `Task` requires an `Owner`. However, the first migration we made for the `Task` object didn't include that requirement. So, even though there's no data in our database's table, Django is doing a pre-check on our migrations to make sure they're compatible and this new migration we're proposing is not.
-
-There are a few ways to deal with this sort of problem:
-
- 1. Blow away the current migration and build a new one that includes the current model configuration
- 2. Add a default value to the `owner` field on the `Task` object
- 3. Allow tasks to have `NULL` values for the `owner` field.
-
-
-
-Option 2 wouldn't make much sense here; we'd be proposing that any `Task` that was created would, by default, be linked to some default owner despite none necessarily existing.
-
-Option 1 would require us to destroy and rebuild our migrations. We should leave those alone.
-
-Let's go with option 3. In this circumstance, it won't be the end of the world if we allow the `Task` table to have null values for the owners; any tasks created from this point forward will necessarily have an owner. If you're in a situation where that isn't an acceptable schema for your database table, blow away your migrations, drop the table, and rebuild the migrations.
-```
-# todo/models.py
-
-from django.db import models
-
-from owner.models import Owner
-
-
-
-class Task(models.Model):
-
- """Tasks for the To Do list."""
-
- name = models.CharField(max_length=256)
-
- note = models.TextField(blank=True, null=True)
-
- creation_date = models.DateTimeField(auto_now_add=True)
-
- due_date = models.DateTimeField(blank=True, null=True)
-
- completed = models.BooleanField(default=False)
-
- owner = models.ForeignKey(Owner, on_delete=models.CASCADE, null=True)
-
-(django-someHash) $ ./manage.py makemigrations
-
-Migrations for 'todo':
-
- todo/migrations/0002_task_owner.py
-
- - Add field owner to task
-
-(django-someHash) $ ./manage.py migrate
-
-Operations to perform:
-
- Apply all migrations: admin, auth, contenttypes, owner, sessions, todo
-
-Running migrations:
-
- Applying todo.0002_task_owner... OK
-
-```
-
-Woo! We have our models! Welcome to the Django way of declaring objects.
-
-For good measure, let's ensure that whenever a `User` is made, it's automatically linked with a new `Owner` object. We can do this using Django's `signals` system. Basically, we say exactly what we intend: "When we get the signal that a new `User` has been constructed, construct a new `Owner` and set that new `User` as that `Owner`'s `user` field." In practice that looks like:
-```
-# owner/models.py
-
-from django.contrib.auth.models import User
-
-from django.db import models
-
-from django.db.models.signals import post_save
-
-from django.dispatch import receiver
-
-
-
-import secrets
-
-
-
-
-
-class Owner(models.Model):
-
- """The object that owns tasks."""
-
- user = models.OneToOneField(User, on_delete=models.CASCADE)
-
- token = models.CharField(max_length=256)
-
-
-
- def __init__(self, *args, **kwargs):
-
- """On construction, set token."""
-
- self.token = secrets.token_urlsafe(64)
-
- super().__init__(*args, **kwargs)
-
-
-
-
-
-@receiver(post_save, sender=User)
-
-def link_user_to_owner(sender, **kwargs):
-
- """If a new User is saved, create a corresponding Owner."""
-
- if kwargs['created']:
-
- owner = Owner(user=kwargs['instance'])
-
- owner.save()
-
-```
-
-We set up a function that listens for signals to be sent from the `User` object built into Django. It's waiting for just after a `User` object has been saved. This can come from either a new `User` or an update to an existing `User`; we discern between the two scenarios within the listening function.
-
-If the thing sending the signal was a newly created instance, `kwargs['created']` will have the value of `True`. We only want to do something if this is `True`. If it's a new instance, we create a new `Owner`, setting its `user` field to be the new `User` instance that was created. After that, we `save()` the new `Owner`. This will commit our change to the database if all is well. It'll fail if the data doesn't validate against the fields we declared.
-
-Now let's talk about how we're going to access the data.
-
-### Accessing model data
-
-In the Flask, Pyramid, and Tornado frameworks, we accessed model data by running queries against some database session. Maybe it was attached to a `request` object, maybe it was a standalone `session` object. Regardless, we had to establish a live connection to the database and query on that connection.
-
-This isn't the way Django works. Django, by default, doesn't leverage any third-party object-relational mapping (ORM) to converse with the database. Instead, Django allows the model classes to maintain their own conversations with the database.
-
-Every model class that inherits from `django.db.models.Model` will have attached to it an `objects` object. This will take the place of the `session` or `dbsession` we've become so familiar with. Let's open the special shell that Django gives us and investigate how this `objects` object works.
-```
-(django-someHash) $ ./manage.py shell
-
-Python 3.7.0 (default, Jun 29 2018, 20:13:13)
-
-[Clang 9.1.0 (clang-902.0.39.2)] on darwin
-
-Type "help", "copyright", "credits" or "license" for more information.
-
-(InteractiveConsole)
-
->>>
-
-```
-
-The Django shell is different from a normal Python shell in that it's aware of the Django project we've been building and can do easy imports of our models, views, settings, etc. without having to worry about installing a package. We can access our models with a simple `import`.
-```
->>> from owner.models import Owner
-
->>> Owner
-
-
-
-```
-
-Currently, we have no `Owner` instances. We can tell by querying for them with `Owner.objects.all()`.
-```
->>> Owner.objects.all()
-
-
-
-```
-
-Anytime we run a query method on the `.objects` object, we'll get a `QuerySet` back. For our purposes, it's effectively a `list`, and this `list` is showing us that it's empty. Let's make an `Owner` by making a `User`.
-```
->>> from django.contrib.auth.models import User
-
->>> new_user = User(username='kenyattamurphy', email='kenyatta.murphy@gmail.com')
-
->>> new_user.set_password('wakandaforever')
-
->>> new_user.save()
-
-```
-
-If we query for all of our `Owner`s now, we should find Kenyatta.
-```
->>> Owner.objects.all()
-
-]>
-
-```
-
-Yay! We've got data!
-
-### Serializing models
-
-We'll be passing data back and forth beyond just "Hello World." As such, we'll want to see some sort of JSON-ified output that represents that data well. Taking that object's data and transforming it into a JSON object for submission across HTTP is a version of data serialization. In serializing data, we're taking the data we currently have and reformatting it to fit some standard, more-easily-digestible form.
-
-If I were doing this with Flask, Pyramid, and Tornado, I'd create a new method on each model to give the user direct access to call `to_json()`. The only job of `to_json()` would be to return a JSON-serializable (i.e. numbers, strings, lists, dicts) dictionary with whatever fields I want to be displayed for the object in question.
-
-It'd probably look something like this for the `Task` object:
-```
-class Task(Base):
-
- ...all the fields...
-
-
-
- def to_json(self):
-
- """Convert task attributes to a JSON-serializable dict."""
-
- return {
-
- 'id': self.id,
-
- 'name': self.name,
-
- 'note': self.note,
-
- 'creation_date': self.creation_date.strftime('%m/%d/%Y %H:%M:%S'),
-
- 'due_date': self.due_date.strftime('%m/%d/%Y %H:%M:%S'),
-
- 'completed': self.completed,
-
- 'user': self.user_id
-
- }
-
-```
-
-It's not fancy, but it does the job.
-
-Django REST Framework, however, provides us with an object that'll not only do that for us but also validate inputs when we want to create new object instances or update existing ones. It's called the [ModelSerializer][15].
-
-Django REST Framework's `ModelSerializer` is effectively documentation for our models. They don't have lives of their own if there are no models attached (for that there's the [Serializer][16] class). Their main job is to accurately represent our model and make the conversion to JSON thoughtless when our model's data needs to be serialized and sent over a wire.
-
-Django REST Framework's `ModelSerializer` works best for simple objects. As an example, imagine that we didn't have that `ForeignKey` on the `Task` object. We could create a serializer for our `Task` that would convert its field values to JSON as necessary with the following declaration:
-```
-# todo/serializers.py
-
-from rest_framework import serializers
-
-from todo.models import Task
-
-
-
-class TaskSerializer(serializers.ModelSerializer):
-
- """Serializer for the Task model."""
-
-
-
- class Meta:
-
- model = Task
-
- fields = ('id', 'name', 'note', 'creation_date', 'due_date', 'completed')
-
-```
-
-Inside our new `TaskSerializer`, we create a `Meta` class. `Meta`'s job here is just to hold information (or metadata) about the thing we're attempting to serialize. Then, we note the specific fields that we want to show. If we wanted to show all the fields, we could just shortcut the process and use `'__all__'`. We could, alternatively, use the `exclude` keyword instead of `fields` to tell Django REST Framework that we want every field except for a select few. We can have as many serializers as we like, so maybe we want one for a small subset of fields and one for all the fields? Go wild here.
-
-In our case, there is a relation between each `Task` and its owner `Owner` that must be reflected here. As such, we need to borrow the `serializers.PrimaryKeyRelatedField` object to specify that each `Task` will have an `Owner` and that relationship is one-to-one. Its owner will be found from the set of all owners that exists. We get that set by doing a query for those owners and returning the results we want to be associated with this serializer: `Owner.objects.all()`. We also need to include `owner` in the list of fields, as we always need an `Owner` associated with a `Task`
-```
-# todo/serializers.py
-
-from rest_framework import serializers
-
-from todo.models import Task
-
-from owner.models import Owner
-
-
-
-class TaskSerializer(serializers.ModelSerializer):
-
- """Serializer for the Task model."""
-
- owner = serializers.PrimaryKeyRelatedField(queryset=Owner.objects.all())
-
-
-
- class Meta:
-
- model = Task
-
- fields = ('id', 'name', 'note', 'creation_date', 'due_date', 'completed', 'owner')
-
-```
-
-Now that this serializer is built, we can use it for all the CRUD operations we'd like to do for our objects:
-
- * If we want to `GET` a JSONified version of a specific `Task`, we can do `TaskSerializer(some_task).data`
- * If we want to accept a `POST` with the appropriate data to create a new `Task`, we can use `TaskSerializer(data=new_data).save()`
- * If we want to update some existing data with a `PUT`, we can say `TaskSerializer(existing_task, data=data).save()`
-
-
-
-We're not including `delete` because we don't really need to do anything with information for a `delete` operation. If you have access to an object you want to delete, just say `object_instance.delete()`.
-
-Here is an example of what some serialized data might look like:
-```
->>> from todo.models import Task
-
->>> from todo.serializers import TaskSerializer
-
->>> from owner.models import Owner
-
->>> from django.contrib.auth.models import User
-
->>> new_user = User(username='kenyatta', email='kenyatta@gmail.com')
-
->>> new_user.save_password('wakandaforever')
-
->>> new_user.save() # creating the User that builds the Owner
-
->>> kenyatta = Owner.objects.first() # grabbing the Owner that is kenyatta
-
->>> new_task = Task(name="Buy roast beef for the Sunday potluck", owner=kenyatta)
-
->>> new_task.save()
-
->>> TaskSerializer(new_task).data
-
-{'id': 1, 'name': 'Go to the supermarket', 'note': None, 'creation_date': '2018-07-31T06:00:25.165013Z', 'due_date': None, 'completed': False, 'owner': 1}
-
-```
-
-There's a lot more you can do with the `ModelSerializer` objects, and I suggest checking [the docs][17] for those greater capabilities. Otherwise, this is as much as we need. It's time to dig into some views.
-
-### Views for reals
-
-We've built the models and the serializers, and now we need to set up the views and URLs for our application. After all, we can't do anything with an application that has no views. We've already seen an example with the `HelloWorld` view above. However, that's always a contrived, proof-of-concept example and doesn't really show what can be done with Django REST Framework's views. Let's clear out the `HelloWorld` view and URL so we can start fresh with our views.
-
-The first view we'll build is the `InfoView`. As in the previous frameworks, we just want to package and send out a dictionary of our proposed routes. The view itself can live in `django_todo.views` since it doesn't pertain to a specific model (and thus doesn't conceptually belong in a specific app).
-```
-# django_todo/views.py
-
-from rest_framework.response import JsonResponse
-
-from rest_framework.views import APIView
-
-
-
-class InfoView(APIView):
-
- """List of routes for this API."""
-
- def get(self, request):
-
- output = {
-
- 'info': 'GET /api/v1',
-
- 'register': 'POST /api/v1/accounts',
-
- 'single profile detail': 'GET /api/v1/accounts/',
-
- 'edit profile': 'PUT /api/v1/accounts/',
-
- 'delete profile': 'DELETE /api/v1/accounts/',
-
- 'login': 'POST /api/v1/accounts/login',
-
- 'logout': 'GET /api/v1/accounts/logout',
-
- "user's tasks": 'GET /api/v1/accounts//tasks',
-
- "create task": 'POST /api/v1/accounts//tasks',
-
- "task detail": 'GET /api/v1/accounts//tasks/',
-
- "task update": 'PUT /api/v1/accounts//tasks/',
-
- "delete task": 'DELETE /api/v1/accounts//tasks/'
-
- }
-
- return JsonResponse(output)
-
-```
-
-This is pretty much identical to what we had in Tornado. Let's hook it up to an appropriate route and be on our way. For good measure, we'll also remove the `admin/` route, as we won't be using the Django administrative backend here.
-```
-# in django_todo/urls.py
-
-from django_todo.views import InfoView
-
-from django.urls import path
-
-
-
-urlpatterns = [
-
- path('api/v1', InfoView.as_view(), name="info"),
-
-]
-
-```
-
-#### Connecting models to views
-
-Let's figure out the next URL, which will be the endpoint for either creating a new `Task` or listing a user's existing tasks. This should exist in a `urls.py` in the `todo` app since this has to deal specifically with `Task` objects instead of being a part of the whole project.
-```
-# in todo/urls.py
-
-from django.urls import path
-
-from todo.views import TaskListView
-
-
-
-urlpatterns = [
-
- path('', TaskListView.as_view(), name="list_tasks")
-
-]
-
-```
-
-What's the deal with this route? We didn't specify a particular user or much of a path at all. Since there would be a couple of routes requiring the base path `/api/v1/accounts//tasks`, why write it again and again when we can just write it once?
-
-Django allows us to take a whole suite of URLs and import them into the base `django_todo/urls.py` file. We can then give every one of those imported URLs the same base path, only worrying about the variable parts when, you know, they vary.
-```
-# in django_todo/urls.py
-
-from django.urls import include, path
-
-from django_todo.views import InfoView
-
-
-
-urlpatterns = [
-
- path('api/v1', InfoView.as_view(), name="info"),
-
- path('api/v1/accounts//tasks', include('todo.urls'))
-
-]
-
-```
-
-And now every URL coming from `todo/urls.py` will be prefixed with the path `api/v1/accounts//tasks`.
-
-Let's build out the view in `todo/views.py`
-```
-# todo/views.py
-
-from django.shortcuts import get_object_or_404
-
-from rest_framework.response import JsonResponse
-
-from rest_framework.views import APIView
-
-
-
-from owner.models import Owner
-
-from todo.models import Task
-
-from todo.serializers import TaskSerializer
-
-
-
-
-
-class TaskListView(APIView):
-
- def get(self, request, username, format=None):
-
- """Get all of the tasks for a given user."""
-
- owner = get_object_or_404(Owner, user__username=username)
-
- tasks = Task.objects.filter(owner=owner).all()
-
- serialized = TaskSerializer(tasks, many=True)
-
- return JsonResponse({
-
- 'username': username,
-
- 'tasks': serialized.data
-
- })
-
-```
-
-There's a lot going on here in a little bit of code, so let's walk through it.
-
-We start out with the same inheritance of the `APIView` that we've been using, laying the groundwork for what will be our view. We override the same `get` method we've overridden before, adding a parameter that allows our view to receive the `username` from the incoming request.
-
-Our `get` method will then use that `username` to grab the `Owner` associated with that user. This `get_object_or_404` function allows us to do just that, with a little something special added for ease of use.
-
-It would make sense that there's no point in looking for tasks if the specified user can't be found. In fact, we'd want to return a 404 error. `get_object_or_404` gets a single object based on whatever criteria we pass in and either returns that object or raises an [Http404 exception][18]. We can set that criteria based on attributes of the object. The `Owner` objects are all attached to a `User` through their `user` attribute. We don't have a `User` object to search with, though. We only have a `username`. So, we say to `get_object_or_404` "when you look for an `Owner`, check to see that the `User` attached to it has the `username` that I want" by specifying `user__username`. That's TWO underscores. When filtering through a QuerySet, the two underscores mean "attribute of this nested object." Those attributes can be as deeply nested as needed.
-
-We now have the `Owner` corresponding to the given username. We use that `Owner` to filter through all the tasks, only retrieving the ones it owns with `Task.objects.filter`. We could've used the same nested-attribute pattern that we did with `get_object_or_404` to drill into the `User` connected to the `Owner` connected to the `Tasks` (`tasks = Task.objects.filter(owner__user__username=username).all()`) but there's no need to get that wild with it.
-
-`Task.objects.filter(owner=owner).all()` will provide us with a `QuerySet` of all the `Task` objects that match our query. Great. The `TaskSerializer` will then take that `QuerySet` and all its data, along with the flag of `many=True` to notify it as being a collection of items instead of just one item, and return a serialized set of results. Effectively a list of dictionaries. Finally, we provide the outgoing response with the JSON-serialized data and the username used for the query.
-
-#### Handling the POST request
-
-The `post` method will look somewhat different from what we've seen before.
-```
-# still in todo/views.py
-
-# ...other imports...
-
-from rest_framework.parsers import JSONParser
-
-from datetime import datetime
-
-
-
-class TaskListView(APIView):
-
- def get(self, request, username, format=None):
-
- ...
-
-
-
- def post(self, request, username, format=None):
-
- """Create a new Task."""
-
- owner = get_object_or_404(Owner, user__username=username)
-
- data = JSONParser().parse(request)
-
- data['owner'] = owner.id
-
- if data['due_date']:
-
- data['due_date'] = datetime.strptime(data['due_date'], '%d/%m/%Y %H:%M:%S')
-
-
-
- new_task = TaskSerializer(data=data)
-
- if new_task.is_valid():
-
- new_task.save()
-
- return JsonResponse({'msg': 'posted'}, status=201)
-
-
-
- return JsonResponse(new_task.errors, status=400)
-
-```
-
-When we receive data from the client, we parse it into a dictionary using `JSONParser().parse(request)`. We add the owner to the data and format the `due_date` for the task if one exists.
-
-Our `TaskSerializer` does the heavy lifting. It first takes in the incoming data and translates it into the fields we specified on the model. It then validates that data to make sure it fits the specified fields. If the data being attached to the new `Task` is valid, it constructs a new `Task` object with that data and commits it to the database. We then send back an appropriate "Yay! We made a new thing!" response. If not, we collect the errors that `TaskSerializer` generated and send those back to the client with a `400 Bad Request` status code.
-
-If we were to build out the `put` view for updating a `Task`, it would look very similar to this. The main difference would be that when we instantiate the `TaskSerializer`, instead of just passing in the new data, we'd pass in the old object and the new data for that object like `TaskSerializer(existing_task, data=data)`. We'd still do the validity check and send back the responses we want to send back.
-
-### Wrapping up
-
-Django as a framework is highly customizable, and everyone has their own way of stitching together a Django project. The way I've written it out here isn't necessarily the exact way that a Django project needs to be set up; it's just a) what I'm familiar with, and b) what leverages Django's management system. Django projects grow in complexity as you separate concepts into their own little silos. You do that so it's easier for multiple people to contribute to the overall project without stepping on each other's toes.
-
-The vast map of files that is a Django project, however, doesn't make it more performant or naturally predisposed to a microservice architecture. On the contrary, it can very easily become a confusing monolith. That may still be useful for your project. It may also make it harder for your project to be manageable, especially as it grows.
-
-Consider your options carefully and use the right tool for the right job. For a simple project like this, Django likely isn't the right tool.
-
-Django is meant to handle multiple sets of models that cover a variety of different project areas that may share some common ground. This project is a small, two-model project with a handful of routes. If we were to build this out more, we'd only have seven routes and still the same two models. It's hardly enough to justify a full Django project.
-
-It would be a great option if we expected this project to expand. This is not one of those projects. This is choosing a flamethrower to light a candle. It's absolute overkill.
-
-Still, a web framework is a web framework, regardless of which one you use for your project. It can take in requests and respond as well as any other, so you do as you wish. Just be aware of what overhead comes with your choice of framework.
-
-That's it! We've reached the end of this series! I hope it has been an enlightening adventure and will help you make more than just the most-familiar choice when you're thinking about how to build out your next project. Make sure to read the documentation for each framework to expand on anything covered in this series (as it's not even the least bit comprehensive). There's a wide world of stuff to get into for each. Happy coding!
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/django-framework
-
-作者:[Nicholas Hunt-Walker][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/nhuntwalker
-[1]:https://opensource.com/article/18/5/pyramid-framework
-[2]:https://opensource.com/article/18/4/flask
-[3]:https://opensource.com/article/18/6/tornado-framework
-[4]:https://www.djangoproject.com
-[5]:https://djangopackages.org/
-[6]:http://www.django-rest-framework.org/
-[7]:http://gunicorn.org/
-[8]:https://docs.pylonsproject.org/projects/waitress/en/latest/
-[9]:https://uwsgi-docs.readthedocs.io/en/latest/
-[10]:https://docs.djangoproject.com/en/2.0/ref/settings/#databases
-[11]:https://pypi.org/project/dj-database-url/
-[12]:http://yellerapp.com/posts/2015-01-12-the-worst-server-setup-you-can-make.html
-[13]:https://docs.djangoproject.com/en/2.0/ref/settings/#std:setting-DATABASE-ENGINE
-[14]:https://www.getpostman.com/
-[15]:http://www.django-rest-framework.org/api-guide/serializers/#modelserializer
-[16]:http://www.django-rest-framework.org/api-guide/serializers/
-[17]:http://www.django-rest-framework.org/api-guide/serializers/#serializers
-[18]:https://docs.djangoproject.com/en/2.0/topics/http/views/#the-http404-exception
diff --git a/sources/tech/20180823 CLI- improved.md b/sources/tech/20180823 CLI- improved.md
index d06bb1b2aa..52edaa28c8 100644
--- a/sources/tech/20180823 CLI- improved.md
+++ b/sources/tech/20180823 CLI- improved.md
@@ -1,3 +1,5 @@
+Translating by DavidChenLiang
+
CLI: improved
======
I'm not sure many web developers can get away without visiting the command line. As for me, I've been using the command line since 1997, first at university when I felt both super cool l33t-hacker and simultaneously utterly out of my depth.
diff --git a/sources/tech/20180823 How To Easily And Safely Manage Cron Jobs In Linux.md b/sources/tech/20180823 How To Easily And Safely Manage Cron Jobs In Linux.md
deleted file mode 100644
index aa4ec0a655..0000000000
--- a/sources/tech/20180823 How To Easily And Safely Manage Cron Jobs In Linux.md
+++ /dev/null
@@ -1,131 +0,0 @@
-How To Easily And Safely Manage Cron Jobs In Linux
-======
-
-
-
-When it comes to schedule tasks in Linux, which utility comes to your mind first? Yeah, you guessed it right. **Cron!** The cron utility helps you to schedule commands/tasks at specific time in Unix-like operating systems. We already published a [**beginners guides to Cron jobs**][1]. I have a few years experience in Linux, so setting up cron jobs is no big deal for me. But, it is not piece of cake for newbies. The noobs may unknowingly do small mistakes while editing plain text crontab and bring down all cron jobs. Just in case, if you think you might mess up with your cron jobs, there is a good alternative way. Say hello to **Crontab UI** , a web-based tool to easily and safely manage cron jobs in Unix-like operating systems.
-
-You don’t need to manually edit the crontab file to create, delete and manage cron jobs. Everything can be done via a web browser with a couple mouse clicks. Crontab UI allows you to easily create, edit, pause, delete, backup cron jobs, and even import, export and deploy jobs on other machines without much hassle. Error log, mailing and hooks support also possible. It is free, open source and written using NodeJS.
-
-### Installing Crontab UI
-
-Installing Crontab UI is just a one-liner command. Make sure you have installed NPM. If you haven’t install npm yet, refer the following link.
-
-Next, run the following command to install Crontab UI.
-```
-$ npm install -g crontab-ui
-
-```
-
-It’s that simple. Let us go ahead and see how to manage cron jobs using Crontab UI.
-
-### Easily And Safely Manage Cron Jobs In Linux
-
-To launch Crontab UI, simply run:
-```
-$ crontab-ui
-
-```
-
-You will see the following output:
-```
-Node version: 10.8.0
-Crontab UI is running at http://127.0.0.1:8000
-
-```
-
-Now, open your web browser and navigate to ****. Make sure the port no 8000 is allowed in your firewall/router.
-
-Please note that you can only access Crontab UI web dashboard within the local system itself.
-
-If you want to run Crontab UI with your system’s IP and custom port (so you can access it from any remote system in the network), use the following command instead:
-```
-$ HOST=0.0.0.0 PORT=9000 crontab-ui
-Node version: 10.8.0
-Crontab UI is running at http://0.0.0.0:9000
-
-```
-
-Now, Crontab UI can be accessed from the any system in the nework using URL – **http:// :9000**.
-
-This is how Crontab UI dashboard looks like.
-
-
-
-As you can see in the above screenshot, Crontab UI dashbaord is very simply. All options are self-explanatory.
-
-To exit Crontab UI, press **CTRL+C**.
-
-**Create, edit, run, stop, delete a cron job**
-
-To create a new cron job, click on “New” button. Enter your cron job details and click Save.
-
- 1. Name the cron job. It is optional.
- 2. The full command you want to run.
- 3. Choose schedule time. You can either choose the quick schedule time, (such as Startup, Hourly, Daily, Weekly, Monthly, Yearly) or set the exact time to run the command. After you choosing the schedule time, the syntax of the cron job will be shown in **Jobs** field.
- 4. Choose whether you want to enable error logging for the particular job.
-
-
-
-Here is my sample cron job.
-
-
-
-As you can see, I have setup a cron job to clear pacman cache at every month.
-
-Similarly, you can create any number of jobs as you want. You will see all cron jobs in the dashboard.
-
-
-
-If you wanted to change any parameter in a cron job, just click on the **Edit** button below the job and modify the parameters as you wish. To run a job immediately, click on the button that says **Run**. To stop a job, click **Stop** button. You can view the log details of any job by clicking on the **Log** button. If the job is no longer required, simply press **Delete** button.
-
-**Backup cron jobs**
-
-To backup all cron jobs, press the Backup from main dashboard and choose OK to confirm the backup.
-
-
-
-You can use this backup in case you messed with the contents of the crontab file.
-
-**Import/Export cron jobs to other systems**
-
-Another notable feature of Crontab UI is you can import, export and deploy cron jobs to other systems. If you have multiple systems on your network that requires the same cron jobs, just press **Export** button and choose the location to save the file. All contents of crontab file will be saved in a file named **crontab.db**.
-
-Here is the contents of the crontab.db file.
-```
-$ cat Downloads/crontab.db
-{"name":"Remove Pacman Cache","command":"rm -rf /var/cache/pacman","schedule":"@monthly","stopped":false,"timestamp":"Thu Aug 23 2018 10:34:19 GMT+0000 (Coordinated Universal Time)","logging":"true","mailing":{},"created":1535020459093,"_id":"lcVc1nSdaceqS1ut"}
-
-```
-
-Then you can transfer the entire crontab.db file to some other system and import its to the new system. You don’t need to manually create cron jobs in all systems. Just create them in one system and export and import all of them to every system on the network.
-
-**Get the contents from or save to existing crontab file**
-
-There are chances that you might have already created some cron jobs using **crontab** command. If so, you can retrieve contents of the existing crontab file by click on the **“Get from crontab”** button in main dashboard.
-
-
-
-Similarly, you can save the newly created jobs using Crontab UI utility to existing crontab file in your system. To do so, just click **Save to crontab** option in the dashboard.
-
-See? Managing cron jobs is not that complicated. Any newbie user can easily maintain any number of jobs without much hassle using Crontab UI. Give it a try and let us know what do you think about this tool. I am all ears!
-
-And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/how-to-easily-and-safely-manage-cron-jobs-in-linux/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.ostechnix.com/author/sk/
-[1]:https://www.ostechnix.com/a-beginners-guide-to-cron-jobs/
diff --git a/sources/tech/20180827 4 tips for better tmux sessions.md b/sources/tech/20180827 4 tips for better tmux sessions.md
deleted file mode 100644
index b6d6a3e4fe..0000000000
--- a/sources/tech/20180827 4 tips for better tmux sessions.md
+++ /dev/null
@@ -1,89 +0,0 @@
-translating by lujun9972
-4 tips for better tmux sessions
-======
-
-
-
-The tmux utility, a terminal multiplexer, lets you treat your terminal as a multi-paned window into your system. You can arrange the configuration, run different processes in each, and generally make better use of your screen. We introduced some readers to this powerful tool [in this earlier article][1]. Here are some tips that will help you get more out of tmux if you’re getting started.
-
-This article assumes your current prefix key is Ctrl+b. If you’ve remapped that prefix, simply substitute your prefix in its place.
-
-### Set your terminal to automatically use tmux
-
-One of the biggest benefits of tmux is being able to disconnect and reconnect to sesions at wilI. This makes remote login sessions more powerful. Have you ever lost a connection and wished you could get back the work you were doing on the remote system? With tmux this problem is solved.
-
-However, you may sometimes find yourself doing work on a remote system, and realize you didn’t start a session. One way to avoid this is to have tmux start or attach every time you login to a system with in interactive shell.
-
-Add this to your remote system’s ~/.bash_profile file:
-
-```
-if [ -z "$TMUX" ]; then
- tmux attach -t default || tmux new -s default
-fi
-```
-
-Then logout of the remote system, and log back in with SSH. You’ll find you’re in a tmux session named default. This session will be regenerated at next login if you exit it. But more importantly, if you detach from it as normal, your work is waiting for you next time you login — especially useful if your connection is interrupted.
-
-Of course you can add this to your local system as well. Note that terminals inside most GUIs won’t use the default session automatically, because they aren’t login shells. While you can change that behavior, it may result in nesting that makes the session less usable, so proceed with caution.
-
-### Use zoom to focus on a single process
-
-While the point of tmux is to offer multiple windows, panes, and processes in a single session, sometimes you need to focus. If you’re in a process and need more space, or to focus on a single task, the zoom command works well. It expands the current pane to take up the entire current window space.
-
-Zoom can be useful in other situations too. For instance, imagine you’re using a terminal window in a graphical desktop. Panes can make it harder to copy and paste multiple lines from inside your tmux session. If you zoom the pane, you can do a clean copy/paste of multiple lines of data with ease.
-
-To zoom into the current pane, hit Ctrl+b, z. When you’re finished with the zoom function, hit the same key combo to unzoom the pane.
-
-### Bind some useful commands
-
-By default tmux has numerous commands available. But it’s helpful to have some of the more common operations bound to keys you can easily remember. Here are some examples you can add to your ~/.tmux.conf file to make sessions more enjoyable:
-
-```
-bind r source-file ~/.tmux.conf \; display "Reloaded config"
-```
-
-This command rereads the commands and bindings in your config file. Once you add this binding, exit any tmux sessions and then restart one. Now after you make any other future changes, simply run Ctrl+b, r and the changes will be part of your existing session.
-
-```
-bind V split-window -h
-bind H split-window
-```
-
-These commands make it easier to split the current window across a vertical axis (note that’s Shift+V) or across a horizontal axis (Shift+H).
-
-If you want to see how all keys are bound, use Ctrl+B, ? to see a list. You may see keys bound in copy-mode first, for when you’re working with copy and paste inside tmux. The prefix mode bindings are where you’ll see ones you’ve added above. Feel free to experiment with your own!
-
-### Use powerline for great justice
-
-[As reported in a previous Fedora Magazine article][2], the powerline utility is a fantastic addition to your shell. But it also has capabilities when used with tmux. Because tmux takes over the entire terminal space, the powerline window can provide more than just a better shell prompt.
-
- [][3]
-
-If you haven’t already, follow the instructions in the [Magazine’s powerline article][4] to install that utility. Then, install the addon [using sudo][5]:
-
-```
-sudo dnf install tmux-powerline
-```
-
-Now restart your session, and you’ll see a spiffy new status line at the bottom. Depending on the terminal width, the default status line now shows your current session ID, open windows, system information, date and time, and hostname. If you change directory into a git-controlled project, you’ll see the branch and color-coded status as well.
-
-Of course, this status bar is highly configurable as well. Enjoy your new supercharged tmux session, and have fun experimenting with it.
-
-
---------------------------------------------------------------------------------
-
-via: https://fedoramagazine.org/4-tips-better-tmux-sessions/
-
-作者:[Paul W. Frields][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[lujun9972](https://github.com/lujun9972)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://fedoramagazine.org/author/pfrields/
-[1]:https://fedoramagazine.org/use-tmux-more-powerful-terminal/
-[2]:https://fedoramagazine.org/add-power-terminal-powerline/
-[3]:https://fedoramagazine.org/wp-content/uploads/2018/08/Screenshot-from-2018-08-25-19-36-53.png
-[4]:https://fedoramagazine.org/add-power-terminal-powerline/
-[5]:https://fedoramagazine.org/howto-use-sudo/
diff --git a/sources/tech/20180827 Solve -error- failed to commit transaction (conflicting files)- In Arch Linux.md b/sources/tech/20180827 Solve -error- failed to commit transaction (conflicting files)- In Arch Linux.md
deleted file mode 100644
index bb0479e7fe..0000000000
--- a/sources/tech/20180827 Solve -error- failed to commit transaction (conflicting files)- In Arch Linux.md
+++ /dev/null
@@ -1,50 +0,0 @@
-translating by lujun9972
-Solve "error: failed to commit transaction (conflicting files)" In Arch Linux
-======
-
-
-
-It’s been a month since I upgraded my Arch Linux desktop. Today, I tried to update my Arch Linux system, and ran into an error that said **“error: failed to commit transaction (conflicting files) stfl: /usr/lib/libstfl.so.0 exists in filesystem”**. It looks like one library (/usr/lib/libstfl.so.0) that exists on my filesystem and pacman can’t upgrade it. If you’re encountered with the same error, here is a quick fix to resolve it.
-
-### Solve “error: failed to commit transaction (conflicting files)” In Arch Linux
-
-You have three options.
-
-1. Simply ignore the problematic **stfl** library from being upgraded and try to update the system again. Refer this guide to know [**how to ignore package from being upgraded**][1].
-
-2. Overwrite the package using command:
-```
-$ sudo pacman -Syu --overwrite /usr/lib/libstfl.so.0
-```
-
-3. Remove stfl library file manually and try to upgrade the system again. Please make sure the intended package is not a dependency to any important package. and check the archlinux.org whether are mentions of this conflict.
-```
-$ sudo rm /usr/lib/libstfl.so.0
-```
-
-Now, try to update the system:
-```
-$ sudo pacman -Syu
-```
-
-I chose the third option and just deleted the file and upgraded my Arch Linux system. It works now!
-
-Hope this helps. More good stuffs to come. Stay tuned!
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/how-to-solve-error-failed-to-commit-transaction-conflicting-files-in-arch-linux/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[lujun9972](https://github.com/lujun9972)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.ostechnix.com/author/sk/
-[1]:https://www.ostechnix.com/safely-ignore-package-upgraded-arch-linux/
diff --git a/sources/tech/20180831 Publishing Markdown to HTML with MDwiki.md b/sources/tech/20180831 Publishing Markdown to HTML with MDwiki.md
index c25239b7ba..769f9ba420 100644
--- a/sources/tech/20180831 Publishing Markdown to HTML with MDwiki.md
+++ b/sources/tech/20180831 Publishing Markdown to HTML with MDwiki.md
@@ -1,3 +1,4 @@
+Translating by z52527
Publishing Markdown to HTML with MDwiki
======
diff --git a/sources/tech/20180906 How To Limit Network Bandwidth In Linux Using Wondershaper.md b/sources/tech/20180906 How To Limit Network Bandwidth In Linux Using Wondershaper.md
deleted file mode 100644
index 11d266e163..0000000000
--- a/sources/tech/20180906 How To Limit Network Bandwidth In Linux Using Wondershaper.md
+++ /dev/null
@@ -1,196 +0,0 @@
-How To Limit Network Bandwidth In Linux Using Wondershaper
-======
-
-
-
-This tutorial will help you to easily limit network bandwidth and shape your network traffic in Unix-like operating systems. By limiting the network bandwidth usage, you can save unnecessary bandwidth consumption’s by applications, such as package managers (pacman, yum, apt), web browsers, torrent clients, download managers etc., and prevent the bandwidth abuse by a single or multiple users in the network. For the purpose of this tutorial, we will be using a command line utility named **Wondershaper**. Trust me, it is not that hard as you may think. It is one of the easiest and quickest way ever I have come across to limit the Internet or local network bandwidth usage in your own Linux system. Read on.
-
-Please be mindful that the aforementioned utility can only limit the incoming and outgoing traffic of your local network interfaces, not the interfaces of your router or modem. In other words, Wondershaper will only limit the network bandwidth in your local system itself, not any other systems in the network. These utility is mainly designed for limiting the bandwidth of one or more network adapters in your local system. Hope you got my point.
-
-Let us see how to use Wondershaper to shape the network traffic.
-
-### Limit Network Bandwidth In Linux Using Wondershaper
-
-**Wondershaper** is simple script used to limit the bandwidth of your system’s network adapter(s). It limits the bandwidth iproute’s tc command, but greatly simplifies its operation.
-
-**Installing Wondershaper**
-
-To install the latest version, git clone wondershaoer repository:
-
-```
-$ git clone https://github.com/magnific0/wondershaper.git
-
-```
-
-Go to the wondershaper directory and install it as show below
-
-```
-$ cd wondershaper
-
-$ sudo make install
-
-```
-
-And, run the following command to start wondershaper service automatically on every reboot.
-
-```
-$ sudo systemctl enable wondershaper.service
-
-$ sudo systemctl start wondershaper.service
-
-```
-
-You can also install using your distribution’s package manager (official or non-official) if you don’t mind the latest version.
-
-Wondershaper is available in [**AUR**][1], so you can install it in Arch-based systems using AUR helper programs such as [**Yay**][2].
-
-```
-$ yay -S wondershaper-git
-
-```
-
-On Debian, Ubuntu, Linux Mint:
-
-```
-$ sudo apt-get install wondershaper
-
-```
-
-On Fedora:
-
-```
-$ sudo dnf install wondershaper
-
-```
-
-On RHEL, CentOS, enable EPEL repository and install wondershaper as shown below.
-
-```
-$ sudo yum install epel-release
-
-$ sudo yum install wondershaper
-
-```
-
-Finally, start wondershaper service automatically on every reboot.
-
-```
-$ sudo systemctl enable wondershaper.service
-
-$ sudo systemctl start wondershaper.service
-
-```
-
-**Usage**
-
-First, find the name of your network interface. Here are some common ways to find the details of a network card.
-
-```
-$ ip addr
-
-$ route
-
-$ ifconfig
-
-```
-
-Once you find the network card name, you can limit the bandwidth rate as shown below.
-
-```
-$ sudo wondershaper -a -d -u
-
-```
-
-For instance, if your network card name is **enp0s8** and you wanted to limit the bandwidth to **1024 Kbps** for **downloads** and **512 kbps** for **uploads** , the command would be:
-
-```
-$ sudo wondershaper -a enp0s8 -d 1024 -u 512
-
-```
-
-Where,
-
- * **-a** : network card name
- * **-d** : download rate
- * **-u** : upload rate
-
-
-
-To clear the limits from a network adapter, simply run:
-
-```
-$ sudo wondershaper -c -a enp0s8
-
-```
-
-Or
-
-```
-$ sudo wondershaper -c enp0s8
-
-```
-
-Just in case, there are more than one network card available in your system, you need to manually set the download/upload rates for each network interface card as described above.
-
-If you have installed Wondershaper by cloning its GitHub repository, there is a configuration named **wondershaper.conf** exists in **/etc/conf.d/** location. Make sure you have set the download or upload rates by modifying the appropriate values(network card name, download/upload rate) in this file.
-
-```
-$ sudo nano /etc/conf.d/wondershaper.conf
-
-[wondershaper]
-# Adapter
-#
-IFACE="eth0"
-
-# Download rate in Kbps
-#
-DSPEED="2048"
-
-# Upload rate in Kbps
-#
-USPEED="512"
-
-```
-
-Here is the sample before Wondershaper:
-
-After enabling Wondershaper:
-
-As you can see, the download rate has been tremendously reduced after limiting the bandwidth using WOndershaper in my Ubuntu 18.o4 LTS server.
-
-For more details, view the help section by running the following command:
-
-```
-$ wondershaper -h
-
-```
-
-Or, refer man pages.
-
-```
-$ man wondershaper
-
-```
-
-As far as tested, Wondershaper worked just fine as described above. Give it a try and let us know what do you think about this utility.
-
-And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned.
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/how-to-limit-network-bandwidth-in-linux-using-wondershaper/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.ostechnix.com/author/sk/
-[1]: https://aur.archlinux.org/packages/wondershaper-git/
-[2]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
diff --git a/sources/tech/20180907 How to Use the Netplan Network Configuration Tool on Linux.md b/sources/tech/20180907 How to Use the Netplan Network Configuration Tool on Linux.md
deleted file mode 100644
index a9d3eb0895..0000000000
--- a/sources/tech/20180907 How to Use the Netplan Network Configuration Tool on Linux.md
+++ /dev/null
@@ -1,230 +0,0 @@
-LuuMing translating
-How to Use the Netplan Network Configuration Tool on Linux
-======
-
-
-
-For years Linux admins and users have configured their network interfaces in the same way. For instance, if you’re a Ubuntu user, you could either configure the network connection via the desktop GUI or from within the /etc/network/interfaces file. The configuration was incredibly easy and never failed to work. The configuration within that file looked something like this:
-
-```
-auto enp10s0
-
-iface enp10s0 inet static
-
-address 192.168.1.162
-
-netmask 255.255.255.0
-
-gateway 192.168.1.100
-
-dns-nameservers 1.0.0.1,1.1.1.1
-
-```
-
-Save and close that file. Restart networking with the command:
-
-```
-sudo systemctl restart networking
-
-```
-
-Or, if you’re not using a non-systemd distribution, you could restart networking the old fashioned way like so:
-
-```
-sudo /etc/init.d/networking restart
-
-```
-
-Your network will restart and the newly configured interface is good to go.
-
-That’s how it’s been done for years. Until now. With certain distributions (such as Ubuntu Linux 18.04), the configuration and control of networking has changed considerably. Instead of that interfaces file and using the /etc/init.d/networking script, we now turn to [Netplan][1]. Netplan is a command line utility for the configuration of networking on certain Linux distributions. Netplan uses YAML description files to configure network interfaces and, from those descriptions, will generate the necessary configuration options for any given renderer tool.
-
-I want to show you how to use Netplan on Linux, to configure a static IP address and a DHCP address. I’ll be demonstrating on Ubuntu Server 18.04. I will give you one word of warning, the .yaml files you create for Netplan must be consistent in spacing, otherwise they’ll fail to work. You don’t have to use a specific spacing for each line, it just has to remain consistent.
-
-### The new configuration files
-
-Open a terminal window (or log into your Ubuntu Server via SSH). You will find the new configuration files for Netplan in the /etc/netplan directory. Change into that directory with the command cd /etc/netplan. Once in that directory, you will probably only see a single file:
-
-```
-01-netcfg.yaml
-
-```
-
-You can create a new file or edit the default. If you opt to edit the default, I suggest making a copy with the command:
-
-```
-sudo cp /etc/netplan/01-netcfg.yaml /etc/netplan/01-netcfg.yaml.bak
-
-```
-
-With your backup in place, you’re ready to configure.
-
-### Network Device Name
-
-Before you configure your static IP address, you’ll need to know the name of device to be configured. To do that, you can issue the command ip a and find out which device is to be used (Figure 1).
-
-![netplan][3]
-
-Figure 1: Finding our device name with the ip a command.
-
-[Used with permission][4]
-
-I’ll be configuring ens5 for a static IP address.
-
-### Configuring a Static IP Address
-
-Open the original .yaml file for editing with the command:
-
-```
-sudo nano /etc/netplan/01-netcfg.yaml
-
-```
-
-The layout of the file looks like this:
-
-network:
-
-Version: 2
-
-Renderer: networkd
-
-ethernets:
-
-DEVICE_NAME:
-
-Dhcp4: yes/no
-
-Addresses: [IP/NETMASK]
-
-Gateway: GATEWAY
-
-Nameservers:
-
-Addresses: [NAMESERVER, NAMESERVER]
-
-Where:
-
- * DEVICE_NAME is the actual device name to be configured.
-
- * yes/no is an option to enable or disable dhcp4.
-
- * IP is the IP address for the device.
-
- * NETMASK is the netmask for the IP address.
-
- * GATEWAY is the address for your gateway.
-
- * NAMESERVER is the comma-separated list of DNS nameservers.
-
-
-
-
-Here’s a sample .yaml file:
-
-```
-network:
-
- version: 2
-
- renderer: networkd
-
- ethernets:
-
- ens5:
-
- dhcp4: no
-
- addresses: [192.168.1.230/24]
-
- gateway4: 192.168.1.254
-
- nameservers:
-
- addresses: [8.8.4.4,8.8.8.8]
-
-```
-
-Edit the above to fit your networking needs. Save and close that file.
-
-Notice the netmask is no longer configured in the form 255.255.255.0. Instead, the netmask is added to the IP address.
-
-### Testing the Configuration
-
-Before we apply the change, let’s test the configuration. To do that, issue the command:
-
-```
-sudo netplan try
-
-```
-
-The above command will validate the configuration before applying it. If it succeeds, you will see Configuration accepted. In other words, Netplan will attempt to apply the new settings to a running system. Should the new configuration file fail, Netplan will automatically revert to the previous working configuration. Should the new configuration work, it will be applied.
-
-### Applying the New Configuration
-
-If you are certain of your configuration file, you can skip the try option and go directly to applying the new options. The command for this is:
-
-```
-sudo netplan apply
-
-```
-
-At this point, you can issue the command ip a to see that your new address configurations are in place.
-
-### Configuring DHCP
-
-Although you probably won’t be configuring your server for DHCP, it’s always good to know how to do this. For example, you might not know what static IP addresses are currently available on your network. You could configure the device for DHCP, get an IP address, and then reconfigure that address as static.
-
-To use DHCP with Netplan, the configuration file would look something like this:
-
-```
-network:
-
- version: 2
-
- renderer: networkd
-
- ethernets:
-
- ens5:
-
- Addresses: []
-
- dhcp4: true
-
- optional: true
-
-```
-
-Save and close that file. Test the file with:
-
-```
-sudo netplan try
-
-```
-
-Netplan should succeed and apply the DHCP configuration. You could then issue the ip a command, get the dynamically assigned address, and then reconfigure a static address. Or, you could leave it set to use DHCP (but seeing as how this is a server, you probably won’t want to do that).
-
-Should you have more than one interface, you could name the second .yaml configuration file 02-netcfg.yaml. Netplan will apply the configuration files in numerical order, so 01 will be applied before 02. Create as many configuration files as needed for your server.
-
-### That’s All There Is
-
-Believe it or not, that’s all there is to using Netplan. Although it is a significant change to how we’re accustomed to configuring network addresses, it’s not all that hard to get used to. But this style of configuration is here to stay… so you will need to get used to it.
-
-Learn more about Linux through the free ["Introduction to Linux" ][5]course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2018/9/how-use-netplan-network-configuration-tool-linux
-
-作者:[Jack Wallen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.linux.com/users/jlwallen
-[1]: https://netplan.io/
-[3]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/netplan_1.jpg?itok=XuIsXWbV (netplan)
-[4]: /licenses/category/used-permission
-[5]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180927 How To Find And Delete Duplicate Files In Linux.md b/sources/tech/20180927 How To Find And Delete Duplicate Files In Linux.md
deleted file mode 100644
index e3a0a9d561..0000000000
--- a/sources/tech/20180927 How To Find And Delete Duplicate Files In Linux.md
+++ /dev/null
@@ -1,441 +0,0 @@
-How To Find And Delete Duplicate Files In Linux
-======
-
-
-
-I always backup the configuration files or any old files to somewhere in my hard disk before edit or modify them, so I can restore them from the backup if I accidentally did something wrong. But the problem is I forgot to clean up those files and my hard disk is filled with a lot of duplicate files after a certain period of time. I feel either too lazy to clean the old files or afraid that I may delete an important files. If you’re anything like me and overwhelming with multiple copies of same files in different backup directories, you can find and delete duplicate files using the tools given below in Unix-like operating systems.
-
-**A word of caution:**
-
-Please be careful while deleting duplicate files. If you’re not careful, it will lead you to [**accidental data loss**][1]. I advice you to pay extra attention while using these tools.
-
-### Find And Delete Duplicate Files In Linux
-
-For the purpose of this guide, I am going to discuss about three utilities namely,
-
- 1. Rdfind,
- 2. Fdupes,
- 3. FSlint.
-
-
-
-These three utilities are free, open source and works on most Unix-like operating systems.
-
-##### 1. Rdfind
-
-**Rdfind** , stands for **r** edundant **d** ata **find** , is a free and open source utility to find duplicate files across and/or within directories and sub-directories. It compares files based on their content, not on their file names. Rdfind uses **ranking** algorithm to classify original and duplicate files. If you have two or more equal files, Rdfind is smart enough to find which is original file, and consider the rest of the files as duplicates. Once it found the duplicates, it will report them to you. You can decide to either delete them or replace them with [**hard links** or **symbolic (soft) links**][2].
-
-**Installing Rdfind**
-
-Rdfind is available in [**AUR**][3]. So, you can install it in Arch-based systems using any AUR helper program like [**Yay**][4] as shown below.
-
-```
-$ yay -S rdfind
-
-```
-
-On Debian, Ubuntu, Linux Mint:
-
-```
-$ sudo apt-get install rdfind
-
-```
-
-On Fedora:
-
-```
-$ sudo dnf install rdfind
-
-```
-
-On RHEL, CentOS:
-
-```
-$ sudo yum install epel-release
-
-$ sudo yum install rdfind
-
-```
-
-**Usage**
-
-Once installed, simply run Rdfind command along with the directory path to scan for the duplicate files.
-
-```
-$ rdfind ~/Downloads
-
-```
-
-
-
-As you see in the above screenshot, Rdfind command will scan ~/Downloads directory and save the results in a file named **results.txt** in the current working directory. You can view the name of the possible duplicate files in results.txt file.
-
-```
-$ cat results.txt
-# Automatically generated
-# duptype id depth size device inode priority name
-DUPTYPE_FIRST_OCCURRENCE 1469 8 9 2050 15864884 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test5.regex
-DUPTYPE_WITHIN_SAME_TREE -1469 8 9 2050 15864886 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test6.regex
-[...]
-DUPTYPE_FIRST_OCCURRENCE 13 0 403635 2050 15740257 1 /home/sk/Downloads/Hyperledger(1).pdf
-DUPTYPE_WITHIN_SAME_TREE -13 0 403635 2050 15741071 1 /home/sk/Downloads/Hyperledger.pdf
-# end of file
-
-```
-
-By reviewing the results.txt file, you can easily find the duplicates. You can remove the duplicates manually if you want to.
-
-Also, you can **-dryrun** option to find all duplicates in a given directory without changing anything and output the summary in your Terminal:
-
-```
-$ rdfind -dryrun true ~/Downloads
-
-```
-
-Once you found the duplicates, you can replace them with either hardlinks or symlinks.
-
-To replace all duplicates with hardlinks, run:
-
-```
-$ rdfind -makehardlinks true ~/Downloads
-
-```
-
-To replace all duplicates with symlinks/soft links, run:
-
-```
-$ rdfind -makesymlinks true ~/Downloads
-
-```
-
-You may have some empty files in a directory and want to ignore them. If so, use **-ignoreempty** option like below.
-
-```
-$ rdfind -ignoreempty true ~/Downloads
-
-```
-
-If you don’t want the old files anymore, just delete duplicate files instead of replacing them with hard or soft links.
-
-To delete all duplicates, simply run:
-
-```
-$ rdfind -deleteduplicates true ~/Downloads
-
-```
-
-If you do not want to ignore empty files and delete them along with all duplicates, run:
-
-```
-$ rdfind -deleteduplicates true -ignoreempty false ~/Downloads
-
-```
-
-For more details, refer the help section:
-
-```
-$ rdfind --help
-
-```
-
-And, the manual pages:
-
-```
-$ man rdfind
-
-```
-
-##### 2. Fdupes
-
-**Fdupes** is yet another command line utility to identify and remove the duplicate files within specified directories and the sub-directories. It is free, open source utility written in **C** programming language. Fdupes identifies the duplicates by comparing file sizes, partial MD5 signatures, full MD5 signatures, and finally performing a byte-by-byte comparison for verification.
-
-Similar to Rdfind utility, Fdupes comes with quite handful of options to perform operations, such as:
-
- * Recursively search duplicate files in directories and sub-directories
- * Exclude empty files and hidden files from consideration
- * Show the size of the duplicates
- * Delete duplicates immediately as they encountered
- * Exclude files with different owner/group or permission bits as duplicates
- * And a lot more.
-
-
-
-**Installing Fdupes**
-
-Fdupes is available in the default repositories of most Linux distributions.
-
-On Arch Linux and its variants like Antergos, Manjaro Linux, install it using Pacman like below.
-
-```
-$ sudo pacman -S fdupes
-
-```
-
-On Debian, Ubuntu, Linux Mint:
-
-```
-$ sudo apt-get install fdupes
-
-```
-
-On Fedora:
-
-```
-$ sudo dnf install fdupes
-
-```
-
-On RHEL, CentOS:
-
-```
-$ sudo yum install epel-release
-
-$ sudo yum install fdupes
-
-```
-
-**Usage**
-
-Fdupes usage is pretty simple. Just run the following command to find out the duplicate files in a directory, for example **~/Downloads**.
-
-```
-$ fdupes ~/Downloads
-
-```
-
-Sample output from my system:
-
-```
-/home/sk/Downloads/Hyperledger.pdf
-/home/sk/Downloads/Hyperledger(1).pdf
-
-```
-
-As you can see, I have a duplicate file in **/home/sk/Downloads/** directory. It shows the duplicates from the parent directory only. How to view the duplicates from sub-directories? Just use **-r** option like below.
-
-```
-$ fdupes -r ~/Downloads
-
-```
-
-Now you will see the duplicates from **/home/sk/Downloads/** directory and its sub-directories as well.
-
-Fdupes can also be able to find duplicates from multiple directories at once.
-
-```
-$ fdupes ~/Downloads ~/Documents/ostechnix
-
-```
-
-You can even search multiple directories, one recursively like below:
-
-```
-$ fdupes ~/Downloads -r ~/Documents/ostechnix
-
-```
-
-The above commands searches for duplicates in “~/Downloads” directory and “~/Documents/ostechnix” directory and its sub-directories.
-
-Sometimes, you might want to know the size of the duplicates in a directory. If so, use **-S** option like below.
-
-```
-$ fdupes -S ~/Downloads
-403635 bytes each:
-/home/sk/Downloads/Hyperledger.pdf
-/home/sk/Downloads/Hyperledger(1).pdf
-
-```
-
-Similarly, to view the size of the duplicates in parent and child directories, use **-Sr** option.
-
-We can exclude empty and hidden files from consideration using **-n** and **-A** respectively.
-
-```
-$ fdupes -n ~/Downloads
-
-$ fdupes -A ~/Downloads
-
-```
-
-The first command will exclude zero-length files from consideration and the latter will exclude hidden files from consideration while searching for duplicates in the specified directory.
-
-To summarize duplicate files information, use **-m** option.
-
-```
-$ fdupes -m ~/Downloads
-1 duplicate files (in 1 sets), occupying 403.6 kilobytes
-
-```
-
-To delete all duplicates, use **-d** option.
-
-```
-$ fdupes -d ~/Downloads
-
-```
-
-Sample output:
-
-```
-[1] /home/sk/Downloads/Hyperledger Fabric Installation.pdf
-[2] /home/sk/Downloads/Hyperledger Fabric Installation(1).pdf
-
-Set 1 of 1, preserve files [1 - 2, all]:
-
-```
-
-This command will prompt you for files to preserve and delete all other duplicates. Just enter any number to preserve the corresponding file and delete the remaining files. Pay more attention while using this option. You might delete original files if you’re not be careful.
-
-If you want to preserve the first file in each set of duplicates and delete the others without prompting each time, use **-dN** option (not recommended).
-
-```
-$ fdupes -dN ~/Downloads
-
-```
-
-To delete duplicates as they are encountered, use **-I** flag.
-
-```
-$ fdupes -I ~/Downloads
-
-```
-
-For more details about Fdupes, view the help section and man pages.
-
-```
-$ fdupes --help
-
-$ man fdupes
-
-```
-
-##### 3. FSlint
-
-**FSlint** is yet another duplicate file finder utility that I use from time to time to get rid of the unnecessary duplicate files and free up the disk space in my Linux system. Unlike the other two utilities, FSlint has both GUI and CLI modes. So, it is more user-friendly tool for newbies. FSlint not just finds the duplicates, but also bad symlinks, bad names, temp files, bad IDS, empty directories, and non stripped binaries etc.
-
-**Installing FSlint**
-
-FSlint is available in [**AUR**][5], so you can install it using any AUR helpers.
-
-```
-$ yay -S fslint
-
-```
-
-On Debian, Ubuntu, Linux Mint:
-
-```
-$ sudo apt-get install fslint
-
-```
-
-On Fedora:
-
-```
-$ sudo dnf install fslint
-
-```
-
-On RHEL, CentOS:
-
-```
-$ sudo yum install epel-release
-
-```
-
-$ sudo yum install fslint
-
-Once it is installed, launch it from menu or application launcher.
-
-This is how FSlint GUI looks like.
-
-
-
-As you can see, the interface of FSlint is user-friendly and self-explanatory. In the **Search path** tab, add the path of the directory you want to scan and click **Find** button on the lower left corner to find the duplicates. Check the recurse option to recursively search for duplicates in directories and sub-directories. The FSlint will quickly scan the given directory and list out them.
-
-
-
-From the list, choose the duplicates you want to clean and select any one of them given actions like Save, Delete, Merge and Symlink.
-
-In the **Advanced search parameters** tab, you can specify the paths to exclude while searching for duplicates.
-
-
-
-**FSlint command line options**
-
-FSlint provides a collection of the following CLI utilities to find duplicates in your filesystem:
-
- * **findup** — find DUPlicate files
- * **findnl** — find Name Lint (problems with filenames)
- * **findu8** — find filenames with invalid utf8 encoding
- * **findbl** — find Bad Links (various problems with symlinks)
- * **findsn** — find Same Name (problems with clashing names)
- * **finded** — find Empty Directories
- * **findid** — find files with dead user IDs
- * **findns** — find Non Stripped executables
- * **findrs** — find Redundant Whitespace in files
- * **findtf** — find Temporary Files
- * **findul** — find possibly Unused Libraries
- * **zipdir** — Reclaim wasted space in ext2 directory entries
-
-
-
-All of these utilities are available under **/usr/share/fslint/fslint/fslint** location.
-
-For example, to find duplicates in a given directory, do:
-
-```
-$ /usr/share/fslint/fslint/findup ~/Downloads/
-
-```
-
-Similarly, to find empty directories, the command would be:
-
-```
-$ /usr/share/fslint/fslint/finded ~/Downloads/
-
-```
-
-To get more details on each utility, for example **findup** , run:
-
-```
-$ /usr/share/fslint/fslint/findup --help
-
-```
-
-For more details about FSlint, refer the help section and man pages.
-
-```
-$ /usr/share/fslint/fslint/fslint --help
-
-$ man fslint
-
-```
-
-##### Conclusion
-
-You know now about three tools to find and delete unwanted duplicate files in Linux. Among these three tools, I often use Rdfind. It doesn’t mean that the other two utilities are not efficient, but I am just happy with Rdfind so far. Well, it’s your turn. Which is your favorite tool and why? Let us know them in the comment section below.
-
-And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/how-to-find-and-delete-duplicate-files-in-linux/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.ostechnix.com/author/sk/
-[1]: https://www.ostechnix.com/prevent-files-folders-accidental-deletion-modification-linux/
-[2]: https://www.ostechnix.com/explaining-soft-link-and-hard-link-in-linux-with-examples/
-[3]: https://aur.archlinux.org/packages/rdfind/
-[4]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
-[5]: https://aur.archlinux.org/packages/fslint/
diff --git a/sources/tech/20180928 A Free And Secure Online PDF Conversion Suite.md b/sources/tech/20180928 A Free And Secure Online PDF Conversion Suite.md
deleted file mode 100644
index afb66e43ee..0000000000
--- a/sources/tech/20180928 A Free And Secure Online PDF Conversion Suite.md
+++ /dev/null
@@ -1,111 +0,0 @@
-A Free And Secure Online PDF Conversion Suite
-======
-
-
-
-We are always in search for a better and more efficient solution that can make our lives more convenient. That is why when you are working with PDF documents you need a fast and reliable tool that you can use in every situation. Therefore, we wanted to introduce you to **EasyPDF** Online PDF Suite for every occasion. The promise behind this tool is that it can make your PDF management easier and we tested it to check that claim.
-
-But first, here are the most important things you need to know about EasyPDF:
-
- * EasyPDF is free and anonymous online PDF Conversion Suite.
- * Convert PDF to Word, Excel, PowerPoint, AutoCAD, JPG, GIF and Text.
- * Create PDF from Word, PowerPoint, JPG, Excel files and many other formats.
- * Manipulate PDFs with PDF Merge, Split and Compress.
- * OCR conversion of scanned PDFs and images.
- * Upload files from your device or the Cloud (Google Drive and DropBox).
- * Available on Windows, Linux, Mac, and smartphones via any browser.
- * Multiple languages supported.
-
-
-
-### EasyPDF User Interface
-
-
-
-One of the first things that catches your eye is the sleek user interface which gives the tool clean and functional environment in where you can work comfortably. The whole experience is even better because there are no ads on a website at all.
-
-All different types of conversions have their dedicated menu with a simple box to add files, so you don’t have to wonder about what you need to do.
-
-Most websites aren’t optimized to work well and run smoothly on mobile phones, but EasyPDF is an exception from that rule. It opens almost instantly on smartphone and is easy to navigate. You can also add it as the shortcut on your home screen from the **three dots menu** on the Chrome app.
-
-
-
-### Functionality
-
-Apart from looking nice, EasyPDF is pretty straightforward to use. You **don’t need to register** or leave an **email** to use the tool. It is completely anonymous. Additionally, it doesn’t put any limitations to the number or size of files for conversion. No installation required either! Cool, yeah?
-
-You choose a desired conversion format, for example, PDF to Word. Select the PDF file you want to convert. You can upload a file from the device by either drag & drop or selecting the file from the folder. There is also an option to upload a document from [**Google Drive**][1] or [**Dropbox**][2].
-
-After you choose the file, press the Convert button to start the conversion process. You won’t wait for a long time to get your file because conversion will finish in a minute. If you have some more files to convert, remember to download the file before you proceed further. If you don’t download the document first, you will lose it.
-
-
-
-For a different type of conversion, return to the homepage.
-
-The currently available types of conversions are:
-
- * **PDF to Word** – Convert PDF documents to Word documents
-
- * **PDF to PowerPoint** – Convert PDF documents to PowerPoint Presentations
-
- * **PDF to Excel** – Convert PDF documents to Excel documents
-
- * **PDF Creation** – Create PDF documents from any type of file (E.g text, doc, odt)
-
- * **Word to PDF** – Convert Word documents to PDF documents
-
- * **JPG to PDF** – Convert JPG images to PDF documents
-
- * **PDF to AutoCAD** – Convert PDF documents to .dwg format (DWG is native format for CAD packages)
-
- * **PDF to Text** – Convert PDF documents to Text documents
-
- * **PDF Split** – Split PDF files into multiple parts
-
- * **PDF Merge** – Merge multiple PDF files into one
-
- * **PDF Compress** – Compress PDF documents
-
- * **PDF to JPG** – Convert PDF documents to JPG images
-
- * **PDF to PNG** – Convert PDF documents to PNG images
-
- * **PDF to GIF** – Convert PDF documents to GIF files
-
- * **OCR Online** –
-
-Convert scanned paper documents
-
-to editable files (E.g Word, Excel, Text)
-
-
-
-
-Want to give it a try? Great! Click the following link and start converting!
-
-[][https://easypdf.com/]
-
-### Conclusion
-
-EasyPDF lives up to its name and enables easier PDF management. As far as I tested EasyPDF service, It offers out of the box conversion feature completely **FREE!** It is fast, secure and reliable. You will find the quality of services most satisfying without having to pay anything or leaving your personal data like email address. Give it a try and who knows maybe you will find your new favorite PDF tool.
-
-And, that’s all for now. More good stuffs to come. Stay tuned!
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/easypdf-a-free-and-secure-online-pdf-conversion-suite/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.ostechnix.com/author/sk/
-[1]: https://www.ostechnix.com/how-to-mount-google-drive-locally-as-virtual-file-system-in-linux/
-[2]: https://www.ostechnix.com/install-dropbox-in-ubuntu-18-04-lts-desktop/
diff --git a/sources/tech/20180928 How to Install Popcorn Time on Ubuntu 18.04 and Other Linux Distributions.md b/sources/tech/20180928 How to Install Popcorn Time on Ubuntu 18.04 and Other Linux Distributions.md
deleted file mode 100644
index 578624aba4..0000000000
--- a/sources/tech/20180928 How to Install Popcorn Time on Ubuntu 18.04 and Other Linux Distributions.md
+++ /dev/null
@@ -1,233 +0,0 @@
-Translating by dianbanjiu How to Install Popcorn Time on Ubuntu 18.04 and Other Linux Distributions
-======
-**Brief: This tutorial shows you how to install Popcorn Time on Ubuntu and other Linux distributions. Some handy Popcorn Time tips have also been discussed.**
-
-[Popcorn Time][1] is an open source [Netflix][2] inspired [torrent][3] streaming application for Linux, Mac and Windows.
-
-With the regular torrents, you have to wait for the download to finish before you could watch the videos.
-
-[Popcorn Time][4] is different. It uses torrent underneath but allows you to start watching the videos (almost) immediately. It’s like you are watching videos on streaming websites like YouTube or Netflix. You don’t have to wait for the download to finish here.
-
-![Popcorn Time in Ubuntu Linux][5]
-Popcorn Time
-
-If you want to watch movies online without those creepy ads, Popcorn Time is a good alternative. Keep in mind that the streaming quality depends on the number of available seeds.
-
-Popcorn Time also provides a nice user interface where you can browse through available movies, tv-series and other contents. If you ever used [Netflix on Linux][6], you will find it’s somewhat a similar experience.
-
-Using torrent to download movies is illegal in several countries where there are strict laws against piracy. In countries like the USA, UK and West European you may even get legal notices. That said, it’s up to you to decide if you want to use it or not. You have been warned.
-(If you still want to take the risk and use Popcorn Time, you should use a VPN service like [Ivacy][7] that has been specifically designed for using Torrents and protecting your identity. Even then it’s not always easy to avoid the snooping authorities.)
-
-Some of the main features of Popcorn Time are:
-
- * Watch movies and TV Series online using Torrent
- * A sleek user interface lets you browse the available movies and TV series
- * Change streaming quality
- * Bookmark content for watching later
- * Download content for offline viewing
- * Ability to enable subtitles by default, change the subtitles size etc
- * Keyboard shortcuts to navigate through Popcorn Time
-
-
-
-### How to install Popcorn Time on Ubuntu and other Linux Distributions
-
-I am using Ubuntu 18.04 in this tutorial but you can use the same instructions for other Linux distributions such as Linux Mint, Debian, Manjaro, Deepin etc.
-
-Let’s see how to install Popcorn time on Linux. It’s really easy actually. Simply follow the instructions and copy paste the commands I have mentioned.
-
-#### Step 1: Download Popcorn Time
-
-You can download Popcorn Time from its official website. The download link is present on the homepage itself.
-
-[Get Popcorn Time](https://popcorntime.sh/)
-
-#### Step 2: Install Popcorn Time
-
-Once you have downloaded Popcorn Time, it’s time to use it. The downloaded file is a tar file that consists of an executable among other files. While you can extract this tar file anywhere, the [Linux convention is to install additional software in][8] /[opt directory.][8]
-
-Create a new directory in /opt:
-
-```
-sudo mkdir /opt/popcorntime
-```
-
-Now go to the Downloads directory.
-
-```
-cd ~/Downloads
-```
-
-Extract the downloaded Popcorn Time files into the newly created /opt/popcorntime directory.
-
-```
-sudo tar Jxf Popcorn-Time-* -C /opt/popcorntime
-```
-
-#### Step 3: Make Popcorn Time accessible for everyone
-
-You would want every user on your system to be able to run Popcorn Time without sudo access, right? To do that, you need to create a [symbolic link][9] to the executable in /usr/bin directory.
-
-```
-ln -sf /opt/popcorntime/Popcorn-Time /usr/bin/Popcorn-Time
-```
-
-#### Step 4: Create desktop launcher for Popcorn Time
-
-So far so good. But you would also like to see Popcorn Time in the application menu, add it to your favorite application list etc.
-
-For that, you need to create a desktop entry.
-
-Open a terminal and create a new file named popcorntime.desktop in /usr/share/applications.
-
-You can use any [command line based text editor][10]. Ubuntu has [Nano][11] installed by default so you can use that.
-
-```
-sudo nano /usr/share/applications/popcorntime.desktop
-```
-
-Insert the following lines here:
-
-```
-[Desktop Entry]
-Version = 1.0
-Type = Application
-Terminal = false
-Name = Popcorn Time
-Exec = /usr/bin/Popcorn-Time
-Icon = /opt/popcorntime/popcorn.png
-Categories = Application;
-```
-
-If you used Nano editor, save it using shortcut Ctrl+X. When asked for saving, enter Y and then press enter again to save and exit.
-
-We are almost there. One last thing to do here is to have the correct icon for Popcorn Time. For that, you can download a Popcorn Time icon and save it as popcorn.png in /opt/popcorntime directory.
-
-You can do that using the command below:
-
-```
-sudo wget -O /opt/popcorntime/popcorn.png https://upload.wikimedia.org/wikipedia/commons/d/df/Pctlogo.png
-
-```
-
-That’s it. Now you can search for Popcorn Time and click on it to launch it.
-
-![Popcorn Time installed on Ubuntu][12]
-Search for Popcorn Time in Menu
-
-On the first launch, you’ll have to accept the terms and conditions.
-
-![Popcorn Time in Ubuntu Linux][13]
-Accept the Terms of Service
-
-Once you do that, you can enjoy the movies and TV shows.
-
-![Watch movies on Popcorn Time][14]
-
-Well, that’s all you needed to install Popcorn Time on Ubuntu or any other Linux distribution. You can start watching your favorite movies straightaway.
-
-However, if you are interested, I would suggest reading these Popcorn Time tips to get more out of it.
-
-[![][15]][16]
-![][17]
-
-### 7 Tips for using Popcorn Time effectively
-
-Now that you have installed Popcorn Time, I am going to tell you some nifty Popcorn Time tricks. I assure you that it will enhance your experience with Popcorn Time multiple folds.
-
-#### 1\. Use advanced settings
-
-Always have the advanced settings enabled. It gives you more options to tweak Popcorn Time. Go to the top right corner and click on the gear symbol. Click on it and check advanced settings on the next screen.
-
-
-
-#### 2\. Watch the movies in VLC or other players
-
-Did you know that you can choose to watch a file in your preferred media player instead of the default Popcorn Time player? Of course, that media player should have been installed in the system.
-
-Now you may ask why would one want to use another player. And my answer is because other players like VLC has hidden features which you might not find in the Popcorn Time player.
-
-For example, if a file has very low volume, you can use VLC to enhance the audio by 400 percent. You can also [synchronize incoherent subtitles with VLC][18]. You can switch between media players before you start to play a file:
-
-
-
-#### 3\. Bookmark movies and watch it later
-
-Just browsing through movies and TV series but don’t have time or mood to watch those? No issues. You can add the movies to the bookmark and can access these bookmarked videos from the Favorites tab. This enables you to create a list of movies you would watch later.
-
-
-
-#### 4\. Check torrent health and seed information
-
-As I had mentioned earlier, your viewing experience in Popcorn Times depends on torrent speed. Good thing is that Popcorn time shows the health of the torrent file so that you can be aware of the streaming speed.
-
-You will see a green/yellow/red dot on the file. Green means there are plenty of seeds and the file will stream easily. Yellow means a medium number of seeds, streaming should be okay. Red means there are very few seeds available and the streaming will be poor or won’t work at all.
-
-
-
-#### 5\. Add custom subtitles
-
-If you need subtitles and it is not available in your preferred language, you can add custom subtitles downloaded from external websites. Get the .srt files and use it inside Popcorn Time:
-
-
-
-This is where VLC comes handy as you can [download subtitles automatically with VLC][19].
-
-
-#### 6\. Save the files for offline viewing
-
-When Popcorn Times stream a content, it downloads it and store temporarily. When you close the app, it’s cleaned out. You can change this behavior so that the downloaded file remains there for your future use.
-
-In the advanced settings, scroll down a bit. Look for Cache directory. You can change this to some other directory like Downloads. This way, even if you close Popcorn Time, the file will be available for viewing.
-
-
-
-#### 7\. Drag and drop external torrent files to play immediately
-
-I bet you did not know about this one. If you don’t find a certain movie on Popcorn Time, download the torrent file from your favorite torrent website. Open Popcorn Time and just drag and drop the torrent file in Popcorn Time. It will start playing the file, depending upon seeds. This way, you don’t need to download the entire file before watching it.
-
-When you drag and drop the torrent file in Popcorn Time, it will give you the option to choose which video file should it play. If there are subtitles in it, it will play automatically or else, you can add external subtitles.
-
-
-
-There are plenty of other features in Popcorn Time. But I’ll stop with my list here and let you explore Popcorn Time on Ubuntu Linux. I hope you find these Popcorn Time tips and tricks useful.
-
-I am repeating again. Using Torrents is illegal in many countries. If you do that, take precaution and use a VPN service. If you are looking for my recommendation, you can go for [Swiss-based privacy company ProtonVPN][20] (of [ProtonMail][21] fame). Singapore based [Ivacy][7] is another good option. If you think these are expensive, you can look for [cheap VPN deals on It’s FOSS Shop][22].
-
-Note: This article contains affiliate links. Please read our [affiliate policy][23].
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/popcorn-time-ubuntu-linux/
-
-作者:[Abhishek Prakash][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/abhishek/
-[1]: https://popcorntime.sh/
-[2]: https://netflix.com/
-[3]: https://en.wikipedia.org/wiki/Torrent_file
-[4]: https://en.wikipedia.org/wiki/Popcorn_Time
-[5]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/popcorn-time-linux.jpeg
-[6]: https://itsfoss.com/netflix-firefox-linux/
-[7]: https://billing.ivacy.com/page/23628
-[8]: http://tldp.org/LDP/Linux-Filesystem-Hierarchy/html/opt.html
-[9]: https://en.wikipedia.org/wiki/Symbolic_link
-[10]: https://itsfoss.com/command-line-text-editors-linux/
-[11]: https://itsfoss.com/nano-3-release/
-[12]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/popcorn-time-ubuntu-menu.jpg
-[13]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/popcorn-time-ubuntu-license.jpeg
-[14]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/popcorn-time-watch-movies.jpeg
-[15]: https://ivacy.postaffiliatepro.com/accounts/default1/vdegzkxbw/7f82d531.png
-[16]: https://billing.ivacy.com/page/23628/7f82d531
-[17]: http://ivacy.postaffiliatepro.com/scripts/vdegzkxiw?aff=23628&a_bid=7f82d531
-[18]: https://itsfoss.com/how-to-synchronize-subtitles-with-movie-quick-tip/
-[19]: https://itsfoss.com/download-subtitles-automatically-vlc-media-player-ubuntu/
-[20]: https://protonvpn.net/?aid=chmod777
-[21]: https://itsfoss.com/protonmail/
-[22]: https://shop.itsfoss.com/search?utf8=%E2%9C%93&query=vpn
-[23]: https://itsfoss.com/affiliate-policy/
diff --git a/sources/tech/20180928 Quiet log noise with Python and machine learning.md b/sources/tech/20180928 Quiet log noise with Python and machine learning.md
new file mode 100644
index 0000000000..f1fe2f1b7f
--- /dev/null
+++ b/sources/tech/20180928 Quiet log noise with Python and machine learning.md
@@ -0,0 +1,110 @@
+Quiet log noise with Python and machine learning
+======
+
+Logreduce saves debugging time by picking out anomalies from mountains of log data.
+
+
+
+Continuous integration (CI) jobs can generate massive volumes of data. When a job fails, figuring out what went wrong can be a tedious process that involves investigating logs to discover the root cause—which is often found in a fraction of the total job output. To make it easier to separate the most relevant data from the rest, the [Logreduce][1] machine learning model is trained using previous successful job runs to extract anomalies from failed runs' logs.
+
+This principle can also be applied to other use cases, for example, extracting anomalies from [Journald][2] or other systemwide regular log files.
+
+### Using machine learning to reduce noise
+
+A typical log file contains many nominal events ("baselines") along with a few exceptions that are relevant to the developer. Baselines may contain random elements such as timestamps or unique identifiers that are difficult to detect and remove. To remove the baseline events, we can use a [k-nearest neighbors pattern recognition algorithm][3] (k-NN).
+
+
+
+Log events must be converted to numeric values for k-NN regression. Using the generic feature extraction tool [HashingVectorizer][4] enables the process to be applied to any type of log. It hashes each word and encodes each event in a sparse matrix. To further reduce the search space, tokenization removes known random words, such as dates or IP addresses.
+
+
+
+Once the model is trained, the k-NN search tells us the distance of each new event from the baseline.
+
+
+
+This [Jupyter notebook][5] demonstrates the process and graphs the sparse matrix vectors.
+
+
+
+### Introducing Logreduce
+
+The Logreduce Python software transparently implements this process. Logreduce's initial goal was to assist with [Zuul CI][6] job failure analyses using the build database, and it is now integrated into the [Software Factory][7] development forge's job logs process.
+
+At its simplest, Logreduce compares files or directories and removes lines that are similar. Logreduce builds a model for each source file and outputs any of the target's lines whose distances are above a defined threshold by using the following syntax: **distance | filename:line-number: line-content**.
+
+```
+$ logreduce diff /var/log/audit/audit.log.1 /var/log/audit/audit.log
+INFO logreduce.Classifier - Training took 21.982s at 0.364MB/s (1.314kl/s) (8.000 MB - 28.884 kilo-lines)
+0.244 | audit.log:19963: type=USER_AUTH acct="root" exe="/usr/bin/su" hostname=managesf.sftests.com
+INFO logreduce.Classifier - Testing took 18.297s at 0.306MB/s (1.094kl/s) (5.607 MB - 20.015 kilo-lines)
+99.99% reduction (from 20015 lines to 1
+
+```
+
+A more advanced Logreduce use can train a model offline to be reused. Many variants of the baselines can be used to fit the k-NN search tree.
+
+```
+$ logreduce dir-train audit.clf /var/log/audit/audit.log.*
+INFO logreduce.Classifier - Training took 80.883s at 0.396MB/s (1.397kl/s) (32.001 MB - 112.977 kilo-lines)
+DEBUG logreduce.Classifier - audit.clf: written
+$ logreduce dir-run audit.clf /var/log/audit/audit.log
+```
+
+Logreduce also implements interfaces to discover baselines for Journald time ranges (days/weeks/months) and Zuul CI job build histories. It can also generate HTML reports that group anomalies found in multiple files in a simple interface.
+
+
+
+### Managing baselines
+
+The key to using k-NN regression for anomaly detection is to have a database of known good baselines, which the model uses to detect lines that deviate too far. This method relies on the baselines containing all nominal events, as anything that isn't found in the baseline will be reported as anomalous.
+
+CI jobs are great targets for k-NN regression because the job outputs are often deterministic and previous runs can be automatically used as baselines. Logreduce features Zuul job roles that can be used as part of a failed job post task in order to issue a concise report (instead of the full job's logs). This principle can be applied to other cases, as long as baselines can be constructed in advance. For example, a nominal system's [SoS report][8] can be used to find issues in a defective deployment.
+
+
+
+### Anomaly classification service
+
+The next version of Logreduce introduces a server mode to offload log processing to an external service where reports can be further analyzed. It also supports importing existing reports and requests to analyze a Zuul build. The services run analyses asynchronously and feature a web interface to adjust scores and remove false positives.
+
+
+
+Reviewed reports can be archived as a standalone dataset with the target log files and the scores for anomalous lines recorded in a flat JSON file.
+
+### Project roadmap
+
+Logreduce is already being used effectively, but there are many opportunities for improving the tool. Plans for the future include:
+
+ * Curating many annotated anomalies found in log files and producing a public domain dataset to enable further research. Anomaly detection in log files is a challenging topic, and having a common dataset to test new models would help identify new solutions.
+ * Reusing the annotated anomalies with the model to refine the distances reported. For example, when users mark lines as false positives by setting their distance to zero, the model could reduce the score of those lines in future reports.
+ * Fingerprinting archived anomalies to detect when a new report contains an already known anomaly. Thus, instead of reporting the anomaly's content, the service could notify the user that the job hit a known issue. When the issue is fixed, the service could automatically restart the job.
+ * Supporting more baseline discovery interfaces for targets such as SOS reports, Jenkins builds, Travis CI, and more.
+
+
+
+If you are interested in getting involved in this project, please contact us on the **#log-classify** Freenode IRC channel. Feedback is always appreciated!
+
+Tristan Cacqueray will present [Reduce your log noise using machine learning][9] at the [OpenStack Summit][10], November 13-15 in Berlin.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/quiet-log-noise-python-and-machine-learning
+
+作者:[Tristan de Cacqueray][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/tristanc
+[1]: https://pypi.org/project/logreduce/
+[2]: http://man7.org/linux/man-pages/man8/systemd-journald.service.8.html
+[3]: https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
+[4]: http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.HashingVectorizer.html
+[5]: https://github.com/TristanCacqueray/anomaly-detection-workshop-opendev/blob/master/datasets/notebook/anomaly-detection-with-scikit-learn.ipynb
+[6]: https://zuul-ci.org
+[7]: https://www.softwarefactory-project.io
+[8]: https://sos.readthedocs.io/en/latest/
+[9]: https://www.openstack.org/summit/berlin-2018/summit-schedule/speakers/4307
+[10]: https://www.openstack.org/summit/berlin-2018/
diff --git a/sources/tech/20180928 What containers can teach us about DevOps.md b/sources/tech/20180928 What containers can teach us about DevOps.md
index 610a68b2d1..33f83fb0f7 100644
--- a/sources/tech/20180928 What containers can teach us about DevOps.md
+++ b/sources/tech/20180928 What containers can teach us about DevOps.md
@@ -1,3 +1,4 @@
+认领:by sd886393
What containers can teach us about DevOps
======
diff --git a/sources/tech/20180929 Use Cozy to Play Audiobooks in Linux.md b/sources/tech/20180929 Use Cozy to Play Audiobooks in Linux.md
new file mode 100644
index 0000000000..8e6583f046
--- /dev/null
+++ b/sources/tech/20180929 Use Cozy to Play Audiobooks in Linux.md
@@ -0,0 +1,138 @@
+Use Cozy to Play Audiobooks in Linux
+======
+**We review Cozy, an audiobook player for Linux. Read to find out if it’s worth to install Cozy on your Linux system or not.**
+
+![Audiobook player for Linux][1]
+
+Audiobooks are a great way to consume literature. Many people who don’t have time to read, choose to listen. Most people, myself included, just use a regular media player like VLC or [MPV][2] for listening to audiobooks on Linux.
+
+Today, we will look at a Linux application built solely for listening to audiobooks.
+
+![][3]Cozy Audiobook Player
+
+### Cozy Audiobook Player for Linux
+
+The [Cozy Audiobook Player][4] is created by [Julian Geywitz][5] from Germany. It is built using both Python and GTK+ 3. According to the site, Julian wrote Cozy on Fedora and optimized it for [elementary OS][6].
+
+The player borrows its layout from iTunes. The player controls are placed along the top of the application The library takes up the rest. You can sort all of your audiobooks based on the title, author and reader, and search very quickly.
+
+![][7]Initial setup
+
+When you first launch [Cozy][8], you are given the option to choose where you will store your audiobook files. Cozy will keep an eye on that folder and update your library as you add new audiobooks. You can also set it up to use an external or network drive.
+
+#### Features of Cozy
+
+Here is a full list of the features that [Cozy][9] has to offer.
+
+ * Import all your audiobooks into Cozy to browse them comfortably
+ * Sort your audiobooks by author, reader & title
+ * Remembers your playback position
+ * Sleep timer
+ * Playback speed control
+ * Search your audiobook library
+ * Add multiple storage locations
+ * Drag & Drop to import new audio books
+ * Support for DRM free mp3, m4a (aac, ALAC, …), flac, ogg, wav files
+ * Mpris integration (Media keys & playback info for the desktop environment)
+ * Developed on Fedora and tested under elementaryOS
+
+
+
+#### Experiencing Cozy
+
+![][10]Audiobook library
+
+At first, I was excited to try our Cozy because I like to listen to audiobooks. However, I ran into a couple of issues. There is no way to edit the information of an audiobook. For example, I downloaded a couple audiobooks from [LibriVox][11] to test it. All three audiobooks were listed under “Unknown” for the reader. There was nothing to edit or change the audiobook info. I guess you could edit all of the files, but that would take quite a bit of time.
+
+When I listen to an audiobook, I like to know what track is currently playing. Cozy only has a single progress bar for the whole audiobook. I know that Cozy is designed to remember where you left off in an audiobook, but if I was going to continue to listen to the audiobook on my phone, I would like to know what track I am on.
+
+![][12]Settings
+
+There was also an option in the setting menu to turn on a dark theme. As you can see in the screenshots, the application has a black theme, to begin with. I turned the option on, but nothing happened. There isn’t even an option to add a theme or change any of the colors. Overall, the application had a feeling of not being finished.
+
+#### Installing Cozy on Linux
+
+If you would like to install Cozy, you have several options for different distros.
+
+##### Ubuntu, Debian, openSUSE, Fedora
+
+Julian used the [openSUSE Build Service][13] to create custom repos for Ubuntu, Debian, openSUSE and Fedora. Each one only takes a couple terminal commands to install.
+
+##### Install Cozy using Flatpak on any Linux distribution (including Ubuntu)
+
+If your [distro supports Flatpak][14], you can install Cozy using the following commands:
+
+```
+flatpak remote-add --user --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
+flatpak install --user flathub com.github.geigi.cozy
+```
+
+##### Install Cozy on elementary OS
+
+If you have elementary OS installed, you can install Cozy from the [built-in App Store][15].
+
+##### Install Cozy on Arch Linux
+
+Cozy is available in the [Arch User Repository][16]. All you have to do is search for `cozy-audiobooks`.
+
+### Where to find free Audiobooks?
+
+In order to try out this application, you will need to find some audiobooks to listen to. My favorite site for audiobooks is [LibriVox][11]. Since [LibriVox][17] depends on volunteers to record audiobooks, the quality can vary. However, there are a number of very talented readers.
+
+Here is a list of free audiobook sources:
+
++ [Open Culture][20]
++ [Project Gutenberg][21]
++ [Digitalbook.io][22]
++ [FreeClassicAudioBooks.com][23]
++ [MindWebs][24]
++ [Scribl][25]
+
+
+### Final Thoughts on Cozy
+
+For now, I think I’ll stick with my preferred audiobook software (VLC) for now. Cozy just doesn’t add anything. I won’t call it a [must-have application for Linux][18] just yet. There is no compelling reason for me to switch. Maybe, I’ll revisit it again in the future, maybe when it hits 1.0.
+
+Take Cozy for a spin. You might come to a different conclusion.
+
+Have you ever used Cozy? If not, what is your favorite audiobook player? What is your favorite source for free audiobooks? Let us know in the comments below.
+
+If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][19].
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/cozy-audiobook-player/
+
+作者:[John Paul][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/john/
+[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/audiobook-player-linux.png
+[2]: https://itsfoss.com/mpv-video-player/
+[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/cozy3.jpg
+[4]: https://cozy.geigi.de/
+[5]: https://github.com/geigi
+[6]: https://elementary.io/
+[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/cozy1.jpg
+[8]: https://github.com/geigi/cozy
+[9]: https://www.patreon.com/geigi
+[10]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/cozy2.jpg
+[11]: https://librivox.org/
+[12]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/cozy4.jpg
+[13]: https://software.opensuse.org//download.html?project=home%3Ageigi&package=com.github.geigi.cozy
+[14]: https://itsfoss.com/flatpak-guide/
+[15]: https://elementary.io/store/
+[16]: https://aur.archlinux.org/
+[17]: https://archive.org/details/librivoxaudio
+[18]: https://itsfoss.com/essential-linux-applications/
+[19]: http://reddit.com/r/linuxusersgroup
+[20]: http://www.openculture.com/freeaudiobooks
+[21]: http://www.gutenberg.org/browse/categories/1
+[22]: https://www.digitalbook.io/
+[23]: http://freeclassicaudiobooks.com/
+[24]: https://archive.org/details/MindWebs_201410
+[25]: https://scribl.com/
diff --git a/translated/talk/20180117 How to get into DevOps.md b/translated/talk/20180117 How to get into DevOps.md
deleted file mode 100644
index ec169be76f..0000000000
--- a/translated/talk/20180117 How to get into DevOps.md
+++ /dev/null
@@ -1,145 +0,0 @@
-
-DevOps 实践指南
-======
-
-
-
-在去年大概一年的时间里,我注意到对“Devops 实践”感兴趣的开发人员和系统管理员突然有了明显的增加。这样的变化也合理:现在开发者只要花很少的钱,调用一些 API, 就能单枪匹马地在一整套分布式基础设施上运行自己的应用, 在这个时代,开发和运维的紧密程度前所未有。我看过许多博客和文章介绍很酷的 DevOps 工具和相关思想,但是给那些希望践行 DevOps 的人以指导和建议的内容,我却很少看到。
-
-这篇文章的目的就是描述一下如何去实践。我的想法基于 Reddit 上 [devops][1] 的一些访谈、聊天和深夜讨论,还有一些随机谈话,一般都发生在享受啤酒和美食的时候。如果你已经开始这样实践,我对你的反馈很感兴趣,请通过 [我的博客][2] 或者 [Twitter][3] 联系我,也可以直接在下面评论。我很乐意听到你们的想法和故事。
-
-### 古代的 IT
-
-了解历史是搞清楚未来的关键,DevOps 也不例外。想搞清楚 DevOps 运动的普及和流行,去了解一下上世纪 90 年代后期和 21 世纪前十年 IT 的情况会有帮助。这是我的经验。
-
-我的第一份工作是在一家大型跨国金融服务公司做 Windows 系统管理员。当时给计算资源扩容需要给 Dell 打电话 (或者像我们公司那样打给 CDW ),并下一个价值数十万美元的订单,包含服务器、网络设备、电缆和软件,所有这些都要运到在线或离线的数据中心去。虽然 VMware 仍在尝试说服企业使用虚拟机运行他们的“性能敏感”型程序是更划算的,但是包括我们在内的很多公司都还忠于使用他们的物理机运行应用。
-
-在我们技术部门,有一个专门做数据中心工程和操作的完整团队,他们的工作包括价格谈判,让荒唐的租赁月费能够下降一点点,还包括保证我们的系统能够正常冷却(如果设备太多,这个事情的难度会呈指数增长)。如果这个团队足够幸运足够有钱,境外数据中心的工作人员对我们所有的服务器型号又都有足够的了解,就能避免在盘后交易中不小心扯错东西。那时候亚马逊 AWS 和 Rackspace 逐渐开始加速扩张,但还远远没到临界规模。
-
-当时我们还有专门的团队来保证硬件上运行着的操作系统和软件能够按照预期工作。这些工程师负责设计可靠的架构以方便给系统打补丁,监控和报警,还要定义基础镜像 (gold image) 的内容。这些大都是通过很多手工实验完成的,很多手工实验是为了编写一个运行说明书 (runbook) 来描述要做的事情,并确保按照它执行后的结果确实在预期内。在我们这么大的组织里,这样做很重要,因为一线和二线的技术支持都是境外的,而他们的培训内容只覆盖到了这些运行说明而已。
-
-(这是我职业生涯前三年的世界。我那时候的梦想是成为制定金本位制的人!)
-
-软件发布则完全是另外一头怪兽。无可否认,我在这方面并没有积累太多经验。但是,从我收集的故事(和最近的经历)来看,当时大部分软件开发的日常大概是这样:
-
- * 开发人员按照技术和功能需求来编写代码,这些需求来自于业务分析人员的会议,但是会议并没有邀请开发人员参加。
- * 开发人员可以选择为他们的代码编写单元测试,以确保在代码里没有任何明显的疯狂行为,比如除以 0 但不抛出异常。
- * 然后开发者会把他们的代码标记为 "Ready for QA."(准备好了接受测试),质量保障的成员会把这个版本的代码发布到他们自己的环境中,这个环境和生产环境可能相似,也可能不相似,甚至和开发环境相比也不一定相似。
- * 故障会在几天或者几个星期内反馈到开发人员那里,这个时长取决于其他业务活动和优先事项。
-
-
-
-虽然系统管理员和开发人员经常有不一致的意见,但是对“变更管理”的痛恨却是一致的。变更管理由高度规范的(就我当时的雇主而言)和非常有必要的规则和程序组成,用来管理一家公司应该什么时候做技术变更,以及如何做。很多公司都按照 [ITIL][4] 来操作, 简单的说,ITIL 问了很多和事情发生的原因、时间、地点和方式相关的问题,而且提供了一个过程,对产生最终答案的决定做审计跟踪。
-
-你可能从我的简短历史课上了解到,当时 IT 的很多很多事情都是手工完成的。这导致了很多错误。错误又导致了很多财产损失。变更管理的工作就是尽量减少这些损失,它常常以这样的形式出现:不管变更的影响和规模大小,每两周才能发布部署一次。周五下午 4 点到周一早上 5 点 59 分这段时间,需要排队等候发布窗口。(讽刺的是,这种流程导致了更多错误,通常还是更严重的那种错误)
-
-### DevOps 不是专家团
-
-你可能在想 "Carlos 你在讲啥啊,什么时候才能说到 Ansible playbooks? ",我热爱 Ansible, 但是请再等一会;下面这些很重要。
-
-你有没有过被分配到过需要跟"DevOps"小组打交道的项目?你有没有依赖过“配置管理”或者“持续集成/持续交付”小组来保证业务流水线设置正确?你有没有在代码开发完的数周之后才参加发布部署的会议?
-
-如果有过,那么你就是在重温历史,这个历史是由上面所有这些导致的。
-
-出于本能,我们喜欢和像自己的人一起工作,这会导致[筒仓][5]的行成。很自然,这种人类特质也会在工作场所表现出来是不足为奇的。我甚至在一个 250 人的创业公司里见到过这样的现象,当时我在那里工作。刚开始的时候,开发人员都在聚在一起工作,彼此深度协作。随着代码变得复杂,开发相同功能的人自然就坐到了一起,解决他们自己的复杂问题。然后按功能划分的小组很快就正式形成了。
-
-在我工作过的很多公司里,系统管理员和开发人员不仅像这样形成了天然的筒仓,而且彼此还有激烈的对抗。开发人员的环境出问题了或者他们的权限太小了,就会对系统管理员很恼火。系统管理员怪开发者无时不刻的不在用各种方式破坏他们的环境,怪开发人员申请的计算资源严重超过他们的需要。双方都不理解对方,更糟糕的是,双方都不愿意去理解对方。
-
-大部分开发人员对操作系统,内核或计算机硬件都不感兴趣。同样的,大部分系统管理员,即使是 Linux 的系统管理员,也都不愿意学习编写代码,他们在大学期间学过一些 C 语言,然后就痛恨它,并且永远都不想再碰 IDE. 所以,开发人员把运行环境的问题甩给围墙外的系统管理员,系统管理员把这些问题和甩过来的其他上百个问题放在一起,做一个优先级安排。每个人都很忙,心怀怨恨的等待着。DevOps 的目的就是解决这种矛盾。
-
-DevOps 不是一个团队,CI/CD 也不是 Jira 系统的一个用户组。DevOps 是一种思考方式。根据这个运动来看,在理想的世界里,开发人员、系统管理员和业务相关人将作为一个团队工作。虽然他们可能不完全了解彼此的世界,可能没有足够的知识去了解彼此的积压任务,但他们在大多数情况下能有一致的看法。
-
-把所有基础设施和业务逻辑都代码化,再串到一个发布部署流水线里,就像是运行在这之上的应用一样。这个理念的基础就是 DevOps. 因为大家都理解彼此,所以人人都是赢家。聊天机器人和易用的监控工具、可视化工具的兴起,背后的基础也是 DevOps.
-
-[Adam Jacob][6] 说的最好:"DevOps 就是企业往软件导向型过渡时我们用来描述操作的词"
-
-### 要实践 DevOps 我需要知道些什么
-
-我经常被问到这个问题,它的答案,和同属于开放式的其他大部分问题一样:视情况而定。
-
-现在“DevOps 工程师”在不同的公司有不同的含义。在软件开发人员比较多但是很少有人懂基础设施的小公司,他们很可能是在找有更多系统管理经验的人。而其他公司,通常是大公司或老公司或又大又老的公司,已经有一个稳固的系统管理团队了,他们在向类似于谷歌 [SRE][7] 的方向做优化,也就是“设计操作功能的软件工程师”。但是,这并不是金科玉律,就像其他技术类工作一样,这个决定很大程度上取决于他的招聘经理。
-
-也就是说,我们一般是在找对深入学习以下内容感兴趣的工程师:
-
- * 如何管理和设计安全、可扩展的云上的平台(通常是在 AWS 上,不过微软的 Azure, 谷歌的 Cloud Platform,还有 DigitalOcean 和 Heroku 这样的 PaaS 提供商,也都很流行)
- * 如何用流行的 [CI/CD][8] 工具,比如 Jenkins,Gocd,还有基于云的 Travis CI 或者 CircleCI,来构造一条优化的发布部署流水线,和发布部署策略。
- * 如何在你的系统中使用基于时间序列的工具,比如 Kibana,Grafana,Splunk,Loggly 或者 Logstash,来监控,记录,并在变化的时候报警,还有
- * 如何使用配置管理工具,例如 Chef,Puppet 或者 Ansible 做到“基础设施即代码”,以及如何使用像 Terraform 或 CloudFormation 的工具发布这些基础设施。
-
-
-
-容器也变得越来越受欢迎。尽管有人对大规模使用 Docker 的现状[表示不满][9],但容器正迅速地成为一种很好的方式来实现在更少的操作系统上运行超高密度的服务和应用,同时提高它们的可靠性。(像 Kubernetes 或者 Mesos 这样的容器编排工具,能在宿主机故障的时候,几秒钟之内重新启动新的容器。)考虑到这些,掌握 Docker 或者 rkt 以及容器编排平台的知识会对你大有帮助。
-
-如果你是希望做 DevOps 实践的系统管理员,你还需要知道如何写代码。Python 和 Ruby 是 DevOps 领域的流行语言,因为他们是可移植的(也就是说可以在任何操作系统上运行),快速的,而且易读易学。它们还支撑着这个行业最流行的配置管理工具(Ansible 是使用 Python 写的,Chef 和 Puppet 是使用 Ruby 写的)以及云平台的 API 客户端(亚马逊 AWS, 微软 Azure, 谷歌 Cloud Platform 的客户端通常会提供 Python 和 Ruby 语言的版本)。
-
-如果你是开发人员,也希望做 DevOps 的实践,我强烈建议你去学习 Unix,Windows 操作系统以及网络基础知识。虽然云计算把很多系统管理的难题抽象化了,但是对慢应用的性能做 debug 的时候,你知道操作系统如何工作的就会有很大的帮助。下文包含了一些这个主题的图书。
-
-如果你觉得这些东西听起来内容太多,大家都是这么想的。幸运的是,有很多小项目可以让你开始探索。其中一个启动项目是 Gary Stafford 的[选举服务](https://github.com/garystafford/voter-service), 一个基于 Java 的简单投票平台。我们要求面试候选人通过一个流水线将该服务从 GitHub 部署到生产环境基础设施上。你可以把这个服务与 Rob Mile 写的了不起的 DevOps [入门教程](https://github.com/maxamg/cd-office-hours)结合起来,学习如何编写流水线。
-
-还有一个熟悉这些工具的好方法,找一个流行的服务,然后只使用 AWS 和配置管理工具来搭建这个服务所需要的基础设施。第一次先手动搭建,了解清楚要做的事情,然后只用 CloudFormation (或者 Terraform) 和 Ansible 重写刚才的手动操作。令人惊讶的是,这就是我们基础设施开发人员为客户所做的大部分日常工作,我们的客户认为这样的工作非常有意义!
-
-### 需要读的书
-
-如果你在找 DevOps 的其他资源,下面这些理论和技术书籍值得一读。
-
-#### 理论书籍
-
- * Gene Kim 写的 [The Phoenix Project (凤凰项目)][10]。这是一本很不错的书,内容涵盖了我上文解释过的历史(写的更生动形象),描述了一个运行在敏捷和 DevOps 之上的公司向精益前进的过程。
- * Terrance Ryan 写的 [Driving Technical Change (布道之道)][11]。非常好的一小本书,讲了大多数技术型组织内的常见性格特点以及如何和他们打交道。这本书对我的帮助比我想象的更多。
- * Tom DeMarco 和 Tim Lister 合著的 [Peopleware (人件)][12]。管理工程师团队的经典图书,有一点过时,但仍然很有价值。
- * Tom Limoncelli 写的 [Time Management for System Administrators (时间管理: 给系统管理员)][13]。这本书主要面向系统管理员,它对很多大型组织内的系统管理员生活做了深入的展示。如果你想了解更多系统管理员和开发人员之间的冲突,这本书可能解释了更多。
- * Eric Ries 写的 [The Lean Startup (精益创业)][14]。描述了 Eric 自己的 3D 虚拟形象公司,IMVU, 发现了如何精益工作,快速失败和更快盈利。
- * Jez Humble 和他的朋友写的[Lean Enterprise (精益企业)][15]。这本书是对精益创业做的改编,以更适应企业,两本书都很棒,都很好的解释了 DevOps 背后的商业动机。
- * Kief Morris 写的 [Infrastructure As Code (基础设施即代码)][16]。关于 "基础设施即代码" 的非常好的入门读物!很好的解释了为什么所有公司都有必要采纳这种做法。
- * Betsy Beyer, Chris Jones, Jennifer Petoff 和 Niall Richard Murphy 合著的 [Site Reliability Engineering (站点可靠性工程师)][17]。一本解释谷歌 SRE 实践的书,也因为是 "DevOps 诞生之前的 DevOps" 被人熟知。在如何处理运行时间、时延和保持工程师快乐方面提供了有趣的看法。
-
-
-
-#### 技术书籍
-
-如果你想找的是让你直接跟代码打交道的书,看这里就对了。
-
- * W. Richard Stevens 的 [TCP/IP Illustrated (TCP/IP 详解)][18]。这是一套经典的(也可以说是最全面的)讲解基本网络协议的巨著,重点介绍了 TCP/IP 协议族。如果你听说过 1,2, 3,4 层网络,而且对深入学习他们感兴趣,那么你需要这本书。
- * Evi Nemeth, Trent Hein 和 Ben Whaley 合著的 [UNIX and Linux System Administration Handbook (UNIX/Linux 系统管理员手册)][19]。一本很好的入门书,介绍 Linux/Unix 如何工作以及如何使用。
- * Don Jones 和 Jeffrey Hicks 合著的 [Learn Windows Powershell In A Month of Lunches (Windows PowerShell实战指南)][20]. 如果你在 Windows 系统下做自动化任务,你需要学习怎么使用 Powershell。这本书能够帮助你。Don Jones 是这方面著名的 MVP。
- * 几乎所有 [James Turnbull][21] 写的东西,针对流行的 DevOps 工具,他发表了很好的技术入门读物。
-
-
-
-不管是在那些把所有应用都直接部署在物理机上的公司,(现在很多公司仍然有充分的理由这样做)还是在那些把所有应用都做成 serverless 的先驱公司,DevOps 都很可能会持续下去。这部分工作很有趣,产出也很有影响力,而且最重要的是,它搭起桥梁衔接了技术和业务之间的缺口。DevOps 是一个值得期待的美好事物。
-
-首次发表在 [Neurons Firing on a Keyboard][22]。使用 CC-BY-SA 协议。
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/1/getting-devops
-
-作者:[Carlos Nunez][a]
-译者:[belitex](https://github.com/belitex)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/carlosonunez
-[1]:https://www.reddit.com/r/devops/
-[2]:https://carlosonunez.wordpress.com/
-[3]:https://twitter.com/easiestnameever
-[4]:https://en.wikipedia.org/wiki/ITIL
-[5]:https://www.psychologytoday.com/blog/time-out/201401/getting-out-your-silo
-[6]:https://twitter.com/adamhjk/status/572832185461428224
-[7]:https://landing.google.com/sre/interview/ben-treynor.html
-[8]:https://en.wikipedia.org/wiki/CI/CD
-[9]:https://thehftguy.com/2016/11/01/docker-in-production-an-history-of-failure/
-[10]:https://itrevolution.com/book/the-phoenix-project/
-[11]:https://pragprog.com/book/trevan/driving-technical-change
-[12]:https://en.wikipedia.org/wiki/Peopleware:_Productive_Projects_and_Teams
-[13]:http://shop.oreilly.com/product/9780596007836.do
-[14]:http://theleanstartup.com/
-[15]:https://info.thoughtworks.com/lean-enterprise-book.html
-[16]:http://infrastructure-as-code.com/book/
-[17]:https://landing.google.com/sre/book.html
-[18]:https://en.wikipedia.org/wiki/TCP/IP_Illustrated
-[19]:http://www.admin.com/
-[20]:https://www.manning.com/books/learn-windows-powershell-in-a-month-of-lunches-third-edition
-[21]:https://jamesturnbull.net/
-[22]:https://carlosonunez.wordpress.com/2017/03/02/getting-into-devops/
diff --git a/translated/talk/20180123 Moving to Linux from dated Windows machines.md b/translated/talk/20180123 Moving to Linux from dated Windows machines.md
new file mode 100644
index 0000000000..b90a166a4d
--- /dev/null
+++ b/translated/talk/20180123 Moving to Linux from dated Windows machines.md
@@ -0,0 +1,63 @@
+从过时的 Windows 机器迁移到 Linux
+======
+
+
+
+每天当我在 ONLYOFFICE 的市场部门工作的时候,我都能看到 Linux 用户在网上讨论我们的办公效率软件。
+我们的产品在 Linux 用户中很受欢迎,这使得我对使用 Linux 作为日常工具的体验非常好奇。
+我的老旧的 Windows XP 机器在性能上非常差,因此我决定了解 Linux 系统(特别是 Ubuntu )并且决定去尝试使用它。
+我的两个同事加入了我的计划。
+
+### 为何选择 Linux ?
+
+我们必须做出改变,首先,我们的老系统在性能方面不够用:我们经历过频繁的崩溃,每当超过两个应用在运行机器就会负载过度,关闭机器时有一半的几率冻结等等。
+这很容易让我们从工作中分心,意味着我们没有我们应有的工作效率了。
+
+升级到 Windows 更新的版本也是一种选择,但这样可能会带来额外的开销,而且我们的软件本身也是要与 Microsoft 的办公软件竞争。
+因此我们在这方面也存在意识形态的问题。
+
+其次,就像我之前提过的, ONLYOFFICE 产品在 Linux 社区内非常受欢迎。
+通过阅读 Linux 用户在使用我们的软件时的体验,我们也对加入他们很感兴趣。
+
+在我们要求转换到 Linux 系统一周后,我们拿到了崭新的装好了 [Kubuntu][1] 的机器。
+我们选择了 16.04 版本,因为这个版本支持 KDE Plasma 5.5 和包括 Dolphin 在内的很多 KDE 应用,同时也包括 LibreOffice 5.1 和 Firefox 45 。
+
+### Linux 让人喜欢的地方
+
+我相信 Linux 最大的优势是它的运行速度,比如,从按下机器的电源按钮到开始工作只需要几秒钟时间。
+从一开始,一切看起来都超乎寻常地快:总体的响应速度,图形界面,甚至包括系统更新的速度。
+
+另一个使我惊奇的事情是跟 Windows 相比, Linux 几乎能让你配置任何东西,包括整个桌面的外观。
+在设置里面,我发现了如何修改各种栏目、按钮和字体的颜色和形状,也可以重新布置任意桌面组件的位置,组合桌面的小工具(甚至包括漫画和颜色选择器)
+我相信我还仅仅只是了解了基本的选项,之后还需要探索这个系统更多著名的定制化选项。
+
+Linux 发行版通常是一个非常安全的环境。
+人们很少在 Linux 系统中使用防病毒的软件,因为很少有人会写病毒程序来攻击 Linux 系统。
+因此你可以拥有很好的系统速度,并且节省了时间和金钱。
+
+总之, Linux 已经改变了我们的日常生活,用一系列的新选项和功能大大震惊了我们。
+仅仅通过短时间的使用,我们已经可以给它总结出以下特性:
+
+ * 操作很快很顺畅
+ * 高度可定制
+ * 对新手很友好
+ * 了解基本组件很有挑战性,但回报丰厚
+ * 安全可靠
+ * 对所有想改变工作场所的人来说都是一次绝佳的体验
+
+你已经从 Windows 或 MacOS 系统换到 Kubuntu 或其他 Linux 变种了么?
+或者你是否正在考虑做出改变?
+请分享你想要采用 Linux 系统的原因,连同你对开源的印象一起写在评论中。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/1/move-to-linux-old-windows
+
+作者:[Michael Korotaev][a]
+译者:[bookug](https://github.com/bookug)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/michaelk
+[1]:https://kubuntu.org/
diff --git a/translated/tech/20140607 Five things that make Go fast.md b/translated/tech/20140607 Five things that make Go fast.md
new file mode 100644
index 0000000000..6adee59e52
--- /dev/null
+++ b/translated/tech/20140607 Five things that make Go fast.md
@@ -0,0 +1,494 @@
+五种加速 Go 的特性
+============================================================
+
+ _Anthony Starks 使用他出色的 Deck 演示工具重构了我原来的基于 Google Slides 的幻灯片。你可以在他的博客上查看他重构后的幻灯片, [mindchunk.blogspot.com.au/2014/06/remixing-with-deck][5]._
+
+* * *
+
+我最近被邀请在 Gocon 发表演讲,这是一个每半年在日本东京举行的精彩 Go 的大会。[Gocon 2014][6] 是一个完全由社区驱动的为期一天的活动,由培训和一整个下午的围绕着 生产环境中的 Go
这个主题的演讲组成.
+
+以下是我的讲义。原文的结构能让我缓慢而清晰的演讲,因此我已经编辑了它使其更可读。
+
+我要感谢 [Bill Kennedy][7] 和 Minux Ma,特别是 [Josh Bleecher Snyder][8],感谢他们在我准备这次演讲中的帮助。
+
+* * *
+
+大家下午好。
+
+我叫 David.
+
+我很高兴今天能来到 Gocon。我想参加这个会议已经两年了,我很感谢主办方能提供给我向你们演讲的机会。
+
+ [][9]
+我想以一个问题开始我的演讲。
+
+为什么选择 Go?
+
+当大家讨论学习或在生产环境中使用 Go 的原因时,答案不一而足,但因为以下三个原因的最多。
+
+ [][10]
+这就是 TOP3 的原因。
+
+第一,并发。
+
+Go 的 并发原语 对于来自 Nodejs,Ruby 或 Python 等单线程脚本语言的程序员,或者来自 C++ 或 Java 等重量级线程模型的语言都很有吸引力。
+
+易于部署。
+
+我们今天从经验丰富的 Gophers 那里听说过,他们非常欣赏部署 Go 应用的简单性。
+
+ [][11]
+
+然后是性能。
+
+我相信人们选择 Go 的一个重要原因是它 _快_。
+
+ [][12]
+
+在今天的演讲中,我想讨论五个有助于提高 Go 性能的特性。
+
+我还将与大家分享 Go 如何实现这些特性的细节。
+
+ [][13]
+
+我要谈的第一个特性是 Go 对于值的高效处理和存储。
+
+ [][14]
+
+这是 Go 中一个值的例子。编译时,`gocon` 正好消耗四个字节的内存。
+
+让我们将 Go 与其他一些语言进行比较
+
+ [][15]
+
+由于 Python 表示变量的方式的开销,使用 Python 存储相同的值会消耗六倍的内存。
+
+Python 使用额外的内存来跟踪类型信息,进行 引用计数 等。
+
+让我们看另一个例子:
+
+ [][16]
+
+与 Go 类似,Java 消耗 4 个字节的内存来存储 `int` 型。
+
+但是,要在像 `List` 或 `Map` 这样的集合中使用此值,编译器必须将其转换为 `Integer` 对象。
+
+ [][17]
+
+因此,Java 中的整数通常消耗 16 到 24 个字节的内存。
+
+为什么这很重要? 内存便宜且充足,为什么这个开销很重要?
+
+ [][18]
+
+这是一张显示 CPU 时钟速度与内存总线速度的图表。
+
+请注意 CPU 时钟速度和内存总线速度之间的差距如何继续扩大。
+
+两者之间的差异实际上是 CPU 花费多少时间等待内存。
+
+ [][19]
+
+自 1960 年代后期以来,CPU 设计师已经意识到了这个问题。
+
+他们的解决方案是一个缓存,一个更小,更快的内存区域,介入 CPU 和主存之间。
+
+ [][20]
+
+这是一个 `Location` 类型,它保存物体在三维空间中的位置。它是用 Go 编写的,因此每个 `Location` 只消耗 24 个字节的存储空间。
+
+我们可以使用这种类型来构造一个容纳 1000 个 `Location` 的数组类型,它只消耗 24000 字节的内存。
+
+在数组内部,`Location` 结构体是顺序存储的,而不是随机存储的 1000 个 `Location` 结构体的指针。
+
+这很重要,因为现在所有 1000 个 `Location` 结构体都按顺序放在缓存中,紧密排列在一起。
+
+ [][21]
+
+Go 允许您创建紧凑的数据结构,避免不必要的填充字节。
+
+紧凑的数据结构能更好地利用缓存。
+
+更好的缓存利用率可带来更好的性能。
+
+ [][22]
+
+函数调用不是无开销的。
+
+ [][23]
+
+调用函数时会发生三件事。
+
+创建一个新的 栈帧,并记录调用者的详细信息。
+
+在函数调用期间可能被覆盖的任何寄存器都将保存到栈中。
+
+处理器计算函数的地址并执行到该新地址的分支。
+
+ [][24]
+
+由于函数调用是非常常见的操作,因此 CPU 设计师一直在努力优化此过程,但他们无法消除开销。
+
+函调固有开销,或重于泰山,或轻于鸿毛,这取决于函数做了什么。
+
+减少函数调用开销的解决方案是 内联。
+
+ [][25]
+
+Go 编译器通过将函数体视为调用者的一部分来内联函数。
+
+内联也有成本,它增加了二进制文件大小。
+
+只有当调用开销与函数所做工作关联度的很大时内联才有意义,因此只有简单的函数才能用于内联。
+
+复杂的函数通常不受调用它们的开销所支配,因此不会内联。
+
+ [][26]
+
+这个例子显示函数 `Double` 调用 `util.Max`。
+
+为了减少调用 `util.Max` 的开销,编译器可以将 `util.Max` 内联到 `Double` 中,就象这样
+
+ [][27]
+
+内联后不再调用 `util.Max`,但是 `Double` 的行为没有改变。
+
+内联并不是 Go 独有的。几乎每种编译或及时编译的语言都执行此优化。但是 Go 的内联是如何实现的?
+
+Go 实现非常简单。编译包时,会标记任何适合内联的小函数,然后照常编译。
+
+然后函数的源代码和编译后版本都会被存储。
+
+ [][28]
+
+此幻灯片显示了 `util.a` 的内容。源代码已经过一些转换,以便编译器更容易快速处理。
+
+当编译器编译 `Double` 时,它看到 `util.Max` 可内联的,并且 `util.Max` 的源代码是可用的。
+
+就会替换原函数中的代码,而不是插入对 `util.Max` 的编译版本的调用。
+
+拥有该函数的源代码可以实现其他优化。
+
+ [][29]
+
+在这个例子中,尽管函数 `Test` 总是返回 `false`,但 `Expensive` 在不执行它的情况下无法知道结果。
+
+当 `Test` 被内联时,我们得到这样的东西
+
+ [][30]
+
+编译器现在知道 `Expensive` 的代码无法访问。
+
+这不仅节省了调用 `Test` 的成本,还节省了编译或运行任何现在无法访问的 `Expensive` 代码。
+
+Go 编译器可以跨文件甚至跨包自动内联函数。还包括从标准库调用的可内联函数的代码。
+
+ [][31]
+
+强制垃圾回收 使 Go 成为一种更简单,更安全的语言。
+
+这并不意味着垃圾回收会使 Go 变慢,或者垃圾回收是程序速度的瓶颈。
+
+这意味着在堆上分配的内存是有代价的。每次 GC 运行时都会花费 CPU 时间,直到释放内存为止。
+
+ [][32]
+
+然而,有另一个地方分配内存,那就是栈。
+
+与 C 不同,它强制您选择是否将值通过 `malloc` 将其存储在堆上,还是通过在函数范围内声明将其储存在栈上;Go 实现了一个名为 逃逸分析 的优化。
+
+ [][33]
+
+逃逸分析决定了对一个值的任何引用是否会从被声明的函数中逃逸。
+
+如果没有引用逃逸,则该值可以安全地存储在栈中。
+
+存储在栈中的值不需要分配或释放。
+
+让我们看一些例子
+
+ [][34]
+
+`Sum` 返回 1 到 100 的整数的和。这是一种相当不寻常的做法,但它说明了逃逸分析的工作原理。
+
+因为切片 `numbers` 仅在 `Sum` 内引用,所以编译器将安排到栈上来存储的 100 个整数,而不是安排到堆上。
+
+没有必要回收 `numbers`,它会在 `Sum` 返回时自动释放。
+
+ [][35]
+
+第二个例子也有点尬。在 `CenterCursor` 中,我们创建一个新的 `Cursor` 对象并在 `c` 中存储指向它的指针。
+
+然后我们将 `c` 传递给 `Center()` 函数,它将 `Cursor` 移动到屏幕的中心。
+
+最后我们打印出那个 'Cursor` 的 X 和 Y 坐标。
+
+即使 `c` 被 `new` 函数分配了空间,它也不会存储在堆上,因为没有引用 `c` 的变量逃逸 `CenterCursor` 函数。
+
+ [][36]
+
+默认情况下,Go 的优化始终处于启用状态。可以使用 `-gcflags = -m` 开关查看编译器的逃逸分析和内联决策。
+
+因为逃逸分析是在编译时执行的,而不是运行时,所以无论垃圾回收的效率如何,栈分配总是比堆分配快。
+
+我将在本演讲的其余部分详细讨论栈。
+
+ [][37]
+
+Go 有 goroutines。 这是 Go 并发的基石。
+
+我想退一步,探索 goroutines 的历史。
+
+最初,计算机一次运行一个进程。在 60 年代,多进程或 分时 的想法变得流行起来。
+
+在分时系统中,操作系统必须通过保护当前进程的现场,然后恢复另一个进程的现场,不断地在这些进程之间切换 CPU 的注意力。
+
+这称为 _进程切换_。
+
+ [][38]
+
+进程切换有三个主要开销。
+
+首先,内核需要保护该进程的所有 CPU 寄存器的现场,然后恢复另一个进程的现场。
+
+内核还需要将 CPU 的映射从虚拟内存刷新到物理内存,因为这些映射仅对当前进程有效。
+
+最后是操作系统 上下文切换 的成本,以及 调度函数 选择占用 CPU 的下一个进程的开销。
+
+ [][39]
+
+现代处理器中有数量惊人的寄存器。我很难在一张幻灯片上排开它们,这可以让你知道保护和恢复它们需要多少时间。
+
+由于进程切换可以在进程执行的任何时刻发生,因此操作系统需要存储所有寄存器的内容,因为它不知道当前正在使用哪些寄存器。
+
+ [][40]
+
+这导致了线程的出生,这些线程在概念上与进程相同,但共享相同的内存空间。
+
+由于线程共享地址空间,因此它们比进程更轻,因此创建速度更快,切换速度更快。
+
+ [][41]
+
+Goroutines 升华了线程的思想。
+
+Goroutines 是 协作式调度的,而不是依靠内核来调度。
+
+当对 Go 运行时调度器 进行显式调用时,goroutine 之间的切换仅发生在明确定义的点上。
+
+编译器知道正在使用的寄存器并自动保存它们。
+
+ [][42]
+
+虽然 goroutine 是协作式调度的,但运行时会为你处理。
+
+Goroutines 可能会给禅让给其他协程时刻是:
+
+* 阻塞式通道发送和接收。
+
+* Go 声明,虽然不能保证会立即调度新的 goroutine。
+
+* 文件和网络操作式的阻塞式系统调用。
+
+* 在被垃圾回收循环停止后。
+
+ [][43]
+
+这个例子说明了上一张幻灯片中描述的一些调度点。
+
+箭头所示的线程从左侧的 `ReadFile` 函数开始。遇到 `os.Open`,它在等待文件操作完成时阻塞线程,因此调度器将线程切换到右侧的 goroutine。
+
+继续执行直到从通道 `c` 中读,并且此时 `os.Open` 调用已完成,因此调度器将线程切换回左侧并继续执行 `file.Read` 函数,然后又被文件 IO 阻塞。
+
+调度器将线程切换回右侧以进行另一个通道操作,该操作在左侧运行期间已解锁,但在通道发送时再次阻塞。
+
+最后,当 `Read` 操作完成并且数据可用时,线程切换回左侧。
+
+ [][44]
+
+这张幻灯片显示了低级语言描述的 `runtime.Syscall` 函数,它是 `os` 包中所有函数的基础。
+
+只要你的代码调用操作系统,就会通过此函数。
+
+对 `entersyscall` 的调用通知运行时该线程即将阻塞。
+
+这允许运行时启动一个新线程,该线程将在当前线程被阻塞时为其他 goroutine 提供服务。
+
+这导致每 Go 进程的操作系统线程相对较少,Go 运行时负责将可运行的 Goroutine 分配给空闲的操作系统线程。
+
+ [][45]
+
+在上一节中,我讨论了 goroutine 如何减少管理许多(有时是数十万个并发执行线程)的开销。
+
+Goroutine故事还有另一面,那就是栈管理,它引导我进入我的最后一个话题。
+
+ [][46]
+
+这是一个进程的内存布局图。我们感兴趣的关键是堆和栈的位置。
+
+传统上,在进程的地址空间内,堆位于内存的底部,位于程序(代码)的上方并向上增长。
+
+栈位于虚拟地址空间的顶部,并向下增长。
+
+ [][47]
+
+因为堆和栈相互覆盖的结果会是灾难性的,操作系统通常会安排在栈和堆之间放置一个不可写内存区域,以确保如果它们发生碰撞,程序将中止。
+
+这称为保护页,有效地限制了进程的栈大小,通常大约为几兆字节。
+
+ [][48]
+
+我们已经讨论过线程共享相同的地址空间,因此对于每个线程,它必须有自己的栈。
+
+由于很难预测特定线程的栈需求,因此为每个线程的栈和保护页面保留了大量内存。
+
+希望是这些区域永远不被使用,而且防护页永远不会被击中。
+
+缺点是随着程序中线程数的增加,可用地址空间的数量会减少。
+
+ [][49]
+
+我们已经看到 Go 运行时将大量的 goroutine 调度到少量线程上,但那些 goroutines 的栈需求呢?
+
+Go 编译器不使用保护页,而是在每个函数调用时插入一个检查,以检查是否有足够的栈来运行该函数。如果没有,运行时可以分配更多的栈空间。
+
+由于这种检查,goroutines 初始栈可以做得更小,这反过来允许 Go 程序员将 goroutines 视为廉价资源。
+
+ [][50]
+
+这是一张显示了 Go 1.2 如何管理栈的幻灯片。
+
+当 `G` 调用 `H` 时,没有足够的空间让 `H` 运行,所以运行时从堆中分配一个新的栈帧,然后在新的栈段上运行 `H`。当 `H` 返回时,栈区域返回到堆,然后返回到 `G`。
+
+ [][51]
+
+这种管理栈的方法通常很好用,但对于某些类型的代码,通常是递归代码,它可能导致程序的内部循环跨越这些栈边界之一。
+
+例如,在程序的内部循环中,函数 `G` 可以在循环中多次调用 `H`,
+
+每次都会导致栈拆分。 这被称为 热分裂 问题。
+
+ [][52]
+
+为了解决热分裂问题,Go 1.3 采用了一种新的栈管理方法。
+
+如果 goroutine 的栈太小,则不会添加和删除其他栈段,而是分配新的更大的栈。
+
+旧栈的内容被复制到新栈,然后 goroutine 使用新的更大的栈继续运行。
+
+在第一次调用 `H` 之后,栈将足够大,对可用栈空间的检查将始终成功。
+
+这解决了热分裂问题。
+
+ [][53]
+
+值,内联,逃逸分析,Goroutines 和分段/复制栈。
+
+这些是我今天选择谈论的五个特性,但它们绝不是使 Go 成为快速的语言的唯一因素,就像人们引用他们学习 Go 的理由的三个原因一样。
+
+这五个特性一样强大,它们不是孤立存在的。
+
+例如,运行时将 goroutine 复用到线程上的方式在没有可扩展栈的情况下几乎没有效率。
+
+内联通过将较小的函数组合成较大的函数来降低栈大小检查的成本。
+
+逃逸分析通过自动将从实例从堆移动到栈来减少垃圾回收器的压力。
+
+逃逸分析还提供了更好的 缓存局部性。
+
+如果没有可增长的栈,逃逸分析可能会对栈施加太大的压力。
+
+ [][54]
+
+* 感谢 Gocon 主办方允许我今天发言
+* twitter / web / email details
+* 感谢 @offbymany,@billkennedy_go 和 Minux 在准备这个演讲的过程中所提供的帮助。
+
+### 相关文章:
+
+1. [听我在 OSCON 上关于 Go 性能的演讲][1]
+
+2. [为什么 Goroutine 的栈是无限大的?][2]
+
+3. [Go 的运行时环境变量的旋风之旅][3]
+
+4. [没有事件循环的性能][4]
+
+--------------------------------------------------------------------------------
+
+作者简介:
+
+David 是来自澳大利亚悉尼的程序员和作者。
+
+自 2011 年 2 月起成为 Go 的 contributor,自 2012 年 4 月起成为 committer。
+
+联系信息
+
+* dave@cheney.net
+* twitter: @davecheney
+
+----------------------
+
+via: https://dave.cheney.net/2014/06/07/five-things-that-make-go-fast
+
+作者:[Dave Cheney ][a]
+译者:[houbaron](https://github.com/houbaron)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://dave.cheney.net/
+[1]:https://dave.cheney.net/2015/05/31/hear-me-speak-about-go-performance-at-oscon
+[2]:https://dave.cheney.net/2013/06/02/why-is-a-goroutines-stack-infinite
+[3]:https://dave.cheney.net/2015/11/29/a-whirlwind-tour-of-gos-runtime-environment-variables
+[4]:https://dave.cheney.net/2015/08/08/performance-without-the-event-loop
+[5]:http://mindchunk.blogspot.com.au/2014/06/remixing-with-deck.html
+[6]:http://ymotongpoo.hatenablog.com/entry/2014/06/01/124350
+[7]:http://www.goinggo.net/
+[8]:https://twitter.com/offbymany
+[9]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-1.jpg
+[10]:https://dave.cheney.net/2014/06/07/five-things-that-make-go-fast/gocon-2014-2
+[11]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-3.jpg
+[12]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-4.jpg
+[13]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-5.jpg
+[14]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-6.jpg
+[15]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-7.jpg
+[16]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-8.jpg
+[17]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-9.jpg
+[18]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-10.jpg
+[19]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-11.jpg
+[20]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-12.jpg
+[21]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-13.jpg
+[22]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-14.jpg
+[23]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-15.jpg
+[24]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-16.jpg
+[25]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-17.jpg
+[26]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-18.jpg
+[27]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-19.jpg
+[28]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-20.jpg
+[29]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-21.jpg
+[30]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-22.jpg
+[31]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-23.jpg
+[32]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-24.jpg
+[33]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-25.jpg
+[34]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-26.jpg
+[35]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-27.jpg
+[36]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-28.jpg
+[37]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-30.jpg
+[38]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-29.jpg
+[39]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-31.jpg
+[40]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-32.jpg
+[41]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-33.jpg
+[42]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-34.jpg
+[43]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-35.jpg
+[44]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-36.jpg
+[45]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-37.jpg
+[46]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-39.jpg
+[47]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-40.jpg
+[48]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-41.jpg
+[49]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-42.jpg
+[50]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-43.jpg
+[51]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-44.jpg
+[52]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-45.jpg
+[53]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-46.jpg
+[54]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-47.jpg
diff --git a/translated/tech/20170810 How we built our first full-stack JavaScript web app in three weeks.md b/translated/tech/20170810 How we built our first full-stack JavaScript web app in three weeks.md
new file mode 100644
index 0000000000..90448211c3
--- /dev/null
+++ b/translated/tech/20170810 How we built our first full-stack JavaScript web app in three weeks.md
@@ -0,0 +1,195 @@
+三周内构建 JavaScript 全栈 web 应用
+============================================================
+
+
+应用 Align 中,用户主页的控制面板
+
+### 从构思到部署应用程序的简单分步指南
+
+我在 Grace Hopper Program 为期三个月的编码训练营即将结束,实际上这篇文章的标题有些纰漏 —— 现在我已经构建了 _三个_ 全栈应用:[从零开始的电子商店(an e-commerce store from scratch)][3]、我个人的 [私人黑客马拉松项目(personal hackathon project)][4],还有这个“三周的结业项目”。这个项目是迄今为止强度最大的 —— 我和另外两名队友共同花费三周的时光 —— 而它也是我在训练营中最引以为豪的成就。这是我目前所构建和涉及的第一款稳定且复杂的应用。
+
+如大多数开发者所知,即使你“知道怎么编写代码”,但真正要制作第一款全栈的应用却是非常困难的。JavaScript 生态系统出奇的大:有包管理器,模块,构建工具,转译器,数据库,库文件,还要对上述所有东西进行选择,难怪如此多的编程新手除了 Codecademy 的教程外,做不了任何东西。这就是为什么我想让你体验这个决策的分布教程,跟着我们队伍的脚印,构建可用的应用。
+
+* * *
+
+首先,简单的说两句。Align 是一个 web 应用,它使用直观的时间线界面帮助用户管理时间、设定长期目标。我们的技术栈有:用于后端服务的 Firebase 和用于前端的 React。我和我的队友在这个短视频中解释的更详细:
+
+[video](https://youtu.be/YacM6uYP2Jo)
+
+展示 Align @ Demo Day Live // 2017 年 7 月 10 日
+
+从第 1 天(我们组建团队的那天)开始,直到最终应用的完成,我们是如何做的?这里是我们采取的步骤纲要:
+
+* * *
+
+### 第 1 步:构思
+
+第一步是弄清楚我们到底要构建什么东西。过去我在 IBM 中当咨询师的时候,我和合作组长一同带领着构思工作组。从那之后,我一直建议小组使用经典的头脑风暴策略,在会议中我们能够提出尽可能多的想法 —— 即使是 “愚蠢的想法” —— 这样每个人的大脑都在思考,没有人因顾虑而不敢发表意见。
+
+
+
+在产生了好几个关于应用的想法时,我们把这些想法分类记录下来,以便更好的理解我们大家都感兴趣的主题。在我们这个小组中,我们看到实现想法的清晰趋势,需要自我改进、设定目标、情怀,还有个人发展。我们最后从中决定了具体的想法:做一个用于设置和管理长期目标的控制面板,有保存记忆的元素,可以根据时间将数据可视化。
+
+从此,我们创作出了一系列用户故事(从一个终端用户的视角,对我们想要拥有的功能进行描述),阐明我们到底想要应用实现什么功能。
+
+### 第 2 步:UX/UI 示意图
+
+接下来,在一块白板上,我们画出了想象中应用的基本视图。结合了用户故事,以便理解在应用基本框架中这些视图将会如何工作。
+
+
+
+
+
+
+
+
+
+
+
+这些骨架确保我们意见统一,提供了可预见的蓝图,让我们向着计划的方向努力。
+
+### 第 3 步:选好数据结构和数据库类型
+
+到了设计数据结构的时候。基于我们的示意图和用户故事,我们在 Google doc 中制作了一个清单,它包含我们将会需要的模型和每个模型应该包含的属性。我们知道需要 “目标(goal)” 模型、“用户(user)”模型、“里程碑(milestone)”模型、“记录(checkin)”模型还有最后的“资源(resource)”模型和“上传(upload)”模型,
+
+
+最初的数据模型结构
+
+在正式确定好这些模型后,我们需要选择某种 _类型_ 的数据库:“关系型的”还是“非关系型的”(也就是“SQL”还是“NoSQL”)。由于基于表的 SQL 数据库需要预定义的格式,而基于文档的 NoSQL 数据库却可以用动态格式描述非结构化数据。
+
+对于我们这个情况,用 SQL 型还是 No-SQL 型的数据库没多大影响,由于下列原因,我们最终选择了 Google 的 NoSQL 云数据库 Firebase:
+
+1. 它能够把用户上传的图片保存在云端并存储起来
+
+2. 它包含 WebSocket 功能,能够实时更新
+
+3. 它能够处理用户验证,并且提供简单的 OAuth 功能。
+
+我们确定了数据库后,就要理解数据模型之间的关系了。由于 Firebase 是 NoSQL 类型,我们无法创建联合表或者设置像 _"记录 (Checkins)属于目标(Goals)"_ 的从属关系。因此我们需要弄清楚 JSON 树是什么样的,对象是怎样嵌套的(或者不是嵌套的关系)。最终,我们构建了像这样的模型:
+
+
+
+我们最终为目标(Goal)对象确定的 Firebase 数据格式。注意里程碑(Milestones)和记录(Checkins)对象嵌套在 Goals 中。
+
+_(注意: 出于性能考虑,Firebase 更倾向于简单、常规的数据结构, 但对于我们这种情况,需要在数据中进行嵌套,因为我们不会从数据库中获取目标(Goal)却不获取相应的子对象里程碑(Milestones)和记录(Checkins)。)_
+
+### 第 4 步:设置好 Github 和敏捷开发工作流
+
+我们知道,从一开始就保持井然有序、执行敏捷开发对我们有极大好处。我们设置好 Github 上的仓库,我们无法直接将代码合并到主(master)分支,这迫使我们互相审阅代码。
+
+
+
+
+我们还在 [Waffle.io][5] 网站上创建了敏捷开发的面板,它是免费的,很容易集成到 Github。我们在 Waffle 面板上罗列出所有用户故事以及需要我们去修复的 bugs。之后当我们开始编码时,我们每个人会为自己正在研究的每一个用户故事创建一个 git 分支,在完成工作后合并这一条条的分支。
+
+
+
+
+我们还开始保持晨会的习惯,讨论前一天的工作和每一个人遇到的阻碍。会议常常决定了当天的流程 —— 哪些人要结对编程,哪些人要独自处理问题。
+
+我认为这种类型的工作流程非常好,因为它让我们能够清楚地找到自己的定位,不用顾虑人际矛盾地高效执行工作。
+
+### 第 5 步: 选择、下载样板文件
+
+由于 JavaScript 的生态系统过于复杂,我们不打算从最底层开始构建应用。把宝贵的时间花在连通 Webpack 构建脚本和加载器,把符号链接指向项目工程这些事情上感觉很没必要。我的团队选择了 [Firebones][6] 框架,因为它恰好适用于我们这个情况,当然还有很多可供选择的开源框架。
+
+### 第 6 步:编写后端 API 路由(或者 Firebase 监听器)
+
+如果我们没有用基于云的数据库,这时就应该开始编写执行数据库查询的后端高速路由了。但是由于我们用的是 Firebase,它本身就是云端的,可以用不同的方式进行代码交互,因此我们只需要设置好一个可用的数据库监听器。
+
+为了确保监听器在工作,我们用代码做出了用于创建目标(Goal)的基本用户表格,实际上当我们完成表格时,就看到数据库执行可更新。数据库就成功连接了!
+
+### 第 7 步:构建 “概念证明”
+
+接下来是为应用创建 “概念证明”,也可以说是实现起来最复杂的基本功能的原型,证明我们的应用 _可以_ 实现。对我们而言,这意味着要找个前端库来实现时间线的渲染,成功连接到 Firebase,显示数据库中的一些种子数据。
+
+
+
+Victory.JS 绘制的简单时间线
+
+我们找到了基于 D3 构建的响应式库 Victory.JS,花了一天时间阅读文档,用 _VictoryLine_ 和 _VictoryScatter_ 组件实现了非常基础的示例,能够可视化地显示数据库中的数据。实际上,这很有用!我们可以开始构建了。
+
+### 第 8 步:用代码实现功能
+
+最后,是时候构建出应用中那些令人期待的功能了。取决于你要构建的应用,这一重要步骤会有些明显差异。我们根据所用的框架,编码出不同的用户故事并保存在 Waffle 上。常常需要同时接触前端和后端代码(比如,创建一个前端表格同时要连接到数据库)。我们实现了包含以下这些大大小小的功能:
+
+* 能够创建新目标(goals)、里程碑(milestones)和记录(checkins)
+
+* 能够删除目标,里程碑和记录
+
+* 能够更改时间线的名称,颜色和详细内容
+
+* 能够缩放时间线
+
+* 能够为资源添加链接
+
+* 能够上传视频
+
+* 在达到相关目标的里程碑和记录时弹出资源和视频
+
+* 集成富文本编辑器
+
+* 用户注册、验证、OAuth 验证
+
+* 弹出查看时间线选项
+
+* 加载画面
+
+有各种原因,这一步花了我们很多时间 —— 这一阶段是产生最多优质代码的阶段,每当我们实现了一个功能,就会有更多的事情要完善。
+
+### 第 9 步: 选择并实现设计方案
+
+当我们使用 MVP 架构实现了想要的功能,就可以开始清理,对它进行美化了。像表单,菜单和登陆栏等组件,我的团队用的是 Material-UI,不需要很多深层次的设计知识,它也能确保每个组件看上去都很圆润光滑。
+
+
+这是我制作的最喜爱功能之一了。它美得令人心旷神怡。
+
+我们花了一点时间来选择颜色方案和编写 CSS ,这让我们在编程中休息了一段美妙的时间。期间我们还设计了 logo 图标,还上传了网站图标。
+
+### 第 10 步: 找出并减少 bug
+
+我们一开始就应该使用测试驱动开发的模式,但时间有限,我们那点时间只够用来实现功能。这意味着最后的两天时间我们花在了模拟我们能够想到的每一种用户流,并从应用中找出 bug。
+
+
+
+这一步是最不具系统性的,但是我们发现了一堆够我们忙乎的 bug,其中一个是在某些情况下加载动画不会结束的 bug,还有一个是资源组件会完全停止运行的 bug。修复 bug 是件令人恼火的事情,但当软件可以运行时,又特别令人满足。
+
+### 第 11 步:应用上线
+
+最后一步是上线应用,这样才可以让用户使用它!由于我们使用 Firebase 存储数据,因此我们使用了 Firebase Hosting,它很直观也很简单。如果你要选择其它的数据库,你可以使用 Heroku 或者 DigitalOcean。一般来讲,可以在主机网站中查看使用说明。
+
+我们还在 Namecheap.com 上购买了一个便宜的域名,这让我们的应用更加完善,很容易被找到。
+
+
+
+* * *
+
+好了,这就是全部的过程 —— 我们都是这款实用的全栈应用的合作开发者。如果要继续讲,那么第 12 步将会是对用户进行 A/B 测试,这样我们才能更好地理解:实际用户与这款应用交互的方式和他们想在 V2 版本中看到的新功能。
+
+但是,现在我们感到非常开心,不仅是因为成品,还因为我们从这个过程中获得了难以估量的知识和理解。点击 [这里][7] 查看 Align 应用!
+
+
+Align 团队:Sara Kladky (左), Melanie Mohn (中), 还有我自己.
+
+--------------------------------------------------------------------------------
+
+via: https://medium.com/ladies-storm-hackathons/how-we-built-our-first-full-stack-javascript-web-app-in-three-weeks-8a4668dbd67c?imm_mid=0f581a&cmp=em-web-na-na-newsltr_20170816
+
+作者:[Sophia Ciocca ][a]
+译者:[BriFuture](https://github.com/BriFuture)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://medium.com/@sophiaciocca?source=post_header_lockup
+[1]:https://medium.com/@sophiaciocca?source=post_header_lockup
+[2]:https://medium.com/@sophiaciocca?source=post_header_lockup
+[3]:https://github.com/limitless-leggings/limitless-leggings
+[4]:https://www.youtube.com/watch?v=qyLoInHNjoc
+[5]:http://www.waffle.io/
+[6]:https://github.com/FullstackAcademy/firebones
+[7]:https://align.fun/
+[8]:https://github.com/align-capstone/align
+[9]:https://github.com/sophiaciocca
+[10]:https://github.com/Kladky
+[11]:https://github.com/melaniemohn
diff --git a/translated/tech/20170926 Managing users on Linux systems.md b/translated/tech/20170926 Managing users on Linux systems.md
new file mode 100644
index 0000000000..719b0575b6
--- /dev/null
+++ b/translated/tech/20170926 Managing users on Linux systems.md
@@ -0,0 +1,222 @@
+# 管理 Linux 系统中的用户
+
+也许你的 Lniux 用户并不是愤怒的公牛,但是当涉及管理他们的账户的时候,能让他们一直开心也是一种挑战。监控他们当前正在访问的东西,追踪他们他们遇到问题时的解决方案,并且保证能把他们在使用系统时出现的重要变动记录下来。这里有一些方法和工具可以使这份工作轻松一点。
+
+### 配置账户
+
+添加和移除账户是管理用户中最简单的一项,但是这里面仍然有很多需要考虑的选项。无论你是用桌面工具或是命令行选项,这都是一个非常自动化的过程。你可以使用命令添加一个新用户,像是 **adduser jdoe**,这同时会触发一系列的事情。使用下一个可用的 UID 可以创建 John 的账户,或许还会被许多用以配置账户的文件所填充。当你运行 adduser 命令加一个新的用户名的时候,它将会提示一些额外的信息,同时解释这是在干什么。
+```
+$ sudo adduser jdoe
+Adding user 'jdoe' ...
+Adding new group `jdoe' (1001) ...
+Adding new user `jdoe' (1001) with group `jdoe' ...
+Creating home directory `/home/jdoe' ...
+Copying files from `/etc/skel' …
+Enter new UNIX password:
+Retype new UNIX password:
+passwd: password updated successfully
+Changing the user information for jdoe
+Enter the new value, or press ENTER for the default
+ Full Name []: John Doe
+ Room Number []:
+ Work Phone []:
+ Home Phone []:
+ Other []:
+Is the information correct? [Y/n] Y
+
+```
+
+像你看到的那样,adduser 将添加用户的信息(到 /etc/passwd 和 /etc/shadow 文件中),创建新的家目录,并用 /etc/skel 里设置的文件填充家目录,提示你分配初始密码和认定信息,然后确认这些信息都是正确的,如果你在最后的提示 “Is the information correct” 处的答案是 “n”,它将回溯你之前所有的回答,允许修改任何你想要修改的地方。
+
+创建好一个用户后,你可能会想要确认一下它是否是你期望的样子,更好的方法是确保在添加第一个帐户**之前**,“自动”选择与您想要查看的内容相匹配。默认有默认的好处,它对于你想知道他们定义在哪里有所用处,以防你想作出一些变动 —— 例如,你不想家目录在 /home 里,你不想用户 UIDs 从 1000 开始,或是你不想家目录下的文件被系统上的**每个人**都可读。
+
+adduser 如何工作的一些细节设置在 /etc/adduser.conf 文件里。这个文件包含的一些设置决定了一个新的账户如何配置,以及它之后的样子。注意,注释和空白行将会在输出中被忽略,因此我们可以更加集中注意在设置上面。
+```
+$ cat /etc/adduser.conf | grep -v "^#" | grep -v "^$"
+DSHELL=/bin/bash
+DHOME=/home
+GROUPHOMES=no
+LETTERHOMES=no
+SKEL=/etc/skel
+FIRST_SYSTEM_UID=100
+LAST_SYSTEM_UID=999
+FIRST_SYSTEM_GID=100
+LAST_SYSTEM_GID=999
+FIRST_UID=1000
+LAST_UID=29999
+FIRST_GID=1000
+LAST_GID=29999
+USERGROUPS=yes
+USERS_GID=100
+DIR_MODE=0755
+SETGID_HOME=no
+QUOTAUSER=""
+SKEL_IGNORE_REGEX="dpkg-(old|new|dist|save)"
+
+```
+
+可以看到,我们有了一个默认的 shell(DSHELL),UIDs(FIRST_UID)的开始数值,家目录(DHOME)的位置,以及启动文件(SKEL)的来源位置。这个文件也会指定分配给家目录(DIR_HOME)的权限。
+
+其中 DIR_HOME 是最重要的设置,它决定了每个家目录被使用的权限。这个设置分配给用户创建的目录权限是 755,家目录的权限将会设置为 rwxr-xr-x。用户可以读其他用户的文件,但是不能修改和移除他们。如果你想要更多的限制,你可以更改这个设置为 750(用户组外的任何人都不可访问)甚至是 700(除用户自己外的人都不可访问)。
+
+任何用户账号在创建之前都可以进行手动修改。例如,你可以编辑 /etc/passwd 或者修改家目录的权限,开始在新服务器上添加用户之前配置 /etc/adduser.conf 可以确保一定的一致性,从长远来看可以节省时间和避免一些麻烦。
+
+/etc/adduser.conf 的修改将会在之后创建的用户上生效。如果你想以不同的方式设置某个特定账户,除了用户名之外,你还可以选择使用 adduser 命令提供账户配置选项。或许你想为某些账户分配不同的 shell,请求特殊的 UID,完全禁用登录。adduser 的帮助页将会为你显示一些配置个人账户的选择。
+
+```
+adduser [options] [--home DIR] [--shell SHELL] [--no-create-home]
+[--uid ID] [--firstuid ID] [--lastuid ID] [--ingroup GROUP | --gid ID]
+[--disabled-password] [--disabled-login] [--gecos GECOS]
+[--add_extra_groups] [--encrypt-home] user
+
+```
+
+每个 Linux 系统现在都会默认把每个用户放入对应的组中。作为一个管理员,你可能会选择以不同的方式去做事。你也许会发现把用户放在一个共享组中可以让你的站点工作的更好,这时,选择使用 adduser 的 --gid 选项去选择一个特定的组。当然,用户总是许多组的成员,因此也有一些选项去管理主要和次要的组。
+
+### 处理用户密码
+
+一直以来,知道其他人的密码都是一个不好的念头,在设置账户时,管理员通常使用一个临时的密码,然后在用户第一次登录时会运行一条命令强制他修改密码。这里是一个例子:
+```
+$ sudo chage -d 0 jdoe
+```
+
+当用户第一次登录的时候,会看到像这样的事情:
+```
+WARNING: Your password has expired.
+You must change your password now and login again!
+Changing password for jdoe.
+(current) UNIX password:
+
+```
+
+### 添加用户到副组
+
+添加用户到副组中,你可能会用如下所示的 usermod 命令 —— 添加用户到组中并确认已经做出变动。
+```
+$ sudo usermod -a -G sudo jdoe
+$ sudo grep sudo /etc/group
+sudo:x:27:shs,jdoe
+
+```
+
+记住在一些组,像是 sudo 或者 wheel 组中,意味着包含特权,一定要特别注意这一点。
+
+### 移除用户,添加组等
+
+Linux 系统也提供了命令去移除账户,添加新的组,移除组等。例如,**deluser** 命令,将会从 /etc/passwd 和 /etc/shadow 中移除用户登录入口,但是会完整保留他的家目录,除非你添加了 --remove-home 或者 --remove-all-files 选项。**addgroup** 命令会添加一个组,按目前组的次序给他下一个 id(在用户组范围内),除非你使用 --gid 选项指定 id。
+```
+$ sudo addgroup testgroup --gid=131
+Adding group `testgroup' (GID 131) ...
+Done.
+
+```
+
+### 管理特权账户
+
+一些 Linux 系统中有一个 wheel 组,它给组中成员赋予了像 root 一样运行命令的能力。在这种情况下,/etc/sudoers 将会引用该组。在 Debian 系统中,这个组被叫做 sudo,但是以相同的方式工作,你在 /etc/sudoers 中可以看到像这样的引用:
+```
+%sudo ALL=(ALL:ALL) ALL
+
+```
+
+这个基础的设定意味着,任何在 wheel 或者 sudo 组中的成员,只要在他们运行的命令之前添加 sudo,就可以以 root 的权限去运行命令。
+
+你可以向 sudoers 文件中添加更多有限的特权 —— 也许给特定用户运行一两个 root 的命令。如果这样做,您还应定期查看 /etc/sudoers 文件以评估用户拥有的权限,以及仍然需要提供的权限。
+
+在下面显示的命令中,我们看到在 /etc/sudoers 中匹配到的行。在这个文件中最有趣的行是,包含能使用 sudo 运行命令的路径设置,以及两个允许通过 sudo 运行命令的组。像刚才提到的那样,单个用户可以通过包含在 sudoers 文件中来获得权限,但是更有实际意义的方法是通过组成员来定义各自的权限。
+```
+# cat /etc/sudoers | grep -v "^#" | grep -v "^$"
+Defaults env_reset
+Defaults mail_badpass
+Defaults secure_path="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin"
+root ALL=(ALL:ALL) ALL
+%admin ALL=(ALL) ALL <== admin group
+%sudo ALL=(ALL:ALL) ALL <== sudo group
+
+```
+
+### 登录检查
+
+你可以通过以下命令查看用户的上一次登录:
+```
+# last jdoe
+jdoe pts/18 192.168.0.11 Thu Sep 14 08:44 - 11:48 (00:04)
+jdoe pts/18 192.168.0.11 Thu Sep 14 13:43 - 18:44 (00:00)
+jdoe pts/18 192.168.0.11 Thu Sep 14 19:42 - 19:43 (00:00)
+
+```
+
+如果你想查看每一个用户上一次的登录情况,你可以通过一个像这样的循环来运行 last 命令:
+```
+$ for user in `ls /home`; do last $user | head -1; done
+
+jdoe pts/18 192.168.0.11 Thu Sep 14 19:42 - 19:43 (00:03)
+
+rocket pts/18 192.168.0.11 Thu Sep 14 13:02 - 13:02 (00:00)
+shs pts/17 192.168.0.11 Thu Sep 14 12:45 still logged in
+
+
+```
+
+此命令仅显示自当前 wtmp 文件变为活跃状态以来已登录的用户。空白行表示用户自那以后从未登录过,但没有将其调出。一个更好的命令是过滤掉在这期间从未登录过的用户的显示:
+```
+$ for user in `ls /home`; do echo -n "$user ";last $user | head -1 | awk '{print substr($0,40)}'; done
+dhayes
+jdoe pts/18 192.168.0.11 Thu Sep 14 19:42 - 19:43
+peanut pts/19 192.168.0.29 Mon Sep 11 09:15 - 17:11
+rocket pts/18 192.168.0.11 Thu Sep 14 13:02 - 13:02
+shs pts/17 192.168.0.11 Thu Sep 14 12:45 still logged
+tsmith
+
+```
+
+这个命令会打印很多,但是可以通过一个脚本使它更加清晰易用。
+```
+#!/bin/bash
+
+for user in `ls /home`
+do
+ echo -n "$user ";last $user | head -1 | awk '{print substr($0,40)}'
+done
+
+```
+
+有时,此类信息可以提醒您用户角色的变动,表明他们可能不再需要相关帐户。
+
+### 与用户沟通
+
+Linux 提供了许多方法和用户沟通。你可以向 /etc/motd 文件中添加信息,当用户从终端登录到服务器时,将会显示这些信息。你也可以通过例如 write(通知单个用户)或者 wall(write 给所有已登录的用户)命令发送通知。
+```
+$ wall System will go down in one hour
+
+Broadcast message from shs@stinkbug (pts/17) (Thu Sep 14 14:04:16 2017):
+
+System will go down in one hour
+
+```
+
+重要的通知应该通过多个管道传递,因为很难预测用户实际会注意到什么。mesage-of-the-day(motd),wall 和 email 通知可以吸引用户大部分的注意力。
+
+### 注意日志文件
+
+更多地注意日志文件上也可以帮你理解用户活动。事实上,/var/log/auth.log 文件将会为你显示用户的登录和注销活动,组的创建等。/var/log/message 或者 /var/log/syslog 文件将会告诉你更多有关系统活动的事情。
+
+### 追踪问题和请求
+
+无论你是否在 Linux 系统上安装了票务系统,跟踪用户遇到的问题以及他们提出的请求都非常重要。如果请求的一部分久久不见回应,用户必然不会高兴。即使是纸质日志也可能是有用的,或者更好的是,有一个电子表格,可以让你注意到哪些问题仍然悬而未决,以及问题的根本原因是什么。确保解决问题和请求非常重要,日志还可以帮助您记住你必须采取的措施来解决几个月甚至几年后重新出现的问题。
+
+### 总结
+
+在繁忙的服务器上管理用户帐户部分取决于从配置良好的默认值开始,部分取决于监控用户活动和遇到的问题。如果用户觉得你对他们的顾虑有所回应并且知道在需要系统升级时会发生什么,他们可能会很高兴。
+
+-----------
+
+via: https://www.networkworld.com/article/3225109/linux/managing-users-on-linux-systems.html
+
+作者:[Sandra Henry-Stocker][a]
+译者:[dianbanjiu](https://github.com/dianbanjiu)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
diff --git a/translated/tech/20180724 75 Most Used Essential Linux Applications of 2018.md b/translated/tech/20180724 75 Most Used Essential Linux Applications of 2018.md
new file mode 100644
index 0000000000..96ca929009
--- /dev/null
+++ b/translated/tech/20180724 75 Most Used Essential Linux Applications of 2018.md
@@ -0,0 +1,985 @@
+2018 年 75 个最常用的 Linux 应用程序
+======
+
+对于许多应用程序来说,2018年是非常好的一年,尤其是免费开源的应用程序。尽管各种 Linux 发行版都自带了很多默认的应用程序,但用户也可以自由地选择使用它们或者其它任何免费或付费替代方案。
+
+下面汇总了[一系列的 Linux 应用程序][3],这些应用程序都能够在 Linux 系统上安装,尽管还有很多其它选择。以下汇总中的任何应用程序都属于其类别中最常用的应用程序,如果你还没有用过,欢迎试用一下!
+
+### 备份工具
+
+#### Rsync
+
+[Rsync][4] 是一个开源的、带宽友好的工具,它用于执行快速的增量文件传输,而且它也是一个免费工具。
+```
+$ rsync [OPTION...] SRC... [DEST]
+
+```
+
+想要了解更多示例和用法,可以参考《[10 个使用 Rsync 命令的实际例子][5]》。
+
+#### Timeshift
+
+[Timeshift][6] 能够通过增量快照来保护用户的系统数据,而且可以按照日期恢复指定的快照,类似于 Mac OS 中的 Time Machine 功能和 Windows 中的系统还原功能。
+
+
+
+### BT(BitTorrent) 客户端
+
+
+
+#### Deluge
+
+[Deluge][7] 是一个漂亮的跨平台 BT 客户端,旨在优化 μTorrent 体验,并向用户免费提供服务。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Deluge`。
+```
+$ sudo add-apt-repository ppa:deluge-team/ppa
+$ sudo apt-get update
+$ sudo apt-get install deluge
+
+```
+
+#### qBittorent
+
+[qBittorent][8] 是一个开源的 BT 客户端,旨在提供类似 μTorrent 的免费替代方案。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `qBittorent`。
+```
+$ sudo add-apt-repository ppa:qbittorrent-team/qbittorrent-stable
+$ sudo apt-get update
+$ sudo apt-get install qbittorrent
+
+```
+
+#### Transmission
+
+[Transmission][9] 是一个强大的 BT 客户端,它主要关注速度和易用性,一般在很多 Linux 发行版上都有预装。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Transmission`。
+```
+$ sudo add-apt-repository ppa:transmissionbt/ppa
+$ sudo apt-get update
+$ sudo apt-get install transmission-gtk transmission-cli transmission-common transmission-daemon
+
+```
+
+### 云存储
+
+
+
+#### Dropbox
+
+[Dropbox][10] 团队在今年早些时候给他们的云服务换了一个名字,也为客户提供了更好的性能和集成了更多应用程序。Dropbox 会向用户免费提供 2 GB 存储空间。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Dropbox`。
+```
+$ cd ~ && wget -O - "https://www.dropbox.com/download?plat=lnx.x86" | tar xzf - [On 32-Bit]
+$ cd ~ && wget -O - "https://www.dropbox.com/download?plat=lnx.x86_64" | tar xzf - [On 64-Bit]
+$ ~/.dropbox-dist/dropboxd
+
+```
+
+#### Google Drive
+
+[Google Drive][11] 是 Google 提供的云服务解决方案,这已经是一个广为人知的服务了。与 Dropbox 一样,可以通过它在所有联网的设备上同步文件。它免费提供了 15 GB 存储空间,包括Gmail、Google 图片、Google 地图等服务。
+
+参考阅读:[5 个适用于 Linux 的 Google Drive 客户端][12]
+
+#### Mega
+
+[Mega][13] 也是一个出色的云存储解决方案,它的亮点除了高度的安全性之外,还有为用户免费提供高达 50 GB 的免费存储空间。它使用端到端加密,以确保用户的数据安全,所以如果忘记了恢复密钥,用户自己也无法访问到存储的数据。
+
+参考阅读:[在 Ubuntu 下载 Mega 云存储客户端][14]
+
+### 命令行编辑器
+
+
+
+#### Vim
+
+[Vim][15] 是 vi 文本编辑器的开源克隆版本,它的主要目的是可以高度定制化并能够处理任何类型的文本。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Vim`。
+```
+$ sudo add-apt-repository ppa:jonathonf/vim
+$ sudo apt update
+$ sudo apt install vim
+
+```
+
+#### Emacs
+
+[Emacs][16] 是一个高度可配置的文本编辑器,最流行的一个分支 GNU Emacs 是用 Lisp 和 C 编写的,它的最大特点是可以自文档化、可扩展和可自定义。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Emacs`。
+```
+$ sudo add-apt-repository ppa:kelleyk/emacs
+$ sudo apt update
+$ sudo apt install emacs25
+
+```
+
+#### Nano
+
+[Nano][17] 是一款功能丰富的命令行文本编辑器,比较适合高级用户。它可以通过多个终端进行不同功能的操作。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Nano`。
+```
+$ sudo add-apt-repository ppa:n-muench/programs-ppa
+$ sudo apt-get update
+$ sudo apt-get install nano
+
+```
+
+### 下载器
+
+
+
+#### Aria2
+
+[Aria2][18] 是一个开源的、轻量级的、多软件源和多协议的命令行下载器,它支持 Metalinks、torrents、HTTP/HTTPS、SFTP 等多种协议。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Aria2`。
+```
+$ sudo apt-get install aria2
+
+```
+
+#### uGet
+
+[uGet][19] 已经成为 Linux 各种发行版中排名第一的开源下载器,它可以处理任何下载任务,包括多连接、队列、类目等。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `uGet`。
+```
+$ sudo add-apt-repository ppa:plushuang-tw/uget-stable
+$ sudo apt update
+$ sudo apt install uget
+
+```
+
+#### XDM
+
+[XDM][20](Xtreme Download Manager)是一个使用 Java 编写的开源下载软件。和其它下载器一样,它可以结合队列、种子、浏览器使用,而且还带有视频采集器和智能调度器。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `XDM`。
+```
+$ sudo add-apt-repository ppa:noobslab/apps
+$ sudo apt-get update
+$ sudo apt-get install xdman
+
+```
+
+### 电子邮件客户端
+
+
+
+#### Thunderbird
+
+[Thunderbird][21] 是最受欢迎的电子邮件客户端之一。它的优点包括免费、开源、可定制、功能丰富,而且最重要的是安装过程也很简便。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Thunderbird`。
+```
+$ sudo add-apt-repository ppa:ubuntu-mozilla-security/ppa
+$ sudo apt-get update
+$ sudo apt-get install thunderbird
+
+```
+
+#### Geary
+
+[Geary][22] 是一个基于 WebKitGTK+ 的开源电子邮件客户端。它是一个免费开源的功能丰富的软件,并被 GNOME 项目收录。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Geary`。
+```
+$ sudo add-apt-repository ppa:geary-team/releases
+$ sudo apt-get update
+$ sudo apt-get install geary
+
+```
+
+#### Evolution
+
+[Evolution][23] 是一个免费开源的电子邮件客户端,可以用于电子邮件、会议日程、备忘录和联系人的管理。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Evolution`。
+```
+$ sudo add-apt-repository ppa:gnome3-team/gnome3-staging
+$ sudo apt-get update
+$ sudo apt-get install evolution
+
+```
+
+### 财务软件
+
+
+
+#### GnuCash
+
+[GnuCash][24] 是一款免费的跨平台开源软件,它适用于个人和中小型企业的财务任务。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `GnuCash`。
+```
+$ sudo sh -c 'echo "deb http://archive.getdeb.net/ubuntu $(lsb_release -sc)-getdeb apps" >> /etc/apt/sources.list.d/getdeb.list'
+$ sudo apt-get update
+$ sudo apt-get install gnucash
+
+```
+
+#### KMyMoney
+
+[KMyMoney][25] 是一个财务管理软件,它可以提供商用或个人理财所需的大部分主要功能。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `KmyMoney`。
+```
+$ sudo add-apt-repository ppa:claydoh/kmymoney2-kde4
+$ sudo apt-get update
+$ sudo apt-get install kmymoney
+
+```
+
+### IDE 和编辑器
+
+
+
+#### Eclipse IDE
+
+[Eclipse][26] 是最广为使用的 Java IDE,它包括一个基本工作空间和一个用于自定义编程环境的强大的的插件配置系统。
+
+关于 Eclipse IDE 的安装,可以参考 [如何在 Debian 和 Ubuntu 上安装 Eclipse IDE][27] 这一篇文章。
+
+#### Netbeans IDE
+
+[Netbeans][28] 是一个相当受用户欢迎的 IDE,它支持使用 Java、PHP、HTML 5、JavaScript、C/C++ 或其他语言编写移动应用,桌面软件和 web 应用。
+
+关于 Netbeans IDE 的安装,可以参考 [如何在 Debian 和 Ubuntu 上安装 Netbeans IDE][29] 这一篇文章。
+
+#### Brackets
+
+[Brackets][30] 是由 Adobe 开发的高级文本编辑器,它带有可视化工具,支持预处理程序,以及用于 web 开发的以设计为中心的用户流程。对于熟悉它的用户,它可以发挥 IDE 的作用。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Brackets`。
+```
+$ sudo add-apt-repository ppa:webupd8team/brackets
+$ sudo apt-get update
+$ sudo apt-get install brackets
+
+```
+
+#### Atom IDE
+
+[Atom IDE][31] 是一个加强版的 Atom 编辑器,它添加了大量扩展和库以提高性能和增加功能。总之,它是各方面都变得更强大了的 Atom 。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Atom`。
+```
+$ sudo apt-get install snapd
+$ sudo snap install atom --classic
+
+```
+
+#### Light Table
+
+[Light Table][32] 号称下一代的 IDE,它提供了数据流量统计和协作编程等的强大功能。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Light Table`。
+```
+$ sudo add-apt-repository ppa:dr-akulavich/lighttable
+$ sudo apt-get update
+$ sudo apt-get install lighttable-installer
+
+```
+
+#### Visual Studio Code
+
+[Visual Studio Code][33] 是由微软开发的代码编辑器,它包含了文本编辑器所需要的最先进的功能,包括语法高亮、自动完成、代码调试、性能统计和图表显示等功能。
+
+参考阅读:[在Ubuntu 下载 Visual Studio Code][34]
+
+### 即时通信工具
+
+
+
+#### Pidgin
+
+[Pidgin][35] 是一个开源的即时通信工具,它几乎支持所有聊天平台,还支持额外扩展功能。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Pidgin`。
+```
+$ sudo add-apt-repository ppa:jonathonf/backports
+$ sudo apt-get update
+$ sudo apt-get install pidgin
+
+```
+
+#### Skype
+
+[Skype][36] 也是一个广为人知的软件了,任何感兴趣的用户都可以在 Linux 上使用。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Skype`。
+```
+$ sudo apt install snapd
+$ sudo snap install skype --classic
+
+```
+
+#### Empathy
+
+[Empathy][37] 是一个支持多协议语音、视频聊天、文本和文件传输的即时通信工具。它还允许用户添加多个服务的帐户,并用其与所有服务的帐户进行交互。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Empathy`。
+```
+$ sudo apt-get install empathy
+
+```
+
+### Linux 防病毒工具
+
+#### ClamAV/ClamTk
+
+[ClamAV][38] 是一个开源的跨平台命令行防病毒工具,用于检测木马、病毒和其他恶意代码。而 [ClamTk][39] 则是它的前端 GUI。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `ClamAV` 和 `ClamTk`。
+```
+$ sudo apt-get install clamav
+$ sudo apt-get install clamtk
+
+```
+
+### Linux 桌面环境
+
+#### Cinnamon
+
+[Cinnamon][40] 是 GNOME 3 的免费开源衍生产品,它遵循传统的 桌面比拟 约定。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Cinnamon`。
+```
+$ sudo add-apt-repository ppa:embrosyn/cinnamon
+$ sudo apt update
+$ sudo apt install cinnamon-desktop-environment lightdm
+
+```
+
+#### Mate
+
+[Mate][41] 桌面环境是 GNOME 2 的衍生和延续,目的是在 Linux 上通过使用传统的桌面比拟提供有一个吸引力的 UI。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Mate`。
+```
+$ sudo apt install tasksel
+$ sudo apt update
+$ sudo tasksel install ubuntu-mate-desktop
+
+```
+
+#### GNOME
+
+[GNOME][42] 是由一些免费和开源应用程序组成的桌面环境,它可以运行在任何 Linux 发行版和大多数 BSD 衍生版本上。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Gnome`。
+```
+$ sudo apt install tasksel
+$ sudo apt update
+$ sudo tasksel install ubuntu-desktop
+
+```
+
+#### KDE
+
+[KDE][43] 由 KDE 社区开发,它为用户提供图形解决方案以控制操作系统并执行不同的计算任务。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `KDE`。
+```
+$ sudo apt install tasksel
+$ sudo apt update
+$ sudo tasksel install kubuntu-desktop
+
+```
+
+### Linux 维护工具
+
+#### GNOME Tweak Tool
+
+[GNOME Tweak Tool][44] 是用于自定义和调整 GNOME 3 和 GNOME Shell 设置的流行工具。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `GNOME Tweak Tool`。
+```
+$ sudo apt install gnome-tweak-tool
+
+```
+
+#### Stacer
+
+[Stacer][45] 是一款用于监控和优化 Linux 系统的免费开源应用程序。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Stacer`。
+```
+$ sudo add-apt-repository ppa:oguzhaninan/stacer
+$ sudo apt-get update
+$ sudo apt-get install stacer
+
+```
+
+#### BleachBit
+
+[BleachBit][46] 是一个免费的磁盘空间清理器,它也可用作隐私管理器和系统优化器。
+
+参考阅读:[在 Ubuntu 下载 BleachBit][47]
+
+### Linux 终端工具
+
+#### GNOME 终端
+
+[GNOME 终端][48] 是 GNOME 的默认终端模拟器。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Gnome Terminal`。
+```
+$ sudo apt-get install gnome-terminal
+
+```
+
+#### Konsole
+
+[Konsole][49] 是 KDE 的一个终端模拟器。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Konsole`。
+```
+$ sudo apt-get install konsole
+
+```
+
+#### Terminator
+
+[Terminator][50] 是一个功能丰富的终端程序,它基于 GNOME 终端,并且专注于整理终端功能。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Terminator`。
+```
+$ sudo apt-get install terminator
+
+```
+
+#### Guake
+
+[Guake][51] 是 GNOME 桌面环境下一个轻量级的可下拉式终端。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Guake`。
+```
+$ sudo apt-get install guake
+
+```
+
+### 多媒体编辑工具
+
+#### Ardour
+
+[Ardour][52] 是一款漂亮的的数字音频工作站,可以完成专业的录制、编辑和混音工作。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Ardour`。
+```
+$ sudo add-apt-repository ppa:dobey/audiotools
+$ sudo apt-get update
+$ sudo apt-get install ardour
+
+```
+
+#### Audacity
+
+[Audacity][53] 是最著名的音频编辑软件之一,它是一款跨平台的开源多轨音频编辑器。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Audacity`。
+```
+$ sudo add-apt-repository ppa:ubuntuhandbook1/audacity
+$ sudo apt-get update
+$ sudo apt-get install audacity
+
+```
+
+#### GIMP
+
+[GIMP][54] 是 Photoshop 的开源替代品中最受欢迎的。这是因为它有多种可自定义的选项、第三方插件以及活跃的用户社区。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Gimp`。
+```
+$ sudo add-apt-repository ppa:otto-kesselgulasch/gimp
+$ sudo apt update
+$ sudo apt install gimp
+
+```
+
+#### Krita
+
+[Krita][55] 是一款开源的绘画程序,它具有美观的 UI 和可靠的性能,也可以用作图像处理工具。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Krita`。
+```
+$ sudo add-apt-repository ppa:kritalime/ppa
+$ sudo apt update
+$ sudo apt install krita
+
+```
+
+#### Lightworks
+
+[Lightworks][56] 是一款功能强大、灵活美观的专业视频编辑工具。它拥有上百种配套的视觉效果功能,可以处理任何编辑任务,毕竟这个软件已经有长达 25 年的视频处理经验。
+
+参考阅读:[在 Ubuntu 下载 Lightworks][57]
+
+#### OpenShot
+
+[OpenShot][58] 是一款屡获殊荣的免费开源视频编辑器,这主要得益于其出色的性能和强大的功能。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Openshot`。
+```
+$ sudo add-apt-repository ppa:openshot.developers/ppa
+$ sudo apt update
+$ sudo apt install openshot-qt
+
+```
+
+#### PiTiV
+
+[Pitivi][59] 也是一个美观的视频编辑器,它有优美的代码库、优质的社区,还支持优秀的协作编辑功能。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `PiTiV`。
+```
+$ flatpak install --user https://flathub.org/repo/appstream/org.pitivi.Pitivi.flatpakref
+$ flatpak install --user http://flatpak.pitivi.org/pitivi.flatpakref
+$ flatpak run org.pitivi.Pitivi//stable
+
+```
+
+### 音乐播放器
+
+#### Rhythmbox
+
+[Rhythmbox][60] 支持海量种类的音乐,目前被认为是最可靠的音乐播放器,并由 Ubuntu 自带。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Rhythmbox`。
+```
+$ sudo add-apt-repository ppa:fossfreedom/rhythmbox
+$ sudo apt-get update
+$ sudo apt-get install rhythmbox
+
+```
+
+#### Lollypop
+
+[Lollypop][61] 是一款较为年轻的开源音乐播放器,它有很多高级选项,包括网络电台,滑动播放和派对模式。尽管功能繁多,它仍然尽量做到简单易管理。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Lollypop`。
+```
+$ sudo add-apt-repository ppa:gnumdk/lollypop
+$ sudo apt-get update
+$ sudo apt-get install lollypop
+
+```
+
+#### Amarok
+
+[Amarok][62] 是一款功能强大的音乐播放器,它有一个直观的 UI 和大量的高级功能,而且允许用户根据自己的偏好去发现新音乐。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Amarok`。
+```
+$ sudo apt-get update
+$ sudo apt-get install amarok
+
+```
+
+#### Clementine
+
+[Clementine][63] 是一款 Amarok 风格的音乐播放器,因此和 Amarok 相似,也有直观的用户界面、先进的控制模块,以及让用户搜索和发现新音乐的功能。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Clementine`。
+```
+$ sudo add-apt-repository ppa:me-davidsansome/clementine
+$ sudo apt-get update
+$ sudo apt-get install clementine
+
+```
+
+#### Cmus
+
+[Cmus][64] 可以说是最高效的的命令行界面音乐播放器了,它具有快速可靠的特点,也支持使用扩展。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Cmus`。
+```
+$ sudo add-apt-repository ppa:jmuc/cmus
+$ sudo apt-get update
+$ sudo apt-get install cmus
+
+```
+
+### 办公软件
+
+#### Calligra 套件
+
+Calligra 套件为用户提供了一套总共 8 个应用程序,涵盖办公、管理、图表等各个范畴。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Calligra` 套件。
+```
+$ sudo apt-get install calligra
+
+```
+
+#### LibreOffice
+
+[LibreOffice][66] 是开源社区中开发过程最活跃的办公套件,它以可靠性著称,也可以通过扩展来添加功能。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `LibreOffice`。
+```
+$ sudo add-apt-repository ppa:libreoffice/ppa
+$ sudo apt update
+$ sudo apt install libreoffice
+
+```
+
+#### WPS Office
+
+[WPS Office][67] 是一款漂亮的办公套件,它有一个很具现代感的 UI。
+
+参考阅读:[在 Ubuntu 安装 WPS Office][68]
+
+### 屏幕截图工具
+
+#### Shutter
+
+[Shutter][69] 允许用户截取桌面的屏幕截图,然后使用一些效果进行编辑,还支持上传和在线共享。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Shutter`。
+```
+$ sudo add-apt-repository -y ppa:shutter/ppa
+$ sudo apt update
+$ sudo apt install shutter
+
+```
+
+#### Kazam
+
+[Kazam][70] 可以用于捕获屏幕截图,它的输出对于任何支持 VP8/WebM 和 PulseAudio 视频播放器都可用。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Kazam`。
+```
+$ sudo add-apt-repository ppa:kazam-team/unstable-series
+$ sudo apt update
+$ sudo apt install kazam python3-cairo python3-xlib
+
+```
+
+#### Gnome Screenshot
+
+[Gnome Screenshot][71] 过去曾经和 Gnome 一起捆绑,但现在已经独立出来。它以易于共享的格式进行截屏。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Gnome Screenshot`。
+```
+$ sudo apt-get update
+$ sudo apt-get install gnome-screenshot
+
+```
+
+### 录屏工具
+
+#### SimpleScreenRecorder
+
+[SimpleScreenRecorder][72] 面世时已经是录屏工具中的佼佼者,现在已成为 Linux 各个发行版中最有效、最易用的录屏工具之一。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `SimpleScreenRecorder`。
+```
+$ sudo add-apt-repository ppa:maarten-baert/simplescreenrecorder
+$ sudo apt-get update
+$ sudo apt-get install simplescreenrecorder
+
+```
+
+#### recordMyDesktop
+
+[recordMyDesktop][73] 是一个开源的会话记录器,它也能记录桌面会话的音频。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `recordMyDesktop`。
+```
+$ sudo apt-get update
+$ sudo apt-get install gtk-recordmydesktop
+
+```
+
+### Text Editors
+
+#### Atom
+
+[Atom][74] 是由 GitHub 开发和维护的可定制文本编辑器。它是开箱即用的,但也可以使用扩展和主题自定义 UI 来增强其功能。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Atom`。
+```
+$ sudo apt-get install snapd
+$ sudo snap install atom --classic
+
+```
+
+#### Sublime Text
+
+[Sublime Text][75] 已经成为目前最棒的文本编辑器。它可定制、轻量灵活(即使打开了大量数据文件和加入了大量扩展),最重要的是可以永久免费使用。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Sublime Text`。
+```
+$ sudo apt-get install snapd
+$ sudo snap install sublime-text
+
+```
+
+#### Geany
+
+[Geany][76] 是一个内存友好的文本编辑器,它具有基本的IDE功能,可以显示加载时间、扩展库函数等。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Geany`。
+```
+$ sudo apt-get update
+$ sudo apt-get install geany
+
+```
+
+#### Gedit
+
+[Gedit][77] 以其简单著称,在很多 Linux 发行版都有预装,它具有文本编辑器都具有的优秀的功能。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Gedit`。
+```
+$ sudo apt-get update
+$ sudo apt-get install gedit
+
+```
+
+### 备忘录软件
+
+#### Evernote
+
+[Evernote][78] 是一款云上的笔记程序,它带有待办列表和提醒功能,能够与不同类型的笔记完美配合。
+
+Evernote 在 Linux 上没有官方提供的软件,但可以参考 [Linux 上的 6 个 Evernote 替代客户端][79] 这篇文章使用其它第三方工具。
+
+#### Everdo
+
+[Everdo][78] 是一款美观,安全,易兼容的备忘软件,可以用于处理待办事项和其它笔记。如果你认为 Evernote 有所不足,相信 Everdo 会是一个好的替代。
+
+参考阅读:[在 Ubuntu 下载 Everdo][80]
+
+#### Taskwarrior
+
+[Taskwarrior][81] 是一个用于管理个人任务的开源跨平台命令行应用,它的速度和无干扰的环境是它的两大特点。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Taskwarrior`。
+```
+$ sudo apt-get update
+$ sudo apt-get install taskwarrior
+
+```
+
+### 视频播放器
+
+#### Banshee
+
+[Banshee][82] 是一个开源的支持多格式的媒体播放器,于 2005 年开始开发并逐渐成长。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Banshee`。
+```
+$ sudo add-apt-repository ppa:banshee-team/ppa
+$ sudo apt-get update
+$ sudo apt-get install banshee
+
+```
+
+#### VLC
+
+[VLC][83] 是我最喜欢的视频播放器,它几乎可以播放任何格式的音频和视频,它还可以播放网络电台、录制桌面会话以及在线播放电影。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `VLC`。
+```
+$ sudo add-apt-repository ppa:videolan/stable-daily
+$ sudo apt-get update
+$ sudo apt-get install vlc
+
+```
+
+#### Kodi
+
+[Kodi][84] 是世界上最着名的媒体播放器之一,它有一个成熟的媒体中心,可以播放本地和远程的多媒体文件。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Kodi`。
+```
+$ sudo apt-get install software-properties-common
+$ sudo add-apt-repository ppa:team-xbmc/ppa
+$ sudo apt-get update
+$ sudo apt-get install kodi
+
+```
+
+#### SMPlayer
+
+[SMPlayer][85] 是 MPlayer 的 GUI 版本,所有流行的媒体格式它都能够处理,并且它还有从 YouTube 和 Chromcast 和下载字幕的功能。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `SMPlayer`。
+```
+$ sudo add-apt-repository ppa:rvm/smplayer
+$ sudo apt-get update
+$ sudo apt-get install smplayer
+
+```
+
+### 虚拟化工具
+
+#### VirtualBox
+
+[VirtualBox][86] 是一个用于操作系统虚拟化的开源应用程序,在服务器、台式机和嵌入式系统上都可以运行。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `VirtualBox`。
+```
+$ wget -q https://www.virtualbox.org/download/oracle_vbox_2016.asc -O- | sudo apt-key add -
+$ wget -q https://www.virtualbox.org/download/oracle_vbox.asc -O- | sudo apt-key add -
+$ sudo apt-get update
+$ sudo apt-get install virtualbox-5.2
+$ virtualbox
+
+```
+
+#### VMWare
+
+[VMware][87] 是一个为客户提供平台虚拟化和云计算服务的数字工作区,是第一个成功将 x86 架构系统虚拟化的工作站。 VMware 工作站的其中一个产品就允许用户在虚拟内存中运行多个操作系统。
+
+参阅 [在 Ubuntu 上安装 VMWare Workstation Pro][88] 可以了解 VMWare 的安装。
+
+### 浏览器
+
+#### Chrome
+
+[Google Chrome][89] 无疑是最受欢迎的浏览器。Chrome 以其速度、简洁、安全、美观而受人喜爱,它遵循了 Google 的界面设计风格,是 web 开发人员不可缺少的浏览器,同时它也是免费开源的。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Google Chrome`。
+```
+$ wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | sudo apt-key add -
+$ sudo sh -c 'echo "deb http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list'
+$ sudo apt-get update
+$ sudo apt-get install google-chrome-stable
+
+```
+
+#### Firefox
+
+[Firefox Quantum][90] 是一款漂亮、快速、完善并且可自定义的浏览器。它也是免费开源的,包含有开发人员所需要的工具,对于初学者也没有任何使用门槛。
+
+使用以下命令在 Ubuntu 和 Debian 安装 `Firefox Quantum`。
+```
+$ sudo add-apt-repository ppa:mozillateam/firefox-next
+$ sudo apt update && sudo apt upgrade
+$ sudo apt install firefox
+
+```
+
+#### Vivaldi
+
+[Vivaldi][91] 是一个基于 Chrome 的免费开源项目,旨在通过添加扩展来使 Chrome 的功能更加完善。色彩丰富的界面,性能良好、灵活性强是它的几大特点。
+
+参考阅读:[在 Ubuntu 下载 Vivaldi][91]
+
+That concludes our list for today. Did I skip a famous title? Tell me about it in the comments section below.
+以上就是我的推荐,你还有更好的软件向大家分享吗?欢迎评论。
+
+--------------------------------------------------------------------------------
+
+via: https://www.fossmint.com/most-used-linux-applications/
+
+作者:[Martins D. Okoi][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[HankChow](https://github.com/HankChow)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.fossmint.com/author/dillivine/
+[1]:https://plus.google.com/share?url=https://www.fossmint.com/most-used-linux-applications/ "Share on Google+"
+[2]:https://www.linkedin.com/shareArticle?mini=true&url=https://www.fossmint.com/most-used-linux-applications/ "Share on LinkedIn"
+[3]:https://www.fossmint.com/awesome-linux-software/
+[4]:https://rsync.samba.org/
+[5]:https://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
+[6]:https://github.com/teejee2008/timeshift
+[7]:https://deluge-torrent.org/
+[8]:https://www.qbittorrent.org/
+[9]:https://transmissionbt.com/
+[10]:https://www.dropbox.com/
+[11]:https://www.google.com/drive/
+[12]:https://www.fossmint.com/best-google-drive-clients-for-linux/
+[13]:https://mega.nz/
+[14]:https://mega.nz/sync!linux
+[15]:https://www.vim.org/
+[16]:https://www.gnu.org/s/emacs/
+[17]:https://www.nano-editor.org/
+[18]:https://aria2.github.io/
+[19]:http://ugetdm.com/
+[20]:http://xdman.sourceforge.net/
+[21]:https://www.thunderbird.net/
+[22]:https://github.com/GNOME/geary
+[23]:https://github.com/GNOME/evolution
+[24]:https://www.gnucash.org/
+[25]:https://kmymoney.org/
+[26]:https://www.eclipse.org/ide/
+[27]:https://www.tecmint.com/install-eclipse-oxygen-ide-in-ubuntu-debian/
+[28]:https://netbeans.org/
+[29]:https://www.tecmint.com/install-netbeans-ide-in-ubuntu-debian-linux-mint/
+[30]:http://brackets.io/
+[31]:https://ide.atom.io/
+[32]:http://lighttable.com/
+[33]:https://code.visualstudio.com/
+[34]:https://code.visualstudio.com/download
+[35]:https://www.pidgin.im/
+[36]:https://www.skype.com/
+[37]:https://wiki.gnome.org/Apps/Empathy
+[38]:https://www.clamav.net/
+[39]:https://dave-theunsub.github.io/clamtk/
+[40]:https://github.com/linuxmint/cinnamon-desktop
+[41]:https://mate-desktop.org/
+[42]:https://www.gnome.org/
+[43]:https://www.kde.org/plasma-desktop
+[44]:https://github.com/nzjrs/gnome-tweak-tool
+[45]:https://github.com/oguzhaninan/Stacer
+[46]:https://www.bleachbit.org/
+[47]:https://www.bleachbit.org/download
+[48]:https://github.com/GNOME/gnome-terminal
+[49]:https://konsole.kde.org/
+[50]:https://gnometerminator.blogspot.com/p/introduction.html
+[51]:http://guake-project.org/
+[52]:https://ardour.org/
+[53]:https://www.audacityteam.org/
+[54]:https://www.gimp.org/
+[55]:https://krita.org/en/
+[56]:https://www.lwks.com/
+[57]:https://www.lwks.com/index.php?option=com_lwks&view=download&Itemid=206
+[58]:https://www.openshot.org/
+[59]:http://www.pitivi.org/
+[60]:https://wiki.gnome.org/Apps/Rhythmbox
+[61]:https://gnumdk.github.io/lollypop-web/
+[62]:https://amarok.kde.org/en
+[63]:https://www.clementine-player.org/
+[64]:https://cmus.github.io/
+[65]:https://www.calligra.org/tour/calligra-suite/
+[66]:https://www.libreoffice.org/
+[67]:https://www.wps.com/
+[68]:http://wps-community.org/downloads
+[69]:http://shutter-project.org/
+[70]:https://launchpad.net/kazam
+[71]:https://gitlab.gnome.org/GNOME/gnome-screenshot
+[72]:http://www.maartenbaert.be/simplescreenrecorder/
+[73]:http://recordmydesktop.sourceforge.net/about.php
+[74]:https://atom.io/
+[75]:https://www.sublimetext.com/
+[76]:https://www.geany.org/
+[77]:https://wiki.gnome.org/Apps/Gedit
+[78]:https://everdo.net/
+[79]:https://www.fossmint.com/evernote-alternatives-for-linux/
+[80]:https://everdo.net/linux/
+[81]:https://taskwarrior.org/
+[82]:http://banshee.fm/
+[83]:https://www.videolan.org/
+[84]:https://kodi.tv/
+[85]:https://www.smplayer.info/
+[86]:https://www.virtualbox.org/wiki/VirtualBox
+[87]:https://www.vmware.com/
+[88]:https://www.tecmint.com/install-vmware-workstation-in-linux/
+[89]:https://www.google.com/chrome/
+[90]:https://www.mozilla.org/en-US/firefox/
+[91]:https://vivaldi.com/
+
diff --git a/translated/tech/20180803 5 Essential Tools for Linux Development.md b/translated/tech/20180803 5 Essential Tools for Linux Development.md
new file mode 100644
index 0000000000..dcb3b3b63e
--- /dev/null
+++ b/translated/tech/20180803 5 Essential Tools for Linux Development.md
@@ -0,0 +1,131 @@
+Linux 开发的五大必备工具
+======
+
+
+
+Linux 已经成为工作、娱乐和个人生活等多个领域的支柱,人们已经越来越离不开它。在 Linux 的帮助下,技术的发展速度超出了人们的想象,Linux 开发的速度也以指数规模增长。因此,越来越多的开发者也不断地加入开源和学习 Linux 开发地潮流当中。在这个过程之中,合适的工具是必不可少的,可喜的是,随着 Linux 的发展,大量适用于 Linux 的开发工具也不断成熟。甚至可以说,这样的工具已经多得有点惊人。
+
+为了选择更合适自己的开发工具,缩小选择范围是很必要的。但是这篇文章并不会要求你必须使用某个工具,而只是缩小到五个工具类别,然后对每个类别提供一个例子。然而,对于大多数类别,都会有不止一种选择。下面我们来看一下。
+
+### 容器
+
+放眼于现实,现在已经是容器的时代了。容器既容易进行部署,又可以方便地构建开发环境。如果你针对的是特定的平台的开发,将开发流程所需要的各种工具都创建到容器映像中是一种很好的方法,只要使用这一个容器映像,就能够快速启动大量运行所需服务的实例。
+
+一个使用容器的最佳范例是使用 [Docker][1],使用容器(或 Docker)有这些好处:
+
+ * 开发环境保持一致
+
+ * 部署后即可运行
+
+ * 易于跨平台部署
+
+ * Docker 映像适用于多种开发环境和语言
+
+ * 部署单个容器或容器集群都并不繁琐
+
+
+
+通过 [Docker Hub][2],几乎可以找到适用于任何平台、任何开发环境、任何服务器,任何服务的映像,几乎可以满足任何一种需求。使用 Docker Hub 中的映像,就相当于免除了搭建开发环境的步骤,可以直接开始开发应用程序、服务器、API 或服务。
+
+Docker 在所有 Linux 平台上都很容易安装,例如可以通过终端输入以下命令在 Ubuntu 上安装 Docker:
+```
+sudo apt-get install docker.io
+
+```
+
+Docker 安装完毕后,就可以从 Docker 仓库中拉取映像,然后开始开发和部署了(如下图)。
+
+![Docker images][4]
+
+
+
+### 版本控制工具
+
+如果你正在开发一个巨大的项目,又或者参与团队开发,版本控制工具是必不可少的,它可以用于记录代码变更、提交代码以及合并代码。如果没有这样的工具,项目几乎无法妥善管理。在 Linux 系统上,[Git][6] 和 [GitHub][7] 的易用性和流行程度是其它版本控制工具无法比拟的。如果你对 Git 和 GitHub 还不太熟悉,可以简单理解为 Git 是在本地计算机上安装的版本控制系统,而 GitHub 则是用于上传和管理项目的远程存储库。 Git 可以安装在大多数的 Linux 发行版上。例如在基于 Debian 的系统上,只需要通过以下这一条简单的命令就可以安装:
+```
+sudo apt-get install git
+
+```
+
+安装完毕后,就可以使用 Git 来实施版本控制了(如下图)。
+
+![Git installed][9]
+
+
+
+Github 会要求用户创建一个帐户。用户可以免费使用 GitHub 来管理非商用项目,当然也可以使用 GitHub 的付费模式(更多相关信息,可以参阅[价格矩阵][10])。
+
+### 文本编辑器
+
+如果没有文本编辑器,在 Linux 上开发将会变得异常艰难。当然,文本编辑器之间孰优孰劣,具体还是要取决于开发者的需求。对于文本编辑器,有人可能会使用 vim、emacs 或 nano,也有人会使用带有 GUI 的编辑器。但由于重点在于开发,我们需要的是一种能够满足开发人员需求的工具。不过我首先要说,vim 对于开发人员来说确实是一个利器,但前提是要对 vim 非常熟悉,在这种前提下,vim 能够满足你的所有需求,甚至还能给你更好的体验。然而,对于一些开发者(尤其是刚开始接触 Linux 的新手)来说,这不仅难以帮助他们快速达成需求,甚至还会是一个需要逾越的障碍。考虑到这篇文章的目标是帮助 Linux 的新手(而不仅仅是为各种编辑器的死忠粉宣传他们拥护的编辑器),我更倾向于使用 GUI 编辑器。
+
+就文本编辑器而论,选择 [Bluefish][11] 一般不会有错。 Bluefish 可以从大部分软件库中安装,它支持项目管理、远程文件多线程操作、搜索和替换、递归打开文件、侧边栏、集成 make/lint/weblint/xmllint、无限制撤销/重做、在线拼写检查、自动恢复、全屏编辑、语法高亮(如下图)、多种语言等等。
+
+![Bluefish][13]
+
+
+
+### IDE
+
+集成开发环境(Integrated Development Environment, IDE)是包含一整套全面的工具、可以实现一站式功能的开发环境。 开发者除了可以使用 IDE 编写代码,还可以编写文档和构建软件。在 Linux 上也有很多适用的 IDE,其中 [Geany][14] 就包含在标准软件库中,它对用户非常友好,功能也相当强大。 Geany 具有语法高亮、代码折叠、自动完成,构建代码片段、自动关闭 XML 和 HTML 标签、调用提示、支持多种文件类型、符号列表、代码导航、构建编译,简单的项目管理和内置的插件系统等强大功能。
+
+Geany 也能在系统上轻松安装,例如执行以下命令在基于 Debian 的 Linux 发行版上安装 Geany:
+```
+sudo apt-get install geany
+
+```
+
+安装完毕后,就可以快速上手这个易用且强大的 IDE 了(如下图)。
+
+![Geany][16]
+
+
+
+### 文本比较工具
+
+有时候会需要比较两个文件的内容来找到它们之间的不同之处,它们可能是同一文件的两个不同副本(有一个经过编译,而另一个没有)。这种情况下,你肯定不想要凭借肉眼来找出差异,而是想要使用像 [Meld][17] 这样的工具。 Meld 是针对开发者的文本比较和合并工具,可以使用 Meld 来发现两个文件之间的差异。虽然你可以使用命令行中的文本比较工具,但就效率而论,Meld 无疑更为优秀。
+
+Meld 可以打开两个文件进行比较,并突出显示文件之间的差异之处。 Meld 还允许用户从两个文件的其中一方合并差异(下图显示了 Meld 同时打开两个文件)。
+
+![Comparing two files][19]
+
+
+
+Meld 也可以通过标准软件如安装,在基于 Debian 的系统上,执行以下命令就可以安装:
+```
+sudo apt-get install meld
+
+```
+
+### 高效地工作
+
+以上提到的五个工具除了帮助你完成工作,而且有助于提高效率。尽管适用于 Linux 开发者的工具有很多,但对于以上几个类别,你最好分别使用一个对应的工具。
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/intro-to-linux/2018/8/5-essential-tools-linux-development
+
+作者:[Jack Wallen][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[HankChow](https://github.com/HankChow)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/jlwallen
+[1]:https://www.docker.com/
+[2]:https://hub.docker.com/
+[4]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_1.jpg?itok=V1Bsbkg9 "Docker images"
+[6]:https://git-scm.com/
+[7]:https://github.com/
+[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_2.jpg?itok=YJjhe4O6 "Git installed"
+[10]:https://github.com/pricing
+[11]:http://bluefish.openoffice.nl/index.html
+[13]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_3.jpg?itok=66A7Svme "Bluefish"
+[14]:https://www.geany.org/
+[16]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_4.jpg?itok=jRcA-0ue "Geany"
+[17]:http://meldmerge.org/
+[19]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_5.jpg?itok=eLkfM9oZ "Comparing two files"
+[20]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
+
diff --git a/translated/tech/20180816 Add YouTube Player Controls To Your Linux Desktop With browser-mpris2 (Chrome Extension).md b/translated/tech/20180816 Add YouTube Player Controls To Your Linux Desktop With browser-mpris2 (Chrome Extension).md
new file mode 100644
index 0000000000..a72b4cdd8d
--- /dev/null
+++ b/translated/tech/20180816 Add YouTube Player Controls To Your Linux Desktop With browser-mpris2 (Chrome Extension).md
@@ -0,0 +1,76 @@
+使用 browser-mpris2(Chrome 扩展)将 YouTube 播放器控件添加到 Linux 桌面
+======
+一个我怀念的 Unity 功能(虽然只使用了一小段时间)是在 Web 浏览器中访问 YouTube 等网站时自动获取 Ubuntu 声音指示器中的播放器控件,因此你可以直接从顶部栏暂停或停止视频,以及浏览视频/歌曲信息和预览。
+
+这个 Unity 功能已经消失很久了,但我正在为 Gnome Shell 寻找类似的东西,然后我遇到了 **[browser-mpris2][1],这是一个为 Google Chrome/Chromium 实现 MPRIS v2 接口的扩展,目前只支持 YouTube**,我想可能会有一些 Linux Uprising 的读者会喜欢这个。
+
+**该扩展还适用于 Opera 和 Vivaldi 等基于 Chromium 的 Web 浏览器。**
+**
+** **browser-mpris2 也支持 Firefox,但因为通过 about:debugging 加载扩展是临时的,而这是 browser-mpris2 所需要的,因此本文不包括 Firefox 的指导。开发人员[打算][2]将来将扩展提交到 Firefox 插件网站上。**
+
+**使用此 Chrome 扩展,你可以在支持 MPRIS2 的 applets 中获得 YouTube 媒体播放器控件(播放、暂停、停止和查找
+)**。例如,如果你使用 Gnome Shell,你可将 YouTube 媒体播放器控件作为永久通知,或者你可以使用 Media Player Indicator 之类的扩展来实现此目的。在 Cinnamon /Linux Mint with Cinnamon 中,它出现在声音 Applet 中。
+
+**我无法在 Unity 上用它**,我不知道为什么。我没有在不同桌面环境(KDE、Xfce、MATE 等)中使用其他支持 MPRIS2 的 applet 尝试此扩展。如果你尝试过,请告诉我们它是否适用于你的桌面环境/支持 MPRIS2 的 applet。
+
+以下是在使用 Gnome Shell 的 Ubuntu 18.04 并装有 Chromium 浏览器的[媒体播放器指示器][3]的截图,其中显示了有关当前正在播放的 YouTube 视频的信息及其控件(播放/暂停,停止和查找):
+
+
+
+在 Linux Mint 19 Cinnamon 中使用其默认声音 applet 和 Chromium 浏览器的截图:
+
+
+
+
+### 如何为 Google Chrom/Chromium安装 browser-mpris2
+
+**1\. 如果你还没有安装 Git 就安装它**
+
+在 Debian/Ubuntu/Linux Mint 中,使用此命令安装 git:
+```
+sudo apt install git
+
+```
+
+**2\. 下载并安装 [browser-mpris2][1] 所需文件。**
+
+下面的命令克隆了 browser-mpris2 的 Git 仓库并将 chrome-mpris2 安装到 `/usr/local/bin/`(在一个你可以保存 browser-mpris2 文件夹的地方运行 “git clone ...” 命令,由于它会被 Chrome/Chromium 使用,你不能删除它):
+```
+git clone https://github.com/otommod/browser-mpris2
+sudo install browser-mpris2/native/chrome-mpris2 /usr/local/bin/
+
+```
+
+**3\. 在基于 Chrome/Chromium 的 Web 浏览器中加载此扩展。**
+
+
+
+打开 Google Chrome、Chromium、Opera 或 Vivaldi 浏览器,进入 Extensions 页面(在 URL 栏中输入 `chrome://extensions`),在屏幕右上角切换到`开发者模式`。然后选择 `Load Unpacked` 并选择 chrome-mpris2 目录(确保没有选择子文件夹)。
+
+复制扩展 ID 并保存它,因为你以后需要它(它类似于这样:`emngjajgcmeiligomkgpngljimglhhii`,但它会与你的不一样,因此确保使用你计算机中的 ID!)。
+
+**4\. 运行 **`install-chrome.py`**(在 `browser-mpris2/native` 文件夹中),指定扩展 id 和 chrome-mpris2 路径。
+
+在终端中使用此命令(将 `REPLACE-THIS-WITH-EXTENSION-ID` 替换为上一步中 `chrome://extensions` 下显示的 browser-mpris2 扩展 ID)安装此扩展:
+```
+browser-mpris2/native/install-chrome.py REPLACE-THIS-WITH-EXTENSION-ID /usr/local/bin/chrome-mpris2
+
+```
+
+你只需要运行此命令一次,无需将其添加到启动或其他类似的地方。你在 Google Chrome 或 Chromium 浏览器中播放的任何 YouTube 视频都应显示在你正在使用的任何 MPRISv2 applet 中。你无需重启 Web 浏览器。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linuxuprising.com/2018/08/add-youtube-player-controls-to-your.html
+
+作者:[Logix][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://plus.google.com/118280394805678839070
+[1]:https://github.com/otommod/browser-mpris2
+[2]:https://github.com/otommod/browser-mpris2/issues/11
+[3]:https://extensions.gnome.org/extension/55/media-player-indicator/
diff --git a/translated/tech/20180816 An introduction to the Django Python web app framework.md b/translated/tech/20180816 An introduction to the Django Python web app framework.md
new file mode 100644
index 0000000000..dc9fd20449
--- /dev/null
+++ b/translated/tech/20180816 An introduction to the Django Python web app framework.md
@@ -0,0 +1,1219 @@
+Python Web 应用程序 Django 框架简介
+=====
+
+
+
+在本系列(由四部分组成)的前三篇文章中,我们讨论了 [Pyramid][1], [Flask][2] 和 [Tornado][3] 这 3 个 Web 框架。我们已经构建了三次相同的应用程序,最终我们遇到了 [Django][4]。总的来说,Django 是目前 Python 开发人员使用的主要 Web 框架,并且不难看出原因。它擅长隐藏大量的配置逻辑,让你专注于能过够快速构建大型应用程序。
+
+也就是说,当涉及到小型项目时,比如我们的待办事项列表应用程序,Django 可能有点像用消防水管来进行水枪大战。让我们来看看它们是如何结合在一起的。
+
+### 关于 Django
+
+Django 将自己定位为“一个高级的 Python Web 框架,它鼓励快速开发和干净,实用的设计。它由经验丰富的开发人员构建,解决了 Web 开发的很多麻烦,因此你可以专注于编写应用程序而无需重新发明轮子”。它真的做到了!这个庞大的 Web 框架附带了非常多的工具,通常在开发过程中,如何将所有内容组合在一起协同工作可能是个谜。
+
+除了框架本身很大,Django 社区也是非常庞大的。事实上,它非常庞大和活跃,以至于有[一个网站][5]致力于为人们收集第三方包,这些第三方包可集成进 Django 来做一大堆事情。包括从身份验证和授权到完全基于 Django 的内容管理系统,电子商务附加组件以及与 Stripe(译注:美版“支付宝”)集成的所有内容。关于不要重新发明轮子:如果你想用 Django 完成一些事情,有人可能已经做过了,你只需将它集成进你的项目就行。
+
+为此,我们希望使用 Django 构建 REST API,因此我们将利用流行的 [Django REST framework][6]。它的工作是将 Django 框架(Django 使用自己的模板引擎构建 HTML 页面)转换为专门用于有效地处理 REST 交互的系统。让我们开始吧。
+
+### Django 启动和配置
+
+```
+$ mkdir django_todo
+
+$ cd django_todo
+
+$ pipenv install --python 3.6
+
+$ pipenv shell
+
+(django-someHash) $ pipenv install django djangorestframework
+
+```
+
+作为参考,我们使用的是 `django-2.0.7` 和 `djangorestframework-3.8.2`。
+
+与 Flask, Tornado 和 Pyramid 不同,我们不需要自己编写 `setup.py` 文件,我们并不是在做一个可安装的 Python 发行版。像很多事情一样,Django 以自己的方式处理这个问题。我们仍然需要一个 `requirements.txt` 文件来跟踪我们在其它地方部署的所有必要安装。但是,就 Django 项目中的目标模块而言,Django 会让我们列出我们想要访问的子目录,然后允许我们从这些目录中导入,就像它们是已安装的包一样。
+
+首先,我们必须创建一个 Django 项目。
+
+当我们安装了 Django 后,我们还安装了命令行脚本 `django-admin`。它的工作是管理所有与 Django 相关的命令,这些命令有助于我们将项目整合在一起,并在我们继续开发的过程中对其进行维护。`django-admin` 并不是让我们从头开始构建整个 Django 生态系统,而是让我们开始使用标准 Django 项目所需的所有必要文件(以及更多)。
+
+调用 `django-admin` 的 `start-project` 命令的语法是 `django-admin startproject <项目名称> <存放目录>`。我们希望文件存于当前的工作目录中,所以:
+```
+(django-someHash) $ django-admin startproject django_todo .
+
+```
+
+输入 `ls` 将显示一个新文件和一个新目录。
+```
+(django-someHash) $ ls
+
+manage.py django_todo
+
+```
+
+`manage.py` 是一个可执行命令行 Python 文件,它最终成为 `django-admin` 的装饰器(to 校正:这里装饰器只是一个语义上的称呼,与 Python 的装饰器不同)。因此,它的工作与 `django-admin` 是一样的:帮助我们管理项目。因此得名 `manage.py`。
+
+它在 `django_todo` 目录里创建了一个新目录 `django_todo`,其代表了我们项目的配置根目录。现在让我们深入研究一下。
+
+### 配置 Django
+
+可以将 `django_todo` 目录称为“配置根”,我们的意思是这个目录包含了通常配置 Django 项目所需的文件。几乎所有这个目录之外的内容都只关注与项目模型,视图,路由等相关的“业务逻辑”。所有连接项目的点都将在这里出现。
+
+在 `django_todo` 目录中调用 `ls` 会显示以下四个文件:
+```
+(django-someHash) $ cd django_todo
+
+(django-someHash) $ ls
+
+__init__.py settings.py urls.py wsgi.py
+
+```
+
+ * `__init__.py` 文件为空,之所以存在是为了将此目录转换为可导入的 Python 包。
+
+ * `settings.py` 是设置大多数配置项的地方。例如项目是否处于 DEBUG 模式,正在使用哪些数据库,Django 应该定位文件的位置等等。它是配置根目录的“主要配置”部分,我们将在一会深入研究。
+
+ * `urls.py` 顾名思义就是设置 URL 的地方。虽然我们不必在此文件中显式写入项目的每个 URL,但我们需要让此文件知道在其他任何地方已声明的 URL。如果此文件未指向其它 URL,则那些 URL 就不存在。
+
+ * `wsgi.py` 用于在生产环境中提供应用程序。就像 Pyramid, Tornado 和 Flask 暴露了一些 “app” 对象一样,它们用来提供配置好的应用程序,Django 也必须暴露一个,就是在这里完成的。它可以和 [Gunicorn][7], [Waitress][8] 或者 [uWSGI][9] 一起配合来提供服务。
+
+#### 设置 settings
+
+看一看 `settings.py`,它里面有大量的配置项,那些只是默认值!这甚至不包括数据库,静态文件,媒体文件,任何集成的钩子,或者可以配置 Django 项目的任何其它几种方式。让我们从上到下看看有什么:
+
+ * `BASE_DIR` 设置目录的绝对路径,或者是 `manage.py` 所在的目录。这对于定位文件非常有用。
+
+ * `SECRET_KEY` 是用于 Django 项目中加密签名的密钥。在实际中,它用于会话,cookie,CSRF 保护和身份验证令牌等。最好在第一次提交之前,尽快应该更改 `SECRET_KEY` 的值并将其放置到环境变量中。
+
+ * `DEBUG` 告诉 Django 是以开发模式还是生产模式运行项目。这是一个非常关键的区别。
+
+ * 在开发模式下,当弹出一个错误时,Django 将显示导致错误的完整堆栈跟踪,以及运行项目所涉及的所有设置和配置。如果在生产环境中将 `DEBUG` 设置为 `True`,这可能是一个巨大的安全问题。
+
+ * 在生产模式下,当出现问题时,Django 会显示一个简单的错误页面,即除错误代码外不提供任何信息。
+
+ * 保护我们项目的一个简单方法是将 `DEBUG` 设置为环境变量,如 `bool(os.environ.get('DEBUG', ''))`。
+ * `ALLOWED_HOSTS` 是应用程序提供服务的主机名的列表。在开发模式中,这可能是空的,但是在生产中,如果为项目提供服务的主机不在 ALLOWED_HOSTS 列表中,Django 项目将无法运行。这是设置为环境变量的另一种情况。
+
+ * `INSTALLED_APPS` 是我们的 Django 项目可以访问的 Django "apps" 列表(将它们视为子目录,稍后会详细介绍)。默认情况下,它将提供:
+ * 内置的 Django admin 网站
+ * Django 的内置认证系统
+ * Django 的数据模型通用管理器
+ * 会话管理
+ * Cookie 和基于会话的消息传递
+ * 站点固有的静态文件的用法,比如 `css` 文件,`js` 文件,任何属于我们网站设计的图片等。
+
+ * `MIDDLEWARE` 顾名思义:帮助 Django 项目运行的中间件。其中很大一部分用于处理各种类型的安全,尽管我们可以根据需要添加其它中间件。
+
+ * `ROOT_URLCONF` 设置基本 URL 配置文件的导入路径。还记得我们之前见过的那个 `urls.py` 吗?默认情况下,Django 指向该文件以此来收集所有的 URL。如果我们想让 Django 在其它地方寻找,我们将在这里设置 URL 位置的导入路径。
+
+ * `TEMPLATES` 是 Django 用于我们网站前端的模板引擎列表,假如我们依靠 Django 来构建我们的 HTML。我们在这里不需要,那就无关紧要了。
+
+ * `WSGI_APPLICATION` 设置我们的 WSGI 应用程序的导入路径 - 在生产环境下使用的东西。默认情况下,它指向 `wsgi.py` 中的 `application` 对象。这很少(如果有的话)需要修改。
+
+ * `DATABASES` 设置 Django 项目将访问那些数据库。必须设置 `default` 数据库。我们可以通过名称设置别的数据库,只要我们提供 `HOST`, `USER`, `PASSWORD`, `PORT`, 数据库名称 `NAME` 和合适的 `ENGINE`。可以想象,这些都是敏感的信息,因此最好将它们隐藏在环境变量中。[查看 Django 文档][10]了解更多详情。
+
+ * 注意:如果不是提供数据库的单个部分,而是提供完整的数据库 URL,请查看 [dj_database_url][11]。
+
+ * `AUTH_PASSWORD_VALIDATORS` 实际上是运行以检查输入密码的函数列表。默认情况下我们有一些,但是如果我们有其它更复杂的验证需求:不仅仅是检查密码是否与用户的属性匹配,是否超过最小长度,是否是 1000 个最常用的密码之一,或者密码完全是数字,我们可以在这里列出它们。
+
+ * `LANGUAGE_CODE` 设置网站的语言。默认情况下它是美国英语,但我们可以将其切换为其它语言。
+
+ * `TIME_ZONE` 是我们 Django 项目后中自动生成的时间戳的时区。我强调坚持使用 UTC 并在其它地方执行任何特定于时区的处理,而不是尝试重新配置此设置。正如[这篇文章][12] 所述,UTC 是所有时区的共同点,因为不需要担心偏移。如果偏移很重要,我们可以根据需要使用与 UTC 的适当偏移来计算它们。
+
+ * `USE_I18N` 将让 Django 使用自己的翻译服务来为前端翻译字符串。I18N = 国际化(“i” 和 “n” 之间的 18 个字符)。
+
+ * `USE_L10N` (L10N = 本地化[在 "l" 和 "n" 之间有 10 个字符]) 如果设置为 `True`,那么将使用数据的公共本地格式。一个很好的例子是日期:在美国它是 MM-DD-YYYY。在欧洲,日期往往写成 DD-MM-YYYY。
+
+ * `STATIC_URL` 是用于提供静态文件的大量设置的一部分。我们将构建一个 REST API,因此我们不需要担心静态文件。通常,这会为每个静态文件的域名设置根路径。所以,如果我们有一个徽标图像,那就是 `http:////logo.gif`。
+
+默认情况下,这些设置已准备就绪。我们必须改变的一个选项是 `DATABASES` 设置。首先,我们创建将要使用的数据库:
+```
+(django-someHash) $ createdb django_todo
+
+```
+
+我们想要像使用 Flask, Pyramid 和 Tornado 一样使用 PostgreSQL 数据库,这意味着我们必须更改 `DATABASES` 设置以允许我们的服务器访问 PostgreSQL 数据库。首先是引擎。默认情况下,数据库引擎是 `django.db.backends.sqlite3`,我们把它改成 `django.db.backends.postgresql`。
+
+有关 Django 可用引擎的更多信息,[查看文档][13]。请注意,尽管技术上可以将 NoSQL 解决方案整合到 Django 项目中,但为了开箱即用,Django 强烈偏向于 SQL 解决方案。
+
+接下来,我们必须为连接参数的不同部分指定键值对。
+
+ * `NAME` 是我们刚刚创建的数据库的名称。
+ * `USER` 是 Postgres 数据库用户名。
+ * `PASSWORD` 是访问数据库所需的密码。
+ * `HOST` 是数据库的主机。当我们在本地开发时,`localhost` 或 `127.0.0.1` 都将起作用。
+ * `PORT` 是我们为 Postgres 开放的端口,它通常是 `5432`。
+
+`settings.py` 希望我们为每个键提供字符串值。但是,这是高度敏感的信息。这对任何负责任的开发人员都不起作用。有几种方法可以解决这个问题,一种是我们需要设置环境变量。
+```
+DATABASES = {
+
+ 'default': {
+
+ 'ENGINE': 'django.db.backends.postgresql',
+
+ 'NAME': os.environ.get('DB_NAME', ''),
+
+ 'USER': os.environ.get('DB_USER', ''),
+
+ 'PASSWORD': os.environ.get('DB_PASS', ''),
+
+ 'HOST': os.environ.get('DB_HOST', ''),
+
+ 'PORT': os.environ.get('DB_PORT', ''),
+
+ }
+
+}
+
+```
+
+在继续之前,请确保设置环境变量或 Django 不起作用(to 校正:这里不清楚原文的意思,什么叫 django 不起作用)。此外,我们需要在此环境中安装 `psycopg2`,以便我们可以与数据库通信。
+
+### Django 路由和视图
+
+让我们在这个项目中实现一些函数。我们将使用 Django REST Framework 来构建 REST API,所以我们必须确保在 `settings.py` 中将 `rest_framework` 添加到 `INSTALLED_APPS` 的末尾。
+```
+INSTALLED_APPS = [
+
+ 'django.contrib.admin',
+
+ 'django.contrib.auth',
+
+ 'django.contrib.contenttypes',
+
+ 'django.contrib.sessions',
+
+ 'django.contrib.messages',
+
+ 'django.contrib.staticfiles',
+
+ 'rest_framework'
+
+]
+
+```
+
+虽然 Django REST Framework 并不专门需要基于类的视图(如 Tornado)来处理传入的请求,但类是编写视图的首选方法。让我们来定义一个类视图。
+
+让我们在 `django_todo` 创建一个名为 `views.py` 的文件。在 `views.py` 中,我们将创建 "Hello, world!" 视图。
+```
+# django_todo/views.py
+
+from rest_framework.response import JsonResponse
+
+from rest_framework.views import APIView
+
+
+class HelloWorld(APIView):
+
+ def get(self, request, format=None):
+
+ """Print 'Hello, world!' as the response body."""
+
+ return JsonResponse("Hello, world!")
+
+```
+
+每个 Django REST Framework 基于类的视图都直接或间接地继承自 `APIView`。`APIView` 处理大量的东西,但为了达到我们的目的,它做了以下特定的事情:
+
+ * 根据 HTTP 方法(例如 GET, POST, PUT, DELETE)来设置引导对应请求所需的方法
+
+ * 用我们需要的所有数据和属性来填充 `request` 对象,以便解析和处理传入的请求
+
+ * 采用 `Response` 或 `JsonResponse`,每个调度方法(即名为 `get`, `post`, `put`, `delete` 的方法)返回并构造格式正确的 HTTP 响应。
+
+终于,我们有一个视图了!它本身没有任何作用,我们需要将它连接到路由。
+
+如果我们跳转到 `django_todo/urls.py`,我们会到达默认的 URL 配置文件。如前所述:如果 Django 项目中的路由不包含在此处,则它不存在。
+
+我们在给定的 `urlpatterns` 列表中添加所需的 URL。默认情况下,我们有一个 url,它里面包含一整套 URL 用于 Django 的内置管理后端系统,但是我们会删除它。
+
+我们还得到一些非常有用的文档字符串,它告诉我们如何向 Django 项目添加路由。我们需要调用 `path()`,伴随三个参数:
+
+ * 所需的路由,作为字符串(没有前导斜线)
+ * 处理该路由的视图函数(只能有一个函数!)
+ * 在 Django 项目中路由的名称
+
+让我们导入 `HelloWorld` 视图并将其附加到主路径 `"/"` 。我们可以从 `urlpatterns` 中删除 `admin` 的路径,因为我们不会使用它。
+
+```
+# django_todo/urls.py, after the big doc string
+
+from django.urls import path
+
+from django_todo.views import HelloWorld
+
+
+
+urlpatterns = [
+
+ path('', HelloWorld.as_view(), name="hello"),
+
+]
+
+```
+
+好吧,这里有一点不同。我们指定的路由只是一个空白字符串,为什么它会工作?Django 假设我们声明的每个路由都以一个前导斜杠开头,我们只是在初始域名后指定资源路由。如果一条路由没有去往一个特定的资源,而只是一个主页,那么该路由是 `""`,或者实际上是“没有资源”。
+
+`HelloWorld` 视图是从我们刚刚创建的 `views.py` 文件导入的。为了执行此导入,我们需要更新 `settings.py` 中的 `INSTALLED_APPS` 列表使其包含 `django_todo`。是的,这有点奇怪。以下是一种理解方式。
+
+`INSTALLED_APPS` 指的是 Django 认为可导入的目录或包的列表。它是 Django 处理项目的各个组件的方式,比如安装了一个包,而不需要经过 `setup.py` 的方式。我们希望将 `django_todo` 目录视为可导入的包,因此我们将该目录包含在 `INSTALLED_APPS` 中。现在,在该目录中的任何模块也是可导入的。所以我们得到了我们的视图。
+
+`path` 函数只将视图函数作为第二个参数,而不仅仅是基于类的视图。幸运的是,所有有效的基于 Django 类的视图都包含 `.as_view()` 方法。它的工作是将基于类的视图的所有优点汇总到一个视图函数中并返回该视图函数。所以,我们永远不必担心转换的工作。相反,我们只需要考虑业务逻辑,让 Django 和 Django REST Framework 处理剩下的事情。
+
+让我们在浏览器中打开它!
+
+Django 提供了自己的本地开发服务器,可通过 `manage.py` 访问。让我们切换到包含 `manage.py` 的目录并输入:
+```
+(django-someHash) $ ./manage.py runserver
+Performing system checks...
+
+System check identified no issues (0 silenced).
+
+August 01, 2018 - 16:47:24
+
+Django version 2.0.7, using settings 'django_todo.settings'
+
+Starting development server at http://127.0.0.1:8000/
+
+Quit the server with CONTROL-C.
+
+```
+
+当 `runserver` 执行时,Django 会检查以确保项目(或多或少)正确连接在一起。这不是万无一失的,但确实会发现一些明显的问题。如果我们的数据库与代码不同步,它会通知我们。毫无遗问,因为我们没有将任何应用程序的东西提交到我们的数据库,但现在这样做还是可以的。让我们访问 `http://127.0.0.1:8000` 来查看 `HelloWorld` 视图的输出。
+
+咦?这不是我们在 Pyramid, Flask 和 Tornado 中看到的明文数据。当使用 Django REST Framework 时,HTTP 响应(在浏览器中查看时)是这样呈现的 HTML,以红色显示我们的实际 JSON 响应。
+
+但不要担心!如果我们在命令行中使用 `curl` 快速访问 `http://127.0.0.1:8000`,我们就不会得到任何花哨的 HTML,只有内容。
+```
+# 注意:在不同的终端口窗口中执行此操作,在虚拟环境之外
+
+$ curl http://127.0.0.1:8000
+
+"Hello, world!"
+
+```
+
+棒极了!
+
+Django REST Framework 希望我们在使用浏览器浏览时拥有一个人性化的界面。这是有道理的,如果在浏览器中查看 JSON,通常是因为人们想要检查它是否正确,或者在设计一些消费者 API 时想要了解 JSON 响应。这很像你从 [Postman][14] 中获得的东西。
+
+无论哪种方式,我们都知道我们的视图工作了!酷!让我们概括一下我们做过的事情:
+
+ 1. 使用 `django-admin startproject <项目名称>` 开始一个项目
+ 2. 使用环境变量来更新 `django_todo/settings.py` 中的 `DEBUG`, `SECRET_KEY`,还有 `DATABASES` 字典
+ 3. 安装 `Django REST Framework`,并将它添加到 `INSTALLED_APPS`
+ 4. 创建 `django_todo/views.py` 来包含我们的第一个类视图,它返回响应 "Hello, world!"
+ 5. 更新 `django_todo/urls.py`,其中包含我们的根路由
+ 6. 在 `django_todo/settings.py` 中更新 `INSTALLED_APPS` 以包含 `django_todo` 包
+
+### 创建模型
+
+现在让我们来创建数据模型吧。
+
+Django 项目的整个基础架构都是围绕数据模型构建的,它是这样编写的,因此每个数据模型够可以拥有自己的小天地,拥有自己的视图,自己与其资源相关的 URL 集合,甚至是自己的测试(如果我们需要(to 校正:这里???))。
+
+如果我们想构建一个简单的 Django 项目,我们可以通过在 `django_todo` 目录中编写我们自己的 `models.py` 文件并将其导入我们的视图来避免这种情况。但是,我们试图以“正确”的方式编写 Django 项目,因此我们应该尽可能地将模型分成 Django 方式的包(to 校正:这里 Django Way™ 有点懵)。
+
+Django Way 涉及创建所谓的 Django “apps”,它本身并不是单独的应用程序,它们没有自己的设置和诸如此类的东西(虽然它们也可以)。但是,它们可以拥有一个人们可能认为属于独立应用程序的东西:
+
+ * 一组自包含的 URL
+ * 一组自包含的 HTML 模板(如果我们想要提供 HTML)
+ * 一个或多个数据模型
+ * 一套自包含的视图
+ * 一套自包含的测试
+
+它们是独立的,因此可以像独立应用程序一样轻松共享。实际上,Django REST Framework 是 Django app 的一个例子。它包含自己的视图和 HTML 模板,用于提供我们的 JSON。我们只是利用这个 Django app 将我们的项目变成一个全面的 RESTful API 而不用那么麻烦。
+
+要为我们的待办事项列表项创建 Django app,我们将要使用 `manage.py` 伴随参数 `startapp`。
+```
+(django-someHash) $ ./manage.py startapp todo
+
+```
+
+`startapp` 命令成功执行后没有输出。我们可以通过使用 `ls` 来检查它是否完成它应该做的事情。
+```
+(django-someHash) $ ls
+
+Pipfile Pipfile.lock django_todo manage.py todo
+
+```
+
+看看:我们有一个全新的 `todo` 目录。让我们看看里面!
+```
+(django-someHash) $ ls todo
+
+__init__.py admin.py apps.py migrations models.py tests.py views.py
+
+```
+
+以下是 `manage.py startapp` 创建的文件:
+
+ * `__init__.py` 是空文件。它之所以存在是因为此目录可看作是模型,视图等的有效导入路径。
+
+ * `admin.py` 不是空文件。它用于在 Django admin 中格式化(to 校正:格式化可能欠妥)这个应用程序的模型,我们在本文中没有涉及到它。
+
+ * `apps.py` 这里基本不起作用。它有助于格式化 Django admin 的模型。
+
+ * `migrations` 是一个包含我们数据模型快照的目录。它用于更新数据库。这是内置数据库管理的少数几个框架之一,其中一部分允许我们更新数据库,而不必拆除它并重建它以更改模式。
+
+ * `models.py` 是数据模型所在。
+
+ * `tests.py` 是测试所在的地方,如果我们需要写测试。
+
+ * `views.py` 用于我们编写的与此 app 中的模型相关的视图。它们不是一定得写在这里。例如,我们可以在 `django_todo/views.py` 中写下我们所有的视图。但是,它在这个 app 中更容易将我们的问题分开。这与覆盖许多概念空间的扩展应用程序之间的关系更加密切。
+
+它并没有为这个 app 创建 `urls.py` 文件,但我们可以自己创建。
+```
+(django-someHash) $ touch todo/urls.py
+
+```
+
+在继续之前,我们应该帮自己一个忙,将这个新 Django 应用程序添加到 `django_todo/settings.py` 中的 `INSTALLED_APPS` 列表中。
+```
+# settings.py
+
+INSTALLED_APPS = [
+
+ 'django.contrib.admin',
+
+ 'django.contrib.auth',
+
+ 'django.contrib.contenttypes',
+
+ 'django.contrib.sessions',
+
+ 'django.contrib.messages',
+
+ 'django.contrib.staticfiles',
+
+ 'rest_framework',
+
+ 'django_todo',
+
+ 'todo' # <--- 添加了这行
+
+]
+
+```
+
+检查 `todo / models.py` 发现 `manage.py` 已经为我们编写了一些代码。不同于在 Flask, Tornado 和 Pyramid 实现中创建模型的方式,Django 不利用第三方来管理数据库会话或构建其对象实例。它全部归入 Django 的 `django.db.models` 子模块。
+
+然而,建立模型的方式或多或少是相同的。要在 Django 中创建模型,我们需要构建一个继承自 `models.Model` 的 `class`,将应用于该模型实例的所有字段都应视为类属性。我们不像过去那样从 SQLAlchemy 导入列和字段类型,而是直接从 `django.db.models` 导入。
+```
+# todo/models.py
+
+from django.db import models
+
+
+class Task(models.Model):
+
+ """Tasks for the To Do list."""
+
+ name = models.CharField(max_length=256)
+
+ note = models.TextField(blank=True, null=True)
+
+ creation_date = models.DateTimeField(auto_now_add=True)
+
+ due_date = models.DateTimeField(blank=True, null=True)
+
+ completed = models.BooleanField(default=False)
+
+```
+
+虽然 Django 的需求和基于 SQLAlchemy 的系统之间存在一些明显的差异,但总体内容和结构或多或少相同。让我们来指出这些差异。
+
+我们不再需要为对象实例声明自动递增 ID 的单独字段。除非我们指定一个不同的字段作为主键,否则 Django 会为我们构建一个。
+
+我们只是直接引用数据类型作为列本身,而不是实例化传递数据类型对象的 `Column` 对象。
+
+`Unicode` 字段变为 `models.CharField` 或 `models.TextField`。`CharField` 用于特定最大长度的小文本字段,而 `TextField` 用于任何数量的文本。
+
+`TextField` 应该是空白的,我们以两种方式指定它。`blank = True` 表示当构建此模型的实例,并且正在验证附加到该字段的数据时,该数据是可以为空的。这与 `null = True` 不同,后者表示当构造此模型类的表时,对应于 `note` 的列将允许空白或为 `NULL`。因此,总而言之,`blank = True` 控制如何将数据添加到模型实例,而 `null = True` 控制如何构建保存该数据的数据库表。
+
+`DateTime` 字段增加了一些属性,并且能够为我们做一些工作,使得我们不必修改类的 `__init__` 方法。对于 `creation_date` 字段,我们指定 `auto_now_add = True`。在实际意义上意味着,当创建一个新模型实例时,Django 将自动记录现在的日期和时间作为该字段的值。这非常方便!
+
+当 `auto_now_add` 及其类似属性 `auto_now` 都没被设置为 `True`时,`DateTimeField` 会像其它字段一样期待数据。它需要提供一个适当的 `datetime` 对象才能生效。`due_date` 列的 `blank` 和 `null` 属性都设置为 `True`,这样待办事项列表中的项目就可以成为将来某个时间点完成,没有确定的日期或时间。
+
+`BooleanField` 最终可以取两个值:`True` 或 `False`。这里,默认值设置为 `False`。
+
+#### 管理数据库
+
+如前所述,Django 有自己的数据库管理方式。我们可以利用 Django 提供的 `manage.py` 脚本,而不必编写任何关于数据库的代码。它不仅可以管理我们数据库的表格构建,还可以管理我们希望对这些表格进行的任何更新,而不必将整个事情搞砸!
+
+因为我们构建了一个新模型,所以我们需要让数据库知道它。首先,我们需要将与此模型对应的模式放入代码中。`manage.py` 的 `makemigrations` 命令对我们构建的模型类及其所有字段进行快照。它将获取该信息并将其打包成一个 Python 脚本,该脚本将存在于特定 Django app 的 `migrations` 目录中。永远不会有理由直接运行这个迁移脚本。它的存在只是为了让 Django 可以使用它作为更新数据库表的基础,或者在我们更新模型类时继承信息。
+```
+(django-someHash) $ ./manage.py makemigrations
+
+Migrations for 'todo':
+
+ todo/migrations/0001_initial.py
+
+ - Create model Task
+
+```
+
+这将查看 `INSTALLED_APPS` 中列出的每个应用程序,并检查这些应用程序中存在的模型。然后,它将检查相应的 `migrations` 目录中的迁移文件,并将它们与每个 `INSTALLED_APPS` 中的模型进行比较。如果模型升级已超出最新迁移所应存在的范围,则将创建一个继承自最新迁移文件的新迁移文件,它将自动命名,并且还会显示一条消息,说明自上次迁移以来发生了哪些更改。
+
+如果你上次处理 Django 项目已经有一段时间了,并且不记得模型是否与迁移同步,那么你无需担心。`makemigrations` 是一个幂等操作。无论你运行 `makemigrations` 一次还是 20 次,`migrations` 目录只有一个与当前模型配置的副本。还有更棒的,当我们运行 `./manage.py runserver` 时,Django 检测到我们的模型与迁移不同步,它会用彩色文本告诉我们以便我们可以做出适当的选择。
+
+下一个要点是至少让每个人访问一次:创建一个迁移文件不会立即影响我们的数据库。当我们运行 `makemigrations` 时,我们准备了 Django 项目来定义如何创建给定的表并最终查找。我们仍在将这些更改应用于数据库。这就是 `migrate` 命令的用途。
+
+```
+(django-someHash) $ ./manage.py migrate
+
+Operations to perform:
+
+ Apply all migrations: admin, auth, contenttypes, sessions, todo
+
+Running migrations:
+
+ Applying contenttypes.0001_initial... OK
+
+ Applying auth.0001_initial... OK
+
+ Applying admin.0001_initial... OK
+
+ Applying admin.0002_logentry_remove_auto_add... OK
+
+ Applying contenttypes.0002_remove_content_type_name... OK
+
+ Applying auth.0002_alter_permission_name_max_length... OK
+
+ Applying auth.0003_alter_user_email_max_length... OK
+
+ Applying auth.0004_alter_user_username_opts... OK
+
+ Applying auth.0005_alter_user_last_login_null... OK
+
+ Applying auth.0006_require_contenttypes_0002... OK
+
+ Applying auth.0007_alter_validators_add_error_messages... OK
+
+ Applying auth.0008_alter_user_username_max_length... OK
+
+ Applying auth.0009_alter_user_last_name_max_length... OK
+
+ Applying sessions.0001_initial... OK
+
+ Applying todo.0001_initial... OK
+
+```
+
+当我们应用迁移时,Django 首先检查其他 `INSTALLED_APPS` 是否有要应用的迁移,它大致按照列出的顺序检查它们。我们希望我们的应用程序最后列出,因为我们希望确保,如果我们的模型依赖于任何 Django 的内置模型,我们所做的数据库更新不会受到依赖性问题的影响。
+
+我们还有另一个要构建的模型:User 模型。但是,自从我们使用 Django 以来,游戏发生了一些变化。许多应用程序需要某种类型的用户模型,Django 的 `django.contrib.auth` 包构建了自己的用户模型供我们使用。如果它不是我们用户需要的身份验证令牌,我们可以继续使用它而不是重新发明轮子。
+
+但是,我们需要那个令牌。我们可以通过两种方式来处理这个问题。
+
+ * 继承自 Django 的 `User` 对象,我们自己的对象通过添加 `token` 字段来扩展它
+ * 创建一个与 Django 的 `User` 对象一对一关系的新对象,其唯一目的是持有一个令牌
+
+我习惯于建立对象关系,所以让我们选择第二种选择。我们称之为 `Owner`,因为它基本上具有与 `User` 类似的内涵,这就是我们想要的。
+
+出于纯粹的懒惰,我们可以在 `todo/models.py` 中包含这个新的 `Owner` 对象,但是不要这样做。`Owner` 没有明确地与任务列表上的项目的创建或维护有关。从概念上讲,`Owner` 只是任务的所有者。甚至有时候我们想要扩展这个 `Owner` 以包含与任务完全无关的其他数据。
+
+为了安全起见,让我们创建一个 `owner` 应用程序,其工作是容纳和处理这个 `Owner` 对象。
+```
+(django-someHash) $ ./manage.py startapp owner
+
+```
+
+不要忘记在 `settings.py` 文件中的 `INSTALLED_APPS` 中添加它。
+```
+INSTALLED_APPS = [
+ 'django.contrib.admin',
+
+ 'django.contrib.auth',
+
+ 'django.contrib.contenttypes',
+
+ 'django.contrib.sessions',
+
+ 'django.contrib.messages',
+
+ 'django.contrib.staticfiles',
+
+ 'rest_framework',
+
+ 'django_todo',
+
+ 'todo',
+
+ 'owner'
+]
+
+```
+
+如果我们查看 Django 项目的根目录,我们现在有两个 Django 应用程序:
+```
+(django-someHash) $ ls
+
+Pipfile Pipfile.lock django_todo manage.py owner todo
+
+```
+
+在 `owner/models.py` 中,让我们构建这个 `Owner` 模型。如前所述,它与 Django 的内置 `User` 对象有一对一的关系。我们可以用 Django 的 `models.OneToOneField` 强制实现这种关系。
+```
+# owner/models.py
+
+from django.db import models
+
+from django.contrib.auth.models import User
+
+import secrets
+
+
+class Owner(models.Model):
+
+ """The object that owns tasks."""
+
+ user = models.OneToOneField(User, on_delete=models.CASCADE)
+
+ token = models.CharField(max_length=256)
+
+
+ def __init__(self, *args, **kwargs):
+
+ """On construction, set token."""
+
+ self.token = secrets.token_urlsafe(64)
+
+ super().__init__(*args, **kwargs)
+
+```
+
+这表示 `Owner` 对象对应到 `User` 对象,每个 `user` 实例有一个 `owner` 实例。`on_delete = models.CASCADE` 表示如果相应的 `User` 被删除,它所对应的 `Owner` 实例也将被删除。让我们运行 `makemigrations` 和 `migrate` 来将这个新模型放入到我们的数据库中。
+```
+(django-someHash) $ ./manage.py makemigrations
+
+Migrations for 'owner':
+
+ owner/migrations/0001_initial.py
+
+ - Create model Owner
+
+(django-someHash) $ ./manage.py migrate
+
+Operations to perform:
+
+ Apply all migrations: admin, auth, contenttypes, owner, sessions, todo
+
+Running migrations:
+
+ Applying owner.0001_initial... OK
+
+```
+
+现在我们的 `Owner` 需要拥有一些 `Task` 对象。它与上面看到的 `OneToOneField` 非常相似,只不过我们会在 `Task` 对象上贴一个 `ForeignKey` 字段指向 `Owner`。
+
+```
+# todo/models.py
+
+from django.db import models
+
+from owner.models import Owner
+
+
+class Task(models.Model):
+
+ """Tasks for the To Do list."""
+
+ name = models.CharField(max_length=256)
+
+ note = models.TextField(blank=True, null=True)
+
+ creation_date = models.DateTimeField(auto_now_add=True)
+
+ due_date = models.DateTimeField(blank=True, null=True)
+
+ completed = models.BooleanField(default=False)
+
+ owner = models.ForeignKey(Owner, on_delete=models.CASCADE)
+
+```
+
+每个待办事项列表任务只有一个可以拥有多个任务的所有者。删除该所有者后,他们拥有的任务都会随之删除。
+
+现在让我们运行 `makemigrations` 来获取我们的数据模型设置的新快照,然后运行 `migrate` 将这些更改应用到我们的数据库。
+
+```
+(django-someHash) django $ ./manage.py makemigrations
+
+You are trying to add a non-nullable field 'owner' to task without a default; we can't do that (the database needs something to populate existing rows).
+
+Please select a fix:
+
+ 1) Provide a one-off default now (will be set on all existing rows with a null value for this column)
+
+ 2) Quit, and let me add a default in models.py
+
+```
+
+不好了!出现了问题!发生了什么?其实,当我们创建 `Owner` 对象并将其作为 `ForeignKey` 添加到 `Task` 时,要求每个 `Task` 都需要一个 `Owner`。但是,我们为 `Task` 对象进行的第一次迁移不包括该要求。因此,即使我们的数据库表中没有数据,Django 也会对我们的迁移进行预先检查,以确保它们兼容,而我们提议的这种新迁移不是。
+
+有几种方法可以解决这类问题:
+
+ 1. 退出当前迁移并构建一个包含当前模型配置的新迁移
+ 2. 将一个默认值添加到 `Task` 对象的 `owner` 字段
+ 3. 允许任务为 `owner` 字段设置 `NULL` 值
+
+方案 2 在这里没有多大意义。我们建议,任何创建的 `Task`,默认情况下都会对应到某个默认所有者,尽管不一定存在。(to 校正:后面这句发意义在哪里?既然它已经说了方案 2 没有意义)
+
+方案 1 要求我们销毁和重建我们的迁移,而我们应该把它们留下。
+
+让我们考虑选项 3。在这种情况下,如果我们允许 `Task` 表为所有者提供空值,它不会很糟糕。从这一点开始创建的任何任务都必然拥有一个所有者。如果你的数据库表不是一个可重新架构的情况下,请删除迁移,删除表并重建迁移。
+```
+# todo/models.py
+
+from django.db import models
+
+from owner.models import Owner
+
+
+class Task(models.Model):
+
+ """Tasks for the To Do list."""
+
+ name = models.CharField(max_length=256)
+
+ note = models.TextField(blank=True, null=True)
+
+ creation_date = models.DateTimeField(auto_now_add=True)
+
+ due_date = models.DateTimeField(blank=True, null=True)
+
+ completed = models.BooleanField(default=False)
+
+ owner = models.ForeignKey(Owner, on_delete=models.CASCADE, null=True)
+
+(django-someHash) $ ./manage.py makemigrations
+
+Migrations for 'todo':
+
+ todo/migrations/0002_task_owner.py
+
+ - Add field owner to task
+
+(django-someHash) $ ./manage.py migrate
+
+Operations to perform:
+
+ Apply all migrations: admin, auth, contenttypes, owner, sessions, todo
+
+Running migrations:
+
+ Applying todo.0002_task_owner... OK
+
+```
+
+酷!我们有模型了!欢迎使用 Django 声明对象的方式。
+
+为了更好地衡量,让我们确保无论何时制作 `User`,它都会自动与新的 `Owner` 对象对应。我们可以使用 Django 的 `signals` 系统来做到这一点。基本上,我们确切地表达了意图:“当我们得到一个新的 `User` 被构造的信号时,构造一个新的 `Owner` 并将新的 `User` 设置为 `Owner` 的 `user` 字段。”在实践中看起来像这样:
+```
+# owner/models.py
+
+from django.contrib.auth.models import User
+
+from django.db import models
+
+from django.db.models.signals import post_save
+
+from django.dispatch import receiver
+
+import secrets
+
+
+class Owner(models.Model):
+
+ """The object that owns tasks."""
+
+ user = models.OneToOneField(User, on_delete=models.CASCADE)
+
+ token = models.CharField(max_length=256)
+
+
+ def __init__(self, *args, **kwargs):
+
+ """On construction, set token."""
+
+ self.token = secrets.token_urlsafe(64)
+
+ super().__init__(*args, **kwargs)
+
+
+@receiver(post_save, sender=User)
+def link_user_to_owner(sender, **kwargs):
+
+ """If a new User is saved, create a corresponding Owner."""
+
+ if kwargs['created']:
+
+ owner = Owner(user=kwargs['instance'])
+
+ owner.save()
+
+```
+
+我们设置了一个函数,用于监听从 Django 中内置的 `User` 对象发送的信号。它正在等待 `User` 对象被保存之后的情况。这可以来自新的 `User` 或对现有 `User` 的更新。我们在监听功能中辨别出两种情况。
+
+如果发送信号的东西是新创建的实例,`kwargs ['created']` 将具有值 `True`。如果是 `True` 的话,我们想做点事情。如果它是一个新实例,我们创建一个新的 `Owner`,将其 `user` 字段设置为创建的新 `User` 实例。之后,我们 `save()` 新的 `Owner`。如果一切正常,这将提交更改到数据库。如果数据没通过我们声明的字段的验证,它将失败。
+
+现在让我们谈谈我们将如何访问数据。
+
+
+### 访问模型数据
+
+在 Flask, Pyramid 和 Tornado 框架中,我们通过对某些数据库会话运行查询来访问模型数据。也许它被附加到 `request` 对象,也许它是一个独立的 `session` 对象。无论如何,我们必须建立与数据库的实时连接并在该连接上进行查询。
+
+这不是 Django 的工作方式。默认情况下,Django 不利用任何第三方对象关系映射(ORM)与数据库进行通信。相反,Django 允许模型类维护自己与数据库的对话。
+
+从 `django.db.models.Model` 继承的每个模型类都会附加一个 `objects` 对象。这将取代我们熟悉的 `session` 或 `dbsession`。让我们打开 Django 给我们的特殊 shell,并研究这个 `objects` 对象是如何工作的。
+```
+(django-someHash) $ ./manage.py shell
+
+Python 3.7.0 (default, Jun 29 2018, 20:13:13)
+[Clang 9.1.0 (clang-902.0.39.2)] on darwin
+Type "help", "copyright", "credits" or "license" for more information.
+(InteractiveConsole)
+
+>>>
+
+```
+
+Django shell 与普通的 Python shell 不同,因为它知道我们正在构建的 Django 项目,可以轻松导入我们的模型,视图,设置等,而不必担心安装包。我们可以通过简单的 `import` 访问我们的模型。
+```
+>>> from owner.models import Owner
+
+>>> Owner
+
+
+
+```
+
+目前,我们没有 `Owner` 实例。我们可以通过 `Owner.objects.all()` 查询它们。
+```
+>>> Owner.objects.all()
+
+
+
+```
+
+无论何时我们在 ` .objects` 对象上运行查询方法,我们都会得到 `QuerySet`。为了我们的目的,它实际上是一个 `list`,这个 `list` 向我们显示它是空的。让我们通过创建一个 `User` 来创建一个 `Owner`。
+```
+>>> from django.contrib.auth.models import User
+
+>>> new_user = User(username='kenyattamurphy', email='kenyatta.murphy@gmail.com')
+
+>>> new_user.set_password('wakandaforever')
+
+>>> new_user.save()
+
+```
+
+如果我们现在查询所有的 `Owner`,我们应该会找到 Kenyatta。
+```
+>>> Owner.objects.all()
+
+]>
+
+```
+
+棒极了!我们得到了数据!
+
+### 序列化模型
+
+我们将在 “Hello World” 之外来回传递数据。因此,我们希望看到某种类似于 JSON 类型的输出,它可以很好地表示数据。获取该对象的数据并将其转换为 JSON 对象以通过 HTTP 提交是数据序列化的一种方式。在序列化数据时,我们正在获取我们目前拥有的数据并重新格式化以适应一些标准的,更易于理解的形式。
+
+如果我用 Flask, Pyramid 和 Tornado 这样做,我会在每个模型上创建一个新方法,让用户可以直接调用 `to_json()`。`to_json()` 的唯一工作是返回一个 JSON 可序列化的(即数字,字符串,列表,词典)字典,其中包含我想要为所讨论的对象显示的任何字段。
+
+对于 `Task` 对象,它可能看起来像这样:
+```
+class Task(Base):
+
+ ...all the fields...
+
+ def to_json(self):
+
+ """Convert task attributes to a JSON-serializable dict."""
+
+ return {
+
+ 'id': self.id,
+
+ 'name': self.name,
+
+ 'note': self.note,
+
+ 'creation_date': self.creation_date.strftime('%m/%d/%Y %H:%M:%S'),
+
+ 'due_date': self.due_date.strftime('%m/%d/%Y %H:%M:%S'),
+
+ 'completed': self.completed,
+
+ 'user': self.user_id
+
+ }
+
+```
+
+这不花哨,但它确实起到了作用。
+
+然而,Django REST Framework 为我们提供了一个对象,它不仅可以为我们这样做,还可以在我们想要创建新对象实例或更新现有实例时验证输入,它被称为 [ModelSerializer][15]。
+
+Django REST Framework 的 `ModelSerializer` 是我们模型的有效文档。如果没有附加模型,它们就没有自己的生命(因为那里有 [Serializer][16] 类)。它们的主要工作是准确地表示我们的模型,并在我们的模型数据需要序列化并通过线路发送时,将其转换为 JSON。
+
+Django REST Framework 的 `ModelSerializer` 最适合简单对象。举个例子,假设我们在 `Task` 对象上没有 `ForeignKey`。我们可以为 `Task` 创建一个序列化器,它将根据需要将其字段值转换为 JSON,声明如下:
+```
+# todo/serializers.py
+
+from rest_framework import serializers
+
+from todo.models import Task
+
+
+class TaskSerializer(serializers.ModelSerializer):
+
+ """Serializer for the Task model."""
+
+ class Meta:
+
+ model = Task
+
+ fields = ('id', 'name', 'note', 'creation_date', 'due_date', 'completed')
+
+```
+
+在我们新的 `TaskSerializer` 中,我们创建了一个 `Meta` 类。`Meta` 的工作就是保存关于我们试图序列化的东西的信息(或元数据)。然后,我们会注意到要显示的特定字段。如果我们想要显示所有字段,我们可以简化过程并使用`'__all __'`。或者,我们可以使用 `exclude` 关键字而不是 `fields` 来告诉 Django REST Framework 我们想要除了少数几个字段以外的每个字段。我们可以拥有尽可能多的序列化器,所以也许我们想要一个用于一小部分字段而一个用于所有字段?在这里都可以。
+
+在我们的例子中,每个 `Task` 和它的所有者 `Owner` 之间都有一个关系,必须在这里反映出来。因此,我们需要借用 `serializers.PrimaryKeyRelatedField` 对象来指定每个 `Task` 都有一个 `Owner`,并且该关系是一对一的。它的 owner 将从存在的所有 owners 的集合中找到。我们通过对这些 owners 进行查询并返回我们想要与此序列化程序关联的结果来获得该集合:`Owner.objects.all()`。我们还需要在字段列表中包含 `owner`,因为我们总是需要一个与 `Task` 相关联的 `Owner`。
+```
+# todo/serializers.py
+
+from rest_framework import serializers
+
+from todo.models import Task
+
+from owner.models import Owner
+
+
+class TaskSerializer(serializers.ModelSerializer):
+
+ """Serializer for the Task model."""
+
+ owner = serializers.PrimaryKeyRelatedField(queryset=Owner.objects.all())
+
+
+ class Meta:
+
+ model = Task
+
+ fields = ('id', 'name', 'note', 'creation_date', 'due_date', 'completed', 'owner')
+
+```
+
+现在构建了这个序列化器,我们可以将它用于我们想要为我们的对象做的所有 CRUD 操作:
+ * 如果我们想要 `GET` 一个特定的 `Task` 的 JSON 类型版本,我们可以做 `TaskSerializer((some_task).data`
+
+ * 如果我们想接受带有适当数据的 `POST` 来创建一个新的 `Task`,我们可以使用 `TaskSerializer(data = new_data).save()`
+
+ * 如果我们想用 `PUT` 更新一些现有数据,我们可以用 `TaskSerializer(existing_task, data = data).save()`
+
+我们没有包括 `delete`,因为我们不需要对 `delete` 操作做任何事情。如果你可以删除一个对象,只需使用 `object_instance.delete()`。
+
+以下是一些序列化数据的示例:
+```
+>>> from todo.models import Task
+
+>>> from todo.serializers import TaskSerializer
+
+>>> from owner.models import Owner
+
+>>> from django.contrib.auth.models import User
+
+>>> new_user = User(username='kenyatta', email='kenyatta@gmail.com')
+
+>>> new_user.save_password('wakandaforever')
+
+>>> new_user.save() # creating the User that builds the Owner
+
+>>> kenyatta = Owner.objects.first() # 找到 kenyatta 的所有者
+
+>>> new_task = Task(name="Buy roast beef for the Sunday potluck", owner=kenyatta)
+
+>>> new_task.save()
+
+>>> TaskSerializer(new_task).data
+
+{'id': 1, 'name': 'Go to the supermarket', 'note': None, 'creation_date': '2018-07-31T06:00:25.165013Z', 'due_date': None, 'completed': False, 'owner': 1}
+
+```
+
+使用 `ModelSerializer` 对象可以做更多的事情,我建议查看[文档][17]以获得更强大的功能。否则,这就是我们所需要的。现在是时候深入视图了。
+
+### 查看视图
+
+我们已经构建了模型和序列化器,现在我们需要为我们的应用程序设置视图和 URL。毕竟,对于没有视图的应用程序,我们无法做任何事情。我们已经看到了上面的 `HelloWorld` 视图的示例。然而,这总是一个人为的,概念验证的例子,并没有真正展示 Django REST Framework 的视图可以做些什么。让我们清除 `HelloWorld` 视图和 URL,这样我们就可以从我们的视图重新开始。
+
+我们要构建的第一个视图是 `InfoView`。与之前的框架一样,我们只想打包并发送一个字典到正确的路由。视图本身可以存在于 `django_todo.views` 中,因为它与特定模型无关(因此在概念上不属于特定应用程序)。
+```
+# django_todo/views.py
+
+from rest_framework.response import JsonResponse
+
+from rest_framework.views import APIView
+
+
+class InfoView(APIView):
+
+ """List of routes for this API."""
+
+ def get(self, request):
+
+ output = {
+
+ 'info': 'GET /api/v1',
+
+ 'register': 'POST /api/v1/accounts',
+
+ 'single profile detail': 'GET /api/v1/accounts/',
+
+ 'edit profile': 'PUT /api/v1/accounts/',
+
+ 'delete profile': 'DELETE /api/v1/accounts/',
+
+ 'login': 'POST /api/v1/accounts/login',
+
+ 'logout': 'GET /api/v1/accounts/logout',
+
+ "user's tasks": 'GET /api/v1/accounts//tasks',
+
+ "create task": 'POST /api/v1/accounts//tasks',
+
+ "task detail": 'GET /api/v1/accounts//tasks/',
+
+ "task update": 'PUT /api/v1/accounts//tasks/',
+
+ "delete task": 'DELETE /api/v1/accounts//tasks/'
+
+ }
+
+ return JsonResponse(output)
+
+```
+
+这与我们在 Tornado 中所拥有的完全相同。让我们将它放置到合适的路由并继续前行。为了更好的测试,我们还将删除 `admin/` 路由,因为我们不会在这里使用 Django 管理后端。
+```
+# in django_todo/urls.py
+
+from django_todo.views import InfoView
+
+from django.urls import path
+
+
+urlpatterns = [
+
+ path('api/v1', InfoView.as_view(), name="info"),
+
+]
+
+```
+
+#### 连接模型与视图
+
+让我们弄清楚下一个 URL,它将是创建新的 `Task` 或列出用户现有任务的入口。这应该存在于 `todo` 应用程序的 `urls.py` 中,因为它必须专门处理 `Task `对象而不是整个项目的一部分。
+```
+# in todo/urls.py
+
+from django.urls import path
+
+from todo.views import TaskListView
+
+
+urlpatterns = [
+
+ path('', TaskListView.as_view(), name="list_tasks")
+
+]
+
+```
+
+这个路由处理的是什么?我们根本没有指定特定用户或路径。由于会有一些路由需要基本路径 `/api/v1/accounts//tasks`,为什么我们只需写一次就能一次又一次地写它?
+
+Django 允许我们获取一整套 URL 并将它们导入 `django_todo/urls.py` 文件。然后,我们可以为这些导入的 URL 中的每一个提供相同的基本路径,只关心可变部分,你知道它们是不同的。
+```
+# in django_todo/urls.py
+
+from django.urls import include, path
+
+from django_todo.views import InfoView
+
+
+urlpatterns = [
+
+ path('api/v1', InfoView.as_view(), name="info"),
+
+ path('api/v1/accounts//tasks', include('todo.urls'))
+
+]
+
+```
+
+现在,来自 `todo/urls.py` 的每个 URL 都将以路径 `api/v1/accounts//tasks` 为前缀。
+
+让我们在 `todo/views.py` 中构建视图。
+```
+# todo/views.py
+
+from django.shortcuts import get_object_or_404
+
+from rest_framework.response import JsonResponse
+
+from rest_framework.views import APIView
+
+
+from owner.models import Owner
+
+from todo.models import Task
+
+from todo.serializers import TaskSerializer
+
+
+class TaskListView(APIView):
+
+ def get(self, request, username, format=None):
+
+ """Get all of the tasks for a given user."""
+
+ owner = get_object_or_404(Owner, user__username=username)
+
+ tasks = Task.objects.filter(owner=owner).all()
+
+ serialized = TaskSerializer(tasks, many=True)
+
+ return JsonResponse({
+
+ 'username': username,
+
+ 'tasks': serialized.data
+
+ })
+
+```
+
+这里有很多代码,让我们来看看吧。
+
+我们从与我们一直使用的 `APIView` 的继承开始,为我们的视图奠定基础。我们覆盖了之前覆盖的相同 `get` 方法,添加了一个参数,允许我们的视图从传入的请求中接收 `username`。
+
+然后我们的 `get` 方法将使用 `username` 来获取与该用户关联的 `Owner`。这个 `get_object_or_404` 函数允许我们这样做,添加一些特殊的东西以方便使用。
+
+如果无法找到指定的用户,那么查找任务是没有意义的。实际上,我们想要返回 404 错误。`get_object_or_404` 根据我们传入的任何条件获取单个对象,并返回该对象或引发 [Http404 异常][18]。我们可以根据对象的属性设置该条件。`Owner` 对象都通过 `user` 属性附加到 `User`。但是,我们没有要搜索的 `User` 对象,我们只有一个 `username`。所以,当你寻找一个 `Owner` 时,我们对 `get_object_or_404` 说:通过指定 `user__username` 来检查附加到它的 `User` 是否具有我想要的 `username`。这是两个下划线。通过 QuerySet 过滤时,这两个下划线表示“此嵌套对象的属性”。这些属性可以根据需要进行深度嵌套。
+
+我们现在拥有与给定用户名相对应的 `Owner`。我们使用 `Owner` 来过滤所有任务,只用 `Task.objects.filter` 检索它拥有的任务。我们可以使用与 `get_object_or_404` 相同的嵌套属性模式来钻入连接到 `Tasks` 的 `Owner` 的 `User`(`tasks = Task.objects.filter(owner__user__username = username)).all()`)但是没有必要那么宽松。
+
+`Task.objects.filter(owner = owner).all()` 将为我们提供与我们的查询匹配的所有 `Task` 对象的`QuerySet`。大。然后,`TaskSerializer` 将获取 `QuerySet` 及其所有数据以及 `many = True` 标志,将其通知为项目集合而不是仅仅一个项目,并返回一系列序列化结果。实际上是一个词典列表。最后,我们使用 JSON 序列化数据和用于查询的用户名提供传出响应。
+
+#### 处理 POST 请求
+
+`post` 方法看起来与我们之前看到的有些不同。
+```
+# still in todo/views.py
+
+# ...other imports...
+
+from rest_framework.parsers import JSONParser
+
+from datetime import datetime
+
+
+class TaskListView(APIView):
+
+ def get(self, request, username, format=None):
+
+ ...
+
+
+ def post(self, request, username, format=None):
+
+ """Create a new Task."""
+
+ owner = get_object_or_404(Owner, user__username=username)
+
+ data = JSONParser().parse(request)
+
+ data['owner'] = owner.id
+
+ if data['due_date']:
+
+ data['due_date'] = datetime.strptime(data['due_date'], '%d/%m/%Y %H:%M:%S')
+
+
+ new_task = TaskSerializer(data=data)
+
+ if new_task.is_valid():
+
+ new_task.save()
+
+ return JsonResponse({'msg': 'posted'}, status=201)
+
+
+ return JsonResponse(new_task.errors, status=400)
+
+```
+
+当我们从客户端接收数据时,我们使用 `JSONParser().parse(request)` 将其解析为字典。我们将所有者添加到数据中并格式化任务的 `due_date`(如果存在)。
+
+我们的 `TaskSerializer` 完成了繁重的任务。它首先接收传入的数据并将其转换为我们在模型上指定的字段。然后验证该数据以确保它适合指定的字段。如果附加到新 `Task` 的数据有效,它将使用该数据构造一个新的 `Task` 对象并将其提交给数据库。然后我们发回适当的“耶!我们做了一件新事!”响应。如果没有,我们收集 `TaskSerializer` 生成的错误,并将这些错误发送回客户端,并返回 `400 Bad Request` 状态代码。
+
+如果我们要构建 `put` 视图来更新 `Task`,它看起来会非常相似。主要区别在于,当我们实例化 `TaskSerializer` 时,我们将传递旧对象和该对象的新数据,如 `TaskSerializer(existing_task,data = data)`。我们仍然会进行有效性检查并发回我们想要发回的回复。
+
+### 总结
+
+Django 作为一个框架是高度可定制的,每个人都有自己的方式拼接 Django 项目。我在这里写出来的方式不一定是 Django 建立项目的确切方式。它只是 a) 我熟悉的方式,以及 b) 利用 Django 的管理系统。当你将概念分成他们自己的小筒仓时,Django 项目的复杂性会增加。这样做是为了让多个人更容易为整个项目做出贡献,而不会麻烦彼此。
+
+然而,作为 Django 项目的大量文件映射并不能使其更高效或自然地偏向于微服务架构。相反,它很容易成为一个令人困惑的巨石,这可能对你的项目仍然有用,它也可能使你的项目难以管理,尤其是随着项目的增长。
+
+仔细考虑你的需求并使用合适的工具来完成正确的工作。对于像这样的简单项目,Django 可能不是合适的工具。
+
+Django 旨在处理多种模型,这些模型涵盖了不同的项目领域,但它们可能有一些共同点。这个项目是一个小型的双模型项目,有一些路由。如果我们要构建更多,我们只有七条路由,但仍然是相同的两个模型。这还不足以证明一个完整的 Django 项目。
+
+如果我们期望这个项目能够扩展,那将是一个很好的选择。这不是其中一个项目。这是选择一个点燃蜡烛的火焰喷射器。这是绝对的矫枉过正。(to 校正:这里有点迷糊)
+
+尽管如此,Web 框架仍然是一个 Web 框架,无论你使用哪个框架。它都可以接收请求并做出任何响应,因此你可以按照自己的意愿进行操作。只需要注意你选择的框架所带来的开销。
+
+就是这样!我们已经到了这个系列的最后!我希望这是一次启发性的冒险。当你在考虑如何构建你的下一个项目时,它将帮助你做出的不仅仅是最熟悉的选择。请务必阅读每个框架的文档,以扩展本系列中涉及的任何内容(因为它没有那么全面)。每个人都有一个广阔的世界。愉快地写代码吧!
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/8/django-framework
+
+作者:[Nicholas Hunt-Walker][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/nhuntwalker
+[1]:https://opensource.com/article/18/5/pyramid-framework
+[2]:https://opensource.com/article/18/4/flask
+[3]:https://opensource.com/article/18/6/tornado-framework
+[4]:https://www.djangoproject.com
+[5]:https://djangopackages.org/
+[6]:http://www.django-rest-framework.org/
+[7]:http://gunicorn.org/
+[8]:https://docs.pylonsproject.org/projects/waitress/en/latest/
+[9]:https://uwsgi-docs.readthedocs.io/en/latest/
+[10]:https://docs.djangoproject.com/en/2.0/ref/settings/#databases
+[11]:https://pypi.org/project/dj-database-url/
+[12]:http://yellerapp.com/posts/2015-01-12-the-worst-server-setup-you-can-make.html
+[13]:https://docs.djangoproject.com/en/2.0/ref/settings/#std:setting-DATABASE-ENGINE
+[14]:https://www.getpostman.com/
+[15]:http://www.django-rest-framework.org/api-guide/serializers/#modelserializer
+[16]:http://www.django-rest-framework.org/api-guide/serializers/
+[17]:http://www.django-rest-framework.org/api-guide/serializers/#serializers
+[18]:https://docs.djangoproject.com/en/2.0/topics/http/views/#the-http404-exception
diff --git a/translated/tech/20180827 Solve -error- failed to commit transaction (conflicting files)- In Arch Linux.md b/translated/tech/20180827 Solve -error- failed to commit transaction (conflicting files)- In Arch Linux.md
new file mode 100644
index 0000000000..d77a63be3d
--- /dev/null
+++ b/translated/tech/20180827 Solve -error- failed to commit transaction (conflicting files)- In Arch Linux.md
@@ -0,0 +1,49 @@
+解决 Arch Linux 中出现的 “error:failed to commit transaction (conflicting files)”
+======
+
+
+
+自我更新 Arch Linux 桌面以来已经有一个月了。今天我试着更新我的 Arch Linux 系统,然后遇到一个错误 **“error:failed to commit transaction (conflicting files) stfl:/usr/lib/libstfl.so.0 exists in filesystem”**。看起来是 pacman 无法更新一个已经存在于文件系统上的库 (/usr/lib/libstfl.so.0)。如果你也遇到了同样的问题,下面是一个快速解决方案。
+
+### 解决 Arch Linux 中出现的 “error:failed to commit transaction (conflicting files)”
+
+有三种方法。
+
+1。简单在升级时忽略导致问题的 **stfl** 库并尝试再次更新系统。请参阅此指南以了解 [**如何在更新时忽略软件包 **][1]。
+
+2。使用命令覆盖这个包:
+```
+$ sudo pacman -Syu --overwrite /usr/lib/libstfl.so.0
+```
+
+3。手工删掉 stfl 库然后再次升级系统。请确保目标包不被其他任何重要的包所依赖。可以通过去 archlinux.org 查看是否有这种冲突。
+```
+$ sudo rm /usr/lib/libstfl.so.0
+```
+
+现在,尝试更新系统:
+```
+$ sudo pacman -Syu
+```
+
+我选择第三种方法,直接删除该文件然后升级 Arch Linux 系统。很有效!
+
+希望本文对你有所帮助。还有更多好东西。敬请期待!
+
+干杯!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-solve-error-failed-to-commit-transaction-conflicting-files-in-arch-linux/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[1]:https://www.ostechnix.com/safely-ignore-package-upgraded-arch-linux/
diff --git a/translated/tech/20180907 How to Use the Netplan Network Configuration Tool on Linux.md b/translated/tech/20180907 How to Use the Netplan Network Configuration Tool on Linux.md
new file mode 100644
index 0000000000..0027aafb6f
--- /dev/null
+++ b/translated/tech/20180907 How to Use the Netplan Network Configuration Tool on Linux.md
@@ -0,0 +1,215 @@
+如何在 Linux 上使用网络配置工具 Netplan
+======
+
+
+
+多年以来 Linux 管理员和用户们使用相同的方式配置他们的网络接口。例如,如果你是 Ubuntu 用户,你能够用桌面 GUI 配置网络连接,也可以在 /etc/network/interfaces 文件里配置。配置相当简单且从未失败。在文件中配置看起来就像这样:
+
+```
+auto enp10s0
+
+iface enp10s0 inet static
+
+address 192.168.1.162
+
+netmask 255.255.255.0
+
+gateway 192.168.1.100
+
+dns-nameservers 1.0.0.1,1.1.1.1
+```
+
+保存并关闭文件。使用命令重启网络:
+
+```
+sudo systemctl restart networking
+```
+
+或者,如果你使用不带systemd 的发行版,你可以通过老办法来重启网络:
+
+```
+sudo /etc/init.d/networking restart
+```
+
+你的网络将会重新启动,新的配置将会生效。
+
+这就是多年以来的做法。但是现在,在某些发行版上(例如 Ubuntu Linux 18.04),网络的配置与控制发生了很大的变化。不需要那个 interfaces 文件和 /etc/init.d/networking 脚本,我们现在转向使用 [Netplan][1]。Netplan 是一个在某些 Linux 发行版上配置网络连接的命令行工具。Netplan 使用 YAML 描述文件来配置网络接口,然后,通过这些描述为任何给定的呈现工具生成必要的配置选项。
+
+我将向你展示如何在 Linux 上使用 Netplan 配置静态 IP 地址和 DHCP 地址。我会在 Ubuntu Server 18.04 上演示。有句忠告,你创建的 .yaml 文件中的间距必须保持一致,否则将会失败。你不用为每行使用特定的间距,只需保持一致就行了。
+
+### 新的配置文件
+
+打开终端窗口(或者通过 SSH 登录进 Ubuntu 服务器)。你会在 /etc/netplan 文件夹下发现 Netplan 的新配置文件。使用 cd/etc/netplan 命令进入到那个文件夹下。一旦进到了那个文件夹,也许你就能够看到一个文件:
+
+```
+01-netcfg.yaml
+```
+
+你可以创建一个新的文件或者是编辑默认文件。如果你打算修改默认文件,我建议你先做一个备份:
+
+```
+sudo cp /etc/netplan/01-netcfg.yaml /etc/netplan/01-netcfg.yaml.bak
+```
+
+备份好后,就可以开始配置了。
+
+### 网络设备名称
+
+在你开始配置静态 IP 之前,你需要知道设备名称。要做到这一点,你可以使用命令 ip a,然后找出哪一个设备将会被用到(图 1)。
+
+![netplan][3]
+
+图 1:使用 ip a 命令找出设备名称
+
+[Used with permission][4] (译注:这是什么鬼?)
+
+我将为 ens5 配置一个静态的 IP。
+
+### 配置静态 IP 地址
+
+使用命令打开原来的 .yaml 文件:
+
+```
+sudo nano /etc/netplan/01-netcfg.yaml
+```
+
+文件的布局看起来就像这样:
+
+network:
+
+Version: 2
+
+Renderer: networkd
+
+ethernets:
+
+DEVICE_NAME:
+
+Dhcp4: yes/no
+
+Addresses: [IP/NETMASK]
+
+Gateway: GATEWAY
+
+Nameservers:
+
+Addresses: [NAMESERVER, NAMESERVER]
+
+其中:
+
+ * DEVICE_NAME 是需要配置设备的实际名称。
+
+ * yes/no 代表是否启用 dhcp4。
+
+ * IP 是设备的 IP 地址。
+
+ * NETMASK 是 IP 地址的掩码。
+
+ * GATEWAY 是网关的地址。
+
+ * NAMESERVER 是由逗号分开的 DNS 服务器列表。
+
+这是一份 .yaml 文件的样例:
+
+```
+network:
+
+ version: 2
+
+ renderer: networkd
+
+ ethernets:
+
+ ens5:
+
+ dhcp4: no
+
+ addresses: [192.168.1.230/24]
+
+ gateway4: 192.168.1.254
+
+ nameservers:
+
+ addresses: [8.8.4.4,8.8.8.8]
+```
+
+编辑上面的文件以达到你想要的效果。保存并关闭文件。
+
+注意,掩码已经不用再配置为 255.255.255.0 这种形式。取而代之的是,掩码已被添加进了 IP 地址中。
+
+### 测试配置
+
+在应用改变之前,让我们测试一下配置。为此,使用命令:
+
+```
+sudo netplan try
+```
+
+上面的命令会在应用配置之前验证其是否有效。如果成功,你就会看到配置被接受。换句话说,Netplan 会尝试将新的配置应用到运行的系统上。如果新的配置失败了,Netplan 会自动地恢复到之前使用的配置。成功后,新的配置就会被使用。
+
+### 应用新的配置
+
+如果你确信配置文件没有问题,你就可以跳过测试环节并且直接使用新的配置。它的命令是:
+
+```
+sudo netplan apply
+```
+
+此时,你可以使用 ip a 看看新的地址是否正确。
+
+### 配置 DHCP
+
+虽然你可能不会配置 DHCP 服务,但通常还是知道比较好。例如,你也许不知道网络上当前可用的静态 IP 地址是多少。你可以为设备配置 DHCP,获取到 IP 地址,然后将那个地址重新配置为静态地址。
+
+在 Netplan 上使用 DHCP,配置文件看起来就像这样:
+
+```
+network:
+
+ version: 2
+
+ renderer: networkd
+
+ ethernets:
+
+ ens5:
+
+ Addresses: []
+
+ dhcp4: true
+
+ optional: true
+```
+
+保存并退出。用下面命令来测试文件:
+
+```
+sudo netplan try
+```
+
+Netplan 应该会成功配置 DHCP 服务。这时你可以使用 ip a 命令得到动态分配的地址,然后重新配置静态地址。或者,你可以直接使用 DHCP 分配的地址(但看看这是一个服务器,你可能不想这样做)。
+
+也许你有不只一个的网络接口,你可以命名第二个 .yaml 文件为 02-netcfg.yaml 。Netplan 会按照数字顺序应用配置文件,因此 01 会在 02 之前使用。根据你的需要创建多个配置文件。
+
+### 就是这些了
+
+不管你信不信,那些就是所有关于使用 Netplan 的东西了。虽然它对于我们习惯性的配置网络地址来说是一个相当大的改变,但并不是所有人都用的惯。但这种配置方式值得一提...因此你会适应的。
+
+在 Linux Foundation 和 edX 上通过 ["Introduction to Linux"] 课程学习更多关于 Linux 的内容。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/intro-to-linux/2018/9/how-use-netplan-network-configuration-tool-linux
+
+作者:[Jack Wallen][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[LuuMing](https://github.com/LuuMing)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linux.com/users/jlwallen
+[1]: https://netplan.io/
+[3]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/netplan_1.jpg?itok=XuIsXWbV (netplan)
+[4]: /licenses/category/used-permission
+[5]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180910 How To List An Available Package Groups In Linux.md b/translated/tech/20180910 How To List An Available Package Groups In Linux.md
similarity index 69%
rename from sources/tech/20180910 How To List An Available Package Groups In Linux.md
rename to translated/tech/20180910 How To List An Available Package Groups In Linux.md
index 754c2d0c3a..b192e6c5f0 100644
--- a/sources/tech/20180910 How To List An Available Package Groups In Linux.md
+++ b/translated/tech/20180910 How To List An Available Package Groups In Linux.md
@@ -1,43 +1,33 @@
-How To List An Available Package Groups In Linux
+如何在 Linux 中列出可用的软件包组
======
-As we know, if we want to install any packages in Linux we need to use the distribution package manager to get it done.
+我们知道,如果想要在 Linux 中安装软件包,可以使用软件包管理器来进行安装。由于系统管理员需要频繁用到软件包管理器,所以它是 Linux 当中的一个重要工具。
-Package manager is playing major role in Linux as this used most of the time by admin.
+但是如果想一次性安装一个软件包组,在 Linux 中有可能吗?又如何通过命令去实现呢?
-If you would like to install group of package in one shot what would be the possible option.
+在 Linux 中确实可以用软件包管理器来达到这样的目的。很多软件包管理器都有这样的选项来实现这个功能,但就我所知,`apt` 或 `apt-get` 软件包管理器却并没有这个选项。因此对基于 Debian 的系统,需要使用的命令是 `tasksel`,而不是 `apt`或 `apt-get` 这样的官方软件包管理器。
-Is it possible in Linux? if so, what would be the command for it.
+在 Linux 中安装软件包组有很多好处。对于 LAMP 来说,安装过程会包含多个软件包,但如果安装软件包组命令来安装,只安装一个包就可以了。
-Yes, this can be done in Linux by using the package manager. Each package manager has their own option to perform this task, as i know apt or apt-get package manager doesn’t has this option.
+当你的团队需要安装 LAMP,但不知道其中具体包含哪些软件包,这个时候软件包组就派上用场了。软件包组是 Linux 系统上一个很方便的工具,它能让你轻松地完成一组软件包的安装。
-For Debian based system we need to use tasksel command instead of official package managers called apt or apt-get.
+软件包组是一组用于公共功能的软件包,包括系统工具、声音和视频。 安装软件包组的过程中,会获取到一系列的依赖包,从而大大节省了时间。
-What is the benefit if we install group of package in Linux? Yes, there is lot of benefit is available in Linux when we install group of package because if you want to install LAMP separately we need to include so many packages but that can be done using single package when we use group of package command.
+**推荐阅读:**
+**(#)** [如何在 Linux 上按照大小列出已安装的软件包][1]
+**(#)** [如何在 Linux 上查看/列出可用的软件包更新][2]
+**(#)** [如何在 Linux 上查看软件包的安装/更新/升级/移除/卸载时间][3]
+**(#)** [如何在 Linux 上查看一个软件包的详细信息][4]
+**(#)** [如何查看一个软件包是否在你的 Linux 发行版上可用][5]
+**(#)** [萌新指导:一个可视化的 Linux 包管理工具][6]
+**(#)** [老手必会:命令行软件包管理器的用法][7]
-Say for example, as you get a request from Application team to install LAMP but you don’t know what are the packages needs to be installed, this is where group of package comes into picture.
+### 如何在 CentOS/RHEL 系统上列出可用的软件包组
-Group option is a handy tool for Linux systems which will install Group of Software in a single click on your system without headache.
+RHEL 和 CentOS 系统使用的是 RPM 软件包,因此可以使用 `yum` 软件包管理器来获取相关的软件包信息。
-A package group is a collection of packages that serve a common purpose, for instance System Tools or Sound and Video. Installing a package group pulls a set of dependent packages, saving time considerably.
+`yum` 是 Yellowdog Updater, Modified 的缩写,它是一个用于基于 RPM 系统(例如 RHEL 和 CentOS)的,开源的命令行软件包管理工具。它是从分发库或其它第三方库中获取、安装、删除、查询和管理 RPM 包的主要工具。
-**Suggested Read :**
-**(#)** [How To List Installed Packages By Size (Largest) On Linux][1]
-**(#)** [How To View/List The Available Packages Updates In Linux][2]
-**(#)** [How To View A Particular Package Installed/Updated/Upgraded/Removed/Erased Date On Linux][3]
-**(#)** [How To View Detailed Information About A Package In Linux][4]
-**(#)** [How To Search If A Package Is Available On Your Linux Distribution Or Not][5]
-**(#)** [Newbies corner – A Graphical frontend tool for Linux Package Manager][6]
-**(#)** [Linux Expert should knows, list of Command line Package Manager & Usage][7]
-
-### How To List An Available Package Groups In CentOS/RHEL Systems
-
-RHEL & CentOS systems are using RPM packages hence we can use the `Yum Package Manager` to get this information.
-
-YUM stands for Yellowdog Updater, Modified is an open-source command-line front-end package-management utility for RPM based systems such as Red Hat Enterprise Linux (RHEL) and CentOS.
-
-Yum is the primary tool for getting, installing, deleting, querying, and managing RPM packages from distribution repositories, as well as other third-party repositories.
-
-**Suggested Read :** [YUM Command To Manage Packages on RHEL/CentOS Systems][8]
+**推荐阅读:** [使用 yum 命令在 RHEL/CentOS 系统上管理软件包][8]
```
# yum grouplist
@@ -82,7 +72,7 @@ Done
```
-If you would like to list what are the packages is associated on it, run the below command. In this example we are going to list what are the packages is associated with “Performance Tools” group.
+如果需要列出相关联的软件包,可以执行以下这个命令。下面的例子是列出和 Performance Tools 组相关联的软件包。
```
# yum groupinfo "Performance Tools"
@@ -116,17 +106,17 @@ Group: Performance Tools
```
-### How To List An Available Package Groups In Fedora
+### 如何在 Fedora 系统上列出可用的软件包组
-Fedora system uses DNF package manager hence we can use the Dnf Package Manager to get this information.
+Fedora 系统使用的是 DNF 软件包管理器,因此可以通过 DNF 软件包管理器来获取相关的信息。
-DNF stands for Dandified yum. We can tell DNF, the next generation of yum package manager (Fork of Yum) using hawkey/libsolv library for backend. Aleš Kozumplík started working on DNF since Fedora 18 and its implemented/launched in Fedora 22 finally.
+DNF 的含义是 Dandified yum。、DNF 软件包管理器是 YUM 软件包管理器的一个分支,它使用 hawkey/libsolv 库作为后端。从 Fedora 18 开始,Aleš Kozumplík 开始着手 DNF 的开发,直到在Fedora 22 开始加入到系统中。
-Dnf command is used to install, update, search & remove packages on Fedora 22 and later system. It automatically resolve dependencies and make it smooth package installation without any trouble.
+`dnf` 命令可以在 Fedora 22 及更高版本上安装、更新、搜索和删除软件包, 它可以自动解决软件包的依赖关系并其顺利安装,不会产生问题。
-Yum replaced by DNF due to several long-term problems in Yum which was not solved. Asked why ? he did not patches the Yum issues. Aleš Kozumplík explains that patching was technically hard and YUM team wont accept the changes immediately and other major critical, YUM is 56K lines but DNF is 29K lies. So, there is no option for further development, except to fork.
+由于一些长期未被解决的问题的存在,YUM 被 DNF 逐渐取代了。而 Aleš Kozumplík 的 DNF 却并未对 yum 的这些问题作出修补,他认为这是技术上的难题,YUM 团队也从不接受这些更改。而且 YUM 的代码量有 5.6 万行,而 DNF 只有 2.9 万行。因此已经不需要沿着 YUM 的方向继续开发了,重新开一个分支才是更好的选择。
-**Suggested Read :** [DNF (Fork of YUM) Command To Manage Packages on Fedora System][9]
+**推荐阅读:** [在 Fedora 系统上使用 DNF 命令管理软件包][9]
```
# dnf grouplist
@@ -180,7 +170,7 @@ Available Groups:
```
-If you would like to list what are the packages is associated on it, run the below command. In this example we are going to list what are the packages is associated with “Editor” group.
+如果需要列出相关联的软件包,可以执行以下这个命令。下面的例子是列出和 Editor 组相关联的软件包。
```
@@ -215,13 +205,13 @@ Group: Editors
zile
```
-### How To List An Available Package Groups In openSUSE System
+### 如何在 openSUSE 系统上列出可用的软件包组
-openSUSE system uses zypper package manager hence we can use the zypper Package Manager to get this information.
+openSUSE 系统使用的是 zypper 软件包管理器,因此可以通过 zypper 软件包管理器来获取相关的信息。
-Zypper is a command line package manager for suse & openSUSE distributions. It’s used to install, update, search & remove packages & manage repositories, perform various queries, and more. Zypper command-line interface to ZYpp system management library (libzypp).
+Zypper 是 suse 和 openSUSE 发行版的命令行包管理器。它可以用于安装、更新、搜索和删除软件包,还有管理存储库,执行各种查询等功能。 Zypper 命令行界面用到了 ZYpp 系统管理库(libzypp)。
-**Suggested Read :** [Zypper Command To Manage Packages On openSUSE & suse Systems][10]
+**推荐阅读:** [在 openSUSE 和 suse 系统使用 zypper 命令管理软件包][10]
```
# zypper patterns
@@ -277,8 +267,7 @@ i | yast2_basis | 20150918-25.1 | @System |
| yast2_install_wf | 20150918-25.1 | Main Repository (OSS) |
```
-If you would like to list what are the packages is associated on it, run the below command. In this example we are going to list what are the packages is associated with “file_server” group.
-Additionally zypper command allows a user to perform the same action with different options.
+如果需要列出相关联的软件包,可以执行以下这个命令。下面的例子是列出和 file_server 组相关联的软件包。另外 `zypper` 还允许用户使用不同的选项执行相同的操作。
```
# zypper info file_server
@@ -317,7 +306,7 @@ Contents :
| yast2-tftp-server | package | Recommended
```
-If you would like to list what are the packages is associated on it, run the below command.
+如果需要列出相关联的软件包,可以执行以下这个命令。
```
# zypper pattern-info file_server
@@ -357,7 +346,7 @@ Contents :
| yast2-tftp-server | package | Recommended
```
-If you would like to list what are the packages is associated on it, run the below command.
+如果需要列出相关联的软件包,可以执行以下这个命令。
```
# zypper info pattern file_server
@@ -396,7 +385,7 @@ Contents :
| yast2-tftp-server | package | Recommended
```
-If you would like to list what are the packages is associated on it, run the below command.
+如果需要列出相关联的软件包,可以执行以下这个命令。
```
# zypper info -t pattern file_server
@@ -436,17 +425,17 @@ Contents :
| yast2-tftp-server | package | Recommended
```
-### How To List An Available Package Groups In Debian/Ubuntu Systems
+### 如何在 Debian/Ubuntu 系统上列出可用的软件包组
-Since APT or APT-GET package manager doesn’t offer this option for Debian/Ubuntu based systems hence, we are using tasksel command to get this information.
+由于 APT 或 APT-GET 软件包管理器没有为基于 Debian/Ubuntu 的系统提供这样的选项,因此需要使用 `tasksel` 命令来获取相关信息。
-[Tasksel][11] is a handy tool for Debian/Ubuntu systems which will install Group of Software in a single click on your system. Tasks are defined in `.desc` files and located at `/usr/share/tasksel`.
+[tasksel][11] 是 Debian/Ubuntu 系统上一个很方便的工具,只需要很少的操作就可以用它来安装好一组软件包。可以在 `/usr/share/tasksel` 目录下的 `.desc` 文件中安排软件包的安装任务。
-By default, tasksel tool installed on Debian system as part of Debian installer but it’s not installed on Ubuntu desktop editions. This functionality is similar to that of meta-packages, like how package managers have.
+默认情况下,`tasksel` 工具是作为 Debian 系统的一部分安装的,但桌面版 Ubuntu 则没有自带 `tasksel`,类似软件包管理器中的元包(meta-packages)。
-Tasksel tool offer a simple user interface based on zenity (popup Graphical dialog box in command line).
+`tasksel` 工具带有一个基于 zenity 的简单用户界面,例如命令行中的弹出图形对话框。
-**Suggested Read :** [Tasksel – Install Group of Software in A Single Click on Debian/Ubuntu][12]
+**推荐阅读:** [使用 tasksel 在 Debian/Ubuntu 系统上快速安装软件包组][12]
```
# tasksel --list-task
@@ -494,20 +483,20 @@ u openssh-server OpenSSH server
u server Basic Ubuntu server
```
-If you would like to list what are the packages is associated on it, run the below command. In this example we are going to list what are the packages is associated with “file_server” group.
+如果需要列出相关联的软件包,可以执行以下这个命令。下面的例子是列出和 lamp-server 组相关联的软件包。
```
# tasksel --task-desc "lamp-server"
Selects a ready-made Linux/Apache/MySQL/PHP server.
```
-### How To List An Available Package Groups In Arch Linux based Systems
+### 如何在基于 Arch Linux 的系统上列出可用的软件包组
-Arch Linux based systems are using pacman package manager hence we can use the pacman Package Manager to get this information.
+基于 Arch Linux 的系统使用的是 pacman 软件包管理器,因此可以通过 pacman 软件包管理器来获取相关的信息。
-pacman stands for package manager utility (pacman). pacman is a command-line utility to install, build, remove and manage Arch Linux packages. pacman uses libalpm (Arch Linux Package Management (ALPM) library) as a back-end to perform all the actions.
+pacman 是 package manager 的缩写。`pacman` 可以用于安装、构建、删除和管理 Arch Linux 软件包。`pacman` 使用 libalpm(Arch Linux Package Management 库,ALPM)作为后端来执行所有操作。
-**Suggested Read :** [Pacman Command To Manage Packages On Arch Linux Based Systems][13]
+**推荐阅读:** [使用 pacman 在基于 Arch Linux 的系统上管理软件包][13]
```
# pacman -Sg
@@ -550,7 +539,7 @@ vim-plugins
```
-If you would like to list what are the packages is associated on it, run the below command. In this example we are going to list what are the packages is associated with “gnome” group.
+如果需要列出相关联的软件包,可以执行以下这个命令。下面的例子是列出和 gnome 组相关联的软件包。
```
# pacman -Sg gnome
@@ -589,7 +578,7 @@ gnome simple-scan
```
-Alternatively we can check the same by running following command.
+也可以执行以下这个命令实现同样的效果。
```
# pacman -S gnome
@@ -609,7 +598,7 @@ Interrupt signal received
```
-To know exactly how many packages is associated on it, run the following command.
+可以执行以下命令检查相关软件包的数量。
```
# pacman -Sg gnome | wc -l
@@ -623,7 +612,7 @@ via: https://www.2daygeek.com/how-to-list-an-available-package-groups-in-linux/
作者:[Prakash Subramanian][a]
选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
+译者:[HankChow](https://github.com/HankChow)
校对:[校对者ID](https://github.com/校对者ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
@@ -642,3 +631,4 @@ via: https://www.2daygeek.com/how-to-list-an-available-package-groups-in-linux/
[11]: https://wiki.debian.org/tasksel
[12]: https://www.2daygeek.com/tasksel-install-group-of-software-in-a-single-click-or-single-command-on-debian-ubuntu/
[13]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
+
diff --git a/translated/tech/20180917 4 scanning tools for the Linux desktop.md b/translated/tech/20180917 4 scanning tools for the Linux desktop.md
deleted file mode 100644
index 89aaad3a89..0000000000
--- a/translated/tech/20180917 4 scanning tools for the Linux desktop.md
+++ /dev/null
@@ -1,72 +0,0 @@
-用于Linux桌面的4个扫描工具
-======
-使用其中一个开源软件驱动扫描仪来实现无纸化办公。
-
-
-
-尽管无纸化世界还没有到来,但越来越多的人通过扫描文件和照片来摆脱纸张的束缚。不过,仅仅拥有一台扫描仪还不足够。你还需要软件来驱动扫描仪。
-
-然而问题是许多扫描仪制造商没有将Linux版本的软件与他们的设备适配在一起。不过在大多数情况下,即使没有也没多大关系。因为在linux桌面上已经有很好的扫描软件了。它们能够与许多扫描仪配合很好的完成工作。
-
-现在就让我们看看四个简单又灵活的开源Linux扫描工具。我已经使用过了下面这些工具(甚至[早在2014年][1]写过关于其中三个工具的文章)并且觉得它们非常有用。希望你也会这样认为。
-
-### Simple Scan
-
-这是我最喜欢的一个软件之一,[Simple Scan][2]小巧,迅速,高效,且易于使用。如果你以前见过它,那是因为Simple Scan是GNOME桌面上的默认扫描程序应用程序,也是许多Linux发行版的默认扫描程序。
-
-你只需单击一下就能扫描文档或照片。扫描过某些内容后,你可以旋转或裁剪它并将其另存为图像(仅限JPEG或PNG格式)或PDF格式。也就是说Simple Scan可能会很慢,即使你用较低分辨率来扫描文档。最重要的是,Simple Scan在扫描时会使用一组全局的默认值,例如150dpi用于文本,300dpi用于照片。你需要进入Simple Scan的首选项才能更改这些设置。
-
-如果你扫描的内容超过了几页,还可以在保存之前重新排序页面。如果有必要的话 - 假如你正在提交已签名的表格 - 你可以使用Simple Scan来发送电子邮件。
-
-### Skanlite
-
-从很多方面来看,[Skanlite][3]是Simple Scan在KDE世界中的表兄弟。虽然Skanlite功能很少,但它可以出色的完成工作。
-
-你可以自己配置这个软件的选项,包括自动保存扫描文件,设置扫描质量以及确定扫描保存位置。 Skanlite可以保存为以下图像格式:JPEG,PNG,BMP,PPM,XBM和XPM。
-
-其中一个很棒的功能是Skanlite能够将你扫描的部分内容保存到单独的文件中。当你想要从照片中删除某人或某物时,这就派上用场了。
-
-### Gscan2pdf
-
-这是我另一个最爱的老软件,[gscan2pdf][4]可能会显得很老旧了,但它仍然包含一些比这里提到的其他软件更好的功能。即便如此,gscan2pdf仍然显得很轻便。
-
-除了以各种图像格式(JPEG,PNG和TIFF)保存扫描外,gscan2pdf还将它们保存为PDF或[DjVu][5]文件。你可以在单击“扫描”按钮之前设置扫描的分辨率,无论是黑白,彩色还是纸张大小,每当你想要更改任何这些设置时,这都会进入gscan2pdf的首选项。你还可以旋转,裁剪和删除页面。
-
-虽然这些都不是真正的杀手级功能,但它们会给你带来更多的灵活性。
-
-### GIMP
-
-你大概会知道[GIMP][6]是一个图像编辑工具。但是你恐怕不知道可以用它来驱动你的扫描仪吧。
-
-你需要安装[XSane][7]扫描软件和GIMP XSane插件。这两个应该都可以从你的Linux发行版的包管理器中获得。在软件里,选择文件>创建>扫描仪/相机。单击扫描仪,然后单击扫描按钮即可进行扫描。
-
-如果这不是你想要的,或者它不起作用,你可以将GIMP和一个叫作[QuiteInsane][8]的插件结合起来。使用任一插件,都能使GIMP成为一个功能强大的扫描软件,它可以让你设置许多选项,如是否扫描彩色或黑白,扫描的分辨率,以及是否压缩结果等。你还可以使用GIMP的工具来修改或应用扫描后的效果。这使得它非常适合扫描照片和艺术品。
-
-### 它们真的能够工作吗?
-
-所有的这些软件在大多数时候都能够在各种硬件上运行良好。我将它们与我过去几年来拥有的多台多功能打印机一起使用 - 无论是使用USB线连接还是通过无线连接。
-
-你可能已经注意到我在前一段中写过“大多数时候运行良好”。这是因为我确实遇到过一个例外:一个便宜的canon多功能打印机。我使用的软件都没有检测到它。最后我不得不下载并安装canon的Linux扫描仪软件才使它工作。
-
-你最喜欢的Linux开源扫描工具是什么?发表评论,分享你的选择。
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/9/linux-scanner-tools
-
-作者:[Scott Nesbitt][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[way-ww](https://github.com/way-ww)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/scottnesbitt
-[1]: https://opensource.com/life/14/8/3-tools-scanners-linux-desktop
-[2]: https://gitlab.gnome.org/GNOME/simple-scan
-[3]: https://www.kde.org/applications/graphics/skanlite/
-[4]: http://gscan2pdf.sourceforge.net/
-[5]: http://en.wikipedia.org/wiki/DjVu
-[6]: http://www.gimp.org/
-[7]: https://en.wikipedia.org/wiki/Scanner_Access_Now_Easy#XSane
-[8]: http://sourceforge.net/projects/quiteinsane/
diff --git a/translated/tech/20180917 Getting started with openmediavault- A home NAS solution.md b/translated/tech/20180917 Getting started with openmediavault- A home NAS solution.md
deleted file mode 100644
index 833180811a..0000000000
--- a/translated/tech/20180917 Getting started with openmediavault- A home NAS solution.md
+++ /dev/null
@@ -1,74 +0,0 @@
-openmediavault入门:一个家庭NAS解决方案
-======
-这个网络附加文件服务提供了一序列功能,�并且易于安装和配置。
-
-
-
-面对许多可供选择的云存储方案,一些人可能会质疑一个家庭网络附加存储服务的价值。毕竟,当所有你的文件存储在云上,你不需要为你自己云服务的维护,更新,和安全担忧。
-
-但是,这不完全对,是不是?你有一个家庭网络,所以你不得不负责维护网络的健康和安全。假定你已经维护一个家庭网络,那么[一个家庭NAS][1]并不会增加额外负担。反而你能从少量的工作中得到许多的好处。
-
-你可以为你家里所有的计算机备份(你也可以备份离线网站).构架一个存储电影,音乐和照片的媒体服务器,无需担心网络连接是否连接。在家里的多台计算机处理大型文件,不需要等待从网络其他随机的计算机传输这些文件过来。另外,可以让NAS与其他服务一起进行双重任务,如托管本地邮件或者家庭Wiki。也许最重要的是,构架家庭NAS,数据完全是你的,始终在控制下和随时可访问的。
-
-接下来的问题是如何选择NAS方案。当然,你可以购买预先建立的解决方案,并在某一天打电话购买,但是这会有什么乐趣呢?实际上,尽管拥有一个能处理一切的设备很棒,但最好还是有一个可以修复和升级的钻机。这是一个我近期发现的解决方案。我选择安装和配置[openmediavault][2]。
-
-### 为什么选择openmediavault?
-
-市面上有不少开源的NAS解决方案,其中有些无可争议的比openmediavault流行。当我询问周遭,例如,[freeNAS][3]最常被推荐给我。那么为什么我不采纳他们的建议呢?毕竟,它被大范围的使用,包含很多的功能,并且提供许多支持选项,[基于FreeNAS官网的一份对比数据][4]。当然这些全部是对的。但是openmediavault也不差。它是基于FreeNAS早期版本,虽然它在下载和功能方面的数量较低,但是对于我的需求而言,它已经相当足够了。
-
-另外一个因素是它让我感到很舒适。openmediavault的底层操作系统是[Debian][5],然而FreeNAS是[FreeBSD][6]。由于我个人对FressBSD不是很熟悉,因此如果我的NAS出现故障,必定会很难在FreeBSD上修复故障。同样的,也会让我觉得很难微调配置或添加服务到机器上。当然,我可以学习FreeBSD和更熟悉它,但是我已经在家里构架了这个NAS;我发现,如果限制给定自己完成构建NAS的“学习机会”的数量,构建NAS往往会更成功。
-
-当然,每个情况都不同,所以你要自己调研,然后作出最适合自己方案的决定。FreeNAS对于许多人似乎都是不错的解决方案。Openmediavault正是适合我的解决方案。
-
-### 安装与配置
-
-在[openmediavault文档]里详细记录了安装步骤,所以我不在这里重述了。如果你曾经安装过任何一个linux版本,大部分安装步骤都是很类似的(虽然在相对丑陋的[Ucurses][9]界面,不像你可能在现代版本的相对美观的安装界面)。我通过使用[专用驱动器][9]指令来安装它。然而,这些指令不但很好,而且相当精炼的。当你搞定这些指令,你安装了一个基本的系统,但是你还需要做很多才能真正构建好NAS来存储任何文件。例如,专用驱动器指令在硬盘驱动上安装openmediavault,但那是操作系统的驱动,而不是和网络上其他计算机共享空间的那个驱动。你需要自己把这些建立起来并且配置好。
-
-你要做的第一件事是加载用来管理的网页界面和修改默认密码。这个密码和之前你安装过程设置的根密码是不同的。这是网页洁面的管理员账号,和默认的账户和密码分别是 `admin` 和 `openmediavault`,当你登入后自然而然地会修改这些配置属性。
-
-#### 设置你的驱动
-
-一旦你安装好openmediavault,你需要它为你做一些工作。逻辑上的第一个步骤是设置好你即将用来作为存储的驱动。在这里,我假定你已经物理上安装好它们了,所以接下来你要做的就是让openmediavault识别和配置它们。第一步是确保这些磁盘是可见的。侧边栏菜单有很多选项,而且被精心的归类了。选择**存储 - > 磁盘**。一旦你点击该菜单,你应该能够看到所有你已经安装到该服务器的驱动,包括那个你已经用来安装openmediavault的驱动。如果你没有在那里看到所有驱动,点击扫描按钮去看它能够接载它们。通常,这不会是一个问题。
-
-当你的文件共享时,你可以独立的挂载和设置这些驱动,但是对于一个文件服务器,你将想要一些冗余驱动。你想要能够把很多驱动当作一个单一卷和能够在某一个驱动出现故障或者空间不足下安装新驱动的情况下恢复你的数据。这意味你将需要一个[RAID][10]。你想要的什么特定类型的RAID的主题是一个深深的兔子洞,是一个值得另写一片文章专门来讲述它(而且已经有很多关于该主题的文章了),但是简而言之是你将需要不仅仅一个驱动和最好的情况下,你的所有驱动都存储一样数量的数据。
-
-openmedia支持所有标准的RAID级别,所以多了解RAID对你很有好处的。可以在**存储 - > RAID管理**配置你的RAID。配置是相当简单:点击创建按钮,在你的RAID阵列里选择你想要的磁盘和你想要使用的RAID级别,和给这个阵列一个名字。openmediavault为你处理剩下的工作。没有混乱的命令行,试图记住‘mdadm'命令的一些标志参数。在我特别的例子,我有六个2TB驱动,并被设置为RAID 10.
-
-当你的RAID构建好了,基本上你已经有一个地方可以存储东西了。你仅仅需要设置一个文件系统。正如你的桌面系统,一个硬盘驱动在没有格式化情况下是没什么用处的。所以下一个你要去的地方的是位于openmediavault控制面板里的 **存储 - > 文件系统**。和配置你的RAID一样,点击创建按钮,然后跟着提示操作。如果你只有一个RAID在你的服务器上,你应该可以看到一个像 `md0`的东西。你也需要选择文件系统的类别。如果你不能确定,选择标准的ext4类型即可。
-
-#### 定义你的共享
-
-亲爱的!你有个地方可以存储文件了。现在你只需要让它在你的家庭网络中可见。可以从在openmediavault控制面板上的**服务**部分上配置。当谈到在网络上设置文件共享,有两个主要的选择:NFS或者SMB/CIFS. 根据以往经验,如果你网络上的所有计算机都是Linux系统,那么你使用NFS会更好。然而,当你家庭网络是一个混合环境,是一个包含Linux,Windows,苹果系统和嵌入式设备的组合,那么SMB/CIF可能会是你合适的选择。
-
-这些选项不是互斥的。实际上,你可以在服务器上运行这些服务和同时拥有这些服务的好处。或者你可以混合起来,如果你有一个特定的设备做特定的任务。不管你的使用场景是怎样,配置这些服务是相当简单。点击你想要的服务,从它配置中激活它,和在网络中设定你想要的共享文件夹为可见。在基于SMB/CIFS共享的情况下,相对于NFS多了一些可用的配置,但是一般用默认配置就挺好的,接着可以在默认基础上修改配置。最酷的事情是它很容易配置,同时也很容易在需要的时候修改配置。
-
-#### 用户配置
-
-基本上已将完成了。你已经在RAID配置你的驱动。你已经用一种文件系统格式化了RAID。和你已经在格式化的RAID上设定了共享文件夹。剩下来的一件事情是配置那些人可以访问这些共享和可以访问多少。这个可以在 **访问权限管理** 配置区设置。使用 **用户** 和 **群组** 选项来设定可以连接到你共享文件加的用户和设定这些共享文件的访问权限。
-
-一旦你完成用户配置,你几乎准备好了。你需要从不同客户端机器访问你的共享,但是这是另外一个可以单独写个文章的话题了。
-
-玩得开心!
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/9/openmediavault
-
-作者:[Jason van Gumster][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[jamelouis](https://github.com/jamelouis)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/mairin
-[1]: https://opensource.com/article/18/8/automate-backups-raspberry-pi
-[2]: https://openmediavault.org
-[3]: https://freenas.org
-[4]: http://www.freenas.org/freenas-vs-openmediavault/
-[5]: https://www.debian.org/
-[6]: https://www.freebsd.org/
-[7]: https://openmediavault.readthedocs.io/en/latest/installation/index.html
-[8]: https://invisible-island.net/ncurses/
-[9]: https://openmediavault.readthedocs.io/en/latest/installation/via_iso.html
-[10]: https://en.wikipedia.org/wiki/RAID
diff --git a/translated/tech/20180918 Linux firewalls- What you need to know about iptables and firewalld.md b/translated/tech/20180918 Linux firewalls- What you need to know about iptables and firewalld.md
deleted file mode 100644
index c3ecb7b1d3..0000000000
--- a/translated/tech/20180918 Linux firewalls- What you need to know about iptables and firewalld.md
+++ /dev/null
@@ -1,178 +0,0 @@
-Linux 防火墙: 关于 iptables 和 firewalld,你需要知道些什么
-======
-
-以下是如何使用 iptables 和 firewalld 工具来管理 Linux 防火墙规则。
-
-
-这篇文章摘自我的书[Linux in Action][1],第二 Manning project 尚未发布。
-
-### 防火墙
-
-
-防火墙是一组规则。当数据包进出受保护的网络时,进出内容(特别是关于其来源、目标和使用的协议等信息)会根据防火墙规则进行检测,以确定是否允许其通过。下面是一个简单的例子:
-
-
-![防火墙过滤请求] [3]
-
-防火墙可以根据协议或基于目标的规则过滤请求。
-
-一方面, [iptables][4] 是 Linux 机器上管理防火墙规则的工具。
-
-另一方面,[firewalld][5]也是 Linux 机器上管理防火墙规则的工具。
-
-你有什么问题吗?如果我告诉你还有另外一种工具,叫做 [nftables][6],这会不会糟蹋你的一天呢?
-
-好吧,我承认整件事确实有点好笑,所以让我解释一下了。这一切都从 Netfilter 开始,在 Linux 内核模块级别, Netfilter 控制访问网络栈。几十年来,管理 Netfilter 钩子的主要命令行工具是 iptables 规则集。
-
-因为调用这些规则所需的语法看起来有点晦涩难懂,所以各种用户友好的实现方式,如[ufw][7] 和 firewalld 被引入作,并为更高级别的 Netfilter 解释器。然而,Ufw 和 firewalld 主要是为解决独立计算机面临的各种问题而设计的。构建全方面的网络解决方案通常需要 iptables,或者从2014年起,它的替代品 nftables (nft 命令行工具)。
-
-
-iptables 没有消失,仍然被广泛使用着。事实上,在未来的许多年里,作为一名管理员,你应该会使用 iptables 来保护的网络。但是nftables 通过操作经典的 Netfilter 工具集带来了一些重要的崭新的功能。
-
-
-从现在开始,我将通过示例展示 firewalld 和 iptables 如何解决简单的连接问题。
-
-### 使用 firewalld 配置 HTTP 访问
-
-正如你能从它的名字中猜到的,firewalld 是 [systemd][8] 家族的一部分。Firewalld 可以安装在 Debian/Ubuntu 机器上,不过, 它默认安装在 RedHat 和 CentOS 上。如果您的计算机上运行着像 Apache 这样的 web 服务器,您可以通过浏览服务器的 web 根目录来确认防火墙是否正在工作。如果网站不可访问,那么 firewalld 正在工作。
-
-你可以使用 `firewall-cmd` 工具从命令行管理 firewalld 设置。添加 `–state` 参数将返回当前防火墙的状态:
-
-```
-# firewall-cmd --state
-running
-```
-
-默认情况下,firewalld 将处于运行状态,并将拒绝所有传入流量,但有几个例外,如 SSH。这意味着你的网站不会有太多的访问者,这无疑会为你节省大量的数据传输成本。然而,这不是你对 web 服务器的要求,你希望打开 HTTP 和 HTTPS 端口,按照惯例,这两个端口分别被指定为80和443。firewalld 提供了两种方法来实现这个功能。一个是通过 `–add-port` 参数,该参数直接引用端口号及其将使用的网络协议(在本例中为TCP )。 另外一个是通过`–permanent` 参数,它告诉 firewalld 在每次服务器启动时加载此规则:
-
-
-```
-# firewall-cmd --permanent --add-port=80/tcp
-# firewall-cmd --permanent --add-port=443/tcp
-```
-
- `–reload` 参数将这些规则应用于当前会话:
-
-```
-# firewall-cmd --reload
-```
-
-查看当前防火墙上的设置, 运行 `–list-services` :
-
-```
-# firewall-cmd --list-services
-dhcpv6-client http https ssh
-```
-
-假设您已经如前所述添加了浏览器访问,那么 HTTP、HTTPS 和 SSH 端口现在都应该是开放的—— `dhcpv6-client` ,它允许 Linux 从本地 DHCP 服务器请求 IPv6 IP地址。
-
-### 使用 iptables 配置锁定的客户信息亭
-
-我相信你已经看到了信息亭——它们是放在机场、图书馆和商务场所的盒子里的平板电脑、触摸屏和ATM类电脑,邀请顾客和路人浏览内容。大多数信息亭的问题是,你通常不希望用户像在自己家一样,把他们当成自己的设备。它们通常不是用来浏览、观看 YouTube 视频或对五角大楼发起拒绝服务攻击的。因此,为了确保它们没有被滥用,你需要锁定它们。
-
-
-一种方法是应用某种信息亭模式,无论是通过巧妙使用Linux显示管理器还是在浏览器级别。但是为了确保你已经堵塞了所有的漏洞,你可能还想通过防火墙添加一些硬网络控制。在下一节中,我将讲解如何使用iptables 来完成。
-
-
-关于使用iptables,有两件重要的事情需要记住:你给规则的顺序非常关键,iptables 规则本身在重新启动后将无法存活。我会一次一个地在解释这些。
-
-### 信息亭项目
-
-为了说明这一切,让我们想象一下,我们为一家名为 BigMart 的大型连锁商店工作。它们已经存在了几十年;事实上,我们想象中的祖父母可能是在那里购物并长大的。但是这些天,BigMart 公司总部的人可能只是在数着亚马逊将他们永远赶下去的时间。
-
-尽管如此,BigMart 的IT部门正在尽他们最大努力提供解决方案,他们向你发放了一些具有 WiFi 功能信息亭设备,你在整个商店的战略位置使用这些设备。其想法是,登录到 BigMart.com 产品页面,允许查找商品特征、过道位置和库存水平。信息亭还允许进入 bigmart-data.com,那里储存着许多图像和视频媒体信息。
-
-除此之外,您还需要允许下载软件包更新。最后,您还希望只允许从本地工作站访问SSH,并阻止其他人登录。下图说明了它将如何工作:
-
-![信息亭流量IP表] [10]
-
-信息亭业务流由 iptables 控制。
-
-### 脚本
-
-以下是 Bash 脚本内容:
-
-```
-#!/bin/bash
-iptables -A OUTPUT -p tcp -d bigmart.com -j ACCEPT
-iptables -A OUTPUT -p tcp -d bigmart-data.com -j ACCEPT
-iptables -A OUTPUT -p tcp -d ubuntu.com -j ACCEPT
-iptables -A OUTPUT -p tcp -d ca.archive.ubuntu.com -j ACCEPT
-iptables -A OUTPUT -p tcp --dport 80 -j DROP
-iptables -A OUTPUT -p tcp --dport 443 -j DROP
-iptables -A INPUT -p tcp -s 10.0.3.1 --dport 22 -j ACCEPT
-iptables -A INPUT -p tcp -s 0.0.0.0/0 --dport 22 -j DROP
-```
-
-我们从基本规则 `-A` 开始分析,它告诉iptables 我们要添加规则。`OUTPUT` 意味着这条规则应该成为输出的一部分。`-p` 表示该规则仅使用TCP协议的数据包,正如`-d` 告诉我们的,目的地址是 [bigmart.com][11]。`-j` 参数作用为数据包符合规则时要采取的操作是 `ACCEPT`。第一条规则表示允许或接受请求。但,最后一条规则表示删除或拒绝的请求。
-
-规则顺序是很重要的。iptables 仅仅允许匹配规则的内容请求通过。一个向外发出的浏览器请求,比如访问[youtube.com][12] 是会通过的,因为这个请求匹配第四条规则,但是当它到达“dport 80”或“dport 443”规则时——取决于是HTTP还是HTTPS请求——它将被删除。iptables不再麻烦检查了,因为那是一场比赛。
-
-另一方面,向ubuntu.com 发出软件升级的系统请求,只要符合其适当的规则,就会通过。显然,我们在这里做的是,只允许向我们的 BigMart 或 Ubuntu 发送 HTTP 或 HTTPS 请求,而不允许向其他目的地发送。
-
-最后两条规则将处理 SSH 请求。因为它不使用端口80或443端口,而是使用22端口,所以之前的两个丢弃规则不会拒绝它。在这种情况下,来自我的工作站的登录请求将被接受,但是对其他任何地方的请求将被拒绝。这一点很重要:确保用于端口22规则的IP地址与您用来登录的机器的地址相匹配——如果不这样做,将立即被锁定。当然,这没什么大不了的,因为按照目前的配置方式,只需重启服务器,iptables 规则就会全部丢失。如果使用 LXC 容器作为服务器并从 LXC 主机登录,则使用主机 IP 地址连接容器,而不是其公共地址。
-
-如果机器的IP发生变化,请记住更新这个规则;否则,你会被拒绝访问。
-
-在家玩(是在某种性虚拟机上)?太好了。创建自己的脚本。现在我可以保存脚本,使用`chmod` 使其可执行,并以`sudo` 的形式运行它。不要担心 `igmart-data.com没找到`错误——当然没找到;它不存在。
-
-```
-chmod +X scriptname.sh
-sudo ./scriptname.sh
-```
-
-你可以使用`cURL` 命令行测试防火墙。请求 ubuntu.com 奏效,但请求 [manning.com][13]是失败的 。
-
-
-```
-curl ubuntu.com
-curl manning.com
-```
-
-### 配置 iptables 以在系统启动时加载
-
-现在,我如何让这些规则在每次 kiosk 启动时自动加载?第一步是将当前规则保存。使用`iptables-save` 工具保存规则文件。将在根目录中创建一个包含规则列表的文件。管道后面跟着 tee 命令,是将我的`sudo` 权限应用于字符串的第二部分:将文件实际保存到否则受限的根目录。
-
-然后我可以告诉系统每次启动时运行一个相关的工具,叫做`iptables-restore` 。我们在上一模块中看到的常规cron 作业,因为它们在设定的时间运行,但是我们不知道什么时候我们的计算机可能会决定崩溃和重启。
-
-有许多方法来处理这个问题。这里有一个:
-
-
-在我的 Linux 机器上,我将安装一个名为 [anacron][14] 的程序,该程序将在 /etc/ 目录中为我们提供一个名为anacrondab 的文件。我将编辑该文件并添加这个 `iptables-restore` 命令,告诉它加载该文件的当前值。引导后一分钟,规则每天(必要时)加载到 iptables 中。我会给作业一个标识符( `iptables-restore` ),然后添加命令本身。如果你在家和我一起这样,你应该通过重启系统来测试一下。
-
-```
-sudo iptables-save | sudo tee /root/my.active.firewall.rules
-sudo apt install anacron
-sudo nano /etc/anacrontab
-1 1 iptables-restore iptables-restore < /root/my.active.firewall.rules
-
-```
-
-我希望这些实际例子已经说明了如何使用 iptables 和 firewalld 来管理基于Linux的防火墙上的连接问题。
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/9/linux-iptables-firewalld
-
-作者:[David Clinton][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[heguangzhi](https://github.com/heguangzhi)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/remyd
-[1]: https://www.manning.com/books/linux-in-action?a_aid=bootstrap-it&a_bid=4ca15fc9&chan=opensource
-[2]: /file/409116
-[3]: https://opensource.com/sites/default/files/uploads/iptables1.jpg (firewall filtering request)
-[4]: https://en.wikipedia.org/wiki/Iptables
-[5]: https://firewalld.org/
-[6]: https://wiki.nftables.org/wiki-nftables/index.php/Main_Page
-[7]: https://en.wikipedia.org/wiki/Uncomplicated_Firewall
-[8]: https://en.wikipedia.org/wiki/Systemd
-[9]: /file/409121
-[10]: https://opensource.com/sites/default/files/uploads/iptables2.jpg (kiosk traffic flow ip tables)
-[11]: http://bigmart.com/
-[12]: http://youtube.com/
-[13]: http://manning.com/
-[14]: https://sourceforge.net/projects/anacron/
diff --git a/translated/tech/20180927 How To Find And Delete Duplicate Files In Linux.md b/translated/tech/20180927 How To Find And Delete Duplicate Files In Linux.md
new file mode 100644
index 0000000000..c1b637bf2f
--- /dev/null
+++ b/translated/tech/20180927 How To Find And Delete Duplicate Files In Linux.md
@@ -0,0 +1,439 @@
+如何在 Linux 中找到并删除重复文件
+======
+
+
+
+在编辑或修改配置文件或旧文件前,我经常会把它们备份到硬盘的某个地方,因此我如果意外地改错了这些文件,我可以从备份中恢复它们。但问题是如果我忘记清理备份文件,一段时间之后,我的磁盘会被这些大量重复文件填满。我觉得要么是懒得清理这些旧文件,要么是担心可能会删掉重要文件。如果你们像我一样,在类 Unix 操作系统中,大量多版本的相同文件放在不同的备份目录,你可以使用下面的工具找到并删除重复文件。
+
+**提醒一句:**
+
+在删除重复文件的时请尽量小心。如果你不小心,也许会导致[**意外丢失数据**][1]。我建议你在使用这些工具的时候要特别注意。
+
+### 在 Linux 中找到并删除重复文件
+
+
+出于本指南的目的,我将讨论下面的三个工具:
+
+ 1. Rdfind
+ 2. Fdupes
+ 3. FSlint
+
+
+
+这三个工具是免费的、开源的,且运行在大多数类 Unix 系统中。
+
+##### 1. Rdfind
+
+**Rdfind** 代表找到找到冗余数据,是一个通过访问目录和子目录来找出重复文件的免费、开源的工具。它是基于文件内容而不是文件名来比较。Rdfind 使用**排序**算法来区分原始文件和重复文件。如果你有两个或者更多的相同文件,Rdfind 会很智能的找到原始文件并认定剩下的文件为重复文件。一旦找到副本文件,它会向你报告。你可以决定是删除还是使用[**硬链接**或者**符号(软)链接**][2]代替它们。
+
+**安装 Rdfind**
+
+Rdfind 存在于 [**AUR**][3] 中。因此,在基于 Arch 的系统中,你可以像下面一样使用任一如 [**Yay**][4] AUR 程序助手安装它。
+
+```
+$ yay -S rdfind
+
+```
+
+在 Debian、Ubuntu、Linux Mint 上:
+
+```
+$ sudo apt-get install rdfind
+
+```
+
+在 Fedora 上:
+
+```
+$ sudo dnf install rdfind
+
+```
+
+在 RHEL、CentOS 上:
+
+```
+$ sudo yum install epel-release
+
+$ sudo yum install rdfind
+
+```
+
+**用法**
+
+一旦安装完成,仅带上目录路径运行 Rdfind 命令就可以扫描重复文件。
+
+```
+$ rdfind ~/Downloads
+
+```
+
+
+
+正如你看到上面的截屏,Rdfind 命令将扫描 ~/Downloads 目录,并将结果存储到当前工作目录下一个名为 **results.txt** 的文件中。你可以在 results.txt 文件中看到可能是重复文件的名字。
+
+```
+$ cat results.txt
+# Automatically generated
+# duptype id depth size device inode priority name
+DUPTYPE_FIRST_OCCURRENCE 1469 8 9 2050 15864884 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test5.regex
+DUPTYPE_WITHIN_SAME_TREE -1469 8 9 2050 15864886 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test6.regex
+[...]
+DUPTYPE_FIRST_OCCURRENCE 13 0 403635 2050 15740257 1 /home/sk/Downloads/Hyperledger(1).pdf
+DUPTYPE_WITHIN_SAME_TREE -13 0 403635 2050 15741071 1 /home/sk/Downloads/Hyperledger.pdf
+# end of file
+
+```
+
+通过检查 results.txt 文件,你可以很容易的找到那些重复文件。如果愿意你可以手动的删除它们。
+
+此外,你可在不修改其他事情情况下使用 **-dryrun** 选项找出所有重复文件,并在终端上输出汇总信息。
+
+```
+$ rdfind -dryrun true ~/Downloads
+
+```
+
+一旦找到重复文件,你可以使用硬链接或符号链接代替他们。
+
+使用硬链接代替所有重复文件,运行:
+
+```
+$ rdfind -makehardlinks true ~/Downloads
+
+```
+
+使用符号链接/软链接代替所有重复文件,运行:
+
+```
+$ rdfind -makesymlinks true ~/Downloads
+
+```
+
+目录中有一些空文件,也许你想忽略他们,你可以像下面一样使用 **-ignoreempty** 选项:
+
+```
+$ rdfind -ignoreempty true ~/Downloads
+
+```
+
+如果你不再想要这些旧文件,删除重复文件,而不是使用硬链接或软链接代替它们。
+
+删除重复文件,就运行:
+
+```
+$ rdfind -deleteduplicates true ~/Downloads
+
+```
+
+如果你不想忽略空文件,并且和所哟重复文件一起删除。运行:
+
+```
+$ rdfind -deleteduplicates true -ignoreempty false ~/Downloads
+
+```
+
+更多细节,参照帮助部分:
+
+```
+$ rdfind --help
+
+```
+
+手册页:
+
+```
+$ man rdfind
+
+```
+
+##### 2. Fdupes
+
+**Fdupes** 是另一个在指定目录以及子目录中识别和移除重复文件的命令行工具。这是一个使用 **C** 语言编写的免费、开源工具。Fdupes 通过对比文件大小、部分 MD5 签名、全部 MD5 签名,最后执行逐个字节对比校验来识别重复文件。
+
+与 Rdfind 工具类似,Fdupes 附带非常少的选项来执行操作,如:
+
+ * 在目录和子目录中递归的搜索重复文件
+ * 从计算中排除空文件和隐藏文件
+ * 显示重复文件大小
+ * 出现重复文件时立即删除
+ * 使用不同的拥有者/组或权限位来排除重复文件
+ * 更多
+
+
+
+**安装 Fdupes**
+
+Fdupes 存在于大多数 Linux 发行版的默认仓库中。
+
+在 Arch Linux 和它的变种如 Antergos、Manjaro Linux 上,如下使用 Pacman 安装它。
+
+```
+$ sudo pacman -S fdupes
+
+```
+
+在 Debian、Ubuntu、Linux Mint 上:
+
+```
+$ sudo apt-get install fdupes
+
+```
+
+在 Fedora 上:
+
+```
+$ sudo dnf install fdupes
+
+```
+
+在 RHEL、CentOS 上:
+
+```
+$ sudo yum install epel-release
+
+$ sudo yum install fdupes
+
+```
+
+**用法**
+
+Fdupes 用法非常简单。仅运行下面的命令就可以在目录中找到重复文件,如:**~/Downloads**.
+
+```
+$ fdupes ~/Downloads
+
+```
+
+我系统中的样例输出:
+
+```
+/home/sk/Downloads/Hyperledger.pdf
+/home/sk/Downloads/Hyperledger(1).pdf
+
+```
+你可以看到,在 **/home/sk/Downloads/** 目录下有一个重复文件。它仅显示了父级目录中的重复文件。如何显示子目录中的重复文件?像下面一样,使用 **-r** 选项。
+
+```
+$ fdupes -r ~/Downloads
+
+```
+
+现在你将看到 **/home/sk/Downloads/** 目录以及子目录中的重复文件。
+
+Fdupes 也可用来从多个目录中迅速查找重复文件。
+
+```
+$ fdupes ~/Downloads ~/Documents/ostechnix
+
+```
+
+你甚至可以搜索多个目录,递归搜索其中一个目录,如下:
+
+```
+$ fdupes ~/Downloads -r ~/Documents/ostechnix
+
+```
+
+上面的命令将搜索 “~/Downloads” 目录,“~/Documents/ostechnix” 目录和它的子目录中的重复文件。
+
+有时,你可能想要知道一个目录中重复文件的大小。你可以使用 **-S** 选项,如下:
+
+```
+$ fdupes -S ~/Downloads
+403635 bytes each:
+/home/sk/Downloads/Hyperledger.pdf
+/home/sk/Downloads/Hyperledger(1).pdf
+
+```
+
+类似的,为了显示父目录和子目录中重复文件的大小,使用 **-Sr** 选项。
+
+我们可以在计算时分别使用 **-n** 和 **-A** 选项排除空白文件以及排除隐藏文件。
+
+```
+$ fdupes -n ~/Downloads
+
+$ fdupes -A ~/Downloads
+
+```
+
+在搜索指定目录的重复文件时,第一个命令将排除零长度文件,后面的命令将排除隐藏文件。
+
+汇总重复文件信息,使用 **-m** 选项。
+
+```
+$ fdupes -m ~/Downloads
+1 duplicate files (in 1 sets), occupying 403.6 kilobytes
+
+```
+
+删除所有重复文件,使用 **-d** 选项。
+
+```
+$ fdupes -d ~/Downloads
+
+```
+
+样例输出:
+
+```
+[1] /home/sk/Downloads/Hyperledger Fabric Installation.pdf
+[2] /home/sk/Downloads/Hyperledger Fabric Installation(1).pdf
+
+Set 1 of 1, preserve files [1 - 2, all]:
+
+```
+
+这个命令将提示你保留还是删除所有其他重复文件。输入任一号码保留相应的文件,并删除剩下的文件。当使用这个选项的时候需要更加注意。如果不小心,你可能会删除原文件。
+
+如果你想要每次保留每个重复文件集合的第一个文件,且无提示的删除其他文件,使用 **-dN** 选项(不推荐)。
+
+```
+$ fdupes -dN ~/Downloads
+
+```
+
+当遇到重复文件时删除它们,使用 **-I** 标志。
+
+```
+$ fdupes -I ~/Downloads
+
+```
+
+关于 Fdupes 的更多细节,查看帮助部分和 man 页面。
+
+```
+$ fdupes --help
+
+$ man fdupes
+
+```
+
+##### 3. FSlint
+
+**FSlint** 是另外一个查找重复文件的工具,有时我用它去掉 Linux 系统中不需要的重复文件并释放磁盘空间。不像另外两个工具,FSlint 有 GUI 和 CLI 两种模式。因此对于新手来说它更友好。FSlint 不仅仅找出重复文件,也找出坏符号链接、坏名字文件、临时文件、坏 IDS、空目录和非剥离二进制文件等等。
+
+**安装 FSlint**
+
+FSlint 存在于 [**AUR**][5],因此你可以使用任一 AUR 助手安装它。
+
+```
+$ yay -S fslint
+
+```
+
+在 Debian、Ubuntu、Linux Mint 上:
+
+```
+$ sudo apt-get install fslint
+
+```
+
+在 Fedora 上:
+
+```
+$ sudo dnf install fslint
+
+```
+
+在 RHEL,CentOS 上:
+
+```
+$ sudo yum install epel-release
+$ sudo yum install fslint
+
+```
+
+一旦安装完成,从菜单或者应用程序启动器启动它。
+
+FSlint GUI 展示如下:
+
+
+
+如你所见,FSlint 接口友好、一目了然。在 **Search path** 栏,添加你要扫描的目录路径,点击左下角 **Find** 按钮查找重复文件。验证递归选项可以在目录和子目录中递归的搜索重复文件。FSlint 将快速的扫描给定的目录并列出重复文件。
+
+
+
+从列表中选择那些要清理的重复文件,也可以选择 Save、Delete、Merge 和 Symlink 操作他们。
+
+在 **Advanced search parameters** 栏,你可以在搜索重复文件的时候指定排除的路径。
+
+
+
+**FSlint 命令行选项**
+
+FSlint 提供下面的 CLI 工具集在你的文件系统中查找重复文件。
+
+ * **findup** — 查找重复文件
+ * **findnl** — 查找 Lint 名称文件(有问题的文件名)
+ * **findu8** — 查找非法的 utf8 编码文件
+ * **findbl** — 查找坏链接(有问题的符号链接)
+ * **findsn** — 查找同名文件(可能有冲突的文件名)
+ * **finded** — 查找空目录
+ * **findid** — 查找死用户的文件
+ * **findns** — 查找非剥离的可执行文件
+ * **findrs** — 查找文件中多于的空白
+ * **findtf** — 查找临时文件
+ * **findul** — 查找可能未使用的库
+ * **zipdir** — 回收 ext2 目录实体下浪费的空间
+
+
+
+所有这些工具位于 **/usr/share/fslint/fslint/fslint** 下面。
+
+
+例如,在给定的目录中查找重复文件,运行:
+
+```
+$ /usr/share/fslint/fslint/findup ~/Downloads/
+
+```
+
+类似的,找出空目录命令是:
+
+```
+$ /usr/share/fslint/fslint/finded ~/Downloads/
+
+```
+
+获取每个工具更多细节,例如:**findup**,运行:
+
+```
+$ /usr/share/fslint/fslint/findup --help
+
+```
+
+关于 FSlint 的更多细节,参照帮助部分和 man 页。
+
+```
+$ /usr/share/fslint/fslint/fslint --help
+
+$ man fslint
+
+```
+
+##### 总结
+
+现在你知道在 Linux 中,使用三个工具来查找和删除不需要的重复文件。这三个工具中,我经常使用 Rdfind。这并不意味着其他的两个工具效率低下,因为到目前为止我更喜欢 Rdfind。好了,到你了。你的最喜欢哪一个工具呢?为什么?在下面的评论区留言让我们知道吧。
+
+就到这里吧。希望这篇文章对你有帮助。更多的好东西就要来了,敬请期待。
+
+谢谢!
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-find-and-delete-duplicate-files-in-linux/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[pygmalion666](https://github.com/pygmalion666)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[1]: https://www.ostechnix.com/prevent-files-folders-accidental-deletion-modification-linux/
+[2]: https://www.ostechnix.com/explaining-soft-link-and-hard-link-in-linux-with-examples/
+[3]: https://aur.archlinux.org/packages/rdfind/
+[4]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
+[5]: https://aur.archlinux.org/packages/fslint/
diff --git a/translated/tech/20180928 A Free And Secure Online PDF Conversion Suite.md b/translated/tech/20180928 A Free And Secure Online PDF Conversion Suite.md
new file mode 100644
index 0000000000..46cc5067f2
--- /dev/null
+++ b/translated/tech/20180928 A Free And Secure Online PDF Conversion Suite.md
@@ -0,0 +1,104 @@
+一款免费且安全的在线PDF转换软件
+======
+
+
+
+我们总在寻找一个更好用且更高效的解决方案,来我们的生活理加方便。 比方说,在处理PDF文档时,你会迫切地想拥有一款工具,它能够在任何情形下都显得快速可靠。在这,我们想向你推荐**EasyPDF**——一款可以胜任所有场合的在线PDF软件。通过大量的测试,我们可以保证:这款工具能够让你的PDF文档管理更加容易。
+
+不过,关于EasyPDF有一些十分重要的事情,你必须知道。
+
+* EasyPDF是免费的、匿名的在线PDF转换软件。
+* 能够将PDF文档转换成Word、Excel、PowerPoint、AutoCAD、JPG, GIF和Text等格式格式的文档。
+* 能够从ord、Excel、PowerPoint等其他格式的文件创建PDF文件。
+* 能够进行PDF文档的合并、分割和压缩。
+* 能够识别扫描的PDF和图片中的内容。
+* 可以从你的设备或者云存储(Google Drive 和 DropBox)中上传文档。
+* 可以在Windows、Linux、Mac和智能手机上通过浏览器来操作。
+* 支持多种语言。
+
+### EasyPDF的用户界面
+
+
+
+EasyPDF最吸引你眼球的就是平滑的用户界面,营造一种整洁的环境,这会让使用者感觉更加舒服。由于网站完全没有一点广告,EasyPDF的整体使用体验相比以前会好很多。
+
+每种不同类型的转换都有它们专门的菜单,只需要简单地向其中添加文件,你并不需要知道太多知识来进行操作。
+
+许多类似网站没有做好相关的优化,使得在手机上的使用体验并不太友好。然而,EasyPDF突破了这一个瓶颈。在智能手机上,EasyPDF几乎可以秒开,并且可以顺畅的操作。你也通过Chrome app的**three dots menu**把EasyPDF添加到手机的主屏幕上。
+
+
+
+### 特性
+
+除了好看的界面,EasyPDF还非常易于使用。为了使用它,你 **不需要注册一个账号** 或者**留下一个邮箱**,它是完全匿名的。另外,EasyPDF也不会对要转换的文件进行数量或者大小的限制,完全不需要安装!酷极了,不是吗?
+
+首先,你需要选择一种想要进行的格式转换,比如,将PDF转换成Word。然后,选择你想要转换的PDF文件。你可以通过两种方式来上传文件:直接拖拉或者从设备上的文件夹进行选择。还可以选择从[**Google Drive**][1] 或 [**Dropbox**][2]来上传文件。
+
+选择要进行格式转换的文件后,点击Convert按钮开始转换过程。转换过程会在一分钟内完成,你并不需要等待太长时间。如果你还有对其他文件进行格式转换,在接着转换前,不要忘了将前面已经转换完成的文件下载保存。不然的话,你将会丢失前面的文件。
+
+
+
+要进行其他类型的格式转换,直接返回到主页。
+
+目前支持的几种格式转换类型如下:
+
+* **PDF to Word** – 将 PDF 文档 转换成 Word 文档
+
+ * **PDF 转换成 PowerPoint** – 将 PDF 文档 转换成 PowerPoint 演示讲稿
+
+ * **PDF 转换成 Excel** – 将 PDF 文档 转换成 Excel 文档
+
+ * **PDF 创建** – 从一些其他类型的文件(如, text, doc, odt)来创建PDF文档
+
+ * **Word 转换成 PDF** – 将 Word 文档 转换成 PDF 文档
+
+ * **JPG 转换成 PDF** – 将 JPG images 转换成 PDF 文档
+
+ * **PDF 转换成 Au转换成CAD** – 将 PDF 文档 转换成 .dwg 格式 (DWG 是 CAD 文件的原生的格式)
+
+ * **PDF 转换成 Text** – 将 PDF 文档 转换成 Text 文档
+
+ * **PDF 分割** – 把 PDF 文件分割成多个部分
+
+ * **PDF 合并** – 把多个PDF文件合并成一个文件
+
+ * **PDF 压缩** – 将 PDF 文档进行压缩
+
+ * **PDF 转换成 JPG** – 将 PDF 文档 转换成 JPG 图片
+
+ * **PDF 转换成 PNG** – 将 PDF 文档 转换成 PNG 图片
+
+ * **PDF 转换成 GIF** – 将 PDF 文档 转换成 GIF 文件
+
+ * **在线文字内容识别** – 将扫描的纸质文档转换成能够进行编辑的文件(如,Word,Excel,Text)
+
+ 想试一试吗?好极了!点击下面的链接,然后开始格式转换吧!
+
+[][https://easypdf.com/]
+
+### 总结
+
+EasyPDF 名符其实,能够让PDF 管理更加容易。就我测试过的 EasyPDF 服务而言,它提供了**完全免费**的简单易用的转换功能。它十分快速、安全和可靠。你会对它的服务质量感到非常满意,因为它不用支付任何费用,也不用留下像邮箱这样的个人信息。值得一试,也许你会找到你自己更喜欢的 PDF 工具。
+
+好吧,我就说这些。更多的好东西还在后后面,请继续关注!
+
+加油!
+
+
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/easypdf-a-free-and-secure-online-pdf-conversion-suite/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/zhousiyu325)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[1]: https://www.ostechnix.com/how-to-mount-google-drive-locally-as-virtual-file-system-in-linux/
+[2]: https://www.ostechnix.com/install-dropbox-in-ubuntu-18-04-lts-desktop/