mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-09 01:30:10 +08:00
commit
dfcabb6044
171
published/20180116 Command Line Heroes- Season 1- OS Wars_2.md
Normal file
171
published/20180116 Command Line Heroes- Season 1- OS Wars_2.md
Normal file
@ -0,0 +1,171 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11296-1.html)
|
||||
[#]: subject: (Command Line Heroes: Season 1: OS Wars)
|
||||
[#]: via: (https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-2-rise-of-linux)
|
||||
[#]: author: (redhat https://www.redhat.com)
|
||||
|
||||
《代码英雄》第一季(2):操作系统战争(下)Linux 崛起
|
||||
======
|
||||
|
||||
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗故事。
|
||||
|
||||

|
||||
|
||||
本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第一季(2):操作系统战争(下)](https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-2-rise-of-linux) 的[音频](https://dts.podtrac.com/redirect.mp3/audio.simplecast.com/2199861a.mp3)脚本。
|
||||
|
||||
> 微软帝国控制着 90% 的用户。操作系统的完全标准化似乎是板上钉钉的事了。但是一个不太可能的英雄出现在开源反叛组织中。戴着眼镜,温文尔雅的<ruby>林纳斯·托瓦兹<rt>Linus Torvalds</rt></ruby>免费发布了他的 Linux® 程序。微软打了个趔趄,并且开始重整旗鼓而来,战场从个人电脑转向互联网。
|
||||
|
||||
**Saron Yitbarek:** 这玩意开着的吗?让我们进一段史诗般的星球大战的开幕吧,开始了。
|
||||
|
||||
配音:第二集:Linux® 的崛起。微软帝国控制着 90% 的桌面用户。操作系统的全面标准化似乎是板上钉钉的事了。然而,互联网的出现将战争的焦点从桌面转向了企业,在该领域,所有商业组织都争相构建自己的服务器。*[00:00:30]*与此同时,一个不太可能的英雄出现在开源反叛组织中。固执、戴着眼镜的 <ruby>林纳斯·托瓦兹<rt>Linus Torvalds</rt></ruby>免费发布了他的 Linux 系统。微软打了个趔趄,并且开始重整旗鼓而来。
|
||||
|
||||
**Saron Yitbarek:** 哦,我们书呆子就是喜欢那样。上一次我们讲到哪了?苹果和微软互相攻伐,试图在一场争夺桌面用户的战争中占据主导地位。*[00:01:00]* 在第一集的结尾,我们看到微软获得了大部分的市场份额。很快,由于互联网的兴起以及随之而来的开发者大军,整个市场都经历了一场地震。互联网将战场从在家庭和办公室中的个人电脑用户转移到拥有数百台服务器的大型商业客户中。
|
||||
|
||||
这意味着巨量资源的迁移。突然间,所有相关企业不仅被迫为服务器空间和网站建设付费,而且还必须集成软件来进行资源跟踪和数据库监控等工作。*[00:01:30]* 你需要很多开发人员来帮助你。至少那时候大家都是这么做的。
|
||||
|
||||
在操作系统之战的第二部分,我们将看到优先级的巨大转变,以及像林纳斯·托瓦兹和<ruby>理查德·斯托尔曼<rt>Richard Stallman</rt></ruby>这样的开源反逆者是如何成功地在微软和整个软件行业的核心地带引发恐惧的。
|
||||
|
||||
我是 Saron Yitbarek,你现在收听的是代码英雄,一款红帽公司原创的播客节目。*[00:02:00]* 每一集,我们都会给你带来“从码开始”改变技术的人的故事。
|
||||
|
||||
好。想象一下你是 1991 年时的微软。你自我感觉良好,对吧?满怀信心。确立了全球主导的地位感觉不错。你已经掌握了与其他企业合作的艺术,但是仍然将大部分开发人员、程序员和系统管理员排除在联盟之外,而他们才是真正的步兵。*[00:02:30]* 这时出现了个叫林纳斯·托瓦兹的芬兰极客。他和他的开源程序员团队正在开始发布 Linux,这个操作系统内核是由他们一起编写出来的。
|
||||
|
||||
坦白地说,如果你是微软公司,你并不会太在意 Linux,甚至不太关心开源运动,但是最终,Linux 的规模变得如此之大,以至于微软不可能不注意到。*[00:03:00]* Linux 第一个版本出现在 1991 年,当时大概有 1 万行代码。十年后,变成了 300 万行代码。如果你想知道,今天则是 2000 万行代码。
|
||||
|
||||
*[00:03:30]* 让我们停留在 90 年代初一会儿。那时 Linux 还没有成为我们现在所知道的庞然大物。这个奇怪的病毒式的操作系统只是正在这个星球上蔓延,全世界的极客和黑客都爱上了它。那时候我还太年轻,但有点希望我曾经经历过那个时候。在那个时候,发现 Linux 就如同进入了一个秘密社团一样。就像其他人分享地下音乐混音带一样,程序员与朋友们分享 Linux CD 集。
|
||||
|
||||
开发者 Tristram Oaten *[00:03:40]* 讲讲你 16 岁时第一次接触 Linux 的故事吧。
|
||||
|
||||
**Tristram Oaten:** 我和我的家人去了红海的 Hurghada 潜水度假。那是一个美丽的地方,强烈推荐。第一天,我喝了自来水。也许,我妈妈跟我说过不要这么做。我整个星期都病得很厉害,没有离开旅馆房间。*[00:04:00]* 当时我只带了一台新安装了 Slackware Linux 的笔记本电脑,我听说过这玩意并且正在尝试使用它。所有的东西都在 8 张 cd 里面。这种情况下,我只能整个星期都去了解这个外星一般的系统。我阅读手册,摆弄着终端。我记得当时我甚至不知道一个点(表示当前目录)和两个点(表示前一个目录)之间的区别。
|
||||
|
||||
*[00:04:30]* 我一点头绪都没有。犯过很多错误,但慢慢地,在这种强迫的孤独中,我突破了障碍,开始理解并明白命令行到底是怎么回事。假期结束时,我没有看过金字塔、尼罗河等任何埃及遗址,但我解锁了现代世界的一个奇迹。我解锁了 Linux,接下来的事大家都知道了。
|
||||
|
||||
**Saron Yitbarek:** 你会从很多人那里听到关于这个故事的不同说法。访问 Linux 命令行是一种革命性的体验。
|
||||
|
||||
**David Cantrell:** *[00:05:00]* 它给了我源代码。我当时的感觉是,“太神奇了。”
|
||||
|
||||
**Saron Yitbarek:** 我们正在参加一个名为 Flock to Fedora 的 2017 年 Linux 开发者大会。
|
||||
|
||||
**David Cantrell:** ……非常有吸引力。我觉得我对这个系统有了更多的控制力,它越来越吸引我。我想,从 1995 年我第一次编译 Linux 内核那时起,我就迷上了它。
|
||||
|
||||
**Saron Yitbarek:** 开发者 David Cantrell 与 Joe Brockmire。
|
||||
|
||||
**Joe Brockmeier:** *[00:05:30]* 我在 Cheap Software 转的时候发现了一套四张 CD 的 Slackware Linux。它看起来来非常令人兴奋而且很有趣,所以我把它带回家,安装在第二台电脑上,开始摆弄它,有两件事情让我感到很兴奋:一个是,我运行的不是 Windows,另一个是 Linux 的开源特性。
|
||||
|
||||
**Saron Yitbarek:** *[00:06:00]* 某种程度上来说,对命令行的使用总是存在的。在开源真正开始流行还要早的几十年前,人们(至少在开发人员中是这样)总是希望能够做到完全控制。让我们回到操作系统大战之前的那个时代,在苹果和微软为他们的 GUI 而战之前。那时也有代码英雄。<ruby>保罗·琼斯<rt>Paul Jones</rt></ruby>教授(在线图书馆 ibiblio.org 的负责人)在那个古老的时代,就是一名开发人员。
|
||||
|
||||
**Paul Jones:** *[00:06:30]* 从本质上讲,互联网在那个时候客户端-服务器架构还是比较少的,而更多的是点对点架构的。确实,我们会说,某种 VAX 到 VAX 的连接(LCTT 译注:DEC 的一种操作系统),某种科学工作站到科学工作站的连接。这并不意味着没有客户端-服务端的架构及应用程序,但这的确意味着,最初的设计是思考如何实现点对点,*[00:07:00]* 它与 IBM 一直在做的东西相对立。IBM 给你的只有哑终端,这种终端只能让你管理用户界面,却无法让你像真正的终端一样为所欲为。
|
||||
|
||||
**Saron Yitbarek:** 图形用户界面在普通用户中普及的同时,在工程师和开发人员中总是存在着一股相反的力量。早在 Linux 出现之前的二十世纪七八十年代,这股力量就存在于 Emacs 和 GNU 中。有了斯托尔曼的自由软件基金会后,总有某些人想要使用命令行,但上世纪 90 年代的 Linux 提供了前所未有的东西。
|
||||
|
||||
*[00:07:30]* Linux 和其他开源软件的早期爱好者是都是先驱。我正站在他们的肩膀上。我们都是。
|
||||
|
||||
你现在收听的是代码英雄,一款由红帽公司原创的播客。这是操作系统大战的第二部分:Linux 崛起。
|
||||
|
||||
**Steven Vaughan-Nichols:** 1998 年的时候,情况发生了变化。
|
||||
|
||||
**Saron Yitbarek:** *[00:08:00]* Steven Vaughan-Nichols 是 zdnet.com 的特约编辑,他已经写了几十年关于技术商业方面的文章了。他将向我们讲述 Linux 是如何慢慢变得越来越流行,直到自愿贡献者的数量远远超过了在 Windows 上工作的微软开发人员的数量的。不过,Linux 从未真正追上微软桌面客户的数量,这也许就是微软最开始时忽略了 Linux 及其开发者的原因。Linux 真正大放光彩的地方是在服务器机房。当企业开始线上业务时,每个企业都需要一个满足其需求的独特编程解决方案。
|
||||
|
||||
*[00:08:30]* WindowsNT 于 1993 年问世,当时它已经在与其他的服务器操作系统展开竞争了,但是许多开发人员都在想,“既然我可以通过 Apache 构建出基于 Linux 的廉价系统,那我为什么要购买 AIX 设备或大型 Windows 设备呢?”关键点在于,Linux 代码已经开始渗透到几乎所有网上的东西中。
|
||||
|
||||
**Steven Vaughan-Nichols:** *[00:09:00]* 令微软感到惊讶的是,它开始意识到,Linux 实际上已经开始有一些商业应用,不是在桌面环境,而是在商业服务器上。因此,他们发起了一场运动,我们称之为 FUD - <ruby>恐惧、不确定和怀疑<rt>fear, uncertainty and double</rt></ruby>。他们说,“哦,Linux 这玩意,真的没有那么好。它不太可靠。你一点都不能相信它”。
|
||||
|
||||
**Saron Yitbarek:** 这种软宣传式的攻击持续了一段时间。微软也不是唯一一个对 Linux 感到紧张的公司。这其实是整个行业在对抗这个奇怪新人的挑战。*[00:09:30]* 例如,任何与 UNIX 有利害关系的人都可能将 Linux 视为篡夺者。有一个案例很著名,那就是 SCO 组织(它发行过一种 UNIX 版本)在过去 10 多年里发起一系列的诉讼,试图阻止 Linux 的传播。SCO 最终失败而且破产了。与此同时,微软一直在寻找机会,他们必须要采取动作,只是不清楚具体该怎么做。
|
||||
|
||||
**Steven Vaughan-Nichols:** *[00:10:00]* 让微软真正担心的是,第二年,在 2000 年的时候,IBM 宣布,他们将于 2001 年投资 10 亿美元在 Linux 上。现在,IBM 已经不再涉足个人电脑业务。(那时)他们还没有走出去,但他们正朝着这个方向前进,他们将 Linux 视为服务器和大型计算机的未来,在这一点上,剧透警告,IBM 是正确的。*[00:10:30]* Linux 将主宰服务器世界。
|
||||
|
||||
**Saron Yitbarek:** 这已经不再仅仅是一群黑客喜欢他们对命令行的绝地武士式的控制了。金钱的投入对 Linux 助力极大。<ruby>Linux 国际<rt>Linux International</rt></ruby>的执行董事 John “Mad Dog” Hall 有一个故事可以解释为什么会这样。我们通过电话与他取得了联系。
|
||||
|
||||
**John Hall:** *[00:11:00]* 我有一个名叫 Dirk Holden 的朋友,他是德国德意志银行的系统管理员,他也参与了个人电脑上早期 X Windows 系统图形项目的工作。有一天我去银行拜访他,我说:“Dirk,你银行里有 3000 台服务器,用的都是 Linux。为什么不用 Microsoft NT 呢?”*[00:11:30]* 他看着我说:“是的,我有 3000 台服务器,如果使用微软的 Windows NT 系统,我需要 2999 名系统管理员。”他继续说道:“而使用 Linux,我只需要四个。”这真是完美的答案。
|
||||
|
||||
**Saron Yitbarek:** 程序员们着迷的这些东西恰好对大公司也极具吸引力。但由于 FUD 的作用,一些企业对此持谨慎态度。*[00:12:00]* 他们听到开源,就想:“开源。这看起来不太可靠,很混乱,充满了 BUG”。但正如那位银行经理所指出的,金钱有一种有趣的方式,可以说服人们克服困境。甚至那些只需要网站的小公司也加入了 Linux 阵营。与一些昂贵的专有选择相比,使用一个廉价的 Linux 系统在成本上是无法比拟的。如果你是一家雇佣专业人员来构建网站的商店,那么你肯定想让他们使用 Linux。
|
||||
|
||||
让我们快进几年。Linux 运行每个人的网站上。Linux 已经征服了服务器世界,然后智能手机也随之诞生。*[00:12:30]* 当然,苹果和他们的 iPhone 占据了相当大的市场份额,而且微软也希望能进入这个市场,但令人惊讶的是,Linux 也在那,已经做好准备了,迫不及待要大展拳脚。
|
||||
|
||||
作家兼记者 James Allworth。
|
||||
|
||||
**James Allworth:** 肯定还有容纳第二个竞争者的空间,那本可以是微软,但是实际上却是 Android,而 Andrid 基本上是基于 Linux 的。众所周知,Android 被谷歌所收购,现在运行在世界上大部分的智能手机上,谷歌在 Linux 的基础上创建了 Android。*[00:13:00]* Linux 使他们能够以零成本从一个非常复杂的操作系统开始。他们成功地实现了这一目标,最终将微软挡在了下一代设备之外,至少从操作系统的角度来看是这样。
|
||||
|
||||
**Saron Yitbarek:** *[00:13:30]* 这可是个大地震,很大程度上,微软有被埋没的风险。John Gossman 是微软 Azure 团队的首席架构师。他还记得当时困扰公司的困惑。
|
||||
|
||||
**John Gossman:** 像许多公司一样,微软也非常担心知识产权污染。他们认为,如果允许开发人员使用开源代码,那么他们可能只是将一些代码复制并粘贴到某些产品中,就会让某种病毒式的许可证生效从而引发未知的风险……他们也很困惑,*[00:14:00]* 我认为,这跟公司文化有关,很多公司,包括微软,都对开源开发的意义和商业模式之间的分歧感到困惑。有一种观点认为,开源意味着你所有的软件都是免费的,人们永远不会付钱。
|
||||
|
||||
**Saron Yitbarek:** 任何投资于旧的、专有软件模型的人都会觉得这里发生的一切对他们构成了威胁。当你威胁到像微软这样的大公司时,是的,他们一定会做出反应。*[00:14:30]* 他们推动所有这些 FUD —— 恐惧、不确定性和怀疑是有道理的。当时,商业运作的方式基本上就是相互竞争。不过,如果是其他公司的话,他们可能还会一直怀恨在心,抱残守缺,但到了 2013 年的微软,一切都变了。
|
||||
|
||||
微软的云计算服务 Azure 上线了,令人震惊的是,它从第一天开始就提供了 Linux 虚拟机。*[00:15:00]* <ruby>史蒂夫·鲍尔默<rt>Steve Ballmer</rt></ruby>,这位把 Linux 称为癌症的首席执行官,已经离开了,代替他的是一位新的有远见的首席执行官<ruby>萨提亚·纳德拉<rt>Satya Nadella</rt></ruby>。
|
||||
|
||||
**John Gossman:** 萨提亚有不同的看法。他属于另一个世代。比保罗、比尔和史蒂夫更年轻的世代,他对开源有不同的看法。
|
||||
|
||||
**Saron Yitbarek:** 还是来自微软 Azure 团队的 John Gossman。
|
||||
|
||||
**John Gossman:** *[00:15:30]* 大约四年前,处于实际需要,我们在 Azure 中添加了 Linux 支持。如果访问任何一家企业客户,你都会发现他们并不会才试着决定是使用 Windows 还是使用 Linux、 使用 .net 还是使用 Java ^TM 。他们在很久以前就做出了决定 —— 大约 15 年前才有这样的一些争论。*[00:16:00]* 现在,我见过的每一家公司都混合了 Linux 和 Java、Windows 和 .net、SQL Server、Oracle 和 MySQL —— 基于专有源代码的产品和开放源代码的产品。
|
||||
|
||||
如果你打算运维一个云服务,允许这些公司在云上运行他们的业务,那么你根本不能告诉他们,“你可以使用这个软件,但你不能使用那个软件。”
|
||||
|
||||
**Saron Yitbarek:** *[00:16:30]* 这正是萨提亚·纳德拉采纳的哲学思想。2014 年秋季,他站在舞台上,希望传递一个重要信息。“微软爱 Linux”。他接着说,“20% 的 Azure 业务量已经是 Linux 了,微软将始终对 Linux 发行版提供一流的支持。”没有哪怕一丝对开源的宿怨。
|
||||
|
||||
为了说明这一点,在他们的背后有一个巨大的标志,上面写着:“Microsoft ❤️ Linux”。哇噢。对我们中的一些人来说,这种转变有点令人震惊,但实际上,无需如此震惊。下面是 Steven Levy,一名科技记者兼作家。
|
||||
|
||||
**Steven Levy:** *[00:17:00]* 当你在踢足球的时候,如果草坪变滑了,那么你也许会换一种不同的鞋子。他们当初就是这么做的。*[00:17:30]* 他们不能否认现实,而且他们里面也有聪明人,所以他们必须意识到,这就是这个世界的运行方式,不管他们早些时候说了什么,即使他们对之前的言论感到尴尬,但是让他们之前关于开源多么可怕的言论影响到现在明智的决策那才真的是疯了。
|
||||
|
||||
**Saron Yitbarek:** 微软低下了它高傲的头。你可能还记得苹果公司,经过多年的孤立无援,最终转向与微软构建合作伙伴关系。现在轮到微软进行 180 度转变了。*[00:18:00]* 经过多年的与开源方式的战斗后,他们正在重塑自己。要么改变,要么死亡。Steven Vaughan-Nichols。
|
||||
|
||||
**Steven Vaughan-Nichols:** 即使是像微软这样规模的公司也无法与数千个开发着包括 Linux 在内的其它大项目的开源开发者竞争。很长时间以来他们都不愿意这么做。前微软首席执行官史蒂夫·鲍尔默对 Linux 深恶痛绝。*[00:18:30]* 由于它的 GPL 许可证,他视 Linux 为一种癌症,但一旦鲍尔默被扫地出门,新的微软领导层说,“这就好像试图命令潮流不要过来,但潮水依然会不断涌进来。我们应该与 Linux 合作,而不是与之对抗。”
|
||||
|
||||
**Saron Tiebreak:** 事实上,互联网技术史上最大的胜利之一就是微软最终决定做出这样的转变。*[00:19:00]* 当然,当微软出现在开源圈子时,老一代的铁杆 Linux 支持者是相当怀疑的。他们不确定自己是否能接受这些家伙,但正如 Vaughan-Nichols 所指出的,今天的微软已经不是以前的微软了。
|
||||
|
||||
**Steven Vaughan-Nichols:** 2017 年的微软既不是史蒂夫·鲍尔默的微软,也不是比尔·盖茨的微软。这是一家完全不同的公司,有着完全不同的方法,而且,一旦使用了开源,你就无法退回到之前。*[00:19:30]* 开源已经吞噬了整个技术世界。从未听说过 Linux 的人可能对它并不了解,但是每次他们访问 Facebook,他们都在运行 Linux。每次执行谷歌搜索时,你都在运行 Linux。
|
||||
|
||||
*[00:20:00]* 每次你用 Android 手机,你都在运行 Linux。它确实无处不在,微软无法阻止它,而且我认为以为微软能以某种方式接管它的想法,太天真了。
|
||||
|
||||
**Saron Yitbarek:** 开源支持者可能一直担心微软会像混入羊群中的狼一样,但事实是,开源软件的本质保护了它无法被完全控制。*[00:20:30]* 没有一家公司能够拥有 Linux 并以某种特定的方式控制它。Greg Kroah-Hartman 是 Linux 基金会的一名成员。
|
||||
|
||||
**Greg Kroah-Hartman:** 每个公司和个人都以自私的方式为 Linux 做出贡献。他们之所以这样做是因为他们想要解决他们所面临的问题,可能是硬件无法工作,或者是他们想要添加一个新功能来做其他事情,又或者想在他们的产品中使用它。这很棒,因为他们会把代码贡献回去,此后每个人都会从中受益,这样每个人都可以用到这份代码。正是因为这种自私,所有的公司,所有的人都能从中受益。
|
||||
|
||||
**Saron Yitbarek:** *[00:21:00]* 微软已经意识到,在即将到来的云战争中,与 Linux 作战就像与空气作战一样。Linux 和开源不是敌人,它们是空气。如今,微软以白金会员的身份加入了 Linux 基金会。他们成为 GitHub 开源项目的头号贡献者。*[00:21:30]* 2017 年 9 月,他们甚至加入了<ruby>开源促进联盟<rt>Open Source Initiative</rt></ruby>。现在,微软在开源许可证下发布了很多代码。微软的 John Gossman 描述了他们开源 .net 时所发生的事情。起初,他们并不认为自己能得到什么回报。
|
||||
|
||||
**John Gossman:** 我们本没有指望来自社区的贡献,然而,三年后,超过 50% 的对 .net 框架库的贡献来自于微软之外。这包括大量的代码。*[00:22:00]* 三星为 .net 提供了 ARM 支持。Intel 和 ARM 以及其他一些芯片厂商已经为 .net 框架贡献了特定于他们处理器的代码生成,以及数量惊人的修复、性能改进等等 —— 既有单个贡献者也有社区。
|
||||
|
||||
**Saron Yitbarek:** 直到几年前,今天的这个微软,这个开放的微软,还是不可想象的。
|
||||
|
||||
*[00:22:30]* 我是 Saron Yitbarek,这里是代码英雄。好吧,我们已经看到了为了赢得数百万桌面用户的爱而战的激烈场面。我们已经看到开源软件在专有软件巨头的背后悄然崛起,并攫取了巨大的市场份额。*[00:23:00]* 我们已经看到了一批批的代码英雄将编程领域变成了我你今天看到的这个样子。如今,大企业正在吸收开源软件,通过这一切,每个人都从他人那里受益。
|
||||
|
||||
在技术的西部荒野,一贯如此。苹果受到施乐的启发,微软受到苹果的启发,Linux 受到 UNIX 的启发。进化、借鉴、不断成长。如果比喻成大卫和歌利亚(LCTT 译注:西方经典的以弱胜强战争中的两个主角)的话,开源软件不再是大卫,但是,你知道吗?它也不是歌利亚。*[00:23:30]* 开源已经超越了传统。它已经成为其他人战斗的战场。随着开源道路变得不可避免,新的战争,那些在云计算中进行的战争,那些在开源战场上进行的战争正在加剧。
|
||||
|
||||
这是 Steven Levy,他是一名作者。
|
||||
|
||||
**Steven Levy:** 基本上,到目前为止,包括微软在内,有四到五家公司,正以各种方式努力把自己打造成为全方位的平台,比如人工智能领域。你能看到智能助手之间的战争,你猜怎么着?*[00:24:00]* 苹果有一个智能助手,叫 Siri。微软有一个,叫 Cortana。谷歌有谷歌助手。三星也有一个智能助手。亚马逊也有一个,叫 Alexa。我们看到这些战斗遍布各地。也许,你可以说,最热门的人工智能平台将控制我们生活中所有的东西,而这五家公司就是在为此而争斗。
|
||||
|
||||
**Saron Yitbarek:** *[00:24:30]* 如果你正在寻找另一个反叛者,它们就像 Linux 奇袭微软那样,偷偷躲在 Facebook、谷歌或亚马逊身后,你也许要等很久,因为正如作家 James Allworth 所指出的,成为一个真正的反叛者只会变得越来越难。
|
||||
|
||||
**James Allworth:** 规模一直以来都是一种优势,但规模优势本质上……怎么说呢,我认为以前它们在本质上是线性的,现在它们在本质上是指数型的了,所以,一旦你开始以某种方法走在前面,另一个新玩家要想赶上来就变得越来越难了。*[00:25:00]* 我认为在互联网时代这大体来说来说是正确的,无论是因为规模,还是数据赋予组织的竞争力的重要性和优势。一旦你走在前面,你就会吸引更多的客户,这就给了你更多的数据,让你能做得更好,这之后,客户还有什么理由选择排名第二的公司呢,难道是因为因为他们落后了这么远么?*[00:25:30]* 我认为在云的时代这个逻辑也不会有什么不同。
|
||||
|
||||
**Saron Yitbarek:** 这个故事始于史蒂夫·乔布斯和比尔·盖茨这样的非凡的英雄,但科技的进步已经呈现出一种众包、有机的感觉。我认为据说我们的开源英雄林纳斯·托瓦兹在第一次发明 Linux 内核时甚至没有一个真正的计划。他无疑是一位才华横溢的年轻开发者,但他也像潮汐前的一滴水一样。*[00:26:00]* 变革是不可避免的。据估计,对于一家专有软件公司来说,用他们老式的、专有的方式创建一个 Linux 发行版将花费他们超过 100 亿美元。这说明了开源的力量。
|
||||
|
||||
最后,这并不是一个专有模型所能与之竞争的东西。成功的公司必须保持开放。这是最大、最终极的教训。*[00:26:30]* 还有一点要记住:当我们连接在一起的时候,我们在已有基础上成长和建设的能力是无限的。不管这些公司有多大,我们都不必坐等他们给我们更好的东西。想想那些为了纯粹的创造乐趣而学习编码的新开发者,那些自己动手丰衣足食的人。
|
||||
|
||||
未来的优秀程序员无管来自何方,只要能够访问代码,他们就能构建下一个大项目。
|
||||
|
||||
*[00:27:00]* 以上就是我们关于操作系统战争的两个故事。这场战争塑造了我们的数字生活。争夺主导地位的斗争从桌面转移到了服务器机房,最终进入了云计算领域。过去的敌人难以置信地变成了盟友,众包的未来让一切都变得开放。*[00:27:30]* 听着,我知道,在这段历史之旅中,还有很多英雄我们没有提到,所以给我们写信吧。分享你的故事。[Redhat.com/commandlineheroes](https://www.redhat.com/commandlineheroes) 。我恭候佳音。
|
||||
|
||||
在本季剩下的时间里,我们将学习今天的英雄们在创造什么,以及他们要经历什么样的战斗才能将他们的创造变为现实。让我们从壮丽的编程一线回来看看更多的传奇故事吧。我们每两周放一集新的博客。几周后,我们将为你带来第三集:敏捷革命。
|
||||
|
||||
*[00:28:00]* 代码英雄是一款红帽公司原创的播客。要想免费自动获得新一集的代码英雄,请订阅我们的节目。只要在苹果播客、Spotify、谷歌 Play,或其他应用中搜索“Command Line Heroes”。然后点击“订阅”。这样你就会第一个知道什么时候有新剧集了。
|
||||
|
||||
我是 Saron Yitbarek。感谢收听。继续编码。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-2-rise-of-linux
|
||||
|
||||
作者:[redhat][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.redhat.com
|
||||
[b]: https://github.com/lujun9972
|
||||
115
published/20180704 BASHing data- Truncated data items.md
Normal file
115
published/20180704 BASHing data- Truncated data items.md
Normal file
@ -0,0 +1,115 @@
|
||||
如何发现截断的数据项
|
||||
======
|
||||
|
||||
**截断**(形容词):缩写、删节、缩减、剪切、剪裁、裁剪、修剪……
|
||||
|
||||
数据项被截断的一种情况是将其输入到数据库字段中,该字段的字符限制比数据项的长度要短。例如,字符串:
|
||||
|
||||
```
|
||||
Yarrow Ravine Rattlesnake Habitat Area, 2 mi ENE of Yermo CA
|
||||
```
|
||||
|
||||
是 60 个字符长。如果你将其输入到具有 50 个字符限制的“位置”字段,则可以获得:
|
||||
|
||||
```
|
||||
Yarrow Ravine Rattlesnake Habitat Area, 2 mi ENE #末尾带有一个空格
|
||||
```
|
||||
|
||||
截断也可能导致数据错误,比如你打算输入:
|
||||
|
||||
```
|
||||
Sally Ann Hunter (aka Sally Cleveland)
|
||||
```
|
||||
|
||||
但是你忘记了闭合的括号:
|
||||
|
||||
```
|
||||
Sally Ann Hunter (aka Sally Cleveland
|
||||
```
|
||||
|
||||
这会让使用数据的用户觉得 Sally 是否有被修剪掉了数据项的其它的别名。
|
||||
|
||||
截断的数据项很难检测。在审核数据时,我使用三种不同的方法来查找可能的截断,但我仍然可能会错过一些。
|
||||
|
||||
**数据项的长度分布。**第一种方法是捕获我在各个字段中找到的大多数截断的数据。我将字段传递给 `awk` 命令,该命令按字段宽度计算数据项,然后我使用 `sort` 以宽度的逆序打印计数。例如,要检查以 `tab` 分隔的文件 `midges` 中的第 33 个字段:
|
||||
|
||||
```
|
||||
awk -F"\t" 'NR>1 {a[length($33)]++} \
|
||||
END {for (i in a) print i FS a[i]}' midges | sort -nr
|
||||
```
|
||||
|
||||
![distro1][1]
|
||||
|
||||
最长的条目恰好有 50 个字符,这是可疑的,并且在该宽度处存在数据项的“凸起”,这更加可疑。检查这些 50 个字符的项目会发现截断:
|
||||
|
||||
![distro2][2]
|
||||
|
||||
我用这种方式检查的其他数据表有 100、200 和 255 个字符的“凸起”。在每种情况下,这种“凸起”都包含明显的截断。
|
||||
|
||||
**未匹配的括号。**第二种方法查找类似 `...(Sally Cleveland` 的数据项。一个很好的起点是数据表中所有标点符号的统计。这里我检查文件 `mag2`:
|
||||
|
||||
```
|
||||
grep -o "[[:punct:]]" file | sort | uniqc
|
||||
```
|
||||
|
||||
![punct][3]
|
||||
|
||||
请注意,`mag2` 中的开括号和闭括号的数量不相等。要查看发生了什么,我使用 `unmatched` 函数,它接受三个参数并检查数据表中的所有字段。第一个参数是文件名,第二个和第三个是开括号和闭括号,用引号括起来。
|
||||
|
||||
```
|
||||
unmatched()
|
||||
{
|
||||
awk -F"\t" -v start="$2" -v end="$3" \
|
||||
'{for (i=1;i<=NF;i++) \
|
||||
if (split($i,a,start) != split($i,b,end)) \
|
||||
print "line "NR", field "i":\n"$i}' "$1"
|
||||
}
|
||||
```
|
||||
|
||||
如果在字段中找到开括号和闭括号之间不匹配,则 `unmatched` 会报告行号和字段号。这依赖于 `awk` 的 `split` 函数,它返回由分隔符分隔的元素数(包括空格)。这个数字总是比分隔符的数量多一个:
|
||||
|
||||
![split][4]
|
||||
|
||||
这里 `ummatched` 检查 `mag2` 中的圆括号并找到一些可能的截断:
|
||||
|
||||
![unmatched][5]
|
||||
|
||||
我使用 `unmatched` 来找到不匹配的圆括号 `()`、方括号 `[]`、花括号 `{}` 和尖括号 `<>`,但该函数可用于任何配对的标点字符。
|
||||
|
||||
**意外的结尾。**第三种方法查找以尾随空格或非终止标点符号结尾的数据项,如逗号或连字符。这可以在单个字段上用 `cut` 用管道输入到 `grep` 完成,或者用 `awk` 一步完成。在这里,我正在检查以制表符分隔的表 `herp5` 的字段 47,并提取可疑数据项及其行号:
|
||||
|
||||
```
|
||||
cut -f47 herp5 | grep -n "[ ,;:-]$"
|
||||
或
|
||||
awk -F"\t" '$47 ~ /[ ,;:-]$/ {print NR": "$47}' herp5
|
||||
```
|
||||
|
||||
![herps5][6]
|
||||
|
||||
用于制表符分隔文件的 awk 命令的全字段版本是:
|
||||
|
||||
```
|
||||
awk -F"\t" '{for (i=1;i<=NF;i++) if ($i ~ /[ ,;:-]$/) \
|
||||
print "line "NR", field "i":\n"$i}' file
|
||||
```
|
||||
|
||||
**谨慎的想法。**在我对字段进行的验证测试期间也会出现截断。例如,我可能会在“年”的字段中检查合理的 4 位数条目,并且有个 `198` 可能是 198n?还是 1898 年?带有丢失字符的截断数据项是个谜。 作为数据审计员,我只能报告(可能的)字符损失,并建议数据编制者或管理者恢复(可能)丢失的字符。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.polydesmida.info/BASHing/2018-07-04.html
|
||||
|
||||
作者:[polydesmida][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.polydesmida.info/
|
||||
[1]:https://www.polydesmida.info/BASHing/img1/2018-07-04_1.png
|
||||
[2]:https://www.polydesmida.info/BASHing/img1/2018-07-04_2.png
|
||||
[3]:https://www.polydesmida.info/BASHing/img1/2018-07-04_3.png
|
||||
[4]:https://www.polydesmida.info/BASHing/img1/2018-07-04_4.png
|
||||
[5]:https://www.polydesmida.info/BASHing/img1/2018-07-04_5.png
|
||||
[6]:https://www.polydesmida.info/BASHing/img1/2018-07-04_6.png
|
||||
@ -0,0 +1,141 @@
|
||||
Linux 上 5 个最好 CAD 软件
|
||||
======
|
||||
|
||||
[计算机辅助设计 (CAD)][1] 是很多工程流程的必不可少的部分。CAD 用于建筑、汽车零部件设计、航天飞机研究、航空、桥梁施工、室内设计,甚至服装和珠宝设计等专业领域。
|
||||
|
||||
在 Linux 上并不原生支持一些专业级 CAD 软件,如 SolidWorks 和 Autodesk AutoCAD。因此,今天,我们将看看排名靠前的 Linux 上可用的 CAD 软件。预知详情,请看下文。
|
||||
|
||||
### Linux 可用的最好的 CAD 软件
|
||||
|
||||
![CAD Software for Linux][2]
|
||||
|
||||
在我们查看这份 Linux 的 CAD 软件列表前,你应该记住一件事,在这里不是所有的应用程序都是开源软件。我们也将包含一些非自由和开源软件的 CAD 软件来帮助普通的 Linux 用户。
|
||||
|
||||
我们为基于 Ubuntu 的 Linux 发行版提供了安装操作指南。对于其它发行版,你可以检查相应的网站来了解安装程序步骤。
|
||||
|
||||
该列表没有任何特殊顺序。在第一顺位的 CAD 应用程序不能认为比在第三顺位的好,以此类推。
|
||||
|
||||
#### 1、FreeCAD
|
||||
|
||||
对于 3D 建模,FreeCAD 是一个极好的选择,它是自由 (免费和自由) 和开源软件。FreeCAD 坚持以构建机械工程和产品设计为目标。FreeCAD 是多平台的,可用于 Windows、Mac OS X+ 以及 Linux。
|
||||
|
||||
![freecad][3]
|
||||
|
||||
尽管 FreeCAD 已经是很多 Linux 用户的选择,应该注意到,FreeCAD 仍然是 0.17 版本,因此,不适用于重要的部署。但是最近开发加速了。
|
||||
|
||||
- [FreeCAD][4]
|
||||
|
||||
FreeCAD 并不专注于 direct-2D 绘图和真实形状的动画,但是它对机械工程相关的设计极好。FreeCAD 的 0.15 版本在 Ubuntu 存储库中可用。你可以通过运行下面的命令安装。
|
||||
|
||||
```
|
||||
sudo apt install freecad
|
||||
```
|
||||
|
||||
为获取新的每日构建(目前 0.17),打开一个终端(`ctrl+alt+t`),并逐个运行下面的命令。
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:freecad-maintainers/freecad-daily
|
||||
sudo apt update
|
||||
sudo apt install freecad-daily
|
||||
```
|
||||
|
||||
#### 2、LibreCAD
|
||||
|
||||
LibreCAD 是一个自由开源的、2D CAD 解决方案。一般来说,CAD 是一个资源密集型任务,如果你有一个相当普通的硬件,那么我建议你使用 LibreCAD ,因为它在资源使用方面真的轻量化。LibreCAD 是几何图形结构方面的一个极好的候选者。
|
||||
|
||||
![librecad][5]
|
||||
|
||||
作为一个 2D 工具,LibreCAD 是好的,但是它不能在 3D 模型和渲染上工作。它有时可能不稳定,但是,它有一个可靠的自动保存,它不会让你的工作浪费。
|
||||
|
||||
- [LibreCAD][6]
|
||||
|
||||
你可以通过运行下面的命令安装 LibreCAD。
|
||||
|
||||
```
|
||||
sudo apt install librecad
|
||||
```
|
||||
|
||||
#### 3、OpenSCAD
|
||||
|
||||
OpenSCAD 是一个自由的 3D CAD 软件。OpenSCAD 非常轻量和灵活。OpenSCAD 不是交互式的。你需要‘编程’模型,OpenSCAD 来解释这些代码来渲染一个可视化模型。在某种意义上说,它是一个编译器。你不能直接绘制模型,而是描述模型。
|
||||
|
||||
![openscad][7]
|
||||
|
||||
OpenSCAD 是这个列表上最复杂的工具,但是,一旦你了解它,它将提供一个令人愉快的工作经历。
|
||||
|
||||
- [OpenSCAD][8]
|
||||
|
||||
你可以使用下面的命令来安装 OpenSCAD。
|
||||
|
||||
```
|
||||
sudo apt-get install openscad
|
||||
```
|
||||
|
||||
#### 4、BRL-CAD
|
||||
|
||||
BRL-CAD 是最老的 CAD 工具之一。它也深受 Linux/UNIX 用户喜爱,因为它与模块化和自由的 *nix 哲学相一致。
|
||||
|
||||
![BRL-CAD rendering by Sean][9]
|
||||
|
||||
BRL-CAD 始于 1979 年,并且,它仍然在积极开发。现在,BRL-CAD 不是 AutoCAD,但是对于像热穿透和弹道穿透等等的运输研究仍然是一个极好的选择。BRL-CAD 构成 CSG 的基础,而不是边界表示。在选择 BRL-CAD 时,你可能需要记住这一点。你可以从它的官方网站下载 BRL-CAD 。
|
||||
|
||||
- [BRL-CAD][10]
|
||||
|
||||
#### 5、DraftSight (非开源)
|
||||
|
||||
如果你习惯在 AutoCAD 上作业。那么,DraftSight 将是完美的替代。
|
||||
|
||||
DraftSight 是一个在 Linux 上可用的极好的 CAD 工具。它有相当类似于 AutoCAD 的工作流,这使得迁移更容易。它甚至提供一种类似的外观和感觉。DrafSight 也兼容 AutoCAD 的 .dwg 文件格式。 但是,DrafSight 是一个 2D CAD 软件。截至当前,它不支持 3D CAD 。
|
||||
|
||||
![draftsight][11]
|
||||
|
||||
尽管 DrafSight 是一款起价 149 美元的商业软件。在 [DraftSight 网站][12]上可获得一个免费版本。你可以下载 .deb 软件包,并在基于 Ubuntu 的发行版上安装它。为了开始使用 DraftSight ,你需要使用你的电子邮件 ID 来注册你的免费版本。
|
||||
|
||||
- [DraftSight][12]
|
||||
|
||||
#### 荣誉提名
|
||||
|
||||
* 随着云计算技术的巨大发展,像 [OnShape][13] 的云 CAD 解决方案已经变得日渐流行。
|
||||
* [SolveSpace][14] 是另一个值得一提的开源软件项目。它支持 3D 模型。
|
||||
* 西门子 NX 是一个在 Windows、Mac OS 及 Linux 上可用的工业级 CAD 解决方案,但是它贵得离谱,所以,在这个列表中被忽略。
|
||||
* 接下来,你有 [LeoCAD][15],它是一个 CAD 软件,在软件中你使用乐高积木来构建东西。你使用这些信息做些什么取决于你。
|
||||
|
||||
### 我对 Linux 上的 CAD 的看法
|
||||
|
||||
尽管在 Linux 上游戏变得流行,我总是告诉我的铁杆游戏朋友坚持使用 Windows。类似地,如果你是一名在你是课程中使用 CAD 的工科学生,我建议你使用学校规定的软件 (AutoCAD、SolidEdge、Catia),这些软件通常只在 Windows 上运行。
|
||||
|
||||
对于高级专业人士来说,当我们讨论行业标准时,这些工具根本达不到标准。
|
||||
|
||||
对于想在 WINE 中运行 AutoCAD 的那些人来说,尽管一些较旧版本的 AutoCAD 可以安装在 WINE 上,它们根本不执行工作,小故障和崩溃严重损害这些体验。
|
||||
|
||||
话虽如此,我高度尊重上述列表中软件的开发者的工作。他们丰富了 FOSS 世界。很高兴看到像 FreeCAD 一样的软件在近些年中加速开发速度。
|
||||
|
||||
好了,今天到此为止。使用下面的评论区与我们分享你的想法,不用忘记分享这篇文章。谢谢。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/cad-software-linux/
|
||||
|
||||
作者:[Aquil Roshan][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/aquil/
|
||||
[1]:https://en.wikipedia.org/wiki/Computer-aided_design
|
||||
[2]:https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/08/cad-software-linux.jpeg
|
||||
[3]:https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/07/freecad.jpg
|
||||
[4]:https://www.freecadweb.org/
|
||||
[5]:https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/07/librecad.jpg
|
||||
[6]:https://librecad.org/
|
||||
[7]:https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/07/openscad.jpg
|
||||
[8]:http://www.openscad.org/
|
||||
[9]:https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/07/brlcad.jpg
|
||||
[10]:https://brlcad.org/
|
||||
[11]:https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/07/draftsight.jpg
|
||||
[12]:https://www.draftsight2018.com/
|
||||
[13]:https://www.onshape.com/
|
||||
[14]:http://solvespace.com/index.pl
|
||||
[15]:https://www.leocad.org/
|
||||
@ -0,0 +1,89 @@
|
||||
区块链能如何补充开源
|
||||
======
|
||||
|
||||
> 了解区块链如何成为去中心化的开源补贴模型。
|
||||
|
||||

|
||||
|
||||
《<ruby>[大教堂与集市][1]<rt>The Cathedral and The Bazaar</rt></ruby>》是 20 年前由<ruby>埃里克·史蒂文·雷蒙德<rt>Eric Steven Raymond<rt></ruby>(ESR)撰写的经典开源故事。在这个故事中,ESR 描述了一种新的革命性的软件开发模型,其中复杂的软件项目是在没有(或者很少的)集中管理的情况下构建的。这个新模型就是<ruby>开源<rt>open source</rt></ruby>。
|
||||
|
||||
ESR 的故事比较了两种模式:
|
||||
|
||||
* 经典模型(由“大教堂”所代表),其中软件由一小群人在封闭和受控的环境中通过缓慢而稳定的发布制作而成。
|
||||
* 以及新模式(由“集市”所代表),其中软件是在开放的环境中制作的,个人可以自由参与,但仍然可以产生一个稳定和连贯的系统。
|
||||
|
||||
开源如此成功的一些原因可以追溯到 ESR 所描述的创始原则。尽早发布、经常发布,并接受许多头脑必然比一个更好的事实,让开源项目进入全世界的人才库(很少有公司能够使用闭源模式与之匹敌)。
|
||||
|
||||
在 ESR 对黑客社区的反思分析 20 年后,我们看到开源成为占据主导地位的的模式。它不再仅仅是为了满足开发人员的个人喜好,而是创新发生的地方。甚至是全球[最大][2]软件公司也正在转向这种模式,以便继续占据主导地位。
|
||||
|
||||
### 易货系统
|
||||
|
||||
如果我们仔细研究开源模型在实践中的运作方式,我们就会意识到它是一个封闭系统,只对开源开发者和技术人员开放。影响项目方向的唯一方法是加入开源社区,了解成文和不成文的规则,学习如何贡献、编码标准等,并自己亲力完成。
|
||||
|
||||
这就是集市的运作方式,也是这个易货系统类比的来源。易货系统是一种交换服务和货物以换取其他服务和货物的方法。在市场中(即软件的构建地)这意味着为了获取某些东西,你必须自己也是一个生产者并回馈一些东西——那就是通过交换你的时间和知识来完成任务。集市是开源开发者与其他开源开发者交互并以开源方式生成开源软件的地方。
|
||||
|
||||
易货系统向前迈出了一大步,从自给自足的状态演变而来,而在自给自足的状态下,每个人都必须成为所有行业的杰出人选。使用易货系统的集市(开源模式)允许具有共同兴趣和不同技能的人们收集、协作和创造个人无法自行创造的东西。易货系统简单,没有现代货币系统那么复杂,但也有一些局限性,例如:
|
||||
|
||||
* 缺乏可分性:在没有共同的交换媒介的情况下,不能将较大的不可分割的商品/价值兑换成较小的商品/价值。例如,如果你想在开源项目中进行一些哪怕是小的更改,有时你可能仍需要经历一个高进入门槛。
|
||||
* 存储价值:如果一个项目对贵公司很重要,你可能需要投入大量投资/承诺。但由于它是开源开发者之间的易货系统,因此拥有强大发言权的唯一方法是雇佣许多开源贡献者,但这并非总是可行的。
|
||||
* 转移价值:如果你投资了一个项目(受过培训的员工、雇用开源开发者)并希望将重点转移到另一个项目,却不可能快速转移(你在上一个项目中拥有的)专业知识、声誉和影响力。
|
||||
* 时间脱钩:易货系统没有为延期或提前承诺提供良好的机制。在开源世界中,这意味着用户无法提前或在未来期间以可衡量的方式表达对项目的承诺或兴趣。
|
||||
|
||||
下面,我们将探讨如何使用集市的后门解决这些限制。
|
||||
|
||||
### 货币系统
|
||||
|
||||
人们因为不同的原因勾连于集市上:有些人在那里学习,有些是出于满足开发者个人的喜好,有些人为大型软件工厂工作。因为在集市中拥有发言权的唯一方法是成为开源社区的一份子并加入这个易货系统,为了在开源世界获得信誉,许多大型软件公司雇用这些开发者并以货币方式支付薪酬。这代表可以使用货币系统来影响集市,开源不再只是为了满足开发者个人的喜好,它也占据全球整体软件生产的重要部分,并且有许多人想要施加影响。
|
||||
|
||||
开源设定了开发人员交互的指导原则,并以分布式方式构建一致的系统。它决定了项目的治理方式、软件的构建方式以及其成果如何分发给用户。它是分散的实体共同构建高质量软件的开放共识模型。但是开源模型并没有包括如何补贴开源的部分,无论是直接还是间接地,通过内在或外在动机的赞助,都与集市无关。
|
||||
|
||||
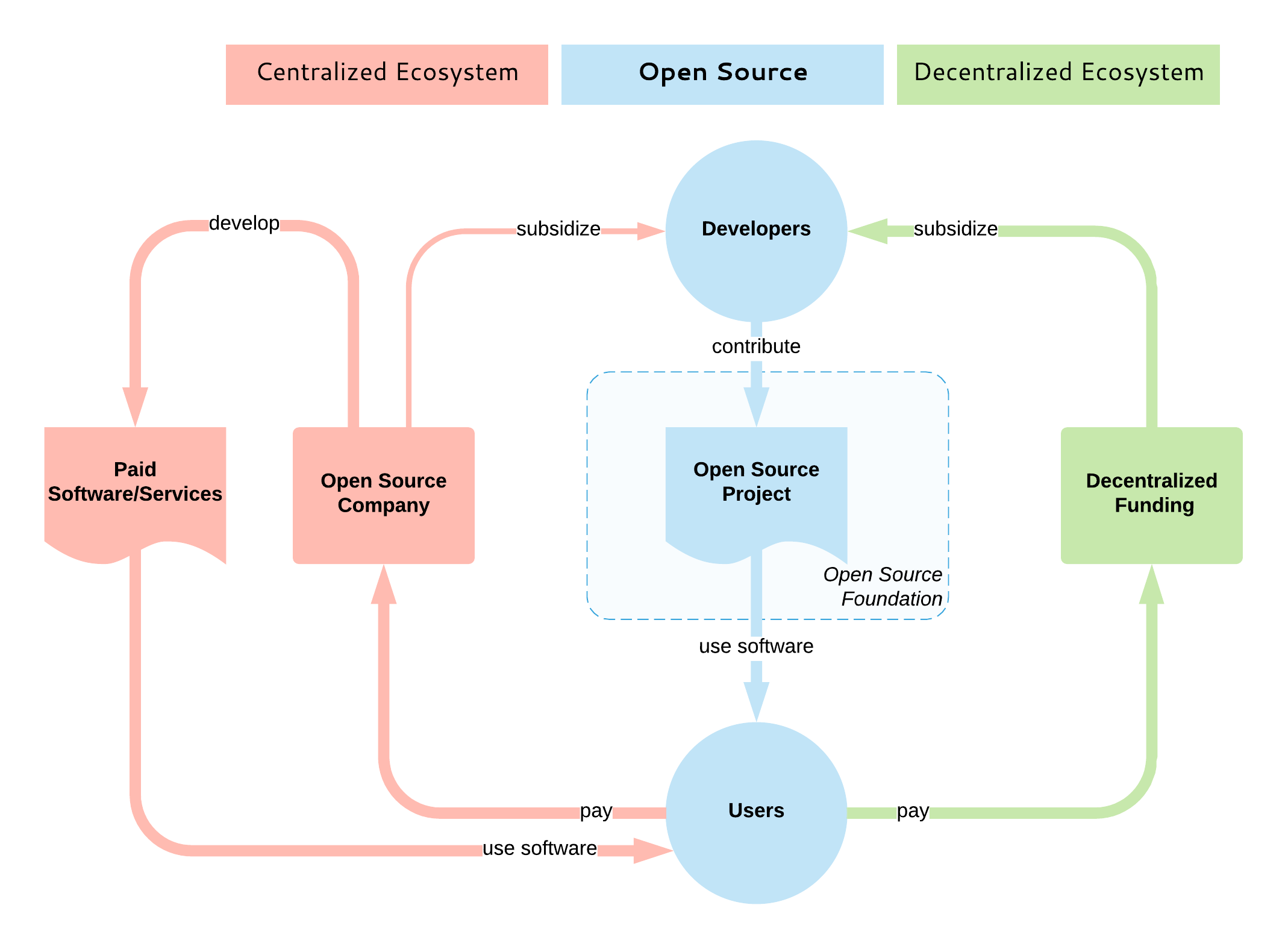
|
||||
|
||||
目前,没有相当于以补贴为目的的去中心化式开源开发模型。大多数开源补贴都是集中式的,通常一家公司通过雇用该项目的主要开源开发者来主导该项目。说实话,这是目前最好的状况,因为它保证了开发人员将长期获得报酬,项目也将继续蓬勃发展。
|
||||
|
||||
项目垄断情景也有例外情况:例如,一些云原生计算基金会(CNCF)项目是由大量的竞争公司开发的。此外,Apache 软件基金会(ASF)旨在通过鼓励不同的贡献者来使他们管理的项目不被单一供应商所主导,但实际上大多数受欢迎的项目仍然是单一供应商项目。
|
||||
|
||||
我们缺少的是一个开放的、去中心化的模式,就像一个没有集中协调和所有权的集市一样,消费者(开源用户)和生产者(开源开发者)在市场力量和开源价值的驱动下相互作用。为了补充开源,这样的模型也必须是开放和去中心化的,这就是为什么我认为区块链技术[最适合][3]的原因。
|
||||
|
||||
旨在补贴开源开发的大多数现有区块链(和非区块链)平台主要针对的是漏洞赏金、小型和零碎的任务。少数人还专注于资助新的开源项目。但并没有多少平台旨在提供维持开源项目持续开发的机制 —— 基本上,这个系统可以模仿开源服务提供商公司或开放核心、基于开源的 SaaS 产品公司的行为:确保开发人员可以获得持续和可预测的激励,并根据激励者(即用户)的优先事项指导项目开发。这种模型将解决上面列出的易货系统的局限性:
|
||||
|
||||
* 允许可分性:如果你想要一些小的修复,你可以支付少量费用,而不是成为项目的开源开发者的全部费用。
|
||||
* 存储价值:你可以在项目中投入大量资金,并确保其持续发展和你的发言权。
|
||||
* 转移价值:在任何时候,你都可以停止投资项目并将资金转移到其他项目中。
|
||||
* 时间脱钩:允许定期定期付款和订阅。
|
||||
|
||||
还有其他好处,纯粹是因为这种基于区块链的系统是透明和去中心化的:根据用户的承诺、开放的路线图承诺、去中心化决策等来量化项目的价值/实用性。
|
||||
|
||||
### 总结
|
||||
|
||||
一方面,我们看到大公司雇用开源开发者并收购开源初创公司甚至基础平台(例如微软收购 GitHub)。许多(甚至大多数)能够长期成功运行的开源项目都集中在单个供应商周围。开源的重要性及其集中化是一个事实。
|
||||
|
||||
另一方面,[维持开源软件][4]的挑战正变得越来越明显,许多人正在更深入地研究这个领域及其基本问题。有一些项目具有很高的知名度和大量的贡献者,但还有许多其他也重要的项目缺乏足够的贡献者和维护者。
|
||||
|
||||
有[许多努力][3]试图通过区块链来解决开源的挑战。这些项目应提高透明度、去中心化和补贴,并在开源用户和开发人员之间建立直接联系。这个领域还很年轻,但是进展很快,随着时间的推移,集市将会有一个加密货币系统。
|
||||
|
||||
如果有足够的时间和足够的技术,去中心化就会发生在很多层面:
|
||||
|
||||
* 互联网是一种去中心化的媒介,它释放了全球分享和获取知识的潜力。
|
||||
* 开源是一种去中心化的协作模式,它释放了全球的创新潜力。
|
||||
* 同样,区块链可以补充开源,成为去中心化的开源补贴模式。
|
||||
|
||||
请在[推特][5]上关注我在这个领域的其他帖子。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/barter-currency-system
|
||||
|
||||
作者:[Bilgin lbryam][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bibryam
|
||||
[1]: http://catb.org/
|
||||
[2]: http://oss.cash/
|
||||
[3]: https://opensource.com/article/18/8/open-source-tokenomics
|
||||
[4]: https://www.youtube.com/watch?v=VS6IpvTWwkQ
|
||||
[5]: http://twitter.com/bibryam
|
||||
48
published/20181113 Eldoc Goes Global.md
Normal file
48
published/20181113 Eldoc Goes Global.md
Normal file
@ -0,0 +1,48 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11306-1.html)
|
||||
[#]: subject: (Eldoc Goes Global)
|
||||
[#]: via: (https://emacsredux.com/blog/2018/11/13/eldoc-goes-global/)
|
||||
[#]: author: (Bozhidar Batsov https://emacsredux.com)
|
||||
|
||||
Emacs:Eldoc 全局化了
|
||||
======
|
||||
|
||||

|
||||
|
||||
最近我注意到 Emacs 25.1 增加了一个名为 `global-eldoc-mode` 的模式,它是流行的 `eldoc-mode` 的一个全局化的变体。而且与 `eldoc-mode` 不同的是,`global-eldoc-mode` 默认是开启的!
|
||||
|
||||
这意味着你可以删除 Emacs 配置中为主模式开启 `eldoc-mode` 的代码了:
|
||||
|
||||
```
|
||||
;; That code is now redundant
|
||||
(add-hook 'emacs-lisp-mode-hook #'eldoc-mode)
|
||||
(add-hook 'ielm-mode-hook #'eldoc-mode)
|
||||
(add-hook 'cider-mode-hook #'eldoc-mode)
|
||||
(add-hook 'cider-repl-mode-hook #'eldoc-mode)
|
||||
```
|
||||
|
||||
[有人说][1] `global-eldoc-mode` 在某些不支持的模式中会有性能问题。我自己从未遇到过,但若你像禁用它则只需要这样:
|
||||
|
||||
```
|
||||
(global-eldoc-mode -1)
|
||||
```
|
||||
|
||||
现在是时候清理我的配置了!删除代码就是这么爽!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://emacsredux.com/blog/2018/11/13/eldoc-goes-global/
|
||||
|
||||
作者:[Bozhidar Batsov][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://emacsredux.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://emacs.stackexchange.com/questions/31414/how-to-globally-disable-eldoc
|
||||
@ -0,0 +1,227 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (laingke)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11373-1.html)
|
||||
[#]: subject: (Create an online store with this Java-based framework)
|
||||
[#]: via: (https://opensource.com/article/19/1/scipio-erp)
|
||||
[#]: author: (Paul Piper https://opensource.com/users/madppiper)
|
||||
|
||||
使用 Java 框架 Scipio ERP 创建一个在线商店
|
||||
======
|
||||
|
||||
> Scipio ERP 具有包罗万象的应用程序和功能。
|
||||
|
||||

|
||||
|
||||
如果,你想在网上销售产品或服务,但要么找不到合适的软件,要么觉得定制成本太高?那么,[Scipio ERP][1] 也许正是你想要的。
|
||||
|
||||
Scipio ERP 是一个基于 Java 的开源的电子商务框架,具有包罗万象的应用程序和功能。这个项目于 2014 年从 [Apache OFBiz][2] 分叉而来,侧重于更好的定制和更现代的吸引力。这个电子商务组件非常丰富,可以在多商店环境中工作,同时支持国际化,具有琳琅满目的产品配置,而且它还兼容现代 HTML 框架。该软件还为许多其他业务场景提供标准应用程序,例如会计、仓库管理或销售团队自动化。它都是高度标准化的,因此易于定制,如果你想要的不仅仅是一个虚拟购物车,这是非常棒的。
|
||||
|
||||
该系统也使得跟上现代 Web 标准变得非常容易。所有界面都是使用系统的“[模板工具包][3]”构建的,这是一个易于学习的宏集,可以将 HTML 与所有应用程序分开。正因为如此,每个应用程序都已经标准化到核心。听起来令人困惑?它真的不是 HTML——它看起来很像 HTML,但你写的内容少了很多。
|
||||
|
||||
### 初始安装
|
||||
|
||||
在你开始之前,请确保你已经安装了 Java 1.8(或更高版本)的 SDK 以及一个 Git 客户端。完成了?太棒了!接下来,切换到 Github 上的主分支:
|
||||
|
||||
```
|
||||
git clone https://github.com/ilscipio/scipio-erp.git
|
||||
cd scipio-erp
|
||||
git checkout master
|
||||
```
|
||||
|
||||
要安装该系统,只需要运行 `./install.sh` 并从命令行中选择任一选项。在开发过程中,最好一直使用 “installation for development”(选项 1),它还将安装一系列演示数据。对于专业安装,你可以修改初始配置数据(“种子数据”),以便自动为你设置公司和目录数据。默认情况下,系统将使用内部数据库运行,但是它[也可以配置][4]使用各种关系数据库,比如 PostgreSQL 和 MariaDB 等。
|
||||
|
||||
![安装向导][6]
|
||||
|
||||
*按照安装向导完成初始配置*
|
||||
|
||||
通过命令 `./start.sh` 启动系统然后打开链接 <https://localhost:8443/setup/> 完成配置。如果你安装了演示数据, 你可以使用用户名 `admin` 和密码 `scipio` 进行登录。在安装向导中,你可以设置公司简介、会计、仓库、产品目录、在线商店和额外的用户配置信息。暂时在产品商店配置界面上跳过网站实体的配置。系统允许你使用不同的底层代码运行多个在线商店;除非你想这样做,一直选择默认值是最简单的。
|
||||
|
||||
祝贺你,你刚刚安装了 Scipio ERP!在界面上操作一两分钟,感受一下它的功能。
|
||||
|
||||
### 捷径
|
||||
|
||||
在你进入自定义之前,这里有一些方便的命令可以帮助你:
|
||||
|
||||
* 创建一个 shop-override:`./ant create-component-shop-override`
|
||||
* 创建一个新组件:`./ant create-component`
|
||||
* 创建一个新主题组件:`./ant create-theme`
|
||||
* 创建管理员用户:`./ant create-admin-user-login`
|
||||
* 各种其他实用功能:`./ant -p`
|
||||
* 用于安装和更新插件的实用程序:`./git-addons help`
|
||||
|
||||
另外,请记下以下位置:
|
||||
|
||||
* 将 Scipio 作为服务运行的脚本:`/tools/scripts/`
|
||||
* 日志输出目录:`/runtime/logs`
|
||||
* 管理应用程序:`<https://localhost:8443/admin/>`
|
||||
* 电子商务应用程序:`<https://localhost:8443/shop/>`
|
||||
|
||||
最后,Scipio ERP 在以下五个主要目录中构建了所有代码:
|
||||
|
||||
* `framework`: 框架相关的源,应用程序服务器,通用界面和配置
|
||||
* `applications`: 核心应用程序
|
||||
* `addons`: 第三方扩展
|
||||
* `themes`: 修改界面外观
|
||||
* `hot-deploy`: 你自己的组件
|
||||
|
||||
除了一些配置,你将在 `hot-deploy` 和 `themes` 目录中进行开发。
|
||||
|
||||
### 在线商店定制
|
||||
|
||||
要真正使系统成为你自己的系统,请开始考虑使用[组件][7]。组件是一种模块化方法,可以覆盖、扩展和添加到系统中。你可以将组件视为独立 Web 模块,可以捕获有关数据库([实体][8])、功能([服务][9])、界面([视图][10])、[事件和操作][11]和 Web 应用程序等的信息。由于组件功能,你可以添加自己的代码,同时保持与原始源兼容。
|
||||
|
||||
运行命令 `./ant create-component-shop-override` 并按照步骤创建你的在线商店组件。该操作将会在 `hot-deploy` 目录内创建一个新目录,该目录将扩展并覆盖原始的电子商务应用程序。
|
||||
|
||||
![组件目录结构][13]
|
||||
|
||||
*一个典型的组件目录结构。*
|
||||
|
||||
你的组件将具有以下目录结构:
|
||||
|
||||
* `config`: 配置
|
||||
* `data`: 种子数据
|
||||
* `entitydef`: 数据库表定义
|
||||
* `script`: Groovy 脚本的位置
|
||||
* `servicedef`: 服务定义
|
||||
* `src`: Java 类
|
||||
* `webapp`: 你的 web 应用程序
|
||||
* `widget`: 界面定义
|
||||
|
||||
此外,`ivy.xml` 文件允许你将 Maven 库添加到构建过程中,`ofbiz-component.xml` 文件定义整个组件和 Web 应用程序结构。除了一些在当前目录所能够看到的,你还可以在 Web 应用程序的 `WEB-INF` 目录中找到 `controller.xml` 文件。这允许你定义请求实体并将它们连接到事件和界面。仅对于界面来说,你还可以使用内置的 CMS 功能,但优先要坚持使用核心机制。在引入更改之前,请熟悉 `/applications/shop/`。
|
||||
|
||||
#### 添加自定义界面
|
||||
|
||||
还记得[模板工具包][3]吗?你会发现它在每个界面都有使用到。你可以将其视为一组易于学习的宏,它用来构建所有内容。下面是一个例子:
|
||||
|
||||
```
|
||||
<@section title="Title">
|
||||
<@heading id="slider">Slider</@heading>
|
||||
<@row>
|
||||
<@cell columns=6>
|
||||
<@slider id="" class="" controls=true indicator=true>
|
||||
<@slide link="#" image="https://placehold.it/800x300">Just some content…</@slide>
|
||||
<@slide title="This is a title" link="#" image="https://placehold.it/800x300"></@slide>
|
||||
</@slider>
|
||||
</@cell>
|
||||
<@cell columns=6>Second column</@cell>
|
||||
</@row>
|
||||
</@section>
|
||||
```
|
||||
|
||||
不是很难,对吧?同时,主题包含 HTML 定义和样式。这将权力交给你的前端开发人员,他们可以定义每个宏的输出,并坚持使用自己的构建工具进行开发。
|
||||
|
||||
我们快点试试吧。首先,在你自己的在线商店上定义一个请求。你将修改此代码。一个内置的 CMS 系统也可以通过 <https://localhost:8443/cms/> 进行访问,它允许你以更有效的方式创建新模板和界面。它与模板工具包完全兼容,并附带可根据你的喜好采用的示例模板。但是既然我们试图在这里理解系统,那么首先让我们采用更复杂的方法。
|
||||
|
||||
打开你商店 `webapp` 目录中的 [controller.xml][14] 文件。控制器会跟踪请求事件并相应地执行操作。下面的操作将会在 `/shop/test` 下创建一个新的请求:
|
||||
|
||||
```
|
||||
<!-- Request Mappings -->
|
||||
<request-map uri="test">
|
||||
<security https="true" auth="false"/>
|
||||
<response name="success" type="view" value="test"/>
|
||||
</request-map>
|
||||
```
|
||||
|
||||
你可以定义多个响应,如果需要,可以在请求中使用事件或服务调用来确定你可能要使用的响应。我选择了“视图”类型的响应。视图是渲染的响应;其他类型是请求重定向、转发等。系统附带各种渲染器,可让你稍后确定输出;为此,请添加以下内容:
|
||||
|
||||
```
|
||||
<!-- View Mappings -->
|
||||
<view-map name="test" type="screen" page="component://mycomponent/widget/CommonScreens.xml#test"/>
|
||||
```
|
||||
|
||||
用你自己的组件名称替换 `my-component`。然后,你可以通过在 `widget/CommonScreens.xml` 文件的标签内添加以下内容来定义你的第一个界面:
|
||||
|
||||
```
|
||||
<screen name="test">
|
||||
<section>
|
||||
<actions>
|
||||
</actions>
|
||||
<widgets>
|
||||
<decorator-screen name="CommonShopAppDecorator" location="component://shop/widget/CommonScreens.xml">
|
||||
<decorator-section name="body">
|
||||
<platform-specific><html><html-template location="component://mycomponent/webapp/mycomponent/test/test.ftl"/></html></platform-specific>
|
||||
</decorator-section>
|
||||
</decorator-screen>
|
||||
</widgets>
|
||||
</section>
|
||||
</screen>
|
||||
```
|
||||
|
||||
商店界面实际上非常模块化,由多个元素组成([小部件、动作和装饰器][15])。为简单起见,请暂时保留原样,并通过添加第一个模板工具包文件来完成新网页。为此,创建一个新的 `webapp/mycomponent/test/test.ftl` 文件并添加以下内容:
|
||||
|
||||
```
|
||||
<@alert type="info">Success!</@alert>
|
||||
```
|
||||
|
||||
![自定义的界面][17]
|
||||
|
||||
*一个自定义的界面。*
|
||||
|
||||
打开 <https://localhost:8443/shop/control/test/> 并惊叹于你自己的成就。
|
||||
|
||||
#### 自定义主题
|
||||
|
||||
通过创建自己的主题来修改商店的界面外观。所有主题都可以作为组件在 `themes` 文件夹中找到。运行命令 `./ant create-theme` 来创建你自己的主题。
|
||||
|
||||
![主题组件布局][19]
|
||||
|
||||
*一个典型的主题组件布局。*
|
||||
|
||||
以下是最重要的目录和文件列表:
|
||||
|
||||
* 主题配置:`data/*ThemeData.xml`
|
||||
* 特定主题封装的 HTML:`includes/*.ftl`
|
||||
* 模板工具包 HTML 定义:`includes/themeTemplate.ftl`
|
||||
* CSS 类定义:`includes/themeStyles.ftl`
|
||||
* CSS 框架: `webapp/theme-title/`
|
||||
|
||||
快速浏览工具包中的 Metro 主题;它使用 Foundation CSS 框架并且充分利用了这个框架。然后,然后,在新构建的 `webapp/theme-title` 目录中设置自己的主题并开始开发。Foundation-shop 主题是一个非常简单的特定于商店的主题实现,你可以将其用作你自己工作的基础。
|
||||
|
||||
瞧!你已经建立了自己的在线商店,准备个性化定制吧!
|
||||
|
||||
![搭建完成的 Scipio ERP 在线商店][21]
|
||||
|
||||
*一个搭建完成的基于 Scipio ERP的在线商店。*
|
||||
|
||||
### 接下来是什么?
|
||||
|
||||
Scipio ERP 是一个功能强大的框架,可简化复杂的电子商务应用程序的开发。为了更完整的理解,请查看项目[文档][7],尝试[在线演示][22],或者[加入社区][23].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/scipio-erp
|
||||
|
||||
作者:[Paul Piper][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[laingke](https://github.com/laingke)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/madppiper
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.scipioerp.com
|
||||
[2]: https://ofbiz.apache.org/
|
||||
[3]: https://www.scipioerp.com/community/developer/freemarker-macros/
|
||||
[4]: https://www.scipioerp.com/community/developer/installation-configuration/configuration/#database-configuration
|
||||
[5]: /file/419711
|
||||
[6]: https://opensource.com/sites/default/files/uploads/setup_step5_sm.jpg (Setup wizard)
|
||||
[7]: https://www.scipioerp.com/community/developer/architecture/components/
|
||||
[8]: https://www.scipioerp.com/community/developer/entities/
|
||||
[9]: https://www.scipioerp.com/community/developer/services/
|
||||
[10]: https://www.scipioerp.com/community/developer/views-requests/
|
||||
[11]: https://www.scipioerp.com/community/developer/events-actions/
|
||||
[12]: /file/419716
|
||||
[13]: https://opensource.com/sites/default/files/uploads/component_structure.jpg (component directory structure)
|
||||
[14]: https://www.scipioerp.com/community/developer/views-requests/request-controller/
|
||||
[15]: https://www.scipioerp.com/community/developer/views-requests/screen-widgets-decorators/
|
||||
[16]: /file/419721
|
||||
[17]: https://opensource.com/sites/default/files/uploads/success_screen_sm.jpg (Custom screen)
|
||||
[18]: /file/419726
|
||||
[19]: https://opensource.com/sites/default/files/uploads/theme_structure.jpg (theme component layout)
|
||||
[20]: /file/419731
|
||||
[21]: https://opensource.com/sites/default/files/uploads/finished_shop_1_sm.jpg (Finished Scipio ERP shop)
|
||||
[22]: https://www.scipioerp.com/demo/
|
||||
[23]: https://forum.scipioerp.com/
|
||||
223
published/20190401 Build and host a website with Git.md
Normal file
223
published/20190401 Build and host a website with Git.md
Normal file
@ -0,0 +1,223 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11303-1.html)
|
||||
[#]: subject: (Build and host a website with Git)
|
||||
[#]: via: (https://opensource.com/article/19/4/building-hosting-website-git)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
用 Git 建立和托管网站
|
||||
======
|
||||
|
||||
> 你可以让 Git 帮助你轻松发布你的网站。在我们《鲜为人知的 Git 用法》系列的第一篇文章中学习如何做到。
|
||||
|
||||

|
||||
|
||||
[Git][2] 是一个少有的能将如此多的现代计算封装到一个程序之中的应用程序,它可以用作许多其他应用程序的计算引擎。虽然它以跟踪软件开发中的源代码更改而闻名,但它还有许多其他用途,可以让你的生活更轻松、更有条理。在这个 Git 系列中,我们将分享七种鲜为人知的使用 Git 的方法。
|
||||
|
||||
创建一个网站曾经是极其简单的,而同时它又是一种黑魔法。回到 Web 1.0 的旧时代(不是每个人都会这样称呼它),你可以打开任何网站,查看其源代码,并对 HTML 及其内联样式和基于表格的布局进行反向工程,在这样的一两个下午之后,你就会感觉自己像一个程序员一样。不过要让你创建的页面放到互联网上,仍然有一些问题,因为这意味着你需要处理服务器、FTP 以及 webroot 目录和文件权限。虽然从那时起,现代网站变得愈加复杂,但如果你让 Git 帮助你,自出版可以同样容易(或更容易!)。
|
||||
|
||||
### 用 Hugo 创建一个网站
|
||||
|
||||
[Hugo][3] 是一个开源的静态站点生成器。静态网站是过去的 Web 的基础(如果你回溯到很久以前,那就是 Web 的*全部*了)。静态站点有几个优点:它们相对容易编写,因为你不必编写代码;它们相对安全,因为页面上没有执行代码;并且它们可以非常快,因为除了在页面上传输的任何内容之外没有任何处理。
|
||||
|
||||
Hugo 并不是唯一一个静态站点生成器。[Grav][4]、[Pico][5]、[Jekyll][6]、[Podwrite][7] 以及许多其他的同类软件都提供了一种创建一个功能最少的、只需要很少维护的网站的简单方法。Hugo 恰好是内置集成了 GitLab 集成的一个静态站点生成器,这意味着你可以使用免费的 GitLab 帐户生成和托管你的网站。
|
||||
|
||||
Hugo 也有一些非常大的用户。例如,如果你曾经去过 [Let's Encrypt](https://letsencrypt.org/) 网站,那么你已经用过了一个用 Hugo 构建的网站。
|
||||
|
||||
![Let's Encrypt website][8]
|
||||
|
||||
#### 安装 Hugo
|
||||
|
||||
Hugo 是跨平台的,你可以在 [Hugo 的入门资源][9]中找到适用于 MacOS、Windows、Linux、OpenBSD 和 FreeBSD 的安装说明。
|
||||
|
||||
如果你使用的是 Linux 或 BSD,最简单的方法是从软件存储库或 ports 树安装 Hugo。确切的命令取决于你的发行版,但在 Fedora 上,你应该输入:
|
||||
|
||||
```
|
||||
$ sudo dnf install hugo
|
||||
```
|
||||
|
||||
通过打开终端并键入以下内容确认你已正确安装:
|
||||
|
||||
```
|
||||
$ hugo help
|
||||
```
|
||||
|
||||
这将打印 `hugo` 命令的所有可用选项。如果你没有看到,你可能没有正确安装 Hugo 或需要[将该命令添加到你的路径][10]。
|
||||
|
||||
#### 创建你的站点
|
||||
|
||||
要构建 Hugo 站点,你必须有个特定的目录结构,通过输入以下命令 Hugo 将为你生成它:
|
||||
|
||||
```
|
||||
$ hugo new site mysite
|
||||
```
|
||||
|
||||
你现在有了一个名为 `mysite` 的目录,它包含构建 Hugo 网站所需的默认目录。
|
||||
|
||||
Git 是你将网站放到互联网上的接口,因此切换到你新的 `mysite` 文件夹,并将其初始化为 Git 存储库:
|
||||
|
||||
```
|
||||
$ cd mysite
|
||||
$ git init .
|
||||
```
|
||||
|
||||
Hugo 与 Git 配合的很好,所以你甚至可以使用 Git 为你的网站安装主题。除非你计划开发你正在安装的主题,否则可以使用 `--depth` 选项克隆该主题的源的最新状态:
|
||||
|
||||
```
|
||||
$ git clone --depth 1 https://github.com/darshanbaral/mero.git themes/mero
|
||||
```
|
||||
|
||||
现在为你的网站创建一些内容:
|
||||
|
||||
```
|
||||
$ hugo new posts/hello.md
|
||||
```
|
||||
|
||||
使用你喜欢的文本编辑器编辑 `content/posts` 目录中的 `hello.md` 文件。Hugo 接受 Markdown 文件,并会在发布时将它们转换为经过主题化的 HTML 文件,因此你的内容必须采用 [Markdown 格式][11]。
|
||||
|
||||
如果要在帖子中包含图像,请在 `static` 目录中创建一个名为 `images` 的文件夹。将图像放入此文件夹,并使用以 `/images` 开头的绝对路径在标记中引用它们。例如:
|
||||
|
||||
```
|
||||

|
||||
```
|
||||
|
||||
#### 选择主题
|
||||
|
||||
你可以在 [themes.gohugo.io][12] 找到更多主题,但最好在测试时保持一个基本主题。标准的 Hugo 测试主题是 [Ananke][13]。某些主题具有复杂的依赖关系,而另外一些主题如果没有复杂的配置的话,也许不会以你预期的方式呈现页面。本例中使用的 Mero 主题捆绑了一个详细的 `config.toml` 配置文件,但是(为了简单起见)我将在这里只提供基本的配置。在文本编辑器中打开名为 `config.toml` 的文件,并添加三个配置参数:
|
||||
|
||||
```
|
||||
languageCode = "en-us"
|
||||
title = "My website on the web"
|
||||
theme = "mero"
|
||||
|
||||
[params]
|
||||
author = "Seth Kenlon"
|
||||
description = "My hugo demo"
|
||||
```
|
||||
|
||||
#### 预览
|
||||
|
||||
在你准备发布之前不必(预先)在互联网上放置任何内容。在你开发网站时,你可以通过启动 Hugo 附带的仅限本地访问的 Web 服务器来预览你的站点。
|
||||
|
||||
```
|
||||
$ hugo server --buildDrafts --disableFastRender
|
||||
```
|
||||
|
||||
打开 Web 浏览器并导航到 <http://localhost:1313> 以查看正在进行的工作。
|
||||
|
||||
### 用 Git 发布到 GitLab
|
||||
|
||||
要在 GitLab 上发布和托管你的站点,请为你的站点内容创建一个存储库。
|
||||
|
||||
要在 GitLab 中创建存储库,请单击 GitLab 的 “Projects” 页面中的 “New Project” 按钮。创建一个名为 `yourGitLabUsername.gitlab.io` 的空存储库,用你的 GitLab 用户名或组名替换 `yourGitLabUsername`。你必须使用此命名方式作为该项目的名称。你也可以稍后为其添加自定义域。
|
||||
|
||||
不要在 GitLab 上包含许可证或 README 文件(因为你已经在本地启动了一个项目,现在添加这些文件会使将你的数据推向 GitLab 时更加复杂,以后你可以随时添加它们)。
|
||||
|
||||
在 GitLab 上创建空存储库后,将其添加为 Hugo 站点的本地副本的远程位置,该站点已经是一个 Git 存储库:
|
||||
|
||||
```
|
||||
$ git remote add origin git@gitlab.com:skenlon/mysite.git
|
||||
```
|
||||
|
||||
创建名为 `.gitlab-ci.yml` 的 GitLab 站点配置文件并输入以下选项:
|
||||
|
||||
```
|
||||
image: monachus/hugo
|
||||
|
||||
variables:
|
||||
GIT_SUBMODULE_STRATEGY: recursive
|
||||
|
||||
pages:
|
||||
script:
|
||||
- hugo
|
||||
artifacts:
|
||||
paths:
|
||||
- public
|
||||
only:
|
||||
- master
|
||||
```
|
||||
|
||||
`image` 参数定义了一个为你的站点提供服务的容器化图像。其他参数是告诉 GitLab 服务器在将新代码推送到远程存储库时要执行的操作的说明。有关 GitLab 的 CI/CD(持续集成和交付)选项的更多信息,请参阅 [GitLab 文档的 CI/CD 部分][14]。
|
||||
|
||||
#### 设置排除的内容
|
||||
|
||||
你的 Git 存储库已配置好,在 GitLab 服务器上构建站点的命令也已设置,你的站点已准备好发布了。对于你的第一个 Git 提交,你必须采取一些额外的预防措施,以便你不会对你不打算进行版本控制的文件进行版本控制。
|
||||
|
||||
首先,将构建你的站点时 Hugo 创建的 `/public` 目录添加到 `.gitignore` 文件。你无需在 Git 中管理已完成发布的站点;你需要跟踪的是你的 Hugo 源文件。
|
||||
|
||||
```
|
||||
$ echo "/public" >> .gitignore
|
||||
```
|
||||
|
||||
如果不创建 Git 子模块,则无法在 Git 存储库中维护另一个 Git 存储库。为了简单起见,请移除嵌入的存储库的 `.git` 目录,以使主题(存储库)只是一个主题(目录)。
|
||||
|
||||
请注意,你**必须**将你的主题文件添加到你的 Git 存储库,以便 GitLab 可以访问该主题。如果不提交主题文件,你的网站将无法成功构建。
|
||||
|
||||
```
|
||||
$ mv themes/mero/.git ~/.local/share/Trash/files/
|
||||
```
|
||||
|
||||
你也可以像使用[回收站][15]一样使用 `trash`:
|
||||
|
||||
```
|
||||
$ trash themes/mero/.git
|
||||
```
|
||||
|
||||
现在,你可以将本地项目目录的所有内容添加到 Git 并将其推送到 GitLab:
|
||||
|
||||
```
|
||||
$ git add .
|
||||
$ git commit -m 'hugo init'
|
||||
$ git push -u origin HEAD
|
||||
```
|
||||
|
||||
### 用 GitLab 上线
|
||||
|
||||
将代码推送到 GitLab 后,请查看你的项目页面。有个图标表示 GitLab 正在处理你的构建。第一次推送代码可能需要几分钟,所以请耐心等待。但是,请不要**一直**等待,因为该图标并不总是可靠地更新。
|
||||
|
||||
![GitLab processing your build][16]
|
||||
|
||||
当你在等待 GitLab 组装你的站点时,请转到你的项目设置并找到 “Pages” 面板。你的网站准备就绪后,它的 URL 就可以用了。该 URL 是 `yourGitLabUsername.gitlab.io/yourProjectName`。导航到该地址以查看你的劳动成果。
|
||||
|
||||
![Previewing Hugo site][17]
|
||||
|
||||
如果你的站点无法正确组装,GitLab 提供了可以深入了解 CI/CD 管道的日志。查看错误消息以找出发生了什么问题。
|
||||
|
||||
### Git 和 Web
|
||||
|
||||
Hugo(或 Jekyll 等类似工具)只是利用 Git 作为 Web 发布工具的一种方式。使用服务器端 Git 挂钩,你可以使用最少的脚本设计你自己的 Git-to-web 工作流。使用 GitLab 的社区版,你可以自行托管你自己的 GitLab 实例;或者你可以使用 [Gitolite][18] 或 [Gitea][19] 等替代方案,并使用本文作为自定义解决方案的灵感来源。祝你玩得开心!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/building-hosting-website-git
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/web_browser_desktop_devlopment_design_system_computer.jpg?itok=pfqRrJgh (web development and design, desktop and browser)
|
||||
[2]: https://git-scm.com/
|
||||
[3]: http://gohugo.io
|
||||
[4]: http://getgrav.org
|
||||
[5]: http://picocms.org/
|
||||
[6]: https://jekyllrb.com
|
||||
[7]: http://slackermedia.info/podwrite/
|
||||
[8]: https://opensource.com/sites/default/files/uploads/letsencrypt-site.jpg (Let's Encrypt website)
|
||||
[9]: https://gohugo.io/getting-started/installing
|
||||
[10]: https://opensource.com/article/17/6/set-path-linux
|
||||
[11]: https://commonmark.org/help/
|
||||
[12]: https://themes.gohugo.io/
|
||||
[13]: https://themes.gohugo.io/gohugo-theme-ananke/
|
||||
[14]: https://docs.gitlab.com/ee/ci/#overview
|
||||
[15]: http://slackermedia.info/trashy
|
||||
[16]: https://opensource.com/sites/default/files/uploads/hugo-gitlab-cicd.jpg (GitLab processing your build)
|
||||
[17]: https://opensource.com/sites/default/files/uploads/hugo-demo-site.jpg (Previewing Hugo site)
|
||||
[18]: http://gitolite.com
|
||||
[19]: http://gitea.io
|
||||
244
published/20190402 Manage your daily schedule with Git.md
Normal file
244
published/20190402 Manage your daily schedule with Git.md
Normal file
@ -0,0 +1,244 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11320-1.html)
|
||||
[#]: subject: (Manage your daily schedule with Git)
|
||||
[#]: via: (https://opensource.com/article/19/4/calendar-git)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
用 Git 管理你的每日行程
|
||||
======
|
||||
|
||||
> 像源代码一样对待时间并在 Git 的帮助下维护你的日历。
|
||||
|
||||

|
||||
|
||||
[Git][2] 是一个少有的能将如此多的现代计算封装到一个程序之中的应用程序,它可以用作许多其他应用程序的计算引擎。虽然它以跟踪软件开发中的源代码更改而闻名,但它还有许多其他用途,可以让你的生活更轻松、更有条理。在这个 Git 系列中,我们将分享七种鲜为人知的使用 Git 的方法。
|
||||
|
||||
今天,我们将使用 Git 来跟踪你的日历。
|
||||
|
||||
### 使用 Git 跟踪你的日程安排
|
||||
|
||||
如果时间本身只是可以管理和版本控制的源代码呢?虽然证明或反驳这种理论可能超出了本文的范围,但在 Git 的帮助下,你可以将时间视为源代码并管理你的日程安排。
|
||||
|
||||
日历的卫冕冠军是 [CalDAV][3] 协议,它支撑了如 [NextCloud][4] 这样的流行的开源及闭源的日历应用程序。CalDAV 没什么问题(评论者,请注意),但它并不适合所有人,除此之外,它还有一种不同于单一文化的鼓舞人心的东西。
|
||||
|
||||
因为我对大量使用 GUI 的 CalDAV 客户端没有兴趣(如果你正在寻找一个好的终端 CalDAV 查看器,请参阅 [khal][5]),我开始研究基于文本的替代方案。基于文本的日历具有在[明文][6]中工作的所有常见好处。它很轻巧,非常便携,只要它结构化,就很容易解析和美化(无论*美丽*对你意味着什么)。
|
||||
|
||||
最重要的是,它正是 Git 旨在管理的内容。
|
||||
|
||||
### Org 模式不是一种可怕的方式
|
||||
|
||||
如果你没有对你的明文添加结构,它很快就会陷入一种天马行空般的混乱,变成恶魔才能懂的符号。幸运的是,有一种用于日历的标记语法,它包含在令人尊敬的生产力 Emacs 模式 —— [Org 模式][7] 中(承认吧,你其实一直想开始使用它)。
|
||||
|
||||
许多人没有意识到 Org 模式的惊人之处在于[你不需要知道甚至不需要使用 Emacs][8]来利用 Org 模式建立的约定。如果你使用 Emacs,你会得到许多很棒的功能,但是如果 Emacs 对你来说太难了,那么你可以实现一个基于 Git 的 Org 模式的日历系统,而不需要安装 Emacs。
|
||||
|
||||
关于 Org 模式你唯一需要知道的部分是它的语法。Org 模式的语法维护成本低、直观。使用 Org 模式而不是 GUI 日历应用程序进行日历记录的最大区别在于工作流程:你可以创建一个任务列表,然后每天分配一个任务,而不是转到日历并查找要安排任务的日期。
|
||||
|
||||
组织模式中的列表使用星号(`*`)作为项目符号。这是我的游戏任务列表:
|
||||
|
||||
```
|
||||
* Gaming
|
||||
** Build Stardrifter character
|
||||
** Read Stardrifter rules
|
||||
** Stardrifter playtest
|
||||
|
||||
** Blue Planet @ Mike's
|
||||
|
||||
** Run Rappan Athuk
|
||||
*** Purchase hard copy
|
||||
*** Skim Rappan Athuk
|
||||
*** Build Rappan Athuk maps in maptool
|
||||
*** Sort Rappan Athuk tokens
|
||||
```
|
||||
|
||||
如果你熟悉 [CommonMark][9] 或 Markdown,你会注意到,Org 模式不是使用空格来创建子任务,而是更明确地使用了其它项目符号。无论你的使用背景和列表是什么,这都是一种构建列表的直观且简单的方法,它显然与 Emacs 没有内在联系(尽管使用 Emacs 为你提供了快捷方式,因此你可以快速地重新排列列表)。
|
||||
|
||||
要将列表转换为日历中的计划任务或事件,请返回并添加关键字 `SCHEDULED` 和(可选)`:CATEGORY:`。
|
||||
|
||||
```
|
||||
* Gaming
|
||||
:CATEGORY: Game
|
||||
** Build Stardrifter character
|
||||
SCHEDULED: <2019-03-22 18:00-19:00>
|
||||
** Read Stardrifter rules
|
||||
SCHEDULED: <2019-03-22 19:00-21:00>
|
||||
** Stardrifter playtest
|
||||
SCHEDULED: <2019-03-25 0900-1300>
|
||||
** Blue Planet @ Mike's
|
||||
SCHEDULED: <2019-03-18 18:00-23:00 +1w>
|
||||
|
||||
and so on...
|
||||
```
|
||||
|
||||
`SCHEDULED` 关键字将该条目标记为你希望收到通知的事件,并且可选的 `:CATEGORY:` 关键字是一个可供你自己使用的任意标记系统(在 Emacs 中,你可以根据类别对条目使用颜色代码)。
|
||||
|
||||
对于重复事件,你可以使用符号(如`+1w`)创建每周事件或 `+2w` 以进行每两周一次的事件,依此类推。
|
||||
|
||||
所有可用于 Org 模式的花哨标记都[记录于文档][10],所以不要犹豫,找到更多技巧来让它满足你的需求。
|
||||
|
||||
### 放进 Git
|
||||
|
||||
如果没有 Git,你的 Org 模式的日程安排只不过是本地计算机上的文件。这是 21 世纪,所以你至少需要可以在手机上使用你的日历,即便不是在你所有的个人电脑上。你可以使用 Git 为自己和他人发布日历。
|
||||
|
||||
首先,为 `.org` 文件创建一个目录。我将我的存储在 `~/cal` 中。
|
||||
|
||||
```
|
||||
$ mkdir ~/cal
|
||||
```
|
||||
|
||||
转到你的目录并使其成为 Git 存储库:
|
||||
|
||||
```
|
||||
$ cd cal
|
||||
$ git init
|
||||
```
|
||||
|
||||
将 `.org` 文件移动到你本地的 Git 存储库。在实践中,我为每个类别维护一个 `.org` 文件。
|
||||
|
||||
```
|
||||
$ mv ~/*.org ~/cal
|
||||
$ ls
|
||||
Game.org Meal.org Seth.org Work.org
|
||||
```
|
||||
|
||||
暂存并提交你的文件:
|
||||
|
||||
```
|
||||
$ git add *.org
|
||||
$ git commit -m 'cal init'
|
||||
```
|
||||
|
||||
### 创建一个 Git 远程源
|
||||
|
||||
要在任何地方提供日历,你必须在互联网上拥有 Git 存储库。你的日历是纯文本,因此任何 Git 存储库都可以。你可以将日历放在 [GitLab][11] 或任何其他公共 Git 托管服务(甚至是专有服务)上,只要你的主机允许,你甚至可以将该存储库标记为私有库。如果你不想将日历发布到你无法控制的服务器,则可以自行托管 Git 存储库,或者为单个用户使用裸存储库,或者使用 [Gitolite][12] 或 [Gitea][13] 等前端服务。
|
||||
|
||||
为了简单起见,我将假设一个自托管的 Git 裸存储库。你可以使用 Git 命令在任何具有 SSH 访问权限的服务器上创建一个远程裸存储库:
|
||||
|
||||
```
|
||||
$ ssh -p 22122 [seth@example.com][14]
|
||||
[remote]$ mkdir cal.git
|
||||
[remote]$ cd cal.git
|
||||
[remote]$ git init --bare
|
||||
[remote]$ exit
|
||||
```
|
||||
|
||||
这个裸存储库可以作为你日历在互联网上的家。
|
||||
|
||||
将其设置为本地 Git 存储库(在你的计算机上,而不是你的服务器上)的远程源:
|
||||
|
||||
```
|
||||
$ git remote add origin seth@example.com:/home/seth/cal.git
|
||||
```
|
||||
|
||||
然后推送你的日历到该服务器:
|
||||
|
||||
```
|
||||
$ git push -u origin HEAD
|
||||
```
|
||||
|
||||
将你的日历放在 Git 存储库中,就可以在任何运行 Git 的设备上使用它。这意味着你可以对计划进行更新和更改,并将更改推送到上游,以便在任何地方进行更新。
|
||||
|
||||
我使用这种方法使我的日历在我的工作笔记本电脑和家庭工作站之间保持同步。由于我每天大部分时间都在使用 Emacs,因此能够在 Emacs 中查看和编辑我的日历是一个很大的便利。对于大多数使用移动设备的人来说也是如此,因此下一步是在移动设备上设置 Org 模式的日历系统。
|
||||
|
||||
### 移动设备上的 Git
|
||||
|
||||
由于你的日历数据是纯文本的,严格来说,你可以在任何可以读取文本文件的设备上“使用”它。这是这个系统之美的一部分;你永远不会缺少原始数据。但是,要按照你希望的现代日历的工作方式将日历集成到移动设备上,你需要两个组件:移动设备上的 Git 客户端和 Org 模式查看器。
|
||||
|
||||
#### 移动设备上的 Git 客户端
|
||||
|
||||
[MGit][15] 是 Android 上的优秀 Git 客户端。同样,iOS 也有 Git 客户端。
|
||||
|
||||
一旦安装了 MGit(或类似的 Git 客户端),你必须克隆日历存储库,以便在你的手机上有副本。要从移动设备访问服务器,必须设置 SSH 密钥进行身份验证。MGit 可以为你生成和存储密钥,你必须将其添加到服务器的 `~/.ssh/authorized_keys` 文件或托管的 Git 的帐户设置中的 SSH 密钥中。
|
||||
|
||||
你必须手动执行此操作。MGit 没有登录你的服务器或托管的 Git 帐户的界面。如果你不这样做,你的移动设备将无法访问你的服务器以访问你的日历数据。
|
||||
|
||||
我是通过将我在 MGit 中生成的密钥文件通过 [KDE Connect][16] 复制到我的笔记本电脑来实现的(但你可以通过蓝牙、SD 卡读卡器或 USB 电缆进行相同操作,具体取决于你访问手机上的数据的首选方法)。 我用这个命令将密钥(一个名为 `calkey` 的文件)复制到我的服务器:
|
||||
|
||||
```
|
||||
$ cat calkey | ssh seth@example.com "cat >> /home/seth/.ssh/authorized_keys"
|
||||
```
|
||||
|
||||
你可能有不同的方法,但如果你曾经将服务器设置为无密码登录,这是完全相同的过程。如果你使用的是 GitLab 等托管的 Git 服务,则必须将密钥文件的内容复制并粘贴到用户帐户的 SSH 密钥面板中。
|
||||
|
||||
![Adding key file data to GitLab][17]
|
||||
|
||||
完成后,你的移动设备可以向你的服务器授权,但仍需要知道在哪里查找你的日历数据。不同的应用程序可能使用不同的表示法,但 MGit 使用普通的旧式 Git-over-SSH。这意味着如果你使用的是非标准 SSH 端口,则必须指定要使用的 SSH 端口:
|
||||
|
||||
```
|
||||
$ git clone ssh://seth@example.com:22122//home/seth/git/cal.git
|
||||
```
|
||||
|
||||
![Specifying SSH port in MGit][18]
|
||||
|
||||
如果你使用其他应用程序,它可能会使用不同的语法,允许你在特殊字段中提供端口,或删除 `ssh://` 前缀。如果遇到问题,请参阅应用程序文档。
|
||||
|
||||
将存储库克隆到手机。
|
||||
|
||||
![Cloned repositories][19]
|
||||
|
||||
很少有 Git 应用程序设置为自动更新存储库。有一些应用程序可以用来自动拉取,或者你可以设置 Git 钩子来推送服务器的更新 —— 但我不会在这里讨论这些。目前,在对日历进行更新后,请务必在 MGit 中手动提取新更改(或者如果在手机上更改了事件,请将更改推送到服务器)。
|
||||
|
||||
![MGit push/pull settings][20]
|
||||
|
||||
#### 移动设备上的日历
|
||||
|
||||
有一些应用程序可以为移动设备上的 Org 模式提供前端。[Orgzly][21] 是一个很棒的开源 Android 应用程序,它为 Org 模式的从 Agenda 模式到 TODO 列表的大多数功能提供了一个界面。安装并启动它。
|
||||
|
||||
从主菜单中,选择“设置同步存储库”,然后选择包含日历文件的目录(即,从服务器克隆的 Git 存储库)。
|
||||
|
||||
给 Orgzly 一点时间来导入数据,然后使用 Orgzly 的[汉堡包][22]菜单选择日程视图。
|
||||
|
||||
![Orgzly's agenda view][23]
|
||||
|
||||
在 Orgzly 的“设置提醒”菜单中,你可以选择在手机上触发通知的事件类型。你可以获得 `SCHEDULED` 任务,`DEADLINE` 任务或任何分配了事件时间的任何通知。如果你将手机用作任务管理器,那么你将永远不会错过 Org 模式和 Orgzly 的活动。
|
||||
|
||||
![Orgzly notification][24]
|
||||
|
||||
Orgzly 不仅仅是一个解析器。你可以编辑和更新事件,甚至标记事件为 `DONE`。
|
||||
|
||||
![Orgzly to-do list][25]
|
||||
|
||||
### 专为你而设计
|
||||
|
||||
关于使用 Org 模式和 Git 的重要一点是,这两个应用程序都非常灵活,并且你可以自定义它们的工作方式和内容,以便它们能够适应你的需求。如果本文中的内容是对你如何组织生活或管理每周时间表的冒犯,但你喜欢此提案提供的其他部分,那么请丢弃你不喜欢的部分。如果需要,你可以在 Emacs 中使用 Org 模式,或者你可以将其用作日历标记。你可以将手机设置为在一天结束时从计算机上拉取 Git 数据,而不是从互联网上的服务器上,或者你可以将计算机配置为在手机插入时同步日历,或者你可以每天管理它,就像你把你工作日所需的所有东西都装到你的手机上一样。这取决于你,而这是关于 Git、Org 模式和开源的最重要的事情。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/calendar-git
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/web-design-monitor-website.png?itok=yUK7_qR0 (website design image)
|
||||
[2]: https://git-scm.com/
|
||||
[3]: https://tools.ietf.org/html/rfc4791
|
||||
[4]: http://nextcloud.com
|
||||
[5]: https://github.com/pimutils/khal
|
||||
[6]: https://plaintextproject.online/
|
||||
[7]: https://orgmode.org
|
||||
[8]: https://opensource.com/article/19/1/productivity-tool-org-mode
|
||||
[9]: https://commonmark.org/
|
||||
[10]: https://orgmode.org/manual/
|
||||
[11]: http://gitlab.com
|
||||
[12]: http://gitolite.com/gitolite/index.html
|
||||
[13]: https://gitea.io/en-us/
|
||||
[14]: mailto:seth@example.com
|
||||
[15]: https://f-droid.org/en/packages/com.manichord.mgit
|
||||
[16]: https://community.kde.org/KDEConnect
|
||||
[17]: https://opensource.com/sites/default/files/uploads/gitlab-add-key.jpg (Adding key file data to GitLab)
|
||||
[18]: https://opensource.com/sites/default/files/uploads/mgit-0.jpg (Specifying SSH port in MGit)
|
||||
[19]: https://opensource.com/sites/default/files/uploads/mgit-1.jpg (Cloned repositories)
|
||||
[20]: https://opensource.com/sites/default/files/uploads/mgit-2.jpg (MGit push/pull settings)
|
||||
[21]: https://f-droid.org/en/packages/com.orgzly/
|
||||
[22]: https://en.wikipedia.org/wiki/Hamburger_button
|
||||
[23]: https://opensource.com/sites/default/files/uploads/orgzly-agenda.jpg (Orgzly's agenda view)
|
||||
[24]: https://opensource.com/sites/default/files/uploads/orgzly-cal-notify.jpg (Orgzly notification)
|
||||
[25]: https://opensource.com/sites/default/files/uploads/orgzly-cal-todo.jpg (Orgzly to-do list)
|
||||
144
published/20190403 Use Git as the backend for chat.md
Normal file
144
published/20190403 Use Git as the backend for chat.md
Normal file
@ -0,0 +1,144 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11342-1.html)
|
||||
[#]: subject: (Use Git as the backend for chat)
|
||||
[#]: via: (https://opensource.com/article/19/4/git-based-chat)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
用 Git 作为聊天应用的后端
|
||||
======
|
||||
|
||||
> GIC 是一个聊天应用程序的原型,展示了一种使用 Git 的新方法。
|
||||
|
||||

|
||||
|
||||
[Git][2] 是一个少有的能将如此多的现代计算封装到一个程序之中的应用程序,它可以用作许多其他应用程序的计算引擎。虽然它以跟踪软件开发中的源代码更改而闻名,但它还有许多其他用途,可以让你的生活更轻松、更有条理。在这个 Git 系列中,我们将分享七种鲜为人知的使用 Git 的方法。
|
||||
|
||||
今天我们来看看 GIC,它是一个基于 Git 的聊天应用。
|
||||
|
||||
### 初识 GIC
|
||||
|
||||
虽然 Git 的作者们可能期望会为 Git 创建前端,但毫无疑问他们从未预料到 Git 会成为某种后端,如聊天客户端的后端。然而,这正是开发人员 Ephi Gabay 用他的实验性的概念验证应用 [GIC][3] 所做的事情:用 [Node.js][4] 编写的聊天客户端,使用 Git 作为其后端数据库。
|
||||
|
||||
GIC 并没有打算用于生产用途。这纯粹是一种编程练习,但它证明了开源技术的灵活性。令人惊讶的是,除了 Node 库和 Git 本身,该客户端只包含 300 行代码。这是这个聊天客户端和开源所反映出来的最好的地方之一:建立在现有工作基础上的能力。眼见为实,你应该自己亲自来了解一下 GIC。
|
||||
|
||||
### 架设起来
|
||||
|
||||
GIC 使用 Git 作为引擎,因此你需要一个空的 Git 存储库为聊天室和记录器提供服务。存储库可以托管在任何地方,只要你和需要访问聊天服务的人可以访问该存储库就行。例如,你可以在 GitLab 等免费 Git 托管服务上设置 Git 存储库,并授予聊天用户对该 Git 存储库的贡献者访问权限。(他们必须能够提交到存储库,因为每个聊天消息都是一个文本的提交。)
|
||||
|
||||
如果你自己托管,请创建一个中心化的裸存储库。聊天中的每个用户必须在裸存储库所在的服务器上拥有一个帐户。你可以使用如 [Gitolite][5] 或 [Gitea][6] 这样的 Git 托管软件创建特定于 Git 的帐户,或者你可以在服务器上为他们提供个人用户帐户,可以使用 `git-shell` 来限制他们只能访问 Git。
|
||||
|
||||
自托管实例的性能最好。无论你是自己托管还是使用托管服务,你创建的 Git 存储库都必须具有一个活跃分支,否则 GIC 将无法在用户聊天时进行提交,因为没有 Git HEAD。确保分支初始化和活跃的最简单方法是在创建存储库时提交 `README` 或许可证文件。如果你没有这样做,你可以在事后创建并提交一个:
|
||||
|
||||
```
|
||||
$ echo "chat logs" > README
|
||||
$ git add README
|
||||
$ git commit -m 'just creating a HEAD ref'
|
||||
$ git push -u origin HEAD
|
||||
```
|
||||
|
||||
### 安装 GIC
|
||||
|
||||
由于 GIC 基于 Git 并使用 Node.js 编写,因此必须首先安装 Git、Node.js 和 Node 包管理器npm(它应该与 Node 捆绑在一起)。安装它们的命令因 Linux 或 BSD 发行版而异,这是 Fedora 上的一个示例命令:
|
||||
|
||||
```
|
||||
$ sudo dnf install git nodejs
|
||||
```
|
||||
|
||||
如果你没有运行 Linux 或 BSD,请按照 [git-scm.com][7] 和 [nodejs.org][8] 上的安装说明进行操作。
|
||||
|
||||
因此,GIC 没有安装过程。每个用户(在此示例中为 Alice 和 Bob)必须将存储库克隆到其硬盘驱动器:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/ephigabay/GIC GIC
|
||||
```
|
||||
|
||||
将目录更改为 GIC 目录并使用 `npm` 安装 Node.js 依赖项:
|
||||
|
||||
```
|
||||
$ cd GIC
|
||||
$ npm install
|
||||
```
|
||||
|
||||
等待 Node 模块下载并安装。
|
||||
|
||||
### 配置 GIC
|
||||
|
||||
GIC 唯一需要的配置是 Git 聊天存储库的位置。编辑 `config.js` 文件:
|
||||
|
||||
```
|
||||
module.exports = {
|
||||
gitRepo: 'seth@example.com:/home/gitchat/chatdemo.git',
|
||||
messageCheckInterval: 500,
|
||||
branchesCheckInterval: 5000
|
||||
};
|
||||
```
|
||||
|
||||
在尝试 GIC 之前测试你与 Git 存储库的连接,以确保你的配置是正确的:
|
||||
|
||||
```
|
||||
$ git clone --quiet seth@example.com:/home/gitchat/chatdemo.git > /dev/null
|
||||
```
|
||||
|
||||
假设你没有收到任何错误,就可以开始聊天了。
|
||||
|
||||
### 用 Git 聊天
|
||||
|
||||
在 GIC 目录中启动聊天客户端:
|
||||
|
||||
```
|
||||
$ npm start
|
||||
```
|
||||
|
||||
客户端首次启动时,必须克隆聊天存储库。由于它几乎是一个空的存储库,因此不会花费很长时间。输入你的消息,然后按回车键发送消息。
|
||||
|
||||
![GIC][10]
|
||||
|
||||
*基于 Git 的聊天客户端。 他们接下来会怎么想?*
|
||||
|
||||
正如问候消息所说,Git 中的分支在 GIC 中就是聊天室或频道。无法在 GIC 的 UI 中创建新分支,但如果你在另一个终端会话或 Web UI 中创建一个分支,它将立即显示在 GIC 中。将一些 IRC 式的命令加到 GIC 中并不需要太多工作。
|
||||
|
||||
聊了一会儿之后,可以看看你的 Git 存储库。由于聊天发生在 Git 中,因此存储库本身也是聊天日志:
|
||||
|
||||
```
|
||||
$ git log --pretty=format:"%p %cn %s"
|
||||
4387984 Seth Kenlon Hey Chani, did you submit a talk for All Things Open this year?
|
||||
36369bb Chani No I didn't get a chance. Did you?
|
||||
[...]
|
||||
```
|
||||
|
||||
### 退出 GIC
|
||||
|
||||
Vim 以来,还没有一个应用程序像 GIC 那么难以退出。你看,没有办法停止 GIC。它会一直运行,直到它被杀死。当你准备停止 GIC 时,打开另一个终端选项卡或窗口并发出以下命令:
|
||||
|
||||
```
|
||||
$ kill `pgrep npm`
|
||||
```
|
||||
|
||||
GIC 是一个新奇的事物。这是一个很好的例子,说明开源生态系统如何鼓励和促进创造力和探索,并挑战我们从不同角度审视应用程序。尝试下 GIC,也许它会给你一些思路。至少,它可以让你与 Git 度过一个下午。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/git-based-chat
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/talk_chat_team_mobile_desktop.png?itok=d7sRtKfQ (Team communication, chat)
|
||||
[2]: https://git-scm.com/
|
||||
[3]: https://github.com/ephigabay/GIC
|
||||
[4]: https://nodejs.org/en/
|
||||
[5]: http://gitolite.com
|
||||
[6]: http://gitea.io
|
||||
[7]: http://git-scm.com
|
||||
[8]: http://nodejs.org
|
||||
[9]: mailto:seth@example.com
|
||||
[10]: https://opensource.com/sites/default/files/uploads/gic.jpg (GIC)
|
||||
@ -0,0 +1,345 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (LuuMing)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11307-1.html)
|
||||
[#]: subject: (A beginner's guide to building DevOps pipelines with open source tools)
|
||||
[#]: via: (https://opensource.com/article/19/4/devops-pipeline)
|
||||
[#]: author: (Bryant Son https://opensource.com/users/brson/users/milindsingh/users/milindsingh/users/dscripter)
|
||||
|
||||
使用开源工具构建 DevOps 流水线的初学者指南
|
||||
======
|
||||
|
||||
> 如果你是 DevOps 新人,请查看这 5 个步骤来构建你的第一个 DevOps 流水线。
|
||||
|
||||

|
||||
|
||||
DevOps 已经成为解决软件开发过程中出现的缓慢、孤立或者其他故障的默认方式。但是当你刚接触 DevOps 并且不确定从哪开始时,就意义不大了。本文探索了什么是 DevOps 流水线并且提供了创建它的 5 个步骤。尽管这个教程并不全面,但可以给你以后上手和扩展打下基础。首先,插入一个小故事。
|
||||
|
||||
### 我的 DevOps 之旅
|
||||
|
||||
我曾经在花旗集团的云小组工作,开发<ruby><rt>Infrastructure as a Service</rt>基础设施即服务</ruby>网页应用来管理花旗的云基础设施,但我经常对研究如何让开发流水线更加高效以及如何带给团队积极的文化感兴趣。我在 Greg Lavender 推荐的书中找到了答案。Greg Lavender 是花旗的云架构和基础设施工程(即 [Phoenix 项目][2])的 CTO。这本书尽管解释的是 DevOps 原理,但它读起来像一本小说。
|
||||
|
||||
书后面的一张表展示了不同公司部署在发布环境上的频率:
|
||||
|
||||
公司 | 部署频率
|
||||
---|---
|
||||
Amazon | 23,000 次/天
|
||||
Google | 5,500 次/天
|
||||
Netflix | 500 次/天
|
||||
Facebook | 1 次/天
|
||||
Twitter | 3 次/周
|
||||
典型企业 | 1 次/9 个月
|
||||
|
||||
Amazon、Google、Netflix 怎么能做到如此之频繁?那是因为这些公司弄清楚了如何去实现一个近乎完美的 DevOps 流水线。
|
||||
|
||||
但在花旗实施 DevOps 之前,情况并非如此。那时候,我的团队拥有不同<ruby>构建阶段<rt>stage</rt></ruby>的环境,但是在开发服务器上的部署非常手工。所有的开发人员都只能访问一个基于 IBM WebSphere Application 社区版的开发环境服务器。问题是当多个用户同时尝试部署时,服务器就会宕机,因此开发人员在部署时就得互相通知,这一点相当痛苦。此外,还存在代码测试覆盖率低、手动部署过程繁琐以及无法根据定义的任务或用户需求跟踪代码部署的问题。
|
||||
|
||||
我意识到必须做些事情,同时也找到了一个有同样感受的同事。我们决定合作去构建一个初始的 DevOps 流水线 —— 他设置了一个虚拟机和一个 Tomcat 服务器,而我则架设了 Jenkins,集成了 Atlassian Jira、BitBucket 和代码覆盖率测试。这个业余项目非常成功:我们近乎全自动化了开发流水线,并在开发服务器上实现了几乎 100% 的正常运行,我们可以追踪并改进代码覆盖率测试,并且 Git 分支能够与部署任务和 jira 任务关联在一起。此外,大多数用来构建 DevOps 所使用的工具都是开源的。
|
||||
|
||||
现在我意识到了我们的 DevOps 流水线是多么的原始,因为我们没有利用像 Jenkins 文件或 Ansible 这样的高级设置。然而,这个简单的过程运作良好,这也许是因为 [Pareto][3] 原则(也被称作 80/20 法则)。
|
||||
|
||||
### DevOps 和 CI/CD 流水线的简要介绍
|
||||
|
||||
如果你问一些人,“什么是 DevOps?”,你或许会得到一些不同的回答。DevOps,就像敏捷,已经发展到涵盖着诸多不同的学科,但大多数人至少会同意这些:DevOps 是一个软件开发实践或一个<ruby>软件开发生命周期<rt>software development lifecycle</rt></ruby>(SDLC),并且它的核心原则是一种文化上的变革 —— 开发人员与非开发人员呼吸着同一片天空的气息,之前手工的事情变得自动化;每个人做着自己擅长的事;同一时间的部署变得更加频繁;吞吐量提升;灵活度增加。
|
||||
|
||||
虽然拥有正确的软件工具并非实现 DevOps 环境所需的唯一东西,但一些工具却是必要的。最关键的一个便是持续集成和持续部署(CI/CD)。在流水线环境中,拥有不同的构建阶段(例如:DEV、INT、TST、QA、UAT、STG、PROD),手动的工作能实现自动化,开发人员可以实现高质量的代码,灵活而且大量部署。
|
||||
|
||||
这篇文章描述了一个构建 DevOps 流水线的五步方法,就像下图所展示的那样,使用开源的工具实现。
|
||||
|
||||
![Complete DevOps pipeline][4]
|
||||
|
||||
闲话少说,让我们开始吧。
|
||||
|
||||
### 第一步:CI/CD 框架
|
||||
|
||||
首先你需要的是一个 CI/CD 工具,Jenkins,是一个基于 Java 的 MIT 许可下的开源 CI/CD 工具,它是推广 DevOps 运动的工具,并已成为了<ruby>事实标准<rt>de facto standard</rt><ruby>。
|
||||
|
||||
所以,什么是 Jenkins?想象它是一种神奇的万能遥控,能够和许多不同的服务器和工具打交道,并且能够将它们统一安排起来。就本身而言,像 Jenkins 这样的 CI/CD 工具本身是没有用的,但随着接入不同的工具与服务器时会变得非常强大。
|
||||
|
||||
Jenkins 仅是众多构建 DevOps 流水线的开源 CI/CD 工具之一。
|
||||
|
||||
名称 | 许可证
|
||||
---|---
|
||||
[Jenkins][5] | Creative Commons 和 MIT
|
||||
[Travis CI][6] | MIT
|
||||
[CruiseControl][7] | BSD
|
||||
[Buildbot][8] | GPL
|
||||
[Apache Gump][9] | Apache 2.0
|
||||
[Cabie][10] | GNU
|
||||
|
||||
下面就是使用 CI/CD 工具时 DevOps 看起来的样子。
|
||||
|
||||
![CI/CD tool][11]
|
||||
|
||||
你的 CI/CD 工具在本地主机上运行,但目前你还不能够做些别的。让我们紧随 DevOps 之旅的脚步。
|
||||
|
||||
### 第二步:源代码控制管理
|
||||
|
||||
验证 CI/CD 工具可以执行某些魔术的最佳(也可能是最简单)方法是与源代码控制管理(SCM)工具集成。为什么需要源代码控制?假设你在开发一个应用。无论你什么时候构建应用,无论你使用的是 Java、Python、C++、Go、Ruby、JavaScript 或任意一种语言,你都在编程。你所编写的程序代码称为源代码。在一开始,特别是只有你一个人工作时,将所有的东西放进本地文件夹里或许都是可以的。但是当项目变得庞大并且邀请其他人协作后,你就需要一种方式来避免共享代码修改时的合并冲突。你也需要一种方式来恢复一个之前的版本——备份、复制并粘贴的方式已经过时了。你(和你的团队)想要更好的解决方式。
|
||||
|
||||
这就是 SCM 变得不可或缺的原因。SCM 工具通过在仓库中保存代码来帮助进行版本控制与多人协作。
|
||||
|
||||
尽管这里有许多 SCM 工具,但 Git 是最标准恰当的。我极力推荐使用 Git,但如果你喜欢这里仍有其他的开源工具。
|
||||
|
||||
名称 | 许可证
|
||||
---|---
|
||||
[Git][12] | GPLv2 & LGPL v2.1
|
||||
[Subversion][13] | Apache 2.0
|
||||
[Concurrent Versions System][14] (CVS) | GNU
|
||||
[Vesta][15] | LGPL
|
||||
[Mercurial][16] | GNU GPL v2+
|
||||
|
||||
拥有 SCM 之后,DevOps 流水线看起来就像这样。
|
||||
|
||||
![Source control management][17]
|
||||
|
||||
CI/CD 工具能够自动化进行源代码检入检出以及完成成员之间的协作。还不错吧?但是,如何才能把它变成可工作的应用程序,使得数十亿人来使用并欣赏它呢?
|
||||
|
||||
### 第三步:自动化构建工具
|
||||
|
||||
真棒!现在你可以检出代码并将修改提交到源代码控制,并且可以邀请你的朋友就源代码控制进行协作。但是到目前为止你还没有构建出应用。要想让它成为一个网页应用,必须将其编译并打包成可部署的包或可执行程序(注意,像 JavaScript 或 PHP 这样的解释型编程语言不需要进行编译)。
|
||||
|
||||
于是就引出了自动化构建工具。无论你决定使用哪一款构建工具,它们都有一个共同的目标:将源代码构建成某种想要的格式,并且将清理、编译、测试、部署到某个位置这些任务自动化。构建工具会根据你的编程语言而有不同,但这里有一些通常使用的开源工具值得考虑。
|
||||
|
||||
名称 | 许可证 | 编程语言
|
||||
---|---|---
|
||||
[Maven][18] | Apache 2.0 | Java
|
||||
[Ant][19] | Apache 2.0 | Java
|
||||
[Gradle][20] | Apache 2.0 | Java
|
||||
[Bazel][21] | Apache 2.0 | Java
|
||||
[Make][22] | GNU | N/A
|
||||
[Grunt][23] | MIT | JavaScript
|
||||
[Gulp][24] | MIT | JavaScript
|
||||
[Buildr][25] | Apache | Ruby
|
||||
[Rake][26] | MIT | Ruby
|
||||
[A-A-P][27] | GNU | Python
|
||||
[SCons][28] | MIT | Python
|
||||
[BitBake][29] | GPLv2 | Python
|
||||
[Cake][30] | MIT | C#
|
||||
[ASDF][31] | Expat (MIT) | LISP
|
||||
[Cabal][32] | BSD | Haskell
|
||||
|
||||
太棒了!现在你可以将自动化构建工具的配置文件放进源代码控制管理系统中,并让你的 CI/CD 工具构建它。
|
||||
|
||||
![Build automation tool][33]
|
||||
|
||||
一切都如此美好,对吧?但是在哪里部署它呢?
|
||||
|
||||
### 第四步:网页应用服务器
|
||||
|
||||
到目前为止,你有了一个可执行或可部署的打包文件。对任何真正有用的应用程序来说,它必须提供某种服务或者接口,所以你需要一个容器来发布你的应用。
|
||||
|
||||
对于网页应用,网页应用服务器就是容器。应用程序服务器提供了环境,让可部署包中的编程逻辑能够被检测到、呈现界面,并通过打开套接字为外部世界提供网页服务。在其他环境下你也需要一个 HTTP 服务器(比如虚拟机)来安装服务应用。现在,我假设你将会自己学习这些东西(尽管我会在下面讨论容器)。
|
||||
|
||||
这里有许多开源的网页应用服务器。
|
||||
|
||||
名称 | 协议 | 编程语言
|
||||
---|---|---
|
||||
[Tomcat][34] | Apache 2.0 | Java
|
||||
[Jetty][35] | Apache 2.0 | Java
|
||||
[WildFly][36] | GNU Lesser Public | Java
|
||||
[GlassFish][37] | CDDL & GNU Less Public | Java
|
||||
[Django][38] | 3-Clause BSD | Python
|
||||
[Tornado][39] | Apache 2.0 | Python
|
||||
[Gunicorn][40] | MIT | Python
|
||||
[Python Paste][41] | MIT | Python
|
||||
[Rails][42] | MIT | Ruby
|
||||
[Node.js][43] | MIT | Javascript
|
||||
|
||||
现在 DevOps 流水线差不多能用了,干得好!
|
||||
|
||||
![Web application server][44]
|
||||
|
||||
尽管你可以在这里停下来并进行进一步的集成,但是代码质量对于应用开发者来说是一件非常重要的事情。
|
||||
|
||||
### 第五步:代码覆盖测试
|
||||
|
||||
实现代码测试件可能是另一个麻烦的需求,但是开发者需要尽早地捕捉程序中的所有错误并提升代码质量来保证最终用户满意度。幸运的是,这里有许多开源工具来测试你的代码并提出改善质量的建议。甚至更好的,大部分 CI/CD 工具能够集成这些工具并将测试过程自动化进行。
|
||||
|
||||
代码测试分为两个部分:“代码测试框架”帮助进行编写与运行测试,“代码质量改进工具”帮助提升代码的质量。
|
||||
|
||||
#### 代码测试框架
|
||||
|
||||
名称 | 许可证 | 编程语言
|
||||
---|---|---
|
||||
[JUnit][45] | Eclipse Public License | Java
|
||||
[EasyMock][46] | Apache | Java
|
||||
[Mockito][47] | MIT | Java
|
||||
[PowerMock][48] | Apache 2.0 | Java
|
||||
[Pytest][49] | MIT | Python
|
||||
[Hypothesis][50] | Mozilla | Python
|
||||
[Tox][51] | MIT | Python
|
||||
|
||||
#### 代码质量改进工具
|
||||
|
||||
名称 | 许可证 | 编程语言
|
||||
---|---|---
|
||||
[Cobertura][52] | GNU | Java
|
||||
[CodeCover][53] | Eclipse Public (EPL) | Java
|
||||
[Coverage.py][54] | Apache 2.0 | Python
|
||||
[Emma][55] | Common Public License | Java
|
||||
[JaCoCo][56] | Eclipse Public License | Java
|
||||
[Hypothesis][50] | Mozilla | Python
|
||||
[Tox][51] | MIT | Python
|
||||
[Jasmine][57] | MIT | JavaScript
|
||||
[Karma][58] | MIT | JavaScript
|
||||
[Mocha][59] | MIT | JavaScript
|
||||
[Jest][60] | MIT | JavaScript
|
||||
|
||||
注意,之前提到的大多数工具和框架都是为 Java、Python、JavaScript 写的,因为 C++ 和 C# 是专有编程语言(尽管 GCC 是开源的)。
|
||||
|
||||
现在你已经运用了代码覆盖测试工具,你的 DevOps 流水线应该就像教程开始那幅图中展示的那样了。
|
||||
|
||||
### 可选步骤
|
||||
|
||||
#### 容器
|
||||
|
||||
正如我之前所说,你可以在虚拟机(VM)或服务器上发布你的应用,但是容器是一个更好的解决方法。
|
||||
|
||||
[什么是容器][61]?简要的介绍就是 VM 需要占用操作系统大量的资源,它提升了应用程序的大小,而容器仅仅需要一些库和配置来运行应用程序。显然,VM 仍有重要的用途,但容器对于发布应用(包括应用程序服务器)来说是一个更为轻量的解决方式。
|
||||
|
||||
尽管对于容器来说也有其他的选择,但是 Docker 和 Kubernetes 更为广泛。
|
||||
|
||||
名称 | 许可证
|
||||
---|---
|
||||
[Docker][62] | Apache 2.0
|
||||
[Kubernetes][63] | Apache 2.0
|
||||
|
||||
了解更多信息,请查看 [Opensource.com][64] 上关于 Docker 和 Kubernetes 的其它文章:
|
||||
|
||||
* [什么是 Docker?][65]
|
||||
* [Docker 简介][66]
|
||||
* [什么是 Kubernetes?][67]
|
||||
* [从零开始的 Kubernetes 实践][68]
|
||||
|
||||
#### 中间件自动化工具
|
||||
|
||||
我们的 DevOps 流水线大部分集中在协作构建与部署应用上,但你也可以用 DevOps 工具完成许多其他的事情。其中之一便是利用它实现<ruby>基础设施管理<rt>Infrastructure as Code</rt></ruby>(IaC)工具,这也是熟知的中间件自动化工具。这些工具帮助完成中间件的自动化安装、管理和其他任务。例如,自动化工具可以用正确的配置下拉应用程序,例如网页服务器、数据库和监控工具,并且部署它们到应用服务器上。
|
||||
|
||||
这里有几个开源的中间件自动化工具值得考虑:
|
||||
|
||||
名称 | 许可证
|
||||
---|---
|
||||
[Ansible][69] | GNU Public
|
||||
[SaltStack][70] | Apache 2.0
|
||||
[Chef][71] | Apache 2.0
|
||||
[Puppet][72] | Apache or GPL
|
||||
|
||||
获取更多中间件自动化工具,查看 [Opensource.com][64] 上的其它文章:
|
||||
|
||||
* [Ansible 快速入门指南][73]
|
||||
* [Ansible 自动化部署策略][74]
|
||||
* [配置管理工具 Top 5][75]
|
||||
|
||||
### 之后的发展
|
||||
|
||||
这只是一个完整 DevOps 流水线的冰山一角。从 CI/CD 工具开始并且探索其他可以自动化的东西来使你的团队更加轻松的工作。并且,寻找[开源通讯工具][76]可以帮助你的团队一起工作的更好。
|
||||
|
||||
发现更多见解,这里有一些非常棒的文章来介绍 DevOps :
|
||||
|
||||
* [什么是 DevOps][77]
|
||||
* [掌握 5 件事成为 DevOps 工程师][78]
|
||||
* [所有人的 DevOps][79]
|
||||
* [在 DevOps 中开始使用预测分析][80]
|
||||
|
||||
使用开源 agile 工具来集成 DevOps 也是一个很好的主意:
|
||||
|
||||
* [什么是 agile ?][81]
|
||||
* [4 步成为一个了不起的 agile 开发者][82]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/devops-pipeline
|
||||
|
||||
作者:[Bryant Son][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[LuMing](https://github.com/LuuMing)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/brson/users/milindsingh/users/milindsingh/users/dscripter
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/network_team_career_hand.png?itok=_ztl2lk_ (Shaking hands, networking)
|
||||
[2]: https://www.amazon.com/dp/B078Y98RG8/
|
||||
[3]: https://en.wikipedia.org/wiki/Pareto_principle
|
||||
[4]: https://opensource.com/sites/default/files/uploads/1_finaldevopspipeline.jpg (Complete DevOps pipeline)
|
||||
[5]: https://github.com/jenkinsci/jenkins
|
||||
[6]: https://github.com/travis-ci/travis-ci
|
||||
[7]: http://cruisecontrol.sourceforge.net
|
||||
[8]: https://github.com/buildbot/buildbot
|
||||
[9]: https://gump.apache.org
|
||||
[10]: http://cabie.tigris.org
|
||||
[11]: https://opensource.com/sites/default/files/uploads/2_runningjenkins.jpg (CI/CD tool)
|
||||
[12]: https://git-scm.com
|
||||
[13]: https://subversion.apache.org
|
||||
[14]: http://savannah.nongnu.org/projects/cvs
|
||||
[15]: http://www.vestasys.org
|
||||
[16]: https://www.mercurial-scm.org
|
||||
[17]: https://opensource.com/sites/default/files/uploads/3_sourcecontrolmanagement.jpg (Source control management)
|
||||
[18]: https://maven.apache.org
|
||||
[19]: https://ant.apache.org
|
||||
[20]: https://gradle.org/
|
||||
[21]: https://bazel.build
|
||||
[22]: https://www.gnu.org/software/make
|
||||
[23]: https://gruntjs.com
|
||||
[24]: https://gulpjs.com
|
||||
[25]: http://buildr.apache.org
|
||||
[26]: https://github.com/ruby/rake
|
||||
[27]: http://www.a-a-p.org
|
||||
[28]: https://www.scons.org
|
||||
[29]: https://www.yoctoproject.org/software-item/bitbake
|
||||
[30]: https://github.com/cake-build/cake
|
||||
[31]: https://common-lisp.net/project/asdf
|
||||
[32]: https://www.haskell.org/cabal
|
||||
[33]: https://opensource.com/sites/default/files/uploads/4_buildtools.jpg (Build automation tool)
|
||||
[34]: https://tomcat.apache.org
|
||||
[35]: https://www.eclipse.org/jetty/
|
||||
[36]: http://wildfly.org
|
||||
[37]: https://javaee.github.io/glassfish
|
||||
[38]: https://www.djangoproject.com/
|
||||
[39]: http://www.tornadoweb.org/en/stable
|
||||
[40]: https://gunicorn.org
|
||||
[41]: https://github.com/cdent/paste
|
||||
[42]: https://rubyonrails.org
|
||||
[43]: https://nodejs.org/en
|
||||
[44]: https://opensource.com/sites/default/files/uploads/5_applicationserver.jpg (Web application server)
|
||||
[45]: https://junit.org/junit5
|
||||
[46]: http://easymock.org
|
||||
[47]: https://site.mockito.org
|
||||
[48]: https://github.com/powermock/powermock
|
||||
[49]: https://docs.pytest.org
|
||||
[50]: https://hypothesis.works
|
||||
[51]: https://github.com/tox-dev/tox
|
||||
[52]: http://cobertura.github.io/cobertura
|
||||
[53]: http://codecover.org/
|
||||
[54]: https://github.com/nedbat/coveragepy
|
||||
[55]: http://emma.sourceforge.net
|
||||
[56]: https://github.com/jacoco/jacoco
|
||||
[57]: https://jasmine.github.io
|
||||
[58]: https://github.com/karma-runner/karma
|
||||
[59]: https://github.com/mochajs/mocha
|
||||
[60]: https://jestjs.io
|
||||
[61]: /resources/what-are-linux-containers
|
||||
[62]: https://www.docker.com
|
||||
[63]: https://kubernetes.io
|
||||
[64]: http://Opensource.com
|
||||
[65]: https://opensource.com/resources/what-docker
|
||||
[66]: https://opensource.com/business/15/1/introduction-docker
|
||||
[67]: https://opensource.com/resources/what-is-kubernetes
|
||||
[68]: https://opensource.com/article/17/11/kubernetes-lightning-talk
|
||||
[69]: https://www.ansible.com
|
||||
[70]: https://www.saltstack.com
|
||||
[71]: https://www.chef.io
|
||||
[72]: https://puppet.com
|
||||
[73]: https://opensource.com/article/19/2/quickstart-guide-ansible
|
||||
[74]: https://opensource.com/article/19/1/automating-deployment-strategies-ansible
|
||||
[75]: https://opensource.com/article/18/12/configuration-management-tools
|
||||
[76]: https://opensource.com/alternatives/slack
|
||||
[77]: https://opensource.com/resources/devops
|
||||
[78]: https://opensource.com/article/19/2/master-devops-engineer
|
||||
[79]: https://opensource.com/article/18/11/how-non-engineer-got-devops
|
||||
[80]: https://opensource.com/article/19/1/getting-started-predictive-analytics-devops
|
||||
[81]: https://opensource.com/article/18/10/what-agile
|
||||
[82]: https://opensource.com/article/19/2/steps-agile-developer
|
||||
261
published/20190409 Working with variables on Linux.md
Normal file
261
published/20190409 Working with variables on Linux.md
Normal file
@ -0,0 +1,261 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11344-1.html)
|
||||
[#]: subject: (Working with variables on Linux)
|
||||
[#]: via: (https://www.networkworld.com/article/3387154/working-with-variables-on-linux.html#tk.rss_all)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
在 Linux 中使用变量
|
||||
======
|
||||
|
||||
> 变量通常看起来像 `$var` 这样,但它们也有 `$1`、`$*`、`$?` 和 `$$` 这种形式。让我们来看看所有这些 `$` 值可以告诉你什么。
|
||||
|
||||

|
||||
|
||||
有许多重要的值都存储在 Linux 系统中,我们称为“变量”,但实际上变量有几种类型,并且一些有趣的命令可以帮助你使用它们。在上一篇文章中,我们研究了[环境变量][2]以及它们定义在何处。在本文中,我们来看一看在命令行和脚本中使用的变量。
|
||||
|
||||
### 用户变量
|
||||
|
||||
虽然在命令行中设置变量非常容易,但是有一些有趣的技巧。要设置变量,你只需这样做:
|
||||
|
||||
```
|
||||
$ myvar=11
|
||||
$ myvar2="eleven"
|
||||
```
|
||||
|
||||
要显示这些值,只需这样做:
|
||||
|
||||
```
|
||||
$ echo $myvar
|
||||
11
|
||||
$ echo $myvar2
|
||||
eleven
|
||||
```
|
||||
|
||||
你也可以使用这些变量。例如,要递增一个数字变量,使用以下任意一个命令:
|
||||
|
||||
```
|
||||
$ myvar=$((myvar+1))
|
||||
$ echo $myvar
|
||||
12
|
||||
$ ((myvar=myvar+1))
|
||||
$ echo $myvar
|
||||
13
|
||||
$ ((myvar+=1))
|
||||
$ echo $myvar
|
||||
14
|
||||
$ ((myvar++))
|
||||
$ echo $myvar
|
||||
15
|
||||
$ let "myvar=myvar+1"
|
||||
$ echo $myvar
|
||||
16
|
||||
$ let "myvar+=1"
|
||||
$ echo $myvar
|
||||
17
|
||||
$ let "myvar++"
|
||||
$ echo $myvar
|
||||
18
|
||||
```
|
||||
|
||||
使用其中的一些,你可以增加一个变量的值。例如:
|
||||
|
||||
```
|
||||
$ myvar0=0
|
||||
$ ((myvar0++))
|
||||
$ echo $myvar0
|
||||
1
|
||||
$ ((myvar0+=10))
|
||||
$ echo $myvar0
|
||||
11
|
||||
```
|
||||
|
||||
通过这些选项,你可能会发现它们是容易记忆、使用方便的。
|
||||
|
||||
你也可以*删除*一个变量 -- 这意味着没有定义它。
|
||||
|
||||
```
|
||||
$ unset myvar
|
||||
$ echo $myvar
|
||||
```
|
||||
|
||||
另一个有趣的选项是,你可以设置一个变量并将其设为**只读**。换句话说,变量一旦设置为只读,它的值就不能改变(除非一些非常复杂的命令行魔法才可以)。这意味着你也不能删除它。
|
||||
|
||||
```
|
||||
$ readonly myvar3=1
|
||||
$ echo $myvar3
|
||||
1
|
||||
$ ((myvar3++))
|
||||
-bash: myvar3: readonly variable
|
||||
$ unset myvar3
|
||||
-bash: unset: myvar3: cannot unset: readonly variable
|
||||
```
|
||||
|
||||
你可以使用这些设置和递增选项中来赋值和操作脚本中的变量,但也有一些非常有用的*内部变量*可以用于在脚本中。注意,你无法重新赋值或增加它们的值。
|
||||
|
||||
### 内部变量
|
||||
|
||||
在脚本中可以使用很多变量来计算参数并显示有关脚本本身的信息。
|
||||
|
||||
* `$1`、`$2`、`$3` 等表示脚本的第一个、第二个、第三个等参数。
|
||||
* `$#` 表示参数的数量。
|
||||
* `$*` 表示所有参数。
|
||||
* `$0` 表示脚本的名称。
|
||||
* `$?` 表示先前运行的命令的返回码(0 代表成功)。
|
||||
* `$$` 显示脚本的进程 ID。
|
||||
* `$PPID` 显示 shell 的进程 ID(脚本的父进程)。
|
||||
|
||||
其中一些变量也适用于命令行,但显示相关信息:
|
||||
|
||||
* `$0` 显示你正在使用的 shell 的名称(例如,-bash)。
|
||||
* `$$` 显示 shell 的进程 ID。
|
||||
* `$PPID` 显示 shell 的父进程的进程 ID(对我来说,是 sshd)。
|
||||
|
||||
为了查看它们的结果,如果我们将所有这些变量都放入一个脚本中,比如:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
echo $0
|
||||
echo $1
|
||||
echo $2
|
||||
echo $#
|
||||
echo $*
|
||||
echo $?
|
||||
echo $$
|
||||
echo $PPID
|
||||
```
|
||||
|
||||
当我们调用这个脚本时,我们会看到如下内容:
|
||||
|
||||
```
|
||||
$ tryme one two three
|
||||
/home/shs/bin/tryme <== 脚本名称
|
||||
one <== 第一个参数
|
||||
two <== 第二个参数
|
||||
3 <== 参数的个数
|
||||
one two three <== 所有的参数
|
||||
0 <== 上一条 echo 命令的返回码
|
||||
10410 <== 脚本的进程 ID
|
||||
10109 <== 父进程 ID
|
||||
```
|
||||
|
||||
如果我们在脚本运行完毕后检查 shell 的进程 ID,我们可以看到它与脚本中显示的 PPID 相匹配:
|
||||
|
||||
```
|
||||
$ echo $$
|
||||
10109 <== shell 的进程 ID
|
||||
```
|
||||
|
||||
当然,比起简单地显示它们的值,更有用的方式是使用它们。我们来看一看它们可能的用处。
|
||||
|
||||
检查是否已提供参数:
|
||||
|
||||
```
|
||||
if [ $# == 0 ]; then
|
||||
echo "$0 filename"
|
||||
exit 1
|
||||
fi
|
||||
```
|
||||
|
||||
检查特定进程是否正在运行:
|
||||
|
||||
```
|
||||
ps -ef | grep apache2 > /dev/null
|
||||
if [ $? != 0 ]; then
|
||||
echo Apache is not running
|
||||
exit
|
||||
fi
|
||||
```
|
||||
|
||||
在尝试访问文件之前验证文件是否存在:
|
||||
|
||||
```
|
||||
if [ $# -lt 2 ]; then
|
||||
echo "Usage: $0 lines filename"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ ! -f $2 ]; then
|
||||
echo "Error: File $2 not found"
|
||||
exit 2
|
||||
else
|
||||
head -$1 $2
|
||||
fi
|
||||
```
|
||||
|
||||
在下面的小脚本中,我们检查是否提供了正确数量的参数、第一个参数是否为数字,以及第二个参数代表的文件是否存在。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
if [ $# -lt 2 ]; then
|
||||
echo "Usage: $0 lines filename"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [[ $1 != [0-9]* ]]; then
|
||||
echo "Error: $1 is not numeric"
|
||||
exit 2
|
||||
fi
|
||||
|
||||
if [ ! -f $2 ]; then
|
||||
echo "Error: File $2 not found"
|
||||
exit 3
|
||||
else
|
||||
echo top of file
|
||||
head -$1 $2
|
||||
fi
|
||||
```
|
||||
|
||||
### 重命名变量
|
||||
|
||||
在编写复杂的脚本时,为脚本的参数指定名称通常很有用,而不是继续将它们称为 `$1`、`$2` 等。等到第 35 行,阅读你脚本的人可能已经忘了 `$2` 表示什么。如果你将一个重要参数的值赋给 `$filename` 或 `$numlines`,那么他就不容易忘记。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
if [ $# -lt 2 ]; then
|
||||
echo "Usage: $0 lines filename"
|
||||
exit 1
|
||||
else
|
||||
numlines=$1
|
||||
filename=$2
|
||||
fi
|
||||
|
||||
if [[ $numlines != [0-9]* ]]; then
|
||||
echo "Error: $numlines is not numeric"
|
||||
exit 2
|
||||
fi
|
||||
|
||||
if [ ! -f $ filename]; then
|
||||
echo "Error: File $filename not found"
|
||||
exit 3
|
||||
else
|
||||
echo top of file
|
||||
head -$numlines $filename
|
||||
fi
|
||||
```
|
||||
|
||||
当然,这个示例脚本只是运行 `head` 命令来显示文件中的前 x 行,但它的目的是显示如何在脚本中使用内部参数来帮助确保脚本运行良好,或在失败时清晰地知道失败原因。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3387154/working-with-variables-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/04/variable-key-keyboard-100793080-large.jpg
|
||||
[2]: https://linux.cn/article-10916-1.html
|
||||
[3]: https://www.youtube.com/playlist?list=PL7D2RMSmRO9J8OTpjFECi8DJiTQdd4hua
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
40
published/20190524 Spell Checking Comments.md
Normal file
40
published/20190524 Spell Checking Comments.md
Normal file
@ -0,0 +1,40 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11294-1.html)
|
||||
[#]: subject: (Spell Checking Comments)
|
||||
[#]: via: (https://emacsredux.com/blog/2019/05/24/spell-checking-comments/)
|
||||
[#]: author: (Bozhidar Batsov https://emacsredux.com)
|
||||
|
||||
Emacs 注释中的拼写检查
|
||||
======
|
||||
|
||||
我出了名的容易拼错单词(特别是在播客当中)。谢天谢地 Emacs 内置了一个名为 `flyspell` 的超棒模式来帮助像我这样的可怜的打字员。flyspell 会在你输入时突出显示拼错的单词 (也就是实时的) 并提供有用的快捷键来快速修复该错误。
|
||||
|
||||
大多输入通常会对派生自 `text-mode`(比如 `markdown-mode`,`adoc-mode` )的主模式启用 `flyspell`,但是它对程序员也有所帮助,可以指出他在注释中的错误。所需要的只是启用 `flyspell-prog-mode`。我通常在所有的编程模式中(至少在 `prog-mode` 派生的模式中)都启用它:
|
||||
|
||||
```
|
||||
(add-hook 'prog-mode-hook #'flyspell-prog-mode)
|
||||
```
|
||||
|
||||
现在当你在注释中输入错误时,就会得到即时反馈了。要修复单词只需要将光标置于单词后,然后按下 `C-c $` (`M-x flyspell-correct-word-before-point`)。(还有许多其他方法可以用 `flyspell` 来纠正拼写错误的单词,但为了简单起见,我们暂时忽略它们。)
|
||||
|
||||
![flyspell_prog_mode.gif][1]
|
||||
|
||||
今天的分享就到这里!我要继续修正这些讨厌的拼写错误了!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://emacsredux.com/blog/2019/05/24/spell-checking-comments/
|
||||
|
||||
作者:[Bozhidar Batsov][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://emacsredux.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://emacsredux.com/assets/images/flyspell_prog_mode.gif
|
||||
@ -0,0 +1,44 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11322-1.html)
|
||||
[#]: subject: (How many browser tabs do you usually have open?)
|
||||
[#]: via: (https://opensource.com/article/19/6/how-many-browser-tabs)
|
||||
[#]: author: (Lauren Pritchett https://opensource.com/users/lauren-pritchett/users/sarahwall/users/ksonney/users/jwhitehurst)
|
||||
|
||||
你通常打开多少个浏览器标签页?
|
||||
======
|
||||
|
||||
> 外加一些提高浏览器效率的技巧。
|
||||
|
||||
![Browser of things][1]
|
||||
|
||||
这里有一个别有用心的问题:你通常一次打开多少个浏览器标签页?你是否有多个窗口,每个窗口都有多个标签页?或者你是一个极简主义者,一次只打开两个标签页。另一种选择是将一个 20 个标签页的浏览器窗口移动到另一个屏幕上去,这样在处理特定任务时它就不会碍事了。你的处理方法在工作、个人和移动浏览器之间有什么不同吗?你的浏览器策略是否与你的[工作习惯][2]有关?
|
||||
|
||||
### 4 个提高浏览器效率的技巧
|
||||
|
||||
1. 了解浏览器快捷键以节省单击。无论你使用 Firefox 还是 Chrome,都有很多快捷键可以让你方便地执行包括切换标签页在内的某些功能。例如,Chrome 可以很方便地打开一个空白的谷歌文档。使用快捷键 `Ctrl + t` 打开一个新标签页,然后键入 `doc.new` 即可。电子表格、幻灯片和表单也可以这样做。
|
||||
2. 用书签文件夹组织最频繁的任务。当开始一项特定的任务时,只需打开文件夹中的所有书签 (`Ctrl + 点击`),就可以快速地从列表中勾选它。
|
||||
3. 使用正确的浏览器扩展。成千上万的浏览器扩展都声称可以提高工作效率。在安装之前,确定你不是仅仅在屏幕上添加更多的干扰而已。
|
||||
4. 使用计时器减少看屏幕的时间。无论你使用的是老式的 egg 定时器还是花哨的浏览器扩展,都没有关系。为了防止眼睛疲劳,执行 20/20/20 规则。每隔 20 分钟,离开屏幕 20 秒,看看 20 英尺以外的东西。
|
||||
|
||||
参加我们的投票来分享你一次打开多少个浏览器标签。请务必在评论中告诉我们你最喜欢的浏览器技巧。
|
||||
|
||||
生产力有两个组成部分——做正确的事情和高效地做那些事情……
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/6/how-many-browser-tabs
|
||||
|
||||
作者:[Lauren Pritchett][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/lauren-pritchett/users/sarahwall/users/ksonney/users/jwhitehurst
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/browser_desktop_website_checklist_metrics.png?itok=OKKbl1UR (Browser of things)
|
||||
[2]: https://enterprisersproject.com/article/2019/1/5-time-wasting-habits-break-new-year
|
||||
@ -0,0 +1,58 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11325-1.html)
|
||||
[#]: subject: (How to stream music with GNOME Internet Radio)
|
||||
[#]: via: (https://opensource.com/article/19/6/gnome-internet-radio)
|
||||
[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdoss/users/r3bl)
|
||||
|
||||
如何使用 GNOME 的 Internet Radio 播放流音乐
|
||||
======
|
||||
|
||||
> 如果你正在寻找一个简单、直观的界面,让你可以播放流媒体,可以尝试一下 GNOME 的 Internet Radio 插件。
|
||||
|
||||

|
||||
|
||||
网络广播是收听世界各地电台节目的好方法。和许多开发人员一样,我喜欢在编写代码时打开电台。你可以使用 [MPlayer][2] 或 [mpv][3] 等终端媒体播放器收听网络广播,我就是这样通过 Linux 命令行收听广播的。但是,如果你喜欢使用图形用户界面 (GUI),你可以尝试一下 [GNOME Internet Radio][4],这是一个用于 GNOME 桌面的漂亮插件。你可以在包管理器中找到它。
|
||||
|
||||
![GNOME Internet Radio plugin][5]
|
||||
|
||||
使用图形桌面操作系统收听网络广播通常需要启动一个应用程序,比如 [Audacious][6] 或 [Rhythmbox][7]。它们有很好的界面,很多选项,以及很酷的音频可视化工具。但如果你只想要一个简单、直观的界面播放你的流媒体,GNOME Internet Radio 就是你的选择。
|
||||
|
||||
安装之后,工具栏中会出现一个小图标,你可以在其中进行所有配置和管理。
|
||||
|
||||
![GNOME Internet Radio icons][8]
|
||||
|
||||
我做的第一件事是进入设置菜单。我启用了以下两个选项:显示标题通知和显示音量调整。
|
||||
|
||||
![GNOME Internet Radio Settings][9]
|
||||
|
||||
GNOME Internet Radio 包含一些预置的电台,并且很容易添加其他电台。只需点击(“+”)符号即可。你需要输入一个频道名称,它可以是你喜欢的任何内容(包括电台名称)和电台地址。例如,我喜欢听 Synthetic FM。我输入名称(Synthetic FM),以及流地址(https://mediaserv38.live-streams.nl:2199/tunein/syntheticfm.pls)。
|
||||
|
||||
然后单击流旁边的星号将其添加到菜单中。
|
||||
|
||||
不管你听什么音乐,不管你选择什么类型,很明显,程序员需要他们的音乐!GNOME Internet Radio 插件使你可以轻松地让你排好喜爱的网络电台。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/6/gnome-internet-radio
|
||||
|
||||
作者:[Alan Formy-Duval][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/alanfdoss/users/r3bl
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/video_editing_folder_music_wave_play.png?itok=-J9rs-My (video editing dashboard)
|
||||
[2]: https://opensource.com/article/18/12/linux-toy-mplayer
|
||||
[3]: https://mpv.io/
|
||||
[4]: https://extensions.gnome.org/extension/836/internet-radio/
|
||||
[5]: https://opensource.com/sites/default/files/uploads/packagemanager_s.png (GNOME Internet Radio plugin)
|
||||
[6]: https://audacious-media-player.org/
|
||||
[7]: https://help.gnome.org/users/rhythmbox/stable/
|
||||
[8]: https://opensource.com/sites/default/files/uploads/titlebaricons.png (GNOME Internet Radio icons)
|
||||
[9]: https://opensource.com/sites/default/files/uploads/gnomeinternetradio_settings.png (GNOME Internet Radio Settings)
|
||||
196
published/20190628 How to Install and Use R on Ubuntu.md
Normal file
196
published/20190628 How to Install and Use R on Ubuntu.md
Normal file
@ -0,0 +1,196 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (guevaraya)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11331-1.html)
|
||||
[#]: subject: (How to Install and Use R on Ubuntu)
|
||||
[#]: via: (https://itsfoss.com/install-r-ubuntu/)
|
||||
[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
|
||||
|
||||
如何在 Ubuntu 上安装和使用 R 语言
|
||||
======
|
||||
|
||||
> 这个教程指导你如何在 Ubuntu 上安装 R 语言。你也将同时学习到如何在 Ubuntu 上用不同方法运行简单的 R 语言程序。
|
||||
|
||||
[R][1],和 Python 一样,它是在统计计算和图形处理上最常用的编程语言,易于处理数据。随着数据分析、数据可视化、数据科学(机器学习热)的火热化,对于想深入这一领域的人来说,它是一个很好的工具。
|
||||
|
||||
R 语言的优点是它的语法非常简练,你可以找到它的很多实际使用的教程或指南。
|
||||
|
||||
本文将介绍包含如何在 Ubuntu 下安装 R 语言,也会介绍在 Linux 下如何运行第一个 R 程序。
|
||||
|
||||
![][2]
|
||||
|
||||
### 如何在 Ubuntu 上安装 R 语言
|
||||
|
||||
R 默认在 Ubuntu 的软件库里。用以下命令很容易安装:
|
||||
|
||||
```
|
||||
sudo apt install r-base
|
||||
```
|
||||
|
||||
请注意这可能会安装一个较老的版本。在我写这篇文字的时候,Ubuntu 提供的是 3.4,但是最新的是3.6。
|
||||
|
||||
*我建议除非你必须使用最新版本,否则直接使用 Ubuntu 的配套版本。*
|
||||
|
||||
#### 如何在 Ubuntu 上安装最新 3.6 版本的 R 环境
|
||||
|
||||
如果想安装最新的版本(或特殊情况指定版本),你必须用 [CRAN][3](Comprehensive R Archive Network)。这个是 R 最新版本的镜像列表。
|
||||
|
||||
如需获取 3.6 的版本,需要添加镜像到你的源索引里。我已经简化其命令如下:
|
||||
|
||||
```
|
||||
sudo add-apt-repository "deb https://cloud.r-project.org/bin/linux/ubuntu $(lsb_release -cs)-cran35/"
|
||||
```
|
||||
|
||||
下面你需要添加密钥到服务器中:
|
||||
|
||||
```
|
||||
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys E298A3A825C0D65DFD57CBB651716619E084DAB9
|
||||
```
|
||||
|
||||
然后更新服务器信息并安装R环境:
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt install r-base
|
||||
```
|
||||
|
||||
就这样安装完成。
|
||||
|
||||
### 如何在 Ubuntu 下使用 R 语言编程
|
||||
|
||||
R 的用法多样,我将介绍运行多个运行 R 语言的方式。
|
||||
|
||||
#### R 语言的交互模式
|
||||
|
||||
安装了 R 语言后,你可以在控制台上直接运行:
|
||||
|
||||
```
|
||||
R
|
||||
```
|
||||
|
||||
这样会打开交互模式:
|
||||
|
||||
![R Interactive Mode][5]
|
||||
|
||||
R 语言的控制台与 Python 和 Haskell 的交互模式很类似。你可以输入 R 命令做一些基本的数学运算,例如:
|
||||
|
||||
```
|
||||
> 20+40
|
||||
[1] 60
|
||||
|
||||
> print ("Hello World!")
|
||||
[1] "Hello World!"
|
||||
```
|
||||
|
||||
你可以测试绘图:
|
||||
|
||||
![R Plotting][6]
|
||||
|
||||
如果想退出可以用 `q()`或按下 `CTRL+c`键。接着你会被提示是否保存工作空间镜像;工作空间是创建变量的环境。
|
||||
|
||||
#### 用 R 脚本运行程序
|
||||
|
||||
第二种运行 R 程序的方式是直接在 Linux 命令行下运行。你可以用 `RScript` 执行,它是一个包含 `r-base` 软件包的工具。
|
||||
|
||||
首先,你需要用你在 [Linux 下常用的编辑器][7]保存 R 程序到文件。文件的扩展名必须是 `.r`。
|
||||
|
||||
下面是一个打印 “Hello World” 的 R 程序。你可以保存其为 `hello.r`。
|
||||
|
||||
```
|
||||
print("Hello World!")
|
||||
a <- rnorm(100)
|
||||
plot(a)
|
||||
```
|
||||
|
||||
用下面命令运行 R 程序:
|
||||
|
||||
```
|
||||
Rscript hello.r
|
||||
```
|
||||
|
||||
你会得到如下输出结果:
|
||||
|
||||
```
|
||||
[1] "Hello World!"
|
||||
```
|
||||
|
||||
结果将会保存到当前工作目录,文件名为 `Rplots.pdf`:
|
||||
|
||||
![Rplots.pdf][8]
|
||||
|
||||
小提示:`Rscript` 默认不会加载 `methods` 包。确保在脚本中[显式加载][9]它。
|
||||
|
||||
#### 在 Ubuntu 下用 RStudio 运行 R 语言
|
||||
|
||||
最常见的 R 环境是 [RStudio][10],这是一个强大的跨平台的开源 IDE。你可以用 deb 文件在 Ubuntu 上安装它。下载 deb 文件的链接如下。你需要向下滚动找到 Ubuntu 下的 DEB 文件。
|
||||
|
||||
- [下载 Ubuntu 的 Rstudio][12]
|
||||
|
||||
下载了 DEB 文件后,直接点击安装。
|
||||
|
||||
下载后从菜单搜索启动它。程序主界面会弹出如下:
|
||||
|
||||
![RStudio 主界面][13]
|
||||
|
||||
现在可以看到和 R 命令终端一样的工作台。
|
||||
|
||||
创建一个文件:点击顶栏 “File” 然后选择 “New File > Rscript”(或 `CTRL+Shift+n`):
|
||||
|
||||
![RStudio 新建文件][15]
|
||||
|
||||
按下 `CTRL+s` 保存文件选择路径和命名:
|
||||
|
||||
![RStudio 保存文件][16]
|
||||
|
||||
这样做了后,点击 “Session > Set Working Directory > To Source File Location” 修改工作目录为你的脚本路径:
|
||||
|
||||
![RStudio 工作目录][17]
|
||||
|
||||
现在一切准备就绪!编写代码然后点击运行。你可以在控制台和图形窗口看到结果:
|
||||
|
||||
![RStudio 运行][18]
|
||||
|
||||
### 结束语
|
||||
|
||||
这篇文章中展示了如何在 Ubuntu 下使用 R 语言。包含了以下几个方面:R 控制台 —— 可用于测试,Rscript —— 终端达人操作,RStudio —— 你想要的 IDE。
|
||||
|
||||
无论你正在从事数据科学或只是热爱数据统计,作为一个数据分析的完美工具,R 都是一个比较好的编程装备。
|
||||
|
||||
你想使用 R 吗?你入门了吗?让我们了解你是如何学习 R 的以及为什么要学习 R!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-r-ubuntu/
|
||||
|
||||
作者:[Sergiu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[guevaraya](https://github.com/guevaraya)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/sergiu/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.r-project.org/
|
||||
[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/06/install-r-on-ubuntu.jpg?resize=800%2C450&ssl=1
|
||||
[3]: https://cran.r-project.org/
|
||||
[4]: https://itsfoss.com/bootable-windows-usb-linux/
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/06/r_interactive_mode.png?fit=800%2C516&ssl=1
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/r_plotting.jpg?fit=800%2C434&ssl=1
|
||||
[7]: https://itsfoss.com/best-modern-open-source-code-editors-for-linux/
|
||||
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/06/rplots_pdf.png?fit=800%2C539&ssl=1
|
||||
[9]: https://www.dummies.com/programming/r/how-to-install-load-and-unload-packages-in-r/
|
||||
[10]: https://www.rstudio.com/
|
||||
[11]: https://itsfoss.com/install-deb-files-ubuntu/
|
||||
[12]: https://www.rstudio.com/products/rstudio/download/#download
|
||||
[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/06/rstudio_home.jpg?fit=800%2C603&ssl=1
|
||||
[14]: https://itsfoss.com/python-setup-linux/
|
||||
[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/rstudio_new_file.png?fit=800%2C392&ssl=1
|
||||
[16]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/06/rstudio_save_file.png?fit=800%2C258&ssl=1
|
||||
[17]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/rstudio_working_directory.png?fit=800%2C394&ssl=1
|
||||
[18]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/rstudio_run.jpg?fit=800%2C626&ssl=1
|
||||
[19]: https://i1.wp.com/images-na.ssl-images-amazon.com/images/I/51oIJTbUlnL._SL160_.jpg?ssl=1
|
||||
[20]: https://www.amazon.com/Learn-R-Day-Steven-Murray-ebook/dp/B00GC2LKOK?SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B00GC2LKOK (Learn R in a Day)
|
||||
[21]: https://www.amazon.com/Learn-R-Day-Steven-Murray-ebook/dp/B00GC2LKOK?SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B00GC2LKOK (Buy on Amazon)
|
||||
|
||||
@ -0,0 +1,227 @@
|
||||
10 个 Linux 中最好的 Visio 替代品
|
||||
======
|
||||
|
||||
> 如果你正在 Linux 中寻找一个好的 Visio 查看器,这里有一些可以在 Linux 中使用的微软 Visio 的替代方案。
|
||||
|
||||
[微软 Visio][1] 是创建或生成关键任务图和矢量表示的绝佳工具。虽然它可能是制作平面图或其他类型图表的好工具 —— 但它既不是免费的,也不是开源的
|
||||
|
||||
此外,微软 Visio 不是一个独立的产品。它与微软 Office 捆绑在一起。我们过去已经看过 [MS Office 的开源替代品][2]。今天我们将看看你可以在 Linux 上使用哪些工具代替 Visio。
|
||||
|
||||
### 适用于 Linux 的最佳 微软 Visio 备选方案
|
||||
|
||||
![用于 Linux 的微软 Visio 备选方案][4]
|
||||
|
||||
此处为强制性免责声明。该列表不是排名。排名第三的产品并不比排名第六的好。
|
||||
|
||||
我还提到了两个可以从 Web 界面使用的非开源 Visio 软件。
|
||||
|
||||
| 软件 | 类型 | 许可证类型 |
|
||||
| --- | --- | --- |
|
||||
| [LibreOffice Draw][6] | 桌面软件 | 自由开源 |
|
||||
| [OpenOffice Draw][10] | 桌面软件 | 自由开源 |
|
||||
| [Dia][12] | 桌面软件 | 自由开源 |
|
||||
| [yED Graph Editor][14] | 桌面和基于 Web | 免费增值 |
|
||||
| [Inkscape][16] | 桌面软件 | 自由开源 |
|
||||
| [Pencil][18] | 桌面和基于 Web | 自由开源 |
|
||||
| [Graphviz][20] | 桌面软件 | 自由开源 |
|
||||
| [darw.io][22] | 桌面和基于 Web | 自由开源 |
|
||||
| [Lucidchart][24] | 基于 Web | 免费增值 |
|
||||
| [Calligra Flow][27] | 桌面软件 | 自由开源 |
|
||||
|
||||
|
||||
### 1、LibreOffice Draw
|
||||
|
||||
![][5]
|
||||
|
||||
LibreOffice Draw 模块是微软 Visio 的最佳开源替代方案之一。在它的帮助下,你可以选择制作一个想法的速写或一个复杂的专业平面布置图来展示。流程图、组织结构图、网络图、小册子、海报等等!所有这些都不需要花一分钱。
|
||||
|
||||
好的是它与 LibreOffice 捆绑在一起,默认情况下安装在大多数 Linux 发行版中。
|
||||
|
||||
#### 主要功能概述:
|
||||
|
||||
* 用于制作宣传册/海报的样式和格式工具
|
||||
* Calc 数据可视化
|
||||
* PDF 文件编辑功能
|
||||
* 通过操作图库中的图片来创建相册
|
||||
* 灵活的绘图工具类似于 微软 Visio (智能连接器,尺寸线等)的工具
|
||||
* 支持 .VSD 文件(打开)
|
||||
|
||||
官网:[LibreOffice Draw][6]
|
||||
|
||||
### 2、Apache OpenOffice Draw
|
||||
|
||||
![][7]
|
||||
|
||||
很多人都知道 OpenOffice(LibreOffice 项目最初就是基于它的),但他们并没有真正意识到 Apache OpenOffice Draw 可以作为微软 Visio 的替代方案。但事实上,它是另一个令人惊奇的开源图表软件工具。与 LibreOffice Draw 不同,它不支持编辑 PDF 文件,但它为任何类型的图表创建提供了绘图工具。
|
||||
|
||||
这只是个警告。仅当你的系统中已经有 OpenOffice 时才使用此工具。这是因为[安装 OpenOffice][8] 是一件痛苦的事情,而且它已经[不再继续开发][9]。
|
||||
|
||||
#### 主要功能概述:
|
||||
|
||||
* 快速创建 3D 形状控制器
|
||||
* 创建作品的 flash 版本(.swf)
|
||||
* 样式和格式工具
|
||||
* 与微软 Visio 类似的灵活绘图工具(智能连接器、尺寸线等)
|
||||
|
||||
官网:[Apache OpenOffice Draw][10]
|
||||
|
||||
### 3、Dia
|
||||
|
||||
![][11]
|
||||
|
||||
Dia 是另一个有趣的开源工具。它可能不像前面提到的那样处于积极开发之中。但是,如果你正在寻找一个自由而开源的替代微软 Visio 的简单而体面的图表,那么 Dia 可能是你的选择。这个工具可能唯一让你失望的地方就是它的用户界面。除此之外,它还允许你为复杂的图使用强大的工具(但它看起来可能不太好 —— 所以我们建议你用于更简单的图)。
|
||||
|
||||
#### 主要功能概述:
|
||||
|
||||
* 它可以通过命令行使用
|
||||
* 样式和格式工具
|
||||
* 用于自定义形状的形状存储库
|
||||
* 与微软 Visio 类似的绘图工具(特殊对象、网格线、图层等)
|
||||
* 跨平台
|
||||
|
||||
官网:[Dia][12]
|
||||
|
||||
### 4、yED Graph Editor
|
||||
|
||||
[视频](https://youtu.be/OmSTwKw7dX4)
|
||||
|
||||
是最受欢迎的免费的微软 Visio 替代方案之一。如果你对它是一个免费软件而不是开源项目有些担心,你仍然可以通过 web 浏览器免费使用 [yED 的实时编辑器][13]。如果你想用一个非常易于使用的界面快速绘制图表,这是最好的建议之一。
|
||||
|
||||
#### 主要功能概述:
|
||||
|
||||
* 拖放功能,方便图表制作
|
||||
* 支持导入外部数据进行链接
|
||||
|
||||
官网:[yED Graph Editor][14]
|
||||
|
||||
### 5、Inkscape
|
||||
|
||||
![][15]
|
||||
|
||||
Inkscape 是一个自由开源的矢量图形编辑器。你将拥有创建流程图或数据流程图的基本功能。它不提供高级的图表绘制工具,而是提供创建更简单图表的基本工具。因此,当你希望通过使用图库中的可用符号,在图库连接器工具的帮助下生成基本图时,Inkscape 可能是你的 Visio 替代品。
|
||||
|
||||
#### 主要功能概述:
|
||||
|
||||
* 连接器工具
|
||||
* 灵活的绘图工具
|
||||
* 广泛的文件格式兼容性
|
||||
|
||||
官网:[Inkscape][16]
|
||||
|
||||
### 6、Pencil 项目
|
||||
|
||||
![][17]
|
||||
|
||||
Pencil 项目是一个令人印象深刻的开源项目,适用于 Windows、Mac 以及 Linux。它具有易于使用的图形界面,使绘图更容易和方便。它有一个很好的内建形状和符号的集合,可以使你的图表看起来很棒。它还内置了 Android 和 iOS UI 模板,可以让你在需要时创建应用程序原型。
|
||||
|
||||
你也可以将其安装为 Firefox 扩展,但该扩展不能使用项目的最新版本。
|
||||
|
||||
#### 主要功能概述:
|
||||
|
||||
* 轻松浏览剪贴画(使用 openclipart.org)
|
||||
* 导出为 ODT 文件/PDF 文件
|
||||
* 图表连接工具
|
||||
* 跨平台
|
||||
|
||||
官网:[Pencil 项目][18]
|
||||
|
||||
### 7、Graphviz
|
||||
|
||||
![][19]
|
||||
|
||||
Graphviz 略有不同。它不是绘图工具,而是专用的图形可视化工具。如果你在网络图中需要多个设计来表示一个节点,那么一定要使用这个工具。当然,你不能用这个工具做平面布置图(至少这不容易)。因此,它最适合于网络图、生物信息学、数据库连接和类似的东西。
|
||||
|
||||
#### 主要功能概述:
|
||||
|
||||
* 支持命令行使用
|
||||
* 支持自定义形状和表格节点布局
|
||||
* 基本样式和格式设置工具
|
||||
|
||||
官网:[Graphviz][20]
|
||||
|
||||
### 8、Draw.io
|
||||
|
||||
[视频](https://youtu.be/Z0D96ZikMkc)
|
||||
|
||||
Draw.io 主要是一个基于 Web 的免费图表工具,它的强大的工具几乎可以制作任何类型的图表。你只需要拖放然后连接它们以创建流程图、ER 图或任何相关的。此外,如果你喜欢该工具,则可以尝试[离线桌面版本][21]。
|
||||
|
||||
#### 主要功能概述:
|
||||
|
||||
* 直接上传到云存储服务
|
||||
* 自定义形状
|
||||
* 样式和格式工具
|
||||
* 跨平台
|
||||
|
||||
官网:[Draw.io][22]
|
||||
|
||||
### 9、Lucidchart
|
||||
|
||||
![][23]
|
||||
|
||||
Lucidchart 是一个基于 Web 的高级图表工具,它提供了一个具有有限功能的免费订阅。你可以使用免费订阅创建几种类型的图表,并将其导出为图像或 PDF。但是,免费版本不支持数据链接和 Visio 导入/导出功能。如果你不需要数据链接功能,Lucidchart 可以说是一个生成漂亮的图表的非常好的工具。
|
||||
|
||||
#### 主要功能概述:
|
||||
|
||||
* 可以集成到 Slack、Jira 核心、Confluence
|
||||
* 能够制作产品模型
|
||||
* 导入 Visio 文件
|
||||
|
||||
官网:[Lucidchart][24]
|
||||
|
||||
### 10、Calligra Flow
|
||||
|
||||
![calligra flow][25]
|
||||
|
||||
Calligra Flow 是 [Calligra 项目][26]的一部分,旨在提供自由开源的软件工具。使用 Calligra flow 你可以轻松地创建网络图、实体关系图、流程图等
|
||||
|
||||
#### 主要功能概述:
|
||||
|
||||
* 各种模具盒
|
||||
* 样式和格式工具
|
||||
|
||||
官网:[Calligra Flow][27]
|
||||
|
||||
### 总结
|
||||
|
||||
既然你已经了解到了这些最好的自由开源的 Visio 替代方案,你对它们有什么看法?
|
||||
|
||||
对于你任何方面的需求,它们是否优于 微软 Visio?另外,如果我们错过了你最喜欢的基于 Linux 的替代微软 Visio 的绘图工具,请在下面的评论中告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/visio-alternatives-linux/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
译者:[ZhiW5217](https://github.com/ZhiW5217)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ankush/
|
||||
[1]:https://products.office.com/en/visio/flowchart-software
|
||||
[2]:https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/
|
||||
[3]:data:image/gif;base64,R0lGODdhAQABAPAAAP///wAAACwAAAAAAQABAEACAkQBADs=
|
||||
[4]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2017/12/visio-alternatives-linux-featured.png
|
||||
[5]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2017/12/libreoffice-draw-microsoft-visio-alternatives.jpg
|
||||
[6]:https://www.libreoffice.org/discover/draw/
|
||||
[7]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2017/12/apache-open-office-draw.jpg
|
||||
[8]:https://itsfoss.com/install-openoffice-ubuntu-linux/
|
||||
[9]:https://itsfoss.com/openoffice-shutdown/
|
||||
[10]:https://www.openoffice.org/product/draw.html
|
||||
[11]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2017/12/dia-screenshot.jpg
|
||||
[12]:http://dia-installer.de/
|
||||
[13]:https://www.yworks.com/products/yed-live
|
||||
[14]:https://www.yworks.com/products/yed
|
||||
[15]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2017/12/inkscape-screenshot.jpg
|
||||
[16]:https://inkscape.org/en/
|
||||
[17]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2017/12/pencil-project.jpg
|
||||
[18]:http://pencil.evolus.vn/Downloads.html
|
||||
[19]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2017/12/graphviz.jpg
|
||||
[20]:http://graphviz.org/
|
||||
[21]:https://about.draw.io/integrations/#integrations_offline
|
||||
[22]:https://about.draw.io/
|
||||
[23]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2017/12/lucidchart-visio-alternative.jpg
|
||||
[24]:https://www.lucidchart.com/
|
||||
[25]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2017/12/calligra-flow.jpg
|
||||
[26]:https://www.calligra.org/
|
||||
[27]:https://www.calligra.org/flow/
|
||||
@ -0,0 +1,173 @@
|
||||
在树莓派上玩怀旧游戏的 5 种方法
|
||||
======
|
||||
|
||||
> 使用这些用于树莓派的开源平台来重温游戏的黄金时代。
|
||||
|
||||

|
||||
|
||||
他们使它们不像过去那样子了,对吧?我是说,电子游戏。
|
||||
|
||||
当然,现在的设备更强大了。<ruby>赛达尔公主<rt>Princess Zelda</rt></ruby>在过去每个边只有 16 个像素,而现在的图像处理能力足够处理她头上的每根头发。今天的处理器打败 1988 年的处理器简直不费吹灰之力。
|
||||
|
||||
但是你知道缺少什么吗?乐趣。
|
||||
|
||||
你有数之不尽的游戏,按下一个按钮就可以完成教程任务。可能有故事情节,当然杀死坏蛋也可以不需要故事情节,你需要的只是跳跃和射击。因此,毫不奇怪,树莓派最持久的流行用途之一就是重温上世纪八九十年代的 8 位和 16 位游戏的黄金时代。但从哪里开始呢?
|
||||
|
||||
在树莓派上有几种方法可以玩怀旧游戏。每一种都有自己的优点和缺点,我将在这里讨论这些。
|
||||
|
||||
### RetroPie
|
||||
|
||||
[RetroPie][1] 可能是树莓派上最受欢迎的复古游戏平台。它是一个可靠的万能选手,是模拟经典桌面和控制台游戏系统的绝佳选择。
|
||||
|
||||

|
||||
|
||||
#### 介绍
|
||||
|
||||
RetroPie 构建在 [Raspbian][2] 上运行。如果你愿意,它也可以安装在现有的 Raspbian 镜像上。它使用 [EmulationStation][3] 作为开源仿真器库(包括 [Libretro][4] 仿真器)的图形前端。
|
||||
|
||||
不过,你要玩游戏其实并不需要理解上面的任何一个词。
|
||||
|
||||
#### 它有什么好处
|
||||
|
||||
入门很容易。你需要做的就是将镜像刻录到 SD 卡,配置你的控制器、复制游戏,然后开始杀死坏蛋。
|
||||
|
||||
它的庞大用户群意味着有大量的支持和信息,活跃的在线社区也可以求助问题。
|
||||
|
||||
除了随 RetroPie 镜像一起安装的仿真器之外,还有一个可以从包管理器安装的庞大的仿真器库,并且它一直在增长。RetroPie 还提供了用户友好的菜单系统来管理这些,可以节省你的时间。
|
||||
|
||||
从 RetroPie 菜单中可以轻松添加 Kodi 和配备了 Chromium 浏览器的 Raspbian 桌面。这意味着你的这套复古游戏装备也适于作为家庭影院、[YouTube][5]、[SoundCloud][6] 以及所有其它“休息室电脑”产品。
|
||||
|
||||
RetroPie 还有许多其它自定义选项:你可以更改菜单中的图形,为不同的模拟器设置不同的控制手柄配置,使你的树莓派文件系统的所有内容对你的本地 Windows 网络可见等等。
|
||||
|
||||
RetroPie 建立在 Raspbian 上,这意味着你可以探索这个树莓派最受欢迎的操作系统。你所发现的大多数树莓派项目和教程都是为 Raspbian 编写的,因此可以轻松地自定义和安装新内容。我已经使用我的 RetroPie 装备作为无线桥接器,在上面安装了 MIDI 合成器,自学了一些 Python,更重要的是,所有这些都没有影响它作为游戏机的用途。
|
||||
|
||||
#### 它有什么不太好的
|
||||
|
||||
RetroPie 的安装简单和易用性在某种程度上是一把双刃剑。你可以在 RetroPie 上玩了很长时间,而甚至没有学习过哪怕像 `sudo apt-get` 这样简单的东西,但这也意味着你错过了很多树莓派的体验。
|
||||
|
||||
但不一定必须如此;当你需要时,命令行仍然存在于底层,但是也许用户与 Bash shell 有点隔离,而使它最终并没有看上去那么可怕、另外,RetroPie 的主菜单只能通过控制手柄操作,当你没有接入手柄时,这可能很烦人,因为你一直将该系统用于游戏之外的事情。
|
||||
|
||||
#### 它适用于谁?
|
||||
|
||||
任何想直接玩一些游戏的人,任何想拥有最大、最好的模拟器库的人,以及任何想在不玩游戏的时候开始探索 Linux 的人。
|
||||
|
||||
### Recalbox
|
||||
|
||||
[Recalbox][7] 是一个较新的树莓派开源模拟器套件。它还支持其它基于 ARM 的小型计算机。
|
||||
|
||||

|
||||
|
||||
#### 介绍
|
||||
|
||||
与 Retropie 一样, Recalbox 基于 EmulationStation 和 Libretro。它的不同之处在于它不是基于 Raspbian 构建的,而是基于它自己的 Linux 发行版:RecalboxOS。
|
||||
|
||||
#### 它有什么好处
|
||||
|
||||
Recalbox 的设置比 RetroPie 更容易。你甚至不需要做 SD 卡镜像;只需复制一些文件即可。它还为一些游戏控制器提供开箱即用的支持,可以让你更快地开始游戏。它预装了 Kodi。这是一个现成的游戏和媒体平台。
|
||||
|
||||
#### 它有什么不太好的
|
||||
|
||||
Recalbox 比 RetroPie 拥有更少的仿真器、更少的自定义选项和更小的用户社区。
|
||||
|
||||
你的 Recalbox 装备可能一直用于模拟器和 Kodi,安装成什么样就是什么样。如果你想深入了解 Linux,你可能需要为 Raspbian 提供一个新的 SD 卡。
|
||||
|
||||
#### 它适用于谁?
|
||||
|
||||
如果你想要绝对简单的复古游戏体验,并且不想玩一些比较少见的游戏平台模拟器,或者你害怕一些技术性工作(也没有兴趣去做),那么 Recalbox 非常适合你。
|
||||
|
||||
对于大多数读者来说,Recalbox 可能最适合推荐给你那些不太懂技术的朋友或亲戚。它超级简单的设置和几乎没什么选项甚至可以让你免去帮助他们解决问题。
|
||||
|
||||
### 做个你自己的
|
||||
|
||||
好,你可能已经注意到 Retropie 和 Recalbox 都是由许多相同的开源组件构建的。那么为什么不自己把它们组合在一起呢?
|
||||
|
||||
#### 介绍
|
||||
|
||||
无论你想要的是什么,开源软件的本质意味着你可以使用现有的模拟器套件作为起点,或者随意使用它们。
|
||||
|
||||
#### 它有什么好处
|
||||
|
||||
如果你想有自己的自定义界面,我想除了亲自动手别无它法。这也是安装在 RetroPie 中没有的仿真器的方法,例如 [BeebEm][8]) 或 [ArcEm][9]。
|
||||
|
||||
#### 它有什么不太好的
|
||||
|
||||
嗯,工作量有点大。
|
||||
|
||||
#### 它适用于谁?
|
||||
|
||||
喜欢鼓捣的人,有动手能力的人,开发者,经验丰富的业余爱好者等。
|
||||
|
||||
### 原生 RISC OS 游戏体验
|
||||
|
||||
现在有一匹黑马:[RISC OS][10],它是 ARM 设备的原始操作系统。
|
||||
|
||||
#### 介绍
|
||||
|
||||
在 ARM 成为世界上最受欢迎的 CPU 架构之前,它最初是作为 Acorn Archimedes 的处理器而开发的。现在看起来这像是一种被遗忘的野兽,但是那几年,它作为世界上最强大的台式计算机独领风骚了好几年,并且吸引了大量的游戏开发项目。
|
||||
|
||||
树莓派中的 ARM 处理器是 Archimedes 的曾孙辈的 CPU,所以我们仍然可以在其上安装 RISC OS,只要做一点工作,就可以让这些游戏运行起来。这与我们到上面所介绍的仿真器方式不同,我们是在玩为该操作系统和 CPU 架构开发的游戏。
|
||||
|
||||
#### 它有什么好处
|
||||
|
||||
这是 RISC OS 的完美展现,这绝对是操作系统的瑰宝,非常值得一试。
|
||||
|
||||
事实上,你使用的是和以前几乎相同的操作系统来加载和玩你的游戏,这使得你的复古游戏装备像是一个时间机器一样,这无疑为该项目增添了一些魅力和复古价值。
|
||||
|
||||
有一些精彩的游戏只在 Archimedes 上发布过。Archimedes 的巨大硬件优势也意味着它通常拥有许多多平台游戏大作的最佳图形和最流畅的游戏体验。这类游戏的版权持有者非常慷慨,可以合法地免费下载它们。
|
||||
|
||||
#### 它有什么不太好的
|
||||
|
||||
安装了 RISC OS 之后,它仍然需要一些努力才能让游戏运行起来。这是 [入门指南][11]。
|
||||
|
||||
对于休息室来说,这绝对不是一个很好的全能选手。没有什么比 [Kodi][12] 更好的了。它有一个网络浏览器 [NetSurf][13],但它在支持现代 Web 方面还需要一些努力。你不会像使用模拟器套件那样得到大量可以玩的游戏。RISC OS Open 对于爱好者来说可以免费下载和使用,而且很多源代码已经开源,尽管由于这个名字,它不是一个 100% 的开源操作系统。
|
||||
|
||||
#### 它适用于谁?
|
||||
|
||||
这是专为追求新奇的人,绝对怀旧的人,想要探索一个来自上世纪 80 年代的有趣的操作系统的人,怀旧过去的 Acorn 机器的人,以及想要一个完全不同的怀旧游戏项目的人而设计的。
|
||||
|
||||
### 终端游戏
|
||||
|
||||
你是否真的需要安装模拟器或者一个异域风情的操作系统才能重温辉煌的日子?为什么不从命令行安装一些原生 Linux 游戏呢?
|
||||
|
||||
#### 介绍
|
||||
|
||||
有一系列原生的 Linux 游戏经过测试可以在 [树莓派][14] 上运行。
|
||||
|
||||
#### 它有什么好处
|
||||
|
||||
你可以使用命令行从程序包安装其中的大部分,然后开始玩。很容易。如果你已经有了一个跑起来的 Raspbian,那么它可能是你运行游戏的最快途径。
|
||||
|
||||
#### 它有什么不太好的
|
||||
|
||||
严格来说,这并不是真正的复古游戏。Linux 诞生于 1991 年,过了一段时间才成为了一个游戏平台。这些不是经典的 8 位和 16 位时代的游戏体验;后来有一些移植的游戏或受复古影响的游戏。
|
||||
|
||||
#### 它适用于谁?
|
||||
|
||||
如果你只是想找点乐子,这没问题。但如果你想重温过去,那就不完全是这样了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/retro-gaming-raspberry-pi
|
||||
|
||||
作者:[James Mawson][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[canhetingsky](https://github.com/canhetingsky)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dxmjames
|
||||
[1]: https://retropie.org.uk/
|
||||
[2]: https://www.raspbian.org/
|
||||
[3]: https://emulationstation.org/
|
||||
[4]: https://www.libretro.com/
|
||||
[5]: https://www.youtube.com/
|
||||
[6]: https://soundcloud.com/
|
||||
[7]: https://www.recalbox.com/
|
||||
[8]: http://www.mkw.me.uk/beebem/
|
||||
[9]: http://arcem.sourceforge.net/
|
||||
[10]: https://opensource.com/article/18/7/gentle-intro-risc-os
|
||||
[11]: https://blog.dxmtechsupport.com.au/playing-badass-acorn-archimedes-games-on-a-raspberry-pi/
|
||||
[12]: https://kodi.tv/
|
||||
[13]: https://www.netsurf-browser.org/
|
||||
[14]: https://www.raspberrypi.org/forums/viewtopic.php?f=78&t=51794
|
||||
@ -0,0 +1,295 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11147-1.html)
|
||||
[#]: subject: (ClusterShell – A Nifty Tool To Run Commands On Cluster Nodes In Parallel)
|
||||
[#]: via: (https://www.2daygeek.com/clustershell-clush-run-commands-on-cluster-nodes-remote-system-in-parallel-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
ClusterShell:一个在集群节点上并行运行命令的好工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
我们过去曾写过两篇如何并行地在多个远程服务器上运行命令的文章:[并行 SSH(PSSH)][1] 和[分布式 Shell(DSH)][2]。今天,我们将讨论相同类型的主题,但它允许我们在集群节点上执行相同的操作。你可能会想,我可以编写一个小的 shell 脚本来实现这个目的,而不是安装这些第三方软件包。
|
||||
|
||||
当然,你是对的,如果要在十几个远程系统中运行一些命令,那么你不需要使用它。但是,你的脚本需要一些时间来完成此任务,因为它是按顺序运行的。想想你要是在一千多台服务器上运行一些命令会是什么样子?在这种情况下,你的脚本用处不大。此外,完成任务需要很长时间。所以,要克服这种问题和情况,我们需要可以在远程计算机上并行运行命令。
|
||||
|
||||
为此,我们需要在一个并行应用程序中使用它。我希望这个解释可以解决你对并行实用程序的疑虑。
|
||||
|
||||
### ClusterShell
|
||||
|
||||
[ClusterShell][3] 是一个事件驱动的开源 Python 库,旨在在服务器场或大型 Linux 集群上并行运行本地或远程命令。(`clush` 即 [ClusterShell][3])。
|
||||
|
||||
它将处理在 HPC 集群上遇到的常见问题,例如在节点组上操作,使用优化过的执行算法运行分布式命令,以及收集结果和合并相同的输出,或检索返回代码。
|
||||
|
||||
ClusterShell 可以利用已安装在系统上的现有远程 shell 设施,如 SSH。
|
||||
|
||||
ClusterShell 的主要目标是通过为开发人员提供轻量级、但可扩展的 Python API 来改进高性能集群的管理。它还提供了 `clush`、`clubak` 和 `cluset`/`nodeset` 等方便的命令行工具,可以让传统的 shell 脚本利用这个库的一些功能。
|
||||
|
||||
ClusterShell 是用 Python 编写的,它需要 Python(v2.6+ 或 v3.4+)才能在你的系统上运行。
|
||||
|
||||
### 如何在 Linux 上安装 ClusterShell?
|
||||
|
||||
ClusterShell 包在大多数发行版的官方包管理器中都可用。因此,使用发行版包管理器工具进行安装。
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 命令][4]来安装 clustershell。
|
||||
|
||||
```
|
||||
$ sudo dnf install clustershell
|
||||
```
|
||||
|
||||
如果系统默认是 Python 2,这会安装 Python 2 模块和工具,可以运行以下命令安装 Python 3 开发包。
|
||||
|
||||
```
|
||||
$ sudo dnf install python3-clustershell
|
||||
```
|
||||
|
||||
在执行 clustershell 安装之前,请确保你已在系统上启用 [EPEL 存储库][5]。
|
||||
|
||||
对于 RHEL/CentOS 系统,使用 [YUM 命令][6] 来安装 clustershell。
|
||||
|
||||
```
|
||||
$ sudo yum install clustershell
|
||||
```
|
||||
|
||||
如果系统默认是 Python 2,这会安装 Python 2 模块和工具,可以运行以下命令安装 Python 3 开发包。
|
||||
|
||||
```
|
||||
$ sudo yum install python34-clustershell
|
||||
```
|
||||
|
||||
对于 openSUSE Leap 系统,使用 [Zypper 命令][7] 来安装 clustershell。
|
||||
|
||||
```
|
||||
$ sudo zypper install clustershell
|
||||
```
|
||||
|
||||
如果系统默认是 Python 2,这会安装 Python 2 模块和工具,可以运行以下命令安装 Python 3 开发包。
|
||||
|
||||
```
|
||||
$ sudo zypper install python3-clustershell
|
||||
```
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][8] 或 [APT 命令][9] 来安装 clustershell。
|
||||
|
||||
```
|
||||
$ sudo apt install clustershell
|
||||
```
|
||||
|
||||
### 如何在 Linux 使用 PIP 安装 ClusterShell?
|
||||
|
||||
可以使用 PIP 安装 ClusterShell,因为它是用 Python 编写的。
|
||||
|
||||
在执行 clustershell 安装之前,请确保你已在系统上启用了 [Python][10] 和 [PIP][11]。
|
||||
|
||||
```
|
||||
$ sudo pip install ClusterShell
|
||||
```
|
||||
|
||||
### 如何在 Linux 上使用 ClusterShell?
|
||||
|
||||
与其他实用程序(如 `pssh` 和 `dsh`)相比,它是直接了当的优秀工具。它有很多选项可以在远程并行执行。
|
||||
|
||||
在开始使用 clustershell 之前,请确保你已启用系统上的[无密码登录][12]。
|
||||
|
||||
以下配置文件定义了系统范围的默认值。你不需要修改这里的任何东西。
|
||||
|
||||
```
|
||||
$ cat /etc/clustershell/clush.conf
|
||||
```
|
||||
|
||||
如果你想要创建一个服务器组,那也可以。默认情况下有一些示例,请根据你的要求执行相同操作。
|
||||
|
||||
```
|
||||
$ cat /etc/clustershell/groups.d/local.cfg
|
||||
```
|
||||
|
||||
只需按以下列格式运行 clustershell 命令即可从给定节点获取信息:
|
||||
|
||||
```
|
||||
$ clush -w 192.168.1.4,192.168.1.9 cat /proc/version
|
||||
192.168.1.9: Linux version 4.15.0-45-generic ([email protected]) (gcc version 7.3.0 (Ubuntu 7.3.0-16ubuntu3)) #48-Ubuntu SMP Tue Jan 29 16:28:13 UTC 2019
|
||||
192.168.1.4: Linux version 3.10.0-957.el7.x86_64 ([email protected]) (gcc version 4.8.5 20150623 (Red Hat 4.8.5-36) (GCC) ) #1 SMP Thu Nov 8 23:39:32 UTC 2018
|
||||
```
|
||||
|
||||
选项:
|
||||
|
||||
* `-w:` 你要运行该命令的节点。
|
||||
|
||||
你可以使用正则表达式而不是使用完整主机名和 IP:
|
||||
|
||||
```
|
||||
$ clush -w 192.168.1.[4,9] uname -r
|
||||
192.168.1.9: 4.15.0-45-generic
|
||||
192.168.1.4: 3.10.0-957.el7.x86_64
|
||||
```
|
||||
|
||||
或者,如果服务器位于同一 IP 系列中,则可以使用以下格式:
|
||||
|
||||
```
|
||||
$ clush -w 192.168.1.[4-9] date
|
||||
192.168.1.6: Mon Mar 4 21:08:29 IST 2019
|
||||
192.168.1.7: Mon Mar 4 21:08:29 IST 2019
|
||||
192.168.1.8: Mon Mar 4 21:08:29 IST 2019
|
||||
192.168.1.5: Mon Mar 4 09:16:30 CST 2019
|
||||
192.168.1.9: Mon Mar 4 21:08:29 IST 2019
|
||||
192.168.1.4: Mon Mar 4 09:16:30 CST 2019
|
||||
```
|
||||
|
||||
clustershell 允许我们以批处理模式运行命令。使用以下格式来实现此目的:
|
||||
|
||||
```
|
||||
$ clush -w 192.168.1.4,192.168.1.9 -b
|
||||
Enter 'quit' to leave this interactive mode
|
||||
Working with nodes: 192.168.1.[4,9]
|
||||
clush> hostnamectl
|
||||
---------------
|
||||
192.168.1.4
|
||||
---------------
|
||||
Static hostname: CentOS7.2daygeek.com
|
||||
Icon name: computer-vm
|
||||
Chassis: vm
|
||||
Machine ID: 002f47b82af248f5be1d67b67e03514c
|
||||
Boot ID: f9b37a073c534dec8b236885e754cb56
|
||||
Virtualization: kvm
|
||||
Operating System: CentOS Linux 7 (Core)
|
||||
CPE OS Name: cpe:/o:centos:centos:7
|
||||
Kernel: Linux 3.10.0-957.el7.x86_64
|
||||
Architecture: x86-64
|
||||
---------------
|
||||
192.168.1.9
|
||||
---------------
|
||||
Static hostname: Ubuntu18
|
||||
Icon name: computer-vm
|
||||
Chassis: vm
|
||||
Machine ID: 27f6c2febda84dc881f28fd145077187
|
||||
Boot ID: f176f2eb45524d4f906d12e2b5716649
|
||||
Virtualization: oracle
|
||||
Operating System: Ubuntu 18.04.2 LTS
|
||||
Kernel: Linux 4.15.0-45-generic
|
||||
Architecture: x86-64
|
||||
clush> free -m
|
||||
---------------
|
||||
192.168.1.4
|
||||
---------------
|
||||
total used free shared buff/cache available
|
||||
Mem: 1838 641 217 19 978 969
|
||||
Swap: 2047 0 2047
|
||||
---------------
|
||||
192.168.1.9
|
||||
---------------
|
||||
total used free shared buff/cache available
|
||||
Mem: 1993 352 1067 1 573 1473
|
||||
Swap: 1425 0 1425
|
||||
clush> w
|
||||
---------------
|
||||
192.168.1.4
|
||||
---------------
|
||||
09:21:14 up 3:21, 3 users, load average: 0.00, 0.01, 0.05
|
||||
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
|
||||
daygeek :0 :0 06:02 ?xdm? 1:28 0.30s /usr/libexec/gnome-session-binary --session gnome-classic
|
||||
daygeek pts/0 :0 06:03 3:17m 0.06s 0.06s bash
|
||||
daygeek pts/1 192.168.1.6 06:03 52:26 0.10s 0.10s -bash
|
||||
---------------
|
||||
192.168.1.9
|
||||
---------------
|
||||
21:13:12 up 3:12, 1 user, load average: 0.08, 0.03, 0.00
|
||||
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
|
||||
daygeek pts/0 192.168.1.6 20:42 29:41 0.05s 0.05s -bash
|
||||
clush> quit
|
||||
```
|
||||
|
||||
如果要在一组节点上运行该命令,请使用以下格式:
|
||||
|
||||
```
|
||||
$ clush -w @dev uptime
|
||||
or
|
||||
$ clush -g dev uptime
|
||||
or
|
||||
$ clush --group=dev uptime
|
||||
|
||||
192.168.1.9: 21:10:10 up 3:09, 1 user, load average: 0.09, 0.03, 0.01
|
||||
192.168.1.4: 09:18:12 up 3:18, 3 users, load average: 0.01, 0.02, 0.05
|
||||
```
|
||||
|
||||
如果要在多个节点组上运行该命令,请使用以下格式:
|
||||
|
||||
```
|
||||
$ clush -w @dev,@uat uptime
|
||||
or
|
||||
$ clush -g dev,uat uptime
|
||||
or
|
||||
$ clush --group=dev,uat uptime
|
||||
|
||||
192.168.1.7: 07:57:19 up 59 min, 1 user, load average: 0.08, 0.03, 0.00
|
||||
192.168.1.9: 20:27:20 up 1:00, 1 user, load average: 0.00, 0.00, 0.00
|
||||
192.168.1.5: 08:57:21 up 59 min, 1 user, load average: 0.00, 0.01, 0.05
|
||||
```
|
||||
|
||||
clustershell 允许我们将文件复制到远程计算机。将本地文件或目录复制到同一个远程节点:
|
||||
|
||||
```
|
||||
$ clush -w 192.168.1.[4,9] --copy /home/daygeek/passwd-up.sh
|
||||
```
|
||||
|
||||
我们可以通过运行以下命令来验证它:
|
||||
|
||||
```
|
||||
$ clush -w 192.168.1.[4,9] ls -lh /home/daygeek/passwd-up.sh
|
||||
192.168.1.4: -rwxr-xr-x. 1 daygeek daygeek 159 Mar 4 09:00 /home/daygeek/passwd-up.sh
|
||||
192.168.1.9: -rwxr-xr-x 1 daygeek daygeek 159 Mar 4 20:52 /home/daygeek/passwd-up.sh
|
||||
```
|
||||
|
||||
将本地文件或目录复制到不同位置的远程节点:
|
||||
|
||||
```
|
||||
$ clush -g uat --copy /home/daygeek/passwd-up.sh --dest /tmp
|
||||
```
|
||||
|
||||
我们可以通过运行以下命令来验证它:
|
||||
|
||||
```
|
||||
$ clush --group=uat ls -lh /tmp/passwd-up.sh
|
||||
192.168.1.7: -rwxr-xr-x. 1 daygeek daygeek 159 Mar 6 07:44 /tmp/passwd-up.sh
|
||||
```
|
||||
|
||||
将文件或目录从远程节点复制到本地系统:
|
||||
|
||||
```
|
||||
$ clush -w 192.168.1.7 --rcopy /home/daygeek/Documents/magi.txt --dest /tmp
|
||||
```
|
||||
|
||||
我们可以通过运行以下命令来验证它:
|
||||
|
||||
```
|
||||
$ ls -lh /tmp/magi.txt.192.168.1.7
|
||||
-rw-r--r-- 1 daygeek daygeek 35 Mar 6 20:24 /tmp/magi.txt.192.168.1.7
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/clustershell-clush-run-commands-on-cluster-nodes-remote-system-in-parallel-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/pssh-parallel-ssh-run-execute-commands-on-multiple-linux-servers/
|
||||
[2]: https://www.2daygeek.com/dsh-run-execute-shell-commands-on-multiple-linux-servers-at-once/
|
||||
[3]: https://cea-hpc.github.io/clustershell/
|
||||
[4]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[5]: https://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-scientific-linux-oracle-linux/
|
||||
[6]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[7]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[8]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[9]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[10]: https://www.2daygeek.com/3-methods-to-install-latest-python3-package-on-centos-6-system/
|
||||
[11]: https://www.2daygeek.com/install-pip-manage-python-packages-linux/
|
||||
[12]: https://www.2daygeek.com/linux-passwordless-ssh-login-using-ssh-keygen/
|
||||
@ -0,0 +1,196 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11145-1.html)
|
||||
[#]: subject: (Best Linux Distributions for Beginners)
|
||||
[#]: via: (https://itsfoss.com/best-linux-beginners/)
|
||||
[#]: author: (Aquil Roshan https://itsfoss.com/author/aquil/)
|
||||
|
||||
最适合于初学者的 Linux 发行版
|
||||
======
|
||||
|
||||
> 在本文中,我们将看到**最适合于初学者的 Linux 发行版**。这将有助于 Linux 新用户选择他们的第一个发行版。
|
||||
|
||||
让我们面对现实,[Linux][1] 可能会给新用户带来巨大的复杂性。但是,带来这种复杂性的并不是 Linux 本身。相反,是“新奇”因素导致了这种情况。并不是怀旧,但我记得第一次使用 Linux 时,我甚至不知道会发生什么。我喜欢它,但最初这对我来说像是逆流游泳一样。
|
||||
|
||||
不知道从何处着手可能是一个令人沮丧的原因,特别是对于那些在 PC 上运行 Windows 之外的其它系统没有概念的人来说。
|
||||
|
||||
Linux 不仅仅是一个操作系统,而是一个理念:在这里大家共同成长,也适合于每个人的不同需要。我们已经介绍过:
|
||||
|
||||
* [Windows 用户的最佳 Linux 发行版][2]
|
||||
* [最佳轻量级 Linux 发行版][3]
|
||||
* [黑客攻击的最佳 Linux 发行版][4]
|
||||
* [最佳 Linux 游戏发行版][5]
|
||||
* [隐私和匿名的最佳 Linux 发行版][6]
|
||||
* [看起来像 MacOS 的最佳 Linux 发行版][7]
|
||||
|
||||
除此之外,还有一些能够特别满足新人需求的发行版。这里有一些这样的适合初学者的 Linux 发行版。你也可以在视频中观看并[订阅我们的 YouTube 频道][8]以获取更多与 Linux 相关的视频。
|
||||
|
||||
[视频](https://youtu.be/QC2B2-gCbbI)
|
||||
|
||||
### 最适合于初学者的 Linux 发行版
|
||||
|
||||
请记住,此列表没有特别的顺序。编制此列表的主要标准是易于安装、开箱即用的硬件和软件、易用性和软件包的可用性。
|
||||
|
||||
#### 1、Ubuntu
|
||||
|
||||
如果你在互联网上研究过 Linux,那么你很可能遇到过 Ubuntu。Ubuntu 是领先的 Linux 发行版之一,它也是开始 Linux 之旅的完美之选。
|
||||
|
||||
![][9]
|
||||
|
||||
Ubuntu 被视为人性化的 Linux,这是因为 Ubuntu 在通用可用性上付出了很多努力。Ubuntu 并不要求你在技术方面懂得很多才能使用它。它打破了 “Linux = 命令行麻烦”这一概念。这是 Ubuntu 飙升到今天的主要优势之一。
|
||||
|
||||
Ubuntu 提供了非常方便的安装程序。这个安装程序以简单的英语(或你想要的任何主要语言)描述安装过程。你甚至可以在实际执行安装过程之前尝试使用 Ubuntu。安装程序提供了简单的选项:
|
||||
|
||||
* 删除旧操作系统以安装 Ubuntu。
|
||||
* 与 Windows 或任何其他现有操作系统[一起][10]安装 Ubuntu(每次启动时都会提供要启动的操作系统的选择列表)。
|
||||
* 让高级用户自行配置分区。
|
||||
|
||||
*初学者提示:如果你不确定该怎么做,请选择第二个选项。*
|
||||
|
||||
Ubuntu 的用户界面采用 GNOME。它简单、高效。你可以通过按 Windows 键搜索从应用程序到文件的任何内容。有什么比这更简单的吗?
|
||||
|
||||
没有驱动程序安装问题,因为 Ubuntu 附带硬件检测器,可以检测、下载和安装适用于你的 PC 的最佳驱动程序。此外,安装会附带所有基本软件,如音乐播放器、视频播放器、办公套件和一些消磨时间的游戏。
|
||||
|
||||
Ubuntu 拥有出色的文档和社区支持。[Ubuntu 论坛][11]和 [Ask Ubuntu][12] 几乎在 Ubuntu 的所有方面都提供了可观的高质量支持。你的一些问题很有可能已经得到了回答,这些答案是适合初学者的。
|
||||
|
||||
请在[官方网站][13]查看并下载 [Ubuntu][13]。
|
||||
|
||||
#### 2、Linux Mint Cinnamon
|
||||
|
||||
多年来,Linux Mint 一直是 [Distrowatch][14] 上的**排名第一的** Linux 发行版。我必须说,这是当之无愧的宝座。Linux Mint 是我个人的最爱之一。它优雅、秀气,提供了卓越的计算体验(开箱即用)。
|
||||
|
||||
![][15]
|
||||
|
||||
Linux Mint 带有 Cinnamon 桌面环境。仍处于熟悉 Linux 软件阶段的 Linux 新用户会发现 Cinnamon 非常有用。所有软件都按类别分组,非常易于访问。虽然这不是一个令人兴奋的功能,但对于不了解 Linux 软件名称的新用户来说,这是一个巨大的好处。
|
||||
|
||||
Linux Mint 很快,在旧电脑上也运行良好。Linux Mint 建立在坚如磐石的 Ubuntu 基础之上。它使用与 Ubuntu 相同的软件存储库。而对于 Ubuntu 软件存储库,仅在广泛测试后 Ubuntu 才会将软件推送在其中。这意味着用户不必处理某些新软件容易出现的意外崩溃和故障,对于新的 Linux 用户来说这可能是一个真正不可接受的。
|
||||
|
||||
![][17]
|
||||
|
||||
Windows 7 爱好者如果没有真的升级到微软 Windows 10 的话,那将会发现 Linux Mint 的可爱。 Linux Mint 桌面非常类似于 Windows 7 桌面。类似的工具栏、类似的菜单、类似的托盘图标都绝对会使 Windows 用户感到十分熟悉。
|
||||
|
||||
就个人而言,我更倾向于向 Linux 世界的新人推荐 Linux Mint,因为 Linux Mint 确实给用户留下了足够的印象,会让他们接受它。对我来说,Linux Mint 应该是面向初学者的 Linux 列表中的首位。
|
||||
|
||||
请在这里查看 [Linux Mint][18],看看 Cinnamon 版。
|
||||
|
||||
#### 3、Zorin OS
|
||||
|
||||
大多数计算机用户是 Windows 用户。当 [Windows 用户拿到一个 Linux][2] 时,他必须经历相当多的“去知识过程”。大量的操作已经固定在我们的肌肉记忆当中。例如,每次要启动应用程序时,鼠标都会移动屏幕的左下角(“开始”菜单)。因此,如果我们能够在 Linux 上找到一些可以缓解这些问题的东西,那就成功了一半了。进入 Zorin OS。
|
||||
|
||||
![][19]
|
||||
|
||||
Zorin OS 是一款基于 Ubuntu 的高度打磨的 Linux 发行版,完全是为 Windows 难民制作的。尽管几乎每个 Linux 发行版都可供任何人使用,但是当桌面看起来太陌生时,有些人可能会不情愿使用。Zorin OS 避开了这个障碍,因为它与 Windows 外观明显相似。
|
||||
|
||||
对 Linux 新手来说,软件包管理器是一个新概念。这就是为什么 Zorin OS 带有一个巨大的(我的意思是真的很大)预安装软件列表。你需要的任何东西,很有可能都已经安装在 Zorin OS 上了。好像这还不够,[Wine 和 PlayOnLinux][20] 也预先安装好了,所以你也可以在这里运行你喜爱的 Windows 软件和[游戏][21]。
|
||||
|
||||
![][22]
|
||||
|
||||
Zorin OS 配备了一款名为 “Zorin look changer” 的惊人的主题引擎。它提供了一些重要的自定义选项和预设,可以使你的操作系统看起来像 Windows 7、XP、2000 甚至是 Mac,你会有宾至如归的感觉。
|
||||
|
||||
![][23]
|
||||
|
||||
正是这些功能使 Zorin OS 成为**适合初学者的最佳 Linux 发行版**。查看 [Zorin OS 网站][24]以了解更多信息和下载该操作系统。
|
||||
|
||||
#### 4、Elementary OS
|
||||
|
||||
我们已经看过了给 Windows 用户准备的 Linux 发行版,让我们为 MacOS 用户也提供一些东西。Elementary OS 成名非常迅速,现在总是被列入顶级发行列表之中,这一切都归功于其美学本质。其灵感来自于 MacOS,Elementary OS 是最美丽的 Linux 发行版之一。
|
||||
|
||||
![][25]
|
||||
|
||||
Elementary OS 是又一个基于 Ubuntu 的操作系统,这意味着操作系统本身无疑是稳定的。Elementary OS 带有 Pantheon 桌面环境。你马上就会注意到它与 MacOS 桌面的相似之处。这对于转换到 Linux 的 MacOS 用户来说是一个优势,因为他们会对桌面非常适应,这确实简化了应对此变化的过程。
|
||||
|
||||
![][26]
|
||||
|
||||
它的菜单简单,可根据用户喜好自定义。该操作系统是零侵入性的,因此你可以真正专注于工作。它附带了非常少量的预安装软件。因此,新用户都不会被庞杂的内容吓跑。但是,嘿,它具备开箱即用所需要的一切。如果需要更多软件,Elementary OS 提供了一个整洁的 AppCenter。它易于访问且简单易用,一切都在一个地方,你可以一键获得所需的所有软件和升级。
|
||||
|
||||
经验表明,[Elementary OS][28] 真的是一个很棒的软件。绝对值得[试一试][28]。
|
||||
|
||||
#### 5、Linux Mint Mate
|
||||
|
||||
许多来了解 Linux 的人都希望让旧电脑焕发新生。随着 Windows 10 的普及,几年前许多具有不错配置的计算机已经变得无力应对。在谷歌上快速搜索一下会建议你在这样的电脑上安装 Linux。通过这种方式,你可以让它们在之后一段时间仍旧能保持水准。如果你正在寻找可以运行在旧计算机上的操作系统,Linux Mint Mate 是一个很棒的 Linux 发行版。
|
||||
|
||||
![][29]
|
||||
|
||||
Linux Mint Mate 非常轻便,资源利用效率高,而仍然是一个漂亮的发行版。它可以在计算能力较弱的计算机上平稳运行。桌面环境没有各种花哨的东西。但它在功能上和任何其他桌面环境相比毫不逊色。这个操作系统是非侵入式的,允许你获得高效的计算体验而不会妨碍你。
|
||||
|
||||
同样,Linux Mint Mate 基于 Ubuntu,具有巨大而坚实的 Ubuntu 软件存储库的优势。它预装了最少数量的必需软件。提供了简便的驱动程序安装和设置管理。
|
||||
|
||||
即使你只有 512 MB 的内存和 9 GB 的硬盘空间(当然是越多越好),你也可以运行 Linux Mint Mate。
|
||||
|
||||
Mate 桌面环境非常简单易用,没有什么费解的地方。对于 Linux 初学者来说,这确实是一个巨大的优势,更有理由 [尝试 Linux Mint Mate][30]。
|
||||
|
||||
#### 6、Manjaro Linux
|
||||
|
||||
好吧。任何一个 Linux 的老用户都会说,即使只是在大方向上,引导新手接触 Arch Linux 都是一种罪过。但是听我说。
|
||||
|
||||
Arch 被认为是专家级 Linux,因为它的安装过程非常复杂。Manajro 和 Arch Linux 有着共同的起源,但它们在其他方面存在很大差异。
|
||||
|
||||
![][31]
|
||||
|
||||
Manajro Linux 具有非常适合初学者的安装程序。许多事情都是自动化的,比如使用“硬件检测”进行驱动程序安装。Manjaro 极大地解决了困扰许多其它 Linux 发行版的硬件驱动程序的麻烦。即使你遇到任何问题,Manjaro 也有很棒的社区支持。
|
||||
|
||||
Manjaro 拥有自己的软件存储库,其维护了最新的软件。虽然优先向用户提供最新软件,但它是以保证稳定性不会受到损害为前提的。这是 Arch 和 Manjaro 之间的主要区别之一。Manjaro 延迟软件包的发布以确保它们绝对稳定并且不会导致回退。你还可以访问 Manjaro 上的 Arch User Repository(AUR),因此你可以随时获得所需的一切。
|
||||
|
||||
如果你想了解更多有关 Manjaro 功能的信息,请阅读我的同事 [John 的 Manjaro Linux 经历以及为什么他会被它迷住][32]。
|
||||
|
||||
![][33]
|
||||
|
||||
Manjaro Linux 有 XFCE、KDE、Gnome、Cinnamon 以及更多桌面环境,请查看[官方网站][34]。
|
||||
|
||||
要安装上述 6 个操作系统中的任何一个,你需要创建一个可启动的 U 盘。如果你当前正在使用 Windows [请使用本指南][35]。Mac OS 用户可以[遵循本指南][36]。
|
||||
|
||||
### 你选择哪个最适合初学者的 Linux 发行版?
|
||||
|
||||
Linux 可能会有学习曲线,但这是一件不会让每个人都感到后悔的事情。进一步获得一个 ISO 文件并体验一下 Linux 吧。如果你已经是 Linux 用户,请分享这篇文章,并帮助人们在这个爱的季节爱上 Linux 吧。加油!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-linux-beginners/
|
||||
|
||||
作者:[Aquil Roshan][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/aquil/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/what-is-linux
|
||||
[2]: https://itsfoss.com/windows-like-linux-distributions/
|
||||
[3]: https://itsfoss.com/lightweight-linux-beginners/
|
||||
[4]: https://itsfoss.com/linux-hacking-penetration-testing/
|
||||
[5]: https://itsfoss.com/linux-gaming-distributions/
|
||||
[6]: https://itsfoss.com/privacy-focused-linux-distributions/
|
||||
[7]: https://itsfoss.com/macos-like-linux-distros/
|
||||
[8]: https://www.youtube.com/c/itsfoss
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/06/ubuntu-18-04-desktop.jpeg?resize=800%2C450&ssl=1
|
||||
[10]: https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
|
||||
[11]: https://ubuntuforums.org/
|
||||
[12]: http://askubuntu.com/
|
||||
[13]: https://www.ubuntu.com/
|
||||
[14]: https://distrowatch.com/
|
||||
[15]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2017/02/LM_Home.jpg?ssl=1
|
||||
[16]: https://itsfoss.com/install-visual-studio-code-ubuntu/
|
||||
[17]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2017/02/LM_SS.jpg?ssl=1
|
||||
[18]: https://linuxmint.com/
|
||||
[19]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2017/02/Zorin.jpg?ssl=1
|
||||
[20]: https://itsfoss.com/use-windows-applications-linux/
|
||||
[21]: https://itsfoss.com/linux-gaming-guide/
|
||||
[22]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2017/02/Zorin-office.jpg?ssl=1
|
||||
[23]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2017/02/OSX.jpg?ssl=1
|
||||
[24]: https://zorinos.com/
|
||||
[25]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2017/02/Pantheon-Desktop.jpg?resize=800%2C500&ssl=1
|
||||
[26]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2017/02/Application-Menu.jpg?ssl=1
|
||||
[27]: https://itsfoss.com/slack-use-linux/
|
||||
[28]: https://elementary.io/
|
||||
[29]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2017/02/mate.jpg?ssl=1
|
||||
[30]: http://blog.linuxmint.com/?p=3182
|
||||
[31]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2017/02/manajro.jpg?ssl=1
|
||||
[32]: https://itsfoss.com/why-use-manjaro-linux/
|
||||
[33]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2017/02/manjaro-kde.jpg?ssl=1
|
||||
[34]: https://manjaro.org/
|
||||
[35]: https://www.ubuntu.com/download/desktop/create-a-usb-stick-on-windows
|
||||
[36]: https://www.ubuntu.com/download/desktop/create-a-usb-stick-on-macos
|
||||
@ -0,0 +1,129 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11160-1.html)
|
||||
[#]: subject: (Convert Markdown files to word processor docs using pandoc)
|
||||
[#]: via: (https://opensource.com/article/19/5/convert-markdown-to-word-pandoc)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt/users/jason-van-gumster/users/kikofernandez)
|
||||
|
||||
使用 pandoc 将 Markdown 转换为格式化文档
|
||||
======
|
||||
|
||||
> 生活在普通文本世界么?以下是无需使用文字处理器而创建别人要的格式化文档的方法。
|
||||
|
||||
![][1]
|
||||
|
||||
如果你生活在[普通文本][2]世界里,总会有人要求你提供格式化文档。我就经常遇到这个问题,特别是在 Day JobTM。虽然我已经给与我合作的开发团队之一介绍了用于撰写和审阅发行说明的 [Docs Like Code][3] 工作流程,但是还有少数人对 GitHub 和使用 [Markdown][4] 没有兴趣,他们更喜欢为特定的专有应用格式化的文档。
|
||||
|
||||
好消息是,你不会被卡在将未格式化的文本复制粘贴到文字处理器的问题当中。使用 [pandoc][5],你可以快速地给人们他们想要的东西。让我们看看如何使用 pandoc 将文档从 Markdown 转换为 Linux 中的文字处理器格式。
|
||||
|
||||
请注意,pandoc 也可用于从两种 BSD([NetBSD][7] 和 [FreeBSD][8])到 Chrome OS、MacOS 和 Windows 等的各种操作系统。
|
||||
|
||||
### 基本转换
|
||||
|
||||
首先,在你的计算机上[安装 pandoc][9]。然后,打开控制台终端窗口,并导航到包含要转换的文件的目录。
|
||||
|
||||
输入此命令以创建 ODT 文件(可以使用 [LibreOffice Writer][10] 或 [AbiWord][11] 等字处理器打开):
|
||||
|
||||
```
|
||||
pandoc -t odt filename.md -o filename.odt
|
||||
```
|
||||
|
||||
记得用实际文件名称替换 `filename`。如果你需要为其他文字处理器(你知道我的意思)创建一个文件,替换命令行的 `odt` 为 `docx`。以下是本文转换为 ODT 文件时的内容:
|
||||
|
||||
![Basic conversion results with pandoc.][12]
|
||||
|
||||
这些转换结果虽然可用,但有点乏味。让我们看看如何为转换后的文档添加更多样式。
|
||||
|
||||
### 带样式转换
|
||||
|
||||
`pandoc` 有一个漂亮的功能,使你可以在将带标记的纯文本文件转换为字处理器格式时指定样式模板。在此文件中,你可以编辑文档中的少量样式,包括控制段落、文章标题和副标题、段落标题、说明、基本的表格和超链接的样式。
|
||||
|
||||
让我们来看看能做什么。
|
||||
|
||||
#### 创建模板
|
||||
|
||||
要设置文档样式,你不能只是使用任何一个模板就行。你需要生成 pandoc 称之为引用模板的文件,这是将文本文件转换为文字处理器文档时使用的模板。要创建此文件,请在终端窗口中键入以下内容:
|
||||
|
||||
```
|
||||
pandoc -o custom-reference.odt --print-default-data-file reference.odt
|
||||
```
|
||||
|
||||
此命令创建一个名为 `custom-reference.odt` 的文件。如果你正在使用其他文字处理程序,请将命令行中的 “odt” 更改为 “docx”。
|
||||
|
||||
在 LibreOffice Writer 中打开模板文件,然后按 `F11` 打开 LibreOffice Writer 的 “样式” 窗格。虽然 [pandoc 手册][13]建议不要对该文件进行其他更改,但我会在必要时更改页面大小并添加页眉和页脚。
|
||||
|
||||
#### 使用模板
|
||||
|
||||
那么,你要如何使用刚刚创建的模板?有两种方法可以做到这一点。
|
||||
|
||||
最简单的方法是将模板放在家目录的 `.pandoc` 文件夹中,如果该文件夹不存在,则必须先创建该文件夹。当转换文档时,`pandoc` 会使用此模板文件。如果你需要多个模板,请参阅下一节了解如何从多个模板中进行选择。
|
||||
|
||||
使用模板的另一种方法是在命令行键入以下转换选项:
|
||||
|
||||
```
|
||||
pandoc -t odt file-name.md --reference-doc=path-to-your-file/reference.odt -o file-name.odt
|
||||
```
|
||||
|
||||
如果你想知道使用自定义模板转换后的文件是什么样的,这是一个示例:
|
||||
|
||||
![A document converted using a pandoc style template.][14]
|
||||
|
||||
#### 选择模板
|
||||
|
||||
很多人只需要一个 `pandoc` 模板,但是,有些人需要不止一个。
|
||||
|
||||
例如,在我的日常工作中,我使用了几个模板:一个带有 DRAFT 水印,一个带有表示内部使用的水印,另一个用于文档的最终版本。每种类型的文档都需要不同的模板。
|
||||
|
||||
如果你有类似的需求,可以像使用单个模板一样创建文件 `custom-reference.odt`,将生成的文件重命名为例如 `custom-reference-draft.odt` 这样的名字,然后在 LibreOffice Writer 中打开它并修改样式。对你需要的每个模板重复此过程。
|
||||
|
||||
接下来,将文件复制到家目录中。如果你愿意,你甚至可以将它们放在 `.pandoc` 文件夹中。
|
||||
|
||||
要在转换时选择特定模板,你需要在终端中运行此命令:
|
||||
|
||||
```
|
||||
pandoc -t odt file-name.md --reference-doc=path-to-your-file/custom-template.odt -o file-name.odt
|
||||
```
|
||||
|
||||
改变 `custom-template.odt` 为你的模板文件名。
|
||||
|
||||
### 结语
|
||||
|
||||
为了不用记住我不经常使用的一组选项,我拼凑了一些简单的、非常蹩脚的单行脚本,这些脚本封装了每个模板的选项。例如,我运行脚本 `todraft.sh` 以使用带有 DRAFT 水印的模板创建文字处理器文档。你可能也想要这样做。
|
||||
|
||||
以下是使用包含 DRAFT 水印的模板的脚本示例:
|
||||
|
||||
```
|
||||
pandoc -t odt $1.md -o $1.odt --reference-doc=~/Documents/pandoc-templates/custom-reference-draft.odt
|
||||
```
|
||||
|
||||
使用 pandoc 是一种不必放弃命令行生活而以人们要求的格式提供文档的好方法。此工具也不仅适用于 Markdown。我在本文中讨论的内容还可以让你在各种标记语言之间创建和转换文档。有关更多详细信息,请参阅前面链接的 [pandoc 官网][5]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/convert-markdown-to-word-pandoc
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt/users/jason-van-gumster/users/kikofernandez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_keyboard_laptop_development_code_woman.png?itok=vbYz6jjb
|
||||
[2]: https://plaintextproject.online/
|
||||
[3]: https://www.docslikecode.com/
|
||||
[4]: https://en.wikipedia.org/wiki/Markdown
|
||||
[5]: https://pandoc.org/
|
||||
[6]: /resources/linux
|
||||
[7]: https://www.netbsd.org/
|
||||
[8]: https://www.freebsd.org/
|
||||
[9]: https://pandoc.org/installing.html
|
||||
[10]: https://www.libreoffice.org/discover/writer/
|
||||
[11]: https://www.abisource.com/
|
||||
[12]: https://opensource.com/sites/default/files/uploads/pandoc-wp-basic-conversion_600_0.png (Basic conversion results with pandoc.)
|
||||
[13]: https://pandoc.org/MANUAL.html
|
||||
[14]: https://opensource.com/sites/default/files/uploads/pandoc-wp-conversion-with-tpl_600.png (A document converted using a pandoc style template.)
|
||||
@ -0,0 +1,54 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11141-1.html)
|
||||
[#]: subject: (Use ImageGlass to quickly view JPG images as a slideshow)
|
||||
[#]: via: (https://opensource.com/article/19/6/use-imageglass-view-jpg-images-slideshow-windows-10)
|
||||
[#]: author: (Jeff Macharyas https://opensource.com/users/jeffmacharyas)
|
||||
|
||||
使用 ImageGlass 以幻灯片形式快速查看 JPG 图像
|
||||
======
|
||||
|
||||
> 想要在 Windows 10 中以幻灯片形式逐个查看文件夹中的图像么?开源软件可以做到。
|
||||
|
||||
![Looking back with binoculars][1]
|
||||
|
||||
欢迎阅读今天的系列文章 “我该如何让它实现?”就我而言,我试图在 Windows 10 上以幻灯片形式查看 JPG 图像的文件夹。像往常一样,我转向开源来解决这个问题。
|
||||
|
||||
在 Mac 上,以幻灯片形式查看 JPG 图像文件夹只需选择文件夹中的所有图像(`Command-A`),然后按 `Option-Command-Y` 即可。之后,你可以使用箭头键向前翻动。当然,在 Windows 中,你可以通过选择第一个图像,然后单击窗口中黄色的**管理**栏,然后选择**幻灯片**来执行类似的操作。在那里,你可以控制速度,但只能做到:慢、中、快。
|
||||
|
||||
我希望像在 Windows 中能像 Mac 一样翻下一张图片。自然地,我 Google 搜索了一下并找到了一个方案。我发现了 [ImageGlass][2] 这个开源应用,其许可证是 [GPL 3.0][3],并且它完美地做到了。这是它的样子:
|
||||
|
||||
![Viewing an image in ImageGlass.][4]
|
||||
|
||||
### 关于 ImageGlass
|
||||
|
||||
ImageGlass 是由 Dương Diệu Pháp 开发的,根据他的网站,他是一名越南开发人员,在 Chainstack 负责前端。他与在美国的 [Kevin Routley][5] 协作,后者“为 ImageGlass 开发新功能”。源代码可以在 [GitHub][6] 上找到。
|
||||
|
||||
ImageGlass 支持最常见的图像格式,包括 JPG、GIF、PNG、WEBP、SVG 和 RAW。用户可以轻松自定义扩展名列表。
|
||||
|
||||
我遇到的具体问题是需要找到一张用于目录封面的图像。不幸的是,它在一个包含数十张照片的文件夹中。在 ImageGlass 中以幻灯片浏览照片,在我想要的照片前停止,并将其下载到我的项目文件夹中变得很容易。开源再次帮助了我,该应用只花了很短的时间下载和使用。
|
||||
|
||||
在 2016 年 3 月 10 日,Jason Baker 在他的文章 [9 款 Picasa 的开源替代品][7] 中将 ImageGlass 列为其中之一。如果你有需求,里面还有一些其他有趣的图像相关工具。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/6/use-imageglass-view-jpg-images-slideshow-windows-10
|
||||
|
||||
作者:[Jeff Macharyas][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jeffmacharyas
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/look-binoculars-sight-see-review.png?itok=NOw2cm39 (Looking back with binoculars)
|
||||
[2]: https://imageglass.org/
|
||||
[3]: https://github.com/d2phap/ImageGlass/blob/master/LICENSE
|
||||
[4]: https://opensource.com/sites/default/files/uploads/imageglass-screenshot.png (Viewing an image in ImageGlass.)
|
||||
[5]: https://github.com/fire-eggs
|
||||
[6]: https://github.com/d2phap/ImageGlass
|
||||
[7]: https://opensource.com/alternatives/picasa
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hopefully2333)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11132-1.html)
|
||||
[#]: subject: (How to Manually Install Security Updates on Debian/Ubuntu?)
|
||||
[#]: via: (https://www.2daygeek.com/manually-install-security-updates-ubuntu-debian/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
@ -10,13 +10,11 @@
|
||||
如何在 Debian/Ubuntu 上手动安装安全更新?
|
||||
======
|
||||
|
||||
在 Linux 上通过命令行安装一个包程序是一件简单的事。
|
||||
|
||||
在一行命令中组合使用多个命令能让你更加简单地完成任务。
|
||||
在 Linux 上通过命令行安装一个包程序是一件简单的事。在一行命令中组合使用多个命令能让你更加简单地完成任务。
|
||||
|
||||
安全更新也同样如此。
|
||||
|
||||
在这个教程里面,我们会向你展示如何查看可用的安全更新,以及如何在 Ubuntu,LinuxMint 等等这些基于 Debian 的系统中安装它们。
|
||||
在这个教程里面,我们会向你展示如何查看可用的安全更新,以及如何在 Ubuntu、LinuxMint 等等这些基于 Debian 的系统中安装它们。
|
||||
|
||||
有三种方法可以完成这件事,下面会详细地描述这三种方法。
|
||||
|
||||
@ -24,25 +22,23 @@
|
||||
|
||||
如果你因为一些应用的依赖问题不能解决,导致不能给所有的系统进行全部更新。那至少,你应该打上安全补丁来让你的系统 100% 符合要求。
|
||||
|
||||
### 如何在 Debian/Ubuntu 上安装 unattended-upgrades?
|
||||
|
||||
默认情况下,你的系统上应该是已经安装了 unattended-upgrades 包的。但是如果你的系统没有装这个包,那么请使用下面的命令来安装它。
|
||||
|
||||
使用 **[APT-GET 命令][1]** 或者 **[APT 命令][2]** 来安装 unattended-upgrades 包.
|
||||
|
||||
```
|
||||
$ sudo apt-get install unattended-upgrades
|
||||
or
|
||||
$ sudo apt install unattended-upgrades
|
||||
```
|
||||
|
||||
### 方法一:如何检查 Debian/Ubuntu 中是否有任何可用的安全更新?
|
||||
|
||||
在进行补丁安装之前,检查可用安全更新列表始终是一个好习惯。它会为你提供将在你的系统中进行更新的软件包的列表。
|
||||
|
||||
默认情况下,你的系统上应该是已经安装了 `unattended-upgrades` 包的。但是如果你的系统没有装这个包,那么请使用下面的命令来安装它。
|
||||
|
||||
使用 [APT-GET 命令][1] 或者 [APT 命令][2] 来安装 `unattended-upgrades` 包。
|
||||
|
||||
```
|
||||
$ sudo apt-get install unattended-upgrades
|
||||
或
|
||||
$ sudo apt install unattended-upgrades
|
||||
```
|
||||
|
||||
**什么是试运行?** 大多数的 Linux 命令都有一个试运行选项,它会给出实际的输出但不会下载或安装任何东西。
|
||||
|
||||
为此,你需要在 unattended-upgrades 命令中添加 --dry-run 选项。
|
||||
为此,你需要在 `unattended-upgrades` 命令中添加 `--dry-run` 选项。
|
||||
|
||||
```
|
||||
$ sudo unattended-upgrade --dry-run -d
|
||||
@ -101,9 +97,9 @@ vim-tiny
|
||||
xxd
|
||||
```
|
||||
|
||||
如果在终端里,上面的命令输出说 **“No packages found that can be upgraded unattended and no pending auto-removals”** , 这意味着你的系统已经是最新的了。
|
||||
如果在终端里,上面的命令输出说 “No packages found that can be upgraded unattended and no pending auto-removals”,这意味着你的系统已经是最新的了。
|
||||
|
||||
### 如何在 Debian/Ubuntu 中安装可用的安全更新?
|
||||
#### 如何在 Debian/Ubuntu 中安装可用的安全更新?
|
||||
|
||||
如果你在上面的命令输出中获得了任意的软件包更新,就运行下面的命令来安装它们。
|
||||
|
||||
@ -111,7 +107,7 @@ xxd
|
||||
$ sudo unattended-upgrade -d
|
||||
```
|
||||
|
||||
除此之外,你也可以使用 apt-get 命令来进行安装。但是这个方法有点棘手,我会建议用户用第一个选项。
|
||||
除此之外,你也可以使用 `apt-get` 命令来进行安装。但是这个方法有点棘手,我会建议用户用第一个选项。
|
||||
|
||||
### 方法二:如何使用 apt-get 命令在 Debian/Ubuntu 中检查是否有可用的安全更新?
|
||||
|
||||
@ -160,7 +156,7 @@ Inst gcc [4:7.3.0-3ubuntu2.1] (4:7.4.0-1ubuntu2.3 Ubuntu:18.04/bionic-updates, U
|
||||
Inst g++ [4:7.3.0-3ubuntu2.1] (4:7.4.0-1ubuntu2.3 Ubuntu:18.04/bionic-updates, Ubuntu:18.04/bionic-security [amd64])
|
||||
```
|
||||
|
||||
### 如何使用 apt-get 命令在 Debian/Ubuntu 系统中安装可用的安全更新?
|
||||
#### 如何使用 apt-get 命令在 Debian/Ubuntu 系统中安装可用的安全更新?
|
||||
|
||||
如果你在上面命令的输出中发现任何的软件包更新。就运行下面的命令来安装它们。
|
||||
|
||||
@ -168,7 +164,7 @@ Inst g++ [4:7.3.0-3ubuntu2.1] (4:7.4.0-1ubuntu2.3 Ubuntu:18.04/bionic-updates, U
|
||||
$ sudo apt-get -s dist-upgrade | grep "^Inst" | grep -i securi | awk -F " " {'print $2'} | xargs apt-get install
|
||||
```
|
||||
|
||||
除此之外,也可以使用 apt 命令来完成。但是这个方法有点棘手,我会建议用户用第一个选项。
|
||||
除此之外,也可以使用 `apt` 命令来完成。但是这个方法有点棘手,我会建议用户用第一个方式。
|
||||
|
||||
### 方法三:如何使用 apt 命令在 Debian/Ubuntu 系统中检查是否有可用的安全更新?
|
||||
|
||||
@ -217,7 +213,7 @@ vim-tiny/bionic-updates,bionic-security 2:8.0.1453-1ubuntu1.1 amd64 [upgradable
|
||||
xxd/bionic-updates,bionic-security 2:8.0.1453-1ubuntu1.1 amd64 [upgradable from: 2:8.0.1453-1ubuntu1]
|
||||
```
|
||||
|
||||
### 如何在 Debian/Ubuntu 系统中使用 apt 命令来安装可用的安全更新?
|
||||
#### 如何在 Debian/Ubuntu 系统中使用 apt 命令来安装可用的安全更新?
|
||||
|
||||
如果你在上面命令的输出中发现任何的软件包更新。就运行下面的命令来安装它们。
|
||||
|
||||
@ -241,7 +237,7 @@ via: https://www.2daygeek.com/manually-install-security-updates-ubuntu-debian/
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
191
published/201907/20190703 Parse arguments with Python.md
Normal file
191
published/201907/20190703 Parse arguments with Python.md
Normal file
@ -0,0 +1,191 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11144-1.html)
|
||||
[#]: subject: (Parse arguments with Python)
|
||||
[#]: via: (https://opensource.com/article/19/7/parse-arguments-python)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth/users/notsag)
|
||||
|
||||
使用 Python 解析参数
|
||||
======
|
||||
|
||||
> 使用 argparse 模块像专业人士一样解析参数。
|
||||
|
||||

|
||||
|
||||
如果你在使用 [Python][2] 进行开发,你可能会在终端中使用命令,即使只是为了启动 Python 脚本或使用 [pip][3] 安装 Python 模块。命令可能简单而单一:
|
||||
|
||||
```
|
||||
$ ls
|
||||
```
|
||||
|
||||
命令也可能需要参数:
|
||||
|
||||
```
|
||||
$ ls example
|
||||
```
|
||||
|
||||
命令也可以有选项或标志:
|
||||
|
||||
```
|
||||
$ ls --color example
|
||||
```
|
||||
|
||||
有时选项也有参数:
|
||||
|
||||
```
|
||||
$ sudo firewall-cmd --list-all --zone home
|
||||
```
|
||||
|
||||
### 参数
|
||||
|
||||
POSIX shell 会自动将你输入的内容作为命令分成数组。例如,这是一个简单的命令:
|
||||
|
||||
```
|
||||
$ ls example
|
||||
```
|
||||
|
||||
命令 `ls` 的位置是 `$0`,参数 `example` 位置是 `$1`。
|
||||
|
||||
你**可以**写一个循环迭代每项。确定它是否是命令、选项还是参数。并据此采取行动。幸运的是,已经有一个名为 [argparse][4] 的模块。
|
||||
|
||||
### argparse
|
||||
|
||||
argparse 模块很容易集成到 Python 程序中,并有多种便利功能。例如,如果你的用户更改选项的顺序或使用一个不带参数的选项(称为**布尔**,意味着选项可以打开或关闭设置),然后另一个需要参数(例如 `--color red`),argparse 可以处理多种情况。如果你的用户忘记了所需的选项,那么 argparse 模块可以提供友好的错误消息。
|
||||
|
||||
要在应用中使用 argparse,首先要定义为用户提供的选项。你可以接受几种不同的参数,而语法一致又简单。
|
||||
|
||||
这是一个简单的例子:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
import argparse
|
||||
import sys
|
||||
|
||||
def getOptions(args=sys.argv[1:]):
|
||||
parser = argparse.ArgumentParser(description="Parses command.")
|
||||
parser.add_argument("-i", "--input", help="Your input file.")
|
||||
parser.add_argument("-o", "--output", help="Your destination output file.")
|
||||
parser.add_argument("-n", "--number", type=int, help="A number.")
|
||||
parser.add_argument("-v", "--verbose",dest='verbose',action='store_true', help="Verbose mode.")
|
||||
options = parser.parse_args(args)
|
||||
return options
|
||||
```
|
||||
|
||||
此示例代码创建一个名为 `getOptions` 的函数,并告诉 Python 查看每个可能的参数,前面有一些可识别的字符串(例如 `--input` 或者 `-i`)。 Python 找到的任何选项都将作为 `options` 对象从函数中返回(`options` 是一个任意名称,且没有特殊含义。它只是一个包含函数已解析的所有参数的摘要的数据对象)。
|
||||
|
||||
默认情况下,Python 将用户给出的任何参数视为字符串。如果需要提取整数(数字),则必须指定选项 `type=int`,如示例代码中的 `--number` 选项。
|
||||
|
||||
如果你有一个只是关闭和打开功能的参数,那么你必须使用 `boolean` 类型,就像示例代码中的 `--verbose` 标志一样。这种选项只保存 `True` 或 `False`,用户用来指定是否使用标志。如果使用该选项,那么会激活 `stored_true`。
|
||||
|
||||
当 `getOptions` 函数运行时,你就可以使用 `options` 对象的内容,并让程序根据用户调用命令的方式做出决定。你可以使用测试打印语句查看 `options` 的内容。将其添加到示例文件的底部:
|
||||
|
||||
```
|
||||
print(getOptions())
|
||||
```
|
||||
|
||||
然后带上参数运行代码:
|
||||
|
||||
```
|
||||
$ python3 ./example.py -i foo -n 4
|
||||
Namespace(input='foo', number=4, output=None, verbose=False)
|
||||
```
|
||||
|
||||
### 检索值
|
||||
|
||||
示例代码中的 `options` 对象包含了用户提供的选项后面的值(或派生的布尔值)。例如,在示例代码中,可以通过 `options.number` 来检索 `--number`。
|
||||
|
||||
```
|
||||
options = getOptions(sys.argv[1:])
|
||||
|
||||
if options.verbose:
|
||||
print("Verbose mode on")
|
||||
else:
|
||||
print("Verbose mode off")
|
||||
|
||||
print(options.input)
|
||||
print(options.output)
|
||||
print(options.number)
|
||||
|
||||
# 这里插入你的 Python 代码
|
||||
```
|
||||
|
||||
示例中的布尔选项 `--verbose` 是通过测试 `options.verbose` 是否为 `True`(意味着用户使用了 `--verbose` 标志)或 `False`(用户没有使用 `--verbose` 标志),并采取相应的措施。
|
||||
|
||||
### 帮助和反馈
|
||||
|
||||
argparse 还包含一个内置的 `--help`(简写 `-h`)选项,它提供了有关如何使用命令的提示。这是从你的代码派生的,因此生成此帮助系统不需要额外的工作:
|
||||
|
||||
```
|
||||
$ ./example.py --help
|
||||
usage: example.py [-h] [-i INPUT] [-o OUTPUT] [-n NUMBER] [-v]
|
||||
|
||||
Parses command.
|
||||
|
||||
optional arguments:
|
||||
-h, --help show this help message and exit
|
||||
-i INPUT, --input INPUT
|
||||
Your input file.
|
||||
-o OUTPUT, --output OUTPUT
|
||||
Your destination output file.
|
||||
-n NUMBER, --number NUMBER
|
||||
A number.
|
||||
-v, --verbose Verbose mode.
|
||||
```
|
||||
|
||||
### 像专业人士一样用 Python 解析
|
||||
|
||||
这是一个简单的示例,来演示如何在 Python 应用中的解析参数以及如何快速有效地记录它的语法。下次编写 Python 脚本时,请使用 argparse 为其提供一些选项。你以后会感到自得,你的命令不会像一个快速的临时脚本,更像是一个“真正的” Unix 命令!
|
||||
|
||||
以下是可用于测试的示例代码:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
# GNU All-Permissive License
|
||||
# Copying and distribution of this file, with or without modification,
|
||||
# are permitted in any medium without royalty provided the copyright
|
||||
# notice and this notice are preserved. This file is offered as-is,
|
||||
# without any warranty.
|
||||
|
||||
import argparse
|
||||
import sys
|
||||
|
||||
def getOptions(args=sys.argv[1:]):
|
||||
parser = argparse.ArgumentParser(description="Parses command.")
|
||||
parser.add_argument("-i", "--input", help="Your input file.")
|
||||
parser.add_argument("-o", "--output", help="Your destination output file.")
|
||||
parser.add_argument("-n", "--number", type=int, help="A number.")
|
||||
parser.add_argument("-v", "--verbose",dest='verbose',action='store_true', help="Verbose mode.")
|
||||
options = parser.parse_args(args)
|
||||
return options
|
||||
|
||||
options = getOptions(sys.argv[1:])
|
||||
|
||||
if options.verbose:
|
||||
print("Verbose mode on")
|
||||
else:
|
||||
print("Verbose mode off")
|
||||
|
||||
print(options.input)
|
||||
print(options.output)
|
||||
print(options.number)
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/parse-arguments-python
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth/users/notsag
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cobol-card-punch-programming-code.png?itok=6W6PUqUi (COBOL punch card)
|
||||
[2]: https://www.python.org/
|
||||
[3]: https://pip.pypa.io/en/stable/installing/
|
||||
[4]: https://pypi.org/project/argparse/
|
||||
@ -0,0 +1,109 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11171-1.html)
|
||||
[#]: subject: (Bash Script to Monitor Messages Log (Warning, Error and Critical) on Linux)
|
||||
[#]: via: (https://www.2daygeek.com/linux-bash-script-to-monitor-messages-log-warning-error-critical-send-email/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
在 Linux 上用 Bash 脚本监控 messages 日志
|
||||
======
|
||||
|
||||
目前市场上有许多开源监控工具可用于监控 Linux 系统的性能。当系统达到指定的阈值限制时,它将发送电子邮件警报。它可以监视 CPU 利用率、内存利用率、交换利用率、磁盘空间利用率等所有内容。
|
||||
|
||||
如果你只有很少的系统并且想要监视它们,那么编写一个小的 shell 脚本可以使你的任务变得非常简单。
|
||||
|
||||
在本教程中,我们添加了一个 shell 脚本来监视 Linux 系统上的 messages 日志。
|
||||
|
||||
我们过去添加了许多有用的 shell 脚本。如果要查看这些内容,请导航至以下链接。
|
||||
|
||||
- [如何使用 shell 脚本监控系统的日常活动?][1]
|
||||
|
||||
此脚本将检查 `/var/log/messages` 文件中的 “warning“、“error” 和 “critical”,如果发现任何有关的东西,就给指定电子邮件地址发邮件。
|
||||
|
||||
如果服务器有许多匹配的字符串,我们就不能经常运行这个可能填满收件箱的脚本,我们可以在一天内运行一次。
|
||||
|
||||
为了解决这个问题,我让脚本以不同的方式触发电子邮件。
|
||||
|
||||
如果 `/var/log/messages` 文件中昨天的日志中找到任何给定字符串,则脚本将向给定的电子邮件地址发送电子邮件警报。
|
||||
|
||||
**注意:**你需要更改电子邮件地址,而不是我们的电子邮件地址。
|
||||
|
||||
```
|
||||
# vi /opt/scripts/os-log-alert.sh
|
||||
```
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
#Set the variable which equal to zero
|
||||
prev_count=0
|
||||
|
||||
count=$(grep -i "`date --date='yesterday' '+%b %e'`" /var/log/messages | egrep -wi 'warning|error|critical' | wc -l)
|
||||
|
||||
if [ "$prev_count" -lt "$count" ] ; then
|
||||
# Send a mail to given email id when errors found in log
|
||||
SUBJECT="WARNING: Errors found in log on "`date --date='yesterday' '+%b %e'`""
|
||||
# This is a temp file, which is created to store the email message.
|
||||
MESSAGE="/tmp/logs.txt"
|
||||
TO="2daygeek@gmail.com"
|
||||
echo "ATTENTION: Errors are found in /var/log/messages. Please Check with Linux admin." >> $MESSAGE
|
||||
echo "Hostname: `hostname`" >> $MESSAGE
|
||||
echo -e "\n" >> $MESSAGE
|
||||
echo "+------------------------------------------------------------------------------------+" >> $MESSAGE
|
||||
echo "Error messages in the log file as below" >> $MESSAGE
|
||||
echo "+------------------------------------------------------------------------------------+" >> $MESSAGE
|
||||
grep -i "`date --date='yesterday' '+%b %e'`" /var/log/messages | awk '{ $3=""; print}' | egrep -wi 'warning|error|critical' >> $MESSAGE
|
||||
mail -s "$SUBJECT" "$TO" < $MESSAGE
|
||||
#rm $MESSAGE
|
||||
fi
|
||||
```
|
||||
|
||||
为 `os-log-alert.sh` 文件设置可执行权限。
|
||||
|
||||
```
|
||||
$ chmod +x /opt/scripts/os-log-alert.sh
|
||||
```
|
||||
|
||||
最后添加一个 cron 任务来自动执行此操作。它将每天 7 点钟运行。
|
||||
|
||||
```
|
||||
# crontab -e
|
||||
```
|
||||
|
||||
```
|
||||
0 7 * * * /bin/bash /opt/scripts/os-log-alert.sh
|
||||
```
|
||||
|
||||
**注意:**你将在每天 7 点收到昨天日志的电子邮件提醒。
|
||||
|
||||
**输出:**你将收到类似下面的电子邮件提醒。
|
||||
|
||||
```
|
||||
ATTENTION: Errors are found in /var/log/messages. Please Check with Linux admin.
|
||||
|
||||
+-----------------------------------------------------+
|
||||
Error messages in the log file as below
|
||||
+-----------------------------------------------------+
|
||||
Jul 3 02:40:11 ns1 kernel: php-fpm[3175]: segfault at 299 ip 000055dfe7cc7e25 sp 00007ffd799d7d38 error 4 in php-fpm[55dfe7a89000+3a7000]
|
||||
Jul 3 02:50:14 ns1 kernel: lmtp[8249]: segfault at 20 ip 00007f9cc05295e4 sp 00007ffc57bca1a0 error 4 in libdovecot-storage.so.0.0.0[7f9cc04df000+148000]
|
||||
Jul 3 15:36:09 ns1 kernel: php-fpm[17846]: segfault at 299 ip 000055dfe7cc7e25 sp 00007ffd799d7d38 error 4 in php-fpm[55dfe7a89000+3a7000]
|
||||
Jul 3 15:45:54 ns1 pure-ftpd: (?@5.188.62.5) [WARNING] Authentication failed for user [daygeek]
|
||||
Jul 3 16:25:36 ns1 pure-ftpd: (?@104.140.148.58) [WARNING] Sorry, cleartext sessions and weak ciphers are not accepted on this server.#012Please reconnect using TLS security mechanisms.
|
||||
Jul 3 16:44:20 ns1 kernel: php-fpm[8979]: segfault at 299 ip 000055dfe7cc7e25 sp 00007ffd799d7d38 error 4 in php-fpm[55dfe7a89000+3a7000]
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-bash-script-to-monitor-messages-log-warning-error-critical-send-email/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/category/shell-script/
|
||||
@ -0,0 +1,95 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11163-1.html)
|
||||
[#]: subject: (How to enable DNS-over-HTTPS (DoH) in Firefox)
|
||||
[#]: via: (https://www.zdnet.com/article/how-to-enable-dns-over-https-doh-in-firefox/)
|
||||
[#]: author: (Catalin Cimpanu https://www.zdnet.com/meet-the-team/us/catalin.cimpanu/)
|
||||
|
||||
如何在 Firefox 中启用 DNS-over-HTTPS(DoH)
|
||||
======
|
||||
|
||||
DNS-over-HTTPS(DoH)协议目前是谈论的焦点,Firefox 是唯一支持它的浏览器。但是,Firefox 默认不启用此功能,用户必须经历许多步骤并修改多个设置才能启动并运行 DoH。
|
||||
|
||||
在开始如何在 Firefox 中启用 DoH 支持的分步教程之前,让我们先描述它的原理。
|
||||
|
||||
### DNS-over-HTTPS 的工作原理
|
||||
|
||||
DNS-over-HTTPS 协议通过获取用户在浏览器中输入的域名,并向 DNS 服务器发送查询,以了解托管该站点的 Web 服务器的 IP 地址。
|
||||
|
||||
这也是正常 DNS 的工作原理。但是,DoH 通过 443 端口的加密 HTTPS 连接接受 DNS 查询将其发送到兼容 DoH 的 DNS 服务器(解析器),而不是在 53 端口上发送纯文本。这样,DoH 就会在常规 HTTPS 流量中隐藏 DNS 查询,因此第三方监听者将无法嗅探流量,并了解用户的 DNS 查询,从而推断他们将要访问的网站。
|
||||
|
||||
此外,DNS-over-HTTPS 的第二个特性是该协议工作在应用层。应用可以带上内部硬编码的 DoH 兼容的 DNS 解析器列表,从而向它们发送 DoH 查询。这种操作模式绕过了系统级别的默认 DNS 设置,在大多数情况下,这些设置是由本地 Internet 服务提供商(ISP)设置的。这也意味着支持 DoH 的应用可以有效地绕过本地 ISP 流量过滤器并访问可能被本地电信公司或当地政府阻止的内容 —— 这也是 DoH 目前被誉为用户隐私和安全的福音的原因。
|
||||
|
||||
这是 DoH 在推出后不到两年的时间里获得相当大的普及的原因之一,同时也是一群[英国 ISP 因为 Mozilla 计划支持 DoH 协议而提名它为 2019 年的“互联网恶棍” (Internet Villian)][1]的原因,ISP 认为 DoH 协议会阻碍他们过滤不良流量的努力。(LCTT 译注:后来这一奖项的提名被取消。)
|
||||
|
||||
作为回应,并且由于英国政府阻止访问侵犯版权内容的复杂情况,以及 ISP 自愿阻止访问虐待儿童网站的情况,[Mozilla 已决定不为英国用户默认启用此功能][2]。
|
||||
|
||||
下面的分步指南将向英国和世界各地的 Firefox 用户展示如何立即启用该功能,而不用等到 Mozilla 将来启用它 —— 如果它会这么做的话。在 Firefox 中有两种启用 DoH 支持的方法。
|
||||
|
||||
### 方法 1:通过 Firefox 设置
|
||||
|
||||
**步骤 1:**进入 Firefox 菜单,选择**工具**,然后选择**首选项**。 可选在 URL 栏中输入 `about:preferences`,然后按下回车。这将打开 Firefox 的首选项。
|
||||
|
||||
**步骤 2:**在**常规**中,向下滚动到**网络设置**,然后按**设置**按钮。
|
||||
|
||||
![DoH section in Firefox settings][3]
|
||||
|
||||
**步骤3:**在弹出窗口中,向下滚动并选择“**Enable DNS over HTTPS**”,然后配置你需要的 DoH 解析器。你可以使用内置的 Cloudflare 解析器(该公司与 Mozilla [达成协议][4],记录更少的 Firefox 用户数据),或者你可以在[这个列表][4]中选择一个。
|
||||
|
||||
![DoH section in Firefox settings][6]
|
||||
|
||||
### 方法 2:通过 about:config
|
||||
|
||||
**步骤 1:**在 URL 栏中输入 `about:config`,然后按回车访问 Firefox 的隐藏配置面板。在这里,用户需要启用和修改三个设置。
|
||||
|
||||
**步骤 2:**第一个设置是 `network.trr.mode`。这打开了 DoH 支持。此设置支持四个值:
|
||||
|
||||
* `0` - 标准 Firefox 安装中的默认值(当前为 5,表示禁用 DoH)
|
||||
* `1` - 启用 DoH,但 Firefox 依据哪个请求更快返回选择使用 DoH 或者常规 DNS
|
||||
* `2` - 启用 DoH,常规 DNS 作为备用
|
||||
* `3` - 启用 DoH,并禁用常规 DNS
|
||||
* `5` - 禁用 DoH
|
||||
|
||||
值为 2 工作得最好
|
||||
|
||||
![DoH in Firefox][7]
|
||||
|
||||
**步骤3:**需要修改的第二个设置是 `network.trr.uri`。这是与 DoH 兼容的 DNS 服务器的 URL,Firefox 将向它发送 DoH DNS 查询。默认情况下,Firefox 使用 Cloudflare 的 DoH服务,地址是:<https://mozilla.cloudflare-dns.com/dns-query>。但是,用户可以使用自己的 DoH 服务器 URL。他们可以从[这个列表][8]中选择其中一个可用的。Mozilla 在 Firefox 中使用 Cloudflare 的原因是因为与这家公司[达成了协议][4],之后 Cloudflare 将收集来自 Firefox 用户的 DoH 查询的非常少的数据。
|
||||
|
||||
[DoH in Firefox][9]
|
||||
|
||||
**步骤4:**第三个设置是可选的,你可以跳过此设置。 但是如果设置不起作用,你可以使用此作为步骤 3 的备用。该选项名为 `network.trr.bootstrapAddress`,它是一个输入字段,用户可以输入步骤 3 中兼容 DoH 的 DNS 解析器的 IP 地址。对于 Cloudflare,它是 1.1.1.1。 对于 Google 服务,它是 8.8.8.8。 如果你使用了另一个 DoH 解析器的 URL,如果有必要的话,你需要追踪那台服务器的 IP 地址并输入。
|
||||
|
||||
![DoH in Firefox][10]
|
||||
|
||||
通常,在步骤 3 中输入的 URL 应该足够了。
|
||||
设置应该立即生效,但如果它们不起作用,请重新启动 Firefox。
|
||||
|
||||
文章信息来源:[Mozilla Wiki][11]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.zdnet.com/article/how-to-enable-dns-over-https-doh-in-firefox/
|
||||
|
||||
作者:[Catalin Cimpanu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.zdnet.com/meet-the-team/us/catalin.cimpanu/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-11068-1.html
|
||||
[2]: https://www.zdnet.com/article/mozilla-no-plans-to-enable-dns-over-https-by-default-in-the-uk/
|
||||
[3]: https://zdnet1.cbsistatic.com/hub/i/2019/07/07/df30c7b0-3a20-4de7-8640-3dea6d249a49/121bd379b6232e1e2a97c35ea8c7764e/doh-settings-1.png
|
||||
[4]: https://developers.cloudflare.com/1.1.1.1/commitment-to-privacy/privacy-policy/firefox/
|
||||
[6]: https://zdnet3.cbsistatic.com/hub/i/2019/07/07/8608af28-2a28-4ff1-952b-9b6d2deb1ea6/b1fc322caaa2c955b1a2fb285daf0e42/doh-settings-2.png
|
||||
[7]: https://zdnet1.cbsistatic.com/hub/i/2019/07/06/0232b3a7-82c6-4a6f-90c1-faf0c090254c/6db9b36509021c460fcc7fe825bb74c5/doh-1.png
|
||||
[8]: https://github.com/curl/curl/wiki/DNS-over-HTTPS#publicly-available-servers
|
||||
[9]: https://zdnet2.cbsistatic.com/hub/i/2019/07/06/4dd1d5c1-6fa7-4f5b-b7cd-b544748edfed/baa7a70ac084861d94a744a57a3147ad/doh-2.png
|
||||
[10]: https://zdnet1.cbsistatic.com/hub/i/2019/07/06/8ec20a28-673c-4a17-8195-16579398e90a/538fe8420f9b24724aeb4a6c8d4f0f0f/doh-3.png
|
||||
[11]: https://wiki.mozilla.org/Trusted_Recursive_Resolver
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11124-1.html)
|
||||
[#]: subject: (10 ways to get started with Linux)
|
||||
[#]: via: (https://opensource.com/article/19/7/ways-get-started-linux)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth/users/don-watkins)
|
||||
@ -12,9 +12,9 @@ Linux 入门十法
|
||||
|
||||
> 想要进入 Linux 之门,试试这十个方法。
|
||||
|
||||
![Penguins gathered together in the Artic][1]
|
||||

|
||||
|
||||
文章《[什么是 Linux 用户?][2]》的作者 Anderson Silva 明确表示,现今人们使用 Linux(在某种程度上)就像使用 Windows 一样,只要你对“使用 Linux”这个事情定义得足够广泛。尽管如此,如果你的生活中没有足够的使用 Linux 的机会,现在正是以前所未有的方式尝试 Linux 的好时机。
|
||||
文章《[什么是 Linux 用户?][2]》的作者 Anderson Silva 明确表示,现今人们使用 Linux(在某种程度上)就像使用 Windows 一样,只要你对“使用 Linux”这个事情定义得足够广义。尽管如此,如果你的生活中没有太多的使用 Linux 的机会,现在正是以前所未有的方式尝试 Linux 的好时机。
|
||||
|
||||
以下是 Linux 入门的十种方法。你可以试试其中一个或者全部试试。
|
||||
|
||||
@ -22,65 +22,65 @@ Linux 入门十法
|
||||
|
||||
![Free shell screenshot][3]
|
||||
|
||||
有很多人在用不上的服务器上运行 Linux (请记住,“Linux 服务器”可以是从最新的超级计算机到丢弃的已经用了 12 年的笔记本电脑中的任何一个)。为了充分利用多余的计算机,许多管理员用这些备用的机器提供了免费的 shell 帐户。
|
||||
有很多人在用不上的服务器上运行 Linux (请记住,“Linux 服务器”可以是从最新的超级计算机到丢弃的、已经用了 12 年的笔记本电脑中的任何一个)。为了充分利用多余的计算机,许多管理员用这些备用的机器提供了免费的 shell 帐户。
|
||||
|
||||
如果你想要登录到 Linux 终端中学习命令、shell 脚本、Python 以及 Web 开发的基础知识,那么免费的 shell 帐户是一种简单、免费的入门方式。这是一个简短的列表:
|
||||
如果你想要登录到 Linux 终端中学习命令、shell 脚本、Python 以及 Web 开发的基础知识,那么免费的 shell 帐户是一种简单、免费的入门方式。下面是一个可以体验一下的简短列表:
|
||||
|
||||
* [Freeshell.de][4] 是一个自 2002 年以来一直在线的公用 Linux 系统。你可以通过 SSH、IPv6 和 OpenSSL 进行访问,以获得 Linux shell 体验,并且可以使用 MySQL 数据库。
|
||||
* [Blinkenshell][5] 提供了一个学习 Unix、使用 IRC、托管简单网站和共享文件的 Linux shell。它自 2006 年以来一直在线。
|
||||
* [SDF 公用 Unix 系统][6]成立于 1987 年,提供了免费的 NetBSD 账户。当然,NetBSD 不是 Linux,但它是开源的 Unix,因此它提供了类似的体验。它也有几个自制应用程序,因此它跨越了老派 BBS 和普通的免费 shell 之间的界限。
|
||||
* [Freeshell.de][4] 是一个自 2002 年以来一直在线服务的公用 Linux 系统。你可以通过 SSH、IPv6 和 OpenSSL 进行访问,以获得 Linux shell 体验,并且可以使用 MySQL 数据库。
|
||||
* [Blinkenshell][5] 提供了一个学习 Unix、使用 IRC、托管简单网站和共享文件的 Linux shell。它自 2006 年以来一直在线服务。
|
||||
* [SDF 公用 Unix 系统][6]成立于 1987 年,提供了免费的 NetBSD 账户。当然,NetBSD 不是 Linux,但它是开源的 Unix,因此它提供了类似的体验。它也有几个自制应用程序,因此它不但有普通的免费 shell,还提供了老派 BBS。
|
||||
|
||||
免费 shell 帐户受到很多滥用,因此你表现出的信任度和参与集体活动的意愿越多,你的体验就越好。你通常可以访问数据库引擎、编译器和高级编程语言(通过特殊请求或小额捐赠来证明声誉)。你还可以要求安装其他软件或库,但需经管理员批准。
|
||||
免费 shell 帐户常会受到滥用,因此你表现出的可信程度和积极参与协作的意愿越多,你的体验就越好。你可以通过专门请求或小额捐赠来证明你的诚意,通常可以访问数据库引擎、编译器和高级编程语言。你还可以要求安装其他软件或库,但需经管理员批准。
|
||||
|
||||
#### 如何使用
|
||||
|
||||
公用 shell 帐户是尝试真正的 Linux 系统的好方法。你无法获得 root 权限这一事实意味着你可学习本地软件管理,而无需做更多的维护工作。你可以做很多实际操作,以完成真正的工作,尽管它们对于学习关键任务还不够。
|
||||
公用 shell 帐户是尝试真正的 Linux 系统的好方法。你无法获得 root 权限这一事实意味着你可以学习本地软件管理,而无需做更多的维护工作。你可以做很多实际操作,以完成真正的工作,尽管它们对于学习关键任务还不够。
|
||||
|
||||
### 2、试试 Windows WSL 2 里面的 Linux
|
||||
|
||||
不管你信不信,微软从 2019 年 6 月开始在 Windows 里面带上了 Linux,这意味着你可以从 Windows 运行 Linux 应用程序,这是第二代的 [Windows 里的 Linux 子系统][7](WSL 2)。虽然它主要针对开发人员,但 Windows 用户会发现 WSL 2 是一个熟悉的桌面上的 Linux 环境,而没有被任何虚拟化占用额外资源。这是一个以进程方式运行在 Windows 机器上的 Linux。在这个时候,它仍然是一个新的动向和正在进行中的工作,因此它可能会发生变化。如果你试图用它承担重任,你可能会遇到一两个错误,但是如果你只是想入门 Linux、学习一些命令,并感受在基于文本的环境如何完成工作,那么 WSL 2 可能正是你所需要的。
|
||||
不管你信不信,微软从 2019 年 6 月开始在 Windows 里面带上了 Linux,这意味着你可以从 Windows 运行 Linux 应用程序,这是 [Windows 里的 Linux 子系统][7]的第二版(WSL 2)。虽然它主要针对开发人员,但 Windows 用户可以发现 WSL 2 是一个来自于他们熟悉的桌面上的 Linux 环境,而没有被任何虚拟化占用额外资源。这是一个以进程方式运行在 Windows 机器上的 Linux。现阶段,它仍然是一个新的动向和正在进行中的工作,因此它可能会发生变化。如果你试图用它承担重任,你可能会遇到一两个错误,但是如果你只是想入门 Linux、学习一些命令,并感受在基于文本的环境如何完成工作,那么 WSL 2 可能正是你所需要的。
|
||||
|
||||
#### 如何使用
|
||||
|
||||
WSL 还没有明确的方向或目的,但它在 Windows 机器上提供了 Linux 环境。你可以获得 root 访问权限,并可以运行 Linux 发行版和应用程序,因此这是一种简单而无缝的学习方式。但是,即使 WSL *是Linux*,它也不能给你典型的 Linux 体验。它是由 Windows 提供的 Linux,而这不太会是你在现实世界中遇到的。WSL 是一个开发和教育工具,但如果你可以使用它,那么你应该试试它。
|
||||
WSL 还没有明确的用途或目的,但它在 Windows 机器上提供了 Linux 环境。你可以获得 root 访问权限,并可以运行 Linux 发行版和应用程序,因此这是一种简单而无缝的学习方式。但是,即使 WSL *是Linux*,它也不能给你典型的 Linux 体验。它是由 Windows 提供的 Linux,而这不太会是你在现实世界中遇到的情况。WSL 是一个开发和教育工具,但如果你可以使用它,那么你应该试试它。
|
||||
|
||||
### 3、把 Linux 放到可启动的 U 盘上
|
||||
|
||||
![Porteus Linux][8]
|
||||
|
||||
便携 Linux 可以安装到 U 盘上随身携带,并用该 U 盘启动你遇到的任何计算机。你可以获得个性化的 Linux 桌面,而无需担心所启动的主机上的数据。计算机不会接触你的 Linux 操作系统,并且你的 Linux 操作系统也不会影响计算机。它非常适合酒店商务中心、图书馆、学校的公共计算机,或者只是给自己一个不时启动 Linux 的借口。
|
||||
便携 Linux 可以安装到 U 盘上随身携带,并用该 U 盘启动你遇到的任何计算机。你可以获得个性化的 Linux 桌面,而无需担心所用于启动的主机上的数据。该计算机上原有的系统不会与你的 Linux 系统相接触,并且你的 Linux 操作系统也不会影响计算机。它非常适合酒店商务中心、图书馆、学校的公共计算机,或者只是给自己一个不时启动 Linux 的借口。
|
||||
|
||||
与许多其他快速取得的 Linux shell 不同,此方法为你提供了一个完整而强大的 Linux 系统,包括桌面环境,可访问你需要的任何软件以及持久的数据存储。
|
||||
与许多其他快速获得的 Linux shell 不同,此方法为你提供了一个完整而强大的 Linux 系统,包括桌面环境,可访问你需要的任何软件以及持久的数据存储。
|
||||
|
||||
这个系统永远不会改变。你要保存的任何数据都将写入压缩的文件系统中,然后在引导时将其作为覆盖层应用于该系统。这种灵活性允许你选择是以持久模式启动,将所有数据保存回 U 盘;还是以临时模式启动,以便一旦关闭电源,你所做的一切都会消失。换句话说,你可以将其用作不受信任的计算机上的安全信息亭或你信任的计算机上的便携式操作系统。
|
||||
|
||||
你可以尝试很多 [U 盘发行版][9],有些桌面环境很少,适用于低功耗计算机,有些适用于完整桌面环境。我偏爱 [Porteus][10] Linux。在过去的八年里,我每天都把它放在我的钥匙链上,在商务旅行中使用它作为我的主要计算平台,如果在工作或家中计算机发生问题,它也会用作工具盘。它是一个可靠而稳定的操作系统,有趣且易于使用。
|
||||
你可以尝试很多 [U 盘发行版][9],有些带有精简的桌面环境,适用于低功耗计算机,而另一些带有完整的桌面环境。我偏爱 [Porteus][10] Linux。在过去的八年里,我每天都把它放在我的钥匙链上,在商务旅行中使用它作为我的主要计算平台,如果在工作场所或家中计算机发生问题,它也会用作工具盘。它是一个可靠而稳定的操作系统,有趣且易于使用。
|
||||
|
||||
在 Mac 或 Windows 上,下载 [Fedora Media Writer][11] 以创建你下载的任何便携式发行版的可启动 U 盘。
|
||||
|
||||
#### 如何使用
|
||||
|
||||
从 U 盘启动一个“实时 Linux”可提供完整的 Linux 发行版。虽然数据存储与你安装到硬盘驱动器的系统略有不同,但其他所有内容都与你在 Linux 桌面上所期望的一样。在便携式 Linux 操作系统上你几乎没有什么不能做的,所以在你的钥匙串上安装一个以解锁你遇到的每台计算机的全部潜力吧。
|
||||
从 U 盘启动一个 “实时 Linux” 可提供完整的 Linux 发行版环境。虽然数据存储与你安装到硬盘驱动器的系统略有不同,但其它的所有内容都与你在 Linux 桌面上所期望的一样。在便携式 Linux 操作系统上你几乎没有什么不能做的,所以在你的钥匙串上挂上一个以解锁你遇到的每台计算机的全部潜力吧。
|
||||
|
||||
### 4、在线导览
|
||||
### 4、在线游览
|
||||
|
||||
![Linux tour screenshot][12]
|
||||
|
||||
Ubuntu 的某个人想到了在浏览器中托管 Ubuntu GNOME 桌面的好主意。想要自己尝试一下,可以打开 Web 浏览器并导航到 [tour.ubuntu.com][13]。你可以选择要演示的活动,也可以跳过单个课程并单击 “四处看看” 按钮。
|
||||
Ubuntu 的某个人想到了在浏览器中托管 Ubuntu GNOME 桌面的好主意。如果想要自己尝试一下,可以打开 Web 浏览器并导航到 [tour.ubuntu.com][13]。你可以选择要演示的活动,也可以跳过单个课程并单击 “<ruby>四处看看<rt>Show Yourself Around</rt></ruby>” 按钮。
|
||||
|
||||
即使你是 Linux 桌面的新用户,你也可能会发现“四处看看”功能比你想象的更还简单。在线游览中,您可以四处看看,查看可用的应用程序,以及查看典型的默认 Linux 桌面。你不能在 Firefox 中调整设置或启动另一个在线导览(这是我尝试的第一件事),虽然你可以完成安装应用程序的动作,但你无法启动它们。 但是,如果你之前从未使用过 Linux 桌面,并且想要看到各种新奇的东西,那这就是一场旋风之旅。
|
||||
即使你是 Linux 桌面的新用户,你也可能会发现“四处看看”功能比你想象的更还简单。在线游览中,你可以四处看看,查看可用的应用程序,以及查看典型的默认 Linux 桌面。你不能在 Firefox 中调整设置或启动另一个在线游览(这是我尝试过的第一件事),虽然你可以完成安装应用程序的动作,但你无法启动它们。但是,如果你之前从未使用过 Linux 桌面,并且想要看到各种新奇的东西,那这就是一场旋风之旅。
|
||||
|
||||
#### 如何使用
|
||||
|
||||
在线导览真的只是一次旅行。如果你从未见过 Linux 桌面,那么这是一个了解它的情况的机会。不是为了正式的使用,而是一个吸引过客的展示。
|
||||
在线游览真的只是一次旅行。如果你从未见过 Linux 桌面,那么这是一个了解它的情况的机会。这不是一个正式的使用,而是一个吸引过客的展示。
|
||||
|
||||
### 5、在浏览器中用 JavaScript 运行 Linux
|
||||
|
||||
![JSLinux][14]
|
||||
|
||||
就在不久之前,虚拟化的计算成本还很高,这仅限于使用高级硬件的用户。而现在虚拟化已被优化到可以由 JavaScript 引擎执行的程度,这要归功于 Fabrice Bellard,它是优秀的开源 [QEMU][15] 机器仿真器和虚拟器的创建者。
|
||||
就在不久之前,虚拟化的计算成本还很高,还仅限于使用先进的硬件的用户。而现在虚拟化已被优化到可以由 JavaScript 引擎执行的程度,这要归功于 Fabrice Bellard,它是优秀的开源 [QEMU][15] 机器仿真器和虚拟器的创建者。
|
||||
|
||||
Bellard 还启动了 JSLinux 项目,该项目允许你在浏览器中运行 Linux 和其他操作系统,算是闲暇时间的一个乐趣。它仍然是一个实验项目,但它是一个技术奇迹。打开 Web 浏览器导航到 [JSLinux][16] 页面,你可以启动基于文本的 Linux shell 或极简的图形 Linux 环境。你可以上传和下载文件到 JSLinux 主机上或(在理论上)将文件发送到一个网络备份位置,因为 JSLinux 可以通过 VPN 套接字访问互联网(尽管上限速度取决于 VPN 服务)。
|
||||
Bellard 还启动了 JSLinux 项目,该项目允许你在浏览器中运行 Linux 和其他操作系统,这算是闲暇时间的一个乐趣。它仍然是一个实验性项目,但它是一个技术奇迹。打开 Web 浏览器导航到 [JSLinux][16] 页面,你可以启动基于文本的 Linux shell 或精简的图形 Linux 环境。你可以上传和下载文件到 JSLinux 主机上或(在理论上可以)将文件发送到一个网络备份位置,因为 JSLinux 可以通过 VPN 套接字访问互联网(尽管上限速度取决于 VPN 服务)。
|
||||
|
||||
#### 如何使用
|
||||
|
||||
@ -88,7 +88,7 @@ Bellard 还启动了 JSLinux 项目,该项目允许你在浏览器中运行 Li
|
||||
|
||||
### 6、阅读关于它的书
|
||||
|
||||
并非每种 Linux 体验都要用计算机。也许你是那种喜欢在开始新事物之前保持距离,先观察和研究的人,或者你可能还不清楚 “Linux” 所包含的内容,或者你喜欢全情投入其中。关于 Linux 如何工作、运行 Linux 的方式以及 Linux 世界中有什么,有很多书可以读。
|
||||
并非每种 Linux 体验都要用到计算机。也许你是那种喜欢在开始新事物之前保持距离先观察和研究的人,或者你可能还不清楚 “Linux” 所包含的内容,或者你喜欢全情投入其中。关于 Linux 如何工作、运行 Linux 的方式以及 Linux 世界中有什么,有很多书可以读。
|
||||
|
||||
你越熟悉开源世界,就越容易理解常用术语,将城市神话与实际经验区分开来。我们不时会发布[图书清单] [17],但我的最爱之一是 Hazel Russman 的《[The Charm of Linux][18]》。这是一个从不同角度巡览 Linux 的过程,是由一位独立作者在发现 Linux 时兴奋之余写作的。
|
||||
|
||||
@ -100,41 +100,41 @@ Bellard 还启动了 JSLinux 项目,该项目允许你在浏览器中运行 Li
|
||||
|
||||
![Raspberry Pi 4][19]
|
||||
|
||||
如果你正在使用[树莓派][20],那么你就正在运行 Linux。Linux 和低功耗计算很容易上手。关于树莓派的好处,除了价格低于 100 美元之外,它的[网站][21]是专为教育而设计的。你可以了解树莓派所做的一切,当你了解之后,就知道了 Linux 可以为你做些什么。
|
||||
如果你正在使用[树莓派][20],那么你就正在运行 Linux。Linux 和低功耗计算很容易上手。关于树莓派的好处,除了价格低于 100 美元之外,它的[网站][21]是专为教育而设计的。你可以了解树莓派所能做的一切,当你了解之后,就知道了 Linux 可以为你做些什么。
|
||||
|
||||
#### 如何使用
|
||||
|
||||
树莓派被设计为低功耗计算机。这意味着你不能像过去那样做那么多的多任务处理,但这是一种避免不堪重负的方便方法。树莓派是学习 Linux 及其附带的所有可能性的好方法,它是发现环保、小型、简化计算能力的有趣方式。并且一定要关注 Opensource.com 上的[提示][22]和[技巧][23]和[有趣的][24][活动] [25],特别是在每年三月份的树莓派之周期间。
|
||||
树莓派被设计为低功耗计算机。这意味着你不能像过去那样做那么多的多任务处理,但这是一种避免不堪重负的方便方法。树莓派是学习 Linux 及其附带的所有可能性的好方法,它是发现环保、小型、简化计算能力的有趣方式。并且一定要关注 Opensource.com 上的[提示][22]、[技巧][23]和[有趣的][24][活动] [25],特别是在每年三月份的树莓派之周的期间。
|
||||
|
||||
### 8、赶上容器热潮
|
||||
|
||||
如果你在神话般的[云][26]的后端附近工作,那么你已经听说过容器热潮。虽然你可以在 Windows、Azure、Mac 和 Linux 上运行 Docker 和 Kubernetes,但你可能不知道容器本身就是 Linux。云计算应用和基础设施实际上是精简的 Linux 系统,部分虚拟化,部分基于裸机。如果启动容器,则会启动微型的超特定的 Linux 发行版。
|
||||
如果你从事于神话般的[云服务][26]的后端工作,那么你已经听说过容器热潮。虽然你可以在 Windows、Azure、Mac 和 Linux 上运行 Docker 和 Kubernetes,但你可能不知道容器本身就是 Linux。云计算应用和基础设施实际上是精简的 Linux 系统,部分虚拟化,部分基于裸机。如果启动容器,则会启动微型的超特定的 Linux 发行版。
|
||||
|
||||
容器与虚拟机或物理服务器[不同][27]。它们不打算用作通用操作系统。但是,如果你在容器中进行开发,你可以停下来四处打量一下,你将了解到 Linux 系统的结构、保存重要文件的位置以及最常见的命令。你甚至可以[在线尝试容器][28],你可以在我的文章中[深入到 Linux 容器的背后][29]了解它们如何工作的。
|
||||
|
||||
#### 如何使用
|
||||
|
||||
根据设计,容器特定于单个任务,但它们是 Linux,因此它们非常灵活。你可以如你预期的使用它们,也可以在你的 Linux 实验当中将容器构建到大部分完整系统中。它虽然不是桌面 Linux 体验,但它是完整的 Linux 体验。
|
||||
根据设计,容器特定于一个单一任务,但它们是 Linux,因此它们非常灵活。你可以如你预期的使用它们,也可以在你的 Linux 实验当中将容器构建到大部分完整系统中。它虽然不提供桌面 Linux 体验,但它是完整的 Linux 体验。
|
||||
|
||||
### 9、以虚拟机方式安装 Linux
|
||||
|
||||
虚拟化是尝试操作系统的简便方法,[VirtualBox][30]是一种很好的开源虚拟化方法。VirtualBox 可以在 Windows 和 Mac 上运行,因此你可以将 Linux 安装为虚拟机(VM)并使用它,就好像它只是一个应用程序一样。如果你不习惯安装操作系统,VirtualBox 也是一种尝试 Linux 的非常安全的方式,而不会意外地将其安装在你通常的操作系统上。
|
||||
虚拟化是尝试操作系统的简便方法,[VirtualBox][30] 是一种很好的开源虚拟化方法。VirtualBox 可以在 Windows 和 Mac 上运行,因此你可以将 Linux 安装为虚拟机(VM)并使用它,就好像它只是一个应用程序一样。如果你不习惯安装操作系统,VirtualBox 也是一种尝试 Linux 的非常安全的方式,而不会意外地将其安装覆盖在你通常的操作系统上。
|
||||
|
||||
#### 如何使用
|
||||
|
||||
将 Linux 作为虚拟机运行既方便又简单,既可以作为试运行使用,也可以在需要 Linux 环境时进行双启动或重启。它功能齐全,因为它使用虚拟硬件,主机操作系统负责驱动你的外围设备。将 Linux 作为虚拟机运行的唯一缺点主要是心理上的。如果你打算使用 Linux 作为主操作系统,但最终默认在宿主操作系统做除了特定于 Linux 的大多数任务,那么虚拟机就会让你失望。否则,虚拟机是现代技术的胜利,在 VirtualBox 中使用 Linux 可以为你提供 Linux 所提供的所有最佳功能。
|
||||
将 Linux 作为虚拟机运行既方便又简单,既可以作为试运行使用,也可以在需要 Linux 环境时进行双启动或重启进入。它功能齐全,因为它使用虚拟硬件,宿主操作系统负责驱动你的外围设备。将 Linux 作为虚拟机运行的唯一缺点主要是心理上的。如果你打算使用 Linux 作为主要操作系统,但最终默认在宿主操作系统上做除了特定于 Linux 的大多数任务,那么虚拟机就会让你失望。否则,虚拟机是现代技术的胜利,在 VirtualBox 中使用 Linux 可以为你提供 Linux 所提供的所有最佳功能。
|
||||
|
||||
### 10、安装一个 Linux
|
||||
|
||||
![Fedora Silverblue][31]
|
||||
|
||||
如果对上述方式有疑问,那么总会有传统的方式。如果你想给予 Linux 应有的关注,你可以下载 Linux,将安装程序刻录到 U 盘(或 DVD,如果你更喜欢光学介质的话),并将其安装在你的计算机上。Linux 是开源的,所以任何想要花时间打包 Linux 的人都可以分发 Linux,并且可以将所有可用的部分分配到通常称为发行版的内容中。询问任何 Linux 用户哪个发行版是“最好的”,你必然会得到一个不同的答案(主要是因为术语“最佳”通常是未定义的)。大多数人都认可你应该使用适合你的 Linux 发行版,这意味着你应该测试一些流行的发行版,并坚持使你的计算机按照你期望的行为行事。这是一种务实和功能性的方法。例如,如果发行版无法识别你的网络摄像头而你希望它可以正常工作,则可以使用一个可识别该网络摄像头的发行版。
|
||||
如果对上述方式有疑问,那么总会有传统的方式。如果你想给予 Linux 应有的关注,你可以下载 Linux,将安装程序刻录到 U 盘(或 DVD,如果你更喜欢光学介质的话),并将其安装在你的计算机上。Linux 是开源的,所以任何想要花时间打包 Linux 的人都可以分发 Linux,并且可以将所有可用的部分分配到通常称为发行版的内容中。无论问哪一个 Linux 用户什么发行版是“最好的”,你必然都会得到一个不同的答案(主要是因为这个术语“最佳”通常是尚未定义的)。大多数人都认可:你应该使用适合你的 Linux 发行版,这意味着你应该测试一些流行的发行版,并坚持使你的计算机按照你期望的行为行事。这是一种务实和功能性的方法。例如,如果发行版无法识别你的网络摄像头而你希望它可以正常工作,则可以使用一个可识别该网络摄像头的发行版。
|
||||
|
||||
如果你之前从未安装过操作系统,你会发现大多数 Linux 发行版都包含友好且简单的安装程序。只需下载一个发行版(它们作为 ISO 文件提供),然后下载 [Fedora Media Writer][11] 来创建一个可启动的安装 U 盘。
|
||||
如果你之前从未安装过操作系统,你会发现大多数 Linux 发行版都包含一个友好且简单的安装程序。只需下载一个发行版(它们以 ISO 文件提供),然后下载 [Fedora Media Writer][11] 来创建一个可启动的安装 U 盘。
|
||||
|
||||
#### 如何使用
|
||||
|
||||
安装 Linux 并将其用作操作系统是迈向熟悉和熟悉它的一步。怎么使用它都可以。你可能会发现你从未了解过所需的必备功能,你可能会比你想象的更多地了解计算机,并且可能会改变你的世界观。或者你可以使用 Linux 桌面,因为它易于下载和安装,或者因为你想要削减某些公司霸主的中间人,或者因为它可以帮助你完成工作。
|
||||
安装 Linux 并将其用作操作系统是迈向熟悉它的一步。怎么使用它都可以。你可能会发现一些你从未了解过的所需的必备功能,你可能会比你想象的更多地了解计算机,并且可能会改变你的世界观。你使用一个 Linux 桌面,或者是因为它易于下载和安装,或者是因为你想要削弱公司中某些人的霸主地位,或者只是因为它可以帮助你完成工作。
|
||||
|
||||
无论你的原因是什么,只需尝试使用上面这些任何(或所有)这些方式。
|
||||
|
||||
@ -145,7 +145,7 @@ via: https://opensource.com/article/19/7/ways-get-started-linux
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11123-1.html)
|
||||
[#]: subject: (Command line quick tips: Permissions)
|
||||
[#]: via: (https://fedoramagazine.org/command-line-quick-tips-permissions/)
|
||||
[#]: author: (Paul W. Frields https://fedoramagazine.org/author/pfrields/)
|
||||
@ -12,37 +12,34 @@
|
||||
|
||||
![][1]
|
||||
|
||||
Fedora 与所有基于 Linux 的系统一样,它提供了一组强大的安全特性。其中一个基本特性是文件和文件夹上的 _权限_。这些权限保护文件和文件夹免受未经授权的访问。本文将简要介绍这些权限,并向你展示如何使用它们共享对文件夹的访问。
|
||||
Fedora 与所有基于 Linux 的系统一样,它提供了一组强大的安全特性。其中一个基本特性是文件和文件夹上的*权限*。这些权限保护文件和文件夹免受未经授权的访问。本文将简要介绍这些权限,并向你展示如何使用它们共享对文件夹的访问。
|
||||
|
||||
### 权限基础
|
||||
|
||||
Fedora 本质上是一个多用户操作系统,它也有 _组_,用户可以是其成员。但是,想象一下一个没有权限概念的多用户系统,不同的登录用户可以随意阅读彼此的内容。你可以想象到这对隐私或安全性并不是很好。
|
||||
Fedora 本质上是一个多用户操作系统,它也有*组*,用户可以是其成员。但是,想象一下一个没有权限概念的多用户系统,不同的登录用户可以随意阅读彼此的内容。你可以想象到这对隐私或安全性并不是很好。
|
||||
|
||||
Fedora 上的任何文件或文件夹都分配了三组权限。第一组用于拥有文件或文件夹的 _用户_,第二组用于拥有它的 _组_,第三组用于其他人,即不是该文件的用户或拥有该文件的组中的用户。有时这被称为 _world_。(to 校正:这个 world 没理解)
|
||||
Fedora 上的任何文件或文件夹都分配了三组权限。第一组用于拥有文件或文件夹的*用户*,第二组用于拥有它的*组*,第三组用于其他人,即既不是该文件的用户也不是拥有该文件的组中的用户。有时这被称为*全世界*。
|
||||
|
||||
### 权限意味着什么
|
||||
|
||||
每组权限都有三种形式:_读_,_写_ 和 _执行_。其中每个都可以用首字母来代替,即 _r_、_w_、_x_。
|
||||
每组权限都有三种形式:*读*、*写*和*执行*。其中每个都可以用首字母来代替,即 `r`、`w`、`x`。
|
||||
|
||||
#### 文件权限
|
||||
|
||||
对于 _文件_,权限的含义如下所示:
|
||||
对于*文件*,权限的含义如下所示:
|
||||
|
||||
* 读(r):可以读取文件内容
|
||||
* 读(`r`):可以读取文件内容
|
||||
* 写(`w`):可以更改文件内容
|
||||
* 执行(`x`):可以执行文件 —— 这主要用于打算直接运行的程序或脚本
|
||||
|
||||
* 写(w):可以更改文件内容
|
||||
|
||||
* 执行(x):可以执行文件 -- 这主要用于打算直接运行的程序或脚本
|
||||
|
||||
|
||||
当你对任何文件进行详细信息列表查看时,可以看到这三组权限。尝试查看系统上的 _/etc/services_ 文件:
|
||||
当你对任何文件进行详细信息列表查看时,可以看到这三组权限。尝试查看系统上的 `/etc/services` 文件:
|
||||
|
||||
```
|
||||
$ ls -l /etc/services
|
||||
-rw-r--r--. 1 root root 692241 Apr 9 03:47 /etc/services
|
||||
```
|
||||
|
||||
注意列表左侧的权限组。如上所述,这些表明三种用户的权限:拥有该文件的用户,拥有该文件的组以及其他人。用户所有者是 _root_,组所有者是 _root_ 组。用户所有者具有对文件的读写权限,_root_ 组中的任何人都只能读取该文件。最后,其他任何人也只能读取该文件。(最左边的破折号显示这是一个常规文件。)
|
||||
注意列表左侧的权限组。如上所述,这些表明三种用户的权限:拥有该文件的用户,拥有该文件的组以及其他人。用户所有者是 `root`,组所有者是 `root` 组。用户所有者具有对文件的读写权限,`root` 组中的任何人都只能读取该文件。最后,其他任何人也只能读取该文件。(最左边的 `-` 显示这是一个常规文件。)
|
||||
|
||||
顺便说一下,你通常会在许多(但不是所有)系统配置文件上发现这组权限,它们只由系统管理员而不是普通用户更改。通常,普通用户需要读取其内容。
|
||||
|
||||
@ -50,19 +47,18 @@ $ ls -l /etc/services
|
||||
|
||||
对于文件夹,权限的含义略有不同:
|
||||
|
||||
* 读(r):可以读取文件夹内容(例如 _ls_ 命令)
|
||||
* 写(w):可以更改文件夹内容(可以在此文件夹中创建或删除文件)
|
||||
* 执行(x):可以搜索文件夹,但无法读取其内容。(这听起来可能很奇怪,但解释起来需要更复杂的文件系统细节,这超出了本文的范围,所以现在就这样吧。)
|
||||
* 读(`r`):可以读取文件夹内容(例如 `ls` 命令)
|
||||
* 写(`w`):可以更改文件夹内容(可以在此文件夹中创建或删除文件)
|
||||
* 执行(`x`):可以搜索文件夹,但无法读取其内容。(这听起来可能很奇怪,但解释起来需要更复杂的文件系统细节,这超出了本文的范围,所以现在就这样吧。)
|
||||
|
||||
|
||||
看一下 _/etc/grub.d_ 文件夹的例子:
|
||||
看一下 `/etc/grub.d` 文件夹的例子:
|
||||
|
||||
```
|
||||
$ ls -ld /etc/grub.d
|
||||
drwx------. 2 root root 4096 May 23 16:28 /etc/grub.d
|
||||
```
|
||||
|
||||
注意最左边的 _d_,它显示这是一个目录或文件夹。权限显示用户所有者(_root_)可以读取、更改和 _cd_ 到此文件夹中。但是,没有其他人可以这样做 - 无论他们是否是 _root_ 组的成员。注意,你不能 _cd_ 进入该文件夹。
|
||||
注意最左边的 `d`,它显示这是一个目录或文件夹。权限显示用户所有者(`root`)可以读取、更改和 `cd` 到此文件夹中。但是,没有其他人可以这样做 —— 无论他们是否是 `root` 组的成员。注意,你不能 `cd` 进入该文件夹。
|
||||
|
||||
```
|
||||
$ cd /etc/grub.d
|
||||
@ -80,9 +76,9 @@ drwx------. 221 paul paul 28672 Jul 3 14:03 /home/paul
|
||||
|
||||
### 创建共享文件夹
|
||||
|
||||
你可以利用此权限功能轻松创建一个文件夹以在组内共享。假设你有一个名为 _finance_ 的小组,其中有几个成员需要共享文档。因为这些是用户文档,所以将它们存储在 _/home_ 文件夹层次结构中是个好主意。
|
||||
你可以利用此权限功能轻松创建一个文件夹以在组内共享。假设你有一个名为 `finance` 的小组,其中有几个成员需要共享文档。因为这些是用户文档,所以将它们存储在 `/home` 文件夹层次结构中是个好主意。
|
||||
|
||||
首先,[使用][2] _[sudo][2]_ 创建一个共享文件夹,并将其设置为 _finance_ 组所有:
|
||||
首先,[使用 sudo][2] 创建一个共享文件夹,并将其设置为 `finance` 组所有:
|
||||
|
||||
```
|
||||
$ sudo mkdir -p /home/shared/finance
|
||||
@ -95,13 +91,14 @@ $ sudo chgrp finance /home/shared/finance
|
||||
drwxr-xr-x. 2 root root 4096 Jul 6 15:35 finance
|
||||
```
|
||||
|
||||
对于金融数据来说,这似乎不是一个好主意。接下来,使用 _chmod_ 命令更改共享文件夹的模式(权限)。注意,使用 _g_ 更改所属组的权限,使用 _o_ 更改其他用户的权限。同样,_u_ 会更改用户所有者的权限:
|
||||
对于金融数据来说,这似乎不是一个好主意。接下来,使用 `chmod` 命令更改共享文件夹的模式(权限)。注意,使用 `g` 更改所属组的权限,使用 `o` 更改其他用户的权限。同样,`u` 会更改用户所有者的权限:
|
||||
|
||||
```
|
||||
$ sudo chmod g+w,o-rx /home/shared/finance
|
||||
```
|
||||
|
||||
生成的权限看起来更好。现在,_finance_ 组中的任何人(或用户所有者 _root_)都可以完全访问该文件夹及其内容:
|
||||
生成的权限看起来更好。现在,`finance` 组中的任何人(或用户所有者 `root`)都可以完全访问该文件夹及其内容:
|
||||
|
||||
```
|
||||
drwxrwx---. 2 root finance 4096 Jul 6 15:35 finance
|
||||
```
|
||||
@ -110,7 +107,7 @@ drwxrwx---. 2 root finance 4096 Jul 6 15:35 finance
|
||||
|
||||
### 其他说明
|
||||
|
||||
还有其他方法可以操作这些权限。例如,你可能希望将此文件夹中的任何文件设置为 _finance_ 组所拥有。这需要本文未涉及的其他设置,但请继续关注杂志,以了解关于该主题的更多信息。
|
||||
还有其他方法可以操作这些权限。例如,你可能希望将此文件夹中的任何文件设置为 `finance` 组所拥有。这需要本文未涉及的其他设置,但请继续关注我们,以了解关于该主题的更多信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -119,7 +116,7 @@ via: https://fedoramagazine.org/command-line-quick-tips-permissions/
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,18 +1,20 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11125-1.html)
|
||||
[#]: subject: (How to install Elasticsearch on MacOS)
|
||||
[#]: via: (https://opensource.com/article/19/7/installing-elasticsearch-macos)
|
||||
[#]: author: (Lauren Maffeo https://opensource.com/users/lmaffeo/users/don-watkins)
|
||||
|
||||
如何在 MacOS 上安装 Elasticsearch
|
||||
======
|
||||
安装 Elasticsearch 很复杂!以下是如何在 Mac 上安装。
|
||||
![magnifying glass on computer screen][1]
|
||||
|
||||
[Elasticsearch][2] 是一个用 Java 开发的开源全文搜索引擎。用户上传 JSON 格式的数据集。然后,Elasticsearch 在向集群索引中的文档添加可搜索引用之前保存原始文档。
|
||||
> 安装 Elasticsearch 很复杂!以下是如何在 Mac 上安装。
|
||||
|
||||

|
||||
|
||||
[Elasticsearch][2] 是一个用 Java 开发的开源全文搜索引擎。用户上传 JSON 格式的数据集。然后,Elasticsearch 在向集群索引中的文档添加可搜索的引用之前先保存原始文档。
|
||||
|
||||
Elasticsearch 创建还不到九年,但它是最受欢迎的企业搜索引擎。Elastic 在 2019 年 6 月 25 日发布了最新的更新版本 7.2.0。
|
||||
|
||||
@ -20,7 +22,7 @@ Elasticsearch 创建还不到九年,但它是最受欢迎的企业搜索引擎
|
||||
|
||||
[Sunbursts][4]、[地理空间数据地图][5]、[关系分析][6]和实时数据面板只是其中几个功能。并且由于 Elasticsearch 的机器学习能力,你可以了解哪些属性可能会影响你的数据(如服务器或 IP 地址)并查找异常模式。
|
||||
|
||||
在上个月的 [DevFest DC][7] 中,[Summer Rankin 博士][8],Booz Allen Hamilton 的首席数据科学家将 TED Talk 的内容数据集上传到了 Elasticsearch,然后使用 Kibana 快速构建了面板。出于好奇,几天后我去了 Elasticsearch 聚会。
|
||||
在上个月的 [DevFest DC][7] 中,Booz Allen Hamilton 的首席数据科学家 [Summer Rankin 博士][8]将 TED Talk 的内容数据集上传到了 Elasticsearch,然后使用 Kibana 快速构建了面板。出于好奇,几天后我去了一个 Elasticsearch 聚会。
|
||||
|
||||
由于本课程针对的是新手,因此我们从第一步开始:在我们的笔记本上安装 Elastic 和 Kibana。如果没有安装这两个包,我们无法将莎士比亚的文本数据集作为测试 JSON 文件创建可视化了。
|
||||
|
||||
@ -28,84 +30,72 @@ Elasticsearch 创建还不到九年,但它是最受欢迎的企业搜索引擎
|
||||
|
||||
### 下载适合 MacOS 的 Elasticsearch
|
||||
|
||||
1. 进入 <https://www.elastic.co/downloads/elasticsearch>,你会看到下面的页面:
|
||||
|
||||
|
||||
1、进入 <https://www.elastic.co/downloads/elasticsearch>,你会看到下面的页面:
|
||||
|
||||
![The Elasticsearch download page.][9]
|
||||
|
||||
2. 在**下载**栏,单击 **MacOS**,将 Elasticsearch TAR 文件(例如,**elasticsearch-7.1.1-darwin-x86_64.tar**)下载到 **Downloads** 文件夹。
|
||||
3. 双击此文件并解压到自己的文件夹中(例如,**elasticsearch-7.1.1**),这其中包含 TAR 中的所有文件。
|
||||
2、在**下载**区,单击 **MacOS**,将 Elasticsearch TAR 文件(例如,`elasticsearch-7.1.1-darwin-x86_64.tar`)下载到 `Downloads` 文件夹。
|
||||
|
||||
3、双击此文件并解压到自己的文件夹中(例如,`elasticsearch-7.1.1`),这其中包含 TAR 中的所有文件。
|
||||
|
||||
|
||||
|
||||
|
||||
**提示**:如果你希望 Elasticsearch 放在另一个文件夹中,现在可以移动。
|
||||
**提示**:如果你希望 Elasticsearch 放在另一个文件夹中,现在可以移动它。
|
||||
|
||||
### 在 MacOS 命令行中运行 Elasticsearch
|
||||
|
||||
如果你愿意,你可以只用命令行运行 Elasticsearch。只需遵循以下流程:
|
||||
|
||||
1. [打开**终端**窗口][10]。
|
||||
2. 在终端窗口中,输入你的 Elasticsearch 文件夹。例如(如果你移动了程序,请将 **Downloads** 更改为正确的路径):
|
||||
1、[打开终端窗口][10]。
|
||||
|
||||
2、在终端窗口中,输入你的 Elasticsearch 文件夹。例如(如果你移动了程序,请将 `Downloads` 更改为正确的路径):
|
||||
|
||||
**$ cd ~Downloads/elasticsearch-1.1.0**
|
||||
```
|
||||
$ cd ~Downloads/elasticsearch-1.1.0
|
||||
```
|
||||
|
||||
3. 切换到 Elasticsearch **bin** 子文件夹,然后启动该程序。例如:
|
||||
3、切换到 Elasticsearch 的 `bin` 子文件夹,然后启动该程序。例如:
|
||||
|
||||
|
||||
|
||||
**$ cd bin $ ./elasticsearch**
|
||||
```
|
||||
$ cd bin
|
||||
$ ./elasticsearch
|
||||
```
|
||||
|
||||
这是我启动 Elasticsearch 1.1.0 时命令行终端显示的一些输出:
|
||||
|
||||
![Terminal output when running Elasticsearch.][11]
|
||||
|
||||
**注意**:默认情况下,Elasticsearch 在前台运行,这可能会导致计算机速度变慢。按 **Ctrl-C** 可以阻止 Elasticsearch 运行。
|
||||
**注意**:默认情况下,Elasticsearch 在前台运行,这可能会导致计算机速度变慢。按 `Ctrl-C` 可以阻止 Elasticsearch 运行。
|
||||
|
||||
### 使用 GUI 运行 Elasticsearch
|
||||
|
||||
如果你更喜欢点击,你可以像这样运行 Elasticsearch:
|
||||
如果你更喜欢点击操作,你可以像这样运行 Elasticsearch:
|
||||
|
||||
1. 打开一个新的 **Finder** 窗口。
|
||||
2. 在左侧 Finder 栏中选择 **Downloads**(如果你将 Elasticsearch 移动了另一个文件夹,请进入它)。
|
||||
3. 打开名为 **elasticsearch-7.1.1** 的文件夹(对于此例)。出现了八个子文件夹。
|
||||
1、打开一个新的 **Finder** 窗口。
|
||||
|
||||
2、在左侧 Finder 栏中选择 `Downloads`(如果你将 Elasticsearch 移动了另一个文件夹,请进入它)。
|
||||
|
||||
3、打开名为 `elasticsearch-7.1.1` 的文件夹(对于此例)。出现了八个子文件夹。
|
||||
|
||||
![The elasticsearch/bin menu.][12]
|
||||
|
||||
4. 打开 **bin** 子文件夹。如上面的截图所示,此子文件夹中有 20 个文件。
|
||||
5. 单击第一个文件,即 **elasticsearch**。
|
||||
|
||||
|
||||
4、打开 `bin` 子文件夹。如上面的截图所示,此子文件夹中有 20 个文件。
|
||||
|
||||
5、单击第一个文件,即 `elasticsearch`。
|
||||
|
||||
请注意,你可能会收到安全警告,如下所示:
|
||||
|
||||
![The security warning dialog box.][13]
|
||||
|
||||
|
||||
这时候要打开程序需要:
|
||||
|
||||
这时候要打开程序:
|
||||
|
||||
1. 在警告对话框中单击 **OK**。
|
||||
2. 打开**系统偏好**。
|
||||
3. 单击**安全和隐私**,打开如下窗口:
|
||||
|
||||
|
||||
|
||||
![Where you can allow your computer to open the downloaded file.][14]
|
||||
|
||||
4. 单击**永远打开**,打开如下所示的确认对话框:
|
||||
|
||||
|
||||
|
||||
![Security confirmation dialog box.][15]
|
||||
|
||||
5. 单击**打开**。会打开一个终端窗口并启动 Elasticsearch。
|
||||
1. 在警告对话框中单击 **OK**。
|
||||
2. 打开**系统偏好**。
|
||||
3. 单击**安全和隐私**,打开如下窗口:
|
||||
|
||||
![Where you can allow your computer to open the downloaded file.][14]
|
||||
4. 单击**永远打开**,打开如下所示的确认对话框:
|
||||
|
||||
![Security confirmation dialog box.][15]
|
||||
5. 单击**打开**。会打开一个终端窗口并启动 Elasticsearch。
|
||||
|
||||
启动过程可能需要一段时间,所以让它继续运行。最终,它将完成,你最后将看到类似这样的输出:
|
||||
|
||||
@ -115,7 +105,7 @@ Elasticsearch 创建还不到九年,但它是最受欢迎的企业搜索引擎
|
||||
|
||||
安装 Elasticsearch 之后,就可以开始探索了!
|
||||
|
||||
该工具的 [Elasticsearch:开始使用][17]指南会根据你的目标指导你。它的介绍视频介绍了在 [Elasticsearch Service][18] 上启动托管集群,执行基本搜索查询,通过创建,读取,更新和删除(CRUD)REST API等方式操作数据的步骤。
|
||||
该工具的 [Elasticsearch:开始使用][17]指南会根据你的目标指导你。它的介绍视频介绍了在 [Elasticsearch Service][18] 上启动托管集群,执行基本搜索查询,通过创建、读取、更新和删除(CRUD)REST API 等方式操作数据的步骤。
|
||||
|
||||
本指南还提供文档链接,开发控制台命令,培训订阅以及 Elasticsearch Service 的免费试用版。此试用版允许你在 AWS 和 GCP 上部署 Elastic 和 Kibana 以支持云中的 Elastic 集群。
|
||||
|
||||
@ -128,7 +118,7 @@ via: https://opensource.com/article/19/7/installing-elasticsearch-macos
|
||||
作者:[Lauren Maffeo][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,149 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11142-1.html)
|
||||
[#]: subject: (Type Linux Commands In Capital Letters To Run Them As Sudo User)
|
||||
[#]: via: (https://www.ostechnix.com/type-linux-commands-in-capital-letters-to-run-them-as-sudo-user/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
用大写字母输入 Linux 命令以将其作为 sudo 用户运行
|
||||
======
|
||||
|
||||
![Type Linux Commands In Capital Letters To Run Them As Sudo User][1]
|
||||
|
||||
我非常喜欢 Linux 社区的原因是他们创建了很多有趣的项目,你很少能在任何其他操作系统中找到它们。不久前,我们看了一个名为 [Hollywood][2] 的有趣项目,它在类 Ubuntu 系统将终端变成了好莱坞技术情景剧的黑客界面。还有一些其他工具,例如 `cowsay`、`fortune`、`sl` 和 `toilet` 等,用来消磨时间自娱自乐!它们可能没有用,但这些程序娱乐性不错并且使用起来很有趣。今天,我偶然发现了另一个名为 `SUDO` 的类似工具。正如名字暗示的那样,你无论何时用大写字母输入 Linux 命令,`SUDO` 程序都会将它们作为 sudo 用户运行!这意味着,你无需在要运行的 Linux 命令前面输入 `sudo`。很酷,不是么?
|
||||
|
||||
### 安装 SUDO
|
||||
|
||||
> 提醒一句:
|
||||
|
||||
> 在安装这个程序(或任何程序)之前,请查看源代码(最后给出的链接),并查看是否包含会损害你的系统的可疑/恶意代码。在 VM 中测试它。如果你喜欢或觉得它很有用,你可以在个人/生产系统中使用它。
|
||||
|
||||
用 Git 克隆 `SUDO` 仓库:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/jthistle/SUDO.git
|
||||
```
|
||||
|
||||
此命令将克隆 SUDO GIT 仓库的内容,并将它们保存在当前目录下的 `SUDO` 的目录中。
|
||||
|
||||
```
|
||||
Cloning into 'SUDO'...
|
||||
remote: Enumerating objects: 42, done.
|
||||
remote: Counting objects: 100% (42/42), done.
|
||||
remote: Compressing objects: 100% (29/29), done.
|
||||
remote: Total 42 (delta 17), reused 30 (delta 12), pack-reused 0
|
||||
Unpacking objects: 100% (42/42), done.
|
||||
```
|
||||
|
||||
切换到 `SUDO` 目录:
|
||||
|
||||
```
|
||||
$ cd SUDO/
|
||||
```
|
||||
|
||||
并使用命令安装它:
|
||||
|
||||
```
|
||||
$ ./install.sh
|
||||
```
|
||||
|
||||
该命令将在 `~/.bashrc` 文件中添加以下行:
|
||||
|
||||
```
|
||||
[...]
|
||||
# SUDO - shout at bash to su commands
|
||||
# Distributed under GNU GPLv2, @jthistle on github
|
||||
|
||||
shopt -s expand_aliases
|
||||
|
||||
IFS_=${IFS}
|
||||
IFS=":" read -ra PATHS <<< "$PATH"
|
||||
|
||||
for i in "${PATHS[@]}"; do
|
||||
for j in $( ls "$i" ); do
|
||||
if [ ${j^^} != $j ] && [ $j != "sudo" ]; then
|
||||
alias ${j^^}="sudo $j"
|
||||
fi
|
||||
done
|
||||
done
|
||||
|
||||
alias SUDO='sudo $(history -p !!)'
|
||||
|
||||
IFS=${IFS_}
|
||||
|
||||
# end SUDO
|
||||
```
|
||||
|
||||
它还会备份你的 `~/.bashrc` 并将其保存为 `~/.bashrc.old`。如果有重大错误,你可以恢复它。
|
||||
|
||||
最后,使用命令更新更改:
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
### 现在,用大写字母中输入 Linux 命令,将它们作为 Sudo 用户运行
|
||||
|
||||
通常我们像下面那样执行需要 sudo/root 权限的命令。
|
||||
|
||||
```
|
||||
$ sudo mkdir /ostechnix
|
||||
```
|
||||
|
||||
对么?没错!上面的命令将在根目录(`/`)中创建名为 `ostechnix` 的目录。让我们使用 `Ctrl + c` 取消。
|
||||
|
||||
一旦安装了 `SUDO`,你就可以**在不使用 sudo 的情况下输入任何大写 Linux 命令**并运行它们。因此,你可以像下面那样运行上面的命令:
|
||||
|
||||
```
|
||||
$ MKDIR /ostechnix
|
||||
$ TOUCH /ostechnix/test.txt
|
||||
$ LS /ostechnix
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
用大写字母输入 Linux 命令以将其作为 sudo 用户运行
|
||||
|
||||
请注意**它无法绕过 sudo 密码**。你仍然需要键入 `sudo` 密码才能执行给定的命令。它只会有助于避免在每个命令前面输入 `sudo`。
|
||||
|
||||
相关阅读:
|
||||
|
||||
* [如何在 Linux 中没有 sudo 密码运行特定命令][4]
|
||||
* [如何恢复用户的 sudo 权限][5]
|
||||
* [如何在 Ubuntu 上为用户授予和删除 sudo 权限][6]
|
||||
* [如何在 Linux 系统中查找所有 sudo 用户][7]
|
||||
* [如何在终端中输入密码时显示星号][8]
|
||||
* [如何更改 Linux 中的 sudo 提示符][9]
|
||||
|
||||
|
||||
当然,输入 `sudo` 只需几秒钟,所以这不是什么大问题。 我必须告诉这是一个用来消磨时间的有趣且无用的项目。 如果你不喜欢它,那就去学习一些有用的东西吧。 如果你喜欢它,试一试,玩得开心!
|
||||
|
||||
资源:
|
||||
|
||||
* [SUDO GitHub 仓库][10]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/type-linux-commands-in-capital-letters-to-run-them-as-sudo-user/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/07/sudo-720x340.png
|
||||
[2]: https://www.ostechnix.com/turn-ubuntu-terminal-hollywood-technical-melodrama-hacker-interface/
|
||||
[3]: https://www.ostechnix.com/wp-content/uploads/2019/07/SUDO-in-action.gif
|
||||
[4]: https://www.ostechnix.com/run-particular-commands-without-sudo-password-linux/
|
||||
[5]: https://www.ostechnix.com/how-to-restore-sudo-privileges-to-a-user/
|
||||
[6]: https://www.ostechnix.com/how-to-grant-and-remove-sudo-privileges-to-users-on-ubuntu/
|
||||
[7]: https://www.ostechnix.com/find-sudo-users-linux-system/
|
||||
[8]: https://www.ostechnix.com/display-asterisks-type-password-terminal/
|
||||
[9]: https://www.ostechnix.com/change-sudo-prompt-linux-unix/
|
||||
[10]: https://github.com/jthistle/SUDO
|
||||
78
published/201907/20190712 MTTR is dead, long live CIRT.md
Normal file
78
published/201907/20190712 MTTR is dead, long live CIRT.md
Normal file
@ -0,0 +1,78 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11155-1.html)
|
||||
[#]: subject: (MTTR is dead, long live CIRT)
|
||||
[#]: via: (https://opensource.com/article/19/7/measure-operational-performance)
|
||||
[#]: author: (Julie Gunderson https://opensource.com/users/juliegund/users/kearnsjd/users/ophir)
|
||||
|
||||
MTTR 已死,CIRT 长存
|
||||
======
|
||||
|
||||
> 通过关注影响业务的事件,CIRT 是衡量运维绩效的更准确方法。
|
||||
|
||||
![Green graph of measurements][1]
|
||||
|
||||
IT 运维圈子的玩法正在发生变化,这意味着过去的规则越来越不合理。机构需要适当环境中的准确的、可理解的、且可操作的指标,以衡量运维绩效并推动关键业务转型。
|
||||
|
||||
越多的客户使用现代工具,他们管理的事件类型的变化越多,将所有这些不同事件粉碎到一个桶中以计算平均解决时间来表示运维绩效的意义就越少,这就是 IT 一直以来在做的事情。
|
||||
|
||||
### 历史与指标
|
||||
|
||||
历史表明,在分析信号以防止错误和误解时,背景信息是关键。例如,在 20 世纪 80 年代,瑞典建立了一个分析水听器信号的系统,以提醒他们在瑞典当地水域出现的俄罗斯潜艇。瑞典人使用了他们认为代表一类俄罗斯潜艇的声学特征 —— 但实际上是鲱鱼在遇到潜在捕食者时释放的[气泡声][2]。这种对指标的误解加剧了各国之间的紧张关系,几乎导致了战争。
|
||||
|
||||
![Funny fish cartoon][3]
|
||||
|
||||
<ruby>平均解决时间<rt>Mean Time To Resolve</rt></ruby>(MTTR)是运维经理用于获得实现目标洞察力的主要运维绩效指标。这是一项基于<ruby>系统可靠性工程<rt>systems reliability engineering</rt></ruby>的古老措施。MTTR 已被许多行业采用,包括制造、设施维护以及最近的 IT 运维,它代表了解决在特定时间段内创建的事件所需的平均时间。
|
||||
|
||||
MTTR 的计算方法是将所有事件(从事件创建时间到解决时间)所需的时间除以事件总数。
|
||||
|
||||
![MTTR formula][4]
|
||||
|
||||
正如它所说的,MTTR 是 **所有** 事件的平均值。MTTR 将高紧急事件和低紧急事件混为一谈。它还会重复计算每个单独的、未分组的事件,并得出有效的解决时间。它包括了在相同上下文中手动解决和自动解决的事件。它将在创建了几天(或几个月)甚至完全被忽略的事件混合在一起。最后,MTTR 包括每个小的瞬态突发事件(在 120 秒内自动关闭的事件),这些突发事件要么是非问题噪音,要么已由机器快速解决。
|
||||
|
||||
![Variability in incident types][5]
|
||||
|
||||
MTTR 将所有事件(无论何种类型)抛入一个桶中,将它们全部混合在一起,并计算整个集合中的“平均”解决时间。这种过于简单化的方法导致运维执行方式的的噪音、错误和误导性指示。
|
||||
|
||||
### 一种衡量绩效的新方法
|
||||
|
||||
<ruby>关键事件响应时间<rt>Critical Incident Response Time</rt></ruby>(CIRT)是评估运维绩效的一种更准确的新方法。PagerDuty 创立了 CIRT 的概念,但该方法可供所有人免费使用。
|
||||
|
||||
CIRT 通过使用以下技术剔除来自信号的噪声,其重点关注最有可能影响业务的事件:
|
||||
|
||||
1. 真正影响(或可能影响)业务的事件很少是低紧急事件,因此要排除所有低紧急事件。
|
||||
2. 真正影响业务的事件很少(如果有的话)可以无需人为干预而通过监控工具自动解决,因此要排除未由人工解决的事件。
|
||||
3. 在 120 秒内解决的短暂、爆发性和瞬态事件几乎不可能是真正影响业务的事件,因此要排除它们。
|
||||
4. 长时间未被注意、提交或忽略(未确认、未解决)的事件很少会对业务造成影响;排除它们。注意:此阈值可以是特定于客户的统计推导数字(例如,高于均值的两个标准差),以避免使用任意数字。
|
||||
5. 由单独警报产生的个别未分组事件并不代表较大的业务影响事件。因此,模拟具有非常保守的阈值(例如,两分钟)的事件分组以计算响应时间。
|
||||
|
||||
应用这些假设对响应时间有什么影响?简而言之,效果非常非常大!
|
||||
|
||||
通过在关键的、影响业务的事件中关注运维绩效,解决时间分布变窄并极大地向左偏移,因为现在它处理类似类型的事件而不是所有事件。
|
||||
|
||||
由于 MTTR 计算的响应时间长得多、人为地偏差,因此它是运维绩效较差的一个指标。另一方面,CIRT 是一项有意的措施,专注于对业务最重要的事件。
|
||||
|
||||
与 CIRT 一起使用的另一个关键措施是确认和解决事故的百分比。这很重要,因为它验证 CIRT(或 MTTA / MTTR)是否值得利用。例如,如果 MTTR 结果很低,比如 10 分钟,那听起来不错,但如果只有 42% 的事件得到解决,那么 MTTR 是可疑的。
|
||||
|
||||
总之,CIRT 和确认、解决事件的百分比形成了一组有价值的指标,可以让你更好地了解运营的执行情况。衡量绩效是提高绩效的第一步,因此这些新措施对于实现机构的可持续、可衡量的改进周期至关重要。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/measure-operational-performance
|
||||
|
||||
作者:[Julie Gunderson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/juliegund/users/kearnsjd/users/ophir
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_lead-steps-measure.png?itok=DG7rFZPk (Green graph of measurements)
|
||||
[2]: http://blogfishx.blogspot.com/2014/05/herring-fart-to-communicate.html
|
||||
[3]: https://opensource.com/sites/default/files/uploads/fish.png (Funny fish cartoon)
|
||||
[4]: https://opensource.com/sites/default/files/uploads/mttr.png (MTTR formula)
|
||||
[5]: https://opensource.com/sites/default/files/uploads/incidents.png (Variability in incident types)
|
||||
@ -0,0 +1,106 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11128-1.html)
|
||||
[#]: subject: (ElectronMail – a Desktop Client for ProtonMail and Tutanota)
|
||||
[#]: via: (https://itsfoss.com/electronmail/)
|
||||
[#]: author: (John Paul https://itsfoss.com/author/john/)
|
||||
|
||||
ElectronMail:ProtonMail 和 Tutanota 的桌面客户端
|
||||
======
|
||||
|
||||
互联网上的大多数人都拥有来自 Google 等大公司的电子邮件帐户,但这些帐户不尊重你的隐私。值得庆幸的是,目前有 [Tutanota][1] 和 [ProtonMail][2] 等具有隐私意识的替代品。问题是并非所有人都有桌面客户端。今天,我们将研究一个为你解决该问题的项目。我们来看看 ElectronMail 吧。
|
||||
|
||||
> ‘Electron’ 警告!
|
||||
|
||||
> 以下应用是使用 Electron 构建的(也就是名为 ElectronMail 的原因之一)。如果使用 Electron 让你感到不安,请将此视为触发警告。
|
||||
|
||||
### ElectronMail:Tutanota 和 ProtonMail 的桌面客户端
|
||||
|
||||
![Electron Mail About][3]
|
||||
|
||||
[ElectronMail][4] 可以简单地视作 ProtonMail 和 Tutanota 的电子邮件客户端。它使用三大技术构建:[Electron][5]、[TypeScript][6] 和 [Angular][7]。它包括以下功能:
|
||||
|
||||
* 针对每个电子邮件提供商提供多帐户支持
|
||||
* 加密本地存储
|
||||
* 适用于 Linux、Windows、macOS 和 FreeBSD
|
||||
* 原生通知系统
|
||||
* 带有未读消息总数的系统托盘图标
|
||||
* 用主密码保护帐户信息
|
||||
* 可切换的视图布局
|
||||
* 可离线访问电子邮件
|
||||
* 电子邮件在本地加密存储
|
||||
* 批量导出电子邮件为 EML 文件
|
||||
* 全文搜索
|
||||
* 内置/预打包的 Web 客户端
|
||||
* 可以为每个帐户配置代理
|
||||
* 拼写检查
|
||||
* 支持双因素身份验证,以提高安全性
|
||||
|
||||
目前,ElectronMail 仅支持 Tutanota 和 ProtonMail。我觉得他们将来会增加更多。根据 [GitHub 页面][4]:“多电子邮件提供商支持。目前支持 ProtonMail 和 Tutanota。”
|
||||
|
||||
ElectronMail 目前是 MIT 许可证。
|
||||
|
||||
#### 如何安装 ElectronMail
|
||||
|
||||
目前,有几种方法可以在 Linux 上安装 ElectronMail。对于Arch 和基于 Arch 的发行版,你可以从[Arch 用户仓库][8]安装它。ElectrionMail 还有一个 Snap 包。要安装它,只需输入 `sudo snap install electron-mail` 即可。
|
||||
|
||||
对于所有其他 Linux 发行版,你可以[下载][9] `.deb` 或 `.rpm` 文件。
|
||||
|
||||
![Electron Mail Inbox][10]
|
||||
|
||||
你也可以[下载][9]用于 Windows 中的 `.exe` 安装程序或用于 macOS 的 `.dmg` 文件。甚至还有给 FreeBSD 用的文件。
|
||||
|
||||
#### 删除 ElectronMail
|
||||
|
||||
如果你安装了 ElectronMail 并确定它不适合你,那么[开发者][12]建议采用几个步骤。 **在卸载应用之前,请务必遵循以下步骤。**
|
||||
|
||||
如果你使用了“保持登录”功能,请单击菜单上的“注销”。这将删除本地保存的主密码。卸载 ElectronMail 后也可以删除主密码,但这涉及编辑系统密钥链。
|
||||
|
||||
你还需要手动删除设置文件夹。在系统托盘中选择应用图标后,单击“打开设置文件夹”可以找到它。
|
||||
|
||||
![Electron Mail Setting][13]
|
||||
|
||||
### 我对 ElectronMail 的看法
|
||||
|
||||
我通常不使用电子邮件客户端。事实上,我主要依赖于 Web 客户端。所以,这个应用对我没太大用处。
|
||||
|
||||
话虽这么说,但是 ElectronMail 看着不错,而且很容易设置。它有大量开箱即用的功能,并且高级功能并不难使用。
|
||||
|
||||
我遇到的一个问题与搜索有关。根据功能列表,ElectronMail 支持全文搜索。但是,Tutanota 的免费版本仅支持有限的搜索。我想知道 ElectronMail 如何处理这个问题。
|
||||
|
||||
最后,ElectronMail 只是一个基于 Web Email 的一个 Electron 封装。我宁愿在浏览器中打开它们,而不是将单独的系统资源用于运行 Electron。如果你只[使用 Tutanota,他们有自己官方的 Electron 桌面客户端][14]。你可以尝试一下。
|
||||
|
||||
我最大的问题是安全性。这是两个非常安全的电子邮件应用的非官方应用。如果有办法捕获你的登录信息或阅读你的电子邮件怎么办?比我聪明的人必须通过源代码才能确定。这始终是一个安全项目的非官方应用的问题。
|
||||
|
||||
你有没有使用过 ElectronMail?你认为是否值得安装 ElectronMail?你最喜欢的邮件客户端是什么?请在下面的评论中告诉我们。
|
||||
|
||||
如果你发现这篇文章很有趣,请花一点时间在社交媒体、Hacker News 或 [Reddit][15] 上分享它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/electronmail/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/tutanota-review/
|
||||
[2]: https://itsfoss.com/protonmail/
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/electron-mail-about.jpg?resize=800%2C500&ssl=1
|
||||
[4]: https://github.com/vladimiry/ElectronMail
|
||||
[5]: https://electronjs.org/
|
||||
[6]: http://www.typescriptlang.org/
|
||||
[7]: https://angular.io/
|
||||
[8]: https://aur.archlinux.org/packages/electronmail-bin
|
||||
[9]: https://github.com/vladimiry/ElectronMail/releases
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/electron-mail-inbox.jpg?ssl=1
|
||||
[12]: https://github.com/vladimiry
|
||||
[14]: https://linux.cn/article-10688-1.html
|
||||
[15]: http://reddit.com/r/linuxusersgroup
|
||||
@ -0,0 +1,72 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (heguangzhi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11130-1.html)
|
||||
[#]: subject: (Become a lifelong learner and succeed at work)
|
||||
[#]: via: (https://opensource.com/open-organization/19/7/informal-learning-adaptability)
|
||||
[#]: author: (Colin Willis https://opensource.com/users/colinwillishttps://opensource.com/users/marcobravo)
|
||||
|
||||
|
||||
成为终身学习者,并在工作中取得成功
|
||||
======
|
||||
|
||||
> 在具有适应性文化的开放组织中,学习应该一直持续 —— 但不会总是出现在正式场合。我们真的明白它是如何工作的吗?
|
||||
|
||||
![Writing in a notebook][1]
|
||||
|
||||
持续学习是指人们为发展自己而进行的持续的、职业驱动的、有意识的学习过程。对于那些自认是持续学习者的人来说,学习从未停止 —— 这些人从日常经历中看到学习机会。与同事进行辩论、反思反馈、在互联网上寻找问题的解决方案、尝试新事物或冒险都是一个人在工作中可以进行的非正式学习活动的例子。
|
||||
|
||||
持续学习是开放组织中任何人的核心能力。毕竟,开放的组织是建立在同行相互思考、争论和行动的基础上的。在开放组织的模棱两可、话语驱动的世界中茁壮成长,每天都需要员工具备这些技能。
|
||||
|
||||
不幸的是,科学文献在传播我们在工作中学习的知识方面、帮助个人欣赏和发展自己的学习能力方面,做得很差。因此,在本文系列中,我将向你介绍非正式学习,并帮助你理解将学习视为一种技能会如何帮助你在任何组织中茁壮成长,尤其是在开放式组织中。
|
||||
|
||||
### 为什么这么正式?
|
||||
|
||||
迄今为止,对组织中学习的科学研究主要集中在正式学习而不是非正式学习的设计、交付和评估上。
|
||||
|
||||
投资于员工知识、技能和能力的发展是一个组织保持其相对于竞争对手优势的重要方式。组织通过创建或购买课程、在线课程、研讨会等来使学习机会正规化。这些课程旨在像个人传授与工作相关的内容,就像学校里的班级一样。对于一个组织来说,提供一门课程是一种简单(如果成本高昂的话)的方法,可以确保其员工的技能或知识保持最新。同样,教室环境是研究人员的天然实验室,使得基于培训的研究和工作不仅可能,而且强大。
|
||||
|
||||
当然,有些东西人们不需要培训来学习;通常,人们通过研究答案、与同事交谈、思考、实验或适应变化来学习。事实上,[最近的评估表明][2] 70% 到 80% 的与工作相关的知识不是在培训中学到的,而是在工作中非正式学到的。这并不是说正规的培训无效;培训可能非常有效,但它是一种精确的干预方式。在工作的大部分方面正式培训一个人是不现实的,尤其是当这些工作变得更加复杂的时候。
|
||||
|
||||
因此,非正式学习,或者任何发生在结构化学习环境之外的学习,对工作场所来说是极其重要的。事实上,[最近的科学证据][3]表明,非正式学习比正式培训更能预测工作表现。
|
||||
|
||||
那么,为什么机构和科学界如此关注培训呢?
|
||||
|
||||
### 循环过程
|
||||
|
||||
除了我前面提到的原因,研究非正式学习可能非常困难。与正式学习不同,非正式学习发生在非结构化环境中,高度依赖于个人,很难或不可能观察到。
|
||||
|
||||
直到最近,大多数关于非正式学习的研究都集中在定义非正式学习的合格特征和确定非正式学习在理论上是如何与工作经验联系在一起的。研究人员描述了一个[动态的周期性过程][4],通过这个过程,个人可以在组织中非正式地学习。
|
||||
|
||||
与正式学习一样,非正式学习发生在非结构化环境中,高度依赖于个人,很难或不可能观察。
|
||||
|
||||
在这个过程中,个人和组织都有创造学习机会的机构。例如,一个人可能对学习某样东西感兴趣,并为此表现出学习行为。组织以向个人提供反馈的形式,可能表明需要学习。这可能是一个糟糕的绩效评估、一个在项目中发表的评论、或者一个不是个人指导的组织环境的更广泛的变化。这些力量在组织环境中(例如,有人尝试了一个新想法,他或她的同事认识到并奖励了这种行为)或者通过在个人的头脑中反思(例如,有人反思了关于他或她的表现的,并决定在学习工作中付出更多的努力)。与培训不同,非正式学习不遵循正式的线性过程。个人可以随时体验过程的任何部分,同时体验过程的多个部分。
|
||||
|
||||
### 开放组织中的非正式学习
|
||||
|
||||
具体而言,在开放组织中,既减少了对等级制度的重视程度,又更加注重对参与式文化的重视程度,这两者都推动了这种非正式的学习。简而言之,开放式组织只是为个人和组织环境提供了更多互动和激发学习的机会。此外,想法和变革需要开放式组织中员工给予更广泛的认同 —— 而认同需要对他人的适应性和洞察力的欣赏。
|
||||
|
||||
也就是说,仅仅增加学习机会并不能保证学习会发生或成功。有人甚至可能会说,开放式组织中常见的模糊性和公开性话语可能会阻止不擅长持续学习的人——同样,随着时间的推移学习的习惯和开放式组织的核心能力——尽可能有效地为组织做出贡献。
|
||||
|
||||
解决这些问题需要一种以一致的方式跟踪非正式学习。最近,科学界呼吁创造衡量非正式学习的方法,这样就可以进行系统的研究来解决非正式学习的前因后果的问题。我自己的研究集中在这一呼吁上,我花了几年时间发展和完善我们对非正式学习行为的理解,以便可以衡量它们。
|
||||
|
||||
在本文系列的第二部分,我将重点介绍我最近在一个开放式组织中进行的一项研究的成果,在该研究中,我测试了我对非正式学习行为的研究,并将它们与更广泛的工作环境和个人工作成果联系起来。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/19/7/informal-learning-adaptability
|
||||
|
||||
作者:[Colin Willis][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/colinwillishttps://opensource.com/users/marcobravo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/notebook-writing-pen.jpg?itok=uA3dCfu_ (Writing in a notebook)
|
||||
[2]: https://www.groupoe.com/images/Accelerating_On-the-Job-Learning_-_White_Paper.pdf
|
||||
[3]: https://www.researchgate.net/publication/316490244_Antecedents_and_Outcomes_of_Informal_Learning_Behaviors_a_Meta-Analysis
|
||||
[4]: https://psycnet.apa.org/record/2008-13469-009
|
||||
128
published/201907/20190716 Save and load Python data with JSON.md
Normal file
128
published/201907/20190716 Save and load Python data with JSON.md
Normal file
@ -0,0 +1,128 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11133-1.html)
|
||||
[#]: subject: (Save and load Python data with JSON)
|
||||
[#]: via: (https://opensource.com/article/19/7/save-and-load-data-python-json)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
使用 Python 处理 JSON 格式的数据
|
||||
======
|
||||
|
||||
> 如果你不希望从头开始创造一种数据格式来存放数据,JSON 是一个很好的选择。如果你对 Python 有所了解,就更加事半功倍了。下面就来介绍一下如何使用 Python 处理 JSON 数据。
|
||||
|
||||
![Cloud and databsae incons][1]
|
||||
|
||||
[JSON][2] 的全称是 <ruby>JavaScript 对象表示法<rt>JavaScript Object Notation</rt></ruby>。这是一种以键值对的形式存储数据的格式,并且很容易解析,因而成为了一种被广泛使用的数据格式。另外,不要因为 JSON 名称而望文生义,JSON 并不仅仅在 JavaScript 中使用,它也可以在其它语言中使用。下文会介绍它是如何在 Python 中使用的。
|
||||
|
||||
首先我们给出一个 JSON 示例:
|
||||
|
||||
```
|
||||
{
|
||||
"name":"tux",
|
||||
"health":"23",
|
||||
"level":"4"
|
||||
}
|
||||
```
|
||||
|
||||
上面是一个和编程语言无关的原生 JSON 数据。熟悉 Python 的人会看出来这个 JSON 数据跟 Python 中的<ruby>字典<rt>dictionary</rt></ruby>长得很像。而这两者之间确实非常相似,如果你对 Python 中的列表和字典数据结构有一定的理解,那么 JSON 理解起来也不难。
|
||||
|
||||
### 使用字典存放数据
|
||||
|
||||
如果你的应用需要存储一些结构复杂的数据,不妨考虑使用 JSON 格式。对比你可能曾经用过的自定义格式的文本配置文件,JSON 提供了更加结构化的可递归的存储格式。同时,Python 自带的 `json` 模块已经提供了可以将 JSON 数据导入/导出应用时所需的所有解析库。因此,你不需要针对 JSON 自行编写代码进行解析,而其他开发人员在与你的应用进行数据交互的时候也不需要去解析新的数据格式。正是这个原因,JSON 在数据交换时被广泛地采用了。
|
||||
|
||||
以下是一段在 Python 中使用嵌套字典的代码:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import json
|
||||
|
||||
# instantiate an empty dict
|
||||
team = {}
|
||||
|
||||
# add a team member
|
||||
team['tux'] = {'health': 23, 'level': 4}
|
||||
team['beastie'] = {'health': 13, 'level': 6}
|
||||
team['konqi'] = {'health': 18, 'level': 7}
|
||||
```
|
||||
|
||||
这段代码声明了一个名为 `team` 的字典,并初始化为一个空字典。
|
||||
|
||||
如果要给这个字典添加内容,首先需要创建一个键,例如上面示例中的 `tux`、`beastie`、`konqi`,然后为这些键一一提供对应的值。上面示例中的值由一个个包含游戏玩家信息的字典充当。
|
||||
|
||||
字典是一种可变的变量。字典中的数据可以随时添加、删除或更新。这样的特性使得字典成为了应用程序存储数据的极好选择。
|
||||
|
||||
### 使用 JSON 格式存储数据
|
||||
|
||||
如果存放在字典中的数据需要持久存储,这些数据就需要写到文件当中。这个时候就需要用到 Python 中的 `json` 模块了:
|
||||
|
||||
```
|
||||
with open('mydata.json', 'w') as f:
|
||||
json.dump(team, f)
|
||||
```
|
||||
|
||||
上面的代码首先创建了一个名为 `mydata.json` 的文件,然后以写模式打开了这个文件,这个被打开的文件以变量 `f` 表示(当然也可以用任何你喜欢的名称,例如 `file`、`output` 等)。而 `json` 模块中的 `dump()` 方法则是用于将一个字典输出到一个文件中。
|
||||
|
||||
从应用中导出数据就是这么简单,同时这些导出的数据是结构化的、可理解的。现在可以查看导出的数据:
|
||||
|
||||
```
|
||||
$ cat mydata.json
|
||||
{"tux": {"health": 23, "level": 4}, "beastie": {"health": 13, "level": 6}, "konqi": {"health": 18, "level": 7}}
|
||||
```
|
||||
|
||||
### 从 JSON 文件中读取数据
|
||||
|
||||
如果已经将数据以 JSON 格式导出到文件中了,也有可能需要将这些数据读回到应用中去。这个时候,可以使用 Python `json` 模块中的 `load()` 方法:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import json
|
||||
|
||||
f = open('mydata.json')
|
||||
team = json.load(f)
|
||||
|
||||
print(team['tux'])
|
||||
print(team['tux']['health'])
|
||||
print(team['tux']['level'])
|
||||
|
||||
print(team['beastie'])
|
||||
print(team['beastie']['health'])
|
||||
print(team['beastie']['level'])
|
||||
|
||||
# when finished, close the file
|
||||
f.close()
|
||||
```
|
||||
|
||||
这个方法实现了和保存文件大致相反的操作。使用一个变量 `f` 来表示打开了的文件,然后使用 `json` 模块中的 `load()` 方法读取文件中的数据并存放到 `team` 变量中。
|
||||
|
||||
其中的 `print()` 展示了如何查看读取到的数据。在过于复杂的字典中迭代调用字典键的时候有可能会稍微转不过弯来,但只要熟悉整个数据的结构,就可以慢慢摸索出其中的逻辑。
|
||||
|
||||
当然,这里使用 `print()` 的方式太不灵活了。你可以将其改写成使用 `for` 循环的形式:
|
||||
|
||||
```
|
||||
for i in team.values():
|
||||
print(i)
|
||||
```
|
||||
|
||||
### 使用 JSON
|
||||
|
||||
如上所述,在 Python 中可以很轻松地处理 JSON 数据。因此只要你的数据符合 JSON 的模式,就可以选择使用 JSON。JSON 非常灵活易用,下次使用 Python 的时候不妨尝试一下。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/save-and-load-data-python-json
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/bus_cloud_database.png?itok=lhhU42fg (Cloud and databsae incons)
|
||||
[2]: https://json.org
|
||||
@ -0,0 +1,126 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11149-1.html)
|
||||
[#]: subject: (Bond WiFi and Ethernet for easier networking mobility)
|
||||
[#]: via: (https://fedoramagazine.org/bond-wifi-and-ethernet-for-easier-networking-mobility/)
|
||||
[#]: author: (Ben Cotton https://fedoramagazine.org/author/bcotton/)
|
||||
|
||||
绑定 WiFi 和以太网,以使网络间移动更轻松
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
有时一个网络接口是不够的。网络绑定允许将多条网络连接与单个逻辑接口一起工作。你可能因为需要给单条连接更多的带宽而这么做,或者你可能希望在有线和无线网络之间来回切换而不会丢失网络连接。
|
||||
|
||||
我是后面一种情况。在家工作的好处之一是,当天气晴朗时,在阳光明媚的阳台而不是在室内工作是很愉快的。但每当我这样做时,我都会失去网络连接。IRC、SSH、VPN,一切都断开了,客户端重连至少需要一会。本文介绍了如何在 Fedora 30 笔记本上设置网络绑定,以便从笔记本扩展坞的有线连接无缝切换到 WiFi。
|
||||
|
||||
在 Linux 中,接口绑定由内核模块 `bonding` 处理。默认情况下,Fedora 没有启用此功能,但它包含在 `kernel-core` 软件包中。这意味着启用接口绑定只需一个命令:
|
||||
|
||||
```
|
||||
sudo modprobe bonding
|
||||
```
|
||||
|
||||
请注意,这只会在你重启之前生效。要永久启用接口绑定,请在 `/etc/modules-load.d` 目录中创建一个名为 `bonding.conf` 的文件,该文件仅包含单词 `bonding`。
|
||||
|
||||
现在你已启用绑定,现在可以创建绑定接口了。首先,你必须获取要绑定的接口的名称。要列出可用的接口,请运行:
|
||||
|
||||
```
|
||||
sudo nmcli device status
|
||||
```
|
||||
|
||||
你将看到如下输出:
|
||||
|
||||
```
|
||||
DEVICE TYPE STATE CONNECTION
|
||||
enp12s0u1 ethernet connected Wired connection 1
|
||||
tun0 tun connected tun0
|
||||
virbr0 bridge connected virbr0
|
||||
wlp2s0 wifi disconnected --
|
||||
p2p-dev-wlp2s0 wifi-p2p disconnected --
|
||||
enp0s31f6 ethernet unavailable --
|
||||
lo loopback unmanaged --
|
||||
virbr0-nic tun unmanaged --
|
||||
```
|
||||
|
||||
在本例中,有两个(有线)以太网接口可用。 `enp12s0u1` 在笔记本电脑扩展坞上,你可以通过 `STATE` 列知道它已连接。另一个是 `enp0s31f6`,是笔记本电脑中的内置端口。还有一个名为 `wlp2s0` 的 WiFi 连接。 `enp12s0u1` 和 `wlp2s0` 是我们在这里感兴趣的两个接口。(请注意,阅读本文无需了解网络设备的命名方式,但如果你感兴趣,可以查看 [systemd.net-naming-scheme 手册页][2]。)
|
||||
|
||||
第一步是创建绑定接口:
|
||||
|
||||
```
|
||||
sudo nmcli connection add type bond ifname bond0 con-name bond0
|
||||
```
|
||||
|
||||
在此示例中,绑定接口名为 `bond0`。`con-name bond0` 将连接名称设置为 `bond0`。直接这样做会有一个名为 `bond-bond0` 的连接。你还可以将连接名设置得更加人性化,例如 “Docking station bond” 或 “Ben”。
|
||||
|
||||
下一步是将接口添加到绑定接口:
|
||||
|
||||
```
|
||||
sudo nmcli connection add type ethernet ifname enp12s0u1 master bond0 con-name bond-ethernet
|
||||
sudo nmcli connection add type wifi ifname wlp2s0 master bond0 ssid Cotton con-name bond-wifi
|
||||
```
|
||||
|
||||
如上所示,连接名称被设置为[更具描述性][3]。请务必使用系统上相应的接口名称替换 `enp12s0u1` 和 `wlp2s0`。对于 WiFi 接口,请使用你自己的网络名称 (SSID)替换我的 “Cotton”。如果你的 WiFi 连接有密码(这当然会有!),你也需要将其添加到配置中。以下假设你使用 [WPA2-PSK][4] 身份验证
|
||||
|
||||
```
|
||||
sudo nmcli connection modify bond-wifi wifi-sec.key-mgmt wpa-psk
|
||||
sudo nmcli connection edit bond-wif
|
||||
```
|
||||
|
||||
第二条命令将进入交互式编辑器,你可以在其中输入密码,而无需将其记录在 shell 历史记录中。输入以下内容,将 `password` 替换为你的实际密码。
|
||||
|
||||
```
|
||||
set wifi-sec.psk password
|
||||
save
|
||||
quit
|
||||
```
|
||||
|
||||
现在,你可以启动你的绑定接口以及你创建的辅助接口。
|
||||
|
||||
```
|
||||
sudo nmcli connection up bond0
|
||||
sudo nmcli connection up bond-ethernet
|
||||
sudo nmcli connection up bond-wifi
|
||||
```
|
||||
|
||||
你现在应该能够在不丢失网络连接的情况下断开有线或无线连接。
|
||||
|
||||
### 警告:使用其他 WiFi 网络时
|
||||
|
||||
在指定的 WiFi 网络间移动时,此配置很有效,但是当远离此网络时,那么绑定中使用的 SSID 就不可用了。从理论上讲,可以为每个使用的 WiFi 连接添加一个接口,但这似乎并不合理。相反,你可以禁用绑定接口:
|
||||
|
||||
```
|
||||
sudo nmcli connection down bond0
|
||||
```
|
||||
|
||||
回到定义的 WiFi 网络时,只需按上述方式启动绑定接口即可。
|
||||
|
||||
### 微调你的绑定
|
||||
|
||||
默认情况下,绑定接口使用“<ruby>轮询<rt>round-robin</rt></ruby>”模式。这会在接口上平均分配负载。但是,如果你有有线和无线连接,你可能希望更喜欢有线连接。 `active-backup` 模式能实现此功能。你可以在创建接口时指定模式和主接口,或者之后使用此命令(绑定接口应该关闭):
|
||||
|
||||
```
|
||||
sudo nmcli connection modify bond0 +bond.options "mode=active-backup,primary=enp12s0u1"
|
||||
```
|
||||
|
||||
[内核文档][5]提供了有关绑定选项的更多信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/bond-wifi-and-ethernet-for-easier-networking-mobility/
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/bcotton/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/07/networkingmobility-816x345.jpg
|
||||
[2]: https://www.freedesktop.org/software/systemd/man/systemd.net-naming-scheme.html
|
||||
[3]: https://en.wikipedia.org/wiki/Master/slave_(technology)#Terminology_concerns
|
||||
[4]: https://en.wikipedia.org/wiki/Wi-Fi_Protected_Access#Target_users_(authentication_key_distribution)
|
||||
[5]: https://www.kernel.org/doc/Documentation/networking/bonding.txt
|
||||
113
published/201907/20190717 How to install Kibana on MacOS.md
Normal file
113
published/201907/20190717 How to install Kibana on MacOS.md
Normal file
@ -0,0 +1,113 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11135-1.html)
|
||||
[#]: subject: (How to install Kibana on MacOS)
|
||||
[#]: via: (https://opensource.com/article/19/7/installing-kibana-macos)
|
||||
[#]: author: (Lauren Maffeo https://opensource.com/users/lmaffeo)
|
||||
|
||||
如何在 MacOS 上安装 Kibana
|
||||
======
|
||||
|
||||
> Elasticsearch 当安装好了之后,Kibana 插件可以为这个功能强大的搜索工具添加可视化功能。
|
||||
|
||||
|
||||
|
||||
在我之前的文章中,我向 Mac 用户介绍了[安装 Elasticsearch][2] 的步骤,这是世界上最受欢迎的企业级搜索引擎。(这里有一篇针对 Linux 用户的[单独文章][3]。)其自然语言处理能力使得 Elasticsearch 在数据集中查找细节方面表现出色。一旦你发现了你需要的数据,如果你已经安装了 [Kibana][4],你可以将它提升到一个新的水平。
|
||||
|
||||
Kibana 是 Elasticsearch 的开源的数据可视化插件。当你在 Elasticsearch 中找到了数据,Kibana 就会帮助你将其放入折线图、[时间序列查询][5]、地理空间地图等。该工具非常适合于必须展示其研究成果的数据科学家,尤其是那些使用开源数据的人。
|
||||
|
||||
### 安装 Kibana
|
||||
|
||||
你需要在 Elasticsearch 之外单独安装 Kibana。因为我安装了 Elasticsearch 7.1.1,所以我将安装 Kibana 1.1。版本的匹配非常重要,Kibana 需要针对相同版本的 Elasticsearch 节点运行。 (Kibana 运行在 node.js 上。)
|
||||
|
||||
以下是我为 MacOS 安装 Kibana 7.1.1 时所遵循的步骤:
|
||||
|
||||
1、确保 Elasticsearch 已下载并运行。如果需要,请参阅上一篇文章。
|
||||
|
||||
**注意**:你至少需要先安装 Elasticsearch 1.4.4 或更高版本才能使用 Kibana。这是因为你需要向 Kibana 提供要连接的 Elasticsearch 实例的 URL 以及你要搜索的 Elasticsearch 索引。通常,最好安装两者的最新版本。
|
||||
|
||||
2、单击[此处][6]下载 Kibana。你将看到如下的网页,它会提示你在**下载**部分的右上角下载 Kibana for Mac:
|
||||
|
||||
![Download Kibana here.][7]
|
||||
|
||||
3、在你的 `Downloads` 文件夹中,打开 .tar 文件以展开它。此操作将创建一个具有相同名称的文件夹(例如,`kibana-7.1.1-darwin-x86_64`)。
|
||||
|
||||
4、如果你希望 Kibana 放在另一个文件夹中,请立即移动它。
|
||||
|
||||
仔细检查 Elasticsearch 是否正在运行,如果没有,请在继续之前启动它。(如果你需要说明,请参阅上一篇文章。)
|
||||
|
||||
### 打开 Kibana 插件
|
||||
|
||||
Elasticsearch 运行起来后,你现在可以启动 Kibana 了。该过程类似于启动 Elasticsearch:
|
||||
|
||||
1、从 Mac 的 `Downloads` 文件夹(或 Kibana 移动到的新文件夹)里,打开 Kibana 文件夹(即 `~Downloads/kibana-7.1.1-darwin-x86_64`)。
|
||||
|
||||
2、打开 `bin` 子文件夹。
|
||||
|
||||
![The Kibana bin folder.][8]
|
||||
|
||||
3、运行 `kibana-plugin`。你可能会遇到上一篇文章中出现的相同安全警告:
|
||||
|
||||
![Security warning][9]
|
||||
|
||||
通常,如果收到此警告,请按照那篇文章中的说明清除警告并打开 Kibana。请注意,如果我在终端中没有运行 Elasticsearch 的情况下打开该插件,我会收到相同的安全警告。要解决此问题,如上一篇文章中所述,打开 Elasticsearch 并在终端中运行它。使用 GUI 启动 Elasticsearch 也应该打开终端。
|
||||
|
||||
然后,我右键单击 `kibana-plugin` 并选择“打开”。这个解决方案对我有用,但你可能需要尝试几次。 我的 Elasticsearch 聚会中的几个人在他们的设备上打开 Kibana 时遇到了一些麻烦。
|
||||
|
||||
### 更改 Kibana 的主机和端口号
|
||||
|
||||
Kibana 的默认设置将其配置为在 `localhost:5601` 上运行。你需要更新文件(在这个例子的情况下)`~Downloads/kibana-7.1.1-darwin-x86_64/config/kibana.yml` 以在运行 Kibana 之前更改主机或端口号。
|
||||
|
||||
![The Kibana config directory.][10]
|
||||
|
||||
以下是我的 Elasticsearch 聚会组里配置 Kibana 时终端的样子,因此默认为 `http://localhost:9200`,这是查询 Elasticsearch 实例时使用的 URL:
|
||||
|
||||
![Configuring Kibana's host and port connections.][11]
|
||||
|
||||
### 从命令行运行 Kibana
|
||||
|
||||
打开插件后,可以从命令行或 GUI 运行 Kibana。这是终端连接到 Elasticsearch 后的样子:
|
||||
|
||||
![Kibana running once it's connected to Elasticsearch.][12]
|
||||
|
||||
与 Elasticsearch 一样,Kibana 默认在前台运行。你可以按 `Ctrl-C` 来停止它。
|
||||
|
||||
### 总结
|
||||
|
||||
Elasticsearch 和 Kibana 是占用大量存储空间的大型软件包。有这么多人一次下载这两个软件包,当我的Elasticsearch 会员和我下载它们两个时,我平均要下载几分钟。这可能是由于 WiFi 不佳和/或用户数量太多,但如果发生同样的事情,请记住这种可能性。
|
||||
|
||||
之后,由于我的笔记本电脑存储空间不足,我无法上传我们正在使用的 JSON 文件。我能够按照讲师的可视化进行操作,但无法实时使用 Kibana。因此,在下载 Elasticsearch 和 Kibana 之前,请确保设备上有足够的空间(至少几千兆字节)来上传和使用这些工具搜索文件。
|
||||
|
||||
要了解有关 Kibana 的更多信息,他们的用户指南[简介][13]是理想的。(你可以根据你正在使用的 Kibana 版本配置该指南。)他们的演示还向你展示了如何[在几分钟内构建仪表板][14],然后进行首次部署。
|
||||
|
||||
玩得开心!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/installing-kibana-macos
|
||||
|
||||
作者:[Lauren Maffeo][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/lmaffeo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/analytics-graphs-charts.png?itok=sersoqbV (Analytics: Charts and Graphs)
|
||||
[2]: https://linux.cn/article-11125-1.html
|
||||
[3]: https://opensource.com/article/19/7/installing-elasticsearch-and-kibana-linux
|
||||
[4]: https://www.elastic.co/products/kibana
|
||||
[5]: https://en.wikipedia.org/wiki/Time_series
|
||||
[6]: https://www.elastic.co/downloads/kibana
|
||||
[7]: https://opensource.com/sites/default/files/uploads/download_kibana.png (Download Kibana here.)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/kibana_bin_folder.png (The Kibana bin folder.)
|
||||
[9]: https://opensource.com/sites/default/files/uploads/security_warning.png (Security warning)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/kibana_config_directory.png (The Kibana config directory.)
|
||||
[11]: https://opensource.com/sites/default/files/uploads/kibana_host_port_config.png (Configuring Kibana's host and port connections.)
|
||||
[12]: https://opensource.com/sites/default/files/uploads/kibana_running.png (Kibana running once it's connected to Elasticsearch.)
|
||||
[13]: https://www.elastic.co/guide/en/kibana/7.2/introduction.html
|
||||
[14]: https://www.elastic.co/webinars/getting-started-kibana?baymax=rtp&elektra=docs&storm=top-video&iesrc=ctr
|
||||
219
published/201907/20190717 Mastering user groups on Linux.md
Normal file
219
published/201907/20190717 Mastering user groups on Linux.md
Normal file
@ -0,0 +1,219 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (0x996)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11148-1.html)
|
||||
[#]: subject: (Mastering user groups on Linux)
|
||||
[#]: via: (https://www.networkworld.com/article/3409781/mastering-user-groups-on-linux.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
掌握 Linux 用户组
|
||||
======
|
||||
|
||||
> 在 Linux 系统中管理用户组并不费力,但相关命令可能比你所知的更为灵活。
|
||||
|
||||
![Scott 97006 \(CC BY 2.0\)][1]
|
||||
|
||||
在 Linux 系统中用户组起着重要作用。用户组提供了一种简单方法供一组用户互相共享文件。用户组也允许系统管理员更加有效地管理用户权限,因为管理员可以将权限分配给用户组而不是逐一分配给单个用户。
|
||||
|
||||
尽管通常只要在系统中添加用户账户就会创建用户组,关于用户组如何工作以及如何运用用户组还有很多需要了解的。
|
||||
|
||||
### 一个用户一个用户组?
|
||||
|
||||
Linux 系统中多数用户账户被设为用户名与用户组名相同。用户 `jdoe` 会被赋予一个名为 `jdoe` 的用户组,且成为该新建用户组的唯一成员。如本例所示,该用户的登录名,用户 id 和用户组 id 在新建账户时会被添加到 `/etc/passwd` 和 `/etc/group` 文件中:
|
||||
|
||||
```
|
||||
$ sudo useradd jdoe
|
||||
$ grep jdoe /etc/passwd
|
||||
jdoe:x:1066:1066:Jane Doe:/home/jdoe:/bin/sh
|
||||
$ grep jdoe /etc/group
|
||||
jdoe:x:1066:
|
||||
```
|
||||
|
||||
这些文件中的配置使系统得以在文本(`jdoe`)和数字(`1066`)这两种用户 id 形式之间互相转换—— `jdoe` 就是 `1006`,且 `1006` 就是 `jdoe`。
|
||||
|
||||
分配给每个用户的 UID(用户 id)和 GID(用户组 id)通常是一样的,并且顺序递增。若上例中 Jane Doe 是最近添加的用户,分配给下一个新用户的用户 id 和用户组 id 很可能都是 1067。
|
||||
|
||||
### GID = UID?
|
||||
|
||||
UID 和 GID 可能不一致。例如,如果你用 `groupadd` 命令添加一个用户组而不指定用户组 id,系统会分配下一个可用的用户组 id(在本例中为 1067)。下一个添加到系统中的用户其 UID 会是 1067 而 GID 则为 1068。
|
||||
|
||||
你可以避免这个问题,方法是添加用户组的时候指定一个较小的用户组 id 而不是接受默认值。在下面的命令中我们添加一个用户组并提供一个 GID,这个 GID 小于用于用户账户的 GID 取值范围。
|
||||
|
||||
```
|
||||
$ sudo groupadd -g 500 devops
|
||||
```
|
||||
|
||||
创建账户时你可以指定一个共享用户组,如果这样对你更合适的话。例如你可能想把新来的开发人员加入同一个 DevOps 用户组而不是一人一个用户组。
|
||||
|
||||
```
|
||||
$ sudo useradd -g staff bennyg
|
||||
$ grep bennyg /etc/passwd
|
||||
bennyg:x:1064:50::/home/bennyg:/bin/sh
|
||||
```
|
||||
|
||||
### 主要用户组和次要用户组
|
||||
|
||||
用户组实际上有两种:<ruby>主要用户组<rt>primary group</rt></ruby>和<ruby>次要用户组<rt>secondary group</rt></ruby>。
|
||||
|
||||
主要用户组是保存在 `/etc/passwd` 文件中的用户组,该用户组在账户创建时配置。当用户创建一个文件时,用户的主要用户组与此文件关联。
|
||||
|
||||
```
|
||||
$ whoami
|
||||
jdoe
|
||||
$ grep jdoe /etc/passwd
|
||||
jdoe:x:1066:1066:John Doe:/home/jdoe:/bin/bash
|
||||
^
|
||||
|
|
||||
+-------- 主要用户组
|
||||
$ touch newfile
|
||||
$ ls -l newfile
|
||||
-rw-rw-r-- 1 jdoe jdoe 0 Jul 16 15:22 newfile
|
||||
^
|
||||
|
|
||||
+-------- 主要用户组
|
||||
```
|
||||
|
||||
用户一旦拥有账户之后被加入的那些用户组是次要用户组。次要用户组成员关系在 `/etc/group` 文件中显示。
|
||||
|
||||
```
|
||||
$ grep devops /etc/group
|
||||
devops:x:500:shs,jadep
|
||||
^
|
||||
|
|
||||
+-------- shs 和 jadep 的次要用户组
|
||||
```
|
||||
|
||||
`/etc/group` 文件给用户组分配组名称(例如 `500` = `devops`)并记录次要用户组成员。
|
||||
|
||||
### 首选的准则
|
||||
|
||||
每个用户是他自己的主要用户组成员,并可以成为任意多个次要用户组成员,这样的一种准则允许用户更加容易地将个人文件和需要与同事分享的文件分开。当用户创建一个文件时,用户所属的不同用户组的成员不一定有访问权限。用户必须用 `chgrp` 命令将文件和次要用户组关联起来。
|
||||
|
||||
### 哪里也不如自己的家目录
|
||||
|
||||
添加新账户时一个重要的细节是 `useradd` 命令并不一定为新用户添加一个<ruby>家目录<rt>/home</rt></ruby>家目录。若你只有某些时候想为用户添加家目录,你可以在 `useradd` 命令中加入 `-m` 选项(可以把它想象成“安家”选项)。
|
||||
|
||||
```
|
||||
$ sudo useradd -m -g devops -c "John Doe" jdoe2
|
||||
```
|
||||
|
||||
此命令中的选项如下:
|
||||
|
||||
* `-m` 创建家目录并在其中生成初始文件
|
||||
* `-g` 指定用户归属的用户组
|
||||
* `-c` 添加账户描述信息(通常是用户的姓名)
|
||||
|
||||
若你希望总是创建家目录,你可以编辑 `/etc/login.defs` 文件来更改默认工作方式。更改或添加 `CREATE_HOME` 变量并将其设置为 `yes`:
|
||||
|
||||
```
|
||||
$ grep CREATE_HOME /etc/login.defs
|
||||
CREATE_HOME yes
|
||||
```
|
||||
|
||||
另一种方法是用自己的账户设置别名从而让 `useradd` 一直带有 `-m` 选项。
|
||||
|
||||
```
|
||||
$ alias useradd=’useradd -m’
|
||||
```
|
||||
|
||||
确保将该别名添加到你的 `~/.bashrc` 文件或类似的启动文件中以使其永久生效。
|
||||
|
||||
### 深入了解 /etc/login.defs
|
||||
|
||||
下面这个命令可列出 `/etc/login.defs` 文件中的全部设置。下面的 `grep` 命令会隐藏所有注释和空行。
|
||||
|
||||
```
|
||||
$ cat /etc/login.defs | grep -v "^#" | grep -v "^$"
|
||||
MAIL_DIR /var/mail
|
||||
FAILLOG_ENAB yes
|
||||
LOG_UNKFAIL_ENAB no
|
||||
LOG_OK_LOGINS no
|
||||
SYSLOG_SU_ENAB yes
|
||||
SYSLOG_SG_ENAB yes
|
||||
FTMP_FILE /var/log/btmp
|
||||
SU_NAME su
|
||||
HUSHLOGIN_FILE .hushlogin
|
||||
ENV_SUPATH PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
|
||||
ENV_PATH PATH=/usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/games
|
||||
TTYGROUP tty
|
||||
TTYPERM 0600
|
||||
ERASECHAR 0177
|
||||
KILLCHAR 025
|
||||
UMASK 022
|
||||
PASS_MAX_DAYS 99999
|
||||
PASS_MIN_DAYS 0
|
||||
PASS_WARN_AGE 7
|
||||
UID_MIN 1000
|
||||
UID_MAX 60000
|
||||
GID_MIN 1000
|
||||
GID_MAX 60000
|
||||
LOGIN_RETRIES 5
|
||||
LOGIN_TIMEOUT 60
|
||||
CHFN_RESTRICT rwh
|
||||
DEFAULT_HOME yes
|
||||
CREATE_HOME yes <===
|
||||
USERGROUPS_ENAB yes
|
||||
ENCRYPT_METHOD SHA512
|
||||
```
|
||||
|
||||
注意此文件中的各种设置会决定用户 id 的取值范围以及密码使用期限和其他设置(如 umask)。
|
||||
|
||||
### 如何显示用户所属的用户组
|
||||
|
||||
出于各种原因用户可能是多个用户组的成员。用户组成员身份给与用户对用户组拥有的文件和目录的访问权限,有时候这种工作方式是至关重要的。要生成某个用户所属用户组的清单,用 `groups` 命令即可。
|
||||
|
||||
```
|
||||
$ groups jdoe
|
||||
jdoe : jdoe adm admin cdrom sudo dip plugdev lpadmin staff sambashare
|
||||
```
|
||||
|
||||
你可以键入不带任何参数的 `groups` 命令来列出你自己的用户组。
|
||||
|
||||
### 如何添加用户至用户组
|
||||
|
||||
如果你想添加一个已有用户至别的用户组,你可以仿照下面的命令操作:
|
||||
|
||||
```
|
||||
$ sudo usermod -a -G devops jdoe
|
||||
```
|
||||
|
||||
你也可以指定逗号分隔的用户组列表来添加一个用户至多个用户组:
|
||||
|
||||
```
|
||||
$ sudo usermod -a -G devops,mgrs jdoe
|
||||
```
|
||||
|
||||
参数 `-a` 意思是“添加”,`-G` 指定用户组列表。
|
||||
|
||||
你可以编辑 `/etc/group` 文件将用户名从用户组成员名单中删除,从而将用户从用户组中移除。`usermod` 命令或许也有个选项用于从用户组中删除某个成员。
|
||||
|
||||
```
|
||||
fish:x:16:nemo,dory,shark
|
||||
|
|
||||
V
|
||||
fish:x:16:nemo,dory
|
||||
```
|
||||
|
||||
### 提要
|
||||
|
||||
添加和管理用户组并非特别困难,但长远来看配置账户时的一致性可使这项工作更容易些。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3409781/mastering-user-groups-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[0x996](https://github.com/0x996)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/07/carrots-100801917-large.jpg
|
||||
[2]: https://www.youtube.com/playlist?list=PL7D2RMSmRO9J8OTpjFECi8DJiTQdd4hua
|
||||
[3]: https://www.networkworld.com/article/3391029/must-know-linux-commands.html
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,145 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11151-1.html)
|
||||
[#]: subject: (How to run virtual machines with virt-manager)
|
||||
[#]: via: (https://fedoramagazine.org/full-virtualization-system-on-fedora-workstation-30/)
|
||||
[#]: author: (Marco Sarti https://fedoramagazine.org/author/msarti/)
|
||||
|
||||
如何使用 virt-manager 运行虚拟机
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
在早些年,在同一台笔记本中运行多个操作系统只能双启动。当时,这些操作系统很难同时运行或彼此交互。许多年过去了,在普通的 PC 上,可以通过虚拟化在一个系统中运行另一个系统。
|
||||
|
||||
最近的 PC 或笔记本(包括价格适中的笔记本电脑)都有硬件虚拟化,可以运行性能接近物理主机的虚拟机。
|
||||
|
||||
虚拟化因此变得常见,它可以用来测试操作系统、学习新技术、创建自己的家庭云、创建自己的测试环境等等。本文将指导你使用 Fedora 上的 Virt Manager 来设置虚拟机。
|
||||
|
||||
### 介绍 QEMU/KVM 和 Libvirt
|
||||
|
||||
与所有其他 Linux 系统一样,Fedora 附带了虚拟化扩展支持。它由作为内核模块之一的 KVM(基于内核的虚拟机)提供支持。
|
||||
|
||||
QEMU 是一个完整的系统仿真器,它可与 KVM 协同工作,允许你使用硬件和外部设备创建虚拟机。
|
||||
|
||||
最后,[libvirt][2] 能让你管理基础设施的 API 层,即创建和运行虚拟机。
|
||||
|
||||
这三个技术都是开源的,我们将在 Fedora Workstation 上安装它们。
|
||||
|
||||
### 安装
|
||||
|
||||
#### 步骤 1:安装软件包
|
||||
|
||||
安装是一个相当简单的操作。 Fedora 仓库提供了 “virtualization” 软件包组,其中包含了你需要的所有包。
|
||||
|
||||
```
|
||||
sudo dnf install @virtualization
|
||||
```
|
||||
|
||||
#### 步骤 2:编辑 libvirtd 配置
|
||||
|
||||
默认情况下,系统管理仅限于 root 用户,如果要启用常规用户,那么必须按以下步骤操作。
|
||||
|
||||
打开 `/etc/libvirt/libvirtd.conf` 进行编辑:
|
||||
|
||||
```
|
||||
sudo vi /etc/libvirt/libvirtd.conf
|
||||
```
|
||||
|
||||
将 UNIX 域套接字组所有者设置为 libvirt:
|
||||
|
||||
```
|
||||
unix_sock_group = "libvirt"
|
||||
```
|
||||
|
||||
调整 UNIX 域套接字的读写权限:
|
||||
|
||||
```
|
||||
unix_sock_rw_perms = "0770"
|
||||
```
|
||||
|
||||
#### 步骤 3:启动并启用 libvirtd 服务
|
||||
|
||||
```
|
||||
sudo systemctl start libvirtd
|
||||
sudo systemctl enable libvirtd
|
||||
```
|
||||
|
||||
#### 步骤 4:将用户添加到组
|
||||
|
||||
为了管理 libvirt 与普通用户,你必须将用户添加到 `libvirt` 组,否则每次启动 `virt-manager` 时,都会要求你输入 sudo 密码。
|
||||
|
||||
```
|
||||
sudo usermod -a -G libvirt $(whoami)
|
||||
```
|
||||
|
||||
这会将当前用户添加到组中。你必须注销并重新登录才能应用更改。
|
||||
|
||||
### 开始使用 virt-manager
|
||||
|
||||
可以通过命令行 (`virsh`) 或通过 `virt-manager` 图形界面管理 libvirt 系统。如果你想做虚拟机自动化配置,那么命令行非常有用,例如使用 [Ansible][3],但在本文中我们将专注于用户友好的图形界面。
|
||||
|
||||
`virt-manager` 界面很简单。主窗口显示连接列表,其中包括本地系统连接。
|
||||
|
||||
连接设置包括虚拟网络和存储定义。你可以定义多个虚拟网络,这些网络可用于在客户端系统之间以及客户端系统和主机之间进行通信。
|
||||
|
||||
### 创建你的第一个虚拟机
|
||||
|
||||
要开始创建新虚拟机,请按下主窗口左上角的按钮:
|
||||
|
||||
![][4]
|
||||
|
||||
向导的第一步需要选择安装模式。你可以选择本地安装介质、网络引导/安装或导入现有虚拟磁盘:
|
||||
|
||||
![][5]
|
||||
|
||||
选择本地安装介质,下一步将需要选择 ISO 镜像路径:
|
||||
|
||||
![ ][6]
|
||||
|
||||
随后的两个步骤能让你调整新虚拟机的 CPU、内存和磁盘大小。最后一步将要求你选择网络选项:如果你希望虚拟机通过 NAT 与外部隔离,请选择默认网络。如果你希望从外部访问虚拟机,那么选择桥接。请注意,如果选择桥接,那么虚拟机则无法与主机通信。
|
||||
|
||||
如果要在启动设置之前查看或更改配置,请选中“安装前自定义配置”:
|
||||
|
||||
![][7]
|
||||
|
||||
虚拟机配置窗口能让你查看和修改硬件配置。你可以添加磁盘、网络接口、更改引导选项等。满意后按“开始安装”:
|
||||
|
||||
![][8]
|
||||
|
||||
此时,你将被重定向到控制台来继续安装操作系统。操作完成后,你可以从控制台访问虚拟机:
|
||||
|
||||
![][9]
|
||||
|
||||
刚刚创建的虚拟机将出现在主窗口的列表中,你还能看到 CPU 和内存占用率的图表:
|
||||
|
||||
![][10]
|
||||
|
||||
libvirt 和 `virt-manager` 是功能强大的工具,它们可以以企业级管理为你的虚拟机提供出色的自定义。如果你需要更简单的东西,请注意 Fedora Workstation [预安装的 GNOME Boxes 已经能够满足基础的虚拟化要求][11]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/full-virtualization-system-on-fedora-workstation-30/
|
||||
|
||||
作者:[Marco Sarti][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/msarti/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/07/virt-manager-816x346.jpg
|
||||
[2]: https://libvirt.org/
|
||||
[3]: https://fedoramagazine.org/get-the-latest-ansible-2-8-in-fedora/
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-09-41-45.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-09-30-53.png
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-10-42-39.png
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-10-43-21.png
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-10-44-58.png
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-10-55-35.png
|
||||
[10]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-11-09-22.png
|
||||
[11]: https://fedoramagazine.org/getting-started-with-virtualization-in-gnome-boxes/
|
||||
@ -0,0 +1,218 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11158-1.html)
|
||||
[#]: subject: (Getting help for Linux shell built-ins)
|
||||
[#]: via: (https://www.networkworld.com/article/3410350/getting-help-for-linux-shell-built-ins.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
获取有关 Linux shell 内置命令的帮助
|
||||
======
|
||||
|
||||
> Linux 内置命令属于用户 shell 的一部分,本文将告诉你如何识别它们并获取使用它们的帮助。
|
||||
|
||||

|
||||
|
||||
Linux 内置命令是内置于 shell 中的命令,很像内置于墙中的书架。与标准 Linux 命令存储在 `/usr/bin` 中的方式不同,你不会找到它们的独立文件,你可能使用过相当多的内置命令,但你不会感觉到它们与 `ls` 和 `pwd` 等命令有何不同。
|
||||
|
||||
内置命令与其他 Linux 命令一样使用,它们可能要比不属于 shell 的类似命令运行得快一些。Bash 内置命令包括 `alias`、`export` 和 `bg` 等。
|
||||
|
||||
正如你担心的那样,因为内置命令是特定于 shell 的,所以它们不会提供手册页。使用 `man` 来查看 `bg`,你会看到这样的东西:
|
||||
|
||||
```
|
||||
$ man bg
|
||||
No manual entry for bg
|
||||
```
|
||||
|
||||
判断内置命令的另一个提示是当你使用 `which` 命令来识别命令的来源时,Bash 不会响应,表示没有与内置命令关联的文件:
|
||||
|
||||
```
|
||||
$ which bg
|
||||
$
|
||||
```
|
||||
|
||||
另一方面,如果你的 shell 是 `/bin/zsh`,你可能会得到一个更有启发性的响应:
|
||||
|
||||
```
|
||||
% which bg
|
||||
bg: shell built-in command
|
||||
```
|
||||
|
||||
bash 提供了额外的帮助信息,但它是通过使用 `help` 命令实现的:
|
||||
|
||||
```
|
||||
$ help bg
|
||||
bg: bg [job_spec ...]
|
||||
Move jobs to the background.
|
||||
|
||||
Place the jobs identified by each JOB_SPEC in the background, as if they
|
||||
had been started with `&'. If JOB_SPEC is not present, the shell's notion
|
||||
of the current job is used.
|
||||
|
||||
Exit Status:
|
||||
Returns success unless job control is not enabled or an error occurs.
|
||||
```
|
||||
|
||||
如果你想要查看 bash 提供的所有内置命令的列表,使用 `compgen -b` 命令。通过管道将命令输出到列中,以获得较好格式的清单。
|
||||
|
||||
```
|
||||
$ compgen -b | column
|
||||
. compgen exit let return typeset
|
||||
: complete export local set ulimit
|
||||
[ compopt false logout shift umask
|
||||
alias continue fc mapfile shopt unalias
|
||||
bg declare fg popd source unset
|
||||
bind dirs getopts printf suspend wait
|
||||
break disown hash pushd test
|
||||
builtin echo help pwd times
|
||||
caller enable history read trap
|
||||
cd eval jobs readarray true
|
||||
command exec kill readonly type
|
||||
```
|
||||
|
||||
如果你使用 `help` 命令,你将看到一个内置命令列表以及简短描述。但是,这个列表被截断了(以 `help` 命令结尾):
|
||||
|
||||
```
|
||||
$ help
|
||||
GNU bash, version 5.0.3(1)-release (x86_64-pc-linux-gnu)
|
||||
These shell commands are defined internally. Type `help' to see this list.
|
||||
Type `help name' to find out more about the function `name'.
|
||||
Use `info bash' to find out more about the shell in general.
|
||||
Use `man -k' or `info' to find out more about commands not in this list.
|
||||
|
||||
A star (*) next to a name means that the command is disabled.
|
||||
|
||||
job_spec [&] history [-c] [-d offset] [n] or histo>
|
||||
(( expression )) if COMMANDS; then COMMANDS; [ elif CO>
|
||||
. filename [arguments] jobs [-lnprs] [jobspec ...] or jobs ->
|
||||
: kill [-s sigspec | -n signum | -sigsp>
|
||||
[ arg... ] let arg [arg ...]
|
||||
[[ expression ]] local [option] name[=value] ...
|
||||
alias [-p] [name[=value] ... ] logout [n]
|
||||
bg [job_spec ...] mapfile [-d delim] [-n count] [-O ori>
|
||||
bind [-lpsvPSVX] [-m keymap] [-f filen> popd [-n] [+N | -N]
|
||||
break [n] printf [-v var] format [arguments]
|
||||
builtin [shell-builtin [arg ...]] pushd [-n] [+N | -N | dir]
|
||||
caller [expr] pwd [-LP]
|
||||
case WORD in [PATTERN [| PATTERN]...) > read [-ers] [-a array] [-d delim] [-i>
|
||||
cd [-L|[-P [-e]] [-@]] [dir] readarray [-d delim] [-n count] [-O o>
|
||||
command [-pVv] command [arg ...] readonly [-aAf] [name[=value] ...] or>
|
||||
compgen [-abcdefgjksuv] [-o option] [-> return [n]
|
||||
complete [-abcdefgjksuv] [-pr] [-DEI] > select NAME [in WORDS ... ;] do COMMA>
|
||||
compopt [-o|+o option] [-DEI] [name ..> set [-abefhkmnptuvxBCHP] [-o option-n>
|
||||
continue [n] shift [n]
|
||||
coproc [NAME] command [redirections] shopt [-pqsu] [-o] [optname ...]
|
||||
declare [-aAfFgilnrtux] [-p] [name[=va> source filename [arguments]
|
||||
dirs [-clpv] [+N] [-N] suspend [-f]
|
||||
disown [-h] [-ar] [jobspec ... | pid . <p>'> test [expr]
|
||||
echo [-neE] [arg ...] time [-p] pipeline
|
||||
enable [-a] [-dnps] [-f filename] [nam> times
|
||||
eval [arg ...] trap [-lp] [[arg] signal_spec ...]
|
||||
exec [-cl] [-a name] [command [argumen> true
|
||||
exit [n] type [-afptP] name [name ...]
|
||||
export [-fn] [name[=value] ...] or exp> typeset [-aAfFgilnrtux] [-p] name[=va>
|
||||
false ulimit [-SHabcdefiklmnpqrstuvxPT] [li>
|
||||
fc [-e ename] [-lnr] [first] [last] or> umask [-p] [-S] [mode]
|
||||
fg [job_spec] unalias [-a] name [name ...]
|
||||
for NAME [in WORDS ... ] ; do COMMANDS> unset [-f] [-v] [-n] [name ...]
|
||||
for (( exp1; exp2; exp3 )); do COMMAND> until COMMANDS; do COMMANDS; done
|
||||
function name { COMMANDS ; } or name (> variables - Names and meanings of som>
|
||||
getopts optstring name [arg] wait [-fn] [id ...]
|
||||
hash [-lr] [-p pathname] [-dt] [name .> while COMMANDS; do COMMANDS; done
|
||||
help [-dms] [pattern ...] { COMMANDS ; }
|
||||
```
|
||||
|
||||
从上面的清单中可以看出,`help` 命令本身就是内置的。
|
||||
|
||||
你可以通过向 `help` 命令提供你感兴趣的内置命令名称来获取关于它们的更多信息,例如 `help dirs`:
|
||||
|
||||
```
|
||||
$ help dirs
|
||||
dirs: dirs [-clpv] [+N] [-N]
|
||||
Display directory stack.
|
||||
|
||||
Display the list of currently remembered directories. Directories
|
||||
find their way onto the list with the `pushd' command; you can get
|
||||
back up through the list with the `popd' command.
|
||||
|
||||
Options:
|
||||
-c clear the directory stack by deleting all of the elements
|
||||
-l do not print tilde-prefixed versions of directories relative
|
||||
to your home directory
|
||||
-p print the directory stack with one entry per line
|
||||
-v print the directory stack with one entry per line prefixed
|
||||
with its position in the stack
|
||||
|
||||
Arguments:
|
||||
+N Displays the Nth entry counting from the left of the list
|
||||
shown by dirs when invoked without options, starting with
|
||||
zero.
|
||||
|
||||
-N Displays the Nth entry counting from the right of the list
|
||||
shown by dirs when invoked without options, starting with
|
||||
zero.
|
||||
|
||||
Exit Status:
|
||||
Returns success unless an invalid option is supplied or an error occurs.
|
||||
```
|
||||
|
||||
内置命令提供了每个 shell 的大部分功能。你使用的任何 shell 都有一些内置命令,但是如何获取这些内置命令的信息可能因 shell 而异。例如,对于 `zsh`,你可以使用 `man zshbuiltins` 命令获得其内置命令的描述。
|
||||
|
||||
```
|
||||
$ man zshbuiltins
|
||||
|
||||
ZSHBUILTINS(1) General Commands Manual ZSHBUILTINS(1)
|
||||
|
||||
NAME
|
||||
zshbuiltins - zsh built-in commands
|
||||
|
||||
SHELL BUILTIN COMMANDS
|
||||
Some shell builtin commands take options as described in individual en‐
|
||||
tries; these are often referred to in the list below as `flags' to avoid
|
||||
confusion with shell options, which may also have an effect on the behav‐
|
||||
iour of builtin commands. In this introductory section, `option' always
|
||||
has the meaning of an option to a command that should be familiar to most
|
||||
command line users.
|
||||
…
|
||||
```
|
||||
|
||||
在这个冗长的手册页中,你将找到一个内置命令列表,其中包含有用的描述,如下摘录中所示:
|
||||
|
||||
```
|
||||
bg [ job ... ]
|
||||
job ... &
|
||||
Put each specified job in the background, or the current job if
|
||||
none is specified.
|
||||
|
||||
bindkey
|
||||
See the section `Zle Builtins' in zshzle(1).
|
||||
|
||||
break [ n ]
|
||||
Exit from an enclosing for, while, until, select or repeat loop.
|
||||
If an arithmetic expression n is specified, then break n levels
|
||||
instead of just one.
|
||||
```
|
||||
|
||||
### 最后
|
||||
|
||||
Linux 内置命令对于每个 shell 都很重要,它的操作类似特定于 shell 的命令一样。如果你经常使用不同的 shell,并注意到你经常使用的某些命令似乎不存在或者不能按预期工作,那么它可能是你使用的其他 shell 之一中的内置命令。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3410350/getting-help-for-linux-shell-built-ins.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/07/linux_penguin-100802549-large.jpg
|
||||
[2]: https://www.youtube.com/playlist?list=PL7D2RMSmRO9J8OTpjFECi8DJiTQdd4hua
|
||||
[3]: https://www.networkworld.com/article/3242170/linux/invaluable-tips-and-tricks-for-troubleshooting-linux.html
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,112 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "hello-wn"
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-11156-1.html"
|
||||
[#]: subject: "How to Create a User Account Without useradd Command in Linux?"
|
||||
[#]: via: "https://www.2daygeek.com/linux-user-account-creation-in-manual-method/"
|
||||
[#]: author: "Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/"
|
||||
|
||||
在 Linux 中不使用 useradd 命令如何创建用户账号
|
||||
========
|
||||
|
||||
Linux 中有三个命令可以用来创建用户账号。你尝试过在 Linux 中手动创建用户吗?我的意思是不使用上面说的三个命令。
|
||||
|
||||
如果你不知道怎么做,本文可以手把手教你,并向你展示细节部分。
|
||||
|
||||
你可能想,这怎么可能?别担心,正如我们多次提到的那样,在 Linux 上任何事都可以搞定。这只是其中一例。
|
||||
|
||||
是的,我们可以做到的。想了解更多吗?
|
||||
|
||||
- [在 Linux 中创建用户的三种方法][1]
|
||||
- [在 Linux 中批量创建用户的两种方法][2]
|
||||
|
||||
话不多说,让我们开始吧。
|
||||
|
||||
首先,我们要找出最后创建的 UID 和 GID 信息。 掌握了这些信息之后,就可以继续下一步。
|
||||
|
||||
```
|
||||
# cat /etc/passwd | tail -1
|
||||
tuser1:x:1153:1154:Test User:/home/tuser1:/bin/bash
|
||||
```
|
||||
|
||||
根据以上输出,最后创建的用户 UID 是 1153,GID 是 1154。为了试验,我们将在系统中添加 `tuser2` 用户。
|
||||
|
||||
现在,在`/etc/passwd` 文件中添加一条用户信息。 总共七个字段,你需要添加一些必要信息。
|
||||
|
||||
```
|
||||
+-----------------------------------------------------------------------+
|
||||
|username:password:UID:GID:Comments:User Home Directory:User Login Shell|
|
||||
+-----------------------------------------------------------------------+
|
||||
| | | | | | |
|
||||
1 2 3 4 5 6 7
|
||||
```
|
||||
|
||||
1. 用户名:这个字段表示用户名称。字符长度必须在 1 到 32 之间。
|
||||
2. 密码(`x`):表示存储在 `/etc/shadow` 文件中的加密密码。
|
||||
3. 用户 ID:表示用户的 ID(UID),每个用户都有独一无二的 UID。UID 0 保留给 root 用户,UID 1-99 保留给系统用户,UID 100-999 保留给系统账号/组。
|
||||
4. 组 ID:表示用户组的 ID(GID),每个用户组都有独一无二的 GID,存储在 `/etc/group` 文件中。
|
||||
5. 注释/用户 ID 信息:这个字段表示备注,用于描述用户信息。
|
||||
6. 主目录(`/home/$USER`):表示用户的主目录。
|
||||
7. shell(`/bin/bash`):表示用户使用的 shell。
|
||||
|
||||
在文件最后添加用户信息。
|
||||
|
||||
```
|
||||
# vi /etc/passwd
|
||||
|
||||
tuser2:x:1154:1155:Test User2:/home/tuser2:/bin/bash
|
||||
```
|
||||
|
||||
你需要创建相同名字的用户组。同样地,在 `/etc/group` 文件中添加用户组信息。
|
||||
|
||||
```
|
||||
# vi /etc/group
|
||||
|
||||
tuser2:x:1155:
|
||||
```
|
||||
|
||||
做完以上两步之后,给用户设置一个密码。
|
||||
|
||||
```
|
||||
# passwd tuser2
|
||||
|
||||
Changing password for user tuser2.
|
||||
New password:
|
||||
Retype new password:
|
||||
passwd: all authentication tokens updated successfully.
|
||||
```
|
||||
|
||||
最后,试着登录新创建的用户。
|
||||
|
||||
```
|
||||
# ssh [email protected]
|
||||
|
||||
[email protected]'s password:
|
||||
Creating directory '/home/tuser2'.
|
||||
|
||||
$ls -la
|
||||
|
||||
total 16
|
||||
drwx------. 2 tuser2 tuser2 59 Jun 17 09:46 .
|
||||
drwxr-xr-x. 15 root root 4096 Jun 17 09:46 ..
|
||||
-rw-------. 1 tuser2 tuser2 18 Jun 17 09:46 .bash_logout
|
||||
-rw-------. 1 tuser2 tuser2 193 Jun 17 09:46 .bash_profile
|
||||
-rw-------. 1 tuser2 tuser2 231 Jun 17 09:46 .bashrc
|
||||
```
|
||||
|
||||
------
|
||||
|
||||
via: https://www.2daygeek.com/linux-user-account-creation-in-manual-method/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hello-wn](https://github.com/hello-wn)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/linux-user-account-creation-useradd-adduser-newusers/
|
||||
[2]: https://www.2daygeek.com/linux-bulk-users-creation-useradd-newusers/
|
||||
328
published/201907/20190724 Master the Linux -ls- command.md
Normal file
328
published/201907/20190724 Master the Linux -ls- command.md
Normal file
@ -0,0 +1,328 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11159-1.html)
|
||||
[#]: subject: (Master the Linux 'ls' command)
|
||||
[#]: via: (https://opensource.com/article/19/7/master-ls-command)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
精通 Linux 的 ls 命令
|
||||
======
|
||||
|
||||
> Linux 的 ls 命令拥有数量惊人的选项,可以提供有关文件的重要信息。
|
||||
|
||||

|
||||
|
||||
`ls` 命令可以列出一个 [POSIX][2] 系统上的文件。这是一个简单的命令,但它经常被低估,不是它能做什么(因为它确实只做了一件事),而是你该如何优化对它的使用。
|
||||
|
||||
要知道在最重要的 10 个终端命令中,这个简单的 `ls` 命令可以排进前三,因为 `ls` 不会*只是*列出文件,它还会告诉你有关它们的重要信息。它会告诉你诸如拥有文件或目录的人、每个文件修改的时间、甚至是什么类型的文件。它的附带功能能让你了解你在哪里、附近有些什么,以及你可以用它们做什么。
|
||||
|
||||
如果你对 `ls` 的体验仅限于你的发行版在 `.bashrc` 中的别名,那么你可能错失了它。
|
||||
|
||||
### GNU 还是 BSD?
|
||||
|
||||
在了解 `ls` 的隐藏能力之前,你必须确定你正在运行哪个 `ls` 命令。有两个最流行的版本:包含在 GNU coreutils 包中的 GNU 版本,以及 BSD 版本。如果你正在运行 Linux,那么你很可能已经安装了 GNU 版本的 `ls`(LCTT 译注:几乎可以完全确定)。如果你正在运行 BSD 或 MacOS,那么你有的是 BSD 版本。本文会介绍它们的不同之处。
|
||||
|
||||
你可以使用 `--version` 选项找出你计算机上的版本:
|
||||
|
||||
```
|
||||
$ ls --version
|
||||
```
|
||||
|
||||
如果它返回有关 GNU coreutils 的信息,那么你拥有的是 GNU 版本。如果它返回一个错误,你可能正在运行的是 BSD 版本(运行 `man ls | head` 以确定)。
|
||||
|
||||
你还应该调查你的发行版可能具有哪些预设选项。终端命令的自定义通常放在 `$HOME/.bashrc` 或 `$HOME/.bash_aliases` 或 `$HOME/.profile` 中,它们是通过将 `ls` 别名化为更复杂的 `ls` 命令来完成的。例如:
|
||||
|
||||
```
|
||||
alias ls='ls --color'
|
||||
```
|
||||
|
||||
发行版提供的预设非常有用,但它们确实很难分辨出哪些是 `ls` 本身的特性,哪些是它的附加选项提供的。你要是想要运行 `ls` 命令本身而不是它的别名,你可以用反斜杠“转义”命令:
|
||||
|
||||
```
|
||||
$ \ls
|
||||
```
|
||||
|
||||
### 分类
|
||||
|
||||
单独运行 `ls` 会以适合你终端的列数列出文件:
|
||||
|
||||
```
|
||||
$ ls ~/example
|
||||
bunko jdk-10.0.2
|
||||
chapterize otf2ttf.ff
|
||||
despacer overtar.sh
|
||||
estimate.sh pandoc-2.7.1
|
||||
fop-2.3 safe_yaml
|
||||
games tt
|
||||
```
|
||||
|
||||
这是有用的信息,但所有这些文件看起来基本相同,没有方便的图标来快速表示出哪个是目录、文本文件或图像等等。
|
||||
|
||||
使用 `-F`(或 GNU 上的长选项 `--classify`)以在每个条目之后显示标识文件类型的指示符:
|
||||
|
||||
```
|
||||
$ ls ~/example
|
||||
bunko jdk-10.0.2/
|
||||
chapterize* otf2ttf.ff*
|
||||
despacer* overtar.sh*
|
||||
estimate.sh pandoc@
|
||||
fop-2.3/ pandoc-2.7.1/
|
||||
games/ tt*
|
||||
```
|
||||
|
||||
使用此选项,终端中列出的项目使用简写符号来按文件类型分类:
|
||||
|
||||
* 斜杠(`/`)表示目录(或“文件夹”)。
|
||||
* 星号(`*`)表示可执行文件。这包括二进制文件(编译代码)以及脚本(具有[可执行权限][3]的文本文件)。
|
||||
* 符号(`@`)表示符号链接(或“别名”)。
|
||||
* 等号(`=`)表示套接字。
|
||||
* 在 BSD 上,百分号(`%`)表示<ruby>涂改<rt>whiteout</rt></ruby>(某些文件系统上的文件删除方法)。
|
||||
* 在 GNU 上,尖括号(`>`)表示<ruby>门<rt>door</rt></ruby>([Illumos][4] 和 Solaris上的进程间通信)。
|
||||
* 竖线(`|`)表示 [FIFO][5] 管道。
|
||||
|
||||
这个选项的一个更简单的版本是 `-p`,它只区分文件和目录。
|
||||
|
||||
(LCTT 译注:在支持彩色的终端上,使用 `--color` 选项可以以不同的颜色来区分文件类型,但要注意如果将输出导入到管道中,则颜色消失。)
|
||||
|
||||
### 长列表
|
||||
|
||||
从 `ls` 获取“长列表”的做法是如此常见,以至于许多发行版将 `ll` 别名为 `ls -l`。长列表提供了许多重要的文件属性,例如权限、拥有每个文件的用户、文件所属的组、文件大小(以字节为单位)以及文件上次更改的日期:
|
||||
|
||||
```
|
||||
$ ls -l
|
||||
-rwxrwx---. 1 seth users 455 Mar 2 2017 estimate.sh
|
||||
-rwxrwxr-x. 1 seth users 662 Apr 29 22:27 factorial
|
||||
-rwxrwx---. 1 seth users 20697793 Jun 29 2018 fop-2.3-bin.tar.gz
|
||||
-rwxrwxr-x. 1 seth users 6210 May 22 10:22 geteltorito
|
||||
-rwxrwx---. 1 seth users 177 Nov 12 2018 html4mutt.sh
|
||||
[...]
|
||||
```
|
||||
|
||||
如果你不想以字节为单位,请添加 `-h` 标志(或 GNU 中的 `--human`)以将文件大小转换为更加人性化的表示方法:
|
||||
|
||||
```
|
||||
$ ls --human
|
||||
-rwxrwx---. 1 seth users 455 Mar 2 2017 estimate.sh
|
||||
-rwxrwxr-x. 1 seth seth 662 Apr 29 22:27 factorial
|
||||
-rwxrwx---. 1 seth users 20M Jun 29 2018 fop-2.3-bin.tar.gz
|
||||
-rwxrwxr-x. 1 seth seth 6.1K May 22 10:22 geteltorito
|
||||
-rwxrwx---. 1 seth users 177 Nov 12 2018 html4mutt.sh
|
||||
```
|
||||
|
||||
要看到更少的信息,你可以带有 `-o` 选项只显示所有者的列,或带有 `-g` 选项只显示所属组的列:
|
||||
|
||||
```
|
||||
$ ls -o
|
||||
-rwxrwx---. 1 seth 455 Mar 2 2017 estimate.sh
|
||||
-rwxrwxr-x. 1 seth 662 Apr 29 22:27 factorial
|
||||
-rwxrwx---. 1 seth 20M Jun 29 2018 fop-2.3-bin.tar.gz
|
||||
-rwxrwxr-x. 1 seth 6.1K May 22 10:22 geteltorito
|
||||
-rwxrwx---. 1 seth 177 Nov 12 2018 html4mutt.sh
|
||||
```
|
||||
|
||||
也可以将两个选项组合使用以显示两者。
|
||||
|
||||
### 时间和日期格式
|
||||
|
||||
`ls` 的长列表格式通常如下所示:
|
||||
|
||||
```
|
||||
-rwxrwx---. 1 seth users 455 Mar 2 2017 estimate.sh
|
||||
-rwxrwxr-x. 1 seth users 662 Apr 29 22:27 factorial
|
||||
-rwxrwx---. 1 seth users 20697793 Jun 29 2018 fop-2.3-bin.tar.gz
|
||||
-rwxrwxr-x. 1 seth users 6210 May 22 10:22 geteltorito
|
||||
-rwxrwx---. 1 seth users 177 Nov 12 2018 html4mutt.sh
|
||||
```
|
||||
|
||||
月份的名字不便于排序,无论是通过计算还是识别(取决于你的大脑是否倾向于喜欢字符串或整数)。你可以使用 `--time-style` 选项和格式名称更改时间戳的格式。可用格式为:
|
||||
|
||||
* `full-iso`:ISO 完整格式(1970-01-01 21:12:00)
|
||||
* `long-iso`:ISO 长格式(1970-01-01 21:12)
|
||||
* `iso`:iso 格式(01-01 21:12)
|
||||
* `locale`:本地化格式(使用你的区域设置)
|
||||
* `posix-STYLE`:POSIX 风格(用区域设置定义替换 `STYLE`)
|
||||
|
||||
你还可以使用 `date` 命令的正式表示法创建自定义样式。
|
||||
|
||||
### 按时间排序
|
||||
|
||||
通常,`ls` 命令按字母顺序排序。你可以使用 `-t` 选项根据文件的最近更改的时间(最新的文件最先列出)进行排序。
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
$ touch foo bar baz
|
||||
$ ls
|
||||
bar baz foo
|
||||
$ touch foo
|
||||
$ ls -t
|
||||
foo bar baz
|
||||
```
|
||||
|
||||
### 列出方式
|
||||
|
||||
`ls` 的标准输出平衡了可读性和空间效率,但有时你需要按照特定方式排列的文件列表。
|
||||
|
||||
要以逗号分隔文件列表,请使用 `-m`:
|
||||
|
||||
```
|
||||
ls -m ~/example
|
||||
bar, baz, foo
|
||||
```
|
||||
|
||||
要强制每行一个文件,请使用 `-1` 选项(这是数字 1,而不是小写的 L):
|
||||
|
||||
```
|
||||
$ ls -1 ~/bin/
|
||||
bar
|
||||
baz
|
||||
foo
|
||||
```
|
||||
|
||||
要按文件扩展名而不是文件名对条目进行排序,请使用 `-X`(这是大写 X):
|
||||
|
||||
```
|
||||
$ ls
|
||||
bar.xfc baz.txt foo.asc
|
||||
$ ls -X
|
||||
foo.asc baz.txt bar.xfc
|
||||
```
|
||||
|
||||
### 隐藏杂项
|
||||
|
||||
在某些 `ls` 列表中有一些你可能不关心的条目。例如,元字符 `.` 和 `..` 分别代表“本目录”和“父目录”。如果你熟悉在终端中如何切换目录,你可能已经知道每个目录都将自己称为 `.`,并将其父目录称为 `..`,因此当你使用 `-a` 选项显示隐藏文件时并不需要它经常提醒你。
|
||||
|
||||
要显示几乎所有隐藏文件(`.` 和 `..` 除外),请使用 `-A` 选项:
|
||||
|
||||
```
|
||||
$ ls -a
|
||||
.
|
||||
..
|
||||
.android
|
||||
.atom
|
||||
.bash_aliases
|
||||
[...]
|
||||
$ ls -A
|
||||
.android
|
||||
.atom
|
||||
.bash_aliases
|
||||
[...]
|
||||
```
|
||||
|
||||
有许多优秀的 Unix 工具有保存备份文件的传统,它们会在保存文件的名称后附加一些特殊字符作为备份文件。例如,在 Vim 中,备份会以在文件名后附加 `~` 字符的文件名保存。
|
||||
|
||||
这些类型的备份文件已经多次使我免于愚蠢的错误,但是经过多年享受它们提供的安全感后,我觉得不需要用视觉证据来证明它们存在。我相信 Linux 应用程序可以生成备份文件(如果它们声称这样做的话),我很乐意相信它们存在 —— 而不用必须看到它们。
|
||||
|
||||
要隐藏备份文件,请使用 `-B` 或 `--ignore-backups` 隐藏常用备份格式(此选项在 BSD 的 `ls` 中不可用):
|
||||
|
||||
```
|
||||
$ ls
|
||||
bar.xfc baz.txt foo.asc~ foo.asc
|
||||
$ ls -B
|
||||
bar.xfc baz.txt foo.asc
|
||||
```
|
||||
|
||||
当然,备份文件仍然存在;它只是过滤掉了,你不必看到它。
|
||||
|
||||
除非另有配置,GNU Emacs 在文件名的开头和结尾添加哈希字符(`#`)来保存备份文件(`#file#`)。其他应用程序可能使用不同的样式。使用什么模式并不重要,因为你可以使用 `--hide` 选项创建自己的排除项:
|
||||
|
||||
```
|
||||
$ ls
|
||||
bar.xfc baz.txt #foo.asc# foo.asc
|
||||
$ ls --hide="#*#"
|
||||
bar.xfc baz.txt foo.asc
|
||||
```
|
||||
|
||||
### 递归地列出目录
|
||||
|
||||
除非你在指定目录上运行 `ls`,否则子目录的内容不会与 `ls` 命令一起列出:
|
||||
|
||||
```
|
||||
$ ls -F
|
||||
example/ quux* xyz.txt
|
||||
$ ls -R
|
||||
quux xyz.txt
|
||||
|
||||
./example:
|
||||
bar.xfc baz.txt #foo.asc# foo.asc
|
||||
```
|
||||
|
||||
### 使用别名使其永久化
|
||||
|
||||
`ls` 命令可能是 shell 会话期间最常使用的命令。这是你的眼睛和耳朵,为你提供上下文信息和确认命令的结果。虽然有很多选项很有用,但 `ls` 之美的一部分就是简洁:两个字符和回车键,你就知道你到底在哪里以及附近有什么。如果你不得不停下思考(更不用说输入)几个不同的选项,它会变得不那么方便,所以通常情况下,即使最有用的选项也不会用了。
|
||||
|
||||
解决方案是为你的 `ls` 命令添加别名,以便在使用它时,你可以获得最关心的信息。
|
||||
|
||||
要在 Bash shell 中为命令创建别名,请在主目录中创建名为 `.bash_aliases` 的文件(必须在开头包含 `.`)。 在此文件中,列出要创建的别名,然后是要为其创建别名的命令。例如:
|
||||
|
||||
```
|
||||
alias ls='ls -A -F -B --human --color'
|
||||
```
|
||||
|
||||
这一行导致你的 Bash shell 将 `ls` 命令解释为 `ls -A -F -B --human --color`。
|
||||
|
||||
你不必仅限于重新定义现有命令,还可以创建自己的别名:
|
||||
|
||||
```
|
||||
alias ll='ls -l'
|
||||
alias la='ls -A'
|
||||
alias lh='ls -h'
|
||||
```
|
||||
|
||||
要使别名起作用,shell 必须知道 `.bash_aliases` 配置文件存在。在编辑器中打开 `.bashrc` 文件(如果它不存在则创建它),并包含以下代码块:
|
||||
|
||||
```
|
||||
if [ -e $HOME/.bash_aliases ]; then
|
||||
source $HOME/.bash_aliases
|
||||
fi
|
||||
```
|
||||
|
||||
每次加载 `.bashrc`(这是一个新的 Bash shell 启动的时候),Bash 会将 `.bash_aliases` 加载到你的环境中。你可以关闭并重新启动 Bash 会话,或者直接强制它执行此操作:
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
如果你忘了你是否有别名命令,`which` 命令可以告诉你:
|
||||
|
||||
```
|
||||
$ which ls
|
||||
alias ls='ls -A -F -B --human --color'
|
||||
/usr/bin/ls
|
||||
```
|
||||
|
||||
如果你将 `ls` 命令别名为带有选项的 `ls` 命令,则可以通过将反斜杠前缀到 `ls` 前来覆盖你的别名。例如,在示例别名中,使用 `-B` 选项隐藏备份文件,这意味着无法使用 `ls` 命令显示备份文件。 可以覆盖该别名以查看备份文件:
|
||||
|
||||
```
|
||||
$ ls
|
||||
bar baz foo
|
||||
$ \ls
|
||||
bar baz baz~ foo
|
||||
```
|
||||
|
||||
### 做一件事,把它做好
|
||||
|
||||
`ls` 命令有很多选项,其中许多是特定用途的或高度依赖于你所使用的终端。在 GNU 系统上查看 `info ls`,或在 GNU 或 BSD 系统上查看 `man ls` 以了解更多选项。
|
||||
|
||||
你可能会觉得奇怪的是,一个以每个工具“做一件事,把它做好”的前提而闻名的系统会让其最常见的命令背负 50 个选项。但是 `ls` 只做一件事:它列出文件,而这 50 个选项允许你控制接收列表的方式,`ls` 的这项工作做得非常、*非常*好。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/master-ls-command
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/sethhttps://opensource.com/users/sambocettahttps://opensource.com/users/scottnesbitthttps://opensource.com/users/sethhttps://opensource.com/users/marcobravohttps://opensource.com/users/sethhttps://opensource.com/users/don-watkinshttps://opensource.com/users/sethhttps://opensource.com/users/jamesfhttps://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/yearbook-haff-rx-linux-file-lead_0.png?itok=-i0NNfDC (Hand putting a Linux file folder into a drawer)
|
||||
[2]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
|
||||
[3]: https://opensource.com/article/19/6/understanding-linux-permissions
|
||||
[4]: https://www.illumos.org/
|
||||
[5]: https://en.wikipedia.org/wiki/FIFO_(computing_and_electronics)
|
||||
@ -0,0 +1,105 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11170-1.html)
|
||||
[#]: subject: (WPS Office on Linux is a Free Alternative to Microsoft Office)
|
||||
[#]: via: (https://itsfoss.com/wps-office-linux/)
|
||||
[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
|
||||
|
||||
WPS Office:Linux 上的 Microsoft Office 的免费替代品
|
||||
======
|
||||
|
||||
> 如果你在寻找 Linux 上 Microsoft Office 免费替代品,那么 WPS Office 是最佳选择之一。它可以免费使用,并兼容 MS Office 文档格式。
|
||||
|
||||
[WPS Office][1] 是一个跨平台的办公生产力套件。它轻巧,并且与 Microsoft Office、Google Docs/Sheets/Slide 和 Adobe PDF 完全兼容。
|
||||
|
||||
对于许多用户而言,WPS Office 足够直观,并且能够满足他们的需求。由于它在外观和兼容性方面与 Microsoft Office 非常相似,因此广受欢迎。
|
||||
|
||||
![WPS Office 2019 All In One Mode][2]
|
||||
|
||||
WPS office 由中国的金山公司创建。对于 Windows 用户而言,WPS Office 有免费版和高级版。对于 Linux 用户,WPS Office 可通过其[社区项目][3]免费获得。
|
||||
|
||||
> **非 FOSS 警告!**
|
||||
|
||||
> WPS Office 不是一个开源软件。因为它对于 Linux 用户免费使用,我们已经在这介绍过它,有时我们也会介绍即使不是开源的 Linux 软件。
|
||||
|
||||
### Linux 上的 WPS Office
|
||||
|
||||
![WPS Office in Linux | Image Credit: Ubuntu Handbook][4]
|
||||
|
||||
WPS Office 有四个主要组件:
|
||||
|
||||
* WPS 文字
|
||||
* WPS 演示
|
||||
* WPS 表格
|
||||
* WPS PDF
|
||||
|
||||
WPS Office 与 MS Office 完全兼容,支持 .doc、.docx、.dotx、.ppt、.pptx、.xls、.xlsx、.docm、.dotm、.xml、.txt、.html、.rtf (等其他),以及它自己的格式(.wps、.wpt)。它还默认包含 Microsoft 字体(以确保兼容性),它可以导出 PDF 并提供超过 10 种语言的拼写检查功能。
|
||||
|
||||
但是,它在 ODT、ODP 和其他开放文档格式方面表现不佳。
|
||||
|
||||
三个主要的 WPS Office 应用都有与 Microsoft Office 非常相似的界面,都有相同的 Ribbon UI。尽管存在细微差别,但使用习惯仍然相对一致。你可以使用 WPS Office 轻松克隆任何 Microsoft Office/LibreOffice 文档。
|
||||
|
||||
![WPS Office Writer][5]
|
||||
|
||||
你可能唯一不喜欢的是一些默认的样式设置(一些标题下面有很多空间等),但这些可以很容易地调整。
|
||||
|
||||
默认情况下,WPS 以 .docx、.pptx 和 .xlsx 文件类型保存文件。你还可以将文档保存到 **[WPS 云][7]**中并与他人协作。另一个不错的功能是能从[这里][8]下载大量模板。
|
||||
|
||||
### 在 Linux 上安装 WPS Office
|
||||
|
||||
WPS 为 Linux 发行版提供 DEB 和 RPM 安装程序。如果你使用的是 Debian/Ubuntu 或基于 Fedora 的发行版,那么安装 WPS Office 就简单了。
|
||||
|
||||
你可以在下载区那下载 Linux 中的 WPS:
|
||||
|
||||
- [下载 WPS Office for Linux][9]
|
||||
|
||||
向下滚动,你将看到最新版本包的链接:
|
||||
|
||||
![WPS Office Download][10]
|
||||
|
||||
下载适合你发行版的文件。只需双击 DEB 或者 RPM 就能[安装它们][11]。这会打开软件中心,你将看到安装选项:
|
||||
|
||||
![WPS Office Install Package][12]
|
||||
|
||||
几秒钟后,应用应该成功安装到你的系统上了!
|
||||
|
||||
你现在可以在“应用程序”菜单中搜索 **WPS**,查找 WPS Office 套件中所有的应用:
|
||||
|
||||
![WPS Applications Menu][13]
|
||||
|
||||
### 你是否使用 WPS Office 或其他软件?
|
||||
|
||||
还有其他 [Microsoft Office 的开源替代方案][14],但它们与 MS Office 的兼容性很差。
|
||||
|
||||
就个人而言,我更喜欢 LibreOffice,但如果你必须要用到 Microsoft Office,你可以尝试在 Linux 上使用 WPS Office。它看起来和 MS Office 类似,并且与 MS 文档格式具有良好的兼容性。它在 Linux 上是免费的,因此你也不必担心 Office 365 订阅。
|
||||
|
||||
你在系统上使用什么办公套件?你曾经在 Linux 上使用过 WPS Office 吗?你的体验如何?
|
||||
|
||||
----------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/wps-office-linux/
|
||||
|
||||
作者:[Sergiu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/sergiu/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.wps.com/
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps2019-all-in-one-mode.png?resize=800%2C526&ssl=1
|
||||
[3]: http://wps-community.org/
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps-2019-Linux.jpg?resize=800%2C450&ssl=1
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps-office-writer.png?resize=800%2C454&ssl=1
|
||||
[7]: https://account.wps.com/?cb=https%3A%2F%2Fdrive.wps.com%2F
|
||||
[8]: https://template.wps.com/
|
||||
[9]: http://wps-community.org/downloads
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps_office_download.jpg?fit=800%2C413&ssl=1
|
||||
[11]: https://itsfoss.com/install-deb-files-ubuntu/
|
||||
[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps_office_install_package.png?fit=800%2C719&ssl=1
|
||||
[13]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps_applications_menu.jpg?fit=800%2C355&ssl=1
|
||||
[14]: https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/
|
||||
@ -0,0 +1,141 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11152-1.html)
|
||||
[#]: subject: (How to Enable Canonical Kernel Livepatch Service on Ubuntu LTS System?)
|
||||
[#]: via: (https://www.2daygeek.com/enable-canonical-kernel-livepatch-service-on-ubuntu-lts-system/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
如何在 Ubuntu LTS 系统上启用 Canonical 的内核实时补丁服务
|
||||
======
|
||||
|
||||

|
||||
|
||||
Canonical 在 Ubuntu 14.04 LTS 系统中引入了<ruby>内核实时补丁服务<rt>Kernel Livepatch Service</rt></ruby>。实时补丁服务允许你安装和应用关键的 Linux 内核安全更新,而无需重新启动系统。这意味着,在应用内核补丁程序后,你无需重新启动系统。而通常情况下,我们需要在安装内核补丁后重启 Linux 服务器才能供系统使用。
|
||||
|
||||
实时修补非常快。大多数内核修复程序只需要几秒钟。Canonical 的实时补丁服务对于不超过 3 个系统的用户无需任何费用。你可以通过命令行在桌面和服务器中启用 Canonical 实时补丁服务。
|
||||
|
||||
这个实时补丁系统旨在解决高级和关键的 Linux 内核安全漏洞。
|
||||
|
||||
有关[支持的系统][1]和其他详细信息,请参阅下表。
|
||||
|
||||
Ubuntu 版本 | 架构 | 内核版本 | 内核变体
|
||||
---|---|---|---
|
||||
Ubuntu 18.04 LTS | 64-bit x86 | 4.15 | 仅 GA 通用和低电压内核
|
||||
Ubuntu 16.04 LTS | 64-bit x86 | 4.4 | 仅 GA 通用和低电压内核
|
||||
Ubuntu 14.04 LTS | 64-bit x86 | 4.4 | 仅 Hardware Enablement 内核
|
||||
|
||||
**注意**:Ubuntu 14.04 中的 Canonical 实时补丁服务 LTS 要求用户在 Trusty 中运行 Ubuntu v4.4 内核。如果你当前没有运行使用该服务,请重新启动到此内核。
|
||||
|
||||
为此,请按照以下步骤操作。
|
||||
|
||||
### 如何获取实时补丁令牌?
|
||||
|
||||
导航到 [Canonical 实时补丁服务页面][2],如果要使用免费服务,请选择“Ubuntu 用户”。它适用于不超过 3 个系统的用户。如果你是 “UA 客户” 或多于 3 个系统,请选择 “Ubuntu customer”。最后,单击 “Get your Livepatch token” 按钮。
|
||||
|
||||
![][4]
|
||||
|
||||
确保你已经在 “Ubuntu One” 中拥有帐号。否则,可以创建一个新的。
|
||||
|
||||
登录后,你将获得你的帐户密钥。
|
||||
|
||||
![][5]
|
||||
|
||||
### 在系统中安装 Snap 守护程序
|
||||
|
||||
实时补丁系统通过快照包安装。因此,请确保在 Ubuntu 系统上安装了 snapd 守护程序。
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
$ sudo apt install snapd
|
||||
```
|
||||
|
||||
### 如何系统中安装和配置实时补丁服务?
|
||||
|
||||
通过运行以下命令安装 `canonical-livepatch` 守护程序。
|
||||
|
||||
```
|
||||
$ sudo snap install canonical-livepatch
|
||||
canonical-livepatch 9.4.1 from Canonical* installed
|
||||
```
|
||||
|
||||
运行以下命令以在 Ubuntu 计算机上启用实时内核补丁程序。
|
||||
|
||||
```
|
||||
$ sudo canonical-livepatch enable xxxxc4xxxx67xxxxbxxxxbxxxxfbxx4e
|
||||
|
||||
Successfully enabled device. Using machine-token: xxxxc4xxxx67xxxxbxxxxbxxxxfbxx4e
|
||||
```
|
||||
|
||||
运行以下命令查看实时补丁机器的状态。
|
||||
|
||||
```
|
||||
$ sudo canonical-livepatch status
|
||||
|
||||
client-version: 9.4.1
|
||||
architecture: x86_64
|
||||
cpu-model: Intel(R) Core(TM) i7-6700HQ CPU @ 2.60GHz
|
||||
last-check: 2019-07-24T12:30:04+05:30
|
||||
boot-time: 2019-07-24T12:11:06+05:30
|
||||
uptime: 19m11s
|
||||
status:
|
||||
- kernel: 4.15.0-55.60-generic
|
||||
running: true
|
||||
livepatch:
|
||||
checkState: checked
|
||||
patchState: nothing-to-apply
|
||||
version: ""
|
||||
fixes: ""
|
||||
```
|
||||
|
||||
使用 `--verbose` 开关运行上述相同的命令,以获取有关实时修补机器的更多信息。
|
||||
|
||||
```
|
||||
$ sudo canonical-livepatch status --verbose
|
||||
```
|
||||
|
||||
如果要手动运行补丁程序,请执行以下命令。
|
||||
|
||||
```
|
||||
$ sudo canonical-livepatch refresh
|
||||
|
||||
Before refresh:
|
||||
|
||||
kernel: 4.15.0-55.60-generic
|
||||
fully-patched: true
|
||||
version: ""
|
||||
|
||||
After refresh:
|
||||
|
||||
kernel: 4.15.0-55.60-generic
|
||||
fully-patched: true
|
||||
version: ""
|
||||
```
|
||||
|
||||
`patchState` 会有以下状态之一:
|
||||
|
||||
* `applied`:未发现任何漏洞
|
||||
* `nothing-to-apply`:成功找到并修补了漏洞
|
||||
* `kernel-upgrade-required`:实时补丁服务无法安装补丁来修复漏洞
|
||||
|
||||
请注意,安装内核补丁与在系统上升级/安装新内核不同。如果安装了新内核,则必须重新引导系统以激活新内核。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/enable-canonical-kernel-livepatch-service-on-ubuntu-lts-system/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://wiki.ubuntu.com/Kernel/Livepatch
|
||||
[2]: https://auth.livepatch.canonical.com/
|
||||
[3]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[4]: https://www.2daygeek.com/wp-content/uploads/2019/07/enable-canonical-livepatch-service-on-ubuntu-lts-system-1.jpg
|
||||
[5]: https://www.2daygeek.com/wp-content/uploads/2019/07/enable-canonical-livepatch-service-on-ubuntu-lts-system-2.jpg
|
||||
@ -0,0 +1,70 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11167-1.html)
|
||||
[#]: subject: (Is This the End of Floppy Disk in Linux? Linus Torvalds Marks Floppy Disks ‘Orphaned’)
|
||||
[#]: via: (https://itsfoss.com/end-of-floppy-disk-in-linux/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Linux 中的软盘走向终结了吗?Torvalds 将软盘的驱动标记为“孤儿”
|
||||
======
|
||||
|
||||
> 在 Linux 内核最近的提交当中,Linus Torvalds 将软盘的驱动程序标记为孤儿。这标志着软盘在 Linux 中步入结束了吗?
|
||||
|
||||
有可能你很多年没见过真正的软盘了。如果你正在寻找带软盘驱动器的计算机,可能需要去博物馆里看看。
|
||||
|
||||
在二十多年前,软盘是用于存储数据和运行操作系统的流行介质。[早期的 Linux 发行版][1]使用软盘进行“分发”。软盘也广泛用于保存和传输数据。
|
||||
|
||||
你有没有想过为什么许多应用程序中的保存图标看起来像软盘?因为它就是软盘啊!软盘常用于保存数据,因此许多应用程序将其用作保存图标,并且这个传统一直延续至今。
|
||||
|
||||
![][2]
|
||||
|
||||
今天我为什么要说起软盘?因为 Linus Torvalds 在一个 Linux 内核代码的提交里标记软盘的驱动程序为“孤儿”。
|
||||
|
||||
### 在 Linux 内核中被标记为“孤儿”的软盘驱动程序
|
||||
|
||||
正如你可以在 [GitHub 镜像上的提交][3]中看到的那样,开发人员 Jiri 不再使用带有软驱的工作计算机了。而如果没有正确的硬件,Jiri 将无法继续开发。这就是 Torvalds 将其标记为孤儿的原因。
|
||||
|
||||
> 越来越难以找到可以实际工作的软盘的物理硬件,虽然 Willy 能够对此进行测试,但我认为从实际的硬件角度来看,这个驱动程序几乎已经死了。目前仍然销售的硬件似乎主要是基于 USB 的,根本不使用这种传统的驱动器。
|
||||
|
||||
![][4]
|
||||
|
||||
### “孤儿”在 Linux 内核中意味着什么?
|
||||
|
||||
“孤儿”意味着没有开发人员能够或愿意支持这部分代码。如果没有其他人出现继续维护和开发它,孤儿模块可能会被弃用并最终删除。
|
||||
|
||||
### 它没有被立即删除
|
||||
|
||||
Torvalds 指出,各种虚拟环境模拟器仍在使用软盘驱动器。所以软盘的驱动程序不会被立即丢弃。
|
||||
|
||||
> 各种 VM 环境中仍然在仿真旧的软盘控制器,因此该驱动程序不会消失,但让我们看看是否有人有兴趣进一步维护它。
|
||||
|
||||
为什么不永远保持内核中的软盘驱动器支持呢?因为这将构成安全威胁。即使没有真正的计算机使用软盘驱动程序,虚拟机仍然拥有它,这将使虚拟机容易受到攻击。
|
||||
|
||||
### 一个时代的终结?
|
||||
|
||||
这将是一个时代的结束还是会有其他人出现并承担起在 Linux 中继续维护软盘驱动程序的责任?只有时间会给出答案。
|
||||
|
||||
在 Linux 内核中,软盘驱动器成为孤儿我不觉得有什么可惜的。
|
||||
|
||||
在过去的十五年里我没有使用过软盘,我怀疑很多人也是如此。那么你呢?你有没有用过软盘?如果是的话,你最后一次使用它的时间是什么时候?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/end-of-floppy-disk-in-linux/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/earliest-linux-distros/
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/floppy-disk-icon-of-saving.png?resize=800%2C300&ssl=1
|
||||
[3]: https://github.com/torvalds/linux/commit/47d6a7607443ea43dbc4d0f371bf773540a8f8f4
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/07/End-of-Floppy-in-Linux.png?resize=800%2C450&ssl=1
|
||||
[5]: https://itsfoss.com/valve-annouces-linux-based-gaming-operating-system-steamos/
|
||||
322
published/20190701 Get modular with Python functions.md
Normal file
322
published/20190701 Get modular with Python functions.md
Normal file
@ -0,0 +1,322 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11295-1.html)
|
||||
[#]: subject: (Get modular with Python functions)
|
||||
[#]: via: (https://opensource.com/article/19/7/get-modular-python-functions)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth/users/xd-deng/users/nhuntwalker/users/don-watkins)
|
||||
|
||||
使用 Python 函数进行模块化
|
||||
======
|
||||
|
||||
> 使用 Python 函数来最大程度地减少重复任务编码工作量。
|
||||
|
||||

|
||||
|
||||
你是否对函数、类、方法、库和模块等花哨的编程术语感到困惑?你是否在与变量作用域斗争?无论你是自学成才的还是经过正式培训的程序员,代码的模块化都会令人困惑。但是类和库鼓励模块化代码,因为模块化代码意味着只需构建一个多用途代码块集合,就可以在许多项目中使用它们来减少编码工作量。换句话说,如果你按照本文对 [Python][2] 函数的研究,你将找到更聪明的工作方法,这意味着更少的工作。
|
||||
|
||||
本文假定你对 Python 很熟(LCTT 译注:稍微熟悉就可以),并且可以编写和运行一个简单的脚本。如果你还没有使用过 Python,请首先阅读我的文章:[Python 简介][3]。
|
||||
|
||||
### 函数
|
||||
|
||||
函数是迈向模块化过程中重要的一步,因为它们是形式化的重复方法。如果在你的程序中,有一个任务需要反复执行,那么你可以将代码放入一个函数中,根据需要随时调用该函数。这样,你只需编写一次代码,就可以随意使用它。
|
||||
|
||||
以下一个简单函数的示例:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
import time
|
||||
|
||||
def Timer():
|
||||
print("Time is " + str(time.time() ))
|
||||
```
|
||||
|
||||
创建一个名为 `mymodularity` 的目录,并将以上函数代码保存为该目录下的 `timestamp.py`。
|
||||
|
||||
除了这个函数,在 `mymodularity` 目录中创建一个名为 `__init__.py` 的文件,你可以在文件管理器或 bash shell 中执行此操作:
|
||||
|
||||
```
|
||||
$ touch mymodularity/__init__.py
|
||||
```
|
||||
|
||||
现在,你已经创建了属于你自己的 Python 库(Python 中称为“模块”),名为 `mymodularity`。它不是一个特别有用的模块,因为它所做的只是导入 `time` 模块并打印一个时间戳,但这只是一个开始。
|
||||
|
||||
要使用你的函数,像对待任何其他 Python 模块一样对待它。以下是一个小应用,它使用你的 `mymodularity` 软件包来测试 Python `sleep()` 函数的准确性。将此文件保存为 `sleeptest.py`,注意要在 `mymodularity` 文件夹 *之外*,因为如果你将它保存在 `mymodularity` *里面*,那么它将成为你的包中的一个模块,你肯定不希望这样。
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import time
|
||||
from mymodularity import timestamp
|
||||
|
||||
print("Testing Python sleep()...")
|
||||
|
||||
# modularity
|
||||
timestamp.Timer()
|
||||
time.sleep(3)
|
||||
timestamp.Timer()
|
||||
```
|
||||
|
||||
在这个简单的脚本中,你从 `mymodularity` 包中调用 `timestamp` 模块两次。从包中导入模块时,通常的语法是从包中导入你所需的模块,然后使用 *模块名称 + 一个点 + 要调用的函数名*(例如 `timestamp.Timer()`)。
|
||||
|
||||
你调用了两次 `Timer()` 函数,所以如果你的 `timestamp` 模块比这个简单的例子复杂些,那么你将节省大量重复代码。
|
||||
|
||||
保存文件并运行:
|
||||
|
||||
```
|
||||
$ python3 ./sleeptest.py
|
||||
Testing Python sleep()...
|
||||
Time is 1560711266.1526039
|
||||
Time is 1560711269.1557732
|
||||
```
|
||||
|
||||
根据测试,Python 中的 `sleep` 函数非常准确:在三秒钟等待之后,时间戳成功且正确地增加了 3,在微秒单位上差距很小。
|
||||
|
||||
Python 库的结构看起来可能令人困惑,但其实它并不是什么魔法。Python *被编程* 为一个包含 Python 代码的目录,并附带一个 `__init__.py` 文件,那么这个目录就会被当作一个包,并且 Python 会首先在当前目录中查找可用模块。这就是为什么语句 `from mymodularity import timestamp` 有效的原因:Python 在当前目录查找名为 `mymodularity` 的目录,然后查找 `timestamp.py` 文件。
|
||||
|
||||
你在这个例子中所做的功能和以下这个非模块化的版本是一样的:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import time
|
||||
from mymodularity import timestamp
|
||||
|
||||
print("Testing Python sleep()...")
|
||||
|
||||
# no modularity
|
||||
print("Time is " + str(time.time() ) )
|
||||
time.sleep(3)
|
||||
print("Time is " + str(time.time() ) )
|
||||
```
|
||||
|
||||
对于这样一个简单的例子,其实没有必要以这种方式编写测试,但是对于编写自己的模块来说,最佳实践是你的代码是通用的,可以将它重用于其他项目。
|
||||
|
||||
通过在调用函数时传递信息,可以使代码更通用。例如,假设你想要使用模块来测试的不是 *系统* 的 `sleep` 函数,而是 *用户自己实现* 的 `sleep` 函数,更改 `timestamp` 代码,使它接受一个名为 `msg` 的传入变量,它将是一个字符串,控制每次调用 `timestamp` 时如何显示:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import time
|
||||
|
||||
# 更新代码
|
||||
def Timer(msg):
|
||||
print(str(msg) + str(time.time() ) )
|
||||
```
|
||||
|
||||
现在函数比以前更抽象了。它仍会打印时间戳,但是它为用户打印的内容 `msg` 还是未定义的。这意味着你需要在调用函数时定义它。
|
||||
|
||||
`Timer` 函数接受的 `msg` 参数是随便命名的,你可以使用参数 `m`、`message` 或 `text`,或是任何对你来说有意义的名称。重要的是,当调用 `timestamp.Timer` 函数时,它接收一个文本作为其输入,将接收到的任何内容放入 `msg` 变量中,并使用该变量完成任务。
|
||||
|
||||
以下是一个测试测试用户正确感知时间流逝能力的新程序:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
from mymodularity import timestamp
|
||||
|
||||
print("Press the RETURN key. Count to 3, and press RETURN again.")
|
||||
|
||||
input()
|
||||
timestamp.Timer("Started timer at ")
|
||||
|
||||
print("Count to 3...")
|
||||
|
||||
input()
|
||||
timestamp.Timer("You slept until ")
|
||||
```
|
||||
|
||||
将你的新程序保存为 `response.py`,运行它:
|
||||
|
||||
```
|
||||
$ python3 ./response.py
|
||||
Press the RETURN key. Count to 3, and press RETURN again.
|
||||
|
||||
Started timer at 1560714482.3772075
|
||||
Count to 3...
|
||||
|
||||
You slept until 1560714484.1628013
|
||||
```
|
||||
|
||||
### 函数和所需参数
|
||||
|
||||
新版本的 `timestamp` 模块现在 *需要* 一个 `msg` 参数。这很重要,因为你的第一个应用程序将无法运行,因为它没有将字符串传递给 `timestamp.Timer` 函数:
|
||||
|
||||
```
|
||||
$ python3 ./sleeptest.py
|
||||
Testing Python sleep()...
|
||||
Traceback (most recent call last):
|
||||
File "./sleeptest.py", line 8, in <module>
|
||||
timestamp.Timer()
|
||||
TypeError: Timer() missing 1 required positional argument: 'msg'
|
||||
```
|
||||
|
||||
你能修复你的 `sleeptest.py` 应用程序,以便它能够与更新后的模块一起正确运行吗?
|
||||
|
||||
### 变量和函数
|
||||
|
||||
通过设计,函数限制了变量的范围。换句话说,如果在函数内创建一个变量,那么这个变量 *只* 在这个函数内起作用。如果你尝试在函数外部使用函数内部出现的变量,就会发生错误。
|
||||
|
||||
下面是对 `response.py` 应用程序的修改,尝试从 `timestamp.Timer()` 函数外部打印 `msg` 变量:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
from mymodularity import timestamp
|
||||
|
||||
print("Press the RETURN key. Count to 3, and press RETURN again.")
|
||||
|
||||
input()
|
||||
timestamp.Timer("Started timer at ")
|
||||
|
||||
print("Count to 3...")
|
||||
|
||||
input()
|
||||
timestamp.Timer("You slept for ")
|
||||
|
||||
print(msg)
|
||||
```
|
||||
|
||||
试着运行它,查看错误:
|
||||
|
||||
```
|
||||
$ python3 ./response.py
|
||||
Press the RETURN key. Count to 3, and press RETURN again.
|
||||
|
||||
Started timer at 1560719527.7862902
|
||||
Count to 3...
|
||||
|
||||
You slept for 1560719528.135406
|
||||
Traceback (most recent call last):
|
||||
File "./response.py", line 15, in <module>
|
||||
print(msg)
|
||||
NameError: name 'msg' is not defined
|
||||
```
|
||||
|
||||
应用程序返回一个 `NameError` 消息,因为没有定义 `msg`。这看起来令人困惑,因为你编写的代码定义了 `msg`,但你对代码的了解比 Python 更深入。调用函数的代码,不管函数是出现在同一个文件中,还是打包为模块,都不知道函数内部发生了什么。一个函数独立地执行它的计算,并返回你想要它返回的内容。这其中所涉及的任何变量都只是 *本地的*:它们只存在于函数中,并且只存在于函数完成其目的所需时间内。
|
||||
|
||||
#### Return 语句
|
||||
|
||||
如果你的应用程序需要函数中特定包含的信息,那么使用 `return` 语句让函数在运行后返回有意义的数据。
|
||||
|
||||
时间就是金钱,所以修改 `timestamp` 函数,以使其用于一个虚构的收费系统:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import time
|
||||
|
||||
def Timer(msg):
|
||||
print(str(msg) + str(time.time() ) )
|
||||
charge = .02
|
||||
return charge
|
||||
```
|
||||
|
||||
现在,`timestamp` 模块每次调用都收费 2 美分,但最重要的是,它返回每次调用时所收取的金额。
|
||||
|
||||
以下一个如何使用 `return` 语句的演示:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
from mymodularity import timestamp
|
||||
|
||||
print("Press RETURN for the time (costs 2 cents).")
|
||||
print("Press Q RETURN to quit.")
|
||||
|
||||
total = 0
|
||||
|
||||
while True:
|
||||
kbd = input()
|
||||
if kbd.lower() == "q":
|
||||
print("You owe $" + str(total) )
|
||||
exit()
|
||||
else:
|
||||
charge = timestamp.Timer("Time is ")
|
||||
total = total+charge
|
||||
```
|
||||
|
||||
在这个示例代码中,变量 `charge` 为 `timestamp.Timer()` 函数的返回,它接收函数返回的任何内容。在本例中,函数返回一个数字,因此使用一个名为 `total` 的新变量来跟踪已经进行了多少更改。当应用程序收到要退出的信号时,它会打印总花费:
|
||||
|
||||
```
|
||||
$ python3 ./charge.py
|
||||
Press RETURN for the time (costs 2 cents).
|
||||
Press Q RETURN to quit.
|
||||
|
||||
Time is 1560722430.345412
|
||||
|
||||
Time is 1560722430.933996
|
||||
|
||||
Time is 1560722434.6027434
|
||||
|
||||
Time is 1560722438.612629
|
||||
|
||||
Time is 1560722439.3649364
|
||||
q
|
||||
You owe $0.1
|
||||
```
|
||||
|
||||
#### 内联函数
|
||||
|
||||
函数不必在单独的文件中创建。如果你只是针对一个任务编写一个简短的脚本,那么在同一个文件中编写函数可能更有意义。唯一的区别是你不必导入自己的模块,但函数的工作方式是一样的。以下是时间测试应用程序的最新迭代:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import time
|
||||
|
||||
total = 0
|
||||
|
||||
def Timer(msg):
|
||||
print(str(msg) + str(time.time() ) )
|
||||
charge = .02
|
||||
return charge
|
||||
|
||||
print("Press RETURN for the time (costs 2 cents).")
|
||||
print("Press Q RETURN to quit.")
|
||||
|
||||
while True:
|
||||
kbd = input()
|
||||
if kbd.lower() == "q":
|
||||
print("You owe $" + str(total) )
|
||||
exit()
|
||||
else:
|
||||
charge = Timer("Time is ")
|
||||
total = total+charge
|
||||
```
|
||||
|
||||
它没有外部依赖(Python 发行版中包含 `time` 模块),产生与模块化版本相同的结果。它的优点是一切都位于一个文件中,缺点是你不能在其他脚本中使用 `Timer()` 函数,除非你手动复制和粘贴它。
|
||||
|
||||
#### 全局变量
|
||||
|
||||
在函数外部创建的变量没有限制作用域,因此它被视为 *全局* 变量。
|
||||
|
||||
全局变量的一个例子是在 `charge.py` 中用于跟踪当前花费的 `total` 变量。`total` 是在函数之外创建的,因此它绑定到应用程序而不是特定函数。
|
||||
|
||||
应用程序中的函数可以访问全局变量,但要将变量传入导入的模块,你必须像发送 `msg` 变量一样将变量传入模块。
|
||||
|
||||
全局变量很方便,因为它们似乎随时随地都可用,但也很难跟踪它们,很难知道哪些变量不再需要了但是仍然在系统内存中停留(尽管 Python 有非常好的垃圾收集机制)。
|
||||
|
||||
但是,全局变量很重要,因为不是所有的变量都可以是函数或类的本地变量。现在你知道了如何向函数传入变量并获得返回,事情就变得容易了。
|
||||
|
||||
### 总结
|
||||
|
||||
你已经学到了很多关于函数的知识,所以开始将它们放入你的脚本中 —— 如果它不是作为单独的模块,那么作为代码块,你不必在一个脚本中编写多次。在本系列的下一篇文章中,我将介绍 Python 类。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/get-modular-python-functions
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth/users/xd-deng/users/nhuntwalker/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/openstack_python_vim_1.jpg?itok=lHQK5zpm
|
||||
[2]: https://www.python.org/
|
||||
[3]: https://opensource.com/article/17/10/python-10
|
||||
@ -0,0 +1,305 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11317-1.html)
|
||||
[#]: subject: (Learn object-oriented programming with Python)
|
||||
[#]: via: (https://opensource.com/article/19/7/get-modular-python-classes)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
使用 Python 学习面对对象的编程
|
||||
======
|
||||
|
||||
> 使用 Python 类使你的代码变得更加模块化。
|
||||
|
||||

|
||||
|
||||
在我上一篇文章中,我解释了如何通过使用函数、创建模块或者两者一起来[使 Python 代码更加模块化][2]。函数对于避免重复多次使用的代码非常有用,而模块可以确保你在不同的项目中复用代码。但是模块化还有另一种方法:类。
|
||||
|
||||
如果你已经听过<ruby>面对对象编程<rt>object-oriented programming</rt></ruby>(OOP)这个术语,那么你可能会对类的用途有一些概念。程序员倾向于将类视为一个虚拟对象,有时与物理世界中的某些东西直接相关,有时则作为某种编程概念的表现形式。无论哪种表示,当你想要在程序中为你或程序的其他部分创建“对象”时,你都可以创建一个类来交互。
|
||||
|
||||
### 没有类的模板
|
||||
|
||||
假设你正在编写一个以幻想世界为背景的游戏,并且你需要这个应用程序能够涌现出各种坏蛋来给玩家的生活带来一些刺激。了解了很多关于函数的知识后,你可能会认为这听起来像是函数的一个教科书案例:需要经常重复的代码,但是在调用时可以考虑变量而只编写一次。
|
||||
|
||||
下面一个纯粹基于函数的敌人生成器实现的例子:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import random
|
||||
|
||||
def enemy(ancestry,gear):
|
||||
enemy=ancestry
|
||||
weapon=gear
|
||||
hp=random.randrange(0,20)
|
||||
ac=random.randrange(0,20)
|
||||
return [enemy,weapon,hp,ac]
|
||||
|
||||
def fight(tgt):
|
||||
print("You take a swing at the " + tgt[0] + ".")
|
||||
hit=random.randrange(0,20)
|
||||
if hit > tgt[3]:
|
||||
print("You hit the " + tgt[0] + " for " + str(hit) + " damage!")
|
||||
tgt[2] = tgt[2] - hit
|
||||
else:
|
||||
print("You missed.")
|
||||
|
||||
|
||||
foe=enemy("troll","great axe")
|
||||
print("You meet a " + foe[0] + " wielding a " + foe[1])
|
||||
print("Type the a key and then RETURN to attack.")
|
||||
|
||||
while True:
|
||||
action=input()
|
||||
|
||||
if action.lower() == "a":
|
||||
fight(foe)
|
||||
|
||||
if foe[2] < 1:
|
||||
print("You killed your foe!")
|
||||
else:
|
||||
print("The " + foe[0] + " has " + str(foe[2]) + " HP remaining")
|
||||
```
|
||||
|
||||
`enemy` 函数创造了一个具有多个属性的敌人,例如谱系、武器、生命值和防御等级。它返回每个属性的列表,表示敌人全部特征。
|
||||
|
||||
从某种意义上说,这段代码创建了一个对象,即使它还没有使用类。程序员将这个 `enemy` 称为*对象*,因为该函数的结果(本例中是一个包含字符串和整数的列表)表示游戏中一个单独但复杂的*东西*。也就是说,列表中字符串和整数不是任意的:它们一起描述了一个虚拟对象。
|
||||
|
||||
在编写描述符集合时,你可以使用变量,以便随时使用它们来生成敌人。这有点像模板。
|
||||
|
||||
在示例代码中,当需要对象的属性时,会检索相应的列表项。例如,要获取敌人的谱系,代码会查询 `foe[0]`,对于生命值,会查询 `foe[2]`,以此类推。
|
||||
|
||||
这种方法没有什么不妥,代码按预期运行。你可以添加更多不同类型的敌人,创建一个敌人类型列表,并在敌人创建期间从列表中随机选择,等等,它工作得很好。实际上,[Lua][3] 非常有效地利用这个原理来近似了一个面对对象模型。
|
||||
|
||||
然而,有时候对象不仅仅是属性列表。
|
||||
|
||||
### 使用对象
|
||||
|
||||
在 Python 中,一切都是对象。你在 Python 中创建的任何东西都是某个预定义模板的*实例*。甚至基本的字符串和整数都是 Python `type` 类的衍生物。你可以在这个交互式 Python shell 中见证:
|
||||
|
||||
```
|
||||
>>> foo=3
|
||||
>>> type(foo)
|
||||
<class 'int'>
|
||||
>>> foo="bar"
|
||||
>>> type(foo)
|
||||
<class 'str'>
|
||||
```
|
||||
|
||||
当一个对象由一个类定义时,它不仅仅是一个属性的集合,Python 类具有各自的函数。从逻辑上讲,这很方便,因为只涉及某个对象类的操作包含在该对象的类中。
|
||||
|
||||
在示例代码中,`fight` 的代码是主应用程序的功能。这对于一个简单的游戏来说是可行的,但对于一个复杂的游戏来说,世界中不仅仅有玩家和敌人,还可能有城镇居民、牲畜、建筑物、森林等等,它们都不需要使用战斗功能。将战斗代码放在敌人的类中意味着你的代码更有条理,在一个复杂的应用程序中,这是一个重要的优势。
|
||||
|
||||
此外,每个类都有特权访问自己的本地变量。例如,敌人的生命值,除了某些功能之外,是不会改变的数据。游戏中的随机蝴蝶不应该意外地将敌人的生命值降低到 0。理想情况下,即使没有类,也不会发生这种情况。但是在具有大量活动部件的复杂应用程序中,确保不需要相互交互的部件永远不会发生这种情况,这是一个非常有用的技巧。
|
||||
|
||||
Python 类也受垃圾收集的影响。当不再使用类的实例时,它将被移出内存。你可能永远不知道这种情况会什么时候发生,但是你往往知道什么时候它不会发生,因为你的应用程序占用了更多的内存,而且运行速度比较慢。将数据集隔离到类中可以帮助 Python 跟踪哪些数据正在使用,哪些不在需要了。
|
||||
|
||||
### 优雅的 Python
|
||||
|
||||
下面是一个同样简单的战斗游戏,使用了 `Enemy` 类:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import random
|
||||
|
||||
class Enemy():
|
||||
def __init__(self,ancestry,gear):
|
||||
self.enemy=ancestry
|
||||
self.weapon=gear
|
||||
self.hp=random.randrange(10,20)
|
||||
self.ac=random.randrange(12,20)
|
||||
self.alive=True
|
||||
|
||||
def fight(self,tgt):
|
||||
print("You take a swing at the " + self.enemy + ".")
|
||||
hit=random.randrange(0,20)
|
||||
|
||||
if self.alive and hit > self.ac:
|
||||
print("You hit the " + self.enemy + " for " + str(hit) + " damage!")
|
||||
self.hp = self.hp - hit
|
||||
print("The " + self.enemy + " has " + str(self.hp) + " HP remaining")
|
||||
else:
|
||||
print("You missed.")
|
||||
|
||||
if self.hp < 1:
|
||||
self.alive=False
|
||||
|
||||
# 游戏开始
|
||||
foe=Enemy("troll","great axe")
|
||||
print("You meet a " + foe.enemy + " wielding a " + foe.weapon)
|
||||
|
||||
# 主函数循环
|
||||
while True:
|
||||
|
||||
print("Type the a key and then RETURN to attack.")
|
||||
|
||||
action=input()
|
||||
|
||||
if action.lower() == "a":
|
||||
foe.fight(foe)
|
||||
|
||||
if foe.alive == False:
|
||||
print("You have won...this time.")
|
||||
exit()
|
||||
```
|
||||
|
||||
这个版本的游戏将敌人作为一个包含相同属性(谱系、武器、生命值和防御)的对象来处理,并添加一个新的属性来衡量敌人时候已被击败,以及一个战斗功能。
|
||||
|
||||
类的第一个函数是一个特殊的函数,在 Python 中称为 `init` 或初始化的函数。这类似于其他语言中的[构造器][4],它创建了类的一个实例,你可以通过它的属性和调用类时使用的任何变量来识别它(示例代码中的 `foe`)。
|
||||
|
||||
### Self 和类实例
|
||||
|
||||
类的函数接受一种你在类之外看不到的新形式的输入:`self`。如果不包含 `self`,那么当你调用类函数时,Python 无法知道要使用的类的*哪个*实例。这就像在一间充满兽人的房间里说:“我要和兽人战斗”,向一个兽人发起。没有人知道你指的是谁,所有兽人就都上来了。
|
||||
|
||||
![Image of an Orc, CC-BY-SA by Buch on opengameart.org][5]
|
||||
|
||||
*CC-BY-SA by Buch on opengameart.org*
|
||||
|
||||
类中创建的每个属性都以 `self` 符号作为前缀,该符号将变量标识为类的属性。一旦派生出类的实例,就用表示该实例的变量替换掉 `self` 前缀。使用这个技巧,你可以在一间满是兽人的房间里说:“我要和谱系是 orc 的兽人战斗”,这样来挑战一个兽人。当 orc 听到 “gorblar.orc” 时,它就知道你指的是谁(他自己),所以你得到是一场公平的战斗而不是斗殴。在 Python 中:
|
||||
|
||||
```
|
||||
gorblar=Enemy("orc","sword")
|
||||
print("The " + gorblar.enemy + " has " + str(gorblar.hp) + " remaining.")
|
||||
```
|
||||
|
||||
通过检索类属性(`gorblar.enemy` 或 `gorblar.hp` 或你需要的任何对象的任何值)而不是查询 `foe[0]`(在函数示例中)或 `gorblar[0]` 来寻找敌人。
|
||||
|
||||
### 本地变量
|
||||
|
||||
如果类中的变量没有以 `self` 关键字作为前缀,那么它就是一个局部变量,就像在函数中一样。例如,无论你做什么,你都无法访问 `Enemy.fight` 类之外的 `hit` 变量:
|
||||
|
||||
```
|
||||
>>> print(foe.hit)
|
||||
Traceback (most recent call last):
|
||||
File "./enclass.py", line 38, in <module>
|
||||
print(foe.hit)
|
||||
AttributeError: 'Enemy' object has no attribute 'hit'
|
||||
|
||||
>>> print(foe.fight.hit)
|
||||
Traceback (most recent call last):
|
||||
File "./enclass.py", line 38, in <module>
|
||||
print(foe.fight.hit)
|
||||
AttributeError: 'function' object has no attribute 'hit'
|
||||
```
|
||||
|
||||
`hit` 变量包含在 Enemy 类中,并且只能“存活”到在战斗中发挥作用。
|
||||
|
||||
### 更模块化
|
||||
|
||||
本例使用与主应用程序相同的文本文档中的类。在一个复杂的游戏中,我们更容易将每个类看作是自己独立的应用程序。当多个开发人员处理同一个应用程序时,你会看到这一点:一个开发人员负责一个类,另一个开发人员负责主程序,只要他们彼此沟通这个类必须具有什么属性,就可以并行地开发这两个代码块。
|
||||
|
||||
要使这个示例游戏模块化,可以把它拆分为两个文件:一个用于主应用程序,另一个用于类。如果它是一个更复杂的应用程序,你可能每个类都有一个文件,或每个逻辑类组有一个文件(例如,用于建筑物的文件,用于自然环境的文件,用于敌人或 NPC 的文件等)。
|
||||
|
||||
将只包含 `Enemy` 类的一个文件保存为 `enemy.py`,将另一个包含其他内容的文件保存为 `main.py`。
|
||||
|
||||
以下是 `enemy.py`:
|
||||
|
||||
```
|
||||
import random
|
||||
|
||||
class Enemy():
|
||||
def __init__(self,ancestry,gear):
|
||||
self.enemy=ancestry
|
||||
self.weapon=gear
|
||||
self.hp=random.randrange(10,20)
|
||||
self.stg=random.randrange(0,20)
|
||||
self.ac=random.randrange(0,20)
|
||||
self.alive=True
|
||||
|
||||
def fight(self,tgt):
|
||||
print("You take a swing at the " + self.enemy + ".")
|
||||
hit=random.randrange(0,20)
|
||||
|
||||
if self.alive and hit > self.ac:
|
||||
print("You hit the " + self.enemy + " for " + str(hit) + " damage!")
|
||||
self.hp = self.hp - hit
|
||||
print("The " + self.enemy + " has " + str(self.hp) + " HP remaining")
|
||||
else:
|
||||
print("You missed.")
|
||||
|
||||
if self.hp < 1:
|
||||
self.alive=False
|
||||
```
|
||||
|
||||
以下是 `main.py`:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import enemy as en
|
||||
|
||||
# game start
|
||||
foe=en.Enemy("troll","great axe")
|
||||
print("You meet a " + foe.enemy + " wielding a " + foe.weapon)
|
||||
|
||||
# main loop
|
||||
while True:
|
||||
|
||||
print("Type the a key and then RETURN to attack.")
|
||||
|
||||
action=input()
|
||||
|
||||
if action.lower() == "a":
|
||||
foe.fight(foe)
|
||||
|
||||
if foe.alive == False:
|
||||
print("You have won...this time.")
|
||||
exit()
|
||||
```
|
||||
|
||||
导入模块 `enemy.py` 使用了一条特别的语句,引用类文件名称而不用带有 `.py` 扩展名,后跟你选择的命名空间指示符(例如,`import enemy as en`)。这个指示符是在你调用类时在代码中使用的。你需要在导入时添加指示符,例如 `en.Enemy`,而不是只使用 `Enemy()`。
|
||||
|
||||
所有这些文件名都是任意的,尽管在原则上不要使用罕见的名称。将应用程序的中心命名为 `main.py` 是一个常见约定,和一个充满类的文件通常以小写形式命名,其中的类都以大写字母开头。是否遵循这些约定不会影响应用程序的运行方式,但它确实使经验丰富的 Python 程序员更容易快速理解应用程序的工作方式。
|
||||
|
||||
在如何构建代码方面有一些灵活性。例如,使用该示例代码,两个文件必须位于同一目录中。如果你只想将类打包为模块,那么必须创建一个名为 `mybad` 的目录,并将你的类移入其中。在 `main.py` 中,你的 `import` 语句稍有变化:
|
||||
|
||||
```
|
||||
from mybad import enemy as en
|
||||
```
|
||||
|
||||
两种方法都会产生相同的结果,但如果你创建的类足够通用,你认为其他开发人员可以在他们的项目中使用它们,那么后者更好。
|
||||
|
||||
无论你选择哪种方式,都可以启动游戏的模块化版本:
|
||||
|
||||
```
|
||||
$ python3 ./main.py
|
||||
You meet a troll wielding a great axe
|
||||
Type the a key and then RETURN to attack.
|
||||
a
|
||||
You take a swing at the troll.
|
||||
You missed.
|
||||
Type the a key and then RETURN to attack.
|
||||
a
|
||||
You take a swing at the troll.
|
||||
You hit the troll for 8 damage!
|
||||
The troll has 4 HP remaining
|
||||
Type the a key and then RETURN to attack.
|
||||
a
|
||||
You take a swing at the troll.
|
||||
You hit the troll for 11 damage!
|
||||
The troll has -7 HP remaining
|
||||
You have won...this time.
|
||||
```
|
||||
|
||||
游戏启动了,它现在更加模块化了。现在你知道了面对对象的应用程序意味着什么,但最重要的是,当你向兽人发起决斗的时候,你知道是哪一个。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/get-modular-python-classes
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_development_programming.png?itok=M_QDcgz5 (Developing code.)
|
||||
[2]: https://linux.cn/article-11295-1.html
|
||||
[3]: https://opensource.com/article/17/4/how-program-games-raspberry-pi
|
||||
[4]: https://opensource.com/article/19/6/what-java-constructor
|
||||
[5]: https://opensource.com/sites/default/files/images/orc-buch-opengameart_cc-by-sa.jpg (CC-BY-SA by Buch on opengameart.org)
|
||||
104
published/20190730 How to manage logs in Linux.md
Normal file
104
published/20190730 How to manage logs in Linux.md
Normal file
@ -0,0 +1,104 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (heguangzhi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11336-1.html)
|
||||
[#]: subject: (How to manage logs in Linux)
|
||||
[#]: via: (https://www.networkworld.com/article/3428361/how-to-manage-logs-in-linux.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
如何在 Linux 中管理日志
|
||||
======
|
||||
|
||||
> Linux 系统上的日志文件包含了**很多**信息——比你有时间查看的还要多。以下是一些建议,告诉你如何正确的使用它们……而不是淹没在其中。
|
||||
|
||||
![Greg Lobinski \(CC BY 2.0\)][1]
|
||||
|
||||
在 Linux 系统上管理日志文件可能非常容易,也可能非常痛苦。这完全取决于你所认为的日志管理是什么。
|
||||
|
||||
如果你认为是如何确保日志文件不会耗尽你的 Linux 服务器上的所有磁盘空间,那么这个问题通常很简单。Linux 系统上的日志文件会自动翻转,系统将只维护固定数量的翻转日志。即便如此,一眼看去一组上百个文件可能会让人不知所措。在这篇文章中,我们将看看日志轮换是如何工作的,以及一些最相关的日志文件。
|
||||
|
||||
### 自动日志轮换
|
||||
|
||||
日志文件是经常轮转的。当前的日志会获得稍微不同的文件名,并建立一个新的日志文件。以系统日志文件为例。对于许多正常的系统 messages 文件来说,这个文件是一个包罗万象的东西。如果你 `cd` 转到 `/var/log` 并查看一下,你可能会看到一系列系统日志文件,如下所示:
|
||||
|
||||
```
|
||||
$ ls -l syslog*
|
||||
-rw-r----- 1 syslog adm 28996 Jul 30 07:40 syslog
|
||||
-rw-r----- 1 syslog adm 71212 Jul 30 00:00 syslog.1
|
||||
-rw-r----- 1 syslog adm 5449 Jul 29 00:00 syslog.2.gz
|
||||
-rw-r----- 1 syslog adm 6152 Jul 28 00:00 syslog.3.gz
|
||||
-rw-r----- 1 syslog adm 7031 Jul 27 00:00 syslog.4.gz
|
||||
-rw-r----- 1 syslog adm 5602 Jul 26 00:00 syslog.5.gz
|
||||
-rw-r----- 1 syslog adm 5995 Jul 25 00:00 syslog.6.gz
|
||||
-rw-r----- 1 syslog adm 32924 Jul 24 00:00 syslog.7.gz
|
||||
```
|
||||
|
||||
轮换发生在每天午夜,旧的日志文件会保留一周,然后删除最早的系统日志文件。`syslog.7.gz` 文件将被从系统中删除,`syslog.6.gz` 将被重命名为 `syslog.7.gz`。日志文件的其余部分将依次改名,直到 `syslog` 变成 `syslog.1` 并创建一个新的 `syslog` 文件。有些系统日志文件会比其他文件大,但是一般来说,没有一个文件可能会变得非常大,并且你永远不会看到超过八个的文件。这给了你一个多星期的时间来回顾它们收集的任何数据。
|
||||
|
||||
某种特定日志文件维护的文件数量取决于日志文件本身。有些文件可能有 13 个。请注意 `syslog` 和 `dpkg` 的旧文件是如何压缩以节省空间的。这里的考虑是你对最近的日志最感兴趣,而更旧的日志可以根据需要用 `gunzip` 解压。
|
||||
|
||||
```
|
||||
# ls -t dpkg*
|
||||
dpkg.log dpkg.log.3.gz dpkg.log.6.gz dpkg.log.9.gz dpkg.log.12.gz
|
||||
dpkg.log.1 dpkg.log.4.gz dpkg.log.7.gz dpkg.log.10.gz
|
||||
dpkg.log.2.gz dpkg.log.5.gz dpkg.log.8.gz dpkg.log.11.gz
|
||||
```
|
||||
|
||||
日志文件可以根据时间和大小进行轮换。检查日志文件时请记住这一点。
|
||||
|
||||
尽管默认值适用于大多数 Linux 系统管理员,但如果你愿意,可以对日志文件轮换进行不同的配置。查看这些文件,如 `/etc/rsyslog.conf` 和 `/etc/logrotate.conf`。
|
||||
|
||||
### 使用日志文件
|
||||
|
||||
对日志文件的管理也包括时不时的使用它们。使用日志文件的第一步可能包括:习惯每个日志文件可以告诉你有关系统如何工作以及系统可能会遇到哪些问题。从头到尾读取日志文件几乎不是一个好的选择,但是当你想了解你的系统运行的情况或者需要跟踪一个问题时,知道如何从日志文件中获取信息会是有很大的好处。这也表明你对每个文件中存储的信息有一个大致的了解了。例如:
|
||||
|
||||
```
|
||||
$ who wtmp | tail -10 显示最近的登录信息
|
||||
$ who wtmp | grep shark 显示特定用户的最近登录信息
|
||||
$ grep "sudo:" auth.log 查看谁在使用 sudo
|
||||
$ tail dmesg 查看(最近的)内核日志
|
||||
$ tail dpkg.log 查看最近安装和更新的软件包
|
||||
$ more ufw.log 查看防火墙活动(假如你使用 ufw)
|
||||
```
|
||||
|
||||
你运行的一些命令也会从日志文件中提取信息。例如,如果你想查看系统重新启动的列表,可以使用如下命令:
|
||||
|
||||
```
|
||||
$ last reboot
|
||||
reboot system boot 5.0.0-20-generic Tue Jul 16 13:19 still running
|
||||
reboot system boot 5.0.0-15-generic Sat May 18 17:26 - 15:19 (21+21:52)
|
||||
reboot system boot 5.0.0-13-generic Mon Apr 29 10:55 - 15:34 (18+04:39)
|
||||
```
|
||||
|
||||
### 使用更高级的日志管理器
|
||||
|
||||
虽然你可以编写脚本来更容易地在日志文件中找到感兴趣的信息,但是你也应该知道有一些非常复杂的工具可用于日志文件分析。一些可以把来自多个来源的信息联系起来,以便更全面地了解你的网络上发生了什么。它们也可以提供实时监控。这些工具,如 [Solarwinds Log & Event Manager][3] 和 [PRTG 网络监视器][4](包括日志监视)浮现在脑海中。
|
||||
|
||||
还有一些免费工具可以帮助分析日志文件。其中包括:
|
||||
|
||||
* Logwatch — 用于扫描系统日志中感兴趣的日志行的程序
|
||||
* Logcheck — 系统日志分析器和报告器
|
||||
|
||||
在接下来的文章中,我将提供一些关于这些工具的见解和帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3428361/how-to-manage-logs-in-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/07/logs-100806633-large.jpg
|
||||
[2]: https://www.youtube.com/playlist?list=PL7D2RMSmRO9J8OTpjFECi8DJiTQdd4hua
|
||||
[3]: https://www.esecurityplanet.com/products/solarwinds-log-event-manager-siem.html
|
||||
[4]: https://www.paessler.com/prtg
|
||||
[5]: https://www.networkworld.com/article/3242170/linux/invaluable-tips-and-tricks-for-troubleshooting-linux.html
|
||||
[6]: https://www.facebook.com/NetworkWorld/
|
||||
[7]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,172 @@
|
||||
IT 灾备:系统管理员对抗自然灾害
|
||||
======
|
||||
|
||||

|
||||
|
||||
> 面对倾泻的洪水或地震时业务需要继续运转。在飓风卡特里娜、桑迪和其他灾难中幸存下来的系统管理员向在紧急状况下负责 IT 的人们分享真实世界中的建议。
|
||||
|
||||
说到自然灾害,2017 年可算是多灾多难。(LCTT 译注:本文发表于 2017 年)飓风哈维、厄玛和玛莉亚给休斯顿、波多黎各、弗罗里达和加勒比造成了严重破坏。此外,西部的野火将多处住宅和商业建筑付之一炬。
|
||||
|
||||
再来一篇关于[有备无患][1]的警示文章 —— 当然其中都是好的建议 —— 是很简单的,但这无法帮助网络管理员应对湿漉漉的烂摊子。那些善意的建议中大多数都假定掌权的人乐于投入资金来实施这些建议。
|
||||
|
||||
我们对真实世界更感兴趣。不如让我们来充分利用这些坏消息。
|
||||
|
||||
一个很好的例子:自然灾害的一个后果是老板可能突然愿意给灾备计划投入预算。如同一个纽约地区的系统管理员所言,“[我发现飓风桑迪的最大好处][2]是我们的客户对 IT 投资更有兴趣了,但愿你也能得到更多预算。”
|
||||
|
||||
不过别指望这种意愿持续很久。任何想提议改进基础设施的系统管理员最好趁热打铁。如同另一位飓风桑迪中幸存下来的 IT 专员懊悔地提及那样,“[对 IT 开支最初的兴趣持续到当年为止][3]。到了第二年,任何尚未开工的计划都因为‘预算约束’被搁置了,大约 6 个月之后则完全被遗忘。”
|
||||
|
||||
在管理层忘记恶劣的自然灾害也可能降临到好公司头上之前提醒他们这点会有所帮助。根据<ruby>商业和家庭安全协会<rt>Institute for Business & Home Safety</rt></ruby>的说法,[自然灾害后歇业的公司中 25% 再也没能重新开业][4]。<ruby>联邦紧急事务管理署<rt>FEMA</rt></ruby>认为这过于乐观。根据他们的统计,“灾后 [40% 的小公司再也没能重新开门营业][5]。”
|
||||
|
||||
如果你是个系统管理员,你能帮忙挽救你的公司。这里有一些幸存者的最好的主意,这些主意是基于他们从过去几次自然灾害中得到的经验。
|
||||
|
||||
### 制订一个计划
|
||||
|
||||
当灯光忽明忽暗,狂风象火车机车一样怒号时,就该启动你的业务持续计划和灾备计划了。
|
||||
|
||||
有太多的系统管理员报告当暴风雨来临时这两个计划中一个也没有。这并不令人惊讶。2014 年<ruby>[灾备预备状态委员会][6]<rt>Disaster Recovery Preparedness Council</rt></ruby>发现[世界范围内被调查的公司中有 73% 没有足够的灾备计划][7]。
|
||||
|
||||
“**足够**”是关键词。正如一个系统管理员 2016 年在 Reddit 上写的那样,“[我们的灾备计划就是一场灾难。][8]我们所有的数据都备份在离这里大约 30 英里的一个<ruby>存储区域网络<rt>SAN</rt></ruby>。我们没有将数据重新上线的硬件,甚至好几天过去了都没能让核心服务器启动运行起来。我们是个年营收 40 亿美元的公司,却不愿为适当的设备投入几十万美元,或是在数据中心添置几台服务器。当添置硬件的提案被提出的时候,我们的管理层说,‘嗐,碰到这种事情的机会能有多大呢’。”
|
||||
|
||||
同一个帖子中另一个人说得更简洁:“眼下我的灾备计划只能在黑暗潮湿的角落里哭泣,但愿没人在乎损失的任何东西。”
|
||||
|
||||
如果你在哭泣,但愿你至少不是独自流泪。任何灾备计划,即便是 IT 部门制订的灾备计划,必须确定[你能跟别人通讯][10],如同系统管理员 Jim Thompson 从卡特里娜飓风中得到的教训:“确保你有一个与人们通讯的计划。在一场严重的区域性灾难期间,你将无法给身处灾区的任何人打电话。”
|
||||
|
||||
有一个选择可能会让有技术头脑的人感兴趣:<ruby>[业余电台][11]<rt>ham radio</rt></ruby>。[它在波多黎各发挥了巨大作用][12]。
|
||||
|
||||
### 列一个愿望清单
|
||||
|
||||
第一步是承认问题。“许多公司实际上对灾备计划不感兴趣,或是消极对待”,[Micro Focus][14] 的首席架构师 [Joshua Focus][13] 说。“将灾备看作业务持续性的一个方面是种不同的视角。所有公司都要应对业务持续性,所以灾备应被视为业务持续性的一部分。”
|
||||
|
||||
IT 部门需要将其需求书面化以确保适当的灾备和业务持续性计划。即使是你不知道如何着手,或尤其是这种时候,也是如此。正如一个系统管理员所言,“我喜欢有一个‘想法转储’,让所有计划、点子、改进措施毫无保留地提出来。(这)[对一类情况尤其有帮助,即当你提议变更][15],并付诸实施,接着 6 个月之后你警告过的状况就要来临。”现在你做好了一切准备并且可以开始讨论:“如同我们之前在 4 月讨论过的那样……”
|
||||
|
||||
因此,当你的管理层对业务持续性计划回应道“嗐,碰到这种事的机会能有多大呢?”的时候你能做些什么呢?有个系统管理员称这也完全是管理层的正常行为。在这种糟糕的处境下,老练的系统管理员建议用书面形式把这些事情记录下来。记录应清楚表明你告知管理层需要采取的措施,且[他们拒绝采纳建议][16]。“总的来说就是有足够的书面材料能让他们搓成一根绳子上吊,”该系统管理员补充道。
|
||||
|
||||
如果那也不起作用,恢复一个被洪水淹没的数据中心的相关经验对你[找个新工作][17]是很有帮助的。
|
||||
|
||||
### 保护有形的基础设施
|
||||
|
||||
“[我们的办公室是幢摇摇欲坠的建筑][18],”飓风哈维重创休斯顿之后有个系统管理员提到。“我们盲目地进入那幢建筑,现场的基础设施糟透了。正是我们给那幢建筑里带去了最不想要的一滴水,现在基础设施整个都沉在水下了。”
|
||||
|
||||
尽管如此,如果你想让数据中心继续运转——或在暴风雨过后恢复运转 —— 你需要确保该场所不仅能经受住你所在地区那些意料中的灾难,而且能经受住那些意料之外的灾难。一个旧金山的系统管理员知道为什么重要的是确保公司的服务器安置在可以承受里氏 7 级地震的建筑内。一家圣路易斯的公司知道如何应对龙卷风。但你应当为所有可能发生的事情做好准备:加州的龙卷风、密苏里州的地震,或[僵尸末日][19](给你在 IT 预算里增加一把链锯提供了充分理由)。
|
||||
|
||||
在休斯顿的情况下,[多数数据中心保持运转][20],因为它们是按照抵御暴风雨和洪水的标准建造的。[Data Foundry][21] 的首席技术官 Edward Henigin 说他们公司的数据中心之一,“专门建造的休斯顿 2 号的设计能抵御 5 级飓风的风速。这个场所的公共供电没有中断,我们得以避免切换到后备发电机。”
|
||||
|
||||
那是好消息。坏消息是伴随着超级飓风桑迪于 2012 年登场,如果[你的数据中心没准备好应对洪水][22],你会陷入一个麻烦不断的世界。一个不能正常运转的数据中心 [Datagram][23] 服务的客户包括 Gawker、Gizmodo 和 Buzzfeed 等知名网站。
|
||||
|
||||
当然,有时候你什么也做不了。正如某个波多黎各圣胡安的系统管理员在飓风厄玛扫过后悲伤地写到,“发电机没油了。服务器机房靠电池在运转但是没有(空调)。[永别了,服务器][24]。”由于 <ruby>MPLS<rt>Multiprotocol Lable Switching</rt></ruby> 线路亦中断,该系统管理员没法切换到灾备措施:“多么充实的一天。”
|
||||
|
||||
总而言之,IT 专业人士需要了解他们所处的地区,了解他们面临的风险并将他们的服务器安置在能抵御当地自然灾害的数据中心内。
|
||||
|
||||
### 关于云的争议
|
||||
|
||||
当暴风雨席卷一切时避免 IT 数据中心失效的最佳方法就是确保灾备数据中心在其他地方。选择地点时需要审慎的决策。你的灾备数据中心不应在会被同一场自然灾害影响到的<ruby>地域<rt>region</rt></ruby>;你的资源应安置在多个<ruby>可用区<rt>availability zone</rt></ruby>内。考虑一下主备数据中心位于一场地震中的同一条断层带上,或是主备数据中心易于受互通河道导致的洪灾影响这类情况。
|
||||
|
||||
有些系统管理员[利用云作为冗余设施][25]。例如,总是用微软 Azure 云存储服务保存副本以确保持久性和高可用性。根据你的选择,Azure 复制功能将你的数据要么拷贝到同一个数据中心要么拷贝到另一个数据中心。多数公有云提供类似的自动备份服务以确保数据安全,不论你的数据中心发生什么情况——除非你的云服务供应商全部设施都在暴风雨的行进路径上。
|
||||
|
||||
昂贵么?是的。跟业务中断 1、2 天一样昂贵么?并非如此。
|
||||
|
||||
信不过公有云?可以考虑 <ruby>colo<rt>colocation</rt></ruby> 服务。有了 colo,你依旧拥有你的硬件,运行你自己的应用,但这些硬件可以远离麻烦。例如飓风哈维期间,一家公司“虚拟地”将它的资源从休斯顿搬到了其位于德克萨斯奥斯汀的 colo。但是那些本地数据中心和 colo 场所需要准备好应对灾难;这点是你选择场所时要考虑的一个因素。举个例子,一个寻找 colo 场所的西雅图系统管理员考虑的“全都是抗震和旱灾应对措施(加固的地基以及补给冷却系统的运水卡车)。”
|
||||
|
||||
### 周围一片黑暗时
|
||||
|
||||
正如 Forrester Research 的分析师 Rachel Dines 在一份为[灾备期刊][27]所做的调查中报告的那样,宣布的灾难中[最普遍的原因就是断电][26]。尽管你能应对一般情况下的断电,飓风、火灾和洪水的考验会超越设备的极限。
|
||||
|
||||
某个系统管理员挖苦式的计划是什么呢?“趁 UPS 完蛋之前把你能关的机器关掉,不能关的就让它崩溃咯。然后,[喝个痛快直到供电恢复][28]。”
|
||||
|
||||
在 2016 年德尔塔和西南航空停电事故之后,IT 员工推动的一个更加严肃的计划是由一个有管理的服务供应商为其客户[部署不间断电源][29]:“对于至关重要的部分,在供电中断时我们结合使用<ruby>简单网络管理协议<rt>SNMP</rt></ruby>信令和 <ruby>PowerChute 网络关机<rt>PowerChute Nrework Shutdown</rt></ruby>客户端来关闭设备。至于重新开机,那取决于客户。有些是自动启动,有些则需要人工干预。”
|
||||
|
||||
另一种做法是用来自两个供电所的供电线路支持数据中心。例如,[西雅图威斯汀大厦数据中心][30]有来自不同供电所的多路 13.4 千伏供电线路,以及多个 480 伏三相变电箱。
|
||||
|
||||
预防严重断电的系统不是“通用的”设备。系统管理员应当[为数据中心请求一台定制的柴油发电机][31]。除了按你特定的需求调整,发电机必须能迅速跳至全速运转并承载全部电力负荷而不致影响系统负载性能。”
|
||||
|
||||
这些发电机也必须加以保护。例如,将你的发电机安置在泛洪区的一楼就不是个聪明的主意。位于纽约<ruby>百老街<rt>Broad street</rt></ruby>的数据中心在超级飓风桑迪期间就是类似情形,备用发电机的燃料油桶在地下室 —— 并且被水淹了。尽管一场[“人力接龙”用容量 5 加仑的水桶将柴油输送到 17 段楼梯之上的发电机][32]使 [Peer 1 Hosting][33] 得以继续运营,但这不是一个切实可行的业务持续计划。
|
||||
|
||||
正如多数数据中心专家所知那样,如果你有时间 —— 假设一个飓风离你有一天的距离 —— 确保你的发电机正常工作,加满油,准备好当供电线路被刮断时立即开启,不管怎样你之前应当每月测试你的发电机。你之前是那么做的,是吧?是就好!
|
||||
|
||||
### 测试你对备份的信心
|
||||
|
||||
普通用户几乎从不备份,检查备份是否实际完好的就更少了。系统管理员对此更加了解。
|
||||
|
||||
有些 [IT 部门在寻求将他们的备份迁移到云端][34]。但有些系统管理员仍对此不买账 —— 他们有很好的理由。最近有人报告,“在用了整整 5 天[从亚马逊 Glacier 恢复了(400 GB)数据][35]之后,我欠了亚马逊将近 200 美元的传输费,并且(我还是)处于未完全恢复状态,还差大约 100 GB 文件。”
|
||||
|
||||
结果是有些系统管理员依然喜欢磁带备份。磁带肯定不够时髦,但正如操作系统专家 Andrew S. Tanenbaum 说的那样,“[永远不要低估一辆装满磁带在高速上飞驰的旅行车的带宽][36]。”
|
||||
|
||||
目前每盘磁带可以存储 10 TB 数据;有的进行中的实验可在磁带上存储高达 200 TB 数据。诸如<ruby>[线性磁带文件系统][37]<rt>Linear Tape File System</rt></ruby>之类的技术允许你象访问网络硬盘一样读取磁带数据。
|
||||
|
||||
然而对许多人而言,磁带[绝对是最后选择的手段][38]。没关系,因为备份应该有大量的可选方案。在这种情况下,一个系统管理员说到,“故障时我们会用这些方法(恢复备份):(Windows)服务器层面的 VSS (Volume Shadow Storage)快照,<ruby>存储区域网络<rt>SAN</rt></ruby>层面的卷快照,以及存储区域网络层面的异地归档快照。但是万一有什么事情发生并摧毁了我们的虚拟机,存储区域网络和备份存储区域网络,我们还是可以取回磁带并恢复数据。”
|
||||
|
||||
当麻烦即将到来时,可使用副本工具如 [Veeam][39],它会为你的服务器创建一个虚拟机副本。若出现故障,副本会自动启动。没有麻烦,没有手忙脚乱,正如某个系统管理员在这个流行的系统管理员帖子中所说,“[我爱你 Veeam][40]。”
|
||||
|
||||
### 网络?什么网络?
|
||||
|
||||
当然,如果员工们无法触及他们的服务,没有任何云、colo 和远程数据中心能帮到你。你不需要一场自然灾害来证明冗余互联网连接的正确性。只需要一台挖断线路的挖掘机或断掉的光缆就能让你在工作中渡过糟糕的一天。
|
||||
|
||||
“理想状态下”,某个系统管理员明智地观察到,“你应该有[两路互联网接入线路连接到有独立基础设施的两个 ISP][41]。例如,你不希望两个 ISP 都依赖于同一根光缆。你也不希望采用两家本地 ISP,并发现他们的上行带宽都依赖于同一家骨干网运营商。”
|
||||
|
||||
聪明的系统管理员知道他们公司的互联网接入线路[必须是商业级别的][43],带有<ruby>服务等级协议<rt>service-level agreement(SLA)</rt></ruby>,其中包含“修复时间”条款。或者更好的是采用<ruby>互联网接入专线<rt></rt>dedicated Internet access</ruby>。技术上这与任何其他互联网接入方式没有区别。区别在于互联网接入专线不是一种“尽力而为”的接入方式,而是你会得到明确规定的专供你使用的带宽并附有服务等级协议。这种专线不便宜,但正如一句格言所说的那样,“速度、可靠性、便宜,只能挑两个。”当你的业务跑在这条线路上并且一场暴风雨即将来袭,“可靠性”必须是你挑的两个之一。
|
||||
|
||||
### 晴空重现之时
|
||||
|
||||
你没法准备应对所有自然灾害,但你可以为其中很多做好计划。有一个深思熟虑且经过测试的灾备和业务持续计划,并逐字逐句严格执行,当竞争对手溺毙的时候,你的公司可以幸存下来。
|
||||
|
||||
### 系统管理员对抗自然灾害:给领导者的教训
|
||||
|
||||
* 你的 IT 员工得说多少次:不要仅仅备份,还得测试备份?
|
||||
* 没电就没公司。确保你的服务器有足够的应急电源来满足业务需要,并确保它们能正常工作。
|
||||
* 如果你的公司在一场自然灾害中幸存下来,或者避开了灾害,明智的系统管理员知道这就是向管理层申请被他们推迟的灾备预算的时候了。因为下次你就未必有这么幸运了。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.hpe.com/us/en/insights/articles/it-disaster-recovery-sysadmins-vs-natural-disasters-1711.html
|
||||
|
||||
作者:[Steven-J-Vaughan-Nichols][a]
|
||||
译者:[0x996](https://github.com/0x996)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.hpe.com/us/en/insights/contributors/steven-j-vaughan-nichols.html
|
||||
[1]:https://www.hpe.com/us/en/insights/articles/what-is-disaster-recovery-really-1704.html
|
||||
[2]:https://www.reddit.com/r/sysadmin/comments/6wricr/dear_houston_tx_sysadmins/
|
||||
[3]:https://www.reddit.com/r/sysadmin/comments/6wricr/dear_houston_tx_sysadmins/dma6gse/
|
||||
[4]:https://disastersafety.org/wp-content/uploads/open-for-business-english.pdf
|
||||
[5]:https://www.fema.gov/protecting-your-businesses
|
||||
[6]:http://drbenchmark.org/about-us/our-council/
|
||||
[7]:https://www.prnewswire.com/news-releases/global-benchmark-study-reveals-73-of-companies-are-unprepared-for-disaster-recovery-248359051.html
|
||||
[8]:https://www.reddit.com/r/sysadmin/comments/3cob1k/what_does_your_disaster_recovery_plan_look_like/csxh8sn/
|
||||
[9]:https://www.hpe.com/us/en/resources/servers/datacenter-trends-challenges.html?jumpid=in_insights~510287587~451research_datacenter~sjvnSysadmin
|
||||
[10]:http://www.theregister.co.uk/2015/07/12/surviving_hurricane_katrina
|
||||
[11]:https://theprepared.com/guides/beginners-guide-amateur-ham-radio-preppers/
|
||||
[12]:http://www.npr.org/2017/09/29/554600989/amateur-radio-operators-stepped-in-to-help-communications-with-puerto-rico
|
||||
[13]:http://www8.hp.com/us/en/software/joshua-brusse.html
|
||||
[14]:https://www.microfocus.com/
|
||||
[15]:https://www.reddit.com/r/sysadmin/comments/6wricr/dear_houston_tx_sysadmins/dma87xv/
|
||||
[16]:https://www.hpe.com/us/en/insights/articles/my-boss-asked-me-to-do-what-how-to-handle-worrying-work-requests-1710.html
|
||||
[17]:https://www.hpe.com/us/en/insights/articles/sysadmin-survival-guide-1707.html
|
||||
[18]:https://www.reddit.com/r/sysadmin/comments/6wk92q/any_houston_admins_executing_their_dr_plans_this/dm8xj0q/
|
||||
[19]:https://community.spiceworks.com/how_to/1243-ensure-your-dr-plan-is-ready-for-a-zombie-apocolypse
|
||||
[20]:http://www.datacenterdynamics.com/content-tracks/security-risk/houston-data-centers-withstand-hurricane-harvey/98867.article
|
||||
[21]:https://www.datafoundry.com/
|
||||
[22]:http://www.datacenterknowledge.com/archives/2012/10/30/major-flooding-nyc-data-centers
|
||||
[23]:https://datagram.com/
|
||||
[24]:https://www.reddit.com/r/sysadmin/comments/6yjb3p/shutting_down_everything_blame_irma/
|
||||
[25]:https://www.hpe.com/us/en/insights/articles/everything-you-need-to-know-about-clouds-and-hybrid-it-1701.html
|
||||
[26]:https://www.drj.com/images/surveys_pdf/forrester/2011Forrester_survey.pdf
|
||||
[27]:https://www.drj.com
|
||||
[28]:https://www.reddit.com/r/sysadmin/comments/4x3mmq/datacenter_power_failure_procedures_what_do_yours/d6c71p1/
|
||||
[29]:https://www.reddit.com/r/sysadmin/comments/4x3mmq/datacenter_power_failure_procedures_what_do_yours/
|
||||
[30]:https://cloudandcolocation.com/datacenters/the-westin-building-seattle-data-center/
|
||||
[31]:https://www.techrepublic.com/article/what-to-look-for-in-a-data-center-backup-generator/
|
||||
[32]:http://www.datacenterknowledge.com/archives/2012/10/31/peer-1-mobilizes-diesel-bucket-brigade-at-75-broad
|
||||
[33]:https://www.cogecopeer1.com/
|
||||
[34]:https://www.reddit.com/r/sysadmin/comments/7a6m7n/aws_glacier_archival/
|
||||
[35]:https://www.reddit.com/r/sysadmin/comments/63mypu/the_dangers_of_cloudberry_and_amazon_glacier_how/
|
||||
[36]:https://en.wikiquote.org/wiki/Andrew_S._Tanenbaum
|
||||
[37]:http://www.snia.org/ltfs
|
||||
[38]:https://www.reddit.com/r/sysadmin/comments/5visaq/backups_how_many_of_you_still_have_tapes/de2d0qm/
|
||||
[39]:https://helpcenter.veeam.com/docs/backup/vsphere/failover.html?ver=95
|
||||
[40]:https://www.reddit.com/r/sysadmin/comments/5rttuo/i_love_you_veeam/
|
||||
[41]:https://www.reddit.com/r/sysadmin/comments/5rmqfx/ars_surviving_a_cloudbased_disaster_recovery_plan/dd90auv/
|
||||
[42]:https://www.hpe.com/us/en/insights/articles/how-do-you-evaluate-cloud-service-agreements-and-slas-very-carefully-1705.html
|
||||
[43]:http://www.e-vergent.com/what-is-dedicated-internet-access/
|
||||
138
published/201908/20171216 Sysadmin 101- Troubleshooting.md
Normal file
138
published/201908/20171216 Sysadmin 101- Troubleshooting.md
Normal file
@ -0,0 +1,138 @@
|
||||
系统管理员入门:排除故障
|
||||
======
|
||||
|
||||

|
||||
|
||||
我通常会严格保持此博客的技术性,将观察、意见等内容保持在最低限度。但是,这篇和接下来的几篇文章将介绍刚进入系统管理/SRE/系统工程师/sysops/devops-ops(无论你想称自己是什么)角色的常见的基础知识。
|
||||
|
||||
请跟我来!
|
||||
|
||||
> “我的网站很慢!”
|
||||
|
||||
我只是随机选择了本文的问题类型,这也可以应用于任何与系统管理员相关的故障排除。我并不是要炫耀那些可以发现最多的信息的最聪明的“金句”。它也不是一个详尽的、一步步指导的、并在最后一个方框中导向“利润”一词的“流程图”。
|
||||
|
||||
我会通过一些例子展示常规的方法。
|
||||
|
||||
示例场景仅用于说明本文目的。它们有时会做一些不适用于所有情况的假设,而且肯定会有很多读者在某些时候说“哦,但我觉得你会发现……”。
|
||||
|
||||
但那可能会让我们错失重点。
|
||||
|
||||
十多年来,我一直在从事于支持工作,或在支持机构工作,有一件事让我一次又一次地感到震惊,这促使我写下了这篇文章。
|
||||
|
||||
**有许多技术人员在遇到问题时的本能反应,就是不管三七二十一去尝试可能的解决方案。**
|
||||
|
||||
*“我的网站很慢,所以”,*
|
||||
|
||||
* 我将尝试增大 `MaxClients`/`MaxRequestWorkers`/`worker_connections`
|
||||
* 我将尝试提升 `innodb_buffer_pool_size`/`effective_cache_size`
|
||||
* 我打算尝试启用 `mod_gzip`(遗憾的是,这是真实的故事)
|
||||
|
||||
*“我曾经看过这个问题,它是因为某种原因造成的 —— 所以我估计还是这个原因,它应该能解决这个问题。”*
|
||||
|
||||
这浪费了很多时间,并会让你在黑暗中盲目乱撞,胡乱鼓捣。
|
||||
|
||||
你的 InnoDB 的缓冲池也许达到 100% 的利用率,但这可能只是因为有人运行了一段时间的一次性大型报告导致的。如果没有排除这种情况,那你就是在浪费时间。
|
||||
|
||||
### 开始之前
|
||||
|
||||
在这里,我应该说明一下,虽然这些建议同样适用于许多角色,但我是从一般的支持系统管理员的角度来撰写的。在一个成熟的内部组织中,或与规模较大的、规范管理的或“企业级”客户合作时,你通常会对一切都进行检测、测量、绘制、整理(甚至不是文字),并发出警报。那么你的方法也往往会有所不同。让我们在这里先忽略这种情况。
|
||||
|
||||
如果你没有这种东西,那就随意了。
|
||||
|
||||
### 澄清问题
|
||||
|
||||
首先确定实际上是什么问题。“慢”可以是多种形式的。是收到第一个字节的时间吗?从糟糕的 Javascript 加载和每页加载要拉取 15 MB 的静态内容,这是一个完全不同类型的问题。是慢,还是比通常慢?这是两个非常不同的解决方案!
|
||||
|
||||
在你着手做某事之前,确保你知道实际报告和遇到的问题。找到问题的根源通常很困难,但即便找不到也必须找到问题本身。
|
||||
|
||||
否则,这相当于系统管理员带着一把刀去参加枪战。
|
||||
|
||||
### 唾手可得
|
||||
|
||||
首次登录可疑服务器时,你可以查找一些常见的嫌疑对象。事实上,你应该这样做!每当我登录到服务器时,我都会发出一些命令来快速检查一些事情:我们是否发生了页交换(`free` / `vmstat`),磁盘是否繁忙(`top` / `iostat` / `iotop`),是否有丢包(`netstat` / `proc` / `net` / `dev`),是否处于连接数过多的状态(`netstat`),有什么东西占用了 CPU(`top`),谁在这个服务器上(`w` / `who`),syslog 和 `dmesg` 中是否有引人注目的消息?
|
||||
|
||||
如果你从 RAID 控制器得到 2000 条抱怨直写式缓存没有生效的消息,那么继续进行是没有意义的。
|
||||
|
||||
这用不了半分钟。如果什么都没有引起你的注意 —— 那么继续。
|
||||
|
||||
### 重现问题
|
||||
|
||||
如果某处确实存在问题,并且找不到唾手可得的信息。
|
||||
|
||||
那么采取所有步骤来尝试重现问题。当你可以重现该问题时,你就可以观察它。**当你能观察到时,你就可以解决。**如果在第一步中尚未显现出或覆盖了问题所在,询问报告问题的人需要采取哪些确切步骤来重现问题。
|
||||
|
||||
对于由太阳耀斑或只能运行在 OS/2 上的客户端引起的问题,重现并不总是可行的。但你的第一个停靠港应该是至少尝试一下!在一开始,你所知道的是“某人认为他们的网站很慢”。对于那些人,他们可能还在用他们的 GPRS 手机,也可能正在安装 Windows 更新。你在这里挖掘得再深也是浪费时间。
|
||||
|
||||
尝试重现!
|
||||
|
||||
### 检查日志
|
||||
|
||||
我对于有必要包括这一点感到很难过。但是我曾经看到有人在运行 `tail /var/log/...` 之后几分钟就不看了。大多数 *NIX 工具都特别喜欢记录日志。任何明显的错误都会在大多数应用程序日志中显得非常突出。检查一下。
|
||||
|
||||
### 缩小范围
|
||||
|
||||
如果没有明显的问题,但你可以重现所报告的问题,那也很棒。所以,你现在知道网站是慢的。现在你已经把范围缩小到:浏览器的渲染/错误、应用程序代码、DNS 基础设施、路由器、防火墙、网卡(所有的)、以太网电缆、负载均衡器、数据库、缓存层、会话存储、Web 服务器软件、应用程序服务器、内存、CPU、RAID 卡、磁盘等等。
|
||||
|
||||
根据设置添加一些其他可能的罪魁祸首。它们也可能是 SAN,也不要忘记硬件 WAF!以及…… 你明白我的意思。
|
||||
|
||||
如果问题是接收到第一个字节的时间,你当然会开始对 Web 服务器去应用上已知的修复程序,就是它响应缓慢,你也觉得几乎就是它,对吧?但是你错了!
|
||||
|
||||
你要回去尝试重现这个问题。只是这一次,你要试图消除尽可能多的潜在问题来源。
|
||||
|
||||
你可以非常轻松地消除绝大多数可能的罪魁祸首:你能从服务器本地重现问题吗?恭喜,你刚刚节省了自己必须尝试修复 BGP 路由的时间。
|
||||
|
||||
如果不能,请尝试使用同一网络上的其他计算机。如果可以的话,至少你可以将防火墙移到你的嫌疑人名单上,(但是要注意一下那个交换机!)
|
||||
|
||||
是所有的连接都很慢吗?虽然服务器是 Web 服务器,但并不意味着你不应该尝试使用其他类型的服务进行重现问题。[netcat][1] 在这些场景中非常有用(但是你的 SSH 连接可能会一直有延迟,这可以作为线索)! 如果这也很慢,你至少知道你很可能遇到了网络问题,可以忽略掉整个 Web 软件及其所有组件的问题。用这个知识(我不收 200 美元)再次从顶部开始,按你的方式由内到外地进行!
|
||||
|
||||
即使你可以在本地复现 —— 仍然有很多“因素”留下。让我们排除一些变量。你能用普通文件重现它吗? 如果 `i_am_a_1kb_file.html` 很慢,你就知道它不是数据库、缓存层或 OS 以外的任何东西和 Web 服务器本身的问题。
|
||||
|
||||
你能用一个需要解释或执行的 `hello_world.(py|php|js|rb..)` 文件重现问题吗?如果可以的话,你已经大大缩小了范围,你可以专注于少数事情。如果 `hello_world` 可以马上工作,你仍然学到了很多东西!你知道了没有任何明显的资源限制、任何满的队列或在任何地方卡住的 IPC 调用,所以这是应用程序正在做的事情或它正在与之通信的事情。
|
||||
|
||||
所有页面都慢吗?或者只是从第三方加载“实时分数数据”的页面慢?
|
||||
|
||||
**这可以归结为:你仍然可以重现这个问题所涉及的最少量的“因素”是什么?**
|
||||
|
||||
我们的示例是一个缓慢的网站,但这同样适用于几乎所有问题。邮件投递?你能在本地投递吗?能发给自己吗?能发给<常见的服务提供者>吗?使用小的、纯文本的消息进行测试。尝试直到遇到 2MB 拥堵时。使用 STARTTLS 和不使用 STARTTLS 呢?按你的方式由内到外地进行!
|
||||
|
||||
这些步骤中的每一步都只需要几秒钟,远远快于实施大多数“可能的”修复方案。
|
||||
|
||||
### 隔离观察
|
||||
|
||||
到目前为止,当你去除特定组件时无法重现问题时,你可能已经偶然发现了问题所在。
|
||||
|
||||
但如果你还没有,或者你仍然不知道**为什么**:一旦你找到了一种方法来重现问题,你和问题之间的“东西”(某个技术术语)最少,那么就该开始隔离和观察了。
|
||||
|
||||
请记住,许多服务可以在前台运行和/或启用调试。对于某些类别的问题,执行此操作通常非常有帮助。
|
||||
|
||||
这也是你的传统武器库发挥作用的地方。`strace`、`lsof`、`netstat`、`GDB`、`iotop`、`valgrind`、语言分析器(cProfile、xdebug、ruby-prof ……)那些类型的工具。
|
||||
|
||||
一旦你走到这一步,你就很少能摆脱剖析器或调试器了。
|
||||
|
||||
[strace][2] 通常是一个非常好的起点。
|
||||
|
||||
你可能会注意到应用程序停留在某个连接到端口 3306 的套接字文件描述符上的特定 `read()` 调用上。你会知道该怎么做。
|
||||
|
||||
转到 MySQL 并再次从顶部开始。显而易见:“等待某某锁”、死锁、`max_connections` ……进而:是所有查询?还是只写请求?只有某些表?还是只有某些存储引擎?等等……
|
||||
|
||||
你可能会注意到调用外部 API 资源的 `connect()` 需要五秒钟才能完成,甚至超时。你会知道该怎么做。
|
||||
|
||||
你可能会注意到,在同一对文件中有 1000 个调用 `fstat()` 和 `open()` 作为循环依赖的一部分。你会知道该怎么做。
|
||||
|
||||
它可能不是那些特别的东西,但我保证,你会发现一些东西。
|
||||
|
||||
如果你只是从这一部分学到一点,那也不错;学习使用 `strace` 吧!**真的**学习它,阅读整个手册页。甚至不要跳过历史部分。`man` 每个你还不知道它做了什么的系统调用。98% 的故障排除会话以 `strace` 而终结。
|
||||
|
||||
---------------------------------------------------------------------
|
||||
|
||||
via: http://northernmost.org/blog/troubleshooting-101/index.html
|
||||
|
||||
作者:[Erik Ljungstrom][a]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://northernmost.org
|
||||
[1]:http://nc110.sourceforge.net/
|
||||
[2]:https://linux.die.net/man/1/strace
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user