mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-29 21:41:00 +08:00
Merge pull request #2203 from liaoishere/master
[translated] 20141008 How to configure HTTP load balancer with HAProxy on Linux
This commit is contained in:
commit
df83a70203
@ -1,275 +0,0 @@
|
||||
liaoishere is translating.
|
||||
|
||||
How to configure HTTP load balancer with HAProxy on Linux
|
||||
================================================================================
|
||||
Increased demand on web based applications and services are putting more and more weight on the shoulders of IT administrators. When faced with unexpected traffic spikes, organic traffic growth, or internal challenges such as hardware failures and urgent maintenance, your web application must remain available, no matter what. Even modern devops and continuous delivery practices can threaten the reliability and consistent performance of your web service.
|
||||
|
||||
Unpredictability or inconsistent performance is not something you can afford. But how can we eliminate these downsides? In most cases a proper load balancing solution will do the job. And today I will show you how to set up HTTP load balancer using [HAProxy][1].
|
||||
|
||||
### What is HTTP load balancing? ###
|
||||
|
||||
HTTP load balancing is a networking solution responsible for distributing incoming HTTP or HTTPS traffic among servers hosting the same application content. By balancing application requests across multiple available servers, a load balancer prevents any application server from becoming a single point of failure, thus improving overall application availability and responsiveness. It also allows you to easily scale in/out an application deployment by adding or removing extra application servers with changing workloads.
|
||||
|
||||
### Where and when to use load balancing? ###
|
||||
|
||||
As load balancers improve server utilization and maximize availability, you should use it whenever your servers start to be under high loads. Or if you are just planning your architecture for a bigger project, it's a good habit to plan usage of load balancer upfront. It will prove itself useful in the future when you need to scale your environment.
|
||||
|
||||
### What is HAProxy? ###
|
||||
|
||||
HAProxy is a popular open-source load balancer and proxy for TCP/HTTP servers on GNU/Linux platforms. Designed in a single-threaded event-driven architecture, HAproxy is capable of handling [10G NIC line rate][2] easily, and is being extensively used in many production environments. Its features include automatic health checks, customizable load balancing algorithms, HTTPS/SSL support, session rate limiting, etc.
|
||||
|
||||
### What are we going to achieve in this tutorial? ###
|
||||
|
||||
In this tutorial, we will go through the process of configuring a HAProxy-based load balancer for HTTP web servers.
|
||||
|
||||
### Prerequisites ###
|
||||
|
||||
You will need at least one, or preferably two web servers to verify functionality of your load balancer. We assume that backend HTTP web servers are already [up and running][3].
|
||||
|
||||
### Install HAProxy on Linux ###
|
||||
|
||||
For most distributions, we can install HAProxy using your distribution's package manager.
|
||||
|
||||
#### Install HAProxy on Debian ####
|
||||
|
||||
In Debian we need to add backports for Wheezy. To do that, please create a new file called "backports.list" in /etc/apt/sources.list.d, with the following content:
|
||||
|
||||
deb http://cdn.debian.net/debian wheezybackports main
|
||||
|
||||
Refresh your repository data and install HAProxy.
|
||||
|
||||
# apt get update
|
||||
# apt get install haproxy
|
||||
|
||||
#### Install HAProxy on Ubuntu ####
|
||||
|
||||
# apt get install haproxy
|
||||
|
||||
#### Install HAProxy on CentOS and RHEL ####
|
||||
|
||||
# yum install haproxy
|
||||
|
||||
### Configure HAProxy ###
|
||||
|
||||
In this tutorial, we assume that there are two HTTP web servers up and running with IP addresses 192.168.100.2 and 192.168.100.3. We also assume that the load balancer will be configured at a server with IP address 192.168.100.4.
|
||||
|
||||
To make HAProxy functional, you need to change a number of items in /etc/haproxy/haproxy.cfg. These changes are described in this section. In case some configuration differs for different GNU/Linux distributions, it will be noted in the paragraph.
|
||||
|
||||
#### 1. Configure Logging ####
|
||||
|
||||
One of the first things you should do is to set up proper logging for your HAProxy, which will be useful for future debugging. Log configuration can be found in the global section of /etc/haproxy/haproxy.cfg. The following are distro-specific instructions for configuring logging for HAProxy.
|
||||
|
||||
**CentOS or RHEL:**
|
||||
|
||||
To enable logging on CentOS/RHEL, replace:
|
||||
|
||||
log 127.0.0.1 local2
|
||||
|
||||
with:
|
||||
|
||||
log 127.0.0.1 local0
|
||||
|
||||
The next step is to set up separate log files for HAProxy in /var/log. For that, we need to modify our current rsyslog configuration. To make the configuration simple and clear, we will create a new file called haproxy.conf in /etc/rsyslog.d/ with the following content.
|
||||
|
||||
$ModLoad imudp
|
||||
$UDPServerRun 514
|
||||
$template Haproxy,"%msg%\n"
|
||||
local0.=info /var/log/haproxy.log;Haproxy
|
||||
local0.notice /var/log/haproxystatus.log;Haproxy
|
||||
local0.* ~
|
||||
|
||||
This configuration will separate all HAProxy messages based on the $template to log files in /var/log. Now restart rsyslog to apply the changes.
|
||||
|
||||
# service rsyslog restart
|
||||
|
||||
**Debian or Ubuntu:**
|
||||
|
||||
To enable logging for HAProxy on Debian or Ubuntu, replace:
|
||||
|
||||
log /dev/log local0
|
||||
log /dev/log local1 notice
|
||||
|
||||
with:
|
||||
|
||||
log 127.0.0.1 local0
|
||||
|
||||
Next, to configure separate log files for HAProxy, edit a file called haproxy.conf (or 49-haproxy.conf in Debian) in /etc/rsyslog.d/ with the following content.
|
||||
|
||||
$ModLoad imudp
|
||||
$UDPServerRun 514
|
||||
$template Haproxy,"%msg%\n"
|
||||
local0.=info /var/log/haproxy.log;Haproxy
|
||||
local0.notice /var/log/haproxystatus.log;Haproxy
|
||||
local0.* ~
|
||||
|
||||
This configuration will separate all HAProxy messages based on the $template to log files in /var/log. Now restart rsyslog to apply the changes.
|
||||
|
||||
# service rsyslog restart
|
||||
|
||||
#### 2. Setting Defaults ####
|
||||
|
||||
The next step is to set default variables for HAProxy. Find the defaults section in /etc/haproxy/haproxy.cfg, and replace it with the following configuration.
|
||||
|
||||
defaults
|
||||
log global
|
||||
mode http
|
||||
option httplog
|
||||
option dontlognull
|
||||
retries 3
|
||||
option redispatch
|
||||
maxconn 20000
|
||||
contimeout 5000
|
||||
clitimeout 50000
|
||||
srvtimeout 50000
|
||||
|
||||
The configuration stated above is recommended for HTTP load balancer use, but it may not be the optimal solution for your environment. In that case, feel free to explore HAProxy man pages to tweak it.
|
||||
|
||||
#### 3. Webfarm Configuration ####
|
||||
|
||||
Webfarm configuration defines the pool of available HTTP servers. Most of the settings for our load balancer will be placed here. Now we will create some basic configuration, where our nodes will be defined. Replace all of the configuration from frontend section until the end of file with the following code:
|
||||
|
||||
listen webfarm *:80
|
||||
mode http
|
||||
stats enable
|
||||
stats uri /haproxy?stats
|
||||
stats realm Haproxy\ Statistics
|
||||
stats auth haproxy:stats
|
||||
balance roundrobin
|
||||
cookie LBN insert indirect nocache
|
||||
option httpclose
|
||||
option forwardfor
|
||||
server web01 192.168.100.2:80 cookie node1 check
|
||||
server web02 192.168.100.3:80 cookie node2 check
|
||||
|
||||
The line "listen webfarm *:80" defines on which interfaces our load balancer will listen. For the sake of the tutorial, I've set that to "*" which makes the load balancer listen on all our interfaces. In a real world scenario, this might be undesirable and should be replaced with an interface that is accessible from the internet.
|
||||
|
||||
stats enable
|
||||
stats uri /haproxy?stats
|
||||
stats realm Haproxy\ Statistics
|
||||
stats auth haproxy:stats
|
||||
|
||||
The above settings declare that our load balancer statistics can be accessed on http://<load-balancer-IP>/haproxy?stats. The access is secured with a simple HTTP authentication with login name "haproxy" and password "stats". These settings should be replaced with your own credentials. If you don't need to have these statistics available, then completely disable them.
|
||||
|
||||
Here is an example of HAProxy statistics.
|
||||
|
||||
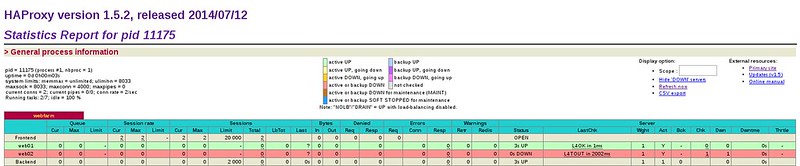
|
||||
|
||||
The line "balance roundrobin" defines the type of load balancing we will use. In this tutorial we will use simple round robin algorithm, which is fully sufficient for HTTP load balancing. HAProxy also offers other types of load balancing:
|
||||
|
||||
- **leastconn**: gives connections to the server with the lowest number of connections.
|
||||
- **source**: hashes the source IP address, and divides it by the total weight of the running servers to decide which server will receive the request.
|
||||
- **uri**: the left part of the URI (before the question mark) is hashed and divided by the total weight of the running servers. The result determines which server will receive the request.
|
||||
- **url_param**: the URL parameter specified in the argument will be looked up in the query string of each HTTP GET request. You can basically lock the request using crafted URL to specific load balancer node.
|
||||
- **hdr(name**): the HTTP header <name> will be looked up in each HTTP request and directed to specific node.
|
||||
|
||||
The line "cookie LBN insert indirect nocache" makes our load balancer store persistent cookies, which allows us to pinpoint which node from the pool is used for a particular session. These node cookies will be stored with a defined name. In our case, I used "LBN", but you can specify any name you like. The node will store its string as a value for this cookie.
|
||||
|
||||
server web01 192.168.100.2:80 cookie node1 check
|
||||
server web02 192.168.100.3:80 cookie node2 check
|
||||
|
||||
The above part is the definition of our pool of web server nodes. Each server is represented with its internal name (e.g., web01, web02). IP address, and unique cookie string. The cookie string can be defined as anything you want. I am using simple node1, node2 ... node(n).
|
||||
|
||||
### Start HAProxy ###
|
||||
|
||||
When you are done with the configuration, it's time to start HAProxy and verify that everything is working as intended.
|
||||
|
||||
#### Start HAProxy on Centos/RHEL ####
|
||||
|
||||
Enable HAProxy to be started after boot and turn it on using:
|
||||
|
||||
# chkconfig haproxy on
|
||||
# service haproxy start
|
||||
|
||||
And of course don't forget to enable port 80 in the firewall as follows.
|
||||
|
||||
**Firewall on CentOS/RHEL 7:**
|
||||
|
||||
# firewallcmd permanent zone=public addport=80/tcp
|
||||
# firewallcmd reload
|
||||
|
||||
**Firewall on CentOS/RHEL 6:**
|
||||
|
||||
Add following line into section ":OUTPUT ACCEPT" of /etc/sysconfig/iptables:
|
||||
|
||||
A INPUT m state state NEW m tcp p tcp dport 80 j ACCEPT
|
||||
|
||||
and restart **iptables**:
|
||||
|
||||
# service iptables restart
|
||||
|
||||
#### Start HAProxy on Debian ####
|
||||
|
||||
#### Start HAProxy with: ####
|
||||
|
||||
# service haproxy start
|
||||
|
||||
Don't forget to enable port 80 in the firewall by adding the following line into /etc/iptables.up.rules:
|
||||
|
||||
A INPUT p tcp dport 80 j ACCEPT
|
||||
|
||||
#### Start HAProxy on Ubuntu ####
|
||||
|
||||
Enable HAProxy to be started after boot by setting "ENABLED" option to "1" in /etc/default/haproxy:
|
||||
|
||||
ENABLED=1
|
||||
|
||||
Start HAProxy:
|
||||
|
||||
# service haproxy start
|
||||
|
||||
and enable port 80 in the firewall:
|
||||
|
||||
# ufw allow 80
|
||||
|
||||
### Test HAProxy ###
|
||||
|
||||
To check whether HAproxy is working properly, we can do the following.
|
||||
|
||||
First, prepare test.php file with the following content:
|
||||
|
||||
<?php
|
||||
header('Content-Type: text/plain');
|
||||
echo "Server IP: ".$_SERVER['SERVER_ADDR'];
|
||||
echo "\nX-Forwarded-for: ".$_SERVER['HTTP_X_FORWARDED_FOR'];
|
||||
?>
|
||||
|
||||
This PHP file will tell us which server (i.e., load balancer) forwarded the request, and what backend web server actually handled the request.
|
||||
|
||||
Place this PHP file in the root directory of both backend web servers. Now use curl command to fetch this PHP file from the load balancer (192.168.100.4).
|
||||
|
||||
$ curl http://192.168.100.4/test.php
|
||||
|
||||
When we run this command multiple times, we should see the following two outputs alternate (due to the round robin algorithm).
|
||||
|
||||
Server IP: 192.168.100.2
|
||||
X-Forwarded-for: 192.168.100.4
|
||||
|
||||
----------
|
||||
|
||||
Server IP: 192.168.100.3
|
||||
X-Forwarded-for: 192.168.100.4
|
||||
|
||||
If we stop one of the two backend web servers, the curl command should still work, directing requests to the other available web server.
|
||||
|
||||
### Summary ###
|
||||
|
||||
By now you should have a fully operational load balancer that supplies your web nodes with requests in round robin mode. As always, feel free to experiment with the configuration to make it more suitable for your infrastructure. I hope this tutorial helped you to make your web projects more resistant and available.
|
||||
|
||||
As most of you already noticed, this tutorial contains settings for only one load balancer. Which means that we have just replaced one single point of failure with another. In real life scenarios you should deploy at least two or three load balancers to cover for any failures that might happen, but that is out of the scope of this tutorial right now.
|
||||
|
||||
If you have any questions or suggestions feel free to post them in the comments and I will do my best to answer or advice.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/haproxy-http-load-balancer-linux.html
|
||||
|
||||
作者:[Jaroslav Štěpánek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/jaroslav
|
||||
[1]:http://www.haproxy.org/
|
||||
[2]:http://www.haproxy.org/10g.html
|
||||
[3]:http://xmodulo.com/how-to-install-lamp-server-on-ubuntu.html
|
||||
@ -0,0 +1,275 @@
|
||||
如何在 Linux 上使用 HAProxy 配置 HTTP 负载均衡器
|
||||
================================================================================
|
||||
随着基于 Web 的应用和服务的增多,IT 系统管理员肩上的责任也越来越重。当遇到不可预期的事件如流量达到高峰,流量增大或者内部的挑战比如硬件的损坏或紧急维修,无论如何,你的 Web 应用都必须要保持可用性。甚至现在流行的 devops 和持续交付也可能威胁到你的 Web 服务的可靠性和性能的一致性。
|
||||
|
||||
不可预测,不一直的性能表现是你无法接受的。但是我们怎样消除这些缺点呢?大多数情况下一个合适的负载均衡解决方案可以解决这个问题。今天我会给你们介绍如何使用 [HAProxy][1] 配置 HTTP 负载均衡器。
|
||||
|
||||
###什么是 HTTP 负载均衡? ###
|
||||
|
||||
HTTP 负载均衡是一个网络解决方案,它将发入的 HTTP 或 HTTPs 请求分配至一组提供相同的 Web 应用内容的服务器用于响应。通过将请求在这样的多个服务器间进行均衡,负载均衡器可以防止服务器出现单点故障,可以提升整体的可用性和响应速度。它还可以让你能够简单的通过添加或者移除服务器来进行横向扩展或收缩,对工作负载进行调整。
|
||||
|
||||
### 什么时候,什么情况下需要使用负载均衡? ###
|
||||
|
||||
负载均衡可以提升服务器的使用性能和最大可用性,当你的服务器开始出现高负载时就可以使用负载均衡。或者你在为一个大型项目设计架构时,在前端使用负载均衡是一个很好的习惯。当你的环境需要扩展的时候它会很有用。
|
||||
|
||||
|
||||
### 什么是 HAProxy? ###
|
||||
|
||||
HAProxy 是一个流行的开源的 GNU/Linux 平台下的 TCP/HTTP 服务器的负载均衡和代理软件。HAProxy 是单线程,事件驱动架构,可以轻松的处理 [10 Gbps 速率][2] 的流量,在生产环境中被广泛的使用。它的功能包括自动健康状态检查,自定义负载均衡算法,HTTPS/SSL 支持,会话速率限制等等。
|
||||
|
||||
### 这个教程要实现怎样的负载均衡 ###
|
||||
|
||||
在这个教程中,我们会为 HTTP Web 服务器配置一个基于 HAProxy 的负载均衡。
|
||||
|
||||
### 准备条件 ###
|
||||
|
||||
你至少要有一台,或者最好是两台 Web 服务器来验证你的负载均衡的功能。我们假设后端的 HTTP Web 服务器已经配置好并[可以运行][3]。
|
||||
You will need at least one, or preferably two web servers to verify functionality of your load balancer. We assume that backend HTTP web servers are already [up and running][3].
|
||||
|
||||
### 在 Linux 中安装 HAProxy ###
|
||||
|
||||
对于大多数的发行版,我们可以使用发行版的包管理器来安装 HAProxy。
|
||||
|
||||
#### 在 Debian 中安装 HAProxy ####
|
||||
|
||||
在 Debian Wheezy 中我们需要添加源,在 /etc/apt/sources.list.d 下创建一个文件 "backports.list" ,写入下面的内容
|
||||
|
||||
deb http://cdn.debian.net/debian wheezybackports main
|
||||
|
||||
刷新仓库的数据,并安装 HAProxy
|
||||
|
||||
# apt get update
|
||||
# apt get install haproxy
|
||||
|
||||
#### 在 Ubuntu 中安装 HAProxy ####
|
||||
|
||||
# apt get install haproxy
|
||||
|
||||
#### 在 CentOS 和 RHEL 中安装 HAProxy ####
|
||||
|
||||
# yum install haproxy
|
||||
|
||||
### 配置 HAProxy ###
|
||||
|
||||
本教程假设有两台运行的 HTTP Web 服务器,它们的 IP 地址是 192.168.100.2 和 192.168.100.3。我们将负载均衡配置在 192.168.100.4 的这台服务器上。
|
||||
|
||||
为了让 HAProxy 工作正常,你需要修改 /etc/haproxy/haproxy.cfg 中的一些选项。我们会在这一节中解释这些修改。一些配置可能因 GNU/Linux 发行版的不同而变化,这些会被标注出来。
|
||||
|
||||
#### 1. 配置日志功能 ####
|
||||
|
||||
你要做的第一件事是为 HAProxy 配置日志功能,在排错时日志将很有用。日志配置可以在 /etc/haproxy/haproxy.cfg 的 global 段中找到他们。下面是针对不同的 Linux 发型版的 HAProxy 日志配置。
|
||||
|
||||
**CentOS 或 RHEL:**
|
||||
|
||||
在 CentOS/RHEL中启用日志,将下面的:
|
||||
|
||||
log 127.0.0.1 local2
|
||||
|
||||
替换为:
|
||||
|
||||
log 127.0.0.1 local0
|
||||
|
||||
然后配置 HAProxy 在 /var/log 中的日志分割,我们需要修改当前的 rsyslog 配置。为了简洁和明了,我们在 /etc/rsyslog.d 下创建一个叫 haproxy.conf 的文件,添加下面的内容:
|
||||
|
||||
$ModLoad imudp
|
||||
$UDPServerRun 514
|
||||
$template Haproxy,"%msg%\n"
|
||||
local0.=info /var/log/haproxy.log;Haproxy
|
||||
local0.notice /var/log/haproxystatus.log;Haproxy
|
||||
local0.* ~
|
||||
|
||||
这个配置会基于 $template 在 /var/log 中分割 HAProxy 日志。现在重启 rsyslog 应用这些更改。
|
||||
|
||||
# service rsyslog restart
|
||||
|
||||
**Debian 或 Ubuntu:**
|
||||
|
||||
在 Debian 或 Ubuntu 中启用日志,将下面的内容
|
||||
|
||||
log /dev/log local0
|
||||
log /dev/log local1 notice
|
||||
|
||||
替换为:
|
||||
|
||||
log 127.0.0.1 local0
|
||||
|
||||
然后为 HAProxy 配置日志分割,编辑 /etc/rsyslog.d/ 下的 haproxy.conf (在 Debian 中可能叫 49-haproxy.conf),写入下面你的内容
|
||||
|
||||
$ModLoad imudp
|
||||
$UDPServerRun 514
|
||||
$template Haproxy,"%msg%\n"
|
||||
local0.=info /var/log/haproxy.log;Haproxy
|
||||
local0.notice /var/log/haproxystatus.log;Haproxy
|
||||
local0.* ~
|
||||
|
||||
这个配置会基于 $template 在 /var/log 中分割 HAProxy 日志。现在重启 rsyslog 应用这些更改。
|
||||
|
||||
# service rsyslog restart
|
||||
|
||||
#### 2. 设置默认选项 ####
|
||||
|
||||
下一步是设置 HAProxy 的默认选项。在 /etc/haproxy/haproxy.cfg 的 default 段中,替换为下面的配置:
|
||||
|
||||
defaults
|
||||
log global
|
||||
mode http
|
||||
option httplog
|
||||
option dontlognull
|
||||
retries 3
|
||||
option redispatch
|
||||
maxconn 20000
|
||||
contimeout 5000
|
||||
clitimeout 50000
|
||||
srvtimeout 50000
|
||||
|
||||
上面的配置是当 HAProxy 为 HTTP 负载均衡时建议使用的,但是并不一定是你的环境的最优方案。你可以自己研究 HAProxy 的手册并配置它。
|
||||
|
||||
#### 3. Web 集群配置 ####
|
||||
|
||||
Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡中的大多数设置都在这里。现在我们会创建一些基本配置,定义我们的节点。将配置文件中从 frontend 段开始的内容全部替换为下面的:
|
||||
|
||||
listen webfarm *:80
|
||||
mode http
|
||||
stats enable
|
||||
stats uri /haproxy?stats
|
||||
stats realm Haproxy\ Statistics
|
||||
stats auth haproxy:stats
|
||||
balance roundrobin
|
||||
cookie LBN insert indirect nocache
|
||||
option httpclose
|
||||
option forwardfor
|
||||
server web01 192.168.100.2:80 cookie node1 check
|
||||
server web02 192.168.100.3:80 cookie node2 check
|
||||
|
||||
"listen webfarm *:80" 定义了负载均衡器监听的地址和端口。为了教程的需要,我设置为 "\*" 表示监听在所有接口上。在真实的场景汇总,这样设置可能不太合适,应该替换为可以从 internet 访问的那个网卡接口。
|
||||
|
||||
stats enable
|
||||
stats uri /haproxy?stats
|
||||
stats realm Haproxy\ Statistics
|
||||
stats auth haproxy:stats
|
||||
|
||||
上面的设置定义了,负载均衡器的状态统计信息可以通过 http://<load-balancer-IP>/haproxy?stats 访问。访问需要简单的 HTTP 认证,用户名为 "haproxy" 密码为 "stats"。这些设置可以替换为你自己的认证方式。如果你不需要状态统计信息,可以完全禁用掉。
|
||||
|
||||
下面是一个 HAProxy 统计信息的例子
|
||||
|
||||

|
||||
|
||||
"balance roundrobin" 这一行表明我们使用的负载均衡类型。这个教程中,我们使用简单的轮询算法,可以完全满足 HTTP 负载均衡的需要。HAProxy 还提供其他的负载均衡类型:
|
||||
|
||||
- **leastconn**:将请求调度至连接数最少的服务器
|
||||
- **source**:对请求的客户端 IP 地址进行哈希计算,根据哈希值和服务器的权重将请求调度至后端服务器。
|
||||
- **uri**:对 URI 的左半部分(问号之前的部分)进行哈希,根据哈希结果和服务器的权重对请求进行调度
|
||||
- **url_param**:根据每个 HTTP GET 请求的 URL 查询参数进行调度,使用固定的请求参数将会被调度至指定的服务器上
|
||||
- **hdr(name**):根据 HTTP 首部中的 <name> 字段来进行调度
|
||||
|
||||
"cookie LBN insert indirect nocache" 这一行表示我们的负载均衡器会存储 cookie 信息,可以将后端服务器池中的节点与某个特定会话绑定。节点的 cookie 存储为一个自定义的名字。这里,我们使用的是 "LBN",你可以指定其他的名称。后端节点会保存这个 cookie 的会话。
|
||||
|
||||
server web01 192.168.100.2:80 cookie node1 check
|
||||
server web02 192.168.100.3:80 cookie node2 check
|
||||
|
||||
上面是我们的 Web 服务器节点的定义。服务器有由内部名称(如web01,web02),IP 地址和唯一的 cookie 字符串表示。cookie 字符串可以自定义,我这里使用的是简单的 node1,node2 ... node(n)
|
||||
|
||||
### 启动 HAProxy ###
|
||||
|
||||
如果你完成了配置,现在启动 HAProxy 并验证是否运行正常。
|
||||
|
||||
#### 在 Centos/RHEL 中启动 HAProxy ####
|
||||
|
||||
让 HAProxy 开机自启,使用下面的命令
|
||||
|
||||
# chkconfig haproxy on
|
||||
# service haproxy start
|
||||
|
||||
当然,防火墙需要开放 80 端口,想下面这样
|
||||
|
||||
**CentOS/RHEL 7 的防火墙**
|
||||
|
||||
# firewallcmd permanent zone=public addport=80/tcp
|
||||
# firewallcmd reload
|
||||
|
||||
**CentOS/RHEL 6 的防火墙**
|
||||
|
||||
把下面内容加至 /etc/sysconfig/iptables 中的 ":OUTPUT ACCEPT" 段中
|
||||
|
||||
A INPUT m state state NEW m tcp p tcp dport 80 j ACCEPT
|
||||
|
||||
重启**iptables**:
|
||||
|
||||
# service iptables restart
|
||||
|
||||
#### 在 Debian 中启动 HAProxy ####
|
||||
|
||||
#### 启动 HAProxy ####
|
||||
|
||||
# service haproxy start
|
||||
|
||||
不要忘了防火墙开放 80 端口,在 /etc/iptables.up.rules 中加入:
|
||||
|
||||
A INPUT p tcp dport 80 j ACCEPT
|
||||
|
||||
#### 在 Ubuntu 中启动HAProxy ####
|
||||
|
||||
让 HAProxy 开机自动启动在 /etc/default/haproxy 中配置
|
||||
|
||||
ENABLED=1
|
||||
|
||||
启动 HAProxy:
|
||||
|
||||
# service haproxy start
|
||||
|
||||
防火墙开放 80 端口:
|
||||
|
||||
# ufw allow 80
|
||||
|
||||
### 测试 HAProxy ###
|
||||
|
||||
检查 HAProxy 是否工作正常,我们可以这样做
|
||||
|
||||
首先准备一个 test.php 文件,文件内容如下
|
||||
|
||||
<?php
|
||||
header('Content-Type: text/plain');
|
||||
echo "Server IP: ".$_SERVER['SERVER_ADDR'];
|
||||
echo "\nX-Forwarded-for: ".$_SERVER['HTTP_X_FORWARDED_FOR'];
|
||||
?>
|
||||
|
||||
这个 PHP 文件会告诉我们哪台服务器(如负载均衡)转发了请求,哪台后端 Web 服务器实际处理了请求。
|
||||
|
||||
将这个 PHP 文件放到两个后端 Web 服务器的 Web 根目录中。然后用 curl 命令通过负载均衡器(192.168.100.4)访问这个文件
|
||||
|
||||
$ curl http://192.168.100.4/test.php
|
||||
|
||||
我们多次使用这个命令此时,会发现交替的输出下面的内容(因为使用了轮询算法):
|
||||
|
||||
Server IP: 192.168.100.2
|
||||
X-Forwarded-for: 192.168.100.4
|
||||
|
||||
----------
|
||||
|
||||
Server IP: 192.168.100.3
|
||||
X-Forwarded-for: 192.168.100.4
|
||||
|
||||
如果我们停掉一台后端 Web 服务,curl 命令仍然正常工作,请求被分发至另一台可用的 Web 服务器。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
现在你有了一个完全可用的负载均衡器,以轮询的模式对你的 Web 节点进行负载均衡。还可以去实验其他的配置选项以适应你的环境。希望这个教程可以帮会组你们的 Web 项目有更好的可用性。
|
||||
|
||||
你可能已经发现了,这个教程只包含单台负载均衡的设置。这意味着我们仍然有单点故障的问题。在真实场景中,你应该至少部署 2 台或者 3 台负载均衡以防止意外发生,但这不是本教程的范围。
|
||||
|
||||
如果 你有任何问题或建议,请在评论中提出,我会尽我的努力回答。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/haproxy-http-load-balancer-linux.html
|
||||
|
||||
作者:[Jaroslav Štěpánek][a]
|
||||
译者:[Liao](https://github.com/liaoishere)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/jaroslav
|
||||
[1]:http://www.haproxy.org/
|
||||
[2]:http://www.haproxy.org/10g.html
|
||||
[3]:http://xmodulo.com/how-to-install-lamp-server-on-ubuntu.html
|
||||
Loading…
Reference in New Issue
Block a user