mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
commit
deed12ab17
87
published/20171120 Adopting Kubernetes step by step.md
Normal file
87
published/20171120 Adopting Kubernetes step by step.md
Normal file
@ -0,0 +1,87 @@
|
||||
一步步采用 Kubernetes
|
||||
============================================================
|
||||
|
||||
### 为什么选择 Docker 和 Kubernetes 呢?
|
||||
|
||||
容器允许我们构建、发布和运行分布式应用。它们使应用程序摆脱了机器限制,可以让我们以一定的方式创建一个复杂的应用程序。
|
||||
|
||||
使用容器编写应用程序可以使开发、QA 更加接近生产环境(如果你努力这样做的话)。通过这样做,可以更快地发布修改,并且可以更快地测试整个系统。
|
||||
|
||||
[Docker][1] 这个容器式平台就是为此为生,可以使软件独立于云提供商。
|
||||
|
||||
但是,即使使用容器,移植应用程序到任何一个云提供商(或私有云)所需的工作量也是不可忽视的。应用程序通常需要自动伸缩组、持久远程磁盘、自动发现等。但是每个云提供商都有不同的机制。如果你想使用这些功能,很快你就会变的依赖于云提供商。
|
||||
|
||||
这正是 [Kubernetes][2] 登场的时候。它是一个容器<ruby>编排<rt>orchestration</rt></ruby>系统,它允许您以一定的标准管理、缩放和部署应用程序的不同部分,并且成为其中的重要工具。它的可移植抽象层兼容主要云的提供商(Google Cloud,Amazon Web Services 和 Microsoft Azure 都支持 Kubernetes)。
|
||||
|
||||
可以这样想象一下应用程序、容器和 Kubernetes。应用程序可以视为一条身边的鲨鱼,它存在于海洋中(在这个例子中,海洋就是您的机器)。海洋中可能还有其他一些宝贵的东西,但是你不希望你的鲨鱼与小丑鱼有什么关系。所以需要把你的鲨鱼(你的应用程序)移动到一个密封的水族馆中(容器)。这很不错,但不是特别的健壮。你的水族馆可能会被打破,或者你想建立一个通道连接到其他鱼类生活的另一个水族馆。也许你想要许多这样的水族馆,以防需要清洁或维护……这正是应用 Kubernetes 集群的作用。
|
||||
|
||||

|
||||
|
||||
*进化到 Kubernetes*
|
||||
|
||||
主流云提供商对 Kubernetes 提供了支持,从开发环境到生产环境,它使您和您的团队能够更容易地拥有几乎相同的环境。这是因为 Kubernetes 不依赖专有软件、服务或基础设施。
|
||||
|
||||
事实上,您可以在您的机器中使用与生产环境相同的部件启动应用程序,从而缩小了开发和生产环境之间的差距。这使得开发人员更了解应用程序是如何构建在一起的,尽管他们可能只负责应用程序的一部分。这也使得在开发流程中的应用程序更容易的快速完成测试。
|
||||
|
||||
### 如何使用 Kubernetes 工作?
|
||||
|
||||
随着更多的人采用 Kubernetes,新的问题出现了;应该如何针对基于集群环境进行开发?假设有 3 个环境,开发、质量保证和生产, 他们如何适应 Kubernetes?这些环境之间仍然存在着差异,无论是在开发周期(例如:在运行中的应用程序中我的代码的变化上花费时间)还是与数据相关的(例如:我不应该在我的质量保证环境中测试生产数据,因为它里面有敏感信息)。
|
||||
|
||||
那么,我是否应该总是在 Kubernetes 集群中编码、构建映像、重新部署服务,在我编写代码时重新创建部署和服务?或者,我是否不应该尽力让我的开发环境也成为一个 Kubernetes 集群(或一组集群)呢?还是,我应该以混合方式工作?
|
||||
|
||||
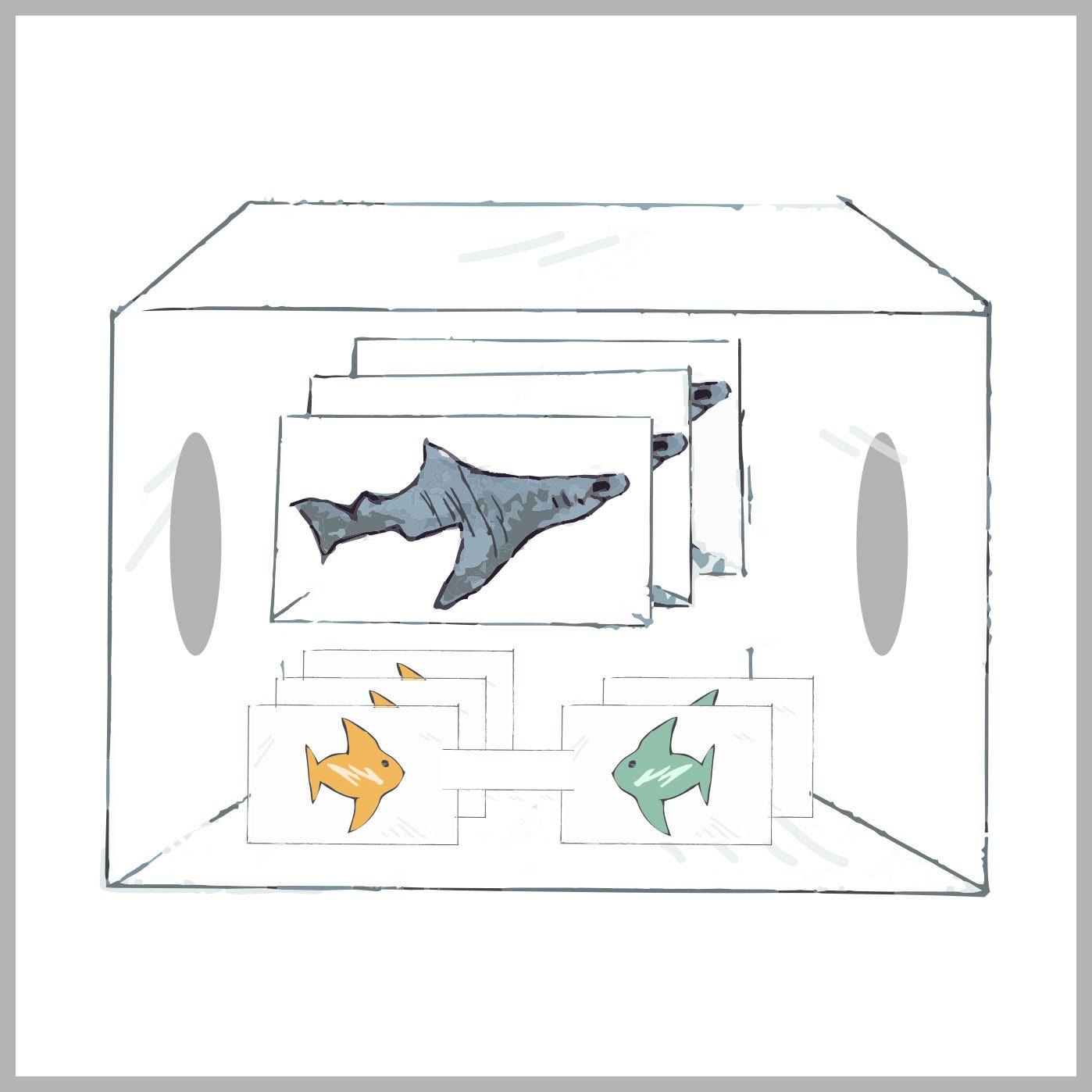
|
||||
|
||||
*用本地集群进行开发*
|
||||
|
||||
如果继续我们之前的比喻,上图两边的洞表示当使其保持在一个开发集群中的同时修改应用程序的一种方式。这通常通过[卷][4]来实现
|
||||
|
||||
### Kubernetes 系列
|
||||
|
||||
本 Kubernetes 系列资源是开源的,可以在这里找到: [https://github.com/red-gate/ks][5] 。
|
||||
|
||||
我们写这个系列作为以不同的方式构建软件的练习。我们试图约束自己在所有环境中都使用 Kubernetes,以便我们可以探索这些技术对数据和数据库的开发和管理造成影响。
|
||||
|
||||
这个系列从使用 Kubernetes 创建基本的 React 应用程序开始,并逐渐演变为能够覆盖我们更多开发需求的系列。最后,我们将覆盖所有应用程序的开发需求,并且理解在数据库生命周期中如何最好地迎合容器和集群。
|
||||
|
||||
以下是这个系列的前 5 部分:
|
||||
|
||||
1. ks1:使用 Kubernetes 构建一个 React 应用程序
|
||||
2. ks2:使用 minikube 检测 React 代码的更改
|
||||
3. ks3:添加一个提供 API 的 Python Web 服务器
|
||||
4. ks4:使 minikube 检测 Python 代码的更改
|
||||
5. ks5:创建一个测试环境
|
||||
|
||||
本系列的第二部分将添加一个数据库,并尝试找出最好的方式来开发我们的应用程序。
|
||||
|
||||
通过在各种环境中运行 Kubernetes,我们被迫在解决新问题的同时也尽量保持开发周期。我们不断尝试 Kubernetes,并越来越习惯它。通过这样做,开发团队都可以对生产环境负责,这并不困难,因为所有环境(从开发到生产)都以相同的方式进行管理。
|
||||
|
||||
### 下一步是什么?
|
||||
|
||||
我们将通过整合数据库和练习来继续这个系列,以找到使用 Kubernetes 获得数据库生命周期的最佳体验方法。
|
||||
|
||||
这个 Kubernetes 系列是由 Redgate 研发部门 Foundry 提供。我们正在努力使数据和容器的管理变得更加容易,所以如果您正在处理数据和容器,我们希望听到您的意见,请直接联系我们的开发团队。 [_foundry@red-gate.com_][6]
|
||||
|
||||
* * *
|
||||
|
||||
我们正在招聘。您是否有兴趣开发产品、创建[未来技术][7] 并采取类似创业的方法(没有风险)?看看我们的[软件工程师 - 未来技术][8]的角色吧,并阅读更多关于在 [英国剑桥][9]的 Redgate 工作的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/ingeniouslysimple/adopting-kubernetes-step-by-step-f93093c13dfe
|
||||
|
||||
作者:[santiago arias][a]
|
||||
译者:[aiwhj](https://github.com/aiwhj)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@santiaago?source=post_header_lockup
|
||||
[1]:https://www.docker.com/what-docker
|
||||
[2]:https://kubernetes.io/
|
||||
[3]:https://www.google.co.uk/search?biw=723&bih=753&tbm=isch&sa=1&ei=p-YCWpbtN8atkwWc8ZyQAQ&q=nemo+fish&oq=nemo+fish&gs_l=psy-ab.3..0i67k1l2j0l2j0i67k1j0l5.5128.9271.0.9566.9.9.0.0.0.0.81.532.9.9.0....0...1.1.64.psy-ab..0.9.526...0i7i30k1j0i7i10i30k1j0i13k1j0i10k1.0.FbAf9xXxTEM
|
||||
[4]:https://kubernetes.io/docs/concepts/storage/volumes/
|
||||
[5]:https://github.com/red-gate/ks
|
||||
[6]:mailto:foundry@red-gate.com
|
||||
[7]:https://www.red-gate.com/foundry/
|
||||
[8]:https://www.red-gate.com/our-company/careers/current-opportunities/software-engineer-future-technologies
|
||||
[9]:https://www.red-gate.com/our-company/careers/living-in-cambridge
|
||||
295
sources/tech/20170216 25 Free Books To Learn Linux For Free.md
Normal file
295
sources/tech/20170216 25 Free Books To Learn Linux For Free.md
Normal file
@ -0,0 +1,295 @@
|
||||
25 Free Books To Learn Linux For Free
|
||||
======
|
||||
Brief: In this article, I'll share with you the best resource to **learn Linux for free**. This is a collection of websites, online video courses and free eBooks.
|
||||
|
||||
**How to learn Linux?**
|
||||
|
||||
This is perhaps the most commonly asked question in our Facebook group for Linux users.
|
||||
|
||||
The answer to this simple looking question 'how to learn Linux' is not at all simple.
|
||||
|
||||
Problem is that different people have different meanings of learning Linux.
|
||||
|
||||
* If someone has never used Linux, be it command line or desktop version, that person might be just wondering to know more about it.
|
||||
* If someone uses Windows as the desktop but have to use Linux command line at work, that person might be interested in learning Linux commands.
|
||||
* If someone has been using Linux for sometimes and is aware of the basics but he/she might want to go to the next level.
|
||||
* If someone is just interested in getting your way around a specific Linux distribution.
|
||||
* If someone is trying to improve or learn Bash scripting which is almost synonymous with Linux command line.
|
||||
* If someone is willing to make a career as a Linux SysAdmin or trying to improve his/her sysadmin skills.
|
||||
|
||||
|
||||
|
||||
You see, the answer to "how do I learn Linux" depends on what kind of Linux knowledge you are seeking. And for this purpose, I have collected a bunch of resources that you could use for learning Linux.
|
||||
|
||||
These free resources include eBooks, video courses, websites etc. And these are divided into sub-categories so that you can easily find what you are looking for when you seek to learn Linux.
|
||||
|
||||
Again, there is no **best way to learn Linux**. It totally up to you how you go about learning Linux, by online web portals, downloaded eBooks, video courses or something else.
|
||||
|
||||
Let's see how you can learn Linux.
|
||||
|
||||
**Disclaimer** : All the books listed here are legal to download. The sources mentioned here are the official sources, as per my knowledge. However, if you find it otherwise, please let me know so that I can take appropriate action.
|
||||
|
||||
![Best Free eBooks to learn Linux for Free][1]
|
||||
|
||||
## 1. Free materials to learn Linux for absolute beginners
|
||||
|
||||
So perhaps you have just heard of Linux from your friends or from a discussion online. You are intrigued about the hype around Linux and you are overwhelmed by the vast information available on the internet but just cannot figure out exactly where to look for to know more about Linux.
|
||||
|
||||
Worry not. Most of us, if not all, have been to your stage.
|
||||
|
||||
### Introduction to Linux by Linux Foundation [Video Course]
|
||||
|
||||
If you have no idea about what is Linux and you want to get started with it, I suggest you to go ahead with the free video course provided by the [Linux Foundation][2] on [edX][3]. Consider it an official course by the organization that 'maintains' Linux. And yes, it is endorsed by [Linus Torvalds][4], the father of Linux himself.
|
||||
|
||||
[Introduction To Linux][5]
|
||||
|
||||
### Linux Journey [Online Portal]
|
||||
|
||||
Not official and perhaps not very popular. But this little website is the perfect place for a no non-sense Linux learning for beginners.
|
||||
|
||||
The website is designed beautifully and is well organized based on the topics. It also has interactive quizzes that you can take after reading a section or chapter. My advice, bookmark this website:
|
||||
|
||||
[Linux Journey][6]
|
||||
|
||||
### Learn Linux in 5 Days [eBook]
|
||||
|
||||
This brilliant eBook is available for free exclusively to It's FOSS readers all thanks to [Linux Training Academy][7].
|
||||
|
||||
Written for absolute beginners in mind, this free Linux eBook gives you a quick overview of Linux, common Linux commands and other things that you need to learn to get started with Linux.
|
||||
|
||||
You can download the book from the page below:
|
||||
|
||||
[Learn Linux In 5 Days][8]
|
||||
|
||||
### The Ultimate Linux Newbie Guide [eBook]
|
||||
|
||||
This is a free to download eBook for Linux beginners. The eBook starts with explaining what is Linux and then go on to provide more practical usage of Linux as a desktop.
|
||||
|
||||
You can download the latest version of this eBook from the link below:
|
||||
|
||||
[The Ultimate Linux Newbie Guide][9]
|
||||
|
||||
## 2. Free Linux eBooks for Beginners to Advanced
|
||||
|
||||
This section lists out those Linux eBooks that are 'complete' in nature.
|
||||
|
||||
What I mean is that these are like academic textbooks that focus on each and every aspects of Linux, well most of it. You can read those as an absolute beginner or you can read those for deeper understanding as an intermediate Linux user. You can also use them for reference even if you are at expert level.
|
||||
|
||||
### Introduction to Linux [eBook]
|
||||
|
||||
Introduction to Linux is a free eBook from [The Linux Documentation Project][10] and it is one of the most popular free Linux books out there. Though I think some parts of this book needs to be updated, it is still a very good book to teach you about Linux, its file system, command line, networking and other related stuff.
|
||||
|
||||
[Introduction To Linux][11]
|
||||
|
||||
### Linux Fundamentals [eBook]
|
||||
|
||||
This free eBook by Paul Cobbaut teaches you about Linux history, installation and focuses on the basic Linux commands you should know. You can get the book from the link below:
|
||||
|
||||
[Linux Fundamentals][12]
|
||||
|
||||
### Advanced Linux Programming [eBook]
|
||||
|
||||
As the name suggests, this is for advanced users who are or want to develop software for Linux. It deals with sophisticated features such as multiprocessing, multi-threading, interprocess communication, and interaction with hardware devices.
|
||||
|
||||
Following the book will help you develop a faster, reliable and secure program that uses the full capability of a GNU/Linux system.
|
||||
|
||||
[Advanced Linux Programming][13]
|
||||
|
||||
### Linux From Scratch [eBook]
|
||||
|
||||
If you think you know enough about Linux and you are a pro, then why not create your own Linux distribution? Linux From Scratch (LFS) is a project that provides you with step-by-step instructions for building your own custom Linux system, entirely from source code.
|
||||
|
||||
Call it DIY Linux but this is a great way to put your Linux expertise to the next level.
|
||||
|
||||
There are various sub-parts of this project, you can check it out on its website and download the books from there.
|
||||
|
||||
[Linux From Scratch][14]
|
||||
|
||||
## 3. Free eBooks to learn Linux command line and Shell scripting
|
||||
|
||||
The real power of Linux lies in the command line and if you want to conquer Linux, you must learn Linux command line and Shell scripting.
|
||||
|
||||
In fact, if you have to work on Linux terminal on your job, having a good knowledge of Linux command line will actually help you in your tasks and perhaps help you in advancing your career as well (as you'll be more efficient).
|
||||
|
||||
In this section, we'll see various Linux commands free eBooks.
|
||||
|
||||
### GNU/Linux Command−Line Tools Summary [eBook]
|
||||
|
||||
This eBook from The Linux Documentation Project is a good place to begin with Linux command line and get acquainted with Shell scripting.
|
||||
|
||||
[GNU/Linux Command−Line Tools Summary][15]
|
||||
|
||||
### Bash Reference Manual from GNU [eBook]
|
||||
|
||||
This is a free eBook to download from [GNU][16]. As the name suggests, it deals with Bash Shell (if I can call that). This book has over 175 pages and it covers a number of topics around Linux command line in Bash.
|
||||
|
||||
You can get it from the link below:
|
||||
|
||||
[Bash Reference Manual][17]
|
||||
|
||||
### The Linux Command Line [eBook]
|
||||
|
||||
This 500+ pages of free eBook by William Shotts is the MUST HAVE for anyone who is serious about learning Linux command line.
|
||||
|
||||
Even if you think you know things about Linux, you'll be amazed at how much this book still teaches you.
|
||||
|
||||
It covers things from beginners to advanced level. I bet that you'll be a hell lot of better Linux user after reading this book. Download it and keep it with you always.
|
||||
|
||||
[The Linux Command Line][18]
|
||||
|
||||
### Bash Guide for Beginners [eBook]
|
||||
|
||||
If you just want to get started with Bash scripting, this could be a good companion for you. The Linux Documentation Project is behind this eBook again and it's the same author who wrote Introduction to Linux eBook (discussed earlier in this article).
|
||||
|
||||
[Bash Guide for Beginners][19]
|
||||
|
||||
### Advanced Bash-Scripting Guide [eBook]
|
||||
|
||||
If you think you already know basics of Bash scripting and you want to take your skills to the next level, this is what you need. This book has over 900+ pages of various advanced commands and their examples.
|
||||
|
||||
[Advanced Bash-Scripting Guide][20]
|
||||
|
||||
### The AWK Programming Language [eBook]
|
||||
|
||||
Not the prettiest book here but if you really need to go deeper with your scripts, this old-yet-gold book could be helpful.
|
||||
|
||||
[The AWK Programming Language][21]
|
||||
|
||||
### Linux 101 Hacks [eBook]
|
||||
|
||||
This 270 pages eBook from The Geek Stuff teaches you the essentials of Linux command lines with easy to follow practical examples. You can get the book from the link below:
|
||||
|
||||
[Linux 101 Hacks][22]
|
||||
|
||||
## 4. Distribution specific free learning material
|
||||
|
||||
This section deals with material that are dedicated to a certain Linux distribution. What we saw so far was the Linux in general, more focused on file systems, commands and other core stuff.
|
||||
|
||||
These books, on the other hand, can be termed as manual or getting started guide for various Linux distributions. So if you are using a certain Linux distribution or planning to use it, you can refer to these resources. And yes, these books are more desktop Linux focused.
|
||||
|
||||
I would also like to add that most Linux distributions have their own wiki or documentation section which are often pretty vast. You can always refer to them when you are online.
|
||||
|
||||
### Ubuntu Manual
|
||||
|
||||
Needless to say that this eBook is for Ubuntu users. It's an independent project that provides Ubuntu manual in the form of free eBook. It is updated for each version of Ubuntu.
|
||||
|
||||
The book is rightly called manual because it is basically a composition of step by step instruction and aimed at absolute beginners to Ubuntu. So, you get to know Unity desktop, how to go around it and find applications etc.
|
||||
|
||||
It's a must have if you never used Ubuntu Unity because it helps you to figure out how to use Ubuntu for your daily usage.
|
||||
|
||||
[Ubuntu Manual][23]
|
||||
|
||||
### For Linux Mint: Just Tell Me Damnit! [eBook]
|
||||
|
||||
A very basic eBook that focuses on Linux Mint. It shows you how to install Linux Mint in a virtual machine, how to find software, install updates and customize the Linux Mint desktop.
|
||||
|
||||
You can download the eBook from the link below:
|
||||
|
||||
[Just Tell Me Damnit!][24]
|
||||
|
||||
### Solus Linux Manual [eBook]
|
||||
|
||||
Caution! This used to be the official manual from Solus Linux but I cannot find its mentioned on Solus Project's website anymore. I don't know if it's outdated or not. But in any case, a little something about Solu Linux won't really hurt, will it?
|
||||
|
||||
[Solus Linux User Guide][25]
|
||||
|
||||
## 5. Free eBooks for SysAdmin
|
||||
|
||||
This section is dedicated to the SysAdmins, the superheroes for developers. I have listed a few free eBooks here for SysAdmin which will surely help anyone who is already a SysAdmin or aspirs to be one. I must add that you should also focus on essential Linux command lines as it will make your job easier.
|
||||
|
||||
### The Debian Administration's Handbook [eBook]
|
||||
|
||||
If you use Debian Linux for your servers, this is your bible. Book starts with Debian history, installation, package management etc and then moves on to cover topics like [LAMP][26], virtual machines, storage management and other core sysadmin stuff.
|
||||
|
||||
[The Debian Administration's Handbook][27]
|
||||
|
||||
### Advanced Linux System Administration [eBook]
|
||||
|
||||
This is an ideal book if you are preparing for [LPI certification][28]. The book deals straightway to the topics essential for sysadmins. So knowledge of Linux command line is a prerequisite in this case.
|
||||
|
||||
[Advanced Linux System Administration][29]
|
||||
|
||||
### Linux System Administration [eBook]
|
||||
|
||||
Another free eBook by Paul Cobbaut. The 370 pages long eBook covers networking, disk management, user management, kernel management, library management etc.
|
||||
|
||||
[Linux System Administration][30]
|
||||
|
||||
### Linux Servers [eBook]
|
||||
|
||||
One more eBook from Paul Cobbaut of [linux-training.be][31]. This book covers web servers, mysql, DHCP, DNS, Samba and other file servers.
|
||||
|
||||
[Linux Servers][32]
|
||||
|
||||
### Linux Networking [eBook]
|
||||
|
||||
Networking is the bread and butter of a SysAdmin, and this book by Paul Cobbaut (again) is a good reference material.
|
||||
|
||||
[Linux Networking][33]
|
||||
|
||||
### Linux Storage [eBook]
|
||||
|
||||
This book by Paul Cobbaut (yes, him again) explains disk management on Linux in detail and introduces a lot of other storage-related technologies.
|
||||
|
||||
[Linux Storage][34]
|
||||
|
||||
### Linux Security [eBook]
|
||||
|
||||
This is the last eBook by Paul Cobbaut in our list here. Security is one of the most important part of a sysadmin's job. This book focuses on file permissions, acls, SELinux, users and passwords etc.
|
||||
|
||||
[Linux Security][35]
|
||||
|
||||
## Your favorite Linux learning material?
|
||||
|
||||
I know that this is a good collection of free Linux eBooks. But this could always be made better.
|
||||
|
||||
If you have some other resources that could be helpful in learning Linux, do share with us. Please note to share only the legal downloads so that I can update this article with your suggestion(s) without any problem.
|
||||
|
||||
I hope you find this article helpful in learning Linux. Your feedback is welcome :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/learn-linux-for-free/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/abhishek/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/02/free-ebooks-linux-800x450.png
|
||||
[2]:https://www.linuxfoundation.org/
|
||||
[3]:https://www.edx.org
|
||||
[4]:https://www.youtube.com/watch?v=eE-ovSOQK0Y
|
||||
[5]:https://www.edx.org/course/introduction-linux-linuxfoundationx-lfs101x-0
|
||||
[6]:https://linuxjourney.com/
|
||||
[7]:https://www.linuxtrainingacademy.com/
|
||||
[8]:https://courses.linuxtrainingacademy.com/itsfoss-ll5d/
|
||||
[9]:https://linuxnewbieguide.org/ulngebook/
|
||||
[10]:http://www.tldp.org/index.html
|
||||
[11]:http://tldp.org/LDP/intro-linux/intro-linux.pdf
|
||||
[12]:http://linux-training.be/linuxfun.pdf
|
||||
[13]:http://advancedlinuxprogramming.com/alp-folder/advanced-linux-programming.pdf
|
||||
[14]:http://www.linuxfromscratch.org/
|
||||
[15]:http://tldp.org/LDP/GNU-Linux-Tools-Summary/GNU-Linux-Tools-Summary.pdf
|
||||
[16]:https://www.gnu.org/home.en.html
|
||||
[17]:https://www.gnu.org/software/bash/manual/bash.pdf
|
||||
[18]:http://linuxcommand.org/tlcl.php
|
||||
[19]:http://www.tldp.org/LDP/Bash-Beginners-Guide/Bash-Beginners-Guide.pdf
|
||||
[20]:http://www.tldp.org/LDP/abs/abs-guide.pdf
|
||||
[21]:https://ia802309.us.archive.org/25/items/pdfy-MgN0H1joIoDVoIC7/The_AWK_Programming_Language.pdf
|
||||
[22]:http://www.thegeekstuff.com/linux-101-hacks-ebook/
|
||||
[23]:https://ubuntu-manual.org/
|
||||
[24]:http://downtoearthlinux.com/resources/just-tell-me-damnit/
|
||||
[25]:https://drive.google.com/file/d/0B5Ymf8oYXx-PWTVJR0pmM3daZUE/view
|
||||
[26]:https://en.wikipedia.org/wiki/LAMP_(software_bundle)
|
||||
[27]:https://debian-handbook.info/about-the-book/
|
||||
[28]:https://www.lpi.org/our-certifications/getting-started
|
||||
[29]:http://www.nongnu.org/lpi-manuals/manual/pdf/GNU-FDL-OO-LPI-201-0.1.pdf
|
||||
[30]:http://linux-training.be/linuxsys.pdf
|
||||
[31]:http://linux-training.be/
|
||||
[32]:http://linux-training.be/linuxsrv.pdf
|
||||
[33]:http://linux-training.be/linuxnet.pdf
|
||||
[34]:http://linux-training.be/linuxsto.pdf
|
||||
[35]:http://linux-training.be/linuxsec.pdf
|
||||
114
sources/tech/20170502 A beginner-s guide to Raspberry Pi 3.md
Normal file
114
sources/tech/20170502 A beginner-s guide to Raspberry Pi 3.md
Normal file
@ -0,0 +1,114 @@
|
||||
A beginner’s guide to Raspberry Pi 3
|
||||
======
|
||||

|
||||
This article is part of a weekly series where I'll create new projects using Raspberry Pi 3. The first article of the series focusses on getting you started and will cover the installation of Raspbian, with PIXEL desktop, setting up networking and some basics.
|
||||
|
||||
### What you need:
|
||||
|
||||
* A Raspberry Pi 3
|
||||
* A 5v 2mAh power supply with mini USB pin
|
||||
* Micro SD card with at least 8GB capacity
|
||||
* Wi-Fi or Ethernet cable
|
||||
* Heat sink
|
||||
* Keyboard and mouse
|
||||
* a PC monitor
|
||||
* A Mac or PC to prepare microSD card.
|
||||
|
||||
|
||||
|
||||
There are many Linux-based operating systems available for Raspberry Pi that you can install directly, but if you're new to the Pi, I suggest NOOBS, the official OS installer for Raspberry Pi that simplifies the process of installing an OS on the device.
|
||||
|
||||
Download NOOBS from [this link][1] on your system. It's a compressed .zip file. If you're on MacOS, just double click on it and MacOS will automatically uncompress the files. If you are on Windows, right-click on it, and select "extract here."
|
||||
|
||||
**[ Give yourself a technology career advantage with[InfoWorld's Deep Dive technology reports and Computerworld's career trends reports][2]. GET A 15% DISCOUNT through Jan. 15, 2017: Use code 8TIISZ4Z. ]**
|
||||
|
||||
If you're running desktop Linux, then how to unzip it really depends on the desktop environment you are running, as different DEs have different ways of doing the same thing. So the easiest way is to use the command line.
|
||||
|
||||
`$ unzip NOOBS.zip`
|
||||
|
||||
Irrespective of the operating system, open the unzipped file and check if the file structure looks like this:
|
||||
|
||||
![content][3] Swapnil Bhartiya
|
||||
|
||||
Now plug the Micro SD card to your PC and format it to the FAT32 file system. On MacOS, use the Disk Utility tool and format the Micro SD card:
|
||||
|
||||
![format][4] Swapnil Bhartiya
|
||||
|
||||
On Windows, just right click on the card and choose the formatting option. If you're on desktop Linux, different DEs use different tools, and covering all the DEs is beyond the scope of this story. I have written a tutorial [using the command line interface on Linux][5] to format an SD card with Fat32 file system.
|
||||
|
||||
Once you have the card formatted in the Fat32 partition, just copy the content of the downloaded NOOBS directory into the root directory of the device. If you are on MacOS or Linux, just rsync the content of NOOBS to the SD card. Open Terminal app in MacOS or Linux and run the rsync command in this format:
|
||||
|
||||
`rsync -avzP /path_of_NOOBS /path_of_sdcard`
|
||||
|
||||
Make sure to select the root directory of the sd card. In my case (on MacOS), it was:
|
||||
|
||||
`rsync -avzP /Users/swapnil/Downloads/NOOBS_v2_2_0/ /Volumes/U/`
|
||||
|
||||
Or you can copy and paste the content. Just make sure that all the files inside the NOOBS directory are copied into the root directory of the Micro SD Card and not inside any sub-directory.
|
||||
|
||||
Now plug the Micro SD Card into the Raspberry Pi 3, connect the monitor, the keyboard and power supply. If you do have wired network, I recommend using it as you will get faster download speed to download and install the base operating system. The device will boot into NOOBS that offers a couple of distributions to install. Choose Raspbian from the first option and follow the on-screen instructions.
|
||||
|
||||
![raspi config][6] Swapnil Bhartiya
|
||||
|
||||
Once the installation is complete, Pi will reboot, and you will be greeted with Raspbian. Now it's time to configure it and run system updates. In most cases, we use Raspberry Pi in headless mode and manage it remotely over the networking using SSH. Which means you don't have to plug in a monitor or keyboard to manage your Pi.
|
||||
|
||||
First of all, we need to configure the network if you are using Wi-Fi. Click on the network icon on the top panel, and select the network from the list and provide it with the password.
|
||||
|
||||
![wireless][7] Swapnil Bhartiya
|
||||
|
||||
Congrats, you are connected wirelessly. Before we proceed with the next step, we need to find the IP address of the device so we can manage it remotely.
|
||||
|
||||
Open Terminal and run this command:
|
||||
|
||||
`ifconfig`
|
||||
|
||||
Now, note down the IP address of the device in the wlan0 section. It should be listed as "inet addr."
|
||||
|
||||
Now it's time to enable SSH and configure the system. Open the terminal on Pi and open raspi-config tool.
|
||||
|
||||
`sudo raspi-config`
|
||||
|
||||
The default user and password for Raspberry Pi is "pi" and "raspberry" respectively. You'll need the password for the above command. The first option of Raspi Config tool is to change the default password, and I heavily recommend changing the password, especially if you want to use it over the network.
|
||||
|
||||
The second option is to change the hostname, which can be useful if you have more than one Pi on the network. A hostname makes it easier to identify each device on the network.
|
||||
|
||||
Then go to Interfacing Options and enable Camera, SSH, and VNC. If you're using the device for an application that involves multimedia, such as a home theater system or PC, then you may also want to change the audio output option. By default the output is set to HDMI, but if you're using external speakers, you need to change the set-up. Go to the Advanced Option tab of Raspi Config tool, and go to Audio. There choose 3.5mm as the default out.
|
||||
|
||||
[Tip: Use arrow keys to navigate and then Enter key to choose. ]
|
||||
|
||||
Once all these changes are applied, the Pi will reboot. You can unplug the monitor and keyboard from your Pi as we will be managing it over the network. Now open Terminal on your local machine. If you're on Windows, you can use Putty or read my article to install Ubuntu Bash on Windows 10.
|
||||
|
||||
Then ssh into your system:
|
||||
|
||||
`ssh pi@IP_ADDRESS_OF_Pi`
|
||||
|
||||
In my case it was:
|
||||
|
||||
`ssh pi@10.0.0.161`
|
||||
|
||||
Provide it with the password and Eureka!, you are logged into your Pi and can now manage the device from a remote machine. If you want to manage your Raspberry Pi over the Internet, read my article on [enabling RealVNC on your machine][8].
|
||||
|
||||
In the next follow-up article, I will talk about using Raspberry Pi to manage your 3D printer remotely.
|
||||
|
||||
**This article is published as part of the IDG Contributor Network.[Want to Join?][9]**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.infoworld.com/article/3176488/linux/a-beginner-s-guide-to-raspberry-pi-3.html
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.infoworld.com/author/Swapnil-Bhartiya/
|
||||
[1]:https://www.raspberrypi.org/downloads/noobs/
|
||||
[2]:http://idgenterprise.selz.com
|
||||
[3]:https://images.techhive.com/images/article/2017/03/content-100711633-large.jpg
|
||||
[4]:https://images.techhive.com/images/article/2017/03/format-100711635-large.jpg
|
||||
[5]:http://www.cio.com/article/3176034/linux/how-to-format-an-sd-card-in-linux.html
|
||||
[6]:https://images.techhive.com/images/article/2017/03/raspi-config-100711634-large.jpg
|
||||
[7]:https://images.techhive.com/images/article/2017/03/wireless-100711636-large.jpeg
|
||||
[8]:http://www.infoworld.com/article/3171682/internet-of-things/how-to-access-your-raspberry-pi-remotely-over-the-internet.html
|
||||
[9]:https://www.infoworld.com/contributor-network/signup.html
|
||||
81
sources/tech/20170924 Simulate System Loads.md
Normal file
81
sources/tech/20170924 Simulate System Loads.md
Normal file
@ -0,0 +1,81 @@
|
||||
translating by lujun9972
|
||||
Simulate System Loads
|
||||
======
|
||||
Sysadmins often need to discover how the performance of an application is affected when the system is under certain types of load. This means that an artificial load must be re-created. It is, of course, possible to install dedicated tools to do this but this option isn't always desirable or possible.
|
||||
|
||||
Every Linux distribution comes with all the tools needed to create load. They are not as configurable as dedicated tools but they will always be present and you already know how to use them.
|
||||
|
||||
### CPU
|
||||
|
||||
The following command will generate a CPU load by compressing a stream of random data and then sending it to `/dev/null`:
|
||||
```
|
||||
cat /dev/urandom | gzip -9 > /dev/null
|
||||
|
||||
```
|
||||
|
||||
If you require a greater load or have a multi-core system simply keep compressing and decompressing the data as many times as you need e.g.:
|
||||
```
|
||||
cat /dev/urandom | gzip -9 | gzip -d | gzip -9 | gzip -d > /dev/null
|
||||
|
||||
```
|
||||
|
||||
Use `CTRL+C` to end the process.
|
||||
|
||||
### RAM
|
||||
|
||||
The following process will reduce the amount of free RAM. It does this by creating a file system in RAM and then writing files to it. You can use up as much RAM as you need to by simply writing more files.
|
||||
|
||||
First, create a mount point then mount a `ramfs` filesystem there:
|
||||
```
|
||||
mkdir z
|
||||
mount -t ramfs ramfs z/
|
||||
|
||||
```
|
||||
|
||||
Then, use `dd` to create a file under that directory. Here a 128MB file is created:
|
||||
```
|
||||
dd if=/dev/zero of=z/file bs=1M count=128
|
||||
|
||||
```
|
||||
|
||||
The size of the file can be set by changing the following operands:
|
||||
|
||||
* **bs=** Block Size. This can be set to any number followed **B** for bytes, **K** for kilobytes, **M** for megabytes or **G** for gigabytes.
|
||||
* **count=** The number of blocks to write.
|
||||
|
||||
|
||||
|
||||
### Disk
|
||||
|
||||
We will create disk I/O by firstly creating a file, and then use a for loop to repeatedly copy it.
|
||||
|
||||
This command uses `dd` to generate a 1GB file of zeros:
|
||||
```
|
||||
dd if=/dev/zero of=loadfile bs=1M count=1024
|
||||
|
||||
```
|
||||
|
||||
The following command starts a for loop that runs 10 times. Each time it runs it will copy `loadfile` over `loadfile1`:
|
||||
```
|
||||
for i in {1..10}; do cp loadfile loadfile1; done
|
||||
|
||||
```
|
||||
|
||||
If you want it to run for a longer or shorter time change the second number in `{1..10}`.
|
||||
|
||||
If you prefer the process to run forever until you kill it with `CTRL+C` use the following command:
|
||||
```
|
||||
while true; do cp loadfile loadfile1; done
|
||||
|
||||
```
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://bash-prompt.net/guides/create-system-load/
|
||||
|
||||
作者:[Elliot Cooper][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://bash-prompt.net
|
||||
@ -0,0 +1,159 @@
|
||||
translating by lujun9972
|
||||
How To Easily Find Awesome Projects And Resources Hosted In GitHub
|
||||
======
|
||||

|
||||
|
||||
Everyday there are hundreds of new additions to the **GitHub** website. Since GitHub has thousands of stuffs, you would be exhausted when searching for a good project. Fortunately, a group of contributors have made a curated lists of awesome stuffs hosted in GitHub. These lists contains a lot of awesome stuffs grouped under different categories such as programming, database, editors, gaming, entertainment and many more. It makes our life much easier to find out any project, software, resource, library, books and all other stuffs hosted in GitHub. A fellow GitHub user went one step ahead and created a command-line utility called **" Awesome-finder"** to find awesome projects and resources on awesome series repositories. This utility helps us to browse through the curated list of awesome lists without leaving the Terminal, without using browser of course.
|
||||
|
||||
In this brief guide, I will show you how to easily browse through the curated list of awesome lists in Unix-like systems.
|
||||
|
||||
### Awesome-finder - Easily Find Awesome Projects And Resources Hosted In GitHub
|
||||
|
||||
#### Installing Awesome-finder
|
||||
|
||||
Awesome can be easily installed using **pip** , a package manager for installing programs developed using Python programming language.
|
||||
|
||||
On **Arch Linux** and its derivatives like **Antergos** , **Manjaro Linux** , you can install pip using command:
|
||||
```
|
||||
sudo pacman -S python-pip
|
||||
```
|
||||
|
||||
On **RHEL** , **CentOS** :
|
||||
```
|
||||
sudo yum install epel-release
|
||||
```
|
||||
```
|
||||
sudo yum install python-pip
|
||||
```
|
||||
|
||||
On **Fedora** :
|
||||
```
|
||||
sudo dnf install epel-release
|
||||
```
|
||||
```
|
||||
sudo dnf install python-pip
|
||||
```
|
||||
|
||||
On **Debian** , **Ubuntu** , **Linux Mint** :
|
||||
```
|
||||
sudo apt-get install python-pip
|
||||
```
|
||||
|
||||
On **SUSE** , **openSUSE** :
|
||||
```
|
||||
sudo zypper install python-pip
|
||||
```
|
||||
|
||||
Once PIP installed, run the following command to install 'Awesome-finder' utility.
|
||||
```
|
||||
sudo pip install awesome-finder
|
||||
```
|
||||
|
||||
#### Usage
|
||||
|
||||
Awesome-finder currently lists the stuffs from the following awesome topics (repositories, of course) from GitHub site:
|
||||
|
||||
* awesome
|
||||
* awesome-android
|
||||
* awesome-elixir
|
||||
* awesome-go
|
||||
* awesome-ios
|
||||
* awesome-java
|
||||
* awesome-javascript
|
||||
* awesome-php
|
||||
* awesome-python
|
||||
* awesome-ruby
|
||||
* awesome-rust
|
||||
* awesome-scala
|
||||
* awesome-swift
|
||||
|
||||
|
||||
|
||||
This list will be updated on regular basis.
|
||||
|
||||
For instance, to view the curated list from awesome-go repository, just type:
|
||||
```
|
||||
awesome go
|
||||
```
|
||||
|
||||
You will see all popular stuffs written using "Go", sorted by alphabetical order.
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
You can navigate through the list using **UP/DOWN** arrows. Once you found the stuff you looking for, choose it and hit **ENTER** key to open the link in your default web browser.
|
||||
|
||||
Similarly,
|
||||
|
||||
* "awesome android" command will search the **awesome-android** repository.
|
||||
* "awesome awesome" command will search the **awesome** repository.
|
||||
* "awesome elixir" command will search the **awesome-elixir**.
|
||||
* "awesome go" will search the **awesome-go**.
|
||||
* "awesome ios" will search the **awesome-ios**.
|
||||
* "awesome java" will search the **awesome-java**.
|
||||
* "awesome javascript" will search the **awesome-javascript**.
|
||||
* "awesome php" will search the **awesome-php**.
|
||||
* "awesome python" will search the **awesome-python**.
|
||||
* "awesome ruby" will search the **awesome-ruby**.
|
||||
* "awesome rust" will search the **awesome-rust**.
|
||||
* "awesome scala" will search the **awesome-scala**.
|
||||
* "awesome swift" will search the **awesome-swift**.
|
||||
|
||||
|
||||
|
||||
Also, it automatically displays the suggestions as you type in the prompt. For instance when I type "dj", it displays the stuffs related to Django.
|
||||
|
||||
[![][1]][3]
|
||||
|
||||
If you wanted to find the awesome things from latest awesome-<topic> (not use cache), use -f or -force flag:
|
||||
```
|
||||
awesome <topic> -f (--force)
|
||||
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```
|
||||
awesome python -f
|
||||
```
|
||||
|
||||
Or,
|
||||
```
|
||||
awesome python --force
|
||||
```
|
||||
|
||||
The above command will display the curated list of stuffs from **awesome-python** GitHub repository.
|
||||
|
||||
Awesome, isn't it?
|
||||
|
||||
To exit from this utility, press **ESC** key. To display help, type:
|
||||
```
|
||||
awesome -h
|
||||
```
|
||||
|
||||
And, that's all for now. Hope this helps. If you find our guides useful, please share them on your social, professional networks, so everyone will benefit from them. Good good stuffs to come. Stay tuned!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_008-1.png ()
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_009.png ()
|
||||
[4]:https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/?share=reddit (Click to share on Reddit)
|
||||
[5]:https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/?share=twitter (Click to share on Twitter)
|
||||
[6]:https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/?share=facebook (Click to share on Facebook)
|
||||
[7]:https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/?share=google-plus-1 (Click to share on Google+)
|
||||
[8]:https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/?share=linkedin (Click to share on LinkedIn)
|
||||
[9]:https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/?share=pocket (Click to share on Pocket)
|
||||
[10]:whatsapp://send?text=How%20To%20Easily%20Find%20Awesome%20Projects%20And%20Resources%20Hosted%20In%20GitHub%20https%3A%2F%2Fwww.ostechnix.com%2Feasily-find-awesome-projects-resources-hosted-github%2F (Click to share on WhatsApp)
|
||||
[11]:https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/?share=telegram (Click to share on Telegram)
|
||||
[12]:https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/?share=email (Click to email this to a friend)
|
||||
[13]:https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/#print (Click to print)
|
||||
@ -0,0 +1,81 @@
|
||||
A 3-step process for making more transparent decisions
|
||||
======
|
||||

|
||||
|
||||
One of the most powerful ways to make your work as a leader more transparent is to take an existing process, open it up for feedback from your team, and then change the process to account for this feedback. The following exercise makes transparency more tangible, and it helps develop the "muscle memory" needed for continually evaluating and adjusting your work with transparency in mind.
|
||||
|
||||
I would argue that you can undertake this activity this with any process--even processes that might seem "off limits," like the promotion or salary adjustment processes. But if that's too big for a first bite, then you might consider beginning with a less sensitive process, such as the travel approval process or your system for searching for candidates to fill open positions on your team. (I've done this with our hiring process and promotion processes, for example.)
|
||||
|
||||
Opening up processes and making them more transparent builds your credibility and enhances trust with team members. It forces you to "walk the transparency walk" in ways that might challenge your assumptions or comfort level. Working this way does create additional work, particularly at the beginning of the process--but, ultimately, this works well for holding managers (like me) accountable to team members, and it creates more consistency.
|
||||
|
||||
### Phase 1: Pick a process
|
||||
|
||||
**Step 1.** Think of a common or routine process your team uses, but one that is not generally open for scrutiny. Some examples might include:
|
||||
|
||||
* Hiring: How are job descriptions created, interview teams selected, candidates screened and final hiring decisions made?
|
||||
* Planning: How are your team or organizational goals determined for the year or quarter?
|
||||
* Promotions: How do you select candidates for promotion, consider them, and decide who gets promoted?
|
||||
* Manager performance appraisals: Who receives the opportunity to provide feedback on manager performance, and how are they able to do it?
|
||||
* Travel: How is the travel budget apportioned, and how do you make decisions about whether to approval travel (or whether to nominate someone for travel)?
|
||||
|
||||
|
||||
|
||||
One of the above examples may resonate with you, or you may identify something else that you feel is more appropriate. Perhaps you've received questions about a particular process, or you find yourself explaining the rationale for a particular kind of decision frequently. Choose something that you are able to control or influence--and something you believe your constituents care about.
|
||||
|
||||
**Step 2.** Now answer the following questions about the process:
|
||||
|
||||
* Is the process currently documented in a place that all constituents know about and can access? If not, go ahead and create that documentation now (it doesn't have to be too detailed; just explain the different steps of the process and how it works). You may find that the process isn't clear or consistent enough to document. In that case, document it the way you think it should work in the ideal case.
|
||||
* Does the completed process documentation explain how decisions are made at various points? For example, in a travel approval process, does it explain how a decision to approve or deny a request is made?
|
||||
* What are the inputs of the process? For example, when determining departmental goals for the year, what data is used for key performance indicators? Whose feedback is sought and incorporated? Who has the opportunity to review or "sign off"?
|
||||
* What assumptions does this process make? For example, in promotion decisions, do you assume that all candidates for promotion will be put forward by their managers at the appropriate time?
|
||||
* What are the outputs of the process? For example, in assessing the performance of the managers, is the result shared with the manager being evaluated? Are any aspects of the review shared more broadly with the manager's direct reports (areas for improvement, for example)?
|
||||
|
||||
|
||||
|
||||
Avoid making judgements when answering the above questions. If the process doesn't clearly explain how a decision is made, that might be fine. The questions are simply an opportunity to assess the current state.
|
||||
|
||||
Next, revise the documentation of the process until you are satisfied that it adequately explains the process and anticipates the potential questions.
|
||||
|
||||
### Phase 2: Gather feedback
|
||||
|
||||
The next phase involves sharing the process with your constituents and asking for feedback. Sharing is easier said than done.
|
||||
|
||||
**Step 1.** Encourage people to provide feedback. Consider a variety of mechanisms for doing this:
|
||||
|
||||
* Post the process somewhere people can find it internally and note where they can make comments or provide feedback. A Google document works great with the ability to comment on specific text or suggest changes directly in the text.
|
||||
* Share the process document via email, inviting feedback
|
||||
* Mention the process document and ask for feedback during team meetings or one-on-one conversations
|
||||
* Give people a time window within which to provide feedback, and send periodic reminders during that window.
|
||||
|
||||
|
||||
|
||||
If you don't get much feedback, don't assume that silence is equal to endorsement. Try asking people directly if they have any idea why feedback is not coming in. Are people too busy? Is the process not as important to people as you thought? Have you effectively articulated what you're asking for?
|
||||
|
||||
**Step 2.** Iterate. As you get feedback about the process, engage the team in revising and iterating on the process. Incorporate ideas and suggestions for improvement, and ask for confirmation that the intended feedback has been applied. If you don't agree with a suggestion, be open to the discussion and ask yourself why you don't agree and what the merits are of one method versus another.
|
||||
|
||||
Setting a timebox for collecting feedback and iterating is helpful to move things forward. Once feedback has been collected and reviewed, discussed and applied, post the final process for the team to review.
|
||||
|
||||
### Phase 3: Implement
|
||||
|
||||
Implementing a process is often the hardest phase of the initiative. But if you've taken account of feedback when revising your process, people should already been anticipating it and will likely be more supportive. The documentation you have from the iterative process above is a great tool to keep you accountable on the implementation.
|
||||
|
||||
**Step 1.** Review requirements for implementation. Many processes that can benefit from increased transparency simply require doing things a little differently, but you do want to review whether you need any other support (tooling, for example).
|
||||
|
||||
**Step 2.** Set a timeline for implementation. Review the timeline with constituents so they know what to expect. If the new process requires a process change for others, be sure to provide enough time for people to adapt to the new behavior, and provide communication and reminders.
|
||||
|
||||
**Step 3.** Follow up. After using the process for 3-6 months, check in with your constituents to see how it's going. Is the new process more transparent? More effective? More predictable? Do you have any lessons learned that could be used to improve the process further?
|
||||
|
||||
### About The Author
|
||||
Sam Knuth;I Have The Privilege To Lead The Customer Content Services Team At Red Hat;Which Produces All Of The Documentation We Provide For Our Customers. Our Goal Is To Provide Customers With The Insights They Need To Be Successful With Open Source Technology In The Enterprise. Connect With Me On Twitter
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/17/9/exercise-in-transparent-decisions
|
||||
|
||||
作者:[a][Sam Knuth]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/samfw
|
||||
@ -0,0 +1,131 @@
|
||||
How to Use the ZFS Filesystem on Ubuntu Linux
|
||||
======
|
||||
There are a myriad of [filesystems available for Linux][1]. So why try a new one? They all work, right? They're not all the same, and some have some very distinct advantages, like ZFS.
|
||||
|
||||
### Why ZFS
|
||||
|
||||
ZFS is awesome. It's a truly modern filesystem with built-in capabilities that make sense for handling loads of data.
|
||||
|
||||
Now, if you're considering ZFS for your ultra-fast NVMe SSD, it might not be the best option. It's slower than others. That's okay, though. It was designed to store huge amounts of data and keep it safe.
|
||||
|
||||
ZFS eliminates the need to set up traditional RAID arrays. Instead, you can create ZFS pools, and even add drives to those pools at any time. ZFS pools behave almost exactly like RAID, but the functionality is built right into the filesystem.
|
||||
|
||||
ZFS also acts like a replacement for LVM, allowing you to partition and manage partitions on the fly without the need to handle things at a lower level and worry about the associated risks.
|
||||
|
||||
It's also a CoW filesystem. Without getting too technical, that means that ZFS protects your data from gradual corruption over time. ZFS creates checksums of files and lets you roll back those files to a previous working version.
|
||||
|
||||
### Installing ZFS
|
||||
|
||||
![Install ZFS on Ubuntu][2]
|
||||
|
||||
Installing ZFS on Ubuntu is very easy, though the process is slightly different for Ubuntu LTS and the latest releases.
|
||||
|
||||
**Ubuntu 16.04 LTS**
|
||||
```
|
||||
sudo apt install zfs
|
||||
```
|
||||
|
||||
**Ubuntu 17.04 and Later**
|
||||
```
|
||||
sudo apt install zfsutils
|
||||
```
|
||||
|
||||
After you have the utilities installed, you can create ZFS drives and partitions using the tools provided by ZFS.
|
||||
|
||||
### Creating Pools
|
||||
|
||||
![Create ZFS Pool][3]
|
||||
|
||||
Pools are the rough equivalent of RAID in ZFS. They are flexible and can easily be manipulated.
|
||||
|
||||
#### RAID0
|
||||
|
||||
RAID0 just pools your drives into what behaves like one giant drive. It can increase your drive speeds, but if one of your drives fails, you're probably going to be out of luck.
|
||||
|
||||
To achieve RAID0 with ZFS, just create a plain pool.
|
||||
```
|
||||
sudo zpool create your-pool /dev/sdc /dev/sdd
|
||||
```
|
||||
|
||||
#### RAID1/MIRROR
|
||||
|
||||
You can achieve RAID1 functionality with the `mirror` keyword in ZFS. Raid1 creates a 1-to-1 copy of your drive. This means that your data is constantly backed up. It also increases performance. Of course, you use half of your storage to the duplication.
|
||||
```
|
||||
sudo zpool create your-pool mirror /dev/sdc /dev/sdd
|
||||
```
|
||||
|
||||
#### RAID5/RAIDZ1
|
||||
|
||||
ZFS implements RAID5 functionality as RAIDZ1. RAID5 requires drives in multiples of three and allows you to keep 2/3 of your storage space by writing backup parity data to 1/3 of the drive space. If one drive fails, the array will remain online, but the failed drive should be replaced ASAP.
|
||||
```
|
||||
sudo zpool create your-pool raidz1 /dev/sdc /dev/sdd /dev/sde
|
||||
```
|
||||
|
||||
#### RAID6/RAIDZ2
|
||||
|
||||
RAID6 is almost exactly like RAID5, but it works in multiples of four instead of multiples of three. It doubles the parity data to allow up to two drives to fail without bringing the array down.
|
||||
```
|
||||
sudo zpool create your-pool raidz2 /dev/sdc /dev/sdd /dev/sde /dev/sdf
|
||||
```
|
||||
|
||||
#### RAID10/Striped Mirror
|
||||
|
||||
RAID10 aims to be the best of both worlds by providing both a speed increase and data redundancy with striping. You need drives in multiples of four and will only have access to half of the space. You can create a pool in RAID10 by creating two mirrors in the same pool command.
|
||||
```
|
||||
sudo zpool create your-pool mirror /dev/sdc /dev/sdd mirror /dev/sde /dev/sdf
|
||||
```
|
||||
|
||||
### Working With Pools
|
||||
|
||||
![ZFS pool Status][4]
|
||||
|
||||
There are also some management tools that you have to work with your pools once you've created them. First, check the status of your pools.
|
||||
```
|
||||
sudo zpool status
|
||||
```
|
||||
|
||||
#### Updates
|
||||
|
||||
When you update ZFS you'll need to update your pools, too. Your pools will notify you of any updates when you check their status. To update a pool, run the following command.
|
||||
```
|
||||
sudo zpool upgrade your-pool
|
||||
```
|
||||
|
||||
You can also upgrade them all.
|
||||
```
|
||||
sudo zpool upgrade -a
|
||||
```
|
||||
|
||||
#### Adding Drives
|
||||
|
||||
You can also add drives to your pools at any time. Tell `zpool` the name of the pool and the location of the drive, and it'll take care of everything.
|
||||
```
|
||||
sudo zpool add your-pool /dev/sdx
|
||||
```
|
||||
|
||||
### Other Thoughts
|
||||
|
||||
![ZFS in File Browser][5]
|
||||
|
||||
ZFS creates a directory in the root filesystem for your pools. You can browse to them by name using your GUI file manager or the CLI.
|
||||
|
||||
ZFS is awesomely powerful, and there are plenty of other things that you can do with it, too, but these are the basics. It is an excellent filesystem for working with loads of storage, even if it is just a RAID array of hard drives that you use for your files. ZFS works excellently with NAS systems, too.
|
||||
|
||||
Regardless of how stable and robust ZFS is, it's always best to back up your data when you implement something new on your hard drives.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/use-zfs-filesystem-ubuntu-linux/
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/nickcongleton/
|
||||
[1]:https://www.maketecheasier.com/best-linux-filesystem-for-ssd/
|
||||
[2]:https://www.maketecheasier.com/assets/uploads/2017/09/zfs-install.jpg (Install ZFS on Ubuntu)
|
||||
[3]:https://www.maketecheasier.com/assets/uploads/2017/09/zfs-create-pool.jpg (Create ZFS Pool)
|
||||
[4]:https://www.maketecheasier.com/assets/uploads/2017/09/zfs-pool-status.jpg (ZFS pool Status)
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2017/09/zfs-pool-open.jpg (ZFS in File Browser)
|
||||
@ -0,0 +1,119 @@
|
||||
translating by lujun9972
|
||||
Connect To Wifi From The Linux Command Line
|
||||
======
|
||||
|
||||
### Objective
|
||||
|
||||
Configure WiFi using only command line utilities.
|
||||
|
||||
### Distributions
|
||||
|
||||
This will work on any major Linux distribution.
|
||||
|
||||
### Requirements
|
||||
|
||||
A working Linux install with root privileges and a compatible wireless network adapter.
|
||||
|
||||
### Difficulty
|
||||
|
||||
Easy
|
||||
|
||||
### Conventions
|
||||
|
||||
* **#** \- requires given command to be executed with root privileges either directly as a root user or by use of `sudo` command
|
||||
* **$** \- given command to be executed as a regular non-privileged user
|
||||
|
||||
|
||||
|
||||
### Introduction
|
||||
|
||||
Lots of people like graphical utilities for managing their computers, but plenty don't too. If you prefer command line utilities, managing WiFi can be a real pain. Well, it doesn't have to be.
|
||||
|
||||
wpa_supplicant can be used as a command line utility. You can actually set it up easily with a simple configuration file.
|
||||
|
||||
### Scan For Your Network
|
||||
|
||||
If you already know your network information, you can skip this step. If not, its a good way to figure out some info about the network you're connecting to.
|
||||
|
||||
wpa_supplicant comes with a tool called `wpa_cli` which provides a command line interface to manage your WiFi connections. You can actually use it to set up everything, but setting up a configuration file seems a bit easier.
|
||||
|
||||
Run `wpa_cli` with root privileges, then scan for networks.
|
||||
```
|
||||
|
||||
# wpa_cli
|
||||
> scan
|
||||
|
||||
```
|
||||
|
||||
The scan will take a couple of minutes, and show you the networks in your area. Notate the one you want to connect to. Type `quit` to exit.
|
||||
|
||||
### Generate a Block and Encrypt Your Password
|
||||
|
||||
There's an even more convenient utility that you can use to begin setting up your configuration file. It takes the name of your network and the password and creates a file with a configuration block for that network with the password encrypted, so it's not stored in plain text.
|
||||
```
|
||||
|
||||
# wpa_passphrase networkname password > /etc/wpa_supplicant/wpa_supplicant.conf
|
||||
|
||||
```
|
||||
|
||||
### Tailor Your Configuration
|
||||
|
||||
Now, you have a configuration file located at `/etc/wpa_supplicant/wpa_supplicant.conf`. It's not much, just the network block with your network name and password, but you can build it out from there.
|
||||
|
||||
Your file up in your favorite editor, and start by deleting the commented out password line. Then, add the following line to the top of the configuration.
|
||||
```
|
||||
ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=wheel
|
||||
|
||||
```
|
||||
|
||||
It just lets users in the `wheel` group manage wpa_supplicant. It can be convenient.
|
||||
|
||||
Add the rest of this to the network block itself.
|
||||
|
||||
If you're connecting to a hidden network, you can add the following line to tell wpa_supplicant to scan it first.
|
||||
```
|
||||
scan_ssid=1
|
||||
|
||||
```
|
||||
|
||||
Next, set the protocol and key management settings. These settings correspond to WPA2.
|
||||
```
|
||||
proto=RSN
|
||||
key_mgmt=WPA-PSK
|
||||
|
||||
```
|
||||
|
||||
The group and pairwise settings tell wpa_supplicant if you're using CCMP, TKIP, or both. For best security, you should only be using CCMP.
|
||||
```
|
||||
group=CCMP
|
||||
pairwise=CCMP
|
||||
|
||||
```
|
||||
|
||||
Finally, set the priority of the network. Higher values will connect first.
|
||||
```
|
||||
priority=10
|
||||
|
||||
```
|
||||
|
||||
|
||||
![Complete WPA_Supplicant Settings][1]
|
||||
Save your configuration and restart wpa_supplicant for the changes to take effect.
|
||||
|
||||
### Closing Thoughts
|
||||
|
||||
Certainly, this method isn't the best for configuring wireless networks on-the-fly, but it works very well for the networks that you connect to on a regular basis.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/connect-to-wifi-from-the-linux-command-line
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org
|
||||
[1]:https://linuxconfig.org/images/wpa-cli-config.jpg
|
||||
@ -0,0 +1,100 @@
|
||||
Linux Gunzip Command Explained with Examples
|
||||
======
|
||||
|
||||
We have [already discussed][1] the **gzip** command in Linux. For starters, the tool is used to compress or expand files. To uncompress, the command offers a command line option **-d** , which can be used in the following way:
|
||||
|
||||
gzip -d [compressed-file-name]
|
||||
|
||||
However, there's an entirely different tool that you can use for uncompressing or expanding archives created by gzip. The tool in question is **gunzip**. In this article, we will discuss the gunzip command using some easy to understand examples. Please note that all examples/instructions mentioned in the tutorial have been tested on Ubuntu 16.04.
|
||||
|
||||
### Linux gunzip command
|
||||
|
||||
So now we know that compressed files can be restored using either 'gzip -d' or the gunzip command. The basic syntax of gunzip is:
|
||||
|
||||
gunzip [compressed-file-name]
|
||||
|
||||
The following Q&A-style examples should give you a better idea of how the tool works:
|
||||
|
||||
### Q1. How to uncompress archives using gunzip?
|
||||
|
||||
This is very simple - just pass the name of the archive file as argument to gunzip.
|
||||
|
||||
gunzip [archive-name]
|
||||
|
||||
For example:
|
||||
|
||||
gunzip file1.gz
|
||||
|
||||
[![How to uncompress archives using gunzip][2]][3]
|
||||
|
||||
### Q2. How to make gunzip not delete archive file?
|
||||
|
||||
As you'd have noticed, the gunzip command deletes the archive file after uncompressing it. However, if you want the archive to stay, you can do that using the **-c** command line option.
|
||||
|
||||
gunzip -c [archive-name] > [outputfile-name]
|
||||
|
||||
For example:
|
||||
|
||||
gunzip -c file1.gz > file1
|
||||
|
||||
[![How to make gunzip not delete archive file][4]][5]
|
||||
|
||||
So you can see that the archive file wasn't deleted in this case.
|
||||
|
||||
### Q3. How to make gunzip put the uncompressed file in some other directory?
|
||||
|
||||
We've already discussed the **-c** option in the previous Q &A. To make gunzip put the uncompressed file in a directory other than the present working directory, just provide the absolute path after the redirection operator.
|
||||
|
||||
gunzip -c [compressed-file] > [/complete/path/to/dest/dir/filename]
|
||||
|
||||
Here's an example:
|
||||
|
||||
gunzip -c file1.gz > /home/himanshu/file1
|
||||
|
||||
### More info
|
||||
|
||||
The following details - taken from the common manpage of gzip/gunzip - should be beneficial for those who want to know more about the command:
|
||||
```
|
||||
gunzip takes a list of files on its command line and replaces each file
|
||||
whose name ends with .gz, -gz, .z, -z, or _z (ignoring case) and which
|
||||
begins with the correct magic number with an uncompressed file without
|
||||
the original extension. gunzip also recognizes the special extensions
|
||||
.tgz and .taz as shorthands for .tar.gz and .tar.Z respectively. When
|
||||
compressing, gzip uses the .tgz extension if necessary instead of trun
|
||||
cating a file with a .tar extension.
|
||||
|
||||
gunzip can currently decompress files created by gzip, zip, compress,
|
||||
compress -H or pack. The detection of the input format is automatic.
|
||||
When using the first two formats, gunzip checks a 32 bit CRC. For pack
|
||||
and gunzip checks the uncompressed length. The standard compress format
|
||||
was not designed to allow consistency checks. However gunzip is some
|
||||
times able to detect a bad .Z file. If you get an error when uncom
|
||||
pressing a .Z file, do not assume that the .Z file is correct simply
|
||||
because the standard uncompress does not complain. This generally means
|
||||
that the standard uncompress does not check its input, and happily gen
|
||||
erates garbage output. The SCO compress -H format (lzh compression
|
||||
method) does not include a CRC but also allows some consistency checks.
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
As far as basic usage is concerned, there isn't much of a learning curve associated with Gunzip. We've covered pretty much everything that a beginner needs to learn about this command in order to start using it. For more information, head to its [man page][6].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-gunzip-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/linux-gzip-command/
|
||||
[2]:https://www.howtoforge.com/images/linux_gunzip_command/gunzip-basic-usage.png
|
||||
[3]:https://www.howtoforge.com/images/linux_gunzip_command/big/gunzip-basic-usage.png
|
||||
[4]:https://www.howtoforge.com/images/linux_gunzip_command/gunzip-c.png
|
||||
[5]:https://www.howtoforge.com/images/linux_gunzip_command/big/gunzip-c.png
|
||||
[6]:https://linux.die.net/man/1/gzip
|
||||
@ -0,0 +1,59 @@
|
||||
Reset Linux Desktop To Default Settings With A Single Command
|
||||
======
|
||||

|
||||
|
||||
A while ago, we shared an article about [**Resetter**][1] - an useful piece of software which is used to reset Ubuntu to factory defaults within few minutes. Using Resetter, anyone can easily reset their Ubuntu system to the state when you installed it in the first time. Today, I stumbled upon a similar thing. No, It's not an application, but a single-line command to reset your Linux desktop settings, tweaks and customization to default state.
|
||||
|
||||
### Reset Linux Desktop To Default Settings
|
||||
|
||||
This command will reset Ubuntu Unity, Gnome and MATE desktops to the default state. I tested this command on both my **Arch Linux MATE** desktop and **Ubuntu 16.04 Unity** desktop. It worked on both systems. I hope it will work on other desktops as well. I don't have any Linux desktop with GNOME as of writing this, so I couldn't confirm it. But, I believe it will work on Gnome DE as well.
|
||||
|
||||
**A word of caution:** Please be mindful that this command will reset all customization and tweaks you made in your system, including the pinned applications in the Unity launcher or Dock, desktop panel applets, desktop indicators, your system fonts, GTK themes, Icon themes, monitor resolution, keyboard shortcuts, window button placement, menu and launcher behaviour etc.
|
||||
|
||||
Good thing is it will only reset the desktop settings. It won't affect the other applications that doesn't use dconf. Also, it won't delete your personal data.
|
||||
|
||||
Now, let us do this. To reset Ubuntu Unity or any other Linux desktop with GNOME/MATE DEs to its default settings, run:
|
||||
```
|
||||
dconf reset -f /
|
||||
```
|
||||
|
||||
This is my Ubuntu 16.04 LTS desktop before running the above command:
|
||||
|
||||
[![][2]][3]
|
||||
|
||||
As you see, I have changed the desktop wallpaper and themes.
|
||||
|
||||
This is how my Ubuntu 16.04 LTS desktop looks like after running that command:
|
||||
|
||||
[![][2]][4]
|
||||
|
||||
Look? Now, my Ubuntu desktop has gone to the factory settings.
|
||||
|
||||
For more details about "dconf" command, refer man pages.
|
||||
```
|
||||
man dconf
|
||||
```
|
||||
|
||||
I personally prefer to use "Resetter" over "dconf" command for this purpose. Because, Resetter provides more options to the users. The users can decide which applications to remove, which applications to keep, whether to keep existing user account or create a new user and many. If you're too lazy to install Resetter, you can just use this "dconf" command to reset your Linux system to default settings within few minutes.
|
||||
|
||||
And, that's all. Hope this helps. I will be soon here with another useful guide. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/reset-linux-desktop-default-settings-single-command/
|
||||
|
||||
作者:[Edwin Arteaga][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com
|
||||
[1]:https://www.ostechnix.com/reset-ubuntu-factory-defaults/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Before-resetting-Ubuntu-to-default-1.png ()
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/After-resetting-Ubuntu-to-default-1.png ()
|
||||
@ -0,0 +1,145 @@
|
||||
Trash-Cli : A Command Line Interface For Trashcan On Linux
|
||||
======
|
||||
Everyone knows about `Trashcan` which is common for all users like Linux, or Windows, or Mac. Whenever you delete a file or folder, it will be moved to trash.
|
||||
|
||||
Note that moving files to the trash does not free up space on the file system until the Trashcan is empty.
|
||||
|
||||
Trash stores deleted files temporarily which help us to restore when it's necessary, if you don't want these files then delete it permanently (empty the trash).
|
||||
|
||||
Make sure, you won't find any files or folders in the trash when you delete using `rm` command. So, think twice before performing rm command. If you did a mistake that's it, it'll go away and you can't restore back. since metadata is not stored on disk nowadays.
|
||||
|
||||
Trash is a feature provided by the desktop manager such as GNOME, KDE, and XFCE, etc, as per [freedesktop.org specification][1]. when you delete a file or folder from file manger then it will go to trash and the trash folder can be found @ `$HOME/.local/share/Trash`.
|
||||
|
||||
Trash folder contains two folder `files` & `info`. Files folder stores actual deleted files and folders & Info folder contains deleted files & folders information such as file path, deleted date & time in separate file.
|
||||
|
||||
You might ask, Why you want CLI utility When having GUI Trashcan, most of the NIX guys (including me) play around CLI instead of GUI even though when they working GUI based system. So, if some one looking for CLI based Trashcan then this is the right choice for them.
|
||||
|
||||
### What's Trash-Cli
|
||||
|
||||
[trash-cli][2] is a command line interface for Trashcan utility compliant with the FreeDesktop.org trash specifications. It stores the name, original path, deletion date, and permissions of each trashed file.
|
||||
|
||||
### How to Install Trash-Cli in Linux
|
||||
|
||||
Trash-Cli is available on most of the Linux distribution official repository, so run the following command to install.
|
||||
|
||||
For **`Debian/Ubuntu`** , use [apt-get command][3] or [apt command][4] to install Trash-Cli.
|
||||
```
|
||||
$ sudo apt install trash-cli
|
||||
|
||||
```
|
||||
|
||||
For **`RHEL/CentOS`** , use [YUM Command][5] to install Trash-Cli.
|
||||
```
|
||||
$ sudo yum install trash-cli
|
||||
|
||||
```
|
||||
|
||||
For **`Fedora`** , use [DNF Command][6] to install Trash-Cli.
|
||||
```
|
||||
$ sudo dnf install trash-cli
|
||||
|
||||
```
|
||||
|
||||
For **`Arch Linux`** , use [Pacman Command][7] to install Trash-Cli.
|
||||
```
|
||||
$ sudo pacman -S trash-cli
|
||||
|
||||
```
|
||||
|
||||
For **`openSUSE`** , use [Zypper Command][8] to install Trash-Cli.
|
||||
```
|
||||
$ sudo zypper in trash-cli
|
||||
|
||||
```
|
||||
|
||||
If you distribution doesn't offer Trash-cli, we can easily install from pip. Your system should have pip package manager, in order to install python packages.
|
||||
```
|
||||
$ sudo pip install trash-cli
|
||||
Collecting trash-cli
|
||||
Downloading trash-cli-0.17.1.14.tar.gz
|
||||
Installing collected packages: trash-cli
|
||||
Running setup.py bdist_wheel for trash-cli ... done
|
||||
Successfully installed trash-cli-0.17.1.14
|
||||
|
||||
```
|
||||
|
||||
### How to Use Trash-Cli
|
||||
|
||||
It's not a big deal since it's offering native syntax. It provides following commands.
|
||||
|
||||
* **`trash-put:`** Delete files and folders.
|
||||
* **`trash-list:`** Pint Deleted files and folders.
|
||||
* **`trash-restore:`** Restore a file or folder from trash.
|
||||
* **`trash-rm:`** Remove individual files from the trashcan.
|
||||
* **`trash-empty:`** Empty the trashcan(s).
|
||||
|
||||
|
||||
|
||||
Let's try some examples to experiment this.
|
||||
|
||||
1) Delete files and folders : In our case, we are going to send a file named `2g.txt` and folder named `magi` to Trash by running following command.
|
||||
```
|
||||
$ trash-put 2g.txt magi
|
||||
|
||||
```
|
||||
|
||||
You can see the same in file manager.
|
||||
|
||||
2) Pint Delete files and folders : To view deleted files and folders, run the following command. As i can see detailed infomation about deleted files and folders such as name, date & time, and file path.
|
||||
```
|
||||
$ trash-list
|
||||
2017-10-01 01:40:50 /home/magi/magi/2g.txt
|
||||
2017-10-01 01:40:50 /home/magi/magi/magi
|
||||
|
||||
```
|
||||
|
||||
3) Restore a file or folder from trash : At any point of time you can restore a files and folders by running following command. It will ask you to enter the choice which you want to restore. In our case, we are going to restore `2g.txt` file, so my option is `0`.
|
||||
```
|
||||
$ trash-restore
|
||||
0 2017-10-01 01:40:50 /home/magi/magi/2g.txt
|
||||
1 2017-10-01 01:40:50 /home/magi/magi/magi
|
||||
What file to restore [0..1]: 0
|
||||
|
||||
```
|
||||
|
||||
4) Remove individual files from the trashcan : If you want to remove specific files from trashcan, run the following command. In our case, we are going to remove `magi` folder.
|
||||
```
|
||||
$ trash-rm magi
|
||||
|
||||
```
|
||||
|
||||
5) Empty the trashcan : To remove everything from the trashcan, run the following command.
|
||||
```
|
||||
$ trash-empty
|
||||
|
||||
```
|
||||
|
||||
6) Remove older then X days file : Alternatively you can remove older then X days files so, run the following command to do it. In our case, we are going to remove `10` days old items from trashcan.
|
||||
```
|
||||
$ trash-empty 10
|
||||
|
||||
```
|
||||
|
||||
trash-cli works great but if you want to try alternative, give a try to [gvfs-trash][9] & [autotrash][10]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/trash-cli-command-line-trashcan-linux-system/
|
||||
|
||||
作者:[2daygeek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/2daygeek/
|
||||
[1]:https://freedesktop.org/wiki/Specifications/trash-spec/
|
||||
[2]:https://github.com/andreafrancia/trash-cli
|
||||
[3]:https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]:https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[5]:https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[6]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[7]:https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[8]:https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[9]:http://manpages.ubuntu.com/manpages/trusty/man1/gvfs-trash.1.html
|
||||
[10]:https://github.com/bneijt/autotrash
|
||||
@ -0,0 +1,89 @@
|
||||
How To Create A Video From PDF Files In Linux
|
||||
======
|
||||

|
||||
|
||||
I have a huge collection of PDF files, mostly Linux tutorials, in my tablet PC. Sometimes I feel too lazy to read them from the tablet. I thought It would be better If I can be able to create a video from PDF files and watch it in a big screen devices like a TV or a Computer. Though I have a little working experience with [**FFMpeg**][1], I am not aware of how to create a movie file using it. After a bit of Google searches, I came up with a good solution. For those who wanted to make a movie file from a set of PDF files, read on. It is not that difficult.
|
||||
|
||||
### Create A Video From PDF Files In Linux
|
||||
|
||||
For this purpose, you need to install **" FFMpeg"** and **" ImageMagick"** software in your system.
|
||||
|
||||
To install FFMpeg, refer the following link.
|
||||
|
||||
Imagemagick is available in the official repositories of most Linux distributions.
|
||||
|
||||
On **Arch Linux** and derivatives such as **Antergos** , **Manjaro Linux** , run the following command to install it.
|
||||
```
|
||||
sudo pacman -S imagemagick
|
||||
```
|
||||
|
||||
**Debian, Ubuntu, Linux Mint:**
|
||||
```
|
||||
sudo apt-get install imagemagick
|
||||
```
|
||||
|
||||
**Fedora:**
|
||||
```
|
||||
sudo dnf install imagemagick
|
||||
```
|
||||
|
||||
**RHEL, CentOS, Scientific Linux:**
|
||||
```
|
||||
sudo yum install imagemagick
|
||||
```
|
||||
|
||||
**SUSE, openSUSE:**
|
||||
```
|
||||
sudo zypper install imagemagick
|
||||
```
|
||||
|
||||
After installing ffmpeg and imagemagick, convert your PDF file image format such as PNG or JPG like below.
|
||||
```
|
||||
convert -density 400 input.pdf picture.png
|
||||
```
|
||||
|
||||
Here, **-density 400** specifies the horizontal resolution of the output image file(s).
|
||||
|
||||
The above command will convert all pages in the given PDF file to PNG format. Each page in the PDF file will be converted into a PNG file and saved in the current directory with file name **picture-1.png** , **picture-2.png** … and so on. It will take a while depending on the number of pages in the input PDF file.
|
||||
|
||||
Once all pages in the PDF converted into PNG format, run the following command to create a video file from the PNG files.
|
||||
```
|
||||
ffmpeg -r 1/10 -i picture-%01d.png -c:v libx264 -r 30 -pix_fmt yuv420p video.mp4
|
||||
```
|
||||
|
||||
Here,
|
||||
|
||||
* **-r 1/10** : Display each image for 10 seconds.
|
||||
* **-i picture-%01d.png** : Reads all pictures that starts with name **" picture-"**, following with 1 digit (%01d) and ending with **.png**. If the images name comes with 2 digits (I.e picture-10.png, picture11.png etc), use (%02d) in the above command.
|
||||
* **-c:v libx264** : Output video codec (i.e h264).
|
||||
* **-r 30** : framerate of output video
|
||||
* **-pix_fmt yuv420p** : Output video resolution
|
||||
* **video.mp4** : Output video file with .mp4 format.
|
||||
|
||||
|
||||
|
||||
Hurrah! The movie file is ready!! You can play it on any devices that supports .mp4 format. Next, I need to find a way to insert a cool music to my video. I hope it won't be difficult either.
|
||||
|
||||
If you wanted it in higher pixel resolution, you don't have to start all over again. Just convert the output video file to any other higher/lower resolution of your choice, say 720p, as shown below.
|
||||
```
|
||||
ffmpeg -i video.mp4 -vf scale=-1:720 video_720p.mp4
|
||||
```
|
||||
|
||||
Please note that creating a video using ffmpeg requires a good configuration PC. While converting videos, ffmpeg will consume most of your system resources. I recommend to do this in high-end system.
|
||||
|
||||
And, that's all for now folks. Hope you find this useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/create-video-pdf-files-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/20-ffmpeg-commands-beginners/
|
||||
@ -0,0 +1,112 @@
|
||||
10 Games You Can Play on Linux with Wine
|
||||
======
|
||||

|
||||
|
||||
Linux _does_ have games. It has a lot of them, actually. Linux is a thriving platform for indie gaming, and it 's not too uncommon for Linux to be supported on day one by top indie titles. In stark contrast, however, Linux is still largely ignored by the big-budget AAA developers, meaning that the games your friends are buzzing about probably won't be getting a Linux port anytime soon.
|
||||
|
||||
It's not all bad, though. Wine, the Windows compatibility layer for Linux, Mac, and BSD systems, is making huge strides in both the number of titles supported and performance. In fact, a lot of big name games now work under Wine. No, you won't get native performance, but they are playable and can actually run very well, depending on your system. Here are some games that it might surprise you can run with Wine on Linux.
|
||||
|
||||
### 10. World of Warcraft
|
||||
|
||||
![World of Warcraft Wine][1]
|
||||
|
||||
The venerable king of MMORPGs is still alive and going strong. Even though it might not be the most graphically advanced game, it still takes some power to crank all the settings up to max. World of Warcraft has actually worked under Wine for years. Until this latest expansion, WoW supported OpenGL for its Mac version, making it very easy to get working under Linux. That's not quite the case anymore.
|
||||
|
||||
You'll need to run WoW with DX9 and will definitely see some benefit from the [Gallium Nine][2] patches, but you can confidently make the switch over to Linux without missing raid night.
|
||||
|
||||
### 9. Skyrim
|
||||
|
||||
![Skyrim Wine][3]
|
||||
|
||||
Skyrim's not exactly new, but it's still fueled by a thriving modding community. You can now easily enjoy Skyrim and its many, many mods if you have a Linux system with enough resources to handle it all. Remember that Wine uses more system power than running the game natively, so account for that in your mod usage.
|
||||
|
||||
### 8. StarCraft II
|
||||
|
||||
![StarCraft II Wine][4]
|
||||
|
||||
StarCraft II is easily one of the most popular RTS games on the market and works very well under Wine. It is actually one of the best performing games under Wine. That means that you can play your favorite RTS on Linux with minimal hassle and near-native performance.
|
||||
|
||||
Given the competitive nature of this game, you obviously need the game to run well. Have no fear there. You should have no problem playing competitively with adequate hardware.
|
||||
|
||||
This is an instance where you'll benefit from the "staging" patches, so continue using them when you're getting the game set up.
|
||||
|
||||
### 7. Fallout 3/New Vegas
|
||||
|
||||
![Fallout 3 Wine][5]
|
||||
|
||||
Before you ask, Fallout 4 is on the verge of working. At the time you're reading this, it might. For now, though, Fallout 3 and New Vegas both work great, both with and without mods. These games run very well under Wine and can even handle loads of mods to keep them fresh and interesting. It doesn't seem like a bad compromise to hold you over until Fallout 4 support matures.
|
||||
|
||||
### 6. Doom (2016)
|
||||
|
||||
![Doom Wine][6]
|
||||
|
||||
Doom is one of the most exciting shooters of the past few years, and it run very well under Wine with the latest versions and the "staging" patches. Both single player and multiplayer work great, and you don't need to spend loads of time configuring Wine and tweaking settings. Doom just works. So, if you're looking for a brutal AAA shooter on Linux, consider giving Doom a try.
|
||||
|
||||
### 5. Guild Wars 2
|
||||
|
||||
![Guild Wars 2 Wine][7]
|
||||
|
||||
Guild War 2 is a sort-of hybrid MMO/dungeon crawler without a monthly fee. It's very popular and boasts some really innovative features for the genre. It also runs smoothly on Linux with Wine.
|
||||
|
||||
Guild Wars 2 isn't some ancient MMO either. It's tried to keep itself modern graphically and has fairly high resolution textures and visual effects for the genre. All of it looks and works very well under Wine.
|
||||
|
||||
### 4. League Of Legends
|
||||
|
||||
![League Of Legends Wine][8]
|
||||
|
||||
There are two top players in the MOBA world: DoTA2 and League of Legends. Valve ported DoTA2 to Linux some time ago, but League of Legends has never been made available to Linux gamers. If you're a Linux user and a fan of League, you can still play your favorite MOBA through Wine.
|
||||
|
||||
League of Legends is an interesting case. The game itself runs fine, but the installer breaks because it requires Adobe Air. There are some installer scripts available from Lutris and PlayOnLinux that get you through the process. Once it's installed, you should have no problem running League and even playing it smoothly in competitive situations.
|
||||
|
||||
### 3. Hearthstone
|
||||
|
||||
![HearthStone Wine][9]
|
||||
|
||||
Hearthstone is a popular and addictive free-to-play digital card game that's available on a variety of platforms … except Linux. Don't worry, it works very well in Wine. Hearthstone is such a lightweight game that it's actually playable through Wine on even the lowest powered systems. That's good news, too, but because Hearthstone is another competitive game where performance matters.
|
||||
|
||||
Hearthstone doesn't require any special configuration or even patches. It just works.
|
||||
|
||||
### 2. Witcher 3
|
||||
|
||||
![Witcher 3 Wine][10]
|
||||
|
||||
If you're surprised to see this one here, you're not alone. With the latest "staging" patches, The Witcher 3 finally works. Despite originally being promised a native release, Linux gamers have had to wait a good long while to get the third installment in the Witcher franchise.
|
||||
|
||||
Don't expect everything to be perfect just yet. Support for Witcher 3 is _very_ new, and some things might not work as expected. That said, if you only have Linux to game on, and you 're willing to deal with a couple of rough edges, you can enjoy this awesome game for the first time with few, if any, troubles.
|
||||
|
||||
### 1. Overwatch
|
||||
|
||||
![Overwatch Wine][11]
|
||||
|
||||
Finally, there's yet another "white whale" for Linux gamers. Overwatch has been an elusive target that many feel should have been working on Wine since day one. Most Blizzard games have. Overwatch was a very different case. It only ever supported DX11, and that was a serious pain point for Wine.
|
||||
|
||||
Overwatch doesn't have the best performance yet, but you can definitely still play Blizzard's wildly popular shooter using a specially-patched version of Wine with the "staging" patches and additional ones just for Overwatch. That means Linux gamers wanted Overwatch so bad that they developed a special set of patches for it.
|
||||
|
||||
There were certainly games left off of this list. Most were just due to popularity or only conditional support under Wine. Other Blizzard games, like Heroes of the Storm and Diablo III also work, but this list would have been even more dominated by Blizzard, and that's not the point.
|
||||
|
||||
If you're going to try playing any of these games, consider using the "staging" or [Gallium Nine versions][2] of Wine. Many of the games here won't work without them. Even still, the latest patches and improvements land in "staging" long before they make it into the mainstream Wine release. Using it will keep you on the leading edge of progress.
|
||||
|
||||
Speaking of progress, right now Wine is making massive strides in DirectX11 support. While that doesn't mean much to Windows gamers, it's a huge deal for Linux. Most new games support DX11 and DX12, and until recently Wine only supported DX9. With DX11 support, Wine is gaining support for loads of games that were previously unplayable. So keep checking regularly to see if your favorite games from Windows started working in Wine. You might be very pleasantly surprised.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/games-play-on-linux-with-wine/
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/nickcongleton/
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2017/09/wow.jpg (World of Warcraft Wine)
|
||||
[2]:https://www.maketecheasier.com/install-wine-gallium-nine-linux
|
||||
[3]:https://www.maketecheasier.com/assets/uploads/2017/09/skyrim.jpg (Skyrim Wine)
|
||||
[4]:https://www.maketecheasier.com/assets/uploads/2017/09/sc2.jpg (StarCraft II Wine)
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2017/09/Fallout_3.jpg (Fallout 3 Wine)
|
||||
[6]:https://www.maketecheasier.com/assets/uploads/2017/09/doom.jpg (Doom Wine)
|
||||
[7]:https://www.maketecheasier.com/assets/uploads/2017/09/gw2.jpg (Guild Wars 2 Wine)
|
||||
[8]:https://www.maketecheasier.com/assets/uploads/2017/09/League_of_legends.jpg (League Of Legends Wine)
|
||||
[9]:https://www.maketecheasier.com/assets/uploads/2017/09/HearthStone.jpg (HearthStone Wine)
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2017/09/witcher3.jpg (Witcher 3 Wine)
|
||||
[11]:https://www.maketecheasier.com/assets/uploads/2017/09/Overwatch.jpg (Overwatch Wine)
|
||||
@ -0,0 +1,176 @@
|
||||
python-hwinfo : Display Summary Of Hardware Information In Linux
|
||||
======
|
||||
Till the date, we have covered most of the utilities which discover Linux system hardware information & configuration but still there are plenty of commands available for the same purpose.
|
||||
|
||||
In that, some of the utilities are display detailed information about all the hardware components and reset will shows only specific device information.
|
||||
|
||||
In this series, today we are going to discuss about [python-hwinfo][1], it is one of the tool that display summary of hardware information and it's configuration in the neat way.
|
||||
|
||||
### What's python-hwinfo
|
||||
|
||||
This is a python library for inspecting hardware and devices by parsing the outputs of system utilities such as lspci and dmidecode.
|
||||
|
||||
It's offering a simple CLI toll which can be used for inspect local, remote and captured hosts. Run the command with sudo to get maximum information.
|
||||
|
||||
Additionally you can execute this on remote server by providing a Server IP or Host name, username, and password. Also you can use this tool to view other utilities captured outputs like demidecode as 'dmidecode.out', /proc/cpuinfo as 'cpuinfo', lspci -nnm as 'lspci-nnm.out', etc,.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [inxi - A Great Tool to Check Hardware Information on Linux][2]
|
||||
**(#)** [Dmidecode - Easy Way To Get Linux System Hardware Information][3]
|
||||
**(#)** [LSHW (Hardware Lister) - A Nifty Tool To Get A Hardware Information On Linux][4]
|
||||
**(#)** [hwinfo (Hardware Info) - A Nifty Tool To Detect System Hardware Information On Linux][5]
|
||||
**(#)** [How To Use lspci, lsscsi, lsusb, And lsblk To Get Linux System Devices Information][6]
|
||||
|
||||
### How to Install python-hwinfo in Linux
|
||||
|
||||
It can be installed through pip package to all major Linux distributions. In order to install python-hwinfo, Make sure your system have python and python-pip packages as a prerequisites.
|
||||
|
||||
pip is a python module bundled with setuptools, it's one of the recommended tool for installing Python packages in Linux.
|
||||
|
||||
For **`Debian/Ubuntu`** , use [APT-GET Command][7] or [APT Command][8] to install pip.
|
||||
```
|
||||
$ sudo apt install python-pip
|
||||
|
||||
```
|
||||
|
||||
For **`RHEL/CentOS`** , use [YUM Command][9] to install pip.
|
||||
```
|
||||
$ sudo yum install python-pip python-devel
|
||||
|
||||
```
|
||||
|
||||
For **`Fedora`** , use [DNF Command][10] to install pip.
|
||||
```
|
||||
$ sudo dnf install python-pip
|
||||
|
||||
```
|
||||
|
||||
For **`Arch Linux`** , use [Pacman Command][11] to install pip.
|
||||
```
|
||||
$ sudo pacman -S python-pip
|
||||
|
||||
```
|
||||
|
||||
For **`openSUSE`** , use [Zypper Command][12] to install pip.
|
||||
```
|
||||
$ sudo zypper python-pip
|
||||
|
||||
```
|
||||
|
||||
Finally, Run the following pip command to install python-hwinfo.
|
||||
```
|
||||
$ sudo pip install python-hwinfo
|
||||
|
||||
```
|
||||
|
||||
### How to Use python-hwinfo in local machine
|
||||
|
||||
Execute the following command to inspect the hardware present on a local machine. The output is much clear and neat which i didn't see in any other commands.
|
||||
|
||||
It's categorized the output in five classes.
|
||||
|
||||
* **`Bios Info:`** It 's contains bios_vendor_name, system_product_name, system_serial_number, system_uuid, system_manufacturer, bios_release_date, and bios_version
|
||||
* **`CPU Info:`** It 's display no of processor, vendor_id, cpu_family, model, stepping, model_name, and cpu_mhz
|
||||
* **`Ethernet Controller Info:`** It 's shows device_bus_id, vendor_name, vendor_id, device_name, device_id, subvendor_name, subvendor_id, subdevice_name, and subdevice_id
|
||||
* **`Storage Controller Info:`** It 's shows vendor_name, vendor_id, device_name, device_id, subvendor_name, subvendor_id, subdevice_name, and subdevice_id
|
||||
* **`GPU Info:`** It 's shows vendor_name, vendor_id, device_name, device_id, subvendor_name, subvendor_id, subdevice_name, and subdevice_id
|
||||
|
||||
|
||||
```
|
||||
$ sudo hwinfo
|
||||
|
||||
Bios Info:
|
||||
|
||||
+----------------------|--------------------------------------+
|
||||
| Key | Value |
|
||||
+----------------------|--------------------------------------+
|
||||
| bios_vendor_name | IBM |
|
||||
| system_product_name | System x3550 M3: -[6102AF1]- |
|
||||
| system_serial_number | RS2IY21 |
|
||||
| chassis_type | Rack Mount Chassis |
|
||||
| system_uuid | 4C4C4544-0051-3210-8052-B2C04F323132 |
|
||||
| system_manufacturer | IBM |
|
||||
| socket_count | 2 |
|
||||
| bios_release_date | 10/21/2014 |
|
||||
| bios_version | -[VLS211TSU-2.51]- |
|
||||
| socket_designation | Socket 1, Socket 2 |
|
||||
+----------------------|--------------------------------------+
|
||||
|
||||
CPU Info:
|
||||
|
||||
+-----------|--------------|------------|-------|----------|------------------------------------------|----------+
|
||||
| processor | vendor_id | cpu_family | model | stepping | model_name | cpu_mhz |
|
||||
+-----------|--------------|------------|-------|----------|------------------------------------------|----------+
|
||||
| 0 | GenuineIntel | 6 | 45 | 7 | Intel(R) Xeon(R) CPU E5-1607 0 @ 3.00GHz | 1200.000 |
|
||||
| 1 | GenuineIntel | 6 | 45 | 7 | Intel(R) Xeon(R) CPU E5-1607 0 @ 3.00GHz | 1200.000 |
|
||||
| 2 | GenuineIntel | 6 | 45 | 7 | Intel(R) Xeon(R) CPU E5-1607 0 @ 3.00GHz | 1200.000 |
|
||||
| 3 | GenuineIntel | 6 | 45 | 7 | Intel(R) Xeon(R) CPU E5-1607 0 @ 3.00GHz | 1200.000 |
|
||||
| 4 | GenuineIntel | 6 | 45 | 7 | Intel(R) Xeon(R) CPU E5-2650 0 @ 2.00GHz | 1200.000 |
|
||||
+-----------|--------------|------------|-------|----------|------------------------------------------|----------+
|
||||
|
||||
Ethernet Controller Info:
|
||||
|
||||
+-------------------|-----------|---------------------------------|-----------|-------------------|--------------|---------------------------------|--------------+
|
||||
| vendor_name | vendor_id | device_name | device_id | subvendor_name | subvendor_id | subdevice_name | subdevice_id |
|
||||
+-------------------|-----------|---------------------------------|-----------|-------------------|--------------|---------------------------------|--------------+
|
||||
| Intel Corporation | 8086 | I350 Gigabit Network Connection | 1521 | Intel Corporation | 8086 | I350 Gigabit Network Connection | 1521 |
|
||||
+-------------------|-----------|---------------------------------|-----------|-------------------|--------------|---------------------------------|--------------+
|
||||
|
||||
Storage Controller Info:
|
||||
|
||||
+-------------------|-----------|----------------------------------------------|-----------|----------------|--------------|----------------|--------------+
|
||||
| vendor_name | vendor_id | device_name | device_id | subvendor_name | subvendor_id | subdevice_name | subdevice_id |
|
||||
+-------------------|-----------|----------------------------------------------|-----------|----------------|--------------|----------------|--------------+
|
||||
| Intel Corporation | 8086 | C600/X79 series chipset IDE-r Controller | 1d3c | Dell | 1028 | [Device 05d2] | 05d2 |
|
||||
| Intel Corporation | 8086 | C600/X79 series chipset SATA RAID Controller | 2826 | Dell | 1028 | [Device 05d2] | 05d2 |
|
||||
+-------------------|-----------|----------------------------------------------|-----------|----------------|--------------|----------------|--------------+
|
||||
|
||||
GPU Info:
|
||||
|
||||
+--------------------|-----------|-----------------------|-----------|--------------------|--------------|----------------|--------------+
|
||||
| vendor_name | vendor_id | device_name | device_id | subvendor_name | subvendor_id | subdevice_name | subdevice_id |
|
||||
+--------------------|-----------|-----------------------|-----------|--------------------|--------------|----------------|--------------+
|
||||
| NVIDIA Corporation | 10de | GK107GL [Quadro K600] | 0ffa | NVIDIA Corporation | 10de | [Device 094b] | 094b |
|
||||
+--------------------|-----------|-----------------------|-----------|--------------------|--------------|----------------|--------------+
|
||||
|
||||
```
|
||||
|
||||
### How to Use python-hwinfo in remote machine
|
||||
|
||||
Execute the following command to inspect the hardware present on a remote machine which required remote server IP, username, and password.
|
||||
```
|
||||
$ hwinfo -m x.x.x.x -u root -p password
|
||||
|
||||
```
|
||||
|
||||
### How to Use python-hwinfo to read captured outputs
|
||||
|
||||
Execute the following command to inspect the hardware present on a local machine. The output is much clear and neat which i didn't see in any other commands.
|
||||
```
|
||||
$ hwinfo -f [Path to file]
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/python-hwinfo-check-display-system-hardware-configuration-information-linux/
|
||||
|
||||
作者:[2DAYGEEK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/2daygeek/
|
||||
[1]:https://github.com/rdobson/python-hwinfo
|
||||
[2]:https://www.2daygeek.com/inxi-system-hardware-information-on-linux/
|
||||
[3]:https://www.2daygeek.com/dmidecode-get-print-display-check-linux-system-hardware-information/
|
||||
[4]:https://www.2daygeek.com/lshw-find-check-system-hardware-information-details-linux/
|
||||
[5]:https://www.2daygeek.com/hwinfo-check-display-detect-system-hardware-information-linux/
|
||||
[6]:https://www.2daygeek.com/check-system-hardware-devices-bus-information-lspci-lsscsi-lsusb-lsblk-linux/
|
||||
[7]:https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[8]:https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[9]:https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[10]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[11]:https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[12]:https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
85
sources/tech/20171006 7 deadly sins of documentation.md
Normal file
85
sources/tech/20171006 7 deadly sins of documentation.md
Normal file
@ -0,0 +1,85 @@
|
||||
7 deadly sins of documentation
|
||||
======
|
||||

|
||||
Documentation seems to be a perennial problem in operations. Everyone agrees that it's important to have, but few believe that their organizations have all the documentation they need. Effective documentation practices can improve incident response, speed up onboarding, and help reduce technical debt--but poor documentation practices can be worse than having no documentation at all.
|
||||
|
||||
### The 7 sins
|
||||
|
||||
Do any of the following scenarios sound familiar?
|
||||
|
||||
* You've got a wiki. And a Google Doc repository. And GitHub docs. And a bunch of text files in your home directory. And notes about problems in email.
|
||||
* You have a doc that explains everything about a service, and you're sure that the information you need to fix this incident in there ... somewhere.
|
||||
* You've got a 500-line Puppet manifest to handle this service ... with no comments. Or comments that reference tickets from two ticketing systems ago.
|
||||
* You have a bunch of archived presentations that discuss all sorts of infrastructure components, but you're not sure how up-to-date they are because you haven't had time to watch them in ages.
|
||||
* You bring someone new into the team and they spend a month asking what various pieces of jargon mean.
|
||||
* You search your wiki and find three separate docs on how this service works, two of which contradict each other entirely, and none of which have been updated in the past year.
|
||||
|
||||
|
||||
|
||||
These are all signs you may have committed at least one of the deadly sins of documentation:
|
||||
|
||||
1\. Repository overload.
|
||||
2\. Burying the lede.
|
||||
3\. Comment neglect.
|
||||
4\. Video addiction.
|
||||
5\. Jargon overuse.
|
||||
6\. Documentation overgrowth.
|
||||
|
||||
But if you've committed any of those sins, chances are you know this one, too:
|
||||
|
||||
7\. One or more of the above is true, but everyone says they don't have time to work on documentation.
|
||||
|
||||
The worst sin of all is thinking that documentation is "extra" work. Those other problems are almost always a result of this mistake. Documentation isn't extra work--it's a necessary part of every project, and if it isn't treated that way, it will be nearly impossible to do well. You wouldn't expect to get good code out of developers without a coherent process for writing, reviewing, and publishing code, and yet we often treat documentation like an afterthought, something that we assume will happen while we get our other work done. If you think your documentation is inadequate, ask yourself these questions:
|
||||
|
||||
* Do your projects include producing documentation as a measurable goal?
|
||||
* Do you have a formal review process for documentation?
|
||||
* Is documentation considered a task for senior members of the team?
|
||||
|
||||
|
||||
|
||||
The worst sin of all is thinking that documentation is "extra" work.
|
||||
|
||||
Those three questions can tell you a lot about whether you treat documentation as extra work or not. If people aren't given the time to write documentation, if there's no process to make sure the documentation that's produced is actually useful, or if documentation is foisted on those members of your team with the weakest grasp on the subjects being covered, it will be difficult to produce anything of decent quality.
|
||||
|
||||
Those three questions can tell you a lot about whether you treat documentation as extra work or not. If people aren't given the time to write documentation, if there's no process to make sure the documentation that's produced is actually useful, or if documentation is foisted on those members of your team with the weakest grasp on the subjects being covered, it will be difficult to produce anything of decent quality.
|
||||
|
||||
This often-dismissive attitude is pervasive in the industry. According to the [GitHub 2017 Open Source Survey][1], the number-one problem with most open source projects is incomplete or confusing documentation. But how many of those projects solicit technical writers to help improve that? How many of us in operations have a technical writer we bring in to help write or improve our documentation?
|
||||
|
||||
### Practice makes (closer to) perfect
|
||||
|
||||
This isn't to say that only a technical writer can produce good documentation, but writing and editing are skills like any other: We'll only get better at it if we work at it, and too few of us do. What are the concrete steps we can take to make it a real priority, as opposed to a nice-to-have?
|
||||
|
||||
For a start, make good documentation a value that your organization champions. Just as reliability needs champions to get prioritized, documentation needs the same thing. Project plans and sprints should include delivering new documentation or updating old documentation, and allocate time for doing so. Make sure people understand that writing good documentation is just as important to their career development as writing good code.
|
||||
|
||||
Additionally, make it easy to keep documentation up to date and for people to find the documentation they need. In this way, you can help perpetuate the virtuous circle of documentation: High-quality docs help people realize the value of documentation and provide examples to follow when they write their own, which in turn will encourage them to create their own.
|
||||
|
||||
To do this, have as few repositories as possible; one or two is optimal (you might want your runbooks to be in Google Docs so they are accessible if the company wiki is down, for instance). If you have more, make sure everyone knows what each repository is for; if Google Docs is for runbooks, verify that all runbooks are there and nowhere else, and that everyone knows that. Ensure that your repositories are searchable and keep a change history, and to improve discoverability, consider adding portals that have frequently used or especially important docs surfaced for easy access. Do not depend on email, chat logs, or tickets as primary sources of documentation.
|
||||
|
||||
Ask new and junior members of your team to review both your code and your documentation. If they don't understand what's going on in your code, or why you made the choices you did, it probably needs to be rewritten and/or commented better. If your docs aren't easy to understand without going down a rabbit hole, they probably need to be revised. Technical documentation should include concrete examples of how processes and behaviors work to help people create mental models. You may find the tips in this article helpful for improving your documentation writing: [10 tips for making your documentation crystal clear][2].
|
||||
|
||||
When you're writing those docs, especially when it comes to runbooks, use the [inverted pyramid format][3]: The most commonly needed or most important information should be as close to the top of the page as possible. Don't combine runbook-style documents and longer-form technical reference; instead, link the two and keep them separate so that runbooks remain streamlined (but can easily be discovered from the reference, and vice versa).
|
||||
|
||||
Using these steps in your documentation can change it from being a nice-to-have (or worse, a burden) into a force multiplier for your operations team. Good docs improve inclusiveness and knowledge transfer, helping your more inexperienced team members solve problems independently, freeing your more senior team members to work on new projects instead of firefighting or training new people. Better yet, well-written, high-quality documentation enables you and your team members to enjoy a weekend off or go on vacation without being on the hook if problems come up.
|
||||
|
||||
Learn more in Chastity Blackwell's talk, [The 7 Deadly Sins of Documentation][4], at [LISA17][5], which will be held October 29-November 3 in San Francisco, California.
|
||||
|
||||
### About The Author
|
||||
|
||||
Chastity Blackwell;Chastity Blackwell Is A Site Reliability Engineer At Yelp;With More Than Years Of Experience In Operations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/7-deadly-sins-documentation
|
||||
|
||||
作者:[Chastity Blackwell][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/cblkwell
|
||||
[1]:http://opensourcesurvey.org/2017/
|
||||
[2]:https://opensource.com/life/16/11/tips-for-clear-documentation
|
||||
[3]:https://en.wikipedia.org/wiki/Inverted_pyramid_(journalism)
|
||||
[4]:https://www.usenix.org/conference/lisa17/conference-program/presentation/blackwell
|
||||
[5]:https://www.usenix.org/conference/lisa17
|
||||
@ -0,0 +1,169 @@
|
||||
How To Convert DEB Packages Into Arch Linux Packages
|
||||
======
|
||||

|
||||
|
||||
We already learned how to [**build packages for multiple platforms**][1], and how to **[build packages from source][2]**. Today, we are going to learn how to convert DEB packages into Arch Linux packages. You might ask, **AUR** is the large software repository on the planet, and almost all software are available in it. Why would I need to convert a DEB package into Arch Linux package? True! However, some packages cannot be compiled (closed source packages) or cannot be built from AUR for various reasons like error during compiling or unavailable files. Or, the developer is too lazy to build a package in AUR or s/he doesn 't like to create an AUR package. In such cases, we can use this quick and dirty method to convert DEB packages into Arch Linux packages.
|
||||
|
||||
### Debtap - Convert DEB Packages Into Arch Linux Packages
|
||||
|
||||
For this purpose, we are going to use an utility called **" Debtap"**. It stands **DEB** **T** o **A** rch (Linux) **P** ackage. Debtap is available in AUR, so you can install it using the AUR helper tools such as [**Pacaur**][3], [**Packer**][4], or [**Yaourt**][5].
|
||||
|
||||
To unstall debtap using pacaur, run:
|
||||
```
|
||||
pacaur -S debtap
|
||||
```
|
||||
|
||||
Using Packer:
|
||||
```
|
||||
packer -S debtap
|
||||
```
|
||||
|
||||
Using Yaourt:
|
||||
```
|
||||
yaourt -S debtap
|
||||
```
|
||||
|
||||
Also, your Arch system should have **bash,** **binutils** , **pkgfile** and **fakeroot ** packages installed.
|
||||
|
||||
After installing Debtap and all above mentioned dependencies, run the following command to create/update pkgfile and debtap database.
|
||||
```
|
||||
sudo debtap -u
|
||||
```
|
||||
|
||||
Sample output would be:
|
||||
```
|
||||
==> Synchronizing pkgfile database...
|
||||
:: Updating 6 repos...
|
||||
download complete: archlinuxfr [ 151.7 KiB 67.5K/s 5 remaining]
|
||||
download complete: multilib [ 319.5 KiB 36.2K/s 4 remaining]
|
||||
download complete: core [ 707.7 KiB 49.5K/s 3 remaining]
|
||||
download complete: testing [ 1716.3 KiB 58.2K/s 2 remaining]
|
||||
download complete: extra [ 7.4 MiB 109K/s 1 remaining]
|
||||
download complete: community [ 16.9 MiB 131K/s 0 remaining]
|
||||
:: download complete in 131.47s < 27.1 MiB 211K/s 6 files >
|
||||
:: waiting for 1 process to finish repacking repos...
|
||||
==> Synchronizing debtap database...
|
||||
% Total % Received % Xferd Average Speed Time Time Time Current
|
||||
Dload Upload Total Spent Left Speed
|
||||
100 34.1M 100 34.1M 0 0 206k 0 0:02:49 0:02:49 --:--:-- 180k
|
||||
% Total % Received % Xferd Average Speed Time Time Time Current
|
||||
Dload Upload Total Spent Left Speed
|
||||
100 814k 100 814k 0 0 101k 0 0:00:08 0:00:08 --:--:-- 113k
|
||||
% Total % Received % Xferd Average Speed Time Time Time Current
|
||||
Dload Upload Total Spent Left Speed
|
||||
100 120k 100 120k 0 0 61575 0 0:00:02 0:00:02 --:--:-- 52381
|
||||
% Total % Received % Xferd Average Speed Time Time Time Current
|
||||
Dload Upload Total Spent Left Speed
|
||||
100 35.4M 100 35.4M 0 0 175k 0 0:03:27 0:03:27 --:--:-- 257k
|
||||
==> Downloading latest virtual packages list...
|
||||
% Total % Received % Xferd Average Speed Time Time Time Current
|
||||
Dload Upload Total Spent Left Speed
|
||||
100 149 0 149 0 0 49 0 --:--:-- 0:00:03 --:--:-- 44
|
||||
100 11890 0 11890 0 0 2378 0 --:--:-- 0:00:05 --:--:-- 8456
|
||||
==> Downloading latest AUR packages list...
|
||||
% Total % Received % Xferd Average Speed Time Time Time Current
|
||||
Dload Upload Total Spent Left Speed
|
||||
100 264k 0 264k 0 0 30128 0 --:--:-- 0:00:09 --:--:-- 74410
|
||||
==> Generating base group packages list...
|
||||
==> All steps successfully completed!
|
||||
```
|
||||
|
||||
You must run the above command at least once.
|
||||
|
||||
Now, it's time for package conversion.
|
||||
|
||||
To convert any DEB package, say **Quadrapassel** , to Arch Linux package using debtap, do:
|
||||
```
|
||||
debtap quadrapassel_3.22.0-1.1_arm64.deb
|
||||
```
|
||||
|
||||
The above command will convert the given .deb file into a Arch Linux package. You will be asked to enter the name of the package maintainer and license. Just enter them and hit ENTER key to start the conversion process.
|
||||
|
||||
The package conversion will take from a few seconds to several minutes depending upon your CPU speed. Grab a cup of coffee.
|
||||
|
||||
Sample output would be:
|
||||
```
|
||||
==> Extracting package data...
|
||||
==> Fixing possible directories structure differencies...
|
||||
==> Generating .PKGINFO file...
|
||||
|
||||
:: Enter Packager name:
|
||||
**quadrapassel**
|
||||
|
||||
:: Enter package license (you can enter multiple licenses comma separated):
|
||||
**GPL**
|
||||
|
||||
*** Creation of .PKGINFO file in progress. It may take a few minutes, please wait...
|
||||
|
||||
Warning: These dependencies (depend = fields) could not be translated into Arch Linux packages names:
|
||||
gsettings-backend
|
||||
|
||||
== > Checking and generating .INSTALL file (if necessary)...
|
||||
|
||||
:: If you want to edit .PKGINFO and .INSTALL files (in this order), press (1) For vi (2) For nano (3) For default editor (4) For a custom editor or any other key to continue:
|
||||
|
||||
==> Generating .MTREE file...
|
||||
|
||||
==> Creating final package...
|
||||
==> Package successfully created!
|
||||
==> Removing leftover files...
|
||||
```
|
||||
|
||||
**Note:** Quadrapassel package is already available in the Arch Linux official repositories. I used it just for demonstration purpose.
|
||||
|
||||
If you don't want to answer any questions during package conversion, use **-q** flag to bypass all questions, except for editing metadata file(s).
|
||||
```
|
||||
debtap -q quadrapassel_3.22.0-1.1_arm64.deb
|
||||
```
|
||||
|
||||
To bypass all questions (not recommended though), use -Q flag.
|
||||
```
|
||||
debtap -Q quadrapassel_3.22.0-1.1_arm64.deb
|
||||
```
|
||||
|
||||
Once the conversion is done, you can install the newly converted package using "pacman" in your Arch system as shown below.
|
||||
```
|
||||
sudo pacman -U <package-name>
|
||||
```
|
||||
|
||||
To display the help section, use **-h** flag:
|
||||
```
|
||||
$ debtap -h
|
||||
Syntax: debtap [options] package_filename
|
||||
|
||||
Options:
|
||||
|
||||
-h --h -help --help Prints this help message
|
||||
-u --u -update --update Update debtap database
|
||||
-q --q -quiet --quiet Bypass all questions, except for editing metadata file(s)
|
||||
-Q --Q -Quiet --Quiet Bypass all questions (not recommended)
|
||||
-s --s -pseudo --pseudo Create a pseudo-64-bit package from a 32-bit .deb package
|
||||
-w --w -wipeout --wipeout Wipeout versions from all dependencies, conflicts etc.
|
||||
-p --p -pkgbuild --pkgbuild Additionally generate a PKGBUILD file
|
||||
-P --P -Pkgbuild --Pkgbuild Generate a PKGBUILD file only
|
||||
```
|
||||
|
||||
And, that's all for now folks. Hope this utility helps. If you find our guides useful, please spend a moment to share them on your social, professional networks and support OSTechNix!
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/convert-deb-packages-arch-linux-packages/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/build-linux-packages-multiple-platforms-easily/
|
||||
[2]:https://www.ostechnix.com/build-packages-source-using-checkinstall/
|
||||
[3]:https://www.ostechnix.com/install-pacaur-arch-linux/
|
||||
[4]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[5]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
@ -0,0 +1,142 @@
|
||||
How to use GNU Stow to manage programs installed from source and dotfiles
|
||||
======
|
||||
|
||||
### Objective
|
||||
|
||||
Easily manage programs installed from source and dotfiles using GNU stow
|
||||
|
||||
### Requirements
|
||||
|
||||
* Root permissions
|
||||
|
||||
|
||||
|
||||
### Difficulty
|
||||
|
||||
EASY
|
||||
|
||||
### Conventions
|
||||
|
||||
* **#** \- requires given command to be executed with root privileges either directly as a root user or by use of `sudo` command
|
||||
* **$** \- given command to be executed as a regular non-privileged user
|
||||
|
||||
|
||||
|
||||
### Introduction
|
||||
|
||||
Sometimes we have to install programs from source: maybe they are not available through standard channels, or maybe we want a specific version of a software. GNU stow is a very nice `symlinks factory` program which helps us a lot by keeping files organized in a very clean and easy to maintain way.
|
||||
|
||||
### Obtaining stow
|
||||
|
||||
Your distribution repositories is very likely to contain `stow`, for example in Fedora, all you have to do to install it is:
|
||||
```
|
||||
# dnf install stow
|
||||
```
|
||||
|
||||
or on Ubuntu/Debian you can install stow by executing:
|
||||
```
|
||||
|
||||
# apt install stow
|
||||
|
||||
```
|
||||
|
||||
In some distributions, stow it's not available in standard repositories, but it can be easily obtained by adding some extra software sources (for example epel in the case of Rhel and CentOS7) or, as a last resort, by compiling it from source: it requires very little dependencies.
|
||||
|
||||
### Compiling stow from source
|
||||
|
||||
The latest available stow version is the `2.2.2`: the tarball is available for download here: `https://ftp.gnu.org/gnu/stow/`.
|
||||
|
||||
Once you have downloaded the sources, you must extract the tarball. Navigate to the directory where you downloaded the package and simply run:
|
||||
```
|
||||
$ tar -xvpzf stow-2.2.2.tar.gz
|
||||
```
|
||||
|
||||
After the sources have been extracted, navigate inside the stow-2.2.2 directory, and to compile the program simply run:
|
||||
```
|
||||
|
||||
$ ./configure
|
||||
$ make
|
||||
|
||||
```
|
||||
|
||||
Finally, to install the package:
|
||||
```
|
||||
# make install
|
||||
```
|
||||
|
||||
By default the package will be installed in the `/usr/local/` directory, but we can change this, specifying the directory via the `--prefix` option of the configure script, or by adding `prefix="/your/dir"` when running the `make install` command.
|
||||
|
||||
At this point, if all worked as expected we should have `stow` installed on our system
|
||||
|
||||
### How does stow work?
|
||||
|
||||
The main concept behind stow it's very well explained in the program manual:
|
||||
```
|
||||
|
||||
The approach used by Stow is to install each package into its own tree,
|
||||
then use symbolic links to make it appear as though the files are
|
||||
installed in the common tree.
|
||||
|
||||
```
|
||||
|
||||
To better understand the working of the package, let's analyze its key concepts:
|
||||
|
||||
#### The stow directory
|
||||
|
||||
The stow directory is the root directory which contains all the `stow packages`, each with their own private subtree. The typical stow directory is `/usr/local/stow`: inside it, each subdirectory represents a `package`
|
||||
|
||||
#### Stow packages
|
||||
|
||||
As said above, the stow directory contains "packages", each in its own separate subdirectory, usually named after the program itself. A package is nothing more than a list of files and directories related to a specific software, managed as an entity.
|
||||
|
||||
#### The stow target directory
|
||||
|
||||
The stow target directory is very a simple concept to explain. It is the directory in which the package files must appear to be installed. By default the stow target directory is considered to be the one above the directory in which stow is invoked from. This behaviour can be easily changed by using the `-t` option (short for --target), which allows us to specify an alternative directory.
|
||||
|
||||
### A practical example
|
||||
|
||||
I believe a well done example is worth 1000 words, so let's show how stow works. Suppose we want to compile and install `libx264`. Lets clone the git repository containing its sources:
|
||||
```
|
||||
$ git clone git://git.videolan.org/x264.git
|
||||
```
|
||||
|
||||
Few seconds after running the command, the "x264" directory will be created, and it will contain the sources, ready to be compiled. We now navigate inside it and run the `configure` script, specifying the /usr/local/stow/libx264 directory as `--prefix`:
|
||||
```
|
||||
$ cd x264 && ./configure --prefix=/usr/local/stow/libx264
|
||||
```
|
||||
|
||||
Then we build the program and install it:
|
||||
```
|
||||
|
||||
$ make
|
||||
# make install
|
||||
|
||||
```
|
||||
|
||||
The directory x264 should have been created inside of the stow directory: it contains all the stuff that would have been normally installed in the system directly. Now, all we have to do, is to invoke stow. We must run the command either from inside the stow directory, by using the `-d` option to specify manually the path to the stow directory (default is the current directory), or by specifying the target with `-t` as said before. We should also provide the name of the package to be stowed as an argument. In this case we run the program from the stow directory, so all we need to type is:
|
||||
```
|
||||
# stow libx264
|
||||
```
|
||||
|
||||
All the files and directories contained in the libx264 package have now been symlinked in the parent directory (/usr/local) of the one from which stow has been invoked, so that, for example, libx264 binaries contained in `/usr/local/stow/x264/bin` are now symlinked in `/usr/local/bin`, files contained in `/usr/local/stow/x264/etc` are now symlinked in `/usr/local/etc` and so on. This way it will appear to the system that the files were installed normally, and we can easily keep track of each program we compile and install. To revert the action, we just use the `-D` option:
|
||||
```
|
||||
# stow -d libx264
|
||||
```
|
||||
|
||||
It is done! The symlinks don't exist anymore: we just "uninstalled" a stow package, keeping our system in a clean and consistent state. At this point it should be clear why stow it's also used to manage dotfiles. A common practice is to have all user-specific configuration files inside a git repository, to manage them easily and have them available everywhere, and then using stow to place them where appropriate, in the user home directory.
|
||||
|
||||
Stow will also prevent you from overriding files by mistake: it will refuse to create symbolic links if the destination file already exists and doesn't point to a package into the stow directory. This situation is called a conflict in stow terminology.
|
||||
|
||||
That's it! For a complete list of options, please consult the stow manpage and don't forget to tell us your opinions about it in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/how-to-use-gnu-stow-to-manage-programs-installed-from-source-and-dotfiles
|
||||
|
||||
作者:[Egidio Docile][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org
|
||||
@ -0,0 +1,61 @@
|
||||
translating by lujun9972
|
||||
The most important Firefox command line options
|
||||
======
|
||||
The Firefox web browser supports a number of command line options that it can be run with to customize startup of the web browser.
|
||||
|
||||
You may have come upon some of them in the past, for instance the command -P "profile name" to start the browser with the specified profile, or -private to start a new private browsing session.
|
||||
|
||||
The following guide lists important command line options for Firefox. It is not a complete list of all available options, as many are used only for specific purposes that have little to no value to users of the browser.
|
||||
|
||||
You find the [complete][1] listing of command line options on the Firefox Developer website. Note that many of the command line options work in other Mozilla-based products, even third-party programs, as well.
|
||||
|
||||
### Important Firefox command line options
|
||||
|
||||
![firefox command line][2]
|
||||
|
||||
**Profile specific options**
|
||||
|
||||
* **-CreateProfile profile name** -- This creates a new user profile, but won't start it right away.
|
||||
* **-CreateProfile "profile name profile dir"** -- Same as above, but will specify a custom profile directory on top of that.
|
||||
* **-ProfileManager** , or **-P** -- Opens the built-in profile manager.
|
||||
* - **P "profile name"** -- Starts Firefox with the specified profile. Profile manager is opened if the specified profile does not exist. Works only if no other instance of Firefox is running.
|
||||
* **-no-remote** -- Add this to the -P commands to create a new instance of the browser. This lets you run multiple profiles at the same time.
|
||||
|
||||
|
||||
|
||||
**Browser specific options**
|
||||
|
||||
* **-headless** -- Start Firefox in headless mode. Requires Firefox 55 on Linux, Firefox 56 on Windows and Mac OS X.
|
||||
* **-new-tab URL** -- loads the specified URL in a new tab in Firefox.
|
||||
* **-new-window URL** -- loads the specified URL in a new Firefox window.
|
||||
* **-private** -- Launches Firefox in private browsing mode. Can be used to run Firefox in private browsing mode all the time.
|
||||
* **-private-window** -- Open a private window.
|
||||
* **-private-window URL** -- Open the URL in a new private window. If a private browsing window is open already, open the URL in that window instead.
|
||||
* **-search term** -- Run the search using the default Firefox search engine.
|
||||
* - **url URL** -- Load the URL in a new tab or window. Can be run without -url, and multiple URLs separated by space can be opened using the command.
|
||||
|
||||
|
||||
|
||||
Other options
|
||||
|
||||
* **-safe-mode** -- Starts Firefox in Safe Mode. You may also hold down the Shift-key while opening Firefox to start the browser in Safe Mode.
|
||||
* **-devtools** -- Start Firefox with Developer Tools loaded and open.
|
||||
* **-inspector URL** -- Inspect the specified address in the DOM Inspector.
|
||||
* **-jsconsole** -- Start Firefox with the Browser Console.
|
||||
* **-tray** -- Start Firefox minimized.
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ghacks.net/2017/10/08/the-most-important-firefox-command-line-options/
|
||||
|
||||
作者:[Martin Brinkmann][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ghacks.net/author/martin/
|
||||
[1]:https://developer.mozilla.org/en-US/docs/Mozilla/Command_Line_Options
|
||||
@ -0,0 +1,131 @@
|
||||
10 layers of Linux container security | Opensource.com
|
||||
======
|
||||

|
||||
|
||||
Containers provide an easy way to package applications and deliver them seamlessly from development to test to production. This helps ensure consistency across a variety of environments, including physical servers, virtual machines (VMs), or private or public clouds. These benefits are leading organizations to rapidly adopt containers in order to easily develop and manage the applications that add business value.
|
||||
|
||||
Enterprises require strong security, and anyone running essential services in containers will ask, "Are containers secure?" and "Can we trust containers with our applications?"
|
||||
|
||||
Securing containers is a lot like securing any running process. You need to think about security throughout the layers of the solution stack before you deploy and run your container. You also need to think about security throughout the application and container lifecycle.
|
||||
|
||||
Try these 10 key elements to secure different layers of the container solution stack and different stages of the container lifecycle.
|
||||
|
||||
### 1. The container host operating system and multi-tenancy
|
||||
|
||||
Containers make it easier for developers to build and promote an application and its dependencies as a unit and to get the most use of servers by enabling multi-tenant application deployments on a shared host. It's easy to deploy multiple applications on a single host, spinning up and shutting down individual containers as needed. To take full advantage of this packaging and deployment technology, the operations team needs the right environment for running containers. Operations needs an operating system that can secure containers at the boundaries, securing the host kernel from container escapes and securing containers from each other.
|
||||
|
||||
### 2. Container content (use trusted sources)
|
||||
|
||||
Containers are Linux processes with isolation and resource confinement that enable you to run sandboxed applications on a shared host kernel. Your approach to securing containers should be the same as your approach to securing any running process on Linux. Dropping privileges is important and still the best practice. Even better is to create containers with the least privilege possible. Containers should run as user, not root. Next, make use of the multiple levels of security available in Linux. Linux namespaces, Security-Enhanced Linux ( [SELinux][1] ), [cgroups][2] , capabilities, and secure computing mode ( [seccomp][3] ) are five of the security features available for securing containers.
|
||||
|
||||
When it comes to security, what's inside your container matters. For some time now, applications and infrastructures have been composed from readily available components. Many of these are open source packages, such as the Linux operating system, Apache Web Server, Red Hat JBoss Enterprise Application Platform, PostgreSQL, and Node.js. Containerized versions of these packages are now also readily available, so you don't have to build your own. But, as with any code you download from an external source, you need to know where the packages originated, who built them, and whether there's any malicious code inside them.
|
||||
|
||||
### 3. Container registries (secure access to container images)
|
||||
|
||||
Your teams are building containers that layer content on top of downloaded public container images, so it's critical to manage access to and promotion of the downloaded container images and the internally built images in the same way other types of binaries are managed. Many private registries support storage of container images. Select a private registry that helps to automate policies for the use of container images stored in the registry.
|
||||
|
||||
### 4. Security and the build process
|
||||
|
||||
In a containerized environment, the software-build process is the stage in the lifecycle where application code is integrated with needed runtime libraries. Managing this build process is key to securing the software stack. Adhering to a "build once, deploy everywhere" philosophy ensures that the product of the build process is exactly what is deployed in production. It's also important to maintain the immutability of your containers--in other words, do not patch running containers; rebuild and redeploy them instead.
|
||||
|
||||
Whether you work in a highly regulated industry or simply want to optimize your team's efforts, design your container image management and build process to take advantage of container layers to implement separation of control, so that the:
|
||||
|
||||
* Operations team manages base images
|
||||
* Architects manage middleware, runtimes, databases, and other such solutions
|
||||
* Developers focus on application layers and just write code
|
||||
|
||||
|
||||
|
||||
Finally, sign your custom-built containers so that you can be sure they are not tampered with between build and deployment.
|
||||
|
||||
### 5. Control what can be deployed within a cluster
|
||||
|
||||
In case anything falls through during the build process, or for situations where a vulnerability is discovered after an image has been deployed, add yet another layer of security in the form of tools for automated, policy-based deployment.
|
||||
|
||||
Let's look at an application that's built using three container image layers: core, middleware, and the application layer. An issue is discovered in the core image and that image is rebuilt. Once the build is complete, the image is pushed to the container platform registry. The platform can detect that the image has changed. For builds that are dependent on this image and have triggers defined, the platform will automatically rebuild the application image, incorporating the fixed libraries.
|
||||
|
||||
Add yet another layer of security in the form of tools for automated, policy-based deployment.
|
||||
|
||||
Once the build is complete, the image is pushed to container platform's internal registry. It immediately detects changes to images in its internal registry and, for applications where triggers are defined, automatically deploys the updated image, ensuring that the code running in production is always identical to the most recently updated image. All these capabilities work together to integrate security capabilities into your continuous integration and continuous deployment (CI/CD) process and pipeline.
|
||||
|
||||
### 6. Container orchestration: Securing the container platform
|
||||
|
||||
Once the build is complete, the image is pushed to container platform's internal registry. It immediately detects changes to images in its internal registry and, for applications where triggers are defined, automatically deploys the updated image, ensuring that the code running in production is always identical to the most recently updated image. All these capabilities work together to integrate security capabilities into your continuous integration and continuous deployment (CI/CD) process and pipeline.
|
||||
|
||||
Of course, applications are rarely delivered in a single container. Even simple applications typically have a frontend, a backend, and a database. And deploying modern microservices applications in containers means deploying multiple containers, sometimes on the same host and sometimes distributed across multiple hosts or nodes, as shown in this diagram.
|
||||
|
||||
When managing container deployment at scale, you need to consider:
|
||||
|
||||
* Which containers should be deployed to which hosts?
|
||||
* Which host has more capacity?
|
||||
* Which containers need access to each other? How will they discover each other?
|
||||
* How will you control access to--and management of--shared resources, like network and storage?
|
||||
* How will you monitor container health?
|
||||
* How will you automatically scale application capacity to meet demand?
|
||||
* How will you enable developer self-service while also meeting security requirements?
|
||||
|
||||
|
||||
|
||||
Given the wealth of capabilities for both developers and operators, strong role-based access control is a critical element of the container platform. For example, the orchestration management servers are a central point of access and should receive the highest level of security scrutiny. APIs are key to automating container management at scale and used to validate and configure the data for pods, services, and replication controllers; perform project validation on incoming requests; and invoke triggers on other major system components.
|
||||
|
||||
### 7. Network isolation
|
||||
|
||||
Deploying modern microservices applications in containers often means deploying multiple containers distributed across multiple nodes. With network defense in mind, you need a way to isolate applications from one another within a cluster. A typical public cloud container service, like Google Container Engine (GKE), Azure Container Services, or Amazon Web Services (AWS) Container Service, are single-tenant services. They let you run your containers on the VM cluster that you initiate. For secure container multi-tenancy, you want a container platform that allows you to take a single cluster and segment the traffic to isolate different users, teams, applications, and environments within that cluster.
|
||||
|
||||
With network namespaces, each collection of containers (known as a "pod") gets its own IP and port range to bind to, thereby isolating pod networks from each other on the node. Pods from different namespaces (projects) cannot send packets to or receive packets from pods and services of a different project by default, with the exception of options noted below. You can use these features to isolate developer, test, and production environments within a cluster; however, this proliferation of IP addresses and ports makes networking more complicated. In addition, containers are designed to come and go. Invest in tools that handle this complexity for you. The preferred tool is a container platform that uses [software-defined networking][4] (SDN) to provide a unified cluster network that enables communication between containers across the cluster.
|
||||
|
||||
### 8. Storage
|
||||
|
||||
Containers are useful for both stateless and stateful applications. Protecting attached storage is a key element of securing stateful services. Container platforms should provide plugins for multiple flavors of storage, including network file systems (NFS), AWS Elastic Block Stores (EBS), GCE Persistent Disks, GlusterFS, iSCSI, RADOS (Ceph), Cinder, etc.
|
||||
|
||||
A persistent volume (PV) can be mounted on a host in any way supported by the resource provider. Providers will have different capabilities, and each PV's access modes are set to the specific modes supported by that particular volume. For example, NFS can support multiple read/write clients, but a specific NFS PV might be exported on the server as read only. Each PV gets its own set of access modes describing that specific PV's capabilities, such as ReadWriteOnce, ReadOnlyMany, and ReadWriteMany.
|
||||
|
||||
### 9. API management, endpoint security, and single sign-on (SSO)
|
||||
|
||||
Securing your applications includes managing application and API authentication and authorization.
|
||||
|
||||
Web SSO capabilities are a key part of modern applications. Container platforms can come with various containerized services for developers to use when building their applications.
|
||||
|
||||
APIs are key to applications composed of microservices. These applications have multiple independent API services, leading to proliferation of service endpoints, which require additional tools for governance. An API management tool is also recommended. All API platforms should offer a variety of standard options for API authentication and security, which can be used alone or in combination, to issue credentials and control access.
|
||||
|
||||
Securing your applications includes managing application and API authentication and authorization.
|
||||
|
||||
These options include standard API keys, application ID and key pairs, and OAuth 2.0.
|
||||
|
||||
### 10. Roles and access management in a cluster federation
|
||||
|
||||
These options include standard API keys, application ID and key pairs, and OAuth 2.0.
|
||||
|
||||
In July 2016, Kubernetes 1.3 introduced [Kubernetes Federated Clusters][5]. This is one of the exciting new features evolving in the Kubernetes upstream, currently in beta in Kubernetes 1.6. Federation is useful for deploying and accessing application services that span multiple clusters running in the public cloud or enterprise datacenters. Multiple clusters can be useful to enable application high availability across multiple availability zones or to enable common management of deployments or migrations across multiple cloud providers, such as AWS, Google Cloud, and Azure.
|
||||
|
||||
When managing federated clusters, you must be sure that your orchestration tools provide the security you need across the different deployment platform instances. As always, authentication and authorization are key--as well as the ability to securely pass data to your applications, wherever they run, and manage application multi-tenancy across clusters. Kubernetes is extending Cluster Federation to include support for Federated Secrets, Federated Namespaces, and Ingress objects.
|
||||
|
||||
### Choosing a container platform
|
||||
|
||||
Of course, it is not just about security. Your container platform needs to provide an experience that works for your developers and your operations team. It needs to offer a secure, enterprise-grade container-based application platform that enables both developers and operators, without compromising the functions needed by each team, while also improving operational efficiency and infrastructure utilization.
|
||||
|
||||
Learn more in Daniel's talk, [Ten Layers of Container Security][6], at [Open Source Summit EU][7], which will be held October 23-26 in Prague.
|
||||
|
||||
### About The Author
|
||||
Daniel Oh;Microservives;Agile;Devops;Java Ee;Container;Openshift;Jboss;Evangelism
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/10-layers-container-security
|
||||
|
||||
作者:[Daniel Oh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/daniel-oh
|
||||
[1]:https://en.wikipedia.org/wiki/Security-Enhanced_Linux
|
||||
[2]:https://en.wikipedia.org/wiki/Cgroups
|
||||
[3]:https://en.wikipedia.org/wiki/Seccomp
|
||||
[4]:https://en.wikipedia.org/wiki/Software-defined_networking
|
||||
[5]:https://kubernetes.io/docs/concepts/cluster-administration/federation/
|
||||
[6]:https://osseu17.sched.com/mobile/#session:f2deeabfc1640d002c1d55101ce81223
|
||||
[7]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||
@ -0,0 +1,88 @@
|
||||
What’s next in DevOps: 5 trends to watch
|
||||
======
|
||||
|
||||

|
||||
|
||||
The term "DevOps" is typically credited [to this 2008 presentation][1] on agile infrastructure and operations. Now ubiquitous in IT vocabulary, the mashup word is less than 10 years old: We're still figuring out this modern way of working in IT.
|
||||
|
||||
Sure, people who have been "doing DevOps" for years have accrued plenty of wisdom along the way. But most DevOps environments - and the mix of people and [culture][2], process and methodology, and tools and technology - are far from mature.
|
||||
|
||||
More change is coming. That's kind of the whole point. "DevOps is a process, an algorithm," says Robert Reeves, CTO at [Datical][3]. "Its entire purpose is to change and evolve over time."
|
||||
|
||||
What should we expect next? Here are some key trends to watch, according to DevOps experts.
|
||||
|
||||
### 1. Expect increasing interdependence between DevOps, containers, and microservices
|
||||
|
||||
The forces driving the proliferation of DevOps culture themselves may evolve. Sure, DevOps will still fundamentally knock down traditional IT silos and bottlenecks, but the reasons for doing so may become more urgent. Exhibits A & B: Growing interest in and [adoption of containers and microservices][4]. The technologies pack a powerful, scalable one-two punch, best paired with planned, [ongoing management][5].
|
||||
|
||||
"One of the major factors impacting DevOps is the shift towards microservices," says Arvind Soni, VP of product at [Netsil][6], adding that containers and orchestration are enabling developers to package and deliver services at an ever-increasing pace. DevOps teams will likely be tasked with helping to fuel that pace and to manage the ongoing complexity of a scalable microservices architecture.
|
||||
|
||||
### 2. Expect fewer safety nets
|
||||
|
||||
DevOps enables teams to build software with greater speed and agility, deploying faster and more frequently, while improving quality and stability. But good IT leaders don't typically ignore risk management, so plenty of early DevOps iterations began with safeguards and fallback positions in place. To get to the next level of speed and agility, more teams will take off their training wheels.
|
||||
|
||||
"As teams mature, they may decide that some of the guard rails that were added early on may not be required anymore," says Nic Grange, CTO of [Retriever Communications][7]. Grange gives the example of a staging server: As DevOps teams mature, they may decide it's no longer necessary, especially if they're rarely catching issues in that pre-production environment. (Grange points out that this move isn't advisable for inexperienced teams.)
|
||||
|
||||
"The team may be at a point where it is confident enough with its monitoring and ability to identify and resolve issues in production," Grange says. "The process of deploying and testing in staging may just be slowing them down without any demonstrable value."
|
||||
|
||||
### 3. Expect DevOps to spread elsewhere
|
||||
|
||||
DevOps brings two traditional IT groups, development and operations, into much closer alignment. As more companies see the benefits in the trenches, the culture is likely to spread. It's already happening in some organizations, evident in the increasing appearance of the term "DevSecOps," which reflects the intentional and much earlier inclusion of security in the software development lifecycle.
|
||||
|
||||
"DevSecOps is not only tools, it is integrating a security mindset into development practices early on," says Derek Weeks, VP and DevOps advocate at [Sonatype][8].
|
||||
|
||||
Doing that isn't a technology challenge, it's a cultural challenge, says [Red Hat][9] security strategist Kirsten Newcomer.
|
||||
|
||||
"Security teams have historically been isolated from development teams - and each team has developed deep expertise in different areas of IT," Newcomer says. "It doesn't need to be this way. Enterprises that care deeply about security and also care deeply about their ability to quickly deliver business value through software are finding ways to move security left in their application development lifecycles. They're adopting DevSecOps by integrating security practices, tooling, and automation throughout the CI/CD pipeline. To do this well, they're integrating their teams - security professionals are embedded with application development teams from inception (design) through to production deployment. Both sides are seeing the value - each team expands their skill sets and knowledge base, making them more valuable technologists. DevOps done right - or DevSecOps - improves IT security."
|
||||
|
||||
Beyond security, look for DevOps expansion into areas such as database teams, QA, and even potentially outside of IT altogether.
|
||||
|
||||
"This is a very DevOps thing to do: Identify areas of friction and resolve them," Datical's Reeves says. "Security and databases are currently the big bottlenecks for companies that have previously adopted DevOps."
|
||||
|
||||
### 4. Expect ROI to increase
|
||||
|
||||
As companies get deeper into their DevOps work, IT teams will be able to show greater return on investment in methodologies, processes, containers, and microservices, says Eric Schabell, global technology evangelist director, Red Hat. "The Holy Grail was to be moving faster, accomplishing more and becoming flexible. As these components find broader adoption and organizations become more vested in their application the results shall appear," Schabell says.
|
||||
|
||||
"Everything has a learning curve with a peak of excitement as the emerging technologies gain our attention, but also go through a trough of disillusionment when the realization hits that applying it all is hard. Finally, we'll start to see a climb out of the trough and reap the benefits that we've been chasing with DevOps, containers, and microservices."
|
||||
|
||||
### 5. Expect success metrics to keep evolving
|
||||
|
||||
"I believe that two of the core tenets of the DevOps culture, automation and measurement, are never 'done,'" says Mike Kail, CTO at [CYBRIC][10] and former CIO at Yahoo. "There will always be opportunities to automate a task or improve upon an already automated solution, and what is important to measure will likely change and expand over time. This maturation process is a continuous journey, not a destination or completed task."
|
||||
|
||||
In the spirit of DevOps, that maturation and learning will also depend on collaboration and sharing. Kail thinks it's still very much early days for Agile methodologies and DevOps culture, and that means plenty of room for growth.
|
||||
|
||||
"As more mature organizations continue to measure actionable metrics, I believe - [I] hope - that those learnings will be broadly shared so we can all learn and improve from them," Kail says.
|
||||
|
||||
As Red Hat technology evangelist [Gordon Haff][11] recently noted, organizations working hard to improve their DevOps metrics are using factors tied to business outcomes. "You probably don't really care about how many lines of code your developers write, whether a server had a hardware failure overnight, or how comprehensive your test coverage is," [writes Haff][12]. "In fact, you may not even directly care about the responsiveness of your website or the rapidity of your updates. But you do care to the degree such metrics can be correlated with customers abandoning shopping carts or leaving for a competitor."
|
||||
|
||||
Some examples of DevOps metrics tied to business outcomes include customer ticket volume (as an indicator of overall customer satisfaction) and Net Promoter Score (the willingness of customers to recommend a company's products or services). For more on this topic, see his full article, [DevOps metrics: Are you measuring what matters? ][12]
|
||||
|
||||
### No rest for the speedy
|
||||
|
||||
By the way, if you were hoping things would get a little more leisurely anytime soon, you're out of luck.
|
||||
|
||||
"If you think releases are fast today, you ain't seen nothing yet," Reeves says. "That's why bringing all stakeholders, including security and database teams, into the DevOps tent is so crucial. The friction caused by these two groups today will only grow as releases increase exponentially."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2017/10/what-s-next-devops-5-trends-watch
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:http://www.jedi.be/presentations/agile-infrastructure-agile-2008.pdf
|
||||
[2]:https://enterprisersproject.com/article/2017/9/5-ways-nurture-devops-culture
|
||||
[3]:https://www.datical.com/
|
||||
[4]:https://enterprisersproject.com/article/2017/9/microservices-and-containers-6-things-know-start-time
|
||||
[5]:https://enterprisersproject.com/article/2017/10/microservices-and-containers-6-management-tips-long-haul
|
||||
[6]:https://netsil.com/
|
||||
[7]:http://retrievercommunications.com/
|
||||
[8]:https://www.sonatype.com/
|
||||
[9]:https://www.redhat.com/en/
|
||||
[10]:https://www.cybric.io/
|
||||
[11]:https://enterprisersproject.com/user/gordon-haff
|
||||
[12]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by zjon
|
||||
|
||||
What is a firewall?
|
||||
======
|
||||
Network-based firewalls have become almost ubiquitous across US enterprises for their proven defense against an ever-increasing array of threats.
|
||||
@ -77,3 +79,5 @@ via: https://www.networkworld.com/article/3230457/lan-wan/what-is-a-firewall-per
|
||||
|
||||
[a]:https://www.networkworld.com/author/Brandon-Butler/
|
||||
[1]:https://www.networkworld.com/article/3236448/lan-wan/what-to-consider-when-deploying-a-next-generation-firewall.html
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,123 @@
|
||||
How to create an e-book chapter template in LibreOffice Writer
|
||||
======
|
||||

|
||||
For many people, using a word processor is the fastest, easiest, and most familiar way to write and publish an e-book. But firing up your word processor and typing away isn't enough--you need to follow a format.
|
||||
|
||||
That's where a template comes in. A template ensures that your book has a consistent look and feel. Luckily, creating a template is quick and easy, and the time and effort you spend on it will give you a better-looking book.
|
||||
|
||||
In this article, I'll walk you through how to create a simple template for writing individual chapters of an e-book using LibreOffice Writer. You can use this template for both PDF and EPUB books and modify it to suit your needs.
|
||||
|
||||
### My approach
|
||||
|
||||
Why am I focusing on creating a template for a chapter rather than one for an entire book? Because it's easier to write and manage individual chapters than it is to work on a single monolithic document.
|
||||
|
||||
By focusing on individual chapters, you can focus on what you need to write. You can easily move those chapters around, and it's less cumbersome to send a reviewer a single chapter rather than your full manuscript. When you've finished writing a chapter, you can simply stitch your chapters together to publish the book (I'll discuss how to do that below). But don't feel that you're stuck with this approach--if you prefer to write in single file, simply adapt the steps described in this article to doing so.
|
||||
|
||||
Let's get started.
|
||||
|
||||
### Setting up the page
|
||||
|
||||
This is important only if you plan to publish your e-book as a PDF. Setting up the page means your book won't comprise a mass of eye-straining text running across the screen.
|
||||
|
||||
Select **Format > Page** to open the **Page Style** window. My PDF e-books are usually 5x8 inches tall (about 13x20cm, for those of us in the metric world). I also set the margins to half an inch (around 1.25 cm). These are my preferred dimensions; use whatever size suits you.
|
||||
|
||||
![LibreOffice Page Style window][2]
|
||||
|
||||
|
||||
The Page Style window in LibreOffice Writer lets you set margins and format the page.
|
||||
|
||||
Next, add a footer to display a page number. Keep the Page Style window open and click the **Footer** tab. Select **Footer on** and click **OK**.
|
||||
|
||||
On the page, click in the footer, then select **Insert > Field > Page Number**. Don't worry about the position and appearance of the page number; we'll take care of that next.
|
||||
|
||||
### Setting up your styles
|
||||
|
||||
Like the template itself, styles provide a consistent look and feel for your documents. If you want to change the font or the size of a heading, for example, you need do it in only one place rather than manually applying formatting to each heading.
|
||||
|
||||
The standard LibreOffice template comes with a number of styles that you can fiddle with to suit your needs. To do that, press **F11** to open the **Styles and Formatting** window.
|
||||
|
||||
### [lo-paragraph-style.png][3]
|
||||
|
||||
![LibreOffice styles and formatting][4]
|
||||
|
||||
|
||||
Change fonts and other details using the Styles and Formatting window.
|
||||
|
||||
Right-click on a style and select **Modify** to edit it. Here are the main styles that I use in every book I write:
|
||||
|
||||
Style Font Spacing/Alignment Heading 1 Liberation Sans, 36 pt 36 pt above, 48 pt below, aligned left Heading 2 Liberation Sans, 18 pt 12 pt above, 12 pt below, aligned left Heading 3 Liberation Sans, 14 pt 12 pt above, 12 pt below, aligned left Text Body Liberation Sans, 12 pt 12 pt above, 12 pt below, aligned left Footer Liberation Sans, 10 pt Aligned center
|
||||
|
||||
### [lo-styles-in-action.png][5]
|
||||
|
||||
![LibreOffice styles in action][6]
|
||||
|
||||
|
||||
Here's what a selected style looks like when applied to ebook content.
|
||||
|
||||
That's usually the bare minimum you need for most books. Feel free to change the fonts and spacing to suit your needs.
|
||||
|
||||
Depending on the type of book you're writing, you might also want to create or modify styles for bullet and number lists, quotes, code samples, figures, etc. Just remember to use fonts and their sizes consistently.
|
||||
|
||||
### Saving your template
|
||||
|
||||
Select **File > Save As**. In the Save dialog box, select _ODF Text Document Template (.ott)_ from the formats list. This saves the document as a template, which you'll be able to quickly call up later.
|
||||
|
||||
The best place to save it is in your LibreOffice templates folder. In Linux, for example, that's in your **/home** directory, under . **config/libreoffice/4/user/template**.
|
||||
|
||||
### Writing your book
|
||||
|
||||
Before you start writing, create a folder on your computer that will hold all the files--chapters, images, notes, etc.--for your book.
|
||||
|
||||
When you're ready to write, fire up LibreOffice Writer and select **File > New > Templates**. Then select your template from the list and click **Open**.
|
||||
|
||||
### [lo-template-list.png][7]
|
||||
|
||||
![LibreOffice Writer template list][8]
|
||||
|
||||
|
||||
Select your template from the list you set up in LibreOffice Writer and begin writing.
|
||||
|
||||
Then save the document with a descriptive name.
|
||||
|
||||
Avoid using conventions like _Chapter 1_ and _Chapter 2_ --at some point, you might decide to shuffle your chapters around, and it can get confusing when you're trying to manage those chapters. You could, however, put chapter numbers, like _Chapter 1_ or _Ch1,_ in the file name. It's easier to rename a file like that if you do wind up rearranging the chapters of your book.
|
||||
|
||||
With that out of the way, start writing. Remember to use the styles in the template to format the text--that's why you created the template, right?
|
||||
|
||||
### Publishing your e-book
|
||||
|
||||
Once you've finished writing a bunch of chapters and are ready to publish them, create a master document. Think of a master document as a container for the chapters you've written. Using a master document, you can quickly assemble your book and rearrange your chapters at will. The LibreOffice help offers detailed instructions for working with [master documents][9].
|
||||
|
||||
Assuming you want to generate a PDF, don't just click the **Export Directly to PDF** button. That will create a decent PDF, but you might want to optimize it. To do that, select **File > Export as PDF** and tweak the settings in the PDF options window. You can learn more about that in the [LibreOffice Writer documentation][10].
|
||||
|
||||
If you want to create an EPUB instead of, or in addition to, a PDF, install the [Writer2EPUB][11] extension. Opensource.com's Bryan Behrenshausen [shares some useful instructions][12] for the extension.
|
||||
|
||||
### Final thoughts
|
||||
|
||||
The template we've created here is bare-bones, but you can use it for a simple book, or as the starting point for building a more complex template. Either way, this template will quickly get you started writing and publishing your e-book.
|
||||
|
||||
### About The Author
|
||||
Scott Nesbitt;I'M A Long-Time User Of Free Open Source Software;Write Various Things For Both Fun;Profit. I Don'T Take Myself Too Seriously;I Do All Of My Own Stunts. You Can Find Me At These Fine Establishments On The Web
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/creating-ebook-chapter-template-libreoffice-writer
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:/file/374456
|
||||
[2]:https://opensource.com/sites/default/files/images/life-uploads/lo-page-style.png (LibreOffice Page Style window)
|
||||
[3]:/file/374461
|
||||
[4]:https://opensource.com/sites/default/files/images/life-uploads/lo-paragraph-style.png (LibreOffice styles and formatting window)
|
||||
[5]:/file/374466
|
||||
[6]:https://opensource.com/sites/default/files/images/life-uploads/lo-styles-in-action.png (Example of LibreOffice styles)
|
||||
[7]:/file/374471
|
||||
[8]:https://opensource.com/sites/default/files/images/life-uploads/lo-template-list.png (Template list - LibreOffice Writer)
|
||||
[9]:https://help.libreoffice.org/Writer/Working_with_Master_Documents_and_Subdocuments
|
||||
[10]:https://help.libreoffice.org/Common/Export_as_PDF
|
||||
[11]:http://writer2epub.it/en/
|
||||
[12]:https://opensource.com/life/13/8/how-create-ebook-open-source-way
|
||||
@ -0,0 +1,43 @@
|
||||
3 Essential Questions to Ask at Your Next Tech Interview
|
||||
======
|
||||

|
||||
|
||||
The annual [Open Source Jobs Report][1] from Dice and The Linux Foundation reveals a lot about prospects for open source professionals and hiring activity in the year ahead. In this year's report, 86 percent of tech professionals said that knowing open source has advanced their careers. Yet what happens with all that experience when it comes time for advancing within their own organization or applying for a new roles elsewhere?
|
||||
|
||||
Interviewing for a new job is never easy. Aside from the complexities of juggling your current work while preparing for a new role, there's the added pressure of coming up with the necessary response when the interviewer asks "Do you have any questions for me?"
|
||||
|
||||
At Dice, we're in the business of careers, advice, and connecting tech professionals with employers. But we also hire tech talent at our organization to work on open source projects. In fact, the Dice platform is based on a number of Linux distributions and we leverage open source databases as the basis for our search functionality. In short, we couldn't run Dice without open source software, therefore it's vital that we hire professionals who understand, and love, open source.
|
||||
|
||||
Over the years, I've learned the importance of asking good questions during an interview. It's an opportunity to learn about your potential new employer, as well as better understand if they are a good match for your skills.
|
||||
|
||||
Here are three essential questions to ask and the reason they're important:
|
||||
|
||||
**1\. What is the company 's position on employees contributing to open source projects or writing code in their spare time?**
|
||||
|
||||
The answer to this question will tell you a lot about the company you're interviewing with. In general, companies will want tech pros who contribute to websites or projects as long as they don't conflict with the work you're doing at that firm. Allowing this outside the company also fosters an entrepreneurial spirt among the tech organization, and teaches tech skills that you may not otherwise get in the normal course of your day.
|
||||
|
||||
**2\. How are projects prioritized here?**
|
||||
|
||||
As all companies have become tech companies, there is often a division between innovative customer facing tech projects versus those that improve the platform itself. Will you be working on keeping the existing platform up to date? Or working on new products for the public? Depending on where your interests lie, the answer could determine if the company is a right fit for you.
|
||||
|
||||
**3\. Who primarily makes decisions on new products and how much input do developers have in the decision-making process?**
|
||||
|
||||
This question is one part understanding who is responsible for innovation at the company (and how close you'll be working with him/her) and one part discovering your career path at the firm. A good company will talk to its developers and open source talent ahead of developing new products. It seems like a no brainer, but it's a step that's sometimes missed and will mean the difference between a collaborative environment or chaotic process ahead of new product releases.
|
||||
|
||||
Interviewing can be stressful, however as 58 percent of companies tell Dice and The Linux Foundation that they need to hire open source talent in the months ahead, it's important to remember the heightened demand puts professionals like you in the driver's seat. Steer your career in the direction you desire.
|
||||
|
||||
[Download ][2] the full 2017 Open Source Jobs Report now.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/os-jobs/2017/12/3-essential-questions-ask-your-next-tech-interview
|
||||
|
||||
作者:[Brian Hostetter][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/brianhostetter
|
||||
[1]:https://www.linuxfoundation.org/blog/2017-jobs-report-highlights-demand-open-source-skills/
|
||||
[2]:http://bit.ly/2017OSSjobsreport
|
||||
@ -0,0 +1,109 @@
|
||||
GeckoLinux Brings Flexibility and Choice to openSUSE
|
||||
======
|
||||

|
||||
I've been a fan of SUSE and openSUSE for a long time. I've always wanted to call myself an openSUSE user, but things seemed to get in the way--mostly [Elementary OS][1]. But every time an openSUSE spin is released, I take notice. Most recently, I was made aware of [GeckoLinux][2]--a unique take (offering both Static and Rolling releases) that offers a few options that openSUSE does not. Consider this list of features:
|
||||
|
||||
* Live DVD / USB image
|
||||
|
||||
* Editions for the following desktops: Cinnamon, XFCE, GNOME, Plasma, Mate, Budgie, LXQt, Barebones
|
||||
|
||||
* Plenty of pre-installed open source desktop programs and proprietary media codecs
|
||||
|
||||
* Beautiful font rendering configured out of the box
|
||||
|
||||
* Advanced Power Management ([TLP][3]) pre-installed
|
||||
|
||||
* Large amount of software available in the preconfigured repositories (preferring packages from the Packman repo--when available)
|
||||
|
||||
* Based on openSUSE (with no repackaging or modification of packages)
|
||||
|
||||
* Desktop programs can be uninstalled, along with all of their dependencies (whereas openSUSE's patterns often cause uninstalled packages to be re-installed automatically)
|
||||
|
||||
* Does not force the installation of additional recommended packages, after initial installation (whereas openSUSE pre-installs patterns that automatically installs recommended package dependencies the first time the package manager is used)
|
||||
|
||||
|
||||
|
||||
|
||||
The choice of desktops alone makes for an intriguing proposition. Keeping a cleaner, lighter system is also something that would appeal to many users--especially in light of laptops running smaller, more efficient solid state drives.
|
||||
|
||||
Let's dig into GeckoLinux and see if it might be your next Linux distribution.
|
||||
|
||||
### Installation
|
||||
|
||||
I don't want to say too much about the installation--as installing Linux has become such a no-brainer these days. I will say that GeckoLinux has streamlined the process to an impressive level. The installation of GeckoLinux took about three minutes total (granted I am running it as a virtual machine on a beast of a host--so resources were not an issue). The difference between installing GeckoLinux and openSUSE Tumbleweed was significant. Whereas GeckoLinux installed in single digits, openSUSE took more 10 minutes to install. Relatively speaking, that's still not long. But we're picking at nits here, so that amount of time should be noted.
|
||||
|
||||
The only hiccup to the installation was the live distro asking for a password for the live user. The live username is linux and the password is, as you probably already guessed, linux. That same password is also the same used for admin tasks (such as running the installer).
|
||||
|
||||
You will also note, there are two icons on the desktop--one to install the OS and another to install language packs. Run the OS installer. Once the installation is complete--and you've booted into your desktop--you can then run the Language installer (if you need the Language packs--Figure 1).
|
||||
|
||||
|
||||
![GeckoLinux ][5]
|
||||
|
||||
Figure 1: Clearly, I chose the GNOME desktop for testing purposes.
|
||||
|
||||
[Used with permission][6]
|
||||
|
||||
After the Language installer finished, you can then remove the installer icon from the desktop by right-clicking it and selecting Move to Trash.
|
||||
|
||||
### Those fonts
|
||||
|
||||
The developer claims beautiful font rendering out of the box. In fact, the developer makes this very statement:
|
||||
|
||||
GeckoLinux comes preconfigured with what many would consider to be good font rendering, whereas many users find openSUSE's default font configuration to be less than desirable.
|
||||
|
||||
Take a glance at Figure 2. Here you see a side by side comparison of openSUSE (on the left) and GeckLinux (on the right). The difference is very subtle, but GeckoLinux does, in fact, best openSUSE out of the box. It's cleaner and easier to read. The developer claims are dead on. Although openSUSE does a very good job of rendering fonts out of the box, GeckoLinux improves on that enough to make a difference. In fact, I'd say it's some of the cleanest (out of the box) looking fonts I've seen on a Linux distribution.
|
||||
|
||||
|
||||
![openSUSE][8]
|
||||
|
||||
Figure 2: openSUSE on the left, GeckoLinux on the right.
|
||||
|
||||
[Used with permission][6]
|
||||
|
||||
I've worked with distributions that don't render fonts well. After hours of writing, those fonts tend to put a strain on my eyes. For anyone that spends a good amount of time staring at words, well-rendered fonts can make the difference between having eye strain or not. The openSUSE font rendering is just slightly blurrier than that of GeckoLinux. That matters.
|
||||
|
||||
### Installed applications
|
||||
|
||||
GeckoLinux does exactly what it claims--installs just what you need. After a complete installation (no post-install upgrading), GeckoLinux comes in at 1.5GB installed. On the other hand, openSUSE's post-install footprint is 4.3GB. In defense of openSUSE, it does install things like GNOME Games, Evolution, GIMP, and more--so much of that space is taken up with added software and dependencies. But if you're looking for a lighter weight take on openSUSE, GeckoLinux is your OS.
|
||||
|
||||
GeckoLinux does come pre-installed with a couple of nice additions--namely the [Clementine][9] Audio player (a favorite of mine), [Thunderbird][10] (instead of Evolution), PulseAudio Volume Control (a must for audio power users), Qt Configuration, GParted, [Pidgen][11], and [VLC][12].
|
||||
|
||||
If you're a developer, you won't find much in the way of development tools on GeckoLinux. But that's no different than openSUSE (even the make command is missing on both). Naturally, all the developer tools you need (to work on Linux) are available to install (either from the command line or from with YaST2).
|
||||
|
||||
### Performance
|
||||
|
||||
Between openSUSE and GeckoLinux, there is very little noticeable difference in performance. Opening Firefox on both resulted in maybe a second or two variation (in favor of GeckoLinux). It should be noted, however, that the installed Firefox on both was quite out of date (52 on GeckoLinux and 53 on openSUSE). Even after a full upgrade on both platforms, Firefox was still listed at release 52 on GeckoLinux, whereas openSUSE did pick up Firefox 57. After downloading the [Firefox Quantum][13] package on GeckoLinux, the application opened immediately--completely blowing away both out of the box experiences on openSUSE and GeckLinux. So the first thing you will want to do is get Firefox upgraded to 57.
|
||||
|
||||
If you're hoping for a significant performance increase over openSUSE, look elsewhere. If you're accustomed to the performance of openSUSE (it not being the sprightliest of platforms), you'll feel right at home with GeckoLinux.
|
||||
|
||||
### The conclusion
|
||||
|
||||
If you're looking for an excuse to venture back into the realm of openSUSE, GeckoLinux might be a good reason. It's slightly better looking, lighter weight, and with similar performance. It's not perfect and, chances are, it won't steal you away from your distribution of choice, but GeckoLinux is a solid entry in the realm of Linux desktops.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][14]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/12/geckolinux-brings-flexibility-and-choice-opensuse
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://elementary.io/
|
||||
[2]:https://geckolinux.github.io/
|
||||
[3]:https://github.com/linrunner/TLP
|
||||
[4]:/files/images/gecko1jpg
|
||||
[5]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gecko_1.jpg?itok=qTvEsSQ1 (GeckoLinux)
|
||||
[6]:/licenses/category/used-permission
|
||||
[7]:/files/images/gecko2jpg
|
||||
[8]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gecko_2.jpg?itok=AKv0x7_J (openSUSE)
|
||||
[9]:https://www.clementine-player.org/
|
||||
[10]:https://www.mozilla.org/en-US/thunderbird/
|
||||
[11]:https://www.pidgin.im/
|
||||
[12]:https://www.videolan.org/vlc/index.html
|
||||
[13]:https://www.mozilla.org/en-US/firefox/
|
||||
[14]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,7 +1,5 @@
|
||||
A tour of containerd 1.0
|
||||
======
|
||||
XiaochenCui translating
|
||||
|
||||
![containerd][1]
|
||||
|
||||
We have done a few talks in the past on different features of containerd, how it was designed, and some of the problems that we have fixed along the way. Containerd is used by Docker, Kubernetes CRI, and a few other projects but this is a post for people who may not know what containerd actually does within these platforms. I would like to do more posts on the feature set and design of containerd in the future but for now, we will start with the basics.
|
||||
|
||||
@ -0,0 +1,114 @@
|
||||
Create a free Apache SSL certificate with Let’s Encrypt on CentOS & RHEL
|
||||
======
|
||||
Let's Encrypt is a free, automated & open certificate authority that is supported by ISRG, Internet Security Research Group. Let's encrypt provides X.509 certificates for TLS (Transport Layer Security) encryption via automated process which includes creation, validation, signing, installation, and renewal of certificates for secure websites.
|
||||
|
||||
In this tutorial, we are going to discuss how to create an apache SSL certificate with Let's Encrypt certificate on Centos/RHEL 6 & 7\. To automate the Let's encrypt process, we will use Let's encrypt recommended ACME client i.e. CERTBOT, there are other ACME Clients as well but we will be using Certbot only.
|
||||
|
||||
Certbot can automate certificate issuance and installation with no downtime, it automatically enables HTTPS on your website. It also has expert modes for people who don't want auto-configuration. It's easy to use, works on many operating systems, and has great documentation.
|
||||
|
||||
**(Recommended Read:[Complete guide for Apache TOMCAT installation on Linux][1])**
|
||||
|
||||
Let's start with Pre-requisites for creating an Apache SSL certificate with Let's Encrypt on CentOS, RHEL 6 &7…..
|
||||
|
||||
|
||||
## Pre-requisites
|
||||
|
||||
**1-** Obviously we will need Apache server to installed on our machine. We can install it with the following command,
|
||||
|
||||
**# yum install httpd**
|
||||
|
||||
For detailed Apache installation procedure, refer to our article[ **Step by Step guide to configure APACHE server.**][2]
|
||||
|
||||
**2-** Mod_ssl should also be installed on the systems. Install it using the following command,
|
||||
|
||||
**# yum install mod_ssl**
|
||||
|
||||
**3-** Epel Repositories should be installed & enables. EPEL repositories are required as not all the dependencies can be resolved with default repos, hence EPEL repos are also required. Install them using the following command,
|
||||
|
||||
**RHEL/CentOS 7**
|
||||
|
||||
**# rpm -Uvh https://dl.fedoraproject.org/pub/epel/7/x86_64/packages/e/epel-release-7-11.noarch.rpm**
|
||||
|
||||
**RHEL/CentOS 6 (64 Bit)**
|
||||
|
||||
**# rpm -Uvh http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm**
|
||||
|
||||
**RHEL/CentOS 6 (32 Bit)**
|
||||
|
||||
**# rpm -Uvh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm**
|
||||
|
||||
Now let's start with procedure to install Let's Encrypt on CentOS /RHEL 7.
|
||||
|
||||
## Let's encrypt on CentOS RHEL 7
|
||||
|
||||
Installation on CentOS 7 can easily performed with yum, with the following command,
|
||||
|
||||
**$ yum install certbot-apache**
|
||||
|
||||
Once installed, we can now create the SSL certificate with following command,
|
||||
|
||||
**$ certbot -apache**
|
||||
|
||||
Now just follow the on screen instructions to generate the certificate. During the setup, you will also be asked to enforce the HTTPS or to use HTTP , select either of the one you like. But if you enforce HTTPS, than all the changes required to use HTTPS will made by certbot setup otherwise we will have to make changes on our own.
|
||||
|
||||
We can also generate certificate for multiple websites with single command,
|
||||
|
||||
**$ certbot -apache -d example.com -d test.com**
|
||||
|
||||
We can also opt to create certificate only, without automatically making any changes to any configuration files, with the following command,
|
||||
|
||||
**$ certbot -apache certonly**
|
||||
|
||||
Certbot issues SSL certificates hae 90 days validity, so we need to renew the certificates before that period is over. Ideal time to renew the certificate would be around 60 days. Run the following command, to renew the certifcate,
|
||||
|
||||
**$ certbot renew**
|
||||
|
||||
We can also automate the renewal process with a crontab job. Open the crontab & create a job,
|
||||
|
||||
**$ crontab -e**
|
||||
|
||||
**0 0 1 * comic core.md Dict.md lctt2014.md lctt2016.md LCTT翻译规范.md LICENSE Makefile published README.md sign.md sources translated 选题模板.txt 中文排版指北.md /usr/bin/certbot renew >> /var/log/letsencrypt.log**
|
||||
|
||||
This job will renew you certificate 1st of every month at 12 AM.
|
||||
|
||||
## Let's Encrypt on CentOS 6
|
||||
|
||||
For using Let's encrypt on Centos 6, there are no cerbot packages for CentOS 6 but that does not mean we can't make use of let's encrypt on CentOS/RHEL 6, instead we can use the certbot script for creating/renewing the certificates. Install the script with the following command,
|
||||
|
||||
**# wget https://dl.eff.org/certbot-auto**
|
||||
|
||||
**# chmod a+x certbot-auto**
|
||||
|
||||
Now we can use it similarly as we used commands for CentOS 7 but instead of certbot, we will use script. To create new certificate,
|
||||
|
||||
**# sh path/certbot-auto -apache -d example.com**
|
||||
|
||||
To create only cert, use
|
||||
|
||||
**# sh path/certbot-auto -apache certonly**
|
||||
|
||||
To renew cert, use
|
||||
|
||||
**# sh path/certbot-auto renew**
|
||||
|
||||
For creating a cron job, use
|
||||
|
||||
**# crontab -e**
|
||||
|
||||
**0 0 1 * comic core.md Dict.md lctt2014.md lctt2016.md LCTT翻译规范.md LICENSE Makefile published README.md sign.md sources translated 选题模板.txt 中文排版指北.md sh path/certbot-auto renew >> /var/log/letsencrypt.log**
|
||||
|
||||
This was our tutorial on how to install and use let's encrypt on CentOS , RHEL 6 & 7 for creating a free SSL certificate for Apache servers. Please do leave your questions or queries down below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/create-free-apache-ssl-certificate-lets-encrypt-on-centos-rhel/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/complete-guide-apache-tomcat-installation-linux/
|
||||
[2]:http://linuxtechlab.com/beginner-guide-configure-apache/
|
||||
@ -0,0 +1,179 @@
|
||||
How To Count The Number Of Files And Folders/Directories In Linux
|
||||
======
|
||||
Hi folks, today again we came with set of tricky commands that help you in many ways. It's kind of manipulation commands which help you to count files and directories in the current directory, recursive count, list of files created by particular user, etc,.
|
||||
|
||||
In this tutorial, we are going to show you, how to use more than one command like, all together to perform some advanced actions using ls, egrep, wc and find command. The below set of commands which helps you in many ways.
|
||||
|
||||
To experiment this, i'm going to create totally 7 files and 2 folders (5 regular files & 2 hidden files). See the below tree command output which clearly shows the files and folder lists.
|
||||
|
||||
**Suggested Read :** [File Manipulation Commands][1]
|
||||
```
|
||||
# tree -a /opt
|
||||
/opt
|
||||
├── magi
|
||||
│ └── 2g
|
||||
│ ├── test5.txt
|
||||
│ └── .test6.txt
|
||||
├── test1.txt
|
||||
├── test2.txt
|
||||
├── test3.txt
|
||||
├── .test4.txt
|
||||
└── test.txt
|
||||
|
||||
2 directories, 7 files
|
||||
|
||||
```
|
||||
|
||||
**Example-1 :** To count current directory files (excluded hidden files). Run the following command to determine how many files there are in the current directory and it doesn't count dotfiles.
|
||||
```
|
||||
# ls -l . | egrep -c '^-'
|
||||
4
|
||||
|
||||
```
|
||||
|
||||
**Details :**
|
||||
|
||||
* `ls` : list directory contents
|
||||
* `-l` : Use a long listing format
|
||||
* `.` : List information about the FILEs (the current directory by default).
|
||||
* `|` : control operator that send the output of one program to another program for further processing.
|
||||
* `egrep` : print lines matching a pattern
|
||||
* `-c` : General Output Control
|
||||
* `'^-'` : This respectively match the empty string at the beginning and end of a line.
|
||||
|
||||
|
||||
|
||||
**Example-2 :** To count current directory files which includes hidden files. This will include dotfiles as well in the current directory.
|
||||
```
|
||||
# ls -la . | egrep -c '^-'
|
||||
5
|
||||
|
||||
```
|
||||
|
||||
**Example-3 :** Run the following command to count current directory files & folders. It will count all together at once.
|
||||
```
|
||||
# ls -1 | wc -l
|
||||
5
|
||||
|
||||
```
|
||||
|
||||
**Details :**
|
||||
|
||||
* `ls` : list directory contents
|
||||
* `-l` : Use a long listing format
|
||||
* `|` : control operator that send the output of one program to another program for further processing.
|
||||
* `wc` : It's a command to print newline, word, and byte counts for each file
|
||||
* `-l` : print the newline counts
|
||||
|
||||
|
||||
|
||||
**Example-4 :** To count current directory files & folders which includes hidden files & directory.
|
||||
```
|
||||
# ls -1a | wc -l
|
||||
8
|
||||
|
||||
```
|
||||
|
||||
**Example-5 :** To count current directory files recursively which includes hidden files.
|
||||
```
|
||||
# find . -type f | wc -l
|
||||
7
|
||||
|
||||
```
|
||||
|
||||
**Details :**
|
||||
|
||||
* `find` : search for files in a directory hierarchy
|
||||
* `-type` : File is of type
|
||||
* `f` : regular file
|
||||
* `wc` : It's a command to print newline, word, and byte counts for each file
|
||||
* `-l` : print the newline counts
|
||||
|
||||
|
||||
|
||||
**Example-6 :** To print directories & files count using tree command (excluded hidden files).
|
||||
```
|
||||
# tree | tail -1
|
||||
2 directories, 5 files
|
||||
|
||||
```
|
||||
|
||||
**Example-7 :** To print directories & files count using tree command which includes hidden files.
|
||||
```
|
||||
# tree -a | tail -1
|
||||
2 directories, 7 files
|
||||
|
||||
```
|
||||
|
||||
**Example-8 :** Run the below command to count directory recursively which includes hidden directory.
|
||||
```
|
||||
# find . -type d | wc -l
|
||||
3
|
||||
|
||||
```
|
||||
|
||||
**Example-9 :** To count the number of files based on file extension. Here we are going to count `.txt` files.
|
||||
```
|
||||
# find . -name "*.txt" | wc -l
|
||||
7
|
||||
|
||||
```
|
||||
|
||||
**Example-10 :** Count all files in the current directory by using the echo command in combination with the wc command. `4` indicates the amount of files in the current directory.
|
||||
```
|
||||
# echo core.md Dict.md lctt2014.md lctt2016.md LCTT翻译规范.md README.md sign.md 选题模板.txt 中文排版指北.md | wc
|
||||
1 4 39
|
||||
|
||||
```
|
||||
|
||||
**Example-11 :** Count all directories in the current directory by using the echo command in combination with the wc command. `1` indicates the amount of directories in the current directory.
|
||||
```
|
||||
# echo comic/ published/ sources/ translated/ | wc
|
||||
1 1 6
|
||||
|
||||
```
|
||||
|
||||
**Example-12 :** Count all files and directories in the current directory by using the echo command in combination with the wc command. `5` indicates the amount of directories and files in the current directory.
|
||||
```
|
||||
# echo * | wc
|
||||
1 5 44
|
||||
|
||||
```
|
||||
|
||||
**Example-13 :** To count number of files in the system (Entire system)
|
||||
```
|
||||
# find / -type f | wc -l
|
||||
69769
|
||||
|
||||
```
|
||||
|
||||
**Example-14 :** To count number of folders in the system (Entire system)
|
||||
```
|
||||
# find / -type d | wc -l
|
||||
8819
|
||||
|
||||
```
|
||||
|
||||
**Example-15 :** Run the following command to count number of files, folders, hardlinks, and symlinks in the system (Entire system)
|
||||
```
|
||||
# find / -type d -exec echo dirs \; -o -type l -exec echo symlinks \; -o -type f -links +1 -exec echo hardlinks \; -o -type f -exec echo files \; | sort | uniq -c
|
||||
8779 dirs
|
||||
69343 files
|
||||
20 hardlinks
|
||||
11646 symlinks
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-count-the-number-of-files-and-folders-directories-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
[1]:https://www.2daygeek.com/empty-a-file-delete-contents-lines-from-a-file-remove-matching-string-from-a-file-remove-empty-blank-lines-from-a-file/
|
||||
253
sources/tech/20171212 Oh My Fish- Make Your Shell Beautiful.md
Normal file
253
sources/tech/20171212 Oh My Fish- Make Your Shell Beautiful.md
Normal file
@ -0,0 +1,253 @@
|
||||
Oh My Fish! Make Your Shell Beautiful
|
||||
======
|
||||

|
||||
|
||||
A few days ago, we discussed how to [**install** **Fish shell**][1], a robust, fully-usable shell that ships with many cool features out of the box such as autosuggestions, built-in search functionality, syntax highlighting, web based configuration and a lot more. Today, we are going to discuss how to make our Fish shell beautiful and elegant using **Oh My Fish** (shortly **omf** ). It is a Fishshell framework that allows you to install packages which extend or modify the look and feel of your shell. It is easy to use, fast and extensible. Using omf, you can easily install themes that enriches the look of your shell and install plugins to tweak your fish shell as per your wish.
|
||||
|
||||
#### Install Oh My Fish
|
||||
|
||||
Installing omf is not a big deal. All you have to do is just run the following command in your fish shell.
|
||||
```
|
||||
curl -L https://get.oh-my.fish | fish
|
||||
```
|
||||
|
||||
[![][2]][3]
|
||||
|
||||
Once the installation has completed, you will see the the prompt has automatically changed as shown in the above picture. Also, you will notice that the current time on the right of the shell window.
|
||||
|
||||
That's it. Let us go ahead and tweak our fish shell.
|
||||
|
||||
#### Now, Let Us Make Our Fish Shell Beautiful
|
||||
|
||||
To list all installed packages, run:
|
||||
```
|
||||
omf list
|
||||
```
|
||||
|
||||
This command will display both the installed themes and plugins. Please note that a package can be either a theme or plugin. Installing packages means installing themes or plugins.
|
||||
|
||||
All official and community supported packages (both plugins and themes) are hosted in the [**main Omf repository**][4]. In this repository, you can see a whole bunch of repositories that contains a lot of plugins and themes.
|
||||
|
||||
Now let us see the list of available and installed themes. To do so, run:
|
||||
```
|
||||
omf theme
|
||||
```
|
||||
|
||||
[![][2]][5]
|
||||
|
||||
As you can see, we have only one installed theme, which is default, and a whole bunch of available themes. You can preview all available themes [**here**][6] before installing it. This page contains all theme details, features, a sample screenshot of each theme and which theme is suitable for whom.
|
||||
|
||||
**Installing a new theme**
|
||||
|
||||
Allow me to install a theme, for example **clearance theme - **a minimalist fish shell theme for people who use git a lot. To do so, run:
|
||||
```
|
||||
omf install clearance
|
||||
```
|
||||
|
||||
[![][2]][7]
|
||||
|
||||
As you see in the above picture, the look of fish prompt has changed immediately after installing the new theme.
|
||||
|
||||
Let me browse through the file system and see how it looks like.
|
||||
|
||||
[![][2]][8]
|
||||
|
||||
Not bad! It is really simple theme. It distinguishes the current working directory, folders and files with different color. As you may notice, it also displays the current working directory on top of the prompt. Currently, **clearance** is my default theme.
|
||||
|
||||
**Changing theme**
|
||||
|
||||
Like I already said, the theme will be applied immediately after installing it. If you have more than one themes, you can switch to a different theme using the following command:
|
||||
```
|
||||
omf theme <theme-name>
|
||||
```
|
||||
|
||||
Example:
|
||||
```
|
||||
omf theme agnoster
|
||||
```
|
||||
|
||||
Now I am using "agnoster" theme. Here is how agnoster theme changed the look of my shell.
|
||||
|
||||
[![][2]][9]
|
||||
|
||||
**Installing Plugins**
|
||||
|
||||
For instance, I am going to install weather plugin. To do so, just run:
|
||||
```
|
||||
omf install weather
|
||||
```
|
||||
|
||||
The weather plugin depends on [jq][10]. So, you might need to install jq as well. It is mostly available in the default repositories of any Linux distro. So, you can install it using the default package manager. For example, the following command will install jq in Arch Linux and its variants.
|
||||
```
|
||||
sudo pacman -S jq
|
||||
```
|
||||
|
||||
Now, check your weather from your fish shell using command:
|
||||
```
|
||||
weather
|
||||
```
|
||||
|
||||
[![][2]][11]
|
||||
|
||||
**Searching packages**
|
||||
|
||||
To search for a theme or plugin, do:
|
||||
```
|
||||
omf search <search_string>
|
||||
```
|
||||
|
||||
Example:
|
||||
```
|
||||
omf search nvm
|
||||
```
|
||||
|
||||
To limit the search to themes, use **-t** flag.
|
||||
```
|
||||
omf search -t chain
|
||||
```
|
||||
|
||||
This command will only search for themes that contains the string "chain".
|
||||
|
||||
To limit the search to plugins, use **-p** flag.
|
||||
```
|
||||
omf search -p emacs
|
||||
```
|
||||
|
||||
**Updating packages**
|
||||
|
||||
To update only the core (omf itself), run:
|
||||
```
|
||||
omf update omf
|
||||
```
|
||||
|
||||
If it is up-to-date, you would see the following output:
|
||||
```
|
||||
Oh My Fish is up to date.
|
||||
You are now using Oh My Fish version 6.
|
||||
Updating https://github.com/oh-my-fish/packages-main master... Done!
|
||||
```
|
||||
|
||||
To update all packages:
|
||||
```
|
||||
omf update
|
||||
```
|
||||
|
||||
To selectively update packages, just include the packages names as shown below.
|
||||
```
|
||||
omf update clearance agnoster
|
||||
```
|
||||
|
||||
**Displaying information about a package**
|
||||
|
||||
When you want to know the information about a theme or plugin, use this command:
|
||||
```
|
||||
omf describe clearance
|
||||
```
|
||||
|
||||
This command will show the information about a package.
|
||||
```
|
||||
Package: clearance
|
||||
Description: A minimalist fish shell theme for people who use git
|
||||
Repository: https://github.com/oh-my-fish/theme-clearance
|
||||
Maintainer:
|
||||
```
|
||||
|
||||
**Removing packages**
|
||||
|
||||
To remove a package, for example emacs, run:
|
||||
```
|
||||
omf remove emacs
|
||||
```
|
||||
|
||||
**Managing Repositories**
|
||||
|
||||
By default, the official repository is added automatically when you install Oh My Fish. This repository contains all packages built by the developers. To manage user-installed package repositories, use this command:
|
||||
```
|
||||
omf repositories [list|add|remove]
|
||||
```
|
||||
|
||||
To list installed repositories, run:
|
||||
```
|
||||
omf repositories list
|
||||
```
|
||||
|
||||
To add a repository:
|
||||
```
|
||||
omf repositories add <URL>
|
||||
```
|
||||
|
||||
Example:
|
||||
```
|
||||
omf repositories add https://github.com/ostechnix/theme-sk
|
||||
```
|
||||
|
||||
To remove a repository:
|
||||
```
|
||||
omf repositories remove <repository-name>
|
||||
```
|
||||
|
||||
**Troubleshooting Oh My Fish**
|
||||
|
||||
Omf is smart enough to help you if things went wrong. It will list what to do to fix an issue. For example, I removed and installed clearance package and got file conflicting error. Luckily, Oh My Fish instructed me what to do before continuing. So, I simply ran the following to know how to fix the error:
|
||||
```
|
||||
omf doctor
|
||||
```
|
||||
|
||||
And fixed the issued the error by running the following command:
|
||||
```
|
||||
rm ~/.config/fish/functions/fish_prompt.fish
|
||||
```
|
||||
|
||||
[![][2]][12]
|
||||
|
||||
Whenever you ran into a problem, just run 'omf doctor' command and try all suggested workarounds.
|
||||
|
||||
**Getting help**
|
||||
|
||||
To display help section, run:
|
||||
```
|
||||
omf -h
|
||||
```
|
||||
|
||||
Or,
|
||||
```
|
||||
omf --help
|
||||
```
|
||||
|
||||
**Uninstalling Oh My Fish**
|
||||
|
||||
To uninstall Oh My Fish, run this command:
|
||||
```
|
||||
omf destroy
|
||||
```
|
||||
|
||||
Go ahead and start customizing your fish shell. For more details, refer the project's GitHub page.
|
||||
|
||||
That's all for now folks. I will be soon here with another interesting guide. Until then, stay tuned with OSTechNix!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://www.ostechnix.com/oh-fish-make-shell-beautiful/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/install-fish-friendly-interactive-shell-linux/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/12/Oh-My-Fish-1-1.png ()
|
||||
[4]:https://github.com/oh-my-fish
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/12/Oh-My-Fish-5.png ()
|
||||
[6]:https://github.com/oh-my-fish/oh-my-fish/blob/master/docs/Themes.md
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/12/Oh-My-Fish-3.png ()
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2017/12/Oh-My-Fish-4.png ()
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2017/12/Oh-My-Fish-6.png ()
|
||||
[10]:https://stedolan.github.io/jq/
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2017/12/Oh-My-Fish-7.png ()
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2017/12/Oh-My-Fish-8.png ()
|
||||
109
sources/tech/20171214 IPv6 Auto-Configuration in Linux.md
Normal file
109
sources/tech/20171214 IPv6 Auto-Configuration in Linux.md
Normal file
@ -0,0 +1,109 @@
|
||||
IPv6 Auto-Configuration in Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
In [Testing IPv6 Networking in KVM: Part 1][1], we learned about unique local addresses (ULAs). In this article, we will learn how to set up automatic IP address configuration for ULAs.
|
||||
|
||||
### When to Use Unique Local Addresses
|
||||
|
||||
Unique local addresses use the fd00::/8 address block, and are similar to our old friends the IPv4 private address classes: 10.0.0.0/8, 172.16.0.0/12, and 192.168.0.0/16. But they are not intended as a direct replacement. IPv4 private address classes and network address translation (NAT) were created to alleviate the shortage of IPv4 addresses, a clever hack that prolonged the life of IPv4 for years after it should have been replaced. IPv6 supports NAT, but I can't think of a good reason to use it. IPv6 isn't just bigger IPv4; it is different and needs different thinking.
|
||||
|
||||
So what's the point of ULAs, especially when we have link-local addresses (fe80::/10) and don't even need to configure them? There are two important differences. One, link-local addresses are not routable, so you can't cross subnets. Two, you control ULAs; choose your own addresses, make subnets, and they are routable.
|
||||
|
||||
Another benefit of ULAs is you don't need an allocation of global unicast IPv6 addresses just for mucking around on your LAN. If you have an allocation from a service provider then you don't need ULAs. You can mix global unicast addresses and ULAs on the same network, but I can't think of a good reason to have both, and for darned sure you don't want to use network address translation (NAT) to make ULAs publicly accessible. That, in my peerless opinion, is daft.
|
||||
|
||||
ULAs are for private networks only and should be blocked from leaving your network, and not allowed to roam the Internet. Which should be simple, just block the whole fd00::/8 range on your border devices.
|
||||
|
||||
### Address Auto-Configuration
|
||||
|
||||
ULAs are not automatic like link-local addresses, but setting up auto-configuration is easy as pie with radvd, the router advertisement daemon. Before you change anything, run `ifconfig` or `ip addr show` to see your existing IP addresses.
|
||||
|
||||
You should install radvd on a dedicated router for production use, but for testing you can install it on any Linux PC on your network. In my little KVM test lab, I installed it on Ubuntu, `apt-get install radvd`. It should not start after installation, because there is no configuration file:
|
||||
```
|
||||
$ sudo systemctl status radvd
|
||||
● radvd.service - LSB: Router Advertising Daemon
|
||||
Loaded: loaded (/etc/init.d/radvd; bad; vendor preset: enabled)
|
||||
Active: active (exited) since Mon 2017-12-11 20:08:25 PST; 4min 59s ago
|
||||
Docs: man:systemd-sysv-generator(8)
|
||||
|
||||
Dec 11 20:08:25 ubunut1 systemd[1]: Starting LSB: Router Advertising Daemon...
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: Starting radvd:
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: * /etc/radvd.conf does not exist or is empty.
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: * See /usr/share/doc/radvd/README.Debian
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: * radvd will *not* be started.
|
||||
Dec 11 20:08:25 ubunut1 systemd[1]: Started LSB: Router Advertising Daemon.
|
||||
|
||||
```
|
||||
|
||||
It's a little confusing with all the start and not started messages, but radvd is not running, which you can verify with good old `ps|grep radvd`. So we need to create `/etc/radvd.conf`. Copy this example, replacing the network interface name on the first line with your interface name:
|
||||
```
|
||||
interface ens7 {
|
||||
AdvSendAdvert on;
|
||||
MinRtrAdvInterval 3;
|
||||
MaxRtrAdvInterval 10;
|
||||
prefix fd7d:844d:3e17:f3ae::/64
|
||||
{
|
||||
AdvOnLink on;
|
||||
AdvAutonomous on;
|
||||
};
|
||||
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
The prefix defines your network address, which is the first 64 bits of the address. The first two characters must be `fd`, then you define the remainder of the prefix, and leave the last 64 bits empty as radvd will assign the last 64 bits. The next 16 bits after the prefix define the subnet, and the remaining bits define the host address. Your subnet size must always be /64. RFC 4193 requires that addresses be randomly generated; see [Testing IPv6 Networking in KVM: Part 1][1] for more information on creating and managing ULAs.
|
||||
|
||||
### IPv6 Forwarding
|
||||
|
||||
IPv6 forwarding must be enabled. This command enables it until restart:
|
||||
```
|
||||
$ sudo sysctl -w net.ipv6.conf.all.forwarding=1
|
||||
|
||||
```
|
||||
|
||||
Uncomment or add this line to `/etc/sysctl.conf` to make it permanent:
|
||||
```
|
||||
net.ipv6.conf.all.forwarding = 1
|
||||
```
|
||||
|
||||
Start the radvd daemon:
|
||||
```
|
||||
$ sudo systemctl stop radvd
|
||||
$ sudo systemctl start radvd
|
||||
|
||||
```
|
||||
|
||||
This example reflects a quirk I ran into on my Ubuntu test system; I always have to stop radvd, no matter what state it is in, and then start it to apply any changes.
|
||||
|
||||
You won't see any output on a successful start, and often not on a failure either, so run `sudo systemctl radvd status`. If there are errors, systemctl will tell you. The most common errors are syntax errors in `/etc/radvd.conf`.
|
||||
|
||||
A cool thing I learned after complaining on Twitter: when you run ` journalctl -xe --no-pager` to debug systemctl errors, your output lines will wrap, and then you can actually read your error messages.
|
||||
|
||||
Now check your hosts to see their new auto-assigned addresses:
|
||||
```
|
||||
$ ifconfig
|
||||
ens7 Link encap:Ethernet HWaddr 52:54:00:57:71:50
|
||||
[...]
|
||||
inet6 addr: fd7d:844d:3e17:f3ae:9808:98d5:bea9:14d9/64 Scope:Global
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
And there it is! Come back next week to learn how to manage DNS for ULAs, so you can use proper hostnames instead of those giant IPv6 addresses.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][2]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/12/ipv6-auto-configuration-linux
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/intro-to-linux/2017/11/testing-ipv6-networking-kvm-part-1
|
||||
[2]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
290
sources/tech/20171214 The Best Linux Apps - Distros of 2017.md
Normal file
290
sources/tech/20171214 The Best Linux Apps - Distros of 2017.md
Normal file
@ -0,0 +1,290 @@
|
||||
The Best Linux Apps & Distros of 2017
|
||||
======
|
||||
[![best linux distros 2017][1]][2]
|
||||
|
||||
**In this post we look back at the best Linux distro and app releases that helped define 2017.**
|
||||
|
||||
'2017 was a fantastic year for Ubuntu and for Linux in general. I can't wait to see what comes next'
|
||||
|
||||
And boy were there a lot of 'em!
|
||||
|
||||
So join us (ideally with from a warm glass of something non-offensive and sweet) as we take a tart look backwards through some key releases from the past 12 months.
|
||||
|
||||
This list is not presented in any sort of order, and all of the entries were sourced from **YOUR** feedback to the survey we shared earlier in the week. If your favourite release didn 't make the list, it's because not enough people voted for it!
|
||||
|
||||
Regardless of your opinions on the apps and Linux distros that are highlighted I'm sure you'll agree that 2017 was a great year for Linux as a platform and for Linux users.
|
||||
|
||||
But enough waffle: on we go!
|
||||
|
||||
## Distros
|
||||
|
||||
### 1\. Ubuntu 17.10 'Artful Aardvark'
|
||||
|
||||
[![Ubuntu 17.10 desktop screenshot][3]][4]
|
||||
|
||||
There's no doubt about it: Ubuntu 17.10 was the year's **biggest** Linux release -- by a clear margin.
|
||||
|
||||
'Ubuntu 17.10 was the year's biggest Linux distro release'
|
||||
|
||||
Canonical [dropped a bombshell in April][5] when it announced it was abandoning its home-grown Unity desktop and jettisoning its (poorly received) mobile ambitions. Most of us were shocked, and few would've been surprised had the distro maker opted to take some time out to figure out what it went next.
|
||||
|
||||
But that …That's just not the Ubuntu way.
|
||||
|
||||
Canonical dived right into developing Ubuntu 17.10 'Artful Aardvark', healing some long held divisions in the process.
|
||||
|
||||
Part reset, part gamble; the Artful Aardvark had the arduous task of replacing the bespoke (patched, forked) Unity desktop with upstream GNOME Shell. It also [opted to make the switch][6] to the new-fangled [Wayland display server protocol][7] by default, too.
|
||||
|
||||
Amazingly, thanks a mix of grit and goodwill, it succeeded. The [Ubuntu 17.10 release][8] emerged on time on October 19, 2017 where it was greeted by warm reviews and a sense of relief!
|
||||
|
||||
The recurring theme among the [Ubuntu 17.10 reviews][9] was the Artful Aardvark was a real **return to form** for the distro. It got people excited about Ubuntu for the first time in a long time.
|
||||
|
||||
And with an long-term support release next up, long may the enthusiasm for it continue!
|
||||
|
||||
### 2\. Solus 3
|
||||
|
||||
[![][10]][11]
|
||||
|
||||
We knew 2017 was going to be a big year for the Solus Linux distro, which is why it made our list of [Linux distros we were most excited for][12] this year.
|
||||
|
||||
'Solus is fast becoming the Linux aficionados' main alternative to Arch'
|
||||
|
||||
Solus is unique distro in that it's not based on another. It uses its home grown Budgie desktop by default, has its own package manager (eopkg) and update procedure, and sets its own criteria for app curation. Solus also backs Canonical's Flatpak rival Snappy.
|
||||
|
||||
The [release of Solus 3][13] in the summer was a particular highlight for this upstart distro. The update packs in improvements across the board, touching on everything from kernel security through to multimedia upgrades.
|
||||
|
||||
Solus 3 also arrived with [Budgie 10.4][14]. A massive upgrade to this GTK-based desktop environment, Budgie 10.4 brings (among other things) greater customisation, a new Settings app, multiple new panel options, applets and transparency, and an improved Raven sidebar.
|
||||
|
||||
Fast becoming the Linux aficionados' main alternative to Arch Linux, Solus is a Linux distro that's going places.
|
||||
|
||||
If you like the look of Budgie you can use it on Ubuntu without damaging your existing desktop. See our [how to install Budgie 10.4 on Ubuntu][14] article for all the necessary details.
|
||||
|
||||
If you get bored over the holidays I highly recommended you [download the Solus MATE edition][15] too. It combines the strength of Solus with the meticulously maintained MATE desktop, a combination that works incredibly well together.
|
||||
|
||||
### 3\. Fedora 27
|
||||
|
||||
[![][16]][17]
|
||||
|
||||
We're not oblivious to what happens beyond the orange bubble and the release of [Fedora 27 Workstation][18] marked another fine update from the folks who like to wear red hats.
|
||||
|
||||
Fedora 27 features GNOME 3.26 (and all the niceties that brings, like color emoji support, folder sharing in Boxes, and so on), ships with LibreOffice 5.4, and "simplifies container storage, delivers containerized services by default" using RedHat's use no-cost RHEL Developer subscriptions.
|
||||
|
||||
[Redhat Press Release for Fedora 27][19]
|
||||
|
||||
## Apps
|
||||
|
||||
### 4\. Firefox 57 (aka 'Firefox Quantum').
|
||||
|
||||
[![firefox quantum on ubuntu][20]][21]
|
||||
|
||||
Ubuntu wasn't the only open-source project to undergo something of 'renewal' this year.
|
||||
|
||||
'Like Ubuntu, Firefox finally got its mojo back this year'
|
||||
|
||||
After years of slow decline and feature creep Mozilla finally did something about Firefox Google Chrome.
|
||||
|
||||
Firefox 57 is such a big release that it even has its own name: Firefox Quantum. And the release truly is a quantum leap in performance and responsiveness. The browser is now speedier than Chrome, makes intelligent use of multi-threaded processes, and has a sleek new look that feels right.
|
||||
|
||||
Like Ubuntu, Firefox has got its mojo back.
|
||||
|
||||
Firefox will roll out support for client side decoration on the GNOME desktop (a feature already available in the latest nightly builds) sometime in 2018. This feature, along with further refinements to the finely-tuned under-the-hood mechanics, will add more icing atop an already fantastic base!
|
||||
|
||||
### 5\. Ubuntu for Windows
|
||||
|
||||
[![][22]][23]
|
||||
|
||||
Yes, I know: it's a little bit odd to list a Windows release in a run-down of Linux releases -- but there is a logic to it!
|
||||
|
||||
Ubuntu on the Windows Store is an admission writ large that Linux is an integral part of the modern software development
|
||||
|
||||
The arrival of [Ubuntu on the Windows Store][24] (along with other Linux distributions) in July was a pretty bizarre sight to see.
|
||||
|
||||
Few could've imagined Microsoft would ever accede to Linux in such a visible manner. Remember: it didn't sneak Linux distros in the through the back door, it went out and boasted about it!
|
||||
|
||||
Some (perhaps rightly) remain uneasy and/or somewhat suspicious over Microsoft's sudden embrace of 'all things open source'. Me? I'm less concerned. Microsoft isn't the hulking great giant it once was, and Linux has become so ubiquitous that the Redmond-based company simply can't ignore it.
|
||||
|
||||
The stocking of Ubuntu, openSUSE and Fedora on the shelves of the Windows Store (albeit for developers) is an admission writ large that Linux is an integral part of the modern software development ecosystem, and one they simply can't replicate, replace or rip-off.
|
||||
|
||||
For many regular Linux will always be preferable to the rather odd hybrid that is the Windows Subsystem for Linux (WSL). But for others, mandated to use Microsoft products for work or study, the leeway to use Linux is a blessing.
|
||||
|
||||
### 6\. GIMP 2.9.6
|
||||
|
||||
[![gimp on ubuntu graphic][25]][26]
|
||||
|
||||
We've written a fair bit about GIMP this year. The famous image editor has benefit from a spur of development activity. We started the year off by talking about the [features in GIMP 2.10][27] we were expecting to see.
|
||||
|
||||
While GIMP 2.10 itself didn't see release in 2017 two sizeable development updates did: GIMP 2.9.6 & GIMP 2.9.8.
|
||||
|
||||
The former of these added ** experimental multi-threading in GEGL** (a fancy way of saying the app can now make better use of multi-core processors). It also added HiDPI tweaks, introduced color coded layer tags, added metadata editor, new filters, crop presets and -- take a breath -- improved the 'quit' dialog.
|
||||
|
||||
### 7\. GNOME Desktop
|
||||
|
||||
[![GNOME 3.26 desktop with apps][28]][29]
|
||||
|
||||
While not strictly and app or a distro release, there were 2 GNOME releases in 2017: the feature-filled [GNOME 3.24 release][30] in March; and the iterative follow-up [GNOME 3.26][31] in September.
|
||||
|
||||
Both release came packed full of new features, and both bought an assembly of refinements, improvements and adjustments,
|
||||
|
||||
**GNOME 3.24 ** features included Night Light, a blue-light filter that can help improve natural sleeping patterns; a new desktop Recipes app; and added short weather forecast snippets to the Message Try.
|
||||
|
||||
**GNOME 3.26** built on the preceding release. It improves the look, feel and responsiveness of the GNOME Shell UI; revamped the Settings apps with a new layout and access to more options; integrates Firefox Sync support with the Web browser app; and tweaks the window animation effects (a bit of a trend this year) to create a more fluid feeling desktop.
|
||||
|
||||
GNOME isn't stopping there. GNOME 3.28 is due for release in March with plenty more changes, improvements and app updates planned. GNOME 3.28 is looking like it will be used in Ubuntu 18.04 LTS.
|
||||
|
||||
### 8\. Atom IDE
|
||||
|
||||
[![Atom IDE][32]][32]
|
||||
|
||||
This year was ripe with code editors, with Sublime Text 3, Visual Studio Code, Atom, Adobe Brackets, Gedit and many others relating updates.
|
||||
|
||||
But, for me, it was rather sudden appearance of **Atom IDE ** that caught my attention.
|
||||
|
||||
[Atom IDE][33] is a set of packages for the Atom code editor that add more traditional [IDE][34] capabilities like context-aware auto-completion, code navigation, diagnostics, and document formatting.
|
||||
|
||||
### 9\. Stacer 1.0.8
|
||||
|
||||
[![Stacer is an Ubuntu cleaner app][35]][36]
|
||||
|
||||
A system cleaner might not sound like the most exciting of tools but **Stacer** makes housekeeping a rather appealing task.
|
||||
|
||||
This year the app binned its Electron-built base in favour of a native C++ core, leading to various performance improvements as a result.
|
||||
|
||||
Stacer has 8 dedicated sections offering control over system maintenance duties, including:
|
||||
|
||||
* **Monitor system resources including CPU**
|
||||
* **Clear caches, logs, obsolete packages etc**
|
||||
* **Bulk remove apps and packages**
|
||||
* **Add/edit/disable start-up applications**
|
||||
|
||||
|
||||
|
||||
The app is now my go-to recommendation for anyone looking for an Ubuntu system cleaner. Which reminds me: I should get around to adding the app to our list of ways to [free up space on Ubuntu][37]… Chores, huh?!
|
||||
|
||||
### 10\. Geary 0.12
|
||||
|
||||
[![Geary 0.11 on Ubuntu 16.04][38]][39]
|
||||
|
||||
The best alternative to Thunderbird on Linux has to be **Geary, ** the open-source email app that works brilliantly with Gmail and other webmail accounts.
|
||||
|
||||
In October [Geary 0.12 was released][40]. This huge update adds a couple of new features to the app and a bucket-load of improvements the ones it already boasts.
|
||||
|
||||
Among the (many) highlights in the Geary 0.12:
|
||||
|
||||
* **Inline images in the email composer**
|
||||
* **Improved interface when displaying conversations**
|
||||
* **Support message archiving for Yahoo! Mail and Outlook.com**
|
||||
* **Keyboard navigation for conversations**
|
||||
|
||||
|
||||
|
||||
Geary 0.12 is available to install on Ubuntu 16.04 LTS and above from the [official Geary PPA][41]. If you're tired of Thunderbird (and the [gorgeous Montrail theme][42] doesn't make it more palatable) I recommend giving Geary a go.
|
||||
|
||||
## Other Odds & Ends
|
||||
|
||||
I said at the outset that it had been a busy year -- and it really has been. Writing a post like this is always a thankless task. So many app, script, theme, and distribution releases happen throughout the year, the majority bringing plenty to the table. I don't want to miss anyone or anything out -- but I must if I ever want to hit publish!
|
||||
|
||||
### Flathub
|
||||
|
||||
[![flathub screenshot][43]][44]
|
||||
|
||||
All this talk of apps means I have to mention the launch of [Flathub][45] this year.
|
||||
|
||||
Flathub is the de facto [Flatpak][46] app store; a centralised repository where the latest versions of your favourite apps live.
|
||||
|
||||
Flatpak really needed something like **Flathub** , and so did users. Now it's really easy to install the latest release of a slate of apps on pretty much any Linux distribution, without having to stress about package dependencies or conflicts.
|
||||
|
||||
Among the apps you can install from Flathub:
|
||||
|
||||
* **Corebird**
|
||||
* **Spotify**
|
||||
* **SuperTuxKart**
|
||||
* **VLC**
|
||||
* **Discord**
|
||||
|
||||
|
||||
* **Telegram Desktop**
|
||||
* **Atom**
|
||||
* **GIMP**
|
||||
* **Geary**
|
||||
* **Skype**
|
||||
|
||||
|
||||
|
||||
And the list is still growing!
|
||||
|
||||
### And! And! And!
|
||||
|
||||
Other apps we loved this year include [continued improvement][47]s to the **Corebird** Twitter client, some [useful new options][48] in the animated Gif maker **Peek** , as well as the arrival of Nylas Mail fork **Mailspring ** and the promising GTK audiobook player **Cozy**.
|
||||
|
||||
**Skype** bought a [bold new look][49] to VoIP fans on Linux desktops, **LibreOffice** (as always) served up continued improvements, and **Signal** launched a [dedicated desktop app.][50].
|
||||
|
||||
A big **CrossOver** update means you can now [run Microsoft Office 2016 on Linux][51]; and we got a handy wizard that makes it easy to [install Adobe Creative Cloud on Linux][52].
|
||||
|
||||
**What was your favourite Linux related release of 2017? Let us know in the comments!**
|
||||
|
||||
Wondering where the games are? Don't panic! We cover the best Linux games of 2017 in a separate post, which we'll published tomorrow.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2017/12/list-best-linux-distros-apps-2017
|
||||
|
||||
作者:[Joey Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/12/best-linux-distros-2017-750x421.jpg
|
||||
[2]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/12/best-linux-distros-2017.jpg
|
||||
[3]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/10/ubuntu-17.10-desktop.jpg (Ubuntu 17.10 desktop screenshot)
|
||||
[4]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/10/ubuntu-17.10-desktop.jpg
|
||||
[5]:http://www.omgubuntu.co.uk/2017/04/ubuntu-18-04-ship-gnome-desktop-not-unity
|
||||
[6]:http://www.omgubuntu.co.uk/2017/08/ubuntu-confirm-wayland-default-17-10
|
||||
[7]:https://en.wikipedia.org/wiki/Wayland_(display_server_protocol)
|
||||
[8]:http://www.omgubuntu.co.uk/2017/10/ubuntu-17-10-release-features
|
||||
[9]:http://www.omgubuntu.co.uk/2017/10/ubuntu-17-10-review-roundup
|
||||
[10]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/12/Budgie-750x422.jpg
|
||||
[11]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/12/Budgie.jpg
|
||||
[12]:http://www.omgubuntu.co.uk/2016/12/6-linux-distributions-2017
|
||||
[13]:https://solus-project.com/2017/08/15/solus-3-released/
|
||||
[14]:http://www.omgubuntu.co.uk/2017/08/install-budgie-desktop-10-4-on-ubuntu
|
||||
[15]:https://soluslond1iso.stroblindustries.com/Solus-3-MATE.iso
|
||||
[16]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/11/firefox-csd-fedora-from-reddit-750x415.png
|
||||
[17]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/11/firefox-csd-fedora-from-reddit.png
|
||||
[18]:https://fedoramagazine.org/whats-new-fedora-27-workstation/
|
||||
[19]:https://www.redhat.com/en/about/press-releases/fedora-27-now-generally-available (Redhat Press Release )
|
||||
[20]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/11/firefox-quantum-ubuntu-screenshot-750x448.jpg (Firefox 57 screenshot on Linux)
|
||||
[21]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/11/firefox-quantum-ubuntu-screenshot.jpg
|
||||
[22]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/07/windows-facebook-750x394.jpg
|
||||
[23]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/07/windows-facebook.jpg
|
||||
[24]:http://www.omgubuntu.co.uk/2017/07/ubuntu-now-available-windows-store
|
||||
[25]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/01/gimp-750x422.jpg
|
||||
[26]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/01/gimp.jpg
|
||||
[27]:http://www.omgubuntu.co.uk/2017/01/plans-for-gimp-2-10
|
||||
[28]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/09/GNOME-326-apps-750x469.jpg
|
||||
[29]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/09/GNOME-326-apps.jpg
|
||||
[30]:http://www.omgubuntu.co.uk/2017/03/gnome-3-24-released-new-features
|
||||
[31]:http://www.omgubuntu.co.uk/2017/09/gnome-3-26-officially-released
|
||||
[32]:https://i.imgur.com/V9DTnL3.jpg
|
||||
[33]:http://blog.atom.io/2017/09/12/announcing-atom-ide.html
|
||||
[34]:https://en.wikipedia.org/wiki/Integrated_development_environment
|
||||
[35]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/08/stacer-ubuntu-cleaner-app-350x200.jpg
|
||||
[36]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/08/stacer-ubuntu-cleaner-app.jpg
|
||||
[37]:http://www.omgubuntu.co.uk/2016/08/5-ways-free-up-space-on-ubuntu
|
||||
[38]:http://www.omgubuntu.co.uk/wp-content/uploads/2016/05/geary-11-1-350x200.jpg
|
||||
[39]:http://www.omgubuntu.co.uk/wp-content/uploads/2016/05/geary-11-1.jpg
|
||||
[40]:http://www.omgubuntu.co.uk/2017/10/install-geary-0-12-on-ubuntu
|
||||
[41]:https://launchpad.net/~geary-team/+archive/ubuntu/releases
|
||||
[42]:http://www.omgubuntu.co.uk/2017/04/a-modern-thunderbird-theme-font
|
||||
[43]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/09/flathub-apps-750x345.jpg
|
||||
[44]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/09/flathub-apps.jpg
|
||||
[45]:http://www.flathub.org/
|
||||
[46]:https://en.wikipedia.org/wiki/Flatpak
|
||||
[47]:http://www.omgubuntu.co.uk/2017/10/gtk-twitter-app-corebird-pushed-new-release
|
||||
[48]:http://www.omgubuntu.co.uk/2017/11/linux-release-roundup-peek-gthumb-more
|
||||
[49]:http://www.omgubuntu.co.uk/2017/10/new-look-skype-for-desktop-released
|
||||
[50]:http://www.omgubuntu.co.uk/2017/11/signal-desktop-app-released
|
||||
[51]:http://www.omgubuntu.co.uk/2017/12/crossover-17-linux
|
||||
[52]:http://www.omgubuntu.co.uk/2017/10/install-adobe-creative-cloud-linux
|
||||
@ -1,90 +0,0 @@
|
||||
一步步采用 Kubernetes
|
||||
============================================================
|
||||
|
||||
为什么选择 Docker 和 Kubernetes 呢?
|
||||
|
||||
容器允许我们构建,发布和运行分布式应用。他们使应用程序摆脱了机器限制,让我们以一定的方式创建一个复杂的应用程序。
|
||||
|
||||
使用容器编写应用程序可以使开发,QA 更加接近生产环境(如果你努力这样做的话)。通过这样做,可以更快地发布修改,并且可以更快地测试整个系统。
|
||||
|
||||
[Docker][1] 可以使软件独立于云提供商的容器化平台。
|
||||
|
||||
但是,即使使用容器,移植应用程序到任何一个云提供商(或私有云)所需的工作量也是非常重要的。应用程序通常需要自动伸缩组,持久远程光盘,自动发现等。但是每个云提供商都有不同的机制。如果你想使用这些功能,很快你就会变的依赖于云提供商。
|
||||
|
||||
这正是 [Kubernetes][2] 登场的时候。它是一个容器编排系统,它允许您以一定的标准管理,缩放和部署应用程序的不同部分,并且成为其中的重要工具。它抽象出来以兼容主要云的提供商(Google Cloud,Amazon Web Services 和 Microsoft Azure 都支持 Kubernetes)。
|
||||
|
||||
通过一个方法来想象一下应用程序,容器和 Kubernetes 。应用程序可以视为一条身边的鲨鱼,它存在于海洋中(在这个例子中,海洋就是您的机器)。海洋中可能还有其他一些宝贵的东西,但是你不希望你的鲨鱼与小丑鱼有什么关系。所以需要把你的鲨鱼(你的应用程序)移动到一个密封的水族馆中(容器)。这很不错,但不是特别的健壮。你的水族馆可能会打破,或者你想建立一个通道连接到其他鱼类生活的另一个水族馆。也许你想要许多这样的水族馆,以防需要清洁或维护... 这正是应用 Kubernetes 集群的地方。
|
||||
|
||||

|
||||
Evolution to Kubernetes
|
||||
|
||||
Kubernetes 由云提供商提供支持,从开发到生产,它使您和您的团队能够更容易地拥有几乎相同的环境。这是因为 Kubernetes 不依赖专有软件,服务或另外一些基础设施。
|
||||
|
||||
事实上,您可以在您的机器中使用与生产环境相同的部件启动应用程序,从而缩小了开发和生产环境之间的差距。这使得开发人员更了解应用程序是如何构建在一起的,尽管他们可能只负责应用程序的一部分。这也使得在开发流程中的应用程序更容易的快速完成测试。
|
||||
|
||||
如何使用 Kubernetes 工作?
|
||||
|
||||
随着更多的人采用 Kubernetes,新的问题出现了;应该如何针对基于集群环境开发?假设有 3 个环境,开发,质量保证和生产, 如何适应 Kubernetes?这些环境之间仍然存在着差异,无论是在开发周期(例如:在正在运行的应用程序中看到修改代码所花费的时间)还是与数据相关的(例如:我不应该在我的质量保证环境中测试生产数据,因为它里面有敏感信息)
|
||||
|
||||
那么,我是否应该总是在 Kubernetes 集群中编码,构建映像,重新部署服务?或者,我是否不应该尽力让我的开发环境也成为一个 Kubernetes 集群的其中之一(或一组集群)呢?还是,我应该以混合方式工作?
|
||||
|
||||

|
||||
Development with a local cluster
|
||||
|
||||
如果继续我们之前的比喻,使其保持在一个开发集群中的同时侧面的通道代表着修改应用程序的一种方式。这通常通过[volumes][4]来实现
|
||||
|
||||
一个 Kubernetes 系列
|
||||
|
||||
Kubernetes 系列资源是开源的,可以在这里找到:
|
||||
|
||||
### [https://github.com/red-gate/ks][5]
|
||||
|
||||
我们写这个系列作为练习以不同的方式构建软件。我们试图约束自己在所有环境中都使用 Kubernetes,以便我们可以探索这些技术对数据和数据库的开发和管理造成影响。
|
||||
|
||||
这个系列从使用 Kubernetes 创建基本的React应用程序开始,并逐渐演变为能够覆盖我们更多开发需求的系列。最后,我们将覆盖所有应用程序的开发需求,并且理解在数据库生命周期中如何最好地迎合容器和集群。
|
||||
|
||||
以下是这个系列的前 5 部分:
|
||||
|
||||
1. ks1: 使用 Kubernetes 构建一个React应用程序
|
||||
|
||||
2. ks2: 使用 minikube 检测 React 代码的更改
|
||||
|
||||
3. ks3: 添加一个提供 API 的 Python Web 服务器
|
||||
|
||||
4. ks4: 使 minikube 检测 Python 代码的更改
|
||||
|
||||
5. ks5: 创建一个测试环境
|
||||
|
||||
本系列的第二部分将添加一个数据库,并尝试找出最好的方式来发展我们的应用程序。
|
||||
|
||||
|
||||
通过在所有环境中运行 Kubernetes,我们被迫在解决新问题的时候也尽量保持开发周期。我们不断尝试 Kubernetes,并越来越习惯它。通过这样做,开发团队都可以对生产环境负责,这并不困难,因为所有环境(从开发到生产)都以相同的方式进行管理。
|
||||
|
||||
下一步是什么?
|
||||
|
||||
我们将通过整合数据库和练习来继续这个系列,以找到使用 Kubernetes 获得数据库生命周期的最佳体验方法。
|
||||
|
||||
这个 Kubernetes 系列是由 Redgate 研发部门的 Foundry 提供。我们正在努力使数据和容器的管理变得更加容易,所以如果您正在处理数据和容器,我们希望听到您的意见,请直接联系我们的开发团队。 [_foundry@red-gate.com_][6]
|
||||
* * *
|
||||
|
||||
我们正在招聘。您是否有兴趣开发产品,创建[未来技术][7] 并采取类似创业的方法(没有风险)?看看我们的[软件工程师 - 未来技术][8]的角色吧,并阅读更多关于在 [英国剑桥][9]的 Redgate 工作的信息。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/ingeniouslysimple/adopting-kubernetes-step-by-step-f93093c13dfe
|
||||
|
||||
作者:[santiago arias][a]
|
||||
译者:[aiwhj](https://github.com/aiwhj)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@santiaago?source=post_header_lockup
|
||||
[1]:https://www.docker.com/what-docker
|
||||
[2]:https://kubernetes.io/
|
||||
[3]:https://www.google.co.uk/search?biw=723&bih=753&tbm=isch&sa=1&ei=p-YCWpbtN8atkwWc8ZyQAQ&q=nemo+fish&oq=nemo+fish&gs_l=psy-ab.3..0i67k1l2j0l2j0i67k1j0l5.5128.9271.0.9566.9.9.0.0.0.0.81.532.9.9.0....0...1.1.64.psy-ab..0.9.526...0i7i30k1j0i7i10i30k1j0i13k1j0i10k1.0.FbAf9xXxTEM
|
||||
[4]:https://kubernetes.io/docs/concepts/storage/volumes/
|
||||
[5]:https://github.com/red-gate/ks
|
||||
[6]:mailto:foundry@red-gate.com
|
||||
[7]:https://www.red-gate.com/foundry/
|
||||
[8]:https://www.red-gate.com/our-company/careers/current-opportunities/software-engineer-future-technologies
|
||||
[9]:https://www.red-gate.com/our-company/careers/living-in-cambridge
|
||||
Loading…
Reference in New Issue
Block a user