mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
commit
decc148937
@ -1,67 +1,70 @@
|
||||
|
||||
Ubunto可以实现这功能吗?-回答4个新用户最常问的问题
|
||||
Ubuntu 有这功能吗?-回答4个新用户最常问的问题
|
||||
================================================================================
|
||||

|
||||
|
||||
**在谷歌输入‘Can Ubunt[u]’,一系列的自动建议会展现在你面前。这些建议都是根据最近搜索用户最频繁检索而形成的。
|
||||
|
||||
对于Linux老用户来说,他们都胸有成竹的回答这些问题。但是对于新用户或者那些还在探索类似Ubuntu是否是值得分配的人,他们不是十分清楚这些答案。这都是中肯,真实而且是基本的问题。
|
||||
对于Linux老用户来说,他们都胸有成竹的回答这些问题。但是对于新用户或者那些还在探索类似Ubuntu这样的发行版是否适合的人来说,他们不是十分清楚这些答案。这都是中肯,真实而且是基本的问题。
|
||||
|
||||
所以,在这片文章,我将会去回答4个最常会被搜索到的"Can Ubuntu...?"问题。
|
||||
|
||||
### Ubuntu可以取代Windows吗?###
|
||||
|
||||

|
||||
Windows 并不是每个人都喜欢 - 或者说是必须的。
|
||||
|
||||
是的。Ubutu(和其他Linux发行版)是可以安装到任何一台有能力运行微软系统的电脑。
|
||||
*Windows 并不是每个人都喜欢或都必须的*
|
||||
|
||||
无论你觉得 **应不应该** 取代它,不变的是,这取决于你自己的需求。
|
||||
是的。Ubuntu(和其他Linux发行版)是可以安装到任何一台有能力运行微软系统的电脑。
|
||||
|
||||
无论你觉得**应不应该**取代它,要不要替换只取决于你自己的需求。
|
||||
|
||||
例如,你在上大学,所需的软件都只是Windows而已。暂时而言,你是不需要完全更换你的系统。对于工作也是同样的道理。如果你工作所用到的软件只是微软Office, Adobe Creative Suite 或者是一个AutoCAD应用程序,不是很建议你更换系统,坚持你现在所用的软件就足够了。
|
||||
|
||||
但是对于那些用Ubuntu完全取代微软的我们,Ubuntu 提供一个安全的桌面工作环境。这个桌面工作环境可以运行与支持很广的硬件环境。基本上,每个东西都有软件的支持,从办公套件到网页浏览器,视频应用程序,音乐应用程序到游戏。
|
||||
但是对于那些用Ubuntu完全取代微软系统的我们,Ubuntu 提供了一个安全的桌面工作环境。这个桌面工作环境可以运行与支持很广的硬件环境。基本上,每个东西都有软件的支持,从办公套件到网页浏览器,视频应用程序,音乐应用程序到游戏。
|
||||
|
||||
### Ubuntu 可以运行 .exe文件吗?###
|
||||
|
||||

|
||||
你可以在Ubuntu运行一些Windows应用程序
|
||||
|
||||
是可以的,尽管这些程序不是一步安装到位,或者不能保证安装成功。这是因为这些软件版本本来就是在Windows下运行的。 这些程序本来就与其他桌面操作系统不兼容,包括Mac OS X 或者 Android (安卓系统)。
|
||||
*你可以在Ubuntu运行一些Windows应用程序*
|
||||
|
||||
那些专门为Ubuntu(和其他Linux发行版本)的软件安装包都是带有“.deb”的文件后缀名。它们的安装过程与安装 .exe 的程序是一样的 -双击安装包,然后根据屏幕提示完成安装。
|
||||
是可以的,尽管这些程序不是一步到位,或者不能保证运行成功。这是因为这些软件原本就是在Windows下运行的,本来就与其他桌面操作系统不兼容,包括Mac OS X 或者 Android (安卓系统)。
|
||||
|
||||
但是Linux是很多样化的。 使用一个名为"Wine"的兼容层,可以运行许多当下很流行的应用程序。 (Wine不是一个模拟器,但是简单来讲是一个速记本。)这些程序不会像在Windows下运行得那么顺畅,或者有着出色的用户界面。然而,它足以满足日常的工作要求。
|
||||
那些专门为Ubuntu(和其他 Debian 系列的 Linux 发行版本)的软件安装包都是带有“.deb”的文件后缀名。它们的安装过程与安装 .exe 的程序是一样的 -双击安装包,然后根据屏幕提示完成安装。 (LCTT 译注:RedHat 系统采用.rpm 文件,其它的也有各种不同的安装包格式,等等,作为初学者,你可以当成是各种压缩包格式来理解)
|
||||
|
||||
一些很出名的Windows软件是可以通过Wine来运行在Ubuntu操作系统上,这包括老版本的Photoshop和微软办公室软件。 有关兼容软件的列表 [参照Wine应用程序数据库][1].
|
||||
但是Linux是很多样化的。它使用一个名为"Wine"的兼容层,可以运行许多当下很流行的应用程序。 (Wine不是一个模拟器,但是简单来看可以当成一个快捷方式。)这些程序不会像在Windows下运行得那么顺畅,或者有着出色的用户界面。然而,它足以满足日常的工作要求。
|
||||
|
||||
一些很出名的Windows软件是可以通过Wine来运行在Ubuntu操作系统上,这包括老版本的Photoshop和微软办公室软件。 有关兼容软件的列表,[参照Wine应用程序数据库][1]。
|
||||
|
||||
### Ubuntu会有病毒吗?###
|
||||
|
||||
|
||||
它可能有错误,但是它并有病毒
|
||||
|
||||
*它可能有错误,但是它并有病毒*
|
||||
|
||||
理论上,它会有病毒。但是,实际上它没有。
|
||||
|
||||
Linux发行版本是建立在一个病毒,蠕虫,隐匿程序都很难被安装,运行或者造成很大影响的环境之下的。
|
||||
|
||||
例如,很多应用程序都是在没有特别管理权限要求,以普通用户权限运行的。病毒的访问系统关键部分的请求也是需要用户管理权限的。很多软件的提供都是从那些维护良好的而且集中的资源库,例如Ubuntu软件中心,而不是一些不知名的网站。 由于这样的管理使得安装一些受感染的软件的几率可以忽略不计。
|
||||
例如,很多应用程序都是在没有特别管理权限要求,以普通用户权限运行的。病毒要访问系统关键部分的请求也是需要用户管理权限的。很多软件的提供都是从那些维护良好的而且集中的资源库,例如Ubuntu软件中心,而不是一些不知名的网站。 由于这样的管理使得安装一些受感染的软件的几率可以忽略不计。
|
||||
|
||||
你应不应该在Ubuntu系统安装杀毒软件?这取决于你自己。为了自己的安心,或者如果你经常通过Wine来使用Windows软件,或者双系统,你可以安装ClamAV。它是一个免费的开源的病毒扫描应用程序。你可以在Ubuntu软件中心找到它。
|
||||
|
||||
你可以在Ubuntu维基百科了解更多关于病毒在Linux或者Ubuntu的信息。 [Ubuntu 维基百科][2].
|
||||
你可以在Ubuntu维基百科了解更多关于病毒在Linux或者Ubuntu的信息。 [Ubuntu 维基百科][2]。
|
||||
|
||||
### 在Ubuntu上可以玩游戏吗?###
|
||||
|
||||
|
||||
Steam有着上百个专门为Linux设计的高质量游戏。
|
||||
|
||||
当然可以!Ubuntu有着多样化的游戏,从传统简单的2D象棋,拼字游戏和扫雷游戏,到很现代化AAA级别的对显卡要求强的游戏。
|
||||
*Steam有着上百个专门为Linux设计的高质量游戏*
|
||||
|
||||
你首先去到 **Ubuntu 软件中心**。这里你会找到很多免费的,开源的和付钱的游戏,包括广受好评的独立制作游戏,像World of Goo 和Braid。当然也有其他传统游戏的提供,例如,Pychess(国际象棋),four-in-a-row和Scrabble clones(猜字拼字游戏)。
|
||||
当然可以!Ubuntu有着多样化的游戏,从传统简单的2D象棋,拼字游戏和扫雷游戏,到很现代化的AAA级别的要求显卡很强的游戏。
|
||||
|
||||
对于游戏狂热爱好者,你可以点击**Steam for Linux**. 在这里你可以找到各种这样最新最好玩的游戏。
|
||||
你首先可以去 **Ubuntu 软件中心**。这里你会找到很多免费的,开源的和收费的游戏,包括广受好评的独立制作游戏,像World of Goo 和Braid。当然也有其他传统游戏的提供,例如,Pychess(国际象棋),four-in-a-row(四子棋)和Scrabble clones(猜字拼字游戏)。
|
||||
|
||||
另外,记得留意这个网站 [Humble Bundle][3]。这些“只买你想要的”的套餐只会持续每个月里面的两周。作为游戏平台,它是Linux特别友好的支持者。因为每当一些新游戏出来的时候,它都保证可以在Linux下搜索到。
|
||||
对于游戏狂热爱好者,你可以安装**Steam for Linux**。在这里你可以找到各种这样最新最好玩的游戏。
|
||||
|
||||
另外,记得留意这个网站:[Humble Bundle][3]。每个月都会有两周的这种“只买你想要的”的套餐。作为游戏平台,它是对Linux特别友好的支持者。因为每当一些新游戏出来的时候,它都保证可以在Linux下搜索到。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -69,7 +72,7 @@ via: http://www.omgubuntu.co.uk/2014/08/ubuntu-can-play-games-replace-windows-qu
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[Shaohao Lin](https://github.com/shaohaolin)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,10 @@
|
||||
使用 GIT 备份 linux 上的网页
|
||||
使用 GIT 备份 linux 上的网页文件
|
||||
================================================================================
|
||||

|
||||
|
||||
BUP 并不单纯是 Git, 而是一款基于 Git 的软件. 一般情况下, 我使用 rsync 来备份我的文件, 而且迄今为止一直工作的很好. 唯一的不足就是无法把文件恢复到某个特定的时间点. 因此, 我开始寻找替代品, 结果发现了 BUP, 一款基于 git 的软件, 它将数据存储在一个仓库中, 并且有将数据恢复到特定时间点的选项.
|
||||
|
||||
要使用 BUP, 你先要初始化一个空的仓库, 然后备份所有文件. 当 BUP 完成一次备份是, 它会创建一个还原点, 你可以过后还原到这里. 它还会创建所有文件的索引, 包括文件的属性和验校和. 当要进行下一个备份是, BUP 会对比文件的属性和验校和, 只保存发生变化的数据. 这样可以节省很多空间.
|
||||
要使用 BUP, 你先要初始化一个空的仓库, 然后备份所有文件. 当 BUP 完成一次备份是, 它会创建一个还原点, 你可以过后还原到这里. 它还会创建所有文件的索引, 包括文件的属性和验校和. 当要进行下一个备份时, BUP 会对比文件的属性和验校和, 只保存发生变化的数据. 这样可以节省很多空间.
|
||||
|
||||
### 安装 BUP (在 Centos 6 & 7 上测试通过) ###
|
||||
|
||||
@ -20,7 +20,8 @@ BUP 并不单纯是 Git, 而是一款基于 Git 的软件. 一般情况下, 我
|
||||
[techarena51@vps ~]$ make test
|
||||
[techarena51@vps ~]$ sudo make install
|
||||
|
||||
对于 debian/ubuntu 用户, 你可以使用 "apt-get build-dep bup". 要获得更多的信心, 可以查看 https://github.com/bup/bup
|
||||
对于 debian/ubuntu 用户, 你可以使用 "apt-get build-dep bup". 要获得更多的信息, 可以查看 https://github.com/bup/bup
|
||||
|
||||
在 CentOS 7 上, 当你运行 "make test" 时可能会出错, 但你可以继续运行 "make install".
|
||||
|
||||
第一步时初始化一个空的仓库, 就像 git 一样.
|
||||
@ -49,7 +50,7 @@ BUP 并不单纯是 Git, 而是一款基于 Git 的软件. 一般情况下, 我
|
||||
|
||||
"BUP save" 会把所有内容分块, 然后把它们作为对象储存. "-n" 选项指定备份名.
|
||||
|
||||
你可以查看一系列备份和已备份文件.
|
||||
你可以查看备份列表和已备份文件.
|
||||
|
||||
[techarena51@vps ~]$ bup ls
|
||||
local-etc techarena51 test
|
||||
@ -88,13 +89,13 @@ BUP 并不单纯是 Git, 而是一款基于 Git 的软件. 一般情况下, 我
|
||||
|
||||
唯一的缺点是你不能把文件恢复到另一个服务器, 你必须通过 SCP 或者 rsync 手动复制文件.
|
||||
|
||||
通过集成的 web 服务器查看备份
|
||||
通过集成的 web 服务器查看备份.
|
||||
|
||||
bup web
|
||||
#specific port
|
||||
bup web :8181
|
||||
|
||||
你可以使用 shell 脚本来运行 bup, 并建立一个每日运行的定时任务
|
||||
你可以使用 shell 脚本来运行 bup, 并建立一个每日运行的定时任务.
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
@ -103,7 +104,7 @@ BUP 并不单纯是 Git, 而是一款基于 Git 的软件. 一般情况下, 我
|
||||
|
||||
BUP 并不完美, 但它的确能够很好地完成任务. 我当然非常愿意看到这个项目的进一步开发, 希望以后能够增加远程恢复的功能.
|
||||
|
||||
你也许喜欢阅读 使用[inotify-tools][1], 一篇关于实时文件同步的文章.
|
||||
你也许喜欢阅读这篇——使用[inotify-tools][1]实时文件同步.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -111,7 +112,7 @@ via: http://techarena51.com/index.php/using-git-backup-website-files-on-linux/
|
||||
|
||||
作者:[Leo G][a]
|
||||
译者:[wangjiezhe](https://github.com/wangjiezhe)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,43 +1,43 @@
|
||||
Linux日历程序California 0.2 发布了
|
||||
================================================================================
|
||||
**随着[上月的Geary和Shotwell的更新][1],非盈利软件套装Yobra又回来了,这次带来的是新的[California][2]日历程序的发布。**
|
||||
**随着[上月的Geary和Shotwell的更新][1],非盈利软件套装Yobra又回来了,同时带来了是新的[California][2]日历程序。**
|
||||
|
||||
一个合格的桌面日历是工作井井有条(和想要井井有条)的必备工具。[广受欢迎Chrome Web Store上的Sunrise应用][3]的发布意味着选择并不像以前那么少了。California又为这个撑腰了。
|
||||
一个合格的桌面日历是工作井井有条(以及想要井井有条)的必备工具。[Chrome Web Store上广受欢迎的Sunrise应用][3]的发布让我们的选择比以前更丰富了,而California又为之增添了新的生力军!
|
||||
|
||||
Yorba的Jim Nelson在Yorba博客上写道:“发生了很多变化“,接着写道:“初次发布比我想的加入了更多的特性。”
|
||||
Yorba的Jim Nelson在Yorba博客上写道:“发生了很多变化“,接着写道:“...很高兴的告诉大家,初次发布比我预想的加入了更多的特性。”
|
||||
|
||||

|
||||
|
||||
California 0.2在GNOME上看上去棒极了。
|
||||
*California 0.2在GNOME上看上去棒极了。*
|
||||
|
||||
最突出的是添加了“自然语言”解析器。这使得添加事件更容易。相反,你可以直接输入“**在下午2点就Nachos会见Sam”接着California就会自动把它安排下接下来的星期一的下午两点,而不必你手动输入位的信息(日期,时间等等)。
|
||||
最突出变化的是添加了“自然语言”解析器。这使得添加事件更容易。你可以直接输入“**在下午2点就Nachos会见Sam**”接着California就会自动把它安排下接下来的星期一的下午两点,而不必你手动输入位的信息(日期,时间等等)。(LCTT 译注:显然你只能输入英文才行)
|
||||
|
||||
|
||||

|
||||
|
||||
当我们在5月份回顾开发版本时这个特性也能工作了,甚至修复了一个问题:重复事件。
|
||||
这个功能和我们我们在5月份评估开发版本时一样好用,甚至还修复了一个bug:事件重复。
|
||||
|
||||
要创建一个重复时间(比如:“每个星期四搜索自己的名字”),你需要在日期前包含文字“every”(每个)。要确保地点也在内(比如:中午12点和Samba De Amigo在Boston Tea Party喝咖啡)。条目中需要有“at”或者“@”。
|
||||
|
||||
至于详细信息,我们可以见[GNOME Wiki上的快速添加页面][4]
|
||||
至于详细信息,我们可以见[GNOME Wiki上的快速添加页面][4]:
|
||||
|
||||
其他的改变包括:
|
||||
|
||||
- 通过‘月’和‘周’查看事件
|
||||
-以‘月’和‘周’视图查看事件
|
||||
-添加/删除 Google,CalDAV和web(.ics)日历
|
||||
- 改进数据服务器整合
|
||||
-添加/编辑/啥是拿出远程事件(包括重复事件)
|
||||
-自然语言计划
|
||||
-F1在线帮助快捷键
|
||||
- 新的动画和弹出窗口
|
||||
-改进数据服务器整合
|
||||
-添加/编辑/删除远程事件(包括重复事件)
|
||||
-用自然语言安排计划
|
||||
-按下F1获取在线帮助
|
||||
-新的动画和弹出窗口
|
||||
|
||||
### 在Ubuntu 14.10上安装 California 0.2 ###
|
||||
|
||||
由于是GNOME 3的程序,可以说这下面程序看起来和感受上更好。
|
||||
作为一个GNOME 3的程序,它在 Gnome 3下运行的外观和体验会更好。
|
||||
|
||||
Yorba没有忽略Ubuntu用户。他们已经努力(也可以说是耐心地)地解决导致Ubuntu需要同时安装GTK+和GNOME的主题问题。结果就是在Ubuntu上程序可能看上去有点错位,但是同样工作的很好。
|
||||
不过,Yorba也没有忽略Ubuntu用户。他们已经努力(也可以说是耐心地)地解决导致Ubuntu需要同时安装GTK+和GNOME的主题问题。结果就是在Ubuntu上程序可能看上去有点错位,但是同样工作的很好。
|
||||
|
||||
California 0.2在[Yorba稳定版软件PPA][5]中可以下载,且只针对Ubuntu 14.10。
|
||||
California 0.2在[Yorba稳定版软件PPA][5]中可以下载,只用于Ubuntu 14.10。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -45,7 +45,7 @@ via: http://www.omgubuntu.co.uk/2014/10/california-calendar-natural-language-par
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -14,13 +14,13 @@ Torvalds以他典型的[放任式][1]的口吻在Linux内核邮件列表中解
|
||||
|
||||
### Linux 3.17有哪些新的? ###
|
||||
|
||||
最为一个新的发布,Linux 3.17 加入了最新的改进,硬件支持,修复等等。范围从有迷惑性的 - 比如:[memfd 和 文件密封补丁][2] - 到大多数人感兴趣的,比如最新硬件的支持。
|
||||
最新版本的 Linux 3.17 加入了最新的改进,硬件支持,修复等等。范围从不明觉厉的 - 比如:[memfd 和 文件密封补丁][2] - 到大多数人感兴趣的,比如最新硬件的支持。
|
||||
|
||||
下面是这次发布的一些亮点的列表,但她们并不详尽。
|
||||
下面是这次发布的一些亮点的列表,但它们并不详尽:
|
||||
|
||||
- Microsoft Xbox One 控制器支持 (没有震动)
|
||||
- Microsoft Xbox One 控制器支持 (没有震动反馈)
|
||||
- 额外的Sony SIXAXIS支持改进
|
||||
- 东芝 “Active Protection Sensor” 支持
|
||||
- 东芝 “主动防护感应器” 支持
|
||||
- 新的包括Rockchip RK3288和AllWinner A23 SoC的ARM芯片支持
|
||||
- 安全计算设备上的“跨线程过滤设置”
|
||||
- 基于Broadcom BCM7XXX板卡的支持(用在不同的机顶盒上)
|
||||
@ -32,9 +32,9 @@ Torvalds以他典型的[放任式][1]的口吻在Linux内核邮件列表中解
|
||||
|
||||
虽然被列为稳定版,但是目前对于大多数人而言只有很少的功能需要我们“现在去安装”。
|
||||
|
||||
但是如果你很耐心- **更重要的是**-有足够的技能去处理从中导致的问题,你可以通过在由Canonical维护的主线内核存档中安装一系列合适的包来在你的Ubuntu 14.10中安装Linux 3.17
|
||||
但是如果你很耐心——**更重要的是**——有足够的技能去处理从中导致的问题,你可以通过在由Canonical维护的主线内核存档中找到一系列合适的包安装在你的Ubuntu 14.10中,升级到Linux 3.17。
|
||||
|
||||
**除非你知道你正在做什么,不要尝试从下面的链接中安装任何东西。**
|
||||
**警告:除非你知道你正在做什么,不要尝试从下面的链接中安装任何东西。**
|
||||
|
||||
- [访问Ubuntu内核主线存档][3]
|
||||
|
||||
@ -44,7 +44,7 @@ via: http://www.omgubuntu.co.uk/2014/10/linux-kernel-3-17-whats-new-improved
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,219 @@
|
||||
Compact Text Editors Great for Remote Editing and Much More
|
||||
================================================================================
|
||||
A text editor is software used for editing plain text files. This type of software has many different uses including modifying configuration files, writing programming language source code, jotting down thoughts, or even making a grocery list. Given that editors can be used for such a diverse range of activities, it is worth spending the time finding an editor that best suites your preferences.
|
||||
|
||||
Whatever the level of sophistication of the editor, they typically have a common set of functionality, such as searching/replacing text, formatting text, importing files, as well as moving text within the file.
|
||||
|
||||
All of these text editors are console based applications which make them ideal for editing files on remote machines. Textadept also provides a graphical user interface, but remains fast and minimalist.
|
||||
|
||||
Console based applications are also light on system resources (very useful on low spec machines), can be faster and more efficient than their graphical counterparts, they do not stop working when X needs to be restarted, and are great for scripting purposes.
|
||||
|
||||
I have selected my favorite open source text editors that are frugal on system resources.
|
||||
|
||||
----------
|
||||
|
||||
### Textadept ###
|
||||
|
||||

|
||||
|
||||
Textadept is a fast, minimalist, and extensible cross-platform open source text editor for programmers. This open source application is written in a mixture of C and Lua and has been optimized for speed and minimalism over the years.
|
||||
|
||||
Textadept is an ideal editor for programmers who want endless extensibility options without sacrificing speed or succumbing to code bloat and featuritis.
|
||||
|
||||
There is also a version available for the terminal, which only depends on ncurses; great for editing on remote machines.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
|
||||
- Lightweight
|
||||
- Minimal design maximizes screen real estate
|
||||
- Self-contained executable – no installation necessary
|
||||
- Entirely keyboard driven
|
||||
- Unlimited split views (GUI version) split the editor window as many times as you like either horizontally or vertically. Please note that Textadept is not a tabbed editor
|
||||
- Support for over 80 programming languages
|
||||
- Powerful snippets and key commands
|
||||
- Code autocompletion and API lookup
|
||||
- Unparalleled extensibility
|
||||
- Bookmarks
|
||||
- Find and Replace
|
||||
- Find in Files
|
||||
- Buffer-based word completion
|
||||
- Adeptsense autocomplete symbols for programming languages and display API documentation
|
||||
- Themes: light, dark, and term
|
||||
- Uses lexers to assign names to buffer elements like comments, strings, and keywords
|
||||
- Sessions
|
||||
- Snapopen
|
||||
- Available modules include support for Java, Python, Ruby and recent file lists
|
||||
- Conforms with the Gnome HIG Human Interface Guidelines
|
||||
- Modules include support for Java, Python, Ruby and recent file lists
|
||||
- Support for editing Lua code. Syntax autocomplete and LuaDoc is available for many Textadept objects as well as Lua’s standard libraries
|
||||
|
||||
- Website: [foicica.com/textadept][1]
|
||||
- Developer: Mitchell and contributors
|
||||
- License: MIT License
|
||||
- Version Number: 7.7
|
||||
|
||||
----------
|
||||
|
||||
### Vim ###
|
||||
|
||||

|
||||
|
||||
Vim is an advanced text editor that seeks to provide the power of the editor 'Vi', with a more complete feature set.
|
||||
|
||||
This editor is very useful for editing programs and other plain ASCII files. All commands are given with normal keyboard characters, so those who can type with ten fingers can work very fast. Additionally, function keys can be defined by the user, and the mouse can be used.
|
||||
|
||||
Vim is often called a "programmer's editor," and is so useful for programming that many consider it to be an entire Integrated Development Environment. However, this application is not only intended for programmers. Vim is highly regarded for all kinds of text editing, from composing email to editing configuration files.
|
||||
|
||||
Vim's interface is based on commands given in a text user interface. Although its graphical user interface, gVim, adds menus and toolbars for commonly used commands, the software's entire functionality is still reliant on its command line mode.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
|
||||
- 3 modes:
|
||||
- - Command mode
|
||||
- - Insert mode
|
||||
- - Command line mode
|
||||
- Unlimited undo
|
||||
- Multiple windows and buffers
|
||||
- Flexible insert mode
|
||||
- Syntax highlighting highlight portions of the buffer in different colors or styles, based on the type of file being edited
|
||||
- Interactive commands
|
||||
- - Marking a line
|
||||
- - vi line buffers
|
||||
- - Shift a block of code
|
||||
- Block operators
|
||||
- Command line history
|
||||
- Extended regular expressions
|
||||
- Edit compressed/archive files (gzip, bzip2, zip, tar)
|
||||
- Filename completion
|
||||
- Block operations
|
||||
- Jump tags
|
||||
- Folding text
|
||||
- Indenting
|
||||
- ctags and cscope intergration
|
||||
- 100% vi compatibility mode
|
||||
- Plugins to add/extend functionality
|
||||
- Macros
|
||||
- vimscript, Vim's internal scripting language
|
||||
- Unicode support
|
||||
- Multi-language support
|
||||
- Integrated On-line help
|
||||
|
||||
- Website: [www.vim.org][2]
|
||||
- Developer: Bram Moolenaar
|
||||
- License: GNU GPL compatible (charityware)
|
||||
- Version Number: 7.4
|
||||
|
||||
----------
|
||||
|
||||
### ne ###
|
||||
|
||||

|
||||
|
||||
ne is a full screen open source text editor. It is intended to be an easier to learn alternative to vi, yet still portable across POSIX-compliant operating systems.
|
||||
|
||||
ne is easy to use for the beginner, but powerful and fully configurable for the wizard, and most sparing in its resource usage.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
|
||||
- Three user interfaces: control keystrokes, command line, and menus; keystrokes and menus are completely configurable
|
||||
- Syntax highlighting
|
||||
- Full support for UTF-8 files, including multiple-column characters
|
||||
- The number of documents and clips, the dimensions of the display, and the file/line lengths are limited only by the integer size of the machine
|
||||
- Simple scripting language where scripts can be generated via an idiotproof record/play method
|
||||
- Unlimited undo/redo capability (can be disabled with a command)
|
||||
- Automatic preferences system based on the extension of the file name being edited
|
||||
- Automatic completion of prefixes using words in your documents as dictionary
|
||||
- File requester with completion features for easy file retrieval;
|
||||
- Extended regular expression search and replace à la emacs and vi
|
||||
- A very compact memory model easily load and modify very large files
|
||||
- Editing of binary files
|
||||
|
||||
- Website: [ne.di.unimi.it][3]
|
||||
- Developer: Sebastiano Vigna (original developer). Additional features added by Todd M. Lewis
|
||||
- License: GNU GPL v3
|
||||
- Version Number: 2.5
|
||||
|
||||
----------
|
||||
|
||||
### Zile ###
|
||||
|
||||

|
||||
|
||||
Zile Is Lossy Emacs (Zile) is a small Emacs clone. Zile is a customizable, self-documenting real-time display editor. Zile was written to be as similar as possible to Emacs; every Emacs user should feel comfortable with Zile.
|
||||
|
||||
Zile is distinguished by a very small RAM memory footprint, of approximately 130kB, and quick editing sessions. It is 8-bit clean, allowing it to be used on any sort of file.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
- Small but fast and powerful
|
||||
- Multi buffer editing with multi level undo
|
||||
- Multi window
|
||||
- Killing, yanking and registers
|
||||
- Minibuffer completion
|
||||
- Auto fill (word wrap)
|
||||
- Registers
|
||||
- Looks like Emacs. Key sequences, function and variable names are identical with Emacs's
|
||||
- Killing
|
||||
- Yanking
|
||||
- Auto line ending detection
|
||||
|
||||
- Website: [www.gnu.org/software/zile][4]
|
||||
- Developer: Reuben Thomas, Sandro Sigala, David A. Capello
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 2.4.11
|
||||
|
||||
----------
|
||||
|
||||
### nano ###
|
||||
|
||||

|
||||
|
||||
nano is a curses-based text editor. It is a clone of Pico, the editor of the Pine email client.
|
||||
|
||||
The nano project was started in 1999 due to licensing issues with the Pine suite (Pine was not distributed under a free software license), and also because Pico lacked some essential features.
|
||||
|
||||
nano aims to emulate the functionality and easy-to-use interface of Pico, while offering additional functionality, but without the tight mailer integration of the Pine/Pico package.
|
||||
|
||||
nano, like Pico, is keyboard-oriented, controlled with control keys.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
- Interactive search and replace
|
||||
- Color syntax highlighting
|
||||
- Go to line and column number
|
||||
- Auto-indentation
|
||||
- Feature toggles
|
||||
- UTF-8 support
|
||||
- Mixed file format auto-conversion
|
||||
- Verbatim input mode
|
||||
- Multiple file buffers
|
||||
- Smooth scrolling
|
||||
- Bracket matching
|
||||
- Customizable quoting string
|
||||
- Backup files
|
||||
- Internationalization support
|
||||
- Filename tab completion
|
||||
|
||||
- Website: [nano-editor.org][5]
|
||||
- Developer: Chris Allegretta, David Lawrence, Jordi Mallach, Adam Rogoyski, Robert Siemborski, Rocco Corsi, David Benbennick, Mike Frysinger
|
||||
- License: GNU GPL v3
|
||||
- Version Number: 2.2.6
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20141011073917230/TextEditors.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://foicica.com/textadept/
|
||||
[2]:http://www.vim.org/
|
||||
[3]:http://ne.di.unimi.it/
|
||||
[4]:http://www.gnu.org/software/zile/
|
||||
[5]:http://nano-editor.org/
|
||||
55
sources/share/20141013 UbuTricks 14.10.08.md
Normal file
55
sources/share/20141013 UbuTricks 14.10.08.md
Normal file
@ -0,0 +1,55 @@
|
||||
UbuTricks 14.10.08
|
||||
================================================================================
|
||||
> An Ubuntu utility that allows you to install the latest versions of popular apps and games
|
||||
|
||||
UbuTricks is a freely distributed script written in Bash and designed from the ground up to help you install the latest version of the most acclaimed games and graphical applications on your Ubuntu Linux operating system, as well as on various other Ubuntu derivatives.
|
||||
|
||||

|
||||
|
||||
### What apps can I install with UbuTricks? ###
|
||||
|
||||
Currently, the latest versions of the Calibre, Fotoxx, Geary, GIMP, Google Earth, HexChat, jAlbum, Kdenlive, LibreOffice, PCManFM, Qmmp, QuiteRSS, QupZilla, Shutter, SMPlayer, Ubuntu Tweak, Wine and XBMC (Kodi), PlayOnLinux, Red Notebook, NeonView, Sunflower, Pale Moon, QupZilla Next, FrostWire and RSSOwl applications can be installed with UbuTricks.
|
||||
|
||||
### What games can I install with UbuTricks? ###
|
||||
|
||||
In addition, the latest versions of the 0 A.D., Battle for Wesnoth, Transmageddon, Unvanquished and VCMI (Heroes III Engine) games can be installed with the UbuTricks program. Users can also install the latest version of the Cinnamon and LXQt desktop environments.
|
||||
|
||||
### Getting started with UbuTricks ###
|
||||
|
||||
The program is distributed as a .sh file (shell script) that can be run from the command-line using the “sh ubutricks.sh” command (without quotes) or make it executable and double-click it from your Home folder or desktop. All you have to do is to select and app or game and click the OK button to install it.
|
||||
|
||||
### How does it work? ###
|
||||
|
||||
When accessed for the first time, the program will display a welcome screen from the get-to, notifying users about how it actually works. There are three methods to install an app or game, via PPA, DEB file or source tarball. Please note that apps and games will be automatically downloaded and installed.
|
||||
|
||||
### What distributions are supported? ###
|
||||
|
||||
Several versions of the Ubuntu Linux operating systems are supported, but if not specified, it will default to the current stable version, Ubuntu 14.04 LTS (Trusty Tahr). At the moment, the program will not work if you don’t have the gksu package installed on your Ubuntu box. It is based on Zenity, which should be installed too.
|
||||
|
||||

|
||||
|
||||
- last updated on:October 9th, 2014, 11:29 GMT
|
||||
- price:FREE!
|
||||
- developed by:Dan Craciun
|
||||
- homepage:[www.tuxarena.com][1]
|
||||
- license type:[GPL (GNU General Public License)][3]
|
||||
- category:ROOT \ Desktop Environment \ Tools
|
||||
|
||||
### Download for UbuTricks: ###
|
||||
|
||||
- [ubutricks.sh][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linux.softpedia.com/get/Desktop-Environment/Tools/UbuTricks-103626.shtml
|
||||
|
||||
作者:[Marius Nestor][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.softpedia.com/editors/browse/marius-nestor
|
||||
[1]:http://www.tuxarena.com/apps/ubutricks/
|
||||
[2]:http://www.tuxarena.com/intro/files/ubutricks.sh
|
||||
[3]:http://www.gnu.org/licenses/gpl-2.0.html
|
||||
@ -0,0 +1,60 @@
|
||||
What is good reference management software on Linux
|
||||
================================================================================
|
||||
Have you ever written a paper so long that you thought you would never see the end of it? If so, you know that the worst part is not dedicating hours on it, but rather that once you are done, you still have to order and format your references into a structured convention-following bibliography. Hopefully for you, Linux has the solution: bibliography/reference management tools. Using the power of BibTex, these programs can help you import your citation sources, and spit out a structured bibliography. Here is a non-exhaustive list of open-source reference management software on Linux.
|
||||
|
||||
### 1. Zotero ###
|
||||
|
||||
|
||||
|
||||
Surely the most famous tool for collecting references, [Zotero][1] is known for being a browser extension. However, there also exists a convenient Linux stand alone program. Among its biggest advantages, Zotero is easy to use, and can be coupled with LibreOffice or other text editors to manage the bibliography of documents. I personally appreciate the interface and the plugin manager. However, Zotero is quickly limited if you have a lot of needs about your bibliography.
|
||||
|
||||
### 2. JabRef ###
|
||||
|
||||
|
||||
|
||||
[JabRef][2] is one of the most advanced tools out there for citation management. You can import from a plethora of format, lookup entries from external databases (like Google Scholar), and export straight to your favorite editor. JabRef integrates your environment nicely, and can even support plugins. And as a final touch, JabRef can connect to your own SQL database. The only downside to all of this is of course the learning curve.
|
||||
|
||||
### 3. KBibTex ###
|
||||
|
||||
|
||||
|
||||
For KDE adepts, the desktop environment has its own dedicated bibliography manager called [KBibTex][3]. And as you might expect from a program of this caliber, the promised quality is delivered. The software is highly customizable, from the shortcuts to the behavior and appearance. It is easy to find duplicates, to preview the results, and to export directly to a LaTeX editor. But the best feature in my opinion is the integration of Bibsonomy, Google Scholar, and even your Zotero account. The only downside is that the interface seems a bit cluttered at first. Hopefully spending enough time in the settings should fix that.
|
||||
|
||||
### 4. Bibfilex ###
|
||||
|
||||
|
||||
|
||||
Capable of running in both Gtk and Qt environment, [Bibfilex][4] is a user friendly bibliography management tool based on Biblatex. Less advanced than JabRef or KBibTex, it is fast and lightweight. Definitely a smart choice for making a bibliography quickly without thinking too much. The interface is slick and reflects just the necessary functions. I give it extra credits for the complete manual that you can get from the official [download page][5]
|
||||
|
||||
5. Pybliographer
|
||||
|
||||
|
||||
|
||||
As indicated by its name, [Pybliographer][6] is a non-graphical tool for bibliography management written in Python. I personally like to use Pybliographic as the graphical front-end. The interface is extremely clear and minimalist. If you just have a few references to export and don't really have time to learn how to use an extensive piece of software, Pybliographer is the place to go. A bit like Bibfilex, the intent is on user-friendliness and quick use.
|
||||
|
||||
### 6. Referencer ###
|
||||
|
||||

|
||||
|
||||
Probably my biggest surprise when doing this list, [Referencer][7] is really appealing to the eye. Capable of integrating itself perfectly with Gnome, it can find and import your documents, look up their reference on the web, and export to LyX, while being sexy and really well designed. The few shortcuts and plugins are a good bonus along with the library style interface.
|
||||
|
||||
To conclude, thanks to these tools, you will not have to worry about long papers anymore, or at least not about the reference section. What did we miss? Is there a bibliography management tool that you prefer? Let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/reference-management-software-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:https://www.zotero.org/
|
||||
[2]:http://jabref.sourceforge.net/
|
||||
[3]:http://home.gna.org/kbibtex/
|
||||
[4]:https://sites.google.com/site/bibfilex/
|
||||
[5]:https://sites.google.com/site/bibfilex/download
|
||||
[6]:http://pybliographer.org/
|
||||
[7]:https://launchpad.net/referencer
|
||||
@ -1,89 +0,0 @@
|
||||
[felixonmars translating...]
|
||||
|
||||
10 Open Source Cloning Software For Linux Users
|
||||
================================================================================
|
||||
> These cloning software take all disk data, convert them into a single .img file and you can copy it to another hard drive.
|
||||
|
||||

|
||||
|
||||
Disk cloning means copying data from a hard disk to another one and you can do this by simple copy & paste. But you cannot copy the hidden files and folders and not the in-use files too. That's when you need a cloning software which can also help you in saving a back-up image from your files and folders. The cloning software takes all disk data, convert them into a single .img file and you can copy it to another hard drive. Here we give you the best 10 Open Source Cloning software:
|
||||
|
||||
### 1. [Clonezilla][1]: ###
|
||||
|
||||
Clonezilla is a Live CD based on Ubuntu and Debian. It clones all your hard drive data and take a backup just like Norton Ghost on Windows but in a more effective way. Clonezilla support many filesystems like ext2, ext3, ext4, btrfs, xfs and others. It also supports BIOS, UEFI, MPR and GPT partitions.
|
||||
|
||||

|
||||
|
||||
### 2. [Redo Backup][2]: ###
|
||||
|
||||
Redo Bakcup is another Live CD tool which clones your drivers easily. It is free and Open Source Live System which has its licence under GPL 3. Its main features include easy GUI boots from CD, no installation, restoration of Linux and Windows systems, access to files with out any log-in, recovery of deleted files and more.
|
||||
|
||||

|
||||
|
||||
### 3. [Mondo Rescue][3]: ###
|
||||
|
||||
Mondo doesn't work like other software. It doesn’t convert your hard drivers into an .img file. It converts them into an .iso image and with Mondo you can also create a custom Live CD using “mindi” which is a special tool developed by Mondo Rescue to clone your data from the Live CD. It supports most Linux distributions, FreeBSD, and it is licensed under GPL.
|
||||
|
||||

|
||||
|
||||
### 4. [Partimage][4]: ###
|
||||
|
||||
This is an open-source software backup, which works under Linux system, by default. It's also available to install from the package manager for most Linux distributions and if you don’t have a Linux system then you can use “SystemRescueCd”. It is a Live CD which includes Partimage by default to do the cloning process that you want. Partimage is very fast in cloning hard drivers.
|
||||
|
||||

|
||||
|
||||
### 5. [FSArchiver][5]: ###
|
||||
|
||||
FSArchiver is a follow-up to Partimage, and it is again a good tool to clone hard disks. It supports cloning Ext4 partitions and NTFS partitions, basic file attributes like owner, permissions, extended attributes like those used by SELinux, basic file system attributes for all Linux file systems and so on.
|
||||
|
||||
### 6. [Partclone][6]: ###
|
||||
|
||||
Partclone is a free tool which clones and restores partitions. Written in C it first appeared in 2007 and it supports many filesystems like ext2, ext3, ext4, xfs, nfs, reiserfs, reiser4, hfs+, btrfs. It is very simple to use and it's licensed under GPL.
|
||||
|
||||
### 7. [doClone][7]: ###
|
||||
|
||||
doClone is a free software project which is developed to clone Linux system partitions easily. It's written in C++ and it supports up to 12 different filesystems. It can preform Grub bootloader restoration and can also transform the clone image to another computer via LAN. It also provides support to live cloning which means you will eb able to clone from the system even if it's running.
|
||||
|
||||

|
||||
|
||||
### 8. [Macrium Reflect Free Edition][8]: ###
|
||||
|
||||
Macrium Reflect Free Edition is claimed to be one of the fastest disk cloning utilities which supports only Windows file systems. It is a fairly straightforward user interface. This software does disk imaging and disk cloning and also allows you to access images from the file manager. It allows you to create a Linux rescue CD and it is compatible with Windows Vista and 7.
|
||||
|
||||

|
||||
|
||||
### 9. [DriveImage XML][9]: ###
|
||||
|
||||
DriveImage XML uses Microsoft VSS for creation of images, quite reliably. With this software you can create "hot" images from a disk, which is still running. XML files store images, which means you can access them from any supporting third-party software. DriveImage XML also allows restoring an image to a machine without any reboot. This software is also compatible with Windows XP, Windows Server 2003, Vista, and 7.
|
||||
|
||||

|
||||
|
||||
### 10. [Paragon Backup & Recovery Free][10]: ###
|
||||
|
||||
Paragon Backup & Recovery Free does a great job when it comes to managing scheduled imaging. This is a free software but it's for personal use only.
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.efytimes.com/e1/fullnews.asp?edid=148039
|
||||
|
||||
作者:Sanchari Banerjee
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://clonezilla.org/
|
||||
[2]:http://redobackup.org/
|
||||
[3]:http://www.mondorescue.org/
|
||||
[4]:http://www.partimage.org/Main_Page
|
||||
[5]:http://www.fsarchiver.org/Main_Page
|
||||
[6]:http://www.partclone.org/
|
||||
[7]:http://doclone.nongnu.org/
|
||||
[8]:http://www.macrium.com/reflectfree.aspx
|
||||
[9]:http://www.runtime.org/driveimage-xml.htm
|
||||
[10]:http://www.paragon-software.com/home/br-free/
|
||||
@ -1,66 +0,0 @@
|
||||
zpl1025
|
||||
What Linux Users Should Know About Open Hardware
|
||||
================================================================================
|
||||
> What Linux users don't know about manufacturing open hardware can lead them to disappointment.
|
||||
|
||||
Business and free software have been intertwined for years, but the two often misunderstand one another. That's not surprising -- what is just a business to one is way of life for the other. But the misunderstanding can be painful, which is why debunking it is a worth the effort.
|
||||
|
||||
An increasingly common case in point: the growing attempts at open hardware, whether from Canonical, Jolla, MakePlayLive, or any of half a dozen others. Whether pundit or end-user, the average free software user reacts with exaggerated enthusiasm when a new piece of hardware is announced, then retreats into disillusionment as delay follows delay, often ending in the cancellation of the entire product.
|
||||
|
||||
It's a cycle that does no one any good, and often breeds distrust – and all because the average Linux user has no idea what's happening behind the news.
|
||||
|
||||
My own experience with bringing products to market is long behind me. However, nothing I have heard suggests that anything has changed. Bringing open hardware or any other product to market remains not just a brutal business, but one heavily stacked against newcomers.
|
||||
|
||||
### Searching for Partners ###
|
||||
|
||||
Both the manufacturing and distribution of digital products is controlled by a relatively small number of companies, whose time can sometimes be booked months in advance. Profit margins can be tight, so like movie studios that buy the rights to an ancient sit-com, the manufacturers usually hope to clone the success of the latest hot product. As Aaron Seigo told me when talking about his efforts to develop the Vivaldi tablet, the manufacturers would much rather prefer someone else take the risk of doing anything new.
|
||||
|
||||
Not only that, but they would prefer to deal with someone with an existing sales record who is likely to bring repeat business.
|
||||
|
||||
Besides, the average newcomer is looking at a product run of a few thousand units. A chip manufacturer would much rather deal with Apple or Samsung, whose order is more likely in the hundreds of thousands.
|
||||
|
||||
Faced with this situation, the makers of open hardware are likely to find themselves cascading down into the list of manufacturers until they can find a second or third tier manufacturer that is willing to take a chance on a small run of something new.
|
||||
|
||||
They might be reduced to buying off-the-shelf components and assembling units themselves, as Seigo tried with Vivaldi. Alternatively, they might do as Canonical did, and find established partners that encourage the industry to take a gamble. Even if they succeed, they have usually taken months longer than they expected in their initial naivety.
|
||||
|
||||
### Staggering to Market ###
|
||||
|
||||
However, finding a manufacturer is only the first obstacle. As Raspberry Pi found out, even if the open hardware producers want only free software in their product, the manufacturers will probably insist that firmware or drivers stay proprietary in the name of protecting trade secrets.
|
||||
|
||||
This situation is guaranteed to set off criticism from potential users, but the open hardware producers have no choice except to compromise their vision. Looking for another manufacturer is not a solution, partly because to do so means more delays, but largely because completely free-licensed hardware does not exist. The industry giants like Samsung have no interest in free hardware, and, being new, the open hardware producers have no clout to demand any.
|
||||
|
||||
Besides, even if free hardware was available, manufacturers could probably not guarantee that it would be used in the next production run. The producers might easily find themselves re-fighting the same battle every time they needed more units.
|
||||
|
||||
As if all this is not enough, at this point the open hardware producer has probably spent 6-12 months haggling. The chances are, the industry standards have shifted, and they may have to start from the beginning again by upgrading specs.
|
||||
|
||||
### A Short and Brutal Shelf Life ###
|
||||
|
||||
Despite these obstacles, hardware with some degree of openness does sometimes get released. But remember the challenges of finding a manufacturer? They have to be repeated all over again with the distributors -- and not just once, but region by region.
|
||||
|
||||
Typically, the distributors are just as conservative as the manufacturers, and just as cautious about dealing with newcomers and new ideas. Even if they agree to add a product to their catalog, the distributors can easily decide not to encourage their representatives to promote it, which means that in a few months they have effectively removed it from the shelves.
|
||||
|
||||
Of course, online sales are a possibility. But meanwhile, the hardware has to be stored somewhere, adding to the cost. Production runs on demand are expensive even in the unlikely event that they are available, and even unassembled units need storage.
|
||||
|
||||
### Weighing the Odds ###
|
||||
|
||||
I have been generalizing wildly here, but anyone who has ever been involved in producing anything will recognize what I am describing as the norm. And just to make matters worse, open hardware producers typically discover the situation as they are going through it. Inevitably, they make mistakes, which adds still more delays.
|
||||
|
||||
But the point is, if you have any sense of the process at all, your knowledge is going to change how you react to news of another attempt at hardware. The process means that, unless a company has been in serious stealth mode, an announcement that a product will be out in six months will rapidly prove to be an outdate guestimate. 12-18 months is more likely, and the obstacles I describe may mean that the product will never actually be released.
|
||||
|
||||
For example, as I write, people are waiting for the emergence of the first Steam Machines, the Linux-based gaming consoles. They are convinced that the Steam Machines will utterly transform both Linux and gaming.
|
||||
|
||||
As a market category, Steam Machines may do better than other new products, because those who are developing them at least have experience developing software products. However, none of the dozen or so Steam Machines in development have produced more than a prototype after almost a year, and none are likely to be available for buying until halfway through 2015. Given the realities of hardware manufacturing, we will be lucky if half of them see daylight. In fact, a release of 2-4 might be more realistic.
|
||||
|
||||
I make that prediction with next to no knowledge of any of the individual efforts. But, having some sense of how hardware manufacturing works, I suspect that it is likely to be closer to what happens next year than all the predictions of a new Golden Age for Linux and gaming. I would be entirely happy being wrong, but the fact remains: what is surprising is not that so many Linux-associated hardware products fail, but that any succeed even briefly.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/what-linux-users-should-know-about-open-hardware-1.html
|
||||
|
||||
作者:[Bruce Byfield][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Bruce-Byfield-6030.html
|
||||
@ -1,201 +0,0 @@
|
||||
诗诗来翻译!disylee
|
||||
How to configure a network printer and scanner on Ubuntu desktop
|
||||
================================================================================
|
||||
In a [previous article][1](注:这篇文章在2014年8月12号的原文里做过,不知道翻译了没有,如果翻译发布了,发布此文章的时候可改成翻译后的链接), we discussed how to install several kinds of printers (and also a network scanner) in a Linux server. Today we will deal with the other end of the line: how to access the network printer/scanner devices from a desktop client.
|
||||
|
||||
### Network Environment ###
|
||||
|
||||
For this setup, our server's (Debian Wheezy 7.2) IP address is 192.168.0.10, and our client's (Ubuntu 12.04) IP address is 192.168.0.105. Note that both boxes are on the same network (192.168.0.0/24). If we want to allow printing from other networks, we need to modify the following section in the cupsd.conf file on the sever:
|
||||
|
||||
<Location />
|
||||
Order allow,deny
|
||||
Allow localhost
|
||||
Allow from XXX.YYY.ZZZ.*
|
||||
</Location>
|
||||
|
||||
(in the above example, we grant access to the printer from localhost and from any system whose IPv4 address starts with XXX.YYY.ZZZ)
|
||||
|
||||
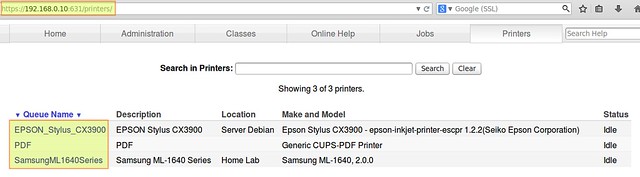
To verify which printers are available on our server, we can either use lpstat command on the server, or browse to the https://192.168.0.10:631/printers page.
|
||||
|
||||
root@debian:~# lpstat -a
|
||||
|
||||
----------
|
||||
|
||||
EPSON_Stylus_CX3900 accepting requests since Mon 18 Aug 2014 10:49:33 AM WARST
|
||||
PDF accepting requests since Mon 06 May 2013 04:46:11 PM WARST
|
||||
SamsungML1640Series accepting requests since Wed 13 Aug 2014 10:13:47 PM WARST
|
||||
|
||||
|
||||
|
||||
### Installing Network Printers in Ubuntu Desktop ###
|
||||
|
||||
In our Ubuntu 12.04 client, we will open the "Printing" menu (Dash -> Printing). Note that in other distributions the name may differ a little (such as "Printers" or "Print & Fax", for example):
|
||||
|
||||

|
||||
|
||||
No printers have been added to our Ubuntu client yet:
|
||||
|
||||

|
||||
|
||||
Here are the steps to install a network printer on Ubuntu desktop client.
|
||||
|
||||
**1)** The "Add" button will fire up the "New Printer" menu. We will choose "Network printer" -> "Find Network Printer" and enter the IP address of our server, then click "Find":
|
||||
|
||||

|
||||
|
||||
**2)** At the bottom we will see the names of the available printers. Let's choose the Samsung printer and press "Forward":
|
||||
|
||||

|
||||
|
||||
**3)** We will be asked to fill in some information about our printer. When we're done, we'll click on "Apply":
|
||||
|
||||

|
||||
|
||||
**4)** We will then be asked whether we want to print a test page. Let’s click on "Print test page":
|
||||
|
||||
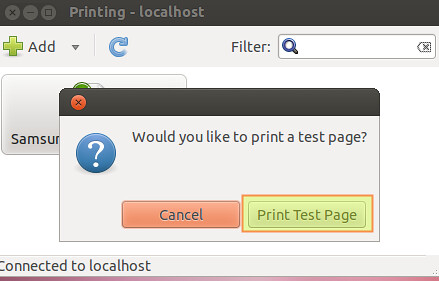
|
||||
|
||||
The print job was created with local id 2:
|
||||
|
||||

|
||||
|
||||
5) Using our server's CUPS web interface, we can observe that the print job has been submitted successfully (Printers -> SamsungML1640Series -> Show completed jobs):
|
||||
|
||||

|
||||
|
||||
We can also display this same information by running the following command on the printer server:
|
||||
|
||||
root@debian:~# cat /var/log/cups/page_log | grep -i samsung
|
||||
|
||||
----------
|
||||
|
||||
SamsungML1640Series root 27 [13/Aug/2014:22:15:34 -0300] 1 1 - localhost Test Page - -
|
||||
SamsungML1640Series gacanepa 28 [18/Aug/2014:11:28:50 -0300] 1 1 - 192.168.0.105 Test Page - -
|
||||
SamsungML1640Series gacanepa 29 [18/Aug/2014:11:45:57 -0300] 1 1 - 192.168.0.105 Test Page - -
|
||||
|
||||
The page_log log file shows every page that has been printed, along with the user who sent the print job, the date & time, and the client's IPv4 address.
|
||||
|
||||
To install the Epson inkjet and PDF printers, we need to repeat steps 1 through 5, and choose the right print queue each time. For example, in the image below we are selecting the PDF printer:
|
||||
|
||||

|
||||
|
||||
However, please note that according to the [CUPS-PDF documentation][2], by default:
|
||||
|
||||
> PDF files will be placed in subdirectories named after the owner of the print job. In case the owner cannot be identified (i.e. does not exist on the server) the output is placed in the directory for anonymous operation (if not disabled in cups-pdf.conf - defaults to /var/spool/cups-pdf/ANONYMOUS/).
|
||||
|
||||
These default directories can be modified by changing the value of the **Out** and **AnonDirName** variables in the /etc/cups/cups-pdf.conf file. Here, ${HOME} is expanded to the user's home directory:
|
||||
|
||||
Out ${HOME}/PDF
|
||||
AnonDirName /var/spool/cups-pdf/ANONYMOUS
|
||||
|
||||
### Network Printing Examples ###
|
||||
|
||||
#### Example #1 ####
|
||||
|
||||
Printing from Ubuntu 12.04, logged on locally as gacanepa (an account with the same name exists on the printer server).
|
||||
|
||||

|
||||
|
||||
After printing to the PDF printer, let's check the contents of the /home/gacanepa/PDF directory on the printer server:
|
||||
|
||||
root@debian:~# ls -l /home/gacanepa/PDF
|
||||
|
||||
----------
|
||||
|
||||
total 368
|
||||
-rw------- 1 gacanepa gacanepa 279176 Aug 18 13:49 Test_Page.pdf
|
||||
-rw------- 1 gacanepa gacanepa 7994 Aug 18 13:50 Untitled1.pdf
|
||||
-rw------- 1 gacanepa gacanepa 74911 Aug 18 14:36 Welcome_to_Conference_-_Thomas_S__Monson.pdf
|
||||
|
||||
The PDF files are created with permissions set to 600 (-rw-------), which means that only the owner (gacanepa in this case) can have access to them. We can change this behavior by editing the value of the **UserUMask** variable in the /etc/cups/cups-pdf.conf file. For example, a umask of 0033 will cause the PDF printer to create files with all permissions for the owner, but read-only privileges to all others.
|
||||
|
||||
root@debian:~# grep -i UserUMask /etc/cups/cups-pdf.conf
|
||||
|
||||
----------
|
||||
|
||||
### Key: UserUMask
|
||||
UserUMask 0033
|
||||
|
||||
For those unfamiliar with umask (aka user file-creation mode mask), it acts as a set of permissions that can be used to control the default file permissions that are set for new files when they are created. Given a certain umask, the final file permissions are calculated by performing a bitwise boolean AND operation between the file base permissions (0666) and the unary bitwise complement of the umask. Thus, for a umask set to 0033, the default permissions for new files will be NOT (0033) AND 0666 = 644 (read / write / execute privileges for the owner, read-only for all others.
|
||||
|
||||
### Example #2 ###
|
||||
|
||||
Printing from Ubuntu 12.04, logged on locally as jdoe (an account with the same name doesn't exist on the server).
|
||||
|
||||
|
||||
|
||||
root@debian:~# ls -l /var/spool/cups-pdf/ANONYMOUS
|
||||
|
||||
----------
|
||||
|
||||
total 5428
|
||||
-rw-rw-rw- 1 nobody nogroup 5543070 Aug 18 15:57 Linux_-_Wikipedia__the_free_encyclopedia.pdf
|
||||
|
||||
The PDF files are created with permissions set to 666 (-rw-rw-rw-), which means that everyone has access to them. We can change this behavior by editing the value of the **AnonUMask** variable in the /etc/cups/cups-pdf.conf file.
|
||||
|
||||
At this point, you may be wondering about this: Why bother to install a network PDF printer when most (if not all) current Linux desktop distributions come with a built-in "Print to file" utility that allows users to create PDF files on-the-fly?
|
||||
|
||||
There are a couple of benefits of using a network PDF printer:
|
||||
|
||||
- A network printer (of whatever kind) lets you print directly from the command line without having to open the file first.
|
||||
- In a network with other operating system installed on the clients, a PDF network printer spares the system administrator from having to install a PDF creator utility on each individual machine (and also the danger of allowing end-users to install such tools).
|
||||
- The network PDF printer allows to print directly to a network share with configurable permissions, as we have seen.
|
||||
|
||||
### Installing a Network Scanner in Ubuntu Desktop ###
|
||||
|
||||
Here are the steps to installing and accessing a network scanner from Ubuntu desktop client. It is assumed that the network scanner server is already up and running as described [here][3].
|
||||
|
||||
**1)** Let us first check whether there is a scanner available on our Ubuntu client host. Without any prior setup, you will see the message saying that "No scanners were identified."
|
||||
|
||||
$ scanimage -L
|
||||
|
||||

|
||||
|
||||
**2)** Now we need to enable saned daemon which comes pre-installed on Ubuntu desktop. To enable it, we need to edit the /etc/default/saned file, and set the RUN variable to yes:
|
||||
|
||||
$ sudo vim /etc/default/saned
|
||||
|
||||
----------
|
||||
|
||||
# Set to yes to start saned
|
||||
RUN=yes
|
||||
|
||||
**3)** Let's edit the /etc/sane.d/net.conf file, and add the IP address of the server where the scanner is installed:
|
||||
|
||||
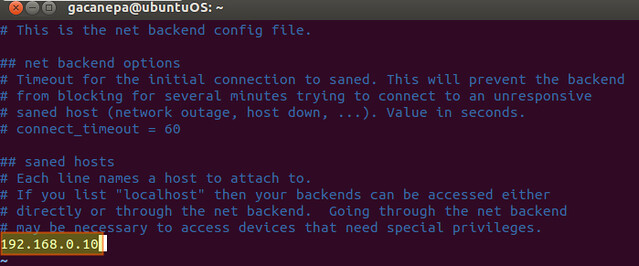
|
||||
|
||||
**4)** Restart saned:
|
||||
|
||||
$ sudo service saned restart
|
||||
|
||||
**5)** Let's see if the scanner is available now:
|
||||
|
||||

|
||||
|
||||
Now we can open "Simple Scan" (or other scanning utility) and start scanning documents. We can rotate, crop, and save the resulting image:
|
||||
|
||||

|
||||
|
||||
### Summary ###
|
||||
|
||||
Having one or more network printers and scanner is a nice convenience in any office or home network, and offers several advantages at the same time. To name a few:
|
||||
|
||||
- Multiple users (connecting from different platforms / places) are able to send print jobs to the printer's queue.
|
||||
- Cost and maintenance savings can be achieved due to hardware sharing.
|
||||
|
||||
I hope this article helps you make use of those advantages.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/configure-network-printer-scanner-ubuntu-desktop.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
[1]:http://xmodulo.com/2014/08/usb-network-printer-and-scanner-server-debian.html
|
||||
[2]:http://www.cups-pdf.de/documentation.shtml
|
||||
[3]:http://xmodulo.com/2014/08/usb-network-printer-and-scanner-server-debian.html#scanner
|
||||
@ -1,138 +0,0 @@
|
||||
johnhoow translating...
|
||||
# Practical Lessons in Peer Code Review #
|
||||
|
||||
Millions of years ago, apes descended from the trees, evolved opposable thumbs and—eventually—turned into human beings.
|
||||
|
||||
We see mandatory code reviews in a similar light: something that separates human from beast on the rolling grasslands of the software
|
||||
development savanna.
|
||||
|
||||
Nonetheless, I sometimes hear comments like these from our team members:
|
||||
|
||||
"Code reviews on this project are a waste of time."
|
||||
"I don't have time to do code reviews."
|
||||
"My release is delayed because my dastardly colleague hasn't done my review yet."
|
||||
"Can you believe my colleague wants me to change something in my code? Please explain to them that the delicate balance of the universe will
|
||||
be disrupted if my pristine, elegant code is altered in any way."
|
||||
|
||||
### Why do we do code reviews? ###
|
||||
|
||||
Let us remember, first of all, why we do code reviews. One of the most important goals of any professional software developer is to
|
||||
continually improve the quality of their work. Even if your team is packed with talented programmers, you aren't going to distinguish
|
||||
yourselves from a capable freelancer unless you work as a team. Code reviews are one of the most important ways to achieve this. In
|
||||
particular, they:
|
||||
|
||||
provide a second pair of eyes to find defects and better ways of doing something.
|
||||
ensure that at least one other person is familiar with your code.
|
||||
help train new staff by exposing them to the code of more experienced developers.
|
||||
promote knowledge sharing by exposing both the reviewer and reviewee to the good ideas and practices of the other.
|
||||
encourage developers to be more thorough in their work since they know it will be reviewed by one of their colleagues.
|
||||
|
||||
### Doing thorough reviews ###
|
||||
|
||||
However, these goals cannot be achieved unless appropriate time and care are devoted to reviews. Just scrolling through a patch, making sure
|
||||
that the indentation is correct and that all the variables use lower camel case, does not constitute a thorough code review. It is
|
||||
instructive to consider pair programming, which is a fairly popular practice and adds an overhead of 100% to all development time, as the
|
||||
baseline for code review effort. You can spend a lot of time on code reviews and still use much less overall engineer time than pair
|
||||
programming.
|
||||
|
||||
My feeling is that something around 25% of the original development time should be spent on code reviews. For example, if a developer takes
|
||||
two days to implement a story, the reviewer should spend roughly four hours reviewing it.
|
||||
|
||||
Of course, it isn't primarily important how much time you spend on a review as long as the review is done correctly. Specifically, you must
|
||||
understand the code you are reviewing. This doesn't just mean that you know the syntax of the language it is written in. It means that you
|
||||
must understand how the code fits into the larger context of the application, component or library it is part of. If you don't grasp all the
|
||||
implications of every line of code, then your reviews are not going to be very valuable. This is why good reviews cannot be done quickly: it
|
||||
takes time to investigate the various code paths that can trigger a given function, to ensure that third-party APIs are used correctly
|
||||
(including any edge cases) and so forth.
|
||||
|
||||
In addition to looking for defects or other problems in the code you are reviewing, you should ensure that:
|
||||
|
||||
All necessary tests are included.
|
||||
Appropriate design documentation has been written.
|
||||
Even developers who are good about writing tests and documentation don't always remember to update them when they change their code. A
|
||||
gentle nudge from the code reviewer when appropriate is vital to ensure that they don't go stale over time.
|
||||
|
||||
### Preventing code review overload ###
|
||||
|
||||
If your team does mandatory code reviews, there is the danger that your code review backlog will build up to the point where it is
|
||||
unmanageable. If you don't do any reviews for two weeks, you can easily have several days of reviews to catch up on. This means that your
|
||||
own development work will take a large and unexpected hit when you finally decide to deal with them. It also makes it a lot harder to do
|
||||
good reviews since proper code reviews require intense and sustained mental effort. It is difficult to keep this up for days on end.
|
||||
|
||||
For this reason, developers should strive to empty their review backlog every day. One approach is to tackle reviews first thing in the
|
||||
morning. By doing all outstanding reviews before you start your own development work, you can keep the review situation from getting out of
|
||||
hand. Some might prefer to do reviews before or after the midday break or at the end of the day. Whenever you do them, by considering code
|
||||
reviews as part of your regular daily work and not a distraction, you avoid:
|
||||
|
||||
Not having time to deal with your review backlog.
|
||||
Delaying a release because your reviews aren't done yet.
|
||||
Posting reviews that are no longer relevant since the code has changed so much in the meantime.
|
||||
Doing poor reviews since you have to rush through them at the last minute.
|
||||
|
||||
### Writing reviewable code ###
|
||||
|
||||
The reviewer is not always the one responsible for out-of-control review backlogs. If my colleague spends a week adding code willy-nilly
|
||||
across a large project then the patch they post is going to be really hard to review. There will be too much to get through in one session.
|
||||
It will be difficult to understand the purpose and underlying architecture of the code.
|
||||
|
||||
This is one of many reasons why it is important to split your work into manageable units. We use scrum methodology so the appropriate unit
|
||||
for us is the story. By making an effort to organize our work by story and submit reviews that pertain only to the specific story we are
|
||||
working on, we write code that is much easier to review. Your team may use another methodology but the principle is the same.
|
||||
|
||||
There are other prerequisites to writing reviewable code. If there are tricky architectural decisions to be made, it makes sense to meet
|
||||
with the reviewer beforehand to discuss them. This will make it much easier for the reviewer to understand your code, since they will know
|
||||
what you are trying to achieve and how you plan to achieve it. This also helps avoid the situation where you have to rewrite large swathes
|
||||
of code after the reviewer suggests a different and better approach.
|
||||
|
||||
Project architecture should be described in detail in your design documentation. This is important anyway since it enables a new project
|
||||
member to get up to speed and understand the existing code base. It has the further advantage of helping a reviewer to do their job
|
||||
properly. Unit tests are also helpful in illustrating to the reviewer how components should be used.
|
||||
|
||||
If you are including third-party code in your patch, commit it separately. It is much harder to review code properly when 9000 lines of
|
||||
jQuery are dropped into the middle.
|
||||
|
||||
One of the most important steps for creating reviewable code is to annotate your code reviews. This means that you go through the review
|
||||
yourself and add comments anywhere you feel that this will help the reviewer to understand what is going on. I have found that annotating
|
||||
code takes relatively little time (often just a few minutes) and makes a massive difference in how quickly and well the code can be
|
||||
reviewed. Of course, code comments have many of the same advantages and should be used where appropriate, but often a review annotation
|
||||
makes more sense. As a bonus, studies have shown that developers find many defects in their own code while rereading and annotating it.
|
||||
|
||||
### Large code refactorings ###
|
||||
|
||||
Sometimes it is necessary to refactor a code base in a way that affects many components. In the case of a large application, this can take
|
||||
several days (or more) and result in a huge patch. In these cases a standard code review may be impractical.
|
||||
|
||||
The best solution is to refactor code incrementally. Figure out a partial change of reasonable scope that results in a working code base and
|
||||
brings you in the direction you want to go. Once that change has been completed and a review posted, proceed to a second incremental change
|
||||
and so forth until the full refactoring has been completed. This might not always be possible, but with thought and planning it is usually
|
||||
realistic to avoid massive monolithic patches when refactoring. It might take more time for the developer to refactor in this way, but it
|
||||
also leads to better quality code as well as making reviews much easier.
|
||||
|
||||
If it really isn't possible to refactor code incrementally (which probably says something about how well the original code was written and
|
||||
organized), one solution might be to do pair programming instead of code reviews while working on the refactoring.
|
||||
|
||||
### Resolving disputes ###
|
||||
|
||||
Your team is doubtless made up of intelligent professionals, and in almost all cases it should be possible to come an agreement when
|
||||
opinions about a specific coding question differ. As a developer, keep an open mind and be prepared to compromise if your reviewer prefers a
|
||||
different approach. Don't take a proprietary attitude to your code and don't take review comments personally. Just because someone feels
|
||||
that you should refactor some duplicated code into a reusable function, it doesn't mean that you are any less of an attractive, brilliant
|
||||
and charming individual.
|
||||
|
||||
As a reviewer, be tactful. Before suggesting changes, consider whether your proposal is really better or just a matter of taste. You will
|
||||
have more success if you choose your battles and concentrate on areas where the original code clearly requires improvement. Say things like
|
||||
"it might be worth considering..." or "some people recommend..." instead of "my pet hamster could write a more efficient sorting algorithm
|
||||
than this."
|
||||
|
||||
If you really can't find middle ground, ask a third developer who both of you respect to take a look and give their opinion.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.salsitasoft.com/practical-lessons-in-peer-code-review/
|
||||
作者:[Matt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
su-kaiyao translating
|
||||
|
||||
Simple guide to forks in GitHub and Git
|
||||
==========================================
|
||||
|
||||
@ -55,4 +57,4 @@ I hope this was a helpful overview of [forking](https://help.github.com/articles
|
||||
|
||||
If you are new to Git and this style of learning appeals to you, I highly recommend the first two chapters of the book [Pro Git](http://git-scm.com/book), which is available online for free.
|
||||
|
||||
If you enjoy learning via videos, I created a [11-part video series](http://www.dataschool.io/git-and-github-videos-for-beginners/) (36 minutes total) introducing Git and GitHub to beginners.
|
||||
If you enjoy learning via videos, I created a [11-part video series](http://www.dataschool.io/git-and-github-videos-for-beginners/) (36 minutes total) introducing Git and GitHub to beginners.
|
||||
|
||||
@ -0,0 +1,106 @@
|
||||
[felixonmars translating...]
|
||||
|
||||
How to configure peer-to-peer VPN on Linux
|
||||
================================================================================
|
||||
A traditional VPN (e.g., OpenVPN, PPTP) is composed of a VPN server and one or more VPN clients connected to the server. When any two VPN clients talk to each other, the VPN server needs to relay VPN traffic between them. The problem of such a hub-and-spoke type of VPN topology is that the VPN server can easily become a performance bottleneck as the number of connected clients increases. The centralized VPN server is also a single point of failure in a sense that if the VPN server goes down, the entire VPN is no longer accessible to any VPN client.
|
||||
|
||||
Peer-to-peer VPN (or P2P VPN) is an alternative VPN model that addresses these problems of the traditional server-client based VPN. In a P2P VPN, there is no longer a centralized VPN server. Any node with a public IP address can bootstrap other nodes into a VPN. Once connected to a VPN, each node can communicate with any other node in the VPN directly, without going through an intermediary server node. When any one node goes down, the rest of nodes in the VPN are not affected. Inter-node latency/bandwidth and VPN scalability naturally improve in such a setting, which is desirable if you want to use a VPN for multi-player gaming or file sharing among many friends.
|
||||
|
||||
There are several open-source implementations of P2P VPN, such as [Tinc][1], peerVPN, and [n2n][2]. In this tutorial, I am going to demonstrate **how to configure a peer-to-peer VPN using** n2n **on Linux**.
|
||||
|
||||
n2n is an open-source (GPLv3) software allowing you to construct an encrypted layer-2/3 peer-to-peer VPN among users. The VPN created by n2n is "NAT-friendly," which means that two users behind different NAT routers can directly talk to each other over the VPN. n2n supports symmetric NAT type which is the most restrictive form of NAT. For that, the VPN traffic of n2n is encapsulated by UDP.
|
||||
|
||||
A n2n VPN is composed of two kinds of nodes: edge node and super node. An edge node is a computer which is connected to a VPN, potentially from behind a NAT router. A super node is a computer with a publicly reachable IP address, which assists with initial signaling for NATed edges. To create a P2P VPN among users, we need at least one super node.
|
||||
|
||||

|
||||
|
||||
### Preparation ###
|
||||
|
||||
In this tutorial, I am going to set up a P2P VPN using three nodes: one super node, and two edge nodes. The only requirement is that edge nodes be able to ping the IP address of the super node. It does not matter whether the edge nodes are behind NAT routers or not.
|
||||
|
||||
### Install n2n on Linux ###
|
||||
|
||||
To construct a P2P VPN using n2n, you need to install n2n on every edge node as well as super node.
|
||||
|
||||
Due to its minimal dependency requirements, n2n can be built easily on most Linux platforms.
|
||||
|
||||
To install n2n on Debian-based system:
|
||||
|
||||
$ sudo apt-get install subversion build-essential libssl-dev
|
||||
$ svn co https://svn.ntop.org/svn/ntop/trunk/n2n
|
||||
$ cd n2n/n2n_v2
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
To install n2n on Red Hat-based system:
|
||||
|
||||
$ sudo yum install subversion gcc-c++ openssl-devel
|
||||
$ svn co https://svn.ntop.org/svn/ntop/trunk/n2n
|
||||
$ cd n2n/n2n_v2
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
### Configure a P2P VPN with n2n ###
|
||||
|
||||
As mentioned before, we need to set up at least one super node which acts as an initial bootstraping server. We assume that the IP address of the super node is 1.1.1.1.
|
||||
|
||||
#### Super node: ####
|
||||
|
||||
On a computer which acts as a super node, run the following command. The "-l <port>" specifies the listening port of the super node. No root privilege is required to run supernode.
|
||||
|
||||
$ supernode -l 5000
|
||||
|
||||
#### Edge node: ####
|
||||
|
||||
On each edge node, use the following command to connect to a P2P VPN. The edge daemon will be running in the background.
|
||||
|
||||
Edge node #1:
|
||||
|
||||
$ sudo edge -d edge0 -a 10.0.0.10 -c mynetwork -u 1000 -g 1000 -k password -l 1.1.1.1:5000 -m ae:e0:4f:e7:47:5b
|
||||
|
||||
Edge node #2:
|
||||
|
||||
$ sudo edge -d edge0 -a 10.0.0.11 -c mynetwork -u 1000 -g 1000 -k password -l 1.1.1.1:5000 -m ae:e0:4f:e7:47:5c
|
||||
|
||||
Here are some explanations on the command-line.
|
||||
|
||||
- The "-d <name>" option specifies the name of a TAP interface being created by edge command.
|
||||
- The "-a <IP-address>" option defines (statically) the VPN IP address to be assigned to the TAP interface. If you want to use DHCP, you need to set up a DHCP server on one of edge nodes, and use "-a dhcp:0.0.0.0" option instead.
|
||||
- The "-c <community-name>" option specifies the name of a VPN group (with a length of up to 16 bytes). This option is used to create multiple VPNs among the same group of nodes.
|
||||
- The "-u" and "-g" options are used to drop root priviledge after creating a TAP interface. The edge daemon will run as the specified user/group ID.
|
||||
- The "-k <key-string>" option specifies a twofish encryption key string to be used. If you want to hide a key-string from the command-line, you can define the key in N2N_KEY environment variable.
|
||||
- The "-l <IP-address:port>" option specifies super node's listening IP address and port number. For redundancy, you can specify up to two different super nodes (e.g., -l <supernode A> -l <supernode B>).
|
||||
- The "-m <mac-address> assigns a static MAC address to a TAP interface. Without this, edge command will randomly generate a MAC address. In fact, hardcoding a static MAC address for a VPN interface is highly recommended. Otherwise, in case you restart edge daemon on a node, ARP cache of other peers will be polluted due to a newly generated MAC addess, and they will not send traffic to the node until the polluted ARP entry is evicted.
|
||||
|
||||
|
||||
|
||||
At this point, you should be able to ping from one edge node to the other using their VPN IP addresses.
|
||||
|
||||
### Troubleshooting ###
|
||||
|
||||
1. You are getting the following error while invoking edge daemon.
|
||||
|
||||
n2n[4405]: ERROR: ioctl() [Operation not permitted][-1]
|
||||
|
||||
Be aware that edge daemon requires superuser privilege when creating a TAP interface. Thus make sure to use root privilege or set SUID for edge command. You can always use "-u" and "-g" option to drop root privilege afterwards.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
n2n can be a quite practical free VPN solution for you. You can easily configure a super node from your own home network or by grabbing a publicly addressable VPS instance from [cloud hosting][3]. Instead of placing sensitive credentials and encryption keys in the hands of a third-party VPN provider, you can use n2n to set up your own low-latency, high bandwidth, scalable P2P VPN among your friends.
|
||||
|
||||
What is your thought on n2n? Share your opinion in the comment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/configure-peer-to-peer-vpn-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/how-to-install-and-configure-tinc-vpn.html
|
||||
[2]:http://www.ntop.org/products/n2n/
|
||||
[3]:http://xmodulo.com/go/digitalocean
|
||||
@ -0,0 +1,157 @@
|
||||
Manage Multiple Logical Volume Management Disks using Striping I/O
|
||||
================================================================================
|
||||
In this article, we are going to see how the logical volumes writes the data to disk by striping I/O. Logical Volume management has one of the cool feature which can write data over multiple disk by striping the I/O.
|
||||
|
||||

|
||||
|
||||
Manage LVM Disks Using Striping I/O
|
||||
|
||||
### What is LVM Striping? ###
|
||||
|
||||
**LVM Striping** is one of the feature which will writes the data over multiple disk, instead of constant write on a single Physical volume.
|
||||
|
||||
#### Features of Striping ####
|
||||
|
||||
- It will increase the performance of disk.
|
||||
- Saves from hard write over and over to a single disk.
|
||||
- Disk fill-up can be reduced using striping over multiple disk.
|
||||
|
||||
In Logical volume management, if we need to create a logical volume the extended will get fully mapped to the volume group and physical volumes. In such situation if one of the **PV** (Physical Volume) gets filled we need to add more extends from other physical volume. Instead, adding more extends to PV, we can point our logical volume to use the particular Physical volumes writing I/O.
|
||||
|
||||
Assume we have **four disks** drives and pointed to four physical volumes, if each physical volume are capable of **100 I/O** totally our volume group will get **400 I/O**.
|
||||
|
||||
If we are not using the **stripe method**, the file system will writes across the underlying physical volume. For example, some data writes to physical volume 100 I/O will be write only to the first (**sdb1**) PV. If we create the logical volume with stripe option while writing, it will write to every four drives by splitting 100 I/O, that means every four drive will receive 25 I/O each.
|
||||
|
||||
This will be done in round robin process. If any one of the logical volume need to be extended, in this situation we can’t add 1 or 2 PV. We have to add all 4 pvs to extend the logical volume size. This is one of the drawback in stripe feature, from this we can know that while creating logical volumes we need to assign the same stripe size over all logical volumes.
|
||||
|
||||
Logical Volume management has these features which we can stripe the data over multiple pvs at the same time. If you are familiar with logical volume you can go head to setup the logical volume stripe. If not then you must need to know about the logical volume managements basics, read below articles to know more about logical volume management.
|
||||
|
||||
#### My Server Setup ####
|
||||
|
||||
Here I’m using **Centos6.5** for my workout. The same steps can be used in RHEL, Oracle Linux, and most of the distributions.
|
||||
|
||||
Operating System : CentOS 6.5
|
||||
IP Address : 192.168.0.222
|
||||
Hostname : tecmint.storage.com
|
||||
|
||||
### Logical Volume management using Striping I/O ###
|
||||
|
||||
For demonstration purpose, I’ve used 4 Hard drives, each drive with 1 GB in Size. Let me show you four drives using ‘**fdisk**‘ command as shown below.
|
||||
|
||||
# fdisk -l | grep sd
|
||||
|
||||

|
||||
|
||||
List Hard Drives
|
||||
|
||||
Now we’ve to create partitions for these 4 hard drives **sdb**, **sdc**, **sdd** and **sde** using ‘**fdisk**‘ command. To create partitions, please follow the **step #4** instructions, given in the **Part 1** of this article (link give above) and make sure you change the type to **LVM (8e)**, while creating partitions.
|
||||
|
||||
# pvcreate /dev/sd[b-e]1 -v
|
||||
|
||||

|
||||
|
||||
Create Physical Volumes in LVM
|
||||
|
||||
Once PV’s created, you can list them using ‘**pvs**‘ command.
|
||||
|
||||
# pvs
|
||||
|
||||

|
||||
|
||||
Verify Physical Volumes
|
||||
|
||||
Now we need to define volume group using those 4 physical volumes. Here I’m defining my volume group with **16MB** of Physical extended size (PE) with volume group named as **vg_strip**.
|
||||
|
||||
# vgcreate -s 16M vg_strip /dev/sd[b-e]1 -v
|
||||
|
||||
The description of above options used in the command.
|
||||
|
||||
- **[b-e]1** – Define your hard drive names such as sdb1, sdc1, sdd1, sde1.
|
||||
- **-s** – Define your physical extent size.
|
||||
- **-v** – verbose.
|
||||
|
||||
Next, verify the newly created volume group using.
|
||||
|
||||
# vgs vg_strip
|
||||
|
||||

|
||||
|
||||
Verify Volume Group
|
||||
|
||||
To get more detailed information about VG, use switch ‘-v‘ with **vgdisplay** command, it will give us a every physical volumes which all used in **vg_strip** volume group.
|
||||
|
||||
# vgdisplay vg_strip -v
|
||||
|
||||

|
||||
|
||||
Volume Group Information
|
||||
|
||||
Back to our topic, now while creating Logical volume, we need to define the stripe value, how data need to write in our logical volumes using stripe method.
|
||||
|
||||
Here I’m creating a logical volume in the name of **lv_tecmint_strp1** with **900MB** size, and it needs to be in **vg_strip** volume group, and I’m defining as 4 stripe, it means the data writes to my logical volume, needs to be stripe over 4 PV’s.
|
||||
|
||||
# lvcreate -L 900M -n lv_tecmint_strp1 -i4 vg_strip
|
||||
|
||||
- **-L** –logical volume size
|
||||
- **-n** –logical volume name
|
||||
- **-i** –stripes
|
||||
|
||||

|
||||
|
||||
Create Logical Volumes
|
||||
|
||||
In the above image, we can see that the default size of stripe-size was **64 KB**, if we need to define our own stripe value, we can use **-I** (Capital I). Just to confirm that the logical volume are created use the following command.
|
||||
|
||||
# lvdisplay vg_strip/lv_tecmint_strp1
|
||||
|
||||

|
||||
|
||||
Confirm Logical Volumes
|
||||
|
||||
Now next question will be, How do we know that stripes are writing to 4 drives?. Here we can use ‘**lvdisplay**‘ and **-m** (display the mapping of logical volumes) command to verify.
|
||||
|
||||
# lvdisplay vg_strip/lv_tecmint_strp1 -m
|
||||
|
||||

|
||||
|
||||
Check Logical Volumes
|
||||
|
||||
To create our defined stripe size, we need to create one logical volume with **1GB** size using my own defined Stripe size of **256KB**. Now I’m going to stripe over only 3 PV’s, here we can define which pvs we want to be striped.
|
||||
|
||||
# lvcreate -L 1G -i3 -I 256 -n lv_tecmint_strp2 vg_strip /dev/sdb1 /dev/sdc1 /dev/sdd1
|
||||
|
||||

|
||||
|
||||
Define Stripe Size
|
||||
|
||||
Next, check the stripe size and which volume does it stripes.
|
||||
|
||||
# lvdisplay vg_strip/lv_tecmint_strp2 -m
|
||||
|
||||

|
||||
|
||||
Check Stripe Size
|
||||
|
||||
It’s time to use a device mapper, for this we use command ‘**dmsetup**‘. It is a low level logical volume management tool which manages logical devices, that use the device-mapper driver. We can see the lvm information using dmsetup command to know the which stripe depends on which drives.
|
||||
|
||||
# dmsetup deps /dev/vg_strip/lv_tecmint_strp[1-2]
|
||||
|
||||

|
||||
|
||||
Device Mapper
|
||||
|
||||
Here we can see that strp1 depend on 4 drives, and strp2 depend on 3 devices.
|
||||
|
||||
Hope you have learnt, that how we can stripe through logical volumes to write the data. For this setup one must know about the basic of logical volume management. In my next article, I will show you how we can migrate in logical volume management, till then stay tuned for updates and don’t forget to give valuable comments about the article.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-multiple-lvm-disks-using-striping-io/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
@ -0,0 +1,209 @@
|
||||
Migrating LVM Partitions to New Logical Volume (Drive) – Part VI
|
||||
================================================================================
|
||||
This is the 6th part of our ongoing Logical Volume Management series, in this article we will show you how to migrate existing logical volumes to other new drive without any downtime. Before moving further, I would like to explain you about LVM Migration and its features.
|
||||
|
||||

|
||||
|
||||
LVM Storage Migration
|
||||
|
||||
### What is LVM Migration? ###
|
||||
|
||||
**LVM** migration is one of the excellent feature, where we can migrate the logical volumes to a new disk without the data-loss and downtime. The purpose of this feature is it to move our data from old disk to a new disk. Usually, we do migrations from one disk to other disk storage, only when an error occur in some disks.
|
||||
|
||||
### Features of Migration ###
|
||||
|
||||
- Moving logical volumes from one disk to other disk.
|
||||
- We can use any type of disk like SATA, SSD, SAS, SAN storage iSCSI or FC.
|
||||
- Migrate disks without data loss and downtime.
|
||||
|
||||
In LVM Migration, we will swap every volumes, file-system and it’s data in the existing storage. For example, if we have a single Logical volume, which has been mapped to one of the physical volume, that physical volume is a physical hard-drive.
|
||||
|
||||
Now if we need to upgrade our server with SSD Hard-drive, what we used to think at first? reformat of disk? No! we don’t have to reformat the server. The LVM has the option to migrate those old SATA Drives with new SSD Drives. The Live migration will support any kind of disks, be it local drive, SAN or Fiber channel too.
|
||||
|
||||
#### My Server Setup ####
|
||||
|
||||
Operating System : CentOS 6.5 Final
|
||||
IP Address : 192.168.0.224
|
||||
System Hostname : lvmmig.tecmintlocal.com
|
||||
|
||||
### Step 1: Check for Present Drives ###
|
||||
|
||||
**1.** Assume we are already having one virtual drive named “**vdb**“, which mapped to one of the logical volume “**tecmint_lv**“. Now we want to migrate this “**vdb**” logical volume drive to some other new storage. Before moving further, first verify that the virtual drive and logical volume names with the help of **fdisk** and lvs commands as shown.
|
||||
|
||||
# fdisk -l | grep vd
|
||||
# lvs
|
||||
|
||||

|
||||
|
||||
Check Logical Volume Disk
|
||||
|
||||
### Step 2: Check for Newly added Drive ###
|
||||
|
||||
**2.** Once we confirm our existing drives, now it’s time to attach our new SSD drive to system and verify newly added drive with the help of fdisk command.
|
||||
|
||||
# fdisk -l | grep dev
|
||||
|
||||

|
||||
|
||||
Check New Added Drive
|
||||
|
||||
**Note**: Did you see in the above screen, that the new drive has been added successfully with name “**/dev/sda**“.
|
||||
|
||||
### Step 3: Check Present Logical and Physical Volume ###
|
||||
|
||||
**3.** Now move forward to create physical volume, volume group and logical volume for migration. Before creating volumes, make sure to check the present logical volume data under **/mnt/lvm** mount point. Use the following commands to list the mounts and check the data.
|
||||
|
||||
# df -h
|
||||
# cd /mnt/lvm
|
||||
# cat tecmint.txt
|
||||
|
||||

|
||||
|
||||
Check Logical Volume Data
|
||||
|
||||
**Note**: For demonstration purpose, we’ve created two files under **/mnt/lvm** mount point, and we migrate these data to a new drive without any downtime.
|
||||
|
||||
**4.** Before migrating, make sure to confirm the names of logical volume and volume group for which physical volume is related to and also confirm which physical volume used to hold this volume group and logical volume.
|
||||
|
||||
# lvs
|
||||
# vgs -o+devices | grep tecmint_vg
|
||||
|
||||

|
||||
|
||||
Confirm Logical Volume Names
|
||||
|
||||
**Note**: Did you see in the above screen, that “**vdb**” holds the volume group **tecmint_vg**.
|
||||
|
||||
### Step 4: Create New Physical Volume ###
|
||||
|
||||
**5.** Before creating Physical Volume in our new added SSD Drive, we need to define the partition using fdisk. Don’t forget to change the Type to LVM(8e), while creating partitions.
|
||||
|
||||
# pvcreate /dev/sda1 -v
|
||||
# pvs
|
||||
|
||||

|
||||
|
||||
Create Physical Volume
|
||||
|
||||
**6.** Next, add the newly created physical volume to existing volume group tecmint_vg using ‘vgextend command’
|
||||
|
||||
# vgextend tecmint_vg /dev/sda1
|
||||
# vgs
|
||||
|
||||

|
||||
|
||||
Add Physical Volume
|
||||
|
||||
**7.** To get the full list of information about volume group use ‘vgdisplay‘ command.
|
||||
|
||||
# vgdisplay tecmint_vg -v
|
||||
|
||||

|
||||
|
||||
List Volume Group Info
|
||||
|
||||
**Note**: In the above screen, we can see at the end of result as our PV has added to the volume group.
|
||||
|
||||
**8.** If in-case, we need to know more information about which devices are mapped, use the ‘**dmsetup**‘ dependency command.
|
||||
|
||||
# lvs -o+devices
|
||||
# dmsetup deps /dev/tecmint_vg/tecmint_lv
|
||||
|
||||
In the above results, there is **1** dependencies (PV) or (Drives) and here **17** were listed. If you want to confirm look into the devices, which has major and minor number of drives that are attached.
|
||||
|
||||
# ls -l /dev | grep vd
|
||||
|
||||

|
||||
|
||||
List Device Information
|
||||
|
||||
**Note**: In the above command, we can see that major number with **252** and minor number **17** is related to **vdb1**. Hope you understood from above command output.
|
||||
|
||||
### Step 5: LVM Mirroring Method ###
|
||||
|
||||
**9.** Now it’s time to do migration using Mirroring method, use ‘**lvconvert**‘ command to migrate data from old logical volume to new drive.
|
||||
|
||||
# lvconvert -m 1 /dev/tecmint_vg/tecmint_lv /dev/sda1
|
||||
|
||||
- **-m** = mirror
|
||||
- **1** = adding a single mirror
|
||||
|
||||

|
||||
|
||||
Mirroring Method Migration
|
||||
|
||||
**Note**: The above migration process will take long time according to our volume size.
|
||||
|
||||
**10.** Once migration process completed, verify the converted mirror.
|
||||
|
||||
# lvs -o+devices
|
||||
|
||||

|
||||
|
||||
Verify Converted Mirror
|
||||
|
||||
**11.** Once you sure that the converted mirror is perfect, you can remove the old virtual disk **vdb1**. The option **-m** will remove the mirror, earlier we’ve used **1** for adding the mirror.
|
||||
|
||||
# lvconvert -m 0 /dev/tecmint_vg/tecmint_lv /dev/vdb1
|
||||
|
||||

|
||||
|
||||
Remove Virtual Disk
|
||||
|
||||
**12.** Once old virtual disk is removed, you can re-check the devices for logical volumes using following command.
|
||||
|
||||
# lvs -o+devices
|
||||
# dmsetup deps /dev/tecmint_vg/tecmint_lv
|
||||
# ls -l /dev | grep sd
|
||||
|
||||

|
||||
|
||||
Check New Mirrored Device
|
||||
|
||||
In the above picture, did you see that our logical volume now depends on **8,1** and has **sda1**. This indicates that our migration process is done.
|
||||
|
||||
**13.** Now verify the files that we’ve migrated from old to new drive. If same data is present at the new drive, that means we have done every steps perfectly.
|
||||
|
||||
# cd /mnt/lvm/
|
||||
# cat tecmin.txt
|
||||
|
||||

|
||||
|
||||
Check Mirrored Data
|
||||
|
||||
**14.** After everything perfectly created, now it’s time to delete the **vdb1** from volume group and later confirm, which devices are depends on our volume group.
|
||||
|
||||
# vgreduce /dev/tecmint_vg /dev/vdb1
|
||||
# vgs -o+devices
|
||||
|
||||
**15.** After removing vdb1 from volume group **tecmint_vg**, still our logical volume is present there because we have migrated it to **sda1** from **vdb1**.
|
||||
|
||||
# lvs
|
||||
|
||||

|
||||
|
||||
Delete Virtual Disk
|
||||
|
||||
### Step 6: LVM pvmove Mirroring Method ###
|
||||
|
||||
**16.** Instead using ‘**lvconvert**’ mirroring command, we use here ‘**pvmove**‘ command with option ‘**-n**‘ (logical volume name) method to mirror data between two devices.
|
||||
|
||||
# pvmove -n /dev/tecmint_vg/tecmint_lv /dev/vdb1 /dev/sda1
|
||||
|
||||
The command is one of the simplest way to mirror the data between two devices, but in real environment **Mirroring** is used more often than **pvmove**.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article, we have seen how to migrate the logical volumes from one drive to other. Hope you have learnt new tricks in logical volume management. For such setup one should must know about the basic of logical volume management. For basic setups, please refer to the links provided on top of the article at requirement section.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/lvm-storage-migration/#comment-331336
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
@ -0,0 +1,79 @@
|
||||
Linux FAQs with Answers--How to burn an ISO or NRG image to a DVD from the command line on Linux
|
||||
================================================================================
|
||||
> **Question**: I need to burn an image file (.iso or .nrg) to a DVD using a DVD writer on my Linux box. Is there a quick and easy way, preferably using a command-line utility, to burn an .iso or .nrg image to a DVD?
|
||||
|
||||
The two most popular formats for image files are ISO (.iso file extension) and NRG (.nrg file extension). The ISO format is a global standard created by ISO (International Organization for Standardization), and therefore is supported natively by most operating systems, allowing a high level of portability. On the other hand, the NRG format is a proprietary format developed by Nero AG, a very popular disc imaging and burning software firm.
|
||||
|
||||
Here is how to burn an .iso or .nrg image to a DVD from the command line on Linux.
|
||||
|
||||
### Convert an NRG Image to ISO Format ###
|
||||
|
||||
Due to ISO's widespread adoption, burning an .iso image to CD/DVD is straightforward. However, burning an .nrg image requires converting the image to .iso format first.
|
||||
|
||||
To convert an .nrg image file to .iso format, you can use nrg2iso, an open source program that converts images created by Nero Burning Rom to standard .iso (ISO9660) files.
|
||||
|
||||
To install **nrg2iso** on Debian and derivatives:
|
||||
|
||||
# aptitude install nrg2iso
|
||||
|
||||
To install **nrg2iso** on Red Hat-based distros:
|
||||
|
||||
# yum install nrg2iso
|
||||
|
||||
On CentOS/RHEL, you need to enable [Repoforge repository][1] before running **yum**.
|
||||
|
||||
Once the nrg2iso package has been installed, use the following command to convert an .nrg image file to .iso format:
|
||||
|
||||
# nrg2iso filename.nrg filename.iso
|
||||
|
||||

|
||||
|
||||
When conversion is complete, an .iso file will appear inside the current working directory:
|
||||
|
||||

|
||||
|
||||
### Burn an .ISO Image File to a DVD ###
|
||||
|
||||
In order to burn an .iso image file to a DVD, we will use a tool called **growisofs**:
|
||||
|
||||
# growisofs -dvd-compat -speed=4 -Z /dev/dvd1=WindowsXPProfessionalSP3Original.iso
|
||||
|
||||
In the above command-line, the "-dvd-compat" option provides maximum media compatibility with DVD-ROM/-Video. In write-once DVD+R or DVD-R context, this results in unappendable recording (closed disk).
|
||||
|
||||
The "-Z /dev/dvd1=filename.iso" option indicates that we burn the .iso file to the media found in the selected device (/dev/dvd1).
|
||||
|
||||
The "-speed=N" parameter specifies a burning speed of a DVD burner, which is directly related to the capability of the drive itself. "-speed=8" will burn at 8x, "-speed=16" at 16x, and so on. Without this parameter, growisofs by default assumes the lowest speed available, which in this case happens to be 4x. You should choose the burning speed from the available speeds in your drive and the type of disks that you have.
|
||||
|
||||
You can find the device name of your DVD burner and its supported writing speed using [this tutorial][2]注:此文在另一篇原文中(20141014 Linux FAQs with Answers--How to detect DVD writer' s device name and its writing speed from the command line on Linux.md),如果也翻译发布了,可修改此链接.
|
||||
|
||||

|
||||
|
||||
When the burning process has been completed, the disk should be automatically ejected from the tray.
|
||||
|
||||
### Check the Integrity of a Burned Media ###
|
||||
|
||||
At this point, you can check the integrity of the burned media by comparing the md5 checksum of the original .iso file with the same checksum of the burned DVD. If both are identical, you can rest assured that the burning was successful.
|
||||
|
||||
However, in case you have converted an .nrg image to .iso using nrg2iso, you need to be aware that nrg2iso creates an .iso file whose size is not a multiple of 2048 (as ordinary .iso files are). Thus, an ordinary comparison between the checksum of this .iso file and the contents of the burned media will differ.
|
||||
|
||||
On the other hand, if you have burned an .iso image that does not come from an .nrg file, you can use the following command to check the integrity of the data recorded in a DVD. Replace "/dev/dvd1" with your own device name.
|
||||
|
||||
# md5sum filename.iso; dd if=/dev/dvd1 bs=2048 count=$(($(stat -c "%s" filename.iso) / 2048)) | md5sum
|
||||
|
||||
The first part of the command (up to the semicolon) calculates the md5 checksum of the .iso file, while the second part reads the contents of the disk present in /dev/dvd1, and pipes them into the md5sum tool. "bs=2048" indicates that dd will use a block sector of 2048 bytes as many times as the size of the original iso file divided by 2048.
|
||||
|
||||

|
||||
|
||||
If the two md5 checksum values are identical, it means that the burned media is valid.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/burn-iso-nrg-image-dvd-command-line.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/how-to-set-up-rpmforge-repoforge-repository-on-centos.html
|
||||
[2]:http://ask.xmodulo.com/detect-dvd-writer-device-name-writing-speed-command-line-linux.html
|
||||
@ -0,0 +1,84 @@
|
||||
Linux FAQs with Answers--How to change date and time from the command line on Linux
|
||||
================================================================================
|
||||
> **Question**: In Linux, how can I change date and time from the command line?
|
||||
|
||||
Keeping the date and time up-to-date in a Linux system is an important responsibility of every Linux user and system administrator. Many applications rely on accurate timing information to operate properly. Besides, inaccurate date and time render timestamp information in log files meaningless, diminishing their usefulness for system inspection and troubleshooting. For production systems, accurate date and time are even more critical. For example, the production in a retail company must be accounted precisely at all times (and stored in a database server) so that the finance department can calculate the expenses and net income of the day, current week, month, and year.
|
||||
|
||||
We must note that there are two kinds of clocks in a Linux machine: the software clock (aka system clock), which is maintained by the kernel, and the (battery-driven) hardware clock, which is used to keep track of time when the machine is powered down. During boot, the kernel sets the system clock to the same time as the hardware clock. Afterwards, both clocks run independent from each other.
|
||||
|
||||
### Method One: Date Command ###
|
||||
|
||||
In Linux, you can use the date command to change the date and time of your system:
|
||||
|
||||
# date --set='NEW_DATE'
|
||||
|
||||
where NEW_DATE is a mostly free format human readable date string such as "Sun, 28 Sep 2014 16:21:42" or "2014-09-29 16:21:42".
|
||||
|
||||
The date format can also be specified to obtain more accurate results:
|
||||
|
||||
# date +FORMAT --set='NEW_DATE'
|
||||
|
||||
For example:
|
||||
|
||||
# date +’%Y%m%d %H%m’ --set='20140928 1518'
|
||||
|
||||
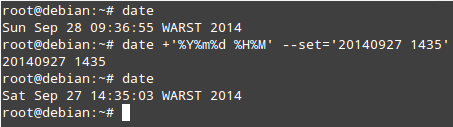
|
||||
|
||||
You can also increment or decrement date or time by a number of days, weeks, months or years, and seconds, minutes or hours, respectively. You may combine date and time parameters in one command as well.
|
||||
|
||||
# date --set='+5 minutes'
|
||||
# date --set='-2 weeks'
|
||||
# date --set='+3 months'
|
||||
# date --set='-3 months +2 weeks -5 minutes'
|
||||
|
||||
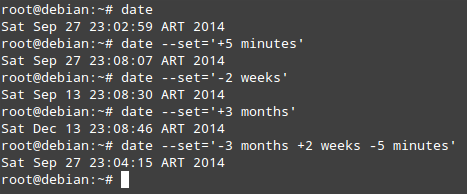
|
||||
|
||||
Finally, set the hardware clock to the current system time:
|
||||
|
||||
# hwclock --systohc
|
||||
|
||||
The purpose of running **hwclock --systohc** is to update the hardware clock with the software clock. This is to correct the systematic drift of the hardware clock, where it consistently gains or loses time at a certain rate.
|
||||
|
||||
On the other hand, if the hardware clock shows correct date and time, but the system clock does not, the latter can be updated as follows:
|
||||
|
||||
# hwclock --hctosys
|
||||
|
||||
In either case, hwclock command synchronizes both clocks. Otherwise, the time will be wrong after the next reboot, since the hardware clock keeps the time when power is turned off. However, keep in mind that this is not applicable to virtual machines, as they cannot access the hardware clock of the host machine directly.
|
||||
|
||||
If the default timezone is not correct on your Linux system, you can change it by following [this guideline][1].
|
||||
|
||||
### Method Two: NTP ###
|
||||
|
||||
Another way to keep your system's date and time accurate is using NTP (network time protocol). On Linux, ntpdate command can synchronize system clock against [public NTP servers][2] using NTP.
|
||||
|
||||
You can install **ntpdate** as follows:
|
||||
|
||||
On Debian and derivatives:
|
||||
|
||||
# aptitude install ntpdate
|
||||
|
||||
On Red Hat-based distributions:
|
||||
|
||||
# yum install ntpdate
|
||||
|
||||
To synchronize system clock using NTP:
|
||||
|
||||
# ntpdate -u <NTP server name or IP address>
|
||||
# hwclock --systohc
|
||||
|
||||

|
||||
|
||||
As opposed to one-time clock sync using ntpdate, you can also set up NTP daemon (ntpd) on your system, so that ntpd always runs in the background, continuously adjusting system clock via NTP. Refer to [this guideline][3] to set up **ntpd**.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/change-date-time-command-line-linux.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://ask.xmodulo.com/change-timezone-linux.html
|
||||
[2]:http://www.pool.ntp.org/
|
||||
[3]:http://xmodulo.com/how-to-synchronize-time-with-ntp.html
|
||||
@ -0,0 +1,90 @@
|
||||
Linux FAQs with Answers--How to change default location of libvirt VM images
|
||||
================================================================================
|
||||
> **Question**: I am using libvirt and virt-manager to create VMs on my Linux system. I noticed that the VM images are stored in /var/lib/libvirt/images directory. Is there a way to change the default location of VM image directory to something else?
|
||||
|
||||
**libvirt** and its GUI front-end **virt-manager** can create and manage VMs using different hypervisors such as KVM and Xen. By default, all the VM images created via **libvirt** go to /var/lib/libvirt/images directory. However, this may not be desirable in some cases. For example, the disk partition where /var/lib/libvirt/images lives may have limited free space. Or you may want to store all VM images in a specific repository for management purposes.
|
||||
|
||||
In fact, you can easily change the default location of the libvirt image directory, or what they call a "storage pool."
|
||||
|
||||
There are two ways to change the default storage pool.
|
||||
|
||||
### Method One: Virt-Manager GUI ###
|
||||
|
||||
If you are using virt-manager GUI program, changing the default storage pool is very easy.
|
||||
|
||||
Go to "Edit" -> "Connection Details" in **virt-manager** menu GUI.
|
||||
|
||||
|
||||
|
||||
You will see the default storage pool as shown below. On the left bottom of the window, click on the cross icon, which will stop the default storage pool. Once the pool is stopped, click on the trash bin icon on the right, which will delete the pool. Note that this action will NOT remove the VM images inside the pool.
|
||||
|
||||
Now click on the plus icon on the far left to add a new storage pool.
|
||||
|
||||
|
||||
|
||||
Type in the name of a new storage pool (e.g., default), and choose the type of the pool. In this case, choose a "filesystem directory" type since we are simply changing a storage pool directory.
|
||||
|
||||
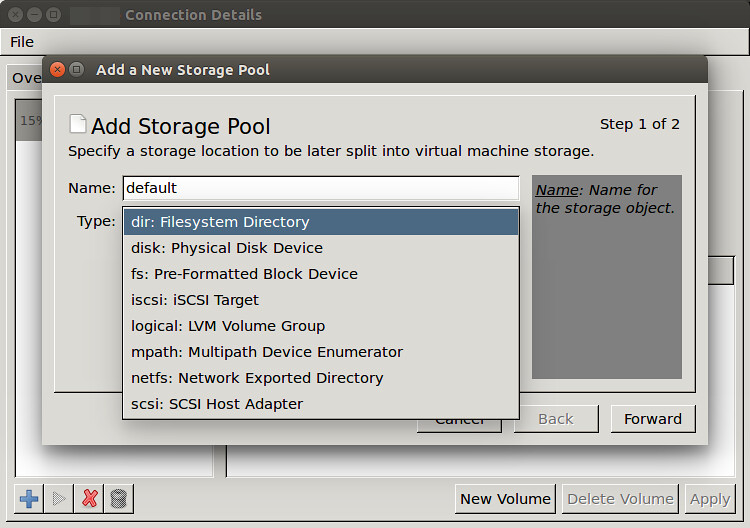
|
||||
|
||||
Type in the path of a new storage pool (e.g., /storage).
|
||||
|
||||
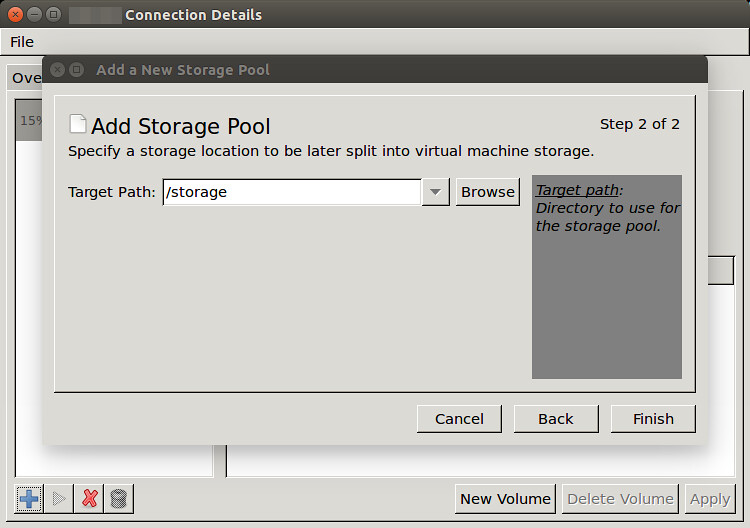
|
||||
|
||||
At this point, the new storage pool should be started, and automatically used when you create a new VM.
|
||||
|
||||
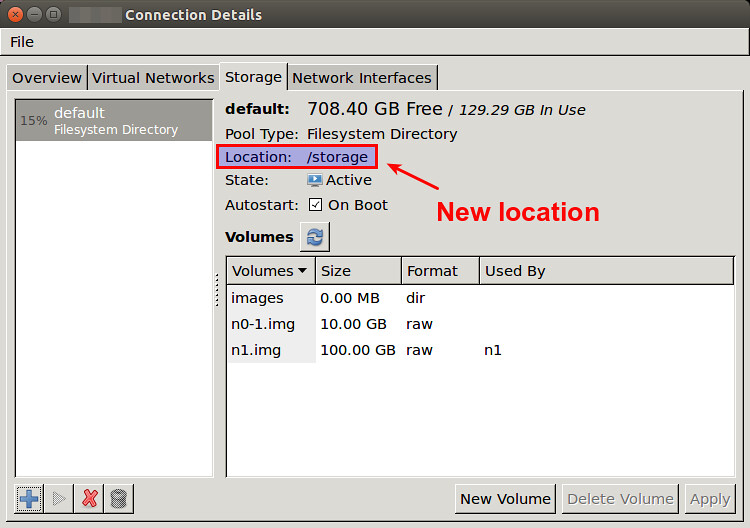
|
||||
|
||||
### Method One: Virsh Command-Line ###
|
||||
|
||||
Another method to change the default storage pool directory is to use **virsh** command line utility which comes with **libvirt** package.
|
||||
|
||||
First, run the following command to dump XML definition of the default storage pool.
|
||||
|
||||
$ virsh pool-dumpxml default > pool.xml
|
||||
|
||||
Open this XML file with a text editor, and change <path> element from /var/lib/libvirt/images to a new location.
|
||||
|
||||
<pool type='dir'>
|
||||
<name>default</name>
|
||||
<uuid>0ec0e393-28a2-e975-feec-0c7356f38d08</uuid>
|
||||
<capacity unit='bytes'>975762788352</capacity>
|
||||
<allocation unit='bytes'>530052247552</allocation>
|
||||
<available unit='bytes'>445710540800</available>
|
||||
<source>
|
||||
</source>
|
||||
<target>
|
||||
<path>/var/lib/libvirt/images</path>
|
||||
<permissions>
|
||||
<mode>0711</mode>
|
||||
<owner>-1</owner>
|
||||
<group>-1</group>
|
||||
</permissions>
|
||||
</target>
|
||||
</pool>
|
||||
|
||||
Remove the current default pool.
|
||||
|
||||
$ virsh pool-destroy default
|
||||
|
||||
----------
|
||||
|
||||
Pool default destroyed
|
||||
|
||||
Now create a new storage pool based on the updated XML file.
|
||||
|
||||
$ virsh pool-create pool.xml
|
||||
|
||||
----------
|
||||
|
||||
Pool default created from pool.xml
|
||||
|
||||
At this point, a default pool has been changed to a new location, and is ready for use.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/change-default-location-libvirt-vm-images.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,68 @@
|
||||
Linux FAQs with Answers--How to create and mount an XFS file system on Linux
|
||||
================================================================================
|
||||
> **Question**: I heard good things about XFS, and would like to create an XFS file system on my disk partition. What are the Linux commands to format and mount an XFS file system?
|
||||
|
||||
[XFS][1] is a high-performance file system which was designed by SGI for their IRIX platform. Since XFS was ported to the Linux kernel in 2001, XFS has remained a preferred choice for many enterprise systems especially with massive amount of data, due to its [high performance][2], architectural scalability and robustness. For example, RHEL/CentOS 7 and Oracle Linux have adopted XFS as their default file system, and SUSE/openSUSE have long been an avid supporter of XFS.
|
||||
|
||||
XFS has a number of unique features that make it stand out among the file system crowd, such as scalable/parallel I/O, journaling for metadata operations, online defragmentation, suspend/resume I/O, delayed allocation for performance, etc.
|
||||
|
||||
If you want to create and mount an XFS file system on your Linux platform, here is how to do it.
|
||||
|
||||
### Install XFS System Utilities ###
|
||||
|
||||
First, you need to install XFS system utilities, which allow you to perform various XFS related administration tasks (e.g., format, [expand][3], repair, setting up quota, change parameters, etc).
|
||||
|
||||
On Debian, Ubuntu or Linux Mint:
|
||||
|
||||
$ sudo apt-get install xfsprogs
|
||||
|
||||
On Fedora, CentOS or RHEL:
|
||||
|
||||
$ sudo yum install xfsprogs
|
||||
|
||||
On Arch Linux:
|
||||
|
||||
$ sudo pacman -S xfsprogs
|
||||
|
||||
### Create an XFS-Formatted Disk Partition ###
|
||||
|
||||
Now let's first prepare a disk partition to create XFS on. Assuming that your disk is located at /dev/sdb, create a partition by:
|
||||
|
||||
$ sudo fdisk /dev/sdb
|
||||
|
||||
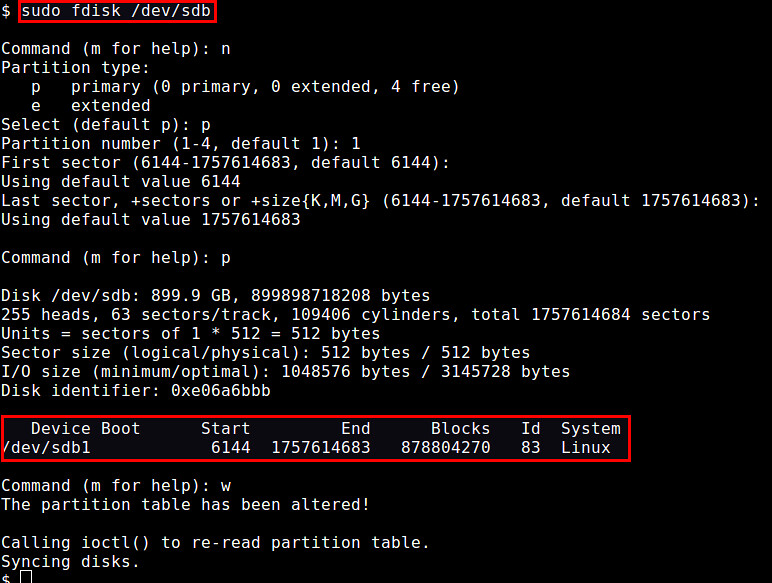
|
||||
|
||||
Let's say the created partition is assigned /dev/sdb1 device name.
|
||||
|
||||
Next, format the partition as XFS using mkfs.xfs command. The "-f" option is needed if the partition has any other file system created on it, and you want to overwrite it.
|
||||
|
||||
$ sudo mkfs.xfs -f /dev/sdb1
|
||||
|
||||
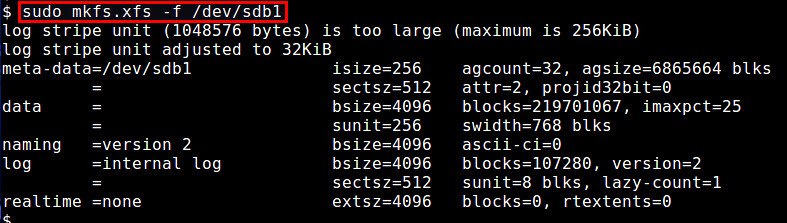
|
||||
|
||||
Now you are ready to mount the formatted partition. Let's assume that /storage is a local mount point for XFS. Go ahead and mount the partition by running:
|
||||
|
||||
$ sudo mount -t xfs /dev/sdb1 /storage
|
||||
|
||||
Verify that XFS mount is succesful by running:
|
||||
|
||||
$ df -Th /storage
|
||||
|
||||
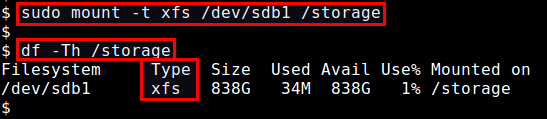
|
||||
|
||||
If you want the XFS partition to be mounted at /storage automatically upon boot, add the following line to /etc/fstab.
|
||||
|
||||
/dev/sdb1 /storage xfs defaults 0 0
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/create-mount-xfs-file-system-linux.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xfs.org/
|
||||
[2]:http://lwn.net/Articles/476263/
|
||||
[3]:http://ask.xmodulo.com/expand-xfs-file-system.html
|
||||
@ -0,0 +1,109 @@
|
||||
Linux FAQs with Answers--How to detect DVD writer’s device name and its writing speed from the command line on Linux
|
||||
================================================================================
|
||||
> **Question**: I want to know the device name assigned to my DVD writer, and also find out how fast I can burn a DVD using the DVD writer. What is a Linux command-line tool to detect the device name of a DVD writer and its writing speed?
|
||||
|
||||
Most consumer PCs and laptops nowadays come with a DVD writer. In Linux, optical drives such as CD/DVD drives are assigned device names by the kernel based on udev rules at the time of booting. There are several ways to detect the writer's device name and its writing speed.
|
||||
|
||||
### Method One ###
|
||||
|
||||
The simplest way to find out the device name associated with a DVD writer is to use dmesg command-line tool, which prints out the message buffer of the kernel. In dmesg output, look for a potential DVD writer:
|
||||
$ dmesg | egrep -i --color 'dvd|cd/rw|writer'
|
||||
|
||||

|
||||
|
||||
The output of the above command will tell you whether a DVD writer is detected on your Linux system, and what the device name assigned to the writer is. In this example, the device name of a DVD writer is "/dev/sr0". This method does not tell you about writing speed, though.
|
||||
|
||||
### Method Two ###
|
||||
|
||||
The second method to get information about your DVD writer is to use lsscsi command, which simply lists all available SCSI devices.
|
||||
|
||||
To install **lsscsi** on Debian-based Linux:
|
||||
|
||||
$ sudo apt-get install lsscsi
|
||||
|
||||
To install lsscsi on Red Hat-based Linux:
|
||||
|
||||
$ sudo yum install lsscsi
|
||||
|
||||
The output of lsscsi command will tell you the name of a DVD writer if successfully detected:
|
||||
|
||||
$ lsscsi
|
||||
|
||||

|
||||
|
||||
This again does not tell you more details about the writer, such as writing speed.
|
||||
|
||||
### Method Three ###
|
||||
|
||||
The third method to obtain information about your DVD writer is to refer to /proc/sys/dev/cdrom/info.
|
||||
|
||||
$ cat /proc/sys/dev/cdrom/info
|
||||
|
||||
----------
|
||||
|
||||
CD-ROM information, Id: cdrom.c 3.20 2003/12/17
|
||||
|
||||
drive name: sr0
|
||||
drive speed: 24
|
||||
drive # of slots: 1
|
||||
Can close tray: 1
|
||||
Can open tray: 1
|
||||
Can lock tray: 1
|
||||
Can change speed: 1
|
||||
Can select disk: 0
|
||||
Can read multisession: 1
|
||||
Can read MCN: 1
|
||||
Reports media changed: 1
|
||||
Can play audio: 1
|
||||
Can write CD-R: 1
|
||||
Can write CD-RW: 1
|
||||
Can read DVD: 1
|
||||
Can write DVD-R: 1
|
||||
Can write DVD-RAM: 1
|
||||
Can read MRW: 1
|
||||
Can write MRW: 1
|
||||
Can write RAM: 1
|
||||
|
||||
In this example, the output tells you that the DVD writer (/dev/sr0) is compatible with x24 CD writing speed (i.e., 24x153.6 KBps), which is equivalent to x3 DVD writing speed (i.e., 3x1385 KBps). The writing speed here is maximum possible speed, and actual writing speed of course depends on the type of media being used (e.g., DVD-RW, DVD+RW, DVD-RAM, etc).
|
||||
|
||||
### Method Four ###
|
||||
|
||||
Another way is to use a command-line utility called wodim. On most Linux distros, this tool, as well as its symbolic link cdrecord, is pre-installed by default.
|
||||
|
||||
# wodim -prcap
|
||||
(or cdrecord -prcap)
|
||||
|
||||
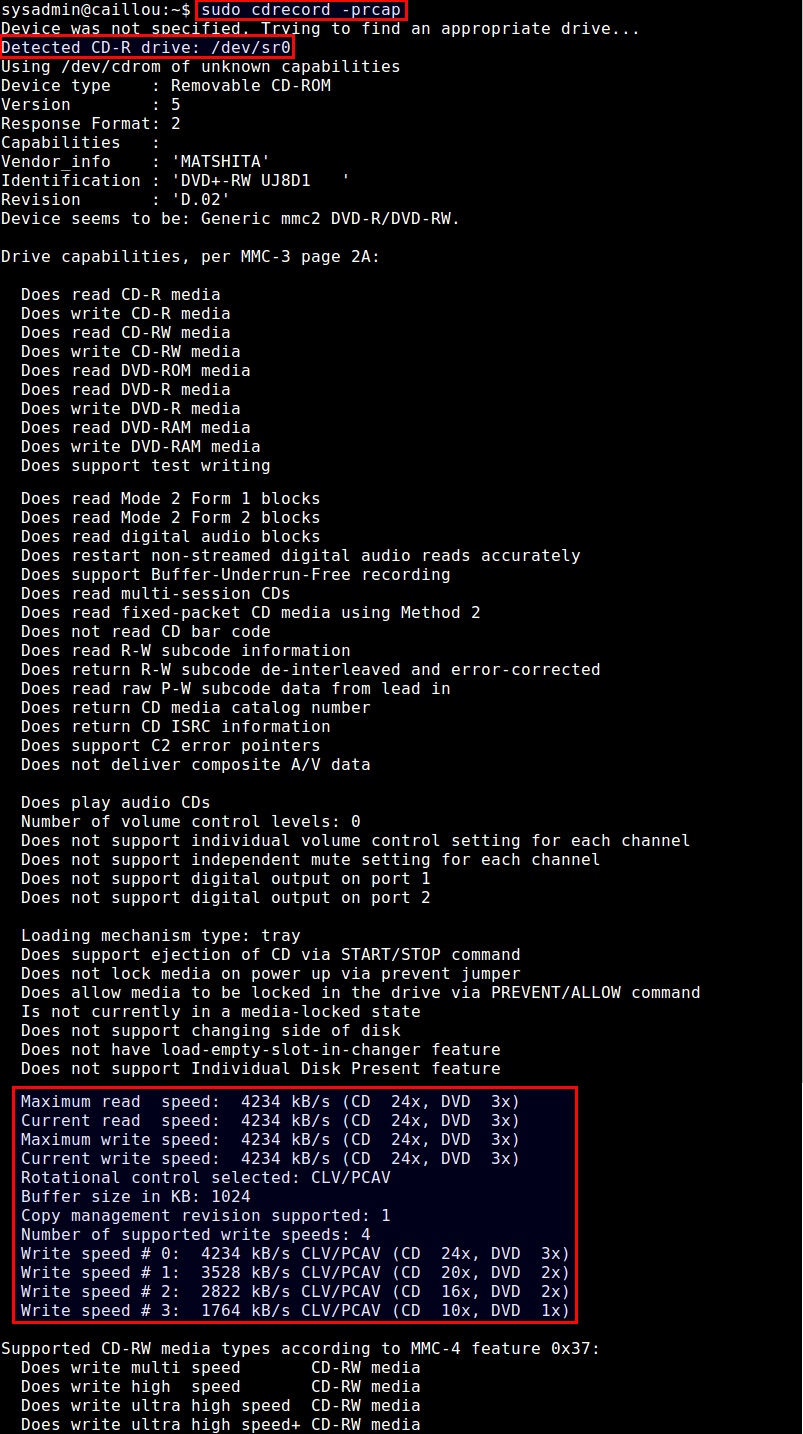
|
||||
|
||||
When invoked without any argument, the wodim command automatically detects a DVD writer, and shows detailed capabilities and maximum read/write speed of the writer. For example, you can find out what media (e.g., CD-R, CD-RW, DVD-RW, DVD-ROM, DVD-R, DVD-RAM, audio CD) are supported by the writer, and what read/write speeds are available. The example output above shows that the DVD writer has maximum x24 writing speed for CDs and maximum x3 writing speed for DVDs.
|
||||
|
||||
Note that the writing speed reported by wodim command will automatically change depending on which CD/DVD media you insert to a DVD burner, reflecting the media specification.
|
||||
|
||||
### Method Five ###
|
||||
|
||||
A yet another way to check DVD burner's writing speed is a tool called dvd+rw-mediainfo, which is part of dvd+rw-tools package (toolchain for DVD+-RW/R media).
|
||||
|
||||
To install **dvd+rw-tools** on Debian-based distros:
|
||||
|
||||
$ sudo apt-get install dvd+rw-tools
|
||||
|
||||
To install dvd+rw-tools on Red Hat-based distros:
|
||||
|
||||
$ sudo yum install dvd+rw-tools
|
||||
|
||||
Unlike other tools, dvd+rw-mediainfo command will not produce any output unless you insert a DVD media to the burner. So after you insert a DVD media, run the following command. Replace "/dev/sr0" with your own device name.
|
||||
|
||||
$ sudo dvd+rw-mediainfo /dev/sr0
|
||||
|
||||

|
||||
|
||||
The **dvd+rw-mediainfo** tool probes the inserted media ("DVD-R" in this example) to find out actual writing speed against the media.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/detect-dvd-writer-device-name-writing-speed-command-line-linux.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,75 @@
|
||||
Linux FAQs with Answers--How to detect and patch Shellshock vulnerability in bash
|
||||
================================================================================
|
||||
> **Question**: I would like to know how to test whether or not my Linux server is vulnerable to bash Shellshock bug, and how to protect my Linux server against the Shellshock exploit.
|
||||
|
||||
On September 24, 2014, a bash vulnerability nicknamed "Shellshock" (aka "Bashdoor" or "Bash bug") was discovered by a security researcher named Stephane Chazelas. This flaw, if exploited, allows a remote attacker to run arbitrary code by exporting function definitions inside specially crafted environment variables before calling the shell. Then the code inside these functions can get executed as soon as bash is invoked.
|
||||
|
||||
Note that Shellshock affects bash versions 1.14 through 4.3 (current), and although at the time of this writing no definitive and complete fix for this vulnerability has been found, and major Linux distributors ([Debian][1], [Red Hat][2], [CentOS][3], [Ubuntu][4], and [Novell/Suse][5]) have released patches that address the bugs related to it ([CVE-2014-6271][6] and [CVE-2014-7169][7]), and recommended updating bash as soon as possible, and continuing to check for updates over the next several days:
|
||||
|
||||
### Test for Shellshock Bug ###
|
||||
|
||||
To check if your Linux system is vulnerable to Shellshock bug, type the following command in a terminal.
|
||||
|
||||
$ env x='() { :;}; echo "Your bash version is vulnerable"' bash -c "echo This is a test"
|
||||
|
||||
(注:上面代码中echo "Your bash version is vulnerable"一句在发布时刷成红色)
|
||||
|
||||
If your Linux system is exposed to Shellshock exploit, the output of the command will be:
|
||||
|
||||
Your bash version is vulnerable
|
||||
This is a test
|
||||
|
||||
In the above command, an environment variable called x is made available to the user environment. It does not contain a value as we know it (but a dummy function definition) followed by an arbitrary command (in red)(注:red这个词在发布时刷成红色), which will be executed before bash is called later on.
|
||||
|
||||
### Apply Fix for Shellshock Bug ###
|
||||
|
||||
You can install the newly released patch for bash as follows.
|
||||
|
||||
On Debian and derivatives:
|
||||
|
||||
# aptitude update && aptitude safe-upgrade bash
|
||||
|
||||
On Red Hat-based distributions:
|
||||
|
||||
# yum update bash
|
||||
|
||||
#### Before patch: ####
|
||||
|
||||
Debian:
|
||||
|
||||

|
||||
|
||||
CentOS:
|
||||
|
||||

|
||||
|
||||
#### After patch: ####
|
||||
|
||||
Debian:
|
||||
|
||||

|
||||
|
||||
CentOS:
|
||||
|
||||

|
||||
|
||||
Note that the version has not changed in each chosen distribution before and after installing the patch - but you can verify that it has been installed by observing the behavior of the update commands (most likely you will be asked beforehand in order to confirm the installation).
|
||||
|
||||
If for some reason you can't install the patch, or if your distribution has not yet released one, it is recommended to use another shell until a fix comes up.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/detect-patch-shellshock-vulnerability-bash.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.debian.org/security/2014/dsa-3032
|
||||
[2]:https://access.redhat.com/articles/1200223
|
||||
[3]:http://centosnow.blogspot.com.ar/2014/09/critical-bash-updates-for-centos-5.html
|
||||
[4]:http://www.ubuntu.com/usn/usn-2362-1/
|
||||
[5]:http://support.novell.com/security/cve/CVE-2014-6271.html
|
||||
[6]:http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2014-6271
|
||||
[7]:http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2014-7169
|
||||
@ -0,0 +1,87 @@
|
||||
为 Linux 用户准备的 10 个开源克隆软件
|
||||
================================================================================
|
||||
> 这些克隆软件会读取整个磁盘的数据,将它们转换成一个 .img 文件,之后你可以将它复制到其他硬盘上。
|
||||
|
||||

|
||||
|
||||
磁盘克隆意味着从一个硬盘复制数据到另一个硬盘上,而且你可以通过简单的复制粘贴来做到。但是你却不能复制隐藏文件和文件夹,以及正在使用中的文件。这便是一个克隆软件可以通过保存一份文件和文件夹的镜像来帮助你的地方。克隆软件会读取整个磁盘的数据,将它们转换成一个 .img 文件,之后你可以将它复制到其他硬盘上。现在我们将要向你介绍最优秀的 10 个开源的克隆软件:
|
||||
|
||||
### 1. [Clonezilla][1]:###
|
||||
|
||||
Clonezilla 是一个基于 Ubuntu 和 Debian 的 Live CD。它可以像 Windows 里的诺顿 Ghost 一样克隆你的磁盘数据和做备份,不过它更有效率。Clonezilla 支持包括 ext2、ext3、ext4、btrfs 和 xfs 在内的很多文件系统。它还支持 BIOS、UEFI、MBR 和 GPT 分区。
|
||||
|
||||

|
||||
|
||||
### 2. [Redo Backup][2]:###
|
||||
|
||||
Redo Backup 是另一个用来方便地克隆磁盘的 Live CD。它是自由和开源的软件,使用 GPL 3 许可协议授权。它的主要功能和特点包括从 CD 引导的简单易用的 GUI、无需安装,可以恢复 Linux 和 Windows 等系统、无需登陆访问文件,以及已删除的文件等。
|
||||
|
||||

|
||||
|
||||
### 3. [Mondo Rescue][3]:###
|
||||
|
||||
Mondo 和其他的软件不大一样,它并不将你的磁盘数据转换为一个 .img 文件,而是将它们转换为一个 .iso 镜像。使用 Mondo,你还可以使用“mindi”——一个由 Mondo Rescue 开发的特别工具——来创建一个自定义的 Live CD,这样你的数据就可以从 Live CD 克隆出来了。它支持大多数 Linux 发行版和 FreeBSD,并使用 GPL 许可协议授权。
|
||||
|
||||

|
||||
|
||||
### 4. [Partimage][4]:###
|
||||
|
||||
这是一个开源的备份软件,默认情况下在 Linux 系统里工作。在大多数发行版中,你都可以从发行版自带的软件包管理工具中安装。如果你没有 Linux 系统,你也可以使用“SystemRescueCd”。它是一个默认包括 Partimage 的 Live CD,可以为你完成备份工作。Partimage 在克隆硬盘方面的性能非常出色。
|
||||
|
||||

|
||||
|
||||
### 5. [FSArchiver][5]:###
|
||||
|
||||
FSArchiver 是 Partimage 的后续产品,而且它也是一个很好的硬盘克隆工具。它支持克隆 Ext4 和 NTFS 分区、基本的文件属性如所有人、权限、SELinux 之类的扩展属性,以及所有 Linux 文件系统的文件系统属性等。
|
||||
|
||||
### 6. [Partclone][6]:###
|
||||
|
||||
Partclone 是一个可以克隆和恢复分区的免费工具。它用 C 语言编写,最早在 2007 年出现,而且支持很多文件系统,包括:ext2、ext3、ext4、xfs、nfs、reiserfs、reiser4、hfs+、btrfs。它的使用十分简便,并且使用 GPL 许可协议授权。
|
||||
|
||||
### 7. [doClone][7]:###
|
||||
|
||||
doClone 是一个免费软件项目,被开发用于轻松地克隆 Linux 系统分区。它由 C++ 编写而成,支持多达 12 种不同的文件系统。它能够修复 Grub 引导器,还能通过局域网传输镜像到另一台计算机。它还提供了热同步功能,这意味着你可以在系统正在运行的时候对它进行克隆操作。
|
||||
|
||||

|
||||
|
||||
### 8. [Macrium Reflect 免费版][8]:###
|
||||
|
||||
Macrium Reflect 免费版被形容为最快的磁盘克隆工具之一,它只支持 Windows 文件系统。它有一个很直观的用户界面。该软件提供了磁盘镜像和克隆操作,还能让你在文件管理器中访问镜像。它允许你创建一个 Linux 应急 CD,并且它与 Windows Vista 和 Windows 7 兼容。
|
||||
|
||||

|
||||
|
||||
### 9. [DriveImage XML][9]:###
|
||||
|
||||
DriveImage XML 使用 Microsoft VSS 来创建镜像,十分可靠。使用这个软件,你可以从一个正在使用的磁盘创建“热”镜像。镜像使用 XML 文件保存,这意味着你可以从任何支持的第三方软件访问它们。DriveImage XML 还允许在不重启的情况下从镜像恢复到机器。这个软件与 Windows XP、Windows Server 2003、Vista 以及 7 兼容。
|
||||
|
||||

|
||||
|
||||
### 10. [Paragon Backup & Recovery 免费版][10]:###
|
||||
|
||||
Paragon Backup & Recovery 免费版在管理镜像计划任务方面十分出色。它是一个免费软件,但是仅能用于个人用途。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.efytimes.com/e1/fullnews.asp?edid=148039
|
||||
|
||||
作者:Sanchari Banerjee
|
||||
译者:[felixonmars](https://github.com/felixonmars)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://clonezilla.org/
|
||||
[2]:http://redobackup.org/
|
||||
[3]:http://www.mondorescue.org/
|
||||
[4]:http://www.partimage.org/Main_Page
|
||||
[5]:http://www.fsarchiver.org/Main_Page
|
||||
[6]:http://www.partclone.org/
|
||||
[7]:http://doclone.nongnu.org/
|
||||
[8]:http://www.macrium.com/reflectfree.aspx
|
||||
[9]:http://www.runtime.org/driveimage-xml.htm
|
||||
[10]:http://www.paragon-software.com/home/br-free/
|
||||
@ -0,0 +1,65 @@
|
||||
Linux用户应该了解一下开源硬件
|
||||
================================================================================
|
||||
> Linux用户不了解一点开源硬件制造相关的事情,他们将会很失望。
|
||||
|
||||
商业软件和免费软件已经互相纠缠很多年了,但是这俩经常误解对方。这并不奇怪 -- 对一方来说是生意,而另一方只是一种生活方式。但是,这种误解会给人带来痛苦,这也是为什么值得花精力去揭露这里面的内幕。
|
||||
|
||||
一个逐渐普遍的现象:对开源硬件的不断尝试,不管是Canonical,Jolla,MakePlayLive,或者其他几个。不管是评论员或终端用户,一般的免费软件用户会为新的硬件平台发布表现出过分的狂热,然后因为不断延期有所醒悟,最终放弃整个产品。
|
||||
|
||||
这是一个没有人获益的怪圈,而且滋生出不信任 - 都是因为一般的Linux用户根本不知道这些新闻背后发生的事情。
|
||||
|
||||
我个人对于把产品推向市场的经验很有限。但是,我还不知道谁能有所突破。推出一个开源硬件或其他产品到市场仍然不仅仅是个残酷的生意,而且严重不利于新加入的厂商。
|
||||
|
||||
### 寻找合作伙伴 ###
|
||||
|
||||
不管是数码产品的生产还是分销都被相对较少的一些公司控制着,有时需要数月的预订。利润率也会很低,所以就像那些购买古老情景喜剧的电影工作室一样,生成商一般也希望复制当前热销产品的成功。像Aaron Seigo在谈到他花精力开发Vivaldi平板时告诉我的,生产商更希望能由其他人去承担开发新产品的风险。
|
||||
|
||||
不仅如此,他们更希望和那些有现成销售记录的有可能带来可复制生意的人合作。
|
||||
|
||||
而且,一般新加入的厂商所关心的产品只有几千的量。芯片制造商更愿意和苹果或三星合作,因为它们的订单很可能是几百K。
|
||||
|
||||
面对这种情形,开源硬件制造者们可能会发现他们在工厂的列表中被淹没了,除非能找到二线或三线厂愿意尝试一下小批量生产新产品。
|
||||
|
||||
他们也许还会沦为采购成品组件再自己组装,就像Seigo尝试Vivaldi时那样做的。或者,他们也许可以像Canonical那样做,寻找一些愿意为这个产业冒险的合作伙伴。而就算他们成功了,一般也会比最初天真的预期延迟数个月。
|
||||
|
||||
### 磕磕碰碰走向市场 ###
|
||||
|
||||
然而,寻找生产商只是第一关。根据树莓派项目的经验,就算开源硬件制造者们只想在他们的产品上运行免费软件,生产商们很可能会以保护商业机密的名义坚持使用专有固件或驱动。
|
||||
|
||||
这样必然会引起潜在用户的批评,但是开源硬件制造者没得选,只能折中他们的愿景。寻找其他生产商也不能解决问题,有一个原因是这样做意味着更多延迟,但是更多的是因为完全免授权费的硬件是不存在的。像三星这样的业内巨头对免费硬件没有任何兴趣,而作为新人,开源硬件制造者也没有影响力去要求什么。
|
||||
|
||||
更何况,就算有免费硬件,生产商也不能保证会用在下一批生产中。制造者们会轻易地发现他们每次需要生产的时候都要重打一样的仗。
|
||||
|
||||
这些都还不够,这个时候开源硬件制造者们也许已经花了6-12个月时间来讨价还价。机会来了,产业标准已经变更,他们也许为了升级产品规格又要从头来过。
|
||||
|
||||
### 短暂而且残忍的货架期 ###
|
||||
|
||||
尽管面对这么多困难,一定程度上开放的硬件也终于推出了。还记得寻找生产商时的挑战吗?对于分销商也会有同样的问题 -- 还不只是一次,而是每个地区都要解决。
|
||||
|
||||
通常,分销商和生成商一样保守,对于和新人或新点子打交道也很谨慎。就算他们同意一个产品上架,他们也轻易能够决定不鼓励自己的销售代表们做推广,这意味着这个产品会在几个月后很有效率地下架。
|
||||
|
||||
当然,在线销售也是可以的。但是同时,硬件还是需要被存放在某个地方,这也会增加成本。而按需生产就算可能的话也将非常昂贵,而且没有组装的元件也需要存放。
|
||||
|
||||
### 衡量整件怪事 ###
|
||||
|
||||
在这里我只是粗略地概括了一下,但是任何涉足过制造的人会认出我形容成标准的东西。而更糟糕的是,开源硬件制造者们通常在这个过程中才会有所觉悟。不可避免,他们也会犯错,从而带来更多的延迟。
|
||||
|
||||
但重点是,一旦你对整个过程有所了解,你对另一个开源硬件进行尝试的消息的反应就会改变。这个过程意味着,除非哪家公司处于严格的保密模式,对于产品将于六个月内发布的声明会很快会被证实是过期的推测。很可能是12-18个月,而且面对之前提过的那些困难很可能意味着这个产品永远不会真正发布。
|
||||
|
||||
举个例子,就像我写的,人们等待第一代Steam Machines面世,它是一台基于Linux的游戏主机。他们相信Steam Machines能彻底改变Linux和游戏。
|
||||
|
||||
作为一个市场分类,Steam Machines也许比其他新产品更有优势,因为参与开发的人员至少有开发软件产品的经验。然而,整整一年过去了Steam Machines的开发成果都还只有原型机,而且直到2015年中都不一定能买到。面对硬件生产的实际情况,就算有一半能见到阳光都是很幸运了。而实际上,能发布2-4台也许更实际。
|
||||
|
||||
我做出这个预测并没有考虑个体努力。但是,对硬件生产的理解,比起那些Linux和游戏的黄金年代之类的预言,我估计这个更靠谱。如果我错了也会很开心,但是事实不会改变:让人吃惊的不是如此多的Linux相关硬件产品失败了,而是那些即使是短暂的成功的产品。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/what-linux-users-should-know-about-open-hardware-1.html
|
||||
|
||||
作者:[Bruce Byfield][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Bruce-Byfield-6030.html
|
||||
@ -0,0 +1,93 @@
|
||||
# Peer Code Review的实战经验 #
|
||||
|
||||
(译者:Code Review中文可以翻译成代码复查,一般由开发待review的代码的成员以外的团队成员来进行这样的工作。由于是专业术语,没有将Code review用中文代替。)
|
||||
|
||||
我有时候会听到我们的团队成员这样议论:
|
||||
|
||||
"项目的Code review 只是浪费时间。"
|
||||
"我没有时间做Code review。"
|
||||
"我的发布时间延迟了,因为我的同时还没有完成我代码的Code review。"
|
||||
"你相信我的同事居然要求我对我的代码做修改吗?请跟他们说代码中的一些联系会被打断如果在我原来代码的基础之上做修改的话。"
|
||||
|
||||
### 为什么要做Code review? ###
|
||||
|
||||
每个专业软件开发者都有一个重要的目标:持续的提高它们的工作质量。即使你团队中都是一些优秀的程序员,你依然不能将你自己与一个有能力的自由职业者区分开来,除非你从团队的角度来工作。Code review是团队工作的一个重要的方面。尤其是:
|
||||
|
||||
代码复查者(reviewer)能从他们的角度来发现问题并且提出更好的解决方案。
|
||||
|
||||
确保至少你团队的另一个其他成员熟悉你的代码,通过给新员工看有经验的开发者的代码能够某种程度上提高他们的水平。
|
||||
|
||||
公开code reviewer和reviewee的想法和经验能够促进团队间的知识的分享。
|
||||
|
||||
能够鼓励开发者将他们的工作进行的更彻底,因为他们知道他们的代码将被其他的人阅读。
|
||||
|
||||
### 在review的过程中的注意点 ###
|
||||
|
||||
但是,由于Code review的时间有限,上面所说的目标未必能全部达到。就算只是想要打一个补丁,都要确保意图是正确的。如果只是将变量名改成骆驼拼写法(camelCase),不算是code review。在开发过程中进行结对编程是有益处的,它能够使两个人得到公平的锻炼。你能够在code review上花许多时间,并且仍然能够比在结对编程中使用更少的时间。
|
||||
|
||||
我的感受是,在项目开发的过程中,25%的时间应该花费在code review上。也就是说,如果开发者用两天的时间来开发一个东西,那么复查者应该使用至少四个小时来审查。
|
||||
|
||||
当然,只要你的review结果准确的话,具体花了多少时间就显得不是那么的重要。重要的是,你能够理解你看的那些代码。这里的理解并不是指你看懂了这些代码书写的语法,而是你要知道这段代码在整个庞大的应用程序,组件或者库中起着什么样的作用。如果你不理解每一行代码的作用,那么换句话说,你的code review就是没有价值的。这就是为什么好的code review不能很快完成的原因。需要时间来探讨各种各样的代码路径,让它们触发一个特定的函数,来确保第三方的API得到了正确的使用(包括一些边缘测试)。
|
||||
|
||||
为了查阅你所审查的代码的缺陷或者是其他问题,你应该确保:
|
||||
|
||||
所有有必要的测试都已经被包含进去。
|
||||
|
||||
合理的设计文档已经被编写。
|
||||
|
||||
再熟练的开发者也不是每次都会记得在他们对代码改动的时候把测试程序和文档更新上去。来自reviewer的一个提醒能够使得测试用例和开发文档不会一直忘了更新。
|
||||
|
||||
### 避免code review负担太大 ###
|
||||
|
||||
如果你的团队没有强制性的code review,当你的code review记录停留在无法管理的节点上时会很危险。如果你已经两周没有进行code review了,你可以花几天的时间来跟上项目的进度。这意味着你自己的开发工作会被阻断,当你想要处理之前遗留下来的code review的时候。这也会使得你很难再确保code review的质量,因为合理的code review需要长期认真的努力。最终会很难持续几天都保持这样的状态。
|
||||
|
||||
由于这个原因,开发者应当每天都完成他们的review任务。一种好办法就是将code review作为你每天的第一件事。在你开始自己的开发工作之前完成所有的code review工作,能够使你从头到尾都集中注意力。有些人可能更喜欢在午休前或午休后或者在傍晚下班前做review。无论你在哪个时间做,都要将code review看作你的工作之一并且不能分心,你要避免:
|
||||
|
||||
没有足够的时间来处理你的review任务。
|
||||
|
||||
由于你的code review工作没有做完导致版本的推迟发布。
|
||||
|
||||
提交不在相关的review由于代码在你review期间已经改动太大。
|
||||
|
||||
因为你要在最后一分钟完成他们一直于review质量太差。
|
||||
|
||||
### 书写易于review的代码 ###
|
||||
|
||||
有时候review没有按时完成并不都是因为代码审查者(reviewer)。如果我的同事使用一周时间在一个大工程中添加了一些乱七八糟的代码,且他们提交的补丁实在是太难以阅读。在一段中有太多的东西要浏览。这样会让人难以理解它的作用,自然会拖慢review的进度。
|
||||
|
||||
为什么将你的工作划分成一些易于管理的片段很重要有很多原因。我们使用scrum方法论(一种软件开发过程方法),因此对我们来说一个合理的单元就是一个story。通过努力将我们的工作使用story组织起来并且只是将review提交到我们正在工作的story上,这样,我们写的代码就会更加易于review。你们的可以使用其他的软件开发方法,但是目的是一样的。
|
||||
|
||||
书写易于review的代码还有其他先决条件。如果要做一些复杂的架构决策,应该让reviewer事先知道并参与讨论。这会让他们之后review你们的代码更加容易,因为他们知道你们正在试图实现什么功能并且知道你们打算如何来实现。这也避免了开发者需要在reviewer提了一个不同的或者更好的解决方案后大片的重写代码。
|
||||
|
||||
项目需要应当在设计文档中详细的描述。这对于一个项目新成员想要快速上手并且理解现有的代码来说非常重要。这从长远角度对于一个reviewer来说也非常有好处。单元测试也有助于reviewer知道一些组件是怎么使用的。
|
||||
|
||||
如果你在你的补丁中包含的第三方的代码,记得单独的提交它。当jQuery的9000行代码被插入到了项目代码的中间,毫无疑问会造成难以阅读。
|
||||
|
||||
创建易读的review代码的另一个非常重要的措施是添加相应的注释代码。这就要求你事先自己做一下review并且在一些你认为会帮助reviewer进行review的地方加上相应的注释。我发现加上注释相对与你来说往往只需要很短的时间(通常是几分钟),但是对于review来说会节约很多的时间。当然,代码注释还有其他相似的好处,应该在合理的地方使用,但往往对code review来说更重要。事实上,有研究表明,开发者在重读并注释他们代码的过程中,通常会发现很多问题。
|
||||
|
||||
### 代码大范围重构的情况 ###
|
||||
|
||||
有时候,有必要重构一段代码使其能够作用于多个其他组件。若是一个大型的应用要这样做,会花费几天甚至是更多的时间,结果是生成一个诺大的补丁包。在这种情况下,进行一个标准的code review可能是不切实际的。
|
||||
|
||||
最好的方法是增量重构你的代码。找出合理范围内的一部分改变,以此为基础来重构。一旦修改和review完成,进入第二个增量。以此类推,直到整个重构完成。这种方法可能不是在所有的情况下都可行,但是尽管如此,也能避免在重构时出现大量的单片补丁。开发者使用这种方式重构可能会花去更多的时间,但这也使得代码质量更高并且之后的review会更简单。
|
||||
|
||||
如果实在是没有条件去通过增量方式重构代码(有人可能会说之前的代码书写并组织的是多么的好),一种解决方案是在重构时进行结对编程来代替code review。
|
||||
|
||||
### 解决团队成员之间的纠纷 ###
|
||||
|
||||
你的团队中都是一些有能力的专家,在一些案例中,完全有可能因为对一个具体编码问题的意见的不同而产生争论。作为一个开发者,应该保持一个开发的头脑并且时刻准备着妥协,当你的reviewer更想要另一种解决方法时。不要对你的代码持有专有的态度,也不要自己持有审查的意见。因为有人会觉得你应该将一些重复的代码写入一个能够复用的函数中去,这并不意味着这是你的问题。
|
||||
|
||||
作为一个reviewer,要灵活。在提出修改建议之前,考虑你的建议是否真的更好或者只是无关紧要。如果你把力气和注意力花在那些原来的代码会明确需要改进的地方会更加成功。你应该说"它或许者的考虑..."或者"一些人建议..."而不是”我的宠物都能写一个比这个更加有效的排序方法"。
|
||||
|
||||
如果你真的决定不了,那就询问另一个你和你的reviewee都尊敬的开发者来听一下你意见并给出建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.salsitasoft.com/practical-lessons-in-peer-code-review/
|
||||
作者:[Matt][a]
|
||||
译者:[john](https://github.com/johnhoow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,245 @@
|
||||
|
||||
如何在ubuntu桌面配置一个网络打印机和扫描仪
|
||||
================================================================================
|
||||
|
||||
|
||||
在[之前的文章中](注:这篇文章在2014年8月12号的原文里做过,不知道翻译了没有,如果翻译发布了,发布此文章的时候可改成翻译后的链接), 我们讨论过如何在Linux服务器安装各种各样的打印机(当然也包括网络扫描仪)。今天我们将来处理另一端:如何通过桌面客户端来访问网络打印机/扫描仪。
|
||||
|
||||
|
||||
### 网络环境 ###
|
||||
|
||||
在这个安装教程中,我们的服务器(Debian Wheezy 7.2版本)的IP地址是192.168.0.10,我们的客户端(Ubuntu 12.04版本)的IP地址是192.168.0.105.注意这两台机器是在同一个网段(192.168.0.0/24).如果我们想允许打印机访问其它网段,我们需要在服务器上修改cupsd.conf文件的以下部分:
|
||||
|
||||
<Location />
|
||||
Order allow,deny
|
||||
Allow localhost
|
||||
Allow from XXX.YYY.ZZZ.*
|
||||
</Location>
|
||||
|
||||
|
||||
(在上述例子中,我们授予打印机从本地或者任何系统能够访问打印机,这些系统的IPv4地址以XXX.YYY.ZZZ开始。
|
||||
|
||||
为了验证哪些打印机可以在我们的服务器上适用,我们也可以在服务器上使用lpstat命令,或者浏览网页https://192.168.0.10:631/printers page.
|
||||
|
||||
root@debian:~# lpstat -a
|
||||
|
||||
----------
|
||||
|
||||
EPSON_Stylus_CX3900 accepting requests since Mon 18 Aug 2014 10:49:33 AM WARST
|
||||
PDF accepting requests since Mon 06 May 2013 04:46:11 PM WARST
|
||||
SamsungML1640Series accepting requests since Wed 13 Aug 2014 10:13:47 PM WARST
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
### 在Ubuntu桌面安装网络打印机 ###
|
||||
|
||||
|
||||
在我们的Ubuntu 12.04的客户端,我们将打开"Printing"菜单(Dash -> Printing).你会注意到在其它发行版中,这个名字也许会有一点差别(例如会叫做"Printers" 或者 "Print & Fax"):
|
||||
|
||||

|
||||
|
||||
|
||||
还没有打印机添加到我们的客户端:
|
||||
|
||||

|
||||
|
||||
下面是在Ubuntu桌面客户端安装一台网络打印机的一些步骤。
|
||||
|
||||
|
||||
**1)** “Add”按钮将弹出New Printer" 菜单。我们将选择"Network printer" -> "Find Network Printer"并输入我们服务器的IP地址,接着点击"Find":
|
||||
|
||||

|
||||
|
||||
|
||||
**2)** 在最下面我们将会看到可使用的打印机的名称。我们来选择这台三星打印机并按"Forward":
|
||||
|
||||

|
||||
|
||||
|
||||
**3)** 我们将会被要求填写一些关于我们打印机的信息。当我们输入完成时,将点击 "Apply"按钮。
|
||||
|
||||

|
||||
|
||||
|
||||
**4)** 我们接下来将被询问是否打印一张测试页。让我们点击"Print test page"吧:
|
||||
|
||||

|
||||
|
||||
|
||||
这个打印任务将被创建为本地id 2:
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
5)适用我们服务器上的CUPS网络借口,我们可以观察到打印任务已经提交成功了(打印机 -> SamsungML1640系列 -> 显示完成任务):
|
||||
|
||||

|
||||
|
||||
|
||||
我们也可以通过在打印机服务器上运行以下命令显示同样信息:
|
||||
|
||||
root@debian:~# cat /var/log/cups/page_log | grep -i samsung
|
||||
|
||||
----------
|
||||
|
||||
SamsungML1640Series root 27 [13/Aug/2014:22:15:34 -0300] 1 1 - localhost Test Page - -
|
||||
SamsungML1640Series gacanepa 28 [18/Aug/2014:11:28:50 -0300] 1 1 - 192.168.0.105 Test Page - -
|
||||
SamsungML1640Series gacanepa 29 [18/Aug/2014:11:45:57 -0300] 1 1 - 192.168.0.105 Test Page - -
|
||||
|
||||
这个page_log日志显示每一页被打印过的信息,只包括哪些用户发送这些打印任务,打印日期&时间,以及客户端的IPv4地址。
|
||||
|
||||
|
||||
要安装Epson喷墨和PDF打印机,我们只需重复第1-5的步骤即可,并每一次选择左边的打印队列。例如,在下图中选择PDF打印机:
|
||||
|
||||

|
||||
|
||||
然而,请注意到根据[CUPS-PDF 文档中][2],根据默认:
|
||||
|
||||
>PDF文件将会被放置在打印作业的所有者命名的子目录内。在这个案例中,打印作业的所有者不能被识别(i.e.不会存在服务器中)输出的内容被放置在匿名操作的文件中。
|
||||
|
||||
|
||||
这些默认的文件夹可以通过改变在/etc/cups/cups-pdf目录中的**Out**值和**AnonDirName**变量来修改。这里,${HOME}被扩展到用户的家目录中:
|
||||
|
||||
Out ${HOME}/PDF
|
||||
AnonDirName /var/spool/cups-pdf/ANONYMOUS
|
||||
|
||||
|
||||
|
||||
### 网络打印实例 ###
|
||||
|
||||
#### 实例 #1 ####
|
||||
|
||||
|
||||
|
||||
从Ubuntu12.04中打印,通常在本地用gacanepa(具有相同名字存在打印机服务器上)。
|
||||
|
||||

|
||||
|
||||
|
||||
打印到PDF打印机之后,让我们来检查打印机服务器上的/home/gacanepa/PDF目录下的内容:
|
||||
|
||||
|
||||
|
||||
root@debian:~# ls -l /home/gacanepa/PDF
|
||||
|
||||
----------
|
||||
|
||||
total 368
|
||||
-rw------- 1 gacanepa gacanepa 279176 Aug 18 13:49 Test_Page.pdf
|
||||
-rw------- 1 gacanepa gacanepa 7994 Aug 18 13:50 Untitled1.pdf
|
||||
-rw------- 1 gacanepa gacanepa 74911 Aug 18 14:36 Welcome_to_Conference_-_Thomas_S__Monson.pdf
|
||||
|
||||
|
||||
|
||||
这个PDF文件被创建时的,权限已经设置为600(-rw-------),这意味着只有打印任务的所有者(在这个例子中是gacanepa )可以访问它们。我们可以通过修改the /etc/cups/cups-pdf.conf文件**UserUMask**变量的值来改变这种行为。例如,0033的umask值将可以使PDF打印者以及其它所有者拥有创建文件的权限,但是只读权限也会赋予给其它所有者。
|
||||
|
||||
root@debian:~# grep -i UserUMask /etc/cups/cups-pdf.conf
|
||||
|
||||
----------
|
||||
|
||||
### Key: UserUMask
|
||||
UserUMask 0033
|
||||
|
||||
|
||||
|
||||
对于那些不熟悉umask(有名用户文件创建模式掩码),它作为一组可以用于控制那些为新文件创建时修改默认权限。给予特定的umask值,在计算最终文件的许可权限时,在文件基本权限(0666)和umask的单项按位补码之间进行按位布尔 AND 运算。因此,如果设置一个umask值为0033,那么新文件默认的权限将不是(0033)AND 0666 = 644的值(文件拥有者具有读/写/执行的权限,其他人拥有只读权限)。
|
||||
|
||||
|
||||
### 实例 #2 ###
|
||||
|
||||
|
||||
在Ubuntu12.04执行打印,本地登录用户为jdoe(同样的帐号名称但是服务器上是不存在的)。
|
||||
|
||||

|
||||
|
||||
root@debian:~# ls -l /var/spool/cups-pdf/ANONYMOUS
|
||||
|
||||
----------
|
||||
|
||||
total 5428
|
||||
-rw-rw-rw- 1 nobody nogroup 5543070 Aug 18 15:57 Linux_-_Wikipedia__the_free_encyclopedia.pdf
|
||||
|
||||
|
||||
这个PDF被创建时赋予的权限是666(-rw-rw-rw-),这意味着每个人都可以访问它们。我们可以通过编辑在/etc/cups/cups-pdf.conf文件中的**AnonUMask**值来改变这种行为。
|
||||
|
||||
|
||||
在这一点上,你也许会疑惑:为什么同样安装一台网络打印机,大多数(当然不是全部)当前的Linux桌面发行版都会内置一个"打印到文件"的功能来允许用户动态创建PDF文件?
|
||||
|
||||
|
||||
使用一台网络PDF打印机有以下好处:
|
||||
|
||||
|
||||
- 一个网络打印机(任何类型的)允许你直接从命令行直接打印,无需首先打开文件。
|
||||
|
||||
- 在其它操作系统上安装一个网络客户端,一个PDF网络打印机备件,于是系统管理员不必再单独需要安装PDF创建者实用程序(也避免了最终用户安装这些工具存在的风险)。
|
||||
|
||||
- 网络PDF打印机允许通过配置权限直接打印一个网络共享,如我们所见的例子。
|
||||
|
||||
### 在Ubuntu桌面安装一个网络扫描仪 ###
|
||||
|
||||
这里是通过Ubuntu桌面客户端安装和访问一台网络扫描仪的一些步骤。假设网络扫描仪服务器已经启动并运行所述[here][3].
|
||||
|
||||
|
||||
**1)**让我们第一步来检查在我们的Ubuntu客户端主机上是否存在一台可用的扫描仪。没有先前的安装,你将会看到信息提示"没有识别到扫描仪."
|
||||
$ scanimage -L
|
||||
|
||||

|
||||
|
||||
|
||||
**2)** 现在我们需要启用saned进程,用来预装Ubuntu桌面。要启用它,我们需要编辑/etc/default/saned文件,并设置RUN变量为yes:
|
||||
$ sudo vim /etc/default/saned
|
||||
|
||||
----------
|
||||
|
||||
# Set to yes to start saned
|
||||
RUN=yes
|
||||
|
||||
|
||||
**3)** 让我们编辑/etc/sane.d/net.conf文件,并在扫描仪安装后添加服务器IP地址:
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
**4)** 重启saned进程:
|
||||
$ sudo service saned restart
|
||||
|
||||
|
||||
|
||||
**5)** 现在让我们来看看扫描仪是否可用:
|
||||

|
||||
|
||||
|
||||
现在我们可以打开"Simple Scan"(或者其它扫描工具)并开始扫描文件。我们可以旋转,修剪,和保存生成的图片:
|
||||
|
||||

|
||||
|
||||
|
||||
### 总结 ###
|
||||
|
||||
|
||||
拥有一或多台网络打印机或扫描仪在任何办公和家庭网络中都是非常方便适用的,并同时提供了许多好处。例举如下:
|
||||
|
||||
- 多用户(从不同的平台/地方)都能够向打印机发送打印作业的队列。
|
||||
|
||||
- 由于硬件共享达到了节约成本和维护的作用。
|
||||
|
||||
我希望这篇文章可以帮助你更充分地利用这些有点。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/configure-network-printer-scanner-ubuntu-desktop.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[disylee](https://github.com/disylee)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
[1]:http://xmodulo.com/2014/08/usb-network-printer-and-scanner-server-debian.html
|
||||
[2]:http://www.cups-pdf.de/documentation.shtml
|
||||
[3]:http://xmodulo.com/2014/08/usb-network-printer-and-scanner-server-debian.html#scanner
|
||||
Loading…
Reference in New Issue
Block a user