mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-25 00:50:15 +08:00
commit
dec36221ff
223
published/20170926 Managing users on Linux systems.md
Normal file
223
published/20170926 Managing users on Linux systems.md
Normal file
@ -0,0 +1,223 @@
|
||||
管理 Linux 系统中的用户
|
||||
======
|
||||

|
||||
|
||||
也许你的 Lniux 用户并不是愤怒的公牛,但是当涉及管理他们的账户的时候,能让他们一直开心也是一种挑战。监控他们当前正在访问的东西,追踪他们他们遇到问题时的解决方案,并且保证能把他们在使用系统时出现的重要变动记录下来。这里有一些方法和工具可以使这份工作轻松一点。
|
||||
|
||||
### 配置账户
|
||||
|
||||
添加和移除账户是管理用户中最简单的一项,但是这里面仍然有很多需要考虑的选项。无论你是用桌面工具或是命令行选项,这都是一个非常自动化的过程。你可以使用命令添加一个新用户,像是 `adduser jdoe`,这同时会触发一系列的事情。使用下一个可用的 UID 可以创建 John 的账户,或许还会被许多用以配置账户的文件所填充。当你运行 `adduser` 命令加一个新的用户名的时候,它将会提示一些额外的信息,同时解释这是在干什么。
|
||||
|
||||
```
|
||||
$ sudo adduser jdoe
|
||||
Adding user 'jdoe' ...
|
||||
Adding new group `jdoe' (1001) ...
|
||||
Adding new user `jdoe' (1001) with group `jdoe' ...
|
||||
Creating home directory `/home/jdoe' ...
|
||||
Copying files from `/etc/skel' …
|
||||
Enter new UNIX password:
|
||||
Retype new UNIX password:
|
||||
passwd: password updated successfully
|
||||
Changing the user information for jdoe
|
||||
Enter the new value, or press ENTER for the default
|
||||
Full Name []: John Doe
|
||||
Room Number []:
|
||||
Work Phone []:
|
||||
Home Phone []:
|
||||
Other []:
|
||||
Is the information correct? [Y/n] Y
|
||||
```
|
||||
|
||||
像你看到的那样,`adduser` 将添加用户的信息(到 `/etc/passwd` 和 `/etc/shadow` 文件中),创建新的家目录,并用 `/etc/skel` 里设置的文件填充家目录,提示你分配初始密码和认定信息,然后确认这些信息都是正确的,如果你在最后的提示 “Is the information correct” 处的答案是 “n”,它将回溯你之前所有的回答,允许修改任何你想要修改的地方。
|
||||
|
||||
创建好一个用户后,你可能会想要确认一下它是否是你期望的样子,更好的方法是确保在添加第一个帐户**之前**,“自动”选择与您想要查看的内容相匹配。默认有默认的好处,它对于你想知道他们定义在哪里有所用处,以防你想作出一些变动 —— 例如,你不想家目录在 `/home` 里,你不想用户 UID 从 1000 开始,或是你不想家目录下的文件被系统上的**每个人**都可读。
|
||||
|
||||
`adduser` 如何工作的一些细节设置在 `/etc/adduser.conf` 文件里。这个文件包含的一些设置决定了一个新的账户如何配置,以及它之后的样子。注意,注释和空白行将会在输出中被忽略,因此我们可以更加集中注意在设置上面。
|
||||
|
||||
```
|
||||
$ cat /etc/adduser.conf | grep -v "^#" | grep -v "^$"
|
||||
DSHELL=/bin/bash
|
||||
DHOME=/home
|
||||
GROUPHOMES=no
|
||||
LETTERHOMES=no
|
||||
SKEL=/etc/skel
|
||||
FIRST_SYSTEM_UID=100
|
||||
LAST_SYSTEM_UID=999
|
||||
FIRST_SYSTEM_GID=100
|
||||
LAST_SYSTEM_GID=999
|
||||
FIRST_UID=1000
|
||||
LAST_UID=29999
|
||||
FIRST_GID=1000
|
||||
LAST_GID=29999
|
||||
USERGROUPS=yes
|
||||
USERS_GID=100
|
||||
DIR_MODE=0755
|
||||
SETGID_HOME=no
|
||||
QUOTAUSER=""
|
||||
SKEL_IGNORE_REGEX="dpkg-(old|new|dist|save)"
|
||||
```
|
||||
|
||||
可以看到,我们有了一个默认的 shell(`DSHELL`),UID(`FIRST_UID`)的开始数值,家目录(`DHOME`)的位置,以及启动文件(`SKEL`)的来源位置。这个文件也会指定分配给家目录(`DIR_HOME`)的权限。
|
||||
|
||||
其中 `DIR_HOME` 是最重要的设置,它决定了每个家目录被使用的权限。这个设置分配给用户创建的目录权限是 `755`,家目录的权限将会设置为 `rwxr-xr-x`。用户可以读其他用户的文件,但是不能修改和移除他们。如果你想要更多的限制,你可以更改这个设置为 `750`(用户组外的任何人都不可访问)甚至是 `700`(除用户自己外的人都不可访问)。
|
||||
|
||||
任何用户账号在创建之前都可以进行手动修改。例如,你可以编辑 `/etc/passwd` 或者修改家目录的权限,开始在新服务器上添加用户之前配置 `/etc/adduser.conf` 可以确保一定的一致性,从长远来看可以节省时间和避免一些麻烦。
|
||||
|
||||
`/etc/adduser.conf` 的修改将会在之后创建的用户上生效。如果你想以不同的方式设置某个特定账户,除了用户名之外,你还可以选择使用 `adduser` 命令提供账户配置选项。或许你想为某些账户分配不同的 shell,请求特殊的 UID,完全禁用登录。`adduser` 的帮助页将会为你显示一些配置个人账户的选择。
|
||||
|
||||
```
|
||||
adduser [options] [--home DIR] [--shell SHELL] [--no-create-home]
|
||||
[--uid ID] [--firstuid ID] [--lastuid ID] [--ingroup GROUP | --gid ID]
|
||||
[--disabled-password] [--disabled-login] [--gecos GECOS]
|
||||
[--add_extra_groups] [--encrypt-home] user
|
||||
```
|
||||
|
||||
每个 Linux 系统现在都会默认把每个用户放入对应的组中。作为一个管理员,你可能会选择以不同的方式去做事。你也许会发现把用户放在一个共享组中可以让你的站点工作的更好,这时,选择使用 `adduser` 的 `--gid` 选项去选择一个特定的组。当然,用户总是许多组的成员,因此也有一些选项去管理主要和次要的组。
|
||||
|
||||
### 处理用户密码
|
||||
|
||||
一直以来,知道其他人的密码都是一个不好的念头,在设置账户时,管理员通常使用一个临时的密码,然后在用户第一次登录时会运行一条命令强制他修改密码。这里是一个例子:
|
||||
|
||||
```
|
||||
$ sudo chage -d 0 jdoe
|
||||
```
|
||||
|
||||
当用户第一次登录的时候,会看到像这样的事情:
|
||||
|
||||
```
|
||||
WARNING: Your password has expired.
|
||||
You must change your password now and login again!
|
||||
Changing password for jdoe.
|
||||
(current) UNIX password:
|
||||
```
|
||||
|
||||
### 添加用户到副组
|
||||
|
||||
添加用户到副组中,你可能会用如下所示的 `usermod` 命令 —— 添加用户到组中并确认已经做出变动。
|
||||
|
||||
```
|
||||
$ sudo usermod -a -G sudo jdoe
|
||||
$ sudo grep sudo /etc/group
|
||||
sudo:x:27:shs,jdoe
|
||||
```
|
||||
|
||||
记住在一些组,像是 `sudo` 或者 `wheel` 组中,意味着包含特权,一定要特别注意这一点。
|
||||
|
||||
### 移除用户,添加组等
|
||||
|
||||
Linux 系统也提供了命令去移除账户、添加新的组、移除组等。例如,`deluser` 命令,将会从 `/etc/passwd` 和 `/etc/shadow` 中移除用户登录入口,但是会完整保留他的家目录,除非你添加了 `--remove-home` 或者 `--remove-all-files` 选项。`addgroup` 命令会添加一个组,按目前组的次序给他下一个 ID(在用户组范围内),除非你使用 `--gid` 选项指定 ID。
|
||||
|
||||
```
|
||||
$ sudo addgroup testgroup --gid=131
|
||||
Adding group `testgroup' (GID 131) ...
|
||||
Done.
|
||||
```
|
||||
|
||||
### 管理特权账户
|
||||
|
||||
一些 Linux 系统中有一个 wheel 组,它给组中成员赋予了像 root 一样运行命令的能力。在这种情况下,`/etc/sudoers` 将会引用该组。在 Debian 系统中,这个组被叫做 `sudo`,但是以相同的方式工作,你在 `/etc/sudoers` 中可以看到像这样的引用:
|
||||
|
||||
```
|
||||
%sudo ALL=(ALL:ALL) ALL
|
||||
```
|
||||
|
||||
这个基础的设定意味着,任何在 wheel 或者 sudo 组中的成员,只要在他们运行的命令之前添加 `sudo`,就可以以 root 的权限去运行命令。
|
||||
|
||||
你可以向 `sudoers` 文件中添加更多有限的特权 —— 也许给特定用户运行一两个 root 的命令。如果这样做,您还应定期查看 `/etc/sudoers` 文件以评估用户拥有的权限,以及仍然需要提供的权限。
|
||||
|
||||
在下面显示的命令中,我们看到在 `/etc/sudoers` 中匹配到的行。在这个文件中最有趣的行是,包含能使用 `sudo` 运行命令的路径设置,以及两个允许通过 `sudo` 运行命令的组。像刚才提到的那样,单个用户可以通过包含在 `sudoers` 文件中来获得权限,但是更有实际意义的方法是通过组成员来定义各自的权限。
|
||||
|
||||
```
|
||||
# cat /etc/sudoers | grep -v "^#" | grep -v "^$"
|
||||
Defaults env_reset
|
||||
Defaults mail_badpass
|
||||
Defaults secure_path="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin"
|
||||
root ALL=(ALL:ALL) ALL
|
||||
%admin ALL=(ALL) ALL <== admin group
|
||||
%sudo ALL=(ALL:ALL) ALL <== sudo group
|
||||
```
|
||||
|
||||
### 登录检查
|
||||
|
||||
你可以通过以下命令查看用户的上一次登录:
|
||||
|
||||
```
|
||||
# last jdoe
|
||||
jdoe pts/18 192.168.0.11 Thu Sep 14 08:44 - 11:48 (00:04)
|
||||
jdoe pts/18 192.168.0.11 Thu Sep 14 13:43 - 18:44 (00:00)
|
||||
jdoe pts/18 192.168.0.11 Thu Sep 14 19:42 - 19:43 (00:00)
|
||||
```
|
||||
|
||||
如果你想查看每一个用户上一次的登录情况,你可以通过一个像这样的循环来运行 `last` 命令:
|
||||
|
||||
```
|
||||
$ for user in `ls /home`; do last $user | head -1; done
|
||||
|
||||
jdoe pts/18 192.168.0.11 Thu Sep 14 19:42 - 19:43 (00:03)
|
||||
|
||||
rocket pts/18 192.168.0.11 Thu Sep 14 13:02 - 13:02 (00:00)
|
||||
shs pts/17 192.168.0.11 Thu Sep 14 12:45 still logged in
|
||||
```
|
||||
|
||||
此命令仅显示自当前 `wtmp` 文件变为活跃状态以来已登录的用户。空白行表示用户自那以后从未登录过,但没有将其调出。一个更好的命令是过滤掉在这期间从未登录过的用户的显示:
|
||||
|
||||
```
|
||||
$ for user in `ls /home`; do echo -n "$user ";last $user | head -1 | awk '{print substr($0,40)}'; done
|
||||
dhayes
|
||||
jdoe pts/18 192.168.0.11 Thu Sep 14 19:42 - 19:43
|
||||
peanut pts/19 192.168.0.29 Mon Sep 11 09:15 - 17:11
|
||||
rocket pts/18 192.168.0.11 Thu Sep 14 13:02 - 13:02
|
||||
shs pts/17 192.168.0.11 Thu Sep 14 12:45 still logged
|
||||
tsmith
|
||||
```
|
||||
|
||||
这个命令会打印很多,但是可以通过一个脚本使它更加清晰易用。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
for user in `ls /home`
|
||||
do
|
||||
echo -n "$user ";last $user | head -1 | awk '{print substr($0,40)}'
|
||||
done
|
||||
```
|
||||
|
||||
有时,此类信息可以提醒您用户角色的变动,表明他们可能不再需要相关帐户。
|
||||
|
||||
### 与用户沟通
|
||||
|
||||
Linux 提供了许多方法和用户沟通。你可以向 `/etc/motd` 文件中添加信息,当用户从终端登录到服务器时,将会显示这些信息。你也可以通过例如 `write`(通知单个用户)或者 `wall`(`write` 给所有已登录的用户)命令发送通知。
|
||||
|
||||
```
|
||||
$ wall System will go down in one hour
|
||||
|
||||
Broadcast message from shs@stinkbug (pts/17) (Thu Sep 14 14:04:16 2017):
|
||||
|
||||
System will go down in one hour
|
||||
```
|
||||
|
||||
重要的通知应该通过多个管道传递,因为很难预测用户实际会注意到什么。mesage-of-the-day(motd),`wall` 和 email 通知可以吸引用户大部分的注意力。
|
||||
|
||||
### 注意日志文件
|
||||
|
||||
更多地注意日志文件上也可以帮你理解用户活动。事实上,`/var/log/auth.log` 文件将会为你显示用户的登录和注销活动,组的创建等。`/var/log/message` 或者 `/var/log/syslog` 文件将会告诉你更多有关系统活动的事情。
|
||||
|
||||
### 追踪问题和请求
|
||||
|
||||
无论你是否在 Linux 系统上安装了票务系统,跟踪用户遇到的问题以及他们提出的请求都非常重要。如果请求的一部分久久不见回应,用户必然不会高兴。即使是纸质日志也可能是有用的,或者更好的是,有一个电子表格,可以让你注意到哪些问题仍然悬而未决,以及问题的根本原因是什么。确保解决问题和请求非常重要,日志还可以帮助您记住你必须采取的措施来解决几个月甚至几年后重新出现的问题。
|
||||
|
||||
### 总结
|
||||
|
||||
在繁忙的服务器上管理用户帐户部分取决于从配置良好的默认值开始,部分取决于监控用户活动和遇到的问题。如果用户觉得你对他们的顾虑有所回应并且知道在需要系统升级时会发生什么,他们可能会很高兴。
|
||||
|
||||
-----------
|
||||
|
||||
via: https://www.networkworld.com/article/3225109/linux/managing-users-on-linux-systems.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
@ -0,0 +1,45 @@
|
||||
书评:《算法之美( Algorithms to Live By )》
|
||||
======
|
||||
|
||||

|
||||
|
||||
又一次为了工作图书俱乐部而读书。除了其它我亲自推荐的书,这是我至今最喜爱的书。
|
||||
|
||||
作为计算机科学基础之一的研究领域是算法:我们如何高效地用计算机程序解决问题?这基本上属于数学领域,但是这很少关于理想的或理论上的解决方案,而是更在于最高效地利用有限的资源获得一个充分(如果不能完美)的答案。其中许多问题要么是日常的生活问题,要么与人们密切相关。毕竟,计算机科学的目的是为了用计算机解决实际问题。《<ruby>算法之美<rt>Algorithms to Live By</rt></ruby>》提出的问题是:“我们可以反过来吗”——我们可以通过学习计算机科学解决问题的方式来帮助我们做出日常决定吗?
|
||||
|
||||
本书的十一个章节有很多有趣的内容,但也有一个有趣的主题:人类早已擅长这一点。很多章节以一个算法研究和对问题的数学分析作为开始,接着深入到探讨如何利用这些结果做出更好的决策,然后讨论关于人类真正会做出的决定的研究,之后,考虑到典型生活情境的限制,会发现人类早就在应用我们提出的最佳算法的特殊版本了。这往往会破坏本书的既定目标,值得庆幸的是,它决不会破坏对一般问题的有趣讨论,即计算机科学如何解决它们,以及我们对这些问题的数学和技术形态的了解。我认为这本书的自助效用比作者打算的少一些,但有很多可供思考的东西。
|
||||
|
||||
(也就是说,值得考虑这种一致性是否太少了,因为人类已经擅长这方面了,更因为我们的算法是根据人类直觉设计的。可能我们的最佳算法只是反映了人类的思想。在某些情况下,我们发现我们的方案和数学上的典范不一样,但是在另一些情况下,它们仍然是我们当下最好的猜想。)
|
||||
|
||||
这是那种章节列表是书评里重要部分的书。这里讨论的算法领域有最优停止、探索和利用决策(什么时候带着你发现的最好东西走,以及什么时候寻觅更好的东西),以及排序、缓存、调度、贝叶斯定理(一般还有预测)、创建模型时的过拟合、放松(解决容易的问题而不是你的实际问题)、随机算法、一系列网络算法,最后还有游戏理论。其中每一项都有有用的见解和发人深省的讨论——这些有时显得十分理论化的概念令人吃惊地很好地映射到了日常生活。这本书以一段关于“可计算的善意”的讨论结束:鼓励减少你自己和你交往的人所需的计算和复杂性惩罚。
|
||||
|
||||
如果你有计算机科学背景(就像我一样),其中许多都是熟悉的概念,而且你因为被普及了很多新东西或许会有疑惑。然而,请给这本书一个机会,类比法没你担忧的那么令人紧张。作者既小心又聪明地应用了这些原则。这本书令人惊喜地通过了一个重要的合理性检查:涉及到我知道或反复思考过的主题的章节很少有或没有明显的错误,而且能讲出有用和重要的事情。比如,调度的那一章节毫不令人吃惊地和时间管理有关,通过直接跳到时间管理问题的核心而胜过了半数的时间管理类书籍:如果你要做一个清单上的所有事情,你做这些事情的顺序很少要紧,所以最难的调度问题是决定不做哪些事情而不是做这些事情的顺序。
|
||||
|
||||
作者在贝叶斯定理这一章节中的观点完全赢得了我的心。本章的许多内容都是关于贝叶斯先验的,以及一个人对过去事件的了解为什么对分析未来的概率很重要。作者接着讨论了著名的棉花糖实验。即给了儿童一个棉花糖以后,儿童被研究者告知如果他们能够克制自己不吃这个棉花糖,等到研究者回来时,会给他们两个棉花糖。克制自己不吃棉花糖(在心理学文献中叫作“延迟满足”)被发现与未来几年更好的生活有关。这个实验多年来一直被引用和滥用于各种各样的宣传,关于选择未来的收益放弃即时的快乐从而拥有成功的生活,以及生活中的失败是因为无法延迟满足。更多的邪恶分析(当然)将这种能力与种族联系在一起,带有可想而知的种族主义结论。
|
||||
|
||||
我对棉花糖实验有点兴趣。这是一个百分百让我愤怒咆哮的话题。
|
||||
|
||||
《算法之美》是我读过的唯一提到了棉花糖实验并应用了我认为更有说服力的分析的书。这不是一个关于儿童天赋的实验,这是一个关于他们的贝叶斯先验的实验。什么时候立即吃棉花糖而不是等待奖励是完全合理的?当他们过去的经历告诉他们成年人不可靠,不可信任,会在不可预测的时间内消失并且撒谎的时候。而且,更好的是,作者用我之前没有听说过的后续研究和观察支持了这一分析,观察到的内容是,一些孩子会等待一段时间然后“放弃”。如果他们下意识地使用具有较差先验的贝叶斯模型,这就完全合情合理。
|
||||
|
||||
这是一本很好的书。它可能在某些地方的尝试有点太勉强(数学上最优停止对于日常生活的适用性比我认为作者想要表现的更加偶然和牵强附会),如果你学过算法,其中一些内容会感到熟悉,但是它的行文思路清晰,简洁,而且编辑得非常好。这本书没有哪一部分对不起它所受到的欢迎,书中的讨论贯穿始终。如果你发现自己“已经知道了这一切”,你可能还会在接下来几页中遇到一个新的概念或一个简洁的解释。有时作者会做一些我从没想到但是回想起来正确的联系,比如将网络协议中的指数退避和司法系统中的选择惩罚联系起来。还有意识到我们的现代通信世界并不是一直联系的,它是不断缓冲的,我们中的许多人正深受缓冲膨胀这一独特现象的苦恼。
|
||||
|
||||
我认为你并不必须是计算机科学专业或者精通数学才能读这本书。如果你想深入,每章的结尾都有许多数学上的细节,但是正文总是易读而清晰,至少就我所知是这样(作为一个以计算机科学为专业并学到了很多数学知识的人,你至少可以有保留地相信我)。即使你已经钻研了多年的算法,这本书仍然可以提供很多东西。
|
||||
|
||||
这本书我读得越多越喜欢。如果你喜欢阅读这种对生活的分析,我当然是赞成的。
|
||||
|
||||
Rating: 9 out of 10
|
||||
|
||||
Reviewed: 2017-10-22
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.eyrie.org/~eagle/reviews/books/1-62779-037-3.html
|
||||
|
||||
作者:[Brian Christian;Tom Griffiths][a]
|
||||
译者:[GraveAccent](https://github.com/GraveAccent)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.eyrie.org
|
||||
[1]:https://www.eyrie.org1-59184-679-X.html
|
||||
@ -0,0 +1,176 @@
|
||||
如何安装并使用 Wireshark
|
||||
======
|
||||
|
||||
[][2]
|
||||
|
||||
Wireshark 是自由开源的、跨平台的基于 GUI 的网络数据包分析器,可用于 Linux、Windows、MacOS、Solaris 等。它可以实时捕获网络数据包,并以人性化的格式呈现。Wireshark 允许我们监控网络数据包直到其微观层面。Wireshark 还有一个名为 `tshark` 的命令行实用程序,它与 Wireshark 执行相同的功能,但它是通过终端而不是 GUI。
|
||||
|
||||
Wireshark 可用于网络故障排除、分析、软件和通信协议开发以及用于教育目的。Wireshark 使用 `pcap` 库来捕获网络数据包。
|
||||
|
||||
Wireshark 具有许多功能:
|
||||
|
||||
* 支持数百项协议检查
|
||||
* 能够实时捕获数据包并保存,以便以后进行离线分析
|
||||
* 许多用于分析数据的过滤器
|
||||
* 捕获的数据可以即时压缩和解压缩
|
||||
* 支持各种文件格式的数据分析,输出也可以保存为 XML、CSV 和纯文本格式
|
||||
* 数据可以从以太网、wifi、蓝牙、USB、帧中继、令牌环等多个接口中捕获
|
||||
|
||||
在本文中,我们将讨论如何在 Ubuntu/Debian 上安装 Wireshark,并将学习如何使用 Wireshark 捕获网络数据包。
|
||||
|
||||
#### 在 Ubuntu 16.04 / 17.10 上安装 Wireshark
|
||||
|
||||
Wireshark 在 Ubuntu 默认仓库中可用,只需使用以下命令即可安装。但有可能得不到最新版本的 wireshark。
|
||||
|
||||
```
|
||||
linuxtechi@nixworld:~$ sudo apt-get update
|
||||
linuxtechi@nixworld:~$ sudo apt-get install wireshark -y
|
||||
```
|
||||
|
||||
因此,要安装最新版本的 wireshark,我们必须启用或配置官方 wireshark 仓库。
|
||||
|
||||
使用下面的命令来配置仓库并安装最新版本的 wireshark 实用程序。
|
||||
|
||||
```
|
||||
linuxtechi@nixworld:~$ sudo add-apt-repository ppa:wireshark-dev/stable
|
||||
linuxtechi@nixworld:~$ sudo apt-get update
|
||||
linuxtechi@nixworld:~$ sudo apt-get install wireshark -y
|
||||
```
|
||||
|
||||
一旦安装了 wireshark,执行以下命令,以便非 root 用户也可以捕获接口的实时数据包。
|
||||
|
||||
```
|
||||
linuxtechi@nixworld:~$ sudo setcap 'CAP_NET_RAW+eip CAP_NET_ADMIN+eip' /usr/bin/dumpcap
|
||||
```
|
||||
|
||||
#### 在 Debian 9 上安装 Wireshark
|
||||
|
||||
Wireshark 包及其依赖项已存在于 debian 9 的默认仓库中,因此要在 Debian 9 上安装最新且稳定版本的 Wireshark,请使用以下命令:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ sudo apt-get update
|
||||
linuxtechi@nixhome:~$ sudo apt-get install wireshark -y
|
||||
```
|
||||
|
||||
在安装过程中,它会提示我们为非超级用户配置 dumpcap,
|
||||
|
||||
选择 `yes` 并回车。
|
||||
|
||||
[][3]
|
||||
|
||||
安装完成后,执行以下命令,以便非 root 用户也可以捕获接口的实时数据包。
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ sudo chmod +x /usr/bin/dumpcap
|
||||
```
|
||||
|
||||
我们还可以使用最新的源代码包在 Ubuntu/Debian 和其它 Linux 发行版上安装 wireshark。
|
||||
|
||||
#### 在 Debian / Ubuntu 系统上使用源代码安装 Wireshark
|
||||
|
||||
首先下载最新的源代码包(写这篇文章时它的最新版本是 2.4.2),使用以下命令:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ wget https://1.as.dl.wireshark.org/src/wireshark-2.4.2.tar.xz
|
||||
```
|
||||
|
||||
然后解压缩包,进入解压缩的目录:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ tar -xf wireshark-2.4.2.tar.xz -C /tmp
|
||||
linuxtechi@nixhome:~$ cd /tmp/wireshark-2.4.2
|
||||
```
|
||||
|
||||
现在我们使用以下命令编译代码:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:/tmp/wireshark-2.4.2$ ./configure --enable-setcap-install
|
||||
linuxtechi@nixhome:/tmp/wireshark-2.4.2$ make
|
||||
```
|
||||
|
||||
最后安装已编译的软件包以便在系统上安装 Wireshark:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:/tmp/wireshark-2.4.2$ sudo make install
|
||||
linuxtechi@nixhome:/tmp/wireshark-2.4.2$ sudo ldconfig
|
||||
```
|
||||
|
||||
在安装后,它将创建一个单独的 Wireshark 组,我们现在将我们的用户添加到组中,以便它可以与 Wireshark 一起使用,否则在启动 wireshark 时可能会出现 “permission denied(权限被拒绝)”错误。
|
||||
|
||||
要将用户添加到 wireshark 组,执行以下命令:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ sudo usermod -a -G wireshark linuxtechi
|
||||
```
|
||||
|
||||
现在我们可以使用以下命令从 GUI 菜单或终端启动 wireshark:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ wireshark
|
||||
```
|
||||
|
||||
#### 在 Debian 9 系统上使用 Wireshark
|
||||
|
||||
[][4]
|
||||
|
||||
点击 Wireshark 图标。
|
||||
|
||||
[][5]
|
||||
|
||||
#### 在 Ubuntu 16.04 / 17.10 上使用 Wireshark
|
||||
|
||||
[][6]
|
||||
|
||||
点击 Wireshark 图标。
|
||||
|
||||
[][7]
|
||||
|
||||
#### 捕获并分析数据包
|
||||
|
||||
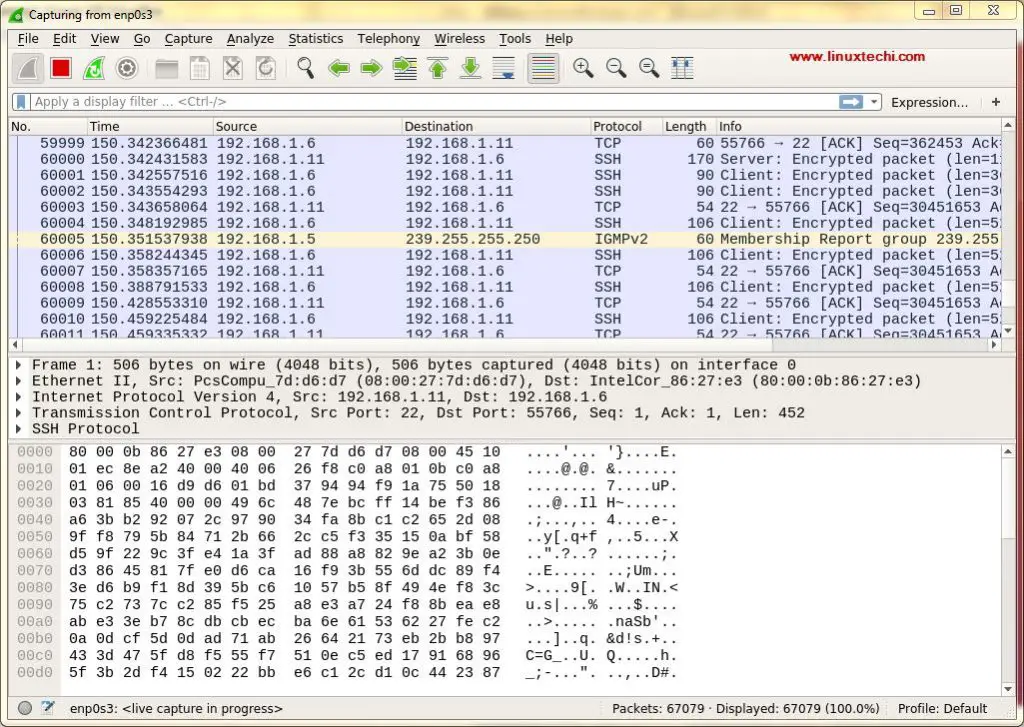
一旦 wireshark 启动,我们就会看到 wireshark 窗口,上面有 Ubuntu 和 Debian 系统的示例。
|
||||
|
||||
[][8]
|
||||
|
||||
所有这些都是我们可以捕获网络数据包的接口。根据你系统上的接口,此屏幕可能与你的不同。
|
||||
|
||||
我们选择 `enp0s3` 来捕获该接口的网络流量。选择接口后,在我们网络上所有设备的网络数据包开始填充(参考下面的屏幕截图):
|
||||
|
||||
[][9]
|
||||
|
||||
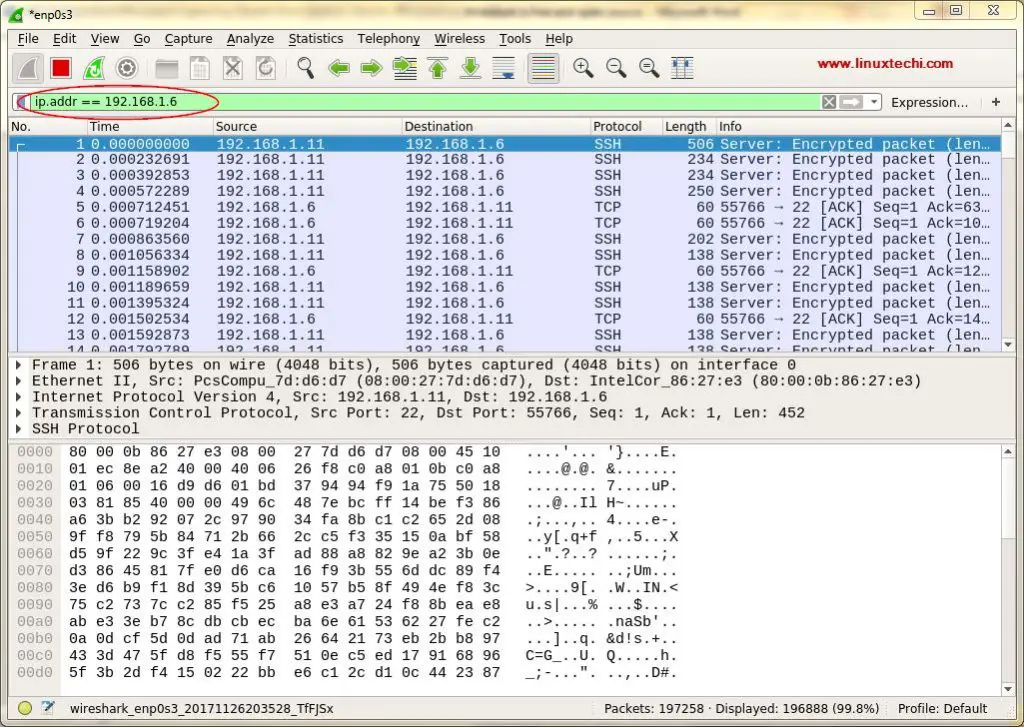
第一次看到这个屏幕,我们可能会被这个屏幕上显示的数据所淹没,并且可能已经想过如何整理这些数据,但不用担心,Wireshark 的最佳功能之一就是它的过滤器。
|
||||
|
||||
我们可以根据 IP 地址、端口号,也可以使用来源和目标过滤器、数据包大小等对数据进行排序和过滤,也可以将两个或多个过滤器组合在一起以创建更全面的搜索。我们也可以在 “Apply a Display Filter(应用显示过滤器)”选项卡中编写过滤规则,也可以选择已创建的规则。要选择之前构建的过滤器,请单击 “Apply a Display Filter(应用显示过滤器)”选项卡旁边的旗帜图标。
|
||||
|
||||
[][10]
|
||||
|
||||
我们还可以根据颜色编码过滤数据,默认情况下,浅紫色是 TCP 流量,浅蓝色是 UDP 流量,黑色标识有错误的数据包,看看这些编码是什么意思,点击 “View -> Coloring Rules”,我们也可以改变这些编码。
|
||||
|
||||
[][11]
|
||||
|
||||
在我们得到我们需要的结果之后,我们可以点击任何捕获的数据包以获得有关该数据包的更多详细信息,这将显示该网络数据包的所有数据。
|
||||
|
||||
Wireshark 是一个非常强大的工具,需要一些时间来习惯并对其进行命令操作,本教程将帮助你入门。请随时在下面的评论框中提出你的疑问或建议。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/install-use-wireshark-debian-9-ubuntu/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxtechi.com/author/pradeep/
|
||||
[1]:https://www.linuxtechi.com/author/pradeep/
|
||||
[2]:https://www.linuxtechi.com/wp-content/uploads/2017/11/wireshark-Debian-9-Ubuntu-16.04-17.10.jpg
|
||||
[3]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Configure-Wireshark-Debian9.jpg
|
||||
[4]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Access-wireshark-debian9.jpg
|
||||
[5]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Wireshark-window-debian9.jpg
|
||||
[6]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Access-wireshark-Ubuntu.jpg
|
||||
[7]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Wireshark-window-Ubuntu.jpg
|
||||
[8]:https://www.linuxtechi.com/wp-content/uploads/2017/11/wireshark-Linux-system.jpg
|
||||
[9]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Capturing-Packet-from-enp0s3-Ubuntu-Wireshark.jpg
|
||||
[10]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Filter-in-wireshark-Ubuntu.jpg
|
||||
[11]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Packet-Colouring-Wireshark.jpg
|
||||
137
published/20180117 How to get into DevOps.md
Normal file
137
published/20180117 How to get into DevOps.md
Normal file
@ -0,0 +1,137 @@
|
||||
DevOps 实践指南
|
||||
======
|
||||
> 这些技巧或许对那些想要践行 DevOps 的系统运维和开发者能有所帮助。
|
||||
|
||||

|
||||
|
||||
在去年大概一年的时间里,我注意到对“Devops 实践”感兴趣的开发人员和系统管理员突然有了明显的增加。这样的变化也合理:现在开发者只要花很少的钱,调用一些 API,就能单枪匹马地在一整套分布式基础设施上运行自己的应用,在这个时代,开发和运维的紧密程度前所未有。我看过许多博客和文章介绍很酷的 DevOps 工具和相关思想,但是给那些希望践行 DevOps 的人以指导和建议的内容,我却很少看到。
|
||||
|
||||
这篇文章的目的就是描述一下如何去实践。我的想法基于 Reddit 上 [devops][1] 的一些访谈、聊天和深夜讨论,还有一些随机谈话,一般都发生在享受啤酒和美食的时候。如果你已经开始这样实践,我对你的反馈很感兴趣,请通过[我的博客][2]或者 [Twitter][3] 联系我,也可以直接在下面评论。我很乐意听到你们的想法和故事。
|
||||
|
||||
### 古代的 IT
|
||||
|
||||
了解历史是搞清楚未来的关键,DevOps 也不例外。想搞清楚 DevOps 运动的普及和流行,去了解一下上世纪 90 年代后期和 21 世纪前十年 IT 的情况会有帮助。这是我的经验。
|
||||
|
||||
我的第一份工作是在一家大型跨国金融服务公司做 Windows 系统管理员。当时给计算资源扩容需要给 Dell 打电话(或者像我们公司那样打给 CDW),并下一个价值数十万美元的订单,包含服务器、网络设备、电缆和软件,所有这些都要运到生产或线下的数据中心去。虽然 VMware 仍在尝试说服企业使用虚拟机运行他们的“性能敏感”型程序是更划算的,但是包括我们在内的很多公司都还是愿意使用他们的物理机运行应用。
|
||||
|
||||
在我们技术部门,有一个专门做数据中心工程和运营的团队,他们的工作包括价格谈判,让荒唐的月租能够降一点点,还包括保证我们的系统能够正常冷却(如果设备太多,这个事情的难度会呈指数增长)。如果这个团队足够幸运足够有钱,境外数据中心的工作人员对我们所有的服务器型号又都有足够的了解,就能避免在盘后交易中不小心搞错东西。那时候亚马逊 AWS 和 Rackspace 逐渐开始加速扩张,但还远远没到临界规模。
|
||||
|
||||
当时我们还有专门的团队来保证硬件上运行着的操作系统和软件能够按照预期工作。这些工程师负责设计可靠的架构以方便给系统打补丁、监控和报警,还要定义<ruby>基础镜像<rt>gold image</rt></ruby>的内容。这些大都是通过很多手工实验完成的,很多手工实验是为了编写一个<ruby>运行说明书<rt>runbook</rt></ruby>来描述要做的事情,并确保按照它执行后的结果确实在预期内。在我们这么大的组织里,这样做很重要,因为一线和二线的技术支持都是境外的,而他们的培训内容只覆盖到了这些运行说明而已。
|
||||
|
||||
(这是我职业生涯前三年的世界。我那时候的梦想是成为制定最高标准的人!)
|
||||
|
||||
软件发布则完全是另外一头怪兽。无可否认,我在这方面并没有积累太多经验。但是,从我收集的故事(和最近的经历)来看,当时大部分软件开发的日常大概是这样:
|
||||
|
||||
* 开发人员按照技术和功能需求来编写代码,这些需求来自于业务分析人员的会议,但是会议并没有邀请开发人员参加。
|
||||
* 开发人员可以选择为他们的代码编写单元测试,以确保在代码里没有任何明显的疯狂行为,比如除以 0 但不抛出异常。
|
||||
* 然后开发者会把他们的代码标记为 “Ready for QA”(准备好了接受测试),质量保障的成员会把这个版本的代码发布到他们自己的环境中,这个环境和生产环境可能相似,也可能不,甚至和开发环境相比也不一定相似。
|
||||
* 故障会在几天或者几个星期内反馈到开发人员那里,这个时长取决于其它业务活动和优先事项。
|
||||
|
||||
虽然系统管理员和开发人员经常有不一致的意见,但是对“变更管理”却一致痛恨。变更管理由高度规范的(就我当时的雇主而言)和非常必要的规则和程序组成,用来管理一家公司应该什么时候做技术变更,以及如何做。很多公司都按照 [ITIL][4] 来操作,简单的说,ITIL 问了很多和事情发生的原因、时间、地点和方式相关的问题,而且提供了一个过程,对产生最终答案的决定做审计跟踪。
|
||||
|
||||
你可能从我的简短历史课上了解到,当时 IT 的很多很多事情都是手工完成的。这导致了很多错误。错误又导致了很多财产损失。变更管理的工作就是尽量减少这些损失,它常常以这样的形式出现:不管变更的影响和规模大小,每两周才能发布部署一次。周五下午 4 点到周一早上 5 点 59 分这段时间,需要排队等候发布窗口。(讽刺的是,这种流程导致了更多错误,通常还是更严重的那种错误)
|
||||
|
||||
### DevOps 不是专家团
|
||||
|
||||
你可能在想 “Carlos 你在讲啥啊,什么时候才能说到 Ansible playbooks?”,我喜欢 Ansible,但是请稍等 —— 下面这些很重要。
|
||||
|
||||
你有没有过被分配到需要跟 DevOps 小组打交道的项目?你有没有依赖过“配置管理”或者“持续集成/持续交付”小组来保证业务流水线设置正确?你有没有在代码开发完的数周之后才参加发布部署的会议?
|
||||
|
||||
如果有过,那么你就是在重温历史,这个历史是由上面所有这些导致的。
|
||||
|
||||
出于本能,我们喜欢和像自己的人一起工作,这会导致[壁垒][5]的形成。很自然,这种人类特质也会在工作场所表现出来是不足为奇的。我甚至在曾经工作过的一个 250 人的创业公司里见到过这样的现象。刚开始的时候,开发人员都在聚在一起工作,彼此深度协作。随着代码变得复杂,开发相同功能的人自然就坐到了一起,解决他们自己的复杂问题。然后按功能划分的小组很快就正式形成了。
|
||||
|
||||
在我工作过的很多公司里,系统管理员和开发人员不仅像这样形成了天然的壁垒,而且彼此还有激烈的对抗。开发人员的环境出问题了或者他们的权限太小了,就会对系统管理员很恼火。系统管理员怪开发人员无时无刻地在用各种方式破坏他们的环境,怪开发人员申请的计算资源严重超过他们的需要。双方都不理解对方,更糟糕的是,双方都不愿意去理解对方。
|
||||
|
||||
大部分开发人员对操作系统,内核或计算机硬件都不感兴趣。同样,大部分系统管理员,即使是 Linux 的系统管理员,也都不愿意学习编写代码,他们在大学期间学过一些 C 语言,然后就痛恨它,并且永远都不想再碰 IDE。所以,开发人员把运行环境的问题甩给围墙外的系统管理员,系统管理员把这些问题和甩过来的其它上百个问题放在一起安排优先级。每个人都忙于怨恨对方。DevOps 的目的就是解决这种矛盾。
|
||||
|
||||
DevOps 不是一个团队,CI/CD 也不是 JIRA 系统的一个用户组。DevOps 是一种思考方式。根据这个运动来看,在理想的世界里,开发人员、系统管理员和业务相关人将作为一个团队工作。虽然他们可能不完全了解彼此的世界,可能没有足够的知识去了解彼此的积压任务,但他们在大多数情况下能有一致的看法。
|
||||
|
||||
把所有基础设施和业务逻辑都代码化,再串到一个发布部署流水线里,就像是运行在这之上的应用一样。这个理念的基础就是 DevOps。因为大家都理解彼此,所以人人都是赢家。聊天机器人和易用的监控工具、可视化工具的兴起,背后的基础也是 DevOps。
|
||||
|
||||
[Adam Jacob][6] 说的最好:“DevOps 就是企业往软件导向型过渡时我们用来描述操作的词。”
|
||||
|
||||
### 要实践 DevOps 我需要知道些什么
|
||||
|
||||
我经常被问到这个问题,它的答案和同属于开放式的其它大部分问题一样:视情况而定。
|
||||
|
||||
现在“DevOps 工程师”在不同的公司有不同的含义。在软件开发人员比较多但是很少有人懂基础设施的小公司,他们很可能是在找有更多系统管理经验的人。而其他公司,通常是大公司或老公司,已经有一个稳固的系统管理团队了,他们在向类似于谷歌 [SRE][7] 的方向做优化,也就是“设计运维功能的软件工程师”。但是,这并不是金科玉律,就像其它技术类工作一样,这个决定很大程度上取决于他的招聘经理。
|
||||
|
||||
也就是说,我们一般是在找对深入学习以下内容感兴趣的工程师:
|
||||
|
||||
* 如何管理和设计安全、可扩展的云平台(通常是在 AWS 上,不过微软的 Azure、Google Cloud Platform,还有 DigitalOcean 和 Heroku 这样的 PaaS 提供商,也都很流行)。
|
||||
* 如何用流行的 [CI/CD][8] 工具,比如 Jenkins、GoCD,还有基于云的 Travis CI 或者 CircleCI,来构造一条优化的发布部署流水线和发布部署策略。
|
||||
* 如何在你的系统中使用基于时间序列的工具,比如 Kibana、Grafana、Splunk、Loggly 或者 Logstash 来监控、记录,并在变化的时候报警。
|
||||
* 如何使用配置管理工具,例如 Chef、Puppet 或者 Ansible 做到“基础设施即代码”,以及如何使用像 Terraform 或 CloudFormation 的工具发布这些基础设施。
|
||||
|
||||
容器也变得越来越受欢迎。尽管有人对大规模使用 Docker 的现状[表示不满][9],但容器正迅速地成为一种很好的方式来实现在更少的操作系统上运行超高密度的服务和应用,同时提高它们的可靠性。(像 Kubernetes 或者 Mesos 这样的容器编排工具,能在宿主机故障的时候,几秒钟之内重新启动新的容器。)考虑到这些,掌握 Docker 或者 rkt 以及容器编排平台的知识会对你大有帮助。
|
||||
|
||||
如果你是希望做 DevOps 实践的系统管理员,你还需要知道如何写代码。Python 和 Ruby 是 DevOps 领域的流行语言,因为它们是可移植的(也就是说可以在任何操作系统上运行)、快速的,而且易读易学。它们还支撑着这个行业最流行的配置管理工具(Ansible 是使用 Python 写的,Chef 和 Puppet 是使用 Ruby 写的)以及云平台的 API 客户端(亚马逊 AWS、微软 Azure、Google Cloud Platform 的客户端通常会提供 Python 和 Ruby 语言的版本)。
|
||||
|
||||
如果你是开发人员,也希望做 DevOps 的实践,我强烈建议你去学习 Unix、Windows 操作系统以及网络基础知识。虽然云计算把很多系统管理的难题抽象化了,但是对应用的性能做调试的时候,如果你知道操作系统如何工作的就会有很大的帮助。下文包含了一些这个主题的图书。
|
||||
|
||||
如果你觉得这些东西听起来内容太多,没关系,大家都是这么想的。幸运的是,有很多小项目可以让你开始探索。其中一个项目是 Gary Stafford 的[选举服务](https://github.com/garystafford/voter-service),一个基于 Java 的简单投票平台。我们要求面试候选人通过一个流水线将该服务从 GitHub 部署到生产环境基础设施上。你可以把这个服务与 Rob Mile 写的了不起的 DevOps [入门教程](https://github.com/maxamg/cd-office-hours)结合起来学习。
|
||||
|
||||
还有一个熟悉这些工具的好方法,找一个流行的服务,然后只使用 AWS 和配置管理工具来搭建这个服务所需要的基础设施。第一次先手动搭建,了解清楚要做的事情,然后只用 CloudFormation(或者 Terraform)和 Ansible 重写刚才的手动操作。令人惊讶的是,这就是我们基础设施开发人员为客户所做的大部分日常工作,我们的客户认为这样的工作非常有意义!
|
||||
|
||||
### 需要读的书
|
||||
|
||||
如果你在找 DevOps 的其它资源,下面这些理论和技术书籍值得一读。
|
||||
|
||||
#### 理论书籍
|
||||
|
||||
* Gene Kim 写的 《<ruby>[凤凰项目][10]<rt>The Phoenix Project</rt></ruby>》。这是一本很不错的书,内容涵盖了我上文解释过的历史(写的更生动形象),描述了一个运行在敏捷和 DevOps 之上的公司向精益前进的过程。
|
||||
* Terrance Ryan 写的 《<ruby>[布道之道][11]<rt>Driving Technical Change</rt></ruby>》。非常好的一小本书,讲了大多数技术型组织内的常见性格特点以及如何和他们打交道。这本书对我的帮助比我想象的更多。
|
||||
* Tom DeMarco 和 Tim Lister 合著的 《<ruby>[人件][12]<rt>Peopleware</rt></ruby>》。管理工程师团队的经典图书,有一点过时,但仍然很有价值。
|
||||
* Tom Limoncelli 写的 《<ruby>[时间管理:给系统管理员][13]<rt>Time Management for System Administrators</rt></ruby>》。这本书主要面向系统管理员,它对很多大型组织内的系统管理员生活做了深入的展示。如果你想了解更多系统管理员和开发人员之间的冲突,这本书可能解释了更多。
|
||||
* Eric Ries 写的 《<ruby>[精益创业][14]<rt>The Lean Startup</rt></ruby>》。描述了 Eric 自己的 3D 虚拟形象公司,IMVU,发现了如何精益工作,快速失败和更快盈利。
|
||||
* Jez Humble 和他的朋友写的 《<ruby>[精益企业][15]<rt>Lean Enterprise</rt></ruby>》。这本书是对精益创业做的改编,以更适应企业,两本书都很棒,都很好地解释了 DevOps 背后的商业动机。
|
||||
* Kief Morris 写的 《<ruby>[基础设施即代码][16]<rt>Infrastructure As Code</rt></ruby>》。关于“基础设施即代码”的非常好的入门读物!很好的解释了为什么所有公司都有必要采纳这种做法。
|
||||
* Betsy Beyer、Chris Jones、Jennifer Petoff 和 Niall Richard Murphy 合著的 《<ruby>[站点可靠性工程师][17]<rt>Site Reliability Engineering</rt></ruby>》。一本解释谷歌 SRE 实践的书,也因为是“DevOps 诞生之前的 DevOps”被人熟知。在如何处理运行时间、时延和保持工程师快乐方面提供了有意思的看法。
|
||||
|
||||
#### 技术书籍
|
||||
|
||||
如果你想找的是让你直接跟代码打交道的书,看这里就对了。
|
||||
|
||||
* W. Richard Stevens 的 《<ruby>[TCP/IP 详解][18]<rt>TCP/IP Illustrated</rt></ruby>》。这是一套经典的(也可以说是最全面的)讲解网络协议基础的巨著,重点介绍了 TCP/IP 协议族。如果你听说过 1、2、3、4 层网络,而且对深入学习它们感兴趣,那么你需要这本书。
|
||||
* Evi Nemeth、Trent Hein 和 Ben Whaley 合著的 《<ruby>[UNIX/Linux 系统管理员手册][19]<rt>UNIX and Linux System Administration Handbook</rt></ruby>》。一本很好的入门书,介绍 Linux/Unix 如何工作以及如何使用。
|
||||
* Don Jones 和 Jeffrey Hicks 合著的 《<ruby>[Windows PowerShell 实战指南][20]<rt>Learn Windows Powershell In A Month of Lunches</rt></ruby>》。如果你在 Windows 系统下做自动化任务,你需要学习怎么使用 Powershell。这本书能够帮助你。Don Jones 是这方面著名的 MVP。
|
||||
* 几乎所有 [James Turnbull][21] 写的东西,针对流行的 DevOps 工具,他发表了很好的技术入门读物。
|
||||
|
||||
不管是在那些把所有应用都直接部署在物理机上的公司,(现在很多公司仍然有充分的理由这样做)还是在那些把所有应用都做成 serverless 的先驱公司,DevOps 都很可能会持续下去。这部分工作很有趣,产出也很有影响力,而且最重要的是,它搭起桥梁衔接了技术和业务之间的缺口。DevOps 是一个值得期待的美好事物。
|
||||
|
||||
首次发表在 [Neurons Firing on a Keyboard][22]。使用 CC-BY-SA 协议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/getting-devops
|
||||
|
||||
作者:[Carlos Nunez][a]
|
||||
译者:[belitex](https://github.com/belitex)
|
||||
校对:[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/carlosonunez
|
||||
[1]: https://www.reddit.com/r/devops/
|
||||
[2]: https://carlosonunez.wordpress.com/
|
||||
[3]: https://twitter.com/easiestnameever
|
||||
[4]: https://en.wikipedia.org/wiki/ITIL
|
||||
[5]: https://www.psychologytoday.com/blog/time-out/201401/getting-out-your-silo
|
||||
[6]: https://twitter.com/adamhjk/status/572832185461428224
|
||||
[7]: https://landing.google.com/sre/interview/ben-treynor.html
|
||||
[8]: https://en.wikipedia.org/wiki/CI/CD
|
||||
[9]: https://thehftguy.com/2016/11/01/docker-in-production-an-history-of-failure/
|
||||
[10]: https://itrevolution.com/book/the-phoenix-project/
|
||||
[11]: https://pragprog.com/book/trevan/driving-technical-change
|
||||
[12]: https://en.wikipedia.org/wiki/Peopleware:_Productive_Projects_and_Teams
|
||||
[13]: http://shop.oreilly.com/product/9780596007836.do
|
||||
[14]: http://theleanstartup.com/
|
||||
[15]: https://info.thoughtworks.com/lean-enterprise-book.html
|
||||
[16]: http://infrastructure-as-code.com/book/
|
||||
[17]: https://landing.google.com/sre/book.html
|
||||
[18]: https://en.wikipedia.org/wiki/TCP/IP_Illustrated
|
||||
[19]: http://www.admin.com/
|
||||
[20]: https://www.manning.com/books/learn-windows-powershell-in-a-month-of-lunches-third-edition
|
||||
[21]: https://jamesturnbull.net/
|
||||
[22]: https://carlosonunez.wordpress.com/2017/03/02/getting-into-devops/
|
||||
@ -0,0 +1,49 @@
|
||||
从过时的 Windows 机器迁移到 Linux
|
||||
======
|
||||
> 这是一个当老旧的 Windows 机器退役时,决定迁移到 Linux 的故事。
|
||||
|
||||

|
||||
|
||||
我在 ONLYOFFICE 的市场部门工作的每一天,我都能看到 Linux 用户在网上讨论我们的办公软件。我们的产品在 Linux 用户中很受欢迎,这使得我对使用 Linux 作为日常工具的体验非常好奇。我的老旧的 Windows XP 机器在性能上非常差,因此我决定了解 Linux 系统(特别是 Ubuntu)并且决定去尝试使用它。我的两个同事也加入了我的计划。
|
||||
|
||||
### 为何选择 Linux ?
|
||||
|
||||
我们必须做出改变,首先,我们的老系统在性能方面不够用:我们经历过频繁的崩溃,每当运行超过两个应用时,机器就会负载过度,关闭机器时有一半的几率冻结等等。这很容易让我们从工作中分心,意味着我们没有我们应有的工作效率了。
|
||||
|
||||
升级到 Windows 的新版本也是一种选择,但这样可能会带来额外的开销,而且我们的软件本身也是要与 Microsoft 的办公软件竞争。因此我们在这方面也存在意识形态的问题。
|
||||
|
||||
其次,就像我之前提过的, ONLYOFFICE 产品在 Linux 社区内非常受欢迎。通过阅读 Linux 用户在使用我们的软件时的体验,我们也对加入他们很感兴趣。
|
||||
|
||||
在我们要求转换到 Linux 系统一周后,我们拿到了崭新的装好了 [Kubuntu][1] 的机器。我们选择了 16.04 版本,因为这个版本支持 KDE Plasma 5.5 和包括 Dolphin 在内的很多 KDE 应用,同时也包括 LibreOffice 5.1 和 Firefox 45 。
|
||||
|
||||
### Linux 让人喜欢的地方
|
||||
|
||||
我相信 Linux 最大的优势是它的运行速度,比如,从按下机器的电源按钮到开始工作只需要几秒钟时间。从一开始,一切看起来都超乎寻常地快:总体的响应速度,图形界面,甚至包括系统更新的速度。
|
||||
|
||||
另一个使我惊奇的事情是跟 Windows 相比, Linux 几乎能让你配置任何东西,包括整个桌面的外观。在设置里面,我发现了如何修改各种栏目、按钮和字体的颜色和形状,也可以重新布置任意桌面组件的位置,组合桌面小工具(甚至包括漫画和颜色选择器)。我相信我还仅仅只是了解了基本的选项,之后还需要探索这个系统更多著名的定制化选项。
|
||||
|
||||
Linux 发行版通常是一个非常安全的环境。人们很少在 Linux 系统中使用防病毒的软件,因为很少有人会写病毒程序来攻击 Linux 系统。因此你可以拥有很好的系统速度,并且节省了时间和金钱。
|
||||
|
||||
总之, Linux 已经改变了我们的日常生活,用一系列的新选项和功能大大震惊了我们。仅仅通过短时间的使用,我们已经可以给它总结出以下特性:
|
||||
|
||||
* 操作很快很顺畅
|
||||
* 高度可定制
|
||||
* 对新手很友好
|
||||
* 了解基本组件很有挑战性,但回报丰厚
|
||||
* 安全可靠
|
||||
* 对所有想改变工作场所的人来说都是一次绝佳的体验
|
||||
|
||||
你已经从 Windows 或 MacOS 系统换到 Kubuntu 或其他 Linux 变种了么?或者你是否正在考虑做出改变?请分享你想要采用 Linux 系统的原因,连同你对开源的印象一起写在评论中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/move-to-linux-old-windows
|
||||
|
||||
作者:[Michael Korotaev][a]
|
||||
译者:[bookug](https://github.com/bookug)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/michaelk
|
||||
[1]:https://kubuntu.org/
|
||||
@ -0,0 +1,203 @@
|
||||
在 React 条件渲染中使用三元表达式和 “&&”
|
||||
=======
|
||||
|
||||

|
||||
|
||||
React 组件可以通过多种方式决定渲染内容。你可以使用传统的 `if` 语句或 `switch` 语句。在本文中,我们将探讨一些替代方案。但要注意,如果你不小心,有些方案会带来自己的陷阱。
|
||||
|
||||
### 三元表达式 vs if/else
|
||||
|
||||
假设我们有一个组件被传进来一个 `name` 属性。 如果这个字符串非空,我们会显示一个问候语。否则,我们会告诉用户他们需要登录。
|
||||
|
||||
这是一个只实现了如上功能的无状态函数式组件(SFC)。
|
||||
|
||||
```
|
||||
const MyComponent = ({ name }) => {
|
||||
if (name) {
|
||||
return (
|
||||
<div className="hello">
|
||||
Hello {name}
|
||||
</div>
|
||||
);
|
||||
}
|
||||
return (
|
||||
<div className="hello">
|
||||
Please sign in
|
||||
</div>
|
||||
);
|
||||
};
|
||||
```
|
||||
|
||||
这个很简单但是我们可以做得更好。这是使用<ruby>三元运算符<rt>conditional ternary operator</rt></ruby>编写的相同组件。
|
||||
|
||||
```
|
||||
const MyComponent = ({ name }) => (
|
||||
<div className="hello">
|
||||
{name ? `Hello ${name}` : 'Please sign in'}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
请注意这段代码与上面的例子相比是多么简洁。
|
||||
|
||||
有几点需要注意。因为我们使用了箭头函数的单语句形式,所以隐含了`return` 语句。另外,使用三元运算符允许我们省略掉重复的 `<div className="hello">` 标记。
|
||||
|
||||
### 三元表达式 vs &&
|
||||
|
||||
正如您所看到的,三元表达式用于表达 `if`/`else` 条件式非常好。但是对于简单的 `if` 条件式怎么样呢?
|
||||
|
||||
让我们看另一个例子。如果 `isPro`(一个布尔值)为真,我们将显示一个奖杯表情符号。我们也要渲染星星的数量(如果不是 0)。我们可以这样写。
|
||||
|
||||
```
|
||||
const MyComponent = ({ name, isPro, stars}) => (
|
||||
<div className="hello">
|
||||
<div>
|
||||
Hello {name}
|
||||
{isPro ? '♨' : null}
|
||||
</div>
|
||||
{stars ? (
|
||||
<div>
|
||||
Stars:{'☆'.repeat(stars)}
|
||||
</div>
|
||||
) : null}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
请注意 `else` 条件返回 `null` 。 这是因为三元表达式要有“否则”条件。
|
||||
|
||||
对于简单的 `if` 条件式,我们可以使用更合适的东西:`&&` 运算符。这是使用 `&&` 编写的相同代码。
|
||||
|
||||
```
|
||||
const MyComponent = ({ name, isPro, stars}) => (
|
||||
<div className="hello">
|
||||
<div>
|
||||
Hello {name}
|
||||
{isPro && '♨'}
|
||||
</div>
|
||||
{stars && (
|
||||
<div>
|
||||
Stars:{'☆'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
没有太多区别,但是注意我们消除了每个三元表达式最后面的 `: null` (`else` 条件式)。一切都应该像以前一样渲染。
|
||||
|
||||
嘿!约翰得到了什么?当什么都不应该渲染时,只有一个 `0`。这就是我上面提到的陷阱。这里有解释为什么:
|
||||
|
||||
[根据 MDN][3],一个逻辑运算符“和”(也就是 `&&`):
|
||||
|
||||
> `expr1 && expr2`
|
||||
|
||||
> 如果 `expr1` 可以被转换成 `false` ,返回 `expr1`;否则返回 `expr2`。 如此,当与布尔值一起使用时,如果两个操作数都是 `true`,`&&` 返回 `true` ;否则,返回 `false`。
|
||||
|
||||
好的,在你开始拔头发之前,让我为你解释它。
|
||||
|
||||
在我们这个例子里, `expr1` 是变量 `stars`,它的值是 `0`,因为 0 是假值,`0` 会被返回和渲染。看,这还不算太坏。
|
||||
|
||||
我会简单地这么写。
|
||||
|
||||
> 如果 `expr1` 是假值,返回 `expr1` ,否则返回 `expr2`。
|
||||
|
||||
所以,当对非布尔值使用 `&&` 时,我们必须让这个假值返回 React 无法渲染的东西,比如说,`false` 这个值。
|
||||
|
||||
我们可以通过几种方式实现这一目标。让我们试试吧。
|
||||
|
||||
```
|
||||
{!!stars && (
|
||||
<div>
|
||||
{'☆'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
```
|
||||
|
||||
注意 `stars` 前的双感叹操作符(`!!`)(呃,其实没有双感叹操作符。我们只是用了感叹操作符两次)。
|
||||
|
||||
第一个感叹操作符会强迫 `stars` 的值变成布尔值并且进行一次“非”操作。如果 `stars` 是 `0` ,那么 `!stars` 会是 `true`。
|
||||
|
||||
然后我们执行第二个`非`操作,所以如果 `stars` 是 `0`,`!!stars` 会是 `false`。正好是我们想要的。
|
||||
|
||||
如果你不喜欢 `!!`,那么你也可以强制转换出一个布尔数比如这样(这种方式我觉得有点冗长)。
|
||||
|
||||
```
|
||||
{Boolean(stars) && (
|
||||
```
|
||||
|
||||
或者只是用比较符产生一个布尔值(有些人会说这样甚至更加语义化)。
|
||||
|
||||
```
|
||||
{stars > 0 && (
|
||||
```
|
||||
|
||||
#### 关于字符串
|
||||
|
||||
空字符串与数字有一样的毛病。但是因为渲染后的空字符串是不可见的,所以这不是那种你很可能会去处理的难题,甚至可能不会注意到它。然而,如果你是完美主义者并且不希望 DOM 上有空字符串,你应采取我们上面对数字采取的预防措施。
|
||||
|
||||
### 其它解决方案
|
||||
|
||||
一种可能的将来可扩展到其他变量的解决方案,是创建一个单独的 `shouldRenderStars` 变量。然后你用 `&&` 处理布尔值。
|
||||
|
||||
```
|
||||
const shouldRenderStars = stars > 0;
|
||||
```
|
||||
|
||||
```
|
||||
return (
|
||||
<div>
|
||||
{shouldRenderStars && (
|
||||
<div>
|
||||
{'☆'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
之后,在将来,如果业务规则要求你还需要已登录,拥有一条狗以及喝淡啤酒,你可以改变 `shouldRenderStars` 的得出方式,而返回的内容保持不变。你还可以把这个逻辑放在其它可测试的地方,并且保持渲染明晰。
|
||||
|
||||
```
|
||||
const shouldRenderStars =
|
||||
stars > 0 && loggedIn && pet === 'dog' && beerPref === 'light`;
|
||||
```
|
||||
|
||||
```
|
||||
return (
|
||||
<div>
|
||||
{shouldRenderStars && (
|
||||
<div>
|
||||
{'☆'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
### 结论
|
||||
|
||||
我认为你应该充分利用这种语言。对于 JavaScript,这意味着为 `if/else` 条件式使用三元表达式,以及为 `if` 条件式使用 `&&` 操作符。
|
||||
|
||||
我们可以回到每处都使用三元运算符的舒适区,但你现在消化了这些知识和力量,可以继续前进 `&&` 取得成功了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
美国运通工程博客的执行编辑 http://aexp.io 以及 @AmericanExpress 的工程总监。MyViews !== ThoseOfMyEmployer.
|
||||
|
||||
----------------
|
||||
|
||||
via: https://medium.freecodecamp.org/conditional-rendering-in-react-using-ternaries-and-logical-and-7807f53b6935
|
||||
|
||||
作者:[Donavon West][a]
|
||||
译者:[GraveAccent](https://github.com/GraveAccent)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@donavon
|
||||
[1]:https://unsplash.com/photos/pKeF6Tt3c08?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[2]:https://unsplash.com/search/photos/road-sign?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[3]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Logical_Operators
|
||||
@ -1,21 +1,22 @@
|
||||
The df Command Tutorial With Examples For Beginners
|
||||
df 命令新手教程
|
||||
======
|
||||
|
||||

|
||||
|
||||
In this guide, we are going to learn to use **df** command. The df command, stands for **D** isk **F** ree, reports file system disk space usage. It displays the amount of disk space available on the file system in a Linux system. The df command is not to be confused with **du** command. Both serves different purposes. The df command reports **how much disk space we have** (i.e free space) whereas the du command reports **how much disk space is being consumed** by the files and folders. Hope I made myself clear. Let us go ahead and see some practical examples of df command, so you can understand it better.
|
||||
在本指南中,我们将学习如何使用 `df` 命令。df 命令是 “Disk Free” 的首字母组合,它报告文件系统磁盘空间的使用情况。它显示一个 Linux 系统中文件系统上可用磁盘空间的数量。`df` 命令很容易与 `du` 命令混淆。它们的用途不同。`df` 命令报告我们拥有多少磁盘空间(空闲磁盘空间),而 `du` 命令报告被文件和目录占用了多少磁盘空间。希望我这样的解释你能更清楚。在继续之前,我们来看一些 `df` 命令的实例,以便于你更好地理解它。
|
||||
|
||||
### The df Command Tutorial With Examples
|
||||
### df 命令使用举例
|
||||
|
||||
**1\. View entire file system disk space usage**
|
||||
#### 1、查看整个文件系统磁盘空间使用情况
|
||||
|
||||
无需任何参数来运行 `df` 命令,以显示整个文件系统磁盘空间使用情况。
|
||||
|
||||
Run df command without any arguments to display the entire file system disk space.
|
||||
```
|
||||
$ df
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
dev 4033216 0 4033216 0% /dev
|
||||
@ -27,25 +28,23 @@ tmpfs 4038880 11636 4027244 1% /tmp
|
||||
/dev/loop0 84096 84096 0 100% /var/lib/snapd/snap/core/4327
|
||||
/dev/sda1 95054 55724 32162 64% /boot
|
||||
tmpfs 807776 28 807748 1% /run/user/1000
|
||||
|
||||
```
|
||||
|
||||
![][2]
|
||||
|
||||
As you can see, the result is divided into six columns. Let us see what each column means.
|
||||
正如你所见,输出结果分为六列。我们来看一下每一列的含义。
|
||||
|
||||
* **Filesystem** – the filesystem on the system.
|
||||
* **1K-blocks** – the size of the filesystem, measured in 1K blocks.
|
||||
* **Used** – the amount of space used in 1K blocks.
|
||||
* **Available** – the amount of available space in 1K blocks.
|
||||
* **Use%** – the percentage that the filesystem is in use.
|
||||
* **Mounted on** – the mount point where the filesystem is mounted.
|
||||
* `Filesystem` – Linux 系统中的文件系统
|
||||
* `1K-blocks` – 文件系统的大小,用 1K 大小的块来表示。
|
||||
* `Used` – 以 1K 大小的块所表示的已使用数量。
|
||||
* `Available` – 以 1K 大小的块所表示的可用空间的数量。
|
||||
* `Use%` – 文件系统中已使用的百分比。
|
||||
* `Mounted on` – 已挂载的文件系统的挂载点。
|
||||
|
||||
#### 2、以人类友好格式显示文件系统硬盘空间使用情况
|
||||
|
||||
在上面的示例中你可能已经注意到了,它使用 1K 大小的块为单位来表示使用情况,如果你以人类友好格式来显示它们,可以使用 `-h` 标志。
|
||||
|
||||
**2\. Display file system disk usage in human readable format**
|
||||
|
||||
As you may noticed in the above examples, the usage is showed in 1k blocks. If you want to display them in human readable format, use **-h** flag.
|
||||
```
|
||||
$ df -h
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
@ -61,11 +60,12 @@ tmpfs 789M 28K 789M 1% /run/user/1000
|
||||
|
||||
```
|
||||
|
||||
Now look at the **Size** and **Avail** columns, the usage is shown in GB and MB.
|
||||
现在,在 `Size` 列和 `Avail` 列,使用情况是以 GB 和 MB 为单位来显示的。
|
||||
|
||||
**3\. Display disk space usage only in MB**
|
||||
#### 3、仅以 MB 为单位来显示文件系统磁盘空间使用情况
|
||||
|
||||
如果仅以 MB 为单位来显示文件系统磁盘空间使用情况,使用 `-m` 标志。
|
||||
|
||||
To view file system disk space usage only in Megabytes, use **-m** flag.
|
||||
```
|
||||
$ df -m
|
||||
Filesystem 1M-blocks Used Available Use% Mounted on
|
||||
@ -78,12 +78,12 @@ tmpfs 3945 12 3933 1% /tmp
|
||||
/dev/loop0 83 83 0 100% /var/lib/snapd/snap/core/4327
|
||||
/dev/sda1 93 55 32 64% /boot
|
||||
tmpfs 789 1 789 1% /run/user/1000
|
||||
|
||||
```
|
||||
|
||||
**4\. List inode information instead of block usage**
|
||||
#### 4、列出节点而不是块的使用情况
|
||||
|
||||
如下所示,我们可以通过使用 `-i` 标记来列出节点而不是块的使用情况。
|
||||
|
||||
We can list inode information instead of block usage by using **-i** flag as shown below.
|
||||
```
|
||||
$ df -i
|
||||
Filesystem Inodes IUsed IFree IUse% Mounted on
|
||||
@ -96,12 +96,12 @@ tmpfs 1009720 3008 1006712 1% /tmp
|
||||
/dev/loop0 12829 12829 0 100% /var/lib/snapd/snap/core/4327
|
||||
/dev/sda1 25688 390 25298 2% /boot
|
||||
tmpfs 1009720 29 1009691 1% /run/user/1000
|
||||
|
||||
```
|
||||
|
||||
**5\. Display the file system type**
|
||||
#### 5、显示文件系统类型
|
||||
|
||||
使用 `-T` 标志显示文件系统类型。
|
||||
|
||||
To display the file system type, use **-T** flag.
|
||||
```
|
||||
$ df -T
|
||||
Filesystem Type 1K-blocks Used Available Use% Mounted on
|
||||
@ -114,27 +114,27 @@ tmpfs tmpfs 4038880 11984 4026896 1% /tmp
|
||||
/dev/loop0 squashfs 84096 84096 0 100% /var/lib/snapd/snap/core/4327
|
||||
/dev/sda1 ext4 95054 55724 32162 64% /boot
|
||||
tmpfs tmpfs 807776 28 807748 1% /run/user/1000
|
||||
|
||||
```
|
||||
|
||||
As you see, there is an extra column (second from left) that shows the file system type.
|
||||
正如你所见,现在出现了显示文件系统类型的额外的列(从左数的第二列)。
|
||||
|
||||
**6\. Display only the specific file system type**
|
||||
#### 6、仅显示指定类型的文件系统
|
||||
|
||||
我们可以限制仅列出某些文件系统。比如,只列出 ext4 文件系统。我们使用 `-t` 标志。
|
||||
|
||||
We can limit the listing to a certain file systems. for example **ext4**. To do so, we use **-t** flag.
|
||||
```
|
||||
$ df -t ext4
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
/dev/sda2 478425016 428790896 25308436 95% /
|
||||
/dev/sda1 95054 55724 32162 64% /boot
|
||||
|
||||
```
|
||||
|
||||
See? This command shows only the ext4 file system disk space usage.
|
||||
看到了吗?这个命令仅显示了 ext4 文件系统的磁盘空间使用情况。
|
||||
|
||||
**7\. Exclude specific file system type**
|
||||
#### 7、不列出指定类型的文件系统
|
||||
|
||||
有时,我们可能需要从结果中去排除指定类型的文件系统。我们可以使用 `-x` 标记达到我们的目的。
|
||||
|
||||
Some times, you may want to exclude a specific file system from the result. This can be achieved by using **-x** flag.
|
||||
```
|
||||
$ df -x ext4
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
@ -145,34 +145,32 @@ tmpfs 4038880 0 4038880 0% /sys/fs/cgroup
|
||||
tmpfs 4038880 11984 4026896 1% /tmp
|
||||
/dev/loop0 84096 84096 0 100% /var/lib/snapd/snap/core/4327
|
||||
tmpfs 807776 28 807748 1% /run/user/1000
|
||||
|
||||
```
|
||||
|
||||
The above command will display all file systems usage, except **ext4**.
|
||||
上面的命令列出了除 ext4 类型以外的全部文件系统。
|
||||
|
||||
**8\. Display usage for a folder**
|
||||
#### 8、显示一个目录的磁盘使用情况
|
||||
|
||||
去显示某个目录的硬盘空间使用情况以及它的挂载点,例如 `/home/sk/` 目录,可以使用如下的命令:
|
||||
|
||||
To display the disk space available and where it is mounted for a folder, for example **/home/sk/** , use this command:
|
||||
```
|
||||
$ df -hT /home/sk/
|
||||
Filesystem Type Size Used Avail Use% Mounted on
|
||||
/dev/sda2 ext4 457G 409G 25G 95% /
|
||||
|
||||
```
|
||||
|
||||
This command shows the file system type, used and available space in human readable form and where it is mounted. If you don’t to display the file system type, just ignore the **-t** flag.
|
||||
这个命令显示文件系统类型、以人类友好格式显示已使用和可用磁盘空间、以及它的挂载点。如果你不想去显示文件系统类型,只需要忽略 `-t` 标志即可。
|
||||
|
||||
更详细的使用情况,请参阅 man 手册页。
|
||||
|
||||
For more details, refer the man pages.
|
||||
```
|
||||
$ man df
|
||||
|
||||
```
|
||||
|
||||
**Recommended read:**
|
||||
|
||||
And, that’s all for today! I hope this was useful. More good stuffs to come. Stay tuned!
|
||||
今天就到此这止!我希望对你有用。还有更多更好玩的东西即将奉上。请继续关注!
|
||||
|
||||
Cheers!
|
||||
再见!
|
||||
|
||||
|
||||
|
||||
@ -181,12 +179,13 @@ Cheers!
|
||||
via: https://www.ostechnix.com/the-df-command-tutorial-with-examples-for-beginners/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/04/df-command.png
|
||||
|
||||
@ -0,0 +1,73 @@
|
||||
一些提高开源代码安全性的工具
|
||||
======
|
||||
|
||||
> 开源软件的迅速普及带来了对健全安全实践的需求。
|
||||
|
||||

|
||||
|
||||
虽然目前开源依然发展势头较好,并被广大的厂商所采用,然而最近由 Black Duck 和 Synopsys 发布的 [2018 开源安全与风险评估报告][1]指出了一些存在的风险,并重点阐述了对于健全安全措施的需求。这份报告的分析资料素材来自经过脱敏后的 1100 个商业代码库,这些代码所涉及:自动化、大数据、企业级软件、金融服务业、健康医疗、物联网、制造业等多个领域。
|
||||
|
||||
这份报告强调开源软件正在被大量的使用,扫描结果中有 96% 的应用都使用了开源组件。然而,报告还指出许多其中存在很多漏洞。具体在 [这里][2]:
|
||||
|
||||
* 令人担心的是扫描的所有结果中,有 78% 的代码库存在至少一个开源的漏洞,平均每个代码库有 64 个漏洞。
|
||||
* 在经过代码审计过后代码库中,发现超过 54% 的漏洞经验证是高危漏洞。
|
||||
* 17% 的代码库包括一种已经早已公开的漏洞,包括:Heartbleed、Logjam、Freak、Drown、Poddle。
|
||||
|
||||
Synopsys 旗下 Black Duck 的技术负责人 Tim Mackey 称,“这份报告清楚的阐述了:随着开源软件正在被企业广泛的使用,企业与组织也应当使用一些工具来检测可能出现在这些开源软件中的漏洞,以及管理其所使用的开源软件的方式是否符合相应的许可证规则。”
|
||||
|
||||
确实,随着越来越具有影响力的安全威胁出现,历史上从未有过我们目前对安全工具和实践的需求。大多数的组织已经意识到网络与系统管理员需要具有相应的较强的安全技能和安全证书。[在一篇文章中][3],我们给出一些具有较大影响力的工具、认证和实践。
|
||||
|
||||
Linux 基金会已经在安全方面提供了许多关于安全的信息与教育资源。比如,Linux 社区提供了许多针对特定平台的免费资源,其中 [Linux 工作站安全检查清单][4] 其中提到了很多有用的基础信息。线上的一些发表刊物也可以提升用户针对某些平台对于漏洞的保护,如:[Fedora 安全指南][5]、[Debian 安全手册][6]。
|
||||
|
||||
目前被广泛使用的私有云平台 OpenStack 也加强了关于基于云的智能安全需求。根据 Linux 基金会发布的 [公有云指南][7]:“据 Gartner 的调研结果,尽管公有云的服务商在安全审查和提升透明度方面做的都还不错,安全问题仍然是企业考虑向公有云转移的最重要的考量之一。”
|
||||
|
||||
无论是对于组织还是个人,千里之堤毁于蚁穴,这些“蚁穴”无论是来自路由器、防火墙、VPN 或虚拟机都可能导致灾难性的后果。以下是一些免费的工具可能对于检测这些漏洞提供帮助:
|
||||
|
||||
* [Wireshark][8],流量包分析工具
|
||||
* [KeePass Password Safe][9],自由开源的密码管理器
|
||||
* [Malwarebytes][10],免费的反病毒和勒索软件工具
|
||||
* [NMAP][11],安全扫描器
|
||||
* [NIKTO][12],开源的 web 服务器扫描器
|
||||
* [Ansible][13],自动化的配置运维工具,可以辅助做安全基线
|
||||
* [Metasploit][14],渗透测试工具,可辅助理解攻击向量
|
||||
|
||||
这里有一些对上面工具讲解的视频。比如 [Metasploit 教学][15]、[Wireshark 教学][16]。还有一些传授安全技能的免费电子书,比如:由 Ibrahim Haddad 博士和 Linux 基金会共同出版的[并购过程中的开源审计][17],里面阐述了多条在技术平台合并过程中,因没有较好的进行开源审计,从而引发的安全问题。当然,书中也记录了如何在这一过程中进行代码合规检查、准备以及文档编写。
|
||||
|
||||
同时,我们 [之前提到的一个免费的电子书][18], 由来自 [The New Stack][19] 编写的“Docker 与容器中的网络、安全和存储”,里面也提到了关于加强容器网络安全的最新技术,以及 Docker 本身可提供的关于提升其网络的安全与效率的最佳实践。这本电子书还记录了关于如何构建安全容器集群的最佳实践。
|
||||
|
||||
所有这些工具和资源,可以在很大的程度上预防安全问题,正如人们所说的未雨绸缪,考虑到一直存在的安全问题,现在就应该开始学习这些安全合规资料与工具。
|
||||
|
||||
想要了解更多的安全、合规以及开源项目问题,点击[这里][20]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/5/free-resources-securing-your-open-source-code
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[sd886393](https://github.com/sd886393)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.blackducksoftware.com/open-source-security-risk-analysis-2018
|
||||
[2]:https://www.prnewswire.com/news-releases/synopsys-report-finds-majority-of-software-plagued-by-known-vulnerabilities-and-license-conflicts-as-open-source-adoption-soars-300648367.html
|
||||
[3]:https://www.linux.com/blog/sysadmin-ebook/2017/8/future-proof-your-sysadmin-career-locking-down-security
|
||||
[4]:https://linux.cn/article-6753-1.html
|
||||
[5]:https://docs.fedoraproject.org/en-US/Fedora/19/html/Security_Guide/index.html
|
||||
[6]:https://www.debian.org/doc/manuals/securing-debian-howto/index.en.html
|
||||
[7]:https://www.linux.com/publications/2016-guide-open-cloud
|
||||
[8]:https://www.wireshark.org/
|
||||
[9]:http://keepass.info/
|
||||
[10]:https://www.malwarebytes.com/
|
||||
[11]:http://searchsecurity.techtarget.co.uk/tip/Nmap-tutorial-Nmap-scan-examples-for-vulnerability-discovery
|
||||
[12]:https://cirt.net/Nikto2
|
||||
[13]:https://www.ansible.com/
|
||||
[14]:https://www.metasploit.com/
|
||||
[15]:http://www.computerweekly.com/tutorial/The-Metasploit-Framework-Tutorial-PDF-compendium-Your-ready-reckoner
|
||||
[16]:https://www.youtube.com/watch?v=TkCSr30UojM
|
||||
[17]:https://www.linuxfoundation.org/resources/open-source-audits-merger-acquisition-transactions/
|
||||
[18]:https://www.linux.com/news/networking-security-storage-docker-containers-free-ebook-covers-essentials
|
||||
[19]:http://thenewstack.io/ebookseries/
|
||||
[20]:https://www.linuxfoundation.org/projects/security-compliance/
|
||||
114
published/20180531 How to create shortcuts in vi.md
Normal file
114
published/20180531 How to create shortcuts in vi.md
Normal file
@ -0,0 +1,114 @@
|
||||
如何在 vi 中创建快捷键
|
||||
======
|
||||
|
||||
> 那些常见编辑任务的快捷键可以使 Vi 编辑器更容易使用,更有效率。
|
||||
|
||||

|
||||
|
||||
学习使用 [vi 文本编辑器][1] 确实得花点功夫,不过 vi 的老手们都知道,经过一小会儿的锻炼,就可以将基本的 vi 操作融汇贯通。我们都知道“肌肉记忆”,那么学习 vi 的过程可以称之为“手指记忆”。
|
||||
|
||||
当你抓住了基础的操作窍门之后,你就可以定制化地配置 vi 的快捷键,从而让其处理的功能更为强大、流畅。我希望下面描述的技术可以加速您的协作、编程和数据操作。
|
||||
|
||||
在开始之前,我想先感谢下 Chris Hermansen(是他雇佣我写了这篇文章)仔细地检查了我的另一篇关于使用 vi 增强版本 [Vim][2] 的文章。当然还有他那些我未采纳的建议。
|
||||
|
||||
首先,我们来说明下面几个惯例设定。我会使用符号 `<RET>` 来代表按下回车,`<SP>` 代表按下空格键,`CTRL-x` 表示一起按下 `Control` 键和 `x` 键(`x` 可以是需要的某个键)。
|
||||
|
||||
使用 `map` 命令来进行按键的映射。第一个例子是 `write` 命令,通常你之前保存使用这样的命令:
|
||||
|
||||
```
|
||||
:w<RET>
|
||||
```
|
||||
|
||||
虽然这里只有三个键,不过考虑到我用这个命令实在是太频繁了,我更想“一键”搞定它。在这里我选择逗号键,它不是标准的 vi 命令集的一部分。这样设置:
|
||||
|
||||
```
|
||||
:map , :wCTRL-v<RET>
|
||||
```
|
||||
|
||||
这里的 `CTRL-v` 事实上是对 `<RET>` 做了转义的操作,如果不加这个的话,默认 `<RET>` 会作为这条映射指令的结束信号,而非映射中的一个操作。 `CTRL-v` 后面所跟的操作会翻译为用户的实际操作,而非该按键平常的操作。
|
||||
|
||||
在上面的映射中,右边的部分会在屏幕中显示为 `:w^M`,其中 `^` 字符就是指代 `control`,完整的意思就是 `CTRL-m`,表示就是系统中一行的结尾。
|
||||
|
||||
目前来说,就很不错了。如果我编辑、创建了十二次文件,这个键位映射就可以省掉了 2*12 次按键。不过这里没有计算你建立这个键位映射所花费的 11 次按键(计算 `CTRL-v` 和 `:` 均为一次按键)。虽然这样已经省了很多次,但是每次打开 vi 都要重新建立这个映射也会觉得非常麻烦。
|
||||
|
||||
幸运的是,这里可以将这些键位映射放到 vi 的启动配置文件中,让其在每次启动的时候自动读取:文件为 `.exrc`,对于 vim 是 `.vimrc`。只需要将这些文件放在你的用户根目录中即可,并在文件中每行写入一个键位映射,之后就会在每次启动 vi 生效直到你删除对应的配置。
|
||||
|
||||
在继续说明 `map` 其他用法以及其他的缩写机制之前,这里在列举几个我常用提高文本处理效率的 map 设置:
|
||||
|
||||
| 映射 | 显示为 |
|
||||
|------|-------|
|
||||
| `:map X :xCTRL-v<RET>` | `:x^M` |
|
||||
| `:map X ,:qCTRL-v<RET>` | `,:q^M` |
|
||||
|
||||
上面的 `map` 指令的意思是写入并关闭当前的编辑文件。其中 `:x` 是 vi 原本的命令,而下面的版本说明之前的 `map` 配置可以继续用作第二个 `map` 键位映射。
|
||||
|
||||
| 映射 | 显示为 |
|
||||
|------|-------|
|
||||
| `:map v :e<SP>` | `:e` |
|
||||
|
||||
上面的指令意思是在 vi 编辑器内部切换文件,使用这个时候,只需要按 `v` 并跟着输入文件名,之后按 `<RET>` 键。
|
||||
|
||||
| 映射 | 显示为 |
|
||||
|------|-------|
|
||||
| `:map CTRL-vCTRL-e :e<SP>#CTRL-v<RET>` | `:e #^M` |
|
||||
|
||||
`#` 在这里是 vi 中标准的符号,意思是最后使用的文件名。所以切换当前与上一个文件的方法就使用上面的映射。
|
||||
|
||||
| 映射 | 显示为 |
|
||||
|------|-------|
|
||||
| `map CTRL-vCTRL-r :!spell %>err &CTRL-v<RET>` | `:!spell %>err&^M` |
|
||||
|
||||
(注意:在两个例子中出现的第一个 `CRTL-v` 在某些 vi 的版本中是不需要的)其中,`:!` 用来运行一个外部的(非 vi 内部的)命令。在这个拼写检查的例子中,`%` 是 vi 中的符号用来指代目前的文件, `>` 用来重定向拼写检查中的输出到 `err` 文件中,之后跟上 `&` 说明该命令是一个后台运行的任务,这样可以保证在拼写检查的同时还可以进行编辑文件的工作。这里我可以键入 `verr<RET>`(使用我之前定义的快捷键 `v` 跟上 `err`),进入 `spell` 输出结果的文件,之后再输入 `CTRL-e` 来回到刚才编辑的文件中。这样我就可以在拼写检查之后,使用 `CTRL-r` 来查看检查的错误,再通过 `CTRL-e` 返回刚才编辑的文件。
|
||||
|
||||
还用很多字符串输入的缩写,也使用了各种 `map` 命令,比如:
|
||||
|
||||
```
|
||||
:map! CTRL-o \fI
|
||||
:map! CTRL-k \fP
|
||||
```
|
||||
|
||||
这个映射允许你使用 `CTRL-o` 作为 `groff` 命令的缩写,从而让让接下来书写的单词有斜体的效果,并使用 `CTRL-k` 进行恢复。
|
||||
|
||||
还有两个类似的映射:
|
||||
|
||||
```
|
||||
:map! rh rhinoceros
|
||||
:map! hi hippopotamus
|
||||
```
|
||||
|
||||
上面的也可以使用 `ab` 命令来替换,就像下面这样(如果想这么用的话,需要首先按顺序运行: 1、 `unmap! rh`,2、`umap! hi`):
|
||||
|
||||
```
|
||||
:ab rh rhinoceros
|
||||
:ab hi hippopotamus
|
||||
```
|
||||
|
||||
在上面 `map!` 的命令中,缩写会马上的展开成原有的单词,而在 `ab` 命令中,单词展开的操作会在输入了空格和标点之后才展开(不过在 Vim 和我的 vi 中,展开的形式与 `map!` 类似)。
|
||||
|
||||
想要取消刚才设定的按键映射,可以对应的输入 `:unmap`、 `unmap!` 或 `:unab`。
|
||||
|
||||
在我使用的 vi 版本中,比较好用的候选映射按键包括 `g`、`K`、`q`、 `v`、 `V`、 `Z`,控制字符包括:`CTRL-a`、`CTRL-c`、 `CTRL-k`、`CTRL-n`、`CTRL-p`、`CTRL-x`;还有一些其他的字符如 `#`、 `*`,当然你也可以使用那些已经在 vi 中有过定义但不经常使用的字符,比如本文选择 `X` 和 `I`,其中 `X` 表示删除左边的字符,并立刻左移当前字符。
|
||||
|
||||
最后,下面的命令
|
||||
|
||||
```
|
||||
:map<RET>
|
||||
:map!<RET>
|
||||
:ab
|
||||
```
|
||||
|
||||
将会显示,目前所有的缩写和键位映射。
|
||||
|
||||
希望上面的技巧能够更好地更高效地帮助你使用 vi。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/shortcuts-vi-text-editor
|
||||
|
||||
作者:[Dan Sonnenschein][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[sd886393](https://github.com/sd886393)
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dannyman
|
||||
[1]:http://ex-vi.sourceforge.net/
|
||||
[2]:https://www.vim.org/
|
||||
@ -0,0 +1,239 @@
|
||||
如何在 Linux 中配置基于密钥认证的 SSH
|
||||
======
|
||||
|
||||

|
||||
|
||||
### 什么是基于 SSH 密钥的认证?
|
||||
|
||||
众所周知,**Secure Shell**,又称 **SSH**,是允许你通过无安全网络(例如 Internet)和远程系统之间安全访问/通信的加密网络协议。无论何时使用 SSH 在无安全网络上发送数据,它都会在源系统上自动地被加密,并且在目的系统上解密。SSH 提供了四种加密方式,**基于密码认证**,**基于密钥认证**,**基于主机认证**和**键盘认证**。最常用的认证方式是基于密码认证和基于密钥认证。
|
||||
|
||||
在基于密码认证中,你需要的仅仅是远程系统上用户的密码。如果你知道远程用户的密码,你可以使用 `ssh user@remote-system-name` 访问各自的系统。另一方面,在基于密钥认证中,为了通过 SSH 通信,你需要生成 SSH 密钥对,并且为远程系统上传 SSH 公钥。每个 SSH 密钥对由私钥与公钥组成。私钥应该保存在客户系统上,公钥应该上传给远程系统。你不应该将私钥透露给任何人。希望你已经对 SSH 和它的认证方式有了基本的概念。
|
||||
|
||||
这篇教程,我们将讨论如何在 Linux 上配置基于密钥认证的 SSH。
|
||||
|
||||
### 在 Linux 上配置基于密钥认证的 SSH
|
||||
|
||||
为方便演示,我将使用 Arch Linux 为本地系统,Ubuntu 18.04 LTS 为远程系统。
|
||||
|
||||
本地系统详情:
|
||||
|
||||
* OS: Arch Linux Desktop
|
||||
* IP address: 192.168.225.37/24
|
||||
|
||||
远程系统详情:
|
||||
|
||||
* OS: Ubuntu 18.04 LTS Server
|
||||
* IP address: 192.168.225.22/24
|
||||
|
||||
### 本地系统配置
|
||||
|
||||
就像我之前所说,在基于密钥认证的方法中,想要通过 SSH 访问远程系统,需要将公钥上传到远程系统。公钥通常会被保存在远程系统的一个 `~/.ssh/authorized_keys` 文件中。
|
||||
|
||||
**注意事项**:不要使用 **root** 用户生成密钥对,这样只有 root 用户才可以使用。使用普通用户创建密钥对。
|
||||
|
||||
现在,让我们在本地系统上创建一个 SSH 密钥对。只需要在客户端系统上运行下面的命令。
|
||||
|
||||
```
|
||||
$ ssh-keygen
|
||||
```
|
||||
|
||||
上面的命令将会创建一个 2048 位的 RSA 密钥对。你需要输入两次密码。更重要的是,记住你的密码。后面将会用到它。
|
||||
|
||||
**样例输出**:
|
||||
|
||||
```
|
||||
Generating public/private rsa key pair.
|
||||
Enter file in which to save the key (/home/sk/.ssh/id_rsa):
|
||||
Enter passphrase (empty for no passphrase):
|
||||
Enter same passphrase again:
|
||||
Your identification has been saved in /home/sk/.ssh/id_rsa.
|
||||
Your public key has been saved in /home/sk/.ssh/id_rsa.pub.
|
||||
The key fingerprint is:
|
||||
SHA256:wYOgvdkBgMFydTMCUI3qZaUxvjs+p2287Tn4uaZ5KyE [email protected]
|
||||
The key's randomart image is:
|
||||
+---[RSA 2048]----+
|
||||
|+=+*= + |
|
||||
|o.o=.* = |
|
||||
|.oo * o + |
|
||||
|. = + . o |
|
||||
|. o + . S |
|
||||
| . E . |
|
||||
| + o |
|
||||
| +.*o+o |
|
||||
| .o*=OO+ |
|
||||
+----[SHA256]-----+
|
||||
```
|
||||
|
||||
如果你已经创建了密钥对,你将看到以下信息。输入 `y` 就会覆盖已存在的密钥。
|
||||
|
||||
```
|
||||
/home/username/.ssh/id_rsa already exists.
|
||||
Overwrite (y/n)?
|
||||
```
|
||||
|
||||
请注意**密码是可选的**。如果你输入了密码,那么每次通过 SSH 访问远程系统时都要求输入密码,除非你使用了 SSH 代理保存了密码。如果你不想要密码(虽然不安全),简单地敲两次回车。不过,我建议你使用密码。从安全的角度来看,使用无密码的 ssh 密钥对不是什么好主意。这种方式应该限定在特殊的情况下使用,例如,没有用户介入的服务访问远程系统。(例如,用 `rsync` 远程备份……)
|
||||
|
||||
如果你已经在个人文件 `~/.ssh/id_rsa` 中有了无密码的密钥,但想要更新为带密码的密钥。使用下面的命令:
|
||||
|
||||
```
|
||||
$ ssh-keygen -p -f ~/.ssh/id_rsa
|
||||
```
|
||||
|
||||
**样例输出**:
|
||||
|
||||
```
|
||||
Enter new passphrase (empty for no passphrase):
|
||||
Enter same passphrase again:
|
||||
Your identification has been saved with the new passphrase.
|
||||
```
|
||||
|
||||
现在,我们已经在本地系统上创建了密钥对。接下来,使用下面的命令将 SSH 公钥拷贝到你的远程 SSH 服务端上。
|
||||
|
||||
```
|
||||
$ ssh-copy-id sk@192.168.225.22
|
||||
```
|
||||
|
||||
在这里,我把本地(Arch Linux)系统上的公钥拷贝到了远程系统(Ubuntu 18.04 LTS)上。从技术上讲,上面的命令会把本地系统 `~/.ssh/id_rsa.pub` 文件中的内容拷贝到远程系统 `~/.ssh/authorized_keys` 中。明白了吗?非常棒。
|
||||
|
||||
输入 `yes` 来继续连接你的远程 SSH 服务端。接着,输入远程系统用户 `sk` 的密码。
|
||||
|
||||
```
|
||||
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
|
||||
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
|
||||
sk@192.168.225.22's password:
|
||||
|
||||
Number of key(s) added: 1
|
||||
|
||||
Now try logging into the machine, with: "ssh 'sk@192.168.225.22'"
|
||||
and check to make sure that only the key(s) you wanted were added.
|
||||
```
|
||||
|
||||
如果你已经拷贝了密钥,但想要替换为新的密码,使用 `-f` 选项覆盖已有的密钥。
|
||||
|
||||
```
|
||||
$ ssh-copy-id -f sk@192.168.225.22
|
||||
```
|
||||
|
||||
我们现在已经成功地将本地系统的 SSH 公钥添加进了远程系统。现在,让我们在远程系统上完全禁用掉基于密码认证的方式。因为我们已经配置了密钥认证,因此不再需要密码认证了。
|
||||
|
||||
### 在远程系统上禁用基于密码认证的 SSH
|
||||
|
||||
你需要在 root 用户或者 `sudo` 执行下面的命令。
|
||||
|
||||
禁用基于密码的认证,你需要在远程系统的终端里编辑 `/etc/ssh/sshd_config` 配置文件:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/ssh/sshd_config
|
||||
```
|
||||
|
||||
找到下面这一行,去掉注释然后将值设为 `no`:
|
||||
|
||||
```
|
||||
PasswordAuthentication no
|
||||
```
|
||||
|
||||
重启 ssh 服务让它生效。
|
||||
|
||||
```
|
||||
$ sudo systemctl restart sshd
|
||||
```
|
||||
|
||||
### 从本地系统访问远程系统
|
||||
|
||||
在本地系统上使用命令 SSH 你的远程服务端:
|
||||
|
||||
```
|
||||
$ ssh sk@192.168.225.22
|
||||
```
|
||||
|
||||
输入密码。
|
||||
|
||||
**样例输出**:
|
||||
|
||||
```
|
||||
Enter passphrase for key '/home/sk/.ssh/id_rsa':
|
||||
Last login: Mon Jul 9 09:59:51 2018 from 192.168.225.37
|
||||
sk@ubuntuserver:~$
|
||||
```
|
||||
|
||||
现在,你就能 SSH 你的远程系统了。如你所见,我们已经使用之前 `ssh-keygen` 创建的密码登录进了远程系统的账户,而不是使用当前账户实际的密码。
|
||||
|
||||
如果你试图从其它客户端系统 ssh(远程系统),你将会得到这条错误信息。比如,我试图通过命令从 CentOS SSH 访问 Ubuntu 系统:
|
||||
|
||||
**样例输出**:
|
||||
|
||||
```
|
||||
The authenticity of host '192.168.225.22 (192.168.225.22)' can't be established.
|
||||
ECDSA key fingerprint is 67:fc:69:b7:d4:4d:fd:6e:38:44:a8:2f:08:ed:f4:21.
|
||||
Are you sure you want to continue connecting (yes/no)? yes
|
||||
Warning: Permanently added '192.168.225.22' (ECDSA) to the list of known hosts.
|
||||
Permission denied (publickey).
|
||||
```
|
||||
|
||||
如你所见,除了 CentOS(LCTT 译注:根据上文,这里应该是 Arch)系统外,我不能通过其它任何系统 SSH 访问我的远程系统 Ubuntu 18.04。
|
||||
|
||||
### 为 SSH 服务端添加更多客户端系统的密钥
|
||||
|
||||
这点非常重要。就像我说过的那样,除非你配置过(在之前的例子中,是 Ubuntu),否则你不能通过 SSH 访问到远程系统。如果我希望给更多客户端予以权限去访问远程 SSH 服务端,我应该怎么做?很简单。你需要在所有的客户端系统上生成 SSH 密钥对并且手动拷贝 ssh 公钥到想要通过 ssh 访问的远程服务端上。
|
||||
|
||||
在客户端系统上创建 SSH 密钥对,运行:
|
||||
|
||||
```
|
||||
$ ssh-keygen
|
||||
```
|
||||
|
||||
输入两次密码。现在,ssh 密钥对已经生成了。你需要手动把公钥(不是私钥)拷贝到远程服务端上。
|
||||
|
||||
使用以下命令查看公钥:
|
||||
|
||||
```
|
||||
$ cat ~/.ssh/id_rsa.pub
|
||||
```
|
||||
|
||||
应该会输出类似下面的信息:
|
||||
|
||||
```
|
||||
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCt3a9tIeK5rPx9p74/KjEVXa6/OODyRp0QLS/sLp8W6iTxFL+UgALZlupVNgFjvRR5luJ9dLHWwc+d4umavAWz708e6Na9ftEPQtC28rTFsHwmyLKvLkzcGkC5+A0NdbiDZLaK3K3wgq1jzYYKT5k+IaNS6vtrx5LDObcPNPEBDt4vTixQ7GZHrDUUk5586IKeFfwMCWguHveTN7ykmo2EyL2rV7TmYq+eY2ZqqcsoK0fzXMK7iifGXVmuqTkAmZLGZK8a3bPb6VZd7KFum3Ezbu4BXZGp7FVhnOMgau2kYeOH/ItKPzpCAn+dg3NAAziCCxnII9b4nSSGz3mMY4Y7 ostechnix@centosserver
|
||||
```
|
||||
|
||||
拷贝所有内容(通过 USB 驱动器或者其它任何介质),然后去你的远程服务端的终端,像下面那样,在 `$HOME` 下创建文件夹叫做 `.ssh`。你需要以 root 身份执行命令(注:不一定需要 root)。
|
||||
|
||||
```
|
||||
$ mkdir -p ~/.ssh
|
||||
```
|
||||
|
||||
现在,将前几步创建的客户端系统的公钥添加进文件中。
|
||||
|
||||
```
|
||||
echo {Your_public_key_contents_here} >> ~/.ssh/authorized_keys
|
||||
```
|
||||
|
||||
在远程系统上重启 ssh 服务。现在,你可以在新的客户端上 SSH 远程服务端了。
|
||||
|
||||
如果觉得手动添加 ssh 公钥有些困难,在远程系统上暂时性启用密码认证,使用 `ssh-copy-id` 命令从本地系统上拷贝密钥,最后禁用密码认证。
|
||||
|
||||
**推荐阅读:**
|
||||
|
||||
* [SSLH – Share A Same Port For HTTPS And SSH][1]
|
||||
* [ScanSSH – Fast SSH Server And Open Proxy Scanner][2]
|
||||
|
||||
好了,到此为止。基于密钥认证的 SSH 提供了一层防止暴力破解的额外保护。如你所见,配置密钥认证一点也不困难。这是一个非常好的方法让你的 Linux 服务端安全可靠。
|
||||
|
||||
不久我会带来另一篇有用的文章。请继续关注 OSTechNix。
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/configure-ssh-key-based-authentication-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[LuuMing](https://github.com/LuuMing)
|
||||
校对:[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/sslh-share-port-https-ssh/
|
||||
[2]: https://www.ostechnix.com/scanssh-fast-ssh-server-open-proxy-scanner/
|
||||
@ -0,0 +1,987 @@
|
||||
75 个最常用的 Linux 应用程序(2018 年)
|
||||
======
|
||||
|
||||

|
||||
|
||||
对于许多应用程序来说,2018 年是非常好的一年,尤其是自由开源的应用程序。尽管各种 Linux 发行版都自带了很多默认的应用程序,但用户也可以自由地选择使用它们或者其它任何免费或付费替代方案。
|
||||
|
||||
下面汇总了[一系列的 Linux 应用程序][3],这些应用程序都能够在 Linux 系统上安装,尽管还有很多其它选择。以下汇总中的任何应用程序都属于其类别中最常用的应用程序,如果你还没有用过,欢迎试用一下!
|
||||
|
||||
### 备份工具
|
||||
|
||||
#### Rsync
|
||||
|
||||
[Rsync][4] 是一个开源的、节约带宽的工具,它用于执行快速的增量文件传输,而且它也是一个免费工具。
|
||||
|
||||
```
|
||||
$ rsync [OPTION...] SRC... [DEST]
|
||||
```
|
||||
|
||||
想要了解更多示例和用法,可以参考《[10 个使用 Rsync 命令的实际例子][5]》。
|
||||
|
||||
#### Timeshift
|
||||
|
||||
[Timeshift][6] 能够通过增量快照来保护用户的系统数据,而且可以按照日期恢复指定的快照,类似于 Mac OS 中的 Time Machine 功能和 Windows 中的系统还原功能。
|
||||
|
||||

|
||||
|
||||
### BT(BitTorrent) 客户端
|
||||
|
||||

|
||||
|
||||
#### Deluge
|
||||
|
||||
[Deluge][7] 是一个漂亮的跨平台 BT 客户端,旨在优化 μTorrent 体验,并向用户免费提供服务。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Deluge。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:deluge-team/ppa
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install deluge
|
||||
```
|
||||
|
||||
#### qBittorent
|
||||
|
||||
[qBittorent][8] 是一个开源的 BT 客户端,旨在提供类似 μTorrent 的免费替代方案。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 qBittorent。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:qbittorrent-team/qbittorrent-stable
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install qbittorrent
|
||||
```
|
||||
|
||||
#### Transmission
|
||||
|
||||
[Transmission][9] 是一个强大的 BT 客户端,它主要关注速度和易用性,一般在很多 Linux 发行版上都有预装。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Transmission。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:transmissionbt/ppa
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install transmission-gtk transmission-cli transmission-common transmission-daemon
|
||||
```
|
||||
|
||||
### 云存储
|
||||
|
||||

|
||||
|
||||
#### Dropbox
|
||||
|
||||
[Dropbox][10] 团队在今年早些时候给他们的云服务换了一个名字,也为客户提供了更好的性能和集成了更多应用程序。Dropbox 会向用户免费提供 2 GB 存储空间。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Dropbox。
|
||||
|
||||
```
|
||||
$ cd ~ && wget -O - "https://www.dropbox.com/download?plat=lnx.x86" | tar xzf - [On 32-Bit]
|
||||
$ cd ~ && wget -O - "https://www.dropbox.com/download?plat=lnx.x86_64" | tar xzf - [On 64-Bit]
|
||||
$ ~/.dropbox-dist/dropboxd
|
||||
```
|
||||
|
||||
#### Google Drive
|
||||
|
||||
[Google Drive][11] 是 Google 提供的云服务解决方案,这已经是一个广为人知的服务了。与 Dropbox 一样,可以通过它在所有联网的设备上同步文件。它免费提供了 15 GB 存储空间,包括Gmail、Google 图片、Google 地图等服务。
|
||||
|
||||
参考阅读:[5 个适用于 Linux 的 Google Drive 客户端][12]
|
||||
|
||||
#### Mega
|
||||
|
||||
[Mega][13] 也是一个出色的云存储解决方案,它的亮点除了高度的安全性之外,还有为用户免费提供高达 50 GB 的免费存储空间。它使用端到端加密,以确保用户的数据安全,所以如果忘记了恢复密钥,用户自己也无法访问到存储的数据。
|
||||
|
||||
参考阅读:[在 Ubuntu 下载 Mega 云存储客户端][14]
|
||||
|
||||
### 命令行编辑器
|
||||
|
||||

|
||||
|
||||
#### Vim
|
||||
|
||||
[Vim][15] 是 vi 文本编辑器的开源克隆版本,它的主要目的是可以高度定制化并能够处理任何类型的文本。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Vim。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:jonathonf/vim
|
||||
$ sudo apt update
|
||||
$ sudo apt install vim
|
||||
```
|
||||
|
||||
#### Emacs
|
||||
|
||||
[Emacs][16] 是一个高度可配置的文本编辑器,最流行的一个分支 GNU Emacs 是用 Lisp 和 C 编写的,它的最大特点是可以自文档化、可扩展和可自定义。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Emacs。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:kelleyk/emacs
|
||||
$ sudo apt update
|
||||
$ sudo apt install emacs25
|
||||
```
|
||||
|
||||
#### Nano
|
||||
|
||||
[Nano][17] 是一款功能丰富的命令行文本编辑器,比较适合高级用户。它可以通过多个终端进行不同功能的操作。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Nano。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:n-muench/programs-ppa
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install nano
|
||||
```
|
||||
|
||||
### 下载器
|
||||
|
||||

|
||||
|
||||
#### Aria2
|
||||
|
||||
[Aria2][18] 是一个开源的、轻量级的、多软件源和多协议的命令行下载器,它支持 Metalink、torrent、HTTP/HTTPS、SFTP 等多种协议。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Aria2。
|
||||
|
||||
```
|
||||
$ sudo apt-get install aria2
|
||||
```
|
||||
|
||||
#### uGet
|
||||
|
||||
[uGet][19] 已经成为 Linux 各种发行版中排名第一的开源下载器,它可以处理任何下载任务,包括多连接、队列、类目等。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 uGet。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:plushuang-tw/uget-stable
|
||||
$ sudo apt update
|
||||
$ sudo apt install uget
|
||||
```
|
||||
|
||||
#### XDM
|
||||
|
||||
[XDM][20](Xtreme Download Manager)是一个使用 Java 编写的开源下载软件。和其它下载器一样,它可以结合队列、种子、浏览器使用,而且还带有视频采集器和智能调度器。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 XDM。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:noobslab/apps
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install xdman
|
||||
```
|
||||
|
||||
### 电子邮件客户端
|
||||
|
||||

|
||||
|
||||
#### Thunderbird
|
||||
|
||||
[Thunderbird][21] 是最受欢迎的电子邮件客户端之一。它的优点包括免费、开源、可定制、功能丰富,而且最重要的是安装过程也很简便。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Thunderbird。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:ubuntu-mozilla-security/ppa
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install thunderbird
|
||||
```
|
||||
|
||||
#### Geary
|
||||
|
||||
[Geary][22] 是一个基于 WebKitGTK+ 的开源电子邮件客户端。它是一个免费开源的功能丰富的软件,并被 GNOME 项目收录。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Geary。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:geary-team/releases
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install geary
|
||||
```
|
||||
|
||||
#### Evolution
|
||||
|
||||
[Evolution][23] 是一个免费开源的电子邮件客户端,可以用于电子邮件、会议日程、备忘录和联系人的管理。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Evolution。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:gnome3-team/gnome3-staging
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install evolution
|
||||
```
|
||||
|
||||
### 财务软件
|
||||
|
||||

|
||||
|
||||
#### GnuCash
|
||||
|
||||
[GnuCash][24] 是一款免费的跨平台开源软件,它适用于个人和中小型企业的财务任务。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 GnuCash。
|
||||
|
||||
```
|
||||
$ sudo sh -c 'echo "deb http://archive.getdeb.net/ubuntu $(lsb_release -sc)-getdeb apps" >> /etc/apt/sources.list.d/getdeb.list'
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install gnucash
|
||||
```
|
||||
|
||||
#### KMyMoney
|
||||
|
||||
[KMyMoney][25] 是一个财务管理软件,它可以提供商用或个人理财所需的大部分主要功能。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 KmyMoney。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:claydoh/kmymoney2-kde4
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install kmymoney
|
||||
```
|
||||
|
||||
### IDE
|
||||
|
||||

|
||||
|
||||
#### Eclipse IDE
|
||||
|
||||
[Eclipse][26] 是最广为使用的 Java IDE,它包括一个基本工作空间和一个用于自定义编程环境的强大的的插件配置系统。
|
||||
|
||||
关于 Eclipse IDE 的安装,可以参考 [如何在 Debian 和 Ubuntu 上安装 Eclipse IDE][27] 这一篇文章。
|
||||
|
||||
#### Netbeans IDE
|
||||
|
||||
[Netbeans][28] 是一个相当受用户欢迎的 IDE,它支持使用 Java、PHP、HTML 5、JavaScript、C/C++ 或其他语言编写移动应用,桌面软件和 web 应用。
|
||||
|
||||
关于 Netbeans IDE 的安装,可以参考 [如何在 Debian 和 Ubuntu 上安装 Netbeans IDE][29] 这一篇文章。
|
||||
|
||||
#### Brackets
|
||||
|
||||
[Brackets][30] 是由 Adobe 开发的高级文本编辑器,它带有可视化工具,支持预处理程序,以及用于 web 开发的以设计为中心的用户流程。对于熟悉它的用户,它可以发挥 IDE 的作用。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Brackets。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:webupd8team/brackets
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install brackets
|
||||
```
|
||||
|
||||
#### Atom IDE
|
||||
|
||||
[Atom IDE][31] 是一个加强版的 Atom 编辑器,它添加了大量扩展和库以提高性能和增加功能。总之,它是各方面都变得更强大了的 Atom 。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Atom。
|
||||
|
||||
```
|
||||
$ sudo apt-get install snapd
|
||||
$ sudo snap install atom --classic
|
||||
```
|
||||
|
||||
#### Light Table
|
||||
|
||||
[Light Table][32] 号称下一代的 IDE,它提供了数据流量统计和协作编程等的强大功能。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Light Table。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:dr-akulavich/lighttable
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install lighttable-installer
|
||||
```
|
||||
|
||||
#### Visual Studio Code
|
||||
|
||||
[Visual Studio Code][33] 是由微软开发的代码编辑器,它包含了文本编辑器所需要的最先进的功能,包括语法高亮、自动完成、代码调试、性能统计和图表显示等功能。
|
||||
|
||||
参考阅读:[在Ubuntu 下载 Visual Studio Code][34]
|
||||
|
||||
### 即时通信工具
|
||||
|
||||

|
||||
|
||||
#### Pidgin
|
||||
|
||||
[Pidgin][35] 是一个开源的即时通信工具,它几乎支持所有聊天平台,还支持额外扩展功能。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Pidgin。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:jonathonf/backports
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install pidgin
|
||||
```
|
||||
|
||||
#### Skype
|
||||
|
||||
[Skype][36] 也是一个广为人知的软件了,任何感兴趣的用户都可以在 Linux 上使用。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Skype。
|
||||
|
||||
```
|
||||
$ sudo apt install snapd
|
||||
$ sudo snap install skype --classic
|
||||
```
|
||||
|
||||
#### Empathy
|
||||
|
||||
[Empathy][37] 是一个支持多协议语音、视频聊天、文本和文件传输的即时通信工具。它还允许用户添加多个服务的帐户,并用其与所有服务的帐户进行交互。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Empathy。
|
||||
|
||||
```
|
||||
$ sudo apt-get install empathy
|
||||
```
|
||||
|
||||
### Linux 防病毒工具
|
||||
|
||||
#### ClamAV/ClamTk
|
||||
|
||||
[ClamAV][38] 是一个开源的跨平台命令行防病毒工具,用于检测木马、病毒和其他恶意代码。而 [ClamTk][39] 则是它的前端 GUI。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 ClamAV 和 ClamTk。
|
||||
|
||||
```
|
||||
$ sudo apt-get install clamav
|
||||
$ sudo apt-get install clamtk
|
||||
```
|
||||
|
||||
### Linux 桌面环境
|
||||
|
||||
#### Cinnamon
|
||||
|
||||
[Cinnamon][40] 是 GNOME 3 的自由开源衍生产品,它遵循传统的 <ruby>桌面比拟<rt>desktop metaphor</rt></ruby> 约定。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Cinnamon。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:embrosyn/cinnamon
|
||||
$ sudo apt update
|
||||
$ sudo apt install cinnamon-desktop-environment lightdm
|
||||
```
|
||||
|
||||
#### Mate
|
||||
|
||||
[Mate][41] 桌面环境是 GNOME 2 的衍生和延续,目的是在 Linux 上通过使用传统的桌面比拟提供有一个吸引力的 UI。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Mate。
|
||||
|
||||
```
|
||||
$ sudo apt install tasksel
|
||||
$ sudo apt update
|
||||
$ sudo tasksel install ubuntu-mate-desktop
|
||||
```
|
||||
|
||||
#### GNOME
|
||||
|
||||
[GNOME][42] 是由一些免费和开源应用程序组成的桌面环境,它可以运行在任何 Linux 发行版和大多数 BSD 衍生版本上。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Gnome。
|
||||
|
||||
```
|
||||
$ sudo apt install tasksel
|
||||
$ sudo apt update
|
||||
$ sudo tasksel install ubuntu-desktop
|
||||
```
|
||||
|
||||
#### KDE
|
||||
|
||||
[KDE][43] 由 KDE 社区开发,它为用户提供图形解决方案以控制操作系统并执行不同的计算任务。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 KDE。
|
||||
|
||||
```
|
||||
$ sudo apt install tasksel
|
||||
$ sudo apt update
|
||||
$ sudo tasksel install kubuntu-desktop
|
||||
```
|
||||
|
||||
### Linux 维护工具
|
||||
|
||||
#### GNOME Tweak Tool
|
||||
|
||||
[GNOME Tweak Tool][44] 是用于自定义和调整 GNOME 3 和 GNOME Shell 设置的流行工具。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 GNOME Tweak Tool。
|
||||
|
||||
```
|
||||
$ sudo apt install gnome-tweak-tool
|
||||
```
|
||||
|
||||
#### Stacer
|
||||
|
||||
[Stacer][45] 是一款用于监控和优化 Linux 系统的免费开源应用程序。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Stacer。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:oguzhaninan/stacer
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install stacer
|
||||
```
|
||||
|
||||
#### BleachBit
|
||||
|
||||
[BleachBit][46] 是一个免费的磁盘空间清理器,它也可用作隐私管理器和系统优化器。
|
||||
|
||||
参考阅读:[在 Ubuntu 下载 BleachBit][47]
|
||||
|
||||
### Linux 终端工具
|
||||
|
||||
#### GNOME 终端
|
||||
|
||||
[GNOME 终端][48] 是 GNOME 的默认终端模拟器。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Gnome 终端。
|
||||
|
||||
```
|
||||
$ sudo apt-get install gnome-terminal
|
||||
```
|
||||
|
||||
#### Konsole
|
||||
|
||||
[Konsole][49] 是 KDE 的一个终端模拟器。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Konsole。
|
||||
|
||||
```
|
||||
$ sudo apt-get install konsole
|
||||
```
|
||||
|
||||
#### Terminator
|
||||
|
||||
[Terminator][50] 是一个功能丰富的终端程序,它基于 GNOME 终端,并且专注于整理终端功能。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Terminator。
|
||||
|
||||
```
|
||||
$ sudo apt-get install terminator
|
||||
```
|
||||
|
||||
#### Guake
|
||||
|
||||
[Guake][51] 是 GNOME 桌面环境下一个轻量级的可下拉式终端。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Guake。
|
||||
|
||||
```
|
||||
$ sudo apt-get install guake
|
||||
```
|
||||
|
||||
### 多媒体编辑工具
|
||||
|
||||
#### Ardour
|
||||
|
||||
[Ardour][52] 是一款漂亮的的<ruby>数字音频工作站<rt>Digital Audio Workstation</rt></ruby>,可以完成专业的录制、编辑和混音工作。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Ardour。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:dobey/audiotools
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install ardour
|
||||
```
|
||||
|
||||
#### Audacity
|
||||
|
||||
[Audacity][53] 是最著名的音频编辑软件之一,它是一款跨平台的开源多轨音频编辑器。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Audacity。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:ubuntuhandbook1/audacity
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install audacity
|
||||
```
|
||||
|
||||
#### GIMP
|
||||
|
||||
[GIMP][54] 是 Photoshop 的开源替代品中最受欢迎的。这是因为它有多种可自定义的选项、第三方插件以及活跃的用户社区。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Gimp。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:otto-kesselgulasch/gimp
|
||||
$ sudo apt update
|
||||
$ sudo apt install gimp
|
||||
```
|
||||
|
||||
#### Krita
|
||||
|
||||
[Krita][55] 是一款开源的绘画程序,它具有美观的 UI 和可靠的性能,也可以用作图像处理工具。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Krita。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:kritalime/ppa
|
||||
$ sudo apt update
|
||||
$ sudo apt install krita
|
||||
```
|
||||
|
||||
#### Lightworks
|
||||
|
||||
[Lightworks][56] 是一款功能强大、灵活美观的专业视频编辑工具。它拥有上百种配套的视觉效果功能,可以处理任何编辑任务,毕竟这个软件已经有长达 25 年的视频处理经验。
|
||||
|
||||
参考阅读:[在 Ubuntu 下载 Lightworks][57]
|
||||
|
||||
#### OpenShot
|
||||
|
||||
[OpenShot][58] 是一款屡获殊荣的免费开源视频编辑器,这主要得益于其出色的性能和强大的功能。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 `Openshot。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:openshot.developers/ppa
|
||||
$ sudo apt update
|
||||
$ sudo apt install openshot-qt
|
||||
```
|
||||
|
||||
#### PiTiV
|
||||
|
||||
[Pitivi][59] 也是一个美观的视频编辑器,它有优美的代码库、优质的社区,还支持优秀的协作编辑功能。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 PiTiV。
|
||||
|
||||
```
|
||||
$ flatpak install --user https://flathub.org/repo/appstream/org.pitivi.Pitivi.flatpakref
|
||||
$ flatpak install --user http://flatpak.pitivi.org/pitivi.flatpakref
|
||||
$ flatpak run org.pitivi.Pitivi//stable
|
||||
```
|
||||
|
||||
### 音乐播放器
|
||||
|
||||
#### Rhythmbox
|
||||
|
||||
[Rhythmbox][60] 支持海量种类的音乐,目前被认为是最可靠的音乐播放器,并由 Ubuntu 自带。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Rhythmbox。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:fossfreedom/rhythmbox
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install rhythmbox
|
||||
```
|
||||
|
||||
#### Lollypop
|
||||
|
||||
[Lollypop][61] 是一款较为年轻的开源音乐播放器,它有很多高级选项,包括网络电台,滑动播放和派对模式。尽管功能繁多,它仍然尽量做到简单易管理。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Lollypop。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:gnumdk/lollypop
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install lollypop
|
||||
```
|
||||
|
||||
#### Amarok
|
||||
|
||||
[Amarok][62] 是一款功能强大的音乐播放器,它有一个直观的 UI 和大量的高级功能,而且允许用户根据自己的偏好去发现新音乐。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Amarok。
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install amarok
|
||||
|
||||
```
|
||||
|
||||
#### Clementine
|
||||
|
||||
[Clementine][63] 是一款 Amarok 风格的音乐播放器,因此和 Amarok 相似,也有直观的用户界面、先进的控制模块,以及让用户搜索和发现新音乐的功能。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Clementine。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:me-davidsansome/clementine
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install clementine
|
||||
```
|
||||
|
||||
#### Cmus
|
||||
|
||||
[Cmus][64] 可以说是最高效的的命令行界面音乐播放器了,它具有快速可靠的特点,也支持使用扩展。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Cmus。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:jmuc/cmus
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install cmus
|
||||
```
|
||||
|
||||
### 办公软件
|
||||
|
||||
#### Calligra 套件
|
||||
|
||||
[Calligra 套件][65]为用户提供了一套总共 8 个应用程序,涵盖办公、管理、图表等各个范畴。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Calligra 套件。
|
||||
|
||||
```
|
||||
$ sudo apt-get install calligra
|
||||
```
|
||||
|
||||
#### LibreOffice
|
||||
|
||||
[LibreOffice][66] 是开源社区中开发过程最活跃的办公套件,它以可靠性著称,也可以通过扩展来添加功能。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 LibreOffice。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:libreoffice/ppa
|
||||
$ sudo apt update
|
||||
$ sudo apt install libreoffice
|
||||
```
|
||||
|
||||
#### WPS Office
|
||||
|
||||
[WPS Office][67] 是一款漂亮的办公套件,它有一个很具现代感的 UI。
|
||||
|
||||
参考阅读:[在 Ubuntu 安装 WPS Office][68]
|
||||
|
||||
### 屏幕截图工具
|
||||
|
||||
#### Shutter
|
||||
|
||||
[Shutter][69] 允许用户截取桌面的屏幕截图,然后使用一些效果进行编辑,还支持上传和在线共享。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Shutter。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository -y ppa:shutter/ppa
|
||||
$ sudo apt update
|
||||
$ sudo apt install shutter
|
||||
```
|
||||
|
||||
#### Kazam
|
||||
|
||||
[Kazam][70] 可以用于捕获屏幕截图,它的输出对于任何支持 VP8/WebM 和 PulseAudio 视频播放器都可用。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Kazam。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:kazam-team/unstable-series
|
||||
$ sudo apt update
|
||||
$ sudo apt install kazam python3-cairo python3-xlib
|
||||
```
|
||||
|
||||
#### Gnome Screenshot
|
||||
|
||||
[Gnome Screenshot][71] 过去曾经和 Gnome 一起捆绑,但现在已经独立出来。它以易于共享的格式进行截屏。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Gnome Screenshot。
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install gnome-screenshot
|
||||
```
|
||||
|
||||
### 录屏工具
|
||||
|
||||
#### SimpleScreenRecorder
|
||||
|
||||
[SimpleScreenRecorder][72] 面世时已经是录屏工具中的佼佼者,现在已成为 Linux 各个发行版中最有效、最易用的录屏工具之一。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 SimpleScreenRecorder。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:maarten-baert/simplescreenrecorder
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install simplescreenrecorder
|
||||
```
|
||||
|
||||
#### recordMyDesktop
|
||||
|
||||
[recordMyDesktop][73] 是一个开源的会话记录器,它也能记录桌面会话的音频。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 recordMyDesktop。
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install gtk-recordmydesktop
|
||||
```
|
||||
|
||||
### 文本编辑器
|
||||
|
||||
#### Atom
|
||||
|
||||
[Atom][74] 是由 GitHub 开发和维护的可定制文本编辑器。它是开箱即用的,但也可以使用扩展和主题自定义 UI 来增强其功能。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Atom。
|
||||
|
||||
```
|
||||
$ sudo apt-get install snapd
|
||||
$ sudo snap install atom --classic
|
||||
```
|
||||
|
||||
#### Sublime Text
|
||||
|
||||
[Sublime Text][75] 已经成为目前最棒的文本编辑器。它可定制、轻量灵活(即使打开了大量数据文件和加入了大量扩展),最重要的是可以永久免费使用。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Sublime Text。
|
||||
|
||||
```
|
||||
$ sudo apt-get install snapd
|
||||
$ sudo snap install sublime-text
|
||||
```
|
||||
|
||||
#### Geany
|
||||
|
||||
[Geany][76] 是一个内存友好的文本编辑器,它具有基本的IDE功能,可以显示加载时间、扩展库函数等。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Geany。
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install geany
|
||||
```
|
||||
|
||||
#### Gedit
|
||||
|
||||
[Gedit][77] 以其简单著称,在很多 Linux 发行版都有预装,它具有文本编辑器都具有的优秀的功能。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Gedit。
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install gedit
|
||||
```
|
||||
|
||||
### 备忘录软件
|
||||
|
||||
#### Evernote
|
||||
|
||||
[Evernote][78] 是一款云上的笔记程序,它带有待办列表和提醒功能,能够与不同类型的笔记完美配合。
|
||||
|
||||
Evernote 在 Linux 上没有官方提供的软件,但可以参考 [Linux 上的 6 个 Evernote 替代客户端][79] 这篇文章使用其它第三方工具。
|
||||
|
||||
#### Everdo
|
||||
|
||||
[Everdo][78] 是一款美观,安全,易兼容的备忘软件,可以用于处理待办事项和其它笔记。如果你认为 Evernote 有所不足,相信 Everdo 会是一个好的替代。
|
||||
|
||||
参考阅读:[在 Ubuntu 下载 Everdo][80]
|
||||
|
||||
#### Taskwarrior
|
||||
|
||||
[Taskwarrior][81] 是一个用于管理个人任务的开源跨平台命令行应用,它的速度和无干扰的环境是它的两大特点。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Taskwarrior。
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install taskwarrior
|
||||
```
|
||||
|
||||
### 视频播放器
|
||||
|
||||
#### Banshee
|
||||
|
||||
[Banshee][82] 是一个开源的支持多格式的媒体播放器,于 2005 年开始开发并逐渐成长。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Banshee。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:banshee-team/ppa
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install banshee
|
||||
```
|
||||
|
||||
#### VLC
|
||||
|
||||
[VLC][83] 是我最喜欢的视频播放器,它几乎可以播放任何格式的音频和视频,它还可以播放网络电台、录制桌面会话以及在线播放电影。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 VLC。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:videolan/stable-daily
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install vlc
|
||||
```
|
||||
|
||||
#### Kodi
|
||||
|
||||
[Kodi][84] 是世界上最着名的媒体播放器之一,它有一个成熟的媒体中心,可以播放本地和远程的多媒体文件。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Kodi。
|
||||
|
||||
```
|
||||
$ sudo apt-get install software-properties-common
|
||||
$ sudo add-apt-repository ppa:team-xbmc/ppa
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install kodi
|
||||
```
|
||||
|
||||
#### SMPlayer
|
||||
|
||||
[SMPlayer][85] 是 MPlayer 的 GUI 版本,所有流行的媒体格式它都能够处理,并且它还有从 YouTube 和 Chromcast 和下载字幕的功能。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 SMPlayer。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:rvm/smplayer
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install smplayer
|
||||
```
|
||||
|
||||
### 虚拟化工具
|
||||
|
||||
#### VirtualBox
|
||||
|
||||
[VirtualBox][86] 是一个用于操作系统虚拟化的开源应用程序,在服务器、台式机和嵌入式系统上都可以运行。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 VirtualBox。
|
||||
|
||||
```
|
||||
$ wget -q https://www.virtualbox.org/download/oracle_vbox_2016.asc -O- | sudo apt-key add -
|
||||
$ wget -q https://www.virtualbox.org/download/oracle_vbox.asc -O- | sudo apt-key add -
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install virtualbox-5.2
|
||||
$ virtualbox
|
||||
```
|
||||
|
||||
#### VMWare
|
||||
|
||||
[VMware][87] 是一个为客户提供平台虚拟化和云计算服务的数字工作区,是第一个成功将 x86 架构系统虚拟化的工作站。 VMware 工作站的其中一个产品就允许用户在虚拟内存中运行多个操作系统。
|
||||
|
||||
参阅 [在 Ubuntu 上安装 VMWare Workstation Pro][88] 可以了解 VMWare 的安装。
|
||||
|
||||
### 浏览器
|
||||
|
||||
#### Chrome
|
||||
|
||||
[Google Chrome][89] 无疑是最受欢迎的浏览器。Chrome 以其速度、简洁、安全、美观而受人喜爱,它遵循了 Google 的界面设计风格,是 web 开发人员不可缺少的浏览器,同时它也是免费开源的。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Google Chrome。
|
||||
|
||||
```
|
||||
$ wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | sudo apt-key add -
|
||||
$ sudo sh -c 'echo "deb http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list'
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install google-chrome-stable
|
||||
```
|
||||
|
||||
#### Firefox
|
||||
|
||||
[Firefox Quantum][90] 是一款漂亮、快速、完善并且可自定义的浏览器。它也是自由开源的,包含有开发人员所需要的工具,对于初学者也没有任何使用门槛。
|
||||
|
||||
使用以下命令在 Ubuntu 和 Debian 安装 Firefox Quantum。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:mozillateam/firefox-next
|
||||
$ sudo apt update && sudo apt upgrade
|
||||
$ sudo apt install firefox
|
||||
```
|
||||
|
||||
#### Vivaldi
|
||||
|
||||
[Vivaldi][91] 是一个基于 Chrome 的自由开源项目,旨在通过添加扩展来使 Chrome 的功能更加完善。色彩丰富的界面,性能良好、灵活性强是它的几大特点。
|
||||
|
||||
参考阅读:[在 Ubuntu 下载 Vivaldi][91]
|
||||
|
||||
以上就是我的推荐,你还有更好的软件向大家分享吗?欢迎评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.fossmint.com/most-used-linux-applications/
|
||||
|
||||
作者:[Martins D. Okoi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.fossmint.com/author/dillivine/
|
||||
[1]:https://plus.google.com/share?url=https://www.fossmint.com/most-used-linux-applications/ "Share on Google+"
|
||||
[2]:https://www.linkedin.com/shareArticle?mini=true&url=https://www.fossmint.com/most-used-linux-applications/ "Share on LinkedIn"
|
||||
[3]:https://www.fossmint.com/awesome-linux-software/
|
||||
[4]:https://rsync.samba.org/
|
||||
[5]:https://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
|
||||
[6]:https://github.com/teejee2008/timeshift
|
||||
[7]:https://deluge-torrent.org/
|
||||
[8]:https://www.qbittorrent.org/
|
||||
[9]:https://transmissionbt.com/
|
||||
[10]:https://www.dropbox.com/
|
||||
[11]:https://www.google.com/drive/
|
||||
[12]:https://www.fossmint.com/best-google-drive-clients-for-linux/
|
||||
[13]:https://mega.nz/
|
||||
[14]:https://mega.nz/sync!linux
|
||||
[15]:https://www.vim.org/
|
||||
[16]:https://www.gnu.org/s/emacs/
|
||||
[17]:https://www.nano-editor.org/
|
||||
[18]:https://aria2.github.io/
|
||||
[19]:http://ugetdm.com/
|
||||
[20]:http://xdman.sourceforge.net/
|
||||
[21]:https://www.thunderbird.net/
|
||||
[22]:https://github.com/GNOME/geary
|
||||
[23]:https://github.com/GNOME/evolution
|
||||
[24]:https://www.gnucash.org/
|
||||
[25]:https://kmymoney.org/
|
||||
[26]:https://www.eclipse.org/ide/
|
||||
[27]:https://www.tecmint.com/install-eclipse-oxygen-ide-in-ubuntu-debian/
|
||||
[28]:https://netbeans.org/
|
||||
[29]:https://www.tecmint.com/install-netbeans-ide-in-ubuntu-debian-linux-mint/
|
||||
[30]:http://brackets.io/
|
||||
[31]:https://ide.atom.io/
|
||||
[32]:http://lighttable.com/
|
||||
[33]:https://code.visualstudio.com/
|
||||
[34]:https://code.visualstudio.com/download
|
||||
[35]:https://www.pidgin.im/
|
||||
[36]:https://www.skype.com/
|
||||
[37]:https://wiki.gnome.org/Apps/Empathy
|
||||
[38]:https://www.clamav.net/
|
||||
[39]:https://dave-theunsub.github.io/clamtk/
|
||||
[40]:https://github.com/linuxmint/cinnamon-desktop
|
||||
[41]:https://mate-desktop.org/
|
||||
[42]:https://www.gnome.org/
|
||||
[43]:https://www.kde.org/plasma-desktop
|
||||
[44]:https://github.com/nzjrs/gnome-tweak-tool
|
||||
[45]:https://github.com/oguzhaninan/Stacer
|
||||
[46]:https://www.bleachbit.org/
|
||||
[47]:https://www.bleachbit.org/download
|
||||
[48]:https://github.com/GNOME/gnome-terminal
|
||||
[49]:https://konsole.kde.org/
|
||||
[50]:https://gnometerminator.blogspot.com/p/introduction.html
|
||||
[51]:http://guake-project.org/
|
||||
[52]:https://ardour.org/
|
||||
[53]:https://www.audacityteam.org/
|
||||
[54]:https://www.gimp.org/
|
||||
[55]:https://krita.org/en/
|
||||
[56]:https://www.lwks.com/
|
||||
[57]:https://www.lwks.com/index.php?option=com_lwks&view=download&Itemid=206
|
||||
[58]:https://www.openshot.org/
|
||||
[59]:http://www.pitivi.org/
|
||||
[60]:https://wiki.gnome.org/Apps/Rhythmbox
|
||||
[61]:https://gnumdk.github.io/lollypop-web/
|
||||
[62]:https://amarok.kde.org/en
|
||||
[63]:https://www.clementine-player.org/
|
||||
[64]:https://cmus.github.io/
|
||||
[65]:https://www.calligra.org/tour/calligra-suite/
|
||||
[66]:https://www.libreoffice.org/
|
||||
[67]:https://www.wps.com/
|
||||
[68]:http://wps-community.org/downloads
|
||||
[69]:http://shutter-project.org/
|
||||
[70]:https://launchpad.net/kazam
|
||||
[71]:https://gitlab.gnome.org/GNOME/gnome-screenshot
|
||||
[72]:http://www.maartenbaert.be/simplescreenrecorder/
|
||||
[73]:http://recordmydesktop.sourceforge.net/about.php
|
||||
[74]:https://atom.io/
|
||||
[75]:https://www.sublimetext.com/
|
||||
[76]:https://www.geany.org/
|
||||
[77]:https://wiki.gnome.org/Apps/Gedit
|
||||
[78]:https://everdo.net/
|
||||
[79]:https://www.fossmint.com/evernote-alternatives-for-linux/
|
||||
[80]:https://everdo.net/linux/
|
||||
[81]:https://taskwarrior.org/
|
||||
[82]:http://banshee.fm/
|
||||
[83]:https://www.videolan.org/
|
||||
[84]:https://kodi.tv/
|
||||
[85]:https://www.smplayer.info/
|
||||
[86]:https://www.virtualbox.org/wiki/VirtualBox
|
||||
[87]:https://www.vmware.com/
|
||||
[88]:https://www.tecmint.com/install-vmware-workstation-in-linux/
|
||||
[89]:https://www.google.com/chrome/
|
||||
[90]:https://www.mozilla.org/en-US/firefox/
|
||||
[91]:https://vivaldi.com/
|
||||
|
||||
125
published/20180803 5 Essential Tools for Linux Development.md
Normal file
125
published/20180803 5 Essential Tools for Linux Development.md
Normal file
@ -0,0 +1,125 @@
|
||||
Linux 开发的五大必备工具
|
||||
======
|
||||
> Linux 上的开发工具如此之多,以至于会担心找不到恰好适合你的。
|
||||
|
||||

|
||||
|
||||
Linux 已经成为工作、娱乐和个人生活等多个领域的支柱,人们已经越来越离不开它。在 Linux 的帮助下,技术的变革速度超出了人们的想象,Linux 开发的速度也以指数规模增长。因此,越来越多的开发者也不断地加入开源和学习 Linux 开发地潮流当中。在这个过程之中,合适的工具是必不可少的,可喜的是,随着 Linux 的发展,大量适用于 Linux 的开发工具也不断成熟。甚至可以说,这样的工具已经多得有点惊人。
|
||||
|
||||
为了选择更合适自己的开发工具,缩小选择范围是很必要的。但是这篇文章并不会要求你必须使用某个工具,而只是缩小到五个工具类别,然后对每个类别提供一个例子。然而,对于大多数类别,都会有不止一种选择。下面我们来看一下。
|
||||
|
||||
### 容器
|
||||
|
||||
放眼于现实,现在已经是容器的时代了。容器既及其容易部署,又可以方便地构建开发环境。如果你针对的是特定的平台的开发,将开发流程所需要的各种工具都创建到容器映像中是一种很好的方法,只要使用这一个容器映像,就能够快速启动大量运行所需服务的实例。
|
||||
|
||||
一个使用容器的最佳范例是使用 [Docker][1],使用容器(或 Docker)有这些好处:
|
||||
|
||||
* 开发环境保持一致
|
||||
* 部署后即可运行
|
||||
* 易于跨平台部署
|
||||
* Docker 映像适用于多种开发环境和语言
|
||||
* 部署单个容器或容器集群都并不繁琐
|
||||
|
||||
通过 [Docker Hub][2],几乎可以找到适用于任何平台、任何开发环境、任何服务器、任何服务的映像,几乎可以满足任何一种需求。使用 Docker Hub 中的映像,就相当于免除了搭建开发环境的步骤,可以直接开始开发应用程序、服务器、API 或服务。
|
||||
|
||||
Docker 在所有 Linux 平台上都很容易安装,例如可以通过终端输入以下命令在 Ubuntu 上安装 Docker:
|
||||
|
||||
```
|
||||
sudo apt-get install docker.io
|
||||
```
|
||||
|
||||
Docker 安装完毕后,就可以从 Docker 仓库中拉取映像,然后开始开发和部署了(如下图)。
|
||||
|
||||
![Docker images][4]
|
||||
|
||||
*图 1: Docker 镜像准备部署*
|
||||
|
||||
### 版本控制工具
|
||||
|
||||
如果你正在开发一个大型项目,又或者参与团队开发,版本控制工具是必不可少的,它可以用于记录代码变更、提交代码以及合并代码。如果没有这样的工具,项目几乎无法妥善管理。在 Linux 系统上,[Git][6] 和 [GitHub][7] 的易用性和流行程度是其它版本控制工具无法比拟的。如果你对 Git 和 GitHub 还不太熟悉,可以简单理解为 Git 是在本地计算机上安装的版本控制系统,而 GitHub 则是用于上传和管理项目的远程存储库。 Git 可以安装在大多数的 Linux 发行版上。例如在基于 Debian 的系统上,只需要通过以下这一条简单的命令就可以安装:
|
||||
|
||||
```
|
||||
sudo apt-get install git
|
||||
```
|
||||
|
||||
安装完毕后,就可以使用 Git 来实施版本控制了(如下图)。
|
||||
|
||||
![Git installed][9]
|
||||
|
||||
*图 2:Git 已经安装,可以用于很多重要任务*
|
||||
|
||||
Github 会要求用户创建一个帐户。用户可以免费使用 GitHub 来管理非商用项目,当然也可以使用 GitHub 的付费模式(更多相关信息,可以参阅[价格矩阵][10])。
|
||||
|
||||
### 文本编辑器
|
||||
|
||||
如果没有文本编辑器,在 Linux 上开发将会变得异常艰难。当然,文本编辑器之间孰优孰劣,具体还是要取决于开发者的需求。对于文本编辑器,有人可能会使用 vim、emacs 或 nano,也有人会使用带有 GUI 的编辑器。但由于重点在于开发,我们需要的是一种能够满足开发人员需求的工具。不过我首先要说,vim 对于开发人员来说确实是一个利器,但前提是要对 vim 非常熟悉,在这种前提下,vim 能够满足你的所有需求,甚至还能给你更好的体验。然而,对于一些开发者(尤其是刚开始接触 Linux 的新手)来说,这不仅难以帮助他们快速达成需求,甚至还会是一个需要逾越的障碍。考虑到这篇文章的目标是帮助 Linux 的新手(而不仅仅是为各种编辑器的死忠粉宣传他们拥护的编辑器),我更倾向于使用 GUI 编辑器。
|
||||
|
||||
就文本编辑器而论,选择 [Bluefish][11] 一般不会有错。 Bluefish 可以从大部分软件库中安装,它支持项目管理、远程文件多线程操作、搜索和替换、递归打开文件、侧边栏、集成 make/lint/weblint/xmllint、无限制撤销/重做、在线拼写检查、自动恢复、全屏编辑、语法高亮(如下图)、多种语言等等。
|
||||
|
||||
![Bluefish][13]
|
||||
|
||||
*图 3:运行在 Ubuntu 18.04 上的 Bluefish*
|
||||
|
||||
### IDE
|
||||
|
||||
<ruby>集成开发环境<rt>Integrated Development Environment</rt></ruby>(IDE)是包含一整套全面的工具、可以实现一站式功能的开发环境。 开发者除了可以使用 IDE 编写代码,还可以编写文档和构建软件。在 Linux 上也有很多适用的 IDE,其中 [Geany][14] 就包含在标准软件库中,它对用户非常友好,功能也相当强大。 Geany 具有语法高亮、代码折叠、自动完成,构建代码片段、自动关闭 XML 和 HTML 标签、调用提示、支持多种文件类型、符号列表、代码导航、构建编译,简单的项目管理和内置的插件系统等强大功能。
|
||||
|
||||
Geany 也能在系统上轻松安装,例如执行以下命令在基于 Debian 的 Linux 发行版上安装 Geany:
|
||||
|
||||
```
|
||||
sudo apt-get install geany
|
||||
```
|
||||
|
||||
安装完毕后,就可以快速上手这个易用且强大的 IDE 了(如下图)。
|
||||
|
||||
![Geany][16]
|
||||
|
||||
*图 4:Geany 可以作为你的 IDE*
|
||||
|
||||
### 文本比较工具
|
||||
|
||||
有时候会需要比较两个文件的内容来找到它们之间的不同之处,它们可能是同一文件的两个不同副本(有一个经过编译,而另一个没有)。这种情况下,你肯定不想要凭借肉眼来找出差异,而是想要使用像 [Meld][17] 这样的工具。 Meld 是针对开发者的文本比较和合并工具,可以使用 Meld 来发现两个文件之间的差异。虽然你可以使用命令行中的文本比较工具,但就效率而论,Meld 无疑更为优秀。
|
||||
|
||||
Meld 可以打开两个文件进行比较,并突出显示文件之间的差异之处。 Meld 还允许用户从两个文件的其中一方合并差异(下图显示了 Meld 同时打开两个文件)。
|
||||
|
||||
![Comparing two files][19]
|
||||
|
||||
*图 5: 以简单差异的模式比较两个文件*
|
||||
|
||||
Meld 也可以通过大多数标准的软件库安装,在基于 Debian 的系统上,执行以下命令就可以安装:
|
||||
|
||||
```
|
||||
sudo apt-get install meld
|
||||
```
|
||||
|
||||
### 高效地工作
|
||||
|
||||
以上提到的五个工具除了帮助你完成工作,而且有助于提高效率。尽管适用于 Linux 开发者的工具有很多,但对于以上几个类别,你最好分别使用一个对应的工具。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/8/5-essential-tools-linux-development
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.docker.com/
|
||||
[2]:https://hub.docker.com/
|
||||
[4]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_1.jpg?itok=V1Bsbkg9 "Docker images"
|
||||
[6]:https://git-scm.com/
|
||||
[7]:https://github.com/
|
||||
[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_2.jpg?itok=YJjhe4O6 "Git installed"
|
||||
[10]:https://github.com/pricing
|
||||
[11]:http://bluefish.openoffice.nl/index.html
|
||||
[13]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_3.jpg?itok=66A7Svme "Bluefish"
|
||||
[14]:https://www.geany.org/
|
||||
[16]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_4.jpg?itok=jRcA-0ue "Geany"
|
||||
[17]:http://meldmerge.org/
|
||||
[19]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_5.jpg?itok=eLkfM9oZ "Comparing two files"
|
||||
[20]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
|
||||
@ -0,0 +1,81 @@
|
||||
5 个给孩子的非常好的 Linux 游戏和教育软件
|
||||
=================
|
||||
|
||||

|
||||
|
||||
Linux 是一个非常强大的操作系统,因此因特网上的大多数服务器都使用它。尽管它算不上是对用户友好的最佳操作系统,但它的多元化还是值的称赞的。对于 Linux 来说,每个人都能在它上面找到他们自己的所需。不论你是用它来写代码、还是用于教学或物联网(IoT),你总能找到一个适合你用的 Linux 发行版。为此,许多人认为 Linux 是未来计算的最佳操作系统。
|
||||
|
||||
未来是属于孩子们的,让孩子们了解 Linux 是他们掌控未来的最佳方式。这个操作系统上或许并没有一些像 FIFA 或 PES 那样的声名赫赫的游戏;但是,它为孩子们提供了一些非常好的教育软件和游戏。这里有五款最好的 Linux 教育软件,可以让你的孩子远离游戏。
|
||||
|
||||
**相关阅读**:[使用一个 Linux 发行版的新手指南][1]
|
||||
|
||||
### 1、GCompris
|
||||
|
||||
如果你正在为你的孩子寻找一款最佳的教育软件,[GCompris][2] 将是你的最好的开端。这款软件专门为 2 到 10 岁的孩子所设计。作为所有的 Linux 教育软件套装的巅峰之作,GCompris 为孩子们提供了大约 100 项活动。它囊括了你期望你的孩子学习的所有内容,从阅读材料到科学、地理、绘画、代数、测验等等。
|
||||
|
||||
![Linux educational software and games][3]
|
||||
|
||||
GCompris 甚至有一项活动可以帮你的孩子学习计算机的相关知识。如果你的孩子还很小,你希望他去学习字母、颜色和形状,GCompris 也有这方面的相关内容。更重要的是,它也为孩子们准备了一些益智类游戏,比如国际象棋、井字棋、好记性、以及猜词游戏。GCompris 并不是一个仅在 Linux 上可运行的游戏。它也可以运行在 Windows 和 Android 上。
|
||||
|
||||
### 2、TuxMath
|
||||
|
||||
很多学生认为数学是门非常难的课程。你可以通过 Linux 教育软件如 [TuxMath][4] 来让你的孩子了解数学技能,从而来改变这种看法。TuxMath 是为孩子开发的顶级的数学教育辅助游戏。在这个游戏中,你的角色是在如雨点般下降的数学问题中帮助 Linux 企鹅 Tux 来保护它的星球。
|
||||
|
||||
![linux-educational-software-tuxmath-1][5]
|
||||
|
||||
在它们落下来毁坏 Tux 的星球之前,找到问题的答案,就可以使用你的激光去帮助 Tux 拯救它的星球。数字问题的难度每过一关就会提升一点。这个游戏非常适合孩子,因为它可以让孩子们去开动脑筋解决问题。而且还有助他们学好数学,以及帮助他们开发智力。
|
||||
|
||||
### 3、Sugar on a Stick
|
||||
|
||||
[Sugar on a Stick][6] 是献给孩子们的学习程序 —— 一个广受好评的全新教学法。这个程序为你的孩子提供一个成熟的教学平台,在那里,他们可以收获创造、探索、发现和思考方面的技能。和 GCompris 一样,Sugar on a Stick 为孩子们带来了包括游戏和谜题在内的大量学习资源。
|
||||
|
||||
![linux-educational-software-sugar-on-a-stick][7]
|
||||
|
||||
关于 Sugar on a Stick 最大的一个好处是你可以将它配置在一个 U 盘上。你只要有一台 X86 的 PC,插入那个 U 盘,然后就可以从 U 盘引导这个发行版。Sugar on a Stick 是由 Sugar 实验室提供的一个项目 —— 这个实验室是一个由志愿者运作的非盈利组织。
|
||||
|
||||
### 4、KDE Edu Suite
|
||||
|
||||
[KDE Edu Suite][8] 是一个用途与众不同的软件包。带来了大量不同领域的应用程序,KDE 社区已经证实,它不仅可以给成年人授权;它还关心年青一代如何适应他们周围的一切。它囊括了一系列孩子们使用的应用程序,从科学到数学、地理等等。
|
||||
|
||||
![linux-educational-software-kde-1][9]
|
||||
|
||||
KDE Edu 套件根据长大后所必需的知识为基础,既能够用作学校的教学软件,也能够作为孩子们的学习 APP。它提供了大量的可免费下载的软件包。KDE Edu 套件在主流的 GNU/Linux 发行版都能安装。
|
||||
|
||||
### 5、Tux Paint
|
||||
|
||||
![linux-educational-software-tux-paint-2][10]
|
||||
|
||||
[Tux Paint][11] 是给孩子们的另一个非常好的 Linux 教育软件。这个屡获殊荣的绘画软件在世界各地被用于帮助培养孩子们的绘画技能,它有一个简洁的、易于使用的界面和有趣的音效,可以高效地帮助孩子去使用这个程序。它也有一个卡通吉祥物去鼓励孩子们使用这个程序。Tux Paint 中有许多绘画工具,它们可以帮助孩子们放飞他们的创意。
|
||||
|
||||
### 总结
|
||||
|
||||
由于这些教育软件深受孩子们的欢迎,许多学校和幼儿园都使用这些程序进行辅助教学。典型的一个例子就是 [Edubuntu][12],它是儿童教育领域中广受老师和家长们欢迎的一个基于 Ubuntu 的发行版。
|
||||
|
||||
Tux Paint 是另一个非常好的例子,它在这些年越来越流行,它大量地用于学校中教孩子们如何绘画。以上的这个清单并不很详细。还有成百上千的对孩子有益的其它 Linux 教育软件和游戏。
|
||||
|
||||
如果你还知道给孩子们的其它非常好的 Linux 教育软件和游戏,在下面的评论区分享给我们吧。
|
||||
|
||||
------
|
||||
|
||||
via: https://www.maketecheasier.com/5-best-linux-software-packages-for-kids/
|
||||
|
||||
作者:[Kenneth Kimari][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/kennkimari/
|
||||
[1]: https://www.maketecheasier.com/beginner-guide-to-using-linux-distro/
|
||||
[2]: http://www.gcompris.net/downloads-en.html
|
||||
[3]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-gcompris.jpg
|
||||
[4]: https://tuxmath.en.uptodown.com/ubuntu
|
||||
[5]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-tuxmath-1.jpg
|
||||
[6]: http://wiki.sugarlabs.org/go/Sugar_on_a_Stick/Downloads
|
||||
[7]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-sugar-on-a-stick.png
|
||||
[8]: https://edu.kde.org/
|
||||
[9]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-kde-1.jpg
|
||||
[10]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-tux-paint-2.jpg
|
||||
[11]: http://www.tuxpaint.org/
|
||||
[12]: http://edubuntu.org/
|
||||
@ -0,0 +1,84 @@
|
||||
Linux 下如何创建 M3U 播放列表
|
||||
======
|
||||
|
||||
> 简介:关于如何在Linux终端中根据乱序文件创建M3U播放列表实现循序播放的小建议。
|
||||
|
||||
![Create M3U playlists in Linux Terminal][1]
|
||||
|
||||
我是外国电视连续剧的粉丝,这些连续剧不太容易从 DVD 或像 [Netflix][2] 这样的流媒体上获得。好在,您可以在 YouTube 上找到一些内容并[从 YouTube 下载][3]。
|
||||
|
||||
现在出现了一个问题。你的文件可能不是按顺序存储的。在 GNU/Linux中,文件不是按数字顺序自然排序的,因此我必须创建 .m3u 播放列表,以便 [MPV 视频播放器][4]可以按顺序播放视频而不是乱顺进行播放。
|
||||
|
||||
同样的,有时候表示第几集的数字是在文件名中间或结尾的,像这样 “My Web Series S01E01.mkv”。这里的剧集信息位于文件名的中间,“S01E01”告诉我们人类这是第一集,后面还有其它剧集。
|
||||
|
||||
因此我要做的事情就是在视频墓中创建一个 .m3u 播放列表,并告诉 MPV 播放这个 .m3u 播放列表,MPV 自然会按顺序播放这些视频.
|
||||
|
||||
### 什么是 M3U 文件?
|
||||
|
||||
[M3U][5] 基本上就是个按特定顺序包含文件名的文本文件。当类似 MPV 或 VLC 这样的播放器打开 M3U 文件时,它会尝试按给定的顺序播放指定文件。
|
||||
|
||||
### 创建 M3U 来按顺序播放音频/视频文件
|
||||
|
||||
就我而言, 我使用了下面命令:
|
||||
|
||||
```
|
||||
$/home/shirish/Videos/web-series-video/$ ls -1v |grep .mkv > /tmp/1.m3u && mv /tmp/1.m3u .
|
||||
```
|
||||
|
||||
然我们拆分一下看看每个部分表示什么意思:
|
||||
|
||||
`ls -1v` = 这就是用普通的 `ls` 来列出目录中的内容. 其中 `-1` 表示每行显示一个文件。而 `-v` 表示根据文本中的数字(版本)进行自然排序。
|
||||
|
||||
`| grep .mkv` = 基本上就是告诉 `ls` 寻找那些以 `.mkv` 结尾的文件。它也可以是 `.mp4` 或其他任何你想要的媒体文件格式。
|
||||
|
||||
通过在控制台上运行命令来进行试运行通常是个好主意:
|
||||
|
||||
```
|
||||
ls -1v |grep .mkv
|
||||
My Web Series S01E01 [Episode 1 Name] Multi 480p WEBRip x264 - xRG.mkv
|
||||
My Web Series S01E02 [Episode 2 Name] Multi 480p WEBRip x264 - xRG.mkv
|
||||
My Web Series S01E03 [Episode 3 Name] Multi 480p WEBRip x264 - xRG.mkv
|
||||
My Web Series S01E04 [Episode 4 Name] Multi 480p WEBRip x264 - xRG.mkv
|
||||
My Web Series S01E05 [Episode 5 Name] Multi 480p WEBRip x264 - xRG.mkv
|
||||
My Web Series S01E06 [Episode 6 Name] Multi 480p WEBRip x264 - xRG.mkv
|
||||
My Web Series S01E07 [Episode 7 Name] Multi 480p WEBRip x264 - xRG.mkv
|
||||
My Web Series S01E08 [Episode 8 Name] Multi 480p WEBRip x264 - xRG.mkv
|
||||
```
|
||||
|
||||
结果显示我要做的是正确的。现在下一步就是让输出以 `.m3u` 播放列表的格式输出。
|
||||
|
||||
```
|
||||
ls -1v |grep .mkv > /tmp/web_playlist.m3u && mv /tmp/web_playlist.m3u .
|
||||
```
|
||||
|
||||
这就在当前目录中创建了 .m3u 文件。这个 .m3u 播放列表只不过是一个 .txt 文件,其内容与上面相同,扩展名为 .m3u 而已。 你也可以手动编辑它,并按照想要的顺序添加确切的文件名。
|
||||
|
||||
之后你只需要这样做:
|
||||
|
||||
```
|
||||
mpv web_playlist.m3u
|
||||
```
|
||||
|
||||
一般来说,MPV 和播放列表的好处在于你不需要一次性全部看完。 您可以一次看任意长时间,然后在下一次查看其余部分。
|
||||
|
||||
我希望写一些有关 MPV 的文章,以及如何制作在媒体文件中嵌入字幕的 mkv 文件,但这是将来的事情了。
|
||||
|
||||
注意: 这是开源软件,不鼓励盗版。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/create-m3u-playlist-linux/
|
||||
|
||||
作者:[Shirsh][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/shirish/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/Create-M3U-Playlists.jpeg
|
||||
[2]:https://itsfoss.com/netflix-open-source-ai/
|
||||
[3]:https://itsfoss.com/download-youtube-linux/
|
||||
[4]:https://itsfoss.com/mpv-video-player/
|
||||
[5]:https://en.wikipedia.org/wiki/M3U
|
||||
@ -0,0 +1,122 @@
|
||||
在 Linux 中安全且轻松地管理 Cron 定时任务
|
||||
======
|
||||
|
||||

|
||||
|
||||
在 Linux 中遇到计划任务的时候,你首先会想到的大概就是 Cron 定时任务了。Cron 定时任务能帮助你在类 Unix 操作系统中计划性地执行命令或者任务。也可以参考一下我们之前的一篇《[关于 Cron 定时任务的新手指导][1]》。对于有一定 Linux 经验的人来说,设置 Cron 定时任务不是什么难事,但对于新手来说就不一定了,他们在编辑 crontab 文件的时候不知不觉中犯的一些小错误,也有可能把整个 Cron 定时任务搞挂了。如果你在处理 Cron 定时任务的时候为了以防万一,可以尝试使用 **Crontab UI**,它是一个可以在类 Unix 操作系统上安全轻松管理 Cron 定时任务的 Web 页面工具。
|
||||
|
||||
Crontab UI 是使用 NodeJS 编写的自由开源软件。有了 Crontab UI,你在创建、删除和修改 Cron 定时任务的时候就不需要手工编辑 Crontab 文件了,只需要打开浏览器稍微操作一下,就能完成上面这些工作。你可以用 Crontab UI 轻松创建、编辑、暂停、删除、备份 Cron 定时任务,甚至还可以简单地做到导入、导出、部署其它机器上的 Cron 定时任务,它还支持错误日志、邮件发送和钩子。
|
||||
|
||||
### 安装 Crontab UI
|
||||
|
||||
只需要一条命令就可以安装好 Crontab UI,但前提是已经安装好 NPM。如果还没有安装 NPM,可以参考《[如何在 Linux 上安装 NodeJS][2]》这篇文章。
|
||||
|
||||
执行这一条命令来安装 Crontab UI。
|
||||
|
||||
```
|
||||
$ npm install -g crontab-ui
|
||||
```
|
||||
|
||||
就是这么简单,下面继续来看看在 Crontab UI 上如何管理 Cron 定时任务。
|
||||
|
||||
### 在 Linux 上安全轻松管理 Cron 定时任务
|
||||
|
||||
执行这一条命令启动 Crontab UI:
|
||||
|
||||
```
|
||||
$ crontab-ui
|
||||
```
|
||||
|
||||
你会看到这样的输出:
|
||||
|
||||
```
|
||||
Node version: 10.8.0
|
||||
Crontab UI is running at http://127.0.0.1:8000
|
||||
```
|
||||
|
||||
首先在你的防火墙和路由器上放开 8000 端口,然后打开浏览器访问 `<http://127.0.0.1:8000>`。
|
||||
|
||||
注意,默认只有在本地才能访问到 Crontab UI 的控制台页面。但如果你想让 Crontab UI 使用系统的 IP 地址和自定义端口,也就是想让其它机器也访问到本地的 Crontab UI,你需要使用以下这个命令:
|
||||
|
||||
```
|
||||
$ HOST=0.0.0.0 PORT=9000 crontab-ui
|
||||
Node version: 10.8.0
|
||||
Crontab UI is running at http://0.0.0.0:9000
|
||||
```
|
||||
|
||||
Crontab UI 就能够通过 `<http://IP-Address>:9000` 这样的 URL 被远程机器访问到了。
|
||||
|
||||
Crontab UI 的控制台页面长这样:
|
||||
|
||||
|
||||
|
||||
从上面的截图就可以看到,Crontab UI 的界面非常简洁,所有选项的含义都能不言自明。
|
||||
|
||||
在终端输入 `Ctrl + C` 就可以关闭 Crontab UI。
|
||||
|
||||
#### 创建、编辑、运行、停止、删除 Cron 定时任务
|
||||
|
||||
点击 “New”,输入 Cron 定时任务的信息并点击 “Save” 保存,就可以创建一个新的 Cron 定时任务了。
|
||||
|
||||
1. 为 Cron 定时任务命名,这是可选的;
|
||||
2. 你想要执行的完整命令;
|
||||
3. 设定计划执行的时间。你可以按照启动、每时、每日、每周、每月、每年这些指标快速指定计划任务,也可以明确指定任务执行的具体时间。指定好计划时间后,“Jobs” 区域就会显示 Cron 定时任务的句式。
|
||||
4. 选择是否为某个 Cron 定时任务记录错误日志。
|
||||
|
||||
这是我的一个 Cron 定时任务样例。
|
||||
|
||||

|
||||
|
||||
如你所见,我设置了一个每月清理 `pacman` 缓存的 Cron 定时任务。你也可以设置多个 Cron 定时任务,都能在控制台页面看到。
|
||||
|
||||
|
||||
|
||||
如果你需要更改 Cron 定时任务中的某些参数,只需要点击 “Edit” 按钮并按照你的需求更改对应的参数。点击 “Run” 按钮可以立即执行 Cron 定时任务,点击 “Stop” 则可以立即停止 Cron 定时任务。如果想要查看某个 Cron 定时任务的详细日志,可以点击 “Log” 按钮。对于不再需要的 Cron 定时任务,就可以按 “Delete” 按钮删除。
|
||||
|
||||
#### 备份 Cron 定时任务
|
||||
|
||||
点击控制台页面的 “Backup” 按钮并确认,就可以备份所有 Cron 定时任务。
|
||||
|
||||
|
||||
|
||||
备份之后,一旦 Crontab 文件出现了错误,就可以使用备份来恢复了。
|
||||
|
||||
#### 导入/导出其它机器上的 Cron 定时任务
|
||||
|
||||
Crontab UI 还有一个令人注目的功能,就是导入、导出、部署其它机器上的 Cron 定时任务。如果同一个网络里的多台机器都需要执行同样的 Cron 定时任务,只需要点击 “Export” 按钮并选择文件的保存路径,所有的 Cron 定时任务都会导出到 `crontab.db` 文件中。
|
||||
|
||||
以下是 `crontab.db` 文件的内容:
|
||||
|
||||
```
|
||||
$ cat Downloads/crontab.db
|
||||
{"name":"Remove Pacman Cache","command":"rm -rf /var/cache/pacman","schedule":"@monthly","stopped":false,"timestamp":"Thu Aug 23 2018 10:34:19 GMT+0000 (Coordinated Universal Time)","logging":"true","mailing":{},"created":1535020459093,"_id":"lcVc1nSdaceqS1ut"}
|
||||
```
|
||||
|
||||
导出成文件以后,你就可以把这个 `crontab.db` 文件放置到其它机器上并导入成 Cron 定时任务,而不需要在每一台主机上手动设置 Cron 定时任务。总之,在一台机器上设置完,导出,再导入到其他机器,就完事了。
|
||||
|
||||
#### 在 Crontab 文件获取/保存 Cron 定时任务
|
||||
|
||||
你可能在使用 Crontab UI 之前就已经使用 `crontab` 命令创建过 Cron 定时任务。如果是这样,你可以点击控制台页面上的 “Get from crontab” 按钮来获取已有的 Cron 定时任务。
|
||||
|
||||
|
||||
|
||||
同样地,你也可以使用 Crontab UI 来将新的 Cron 定时任务保存到 Crontab 文件中,只需要点击 “Save to crontab” 按钮就可以了。
|
||||
|
||||
管理 Cron 定时任务并没有想象中那么难,即使是新手使用 Crontab UI 也能轻松管理 Cron 定时任务。赶快开始尝试并发表一下你的看法吧。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-easily-and-safely-manage-cron-jobs-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/a-beginners-guide-to-cron-jobs/
|
||||
[2]:https://www.ostechnix.com/install-node-js-linux/
|
||||
|
||||
109
published/20180824 5 cool music player apps.md
Normal file
109
published/20180824 5 cool music player apps.md
Normal file
@ -0,0 +1,109 @@
|
||||
5 个很酷的音乐播放器
|
||||
======
|
||||
|
||||

|
||||
|
||||
你喜欢音乐吗?那么 Fedora 中可能有你正在寻找的东西。本文介绍在 Fedora 上运行的各种音乐播放器。无论你有庞大的音乐库,还是小一些的,抑或根本没有,你都可以用到音乐播放器。这里有四个图形程序和一个基于终端的音乐播放器,可以让你挑选。
|
||||
|
||||
### Quod Libet
|
||||
|
||||
Quod Libet 是一个完备的大型音频库管理器。如果你有一个庞大的音频库,你不想只是听,也想要管理,Quod Libet 可能是一个很好的选择。
|
||||
|
||||
![][1]
|
||||
|
||||
Quod Libet 可以从磁盘上的多个位置导入音乐,并允许你编辑音频文件的标签 —— 因此一切都在你的控制之下。此外,它还有各种插件可用,从简单的均衡器到 [last.fm][2] 同步。你也可以直接从 [Soundcloud][3] 搜索和播放音乐。
|
||||
|
||||
Quod Libet 在 HiDPI 屏幕上工作得很好,它有 Fedora 的 RPM 包,如果你运行 [Silverblue][5],它在 [Flathub][4] 中也有。使用 Gnome Software 或命令行安装它:
|
||||
|
||||
```
|
||||
$ sudo dnf install quodlibet
|
||||
```
|
||||
|
||||
### Audacious
|
||||
|
||||
如果你喜欢简单的音乐播放器,甚至可能看起来像传说中的 Winamp,Audacious 可能是你的不错选择。
|
||||
|
||||
![][6]
|
||||
|
||||
Audacious 可能不直接管理你的所有音乐,但你如果想将音乐按文件组织起来,它能做得很好。你还可以导出和导入播放列表,而无需重新组织音乐文件本身。
|
||||
|
||||
此外,你可以让它看起来像 Winamp。要让它与上面的截图相同,请进入 “Settings/Appearance”,选择顶部的 “Winamp Classic Interface”,然后选择右下方的 “Refugee” 皮肤。就这么简单。
|
||||
|
||||
Audacious 在 Fedora 中作为 RPM 提供,可以使用 Gnome Software 或在终端运行以下命令安装:
|
||||
|
||||
```
|
||||
$ sudo dnf install audacious
|
||||
```
|
||||
|
||||
### Lollypop
|
||||
|
||||
Lollypop 是一个音乐播放器,它与 GNOME 集成良好。如果你喜欢 GNOME 的外观,并且想要一个集成良好的音乐播放器,Lollypop 可能适合你。
|
||||
|
||||
![][7]
|
||||
|
||||
除了与 GNOME Shell 的良好视觉集成之外,它还可以很好地用于 HiDPI 屏幕,并支持暗色主题。
|
||||
|
||||
额外地,Lollypop 有一个集成的封面下载器和一个所谓的派对模式(右上角的音符按钮),它可以自动选择和播放音乐。它还集成了 [last.fm][2] 或 [libre.fm][8] 等在线服务。
|
||||
|
||||
它有 Fedora 的 RPM 也有用于 [Silverblue][5] 工作站的 [Flathub][4],使用 Gnome Software 或终端进行安装:
|
||||
|
||||
```
|
||||
$ sudo dnf install lollypop
|
||||
```
|
||||
|
||||
### Gradio
|
||||
|
||||
如果你没有任何音乐但仍想听怎么办?或者你只是喜欢收音机?Gradio 就是为你准备的。
|
||||
|
||||
![][9]
|
||||
|
||||
Gradio 是一个简单的收音机,它允许你搜索和播放网络电台。你可以按国家、语言或直接搜索找到它们。额外地,它可视化地集成到了 GNOME Shell 中,可以与 HiDPI 屏幕配合使用,并且可以选择黑暗主题。
|
||||
|
||||
可以在 [Flathub][4] 中找到 Gradio,它同时可以运行在 Fedora Workstation 和 [Silverblue][5] 中。使用 Gnome Software 安装它。
|
||||
|
||||
### sox
|
||||
|
||||
你喜欢使用终端在工作时听一些音乐吗?多亏有了 sox,你不必离开终端。
|
||||
|
||||
![][10]
|
||||
|
||||
sox 是一个非常简单的基于终端的音乐播放器。你需要做的就是运行如下命令:
|
||||
|
||||
```
|
||||
$ play file.mp3
|
||||
```
|
||||
|
||||
接着 sox 就会为你播放。除了单独的音频文件外,sox 还支持 m3u 格式的播放列表。
|
||||
|
||||
此外,因为 sox 是基于终端的程序,你可以通过 ssh 运行它。你有一个带扬声器的家用服务器吗?或者你想从另一台电脑上播放音乐吗?尝试将它与 [tmux][11] 一起使用,这样即使会话关闭也可以继续听。
|
||||
|
||||
sox 在 Fedora 中以 RPM 提供。运行下面的命令安装:
|
||||
|
||||
```
|
||||
$ sudo dnf install sox
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/5-cool-music-player-apps/
|
||||
|
||||
作者:[Adam Šamalík][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/asamalik/
|
||||
[1]:https://fedoramagazine.org/wp-content/uploads/2018/08/qodlibet-768x555.png
|
||||
[2]:https://last.fm
|
||||
[3]:https://soundcloud.com/
|
||||
[4]:https://flathub.org/home
|
||||
[5]:https://teamsilverblue.org/
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/08/audacious-768x348.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/08/lollypop-768x439.png
|
||||
[8]:https://libre.fm
|
||||
[9]:https://fedoramagazine.org/wp-content/uploads/2018/08/gradio-768x499.png
|
||||
[10]:https://fedoramagazine.org/wp-content/uploads/2018/08/sox-768x457.png
|
||||
[11]:https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
88
published/20180827 4 tips for better tmux sessions.md
Normal file
88
published/20180827 4 tips for better tmux sessions.md
Normal file
@ -0,0 +1,88 @@
|
||||
更好利用 tmux 会话的 4 个技巧
|
||||
======
|
||||
|
||||

|
||||
|
||||
tmux 是一个终端多路复用工具,它可以让你系统上的终端支持多面板。你可以排列面板位置,在每个面板运行不同进程,这通常可以更好的地利用你的屏幕。我们在 [这篇早期的文章][1] 中向读者介绍过这一强力工具。如果你已经开始使用 tmux 了,那么这里有一些技巧可以帮你更好地使用它。
|
||||
|
||||
本文假设你当前的前缀键是 `Ctrl+b`。如果你已重新映射该前缀,只需在相应位置替换为你定义的前缀即可。
|
||||
|
||||
### 设置终端为自动使用 tmux
|
||||
|
||||
使用 tmux 的一个最大好处就是可以随意的从会话中断开和重连。这使得远程登录会话功能更加强大。你有没有遇到过丢失了与远程系统的连接,然后好希望能够恢复在远程系统上做过的那些工作的情况?tmux 能够解决这一问题。
|
||||
|
||||
然而,有时在远程系统上工作时,你可能会忘记开启会话。避免出现这一情况的一个方法就是每次通过交互式 shell 登录系统时都让 tmux 启动或附加上一个会话。
|
||||
|
||||
在你远程系统上的 `~/.bash_profile` 文件中加入下面内容:
|
||||
|
||||
```
|
||||
if [ -z "$TMUX" ]; then
|
||||
tmux attach -t default || tmux new -s default
|
||||
fi
|
||||
```
|
||||
|
||||
然后注销远程系统,并使用 SSH 重新登录。你会发现你处在一个名为 `default` 的 tmux 会话中了。如果退出该会话,则下次登录时还会重新生成此会话。但更重要的是,若您正常地从会话中分离,那么下次登录时你会发现之前工作并没有丢失 - 这在连接中断时非常有用。
|
||||
|
||||
你当然也可以将这段配置加入本地系统中。需要注意的是,大多数 GUI 界面的终端并不会自动使用这个 `default` 会话,因此它们并不是登录 shell。虽然你可以修改这一行为,但它可能会导致终端嵌套执行附加到 tmux 会话这一动作,从而导致会话不太可用,因此当进行此操作时请一定小心。
|
||||
|
||||
### 使用缩放功能使注意力专注于单个进程
|
||||
|
||||
虽然 tmux 的目的就是在单个会话中提供多窗口、多面板和多进程的能力,但有时候你需要专注。如果你正在与一个进程进行交互并且需要更多空间,或需要专注于某个任务,则可以使用缩放命令。该命令会将当前面板扩展,占据整个当前窗口的空间。
|
||||
|
||||
缩放在其他情况下也很有用。比如,想象你在图形桌面上运行一个终端窗口。面板会使得从 tmux 会话中拷贝和粘帖多行内容变得相对困难。但若你缩放了面板,就可以很容易地对多行数据进行拷贝/粘帖。
|
||||
|
||||
要对当前面板进行缩放,按下 `Ctrl+b, z`。需要恢复的话,按下相同按键组合来恢复面板。
|
||||
|
||||
### 绑定一些有用的命令
|
||||
|
||||
tmux 默认有大量的命令可用。但将一些更常用的操作绑定到容易记忆的快捷键会很有用。下面一些例子可以让会话变得更好用,你可以添加到 `~/.tmux.conf` 文件中:
|
||||
|
||||
```
|
||||
bind r source-file ~/.tmux.conf \; display "Reloaded config"
|
||||
```
|
||||
|
||||
该命令重新读取你配置文件中的命令和键绑定。添加该条绑定后,退出任意一个 tmux 会话然后重启一个会话。现在你做了任何更改后,只需要简单的按下 `Ctrl+b, r` 就能将修改的内容应用到现有的会话中了。
|
||||
|
||||
```
|
||||
bind V split-window -h
|
||||
bind H split-window
|
||||
```
|
||||
|
||||
这些命令可以很方便地对窗口进行横向切分(按下 `Shift+V`)和纵向切分(`Shift+H`)。
|
||||
|
||||
若你想查看所有绑定的快捷键,按下 `Ctrl+B, ?` 可以看到一个列表。你首先看到的应该是复制模式下的快捷键绑定,表示的是当你在 tmux 中进行复制粘帖时对应的快捷键。你添加的那两个键绑定会在<ruby>前缀模式<rt>prefix mode</rt></ruby>中看到。请随意把玩吧!
|
||||
|
||||
### 使用 powerline 更清晰
|
||||
|
||||
[如前文所示][2],powerline 工具是对 shell 的绝佳补充。而且它也兼容在 tmux 中使用。由于 tmux 接管了整个终端空间,powerline 窗口能提供的可不仅仅是更好的 shell 提示那么简单。
|
||||
|
||||
[][3]
|
||||
|
||||
如果你还没有这么做,按照 [这篇文章][4] 中的指示来安装该工具。然后[使用 sudo][5] 来安装附件:
|
||||
|
||||
```
|
||||
sudo dnf install tmux-powerline
|
||||
```
|
||||
|
||||
接着重启会话,就会在底部看到一个漂亮的新状态栏。根据终端的宽度,默认的状态栏会显示你当前会话 ID、打开的窗口、系统信息、日期和时间,以及主机名。若你进入了使用 git 进行版本控制的项目目录中还能看到分支名和用色彩标注的版本库状态。
|
||||
|
||||
当然,这个状态栏具有很好的可配置性。享受你新增强的 tmux 会话吧,玩的开心点。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-tips-better-tmux-sessions/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/pfrields/
|
||||
[1]:https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
[2]:https://fedoramagazine.org/add-power-terminal-powerline/
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/08/Screenshot-from-2018-08-25-19-36-53.png
|
||||
[4]:https://fedoramagazine.org/add-power-terminal-powerline/
|
||||
[5]:https://fedoramagazine.org/howto-use-sudo/
|
||||
@ -0,0 +1,77 @@
|
||||
如何在 Ubuntu 上安装 Cinnamon 桌面环境
|
||||
======
|
||||
|
||||
> 这篇教程将会为你展示如何在 Ubuntu 上安装 Cinnamon 桌面环境。
|
||||
|
||||
[Cinnamon][1] 是 [Linux Mint][2] 的默认桌面环境。不同于 Ubuntu 的 Unity 桌面环境,Cinnamon 是一个更加传统而优雅的桌面环境,其带有底部面板和应用菜单。由于 Cinnamon 桌面以及它类 Windows 的用户界面,许多桌面用户[相较于 Ubuntu 更喜欢 Linux Mint][3]。
|
||||
|
||||
现在你无需[安装 Linux Mint][4] 就能够体验到 Cinnamon了。在这篇教程,我将会展示给你如何在 Ubuntu 18.04,16.04 和 14.04 上安装 Cinnamon。
|
||||
|
||||
在 Ubuntu 上安装 Cinnamon 之前,有一些事情需要你注意。有时候,安装的额外桌面环境可能会与你当前的桌面环境有冲突。可能导致会话、应用程序或功能等的崩溃。这就是为什么你需要在做这个决定时谨慎一点的原因。
|
||||
|
||||
### 如何在 Ubuntu 上安装 Cinnamon 桌面环境
|
||||
|
||||
![如何在 Ubuntu 上安装 Cinnamon 桌面环境][5]
|
||||
|
||||
过去有 Cinnamon 团队为 Ubuntu 提供的一系列的官方 PPA,但现在都已经失效了。不过不用担心,还有一个非官方的 PPA,而且它运行的很完美。这个 PPA 里包含了最新的 Cinnamon 版本。
|
||||
|
||||
```
|
||||
sudo add-apt-repository
|
||||
ppa:embrosyn/cinnamon
|
||||
sudo apt update && sudo apt install cinnamon
|
||||
```
|
||||
|
||||
下载的大小大概是 150 MB(如果我没记错的话)。这其中提供的 Nemo(Cinnamon 的文件管理器,基于 Nautilus)和 Cinnamon 控制中心。这些东西提供了一个更加接近于 Linux Mint 的感觉。
|
||||
|
||||
### 在 Ubuntu 上使用 Cinnamon 桌面环境
|
||||
|
||||
Cinnamon 安装完成后,退出当前会话,在登录界面,点击用户名旁边的 Ubuntu 符号:
|
||||
|
||||

|
||||
|
||||
之后,它将会显示所有系统可用的桌面环境。选择 Cinnamon。
|
||||
|
||||

|
||||
|
||||
现在你应该已经登录到有着 Cinnamon 桌面环境的 Ubuntu 中了。你还可以通过同样的方式再回到 Unity 桌面。这里有一张以 Cinnamon 做为桌面环境的 Ubuntu 桌面截图。
|
||||
|
||||

|
||||
|
||||
看起来是不是像极了 Linux Mint。此外,我并没有发现任何有关 Cinnamon 和 Unity 的兼容性问题。在 Unity 和 Cinnamon 来回切换,它们也依旧工作的很完美。
|
||||
|
||||
#### 从 Ubuntu 卸载 Cinnamon
|
||||
|
||||
如果你想卸载 Cinnamon,可以使用 PPA Purge 来完成。首先安装 PPA Purge:
|
||||
|
||||
```
|
||||
sudo apt-get install ppa-purge
|
||||
```
|
||||
|
||||
安装完成之后,使用下面的命令去移除该 PPA:
|
||||
|
||||
```
|
||||
sudo ppa-purge ppa:embrosyn/cinnamon
|
||||
```
|
||||
|
||||
更多的信息,我建议你去阅读 [如何从 Linux 移除 PPA][6] 这篇文章。
|
||||
|
||||
我希望这篇文章能够帮助你在 Ubuntu 上安装 Cinnamon。也可以分享一下你使用 Cinnamon 的经验。
|
||||
|
||||
------
|
||||
|
||||
via: https://itsfoss.com/install-cinnamon-on-ubuntu/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: http://cinnamon.linuxmint.com/
|
||||
[2]: http://www.linuxmint.com/
|
||||
[3]: https://itsfoss.com/linux-mint-vs-ubuntu/
|
||||
[4]: https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/
|
||||
[5]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/install-cinnamon-ubuntu.png
|
||||
[6]: https://itsfoss.com/how-to-remove-or-delete-ppas-quick-tip/
|
||||
@ -0,0 +1,143 @@
|
||||
Cloud Commander:一个有控制台和编辑器的 Web 文件管理器
|
||||
======
|
||||
|
||||

|
||||
|
||||
**Cloud Commander** 是一个基于 web 的文件管理程序,它允许你通过任何计算机、移动端或平板电脑的浏览器查看、访问或管理系统文件或文件夹。它有两个简单而又经典的面板,并且会像你设备的显示尺寸一样自动转换大小。它也拥有两款内置的叫做 **Dword** 和 **Edward** 的文本编辑器,它们支持语法高亮,并带有一个支持系统命令行的控制台。因此,您可以随时随地编辑文件。Cloud Commander 服务器是一款在 Linux、Windows、Mac OS X 运行的跨平台应用,而且该应用客户端可以在任何一款浏览器上运行。它是用 **JavaScript/Node.Js** 写的,并使用 **MIT** 许可证。
|
||||
|
||||
在这个简易教程中,让我们看一看如何在 Ubuntu 18.04 LTS 服务器上安装 Cloud Commander。
|
||||
|
||||
### 前提条件
|
||||
|
||||
像我之前提到的,是用 Node.js 写的。所以为了安装 Cloud Commander,我们需要首先安装 Node.js。要执行安装,参考下面的指南。
|
||||
|
||||
- [如何在 Linux 上安装 Node.js](https://www.ostechnix.com/install-node-js-linux/)
|
||||
|
||||
### 安装 Cloud Commander
|
||||
|
||||
在安装 Node.js 之后,运行下列命令安装 Cloud Commander:
|
||||
|
||||
```
|
||||
$ npm i cloudcmd -g
|
||||
```
|
||||
|
||||
祝贺!Cloud Commander 已经安装好了。让我们往下继续看看 Cloud Commander 的基本使用。
|
||||
|
||||
### 开始使用 Cloud Commander
|
||||
|
||||
运行以下命令启动 Cloud Commander:
|
||||
|
||||
```
|
||||
$ cloudcmd
|
||||
```
|
||||
|
||||
**输出示例:**
|
||||
|
||||
```
|
||||
url: http://localhost:8000
|
||||
```
|
||||
|
||||
现在,打开你的浏览器并转到链接:`http://localhost:8000` 或 `http://IP-address:8000`。
|
||||
|
||||
从现在开始,您可以直接在本地系统或远程系统或移动设备,平板电脑等Web浏览器中创建,删除,查看,管理文件或文件夹。
|
||||
|
||||
![][2]
|
||||
|
||||
如你所见上面的截图,Clouder Commander 有两个面板,十个热键 (`F1` 到 `F10`),还有控制台。
|
||||
|
||||
每个热键执行的都是一个任务。
|
||||
|
||||
* `F1` – 帮助
|
||||
* `F2` – 重命名文件/文件夹
|
||||
* `F3` – 查看文件/文件夹
|
||||
* `F4` – 编辑文件
|
||||
* `F5` – 复制文件/文件夹
|
||||
* `F6` – 移动文件/文件夹
|
||||
* `F7` – 创建新目录
|
||||
* `F8` – 删除文件/文件夹
|
||||
* `F9` – 打开菜单
|
||||
* `F10` – 打开设置
|
||||
|
||||
#### Cloud Commmander 控制台
|
||||
|
||||
点击控制台图标。这即将打开系统默认的命令行界面。
|
||||
|
||||
![][3]
|
||||
|
||||
在此控制台中,您可以执行各种管理任务,例如安装软件包、删除软件包、更新系统等。您甚至可以关闭或重新引导系统。 因此,Cloud Commander 不仅仅是一个文件管理器,还具有远程管理工具的功能。
|
||||
|
||||
#### 创建文件/文件夹
|
||||
|
||||
要创建新的文件或文件夹就右键单击任意空位置并找到 “New - >File or Directory”。
|
||||
|
||||
![][4]
|
||||
|
||||
#### 查看文件
|
||||
|
||||
你可以查看图片,查看音视频文件。
|
||||
|
||||
![][5]
|
||||
|
||||
#### 上传文件
|
||||
|
||||
另一个很酷的特性是我们可以从任何系统或设备简单地上传一个文件到 Cloud Commander 系统。
|
||||
|
||||
要上传文件,右键单击 Cloud Commander 面板的任意空白处,并且单击“Upload”选项。
|
||||
|
||||
![][6]
|
||||
|
||||
选择你想要上传的文件。
|
||||
|
||||
另外,你也可以上传来自像 Google 云盘、Dropbox、Amazon 云盘、Facebook、Twitter、Gmail、GitHub、Picasa、Instagram 还有很多的云服务上的文件。
|
||||
|
||||
要从云端上传文件, 右键单击面板的任意空白处,并且右键单击面板任意空白处并选择“Upload from Cloud”。
|
||||
|
||||
![][7]
|
||||
|
||||
选择任意一个你选择的网络服务,例如谷歌云盘。点击“Connect to Google drive”按钮。
|
||||
|
||||
![][8]
|
||||
|
||||
下一步,用 Cloud Commander 验证你的谷歌云端硬盘,从谷歌云端硬盘选择文件并点击“Upload”。
|
||||
|
||||
![][9]
|
||||
|
||||
#### 更新 Cloud Commander
|
||||
|
||||
要更新到最新的可用版本,执行下面的命令:
|
||||
|
||||
```
|
||||
$ npm update cloudcmd -g
|
||||
```
|
||||
|
||||
#### 总结
|
||||
|
||||
据我测试,它运行很好。在我的 Ubuntu 服务器测试期间,我没有遇到任何问题。此外,Cloud Commander 不仅是基于 Web 的文件管理器,还可以充当执行大多数 Linux 管理任务的远程管理工具。 您可以创建文件/文件夹、重命名、删除、编辑和查看它们。此外,您可以像在终端中在本地系统中那样安装、更新、升级和删除任何软件包。当然,您甚至可以从 Cloud Commander 控制台本身关闭或重启系统。 还有什么需要的吗? 尝试一下,你会发现它很有用。
|
||||
|
||||
目前为止就这样吧。 我将很快在这里发表另一篇有趣的文章。 在此之前,请继续关注我们。
|
||||
|
||||
祝贺!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/cloud-commander-a-web-file-manager-with-console-and-editor/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[fuzheng1998](https://github.com/fuzheng1998)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-Commander-Google-Chrome_006-4.jpg
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-Commander-Google-Chrome_007-2.jpg
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-commander-file-folder-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-Commander-home-sk-Google-Chrome_008-1.jpg
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2016/05/cloud-commander-upload-2.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2016/05/upload-from-cloud-1.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-Commander-home-sk-Google-Chrome_009-2.jpg
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-Commander-home-sk-Google-Chrome_010-1.jpg
|
||||
@ -1,4 +1,4 @@
|
||||
Trash-Cli : Linux 上的命令行回收站工具
|
||||
Trash-Cli:Linux 上的命令行回收站工具
|
||||
======
|
||||
|
||||
相信每个人都对<ruby>回收站<rt>trashcan</rt></ruby>很熟悉,因为无论是对 Linux 用户,还是 Windows 用户,或者 Mac 用户来说,它都很常见。当你删除一个文件或目录的时候,该文件或目录会被移动到回收站中。
|
||||
@ -33,31 +33,27 @@ $ sudo apt install trash-cli
|
||||
|
||||
```
|
||||
$ sudo yum install trash-cli
|
||||
|
||||
```
|
||||
|
||||
对于 Fedora 用户,使用 [dnf][6] 命令来安装 Trash-Cli:
|
||||
|
||||
```
|
||||
$ sudo dnf install trash-cli
|
||||
|
||||
```
|
||||
|
||||
对于 Arch Linux 用户,使用 [pacman][7] 命令来安装 Trash-Cli:
|
||||
|
||||
```
|
||||
$ sudo pacman -S trash-cli
|
||||
|
||||
```
|
||||
|
||||
对于 openSUSE 用户,使用 [zypper][8] 命令来安装 Trash-Cli:
|
||||
|
||||
```
|
||||
$ sudo zypper in trash-cli
|
||||
|
||||
```
|
||||
|
||||
如果你的发行版中没有提供 Trash-Cli 的安装包,那么你也可以使用 pip 来安装。为了能够安装 python 包,你的系统中应该会有 pip 包管理器。
|
||||
如果你的发行版中没有提供 Trash-Cli 的安装包,那么你也可以使用 `pip` 来安装。为了能够安装 python 包,你的系统中应该会有 `pip` 包管理器。
|
||||
|
||||
```
|
||||
$ sudo pip install trash-cli
|
||||
@ -66,7 +62,6 @@ Collecting trash-cli
|
||||
Installing collected packages: trash-cli
|
||||
Running setup.py bdist_wheel for trash-cli ... done
|
||||
Successfully installed trash-cli-0.17.1.14
|
||||
|
||||
```
|
||||
|
||||
### 如何使用 Trash-Cli
|
||||
@ -81,7 +76,7 @@ Trash-Cli 的使用不难,因为它提供了一个很简单的语法。Trash-C
|
||||
|
||||
下面,让我们通过一些例子来试验一下。
|
||||
|
||||
1)删除文件和目录:在这个例子中,我们通过运行下面这个命令,将 2g.txt 这一文件和 magi 这一文件夹移动到回收站中。
|
||||
1) 删除文件和目录:在这个例子中,我们通过运行下面这个命令,将 `2g.txt` 这一文件和 `magi` 这一文件夹移动到回收站中。
|
||||
|
||||
```
|
||||
$ trash-put 2g.txt magi
|
||||
@ -89,7 +84,7 @@ $ trash-put 2g.txt magi
|
||||
|
||||
和你在文件管理器中看到的一样。
|
||||
|
||||
2)列出被删除了的文件和目录:为了查看被删除了的文件和目录,你需要运行下面这个命令。之后,你可以在输出中看到被删除文件和目录的详细信息,比如名字、删除日期和时间,以及文件路径。
|
||||
2) 列出被删除了的文件和目录:为了查看被删除了的文件和目录,你需要运行下面这个命令。之后,你可以在输出中看到被删除文件和目录的详细信息,比如名字、删除日期和时间,以及文件路径。
|
||||
|
||||
```
|
||||
$ trash-list
|
||||
@ -97,7 +92,7 @@ $ trash-list
|
||||
2017-10-01 01:40:50 /home/magi/magi/magi
|
||||
```
|
||||
|
||||
3)从回收站中恢复文件或目录:任何时候,你都可以通过运行下面这个命令来恢复文件和目录。它将会询问你来选择你想要恢复的文件或目录。在这个例子中,我打算恢复 2g.txt 文件,所以我的选择是 0 。
|
||||
3) 从回收站中恢复文件或目录:任何时候,你都可以通过运行下面这个命令来恢复文件和目录。它将会询问你来选择你想要恢复的文件或目录。在这个例子中,我打算恢复 `2g.txt` 文件,所以我的选择是 `0` 。
|
||||
|
||||
```
|
||||
$ trash-restore
|
||||
@ -106,7 +101,7 @@ $ trash-restore
|
||||
What file to restore [0..1]: 0
|
||||
```
|
||||
|
||||
4)从回收站中删除文件:如果你想删除回收站中的特定文件,那么可以运行下面这个命令。在这个例子中,我将删除 magi 目录。
|
||||
4) 从回收站中删除文件:如果你想删除回收站中的特定文件,那么可以运行下面这个命令。在这个例子中,我将删除 `magi` 目录。
|
||||
|
||||
```
|
||||
$ trash-rm magi
|
||||
@ -118,11 +113,10 @@ $ trash-rm magi
|
||||
$ trash-empty
|
||||
```
|
||||
|
||||
6)删除超过 X 天的垃圾文件:或者,你可以通过运行下面这个命令来删除回收站中超过 X 天的文件。在这个例子中,我将删除回收站中超过 10 天的项目。
|
||||
6)删除超过 X 天的垃圾文件:或者,你可以通过运行下面这个命令来删除回收站中超过 X 天的文件。在这个例子中,我将删除回收站中超过 `10` 天的项目。
|
||||
|
||||
```
|
||||
$ trash-empty 10
|
||||
|
||||
```
|
||||
|
||||
Trash-Cli 可以工作的很好,但是如果你想尝试它的一些替代品,那么你也可以试一试 [gvfs-trash][9] 和 [autotrash][10] 。
|
||||
@ -133,7 +127,7 @@ via: https://www.2daygeek.com/trash-cli-command-line-trashcan-linux-system/
|
||||
|
||||
作者:[2daygeek][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
132
published/201809/20171124 How do groups work on Linux.md
Normal file
132
published/201809/20171124 How do groups work on Linux.md
Normal file
@ -0,0 +1,132 @@
|
||||
“用户组”在 Linux 上到底是怎么工作的?
|
||||
========
|
||||
|
||||
嗨!就在上周,我还自认为对 Linux 上的用户和组的工作机制了如指掌。我认为它们的关系是这样的:
|
||||
|
||||
1. 每个进程都属于一个用户(比如用户 `julia`)
|
||||
2. 当这个进程试图读取一个被某个组所拥有的文件时, Linux 会
|
||||
a. 先检查用户`julia` 是否有权限访问文件。(LCTT 译注:此处应该是指检查文件的所有者是否就是 `julia`)
|
||||
b. 检查 `julia` 属于哪些组,并进一步检查在这些组里是否有某个组拥有这个文件或者有权限访问这个文件。
|
||||
3. 如果上述 a、b 任一为真(或者“其它”位设为有权限访问),那么这个进程就有权限访问这个文件。
|
||||
|
||||
比如说,如果一个进程被用户 `julia` 拥有并且 `julia` 在`awesome` 组,那么这个进程就能访问下面这个文件。
|
||||
|
||||
```
|
||||
r--r--r-- 1 root awesome 6872 Sep 24 11:09 file.txt
|
||||
```
|
||||
|
||||
然而上述的机制我并没有考虑得非常清楚,如果你硬要我阐述清楚,我会说进程可能会在**运行时**去检查 `/etc/group` 文件里是否有某些组拥有当前的用户。
|
||||
|
||||
### 然而这并不是 Linux 里“组”的工作机制
|
||||
|
||||
我在上个星期的工作中发现了一件有趣的事,事实证明我前面的理解错了,我对组的工作机制的描述并不准确。特别是 Linux **并不会**在进程每次试图访问一个文件时就去检查这个进程的用户属于哪些组。
|
||||
|
||||
我在读了《[Linux 编程接口][1]》这本书的第九章(“进程资格”)后才恍然大悟(这本书真是太棒了),这才是组真正的工作方式!我意识到之前我并没有真正理解用户和组是怎么工作的,我信心满满的尝试了下面的内容并且验证到底发生了什么,事实证明现在我的理解才是对的。
|
||||
|
||||
### 用户和组权限检查是怎么完成的
|
||||
|
||||
现在这些关键的知识在我看来非常简单! 这本书的第九章上来就告诉我如下事实:用户和组 ID 是**进程的属性**,它们是:
|
||||
|
||||
* 真实用户 ID 和组 ID;
|
||||
* 有效用户 ID 和组 ID;
|
||||
* 保存的 set-user-ID 和保存的 set-group-ID;
|
||||
* 文件系统用户 ID 和组 ID(特定于 Linux);
|
||||
* 补充的组 ID;
|
||||
|
||||
这说明 Linux **实际上**检查一个进程能否访问一个文件所做的组检查是这样的:
|
||||
|
||||
* 检查一个进程的组 ID 和补充组 ID(这些 ID 就在进程的属性里,**并不是**实时在 `/etc/group` 里查找这些 ID)
|
||||
* 检查要访问的文件的访问属性里的组设置
|
||||
* 确定进程对文件是否有权限访问(LCTT 译注:即文件的组是否是以上的组之一)
|
||||
|
||||
通常当访问控制的时候使用的是**有效**用户/组 ID,而不是**真实**用户/组 ID。技术上来说当访问一个文件时使用的是**文件系统**的 ID,它们通常和有效用户/组 ID 一样。(LCTT 译注:这句话针对 Linux 而言。)
|
||||
|
||||
### 将一个用户加入一个组并不会将一个已存在的进程(的用户)加入那个组
|
||||
|
||||
下面是一个有趣的例子:如果我创建了一个新的组:`panda` 组并且将我自己(`bork`)加入到这个组,然后运行 `groups` 来检查我是否在这个组里:结果是我(`bork`)竟然不在这个组?!
|
||||
|
||||
```
|
||||
bork@kiwi~> sudo addgroup panda
|
||||
Adding group `panda' (GID 1001) ...
|
||||
Done.
|
||||
bork@kiwi~> sudo adduser bork panda
|
||||
Adding user `bork' to group `panda' ...
|
||||
Adding user bork to group panda
|
||||
Done.
|
||||
bork@kiwi~> groups
|
||||
bork adm cdrom sudo dip plugdev lpadmin sambashare docker lxd
|
||||
|
||||
```
|
||||
|
||||
`panda` 并不在上面的组里!为了再次确定我们的发现,让我们建一个文件,这个文件被 `panda` 组拥有,看看我能否访问它。
|
||||
|
||||
```
|
||||
$ touch panda-file.txt
|
||||
$ sudo chown root:panda panda-file.txt
|
||||
$ sudo chmod 660 panda-file.txt
|
||||
$ cat panda-file.txt
|
||||
cat: panda-file.txt: Permission denied
|
||||
```
|
||||
|
||||
好吧,确定了,我(`bork`)无法访问 `panda-file.txt`。这一点都不让人吃惊,我的命令解释器并没有将 `panda` 组作为补充组 ID,运行 `adduser bork panda` 并不会改变这一点。
|
||||
|
||||
### 那进程一开始是怎么得到用户的组的呢?
|
||||
|
||||
这真是个非常令人困惑的问题,对吗?如果进程会将组的信息预置到进程的属性里面,进程在初始化的时候怎么取到组的呢?很明显你无法给你自己指定更多的组(否则就会和 Linux 访问控制的初衷相违背了……)
|
||||
|
||||
有一点还是很清楚的:一个新的进程是怎么从我的命令行解释器(`/bash/fish`)里被**执行**而得到它的组的。(新的)进程将拥有我的用户 ID(`bork`),并且进程属性里还有很多组 ID。从我的命令解释器里执行的所有进程是从这个命令解释器里 `fork()` 而来的,所以这个新进程得到了和命令解释器同样的组。
|
||||
|
||||
因此一定存在一个“第一个”进程来把你的组设置到进程属性里,而所有由此进程而衍生的进程将都设置这些组。而那个“第一个”进程就是你的<ruby>登录程序<rt>login shell</rt></ruby>,在我的笔记本电脑上,它是由 `login` 程序(`/bin/login`)实例化而来。登录程序以 root 身份运行,然后调用了一个 C 的库函数 —— `initgroups` 来设置你的进程的组(具体来说是通过读取 `/etc/group` 文件),因为登录程序是以 root 运行的,所以它能设置你的进程的组。
|
||||
|
||||
### 让我们再登录一次
|
||||
|
||||
好了!假如说我们正处于一个登录程序中,而我又想刷新我的进程的组设置,从我们前面所学到的进程是怎么初始化组 ID 的,我应该可以通过再次运行登录程序来刷新我的进程组并启动一个新的登录命令!
|
||||
|
||||
让我们试试下边的方法:
|
||||
|
||||
```
|
||||
$ sudo login bork
|
||||
$ groups
|
||||
bork adm cdrom sudo dip plugdev lpadmin sambashare docker lxd panda
|
||||
$ cat panda-file.txt # it works! I can access the file owned by `panda` now!
|
||||
```
|
||||
|
||||
当然,成功了!现在由登录程序衍生的程序的用户是组 `panda` 的一部分了!太棒了!这并不会影响我其他的已经在运行的登录程序(及其子进程),如果我真的希望“所有的”进程都能对 `panda` 组有访问权限。我必须完全的重启我的登录会话,这意味着我必须退出我的窗口管理器然后再重新登录。(LCTT 译注:即更新进程树的树根进程,这里是窗口管理器进程。)
|
||||
|
||||
### newgrp 命令
|
||||
|
||||
在 Twitter 上有人告诉我如果只是想启动一个刷新了组信息的命令解释器的话,你可以使用 `newgrp`(LCTT 译注:不启动新的命令解释器),如下:
|
||||
|
||||
```
|
||||
sudo addgroup panda
|
||||
sudo adduser bork panda
|
||||
newgrp panda # starts a new shell, and you don't have to be root to run it!
|
||||
```
|
||||
|
||||
你也可以用 `sg panda bash` 来完成同样的效果,这个命令能启动一个`bash` 登录程序,而这个程序就有 `panda` 组。
|
||||
|
||||
### seduid 将设置有效用户 ID
|
||||
|
||||
其实我一直对一个进程如何以 `setuid root` 的权限来运行意味着什么有点似是而非。现在我知道了,事实上所发生的是:`setuid` 设置了
|
||||
“有效用户 ID”! 如果我(`julia`)运行了一个 `setuid root` 的进程( 比如 `passwd`),那么进程的**真实**用户 ID 将为 `julia`,而**有效**用户 ID 将被设置为 `root`。
|
||||
|
||||
`passwd` 需要以 root 权限来运行,但是它能看到进程的真实用户 ID 是 `julia` ,是 `julia` 启动了这个进程,`passwd` 会阻止这个进程修改除了 `julia` 之外的用户密码。
|
||||
|
||||
### 就是这些了!
|
||||
|
||||
在《[Linux 编程接口][1]》这本书里有很多 Linux 上一些功能的罕见使用方法以及 Linux 上所有的事物到底是怎么运行的详细解释,这里我就不一一展开了。那本书棒极了,我上面所说的都在该书的第九章,这章在 1300 页的书里只占了 17 页。
|
||||
|
||||
我最爱这本书的一点是我只用读 17 页关于用户和组是怎么工作的内容,而这区区 17 页就能做到内容完备、详实有用。我不用读完所有的 1300 页书就能得到有用的东西,太棒了!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/11/20/groups/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
译者:[DavidChen](https://github.com/DavidChenLiang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/
|
||||
[1]:http://man7.org/tlpi/
|
||||
@ -1,29 +1,28 @@
|
||||
|
||||
我从编程面试中学到的
|
||||
============================================================
|
||||
|
||||
======
|
||||
|
||||

|
||||
聊聊白板编程面试
|
||||
|
||||
在2017年,我参加了[Grace Hopper Celebration][1]‘计算机行业中的女性’这一活动。这个活动是这类科技活动中最大的一个。共有17,000名女性IT工作者参加。
|
||||
*聊聊白板编程面试*
|
||||
|
||||
这个会议有个大型的配套招聘会,会上有招聘公司来面试会议参加者。有些人甚至现场拿到offer。我在现场晃荡了一下,注意到一些应聘者看上去非常紧张忧虑。我还隐隐听到应聘者之间的谈话,其中一些人谈到在面试中做的并不好。
|
||||
在 2017 年,我参加了 ‘计算机行业中的女性’ 的[Grace Hopper 庆祝活动][1]。这个活动是这类科技活动中最大的一个。共有 17,000 名女性IT工作者参加。
|
||||
|
||||
我走近我听到谈话的那群人并和她们聊了起来并给了一些面试上的小建议。我想我的建议还是比较偏基本的,如“(在面试时)一开始给出个能工作的解决方案也还说的过去”之类的,但是当她们听到我的一些其他的建议时还是颇为吃惊。
|
||||
这个会议有个大型的配套招聘会,会上有招聘公司来面试会议参加者。有些人甚至现场拿到 offer。我在现场晃荡了一下,注意到一些应聘者看上去非常紧张忧虑。我还隐隐听到应聘者之间的谈话,其中一些人谈到在面试中做的并不好。
|
||||
|
||||
为了能更多的帮到像她们一样的白面面试者,我收集了一些过去对我有用的小点子,这些小点子我已经发表在了[prodcast episode][2]上。它们也是这篇文章的主题。
|
||||
我走近我听到谈话的那群人并和她们聊了起来并给了一些面试上的小建议。我想我的建议还是比较偏基本的,如“(在面试时)一开始给出个能工作的解决方案也还说的过去”之类的,但是当她们听到我的一些其他的建议时还是颇为吃惊。
|
||||
|
||||
为了能更多的帮到像她们一样的小白面试者,我收集了一些过去对我有用的小点子,这些小点子我已经发表在了 [prodcast episode][2] 上。它们也是这篇文章的主题。
|
||||
|
||||
为了实习生职位和全职工作,我做过很多次的面试。当我还在大学主修计算机科学时,学校每个秋季学期都有招聘会,第一轮招聘会在校园里举行。(我在第一和最后一轮都搞砸过。)不过,每次面试后,我都会反思哪些方面我能做的更好,我还会和朋友们做模拟面试,这样我就能从他们那儿得到更多的面试反馈。
|
||||
|
||||
不管我们怎么样找工作: 工作中介,网络,或者学校招聘,他们的招聘流程中都会涉及到技术面试:
|
||||
不管我们怎么样找工作: 工作中介、网络,或者学校招聘,他们的招聘流程中都会涉及到技术面试:
|
||||
|
||||
近年来,我注意到了一些新的不同的面试形式出现了:
|
||||
|
||||
* 与招聘方的一位工程师结对编程
|
||||
* 网络在线测试及在线编码
|
||||
* 白板编程(LCTT译者注: 这种形式应该不新了)
|
||||
|
||||
* 白板编程(LCTT 译注: 这种形式应该不新了)
|
||||
|
||||
我将重点谈谈白板面试,这种形式我经历的最多。我有过很多次面试,有些挺不错的,有些被我搞砸了。
|
||||
|
||||
@ -31,7 +30,7 @@
|
||||
|
||||
首先,我想回顾一下我做的不好的地方。知错能改,善莫大焉。
|
||||
|
||||
当面试者提出一个要我解决的问题时, 我立即马上立刻开始在白板上写代码,_什么都不问。_
|
||||
当面试者提出一个要我解决的问题时, 我立即马上立刻开始在白板上写代码,_什么都不问。_
|
||||
|
||||
这里我犯了两个错误:
|
||||
|
||||
@ -41,7 +40,7 @@
|
||||
|
||||
#### 只会默默思考,不去记录想法或和面试官沟通
|
||||
|
||||
在面试中,很多时候我也会傻傻站在那思考,什么都不写。我和一个朋友模拟面试的时候,他告诉我因为他曾经和我一起工作过所以他知道我在思考,但是如果他是个陌生的面试官的话,他会觉得要么我正站在那冥思苦想,毫无头绪。不要急匆匆的直奔解题而去是很重要的。花点时间多想想各种解题的可能性。有时候面试官会乐意和你一起探索解题的步骤。不管怎样,这就是在一家公司开工作会议的的普遍方式,大家各抒己见,一起讨论如何解决问题。
|
||||
在面试中,很多时候我也会傻傻站在那思考,什么都不写。我和一个朋友模拟面试的时候,他告诉我因为他曾经和我一起工作过所以他知道我在思考,但是如果他是个陌生的面试官的话,他会觉得我正站在那冥思苦想,毫无头绪。不要急匆匆的直奔解题而去是很重要的。花点时间多想想各种解题的可能性。有时候面试官会乐意和你一起探索解题的步骤。不管怎样,这就是在一家公司开工作会议的的普遍方式,大家各抒己见,一起讨论如何解决问题。
|
||||
|
||||
### 想到一个解题方法
|
||||
|
||||
@ -50,30 +49,27 @@
|
||||
这是对我管用的步骤:
|
||||
|
||||
1. 头脑风暴
|
||||
|
||||
2. 写代码
|
||||
|
||||
3. 处理错误路径
|
||||
|
||||
4. 测试
|
||||
|
||||
#### 1\. 头脑风暴
|
||||
#### 1、 头脑风暴
|
||||
|
||||
对我来说,我会首先通过一些例子来视觉化我要解决的问题。比如说如果这个问题和数据结构中的树有关,我就会从树底层的空节点开始思考,如何处理一个节点的情况呢?两个节点呢?三个节点呢?这能帮助你从具体例子里抽象出你的解决方案。
|
||||
|
||||
在白板上先写下你的算法要做的事情列表。这样做,你往往能在开始写代码前就发现bug和缺陷(不过你可得掌握好时间)。我犯过的一个错误是我花了过多的时间在澄清问题和头脑风暴上,最后几乎没有留下时间给我写代码。你的面试官可能没有机会看你在白板上写下代码,这可太糟了。你可以带块手表,或者房间有钟的话,你也可以抬头看看时间。有些时候面试者会提醒你你已经得到了所有的信息(这时你就不要再问别的了),'我想我们已经把所有需要的信息都澄清了,让我们写代码实现吧'
|
||||
在白板上先写下你的算法要做的事情列表。这样做,你往往能在开始写代码前就发现 bug 和缺陷(不过你可得掌握好时间)。我犯过的一个错误是我花了过多的时间在澄清问题和头脑风暴上,最后几乎没有留下时间给我写代码。你的面试官可能没有机会看你在白板上写下代码,这可太糟了。你可以带块手表,或者房间有钟的话,你也可以抬头看看时间。有些时候面试者会提醒你你已经得到了所有的信息(这时你就不要再问别的了),“我想我们已经把所有需要的信息都澄清了,让我们写代码实现吧”。
|
||||
|
||||
#### 2\. 开始写代码,一气呵成
|
||||
#### 2、 开始写代码,一气呵成
|
||||
|
||||
如果你还没有得到问题的完美解决方法,从最原始的解法开始总的可以的。当你在向面试官解释最显而易见的解法时,你要想想怎么去完善它,并指明这种做法是最原始,未加优化的。(请熟悉算法中的O()的概念,这对面试非常有用。)在向面试者提交前请仔细检查你的解决方案两三遍。面试者有时会给你些提示, ‘还有更好的方法吗?’,这句话的意思是面试官提示你有更优化的解决方案。
|
||||
如果你还没有得到问题的完美解决方法,从最原始的解法开始总是可以的。当你在向面试官解释最显而易见的解法时,你要想想怎么去完善它,并指明这种做法是最原始的,未加优化的。(请熟悉算法中的 `O()` 的概念,这对面试非常有用。)在向面试者提交前请仔细检查你的解决方案两三遍。面试者有时会给你些提示, “还有更好的方法吗?”,这句话的意思是面试官提示你有更优化的解决方案。
|
||||
|
||||
#### 3\. 错误处理
|
||||
#### 3、 错误处理
|
||||
|
||||
当你在编码时,对你想做错误处理的代码行做个注释。当面试者说,'很好,这里你想到了错误处理。你想怎么处理呢?抛出异常还是返回错误码?',这将给你个机会去引出关于代码质量的一番讨论。当然,这种地方提出几个就够了。有时,面试者为了节省编码的时间,会告诉你可以假设外界输入的参数都已经通过了校验。不管怎样,你都要展现你对错误处理和编码质量的重要性的认识。
|
||||
当你在编码时,对你想做错误处理的代码行做个注释。当面试者说,“很好,这里你想到了错误处理。你想怎么处理呢?抛出异常还是返回错误码?”,这将给你个机会去引出关于代码质量的一番讨论。当然,这种地方提出几个就够了。有时,面试者为了节省编码的时间,会告诉你可以假设外界输入的参数都已经通过了校验。不管怎样,你都要展现你对错误处理和编码质量的重要性的认识。
|
||||
|
||||
#### 4\. 测试
|
||||
#### 4、 测试
|
||||
|
||||
在编码完成后,用你在前面头脑风暴中写的用例来在你脑子里“跑”一下你的代码,确定万无一失。例如你可以说,‘让我用前面写下的树的例子来跑一下我的代码,如果是一个节点是什么结果,如果是两个节点是什么结果。。。’
|
||||
在编码完成后,用你在前面头脑风暴中写的用例来在你脑子里“跑”一下你的代码,确定万无一失。例如你可以说,“让我用前面写下的树的例子来跑一下我的代码,如果是一个节点是什么结果,如果是两个节点是什么结果……”
|
||||
|
||||
在你结束之后,面试者有时会问你你将会怎么测试你的代码,你会涉及什么样的测试用例。我建议你用下面不同的分类来组织你的错误用例:
|
||||
|
||||
@ -83,7 +79,7 @@
|
||||
2. 错误用例
|
||||
3. 期望的正常用例
|
||||
|
||||
对于性能测试,要考虑极端数量下的情况。例如,如果问题是关于列表的,你可以说你将会使用一个非常大的列表以及的非常小的列表来测试。如果和数字有关,你将会测试系统中的最大整数和最小整数。我建议读一些有关软件测试的书来得到更多的知识。在这个领域我最喜欢的书是[How We Test Software at Microsoft][3]。
|
||||
对于性能测试,要考虑极端数量下的情况。例如,如果问题是关于列表的,你可以说你将会使用一个非常大的列表以及的非常小的列表来测试。如果和数字有关,你将会测试系统中的最大整数和最小整数。我建议读一些有关软件测试的书来得到更多的知识。在这个领域我最喜欢的书是 《[我们在微软如何测试软件][3]》。
|
||||
|
||||
对于错误用例,想一下什么是期望的错误情况并一一写下。
|
||||
|
||||
@ -91,50 +87,45 @@
|
||||
|
||||
### “你还有什么要问我的吗?”
|
||||
|
||||
面试最后总是会留几分钟给你问问题。我建议你在面试前写下你想问的问题。千万别说,‘我没什么问题了’,就算你觉得面试砸了或者你对这间公司不怎么感兴趣,你总有些东西可以问问。你甚至可以问面试者他最喜欢自己的工作什么,最讨厌自己的工作什么。或者你可以问问面试官的工作具体是什么,在用什么技术和实践。不要因为觉得自己在面试中做的不好而心灰意冷,不想问什么问题。
|
||||
面试最后总是会留几分钟给你问问题。我建议你在面试前写下你想问的问题。千万别说,“我没什么问题了”,就算你觉得面试砸了或者你对这间公司不怎么感兴趣,你总有些东西可以问问。你甚至可以问面试者他最喜欢自己的工作什么,最讨厌自己的工作什么。或者你可以问问面试官的工作具体是什么,在用什么技术和实践。不要因为觉得自己在面试中做的不好而心灰意冷,不想问什么问题。
|
||||
|
||||
### 申请一份工作
|
||||
|
||||
|
||||
关于找工作申请工作,有人曾经告诉我,你应该去找你真正有激情工作的地方。去找一家你喜欢的公司,或者你喜欢使用的产品,看看你能不能去那儿工作。
|
||||
关于找工作和申请工作,有人曾经告诉我,你应该去找你真正有激情工作的地方。去找一家你喜欢的公司,或者你喜欢使用的产品,看看你能不能去那儿工作。
|
||||
|
||||
我个人并不推荐你用上述的方法去找工作。你会排除很多很好的公司,特别是你是在找实习工作或者入门级的职位时。
|
||||
|
||||
你也可以集中在其他的一些目标上。如:我想从这个工作里得到哪方面的更多经验?这个工作是关于云计算?Web开发?或是人工智能?当在招聘会上与招聘公司沟通是,看看他们的工作单位有没有在这些领域的。你可能会在一家并非在你的想去公司列表上的公司(或非盈利机构)里找到你想找的职位。
|
||||
你也可以集中在其他的一些目标上。如:我想从这个工作里得到哪方面的更多经验?这个工作是关于云计算?Web 开发?或是人工智能?当在招聘会上与招聘公司沟通时,看看他们的工作单位有没有在这些领域的。你可能会在一家并非在你的想去公司列表上的公司(或非盈利机构)里找到你想找的职位。
|
||||
|
||||
#### 换组
|
||||
|
||||
在这家公司里的第一个组里呆了一年半以后,我觉得是时候去探索一下不同的东西了。我找到了一个我喜欢的组并进行了4轮面试。结果我搞砸了。
|
||||
|
||||
|
||||
我什么都没有准备,甚至都没在白板上练练手。我当时的逻辑是,如果我都已经在一家公司干了快2年了,我还需要练什么?我完全错了,我在接下去的白板面试中跌跌撞撞。我的板书写得太小,而且因为没有从最左上角开始写代码,我的代码大大超出了一个白板的空间,这些都导致了白板面试失败。
|
||||
在这家公司里的第一个组里呆了一年半以后,我觉得是时候去探索一下不同的东西了。我找到了一个我喜欢的组并进行了 4 轮面试。结果我搞砸了。
|
||||
|
||||
我什么都没有准备,甚至都没在白板上练练手。我当时的逻辑是,如果我都已经在一家公司干了快 2 年了,我还需要练什么?我完全错了,我在接下去的白板面试中跌跌撞撞。我的板书写得太小,而且因为没有从最左上角开始写代码,我的代码大大超出了一个白板的空间,这些都导致了白板面试失败。
|
||||
|
||||
我在面试前也没有刷过数据结构和算法题。如果我做了的话,我将会在面试中更有信心。就算你已经在一家公司担任了软件工程师,在你去另外一个组面试前,我强烈建议你在一块白板上演练一下如何写代码。
|
||||
|
||||
对于换项目组这件事,如果你是在公司内部换组的话,事先能同那个组的人非正式聊聊会很有帮助。对于这一点,我发现几乎每个人都很乐于和你一起吃个午饭。人一般都会在中午有空,约不到人或者别人正好有会议冲突的风险会很低。这是一种非正式的途径来了解你想去的组正在干什么,以及这个组成员个性是怎么样的。相信我,你能从一次午餐中得到很多信息,这可会对你的正式面试帮助不小。
|
||||
|
||||
对于换项目组这件事,如果你是在公司内部换组的话,事先能同那个组的人非正式聊聊会很有帮助。对于这一点,我发现几乎每个人都很乐于和你一起吃个午饭。人一般都会在中午有空,约不到人或者别人正好有会议冲突的风险会很低。这是一种非正式的途径来了解你想去的组正在干什么,以及这个组成员个性是怎么样的。相信我, 你能从一次午餐中得到很多信息,这可会对你的正式面试帮助不小。
|
||||
非常重要的一点是,你在面试一个特定的组时,就算你在面试中做的很好,因为文化不契合的原因,你也很可能拿不到 offer。这也是为什么我一开始就想去见见组里不同的人的原因(有时这也不太可能),我希望你不要被一次拒绝所击倒,请保持开放的心态,选择新的机会,并多多练习。
|
||||
|
||||
|
||||
非常重要的一点是,你在面试一个特定的组时,就算你在面试中做的很好,因为文化不契合的原因,你也很可能拿不到offer。这也是为什么我一开始就想去见见组里不同的人的原因(有时这也不太可能),我希望你不要被一次拒绝所击倒,请保持开放的心态,选择新的机会,并多多练习。
|
||||
|
||||
|
||||
以上内容来自["Programming interviews"][4] 章节,选自 [The Women in Tech Show: Technical Interviews with Prominent Women in Tech][5]
|
||||
以上内容选自 《[The Women in Tech Show: Technical Interviews with Prominent Women in Tech][5]》的 “[编程面试][4]”章节,
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
|
||||
微软研究院Software Engineer II, www.thewomenintechshow.com站长,所有观点都只代表本人意见。
|
||||
微软研究院 Software Engineer II, www.thewomenintechshow.com 站长,所有观点都只代表本人意见。
|
||||
|
||||
------------
|
||||
|
||||
via: https://medium.freecodecamp.org/what-i-learned-from-programming-interviews-29ba49c9b851
|
||||
|
||||
作者:[Edaena Salinas ][a]
|
||||
译者:DavidChenLiang (https://github.com/DavidChenLiang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
作者:[Edaena Salinas][a]
|
||||
译者:[DavidChenLiang](https://github.com/DavidChenLiang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,65 +1,58 @@
|
||||
你没听说过的 Go 语言惊人优点
|
||||
============================================================
|
||||
=========
|
||||
|
||||

|
||||
|
||||
来自 [https://github.com/ashleymcnamara/gophers][1] 的图稿
|
||||
*来自 [https://github.com/ashleymcnamara/gophers][1] 的图稿*
|
||||
|
||||
在这篇文章中,我将讨论为什么你需要尝试一下 Go,以及应该从哪里学起。
|
||||
在这篇文章中,我将讨论为什么你需要尝试一下 Go 语言,以及应该从哪里学起。
|
||||
|
||||
Golang 是可能是最近几年里你经常听人说起的编程语言。尽管它在 2009 年已经发布,但它最近才开始流行起来。
|
||||
Go 语言是可能是最近几年里你经常听人说起的编程语言。尽管它在 2009 年已经发布了,但它最近才开始流行起来。
|
||||
|
||||
|
||||
|
||||
根据 Google 趋势,Golang 语言非常流行。
|
||||
*根据 Google 趋势,Go 语言非常流行。*
|
||||
|
||||
这篇文章不会讨论一些你经常看到的 Golang 的主要特性。
|
||||
这篇文章不会讨论一些你经常看到的 Go 语言的主要特性。
|
||||
|
||||
相反,我想向您介绍一些相当小众但仍然很重要的功能。在您决定尝试Go后,您才会知道这些功能。
|
||||
相反,我想向您介绍一些相当小众但仍然很重要的功能。只有在您决定尝试 Go 语言后,您才会知道这些功能。
|
||||
|
||||
这些都是表面上没有体现出来的惊人特性,但它们可以为您节省数周或数月的工作量。而且这些特性还可以使软件开发更加愉快。
|
||||
|
||||
阅读本文不需要任何语言经验,所以不比担心 Golang 对你来说是新的事物。如果你想了解更多,可以看看我在底部列出的一些额外的链接,。
|
||||
阅读本文不需要任何语言经验,所以不必担心你还不了解 Go 语言。如果你想了解更多,可以看看我在底部列出的一些额外的链接。
|
||||
|
||||
我们将讨论以下主题:
|
||||
|
||||
* GoDoc
|
||||
|
||||
* 静态代码分析
|
||||
|
||||
* 内置的测试和分析框架
|
||||
|
||||
* 竞争条件检测
|
||||
|
||||
* 学习曲线
|
||||
|
||||
* 反射(Reflection)
|
||||
|
||||
* Opinionatedness(专制独裁的 Go)
|
||||
|
||||
* 反射
|
||||
* Opinionatedness
|
||||
* 文化
|
||||
|
||||
请注意,这个列表不遵循任何特定顺序来讨论。
|
||||
|
||||
### GoDoc
|
||||
|
||||
Golang 非常重视代码中的文档,简洁也是如此。
|
||||
Go 语言非常重视代码中的文档,所以也很简洁。
|
||||
|
||||
[GoDoc][4] 是一个静态代码分析工具,可以直接从代码中创建漂亮的文档页面。GoDoc 的一个显着特点是它不使用任何其他的语言,如 JavaDoc,PHPDoc 或 JSDoc 来注释代码中的结构,只需要用英语。
|
||||
[GoDoc][4] 是一个静态代码分析工具,可以直接从代码中创建漂亮的文档页面。GoDoc 的一个显著特点是它不使用任何其他的语言,如 JavaDoc、PHPDoc 或 JSDoc 来注释代码中的结构,只需要用英语。
|
||||
|
||||
它使用从代码中获取的尽可能多的信息来概述、构造和格式化文档。它有多而全的功能,比如:交叉引用,代码示例以及一个指向版本控制系统仓库的链接。
|
||||
它使用从代码中获取的尽可能多的信息来概述、构造和格式化文档。它有多而全的功能,比如:交叉引用、代码示例,并直接链接到你的版本控制系统仓库。
|
||||
|
||||
而你需要做的只有添加一些好的,像 `// MyFunc transforms Foo into Bar` 这样子的注释,而这些注释也会反映在的文档中。你甚至可以添加一些通过网络接口或者在本地可以实际运行的 [代码示例][5]。
|
||||
而你需要做的只有添加一些像 `// MyFunc transforms Foo into Bar` 这样子的老牌注释,而这些注释也会反映在的文档中。你甚至可以添加一些通过网络界面或者在本地可以实际运行的 [代码示例][5]。
|
||||
|
||||
GoDoc 是 Go 的唯一文档引擎,供整个社区使用。这意味着用 Go 编写的每个库或应用程序都具有相同的文档格式。从长远来看,它可以帮你在浏览这些文档时节省大量时间。
|
||||
GoDoc 是 Go 的唯一文档引擎,整个社区都在使用。这意味着用 Go 编写的每个库或应用程序都具有相同的文档格式。从长远来看,它可以帮你在浏览这些文档时节省大量时间。
|
||||
|
||||
例如,这是我最近一个小项目的 GoDoc 页面:[pullkee — GoDoc][6]。
|
||||
|
||||
### 静态代码分析
|
||||
|
||||
Go 严重依赖于静态代码分析。例子包括 godoc 文档,gofmt 代码格式化,golint 代码风格统一,等等。
|
||||
Go 严重依赖于静态代码分析。例如用于文档的 [godoc][7],用于代码格式化的 [gofmt][8],用于代码风格的 [golint][9],等等。
|
||||
|
||||
其中有很多甚至全部包含在类似 [gometalinter][10] 的项目中,这些将它们全部组合成一个实用程序。
|
||||
它们是如此之多,甚至有一个总揽了它们的项目 [gometalinter][10] ,将它们组合成了单一的实用程序。
|
||||
|
||||
这些工具通常作为独立的命令行应用程序实现,并可轻松与任何编码环境集成。
|
||||
|
||||
@ -67,21 +60,21 @@ Go 严重依赖于静态代码分析。例子包括 godoc 文档,gofmt 代码
|
||||
|
||||
创建自己的分析器非常简单,因为 Go 有专门的内置包来解析和加工 Go 源码。
|
||||
|
||||
你可以从这个链接中了解到更多相关内容: [GothamGo Kickoff Meetup: Go Static Analysis Tools by Alan Donovan][11].
|
||||
你可以从这个链接中了解到更多相关内容: [GothamGo Kickoff Meetup: Alan Donovan 的 Go 静态分析工具][11]。
|
||||
|
||||
### 内置的测试和分析框架
|
||||
|
||||
您是否曾尝试为一个从头开始的 Javascript 项目选择测试框架?如果是这样,你可能会明白经历这种分析瘫痪的斗争。您可能也意识到您没有使用其中 80% 的框架。
|
||||
您是否曾尝试为一个从头开始的 JavaScript 项目选择测试框架?如果是这样,你或许会理解经历这种<ruby>过度分析<rt>analysis paralysis</rt></ruby>的痛苦。您可能也意识到您没有使用其中 80% 的框架。
|
||||
|
||||
一旦您需要进行一些可靠的分析,问题就会重复出现。
|
||||
|
||||
Go 附带内置测试工具,旨在简化和提高效率。它为您提供了最简单的 API,并做出最小的假设。您可以将它用于不同类型的测试,分析,甚至可以提供可执行代码示例。
|
||||
Go 附带内置测试工具,旨在简化和提高效率。它为您提供了最简单的 API,并做出最小的假设。您可以将它用于不同类型的测试、分析,甚至可以提供可执行代码示例。
|
||||
|
||||
它可以开箱即用地生成持续集成友好的输出,而且它的用法很简单,只需运行 `go test`。当然,它还支持高级功能,如并行运行测试,跳过标记代码,以及其他更多功能。
|
||||
它可以开箱即用地生成便于持续集成的输出,而且它的用法很简单,只需运行 `go test`。当然,它还支持高级功能,如并行运行测试,跳过标记代码,以及其他更多功能。
|
||||
|
||||
### 竞争条件检测
|
||||
|
||||
您可能已经了解了 Goroutines,它们在 Go 中用于实现并发代码执行。如果你未曾了解过,[这里][12]有一个非常简短的解释。
|
||||
您可能已经听说了 Goroutine,它们在 Go 中用于实现并发代码执行。如果你未曾了解过,[这里][12]有一个非常简短的解释。
|
||||
|
||||
无论具体技术如何,复杂应用中的并发编程都不容易,部分原因在于竞争条件的可能性。
|
||||
|
||||
@ -93,13 +86,13 @@ Go 附带内置测试工具,旨在简化和提高效率。它为您提供了
|
||||
|
||||
### 学习曲线
|
||||
|
||||
您可以在一个晚上学习所有 Go 的语言功能。我是认真的。当然,还有标准库,以及不同,更具体领域的最佳实践。但是两个小时就足以让你自信地编写一个简单的 HTTP 服务器或命令行应用程序。
|
||||
您可以在一个晚上学习**所有**的 Go 语言功能。我是认真的。当然,还有标准库,以及不同的,更具体领域的最佳实践。但是两个小时就足以让你自信地编写一个简单的 HTTP 服务器或命令行应用程序。
|
||||
|
||||
Golang 拥有[出色的文档][14],大部分高级主题已经在博客上进行了介绍:[The Go Programming Language Blog][15]。
|
||||
Go 语言拥有[出色的文档][14],大部分高级主题已经在他们的博客上进行了介绍:[Go 编程语言博客][15]。
|
||||
|
||||
比起 Java(以及 Java 家族的语言),Javascript,Ruby,Python 甚至 PHP,你可以更轻松地把 Go 语言带到你的团队中。由于环境易于设置,您的团队在完成第一个生产代码之前需要进行的投资要小得多。
|
||||
比起 Java(以及 Java 家族的语言)、Javascript、Ruby、Python 甚至 PHP,你可以更轻松地把 Go 语言带到你的团队中。由于环境易于设置,您的团队在完成第一个生产代码之前需要进行的投资要小得多。
|
||||
|
||||
### 反射(Reflection)
|
||||
### 反射
|
||||
|
||||
代码反射本质上是一种隐藏在编译器下并访问有关语言结构的各种元信息的能力,例如变量或函数。
|
||||
|
||||
@ -107,19 +100,19 @@ Golang 拥有[出色的文档][14],大部分高级主题已经在博客上进
|
||||
|
||||
此外,Go [没有实现一个名为泛型的概念][16],这使得以抽象方式处理多种类型更具挑战性。然而,由于泛型带来的复杂程度,许多人认为不实现泛型对语言实际上是有益的。我完全同意。
|
||||
|
||||
根据 Go 的理念(这是一个单独的主题),您应该努力不要过度设计您的解决方案。这也适用于动态类型编程。尽可能坚持使用静态类型,并在确切知道要处理的类型时使用接口(interfaces)。接口在 Go 中非常强大且无处不在。
|
||||
根据 Go 的理念(这是一个单独的主题),您应该努力不要过度设计您的解决方案。这也适用于动态类型编程。尽可能坚持使用静态类型,并在确切知道要处理的类型时使用<ruby>接口<rt>interface</rt></ruby>。接口在 Go 中非常强大且无处不在。
|
||||
|
||||
但是,仍然存在一些情况,你无法知道你处理的数据类型。一个很好的例子是 JSON。您可以在应用程序中来回转换所有类型的数据。字符串,缓冲区,各种数字,嵌套结构等。
|
||||
但是,仍然存在一些情况,你无法知道你处理的数据类型。一个很好的例子是 JSON。您可以在应用程序中来回转换所有类型的数据。字符串、缓冲区、各种数字、嵌套结构等。
|
||||
|
||||
为了解决这个问题,您需要一个工具来检查运行时的数据并根据其类型和结构采取不同行为。反射(Reflect)可以帮到你。Go 拥有一流的反射包,使您的代码能够像 Javascript 这样的语言一样动态。
|
||||
为了解决这个问题,您需要一个工具来检查运行时的数据并根据其类型和结构采取不同行为。<ruby>反射<rt>Reflect</rt></ruby>可以帮到你。Go 拥有一流的反射包,使您的代码能够像 Javascript 这样的语言一样动态。
|
||||
|
||||
一个重要的警告是知道你使用它所带来的代价 - 并且只有知道在没有更简单的方法时才使用它。
|
||||
一个重要的警告是知道你使用它所带来的代价 —— 并且只有知道在没有更简单的方法时才使用它。
|
||||
|
||||
你可以在这里阅读更多相关信息: [反射的法则 — Go 博客][18].
|
||||
|
||||
您还可以在此处阅读 JSON 包源码中的一些实际代码: [src/encoding/json/encode.go — Source Code][19]
|
||||
|
||||
### Opinionatedness
|
||||
### Opinionatedness(专制独裁的 Go)
|
||||
|
||||
顺便问一下,有这样一个单词吗?
|
||||
|
||||
@ -127,9 +120,9 @@ Golang 拥有[出色的文档][14],大部分高级主题已经在博客上进
|
||||
|
||||
这有时候基本上让我卡住了。我需要花时间思考这些事情而不是编写代码并满足用户。
|
||||
|
||||
首先,我应该注意到我完全可以得到这些惯例的来源,它总是来源于你或者你的团队。无论如何,即使是一群经验丰富的 Javascript 开发人员也可以轻松地发现自己拥有完全不同的工具和范例的大部分经验,以实现相同的结果。
|
||||
首先,我应该注意到我完全知道这些惯例的来源,它总是来源于你或者你的团队。无论如何,即使是一群经验丰富的 Javascript 开发人员也很容易发现他们在实现相同的结果时,而大部分的经验却是在完全不同的工具和范例上。
|
||||
|
||||
这导致整个团队中分析的瘫痪,并且使得个体之间更难以相互协作。
|
||||
这导致整个团队中出现过度分析,并且使得个体之间更难以相互协作。
|
||||
|
||||
嗯,Go 是不同的。即使您对如何构建和维护代码有很多强烈的意见,例如:如何命名,要遵循哪些结构模式,如何更好地实现并发。但你只有一个每个人都遵循的风格指南。你只有一个内置在基本工具链中的测试框架。
|
||||
|
||||
@ -141,11 +134,11 @@ Golang 拥有[出色的文档][14],大部分高级主题已经在博客上进
|
||||
|
||||
人们说,每当你学习一门新的口语时,你也会沉浸在说这种语言的人的某些文化中。因此,您学习的语言越多,您可能会有更多的变化。
|
||||
|
||||
编程语言也是如此。无论您将来如何应用新的编程语言,它总能给的带来新的编程视角或某些特别的技术。
|
||||
编程语言也是如此。无论您将来如何应用新的编程语言,它总能给你带来新的编程视角或某些特别的技术。
|
||||
|
||||
无论是函数式编程,模式匹配(pattern matching)还是原型继承(prototypal inheritance)。一旦你学会了它们,你就可以随身携带这些编程思想,这扩展了你作为软件开发人员所拥有的问题解决工具集。它们也改变了你阅读高质量代码的方式。
|
||||
无论是函数式编程,<ruby>模式匹配<rt>pattern matching</rt></ruby>还是<ruby>原型继承<rt>prototypal inheritance</rt></ruby>。一旦你学会了它们,你就可以随身携带这些编程思想,这扩展了你作为软件开发人员所拥有的问题解决工具集。它们也改变了你阅读高质量代码的方式。
|
||||
|
||||
而 Go 在方面有一项了不起的财富。Go 文化的主要支柱是保持简单,脚踏实地的代码,而不会产生许多冗余的抽象概念,并将可维护性放在首位。大部分时间花费在代码的编写工作上,而不是在修补工具和环境或者选择不同的实现方式上,这也是 Go文化的一部分。
|
||||
而 Go 在这方面有一项了不起的财富。Go 文化的主要支柱是保持简单,脚踏实地的代码,而不会产生许多冗余的抽象概念,并将可维护性放在首位。大部分时间花费在代码的编写工作上,而不是在修补工具和环境或者选择不同的实现方式上,这也是 Go 文化的一部分。
|
||||
|
||||
Go 文化也可以总结为:“应当只用一种方法去做一件事”。
|
||||
|
||||
@ -161,12 +154,11 @@ Go 文化也可以总结为:“应当只用一种方法去做一件事”。
|
||||
|
||||
这不是 Go 的所有惊人的优点的完整列表,只是一些被人低估的特性。
|
||||
|
||||
请尝试一下从 [Go 之旅(A Tour of Go)][20]来开始学习 Go,这将是一个令人惊叹的开始。
|
||||
请尝试一下从 [Go 之旅][20] 来开始学习 Go,这将是一个令人惊叹的开始。
|
||||
|
||||
如果您想了解有关 Go 的优点的更多信息,可以查看以下链接:
|
||||
|
||||
* [你为什么要学习 Go? - Keval Patel][2]
|
||||
|
||||
* [告别Node.js - TJ Holowaychuk][3]
|
||||
|
||||
并在评论中分享您的阅读感悟!
|
||||
@ -175,30 +167,16 @@ Go 文化也可以总结为:“应当只用一种方法去做一件事”。
|
||||
|
||||
不断为您的工作寻找最好的工具!
|
||||
|
||||
* * *
|
||||
|
||||
If you like this article, please consider following me for more, and clicking on those funny green little hands right below this text for sharing. 👏👏👏
|
||||
|
||||
Check out my [Github][21] and follow me on [Twitter][22]!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Software Engineer and Traveler. Coding for fun. Javascript enthusiast. Tinkering with Golang. A lot into SOA and Docker. Architect at Velvica.
|
||||
|
||||
------------
|
||||
|
||||
|
||||
-------------------------------------------------------
|
||||
via: https://medium.freecodecamp.org/here-are-some-amazing-advantages-of-go-that-you-dont-hear-much-about-1af99de3b23a
|
||||
|
||||
作者:[Kirill Rogovoy][a]
|
||||
译者:[译者ID](https://github.com/imquanquan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[imquanquan](https://github.com/imquanquan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[a]:https://twitter.com/krogovoy
|
||||
[1]:https://github.com/ashleymcnamara/gophers
|
||||
[2]:https://medium.com/@kevalpatel2106/why-should-you-learn-go-f607681fad65
|
||||
[3]:https://medium.com/@tjholowaychuk/farewell-node-js-4ba9e7f3e52b
|
||||
89
published/201809/20180308 What is open source programming.md
Normal file
89
published/201809/20180308 What is open source programming.md
Normal file
@ -0,0 +1,89 @@
|
||||
何谓开源编程?
|
||||
======
|
||||
|
||||
> 开源就是丢一些代码到 GitHub 上。了解一下它是什么,以及不是什么?
|
||||
|
||||

|
||||
|
||||
最简单的来说,开源编程就是编写一些大家可以随意取用、修改的代码。但你肯定听过关于 Go 语言的那个老笑话,说 Go 语言“简单到看一眼就可以明白规则,但需要一辈子去学会运用它”。其实写开源代码也是这样的。往 GitHub、Bitbucket、SourceForge 等网站或者是你自己的博客或网站上丢几行代码不是难事,但想要卓有成效,还需要个人的努力付出和高瞻远瞩。
|
||||
|
||||

|
||||
|
||||
### 我们对开源编程的误解
|
||||
|
||||
首先我要说清楚一点:把你的代码放在 GitHub 的公开仓库中并不意味着把你的代码开源了。在几乎全世界,根本不用创作者做什么,只要作品形成,版权就随之而生了。在创作者进行授权之前,只有作者可以行使版权相关的权力。未经创作者授权的代码,不论有多少人在使用,都是一颗定时炸弹,只有愚蠢的人才会去用它。
|
||||
|
||||
有些创作者很善良,认为“很明显我的代码是免费提供给大家使用的。”,他也并不想起诉那些用了他的代码的人,但这并不意味着这些代码可以放心使用。不论在你眼中创作者们多么善良,他们都 *有权力* 起诉任何使用、修改代码,或未经明确授权就将代码嵌入的人。
|
||||
|
||||
很明显,你不应该在没有指定开源许可证的情况下将你的源代码发布到网上然后期望别人使用它并为其做出贡献。我建议你也尽量避免使用这种代码,甚至疑似未授权的也不要使用。如果你开发了一个函数和例程,它和之前一个疑似未授权代码很像,源代码作者就可以对你就侵权提起诉讼。
|
||||
|
||||
举个例子,Jill Schmill 写了 AwesomeLib 然后未明确授权就把它放到了 GitHub 上,就算 Jill Schmill 不起诉任何人,只要她把 AwesomeLib 的完整版权都卖给 EvilCorp,EvilCorp 就会起诉之前违规使用这段代码的人。这种行为就好像是埋下了计算机安全隐患,总有一天会为人所用。
|
||||
|
||||
没有许可证的代码的危险的,切记。
|
||||
|
||||
### 选择恰当的开源许可证
|
||||
|
||||
假设你正要写一个新程序,而且打算让人们以开源的方式使用它,你需要做的就是选择最贴合你需求的[许可证][1]。和宣传中说的一样,你可以从 GitHub 所支持的 [choosealicense.com][2] 开始。这个网站设计得像个简单的问卷,特别方便快捷,点几下就能找到合适的许可证。
|
||||
|
||||
警示:在选择许可证时不要过于自负,如果你选的是 [Apache 许可证][3]或者 [GPLv3][4] 这种广为使用的许可证,人们很容易理解他们和你都有什么权利,你也不需要请律师来排查其中的漏洞。你选择的许可证使用的人越少,带来的麻烦就越多。
|
||||
|
||||
最重要的一点是: *千万不要试图自己制造许可证!* 自己制造许可证会给大家带来更多的困惑和困扰,不要这样做。如果在现有的许可证中确实找不到你需要的条款,你可以在现有的许可证中附加上你的要求,并且重点标注出来,提醒使用者们注意。
|
||||
|
||||
我知道有些人会站出来说:“我才懒得管什么许可证,我已经把代码发到<ruby>公开领域<rt>public domain</rt></ruby>了。”但问题是,公开领域的法律效力并不是受全世界认可的。在不同的国家,公开领域的效力和表现形式不同。在有些国家的政府管控下,你甚至不可以把自己的源代码发到公开领域。万幸,[Unlicense][5] 可以弥补这些漏洞,它语言简洁,使用几个词清楚地描述了“就把它放到公开领域”,但其效力为全世界认可。
|
||||
|
||||
### 怎样引入许可证
|
||||
|
||||
确定使用哪个许可证之后,你需要清晰而无疑义地指定它。如果你是在 GitHub、GitLab 或 BitBucket 这几个网站发布,你需要构建很多个文件夹,在根文件夹中,你应把许可证创建为一个以 `LICENSE.txt` 命名的明文文件。
|
||||
|
||||
创建 `LICENSE.txt` 这个文件之后还有其它事要做。你需要在每个重要文件的头部添加注释块来申明许可证。如果你使用的是一个现有的许可证,这一步对你来说十分简便。一个 `# 项目名 (c)2018 作者名,GPLv3 许可证,详情见 https://www.gnu.org/licenses/gpl-3.0.en.html` 这样的注释块比隐约指代的许可证的效力要强得多。
|
||||
|
||||
如果你是要发布在自己的网站上,步骤也差不多。先创建 `LICENSE.txt` 文件,放入许可证,再表明许可证出处。
|
||||
|
||||
### 开源代码的不同之处
|
||||
|
||||
开源代码和专有代码的一个主要区别是开源代码写出来就是为了给别人看的。我是个 40 多岁的系统管理员,已经写过许许多多的代码。最开始我写代码是为了工作,为了解决公司的问题,所以其中大部分代码都是专有代码。这种代码的目的很简单,只要能在特定场合通过特定方式发挥作用就行。
|
||||
|
||||
开源代码则大不相同。在写开源代码时,你知道它可能会被用于各种各样的环境中。也许你的用例的环境条件很局限,但你仍旧希望它能在各种环境下发挥理想的效果。不同的人使用这些代码时会出现各种用例,你会看到各类冲突,还有你没有考虑过的思路。虽然代码不一定要满足所有人,但至少应该得体地处理他们遇到的问题,就算解决不了,也可以转换回常见的逻辑,不会给使用者添麻烦。(例如“第 583 行出现零除错误”就不能作为错误地提供命令行参数的响应结果)
|
||||
|
||||
你的源代码也可能逼疯你,尤其是在你一遍又一遍地修改错误的函数或是子过程后,终于出现了你希望的结果,这时你不会叹口气就继续下一个任务,你会把过程清理干净,因为你不会愿意别人看出你一遍遍尝试的痕迹。比如你会把 `$variable`、`$lol` 全都换成有意义的 `$iterationcounter` 和 `$modelname`。这意味着你要认真专业地进行注释(尽管对于你所处的背景知识热度来说它并不难懂),因为你期望有更多的人可以使用你的代码。
|
||||
|
||||
这个过程难免有些痛苦沮丧,毕竟这不是你常做的事,会有些不习惯。但它会使你成为一位更好的程序员,也会让你的代码升华。即使你的项目只有你一位贡献者,清理代码也会节约你后期的很多工作,相信我一年后你再看你的 app 代码时,你会庆幸自己写下的是 `$modelname`,还有清晰的注释,而不是什么不知名的数列,甚至连 `$lol` 也不是。
|
||||
|
||||
### 你并不是为你一人而写
|
||||
|
||||
开源的真正核心并不是那些代码,而是社区。更大的社区的项目维持时间更长,也更容易为人们所接受。因此不仅要加入社区,还要多多为社区发展贡献思路,让自己的项目能够为社区所用。
|
||||
|
||||
蝙蝠侠为了完成目标暗中独自花了很大功夫,你用不着这样,你可以登录 Twitter、Reddit,或者给你项目的相关人士发邮件,发布你正在筹备新项目的消息,仔细聊聊项目的设计初衷和你的计划,让大家一起帮忙,向大家征集数据输入,类似的使用案例,把这些信息整合起来,用在你的代码里。你不用接受所有的建议和请求,但你要对它有个大概把握,这样在你之后完善时可以躲过一些陷阱。
|
||||
|
||||
发布了首次通告这个过程还不算完整。如果你希望大家能够接受你的作品并且使用它,你就要以此为初衷来设计。公众说不定可以帮到你,你不必对公开这件事如临大敌。所以不要闭门造车,既然你是为大家而写,那就开设一个真实、公开的项目,想象你在社区的帮助和监督下,认真地一步步完成它。
|
||||
|
||||
### 建立项目的方式
|
||||
|
||||
你可以在 GitHub、GitLab 或 BitBucket 上免费注册账号来管理你的项目。注册之后,创建知识库,建立 `README` 文件,分配一个许可证,一步步写入代码。这样可以帮你建立好习惯,让你之后和现实中的团队一起工作时,也能目的清晰地朝着目标稳妥地开展工作。这样你做得越久,就越有兴趣 —— 通常会有用户先对你的项目产生兴趣。
|
||||
|
||||
用户会开始提一些问题,这会让你开心也会让你不爽,你应该亲切礼貌地对待他们,就算他们很多人对项目有很多误解甚至根本不知道你的项目做的是什么,你也应该礼貌专业地对待。一方面,你可以引导他们,让他们了解你在干什么。另一方面,他们也会慢慢地将你带入更大的社区。
|
||||
|
||||
如果你的项目很受用户青睐,总会有高级开发者出现,并表示出兴趣。这也许是好事,也可能激怒你。最开始你可能只会做简单的问题修复,但总有一天你会收到拉取请求,有可能是硬编码或特殊用例(可能会让项目变得难以维护),它可能改变你项目的作用域,甚至改变你项目的初衷。你需要学会分辨哪个有贡献,根据这个决定合并哪个,婉拒哪个。
|
||||
|
||||
### 我们为什么要开源?
|
||||
|
||||
开源听起来任务繁重,它也确实是这样。但它对你也有很多好处。它可以在无形之中磨练你,让你写出纯净持久的代码,也教会你与人沟通,团队协作。对于一个志向远大的专业开发者来说,它是最好的简历素材。你的未来雇主很有可能点开你的仓库,了解你的能力范围;而社区项目的开发者也有可能给你带来工作。
|
||||
|
||||
最后,为开源工作,意味着个人的提升,因为你在做的事不是为了你一个人,这比养活自己重要得多。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/what-open-source-programming
|
||||
|
||||
作者:[Jim Salter][a]
|
||||
译者:[Valoniakim](https://github.com/Valoniakim)
|
||||
校对:[wxy](https://github.com/wxy)、[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jim-salter
|
||||
[1]: https://opensource.com/tags/licensing
|
||||
[2]: https://choosealicense.com/
|
||||
[3]: https://choosealicense.com/licenses/apache-2.0/
|
||||
[4]: https://choosealicense.com/licenses/gpl-3.0/
|
||||
[5]: https://choosealicense.com/licenses/unlicense/
|
||||
@ -0,0 +1,155 @@
|
||||
用 Hugo 30 分钟搭建静态博客
|
||||
======
|
||||
> 了解 Hugo 如何使构建网站变得有趣。
|
||||
|
||||

|
||||
|
||||
你是不是强烈地想搭建博客来将自己对软件框架等的探索学习成果分享呢?你是不是面对缺乏指导文档而一团糟的项目就有一种想去改变它的冲动呢?或者换个角度,你是不是十分期待能创建一个属于自己的个人博客网站呢?
|
||||
|
||||
很多人在想搭建博客之前都有一些严重的迟疑顾虑:感觉自己缺乏内容管理系统(CMS)的相关知识,更缺乏时间去学习这些知识。现在,如果我说不用花费大把的时间去学习 CMS 系统、学习如何创建一个静态网站、更不用操心如何去强化网站以防止它受到黑客攻击的问题,你就可以在 30 分钟之内创建一个博客?你信不信?利用 Hugo 工具,就可以实现这一切。
|
||||
|
||||
|
||||
|
||||
Hugo 是一个基于 Go 语言开发的静态站点生成工具。也许你会问,为什么选择它?
|
||||
|
||||
* 无需数据库、无需需要各种权限的插件、无需跑在服务器上的底层平台,更没有额外的安全问题。
|
||||
* 都是静态站点,因此拥有轻量级、快速响应的服务性能。此外,所有的网页都是在部署的时候生成,所以服务器负载很小。
|
||||
* 极易操作的版本控制。一些 CMS 平台使用它们自己的版本控制软件(VCS)或者在网页上集成 Git 工具。而 Hugo,所有的源文件都可以用你所选的 VCS 软件来管理。
|
||||
|
||||
### 0-5 分钟:下载 Hugo,生成一个网站
|
||||
|
||||
直白的说,Hugo 使得写一个网站又一次变得有趣起来。让我们来个 30 分钟计时,搭建一个网站。
|
||||
|
||||
为了简化 Hugo 安装流程,这里直接使用 Hugo 可执行安装文件。
|
||||
|
||||
1. 下载和你操作系统匹配的 Hugo [版本][2];
|
||||
2. 压缩包解压到指定路径,例如 windows 系统的 `C:\hugo_dir` 或者 Linux 系统的 `~/hugo_dir` 目录;下文中的变量 `${HUGO_HOME}` 所指的路径就是这个安装目录;
|
||||
3. 打开命令行终端,进入安装目录:`cd ${HUGO_HOME}`;
|
||||
4. 确认 Hugo 已经启动:
|
||||
* Unix 系统:`${HUGO_HOME}/[hugo version]`;
|
||||
* Windows 系统:`${HUGO_HOME}\[hugo.exe version]`,例如:cmd 命令行中输入:`c:\hugo_dir\hugo version`。
|
||||
|
||||
为了书写上的简化,下文中的 `hugo` 就是指 hugo 可执行文件所在的路径(包括可执行文件),例如命令 `hugo version` 就是指命令 `c:\hugo_dir\hugo version` 。(LCTT 译注:可以把 hugo 可执行文件所在的路径添加到系统环境变量下,这样就可以直接在终端中输入 `hugo version`)
|
||||
|
||||
如果命令 `hugo version` 报错,你可能下载了错误的版本。当然,有很多种方法安装 Hugo,更多详细信息请查阅 [官方文档][3]。最稳妥的方法就是把 Hugo 可执行文件放在某个路径下,然后执行的时候带上路径名
|
||||
5. 创建一个新的站点来作为你的博客,输入命令:`hugo new site awesome-blog`;
|
||||
6. 进入新创建的路径下: `cd awesome-blog`;
|
||||
|
||||
恭喜你!你已经创建了自己的新博客。
|
||||
|
||||
### 5-10 分钟:为博客设置主题
|
||||
|
||||
Hugo 中你可以自己构建博客的主题或者使用网上已经有的一些主题。这里选择 [Kiera][4] 主题,因为它简洁漂亮。按以下步骤来安装该主题:
|
||||
|
||||
1. 进入主题所在目录:`cd themes`;
|
||||
2. 克隆主题:`git clone https://github.com/avianto/hugo-kiera kiera`。如果你没有安装 Git 工具:
|
||||
* 从 [Github][5] 上下载 hugo 的 .zip 格式的文件;
|
||||
* 解压该 .zip 文件到你的博客主题 `theme` 路径;
|
||||
* 重命名 `hugo-kiera-master` 为 `kiera`;
|
||||
3. 返回博客主路径:`cd awesome-blog`;
|
||||
4. 激活主题;通常来说,主题(包括 Kiera)都自带文件夹 `exampleSite`,里面存放了内容配置的示例文件。激活 Kiera 主题需要拷贝它提供的 `config.toml` 到你的博客下:
|
||||
* Unix 系统:`cp themes/kiera/exampleSite/config.toml .`;
|
||||
* Windows 系统:`copy themes\kiera\exampleSite\config.toml .`;
|
||||
* 选择 `Yes` 来覆盖原有的 `config.toml`;
|
||||
|
||||
5. ( 可选操作 )你可以选择可视化的方式启动服务器来验证主题是否生效:`hugo server -D` 然后在浏览器中输入 `http://localhost:1313`。可用通过在终端中输入 `Crtl+C` 来停止服务器运行。现在你的博客还是空的,但这也给你留了写作的空间。它看起来如下所示:
|
||||
|
||||
|
||||
|
||||
你已经成功的给博客设置了主题!你可以在官方 [Hugo 主题][4] 网站上找到上百种漂亮的主题供你使用。
|
||||
|
||||
### 10-20 分钟:给博客添加内容
|
||||
|
||||
对于碗来说,它是空的时候用处最大,可以用来盛放东西;但对于博客来说不是这样,空博客几乎毫无用处。在这一步,你将会给博客添加内容。Hugo 和 Kiera 主题都为这个工作提供了方便性。按以下步骤来进行你的第一次提交:
|
||||
|
||||
1. archetypes 将会是你的内容模板。
|
||||
2. 添加主题中的 archtypes 至你的博客:
|
||||
* Unix 系统: `cp themes/kiera/archetypes/* archetypes/`
|
||||
* Windows 系统:`copy themes\kiera\archetypes\* archetypes\`
|
||||
* 选择 `Yes` 来覆盖原来的 `default.md` 内容架构类型
|
||||
|
||||
3. 创建博客 posts 目录:
|
||||
* Unix 系统: `mkdir content/posts`
|
||||
* Windows 系统: `mkdir content\posts`
|
||||
|
||||
4. 利用 Hugo 生成你的 post:
|
||||
* Unix 系统:`hugo nes posts/first-post.md`;
|
||||
* Windows 系统:`hugo new posts\first-post.md`;
|
||||
|
||||
5. 在文本编辑器中打开这个新建的 post 文件:
|
||||
* Unix 系统:`gedit content/posts/first-post.md`;
|
||||
* Windows 系统:`notepadd content\posts\first-post.md`;
|
||||
|
||||
此刻,你可以疯狂起来了。注意到你的提交文件中包括两个部分。第一部分是以 `+++` 符号分隔开的。它包括了提交文档的主要数据,例如名称、时间等。在 Hugo 中,这叫做前缀。在前缀之后,才是正文。下面编辑第一个提交文件内容:
|
||||
|
||||
```
|
||||
+++
|
||||
title = "First Post"
|
||||
date = 2018-03-03T13:23:10+01:00
|
||||
draft = false
|
||||
tags = ["Getting started"]
|
||||
categories = []
|
||||
+++
|
||||
|
||||
Hello Hugo world! No more excuses for having no blog or documentation now!
|
||||
```
|
||||
|
||||
现在你要做的就是启动你的服务器:`hugo server -D`;然后打开浏览器,输入 `http://localhost:1313/`。
|
||||
|
||||

|
||||
|
||||
### 20-30 分钟:调整网站
|
||||
|
||||
前面的工作很完美,但还有一些问题需要解决。例如,简单地命名你的站点:
|
||||
|
||||
1. 终端中按下 `Ctrl+C` 以停止服务器。
|
||||
2. 打开 `config.toml`,编辑博客的名称,版权,你的姓名,社交网站等等。
|
||||
|
||||
当你再次启动服务器后,你会发现博客私人订制味道更浓了。不过,还少一个重要的基础内容:主菜单。快速的解决这个问题。返回 `config.toml` 文件,在末尾插入如下一段:
|
||||
|
||||
```
|
||||
[[menu.main]]
|
||||
name = "Home" #Name in the navigation bar
|
||||
weight = 10 #The larger the weight, the more on the right this item will be
|
||||
url = "/" #URL address
|
||||
[[menu.main]]
|
||||
name = "Posts"
|
||||
weight = 20
|
||||
url = "/posts/"
|
||||
```
|
||||
|
||||
上面这段代码添加了 `Home` 和 `Posts` 到主菜单中。你还需要一个 `About` 页面。这次是创建一个 `.md` 文件,而不是编辑 `config.toml` 文件:
|
||||
|
||||
1. 创建 `about.md` 文件:`hugo new about.md` 。注意它是 `about.md`,不是 `posts/about.md`。该页面不是博客提交内容,所以你不想它显示到博客内容提交当中吧。
|
||||
2. 用文本编辑器打开该文件,输入如下一段:
|
||||
|
||||
```
|
||||
+++
|
||||
title = "About"
|
||||
date = 2018-03-03T13:50:49+01:00
|
||||
menu = "main" #Display this page on the nav menu
|
||||
weight = "30" #Right-most nav item
|
||||
meta = "false" #Do not display tags or categories
|
||||
+++
|
||||
|
||||
> Waves are the practice of the water. Shunryu Suzuki
|
||||
```
|
||||
|
||||
当你启动你的服务器并输入:`http://localhost:1313/`,你将会看到你的博客。(访问我 Gihub 主页上的 [例子][6] )如果你想让文章的菜单栏和 Github 相似,给 `themes/kiera/static/css/styles.css` 打上这个 [补丁][7]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/start-blog-30-minutes-hugo
|
||||
|
||||
作者:[Marek Czernek][a]
译者:[jrg](https://github.com/jrglinux)
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mczernek
|
||||
[1]:https://gohugo.io/
|
||||
[2]:https://github.com/gohugoio/hugo/releases
|
||||
[3]:https://gohugo.io/getting-started/installing/
|
||||
[4]:https://themes.gohugo.io/
|
||||
[5]:https://github.com/avianto/hugo-kiera
|
||||
[6]:https://m-czernek.github.io/awesome-blog/
|
||||
[7]:https://github.com/avianto/hugo-kiera/pull/18/files
|
||||
181
published/201809/20180516 Manipulating Directories in Linux.md
Normal file
181
published/201809/20180516 Manipulating Directories in Linux.md
Normal file
@ -0,0 +1,181 @@
|
||||
在 Linux 上操作目录
|
||||
======
|
||||
|
||||

|
||||
|
||||
> 让我们继续学习一下 Linux 文件系统的树形结构,并展示一下如何在其中创建你的目录。
|
||||
|
||||
如果你不熟悉本系列(以及 Linux),[请查看我们的第一部分][1]。在那篇文章中,我们贯穿了 Linux 文件系统的树状结构(或者更确切地说是<ruby>文件层次结构标准<rt>File Hierarchy Standard</rt></ruby>,FHS)。我建议你仔细阅读,确保你理解自己能安全的做哪些操作。因为这一次,我将向你展示目录操作的魅力。
|
||||
|
||||
### 新建目录
|
||||
|
||||
在破坏之前,先让我们来创建。首先,打开一个终端窗口并使用命令 `mkdir` 创建一个新目录,如下所示:
|
||||
|
||||
```
|
||||
mkdir <directoryname>
|
||||
```
|
||||
如果你只输入了目录名称,该目录将显示在您当前所在目录中。如果你刚刚打开一个终端,你当前位置为你的家目录。在这个例子中,我们展示了将要创建的目录与你当前所处位置的关系:
|
||||
|
||||
```
|
||||
$ pwd # 告知你当前所在位置(参见第一部分)
|
||||
/home/<username>
|
||||
$ mkdir newdirectory # 创建 /home/<username>/newdirectory
|
||||
```
|
||||
|
||||
(注:你不用输入 `#` 后面的文本。`#` 后面的文本为注释内容,用于解释发生了什么。它会被 shell 忽略,不会被执行)。
|
||||
|
||||
你可以在当前位置中已经存在的某个目录下创建新的目录,方法是在命令行中指定它:
|
||||
|
||||
```
|
||||
mkdir Documents/Letters
|
||||
```
|
||||
|
||||
这将在 `Documents` 目录中创建 `Letters` 目录。
|
||||
|
||||
你还可以在路径中使用 `..` 在当前目录的上一级目录中创建目录。假设你进入刚刚创建的 `Documents/Letters/` 目录,并且想要创建`Documents/Memos/` 目录。你可以这样做:
|
||||
|
||||
```
|
||||
cd Documents/Letters # 进入到你刚刚创建的 Letters/ 目录
|
||||
mkdir ../Memos
|
||||
```
|
||||
|
||||
同样,以上所有内容都是相对于你当前的位置做的。这就是使用了相对路径。
|
||||
|
||||
你还可以使用目录的绝对路径:这意味着告诉 `mkdir` 命令将目录放在和根目录(`/`)有关的位置:
|
||||
|
||||
```
|
||||
mkdir /home/<username>/Documents/Letters
|
||||
```
|
||||
|
||||
在上面的命令中将 `<username>` 更改为你的用户名,这相当于从你的主目录执行 `mkdir Documents/Letters`,通过使用绝对路径你可以在目录树中的任何位置完成这项工作。
|
||||
|
||||
无论你使用相对路径还是绝对路径,只要命令成功执行,`mkdir` 将静默的创建新目录,而没有任何明显的反馈。只有当遇到某种问题时,`mkdir`才会在你敲下回车键后打印一些反馈。
|
||||
|
||||
与大多数其他命令行工具一样,`mkdir` 提供了几个有趣的选项。 `-p` 选项特别有用,因为它允许你嵌套创建目录,即使目录不存在也可以。例如,要在 `Documents/` 中创建一个目录存放写给妈妈的信,你可以这样做:
|
||||
|
||||
```
|
||||
mkdir -p Documents/Letters/Family/Mom
|
||||
```
|
||||
|
||||
`mkdir` 会创建 `Mom/` 之上的整个目录分支,并且也会创建 `Mom/` 目录,无论其上的目录在你敲入该命令时是否已经存在。
|
||||
|
||||
你也可以用空格来分隔目录名,来同时创建几个目录:
|
||||
|
||||
```
|
||||
mkdir Letters Memos Reports
|
||||
```
|
||||
|
||||
这将在当前目录下创建目录 `Letters`、`Memos` 和 `Reports`。
|
||||
|
||||
### 目录名中可怕的空格
|
||||
|
||||
……这带来了目录名称中关于空格的棘手问题。你能在目录名中使用空格吗?是的你可以。那么建议你使用空格吗?不,绝对不建议。空格使一切变得更加复杂,并且可能是危险的操作。
|
||||
|
||||
假设您要创建一个名为 `letters mom/` 的目录。如果你不知道如何更好处理,你可能会输入:
|
||||
|
||||
```
|
||||
mkdir letters mom
|
||||
```
|
||||
|
||||
但这是错误的!错误的!错误的!正如我们在上面介绍的,这将创建两个目录 `letters/` 和 `mom/`,而不是一个目录 `letters mom/`。
|
||||
|
||||
得承认这是一个小麻烦:你所要做的就是删除这两个目录并重新开始,这没什么大不了。
|
||||
|
||||
可是等等!删除目录可是个危险的操作。想象一下,你使用图形工具[Dolphin][2] 或 [Nautilus][3] 创建了目录 `letters mom/`。如果你突然决定从终端删除目录 `letters mom`,并且您在同一目录下有另一个名为 `letters` 的目录,并且该目录中包含重要的文档,结果你为了删除错误的目录尝试了以下操作:
|
||||
|
||||
```
|
||||
rmdir letters mom
|
||||
```
|
||||
|
||||
你将会有删除目录 letters 的风险。这里说“风险”,是因为幸运的是`rmdir` 这条用于删除目录的指令,有一个内置的安全措施,如果你试图删除一个非空目录时,它会发出警告。
|
||||
|
||||
但是,下面这个:
|
||||
|
||||
```
|
||||
rm -Rf letters mom
|
||||
```
|
||||
|
||||
(注:这是删除目录及其内容的一种非常标准的方式)将完全删除 `letters/` 目录,甚至永远不会告诉你刚刚发生了什么。)
|
||||
|
||||
`rm` 命令用于删除文件和目录。当你将它与选项 `-R`(递归删除)和 `-f`(强制删除)一起使用时,它会深入到目录及其子目录中,删除它们包含的所有文件,然后删除子目录本身,然后它将删除所有顶层目录中的文件,再然后是删除目录本身。
|
||||
|
||||
`rm -Rf` 是你必须非常小心处理的命令。
|
||||
|
||||
我的建议是,你可以使用下划线来代替空格,但如果你仍然坚持使用空格,有两种方法可以使它们起作用。您可以使用单引号或双引号,如下所示:
|
||||
|
||||
```
|
||||
mkdir 'letters mom'
|
||||
mkdir "letters dad"
|
||||
```
|
||||
|
||||
或者,你可以转义空格。有些字符对 shell 有特殊意义。正如你所见,空格用于在命令行上分隔选项和参数。 “分离选项和参数”属于“特殊含义”范畴。当你想让 shell 忽略一个字符的特殊含义时,你需要转义,你可以在它前面放一个反斜杠(`\`)如:
|
||||
|
||||
```
|
||||
mkdir letters\ mom
|
||||
mkdir letter\ dad
|
||||
```
|
||||
|
||||
还有其他特殊字符需要转义,如撇号或单引号(`'`),双引号(`“`)和&符号(`&`):
|
||||
|
||||
```
|
||||
mkdir mom\ \&\ dad\'s\ letters
|
||||
```
|
||||
|
||||
我知道你在想什么:如果反斜杠有一个特殊的含义(即告诉 shell 它必须转义下一个字符),这也使它成为一个特殊的字符。然后,你将如何转义转义字符(`\`)?
|
||||
|
||||
事实证明,你转义任何其他特殊字符都是同样的方式:
|
||||
|
||||
```
|
||||
mkdir special\\characters
|
||||
```
|
||||
|
||||
这将生成一个名为 `special\characters/` 的目录。
|
||||
|
||||
感觉困惑?当然。这就是为什么你应该避免在目录名中使用特殊字符,包括空格。
|
||||
|
||||
以防误操作你可以参考下面这个记录特殊字符的列表。(LCTT 译注:此处原文链接丢失。)
|
||||
|
||||
### 总结
|
||||
|
||||
* 使用 `mkdir <directory name>` 创建新目录。
|
||||
* 使用 `rmdir <directory name>` 删除目录(仅在目录为空时才有效)。
|
||||
* 使用 `rm -Rf <directory name>` 来完全删除目录及其内容 —— 请务必谨慎使用。
|
||||
* 使用相对路径创建相对于当前目录的目录: `mkdir newdir`。
|
||||
* 使用绝对路径创建相对于根目录(`/`)的目录: `mkdir /home/<username>/newdir`。
|
||||
* 使用 `..` 在当前目录的上级目录中创建目录: `mkdir ../newdir`。
|
||||
* 你可以通过在命令行上使用空格分隔目录名来创建多个目录: `mkdir onedir twodir threedir`。
|
||||
* 同时创建多个目录时,你可以混合使用相对路径和绝对路径: `mkdir onedir twodir /home/<username>/threedir`。
|
||||
* 在目录名称中使用空格和特殊字符真的会让你很头疼,你最好不要那样做。
|
||||
|
||||
有关更多信息,您可以查看 `mkdir`、`rmdir` 和 `rm` 的手册:
|
||||
|
||||
```
|
||||
man mkdir
|
||||
man rmdir
|
||||
man rm
|
||||
```
|
||||
|
||||
要退出手册页,请按键盘 `q` 键。
|
||||
|
||||
### 下次预告
|
||||
|
||||
在下一部分中,你将学习如何创建、修改和删除文件,以及你需要了解的有关权限和特权的所有信息!
|
||||
|
||||
通过 Linux 基金会和 edX 免费提供的[“Introduction to Linux”][4]课程了解有关Linux的更多信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/5/manipulating-directories-linux
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[way-ww](https://github.com/way-ww)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/bro66
|
||||
[1]:https://linux.cn/article-9798-1.html
|
||||
[2]:https://userbase.kde.org/Dolphin
|
||||
[3]:https://projects-old.gnome.org/nautilus/screenshots.html
|
||||
[4]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
53
published/201809/20180518 Mastering CI-CD at OpenDev.md
Normal file
53
published/201809/20180518 Mastering CI-CD at OpenDev.md
Normal file
@ -0,0 +1,53 @@
|
||||
在 OpenDev 大会上学习 CI/CD
|
||||
======
|
||||
> 未来的开发工作需要非常精通 CI/CD 流程。
|
||||
|
||||
|
||||
|
||||
在 2017 年启动后,OpenDev 大会现在已是一个年度活动。在去年 9 月的首届活动上,会议的重点是边缘计算。今年的活动,于 5 月 22 - 23 日举行,会议的重点是持续集成和持续发布 (CI/CD),并与 OpenStack 峰会一起在温哥华举行。
|
||||
|
||||
基于我在 OpenStack 项目的 CI/CD 系统的技术背景和我近期进入容器下的 CI/CD 方面的经验,我被邀请加入 OpenDev CI/CD 计划委员会。今天我经常借助很多开源技术,例如 [Jenkins][3]、[GitLab][2]、[Spinnaker][4] 和 [Artifactory][5] 来讨论 CI/CD 流程。
|
||||
|
||||
这次活动对我来说是很激动人心的,因为我们将在这个活动中融合两个开源基础设施理念。首先,我们将讨论可以被任何组织使用的 CI/CD 工具。为此目的,在 [讲演][6] 中,我们将听到关于开源 CI/CD 工具的使用讲演,一场来自 Boris Renski 的关于 Spinnaker 的讲演,和一场来自 Jim Blair 的关于 [Zuul][7] 的讲演。同时,讲演会涉及关于开源技术的偏好的高级别话题,特别是那种跨社区的和本身就是开源项目的。从Fatih Degirmenci 和 Daniel Farrel 那里,我们将听到关于在不同社区分享持续发布实践经历,接着 Benjamin Mako Hill 会为我们带来一场关于为什么自由软件需要自由工具的分享。
|
||||
|
||||
在分享 CI/CD 相对新颖的特性后,接下来的活动是对话、研讨会和协作讨论的混合组合。当从人们所提交的讲座和研讨会中进行选择,并提出协作讨论主题时,我们希望确保有一个多样灵活的日程表,这样任何参与者都能在 CI/CD 活动进程中发现有趣的东西。
|
||||
|
||||
这些讲座会是标准的会议风格,选择涵盖关键主题,如制定 CI/CD 流程,在实践 DevOps 时提升安全性,以及更具体的解决方案,如基于容器关于 Kubernetes 的 [Aptomi][8] 和在 ETSI NFV 环境下 CI/CD。这些会话的大部分将会是作为给新接触 CI/CD 或这些特定技术的参与者关于这些话题和理念的简介。
|
||||
|
||||
交互式的研讨会会持续相对比较长的时间,参与者将会在思想上得到特定的体验。这些研讨会包括 “[在持续集成任务中的异常检测][9]”、“[如何安装 Zuul 和配置第一个任务][10]”,和“[Spinnake 101:快速可靠的软件发布][11]”。(注意这些研讨会空间是有限的,所以设立了一个 RSVP 系统。你们将会在会议的链接里找到一个 RSVP 的按钮。)
|
||||
|
||||
可能最让我最兴奋的是协作讨论,这些协作讨论占据了一半以上的活动安排。协作讨论的主题由计划委员会选取。计划委员会根据我们在社区里所看到来选取对应的主题。这是“鱼缸”风格式的会议,通常是几个人聚在一个房间里围绕着 CI/CD 讨论某一个主题。
|
||||
|
||||
这次会议风格的理念是来自于开发者峰会,最初是由 Ubuntu 社区提出,接着 OpenStack 社区也在活动上采纳。这些协作讨论的主题包含不同的会议,这些会议是关于 CI/CD 基础,可以鼓励跨社区协作的提升举措,在组织里推行 CI/CD 文化,和为什么开源 CI/CD 工具如此重要。采用共享文档来做会议笔记,以确保尽可能的在会议的过程中分享知识。在讨论过程中,提出行动项目也是很常见的,因此社区成员可以推动和所涉及的主题相关的倡议。
|
||||
|
||||
活动将以联合总结会议结束。联合总结会议将总结来自协同讨论的关键点和为即将在这个领域工作的参与者指出可选的职业范围。
|
||||
|
||||
可以在 [OpenStack 峰会注册页][13] 上注册参加活动。或者可以在温哥华唯一指定售票的会议中心购买活动的入场券,价格是 $199。更多关于票和全部的活动安排见官网 [OpenDev 网站][1]。
|
||||
|
||||
我希望你们能够加入我们,并在温哥华渡过令人激动的两天,并且在这两天的活动中学习,协作和在 CI/CD 取得进展。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/opendev
|
||||
|
||||
作者:[Elizabeth K.Joseph][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jamelouis](https://github.com/jamelouis)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/pleia2
|
||||
[1]:http://2018.opendevconf.com/
|
||||
[2]:https://about.gitlab.com/
|
||||
[3]:https://jenkins.io/
|
||||
[4]:https://www.spinnaker.io/
|
||||
[5]:https://jfrog.com/artifactory/
|
||||
[6]:http://2018.opendevconf.com/schedule/
|
||||
[7]:https://zuul-ci.org/
|
||||
[8]:http://aptomi.io/
|
||||
[9]:https://www.openstack.org/summit/vancouver-2018/summit-schedule/events/21692/anomaly-detection-in-continuous-integration-jobs
|
||||
[10]:https://www.openstack.org/summit/vancouver-2018/summit-schedule/events/21693/how-to-install-zuul-and-configure-your-first-jobs
|
||||
[11]:https://www.openstack.org/summit/vancouver-2018/summit-schedule/events/21699/spinnaker-101-releasing-software-with-velocity-and-confidence
|
||||
[12]:https://www.openstack.org/summit/vancouver-2018/summit-schedule/events/21831/opendev-cicd-joint-collab-conclusion
|
||||
[13]:https://www.eventbrite.com/e/openstack-summit-may-2018-vancouver-tickets-40845826968?aff=VancouverSummit2018
|
||||
@ -1,152 +1,153 @@
|
||||
Git 使用简介
|
||||
======
|
||||
> 我将向你介绍让 Git 的启动、运行,并和 GitHub 一起使用的基础知识。
|
||||
|
||||

|
||||
|
||||
如果你是一个开发者,那你应该熟悉许多开发工具。你已经花了多年时间来学习一种或者多种编程语言并完善你的技巧。你可以熟练运用图形工具或者命令行工具开发。在你看来,没有任何事可以阻挡你。你的代码, 好像你的思想和你的手指一样,将会创建一个优雅的,完美评价的应用程序,并会风靡世界。
|
||||
如果你是一个开发者,那你应该熟悉许多开发工具。你已经花了多年时间来学习一种或者多种编程语言并打磨你的技巧。你可以熟练运用图形工具或者命令行工具开发。在你看来,没有任何事可以阻挡你。你的代码, 好像你的思想和你的手指一样,将会创建一个优雅的,完美评价的应用程序,并会风靡世界。
|
||||
|
||||
然而,如果你和其他人共同开发一个项目会发生什么呢?或者,你开发的应用程序变地越来越大,下一步你将如何去做?如果你想成功地和其他开发者合作,你定会想用一个分布式版本控制系统。使用这样一个系统,合作开发一个项目变得非常高效和可靠。这样的一个系统便是 [Git][1]。还有一个叫 [GitHub][2] 的方便的存储仓库,来存储你的项目代码,这样你的团队可以检查和修改代码。
|
||||
然而,如果你和其他人共同开发一个项目会发生什么呢?或者,你开发的应用程序变地越来越大,下一步你将如何去做?如果你想成功地和其他开发者合作,你定会想用一个分布式版本控制系统。使用这样一个系统,合作开发一个项目变得非常高效和可靠。这样的一个系统便是 [Git][1]。还有一个叫 [GitHub][2] 的方便的存储仓库,用来存储你的项目代码,这样你的团队可以检查和修改代码。
|
||||
|
||||
我将向你介绍让 Git 的启动、运行,并和 GitHub 一起使用的基础知识,可以让你的应用程序的开发可以提升到一个新的水平。我将在 Ubuntu 18.04 上进行演示,因此如果您选择的发行版本不同,您只需要修改 Git 安装命令以适合你的发行版的软件包管理器。
|
||||
|
||||
我将向你介绍让 Git 的启动、运行,并和 GitHub 一起使用的基础知识,可以让你的应用程序的开发可以提升到一个新的水平。 我将在 Ubuntu 18.04 上进行演示,因此如果您选择的发行版本不同,您只需要修改 Git 安装命令以适合你的发行版的软件包管理器。
|
||||
### Git 和 GitHub
|
||||
|
||||
第一件事就是创建一个免费的 GitHub 账号,打开 [GitHub 注册页面][3],然后填上需要的信息。完成这个之后,你就注备好开始安装 Git 了(这两件事谁先谁后都可以)。
|
||||
|
||||
安装 Git 非常简单,打开一个命令行终端,并输入命令:
|
||||
|
||||
```
|
||||
sudo apt install git-all
|
||||
|
||||
```
|
||||
|
||||
这将会安装大量依赖包,但是你将了解使用 Git 和 GitHub 所需的一切。
|
||||
|
||||
注意:我使用 Git 来下载程序的安装源码。有许多时候,内置的软件管理器不提供某个软件,除了去第三方库中下载源码,我经常去这个软件项目的 Git 主页,像这样克隆:
|
||||
附注:我使用 Git 来下载程序的安装源码。有许多时候,内置的软件管理器不提供某个软件,除了去第三方库中下载源码,我经常去这个软件项目的 Git 主页,像这样克隆:
|
||||
|
||||
```
|
||||
git clone ADDRESS
|
||||
|
||||
```
|
||||
ADDRESS就是那个软件项目的 Git 主页。这样我就可以确保自己安装那个软件的最新发行版了。
|
||||
|
||||
创建一个本地仓库并添加一个文件。
|
||||
下一步就是在你的电脑里创建一个本地仓库(本文称之为newproject,位于~/目录下),打开一个命令行终端,并输入下面的命令:
|
||||
“ADDRESS” 就是那个软件项目的 Git 主页。这样我就可以确保自己安装那个软件的最新发行版了。
|
||||
|
||||
### 创建一个本地仓库并添加一个文件
|
||||
|
||||
下一步就是在你的电脑里创建一个本地仓库(本文称之为 newproject,位于 `~/` 目录下),打开一个命令行终端,并输入下面的命令:
|
||||
|
||||
```
|
||||
cd ~/
|
||||
|
||||
mkdir newproject
|
||||
|
||||
cd newproject
|
||||
|
||||
```
|
||||
|
||||
现在你需要初始化这个仓库。在 ~/newproject 目录下,输入命令 git init,当命令运行完,你就可以看到一个刚刚创建的空的 Git 仓库了(图1)。
|
||||
现在你需要初始化这个仓库。在 `~/newproject` 目录下,输入命令 `git init`,当命令运行完,你就可以看到一个刚刚创建的空的 Git 仓库了(图1)。
|
||||
|
||||
![new repository][5]
|
||||
|
||||
图 1:初始化完成的新仓库
|
||||
*图 1: 初始化完成的新仓库*
|
||||
|
||||
[使用许可][6]
|
||||
|
||||
下一步就是往项目里添加文件。我们在项目根目录(~/newproject)输入下面的命令:
|
||||
下一步就是往项目里添加文件。我们在项目根目录(`~/newproject`)输入下面的命令:
|
||||
|
||||
```
|
||||
touch readme.txt
|
||||
|
||||
```
|
||||
|
||||
现在项目里多了个空文件。输入 git status 来验证 Git 已经检测到多了个新文件(图2)。
|
||||
现在项目里多了个空文件。输入 `git status` 来验证 Git 已经检测到多了个新文件(图2)。
|
||||
|
||||
![readme][8]
|
||||
|
||||
图 2: Git 检测到新文件readme.txt
|
||||
|
||||
[使用许可][6]
|
||||
*图 2: Git 检测到新文件readme.txt*
|
||||
|
||||
即使 Git 检测到新的文件,但它并没有被真正的加入这个项目仓库。为此,你要输入下面的命令:
|
||||
|
||||
```
|
||||
git add readme.txt
|
||||
|
||||
```
|
||||
|
||||
一旦完成这个命令,再输入 git status 命令,可以看到,readme.txt 已经是这个项目里的新文件了(图3)。
|
||||
一旦完成这个命令,再输入 `git status` 命令,可以看到,`readme.txt` 已经是这个项目里的新文件了(图3)。
|
||||
|
||||
![file added][10]
|
||||
|
||||
图 3: 我们的文件已经被添加进临时环境
|
||||
*图 3: 我们的文件已经被添加进临时环境*
|
||||
|
||||
[使用许可][6]
|
||||
### 第一次提交
|
||||
当新文件添加进临时环境之后,我们现在就准备好第一次提交了。什么是提交呢?它是很简单的,一次提交就是记录你更改的项目的文件。创建一次提交也是非常简单的。但是,为提交创建一个描述信息非常重要。通过这样做,你将添加有关提交包含的内容的注释,比如你对文件做出的修改。然而,在这样做之前,我们需要确认我们的 Git 账户,输入以下命令:
|
||||
|
||||
当新文件添加进临时环境之后,我们现在就准备好创建第一个<ruby>提交<rt>commit</rt></ruby>了。什么是提交呢?简单的说,一个提交就是你更改的项目的文件的记录。创建一个提交也是非常简单的。但是,为提交包含一个描述信息非常重要。通过这样做,你可以添加有关该提交包含的内容的注释,比如你对文件做出的何种修改。然而,在这样做之前,我们需要告知 Git 我们的账户,输入以下命令:
|
||||
|
||||
```
|
||||
git config --global user.email EMAIL
|
||||
|
||||
git config --global user.name “FULL NAME”
|
||||
|
||||
```
|
||||
EMAIL 即你的 email 地址,FULL NAME 则是你的姓名。现在你可以通过以下命令创建一个提交:
|
||||
|
||||
“EMAIL” 即你的 email 地址,“FULL NAME” 则是你的姓名。
|
||||
|
||||
现在你可以通过以下命令创建一个提交:
|
||||
|
||||
```
|
||||
git commit -m “Descriptive Message”
|
||||
|
||||
```
|
||||
Descriptive Message 即为你的提交的描述性信息。比如,当你第一次提交是提交一个 readme.txt 文件,你可以这样提交:
|
||||
|
||||
“Descriptive Message” 即为你的提交的描述性信息。比如,当你第一个提交是提交一个 `readme.txt` 文件,你可以这样提交:
|
||||
|
||||
```
|
||||
git commit -m “First draft of readme.txt file”
|
||||
|
||||
```
|
||||
|
||||
你可以看到输出显示一个文件已经修改,并且,为 readnme.txt 创建了一个新模式(图4)
|
||||
你可以看到输出表明一个文件已经修改,并且,为 `readme.txt` 创建了一个新的文件模式(图4)
|
||||
|
||||
![success][12]
|
||||
|
||||
图4:提交成功
|
||||
*图4:提交成功*
|
||||
|
||||
|
||||
### 创建分支并推送至 GitHub
|
||||
|
||||
分支是很重要的,它允许你在项目状态间中移动。假如,你想给你的应用创建一个新的特性。为了这样做,你创建了个新分支。一旦你完成你的新特性,你可以把这个新分支合并到你的主分支中去,使用以下命令创建一个新分支:
|
||||
|
||||
[使用许可][6]
|
||||
### 创建分支并推送至GitHub
|
||||
分支是很重要的,它允许你从项目状态间中移动。假如,你想给你的应用创建一个新的特性。为了这样做,你创建了个新分支。一旦你完成你的新特性,你可以把这个新分支合并到你的主分支中去,使用以下命令创建一个新分支:
|
||||
```
|
||||
git checkout -b BRANCH
|
||||
|
||||
```
|
||||
BRANCH 即为你新分支的名字,一旦执行完命令,输入 git branch 命令来查看是否创建了新分支(图5)
|
||||
|
||||
“BRANCH” 即为你新分支的名字,一旦执行完命令,输入 `git branch` 命令来查看是否创建了新分支(图5)
|
||||
|
||||
![featureX][14]
|
||||
|
||||
图5:名为 featureX 的新分支
|
||||
*图5:名为 featureX 的新分支*
|
||||
|
||||
[使用许可][6]
|
||||
|
||||
接下来,我们需要在GitHub上创建一个仓库。 登录GitHub帐户,请单击帐户主页上的“新建仓库”按钮。 填写必要的信息,然后单击Create repository(图6)。
|
||||
接下来,我们需要在 GitHub 上创建一个仓库。 登录 GitHub 帐户,请单击帐户主页上的“New Repository”按钮。 填写必要的信息,然后单击 “Create repository”(图6)。
|
||||
|
||||
![new repository][16]
|
||||
|
||||
图6:在 GitHub 上新建一个仓库
|
||||
*图6:在 GitHub 上新建一个仓库*
|
||||
|
||||
[使用许可][6]
|
||||
在创建完一个仓库之后,你可以看到一个用于推送本地仓库的地址。若要推送,返回命令行窗口(`~/newproject` 目录中),输入以下命令:
|
||||
|
||||
在创建完一个仓库之后,你可以看到一个用于推送本地仓库的地址。若要推送,返回命令行窗口( ~/newproject 目录中),输入以下命令:
|
||||
```
|
||||
git remote add origin URL
|
||||
|
||||
git push -u origin master
|
||||
|
||||
```
|
||||
URL 即为我们 GitHub 上新建的仓库地址。
|
||||
|
||||
“URL” 即为我们 GitHub 上新建的仓库地址。
|
||||
|
||||
系统会提示您,输入 GitHub 的用户名和密码,一旦授权成功,你的项目将会被推送到 GitHub 仓库中。
|
||||
|
||||
### 拉取项目
|
||||
|
||||
如果你的同事改变了你们 GitHub 上项目的代码,并且已经合并那些更改,你可以拉取那些项目文件到你的本地机器,这样,你系统中的文件就可以和远程用户的文件保持匹配。你可以输入以下命令来做这件事( ~/newproject 在目录中),
|
||||
如果你的同事改变了你们 GitHub 上项目的代码,并且已经合并那些更改,你可以拉取那些项目文件到你的本地机器,这样,你系统中的文件就可以和远程用户的文件保持匹配。你可以输入以下命令来做这件事(`~/newproject` 在目录中),
|
||||
|
||||
```
|
||||
git pull origin master
|
||||
|
||||
```
|
||||
|
||||
以上的命令可以拉取任何新文件或修改过的文件到你的本地仓库。
|
||||
|
||||
### 基础
|
||||
|
||||
这就是从命令行使用 Git 来处理存储在 GitHub 上的项目的基础知识。 还有很多东西需要学习,所以我强烈建议你使用 man git,man git-push 和 man git-pull 命令来更深入地了解 git 命令可以做什么。
|
||||
这就是从命令行使用 Git 来处理存储在 GitHub 上的项目的基础知识。 还有很多东西需要学习,所以我强烈建议你使用 `man git`,`man git-push` 和 `man git-pull` 命令来更深入地了解 `git` 命令可以做什么。
|
||||
|
||||
开发快乐!
|
||||
|
||||
了解更多关于 Linux的 内容,请访问来自 Linux 基金会和 edX 的免费的 ["Introduction to Linux" ][17]课程。
|
||||
了解更多关于 Linux 的 内容,请访问来自 Linux 基金会和 edX 的免费的 ["Introduction to Linux"][17]课程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -155,7 +156,7 @@ via: https://www.linux.com/learn/intro-to-linux/2018/7/introduction-using-git
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[distant1219](https://github.com/distant1219)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,77 @@
|
||||
如何使用 Apache 构建 URL 缩短服务
|
||||
======
|
||||
> 用 Apache HTTP 服务器的 mod_rewrite 功能创建你自己的短链接。
|
||||
|
||||

|
||||
|
||||
很久以前,人们开始在 Twitter 上分享链接。140 个字符的限制意味着 URL 可能消耗一条推文的大部分(或全部),因此人们使用 URL 缩短服务。最终,Twitter 加入了一个内置的 URL 缩短服务([t.co][1])。
|
||||
|
||||
字符数现在不重要了,但还有其他原因要缩短链接。首先,缩短服务可以提供分析功能 —— 你可以看到你分享的链接的受欢迎程度。它还简化了制作易于记忆的 URL。例如,[bit.ly/INtravel][2] 比<https://www.in.gov/ai/appfiles/dhs-countyMap/dhsCountyMap.html>更容易记住。如果你想预先共享一个链接,但还不知道最终地址,这时 URL 缩短服务可以派上用场。。
|
||||
|
||||
与任何技术一样,URL 缩短服务并非都是正面的。通过屏蔽最终地址,缩短的链接可用于指向恶意或冒犯性内容。但是,如果你仔细上网,URL 缩短服务是一个有用的工具。
|
||||
|
||||
我们之前在网站上[发布过缩短服务的文章][3],但也许你想要运行一些由简单的文本文件支持的缩短服务。在本文中,我们将展示如何使用 Apache HTTP 服务器的 mod_rewrite 功能来设置自己的 URL 缩短服务。如果你不熟悉 Apache HTTP 服务器,请查看 David Both 关于[安装和配置][4]它的文章。
|
||||
|
||||
### 创建一个 VirtualHost
|
||||
|
||||
在本教程中,我假设你购买了一个很酷的域名,你将它专门用于 URL 缩短服务。例如,我的网站是 [funnelfiasco.com][5],所以我买了 [funnelfias.co][6] 用于我的 URL 缩短服务(好吧,它不是很短,但它可以满足我的虚荣心)。如果你不将缩短服务作为单独的域运行,请跳到下一部分。
|
||||
|
||||
第一步是设置将用于 URL 缩短服务的 VirtualHost。有关 VirtualHost 的更多信息,请参阅 [David Both 的文章][7]。这步只需要几行:
|
||||
|
||||
```
|
||||
<VirtualHost *:80>
|
||||
ServerName funnelfias.co
|
||||
</VirtualHost>
|
||||
```
|
||||
|
||||
### 创建重写规则
|
||||
|
||||
此服务使用 HTTPD 的重写引擎来重写 URL。如果你在上面的部分中创建了 VirtualHost,则下面的配置跳到你的 VirtualHost 部分。否则跳到服务器的 VirtualHost 或主 HTTPD 配置。
|
||||
|
||||
```
|
||||
RewriteEngine on
|
||||
RewriteMap shortlinks txt:/data/web/shortlink/links.txt
|
||||
RewriteRule ^/(.+)$ ${shortlinks:$1} [R=temp,L]
|
||||
```
|
||||
|
||||
第一行只是启用重写引擎。第二行在文本文件构建短链接的映射。上面的路径只是一个例子。你需要使用系统上使用有效路径(确保它可由运行 HTTPD 的用户帐户读取)。最后一行重写 URL。在此例中,它接受任何字符并在重写映射中查找它们。你可能希望重写时使用特定的字符串。例如,如果你希望所有缩短的链接都是 “slX”(其中 X 是数字),则将上面的 `(.+)` 替换为 `(sl\d+)`。
|
||||
|
||||
我在这里使用了临时重定向(HTTP 302)。这能让我稍后更新目标 URL。如果希望短链接始终指向同一目标,则可以使用永久重定向(HTTP 301)。用 `permanent` 替换第三行的 `temp`。
|
||||
|
||||
### 构建你的映射
|
||||
|
||||
编辑配置文件 `RewriteMap` 行中的指定文件。格式是空格分隔的键值存储。在每一行上放一个链接:
|
||||
|
||||
```
|
||||
osdc https://opensource.com/users/bcotton
|
||||
twitter https://twitter.com/funnelfiasco
|
||||
swody1 https://www.spc.noaa.gov/products/outlook/day1otlk.html
|
||||
```
|
||||
|
||||
### 重启 HTTPD
|
||||
|
||||
最后一步是重启 HTTPD 进程。这是通过 `systemctl restart httpd` 或类似命令完成的(命令和守护进程名称可能因发行版而不同)。你的链接缩短服务现已启动并运行。当你准备编辑映射时,无需重新启动 Web 服务器。你所要做的就是保存文件,Web 服务器将获取到差异。
|
||||
|
||||
### 未来的工作
|
||||
|
||||
此示例为你提供了基本的 URL 缩短服务。如果你想将开发自己的管理接口作为学习项目,它可以作为一个很好的起点。或者你可以使用它分享容易记住的链接到那些容易忘记的 URL。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/apache-url-shortener
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bcotton
|
||||
[1]:http://t.co
|
||||
[2]:http://bit.ly/INtravel
|
||||
[3]:https://opensource.com/article/17/3/url-link-shortener
|
||||
[4]:https://opensource.com/article/18/2/how-configure-apache-web-server
|
||||
[5]:http://funnelfiasco.com
|
||||
[6]:http://funnelfias.co
|
||||
[7]:https://opensource.com/article/18/3/configuring-multiple-web-sites-apache
|
||||
@ -1,47 +1,48 @@
|
||||
PKI 和 密码学中的私钥的角色
|
||||
公钥基础设施和密码学中的私钥的角色
|
||||
======
|
||||
> 了解如何验证某人所声称的身份。
|
||||
|
||||

|
||||
|
||||
在[上一篇文章][1]中,我们概述了密码学并讨论了密码学的核心概念:<ruby>保密性<rt>confidentiality</rt></ruby> (让数据保密),<ruby>完整性<rt>integrity</rt></ruby> (防止数据被篡改)和<ruby>身份认证<rt>authentication</rt></ruby> (确认数据源的<ruby>身份<rt>identity</rt></ruby>)。由于要在存在各种身份混乱的现实世界中完成身份认证,人们逐渐建立起一个复杂的<ruby>技术生态体系<rt>technological ecosystem</rt></ruby>,用于证明某人就是其声称的那个人。在本文中,我们将大致介绍这些体系是如何工作的。
|
||||
在[上一篇文章][1]中,我们概述了密码学并讨论了密码学的核心概念:<ruby>保密性<rt>confidentiality</rt></ruby> (让数据保密)、<ruby>完整性<rt>integrity</rt></ruby> (防止数据被篡改)和<ruby>身份认证<rt>authentication</rt></ruby> (确认数据源的<ruby>身份<rt>identity</rt></ruby>)。由于要在存在各种身份混乱的现实世界中完成身份认证,人们逐渐建立起一个复杂的<ruby>技术生态体系<rt>technological ecosystem</rt></ruby>,用于证明某人就是其声称的那个人。在本文中,我们将大致介绍这些体系是如何工作的。
|
||||
|
||||
### 公钥密码学及数字签名快速回顾
|
||||
### 快速回顾公钥密码学及数字签名
|
||||
|
||||
互联网世界中的身份认证依赖于公钥密码学,其中密钥分为两部分:拥有者需要保密的私钥和可以对外公开的公钥。经过公钥加密过的数据,只能用对应的私钥解密。举个例子,对于希望与[记者][2]建立联系的举报人来说,这个特性非常有用。但就本文介绍的内容而言,私钥更重要的用途是与一个消息一起创建一个<ruby>数字签名<rt>digital signature</rt></ruby>,用于提供完整性和身份认证。
|
||||
|
||||
在实际应用中,我们签名的并不是真实消息,而是经过<ruby>密码学哈希函数<rt>cryptographic hash function</rt></ruby>处理过的消息<ruby>摘要<rt>digest</rt></ruby>。要发送一个包含源代码的压缩文件,发送者会对该压缩文件的 256 比特长度的 [SHA-256][3] 摘要而不是文件本身进行签名,然后用明文发送该压缩包(和签名)。接收者会独立计算收到文件的 SHA-256 摘要,然后结合该摘要、收到的签名及发送者的公钥,使用签名验证算法进行验证。验证过程取决于加密算法,加密算法不同,验证过程也相应不同;而且,由于不断发现微妙的触发条件,签名验证[漏洞][4]依然[层出不穷][5]。如果签名验证通过,说明文件在传输过程中没有被篡改而且来自于发送者,这是因为只有发送者拥有创建签名所需的私钥。
|
||||
在实际应用中,我们签名的并不是真实消息,而是经过<ruby>密码学哈希函数<rt>cryptographic hash function</rt></ruby>处理过的消息<ruby>摘要<rt>digest</rt></ruby>。要发送一个包含源代码的压缩文件,发送者会对该压缩文件的 256 比特长度的 [SHA-256][3] 摘要进行签名,而不是文件本身进行签名,然后用明文发送该压缩包(和签名)。接收者会独立计算收到文件的 SHA-256 摘要,然后结合该摘要、收到的签名及发送者的公钥,使用签名验证算法进行验证。验证过程取决于加密算法,加密算法不同,验证过程也相应不同;而且,很微妙的是签名验证[漏洞][4]依然[层出不穷][5]。如果签名验证通过,说明文件在传输过程中没有被篡改而且来自于发送者,这是因为只有发送者拥有创建签名所需的私钥。
|
||||
|
||||
### 方案中缺失的环节
|
||||
|
||||
上述方案中缺失了一个重要的环节:我们从哪里获得发送者的公钥?发送者可以将公钥与消息一起发送,但除了发送者的自我宣称,我们无法核验其身份。假设你是一名银行柜员,一名顾客走过来向你说,“你好,我是 Jane Doe,我要取一笔钱”。当你要求其证明身份时,她指着衬衫上贴着的姓名标签说道,“看,Jane Doe!”。如果我是这个柜员,我会礼貌的拒绝她的请求。
|
||||
|
||||
如果你认识发送者,你们可以私下见面并彼此交换公钥。如果你并不认识发送者,你们可以私下见面,检查对方的证件,确认真实性后接受对方的公钥。为提高流程效率,你可以举办聚会并邀请一堆人,检查他们的证件,然后接受他们的公钥。此外,如果你认识并信任 Jane Doe (尽管她在银行的表现比较反常),Jane 可以参加聚会,收集大家的公钥然后交给你。事实上,Jane 可以使用她自己的私钥对这些公钥(及对应的身份信息)进行签名,进而你可以从一个[线上密钥库][7]获取公钥(及对应的身份信息)并信任已被 Jane 签名的那部分。如果一个人的公钥被很多你信任的人(即使你并不认识他们)签名,你也可能选择信任这个人。按照这种方式,你可以建立一个[<ruby>信任网络<rt>Web of Trust</rt></ruby>][8]。
|
||||
如果你认识发送者,你们可以私下见面并彼此交换公钥。如果你并不认识发送者,你们可以私下见面,检查对方的证件,确认真实性后接受对方的公钥。为提高流程效率,你可以举办[聚会][6]并邀请一堆人,检查他们的证件,然后接受他们的公钥。此外,如果你认识并信任 Jane Doe(尽管她在银行的表现比较反常),Jane 可以参加聚会,收集大家的公钥然后交给你。事实上,Jane 可以使用她自己的私钥对这些公钥(及对应的身份信息)进行签名,进而你可以从一个[线上密钥库][7]获取公钥(及对应的身份信息)并信任已被 Jane 签名的那部分。如果一个人的公钥被很多你信任的人(即使你并不认识他们)签名,你也可能选择信任这个人。按照这种方式,你可以建立一个<ruby>[信任网络][8]<rt>Web of Trust</rt></ruby>。
|
||||
|
||||
但事情也变得更加复杂:我们需要建立一种标准的编码机制,可以将公钥和其对应的身份信息编码成一个<ruby>数字捆绑<rt>digital bundle</rt></ruby>,以便我们进一步进行签名。更准确的说,这类数字捆绑被称为<ruby>证书<rt>cerificates</rt></ruby>。我们还需要可以创建、使用和管理这些证书的工具链。满足诸如此类的各种需求的方案构成了<ruby>公钥基础设施<rt>public key infrastructure, PKI</rt></ruby>。
|
||||
但事情也变得更加复杂:我们需要建立一种标准的编码机制,可以将公钥和其对应的身份信息编码成一个<ruby>数字捆绑<rt>digital bundle</rt></ruby>,以便我们进一步进行签名。更准确的说,这类数字捆绑被称为<ruby>证书<rt>cerificate</rt></ruby>。我们还需要可以创建、使用和管理这些证书的工具链。满足诸如此类的各种需求的方案构成了<ruby>公钥基础设施<rt>public key infrastructure</rt></ruby>(PKI)。
|
||||
|
||||
### 比信任网络更进一步
|
||||
|
||||
你可以用人际关系网类比信任网络。如果人们之间广泛互信,可以很容易找到(两个人之间的)一条<ruby>短信任链<rt>short path of trust</rt></ruby>:不妨以社交圈为例。基于 [GPG][9] 加密的邮件依赖于信任网络,([理论上][10])只适用于与少量朋友、家庭或同事进行联系的情形。
|
||||
你可以用人际关系网类比信任网络。如果人们之间广泛互信,可以很容易找到(两个人之间的)一条<ruby>短信任链<rt>short path of trust</rt></ruby>:就像一个社交圈。基于 [GPG][9] 加密的邮件依赖于信任网络,([理论上][10])只适用于与少量朋友、家庭或同事进行联系的情形。
|
||||
|
||||
(LCTT 译注:作者提到的“短信任链”应该是暗示“六度空间理论”,即任意两个陌生人之间所间隔的人一般不会超过 6 个。对 GPG 的唱衰,一方面是因为密钥管理的复杂性没有改善,另一方面 Yahoo 和 Google 都提出了更便利的端到端加密方案。)
|
||||
|
||||
在实际应用中,信任网络有一些[<ruby>"硬伤"<rt>significant problems</rt></ruby>][11],主要是在可扩展性方面。当网络规模逐渐增大或者人们之间的连接逐渐降低时,信任网络就会慢慢失效。如果信任链逐渐变长,信任链中某人有意或无意误签证书的几率也会逐渐增大。如果信任链不存在,你不得不自己创建一条信任链;具体而言,你与其它组织建立联系,验证它们的密钥符合你的要求。考虑下面的场景,你和你的朋友要访问一个从未使用过的在线商店。你首先需要核验网站所用的公钥属于其对应的公司而不是伪造者,进而建立安全通信信道,最后完成下订单操作。核验公钥的方法包括去实体店、打电话等,都比较麻烦。这样会导致在线购物变得不那么便利(或者说不那么安全,毕竟很多人会图省事,不去核验密钥)。
|
||||
在实际应用中,信任网络有一些“<ruby>[硬伤][11]<rt>significant problems</rt></ruby>”,主要是在可扩展性方面。当网络规模逐渐增大或者人们之间的连接较少时,信任网络就会慢慢失效。如果信任链逐渐变长,信任链中某人有意或无意误签证书的几率也会逐渐增大。如果信任链不存在,你不得不自己创建一条信任链,与其它组织建立联系,验证它们的密钥以符合你的要求。考虑下面的场景,你和你的朋友要访问一个从未使用过的在线商店。你首先需要核验网站所用的公钥属于其对应的公司而不是伪造者,进而建立安全通信信道,最后完成下订单操作。核验公钥的方法包括去实体店、打电话等,都比较麻烦。这样会导致在线购物变得不那么便利(或者说不那么安全,毕竟很多人会图省事,不去核验密钥)。
|
||||
|
||||
如果世界上有那么几个格外值得信任的人,他们专门负责核验和签发网站证书,情况会怎样呢?你可以只信任他们,那么浏览互联网也会变得更加容易。整体来看,这就是当今互联网的工作方式。那些“格外值得信任的人”就是被称为<ruby>证书颁发机构<rt>cerificate authorities, CAs</rt></ruby>的公司。当网站希望获得公钥签名时,只需向 CA 提交<ruby>证书签名请求<rt>certificate signing request</rt></ruby>。
|
||||
如果世界上有那么几个格外值得信任的人,他们专门负责核验和签发网站证书,情况会怎样呢?你可以只信任他们,那么浏览互联网也会变得更加容易。整体来看,这就是当今互联网的工作方式。那些“格外值得信任的人”就是被称为<ruby>证书颁发机构<rt>cerificate authoritie</rt></ruby>(CA)的公司。当网站希望获得公钥签名时,只需向 CA 提交<ruby>证书签名请求<rt>certificate signing request</rt></ruby>(CSR)。
|
||||
|
||||
CSR 类似于包括公钥和身份信息(在本例中,即服务器的主机名)的<ruby>存根<rt>stub</rt></ruby>证书,但CA 并不会直接对 CSR 本身进行签名。CA 在签名之前会进行一些验证。对于一些证书类型(LCTT 译注:<ruby>DV<rt>Domain Validated</rt></ruby> 类型),CA 只验证申请者的确是 CSR 中列出主机名对应域名的控制者(例如通过邮件验证,让申请者完成指定的域名解析)。[对于另一些证书类型][12] (LCTT 译注:链接中提到<ruby>EV<rt>Extended Validated</rt></ruby> 类型,其实还有 <ruby>OV<rt>Organization Validated</rt></ruby> 类型),CA 还会检查相关法律文书,例如公司营业执照等。一旦验证完成,CA(一般在申请者付费后)会从 CSR 中取出数据(即公钥和身份信息),使用 CA 自己的私钥进行签名,创建一个(签名)证书并发送给申请者。申请者将该证书部署在网站服务器上,当用户使用 HTTPS (或其它基于 [TLS][13] 加密的协议)与服务器通信时,该证书被分发给用户。
|
||||
CSR 类似于包括公钥和身份信息(在本例中,即服务器的主机名)的<ruby>存根<rt>stub</rt></ruby>证书,但 CA 并不会直接对 CSR 本身进行签名。CA 在签名之前会进行一些验证。对于一些证书类型(LCTT 译注:<ruby>域名证实<rt>Domain Validated</rt></ruby>(DV) 类型),CA 只验证申请者的确是 CSR 中列出主机名对应域名的控制者(例如通过邮件验证,让申请者完成指定的域名解析)。[对于另一些证书类型][12] (LCTT 译注:链接中提到<ruby>扩展证实<rt>Extended Validated</rt></ruby>(EV)类型,其实还有 <ruby>OV<rt>Organization Validated</rt></ruby> 类型),CA 还会检查相关法律文书,例如公司营业执照等。一旦验证完成,CA(一般在申请者付费后)会从 CSR 中取出数据(即公钥和身份信息),使用 CA 自己的私钥进行签名,创建一个(签名)证书并发送给申请者。申请者将该证书部署在网站服务器上,当用户使用 HTTPS (或其它基于 [TLS][13] 加密的协议)与服务器通信时,该证书被分发给用户。
|
||||
|
||||
当用户访问该网站时,浏览器获取该证书,接着检查证书中的主机名是否与当前正在连接的网站一致(下文会详细说明),核验 CA 签名有效性。如果其中一步验证不通过,浏览器会给出安全警告并切断与网站的连接。反之,如果验证通过,浏览器会使用证书中的公钥核验服务器发送的签名信息,确认该服务器持有该证书的私钥。有几种算法用于协商后续通信用到的<ruby>共享密钥<rt>shared secret key</rt></ruby>,其中一种也用到了服务器发送的签名信息。<ruby>密钥交换<rt>Key exchange</rt></ruby>算法不在本文的讨论范围,可以参考这个[视频][14],其中仔细说明了一种密钥交换算法。
|
||||
当用户访问该网站时,浏览器获取该证书,接着检查证书中的主机名是否与当前正在连接的网站一致(下文会详细说明),核验 CA 签名有效性。如果其中一步验证不通过,浏览器会给出安全警告并切断与网站的连接。反之,如果验证通过,浏览器会使用证书中的公钥来核验该服务器发送的签名信息,确认该服务器持有该证书的私钥。有几种算法用于协商后续通信用到的<ruby>共享密钥<rt>shared secret key</rt></ruby>,其中一种也用到了服务器发送的签名信息。<ruby>密钥交换<rt>key exchange</rt></ruby>算法不在本文的讨论范围,可以参考这个[视频][14],其中仔细说明了一种密钥交换算法。
|
||||
|
||||
### 建立信任
|
||||
|
||||
你可能会问,“如果 CA 使用其私钥对证书进行签名,也就意味着我们需要使用 CA 的公钥验证证书。那么 CA 的公钥从何而来,谁对其进行签名呢?” 答案是 CA 对自己签名!可以使用证书公钥对应的私钥,对证书本身进行签名!这类签名证书被称为是<ruby>自签名的<rt>self-signed</rt></ruby>;在 PKI 体系下,这意味着对你说“相信我”。(为了表达方便,人们通常说用证书进行了签名,虽然真正用于签名的私钥并不在证书中。)
|
||||
|
||||
通过遵守[浏览器][15]和[操作系统][16]供应商建立的规则,CA 表明自己足够可靠并寻求加入到浏览器或操作系统预装的一组自签名证书中。这些证书被称为“<ruby>信任锚<rt>trust anchors</rt></ruby>”或 <ruby>CA 根证书<rt>root CA certificates</rt></ruby>,被存储在根证书区,我们<ruby>约定<rt>implicitly</rt></ruby>信任该区域内的证书。
|
||||
通过遵守[浏览器][15]和[操作系统][16]供应商建立的规则,CA 表明自己足够可靠并寻求加入到浏览器或操作系统预装的一组自签名证书中。这些证书被称为“<ruby>信任锚<rt>trust anchor</rt></ruby>”或 <ruby>CA 根证书<rt>root CA certificate</rt></ruby>,被存储在根证书区,我们<ruby>约定<rt>implicitly</rt></ruby>信任该区域内的证书。
|
||||
|
||||
CA 也可以签发一种特殊的证书,该证书自身可以作为 CA。在这种情况下,它们可以生成一个证书链。要核验证书链,需要从“信任锚”(也就是 CA 根证书)开始,使用当前证书的公钥核验下一层证书的签名(或其它一些信息)。按照这个方式依次核验下一层证书,直到证书链底部。如果整个核验过程没有问题,信任链也建立完成。当向 CA 付费为网站签发证书时,实际购买的是将证书放置在证书链下的权利。CA 将卖出的证书标记为“不可签发子证书”,这样它们可以在适当的长度终止信任链(防止其继续向下扩展)。
|
||||
|
||||
为何要使用长度超过 2 的信任链呢?毕竟网站的证书可以直接被 CA 根证书签名。在实际应用中,很多因素促使 CA 创建<ruby>中间 CA 证书<rt>intermediate CA certificate</rt></ruby>,最主要是为了方便。由于价值连城,CA 根证书对应的私钥通常被存放在特定的设备中,一种需要多人解锁的<ruby>硬件安全模块<rt>hardware security module, HSM</rt></ruby>,该模块完全离线并被保管在配备监控和报警设备的[地下室][18]中。
|
||||
为何要使用长度超过 2 的信任链呢?毕竟网站的证书可以直接被 CA 根证书签名。在实际应用中,很多因素促使 CA 创建<ruby>中间 CA 证书<rt>intermediate CA certificate</rt></ruby>,最主要是为了方便。由于价值连城,CA 根证书对应的私钥通常被存放在特定的设备中,一种需要多人解锁的<ruby>硬件安全模块<rt>hardware security module</rt></ruby>(HSM),该模块完全离线并被保管在配备监控和报警设备的[地下室][18]中。
|
||||
|
||||
<ruby>CA/浏览器论坛<rt>CAB Forum, CA/Browser Forum</rt></ruby>负责管理 CA,[要求][19]任何与 CA 根证书(LCTT 译注:就像前文提到的那样,这里是指对应的私钥)相关的操作必须由人工完成。设想一下,如果每个证书请求都需要员工将请求内容拷贝到保密介质中、进入地下室、与同事一起解锁 HSM、(使用 CA 根证书对应的私钥)签名证书,最后将签名证书从保密介质中拷贝出来;那么每天为大量网站签发证书是相当繁重乏味的工作。因此,CA 创建内部使用的中间 CA,用于证书签发自动化。
|
||||
|
||||
@ -72,12 +73,12 @@ via: https://opensource.com/article/18/7/private-keys
|
||||
作者:[Alex Wood][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/awood
|
||||
[1]:https://opensource.com/article/18/5/cryptography-pki
|
||||
[1]:https://linux.cn/article-9792-1.html
|
||||
[2]:https://theintercept.com/2014/10/28/smuggling-snowden-secrets/
|
||||
[3]:https://en.wikipedia.org/wiki/SHA-2
|
||||
[4]:https://www.ietf.org/mail-archive/web/openpgp/current/msg00999.html
|
||||
@ -1,80 +1,84 @@
|
||||
这 7 个 Python 库让你写出更易维护的代码
|
||||
让 Python 代码更易维护的七种武器
|
||||
======
|
||||
|
||||
> 检查你的代码的质量,通过这些外部库使其更易维护。
|
||||
|
||||

|
||||
|
||||
> 可读性很重要。
|
||||
> — [Python 之禅(The Zen of Python)][1], Tim Peters
|
||||
> — <ruby>[Python 之禅][1]<rt>The Zen of Python</rt></ruby>,Tim Peters
|
||||
|
||||
尽管很多项目一开始的时候就有可读性和编码标准的要求,但随着项目进入“维护模式”,这些要求都会变得虎头蛇尾。然而,在代码库中保持一致的代码风格和测试标准能够显著减轻维护的压力,也能确保新的开发者能够快速了解项目的情况,同时能更好地保持应用程序的运行良好。
|
||||
随着软件项目进入“维护模式”,对可读性和编码标准的要求很容易落空(甚至从一开始就没有建立过那些标准)。然而,在代码库中保持一致的代码风格和测试标准能够显著减轻维护的压力,也能确保新的开发者能够快速了解项目的情况,同时能更好地全程保持应用程序的质量。
|
||||
|
||||
使用外部库来检查代码的质量不失为保护项目未来可维护性的一个好方法。以下会推荐一些我们最喜爱的[检查代码][2](包括检查 PEP 8 和其它代码风格错误)的库,用它们来强制保持代码风格一致,并确保在项目成熟时有一个可接受的测试覆盖率。
|
||||
|
||||
### 检查你的代码风格
|
||||
|
||||
使用外部库来检查代码运行情况不失为保护项目未来可维护性的一个好方法。以下会推荐一些我们最喜爱的[检查代码][2](包括检查 PEP 8 和其它代码风格错误)的库,用它们来强制保持代码风格一致,并确保在项目成熟时有一个可接受的测试覆盖率。
|
||||
[PEP 8][3] 是 Python 代码风格规范,它规定了类似行长度、缩进、多行表达式、变量命名约定等内容。尽管你的团队自身可能也会有稍微不同于 PEP 8 的代码风格规范,但任何代码风格规范的目标都是在代码库中强制实施一致的标准,使代码的可读性更强、更易于维护。下面三个库就可以用来帮助你美化代码。
|
||||
|
||||
[PEP 8][3]是Python代码风格规范,规定了行长度,缩进,多行表达式、变量命名约定等内容。尽管你的团队自身可能也会有不同于 PEP 8 的代码风格规范,但任何代码风格规范的目标都是在代码库中强制实施一致的标准,使代码的可读性更强、更易于维护。下面三个库就可以用来帮助你美化代码。
|
||||
#### 1、 Pylint
|
||||
|
||||
#### 1\. Pylint
|
||||
[Pylint][4] 是一个检查违反 PEP 8 规范和常见错误的库。它在一些流行的[编辑器和 IDE][5] 中都有集成,也可以单独从命令行运行。
|
||||
|
||||
[Pylint][4] 是一个检查违反 PEP 8 规范和常见错误的库。它在一些流行的编辑器和 IDE 中都有集成,也可以单独从命令行运行。
|
||||
|
||||
执行 `pip install pylint`安装 Pylint 。然后运行 `pylint [options] path/to/dir` 或者 `pylint [options] path/to/module.py` 就可以在命令行中使用 Pylint,它会向控制台输出代码中违反规范和出现错误的地方。
|
||||
执行 `pip install pylint` 安装 Pylint 。然后运行 `pylint [options] path/to/dir` 或者 `pylint [options] path/to/module.py` 就可以在命令行中使用 Pylint,它会向控制台输出代码中违反规范和出现错误的地方。
|
||||
|
||||
你还可以使用 `pylintrc` [配置文件][6]来自定义 Pylint 对哪些代码错误进行检查。
|
||||
|
||||
#### 2\. Flake8
|
||||
#### 2、 Flake8
|
||||
|
||||
对 [Flake8][7] 的描述是“将 PEP 8、Pyflakes(类似 Pylint)、McCabe(代码复杂性检查器)、第三方插件整合到一起,以检查 Python 代码风格和质量的一个 Python 工具”。
|
||||
[Flake8][7] 是“将 PEP 8、Pyflakes(类似 Pylint)、McCabe(代码复杂性检查器)和第三方插件整合到一起,以检查 Python 代码风格和质量的一个 Python 工具”。
|
||||
|
||||
执行 `pip install flake8` 安装 flake8 ,然后执行 `flake8 [options] path/to/dir` 或者 `flake8 [options] path/to/module.py` 可以查看报出的错误和警告。
|
||||
|
||||
和 Pylint 类似,Flake8 允许通过[配置文件][8]来自定义检查的内容。它有非常清晰的文档,包括一些有用的[提交钩子][9],可以将自动检查代码纳入到开发工作流程之中。
|
||||
|
||||
Flake8 也允许集成到一些流行的编辑器和 IDE 当中,但在文档中并没有详细说明。要将 Flake8 集成到喜欢的编辑器或 IDE 中,可以搜索插件(例如 [Sublime Text 的 Flake8 插件][10])。
|
||||
Flake8 也可以集成到一些流行的编辑器和 IDE 当中,但在文档中并没有详细说明。要将 Flake8 集成到喜欢的编辑器或 IDE 中,可以搜索插件(例如 [Sublime Text 的 Flake8 插件][10])。
|
||||
|
||||
#### 3\. Isort
|
||||
#### 3、 Isort
|
||||
|
||||
[Isort][11] 这个库能将你在项目中导入的库按字母顺序,并将其[正确划分为不同部分][12](例如标准库、第三方库,自建的库等)。这样提高了代码的可读性,并且可以在导入的库较多的时候轻松找到各个库。
|
||||
[Isort][11] 这个库能将你在项目中导入的库按字母顺序排序,并将其[正确划分为不同部分][12](例如标准库、第三方库、自建的库等)。这样提高了代码的可读性,并且可以在导入的库较多的时候轻松找到各个库。
|
||||
|
||||
执行 `pip install isort` 安装 isort,然后执行 `isort path/to/module.py` 就可以运行了。文档中还提供了更多的配置项,例如通过配置 `.isort.cfg` 文件来决定 isort 如何处理一个库的多行导入。
|
||||
执行 `pip install isort` 安装 isort,然后执行 `isort path/to/module.py` 就可以运行了。[文档][13]中还提供了更多的配置项,例如通过[配置][14] `.isort.cfg` 文件来决定 isort 如何处理一个库的多行导入。
|
||||
|
||||
和 Flake8、Pylint 一样,isort 也提供了将其与流行的[编辑器和 IDE][15] 集成的插件。
|
||||
|
||||
### 共享代码风格
|
||||
### 分享你的代码风格
|
||||
|
||||
每次文件发生变动之后都用命令行手动检查代码是一件痛苦的事,你可能也不太喜欢通过运行 IDE 中某个插件来实现这个功能。同样地,你的同事可能会用不同的代码检查方式,也许他们的编辑器中也没有安装插件,甚至自己可能也不会严格检查代码和按照警告来更正代码。总之,你共享的代码库将会逐渐地变得混乱且难以阅读。
|
||||
每次文件发生变动之后都用命令行手动检查代码是一件痛苦的事,你可能也不太喜欢通过运行 IDE 中某个插件来实现这个功能。同样地,你的同事可能会用不同的代码检查方式,也许他们的编辑器中也没有那种插件,甚至你自己可能也不会严格检查代码和按照警告来更正代码。总之,你分享出来的代码库将会逐渐地变得混乱且难以阅读。
|
||||
|
||||
一个很好的解决方案是使用一个库,自动将代码按照 PEP 8 规范进行格式化。我们推荐的三个库都有不同的自定义级别来控制如何格式化代码。其中有一些设置较为特殊,例如 Pylint 和 Flake8 ,你需要先行测试,看看是否有你无法忍受蛋有不能修改的默认配置。
|
||||
一个很好的解决方案是使用一个库,自动将代码按照 PEP 8 规范进行格式化。我们推荐的三个库都有不同的自定义级别来控制如何格式化代码。其中有一些设置较为特殊,例如 Pylint 和 Flake8 ,你需要先行测试,看看是否有你无法忍受但又不能修改的默认配置。
|
||||
|
||||
#### 4\. Autopep8
|
||||
#### 4、 Autopep8
|
||||
|
||||
[Autopep8][16] 可以自动格式化指定的模块中的代码,包括重新缩进行,修复缩进,删除多余的空格,并重构常见的比较错误(例如布尔值和 `None` 值)。你可以查看文档中完整的[更正列表][17]。
|
||||
[Autopep8][16] 可以自动格式化指定的模块中的代码,包括重新缩进行、修复缩进、删除多余的空格,并重构常见的比较错误(例如布尔值和 `None` 值)。你可以查看文档中完整的[更正列表][17]。
|
||||
|
||||
运行 `pip install --upgrade autopep8` 安装 autopep8。然后执行 `autopep8 --in-place --aggressive --aggressive <filename>` 就可以重新格式化你的代码。`aggressive` 标记的数量表示 auotopep8 在代码风格控制上有多少控制权。在这里可以详细了解 [aggressive][18] 选项。
|
||||
运行 `pip install --upgrade autopep8` 安装 Autopep8。然后执行 `autopep8 --in-place --aggressive --aggressive <filename>` 就可以重新格式化你的代码。`aggressive` 选项的数量表示 Auotopep8 在代码风格控制上有多少控制权。在这里可以详细了解 [aggressive][18] 选项。
|
||||
|
||||
#### 5\. Yapf
|
||||
#### 5、 Yapf
|
||||
|
||||
[Yapf][19] 是另一种有自己的[配置项][20]列表的重新格式化代码的工具。它与 autopep8 的不同之处在于它不仅会指出代码中违反 PEP 8 规范的地方,还会对没有违反 PEP 8 但代码风格不一致的地方重新格式化,旨在令代码的可读性更强。
|
||||
[Yapf][19] 是另一种有自己的[配置项][20]列表的重新格式化代码的工具。它与 Autopep8 的不同之处在于它不仅会指出代码中违反 PEP 8 规范的地方,还会对没有违反 PEP 8 但代码风格不一致的地方重新格式化,旨在令代码的可读性更强。
|
||||
|
||||
执行`pip install yapf` 安装 Yapf,然后执行 `yapf [options] path/to/dir` 或 `yapf [options] path/to/module.py` 可以对代码重新格式化。
|
||||
执行 `pip install yapf` 安装 Yapf,然后执行 `yapf [options] path/to/dir` 或 `yapf [options] path/to/module.py` 可以对代码重新格式化。[定制选项][20]的完整列表在这里。
|
||||
|
||||
#### 6\. Black
|
||||
#### 6、 Black
|
||||
|
||||
[Black][21] 在代码检查工具当中算是比较新的一个。它与 autopep8 和 Yapf 类似,但限制较多,没有太多的自定义选项。这样的好处是你不需要去决定使用怎么样的代码风格,让 black 来给你做决定就好。你可以在这里查阅 black 的[自定义选项][22]以及[如何在配置文件中对其进行设置][23]。
|
||||
[Black][21] 在代码检查工具当中算是比较新的一个。它与 Autopep8 和 Yapf 类似,但限制较多,没有太多的自定义选项。这样的好处是你不需要去决定使用怎么样的代码风格,让 Black 来给你做决定就好。你可以在这里查阅 Black [有限的自定义选项][22]以及[如何在配置文件中对其进行设置][23]。
|
||||
|
||||
Black 依赖于 Python 3.6+,但它可以格式化用 Python 2 编写的代码。执行 `pip install black` 安装 black,然后执行 `black path/to/dir` 或 `black path/to/module.py` 就可以使用 black 优化你的代码。
|
||||
Black 依赖于 Python 3.6+,但它可以格式化用 Python 2 编写的代码。执行 `pip install black` 安装 Black,然后执行 `black path/to/dir` 或 `black path/to/module.py` 就可以使用 Black 优化你的代码。
|
||||
|
||||
### 检查你的测试覆盖率
|
||||
|
||||
如果你正在进行测试工作,你需要确保提交到代码库的新代码都已经测试通过,并且不会降低测试覆盖率。虽然测试覆盖率不是衡量测试有效性和充分性的唯一指标,但它是确保项目遵循基本测试标准的一种方法。对于计算测试覆盖率,我们推荐使用 Coverage 这个库。
|
||||
如果你正在进行编写测试,你需要确保提交到代码库的新代码都已经测试通过,并且不会降低测试覆盖率。虽然测试覆盖率不是衡量测试有效性和充分性的唯一指标,但它是确保项目遵循基本测试标准的一种方法。对于计算测试覆盖率,我们推荐使用 Coverage 这个库。
|
||||
|
||||
#### 7\. Coverage
|
||||
#### 7、 Coverage
|
||||
|
||||
[Coverage][24] 有数种显示测试覆盖率的方式,包括将结果输出到控制台或 HTML 页面,并指出哪些具体哪些地方没有被覆盖到。你可以通过配置文件自定义 Coverage 检查的内容,让你更方便使用。
|
||||
[Coverage][24] 有数种显示测试覆盖率的方式,包括将结果输出到控制台或 HTML 页面,并指出哪些具体哪些地方没有被覆盖到。你可以通过[配置文件][25]自定义 Coverage 检查的内容,让你更方便使用。
|
||||
|
||||
执行 `pip install coverage` 安装 Converage 。然后执行 `coverage [path/to/module.py] [args]` 可以运行程序并查看输出结果。如果要查看哪些代码行没有被覆盖,执行 `coverage report -m` 即可。
|
||||
|
||||
持续集成(Continuous integration, CI)是在合并和部署代码之前自动检查代码风格错误和测试覆盖率最小值的过程。很多免费或付费的工具都可以用于执行这项工作,具体的过程不在本文中赘述,但 CI 过程是令代码更易读和更易维护的重要步骤,关于这一部分可以参考 [Travis CI][26] 和 [Jenkins][27]。
|
||||
### 持续集成工具
|
||||
|
||||
<ruby>持续集成<rt>Continuous integration</rt></ruby>(CI)是在合并和部署代码之前自动检查代码风格错误和测试覆盖率最小值的过程。很多免费或付费的工具都可以用于执行这项工作,具体的过程不在本文中赘述,但 CI 过程是令代码更易读和更易维护的重要步骤,关于这一部分可以参考 [Travis CI][26] 和 [Jenkins][27]。
|
||||
|
||||
以上这些只是用于检查 Python 代码的各种工具中的其中几个。如果你有其它喜爱的工具,欢迎在评论中分享。
|
||||
|
||||
@ -85,7 +89,7 @@ via: https://opensource.com/article/18/7/7-python-libraries-more-maintainable-co
|
||||
作者:[Jeff Triplett][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
162
published/201809/20180804 Installing Andriod on VirtualBox.md
Normal file
162
published/201809/20180804 Installing Andriod on VirtualBox.md
Normal file
@ -0,0 +1,162 @@
|
||||
在 VirtualBox 中安装 Android 系统
|
||||
======
|
||||
|
||||
如果你正在开发 Android 应用,也许会遇到小麻烦。诚然,ios 移动开发有 macOS 系统平台为其提供友好便利性, Android 开发仅有支持少部分 Android 系统(其中还包括可穿戴设备系统)的 Android Studio 工具。
|
||||
|
||||
毋庸置疑,所有的二进制工具、SDK 工具、开发框架工具以及调试器都会产生大量日志和其他各种文件,使得你的文件系统很混乱。一个有效的解决方法就是在 VirtualBox 中安装 Android 系统,这样还解决了 Android 开发中最为棘手问题之一 —— 设备模拟器。你可以在该虚拟机里测试应用程序,也可以使用 Android 的内部功能。因此,让我们迫不及待的开始吧!
|
||||
|
||||
### 准备工作
|
||||
|
||||
首先,你需要在你的系统上安装 VirtualBox,可从[这里][1]下载 Windows 版本、macOS 版本或者各种 Linux 版本的 VitualBox。然后,你需要一个能在 x86 平台运行的 Android 镜像,因为 VirtualBox 为虚拟机提供运行 x86 或者 x86\_64(即 AMD64)平台的功能。
|
||||
|
||||
虽然大部分 Android 设备都在 ARM 上运行,但我们依然可以从 [Android on x86 项目][2] 中获得帮助。这些优秀的开发者已经将 Android 移植到 x86 平台上运行(包括实体机和虚拟机),我们可以下载最新版本的 Android 7.1。你也可以用之前更为稳定的版本,本文写作时最新稳定版是 Android 6.0。
|
||||
|
||||
### 创建 VM 虚拟机
|
||||
|
||||
打开 VirtualBox,单击左上角的 “新建” 按钮,在弹出的窗口中选择 “类型:Linux” ,然后根据下载的 ISO 镜像来确定版本,x86 对应 “32-bit”,x86_64 对应 “64-bit”,此处选择 “Linux 2.6 / 3.x / 4.x (64-bit)”。
|
||||
|
||||
RAM 大小设置为 2 GB 到你系统能提供的最大内存之间。如果你想模拟真实的使用环境你可以设置 6 GB RAM 和 32 GB ROM。
|
||||
|
||||
![][3]
|
||||
|
||||
![][4]
|
||||
|
||||
创建完成后,你还需要做一些设置,添加更多的处理器核心,提高开机显示内存。在 VM 上打开设置选项,“设置 -> 系统 -> 处理器”,如果硬件条件允许,可以多分配一些处理器。
|
||||
|
||||
![][5]
|
||||
|
||||
在 “设置 -> 显示 -> 显存大小” 中,你可以分配一大块内存并开启 3D 加速功能。
|
||||
|
||||
![][6]
|
||||
|
||||
现在我们可以启动 VM 虚拟机了。
|
||||
|
||||
### 安装 Android
|
||||
|
||||
首次启动 VM 虚拟机,VirtualBox 会提示你需要提供启动媒介,选择之前下载好的Android 镜像。
|
||||
|
||||
![][7]
|
||||
|
||||
下一步,如果想长时间使用 Android,选择 “Installation” 选项,你也可以选择 Live 模式体验 Android 环境。
|
||||
|
||||
![][8]
|
||||
|
||||
按回车键。
|
||||
|
||||
#### 分区
|
||||
|
||||
分区是通过文本界面操作,并没有友好的 GUI 界面,所以每个操作都需要小心对待。例如,在第一屏中还没有创建分区并且只检测到原始(虚拟)硬盘时显示如下。
|
||||
|
||||
![][9]
|
||||
|
||||
红色字母 `C` 和 `D` 表明 `C` 开头选项可以创建或者修改分区,`D` 开头选项可以检测设备。你可以选择 `D` 开头选项,然后它就会检测硬盘,也可不进行这步操作,因为在启动的时候它会自动检测。
|
||||
|
||||
我们选择 `C` 开头选项,在虚拟盘中创建分区。官方不推荐使用 GPT 格式,所以我们选择 “No” 并按回车键。
|
||||
|
||||
![][10]
|
||||
|
||||
现在你被引导到 fdisk 工具页面。
|
||||
|
||||
![][11]
|
||||
|
||||
为了简洁起见,我们就只创建一个较大的分区,使用方向键来选择 “New” ,然后选择 “Primary”,按回车键以确认。
|
||||
|
||||
![][12]
|
||||
|
||||
分区大小系统已经为你计算好了,按回车键确认。
|
||||
|
||||
![][13]
|
||||
|
||||
这个分区就是 Android 系统所在的分区,所以需要它是可启动的。选择 “Bootable”,然后按回车键(上方表格中 “Flags” 标志下面会出现 “boot” 标志),进一步,选择 “Write” 选项,保存刚才的操作记录并写入分区表。
|
||||
|
||||
![][14]
|
||||
|
||||
现在你可以选择退出分区工具,然后继续安装过程。
|
||||
|
||||
![][15]
|
||||
|
||||
#### 文件系统格式化为 EXT4 并安装 Android
|
||||
|
||||
在“Choose Partition”分区页面上会出现一个刚刚我们创建的分区,选择它并点击“OK”进入。
|
||||
|
||||
![][16]
|
||||
|
||||
在下一个菜单中选择 Ext4 作为实际的文件系统,在下一页中选择 “Yes” 然后格式化开始。会提示是否安装 GRUB 引导工具以及是否允许在目录 `/system` 进行读写,都选择 “Yes” 。现在,安装进程开始。
|
||||
|
||||
安装完成后,当系统提示可以重启的时候你可以安全地重启系统。在重启之前,你可以先关机,然后在 VitualBox 的 “设置 -> 存储” 中检查 Android iso 镜像是否还连接在虚拟机上,如果在,将它移除。
|
||||
|
||||
![][17]
|
||||
|
||||
移除安装媒介并保存修改,再去启动 VM 虚拟机。
|
||||
|
||||
#### 运行 Android
|
||||
|
||||
在 GRUB 引导界面,有调试模式和普通模式的选项。我们选择默认选项,如下图所示。
|
||||
|
||||
![][18]
|
||||
|
||||
如果一切正常,你将会看到如下界面:
|
||||
|
||||
![][19]
|
||||
|
||||
如今的 Android 系统使用触摸交互而不是鼠标。不过 Android-x86 平台提供了鼠标操作支持,但开始时可能需要方向键来辅助操作。
|
||||
|
||||
![][20]
|
||||
|
||||
移动到”let’s go“按钮并按下回车键。选择 “Set up as new” 选项,回车确认。
|
||||
|
||||
![][21]
|
||||
|
||||
在提示用谷歌账户登陆之前,系统检查更新并检测设备信息。你可以跳过这一步,直接去设置日期和时间、用户名等。
|
||||
|
||||
还有一些其他的选项,和让你设置一个新的 Android 设备类似。选择 “I Agree” 选项同意有关更新、服务等的相应的选项,当然谷歌的服务条款是不得不同意的。
|
||||
|
||||
![][22]
|
||||
|
||||
在这之后,因为它是个虚拟机,所以可能需要添加额外的 email 账户来设置 “On-body detection”,大部分的选项对我们来说都没有多大作用,因此可以选择 ”All Set“。
|
||||
|
||||
接下来,它会提示你选择主屏应用,这个根据个人需求选择。现在我们进入了一个虚拟的 Android 系统。
|
||||
|
||||
![][23]
|
||||
|
||||
如果你需要在 VM 做一些交互测试,有个可触摸屏幕会提供很大的方便,因为那样才更接近真实使用环境。
|
||||
|
||||
希望这篇教程会给你带来帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxhint.com/install_android_virtualbox/
|
||||
|
||||
作者:[Ranvir Singh][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jrglinux](https://github.com/jrglinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxhint.com/author/sranvir155/
|
||||
[1]:https://www.virtualbox.org/wiki/Downloads
|
||||
[2]:http://www.android-x86.org/
|
||||
[3]:https://linuxhint.com/wp-content/uploads/2018/08/a.png
|
||||
[4]:https://linuxhint.com/wp-content/uploads/2018/08/a1.png
|
||||
[5]:https://linuxhint.com/wp-content/uploads/2018/08/a2.png
|
||||
[6]:https://linuxhint.com/wp-content/uploads/2018/08/a3.png
|
||||
[7]:https://linuxhint.com/wp-content/uploads/2018/08/a4.png
|
||||
[8]:https://linuxhint.com/wp-content/uploads/2018/08/a5.png
|
||||
[9]:https://linuxhint.com/wp-content/uploads/2018/08/a6.png
|
||||
[10]:https://linuxhint.com/wp-content/uploads/2018/08/a7.png
|
||||
[11]:https://linuxhint.com/wp-content/uploads/2018/08/a8.png
|
||||
[12]:https://linuxhint.com/wp-content/uploads/2018/08/a9.png
|
||||
[13]:https://linuxhint.com/wp-content/uploads/2018/08/a10.png
|
||||
[14]:https://linuxhint.com/wp-content/uploads/2018/08/a11.png
|
||||
[15]:https://linuxhint.com/wp-content/uploads/2018/08/a12.png
|
||||
[16]:https://linuxhint.com/wp-content/uploads/2018/08/a13.png
|
||||
[17]:https://linuxhint.com/wp-content/uploads/2018/08/a14.png
|
||||
[18]:https://linuxhint.com/wp-content/uploads/2018/08/a16.png
|
||||
[19]:https://linuxhint.com/wp-content/uploads/2018/08/a17.png
|
||||
[20]:https://linuxhint.com/wp-content/uploads/2018/08/a18.png
|
||||
[21]:https://linuxhint.com/wp-content/uploads/2018/08/a19.png
|
||||
[22]:https://linuxhint.com/wp-content/uploads/2018/08/a20.png
|
||||
[23]:https://linuxhint.com/wp-content/uploads/2018/08/a21.png
|
||||
|
||||
|
||||
@ -16,12 +16,8 @@ Linux DNS 查询剖析(第四部分)
|
||||
|
||||
在第四部分中,我将介绍容器如何完成 DNS 查询。你想的没错,也不是那么简单。
|
||||
|
||||
* * *
|
||||
|
||||
### 1) Docker 和 DNS
|
||||
|
||||
============================================================
|
||||
|
||||
在 [Linux DNS 查询剖析(第三部分)][3] 中,我们介绍了 `dnsmasq`,其工作方式如下:将 DNS 查询指向到 localhost 地址 `127.0.0.1`,同时启动一个进程监听 `53` 端口并处理查询请求。
|
||||
|
||||
在按上述方式配置 DNS 的主机上,如果运行了一个 Docker 容器,容器内的 `/etc/resolv.conf` 文件会是怎样的呢?
|
||||
@ -72,29 +68,29 @@ google.com. 112 IN A 172.217.23.14
|
||||
|
||||
在这个问题上,Docker 的解决方案是忽略所有可能的复杂情况,即无论主机中使用什么 DNS 服务器,容器内都使用 Google 的 DNS 服务器 `8.8.8.8` 和 `8.8.4.4` 完成 DNS 查询。
|
||||
|
||||
_我的经历:在 2013 年,我遇到了使用 Docker 以来的第一个问题,与 Docker 的这种 DNS 解决方案密切相关。我们公司的网络屏蔽了 `8.8.8.8` 和 `8.8.4.4`,导致容器无法解析域名。_
|
||||
_我的经历:在 2013 年,我遇到了使用 Docker 以来的第一个问题,与 Docker 的这种 DNS 解决方案密切相关。我们公司的网络屏蔽了 `8.8.8.8` 和 `8.8.4.4`,导致容器无法解析域名。_
|
||||
|
||||
这就是 Docker 容器的情况,但对于包括 Kubernetes 在内的容器 _<ruby>编排引擎<rt>orchestrators</rt></ruby>_,情况又有些不同。
|
||||
这就是 Docker 容器的情况,但对于包括 Kubernetes 在内的容器 <ruby>编排引擎<rt>orchestrators</rt></ruby>,情况又有些不同。
|
||||
|
||||
### 2) Kubernetes 和 DNS
|
||||
|
||||
在 Kubernetes 中,最小部署单元是 `pod`;`pod` 是一组相互协作的容器,共享 IP 地址(和其它资源)。
|
||||
在 Kubernetes 中,最小部署单元是 pod;它是一组相互协作的容器,共享 IP 地址(和其它资源)。
|
||||
|
||||
Kubernetes 面临的一个额外的挑战是,将 Kubernetes 服务请求(例如,`myservice.kubernetes.io`)通过对应的<ruby>解析器<rt>resolver</rt></ruby>,转发到具体服务地址对应的<ruby>内网地址<rt>private network</rt></ruby>。这里提到的服务地址被称为归属于“<ruby>集群域<rt>cluster domain</rt></ruby>”。集群域可由管理员配置,根据配置可以是 `cluster.local` 或 `myorg.badger` 等。
|
||||
|
||||
在 Kubernetes 中,你可以为 `pod` 指定如下四种 `pod` 内 DNS 查询的方式。
|
||||
在 Kubernetes 中,你可以为 pod 指定如下四种 pod 内 DNS 查询的方式。
|
||||
|
||||
* Default
|
||||
**Default**
|
||||
|
||||
在这种(名称容易让人误解)的方式中,`pod` 与其所在的主机采用相同的 DNS 查询路径,与前面介绍的主机 DNS 查询一致。我们说这种方式的名称容易让人误解,因为该方式并不是默认选项!`ClusterFirst` 才是默认选项。
|
||||
在这种(名称容易让人误解)的方式中,pod 与其所在的主机采用相同的 DNS 查询路径,与前面介绍的主机 DNS 查询一致。我们说这种方式的名称容易让人误解,因为该方式并不是默认选项!`ClusterFirst` 才是默认选项。
|
||||
|
||||
如果你希望覆盖 `/etc/resolv.conf` 中的条目,你可以添加到 `kubelet` 的配置中。
|
||||
|
||||
* ClusterFirst
|
||||
**ClusterFirst**
|
||||
|
||||
在 `ClusterFirst` 方式中,遇到 DNS 查询请求会做有选择的转发。根据配置的不同,有以下两种方式:
|
||||
|
||||
第一种方式配置相对古老但更简明,即采用一个规则:如果请求的域名不是集群域的子域,那么将其转发到 `pod` 所在的主机。
|
||||
第一种方式配置相对古老但更简明,即采用一个规则:如果请求的域名不是集群域的子域,那么将其转发到 pod 所在的主机。
|
||||
|
||||
第二种方式相对新一些,你可以在内部 DNS 中配置选择性转发。
|
||||
|
||||
@ -115,27 +111,27 @@ data:
|
||||
|
||||
在 `stubDomains` 条目中,可以为特定域名指定特定的 DNS 服务器;而 `upstreamNameservers` 条目则给出,待查询域名不是集群域子域情况下用到的 DNS 服务器。
|
||||
|
||||
这是通过在一个 `pod` 中运行我们熟知的 `dnsmasq` 实现的。
|
||||
这是通过在一个 pod 中运行我们熟知的 `dnsmasq` 实现的。
|
||||
|
||||

|
||||
|
||||
剩下两种选项都比较小众:
|
||||
|
||||
* ClusterFirstWithHostNet
|
||||
**ClusterFirstWithHostNet**
|
||||
|
||||
适用于 `pod` 使用主机网络的情况,例如绕开 Docker 网络配置,直接使用与 `pod` 对应主机相同的网络。
|
||||
适用于 pod 使用主机网络的情况,例如绕开 Docker 网络配置,直接使用与 pod 对应主机相同的网络。
|
||||
|
||||
* None
|
||||
**None**
|
||||
|
||||
`None` 意味着不改变 DNS,但强制要求你在 `pod` <ruby>规范文件<rt>specification</rt></ruby>的 `dnsConfig` 条目中指定 DNS 配置。
|
||||
|
||||
### CoreDNS 即将到来
|
||||
|
||||
除了上面提到的那些,一旦 `CoreDNS` 取代Kubernetes 中的 `kube-dns`,情况还会发生变化。`CoreDNS` 相比 `kube-dns` 具有可配置性更高、效率更高等优势。
|
||||
除了上面提到的那些,一旦 `CoreDNS` 取代 Kubernetes 中的 `kube-dns`,情况还会发生变化。`CoreDNS` 相比 `kube-dns` 具有可配置性更高、效率更高等优势。
|
||||
|
||||
如果想了解更多,参考[这里][5]。
|
||||
|
||||
如果你对 OpenShift 的网络感兴趣,我曾写过一篇[文章][6]可供你参考。但文章中 OpenShift 的版本是 `3.6`,可能有些过时。
|
||||
如果你对 OpenShift 的网络感兴趣,我曾写过一篇[文章][6]可供你参考。但文章中 OpenShift 的版本是 3.6,可能有些过时。
|
||||
|
||||
### 第四部分总结
|
||||
|
||||
@ -152,14 +148,14 @@ via: https://zwischenzugs.com/2018/08/06/anatomy-of-a-linux-dns-lookup-part-iv/
|
||||
|
||||
作者:[zwischenzugs][a]
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://zwischenzugs.com/
|
||||
[1]:https://zwischenzugs.com/2018/06/08/anatomy-of-a-linux-dns-lookup-part-i/
|
||||
[2]:https://zwischenzugs.com/2018/06/18/anatomy-of-a-linux-dns-lookup-part-ii/
|
||||
[3]:https://zwischenzugs.com/2018/07/06/anatomy-of-a-linux-dns-lookup-part-iii/
|
||||
[1]:https://linux.cn/article-9943-1.html
|
||||
[2]:https://linux.cn/article-9949-1.html
|
||||
[3]:https://linux.cn/article-9972-1.html
|
||||
[4]:https://kubernetes.io/docs/tasks/administer-cluster/dns-custom-nameservers/#impacts-on-pods
|
||||
[5]:https://coredns.io/
|
||||
[6]:https://zwischenzugs.com/2017/10/21/openshift-3-6-dns-in-pictures/
|
||||
@ -3,46 +3,45 @@
|
||||
|
||||

|
||||
|
||||
有效管理待办事项可以为你的工作效率创造奇迹。有些人更喜欢在文本中保存待办事项,甚至只使用记事本和笔。对于需要更多待办事项功能的用户,他们通常会使用应用程序。在本文中,我们将重点介绍 4 个图形程序和一个基于终端的工具来管理待办事项。
|
||||
有效管理待办事项(to-do)可以为你的工作效率创造奇迹。有些人更喜欢在文本中保存待办事项,甚至只使用记事本和笔。对于需要更多待办事项功能的用户,他们通常会使用应用程序。在本文中,我们将重点介绍 4 个图形程序和一个基于终端的工具来管理待办事项。
|
||||
|
||||
### GNOME To Do
|
||||
|
||||
GNOME To Do][1] 是专为 GNOME 桌面(Fedora Workstation 的默认桌面)设计的个人任务管理器。将 GNOME To Do 与其他程序进行比较时,它有一系列简洁的功能。
|
||||
[GNOME To Do][1] 是专为 GNOME 桌面(Fedora Workstation 的默认桌面)设计的个人任务管理器。GNOME To Do 与其他程序进行比较,它有一系列简洁的功能。
|
||||
|
||||
GNOME To Do 提供列表形式的任务组织,并能为该列表指定颜色。此外,可以为各个任务分配截止日期和优先级,以及每项任务的注释。此外,GNOME To Do 还支持扩展,能添加更多功能,包括支持 [todo.txt][2] 以及与 [todoist][3] 等在线服务同步。
|
||||
GNOME To Do 提供列表形式的任务组织方式,并能为该列表指定颜色。此外,可以为各个任务分配截止日期和优先级,以及每项任务的注释。此外,GNOME To Do 还支持扩展,能添加更多功能,包括支持 [todo.txt][2] 以及与 [todoist][3] 等在线服务同步。
|
||||
|
||||
![][4]
|
||||
|
||||
使用软件中心或者在终端中使用下面的命令安装 GNOME To Do:
|
||||
|
||||
```
|
||||
sudo dnf install gnome-todo
|
||||
|
||||
```
|
||||
|
||||
### Getting things GNOME!
|
||||
|
||||
、在 GNOME To Do 存在之前,在 GNOME 上追踪任务的首选程序是 [Getting things GNOME!][5] 这个稍来的 GNOME 程序有多个窗口层,能然你同时显示多个任务的细节。GTG 没有任务列表,它能在任务中添加子任务,甚至在子任务中添加子任务。GTG 同样能添加截止日期和开始日期。通过插件同步其他程序和服务也是可能的。
|
||||
在 GNOME To Do 出现之前,在 GNOME 上追踪任务的首选程序是 [Getting things GNOME!][5] 这个老式的 GNOME 程序采用多窗口布局,能让你同时显示多个任务的细节。GTG 没有任务列表,它能在任务中添加子任务,甚至在子任务中添加子任务。GTG 同样能添加截止日期和开始日期。也可以通过插件同步其他程序和服务。
|
||||
|
||||
![][6]
|
||||
|
||||
在软件中心或者在终端中使用下面的命令安装 Getting Things GNOME:
|
||||
|
||||
```
|
||||
sudo dnf install gtg
|
||||
|
||||
```
|
||||
|
||||
### Go For It!
|
||||
|
||||
[Go For It!][7] 是一个超级简单的任务管理程序。它能简单地创建一个任务列表,并在完成后标记它们。它没有组任务,也不能创建子任务。默认 Go For It! 将任务存储在 todo.txt 中,这能更方便地同步到在线服务或者其他程序中。额外地,Go For It! 包含了一个简单定时器来追踪你在当前任务花费了多少时间。
|
||||
[Go For It!][7] 是一个超级简单的任务管理程序。它能简单地创建一个任务列表,并在完成后标记它们。它不能将任务分组,也不能创建子任务。Go For It! 默认将任务存储为 todo.txt 格式,这能更方便地同步到在线服务或者其他程序中。额外地,Go For It! 包含了一个简单定时器来追踪你在当前任务花费了多少时间。
|
||||
|
||||
![][8]
|
||||
|
||||
Go For It 能在 Flathub 应用仓库中找到。要安装它,只需[启用 Flathub 作为软件源][9],接着在软件中心中安装。
|
||||
|
||||
Go For It! 能在 Flathub 应用仓库中找到。要安装它,只需[启用 Flathub 作为软件源][9],接着在软件中心中安装。
|
||||
|
||||
### Agenda
|
||||
|
||||
如果你在寻找一款非常简单的待办应用,[Agenda][10] 非常合适。创建任务,标记完成,接着从列表中删除它们。Agenda 会在你删除它们之前显示所有任务(完成或者进行中)。
|
||||
如果你在寻找一款非常简单的待办应用,非 [Agenda][10] 莫属。创建任务,标记完成,接着从列表中删除它们。Agenda 会在你删除它们之前一直显示所有任务(完成的或者进行中)。
|
||||
|
||||
![][11]
|
||||
|
||||
@ -57,12 +56,11 @@ Agenda 能从 Flathub 应用仓库下载。要安装它,只需[启用 Flathub
|
||||
![][14]
|
||||
|
||||
在终端中使用这个命令安装 Taskwarrior:
|
||||
|
||||
```
|
||||
sudo dnf install task
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/5-tools-to-manage-your-to-do-list-on-fedora/
|
||||
@ -70,7 +68,7 @@ via: https://fedoramagazine.org/5-tools-to-manage-your-to-do-list-on-fedora/
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -88,4 +86,4 @@ via: https://fedoramagazine.org/5-tools-to-manage-your-to-do-list-on-fedora/
|
||||
[11]:https://fedoramagazine.org/wp-content/uploads/2018/08/agenda.png
|
||||
[12]:https://taskwarrior.org/
|
||||
[13]:https://fedoramagazine.org/getting-started-taskwarrior/
|
||||
[14]:https://fedoramagazine.org/wp-content/uploads/2018/08/taskwarrior.png
|
||||
[14]:https://fedoramagazine.org/wp-content/uploads/2018/08/taskwarrior.png
|
||||
@ -0,0 +1,78 @@
|
||||
|
||||
Steam 让我们在 Linux 上玩 Windows 的游戏更加容易
|
||||
======
|
||||
|
||||
![Steam Wallpaper][1]
|
||||
|
||||
总所周知,[Linux 游戏][2]库中的游戏只有 Windows 游戏库中的一部分,实际上,许多人甚至都不会考虑将操作系统[转换为 Linux][3],原因很简单,因为他们喜欢的游戏,大多数都不能在这个平台上运行。
|
||||
|
||||
在撰写本文时,Steam 上已有超过 5000 种游戏可以在 Linux 上运行,而 Steam 上的游戏总数已经接近 27000 种了。现在 5000 种游戏可能看起来很多,但还没有达到 27000 种,确实没有。
|
||||
|
||||
虽然几乎所有的新的<ruby>独立游戏<rt>indie game</rt></ruby>都是在 Linux 中推出的,但我们仍然无法在这上面玩很多的 [3A 大作][4]。对我而言,虽然这其中有很多游戏我都很希望能有机会玩,但这从来都不是一个非黑即白的问题。因为我主要是玩独立游戏和[复古游戏][5],所以几乎所有我喜欢的游戏都可以在 Linux 系统上运行。
|
||||
|
||||
### 认识 Proton,Steam 的一个 WINE 复刻
|
||||
|
||||
现在,这个问题已经成为过去式了,因为本周 Valve [宣布][6]要对 Steam Play 进行一次更新,此次更新会将一个名为 Proton 的 Wine 复刻版本添加到 Linux 客户端中。是的,这个工具是开源的,Valve 已经在 [GitHub][7] 上开源了源代码,但该功能仍然处于测试阶段,所以你必须使用测试版的 Steam 客户端才能使用这项功能。
|
||||
|
||||
#### 使用 proton ,可以在 Linux 系统上通过 Steam 运行更多 Windows 游戏
|
||||
|
||||
这对我们这些 Linux 用户来说,实际上意味着什么?简单来说,这意味着我们可以在 Linux 电脑上运行全部 27000 种游戏,而无需配置像 [PlayOnLinux][8] 或 [Lutris][9] 这样的东西。我要告诉你的是,配置这些东西有时候会非常让人头疼。
|
||||
|
||||
对此更为复杂的答案是,某种原因听起来非常美好。虽然在理论上,你可以用这种方式在 Linux 上玩所有的 Windows 平台上的游戏。但只有一少部分游戏在推出时会正式支持 Linux。这少部分游戏包括 《DOOM》、《最终幻想 VI》、《铁拳 7》、《星球大战:前线 2》,和其他几个。
|
||||
|
||||
#### 你可以在 Linux 上玩所有的 Windows 游戏(理论上)
|
||||
|
||||
虽然目前该列表只有大约 30 个游戏,你可以点击“为所有游戏启用 Steam Play”复选框来强制使用 Steam 的 Proton 来安装和运行任意游戏。但你最好不要有太高的期待,它们的稳定性和性能表现不一定有你希望的那么好,所以请把期望值压低一点。
|
||||
|
||||
![Steam Play][10]
|
||||
|
||||
据[这份报告][13],已经有超过一千个游戏可以在 Linux 上玩了。按[此指南][14]来了解如何启用 Steam Play 测试版本。
|
||||
|
||||
#### 体验 Proton,没有我想的那么烂
|
||||
|
||||
例如,我安装了一些难度适中的游戏,使用 Proton 来进行安装。其中一个是《上古卷轴 4:湮没》,在我玩这个游戏的两个小时里,它只崩溃了一次,而且几乎是紧跟在游戏教程的自动保存点之后。
|
||||
|
||||
我有一块英伟达 Gtx 1050 Ti 的显卡。所以我可以使用 1080P 的高配置来玩这个游戏。而且我没有遇到除了这次崩溃之外的任何问题。我唯一真正感到不爽的只有它的帧数没有原本的高。在 90% 的时间里,游戏的帧数都在 60 帧以上,但我知道它的帧数应该能更高。
|
||||
|
||||
我安装和运行的其他所有游戏都运行得很完美,虽然我还没有较长时间地玩过它们中的任何一个。我安装的游戏中包括《森林》、《丧尸围城 4》和《刺客信条 2》。(你觉得我这是喜欢恐怖游戏吗?)
|
||||
|
||||
#### 为什么 Steam(仍然)要下注在 Linux 上?
|
||||
|
||||
现在,一切都很好,这件事为什么会发生呢?为什么 Valve 要花费时间,金钱和资源来做这样的事?我倾向于认为,他们这样做是因为他们懂得 Linux 社区的价值,但是如果要我老实地说,我不相信我们和它有任何的关系。
|
||||
|
||||
如果我一定要在这上面花钱,我想说 Valve 开发了 Proton,因为他们还没有放弃 [Steam Machine][11]。因为 [Steam OS][12] 是基于 Linux 的发行版,在这类东西上面投资可以获取最大的利润,Steam OS 上可用的游戏越多,就会有更多的人愿意购买 Steam Machine。
|
||||
|
||||
可能我是错的,但是我敢打赌啊,我们会在不远的未来看到新一批的 Steam Machine。可能我们会在一年内看到它们,也有可能我们再等五年都见不到,谁知道呢!
|
||||
|
||||
无论哪种方式,我所知道的是,我终于能兴奋地从我的 Steam 游戏库里玩游戏了。这个游戏库是多年来我通过各种慈善包、促销码和不定时地买的游戏慢慢积累的,只不过是想试试让它在 Lutris 中运行。
|
||||
|
||||
#### 为 Linux 上越来越多的游戏而激动?
|
||||
|
||||
你怎么看?你对此感到激动吗?或者说你会害怕只有很少的开发者会开发 Linux 平台上的游戏,因为现在几乎没有需求?Valve 喜欢 Linux 社区,还是说他们喜欢钱?请在下面的评论区告诉我们您的想法,然后重新搜索来查看更多类似这样的开源软件方面的文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/steam-play-proton/
|
||||
|
||||
作者:[Phillip Prado][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/phillip/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/steam-wallpaper.jpeg
|
||||
[2]:https://itsfoss.com/linux-gaming-guide/
|
||||
[3]:https://itsfoss.com/reasons-switch-linux-windows-xp/
|
||||
[4]:https://itsfoss.com/triplea-game-review/
|
||||
[5]:https://itsfoss.com/play-retro-games-linux/
|
||||
[6]:https://steamcommunity.com/games/221410
|
||||
[7]:https://github.com/ValveSoftware/Proton/
|
||||
[8]:https://www.playonlinux.com/en/
|
||||
[9]:https://lutris.net/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/SteamProton.jpg
|
||||
[11]:https://store.steampowered.com/sale/steam_machines
|
||||
[12]:https://itsfoss.com/valve-annouces-linux-based-gaming-operating-system-steamos/
|
||||
[13]:https://spcr.netlify.com/
|
||||
[14]:https://itsfoss.com/steam-play/
|
||||
@ -0,0 +1,118 @@
|
||||
怎样解决 Ubuntu 中的 “sub process usr bin dpkg returned an error code 1” 错误
|
||||
======
|
||||
|
||||
> 如果你在 Ubuntu Linux 上安装软件时遇到 “sub process usr bin dpkg returned an error code 1”,请按照以下步骤进行修复。
|
||||
|
||||
Ubuntu 和其他基于 Debian 的发行版中的一个常见问题是已经损坏的包。你尝试更新系统或安装新软件包时会遇到类似 “Sub-process /usr/bin/dpkg returned an error code” 的错误。
|
||||
|
||||
这就是前几天发生在我身上的事。我试图在 Ubuntu 中安装一个电台程序时,它给我了这个错误:
|
||||
|
||||
```
|
||||
Unpacking python-gst-1.0 (1.6.2-1build1) ...
|
||||
Selecting previously unselected package radiotray.
|
||||
Preparing to unpack .../radiotray_0.7.3-5ubuntu1_all.deb ...
|
||||
Unpacking radiotray (0.7.3-5ubuntu1) ...
|
||||
Processing triggers for man-db (2.7.5-1) ...
|
||||
Processing triggers for desktop-file-utils (0.22-1ubuntu5.2) ...
|
||||
Processing triggers for bamfdaemon (0.5.3~bzr0+16.04.20180209-0ubuntu1) ...
|
||||
Rebuilding /usr/share/applications/bamf-2.index...
|
||||
Processing triggers for gnome-menus (3.13.3-6ubuntu3.1) ...
|
||||
Processing triggers for mime-support (3.59ubuntu1) ...
|
||||
Setting up polar-bookshelf (1.0.0-beta56) ...
|
||||
ln: failed to create symbolic link '/usr/local/bin/polar-bookshelf': No such file or directory
|
||||
dpkg: error processing package polar-bookshelf (--configure):
|
||||
subprocess installed post-installation script returned error exit status 1
|
||||
Setting up python-appindicator (12.10.1+16.04.20170215-0ubuntu1) ...
|
||||
Setting up python-gst-1.0 (1.6.2-1build1) ...
|
||||
Setting up radiotray (0.7.3-5ubuntu1) ...
|
||||
Errors were encountered while processing:
|
||||
polar-bookshelf
|
||||
E: Sub-process /usr/bin/dpkg returned an error code (1)
|
||||
|
||||
```
|
||||
|
||||
这里最后三行非常重要。
|
||||
|
||||
```
|
||||
Errors were encountered while processing:
|
||||
polar-bookshelf
|
||||
E: Sub-process /usr/bin/dpkg returned an error code (1)
|
||||
```
|
||||
|
||||
它告诉我 polar-bookshelf 包引发了问题。这可能对你如何修复这个错误至关重要。
|
||||
|
||||
### 修复 Sub-process /usr/bin/dpkg returned an error code (1)
|
||||
|
||||
![Fix update errors in Ubuntu Linux][1]
|
||||
|
||||
让我们尝试修复这个损坏的错误包。我将展示几种你可以逐一尝试的方法。最初的那些易于使用,几乎不用动脑子。
|
||||
|
||||
在试了这里讨论的每一种方法之后,你应该尝试运行 `sudo apt update`,接着尝试安装新的包或升级。
|
||||
|
||||
#### 方法 1:重新配包数据库
|
||||
|
||||
你可以尝试的第一种方法是重新配置包数据库。数据库可能在安装包时损坏了。重新配置通常可以解决问题。
|
||||
|
||||
```
|
||||
sudo dpkg --configure -a
|
||||
```
|
||||
|
||||
#### 方法 2:强制安装
|
||||
|
||||
如果是之前包安装过程被中断,你可以尝试强制安装。
|
||||
|
||||
```
|
||||
sudo apt-get install -f
|
||||
```
|
||||
|
||||
#### 方法3:尝试删除有问题的包
|
||||
|
||||
如果这不是你的问题,你可以尝试手动删除包。但不要对 Linux 内核包(以 linux- 开头)执行此操作。
|
||||
|
||||
```
|
||||
sudo apt remove
|
||||
```
|
||||
|
||||
#### 方法 4:删除有问题的包中的信息文件
|
||||
|
||||
这应该是你最后的选择。你可以尝试从 `/var/lib/dpkg/info` 中删除与相关软件包关联的文件。
|
||||
|
||||
**你需要了解一些基本的 Linux 命令来了解发生了什么以及如何对应你的问题**
|
||||
|
||||
就我而言,我在 polar-bookshelf 中遇到问题。所以我查找了与之关联的文件:
|
||||
|
||||
```
|
||||
ls -l /var/lib/dpkg/info | grep -i polar-bookshelf
|
||||
-rw-r--r-- 1 root root 2324811 Aug 14 19:29 polar-bookshelf.list
|
||||
-rw-r--r-- 1 root root 2822824 Aug 10 04:28 polar-bookshelf.md5sums
|
||||
-rwxr-xr-x 1 root root 113 Aug 10 04:28 polar-bookshelf.postinst
|
||||
-rwxr-xr-x 1 root root 84 Aug 10 04:28 polar-bookshelf.postrm
|
||||
```
|
||||
|
||||
现在我需要做的就是删除这些文件:
|
||||
|
||||
```
|
||||
sudo mv /var/lib/dpkg/info/polar-bookshelf.* /tmp
|
||||
```
|
||||
|
||||
使用 `sudo apt update`,接着你应该就能像往常一样安装软件了。
|
||||
|
||||
#### 哪种方法适合你(如果有效)?
|
||||
|
||||
我希望这篇快速文章可以帮助你修复 “E: Sub-process /usr/bin/dpkg returned an error code (1)” 的错误。
|
||||
|
||||
如果它对你有用,是那种方法?你是否设法使用其他方法修复此错误?如果是,请分享一下以帮助其他人解决此问题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/dpkg-returned-an-error-code-1/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/fix-common-update-errors-ubuntu.jpeg
|
||||
@ -1,26 +1,27 @@
|
||||
如何在 Linux 上使用 tcpdump 命令捕获和分析数据包
|
||||
======
|
||||
tcpdump 是一个有名的命令行**数据包分析**工具。我们可以使用 tcpdump 命令捕获实时 TCP/IP 数据包,这些数据包也可以保存到文件中。之后这些捕获的数据包可以通过 tcpdump 命令进行分析。tcpdump 命令在网络级故障排除时变得非常方便。
|
||||
|
||||
`tcpdump` 是一个有名的命令行**数据包分析**工具。我们可以使用 `tcpdump` 命令捕获实时 TCP/IP 数据包,这些数据包也可以保存到文件中。之后这些捕获的数据包可以通过 `tcpdump` 命令进行分析。`tcpdump` 命令在网络层面进行故障排除时变得非常方便。
|
||||
|
||||

|
||||
|
||||
tcpdump 在大多数 Linux 发行版中都能用,对于基于 Debian 的Linux,可以使用 apt 命令安装它
|
||||
`tcpdump` 在大多数 Linux 发行版中都能用,对于基于 Debian 的Linux,可以使用 `apt` 命令安装它。
|
||||
|
||||
```
|
||||
# apt install tcpdump -y
|
||||
```
|
||||
|
||||
在基于 RPM 的 Linux 操作系统上,可以使用下面的 yum 命令安装 tcpdump
|
||||
在基于 RPM 的 Linux 操作系统上,可以使用下面的 `yum` 命令安装 `tcpdump`。
|
||||
|
||||
```
|
||||
# yum install tcpdump -y
|
||||
```
|
||||
|
||||
当我们在没用任何选项的情况下运行 tcpdump 命令时,它将捕获所有接口的数据包。因此,要停止或取消 tcpdump 命令,请输入 '**ctrl+c**'。在本教程中,我们将使用不同的实例来讨论如何捕获和分析数据包,
|
||||
当我们在没用任何选项的情况下运行 `tcpdump` 命令时,它将捕获所有接口的数据包。因此,要停止或取消 `tcpdump` 命令,请键入 `ctrl+c`。在本教程中,我们将使用不同的实例来讨论如何捕获和分析数据包。
|
||||
|
||||
### 示例: 1) 从特定接口捕获数据包
|
||||
### 示例:1)从特定接口捕获数据包
|
||||
|
||||
当我们在没用任何选项的情况下运行 tcpdump 命令时,它将捕获所有接口上的数据包,因此,要从特定接口捕获数据包,请使用选项 '**-i**',后跟接口名称。
|
||||
当我们在没用任何选项的情况下运行 `tcpdump` 命令时,它将捕获所有接口上的数据包,因此,要从特定接口捕获数据包,请使用选项 `-i`,后跟接口名称。
|
||||
|
||||
语法:
|
||||
|
||||
@ -28,7 +29,7 @@ tcpdump 在大多数 Linux 发行版中都能用,对于基于 Debian 的Linux
|
||||
# tcpdump -i {接口名}
|
||||
```
|
||||
|
||||
假设我想从接口“enp0s3”捕获数据包
|
||||
假设我想从接口 `enp0s3` 捕获数据包。
|
||||
|
||||
输出将如下所示,
|
||||
|
||||
@ -49,21 +50,21 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
|
||||
```
|
||||
|
||||
### 示例: 2) 从特定接口捕获特定数量数据包
|
||||
### 示例:2)从特定接口捕获特定数量数据包
|
||||
|
||||
假设我们想从特定接口(如“enp0s3”)捕获12个数据包,这可以使用选项 '**-c {数量} -I {接口名称}**' 轻松实现
|
||||
假设我们想从特定接口(如 `enp0s3`)捕获 12 个数据包,这可以使用选项 `-c {数量} -I {接口名称}` 轻松实现。
|
||||
|
||||
```
|
||||
root@compute-0-1 ~]# tcpdump -c 12 -i enp0s3
|
||||
```
|
||||
|
||||
上面的命令将生成如下所示的输出
|
||||
上面的命令将生成如下所示的输出,
|
||||
|
||||
[![N-Number-Packsets-tcpdump-interface][1]][2]
|
||||
|
||||
### 示例: 3) 显示 tcpdump 的所有可用接口
|
||||
### 示例:3)显示 tcpdump 的所有可用接口
|
||||
|
||||
使用 '**-D**' 选项显示 tcpdump 命令的所有可用接口,
|
||||
使用 `-D` 选项显示 `tcpdump` 命令的所有可用接口,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -D
|
||||
@ -86,11 +87,11 @@ root@compute-0-1 ~]# tcpdump -c 12 -i enp0s3
|
||||
[[email protected] ~]#
|
||||
```
|
||||
|
||||
我正在我的一个openstack计算节点上运行tcpdump命令,这就是为什么在输出中你会看到数字接口、标签接口、网桥和vxlan接口
|
||||
我正在我的一个 openstack 计算节点上运行 `tcpdump` 命令,这就是为什么在输出中你会看到数字接口、标签接口、网桥和 vxlan 接口
|
||||
|
||||
### 示例: 4) 捕获带有可读时间戳(-tttt 选项)的数据包
|
||||
### 示例:4)捕获带有可读时间戳的数据包(`-tttt` 选项)
|
||||
|
||||
默认情况下,在tcpdump命令输出中,没有显示可读性好的时间戳,如果您想将可读性好的时间戳与每个捕获的数据包相关联,那么使用 '**-tttt**'选项,示例如下所示,
|
||||
默认情况下,在 `tcpdump` 命令输出中,不显示可读性好的时间戳,如果您想将可读性好的时间戳与每个捕获的数据包相关联,那么使用 `-tttt` 选项,示例如下所示,
|
||||
|
||||
```
|
||||
[[email protected] ~]# tcpdump -c 8 -tttt -i enp0s3
|
||||
@ -108,12 +109,11 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
134 packets received by filter
|
||||
69 packets dropped by kernel
|
||||
[[email protected] ~]#
|
||||
|
||||
```
|
||||
|
||||
### 示例: 5) 捕获数据包并将其保存到文件( -w 选项)
|
||||
### 示例:5)捕获数据包并将其保存到文件(`-w` 选项)
|
||||
|
||||
使用 tcpdump 命令中的 '**-w**' 选项将捕获的 TCP/IP 数据包保存到一个文件中,以便我们可以在将来分析这些数据包以供进一步分析。
|
||||
使用 `tcpdump` 命令中的 `-w` 选项将捕获的 TCP/IP 数据包保存到一个文件中,以便我们可以在将来分析这些数据包以供进一步分析。
|
||||
|
||||
语法:
|
||||
|
||||
@ -121,9 +121,9 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
# tcpdump -w 文件名.pcap -i {接口名}
|
||||
```
|
||||
|
||||
注意:文件扩展名必须为 **.pcap**
|
||||
注意:文件扩展名必须为 `.pcap`。
|
||||
|
||||
假设我要把 '**enp0s3**' 接口捕获到的包保存到文件名为 **enp0s3-26082018.pcap**
|
||||
假设我要把 `enp0s3` 接口捕获到的包保存到文件名为 `enp0s3-26082018.pcap`。
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w enp0s3-26082018.pcap -i enp0s3
|
||||
@ -140,24 +140,23 @@ tcpdump: listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 b
|
||||
[root@compute-0-1 ~]# ls
|
||||
anaconda-ks.cfg enp0s3-26082018.pcap
|
||||
[root@compute-0-1 ~]#
|
||||
|
||||
```
|
||||
|
||||
捕获并保存大小**大于 N 字节**的数据包
|
||||
捕获并保存大小**大于 N 字节**的数据包。
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w enp0s3-26082018-2.pcap greater 1024
|
||||
```
|
||||
|
||||
捕获并保存大小**小于 N 字节**的数据包
|
||||
捕获并保存大小**小于 N 字节**的数据包。
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w enp0s3-26082018-3.pcap less 1024
|
||||
```
|
||||
|
||||
### 示例: 6) 从保存的文件中读取数据包( -r 选项)
|
||||
### 示例:6)从保存的文件中读取数据包(`-r` 选项)
|
||||
|
||||
在上面的例子中,我们已经将捕获的数据包保存到文件中,我们可以使用选项 '**-r**' 从文件中读取这些数据包,例子如下所示,
|
||||
在上面的例子中,我们已经将捕获的数据包保存到文件中,我们可以使用选项 `-r` 从文件中读取这些数据包,例子如下所示,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -r enp0s3-26082018.pcap
|
||||
@ -183,12 +182,11 @@ p,TS val 81359114 ecr 81350901], length 508
|
||||
2018-08-25 22:03:17.647502 IP controller0.example.com.amqp > compute-0-1.example.com.57788: Flags [.], ack 1956, win 1432, options [nop,nop,TS val 813
|
||||
52753 ecr 81359114], length 0
|
||||
.........................................................................................................................
|
||||
|
||||
```
|
||||
|
||||
### 示例: 7) 仅捕获特定接口上的 IP 地址数据包( -n 选项)
|
||||
### 示例:7)仅捕获特定接口上的 IP 地址数据包(`-n` 选项)
|
||||
|
||||
使用 tcpdump 命令中的 -n 选项,我们能只捕获特定接口上的 IP 地址数据包,示例如下所示,
|
||||
使用 `tcpdump` 命令中的 `-n` 选项,我们能只捕获特定接口上的 IP 地址数据包,示例如下所示,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -n -i enp0s3
|
||||
@ -211,19 +209,18 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
22:22:28.539595 IP 169.144.0.1.39406 > 169.144.0.20.ssh: Flags [.], ack 1572, win 9086, options [nop,nop,TS val 20666614 ecr 82510006], length 0
|
||||
22:22:28.539760 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 1572:1912, ack 1, win 291, options [nop,nop,TS val 82510007 ecr 20666614], length 340
|
||||
.........................................................................
|
||||
|
||||
```
|
||||
|
||||
您还可以使用 tcpdump 命令中的 -c 和 -N 选项捕获 N 个 IP 地址包,
|
||||
您还可以使用 `tcpdump` 命令中的 `-c` 和 `-N` 选项捕获 N 个 IP 地址包,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -c 25 -n -i enp0s3
|
||||
```
|
||||
|
||||
|
||||
### 示例: 8) 仅捕获特定接口上的TCP数据包
|
||||
### 示例:8)仅捕获特定接口上的 TCP 数据包
|
||||
|
||||
在 tcpdump 命令中,我们能使用 '**tcp**' 选项来只捕获TCP数据包,
|
||||
在 `tcpdump` 命令中,我们能使用 `tcp` 选项来只捕获 TCP 数据包,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -i enp0s3 tcp
|
||||
@ -241,9 +238,9 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
...................................................................................................................................................
|
||||
```
|
||||
|
||||
### 示例: 9) 从特定接口上的特定端口捕获数据包
|
||||
### 示例:9)从特定接口上的特定端口捕获数据包
|
||||
|
||||
使用 tcpdump 命令,我们可以从特定接口 enp0s3 上的特定端口(例如 22 )捕获数据包
|
||||
使用 `tcpdump` 命令,我们可以从特定接口 `enp0s3` 上的特定端口(例如 22)捕获数据包。
|
||||
|
||||
语法:
|
||||
|
||||
@ -262,13 +259,12 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
22:54:55.038564 IP 169.144.0.1.39406 > compute-0-1.example.com.ssh: Flags [.], ack 940, win 9177, options [nop,nop,TS val 21153238 ecr 84456505], length 0
|
||||
22:54:55.038708 IP compute-0-1.example.com.ssh > 169.144.0.1.39406: Flags [P.], seq 940:1304, ack 1, win 291, options [nop,nop,TS val 84456506 ecr 21153238], length 364
|
||||
............................................................................................................................
|
||||
[root@compute-0-1 ~]#
|
||||
```
|
||||
|
||||
|
||||
### 示例: 10) 在特定接口上捕获来自特定来源 IP 的数据包
|
||||
### 示例:10)在特定接口上捕获来自特定来源 IP 的数据包
|
||||
|
||||
在tcpdump命令中,使用 '**src**' 关键字后跟 '**IP 地址**',我们可以捕获来自特定来源 IP 的数据包,
|
||||
在 `tcpdump` 命令中,使用 `src` 关键字后跟 IP 地址,我们可以捕获来自特定来源 IP 的数据包,
|
||||
|
||||
语法:
|
||||
|
||||
@ -296,17 +292,16 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
10 packets captured
|
||||
12 packets received by filter
|
||||
0 packets dropped by kernel
|
||||
[root@compute-0-1 ~]#
|
||||
|
||||
```
|
||||
|
||||
### 示例: 11) 在特定接口上捕获来自特定目的IP的数据包
|
||||
### 示例:11)在特定接口上捕获来自特定目的 IP 的数据包
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
# tcpdump -n -i {接口名} dst {IP 地址}
|
||||
```
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -n -i enp0s3 dst 169.144.0.1
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
@ -318,42 +313,39 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
23:10:43.522157 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 800:996, ack 1, win 291, options [nop,nop,TS val 85404989 ecr 21390359], length 196
|
||||
23:10:43.522346 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 996:1192, ack 1, win 291, options [nop,nop,TS val 85404989 ecr 21390359], length 196
|
||||
.........................................................................................
|
||||
|
||||
```
|
||||
|
||||
### 示例: 12) 捕获两台主机之间的 TCP 数据包通信
|
||||
### 示例:12)捕获两台主机之间的 TCP 数据包通信
|
||||
|
||||
假设我想捕获两台主机 169.144.0.1 和 169.144.0.20 之间的 TCP 数据包,示例如下所示,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w two-host-tcp-comm.pcap -i enp0s3 tcp and \(host 169.144.0.1 or host 169.144.0.20\)
|
||||
|
||||
```
|
||||
|
||||
使用 tcpdump 命令只捕获两台主机之间的 SSH 数据包流,
|
||||
使用 `tcpdump` 命令只捕获两台主机之间的 SSH 数据包流,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w ssh-comm-two-hosts.pcap -i enp0s3 src 169.144.0.1 and port 22 and dst 169.144.0.20 and port 22
|
||||
|
||||
```
|
||||
|
||||
示例: 13) 捕获两台主机之间的 UDP 网络数据包(来回)
|
||||
### 示例:13)捕获两台主机之间(来回)的 UDP 网络数据包
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
# tcpdump -w -s -i udp and \(host and host \)
|
||||
```
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w two-host-comm.pcap -s 1000 -i enp0s3 udp and \(host 169.144.0.10 and host 169.144.0.20\)
|
||||
|
||||
```
|
||||
|
||||
### 示例: 14) 捕获十六进制和ASCII格式的数据包
|
||||
### 示例:14)捕获十六进制和 ASCII 格式的数据包
|
||||
|
||||
使用 tcpdump 命令,我们可以以 ASCII 和十六进制格式捕获 TCP/IP 数据包,
|
||||
使用 `tcpdump` 命令,我们可以以 ASCII 和十六进制格式捕获 TCP/IP 数据包,
|
||||
|
||||
要使用** -A **选项捕获ASCII格式的数据包,示例如下所示:
|
||||
要使用 `-A` 选项捕获 ASCII 格式的数据包,示例如下所示:
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -c 10 -A -i enp0s3
|
||||
@ -376,7 +368,7 @@ root@compute-0-1 @..........
|
||||
..................................................................................................................................................
|
||||
```
|
||||
|
||||
要同时以十六进制和 ASCII 格式捕获数据包,请使用** -XX **选项
|
||||
要同时以十六进制和 ASCII 格式捕获数据包,请使用 `-XX` 选项。
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -c 10 -XX -i enp0s3
|
||||
@ -406,10 +398,9 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
0x0030: 3693 7c0e 0000 0101 080a 015a a734 0568 6.|........Z.4.h
|
||||
0x0040: 39af
|
||||
.......................................................................
|
||||
|
||||
```
|
||||
|
||||
这就是本文的全部内容,我希望您能了解如何使用 tcpdump 命令捕获和分析 TCP/IP 数据包。请分享你的反馈和评论。
|
||||
这就是本文的全部内容,我希望您能了解如何使用 `tcpdump` 命令捕获和分析 TCP/IP 数据包。请分享你的反馈和评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -418,7 +409,7 @@ via: https://www.linuxtechi.com/capture-analyze-packets-tcpdump-command-linux/
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[ypingcn](https://github.com/ypingcn)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,161 @@
|
||||
Bat:一种具有语法高亮和 Git 集成的 Cat 类命令
|
||||
======
|
||||
|
||||

|
||||
|
||||
在类 UNIX 系统中,我们使用 `cat` 命令去打印和连接文件。使用 `cat` 命令,我们能将文件目录打印到到标准输出,合成几个文件为一个目标文件,还有追加几个文件到目标文件中。今天,我偶然发现一个具有相似作用的命令叫做 “Bat” ,它是 `cat` 命令的一个克隆版,具有一些例如语法高亮、 Git 集成和自动分页等非常酷的特性。在这个简略指南中,我们将讲述如何在 Linux 中安装和使用 `bat` 命令。
|
||||
|
||||
### 安装
|
||||
|
||||
Bat 可以在 Arch Linux 的默认软件源中获取。 所以你可以使用 `pacman` 命令在任何基于 arch 的系统上来安装它。
|
||||
|
||||
```
|
||||
$ sudo pacman -S bat
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 等系统中,从其[发布页面][1]下载 **.deb** 文件,然后用下面的命令来安装。
|
||||
|
||||
```
|
||||
$ sudo apt install gdebi
|
||||
$ sudo gdebi bat_0.5.0_amd64.deb
|
||||
```
|
||||
|
||||
对于其他系统,你也许需要从软件源编译并安装。确保你已经安装了 Rust 1.26 或者更高版本。
|
||||
|
||||
然后运行以下命令来安装 Bat:
|
||||
|
||||
```
|
||||
$ cargo install bat
|
||||
```
|
||||
|
||||
或者,你可以从 [Linuxbrew][2] 软件包管理中来安装它。
|
||||
|
||||
```
|
||||
$ brew install bat
|
||||
```
|
||||
|
||||
### bat 命令的使用
|
||||
|
||||
`bat` 命令的使用与 `cat` 命令的使用非常相似。
|
||||
|
||||
使用 `bat` 命令创建一个新的文件:
|
||||
|
||||
```
|
||||
$ bat > file.txt
|
||||
```
|
||||
|
||||
使用 `bat` 命令来查看文件内容,只需要:
|
||||
|
||||
```
|
||||
$ bat file.txt
|
||||
```
|
||||
|
||||
你能同时查看多个文件:
|
||||
|
||||
```
|
||||
$ bat file1.txt file2.txt
|
||||
```
|
||||
|
||||
将多个文件的内容合并至一个单独文件中:
|
||||
|
||||
```
|
||||
$ bat file1.txt file2.txt file3.txt > document.txt
|
||||
```
|
||||
|
||||
就像我之前提到的那样,除了浏览和编辑文件以外,`bat` 命令有一些非常酷的特性。
|
||||
|
||||
`bat` 命令支持大多数编程和标记语言的<ruby>语法高亮<rt>syntax highlighting</rt></ruby>。比如,下面这个例子。我将使用 `cat` 和 `bat` 命令来展示 `reverse.py` 的内容。
|
||||
|
||||
|
||||
|
||||
你注意到区别了吗? `cat` 命令以纯文本格式显示文件的内容,而 `bat` 命令显示了语法高亮和整齐的文本对齐格式。更好了不是吗?
|
||||
|
||||
如果你只想显示行号(而没有表格)使用 `-n` 标记。
|
||||
|
||||
```
|
||||
$ bat -n reverse.py
|
||||
```
|
||||
|
||||

|
||||
|
||||
另一个 `bat` 命令中值得注意的特性是它支持<ruby>自动分页<rt>automatic paging</rt></ruby>。 它的意思是当文件的输出对于屏幕来说太大的时候,`bat` 命令自动将自己的输出内容传输到 `less` 命令中,所以你可以一页一页的查看输出内容。
|
||||
|
||||
让我给你看一个例子,使用 `cat` 命令查看跨多个页面的文件的内容时,提示符会快速跳至文件的最后一页,你看不到内容的开头和中间部分。
|
||||
|
||||
看一下下面的输出:
|
||||
|
||||

|
||||
|
||||
正如你所看到的,`cat` 命令显示了文章的最后一页。
|
||||
|
||||
所以你也许需要去将使用 `cat` 命令的输出传输到 `less` 命令中去从开头一页一页的查看内容。
|
||||
|
||||
```
|
||||
$ cat reverse.py | less
|
||||
```
|
||||
|
||||
现在你可以使用回车键去一页一页的查看输出。然而当你使用 `bat` 命令时这些都是不必要的。`bat` 命令将自动传输跨越多个页面的文件的输出。
|
||||
|
||||
```
|
||||
$ bat reverse.py
|
||||
```
|
||||
|
||||

|
||||
|
||||
现在按下回车键去往下一页。
|
||||
|
||||
`bat` 命令也支持 <ruby>Git 集成<rt>**GIT integration**</rt></ruby>,这样您就可以轻松查看/编辑 Git 存储库中的文件。 它与 Git 连接可以显示关于索引的修改。(看左栏)
|
||||
|
||||

|
||||
|
||||
### 定制 Bat
|
||||
|
||||
如果你不喜欢默认主题,你也可以修改它。Bat 同样有修改它的选项。
|
||||
|
||||
若要显示可用主题,只需运行:
|
||||
|
||||
```
|
||||
$ bat --list-themes
|
||||
1337
|
||||
DarkNeon
|
||||
Default
|
||||
GitHub
|
||||
Monokai Extended
|
||||
Monokai Extended Bright
|
||||
Monokai Extended Light
|
||||
Monokai Extended Origin
|
||||
TwoDark
|
||||
```
|
||||
|
||||
|
||||
要使用其他主题,例如 TwoDark,请运行:
|
||||
|
||||
```
|
||||
$ bat --theme=TwoDark file.txt
|
||||
```
|
||||
|
||||
如果你想永久改变主题,在你的 shells 启动文件中加入 `export BAT_THEME="TwoDark"`。
|
||||
|
||||
`bat` 还可以选择修改输出的外观。使用 `--style` 选项来修改输出外观。仅显示 Git 的更改和行号但不显示网格和文件头,请使用 `--style=numbers,changes`。
|
||||
|
||||
更多详细信息,请参阅 Bat 项目的 GitHub 库(链接在文末)。
|
||||
|
||||
最好,这就是目前的全部内容了。希望这篇文章会帮到你。更多精彩文章即将到来,敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/bat-a-cat-clone-with-syntax-highlighting-and-git-integration/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[z52527](https://github.com/z52527)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://github.com/sharkdp/bat/releases
|
||||
[2]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
@ -0,0 +1,89 @@
|
||||
如何使用 Steam Play 在 Linux 上玩仅限 Windows 的游戏
|
||||
======
|
||||
|
||||
> Steam 的新实验功能允许你在 Linux 上玩仅限 Windows 的游戏。以下是如何在 Steam 中使用此功能。
|
||||
|
||||
你已经听说过这个消息。游戏发行平台 [Steam 正在复刻一个 WINE 分支来允许你玩仅限于 Windows 上的游戏][1]。对于 Linux 用户来说,这绝对是一个好消息,因为我们总抱怨 Linux 的游戏数量不足。
|
||||
|
||||
这个新功能仍处于测试阶段,但你现在可以在 Linux 上试用它并在 Linux 上玩仅限 Windows 的游戏。让我们看看如何做到这一点。
|
||||
|
||||
### 使用 Steam Play 在 Linux 中玩仅限 Windows 的游戏
|
||||
|
||||
![Play Windows-only games on Linux][2]
|
||||
|
||||
你需要先安装 Steam。Steam 适用于所有主要 Linux 发行版。我已经详细介绍了[在 Ubuntu 上安装 Steam][3],如果你还没有安装 Steam,你可以参考那篇文章。
|
||||
|
||||
安装了 Steam 并且你已登录到 Steam 帐户,就可以了解如何在 Steam Linux 客户端中启用 Windows 游戏。
|
||||
|
||||
#### 步骤 1:进入帐户设置
|
||||
|
||||
运行 Steam 客户端。在左上角,单击 “Steam”,然后单击 “Settings”。
|
||||
|
||||
![Enable steam play beta on Linux][4]
|
||||
|
||||
#### 步骤 2:选择加入测试计划
|
||||
|
||||
在“Settings”中,从左侧窗口中选择“Account”,然后单击 “Beta participation” 下的 “CHANGE” 按钮。
|
||||
|
||||
![Enable beta feature in Steam Linux][5]
|
||||
|
||||
你应该在此处选择 “Steam Beta Update”。
|
||||
|
||||
![Enable beta feature in Steam Linux][6]
|
||||
|
||||
在此处保存设置后,Steam 将重新启动并下载新的测试版更新。
|
||||
|
||||
#### 步骤 3:启用 Steam Play 测试版
|
||||
|
||||
下载好 Steam 新的测试版更新后,它将重新启动。到这里就差不多了。
|
||||
|
||||
再次进入“Settings”。你现在可以在左侧窗口看到新的 “Steam Play” 选项。单击它并选中复选框:
|
||||
|
||||
* Enable Steam Play for supported titles (你可以玩列入白名单的 Windows 游戏)
|
||||
* Enable Steam Play for all titles (你可以尝试玩所有仅限 Windows 的游戏)
|
||||
|
||||
![Play Windows games on Linux using Steam Play][7]
|
||||
|
||||
我不记得 Steam 是否会再次重启,但我想这无所谓。你现在应该可以在 Linux 上看到安装仅限 Windows 的游戏的选项了。
|
||||
|
||||
比如,我的 Steam 库中有《Age of Empires》,正常情况下这个在 Linux 中没有。但我在 Steam Play 测试版启用所有 Windows 游戏后,现在我可以选择在 Linux 上安装《Age of Empires》了。
|
||||
|
||||
![Install Windows-only games on Linux using Steam][8]
|
||||
|
||||
*现在可以在 Linux 上安装仅限 Windows 的游戏*
|
||||
|
||||
### 有关 Steam Play 测试版功能的信息
|
||||
|
||||
在 Linux 上使用 Steam Play 测试版玩仅限 Windows 的游戏有一些事情你需要知道并且牢记。
|
||||
|
||||
* 目前,[只有 27 个 Steam Play 中的 Windows 游戏被列入白名单][9]。这些白名单游戏可以在 Linux 上无缝运行。
|
||||
* 你可以使用 Steam Play 测试版尝试任何 Windows 游戏,但它可能不是总能运行。有些游戏有时会崩溃,而某些游戏可能根本无法运行。
|
||||
* 在测试版中,你无法 Steam 商店中看到适用于 Linux 的 Windows 限定游戏。你必须自己尝试游戏或参考[这个社区维护的列表][10]以查看该 Windows 游戏的兼容性状态。你也可以通过填写[此表][11]来为列表做出贡献。
|
||||
* 如果你在 Windows 中通过 Steam 下载了游戏,你可以[在 Linux 和 Windows 之间共享 Steam 游戏文件][12]来节省下载的数据。
|
||||
|
||||
我希望本教程能帮助你在 Linux 上运行仅限 Windows 的游戏。你期待在 Linux 上玩哪些游戏?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/steam-play/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://linux.cn/article-10054-1.html
|
||||
[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/play-windows-games-on-linux-featured.jpeg
|
||||
[3]:https://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta.jpeg
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-2.jpeg
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-3.jpeg
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-4.jpeg
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/install-windows-games-linux.jpeg
|
||||
[9]:https://steamcommunity.com/games/221410
|
||||
[10]:https://docs.google.com/spreadsheets/d/1DcZZQ4HL_Ol969UbXJmFG8TzOHNnHoj8Q1f8DIFe8-8/htmlview?sle=true#
|
||||
[11]:https://docs.google.com/forms/d/e/1FAIpQLSeefaYQduMST_lg0IsYxZko8tHLKe2vtVZLFaPNycyhY4bidQ/viewform
|
||||
[12]:https://linux.cn/article-8027-1.html
|
||||
@ -1,31 +1,33 @@
|
||||
使用 PySimpleGUI 轻松为程序和脚本增加 GUI
|
||||
======
|
||||
|
||||
> 五分钟创建定制 GUI。
|
||||
|
||||

|
||||
|
||||
对于 `.exe` 类型的程序文件,我们可以通过双击鼠标左键打开;但对于 `.py` 类型的 Python 程序,几乎不会有人尝试同样的操作。对于一个(非程序员类型的)典型用户,他们双击打开 `.exe` 文件时预期弹出一个可以交互的窗体。基于 `Tkinter`,可以通过<ruby>标准 Python 安装<rt>standard Python installations</rt></ruby>的方式提供 GUI,但很多程序都不太可能这样做。
|
||||
对于 `.exe` 类型的程序文件,我们可以通过双击鼠标左键打开;但对于 `.py` 类型的 Python 程序,几乎不会有人尝试同样的操作。对于一个(非程序员类型的)典型用户,他们双击打开 `.exe` 文件时预期弹出一个可以交互的窗体。基于 Tkinter,可以通过<ruby>标准 Python 安装<rt>standard Python installations</rt></ruby>的方式提供 GUI,但很多程序都不太可能这样做。
|
||||
|
||||
如果打开 Python 程序并进入 GUI 界面变得如此容易,以至于真正的初学者也可以掌握,会怎样呢?会有人感兴趣并使用吗?这个问题不好回答,因为直到今天创建自定义 GUI 布局仍不是件容易的事情。
|
||||
|
||||
在为程序或脚本增加 GUI 这件事上,似乎存在能力的“错配”。(缺乏这方面能力的)真正的初学者被迫只能使用命令行方式,而很多(具备这方面能力的)高级程序员却不愿意花时间创建一个 `Tkinter` GUI。
|
||||
在为程序或脚本增加 GUI 这件事上,似乎存在能力的“错配”。(缺乏这方面能力的)真正的初学者被迫只能使用命令行方式,而很多(具备这方面能力的)高级程序员却不愿意花时间创建一个 Tkinter GUI。
|
||||
|
||||
### GUI 框架
|
||||
|
||||
Python 的 GUI 框架并不少,其中 `Tkinter`,`wxPython`,`Qt` 和 `Kivy` 是几种比较主流的框架。此外,还有不少在上述框架基础上封装的简化框架,例如 `EasyGUI`,`PyGUI` 和 `Pyforms` 等。
|
||||
Python 的 GUI 框架并不少,其中 Tkinter,wxPython,Qt 和 Kivy 是几种比较主流的框架。此外,还有不少在上述框架基础上封装的简化框架,例如 EasyGUI,PyGUI 和 Pyforms 等。
|
||||
|
||||
但问题在于,对于初学者(这里是指编程经验不超过 6 个月的用户)而言,即使是最简单的主流框架,他们也无从下手;他们也可以选择封装过的(简化)框架,但仍难以甚至无法创建自定义 GUI <ruby>布局<rt>layout</rt></ruby>。即便学会了某种(简化)框架,也需要编写连篇累牍的代码。
|
||||
|
||||
[`PySimpleGUI`][1] 尝试解决上述 GUI 难题,它提供了一种简单明了、易于理解、方便自定义的 GUI 接口。如果使用 `PySimpleGUI`,很多复杂的 GUI 也仅需不到 20 行代码。
|
||||
[PySimpleGUI][1] 尝试解决上述 GUI 难题,它提供了一种简单明了、易于理解、方便自定义的 GUI 接口。如果使用 PySimpleGUI,很多复杂的 GUI 也仅需不到 20 行代码。
|
||||
|
||||
### 秘诀
|
||||
|
||||
`PySimpleGUI` 极为适合初学者的秘诀在于,它已经包含了绝大多数原本需要用户编写的代码。`PySimpleGUI` 处理按钮<ruby>回调<rt>callback</rt></ruby>,无需用户编写代码。对于初学者,在几周内掌握函数的概念已经不容易了,要求其理解回调函数似乎有些强人所难。
|
||||
PySimpleGUI 极为适合初学者的秘诀在于,它已经包含了绝大多数原本需要用户编写的代码。PySimpleGUI 会处理按钮<ruby>回调<rt>callback</rt></ruby>,无需用户编写代码。对于初学者,在几周内掌握函数的概念已经不容易了,要求其理解回调函数似乎有些强人所难。
|
||||
|
||||
在大部分 GUI 框架中,布局 GUI <ruby>小部件<rt>widgets</rt></ruby>通常需要写一些代码,每个小部件至少 1-2 行。`PySimpleGUI` 使用了“auto-packer”技术,可以自动创建布局。因而,布局 GUI 窗口不再需要 `pack` 或 `grid` 系统。
|
||||
在大部分 GUI 框架中,布局 GUI <ruby>小部件<rt>widgets</rt></ruby>通常需要写一些代码,每个小部件至少 1-2 行。PySimpleGUI 使用了 “auto-packer” 技术,可以自动创建布局。因而,布局 GUI 窗口不再需要 pack 或 grid 系统。
|
||||
|
||||
(LCTT 译注:这里提到的 `pack` 和 `grid` 都是 `Tkinter` 的布局管理器,另外一种叫做 `place`)
|
||||
(LCTT 译注:这里提到的 pack 和 grid 都是 Tkinter 的布局管理器,另外一种叫做 place 。)
|
||||
|
||||
最后,`PySimpleGUI` 框架编写中有效利用 Python 语言特性,降低用户代码量并简化GUI 数据返回的方式。在<ruby>窗体<rt>form</rt></ruby>布局中创建小部件时,小部件会被部署到对应的布局中,无需额外的代码。
|
||||
最后,PySimpleGUI 框架编写中有效地利用了 Python 语言特性,降低用户代码量并简化 GUI 数据返回的方式。在<ruby>窗体<rt>form</rt></ruby>布局中创建小部件时,小部件会被部署到对应的布局中,无需额外的代码。
|
||||
|
||||
### GUI 是什么?
|
||||
|
||||
@ -37,13 +39,13 @@ button, values = GUI_Display(gui_layout)
|
||||
|
||||
绝大多数 GUI 支持的用户行为包括鼠标点击(例如,“确认”,“取消”,“保存”,“是”和“否”等)和内容输入。GUI 本质上可以归结为一行代码。
|
||||
|
||||
这也正是 `PySimpleGUI` (简单 GUI 模式)的工作原理。当执行命令显示 GUI 后,除非点击鼠标关闭窗体,否则不会执行任何代码。
|
||||
这也正是 PySimpleGUI (的简单 GUI 模式)的工作原理。当执行命令显示 GUI 后,除非点击鼠标关闭窗体,否则不会执行任何代码。
|
||||
|
||||
当然还有更复杂的 GUI,其中鼠标点击后窗口并不关闭;例如,机器人的远程控制界面,聊天窗口等。这类复杂的窗体也可以用 `PySimpleGUI` 创建。
|
||||
当然还有更复杂的 GUI,其中鼠标点击后窗口并不关闭;例如,机器人的远程控制界面,聊天窗口等。这类复杂的窗体也可以用 PySimpleGUI 创建。
|
||||
|
||||
### 快速创建 GUI
|
||||
|
||||
`PySimpleGUI` 什么时候有用呢?显然,是你需要 GUI 的时候。仅需不超过 5 分钟,就可以让你创建并尝试 GUI。最便捷的 GUI 创建方式就是从 [PySimpleGUI 经典实例][2]中拷贝一份代码。具体操作流程如下:
|
||||
PySimpleGUI 什么时候有用呢?显然,是你需要 GUI 的时候。仅需不超过 5 分钟,就可以让你创建并尝试 GUI。最便捷的 GUI 创建方式就是从 [PySimpleGUI 经典实例][2]中拷贝一份代码。具体操作流程如下:
|
||||
|
||||
* 找到一个与你需求最接近的 GUI
|
||||
* 从经典实例中拷贝代码
|
||||
@ -93,13 +95,14 @@ button, (name,) = form.LayoutAndRead(layout)
|
||||
|
||||
### 5 分钟内创建一个自定义 GUI
|
||||
|
||||
在简单布局的基础上,通过修改经典实例中的代码,5 分钟内即可使用 `PySimpleGUI` 创建自定义布局。
|
||||
在简单布局的基础上,通过修改经典实例中的代码,5 分钟内即可使用 PySimpleGUI 创建自定义布局。
|
||||
|
||||
在 `PySimpleGUI` 中,<ruby>小部件<rt>widgets</rt></ruby>被称为<ruby>元素<rt>elements</rt></ruby>。元素的名称与编码中使用的名称保持一致。
|
||||
在 PySimpleGUI 中,<ruby>小部件<rt>widgets</rt></ruby>被称为<ruby>元素<rt>elements</rt></ruby>。元素的名称与编码中使用的名称保持一致。
|
||||
|
||||
(LCTT 译注:`Tkinter` 中使用小部件这个词)
|
||||
(LCTT 译注:Tkinter 中使用小部件这个词)
|
||||
|
||||
#### 核心元素
|
||||
|
||||
```
|
||||
Text
|
||||
InputText
|
||||
@ -121,7 +124,7 @@ Column
|
||||
|
||||
#### 元素简写
|
||||
|
||||
`PySimpleGUI` 还包含两种元素简写方式。一种是元素类型名称简写,例如 `T` 用作 `Text` 的简写;另一种是元素参数被配置了默认值,你可以无需指定所有参数,例如 `Submit` 按钮默认的文本就是“Submit”。
|
||||
PySimpleGUI 还包含两种元素简写方式。一种是元素类型名称简写,例如 `T` 用作 `Text` 的简写;另一种是元素参数被配置了默认值,你可以无需指定所有参数,例如 `Submit` 按钮默认的文本就是 “Submit”。
|
||||
|
||||
```
|
||||
T = Text
|
||||
@ -164,9 +167,9 @@ RealtimeButton
|
||||
|
||||
(LCTT 译注:其实就是返回 `Button` 类实例的函数)
|
||||
|
||||
上面就是 `PySimpleGUI` 支持的全部元素。如果不在上述列表之中,就不会在你的窗口布局中生效。
|
||||
上面就是 PySimpleGUI 支持的全部元素。如果不在上述列表之中,就不会在你的窗口布局中生效。
|
||||
|
||||
(LCTT 译注:上述都是 `PySimpleGUI` 的类名、类别名或返回实例的函数,自然只能使用列表内的。)
|
||||
(LCTT 译注:上述都是 PySimpleGUI 的类名、类别名或返回实例的函数,自然只能使用列表内的。)
|
||||
|
||||
#### GUI 设计模式
|
||||
|
||||
@ -182,7 +185,7 @@ form = sg.FlexForm('Simple data entry form')
|
||||
button, values = form.LayoutAndRead(layout)
|
||||
```
|
||||
|
||||
(LCTT 译注:这段代码无法运行,只是为了说明每个程序都会用到的设计模式)
|
||||
(LCTT 译注:这段代码无法运行,只是为了说明每个程序都会用到的设计模式。)
|
||||
|
||||
对于绝大多数 GUI,编码流程如下:
|
||||
|
||||
@ -190,7 +193,7 @@ button, values = form.LayoutAndRead(layout)
|
||||
* 以“列表的列表”的形式定义 GUI
|
||||
* 展示 GUI 并获取元素的值
|
||||
|
||||
上述流程与 `PySimpleGUI` 设计模式部分的代码一一对应。
|
||||
上述流程与 PySimpleGUI 设计模式部分的代码一一对应。
|
||||
|
||||
#### GUI 布局
|
||||
|
||||
@ -201,7 +204,6 @@ button, values = form.LayoutAndRead(layout)
|
||||
```
|
||||
layout = [ [Text('Row 1')],
|
||||
[Text('Row 2'), Checkbox('Checkbox 1', OK()), Checkbox('Checkbox 2'), OK()] ]
|
||||
|
||||
```
|
||||
|
||||
上述布局对应的效果如下:
|
||||
@ -220,24 +222,24 @@ button, values = form.LayoutAndRead(layout)
|
||||
|
||||
窗体返回的结果由两部分组成:一部分是被点击按钮的名称,另一部分是一个列表,包含所有用户输入窗体的值。
|
||||
|
||||
在这个例子中,窗体显示后用户直接点击 `OK` 按钮,返回的结果如下:
|
||||
在这个例子中,窗体显示后用户直接点击 “OK” 按钮,返回的结果如下:
|
||||
|
||||
```
|
||||
button == 'OK'
|
||||
values == [False, False]
|
||||
```
|
||||
|
||||
`Checkbox` 类型元素返回 `True` 或 `False` 类型的值。由于默认处于未选中状态,两个元素的值都是 `False`。
|
||||
Checkbox 类型元素返回 `True` 或 `False` 类型的值。由于默认处于未选中状态,两个元素的值都是 `False`。
|
||||
|
||||
### 显示元素的值
|
||||
|
||||
一旦从 GUI 获取返回值,检查返回变量中的值是个不错的想法。与其使用 `print` 语句进行打印,我们不妨坚持使用 GUI 并在一个窗口中输出这些值。
|
||||
|
||||
(LCTT 译注:考虑使用的是 Python 3 版本,`print` 应该是函数而不是语句)
|
||||
(LCTT 译注:考虑使用的是 Python 3 版本,`print` 应该是函数而不是语句。)
|
||||
|
||||
在 `PySimpleGUI` 中,有多种消息框可供选取。传递给消息框(函数)的数据会被显示在消息框中;函数可以接受任意数目的参数,你可以轻松的将所有要查看的变量展示出来。
|
||||
在 PySimpleGUI 中,有多种消息框可供选取。传递给消息框(函数)的数据会被显示在消息框中;函数可以接受任意数目的参数,你可以轻松的将所有要查看的变量展示出来。
|
||||
|
||||
在 `PySimpleGUI` 中,最常用的消息框是 `MsgBox`。要展示上面例子中的数据,只需编写一行代码:
|
||||
在 PySimpleGUI 中,最常用的消息框是 `MsgBox`。要展示上面例子中的数据,只需编写一行代码:
|
||||
|
||||
```
|
||||
MsgBox('The GUI returned:', button, values)
|
||||
@ -245,7 +247,7 @@ MsgBox('The GUI returned:', button, values)
|
||||
|
||||
### 整合
|
||||
|
||||
好了,你已经了解了基础知识,让我们创建一个包含尽可能多 `PySimpleGUI` 元素的窗体吧!此外,为了更好的感观效果,我们将采用绿色/棕褐色的配色方案。
|
||||
好了,你已经了解了基础知识,让我们创建一个包含尽可能多 PySimpleGUI 元素的窗体吧!此外,为了更好的感观效果,我们将采用绿色/棕褐色的配色方案。
|
||||
|
||||
```
|
||||
import PySimpleGUI as sg
|
||||
@ -284,7 +286,7 @@ button, values = form.LayoutAndRead(layout)
|
||||
sg.MsgBox(button, values)
|
||||
```
|
||||
|
||||
看上面要写不少代码,但如果你试着直接使用 `Tkinter` 框架实现同样的 GUI,你很快就会发现 `PySimpleGUI` 版本的代码是多么的简洁。
|
||||
看上面要写不少代码,但如果你试着直接使用 Tkinter 框架实现同样的 GUI,你很快就会发现 PySimpleGUI 版本的代码是多么的简洁。
|
||||
|
||||
|
||||
|
||||
@ -317,7 +319,7 @@ else:
|
||||
|
||||
#### 安装方式
|
||||
|
||||
支持 `Tkinter` 的系统就支持 `PySimpleGUI`,甚至包括<ruby>树莓派<rt>Raspberry Pi</rt></ruby>,但你需要使用 Python 3。
|
||||
支持 Tkinter 的系统就支持 PySimpleGUI,甚至包括<ruby>树莓派<rt>Raspberry Pi</rt></ruby>,但你需要使用 Python 3。
|
||||
|
||||
```
|
||||
pip install PySimpleGUI
|
||||
@ -336,7 +338,7 @@ via: https://opensource.com/article/18/8/pysimplegui
|
||||
作者:[Mike Barnett][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,109 @@
|
||||
6 个打造你自己的 VPN 的开源工具
|
||||
======
|
||||
|
||||
> 想尝试建立您自己的 VPN,但是不确定从哪里开始吗?
|
||||
|
||||

|
||||
|
||||
如果您想尝试建立您自己的 VPN,但是不确定从哪里开始,那么您来对地方了。我将比较 6 个在您自己的服务器上搭建和使用 VPN 的最好的自由和开源工具。不管您是想为您的企业建立站点到站点的 VPN,还是只是想创建一个远程代理访问以解除访问限制并对 ISP 隐藏你的互联网流量,都可以通过 VPN 来达成。
|
||||
|
||||
根据您的需求和条件,并参考您自己的技术特长、环境以及您想要通过 VPN 实现的目标。需要考虑以下因素:
|
||||
|
||||
* VPN 协议
|
||||
* 客户端的数量和设备类型
|
||||
* 服务端的兼容性
|
||||
* 需要的技术专业能力
|
||||
|
||||
### Algo
|
||||
|
||||
[Algo][1] 是从下往上设计的,可以为需要互联网安全代理的商务旅客创建 VPN 专用网。它“只包括您所需要的最小化的软件”,这意味着为了简单而牺牲了可扩展性。Algo 是基于 StrongSwan 的,但是删除了所有您不需要的东西,这有另外一个好处,那就是去除了新手可能不会注意到的安全漏洞。
|
||||
|
||||
作为额外的奖励,它甚至可以屏蔽广告!
|
||||
|
||||
Algo 只支持 IKEv2 协议和 Wireguard。因为对 IKEv2 的支持现在已经内置在大多数设备中,所以它不需要像 OpenVPN 这样的客户端应用程序。Algo 可以使用 Ansible 在 Ubuntu (首选选项)、Windows、RedHat、CentOS 和 FreeBSD 上部署。 使用 Ansible 可以自动化安装,它会根据您对一组简短的问题的回答来配置服务。卸载和重新部署也非常容易。
|
||||
|
||||
Algo 可能是在本文中安装和部署最简单和最快的 VPN。它非常简洁,考虑周全。如果您不需要其他工具提供的高级功能,只需要一个安全代理,这是一个很好的选择。请注意,Algo 明确表示,它不是为了解除地理封锁或逃避审查,主要是为了加密。
|
||||
|
||||
### Streisand
|
||||
|
||||
[Streisand][2] 可以使用一个命令安装在任何 Ubuntu 16.04 服务器上;这个过程大约需要 10 分钟。它支持 L2TP、OpenConnect、OpenSSH、OpenVPN、Shadowsocks、Stunnel、Tor bridge 和 WireGuard。根据您选择的协议,您可能需要安装客户端应用程序。
|
||||
|
||||
在很多方面,Streisand 与 Algo 相似,但是它提供了更多的协议和定制。这需要更多的工作来管理和维护,但也更加灵活。注意 Streisand 不支持 IKEv2。因为它的多功能性,我认为 Streisand 在某国和土耳其这样的地方绕过审查制度更有效,但是 Algo 的安装更容易和更快。
|
||||
|
||||
使用 Ansible 可以自动化安装,所以不需要太多的专业技术知识。通过向用户发送自定义生成的连接指令,包括服务器 SSL 证书的嵌入副本,可以轻松添加更多用户。
|
||||
|
||||
卸载 Streisand 是一个快速无痛的过程,您也可以随时重新部署。
|
||||
|
||||
### OpenVPN
|
||||
|
||||
[OpenVPN][3] 要求客户端和服务器应用程序使用其同名的协议建立 VPN 连接。OpenVPN 可以根据您的需求进行调整和定制,但它也需要更多专业技术知识。它支持远程访问和站点到站点配置;如果您计划使用 VPN 作为互联网代理,前者是您所需要的。因为在大多数设备上使用 OpenVPN 需要客户端应用程序,所以最终用户必须保持更新。
|
||||
|
||||
服务器端您可以选择部署在云端或你自己的 Linux 服务器上。兼容的发行版包括 CentOS 、Ubuntu 、Debian 和 openSUSE。Windows 、MacOS 、iOS 和 Android 都有客户端应用程序,其他设备也有非官方应用程序。企业可以选择设置一个 OpenVPN 接入服务器,但是对于想要使用社区版的个人来说,这可能有点过分。
|
||||
|
||||
OpenVPN 使用静态密钥加密来配置相对容易,但并不十分安全。相反,我建议使用 [easy-rsa][4] 来设置它,这是一个密钥管理包,可以用来设置公钥基础设施(PKI)。这允许您一次连接多个设备,并因此得到<ruby>完美前向保密<rt>perfect forward secrecy</rt></ruby>和其他好处的保护。OpenVPN 使用 SSL/TLS 进行加密,而且您可以在配置中指定 DNS 服务器。
|
||||
|
||||
OpenVPN 可以穿透防火墙和 NAT 防火墙,这意味着您可以使用它绕过可能会阻止连接的网关和防火墙。它同时支持 TCP 和 UDP 传输。
|
||||
|
||||
### StrongSwan
|
||||
|
||||
您可能会遇到一些名称中有 “Swan” 的各种 VPN 工具。FreeS/WAN 、OpenSwan、LibreSwan 和 [strongSwan][5] 都是同一个项目的分叉,后者是我个人最喜欢的。在服务器端,strongSwan 可以运行在 Linux 2.6、3.x 和 4x 内核、Android、FreeBSD、macOS、iOS 和 Windows 上。
|
||||
|
||||
StrongSwan 使用 IKEv2 协议和 IPSec 。与 OpenVPN 相比,IKEv2 连接速度更快,同时提供了很好的速度和安全性。如果您更喜欢不需要在客户端安装额外应用程序的协议,这将非常有用,因为现在生产的大多数新设备都支持 IKEv2,包括 Windows、MacOS、iOS 和 Android。
|
||||
|
||||
StrongSwan 并不特别容易使用,尽管文档不错,但它使用的词汇与大多数其他工具不同,这可能会让人比较困惑。它的模块化设计让它对企业来说很棒,但这也意味着它不是很精简。这当然不像 Algo 或 Streisand 那么简单。
|
||||
|
||||
访问控制可以基于使用 X.509 属性证书的组成员身份,这是 strongSwan 独有的功能。它支持用于集成到其他环境(如 Windows Active Directory)中的 EAP 身份验证方法。strongSwan 可以穿透NAT 网络防火墙。
|
||||
|
||||
### SoftEther
|
||||
|
||||
[SoftEther][6] 是由日本筑波大学的一名研究生发起的一个项目。SoftEther VPN 服务器和 VPN 网桥可以运行在 Windows、Linux、OSX、FreeBSD 和 Solaris 上,而客户端应用程序可以运行在 Windows、Linux 和 MacOS 上。VPN 网桥主要用于需要设置站点到站点 VPN 的企业,因此单个用户只需要服务器和客户端程序来设置远程访问。
|
||||
|
||||
SoftEther 支持 OpenVPN、L2TP、SSTP 和 EtherIP 协议,由于采用“基于 HTTPS 的以太网”伪装,它自己的 SoftEther 协议声称能够免疫深度数据包检测。SoftEther 还做了一些调整,以减少延迟并增加吞吐量。此外,SoftEther 还包括一个克隆功能,允许您轻松地从 OpenVPN 过渡到 SoftEther。
|
||||
|
||||
SoftEther 可以穿透 NAT 防火墙并绕过防火墙。在只允许 ICMP 和 DNS 数据包的受限网络上,您可以利用 SoftEther 的基于 ICMP 或 DNS 的 VPN 方式来穿透防火墙。SoftEther 可与 IPv4 和 IPv6 一起工作。
|
||||
|
||||
SoftEther 比 OpenVPN 和 strongSwan 更容易设置,但比 Streisand 和 Algo 要复杂。
|
||||
|
||||
### WireGuard
|
||||
|
||||
[WireGuard][7] 是这个名单上最新的工具;它太新了,甚至还没有完成。也就是说,它为部署 VPN 提供了一种快速简便的方法。它旨在通过使 IPSec 更简单、更精简来改进它,就像 SSH 一样。
|
||||
|
||||
与 OpenVPN 一样,WireGuard 既是一种协议,也是一种用于部署使用所述协议的 VPN 的软件工具。一个关键特性是“加密密钥路由”,它将公钥与隧道内允许的 IP 地址列表相关联。
|
||||
|
||||
WireGuard 可用于 Ubuntu、Debian、Fedora、CentOS、MacOS、Windows 和安卓系统。WireGuard 可在 IPv4 和 IPv6 上工作。
|
||||
|
||||
WireGuard 比大多数其他 VPN 协议轻得多,它只在需要发送数据时才发送数据包。
|
||||
|
||||
开发人员说,WireGuard 还不应该被信任,因为它还没有被完全审计过,但是欢迎你给它一个机会。这可能是下一个热门!
|
||||
|
||||
### 自制 VPN vs. 商业 VPN
|
||||
|
||||
制作您自己的 VPN 为您的互联网连接增加了一层隐私和安全,但是如果您是唯一一个使用它的人,那么装备精良的第三方,比如政府机构,将很容易追踪到你的活动。
|
||||
|
||||
此外,如果您计划使用您的 VPN 来解锁地理锁定的内容,自制的 VPN 可能不是最好的选择。因为您只能从一个 IP 地址连接,所以你的 VPN 服务器很容易被阻止。
|
||||
|
||||
好的商业 VPN 不存在这些问题。有了像 [ExpressVPN][8] 这样的提供商,您可以与数十甚至数百个其他用户共享服务器的 IP 地址,这使得跟踪一个用户的活动几乎变得不可能。您也可以从成百上千的服务器中选择,所以如果其中一台被列入黑名单,你可以切换到另一台。
|
||||
|
||||
然而,商业 VPN 的权衡是,您必须相信提供商不会窥探您的互联网流量。一定要选择一个有明确的无日志政策的信誉良好的供应商。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/open-source-tools-vpn
|
||||
|
||||
作者:[Paul Bischoff][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/paulbischoff
|
||||
[1]: https://blog.trailofbits.com/2016/12/12/meet-algo-the-vpn-that-works/
|
||||
[2]: https://github.com/StreisandEffect/streisand
|
||||
[3]: https://openvpn.net/
|
||||
[4]: https://github.com/OpenVPN/easy-rsa
|
||||
[5]: https://www.strongswan.org/
|
||||
[6]: https://www.softether.org/
|
||||
[7]: https://www.wireguard.com/
|
||||
[8]: https://www.comparitech.com/vpn/reviews/expressvpn/
|
||||
@ -1,16 +1,17 @@
|
||||
如何在 Ubuntu 18.04 和其他 Linux 发行版中创建照片幻灯片
|
||||
如何在 Ubuntu 和其他 Linux 发行版中创建照片幻灯片
|
||||
======
|
||||
|
||||
创建照片幻灯片只需点击几下。以下是如何在 Ubuntu 18.04 和其他 Linux 发行版中制作照片幻灯片。
|
||||
|
||||
![How to create slideshow of photos in Ubuntu Linux][1]
|
||||
|
||||
想象一下,你的朋友和亲戚正在拜访你,并请求你展示最近的活动/旅行照片。
|
||||
想象一下,你的朋友和亲戚正在拜访你,并请你展示最近的活动/旅行照片。
|
||||
|
||||
你将照片保存在计算机上,并整齐地放在单独的文件夹中。你邀请计算机附近的所有人。你进入该文件夹,单击其中一张图片,然后按箭头键逐个显示照片。
|
||||
|
||||
但那太累了!如果这些图片每隔几秒自动更改一次,那将会好很多。
|
||||
|
||||
这称之为为幻灯片,我将向你展示如何在 Ubuntu 中创建照片幻灯片。这能让你在文件夹中循环播放图片并以全屏模式显示它们。
|
||||
这称之为幻灯片,我将向你展示如何在 Ubuntu 中创建照片幻灯片。这能让你在文件夹中循环播放图片并以全屏模式显示它们。
|
||||
|
||||
### 在 Ubuntu 18.04 和其他 Linux 发行版中创建照片幻灯片
|
||||
|
||||
@ -20,19 +21,19 @@
|
||||
|
||||
如果你在 Ubuntu 18.04 或任何其他发行版中使用 GNOME,那么你很幸运。Gnome 的默认图像浏览器,Eye of GNOME,能够在当前文件夹中显示图片的幻灯片。
|
||||
|
||||
只需单击其中一张图片,你将在程序的右上角菜单中看到设置选项。它看起来像三条横栏堆在彼此的顶部。
|
||||
只需单击其中一张图片,你将在程序的右上角菜单中看到设置选项。它看起来像堆叠在一起的三条横栏。
|
||||
|
||||
你会在这里看到几个选项。勾选幻灯片选项,它将全屏显示图像。
|
||||
|
||||
![How to create slideshow of photos in Ubuntu Linux][2]
|
||||
|
||||
默认情况下,图像以 5 秒的间隔变化。你可以进入 Preferences->Slideshow 来更改幻灯片放映间隔。
|
||||
默认情况下,图像以 5 秒的间隔变化。你可以进入 “Preferences -> Slideshow” 来更改幻灯片放映间隔。
|
||||
|
||||
![change slideshow interval in Ubuntu][3]Changing slideshow interval
|
||||
![change slideshow interval in Ubuntu][3]
|
||||
|
||||
#### 方法 2:使用 Shotwell Photo Manager 进行照片幻灯片放映
|
||||
|
||||
[Shotwell][4] 是一种流行的[ Linux 照片管理程序][5]。适用于所有主要的 Linux 发行版。
|
||||
[Shotwell][4] 是一款流行的 [Linux 照片管理程序][5]。适用于所有主要的 Linux 发行版。
|
||||
|
||||
如果尚未安装,请在你的发行版软件中心中搜索 Shotwell 并安装。
|
||||
|
||||
@ -55,7 +56,7 @@ via: https://itsfoss.com/photo-slideshow-ubuntu/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,37 +1,36 @@
|
||||
|
||||
|
||||
增强 Vim 编辑器,提高编辑效率
|
||||
======
|
||||
> 这 20 多个有用的命令可以增强你使用 Vi 的体验。
|
||||
|
||||

|
||||
|
||||
编者注:标题和文章最初提到的 `vi` 编辑器,现已更新为编辑器的正确名称:`Vim`。
|
||||
*编者注:标题和文章最初称呼的 `vi` 编辑器,现已更新为编辑器的正确名称:`Vim`。*
|
||||
|
||||
`Vim` 作为一款功能强大、选项丰富的编辑器,为许多用户所热爱。本文介绍了一些在 `Vim` 中默认未启用但实际非常有用的选项。虽然可以在每个 `Vim` 会话中单独启用,但为了创建一个开箱即用的高效编辑环境,还是建议在 `Vim` 的配置文件中配置这些命令。
|
||||
|
||||
## 开始前的准备
|
||||
### 开始前的准备
|
||||
|
||||
这里所说的选项或配置均位于用户主目录中的 `Vim` 启动配置文件 `.vimrc`。 按照下面的说明在 `.vimrc` 中设置选项:
|
||||
|
||||
(注意:`vimrc` 文件也用于 `Linux` 中的全局配置,如 `/etc/vimrc` 或 `/etc/vim/vimrc`。本文所说的 `.vimrc` 均是指位于用户主目录中的 `.vimrc` 文件。)
|
||||
|
||||
`Linux` 系统中:
|
||||
Linux 系统中:
|
||||
|
||||
* 用 `Vim` 打开 `.vimrc` 文件: `vim ~/.vimrc`
|
||||
* 复制本文最后的 `选项列表` 粘贴到 `.vimrc` 文件
|
||||
* 保存并关闭 (`:wq`)
|
||||
|
||||
译者注:此处不建议使用 `Vim` 编辑 `.vimrc` 文件,因为很可能无法粘贴成功,可以选择 `gedit` 编辑器编辑 `.vimrc` 文件。
|
||||
(LCTT 译注:此处不建议使用 `Vim` 编辑 `.vimrc` 文件,因为很可能无法粘贴成功,可以选择 `gedit` 编辑器编辑 `.vimrc` 文件。)
|
||||
|
||||
`Windows` 系统中:
|
||||
Windows 系统中:
|
||||
|
||||
* 首先,[安装 gvim][1]
|
||||
* 打开 `gvim`
|
||||
* 单击 `编辑` -> `启动设置`,打开 `.vimrc` 文件
|
||||
* 复制本文最后的 `选项列表` 粘贴到 `.vimrc` 文件
|
||||
* 单击 `文件` -> `保存`
|
||||
* 单击 “编辑” -> “启动设置”,打开 `_vimrc` 文件
|
||||
* 复制本文最后的 “选项列表” 粘贴到 `_vimrc` 文件
|
||||
* 单击 “文件” -> “保存”
|
||||
|
||||
译者注:此处应注意不要使用 `Windows` 自带的记事本编辑该 `.vimrc` 文件。
|
||||
(LCTT 译注:此处应注意不要使用 `Windows` 自带的记事本编辑该 `_vimrc` 文件,否则可能会因为行结束符不同而导致问题。)
|
||||
|
||||
下面,我们将深入研究提高 `Vim` 编辑效率的选项。主要分为以下几类:
|
||||
|
||||
@ -42,7 +41,7 @@
|
||||
5. 拼写
|
||||
6. 其他选项
|
||||
|
||||
## 1. 缩进 & 制表符
|
||||
### 1. 缩进 & 制表符
|
||||
|
||||
使 `Vim` 在创建新行的时候使用与上一行同样的缩进:
|
||||
|
||||
@ -58,7 +57,7 @@ set smartindent
|
||||
|
||||
注意:`Vim` 具有语言感知功能,且其默认设置可以基于文件中的编程语言来改变配置以提高效率。有许多默认的配置选项,包括 `axs cindent`,`cinoptions`,`indentexpr` 等,没有在这里说明。 `syn` 是一个非常有用的命令,用于设置文件的语法以更改显示模式。
|
||||
|
||||
译者注:这里的 `syn` 是指 `syntax`,可用于设置文件所用的编程语言,开启对应的语法高亮,以及执行自动事件 (`autocmd`)。
|
||||
(LCTT 译注:这里的 `syn` 是指 `syntax`,可用于设置文件所用的编程语言,开启对应的语法高亮,以及执行自动事件 (`autocmd`)。)
|
||||
|
||||
设置文件里的制表符 `(TAB)` 的宽度(以空格的数量表示):
|
||||
|
||||
@ -80,7 +79,7 @@ set expandtab
|
||||
|
||||
注意:这可能会导致依赖于制表符的 `Python` 等编程语言出现问题。这时,你可以根据文件类型设置该选项(请参考 `autocmd`)。
|
||||
|
||||
## 2. 显示 & 格式化
|
||||
### 2. 显示 & 格式化
|
||||
|
||||
要在每行的前面显示行号:
|
||||
|
||||
@ -102,9 +101,9 @@ set textwidth=80
|
||||
set wrapmargin=2
|
||||
```
|
||||
|
||||
译者注:如果 `textwidth` 选项不等于零,本选项无效。
|
||||
(LCTT 译注:如果 `textwidth` 选项不等于零,本选项无效。)
|
||||
|
||||
插入括号时,短暂地跳转到匹配的括号:
|
||||
当光标遍历文件时经过括号时,高亮标识匹配的括号:
|
||||
|
||||
```vim
|
||||
set showmatch
|
||||
@ -112,7 +111,7 @@ set showmatch
|
||||
|
||||
|
||||
|
||||
## 3. 搜索
|
||||
### 3. 搜索
|
||||
|
||||
高亮搜索内容的所有匹配位置:
|
||||
|
||||
@ -144,20 +143,22 @@ set smartcase
|
||||
|
||||
例如,如果文件内容是:
|
||||
|
||||
> test\
|
||||
> Test
|
||||
```
|
||||
test
|
||||
Test
|
||||
```
|
||||
|
||||
当打开 `ignorecase` 和 `smartcase` 选项时,搜索 `test` 时的突出显示:
|
||||
|
||||
> <font color=yellow>test</font>\
|
||||
> <font color=yellow>test</font>
|
||||
> <font color=yellow>Test</font>
|
||||
|
||||
搜索 `Test` 时的突出显示:
|
||||
|
||||
> test\
|
||||
> test
|
||||
> <font color=yellow>Test</font>
|
||||
|
||||
## 4. 浏览 & 滚动
|
||||
### 4. 浏览 & 滚动
|
||||
|
||||
为获得更好的视觉体验,你可能希望将光标放在窗口中间而不是第一行,以下选项使光标距窗口上下保留 5 行。
|
||||
|
||||
@ -165,7 +166,7 @@ set smartcase
|
||||
set scrolloff=5
|
||||
```
|
||||
|
||||
一个例子:
|
||||
一个例子:
|
||||
|
||||
第一张图中 `scrolloff=0`,第二张图中 `scrolloff=5`。
|
||||
|
||||
@ -181,7 +182,7 @@ set laststatus=2
|
||||
|
||||
|
||||
|
||||
## 5. 拼写
|
||||
### 5. 拼写
|
||||
|
||||
`Vim` 有一个内置的拼写检查器,对于文本编辑和编码非常有用。`Vim` 可以识别文件类型并仅对代码中的注释进行拼写检查。使用下面的选项打开英语拼写检查:
|
||||
|
||||
@ -189,9 +190,9 @@ set laststatus=2
|
||||
set spell spelllang=en_us
|
||||
```
|
||||
|
||||
译者注:中文、日文或其它东亚语字符通常会在打开拼写检查时被标为拼写错误,因为拼写检查不支持这些语种,可以在 `spelllang` 选项中加入 `cjk` 来忽略这些错误标注。
|
||||
(LCTT 译注:中文、日文或其它东亚语字符通常会在打开拼写检查时被标为拼写错误,因为拼写检查不支持这些语种,可以在 `spelllang` 选项中加入 `cjk` 来忽略这些错误标注。)
|
||||
|
||||
## 6. 其他选项
|
||||
### 6. 其他选项
|
||||
|
||||
禁止创建备份文件:启用此选项后,`Vim` 将在覆盖文件前创建一个备份,文件成功写入后保留该备份。如果不想保留该备份文件,可以按下面的方式关闭:
|
||||
|
||||
@ -229,9 +230,7 @@ set errorbells
|
||||
set visualbell
|
||||
```
|
||||
|
||||
## 惊喜
|
||||
|
||||
vi provides long-format as well as short-format commands. Either format can be used to set or unset the configuration.
|
||||
### 惊喜
|
||||
|
||||
`Vim` 提供长格式和短格式命令,两种格式都可用于设置或取消选项配置。
|
||||
|
||||
@ -247,8 +246,6 @@ set autoindent
|
||||
set ai
|
||||
```
|
||||
|
||||
To see the current configuration setting of a command without changing its current value, use `?` at the end:
|
||||
|
||||
要在不更改选项当前值的情况下查看其当前设置,可以在 `Vim` 的命令行上使用在末尾加上 `?` 的命令:
|
||||
|
||||
```vim
|
||||
@ -273,71 +270,43 @@ set noautoindent
|
||||
|
||||
|
||||
|
||||
注意:此处列出的命令仅对 `Linux` 上的 `Vim 7.4` 版本和 `Windows` 上的 `Vim 8.0` 版本进行了测试。
|
||||
注意:此处列出的命令仅对 Linux 上的 Vim 7.4 版本和 Windows 上的 Vim 8.0 版本进行了测试。
|
||||
|
||||
这些有用的命令肯定会增强您的 `Vim` 使用体验。你会推荐哪些其他有用的命令?
|
||||
|
||||
## 选项列表
|
||||
### 选项列表
|
||||
|
||||
复制该选项列表粘贴到 `.vimrc` 文件中:
|
||||
|
||||
```vim
|
||||
" Indentation & Tabs
|
||||
|
||||
set autoindent
|
||||
|
||||
set smartindent
|
||||
|
||||
set tabstop=4
|
||||
|
||||
set shiftwidth=4
|
||||
|
||||
set expandtab
|
||||
|
||||
set smarttab
|
||||
|
||||
" Display & format
|
||||
|
||||
set number
|
||||
|
||||
set textwidth=80
|
||||
|
||||
set wrapmargin=2
|
||||
|
||||
set showmatch
|
||||
|
||||
" Search
|
||||
|
||||
set hlsearch
|
||||
|
||||
set incsearch
|
||||
|
||||
set ignorecase
|
||||
|
||||
set smartcase
|
||||
|
||||
" Browse & Scroll
|
||||
|
||||
set scrolloff=5
|
||||
|
||||
set laststatus=2
|
||||
|
||||
" Spell
|
||||
|
||||
set spell spelllang=en_us
|
||||
|
||||
" Miscellaneous
|
||||
|
||||
set nobackup
|
||||
|
||||
set noswapfile
|
||||
|
||||
set autochdir
|
||||
|
||||
set undofile
|
||||
|
||||
set visualbell
|
||||
|
||||
set errorbells
|
||||
```
|
||||
|
||||
@ -348,9 +317,9 @@ via: https://opensource.com/article/18/9/vi-editor-productivity-powerhouse
|
||||
作者:[Girish Managoli][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[idea2act](https://github.com/idea2act)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[apemost](https://github.com/apemost), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/gammay
|
||||
[1]: https://www.vim.org/download.php#pc
|
||||
[1]: https://www.vim.org/download.php#pc
|
||||
@ -1,24 +1,24 @@
|
||||
用 zsh 提高生产力的5个 tips
|
||||
用 zsh 提高生产力的 5 个技巧
|
||||
======
|
||||
> zsh 提供了数之不尽的功能和特性,这里有五个可以让你在命令行暴增效率的方法。
|
||||
|
||||

|
||||
|
||||
Z shell (亦称 zsh) 是 *unx 系统中的命令解析器 。 它跟 `sh` (Bourne shell) 家族的其他解析器 ( 如 `bash` 和 `ksh` ) 有着相似的特点,但它还提供了大量的高级特性以及强大的命令行编辑功能(选项?),如增强版tab补全。
|
||||
Z shell([zsh][1])是 Linux 和类 Unix 系统中的一个[命令解析器][2]。 它跟 sh (Bourne shell) 家族的其它解析器(如 bash 和 ksh)有着相似的特点,但它还提供了大量的高级特性以及强大的命令行编辑功能,如增强版 Tab 补全。
|
||||
|
||||
由于 zsh 有好几百页的文档去描述他的特性,所以我无法在这里阐明 zsh 的所有功能。在本文,我会列出5个 tips,让你通过使用 zsh 来提高你的生产力。
|
||||
在这里不可能涉及到 zsh 的所有功能,[描述][3]它的特性需要好几百页。在本文中,我会列出 5 个技巧,让你通过在命令行使用 zsh 来提高你的生产力。
|
||||
|
||||
### 1\. 主题和插件
|
||||
### 1、主题和插件
|
||||
|
||||
多年来,开源社区已经为 zsh 开发了数不清的主题和插件。主题是预定义提示符的配置,而插件则是一组常用的别名命令和功能,让你更方便的使用一种特定的命令或者编程语言。
|
||||
多年来,开源社区已经为 zsh 开发了数不清的主题和插件。主题是一个预定义提示符的配置,而插件则是一组常用的别名命令和函数,可以让你更方便的使用一种特定的命令或者编程语言。
|
||||
|
||||
如果你现在想开始用 zsh 的主题和插件,那么使用 zsh 的配置框架 (configuiration framework) 是你最快的入门方式。在众多的配置框架中,最受欢迎的则是 [Oh My Zsh][4]。在默认配置中,他就已经为 zsh 启用了一些合理的配置,同时它也自带多个主题和插件。
|
||||
如果你现在想开始用 zsh 的主题和插件,那么使用一种 zsh 的配置框架是你最快的入门方式。在众多的配置框架中,最受欢迎的则是 [Oh My Zsh][4]。在默认配置中,它就已经为 zsh 启用了一些合理的配置,同时它也自带上百个主题和插件。
|
||||
|
||||
由于主题会在你的命令行提示符之前添加一些常用的信息,比如你 Git 仓库的状态,或者是当前使用的 Python 虚拟环境,所以它会让你的工作更高效。只需要看到这些信息,你就不用再敲命令去重新获取它们,而且这些提示也相当酷炫。
|
||||
下图就是我(作者)选用的主题 [Powerlevel9k][5]
|
||||
主题会在你的命令行提示符之前添加一些有用的信息,比如你 Git 仓库的状态,或者是当前使用的 Python 虚拟环境,所以它会让你的工作更高效。只需要看到这些信息,你就不用再敲命令去重新获取它们,而且这些提示也相当酷炫。下图就是我选用的主题 [Powerlevel9k][5]:
|
||||
|
||||
![zsh Powerlevel9K theme][7]
|
||||
|
||||
zsh 主题 Powerlevel9k
|
||||
*zsh 主题 Powerlevel9k*
|
||||
|
||||
除了主题,Oh my Zsh 还自带了大量常用的 zsh 插件。比如,通过启用 Git 插件,你可以用一组简便的命令别名操作 Git, 比如
|
||||
|
||||
@ -36,39 +36,37 @@ gcs='git commit -S'
|
||||
glg='git log --stat'
|
||||
```
|
||||
|
||||
zsh 还有许多插件是用于多种编程语言,打包系统和一些平时在命令行中常用的工具。
|
||||
以下是我(作者) Ferdora 工作站中用到的插件表:
|
||||
zsh 还有许多插件可以用于许多编程语言、打包系统和一些平时在命令行中常用的工具。以下是我 Ferdora 工作站中用到的插件表:
|
||||
|
||||
```
|
||||
git golang fedora docker oc sudo vi-mode virtualenvwrapper
|
||||
```
|
||||
|
||||
### 2\. 智能的命令别名
|
||||
### 2、智能的命令别名
|
||||
|
||||
命令别名在 zsh 中十分常用。为你常用的命令定义别名可以节省你的打字时间。Oh My Zsh 默认配置了一些常用的命令别名,包括目录导航命令别名,为常用的命令添加额外的选项,比如:
|
||||
命令别名在 zsh 中十分有用。为你常用的命令定义别名可以节省你的打字时间。Oh My Zsh 默认配置了一些常用的命令别名,包括目录导航命令别名,为常用的命令添加额外的选项,比如:
|
||||
|
||||
```
|
||||
ls='ls --color=tty'
|
||||
grep='grep --color=auto --exclude-dir={.bzr,CVS,.git,.hg,.svn}'
|
||||
```
|
||||
|
||||
除了命令别名以外, zsh 还自带两种额外常用的别名类型:后缀别名和全局别名。
|
||||
|
||||
除了命令别名意外, zsh 还自带两种额外常用的别名类型:后缀别名和全局别名。
|
||||
|
||||
后缀别名可以让你在基于文件后缀的前提下,在命令行中利用指定程序打开这个文件。比如,要用 vim 打开 YAML 文件,可以定义以下命令行别名:
|
||||
后缀别名可以让你基于文件后缀,在命令行中利用指定程序打开这个文件。比如,要用 vim 打开 YAML 文件,可以定义以下命令行别名:
|
||||
|
||||
```
|
||||
alias -s {yml,yaml}=vim
|
||||
```
|
||||
|
||||
现在,如果你在命令行中输入任何后缀名为 `yml` 或 `yaml` 文件, zsh 都会用 vim 打开这个文件
|
||||
现在,如果你在命令行中输入任何后缀名为 `yml` 或 `yaml` 文件, zsh 都会用 vim 打开这个文件。
|
||||
|
||||
```
|
||||
$ playbook.yml
|
||||
# Opens file playbook.yml using vim
|
||||
```
|
||||
|
||||
全局别名可以让你在使用命令行的任何时刻创建命令别名,而不仅仅是在开始的时候。这个在你想替换常用文件名或者管道命令的时候就显得非常有用了。比如
|
||||
全局别名可以让你创建一个可在命令行的任何地方展开的别名,而不仅仅是在命令开始的时候。这个在你想替换常用文件名或者管道命令的时候就显得非常有用了。比如:
|
||||
|
||||
```
|
||||
alias -g G='| grep -i'
|
||||
@ -84,9 +82,9 @@ drwxr-xr-x. 6 rgerardi rgerardi 4096 Aug 24 14:51 Downloads
|
||||
|
||||
接着,我们就来看看 zsh 是如何导航文件系统的。
|
||||
|
||||
### 3\. 便捷的目录导航
|
||||
### 3、便捷的目录导航
|
||||
|
||||
当你使用命令行的时候, 在不同的目录之间切换访问是最常见的工作了。 zsh 提供了一些十分有用的目录导航功能来简化这个操作。这些功能已经集成到 Oh My Zsh 中了, 而你可以用以下命令来启用它
|
||||
当你使用命令行的时候,在不同的目录之间切换访问是最常见的工作了。 zsh 提供了一些十分有用的目录导航功能来简化这个操作。这些功能已经集成到 Oh My Zsh 中了, 而你可以用以下命令来启用它
|
||||
|
||||
```
|
||||
setopt autocd autopushd \ pushdignoredups
|
||||
@ -104,7 +102,7 @@ $ pwd
|
||||
|
||||
如果想要回退,只要输入 `-`:
|
||||
|
||||
Zsh 会记录你访问过的目录,这样下次你就可以快速切换到这些目录中。如果想要看这个目录列表,只要输入 `dirs -v`:
|
||||
zsh 会记录你访问过的目录,这样下次你就可以快速切换到这些目录中。如果想要看这个目录列表,只要输入 `dirs -v`:
|
||||
|
||||
```
|
||||
$ dirs -v
|
||||
@ -168,7 +166,7 @@ $ pwd
|
||||
/tmp
|
||||
```
|
||||
|
||||
最后,你可以在 zsh 中利用 Tab 来自动补全目录名称。你可以先输入目录的首字母,然后用 `TAB` 来补全它们:
|
||||
最后,你可以在 zsh 中利用 Tab 来自动补全目录名称。你可以先输入目录的首字母,然后按 `TAB` 键来补全它们:
|
||||
|
||||
```
|
||||
$ pwd
|
||||
@ -179,22 +177,22 @@ $ Projects/Opensource.com/zsh-5tips/
|
||||
|
||||
以上仅仅是 zsh 强大的 Tab 补全系统中的一个功能。接来下我们来探索它更多的功能。
|
||||
|
||||
### 4\. 先进的 Tab 补全
|
||||
### 4、先进的 Tab 补全
|
||||
|
||||
Zsh 强大的补全系统是它其中一个卖点。为了简便起见,我称它为 Tab 补全,然而在系统底层,它不仅仅只做一件事。这里通常包括扩展以及命令的补全,我会在这里同时讨论它们。如果想了解更多,详见 [用户手册][8] ( [User's Guide][8] )。
|
||||
zsh 强大的补全系统是它的卖点之一。为了简便起见,我称它为 Tab 补全,然而在系统底层,它起到了几个作用。这里通常包括展开以及命令补全,我会在这里用讨论它们。如果想了解更多,详见 [用户手册][8]。
|
||||
|
||||
在 Oh My Zsh 中,命令补全是默认启用的。要启用它,你只要在 `.zshrc` 文件中添加以下命令:
|
||||
|
||||
在 Oh My Zsh 中,命令补全是默认可用的。要启用它,你只要在 `.zshrc` 文件中添加以下命令:
|
||||
```
|
||||
autoload -U compinit
|
||||
compinit
|
||||
```
|
||||
|
||||
Zsh 的补全系统非常智能。他会根据当前上下文来进行命令的提示——比如,你输入了 `cd` 和 `TAB`,zsh 只会为你提示目录名,因为它知道
|
||||
当前的 `cd` 没有任何作用。
|
||||
zsh 的补全系统非常智能。它会尝试唯一提示可用在当前上下文环境中的项目 —— 比如,你输入了 `cd` 和 `TAB`,zsh 只会为你提示目录名,因为它知道其它的项目放在 `cd` 后面没用。
|
||||
|
||||
反之,如果你使用 `ssh` 或者 `ping` 这类与用户或者主机相关的命令, zsh 便会提示用户名。
|
||||
反之,如果你使用与用户相关的命令便会提示用户名,而 `ssh` 或者 `ping` 这类则会提示主机名。
|
||||
|
||||
`zsh` 拥有一个巨大而又完整的库,因此它能识别许多不同的命令。比如,如果你使用 `tar` 命令, 你可以按 Tab 键,他会为你展示一个可以用于解压的文件列表:
|
||||
zsh 拥有一个巨大而又完整的库,因此它能识别许多不同的命令。比如,如果你使用 `tar` 命令, 你可以按 `TAB` 键,它会为你展示一个可以用于解压的文件列表:
|
||||
|
||||
```
|
||||
$ tar -xzvf test1.tar.gz test1/file1 (TAB)
|
||||
@ -221,7 +219,7 @@ $ git add (TAB)
|
||||
$ git add zsh-5tips.md
|
||||
```
|
||||
|
||||
zsh 还能识别命令行选项,同时他只会提示与选中子命令相关的命令列表:
|
||||
zsh 还能识别命令行选项,同时它只会提示与选中子命令相关的命令列表:
|
||||
|
||||
```
|
||||
$ git commit - (TAB)
|
||||
@ -243,27 +241,27 @@ $ git commit - (TAB)
|
||||
... TRUNCATED ...
|
||||
```
|
||||
|
||||
在按 `TAB` 键之后,你可以使用方向键来选择你想用的命令。现在你就不用记住所有的 Git 命令项了。
|
||||
在按 `TAB` 键之后,你可以使用方向键来选择你想用的命令。现在你就不用记住所有的 `git` 命令项了。
|
||||
|
||||
zsh 还有很多有用的功能。当你用它的时候,你就知道哪些对你才是最有用的。
|
||||
|
||||
### 5\. 命令行编辑与历史记录
|
||||
### 5、命令行编辑与历史记录
|
||||
|
||||
Zsh 的命令行编辑功能也十分有效。默认条件下,他是模拟 emacs 编辑器的。如果你是跟我一样更喜欢用 vi/vim,你可以用以下命令启用 vi 编辑。
|
||||
zsh 的命令行编辑功能也十分有用。默认条件下,它是模拟 emacs 编辑器的。如果你是跟我一样更喜欢用 vi/vim,你可以用以下命令启用 vi 的键绑定。
|
||||
|
||||
```
|
||||
$ bindkey -v
|
||||
```
|
||||
|
||||
如果你使用 Oh My Zsh,`vi-mode` 插件可以启用额外的绑定,同时会在你的命令提示符上增加 vi 的模式提示--这个非常有用。
|
||||
如果你使用 Oh My Zsh,`vi-mode` 插件可以启用额外的绑定,同时会在你的命令提示符上增加 vi 的模式提示 —— 这个非常有用。
|
||||
|
||||
当启用 vi 的绑定后,你可以再命令行中使用 vi 命令进行编辑。比如,输入 `ESC+/` 来查找命令行记录。在查找的时候,输入 `n` 来找下一个匹配行,输入 `N` 来找上一个。输入 `ESC` 后,最常用的 vi 命令有以下几个,如输入 `0` 跳转到第一行,输入 `$` 跳转到最后一行,输入 `i` 来插入文本,输入 `a` 来追加文本等等,一些直接操作的命令也同样有效,比如输入 `cw` 来修改单词。
|
||||
当启用 vi 的绑定后,你可以在命令行中使用 vi 命令进行编辑。比如,输入 `ESC+/` 来查找命令行记录。在查找的时候,输入 `n` 来找下一个匹配行,输入 `N` 来找上一个。输入 `ESC` 后,常用的 vi 命令都可以使用,如输入 `0` 跳转到行首,输入 `$` 跳转到行尾,输入 `i` 来插入文本,输入 `a` 来追加文本等等,即使是跟随的命令也同样有效,比如输入 `cw` 来修改单词。
|
||||
|
||||
除了命令行编辑,如果你想修改或重新执行之前使用过的命令,zsh 还提供几个常用的命令行历史功能。比如,你打错了一个命令,输入 `fc`,你可以在你偏好的编辑器中修复最后一条命令。使用哪个编辑是参照 `$EDITOR` 变量的,而默认是使用 vi。
|
||||
|
||||
另外一个有用的命令是 `r`, 他会重新执行上一条命令;而 `r <WORD>` 则会执行上一条包含 `WORD` 的命令。
|
||||
另外一个有用的命令是 `r`, 它会重新执行上一条命令;而 `r <WORD>` 则会执行上一条包含 `WORD` 的命令。
|
||||
|
||||
最后,输入两个感叹号( `!!` ),可以在命令行中回溯最后一条命令。这个十分有用,比如,当你忘记使用 `sudo` 去执行需要权限的命令时:
|
||||
最后,输入两个感叹号(`!!`),可以在命令行中回溯最后一条命令。这个十分有用,比如,当你忘记使用 `sudo` 去执行需要权限的命令时:
|
||||
|
||||
```
|
||||
$ less /var/log/dnf.log
|
||||
@ -274,19 +272,16 @@ $ sudo less /var/log/dnf.log
|
||||
|
||||
这个功能让查找并且重新执行之前命令的操作更加方便。
|
||||
|
||||
### 何去何从?
|
||||
### 下一步呢?
|
||||
|
||||
这里仅仅介绍了几个可以让你提高生产率的 zsh 特性;其实还有更多功能带你发掘;想知道更多的信息,你可以访问以下的资源:
|
||||
这里仅仅介绍了几个可以让你提高生产率的 zsh 特性;其实还有更多功能有待你的发掘;想知道更多的信息,你可以访问以下的资源:
|
||||
|
||||
[An Introduction to the Z Shell][9]
|
||||
- [An Introduction to the Z Shell][9]
|
||||
- [A User's Guide to ZSH][10]
|
||||
- [Archlinux Wiki][11]
|
||||
- [zsh-lovers][12]
|
||||
|
||||
[A User's Guide to ZSH][10]
|
||||
|
||||
[Archlinux Wiki][11]
|
||||
|
||||
[zsh-lovers][12]
|
||||
|
||||
你有使用 zsh 提高生产力的tips可以分享吗?我(作者)很乐意在下方评论看到它们。
|
||||
你有使用 zsh 提高生产力的技巧可以分享吗?我很乐意在下方评论中看到它们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -295,7 +290,7 @@ via: https://opensource.com/article/18/9/tips-productivity-zsh
|
||||
作者:[Ricardo Gerardi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[tnuoccalanosrep](https://github.com/tnuoccalanosrep)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,49 +3,49 @@
|
||||
|
||||

|
||||
|
||||
多播 DNS 或 mDNS 允许系统通过在广播查询局域网中的其他资源。Fedora 用户经常在没有复杂名称服务的路由器上拥有多个 Linux 系统。在这种情况下,mDNS 允许你按名称与多个系统通信 - 多数情况下不用路由器。你也不必在所有本地系统上同步类似 /etc/hosts 之类的文件。本文介绍如何设置它。
|
||||
mDNS(<ruby>多播 DNS<rt>Multicast DNS</rt></ruby>)允许系统在局域网中广播查询其他资源的名称。Fedora 用户经常在没有复杂名称服务的路由器上接有多个 Linux 系统。在这种情况下,mDNS 允许你按名称与多个系统通信 —— 多数情况下不用路由器。你也不必在所有本地系统上同步类似 `/etc/hosts` 之类的文件。本文介绍如何设置它。
|
||||
|
||||
mDNS 是一个零配置网络服务,它已经诞生了很长一段时间。Fedora 将 Avahi (包含 mDNS 的零配置系统)作为工作站的一部分。 (mDNS 也是 Bonjour 的一部分,可在 Mac OS 上找到。)
|
||||
mDNS 是一个零配置网络服务,它已经诞生了很长一段时间。Fedora Workstation 带有零配置系统 Avahi(它包含 mDNS)。 (mDNS 也是 Bonjour 的一部分,可在 Mac OS 上找到。)
|
||||
|
||||
本文假设你有两个系统运行受支持的 Fedora 版本(27 或 28)。它们的主机名是 castor 和 pollux。
|
||||
|
||||
### 安装包
|
||||
|
||||
确保系统上安装了 nss-mdns 和 avahi 软件包。你可能是不同的版本,这也没问题:
|
||||
|
||||
```
|
||||
$ rpm -q nss-mdns avahi
|
||||
nss-mdns-0.14.1-1.fc28.x86_64
|
||||
avahi-0.7-13.fc28.x86_64
|
||||
|
||||
```
|
||||
|
||||
Fedora Workstation 默认提供这两个包。如果不存在,请安装它们:
|
||||
|
||||
```
|
||||
$ sudo dnf install nss-mdns avahi
|
||||
|
||||
```
|
||||
|
||||
确保 avahi-daemon.service 单元已启用并正在运行。同样,这是 Fedora Workstation 的默认设置。
|
||||
确保 `avahi-daemon.service` 单元已启用并正在运行。同样,这是 Fedora Workstation 的默认设置。
|
||||
|
||||
```
|
||||
$ sudo systemctl enable --now avahi-daemon.service
|
||||
|
||||
```
|
||||
|
||||
虽然是可选的,但你可能还需要安装 avahi-tools 软件包。该软件包包括许多方便的程序,用于检查系统上的零配置服务的工作情况。使用这个 sudo 命令:
|
||||
虽然是可选的,但你可能还需要安装 avahi-tools 软件包。该软件包包括许多方便的程序,用于检查系统上的零配置服务的工作情况。使用这个 `sudo` 命令:
|
||||
|
||||
```
|
||||
$ sudo dnf install avahi-tools
|
||||
|
||||
```
|
||||
|
||||
/etc/nsswitch.conf 控制系统使用哪个服务用于解析,以及它们的顺序。你应该在那个文件中看到这样的一行:
|
||||
`/etc/nsswitch.conf` 控制系统使用哪个服务用于解析,以及它们的顺序。你应该在那个文件中看到这样的一行:
|
||||
|
||||
```
|
||||
hosts: files mdns4_minimal [NOTFOUND=return] dns myhostname
|
||||
|
||||
```
|
||||
|
||||
注意命令 mdns4_minimal [NOTFOUND=return]。它们告诉你的系统使用多播 DNS 解析程序将主机名解析为 IP 地址。即使该服务有效,如果名称无法解析,也会尝试其余服务。
|
||||
注意命令 `mdns4_minimal [NOTFOUND=return]`。它们告诉你的系统使用多播 DNS 解析程序将主机名解析为 IP 地址。即使该服务有效,如果名称无法解析,也会尝试其余服务。
|
||||
|
||||
如果你没有看到与此类似的配置,则可以对其进行编辑(以 root 用户身份)。但是,nss-mdns 包会为你处理此问题。如果你对自己编辑它感到不舒服,请删除并重新安装该软件包以修复该文件。
|
||||
如果你没有看到与此类似的配置,则可以(以 root 用户身份)对其进行编辑。但是,nss-mdns 包会为你处理此问题。如果你对自己编辑它感到不舒服,请删除并重新安装该软件包以修复该文件。
|
||||
|
||||
在**两个系统**中执行同样的步骤 。
|
||||
|
||||
@ -53,42 +53,36 @@ hosts: files mdns4_minimal [NOTFOUND=return] dns myhostname
|
||||
|
||||
现在你已完成常见的配置工作,请使用以下方法之一设置每个主机的名称:
|
||||
|
||||
1. 如果你正在使用 Fedora Workstation,[你可以使用这个步骤][1]。
|
||||
|
||||
2. 如果没有,请使用 hostnamectl 来做。在第一台机器上这么做:
|
||||
```
|
||||
$ hostnamectl set-hostname castor
|
||||
|
||||
```
|
||||
|
||||
3. 你还可以编辑 /etc/avahi/avahi-daemon.conf,删除主机名设置行上的注释,并在那里设置名称。但是,默认情况下,Avahi 使用系统提供的主机名,因此你**不应该**需要此方法。
|
||||
1. 如果你正在使用 Fedora Workstation,[你可以使用这个步骤][1]。
|
||||
2. 如果没有,请使用 `hostnamectl` 来做。在第一台机器上这么做:`$ hostnamectl set-hostname castor`。
|
||||
3. 你还可以编辑 `/etc/avahi/avahi-daemon.conf`,删除主机名设置行上的注释,并在那里设置名称。但是,默认情况下,Avahi 使用系统提供的主机名,因此你**不应该**需要此方法。
|
||||
|
||||
接下来,重启 Avahi 守护进程,以便它接收更改:
|
||||
|
||||
```
|
||||
$ sudo systemctl restart avahi-daemon.service
|
||||
|
||||
```
|
||||
|
||||
然后正确设置另一台机器:
|
||||
|
||||
```
|
||||
$ hostnamectl set-hostname pollux
|
||||
$ sudo systemctl restart avahi-daemon.service
|
||||
|
||||
```
|
||||
|
||||
只要你的路由器没有禁止 mDNS 流量,你现在应该能够登录到 castor 并 ping 通另一台机器。你应该使用默认的 .local 域名,以便解析正常工作:
|
||||
|
||||
```
|
||||
$ ping pollux.local
|
||||
PING pollux.local (192.168.0.1) 56(84) bytes of data.
|
||||
64 bytes from 192.168.0.1 (192.168.0.1): icmp_seq=1 ttl=64 time=3.17 ms
|
||||
64 bytes from 192.168.0.1 (192.168.0.1): icmp_seq=2 ttl=64 time=1.24 ms
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
如果你在 pollux ping castor.local,同样的技巧也适用 。现在在网络中访问你的系统更方便了!
|
||||
如果你在 pollux `ping castor.local`,同样的技巧也适用。现在在网络中访问你的系统更方便了!
|
||||
|
||||
此外,如果你的路由器宣传这个服务,请不要感到惊讶。现代 WiFi 和有线路由器通常提供这些服务,以使消费者的生活更轻松。
|
||||
此外,如果你的路由器也支持这个服务,请不要感到惊讶。现代 WiFi 和有线路由器通常提供这些服务,以使消费者的生活更轻松。
|
||||
|
||||
此过程适用于大多数系统。但是,如果遇到麻烦,请使用 avahi-browse 和 avahi-tools 软件包中的其他工具来查看可用的服务。
|
||||
|
||||
@ -97,10 +91,7 @@ PING pollux.local (192.168.0.1) 56(84) bytes of data.
|
||||
|
||||
via: https://fedoramagazine.org/find-systems-easily-lan-mdns/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
作者:[Paul W. Frields][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[geekpi](https://github.com/geekpi)
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,245 @@
|
||||
最好的 3 个开源 JavaScript 图表库
|
||||
======
|
||||
> 图表及其它可视化方式让传递数据的信息变得更简单。
|
||||
|
||||

|
||||
|
||||
对于数据可视化和制作精美网站来说,图表和图形很重要。视觉上的展示让分析大块数据及传递信息变得更简单。JavaScript 图表库能让数据以极好的、易于理解的和交互的方式进行可视化,还能够优化你的网站设计。
|
||||
|
||||
本文会带你学习最好的 3 个开源 JavaScript 图表库。
|
||||
|
||||
### 1、 Chart.js
|
||||
|
||||
[Chart.js][1] 是一个开源的 JavaScript 库,你可以在自己的应用中用它创建生动美丽和交互式的图表。使用它需要遵循 MIT 协议。
|
||||
|
||||
使用 Chart.js,你可以创建各种各样令人印象深刻的图表和图形,包括条形图、折线图、范围图、线性标度和散点图。它可以响应各种设备,使用 HTML5 Canvas 元素进行绘制。
|
||||
|
||||
示例代码如下,它使用该库绘制了一个条形图。本例中我们使用 Chart.js 的内容分发网络(CDN)来包含这个库。注意这里使用的数据仅用于展示。
|
||||
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
<script src="https://cdnjs.cloudflare.com/ajax/libs/Chart.js/2.5.0/Chart.min.js"></script>
|
||||
</head>
|
||||
|
||||
<body>
|
||||
|
||||
<canvas id="bar-chart" width=300" height="150"></canvas>
|
||||
|
||||
<script>
|
||||
|
||||
new Chart(document.getElementById("bar-chart"), {
|
||||
type: 'bar',
|
||||
data: {
|
||||
labels: ["North America", "Latin America", "Europe", "Asia", "Africa"],
|
||||
datasets: [
|
||||
{
|
||||
label: "Number of developers (millions)",
|
||||
backgroundColor: ["red", "blue","yellow","green","pink"],
|
||||
data: [7,4,6,9,3]
|
||||
}
|
||||
]
|
||||
},
|
||||
options: {
|
||||
legend: { display: false },
|
||||
title: {
|
||||
display: true,
|
||||
text: 'Number of Developers in Every Continent'
|
||||
},
|
||||
|
||||
scales: {
|
||||
yAxes: [{
|
||||
ticks: {
|
||||
beginAtZero:true
|
||||
}
|
||||
}]
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
});
|
||||
</script>
|
||||
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
如你所见,通过设置 `type` 和 `bar` 来构造条形图。你可以把条形体的方向改成其他类型 —— 比如把 `type` 设置成 `horizontalBar`。
|
||||
|
||||
在 `backgroundColor` 数组参数中提供颜色类型,就可以设置条形图的颜色。
|
||||
|
||||
颜色被分配给关联数组中相同索引的标签和数据。例如,第二个标签 “Latin American”,颜色会是 “蓝色(blue)”(第二个颜色),数值是 4(data 中的第二个数字)。
|
||||
|
||||
代码的执行结果如下。
|
||||
|
||||
|
||||
|
||||
### 2、 Chartist.js
|
||||
|
||||
[Chartist.js][2] 是一个简单的 JavaScript 动画库,你能够自制美丽的响应式图表,或者进行其他创作。使用它需要遵循 WTFPL 或者 MIT 协议。
|
||||
|
||||
这个库是由一些对现有图表工具不满的开发者进行开发的,它可以为设计师或程序员提供美妙的功能。
|
||||
|
||||
在项目中包含 Chartist.js 库后,你可以使用它们来创建各式各样的图表,包括动画,条形图和折线图。它使用 SVG 来动态渲染图表。
|
||||
|
||||
这里是使用该库绘制一个饼图的例子。
|
||||
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
|
||||
<link href="https//cdn.jsdelivr.net/chartist.js/latest/chartist.min.css" rel="stylesheet" type="text/css" />
|
||||
|
||||
<style>
|
||||
.ct-series-a .ct-slice-pie {
|
||||
fill: hsl(100, 20%, 50%); /* filling pie slices */
|
||||
stroke: white; /*giving pie slices outline */
|
||||
stroke-width: 5px; /* outline width */
|
||||
}
|
||||
|
||||
.ct-series-b .ct-slice-pie {
|
||||
fill: hsl(10, 40%, 60%);
|
||||
stroke: white;
|
||||
stroke-width: 5px;
|
||||
}
|
||||
|
||||
.ct-series-c .ct-slice-pie {
|
||||
fill: hsl(120, 30%, 80%);
|
||||
stroke: white;
|
||||
stroke-width: 5px;
|
||||
}
|
||||
|
||||
.ct-series-d .ct-slice-pie {
|
||||
fill: hsl(90, 70%, 30%);
|
||||
stroke: white;
|
||||
stroke-width: 5px;
|
||||
}
|
||||
.ct-series-e .ct-slice-pie {
|
||||
fill: hsl(60, 140%, 20%);
|
||||
stroke: white;
|
||||
stroke-width: 5px;
|
||||
}
|
||||
|
||||
</style>
|
||||
</head>
|
||||
|
||||
<body>
|
||||
|
||||
<div class="ct-chart ct-golden-section"></div>
|
||||
|
||||
<script src="https://cdn.jsdelivr.net/chartist.js/latest/chartist.min.js"></script>
|
||||
|
||||
<script>
|
||||
|
||||
var data = {
|
||||
series: [45, 35, 20]
|
||||
};
|
||||
|
||||
var sum = function(a, b) { return a + b };
|
||||
|
||||
new Chartist.Pie('.ct-chart', data, {
|
||||
labelInterpolationFnc: function(value) {
|
||||
return Math.round(value / data.series.reduce(sum) * 100) + '%';
|
||||
}
|
||||
});
|
||||
</script>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
使用 Chartist JavaScript 库,你可以使用各种预先构建好的 CSS 样式,而不是在项目中指定各种与样式相关的部分。你可以使用这些样式来设置已创建的图表的外观。
|
||||
|
||||
比如,预创建的 CSS 类 `.ct-chart` 是用来构建饼状图的容器。还有 `.ct-golden-section` 类可用于获取纵横比,它基于响应式设计进行缩放,帮你解决了计算固定尺寸的麻烦。Chartist 还提供了其它类别的比例容器,你可以在自己的项目中使用它们。
|
||||
|
||||
为了给各个扇形设置样式,可以使用默认的 `.ct-serials-a` 类。字母 `a` 是根据系列的数量变化的(a、b、c,等等),因此它与每个要设置样式的扇形相对应。
|
||||
|
||||
`Chartist.Pie` 方法用来创建一个饼状图。要创建另一种类型的图表,比如折线图,请使用 `Chartist.Line`。
|
||||
|
||||
代码的执行结果如下。
|
||||
|
||||
|
||||
|
||||
### 3、 D3.js
|
||||
|
||||
[D3.js][3] 是另一个好用的开源 JavaScript 图表库。使用它需要遵循 BSD 许可证。D3 的主要用途是,根据提供的数据,处理和添加文档的交互功能,。
|
||||
|
||||
借助这个 3D 动画库,你可以通过 HTML5、SVG 和 CSS 来可视化你的数据,并且让你的网站变得更精美。更重要的是,使用 D3,你可以把数据绑定到文档对象模型(DOM)上,然后使用基于数据的函数改变文档。
|
||||
|
||||
示例代码如下,它使用该库绘制了一个简单的条形图。
|
||||
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
|
||||
<style>
|
||||
.chart div {
|
||||
font: 15px sans-serif;
|
||||
background-color: lightblue;
|
||||
text-align: right;
|
||||
padding:5px;
|
||||
margin:5px;
|
||||
color: white;
|
||||
font-weight: bold;
|
||||
}
|
||||
|
||||
</style>
|
||||
</head>
|
||||
|
||||
<body>
|
||||
|
||||
<div class="chart"></div>
|
||||
|
||||
<script src="https://cdnjs.cloudflare.com/ajax/libs/d3/5.5.0/d3.min.js"></script>
|
||||
|
||||
<script>
|
||||
|
||||
var data = [342,222,169,259,173];
|
||||
|
||||
d3.select(".chart")
|
||||
.selectAll("div")
|
||||
.data(data)
|
||||
.enter()
|
||||
.append("div")
|
||||
.style("width", function(d){ return d + "px"; })
|
||||
.text(function(d) { return d; });
|
||||
|
||||
|
||||
</script>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
使用 D3 库的主要概念是应用 CSS 样式选择器来定位 DOM 节点,然后对其执行操作,就像其它的 DOM 框架,比如 JQuery。
|
||||
|
||||
将数据绑定到文档上后,.`enter()` 函数会被调用,为即将到来的数据构建新的节点。所有在 .`enter()` 之后调用的方法会为数据中的每一个项目调用一次。
|
||||
|
||||
代码的执行结果如下。
|
||||
|
||||
|
||||
|
||||
### 总结
|
||||
|
||||
[JavaScript][4] 图表库提供了强大的工具,你可以将自己的网络资源进行数据可视化。通过这三个开源库,你可以把自己的网站变得更好看,更容易使用。
|
||||
|
||||
你知道其它强大的用于创造 JavaScript 动画效果的前端库吗?请在下方的评论区留言分享。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/open-source-javascript-chart-libraries
|
||||
|
||||
作者:[Dr.Michael J.Garbade][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[BriFuture](https://github.com/brifuture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/drmjg
|
||||
[1]: https://www.chartjs.org/
|
||||
[2]: https://gionkunz.github.io/chartist-js/
|
||||
[3]: https://d3js.org/
|
||||
[4]: https://www.liveedu.tv/guides/programming/javascript/
|
||||
@ -1,33 +1,33 @@
|
||||
Flash Player 的两种开源替代方案
|
||||
======
|
||||
> Adobe 将于 2020 年终止对 Flash 媒体播放器的支持,但仍有很多人们希望访问的 Flash 视频。这里有两个开源的替代品或许可以帮到你。
|
||||
|
||||

|
||||
|
||||
2017 年 7 月,Adobe 为 Flash Media Player 敲响了[丧钟][1],宣布将在 2020 年终止对曾经无处不在的在线视频播放器的支持。但事实上,在一系列损害了其声誉的零日攻击后,Flash 的份额在过去的 8 年一直在下跌。苹果公司在 2010 年宣布它不会支持这项技术后,其未来趋于黯淡,并且在谷歌停止在 Chrome 浏览器中默认启用 Flash(支持 HTML5)后,它的消亡在 2016 年加速。
|
||||
2017 年 7 月,Adobe 为 Flash Media Player 敲响了[丧钟][1],宣布将在 2020 年终止对曾经无处不在的在线视频播放器的支持。但事实上,在一系列损害了其声誉的零日攻击后,Flash 的份额在过去的 8 年一直在下跌。苹果公司在 2010 年宣布它不会支持这项技术后,其未来趋于黯淡,并且在谷歌停止在 Chrome 浏览器中默认启用 Flash(支持 HTML5)后,它的消亡在 2016 年进一步加速。
|
||||
|
||||
即便如此,Adobe 仍然每月发布该软件的更新,截至 2018 年 8 月,它在网站的使用率从 2011 年的 28.5% 下降到[仅 4.4%] [2]。还有更多证据表明 Flash 的下滑:谷歌工程总监 [Parisa Tabriz 说][3]通过浏览器访问 Flash 内容的 Chrome 用户数量从 2014 年的 80% 下降到 2018 年的 8%。
|
||||
|
||||
尽管如今很少有视频创作者以 Flash 格式发布,但仍有很多人们希望在未来几年内访问的 Flash 视频。鉴于官方支持的日期已经屈指可数,开源软件创建者有很好的机会介入 Adobe Flash Media Player 的替代品。这其中两个应用是 Lightspark 和 GNU Gnash。它们都不是完美的替代品,但来自贡献者的帮助可以使它们成为可行的替代品。
|
||||
尽管如今很少有视频创作者以 Flash 格式发布,但仍有很多人们希望在未来几年内访问的 Flash 视频。鉴于官方支持的日期已经屈指可数,开源软件创建者有很好的机会涉足 Adobe Flash 媒体播放器的替代品。这其中两个应用是 Lightspark 和 GNU Gnash。它们都不是完美的替代品,但来自贡献者的帮助可以使它们成为可行的替代品。
|
||||
|
||||
### Lightspark
|
||||
|
||||
[Lightspark][4] 是 Linux 上的 Flash Player 替代品。虽然它仍处于 alpha 状态,但自从 Adobe 在 2017 宣布废弃 Adobe 以来,开发速度已经加快。据其网站称,Lightspark 实现了 60% 的 Flash API,可在许多流行网站包括 BBC 新闻、Google Play 音乐和亚马逊音乐上[使用][5]。
|
||||
|
||||
Lightspark 是用 C++/C 编写的,并在 [LGPLv3][6] 下许可。该项目列出了 41 个贡献者,并正在积极征求错误报告和其他贡献。有关更多信息,请查看其[ GitHub 仓库][5]。
|
||||
Lightspark 是用 C++/C 编写的,并在 [LGPLv3][6] 下许可。该项目列出了 41 个贡献者,并正在积极征求错误报告和其他贡献。有关更多信息,请查看其 [GitHub 仓库][5]。
|
||||
|
||||
### GNU Gnash
|
||||
|
||||
[GNU Gnash][7] 是一个用于 GNU/Linux 操作系统,包括 Ubuntu、Fedora 和 Debian 的 Flash Player。它作为独立软件和插件可用于 Firefox 和 Konqueror 浏览器中。
|
||||
|
||||
Gnash 的主要缺点是它不支持最新版本的 Flash 文件 - 它支持大多数 Flash SWF v7 功能,一些 v8 和 v9 功能,不支持 v10 文件。它处于测试阶段,由于它在[ GNU GPLv3 或更高版本][8]下许可,因此你可以帮助实现它的现代化。访问其[项目页面][9]获取更多信息。
|
||||
Gnash 的主要缺点是它不支持最新版本的 Flash 文件 —— 它支持大多数 Flash SWF v7 功能,一些 v8 和 v9 功能,不支持 v10 文件。它处于测试阶段,由于它在 [GNU GPLv3 或更高版本][8]下许可,因此你可以帮助实现它的现代化。访问其[项目页面][9]获取更多信息。
|
||||
|
||||
### 想要创建Flash吗?
|
||||
### 想要创建 Flash 吗?
|
||||
|
||||
* 仅因为大多数人都不会发布 Flash 视频,但这并不意味着永远不需要创建 SWF 文件。如果你发现自己需要,这两个开源工具可能会有所帮助:
|
||||
|
||||
* [Motion-Twin ActionScript 2 编译器][10](MTASC):一个命令行编译器,它可以在没有 Adobe Animate(Adobe 当前的视频创建软件)的情况下生成 SWF 文件。
|
||||
* [Ming][11]:用 C 编写的可以生成 SWF 文件的库。它还包含一些可用于处理 Flash 的[程序][12]。
|
||||
仅因为大多数人都不会发布 Flash 视频,但这并不意味着永远不需要创建 SWF 文件。如果你发现自己需要,这两个开源工具可能会有所帮助:
|
||||
|
||||
* [Motion-Twin ActionScript 2 编译器][10](MTASC):一个命令行编译器,它可以在没有 Adobe Animate(Adobe 当前的视频创建软件)的情况下生成 SWF 文件。
|
||||
* [Ming][11]:用 C 编写的可以生成 SWF 文件的库。它还包含一些可用于处理 Flash 的[程序][12]。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -37,7 +37,7 @@ via: https://opensource.com/alternatives/flash-media-player
|
||||
作者:[Opensource.com][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,124 @@
|
||||
Autotrash:一个自动清除旧垃圾的命令行工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
**Autotrash** 是一个命令行程序,它用于自动清除旧的已删除文件。它将清除超过指定天数的在回收站中的文件。你不需要清空回收站或执行 `SHIFT+DELETE` 以永久清除文件/文件夹。Autortrash 将处理回收站中的内容,并在特定时间段后自动删除它们。简而言之,Autotrash 永远不会让你的垃圾变得太大。
|
||||
|
||||
### 安装 Autotrash
|
||||
|
||||
Autotrash 默认存在于基于 Debian 系统的仓库中。要在 Debian、Ubuntu、Linux Mint 上安装 `autotrash`,请运行:
|
||||
|
||||
```
|
||||
$ sudo apt-get install autotrash
|
||||
```
|
||||
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo dnf install autotrash
|
||||
```
|
||||
|
||||
对于 Arch linux 及其变体,你可以使用任何 AUR 助手程序, 如 [**Yay**][1] 安装它。
|
||||
|
||||
```
|
||||
$ yay -S autotrash-git
|
||||
```
|
||||
|
||||
### 自动清除旧的垃圾文件
|
||||
|
||||
每当你运行 `autotrash` 时,它会扫描你的 `~/.local/share/Trash/info` 目录并读取 `.trashinfo` 以找出它们的删除日期。如果文件已在回收站中超过指定的日期,那么就会删除它们。
|
||||
|
||||
让我举几个例子。
|
||||
|
||||
要删除回收站中超过 30 天的文件,请运行:
|
||||
|
||||
```
|
||||
$ autotrash -d 30
|
||||
```
|
||||
|
||||
如上例所示,如果回收站中的文件超过 30 天,Autotrash 会自动将其从回收站中删除。你无需手动删除它们。只需将没用的文件放到回收站即可忘记。Autotrash 将处理已删除的文件。
|
||||
|
||||
以上命令仅处理当前登录用户的垃圾目录。如果要使 autotrash 处理所有用户的垃圾目录(不仅仅是在你的家目录中),请使用 `-t` 选项,如下所示。
|
||||
|
||||
```
|
||||
$ autotrash -td 30
|
||||
```
|
||||
|
||||
Autotrash 还允许你根据回收站可用容量或磁盘可用空间来删除已删除的文件。
|
||||
|
||||
例如,看下下面的例子:
|
||||
|
||||
```
|
||||
$ autotrash --max-free 1024 -d 30
|
||||
```
|
||||
|
||||
根据上面的命令,如果回收站的剩余的空间少于 **1GB**,那么 autotrash 将从回收站中清除超过 **30 天**的已删除文件。如果你的回收站空间不足,这可能很有用。
|
||||
|
||||
我们还可以从回收站中按最早的时间清除文件直到回收站至少有 1GB 的空间。
|
||||
|
||||
```
|
||||
$ autotrash --min-free 1024
|
||||
```
|
||||
|
||||
在这种情况下,对旧的已删除文件没有限制。
|
||||
|
||||
你可以将这两个选项(`--min-free` 和 `--max-free`)组合在一个命令中,如下所示。
|
||||
|
||||
```
|
||||
$ autotrash --max-free 2048 --min-free 1024 -d 30
|
||||
```
|
||||
|
||||
根据上面的命令,如果可用空间小于 **2GB**,`autotrash` 将读取回收站,接着关注容量。此时,删除超过 30 天的文件,如果少于 **1GB** 的可用空间,则删除更新的文件。
|
||||
|
||||
如你所见,所有命令都应由用户手动运行。你可能想知道,我该如何自动执行此任务?这很容易!只需将 `autotrash` 添加为 crontab 任务即可。现在,命令将在计划的时间自动运行,并根据定义的选项清除回收站中的文件。
|
||||
|
||||
要在 crontab 中添加这些命令,请运行:
|
||||
|
||||
```
|
||||
$ crontab -e
|
||||
```
|
||||
|
||||
添加任务,例如:
|
||||
|
||||
```
|
||||
@daily /usr/bin/autotrash -d 30
|
||||
```
|
||||
|
||||
现在,autotrash 将每天清除回收站中超过 30 天的文件。
|
||||
|
||||
有关计划任务的更多详细信息,请参阅以下链接。
|
||||
|
||||
+ [Cron 任务的初学者指南]][2]
|
||||
+ [如何在 Linux 中轻松安全地管理 Cron 作业]][3]
|
||||
|
||||
请注意,如果你无意中删除了任何重要文件,它们将在规定的日期后永久消失,所以请小心。
|
||||
|
||||
请参阅手册页以了解有关 Autotrash 的更多信息。
|
||||
|
||||
```
|
||||
$ man autotrash
|
||||
```
|
||||
|
||||
清空回收站或按 `SHIFT+DELETE` 永久删除 Linux 系统中没用的东西没什么大不了的。它只需要几秒钟。但是,如果你需要额外的程序来处理垃圾文件,Autotrash 可能会有所帮助。试一下,看看它是如何工作的。
|
||||
|
||||
就是这些了。希望这个有用。还有更多的好东西。
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/autotrash-a-cli-tool-to-automatically-purge-old-trashed-files/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[2]: https://www.ostechnix.com/a-beginners-guide-to-cron-jobs/
|
||||
[3]: https://www.ostechnix.com/how-to-easily-and-safely-manage-cron-jobs-in-linux/
|
||||
@ -0,0 +1,74 @@
|
||||
开源与烹饪有什么相似之处?
|
||||
======
|
||||
|
||||

|
||||
|
||||
有什么好的方法,既可以宣传开源的精神又不用写代码呢?这里有个点子:“<ruby>开源食堂<rt>open source cooking</rt></ruby>”。在过去的 8 年间,这就是我们在慕尼黑做的事情。
|
||||
|
||||
开源食堂已经是我们常规的开源宣传活动了,因为我们发现开源与烹饪有很多共同点。
|
||||
|
||||
### 协作烹饪
|
||||
|
||||
[慕尼黑开源聚会][1]自 2009 年 7 月在 [Café Netzwerk][2] 创办以来,已经组织了若干次活动,活动一般在星期五的晚上组织。该聚会为开源项目工作者或者开源爱好者们提供了相互认识的方式。我们的信条是:“<ruby>每四周的星期五属于自由软件<rt>Every fourth Friday for free software</rt></ruby>”。当然在一些周末,我们还会举办一些研讨会。那之后,我们很快加入了很多其他的活动,包括白香肠早餐、桑拿与烹饪活动。
|
||||
|
||||
事实上,第一次开源烹饪聚会举办的有些混乱,但是我们经过这 8 年来以及 15 次的活动,已经可以为 25-30 个与会者提供丰盛的美食了。
|
||||
|
||||
回头看看这些夜晚,我们愈发发现共同烹饪与开源社区协作之间,有很多相似之处。
|
||||
|
||||
### 烹饪步骤中的自由开源精神
|
||||
|
||||
这里是几个烹饪与开源精神相同的地方:
|
||||
|
||||
* 我们乐于合作且朝着一个共同的目标前进
|
||||
* 我们成了一个社区
|
||||
* 由于我们有相同的兴趣与爱好,我们可以更多的了解我们自身与他人,并且可以一同协作
|
||||
* 我们也会犯错,但我们会从错误中学习,并为了共同的利益去分享关于错误的经验,从而让彼此避免再犯相同的错误
|
||||
* 每个人都会贡献自己擅长的事情,因为每个人都有自己的一技之长
|
||||
* 我们会动员其他人去做出贡献并加入到我们之中
|
||||
* 虽说协作是关键,但难免会有点混乱
|
||||
* 每个人都会从中收益
|
||||
|
||||
### 烹饪中的开源气息
|
||||
|
||||
同很多成功的开源聚会一样,开源烹饪也需要一些协作和组织结构。在每次活动之前,我们会组织所有的成员对菜单进行投票,而不单单是直接给每个人分一角披萨,我们希望真正的作出一道美味,迄今为止我们做过日本、墨西哥、匈牙利、印度等地区风味的美食,限于篇幅就不一一列举了。
|
||||
|
||||
就像在生活中,共同烹饪同样需要各个成员之间相互的尊重和理解,所以我们也会试着为素食主义者、食物过敏者、或者对某些事物有偏好的人提供针对性的事物。正式开始烹饪之前,在家预先进行些小规模的测试会非常有帮助(和乐趣!)
|
||||
|
||||
可扩展性也很重要,在杂货店采购必要的食材很容易就消耗掉 3 个小时。所以我们使用一些表格工具(自然是 LibreOffice Calc)来做一些所需要的食材以及相应的成本。
|
||||
|
||||
我们会同志愿者一起,对于每次晚餐我们都有一个“包维护者”,从而及时的制作出菜单并在问题产生的时候寻找一些独到的解决方法。
|
||||
|
||||
虽然不是所有人都是大厨,但是只要给与一些帮助,并比较合理的分配任务和责任,就很容易让每个人都参与其中。某种程度上来说,处理 18kg 的西红柿和 100 个鸡蛋都不会让你觉得是件难事,相信我!唯一的限制是一个烤炉只有四个灶,所以可能是时候对基础设施加大投入了。
|
||||
|
||||
发布有时间要求,当然要求也不那么严格,我们通常会在 21:30 和 01:30 之间的相当“灵活”时间内供应主菜,即便如此,这个时间也是硬性的发布规定。
|
||||
|
||||
最后,像很多开源项目一样,烹饪文档同样有提升的空间。类似洗碟子这样的扫尾工作同样也有可优化的地方。
|
||||
|
||||
### 未来的一些新功能点
|
||||
|
||||
我们预计的一些想法包括:
|
||||
|
||||
* 在其他的国家开展活动
|
||||
* 购买和烹饪一个价值 700 欧元的大南瓜,并且
|
||||
* 找家可以为我们采购提供折扣的商店
|
||||
|
||||
最后一点,也是开源软件的动机:永远记住,还有一些人们生活在阴影中,他们为没有同等的权限去访问资源而苦恼着。我们如何通过开源的精神去帮助他们呢?
|
||||
|
||||
一想到这点,我便期待这下一次的开源烹饪聚会。如果读了上面的东西让你觉得不够完美,并且想自己运作这样的活动,我们非常乐意你能够借鉴我们的想法,甚至抄袭一个。我们也乐意你能够参与到我们其中,甚至做一些演讲和问答。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/open-source-cooking
|
||||
|
||||
作者:[Florian Effenberger][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[sd886393](https://github.com/sd886393)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/floeff
|
||||
[1]: https://www.opensourcetreffen.de/
|
||||
[2]: http://www.cafe-netzwerk.de/
|
||||
[3]: https://blog.effenberger.org/2018/05/28/what-do-open-source-and-cooking-have-in-common/
|
||||
[4]: https://en.wikipedia.org/wiki/Free_and_open-source_software
|
||||
@ -3,23 +3,23 @@
|
||||
|
||||
![ZFS filesystem][9]
|
||||
|
||||
今天,我们来谈论一下 ZFS,一个高级文件系统。我们将讨论 ZFS 从何而来,它是什么,以及为什么它在科技界和企业界如此受欢迎。
|
||||
今天,我们来谈论一下 ZFS,一个先进的文件系统。我们将讨论 ZFS 从何而来,它是什么,以及为什么它在科技界和企业界如此受欢迎。
|
||||
|
||||
虽然我是一个美国人,但我更喜欢读成 ZedFS 而不是 ZeeFS,因为前者听起来更酷一些。你可以根据你的个人喜好来发音。
|
||||
|
||||
注意:在这篇文章中,你将会看到很多次 ZFS。当我在谈论特性和安装的时候,我所指的是 OpenZFS 。自从 Oracle 公司放弃 OpenSolaris 项目之后,ZFS(由 Oracle 公司开发)和 OpenZFS 已经走向了不同的发展道路。
|
||||
> 注意:在这篇文章中,你将会看到 ZFS 被提到很多次。当我在谈论特性和安装的时候,我所指的是 OpenZFS 。自从<ruby>甲骨文<rt>Oracle</rt></ruby>公司放弃 OpenSolaris 项目之后,ZFS(由甲骨文公司开发)和 OpenZFS 已经走向了不同的发展道路。(后面详述)
|
||||
|
||||
### ZFS 的历史
|
||||
|
||||
Z 文件系统(ZFS)是在 2001 年由 [Matthew Ahrens 和 Jeff Bonwick][1] 开发的。ZFS 是作为 Sun 公司的[<ruby>微系统<rt>MicroSystem</rt></ruby>][2] [OpenSolaris][3] 的下一代文件系统而设计的。在 2008 年,ZFS 被移植到了 FreeBSD 。同一年,一个新的项目也开始了:[ZFS to Linux][4] 。然而,由于 ZFS 是[通用开发和发布许可证(CDDL)][5]许可的,它和 [GNU 通用公共许可证][6] 不兼容,因此不能将它迁移到 Linux 内核中。为了解决这个问题,绝大多数 Linux 发行版提供了一些方法来安装 ZFS 。
|
||||
<ruby>Z 文件系统<rt>Z File System</rt></ruby>(ZFS)是由 [Matthew Ahrens 和 Jeff Bonwick][1] 在 2001 年开发的。ZFS 是作为[<ruby>太阳微系统<rt>Sun MicroSystem</rt></ruby>][2] 公司的 [OpenSolaris][3] 的下一代文件系统而设计的。在 2008 年,ZFS 被移植到了 FreeBSD 。同一年,一个移植 [ZFS 到 Linux][4] 的项目也启动了。然而,由于 ZFS 是<ruby>[通用开发和发布许可证][5]<rt>Common Development and Distribution License</rt></ruby>(CDDL)许可的,它和 [GNU 通用公共许可证][6] 不兼容,因此不能将它迁移到 Linux 内核中。为了解决这个问题,绝大多数 Linux 发行版提供了一些方法来安装 ZFS 。
|
||||
|
||||
在 Oracle 公司收购 Sun 公司之后不久,微系统 OpenSolaris 就闭源了,这使得 ZFS 的最新开发也闭源了。许多 ZFS 开发者对这件事情非常不开心。[三分之二的 ZFS 核心开发者][1],包括 Ahrens 和 Bonwick,因为这个决定而离开了 Oracle 公司。他们加入其他公司,并于 2013 年 9 月创立了 [OpenZFS][7] 这一项目。该项目引领着 ZFS 的开源开发。
|
||||
在甲骨文公司收购太阳微系统公司之后不久,OpenSolaris 就闭源了,这使得 ZFS 的之后的开发也变成闭源的了。许多 ZFS 开发者对这件事情非常不满。[三分之二的 ZFS 核心开发者][1],包括 Ahrens 和 Bonwick,因为这个决定而离开了甲骨文公司。他们加入了其它公司,并于 2013 年 9 月创立了 [OpenZFS][7] 这一项目。该项目引领着 ZFS 的开源开发。
|
||||
|
||||
让我们回到上面提到的许可证问题上。既然 OpenZFS 项目已经和 Oracle 公司分离开了,有人可能好奇他们为什么不使用和 GPL 兼容的许可证,这样就可以把它加入到 Linux 内核中了。根据 [OpenZFS 官网][8] 的介绍,更改许可证需要联系所有为当前 OpenZFS 实现贡献过代码的人(包括初始公共 ZFS 代码以及 OpenSolaris 代码),并得到他们的许可才行。这几乎是不可能的(因为一些贡献者可能已经去世了或者很难找到),因此他们决定保留原来的许可证。
|
||||
让我们回到上面提到的许可证问题上。既然 OpenZFS 项目已经和 Oracle 公司分离开了,有人可能好奇他们为什么不使用和 GPL 兼容的许可证,这样就可以把它加入到 Linux 内核中了。根据 [OpenZFS 官网][8] 的介绍,更改许可证需要联系所有为当前 OpenZFS 实现贡献过代码的人(包括初始的公共 ZFS 代码以及 OpenSolaris 代码),并得到他们的许可才行。这几乎是不可能的(因为一些贡献者可能已经去世了或者很难找到),因此他们决定保留原来的许可证。
|
||||
|
||||
### ZFS 是什么,它有什么特性?
|
||||
|
||||
正如前面所说过的,ZFS 是一个高级文件系统。因此,它有一些有趣的[特性][10]。比如:
|
||||
正如前面所说过的,ZFS 是一个先进的文件系统。因此,它有一些有趣的[特性][10]。比如:
|
||||
|
||||
* 存储池
|
||||
* 写时拷贝
|
||||
@ -27,28 +27,27 @@ Z 文件系统(ZFS)是在 2001 年由 [Matthew Ahrens 和 Jeff Bonwick][1]
|
||||
* 数据完整性验证和自动修复
|
||||
* RAID-Z
|
||||
* 最大单个文件大小为 16 EB(1 EB = 1024 PB)
|
||||
* 最大 256 万亿的四次方 ZB(1 ZB = 1024 EB)的存储
|
||||
|
||||
|
||||
* 最大 256 千万亿(256*10^15 )的 ZB(1 ZB = 1024 EB)的存储
|
||||
|
||||
让我们来深入了解一下其中一些特性。
|
||||
|
||||
#### 存储池
|
||||
|
||||
与大多数文件系统不同,ZFS 结合了文件系统和卷管理器的特性。这意味着,它与其他文件系统不同,ZFS 可以创建跨域一系列硬盘或池的文件系统。不仅如此,你还可以通过添加硬盘来增大池的存储容量。ZFS 可以进行[分区和格式化][11]。
|
||||
与大多数文件系统不同,ZFS 结合了文件系统和卷管理器的特性。这意味着,它与其他文件系统不同,ZFS 可以创建跨越一系列硬盘或池的文件系统。不仅如此,你还可以通过添加硬盘来增大池的存储容量。ZFS 可以进行[分区和格式化][11]。
|
||||
|
||||
![Pooled storage in ZFS][12]
|
||||
|
||||
*ZFS 存储池*
|
||||
|
||||
#### 写时拷贝
|
||||
|
||||
[<ruby>写时拷贝<rt>Copy-on-write</rt></ruby>][13]是另一个有趣并且很酷的特性。在大多数文件系统上,当数据被重写时,它将永久丢失。而在 ZFS 中,新数据会写到不同的块。写完成之后,更新文件系统元数据信息,使之指向新的数据块(LCTT 译注:更新之后,原数据块成为磁盘上的垃圾,需要有对应的垃圾回收机制)。这确保了如果在写新数据的时候系统崩溃(或者发生其它事,比如突然断电),那么原数据将会保存下来。这也意味着,在系统发生崩溃之后,不需要运行 [fsck][14] 来检查和修复文件系统。
|
||||
<ruby>[写时拷贝][13]<rt>Copy-on-write</rt></ruby>是另一个有趣并且很酷的特性。在大多数文件系统上,当数据被重写时,它将永久丢失。而在 ZFS 中,新数据会写到不同的块。写完成之后,更新文件系统元数据信息,使之指向新的数据块(LCTT 译注:更新之后,原数据块成为磁盘上的垃圾,需要有对应的垃圾回收机制)。这确保了如果在写新数据的时候系统崩溃(或者发生其它事,比如突然断电),那么原数据将会保存下来。这也意味着,在系统发生崩溃之后,不需要运行 [fsck][14] 来检查和修复文件系统。
|
||||
|
||||
#### 快照
|
||||
|
||||
写时拷贝使得 ZFS 有了另一个特性:<ruby>快照<rt>snapshots</rt></ruby>。ZFS 使用快照来跟踪文件系统中的更改。[快照][13]包含文件系统的原始版本(文件系统的一个只读版本),实时文件系统则包含了自从快照创建之后的任何更改。没有使用额外的空间。因为新数据将会写到实时文件系统新分配的块上。如果一个文件被删除了,那么它在快照中的索引也会被删除。所以,快照主要是用来跟踪文件的更改,而不是文件的增加和创建。
|
||||
|
||||
快照可以挂载成只读的,以用来恢复一个文件的过去版本。实时系统也可以回滚到之前的快照。回滚之后,自从快照创建之后的所有更改将会丢失。
|
||||
快照可以挂载成只读的,以用来恢复一个文件的过去版本。实时文件系统也可以回滚到之前的快照。回滚之后,自从快照创建之后的所有更改将会丢失。
|
||||
|
||||
#### 数据完整性验证和自动修复
|
||||
|
||||
@ -56,11 +55,11 @@ Z 文件系统(ZFS)是在 2001 年由 [Matthew Ahrens 和 Jeff Bonwick][1]
|
||||
|
||||
#### RAID-Z
|
||||
|
||||
ZFS 不需要任何额外软件或硬件就可以处理 RAID(磁盘阵列)。毫无奇怪,因为 ZFS 有自己的 RAID 实现:RAID-Z 。RAID-Z 是 RAID-5 的一个变种,不过它克服了 RAID-5 的写漏洞:意外重启之后,数据和校验信息会变得不同步(LCTT 译注:RAID-5 的 stripe 在正写数据时,如果这时候电源中断,那么奇偶校验数据将跟该部分数据不同步,因此前边的写无效;RAID-Z 用了 “variable-width RAID stripes” 技术,因此所有的写都是 full-stripe writes)。为了使用基本级别的 [RAID-Z][15](RAID-Z1),你需要至少三块磁盘,其中两块用来存储数据,另外一块用来存储[奇偶校验信息][16]。而RAID-Z2 需要至少两块磁盘存储数据以及两块磁盘存储校验信息。RAID-Z3 需要至少两块磁盘存储数据以及三块磁盘存储校验信息。另外,只能向 RAID-Z 池中加入偶数倍的磁盘,而不能是奇数倍的。
|
||||
ZFS 不需要任何额外软件或硬件就可以处理 RAID(磁盘阵列)。毫不奇怪,因为 ZFS 有自己的 RAID 实现:RAID-Z 。RAID-Z 是 RAID-5 的一个变种,不过它克服了 RAID-5 的写漏洞:意外重启之后,数据和校验信息会变得不同步(LCTT 译注:RAID-5 的条带在正写入数据时,如果这时候电源中断,那么奇偶校验数据将跟该部分数据不同步,因此前边的写无效;RAID-Z 用了 “可变宽的 RAID 条带” 技术,因此所有的写都是全条带写入)。为了使用[基本级别的 RAID-Z][15](RAID-Z1),你需要至少三块磁盘,其中两块用来存储数据,另外一块用来存储[奇偶校验信息][16]。而 RAID-Z2 需要至少两块磁盘存储数据以及两块磁盘存储校验信息。RAID-Z3 需要至少两块磁盘存储数据以及三块磁盘存储校验信息。另外,只能向 RAID-Z 池中加入偶数倍的磁盘,而不能是奇数倍的。
|
||||
|
||||
#### 巨大的存储潜力
|
||||
|
||||
创建 ZFS 的时候,它就被设计成了[最后一个文件系统][17] 。那时候,大多数文件系统都是 64 位的,ZFS 的创建者决定直接跳到 128 位,等到将来再来证明这是对的。这意味着 ZFS 的容量大小是 32 位或 64 位文件系统的 160 亿亿倍。事实上,Jeff Bonwick(其中一个创建者)说:“完全填满一个 128 位的存储池所需要的[能量][18],从字面上讲,比煮沸海洋需要的还多。”
|
||||
创建 ZFS 的时候,它是作为[最后一个文件系统][17]而设计的 。那时候,大多数文件系统都是 64 位的,ZFS 的创建者决定直接跳到 128 位,等到将来再来证明这是对的。这意味着 ZFS 的容量大小是 32 位或 64 位文件系统的 1600 亿亿倍。事实上,Jeff Bonwick(其中一个创建者)说:“完全填满一个 128 位的存储池所需要的[能量][18],从字面上讲,比煮沸海洋需要的还多。”
|
||||
|
||||
### 如何安装 ZFS?
|
||||
|
||||
@ -85,7 +84,7 @@ via: https://itsfoss.com/what-is-zfs/
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,173 @@
|
||||
每位 Ubuntu 18.04 用户都应该知道的快捷键
|
||||
======
|
||||
|
||||
了解快捷键能够提升您的生产力。这里有一些实用的 Ubuntu 快捷键助您像专业人士一样使用 Ubuntu。
|
||||
|
||||
您可以用键盘和鼠标组合来使用操作系统。
|
||||
|
||||
> 注意:本文中提到的键盘快捷键适用于 Ubuntu 18.04 GNOME 版。 通常,它们中的大多数(或者全部)也适用于其他的 Ubuntu 版本,但我不能够保证。
|
||||
|
||||
![Ubuntu keyboard shortcuts][1]
|
||||
|
||||
### 实用的 Ubuntu 快捷键
|
||||
|
||||
让我们来看一看 Ubuntu GNOME 必备的快捷键吧!通用的快捷键如 `Ctrl+C`(复制)、`Ctrl+V`(粘贴)或者 `Ctrl+S`(保存)不再赘述。
|
||||
|
||||
注意:Linux 中的 Super 键即键盘上带有 Windows 图标的键,本文中我使用了大写字母,但这不代表你需要按下 `shift` 键,比如,`T` 代表键盘上的 ‘t’ 键,而不代表 `Shift+t`。
|
||||
|
||||
#### 1、 Super 键:打开活动搜索界面
|
||||
|
||||
使用 `Super` 键可以打开活动菜单。如果你只能在 Ubuntu 上使用一个快捷键,那只能是 `Super` 键。
|
||||
|
||||
想要打开一个应用程序?按下 `Super` 键然后搜索应用程序。如果搜索的应用程序未安装,它会推荐来自应用中心的应用程序。
|
||||
|
||||
想要看看有哪些正在运行的程序?按下 `Super` 键,屏幕上就会显示所有正在运行的 GUI 应用程序。
|
||||
|
||||
想要使用工作区吗?只需按下 `Super` 键,您就可以在屏幕右侧看到工作区选项。
|
||||
|
||||
#### 2、 Ctrl+Alt+T:打开 Ubuntu 终端窗口
|
||||
|
||||
![Ubuntu Terminal Shortcut][2]
|
||||
|
||||
*使用 Ctrl+alt+T 来打开终端窗口*
|
||||
|
||||
想要打开一个新的终端,您只需使用快捷键 `Ctrl+Alt+T`。这是我在 Ubuntu 中最喜欢的键盘快捷键。 甚至在我的许多 FOSS 教程中,当需要打开终端窗口是,我都会提到这个快捷键。
|
||||
|
||||
#### 3、 Super+L 或 Ctrl+Alt+L:锁屏
|
||||
|
||||
当您离开电脑时锁定屏幕,是最基本的安全习惯之一。您可以使用 `Super+L` 快捷键,而不是繁琐地点击屏幕右上角然后选择锁定屏幕选项。
|
||||
|
||||
有些系统也会使用 `Ctrl+Alt+L` 键锁定屏幕。
|
||||
|
||||
#### 4、 Super+D or Ctrl+Alt+D:显示桌面
|
||||
|
||||
按下 `Super+D` 可以最小化所有正在运行的应用程序窗口并显示桌面。
|
||||
|
||||
再次按 `Super+D` 将重新打开所有正在运行的应用程序窗口,像之前一样。
|
||||
|
||||
您也可以使用 `Ctrl+Alt+D` 来实现此目的。
|
||||
|
||||
#### 5、 Super+A:显示应用程序菜单
|
||||
|
||||
您可以通过单击屏幕左下角的 9 个点打开 Ubuntu 18.04 GNOME 中的应用程序菜单。 但是一个更快捷的方法是使用 `Super+A` 快捷键。
|
||||
|
||||
它将显示应用程序菜单,您可以在其中查看或搜索系统上已安装的应用程序。
|
||||
|
||||
您可以使用 `Esc` 键退出应用程序菜单界面。
|
||||
|
||||
#### 6、 Super+Tab 或 Alt+Tab:在运行中的应用程序间切换
|
||||
|
||||
如果您运行的应用程序不止一个,则可以使用 `Super+Tab` 或 `Alt+Tab` 快捷键在应用程序之间切换。
|
||||
|
||||
按住 `Super` 键同时按下 `Tab` 键,即可显示应用程序切换器。 按住 `Super` 的同时,继续按下 `Tab` 键在应用程序之间进行选择。 当光标在所需的应用程序上时,松开 `Super` 和 `Tab` 键。
|
||||
|
||||
默认情况下,应用程序切换器从左向右移动。 如果要从右向左移动,可使用 `Super+Shift+Tab` 快捷键。
|
||||
|
||||
在这里您也可以用 `Alt` 键代替 `Super` 键。
|
||||
|
||||
> 提示:如果有多个应用程序实例,您可以使用 Super+` 快捷键在这些实例之间切换。
|
||||
|
||||
#### 7、 Super+箭头:移动窗口位置
|
||||
|
||||
<https://player.vimeo.com/video/289091549>
|
||||
|
||||
这个快捷键也适用于 Windows 系统。 使用应用程序时,按下 `Super+左箭头`,应用程序将贴合屏幕的左边缘,占用屏幕的左半边。
|
||||
|
||||
同样,按下 `Super+右箭头`会使应用程序贴合右边缘。
|
||||
|
||||
按下 `Super+上箭头`将最大化应用程序窗口,`Super+下箭头`将使应用程序恢复到其正常的大小。
|
||||
|
||||
#### 8、 Super+M:切换到通知栏
|
||||
|
||||
GNOME 中有一个通知栏,您可以在其中查看系统和应用程序活动的通知,这里也有一个日历。
|
||||
|
||||
![Notification Tray Ubuntu 18.04 GNOME][3]
|
||||
|
||||
*通知栏*
|
||||
|
||||
使用 `Super+M` 快捷键,您可以打开此通知栏。 如果再次按这些键,将关闭打开的通知托盘。
|
||||
|
||||
使用 `Super+V` 也可实现相同的功能。
|
||||
|
||||
#### 9、 Super+空格:切换输入法(用于多语言设置)
|
||||
|
||||
如果您使用多种语言,可能您的系统上安装了多个输入法。 例如,我需要在 Ubuntu 上同时使用[印地语] [4]和英语,所以我安装了印地语(梵文)输入法以及默认的英语输入法。
|
||||
|
||||
如果您也使用多语言设置,则可以使用 `Super+空格` 快捷键快速更改输入法。
|
||||
|
||||
#### 10、 Alt+F2:运行控制台
|
||||
|
||||
这适用于高级用户。 如果要运行快速命令,而不是打开终端并在其中运行命令,则可以使用 `Alt+F2` 运行控制台。
|
||||
|
||||
![Alt+F2 to run commands in Ubuntu][5]
|
||||
|
||||
*控制台*
|
||||
|
||||
当您使用只能在终端运行的应用程序时,这尤其有用。
|
||||
|
||||
#### 11、 Ctrl+Q:关闭应用程序窗口
|
||||
|
||||
如果您有正在运行的应用程序,可以使用 `Ctrl+Q` 快捷键关闭应用程序窗口。您也可以使用 `Ctrl+W` 来实现此目的。
|
||||
|
||||
`Alt+F4` 是关闭应用程序窗口更“通用”的快捷方式。
|
||||
|
||||
它不适用于一些应用程序,如 Ubuntu 中的默认终端。
|
||||
|
||||
#### 12、 Ctrl+Alt+箭头:切换工作区
|
||||
|
||||
![Workspace switching][6]
|
||||
|
||||
*切换工作区*
|
||||
|
||||
如果您是使用工作区的重度用户,可以使用 `Ctrl+Alt+上箭头`和 `Ctrl+Alt+下箭头`在工作区之间切换。
|
||||
|
||||
#### 13、 Ctrl+Alt+Del:注销
|
||||
|
||||
不!在 Linux 中使用著名的快捷键 `Ctrl+Alt+Del` 并不会像在 Windows 中一样打开任务管理器(除非您使用自定义快捷键)。
|
||||
|
||||
![Log Out Ubuntu][7]
|
||||
|
||||
*注销*
|
||||
|
||||
在普通的 GNOME 桌面环境中,您可以使用 `Ctrl+Alt+Del` 键打开关机菜单,但 Ubuntu 并不总是遵循此规范,因此当您在 Ubuntu 中使用 `Ctrl+Alt+Del` 键时,它会打开注销菜单。
|
||||
|
||||
### 在 Ubuntu 中使用自定义键盘快捷键
|
||||
|
||||
您不是只能使用默认的键盘快捷键,您可以根据需要创建自己的自定义键盘快捷键。
|
||||
|
||||
转到“设置->设备->键盘”,您将在这里看到系统的所有键盘快捷键。向下滚动到底部,您将看到“自定义快捷方式”选项。
|
||||
|
||||
![Add custom keyboard shortcut in Ubuntu][8]
|
||||
|
||||
您需要提供易于识别的快捷键名称、使用快捷键时运行的命令,以及您自定义的按键组合。
|
||||
|
||||
### Ubuntu 中你最喜欢的键盘快捷键是什么?
|
||||
|
||||
快捷键无穷无尽。如果需要,你可以看一看所有可能的 [GNOME 快捷键][9],看其中有没有你需要用到的快捷键。
|
||||
|
||||
您可以学习使用您经常使用应用程序的快捷键,这是很有必要的。例如,我使用 Kazam 进行[屏幕录制][10],键盘快捷键帮助我方便地暂停和开始录像。
|
||||
|
||||
您最喜欢、最离不开的 Ubuntu 快捷键是什么?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-shortcuts/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[XiatianSummer](https://github.com/XiatianSummer)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/ubuntu-keyboard-shortcuts.jpeg
|
||||
[2]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/ubuntu-terminal-shortcut.jpg
|
||||
[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/notification-tray-ubuntu-gnome.jpeg
|
||||
[4]: https://itsfoss.com/type-indian-languages-ubuntu/
|
||||
[5]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/console-alt-f2-ubuntu-gnome.jpeg
|
||||
[6]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/workspace-switcher-ubuntu.png
|
||||
[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/log-out-ubuntu.jpeg
|
||||
[8]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/custom-keyboard-shortcut.jpg
|
||||
[9]: https://wiki.gnome.org/Design/OS/KeyboardShortcuts
|
||||
[10]: https://itsfoss.com/best-linux-screen-recorders/
|
||||
110
published/201809/20180910 3 open source log aggregation tools.md
Normal file
110
published/201809/20180910 3 open source log aggregation tools.md
Normal file
@ -0,0 +1,110 @@
|
||||
3 个开源日志聚合工具
|
||||
======
|
||||
|
||||
> 日志聚合系统可以帮助我们进行故障排除和其它任务。以下是三个主要工具介绍。
|
||||
|
||||

|
||||
|
||||
<ruby>指标聚合<rt>metrics aggregation</rt></ruby>与<ruby>日志聚合<rt>log aggregation</rt></ruby>有何不同?日志不能包括指标吗?日志聚合系统不能做与指标聚合系统相同的事情吗?
|
||||
|
||||
这些是我经常听到的问题。我还看到供应商推销他们的日志聚合系统作为所有可观察问题的解决方案。日志聚合是一个有价值的工具,但它通常对时间序列数据的支持不够好。
|
||||
|
||||
时间序列的指标聚合系统中几个有价值的功能是专门为时间序列数据定制的<ruby>固定间隔<rt>regular interval</rt></ruby>和存储系统。固定间隔允许用户不断地收集实时的数据结果。如果要求日志聚合系统以固定间隔收集指标数据,它也可以。但是,它的存储系统没有针对指标聚合系统中典型的查询类型进行优化。使用日志聚合工具中的存储系统处理这些查询将花费更多的资源和时间。
|
||||
|
||||
所以,我们知道日志聚合系统可能不适合时间序列数据,但是它有什么好处呢?日志聚合系统是收集事件数据的好地方。这些无规律的活动是非常重要的。最好的例子为 web 服务的访问日志,这些很重要,因为我们想知道什么正在访问我们的系统,什么时候访问的。另一个例子是应用程序错误记录 —— 因为它不是正常的操作记录,所以在故障排除过程中可能很有价值的。
|
||||
|
||||
日志记录的一些规则:
|
||||
|
||||
* **须**包含时间戳
|
||||
* **须**格式化为 JSON
|
||||
* **不**记录无关紧要的事件
|
||||
* **须**记录所有应用程序的错误
|
||||
* **可**记录警告错误
|
||||
* **可**开关的日志记录
|
||||
* **须**以可读的形式记录信息
|
||||
* **不**在生产环境中记录信息
|
||||
* **不**记录任何无法阅读或反馈的内容
|
||||
|
||||
### 云的成本
|
||||
|
||||
当研究日志聚合工具时,云服务可能看起来是一个有吸引力的选择。然而,这可能会带来巨大的成本。当跨数百或数千台主机和应用程序聚合时,日志数据是大量的。在基于云的系统中,数据的接收、存储和检索是昂贵的。
|
||||
|
||||
以一个真实的系统来参考,大约 500 个节点和几百个应用程序的集合每天产生 200GB 的日志数据。这个系统可能还有改进的空间,但是在许多 SaaS 产品中,即使将它减少一半,每月也要花费将近 10000 美元。而这通常仅保留 30 天,如果你想查看一年一年的趋势数据,就不可能了。
|
||||
|
||||
并不是要不使用这些基于云的系统,尤其是对于较小的组织它们可能非常有价值的。这里的目的是指出可能会有很大的成本,当这些成本很高时,就可能令人非常的沮丧。本文的其余部分将集中讨论自托管的开源和商业解决方案。
|
||||
|
||||
### 工具选择
|
||||
|
||||
#### ELK
|
||||
|
||||
[ELK][1],即 Elasticsearch、Logstash 和 Kibana 简称,是最流行的开源日志聚合工具。它被 Netflix、Facebook、微软、LinkedIn 和思科使用。这三个组件都是由 [Elastic][2] 开发和维护的。[Elasticsearch][3] 本质上是一个 NoSQL 数据库,以 Lucene 搜索引擎实现的。[Logstash][4] 是一个日志管道系统,可以接收数据,转换数据,并将其加载到像 Elasticsearch 这样的应用中。[Kibana][5] 是 Elasticsearch 之上的可视化层。
|
||||
|
||||
几年前,引入了 Beats 。Beats 是数据采集器。它们简化了将数据运送到 Logstash 的过程。用户不需要了解每种日志的正确语法,而是可以安装一个 Beats 来正确导出 NGINX 日志或 Envoy 代理日志,以便在 Elasticsearch 中有效地使用它们。
|
||||
|
||||
安装生产环境级 ELK 套件时,可能会包括其他几个部分,如 [Kafka][6]、[Redis][7] 和 [NGINX][8]。此外,用 Fluentd 替换 Logstash 也很常见,我们将在后面讨论。这个系统操作起来很复杂,这在早期导致了很多问题和抱怨。目前,这些问题基本上已经被修复,不过它仍然是一个复杂的系统,如果你使用少部分的功能,建议不要使用它了。
|
||||
|
||||
也就是说,有其它可用的服务,所以你不必苦恼于此。可以使用 [Logz.io][9],但是如果你有很多数据,它的标价有点高。当然,你可能规模比较小,没有很多数据。如果你买不起 Logz.io,你可以看看 [AWS Elasticsearch Service][10] (ES) 。ES 是 Amazon Web Services (AWS) 提供的一项服务,它很容易就可以让 Elasticsearch 马上工作起来。它还拥有使用 Lambda 和 S3 将所有AWS 日志记录到 ES 的工具。这是一个更便宜的选择,但是需要一些管理操作,并有一些功能限制。
|
||||
|
||||
ELK 套件的母公司 Elastic [提供][11] 一款更强大的产品,它使用<ruby>开源核心<rt>open core</rt></ruby>模式,为分析工具和报告提供了额外的选项。它也可以在谷歌云平台或 AWS 上托管。由于这种工具和托管平台的组合提供了比大多数 SaaS 选项更加便宜,这也许是最好的选择,并且很有用。该系统可以有效地取代或提供 [安全信息和事件管理][12](SIEM)系统的功能。
|
||||
|
||||
ELK 套件通过 Kibana 提供了很好的可视化工具,但是它缺少警报功能。Elastic 在付费的 X-Pack 插件中提供了警报功能,但是在开源系统没有内置任何功能。Yelp 已经开发了一种解决这个问题的方法,[ElastAlert][13],不过还有其他方式。这个额外的软件相当健壮,但是它增加了已经复杂的系统的复杂性。
|
||||
|
||||
#### Graylog
|
||||
|
||||
[Graylog][14] 最近越来越受欢迎,但它是在 2010 年由 Lennart Koopmann 创建并开发的。两年后,一家公司以同样的名字诞生了。尽管它的使用者越来越多,但仍然远远落后于 ELK 套件。这也意味着它具有较少的社区开发特征,但是它可以使用与 ELK 套件相同的 Beats 。由于 Graylog Collector Sidecar 使用 [Go][15] 编写,所以 Graylog 在 Go 社区赢得了赞誉。
|
||||
|
||||
Graylog 使用 Elasticsearch、[MongoDB][16] 和底层的 Graylog Server 。这使得它像 ELK 套件一样复杂,也许还要复杂一些。然而,Graylog 附带了内置于开源版本中的报警功能,以及其他一些值得注意的功能,如流、消息重写和地理定位。
|
||||
|
||||
流功能可以允许数据在被处理时被实时路由到特定的 Stream。使用此功能,用户可以在单个 Stream 中看到所有数据库错误,在另外的 Stream 中看到 web 服务器错误。当添加新项目或超过阈值时,甚至可以基于这些 Stream 提供警报。延迟可能是日志聚合系统中最大的问题之一,Stream 消除了 Graylog 中的这一问题。一旦日志进入,它就可以通过 Stream 路由到其他系统,而无需完全处理好。
|
||||
|
||||
消息重写功能使用开源规则引擎 [Drools][17] 。允许根据用户定义的规则文件评估所有传入的消息,从而可以删除消息(称为黑名单)、添加或删除字段或修改消息。
|
||||
|
||||
Graylog 最酷的功能或许是它的地理定位功能,它支持在地图上绘制 IP 地址。这是一个相当常见的功能,在 Kibana 也可以这样使用,但是它增加了很多价值 —— 特别是如果你想将它用作 SIEM 系统。地理定位功能在系统的开源版本中提供。
|
||||
|
||||
如果你需要的话,Graylog 公司会提供对开源版本的收费支持。它还为其企业版提供了一个开源核心模式,提供存档、审计日志记录和其他支持。其它提供支持或托管服务的不太多,如果你不需要 Graylog 公司的,你可以托管。
|
||||
|
||||
#### Fluentd
|
||||
|
||||
[Fluentd][18] 是 [Treasure Data][19] 开发的,[CNCF][20] 已经将它作为一个孵化项目。它是用 C 和 Ruby 编写的,并被 [AWS][21] 和 [Google Cloud][22] 所推荐。Fluentd 已经成为许多系统中 logstach 的常用替代品。它可以作为一个本地聚合器,收集所有节点日志并将其发送到中央存储系统。它不是日志聚合系统。
|
||||
|
||||
它使用一个强大的插件系统,提供不同数据源和数据输出的快速和简单的集成功能。因为有超过 500 个插件可用,所以你的大多数用例都应该包括在内。如果没有,这听起来是一个为开源社区做出贡献的机会。
|
||||
|
||||
Fluentd 由于占用内存少(只有几十兆字节)和高吞吐量特性,是 Kubernetes 环境中的常见选择。在像 [Kubernetes][23] 这样的环境中,每个 pod 都有一个 Fluentd 附属件 ,内存消耗会随着每个新 pod 的创建而线性增加。在这种情况下,使用 Fluentd 将大大降低你的系统利用率。这对于 Java 开发的工具来说是一个常见的问题,这些工具旨在为每个节点运行一个工具,而内存开销并不是主要问题。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/open-source-log-aggregation-tools
|
||||
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barkerd427
|
||||
[1]: https://www.elastic.co/webinars/introduction-elk-stack
|
||||
[2]: https://www.elastic.co/
|
||||
[3]: https://www.elastic.co/products/elasticsearch
|
||||
[4]: https://www.elastic.co/products/logstash
|
||||
[5]: https://www.elastic.co/products/kibana
|
||||
[6]: http://kafka.apache.org/
|
||||
[7]: https://redis.io/
|
||||
[8]: https://www.nginx.com/
|
||||
[9]: https://logz.io/
|
||||
[10]: https://aws.amazon.com/elasticsearch-service/
|
||||
[11]: https://www.elastic.co/cloud
|
||||
[12]: https://en.wikipedia.org/wiki/Security_information_and_event_management
|
||||
[13]: https://github.com/Yelp/elastalert
|
||||
[14]: https://www.graylog.org/
|
||||
[15]: https://opensource.com/tags/go
|
||||
[16]: https://www.mongodb.com/
|
||||
[17]: https://www.drools.org/
|
||||
[18]: https://www.fluentd.org/
|
||||
[19]: https://www.treasuredata.com/
|
||||
[20]: https://www.cncf.io/
|
||||
[21]: https://aws.amazon.com/blogs/aws/all-your-data-fluentd/
|
||||
[22]: https://cloud.google.com/logging/docs/agent/
|
||||
[23]: https://opensource.com/resources/what-is-kubernetes
|
||||
|
||||
@ -5,13 +5,13 @@
|
||||
|
||||
今时今日,无论在家里的沙发上,还是在外面的咖啡厅,只要打开笔记本电脑,连上 Wi-Fi,就能通过网络与外界保持联系。但现在的 Wi-Fi 热点们大都能够通过[每张网卡对应的唯一 MAC 地址][1]来追踪你的设备。下面就来看一下如何避免被追踪。
|
||||
|
||||
现在很多人已经开始注重个人隐私这个问题。个人隐私问题并不仅仅指防止他人能够访问到你电脑上的私有内容(这又是另一个问题了),而更多的是指可追踪性,也就是是否能够被轻易地统计和追踪到。大家都应该[对此更加重视][2]。同时,这方面的底线是,服务提供者在得到了用户的授权后才能对用户进行追踪,例如机场的计时 Wi-Fi 只有在用户授权后才能够使用。
|
||||
现在很多人已经开始注重个人隐私这个问题。个人隐私问题并不仅仅指防止他人能够访问到你电脑上的私有内容(这又是另一个问题了),而更多的是指<ruby>可追踪性<rt>legibility</rt></ruby>,也就是是否能够被轻易地统计和追踪到。大家都应该[对此更加重视][2]。同时,这方面的底线是,服务提供者在得到了用户的授权后才能对用户进行追踪,例如机场的计时 Wi-Fi 只有在用户授权后才能够使用。
|
||||
|
||||
因为固定的 MAC 地址能被轻易地追踪到,所以应该定时进行更换,随机的 MAC 地址是一个好的选择。由于 MAC 地址一般只在局域网内使用,因此随机的 MAC 地址也不太容易产生[冲突][3]。
|
||||
因为固定的 MAC 地址能被轻易地追踪到,所以应该定时进行更换,随机的 MAC 地址是一个好的选择。由于 MAC 地址一般只在局域网内使用,因此随机的 MAC 地址也不大会产生[冲突][3]。
|
||||
|
||||
### 配置 NetworkManager
|
||||
|
||||
要将随机的 MAC 地址默认应用与所有的 Wi-Fi 连接,需要创建 /etc/NetworkManager/conf.d/00-macrandomize.conf 这个文件:
|
||||
要将随机的 MAC 地址默认地用于所有的 Wi-Fi 连接,需要创建 `/etc/NetworkManager/conf.d/00-macrandomize.conf` 这个文件:
|
||||
|
||||
```
|
||||
[device]
|
||||
@ -21,51 +21,47 @@ wifi.scan-rand-mac-address=yes
|
||||
wifi.cloned-mac-address=stable
|
||||
ethernet.cloned-mac-address=stable
|
||||
connection.stable-id=${CONNECTION}/${BOOT}
|
||||
|
||||
```
|
||||
|
||||
然后重启 NetworkManager :
|
||||
|
||||
```
|
||||
systemctl restart NetworkManager
|
||||
|
||||
```
|
||||
|
||||
以上配置文件中,将 cloned-mac-address 的值设置为 stable 就可以在每次 NetworkManager 激活连接的时候都生成相同的 MAC 地址,但连接时使用不同的 MAC 地址。如果要在每次激活连接时获得随机的 MAC 地址,需要将 cloned-mac-address 的值设置为 random。
|
||||
以上配置文件中,将 `cloned-mac-address` 的值设置为 `stable` 就可以在每次 NetworkManager 激活连接的时候都生成相同的 MAC 地址,但连接时使用不同的 MAC 地址。如果要在每次激活连接时也获得随机的 MAC 地址,需要将 `cloned-mac-address` 的值设置为 `random`。
|
||||
|
||||
设置为 stable 可以从 DHCP 获取相同的 IP 地址,也可以让 Wi-Fi 的强制主页根据 MAC 地址记住你的登录状态。如果设置为 random ,在每次连接的时候都需要重新认证(或者点击“我同意”),在使用机场 Wi-Fi 的时候会需要到这种 random 模式。可以在 NetworkManager 的[博客文章][4]中参阅到有关使用 nmcli 从终端配置特定连接的详细说明。
|
||||
设置为 `stable` 可以从 DHCP 获取相同的 IP 地址,也可以让 Wi-Fi 的<ruby>[强制主页](https://en.wikipedia.org/wiki/Captive_portal)<rt>captive portal</rt></ruby>根据 MAC 地址记住你的登录状态。如果设置为 `random` ,在每次连接的时候都需要重新认证(或者点击“我同意”),在使用机场 Wi-Fi 的时候会需要到这种 `random` 模式。可以在这篇 NetworkManager 的[博客文章][4]中参阅到有关使用 `nmcli` 从终端配置特定连接的详细说明。
|
||||
|
||||
使用 ip link 命令可以查看当前的 MAC 地址,MAC 地址将会显示在 ether 一词的后面。
|
||||
使用 `ip link` 命令可以查看当前的 MAC 地址,MAC 地址将会显示在 `ether` 一词的后面。
|
||||
|
||||
```
|
||||
$ ip link
|
||||
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
|
||||
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
|
||||
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
|
||||
2: enp2s0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN mode DEFAULT group default qlen 1000
|
||||
link/ether 52:54:00:5f:d5:4e brd ff:ff:ff:ff:ff:ff
|
||||
link/ether 52:54:00:5f:d5:4e brd ff:ff:ff:ff:ff:ff
|
||||
3: wlp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DORMANT group default qlen 1000
|
||||
link/ether 52:54:00:03:23:59 brd ff:ff:ff:ff:ff:ff
|
||||
|
||||
link/ether 52:54:00:03:23:59 brd ff:ff:ff:ff:ff:ff
|
||||
```
|
||||
|
||||
### 什么时候不能随机化 MAC 地址
|
||||
|
||||
当然,在某些情况下确实需要能被追踪到。例如在家用网络中,可能需要将路由器配置为对电脑分配一致的 IP 地址以进行端口转发;再例如公司的雇主可能需要根据 MAC 地址来提供 Wi-Fi 服务,这时候就需要进行追踪。要更改特定的 Wi-Fi 连接,请使用 nmcli 查看 NetworkManager 连接并显示当前设置:
|
||||
当然,在某些情况下确实需要能被追踪到。例如在家用网络中,可能需要将路由器配置为对电脑分配一致的 IP 地址以进行端口转发;再例如公司的雇主可能需要根据 MAC 地址来提供 Wi-Fi 服务,这时候就需要进行追踪。要更改特定的 Wi-Fi 连接,请使用 `nmcli` 查看 NetworkManager 连接并显示当前设置:
|
||||
|
||||
```
|
||||
$ nmcli c | grep wifi
|
||||
Amtrak_WiFi 5f4b9f75-9e41-47f8-8bac-25dae779cd87 wifi --
|
||||
StaplesHotspot de57940c-32c2-468b-8f96-0a3b9a9b0a5e wifi --
|
||||
MyHome e8c79829-1848-4563-8e44-466e14a3223d wifi wlp1s0
|
||||
Amtrak_WiFi 5f4b9f75-9e41-47f8-8bac-25dae779cd87 wifi --
|
||||
StaplesHotspot de57940c-32c2-468b-8f96-0a3b9a9b0a5e wifi --
|
||||
MyHome e8c79829-1848-4563-8e44-466e14a3223d wifi wlp1s0
|
||||
...
|
||||
$ nmcli c show 5f4b9f75-9e41-47f8-8bac-25dae779cd87 | grep cloned
|
||||
802-11-wireless.cloned-mac-address: --
|
||||
802-11-wireless.cloned-mac-address: --
|
||||
$ nmcli c show e8c79829-1848-4563-8e44-466e14a3223d | grep cloned
|
||||
802-11-wireless.cloned-mac-address: stable
|
||||
|
||||
802-11-wireless.cloned-mac-address: stable
|
||||
```
|
||||
|
||||
以下这个例子使用 Amtrak 的完全随机 MAC 地址(使用默认配置)和 MyHome 的永久 MAC 地址(使用 stable 配置)。永久 MAC 地址是在硬件生产的时候分配到网络接口上的,网络管理员能够根据永久 MAC 地址来查看[设备的制造商 ID][5]。
|
||||
这个例子在 Amtrak 使用完全随机 MAC 地址(使用默认配置)和 MyHome 的永久 MAC 地址(使用 `stable` 配置)。永久 MAC 地址是在硬件生产的时候分配到网络接口上的,网络管理员能够根据永久 MAC 地址来查看[设备的制造商 ID][5]。
|
||||
|
||||
更改配置并重新连接活动的接口:
|
||||
|
||||
@ -76,7 +72,6 @@ $ nmcli c down e8c79829-1848-4563-8e44-466e14a3223d
|
||||
$ nmcli c up e8c79829-1848-4563-8e44-466e14a3223d
|
||||
$ ip link
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
你还可以安装 NetworkManager-tui ,就可以通过可视化界面菜单来编辑连接。
|
||||
@ -92,7 +87,7 @@ via: https://fedoramagazine.org/randomize-mac-address-nm/
|
||||
作者:[sheogorath][a],[Stuart D Gathman][b]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user