, so we put it into the `css`method of response object we have (line `46`). After that, we just need to get the URL of the blog post. It is easily achieved by `'./a/@href'` XPath string, which takes the `href` attribute of tag found as direct child of our
.
+
+### Finding traffic data
+
+The next task is estimating the number of views per day each of the blogs receives. There are [various options][45] to get such data, both free and paid. After quick googling I decided to stick to this simple and free to use website [www.statshow.com][46]. The Spider for this website should take as an input blog URLs we’ve obtained in the previous step, go through them and add traffic information. Spider initialization looks like this:
+
+```
+class TrafficSpider(scrapy.Spider):
+ name = 'traffic'
+ allowed_domains = ['www.statshow.com']
+
+ def __init__(self, blogs_data):
+ super(TrafficSpider, self).__init__()
+ self.blogs_data = blogs_data
+```
+
+[view raw][12][traffic.py][13] hosted with
+
+ by [GitHub][14]
+
+`blogs_data` is expected to be list of dictionaries in the form: `{"rank": 70, "url": "www.stat.washington.edu", "query": "Python"}`.
+
+Request building function looks like this:
+
+```
+ def start_requests(self):
+ url_template = urllib.parse.urlunparse(
+ ['http', self.allowed_domains[0], '/www/{path}', '', '', ''])
+ for blog in self.blogs_data:
+ url = url_template.format(path=blog['url'])
+ request = SplashRequest(url, endpoint='render.html',
+ args={'wait': 0.5}, meta={'blog': blog})
+ yield request
+```
+
+[view raw][15][traffic.py][16] hosted with
+
+ by [GitHub][17]
+
+It’s quite simple, we just add `/www/web-site-url/` string to the `'www.statshow.com'` url.
+
+Now let’s see how does the parser look:
+
+```
+ def parse(self, response):
+ site_data = response.xpath('//div[@id="box_1"]/span/text()').extract()
+ views_data = list(filter(lambda r: '$' not in r, site_data))
+ if views_data:
+ blog_data = response.meta.get('blog')
+ traffic_data = {
+ 'daily_page_views': int(views_data[0].translate({ord(','): None})),
+ 'daily_visitors': int(views_data[1].translate({ord(','): None}))
+ }
+ blog_data.update(traffic_data)
+ yield blog_data
+```
+
+[view raw][18][traffic.py][19] hosted with
+
+ by [GitHub][20]
+
+Similarly to the blog parsing routine, we just make our way through the sample return page of the StatShow and track down the elements containing daily page views and daily visitors. Both of these parameters identify website popularity, so we’ll just pick page views for our analysis.
+
+### Part II: Analysis
+
+The next part is analyzing all the data we got after scraping. We then visualize the prepared data sets with the lib called [Bokeh][47]. I don’t give the runner/visualization code here but it can be found in the [GitHub repo][48] in addition to everything else you see in this post.
+
+The initial result set has few outlying items representing websites with HUGE amount of traffic (such as google.com, linkedin.com, Oracle.com etc.). They obviously shouldn’t be considered. Even if some of those have blogs, they aren’t language specific. That’s why we filter the outliers based on the approach suggested in [this StackOverflow answer][36].
+
+### Language popularity comparison
+
+At first, let’s just make a head-to-head comparison of all the languages we have and see which one has most daily views among the top 100 blogs.
+
+Here’s the function that can take care of such a task:
+
+
+```
+def get_languages_popularity(data):
+ query_sorted_data = sorted(data, key=itemgetter('query'))
+ result = {'languages': [], 'views': []}
+ popularity = []
+ for k, group in groupby(query_sorted_data, key=itemgetter('query')):
+ group = list(group)
+ daily_page_views = map(lambda r: int(r['daily_page_views']), group)
+ total_page_views = sum(daily_page_views)
+ popularity.append((group[0]['query'], total_page_views))
+ sorted_popularity = sorted(popularity, key=itemgetter(1), reverse=True)
+ languages, views = zip(*sorted_popularity)
+ result['languages'] = languages
+ result['views'] = views
+ return result
+
+```
+
+[view raw][21][analysis.py][22] hosted with
+
+ by [GitHub][23]
+
+Here we first group our data by languages (‘query’ key in the dict) and then use python’s `groupby`wonderful function borrowed from SQL to generate groups of items from our data list, each representing some programming language. Afterwards, we calculate total page views for each language on line `14` and then add tuples of the form `('Language', rank)` in the `popularity`list. After the loop, we sort the popularity data based on the total views and unpack these tuples in 2 separate lists and return those in the `result` variable.
+
+There was some huge deviation in the initial dataset. I checked what was going on and realized that if I make query “C” in the [blogsearchengine.org][37], I get lots of irrelevant links, containing “C” letter somewhere. So, I had to exclude C from the analysis. It almost doesn’t happen with “R” in contrast as well as other C-like names: “C++”, “C#”.
+
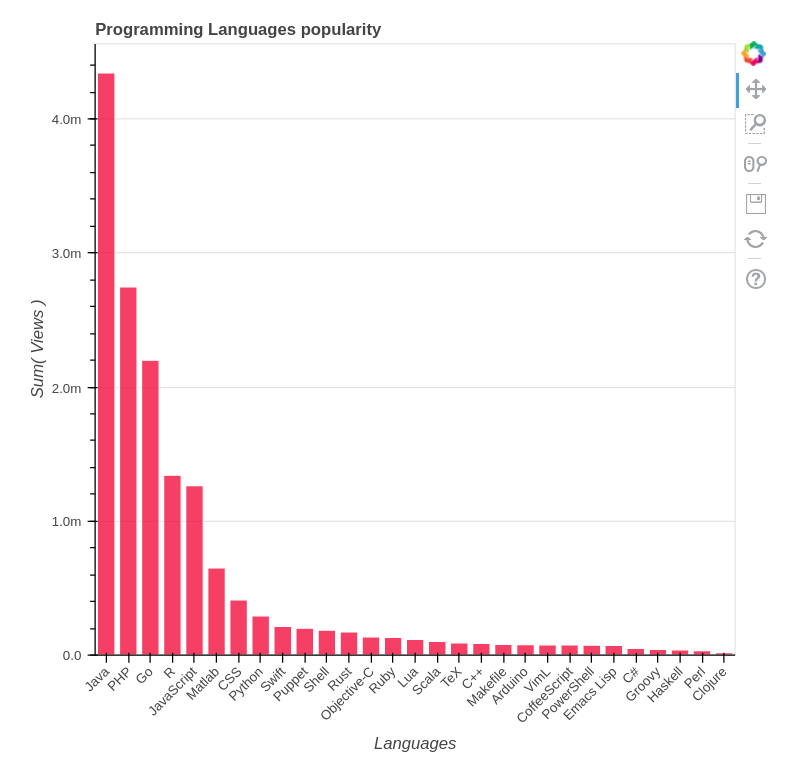
+So, if we remove C from the consideration and look at other languages, we can see the following picture:
+
+
+
+Evaluation. Java made it with over 4 million views daily, PHP and Go have over 2 million, R and JavaScript close up the “million scorers” list.
+
+### Daily Page Views vs Google Ranking
+
+Let’s now take a look at the connection between the number of daily views and Google ranking of blogs. Logically, less popular blogs should be further in ranking, It’s not so easy though, as other factors influence ranking as well, for example, if the article in the less popular blog is more recent, it’ll likely pop up first.
+
+The data preparation is performed in the following fashion:
+
+```
+def get_languages_popularity(data):
+ query_sorted_data = sorted(data, key=itemgetter('query'))
+ result = {'languages': [], 'views': []}
+ popularity = []
+ for k, group in groupby(query_sorted_data, key=itemgetter('query')):
+ group = list(group)
+ daily_page_views = map(lambda r: int(r['daily_page_views']), group)
+ total_page_views = sum(daily_page_views)
+ popularity.append((group[0]['query'], total_page_views))
+ sorted_popularity = sorted(popularity, key=itemgetter(1), reverse=True)
+ languages, views = zip(*sorted_popularity)
+ result['languages'] = languages
+ result['views'] = views
+ return result
+```
+
+[view raw][24][analysis.py][25] hosted with
+
+ by [GitHub][26]
+
+The function accepts scraped data and list of languages to consider. We sort the data in the same way we did for languages popularity. Afterwards, in a similar language grouping loop, we build `(rank, views_number)` tuples (with 1-based ranks) that are being converted to 2 separate lists. This pair of lists is then written to the resulting dictionary.
+
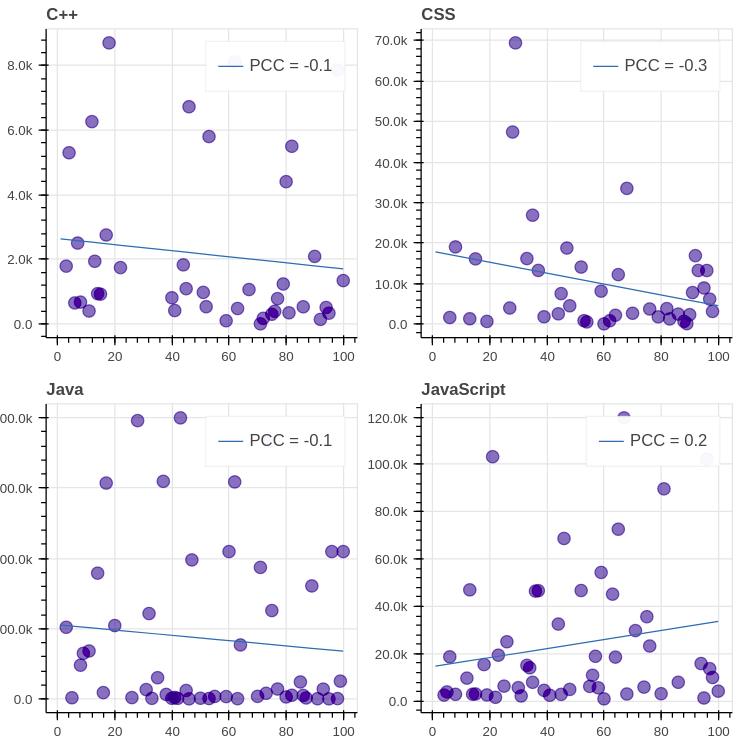
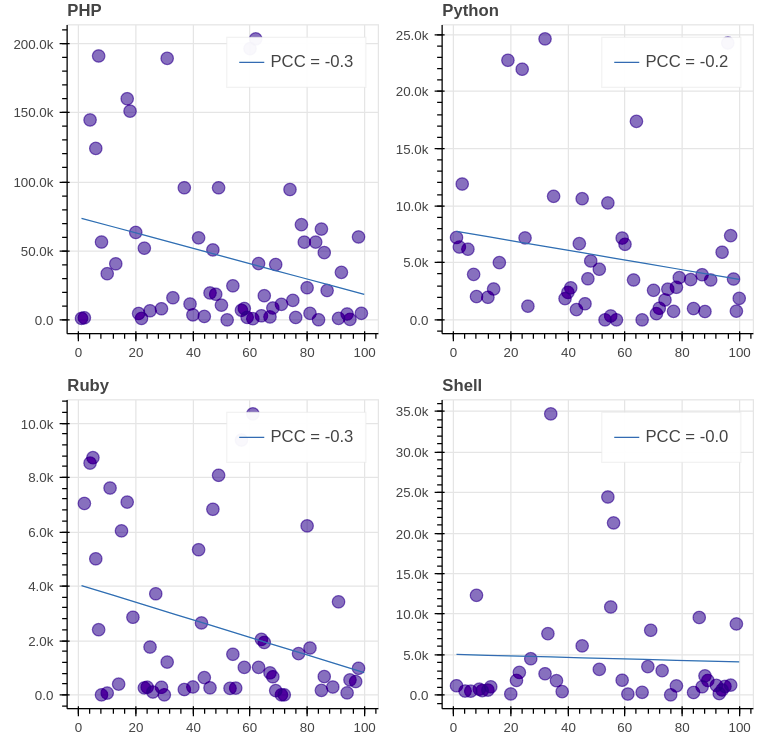
+The results for the top 8 GitHub languages (except C) are the following:
+
+
+
+
+
+Evaluation. We see that the [PCC (Pearson correlation coefficient)][49] of all graphs is far from 1/-1, which signifies lack of correlation between the daily views and the ranking. It’s important to note though that in most of the graphs (7 out of 8) the correlation is negative, which means that decrease in ranking leads to decrease in views indeed.
+
+### Conclusion
+
+So, according to our analysis, Java is by far most popular programming language, followed by PHP, Go, R and JavaScript. Neither of top 8 languages has a strong correlation between daily views and ranking in Google, so you can definitely get high in search results even if you’re just starting your blogging path. What exactly is required for that top hit a topic for another discussion though.
+
+These results are quite biased and can’t be taken into consideration without additional analysis. At first, it would be a good idea to collect more traffic feeds for an extended period of time and then analyze the mean (median?) values of daily views and rankings. Maybe I’ll return to it sometime in the future.
+
+### References
+
+1. Scraping:
+
+1. [blog.scrapinghub.com: Handling Javascript In Scrapy With Splash][27]
+
+2. [BlogSearchEngine.org][28]
+
+3. [twingly.com: Twingly Real-Time Blog Search][29]
+
+4. [searchblogspot.com: finding blogs on blogspot platform][30]
+
+3. Traffic estimation:
+
+1. [labnol.org: Find Out How Much Traffic a Website Gets][31]
+
+2. [quora.com: What are the best free tools that estimate visitor traffic…][32]
+
+3. [StatShow.com: The Stats Maker][33]
+
+--------------------------------------------------------------------------------
+
+via: https://www.databrawl.com/2017/10/08/blog-analysis/
+
+作者:[Serge Mosin ][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.databrawl.com/author/svmosingmail-com/
+[1]:https://bokeh.pydata.org/
+[2]:https://bokeh.pydata.org/
+[3]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/blogs.py
+[4]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-blogs-py
+[5]:https://github.com/
+[6]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/blogs.py
+[7]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-blogs-py
+[8]:https://github.com/
+[9]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/blogs.py
+[10]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-blogs-py
+[11]:https://github.com/
+[12]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/traffic.py
+[13]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-traffic-py
+[14]:https://github.com/
+[15]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/traffic.py
+[16]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-traffic-py
+[17]:https://github.com/
+[18]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/traffic.py
+[19]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-traffic-py
+[20]:https://github.com/
+[21]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/analysis.py
+[22]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-analysis-py
+[23]:https://github.com/
+[24]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/analysis.py
+[25]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-analysis-py
+[26]:https://github.com/
+[27]:https://blog.scrapinghub.com/2015/03/02/handling-javascript-in-scrapy-with-splash/
+[28]:http://www.blogsearchengine.org/
+[29]:https://www.twingly.com/
+[30]:http://www.searchblogspot.com/
+[31]:https://www.labnol.org/internet/find-website-traffic-hits/8008/
+[32]:https://www.quora.com/What-are-the-best-free-tools-that-estimate-visitor-traffic-for-a-given-page-on-a-particular-website-that-you-do-not-own-or-operate-3rd-party-sites
+[33]:http://www.statshow.com/
+[34]:https://docs.scrapy.org/en/latest/intro/tutorial.html
+[35]:https://blog.scrapinghub.com/2015/03/02/handling-javascript-in-scrapy-with-splash/
+[36]:https://stackoverflow.com/a/16562028/1573766
+[37]:http://blogsearchengine.org/
+[38]:https://github.com/Databrawl/blog_analysis
+[39]:https://scrapy.org/
+[40]:https://github.com/scrapinghub/splash
+[41]:https://en.wikipedia.org/wiki/Google_Custom_Search
+[42]:http://www.blogsearchengine.org/
+[43]:http://www.blogsearchengine.org/
+[44]:https://doc.scrapy.org/en/latest/topics/shell.html
+[45]:https://www.labnol.org/internet/find-website-traffic-hits/8008/
+[46]:http://www.statshow.com/
+[47]:https://bokeh.pydata.org/en/latest/
+[48]:https://github.com/Databrawl/blog_analysis
+[49]:https://en.wikipedia.org/wiki/Pearson_correlation_coefficient
+[50]:https://www.databrawl.com/author/svmosingmail-com/
+[51]:https://www.databrawl.com/2017/10/08/
diff --git a/sources/tech/20171009 Building an Open Standard for Distributed Messaging Introducing OpenMessaging.md b/sources/tech/20171009 Building an Open Standard for Distributed Messaging Introducing OpenMessaging.md
new file mode 100644
index 0000000000..13cb4bfcbb
--- /dev/null
+++ b/sources/tech/20171009 Building an Open Standard for Distributed Messaging Introducing OpenMessaging.md
@@ -0,0 +1,52 @@
+Building an Open Standard for Distributed Messaging: Introducing OpenMessaging
+============================================================
+
+
+Through a collaborative effort from enterprises and communities invested in cloud, big data, and standard APIs, I’m excited to welcome the OpenMessaging project to The Linux Foundation. The OpenMessaging community’s goal is to create a globally adopted, vendor-neutral, and open standard for distributed messaging that can be deployed in cloud, on-premise, and hybrid use cases.
+
+Alibaba, Yahoo!, Didi, and Streamlio are the founding project contributors. The Linux Foundation has worked with the initial project community to establish a governance model and structure for the long-term benefit of the ecosystem working on a messaging API standard.
+
+As more companies and developers move toward cloud native applications, challenges are developing at scale with messaging and streaming applications. These include interoperability issues between platforms, lack of compatibility between wire-level protocols and a lack of standard benchmarking across systems.
+
+In particular, when data transfers across different messaging and streaming platforms, compatibility problems arise, meaning additional work and maintenance cost. Existing solutions lack standardized guidelines for load balance, fault tolerance, administration, security, and streaming features. Current systems don’t satisfy the needs of modern cloud-oriented messaging and streaming applications. This can lead to redundant work for developers and makes it difficult or impossible to meet cutting-edge business demands around IoT, edge computing, smart cities, and more.
+
+Contributors to OpenMessaging are looking to improve distributed messaging by:
+
+* Creating a global, cloud-oriented, vendor-neutral industry standard for distributed messaging
+
+* Facilitating a standard benchmark for testing applications
+
+* Enabling platform independence
+
+* Targeting cloud data streaming and messaging requirements with scalability, flexibility, isolation, and security built in
+
+* Fostering a growing community of contributing developers
+
+You can learn more about the new project and how to participate here: [http://openmessaging.cloud][1]
+
+These are some of the organizations supporting OpenMessaging:
+
+“We have focused on the messaging and streaming field for years, during which we explored Corba notification, JMS and other standards to try to solve our stickiest business requirements. After evaluating the available alternatives, Alibaba chose to create a new cloud-oriented messaging standard, OpenMessaging, which is a vendor-neutral and language-independent and provides industrial guidelines for areas like finance, e-commerce, IoT, and big data. Moreover, it aims to develop messaging and streaming applications across heterogeneous systems and platforms. We hope it can be open, simple, scalable, and interoperable. In addition, we want to build an ecosystem according to this standard, such as benchmark, computation, and various connectors. We would like to have new contributions and hope everyone can work together to push the OpenMessaging standard forward.” _— Von Gosling, senior architect at Alibaba, co-creator of Apache RocketMQ, and original initiator of OpenMessaging_
+
+“As the sophistication and scale of applications’ messaging needs continue to grow, lack of a standard interface has created complexity and inflexibility barriers for developers and organizations. Streamlio is excited to work with other leaders to launch the OpenMessaging standards initiative in order to give customers easy access to high-performance, low-latency messaging solutions like Apache Pulsar that offer the durability, consistency, and availability that organizations require.” _— Matteo Merli, software engineer at Streamlio, co-creator of Apache Pulsar, and member of Apache BookKeeper PMC_
+
+“Oath–a Verizon subsidiary of leading media and tech brands including Yahoo and AOL– supports open, collaborative initiatives and is glad to join the OpenMessaging project.” _— _ _Joe Francis, director, Core Platforms_
+
+“In Didi, we have defined a private set of producer API and consumer API to hide differences among open source MQs such as Apache Kafka, Apache RocketMQ, etc. as well as to provide additional customized features. We are planning to release these to the open source community. So far, we have accumulated a lot of experience on MQs and API unification, and are willing to work in OpenMessaging to construct a common standard of APIs together with others. We sincerely believe that a unified and widely accepted API standard can benefit MQ technology and applications that rely on it.” _— Neil Qi, architect at Didi_
+
+“There are many different open source messaging solutions, including Apache ActiveMQ, Apache RocketMQ, Apache Pulsar, and Apache Kafka. The lack of an industry-wide, scalable messaging standard makes evaluating a suitable solution difficult. We are excited to support the joint effort from multiple open source projects working together to define a scalable, open messaging specification. Apache BookKeeper has been successfully deployed in production at Yahoo (via Apache Pulsar) and Twitter (via Apache DistributedLog) as their durable, high-performance, low-latency storage foundation for their enterprise-grade messaging systems. We are excited to join the OpenMessaging effort to help other projects address common problems like low-latency durability, consistency and availability in messaging solutions.” _— Sijie Guo, co-founder of Streamlio, PMC chair of Apache BookKeeper, and co-creator of Apache DistributedLog_
+
+--------------------------------------------------------------------------------
+
+via: https://www.linuxfoundation.org/blog/building-open-standard-distributed-messaging-introducing-openmessaging/
+
+作者:[Mike Dolan][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linuxfoundation.org/author/mdolan/
+[1]:http://openmessaging.cloud/
+[2]:https://www.linuxfoundation.org/author/mdolan/
+[3]:https://www.linuxfoundation.org/category/blog/
diff --git a/sources/tech/20171009 Considering Pythons Target Audience.md b/sources/tech/20171009 Considering Pythons Target Audience.md
new file mode 100644
index 0000000000..8ca5c86be7
--- /dev/null
+++ b/sources/tech/20171009 Considering Pythons Target Audience.md
@@ -0,0 +1,283 @@
+[Considering Python's Target Audience][40]
+============================================================
+
+Who is Python being designed for?
+
+* [Use cases for Python's reference interpreter][8]
+
+* [Which audience does CPython primarily serve?][9]
+
+* [Why is this relevant to anything?][10]
+
+* [Where does PyPI fit into the picture?][11]
+
+* [Why are some APIs changed when adding them to the standard library?][12]
+
+* [Why are some APIs added in provisional form?][13]
+
+* [Why are only some standard library APIs upgraded?][14]
+
+* [Will any parts of the standard library ever be independently versioned?][15]
+
+* [Why do these considerations matter?][16]
+
+Several years ago, I [highlighted][38] "CPython moves both too fast and too slowly" as one of the more common causes of conflict both within the python-dev mailing list, as well as between the active CPython core developers and folks that decide that participating in that process wouldn't be an effective use of their personal time and energy.
+
+I still consider that to be the case, but it's also a point I've spent a lot of time reflecting on in the intervening years, as I wrote that original article while I was still working for Boeing Defence Australia. The following month, I left Boeing for Red Hat Asia-Pacific, and started gaining a redistributor level perspective on [open source supply chain management][39] in large enterprises.
+
+### [Use cases for Python's reference interpreter][17]
+
+While it's a gross oversimplification, I tend to break down CPython's use cases as follows (note that these categories aren't fully distinct, they're just aimed at focusing my thinking on different factors influencing the rollout of new software features and versions):
+
+* Education: educator's main interest is in teaching ways of modelling and manipulating the world computationally, _not_ writing or maintaining production software). Examples:
+ * Australia's [Digital Curriculum][1]
+
+ * Lorena A. Barba's [AeroPython][2]
+
+* Personal automation & hobby projects: software where the main, and often only, user is the individual that wrote it. Examples:
+ * my Digital Blasphemy [image download notebook][3]
+
+ * Paul Fenwick's (Inter)National [Rick Astley Hotline][4]
+
+* Organisational process automation: software where the main, and often only, user is the organisation it was originally written to benefit. Examples:
+ * CPython's [core workflow tools][5]
+
+ * Development, build & release management tooling for Linux distros
+
+* Set-and-forget infrastructure: software where, for sometimes debatable reasons, in-life upgrades to the software itself are nigh impossible, but upgrades to the underlying platform may be feasible. Examples:
+ * most self-managed corporate and institutional infrastructure (where properly funded sustaining engineering plans are disturbingly rare)
+
+ * grant funded software (where maintenance typically ends when the initial grant runs out)
+
+ * software with strict certification requirements (where recertification is too expensive for routine updates to be economically viable unless absolutely essential)
+
+ * Embedded software systems without auto-upgrade capabilities
+
+* Continuously upgraded infrastructure: software with a robust sustaining engineering model, where dependency and platform upgrades are considered routine, and no more concerning than any other code change. Examples:
+ * Facebook's Python service infrastructure
+
+ * Rolling release Linux distributions
+
+ * most public PaaS and serverless environments (Heroku, OpenShift, AWS Lambda, Google Cloud Functions, Azure Cloud Functions, etc)
+
+* Intermittently upgraded standard operating environments: environments that do carry out routine upgrades to their core components, but those upgrades occur on a cycle measured in years, rather than weeks or months. Examples:
+ * [VFX Platform][6]
+
+ * LTS Linux distributions
+
+ * CPython and the Python standard library
+
+ * Infrastructure management & orchestration tools (e.g. OpenStack, Ansible)
+
+ * Hardware control systems
+
+* Ephemeral software: software that tends to be used once and then discarded or ignored, rather than being subsequently upgraded in place. Examples:
+ * Ad hoc automation scripts
+
+ * Single-player games with a defined "end" (once you've finished them, even if you forget to uninstall them, you probably won't reinstall them on a new device)
+
+ * Single-player games with little or no persistent state (if you uninstall and reinstall them, it doesn't change much about your play experience)
+
+ * Event-specific applications (the application was tied to a specific physical event, and once the event is over, that app doesn't matter any more)
+
+* Regular use applications: software that tends to be regularly upgraded after deployment. Examples:
+ * Business management software
+
+ * Personal & professional productivity applications (e.g. Blender)
+
+ * Developer tools & services (e.g. Mercurial, Buildbot, Roundup)
+
+ * Multi-player games, and other games with significant persistent state, but no real defined "end"
+
+ * Embedded software systems with auto-upgrade capabilities
+
+* Shared abstraction layers: software components that are designed to make it possible to work effectively in a particular problem domain even if you don't personally grasp all the intricacies of that domain yet. Examples:
+ * most runtime libraries and frameworks fall into this category (e.g. Django, Flask, Pyramid, SQL Alchemy, NumPy, SciPy, requests)
+
+ * many testing and type inference tools also fit here (e.g. pytest, Hypothesis, vcrpy, behave, mypy)
+
+ * plugins for other applications (e.g. Blender plugins, OpenStack hardware adapters)
+
+ * the standard library itself represents the baseline "world according to Python" (and that's an [incredibly complex][7] world view)
+
+### [Which audience does CPython primarily serve?][18]
+
+Ultimately, the main audiences that CPython and the standard library specifically serve are those that, for whatever reason, aren't adequately served by the combination of a more limited standard library and the installation of explicitly declared third party dependencies from PyPI.
+
+To oversimplify the above review of different usage and deployment models even further, it's possible to summarise the single largest split in Python's user base as the one between those that are using Python as a _scripting language_ for some environment of interest, and those that are using it as an _application development language_ , where the eventual artifact that will be distributed is something other than the script that they're working on.
+
+Typical developer behaviours when using Python as a scripting language include:
+
+* the main working unit consists of a single Python file (or Jupyter notebook!), rather than a directory of Python and metadata files
+
+* there's no separate build step of any kind - the script is distributed _as_ a script, similar to the way standalone shell scripts are distributed
+
+* there's no separate install step (other than downloading the file to an appropriate location), as it is expected that the required runtime environment will be preconfigured on the destination system
+
+* no explicit dependencies stated, except perhaps a minimum Python version, or else a statement of the expected execution environment. If dependencies outside the standard library are needed, they're expected to be provided by the environment being scripted (whether that's an operating system, a data analysis platform, or an application that embeds a Python runtime)
+
+* no separate test suite, with the main test of correctness being "Did the script do what you wanted it to do with the input that you gave it?"
+
+* if testing prior to live execution is needed, it will be in the form of a "dry run" or "preview" mode that conveys to the user what the software _would_ do if run that way
+
+* if static code analysis tools are used at all, it's via integration into the user's software development environment, rather than being set up separately for each individual script
+
+By contrast, typical developer behaviours when using Python as an application development language include:
+
+* the main working unit consists of a directory of Python and metadata files, rather than a single Python file
+
+* these is a separate build step to prepare the application for publication, even if it's just bundling the files together into a Python sdist, wheel or zipapp archive
+
+* whether there's a separate install step to prepare the application for use will depend on how the application is packaged, and what the supported target environments are
+
+* external dependencies are expressed in a metadata file, either directly in the project directory (e.g. `pyproject.toml`, `requirements.txt`, `Pipfile`), or as part of the generated publication archive (e.g. `setup.py`, `flit.ini`)
+
+* a separate test suite exists, either as unit tests for the Python API, integration tests for the functional interfaces, or a combination of the two
+
+* usage of static analysis tools is configured at the project level as part of its testing regime, rather than being dependent on
+
+As a result of that split, the main purpose that CPython and the standard library end up serving is to define the redistributor independent baseline of assumed functionality for educational and ad hoc Python scripting environments 3-5 years after the corresponding CPython feature release.
+
+For ad hoc scripting use cases, that 3-5 year latency stems from a combination of delays in redistributors making new releases available to their users, and users of those redistributed versions taking time to revise their standard operating environments.
+
+In the case of educational environments, educators need that kind of time to review the new features and decide whether or not to incorporate them into the courses they offer their students.
+
+### [Why is this relevant to anything?][19]
+
+This post was largely inspired by the Twitter discussion following on from [this comment of mine][20] citing the Provisional API status defined in [PEP 411][21] as an example of an open source project issuing a de facto invitation to users to participate more actively in the design & development process as co-creators, rather than only passively consuming already final designs.
+
+The responses included several expressions of frustration regarding the difficulty of supporting provisional APIs in higher level libraries, without those libraries making the provisional status transitive, and hence limiting support for any related features to only the latest version of the provisional API, and not any of the earlier iterations.
+
+My [main reaction][22] was to suggest that open source publishers should impose whatever support limitations they need to impose to make their ongoing maintenance efforts personally sustainable. That means that if supporting older iterations of provisional APIs is a pain, then they should only be supported if the project developers themselves need that, or if somebody is paying them for the inconvenience. This is similar to my view on whether or not volunteer-driven projects should support older commercial LTS Python releases for free when it's a hassle for them to do: I [don't think they should][23], as I expect most such demands to be stemming from poorly managed institutional inertia, rather than from genuine need (and if the need _is_ genuine, then it should instead be possible to find some means of paying to have it addressed).
+
+However, my [second reaction][24], was to realise that even though I've touched on this topic over the years (e.g. in the original 2011 article linked above, as well as in Python 3 Q & A answers [here][25], [here][26], and [here][27], and to a lesser degree in last year's article on the [Python Packaging Ecosystem][28]), I've never really attempted to directly explain the impact it has on the standard library design process.
+
+And without that background, some aspects of the design process, such as the introduction of provisional APIs, or the introduction of inspired-by-but-not-the-same-as, seem completely nonsensical, as they appear to be an attempt to standardise APIs without actually standardising them.
+
+### [Where does PyPI fit into the picture?][29]
+
+The first hurdle that _any_ proposal sent to python-ideas or python-dev has to clear is answering the question "Why isn't a module on PyPI good enough?". The vast majority of proposals fail at this step, but there are several common themes for getting past it:
+
+* rather than downloading a suitable third party library, novices may be prone to copying & pasting bad advice from the internet at large (e.g. this is why the `secrets` library now exists: to make it less likely people will use the `random` module, which is intended for games and statistical simulations, for security-sensitive purposes)
+
+* the module is intended to provide a reference implementation and to enable interoperability between otherwise competing implementations, rather than necessarily being all things to all people (e.g. `asyncio`, `wsgiref`, `unittest``, and `logging` all fall into this category)
+
+* the module is intended for use in other parts of the standard library (e.g. `enum` falls into this category, as does `unittest`)
+
+* the module is designed to support a syntactic addition to the language (e.g. the `contextlib`, `asyncio` and `typing` modules fall into this category)
+
+* the module is just plain useful for ad hoc scripting purposes (e.g. `pathlib`, and `ipaddress` fall into this category)
+
+* the module is useful in an educational context (e.g. the `statistics` module allows for interactive exploration of statistic concepts, even if you wouldn't necessarily want to use it for full-fledged statistical analysis)
+
+Passing this initial "Is PyPI obviously good enough?" check isn't enough to ensure that a module will be accepted for inclusion into the standard library, but it's enough to shift the question to become "Would including the proposed library result in a net improvement to the typical introductory Python software developer experience over the next few years?"
+
+The introduction of `ensurepip` and `venv` modules into the standard library also makes it clear to redistributors that we expect Python level packaging and installation tools to be supported in addition to any platform specific distribution mechanisms.
+
+### [Why are some APIs changed when adding them to the standard library?][30]
+
+While existing third party modules are sometimes adopted wholesale into the standard library, in other cases, what actually gets added is a redesigned and reimplemented API that draws on the user experience of the existing API, but drops or revises some details based on the additional design considerations and privileges that go with being part of the language's reference implementation.
+
+For example, unlike its popular third party predecessor, `path.py`, ``pathlib` does _not_ define string subclasses, but instead independent types. Solving the resulting interoperability challenges led to the definition of the filesystem path protocol, allowing a wider range of objects to be used with interfaces that work with filesystem paths.
+
+The API design for the `ipaddress` module was adjusted to explicitly separate host interface definitions (IP addresses associated with particular IP networks) from the definitions of addresses and networks in order to serve as a better tool for teaching IP addressing concepts, whereas the original `ipaddr` module is less strict in the way it uses networking terminology.
+
+In other cases, standard library modules are constructed as a synthesis of multiple existing approaches, and may also rely on syntactic features that didn't exist when the APIs for pre-existing libraries were defined. Both of these considerations apply for the `asyncio` and `typing` modules, while the latter consideration applies for the `dataclasses` API being considered in PEP 557 (which can be summarised as "like attrs, but using variable annotations for field declarations").
+
+The working theory for these kinds of changes is that the existing libraries aren't going away, and their maintainers often aren't all that interested in putitng up with the constraints associated with standard library maintenance (in particular, the relatively slow release cadence). In such cases, it's fairly common for the documentation of the standard library version to feature a "See Also" link pointing to the original module, especially if the third party version offers additional features and flexibility that were omitted from the standard library module.
+
+### [Why are some APIs added in provisional form?][31]
+
+While CPython does maintain an API deprecation policy, we generally prefer not to use it without a compelling justification (this is especially the case while other projects are attempting to maintain compatibility with Python 2.7).
+
+However, when adding new APIs that are inspired by existing third party ones without being exact copies of them, there's a higher than usual risk that some of the design decisions may turn out to be problematic in practice.
+
+When we consider the risk of such changes to be higher than usual, we'll mark the related APIs as provisional, indicating that conservative end users may want to avoid relying on them at all, and that developers of shared abstraction layers may want to consider imposing stricter than usual constraints on which versions of the provisional API they're prepared to support.
+
+### [Why are only some standard library APIs upgraded?][32]
+
+The short answer here is that the main APIs that get upgraded are those where:
+
+* there isn't likely to be a lot of external churn driving additional updates
+
+* there are clear benefits for either ad hoc scripting use cases or else in encouraging future interoperability between multiple third party solutions
+
+* a credible proposal is submitted by folks interested in doing the work
+
+If the limitations of an existing module are mainly noticeable when using the module for application development purposes (e.g. `datetime`), if redistributors already tend to make an improved alternative third party option readily available (e.g. `requests`), or if there's a genuine conflict between the release cadence of the standard library and the needs of the package in question (e.g. `certifi`), then the incentives to propose a change to the standard library version tend to be significantly reduced.
+
+This is essentially the inverse to the question about PyPI above: since PyPI usually _is_ a sufficiently good distribution mechanism for application developer experience enhancements, it makes sense for such enhancements to be distributed that way, allowing redistributors and platform providers to make their own decisions about what they want to include as part of their default offering.
+
+Changing CPython and the standard library only comes into play when there is perceived value in changing the capabilities that can be assumed to be present by default in 3-5 years time.
+
+### [Will any parts of the standard library ever be independently versioned?][33]
+
+Yes, it's likely the bundling model used for `ensurepip` (where CPython releases bundle a recent version of `pip` without actually making it part of the standard library) may be applied to other modules in the future.
+
+The most probable first candidate for that treatment would be the `distutils` build system, as switching to such a model would allow the build system to be more readily kept consistent across multiple releases.
+
+Other potential candidates for this kind of treatment would be the Tcl/Tk graphics bindings, and the IDLE editor, which are already unbundled and turned into an optional addon installations by a number of redistributors.
+
+### [Why do these considerations matter?][34]
+
+By the very nature of things, the folks that tend to be most actively involved in open source development are those folks working on open source applications and shared abstraction layers.
+
+The folks writing ad hoc scripts or designing educational exercises for their students often won't even think of themselves as software developers - they're teachers, system administrators, data analysts, quants, epidemiologists, physicists, biologists, business analysts, market researchers, animators, graphical designers, etc.
+
+When all we have to worry about for a language is the application developer experience, then we can make a lot of simplifying assumptions around what people know, the kinds of tools they're using, the kinds of development processes they're following, and the ways they're going to be building and deploying their software.
+
+Things get significantly more complicated when an application runtime _also_ enjoys broad popularity as a scripting engine. Doing either job well is already difficult, and balancing the needs of both audiences as part of a single project leads to frequent incomprehension and disbelief on both sides.
+
+This post isn't intended to claim that we never make incorrect decisions as part of the CPython development process - it's merely pointing out that the most reasonable reaction to seemingly nonsensical feature additions to the Python standard library is going to be "I'm not part of the intended target audience for that addition" rather than "I have no interest in that, so it must be a useless and pointless addition of no value to anyone, added purely to annoy me".
+
+--------------------------------------------------------------------------------
+
+via: http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html
+
+作者:[Nick Coghlan ][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.curiousefficiency.org/pages/about.html
+[1]:https://aca.edu.au/#home-unpack
+[2]:https://github.com/barbagroup/AeroPython
+[3]:https://nbviewer.jupyter.org/urls/bitbucket.org/ncoghlan/misc/raw/default/notebooks/Digital%20Blasphemy.ipynb
+[4]:https://github.com/pjf/rickastley
+[5]:https://github.com/python/core-workflow
+[6]:http://www.vfxplatform.com/
+[7]:http://www.curiousefficiency.org/posts/2015/10/languages-to-improve-your-python.html#broadening-our-horizons
+[8]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#use-cases-for-python-s-reference-interpreter
+[9]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#which-audience-does-cpython-primarily-serve
+[10]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-is-this-relevant-to-anything
+[11]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#where-does-pypi-fit-into-the-picture
+[12]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-are-some-apis-changed-when-adding-them-to-the-standard-library
+[13]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-are-some-apis-added-in-provisional-form
+[14]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-are-only-some-standard-library-apis-upgraded
+[15]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#will-any-parts-of-the-standard-library-ever-be-independently-versioned
+[16]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-do-these-considerations-matter
+[17]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id1
+[18]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id2
+[19]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id3
+[20]:https://twitter.com/ncoghlan_dev/status/916994106819088384
+[21]:https://www.python.org/dev/peps/pep-0411/
+[22]:https://twitter.com/ncoghlan_dev/status/917092464355241984
+[23]:http://www.curiousefficiency.org/posts/2015/04/stop-supporting-python26.html
+[24]:https://twitter.com/ncoghlan_dev/status/917088410162012160
+[25]:http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html#wouldn-t-a-python-2-8-release-help-ease-the-transition
+[26]:http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html#doesn-t-this-make-python-look-like-an-immature-and-unstable-platform
+[27]:http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html#what-about-insert-other-shiny-new-feature-here
+[28]:http://www.curiousefficiency.org/posts/2016/09/python-packaging-ecosystem.html
+[29]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id4
+[30]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id5
+[31]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id6
+[32]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id7
+[33]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id8
+[34]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id9
+[35]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#
+[36]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#disqus_thread
+[37]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.rst
+[38]:http://www.curiousefficiency.org/posts/2011/04/musings-on-culture-of-python-dev.html
+[39]:http://community.redhat.com/blog/2015/02/the-quid-pro-quo-of-open-infrastructure/
+[40]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#
diff --git a/sources/tech/20171009 CyberShaolin Teaching the Next Generation of Cybersecurity Experts.md b/sources/tech/20171009 CyberShaolin Teaching the Next Generation of Cybersecurity Experts.md
new file mode 100644
index 0000000000..23704fa46d
--- /dev/null
+++ b/sources/tech/20171009 CyberShaolin Teaching the Next Generation of Cybersecurity Experts.md
@@ -0,0 +1,57 @@
+CyberShaolin: Teaching the Next Generation of Cybersecurity Experts
+============================================================
+
+
+
+Reuben Paul, co-founder of CyberShaolin, will speak at Open Source Summit in Prague, highlighting the importance of cybersecurity awareness for kids.
+
+Reuben Paul is not the only kid who plays video games, but his fascination with games and computers set him on a unique journey of curiosity that led to an early interest in cybersecurity education and advocacy and the creation of CyberShaolin, an organization that helps children understand the threat of cyberattacks. Paul, who is now 11 years old, will present a keynote talk at [Open Source Summit in Prague][2], sharing his experiences and highlighting insecurities in toys, devices, and other technologies in daily use.
+
+
+
+Reuben Paul, co-founder of CyberShaolin
+
+We interviewed Paul to hear the story of his journey and to discuss CyberShaolin and its mission to educate, equip, and empower kids (and their parents) with knowledge of cybersecurity dangers and defenses. Linux.com: When did your fascination with computers start? Reuben Paul: My fascination with computers started with video games. I like mobile phone games as well as console video games. When I was about 5 years old (I think), I was playing the “Asphalt” racing game by Gameloft on my phone. It was a simple but fun game. I had to touch on the right side of the phone to go fast and touch the left side of the phone to slow down. I asked my dad, “How does the game know where I touch?”
+
+He researched and found out that the phone screen was an xy coordinate system and so he told me that if the x value was greater than half the width of the phone screen, then it was a touch on the right side. Otherwise, it was a touch on the left side. To help me better understand how this worked, he gave me the equation to graph a straight line, which was y = mx + b and asked, “Can you find the y value for each x value?” After about 30 minutes, I calculated the y value for each of the x values he gave me.
+
+“When my dad realized that I was able to learn some fundamental logics of programming, he introduced me to Scratch and I wrote my first game — called “Big Fish eats Small Fish” — using the x and y values of the mouse pointer in the game. Then I just kept falling in love with computers.Paul, who is now 11 years old, will present a keynote talk at [Open Source Summit in Prague][1], sharing his experiences and highlighting insecurities in toys, devices, and other technologies in daily use.
+
+Linux.com: What got you interested in cybersecurity? Paul: My dad, Mano Paul, used to train his business clients on cybersecurity. Whenever he worked from his home office, I would listen to his phone conversations. By the time I was 6 years old, I knew about things like the Internet, firewalls, and the cloud. When my dad realized I had the interest and the potential for learning, he started teaching me security topics like social engineering techniques, cloning websites, man-in-the-middle attack techniques, hacking mobile apps, and more. The first time I got a meterpreter shell from a test target machine, I felt like Peter Parker who had just discovered his Spiderman abilities.
+
+Linux.com: How and why did you start CyberShaolin? Paul: When I was 8 years old, I gave my first talk on “InfoSec from the mouth of babes (or an 8 year old)” in DerbyCon. It was in September of 2014\. After that conference, I received several invitations and before the end of 2014, I had keynoted at three other conferences.
+
+So, when kids started hearing me speak at these different conferences, they started writing to me and asking me to teach them. I told my parents that I wanted to teach other kids, and they asked me how. I said, “Maybe I can make some videos and publish them on channels like YouTube.” They asked me if I wanted to charge for my videos, and I said “No.” I want my videos to be free and accessible to any child anywhere in the world. This is how CyberShaolin was created.
+
+Linux.com: What’s the goal of CyberShaolin? Paul: CyberShaolin is the non-profit organization that my parents helped me found. Its mission is to educate, equip, and empower kids (and their parents) with knowledge of cybersecurity dangers and defenses, using videos and other training material that I develop in my spare time from school, along with kung fu, gymnastics, swimming, inline hockey, piano, and drums. I have published about a dozen videos so far on the www.CyberShaolin.org website and plan to develop more. I would also like to make games and comics to support security learning.
+
+CyberShaolin comes from two words: Cyber and Shaolin. The word cyber is of course from technology. Shaolin comes from the kung fu martial art form in which my dad and are I are both second degree black belt holders. In kung fu, we have belts to show our progress of knowledge, and you can think of CyberShaolin like digital kung fu where kids can become Cyber Black Belts, after learning and taking tests on our website.
+
+Linux.com: How important do you think is it for children to understand cybersecurity? Paul: We are living in a time when technology and devices are not only in our homes but also in our schools and pretty much any place you go. The world is also getting very connected with the Internet of Things, which can easily become the Internet of Threats. Children are one of the main users of these technologies and devices. Unfortunately, these devices and apps on these devices are not very secure and can cause serious problems to children and families. For example, I recently (in May 2017) demonstrated how I could hack into a smart toy teddy bear and turn it into a remote spying device. Children are also the next generation. If they are not aware and trained in cybersecurity, then the future (our future) will not be very good.
+
+Linux.com: How does the project help children? Paul:As I mentioned before, CyberShaolin’s mission is to educate, equip, and empower kids (and their parents) with knowledge of cybersecurity dangers and defenses.
+
+As kids are educated about cybersecurity dangers like cyber bullying, man-in-the-middle, phishing, privacy, online threats, mobile threats, etc., they will be equipped with knowledge and skills, which will empower them to make cyber-wise decisions and stay safe and secure in cyberspace. And, just as I would never use my kung fu skills to harm someone, I expect all CyberShaolin graduates to use their cyber kung fu skills to create a secure future, for the good of humanity.
+
+--------------------------------------------------------------------------------
+作者简介:
+
+Swapnil Bhartiya is a journalist and writer who has been covering Linux and Open Source for more than 10 years.
+
+-------------------------
+
+via: https://www.linuxfoundation.org/blog/cybershaolin-teaching-next-generation-cybersecurity-experts/
+
+作者:[Swapnil Bhartiya][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linuxfoundation.org/author/sbhartiya/
+[1]:http://events.linuxfoundation.org/events/open-source-summit-europe
+[2]:http://events.linuxfoundation.org/events/open-source-summit-europe
+[3]:https://www.linuxfoundation.org/author/sbhartiya/
+[4]:https://www.linuxfoundation.org/category/blog/
+[5]:https://www.linuxfoundation.org/category/campaigns/events-campaigns/
+[6]:https://www.linuxfoundation.org/category/blog/qa/
diff --git a/sources/tech/20171009 Examining network connections on Linux systems.md b/sources/tech/20171009 Examining network connections on Linux systems.md
new file mode 100644
index 0000000000..299aef18e2
--- /dev/null
+++ b/sources/tech/20171009 Examining network connections on Linux systems.md
@@ -0,0 +1,217 @@
+Examining network connections on Linux systems
+============================================================
+
+### Linux systems provide a lot of useful commands for reviewing network configuration and connections. Here's a look at a few, including ifquery, ifup, ifdown and ifconfig.
+
+
+There are a lot of commands available on Linux for looking at network settings and connections. In today's post, we're going to run through some very handy commands and see how they work.
+
+### ifquery command
+
+One very useful command is the **ifquery** command. This command should give you a quick list of network interfaces. However, you might only see something like this —showing only the loopback interface:
+
+```
+$ ifquery --list
+lo
+```
+
+If this is the case, your **/etc/network/interfaces** file doesn't include information on network interfaces except for the loopback interface. You can add lines like the last two in the example below — assuming DHCP is used to assign addresses — if you'd like it to be more useful.
+
+```
+# interfaces(5) file used by ifup(8) and ifdown(8)
+auto lo
+iface lo inet loopback
+auto eth0
+iface eth0 inet dhcp
+```
+
+### ifup and ifdown commands
+
+The related **ifup** and **ifdown** commands can be used to bring network connections up and shut them down as needed provided this file has the required descriptive data. Just keep in mind that "if" means "interface" in these commands just as it does in the **ifconfig** command, not "if" as in "if I only had a brain".
+
+
+
+### ifconfig command
+
+The **ifconfig** command, on the other hand, doesn't read the /etc/network/interfaces file at all and still provides quite a bit of useful information on network interfaces -- configuration data along with packet counts that tell you how busy each interface has been. The ifconfig command can also be used to shut down and restart network interfaces (e.g., ifconfig eth0 down).
+
+```
+$ ifconfig eth0
+eth0 Link encap:Ethernet HWaddr 00:1e:4f:c8:43:fc
+ inet addr:192.168.0.6 Bcast:192.168.0.255 Mask:255.255.255.0
+ inet6 addr: fe80::b44b:bdb6:2527:6ae9/64 Scope:Link
+ UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
+ RX packets:60474 errors:0 dropped:0 overruns:0 frame:0
+ TX packets:33463 errors:0 dropped:0 overruns:0 carrier:0
+ collisions:0 txqueuelen:1000
+ RX bytes:43922053 (43.9 MB) TX bytes:4000460 (4.0 MB)
+ Interrupt:21 Memory:fe9e0000-fea00000
+```
+
+The RX and TX packet counts in this output are extremely low. In addition, no errors or packet collisions have been reported. The **uptime** command will likely confirm that this system has only recently been rebooted.
+
+The broadcast (Bcast) and network mask (Mask) addresses shown above indicate that the system is operating on a Class C equivalent network (the default) so local addresses will range from 192.168.0.1 to 192.168.0.254.
+
+### netstat command
+
+The **netstat** command provides information on routing and network connections. The **netstat -rn** command displays the system's routing table.
+
+
+
+```
+$ netstat -rn
+Kernel IP routing table
+Destination Gateway Genmask Flags MSS Window irtt Iface
+0.0.0.0 192.168.0.1 0.0.0.0 UG 0 0 0 eth0
+169.254.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0
+192.168.0.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
+```
+
+That **169.254.0.0** entry in the above output is only necessary if you are using or planning to use link-local communications. You can comment out the related lines in the **/etc/network/if-up.d/avahi-autoipd** file like this if this is not the case:
+
+```
+$ tail -12 /etc/network/if-up.d/avahi-autoipd
+#if [ -x /bin/ip ]; then
+# # route already present?
+# ip route show | grep -q '^169.254.0.0/16[[:space:]]' && exit 0
+#
+# /bin/ip route add 169.254.0.0/16 dev $IFACE metric 1000 scope link
+#elif [ -x /sbin/route ]; then
+# # route already present?
+# /sbin/route -n | egrep -q "^169.254.0.0[[:space:]]" && exit 0
+#
+# /sbin/route add -net 169.254.0.0 netmask 255.255.0.0 dev $IFACE metric 1000
+#fi
+```
+
+### netstat -a command
+
+The **netstat -a** command will display **_all_** network connections. To limit this to listening and established connections (generally much more useful), use the **netstat -at** command instead.
+
+```
+$ netstat -at
+Active Internet connections (servers and established)
+Proto Recv-Q Send-Q Local Address Foreign Address State
+tcp 0 0 *:ssh *:* LISTEN
+tcp 0 0 localhost:ipp *:* LISTEN
+tcp 0 0 localhost:smtp *:* LISTEN
+tcp 0 256 192.168.0.6:ssh 192.168.0.32:53550 ESTABLISHED
+tcp6 0 0 [::]:http [::]:* LISTEN
+tcp6 0 0 [::]:ssh [::]:* LISTEN
+tcp6 0 0 ip6-localhost:ipp [::]:* LISTEN
+tcp6 0 0 ip6-localhost:smtp [::]:* LISTEN
+```
+
+### netstat -rn command
+
+The **netstat -rn** command displays the system's routing table. The 192.168.0.1 address is the local gateway (Flags=UG).
+
+```
+$ netstat -rn
+Kernel IP routing table
+Destination Gateway Genmask Flags MSS Window irtt Iface
+0.0.0.0 192.168.0.1 0.0.0.0 UG 0 0 0 eth0
+192.168.0.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
+```
+
+### host command
+
+The **host** command works a lot like **nslookup** by looking up the remote system's IP address, but also provides the system's mail handler.
+
+```
+$ host world.std.com
+world.std.com has address 192.74.137.5
+world.std.com mail is handled by 10 smtp.theworld.com.
+```
+
+### nslookup command
+
+The **nslookup** also provides information on the system (in this case, the local system) that is providing DNS lookup services.
+
+```
+$ nslookup world.std.com
+Server: 127.0.1.1
+Address: 127.0.1.1#53
+
+Non-authoritative answer:
+Name: world.std.com
+Address: 192.74.137.5
+```
+
+### dig command
+
+The **dig** command provides quitea lot of information on connecting to a remote system -- including the name server we are communicating with and how long the query takes to respond and is often used for troubleshooting.
+
+```
+$ dig world.std.com
+
+; <<>> DiG 9.10.3-P4-Ubuntu <<>> world.std.com
+;; global options: +cmd
+;; Got answer:
+;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 28679
+;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
+
+;; OPT PSEUDOSECTION:
+; EDNS: version: 0, flags:; udp: 512
+;; QUESTION SECTION:
+;world.std.com. IN A
+
+;; ANSWER SECTION:
+world.std.com. 78146 IN A 192.74.137.5
+
+;; Query time: 37 msec
+;; SERVER: 127.0.1.1#53(127.0.1.1)
+;; WHEN: Mon Oct 09 13:26:46 EDT 2017
+;; MSG SIZE rcvd: 58
+```
+
+### nmap command
+
+The **nmap** command is most frequently used to probe remote systems, but can also be used to report on the services being offered by the local system. In the output below, we can see that ssh is available for logins, that smtp is servicing email, that a web site is active, and that an ipp print service is running.
+
+```
+$ nmap localhost
+
+Starting Nmap 7.01 ( https://nmap.org ) at 2017-10-09 15:01 EDT
+Nmap scan report for localhost (127.0.0.1)
+Host is up (0.00016s latency).
+Not shown: 996 closed ports
+PORT STATE SERVICE
+22/tcp open ssh
+25/tcp open smtp
+80/tcp open http
+631/tcp open ipp
+
+Nmap done: 1 IP address (1 host up) scanned in 0.09 seconds
+```
+
+Linux systems provide a lot of useful commands for reviewing their network configuration and connections. If you run out of commands to explore, keep in mind that **apropos network** might point you toward even more.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3230519/linux/examining-network-connections-on-linux-systems.html
+
+作者:[Sandra Henry-Stocker][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
+[1]:https://www.networkworld.com/article/3221393/linux/review-considering-oracle-linux-is-a-no-brainer-if-you-re-an-oracle-shop.html
+[2]:https://www.networkworld.com/article/3221393/linux/review-considering-oracle-linux-is-a-no-brainer-if-you-re-an-oracle-shop.html#tk.nww_nsdr_ndxprmomod
+[3]:https://www.networkworld.com/article/3221423/linux/review-suse-linux-enterprise-server-12-sp2-scales-well-supports-3rd-party-virtualization.html
+[4]:https://www.networkworld.com/article/3221423/linux/review-suse-linux-enterprise-server-12-sp2-scales-well-supports-3rd-party-virtualization.html#tk.nww_nsdr_ndxprmomod
+[5]:https://www.networkworld.com/article/3221476/linux/review-free-linux-fedora-server-offers-upgrades-as-they-become-available-no-wait.html
+[6]:https://www.networkworld.com/article/3221476/linux/review-free-linux-fedora-server-offers-upgrades-as-they-become-available-no-wait.html#tk.nww_nsdr_ndxprmomod
+[7]:https://www.networkworld.com/article/3227929/linux/making-good-use-of-the-files-in-proc.html
+[8]:https://www.networkworld.com/article/3221415/linux/linux-commands-for-managing-partitioning-troubleshooting.html
+[9]:https://www.networkworld.com/article/2225768/cisco-subnet/dual-protocol-routing-with-raspberry-pi.html
+[10]:https://www.networkworld.com/video/51206/solo-drone-has-linux-smarts-gopro-mount
+[11]:https://www.networkworld.com/insider
+[12]:https://www.networkworld.com/article/3227929/linux/making-good-use-of-the-files-in-proc.html
+[13]:https://www.networkworld.com/article/3221415/linux/linux-commands-for-managing-partitioning-troubleshooting.html
+[14]:https://www.networkworld.com/video/51206/solo-drone-has-linux-smarts-gopro-mount
+[15]:https://www.networkworld.com/video/51206/solo-drone-has-linux-smarts-gopro-mount
+[16]:https://www.flickr.com/photos/cogdog/4317096083/in/photolist-7zufg6-8JS2ym-bmDGsu-cnYW2C-mnrvP-a1s6VU-4ThA5-33B4ME-7GHEod-ERKLhX-5iPi6m-dTZAW6-UC6wyi-dRCJAZ-dq4wxW-peQyWU-8AGfjw-8wGAqs-4oLjd2-4T6pXM-dQua38-UKngxR-5kQwHN-ejjXMo-q4YvvL-7AUF3h-39ya27-7HiWfp-TosWda-6L3BZn-uST4Hi-TkRW8U-H7zBu-oDkNvU-6T2pZg-dQEbs9-39hxfS-5pBhQL-eR6iKT-7dgDwk-W15qVn-nVQHN3-mdRj8-75tqVh-RajJsC-7gympc-7dwxjt-9EadYN-p1qH1G-6rZhh6
+[17]:https://creativecommons.org/licenses/by/2.0/legalcode
diff --git a/sources/tech/20171010 Changes in Password Best Practices.md b/sources/tech/20171010 Changes in Password Best Practices.md
new file mode 100644
index 0000000000..8b1c611171
--- /dev/null
+++ b/sources/tech/20171010 Changes in Password Best Practices.md
@@ -0,0 +1,35 @@
+translating----geekpi
+
+### Changes in Password Best Practices
+
+NIST recently published its four-volume [_SP800-63b Digital Identity Guidelines_][3] . Among other things, it makes three important suggestions when it comes to passwords:
+
+1. Stop it with the annoying password complexity rules. They make passwords harder to remember. They increase errors because artificially complex passwords are harder to type in. And they [don't help][1] that much. It's better to allow people to use pass phrases.
+
+2. Stop it with password expiration. That was an [old idea for an old way][2] we used computers. Today, don't make people change their passwords unless there's indication of compromise.
+
+3. Let people use password managers. This is how we deal with all the passwords we need.
+
+These password rules were failed attempts to [fix the user][4]. Better we fix the security systems.
+
+--------------------------------------------------------------------------------
+
+作者简介:
+
+I've been writing about security issues on my blog since 2004, and in my monthly newsletter since 1998. I write books, articles, and academic papers. Currently, I'm the Chief Technology Officer of IBM Resilient, a fellow at Harvard's Berkman Center, and a board member of EFF.
+
+-----------------
+
+via: https://www.schneier.com/blog/archives/2017/10/changes_in_pass.html
+
+作者:[Bruce Schneier][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.schneier.com/blog/about/
+[1]:https://www.wsj.com/articles/the-man-who-wrote-those-password-rules-has-a-new-tip-n3v-r-m1-d-1502124118
+[2]:https://securingthehuman.sans.org/blog/2017/03/23/time-for-password-expiration-to-die
+[3]:http://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-63b.pdf
+[4]:http://ieeexplore.ieee.org/document/7676198/?reload=true
diff --git a/sources/tech/20171010 In Device We Trust Measure Twice Compute Once with Xen Linux TPM 2.0 and TXT.md b/sources/tech/20171010 In Device We Trust Measure Twice Compute Once with Xen Linux TPM 2.0 and TXT.md
new file mode 100644
index 0000000000..20c14074c6
--- /dev/null
+++ b/sources/tech/20171010 In Device We Trust Measure Twice Compute Once with Xen Linux TPM 2.0 and TXT.md
@@ -0,0 +1,94 @@
+In Device We Trust: Measure Twice, Compute Once with Xen, Linux, TPM 2.0 and TXT
+============================================================
+
+
+
+Xen virtualization enables innovative applications to be economically integrated with measured, interoperable software components on general-purpose hardware.[Creative Commons Zero][1]Pixabay
+
+Is it a small tablet or large phone? Is it a phone or broadcast sensor? Is it a server or virtual desktop cluster? Is x86 emulating ARM, or vice-versa? Is Linux inspiring Windows, or the other way around? Is it microcode or hardware? Is it firmware or software? Is it microkernel or hypervisor? Is it a security or quality update? _Is anything in my device the same as yesterday? When we observe our evolving devices and their remote services, what can we question and measure?_
+
+### General Purpose vs. Special Purpose Ecosystems
+
+The general-purpose computer now lives in a menagerie of special-purpose devices and information appliances. Yet software and hardware components _within_ devices are increasingly flexible, blurring category boundaries. With hardware virtualization on x86 and ARM platforms, the ecosystems of multiple operating systems can coexist on a single device. Can a modular and extensible multi-vendor architecture compete with the profitability of vertically integrated products from a single vendor?
+
+Operating systems evolved alongside applications for lucrative markets. PC desktops were driven by business productivity and media creation. Web browsers abstracted OS differences, as software revenue shifted to e-commerce, services, and advertising. Mobile devices added sensors, radios and hardware decoders for content and communication. Apple, now the most profitable computer company, vertically integrates software and services with sensors and hardware. Other companies monetize data, increasing demand for memory and storage optimization.
+
+Some markets require security or safety certifications: automotive, aviation, marine, cross domain, industrial control, finance, energy, medical, and embedded devices. As software "eats the world," how can we [modernize][5]vertical markets without the economies of scale seen in enterprise and consumer markets? One answer comes from device architectures based on hardware virtualization, Xen, [disaggregation][6], OpenEmbedded Linux and measured launch. [OpenXT][7] derivatives use this extensible, open-source base to enforce policy for specialized applications on general-purpose hardware, while reusing interoperable components.
+
+[OpenEmbedded][8] Linux supports a range of x86 and ARM devices, while Xen isolates operating systems and [unikernels][9]. Applications and drivers from multiple ecosystems can run concurrently, expanding technical and licensing options. Special-purpose software can be securely composed with general-purpose software in isolated VMs, anchored by a hardware-assisted root of trust defined by customer and OEM policies. This architecture allows specialist software vendors to share platform and hardware support costs, while supporting emerging and legacy software ecosystems that have different rates of change.
+
+### On the Shoulders of Hardware, Firmware and Software Developers
+
+### 
+
+ _System Architecture, from NIST SP800-193 (Draft), Platform Firmware Resiliency_
+
+By the time a user-facing software application begins executing on a powered-on hardware device, an array of firmware and software is already running on the platform. Special-purpose applications’ security and safety assertions are dependent on platform firmware and the developers of a computing device’s “root of trust.”
+
+If we consider the cosmological “[Turtles All The Way Down][2]” question for a computing device, the root of trust is the lowest-level combination of hardware, firmware and software that is initially trusted to perform critical security functions and persist state. Hardware components used in roots of trust include the TCG's Trusted Platform Module ([TPM][10]), ARM’s [TrustZone][11]-enabled Trusted Execution Environment ([TEE][12]), Apple’s [Secure Enclave][13] co-processor ([SEP][14]), and Intel's Management Engine ([ME][15]) in x86 CPUs. [TPM 2.0][16]was approved as an ISO standard in 2015 and is widely available in 2017 devices.
+
+TPMs enable key authentication, integrity measurement and remote attestation. TPM key generation uses a hardware random number generator, with private keys that never leave the chip. TPM integrity measurement functions ensure that sensitive data like private keys are only used by trusted code. When software is provisioned, its cryptographic hash is used to extend a chain of hashes in TPM Platform Configuration Registers (PCRs). When the device boots, sensitive data is only unsealed if measurements of running software can recreate the PCR hash chain that was present at the time of sealing. PCRs record the aggregate result of extending hashes, while the TPM Event Log records the hash chain.
+
+Measurements are calculated by hardware, firmware and software external to the TPM. There are Static (SRTM) and Dynamic (DRTM) Roots of Trust for Measurement. SRTM begins at device boot when the BIOS boot block measures BIOS before execution. The BIOS then execute, extending configuration and option ROM measurements into static PCRs 0-7\. TPM-aware boot loaders like TrustedGrub can extend a measurement chain from BIOS up to the [Linux kernel][17]. These software identity measurements enable relying parties to make trusted decisions within [specific workflows][18].
+
+DRTM enables "late launch" of a trusted environment from an untrusted one at an arbitrary time, using Intel's Trusted Execution Technology ([TXT][19]) or AMD's Secure Virtual Machine ([SVM][20]). With Intel TXT, the CPU instruction SENTER resets CPUs to a known state, clears dynamic PCRs 17-22 and validates the Intel SINIT ACM binary to measure Intel’s tboot MLE, which can then measure Xen, Linux or other components. In 2008, Carnegie Mellon's [Flicker][21] used late launch to minimize the Trusted Computing Base (TCB) for isolated execution of sensitive code on AMD devices, during the interval between suspend/resume of untrusted Linux.
+
+If DRTM enables launch of a trusted Xen or Linux environment without reboot, is SRTM still needed? Yes, because [attacks][22] are possible via privileged System Management Mode (SMM) firmware, UEFI Boot/Runtime Services, Intel ME firmware, or Intel Active Management Technology (AMT) firmware. Measurements for these components can be extended into static PCRs, to ensure they have not been modified since provisioning. In 2015, Intel released documentation and reference code for an SMI Transfer Monitor ([STM][23]), which can isolate SMM firmware on VT-capable systems. As of September 2017, an OEM-supported STM is not yet available to improve the security of Intel TXT.
+
+Can customers secure devices while retaining control over firmware? UEFI Secure Boot requires a signed boot loader, but customers can define root certificates. Intel [Boot Guard][24] provides OEMs with validation of the BIOS boot block. _Verified Boot_ requires a signed boot block and the OEM's root certificate is fused into the CPU to restrict firmware. _Measured Boot_ extends the boot block hash into a TPM PCR, where it can be used for measured launch of customer-selected firmware. Sadly, no OEM has yet shipped devices which implement ONLY the Measured Boot option of Boot Guard.
+
+### Measured Launch with Xen on General Purpose Devices
+
+[OpenXT 7.0][25] has entered release candidate status, with support for Kaby Lake devices, TPM 2.0, OE [meta-measured][3], and [forward seal][26] (upgrade with pre-computed PCRs).
+
+[OpenXT 6.0][27] on a Dell T20 Haswell Xeon microserver, after adding a SATA controller, low-power AMD GPU and dual-port Broadcom NIC, can be configured with measured launch of Windows 7 GPU p/t, FreeNAS 9.3 SATA p/t, pfSense 2.3.4, Debian Wheezy, OpenBSD 6.0, and three NICs, one per passthrough driver VM.
+
+Does this demonstrate a storage device, build server, firewall, middlebox, desktop, or all of the above? With architectures similar to [Qubes][28] and [OpenXT][29] derivatives, we can combine specialized applications with best-of-breed software from multiple ecosystems. A strength of one operating system can address the weakness of another.
+
+### Measurement and Complexity in Software Supply Chains
+
+While ransomware trumpets cryptocurrency demands to shocked users, low-level malware often emulates Sherlock Holmes: the user sees no one. Malware authors modify code behavior in response to “our method of questioning”, simulating heisenbugs. As system architects pile abstractions, [self-similarity][30] appears as hardware, microcode, emulator, firmware, microkernel, hypervisor, operating system, virtual machine, namespace, nesting, runtime, and compiler expand onto neighboring territory. There are no silver bullets to neutralize these threats, but cryptographic measurement of source code and stateless components enables whitelisting and policy enforcement in multi-vendor supply chains.
+
+Even for special-purpose devices, the user experience bar is defined by mass-market computing. Meanwhile, Moore’s Law is ending, ARM remains fragmented, x86 PC volume is flat, new co-processors and APIs multiply, threats mutate and demand for security expertise outpaces the talent pool. In vertical markets which need usable, securable and affordable special-purpose devices, Xen virtualization enables innovative applications to be economically integrated with measured, interoperable software components on general-purpose hardware. OpenXT is an open-source showcase for this scalable ecosystem. Further work is planned on reference architectures for measured disaggregation with Xen and OpenEmbedded Linux.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog//event/elce/2017/10/device-we-trust-measure-twice-compute-once-xen-linux-tpm-20-and-txt
+
+作者:[RICH PERSAUD][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/rpersaud
+[1]:https://www.linux.com/licenses/category/creative-commons-zero
+[2]:https://en.wikipedia.org/wiki/Turtles_all_the_way_down
+[3]:https://layers.openembedded.org/layerindex/branch/master/layer/meta-measured/
+[4]:https://www.linux.com/files/images/puzzlejpg
+[5]:http://mailchi.mp/iotpodcast/stacey-on-iot-if-ge-cant-master-industrial-iot-who-can
+[6]:https://www.xenproject.org/directory/directory/research/45-breaking-up-is-hard-to-do-security-and-functionality-in-a-commodity-hypervisor.html
+[7]:http://openxt.org/
+[8]:https://wiki.xenproject.org/wiki/Category:OpenEmbedded
+[9]:https://wiki.xenproject.org/wiki/Unikernels
+[10]:http://www.cs.unh.edu/~it666/reading_list/Hardware/tpm_fundamentals.pdf
+[11]:https://developer.arm.com/technologies/trustzone
+[12]:https://www.arm.com/products/processors/technologies/trustzone/tee-smc.php
+[13]:http://mista.nu/research/sep-paper.pdf
+[14]:https://www.blackhat.com/docs/us-16/materials/us-16-Mandt-Demystifying-The-Secure-Enclave-Processor.pdf
+[15]:https://link.springer.com/book/10.1007/978-1-4302-6572-6
+[16]:https://fosdem.org/2017/schedule/event/tpm2/attachments/slides/1517/export/events/attachments/tpm2/slides/1517/FOSDEM___TPM2_0_practical_usage.pdf
+[17]:https://mjg59.dreamwidth.org/48897.html
+[18]:https://docs.microsoft.com/en-us/windows/threat-protection/secure-the-windows-10-boot-process
+[19]:https://www.intel.com/content/www/us/en/software-developers/intel-txt-software-development-guide.html
+[20]:http://support.amd.com/TechDocs/24593.pdf
+[21]:https://www.cs.unc.edu/~reiter/papers/2008/EuroSys.pdf
+[22]:http://invisiblethingslab.com/resources/bh09dc/Attacking%20Intel%20TXT%20-%20paper.pdf
+[23]:https://firmware.intel.com/content/smi-transfer-monitor-stm
+[24]:https://software.intel.com/en-us/blogs/2015/02/20/tricky-world-securing-firmware
+[25]:https://openxt.atlassian.net/wiki/spaces/OD/pages/96567309/OpenXT+7.x+Builds
+[26]:https://openxt.atlassian.net/wiki/spaces/DC/pages/81035265/Measured+Launch
+[27]:https://openxt.atlassian.net/wiki/spaces/OD/pages/96436271/OpenXT+6.x+Builds
+[28]:http://qubes-os.org/
+[29]:http://openxt.org/
+[30]:https://en.m.wikipedia.org/wiki/Self-similarity
diff --git a/sources/tech/20171011 Why Linux Works.md b/sources/tech/20171011 Why Linux Works.md
new file mode 100644
index 0000000000..d53bf4a15d
--- /dev/null
+++ b/sources/tech/20171011 Why Linux Works.md
@@ -0,0 +1,93 @@
+Why Linux Works
+============================================================
+
+_Amid the big cash and fierce corporate jockeying around Linux, it’s the developers who truly give the operating system its vitality._
+
+The [Linux community][7] works, it turns out, because the Linux community isn’t too concerned about work, per se. As much as Linux has come to dominate many areas of corporate computing – from HPC to mobile to cloud – the engineers who write the Linux kernel tend to focus on the code itself, rather than their corporate interests therein.
+
+Such is one prominent conclusion that emerges from [Dawn Foster’s doctoral work][8], examining collaboration on the Linux kernel. Foster, a former community lead at Intel and Puppet Labs, notes, “Many people consider themselves a Linux kernel developer first, an employee second.”
+
+With all the “foundation washing” corporations have inflicted upon various open source projects, hoping to hide corporate prerogatives behind a mask of supposed community, Linux has managed to keep itself pure. The question is how.
+
+**Follow the Money**
+
+After all, if any open source project should lend itself to corporate greed, it’s Linux. Back in 2008, [the Linux ecosystem was estimated to top $25 billion in value][9]. Nearly 10 years later, that number must be multiples bigger, with much of our current cloud, mobile, and big data infrastructure dependent on Linux. Even within a single company like Oracle, Linux delivers billions of dollars in value.
+
+Small wonder, then, that there’s such a landgrab to influence the direction of Linux through code.
+
+Take a look at the most active contributors to Linux over the last year and it’s enterprise “turtles” all the way down, as captured in the [Linux Foundation’s latest report][10]:
+
+
+
+Each of these corporations spends significant quantities of cash to pay developers to contribute free software, and each is banking on a return on these investments. Because of the potential for undue corporate influence over Linux, [some have cried foul][11] on the supposed shepherd of Linux development, the Linux Foundation. This criticism has become more pronounced of late as erstwhile enemies of open source like Microsoft have bought their way into the Linux Foundation.
+
+But this is a false foe and, frankly, an outdated one.
+
+While it’s true that corporate interests line up to throw cash at the Linux Foundation, it’s just as true that this cash doesn’t buy them influence over code. In the best open source communities, cash helps to fund developers, but those developers in turn focus on code before corporation. As Linux Foundation executive director [Jim Zemlin has stressed][12]:
+
+“The technical roles in our projects are separate from corporations. No one’s commits are tagged with their corporate identity: code talks loudest in Linux Foundation projects. Developers in our projects can move from one firm to another and their role in the projects will remain unchanged. Subsequent commercial or government adoption of that code creates value, which in turn can be reinvested in a project. This virtuous cycle benefits all, and is the goal of any of our projects.”
+
+Anyone that has read [Linus Torvalds’][13] mailing list commentaries can’t possibly believe that he’s a dupe of this or that corporation. The same holds true for other prominent contributors. While they are almost universally employed by big corporations, it’s generally the case that the corporations pay developers for work they’re already predisposed to do and, in fact, are doing.
+
+After all, few corporations would have the patience or risk profile necessary to fund a bunch of newbie Linux kernel hackers and wait around for years for some of them to _maybe_ contribute enough quality code to merit a position of influence on the kernel team. So they opt to hire existing, trusted developers. As noted in the [2016 Linux Foundation report][14], “The number of unpaid developers continue[d] its slow decline, as Linux kernel development proves an increasingly valuable skill sought by employers, ensuring experienced kernel developers do not stay unpaid for long.”
+
+Such trust is bought with code, however, not corporate cash. So none of those Linux kernel developers is going to sell out the trust they’ve earned for a brief stint of cash that will quickly fade when an emerging conflict of interest compromises the quality of their code. It makes no sense.
+
+**Not Kumbaya, but not Game of Thrones, Either**
+
+Ultimately, Linux kernel development is about identity, something Foster’s research calls out.
+
+Working for Google may be nice, and perhaps carries with it a decent title and free drycleaning. Being the maintainer for a key subsystem of the Linux kernel, however, is even harder to come by and carries with it the promise of assured, highly lucrative employment by any number of companies.
+
+As Foster writes, “Even when they enjoy their current job and like their employer, most [Linux kernel developers] tend to look at the employment relationship as something temporary, whereas their identity as a kernel developer is viewed as more permanent and more important.”
+
+Because of this identity as a Linux kernel developer first, and corporate citizen second, Linux kernel developers can comfortably collaborate even with their employer’s fiercest competitors. This works because the employers ultimately have limited ability to steer their developers’ work, for reasons noted above. Foster delves into this issue:
+
+“Although companies do sometimes influence the areas where their employees contribute, individuals have quite a bit of freedom in how they do the work. Many receive little direction for their day-to-day work, with a high degree of trust from their employers to do useful work. However, occasionally they are asked to do some specific piece of work or to take an interest in a particular area that is important for the company.
+
+Many kernel developers also collaborate with their competitors on a regular basis, where they interact with each other as individuals without focusing on the fact that their employers compete with each other. This was something I saw a lot of when I was working at Intel, because our kernel developers worked with almost all of our major competitors.”
+
+The corporations may compete on chips that run Linux, or distributions of Linux, or other software enabled by a robust operating system, but the developers focus on just one thing: making the best Linux possible. Again, this works because their identity is tied to Linux, not the firewall they sit behind while they code.
+
+Foster has illustrated this interaction for the USB subsystem mailing list (between 2013 and 2015), with darker lines portraying heavier email interaction between companies:
+
+
+
+In pricing discussions the obvious interaction between a number of companies might raise suspicions among antitrust authorities, but in Linux land it’s simply business as usual. This results in a better OS for all the parties to go out and bludgeon each other with in free market competition.
+
+**Finding the Right Balance**
+
+Such “coopetition,” as Novell founder Ray Noorda might have styled it, exists among the best open source communities, but only works where true community emerges. It’s tough, for example, for a project dominated by a single vendor to achieve the right collaborative tension. [Kubernetes][15], launched by Google, suggests it’s possible, but other projects like Docker have struggled to reach the same goal, in large part because they have been unwilling to give up technical leadership over their projects.
+
+Perhaps Kubernetes worked so well because Google didn’t feel the need to dominate and, in fact, _wants_ other companies to take on the mantle of development leadership. With a fantastic code base that solves a major industry need, a project like Kubernetes is well-positioned to succeed so long as Google both helps to foster it and then gets out of the way, which it has, encouraging significant contributions from Red Hat and others.
+
+Kubernetes, however, is the exception, just as Linux was before it. To succeed _because of_ corporate greed, there has to be a lot of it, and balanced between competing interests. If a project is governed by just one company’s self-interest, generally reflected in its technical governance, no amount of open source licensing will be enough to shake it free of that corporate influence.
+
+Linux works, in short, because so many companies want to control it and can’t, due to its industry importance, making it far more profitable for a developer to build her career as a _Linux developer_ rather than a Red Hat (or Intel or Oracle or…) engineer.
+
+--------------------------------------------------------------------------------
+
+via: https://www.datamation.com/open-source/why-linux-works.html
+
+作者:[Matt Asay][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.datamation.com/author/Matt-Asay-1133910.html
+[1]:https://www.datamation.com/feedback/https://www.datamation.com/open-source/why-linux-works.html
+[2]:https://www.datamation.com/author/Matt-Asay-1133910.html
+[3]:https://www.datamation.com/e-mail/https://www.datamation.com/open-source/why-linux-works.html
+[4]:https://www.datamation.com/print/https://www.datamation.com/open-source/why-linux-works.html
+[5]:https://www.datamation.com/open-source/why-linux-works.html#comment_form
+[6]:https://www.datamation.com/author/Matt-Asay-1133910.html
+[7]:https://www.datamation.com/open-source/
+[8]:https://opensource.com/article/17/10/collaboration-linux-kernel
+[9]:http://www.osnews.com/story/20416/Linux_Ecosystem_Worth_25_Billion
+[10]:https://www.linux.com/publications/linux-kernel-development-how-fast-it-going-who-doing-it-what-they-are-doing-and-who-5
+[11]:https://www.datamation.com/open-source/the-linux-foundation-and-the-uneasy-alliance.html
+[12]:https://thenewstack.io/linux-foundation-critics/
+[13]:https://github.com/torvalds
+[14]:https://www.linux.com/publications/linux-kernel-development-how-fast-it-going-who-doing-it-what-they-are-doing-and-who-5
+[15]:https://kubernetes.io/
diff --git a/sources/tech/20171012 Linux Networking Hardware for Beginners Think Software.md b/sources/tech/20171012 Linux Networking Hardware for Beginners Think Software.md
new file mode 100644
index 0000000000..5f1d67a9c8
--- /dev/null
+++ b/sources/tech/20171012 Linux Networking Hardware for Beginners Think Software.md
@@ -0,0 +1,78 @@
+translating by sugarfillet
+Linux Networking Hardware for Beginners: Think Software
+============================================================
+
+
+Without routers and bridges, we would be lonely little islands; learn more in this networking tutorial.[Creative Commons Zero][3]Pixabay
+
+Last week, we learned about [LAN (local area network) hardware][7]. This week, we'll learn about connecting networks to each other, and some cool hacks for mobile broadband.
+
+### Routers
+
+Network routers are everything in computer networking, because routers connect networks. Without routers we would be lonely little islands. Figure 1 shows a simple wired LAN (local area network) with a wireless access point, all connected to the Internet. Computers on the LAN connect to an Ethernet switch, which connects to a combination firewall/router, which connects to the big bad Internet through whatever interface your Internet service provider (ISP) provides, such as cable box, DSL modem, satellite uplink...like everything in computing, it's likely to be a box with blinky lights. When your packets leave your LAN and venture forth into the great wide Internet, they travel from router to router until they reach their destination.
+
+### [fig-1.png][4]
+
+
+Figure 1: A simple wired LAN with a wireless access point.[Used with permission][1]
+
+A router can look like pretty much anything: a nice little specialized box that does only routing and nothing else, a bigger box that provides routing, firewall, name services, and VPN gateway, a re-purposed PC or laptop, a Raspberry Pi or Arduino, stout little single-board computers like PC Engines...for all but the most demanding uses, ordinary commodity hardware works fine. The highest-end routers use specialized hardware that is designed to move the maximum number of packets per second. They have multiple fat data buses, multiple CPUs, and super-fast memory. (Look up Juniper and Cisco routers to see what high-end routers look like, and what's inside.)
+
+A wireless access point connects to your LAN either as an Ethernet bridge or a router. A bridge extends the network, so hosts on both sides of the bridge are on the same network. A router connects two different networks.
+
+### Network Topology
+
+There are multitudes of ways to set up your LAN. You can put all hosts on a single flat network. You can divide it up into different subnets. You can divide it into virtual LANs, if your switch supports this.
+
+A flat network is the simplest; just plug everyone into the same switch. If one switch isn't enough you can connect switches to each other. Some switches have special uplink ports, some don't care which ports you connect, and you may need to use a crossover Ethernet cable, so check your switch documentation.
+
+Flat networks are the easiest to administer. You don't need routers and don't have to calculate subnets, but there are some downsides. They don't scale, so when they get too large they get bogged down by broadcast traffic. Segmenting your LAN provides a bit of security, and makes it easier to manage larger networks by dividing it into manageable chunks. Figure 2 shows a simplified LAN divided into two subnets: internal wired and wireless hosts, and one for servers that host public services. The subnet that contains the public-facing servers is called a DMZ, demilitarized zone (ever notice all the macho terminology for jobs that are mostly typing on a computer?) because it is blocked from all internal access.
+
+### [fig-2.png][5]
+
+
+Figure 2: A simplified LAN divided into two subnets.[Used with permission][2]
+
+Even in a network as small as Figure 2 there are several ways to set it up. You can put your firewall and router on a single device. You could have a dedicated Internet link for the DMZ, divorcing it completely from your internal network. Which brings us to our next topic: it's all software.
+
+### Think Software
+
+You may have noticed that of the hardware we have discussed in this little series, only network interfaces, switches, and cabling are special-purpose hardware. Everything else is general-purpose commodity hardware, and it's the software that defines its purpose. Linux is a true networking operating system, and it supports a multitude of network operations: VLANs, firewall, router, Internet gateway, VPN gateway, Ethernet bridge, Web/mail/file/etc. servers, load-balancer, proxy, quality of service, multiple authenticators, trunking, failover...you can run your entire network on commodity hardware with Linux. You can even use Linux to simulate an Ethernet switch with LISA (LInux Switching Appliance) and vde2.
+
+There are specialized distributions for small hardware like DD-WRT, OpenWRT, and the Raspberry Pi distros, and don't forget the BSDs and their specialized offshoots like the pfSense firewall/router, and the FreeNAS network-attached storage server.
+
+You know how some people insist there is a difference between a hardware firewall and a software firewall? There isn't. That's like saying there is a hardware computer and a software computer.
+
+### Port Trunking and Ethernet Bonding
+
+Trunking and bonding, also called link aggregation, is combining two Ethernet channels into one. Some Ethernet switches support port trunking, which is combining two switch ports to combine their bandwidth into a single link. This is a nice way to make a bigger pipe to a busy server.
+
+You can do the same thing with Ethernet interfaces, and the bonding driver is built-in to the Linux kernel, so you don't need any special hardware.
+
+### Bending Mobile Broadband to your Will
+
+I expect that mobile broadband is going to grow in the place of DSL and cable Internet. I live near a city of 250,000 population, but outside the city limits good luck getting Internet, even though there is a large population to serve. My little corner of the world is 20 minutes from town, but it might as well be the moon as far as Internet service providers are concerned. My only option is mobile broadband; there is no dialup, satellite Internet is sold out (and it sucks), and haha lol DSL, cable, or fiber. That doesn't stop ISPs from stuffing my mailbox with flyers for Xfinity and other high-speed services my area will never see.
+
+I tried AT&T, Verizon, and T-Mobile. Verizon has the strongest coverage, but Verizon and AT&T are expensive. I'm at the edge of T-Mobile coverage, but they give the best deal by far. To make it work, I had to buy a weBoost signal booster and ZTE mobile hotspot. Yes, you can use a smartphone as a hotspot, but the little dedicated hotspots have stronger radios. If you're thinking you might want a signal booster, I have nothing but praise for weBoost because their customer support is superb, and they will do their best to help you. Set it up with the help of a great little app that accurately measures signal strength, [SignalCheck Pro][8]. They have a free version with fewer features; spend the two bucks to get the pro version, you won't be sorry.
+
+The little ZTE hotspots serve up to 15 hosts and have rudimentary firewalls. But we can do better: get something like the Linksys WRT54GL, replace the stock firmware with Tomato, OpenWRT, or DD-WRT, and then you have complete control of your firewall rules, routing, and any other services you want to set up.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/intro-to-linux/2017/10/linux-networking-hardware-beginners-think-software
+
+作者:[CARLA SCHRODER][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/cschroder
+[1]:https://www.linux.com/licenses/category/used-permission
+[2]:https://www.linux.com/licenses/category/used-permission
+[3]:https://www.linux.com/licenses/category/creative-commons-zero
+[4]:https://www.linux.com/files/images/fig-1png-7
+[5]:https://www.linux.com/files/images/fig-2png-4
+[6]:https://www.linux.com/files/images/soderskar-islandjpg
+[7]:https://www.linux.com/learn/intro-to-linux/2017/10/linux-networking-hardware-beginners-lan-hardware
+[8]:http://www.bluelinepc.com/signalcheck/
diff --git a/sources/tech/20171012 Q Whys Oracle so two-faced over open source A. Moolah wonga dosh.md b/sources/tech/20171012 Q Whys Oracle so two-faced over open source A. Moolah wonga dosh.md
new file mode 100644
index 0000000000..b9669c3fa3
--- /dev/null
+++ b/sources/tech/20171012 Q Whys Oracle so two-faced over open source A. Moolah wonga dosh.md
@@ -0,0 +1,94 @@
+Q. Why's Oracle so two-faced over open source? A. Moolah, wonga, dosh
+============================================================
+
+### And lobbying US government against it is NOT modernising IT
+
+
+
+Oracle loves open source. Except when the database giant hates open source. Which, according to its recent lobbying of the US federal government, seems to be "most of the time".
+
+Yes, Oracle has recently joined the Cloud Native Computing Foundation (CNCF) to up its support for open-source Kubernetes and, yes, it has long supported (and contributed to) Linux. And, yes, Oracle has even gone so far as to (finally) open up Java development by putting it under a foundation's stewardship.
+
+Yet this same, seemingly open Oracle has actively hammered the US government to consider that "there is no math that can justify open source from a cost perspective as the cost of support plus the opportunity cost of forgoing features, functions, automation and security overwhelm any presumed cost savings."
+
+That punch to the face was delivered in a letter to Christopher Liddell, a former Microsoft CFO and now director of Trump's American Technology Council, by Kenneth Glueck, Oracle senior vice president.
+
+The US government had courted input on its IT modernisation programme. Others writing back to Liddell included AT&T, Cisco, Microsoft and VMware.
+
+In other words, based on its letter, what Oracle wants us to believe is that open source leads to greater costs and poorly secured, limply featured software. Nor is Oracle content to leave it there, also arguing that open source is exactly how the private sector does _not_ function, seemingly forgetting that most of the leading infrastructure, big data, and mobile software today is open source.
+
+Details!
+
+Rather than take this counterproductive detour into self-serving silliness, Oracle would do better to follow Microsoft's path. Microsoft, too, used to Janus-face its way through open source, simultaneously supporting and bashing it. Only under chief executive Satya Nadella's reign did Microsoft realise it's OK to fully embrace open source, and its financial results have loved the commitment. Oracle has much to learn, and emulate, in Microsoft's approach.
+
+### I love you, you're perfect. Now change
+
+Oracle has never been particularly warm and fuzzy about open source. As founder Larry Ellison might put it, Oracle is a profit-seeking corporation, not a peace-loving charity. To the extent that Oracle embraces open source, therefore it does so for financial reward, just like every other corporation.
+
+Few, however, are as blunt as Oracle about this fact of corporate open-source life. As Ellison told the _Financial Times_ back in 2006: "If an open-source product gets good enough, we'll simply take it. So the great thing about open source is nobody owns it – a company like Oracle is free to take it for nothing, include it in our products and charge for support, and that's what we'll do.
+
+"So it is not disruptive at all – you have to find places to add value. Once open source gets good enough, competing with it would be insane... We don't have to fight open source, we have to exploit open source."
+
+"Exploit" sounds about right. While Oracle doesn't crack the top-10 corporate contributors to the Linux kernel, it does register a respectable number 12, which helps it influence the platform enough to feel comfortable building its IaaS offering on Linux (and Xen for virtualisation). Oracle has also managed to continue growing MySQL's clout in the industry while improving it as a product and business. As for Kubernetes, Oracle's decision to join the CNCF also came with P&L strings attached. "CNCF technologies such as Kubernetes, Prometheus, gRPC and OpenTracing are critical parts of both our own and our customers' development toolchains," [said Mark Cavage][3], vice president of software development at Oracle.
+
+One can argue that Oracle has figured out the exploitation angle reasonably well.
+
+This, however, refers to the right kind of exploitation, the kind that even free software activist Richard Stallman can love (or, at least, tolerate). But when it comes to government lobbying, Oracle looks a lot more like Mr Hyde than Dr Jekyll.
+
+### Lies, damned lies, and Oracle lobbying
+
+The current US president has many problems (OK, _many, many_ problems), but his decision to follow the Obama administration's support for IT modernisation is commendable. Most recently, the Trump White House asked for [feedback][4] on how best to continue improving government IT. Oracle's [response][5] is high comedy in many respects.
+
+As TechDirt's Mike Masnick [summarises][6], Oracle's "latest crusade is against open-source technology being used by the federal government – and against the government hiring people out of Silicon Valley to help create more modern systems. Instead, Oracle would apparently prefer the government just give it lots of money." Oracle is very good at making lots of money. As such, its request for even more isn't too surprising.
+
+What is surprising is the brazenness of its position. As Masnick opines: "The sheer contempt found in Oracle's submission on IT modernization is pretty stunning." Why? Because Oracle contradicts much that it publicly states in other forums about open source and innovation. More than this, Oracle contradicts much of what we now know is essential to competitive differentiation in an increasingly software and data-driven world.
+
+Take, for example, Oracle's contention that "significant IT development expertise is not... central to successful modernization efforts".
+
+What? In our "software is eating the world" existence Oracle clearly believes that CIOs are buyers, not doers: "The most important skill set of CIOs today is to critically compete and evaluate commercial alternatives to capture the benefits of innovation conducted at scale, and then to manage the implementation of those technologies efficiently."
+
+While there is some truth to Oracle's claim – every project shouldn't be a custom one-off that must be supported forever – it's crazy to think that a CIO – government or otherwise – is doing their job effectively by simply shovelling cash into vendors' bank accounts.
+
+Indeed, as Masnick points out: "If it weren't for Oracle's failures, there might not even be a USDS [the US Digital Service created in 2014 to modernise federal IT]. USDS really grew out of the emergency hiring of some top-notch internet engineers in response to the Healthcare.gov rollout debacle. And if you don't recall, a big part of that debacle was blamed on Oracle's technology."
+
+In short, [blindly giving money to Oracle][7] and other big vendors is the opposite of IT modernisation.
+
+In its letter to Liddell, Oracle proceeded to make the fantastic (by which I mean "silly and false") claim that "the fact is that the use of open-source software has been declining rapidly in the private sector". What?!? This is so incredibly untrue that Oracle should score points for being willing to say it out loud. Take a stroll through the most prominent software in big data (Hadoop, Spark, Kafka, etc.), mobile (Android), application development (Kubernetes, Docker), machine learning/AI (TensorFlow, MxNet), and compare it to Oracle's statement. One conclusion must be that Oracle believes its CIO audience is incredibly stupid.
+
+Oracle then tells a half-truth by declaring: "There is no math that can justify open source from a cost perspective." How so? Because "the cost of support plus the opportunity cost of forgoing features, functions, automation and security overwhelm any presumed cost savings." Which I guess is why Oracle doesn't use any open source like Linux, Kubernetes, etc. in its services.
+
+Oops.
+
+### The Vendor Formerly Known As Satan
+
+The thing is, Oracle doesn't need to do this and, for its own good, shouldn't do this. After all, we already know how this plays out. We need only look at what happened with Microsoft.
+
+Remember when Microsoft wanted us to "[get the facts][8]" about Linux? Now it's a big-time contributor to Linux. Remember when it told us open source was anti-American and a cancer? Now it aggressively contributes to a huge variety of open-source projects, some of them homegrown in Redmond, and tells the world that "Microsoft [loves][9] open source." Of course, Microsoft loves open source for the same reason any corporation does: it drives revenue as developers look to build applications filled with open-source components on Azure. There's nothing wrong with that.
+
+Would Microsoft prefer government IT to purchase SQL Server instead of open-source-licensed PostgreSQL? Sure. But look for a [single line][10] in its response to the Trump executive order that signals "open source is bad". You won't find it. Why? Because Microsoft understands that open source is a friend, not foe, and has learned how to monetise it.
+
+Microsoft, in short, is no longer conflicted about open source. It can compete at the product level while embracing open source at the project level, which helps fuel its overall product and business strategy. Oracle isn't there yet, and is still stuck where Microsoft was a decade ago.
+
+It's time to grow up, Oracle. For a company that builds great software and understands that it increasingly needs to depend on open source to build that software, it's disingenuous at best to lobby the US government to put the freeze on open source. Oracle needs to learn from Microsoft, stop worrying and love the open-source bomb. It was a key ingredient in Microsoft's resurgence. Maybe it could help Oracle get a cloud clue, too.
+
+--------------------------------------------------------------------------------
+
+via: https://www.theregister.co.uk/2017/10/12/oracle_must_grow_up_on_open_source/
+
+作者:[ Matt Asay ][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.theregister.co.uk/Author/2905
+[1]:https://www.theregister.co.uk/Author/2905
+[2]:https://forums.theregister.co.uk/forum/1/2017/10/12/oracle_must_grow_up_on_open_source/
+[3]:https://www.oracle.com/corporate/pressrelease/oracle-joins-cncf-091317.html
+[4]:https://www.whitehouse.gov/the-press-office/2017/05/11/presidential-executive-order-strengthening-cybersecurity-federal
+[5]:https://github.com/GSA/modernization/issues/41
+[6]:https://www.techdirt.com/articles/20170930/00522238319/oracle-tells-white-house-stop-hiring-silicon-valley-people-ditch-open-source.shtml
+[7]:http://www.nytimes.com/2013/12/01/us/politics/inside-the-race-to-rescue-a-health-site-and-obama.html?pagewanted=all
+[8]:http://www.zdnet.com/article/microsoft-kills-its-get-the-facts-anti-linux-site/
+[9]:https://channel9.msdn.com/Events/Ignite/2016/BRK2158
+[10]:https://github.com/GSA/modernization/issues/98
diff --git a/sources/tech/20171013 6 reasons open source is good for business.md b/sources/tech/20171013 6 reasons open source is good for business.md
new file mode 100644
index 0000000000..df33ca2f0d
--- /dev/null
+++ b/sources/tech/20171013 6 reasons open source is good for business.md
@@ -0,0 +1,79 @@
+6 reasons open source is good for business
+============================================================
+
+### Here's why businesses should choose the open source model.
+
+
+Image by : opensource.com
+
+At a fundamental level, open source solutions are better than proprietary ones. Want to know why? Here are six reasons why businesses and government organizations benefit from using open source technology.
+
+### 1\. Easier vendor vetting
+
+Before you invest engineering and financial resources in integrating a product into your infrastructure, you need to know you picked the right one. You want a product that is actively developed, one that brings regular security updates and bugfixes as well as innovations when your business needs them. This last point is more important than you might think: yes, a solution has to fit your requirements. But requirements change as the market matures and your business evolves. If the product doesn't change with them, you have a costly migration ahead.
+
+How do you know you're not putting your time and money into a product that is dying? In open source, you don't have to take a vendor at its word. You can compare vendors by looking at the [development velocity and health of the community][3] that's developing it. A more active, diverse, and healthy community will result in a better product one or two years down the line—an important thing to consider. Of course, as this [blog about enterprise open source][4] points out, the vendor must be capable of handling the instability that comes from innovation within the development project. Look for a vendor with a long support cycle to avoid that upgrade mill.
+
+### 2\. Longevity from independence
+
+Forbes notes that [90% of all startups fail][5] and less than half of small and midsize businesses survive beyond five years. Whenever you have to migrate to a new vendor, you incur huge costs, so it's best to avoid products that only one vendor can sustain.
+
+Open source enables communities to build software collaboratively. For example, OpenStack is [built by dozens of companies and individual volunteers][6], providing customers certainty that, no matter what happens to any individual vendor, there will always be a vendor available to provide support. With open source, a business makes a long-term investment in the development team's efforts to implement the product. Access to the source code ensures that you will always be able to hire someone from the pool of contributors to keep your deployment alive as long as you need it. Of course, without a big, active community there are few contributors to hire from, so the number of people actively contributing is important.
+
+### 3\. Security
+
+Security is a complicated thing, which is why open development is a key factor and a precondition for creating secure solutions. And security is getting more important every day. When development happens in the open, you can directly verify if a vendor is actively pursuing security and watch how it treats security issues. The ability to study the source and perform independent code audits makes it possible to find and fix security issues early. Some vendors offer [bug bounties][7] of thousands of dollars as extra incentive for the community to uncover security flaws and to show confidence in their products.
+
+Beyond code, open development also means open processes, so you can check and see whether a vendor follows baseline industry-standard development processes recommended by ISO27001, [Cloud Security Principles][8] and others. Of course, an external review by a trusted party, like we at Nextcloud did with [the NCC Group][9], offers additional assurance.
+
+### 4\. More customer focus
+
+Because users and customers can directly see and get involved in development, open source projects are typically more aligned with their users' needs than closed source software, which often focuses on ticking checkboxes for the marketing team. You will also notice that open source projects tend to develop in a "wider" way. Whereas a commercial vendor might focus on one specific thing, a community has many "irons in the fire" and is working on a wide range of features, all of interest to an individual or small group of contributing companies or individuals. This leads to fewer easily marketable releases, as it isn't all about one thing, rather a mix-and-match of various improvements. But it creates a far more valuable product for the users.
+
+### 5\. Better support
+
+A proprietary vendor is often the one and only party who can help you if there are problems. If they don't offer support the way you need it or charge a huge premium for adjustments your business needs, tough luck. Support for proprietary software is a typical "[lemon market][10]." With open source, the vendor either provides great support or others will fill the gap—it's the free market at its finest, ensuring you get the very best support possible.
+
+### 6\. Better licensing
+
+Typical software licenses are [full of nasty clauses][11], usually topped off with forced arbitrage so you won't even have a chance to sue if the vendor misbehaves. Part of the problem is that you merely license a right to use the software, often entirely at the vendor's discretion. You get no ownership, nor any rights if the software doesn't work or stops working, or if the vendor demands more payments. Open source licenses like the GPL are specifically designed to protect the customer rather than the vendor, ensuring you get to use the software however you need and without arbitrary limitations, for as long as you like.
+
+Thanks to their wide usage, the implications of the GPL and its derivative licenses are widely understood. For example, you can be assured that the license allows your existing (open or closed) infrastructure to connect with it through well-defined APIs, has no restrictions on time or number of users, and won't force you to open configurations or intellectual property (e.g., company logos).
+
+This also makes compliance easier; with proprietary software, you have harsh compliance clauses with large fines. Worse is what happens with some open core products that ship as a mix of GPL and proprietary software; these [can breach a license][12] and put customers at risk. And, as Gartner points out, an open core model means you get [none of the benefits of open source][13]. A pure open source licensed product avoids all these issues. Instead, you have just one compliance rule: If you make modifications to the code (not configuration, logos, or anything like that), you have to share them with those you distribute the software to _if_ they ask.
+
+Clearly open sou
+
+--------------------------------------------------------------------------------
+
+作者简介:
+
+Jos Poortvliet - People person, technology enthusiast and all-things-open evangelist. Head of marketing at Nextcloud, previously community manager at ownCloud and SUSE and a long time KDE marketing veteran, loves biking through Berlin and cooking for friends and family. Find my [personal blog here][16].
+
+-----------------
+
+via: https://opensource.com/article/17/10/6-reasons-choose-open-source-software
+
+作者:[Jos Poortvliet Feed ][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/jospoortvliet
+[1]:https://opensource.com/article/17/10/6-reasons-choose-open-source-software?rate=um7KfpRlV5lROQDtqJVlU4y8lBa9rsZ0-yr2aUd8fXY
+[2]:https://opensource.com/user/27446/feed
+[3]:https://nextcloud.com/blog/nextcloud-the-most-active-open-source-file-sync-and-share-project/
+[4]:http://www.redhat-cloudstrategy.com/open-source-for-business-people/
+[5]:http://www.forbes.com/sites/neilpatel/2015/01/16/90-of-startups-will-fail-heres-what-you-need-to-know-about-the-10/
+[6]:http://stackalytics.com/
+[7]:https://hackerone.com/nextcloud
+[8]:https://www.ncsc.gov.uk/guidance/implementing-cloud-security-principles
+[9]:https://nextcloud.com/secure
+[10]:https://en.wikipedia.org/wiki/The_Market_for_Lemons
+[11]:http://boingboing.net/2016/11/01/why-are-license-agreements.html
+[12]:https://www.gnu.org/licenses/gpl-faq.en.html#GPLPluginsInNF
+[13]:http://blogs.gartner.com/brian_prentice/2010/03/31/open-core-the-emperors-new-clothes/
+[14]:https://opensource.com/users/jospoortvliet
+[15]:https://opensource.com/users/jospoortvliet
+[16]:http://blog.jospoortvliet.com/
diff --git a/sources/tech/20171013 NixOS Linux Lets You Configure Your OS Before Installing.md b/sources/tech/20171013 NixOS Linux Lets You Configure Your OS Before Installing.md
new file mode 100644
index 0000000000..84e476823c
--- /dev/null
+++ b/sources/tech/20171013 NixOS Linux Lets You Configure Your OS Before Installing.md
@@ -0,0 +1,166 @@
+Martin translating
+
+NixOS Linux Lets You Configure Your OS Before Installing
+============================================================
+
+
+Configuration is key to a successful installation of NixOS.[Creative Commons Zero][4]Pixabay
+
+I’ve been using Linux for a very long time. Over the years, I’ve been incredibly happy with how the open source landscape has evolved. One particular area that has come quite a long way is the installation of various distributions. Once upon a time, installing Linux was a task best left to those who had considerable tech skills. Now, if you can install an app, you can install Linux. It’s that simple. And that, my friends, is a very good thing—especially when it comes to drawing in new users. The fact that you can install the entire Linux operating system faster than a Windows user can run an update says quite a bit.
+
+But every so often, I like to see something different—something that might remind me from where I came. That’s exactly what happened when I came into [NixOS][9]. To be quite honest, I had assumed this would be just another Linux distribution that offered the standard features, with the KDE Plasma 5 interface.
+
+Boy was I wrong.
+
+After [downloading the ISO image][10], I figured up [VirtualBox][11] and created a new virtual machine, using the downloaded image. Once the VM booted, I found myself at a Bash login instructing me that the root account had an empty password and how to start a GUI display manager (Figure 1).
+
+### [nixos_1.jpg][5]
+
+
+
+Figure 1: The first contact with NIXOS might be a bit jarring for some.[Used with permission][1]
+
+“Okay,” I thought, “let’s fire this up and see what happens.”
+
+Once the GUI was up and running (KDE Plasma 5), I didn’t see the usual “Install” button. Turns out, NixOS is one of those fascinating distributions that has you configure your OS before you install it. Let’s take a look at how that is done.
+
+### Pre-install configuration
+
+The first thing you must do is create a partition. Since the NixOS installer doesn’t include a partition tool, you can fire up the included GParted application (Figure 2) and create an EXT4 partition.
+
+### [nixos_2.jpg][6]
+
+
+
+Figure 2: Partitioning the drive before installation.[Used with permission][2]
+
+With your partition created, mount it with the command _mount /dev/sdX /mnt _ (Where sdX is the location of your newly created partition).
+
+You now must generate a configuration file. To do this, issue the command:
+
+```
+nixos-generate-config --root /mnt
+```
+
+The above command will create two files (found in the _/mnt/etc/nixos_ directory):
+
+* configuration.nix — The default configuration file.
+
+* hardware-configuration.nix — The hardware configuration (this is not to be edited).
+
+Issue the command _nano /mnt/etc/nixos/configuration.nix_ . Within this file, we need to take care of a few edits. The first change is to set the option for the boot loader. Look for the line:
+
+```
+# boot.loader.grub.device = “/dev/sda”; # or “nodev” for efi only
+```
+
+Remove the # sign at the beginning of the line to uncomment this option (making sure /dev/sda is the name of your newly created partition).
+
+Within the configuration file, you can also set your timezone and add packages to be installed. You will see a commented out sample for package installation that looks like:
+
+```
+# List packages installed in system profile. To search by name, run:
+
+# nix-env -aqP | grep wget
+
+# environment.systemPackages = with pkgs; [
+
+# wget vim
+
+# ];
+```
+
+If you want to add packages, during installation, comment out that section and add the packages you like. Say, for instance, you want to add LibreOffice into the mix. You could uncomment the above section to reflect:
+
+```
+# List packages installed in system profile. To search by name, run:
+
+nix-env -aqP | grep wget
+
+environment.systemPackages = with pkgs; [
+
+libreoffice wget vim
+
+];
+```
+
+You can find the exact name of the package by issuing the command _nix-env -aqP | grep PACKAGENAME _ (where PACKAGENAME is the name of the package you’re looking for). If you don’t want to issue the command, you can always search the [NixOS packages database.][12]
+
+After you’ve added all the necessary packages, there is one more thing you must do (if you want to be able to log into the desktop. I will assume you’re going to stick with the KDE Plasma 5 desktop. Go to the bottom of the configuration file and add the following before the final } bracket:
+
+```
+services.xserver = {
+
+ enable = true;
+
+ displayManager.sddm.enable = true;
+
+ desktopManager.plasma5.enable = true;
+
+};
+```
+
+You can find out more options for the configuration file, within the [NixOS official documentation][13]. Save and close the configuration file.
+
+### Installation
+
+Once you have your configuration exactly how you like it, issue the command (as the root user) nixos-install. Depending upon how many packages you’ve included for installation, the time it takes to complete this task will vary. When it does complete, you can then issue the command reboot and you will (when the reboot completes) be greeted by the KDE Plasma 5 login manager (Figure 3).
+
+### [nixos_3.jpg][7]
+
+
+
+Figure 3: The KDE Plasma 5 login manager.[Used with permission][3]
+
+### Post-install
+
+One of the first two things you’ll need to do is give the root user a password (issue the command _passwd_ to change the default) and add a standard user. This is done as you would with any Linux distribution. Log in as the root user and then, at a terminal window, issue the command:
+
+```
+useradd -m USER
+```
+
+Where USER is the name of the user you want to add. Next give the user a password with the command:
+
+```
+passwd USER
+```
+
+Where USER is the name of the user just added. You will be prompted to type and verify the new password. You can then log into NixOS as that standard user.
+
+Once you have NixOS installed and running, you can then add new packages to the system, but not via the standard means. If you find you need to install something new, you have to go back to the configuration file (which is now located in _/etc/nixos/_ ), add the packages in the same location you did prior to installation, and then issue the command (as root):
+
+```
+nixos-rebuild switch
+```
+
+Once the command completes, you can then use the newly installed packages.
+
+### Enjoy NixOS
+
+At this point, NixOS is up and running, with all the software you need and the KDE Plasma 5 desktop interface. Not only have you installed Linux, but you’ve installed a Linux distribution customized to meet your exact needs. Enjoy the experience and enjoy NixOS.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/intro-to-linux/2017/10/nixos-linux-lets-you-configure-your-os-installing
+
+作者:[JACK WALLEN][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/jlwallen
+[1]:https://www.linux.com/licenses/category/used-permission
+[2]:https://www.linux.com/licenses/category/used-permission
+[3]:https://www.linux.com/licenses/category/used-permission
+[4]:https://www.linux.com/licenses/category/creative-commons-zero
+[5]:https://www.linux.com/files/images/nixos1jpg
+[6]:https://www.linux.com/files/images/nixos2jpg
+[7]:https://www.linux.com/files/images/nixos3jpg
+[8]:https://www.linux.com/files/images/configurationjpg
+[9]:https://nixos.org/
+[10]:https://nixos.org/nixos/download.html
+[11]:https://www.virtualbox.org/wiki/Downloads
+[12]:https://nixos.org/nixos/packages.html
+[13]:https://nixos.org/nixos/manual/index.html#ch-configuration
diff --git a/sources/tech/20171013 What is Grafeas Better auditing for containers.md b/sources/tech/20171013 What is Grafeas Better auditing for containers.md
new file mode 100644
index 0000000000..f99718a1fb
--- /dev/null
+++ b/sources/tech/20171013 What is Grafeas Better auditing for containers.md
@@ -0,0 +1,62 @@
+translating---geekpi
+
+What is Grafeas? Better auditing for containers
+============================================================
+
+### Google's Grafeas provides a common API for metadata about containers, from image and build details to security vulnerabilities
+
+
+Thinkstock
+
+The software we run has never been more difficult to vouchsafe than it is today. It is scattered between local deployments and cloud services, built with open source components that aren’t always a known quantity, and delivered on a fast-moving schedule, making it a challenge to guarantee safety or quality.
+
+The end result is software that is hard to audit, reason about, secure, and manage. It is difficult not just to know what a VM or container was built with, but what has been added or removed or changed and by whom. [Grafeas][5], originally devised by Google, is intended to make these questions easier to answer.
+
+
+### What is Grafeas?
+
+Grafeas is an open source project that defines a metadata API for software components. It is meant to provide a uniform metadata schema that allows VMs, containers, JAR files, and other software artifacts to describe themselves to the environments they run in and to the users that manage them. The goal is to allow processes like auditing the software used in a given environment, and auditing the changes made to that software, to be done in a consistent and reliable way.
+
+Grafeas provides APIs for two kinds of metadata, notes and occurrences:
+
+
+* Notesare details about some aspect of the software artifact in question. This can be a description of a known software vulnerability, details about how the software was built (the builder version, its checksum, etc.), a history of its deployment, and so on.
+
+* Occurrences are instances of notes, with details about where and how they were created. Details of a known software vulnerability, for instance, could have occurrence information describing which vulnerability scanner detected it, when it was detected, and whether or not the vulnerability has been addressed.
+
+Both notes and occurrences are stored in a repository. Each note and occurrence is tracked using an identifier that distinguishes it and makes it unique.
+
+The Grafeas spec includes several basic schemas for types of notes. The package vulnerability schema, for instance, describes how to store note information for a CVE or vulnerability description. Right now there is no formal process for accepting new schema types, but [plans are on the table][6] for creating such a process.
+
+### Grafeas clients and third-party support
+
+Right now, Grafeas exists mainly as a spec and a reference implementation, [available on GitHub][7]. Clients for [Go][8], [Python][9], and [Java ][10]are all available, [generated by Swagger][11], so clients for other languages shouldn’t be hard to produce.
+
+One key way Google plans to allow Grafeas to be widely used is through Kubernetes. A policy engine for Kubernetes, called Kritis, allows actions to be taken on containers based on their Grafeas metadata.
+
+Several companies in addition to Google have announced plans for adding Grafeas support to existing products. CoreOS, for instance, is looking at how Grafeas can be integrated with Tectonic, and both [Red Hat][12] and [IBM][13] are planning to add Grafeas integrations to their container products and services.
+
+--------------------------------------------------------------------------------
+
+via: https://www.infoworld.com/article/3230462/security/what-is-grafeas-better-auditing-for-containers.html
+
+作者:[Serdar Yegulalp ][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.infoworld.com/author/Serdar-Yegulalp/
+[1]:https://www.infoworld.com/author/Serdar-Yegulalp/
+[2]:https://www.infoworld.com/author/Serdar-Yegulalp/
+[3]:https://www.infoworld.com/article/3207686/cloud-computing/how-to-get-started-with-kubernetes.html#tk.ifw-infsb
+[4]:https://www.infoworld.com/newsletters/signup.html#tk.ifw-infsb
+[5]:http://grafeas.io/
+[6]:https://github.com/Grafeas/Grafeas/issues/38
+[7]:https://github.com/grafeas/grafeas
+[8]:https://github.com/Grafeas/client-go
+[9]:https://github.com/Grafeas/client-python
+[10]:https://github.com/Grafeas/client-java
+[11]:https://www.infoworld.com/article/2902750/application-development/manage-apis-with-swagger.html
+[12]:https://www.redhat.com/en/blog/red-hat-google-cloud-and-other-industry-leaders-join-together-standardize-kubernetes-service-component-auditing-and-policy-enforcement
+[13]:https://developer.ibm.com/dwblog/2017/grafeas/
diff --git a/translated/talk/20170310 Why DevOps is the end of security as we know it.md b/translated/talk/20170310 Why DevOps is the end of security as we know it.md
deleted file mode 100644
index 2044247476..0000000000
--- a/translated/talk/20170310 Why DevOps is the end of security as we know it.md
+++ /dev/null
@@ -1,67 +0,0 @@
-# 为什么 DevOps 是我们所知道的安全的终结
-
-
-
-安全可能是一个艰难的销售。在企业管理者迫使开发团队尽快发布程序的环境下,很难说服他们花费有限的周期来修补安全漏洞。但是鉴于所有网络攻击中有 84% 发生在应用层,组织无法承担其开发团队不包括安全性带来的后果。
-
-DevOps 的崛起为许多安全领导者带来了困境。Sonatype 的前 CTO [Josh Corman][2] 说:“这是对安全的威胁,但这是安全变得更好的机会。” Corman 是一个坚定的[整合安全和 DevOps 实践来创建 “坚固的 DevOps”][3]的倡导者。_Business Insights_ 与 Corman 谈论了安全和 DevOps 共同的价值,以及这些共同价值如何帮助组织受到更少受到中断和攻击的影响。
-
-DevOps 中真正的安全状态是什么?[获取报告][1]
-
-### 安全和 DevOps 实践如何互惠互利?
-
-** Josh Corman:** 一个主要的例子是 DevOps 团队对所有可测量的东西进行检测的倾向。安全性一直在寻找更多的情报和遥测。你可以采纳许多 DevOps 团队正在测量的内容, 并将这些信息输入到你的日志管理或 SIEM (安全信息和事件管理系统)。
-
-一个 OODA 循环(观察、定向、决定、行为)的前提是有足够普遍的眼睛和耳朵, 以注意到窃窃私语和回声。DevOps 为你提供无处不在的仪器。
-
-### 他们有分享的其他文化态度吗?
-
-** JC:** “严肃对待你的代码”是一个共同的价值。例如,由 Netflix 编写的软件工具 Chaos Monkey 是 DevOps 团队的分水岭。它是为了测试亚马逊网络服务的弹性和可恢复性,Chaos Monkey 使得 Netflix 团队更加强大,更容易为中断做好准备。
-
-所以现在有个想法是我们的系统需要测试,因此,James Wickett 和我和其他人决定做一个邪恶的、武装的 Chaos Monkey,这就是 GAUNTLT 项目的来由。它基本上是一堆安全测试, 可以在 DevOps 周期和 DevOps 工具链中使用。它也有非常 DevOps 友好的API。
-
-### 企业安全和 DevOps 价值在哪里相交?
-
-** JC:** 两个团队都认为复杂性是一切事情的敌人。例如,[安全人员和坚固 DevOps 人员][4]实际上可以说:“看,我们在我们的项目中使用了 11 个日志框架 - 也许我们不需要那么多,也许攻击面和复杂性可能会让我们受到伤害或者损害产品的质量或可用性。”
-
-复杂性往往是许多事情的敌人。通常情况下,你不会很难说服 DevOps 团队在架构层面使用更好的建筑材料:使用最新的,最不易受攻击的版本,并使用较少的。
-
-### “更好的建筑材料”是什么意思?
-
-** JC:** 我是世界上最大的开源仓库的保管人,所以我能看到他们在使用哪些版本,里面有哪些漏洞,何时不为漏洞进行修复, 以及多久。例如,某些日志记录框架不会修复任何错误。其中一些在 90 天内修复了大部分的安全漏洞。人们越来越多地遭到破坏,因为他们使用了一个没有安全的框架。
-
-除此之外,即使你不知道日志框架的质量,拥有 11 个不同的框架会变得非常笨重、出现 bug,还有额外的工作和复杂性。你暴露在漏洞中的风险要大得多。你想花时间在修复大量的缺陷上,还是在制造下一个大的破坏性的事情上?
-
-[坚固的 DevOps 的关键是软件供应链管理][5],其中包含三个原则:使用更少和更好的供应商、使用这些供应商的最高质量的部分、并跟踪这些部分,以便在发生错误时,你可以有一个及时和敏捷的响应。
-
-### 所以改变管理也很重要。
-
-** JC:** 是的,这是另一个共同的价值。我发现,当一家公司想要执行诸如异常检测或净流量分析等安全测试时,他们需要知道“正常”的样子。让人们失误的许多基本事情与仓库和补丁管理有关。
-
-我在 _Verizon 数据泄露调查报告中看到_,去年成功利用 97% 的漏洞追踪后只有 10 个 CVE(常见漏洞和风险),而这 10 个已经被修复了十多年。所以,我们羞于谈论高级间谍活动。我们没有做基本的补丁。现在,我不是说如果你修复这 10 个CVE,那么你就没有被利用,而这占据了人们实际失误的最大份额。
-
-[DevOps 自动化工具][6]的好处是它们已经成为一个意外的变更管理数据库。这真实反应了谁在哪里什么时候做了更改。这是一个巨大的胜利,因为我们经常对安全性有最大影响的因素无法控制。你承受了 CIO 和 CTO 做出的选择的后果。随着 IT 通过自动化变得更加严格和可重复,你可以减少人为错误的机会,并可在哪里发生变化更加可追溯。
-
-### 你说什么是最重要的共同价值?
-
-** JC:** DevOps 涉及过程和工具链,但我认为定义属性是文化,特别是移情。 DevOps 有用是因为开发人员和运维团队更好地了解彼此,并能做出更明智的决策。不是在解决孤岛中的问题,而是为了活动流程和目标解决。如果你向 DevOps 的团队展示安全如何能使他们变得更好,那么作为回馈他们往往会问:“那么, 我们是否有任何选择让你的生活更轻松?”因为他们通常不知道他们做的 X、Y 或 Z 的选择使它无法包含安全性。
-
-对于安全团队,驱动价值的方法之一是在寻求帮助之前变得更有所帮助,在我们告诉 DevOps 团队要做什么之前提供定性和定量的价值。你必须获得 DevOps 团队的信任,并获得发挥的权利,然后才能得到回报。它通常比你想象的快很多。
-
---------------------------------------------------------------------------------
-
-via: https://techbeacon.com/why-devops-end-security-we-know-it
-
-作者:[Mike Barton][a]
-译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://twitter.com/intent/follow?original_referer=https%3A%2F%2Ftechbeacon.com%2Fwhy-devops-end-security-we-know-it%3Fimm_mid%3D0ee8c5%26cmp%3Dem-webops-na-na-newsltr_20170310&ref_src=twsrc%5Etfw®ion=follow_link&screen_name=mikebarton&tw_p=followbutton
-[1]:https://techbeacon.com/resources/application-security-devops-true-state?utm_source=tb&utm_medium=article&utm_campaign=inline-cta
-[2]:https://twitter.com/joshcorman
-[3]:https://techbeacon.com/want-rugged-devops-team-your-release-security-engineers
-[4]:https://techbeacon.com/rugged-devops-rsa-6-takeaways-security-ops-pros
-[5]:https://techbeacon.com/josh-corman-security-devops-how-shared-team-values-can-reduce-threats
-[6]:https://techbeacon.com/devops-automation-best-practices-how-much-too-much
diff --git a/translated/tech/20160511 LEDE and OpenWrt.md b/translated/tech/20160511 LEDE and OpenWrt.md
deleted file mode 100644
index 17d22d0eb8..0000000000
--- a/translated/tech/20160511 LEDE and OpenWrt.md
+++ /dev/null
@@ -1,95 +0,0 @@
-LEDE 和 OpenWrt
-===================
-
- [OpenWrt][1] 项目可能是最广为人知的 Linux 发行版,对于家用 WiFi 路由器和接入点; 12 年多以前,它产自现在有名的 Linksys WRT54G 路由器的源代码。五月初,OpenWrt 用户社区陷入一片巨大的混乱中,当一群 OpenWrt 代码开发者 [宣布][2] 他们将开始着手 OpenWrt 的一个副产品 (或,可能,一个分支)叫 [Linux 嵌入开发环境][3] (LEDE)时。为什么产生分裂对公众来说并不明朗,而且 LEDE 宣言惊到了一些其他 OpenWrt 开发者也暗示这团队的内部矛盾。
-
- LEDE 宣言被 Jo-Philipp Wich 于五月三日发往所有 OpenWrt 开发者列表和新 LEDE 开发者列表。它描述 LEDE 为"OpenWrt 社区的一次重启" 和 "OpenWrt 项目的一个副产品" 希望产生一个 Linux 嵌入式开发社区 "注重透明性、合作和权利分散。"
-
-给出的重启的原因是 OpenWrt 遭受着长期以来存在且不能从内部解决的问题——换句话说,关于内部处理方式和政策。例如,宣言称,开发者的数目在不断减少,却没有接纳新开发者的方式(而且貌似没有授权委托访问给新开发者的方法)。项目架构不可靠(例如,这么多年来服务器挂掉在这个项目中也引发了相当多的矛盾),宣言说到,但是内部不合和单点错误阻止了修复它。内部和从这个项目到外面世界也存在着"交流、透明度和合作"的普遍缺失。最后,一些技术缺陷被引用:不充分的测试、缺乏常规维护,和窘迫的稳固性与文档。
-
-该宣言继续描述 LEDE 重启将解决这些问题。所有交流频道都会打开供公众使用,决策将在项目范围内投票决出,合并政策将放宽等等。更详细的说明可以在 LEDE 站点的 [rules][4] 页找到。其他特别之处中,它说将贡献者将只有一个阶级(也就是,没有“代码开发者”这样拥有额外权利的群体),简单的少数服从多数投票作出决定,并且任何被这个项目管理的架构必须有三个以上管理员账户。在 LEDE 邮件列表, Hauke Mehrtens [补充][5] 到项目将会努力修补发送上游消息——过去 OpenWrt 被批判的一点,尤其是有关内核。
-
-除了 Wich,这个宣言被 OpenWrt 贡献者 John Crispin、 Daniel Golle、 Felix Fietkau、 Mehrtens、 Matthias Schiffer 和 Steven Barth 共同创作。以给其他有兴趣参与的人访问 LEDE 站点的邀请为结尾。
-
-#### 回应和问题
-
-有人可能会猜想 LEDE 组织者预期他们的宣言会有或积极或消极的反响。毕竟,细读宣言中批判 OpenWrt 项目暗示了有一些 OpenWrt 项目成员 LEDE 阵营发现难以共事(“单点错误” 或 “内部不和”阻止了架构修复,例如)
-
-并且,确实,有很多消极回应。创立者之一 Mike Baker [回应][6] 了一些警告,反驳所有 LEDE 宣言中的结论并称“短语像‘重启’都是含糊不清且具有误导性的而且 LEDE 项目定义它的真实本质失败了。”与此同时,有人关闭了那些在 LEDE 上署名的开发者在 @openwrt.org 的邮件入口;当 Fietkau [提出反对][7], Baker [回复][8]账户“暂时停用”因为“还不确定 LEDE 代表 OpenWrt。” Imre Kaloz, 另一个 OpenWrt 核心成员,[写][9]到“ LEDE 团队生出了大多数 [破] 事儿”在 OpenWrt 里这就是现在所抱怨的。
-
-但是大多数 OpenWrt 列表的回应对该宣言表示疑惑。列表成员不明确 LEDE 团队是否将为 OpenWrt [继续贡献][10],或导致了这个分支的机构的[确切本质][11]和内部问题是什么。 Baker的第一反应是后悔在宣言中引用的那些问题缺乏公开讨论:“我们意识到当前的 OpenWrt 项目遭受着许多的问题,”但“我们希望有机会去讨论并尝试着解决”它们。 Baker 作出结论:
-
-我们强调我们确实希望有一个公开的讨论和解决即将到来的事情。我们的目标是与所有能够且希望对 OpenWrt 作出贡献的参与者共事,包括 LEDE 团队。
-
-除了有关新项目的初心的问题之外,一些列表贡献者提出 LEDE 是否与 OpenWrt 有相同的使用场景定位,给新项目取一个听起来更一般的名字的疑惑。此外,许多人,像 Roman Yeryomin,[表示疑惑][12]为什么这些问题需要 LEDE 团队的离开(来解决),特别是,与此同时, LEDE 团队由大部分活跃核心 OpenWrt 开发者构成。一些列表贡献者,像 Michael Richardson,甚至不清楚[谁还会开发][13] OpenWrt。
-
-#### 澄清
-
-LEDE 团队尝试着深入阐释他们的境况。在 Fietkau 给 Baker 的回复中,他说在 OpenWrt 内部关于有目的地改变的讨论会很快变得“有毒,”因此导致没有进展。而且:
-
-这些讨论的要点在于那些掌握着框架关键部分的人精力有限却拒绝他人的加入和帮助,甚至是面对无法及时解决的重要问题时。
-
-这种像单点错误一样的事已经持续了很多年了,没有任何有意义的进展来解决它。
-
- Wich 和 Fietkau 都没有明显指出特别的个体,虽然其他在列表的人可能会想这个基础建设和内部讨论——在 OpenWrt 找出问题针对某些人。 Daniel Dickinson [陈述][14]到:
-
-我的印象是 Kaloz (至少) 以基础建设为胁来保持控制,并且基本问题是 OpenWrt 是*不*民主的,而且忽视那些真正在 openwrt 工作的人想要的是什么无视他们的愿望,因为他/他们把握着要害。
-
-另一方面, Luka Perkov [指出][15] 很多 OpemWrt 开发者想从 Subversion 转移到 Git,但 Fietkau 负责块修改。
-
-清晰的是 OpenWrt 的管理结构并非如预期应用,结果导致,个人冲突爆发而且能够自立门户或者块有预谋地变更,因为没有规定好的程序。明显,这不是一个能长期持续的模式。
-
-五月6日, Crispin 以新思路[写给][16] OpenWrt 列表成员,尝试着重构 LEDE 项目宣言。这不是,他说,意味着“敌对或分裂”行为,只是与性能不良的 OpenWrt 结构做个清晰的划分并以新的方式开始。问题在于“不要局限于一次单独的时间,一个人或者一次口水战,”他说。“我们想与过去自己造成的错误和作出过很多次的错误管理决定分开” Crispin 也承认宣言没有把握好,说 LEDE 团队 “弄糟了开始的政纲。”
-
-Crispin 的邮件似乎没能使 Kaloz 满意, 她[坚持认为][17] Crispin (作为发行经理)和 Fietkau (作为领头开发者)可以轻易地在 OpenWrt 内部作出想要的改变。 但是讨论的线索后来变得沉寂;之后 LEDE 或者 OpenWrt 哪边会发生什么还有待观察。
-
-#### 目的
-
-对于那些仍在寻找 LEDE 认为有问题的事情更多的细节的 OpenWrt 成员,有更多的信息来源可以为这个问题提供线索。在公众宣言之前,LEDE 组织花了几周谈论他们的计划,会议的 IRC 日志现已[推出][18]。特别有趣的是3月30日[会议][19],包含了这个项目目标的细节讨论。
-
-有些关于 OpenWrt 的架构特定的抱怨包含在内,像项目的 Trac issue 追踪者的缺点。它充斥着不完整的漏洞报告和“我也是”评论, Wich 说,结果,几乎没有贡献者使用它。此外,人们对这件事感到困惑,漏洞在 Github 上也正被追踪,使得问题应该在哪里被讨论不明了。
-
-IRC 讨论也定下了开发流程本身。LEDE 团队想作出些改变,以合并到主干的 staging trees 的使用为开端,与 OpenWrt 使用的 commit-directly-to-master 方式不同。项目也将提供基于时间的发行版并鼓励用户测试通过只发行已被成功测试的二进制模块,由社区而不是核心开发者,在实际的硬件上。
-
-最后,IRC 讨论确定了 LEDE 团队的目的不是用它的宣言吓唬 OpenWrt 。 Crispin 提到 LEDE 首先是“半公开的”并渐渐做得更公开。 Wich 解释说他希望 LEDE 是“中立的、专业的并打开大门欢迎 OpenWrt 以便将来的合并”不幸的是,前期发起并不是做得很好。
-
-在邮件中, Fietkau 补充道核心 OpenWrt 开发者确实在任务中遇到了像补丁复审和维护这些让他们完成不了其他工作——比如配置下载镜像和改良架构系统的瓶颈。在 LEDE 宣言之后短短几天内,他说,团队成功解决了镜像和建设系统任务,而这些已被搁置多年。
-
-很多我们在 LEDE 所做是基于移动到 Github 分散包的开发和放开包应如何被维护的控制的经验。这样最终有效减少了我们的工作量而且我们有了很多更活跃的开发者。
-
-我们真的希望为核心开发做一些类似的事,但是根据我们想作出更大改变的经验,我们觉得在 OpenWrt 项目内做不到。
-
-修复架构也将收获其他好处,他说,就比如为管理用于同意发行的密码。团队正在考虑附加一些没有上游补丁的情况,像需要补丁的描述和为什么没有发送到上游的解释。他也提到很多留下的 OpenWrt 开发者表示有兴趣加入 LEDE,相关当事人正试图弄清楚他们是否会重新合并项目。
-
-有人希望 LEDE 更为干脆的管理模式和更为透明的分工会在 OpenWrt 困扰的方面取得成功。解决最初的宣言中诟病的沟通方面的问题会是最大的障碍。如果那个过程处理得好,那么,未来 LEDE 和 OpenWrt 可能找到共同之处并协作。否则,之后两个团队可能一起被逼到拥有比以前更少资源,这是开发者或用户不想看到的。
-
---------------------------------------------------------------------------------
-
-via: https://lwn.net/Articles/686767/
-
-作者:[Nathan Willis ][a]
-译者:[XYenChi](https://github.com/XYenChi)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://lwn.net/Articles/686767/
-[1]:https://openwrt.org/
-[2]:https://lwn.net/Articles/686180/
-[3]:https://www.lede-project.org/
-[4]:https://www.lede-project.org/rules.html
-[5]:http://lists.infradead.org/pipermail/lede-dev/2016-May/000080.html
-[6]:https://lwn.net/Articles/686988/
-[7]:https://lwn.net/Articles/686989/
-[8]:https://lwn.net/Articles/686990/
-[9]:https://lwn.net/Articles/686991/
-[10]:https://lwn.net/Articles/686995/
-[11]:https://lwn.net/Articles/686996/
-[12]:https://lwn.net/Articles/686992/
-[13]:https://lwn.net/Articles/686993/
-[14]:https://lwn.net/Articles/686998/
-[15]:https://lwn.net/Articles/687001/
-[16]:https://lwn.net/Articles/687003/
-[17]:https://lwn.net/Articles/687004/
-[18]:http://meetings.lede-project.org/lede-adm/2016/?C=M;O=A
-[19]:http://meetings.lede-project.org/lede-adm/2016/lede-adm.2016-03-30-11.05.log.html
diff --git a/translated/tech/20170617 What all you need to know about HTML5.md b/translated/tech/20170617 What all you need to know about HTML5.md
deleted file mode 100644
index ccb3d8af14..0000000000
--- a/translated/tech/20170617 What all you need to know about HTML5.md
+++ /dev/null
@@ -1,272 +0,0 @@
-你需要了解的关于 HTML5 的所有信息
-============================================================
-
-
- __
-
- _HTML5 是 HTML 的第五版且是当前的版本,它是用于在万维网上构建和呈现内容的标记语言。本文将帮助读者了解它。_
-
-HTML5 通过 W3C 和 Web 超文本应用技术工作组之间的合作发展起来。它是一个更高版本的 HTML,它的许多新元素使你的页面更加语义化和动态。它是为所有人提供更好的 Web 体验而开发的。HTML5 提供了很多的功能,使 Web 更加动态和交互。
-
-HTML5 的新功能是:
-
-* 新标签,如
和
-
-* 用于 2D 绘图的