mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-31 23:30:11 +08:00
Merge pull request #2 from LCTT/master
This commit is contained in:
commit
dd830d5a0a
95
published/20160511 LEDE and OpenWrt.md
Normal file
95
published/20160511 LEDE and OpenWrt.md
Normal file
@ -0,0 +1,95 @@
|
||||
LEDE 和 OpenWrt 分裂之争
|
||||
===================
|
||||
|
||||
对于家用 WiFi 路由器和接入点来说,[OpenWrt][1] 项目可能是最广为人知的 Linux 发行版;在 12 年以前,它产自现在有名的 Linksys WRT54G 路由器的源代码。(2016 年)五月初,当一群 OpenWrt 核心开发者 [宣布][2] 他们将开始着手 OpenWrt 的一个副产品 (或者,可能算一个分支)叫 [Linux 嵌入开发环境][3] (LEDE)时,OpenWrt 用户社区陷入一片巨大的混乱中。为什么产生分裂对公众来说并不明朗,而且 LEDE 宣言惊到了一些其他 OpenWrt 开发者也暗示这团队的内部矛盾。
|
||||
|
||||
LEDE 宣言被 Jo-Philipp Wich 于五月三日发往所有 OpenWrt 开发者列表和新 LEDE 开发者列表。它将 LEDE 描述为“OpenWrt 社区的一次重启” 和 “OpenWrt 项目的一个副产品” ,希望产生一个 “注重透明性、合作和权利分散”的 Linux 嵌入式开发社区。
|
||||
|
||||
给出的重启的原因是 OpenWrt 遭受着长期以来存在且不能从内部解决的问题 —— 换句话说,关于内部处理方式和政策。例如,宣言称,开发者的数目在不断减少,却没有接纳新开发者的方式(而且貌似没有授权委托访问给新开发者的方法)。宣言说到,项目的基础设施不可靠(例如,去年服务器挂掉在这个项目中也引发了相当多的矛盾),但是内部不合和单点错误阻止了修复它。内部和从这个项目到外面世界也存在着“交流、透明度和合作”的普遍缺失。最后,一些技术缺陷被引述:不充分的测试、缺乏常规维护,以及窘迫的稳固性与文档。
|
||||
|
||||
该宣言继续描述 LEDE 重启将怎样解决这些问题。所有交流频道都会打开供公众使用,决策将在项目范围内的投票决出,合并政策将放宽等等。更详细的说明可以在 LEDE 站点的[规则][4]页找到。其他细节中,它说贡献者将只有一个阶级(也就是,没有“核心开发者”这样拥有额外权利的群体),简单的少数服从多数投票作出决定,并且任何被这个项目管理的基础设施必须有三个以上管理员账户。在 LEDE 邮件列表, Hauke Mehrtens [补充][5]到,该项目将会努力把补丁投递到上游项目 —— 这是过去 OpenWrt 被批判的一点,尤其是对 Linux 内核。
|
||||
|
||||
除了 Wich,这个宣言被 OpenWrt 贡献者 John Crispin、 Daniel Golle、 Felix Fietkau、 Mehrtens、 Matthias Schiffer 和 Steven Barth 共同签署,并以给其他有兴趣参与的人访问 LEDE 站点的邀请作为了宣言结尾。
|
||||
|
||||
### 回应和问题
|
||||
|
||||
有人可能会猜想 LEDE 组织者预期他们的宣言会有或积极或消极的反响。毕竟,细读宣言中批判 OpenWrt 项目暗示了 LEDE 阵营发现有一些 OpenWrt 项目成员难以共事(例如,“单点错误” 或 “内部不和”阻止了基础设施的修复)。
|
||||
|
||||
并且,确实,有很多消极回应。OpenWrt 创立者之一 Mike Baker [回应][6] 了一些警告,反驳所有 LEDE 宣言中的结论并称“像‘重启’这样的词语都是含糊不清的,且具有误导性的,而且 LEDE 项目未能揭晓其真实本质。”与此同时,有人关闭了那些在 LEDE 宣言上署名的开发者的 @openwrt.org 邮件入口;当 Fietkau [提出反对][7], Baker [回复][8]账户“暂时停用”是因为“还不确定 LEDE 能不能代表 OpenWrt。” 另一个 OpenWrt 核心成员 Imre Kaloz [写][9]到,他们现在所抱怨的 OpenWrt 的“大多数[破]事就是 LEDE 团队弄出来的”。
|
||||
|
||||
但是大多数 OpenWrt 列表的回应对该宣言表示困惑。邮件列表成员不明确 LEDE 团队是否将对 OpenWrt [继续贡献][10],或导致了这次分裂的架构和内部问题的[确切本质][11]是什么。 Baker 的第一反应是对宣言中引述的那些问题缺乏公开讨论表示难过:“我们意识到当前的 OpenWrt 项目遭受着许多的问题,”但“我们希望有机会去讨论并尝试着解决”它们。 Baker 作出结论:
|
||||
|
||||
> 我们想强调,我们确实希望能够公开的讨论,并解决掉手头事情。我们的目标是与所有能够且希望对 OpenWrt 作出贡献的参与者共事,包括 LEDE 团队。
|
||||
|
||||
除了有关新项目的初心的问题之外,一些邮件列表订阅者提出了 LEDE 是否与 OpenWrt 有相同的使用场景定位,给新项目取一个听起来更一般的名字的疑惑。此外,许多人,像 Roman Yeryomin,对为什么这些问题需要 LEDE 团队的离开(来解决)[表示了疑惑][12],特别是,与此同时,LEDE 团队由大部分活跃核心 OpenWrt 开发者构成。一些列表订阅者,像 Michael Richardson,甚至不清楚[谁还会继续开发][13] OpenWrt。
|
||||
|
||||
### 澄清
|
||||
|
||||
LEDE 团队尝试着深入阐释他们的境况。在 Fietkau 给 Baker 的回复中,他说在 OpenWrt 内部关于有目的地改变的讨论会很快变得“有毒,”因此导致没有进展。而且:
|
||||
|
||||
> 这些讨论的要点在于那些掌握着基础设施关键部分的人精力有限却拒绝他人的加入和帮助,甚至是面对无法及时解决的重要问题时也是这样。
|
||||
|
||||
> 这种像单点错误一样的事已经持续了很多年了,没有任何有意义的进展来解决它。
|
||||
|
||||
Wich 和 Fietkau 都没有明显指出具体的人,虽然在列表的其他人可能会想到这个基础设施和 OpenWrt 的内部决策问题要归咎于某些人。 Daniel Dickinson [陈述][14]到:
|
||||
|
||||
> 我的印象是 Kaloz (至少) 以基础设施为胁来保持控制,并且根本性的问题是 OpenWrt 是*不*民主的,而且忽视那些真正在 OpenWrt 工作的人想要的是什么,无视他们的愿望,因为他/他们把控着要害。
|
||||
|
||||
另一方面, Luka Perkov [指出][15] 很多 OpemWrt 开发者想从 Subversion 转移到 Git,但 Fietkau 却阻止这种变化。
|
||||
|
||||
看起来是 OpenWrt 的管理结构并非如预期般发挥作用,其结果导致个人冲突爆发,而且由于没有完好定义的流程,某些人能够简单的忽视或阻止提议的变化。明显,这不是一个能长期持续的模式。
|
||||
|
||||
五月六日,Crispin 在一个新的帖子中[写给][16] OpenWrt 列表,尝试着重构 LEDE 项目宣言。他说,这并不是意味着“敌对或分裂”行为,只是与结构失衡的 OpenWrt 做个清晰的划分并以新的方式开始。问题在于“不要归咎于一次单独的事件、一个人或者一次口水战”,他说,“我们想与过去自己造成的错误和多次作出的错误管理决定分开”。 Crispin 也承认宣言没有把握好,说 LEDE 团队 “弄糟了发起纲领。”
|
||||
|
||||
Crispin 的邮件似乎没能使 Kaloz 满意,她[坚持认为][17] Crispin(作为发行经理)和 Fietkau(作为领头开发者)可以轻易地在 OpenWrt 内部作出想要的改变。但是讨论的下文后来变得沉寂;之后 LEDE 或者 OpenWrt 哪边会发生什么还有待观察。
|
||||
|
||||
### 目的
|
||||
|
||||
对于那些想要探究 LEDE 所认为有问题的事情的更多细节的 OpenWrt 成员来说,有更多的信息来源可以为这个问题提供线索。在公众宣言之前,LEDE 组织花了几周谈论他们的计划,会议的 IRC 日志现已[发布][18]。特别有趣的是,三月三十日的[会议][19]包含了这个项目目标的细节讨论。
|
||||
|
||||
其中包括一些针对 OpenWrt 的基础设施的抱怨,像项目的 Trac 工单追踪器的缺点。它充斥着不完整的漏洞报告和“我也是”的评论,Wich 说,结果几乎没有贡献者使用它。此外,他们也在 Github 上追踪 bug,人们对这件事感到困惑,这使得工单应该在哪里讨论不明了。
|
||||
|
||||
这些 IRC 讨论也定下了开发流程本身。LEDE 团队想作出些改变,以使用会合并到主干的阶段开发分支为开端,与 OpenWrt 所使用的“直接提交到主干”方式不同。该项目也将提供基于时间的发行版,并通过只发行已被成功测试的二进制模块来鼓励用户测试,由社区而不是核心开发者在实际的硬件上进行测试。
|
||||
|
||||
最后,这些 IRC 讨论也确定了 LEDE 团队的目的不是用它的宣言吓唬 OpenWrt。Crispin 提到 LEDE 首先是“半公开的”并渐渐做得更公开。 Wich 解释说他希望 LEDE 是“中立的、专业的,并打开大门欢迎 OpenWrt 以便将来的合并”。不幸的是,前期发起工作并不是做得很好。
|
||||
|
||||
在一封邮件中, Fietkau 补充到 OpenWrt 核心开发者确实在任务中遇到瓶颈,像补丁复审和基础设施维护这些事情让他们完成不了其他工作,比如配置下载镜像和改良构建系统。在 LEDE 宣言之后短短几天内,他说,团队成功解决了镜像和构建系统任务,而这些已被搁置多年。
|
||||
|
||||
> 我们在 LEDE 所做的事情很多是基于转移到 Github 的去中心化软件包开发经验,并放弃了软件包应如何被维护的许多控制。这样最终有效减少了我们的工作量,而且我们有了很多更活跃的开发者。
|
||||
|
||||
> 我们真的希望为核心开发做一些类似的事,但是基于我们想作出更大改变的经验,我们觉得在 OpenWrt 项目内做不到。
|
||||
|
||||
修复基础设施也将收获其他好处,他说,就比如改进了用于管理签署发布版本的密码的系统。团队正在考虑在某些情况下非上游补丁的规则,像需要补丁的描述和为什么没有发送到上游的解释。他也提到很多留下的 OpenWrt 开发者表示有兴趣加入 LEDE,相关当事人正试图弄清楚他们是否会重新合并该项目。
|
||||
|
||||
有人希望 LEDE 更为扁平的管理模式和更为透明的分工会在困扰 OpenWrt 的方面取得成功。解决最初的宣言中被诟病的沟通方面的问题会是最大的障碍。如果那个过程处理得好,那么,未来 LEDE 和 OpenWrt 可能能够求同存异并协作。否则,之后两个团队可能一起被迫发展到比以前拥有更少资源的方向,这也许不是开发者或用户想看到的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://lwn.net/Articles/686767/
|
||||
|
||||
作者:[Nathan Willis][a]
|
||||
译者:[XYenChi](https://github.com/XYenChi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://lwn.net/Articles/686767/
|
||||
[1]:https://openwrt.org/
|
||||
[2]:https://lwn.net/Articles/686180/
|
||||
[3]:https://www.lede-project.org/
|
||||
[4]:https://www.lede-project.org/rules.html
|
||||
[5]:http://lists.infradead.org/pipermail/lede-dev/2016-May/000080.html
|
||||
[6]:https://lwn.net/Articles/686988/
|
||||
[7]:https://lwn.net/Articles/686989/
|
||||
[8]:https://lwn.net/Articles/686990/
|
||||
[9]:https://lwn.net/Articles/686991/
|
||||
[10]:https://lwn.net/Articles/686995/
|
||||
[11]:https://lwn.net/Articles/686996/
|
||||
[12]:https://lwn.net/Articles/686992/
|
||||
[13]:https://lwn.net/Articles/686993/
|
||||
[14]:https://lwn.net/Articles/686998/
|
||||
[15]:https://lwn.net/Articles/687001/
|
||||
[16]:https://lwn.net/Articles/687003/
|
||||
[17]:https://lwn.net/Articles/687004/
|
||||
[18]:http://meetings.lede-project.org/lede-adm/2016/?C=M;O=A
|
||||
[19]:http://meetings.lede-project.org/lede-adm/2016/lede-adm.2016-03-30-11.05.log.html
|
||||
@ -0,0 +1,86 @@
|
||||
促使项目团队作出改变的五步计划
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
目的是任何团队组建的首要之事。如果一个人足以实现那个目的,那么就没有必要组成团队。而且如果没有重要目标,你根本不需要一个团队。但只要任务需要的专业知识比一个人所拥有的更多,我们就会遇到集体参与的问题——如果处理不当,会使你脱离正轨。
|
||||
|
||||
想象一群人困在洞穴中。没有一个人具备如何出去的全部知识,所以每个人要协作,心路常开,在想要做的事情上尽力配合。当(且仅当)组建了适当的工作团队之后,才能为实现团队的共同目标创造出合适的环境。
|
||||
|
||||
但确实有人觉得待在洞穴中很舒适而且只想待在那里。在组织里,领导者们如何掌控那些实际上抵触改善、待在洞穴中觉得舒适的人?同时该如何找到拥有共同目标但是不在自己组织的人?
|
||||
|
||||
我从事指导国际销售培训,刚开始甚至很少有人认为我的工作有价值。所以,我想出一套使他们信服的战术。那个战术非常成功以至于我决定深入研究它并与各位[分享][2]。
|
||||
|
||||
### 获得支持
|
||||
|
||||
为了建立公司强大的企业文化,有人会反对改变,并且从幕后打压任何改变的提议。他们希望每个人都待在那个舒适的洞穴里。例如,当我第一次接触到海外销售培训,我受到了一些关键人物的严厉阻挠。他们迫使其他人相信某个东京人做不了销售培训——只要基本的产品培训就行了。
|
||||
|
||||
尽管我最终解决了这个问题,但我那时候真的不知道该怎么办。所以,我开始研究顾问们在改变公司里抗拒改变的人的想法这个问题上该如何给出建议。从学者 [Laurence Haughton][3] 的研究中,我发现一般对于改变的提议,组织中 83% 的人最开始不会支持你。大约 17% _会_从一开始就支持你,但是只要看到一个实验案例成功之后,他们觉得这个主意安全可行了,60% 的人会支持你。最后,有部分人会反对任何改变,无论它有多棒。
|
||||
|
||||
我研究的步骤:
|
||||
|
||||
* 从试验项目开始
|
||||
* 开导洞穴人
|
||||
* 快速跟进
|
||||
* 开导洞穴首领
|
||||
* 全局展开
|
||||
|
||||
### 1、 从试验项目开始
|
||||
|
||||
找到高价值且成功率较高的项目——而不是大的、成本高的、周期长的、全局的行动。然后,找到能看到项目价值、理解它的价值并能为之奋斗的关键人物。这些人不应该只是“老好人”或者“朋友”;他们必须相信项目的目标而且拥有推进项目的能力或经验。不要急于求成。只要足够支持你研究并保持进度即可。
|
||||
|
||||
个人而言,我在新加坡的一个小型车辆代理商那里举办了自己的第一场销售研讨会。虽然并不是特别成功,但足以让人们开始讨论销售训练会达到怎样的效果。那时候的我困在洞穴里(那是一份我不想做的工作)。这个试验销售训练是我走出困境的蓝图。
|
||||
|
||||
### 2、 开导洞穴人
|
||||
|
||||
洞穴(CAVE)实际上是我从 Laurence Haughton 那里听来的缩略词。它代表着 Citizens Against Virtually Everything。(LCTT 译注,此处一语双关前文提及的洞穴。)
|
||||
|
||||
你得辨别这些人,因为他们会暗地里阻挠项目的进展,特别是早期脆弱的时候。他们容易黑化:总是消极。他们频繁使用“但是”、“如果”和“为什么”,只是想推脱你。他们询问轻易不可得的细节信息。他们花费过多的时间在问题上,而不是寻找解决方案。他们认为每个失败都是一个趋势。他们总是对人而不是对事。他们作出反对建议的陈述却又不能简单确认。
|
||||
|
||||
避开洞穴人;不要让他们太早加入项目的讨论。他们固守成见,因为他们看不到改变所具有的价值。他们安居于洞穴,所以试着让他们去做些其他事。你应该找出我上面提到那 17% 的人群中的关键人物,那些想要改变的人,并且跟他们开一个非常隐秘的准备会。
|
||||
|
||||
我在五十铃汽车(股东之一是通用汽车公司)的时候,销售训练项目开始于一个销往世界上其他小国家的合资分销商,主要是非洲、南亚、拉丁美洲和中东。我的个人团队由通用汽车公司雪佛兰的人、五十铃产品经理和分公司的销售计划员工组成。隔绝其他任何人于这个圈子之外。
|
||||
|
||||
### 3、 快速跟进
|
||||
|
||||
洞穴人总是慢吞吞的,那么你就迅速行动起来。如果你在他们参与之前就有了小成就的经历,他们对你团队产生消极影响的能力将大大减弱——你要在他们提出之前就解决他们必然反对的问题。再一次,选择一个成功率高的试验项目,很快能出结果的。然后宣传成功,就像广告上的加粗标题。
|
||||
|
||||
当我在新加坡研讨会上所言开始流传时,其他地区开始意识到销售训练的好处。仅在新加坡研讨会之后,我就被派到马来西亚开展了四次以上。
|
||||
|
||||
### 4、 开导洞穴首领
|
||||
|
||||
只要你取得了第一个小项目的成功,就针对能影响洞穴首领的关键人物推荐项目。让团队继续该项目以告诉关键人物成功的经历。一线人员甚至顾客也能提供有力的证明。 洞穴管理者往往只着眼于销量和收益,那么就宣扬项目在降低开支、减少浪费和增加销量方面的价值。
|
||||
|
||||
自新加坡的第一次研讨会及之后,我向直接掌握了五十铃销售渠道的前线销售部门员工和通用汽车真正想看到进展的人极力宣传他们的成功。当他们接受了之后,他们会向上级提出培训请求并让其看到分公司销量的提升。
|
||||
|
||||
### 5、 全局展开
|
||||
|
||||
一旦一把手站在了自己这边,立马向整个组织宣告成功的试验项目。讨论项目的扩展。
|
||||
|
||||
用上面的方法,在 21 年的职业生涯中,我在世界各地超过 60 个国家举办了研讨会。我确实走出了洞穴——并且真的看到了广阔的世界。
|
||||
|
||||
(题图:opensource.com)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Ron McFarland - Ron McFarland 已在日本工作 40 年,从事国际销售、销售管理和在世界范围内扩展销售业务 30 载有余。他曾去过或就职于 80 多个国家。在过去的 14 年里, Ron 为总部位于东京的日本硬件切割厂在美国和欧洲各地建立分销商。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/17/1/escape-the-cave
|
||||
|
||||
作者:[Ron McFarland][a]
|
||||
译者:[XYenChi](https://github.com/XYenChi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ron-mcfarland
|
||||
[1]:https://opensource.com/open-organization/17/1/escape-the-cave?rate=dBJIKVJy720uFj0PCfa1JXDZKkMwozxV8TB2qJnoghM
|
||||
[2]:http://www.slideshare.net/RonMcFarland1/creating-change-58994683
|
||||
[3]:http://www.laurencehaughton.com/
|
||||
[4]:https://opensource.com/user/68021/feed
|
||||
[5]:https://opensource.com/open-organization/17/1/escape-the-cave#comments
|
||||
[6]:https://opensource.com/users/ron-mcfarland
|
||||
@ -0,0 +1,66 @@
|
||||
为什么 DevOps 如我们所知道的那样,是安全的终结
|
||||
==========
|
||||
|
||||

|
||||
|
||||
安全难以推行。在企业管理者迫使开发团队尽快发布程序的大环境下,很难说服他们花费有限的时间来修补安全漏洞。但是鉴于所有网络攻击中有 84% 发生在应用层,作为一个组织是无法承担其开发团队不包括安全性带来的后果。
|
||||
|
||||
DevOps 的崛起为许多安全负责人带来了困境。Sonatype 的前 CTO [Josh Corman][2] 说:“这是对安全的威胁,但这也是让安全变得更好的机会。” Corman 是一个坚定的[将安全和 DevOps 实践整合起来创建 “坚固的 DevOps”][3]的倡导者。_Business Insights_ 与 Corman 谈论了安全和 DevOps 共同的价值,以及这些共同价值如何帮助组织更少地受到中断和攻击的影响。
|
||||
|
||||
### 安全和 DevOps 实践如何互惠互利?
|
||||
|
||||
**Josh Corman:** 一个主要的例子是 DevOps 团队对所有可测量的东西进行检测的倾向。安全性一直在寻找更多的情报和遥测。你可以获取许多 DevOps 团队正在测量的信息,并将这些信息输入到你的日志管理或 SIEM (安全信息和事件管理系统)。
|
||||
|
||||
一个 OODA 循环(<ruby>观察<rt>observe</rt></ruby>、<ruby>定向<rt>orient</rt></ruby>、<ruby>决定<rt>decide</rt></ruby>、<ruby>行为<rt>act</rt></ruby>)的前提是有足够普遍的眼睛和耳朵,以注意到窃窃私语和回声。DevOps 为你提供无处不在的仪器。
|
||||
|
||||
### 他们有分享其他文化观点吗?
|
||||
|
||||
**JC:** “严肃对待你的代码”是一个共同的价值观。例如,由 Netflix 编写的软件工具 Chaos Monkey 是 DevOps 团队的分水岭。它是为了测试亚马逊网络服务的弹性和可恢复性而创建的,Chaos Monkey 使得 Netflix 团队更加强大,更容易为中断做好准备。
|
||||
|
||||
所以现在有个想法是我们的系统需要测试,因此,James Wickett 和我及其他人决定做一个邪恶的、带有攻击性的 Chaos Monkey,这就是 GAUNTLT 项目的来由。它基本上是一堆安全测试, 可以在 DevOps 周期和 DevOps 工具链中使用。它也有非常适合 DevOps 的API。
|
||||
|
||||
### 企业安全和 DevOps 价值在哪里相交?
|
||||
|
||||
**JC:** 这两个团队都认为复杂性是一切事情的敌人。例如,[安全人员和 Rugged DevOps 人员][4]实际上可以说:“看,我们在我们的项目中使用了 11 个日志框架 - 也许我们不需要那么多,也许攻击面和复杂性可能会让我们受到伤害或者损害产品的质量或可用性。”
|
||||
|
||||
复杂性往往是许多事情的敌人。通常情况下,你不会很难说服 DevOps 团队在架构层面使用更好的建筑材料:使用最新的、最不易受攻击的版本,并使用较少的组件。
|
||||
|
||||
### “更好的建筑材料”是什么意思?
|
||||
|
||||
**JC:** 我是世界上最大的开源仓库的保管人,所以我能看到他们在使用哪些版本,里面有哪些漏洞,何时他们没有修复漏洞,以及等了多久。例如,某些日志记录框架从不会修复任何错误。其中一些会在 90 天内修复了大部分的安全漏洞。人们越来越多地遭到攻击,因为他们使用了一个毫无安全的框架。
|
||||
|
||||
除此之外,即使你不知道日志框架的质量,拥有 11 个不同的框架会变得非常笨重、出现 bug,还有额外的工作和复杂性。你暴露在漏洞中的风险是非常大的。你想把时间花在修复大量的缺陷上,还是在制造下一个大的破坏性的事情上?
|
||||
|
||||
[Rugged DevOps 的关键是软件供应链管理][5],其中包含三个原则:使用更少和更好的供应商、使用这些供应商的最高质量的部分、并跟踪这些部分,以便在发生错误时,你可以有一个及时和敏捷的响应。
|
||||
|
||||
### 所以变更管理也很重要。
|
||||
|
||||
**JC:** 是的,这是另一个共同的价值。我发现,当一家公司想要执行诸如异常检测或净流量分析等安全测试时,他们需要知道“正常”的样子。让人们失误的许多基本事情与仓库和补丁管理有关。
|
||||
|
||||
我在 _Verizon 数据泄露调查报告_中看到,追踪去年被成功利用的漏洞后,其中 97% 归结为 10 个 CVE(常见漏洞和风险),而这 10 个已经被修复了十多年。所以,我们羞于谈论高级间谍活动。我们没有做基本的补丁工作。现在,我不是说如果你修复这 10 个CVE,那么你就没有被利用,而是这占据了人们实际失误的最大份额。
|
||||
|
||||
[DevOps 自动化工具][6]的好处是它们已经成为一个意外的变更管理数据库。其真实反应了谁在哪里什么时候做了变更。这是一个巨大的胜利,因为我们经常对安全性有最大影响的因素无法控制。你承受了 CIO 和 CTO 做出的选择的后果。随着 IT 通过自动化变得更加严格和可重复,你可以减少人为错误的机会,并且哪里发生了变化更加可追溯。
|
||||
|
||||
### 你认为什么是最重要的共同价值?
|
||||
|
||||
**JC:** DevOps 涉及到过程和工具链,但我认为定义这种属性的是文化,特别是同感。 DevOps 有用是因为开发人员和运维团队能够更好地了解彼此,并做出更明智的决策。不是在解决孤岛中的问题,而是为了活动流程和目标解决。如果你向 DevOps 的团队展示安全如何能使他们变得更好,那么作为回馈他们往往会问:“那么,我们是否有任何选择让你的生活更轻松?”因为他们通常不知道他们做的 X、Y 或 Z 的选择使它无法包含安全性。
|
||||
|
||||
对于安全团队,驱动价值的方法之一是在寻求帮助之前变得更有所帮助,在我们告诉 DevOps 团队要做什么之前提供定性和定量的价值。你必须获得 DevOps 团队的信任,并获得发挥的权利,然后才能得到回报。它通常比你想象的快很多。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://techbeacon.com/why-devops-end-security-we-know-it
|
||||
|
||||
作者:[Mike Barton][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/intent/follow?original_referer=https%3A%2F%2Ftechbeacon.com%2Fwhy-devops-end-security-we-know-it%3Fimm_mid%3D0ee8c5%26cmp%3Dem-webops-na-na-newsltr_20170310&ref_src=twsrc%5Etfw®ion=follow_link&screen_name=mikebarton&tw_p=followbutton
|
||||
[1]:https://techbeacon.com/resources/application-security-devops-true-state?utm_source=tb&utm_medium=article&utm_campaign=inline-cta
|
||||
[2]:https://twitter.com/joshcorman
|
||||
[3]:https://techbeacon.com/want-rugged-devops-team-your-release-security-engineers
|
||||
[4]:https://techbeacon.com/rugged-devops-rsa-6-takeaways-security-ops-pros
|
||||
[5]:https://techbeacon.com/josh-corman-security-devops-how-shared-team-values-can-reduce-threats
|
||||
[6]:https://techbeacon.com/devops-automation-best-practices-how-much-too-much
|
||||
@ -1,21 +1,23 @@
|
||||
OpenGL 与 Go 教程第三节:实现游戏
|
||||
OpenGL 与 Go 教程(三)实现游戏
|
||||
============================================================
|
||||
|
||||
[第一节: Hello, OpenGL][8] | [第二节: 绘制游戏面板][9] | [第三节:实现游戏功能][10]
|
||||
- [第一节: Hello, OpenGL][8]
|
||||
- [第二节: 绘制游戏面板][9]
|
||||
- [第三节:实现游戏功能][10]
|
||||
|
||||
该教程的完整源代码可以从 [GitHub][11] 上获得。
|
||||
该教程的完整源代码可以从 [GitHub][11] 上找到。
|
||||
|
||||
欢迎回到《OpenGL 与 Go 教程》!如果你还没有看过 [第一节][12] 和 [第二节][13],那就要回过头去看一看。
|
||||
|
||||
到目前为止,你应该懂得如何创建网格系统以及创建代表方格中每一个单元的格子阵列。现在可以开始把网格当作游戏面板实现《Conway's Game of Life》。
|
||||
到目前为止,你应该懂得如何创建网格系统以及创建代表方格中每一个单元的格子阵列。现在可以开始把网格当作游戏面板实现<ruby>康威生命游戏<rt>Conway's Game of Life</rt></ruby>。
|
||||
|
||||
开始吧!
|
||||
|
||||
### 实现 《Conway’s Game》
|
||||
### 实现康威生命游戏
|
||||
|
||||
《Conway's Game》的其中一个要点是所有 cell 必须同时基于当前 cell 在面板中的状态确定下一个 cell 的状态。也就是说如果 Cell (X=3,Y=4)在计算过程中状态发生了改变,那么邻近的 cell (X=4,Y=4)必须基于(X=3,T=4)的状态决定自己的状态变化,而不是基于自己现在的状态。简单的讲,这意味着我们必须遍历 cell ,确定下一个 cell 的状态,在绘制之前,不改变他们的当前状态,然后在下一次循环中我们将新状态应用到游戏里,依此循环往复。
|
||||
康威生命游戏的其中一个要点是所有<ruby>细胞<rt>cell</rt></ruby>必须同时基于当前细胞在面板中的状态确定下一个细胞的状态。也就是说如果细胞 `(X=3,Y=4)` 在计算过程中状态发生了改变,那么邻近的细胞 `(X=4,Y=4)` 必须基于 `(X=3,Y=4)` 的状态决定自己的状态变化,而不是基于自己现在的状态。简单的讲,这意味着我们必须遍历细胞,确定下一个细胞的状态,而在绘制之前不改变他们的当前状态,然后在下一次循环中我们将新状态应用到游戏里,依此循环往复。
|
||||
|
||||
为了完成这个功能,我们需要在 cell 结构体中添加两个布尔型变量:
|
||||
为了完成这个功能,我们需要在 `cell` 结构体中添加两个布尔型变量:
|
||||
|
||||
```
|
||||
type cell struct {
|
||||
@ -29,6 +31,8 @@ type cell struct {
|
||||
}
|
||||
```
|
||||
|
||||
这里我们添加了 `alive` 和 `aliveNext`,前一个是细胞当前的专题,后一个是经过计算后下一回合的状态。
|
||||
|
||||
现在添加两个函数,我们会用它们来确定 cell 的状态:
|
||||
|
||||
```
|
||||
@ -39,22 +43,22 @@ func (c *cell) checkState(cells [][]*cell) {
|
||||
|
||||
liveCount := c.liveNeighbors(cells)
|
||||
if c.alive {
|
||||
// 1\. 当任何一个存活的 cell 的附近少于 2 个存活的 cell 时,该 cell 将会消亡,就像人口过少所导致的结果一样
|
||||
// 1. 当任何一个存活的 cell 的附近少于 2 个存活的 cell 时,该 cell 将会消亡,就像人口过少所导致的结果一样
|
||||
if liveCount < 2 {
|
||||
c.aliveNext = false
|
||||
}
|
||||
|
||||
// 2\. 当任何一个存活的 cell 的附近有 2 至 3 个存活的 cell 时,该 cell 在下一代中仍然存活。
|
||||
// 2. 当任何一个存活的 cell 的附近有 2 至 3 个存活的 cell 时,该 cell 在下一代中仍然存活。
|
||||
if liveCount == 2 || liveCount == 3 {
|
||||
c.aliveNext = true
|
||||
}
|
||||
|
||||
// 3\. 当任何一个存活的 cell 的附近多于 3 个存活的 cell 时,该 cell 将会消亡,就像人口过多所导致的结果一样
|
||||
// 3. 当任何一个存活的 cell 的附近多于 3 个存活的 cell 时,该 cell 将会消亡,就像人口过多所导致的结果一样
|
||||
if liveCount > 3 {
|
||||
c.aliveNext = false
|
||||
}
|
||||
} else {
|
||||
// 4\. 任何一个消亡的 cell 附近刚好有 3 个存活的 cell,该 cell 会变为存活的状态,就像重生一样。
|
||||
// 4. 任何一个消亡的 cell 附近刚好有 3 个存活的 cell,该 cell 会变为存活的状态,就像重生一样。
|
||||
if liveCount == 3 {
|
||||
c.aliveNext = true
|
||||
}
|
||||
@ -95,9 +99,11 @@ func (c *cell) liveNeighbors(cells [][]*cell) int {
|
||||
}
|
||||
```
|
||||
|
||||
更加值得注意的是 liveNeighbors 函数里在返回地方,我们返回的是当前处于存活状态的 cell 的邻居个数。我们定义了一个叫做 add 的内嵌函数,它会对 X 和 Y 坐标做一些重复性的验证。它所做的事情是检查我们传递的数字是否超出了范围——比如说,如果 cell(X=0,Y=5)想要验证它左边的 cell,它就得验证面板另一边的 cell(X=9,Y=5),Y 轴与之类似。
|
||||
在 `checkState` 中我们设置当前状态(`alive`) 等于我们最近迭代结果(`aliveNext`)。接下来我们计数邻居数量,并根据游戏的规则来决定 `aliveNext` 状态。该规则是比较清晰的,而且我们在上面的代码当中也有说明,所以这里不再赘述。
|
||||
|
||||
在 add 内嵌函数后面,我们给当前 cell 附近的八个 cell 分别调用 add 函数,示意如下:
|
||||
更加值得注意的是 `liveNeighbors` 函数里,我们返回的是当前处于存活(`alive`)状态的细胞的邻居个数。我们定义了一个叫做 `add` 的内嵌函数,它会对 `X` 和 `Y` 坐标做一些重复性的验证。它所做的事情是检查我们传递的数字是否超出了范围——比如说,如果细胞 `(X=0,Y=5)` 想要验证它左边的细胞,它就得验证面板另一边的细胞 `(X=9,Y=5)`,Y 轴与之类似。
|
||||
|
||||
在 `add` 内嵌函数后面,我们给当前细胞附近的八个细胞分别调用 `add` 函数,示意如下:
|
||||
|
||||
```
|
||||
[
|
||||
@ -109,9 +115,9 @@ func (c *cell) liveNeighbors(cells [][]*cell) int {
|
||||
]
|
||||
```
|
||||
|
||||
在该示意中,每一个叫做 N 的 cell 是与 C 相邻的 cell。
|
||||
在该示意中,每一个叫做 N 的细胞是 C 的邻居。
|
||||
|
||||
现在是我们的主函数,在我们执行循环核心游戏的地方,调用每个 cell 的 checkState 函数进行绘制:
|
||||
现在是我们的 `main` 函数,这里我们执行核心游戏循环,调用每个细胞的 `checkState` 函数进行绘制:
|
||||
|
||||
```
|
||||
func main() {
|
||||
@ -129,6 +135,8 @@ func main() {
|
||||
}
|
||||
```
|
||||
|
||||
现在我们的游戏逻辑全都设置好了,我们需要修改细胞绘制函数来跳过绘制不存活的细胞:
|
||||
|
||||
```
|
||||
func (c *cell) draw() {
|
||||
if !c.alive {
|
||||
@ -140,7 +148,10 @@ func (c *cell) draw() {
|
||||
}
|
||||
```
|
||||
|
||||
现在完善这个函数。回到 makeCells 函数,我们用 0.0 到 1.0 之间的一个随机数来设置游戏的初始状态。我们会定义一个大小为 0.15 的常量阈值,也就是说每个 cell 都有 15% 的几率处于存活状态。
|
||||
如果我们现在运行这个游戏,你将看到一个纯黑的屏幕,而不是我们辛苦工作后应该看到生命模拟。为什么呢?其实这正是模拟在工作。因为我们没有活着的细胞,所以就一个都不会绘制出来。
|
||||
|
||||
|
||||
现在完善这个函数。回到 `makeCells` 函数,我们用 `0.0` 到 `1.0` 之间的一个随机数来设置游戏的初始状态。我们会定义一个大小为 `0.15` 的常量阈值,也就是说每个细胞都有 15% 的几率处于存活状态。
|
||||
|
||||
```
|
||||
import (
|
||||
@ -174,11 +185,13 @@ func makeCells() [][]*cell {
|
||||
}
|
||||
```
|
||||
|
||||
接下来在循环中,在用 newCell 函数创造一个新的 cell 时,我们根据随机数的大小设置它的存活状态,随机数在 0.0 到 1.0 之间,如果比阈值(0.15)小,就是存活状态。再次强调,这意味着每个 cell 在开始时都有 15% 的几率是存活的。你可以修改数值大小,增加或者减少当前游戏中存活的 cell。我们还把 aliveNext 设成 alive 状态,否则在第一次迭代之后我们会发现一大片 cell 消亡了,这是因为 aliveNext 将永远是 false。
|
||||
我们首先增加两个引入:随机(`math/rand`)和时间(`time`),并定义我们的常量阈值。然后在 `makeCells` 中我们使用当前时间作为随机种子,给每个游戏一个独特的起始状态。你也可也指定一个特定的种子值,来始终得到一个相同的游戏,这在你想重放某个有趣的模拟时很有用。
|
||||
|
||||
现在接着往下看,运行它,你很有可能看到 cell 们一闪而过,但你却无法理解这是为什么。原因可能在于你的电脑太快了,在你能够看清楚之前就运行了(甚至完成了)模拟过程。
|
||||
接下来在循环中,在用 `newCell` 函数创造一个新的细胞时,我们根据随机浮点数的大小设置它的存活状态,随机数在 `0.0` 到 `1.0` 之间,如果比阈值(`0.15`)小,就是存活状态。再次强调,这意味着每个细胞在开始时都有 15% 的几率是存活的。你可以修改数值大小,增加或者减少当前游戏中存活的细胞。我们还把 `aliveNext` 设成 `alive` 状态,否则在第一次迭代之后我们会发现一大片细胞消亡了,这是因为 `aliveNext` 将永远是 `false`。
|
||||
|
||||
降低游戏速度,在主循环中引入一个 frames-per-second 限制:
|
||||
现在继续运行它,你很有可能看到细胞们一闪而过,但你却无法理解这是为什么。原因可能在于你的电脑太快了,在你能够看清楚之前就运行了(甚至完成了)模拟过程。
|
||||
|
||||
让我们降低游戏速度,在主循环中引入一个帧率(FPS)限制:
|
||||
|
||||
```
|
||||
const (
|
||||
@ -223,7 +236,7 @@ const (
|
||||
)
|
||||
```
|
||||
|
||||

|
||||

|
||||
|
||||
试着修改常量,看看它们是怎么影响模拟过程的 —— 这是你用 Go 语言写的第一个 OpenGL 程序,很酷吧?
|
||||
|
||||
@ -231,20 +244,18 @@ const (
|
||||
|
||||
这是《OpenGL 与 Go 教程》的最后一节,但是这不意味着到此而止。这里有些新的挑战,能够增进你对 OpenGL (以及 Go)的理解。
|
||||
|
||||
1. 给每个 cell 一种不同的颜色。
|
||||
2. 让用户能够通过命令行参数指定格子尺寸,帧率,种子和阈值。在 GitHub 上的 [github.com/KyleBanks/conways-gol][4] 里你可以看到一个已经实现的程序。
|
||||
1. 给每个细胞一种不同的颜色。
|
||||
2. 让用户能够通过命令行参数指定格子尺寸、帧率、种子和阈值。在 GitHub 上的 [github.com/KyleBanks/conways-gol][4] 里你可以看到一个已经实现的程序。
|
||||
3. 把格子的形状变成其它更有意思的,比如六边形。
|
||||
4. 用颜色表示 cell 的状态 —— 比如,在第一帧把存活状态的格子设成绿色,如果它们存活了超过三帧的时间,就变成黄色。
|
||||
5. 如果模拟过程结束了,就自动关闭窗口,也就是说所有 cell 都消亡了,或者是最后两帧里没有格子的状态有改变。
|
||||
4. 用颜色表示细胞的状态 —— 比如,在第一帧把存活状态的格子设成绿色,如果它们存活了超过三帧的时间,就变成黄色。
|
||||
5. 如果模拟过程结束了,就自动关闭窗口,也就是说所有细胞都消亡了,或者是最后两帧里没有格子的状态有改变。
|
||||
6. 将着色器源代码放到单独的文件中,而不是把它们用字符串的形式放在 Go 的源代码中。
|
||||
|
||||
### 总结
|
||||
|
||||
希望这篇教程对想要入门 OpenGL (或者是 Go)的人有所帮助!这很有趣,因此我也希望理解学习它也很有趣。
|
||||
|
||||
正如我所说的,OpenGL 可能是非常恐怖的,但只要你开始着手了就不会太差。你只用制定一个个可达成的小目标,然后享受每一次成功,因为尽管 OpenGL 不会总像它看上去的那么难,但也肯定有些难懂的东西。我发现,当遇到一个难于用 go-gl 方式理解的 OpenGL 问题时,你总是可以参考一下在网上更流行的当作教程的 C 语言代码,这很有用。通常 C 语言和 Go 语言的唯一区别是在 Go 中,gl 的前缀是 gl. 而不是 GL_。这极大地增加了你的绘制知识!
|
||||
|
||||
[第一节: Hello, OpenGL][14] | [第二节: 绘制游戏面板][15] | [第三节:实现游戏功能][16]
|
||||
正如我所说的,OpenGL 可能是非常恐怖的,但只要你开始着手了就不会太差。你只用制定一个个可达成的小目标,然后享受每一次成功,因为尽管 OpenGL 不会总像它看上去的那么难,但也肯定有些难懂的东西。我发现,当遇到一个难于理解用 go-gl 生成的代码的 OpenGL 问题时,你总是可以参考一下在网上更流行的当作教程的 C 语言代码,这很有用。通常 C 语言和 Go 语言的唯一区别是在 Go 中,gl 函数的前缀是 `gl.` 而不是 `gl`,常量的前缀是 `gl` 而不是 `GL_`。这可以极大地增加了你的绘制知识!
|
||||
|
||||
该教程的完整源代码可从 [GitHub][17] 上获得。
|
||||
|
||||
@ -419,22 +430,22 @@ func (c *cell) checkState(cells [][]*cell) {
|
||||
|
||||
liveCount := c.liveNeighbors(cells)
|
||||
if c.alive {
|
||||
// 1\. 当任何一个存活的 cell 的附近少于 2 个存活的 cell 时,该 cell 将会消亡,就像人口过少所导致的结果一样
|
||||
// 1. 当任何一个存活的 cell 的附近少于 2 个存活的 cell 时,该 cell 将会消亡,就像人口过少所导致的结果一样
|
||||
if liveCount < 2 {
|
||||
c.aliveNext = false
|
||||
}
|
||||
|
||||
// 2\. 当任何一个存活的 cell 的附近有 2 至 3 个存活的 cell 时,该 cell 在下一代中仍然存活。
|
||||
// 2. 当任何一个存活的 cell 的附近有 2 至 3 个存活的 cell 时,该 cell 在下一代中仍然存活。
|
||||
if liveCount == 2 || liveCount == 3 {
|
||||
c.aliveNext = true
|
||||
}
|
||||
|
||||
// 3\. 当任何一个存活的 cell 的附近多于 3 个存活的 cell 时,该 cell 将会消亡,就像人口过多所导致的结果一样
|
||||
// 3. 当任何一个存活的 cell 的附近多于 3 个存活的 cell 时,该 cell 将会消亡,就像人口过多所导致的结果一样
|
||||
if liveCount > 3 {
|
||||
c.aliveNext = false
|
||||
}
|
||||
} else {
|
||||
// 4\. 任何一个消亡的 cell 附近刚好有 3 个存活的 cell,该 cell 会变为存活的状态,就像重生一样。
|
||||
// 4. 任何一个消亡的 cell 附近刚好有 3 个存活的 cell,该 cell 会变为存活的状态,就像重生一样。
|
||||
if liveCount == 3 {
|
||||
c.aliveNext = true
|
||||
}
|
||||
@ -570,9 +581,9 @@ func compileShader(source string, shaderType uint32) (uint32, error) {
|
||||
|
||||
via: https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
||||
|
||||
作者:[kylewbanks ][a]
|
||||
作者:[kylewbanks][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -584,14 +595,14 @@ via: https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing
|
||||
[5]:https://kylewbanks.com/category/golang
|
||||
[6]:https://kylewbanks.com/category/opengl
|
||||
[7]:https://twitter.com/kylewbanks
|
||||
[8]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl
|
||||
[9]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board
|
||||
[8]:https://linux.cn/article-8933-1.html
|
||||
[9]:https://linux.cn/article-8937-1.html
|
||||
[10]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
||||
[11]:https://github.com/KyleBanks/conways-gol
|
||||
[12]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl
|
||||
[12]:https://linux.cn/article-8933-1.html
|
||||
[13]:https://kylewbanks.com/blog/[Part%202:%20Drawing%20the%20Game%20Board](/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board)
|
||||
[14]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl
|
||||
[15]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board
|
||||
[14]:https://linux.cn/article-8933-1.html
|
||||
[15]:https://linux.cn/article-8937-1.html
|
||||
[16]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
||||
[17]:https://github.com/KyleBanks/conways-gol
|
||||
[18]:https://twitter.com/kylewbanks
|
||||
@ -0,0 +1,211 @@
|
||||
介绍 Flashback,一个互联网模拟工具
|
||||
============================================================
|
||||
|
||||
> Flashback 用于测试目的来模拟 HTTP 和 HTTPS 资源,如 Web 服务和 REST API。
|
||||
|
||||

|
||||
|
||||
在 LinkedIn,我们经常开发需要与第三方网站交互的 Web 应用程序。我们还采用自动测试,以确保我们的软件在发布到生产环境之前的质量。然而,测试只是在它可靠时才有用。
|
||||
|
||||
考虑到这一点,有外部依赖关系的测试是有很大的问题的,例如在第三方网站上。这些外部网站可能会没有通知地发生改变、遭受停机,或者由于互联网的不可靠性暂时无法访问。
|
||||
|
||||
如果我们的一个测试依赖于能够与第三方网站通信,那么任何故障的原因都很难确定。失败可能是因为 LinkedIn 的内部变更、第三方网站的维护人员进行的外部变更,或网络基础设施的问题。你可以想像,与第三方网站的交互可能会有很多失败的原因,因此你可能想要知道,我将如何处理这个问题?
|
||||
|
||||
好消息是有许多互联网模拟工具可以帮助。其中一个是 [Betamax][4]。它通过拦截 Web 应用程序发起的 HTTP 连接,之后进行重放的方式来工作。对于测试,Betamax 可以用以前记录的响应替换 HTTP 上的任何交互,它可以非常可靠地提供这个服务。
|
||||
|
||||
最初,我们选择在 LinkedIn 的自动化测试中使用 Betamax。它工作得很好,但我们遇到了一些问题:
|
||||
|
||||
* 出于安全考虑,我们的测试环境没有接入互联网。然而,与大多数代理一样,Betamax 需要 Internet 连接才能正常运行。
|
||||
* 我们有许多需要使用身份验证协议的情况,例如 OAuth 和 OpenId。其中一些协议需要通过 HTTP 进行复杂的交互。为了模拟它们,我们需要一个复杂的模型来捕获和重放请求。
|
||||
|
||||
为了应对这些挑战,我们决定基于 Betamax 的思路,构建我们自己的互联网模拟工具,名为 Flashback。我们也很自豪地宣布 Flashback 现在是开源的。
|
||||
|
||||
### 什么是 Flashback?
|
||||
|
||||
Flashback 用于测试目的来模拟 HTTP 和 HTTPS 资源,如 Web 服务和 [REST][5] API。它记录 HTTP/HTTPS 请求并重放以前记录的 HTTP 事务 - 我们称之为“<ruby>场景<rt>scene</rt></ruby>”,这样就不需要连接到 Internet 才能完成测试。
|
||||
|
||||
Flashback 也可以根据请求的部分匹配重放场景。它使用的是“匹配规则”。匹配规则将传入请求与先前记录的请求相关联,然后将其用于生成响应。例如,以下代码片段实现了一个基本匹配规则,其中测试方法“匹配”[此 URL][6]的传入请求。
|
||||
|
||||
HTTP 请求通常包含 URL、方法、标头和正文。Flashback 允许为这些组件的任意组合定义匹配规则。Flashback 还允许用户向 URL 查询参数,标头和正文添加白名单或黑名单标签。
|
||||
|
||||
例如,在 OAuth 授权流程中,请求查询参数可能如下所示:
|
||||
|
||||
```
|
||||
oauth_consumer_key="jskdjfljsdklfjlsjdfs",
|
||||
oauth_nonce="ajskldfjalksjdflkajsdlfjasldfja;lsdkj",
|
||||
oauth_signature="asdfjaklsdjflasjdflkajsdklf",
|
||||
oauth_signature_method="HMAC-SHA1",
|
||||
oauth_timestamp="1318622958",
|
||||
oauth_token="asdjfkasjdlfajsdklfjalsdjfalksdjflajsdlfa",
|
||||
oauth_version="1.0"
|
||||
```
|
||||
|
||||
这些值许多将随着每个请求而改变,因为 OAuth 要求客户端每次为 `oauth_nonce` 生成一个新值。在我们的测试中,我们需要验证 `oauth_consumer_key`、`oauth_signature_method` 和 `oauth_version` 的值,同时确保 `oauth_nonce`、`oauth_signature`、`oauth_timestamp` 和 `oauth_token` 存在于请求中。Flashback 使我们有能力创建我们自己的匹配规则来实现这一目标。此功能允许我们测试随时间变化的数据、签名、令牌等的请求,而客户端没有任何更改。
|
||||
|
||||
这种灵活的匹配和在不连接互联网的情况下运行的功能是 Flashback 与其他模拟解决方案不同的特性。其他一些显著特点包括:
|
||||
|
||||
* Flashback 是一种跨平台和跨语言解决方案,能够测试 JVM(Java虚拟机)和非 JVM(C++、Python 等)应用程序。
|
||||
* Flashback 可以随时生成 SSL/TLS 证书,以模拟 HTTPS 请求的安全通道。
|
||||
|
||||
### 如何记录 HTTP 事务
|
||||
|
||||
使用 Flashback 记录 HTTP 事务以便稍后重放是一个比较简单的过程。在我们深入了解流程之前,我们首先列出一些术语:
|
||||
|
||||
* `Scene` :场景存储以前记录的 HTTP 事务 (以 JSON 格式),它可以在以后重放。例如,这里是一个[Flashback 场景][1]示例。
|
||||
* `Root Path` :根路径是包含 Flashback 场景数据的目录的文件路径。
|
||||
* `Scene Name` :场景名称是给定场景的名称。
|
||||
* `Scene Mode` :场景模式是使用场景的模式, 即“录制”或“重放”。
|
||||
* `Match Rule` :匹配规则确定传入的客户端请求是否与给定场景的内容匹配的规则。
|
||||
* `Flashback Proxy` :Flashback 代理是一个 HTTP 代理,共有录制和重放两种操作模式。
|
||||
* `Host` 和 `Port` :代理主机和端口。
|
||||
|
||||
为了录制场景,你必须向目的地址发出真实的外部请求,然后 HTTPS 请求和响应将使用你指定的匹配规则存储在场景中。在录制时,Flashback 的行为与典型的 MITM(中间人)代理完全相同 - 只有在重放模式下,连接流和数据流仅限于客户端和代理之间。
|
||||
|
||||
要实际看下 Flashback,让我们创建一个场景,通过执行以下操作捕获与 example.org 的交互:
|
||||
|
||||
1、 取回 Flashback 的源码:
|
||||
|
||||
```
|
||||
git clone https://github.com/linkedin/flashback.git
|
||||
```
|
||||
|
||||
2、 启动 Flashback 管理服务器:
|
||||
|
||||
```
|
||||
./startAdminServer.sh -port 1234
|
||||
```
|
||||
|
||||
3、 注意上面的 Flashback 将在本地端口 5555 上启动录制模式。匹配规则需要完全匹配(匹配 HTTP 正文、标题和 URL)。场景将存储在 `/tmp/test1` 下。
|
||||
|
||||
4、 Flashback 现在可以记录了,所以用它来代理对 example.org 的请求:
|
||||
|
||||
```
|
||||
curl http://www.example.org -x localhost:5555 -X GET
|
||||
```
|
||||
|
||||
5、 Flashback 可以(可选)在一个记录中记录多个请求。要完成录制,[关闭 Flashback][8]。
|
||||
|
||||
6、 要验证已记录的内容,我们可以在输出目录(`/tmp/test1`)中查看场景的内容。它应该[包含以下内容][9]。
|
||||
|
||||
[在 Java 代码中使用 Flashback][10]也很容易。
|
||||
|
||||
### 如何重放 HTTP 事务
|
||||
|
||||
要重放先前存储的场景,请使用与录制时使用的相同的基本设置。唯一的区别是[将“场景模式”设置为上述步骤 3 中的“播放”][11]。
|
||||
|
||||
验证响应来自场景而不是外部源的一种方法,是在你执行步骤 1 到 6 时临时禁用 Internet 连接。另一种方法是修改场景文件,看看响应是否与文件中的相同。
|
||||
|
||||
这是 [Java 中的一个例子][12]。
|
||||
|
||||
### 如何记录并重播 HTTPS 事务
|
||||
|
||||
使用 Flashback 记录并重放 HTTPS 事务的过程非常类似于 HTTP 事务的过程。但是,需要特别注意用于 HTTPS SSL 组件的安全证书。为了使 Flashback 作为 MITM 代理,必须创建证书颁发机构(CA)证书。在客户端和 Flashback 之间创建安全通道时将使用此证书,并允许 Flashback 检查其代理的 HTTPS 请求中的数据。然后将此证书存储为受信任的源,以便客户端在进行调用时能够对 Flashback 进行身份验证。有关如何创建证书的说明,有很多[类似这样][13]的资源是非常有帮助的。大多数公司都有自己的管理和获取证书的内部策略 - 请务必用你们自己的方法。
|
||||
|
||||
这里值得一提的是,Flashback 仅用于测试目的。你可以随时随地将 Flashback 与你的服务集成在一起,但需要注意的是,Flashback 的记录功能将需要存储所有的数据,然后在重放模式下使用它。我们建议你特别注意确保不会无意中记录或存储敏感成员数据。任何可能违反贵公司数据保护或隐私政策的行为都是你的责任。
|
||||
|
||||
一旦涉及安全证书,HTTP 和 HTTPS 之间在记录设置方面的唯一区别是添加了一些其他参数。
|
||||
|
||||
* `RootCertificateInputStream`: 表示 CA 证书文件路径或流。
|
||||
* `RootCertificatePassphrase`: 为 CA 证书创建的密码。
|
||||
* `CertificateAuthority`: CA 证书的属性
|
||||
|
||||
[查看 Flashback 中用于记录 HTTPS 事务的代码][14],它包括上述条目。
|
||||
|
||||
用 Flashback 重放 HTTPS 事务的过程与录制相同。唯一的区别是场景模式设置为“播放”。这在[此代码][15]中演示。
|
||||
|
||||
### 支持动态修改
|
||||
|
||||
为了测试灵活性,Flashback 允许你动态地更改场景和匹配规则。动态更改场景允许使用不同的响应(如 `success`、`time_out`、`rate_limit` 等)测试相同的请求。[场景更改][16]仅适用于我们已经 POST 更新外部资源的场景。以下图为例。
|
||||
|
||||

|
||||
|
||||
能够动态[更改匹配规则][17]可以使我们测试复杂的场景。例如,我们有一个使用情况,要求我们测试 Twitter 的公共和私有资源的 HTTP 调用。对于公共资源,HTTP 请求是不变的,所以我们可以使用 “MatchAll” 规则。然而,对于私人资源,我们需要使用 OAuth 消费者密码和 OAuth 访问令牌来签名请求。这些请求包含大量具有不可预测值的参数,因此静态 MatchAll 规则将无法正常工作。
|
||||
|
||||
### 使用案例
|
||||
|
||||
在 LinkedIn,Flashback 主要用于在集成测试中模拟不同的互联网提供商,如下图所示。第一张图展示了 LinkedIn 生产数据中心内的一个内部服务,通过代理层,与互联网提供商(如 Google)进行交互。我们想在测试环境中测试这个内部服务。
|
||||
|
||||

|
||||
|
||||
第二和第三张图表展示了我们如何在不同的环境中录制和重放场景。记录发生在我们的开发环境中,用户在代理启动的同一端口上启动 Flashback。从内部服务到提供商的所有外部请求将通过 Flashback 而不是我们的代理层。在必要场景得到记录后,我们可以将其部署到我们的测试环境中。
|
||||
|
||||

|
||||
|
||||
在测试环境(隔离并且没有 Internet 访问)中,Flashback 在与开发环境相同的端口上启动。所有 HTTP 请求仍然来自内部服务,但响应将来自 Flashback 而不是 Internet 提供商。
|
||||
|
||||

|
||||
|
||||
### 未来方向
|
||||
|
||||
我们希望将来可以支持非 HTTP 协议(如 FTP 或 JDBC),甚至可以让用户使用 MITM 代理框架来自行注入自己的定制协议。我们将继续改进 Flashback 设置 API,使其更容易支持非 Java 语言。
|
||||
|
||||
### 现在为一个开源项目
|
||||
|
||||
我们很幸运能够在 GTAC 2015 上发布 Flashback。在展会上,有几名观众询问是否将 Flashback 作为开源项目发布,以便他们可以将其用于自己的测试工作。
|
||||
|
||||
### Google TechTalks:GATC 2015 - 模拟互联网
|
||||
|
||||
<iframe allowfullscreen="" frameborder="0" height="315" src="https://www.youtube.com/embed/6gPNrujpmn0?origin=https://opensource.com&enablejsapi=1" width="560" id="6gPNrujpmn0" data-sdi="true"></iframe>
|
||||
|
||||
我们很高兴地宣布,Flashback 现在以 BSD 两句版许可证开源。要开始使用,请访问 [Flashback GitHub 仓库][18]。
|
||||
|
||||
_该文原始发表在[LinkedIn 工程博客上][2]。获得转载许可_
|
||||
|
||||
### 致谢
|
||||
|
||||
Flashback 由 [Shangshang Feng][19]、[Yabin Kang][20] 和 [Dan Vinegrad][21] 创建,并受到 [Betamax][22] 启发。特别感谢 [Hwansoo Lee][23]、[Eran Leshem][24]、[Kunal Kandekar][25]、[Keith Dsouza][26] 和 [Kang Wang][27] 帮助审阅代码。同样感谢我们的管理层 - [Byron Ma][28]、[Yaz Shimizu][29]、[Yuliya Averbukh][30]、[Christopher Hazlett][31] 和 [Brandon Duncan][32] - 感谢他们在开发和开源 Flashback 中的支持。
|
||||
|
||||
|
||||
(题图:Opensource.com)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Shangshang Feng - Shangshang 是 LinkedIn 纽约市办公室的高级软件工程师。在 LinkedIn 他从事了三年半的网关平台工作。在加入 LinkedIn 之前,他曾在 Thomson Reuters 和 ViewTrade 证券的基础设施团队工作。
|
||||
|
||||
---------
|
||||
|
||||
via: https://opensource.com/article/17/4/flashback-internet-mocking-tool
|
||||
|
||||
作者:[Shangshang Feng][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/shangshangfeng
|
||||
[1]:https://gist.github.com/anonymous/17d226050d8a9b79746a78eda9292382
|
||||
[2]:https://engineering.linkedin.com/blog/2017/03/flashback-mocking-tool
|
||||
[3]:https://opensource.com/article/17/4/flashback-internet-mocking-tool?rate=Jwt7-vq6jP9kS7gOT6f6vgwVlZupbyzWsVXX41ikmGk
|
||||
[4]:https://github.com/betamaxteam/betamax
|
||||
[5]:https://en.wikipedia.org/wiki/Representational_state_transfer
|
||||
[6]:https://gist.github.com/anonymous/91637854364287b38897c0970aad7451
|
||||
[7]:https://gist.github.com/anonymous/2f5271191edca93cd2e03ce34d1c2b62
|
||||
[8]:https://gist.github.com/anonymous/f899ebe7c4246904bc764b4e1b93c783
|
||||
[9]:https://gist.github.com/sf1152/c91d6d62518fe62cc87157c9ce0e60cf
|
||||
[10]:https://gist.github.com/anonymous/fdd972f1dfc7363f4f683a825879ce19
|
||||
[11]:https://gist.github.com/anonymous/ae1c519a974c3bc7de2a925254b6550e
|
||||
[12]:https://gist.github.com/anonymous/edcc1d60847d51b159c8fd8a8d0a5f8b
|
||||
[13]:https://jamielinux.com/docs/openssl-certificate-authority/introduction.html
|
||||
[14]:https://gist.github.com/anonymous/091d13179377c765f63d7bf4275acc11
|
||||
[15]:https://gist.github.com/anonymous/ec6a0fd07aab63b7369bf8fde69c1f16
|
||||
[16]:https://gist.github.com/anonymous/1f1660280acb41277fbe2c257bab2217
|
||||
[17]:https://gist.github.com/anonymous/0683c43f31bd916b76aff348ff87f51b
|
||||
[18]:https://github.com/linkedin/flashback
|
||||
[19]:https://www.linkedin.com/in/shangshangfeng
|
||||
[20]:https://www.linkedin.com/in/benykang
|
||||
[21]:https://www.linkedin.com/in/danvinegrad/
|
||||
[22]:https://github.com/betamaxteam/betamax
|
||||
[23]:https://www.linkedin.com/in/hwansoo/
|
||||
[24]:https://www.linkedin.com/in/eranl/
|
||||
[25]:https://www.linkedin.com/in/kunalkandekar/
|
||||
[26]:https://www.linkedin.com/in/dsouzakeith/
|
||||
[27]:https://www.linkedin.com/in/kang-wang-44960b4/
|
||||
[28]:https://www.linkedin.com/in/byronma/
|
||||
[29]:https://www.linkedin.com/in/yazshimizu/
|
||||
[30]:https://www.linkedin.com/in/yuliya-averbukh-818a41/
|
||||
[31]:https://www.linkedin.com/in/chazlett/
|
||||
[32]:https://www.linkedin.com/in/dudcat/
|
||||
[33]:https://opensource.com/user/125361/feed
|
||||
[34]:https://opensource.com/users/shangshangfeng
|
||||
@ -1,21 +1,13 @@
|
||||
当你只想将事情搞定时,为什么开放式工作这么难?
|
||||
============================================================
|
||||
|
||||
### 学习使用开放式决策框架来写一本书
|
||||
> 学习使用开放式决策框架来写一本书
|
||||
|
||||

|
||||
>图片来源 : opensource.com
|
||||

|
||||
|
||||
GSD(get stuff done 的缩写,即搞定)指导着我的工作方式。数年来,我将各种方法论融入我日常工作的习惯中,包括精益方法的反馈循环,和敏捷开发的迭代优化,以此来更好地 GSD(如果把 GSD 当作动词的话)。这意味着我必须非常有效地利用我的时间:列出清晰,各自独立的目标;标记已完成的项目;用迭代的方式地持续推进项目进度。但是当我们默认使用开放的时仍然能够 GSD 吗?又或者 GSD 的方法完全行不通呢?大多数人都认为这会导致糟糕的状况,但我发现事实并不一定这样。
|
||||
GSD(get stuff done 的缩写,即搞定)指导着我的工作方式。数年来,我将各种方法论融入我日常工作的习惯中,包括精益方法的反馈循环,和敏捷开发的迭代优化,以此来更好地 GSD(如果把 GSD 当作动词的话)。这意味着我必须非常有效地利用我的时间:列出清晰、各自独立的目标;标记已完成的项目;用迭代的方式地持续推进项目进度。但是当我们以开放为基础时仍然能够 GSD 吗?又或者 GSD 的方法完全行不通呢?大多数人都认为这会导致糟糕的状况,但我发现事实并不一定这样。
|
||||
|
||||
在开放的环境中工作,遵循[开放式决策框架][6]中的指导,会让项目起步变慢。但是在最近的一个项目中,我们作出了一个决定,一个从开始就正确的决定:以开放的方式工作,并与我们的社群一起合作。
|
||||
|
||||
关于开放式组织的资料
|
||||
|
||||
* [下载《开放式组织 IT 文化变革指南》][1]
|
||||
* [下载《开放式组织领袖手册》][2]
|
||||
* [什么是开放式组织][3]
|
||||
* [什么是开放决策][4]
|
||||
在开放的环境中工作,遵循<ruby>[开放式决策框架][6]<rt>Open Decision Framework</rt></ruby>中的指导,会让项目起步变慢。但是在最近的一个项目中,我们作出了一个决定,一个从开始就正确的决定:以开放的方式工作,并与我们的社群一起合作。
|
||||
|
||||
这是我们能做的最好的决定。
|
||||
|
||||
@ -23,13 +15,13 @@ GSD(get stuff done 的缩写,即搞定)指导着我的工作方式。数
|
||||
|
||||
### 建立社区
|
||||
|
||||
2014 年 10 月,我接手了一个新的项目:当时红帽的 CEO Jim Whitehurst 即将推出一本新书《开放式组织》,我要根据书中提出的概念,建立一个社区。“太棒了,这听起来是一个挑战,我加入了!”我这样想。但不久,[冒牌者综合征][7]便出现了,我又开始想:“我们究竟要做什么呢?怎样才算成功呢?”
|
||||
2014 年 10 月,我接手了一个新的项目:当时红帽的 CEO Jim Whitehurst 即将推出一本新书<ruby>《开放式组织》<rt>The Open Organization</rt></ruby>,我要根据书中提出的概念,建立一个社区。“太棒了,这听起来是一个挑战,我加入了!”我这样想。但不久,[冒牌者综合征][7]便出现了,我又开始想:“我们究竟要做什么呢?怎样才算成功呢?”
|
||||
|
||||
让我剧透一下,在这本书的结尾处,Jim 鼓励读者访问 Opensource.com,继续探讨 21 世纪的开放和管理。所以,在 2015 年 5 月,我们的团队在网站上建立了一个新的板块来讨论这些想法。我们计划讲一些故事,就像我们在 Opensource.com 上常做的那样,只不过这次围绕着书中的观点与概念。之后,我们每周都发布新的文章,在 Twitter 上举办了一个在线的读书俱乐部,还将《开放式组织》打造成了系列书籍。
|
||||
|
||||
我们内部独自完成了该系列书籍的前三期,每隔六个月发布一期。每完成一期,我们就向社区发布。然后我们继续完成下一期的工作,如此循环下去。
|
||||
|
||||
这种工作方式,让我们看到了很大的成功。近 3000 人订阅了[该系列的新书][9],《开放式组织领袖手册》。我们用 6 个月的周期来完成这个项目,这样新书的发行日正好是前书的两周年纪念日。
|
||||
这种工作方式,让我们看到了很大的成功。近 3000 人订阅了[该系列的新书][9]:《开放式组织领袖手册》。我们用 6 个月的周期来完成这个项目,这样新书的发行日正好是前书的两周年纪念日。
|
||||
|
||||
在这样的背景下,我们完成这本书的方式是简单直接的:针对开放工作这个主题,我们收集了最好的故事,并将它们组织起来形成文章,招募作者填补一些内容上的空白,使用开源工具调整字体样式,与设计师一起完成封面,最终发布这本书。这样的工作方式使得我们能按照自己的时间线(GSD)全速前进。到[第三本书][10]时,我们的工作流已经基本完善了。
|
||||
|
||||
@ -39,59 +31,55 @@ GSD(get stuff done 的缩写,即搞定)指导着我的工作方式。数
|
||||
|
||||
开放式决策框架列出了组成开放决策制定过程的 4 个阶段。下面是我们在每个阶段中的工作情况(以及开放是如何帮助完成工作的)。
|
||||
|
||||
### 1\. 构思
|
||||
#### 1、 构思
|
||||
|
||||
我们首先写了一份草稿,罗列了对项目设想的愿景。我们需要拿出东西来和潜在的“顾客”分享(在这个例子中,“顾客”指潜在的利益相关者和作者)。然后我们约了一些领域专家面谈,这些专家能够给我们直接的诚实的意见。这些专家表现出的热情与他们提供的指导验证了我们的想法,同时提出了反馈意见使我们能继续向前。如果我们没有得到这些验证,我们会退回到我们最初的想法,再决定从哪里重新开始。
|
||||
|
||||
### 2\. 计划与研究
|
||||
#### 2、 计划与研究
|
||||
|
||||
经过几次面谈,我们准备在 [Opensource.com 上公布这个项目][11]。同时,我们在 [Github 上也公布了这个项目][12], 提供了项目描述,预计的时间线,并阐明了我们所受的约束。这次公布得到了很好的效果,我们最初计划的目录中欠缺了一些内容,在项目公布之后的 72 小时内就被补充完整了。另外(也是更重要的),读者针对一些章节,提出了本不在我们计划中的想法,但是读者觉得这些想法能够补充我们最初设想的版本。
|
||||
经过几次面谈,我们准备在 [Opensource.com 上公布这个项目][11]。同时,我们在 [Github 上也启动了这个项目][12],提供了项目描述、预计的时间线,并阐明了我们所受的约束。这次公布得到了很好的效果,我们最初计划的目录中欠缺了一些内容,在项目公布之后的 72 小时内就被补充完整了。另外(也是更重要的),读者针对一些章节,提出了本不在我们计划中的想法,但是读者觉得这些想法能够补充我们最初设想的版本。
|
||||
|
||||
我们体会到了 [Linus 法则][16]: "With more eyes, all _typos_ are shallow."
|
||||
回顾过去,我觉得在项目的第一和第二个阶段,开放项目并不会影响我们搞定项目的能力。事实上,这样工作有一个很大的好处:发现并填补内容的空缺。我们不只是填补了空缺,我们是迅速地填补了空缺,并且还是用我们自己从未考虑过的点子。这并不一定要求我们做更多的工作,只是改变了我们的工作方式。我们动用有限的人脉,邀请别人来写作,再组织收到的内容,设置上下文,将人们导向正确的方向。
|
||||
|
||||
回顾过去,我觉得在项目的第一和第二个阶段,开放项目并不会影响我们搞定项目的能力。事实上,这样工作有一个很大的好处:发现并填补内容的空缺。我们不只是填补了空缺,我们是迅速地就填补了空缺,并且还是用我们自己从未考虑过的点子。这并不一定要求我们做更多的工作,只是改变了我们的工作方式。我们动用有限的人脉,邀请别人来写作,再组织收到的内容,设置上下文,将人们导向正确的方向。
|
||||
|
||||
### 3\. 设计,开发和测试
|
||||
#### 3、 设计,开发和测试
|
||||
|
||||
项目的这个阶段完全围绕项目管理,管理一些像猫一样特立独行的人,并处理项目的预期。我们有明确的截止时间,我们提前沟通,频繁沟通。我们还使用了一个战略:列出了贡献者和利益相关者,在项目的整个过程中向他们告知项目的进度,尤其是我们在 Github 上标出的里程碑。
|
||||
|
||||
最后,我们的书需要一个名字。我们收集了许多反馈,指出书名应该是什么,更重要的反馈指出了书名不应该是什么。我们通过 [Github 上的 issue][13] 收集反馈意见,并公开表示我们的团队将作最后的决定。当我们准备宣布最后的书名时,我的同事 Bryan Behrenshausen 做了很好的工作,[分享了我们作出决定的过程][14]。人们似乎对此感到高兴——即使他们不同意我们最后的书名。
|
||||
最后,我们的书需要一个名字。我们收集了许多反馈,指出书名应该是什么,更重要的是反馈指出了书名不应该是什么。我们通过 [Github 上的工单][13]收集反馈意见,并公开表示我们的团队将作最后的决定。当我们准备宣布最后的书名时,我的同事 Bryan Behrenshausen 做了很好的工作,[分享了我们作出决定的过程][14]。人们似乎对此感到高兴——即使他们不同意我们最后的书名。
|
||||
|
||||
书的“测试”阶段需要大量的[校对][15]。社区成员真的参与到回答这个“求助”贴中来。我们在 GitHub issue 上收到了大约 80 条意见,汇报校对工作的进度(更不用说通过电子邮件和其他反馈渠道获得的许多额外的反馈)。
|
||||
书的“测试”阶段需要大量的[校对][15]。社区成员真的参与到回答这个“求助”贴中来。我们在 GitHub 工单上收到了大约 80 条意见,汇报校对工作的进度(更不用说通过电子邮件和其他反馈渠道获得的许多额外的反馈)。
|
||||
|
||||
关于搞定任务:在这个阶段,我们亲身体会了 [Linus 法则][16]:"With more eyes, all _typos_ are shallow." 如果我们像前三本书一样自己独立完成,那么整个校对的负担就会落在我们的肩上(就像这些书一样)!相反,社区成员慷慨地帮我们承担了校对的重担,我们的工作从自己校对(尽管我们仍然做了很多工作)转向管理所有的 change requests。对我们团队来说,这是一个受大家欢迎的改变;对社区来说,这是一个参与的机会。如果我们自己做的话,我们肯定能更快地完成校对,但是在开放的情况下,我们在截止日期之前发现了更多的错误,这一点毋庸置疑。
|
||||
关于搞定任务:在这个阶段,我们亲身体会了 [Linus 法则][16]:“<ruby>众目之下,_笔误_无所遁形。<rt>With more eyes, all _typos_ are shallow.</rt></ruby>” 如果我们像前三本书一样自己独立完成,那么整个校对的负担就会落在我们的肩上(就像这些书一样)!相反,社区成员慷慨地帮我们承担了校对的重担,我们的工作从自己校对(尽管我们仍然做了很多工作)转向管理所有的 change requests。对我们团队来说,这是一个受大家欢迎的改变;对社区来说,这是一个参与的机会。如果我们自己做的话,我们肯定能更快地完成校对,但是在开放的情况下,我们在截止日期之前发现了更多的错误,这一点毋庸置疑。
|
||||
|
||||
### 4\. Launch
|
||||
|
||||
### 4\. 发布
|
||||
#### 4、 发布
|
||||
|
||||
好了,我们现在推出了这本书的最终版本。(或者只是第一版?)
|
||||
|
||||
遵循开放决策框架是《IT 文化变革指南》成功的关键。
|
||||
|
||||
我们把发布分为两个阶段。首先,根据我们的公开的项目时间表,在最终日期之前的几天,我们安静地推出了这本书,以便让我们的社区贡献者帮助我们测试[下载表格][17]。第二阶段也就是现在,这本书的[通用版][18]的正式公布。当然,我们在发布后的仍然接受反馈,开源方式也正是如此。
|
||||
|
||||
### 成就解锁
|
||||
|
||||
遵循开放式决策框架是《IT 文化变革指南》成功的关键。通过与客户和利益相关者的合作,分享我们的制约因素,工作透明化,我们甚至超出了自己对图书项目的期望。
|
||||
遵循开放式决策框架是<ruby>《IT 文化变革指南》<rt>Guide to IT Culture Change</rt></ruby>成功的关键。通过与客户和利益相关者的合作,分享我们的制约因素,工作透明化,我们甚至超出了自己对图书项目的期望。
|
||||
|
||||
我对整个项目中的合作,反馈和活动感到非常满意。虽然有一段时间内没有像我想要的那样快速完成任务,这让我有一种焦虑感,但我很快就意识到,开放这个过程实际上让我们能完成更多的事情。基于上面我的概述这一点显而易见。
|
||||
|
||||
所以也许我应该重新考虑我的 GSD 心态,并将其扩展到 GMD:Get **more** done,搞定**更多**工作,并且就这个例子说,取得更好的结果。
|
||||
所以也许我应该重新考虑我的 GSD 心态,并将其扩展到 GMD:Get **More** Done,搞定**更多**工作,并且就这个例子说,取得更好的结果。
|
||||
|
||||
(题图:opensource.com)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jason Hibbets - Jason Hibbets 是 Red Hat 企业营销中的高级社区传播者,也是 Opensource.com 的社区经理。 他自2003年以来一直在 Red Hat,并且是开源城市基金会的创立者。之前的职位包括高级营销专员,项目经理,Red Hat 知识库维护人员和支持工程师。
|
||||
Jason Hibbets - Jason Hibbets 是 Red Hat 企业营销中的高级社区传播者,也是 Opensource.com 的社区经理。 他自2003 年以来一直在 Red Hat,并且是开源城市基金会的创立者。之前的职位包括高级营销专员、项目经理、Red Hat 知识库维护人员和支持工程师。
|
||||
|
||||
-----------
|
||||
|
||||
via: https://opensource.com/open-organization/17/6/working-open-and-gsd
|
||||
|
||||
作者:[Jason Hibbets ][a]
|
||||
作者:[Jason Hibbets][a]
|
||||
译者:[explosic4](https://github.com/explosic4)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
311
published/20170617 What all you need to know about HTML5.md
Normal file
311
published/20170617 What all you need to know about HTML5.md
Normal file
@ -0,0 +1,311 @@
|
||||
关于 HTML5 你需要了解的基础知识
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> HTML5 是第五个且是当前的 HTML 版本,它是用于在万维网上构建和呈现内容的标记语言。本文将帮助读者了解它。
|
||||
|
||||
HTML5 通过 W3C 和<ruby>Web 超文本应用技术工作组<rt>Web Hypertext Application Technology Working Group</rt></ruby>之间的合作发展起来。它是一个更高版本的 HTML,它的许多新元素可以使你的页面更加语义化和动态。它是为所有人提供更好的 Web 体验而开发的。HTML5 提供了很多的功能,使 Web 更加动态和交互。
|
||||
|
||||
HTML5 的新功能是:
|
||||
|
||||
* 新标签,如 `<header>` 和 `<section>`
|
||||
* 用于 2D 绘图的 `<canvas>` 元素
|
||||
* 本地存储
|
||||
* 新的表单控件,如日历、日期和时间
|
||||
* 新媒体功能
|
||||
* 地理位置
|
||||
|
||||
HTML5 还不是正式标准(LCTT 译注:HTML5 已于 2014 年成为“推荐标准”),因此,并不是所有的浏览器都支持它或其中一些功能。开发 HTML5 背后最重要的原因之一是防止用户下载并安装像 Silverlight 和 Flash 这样的多个插件。
|
||||
|
||||
**新标签和元素**
|
||||
|
||||
- **语义化元素:** 图 1 展示了一些有用的语义化元素。
|
||||
- **表单元素:** HTML5 中的表单元素如图 2 所示。
|
||||
- **图形元素:** HTML5 中的图形元素如图 3 所示。
|
||||
- **媒体元素:** HTML5 中的新媒体元素如图 4 所示。
|
||||
|
||||
|
||||
[][3]
|
||||
|
||||
*图 1:语义化元素*
|
||||
|
||||
[][4]
|
||||
|
||||
*图 2:表单元素*
|
||||
|
||||
[][5]
|
||||
|
||||
*图 3:图形元素*
|
||||
|
||||
[][6]
|
||||
|
||||
*图 4:媒体元素*
|
||||
|
||||
### HTML5 的高级功能
|
||||
|
||||
#### 地理位置
|
||||
|
||||
这是一个 HTML5 API,用于获取网站用户的地理位置,用户必须首先允许网站获取他或她的位置。这通常通过按钮和/或浏览器弹出窗口来实现。所有最新版本的 Chrome、Firefox、IE、Safari 和 Opera 都可以使用 HTML5 的地理位置功能。
|
||||
|
||||
地理位置的一些用途是:
|
||||
|
||||
* 公共交通网站
|
||||
* 出租车及其他运输网站
|
||||
* 电子商务网站计算运费
|
||||
* 旅行社网站
|
||||
* 房地产网站
|
||||
* 在附近播放的电影的电影院网站
|
||||
* 在线游戏
|
||||
* 网站首页提供本地标题和天气
|
||||
* 工作职位可以自动计算通勤时间
|
||||
|
||||
**工作原理:** 地理位置通过扫描位置信息的常见源进行工作,其中包括以下:
|
||||
|
||||
* 全球定位系统(GPS)是最准确的
|
||||
* 网络信号 - IP地址、RFID、Wi-Fi 和蓝牙 MAC地址
|
||||
* GSM/CDMA 蜂窝 ID
|
||||
* 用户输入
|
||||
|
||||
该 API 提供了非常方便的函数来检测浏览器中的地理位置支持:
|
||||
|
||||
```
|
||||
if (navigator.geolocation) {
|
||||
// do stuff
|
||||
}
|
||||
```
|
||||
`getCurrentPosition` API 是使用地理位置的主要方法。它检索用户设备的当前地理位置。该位置被描述为一组地理坐标以及航向和速度。位置信息作为位置对象返回。
|
||||
|
||||
语法是:
|
||||
|
||||
```
|
||||
getCurrentPosition(showLocation, ErrorHandler, options);
|
||||
```
|
||||
|
||||
* `showLocation`:定义了检索位置信息的回调方法。
|
||||
* `ErrorHandler`(可选):定义了在处理异步调用时发生错误时调用的回调方法。
|
||||
* `options` (可选): 定义了一组用于检索位置信息的选项。
|
||||
|
||||
我们可以通过两种方式向用户提供位置信息:测地和民用。
|
||||
|
||||
1. 描述位置的测地方式直接指向纬度和经度。
|
||||
2. 位置信息的民用表示法是人类可读的且容易理解。
|
||||
|
||||
如下表 1 所示,每个属性/参数都具有测地和民用表示。
|
||||
|
||||
[][7]
|
||||
|
||||
图 5 包含了一个位置对象返回的属性集。
|
||||
|
||||
[][8]
|
||||
|
||||
*图5:位置对象属性*
|
||||
|
||||
#### 网络存储
|
||||
|
||||
在 HTML 中,为了在本机存储用户数据,我们需要使用 JavaScript cookie。为了避免这种情况,HTML5 已经引入了 Web 存储,网站利用它在本机上存储用户数据。
|
||||
|
||||
与 Cookie 相比,Web 存储的优点是:
|
||||
|
||||
* 更安全
|
||||
* 更快
|
||||
* 存储更多的数据
|
||||
* 存储的数据不会随每个服务器请求一起发送。只有在被要求时才包括在内。这是 HTML5 Web 存储超过 Cookie 的一大优势。
|
||||
|
||||
有两种类型的 Web 存储对象:
|
||||
|
||||
1. 本地 - 存储没有到期日期的数据。
|
||||
2. 会话 - 仅存储一个会话的数据。
|
||||
|
||||
**如何工作:** `localStorage` 和 `sessionStorage` 对象创建一个 `key=value` 对。比如: `key="Name"`,` value="Palak"`。
|
||||
|
||||
这些存储为字符串,但如果需要,可以使用 JavaScript 函数(如 `parseInt()` 和 `parseFloat()`)进行转换。
|
||||
|
||||
下面给出了使用 Web 存储对象的语法:
|
||||
|
||||
- 存储一个值:
|
||||
- `localStorage.setItem("key1", "value1");`
|
||||
- `localStorage["key1"] = "value1";`
|
||||
- 得到一个值:
|
||||
- `alert(localStorage.getItem("key1"));`
|
||||
- `alert(localStorage["key1"]);`
|
||||
- 删除一个值:
|
||||
-`removeItem("key1");`
|
||||
- 删除所有值:
|
||||
- `localStorage.clear();`
|
||||
|
||||
#### 应用缓存(AppCache)
|
||||
|
||||
使用 HTML5 AppCache,我们可以使 Web 应用程序在没有 Internet 连接的情况下脱机工作。除 IE 之外,所有浏览器都可以使用 AppCache(截止至此时)。
|
||||
|
||||
应用缓存的优点是:
|
||||
|
||||
* 网页浏览可以脱机
|
||||
* 页面加载速度更快
|
||||
* 服务器负载更小
|
||||
|
||||
`cache manifest` 是一个简单的文本文件,其中列出了浏览器应缓存的资源以进行脱机访问。 `manifest` 属性可以包含在文档的 HTML 标签中,如下所示:
|
||||
|
||||
```
|
||||
<html manifest="test.appcache">
|
||||
...
|
||||
</html>
|
||||
```
|
||||
|
||||
它应该在你要缓存的所有页面上。
|
||||
|
||||
缓存的应用程序页面将一直保留,除非:
|
||||
|
||||
1. 用户清除它们
|
||||
2. `manifest` 被修改
|
||||
3. 缓存更新
|
||||
|
||||
#### 视频
|
||||
|
||||
在 HTML5 发布之前,没有统一的标准来显示网页上的视频。大多数视频都是通过 Flash 等不同的插件显示的。但 HTML5 规定了使用 video 元素在网页上显示视频的标准方式。
|
||||
|
||||
目前,video 元素支持三种视频格式,如表 2 所示。
|
||||
|
||||
[][9]
|
||||
|
||||
下面的例子展示了 video 元素的使用:
|
||||
|
||||
```
|
||||
<! DOCTYPE HTML>
|
||||
<html>
|
||||
<body>
|
||||
|
||||
<video src=" vdeo.ogg" width="320" height="240" controls="controls">
|
||||
|
||||
This browser does not support the video element.
|
||||
|
||||
</video>
|
||||
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
例子使用了 Ogg 文件,并且可以在 Firefox、Opera 和 Chrome 中使用。要使视频在 Safari 和未来版本的 Chrome 中工作,我们必须添加一个 MPEG4 和 WebM 文件。
|
||||
|
||||
`video` 元素允许多个 `source` 元素。`source` 元素可以链接到不同的视频文件。浏览器将使用第一个识别的格式,如下所示:
|
||||
|
||||
```
|
||||
<video width="320" height="240" controls="controls">
|
||||
<source src="vdeo.ogg" type="video/ogg" />
|
||||
<source src=" vdeo.mp4" type="video/mp4" />
|
||||
<source src=" vdeo.webm" type="video/webm" />
|
||||
This browser does not support the video element.
|
||||
</video>
|
||||
```
|
||||
|
||||
[][10]
|
||||
|
||||
*图6:Canvas 的输出*
|
||||
|
||||
#### 音频
|
||||
|
||||
对于音频,情况类似于视频。在 HTML5 发布之前,在网页上播放音频没有统一的标准。大多数音频也通过 Flash 等不同的插件播放。但 HTML5 规定了通过使用音频元素在网页上播放音频的标准方式。音频元素用于播放声音文件和音频流。
|
||||
|
||||
目前,HTML5 `audio` 元素支持三种音频格式,如表 3 所示。
|
||||
|
||||
[][11]
|
||||
|
||||
`audio` 元素的使用如下所示:
|
||||
|
||||
```
|
||||
<! DOCTYPE HTML>
|
||||
<html>
|
||||
<body>
|
||||
|
||||
<audio src=" song.ogg" controls="controls">
|
||||
|
||||
This browser does not support the audio element.
|
||||
|
||||
</video>
|
||||
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
此例使用 Ogg 文件,并且可以在 Firefox、Opera 和 Chrome 中使用。要在 Safari 和 Chrome 的未来版本中使 audio 工作,我们必须添加一个 MP3 和 Wav 文件。
|
||||
|
||||
`audio` 元素允许多个 `source` 元素,它可以链接到不同的音频文件。浏览器将使用第一个识别的格式,如下所示:
|
||||
|
||||
```
|
||||
<audio controls="controls">
|
||||
<source src="song.ogg" type="audio/ogg" />
|
||||
<source src="song.mp3" type="audio/mpeg" />
|
||||
|
||||
This browser does not support the audio element.
|
||||
|
||||
</audio>
|
||||
```
|
||||
|
||||
#### 画布(Canvas)
|
||||
|
||||
要在网页上创建图形,HTML5 使用 画布 API。我们可以用它绘制任何东西,并且它使用 JavaScript。它通过避免从网络下载图像而提高网站性能。使用画布,我们可以绘制形状和线条、弧线和文本、渐变和图案。此外,画布可以让我们操作图像中甚至视频中的像素。你可以将 `canvas` 元素添加到 HTML 页面,如下所示:
|
||||
|
||||
```
|
||||
<canvas id="myCanvas" width="200" height="100"></canvas>
|
||||
```
|
||||
|
||||
画布元素不具有绘制元素的功能。我们可以通过使用 JavaScript 来实现绘制。所有绘画应在 JavaScript 中。
|
||||
|
||||
```
|
||||
<script type="text/javascript">
|
||||
var c=document.getElementById("myCanvas");
|
||||
var cxt=c.getContext("2d");
|
||||
cxt.fillStyle="blue";
|
||||
cxt.storkeStyle = "red";
|
||||
cxt.fillRect(10,10,100,100);
|
||||
cxt.storkeRect(10,10,100,100);
|
||||
</script>
|
||||
```
|
||||
|
||||
以上脚本的输出如图 6 所示。
|
||||
|
||||
你可以绘制许多对象,如弧、圆、线/垂直梯度等。
|
||||
|
||||
### HTML5 工具
|
||||
|
||||
为了有效操作,所有熟练的或业余的 Web 开发人员/设计人员都应该使用 HTML5 工具,当需要设置工作流/网站或执行重复任务时,这些工具非常有帮助。它们提高了网页设计的可用性。
|
||||
|
||||
以下是一些帮助创建很棒的网站的必要工具。
|
||||
|
||||
- **HTML5 Maker:** 用来在 HTML、JavaScript 和 CSS 的帮助下与网站内容交互。非常容易使用。它还允许我们开发幻灯片、滑块、HTML5 动画等。
|
||||
- **Liveweave:** 用来测试代码。它减少了保存代码并将其加载到屏幕上所花费的时间。在编辑器中粘贴代码即可得到结果。它非常易于使用,并为一些代码提供自动完成功能,这使得开发和测试更快更容易。
|
||||
- **Font dragr:** 在浏览器中预览定制的 Web 字体。它会直接载入该字体,以便你可以知道看起来是否正确。也提供了拖放界面,允许你拖动字形、Web 开放字体和矢量图形来马上测试。
|
||||
- **HTML5 Please:** 可以让我们找到与 HTML5 相关的任何内容。如果你想知道如何使用任何一个功能,你可以在 HTML Please 中搜索。它提供了支持的浏览器和设备的有用资源的列表,语法,以及如何使用元素的一般建议等。
|
||||
- **Modernizr:** 这是一个开源工具,用于给访问者浏览器提供最佳体验。使用此工具,你可以检测访问者的浏览器是否支持 HTML5 功能,并加载相应的脚本。
|
||||
- **Adobe Edge Animate:** 这是必须处理交互式 HTML 动画的 HTML5 开发人员的有用工具。它用于数字出版、网络和广告领域。此工具允许用户创建无瑕疵的动画,可以跨多个设备运行。
|
||||
- **Video.js:** 这是一款基于 JavaScript 的 HTML5 视频播放器。如果要将视频添加到你的网站,你应该使用此工具。它使视频看起来不错,并且是网站的一部分。
|
||||
- **The W3 Validator:** W3 验证工具测试 HTML、XHTML、SMIL、MathML 等中的网站标记的有效性。要测试任何网站的标记有效性,你必须选择文档类型为 HTML5 并输入你网页的 URL。这样做之后,你的代码将被检查,并将提供所有错误和警告。
|
||||
- **HTML5 Reset:** 此工具允许开发人员在 HTML5 中重写旧网站的代码。你可以使用这些工具为你网站的访问者提供一个良好的网络体验。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
Palak Shah
|
||||
|
||||
作者是高级软件工程师。她喜欢探索新技术,学习创新概念。她也喜欢哲学。你可以通过 palak311@gmail.com 联系她。
|
||||
|
||||
--------------------
|
||||
via: http://opensourceforu.com/2017/06/introduction-to-html5/
|
||||
|
||||
作者:[Palak Shah][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://opensourceforu.com/author/palak-shah/
|
||||
[1]:http://opensourceforu.com/2017/06/introduction-to-html5/#disqus_thread
|
||||
[2]:http://opensourceforu.com/author/palak-shah/
|
||||
[3]:http://opensourceforu.com/wp-content/uploads/2017/05/Figure-1-7.jpg
|
||||
[4]:http://opensourceforu.com/wp-content/uploads/2017/05/Figure-2-5.jpg
|
||||
[5]:http://opensourceforu.com/wp-content/uploads/2017/05/Figure-3-2.jpg
|
||||
[6]:http://opensourceforu.com/wp-content/uploads/2017/05/Figure-4-2.jpg
|
||||
[7]:http://opensourceforu.com/wp-content/uploads/2017/05/table-1.jpg
|
||||
[8]:http://opensourceforu.com/wp-content/uploads/2017/05/Figure5-1.jpg
|
||||
[9]:http://opensourceforu.com/wp-content/uploads/2017/05/table-2.jpg
|
||||
[10]:http://opensourceforu.com/wp-content/uploads/2017/05/Figure6-1.jpg
|
||||
[11]:http://opensourceforu.com/wp-content/uploads/2017/05/table-3.jpg
|
||||
80
published/20170707 The changing face of the hybrid cloud.md
Normal file
80
published/20170707 The changing face of the hybrid cloud.md
Normal file
@ -0,0 +1,80 @@
|
||||
混合云的变化
|
||||
============================================================
|
||||
|
||||
> 围绕云计算的概念和术语仍然很新,但是也在不断的改进。
|
||||
|
||||
|
||||

|
||||
|
||||
不管怎么看,云计算也只有十多年的发展时间。一些我们习以为常的云计算的概念和术语仍然很新。美国国家标准与技术研究所(NIST)文档显示,一些已经被熟悉的术语定义在 2011 年才被发布,例如基础设施即服务(IaaS),而在此之前它就以草案的形式广泛流传。
|
||||
|
||||
在该文档中其它定义中,有一个叫做<ruby>混合云<rt>hybrid cloud</rt></ruby>。让我们回溯一下该术语在这段期间的变化是很有启发性的。云基础设施已经超越了相对简单的分类。此外,它还强调了开源软件的使用者所熟悉的优先级,例如灵活性、可移植性、选择性,已经被运用到了混合云上。
|
||||
|
||||
NIST 对混合云最初的定义主要集中于<ruby>云爆发<rt>cloud bursting</rt></ruby>,你能使用内部的基础设施去处理一个基本的计算负荷,但是如果你的负荷量暴涨,可以将多出来的转为使用公有云。与之密切联系的是加强私有云与公有云之间 API 的兼容性,甚至是创造一个现货市场来提供最便宜的容量。
|
||||
|
||||
Nick Carr 在 [The Big Switch][10] 一书中提出一个概念,云是一种计算单元,其与输电网类似。这个故事不错,但是即使在早期,[这种类比的局限性也变得很明显][11]。计算不是以电流方式呈现的一种物品。需要关注的是,公有云提供商以及 OpenStack 一类的开源云软件激增的新功能,可见许多用户并不仅仅是寻找最便宜的通用计算能力。
|
||||
|
||||
云爆发的概念基本上忽略了计算是与数据相联系的现实,你不可能只移动洪水般突如其来的数据而不承担巨大的带宽费用,以及不用为转移需要花费的时间而操作。Dave McCrory 发明了 “<ruby>数据引力<rt>data gravity</rt></ruby>”一词去描述这个限制。
|
||||
|
||||
那么既然混合云有如此负面的情况,为什么我们现在还要再讨论混合云?
|
||||
|
||||
正如我说的,混合云的最初的构想是在云爆发的背景下诞生的。云爆发强调的是快速甚至是即时的将工作环境从一个云转移到另一个云上;然而,混合云也意味着应用和数据的移植性。确实,如之前 [2011 年我在 CNET 的文章][12]中写到:“我认为过度关注于全自动的工作转换给我们自己造成了困扰,我们真正应该关心的是,如果供应商不能满意我们的需求或者尝试将我们锁定在其平台上时,我们是否有将数据从一个地方到另一个地方的迁移能力。”
|
||||
|
||||
从那以后,探索云之间的移植性有了进一步的进展。
|
||||
|
||||
Linux 是云移植性的关键,因为它能运行在各种地方,无论是从裸机到内部虚拟基础设施,还是从私有云到公有云。Linux 提供了一个完整、可靠的平台,其具有稳定的 API 接口,且可以依靠这些接口编写程序。
|
||||
|
||||
被广泛采纳的容器进一步加强了 Linux 提供应用在云之间移植的能力。通过提供一个包含了应用的基础配置环境的镜像,应用在开发、测试和最终运行环境之间移动时容器提供了可移植性和兼容性。
|
||||
|
||||
Linux 容器被应用到要求可移植性、可配置性以及独立性的许多方面上。不管是预置的云,还是公有云,以及混合云都是如此。
|
||||
|
||||
容器使用的是基于镜像的部署模式,这让在不同环境中分享一个应用或者具有全部基础环境的服务集变得容易了。
|
||||
|
||||
在 OCI 支持下开发的规范定义了容器镜像的内容及其所依赖、环境、参数和一些镜像正确运行所必须的要求。在标准化的作用下,OCI 为许多其它工具提供了一个机会,它们现在可以依靠稳定的运行环境和镜像规范了。
|
||||
|
||||
同时,通过 Gluster 和 Ceph 这类的开源技术,分布式存储能提供数据在云上的可移植性。 物理约束限制了如何快速简单地把数据从一个地方移动到另一个地方;然而,随着组织部署和使用不同类型的基础架构,他们越来越渴望一个不受物理、虚拟和云资源限制的开放的软件定义储存平台。
|
||||
|
||||
尤其是在数据存储需求飞速增长的情况下,由于预测分析,物联网和实时监控的趋势。[2016 年的一项研究表明][13],98% 的 IT 决策者认为一个更敏捷的存储解决方案对他们的组织是有利的。在同一个研究中,他们列举出不恰当的存储基础设施是最令他们组织受挫的事情之一。
|
||||
|
||||
混合云表现出的是提供在不同计算能力和资源之间合适的移植性和兼容性。其不仅仅是将私有云和公有云同时运用在一个应用中。它是一套多种类型的服务,其中的一部分可能是你们 IT 部门建立和操作的,而另一部分可能来源于外部。
|
||||
|
||||
它们可能是软件即服务(SaaS)应用的混合,例如邮件和客户关系管理(CRM)。被 Kubernetes 这类开源软件协调在一起的容器平台越来越受新开发应用的欢迎。你的组织可能正在运用某一家大型云服务提供商来做一些事情。同时你也能在私有云或更加传统的内部基础设施上操作一些你自己的基础设施。
|
||||
|
||||
这就是现在混合云的现状,它能被归纳为两个选择,选择最合适的基础设施和服务,以及选择把应用和数据从一个地方移动到另一个你想的地方。
|
||||
|
||||
**相关阅读: [多重云和混合云有什么不同?][6]**
|
||||
|
||||
(题图 : [Flickr 使用者: theaucitron][9] (CC BY-SA 2.0))
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Gordon Haff 是红帽云的布道者,常受到业内和客户的高度赞赏,帮助红帽云组合方案的发展。他是《Computing Next: How the Cloud Opens the Future》的作者,除此之外他还有许多出版物。在红帽之前,Gordon 写了大量的研究简报,经常被纽约时报等出版物在 IT 类话题上引用,在产品和市场策略上给予客户建议。他职业生涯的早期,在 Data General 他负责将各种不同的计算机系统,从微型计算机到大型的 UNIX 服务器,引入市场。他有麻省理工学院和达特茅斯学院的工程学位,还是康奈尔大学约翰逊商学院的工商管理学硕士。
|
||||
|
||||
-----
|
||||
|
||||
via: https://opensource.com/article/17/7/hybrid-cloud
|
||||
|
||||
作者:[Gordon Haff (Red Hat)][a]
|
||||
译者:[ZH1122](https://github.com/ZH1122)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ghaff
|
||||
[1]:https://opensource.com/resources/cloud?src=cloud_resource_menu1
|
||||
[2]:https://opensource.com/resources/what-is-openstack?src=cloud_resource_menu2
|
||||
[3]:https://opensource.com/resources/what-is-kubernetes?src=cloud_resource_menu3
|
||||
[4]:https://opensource.com/16/12/yearbook-why-operating-system-matters?src=cloud_resource_menu4
|
||||
[5]:https://opensource.com/business/16/10/interview-andy-cathrow-anchore?src=cloud_resource_menu5
|
||||
[6]:https://enterprisersproject.com/article/2017/7/multi-cloud-vs-hybrid-cloud-whats-difference
|
||||
[7]:https://opensource.com/article/17/7/hybrid-cloud?rate=ztmV2D_utD03cID1u41Al08w0XFm6rXXwCJdTwqI4iw
|
||||
[8]:https://opensource.com/user/21220/feed
|
||||
[9]:https://www.flickr.com/photos/theaucitron/5810163712/in/photolist-5p9nh3-6EkSKG-6EgGEF-9hYBcr-abCSpq-9zbjDz-4PVqwm-9RqBfq-abA2T4-4nXfwv-9RQkdN-dmjSdA-84o2ER-abA2Wp-ehyhPC-7oFYrc-4nvqBz-csMQXb-nRegFf-ntS23C-nXRyaB-6Xw3Mq-cRMaCq-b6wkkP-7u8sVQ-yqcg-6fTmk7-bzm3vU-6Xw3vL-6EkzCQ-d3W8PG-5MoveP-oMWsyY-jtMME6-XEMwS-2SeRXT-d2hjzJ-p2ZZVZ-7oFYoX-84r6Mo-cCizvm-gnnsg5-77YfPx-iDjqK-8gszbW-6MUZEZ-dhtwtk-gmpTob-6TBJ8p-mWQaAC/
|
||||
[10]:http://www.nicholascarr.com/?page_id=21
|
||||
[11]:https://www.cnet.com/news/there-is-no-big-switch-for-cloud-computing/
|
||||
[12]:https://www.cnet.com/news/cloudbursting-or-just-portable-clouds/
|
||||
[13]:https://www.redhat.com/en/technologies/storage/vansonbourne
|
||||
[14]:https://opensource.com/users/ghaff
|
||||
[15]:https://opensource.com/users/ghaff
|
||||
@ -1,22 +1,17 @@
|
||||
translating by sugarfillet
|
||||
Functional testing Gtk+ applications in C
|
||||
============================================================
|
||||
用 C 语言对 Gtk+ 应用进行功能测试
|
||||
========
|
||||
|
||||
### Learn how to test your application's function with this simple tutorial.
|
||||
> 这个简单教程教你如何测试你应用的功能
|
||||
|
||||

|
||||
|
||||

|
||||
Image by :
|
||||
自动化测试用来保证你程序的质量以及让它以预想的运行。单元测试只是检测你算法的某一部分,而并不注重各组件间的适应性。这就是为什么会有功能测试,它有时也称为集成测试。
|
||||
|
||||
opensource.com
|
||||
功能测试简单地与你的用户界面进行交互,无论它是网站还是桌面应用。为了展示功能测试如何工作,我们以测试一个 Gtk+ 应用为例。为了简单起见,这个教程里,我们使用 Gtk+ 2.0 教程的示例。
|
||||
|
||||
Automated tests are required to ensure your program's quality and that it works as expected. Unit tests examine only certain parts of your algorithm, but don't look at how each component fits together. That's where functional testing, sometimes referred as integration testing, comes in.
|
||||
### 基础设置
|
||||
|
||||
A functional test basically interacts with your user interface, whether through a website or a desktop application. To show you how that works, let's look at how to test a Gtk+ application. For simplicity, in this tutorial let's use the [Tictactoe][6] example from the Gtk+ 2.0 tutorial.
|
||||
|
||||
### Basic setup
|
||||
|
||||
For every functional test, you usually define some global variables, such as "user interaction delay" or "timeout until a failure is indicated" (i.e., when an event doesn't occur until the specified time and the application is doomed).
|
||||
对于每一个功能测试,你通常需要定义一些全局变量,比如 “用户交互时延” 或者 “失败的超时时间”(也就是说,如果在指定的时间内一个事件没有发生,程序就要中断)。
|
||||
|
||||
```
|
||||
#define TTT_FUNCTIONAL_TEST_UTIL_IDLE_CONDITION(f) ((TttFunctionalTestUtilIdleCondition)(f))
|
||||
@ -29,7 +24,7 @@ struct timespec ttt_functional_test_util_default_timeout = {
|
||||
};
|
||||
```
|
||||
|
||||
Now we can implement our dead-time functions. Here, we'll use the **usleep** function in order to get the desired delay.
|
||||
现在我们可以实现我们自己的超时函数。这里,为了能够得到期望的延迟,我们采用 `usleep` 函数。
|
||||
|
||||
```
|
||||
void
|
||||
@ -45,7 +40,7 @@ ttt_functional_test_util_reaction_time_long()
|
||||
}
|
||||
```
|
||||
|
||||
The timeout function delays execution until a state of a control is applied. It is useful for actions that are applied asynchronously, and that is why it delays for a longer period of time.
|
||||
直到获得控制状态,超时函数才会推迟执行。这对于一个异步执行的动作很有帮助,这也是为什么采用这么长的时延。
|
||||
|
||||
```
|
||||
void
|
||||
@ -74,17 +69,16 @@ ttt_functional_test_util_idle_condition_and_timeout(
|
||||
}
|
||||
```
|
||||
|
||||
### Interacting with the graphical user interface
|
||||
### 与图形化用户界面交互
|
||||
|
||||
In order to simulate user interaction, the [**Gdk library**][7] provides the functions we need. To do our work here, we need only these three functions:
|
||||
为了模拟用户交互的操作, [Gdk 库][7] 为我们提供了一些需要的函数。要完成我们的工作,我们只需要如下 3 个函数:
|
||||
|
||||
* gdk_display_warp_pointer()
|
||||
* `gdk_display_warp_pointer()`
|
||||
* `gdk_test_simulate_button()`
|
||||
* `gdk_test_simulate_key()`
|
||||
|
||||
* gdk_test_simulate_button()
|
||||
|
||||
* gdk_test_simulate_key()
|
||||
|
||||
For instance, to test a button click, we do the following:
|
||||
举个例子,为了测试按钮点击,我们可以这么做:
|
||||
|
||||
```
|
||||
gboolean
|
||||
@ -151,7 +145,8 @@ ttt_functional_test_util_button_click(GtkButton *button)
|
||||
}
|
||||
```
|
||||
|
||||
We want to ensure the button has an active state, so we provide an idle-condition function:
|
||||
|
||||
我们想要保证按钮处于激活状态,因此我们提供一个空闲条件函数:
|
||||
|
||||
```
|
||||
gboolean
|
||||
@ -176,11 +171,12 @@ ttt_functional_test_util_idle_test_toggle_active(
|
||||
}
|
||||
```
|
||||
|
||||
### The test scenario
|
||||
|
||||
Since the Tictactoe program is very simple, we just need to ensure that a [**GtkToggleButton**][8] was clicked. The functional test can proceed once it asserts the button entered the active state. To click the buttons, we use the handy **util** function provided above.
|
||||
### 测试场景
|
||||
|
||||
For illustration, let's assume player A wins immediately by filling the very first row, because player B is not paying attention and just filled the second row:
|
||||
因为这个 Tictactoe 程序非常简单,我们只需要确保点击了一个 [**GtkToggleButton**][8] 按钮即可。一旦该按钮肯定进入了激活状态,功能测试就可以执行。为了点击按钮,我们使用上面提到的很方便的 `util` 函数。
|
||||
|
||||
如图所示,我们假设,填满第一行,玩家 A 就赢,因为玩家 B 没有注意,只填充了第二行。
|
||||
|
||||
```
|
||||
GtkWindow *window;
|
||||
@ -265,18 +261,21 @@ main(int argc, char **argv)
|
||||
}
|
||||
```
|
||||
|
||||
(题图:opensource.com)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Joël Krähemann - Free software enthusiast with a strong knowledge about the C programming language. I don't fear any code complexity as long it is written in a simple manner. As developer of Advanced Gtk+ Sequencer I know how challenging multi-threaded applications can be and with it we have a great basis for future demands.my personal website
|
||||
|
||||
Joël Krähemann - 精通 C 语言编程的自由软件爱好者。不管代码多复杂,它也是一点点写成的。作为高级的 Gtk+ 程序开发者,我知道多线程编程有多大的挑战性,有了多线程编程,我们就有了未来需求的良好基础。
|
||||
|
||||
----
|
||||
via: https://opensource.com/article/17/7/functional-testing
|
||||
|
||||
作者:[Joël Krähemann][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[sugarfillet](https://github.com/sugarfillet)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,160 @@
|
||||
动态端口转发:安装带有 SSH 的 SOCKS 服务器
|
||||
=================
|
||||
|
||||
在上一篇文章([通过 SSH 实现 TCP / IP 隧道(端口转发):使用 OpenSSH 可能的 8 种场景][17])中,我们看到了处理端口转发的所有可能情况,不过那只是静态端口转发。也就是说,我们只介绍了通过 SSH 连接来访问另一个系统的端口的情况。
|
||||
|
||||
在那篇文章中,我们未涉及动态端口转发,此外一些读者没看过该文章,本篇文章中将尝试补充完整。
|
||||
|
||||
当我们谈论使用 SSH 进行动态端口转发时,我们说的是将 SSH 服务器转换为 [SOCKS][2] 服务器。那么什么是 SOCKS 服务器?
|
||||
|
||||
你知道 [Web 代理][3]是用来做什么的吗?答案可能是肯定的,因为很多公司都在使用它。它是一个直接连接到互联网的系统,允许没有互联网访问的[内部网][4]客户端让其浏览器通过代理来(尽管也有[透明代理][5])浏览网页。Web 代理除了允许输出到 Internet 之外,还可以缓存页面、图像等。已经由某客户端下载的资源,另一个客户端不必再下载它们。此外,它还可以过滤内容并监视用户的活动。当然了,它的基本功能是转发 HTTP 和 HTTPS 流量。
|
||||
|
||||
一个 SOCKS 服务器提供的服务类似于公司内部网络提供的代理服务器服务,但不限于 HTTP/HTTPS,它还允许转发任何 TCP/IP 流量(SOCKS 5 也支持 UDP)。
|
||||
|
||||
例如,假设我们希望在一个没有直接连接到互联网的内部网上通过 Thunderbird 使用 POP3 、 ICMP 和 SMTP 的邮件服务。如果我们只有一个 web 代理可以用,我们可以使用的唯一的简单方式是使用某个 webmail(也可以使用 [Thunderbird 的 Webmail 扩展][6])。我们还可以通过 [HTTP 隧道][7]来起到代理的用途。但最简单的方式是在网络中设置一个 SOCKS 服务器,它可以让我们使用 POP3、ICMP 和 SMTP,而不会造成任何的不便。
|
||||
|
||||
虽然有很多软件可以配置非常专业的 SOCKS 服务器,但用 OpenSSH 设置一个只需要简单的一条命令:
|
||||
|
||||
```
|
||||
Clientessh $ ssh -D 1080 user@servidorssh
|
||||
```
|
||||
|
||||
或者我们可以改进一下:
|
||||
|
||||
```
|
||||
Clientessh $ ssh -fN -D 0.0.0.0:1080 user@servidorssh
|
||||
```
|
||||
|
||||
其中:
|
||||
|
||||
* 选项 `-D` 类似于选项为 `-L` 和 `-R` 的静态端口转发。像那些一样,我们可以让客户端只监听本地请求或从其他节点到达的请求,具体取决于我们将请求关联到哪个地址:
|
||||
```
|
||||
-D [bind_address:] port
|
||||
```
|
||||
|
||||
在静态端口转发中可以看到,我们使用选项 `-R` 进行反向端口转发,而动态转发是不可能的。我们只能在 SSH 客户端创建 SOCKS 服务器,而不能在 SSH 服务器端创建。
|
||||
* 1080 是 SOCKS 服务器的典型端口,正如 8080 是 Web 代理服务器的典型端口一样。
|
||||
* 选项 `-N` 防止实际启动远程 shell 交互式会话。当我们只用 `ssh` 来建立隧道时很有用。
|
||||
* 选项 `-f` 会使 `ssh` 停留在后台并将其与当前 shell 分离,以便使该进程成为守护进程。如果没有选项 `-N`(或不指定命令),则不起作用,否则交互式 shell 将与后台进程不兼容。
|
||||
|
||||
使用 [PuTTY][8] 也可以非常简单地进行端口重定向。与 `ssh -D 0.0.0.0:1080` 相当的配置如下:
|
||||
|
||||

|
||||
|
||||
对于通过 SOCKS 服务器访问另一个网络的应用程序,如果应用程序提供了对 SOCKS 服务器的特别支持,就会非常方便(虽然不是必需的),就像浏览器支持使用代理服务器一样。作为一个例子,如 Firefox 或 Internet Explorer 这样的浏览器使用 SOCKS 服务器访问另一个网络的应用程序:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
注意:上述截图来自 [IE for Linux][1] :如果您需要在 Linux 上使用 Internet Explorer,强烈推荐!
|
||||
|
||||
然而,最常见的浏览器并不要求 SOCKS 服务器,因为它们通常与代理服务器配合得更好。
|
||||
|
||||
不过,Thunderbird 也支持 SOCKS,而且很有用:
|
||||
|
||||

|
||||
|
||||
另一个例子:[Spotify][9] 客户端同样支持 SOCKS:
|
||||
|
||||

|
||||
|
||||
需要关注一下名称解析。有时我们会发现,在目前的网络中,我们无法解析 SOCKS 服务器另一端所要访问的系统的名称。SOCKS 5 还允许我们通过隧道传播 DNS 请求( 因为 SOCKS 5 允许我们使用 UDP)并将它们发送到另一端:可以指定是本地还是远程解析(或者也可以两者都试试)。支持此功能的应用程序也必须考虑到这一点。例如,Firefox 具有参数 `network.proxy.socks_remote_dns`(在 `about:config` 中),允许我们指定远程解析。而默认情况下,它在本地解析。
|
||||
|
||||
Thunderbird 也支持参数 `network.proxy.socks_remote_dns`,但由于没有地址栏来放置 `about:config`,我们需要改变它,就像在 [MozillaZine:about:config][10] 中读到的,依次点击 工具 → 选项 → 高级 → 常规 → 配置编辑器(按钮)。
|
||||
|
||||
没有对 SOCKS 特别支持的应用程序可以被 <ruby>sock 化<rt>socksified</rt></ruby>。这对于使用 TCP/IP 的许多应用程序都没有问题,但并不是全部。“sock 化” 需要加载一个额外的库,它可以检测对 TCP/IP 堆栈的请求,并修改请求,以通过 SOCKS 服务器重定向,从而不需要特别编程来支持 SOCKS 便可以正常通信。
|
||||
|
||||
在 Windows 和 [Linux][18] 上都有 “Sock 化工具”。
|
||||
|
||||
对于 Windows,我们举个例子,SocksCap 是一种闭源,但对非商业使用免费的产品,我使用了很长时间都十分满意。SocksCap 由一家名为 Permeo 的公司开发,该公司是创建 SOCKS 参考技术的公司。Permeo 被 [Blue Coat][11] 买下后,它[停止了 SocksCap 项目][12]。现在你仍然可以在互联网上找到 `sc32r240.exe` 文件。[FreeCap][13] 也是面向 Windows 的免费代码项目,外观和使用都非常类似于 SocksCap。然而,它工作起来更加糟糕,多年来一直没有缺失维护。看起来,它的作者倾向于推出需要付款的新产品 [WideCap][14]。
|
||||
|
||||
这是 SocksCap 的一个界面,可以看到我们 “sock 化” 了的几个应用程序。当我们从这里启动它们时,这些应用程序将通过 SOCKS 服务器访问网络:
|
||||
|
||||

|
||||
|
||||
在配置对话框中可以看到,如果选择了协议 SOCKS 5,我们可以选择在本地或远程解析名称:
|
||||
|
||||

|
||||
|
||||
在 Linux 上,如同往常一样,对某个远程命令我们都有许多替代方案。在 Debian/Ubuntu 中,命令行:
|
||||
|
||||
```
|
||||
$ Apt-cache search socks
|
||||
```
|
||||
|
||||
的输出会告诉我们很多。
|
||||
|
||||
最著名的是 [tsocks][15] 和 [proxychains][16]。它们的工作方式大致相同:只需用它们启动我们想要 “sock 化” 的应用程序就行。使用 `proxychains` 的 `wget` 的例子:
|
||||
|
||||
```
|
||||
$ Proxychains wget http://www.google.com
|
||||
ProxyChains-3.1 (http://proxychains.sf.net)
|
||||
--19: 13: 20-- http://www.google.com/
|
||||
Resolving www.google.com ...
|
||||
DNS-request | Www.google.com
|
||||
| S-chain | - <- - 10.23.37.3:1080-<><>-4.2.2.2:53-<><>-OK
|
||||
| DNS-response | Www.google.com is 72.14.221.147
|
||||
72.14.221.147
|
||||
Connecting to www.google.com | 72.14.221.147 |: 80 ...
|
||||
| S-chain | - <- - 10.23.37.3:1080-<><>-72.14.221.147:80-<><>-OK
|
||||
Connected.
|
||||
HTTP request sent, awaiting response ... 200 OK
|
||||
Length: unspecified [text / html]
|
||||
Saving to: `index.html '
|
||||
|
||||
[<=>] 6,016 24.0K / s in 0.2s
|
||||
|
||||
19:13:21 (24.0 KB / s) - `index.html 'saved [6016]
|
||||
```
|
||||
|
||||
要让它可以工作,我们必须在 `/etc/proxychains.conf` 中指定要使用的代理服务器:
|
||||
|
||||
```
|
||||
[ProxyList]
|
||||
Socks5 clientessh 1080
|
||||
```
|
||||
|
||||
我们也设置远程进行 DNS 请求:
|
||||
|
||||
```
|
||||
# Proxy DNS requests - no leak for DNS data
|
||||
Proxy_dns
|
||||
```
|
||||
|
||||
另外,在前面的输出中,我们已经看到了同一个 `proxychains` 的几条信息性的消息, 非 `wget` 的行是标有字符串 `|DNS-request|`、`|S-chain|` 或 `|DNS-response|` 的。如果我们不想看到它们,也可以在配置中进行调整:
|
||||
|
||||
```
|
||||
# Quiet mode (no output from library)
|
||||
Quiet_mode
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://wesharethis.com/2017/07/15/dynamic-port-forwarding-mount-socks-server-ssh/
|
||||
|
||||
作者:[Ahmad][a]
|
||||
译者:[firmianay](https://github.com/firmianay)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://wesharethis.com/author/ahmad/
|
||||
[1]:https://wesharethis.com/goto/http://www.tatanka.com.br/ies4linux/page/Main_Page
|
||||
[2]:https://wesharethis.com/goto/http://en.wikipedia.org/wiki/SOCKS
|
||||
[3]:https://wesharethis.com/goto/http://en.wikipedia.org/wiki/Proxy_server
|
||||
[4]:https://wesharethis.com/goto/http://en.wikipedia.org/wiki/Intranet
|
||||
[5]:https://wesharethis.com/goto/http://en.wikipedia.org/wiki/Proxy_server#Transparent_and_non-transparent_proxy_server
|
||||
[6]:https://wesharethis.com/goto/http://webmail.mozdev.org/
|
||||
[7]:https://wesharethis.com/goto/http://en.wikipedia.org/wiki/HTTP_tunnel_(software)
|
||||
[8]:https://wesharethis.com/goto/http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html
|
||||
[9]:https://wesharethis.com/goto/https://www.spotify.com/int/download/linux/
|
||||
[10]:https://wesharethis.com/goto/http://kb.mozillazine.org/About:config
|
||||
[11]:https://wesharethis.com/goto/http://www.bluecoat.com/
|
||||
[12]:https://wesharethis.com/goto/http://www.bluecoat.com/products/sockscap
|
||||
[13]:https://wesharethis.com/goto/http://www.freecap.ru/eng/
|
||||
[14]:https://wesharethis.com/goto/http://widecap.ru/en/support/
|
||||
[15]:https://wesharethis.com/goto/http://tsocks.sourceforge.net/
|
||||
[16]:https://wesharethis.com/goto/http://proxychains.sourceforge.net/
|
||||
[17]:https://linux.cn/article-8945-1.html
|
||||
[18]:https://wesharethis.com/2017/07/10/linux-swap-partition/
|
||||
325
published/20170909 12 cool things you can do with GitHub.md
Normal file
325
published/20170909 12 cool things you can do with GitHub.md
Normal file
@ -0,0 +1,325 @@
|
||||
12 件可以用 GitHub 完成的很酷的事情
|
||||
============================================================
|
||||
|
||||
我不能为我的人生想出一个引子来,所以……
|
||||
|
||||
### #1 在 GitHub.com 上编辑代码
|
||||
|
||||
我想我要开始介绍的第一件事是多数人都已经知道的(尽管我一周之前还不知道)。
|
||||
|
||||
当你登录到 GitHub ,查看一个文件时(任何文本文件,任何版本库),右上方会有一只小铅笔。点击它,你就可以编辑文件了。 当你编辑完成后,GitHub 会给出文件变更的建议,然后为你<ruby>复刻<rt>fork</rt></ruby>该仓库并创建一个<ruby>拉取请求<rt>pull request</rt></ruby>(PR)。
|
||||
|
||||
是不是很疯狂?它为你创建了一个复刻!
|
||||
|
||||
你不需要自己去复刻、拉取,然后本地修改,再推送,然后创建一个 PR。
|
||||
|
||||
|
||||
|
||||
*不是一个真正的 PR*
|
||||
|
||||
这对于修改错误拼写以及编辑代码时的一些糟糕的想法是很有用的。
|
||||
|
||||
### #2 粘贴图像
|
||||
|
||||
在评论和<ruby>工单<rt>issue</rt></ruby>的描述中并不仅限于使用文字。你知道你可以直接从剪切板粘贴图像吗? 在你粘贴的时候,你会看到图片被上传 (到云端,这毫无疑问),并转换成 markdown 显示的图片格式。
|
||||
|
||||
棒极了。
|
||||
|
||||
### #3 格式化代码
|
||||
|
||||
如果你想写一个代码块的话,你可以用三个反引号(```)作为开始 —— 就像你在浏览 [精通 Markdown][3] 时所学到的一样 —— 而且 GitHub 会尝试去推测你所写下的编程语言。
|
||||
|
||||
但如果你粘贴的像是 Vue、Typescript 或 JSX 这样的代码,你就需要明确指出才能获得高亮显示。
|
||||
|
||||
在首行注明 ````jsx`:
|
||||
|
||||
|
||||
|
||||
…这意味着代码段已经正确的呈现:
|
||||
|
||||
|
||||
|
||||
(顺便说一下,这些用法也可以用到 gist。 如果你给一个 gist 用上 `.jsx` 扩展名,你的 JSX 语法就会高亮显示。)
|
||||
|
||||
这里是[所有被支持的语法][4]的清单。
|
||||
|
||||
### #4 用 PR 中的魔法词来关闭工单
|
||||
|
||||
比方说你已经创建了一个用来修复 `#234` 工单的拉取请求。那么你就可以把 `fixes #234` 这段文字放在你的 PR 的描述中(或者是在 PR 的评论的任何位置)。
|
||||
|
||||
接下来,在合并 PR 时会自动关闭与之对应的工单。这是不是很酷?
|
||||
|
||||
这里是[更详细的学习帮助][5]。
|
||||
|
||||
### #5 链接到评论
|
||||
|
||||
是否你曾经想要链接到一个特定的评论但却无从着手?这是因为你不知道如何去做到这些。不过那都过去了,我的朋友,我告诉你啊,点击紧挨着名字的日期或时间,这就是如何链接到一个评论的方法。
|
||||
|
||||
|
||||
|
||||
*嘿,这里有 gaearon 的照片!*
|
||||
|
||||
### #6 链接到代码
|
||||
|
||||
那么你想要链接到代码的特定行么。我了解了。
|
||||
|
||||
试试这个:在查看文件的时候,点击挨着代码的行号。
|
||||
|
||||
哇哦,你看到了么?URL 更新了,加上了行号!如果你按下 `Shift` 键并点击其他的行号,格里格里巴巴变!URL 再一次更新并且现在出现了行范围的高亮。
|
||||
|
||||
分享这个 URL 将会链接到这个文件的那些行。但等一下,链接所指向的是当前分支。如果文件发生变更了怎么办?也许一个文件当前状态的<ruby>永久链接<rt>permalink</rt></ruby>就是你以后需要的。
|
||||
|
||||
我比较懒,所以我已经在一张截图中做完了上面所有的步骤:
|
||||
|
||||
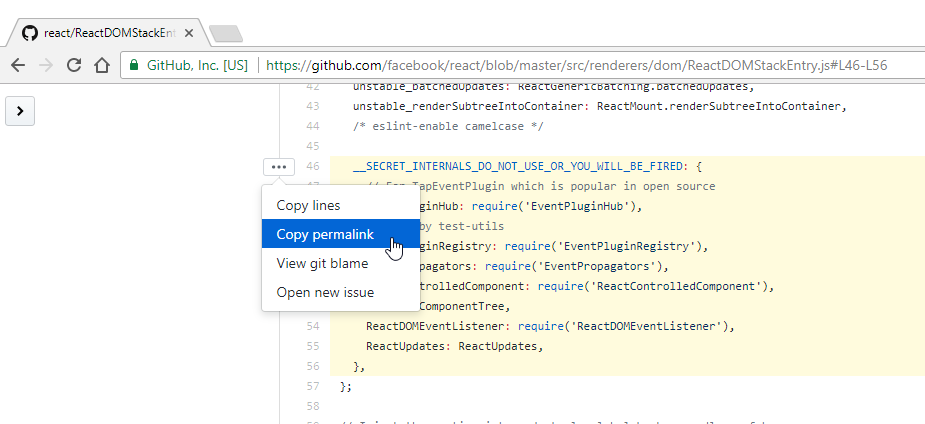
|
||||
|
||||
*说起 URL…*
|
||||
|
||||
### #7 像命令行一样使用 GitHub URL
|
||||
|
||||
使用 UI 来浏览 GitHub 有着很好的体验。但有些时候最快到达你想去的地方的方法就是在地址栏输入。举个例子,如果我想要跳转到一个我正在工作的分支,然后查看与 master 分支的差异,我就可以在我的仓库名称的后边输入 `/compare/branch-name` 。
|
||||
|
||||
这样就会访问到指定分支的 diff 页面。
|
||||
|
||||
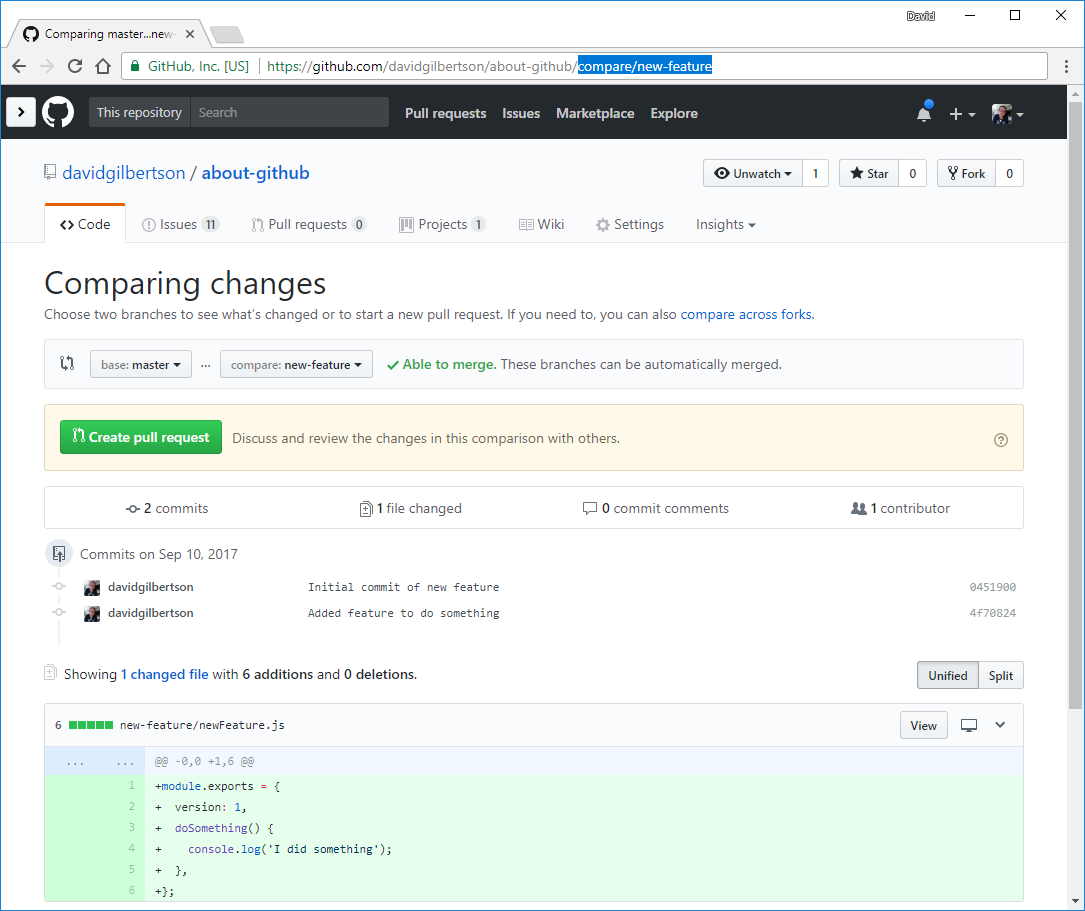
|
||||
|
||||
然而这就是与 master 分支的 diff,如果我要与 develoment 分支比较,我可以输入 `/compare/development...my-branch`。
|
||||
|
||||
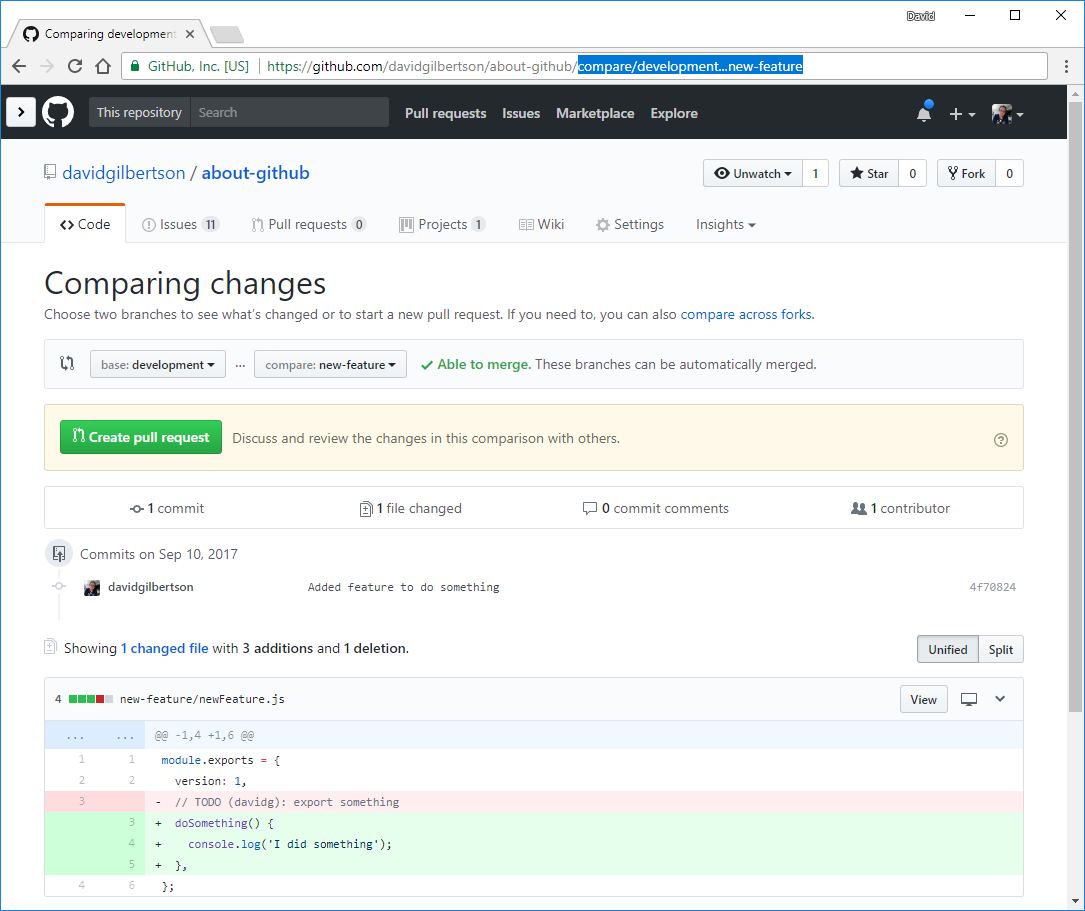
|
||||
|
||||
对于你这种键盘快枪手来说,`ctrl`+`L` 或 `cmd`+`L` 将会向上跳转光标进入 URL 那里(至少在 Chrome 中是这样)。这(再加上你的浏览器会自动补全)能够成为一种在分支间跳转的便捷方式。
|
||||
|
||||
专家技巧:使用方向键在 Chrome 的自动完成建议中移动同时按 `shift`+`delete` 来删除历史条目(例如,一旦分支被合并后)。
|
||||
|
||||
(我真的好奇如果我把快捷键写成 `shift + delete` 这样的话,是不是读起来会更加容易。但严格来说 ‘+’ 并不是快捷键的一部分,所以我并不觉得这很舒服。这一点纠结让 _我_ 整晚难以入睡,Rhonda。)
|
||||
|
||||
### #8 在工单中创建列表
|
||||
|
||||
你想要在你的<ruby>工单<rt>issue</rt></ruby>中看到一个复选框列表吗?
|
||||
|
||||
|
||||
|
||||
你想要在工单列表中显示为一个漂亮的 “2 of 5” 进度条吗?
|
||||
|
||||
|
||||
|
||||
很好!你可以使用这些的语法创建交互式的复选框:
|
||||
|
||||
```
|
||||
- [ ] Screen width (integer)
|
||||
- [x] Service worker support
|
||||
- [x] Fetch support
|
||||
- [ ] CSS flexbox support
|
||||
- [ ] Custom elements
|
||||
```
|
||||
|
||||
它的表示方法是空格、破折号、再空格、左括号、填入空格(或者一个 `x` ),然后封闭括号,接着空格,最后是一些话。
|
||||
|
||||
然后你可以实际选中或取消选中这些框!出于一些原因这些对我来说看上去就像是技术魔法。你可以_选中_这些框! 同时底层的文本会进行更新。
|
||||
|
||||
他们接下来会想到什么魔法?
|
||||
|
||||
噢,如果你在一个<ruby>项目面板<rt>project board</rt></ruby>上有这些工单的话,它也会在这里显示进度:
|
||||
|
||||
|
||||
|
||||
如果在我提到“在一个项目面板上”时你不知道我在说些什么,那么你会在本页下面进一步了解。
|
||||
|
||||
比如,在本页面下 2 厘米的地方。
|
||||
|
||||
### #9 GitHub 上的项目面板
|
||||
|
||||
我常常在大项目中使用 Jira 。而对于个人项目我总是会使用 Trello 。我很喜欢它们两个。
|
||||
|
||||
当我学会 GitHub 的几周后,它也有了自己的项目产品,就在我的仓库上的 Project 标签,我想我会照搬一套我已经在 Trello 上进行的任务。
|
||||
|
||||
|
||||
|
||||
*没有一个是有趣的任务*
|
||||
|
||||
这里是在 GitHub 项目上相同的内容:
|
||||
|
||||
|
||||
|
||||
*你的眼睛最终会适应这种没有对比的显示*
|
||||
|
||||
出于速度的缘故,我把上面所有的都添加为 “<ruby>备注<rt>note</rt></ruby>” —— 意思是它们不是真正的 GitHub 工单。
|
||||
|
||||
但在 GitHub 上,管理任务的能力被集成在版本库的其他地方 —— 所以你可能想要从仓库添加已有的工单到面板上。
|
||||
|
||||
你可以点击右上角的<ruby>添加卡片<rt>Add Cards</rt></ruby>,然后找你想要添加的东西。在这里,特殊的[搜索语法][6]就派上用场了,举个例子,输入 `is:pr is:open` 然后现在你可以拖动任何开启的 PR 到项目面板上,或者要是你想清理一些 bug 的话就输入 `label:bug`。
|
||||
|
||||
|
||||
|
||||
亦或者你可以将现有的备注转换为工单。
|
||||
|
||||
|
||||
|
||||
再或者,从一个现有工单的屏幕上,把它添加到右边面板的项目上。
|
||||
|
||||
|
||||
|
||||
它们将会进入那个项目面板的分类列表,这样你就能决定放到哪一类。
|
||||
|
||||
在实现那些任务的同一个仓库下放置任务的内容有一个巨大(超大)的好处。这意味着今后的几年你能够在一行代码上做一个 `git blame`,可以让你找出最初在这个任务背后写下那些代码的根据,而不需要在 Jira、Trello 或其它地方寻找蛛丝马迹。
|
||||
|
||||
#### 缺点
|
||||
|
||||
在过去的三周我已经对所有的任务使用 GitHub 取代 Jira 进行了测试(在有点看板风格的较小规模的项目上) ,到目前为止我都很喜欢。
|
||||
|
||||
但是我无法想象在 scrum(LCTT 译注:迭代式增量软件开发过程)项目上使用它,我想要在那里完成正确的工期估算、开发速度的测算以及所有的好东西怕是不行。
|
||||
|
||||
好消息是,GitHub 项目只有很少一些“功能”,并不会让你花很长时间去评估它是否值得让你去切换。因此要不要试试,你自己看着办。
|
||||
|
||||
无论如何,我_听说过_ [ZenHub][7] 并且在 10 分钟前第一次打开了它。它是对 GitHub 高效的延伸,可以让你估计你的工单并创建 epic 和 dependency。它也有 velocity 和<ruby>燃尽图<rt>burndown chart</rt></ruby>功能;这看起来_可能是_世界上最棒的东西了。
|
||||
|
||||
延伸阅读: [GitHub help on Projects][8]。
|
||||
|
||||
### #10 GitHub 维基
|
||||
|
||||
对于一堆非结构化页面(就像维基百科一样), GitHub <ruby>维基<rt>wiki</rt></ruby>提供的(下文我会称之为 Gwiki)就很优秀。
|
||||
|
||||
结构化的页面集合并没那么多,比如说你的文档。这里没办法说“这个页面是那个页面的子页”,或者有像‘下一节’和‘上一节’这样的按钮。Hansel 和 Gretel 将会完蛋,因为这里没有面包屑导航(LCTT 译注:引自童话故事《糖果屋》)。
|
||||
|
||||
(边注,你有_读过_那个故事吗? 这是个残酷的故事。两个混蛋小子将饥肠辘辘的老巫婆烧死在_她自己的火炉_里。毫无疑问她是留下来收拾残局的。我想这就是为什么如今的年轻人是如此的敏感 —— 今天的睡前故事太不暴力了。)
|
||||
|
||||
继续 —— 把 Gwiki 拿出来接着讲,我输入一些 NodeJS 文档中的内容作为维基页面,然后创建一个侧边栏以模拟一些真实结构。这个侧边栏会一直存在,尽管它无法高亮显示你当前所在的页面。
|
||||
|
||||
其中的链接必须手动维护,但总的来说,我认为这已经很好了。如果你觉得有需要的话可以[看一下][9]。
|
||||
|
||||
|
||||
|
||||
它将不会与像 GitBook(它使用了 [Redux 文档][10])或定制的网站这样的东西相比较。但它八成够用了,而且它就在你的仓库里。
|
||||
|
||||
我是它的一个粉丝。
|
||||
|
||||
我的建议:如果你已经拥有不止一个 `README.md` 文件,并且想要一些不同的页面作为用户指南或是更详细的文档,那么下一步你就需要停止使用 Gwiki 了。
|
||||
|
||||
如果你开始觉得缺少的结构或导航非常有必要的话,去切换到其他的产品吧。
|
||||
|
||||
### #11 GitHub 页面(带有 Jekyll)
|
||||
|
||||
你可能已经知道了可以使用 GitHub <ruby>页面<rt>Pages</rt></ruby> 来托管静态站点。如果你不知道的话现在就可以去试试。不过这一节确切的说是关于使用 Jekyll 来构建一个站点。
|
||||
|
||||
最简单的来说, GitHub 页面 + Jekyll 会将你的 `README.md` 呈现在一个漂亮的主题中。举个例子,看看我的 [关于 github][11] 中的 readme 页面:
|
||||
|
||||
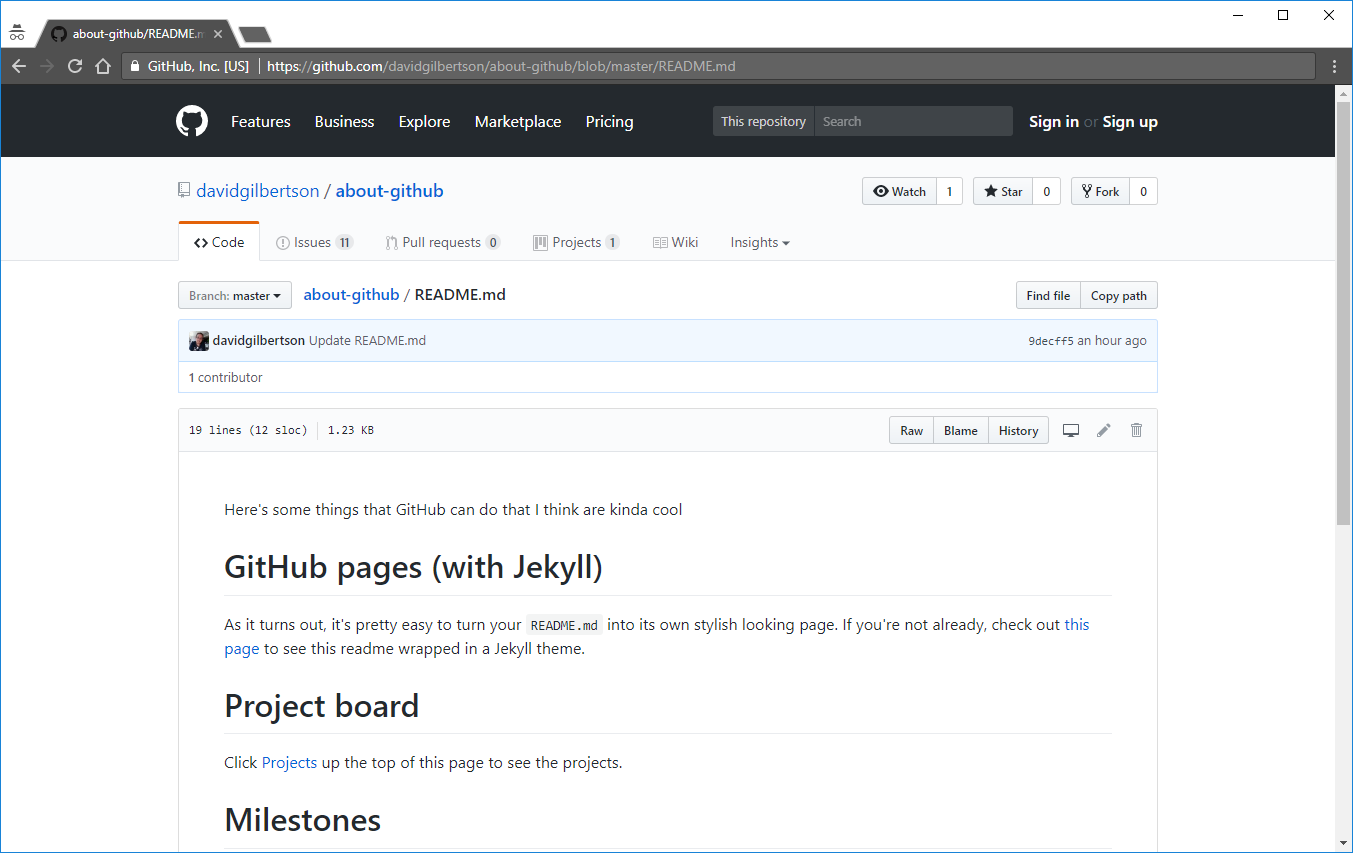
|
||||
|
||||
点击 GitHub 上我的站点的<ruby>设置<rt>settings</rt></ruby>标签,开启 GitHub 页面功能,然后挑选一个 Jekyll 主题……
|
||||
|
||||
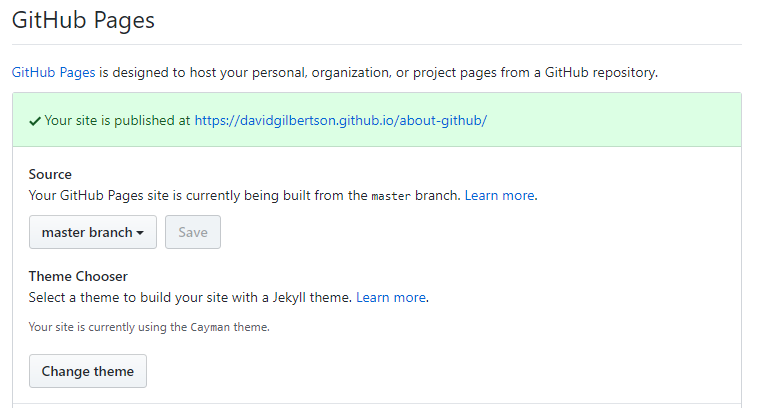
|
||||
|
||||
我就会得到一个 [Jekyll 主题的页面][12]:
|
||||
|
||||
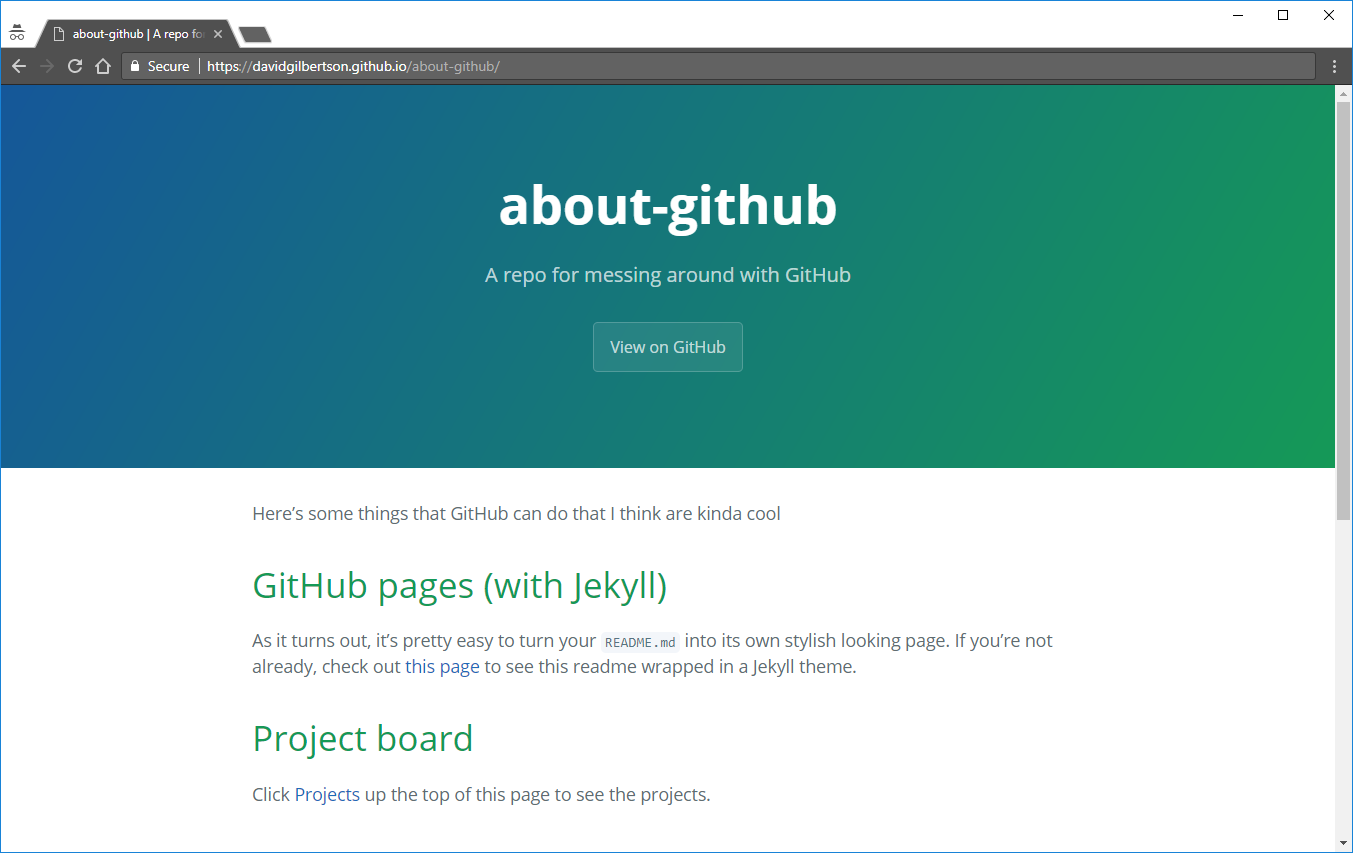
|
||||
|
||||
由此我可以构建一个主要基于易于编辑的 markdown 文件的静态站点,其本质上是把 GitHub 变成一个 CMS(LCTT 译注:内容管理系统)。
|
||||
|
||||
我还没有真正的使用过它,但这就是 React 和 Bootstrap 网站构建的过程,所以并不可怕。
|
||||
|
||||
注意,在本地运行它需要 Ruby (Windows 用户会彼此交换一下眼神,然后转头看向其它的方向。macOS 用户会发出这样这样的声音 “出什么问题了,你要去哪里?Ruby 可是一个通用平台!GEMS 万岁!”)。
|
||||
|
||||
(这里也有必要加上,“暴力或威胁的内容或活动” 在 GitHub 页面上是不允许的,因此你不能去部署你的 Hansel 和 Gretel 重启之旅了。)
|
||||
|
||||
#### 我的意见
|
||||
|
||||
为了这篇文章,我对 GitHub 页面 + Jekyll 研究越多,就越觉得这件事情有点奇怪。
|
||||
|
||||
“拥有你自己的网站,让所有的复杂性远离”这样的想法是很棒的。但是你仍然需要在本地生成配置。而且可怕的是需要为这样“简单”的东西使用很多 CLI(LCTT 译注:命令行界面)命令。
|
||||
|
||||
我只是略读了[入门部分][13]的七页,给我的感觉像是_我才是_那个小白。此前我甚至从来没有学习过所谓简单的 “Front Matter” 的语法或者所谓简单的 “Liquid 模板引擎” 的来龙去脉。
|
||||
|
||||
我宁愿去手工编写一个网站。
|
||||
|
||||
老实说我有点惊讶 Facebook 使用它来写 React 文档,因为他们能够用 React 来构建他们的帮助文档,并且在一天之内[预渲染到静态的 HTML 文件][14]。
|
||||
|
||||
他们所需要做的就是利用已有的 Markdown 文件,就像跟使用 CMS 一样。
|
||||
|
||||
我想是这样……
|
||||
|
||||
### #12 使用 GitHub 作为 CMS
|
||||
|
||||
比如说你有一个带有一些文本的网站,但是你并不想在 HTML 的标记中储存那些文本。
|
||||
|
||||
取而代之,你想要把这堆文本存放到某个地方,以便非开发者也可以很容易地编辑。也许要使用某种形式的版本控制。甚至还可能需要一个审查过程。
|
||||
|
||||
这里是我的建议:在你的版本库中使用 markdown 文件存储文本。然后在你的前端使用插件来获取这些文本块并在页面呈现。
|
||||
|
||||
我是 React 的支持者,因此这里有一个 `<Markdown>` 插件的示例,给出一些 markdown 的路径,它就会被获取、解析,并以 HTML 的形式呈现。
|
||||
|
||||
(我正在使用 [marked][1] npm 包来将 markdown 解析为 HTML。)
|
||||
|
||||
这里是我的示例仓库 [/text-snippets][2],里边有一些 markdown 文件 。
|
||||
|
||||
(你也可以使用 GitHub API 来[获取内容][15] —— 但我不确定你是否能搞定。)
|
||||
|
||||
你可以像这样使用插件:
|
||||
|
||||
如此,GitHub 就是你的 CMS 了,可以说,不管有多少文本块都可以放进去。
|
||||
|
||||
上边的示例只是在浏览器上安装好插件后获取 markdown 。如果你想要一个静态站点那么你需要服务器端渲染。
|
||||
|
||||
有个好消息!没有什么能阻止你从服务器中获取所有的 markdown 文件 (并配上各种为你服务的缓存策略)。如果你沿着这条路继续走下去的话,你可能会想要去试试使用 GitHub API 去获取目录中的所有 markdown 文件的列表。
|
||||
|
||||
### 奖励环节 —— GitHub 工具!
|
||||
|
||||
我曾经使用过一段时间的 [Chrome 的扩展 Octotree][16],而且现在我推荐它。虽然不是吐血推荐,但不管怎样我还是推荐它。
|
||||
|
||||
它会在左侧提供一个带有树状视图的面板以显示当前你所查看的仓库。
|
||||
|
||||
|
||||
|
||||
从[这个视频][17]中我了解到了 [octobox][18] ,到目前为止看起来还不错。它是一个 GitHub 工单的收件箱。这一句介绍就够了。
|
||||
|
||||
说到颜色,在上面所有的截图中我都使用了亮色主题,所以希望不要闪瞎你的双眼。不过说真的,我看到的其他东西都是黑色的主题,为什么我非要忍受 GitHub 这个苍白的主题呐?
|
||||
|
||||
|
||||
|
||||
这是由 Chrome 扩展 [Stylish][19](它可以在任何网站使用主题)和 [GitHub Dark][20] 风格的一个组合。要完全黑化,那黑色主题的 Chrome 开发者工具(这是内建的,在设置中打开) 以及 [Atom One Dark for Chrome 主题][21]你肯定也需要。
|
||||
|
||||
### Bitbucket
|
||||
|
||||
这些内容不适合放在这篇文章的任何地方,但是如果我不称赞 Bitbucket 的话,那就不对了。
|
||||
|
||||
两年前我开始了一个项目并花了大半天时间评估哪一个 git 托管服务更适合,最终 Bitbucket 赢得了相当不错的成绩。他们的代码审查流程遥遥领先(这甚至比 GitHub 拥有的指派审阅者的概念要早很长时间)。
|
||||
|
||||
GitHub 后来在这次审查竞赛中追了上来,干的不错。不幸的是在过去的一年里我没有机会再使用 Bitbucket —— 也许他们依然在某些方面领先。所以,我会力劝每一个选择 git 托管服务的人考虑一下 Bitbucket 。
|
||||
|
||||
### 结尾
|
||||
|
||||
就是这样!我希望这里至少有三件事是你此前并不知道的,祝好。
|
||||
|
||||
修订:在评论中有更多的技巧;请尽管留下你自己喜欢的技巧。真的,真心祝好。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/12-cool-things-you-can-do-with-github-f3e0424cf2f0
|
||||
|
||||
作者:[David Gilbertson][a]
|
||||
译者:[softpaopao](https://github.com/softpaopao)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@david.gilbertson
|
||||
[1]:https://www.npmjs.com/package/marked
|
||||
[2]:https://github.com/davidgilbertson/about-github/tree/master/text-snippets
|
||||
[3]:https://guides.github.com/features/mastering-markdown/
|
||||
[4]:https://github.com/github/linguist/blob/fc1404985abb95d5bc33a0eba518724f1c3c252e/vendor/README.md
|
||||
[5]:https://help.github.com/articles/closing-issues-using-keywords/
|
||||
[6]:https://help.github.com/articles/searching-issues-and-pull-requests/
|
||||
[7]:https://www.zenhub.com/
|
||||
[8]:https://help.github.com/articles/tracking-the-progress-of-your-work-with-project-boards/
|
||||
[9]:https://github.com/davidgilbertson/about-github/wiki
|
||||
[10]:http://redux.js.org/
|
||||
[11]:https://github.com/davidgilbertson/about-github
|
||||
[12]:https://davidgilbertson.github.io/about-github/
|
||||
[13]:https://jekyllrb.com/docs/home/
|
||||
[14]:https://github.com/facebookincubator/create-react-app/blob/master/packages/react-scripts/template/README.md#pre-rendering-into-static-html-files
|
||||
[15]:https://developer.github.com/v3/repos/contents/#get-contents
|
||||
[16]:https://chrome.google.com/webstore/detail/octotree/bkhaagjahfmjljalopjnoealnfndnagc?hl=en-US
|
||||
[17]:https://www.youtube.com/watch?v=NhlzMcSyQek&index=2&list=PLNYkxOF6rcIB3ci6nwNyLYNU6RDOU3YyL
|
||||
[18]:https://octobox.io/
|
||||
[19]:https://chrome.google.com/webstore/detail/stylish-custom-themes-for/fjnbnpbmkenffdnngjfgmeleoegfcffe/related?hl=en
|
||||
[20]:https://userstyles.org/styles/37035/github-dark
|
||||
[21]:https://chrome.google.com/webstore/detail/atom-one-dark-theme/obfjhhknlilnfgfakanjeimidgocmkim?hl=en
|
||||
@ -0,0 +1,57 @@
|
||||
如何让网站不下线而从 Redis 2 迁移到 Redis 3
|
||||
============================================================
|
||||
|
||||
我们在 Sky Betting&Gaming 中使用 [Redis][2] 作为共享内存缓存,用于那些需要跨 API 服务器或者 Web 服务器鉴别令牌之类的操作。在 Core Tribe 内,它用来帮助处理日益庞大的登录数量,特别是在繁忙的时候,我们在一分钟内登录数量会超过 20,000 人。这在很大程度上适用于数据存放在大量服务器的情况下(在 SSO 令牌用于 70 台 Apache HTTPD 服务器的情况下)。我们最近着手升级 Redis 服务器,此升级旨在使用 Redis 3.2 提供的原生集群功能。这篇博客希望解释为什么我们要使用集群、我们遇到的问题以及我们的解决方案。
|
||||
|
||||
### 在开始阶段(或至少在升级之前)
|
||||
|
||||
我们的传统缓存中每个缓存都包括一对 Redis 服务器,使用 keepalive 确保始终有一个主节点监听<ruby>浮动 IP <rt>floating IP</rt></ruby>地址。当出现问题时,这些服务器对需要很大的精力来进行管理,而故障模式有时是非常各种各样的。有时,只允许读取它所持有的数据,而不允许写入的从属节点却会得到浮动 IP 地址,这种问题是相对容易诊断的,但会让无论哪个程序试图使用该缓存时都很麻烦。
|
||||
|
||||
### 新的应用程序
|
||||
|
||||
因此,这种情况下,我们需要构建一个新的应用程序,一个使用<ruby>共享内存缓存<rt>shared in-memory cache</rt></ruby>的应用程序,但是我们不希望对该缓存进行迂回的故障切换过程。因此,我们的要求是共享的内存缓存,没有单点故障,可以使用尽可能少的人为干预来应对多种不同的故障模式,并且在事件恢复之后也能够在很少的人为干预下恢复,一个额外的要求是提高缓存的安全性,以减少数据泄露的范围(稍后再说)。当时 Redis Sentinel 看起来很有希望,并且有许多程序支持代理 Redis 连接,比如 [twemproxy][3]。这会导致还要安装其它很多组件,它应该有效,并且人际交互最少,但它复杂而需要运行大量的服务器和服务,并且相互通信。
|
||||
|
||||

|
||||
|
||||
将会有大量的应用服务器与 twemproxy 进行通信,这会将它们的调用路由到合适的 Redis 主节点,twemproxy 将从 sentinal 集群获取主节点的信息,它将控制哪台 Redis 实例是主,哪台是从。这个设置是复杂的,而且仍有单点故障,它依赖于 twemproxy 来处理分片,来连接到正确的 Redis 实例。它具有对应用程序透明的优点,所以我们可以在理论上做到将现有的应用程序转移到这个 Redis 配置,而不用改变应用程序。但是我们要从头开始构建一个应用程序,所以迁移应用程序不是一个必需条件。
|
||||
|
||||
幸运的是,这个时候,Redis 3.2 出来了,而且内置了原生集群,消除了对单一 sentinel 集群需要。
|
||||
|
||||

|
||||
|
||||
它有一个更简单的设置,但 twemproxy 不支持 Redis 集群分片,它能为你分片数据,但是如果尝试在与分片不一致的集群中这样做会导致问题。有参考的指南可以使其匹配,但是集群可以自动改变形式,并改变分片的设置方式。它仍然有单点故障。正是在这一点上,我将永远感谢我的一位同事发现了一个 Node.js 的 Redis 的集群发现驱动程序,让我们完全放弃了 twemproxy。
|
||||
|
||||

|
||||
|
||||
因此,我们能够自动分片数据,故障转移和故障恢复基本上是自动的。应用程序知道哪些节点存在,并且在写入数据时,如果写入错误的节点,集群将自动重定向该写入。这是被选的配置,这让我们共享的内存缓存相当健壮,可以没有干预地应付基本的故障模式。在测试期间,我们的确发现了一些缺陷。复制是在一个接一个节点的基础上进行的,因此如果我们丢失了一个主节点,那么它的从节点会成为一个单点故障,直到死去的节点恢复服务,也只有主节点对集群健康投票,所以如果我们一下失去太多主节点,那么集群无法自我恢复。但这比我们过去的好。
|
||||
|
||||
### 向前进
|
||||
|
||||
随着使用集群 Redis 配置的新程序,我们对于老式 Redis 实例的状态变得越来越不适应,但是新程序与现有程序的规模并不相同(超过 30GB 的内存专用于我们最大的老式 Redis 实例数据库)。因此,随着 Redis 集群在底层得到了证实,我们决定迁移老式的 Redis 实例到新的 Redis 集群中。
|
||||
|
||||
由于我们有一个原生支持 Redis 集群的 Node.js Redis 驱动程序,因此我们开始将 Node.js 程序迁移到 Redis 集群。但是,如何将数十亿字节的数据从一个地方移动到另一个地方,而不会造成重大问题?特别是考虑到这些数据是认证令牌,所以如果它们错了,我们的终端用户将会被登出。一个选择是要求网站完全下线,将所有内容都指向新的 Redis 群集,并将数据迁移到其中,以希望获得最佳效果。另一个选择是切换到新集群,并强制所有用户再次登录。由于显而易见的原因,这些都不是非常合适的。我们决定采取的替代方法是将数据同时写入老式 Redis 实例和正在替换它的集群,同时随着时间的推移,我们将逐渐更多地向该集群读取。由于数据的有效期有限(令牌在几个小时后到期),这种方法可以导致零停机,并且不会有数据丢失的风险。所以我们这么做了。迁移是成功的。
|
||||
|
||||
剩下的就是服务于我们的 PHP 代码(其中还有一个项目是有用的,其它的最终是没必要的)的 Redis 的实例了,我们在这过程中遇到了一个困难,实际上是两个。首先,也是最紧迫的是找到在 PHP 中使用的 Redis 集群发现驱动程序,还要是我们正在使用的 PHP 版本。这被证明是可行的,因为我们升级到了最新版本的 PHP。我们选择的驱动程序不喜欢使用 Redis 的授权方式,因此我们决定使用 Redis 集群作为一个额外的安全步骤 (我告诉你,这将有更多的安全性)。当我们用 Redis 集群替换每个老式 Redis 实例时,修复似乎很直接,将 Redis 授权关闭,这样它将会响应所有的请求。然而,这并不是真的,由于某些原因,Redis 集群不会接受来自 Web 服务器的连接。 Redis 在版本 3 中引入的称为“保护模式”的新安全功能将在 Redis 绑定到任何接口时将停止监听来自外部 IP 地址的连接,并无需配置 Redis 授权密码。这被证明相当容易修复,但让我们保持警惕。
|
||||
|
||||
### 现在?
|
||||
|
||||
这就是我们现在的情况。我们已经迁移了我们的一些老式 Redis 实例,并且正在迁移其余的。我们通过这样做解决了我们的一些技术债务,并提高了我们的平台的稳定性。使用 Redis 集群,我们还可以扩展内存数据库并扩展它们。 Redis 是单线程的,所以只要在单个实例中留出更多的内存就会可以得到这么多的增长,而且我们已经紧跟在这个限制后面。我们期待着从新的集群中获得改进的性能,同时也为我们提供了扩展和负载均衡的更多选择。
|
||||
|
||||
### 未来怎么样?
|
||||
|
||||
我们解决了一些技术性债务,这使我们的服务更容易支持,更加稳定。但这并不意味着这项工作完成了,Redis 4 似乎有一些我们可能想要研究的功能。而且 Redis 并不是我们使用的唯一软件。我们将继续努力改进平台,缩短处理技术债务的时间,但随着客户群体的扩大,我们力求提供更丰富的服务,我们总是会遇到需要改进的事情。下一个挑战可能与每分钟超过 20,000次 登录到超过 40,000 次甚至更高的扩展有关。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://engineering.skybettingandgaming.com/2017/09/25/redis-2-to-redis-3/
|
||||
|
||||
作者:[Craig Stewart][a]
|
||||
译者:[ ](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://engineering.skybettingandgaming.com/authors#craig_stewart
|
||||
[1]:http://engineering.skybettingandgaming.com/category/devops/
|
||||
[2]:https://redis.io/
|
||||
[3]:https://github.com/twitter/twemproxy
|
||||
@ -0,0 +1,92 @@
|
||||
如何在一个 U 盘上安装多个 Linux 发行版
|
||||
============================================================
|
||||
|
||||
> 概要:本教程介绍如何在一个 U 盘上安装多个 Linux 发行版。这样,你可以在单个 U 盘上享受多个<ruby>现场版<rt>live</rt></ruby> Linux 发行版了。
|
||||
|
||||
我喜欢通过 U 盘尝试不同的 Linux 发行版。它让我可以在真实的硬件上测试操作系统,而不是虚拟化的环境中。此外,我可以将 USB 插入任何系统(比如 Windows 系统),做任何我想要的事情,以及享受相同的 Linux 体验。而且,如果我的系统出现问题,我可以使用 U 盘恢复!
|
||||
|
||||
创建单个[可启动的现场版 Linux USB][8] 很简单,你只需下载一个 ISO 文件并将其刻录到 U 盘。但是,如果你想尝试多个 Linux 发行版呢?你可以使用多个 U 盘,也可以覆盖同一个 U 盘以尝试其他 Linux 发行版。但这两种方法都不是很方便。
|
||||
|
||||
那么,有没有在单个 U 盘上安装多个 Linux 发行版的方式呢?我们将在本教程中看到如何做到这一点。
|
||||
|
||||
### 如何创建有多个 Linux 发行版的可启动 USB
|
||||
|
||||

|
||||
|
||||
我们有一个工具正好可以做到_在单个 U 盘上保留多个 Linux 发行版_。你所需要做的只是选择要安装的发行版。在本教程中,我们将介绍_如何在 U 盘中安装多个 Linux 发行版_用于<ruby>现场会话<rt>live session</rt></ruby>。
|
||||
|
||||
要确保你有一个足够大的 U 盘,以便在它上面安装多个 Linux 发行版,一个 8 GB 的 U 盘应该足够用于三四个 Linux 发行版。
|
||||
|
||||
#### 步骤 1
|
||||
|
||||
[MultiBootUSB][9] 是一个自由、开源的跨平台应用程序,允许你创建具有多个 Linux 发行版的 U 盘。它还支持在任何时候卸载任何发行版,以便你回收驱动器上的空间用于另一个发行版。
|
||||
|
||||
下载 .deb 包并双击安装。
|
||||
|
||||
[下载 MultiBootUSB][10]
|
||||
|
||||
#### 步骤 2
|
||||
|
||||
推荐的文件系统是 FAT32,因此在创建多引导 U 盘之前,请确保格式化 U 盘。
|
||||
|
||||
#### 步骤 3
|
||||
|
||||
下载要安装的 Linux 发行版的 ISO 镜像。
|
||||
|
||||
#### 步骤 4
|
||||
|
||||
完成这些后,启动 MultiBootUSB。
|
||||
|
||||

|
||||
|
||||
主屏幕要求你选择 U 盘和你打算放到 U 盘上的 Linux 发行版镜像文件。
|
||||
|
||||
MultiBootUSB 支持 Ubuntu、Fedora 和 Debian 发行版的持久化,这意味着对 Linux 发行版的现场版本所做的更改将保存到 USB 上。
|
||||
|
||||
你可以通过拖动 MultiBootUSB 选项卡下的滑块来选择持久化大小。持久化为你提供了在运行时将更改保存到 U 盘的选项。
|
||||
|
||||

|
||||
|
||||
#### 步骤 5
|
||||
|
||||
单击“安装发行版”选项并继续安装。在显示成功的安装消息之前,需要一些时间才能完成。
|
||||
|
||||
你现在可以在已安装部分中看到发行版了。对于另外的操作系统,重复该过程。这是我安装 Ubuntu 16.10 和 Fedora 24 后的样子。
|
||||
|
||||

|
||||
|
||||
#### 步骤 6
|
||||
|
||||
下次通过 USB 启动时,我可以选择任何一个发行版。
|
||||
|
||||

|
||||
|
||||
只要你的 U 盘允许,你可以添加任意数量的发行版。要删除发行版,请从列表中选择它,然后单击卸载发行版。
|
||||
|
||||
### 最后的话
|
||||
|
||||
MultiBootUSB 真的很便于在 U 盘上安装多个 Linux 发行版。只需点击几下,我就有两个我最喜欢的操作系统的工作盘了,我可以在任何系统上启动它们。
|
||||
|
||||
如果你在安装或使用 MultiBootUSB 时遇到任何问题,请在评论中告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/multiple-linux-one-usb/
|
||||
|
||||
作者:[Ambarish Kumar][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ambarish/
|
||||
[1]:https://itsfoss.com/author/ambarish/
|
||||
[2]:https://itsfoss.com/multiple-linux-one-usb/#comments
|
||||
[3]:https://www.facebook.com/share.php?u=https%3A%2F%2Fitsfoss.com%2Fmultiple-linux-one-usb%2F%3Futm_source%3Dfacebook%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[4]:https://twitter.com/share?original_referer=/&text=How+to+Install+Multiple+Linux+Distributions+on+One+USB&url=https://itsfoss.com/multiple-linux-one-usb/%3Futm_source%3Dtwitter%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare&via=itsfoss2
|
||||
[5]:https://plus.google.com/share?url=https%3A%2F%2Fitsfoss.com%2Fmultiple-linux-one-usb%2F%3Futm_source%3DgooglePlus%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[6]:https://www.linkedin.com/cws/share?url=https%3A%2F%2Fitsfoss.com%2Fmultiple-linux-one-usb%2F%3Futm_source%3DlinkedIn%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[7]:https://www.reddit.com/submit?url=https://itsfoss.com/multiple-linux-one-usb/&title=How+to+Install+Multiple+Linux+Distributions+on+One+USB
|
||||
[8]:https://itsfoss.com/create-live-usb-of-ubuntu-in-windows/
|
||||
[9]:http://multibootusb.org/
|
||||
[10]:https://github.com/mbusb/multibootusb/releases/download/v8.8.0/python3-multibootusb_8.8.0-1_all.deb
|
||||
@ -0,0 +1,51 @@
|
||||
见多识广的 Pornhub 人工智能比你认识更多的 XXX 明星
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
你有没有想过,之所以能够根据自己不同兴趣的组合搜索到需要的视频,是因为有那些每日浏览无数视频内容且对它们进行分类和标记的可怜人存在,然而这些看不见的英雄们却在人工智能面前变得英雄无用武之地。
|
||||
|
||||
世界上最大的 XXX 电影分享网站 Pornhub 宣布,它将推出新的 AI 模型,利用计算机视觉技术自动检测和识别 XXX 明星的名字。
|
||||
|
||||
根据 X-rated 网站的消息,目前该算法经过训练后已经通过简单的扫描和对镜头的理解,可以识别超过 1 万名 XXX 明星。Pornhub 说,通过向此 AI 模型输入数千个视频和 XXX 明星的正式照片,以让它学习如何返回准确的名字。
|
||||
|
||||
为了减小错误,这个成人网站将向用户求证由 AI 提供的标签和分类是否合适。用户可以根据结果的准确度,提出支持或是反对。这将会让算法变得更加智能。
|
||||
|
||||
|
||||
|
||||
“现在,用户可以根据自身喜好寻找指定的 XXX 明星,我们也能够返回给用户尽可能精确的搜索结果,” PornHub 副总裁 Corey Price 说。“毫无疑问,我们的模型也将在未来的发展中扮演关键角色,尤其是考虑到每天有超过 1 万个的视频添加到网站上。”
|
||||
|
||||
“事实上,在过去的一个月里,我们测试了这个模型的测试版本,它(每天)可以扫描 5 万段视频,并且向视频添加或者移除标签。”
|
||||
|
||||
除了识别表演者,该算法还能区分不同类别的内容:比如在 “Public” 类别下的是户外拍摄的视频,以及 “Blonde” 类别下的视频应该至少有名金发女郎。
|
||||
|
||||
XXX 公司计划明年在 AI 模型的帮助下,对全部 500 万个视频编目,希望能让用户更容易找到与他们的期望最接近的视频片段。
|
||||
|
||||
早先就有研究人员借助计算机视觉算法对 XXX 电影进行描述。之前就有一名开发者使用微软的人工智能技术来构建这个机器人,它可以整天[观察和解读][2]各种内容。
|
||||
|
||||
Pornhub 似乎让这一想法更进一步,这些那些遍布全球的视频审看员的噩梦。
|
||||
|
||||
虽然人工智能被发展到这个方面可能会让你感觉有些不可思议,但 XXX 业因其对搜索引擎优化技术的狂热追求而[闻名][3]。
|
||||
|
||||
事实上,[成人内容服务][4]一直以来都[有广泛市场][5],且[受众不分年龄][6],这也是这些公司盈利的重要组成部分。
|
||||
|
||||
但是,这些每日阅片无数、兢兢业业为其分类的人们可能很快就会成为自动化威胁的牺牲品。但从好的一面看,他们终于有机会坐下来[让自动化为他们工作][7]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://thenextweb.com/artificial-intelligence/2017/10/11/pornhub-ai-watch-tag/
|
||||
|
||||
作者:[MIX][a]
|
||||
译者:[东风唯笑](https://github.com/dongfengweixiao)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://thenextweb.com/author/dimitarmihov/
|
||||
[1]:https://thenextweb.com/author/dimitarmihov/
|
||||
[2]:https://thenextweb.com/shareables/2017/03/03/porn-bot-microsoft-ai-pornhub/?amp=1
|
||||
[3]:https://moz.com/ugc/yes-dear-there-is-porn-seo-and-we-can-learn-a-lot-from-it
|
||||
[4]:https://www.upwork.com/job/Native-English-Speaker-Required-For-Video-Titles-Descriptions_~0170f127db07b9232b/
|
||||
[5]:https://www.quora.com/How-do-adult-sites-practice-SEO
|
||||
[6]:https://www.blackhatworld.com/seo/adult-looking-for-content-writer-for-porn-site.502731/
|
||||
[7]:https://thenextweb.com/gear/2017/07/07/fleshlight-launch-review-masturbation/?amp=1
|
||||
@ -1,86 +0,0 @@
|
||||
XYenChi is translating
|
||||
A 5-step plan to encourage your team to make changes on your project
|
||||
============================================================
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
Purpose is the first thing to consider when you're assembling any team. If one person could achieve that purpose, then forming the team would be unnecessary. And if there was no main purpose, then you wouldn't need a team at all. But as soon as the task requires more expertise than a single person has, we encounter the issue of collective participation—an issue that, if not handled properly, could derail you.
|
||||
|
||||
Imagine a group of people trapped in a cave. No single person has full knowledge of how to get out, so everyone will need to work together, be open, and act collaboratively if they're going to do it. After (and only after) assembling the right task force can someone create the right environment for achieving the team's shared purpose.
|
||||
|
||||
But some people are actually very comfortable in the cave and would like to just stay there. In organizations, how do leaders handle individuals who actually _resist_ productive change, people who are comfortable in the cave? And how do they go about finding people who do share their purpose but aren't in their organizations?
|
||||
|
||||
I made a career conducting sales training internationally, but when I began, few people even thought my work had value. So, I somehow devised a strategy for convincing them otherwise. That strategy was so successful that I decided to study it in depth and [share it][2] with others.
|
||||
|
||||
### Gaining support
|
||||
|
||||
In established companies with strong corporate cultures, there are people that will fight change and, from behind the scenes, will fight any proposal for change. They want everyone to stay in that comfortable cave. When I was first approached to give overseas sales training, for example, I received heavy resistance from some key people. They pushed to convince others that someone in Tokyo could not provide sales training—only basic product training would be successful.
|
||||
|
||||
I somehow solved this problem, but didn't really know how I did it at the time. So, I started studying what consultants recommend about how to change the thinking in companies that resisted to change. From one study by researcher [Laurence Haughton][3], I learned that for the average change proposal, 83% of people in your organization will not support you from the beginning. Roughly 17% _will_ support you from the beginning, but 60% of the people would support you only after seeing a pilot case succeed, when they can actually see that the idea is safe to try. Lastly, there are some people who will fight any change, no matter how good it is.
|
||||
|
||||
Here are the steps I learned:
|
||||
|
||||
* Start with a pilot project
|
||||
* Outsmart the CAVE people
|
||||
* Follow through fast
|
||||
* Outsmart the CAVE bosses
|
||||
* Move to full operation.
|
||||
|
||||
### 1\. Start with a pilot project
|
||||
|
||||
Find a project with both high value and a high chance for success—not a large, expensive, long-term, global activity. Then, find key people who can see the value of the project, who understand its value, and who will fight for it. These people should not just be "nice guys" or "friends"; they must believe in its purpose and have some skills/experience that will help move the project forward. And don't shoot for a huge success the first time. It should be just successful enough to permit you to learn and keep moving forward.
|
||||
|
||||
In my case, I held my first sales seminar in Singapore at a small vehicle dealership. It was not a huge success, but it was successful enough that people started talking about what quality sales training could achieve. At that time, I was stuck in a cave (a job I didn't want to do). This pilot sales training was my road map to get out of my cave.
|
||||
|
||||
### 2\. Outsmart the CAVE people
|
||||
|
||||
CAVE is actually an acronym I learned from Laurence Haughton. It stands for Citizens Against Virtually Everything.
|
||||
|
||||
You must identify these people, because they will covertly attempt to block any progress in your project, especially in the early stages when it is most vulnerable. They're easy to spot: They are always negative. They use "but," "if," and "why," in excess, just to stall you. They ask for detailed information when it isn't available easily. They spend too much time on the problem, not looking for any solution. They think every failure is the beginning of a trend. They often attack people instead of studying the problem. They make statements that are counterproductive but cannot be confirmed easily.
|
||||
|
||||
Avoid the CAVE people; do not let them into the discussion of the project too early. They've adopted the attitude they have because they don't see value in the changes required. They are comfortable in the cave. So try to get them to do something else. You should seek out key people in the 17% group I mentioned above, people that want change, and have very private preparation meetings with them.
|
||||
|
||||
When I was in Isuzu Motors (partly owned by General Motors), the sales training project started in a joint venture distribution company that sold to the smaller countries in the world, mainly in Africa, Southeast Asia, Latin America and the Middle East. My private team was made up of a GM person from Chevrolet, an Isuzu product planning executive and that distribution company's sales planning staff. I kept everyone else out of the loop.
|
||||
|
||||
### 3\. Follow through fast
|
||||
|
||||
CAVE people like to go slowly, so act quickly. Their ability to negatively influence your project will weaken if you have a small success story before they are involved—if you've managed to address their inevitable objections before they can even express them. Again, choose a pilot project with a high chance of success, something that can show quick results. Then promote that success, like a bold headline on an advertisement.
|
||||
|
||||
Once the word of my successful seminar in Singapore began to circulate, other regions started realizing the benefits of sales training. Just after that Singapore seminar, I was commissioned to give four more in Malaysia.
|
||||
|
||||
### 4\. Outsmart CAVE bosses
|
||||
|
||||
Once you have your first mini-project success, promote the project in a targeted way to key leaders who could influence any CAVE bosses. Get the team that worked on the project to tell key people the success story. Front line personnel and/or even customers can provide powerful testimonials as well. CAVE managers often concern themselves only with sales and profits, so promote the project's value in terms of cost savings, reduced waste, and increased sales.
|
||||
|
||||
From that first successful seminar in Singapore and others that followed, I promoted heavily their successes to key front line sales department staff handling Isuzu's direct sales channels and General Motors channels that really wanted to see progress. After giving their acceptance, they took their training requests to their superiors sighting the sales increase that occurred in the distribution company.
|
||||
|
||||
### 5\. Move to full operation
|
||||
|
||||
Once top management is on board, announce to the entire organization the successful pilot projects. Have discussions for expanding on the project.
|
||||
|
||||
Using the above procedures, I gave seminars in more than 60 countries worldwide over a 21-year career. So I did get out of the cave—and really saw a lot of the world.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Ron McFarland - Ron McFarland has been working in Japan for 40 years, and he's spent more than 30 of them in international sales, sales management training, and expanding sales worldwide. He's worked in or been to more than 80 countries. Over the past 14 years, Ron has established distributors in the United States and throughout Europe for a Tokyo-headquartered, Japanese hardware cutting tool manufacturer.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/17/1/escape-the-cave
|
||||
|
||||
作者:[Ron McFarland][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ron-mcfarland
|
||||
[1]:https://opensource.com/open-organization/17/1/escape-the-cave?rate=dBJIKVJy720uFj0PCfa1JXDZKkMwozxV8TB2qJnoghM
|
||||
[2]:http://www.slideshare.net/RonMcFarland1/creating-change-58994683
|
||||
[3]:http://www.laurencehaughton.com/
|
||||
[4]:https://opensource.com/user/68021/feed
|
||||
[5]:https://opensource.com/open-organization/17/1/escape-the-cave#comments
|
||||
[6]:https://opensource.com/users/ron-mcfarland
|
||||
@ -1,211 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Introducing Flashback, an Internet mocking tool
|
||||
============================================================
|
||||
|
||||
> Flashback is designed to mock HTTP and HTTPS resources, like web services and REST APIs, for testing purposes.
|
||||
|
||||

|
||||
>Image by : Opensource.com
|
||||
|
||||
At LinkedIn, we often develop web applications that need to interact with third-party websites. We also employ automatic testing to ensure the quality of our software before it is shipped to production. However, a test is only as useful as it is reliable.
|
||||
|
||||
With that in mind, it can be highly problematic for a test to have external dependencies, such as on a third-party website, for instance. These external sites may change without notice, suffer from downtime, or otherwise become temporarily inaccessible, as the Internet is not 100% reliable.
|
||||
|
||||
If one of our tests relies on being able to communicate with a third-party website, the cause of any failures is hard to pinpoint. A failure could be due to an internal change at LinkedIn, an external change made by the maintainers of the third-party website, or an issue with the network infrastructure. As you can imagine, there are many reasons why interactions with a third-party website may fail, so you may wonder, how will I deal with this problem?
|
||||
|
||||
The good news is that there are many Internet mocking tools that can help. One such tool is [Betamax][4]. It works by intercepting HTTP connections initiated by a web application and then later replaying them. For a test, Betamax can be used to replace any interaction over HTTP with previously recorded responses, which can be served very reliably.
|
||||
|
||||
Initially, we chose to use Betamax in our test automation at LinkedIn. It worked quite well, but we ran into a few problems:
|
||||
|
||||
* For security reasons, our test environment does not have Internet access; however, as with most proxies, Betamax requires an Internet connection to function properly.
|
||||
* We have many use cases that require using authentication protocols, such as OAuth and OpenId. Some of these protocols require complex interactions over HTTP. In order to mock them, we needed a sophisticated model for capturing and replaying the requests.
|
||||
|
||||
To address these challenges, we decided to build upon ideas established by Betamax and create our own Internet mocking tool, called Flashback. We are also proud to announce that Flashback is now open source.
|
||||
|
||||
### What is Flashback?
|
||||
|
||||
Flashback is designed to mock HTTP and HTTPS resources, like web services and [REST][5] APIs, for testing purposes. It records HTTP/HTTPS requests and plays back a previously recorded HTTP transaction—which we call a "scene"—so that no external connection to the Internet is required in order to complete testing.
|
||||
|
||||
Flashback can also replay scenes based on the partial matching of requests. It does so using "match rules." A match rule associates an incoming request with a previously recorded request, which is then used to generate a response. For example, the following code snippet implements a basic match rule, where the test method "matches" an incoming request via [this URL][6].
|
||||
|
||||
HTTP requests generally contain a URL, method, headers, and body. Flashback allows match rules to be defined for any combination of these components. Flashback also allows users to add whitelist or blacklist labels to URL query parameters, headers, and the body.
|
||||
|
||||
For instance, in an OAuth authorization flow, the request query parameters may look like the following:
|
||||
|
||||
```
|
||||
oauth_consumer_key="jskdjfljsdklfjlsjdfs",
|
||||
oauth_nonce="ajskldfjalksjdflkajsdlfjasldfja;lsdkj",
|
||||
oauth_signature="asdfjaklsdjflasjdflkajsdklf",
|
||||
oauth_signature_method="HMAC-SHA1",
|
||||
oauth_timestamp="1318622958",
|
||||
oauth_token="asdjfkasjdlfajsdklfjalsdjfalksdjflajsdlfa",
|
||||
oauth_version="1.0"
|
||||
```
|
||||
|
||||
Many of these values will change with every request because OAuth requires clients to generate a new value for **oauth_nonce** every time. In our testing, we need to verify values of **oauth_consumer_key, oauth_signature_method**, and **oauth_version** while also making sure that **oauth_nonce**, **oauth_signature**, **oauth_timestamp**, and **oauth_token** exist in the request. Flashback gives us the ability to create our own match rules to achieve this goal. This feature lets us test requests with time-varying data, signatures, tokens, etc. without any changes on the client side.
|
||||
|
||||
This flexible matching and the ability to function without connecting to the Internet are the attributes that separate Flashback from other mocking solutions. Some other notable features include:
|
||||
|
||||
* Flashback is a cross-platform and cross-language solution, with the ability to test both JVM (Java Virtual Machine) and non-JVM (C++, Python, etc.) apps.
|
||||
* Flashback can generate SSL/TLS certificates on the fly to emulate secured channels for HTTPS requests.
|
||||
|
||||
### How to record an HTTP transaction
|
||||
|
||||
Recording an HTTP transaction for later playback using Flashback is a relatively straightforward process. Before we dive into the procedure, let us first lay out some terminology:
|
||||
|
||||
* A** Scene** stores previously recorded HTTP transactions (in JSON format) that can be replayed later. For example, here is one sample [Flashback scene][1].
|
||||
* The **Root Path** is the file path of the directory that contains the Flashback scene data.
|
||||
* A **Scene Name** is the name of a given scene.
|
||||
* A **Scene Mode** is the mode in which the scene is being used—either "record" or "playback."
|
||||
* A **Match Rule** is a rule that determines if the incoming client request matches the contents of a given scene.
|
||||
* **Flashback Proxy** is an HTTP proxy with two modes of operation, record and playback.
|
||||
* **Host** and **port** are the proxy host and port.
|
||||
|
||||
In order to record a scene, you must make a real, external request to the destination, and the HTTPS request and response will then be stored in the scene with the match rule that you have specified. When recording, Flashback behaves exactly like a typical MITM (Man in the Middle) proxy—it is only in playback mode that the connection flow and data flow are restricted to just between the client and the proxy.
|
||||
|
||||
To see Flashback in action, let us create a scene that captures an interaction with example.org by doing the following:
|
||||
|
||||
1\. Check out the Flashback source code:
|
||||
|
||||
```
|
||||
git clone https://github.com/linkedin/flashback.git
|
||||
```
|
||||
|
||||
2\. Start the Flashback admin server:
|
||||
|
||||
```
|
||||
./startAdminServer.sh -port 1234
|
||||
```
|
||||
|
||||
3\. Start the [Flashback Proxy][7]. Note the Flashback above will be started in record mode on localhost, port 5555\. The match rule requires an exact match (match HTTP body, headers, and URL). The scene will be stored under **/tmp/test1**.
|
||||
|
||||
4\. Flashback is now ready to record, so use it to proxy a request to example.org:
|
||||
|
||||
```
|
||||
curl http://www.example.org -x localhost:5555 -X GET
|
||||
```
|
||||
|
||||
5\. Flashback can (optionally) record multiple requests in a single. To finish recording, [shut down Flashback][8].
|
||||
|
||||
6\. To verify what has been recorded, we can view the contents of the scene in the output directory (**/tmp/test1**). It should [contain the following][9].
|
||||
|
||||
It's also easy to [use Flashback in your Java code][10].
|
||||
|
||||
### How to replay an HTTP transaction
|
||||
|
||||
To replay a previously stored scene, use the same basic setup as is used when recording; the only difference is that you [set the "Scene Mode" to "playback" in Step 3 above][11].
|
||||
|
||||
One way to verify that the response is from the scene, and not the external source, is to disable your Internet connectivity temporarily when you go through Steps 1 through 6\. Another way is to modify your scene file and see if the response is the same as what you have in the file.
|
||||
|
||||
Here is [an example in Java][12].
|
||||
|
||||
### How to record and replay an HTTPS transaction
|
||||
|
||||
The process for recording and replaying an HTTPS transaction with Flashback is very similar to that used for HTTP transactions. However, special care needs to be given to the security certificates used for the SSL component of HTTPS. In order for Flashback to act as a MITM proxy, creating a Certificate Authority (CA) certificate is necessary. This certificate will be used during the creation of the secure channel between the client and Flashback, and will allow Flashback to inspect the data in HTTPS requests it proxies. This certificate should then be stored as a trusted source so that the client will be able to authenticate Flashback when making calls to it. For instructions on how to create a certificate, there are many resources [like this one][13] that can be quite helpful. Most companies have their own internal policies for administering and securing certificates—be sure to follow yours.
|
||||
|
||||
It is worth noting here that Flashback is intended to be used for testing purposes only. Feel free to integrate Flashback with your service whenever you need it, but note that the record feature of Flashback will need to store everything from the wire, then use it during the replay mode. We recommend that you pay extra attention to ensure that no sensitive member data is being recorded or stored inadvertently. Anything that may violate your company's data protection or privacy policy is your responsibility.
|
||||
|
||||
Once the security certificate is accounted for, the only difference between HTTP and HTTPS in terms of setup for recording is the addition of a few further parameters.
|
||||
|
||||
* **RootCertificateInputStream**: This can be either a stream or file path that indicates the CA certificate's filename.
|
||||
* **RootCertificatePassphrase**: This is the passphrase created for the CA certificate.
|
||||
* **CertificateAuthority**: These are the CA certificate's properties.
|
||||
|
||||
[View the code used to record an HTTPS transaction][14] with Flashback, including the above terms.
|
||||
|
||||
Replaying an HTTPS transaction with Flashback uses the same process as recording. The only difference is that the scene mode is set to "playback." This is demonstrated in [this code][15].
|
||||
|
||||
### Supporting dynamic changes
|
||||
|
||||
In order to allow for flexibility in testing, Flashback lets you dynamically change scenes and match rules. Changing scenes dynamically allows for testing the same requests with different responses, such as success, **time_out**, **rate_limit**, etc. [Scene changes][16] only apply to scenarios where we have POSTed data to update the external resource. See the following diagram as an example.
|
||||
|
||||

|
||||
|
||||
Being able to [change the match rule][17] dynamically allows us to test complicated scenarios. For example, we have a use case that requires us to test HTTP calls to both public and private resources of Twitter. For public resources, the HTTP requests are constant, so we can use the "MatchAll" rule. However, for private resources, we need to sign requests with an OAuth consumer secret and an OAuth access token. These requests contain a lot of parameters that have unpredictable values, so the static MatchAll rule wouldn't work.
|
||||
|
||||
### Use cases
|
||||
|
||||
At LinkedIn, Flashback is mainly used for mocking different Internet providers in integration tests, as illustrated in the diagrams below. The first diagram shows an internal service inside a LinkedIn production data center interacting with Internet providers (such as Google) via a proxy layer. We want to test this internal service in a testing environment.
|
||||
|
||||

|
||||
|
||||
The second and third diagrams show how we can record and playback scenes in different environments. Recording happens in our dev environment, where the user starts Flashback on the same port as the proxy started. All external requests from the internal service to providers will go through Flashback instead of our proxy layer. After the necessary scenes get recorded, we can deploy them to our test environment.
|
||||
|
||||

|
||||
|
||||
In the test environment (which is isolated and has no Internet access), Flashback is started on the same port as in the dev environment. All HTTP requests are still coming from the internal service, but the responses will come from Flashback instead of the Internet providers.
|
||||
|
||||

|
||||
|
||||
### Future directions
|
||||
|
||||
We'd like to see if we can support non-HTTP protocols, such as FTP or JDBC, in the future, and maybe even give users the flexibility to inject their own customized protocol using the MITM proxy framework. We will continue improving the Flashback setup API to make supporting non-Java languages easier.
|
||||
|
||||
### Now available as an open source project
|
||||
|
||||
We were fortunate enough to present Flashback at GTAC 2015\. At the show, several members of the audience asked if we would be releasing Flashback as an open source project so they could use it for their own testing efforts.
|
||||
|
||||
### Google TechTalks: GATC 2015—Mock the Internet
|
||||
|
||||
<iframe allowfullscreen="" frameborder="0" height="315" src="https://www.youtube.com/embed/6gPNrujpmn0?origin=https://opensource.com&enablejsapi=1" width="560" id="6gPNrujpmn0" data-sdi="true"></iframe>
|
||||
|
||||
We're happy to announce that Flashback is now open source and is available under a BSD (Berkeley Software Distribution) two-clause license. To get started, visit the [Flashback GitHub repo][18].
|
||||
|
||||
_Originally posted on the [LinkedIn Engineering blog][2]. Reposted with permission._
|
||||
|
||||
### Acknowledgements
|
||||
|
||||
Flashback was created by [Shangshang Feng][19], [Yabin Kang][20], and [Dan Vinegrad][21], and inspired by [Betamax][22]. Special thanks to [Hwansoo Lee][23], [Eran Leshem][24], [Kunal Kandekar][25], [Keith Dsouza][26], and [Kang Wang][27] for help with code reviews. We would also thank our management—[Byron Ma][28], [Yaz Shimizu][29], [Yuliya Averbukh][30], [Christopher Hazlett][31], and [Brandon Duncan][32]—for their support in the development and open sourcing of Flashback.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Shangshang Feng - Shangshang is senior software engineer in LinkedIn's NYC office. He spent the last three and half years working on a gateway platform at LinkedIn. Before LinkedIn, he worked on infrastructure teams at Thomson Reuters and ViewTrade securities.
|
||||
|
||||
---------
|
||||
|
||||
via: https://opensource.com/article/17/4/flashback-internet-mocking-tool
|
||||
|
||||
作者:[ Shangshang Feng][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/shangshangfeng
|
||||
[1]:https://gist.github.com/anonymous/17d226050d8a9b79746a78eda9292382
|
||||
[2]:https://engineering.linkedin.com/blog/2017/03/flashback-mocking-tool
|
||||
[3]:https://opensource.com/article/17/4/flashback-internet-mocking-tool?rate=Jwt7-vq6jP9kS7gOT6f6vgwVlZupbyzWsVXX41ikmGk
|
||||
[4]:https://github.com/betamaxteam/betamax
|
||||
[5]:https://en.wikipedia.org/wiki/Representational_state_transfer
|
||||
[6]:https://gist.github.com/anonymous/91637854364287b38897c0970aad7451
|
||||
[7]:https://gist.github.com/anonymous/2f5271191edca93cd2e03ce34d1c2b62
|
||||
[8]:https://gist.github.com/anonymous/f899ebe7c4246904bc764b4e1b93c783
|
||||
[9]:https://gist.github.com/sf1152/c91d6d62518fe62cc87157c9ce0e60cf
|
||||
[10]:https://gist.github.com/anonymous/fdd972f1dfc7363f4f683a825879ce19
|
||||
[11]:https://gist.github.com/anonymous/ae1c519a974c3bc7de2a925254b6550e
|
||||
[12]:https://gist.github.com/anonymous/edcc1d60847d51b159c8fd8a8d0a5f8b
|
||||
[13]:https://jamielinux.com/docs/openssl-certificate-authority/introduction.html
|
||||
[14]:https://gist.github.com/anonymous/091d13179377c765f63d7bf4275acc11
|
||||
[15]:https://gist.github.com/anonymous/ec6a0fd07aab63b7369bf8fde69c1f16
|
||||
[16]:https://gist.github.com/anonymous/1f1660280acb41277fbe2c257bab2217
|
||||
[17]:https://gist.github.com/anonymous/0683c43f31bd916b76aff348ff87f51b
|
||||
[18]:https://github.com/linkedin/flashback
|
||||
[19]:https://www.linkedin.com/in/shangshangfeng
|
||||
[20]:https://www.linkedin.com/in/benykang
|
||||
[21]:https://www.linkedin.com/in/danvinegrad/
|
||||
[22]:https://github.com/betamaxteam/betamax
|
||||
[23]:https://www.linkedin.com/in/hwansoo/
|
||||
[24]:https://www.linkedin.com/in/eranl/
|
||||
[25]:https://www.linkedin.com/in/kunalkandekar/
|
||||
[26]:https://www.linkedin.com/in/dsouzakeith/
|
||||
[27]:https://www.linkedin.com/in/kang-wang-44960b4/
|
||||
[28]:https://www.linkedin.com/in/byronma/
|
||||
[29]:https://www.linkedin.com/in/yazshimizu/
|
||||
[30]:https://www.linkedin.com/in/yuliya-averbukh-818a41/
|
||||
[31]:https://www.linkedin.com/in/chazlett/
|
||||
[32]:https://www.linkedin.com/in/dudcat/
|
||||
[33]:https://opensource.com/user/125361/feed
|
||||
[34]:https://opensource.com/users/shangshangfeng
|
||||
@ -1,93 +0,0 @@
|
||||
Translating by ZH1122
|
||||
The changing face of the hybrid cloud
|
||||
============================================================
|
||||
|
||||
### Terms and concepts around cloud computing are still new, but evolving.
|
||||
|
||||
|
||||

|
||||
Image credits :
|
||||
|
||||
[Flickr user: theaucitron][9] (CC BY-SA 2.0)
|
||||
|
||||
Depending upon the event you use to start the clock, cloud computing is only a little more than 10 years old. Some terms and concepts around cloud computing that we take for granted today are newer still. The National Institute of Standards and Technology (NIST) document that defined now-familiar cloud terminology—such as Infrastructure-as-a-Service (IaaS)—was only published in 2011, although it widely circulated in draft form for a while before that.
|
||||
|
||||
Among other definitions in that document was one for _hybrid cloud_ . Looking at how that term has shifted during the intervening years is instructive. Cloud-based infrastructures have moved beyond a relatively simplistic taxonomy. Also, it highlights how priorities familiar to adopters of open source software—such as flexibility, portability, and choice—have made their way to the hybrid cloud.
|
||||
|
||||
Explore the open source cloud
|
||||
|
||||
* [What is the cloud?][1]
|
||||
|
||||
* [What is OpenStack?][2]
|
||||
|
||||
* [What is Kubernetes?][3]
|
||||
|
||||
* [Why the operating system matters for containers][4]
|
||||
|
||||
* [Keeping Linux containers safe and secure][5]
|
||||
|
||||
NIST's original hybrid cloud definition was primarily focused on cloud bursting, the idea that you might use on-premise infrastructure to handle a base computing load, but that you could "burst" out to a public cloud if your usage spiked. Closely related were efforts to provide API compatibility between private clouds and public cloud providers and even to create spot markets to purchase capacity wherever it was cheapest.
|
||||
|
||||
Implicit in all this was the idea of the cloud as a sort of standardized compute utility with clear analogs to the electrical grid, a concept probably most popularized by author Nick Carr in his book [_The Big Switch_][10] . It made for a good story but, even early on, the [limitations of the analogy became evident][11]. Computing isn't a commodity in the manner of electricity. One need look no further than the proliferation of new features by all of the major public cloud providers—as well as in open source cloud software such as OpenStack—to see that many users aren't simply looking for generic computing cycles at the lowest price.
|
||||
|
||||
The cloud bursting idea also largely ignored the reality that computing is usually associated with data and you can't just move large quantities of data around instantaneously without incurring big bandwidth bills and having to worry about the length of time those transfers take. Dave McCrory coined the term _data gravity_ to describe this limitation.
|
||||
|
||||
Given this rather negative picture I've painted, why are we talking about hybrid clouds so much today?
|
||||
|
||||
As I've discussed, hybrid clouds were initially thought of mostly in the context of cloud bursting. And cloud bursting perhaps most emphasized rapid, even real-time, shifts of workloads from one cloud to another; however, hybrid clouds also implied application and data portability. Indeed, as [I wrote in a CNET post][12] back in 2011: "I think we do ourselves a disservice by obsessing too much with 'automagical' workload shifting—when what we really care about is the ability to just move from one place to another if a vendor isn't meeting our requirements or is trying to lock us in."
|
||||
|
||||
Since then, thinking about portability across clouds has evolved even further.
|
||||
|
||||
Linux always has been a key component of cloud portability because it can run on everything from bare-metal to on-premise virtualized infrastructures, and from private clouds to public clouds. Linux provides a well-established, reliable platform with a stable API contract against which applications can be written.
|
||||
|
||||
The widespread adoption of containers has further enhanced the ability of Linux to provide application portability across clouds. By providing an image that also contains an application's dependencies, a container provides portability and consistency as applications move from development, to testing, and finally to production.
|
||||
|
||||
Linux containers can be applied in many different ways to problems where ultimate portability, configurability, and isolation are needed. This is true whether running on-premise, in a public cloud, or a hybrid of the two.
|
||||
|
||||
Container tools use an image-based deployment model. This makes sharing an application or set of services with all of their dependencies across multiple environments easy.
|
||||
|
||||
Specifications developed under the auspices of the Open Container Initiative (OCI) work together to define the contents of a container image and those dependencies, environments, arguments, and so forth necessary for the image to be run properly. As a result of these standardization efforts, the OCI has opened the door for many other tooling efforts that can now depend on stable runtime and image specs.
|
||||
|
||||
At the same time, distributed storage can provide data portability across clouds using open source technologies such as Gluster and Ceph. Physical constraints will always impose limits on how quickly and easily data can be moved from one location to another; however, as organizations deploy and use different types of infrastructure, they increasingly desire open, software-defined storage platforms that scales across physical, virtual, and cloud resources.
|
||||
|
||||
This is especially the case as data storage requirements grow rapidly, because of trends in predictive analytics, internet-of-things, and real-time monitoring. In [one 2016 study][13], 98% of IT decision makers said a more agile storage solution could benefit their organization. In the same study, they listed inadequate storage infrastructure as one of the greatest frustrations that their organizations experience.
|
||||
|
||||
And it's really this idea of providing appropriate portability and consistency across a heterogeneous set of computing capabilities and resources that embodies what hybrid cloud has become. Hybrid cloud is not so much about using a private cloud and a public cloud in concert for the same applications. It's about using a set of services of many types, some of which are probably built and operated by your IT department, and some of which are probably sourced externally.
|
||||
|
||||
They'll probably be a mix of Software-as-a-Service applications, such as email and customer relationship management. Container platforms, orchestrated by open source software such as Kubernetes, are increasingly popular for developing new applications. Your organization likely is using one of the big public cloud providers for _something_ . And you're almost certain to be operating some of your own infrastructure, whether it's a private cloud or more traditional on-premise infrastructure.
|
||||
|
||||
This is the face of today's hybrid cloud, which really can be summed up as choice—choice to select the most appropriate types of infrastructure and services, and choice to move applications and data from one location to another when you want to.
|
||||
|
||||
**_Also read: [Multi-cloud vs. hybrid cloud: What's the difference?][6]_**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Gordon Haff is Red Hat’s cloud evangelist, is a frequent and highly acclaimed speaker at customer and industry events, and helps develop strategy across Red Hat’s full portfolio of cloud solutions. He is the author of Computing Next: How the Cloud Opens the Future in addition to numerous other publications. Prior to Red Hat, Gordon wrote hundreds of research notes, was frequently quoted in publications like The New York Times on a wide range of IT topics, and advised clients on product and marketing strategies. Earlier in his career, he was responsible for bringing a wide range of computer systems, from minicomputers to large UNIX servers, to market while at Data General. Gordon has engineering degrees from MIT and Dartmouth and an MBA from Cornell’s Johnson School.
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/7/hybrid-cloud
|
||||
|
||||
作者:[ Gordon Haff (Red Hat) ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ghaff
|
||||
[1]:https://opensource.com/resources/cloud?src=cloud_resource_menu1
|
||||
[2]:https://opensource.com/resources/what-is-openstack?src=cloud_resource_menu2
|
||||
[3]:https://opensource.com/resources/what-is-kubernetes?src=cloud_resource_menu3
|
||||
[4]:https://opensource.com/16/12/yearbook-why-operating-system-matters?src=cloud_resource_menu4
|
||||
[5]:https://opensource.com/business/16/10/interview-andy-cathrow-anchore?src=cloud_resource_menu5
|
||||
[6]:https://enterprisersproject.com/article/2017/7/multi-cloud-vs-hybrid-cloud-whats-difference
|
||||
[7]:https://opensource.com/article/17/7/hybrid-cloud?rate=ztmV2D_utD03cID1u41Al08w0XFm6rXXwCJdTwqI4iw
|
||||
[8]:https://opensource.com/user/21220/feed
|
||||
[9]:https://www.flickr.com/photos/theaucitron/5810163712/in/photolist-5p9nh3-6EkSKG-6EgGEF-9hYBcr-abCSpq-9zbjDz-4PVqwm-9RqBfq-abA2T4-4nXfwv-9RQkdN-dmjSdA-84o2ER-abA2Wp-ehyhPC-7oFYrc-4nvqBz-csMQXb-nRegFf-ntS23C-nXRyaB-6Xw3Mq-cRMaCq-b6wkkP-7u8sVQ-yqcg-6fTmk7-bzm3vU-6Xw3vL-6EkzCQ-d3W8PG-5MoveP-oMWsyY-jtMME6-XEMwS-2SeRXT-d2hjzJ-p2ZZVZ-7oFYoX-84r6Mo-cCizvm-gnnsg5-77YfPx-iDjqK-8gszbW-6MUZEZ-dhtwtk-gmpTob-6TBJ8p-mWQaAC/
|
||||
[10]:http://www.nicholascarr.com/?page_id=21
|
||||
[11]:https://www.cnet.com/news/there-is-no-big-switch-for-cloud-computing/
|
||||
[12]:https://www.cnet.com/news/cloudbursting-or-just-portable-clouds/
|
||||
[13]:https://www.redhat.com/en/technologies/storage/vansonbourne
|
||||
[14]:https://opensource.com/users/ghaff
|
||||
[15]:https://opensource.com/users/ghaff
|
||||
@ -1,537 +0,0 @@
|
||||
UP – deploy serverless apps in seconds
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Last year I wrote [Blueprints for Up][1], describing how most of the building blocks are available to create a great serverless experience on AWS with minimal effort. This post talks about the initial alpha release of [Up][2].
|
||||
|
||||
Why focus on serverless? For starters it’s cost-effective since you pay on-demand, only for what you use. Serverless options are self-healing, as each request is isolated and considered to be “stateless.” And finally it scales indefinitely with ease — there are no machines or clusters to manage. Deploy your code and you’re done.
|
||||
|
||||
Roughly a month ago I decided to start working on it over at [apex/up][3], and wrote the first small serverless sample application [tj/gh-polls][4] for live SVG GitHub user polls. It worked well and costs less than $1/month to serve millions of polls, so I thought I’d go ahead with the project and see if I can offer open-source and commercial variants.
|
||||
|
||||
The long-term goal is to provide a “Bring your own Heroku” of sorts, supporting many platforms. While Platform-as-a-Service is nothing new, the serverless ecosystem is making this kind of program increasingly trivial. This said, AWS and others often suffer in terms of UX due to the flexibility they provide. Up abstracts the complexity away, while still providing you with a virtually ops-free solution.
|
||||
|
||||
### Installation
|
||||
|
||||
You can install Up with the following command, and view the [temporary documentation][5] to get started. Or if you’re sketched out by install scripts, grab a [binary release][6]. (Keep in mind that this project is still early on.)
|
||||
|
||||
```
|
||||
curl -sfL https://raw.githubusercontent.com/apex/up/master/install.sh | sh
|
||||
```
|
||||
|
||||
To upgrade to the latest version at any time just run:
|
||||
|
||||
```
|
||||
up upgrade
|
||||
```
|
||||
|
||||
You may also install via NPM:
|
||||
|
||||
```
|
||||
npm install -g up
|
||||
```
|
||||
|
||||
### Features
|
||||
|
||||
What features does the early alpha provide? Let’s take a look! Keep in mind that Up is not a hosted service, so you’ll need an AWS account and [AWS credentials][8]. If you’re not familiar at all with AWS you may want to hold off until that process is streamlined.
|
||||
|
||||
The first question I always get is: how does up(1) differ from [apex(1)][9]? Apex focuses on deploying functions, for pipelines and event processing, while Up focuses on apps, apis, and static sites, aka single deployable units. Apex does not provision API Gateway, SSL certs, or DNS for you, nor does it provide URL rewriting, script injection and so on.
|
||||
|
||||
#### Single command serverless apps
|
||||
|
||||
Up lets you deploy apps, apis, and static sites with a single command. To create an application all you need is a single file, in the case of Node.js, an `./app.js` listening on `PORT` which is provided by Up. Note that if you’re using a `package.json` Up will detect and utilize the `start` and `build`scripts.
|
||||
|
||||
```
|
||||
const http = require('http')
|
||||
const { PORT = 3000 } = process.env
|
||||
```
|
||||
|
||||
```
|
||||
http.createServer((req, res) => {
|
||||
res.end('Hello World\n')
|
||||
}).listen(PORT)
|
||||
```
|
||||
|
||||
Additional [runtimes][10] are supported out of the box, such as `main.go` for Golang, so you can deploy Golang, Python, Crystal, or Node.js applications in seconds.
|
||||
|
||||
```
|
||||
package main
|
||||
```
|
||||
|
||||
```
|
||||
import (
|
||||
"fmt"
|
||||
"log"
|
||||
"net/http"
|
||||
"os"
|
||||
)
|
||||
```
|
||||
|
||||
```
|
||||
func main() {
|
||||
addr := ":" + os.Getenv("PORT")
|
||||
http.HandleFunc("/", hello)
|
||||
log.Fatal(http.ListenAndServe(addr, nil))
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
func hello(w http.ResponseWriter, r *http.Request) {
|
||||
fmt.Fprintln(w, "Hello World from Go")
|
||||
}
|
||||
```
|
||||
|
||||
To deploy the application type `up` to create the resources required, and deploy the application itself. There are no smoke and mirrors here, once it says “complete”, you’re done, the app is immediately available — there is no remote build process.
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
|
||||
|
||||
The subsequent deploys will be even quicker since the stack is already provisioned:
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
|
||||
|
||||
Test out your app with `up url --open` to view it in the browser, `up url --copy` to save the URL to the clipboard, or try it with curl:
|
||||
|
||||
```
|
||||
curl `up url`
|
||||
Hello World
|
||||
```
|
||||
|
||||
To delete the app and its resources just type `up stack delete`:
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
|
||||
|
||||
Deploy to the staging or production environments using `up staging` or `up production` , and `up url --open production` for example. Note that custom domains are not yet available, [they will be shortly][11]. Later you’ll also be able to “promote” a release to other stages.
|
||||
|
||||
#### Reverse proxy
|
||||
|
||||
One feature which makes Up unique is that it doesn’t just simply deploy your code, it places a Golang reverse proxy in front of your application. This provides many features such as URL rewriting, redirection, script injection and more, which we’ll look at further in the post.
|
||||
|
||||
#### Infrastructure as code
|
||||
|
||||
Up follows modern best practices in terms of configuration, as all changes to the infrastructure can be previewed before applying, and the use of IAM policies can also restrict developer access to prevent mishaps. A side benefit is that it helps self-document your infrastructure as well.
|
||||
|
||||
Here’s an example of configuring some (dummy) DNS records and free SSL certificates via AWS ACM which utilizes LetsEncrypt.
|
||||
|
||||
```
|
||||
{
|
||||
"name": "app",
|
||||
"dns": {
|
||||
"myapp.com": [
|
||||
{
|
||||
"name": "myapp.com",
|
||||
"type": "A",
|
||||
"ttl": 300,
|
||||
"value": ["35.161.83.243"]
|
||||
},
|
||||
{
|
||||
"name": "blog.myapp.com",
|
||||
"type": "CNAME",
|
||||
"ttl": 300,
|
||||
"value": ["34.209.172.67"]
|
||||
},
|
||||
{
|
||||
"name": "api.myapp.com",
|
||||
"type": "A",
|
||||
"ttl": 300,
|
||||
"value": ["54.187.185.18"]
|
||||
}
|
||||
]
|
||||
},
|
||||
"certs": [
|
||||
{
|
||||
"domains": ["myapp.com", "*.myapp.com"]
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
When you deploy the application the first time via `up` all the permissions required, API Gateway, Lambda function, ACM certs, Route53 DNS records and others are created for you.
|
||||
|
||||
[ChangeSets][12] are not yet implemented but you will be able to preview further changes with `up stack plan` and commit them with `up stack apply`, much like you would with Terraform.
|
||||
|
||||
Check out the [configuration documentation][13] for more information.
|
||||
|
||||
#### Global deploys
|
||||
|
||||
The `regions` array allows you to specify target regions for your app. For example if you’re only interested in a single region you’d use:
|
||||
|
||||
```
|
||||
{
|
||||
"regions": ["us-west-2"]
|
||||
}
|
||||
```
|
||||
|
||||
If your customers are concentrated in North America, you may want to use all of the US and CA regions:
|
||||
|
||||
```
|
||||
{
|
||||
"regions": ["us-*", "ca-*"]
|
||||
}
|
||||
```
|
||||
|
||||
Lastly of course you can target all 14 regions currently supported:
|
||||
|
||||
```
|
||||
{
|
||||
"regions": ["*"]
|
||||
}
|
||||
```
|
||||
|
||||
Multi-region support is still a work-in-progress as a few new AWS features are required to tie things together.
|
||||
|
||||
#### Static file serving
|
||||
|
||||
Up supports static file serving out of the box, with HTTP cache support, so you can use CloudFront or any other CDN in front of your application to dramatically reduce latency.
|
||||
|
||||
By default the working directory is served (`.`) when `type` is “static”, however you may provide a `static.dir` as well:
|
||||
|
||||
```
|
||||
{ "name": "app", "type": "static", "static": { "dir": "public" }}
|
||||
```
|
||||
|
||||
#### Build hooks
|
||||
|
||||
The build hooks allow you to define custom actions when deploying or performing other operations. A common example would be to bundle Node.js apps using Webpack or Browserify, greatly reducing the file size, as node_modules is _huge_ .
|
||||
|
||||
```
|
||||
{
|
||||
"name": "app",
|
||||
"hooks": {
|
||||
"build": "browserify --node server.js > app.js",
|
||||
"clean": "rm app.js"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### Script and stylesheet injection
|
||||
|
||||
Up allows you to inject scripts and styles, either inline or paths in a declarative manner. It even supports a number of “canned” scripts for Google Analytics and [Segment][14], just copy & paste your write key.
|
||||
|
||||
```
|
||||
{
|
||||
"name": "site",
|
||||
"type": "static",
|
||||
"inject": {
|
||||
"head": [
|
||||
{
|
||||
"type": "segment",
|
||||
"value": "API_KEY"
|
||||
},
|
||||
{
|
||||
"type": "inline style",
|
||||
"file": "/css/primer.css"
|
||||
}
|
||||
],
|
||||
"body": [
|
||||
{
|
||||
"type": "script",
|
||||
"value": "/app.js"
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### Rewrites and redirects
|
||||
|
||||
Up supports redirects and URL rewriting via the `redirects` object, which maps path patterns to a new location. If `status` is omitted (or 200) then it is a rewrite, otherwise it is a redirect.
|
||||
|
||||
```
|
||||
{
|
||||
"name": "app",
|
||||
"type": "static",
|
||||
"redirects": {
|
||||
"/blog": {
|
||||
"location": "https://blog.apex.sh/",
|
||||
"status": 301
|
||||
},
|
||||
"/docs/:section/guides/:guide": {
|
||||
"location": "/help/:section/:guide",
|
||||
"status": 302
|
||||
},
|
||||
"/store/*": {
|
||||
"location": "/shop/:splat"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
A common use-case for rewrites is for SPAs (Single Page Apps), where you want to serve the `index.html` file regardless of the path. Unless of course the file exists.
|
||||
|
||||
```
|
||||
{
|
||||
"name": "app",
|
||||
"type": "static",
|
||||
"redirects": {
|
||||
"/*": {
|
||||
"location": "/",
|
||||
"status": 200
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
If you want to force the rule regardless of a file existing, just add `"force": true` .
|
||||
|
||||
#### Environment variables
|
||||
|
||||
Secrets will be in the next release, however for now plain-text environment variables are supported:
|
||||
|
||||
```
|
||||
{
|
||||
"name": "api",
|
||||
"environment": {
|
||||
"API_FEATURE_FOO": "1",
|
||||
"API_FEATURE_BAR": "0"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### CORS support
|
||||
|
||||
The [CORS][16] support allows you to to specify which (if any) domains can access your API from the browser. If you wish to allow any site to access your API, just enable it:
|
||||
|
||||
```
|
||||
{
|
||||
"cors": {
|
||||
"enable": true
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
You can also customize access, for example restricting API access to your front-end or SPA only.
|
||||
|
||||
```
|
||||
{
|
||||
"cors": {
|
||||
"allowed_origins": ["https://myapp.com"],
|
||||
"allowed_methods": ["HEAD", "GET", "POST", "PUT", "DELETE"],
|
||||
"allowed_headers": ["Content-Type", "Authorization"]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### Logging
|
||||
|
||||
For the low price of $0.5/GB you can utilize CloudWatch logs for structured log querying and tailing. Up implements a custom [query language][18] used to improve upon what CloudWatch provides, purpose-built for querying structured JSON logs.
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
|
||||
|
||||
You can query existing logs:
|
||||
|
||||
```
|
||||
up logs
|
||||
```
|
||||
|
||||
Tail live logs:
|
||||
|
||||
```
|
||||
up logs -f
|
||||
```
|
||||
|
||||
Or filter on either of them, for example only showing 200 GET / HEAD requests that take more than 5 milliseconds to complete:
|
||||
|
||||
```
|
||||
up logs 'method in ("GET", "HEAD") status = 200 duration >= 5'
|
||||
```
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
|
||||
|
||||
The query language is quite flexible, here are some more examples from `up help logs`
|
||||
|
||||
```
|
||||
Show logs from the past 5 minutes.
|
||||
$ up logs
|
||||
```
|
||||
|
||||
```
|
||||
Show logs from the past 30 minutes.
|
||||
$ up logs -s 30m
|
||||
```
|
||||
|
||||
```
|
||||
Show logs from the past 5 hours.
|
||||
$ up logs -s 5h
|
||||
```
|
||||
|
||||
```
|
||||
Show live log output.
|
||||
$ up logs -f
|
||||
```
|
||||
|
||||
```
|
||||
Show error logs.
|
||||
$ up logs error
|
||||
```
|
||||
|
||||
```
|
||||
Show error and fatal logs.
|
||||
$ up logs 'error or fatal'
|
||||
```
|
||||
|
||||
```
|
||||
Show non-info logs.
|
||||
$ up logs 'not info'
|
||||
```
|
||||
|
||||
```
|
||||
Show logs with a specific message.
|
||||
$ up logs 'message = "user login"'
|
||||
```
|
||||
|
||||
```
|
||||
Show 200 responses with latency above 150ms.
|
||||
$ up logs 'status = 200 duration > 150'
|
||||
```
|
||||
|
||||
```
|
||||
Show 4xx and 5xx responses.
|
||||
$ up logs 'status >= 400'
|
||||
```
|
||||
|
||||
```
|
||||
Show emails containing @apex.sh.
|
||||
$ up logs 'user.email contains "@apex.sh"'
|
||||
```
|
||||
|
||||
```
|
||||
Show emails ending with @apex.sh.
|
||||
$ up logs 'user.email = "*@apex.sh"'
|
||||
```
|
||||
|
||||
```
|
||||
Show emails starting with tj@.
|
||||
$ up logs 'user.email = "tj@*"'
|
||||
```
|
||||
|
||||
```
|
||||
Show errors from /tobi and /loki
|
||||
$ up logs 'error and (path = "/tobi" or path = "/loki")'
|
||||
```
|
||||
|
||||
```
|
||||
Show the same as above with 'in'
|
||||
$ up logs 'error and path in ("/tobi", "/loki")'
|
||||
```
|
||||
|
||||
```
|
||||
Show logs with a more complex query.
|
||||
$ up logs 'method in ("POST", "PUT") ip = "207.*" status = 200 duration >= 50'
|
||||
```
|
||||
|
||||
```
|
||||
Pipe JSON error logs to the jq tool.
|
||||
$ up logs error | jq
|
||||
```
|
||||
|
||||
Note that the `and` keyword is implied, though you can use it if you prefer.
|
||||
|
||||
#### Cold start times
|
||||
|
||||
This is a property of AWS Lambda as a platform, but the cold start times are typically well below 1 second, and in the future I plan on providing an option to keep them warm.
|
||||
|
||||
#### Config validation
|
||||
|
||||
The `up config` command outputs the resolved configuration, complete with defaults and inferred runtime settings – it also serves the dual purpose of validating configuration, as any error will result in exit > 0.
|
||||
|
||||
#### Crash recovery
|
||||
|
||||
Another benefit of using Up as a reverse proxy is performing crash recovery — restarting your server upon crashes and re-attempting the request before responding to the client with an error.
|
||||
|
||||
For example suppose your Node.js application crashes with an uncaught exception due to an intermittent database issue, Up can retry this request before ever responding to the client. Later this behaviour will be more customizable.
|
||||
|
||||
#### Continuous integration friendly
|
||||
|
||||
It’s hard to call this a feature, but thanks to Golang’s relatively small and isolated binaries, you can install Up in a CI in a second or two.
|
||||
|
||||
#### HTTP/2
|
||||
|
||||
Up supports HTTP/2 out of the box via API Gateway, reducing the latency for serving apps and sites with with many assets. I’ll do more comprehensive testing against many platforms in the future, but Up’s latency is already favourable:
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
|
||||
|
||||
#### Error pages
|
||||
|
||||
Up provides a default error page which you may customize with `error_pages` if you’d like to provide a support email or tweak the color.
|
||||
|
||||
```
|
||||
{ "name": "site", "type": "static", "error_pages": { "variables": { "support_email": "support@apex.sh", "color": "#228ae6" } }}
|
||||
```
|
||||
|
||||
By default it looks like this:
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
|
||||
|
||||
If you’d like to provide custom templates you may create one or more of the following files. The most specific file takes precedence.
|
||||
|
||||
* `error.html` – Matches any 4xx or 5xx
|
||||
|
||||
* `5xx.html` – Matches any 5xx error
|
||||
|
||||
* `4xx.html` – Matches any 4xx error
|
||||
|
||||
* `CODE.html` – Matches a specific code such as 404.html
|
||||
|
||||
Check out the [docs][22] to read more about templating.
|
||||
|
||||
### Scaling and cost
|
||||
|
||||
So you’ve made it this far, but how well does Up scale? Currently API Gateway and AWS are the target platform, so you’re not required to make any changes in order to scale, just deploy your code and it’s done. You pay only for what you actually use, on-demand, and no manual intervention is required for scaling.
|
||||
|
||||
AWS offers 1,000,000 requests per month for free, but you can use [http://serverlesscalc.com][23] to plug in your expected traffic. In the future Up will provide additional platforms, so that if one becomes prohibitively expensive, you can migrate to another!
|
||||
|
||||
### The Future
|
||||
|
||||
That’s all for now! It may not look like much, but it’s clocking-in above 10,000 lines of code already, and I’ve just begun development. Take a look at the issue queue for a small look at what to expect in the future, assuming the project becomes sustainable.
|
||||
|
||||
If you find the free version useful please consider donating on [OpenCollective][24], as I do not make any money working on it. I will be working on early access to the Pro version shortly, with a discounted annual price for early adopters. Either the Pro or Enterprise editions will provide the source as well, so internal hotfixes and customizations can be made.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.freecodecamp.org/up-b3db1ca930ee
|
||||
|
||||
作者:[TJ Holowaychuk ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@tjholowaychuk?source=post_header_lockup
|
||||
[1]:https://medium.com/@tjholowaychuk/blueprints-for-up-1-5f8197179275
|
||||
[2]:https://github.com/apex/up
|
||||
[3]:https://github.com/apex/up
|
||||
[4]:https://github.com/tj/gh-polls
|
||||
[5]:https://github.com/apex/up/tree/master/docs
|
||||
[6]:https://github.com/apex/up/releases
|
||||
[7]:https://raw.githubusercontent.com/apex/up/master/install.sh
|
||||
[8]:https://github.com/apex/up/blob/master/docs/aws-credentials.md
|
||||
[9]:https://github.com/apex/apex
|
||||
[10]:https://github.com/apex/up/blob/master/docs/runtimes.md
|
||||
[11]:https://github.com/apex/up/issues/166
|
||||
[12]:https://github.com/apex/up/issues/115
|
||||
[13]:https://github.com/apex/up/blob/master/docs/configuration.md
|
||||
[14]:https://segment.com/
|
||||
[15]:https://blog.apex.sh/
|
||||
[16]:https://developer.mozilla.org/en-US/docs/Web/HTTP/Access_control_CORS
|
||||
[17]:https://myapp.com/
|
||||
[18]:https://github.com/apex/up/blob/master/internal/logs/parser/grammar.peg
|
||||
[19]:http://twitter.com/apex
|
||||
[20]:http://twitter.com/apex
|
||||
[21]:http://twitter.com/apex
|
||||
[22]:https://github.com/apex/up/blob/master/docs/configuration.md#error-pages
|
||||
[23]:http://serverlesscalc.com/
|
||||
[24]:https://opencollective.com/apex-up
|
||||
114
sources/tech/20170928 3 Python web scrapers and crawlers.md
Normal file
114
sources/tech/20170928 3 Python web scrapers and crawlers.md
Normal file
@ -0,0 +1,114 @@
|
||||
3 Python web scrapers and crawlers
|
||||
============================================================
|
||||
|
||||
### Check out these great Python tools for crawling and scraping the web, and parsing out the data you need.
|
||||
|
||||
|
||||

|
||||
Image credits : [You as a Machine][13]. Modified by Rikki Endsley. [CC BY-SA 2.0][14].
|
||||
|
||||
In a perfect world, all of the data you need would be cleanly presented in an open and well-documented format that you could easily download and use for whatever purpose you need.
|
||||
|
||||
In the real world, data is messy, rarely packaged how you need it, and often out-of-date.
|
||||
|
||||
More Python Resources
|
||||
|
||||
* [What is Python?][1]
|
||||
|
||||
* [Top Python IDEs][2]
|
||||
|
||||
* [Top Python GUI frameworks][3]
|
||||
|
||||
* [Latest Python content][4]
|
||||
|
||||
* [More developer resources][5]
|
||||
|
||||
Often, the information you need is trapped inside of a website. While some websites make an effort to present data in a clean, structured data format, many do not. [Crawling][33], [scraping][34], processing, and cleaning data is a necessary activity for a whole host of activities from mapping a website's structure to collecting data that's in a web-only format, or perhaps, locked away in a proprietary database.
|
||||
|
||||
Sooner or later, you're going to find a need to do some crawling and scraping to get the data you need, and almost certainly you're going to need to do a little coding to get it done right. How you do this is up to you, but I've found the Python community to be a great provider of tools, frameworks, and documentation for grabbing data off of websites.
|
||||
|
||||
Before we jump in, just a quick request: think before you do, and be nice. In the context of scraping, this can mean a lot of things. Don't crawl websites just to duplicate them and present someone else's work as your own (without permission, of course). Be aware of copyrights and licensing, and how each might apply to whatever you have scraped. Respect [robots.txt][15] files. And don't hit a website so frequently that the actual human visitors have trouble accessing the content.
|
||||
|
||||
With that caution stated, here are some great Python tools for crawling and scraping the web, and parsing out the data you need.
|
||||
|
||||
### Pyspider
|
||||
|
||||
Let's kick things off with [pyspider][16], a web-crawler with a web-based user interface that makes it easy to keep track of multiple crawls. It's an extensible option, with multiple backend databases and message queues supported, and several handy features baked in, from prioritization to the ability to retry failed pages, crawling pages by age, and others. Pyspider supports both Python 2 and 3, and for faster crawling, you can use it in a distributed format with multiple crawlers going at once.
|
||||
|
||||
Pyspyder's basic usage is well [documented][17] including sample code snippets, and you can check out an [online demo][18] to get a sense of the user interface. Licensed under the Apache 2 license, pyspyder is still being actively developed on GitHub.
|
||||
|
||||
### MechanicalSoup
|
||||
|
||||
[MechanicalSoup][19] is a crawling library built around the hugely-popular and incredibly versatile HTML parsing library [Beautiful Soup][20]. If your crawling needs are fairly simple, but require you to check a few boxes or enter some text and you don't want to build your own crawler for this task, it's a good option to consider.
|
||||
|
||||
MechanicalSoup is licensed under an MIT license. For more on how to use it, check out the example source file [example.py][21] on the project's GitHub page. Unfortunately, the project does not have robust documentation at this time
|
||||
|
||||
### Scrapy
|
||||
|
||||
[Scrapy][22] is a scraping framework supported by an active community with which you can build your own scraping tool. In addition to scraping and parsing tools, it can easily export the data it collects in a number of formats like JSON or CSV and store the data on a backend of your choosing. It also has a number of built-in extensions for tasks like cookie handling, user-agent spoofing, restricting crawl depth, and others, as well as an API for easily building your own additions.
|
||||
|
||||
For an introduction to Scrapy, check out the [online documentation][23] or one of their many [community][24] resources, including an IRC channel, Subreddit, and a healthy following on their StackOverflow tag. Scrapy's code base can be found [on GitHub][25] under a 3-clause BSD license.
|
||||
|
||||
If you're not all that comfortable with coding, [Portia][26] provides a visual interface that makes it easier. A hosted version is available at [scrapinghub.com][27].
|
||||
|
||||
### Others
|
||||
|
||||
* [Cola][6] describes itself as a “high-level distributed crawling framework” that might meet your needs if you're looking for a Python 2 approach, but note that it has not been updated in over two years.
|
||||
|
||||
* [Demiurge][7], which supports both Python 2 and Python 3, is another potential candidate to look at, although development on this project is relatively quiet as well.
|
||||
|
||||
* [Feedparser][8] might be a helpful project to check out if the data you are trying to parse resides primarily in RSS or Atom feeds.
|
||||
|
||||
* [Lassie][9] makes it easy to retrieve basic content like a description, title, keywords, or a list of images from a webpage.
|
||||
|
||||
* [RoboBrowser][10] is another simple library for Python 2 or 3 with basic functionality, including button-clicking and form-filling. Though it hasn't been updated in a while, it's still a reasonable choice.
|
||||
|
||||
* * *
|
||||
|
||||
This is far from a comprehensive list, and of course, if you're a master coder you may choose to take your own approach rather than use one of these frameworks. Or, perhaps, you've found a great alternative built for a different language. For example, Python coders would probably appreciate checking out the [Python bindings][28] for [Selenium][29] for sites that are trickier to crawl without using an actual web browser. If you've got a favorite tool for crawling and scraping, let us know in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/resources/python/web-scraper-crawler
|
||||
|
||||
作者:[Jason Baker ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:https://opensource.com/resources/python?intcmp=7016000000127cYAAQ
|
||||
[2]:https://opensource.com/resources/python/ides?intcmp=7016000000127cYAAQ
|
||||
[3]:https://opensource.com/resources/python/gui-frameworks?intcmp=7016000000127cYAAQ
|
||||
[4]:https://opensource.com/tags/python?intcmp=7016000000127cYAAQ
|
||||
[5]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ
|
||||
[6]:https://github.com/chineking/cola
|
||||
[7]:https://github.com/matiasb/demiurge
|
||||
[8]:https://github.com/kurtmckee/feedparser
|
||||
[9]:https://github.com/michaelhelmick/lassie
|
||||
[10]:https://github.com/jmcarp/robobrowser
|
||||
[11]:https://opensource.com/resources/python/web-scraper-crawler?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007&rate=Wn1vUb9FpPK-IGQ1waRzgdIsDN3pXBH6rO2xnjoK_t4
|
||||
[12]:https://opensource.com/user/19894/feed
|
||||
[13]:https://www.flickr.com/photos/youasamachine/8025582590/in/photolist-decd6C-7pkccp-aBfN9m-8NEffu-3JDbWb-aqf5Tx-7Z9MTZ-rnYTRu-3MeuPx-3yYwA9-6bSLvd-irmvxW-5Asr4h-hdkfCA-gkjaSQ-azcgct-gdV5i4-8yWxCA-9G1qDn-5tousu-71V8U2-73D4PA-iWcrTB-dDrya8-7GPuxe-5pNb1C-qmnLwy-oTxwDW-3bFhjL-f5Zn5u-8Fjrua-bxcdE4-ddug5N-d78G4W-gsYrFA-ocrBbw-pbJJ5d-682rVJ-7q8CbF-7n7gDU-pdfgkJ-92QMx2-aAmM2y-9bAGK1-dcakkn-8rfyTz-aKuYvX-hqWSNP-9FKMkg-dyRPkY
|
||||
[14]:https://creativecommons.org/licenses/by/2.0/
|
||||
[15]:http://www.robotstxt.org/
|
||||
[16]:https://github.com/binux/pyspider
|
||||
[17]:http://docs.pyspider.org/en/latest/
|
||||
[18]:http://demo.pyspider.org/
|
||||
[19]:https://github.com/hickford/MechanicalSoup
|
||||
[20]:https://www.crummy.com/software/BeautifulSoup/
|
||||
[21]:https://github.com/hickford/MechanicalSoup/blob/master/example.py
|
||||
[22]:https://scrapy.org/
|
||||
[23]:https://doc.scrapy.org/en/latest/
|
||||
[24]:https://scrapy.org/community/
|
||||
[25]:https://github.com/scrapy/scrapy
|
||||
[26]:https://github.com/scrapinghub/portia
|
||||
[27]:https://portia.scrapinghub.com/
|
||||
[28]:https://selenium-python.readthedocs.io/
|
||||
[29]:https://github.com/SeleniumHQ/selenium
|
||||
[30]:https://opensource.com/users/jason-baker
|
||||
[31]:https://opensource.com/users/jason-baker
|
||||
[32]:https://opensource.com/resources/python/web-scraper-crawler?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#comments
|
||||
[33]:https://en.wikipedia.org/wiki/Web_crawler
|
||||
[34]:https://en.wikipedia.org/wiki/Web_scraping
|
||||
@ -0,0 +1,215 @@
|
||||
12 Practices every Android Development Beginner should know — Part 1
|
||||
============================================================
|
||||
|
||||
### One practice at a time to become a better Android beginner
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
It’s been more than 12 years since Andy Rubin and team started working on the idea of a mobile operating system that would change the way mobile phones, rather smartphones were seen by consumers as well as the people who developed software for it. Smartphones back then were limited to texting and checking emails (and of course, making phone calls), giving users and developers a boundary to work within.
|
||||
|
||||
Android, the breaker of chains, with its excellent framework design gave both the parties the freedom to explore more than just a limited set of functionalities. One would argue that the iPhone brought the revolution in the mobile industry, but the thing is no matter how cool (and pricey, eh?) an iPhone is, it again brings that boundary, that limitation we never wanted.
|
||||
|
||||
However, as Uncle Ben said — with great power comes great responsibility — we also need to be extra careful with our Android application design approach. I have often seen, in many courses offered, the negligence to teach beginners that value, the value to understand the architecture well enough before starting. We just throw things at people without correctly explaining what the upsides and downsides are, how they impact design or what to use, what not to.
|
||||
|
||||
In this post, we will see some of the practices that a beginner or an intermediate (if missed any) level developer should know in order to get better out of the Android framework. This post will be followed by more in this series of posts where we will talk about more such useful practices. Let’s begin.
|
||||
|
||||
* * *
|
||||
|
||||
### 1\. Difference between @+id and @id
|
||||
|
||||
In order to access a widget (or component) in Java or to make others dependent on it, we need a unique value to represent it. That unique value is provided by android:id attribute which essentially adds id provided as a suffix to @+id/ to the _id resource file_ for others to query. An id for Toolbar can be defined like this,
|
||||
|
||||
```
|
||||
android:id=”@+id/toolbar
|
||||
```
|
||||
|
||||
The following id can now be tracked by _findViewById(…)_ which looks for it in the res file for id, or simply R.id directory and returns the type of View in question.
|
||||
|
||||
The other one, @id, behaves the same as findViewById(…) — looks for the component by the id provided but is reserved for layouts only. The most general use of it is to place a component relative to the component it returns.
|
||||
|
||||
```
|
||||
android:layout_below=”@id/toolbar”
|
||||
```
|
||||
|
||||
### 2\. Using @string res for providing Strings in XML
|
||||
|
||||
In simpler words, don’t use hard coded strings in XML. The reason behind it is fairly simple. When we use hard coded string in XML, we often use the same word over and over again. Just imagine the nightmare of changing the same word at multiple places which could have been just one had it been a string resource. The other benefit it provides is multi-language support as different string resource files can be created for different languages.
|
||||
|
||||
```
|
||||
android:text=”My Awesome Application”
|
||||
```
|
||||
|
||||
When using hard coded strings, you will often see a warning over the use of such strings in Android Studio, offering to change that hard coded string into a string resource. Try clicking on them and then hitting ALT + ENTER to get the resource extractor. You can also go to strings.xml located in values folder under res and declare a string resource like this,
|
||||
|
||||
```
|
||||
<string name=”app_name”>My Awesome Application</string>
|
||||
```
|
||||
|
||||
and then use it in place of the hard coded string,
|
||||
|
||||
```
|
||||
android:text=”@string/app_name”
|
||||
```
|
||||
|
||||
### 3\. Using @android and ?attr constants
|
||||
|
||||
This is a fairly effective practice to use predefined constants instead of declaring new ones. Take an example of #ffffff or white color which is used several times in a layout. Now instead of writing #ffffff every single time, or declaring a color resource for white, we could directly use this,
|
||||
|
||||
```
|
||||
@android:color/white
|
||||
```
|
||||
|
||||
Android has several color constants declared mainly for general colors like white, black or pink. It’s best use case is setting transparent color with,
|
||||
|
||||
```
|
||||
@android:color/transparent
|
||||
```
|
||||
|
||||
Another constant holder is ?attr which is used for setting predefined attribute values to different attributes. Just take an example of a custom Toolbar. This Toolbar needs a defined width and height. The width can be normally set to MATCH_PARENT, but what about height? Most of us aren’t aware of the guidelines, and we simply set the desired height that seems fitting. That’s wrong practice. Instead of setting our own height, we should rather be using,
|
||||
|
||||
```
|
||||
android:layout_height=”?attr/actionBarSize”
|
||||
```
|
||||
|
||||
Another use of ?attr is to draw ripples on views when clicked. SelectableItemBackground is a predefined drawable that can be set as background to any view which needs ripple effect,
|
||||
|
||||
```
|
||||
android:background=”?attr/selectableItemBackground”
|
||||
```
|
||||
|
||||
or we can use
|
||||
|
||||
```
|
||||
android:background=”?attr/selectableItemBackgroundBorderless”
|
||||
```
|
||||
|
||||
to enable borderless ripple.
|
||||
|
||||
### 4\. Difference between SP and DP
|
||||
|
||||
While there’s no real difference between these two, it’s important to know what these two are, and where to use them to best results.
|
||||
|
||||
SP or Scale-independent pixels are recommended for use with TextViews which require the font size to not change with display (density). Instead, the content of a TextView needs to scale as per the needs of a user, or simply the font size preferred by the user.
|
||||
|
||||
With anything else that needs dimension or position, DP or Density-independent pixels can be used. As mentioned earlier, DP and SP are same things, it’s just that DP scales well with changing densities as the Android System dynamically calculates the pixels from it making it suitable for use on components that need to look and feel the same on different devices with different display densities.
|
||||
|
||||
### 5\. Use of Drawables and Mipmaps
|
||||
|
||||
This is the most confusing of them all — How are drawable and mipmap different?
|
||||
|
||||
While it may seem that both serve the same purpose, they are inherentaly different. Mipmaps are meant to be used for storing icons, where as drawables are for any other format. Let’s see how they are used by the system internally and why not to use one in place of the other.
|
||||
|
||||
You’ll notice that your application has several mipmap and drawable folders, each representing a different display resolution. When it comes to choosing from Drawable folder, the system chooses from the folder that belongs to current device density. However, with Mipmap, the system can choose an icon from any folder that fits the need mainly because some launchers display larger icons than intended, so system chooses the next size up.
|
||||
|
||||
In short, use mipmaps for icons or markers that see a change in resolution when used on different device densities and use drawable for other resource types that can be stripped out when required.
|
||||
|
||||
For example, a Nexus 5 is xxhdpi. Now when we put icons in mipmap folders, all the folders of mipmap will be retained. But when it comes to drawable, only drawable-xxhdpi will be retained, terming any other folder useless.
|
||||
|
||||
### 6\. Using Vector Drawables
|
||||
|
||||
It’s a very common practice to add multiple versions (sizes) of the same asset in order to support different screen densities. While this approach may work, it also adds certain performance overheads like larger apk size and extra development effort. To eliminate these overheads, Android team at Google announced the addition of Vector Drawables.
|
||||
|
||||
Vector Drawables are SVGs (scaled vector graphics) but in XML representing an image drawn using a set of dots, lines and curves with fill colors. The very fact that Vector Drawables are made of lines and dots, gives them the ability to scale at different densities without losing resolution. The other associated benefit with Vector Drawables is the ease of animation. Add multiple vector drawables in a single AnimatedVectorDrawable file and we’re good to go instead of adding multiple images and handling them separately.
|
||||
|
||||
```
|
||||
<vector xmlns:android=”http://schemas.android.com/apk/res/android"
|
||||
android:width=”24dp”
|
||||
android:height=”24dp”
|
||||
android:viewportWidth=”24.0"
|
||||
android:viewportHeight=”24.0">
|
||||
```
|
||||
|
||||
```
|
||||
<path android:fillColor=”#69cdff” android:pathData=”M3,18h18v-2L3,16v2zM3,13h18v-2L3,11v2zM3,6v2h18L21,6L3,6z”/>
|
||||
```
|
||||
|
||||
```
|
||||
</vector>
|
||||
```
|
||||
|
||||
The above vector definition will result in the following drawable,
|
||||
|
||||

|
||||
|
||||
To Add a vector drawable to your android project, right click on app module of your project, then New >> Vector Assets.This will get you Asset Studio which gives you two options to configure vector drawable. First, picking from Material Icons and second, choosing a local SVG or PSD file.
|
||||
|
||||
Google recommends using Material Icons for anything app related to maintain continuity and feel of Android. Be sure to check out all of the icons [here][1].
|
||||
|
||||
### 7\. Setting End/Start Margin
|
||||
|
||||
This is one of the easiest things people miss out on. Margin! Sure adding margin is easy but what about supporting older platforms?
|
||||
|
||||
Start and End are supersets of Left and Right respectively, so if the application has minSdkVersion 17 or less, start or end margin/padding is required with older left/right. On platforms where start and end are missing, these two can be safely ignored for left/right. Sample declaration looks like this,
|
||||
|
||||
```
|
||||
android:layout_marginEnd=”20dp”
|
||||
android:paddingStart=”20dp”
|
||||
```
|
||||
|
||||
### 8\. Using Getter/Setter Generator
|
||||
|
||||
One of the most frustrating things to do while creating a holder class (which simply holds variable data) is creating multiple getters and setters — Copy/paste method body and rename them for each variable.
|
||||
|
||||
Luckily, Android Studio has a solution for it. It goes like this — declare all the variables you need inside the class, and go to Toolbar >> Code. The Shortcut for it is ALT + Insert. Clicking Code will get you Generate, tap on it and among many other options, there will be Getter and Setter option. Tapping on it while maintaining focus on your class page will add all the getters and setters to the class (handle the previous window on your own). Neat, isn’t it?
|
||||
|
||||
### 9\. Using Override/Implement Generator
|
||||
|
||||
Another helpful generator. Writing custom classes and extending them is easy but what about classes you have little idea about. Take PagerAdapter for example. You want a ViewPager to show a few pages and for that, you will need a custom PagerAdapter that will work as you define inside its overridden methods. But where are those methods? Android Studio may be gracious enough to force you to add a constructor to your custom class or even to give a short cut for (that’s you ALT + Enter), but the rest of the (abstract) methods from parent PagerAdapter need to be added manually which I am sure is tiring for most of us.
|
||||
|
||||
To get a list of all the overridden methods available, go to Code >> Generate and Override method or Implement methods, which ever is your need. You can even choose to add multiple methods to your class, just hold Ctrl and select methods and hit OK.
|
||||
|
||||
### 10\. Understanding Contexts Properly
|
||||
|
||||
Context is scary and I believe a lot of beginners never care to understand the architecture of Context class — what it is, and why is it needed everywhere.
|
||||
|
||||
In simpler terms, it is the one that binds all that you see on the screen together. All the views (or their extensions) are tied to the current environment using Context. Context is responsible for allowing access to application level resources such as density or current activity associated with it. Activities, Services, and Application all implement Context interface to provide other to-be-associated components in-house resources. Take an example of a TextView which has to be added to MainActivity. You would notice while creating an object that the TextView constructor needs Context. This is to resolve any resources needed within TextView definition. Say TextView needs to internally load the Roboto font. For doing this, TextView needs Context. Also when we are providing context (or this) to TextView, we’re telling it to bind with the current activity’s lifecycle.
|
||||
|
||||
Another key use of Context is to initiate application level operations such as initiating a library. A library lives through out the application lifecycle and thus it needs to be initiated with getApplicationContext() instead of _getContext_ or _this_ or _getActivity()_ . It’s important to know the correct use of different Context types to avoid a memory leak. Other uses of Context includes starting an Activity or Service. Remember startActivity(…)? When you need to change Activity from a non-activity class, you will need a context object to access startActivity method since it belongs to the Context class, not Activity class.
|
||||
|
||||
```
|
||||
getContext().startActivity(getContext(), SecondActivity.class);
|
||||
```
|
||||
|
||||
If you want to know more about the behavior of Context, go [here][2] or [here][3]. The first one is a nice article on Contexts and where to use them while the latter is Android documentation for Context which has elaborately explained all of its available features — methods, static flags and more.
|
||||
|
||||
### Bonus #1: Formatting Code
|
||||
|
||||
Who doesn’t like clean, properly formatted code? Well, almost every one of us working on classes that tend to go up to 1000 lines in size want our code to stay structured. And it’s not that only larger classes need formatting, even smaller modular classes need to make sure code remains readable.
|
||||
|
||||
With Android Studio, or any of the JetBrains IDEs you don’t even need to care about manually structuring your code like adding indentation or space before =. Write code the way you want and when you feel like formatting it, just hit ALT + CTRL + L on Windows or ALT + CTRL + SHIFT + L on Linux. *Code Auto-Formatted*
|
||||
|
||||
### Bonus #2: Using Libraries
|
||||
|
||||
One of the key principles of Object Oriented Programming is to increase reuse of code or rather decrease the habit of reinventing the wheel. It’s a very common approach that a lot of beginners follow wrongly. The approach has two ends,
|
||||
|
||||
- Don’t use libraries, write every code on your own.
|
||||
|
||||
- Use a library for everything.
|
||||
|
||||
Going completely to either of the ends is wrong practice. If you go to the first end, you’re going to eat up a lot of resources just to live up to your pride to own everything. Plus chances are there that your code will be less tested than that library you should have gone with, increasing the chances of a buggy module. Don’t reinvent the wheel when there is a limited resource. Go with a tested library and when you’ve got the complete idea and resources, replace the library with your own reliable code.
|
||||
|
||||
With the second end, there is an even bigger issue — reliance on foreign code. Don’t get used to the idea of relying on others code for everything. Write your own code for things that need lesser resources or things that are within your reach. You don’t need a library that sets up custom TypeFaces (fonts) for you, that you can do on your own.
|
||||
|
||||
So remember, stay in the middle of the two ends — don’t reinvent everything but also don’t over-rely on foreign code. Stay neutral and code to your abilities.
|
||||
|
||||
* * *
|
||||
|
||||
This article was first published on [What’s That Lambda][4]. Be sure to visit for more articles like this one on Android, Node.js, Angular.js and more.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://android.jlelse.eu/12-practices-every-android-beginner-should-know-cd43c3710027
|
||||
|
||||
作者:[ Nilesh Singh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://android.jlelse.eu/@nileshsingh?source=post_header_lockup
|
||||
[1]:https://material.io/icons/
|
||||
[2]:https://blog.mindorks.com/understanding-context-in-android-application-330913e32514
|
||||
[3]:https://developer.android.com/reference/android/content/Context.html
|
||||
[4]:https://www.whatsthatlambda.com/android/android-dev-101-things-every-beginner-must-know
|
||||
@ -0,0 +1,421 @@
|
||||
High Dynamic Range (HDR) Imaging using OpenCV (C++/Python)
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
In this tutorial, we will learn how to create a High Dynamic Range (HDR) image using multiple images taken with different exposure settings. We will share code in both C++ and Python.
|
||||
|
||||
### What is High Dynamic Range (HDR) imaging?
|
||||
|
||||
Most digital cameras and displays capture or display color images as 24-bits matrices. There are 8-bits per color channel and the pixel values are therefore in the range 0 – 255 for each channel. In other words, a regular camera or a display has a limited dynamic range.
|
||||
|
||||
However, the world around us has a very large dynamic range. It can get pitch black inside a garage when the lights are turned off and it can get really bright if you are looking directly at the Sun. Even without considering those extremes, in everyday situations, 8-bits are barely enough to capture the scene. So, the camera tries to estimate the lighting and automatically sets the exposure so that the most interesting aspect of the image has good dynamic range, and the parts that are too dark and too bright are clipped off to 0 and 255 respectively.
|
||||
|
||||
In the Figure below, the image on the left is a normally exposed image. Notice the sky in the background is completely washed out because the camera decided to use a setting where the subject (my son) is properly photographed, but the bright sky is washed out. The image on the right is an HDR image produced by the iPhone.
|
||||
|
||||
[][3]
|
||||
|
||||
How does an iPhone capture an HDR image? It actually takes 3 images at three different exposures. The images are taken in quick succession so there is almost no movement between the three shots. The three images are then combined to produce the HDR image. We will see the details in the next section.
|
||||
|
||||
The process of combining different images of the same scene acquired under different exposure settings is called High Dynamic Range (HDR) imaging.
|
||||
|
||||
### How does High Dynamic Range (HDR) imaging work?
|
||||
|
||||
In this section, we will go through the steps of creating an HDR image using OpenCV.
|
||||
|
||||
To easily follow this tutorial, please [download][4] the C++ and Python code and images by clicking [here][5]. If you are interested to learn more about AI, Computer Vision and Machine Learning, please [subscribe][6] to our newsletter.
|
||||
|
||||
### Step 1: Capture multiple images with different exposures
|
||||
|
||||
When we take a picture using a camera, we have only 8-bits per channel to represent the dynamic range ( brightness range ) of the scene. But we can take multiple images of the scene at different exposures by changing the shutter speed. Most SLR cameras have a feature called Auto Exposure Bracketing (AEB) that allows us to take multiple pictures at different exposures with just one press of a button. If you are using an iPhone, you can use this [AutoBracket HDR app][7] and if you are an android user you can try [A Better Camera app][8].
|
||||
|
||||
Using AEB on a camera or an auto bracketing app on the phone, we can take multiple pictures quickly one after the other so the scene does not change. When we use HDR mode in an iPhone, it takes three pictures.
|
||||
|
||||
1. An underexposed image: This image is darker than the properly exposed image. The goal is the capture parts of the image that very bright.
|
||||
|
||||
2. A properly exposed image: This is the regular image the camera would have taken based on the illumination it has estimated.
|
||||
|
||||
3. An overexposed image: This image is brighter than the properly exposed image. The goal is the capture parts of the image that very dark.
|
||||
|
||||
However, if the dynamic range of the scene is very large, we can take more than three pictures to compose the HDR image. In this tutorial, we will use 4 images taken with exposure time 1/30, 0.25, 2.5 and 15 seconds. The thumbnails are shown below.
|
||||
|
||||
[][9]
|
||||
|
||||
The information about the exposure time and other settings used by an SLR camera or a Phone are usually stored in the EXIF metadata of the JPEG file. Check out this [link][10] to see EXIF metadata stored in a JPEG file in Windows and Mac. Alternatively, you can use my favorite command line utility for EXIF called [EXIFTOOL ][11].
|
||||
|
||||
Let’s start by reading in the images are assigning the exposure times
|
||||
|
||||
C++
|
||||
|
||||
```
|
||||
void readImagesAndTimes(vector<Mat> &images, vector<float> ×)
|
||||
{
|
||||
|
||||
int numImages = 4;
|
||||
|
||||
// List of exposure times
|
||||
static const float timesArray[] = {1/30.0f,0.25,2.5,15.0};
|
||||
times.assign(timesArray, timesArray + numImages);
|
||||
|
||||
// List of image filenames
|
||||
static const char* filenames[] = {"img_0.033.jpg", "img_0.25.jpg", "img_2.5.jpg", "img_15.jpg"};
|
||||
for(int i=0; i < numImages; i++)
|
||||
{
|
||||
Mat im = imread(filenames[i]);
|
||||
images.push_back(im);
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
Python
|
||||
|
||||
```
|
||||
def readImagesAndTimes():
|
||||
# List of exposure times
|
||||
times = np.array([ 1/30.0, 0.25, 2.5, 15.0 ], dtype=np.float32)
|
||||
|
||||
# List of image filenames
|
||||
filenames = ["img_0.033.jpg", "img_0.25.jpg", "img_2.5.jpg", "img_15.jpg"]
|
||||
images = []
|
||||
for filename in filenames:
|
||||
im = cv2.imread(filename)
|
||||
images.append(im)
|
||||
|
||||
return images, times
|
||||
```
|
||||
|
||||
### Step 2: Align Images
|
||||
|
||||
Misalignment of images used in composing the HDR image can result in severe artifacts. In the Figure below, the image on the left is an HDR image composed using unaligned images and the image on the right is one using aligned images. By zooming into a part of the image, shown using red circles, we see severe ghosting artifacts in the left image.
|
||||
|
||||
[][12]
|
||||
|
||||
Naturally, while taking the pictures for creating an HDR image, professional photographer mount the camera on a tripod. They also use a feature called [mirror lockup][13] to reduce additional vibrations. Even then, the images may not be perfectly aligned because there is no way to guarantee a vibration-free environment. The problem of alignment gets a lot worse when images are taken using a handheld camera or a phone.
|
||||
|
||||
Fortunately, OpenCV provides an easy way to align these images using `AlignMTB`. This algorithm converts all the images to median threshold bitmaps (MTB). An MTB for an image is calculated by assigning the value 1 to pixels brighter than median luminance and 0 otherwise. An MTB is invariant to the exposure time. Therefore, the MTBs can be aligned without requiring us to specify the exposure time.
|
||||
|
||||
MTB based alignment is performed using the following lines of code.
|
||||
|
||||
C++
|
||||
|
||||
```
|
||||
// Align input images
|
||||
Ptr<AlignMTB> alignMTB = createAlignMTB();
|
||||
alignMTB->process(images, images);
|
||||
```
|
||||
|
||||
Python
|
||||
|
||||
```
|
||||
# Align input images
|
||||
alignMTB = cv2.createAlignMTB()
|
||||
alignMTB.process(images, images)
|
||||
```
|
||||
|
||||
### Step 3: Recover the Camera Response Function
|
||||
|
||||
The response of a typical camera is not linear to scene brightness. What does that mean? Suppose, two objects are photographed by a camera and one of them is twice as bright as the other in the real world. When you measure the pixel intensities of the two objects in the photograph, the pixel values of the brighter object will not be twice that of the darker object! Without estimating the Camera Response Function (CRF), we will not be able to merge the images into one HDR image.
|
||||
|
||||
What does it mean to merge multiple exposure images into an HDR image?
|
||||
|
||||
Consider just ONE pixel at some location (x,y) of the images. If the CRF was linear, the pixel value would be directly proportional to the exposure time unless the pixel is too dark ( i.e. nearly 0 ) or too bright ( i.e. nearly 255) in a particular image. We can filter out these bad pixels ( too dark or too bright ), and estimate the brightness at a pixel by dividing the pixel value by the exposure time and then averaging this brightness value across all images where the pixel is not bad ( too dark or too bright ). We can do this for all pixels and obtain a single image where all pixels are obtained by averaging “good” pixels.
|
||||
|
||||
But the CRF is not linear and we need to make the image intensities linear before we can merge/average them by first estimating the CRF.
|
||||
|
||||
The good news is that the CRF can be estimated from the images if we know the exposure times for each image. Like many problems in computer vision, the problem of finding the CRF is set up as an optimization problem where the goal is to minimize an objective function consisting of a data term and a smoothness term. These problems usually reduce to a linear least squares problem which are solved using Singular Value Decomposition (SVD) that is part of all linear algebra packages. The details of the CRF recovery algorithm are in the paper titled [Recovering High Dynamic Range Radiance Maps from Photographs][14].
|
||||
|
||||
Finding the CRF is done using just two lines of code in OpenCV using `CalibrateDebevec` or `CalibrateRobertson`. In this tutorial we will use `CalibrateDebevec`
|
||||
|
||||
C++
|
||||
|
||||
```
|
||||
// Obtain Camera Response Function (CRF)
|
||||
Mat responseDebevec;
|
||||
Ptr<CalibrateDebevec> calibrateDebevec = createCalibrateDebevec();
|
||||
calibrateDebevec->process(images, responseDebevec, times);
|
||||
|
||||
```
|
||||
|
||||
Python
|
||||
|
||||
```
|
||||
# Obtain Camera Response Function (CRF)
|
||||
calibrateDebevec = cv2.createCalibrateDebevec()
|
||||
responseDebevec = calibrateDebevec.process(images, times)
|
||||
```
|
||||
|
||||
The figure below shows the CRF recovered using the images for the red, green and blue channels.
|
||||
|
||||
[][15]
|
||||
|
||||
### Step 4: Merge Images
|
||||
|
||||
Once the CRF has been estimated, we can merge the exposure images into one HDR image using `MergeDebevec`. The C++ and Python code is shown below.
|
||||
|
||||
C++
|
||||
|
||||
```
|
||||
// Merge images into an HDR linear image
|
||||
Mat hdrDebevec;
|
||||
Ptr<MergeDebevec> mergeDebevec = createMergeDebevec();
|
||||
mergeDebevec->process(images, hdrDebevec, times, responseDebevec);
|
||||
// Save HDR image.
|
||||
imwrite("hdrDebevec.hdr", hdrDebevec);
|
||||
```
|
||||
|
||||
Python
|
||||
|
||||
```
|
||||
# Merge images into an HDR linear image
|
||||
mergeDebevec = cv2.createMergeDebevec()
|
||||
hdrDebevec = mergeDebevec.process(images, times, responseDebevec)
|
||||
# Save HDR image.
|
||||
cv2.imwrite("hdrDebevec.hdr", hdrDebevec)
|
||||
```
|
||||
|
||||
The HDR image saved above can be loaded in Photoshop and tonemapped. An example is shown below.
|
||||
|
||||
[][16] HDR Photoshop tone mapping
|
||||
|
||||
### Step 5: Tone mapping
|
||||
|
||||
Now we have merged our exposure images into one HDR image. Can you guess the minimum and maximum pixel values for this image? The minimum value is obviously 0 for a pitch black condition. What is the theoretical maximum value? Infinite! In practice, the maximum value is different for different situations. If the scene contains a very bright light source, we will see a very large maximum value.
|
||||
|
||||
Even though we have recovered the relative brightness information using multiple images, we now have the challenge of saving this information as a 24-bit image for display purposes.
|
||||
|
||||
The process of converting a High Dynamic Range (HDR) image to an 8-bit per channel image while preserving as much detail as possible is called Tone mapping.
|
||||
|
||||
There are several tone mapping algorithms. OpenCV implements four of them. The thing to keep in mind is that there is no right way to do tone mapping. Usually, we want to see more detail in the tonemapped image than in any one of the exposure images. Sometimes the goal of tone mapping is to produce realistic images and often times the goal is to produce surreal images. The algorithms implemented in OpenCV tend to produce realistic and therefore less dramatic results.
|
||||
|
||||
Let’s look at the various options. Some of the common parameters of the different tone mapping algorithms are listed below.
|
||||
|
||||
1. gamma : This parameter compresses the dynamic range by applying a gamma correction. When gamma is equal to 1, no correction is applied. A gamma of less than 1 darkens the image, while a gamma greater than 1 brightens the image.
|
||||
|
||||
2. saturation : This parameter is used to increase or decrease the amount of saturation. When saturation is high, the colors are richer and more intense. Saturation value closer to zero, makes the colors fade away to grayscale.
|
||||
|
||||
3. contrast : Controls the contrast ( i.e. log (maxPixelValue/minPixelValue) ) of the output image.
|
||||
|
||||
Let us explore the four tone mapping algorithms available in OpenCV.
|
||||
|
||||
#### Drago Tonemap
|
||||
|
||||
The parameters for Drago Tonemap are shown below
|
||||
|
||||
```
|
||||
createTonemapDrago
|
||||
(
|
||||
float gamma = 1.0f,
|
||||
float saturation = 1.0f,
|
||||
float bias = 0.85f
|
||||
)
|
||||
```
|
||||
|
||||
Here, bias is the value for bias function in [0, 1] range. Values from 0.7 to 0.9 usually give the best results. The default value is 0.85\. For more technical details, please see this [paper][17].
|
||||
|
||||
The C++ and Python code are shown below. The parameters were obtained by trial and error. The final output is multiplied by 3 just because it gave the most pleasing results.
|
||||
|
||||
C++
|
||||
|
||||
```
|
||||
// Tonemap using Drago's method to obtain 24-bit color image
|
||||
Mat ldrDrago;
|
||||
Ptr<TonemapDrago> tonemapDrago = createTonemapDrago(1.0, 0.7);
|
||||
tonemapDrago->process(hdrDebevec, ldrDrago);
|
||||
ldrDrago = 3 * ldrDrago;
|
||||
imwrite("ldr-Drago.jpg", ldrDrago * 255);
|
||||
```
|
||||
|
||||
Python
|
||||
|
||||
```
|
||||
# Tonemap using Drago's method to obtain 24-bit color image
|
||||
tonemapDrago = cv2.createTonemapDrago(1.0, 0.7)
|
||||
ldrDrago = tonemapDrago.process(hdrDebevec)
|
||||
ldrDrago = 3 * ldrDrago
|
||||
cv2.imwrite("ldr-Drago.jpg", ldrDrago * 255)
|
||||
```
|
||||
|
||||
Result
|
||||
|
||||
[][18] HDR tone mapping using Drago’s algorithm
|
||||
|
||||
#### Durand Tonemap
|
||||
|
||||
The parameters for Durand Tonemap are shown below.
|
||||
|
||||
```
|
||||
createTonemapDurand
|
||||
(
|
||||
float gamma = 1.0f,
|
||||
float contrast = 4.0f,
|
||||
float saturation = 1.0f,
|
||||
float sigma_space = 2.0f,
|
||||
float sigma_color = 2.0f
|
||||
);
|
||||
```
|
||||
The algorithm is based on the decomposition of the image into a base layer and a detail layer. The base layer is obtained using an edge-preserving filter called the bilateral filter. sigma_space and sigma_color are the parameters of the bilateral filter that control the amount of smoothing in the spatial and color domains respectively.
|
||||
|
||||
For more details, check out this [paper][19].
|
||||
|
||||
C++
|
||||
|
||||
```
|
||||
// Tonemap using Durand's method obtain 24-bit color image
|
||||
Mat ldrDurand;
|
||||
Ptr<TonemapDurand> tonemapDurand = createTonemapDurand(1.5,4,1.0,1,1);
|
||||
tonemapDurand->process(hdrDebevec, ldrDurand);
|
||||
ldrDurand = 3 * ldrDurand;
|
||||
imwrite("ldr-Durand.jpg", ldrDurand * 255);
|
||||
```
|
||||
Python
|
||||
|
||||
```
|
||||
# Tonemap using Durand's method obtain 24-bit color image
|
||||
tonemapDurand = cv2.createTonemapDurand(1.5,4,1.0,1,1)
|
||||
ldrDurand = tonemapDurand.process(hdrDebevec)
|
||||
ldrDurand = 3 * ldrDurand
|
||||
cv2.imwrite("ldr-Durand.jpg", ldrDurand * 255)
|
||||
```
|
||||
|
||||
Result
|
||||
|
||||
[][20] HDR tone mapping using Durand’s algorithm
|
||||
|
||||
#### Reinhard Tonemap
|
||||
|
||||
```
|
||||
|
||||
createTonemapReinhard
|
||||
(
|
||||
float gamma = 1.0f,
|
||||
float intensity = 0.0f,
|
||||
float light_adapt = 1.0f,
|
||||
float color_adapt = 0.0f
|
||||
)
|
||||
```
|
||||
|
||||
The parameter intensity should be in the [-8, 8] range. Greater intensity value produces brighter results. light_adapt controls the light adaptation and is in the [0, 1] range. A value of 1 indicates adaptation based only on pixel value and a value of 0 indicates global adaptation. An in-between value can be used for a weighted combination of the two. The parameter color_adapt controls chromatic adaptation and is in the [0, 1] range. The channels are treated independently if the value is set to 1 and the adaptation level is the same for every channel if the value is set to 0\. An in-between value can be used for a weighted combination of the two.
|
||||
|
||||
For more details, check out this [paper][21].
|
||||
|
||||
C++
|
||||
|
||||
```
|
||||
// Tonemap using Reinhard's method to obtain 24-bit color image
|
||||
Mat ldrReinhard;
|
||||
Ptr<TonemapReinhard> tonemapReinhard = createTonemapReinhard(1.5, 0,0,0);
|
||||
tonemapReinhard->process(hdrDebevec, ldrReinhard);
|
||||
imwrite("ldr-Reinhard.jpg", ldrReinhard * 255);
|
||||
```
|
||||
|
||||
Python
|
||||
|
||||
```
|
||||
# Tonemap using Reinhard's method to obtain 24-bit color image
|
||||
tonemapReinhard = cv2.createTonemapReinhard(1.5, 0,0,0)
|
||||
ldrReinhard = tonemapReinhard.process(hdrDebevec)
|
||||
cv2.imwrite("ldr-Reinhard.jpg", ldrReinhard * 255)
|
||||
```
|
||||
|
||||
Result
|
||||
|
||||
[][22] HDR tone mapping using Reinhard’s algorithm
|
||||
|
||||
#### Mantiuk Tonemap
|
||||
|
||||
```
|
||||
createTonemapMantiuk
|
||||
(
|
||||
float gamma = 1.0f,
|
||||
float scale = 0.7f,
|
||||
float saturation = 1.0f
|
||||
)
|
||||
```
|
||||
|
||||
The parameter scale is the contrast scale factor. Values from 0.6 to 0.9 produce best results.
|
||||
|
||||
For more details, check out this [paper][23]
|
||||
|
||||
C++
|
||||
|
||||
```
|
||||
// Tonemap using Mantiuk's method to obtain 24-bit color image
|
||||
Mat ldrMantiuk;
|
||||
Ptr<TonemapMantiuk> tonemapMantiuk = createTonemapMantiuk(2.2,0.85, 1.2);
|
||||
tonemapMantiuk->process(hdrDebevec, ldrMantiuk);
|
||||
ldrMantiuk = 3 * ldrMantiuk;
|
||||
imwrite("ldr-Mantiuk.jpg", ldrMantiuk * 255);
|
||||
```
|
||||
|
||||
Python
|
||||
|
||||
```
|
||||
# Tonemap using Mantiuk's method to obtain 24-bit color image
|
||||
tonemapMantiuk = cv2.createTonemapMantiuk(2.2,0.85, 1.2)
|
||||
ldrMantiuk = tonemapMantiuk.process(hdrDebevec)
|
||||
ldrMantiuk = 3 * ldrMantiuk
|
||||
cv2.imwrite("ldr-Mantiuk.jpg", ldrMantiuk * 255)
|
||||
```
|
||||
|
||||
Result
|
||||
|
||||
[][24] HDR Tone mapping using Mantiuk’s algorithm
|
||||
|
||||
### Subscribe & Download Code
|
||||
|
||||
If you liked this article and would like to download code (C++ and Python) and example images used in this post, please [subscribe][25] to our newsletter. You will also receive a free [Computer Vision Resource][26]Guide. In our newsletter, we share OpenCV tutorials and examples written in C++/Python, and Computer Vision and Machine Learning algorithms and news.
|
||||
|
||||
[Subscribe Now][27]
|
||||
|
||||
Image Credits
|
||||
The four exposure images used in this post are licensed under [CC BY-SA 3.0][28] and were downloaded from [Wikipedia’s HDR page][29]. They were photographed by Kevin McCoy.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I am an entrepreneur with a love for Computer Vision and Machine Learning with a dozen years of experience (and a Ph.D.) in the field.
|
||||
|
||||
In 2007, right after finishing my Ph.D., I co-founded TAAZ Inc. with my advisor Dr. David Kriegman and Kevin Barnes. The scalability, and robustness of our computer vision and machine learning algorithms have been put to rigorous test by more than 100M users who have tried our products.
|
||||
|
||||
---------------------------
|
||||
|
||||
via: http://www.learnopencv.com/high-dynamic-range-hdr-imaging-using-opencv-cpp-python/
|
||||
|
||||
作者:[ SATYA MALLICK ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.learnopencv.com/about/
|
||||
[1]:http://www.learnopencv.com/author/spmallick/
|
||||
[2]:http://www.learnopencv.com/high-dynamic-range-hdr-imaging-using-opencv-cpp-python/#disqus_thread
|
||||
[3]:http://www.learnopencv.com/wp-content/uploads/2017/09/high-dynamic-range-hdr.jpg
|
||||
[4]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr.zip
|
||||
[5]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr.zip
|
||||
[6]:https://bigvisionllc.leadpages.net/leadbox/143948b73f72a2%3A173c9390c346dc/5649050225344512/
|
||||
[7]:https://itunes.apple.com/us/app/autobracket-hdr/id923626339?mt=8&ign-mpt=uo%3D8
|
||||
[8]:https://play.google.com/store/apps/details?id=com.almalence.opencam&hl=en
|
||||
[9]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-image-sequence.jpg
|
||||
[10]:https://www.howtogeek.com/289712/how-to-see-an-images-exif-data-in-windows-and-macos
|
||||
[11]:https://www.sno.phy.queensu.ca/~phil/exiftool
|
||||
[12]:http://www.learnopencv.com/wp-content/uploads/2017/10/aligned-unaligned-hdr-comparison.jpg
|
||||
[13]:https://www.slrlounge.com/workshop/using-mirror-up-mode-mirror-lockup
|
||||
[14]:http://www.pauldebevec.com/Research/HDR/debevec-siggraph97.pdf
|
||||
[15]:http://www.learnopencv.com/wp-content/uploads/2017/10/camera-response-function.jpg
|
||||
[16]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-Photoshop-Tonemapping.jpg
|
||||
[17]:http://resources.mpi-inf.mpg.de/tmo/logmap/logmap.pdf
|
||||
[18]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-Drago.jpg
|
||||
[19]:https://people.csail.mit.edu/fredo/PUBLI/Siggraph2002/DurandBilateral.pdf
|
||||
[20]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-Durand.jpg
|
||||
[21]:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.106.8100&rep=rep1&type=pdf
|
||||
[22]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-Reinhard.jpg
|
||||
[23]:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.60.4077&rep=rep1&type=pdf
|
||||
[24]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-Mantiuk.jpg
|
||||
[25]:https://bigvisionllc.leadpages.net/leadbox/143948b73f72a2%3A173c9390c346dc/5649050225344512/
|
||||
[26]:https://bigvisionllc.leadpages.net/leadbox/143948b73f72a2%3A173c9390c346dc/5649050225344512/
|
||||
[27]:https://bigvisionllc.leadpages.net/leadbox/143948b73f72a2%3A173c9390c346dc/5649050225344512/
|
||||
[28]:https://creativecommons.org/licenses/by-sa/3.0/
|
||||
[29]:https://en.wikipedia.org/wiki/High-dynamic-range_imaging
|
||||
256
sources/tech/20171002 Scaling the GitLab database.md
Normal file
256
sources/tech/20171002 Scaling the GitLab database.md
Normal file
@ -0,0 +1,256 @@
|
||||
Scaling the GitLab database
|
||||
============================================================
|
||||
|
||||
An in-depth look at the challenges faced when scaling the GitLab database and the solutions we applied to help solve the problems with our database setup.
|
||||
|
||||
For a long time GitLab.com used a single PostgreSQL database server and a single replica for disaster recovery purposes. This worked reasonably well for the first few years of GitLab.com's existence, but over time we began seeing more and more problems with this setup. In this article we'll take a look at what we did to help solve these problems for both GitLab.com and self-hosted GitLab instances.
|
||||
|
||||
For example, the database was under constant pressure, with CPU utilization hovering around 70 percent almost all the time. Not because we used all available resources in the best way possible, but because we were bombarding the server with too many (badly optimized) queries. We realized we needed a better setup that would allow us to balance the load and make GitLab.com more resilient to any problems that may occur on the primary database server.
|
||||
|
||||
When tackling these problems using PostgreSQL there are essentially four techniques you can apply:
|
||||
|
||||
1. Optimize your application code so the queries are more efficient (and ideally use fewer resources).
|
||||
|
||||
2. Use a connection pooler to reduce the number of database connections (and associated resources) necessary.
|
||||
|
||||
3. Balance the load across multiple database servers.
|
||||
|
||||
4. Shard your database.
|
||||
|
||||
Optimizing the application code is something we have been working on actively for the past two years, but it's not a final solution. Even if you improve performance, when traffic also increases you may still need to apply the other two techniques. For the sake of this article we'll skip over this particular subject and instead focus on the other techniques.
|
||||
|
||||
### Connection pooling
|
||||
|
||||
In PostgreSQL a connection is handled by starting an OS process which in turn needs a number of resources. The more connections (and thus processes), the more resources your database will use. PostgreSQL also enforces a maximum number of connections as defined in the [max_connections][5] setting. Once you hit this limit PostgreSQL will reject new connections. Such a setup can be illustrated using the following diagram:
|
||||
|
||||

|
||||
|
||||
Here our clients connect directly to PostgreSQL, thus requiring one connection per client.
|
||||
|
||||
By pooling connections we can have multiple client-side connections reuse PostgreSQL connections. For example, without pooling we'd need 100 PostgreSQL connections to handle 100 client connections; with connection pooling we may only need 10 or so PostgreSQL connections depending on our configuration. This means our connection diagram will instead look something like the following:
|
||||
|
||||

|
||||
|
||||
Here we show an example where four clients connect to pgbouncer but instead of using four PostgreSQL connections we only need two of them.
|
||||
|
||||
For PostgreSQL there are two connection poolers that are most commonly used:
|
||||
|
||||
* [pgbouncer][1]
|
||||
|
||||
* [pgpool-II][2]
|
||||
|
||||
pgpool is a bit special because it does much more than just connection pooling: it has a built-in query caching mechanism, can balance load across multiple databases, manage replication, and more.
|
||||
|
||||
On the other hand pgbouncer is much simpler: all it does is connection pooling.
|
||||
|
||||
### Database load balancing
|
||||
|
||||
Load balancing on the database level is typically done by making use of PostgreSQL's "[hot standby][6]" feature. A hot-standby is a PostgreSQL replica that allows you to run read-only SQL queries, contrary to a regular standby that does not allow any SQL queries to be executed. To balance load you'd set up one or more hot-standby servers and somehow balance read-only queries across these hosts while sending all other operations to the primary. Scaling such a setup is fairly easy: simply add more hot-standby servers (if necessary) as your read-only traffic increases.
|
||||
|
||||
Another benefit of this approach is having a more resilient database cluster. Web requests that only use a secondary can continue to operate even if the primary server is experiencing issues; though of course you may still run into errors should those requests end up using the primary.
|
||||
|
||||
This approach however can be quite difficult to implement. For example, explicit transactions must be executed on the primary since they may contain writes. Furthermore, after a write we want to continue using the primary for a little while because the changes may not yet be available on the hot-standby servers when using asynchronous replication.
|
||||
|
||||
### Sharding
|
||||
|
||||
Sharding is the act of horizontally partitioning your data. This means that data resides on specific servers and is retrieved using a shard key. For example, you may partition data per project and use the project ID as the shard key. Sharding a database is interesting when you have a very high write load (as there's no other easy way of balancing writes other than perhaps a multi-master setup), or when you have _a lot_ of data and you can no longer store it in a conventional manner (e.g. you simply can't fit it all on a single disk).
|
||||
|
||||
Unfortunately the process of setting up a sharded database is a massive undertaking, even when using software such as [Citus][7]. Not only do you need to set up the infrastructure (which varies in complexity depending on whether you run it yourself or use a hosted solution), but you also need to adjust large portions of your application to support sharding.
|
||||
|
||||
### Cases against sharding
|
||||
|
||||
On GitLab.com the write load is typically very low, with most of the database queries being read-only queries. In very exceptional cases we may spike to 1500 tuple writes per second, but most of the time we barely make it past 200 tuple writes per second. On the other hand we can easily read up to 10 million tuples per second on any given secondary.
|
||||
|
||||
Storage-wise, we also don't use that much data: only about 800 GB. A large portion of this data is data that is being migrated in the background. Once those migrations are done we expect our database to shrink in size quite a bit.
|
||||
|
||||
Then there's the amount of work required to adjust the application so all queries use the right shard keys. While quite a few of our queries usually include a project ID which we could use as a shard key, there are also many queries where this isn't the case. Sharding would also affect the process of contributing changes to GitLab as every contributor would now have to make sure a shard key is present in their queries.
|
||||
|
||||
Finally, there is the infrastructure that's necessary to make all of this work. Servers have to be set up, monitoring has to be added, engineers have to be trained so they are familiar with this new setup, the list goes on. While hosted solutions may remove the need for managing your own servers it doesn't solve all problems. Engineers still have to be trained and (most likely very expensive) bills have to be paid. At GitLab we also highly prefer to ship the tools we need so the community can make use of them. This means that if we were going to shard the database we'd have to ship it (or at least parts of it) in our Omnibus packages. The only way you can make sure something you ship works is by running it yourself, meaning we wouldn't be able to use a hosted solution.
|
||||
|
||||
Ultimately we decided against sharding the database because we felt it was an expensive, time-consuming, and complex solution to a problem we do not have.
|
||||
|
||||
### Connection pooling for GitLab
|
||||
|
||||
For connection pooling we had two main requirements:
|
||||
|
||||
1. It has to work well (obviously).
|
||||
|
||||
2. It has to be easy to ship in our Omnibus packages so our users can also take advantage of the connection pooler.
|
||||
|
||||
Reviewing the two solutions (pgpool and pgbouncer) was done in two steps:
|
||||
|
||||
1. Perform various technical tests (does it work, how easy is it to configure, etc).
|
||||
|
||||
2. Find out what the experiences are of other users of the solution, what problems they ran into and how they dealt with them, etc.
|
||||
|
||||
pgpool was the first solution we looked into, mostly because it seemed quite attractive based on all the features it offered. Some of the data from our tests can be found in [this][8] comment.
|
||||
|
||||
Ultimately we decided against using pgpool based on a number of factors. For example, pgpool does not support sticky connections. This is problematic when performing a write and (trying to) display the results right away. Imagine creating an issue and being redirected to the page, only to run into an HTTP 404 error because the server used for any read-only queries did not yet have the data. One way to work around this would be to use synchronous replication, but this brings many other problems to the table; problems we prefer to avoid.
|
||||
|
||||
Another problem is that pgpool's load balancing logic is decoupled from your application and operates by parsing SQL queries and sending them to the right server. Because this happens outside of your application you have very little control over which query runs where. This may actually be beneficial to some because you don't need additional application logic, but it also prevents you from adjusting the routing logic if necessary.
|
||||
|
||||
Configuring pgpool also proved quite difficult due to the sheer number of configuration options. Perhaps the final nail in the coffin was the feedback we got on pgpool from those having used it in the past. The feedback we received regarding pgpool was usually negative, though not very detailed in most cases. While most of the complaints appeared to be related to earlier versions of pgpool it still made us doubt if using it was the right choice.
|
||||
|
||||
The feedback combined with the issues described above ultimately led to us deciding against using pgpool and using pgbouncer instead. We performed a similar set of tests with pgbouncer and were very satisfied with it. It's fairly easy to configure (and doesn't have that much that needs configuring in the first place), relatively easy to ship, focuses only on connection pooling (and does it really well), and had very little (if any) noticeable overhead. Perhaps my only complaint would be that the pgbouncer website can be a little bit hard to navigate.
|
||||
|
||||
Using pgbouncer we were able to drop the number of active PostgreSQL connections from a few hundred to only 10-20 by using transaction pooling. We opted for using transaction pooling since Rails database connections are persistent. In such a setup, using session pooling would prevent us from being able to reduce the number of PostgreSQL connections, thus brining few (if any) benefits. By using transaction pooling we were able to drop PostgreSQL's `max_connections` setting from 3000 (the reason for this particular value was never really clear) to 300\. pgbouncer is configured in such a way that even at peak capacity we will only need 200 connections; giving us some room for additional connections such as `psql` consoles and maintenance tasks.
|
||||
|
||||
A side effect of using transaction pooling is that you cannot use prepared statements, as the `PREPARE` and `EXECUTE` commands may end up running in different connections; producing errors as a result. Fortunately we did not measure any increase in response timings when disabling prepared statements, but we _did_ measure a reduction of roughly 20 GB in memory usage on our database servers.
|
||||
|
||||
To ensure both web requests and background jobs have connections available we set up two separate pools: one pool of 150 connections for background processing, and a pool of 50 connections for web requests. For web requests we rarely need more than 20 connections, but for background processing we can easily spike to a 100 connections simply due to the large number of background processes running on GitLab.com.
|
||||
|
||||
Today we ship pgbouncer as part of GitLab EE's High Availability package. For more information you can refer to ["Omnibus GitLab PostgreSQL High Availability."][9]
|
||||
|
||||
### Database load balancing for GitLab
|
||||
|
||||
With pgpool and its load balancing feature out of the picture we needed something else to spread load across multiple hot-standby servers.
|
||||
|
||||
For (but not limited to) Rails applications there is a library called [Makara][10] which implements load balancing logic and includes a default implementation for ActiveRecord. Makara however has some problems that were a deal-breaker for us. For example, its support for sticky connections is very limited: when you perform a write the connection will stick to the primary using a cookie, with a fixed TTL. This means that if replication lag is greater than the TTL you may still end up running a query on a host that doesn't have the data you need.
|
||||
|
||||
Makara also requires you to configure quite a lot, such as all the database hosts and their roles, with no service discovery mechanism (our current solution does not yet support this either, though it's planned for the near future). Makara also [does not appear to be thread-safe][11], which is problematic since Sidekiq (the background processing system we use) is multi-threaded. Finally, we wanted to have control over the load balancing logic as much as possible.
|
||||
|
||||
Besides Makara there's also [Octopus][12] which has some load balancing mechanisms built in. Octopus however is geared towards database sharding and not just balancing of read-only queries. As a result we did not consider using Octopus.
|
||||
|
||||
Ultimately this led to us building our own solution directly into GitLab EE. The merge request adding the initial implementation can be found [here][13], though some changes, improvements, and fixes were applied later on.
|
||||
|
||||
Our solution essentially works by replacing `ActiveRecord::Base.connection` with a proxy object that handles routing of queries. This ensures we can load balance as many queries as possible, even queries that don't originate directly from our own code. This proxy object in turn determines what host a query is sent to based on the methods called, removing the need for parsing SQL queries.
|
||||
|
||||
### Sticky connections
|
||||
|
||||
Sticky connections are supported by storing a pointer to the current PostgreSQL WAL position the moment a write is performed. This pointer is then stored in Redis for a short duration at the end of a request. Each user is given their own key so that the actions of one user won't lead to all other users being affected. In the next request we get the pointer and compare this with all the secondaries. If all secondaries have a WAL pointer that exceeds our pointer we know they are in sync and we can safely use a secondary for our read-only queries. If one or more secondaries are not yet in sync we will continue using the primary until they are in sync. If no write is performed for 30 seconds and all the secondaries are still not in sync we'll revert to using the secondaries in order to prevent somebody from ending up running queries on the primary forever.
|
||||
|
||||
Checking if a secondary has caught up is quite simple and is implemented in `Gitlab::Database::LoadBalancing::Host#caught_up?` as follows:
|
||||
|
||||
```
|
||||
def caught_up?(location)
|
||||
string = connection.quote(location)
|
||||
|
||||
query = "SELECT NOT pg_is_in_recovery() OR " \
|
||||
"pg_xlog_location_diff(pg_last_xlog_replay_location(), #{string}) >= 0 AS result"
|
||||
|
||||
row = connection.select_all(query).first
|
||||
|
||||
row && row['result'] == 't'
|
||||
ensure
|
||||
release_connection
|
||||
end
|
||||
|
||||
```
|
||||
|
||||
Most of the code here is standard Rails code to run raw queries and grab the results. The most interesting part is the query itself, which is as follows:
|
||||
|
||||
```
|
||||
SELECT NOT pg_is_in_recovery()
|
||||
OR pg_xlog_location_diff(pg_last_xlog_replay_location(), WAL-POINTER) >= 0 AS result"
|
||||
|
||||
```
|
||||
|
||||
Here `WAL-POINTER` is the WAL pointer as returned by the PostgreSQL function `pg_current_xlog_insert_location()`, which is executed on the primary. In the above code snippet the pointer is passed as an argument, which is then quoted/escaped and passed to the query.
|
||||
|
||||
Using the function `pg_last_xlog_replay_location()` we can get the WAL pointer of a secondary, which we can then compare to our primary pointer using `pg_xlog_location_diff()`. If the result is greater than 0 we know the secondary is in sync.
|
||||
|
||||
The check `NOT pg_is_in_recovery()` is added to ensure the query won't fail when a secondary that we're checking was _just_ promoted to a primary and our GitLab process is not yet aware of this. In such a case we simply return `true` since the primary is always in sync with itself.
|
||||
|
||||
### Background processing
|
||||
|
||||
Our background processing code _always_ uses the primary since most of the work performed in the background consists of writes. Furthermore we can't reliably use a hot-standby as we have no way of knowing whether a job should use the primary or not as many jobs are not directly tied into a user.
|
||||
|
||||
### Connection errors
|
||||
|
||||
To deal with connection errors our load balancer will not use a secondary if it is deemed to be offline, plus connection errors on any host (including the primary) will result in the load balancer retrying the operation a few times. This ensures that we don't immediately display an error page in the event of a hiccup or a database failover. While we also deal with [hot standby conflicts][14] on the load balancer level we ended up enabling `hot_standby_feedback` on our secondaries as doing so solved all hot-standby conflicts without having any negative impact on table bloat.
|
||||
|
||||
The procedure we use is quite simple: for a secondary we'll retry a few times with no delay in between. For a primary we'll retry the operation a few times using an exponential backoff.
|
||||
|
||||
For more information you can refer to the source code in GitLab EE:
|
||||
|
||||
* [https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing.rb][3]
|
||||
|
||||
* [https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing][4]
|
||||
|
||||
Database load balancing was first introduced in GitLab 9.0 and _only_ supports PostgreSQL. More information can be found in the [9.0 release post][15] and the [documentation][16].
|
||||
|
||||
### Crunchy Data
|
||||
|
||||
In parallel to working on implementing connection pooling and load balancing we were working with [Crunchy Data][17]. Until very recently I was the only [database specialist][18] which meant I had a lot of work on my plate. Furthermore my knowledge of PostgreSQL internals and its wide range of settings is limited (or at least was at the time), meaning there's only so much I could do. Because of this we hired Crunchy to help us out with identifying problems, investigating slow queries, proposing schema optimisations, optimising PostgreSQL settings, and much more.
|
||||
|
||||
For the duration of this cooperation most work was performed in confidential issues so we could share private data such as log files. With the cooperation coming to an end we have removed sensitive information from some of these issues and opened them up to the public. The primary issue was [gitlab-com/infrastructure#1448][19], which in turn led to many separate issues being created and resolved.
|
||||
|
||||
The benefit of this cooperation was immense as it helped us identify and solve many problems, something that would have taken me months to identify and solve if I had to do this all by myself.
|
||||
|
||||
Fortunately we recently managed to hire our [second database specialist][20] and we hope to grow the team more in the coming months.
|
||||
|
||||
### Combining connection pooling and database load balancing
|
||||
|
||||
Combining connection pooling and database load balancing allowed us to drastically reduce the number of resources necessary to run our database cluster as well as spread load across our hot-standby servers. For example, instead of our primary having a near constant CPU utilisation of 70 percent today it usually hovers between 10 percent and 20 percent, while our two hot-standby servers hover around 20 percent most of the time:
|
||||
|
||||

|
||||
|
||||
Here `db3.cluster.gitlab.com` is our primary while the other two hosts are our secondaries.
|
||||
|
||||
Other load-related factors such as load averages, disk usage, and memory usage were also drastically improved. For example, instead of the primary having a load average of around 20 it barely goes above an average of 10:
|
||||
|
||||
|
||||
|
||||
During the busiest hours our secondaries serve around 12 000 transactions per second (roughly 740 000 per minute), while the primary serves around 6 000 transactions per second (roughly 340 000 per minute):
|
||||
|
||||

|
||||
|
||||
Unfortunately we don't have any data on the transaction rates prior to deploying pgbouncer and our database load balancer.
|
||||
|
||||
An up-to-date overview of our PostgreSQL statistics can be found at our [public Grafana dashboard][21].
|
||||
|
||||
Some of the settings we have set for pgbouncer are as follows:
|
||||
|
||||
| Setting | Value |
|
||||
| --- | --- |
|
||||
| default_pool_size | 100 |
|
||||
| reserve_pool_size | 5 |
|
||||
| reserve_pool_timeout | 3 |
|
||||
| max_client_conn | 2048 |
|
||||
| pool_mode | transaction |
|
||||
| server_idle_timeout | 30 |
|
||||
|
||||
With that all said there is still some work left to be done such as: implementing service discovery ([#2042][22]), improving how we check if a secondary is available ([#2866][23]), and ignoring secondaries that are too far behind the primary ([#2197][24]).
|
||||
|
||||
It's worth mentioning that we currently do not have any plans of turning our load balancing solution into a standalone library that you can use outside of GitLab, instead our focus is on providing a solid load balancing solution for GitLab EE.
|
||||
|
||||
If this has gotten you interested and you enjoy working with databases, improving application performance, and adding database-related features to GitLab (such as [service discovery][25]) you should definitely check out the [job opening][26] and the [database specialist handbook entry][27] for more information.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://about.gitlab.com/2017/10/02/scaling-the-gitlab-database/
|
||||
|
||||
作者:[Yorick Peterse ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://about.gitlab.com/team/#yorickpeterse
|
||||
[1]:https://pgbouncer.github.io/
|
||||
[2]:http://pgpool.net/mediawiki/index.php/Main_Page
|
||||
[3]:https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing.rb
|
||||
[4]:https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing
|
||||
[5]:https://www.postgresql.org/docs/9.6/static/runtime-config-connection.html#GUC-MAX-CONNECTIONS
|
||||
[6]:https://www.postgresql.org/docs/9.6/static/hot-standby.html
|
||||
[7]:https://www.citusdata.com/
|
||||
[8]:https://gitlab.com/gitlab-com/infrastructure/issues/259#note_23464570
|
||||
[9]:https://docs.gitlab.com/ee/administration/high_availability/alpha_database.html
|
||||
[10]:https://github.com/taskrabbit/makara
|
||||
[11]:https://github.com/taskrabbit/makara/issues/151
|
||||
[12]:https://github.com/thiagopradi/octopus
|
||||
[13]:https://gitlab.com/gitlab-org/gitlab-ee/merge_requests/1283
|
||||
[14]:https://www.postgresql.org/docs/current/static/hot-standby.html#HOT-STANDBY-CONFLICT
|
||||
[15]:https://about.gitlab.com/2017/03/22/gitlab-9-0-released/
|
||||
[16]:https://docs.gitlab.com/ee/administration/database_load_balancing.html
|
||||
[17]:https://www.crunchydata.com/
|
||||
[18]:https://about.gitlab.com/handbook/infrastructure/database/
|
||||
[19]:https://gitlab.com/gitlab-com/infrastructure/issues/1448
|
||||
[20]:https://gitlab.com/_stark
|
||||
[21]:http://monitor.gitlab.net/dashboard/db/postgres-stats?refresh=5m&orgId=1
|
||||
[22]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2042
|
||||
[23]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2866
|
||||
[24]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2197
|
||||
[25]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2042
|
||||
[26]:https://about.gitlab.com/jobs/specialist/database/
|
||||
[27]:https://about.gitlab.com/handbook/infrastructure/database/
|
||||
@ -0,0 +1,168 @@
|
||||
[Streams: a new general purpose data structure in Redis.][1]
|
||||
==================================
|
||||
|
||||
|
||||
Until a few months ago, for me streams were no more than an interesting and relatively straightforward concept in the context of messaging. After Kafka popularized the concept, I mostly investigated their usefulness in the case of Disque, a message queue that is now headed to be translated into a Redis 4.2 module. Later I decided that Disque was all about AP messaging, which is, fault tolerance and guarantees of delivery without much efforts from the client, so I decided that the concept of streams was not a good match in that case.
|
||||
|
||||
However, at the same time, there was a problem in Redis, that was not taking me relaxed about the data structures exported by default. There is some kind of gap between Redis lists, sorted sets, and Pub/Sub capabilities. You can kindly use all these tools in order to model a sequence of messages or events, but with different tradeoffs. Sorted sets are memory hungry, can’t model naturally the same message delivered again and again, clients can’t block for new messages. Because a sorted set is not a sequential data structure, it’s a set where elements can be moved around changing their scores: no wonder if it was not a good match for things like time series. Lists have different problems creating similar applicability issues in certain use cases: you cannot explore what is in the middle of a list because the access time in that case is linear. Moreover no fan-out is possible, blocking operations on list serve a single element to a single client. Nor there was a fixed element identifier in lists, in order to say: given me things starting from that element. For one-to-many workloads there is Pub/Sub, which is great in many cases, but for certain things you do not want fire-and-forget: to retain a history is important, not just to refetch messages after a disconnection, also because certain list of messages, like time series, are very important to explore with range queries: what were my temperature readings in this 10 seconds range?
|
||||
|
||||
The way I tried to address the above problems, was planning a generalization of sorted sets and lists into a unique more flexible data structure, however my design attempts ended almost always in making the resulting data structure ways more artificial than the current ones. One good thing about Redis is that the data structures exported resemble more the natural computer science data structures, than, “this API that Salvatore invented”. So in the end, I stopped my attempts, and said, ok that’s what we can provide so far, maybe I’ll add some history to Pub/Sub, or some more flexibility to lists access patterns in the future. However every time an user approached me during a conference saying “how would you model time series in Redis?” or similar related questions, my face turned green.
|
||||
|
||||
Genesis
|
||||
=======
|
||||
|
||||
After the introduction of modules in Redis 4.0, users started to see how to fix this problem themselves. One of them, Timothy Downs, wrote me the following over IRC:
|
||||
|
||||
<forkfork> the module I'm planning on doing is to add a transaction log style data type - meaning that a very large number of subscribers can do something like pub sub without a lot of redis memory growth
|
||||
<forkfork> subscribers keeping their position in a message queue rather than having redis maintain where each consumer is up to and duplicating messages per subscriber
|
||||
|
||||
This captured my imagination. I thought about it a few days, and realized that this could be the moment when we could solve all the above problems at once. What I needed was to re-imagine the concept of “log”. It is a basic programming element, everybody is used to it, because it’s just as simple as opening a file in append mode and writing data to it in some format. However Redis data structures must be abstract. They are in memory, and we use RAM not just because we are lazy, but because using a few pointers, we can conceptualize data structures and make them abstract, to allow them to break free from the obvious limits. For instance normally a log has several problems: the offset is not logical, but is an actual bytes offset, what if we want logical offsets that are related to the time an entry was inserted? We have range queries for free. Similarly, a log is often hard to garbage collect: how to remove old elements in an append only data structure? Well, in our idealized log, we just say we want at max this number of entries, and the old ones will go away, and so forth.
|
||||
|
||||
While I was trying to write a specification starting from the seed idea of Timothy, I was working to a radix tree implementation that I was using for Redis Cluster, to optimize certain parts of its internals. This provided the ground in order to implement a very space efficient log, that was still accessible in logarithmic time to get ranges. At the same time I started reading about Kafka streams to get other interesting ideas that could fit well into my design, and this resulted into getting the concept of Kafka consumer groups, and idealizing it again for Redis and the in-memory use case. However the specification remained just a specification for months, at the point that after some time I rewrote it almost from scratch in order to upgrade it with many hints that I accumulated talking with people about this upcoming addition to Redis. I wanted Redis streams to be a very good use case for time series especially, not just for other kind of events and messaging applications.
|
||||
|
||||
Let’s write some code
|
||||
=====================
|
||||
|
||||
Back from Redis Conf, during the summertime, I was implementing a library called “listpack”. This library is just the successor of ziplist.c, that is, a data structure that can represent a list of string elements inside a single allocation. It’s just a very specialized serialization format, with the peculiarity of being parsable also in reverse order, from right to left: something needed in order to substitute ziplists in all the use cases.
|
||||
|
||||
Mixing radix trees + listpacks, it is possible to easily build a log that is at the same time very space efficient, and indexed, that means, allowing for random access by IDs and time. Once this was ready, I started to write the code in order to implement the stream data structure. I’m still finishing the implementation, however at this point, inside the Redis “streams” branch at Github, there is enough to start playing and having fun. I don’t claim that the API is 100% final, but there are two interesting facts: one is that at this point, only the consumer groups are missing, plus a number of less important commands to manipulate the stream, but all the big things are implemented already. The second is the decision to backport all the stream work back into the 4.0 branch in about two months, once everything looks stable. It means that Redis users will not have to wait for Redis 4.2 in order to use streams, they will be available ASAP for production usage. This is possible because being a new data structure, almost all the code changes are self-contained into the new code. With the exception of the blocking list operations: the code was refactored so that we share the same code for streams and lists blocking operations, with a great simplification of the Redis internals.
|
||||
|
||||
Tutorial: welcome to Redis Streams
|
||||
==================================
|
||||
|
||||
In some way, you can think at streams as a supercharged version of Redis lists. Streams elements are not just a single string, they are more objects composed of fields and values. Range queries are possible and fast. Each entry in a stream has an ID, which is a logical offset. Different clients can blocking-wait for elements with IDs greater than a specified one. A fundamental command of Redis streams is XADD. Yes, all the Redis stream commands are prefixed by an “X”.
|
||||
|
||||
> XADD mystream * sensor-id 1234 temperature 10.5
|
||||
1506871964177.0
|
||||
|
||||
The XADD command will append the specified entry as a new element to the specified stream “mystream”. The entry, in the example above, has two fields: sensor-id and temperature, however each entry in the same stream can have different fields. Using the same field names will just lead to better memory usage. An interesting thing is also that the fields order is guaranteed to be retained. XADD returns the ID of the just inserted entry, because with the asterisk in the third argument, we asked the command to auto-generate the ID. This is almost always what you want, but it is possible also to force a specific ID, for instance in order to replicate the command to slaves and AOF files.
|
||||
|
||||
The ID is composed of two parts: a millisecond time and a sequence number. 1506871964177 is the millisecond time, and is just a Unix time with millisecond resolution. The number after the dot, 0, is the sequence number, and is used in order to distinguish entries added in the same millisecond. Both numbers are 64 bit unsigned integers. This means that we can add all the entries we want in a stream, even in the same millisecond. The millisecond part of the ID is obtained using the maximum between the current local time of the Redis server generating the ID, and the last entry inside the stream. So even if, for instance, the computer clock jumps backward, the IDs will continue to be incremental. In some way you can think stream entry IDs as whole 128 bit numbers. However the fact that they have a correlation with the local time of the instance where they are added, means that we have millisecond precision range queries for free.
|
||||
|
||||
As you can guess, adding two entries in a very fast way, will result in only the sequence number to be incremented. We can simulate the “fast insertion” simply with a MULTI/EXEC block:
|
||||
|
||||
> MULTI
|
||||
OK
|
||||
> XADD mystream * foo 10
|
||||
QUEUED
|
||||
> XADD mystream * bar 20
|
||||
QUEUED
|
||||
> EXEC
|
||||
1) 1506872463535.0
|
||||
2) 1506872463535.1
|
||||
|
||||
The above example also shows how we can use different fields for different entries without having to specifying any schema initially. What happens however is that every first message of every block (that usually contains something in the range of 50-150 messages) is used as reference, and successive entries having the same fields are compressed with a single flag saying “same fields of the first entry in this block”. So indeed using the same fields for successive messages saves a lot of memory, even when the set of fields slowly change over time.
|
||||
|
||||
In order to retrieve data from the stream there are two ways: range queries, that are implemented by the XRANGE command, and streaming, implemented by the XREAD command. XRANGE just fetches a range of items from start to stop, inclusive. So for instance I can fetch a single item, if I know its ID, with:
|
||||
|
||||
> XRANGE mystream 1506871964177.0 1506871964177.0
|
||||
1) 1) 1506871964177.0
|
||||
2) 1) "sensor-id"
|
||||
2) "1234"
|
||||
3) "temperature"
|
||||
4) "10.5"
|
||||
|
||||
However you can use the special start symbol of “-“ and the special stop symbol of “+” to signify the minimum and maximum ID possible. It’s also possible to use the COUNT option in order to limit the amount of entries returned. A more complex XRANGE example is the following:
|
||||
|
||||
> XRANGE mystream - + COUNT 2
|
||||
1) 1) 1506871964177.0
|
||||
2) 1) "sensor-id"
|
||||
2) "1234"
|
||||
3) "temperature"
|
||||
4) "10.5"
|
||||
2) 1) 1506872463535.0
|
||||
2) 1) "foo"
|
||||
2) "10"
|
||||
|
||||
Here we are reasoning in terms of ranges of IDs, however you can use XRANGE in order to get a specific range of elements in a given time range, because you can omit the “sequence” part of the IDs. So what you can do is to just specify times in milliseconds. The following means: “Give me 10 entries starting from the Unix time 1506872463”:
|
||||
|
||||
127.0.0.1:6379> XRANGE mystream 1506872463000 + COUNT 10
|
||||
1) 1) 1506872463535.0
|
||||
2) 1) "foo"
|
||||
2) "10"
|
||||
2) 1) 1506872463535.1
|
||||
2) 1) "bar"
|
||||
2) "20"
|
||||
|
||||
A final important thing to note about XRANGE is that, given that we receive the IDs in the reply, and the immediately successive ID is trivially obtained just incrementing the sequence part of the ID, it is possible to use XRANGE to incrementally iterate the whole stream, receiving for every call the specified number of elements. After the *SCAN family of commands in Redis, that allowed iteration of Redis data structures *despite* the fact they were not designed for being iterated, I avoided to make the same error again.
|
||||
|
||||
Streaming with XREAD: blocking for new data
|
||||
===========================================
|
||||
|
||||
XRANGE is perfect when we want to access our stream to get ranges by ID or time, or single elements by ID. However in the case of streams that different clients must consume as data arrives, this is not good enough and would require some form of pooling (that could be a good idea for *certain* applications that just connect from time to time to get data).
|
||||
|
||||
The XREAD command is designed in order to read, at the same time, from multiple streams just specifying the ID of the last entry in the stream we got. Moreover we can request to block if no data is available, to be unblocked when data arrives. Similarly to what happens with blocking list operations, but here data is not consumed from the stream, and multiple clients can access the same data at the same time.
|
||||
|
||||
This is a canonical example of XREAD call:
|
||||
|
||||
> XREAD BLOCK 5000 STREAMS mystream otherstream $ $
|
||||
|
||||
And it means: get data from “mystream” and “otherstream”. If no data is available, block the client, with a timeout of 5000 milliseconds. After the STREAMS option we specify the keys we want to listen for, and the last ID we have. However a special ID of “$” means: assume I’ve all the elements that there are in the stream right now, so give me just starting from the next element arriving.
|
||||
|
||||
If, from another client, I send the commnad:
|
||||
|
||||
> XADD otherstream * message “Hi There”
|
||||
|
||||
This is what happens on the XREAD side:
|
||||
|
||||
1) 1) "otherstream"
|
||||
2) 1) 1) 1506935385635.0
|
||||
2) 1) "message"
|
||||
2) "Hi There"
|
||||
|
||||
We get the key that received data, together with the data received. In the next call, we’ll likely use the ID of the last message received:
|
||||
|
||||
> XREAD BLOCK 5000 STREAMS mystream otherstream $ 1506935385635.0
|
||||
|
||||
And so forth. However note that with this usage pattern, it is possible that the client will connect again after a very big delay (because it took time to process messages, or for any other reason). In such a case, in the meantime, a lot of messages could pile up, so it is wise to always use the COUNT option with XREAD, in order to make sure the client will not be flooded with messages and the server will not have to lose too much time just serving tons of messages to a single client.
|
||||
|
||||
Capped streams
|
||||
==============
|
||||
|
||||
So far so good… however streams at some point have to remove old messages. Fortunately this is possible with the MAXLEN option of the XADD command:
|
||||
|
||||
> XADD mystream MAXLEN 1000000 * field1 value1 field2 value2
|
||||
|
||||
This basically means, if the stream, after adding the new element is found to have more than 1 million messages, remove old messages so that the length returns back to 1 million elements. It’s just like using RPUSH + LTRIM with lists, but this time we have a built-in mechanism to do so. However note that the above means that every time we add a new message, we have also to incur in the work needed in order to remove a message from the other side of the stream. This takes some CPU, so it is possible to use the “~” symbol before the count in MAXLEN, in order to specify that we are not really demanding *exactly* 1 million messages, but if there are a few more it’s not a big problem:
|
||||
|
||||
> XADD mystream MAXLEN ~ 1000000 * foo bar
|
||||
|
||||
This way XADD will remove messages only when it can remove a whole node. This will make having the capped stream almost for free compared to vanilla XADD.
|
||||
|
||||
Consumer groups (work in progress)
|
||||
==================================
|
||||
|
||||
This is the first of the features that is not already implemented in Redis, but is a work in progress. It is also the idea more clearly inspired by Kafka, even if implemented here in a pretty different way. The gist is that with XREAD, clients can also add a “GROUP <name>” option. Automatically all the clients in the same group will get *different* messages. Of course there could be multiple groups reading from the same stream, in such cases all groups will receive duplicates of the same messages arriving in the stream, but within each group, messages will not be repeated.
|
||||
|
||||
An extension to groups is that it will be possible to specify a “RETRY <milliseconds>” option when groups are specified: in this case, if messages are not acknowledged for processing with XACK, they will be delivered again after the specified amount of milliseconds. This provides some best effort reliability to the delivering of the messages, in case the client has no private means to mark messages as processed. This part is a work in progress as well.
|
||||
|
||||
Memory usage and saving loading times
|
||||
=====================================
|
||||
|
||||
Because of the design used to model Redis streams, the memory usage is remarkably low. It depends on the number of fields, values, and their lengths, but for simple messages we are at a few millions of messages for every 100 MB of used memory. Moreover, the format is conceived to need very minimal serialization: the listpack blocks that are stored as radix tree nodes, have the same representation on disk and in memory, so they are trivially stored and read. For instance Redis can read 5 million entries from the RDB file in 0.3 seconds.
|
||||
This makes replication and persistence of streams very efficient.
|
||||
|
||||
It is planned to also allow deletion of items in the middle. This is only partially implemented, but the strategy is to mark entries as deleted in the entry flag, and when a given ratio between entries and deleted entires is reached, the block is rewritten to collect the garbage, and if needed it is glued to another adjacent block in order to avoid fragmentation.
|
||||
|
||||
Conclusions end ETA
|
||||
===================
|
||||
|
||||
Redis streams will be part of Redis stable in the 4.0 series before the end of the year. I think that this general purpose data structure is going to put a huge patch in order for Redis to cover a lot of use cases that were hard to cover: that means that you had to be creative in order to abuse the current data structures to fix certain problems. One very important use case is time series, but my feeling is that also streaming of messages for other use cases via TREAD is going to be very interesting both as replacement for Pub/Sub applications that need more reliability than fire-and-forget, and for completely new use cases. For now, if you want to start to evaluate the new capabilities in the context of your problems, just fetch the “streams” branch at Github and start playing. After all bug reports are welcome :-)
|
||||
|
||||
If you like videos, a real-time session showing streams is here: https://www.youtube.com/watch?v=ELDzy9lCFHQ
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://antirez.com/news/114
|
||||
|
||||
作者:[antirez ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://antirez.com/
|
||||
[1]:http://antirez.com/news/114
|
||||
[2]:http://antirez.com/user/antirez
|
||||
[3]:https://www.youtube.com/watch?v=ELDzy9lCFHQ
|
||||
300
sources/tech/20171004 Concurrent Servers Part 2 - Threads.md
Normal file
300
sources/tech/20171004 Concurrent Servers Part 2 - Threads.md
Normal file
@ -0,0 +1,300 @@
|
||||
[Concurrent Servers: Part 2 - Threads][19]
|
||||
============================================================
|
||||
|
||||
GitFuture is Translating
|
||||
|
||||
This is part 2 of a series on writing concurrent network servers. [Part 1][20] presented the protocol implemented by the server, as well as the code for a simple sequential server, as a baseline for the series.
|
||||
|
||||
In this part, we're going to look at multi-threading as one approach to concurrency, with a bare-bones threaded server implementation in C, as well as a thread pool based implementation in Python.
|
||||
|
||||
All posts in the series:
|
||||
|
||||
* [Part 1 - Introduction][8]
|
||||
|
||||
* [Part 2 - Threads][9]
|
||||
|
||||
* [Part 3 - Event-driven][10]
|
||||
|
||||
### The multi-threaded approach to concurrent server design
|
||||
|
||||
When discussing the performance of the sequential server in part 1, it was immediately obvious that a lot of compute resources are wasted while the server processes a client connection. Even assuming a client that sends messages immediately and doesn't do any waiting, network communication is still involved; networks tend to be millions (or more) times slower than a modern CPU, so the CPU running the sequential server will spend the vast majority of time in gloriuos boredom waiting for new socket traffic to arrive.
|
||||
|
||||
Here's a chart showing how sequential client processing happens over time:
|
||||
|
||||
|
||||
|
||||
The diagrams shows 3 clients. The diamond shapes denote the client's "arrival time" (the time at which the client attempted to connect to the server). The black lines denote "wait time" (the time clients spent waiting for the server to actually accept their connection), and the colored bars denote actual "processing time" (the time server and client are interacting using the protocol). At the end of the colored bar, the client disconnects.
|
||||
|
||||
In the diagram above, even though the green and orange clients arrived shortly after the blue one, they have to wait for a while until the server is done with the blue client. At this point the green client is accepted, while the orange one has to wait even longer.
|
||||
|
||||
A multi-threaded server would launch multiple control threads, letting the OS manage concurrency on the CPU (and across multiple CPU cores). When a client connects, a thread is created to serve it, while the server is ready to accept more clients in the main thread. The time chart for this mode looks like the following:
|
||||
|
||||
|
||||
|
||||
### One thread per client, in C using pthreads
|
||||
|
||||
Our [first code sample][11] in this post is a simple "one thread per client" server, written in C using the foundational [pthreads API][12] for multi-threading. Here's the main loop:
|
||||
|
||||
```
|
||||
while (1) {
|
||||
struct sockaddr_in peer_addr;
|
||||
socklen_t peer_addr_len = sizeof(peer_addr);
|
||||
|
||||
int newsockfd =
|
||||
accept(sockfd, (struct sockaddr*)&peer_addr, &peer_addr_len);
|
||||
|
||||
if (newsockfd < 0) {
|
||||
perror_die("ERROR on accept");
|
||||
}
|
||||
|
||||
report_peer_connected(&peer_addr, peer_addr_len);
|
||||
pthread_t the_thread;
|
||||
|
||||
thread_config_t* config = (thread_config_t*)malloc(sizeof(*config));
|
||||
if (!config) {
|
||||
die("OOM");
|
||||
}
|
||||
config->sockfd = newsockfd;
|
||||
pthread_create(&the_thread, NULL, server_thread, config);
|
||||
|
||||
// Detach the thread - when it's done, its resources will be cleaned up.
|
||||
// Since the main thread lives forever, it will outlive the serving threads.
|
||||
pthread_detach(the_thread);
|
||||
}
|
||||
```
|
||||
|
||||
And this is the `server_thread` function:
|
||||
|
||||
```
|
||||
void* server_thread(void* arg) {
|
||||
thread_config_t* config = (thread_config_t*)arg;
|
||||
int sockfd = config->sockfd;
|
||||
free(config);
|
||||
|
||||
// This cast will work for Linux, but in general casting pthread_id to an
|
||||
// integral type isn't portable.
|
||||
unsigned long id = (unsigned long)pthread_self();
|
||||
printf("Thread %lu created to handle connection with socket %d\n", id,
|
||||
sockfd);
|
||||
serve_connection(sockfd);
|
||||
printf("Thread %lu done\n", id);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
The thread "configuration" is passed as a `thread_config_t` structure:
|
||||
|
||||
```
|
||||
typedef struct { int sockfd; } thread_config_t;
|
||||
```
|
||||
|
||||
The `pthread_create` call in the main loop launches a new thread that runs the `server_thread` function. This thread terminates when `server_thread` returns. In turn, `server_thread` returns when `serve_connection` returns.`serve_connection` is exactly the same function from part 1.
|
||||
|
||||
In part 1 we used a script to launch multiple clients concurrently and observe how the server handles them. Let's do the same with the multithreaded server:
|
||||
|
||||
```
|
||||
$ python3.6 simple-client.py -n 3 localhost 9090
|
||||
INFO:2017-09-20 06:31:56,632:conn1 connected...
|
||||
INFO:2017-09-20 06:31:56,632:conn2 connected...
|
||||
INFO:2017-09-20 06:31:56,632:conn0 connected...
|
||||
INFO:2017-09-20 06:31:56,632:conn1 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-20 06:31:56,632:conn2 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-20 06:31:56,632:conn0 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-20 06:31:56,633:conn1 received b'b'
|
||||
INFO:2017-09-20 06:31:56,633:conn2 received b'b'
|
||||
INFO:2017-09-20 06:31:56,633:conn0 received b'b'
|
||||
INFO:2017-09-20 06:31:56,670:conn1 received b'cdbcuf'
|
||||
INFO:2017-09-20 06:31:56,671:conn0 received b'cdbcuf'
|
||||
INFO:2017-09-20 06:31:56,671:conn2 received b'cdbcuf'
|
||||
INFO:2017-09-20 06:31:57,634:conn1 sending b'xyz^123'
|
||||
INFO:2017-09-20 06:31:57,634:conn2 sending b'xyz^123'
|
||||
INFO:2017-09-20 06:31:57,634:conn1 received b'234'
|
||||
INFO:2017-09-20 06:31:57,634:conn0 sending b'xyz^123'
|
||||
INFO:2017-09-20 06:31:57,634:conn2 received b'234'
|
||||
INFO:2017-09-20 06:31:57,634:conn0 received b'234'
|
||||
INFO:2017-09-20 06:31:58,635:conn1 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-20 06:31:58,635:conn2 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-20 06:31:58,636:conn1 received b'36bc1111'
|
||||
INFO:2017-09-20 06:31:58,636:conn2 received b'36bc1111'
|
||||
INFO:2017-09-20 06:31:58,637:conn0 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-20 06:31:58,637:conn0 received b'36bc1111'
|
||||
INFO:2017-09-20 06:31:58,836:conn2 disconnecting
|
||||
INFO:2017-09-20 06:31:58,836:conn1 disconnecting
|
||||
INFO:2017-09-20 06:31:58,837:conn0 disconnecting
|
||||
```
|
||||
|
||||
Indeed, all clients connected at the same time, and their communication with the server occurs concurrently.
|
||||
|
||||
### Challenges with one thread per client
|
||||
|
||||
Even though threads are fairly efficient in terms of resource usage on modern OSes, the approach outlined in the previous section can still present challenges with some workloads.
|
||||
|
||||
Imagine a scenario where many clients are connecting simultaneously, and some of the sessions are long-lived. This means that many threads may be active at the same time in the server. Too many threads can consume a large amount of memory and CPU time just for the context switching [[1]][13]. An alternative way to look at it is as a security problem: this design makes it the server an easy target for a [DoS attack][14] - connect a few 100,000s of clients at the same time and let them all sit idle - this will likely kill the server due to excessive resource usage.
|
||||
|
||||
A larger problem occurs when there's a non-trivial amount of CPU-bound computation the server has to do for each client. In this case, swamping the server is considerably easier - just a few dozen clients can bring a server to its knees.
|
||||
|
||||
For these reasons, it's prudent the do some _rate-limiting_ on the number of concurrent clients handled by a multi-threaded server. There's a number of ways to do this. The simplest that comes to mind is simply count the number of clients currently connected and restrict that number to some quantity (that was determined by careful benchmarking, hopefully). A variation on this approach that's very popular in concurrent application design is using a _thread pool_ .
|
||||
|
||||
### Thread pools
|
||||
|
||||
The idea of a [thread pool][15] is simple, yet powerful. The server creates a number of working threads that all expect to get tasks from some queue. This is the "pool". Then, each client connection is dispatched as a task to the pool. As long as there's an idle thread in the pool, it's handed the task. If all the threads in the pool are currently busy, the server blocks until the pool accepts the task (which happens after one of the busy threads finished processing its current task and went back to an idle state).
|
||||
|
||||
Here's a diagram showing a pool of 4 threads, each processing a task. Tasks (client connections in our case) are waiting until one of the threads in the pool is ready to accept new tasks.
|
||||
|
||||
|
||||
|
||||
It should be fairly obvious that the thread pool approach provides a rate-limiting mechanism in its very definition. We can decide ahead of time how many threads we want our server to have. Then, this is the maximal number of clients processed concurrently - the rest are waiting until one of the threads becomes free. If we have 8 threads in the pool, 8 is the maximal number of concurrent clients the server handles - even if thousands are attempting to connect simultaneously.
|
||||
|
||||
How do we decide how many threads should be in the pool? By a careful analysis of the problem domain, benchmarking, experimentation and also by the HW we have. If we have a single-core cloud instance that's one answer, if we have a 100-core dual socket server available, the answer is different. Picking the thread pool size can also be done dynamically at runtime based on load - I'll touch upon this topic in future posts in this series.
|
||||
|
||||
Servers that use thread pools manifest _graceful degradation_ in the face of high load - clients are accepted at some steady rate, potentially slower than their rate of arrival for some periods of time; that said, no matter how many clients are trying to connect simultaneously, the server will remain responsive and will just churn through the backlog of clients to its best ability. Contrast this with the one-thread-per-client server which can merrily accept a large number of clients until it gets overloaded, at which point it's likely to either crash or start working very slowly for _all_ processed clients due to resource exhaustion (such as virtual memory thrashing).
|
||||
|
||||
### Using a thread pool for our network server
|
||||
|
||||
For [this variation of the server][16] I've switched to Python, which comes with a robust implementation of a thread pool in the standard library (`ThreadPoolExecutor` from the `concurrent.futures` module) [[2]][17].
|
||||
|
||||
This server creates a thread pool, then loops to accept new clients on the main listening socket. Each connected client is dispatched into the pool with `submit`:
|
||||
|
||||
```
|
||||
pool = ThreadPoolExecutor(args.n)
|
||||
sockobj = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||||
sockobj.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||||
sockobj.bind(('localhost', args.port))
|
||||
sockobj.listen(15)
|
||||
|
||||
try:
|
||||
while True:
|
||||
client_socket, client_address = sockobj.accept()
|
||||
pool.submit(serve_connection, client_socket, client_address)
|
||||
except KeyboardInterrupt as e:
|
||||
print(e)
|
||||
sockobj.close()
|
||||
```
|
||||
|
||||
The `serve_connection` function is very similar to its C counterpart, serving a single client until the client disconnects, while following our protocol:
|
||||
|
||||
```
|
||||
ProcessingState = Enum('ProcessingState', 'WAIT_FOR_MSG IN_MSG')
|
||||
|
||||
def serve_connection(sockobj, client_address):
|
||||
print('{0} connected'.format(client_address))
|
||||
sockobj.sendall(b'*')
|
||||
state = ProcessingState.WAIT_FOR_MSG
|
||||
|
||||
while True:
|
||||
try:
|
||||
buf = sockobj.recv(1024)
|
||||
if not buf:
|
||||
break
|
||||
except IOError as e:
|
||||
break
|
||||
for b in buf:
|
||||
if state == ProcessingState.WAIT_FOR_MSG:
|
||||
if b == ord(b'^'):
|
||||
state = ProcessingState.IN_MSG
|
||||
elif state == ProcessingState.IN_MSG:
|
||||
if b == ord(b'$'):
|
||||
state = ProcessingState.WAIT_FOR_MSG
|
||||
else:
|
||||
sockobj.send(bytes([b + 1]))
|
||||
else:
|
||||
assert False
|
||||
|
||||
print('{0} done'.format(client_address))
|
||||
sys.stdout.flush()
|
||||
sockobj.close()
|
||||
```
|
||||
|
||||
Let's see how the thread pool size affects the blocking behavior for multiple concurrent clients. For demonstration purposes, I'll run the threadpool server with a pool size of 2 (only two threads are created to service clients):
|
||||
|
||||
```
|
||||
$ python3.6 threadpool-server.py -n 2
|
||||
```
|
||||
|
||||
And in a separate terminal, let's run the client simulator again, with 3 concurrent clients:
|
||||
|
||||
```
|
||||
$ python3.6 simple-client.py -n 3 localhost 9090
|
||||
INFO:2017-09-22 05:58:52,815:conn1 connected...
|
||||
INFO:2017-09-22 05:58:52,827:conn0 connected...
|
||||
INFO:2017-09-22 05:58:52,828:conn1 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-22 05:58:52,828:conn0 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-22 05:58:52,828:conn1 received b'b'
|
||||
INFO:2017-09-22 05:58:52,828:conn0 received b'b'
|
||||
INFO:2017-09-22 05:58:52,867:conn1 received b'cdbcuf'
|
||||
INFO:2017-09-22 05:58:52,867:conn0 received b'cdbcuf'
|
||||
INFO:2017-09-22 05:58:53,829:conn1 sending b'xyz^123'
|
||||
INFO:2017-09-22 05:58:53,829:conn0 sending b'xyz^123'
|
||||
INFO:2017-09-22 05:58:53,830:conn1 received b'234'
|
||||
INFO:2017-09-22 05:58:53,831:conn0 received b'2'
|
||||
INFO:2017-09-22 05:58:53,831:conn0 received b'34'
|
||||
INFO:2017-09-22 05:58:54,831:conn1 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-22 05:58:54,832:conn1 received b'36bc1111'
|
||||
INFO:2017-09-22 05:58:54,832:conn0 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-22 05:58:54,833:conn0 received b'36bc1111'
|
||||
INFO:2017-09-22 05:58:55,032:conn1 disconnecting
|
||||
INFO:2017-09-22 05:58:55,032:conn2 connected...
|
||||
INFO:2017-09-22 05:58:55,033:conn2 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-22 05:58:55,033:conn0 disconnecting
|
||||
INFO:2017-09-22 05:58:55,034:conn2 received b'b'
|
||||
INFO:2017-09-22 05:58:55,071:conn2 received b'cdbcuf'
|
||||
INFO:2017-09-22 05:58:56,036:conn2 sending b'xyz^123'
|
||||
INFO:2017-09-22 05:58:56,036:conn2 received b'234'
|
||||
INFO:2017-09-22 05:58:57,037:conn2 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-22 05:58:57,038:conn2 received b'36bc1111'
|
||||
INFO:2017-09-22 05:58:57,238:conn2 disconnecting
|
||||
```
|
||||
|
||||
Recall the behavior of previously discussed servers:
|
||||
|
||||
1. In the sequential server, all connections were serialized. One finished, and only then the next started.
|
||||
|
||||
2. In the thread-per-client server earlier in this post, all connections wer accepted and serviced concurrently.
|
||||
|
||||
Here we see another possibility: two connections are serviced concurrently, and only when one of them is done the third is admitted. This is a direct result of the thread pool size set to 2\. For a more realistic use case we'd set the thread pool size to much higher, depending on the machine and the exact protocol. This buffering behavior of thread pools is well understood - I've written about it more in detail [just a few months ago][18] in the context of Clojure's `core.async` module.
|
||||
|
||||
### Summary and next steps
|
||||
|
||||
This post discusses multi-threading as a means of concurrency in network servers. The one-thread-per-client approach is presented for an initial discussion, but this method is not common in practice since it's a security hazard.
|
||||
|
||||
Thread pools are much more common, and most popular programming languages have solid implementations (for some, like Python, it's in the standard library). The thread pool server presented here doesn't suffer from the problems of one-thread-per-client.
|
||||
|
||||
However, threads are not the only way to handle multiple clients concurrently. In the next post we're going to look at some solutions using _asynchronous_ , or _event-driven_ programming.
|
||||
|
||||
* * *
|
||||
|
||||
[[1]][1] To be fair, modern Linux kernels can tolerate a significant number of concurrent threads - as long as these threads are mostly blocked on I/O, of course. [Here's a sample program][2] that launches a configurable number of threads that sleep in a loop, waking up every 50 ms. On my 4-core Linux machine I can easily launch 10000 threads; even though these threads sleep almost all the time, they still consume between one and two cores for the context switching. Also, they occupy 80 GB of virtual memory (8 MB is the default per-thread stack size for Linux). More realistic threads that actually use memory and not just sleep in a loop can therefore exhaust the physical memory of a machine fairly quickly.
|
||||
|
||||
[[2]][3] Implementing a thread pool from scratch is a fun exercise, but I'll leave it for another day. I've written about hand-rolled [thread pools for specific tasks][4] in the past. That's in Python; doing it in C would be more challenging, but shouldn't take more than a few of hours for an experienced programmer.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://eli.thegreenplace.net/pages/about
|
||||
[1]:https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/#id1
|
||||
[2]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/threadspammer.c
|
||||
[3]:https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/#id2
|
||||
[4]:http://eli.thegreenplace.net/2011/12/27/python-threads-communication-and-stopping
|
||||
[5]:https://eli.thegreenplace.net/tag/concurrency
|
||||
[6]:https://eli.thegreenplace.net/tag/c-c
|
||||
[7]:https://eli.thegreenplace.net/tag/python
|
||||
[8]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
[9]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[10]:http://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
[11]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/threaded-server.c
|
||||
[12]:http://eli.thegreenplace.net/2010/04/05/pthreads-as-a-case-study-of-good-api-design
|
||||
[13]:https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/#id3
|
||||
[14]:https://en.wikipedia.org/wiki/Denial-of-service_attack
|
||||
[15]:https://en.wikipedia.org/wiki/Thread_pool
|
||||
[16]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/threadpool-server.py
|
||||
[17]:https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/#id4
|
||||
[18]:http://eli.thegreenplace.net/2017/clojure-concurrency-and-blocking-with-coreasync/
|
||||
[19]:https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[20]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
@ -0,0 +1,622 @@
|
||||
[Concurrent Servers: Part 3 - Event-driven][25]
|
||||
============================================================
|
||||
|
||||
GitFuture is Translating
|
||||
|
||||
This is part 3 of a series of posts on writing concurrent network servers. [Part 1][26] introduced the series with some building blocks, and [part 2 - Threads][27] discussed multiple threads as one viable approach for concurrency in the server.
|
||||
|
||||
Another common approach to achieve concurrency is called _event-driven programming_ , or alternatively _asynchronous_ programming [[1]][28]. The range of variations on this approach is very large, so we're going to start by covering the basics - using some of the fundamental APIs than form the base of most higher-level approaches. Future posts in the series will cover higher-level abstractions, as well as various hybrid approaches.
|
||||
|
||||
All posts in the series:
|
||||
|
||||
* [Part 1 - Introduction][12]
|
||||
|
||||
* [Part 2 - Threads][13]
|
||||
|
||||
* [Part 3 - Event-driven][14]
|
||||
|
||||
### Blocking vs. nonblocking I/O
|
||||
|
||||
As an introduction to the topic, let's talk about the difference between blocking and nonblocking I/O. Blocking I/O is easier to undestand, since this is the "normal" way we're used to I/O APIs working. While receiving data from a socket, a call to `recv` _blocks_ until some data is received from the peer connected to the other side of the socket. This is precisely the issue with the sequential server of part 1.
|
||||
|
||||
So blocking I/O has an inherent performance problem. We saw one way to tackle this problem in part 2, using multiple threads. As long as one thread is blocked on I/O, other threads can continue using the CPU. In fact, blocking I/O is usually very efficient on resource usage while the thread is waiting - the thread is put to sleep by the OS and only wakes up when whatever it was waiting for is available.
|
||||
|
||||
_Nonblocking_ I/O is a different approach. When a socket is set to nonblocking mode, a call to `recv` (and to `send`, but let's just focus on receiving here) will always return very quickly, even if there's no data to receive. In this case, it will return a special error status [[2]][15] notifying the caller that there's no data to receive at this time. The caller can then go do something else, or try to call `recv` again.
|
||||
|
||||
The difference between blocking and nonblocking `recv` is easiest to demonstrate with a simple code sample. Here's a small program that listens on a socket, continuously blocking on `recv`; when `recv` returns data, the program just reports how many bytes were received [[3]][16]:
|
||||
|
||||
```
|
||||
int main(int argc, const char** argv) {
|
||||
setvbuf(stdout, NULL, _IONBF, 0);
|
||||
|
||||
int portnum = 9988;
|
||||
if (argc >= 2) {
|
||||
portnum = atoi(argv[1]);
|
||||
}
|
||||
printf("Listening on port %d\n", portnum);
|
||||
|
||||
int sockfd = listen_inet_socket(portnum);
|
||||
struct sockaddr_in peer_addr;
|
||||
socklen_t peer_addr_len = sizeof(peer_addr);
|
||||
|
||||
int newsockfd = accept(sockfd, (struct sockaddr*)&peer_addr, &peer_addr_len);
|
||||
if (newsockfd < 0) {
|
||||
perror_die("ERROR on accept");
|
||||
}
|
||||
report_peer_connected(&peer_addr, peer_addr_len);
|
||||
|
||||
while (1) {
|
||||
uint8_t buf[1024];
|
||||
printf("Calling recv...\n");
|
||||
int len = recv(newsockfd, buf, sizeof buf, 0);
|
||||
if (len < 0) {
|
||||
perror_die("recv");
|
||||
} else if (len == 0) {
|
||||
printf("Peer disconnected; I'm done.\n");
|
||||
break;
|
||||
}
|
||||
printf("recv returned %d bytes\n", len);
|
||||
}
|
||||
|
||||
close(newsockfd);
|
||||
close(sockfd);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
The main loop repeatedly calls `recv` and reports what it returned (recall that `recv` returns 0 when the peer has disconnected). To try it out, we'll run this program in one terminal, and in a separate terminal connect to it with `nc`, sending a couple of short lines, separated by a delay of a couple of seconds:
|
||||
|
||||
```
|
||||
$ nc localhost 9988
|
||||
hello # wait for 2 seconds after typing this
|
||||
socket world
|
||||
^D # to end the connection>
|
||||
```
|
||||
|
||||
The listening program will print the following:
|
||||
|
||||
```
|
||||
$ ./blocking-listener 9988
|
||||
Listening on port 9988
|
||||
peer (localhost, 37284) connected
|
||||
Calling recv...
|
||||
recv returned 6 bytes
|
||||
Calling recv...
|
||||
recv returned 13 bytes
|
||||
Calling recv...
|
||||
Peer disconnected; I'm done.
|
||||
```
|
||||
|
||||
Now let's try a nonblocking version of the same listening program. Here it is:
|
||||
|
||||
```
|
||||
int main(int argc, const char** argv) {
|
||||
setvbuf(stdout, NULL, _IONBF, 0);
|
||||
|
||||
int portnum = 9988;
|
||||
if (argc >= 2) {
|
||||
portnum = atoi(argv[1]);
|
||||
}
|
||||
printf("Listening on port %d\n", portnum);
|
||||
|
||||
int sockfd = listen_inet_socket(portnum);
|
||||
struct sockaddr_in peer_addr;
|
||||
socklen_t peer_addr_len = sizeof(peer_addr);
|
||||
|
||||
int newsockfd = accept(sockfd, (struct sockaddr*)&peer_addr, &peer_addr_len);
|
||||
if (newsockfd < 0) {
|
||||
perror_die("ERROR on accept");
|
||||
}
|
||||
report_peer_connected(&peer_addr, peer_addr_len);
|
||||
|
||||
// Set nonblocking mode on the socket.
|
||||
int flags = fcntl(newsockfd, F_GETFL, 0);
|
||||
if (flags == -1) {
|
||||
perror_die("fcntl F_GETFL");
|
||||
}
|
||||
|
||||
if (fcntl(newsockfd, F_SETFL, flags | O_NONBLOCK) == -1) {
|
||||
perror_die("fcntl F_SETFL O_NONBLOCK");
|
||||
}
|
||||
|
||||
while (1) {
|
||||
uint8_t buf[1024];
|
||||
printf("Calling recv...\n");
|
||||
int len = recv(newsockfd, buf, sizeof buf, 0);
|
||||
if (len < 0) {
|
||||
if (errno == EAGAIN || errno == EWOULDBLOCK) {
|
||||
usleep(200 * 1000);
|
||||
continue;
|
||||
}
|
||||
perror_die("recv");
|
||||
} else if (len == 0) {
|
||||
printf("Peer disconnected; I'm done.\n");
|
||||
break;
|
||||
}
|
||||
printf("recv returned %d bytes\n", len);
|
||||
}
|
||||
|
||||
close(newsockfd);
|
||||
close(sockfd);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
A couple of notable differences from the blocking version:
|
||||
|
||||
1. The `newsockfd` socket returned by `accept` is set to nonblocking mode by calling `fcntl`.
|
||||
|
||||
2. When examining the return status of `recv`, we check whether `errno` is set to a value saying that no data is available for receiving. In this case we just sleep for 200 milliseconds and continue to the next iteration of the loop.
|
||||
|
||||
The same expermient with `nc` yields the following printout from this nonblocking listener:
|
||||
|
||||
```
|
||||
$ ./nonblocking-listener 9988
|
||||
Listening on port 9988
|
||||
peer (localhost, 37288) connected
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
recv returned 6 bytes
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
recv returned 13 bytes
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Peer disconnected; I'm done.
|
||||
```
|
||||
|
||||
As an exercise, add a timestamp to the printouts and convince yourself that the total time elapsed between fruitful calls to `recv` is more or less the delay in typing the lines into `nc` (rounded to the next 200 ms).
|
||||
|
||||
So there we have it - using nonblocking `recv` makes it possible for the listener the check in with the socket, and regain control if no data is available yet. Another word to describe this in the domain of programming is _polling_ - the main program periodically polls the socket for its readiness.
|
||||
|
||||
It may seem like a potential solution to the sequential serving issue. Nonblocking `recv` makes it possible to work with multiple sockets simulatenously, polling them for data and only handling those that have new data. This is true - concurrent servers _could_ be written this way; but in reality they don't, because the polling approach scales very poorly.
|
||||
|
||||
First, the 200 ms delay I introduced in the code above is nice for the demonstration (the listener prints only a few lines of "Calling recv..." between my typing into `nc` as opposed to thousands), but it also incurs a delay of up to 200 ms to the server's response time, which is almost certainly undesirable. In real programs the delay would have to be much shorter, and the shorter the sleep, the more CPU the process consumes. These are cycles consumed for just waiting, which isn't great, especially on mobile devices where power matters.
|
||||
|
||||
But the bigger problem happens when we actually have to work with multiple sockets this way. Imagine this listener is handling 1000 clients concurrently. This means that in every loop iteration, it has to do a nonblocking `recv` on _each and every one of those 1000 sockets_ , looking for one which has data ready. This is terribly inefficient, and severely limits the number of clients this server can handle concurrently. There's a catch-22 here: the longer we wait between polls, the less responsive the server is; the shorter we wait, the more CPU resources we burn on useless polling.
|
||||
|
||||
Frankly, all this polling also feels like useless work. Surely somewhere in the OS it is known which socket is actually ready with data, so we don't have to scan all of them. Indeed, it is, and the rest of this post will showcase a couple of APIs that let us handle multiple clients much more gracefully.
|
||||
|
||||
### select
|
||||
|
||||
The `select` system call is a portable (POSIX), venerable part of the standard Unix API. It was designed precisely for the problem described towards the end of the previous section - to allow a single thread to "watch" a non-trivial number of file descriptors [[4]][17] for changes, without needlessly spinning in a polling loop. I don't plan to include a comprehensive tutorial for `select` in this post - there are many websites and book chapters for that - but I will describe its API in the context of the problem we're trying to solve, and will present a fairly complete example.
|
||||
|
||||
`select` enables _I/O multiplexing_ - monitoring multiple file descriptors to see if I/O is possible on any of them.
|
||||
|
||||
```
|
||||
int select(int nfds, fd_set *readfds, fd_set *writefds,
|
||||
fd_set *exceptfds, struct timeval *timeout);
|
||||
```
|
||||
|
||||
`readfds` points to a buffer of file descriptors we're watching for read events; `fd_set` is an opaque data structure users manipulate using `FD_*` macros. `writefds` is the same for write events. `nfds` is the highest file descriptor number (file descriptors are just integers) in the watched buffers. `timeout` lets the user specify how long `select` should block waiting for one of the file descriptors to be ready (`timeout == NULL` means block indefinitely). I'll ignore `exceptfds` for now.
|
||||
|
||||
The contract of calling `select` is as follows:
|
||||
|
||||
1. Prior to the call, the user has to create `fd_set` instances for all the different kinds of descriptors to watch. If we want to watch for both read events and write events, both `readfds` and `writefds` should be created and populated.
|
||||
|
||||
2. The user uses `FD_SET` to set specific descriptors to watch in the set. For example, if we want to watch descriptors 2, 7 and 10 for read events, we call `FD_SET` three times on `readfds`, once for each of 2, 7 and 10.
|
||||
|
||||
3. `select` is called.
|
||||
|
||||
4. When `select` returns (let's ignore timeouts for now), it says how many descriptors in the sets passed to it are ready. It also modifies the `readfds` and `writefds` sets to mark only those descriptors that are ready. All the other descriptors are cleared.
|
||||
|
||||
5. At this point the user has to iterate over `readfds` and `writefds` to find which descriptors are ready (using `FD_ISSET`).
|
||||
|
||||
As a complete example, I've reimplemented our protocol in a concurrent server that uses `select`. The [full code is here][18]; what follows is some highlights from the code, with explanations. Warning: this code sample is fairly substantial - so feel free to skip it on first reading if you're short on time.
|
||||
|
||||
### A concurrent server using select
|
||||
|
||||
Using an I/O multiplexing API like `select` imposes certain constraints on the design of our server; these may not be immediately obvious, but are worth discussing since they are key to understanding what event-driven programming is all about.
|
||||
|
||||
Most importantly, always keep in mind that such an approach is, in its core, single-threaded [[5]][19]. The server really is just doing _one thing at a time_ . Since we want to handle multiple clients concurrently, we'll have to structure the code in an unusual way.
|
||||
|
||||
First, let's talk about the main loop. How would that look? To answer this question let's imagine our server during a flurry of activity - what should it watch for? Two kinds of socket activities:
|
||||
|
||||
1. New clients trying to connect. These clients should be `accept`-ed.
|
||||
|
||||
2. Existing client sending data. This data has to go through the usual protocol described in [part 1][11], with perhaps some data being sent back.
|
||||
|
||||
Even though these two activities are somewhat different in nature, we'll have to mix them into the same loop, because there can only be one main loop. Our loop will revolve around calls to `select`. This `select` call will watch for the two kinds of events described above.
|
||||
|
||||
Here's the part of the code that sets up the file descriptor sets and kicks off the main loop with a call to `select`:
|
||||
|
||||
```
|
||||
// The "master" sets are owned by the loop, tracking which FDs we want to
|
||||
// monitor for reading and which FDs we want to monitor for writing.
|
||||
fd_set readfds_master;
|
||||
FD_ZERO(&readfds_master);
|
||||
fd_set writefds_master;
|
||||
FD_ZERO(&writefds_master);
|
||||
|
||||
// The listenting socket is always monitored for read, to detect when new
|
||||
// peer connections are incoming.
|
||||
FD_SET(listener_sockfd, &readfds_master);
|
||||
|
||||
// For more efficiency, fdset_max tracks the maximal FD seen so far; this
|
||||
// makes it unnecessary for select to iterate all the way to FD_SETSIZE on
|
||||
// every call.
|
||||
int fdset_max = listener_sockfd;
|
||||
|
||||
while (1) {
|
||||
// select() modifies the fd_sets passed to it, so we have to pass in copies.
|
||||
fd_set readfds = readfds_master;
|
||||
fd_set writefds = writefds_master;
|
||||
|
||||
int nready = select(fdset_max + 1, &readfds, &writefds, NULL, NULL);
|
||||
if (nready < 0) {
|
||||
perror_die("select");
|
||||
}
|
||||
...
|
||||
```
|
||||
|
||||
A couple of points of interest here:
|
||||
|
||||
1. Since every call to `select` overwrites the sets given to the function, the caller has to maintain a "master" set to keep track of all the active sockets it monitors across loop iterations.
|
||||
|
||||
2. Note how, initially, the only socket we care about is `listener_sockfd`, which is the original socket on which the server accepts new clients.
|
||||
|
||||
3. The return value of `select` is the number of descriptors that are ready among those in the sets passed as arguments. The sets are modified by `select` to mark ready descriptors. The next step is iterating over the descriptors.
|
||||
|
||||
```
|
||||
...
|
||||
for (int fd = 0; fd <= fdset_max && nready > 0; fd++) {
|
||||
// Check if this fd became readable.
|
||||
if (FD_ISSET(fd, &readfds)) {
|
||||
nready--;
|
||||
|
||||
if (fd == listener_sockfd) {
|
||||
// The listening socket is ready; this means a new peer is connecting.
|
||||
...
|
||||
} else {
|
||||
fd_status_t status = on_peer_ready_recv(fd);
|
||||
if (status.want_read) {
|
||||
FD_SET(fd, &readfds_master);
|
||||
} else {
|
||||
FD_CLR(fd, &readfds_master);
|
||||
}
|
||||
if (status.want_write) {
|
||||
FD_SET(fd, &writefds_master);
|
||||
} else {
|
||||
FD_CLR(fd, &writefds_master);
|
||||
}
|
||||
if (!status.want_read && !status.want_write) {
|
||||
printf("socket %d closing\n", fd);
|
||||
close(fd);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
This part of the loop checks the _readable_ descriptors. Let's skip the listener socket (for the full scoop - [read the code][20]) and see what happens when one of the client sockets is ready. When this happens, we call a _callback_ function named `on_peer_ready_recv` with the file descriptor for the socket. This call means the client connected to that socket sent some data and a call to `recv` on the socket isn't expected to block [[6]][21]. This callback returns a struct of type `fd_status_t`:
|
||||
|
||||
```
|
||||
typedef struct {
|
||||
bool want_read;
|
||||
bool want_write;
|
||||
} fd_status_t;
|
||||
```
|
||||
|
||||
Which tells the main loop whether the socket should be watched for read events, write events, or both. The code above shows how `FD_SET` and `FD_CLR` are called on the appropriate descriptor sets accordingly. The code for a descriptor being ready for writing in the main loop is similar, except that the callback it invokes is called `on_peer_ready_send`.
|
||||
|
||||
Now it's time to look at the code for the callback itself:
|
||||
|
||||
```
|
||||
typedef enum { INITIAL_ACK, WAIT_FOR_MSG, IN_MSG } ProcessingState;
|
||||
|
||||
#define SENDBUF_SIZE 1024
|
||||
|
||||
typedef struct {
|
||||
ProcessingState state;
|
||||
|
||||
// sendbuf contains data the server has to send back to the client. The
|
||||
// on_peer_ready_recv handler populates this buffer, and on_peer_ready_send
|
||||
// drains it. sendbuf_end points to the last valid byte in the buffer, and
|
||||
// sendptr at the next byte to send.
|
||||
uint8_t sendbuf[SENDBUF_SIZE];
|
||||
int sendbuf_end;
|
||||
int sendptr;
|
||||
} peer_state_t;
|
||||
|
||||
// Each peer is globally identified by the file descriptor (fd) it's connected
|
||||
// on. As long as the peer is connected, the fd is uqique to it. When a peer
|
||||
// disconnects, a new peer may connect and get the same fd. on_peer_connected
|
||||
// should initialize the state properly to remove any trace of the old peer on
|
||||
// the same fd.
|
||||
peer_state_t global_state[MAXFDS];
|
||||
|
||||
fd_status_t on_peer_ready_recv(int sockfd) {
|
||||
assert(sockfd < MAXFDs);
|
||||
peer_state_t* peerstate = &global_state[sockfd];
|
||||
|
||||
if (peerstate->state == INITIAL_ACK ||
|
||||
peerstate->sendptr < peerstate->sendbuf_end) {
|
||||
// Until the initial ACK has been sent to the peer, there's nothing we
|
||||
// want to receive. Also, wait until all data staged for sending is sent to
|
||||
// receive more data.
|
||||
return fd_status_W;
|
||||
}
|
||||
|
||||
uint8_t buf[1024];
|
||||
int nbytes = recv(sockfd, buf, sizeof buf, 0);
|
||||
if (nbytes == 0) {
|
||||
// The peer disconnected.
|
||||
return fd_status_NORW;
|
||||
} else if (nbytes < 0) {
|
||||
if (errno == EAGAIN || errno == EWOULDBLOCK) {
|
||||
// The socket is not *really* ready for recv; wait until it is.
|
||||
return fd_status_R;
|
||||
} else {
|
||||
perror_die("recv");
|
||||
}
|
||||
}
|
||||
bool ready_to_send = false;
|
||||
for (int i = 0; i < nbytes; ++i) {
|
||||
switch (peerstate->state) {
|
||||
case INITIAL_ACK:
|
||||
assert(0 && "can't reach here");
|
||||
break;
|
||||
case WAIT_FOR_MSG:
|
||||
if (buf[i] == '^') {
|
||||
peerstate->state = IN_MSG;
|
||||
}
|
||||
break;
|
||||
case IN_MSG:
|
||||
if (buf[i] == '$') {
|
||||
peerstate->state = WAIT_FOR_MSG;
|
||||
} else {
|
||||
assert(peerstate->sendbuf_end < SENDBUF_SIZE);
|
||||
peerstate->sendbuf[peerstate->sendbuf_end++] = buf[i] + 1;
|
||||
ready_to_send = true;
|
||||
}
|
||||
break;
|
||||
}
|
||||
}
|
||||
// Report reading readiness iff there's nothing to send to the peer as a
|
||||
// result of the latest recv.
|
||||
return (fd_status_t){.want_read = !ready_to_send,
|
||||
.want_write = ready_to_send};
|
||||
}
|
||||
```
|
||||
|
||||
A `peer_state_t` is the full state object used to represent a client connection between callback calls from the main loop. Since a callback is invoked on some partial data sent by the client, it cannot assume it will be able to communicate with the client continuously, and it has to run quickly without blocking. It never blocks because the socket is set to non-blocking mode and `recv` will always return quickly. Other than calling `recv`, all this handler does is manipulate the state - there are no additional calls that could potentially block.
|
||||
|
||||
An an exercise, can you figure out why this code needs an extra state? Our servers so far in the series managed with just two states, but this one needs three.
|
||||
|
||||
Let's also have a look at the "socket ready to send" callback:
|
||||
|
||||
```
|
||||
fd_status_t on_peer_ready_send(int sockfd) {
|
||||
assert(sockfd < MAXFDs);
|
||||
peer_state_t* peerstate = &global_state[sockfd];
|
||||
|
||||
if (peerstate->sendptr >= peerstate->sendbuf_end) {
|
||||
// Nothing to send.
|
||||
return fd_status_RW;
|
||||
}
|
||||
int sendlen = peerstate->sendbuf_end - peerstate->sendptr;
|
||||
int nsent = send(sockfd, peerstate->sendbuf, sendlen, 0);
|
||||
if (nsent == -1) {
|
||||
if (errno == EAGAIN || errno == EWOULDBLOCK) {
|
||||
return fd_status_W;
|
||||
} else {
|
||||
perror_die("send");
|
||||
}
|
||||
}
|
||||
if (nsent < sendlen) {
|
||||
peerstate->sendptr += nsent;
|
||||
return fd_status_W;
|
||||
} else {
|
||||
// Everything was sent successfully; reset the send queue.
|
||||
peerstate->sendptr = 0;
|
||||
peerstate->sendbuf_end = 0;
|
||||
|
||||
// Special-case state transition in if we were in INITIAL_ACK until now.
|
||||
if (peerstate->state == INITIAL_ACK) {
|
||||
peerstate->state = WAIT_FOR_MSG;
|
||||
}
|
||||
|
||||
return fd_status_R;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Same here - the callback calls a non-blocking `send` and performs state manipulation. In asynchronous code, it's critical for callbacks to do their work quickly - any delay blocks the main loop from making progress, and thus blocks the whole server from handling other clients.
|
||||
|
||||
Let's once again repeat a run of the server with the script that connects 3 clients simultaneously. In one terminal window we'll run:
|
||||
|
||||
```
|
||||
$ ./select-server
|
||||
```
|
||||
|
||||
In another:
|
||||
|
||||
```
|
||||
$ python3.6 simple-client.py -n 3 localhost 9090
|
||||
INFO:2017-09-26 05:29:15,864:conn1 connected...
|
||||
INFO:2017-09-26 05:29:15,864:conn2 connected...
|
||||
INFO:2017-09-26 05:29:15,864:conn0 connected...
|
||||
INFO:2017-09-26 05:29:15,865:conn1 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-26 05:29:15,865:conn2 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-26 05:29:15,865:conn0 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-26 05:29:15,865:conn1 received b'bcdbcuf'
|
||||
INFO:2017-09-26 05:29:15,865:conn2 received b'bcdbcuf'
|
||||
INFO:2017-09-26 05:29:15,865:conn0 received b'bcdbcuf'
|
||||
INFO:2017-09-26 05:29:16,866:conn1 sending b'xyz^123'
|
||||
INFO:2017-09-26 05:29:16,867:conn0 sending b'xyz^123'
|
||||
INFO:2017-09-26 05:29:16,867:conn2 sending b'xyz^123'
|
||||
INFO:2017-09-26 05:29:16,867:conn1 received b'234'
|
||||
INFO:2017-09-26 05:29:16,868:conn0 received b'234'
|
||||
INFO:2017-09-26 05:29:16,868:conn2 received b'234'
|
||||
INFO:2017-09-26 05:29:17,868:conn1 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-26 05:29:17,869:conn1 received b'36bc1111'
|
||||
INFO:2017-09-26 05:29:17,869:conn0 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-26 05:29:17,870:conn0 received b'36bc1111'
|
||||
INFO:2017-09-26 05:29:17,870:conn2 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-26 05:29:17,870:conn2 received b'36bc1111'
|
||||
INFO:2017-09-26 05:29:18,069:conn1 disconnecting
|
||||
INFO:2017-09-26 05:29:18,070:conn0 disconnecting
|
||||
INFO:2017-09-26 05:29:18,070:conn2 disconnecting
|
||||
```
|
||||
|
||||
Similarly to the threaded case, there's no delay between clients - they are all handled concurrently. And yet, there are no threads in sight in `select-server`! The main loop _multiplexes_ all the clients by efficient polling of multiple sockets using `select`. Recall the sequential vs. multi-threaded client handling diagrams from [part 2][22]. For our `select-server`, the time flow for three clients looks something like this:
|
||||
|
||||
|
||||
|
||||
All clients are handled concurrently within the same thread, by multiplexing - doing some work for a client, switching to another, then another, then going back to the original client, etc. Note that there's no specific round-robin order here - the clients are handled when they send data to the server, which really depends on the client.
|
||||
|
||||
### Synchronous, asynchronous, event-driven, callback-based
|
||||
|
||||
The `select-server` code sample provides a good background for discussing just what is meant by "asynchronous" programming, and how it relates to event-driven and callback-based programming, because all these terms are common in the (rather inconsistent) discussion of concurrent servers.
|
||||
|
||||
Let's start with a quote from `select`'s man page:
|
||||
|
||||
> select, pselect, FD_CLR, FD_ISSET, FD_SET, FD_ZERO - synchronous I/O multiplexing
|
||||
|
||||
So `select` is for _synchronous_ multiplexing. But I've just presented a substantial code sample using `select` as an example of an _asynchronous_ server; what gives?
|
||||
|
||||
The answer is: it depends on your point of view. Synchronous is often used as a synonym for blocking, and the calls to `select` are, indeed, blocking. So are the calls to `send` and `recv` in the sequential and threaded servers presented in parts 1 and 2\. So it is fair to say that `select` is a _synchronous_ API. However, the server design emerging from the use of `select` is actually _asynchronous_ , or _callback-based_ , or _event-driven_ . Note that the `on_peer_*` functions presented in this post are callbacks; they should never block, and they get invoked due to network events. They can get partial data, and are expected to retain coherent state in-between invocations.
|
||||
|
||||
If you've done any amont of GUI programming in the past, all of this is very familiar. There's an "event loop" that's often entirely hidden in frameworks, and the application's "business logic" is built out of callbacks that get invoked by the event loop due to various events - user mouse clicks, menu selections, timers firing, data arriving on sockets, etc. The most ubiquitous model of programming these days is, of course, client-side Javascript, which is written as a bunch of callbacks invoked by user activity on a web page.
|
||||
|
||||
### The limitations of select
|
||||
|
||||
Using `select` for our first example of an asynchronous server makes sense to present the concept, and also because `select` is such an ubiquitous and portable API. But it also has some significant limitations that manifest when the number of watched file descriptors is very large:
|
||||
|
||||
1. Limited file descriptor set size.
|
||||
|
||||
2. Bad performance.
|
||||
|
||||
Let's start with the file descriptor size. `FD_SETSIZE` is a compile-time constant that's usually equal to 1024 on modern systems. It's hard-coded deep in the guts of `glibc`, and isn't easy to modify. It limits the number of file descriptors a `select` call can watch to 1024\. These days folks want to write servers that handle 10s of thousands of concurrent clients and more, so this problem is real. There are workarounds, but they aren't portable and aren't easy.
|
||||
|
||||
The bad performance issue is a bit more subtle, but still very serious. Note that when `select` returns, the information it provides to the caller is the number of "ready" descriptors, and the updated descriptor sets. The descriptor sets map from desrciptor to "ready/not ready" but they don't provide a way to iterate over all the ready descriptors efficiently. If there's only a single descriptor that is ready in the set, in the worst case the caller has to iterate over _the entire set_ to find it. This works OK when the number of descriptors watched is small, but if it gets to high numbers this overhead starts hurting [[7]][23].
|
||||
|
||||
For these reasons `select` has recently fallen out of favor for writing high-performance concurrent servers. Every popular OS has its own, non-portable APIs that permit users to write much more performant event loops; higher-level interfaces like frameworks and high-level languages usually wrap these APIs in a single portable interface.
|
||||
|
||||
### epoll
|
||||
|
||||
As an example, let's look at `epoll`, Linux's solution to the high-volume I/O event notification problem. The key to `epoll`'s efficiency is greater cooperation from the kernel. Instead of using a file descriptor set, `epoll_wait`fills a buffer with events that are currently ready. Only the ready events are added to the buffer, so there is no need to iterate over _all_ the currently watched file descriptors in the client. This changes the process of discovering which descriptors are ready from O(N) in `select`'s case to O(1).
|
||||
|
||||
A full presentation of the `epoll` API is not the goal here - there are plenty of online resources for that. As you may have guessed, though, I am going to write yet another version of our concurrent server - this time using `epoll` instead of `select`. The full code sample [is here][24]. In fact, since the vast majority of the code is the same as `select-server`, I'll only focus on the novelty - the use of `epoll` in the main loop:
|
||||
|
||||
```
|
||||
struct epoll_event accept_event;
|
||||
accept_event.data.fd = listener_sockfd;
|
||||
accept_event.events = EPOLLIN;
|
||||
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, listener_sockfd, &accept_event) < 0) {
|
||||
perror_die("epoll_ctl EPOLL_CTL_ADD");
|
||||
}
|
||||
|
||||
struct epoll_event* events = calloc(MAXFDS, sizeof(struct epoll_event));
|
||||
if (events == NULL) {
|
||||
die("Unable to allocate memory for epoll_events");
|
||||
}
|
||||
|
||||
while (1) {
|
||||
int nready = epoll_wait(epollfd, events, MAXFDS, -1);
|
||||
for (int i = 0; i < nready; i++) {
|
||||
if (events[i].events & EPOLLERR) {
|
||||
perror_die("epoll_wait returned EPOLLERR");
|
||||
}
|
||||
|
||||
if (events[i].data.fd == listener_sockfd) {
|
||||
// The listening socket is ready; this means a new peer is connecting.
|
||||
...
|
||||
} else {
|
||||
// A peer socket is ready.
|
||||
if (events[i].events & EPOLLIN) {
|
||||
// Ready for reading.
|
||||
...
|
||||
} else if (events[i].events & EPOLLOUT) {
|
||||
// Ready for writing.
|
||||
...
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
We start by configuring `epoll` with a call to `epoll_ctl`. In this case, the configuration amounts to adding the listening socket to the descriptors `epoll` is watching for us. We then allocate a buffer of ready events to pass to `epoll` for modification. The call to `epoll_wait` in the main loop is where the magic's at. It blocks until one of the watched descriptors is ready (or until a timeout expires), and returns the number of ready descriptors. This time, however, instead of blindly iterating over all the watched sets, we know that `epoll_write` populated the `events` buffer passed to it with the ready events, from 0 to `nready-1`, so we iterate only the strictly necessary number of times.
|
||||
|
||||
To reiterate this critical difference from `select`: if we're watching 1000 descriptors and two become ready, `epoll_waits` returns `nready=2` and populates the first two elements of the `events` buffer - so we only "iterate" over two descriptors. With `select` we'd still have to iterate over 1000 descriptors to find out which ones are ready. For this reason `epoll` scales much better than `select` for busy servers with many active sockets.
|
||||
|
||||
The rest of the code is straightforward, since we're already familiar with `select-server`. In fact, all the "business logic" of `epoll-server` is exactly the same as for `select-server` - the callbacks consist of the same code.
|
||||
|
||||
This similarity is tempting to exploit by abstracting away the event loop into a library/framework. I'm going to resist this itch, because so many great programmers succumbed to it in the past. Instead, in the next post we're going to look at `libuv` - one of the more popular event loop abstractions emerging recently. Libraries like `libuv` allow us to write concurrent asynchronous servers without worrying about the greasy details of the underlying system calls.
|
||||
|
||||
* * *
|
||||
|
||||
|
||||
[[1]][1] I tried enlightening myself on the actual semantic difference between the two by doing some web browsing and reading, but got a headache fairly quickly. There are many different opinions ranging from "they're the same thing", to "one is a subset of another" to "they're completely different things". When faced with such divergent views on the semantics, it's best to abandon the issue entirely, focusing instead on specific examples and use cases.
|
||||
|
||||
[[2]][2] POSIX mandates that this can be either `EAGAIN` or `EWOULDBLOCK`, and portable applications should check for both.
|
||||
|
||||
[[3]][3] Similarly to all C samples in this series, this code uses some helper utilities to set up listening sockets. The full code for these utilities lives in the `utils` module [in the repository][4].
|
||||
|
||||
[[4]][5] `select` is not a network/socket-specific function; it watches arbitrary file descriptors, which could be disk files, pipes, terminals, sockets or anything else Unix systems represent with file descriptors. In this post we're focusing on its uses for sockets, of course.
|
||||
|
||||
[[5]][6] There are ways to intermix event-driven programming with multiple threads, but I'll defer this discussion to later in the series.
|
||||
|
||||
|
||||
[[6]][7] Due to various non-trivial reasons it could _still_ block, even after `select` says it's ready. Therefore, all sockets opened by this server are set to nonblocking mode, and if the call to `recv` or `send` returns `EAGAIN` or `EWOULDBLOCK`, the callbacks just assumed no event really happened. Read the code sample comments for more details.
|
||||
|
||||
|
||||
[[7]][8] Note that this still isn't as bad as the asynchronous polling example presented earlier in the post. The polling has to happen _all the time_ , while `select` actually blocks until one or more sockets are ready for reading/writing; far less CPU time is wasted with `select` than with repeated polling.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://eli.thegreenplace.net/pages/about
|
||||
[1]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id1
|
||||
[2]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id3
|
||||
[3]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id4
|
||||
[4]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/utils.h
|
||||
[5]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id5
|
||||
[6]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id6
|
||||
[7]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id8
|
||||
[8]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id9
|
||||
[9]:https://eli.thegreenplace.net/tag/concurrency
|
||||
[10]:https://eli.thegreenplace.net/tag/c-c
|
||||
[11]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
[12]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
[13]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[14]:http://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
[15]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id11
|
||||
[16]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id12
|
||||
[17]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id13
|
||||
[18]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/select-server.c
|
||||
[19]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id14
|
||||
[20]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/select-server.c
|
||||
[21]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id15
|
||||
[22]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[23]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id16
|
||||
[24]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/epoll-server.c
|
||||
[25]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
[26]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
[27]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[28]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id10
|
||||
@ -0,0 +1,201 @@
|
||||
Create a Clean-Code App with Kotlin Coroutines and Android Architecture Components
|
||||
============================================================
|
||||
|
||||
### Full demo weather app included.
|
||||
|
||||
Android development is evolving fast. A lot of developers and companies are trying to address common problems and create some great tools or libraries that can totally change the way we structure our apps.
|
||||
|
||||
|
||||

|
||||
|
||||
We get excited by the new possibilities, but it’s difficult to find time to rewrite our app to really benefit from a new programming style. But what if we actually start a new project? Which of those breakthrough ideas to employ? Which solutions are stable enough? Should we use RxJava extensively and structure our app with reactive-first mindset?
|
||||
|
||||
> The Cycle.js library (by [André Staltz][6]) contains a great explanation of reactive-first mindset: [Cycle.js — Streams][7].
|
||||
|
||||
Rx is highly composable and it has great potential, but it’s so different from regular object-oriented programming style, that it will be really hard to understand for any developer without RxJava experience.
|
||||
|
||||
There are more questions to ask before starting a new project. For example:
|
||||
|
||||
* Should we use Kotlin instead of Java?
|
||||
(actually here the answer is simple: [YES][1])
|
||||
|
||||
* Should we use experimental Kotlin Coroutines? (which, again, promote totally new programming style)
|
||||
|
||||
* Should we use the new experimental library from Google:
|
||||
Android Architecture Components?
|
||||
|
||||
It’s necessary to try it all first in a small app to really make an informed decision. This is exactly what [I did][8], getting some useful insights in the process. If you want to find out what I learned, read on!
|
||||
|
||||
### About [The App][9]
|
||||
|
||||
The aim of the experiment was to create an [app][10] that downloads weather data for cities selected by user and then displays forecasts with graphical charts (and some fancy animations). It’s simple, yet it contains most of the typical features of Android projects.
|
||||
|
||||
It turns out that coroutines and architecture components play really well together and give us clean app architecture with good separation of concerns. Coroutines allow to express ideas in a natural and concise way. Suspendable functions are great if you want to code line-by-line the exact logic you have in mind — even if you need to make some asynchronous calls in between.
|
||||
|
||||
Also: no more jumping between callbacks. In this example app, coroutines also completely removed the need of using RxJava. Functions with suspendable points are easier to read and understand than some RxJava operator chains — these chains can quickly become too _functional. _ ;-)
|
||||
|
||||
> Having said that, I don’t think that RxJava can be replaced with coroutines in every use case. Observables give us a different kind of expressiveness that can not be mapped one to one to suspendable functions. In particular once constructed observable operator chain allow many events to flow through it, while a suspendable point resumes only once per invocation.
|
||||
|
||||
Back to our weather app:
|
||||
You can watch it in action below — but beware, I’m not a designer. :-)
|
||||
Chart animations show how easily you can implement them arbitrarily by hand with simple coroutine — without any ObjectAnimators, Interpolators, Evaluators, PropertyValuesHolders, etc.
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
** 此处有iframe,请手动处理 **
|
||||
|
||||
The most important source code snippets are displayed below. However, if you’d like to see the full project, it’s available [on GitHub.][11]
|
||||
|
||||
[https://github.com/elpassion/crweather][12]
|
||||
|
||||
There is not a lot of code and it should be easy to go through.
|
||||
|
||||
I will present the app structure starting from the network layer. Then I will move to the business logic (in the [MainModel.kt][13] file) which is _(almost)_ not Android-specific. And finish with the UI part (which obviously is Android-specific).
|
||||
|
||||
Here is the general architecture diagram with text reference numbers added for your convenience. I will especially focus on _green_ elements — _suspendable functions_ and _actors_ (an actor is a really useful kind of _coroutine builder_ ).
|
||||
|
||||
> The actor model in general is a mathematical model of concurrent computation — more about it in my next blog post.
|
||||
|
||||
|
||||
|
||||
|
||||
### 01 Weather Service
|
||||
|
||||
This service downloads weather forecasts for a given city from [Open Weather Map][14] REST API.
|
||||
|
||||
I use simple but powerful library from [Square][15] called [Retrofit][16]. I guess by now every Android developer knows it, but in case you never used it: it’s the most popular HTTP client on Android. It makes network calls and parses responses to [POJO][17]. Nothing fancy here — just a typical Retrofit configuration. I plug in the [Moshi][18] converter to convert JSON responses to data classes.
|
||||
|
||||
|
||||
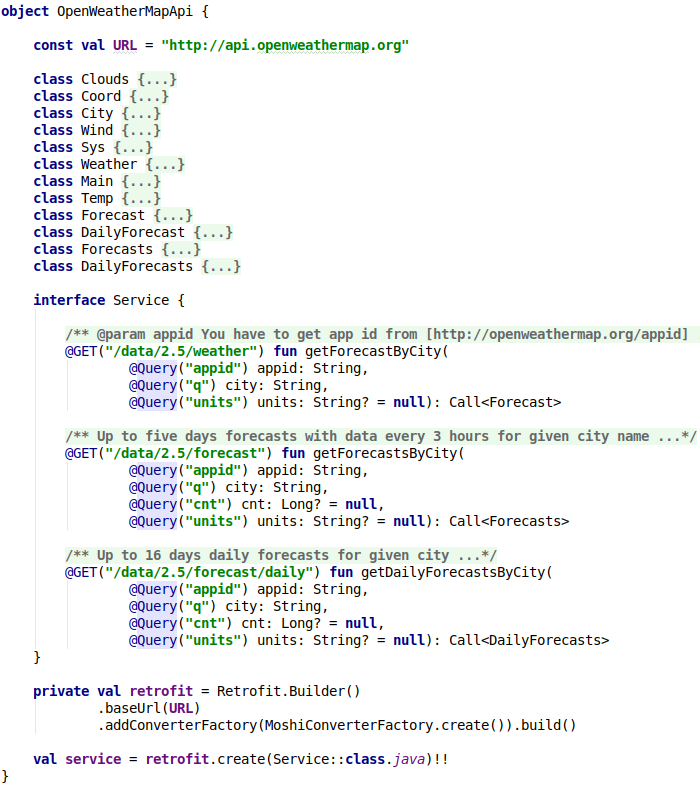
|
||||
[https://github.com/elpassion/crweather/…/OpenWeatherMapApi.kt][2]
|
||||
|
||||
One important thing to note here is that I set a return types of functions generated by Retrofit to: [Call][19].
|
||||
|
||||
I use [Call.enqueue(Callback)][20] to actually make a call to Open Weather Map. I don’t use any [call adapter][21] provided by Retrofit, because I wrap the Call object in the _suspendable function_ myself.
|
||||
|
||||
### 02 Utils
|
||||
|
||||
This is where we enter the ([brave new][22]) _coroutines_ world: we want to create a generic _suspendable function_ that wraps a [Call][23] object.
|
||||
|
||||
> I assume you know at least the very basics of coroutines. Please read the first chapter of [Coroutines Guide][24] (written by [Roman Elizarov][25]) if you don’t.
|
||||
|
||||
It will be an extension function: [_suspend_ fun Call<T>.await()][26] that invokes the [Call.enqueue(…)][27] (to actually make a network call), then _suspends_ and later _resumes_ (when the response comes back).
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||

|
||||
[https://github.com/elpassion/crweather/…/CommonUtils.kt][3]
|
||||
|
||||
To turn any asynchronous computation into a _suspendable function,_ we use the [suspendCoroutine][28] function from The Kotlin Standard Library. It gives us a [Continuation][29] object which is kind of a universal callback. We just have to call its [resume][30] method (or [resumeWithException][31]) anytime we want our new _suspendable function_ to resume (normally or by throwing an exception).
|
||||
|
||||
The next step will be to use our new _suspend_ fun Call<T>.await() function to convert asynchronous functions generated by Retrofit into convenient _suspendable functions_ .
|
||||
|
||||
### 03 Repository
|
||||
|
||||
The Repository object is a source of the data ([charts][32]) displayed in our app.
|
||||
|
||||
|
||||
|
||||

|
||||
[https://github.com/elpassion/crweather/…/Repository.kt][4]
|
||||
|
||||
Here we have some private _suspendable functions_ created by applying our _suspend_ fun Call<T>.await() extension to weather service functions. This way all of them return ready to use data like Forecast instead of Call<Forecast>. Then we use it in our one public _suspendable function_ : _suspend_ fun getCityCharts(city: String): List<Chart>. It converts the data from api to a ready to display list of charts. I use some custom extension properties on List<DailyForecast> to actually convert the data to List<Chart>. Important note: only _suspendable functions_ can call other _suspendable functions_ .
|
||||
|
||||
> We have the [appid][33] hardcoded here for simplicity. Please generate new appid [here][34]if you want to test the app — this hardcoded one will be automatically blocked for 24h if it is used too frequently by too many people.
|
||||
|
||||
In the next step we will create the main app model (implementing the Android [ViewModel][35] architecture component), that uses an _actor (coroutine builder)_ to implement the application logic.
|
||||
|
||||
### 04 Model
|
||||
|
||||
In this app we only have one simple model: [MainModel][36] : [ViewModel][37] used by our one activity: [MainActivity][38].
|
||||
|
||||
|
||||
|
||||
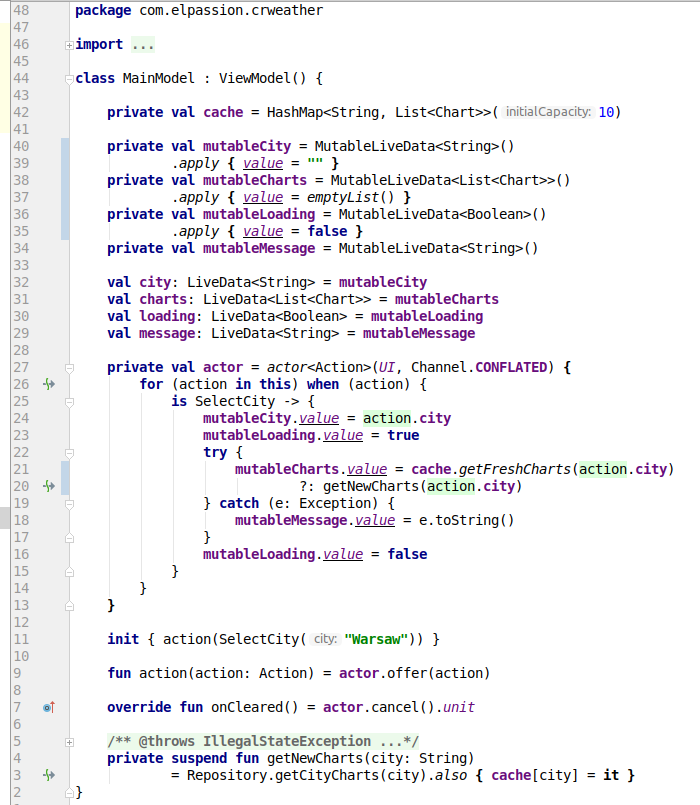
|
||||
[https://github.com/elpassion/crweather/…/MainModel.kt][5]
|
||||
|
||||
This class represents the app itself. It will be instantiated by our activity (actually by the Android system [ViewModelProvider][39]), but it will survive configuration changes such as a screen rotation — new activity instance will get the same model instance. We don’t have to worry about activity lifecycle here at all. Instead of implementing all those activity lifecycle related methods (onCreate, onDestroy, …), we have just one onCleared() method called when the user exits the app.
|
||||
|
||||
> To be precise onCleared method is called when the activity is finished.
|
||||
|
||||
Even though we are not tightly coupled to activity lifecycle anymore, we still have to somehow publish current state of our app model to display it somewhere (in the activity). This is where the [LiveData][40] comes into play.
|
||||
|
||||
The [LiveData][41] is like [RxJava][42] [BehaviorSubject][43] reinvented once again… It holds a mutable value that is observable. The most important difference is how we subscribe to it and we will see it later in the [MainActivity][44].
|
||||
|
||||
> Also LiveData doesn’t have all those powerful composable operators Observable has. There are only some simple [Transformations][45].
|
||||
|
||||
> Another difference is that LiveData is Android-specific and RxJava subjects are not, so they can be easily tested with regular non-android JUnit tests.
|
||||
|
||||
> Yet another difference is that LiveData is “lifecycle aware” — more about it in my next posts, where I present the [MainActivity][46] class.
|
||||
|
||||
In here we are actually using the [MutableLiveData][47] : [LiveData][48] objects that allow to push new values into it freely. The app state is represented by four LiveData objects: city, charts, loading, and message. The most important of these is the charts: LiveData<List<Chart>> object which represents current list of charts to display.
|
||||
|
||||
All the work of changing the app state and reacting to user actions is performed by an _ACTOR_ .
|
||||
|
||||
_Actors_ are awesome and will be explained in my next blog post :-)
|
||||
|
||||
### Summary
|
||||
|
||||
We have already prepared everything for our main _actor_ . And if you look at the _actor_ code itself — you can (kind of) see how it works even without knowing _coroutines_ or _actors_ theory. Even though it has only a few lines, it actually contains all important business logic of this app. The magic is where we call _suspendable functions_ (marked by gray arrows with green line). One _suspendable point_ is the iteration over user actions and second is the network call. Thanks to _coroutines_ it looks like synchronous blocking code but it doesn’t block the thread at all.
|
||||
|
||||
Stay tuned for my next post, where I will explain _actors_ (and _channels_ ) in detail.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.elpassion.com/create-a-clean-code-app-with-kotlin-coroutines-and-android-architecture-components-f533b04b5431
|
||||
|
||||
作者:[Marek Langiewicz][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.elpassion.com/@marek.langiewicz?source=post_header_lockup
|
||||
[1]:https://www.quora.com/Does-Kotlin-make-Android-development-easier-and-faster/answer/Michal-Przadka?srid=Gu6q
|
||||
[2]:https://github.com/elpassion/crweather/blob/master/app/src/main/java/com/elpassion/crweather/OpenWeatherMapApi.kt
|
||||
[3]:https://github.com/elpassion/crweather/blob/master/app/src/main/java/com/elpassion/crweather/CommonUtils.kt
|
||||
[4]:https://github.com/elpassion/crweather/blob/master/app/src/main/java/com/elpassion/crweather/Repository.kt
|
||||
[5]:https://github.com/elpassion/crweather/blob/master/app/src/main/java/com/elpassion/crweather/MainModel.kt
|
||||
[6]:https://medium.com/@andrestaltz
|
||||
[7]:https://cycle.js.org/streams.html
|
||||
[8]:https://github.com/elpassion/crweather
|
||||
[9]:https://github.com/elpassion/crweather
|
||||
[10]:https://github.com/elpassion/crweather
|
||||
[11]:https://github.com/elpassion/crweather
|
||||
[12]:https://github.com/elpassion/crweather
|
||||
[13]:https://github.com/elpassion/crweather/blob/master/app/src/main/java/com/elpassion/crweather/MainModel.kt
|
||||
[14]:http://openweathermap.org/api
|
||||
[15]:https://github.com/square
|
||||
[16]:http://square.github.io/retrofit/
|
||||
[17]:https://en.wikipedia.org/wiki/Plain_old_Java_object
|
||||
[18]:https://github.com/square/retrofit/tree/master/retrofit-converters/moshi
|
||||
[19]:https://github.com/square/retrofit/blob/master/retrofit/src/main/java/retrofit2/Call.java
|
||||
[20]:https://github.com/square/retrofit/blob/b3ea768567e9e1fb1ba987bea021dbc0ead4acd4/retrofit/src/main/java/retrofit2/Call.java#L48
|
||||
[21]:https://github.com/square/retrofit/tree/master/retrofit-adapters
|
||||
[22]:https://www.youtube.com/watch?v=_Lvf7Zu4XJU
|
||||
[23]:https://github.com/square/retrofit/blob/master/retrofit/src/main/java/retrofit2/Call.java
|
||||
[24]:https://github.com/Kotlin/kotlinx.coroutines/blob/master/coroutines-guide.md
|
||||
[25]:https://medium.com/@elizarov
|
||||
[26]:https://github.com/elpassion/crweather/blob/9c3e3cb803b7e4fffbb010ff085ac56645c9774d/app/src/main/java/com/elpassion/crweather/CommonUtils.kt#L24
|
||||
[27]:https://github.com/square/retrofit/blob/b3ea768567e9e1fb1ba987bea021dbc0ead4acd4/retrofit/src/main/java/retrofit2/Call.java#L48
|
||||
[28]:https://github.com/JetBrains/kotlin/blob/8f452ed0467e1239a7639b7ead3fb7bc5c1c4a52/libraries/stdlib/src/kotlin/coroutines/experimental/CoroutinesLibrary.kt#L89
|
||||
[29]:https://github.com/JetBrains/kotlin/blob/8fa8ba70558cfd610d91b1c6ba55c37967ac35c5/libraries/stdlib/src/kotlin/coroutines/experimental/Coroutines.kt#L23
|
||||
[30]:https://github.com/JetBrains/kotlin/blob/8fa8ba70558cfd610d91b1c6ba55c37967ac35c5/libraries/stdlib/src/kotlin/coroutines/experimental/Coroutines.kt#L32
|
||||
[31]:https://github.com/JetBrains/kotlin/blob/8fa8ba70558cfd610d91b1c6ba55c37967ac35c5/libraries/stdlib/src/kotlin/coroutines/experimental/Coroutines.kt#L38
|
||||
[32]:https://github.com/elpassion/crweather/blob/master/app/src/main/java/com/elpassion/crweather/DataTypes.kt
|
||||
[33]:http://openweathermap.org/appid
|
||||
[34]:http://openweathermap.org/appid
|
||||
[35]:https://developer.android.com/topic/libraries/architecture/viewmodel.html
|
||||
[36]:https://github.com/elpassion/crweather/blob/master/app/src/main/java/com/elpassion/crweather/MainModel.kt
|
||||
[37]:https://developer.android.com/topic/libraries/architecture/viewmodel.html
|
||||
[38]:https://github.com/elpassion/crweather/blob/master/app/src/main/java/com/elpassion/crweather/MainActivity.kt
|
||||
[39]:https://developer.android.com/reference/android/arch/lifecycle/ViewModelProvider.html
|
||||
[40]:https://developer.android.com/topic/libraries/architecture/livedata.html
|
||||
[41]:https://developer.android.com/topic/libraries/architecture/livedata.html
|
||||
[42]:https://github.com/ReactiveX/RxJava
|
||||
[43]:https://github.com/ReactiveX/RxJava/wiki/Subject
|
||||
[44]:https://github.com/elpassion/crweather/blob/master/app/src/main/java/com/elpassion/crweather/MainActivity.kt
|
||||
[45]:https://developer.android.com/reference/android/arch/lifecycle/Transformations.html
|
||||
[46]:https://github.com/elpassion/crweather/blob/master/app/src/main/java/com/elpassion/crweather/MainActivity.kt
|
||||
[47]:https://developer.android.com/reference/android/arch/lifecycle/MutableLiveData.html
|
||||
[48]:https://developer.android.com/topic/libraries/architecture/livedata.html
|
||||
@ -0,0 +1,517 @@
|
||||
"Translating by syys96"
|
||||
How to Install Software from Source Code… and Remove it Afterwards
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
_Brief: This detailed guide explains how to install a program from source code in Linux and how to remove the software installed from the source code._
|
||||
|
||||
One of the greatest strength of your Linux distribution is its package manager and the associated software repository. With them, you have all the necessary tools and resources to download and install a new software on your computer in a completely automated manner.
|
||||
|
||||
But despite all their efforts, the package maintainers cannot handle each and every use cases. Nor can they package all the software available out there. So there are still situations where you will have to compile and install a new software by yourself. As of myself, the most common reason, by far, I have to compile some software is when I need to run a very specific version. Or because I want to modify the source code or use some fancy compilation options.
|
||||
|
||||
If your needs belong to that latter category, there are chances you already know what you do. But for the vast majority of Linux users, compiling and installing a software from the sources for the first time might look like an initiation ceremony: somewhat frightening; but with the promise to enter a new world of possibilities and to be part of a privileged community if you overcome that.
|
||||
|
||||
[Suggested readHow To Install And Remove Software In Ubuntu [Complete Guide]][8]
|
||||
|
||||
### A. Installing software from source code in Linux
|
||||
|
||||
And that’s exactly what we will do here. For the purpose of that article, let’s say I need to install [NodeJS][9] 8.1.1 on my system. That version exactly. A version which is not available from the Debian repository:
|
||||
|
||||
```
|
||||
sh$ apt-cache madison nodejs | grep amd64
|
||||
nodejs | 6.11.1~dfsg-1 | http://deb.debian.org/debian experimental/main amd64 Packages
|
||||
nodejs | 4.8.2~dfsg-1 | http://ftp.fr.debian.org/debian stretch/main amd64 Packages
|
||||
nodejs | 4.8.2~dfsg-1~bpo8+1 | http://ftp.fr.debian.org/debian jessie-backports/main amd64 Packages
|
||||
nodejs | 0.10.29~dfsg-2 | http://ftp.fr.debian.org/debian jessie/main amd64 Packages
|
||||
nodejs | 0.10.29~dfsg-1~bpo70+1 | http://ftp.fr.debian.org/debian wheezy-backports/main amd64 Packages
|
||||
```
|
||||
|
||||
### Step 1: Getting the source code from GitHub
|
||||
|
||||
Like many open-source projects, the sources of NodeJS can be found on GitHub: [https://github.com/nodejs/node][10]
|
||||
|
||||
So, let’s go directly there.
|
||||
|
||||

|
||||
|
||||
If you’re not familiar with [GitHub][11], [git][12] or any other [version control system][13] worth mentioning the repository contains the current source for the software, as well as a history of all the modifications made through the years to that software. Eventually up to the very first line written for that project. For the developers, keeping that history has many advantages. For us today, the main one is we will be able to get the sources from for the project as they were at any given point in time. More precisely, I will be able to get the sources as they were when the 8.1.1 version I want was released. Even if there were many modifications since then.
|
||||
|
||||

|
||||
|
||||
On GitHub, you can use the “branch” button to navigate between different versions of the software. [“Branch” and “tags” are somewhat related concepts in Git][14]. Basically, the developers create “branch” and “tags” to keep track of important events in the project history, like when they start working on a new feature or when they publish a release. I will not go into the details here, all you need to know is I’m looking for the version _tagged_ “v8.1.1”
|
||||
|
||||

|
||||
|
||||
After having chosen on the “v8.1.1” tag, the page is refreshed, the most obvious change being the tag now appears as part of the URL. In addition, you will notice the file change date are different too. The source tree you are now seeing is the one that existed at the time the v8.1.1 tag was created. In some sense, you can think of a version control tool like git as a time travel machine, allowing you to go back and forth into a project history.
|
||||
|
||||

|
||||
|
||||
At this point, we can download the sources of NodeJS 8.1.1\. You can’t miss the big blue button suggesting to download the ZIP archive of the project. As of myself, I will download and extract the ZIP from the command line for the sake of the explanation. But if you prefer using a [GUI][15] tool, don’t hesitate to do that instead:
|
||||
|
||||
```
|
||||
wget https://github.com/nodejs/node/archive/v8.1.1.zip
|
||||
unzip v8.1.1.zip
|
||||
cd node-8.1.1/
|
||||
```
|
||||
|
||||
Downloading the ZIP archive works great. But if you want to do it “like a pro”, I would suggest using directly the `git` tool to download the sources. It is not complicated at all— and it will be a nice first contact with a tool you will often encounter:
|
||||
|
||||
```
|
||||
# first ensure git is installed on your system
|
||||
sh$ sudo apt-get install git
|
||||
# Make a shallow clone the NodeJS repository at v8.1.1
|
||||
sh$ git clone --depth 1 \
|
||||
--branch v8.1.1 \
|
||||
https://github.com/nodejs/node
|
||||
sh$ cd node/
|
||||
```
|
||||
|
||||
By the way, if you have any issue, just consider that first part of this article as a general introduction. Later I have more detailed explanations for Debian- and ReadHat-based distributions in order to help you troubleshoot common issues.
|
||||
|
||||
Anyway, whenever you downloaded the source using `git` or as a ZIP archive, you should now have exactly the same source files in the current directory:
|
||||
|
||||
```
|
||||
sh$ ls
|
||||
android-configure BUILDING.md common.gypi doc Makefile src
|
||||
AUTHORS CHANGELOG.md configure GOVERNANCE.md node.gyp test
|
||||
benchmark CODE_OF_CONDUCT.md CONTRIBUTING.md lib node.gypi tools
|
||||
BSDmakefile COLLABORATOR_GUIDE.md deps LICENSE README.md vcbuild.bat
|
||||
```
|
||||
|
||||
### Step 2: Understanding the Build System of the program
|
||||
|
||||
We usually talk about “compiling the sources”, but the compilation is only one of the phases required to produce a working software from its source. A build system is a set of tool and practices used to automate and articulate those different tasks in order to build entirely the software just by issuing few commands.
|
||||
|
||||
If the concept is simple, the reality is somewhat more complicated. Because different projects or programming language may have different requirements. Or because of the programmer’s tastes. Or the supported platforms. Or for historical reason. Or… or.. there is an almost endless list of reasons to choose or create another build system. All that to say there are many different solutions used out there.
|
||||
|
||||
NodeJS uses a [GNU-style build system][16]. This is a popular choice in the open source community. And once again, a good way to start your journey.
|
||||
|
||||
Writing and tuning a build system is a pretty complex task. But for the “end user”, GNU-style build systems resume themselves in using two tools: `configure` and `make`.
|
||||
|
||||
The `configure` file is a project-specific script that will check the destination system configuration and available feature in order to ensure the project can be built, eventually dealing with the specificities of the current platform.
|
||||
|
||||
An important part of a typical `configure` job is to build the `Makefile`. That is the file containing the instructions required to effectively build the project.
|
||||
|
||||
The [`make` tool][17]), on the other hand, is a POSIX tool available on any Unix-like system. It will read the project-specific `Makefile` and perform the required operations to build and install your program.
|
||||
|
||||
But, as always in the Linux world, you still have some latency to customize the build for your specific needs.
|
||||
|
||||
```
|
||||
./configure --help
|
||||
```
|
||||
|
||||
The `configure -help` command will show you all the available configuration options. Once again, this is very project-specific. And to be honest, it is sometimes required to dig into the project before fully understand the meaning of each and every configure option.
|
||||
|
||||
But there is at least one standard GNU Autotools option that you must know: the `--prefix` option. This has to do with the file system hierarchy and the place your software will be installed.
|
||||
|
||||
[Suggested read8 Vim Tips And Tricks That Will Make You A Pro User][18]
|
||||
|
||||
### Step 3: The FHS
|
||||
|
||||
The Linux file system hierarchy on a typical distribution mostly comply with the [Filesystem Hierarchy Standard (FHS)][19]
|
||||
|
||||
That standard explains the purpose of the various directories of your system: `/usr`, `/tmp`, `/var` and so on.
|
||||
|
||||
When using the GNU Autotools— and most other build systems— the default installation location for your new software will be `/usr/local`. Which is a good choice as according to the FSH _“The /usr/local hierarchy is for use by the system administrator when installing software locally? It needs to be safe from being overwritten when the system software is updated. It may be used for programs and data that are shareable amongst a group of hosts, but not found in /usr.”_
|
||||
|
||||
The `/usr/local` hierarchy somehow replicates the root directory, and you will find there `/usr/local/bin` for the executable programs, `/usr/local/lib` for the libraries, `/usr/local/share` for architecture independent files and so on.
|
||||
|
||||
The only issue when using the `/usr/local` tree for custom software installation is the files for all your software will be mixed there. Especially, after having installed a couple of software, it will be hard to track to which file exactly of `/usr/local/bin` and `/usr/local/lib` belongs to which software. That will not cause any issue to the system though. After all, `/usr/bin` is just about the same mess. But that will become an issue the day you will want to remove a manually installed software.
|
||||
|
||||
To solve that issue, I usually prefer installing custom software in the `/opt`sub-tree instead. Once again, to quote the FHS:
|
||||
|
||||
_”/opt is reserved for the installation of add-on application software packages.
|
||||
|
||||
A package to be installed in /opt must locate its static files in a separate /opt/<package> or /opt/<provider> directory tree, where <package> is a name that describes the software package and <provider> is the provider’s LANANA registered name.”_
|
||||
|
||||
So we will create a sub-directory of `/opt` specifically for our custom NodeJS installation. And if someday I want to remove that software, I will simply have to remove that directory:
|
||||
|
||||
```
|
||||
sh$ sudo mkdir /opt/node-v8.1.1
|
||||
sh$ sudo ln -sT node-v8.1.1 /opt/node
|
||||
# What is the purpose of the symbolic link above?
|
||||
# Read the article till the end--then try to answer that
|
||||
# question in the comment section!
|
||||
|
||||
sh$ ./configure --prefix=/opt/node-v8.1.1
|
||||
sh$ make -j9 && echo ok
|
||||
# -j9 means run up to 9 parallel tasks to build the software.
|
||||
# As a rule of thumb, use -j(N+1) where N is the number of cores
|
||||
# of your system. That will maximize the CPU usage (one task per
|
||||
# CPU thread/core + a provision of one extra task when a process
|
||||
# is blocked by an I/O operation.
|
||||
```
|
||||
|
||||
Anything but “ok” after the `make` command has completed would mean there was an error during the build process. As we ran a parallel build because of the `-j` option, it is not always easy to retrieve the error message given the large volume of output produced by the build system.
|
||||
|
||||
In the case of issue, just restart `make`, but without the `-j` option this time. And the error should appear near the end of the output:
|
||||
|
||||
```
|
||||
sh$ make
|
||||
```
|
||||
|
||||
Finally, once the compilation has gone to the end, you can install your software to its location by running the command:
|
||||
|
||||
```
|
||||
sh$ sudo make install
|
||||
```
|
||||
|
||||
And test it:
|
||||
|
||||
```
|
||||
sh$ /opt/node/bin/node --version
|
||||
v8.1.1
|
||||
```
|
||||
|
||||
### B. What if things go wrong while installing from source code?
|
||||
|
||||
What I’ve explained above is mostly what you can see on the “build instruction” page of a well-documented project. But given this article goal is to let you compile your first software from sources, it might worth taking the time to investigate some common issues. So, I will do the whole procedure again, but this time from a fresh and minimal Debian 9.0 and CentOS 7.0 systems. So you can see the error I encountered and how I solved them.
|
||||
|
||||
### From Debian 9.0 “Stretch”
|
||||
|
||||
```
|
||||
itsfoss@debian:~$ git clone --depth 1 \
|
||||
--branch v8.1.1 \
|
||||
https://github.com/nodejs/node
|
||||
-bash: git: command not found
|
||||
```
|
||||
|
||||
This problem is quite easy to diagnosis and solve. Just install the `git` package:
|
||||
|
||||
```
|
||||
itsfoss@debian:~$ sudo apt-get install git
|
||||
```
|
||||
|
||||
```
|
||||
itsfoss@debian:~$ git clone --depth 1 \
|
||||
--branch v8.1.1 \
|
||||
https://github.com/nodejs/node && echo ok
|
||||
[...]
|
||||
ok
|
||||
```
|
||||
|
||||
```
|
||||
itsfoss@debian:~/node$ sudo mkdir /opt/node-v8.1.1
|
||||
itsfoss@debian:~/node$ sudo ln -sT node-v8.1.1 /opt/node
|
||||
```
|
||||
|
||||
No problem here.
|
||||
|
||||
```
|
||||
itsfoss@debian:~/node$ ./configure --prefix=/opt/node-v8.1.1/
|
||||
WARNING: failed to autodetect C++ compiler version (CXX=g++)
|
||||
WARNING: failed to autodetect C compiler version (CC=gcc)
|
||||
Node.js configure error: No acceptable C compiler found!
|
||||
Please make sure you have a C compiler installed on your system and/or
|
||||
consider adjusting the CC environment variable if you installed
|
||||
it in a non-standard prefix.
|
||||
```
|
||||
|
||||
Obviously, to compile a project, you need a compiler. NodeJS being written using the [C++ language][20], we need a C++ [compiler][21]. Here I will install `g++`, the GNU C++ compiler for that purpose:
|
||||
|
||||
```
|
||||
itsfoss@debian:~/node$ sudo apt-get install g++
|
||||
itsfoss@debian:~/node$ ./configure --prefix=/opt/node-v8.1.1/ && echo ok
|
||||
[...]
|
||||
ok
|
||||
```
|
||||
|
||||
```
|
||||
itsfoss@debian:~/node$ make -j9 && echo ok
|
||||
-bash: make: command not found
|
||||
```
|
||||
|
||||
One other missing tool. Same symptoms. Same solution:
|
||||
|
||||
```
|
||||
itsfoss@debian:~/node$ sudo apt-get install make
|
||||
itsfoss@debian:~/node$ make -j9 && echo ok
|
||||
[...]
|
||||
ok
|
||||
```
|
||||
|
||||
```
|
||||
itsfoss@debian:~/node$ sudo make install
|
||||
[...]
|
||||
itsfoss@debian:~/node$ /opt/node/bin/node --version
|
||||
v8.1.1
|
||||
```
|
||||
|
||||
Success!
|
||||
|
||||
Please notice: I’ve installed the various tools one by one to show how to diagnosis the compilation issues and to show you the typical solution to solve those issues. But if you search more about that topic or read other tutorials, you will discover that most distributions have “meta-packages” acting as an umbrella to install some or all the typical tools used for compiling a software. On Debian-based systems, you will probably encounter the [build-essentials][22]package for that purpose. And on Red-Hat-based distributions, that will be the _“Development Tools”_ group.
|
||||
|
||||
### From CentOS 7.0
|
||||
|
||||
```
|
||||
[itsfoss@centos ~]$ git clone --depth 1 \
|
||||
--branch v8.1.1 \
|
||||
https://github.com/nodejs/node
|
||||
-bash: git: command not found
|
||||
```
|
||||
|
||||
Command not found? Just install it using the `yum` package manager:
|
||||
|
||||
```
|
||||
[itsfoss@centos ~]$ sudo yum install git
|
||||
```
|
||||
|
||||
```
|
||||
[itsfoss@centos ~]$ git clone --depth 1 \
|
||||
--branch v8.1.1 \
|
||||
https://github.com/nodejs/node && echo ok
|
||||
[...]
|
||||
ok
|
||||
```
|
||||
|
||||
```
|
||||
[itsfoss@centos ~]$ sudo mkdir /opt/node-v8.1.1
|
||||
[itsfoss@centos ~]$ sudo ln -sT node-v8.1.1 /opt/node
|
||||
```
|
||||
|
||||
```
|
||||
[itsfoss@centos ~]$ cd node
|
||||
[itsfoss@centos node]$ ./configure --prefix=/opt/node-v8.1.1/
|
||||
WARNING: failed to autodetect C++ compiler version (CXX=g++)
|
||||
WARNING: failed to autodetect C compiler version (CC=gcc)
|
||||
Node.js configure error: No acceptable C compiler found!
|
||||
|
||||
Please make sure you have a C compiler installed on your system and/or
|
||||
consider adjusting the CC environment variable if you installed
|
||||
it in a non-standard prefix.
|
||||
```
|
||||
|
||||
You guess it: NodeJS is written using the C++ language, but my system lacks the corresponding compiler. Yum to the rescue. As I’m not a regular CentOS user, I actually had to search on the Internet the exact name of the package containing the g++ compiler. Leading me to that page: [https://superuser.com/questions/590808/yum-install-gcc-g-doesnt-work-anymore-in-centos-6-4][23]
|
||||
|
||||
```
|
||||
[itsfoss@centos node]$ sudo yum install gcc-c++
|
||||
[itsfoss@centos node]$ ./configure --prefix=/opt/node-v8.1.1/ && echo ok
|
||||
[...]
|
||||
ok
|
||||
```
|
||||
|
||||
```
|
||||
[itsfoss@centos node]$ make -j9 && echo ok
|
||||
[...]
|
||||
ok
|
||||
```
|
||||
|
||||
```
|
||||
[itsfoss@centos node]$ sudo make install && echo ok
|
||||
[...]
|
||||
ok
|
||||
```
|
||||
|
||||
```
|
||||
[itsfoss@centos node]$ /opt/node/bin/node --version
|
||||
v8.1.1
|
||||
```
|
||||
|
||||
Success. Again.
|
||||
|
||||
### C. Making changes to the software installed from source code
|
||||
|
||||
You may install a software from the source because you need a very specific version not available in your distribution repository. Or because you want to _modify_ that program. Either to fix a bug or add a feature. After all, open-source is all about that. So I will take that opportunity to give you a taste of the power you have at hand now you are able to compile your own software.
|
||||
|
||||
Here, we will make a minor change to the sources of NodeJS. And we will see if our change will be incorporated into the compiled version of the software:
|
||||
|
||||
Open the file `node/src/node.cc` in your favorite [text editor][24] (vim, nano, gedit, … ). And try to locate that fragment of code:
|
||||
|
||||
```
|
||||
if (debug_options.ParseOption(argv[0], arg)) {
|
||||
// Done, consumed by DebugOptions::ParseOption().
|
||||
} else if (strcmp(arg, "--version") == 0 || strcmp(arg, "-v") == 0) {
|
||||
printf("%s\n", NODE_VERSION);
|
||||
exit(0);
|
||||
} else if (strcmp(arg, "--help") == 0 || strcmp(arg, "-h") == 0) {
|
||||
PrintHelp();
|
||||
exit(0);
|
||||
}
|
||||
```
|
||||
|
||||
It is around [line 3830 of the file][25]. Then modify the line containing `printf` to match that one instead:
|
||||
|
||||
```
|
||||
printf("%s (compiled by myself)\n", NODE_VERSION);
|
||||
```
|
||||
|
||||
Then head back to your terminal. Before going further— and to give you some more insight of the power behind git— you can check if you’ve modified the right file:
|
||||
|
||||
```
|
||||
diff --git a/src/node.cc b/src/node.cc
|
||||
index bbce1022..a5618b57 100644
|
||||
--- a/src/node.cc
|
||||
+++ b/src/node.cc
|
||||
@@ -3828,7 +3828,7 @@ static void ParseArgs(int* argc,
|
||||
if (debug_options.ParseOption(argv[0], arg)) {
|
||||
// Done, consumed by DebugOptions::ParseOption().
|
||||
} else if (strcmp(arg, "--version") == 0 || strcmp(arg, "-v") == 0) {
|
||||
- printf("%s\n", NODE_VERSION);
|
||||
+ printf("%s (compiled by myself)\n", NODE_VERSION);
|
||||
exit(0);
|
||||
} else if (strcmp(arg, "--help") == 0 || strcmp(arg, "-h") == 0) {
|
||||
PrintHelp();
|
||||
```
|
||||
|
||||
You should see a “-” (minus sign) before the line as it was before you changed it. And a “+” (plus sign) before the line after your changes.
|
||||
|
||||
It is now time to recompile and re-install your software:
|
||||
|
||||
```
|
||||
make -j9 && sudo make install && echo ok
|
||||
[...]
|
||||
ok
|
||||
```
|
||||
|
||||
This times, the only reason it might fail is that you’ve made a typo while changing the code. If this is the case, re-open the `node/src/node.cc` file in your text editor and fix the mistake.
|
||||
|
||||
Once you’ve managed to compile and install that new modified NodeJS version, you will be able to check if your modifications were actually incorporated into the software:
|
||||
|
||||
```
|
||||
itsfoss@debian:~/node$ /opt/node/bin/node --version
|
||||
v8.1.1 (compiled by myself)
|
||||
```
|
||||
|
||||
Congratulations! You’ve made your first change to an open-source program!
|
||||
|
||||
### D. Let the shell locate our custom build software
|
||||
|
||||
You may have noticed until now, I always launched my newly compiled NodeJS software by specifying the absolute path to the binary file.
|
||||
|
||||
```
|
||||
/opt/node/bin/node
|
||||
```
|
||||
|
||||
It works. But this is annoying, to say the least. There are actually two common ways of fixing that. But to understand them, you must first know your shell locates the executable files by looking for them only into the directories specified by the `PATH` [environment variable][26].
|
||||
|
||||
```
|
||||
itsfoss@debian:~/node$ echo $PATH
|
||||
/usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/games
|
||||
```
|
||||
|
||||
Here, on that Debian system, if you do not specify explicitly any directory as part of a command name, the shell will first look for that executable programs into `/usr/local/bin`, then if not found into `/usr/bin`, then if not found into `/bin` then if not found into `/usr/local/games` then if not found into `/usr/games`, then if not found … the shell will report an error _“command not found”_ .
|
||||
|
||||
Given that, we have two way to make a command accessible to the shell: by adding it to one of the already configured `PATH` directories. Or by adding the directory containing our executable file to the `PATH`.
|
||||
|
||||
### Adding a link from /usr/local/bin
|
||||
|
||||
Just _copying_ the node binary executable from `/opt/node/bin` to `/usr/local/bin` would be a bad idea since by doing so, the executable program would no longer be able to locate the other required components belonging to `/opt/node/` (it’s a common practice for a software to locate its resource files relative to its own location).
|
||||
|
||||
So, the traditional way of doing that is by using a symbolic link:
|
||||
|
||||
```
|
||||
itsfoss@debian:~/node$ sudo ln -sT /opt/node/bin/node /usr/local/bin/node
|
||||
itsfoss@debian:~/node$ which -a node || echo not found
|
||||
/usr/local/bin/node
|
||||
itsfoss@debian:~/node$ node --version
|
||||
v8.1.1 (compiled by myself)
|
||||
```
|
||||
|
||||
This is a simple and effective solution, especially if a software package is made of just few well known executable programs— since you have to create a symbolic link for each and every user-invokable commands. For example, if you’re familiar with NodeJS, you know the `npm` companion application I should symlink from `/usr/local/bin` too. But I let that to you as an exercise.
|
||||
|
||||
### Modifying the PATH
|
||||
|
||||
First, if you tried the preceding solution, remove the node symbolic link created previously to start from a clear state:
|
||||
|
||||
```
|
||||
itsfoss@debian:~/node$ sudo rm /usr/local/bin/node
|
||||
itsfoss@debian:~/node$ which -a node || echo not found
|
||||
not found
|
||||
```
|
||||
|
||||
And now, here is the magic command to change your `PATH`:
|
||||
|
||||
```
|
||||
itsfoss@debian:~/node$ export PATH="/opt/node/bin:${PATH}"
|
||||
itsfoss@debian:~/node$ echo $PATH
|
||||
/opt/node/bin:/usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/games
|
||||
```
|
||||
|
||||
Simply said, I replaced the content of the `PATH` environment variable by its previous content, but prefixed by `/opt/node/bin`. So, as you can imagine it now, the shell will look first into the `/opt/node/bin` directory for executable programs. We can confirm that using the `which` command:
|
||||
|
||||
```
|
||||
itsfoss@debian:~/node$ which -a node || echo not found
|
||||
/opt/node/bin/node
|
||||
itsfoss@debian:~/node$ node --version
|
||||
v8.1.1 (compiled by myself)
|
||||
```
|
||||
|
||||
Whereas the “link” solution is permanent as soon as you’ve created the symbolic link into `/usr/local/bin`, the `PATH` change is effective only into the current shell. I let you do some researches by yourself to know how to make changes of the `PATH` permanents. As a hint, it has to do with your “profile”. If you find the solution, don’t hesitate to share that with the other readers by using the comment section below!
|
||||
|
||||
### E. How to remove that newly installed software from source code
|
||||
|
||||
Since our custom compiled NodeJS software sits completely in the `/opt/node-v8.1.1` directory, removing that software is not more work than using the `rm` command to remove that directory:
|
||||
|
||||
```
|
||||
sudo rm -rf /opt/node-v8.1.1
|
||||
```
|
||||
|
||||
BEWARE: `sudo` and `rm -rf` are a dangerous cocktail! Always check your command twice before pressing the “enter” key. You won’t have any confirmation message and no undelete if you remove the wrong directory…
|
||||
|
||||
Then, if you’ve modified your `PATH`, you will have to revert those changes. Which is not complicated at all.
|
||||
|
||||
And if you’ve created links from `/usr/local/bin` you will have to remove them all:
|
||||
|
||||
```
|
||||
itsfoss@debian:~/node$ sudo find /usr/local/bin \
|
||||
-type l \
|
||||
-ilname "/opt/node/*" \
|
||||
-print -delete
|
||||
/usr/local/bin/node
|
||||
```
|
||||
|
||||
### Wait? Where was the Dependency Hell?
|
||||
|
||||
As a final comment, if you read about compiling your own custom software, you might have heard about the [dependency hell][27]. This is a nickname for that annoying situation where before being able to successfully compile a software, you must first compile a pre-requisite library, which in its turn requires another library that might in its turn be incompatible with some other software you’ve already installed.
|
||||
|
||||
Part of the job of the package maintainers of your distribution is to actually resolve that dependency hell and to ensure the various software of your system are using compatible libraries and are installed in the right order.
|
||||
|
||||
In that article, I chose on purpose to install NodeJS as it virtually doesn’t have dependencies. I said “virtually” because, in fact, it _has_ dependencies. But the source code of those dependencies are present in the source repository of the project (in the `node/deps` subdirectory), so you don’t have to download and install them manually before hand.
|
||||
|
||||
But if you’re interested in understanding more about that problem and learn how to deal with it, let me know that using the comment section below: that would be a great topic for a more advanced article!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Engineer by Passion, Teacher by Vocation. My goals : to share my enthusiasm for what I teach and prepare my students to develop their skills by themselves. You can find me on my website as well.
|
||||
|
||||
--------------------
|
||||
|
||||
via: https://itsfoss.com/install-software-from-source-code/
|
||||
|
||||
作者:[Sylvain Leroux ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/sylvain/
|
||||
[1]:https://itsfoss.com/author/sylvain/
|
||||
[2]:https://itsfoss.com/install-software-from-source-code/#comments
|
||||
[3]:https://www.facebook.com/share.php?u=https%3A%2F%2Fitsfoss.com%2Finstall-software-from-source-code%2F%3Futm_source%3Dfacebook%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[4]:https://twitter.com/share?original_referer=/&text=How+to+Install+Software+from+Source+Code%E2%80%A6+and+Remove+it+Afterwards&url=https://itsfoss.com/install-software-from-source-code/%3Futm_source%3Dtwitter%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare&via=Yes_I_Know_IT
|
||||
[5]:https://plus.google.com/share?url=https%3A%2F%2Fitsfoss.com%2Finstall-software-from-source-code%2F%3Futm_source%3DgooglePlus%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[6]:https://www.linkedin.com/cws/share?url=https%3A%2F%2Fitsfoss.com%2Finstall-software-from-source-code%2F%3Futm_source%3DlinkedIn%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[7]:https://www.reddit.com/submit?url=https://itsfoss.com/install-software-from-source-code/&title=How+to+Install+Software+from+Source+Code%E2%80%A6+and+Remove+it+Afterwards
|
||||
[8]:https://itsfoss.com/remove-install-software-ubuntu/
|
||||
[9]:https://nodejs.org/en/
|
||||
[10]:https://github.com/nodejs/node
|
||||
[11]:https://en.wikipedia.org/wiki/GitHub
|
||||
[12]:https://en.wikipedia.org/wiki/Git
|
||||
[13]:https://en.wikipedia.org/wiki/Version_control
|
||||
[14]:https://stackoverflow.com/questions/1457103/how-is-a-tag-different-from-a-branch-which-should-i-use-here
|
||||
[15]:https://en.wikipedia.org/wiki/Graphical_user_interface
|
||||
[16]:https://en.wikipedia.org/wiki/GNU_Build_System
|
||||
[17]:https://en.wikipedia.org/wiki/Make_%28software
|
||||
[18]:https://itsfoss.com/pro-vim-tips/
|
||||
[19]:http://www.pathname.com/fhs/
|
||||
[20]:https://en.wikipedia.org/wiki/C%2B%2B
|
||||
[21]:https://en.wikipedia.org/wiki/Compiler
|
||||
[22]:https://packages.debian.org/sid/build-essential
|
||||
[23]:https://superuser.com/questions/590808/yum-install-gcc-g-doesnt-work-anymore-in-centos-6-4
|
||||
[24]:https://en.wikipedia.org/wiki/List_of_text_editors
|
||||
[25]:https://github.com/nodejs/node/blob/v8.1.1/src/node.cc#L3830
|
||||
[26]:https://en.wikipedia.org/wiki/Environment_variable
|
||||
[27]:https://en.wikipedia.org/wiki/Dependency_hell
|
||||
@ -0,0 +1,412 @@
|
||||
A Large-Scale Study of Programming Languages and Code Quality in GitHub
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
What is the effect of programming languages on software quality? This question has been a topic of much debate for a very long time. In this study, we gather a very large data set from GitHub (728 projects, 63 million SLOC, 29,000 authors, 1.5 million commits, in 17 languages) in an attempt to shed some empirical light on this question. This reasonably large sample size allows us to use a mixed-methods approach, combining multiple regression modeling with visualization and text analytics, to study the effect of language features such as static versus dynamic typing and allowing versus disallowing type confusion on software quality. By triangulating findings from different methods, and controlling for confounding effects such as team size, project size, and project history, we report that language design does have a significant, but modest effect on software quality. Most notably, it does appear that disallowing type confusion is modestly better than allowing it, and among functional languages, static typing is also somewhat better than dynamic typing. We also find that functional languages are somewhat better than procedural languages. It is worth noting that these modest effects arising from language design are overwhelmingly dominated by the process factors such as project size, team size, and commit size. However, we caution the reader that even these modest effects might quite possibly be due to other, intangible process factors, for example, the preference of certain personality types for functional, static languages that disallow type confusion.
|
||||
|
||||
[Back to Top][46]
|
||||
|
||||
### 1\. Introduction
|
||||
|
||||
A variety of debates ensue during discussions whether a given programming language is "the right tool for the job." While some of these debates may appear to be tinged with an almost religious fervor, most agree that programming language choice can impact both the coding process and the resulting artifact.
|
||||
|
||||
Advocates of strong, static typing tend to believe that the static approach catches defects early; for them, an ounce of prevention is worth a pound of cure. Dynamic typing advocates argue, however, that conservative static type checking is wasteful of developer resources, and that it is better to rely on strong dynamic type checking to catch type errors as they arise. These debates, however, have largely been of the armchair variety, supported only by anecdotal evidence.
|
||||
|
||||
This is perhaps not unreasonable; obtaining empirical evidence to support such claims is a challenging task given the number of other factors that influence software engineering outcomes, such as code quality, language properties, and usage domains. Considering, for example, software quality, there are a number of well-known influential factors, such as code size,[6][1] team size,[2][2]and age/maturity.[9][3]
|
||||
|
||||
Controlled experiments are one approach to examining the impact of language choice in the face of such daunting confounds, however, owing to cost, such studies typically introduce a confound of their own, that is, limited scope. The tasks completed in such studies are necessarily limited and do not emulate _real world_ development. There have been several such studies recently that use students, or compare languages with static or dynamic typing through an experimental factor.[7][4], [12][5],[15][6]
|
||||
|
||||
Fortunately, we can now study these questions over a large body of real-world software projects. GitHub contains many projects in multiple languages that substantially vary across size, age, and number of developers. Each project repository provides a detailed record, including contribution history, project size, authorship, and defect repair. We then use a variety of tools to study the effects of language features on defect occurrence. Our approach is best described as mixed-methods, or triangulation[5][7] approach; we use text analysis, clustering, and visualization to confirm and support the findings of a quantitative regression study. This empirical approach helps us to understand the practical impact of programming languages, as they are used colloquially by developers, on software quality.
|
||||
|
||||
[Back to Top][47]
|
||||
|
||||
### 2\. Methodology
|
||||
|
||||
Our methods are typical of large scale observational studies in software engineering. We first gather our data from several sources using largely automated methods. We then filter and clean the data in preparation for building a statistical model. We further validate the model using qualitative methods. Filtering choices are driven by a combination of factors including the nature of our research questions, the quality of the data and beliefs about which data is most suitable for statistical study. In particular, GitHub contains many projects written in a large number of programming languages. For this study, we focused our data collection efforts on the most popular projects written in the most popular languages. We choose statistical methods appropriate for evaluating the impact of factors on count data.
|
||||
|
||||

|
||||
**2.1\. Data collection**
|
||||
|
||||
We choose the top 19 programming languages from GitHub. We disregard CSS, Shell script, and Vim script as they are not considered to be general purpose languages. We further include `Typescript`, a typed superset of `JavaScript`. Then, for each of the studied languages we retrieve the top 50 projects that are primarily written in that language. In total, we analyze 850 projects spanning 17 different languages.
|
||||
|
||||
Our language and project data was extracted from the _GitHub Archive_ , a database that records all public GitHub activities. The archive logs 18 different GitHub events including new commits, fork events, pull request, developers' information, and issue tracking of all the open source GitHub projects on an hourly basis. The archive data is uploaded to Google BigQuery to provide an interface for interactive data analysis.
|
||||
|
||||
**Identifying top languages.** We aggregate projects based on their primary language. Then we select the languages with the most projects for further analysis, as shown in [Table 1][48]. A given project can use many languages; assigning a single language to it is difficult. Github Archive stores information gathered from GitHub Linguist which measures the language distribution of a project repository using the source file extensions. The language with the maximum number of source files is assigned as the _primary language_ of the project.
|
||||
|
||||
[][49]
|
||||
**Table 1\. Top 3 projects in each language.**
|
||||
|
||||
**Retrieving popular projects.** For each selected language, we filter the project repositories written primarily in that language by its popularity based on the associated number of _stars._ This number indicates how many people have actively expressed interest in the project, and is a reasonable proxy for its popularity. Thus, the top 3 projects in C are _linux, git_ , and _php-src_ ; and for C++ they are _node-webkit, phantomjs_ , and _mongo_ ; and for `Java` they are _storm, elasticsearch_ , and _ActionBarSherlock._ In total, we select the top 50 projects in each language.
|
||||
|
||||
To ensure that these projects have a sufficient development history, we drop the projects with fewer than 28 commits (28 is the first quartile commit count of considered projects). This leaves us with 728 projects. [Table 1][50] shows the top 3 projects in each language.
|
||||
|
||||
**Retrieving project evolution history.** For each of 728 projects, we downloaded the non-merged commits, commit logs, author date, and author name using _git._ We compute code churn and the number of files modified per commit from the number of added and deleted lines per file. We retrieve the languages associated with each commit from the extensions of the modified files (a commit can have multiple language tags). For each commit, we calculate its _commit age_ by subtracting its commit date from the first commit of the corresponding project. We also calculate other project-related statistics, including maximum commit age of a project and the total number of developers, used as control variables in our regression model, and discussed in Section 3\. We identify bug fix commits made to individual projects by searching for error related keywords: "error," "bug," "fix," "issue," "mistake," "incorrect," "fault," "defect," and "flaw," in the commit log, similar to a prior study.[18][8]
|
||||
|
||||
[Table 2][51] summarizes our data set. Since a project may use multiple languages, the second column of the table shows the total number of projects that use a certain language at some capacity. We further exclude some languages from a project that have fewer than 20 commits in that language, where 20 is the first quartile value of the total number of commits per project per language. For example, we find 220 projects that use more than 20 commits in C. This ensures sufficient activity for each language–project pair.
|
||||
|
||||
[][52]
|
||||
**Table 2\. Study subjects.**
|
||||
|
||||
In summary, we study 728 projects developed in 17 languages with 18 years of history. This includes 29,000 different developers, 1.57 million commits, and 564,625 bug fix commits.
|
||||
|
||||

|
||||
**2.2\. Categorizing languages**
|
||||
|
||||
We define language classes based on several properties of the language thought to influence language quality,[7][9], [8][10], [12][11] as shown in [Table 3][53]. The _Programming Paradigm_ indicates whether the project is written in an imperative procedural, imperative scripting, or functional language. In the rest of the paper, we use the terms procedural and scripting to indicate imperative procedural and imperative scripting respectively.
|
||||
|
||||
[][54]
|
||||
**Table 3\. Different types of language classes.**
|
||||
|
||||
_Type Checking_ indicates static or dynamic typing. In statically typed languages, type checking occurs at compile time, and variable names are bound to a value and to a type. In addition, expressions (including variables) are classified by types that correspond to the values they might take on at run-time. In dynamically typed languages, type checking occurs at run-time. Hence, in the latter, it is possible to bind a variable name to objects of different types in the same program.
|
||||
|
||||
_Implicit Type Conversion_ allows access of an operand of type T1 as a different type T2, without an explicit conversion. Such implicit conversion may introduce type-confusion in some cases, especially when it presents an operand of specific type T1, as an instance of a different type T2\. Since not all implicit type conversions are immediately a problem, we operationalize our definition by showing examples of the implicit type confusion that can happen in all the languages we identified as allowing it. For example, in languages like `Perl, JavaScript`, and `CoffeeScript` adding a string to a number is permissible (e.g., "5" + 2 yields "52"). The same operation yields 7 in `Php`. Such an operation is not permitted in languages such as `Java` and `Python` as they do not allow implicit conversion. In C and C++ coercion of data types can result in unintended results, for example, `int x; float y; y=3.5; x=y`; is legal C code, and results in different values for x and y, which, depending on intent, may be a problem downstream.[a][12] In `Objective-C` the data type _id_ is a generic object pointer, which can be used with an object of any data type, regardless of the class.[b][13] The flexibility that such a generic data type provides can lead to implicit type conversion and also have unintended consequences.[c][14]Hence, we classify a language based on whether its compiler _allows_ or _disallows_ the implicit type conversion as above; the latter explicitly detects type confusion and reports it.
|
||||
|
||||
Disallowing implicit type conversion could result from static type inference within a compiler (e.g., with `Java`), using a type-inference algorithm such as Hindley[10][15] and Milner,[17][16] or at run-time using a dynamic type checker. In contrast, a type-confusion can occur silently because it is either undetected or is unreported. Either way, implicitly allowing type conversion provides flexibility but may eventually cause errors that are difficult to localize. To abbreviate, we refer to languages allowing implicit type conversion as _implicit_ and those that disallow it as _explicit._
|
||||
|
||||
_Memory Class_ indicates whether the language requires developers to manage memory. We treat `Objective-C` as unmanaged, in spite of it following a hybrid model, because we observe many memory errors in its codebase, as discussed in RQ4 in Section 3.
|
||||
|
||||
Note that we classify and study the languages as they are colloquially used by developers in real-world software. For example, `TypeScript` is intended to be used as a static language, which disallows implicit type conversion. However, in practice, we notice that developers often (for 50% of the variables, and across `TypeScript`-using projects in our dataset) use the `any` type, a catch-all union type, and thus, in practice, `TypeScript` allows dynamic, implicit type conversion. To minimize the confusion, we exclude `TypeScript` from our language classifications and the corresponding model (see [Table 3][55] and [7][56]).
|
||||
|
||||

|
||||
**2.3\. Identifying project domain**
|
||||
|
||||
We classify the studied projects into different domains based on their features and function using a mix of automated and manual techniques. The projects in GitHub come with `project descriptions` and README files that describe their features. We used Latent Dirichlet Allocation (LDA)[3][17] to analyze this text. Given a set of documents, LDA identifies a set of topics where each topic is represented as probability of generating different words. For each document, LDA also estimates the probability of assigning that document to each topic.
|
||||
|
||||
We detect 30 distinct domains, that is, topics, and estimate the probability that each project belonging to each domain. Since these auto-detected domains include several project-specific keywords, for example, facebook, it is difficult to identify the underlying common functions. In order to assign a meaningful name to each domain, we manually inspect each of the 30 domains to identify projectname-independent, domain-identifying keywords. We manually rename all of the 30 auto-detected domains and find that the majority of the projects fall under six domains: Application, Database, CodeAnalyzer, Middleware, Library, and Framework. We also find that some projects do not fall under any of the above domains and so we assign them to a catchall domain labeled as _Other_ . This classification of projects into domains was subsequently checked and confirmed by another member of our research group. [Table 4][57] summarizes the identified domains resulting from this process.
|
||||
|
||||
[][58]
|
||||
**Table 4\. Characteristics of domains.**
|
||||
|
||||

|
||||
**2.4\. Categorizing bugs**
|
||||
|
||||
While fixing software bugs, developers often leave important information in the commit logs about the nature of the bugs; for example, why the bugs arise and how to fix the bugs. We exploit such information to categorize the bugs, similar to Tan _et al._ [13][18], [24][19]
|
||||
|
||||
First, we categorize the bugs based on their _Cause_ and _Impact. Causes_ are further classified into disjoint subcategories of errors: Algorithmic, Concurrency, Memory, generic Programming, and Unknown. The bug _Impact_ is also classified into four disjoint subcategories: Security, Performance, Failure, and Other unknown categories. Thus, each bug-fix commit also has an induced Cause and an Impact type. [Table 5][59] shows the description of each bug category. This classification is performed in two phases:
|
||||
|
||||
[][60]
|
||||
**Table 5\. Categories of bugs and their distribution in the whole dataset.**
|
||||
|
||||
**(1) Keyword search.** We randomly choose 10% of the bug-fix messages and use a keyword based search technique to automatically categorize them as potential bug types. We use this annotation, separately, for both Cause and Impact types. We chose a restrictive set of keywords and phrases, as shown in [Table 5][61]. Such a restrictive set of keywords and phrases helps reduce false positives.
|
||||
|
||||
**(2) Supervised classification.** We use the annotated bug fix logs from the previous step as training data for supervised learning techniques to classify the remainder of the bug fix messages by treating them as test data. We first convert each bug fix message to a bag-of- words. We then remove words that appear only once among all of the bug fix messages. This reduces project specific keywords. We also stem the bag-of- words using standard natural language processing techniques. Finally, we use Support Vector Machine to classify the test data.
|
||||
|
||||
To evaluate the accuracy of the bug classifier, we manually annotated 180 randomly chosen bug fixes, equally distributed across all of the categories. We then compare the result of the automatic classifier with the manually annotated data set. The performance of this process was acceptable with precision ranging from a low of 70% for performance bugs to a high of 100% for concurrency bugs with an average of 84%. Recall ranged from 69% to 91% with an average of 84%.
|
||||
|
||||
The result of our bug classification is shown in [Table 5][62]. Most of the defect causes are related to generic programming errors. This is not surprising as this category involves a wide variety of programming errors such as type errors, typos, compilation error, etc. Our technique could not classify 1.04% of the bug fix messages in any Cause or Impact category; we classify these as Unknown.
|
||||
|
||||

|
||||
**2.5\. Statistical methods**
|
||||
|
||||
We model the number of defective commits against other factors related to software projects using regression. All models use _negative binomial regression_ (NBR) to model the counts of project attributes such as the number of commits. NBR is a type of generalized linear model used to model non-negative integer responses.[4][20]
|
||||
|
||||
In our models we control for several language per-project dependent factors that are likely to influence the outcome. Consequently, each (language, project) pair is a row in our regression and is viewed as a sample from the population of open source projects. We log-transform dependent count variables as it stabilizes the variance and usually improves the model fit.[4][21] We verify this by comparing transformed with non transformed data using the AIC and Vuong's test for non-nested models.
|
||||
|
||||
To check that excessive multicollinearity is not an issue, we compute the variance inflation factor of each dependent variable in all of the models with a conservative maximum value of 5.[4][22]We check for and remove high leverage points through visual examination of the residuals versus leverage plot for each model, looking for both separation and large values of Cook's distance.
|
||||
|
||||
We employ _effects_ , or _contrast_ , coding in our study to facilitate interpretation of the language coefficients.[4][23] Weighted effects codes allow us to compare each language to the average effect across all languages while compensating for the unevenness of language usage across projects.[23][24]To test for the relationship between two factor variables we use a Chi-square test of independence.[14][25] After confirming a dependence we use Cramer's V, an _r_ × _c_ equivalent of the phi coefficient for nominal data, to establish an effect size.
|
||||
|
||||
[Back to Top][63]
|
||||
|
||||
### 3\. Results
|
||||
|
||||
We begin with a straightforward question that directly addresses the core of what some fervently believe must be true, namely:
|
||||
|
||||
**RQ1\. Are some languages more defect-prone than others?**
|
||||
|
||||
We use a regression model to compare the impact of each language on the number of defects with the average impact of all languages, against defect fixing commits (see [Table 6][64]).
|
||||
|
||||
[][65]
|
||||
**Table 6\. Some languages induce fewer defects than other languages.**
|
||||
|
||||
We include some variables as controls for factors that will clearly influence the response. Project age is included as older projects will generally have a greater number of defect fixes. Trivially, the number of commits to a project will also impact the response. Additionally, the number of developers who touch a project and the raw size of the project are both expected to grow with project activity.
|
||||
|
||||
The sign and magnitude of the estimated coefficients in the above model relates the predictors to the outcome. The first four variables are control variables and we are not interested in their impact on the outcome other than to say that they are all positive and significant. The language variables are indicator variables, viz. factor variables, for each project. The coefficient compares each language to the grand weighted mean of all languages in all projects. The language coefficients can be broadly grouped into three general categories. The first category is those for which the coefficient is statistically insignificant and the modeling procedure could not distinguish the coefficient from zero. These languages may behave similar to the average or they may have wide variance. The remaining coefficients are significant and either positive or negative. For those with positive coefficients we can expect that the language is associated with a greater number of defect fixes. These languages include `C, C++, Objective-C, Php`, and `Python`. The languages `Clojure, Haskell, Ruby`, and `Scala`, all have negative coefficients implying that these languages are less likely than average to result in defect fixing commits.
|
||||
|
||||
One should take care not to overestimate the impact of language on defects. While the observed relationships are statistically significant, the effects are quite small. Analysis of deviance reveals that language accounts for less than 1% of the total explained deviance.
|
||||
|
||||
[][66]
|
||||
|
||||
We can read the model coefficients as the expected change in the log of the response for a one unit change in the predictor with all other predictors held constant; that is, for a coefficient _β<sub style="border: 0px; outline: 0px; font-size: smaller; vertical-align: sub; background: transparent;">i</sub>_ , a one unit change in _β<sub style="border: 0px; outline: 0px; font-size: smaller; vertical-align: sub; background: transparent;">i</sub>_ yields an expected change in the response of e _βi_ . For the factor variables, this expected change is compared to the average across all languages. Thus, if, for some number of commits, a particular project developed in an _average_ language had four defective commits, then the choice to use C++ would mean that we should expect one additional defective commit since e0.18 × 4 = 4.79\. For the same project, choosing `Haskell` would mean that we should expect about one fewer defective commit as _e_ −0.26 × 4 = 3.08\. The accuracy of this prediction depends on all other factors remaining the same, a challenging proposition for all but the most trivial of projects. All observational studies face similar limitations; we address this concern in more detail in Section 5.
|
||||
|
||||
**Result 1:** _Some languages have a greater association with defects than other languages, although the effect is small._
|
||||
|
||||
In the remainder of this paper we expand on this basic result by considering how different categories of application, defect, and language, lead to further insight into the relationship between languages and defect proneness.
|
||||
|
||||
Software bugs usually fall under two broad categories: (1) _Domain Specific bug_ : specific to project function and do not depend on the underlying programming language. (2) _Generic bug_ : more generic in nature and has less to do with project function, for example, typeerrors, concurrency errors, etc.
|
||||
|
||||
Consequently, it is reasonable to think that the interaction of application domain and language might impact the number of defects within a project. Since some languages are believed to excel at some tasks more so than others, for example, C for low level work, or `Java` for user applications, making an inappropriate choice might lead to a greater number of defects. To study this we should ideally ignore the domain specific bugs, as generic bugs are more likely to depend on the programming language featured. However, since a domain-specific bugs may also arise due to a generic programming error, it is difficult to separate the two. A possible workaround is to study languages while controlling the domain. Statistically, however, with 17 languages across 7 domains, the large number of terms would be challenging to interpret given the sample size.
|
||||
|
||||
Given this, we first consider testing for the dependence between domain and language usage within a project, using a Chi-square test of independence. Of 119 cells, 46, that is, 39%, are below the value of 5 which is too high. No more than 20% of the counts should be below 5.[14][26] We include the value here for completeness[d][27]; however, the low strength of association of 0.191 as measured by Cramer's V, suggests that any relationship between domain and language is small and that inclusion of domain in regression models would not produce meaningful results.
|
||||
|
||||
One option to address this concern would be to remove languages or combine domains, however, our data here presents no clear choices. Alternatively, we could combine languages; this choice leads to a related but slightly different question.
|
||||
|
||||
**RQ2\. Which language properties relate to defects?**
|
||||
|
||||
Rather than considering languages individually, we aggregate them by language class, as described in Section 2.2, and analyze the relationship to defects. Broadly, each of these properties divides languages along lines that are often discussed in the context of errors, drives user debate, or has been the subject of prior work. Since the individual properties are highly correlated, we create six model factors that combine all of the individual factors across all of the languages in our study. We then model the impact of the six different factors on the number of defects while controlling for the same basic covariates that we used in the model in _RQ1_ .
|
||||
|
||||
As with language (earlier in [Table 6][67]), we are comparing language _classes_ with the average behavior across all language classes. The model is presented in [Table 7][68]. It is clear that `Script-Dynamic-Explicit-Managed` class has the smallest magnitude coefficient. The coefficient is insignificant, that is, the z-test for the coefficient cannot distinguish the coefficient from zero. Given the magnitude of the standard error, however, we can assume that the behavior of languages in this class is very close to the average across all languages. We confirm this by recoding the coefficient using `Proc-Static-Implicit-Unmanaged` as the base level and employing treatment, or dummy coding that compares each language class with the base level. In this case, `Script-Dynamic-Explicit-Managed` is significantly different with _p_ = 0.00044\. We note here that while choosing different coding methods affects the coefficients and z-scores, the models are identical in all other respects. When we change the coding we are rescaling the coefficients to reflect the comparison that we wish to make.[4][28] Comparing the other language classes to the grand mean, `Proc-Static-Implicit-Unmanaged` languages are more likely to induce defects. This implies that either implicit type conversion or memory management issues contribute to greater defect proneness as compared with other procedural languages.
|
||||
|
||||
[][69]
|
||||
**Table 7\. Functional languages have a smaller relationship to defects than other language classes whereas procedural languages are greater than or similar to the average.**
|
||||
|
||||
Among scripting languages we observe a similar relationship between languages that allow versus those that do not allow implicit type conversion, providing some evidence that implicit type conversion (vs. explicit) is responsible for this difference as opposed to memory management. We cannot state this conclusively given the correlation between factors. However when compared to the average, as a group, languages that do not allow implicit type conversion are less error-prone while those that do are more error-prone. The contrast between static and dynamic typing is also visible in functional languages.
|
||||
|
||||
The functional languages as a group show a strong difference from the average. Statically typed languages have a substantially smaller coefficient yet both functional language classes have the same standard error. This is strong evidence that functional static languages are less error-prone than functional dynamic languages, however, the z-tests only test whether the coefficients are different from zero. In order to strengthen this assertion, we recode the model as above using treatment coding and observe that the `Functional-Static-Explicit-Managed` language class is significantly less defect-prone than the `Functional-Dynamic-Explicit-Managed`language class with _p_ = 0.034.
|
||||
|
||||
[][70]
|
||||
|
||||
As with language and defects, the relationship between language class and defects is based on a small effect. The deviance explained is similar, albeit smaller, with language class explaining much less than 1% of the deviance.
|
||||
|
||||
We now revisit the question of application domain. Does domain have an interaction with language class? Does the choice of, for example, a functional language, have an advantage for a particular domain? As above, a Chi-square test for the relationship between these factors and the project domain yields a value of 99.05 and _df_ = 30 with _p_ = 2.622e–09 allowing us to reject the null hypothesis that the factors are independent. Cramer's-V yields a value of 0.133, a weak level of association. Consequently, although there is some relation between domain and language, there is only a weak relationship between domain and language class.
|
||||
|
||||
**Result 2:** _There is a small but significant relationship between language class and defects. Functional languages are associated with fewer defects than either procedural or scripting languages._
|
||||
|
||||
It is somewhat unsatisfying that we do not observe a strong association between language, or language class, and domain within a project. An alternative way to view this same data is to disregard projects and aggregate defects over all languages and domains. Since this does not yield independent samples, we do not attempt to analyze it statistically, rather we take a descriptive, visualization-based approach.
|
||||
|
||||
We define _Defect Proneness_ as the ratio of bug fix commits over total commits per language per domain. [Figure 1][71] illustrates the interaction between domain and language using a heat map, where the defect proneness increases from lighter to darker zone. We investigate which language factors influence defect fixing commits across a collection of projects written across a variety of languages. This leads to the following research question:
|
||||
|
||||
[][72]
|
||||
**Figure 1\. Interaction of language's defect proneness with domain. Each cell in the heat map represents defect proneness of a language (row header) for a given domain (column header). The "Overall" column represents defect proneness of a language over all the domains. The cells with white cross mark indicate null value, that is, no commits were made corresponding to that cell.**
|
||||
|
||||
**RQ3\. Does language defect proneness depend on domain?**
|
||||
|
||||
In order to answer this question we first filtered out projects that would have been viewed as outliers, filtered as high leverage points, in our regression models. This was necessary here as, even though this is a nonstatistical method, some relationships could impact visualization. For example, we found that a single project, Google's v8, a `JavaScript` project, was responsible for all of the errors in Middleware. This was surprising to us since `JavaScript` is typically not used for Middleware. This pattern repeats in other domains, consequently, we filter out the projects that have defect density below 10 and above 90 percentile. The result is in [Figure 1][73].
|
||||
|
||||
We see only a subdued variation in this heat map which is a result of the inherent defect proneness of the languages as seen in RQ1\. To validate this, we measure the pairwise rank correlation between the language defect proneness for each domain with the overall. For all of the domains except Database, the correlation is positive, and p-values are significant (<0.01). Thus, w.r.t. defect proneness, the language ordering in each domain is strongly correlated with the overall language ordering.
|
||||
|
||||
[][74]
|
||||
|
||||
**Result 3:** _There is no general relationship between application domain and language defect proneness._
|
||||
|
||||
We have shown that different languages induce a larger number of defects and that this relationship is not only related to particular languages but holds for general classes of languages; however, we find that the type of project does not mediate this relationship to a large degree. We now turn our attention to categorization of the response. We want to understand how language relates to specific kinds of defects and how this relationship compares to the more general relationship that we observe. We divide the defects into categories as described in [Table 5][75] and ask the following question:
|
||||
|
||||
**RQ4\. What is the relation between language and bug category?**
|
||||
|
||||
We use an approach similar to RQ3 to understand the relation between languages and bug categories. First, we study the relation between bug categories and language class. A heat map ([Figure 2][76]) shows aggregated defects over language classes and bug types. To understand the interaction between bug categories and languages, we use an NBR regression model for each category. For each model we use the same control factors as RQ1 as well as languages encoded with weighted effects to predict defect fixing commits.
|
||||
|
||||
[][77]
|
||||
**Figure 2\. Relation between bug categories and language class. Each cell represents percentage of bug fix commit out of all bug fix commits per language class (row header) per bug category (column header). The values are normalized column wise.**
|
||||
|
||||
The results along with the anova value for language are shown in [Table 8][78]. The overall deviance for each model is substantially smaller and the proportion explained by language for a specific defect type is similar in magnitude for most of the categories. We interpret this relationship to mean that language has a greater impact on specific categories of bugs, than it does on bugs overall. In the next section we expand on these results for the bug categories with significant bug counts as reported in [Table 5][79]. However, our conclusion generalizes for all categories.
|
||||
|
||||
[][80]
|
||||
**Table 8\. While the impact of language on defects varies across defect category, language has a greater impact on specific categories than it does on defects in general.**
|
||||
|
||||
**Programming errors.** Generic programming errors account for around 88.53% of all bug fix commits and occur in all the language classes. Consequently, the regression analysis draws a similar conclusion as of RQ1 (see [Table 6][81]). All languages incur programming errors such as faulty error-handling, faulty definitions, typos, etc.
|
||||
|
||||
**Memory errors.** Memory errors account for 5.44% of all the bug fix commits. The heat map in [Figure 2][82] shows a strong relationship between `Proc-Static-Implicit-Unmanaged` class and memory errors. This is expected as languages with unmanaged memory are known for memory bugs. [Table 8][83]confirms that such languages, for example, C, C++, and `Objective-C` introduce more memory errors. Among the managed languages, `Java` induces more memory errors, although fewer than the unmanaged languages. Although `Java` has its own garbage collector, memory leaks are not surprising since unused object references often prevent the garbage collector from reclaiming memory.[11][29] In our data, 28.89% of all the memory errors in `Java` are the result of a memory leak. In terms of effect size, language has a larger impact on memory defects than all other _cause_ categories.
|
||||
|
||||
**Concurrency errors.** 1.99% of the total bug fix commits are related to concurrency errors. The heat map shows that `Proc-Static-Implicit-Unmanaged` dominates this error type. C and C++ introduce 19.15% and 7.89% of the errors, and they are distributed across the projects.
|
||||
|
||||
[][84]
|
||||
|
||||
Both of the `Static-Strong-Managed` language classes are in the darker zone in the heat map confirming, in general static languages produce more concurrency errors than others. Among the dynamic languages, only `Erlang` is more prone to concurrency errors, perhaps relating to the greater use of this language for concurrent applications. Likewise, the negative coefficients in [Table 8][85] shows that projects written in dynamic languages like `Ruby` and `Php` have fewer concurrency errors. Note that, certain languages like `JavaScript, CoffeeScript`, and `TypeScript` do not support concurrency, in its traditional form, while `Php` has a limited support depending on its implementations. These languages introduce artificial zeros in the data, and thus the concurrency model coefficients in [Table 8][86] for those languages cannot be interpreted like the other coefficients. Due to these artificial zeros, the average over all languages in this model is smaller, which may affect the sizes of the coefficients, since they are given w.r.t. the average, but it will not affect their relative relationships, which is what we are after.
|
||||
|
||||
A textual analysis based on word-frequency of the bug fix messages suggests that most of the concurrency errors occur due to a race condition, deadlock, or incorrect synchronization, as shown in the table above. Across all language, race conditions are the most frequent cause of such errors, for example, 92% in `Go`. The enrichment of race condition errors in `Go` is probably due to an accompanying race-detection tool that may help developers locate races. The synchronization errors are primarily related to message passing interface (MPI) or shared memory operation (SHM). `Erlang` and `Go` use MPI[e][30] for inter-thread communication, which explains why these two languages do not have any SHM related errors such as locking, mutex, etc. In contrast, projects in the other languages use SHM primitives for communication and can thus may have locking-related errors.
|
||||
|
||||
**Security and other impact errors.** Around 7.33% of all the bug fix commits are related to Impact errors. Among them `Erlang, C++`, and `Python` associate with more security errors than average ([Table 8][87]). `Clojure` projects associate with fewer security errors ([Figure 2][88]). From the heat map we also see that `Static` languages are in general more prone to failure and performance errors, these are followed by `Functional-Dynamic-Explicit-Managed` languages such as `Erlang`. The analysis of deviance results confirm that language is strongly associated with failure impacts. While security errors are the weakest among the categories, the deviance explained by language is still quite strong when compared with the residual deviance.
|
||||
|
||||
**Result 4:** _Defect types are strongly associated with languages; some defect type like memory errors and concurrency errors also depend on language primitives. Language matters more for specific categories than it does for defects overall._
|
||||
|
||||
[Back to Top][89]
|
||||
|
||||
### 4\. Related Work
|
||||
|
||||
Prior work on programming language comparison falls in three categories:
|
||||
|
||||
**(1) _Controlled experiment._** For a given task, developers are monitored while programming in different languages. Researchers then compare outcomes such as development effort and program quality. Hanenberg[7][31] compared static versus dynamic typing by monitoring 48 programmers for 27 h while developing a parser program. He found no significant difference in code quality between the two; however, dynamic type-based languages were found to have shorter development time. Their study was conducted with undergraduate students in a lab setting with custom-designed language and IDE. Our study, by contrast is a field study of popular software applications. While we can only indirectly (and _post facto_ ) control for confounding factors using regression, we benefit from much larger sample sizes, and more realistic, widely-used software. We find that statically typed languages in general are less defect-prone than the dynamic types, and that disallowing implicit type conversion is better than allowing it, in the same regard. The effect sizes are modest; it could be reasonably argued that they are visible here precisely because of the large sample sizes.
|
||||
|
||||
Harrison et al.[8][32] compared C++, a procedural language, with `SML`, a functional language, finding no significant difference in total number of errors, although `SML` has higher defect density than C++. `SML` was not represented in our data, which however, suggest that functional languages are generally less defect-prone than procedural languages. Another line of work primarily focuses on comparing development effort across different languages.[12][33], [20][34] However, they do not analyze language defect proneness.
|
||||
|
||||
**(2) _Surveys._** Meyerovich and Rabkin[16][35] survey developers' views of programming languages, to study why some languages are more popular than others. They report strong influence from non-linguistic factors: prior language skills, availability of open source tools, and existing legacy systems. Our study also confirms that the availability of external tools also impacts software quality; for example, concurrency bugs in `Go` (see RQ4 in Section 3).
|
||||
|
||||
**(3) _Repository mining._** Bhattacharya and Neamtiu[1][36] study four projects developed in both C and C++ and find that the software components developed in C++ are in general more reliable than C. We find that both C and C++ are more defect-prone than average. However, for certain bug types like concurrency errors, C is more defect-prone than C++ (see RQ4 in Section 3).
|
||||
|
||||
[Back to Top][90]
|
||||
|
||||
### 5\. Threats to Validity
|
||||
|
||||
We recognize few threats to our reported results. First, to identify bug fix commits we rely on the keywords that developers often use to indicate a bug fix. Our choice was deliberate. We wanted to capture the issues that developers continuously face in an ongoing development process, rather than reported bugs. However, this choice possesses threats of over estimation. Our categorization of domains is subject to interpreter bias, although another member of our group verified the categories. Also, our effort to categorize bug fix commits could potentially be tainted by the initial choice of keywords. The descriptiveness of commit logs vary across projects. To mitigate these threats, we evaluate our classification against manual annotation as discussed in Section 2.4.
|
||||
|
||||
We determine the language of a file based on its extension. This can be error-prone if a file written in a different language takes a common language extension that we have studied. To reduce such error, we manually verified language categorization against a randomly sampled file set.
|
||||
|
||||
To interpret language class in Section 2.2, we make certain assumptions based on how a language property is most commonly used, as reflected in our data set, for example, we classify `Objective-C` as unmanaged memory type rather than hybrid. Similarly, we annotate `Scala` as functional and C# as procedural, although both support either design choice.[19][37], [21][38] We do not distinguish object-oriented languages (OOP) from procedural languages in this work as there is no clear distinction, the difference largely depends on programming style. We categorize C++ as allowing implicit type conversion because a memory region of a certain type can be treated differently using pointer manipulation.[22][39] We note that most C++ compilers can detect type errors at compile time.
|
||||
|
||||
Finally, we associate defect fixing commits to language properties, although they could reflect reporting style or other developer properties. Availability of external tools or libraries may also impact the extent of bugs associated with a language.
|
||||
|
||||
[Back to Top][91]
|
||||
|
||||
### 6\. Conclusion
|
||||
|
||||
We have presented a large-scale study of language type and use as it relates to software quality. The Github data we used is characterized by its complexity and variance along multiple dimensions. Our sample size allows a mixed-methods study of the effects of language, and of the interactions of language, domain, and defect type while controlling for a number of confounds. The data indicates that functional languages are better than procedural languages; it suggests that disallowing implicit type conversion is better than allowing it; that static typing is better than dynamic; and that managed memory usage is better than unmanaged. Further, that the defect proneness of languages in general is not associated with software domains. Additionally, languages are more related to individual bug categories than bugs overall.
|
||||
|
||||
On the other hand, even large datasets become small and insufficient when they are sliced and diced many ways simultaneously. Consequently, with an increasing number of dependent variables it is difficult to answer questions about a specific variable's effect, especially where variable interactions exist. Hence, we are unable to quantify the specific effects of language type on usage. Additional methods such as surveys could be helpful here. Addressing these challenges remains for future work.
|
||||
|
||||
[Back to Top][92]
|
||||
|
||||
### Acknowledgments
|
||||
|
||||
This material is based upon work supported by the National Science Foundation under grant nos. 1445079, 1247280, 1414172, 1446683 and from AFOSR award FA955-11-1-0246.
|
||||
|
||||
[Back to Top][93]
|
||||
|
||||
### References
|
||||
|
||||
1\. Bhattacharya, P., Neamtiu, I. Assessing programming language impact on development and maintenance: A study on C and C++. In _Proceedings of the 33rd International Conference on Software Engineering, ICSE'11_ (New York, NY USA, 2011). ACM, 171–180.
|
||||
|
||||
2\. Bird, C., Nagappan, N., Murphy, B., Gall, H., Devanbu, P. Don't touch my code! Examining the effects of ownership on software quality. In _Proceedings of the 19th ACM SIGSOFT Symposium and the 13th European Conference on Foundations of Software Engineering_ (2011). ACM, 4–14.
|
||||
|
||||
3\. Blei, D.M. Probabilistic topic models. _Commun. ACM 55_ , 4 (2012), 77–84.
|
||||
|
||||
4\. Cohen, J. _Applied Multiple Regression/Correlation Analysis for the Behavioral Sciences._ Lawrence Erlbaum, 2003.
|
||||
|
||||
5\. Easterbrook, S., Singer, J., Storey, M.-A., Damian, D. Selecting empirical methods for software engineering research. In _Guide to Advanced Empirical Software Engineering_ (2008). Springer, 285–311.
|
||||
|
||||
6\. El Emam, K., Benlarbi, S., Goel, N., Rai, S.N. The confounding effect of class size on the validity of object-oriented metrics. _IEEE Trans. Softw. Eng. 27_ , 7 (2001), 630–650.
|
||||
|
||||
7\. Hanenberg, S. An experiment about static and dynamic type systems: Doubts about the positive impact of static type systems on development time. In _Proceedings of the ACM International Conference on Object Oriented Programming Systems Languages and Applications, OOPSLA'10_ (New York, NY, USA, 2010). ACM, 22–35.
|
||||
|
||||
8\. Harrison, R., Smaraweera, L., Dobie, M., Lewis, P. Comparing programming paradigms: An evaluation of functional and object-oriented programs. _Softw. Eng. J. 11_ , 4 (1996), 247–254.
|
||||
|
||||
9\. Harter, D.E., Krishnan, M.S., Slaughter, S.A. Effects of process maturity on quality, cycle time, and effort in software product development. _Manage. Sci. 46_ 4 (2000), 451–466.
|
||||
|
||||
10\. Hindley, R. The principal type-scheme of an object in combinatory logic. _Trans. Am. Math. Soc._ (1969), 29–60.
|
||||
|
||||
11\. Jump, M., McKinley, K.S. Cork: Dynamic memory leak detection for garbage-collected languages. In _ACM SIGPLAN Notices_ , Volume 42 (2007). ACM, 31–38.
|
||||
|
||||
12\. Kleinschmager, S., Hanenberg, S., Robbes, R., Tanter, É., Stefik, A. Do static type systems improve the maintainability of software systems? An empirical study. In _2012 IEEE 20th International Conference on Program Comprehension (ICPC)_ (2012). IEEE, 153–162.
|
||||
|
||||
13\. Li, Z., Tan, L., Wang, X., Lu, S., Zhou, Y., Zhai, C. Have things changed now? An empirical study of bug characteristics in modern open source software. In _ASID'06: Proceedings of the 1st Workshop on Architectural and System Support for Improving Software Dependability_ (October 2006).
|
||||
|
||||
14\. Marques De Sá, J.P. _Applied Statistics Using SPSS, Statistica and Matlab_ , 2003.
|
||||
|
||||
15\. Mayer, C., Hanenberg, S., Robbes, R., Tanter, É., Stefik, A. An empirical study of the influence of static type systems on the usability of undocumented software. In _ACM SIGPLAN Notices_ , Volume 47 (2012). ACM, 683–702.
|
||||
|
||||
16\. Meyerovich, L.A., Rabkin, A.S. Empirical analysis of programming language adoption. In _Proceedings of the 2013 ACM SIGPLAN International Conference on Object Oriented Programming Systems Languages & Applications_ (2013). ACM, 1–18.
|
||||
|
||||
17\. Milner, R. A theory of type polymorphism in programming. _J. Comput. Syst. Sci. 17_ , 3 (1978), 348–375.
|
||||
|
||||
18\. Mockus, A., Votta, L.G. Identifying reasons for software changes using historic databases. In _ICSM'00\. Proceedings of the International Conference on Software Maintenance_ (2000). IEEE Computer Society, 120.
|
||||
|
||||
19\. Odersky, M., Spoon, L., Venners, B. _Programming in Scala._ Artima Inc, 2008.
|
||||
|
||||
20\. Pankratius, V., Schmidt, F., Garretón, G. Combining functional and imperative programming for multicore software: An empirical study evaluating scala and java. In _Proceedings of the 2012 International Conference on Software Engineering_ (2012). IEEE Press, 123–133.
|
||||
|
||||
21\. Petricek, T., Skeet, J. _Real World Functional Programming: With Examples in F# and C#._ Manning Publications Co., 2009.
|
||||
|
||||
22\. Pierce, B.C. _Types and Programming Languages._ MIT Press, 2002.
|
||||
|
||||
23\. Posnett, D., Bird, C., Dévanbu, P. An empirical study on the influence of pattern roles on change-proneness. _Emp. Softw. Eng. 16_ , 3 (2011), 396–423.
|
||||
|
||||
24\. Tan, L., Liu, C., Li, Z., Wang, X., Zhou, Y., Zhai, C. Bug characteristics in open source software. _Emp. Softw. Eng._ (2013).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007
|
||||
|
||||
作者:[ Baishakhi Ray][a], [Daryl Posnett][b], [Premkumar Devanbu][c], [Vladimir Filkov ][d]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://delivery.acm.org/10.1145/3130000/3126905/mailto:rayb@virginia.edu
|
||||
[b]:http://delivery.acm.org/10.1145/3130000/3126905/mailto:dpposnett@ucdavis.edu
|
||||
[c]:http://delivery.acm.org/10.1145/3130000/3126905/mailto:devanbu@cs.ucdavis.edu
|
||||
[d]:http://delivery.acm.org/10.1145/3130000/3126905/mailto:filkov@cs.ucdavis.edu
|
||||
[1]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R6
|
||||
[2]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R2
|
||||
[3]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R9
|
||||
[4]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R7
|
||||
[5]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R12
|
||||
[6]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R15
|
||||
[7]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R5
|
||||
[8]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R18
|
||||
[9]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R7
|
||||
[10]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R8
|
||||
[11]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R12
|
||||
[12]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#FNA
|
||||
[13]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#FNB
|
||||
[14]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#FNC
|
||||
[15]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R10
|
||||
[16]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R17
|
||||
[17]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R3
|
||||
[18]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R13
|
||||
[19]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R24
|
||||
[20]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R4
|
||||
[21]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R4
|
||||
[22]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R4
|
||||
[23]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R4
|
||||
[24]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R23
|
||||
[25]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R14
|
||||
[26]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R14
|
||||
[27]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#FND
|
||||
[28]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R4
|
||||
[29]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R11
|
||||
[30]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#FNE
|
||||
[31]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R7
|
||||
[32]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R8
|
||||
[33]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R12
|
||||
[34]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R20
|
||||
[35]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R16
|
||||
[36]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R1
|
||||
[37]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R19
|
||||
[38]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R21
|
||||
[39]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R22
|
||||
[40]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#comments
|
||||
[41]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#
|
||||
[42]:https://cacm.acm.org/about-communications/mobile-apps/
|
||||
[43]:http://dl.acm.org/citation.cfm?id=3144574.3126905&coll=portal&dl=ACM
|
||||
[44]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/pdf
|
||||
[45]:http://dl.acm.org/ft_gateway.cfm?id=3126905&ftid=1909469&dwn=1
|
||||
[46]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
[47]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
[48]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t1.jpg
|
||||
[49]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t1.jpg
|
||||
[50]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t1.jpg
|
||||
[51]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t2.jpg
|
||||
[52]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t2.jpg
|
||||
[53]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t3.jpg
|
||||
[54]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t3.jpg
|
||||
[55]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t3.jpg
|
||||
[56]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t7.jpg
|
||||
[57]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t4.jpg
|
||||
[58]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t4.jpg
|
||||
[59]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg
|
||||
[60]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg
|
||||
[61]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg
|
||||
[62]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg
|
||||
[63]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
[64]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t6.jpg
|
||||
[65]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t6.jpg
|
||||
[66]:http://deliveryimages.acm.org/10.1145/3130000/3126905/ut1.jpg
|
||||
[67]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t6.jpg
|
||||
[68]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t7.jpg
|
||||
[69]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t7.jpg
|
||||
[70]:http://deliveryimages.acm.org/10.1145/3130000/3126905/ut2.jpg
|
||||
[71]:http://deliveryimages.acm.org/10.1145/3130000/3126905/f1.jpg
|
||||
[72]:http://deliveryimages.acm.org/10.1145/3130000/3126905/f1.jpg
|
||||
[73]:http://deliveryimages.acm.org/10.1145/3130000/3126905/f1.jpg
|
||||
[74]:http://deliveryimages.acm.org/10.1145/3130000/3126905/ut3.jpg
|
||||
[75]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg
|
||||
[76]:http://deliveryimages.acm.org/10.1145/3130000/3126905/f2.jpg
|
||||
[77]:http://deliveryimages.acm.org/10.1145/3130000/3126905/f2.jpg
|
||||
[78]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg
|
||||
[79]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg
|
||||
[80]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg
|
||||
[81]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t6.jpg
|
||||
[82]:http://deliveryimages.acm.org/10.1145/3130000/3126905/f2.jpg
|
||||
[83]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg
|
||||
[84]:http://deliveryimages.acm.org/10.1145/3130000/3126905/ut4.jpg
|
||||
[85]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg
|
||||
[86]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg
|
||||
[87]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg
|
||||
[88]:http://deliveryimages.acm.org/10.1145/3130000/3126905/f2.jpg
|
||||
[89]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
[90]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
[91]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
[92]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
[93]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
351
sources/tech/20171008 8 best languages to blog about.md
Normal file
351
sources/tech/20171008 8 best languages to blog about.md
Normal file
@ -0,0 +1,351 @@
|
||||
8 best languages to blog about
|
||||
============================================================
|
||||
|
||||
|
||||
TL;DR: In this post we’re going to do some metablogging and analyze different blogs popularity against their ranking in Google. All the code is on [GitHub repo][38].
|
||||
|
||||
### The idea
|
||||
|
||||
I’ve been wondering, how many page views actually do different blogs get daily, as well as what programming languages are most popular today among blog reading audience. It was also interesting to me, whether Google ranking of websites directly correlates with their popularity.
|
||||
|
||||
In order to answer these questions, I decided to make a Scrapy project that will scrape some data and then perform certain Data Analysis and Data Visualization on the obtained information.
|
||||
|
||||
### Part I: Scraping
|
||||
|
||||
We will use [Scrapy][39] for our endeavors, as it provides clean and robust framework for scraping and managing feeds of processed requests. We’ll also use [Splash][40] in order to parse Javascript pages we’ll have to deal with. Splash uses its own Web server that acts like a proxy and processes the Javascript response before redirecting it further to our Spider process.
|
||||
|
||||
I don’t describe Scrapy project setup here as well as Splash integration. You can find example of Scrapy project backbone [here][34] and Scrapy+Splash guide [here][35].
|
||||
|
||||
### Getting relevant blogs
|
||||
|
||||
The first step is obviously getting the data. We’ll need Google search results about programming blogs. See, if we just start scraping Google itself with, let’s say query “Python”, we’ll get lots of other stuff besides blogs. What we need is some kind of filtering that leaves exclusively blogs in the results set. Luckily, there is a thing called [Google Custom Search Engine][41], that achieves exactly that. There’s also this website [www.blogsearchengine.org][42] that performs exactly what we need, delegating user requests to CSE, so we can look at its queries and repeat them.
|
||||
|
||||
So what we’re going to do is go to [www.blogsearchengine.org][43] and search for “python” having Network tab in Chrome Developer tools open by our side. Here’s the screenshot of what we’re going to see.
|
||||
|
||||

|
||||
|
||||
The highlighted query is the one that blogsearchengine delegates to Google, so we’re just going to copy it and use in our scraper.
|
||||
|
||||
The blog scraping spider class would then look like this:
|
||||
|
||||
```
|
||||
class BlogsSpider(scrapy.Spider):
|
||||
name = 'blogs'
|
||||
allowed_domains = ['cse.google.com']
|
||||
|
||||
def __init__(self, queries):
|
||||
super(BlogsSpider, self).__init__()
|
||||
self.queries = queries
|
||||
```
|
||||
|
||||
[view raw][3][blogs.py][4] hosted with
|
||||
|
||||
by [GitHub][5]
|
||||
|
||||
Unlike typical Scrapy spiders, ours has overridden `__init__` method that accepts additional argument `queries` that specifies the list of queries we want to perform.
|
||||
|
||||
Now, the most important part is the actual query building and execution. This process is performed in the `start_requests` Spider’s method, which we happily override as well:
|
||||
|
||||
|
||||
```
|
||||
def start_requests(self):
|
||||
params_dict = {
|
||||
'cx': ['partner-pub-9634067433254658:5laonibews6'],
|
||||
'cof': ['FORID:10'],
|
||||
'ie': ['ISO-8859-1'],
|
||||
'q': ['query'],
|
||||
'sa.x': ['0'],
|
||||
'sa.y': ['0'],
|
||||
'sa': ['Search'],
|
||||
'ad': ['n9'],
|
||||
'num': ['10'],
|
||||
'rurl': [
|
||||
'http://www.blogsearchengine.org/search.html?cx=partner-pub'
|
||||
'-9634067433254658%3A5laonibews6&cof=FORID%3A10&ie=ISO-8859-1&'
|
||||
'q=query&sa.x=0&sa.y=0&sa=Search'
|
||||
],
|
||||
'siteurl': ['http://www.blogsearchengine.org/']
|
||||
}
|
||||
|
||||
params = urllib.parse.urlencode(params_dict, doseq=True)
|
||||
url_template = urllib.parse.urlunparse(
|
||||
['https', self.allowed_domains[0], '/cse',
|
||||
'', params, 'gsc.tab=0&gsc.q=query&gsc.page=page_num'])
|
||||
for query in self.queries:
|
||||
for page_num in range(1, 11):
|
||||
url = url_template.replace('query', urllib.parse.quote(query))
|
||||
url = url.replace('page_num', str(page_num))
|
||||
yield SplashRequest(url, self.parse, endpoint='render.html',
|
||||
args={'wait': 0.5})
|
||||
```
|
||||
|
||||
[view raw][6][blogs.py][7] hosted with
|
||||
|
||||
by [GitHub][8]
|
||||
|
||||
Here you can see quite complex `params_dict` dictionary holding all the parameters of the Google CSE URL we found earlier. We then prepare `url_template` with everything but query and page number filled. We request 10 pages about each programming language, each page contains 10 links, so it’s 100 different blogs for each language to analyze.
|
||||
|
||||
On lines `42-43` we use special `SplashRequest` instead of Scrapy’s own Request class, which wraps internal redirect logic of Splash library, so we don’t have to worry about that. Neat.
|
||||
|
||||
Finally, here’s the parsing routine:
|
||||
|
||||
```
|
||||
def parse(self, response):
|
||||
urls = response.css('div.gs-title.gsc-table-cell-thumbnail') \
|
||||
.xpath('./a/@href').extract()
|
||||
gsc_fragment = urllib.parse.urlparse(response.url).fragment
|
||||
fragment_dict = urllib.parse.parse_qs(gsc_fragment)
|
||||
page_num = int(fragment_dict['gsc.page'][0])
|
||||
query = fragment_dict['gsc.q'][0]
|
||||
page_size = len(urls)
|
||||
for i, url in enumerate(urls):
|
||||
parsed_url = urllib.parse.urlparse(url)
|
||||
rank = (page_num - 1) * page_size + i
|
||||
yield {
|
||||
'rank': rank,
|
||||
'url': parsed_url.netloc,
|
||||
'query': query
|
||||
}
|
||||
```
|
||||
|
||||
[view raw][9][blogs.py][10] hosted with
|
||||
|
||||
by [GitHub][11]
|
||||
|
||||
The heart and soul of any scraper is parser’s logic. There are multiple ways to understand the response page structure and build the XPath query string. You can use [Scrapy shell][44] to try and adjust your XPath query on the fly, without running a spider. I prefer a more visual method though. It involves Google Chrome’s Developer console again. Simply right-click the element you want to get in your spider and press Inspect. It opens the console with HTML code set to the place where it’s being defined. In our case, we want to get the actual search result links. Their source location looks like this:
|
||||
|
||||

|
||||
|
||||
So, after looking at the element description we see that the <div> we’re searching for has `.gsc-table-cell-thumbnail` CSS class and is a child of the `.gs-title` <div>, so we put it into the `css`method of response object we have (line `46`). After that, we just need to get the URL of the blog post. It is easily achieved by `'./a/@href'` XPath string, which takes the `href` attribute of tag found as direct child of our <div>.
|
||||
|
||||
### Finding traffic data
|
||||
|
||||
The next task is estimating the number of views per day each of the blogs receives. There are [various options][45] to get such data, both free and paid. After quick googling I decided to stick to this simple and free to use website [www.statshow.com][46]. The Spider for this website should take as an input blog URLs we’ve obtained in the previous step, go through them and add traffic information. Spider initialization looks like this:
|
||||
|
||||
```
|
||||
class TrafficSpider(scrapy.Spider):
|
||||
name = 'traffic'
|
||||
allowed_domains = ['www.statshow.com']
|
||||
|
||||
def __init__(self, blogs_data):
|
||||
super(TrafficSpider, self).__init__()
|
||||
self.blogs_data = blogs_data
|
||||
```
|
||||
|
||||
[view raw][12][traffic.py][13] hosted with
|
||||
|
||||
by [GitHub][14]
|
||||
|
||||
`blogs_data` is expected to be list of dictionaries in the form: `{"rank": 70, "url": "www.stat.washington.edu", "query": "Python"}`.
|
||||
|
||||
Request building function looks like this:
|
||||
|
||||
```
|
||||
def start_requests(self):
|
||||
url_template = urllib.parse.urlunparse(
|
||||
['http', self.allowed_domains[0], '/www/{path}', '', '', ''])
|
||||
for blog in self.blogs_data:
|
||||
url = url_template.format(path=blog['url'])
|
||||
request = SplashRequest(url, endpoint='render.html',
|
||||
args={'wait': 0.5}, meta={'blog': blog})
|
||||
yield request
|
||||
```
|
||||
|
||||
[view raw][15][traffic.py][16] hosted with
|
||||
|
||||
by [GitHub][17]
|
||||
|
||||
It’s quite simple, we just add `/www/web-site-url/` string to the `'www.statshow.com'` url.
|
||||
|
||||
Now let’s see how does the parser look:
|
||||
|
||||
```
|
||||
def parse(self, response):
|
||||
site_data = response.xpath('//div[@id="box_1"]/span/text()').extract()
|
||||
views_data = list(filter(lambda r: '$' not in r, site_data))
|
||||
if views_data:
|
||||
blog_data = response.meta.get('blog')
|
||||
traffic_data = {
|
||||
'daily_page_views': int(views_data[0].translate({ord(','): None})),
|
||||
'daily_visitors': int(views_data[1].translate({ord(','): None}))
|
||||
}
|
||||
blog_data.update(traffic_data)
|
||||
yield blog_data
|
||||
```
|
||||
|
||||
[view raw][18][traffic.py][19] hosted with
|
||||
|
||||
by [GitHub][20]
|
||||
|
||||
Similarly to the blog parsing routine, we just make our way through the sample return page of the StatShow and track down the elements containing daily page views and daily visitors. Both of these parameters identify website popularity, so we’ll just pick page views for our analysis.
|
||||
|
||||
### Part II: Analysis
|
||||
|
||||
The next part is analyzing all the data we got after scraping. We then visualize the prepared data sets with the lib called [Bokeh][47]. I don’t give the runner/visualization code here but it can be found in the [GitHub repo][48] in addition to everything else you see in this post.
|
||||
|
||||
The initial result set has few outlying items representing websites with HUGE amount of traffic (such as google.com, linkedin.com, Oracle.com etc.). They obviously shouldn’t be considered. Even if some of those have blogs, they aren’t language specific. That’s why we filter the outliers based on the approach suggested in [this StackOverflow answer][36].
|
||||
|
||||
### Language popularity comparison
|
||||
|
||||
At first, let’s just make a head-to-head comparison of all the languages we have and see which one has most daily views among the top 100 blogs.
|
||||
|
||||
Here’s the function that can take care of such a task:
|
||||
|
||||
|
||||
```
|
||||
def get_languages_popularity(data):
|
||||
query_sorted_data = sorted(data, key=itemgetter('query'))
|
||||
result = {'languages': [], 'views': []}
|
||||
popularity = []
|
||||
for k, group in groupby(query_sorted_data, key=itemgetter('query')):
|
||||
group = list(group)
|
||||
daily_page_views = map(lambda r: int(r['daily_page_views']), group)
|
||||
total_page_views = sum(daily_page_views)
|
||||
popularity.append((group[0]['query'], total_page_views))
|
||||
sorted_popularity = sorted(popularity, key=itemgetter(1), reverse=True)
|
||||
languages, views = zip(*sorted_popularity)
|
||||
result['languages'] = languages
|
||||
result['views'] = views
|
||||
return result
|
||||
|
||||
```
|
||||
|
||||
[view raw][21][analysis.py][22] hosted with
|
||||
|
||||
by [GitHub][23]
|
||||
|
||||
Here we first group our data by languages (‘query’ key in the dict) and then use python’s `groupby`wonderful function borrowed from SQL to generate groups of items from our data list, each representing some programming language. Afterwards, we calculate total page views for each language on line `14` and then add tuples of the form `('Language', rank)` in the `popularity`list. After the loop, we sort the popularity data based on the total views and unpack these tuples in 2 separate lists and return those in the `result` variable.
|
||||
|
||||
There was some huge deviation in the initial dataset. I checked what was going on and realized that if I make query “C” in the [blogsearchengine.org][37], I get lots of irrelevant links, containing “C” letter somewhere. So, I had to exclude C from the analysis. It almost doesn’t happen with “R” in contrast as well as other C-like names: “C++”, “C#”.
|
||||
|
||||
So, if we remove C from the consideration and look at other languages, we can see the following picture:
|
||||
|
||||
|
||||
|
||||
Evaluation. Java made it with over 4 million views daily, PHP and Go have over 2 million, R and JavaScript close up the “million scorers” list.
|
||||
|
||||
### Daily Page Views vs Google Ranking
|
||||
|
||||
Let’s now take a look at the connection between the number of daily views and Google ranking of blogs. Logically, less popular blogs should be further in ranking, It’s not so easy though, as other factors influence ranking as well, for example, if the article in the less popular blog is more recent, it’ll likely pop up first.
|
||||
|
||||
The data preparation is performed in the following fashion:
|
||||
|
||||
```
|
||||
def get_languages_popularity(data):
|
||||
query_sorted_data = sorted(data, key=itemgetter('query'))
|
||||
result = {'languages': [], 'views': []}
|
||||
popularity = []
|
||||
for k, group in groupby(query_sorted_data, key=itemgetter('query')):
|
||||
group = list(group)
|
||||
daily_page_views = map(lambda r: int(r['daily_page_views']), group)
|
||||
total_page_views = sum(daily_page_views)
|
||||
popularity.append((group[0]['query'], total_page_views))
|
||||
sorted_popularity = sorted(popularity, key=itemgetter(1), reverse=True)
|
||||
languages, views = zip(*sorted_popularity)
|
||||
result['languages'] = languages
|
||||
result['views'] = views
|
||||
return result
|
||||
```
|
||||
|
||||
[view raw][24][analysis.py][25] hosted with
|
||||
|
||||
by [GitHub][26]
|
||||
|
||||
The function accepts scraped data and list of languages to consider. We sort the data in the same way we did for languages popularity. Afterwards, in a similar language grouping loop, we build `(rank, views_number)` tuples (with 1-based ranks) that are being converted to 2 separate lists. This pair of lists is then written to the resulting dictionary.
|
||||
|
||||
The results for the top 8 GitHub languages (except C) are the following:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Evaluation. We see that the [PCC (Pearson correlation coefficient)][49] of all graphs is far from 1/-1, which signifies lack of correlation between the daily views and the ranking. It’s important to note though that in most of the graphs (7 out of 8) the correlation is negative, which means that decrease in ranking leads to decrease in views indeed.
|
||||
|
||||
### Conclusion
|
||||
|
||||
So, according to our analysis, Java is by far most popular programming language, followed by PHP, Go, R and JavaScript. Neither of top 8 languages has a strong correlation between daily views and ranking in Google, so you can definitely get high in search results even if you’re just starting your blogging path. What exactly is required for that top hit a topic for another discussion though.
|
||||
|
||||
These results are quite biased and can’t be taken into consideration without additional analysis. At first, it would be a good idea to collect more traffic feeds for an extended period of time and then analyze the mean (median?) values of daily views and rankings. Maybe I’ll return to it sometime in the future.
|
||||
|
||||
### References
|
||||
|
||||
1. Scraping:
|
||||
|
||||
1. [blog.scrapinghub.com: Handling Javascript In Scrapy With Splash][27]
|
||||
|
||||
2. [BlogSearchEngine.org][28]
|
||||
|
||||
3. [twingly.com: Twingly Real-Time Blog Search][29]
|
||||
|
||||
4. [searchblogspot.com: finding blogs on blogspot platform][30]
|
||||
|
||||
3. Traffic estimation:
|
||||
|
||||
1. [labnol.org: Find Out How Much Traffic a Website Gets][31]
|
||||
|
||||
2. [quora.com: What are the best free tools that estimate visitor traffic…][32]
|
||||
|
||||
3. [StatShow.com: The Stats Maker][33]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.databrawl.com/2017/10/08/blog-analysis/
|
||||
|
||||
作者:[Serge Mosin ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.databrawl.com/author/svmosingmail-com/
|
||||
[1]:https://bokeh.pydata.org/
|
||||
[2]:https://bokeh.pydata.org/
|
||||
[3]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/blogs.py
|
||||
[4]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-blogs-py
|
||||
[5]:https://github.com/
|
||||
[6]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/blogs.py
|
||||
[7]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-blogs-py
|
||||
[8]:https://github.com/
|
||||
[9]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/blogs.py
|
||||
[10]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-blogs-py
|
||||
[11]:https://github.com/
|
||||
[12]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/traffic.py
|
||||
[13]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-traffic-py
|
||||
[14]:https://github.com/
|
||||
[15]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/traffic.py
|
||||
[16]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-traffic-py
|
||||
[17]:https://github.com/
|
||||
[18]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/traffic.py
|
||||
[19]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-traffic-py
|
||||
[20]:https://github.com/
|
||||
[21]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/analysis.py
|
||||
[22]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-analysis-py
|
||||
[23]:https://github.com/
|
||||
[24]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/analysis.py
|
||||
[25]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-analysis-py
|
||||
[26]:https://github.com/
|
||||
[27]:https://blog.scrapinghub.com/2015/03/02/handling-javascript-in-scrapy-with-splash/
|
||||
[28]:http://www.blogsearchengine.org/
|
||||
[29]:https://www.twingly.com/
|
||||
[30]:http://www.searchblogspot.com/
|
||||
[31]:https://www.labnol.org/internet/find-website-traffic-hits/8008/
|
||||
[32]:https://www.quora.com/What-are-the-best-free-tools-that-estimate-visitor-traffic-for-a-given-page-on-a-particular-website-that-you-do-not-own-or-operate-3rd-party-sites
|
||||
[33]:http://www.statshow.com/
|
||||
[34]:https://docs.scrapy.org/en/latest/intro/tutorial.html
|
||||
[35]:https://blog.scrapinghub.com/2015/03/02/handling-javascript-in-scrapy-with-splash/
|
||||
[36]:https://stackoverflow.com/a/16562028/1573766
|
||||
[37]:http://blogsearchengine.org/
|
||||
[38]:https://github.com/Databrawl/blog_analysis
|
||||
[39]:https://scrapy.org/
|
||||
[40]:https://github.com/scrapinghub/splash
|
||||
[41]:https://en.wikipedia.org/wiki/Google_Custom_Search
|
||||
[42]:http://www.blogsearchengine.org/
|
||||
[43]:http://www.blogsearchengine.org/
|
||||
[44]:https://doc.scrapy.org/en/latest/topics/shell.html
|
||||
[45]:https://www.labnol.org/internet/find-website-traffic-hits/8008/
|
||||
[46]:http://www.statshow.com/
|
||||
[47]:https://bokeh.pydata.org/en/latest/
|
||||
[48]:https://github.com/Databrawl/blog_analysis
|
||||
[49]:https://en.wikipedia.org/wiki/Pearson_correlation_coefficient
|
||||
[50]:https://www.databrawl.com/author/svmosingmail-com/
|
||||
[51]:https://www.databrawl.com/2017/10/08/
|
||||
@ -0,0 +1,52 @@
|
||||
Building an Open Standard for Distributed Messaging: Introducing OpenMessaging
|
||||
============================================================
|
||||
|
||||
|
||||
Through a collaborative effort from enterprises and communities invested in cloud, big data, and standard APIs, I’m excited to welcome the OpenMessaging project to The Linux Foundation. The OpenMessaging community’s goal is to create a globally adopted, vendor-neutral, and open standard for distributed messaging that can be deployed in cloud, on-premise, and hybrid use cases.
|
||||
|
||||
Alibaba, Yahoo!, Didi, and Streamlio are the founding project contributors. The Linux Foundation has worked with the initial project community to establish a governance model and structure for the long-term benefit of the ecosystem working on a messaging API standard.
|
||||
|
||||
As more companies and developers move toward cloud native applications, challenges are developing at scale with messaging and streaming applications. These include interoperability issues between platforms, lack of compatibility between wire-level protocols and a lack of standard benchmarking across systems.
|
||||
|
||||
In particular, when data transfers across different messaging and streaming platforms, compatibility problems arise, meaning additional work and maintenance cost. Existing solutions lack standardized guidelines for load balance, fault tolerance, administration, security, and streaming features. Current systems don’t satisfy the needs of modern cloud-oriented messaging and streaming applications. This can lead to redundant work for developers and makes it difficult or impossible to meet cutting-edge business demands around IoT, edge computing, smart cities, and more.
|
||||
|
||||
Contributors to OpenMessaging are looking to improve distributed messaging by:
|
||||
|
||||
* Creating a global, cloud-oriented, vendor-neutral industry standard for distributed messaging
|
||||
|
||||
* Facilitating a standard benchmark for testing applications
|
||||
|
||||
* Enabling platform independence
|
||||
|
||||
* Targeting cloud data streaming and messaging requirements with scalability, flexibility, isolation, and security built in
|
||||
|
||||
* Fostering a growing community of contributing developers
|
||||
|
||||
You can learn more about the new project and how to participate here: [http://openmessaging.cloud][1]
|
||||
|
||||
These are some of the organizations supporting OpenMessaging:
|
||||
|
||||
“We have focused on the messaging and streaming field for years, during which we explored Corba notification, JMS and other standards to try to solve our stickiest business requirements. After evaluating the available alternatives, Alibaba chose to create a new cloud-oriented messaging standard, OpenMessaging, which is a vendor-neutral and language-independent and provides industrial guidelines for areas like finance, e-commerce, IoT, and big data. Moreover, it aims to develop messaging and streaming applications across heterogeneous systems and platforms. We hope it can be open, simple, scalable, and interoperable. In addition, we want to build an ecosystem according to this standard, such as benchmark, computation, and various connectors. We would like to have new contributions and hope everyone can work together to push the OpenMessaging standard forward.” _— Von Gosling, senior architect at Alibaba, co-creator of Apache RocketMQ, and original initiator of OpenMessaging_
|
||||
|
||||
“As the sophistication and scale of applications’ messaging needs continue to grow, lack of a standard interface has created complexity and inflexibility barriers for developers and organizations. Streamlio is excited to work with other leaders to launch the OpenMessaging standards initiative in order to give customers easy access to high-performance, low-latency messaging solutions like Apache Pulsar that offer the durability, consistency, and availability that organizations require.” _— Matteo Merli, software engineer at Streamlio, co-creator of Apache Pulsar, and member of Apache BookKeeper PMC_
|
||||
|
||||
“Oath–a Verizon subsidiary of leading media and tech brands including Yahoo and AOL– supports open, collaborative initiatives and is glad to join the OpenMessaging project.” _— _ _Joe Francis, director, Core Platforms_
|
||||
|
||||
“In Didi, we have defined a private set of producer API and consumer API to hide differences among open source MQs such as Apache Kafka, Apache RocketMQ, etc. as well as to provide additional customized features. We are planning to release these to the open source community. So far, we have accumulated a lot of experience on MQs and API unification, and are willing to work in OpenMessaging to construct a common standard of APIs together with others. We sincerely believe that a unified and widely accepted API standard can benefit MQ technology and applications that rely on it.” _— Neil Qi, architect at Didi_
|
||||
|
||||
“There are many different open source messaging solutions, including Apache ActiveMQ, Apache RocketMQ, Apache Pulsar, and Apache Kafka. The lack of an industry-wide, scalable messaging standard makes evaluating a suitable solution difficult. We are excited to support the joint effort from multiple open source projects working together to define a scalable, open messaging specification. Apache BookKeeper has been successfully deployed in production at Yahoo (via Apache Pulsar) and Twitter (via Apache DistributedLog) as their durable, high-performance, low-latency storage foundation for their enterprise-grade messaging systems. We are excited to join the OpenMessaging effort to help other projects address common problems like low-latency durability, consistency and availability in messaging solutions.” _— Sijie Guo, co-founder of Streamlio, PMC chair of Apache BookKeeper, and co-creator of Apache DistributedLog_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxfoundation.org/blog/building-open-standard-distributed-messaging-introducing-openmessaging/
|
||||
|
||||
作者:[Mike Dolan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxfoundation.org/author/mdolan/
|
||||
[1]:http://openmessaging.cloud/
|
||||
[2]:https://www.linuxfoundation.org/author/mdolan/
|
||||
[3]:https://www.linuxfoundation.org/category/blog/
|
||||
283
sources/tech/20171009 Considering Pythons Target Audience.md
Normal file
283
sources/tech/20171009 Considering Pythons Target Audience.md
Normal file
@ -0,0 +1,283 @@
|
||||
[Considering Python's Target Audience][40]
|
||||
============================================================
|
||||
|
||||
Who is Python being designed for?
|
||||
|
||||
* [Use cases for Python's reference interpreter][8]
|
||||
|
||||
* [Which audience does CPython primarily serve?][9]
|
||||
|
||||
* [Why is this relevant to anything?][10]
|
||||
|
||||
* [Where does PyPI fit into the picture?][11]
|
||||
|
||||
* [Why are some APIs changed when adding them to the standard library?][12]
|
||||
|
||||
* [Why are some APIs added in provisional form?][13]
|
||||
|
||||
* [Why are only some standard library APIs upgraded?][14]
|
||||
|
||||
* [Will any parts of the standard library ever be independently versioned?][15]
|
||||
|
||||
* [Why do these considerations matter?][16]
|
||||
|
||||
Several years ago, I [highlighted][38] "CPython moves both too fast and too slowly" as one of the more common causes of conflict both within the python-dev mailing list, as well as between the active CPython core developers and folks that decide that participating in that process wouldn't be an effective use of their personal time and energy.
|
||||
|
||||
I still consider that to be the case, but it's also a point I've spent a lot of time reflecting on in the intervening years, as I wrote that original article while I was still working for Boeing Defence Australia. The following month, I left Boeing for Red Hat Asia-Pacific, and started gaining a redistributor level perspective on [open source supply chain management][39] in large enterprises.
|
||||
|
||||
### [Use cases for Python's reference interpreter][17]
|
||||
|
||||
While it's a gross oversimplification, I tend to break down CPython's use cases as follows (note that these categories aren't fully distinct, they're just aimed at focusing my thinking on different factors influencing the rollout of new software features and versions):
|
||||
|
||||
* Education: educator's main interest is in teaching ways of modelling and manipulating the world computationally, _not_ writing or maintaining production software). Examples:
|
||||
* Australia's [Digital Curriculum][1]
|
||||
|
||||
* Lorena A. Barba's [AeroPython][2]
|
||||
|
||||
* Personal automation & hobby projects: software where the main, and often only, user is the individual that wrote it. Examples:
|
||||
* my Digital Blasphemy [image download notebook][3]
|
||||
|
||||
* Paul Fenwick's (Inter)National [Rick Astley Hotline][4]
|
||||
|
||||
* Organisational process automation: software where the main, and often only, user is the organisation it was originally written to benefit. Examples:
|
||||
* CPython's [core workflow tools][5]
|
||||
|
||||
* Development, build & release management tooling for Linux distros
|
||||
|
||||
* Set-and-forget infrastructure: software where, for sometimes debatable reasons, in-life upgrades to the software itself are nigh impossible, but upgrades to the underlying platform may be feasible. Examples:
|
||||
* most self-managed corporate and institutional infrastructure (where properly funded sustaining engineering plans are disturbingly rare)
|
||||
|
||||
* grant funded software (where maintenance typically ends when the initial grant runs out)
|
||||
|
||||
* software with strict certification requirements (where recertification is too expensive for routine updates to be economically viable unless absolutely essential)
|
||||
|
||||
* Embedded software systems without auto-upgrade capabilities
|
||||
|
||||
* Continuously upgraded infrastructure: software with a robust sustaining engineering model, where dependency and platform upgrades are considered routine, and no more concerning than any other code change. Examples:
|
||||
* Facebook's Python service infrastructure
|
||||
|
||||
* Rolling release Linux distributions
|
||||
|
||||
* most public PaaS and serverless environments (Heroku, OpenShift, AWS Lambda, Google Cloud Functions, Azure Cloud Functions, etc)
|
||||
|
||||
* Intermittently upgraded standard operating environments: environments that do carry out routine upgrades to their core components, but those upgrades occur on a cycle measured in years, rather than weeks or months. Examples:
|
||||
* [VFX Platform][6]
|
||||
|
||||
* LTS Linux distributions
|
||||
|
||||
* CPython and the Python standard library
|
||||
|
||||
* Infrastructure management & orchestration tools (e.g. OpenStack, Ansible)
|
||||
|
||||
* Hardware control systems
|
||||
|
||||
* Ephemeral software: software that tends to be used once and then discarded or ignored, rather than being subsequently upgraded in place. Examples:
|
||||
* Ad hoc automation scripts
|
||||
|
||||
* Single-player games with a defined "end" (once you've finished them, even if you forget to uninstall them, you probably won't reinstall them on a new device)
|
||||
|
||||
* Single-player games with little or no persistent state (if you uninstall and reinstall them, it doesn't change much about your play experience)
|
||||
|
||||
* Event-specific applications (the application was tied to a specific physical event, and once the event is over, that app doesn't matter any more)
|
||||
|
||||
* Regular use applications: software that tends to be regularly upgraded after deployment. Examples:
|
||||
* Business management software
|
||||
|
||||
* Personal & professional productivity applications (e.g. Blender)
|
||||
|
||||
* Developer tools & services (e.g. Mercurial, Buildbot, Roundup)
|
||||
|
||||
* Multi-player games, and other games with significant persistent state, but no real defined "end"
|
||||
|
||||
* Embedded software systems with auto-upgrade capabilities
|
||||
|
||||
* Shared abstraction layers: software components that are designed to make it possible to work effectively in a particular problem domain even if you don't personally grasp all the intricacies of that domain yet. Examples:
|
||||
* most runtime libraries and frameworks fall into this category (e.g. Django, Flask, Pyramid, SQL Alchemy, NumPy, SciPy, requests)
|
||||
|
||||
* many testing and type inference tools also fit here (e.g. pytest, Hypothesis, vcrpy, behave, mypy)
|
||||
|
||||
* plugins for other applications (e.g. Blender plugins, OpenStack hardware adapters)
|
||||
|
||||
* the standard library itself represents the baseline "world according to Python" (and that's an [incredibly complex][7] world view)
|
||||
|
||||
### [Which audience does CPython primarily serve?][18]
|
||||
|
||||
Ultimately, the main audiences that CPython and the standard library specifically serve are those that, for whatever reason, aren't adequately served by the combination of a more limited standard library and the installation of explicitly declared third party dependencies from PyPI.
|
||||
|
||||
To oversimplify the above review of different usage and deployment models even further, it's possible to summarise the single largest split in Python's user base as the one between those that are using Python as a _scripting language_ for some environment of interest, and those that are using it as an _application development language_ , where the eventual artifact that will be distributed is something other than the script that they're working on.
|
||||
|
||||
Typical developer behaviours when using Python as a scripting language include:
|
||||
|
||||
* the main working unit consists of a single Python file (or Jupyter notebook!), rather than a directory of Python and metadata files
|
||||
|
||||
* there's no separate build step of any kind - the script is distributed _as_ a script, similar to the way standalone shell scripts are distributed
|
||||
|
||||
* there's no separate install step (other than downloading the file to an appropriate location), as it is expected that the required runtime environment will be preconfigured on the destination system
|
||||
|
||||
* no explicit dependencies stated, except perhaps a minimum Python version, or else a statement of the expected execution environment. If dependencies outside the standard library are needed, they're expected to be provided by the environment being scripted (whether that's an operating system, a data analysis platform, or an application that embeds a Python runtime)
|
||||
|
||||
* no separate test suite, with the main test of correctness being "Did the script do what you wanted it to do with the input that you gave it?"
|
||||
|
||||
* if testing prior to live execution is needed, it will be in the form of a "dry run" or "preview" mode that conveys to the user what the software _would_ do if run that way
|
||||
|
||||
* if static code analysis tools are used at all, it's via integration into the user's software development environment, rather than being set up separately for each individual script
|
||||
|
||||
By contrast, typical developer behaviours when using Python as an application development language include:
|
||||
|
||||
* the main working unit consists of a directory of Python and metadata files, rather than a single Python file
|
||||
|
||||
* these is a separate build step to prepare the application for publication, even if it's just bundling the files together into a Python sdist, wheel or zipapp archive
|
||||
|
||||
* whether there's a separate install step to prepare the application for use will depend on how the application is packaged, and what the supported target environments are
|
||||
|
||||
* external dependencies are expressed in a metadata file, either directly in the project directory (e.g. `pyproject.toml`, `requirements.txt`, `Pipfile`), or as part of the generated publication archive (e.g. `setup.py`, `flit.ini`)
|
||||
|
||||
* a separate test suite exists, either as unit tests for the Python API, integration tests for the functional interfaces, or a combination of the two
|
||||
|
||||
* usage of static analysis tools is configured at the project level as part of its testing regime, rather than being dependent on
|
||||
|
||||
As a result of that split, the main purpose that CPython and the standard library end up serving is to define the redistributor independent baseline of assumed functionality for educational and ad hoc Python scripting environments 3-5 years after the corresponding CPython feature release.
|
||||
|
||||
For ad hoc scripting use cases, that 3-5 year latency stems from a combination of delays in redistributors making new releases available to their users, and users of those redistributed versions taking time to revise their standard operating environments.
|
||||
|
||||
In the case of educational environments, educators need that kind of time to review the new features and decide whether or not to incorporate them into the courses they offer their students.
|
||||
|
||||
### [Why is this relevant to anything?][19]
|
||||
|
||||
This post was largely inspired by the Twitter discussion following on from [this comment of mine][20] citing the Provisional API status defined in [PEP 411][21] as an example of an open source project issuing a de facto invitation to users to participate more actively in the design & development process as co-creators, rather than only passively consuming already final designs.
|
||||
|
||||
The responses included several expressions of frustration regarding the difficulty of supporting provisional APIs in higher level libraries, without those libraries making the provisional status transitive, and hence limiting support for any related features to only the latest version of the provisional API, and not any of the earlier iterations.
|
||||
|
||||
My [main reaction][22] was to suggest that open source publishers should impose whatever support limitations they need to impose to make their ongoing maintenance efforts personally sustainable. That means that if supporting older iterations of provisional APIs is a pain, then they should only be supported if the project developers themselves need that, or if somebody is paying them for the inconvenience. This is similar to my view on whether or not volunteer-driven projects should support older commercial LTS Python releases for free when it's a hassle for them to do: I [don't think they should][23], as I expect most such demands to be stemming from poorly managed institutional inertia, rather than from genuine need (and if the need _is_ genuine, then it should instead be possible to find some means of paying to have it addressed).
|
||||
|
||||
However, my [second reaction][24], was to realise that even though I've touched on this topic over the years (e.g. in the original 2011 article linked above, as well as in Python 3 Q & A answers [here][25], [here][26], and [here][27], and to a lesser degree in last year's article on the [Python Packaging Ecosystem][28]), I've never really attempted to directly explain the impact it has on the standard library design process.
|
||||
|
||||
And without that background, some aspects of the design process, such as the introduction of provisional APIs, or the introduction of inspired-by-but-not-the-same-as, seem completely nonsensical, as they appear to be an attempt to standardise APIs without actually standardising them.
|
||||
|
||||
### [Where does PyPI fit into the picture?][29]
|
||||
|
||||
The first hurdle that _any_ proposal sent to python-ideas or python-dev has to clear is answering the question "Why isn't a module on PyPI good enough?". The vast majority of proposals fail at this step, but there are several common themes for getting past it:
|
||||
|
||||
* rather than downloading a suitable third party library, novices may be prone to copying & pasting bad advice from the internet at large (e.g. this is why the `secrets` library now exists: to make it less likely people will use the `random` module, which is intended for games and statistical simulations, for security-sensitive purposes)
|
||||
|
||||
* the module is intended to provide a reference implementation and to enable interoperability between otherwise competing implementations, rather than necessarily being all things to all people (e.g. `asyncio`, `wsgiref`, `unittest``, and `logging` all fall into this category)
|
||||
|
||||
* the module is intended for use in other parts of the standard library (e.g. `enum` falls into this category, as does `unittest`)
|
||||
|
||||
* the module is designed to support a syntactic addition to the language (e.g. the `contextlib`, `asyncio` and `typing` modules fall into this category)
|
||||
|
||||
* the module is just plain useful for ad hoc scripting purposes (e.g. `pathlib`, and `ipaddress` fall into this category)
|
||||
|
||||
* the module is useful in an educational context (e.g. the `statistics` module allows for interactive exploration of statistic concepts, even if you wouldn't necessarily want to use it for full-fledged statistical analysis)
|
||||
|
||||
Passing this initial "Is PyPI obviously good enough?" check isn't enough to ensure that a module will be accepted for inclusion into the standard library, but it's enough to shift the question to become "Would including the proposed library result in a net improvement to the typical introductory Python software developer experience over the next few years?"
|
||||
|
||||
The introduction of `ensurepip` and `venv` modules into the standard library also makes it clear to redistributors that we expect Python level packaging and installation tools to be supported in addition to any platform specific distribution mechanisms.
|
||||
|
||||
### [Why are some APIs changed when adding them to the standard library?][30]
|
||||
|
||||
While existing third party modules are sometimes adopted wholesale into the standard library, in other cases, what actually gets added is a redesigned and reimplemented API that draws on the user experience of the existing API, but drops or revises some details based on the additional design considerations and privileges that go with being part of the language's reference implementation.
|
||||
|
||||
For example, unlike its popular third party predecessor, `path.py`, ``pathlib` does _not_ define string subclasses, but instead independent types. Solving the resulting interoperability challenges led to the definition of the filesystem path protocol, allowing a wider range of objects to be used with interfaces that work with filesystem paths.
|
||||
|
||||
The API design for the `ipaddress` module was adjusted to explicitly separate host interface definitions (IP addresses associated with particular IP networks) from the definitions of addresses and networks in order to serve as a better tool for teaching IP addressing concepts, whereas the original `ipaddr` module is less strict in the way it uses networking terminology.
|
||||
|
||||
In other cases, standard library modules are constructed as a synthesis of multiple existing approaches, and may also rely on syntactic features that didn't exist when the APIs for pre-existing libraries were defined. Both of these considerations apply for the `asyncio` and `typing` modules, while the latter consideration applies for the `dataclasses` API being considered in PEP 557 (which can be summarised as "like attrs, but using variable annotations for field declarations").
|
||||
|
||||
The working theory for these kinds of changes is that the existing libraries aren't going away, and their maintainers often aren't all that interested in putitng up with the constraints associated with standard library maintenance (in particular, the relatively slow release cadence). In such cases, it's fairly common for the documentation of the standard library version to feature a "See Also" link pointing to the original module, especially if the third party version offers additional features and flexibility that were omitted from the standard library module.
|
||||
|
||||
### [Why are some APIs added in provisional form?][31]
|
||||
|
||||
While CPython does maintain an API deprecation policy, we generally prefer not to use it without a compelling justification (this is especially the case while other projects are attempting to maintain compatibility with Python 2.7).
|
||||
|
||||
However, when adding new APIs that are inspired by existing third party ones without being exact copies of them, there's a higher than usual risk that some of the design decisions may turn out to be problematic in practice.
|
||||
|
||||
When we consider the risk of such changes to be higher than usual, we'll mark the related APIs as provisional, indicating that conservative end users may want to avoid relying on them at all, and that developers of shared abstraction layers may want to consider imposing stricter than usual constraints on which versions of the provisional API they're prepared to support.
|
||||
|
||||
### [Why are only some standard library APIs upgraded?][32]
|
||||
|
||||
The short answer here is that the main APIs that get upgraded are those where:
|
||||
|
||||
* there isn't likely to be a lot of external churn driving additional updates
|
||||
|
||||
* there are clear benefits for either ad hoc scripting use cases or else in encouraging future interoperability between multiple third party solutions
|
||||
|
||||
* a credible proposal is submitted by folks interested in doing the work
|
||||
|
||||
If the limitations of an existing module are mainly noticeable when using the module for application development purposes (e.g. `datetime`), if redistributors already tend to make an improved alternative third party option readily available (e.g. `requests`), or if there's a genuine conflict between the release cadence of the standard library and the needs of the package in question (e.g. `certifi`), then the incentives to propose a change to the standard library version tend to be significantly reduced.
|
||||
|
||||
This is essentially the inverse to the question about PyPI above: since PyPI usually _is_ a sufficiently good distribution mechanism for application developer experience enhancements, it makes sense for such enhancements to be distributed that way, allowing redistributors and platform providers to make their own decisions about what they want to include as part of their default offering.
|
||||
|
||||
Changing CPython and the standard library only comes into play when there is perceived value in changing the capabilities that can be assumed to be present by default in 3-5 years time.
|
||||
|
||||
### [Will any parts of the standard library ever be independently versioned?][33]
|
||||
|
||||
Yes, it's likely the bundling model used for `ensurepip` (where CPython releases bundle a recent version of `pip` without actually making it part of the standard library) may be applied to other modules in the future.
|
||||
|
||||
The most probable first candidate for that treatment would be the `distutils` build system, as switching to such a model would allow the build system to be more readily kept consistent across multiple releases.
|
||||
|
||||
Other potential candidates for this kind of treatment would be the Tcl/Tk graphics bindings, and the IDLE editor, which are already unbundled and turned into an optional addon installations by a number of redistributors.
|
||||
|
||||
### [Why do these considerations matter?][34]
|
||||
|
||||
By the very nature of things, the folks that tend to be most actively involved in open source development are those folks working on open source applications and shared abstraction layers.
|
||||
|
||||
The folks writing ad hoc scripts or designing educational exercises for their students often won't even think of themselves as software developers - they're teachers, system administrators, data analysts, quants, epidemiologists, physicists, biologists, business analysts, market researchers, animators, graphical designers, etc.
|
||||
|
||||
When all we have to worry about for a language is the application developer experience, then we can make a lot of simplifying assumptions around what people know, the kinds of tools they're using, the kinds of development processes they're following, and the ways they're going to be building and deploying their software.
|
||||
|
||||
Things get significantly more complicated when an application runtime _also_ enjoys broad popularity as a scripting engine. Doing either job well is already difficult, and balancing the needs of both audiences as part of a single project leads to frequent incomprehension and disbelief on both sides.
|
||||
|
||||
This post isn't intended to claim that we never make incorrect decisions as part of the CPython development process - it's merely pointing out that the most reasonable reaction to seemingly nonsensical feature additions to the Python standard library is going to be "I'm not part of the intended target audience for that addition" rather than "I have no interest in that, so it must be a useless and pointless addition of no value to anyone, added purely to annoy me".
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html
|
||||
|
||||
作者:[Nick Coghlan ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.curiousefficiency.org/pages/about.html
|
||||
[1]:https://aca.edu.au/#home-unpack
|
||||
[2]:https://github.com/barbagroup/AeroPython
|
||||
[3]:https://nbviewer.jupyter.org/urls/bitbucket.org/ncoghlan/misc/raw/default/notebooks/Digital%20Blasphemy.ipynb
|
||||
[4]:https://github.com/pjf/rickastley
|
||||
[5]:https://github.com/python/core-workflow
|
||||
[6]:http://www.vfxplatform.com/
|
||||
[7]:http://www.curiousefficiency.org/posts/2015/10/languages-to-improve-your-python.html#broadening-our-horizons
|
||||
[8]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#use-cases-for-python-s-reference-interpreter
|
||||
[9]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#which-audience-does-cpython-primarily-serve
|
||||
[10]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-is-this-relevant-to-anything
|
||||
[11]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#where-does-pypi-fit-into-the-picture
|
||||
[12]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-are-some-apis-changed-when-adding-them-to-the-standard-library
|
||||
[13]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-are-some-apis-added-in-provisional-form
|
||||
[14]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-are-only-some-standard-library-apis-upgraded
|
||||
[15]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#will-any-parts-of-the-standard-library-ever-be-independently-versioned
|
||||
[16]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-do-these-considerations-matter
|
||||
[17]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id1
|
||||
[18]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id2
|
||||
[19]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id3
|
||||
[20]:https://twitter.com/ncoghlan_dev/status/916994106819088384
|
||||
[21]:https://www.python.org/dev/peps/pep-0411/
|
||||
[22]:https://twitter.com/ncoghlan_dev/status/917092464355241984
|
||||
[23]:http://www.curiousefficiency.org/posts/2015/04/stop-supporting-python26.html
|
||||
[24]:https://twitter.com/ncoghlan_dev/status/917088410162012160
|
||||
[25]:http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html#wouldn-t-a-python-2-8-release-help-ease-the-transition
|
||||
[26]:http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html#doesn-t-this-make-python-look-like-an-immature-and-unstable-platform
|
||||
[27]:http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html#what-about-insert-other-shiny-new-feature-here
|
||||
[28]:http://www.curiousefficiency.org/posts/2016/09/python-packaging-ecosystem.html
|
||||
[29]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id4
|
||||
[30]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id5
|
||||
[31]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id6
|
||||
[32]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id7
|
||||
[33]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id8
|
||||
[34]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id9
|
||||
[35]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#
|
||||
[36]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#disqus_thread
|
||||
[37]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.rst
|
||||
[38]:http://www.curiousefficiency.org/posts/2011/04/musings-on-culture-of-python-dev.html
|
||||
[39]:http://community.redhat.com/blog/2015/02/the-quid-pro-quo-of-open-infrastructure/
|
||||
[40]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#
|
||||
@ -0,0 +1,57 @@
|
||||
CyberShaolin: Teaching the Next Generation of Cybersecurity Experts
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Reuben Paul, co-founder of CyberShaolin, will speak at Open Source Summit in Prague, highlighting the importance of cybersecurity awareness for kids.
|
||||
|
||||
Reuben Paul is not the only kid who plays video games, but his fascination with games and computers set him on a unique journey of curiosity that led to an early interest in cybersecurity education and advocacy and the creation of CyberShaolin, an organization that helps children understand the threat of cyberattacks. Paul, who is now 11 years old, will present a keynote talk at [Open Source Summit in Prague][2], sharing his experiences and highlighting insecurities in toys, devices, and other technologies in daily use.
|
||||
|
||||

|
||||
|
||||
Reuben Paul, co-founder of CyberShaolin
|
||||
|
||||
We interviewed Paul to hear the story of his journey and to discuss CyberShaolin and its mission to educate, equip, and empower kids (and their parents) with knowledge of cybersecurity dangers and defenses. Linux.com: When did your fascination with computers start? Reuben Paul: My fascination with computers started with video games. I like mobile phone games as well as console video games. When I was about 5 years old (I think), I was playing the “Asphalt” racing game by Gameloft on my phone. It was a simple but fun game. I had to touch on the right side of the phone to go fast and touch the left side of the phone to slow down. I asked my dad, “How does the game know where I touch?”
|
||||
|
||||
He researched and found out that the phone screen was an xy coordinate system and so he told me that if the x value was greater than half the width of the phone screen, then it was a touch on the right side. Otherwise, it was a touch on the left side. To help me better understand how this worked, he gave me the equation to graph a straight line, which was y = mx + b and asked, “Can you find the y value for each x value?” After about 30 minutes, I calculated the y value for each of the x values he gave me.
|
||||
|
||||
“When my dad realized that I was able to learn some fundamental logics of programming, he introduced me to Scratch and I wrote my first game — called “Big Fish eats Small Fish” — using the x and y values of the mouse pointer in the game. Then I just kept falling in love with computers.Paul, who is now 11 years old, will present a keynote talk at [Open Source Summit in Prague][1], sharing his experiences and highlighting insecurities in toys, devices, and other technologies in daily use.
|
||||
|
||||
Linux.com: What got you interested in cybersecurity? Paul: My dad, Mano Paul, used to train his business clients on cybersecurity. Whenever he worked from his home office, I would listen to his phone conversations. By the time I was 6 years old, I knew about things like the Internet, firewalls, and the cloud. When my dad realized I had the interest and the potential for learning, he started teaching me security topics like social engineering techniques, cloning websites, man-in-the-middle attack techniques, hacking mobile apps, and more. The first time I got a meterpreter shell from a test target machine, I felt like Peter Parker who had just discovered his Spiderman abilities.
|
||||
|
||||
Linux.com: How and why did you start CyberShaolin? Paul: When I was 8 years old, I gave my first talk on “InfoSec from the mouth of babes (or an 8 year old)” in DerbyCon. It was in September of 2014\. After that conference, I received several invitations and before the end of 2014, I had keynoted at three other conferences.
|
||||
|
||||
So, when kids started hearing me speak at these different conferences, they started writing to me and asking me to teach them. I told my parents that I wanted to teach other kids, and they asked me how. I said, “Maybe I can make some videos and publish them on channels like YouTube.” They asked me if I wanted to charge for my videos, and I said “No.” I want my videos to be free and accessible to any child anywhere in the world. This is how CyberShaolin was created.
|
||||
|
||||
Linux.com: What’s the goal of CyberShaolin? Paul: CyberShaolin is the non-profit organization that my parents helped me found. Its mission is to educate, equip, and empower kids (and their parents) with knowledge of cybersecurity dangers and defenses, using videos and other training material that I develop in my spare time from school, along with kung fu, gymnastics, swimming, inline hockey, piano, and drums. I have published about a dozen videos so far on the www.CyberShaolin.org website and plan to develop more. I would also like to make games and comics to support security learning.
|
||||
|
||||
CyberShaolin comes from two words: Cyber and Shaolin. The word cyber is of course from technology. Shaolin comes from the kung fu martial art form in which my dad and are I are both second degree black belt holders. In kung fu, we have belts to show our progress of knowledge, and you can think of CyberShaolin like digital kung fu where kids can become Cyber Black Belts, after learning and taking tests on our website.
|
||||
|
||||
Linux.com: How important do you think is it for children to understand cybersecurity? Paul: We are living in a time when technology and devices are not only in our homes but also in our schools and pretty much any place you go. The world is also getting very connected with the Internet of Things, which can easily become the Internet of Threats. Children are one of the main users of these technologies and devices. Unfortunately, these devices and apps on these devices are not very secure and can cause serious problems to children and families. For example, I recently (in May 2017) demonstrated how I could hack into a smart toy teddy bear and turn it into a remote spying device. Children are also the next generation. If they are not aware and trained in cybersecurity, then the future (our future) will not be very good.
|
||||
|
||||
Linux.com: How does the project help children? Paul:As I mentioned before, CyberShaolin’s mission is to educate, equip, and empower kids (and their parents) with knowledge of cybersecurity dangers and defenses.
|
||||
|
||||
As kids are educated about cybersecurity dangers like cyber bullying, man-in-the-middle, phishing, privacy, online threats, mobile threats, etc., they will be equipped with knowledge and skills, which will empower them to make cyber-wise decisions and stay safe and secure in cyberspace. And, just as I would never use my kung fu skills to harm someone, I expect all CyberShaolin graduates to use their cyber kung fu skills to create a secure future, for the good of humanity.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
作者简介:
|
||||
|
||||
Swapnil Bhartiya is a journalist and writer who has been covering Linux and Open Source for more than 10 years.
|
||||
|
||||
-------------------------
|
||||
|
||||
via: https://www.linuxfoundation.org/blog/cybershaolin-teaching-next-generation-cybersecurity-experts/
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxfoundation.org/author/sbhartiya/
|
||||
[1]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||
[2]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||
[3]:https://www.linuxfoundation.org/author/sbhartiya/
|
||||
[4]:https://www.linuxfoundation.org/category/blog/
|
||||
[5]:https://www.linuxfoundation.org/category/campaigns/events-campaigns/
|
||||
[6]:https://www.linuxfoundation.org/category/blog/qa/
|
||||
@ -0,0 +1,217 @@
|
||||
Examining network connections on Linux systems
|
||||
============================================================
|
||||
|
||||
### Linux systems provide a lot of useful commands for reviewing network configuration and connections. Here's a look at a few, including ifquery, ifup, ifdown and ifconfig.
|
||||
|
||||
|
||||
There are a lot of commands available on Linux for looking at network settings and connections. In today's post, we're going to run through some very handy commands and see how they work.
|
||||
|
||||
### ifquery command
|
||||
|
||||
One very useful command is the **ifquery** command. This command should give you a quick list of network interfaces. However, you might only see something like this —showing only the loopback interface:
|
||||
|
||||
```
|
||||
$ ifquery --list
|
||||
lo
|
||||
```
|
||||
|
||||
If this is the case, your **/etc/network/interfaces** file doesn't include information on network interfaces except for the loopback interface. You can add lines like the last two in the example below — assuming DHCP is used to assign addresses — if you'd like it to be more useful.
|
||||
|
||||
```
|
||||
# interfaces(5) file used by ifup(8) and ifdown(8)
|
||||
auto lo
|
||||
iface lo inet loopback
|
||||
auto eth0
|
||||
iface eth0 inet dhcp
|
||||
```
|
||||
|
||||
### ifup and ifdown commands
|
||||
|
||||
The related **ifup** and **ifdown** commands can be used to bring network connections up and shut them down as needed provided this file has the required descriptive data. Just keep in mind that "if" means "interface" in these commands just as it does in the **ifconfig** command, not "if" as in "if I only had a brain".
|
||||
|
||||
<aside class="nativo-promo smartphone" id="" style="overflow: hidden; margin-bottom: 16px; max-width: 620px;"></aside>
|
||||
|
||||
### ifconfig command
|
||||
|
||||
The **ifconfig** command, on the other hand, doesn't read the /etc/network/interfaces file at all and still provides quite a bit of useful information on network interfaces -- configuration data along with packet counts that tell you how busy each interface has been. The ifconfig command can also be used to shut down and restart network interfaces (e.g., ifconfig eth0 down).
|
||||
|
||||
```
|
||||
$ ifconfig eth0
|
||||
eth0 Link encap:Ethernet HWaddr 00:1e:4f:c8:43:fc
|
||||
inet addr:192.168.0.6 Bcast:192.168.0.255 Mask:255.255.255.0
|
||||
inet6 addr: fe80::b44b:bdb6:2527:6ae9/64 Scope:Link
|
||||
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
|
||||
RX packets:60474 errors:0 dropped:0 overruns:0 frame:0
|
||||
TX packets:33463 errors:0 dropped:0 overruns:0 carrier:0
|
||||
collisions:0 txqueuelen:1000
|
||||
RX bytes:43922053 (43.9 MB) TX bytes:4000460 (4.0 MB)
|
||||
Interrupt:21 Memory:fe9e0000-fea00000
|
||||
```
|
||||
|
||||
The RX and TX packet counts in this output are extremely low. In addition, no errors or packet collisions have been reported. The **uptime** command will likely confirm that this system has only recently been rebooted.
|
||||
|
||||
The broadcast (Bcast) and network mask (Mask) addresses shown above indicate that the system is operating on a Class C equivalent network (the default) so local addresses will range from 192.168.0.1 to 192.168.0.254.
|
||||
|
||||
### netstat command
|
||||
|
||||
The **netstat** command provides information on routing and network connections. The **netstat -rn** command displays the system's routing table.
|
||||
|
||||
<aside class="nativo-promo tablet desktop" id="" style="overflow: hidden; margin-bottom: 16px; max-width: 620px;"></aside>
|
||||
|
||||
```
|
||||
$ netstat -rn
|
||||
Kernel IP routing table
|
||||
Destination Gateway Genmask Flags MSS Window irtt Iface
|
||||
0.0.0.0 192.168.0.1 0.0.0.0 UG 0 0 0 eth0
|
||||
169.254.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0
|
||||
192.168.0.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
|
||||
```
|
||||
|
||||
That **169.254.0.0** entry in the above output is only necessary if you are using or planning to use link-local communications. You can comment out the related lines in the **/etc/network/if-up.d/avahi-autoipd** file like this if this is not the case:
|
||||
|
||||
```
|
||||
$ tail -12 /etc/network/if-up.d/avahi-autoipd
|
||||
#if [ -x /bin/ip ]; then
|
||||
# # route already present?
|
||||
# ip route show | grep -q '^169.254.0.0/16[[:space:]]' && exit 0
|
||||
#
|
||||
# /bin/ip route add 169.254.0.0/16 dev $IFACE metric 1000 scope link
|
||||
#elif [ -x /sbin/route ]; then
|
||||
# # route already present?
|
||||
# /sbin/route -n | egrep -q "^169.254.0.0[[:space:]]" && exit 0
|
||||
#
|
||||
# /sbin/route add -net 169.254.0.0 netmask 255.255.0.0 dev $IFACE metric 1000
|
||||
#fi
|
||||
```
|
||||
|
||||
### netstat -a command
|
||||
|
||||
The **netstat -a** command will display **_all_** network connections. To limit this to listening and established connections (generally much more useful), use the **netstat -at** command instead.
|
||||
|
||||
```
|
||||
$ netstat -at
|
||||
Active Internet connections (servers and established)
|
||||
Proto Recv-Q Send-Q Local Address Foreign Address State
|
||||
tcp 0 0 *:ssh *:* LISTEN
|
||||
tcp 0 0 localhost:ipp *:* LISTEN
|
||||
tcp 0 0 localhost:smtp *:* LISTEN
|
||||
tcp 0 256 192.168.0.6:ssh 192.168.0.32:53550 ESTABLISHED
|
||||
tcp6 0 0 [::]:http [::]:* LISTEN
|
||||
tcp6 0 0 [::]:ssh [::]:* LISTEN
|
||||
tcp6 0 0 ip6-localhost:ipp [::]:* LISTEN
|
||||
tcp6 0 0 ip6-localhost:smtp [::]:* LISTEN
|
||||
```
|
||||
|
||||
### netstat -rn command
|
||||
|
||||
The **netstat -rn** command displays the system's routing table. The 192.168.0.1 address is the local gateway (Flags=UG).
|
||||
|
||||
```
|
||||
$ netstat -rn
|
||||
Kernel IP routing table
|
||||
Destination Gateway Genmask Flags MSS Window irtt Iface
|
||||
0.0.0.0 192.168.0.1 0.0.0.0 UG 0 0 0 eth0
|
||||
192.168.0.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
|
||||
```
|
||||
|
||||
### host command
|
||||
|
||||
The **host** command works a lot like **nslookup** by looking up the remote system's IP address, but also provides the system's mail handler.
|
||||
|
||||
```
|
||||
$ host world.std.com
|
||||
world.std.com has address 192.74.137.5
|
||||
world.std.com mail is handled by 10 smtp.theworld.com.
|
||||
```
|
||||
|
||||
### nslookup command
|
||||
|
||||
The **nslookup** also provides information on the system (in this case, the local system) that is providing DNS lookup services.
|
||||
|
||||
```
|
||||
$ nslookup world.std.com
|
||||
Server: 127.0.1.1
|
||||
Address: 127.0.1.1#53
|
||||
|
||||
Non-authoritative answer:
|
||||
Name: world.std.com
|
||||
Address: 192.74.137.5
|
||||
```
|
||||
|
||||
### dig command
|
||||
|
||||
The **dig** command provides quitea lot of information on connecting to a remote system -- including the name server we are communicating with and how long the query takes to respond and is often used for troubleshooting.
|
||||
|
||||
```
|
||||
$ dig world.std.com
|
||||
|
||||
; <<>> DiG 9.10.3-P4-Ubuntu <<>> world.std.com
|
||||
;; global options: +cmd
|
||||
;; Got answer:
|
||||
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 28679
|
||||
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
|
||||
|
||||
;; OPT PSEUDOSECTION:
|
||||
; EDNS: version: 0, flags:; udp: 512
|
||||
;; QUESTION SECTION:
|
||||
;world.std.com. IN A
|
||||
|
||||
;; ANSWER SECTION:
|
||||
world.std.com. 78146 IN A 192.74.137.5
|
||||
|
||||
;; Query time: 37 msec
|
||||
;; SERVER: 127.0.1.1#53(127.0.1.1)
|
||||
;; WHEN: Mon Oct 09 13:26:46 EDT 2017
|
||||
;; MSG SIZE rcvd: 58
|
||||
```
|
||||
|
||||
### nmap command
|
||||
|
||||
The **nmap** command is most frequently used to probe remote systems, but can also be used to report on the services being offered by the local system. In the output below, we can see that ssh is available for logins, that smtp is servicing email, that a web site is active, and that an ipp print service is running.
|
||||
|
||||
```
|
||||
$ nmap localhost
|
||||
|
||||
Starting Nmap 7.01 ( https://nmap.org ) at 2017-10-09 15:01 EDT
|
||||
Nmap scan report for localhost (127.0.0.1)
|
||||
Host is up (0.00016s latency).
|
||||
Not shown: 996 closed ports
|
||||
PORT STATE SERVICE
|
||||
22/tcp open ssh
|
||||
25/tcp open smtp
|
||||
80/tcp open http
|
||||
631/tcp open ipp
|
||||
|
||||
Nmap done: 1 IP address (1 host up) scanned in 0.09 seconds
|
||||
```
|
||||
|
||||
Linux systems provide a lot of useful commands for reviewing their network configuration and connections. If you run out of commands to explore, keep in mind that **apropos network** might point you toward even more.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3230519/linux/examining-network-connections-on-linux-systems.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://www.networkworld.com/article/3221393/linux/review-considering-oracle-linux-is-a-no-brainer-if-you-re-an-oracle-shop.html
|
||||
[2]:https://www.networkworld.com/article/3221393/linux/review-considering-oracle-linux-is-a-no-brainer-if-you-re-an-oracle-shop.html#tk.nww_nsdr_ndxprmomod
|
||||
[3]:https://www.networkworld.com/article/3221423/linux/review-suse-linux-enterprise-server-12-sp2-scales-well-supports-3rd-party-virtualization.html
|
||||
[4]:https://www.networkworld.com/article/3221423/linux/review-suse-linux-enterprise-server-12-sp2-scales-well-supports-3rd-party-virtualization.html#tk.nww_nsdr_ndxprmomod
|
||||
[5]:https://www.networkworld.com/article/3221476/linux/review-free-linux-fedora-server-offers-upgrades-as-they-become-available-no-wait.html
|
||||
[6]:https://www.networkworld.com/article/3221476/linux/review-free-linux-fedora-server-offers-upgrades-as-they-become-available-no-wait.html#tk.nww_nsdr_ndxprmomod
|
||||
[7]:https://www.networkworld.com/article/3227929/linux/making-good-use-of-the-files-in-proc.html
|
||||
[8]:https://www.networkworld.com/article/3221415/linux/linux-commands-for-managing-partitioning-troubleshooting.html
|
||||
[9]:https://www.networkworld.com/article/2225768/cisco-subnet/dual-protocol-routing-with-raspberry-pi.html
|
||||
[10]:https://www.networkworld.com/video/51206/solo-drone-has-linux-smarts-gopro-mount
|
||||
[11]:https://www.networkworld.com/insider
|
||||
[12]:https://www.networkworld.com/article/3227929/linux/making-good-use-of-the-files-in-proc.html
|
||||
[13]:https://www.networkworld.com/article/3221415/linux/linux-commands-for-managing-partitioning-troubleshooting.html
|
||||
[14]:https://www.networkworld.com/video/51206/solo-drone-has-linux-smarts-gopro-mount
|
||||
[15]:https://www.networkworld.com/video/51206/solo-drone-has-linux-smarts-gopro-mount
|
||||
[16]:https://www.flickr.com/photos/cogdog/4317096083/in/photolist-7zufg6-8JS2ym-bmDGsu-cnYW2C-mnrvP-a1s6VU-4ThA5-33B4ME-7GHEod-ERKLhX-5iPi6m-dTZAW6-UC6wyi-dRCJAZ-dq4wxW-peQyWU-8AGfjw-8wGAqs-4oLjd2-4T6pXM-dQua38-UKngxR-5kQwHN-ejjXMo-q4YvvL-7AUF3h-39ya27-7HiWfp-TosWda-6L3BZn-uST4Hi-TkRW8U-H7zBu-oDkNvU-6T2pZg-dQEbs9-39hxfS-5pBhQL-eR6iKT-7dgDwk-W15qVn-nVQHN3-mdRj8-75tqVh-RajJsC-7gympc-7dwxjt-9EadYN-p1qH1G-6rZhh6
|
||||
[17]:https://creativecommons.org/licenses/by/2.0/legalcode
|
||||
35
sources/tech/20171010 Changes in Password Best Practices.md
Normal file
35
sources/tech/20171010 Changes in Password Best Practices.md
Normal file
@ -0,0 +1,35 @@
|
||||
translating----geekpi
|
||||
|
||||
### Changes in Password Best Practices
|
||||
|
||||
NIST recently published its four-volume [_SP800-63b Digital Identity Guidelines_][3] . Among other things, it makes three important suggestions when it comes to passwords:
|
||||
|
||||
1. Stop it with the annoying password complexity rules. They make passwords harder to remember. They increase errors because artificially complex passwords are harder to type in. And they [don't help][1] that much. It's better to allow people to use pass phrases.
|
||||
|
||||
2. Stop it with password expiration. That was an [old idea for an old way][2] we used computers. Today, don't make people change their passwords unless there's indication of compromise.
|
||||
|
||||
3. Let people use password managers. This is how we deal with all the passwords we need.
|
||||
|
||||
These password rules were failed attempts to [fix the user][4]. Better we fix the security systems.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I've been writing about security issues on my blog since 2004, and in my monthly newsletter since 1998. I write books, articles, and academic papers. Currently, I'm the Chief Technology Officer of IBM Resilient, a fellow at Harvard's Berkman Center, and a board member of EFF.
|
||||
|
||||
-----------------
|
||||
|
||||
via: https://www.schneier.com/blog/archives/2017/10/changes_in_pass.html
|
||||
|
||||
作者:[Bruce Schneier][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.schneier.com/blog/about/
|
||||
[1]:https://www.wsj.com/articles/the-man-who-wrote-those-password-rules-has-a-new-tip-n3v-r-m1-d-1502124118
|
||||
[2]:https://securingthehuman.sans.org/blog/2017/03/23/time-for-password-expiration-to-die
|
||||
[3]:http://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-63b.pdf
|
||||
[4]:http://ieeexplore.ieee.org/document/7676198/?reload=true
|
||||
@ -0,0 +1,94 @@
|
||||
In Device We Trust: Measure Twice, Compute Once with Xen, Linux, TPM 2.0 and TXT
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Xen virtualization enables innovative applications to be economically integrated with measured, interoperable software components on general-purpose hardware.[Creative Commons Zero][1]Pixabay
|
||||
|
||||
Is it a small tablet or large phone? Is it a phone or broadcast sensor? Is it a server or virtual desktop cluster? Is x86 emulating ARM, or vice-versa? Is Linux inspiring Windows, or the other way around? Is it microcode or hardware? Is it firmware or software? Is it microkernel or hypervisor? Is it a security or quality update? _Is anything in my device the same as yesterday? When we observe our evolving devices and their remote services, what can we question and measure?_
|
||||
|
||||
### General Purpose vs. Special Purpose Ecosystems
|
||||
|
||||
The general-purpose computer now lives in a menagerie of special-purpose devices and information appliances. Yet software and hardware components _within_ devices are increasingly flexible, blurring category boundaries. With hardware virtualization on x86 and ARM platforms, the ecosystems of multiple operating systems can coexist on a single device. Can a modular and extensible multi-vendor architecture compete with the profitability of vertically integrated products from a single vendor?
|
||||
|
||||
Operating systems evolved alongside applications for lucrative markets. PC desktops were driven by business productivity and media creation. Web browsers abstracted OS differences, as software revenue shifted to e-commerce, services, and advertising. Mobile devices added sensors, radios and hardware decoders for content and communication. Apple, now the most profitable computer company, vertically integrates software and services with sensors and hardware. Other companies monetize data, increasing demand for memory and storage optimization.
|
||||
|
||||
Some markets require security or safety certifications: automotive, aviation, marine, cross domain, industrial control, finance, energy, medical, and embedded devices. As software "eats the world," how can we [modernize][5]vertical markets without the economies of scale seen in enterprise and consumer markets? One answer comes from device architectures based on hardware virtualization, Xen, [disaggregation][6], OpenEmbedded Linux and measured launch. [OpenXT][7] derivatives use this extensible, open-source base to enforce policy for specialized applications on general-purpose hardware, while reusing interoperable components.
|
||||
|
||||
[OpenEmbedded][8] Linux supports a range of x86 and ARM devices, while Xen isolates operating systems and [unikernels][9]. Applications and drivers from multiple ecosystems can run concurrently, expanding technical and licensing options. Special-purpose software can be securely composed with general-purpose software in isolated VMs, anchored by a hardware-assisted root of trust defined by customer and OEM policies. This architecture allows specialist software vendors to share platform and hardware support costs, while supporting emerging and legacy software ecosystems that have different rates of change.
|
||||
|
||||
### On the Shoulders of Hardware, Firmware and Software Developers
|
||||
|
||||
### 
|
||||
|
||||
_System Architecture, from NIST SP800-193 (Draft), Platform Firmware Resiliency_
|
||||
|
||||
By the time a user-facing software application begins executing on a powered-on hardware device, an array of firmware and software is already running on the platform. Special-purpose applications’ security and safety assertions are dependent on platform firmware and the developers of a computing device’s “root of trust.”
|
||||
|
||||
If we consider the cosmological “[Turtles All The Way Down][2]” question for a computing device, the root of trust is the lowest-level combination of hardware, firmware and software that is initially trusted to perform critical security functions and persist state. Hardware components used in roots of trust include the TCG's Trusted Platform Module ([TPM][10]), ARM’s [TrustZone][11]-enabled Trusted Execution Environment ([TEE][12]), Apple’s [Secure Enclave][13] co-processor ([SEP][14]), and Intel's Management Engine ([ME][15]) in x86 CPUs. [TPM 2.0][16]was approved as an ISO standard in 2015 and is widely available in 2017 devices.
|
||||
|
||||
TPMs enable key authentication, integrity measurement and remote attestation. TPM key generation uses a hardware random number generator, with private keys that never leave the chip. TPM integrity measurement functions ensure that sensitive data like private keys are only used by trusted code. When software is provisioned, its cryptographic hash is used to extend a chain of hashes in TPM Platform Configuration Registers (PCRs). When the device boots, sensitive data is only unsealed if measurements of running software can recreate the PCR hash chain that was present at the time of sealing. PCRs record the aggregate result of extending hashes, while the TPM Event Log records the hash chain.
|
||||
|
||||
Measurements are calculated by hardware, firmware and software external to the TPM. There are Static (SRTM) and Dynamic (DRTM) Roots of Trust for Measurement. SRTM begins at device boot when the BIOS boot block measures BIOS before execution. The BIOS then execute, extending configuration and option ROM measurements into static PCRs 0-7\. TPM-aware boot loaders like TrustedGrub can extend a measurement chain from BIOS up to the [Linux kernel][17]. These software identity measurements enable relying parties to make trusted decisions within [specific workflows][18].
|
||||
|
||||
DRTM enables "late launch" of a trusted environment from an untrusted one at an arbitrary time, using Intel's Trusted Execution Technology ([TXT][19]) or AMD's Secure Virtual Machine ([SVM][20]). With Intel TXT, the CPU instruction SENTER resets CPUs to a known state, clears dynamic PCRs 17-22 and validates the Intel SINIT ACM binary to measure Intel’s tboot MLE, which can then measure Xen, Linux or other components. In 2008, Carnegie Mellon's [Flicker][21] used late launch to minimize the Trusted Computing Base (TCB) for isolated execution of sensitive code on AMD devices, during the interval between suspend/resume of untrusted Linux.
|
||||
|
||||
If DRTM enables launch of a trusted Xen or Linux environment without reboot, is SRTM still needed? Yes, because [attacks][22] are possible via privileged System Management Mode (SMM) firmware, UEFI Boot/Runtime Services, Intel ME firmware, or Intel Active Management Technology (AMT) firmware. Measurements for these components can be extended into static PCRs, to ensure they have not been modified since provisioning. In 2015, Intel released documentation and reference code for an SMI Transfer Monitor ([STM][23]), which can isolate SMM firmware on VT-capable systems. As of September 2017, an OEM-supported STM is not yet available to improve the security of Intel TXT.
|
||||
|
||||
Can customers secure devices while retaining control over firmware? UEFI Secure Boot requires a signed boot loader, but customers can define root certificates. Intel [Boot Guard][24] provides OEMs with validation of the BIOS boot block. _Verified Boot_ requires a signed boot block and the OEM's root certificate is fused into the CPU to restrict firmware. _Measured Boot_ extends the boot block hash into a TPM PCR, where it can be used for measured launch of customer-selected firmware. Sadly, no OEM has yet shipped devices which implement ONLY the Measured Boot option of Boot Guard.
|
||||
|
||||
### Measured Launch with Xen on General Purpose Devices
|
||||
|
||||
[OpenXT 7.0][25] has entered release candidate status, with support for Kaby Lake devices, TPM 2.0, OE [meta-measured][3], and [forward seal][26] (upgrade with pre-computed PCRs).
|
||||
|
||||
[OpenXT 6.0][27] on a Dell T20 Haswell Xeon microserver, after adding a SATA controller, low-power AMD GPU and dual-port Broadcom NIC, can be configured with measured launch of Windows 7 GPU p/t, FreeNAS 9.3 SATA p/t, pfSense 2.3.4, Debian Wheezy, OpenBSD 6.0, and three NICs, one per passthrough driver VM.
|
||||
|
||||
Does this demonstrate a storage device, build server, firewall, middlebox, desktop, or all of the above? With architectures similar to [Qubes][28] and [OpenXT][29] derivatives, we can combine specialized applications with best-of-breed software from multiple ecosystems. A strength of one operating system can address the weakness of another.
|
||||
|
||||
### Measurement and Complexity in Software Supply Chains
|
||||
|
||||
While ransomware trumpets cryptocurrency demands to shocked users, low-level malware often emulates Sherlock Holmes: the user sees no one. Malware authors modify code behavior in response to “our method of questioning”, simulating heisenbugs. As system architects pile abstractions, [self-similarity][30] appears as hardware, microcode, emulator, firmware, microkernel, hypervisor, operating system, virtual machine, namespace, nesting, runtime, and compiler expand onto neighboring territory. There are no silver bullets to neutralize these threats, but cryptographic measurement of source code and stateless components enables whitelisting and policy enforcement in multi-vendor supply chains.
|
||||
|
||||
Even for special-purpose devices, the user experience bar is defined by mass-market computing. Meanwhile, Moore’s Law is ending, ARM remains fragmented, x86 PC volume is flat, new co-processors and APIs multiply, threats mutate and demand for security expertise outpaces the talent pool. In vertical markets which need usable, securable and affordable special-purpose devices, Xen virtualization enables innovative applications to be economically integrated with measured, interoperable software components on general-purpose hardware. OpenXT is an open-source showcase for this scalable ecosystem. Further work is planned on reference architectures for measured disaggregation with Xen and OpenEmbedded Linux.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog//event/elce/2017/10/device-we-trust-measure-twice-compute-once-xen-linux-tpm-20-and-txt
|
||||
|
||||
作者:[RICH PERSAUD][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/rpersaud
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://en.wikipedia.org/wiki/Turtles_all_the_way_down
|
||||
[3]:https://layers.openembedded.org/layerindex/branch/master/layer/meta-measured/
|
||||
[4]:https://www.linux.com/files/images/puzzlejpg
|
||||
[5]:http://mailchi.mp/iotpodcast/stacey-on-iot-if-ge-cant-master-industrial-iot-who-can
|
||||
[6]:https://www.xenproject.org/directory/directory/research/45-breaking-up-is-hard-to-do-security-and-functionality-in-a-commodity-hypervisor.html
|
||||
[7]:http://openxt.org/
|
||||
[8]:https://wiki.xenproject.org/wiki/Category:OpenEmbedded
|
||||
[9]:https://wiki.xenproject.org/wiki/Unikernels
|
||||
[10]:http://www.cs.unh.edu/~it666/reading_list/Hardware/tpm_fundamentals.pdf
|
||||
[11]:https://developer.arm.com/technologies/trustzone
|
||||
[12]:https://www.arm.com/products/processors/technologies/trustzone/tee-smc.php
|
||||
[13]:http://mista.nu/research/sep-paper.pdf
|
||||
[14]:https://www.blackhat.com/docs/us-16/materials/us-16-Mandt-Demystifying-The-Secure-Enclave-Processor.pdf
|
||||
[15]:https://link.springer.com/book/10.1007/978-1-4302-6572-6
|
||||
[16]:https://fosdem.org/2017/schedule/event/tpm2/attachments/slides/1517/export/events/attachments/tpm2/slides/1517/FOSDEM___TPM2_0_practical_usage.pdf
|
||||
[17]:https://mjg59.dreamwidth.org/48897.html
|
||||
[18]:https://docs.microsoft.com/en-us/windows/threat-protection/secure-the-windows-10-boot-process
|
||||
[19]:https://www.intel.com/content/www/us/en/software-developers/intel-txt-software-development-guide.html
|
||||
[20]:http://support.amd.com/TechDocs/24593.pdf
|
||||
[21]:https://www.cs.unc.edu/~reiter/papers/2008/EuroSys.pdf
|
||||
[22]:http://invisiblethingslab.com/resources/bh09dc/Attacking%20Intel%20TXT%20-%20paper.pdf
|
||||
[23]:https://firmware.intel.com/content/smi-transfer-monitor-stm
|
||||
[24]:https://software.intel.com/en-us/blogs/2015/02/20/tricky-world-securing-firmware
|
||||
[25]:https://openxt.atlassian.net/wiki/spaces/OD/pages/96567309/OpenXT+7.x+Builds
|
||||
[26]:https://openxt.atlassian.net/wiki/spaces/DC/pages/81035265/Measured+Launch
|
||||
[27]:https://openxt.atlassian.net/wiki/spaces/OD/pages/96436271/OpenXT+6.x+Builds
|
||||
[28]:http://qubes-os.org/
|
||||
[29]:http://openxt.org/
|
||||
[30]:https://en.m.wikipedia.org/wiki/Self-similarity
|
||||
93
sources/tech/20171011 Why Linux Works.md
Normal file
93
sources/tech/20171011 Why Linux Works.md
Normal file
@ -0,0 +1,93 @@
|
||||
Why Linux Works
|
||||
============================================================
|
||||
|
||||
_Amid the big cash and fierce corporate jockeying around Linux, it’s the developers who truly give the operating system its vitality._
|
||||
|
||||
The [Linux community][7] works, it turns out, because the Linux community isn’t too concerned about work, per se. As much as Linux has come to dominate many areas of corporate computing – from HPC to mobile to cloud – the engineers who write the Linux kernel tend to focus on the code itself, rather than their corporate interests therein.
|
||||
|
||||
Such is one prominent conclusion that emerges from [Dawn Foster’s doctoral work][8], examining collaboration on the Linux kernel. Foster, a former community lead at Intel and Puppet Labs, notes, “Many people consider themselves a Linux kernel developer first, an employee second.”
|
||||
|
||||
With all the “foundation washing” corporations have inflicted upon various open source projects, hoping to hide corporate prerogatives behind a mask of supposed community, Linux has managed to keep itself pure. The question is how.
|
||||
|
||||
**Follow the Money**
|
||||
|
||||
After all, if any open source project should lend itself to corporate greed, it’s Linux. Back in 2008, [the Linux ecosystem was estimated to top $25 billion in value][9]. Nearly 10 years later, that number must be multiples bigger, with much of our current cloud, mobile, and big data infrastructure dependent on Linux. Even within a single company like Oracle, Linux delivers billions of dollars in value.
|
||||
|
||||
Small wonder, then, that there’s such a landgrab to influence the direction of Linux through code.
|
||||
|
||||
Take a look at the most active contributors to Linux over the last year and it’s enterprise “turtles” all the way down, as captured in the [Linux Foundation’s latest report][10]:
|
||||
|
||||

|
||||
|
||||
Each of these corporations spends significant quantities of cash to pay developers to contribute free software, and each is banking on a return on these investments. Because of the potential for undue corporate influence over Linux, [some have cried foul][11] on the supposed shepherd of Linux development, the Linux Foundation. This criticism has become more pronounced of late as erstwhile enemies of open source like Microsoft have bought their way into the Linux Foundation.
|
||||
|
||||
But this is a false foe and, frankly, an outdated one.
|
||||
|
||||
While it’s true that corporate interests line up to throw cash at the Linux Foundation, it’s just as true that this cash doesn’t buy them influence over code. In the best open source communities, cash helps to fund developers, but those developers in turn focus on code before corporation. As Linux Foundation executive director [Jim Zemlin has stressed][12]:
|
||||
|
||||
“The technical roles in our projects are separate from corporations. No one’s commits are tagged with their corporate identity: code talks loudest in Linux Foundation projects. Developers in our projects can move from one firm to another and their role in the projects will remain unchanged. Subsequent commercial or government adoption of that code creates value, which in turn can be reinvested in a project. This virtuous cycle benefits all, and is the goal of any of our projects.”
|
||||
|
||||
Anyone that has read [Linus Torvalds’][13] mailing list commentaries can’t possibly believe that he’s a dupe of this or that corporation. The same holds true for other prominent contributors. While they are almost universally employed by big corporations, it’s generally the case that the corporations pay developers for work they’re already predisposed to do and, in fact, are doing.
|
||||
|
||||
After all, few corporations would have the patience or risk profile necessary to fund a bunch of newbie Linux kernel hackers and wait around for years for some of them to _maybe_ contribute enough quality code to merit a position of influence on the kernel team. So they opt to hire existing, trusted developers. As noted in the [2016 Linux Foundation report][14], “The number of unpaid developers continue[d] its slow decline, as Linux kernel development proves an increasingly valuable skill sought by employers, ensuring experienced kernel developers do not stay unpaid for long.”
|
||||
|
||||
Such trust is bought with code, however, not corporate cash. So none of those Linux kernel developers is going to sell out the trust they’ve earned for a brief stint of cash that will quickly fade when an emerging conflict of interest compromises the quality of their code. It makes no sense.
|
||||
|
||||
**Not Kumbaya, but not Game of Thrones, Either**
|
||||
|
||||
Ultimately, Linux kernel development is about identity, something Foster’s research calls out.
|
||||
|
||||
Working for Google may be nice, and perhaps carries with it a decent title and free drycleaning. Being the maintainer for a key subsystem of the Linux kernel, however, is even harder to come by and carries with it the promise of assured, highly lucrative employment by any number of companies.
|
||||
|
||||
As Foster writes, “Even when they enjoy their current job and like their employer, most [Linux kernel developers] tend to look at the employment relationship as something temporary, whereas their identity as a kernel developer is viewed as more permanent and more important.”
|
||||
|
||||
Because of this identity as a Linux kernel developer first, and corporate citizen second, Linux kernel developers can comfortably collaborate even with their employer’s fiercest competitors. This works because the employers ultimately have limited ability to steer their developers’ work, for reasons noted above. Foster delves into this issue:
|
||||
|
||||
“Although companies do sometimes influence the areas where their employees contribute, individuals have quite a bit of freedom in how they do the work. Many receive little direction for their day-to-day work, with a high degree of trust from their employers to do useful work. However, occasionally they are asked to do some specific piece of work or to take an interest in a particular area that is important for the company.
|
||||
|
||||
Many kernel developers also collaborate with their competitors on a regular basis, where they interact with each other as individuals without focusing on the fact that their employers compete with each other. This was something I saw a lot of when I was working at Intel, because our kernel developers worked with almost all of our major competitors.”
|
||||
|
||||
The corporations may compete on chips that run Linux, or distributions of Linux, or other software enabled by a robust operating system, but the developers focus on just one thing: making the best Linux possible. Again, this works because their identity is tied to Linux, not the firewall they sit behind while they code.
|
||||
|
||||
Foster has illustrated this interaction for the USB subsystem mailing list (between 2013 and 2015), with darker lines portraying heavier email interaction between companies:
|
||||
|
||||

|
||||
|
||||
In pricing discussions the obvious interaction between a number of companies might raise suspicions among antitrust authorities, but in Linux land it’s simply business as usual. This results in a better OS for all the parties to go out and bludgeon each other with in free market competition.
|
||||
|
||||
**Finding the Right Balance**
|
||||
|
||||
Such “coopetition,” as Novell founder Ray Noorda might have styled it, exists among the best open source communities, but only works where true community emerges. It’s tough, for example, for a project dominated by a single vendor to achieve the right collaborative tension. [Kubernetes][15], launched by Google, suggests it’s possible, but other projects like Docker have struggled to reach the same goal, in large part because they have been unwilling to give up technical leadership over their projects.
|
||||
|
||||
Perhaps Kubernetes worked so well because Google didn’t feel the need to dominate and, in fact, _wants_ other companies to take on the mantle of development leadership. With a fantastic code base that solves a major industry need, a project like Kubernetes is well-positioned to succeed so long as Google both helps to foster it and then gets out of the way, which it has, encouraging significant contributions from Red Hat and others.
|
||||
|
||||
Kubernetes, however, is the exception, just as Linux was before it. To succeed _because of_ corporate greed, there has to be a lot of it, and balanced between competing interests. If a project is governed by just one company’s self-interest, generally reflected in its technical governance, no amount of open source licensing will be enough to shake it free of that corporate influence.
|
||||
|
||||
Linux works, in short, because so many companies want to control it and can’t, due to its industry importance, making it far more profitable for a developer to build her career as a _Linux developer_ rather than a Red Hat (or Intel or Oracle or…) engineer.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datamation.com/open-source/why-linux-works.html
|
||||
|
||||
作者:[Matt Asay][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.datamation.com/author/Matt-Asay-1133910.html
|
||||
[1]:https://www.datamation.com/feedback/https://www.datamation.com/open-source/why-linux-works.html
|
||||
[2]:https://www.datamation.com/author/Matt-Asay-1133910.html
|
||||
[3]:https://www.datamation.com/e-mail/https://www.datamation.com/open-source/why-linux-works.html
|
||||
[4]:https://www.datamation.com/print/https://www.datamation.com/open-source/why-linux-works.html
|
||||
[5]:https://www.datamation.com/open-source/why-linux-works.html#comment_form
|
||||
[6]:https://www.datamation.com/author/Matt-Asay-1133910.html
|
||||
[7]:https://www.datamation.com/open-source/
|
||||
[8]:https://opensource.com/article/17/10/collaboration-linux-kernel
|
||||
[9]:http://www.osnews.com/story/20416/Linux_Ecosystem_Worth_25_Billion
|
||||
[10]:https://www.linux.com/publications/linux-kernel-development-how-fast-it-going-who-doing-it-what-they-are-doing-and-who-5
|
||||
[11]:https://www.datamation.com/open-source/the-linux-foundation-and-the-uneasy-alliance.html
|
||||
[12]:https://thenewstack.io/linux-foundation-critics/
|
||||
[13]:https://github.com/torvalds
|
||||
[14]:https://www.linux.com/publications/linux-kernel-development-how-fast-it-going-who-doing-it-what-they-are-doing-and-who-5
|
||||
[15]:https://kubernetes.io/
|
||||
@ -0,0 +1,78 @@
|
||||
translating by sugarfillet
|
||||
Linux Networking Hardware for Beginners: Think Software
|
||||
============================================================
|
||||
|
||||

|
||||
Without routers and bridges, we would be lonely little islands; learn more in this networking tutorial.[Creative Commons Zero][3]Pixabay
|
||||
|
||||
Last week, we learned about [LAN (local area network) hardware][7]. This week, we'll learn about connecting networks to each other, and some cool hacks for mobile broadband.
|
||||
|
||||
### Routers
|
||||
|
||||
Network routers are everything in computer networking, because routers connect networks. Without routers we would be lonely little islands. Figure 1 shows a simple wired LAN (local area network) with a wireless access point, all connected to the Internet. Computers on the LAN connect to an Ethernet switch, which connects to a combination firewall/router, which connects to the big bad Internet through whatever interface your Internet service provider (ISP) provides, such as cable box, DSL modem, satellite uplink...like everything in computing, it's likely to be a box with blinky lights. When your packets leave your LAN and venture forth into the great wide Internet, they travel from router to router until they reach their destination.
|
||||
|
||||
### [fig-1.png][4]
|
||||
|
||||

|
||||
Figure 1: A simple wired LAN with a wireless access point.[Used with permission][1]
|
||||
|
||||
A router can look like pretty much anything: a nice little specialized box that does only routing and nothing else, a bigger box that provides routing, firewall, name services, and VPN gateway, a re-purposed PC or laptop, a Raspberry Pi or Arduino, stout little single-board computers like PC Engines...for all but the most demanding uses, ordinary commodity hardware works fine. The highest-end routers use specialized hardware that is designed to move the maximum number of packets per second. They have multiple fat data buses, multiple CPUs, and super-fast memory. (Look up Juniper and Cisco routers to see what high-end routers look like, and what's inside.)
|
||||
|
||||
A wireless access point connects to your LAN either as an Ethernet bridge or a router. A bridge extends the network, so hosts on both sides of the bridge are on the same network. A router connects two different networks.
|
||||
|
||||
### Network Topology
|
||||
|
||||
There are multitudes of ways to set up your LAN. You can put all hosts on a single flat network. You can divide it up into different subnets. You can divide it into virtual LANs, if your switch supports this.
|
||||
|
||||
A flat network is the simplest; just plug everyone into the same switch. If one switch isn't enough you can connect switches to each other. Some switches have special uplink ports, some don't care which ports you connect, and you may need to use a crossover Ethernet cable, so check your switch documentation.
|
||||
|
||||
Flat networks are the easiest to administer. You don't need routers and don't have to calculate subnets, but there are some downsides. They don't scale, so when they get too large they get bogged down by broadcast traffic. Segmenting your LAN provides a bit of security, and makes it easier to manage larger networks by dividing it into manageable chunks. Figure 2 shows a simplified LAN divided into two subnets: internal wired and wireless hosts, and one for servers that host public services. The subnet that contains the public-facing servers is called a DMZ, demilitarized zone (ever notice all the macho terminology for jobs that are mostly typing on a computer?) because it is blocked from all internal access.
|
||||
|
||||
### [fig-2.png][5]
|
||||
|
||||

|
||||
Figure 2: A simplified LAN divided into two subnets.[Used with permission][2]
|
||||
|
||||
Even in a network as small as Figure 2 there are several ways to set it up. You can put your firewall and router on a single device. You could have a dedicated Internet link for the DMZ, divorcing it completely from your internal network. Which brings us to our next topic: it's all software.
|
||||
|
||||
### Think Software
|
||||
|
||||
You may have noticed that of the hardware we have discussed in this little series, only network interfaces, switches, and cabling are special-purpose hardware. Everything else is general-purpose commodity hardware, and it's the software that defines its purpose. Linux is a true networking operating system, and it supports a multitude of network operations: VLANs, firewall, router, Internet gateway, VPN gateway, Ethernet bridge, Web/mail/file/etc. servers, load-balancer, proxy, quality of service, multiple authenticators, trunking, failover...you can run your entire network on commodity hardware with Linux. You can even use Linux to simulate an Ethernet switch with LISA (LInux Switching Appliance) and vde2.
|
||||
|
||||
There are specialized distributions for small hardware like DD-WRT, OpenWRT, and the Raspberry Pi distros, and don't forget the BSDs and their specialized offshoots like the pfSense firewall/router, and the FreeNAS network-attached storage server.
|
||||
|
||||
You know how some people insist there is a difference between a hardware firewall and a software firewall? There isn't. That's like saying there is a hardware computer and a software computer.
|
||||
|
||||
### Port Trunking and Ethernet Bonding
|
||||
|
||||
Trunking and bonding, also called link aggregation, is combining two Ethernet channels into one. Some Ethernet switches support port trunking, which is combining two switch ports to combine their bandwidth into a single link. This is a nice way to make a bigger pipe to a busy server.
|
||||
|
||||
You can do the same thing with Ethernet interfaces, and the bonding driver is built-in to the Linux kernel, so you don't need any special hardware.
|
||||
|
||||
### Bending Mobile Broadband to your Will
|
||||
|
||||
I expect that mobile broadband is going to grow in the place of DSL and cable Internet. I live near a city of 250,000 population, but outside the city limits good luck getting Internet, even though there is a large population to serve. My little corner of the world is 20 minutes from town, but it might as well be the moon as far as Internet service providers are concerned. My only option is mobile broadband; there is no dialup, satellite Internet is sold out (and it sucks), and haha lol DSL, cable, or fiber. That doesn't stop ISPs from stuffing my mailbox with flyers for Xfinity and other high-speed services my area will never see.
|
||||
|
||||
I tried AT&T, Verizon, and T-Mobile. Verizon has the strongest coverage, but Verizon and AT&T are expensive. I'm at the edge of T-Mobile coverage, but they give the best deal by far. To make it work, I had to buy a weBoost signal booster and ZTE mobile hotspot. Yes, you can use a smartphone as a hotspot, but the little dedicated hotspots have stronger radios. If you're thinking you might want a signal booster, I have nothing but praise for weBoost because their customer support is superb, and they will do their best to help you. Set it up with the help of a great little app that accurately measures signal strength, [SignalCheck Pro][8]. They have a free version with fewer features; spend the two bucks to get the pro version, you won't be sorry.
|
||||
|
||||
The little ZTE hotspots serve up to 15 hosts and have rudimentary firewalls. But we can do better: get something like the Linksys WRT54GL, replace the stock firmware with Tomato, OpenWRT, or DD-WRT, and then you have complete control of your firewall rules, routing, and any other services you want to set up.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/10/linux-networking-hardware-beginners-think-software
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[4]:https://www.linux.com/files/images/fig-1png-7
|
||||
[5]:https://www.linux.com/files/images/fig-2png-4
|
||||
[6]:https://www.linux.com/files/images/soderskar-islandjpg
|
||||
[7]:https://www.linux.com/learn/intro-to-linux/2017/10/linux-networking-hardware-beginners-lan-hardware
|
||||
[8]:http://www.bluelinepc.com/signalcheck/
|
||||
@ -0,0 +1,94 @@
|
||||
Q. Why's Oracle so two-faced over open source? A. Moolah, wonga, dosh
|
||||
============================================================
|
||||
|
||||
### And lobbying US government against it is NOT modernising IT
|
||||
|
||||

|
||||
|
||||
Oracle loves open source. Except when the database giant hates open source. Which, according to its recent lobbying of the US federal government, seems to be "most of the time".
|
||||
|
||||
Yes, Oracle has recently joined the Cloud Native Computing Foundation (CNCF) to up its support for open-source Kubernetes and, yes, it has long supported (and contributed to) Linux. And, yes, Oracle has even gone so far as to (finally) open up Java development by putting it under a foundation's stewardship.
|
||||
|
||||
Yet this same, seemingly open Oracle has actively hammered the US government to consider that "there is no math that can justify open source from a cost perspective as the cost of support plus the opportunity cost of forgoing features, functions, automation and security overwhelm any presumed cost savings."
|
||||
|
||||
That punch to the face was delivered in a letter to Christopher Liddell, a former Microsoft CFO and now director of Trump's American Technology Council, by Kenneth Glueck, Oracle senior vice president.
|
||||
|
||||
The US government had courted input on its IT modernisation programme. Others writing back to Liddell included AT&T, Cisco, Microsoft and VMware.
|
||||
|
||||
In other words, based on its letter, what Oracle wants us to believe is that open source leads to greater costs and poorly secured, limply featured software. Nor is Oracle content to leave it there, also arguing that open source is exactly how the private sector does _not_ function, seemingly forgetting that most of the leading infrastructure, big data, and mobile software today is open source.
|
||||
|
||||
Details!
|
||||
|
||||
Rather than take this counterproductive detour into self-serving silliness, Oracle would do better to follow Microsoft's path. Microsoft, too, used to Janus-face its way through open source, simultaneously supporting and bashing it. Only under chief executive Satya Nadella's reign did Microsoft realise it's OK to fully embrace open source, and its financial results have loved the commitment. Oracle has much to learn, and emulate, in Microsoft's approach.
|
||||
|
||||
### I love you, you're perfect. Now change
|
||||
|
||||
Oracle has never been particularly warm and fuzzy about open source. As founder Larry Ellison might put it, Oracle is a profit-seeking corporation, not a peace-loving charity. To the extent that Oracle embraces open source, therefore it does so for financial reward, just like every other corporation.
|
||||
|
||||
Few, however, are as blunt as Oracle about this fact of corporate open-source life. As Ellison told the _Financial Times_ back in 2006: "If an open-source product gets good enough, we'll simply take it. So the great thing about open source is nobody owns it – a company like Oracle is free to take it for nothing, include it in our products and charge for support, and that's what we'll do.
|
||||
|
||||
"So it is not disruptive at all – you have to find places to add value. Once open source gets good enough, competing with it would be insane... We don't have to fight open source, we have to exploit open source."
|
||||
|
||||
"Exploit" sounds about right. While Oracle doesn't crack the top-10 corporate contributors to the Linux kernel, it does register a respectable number 12, which helps it influence the platform enough to feel comfortable building its IaaS offering on Linux (and Xen for virtualisation). Oracle has also managed to continue growing MySQL's clout in the industry while improving it as a product and business. As for Kubernetes, Oracle's decision to join the CNCF also came with P&L strings attached. "CNCF technologies such as Kubernetes, Prometheus, gRPC and OpenTracing are critical parts of both our own and our customers' development toolchains," [said Mark Cavage][3], vice president of software development at Oracle.
|
||||
|
||||
One can argue that Oracle has figured out the exploitation angle reasonably well.
|
||||
|
||||
This, however, refers to the right kind of exploitation, the kind that even free software activist Richard Stallman can love (or, at least, tolerate). But when it comes to government lobbying, Oracle looks a lot more like Mr Hyde than Dr Jekyll.
|
||||
|
||||
### Lies, damned lies, and Oracle lobbying
|
||||
|
||||
The current US president has many problems (OK, _many, many_ problems), but his decision to follow the Obama administration's support for IT modernisation is commendable. Most recently, the Trump White House asked for [feedback][4] on how best to continue improving government IT. Oracle's [response][5] is high comedy in many respects.
|
||||
|
||||
As TechDirt's Mike Masnick [summarises][6], Oracle's "latest crusade is against open-source technology being used by the federal government – and against the government hiring people out of Silicon Valley to help create more modern systems. Instead, Oracle would apparently prefer the government just give it lots of money." Oracle is very good at making lots of money. As such, its request for even more isn't too surprising.
|
||||
|
||||
What is surprising is the brazenness of its position. As Masnick opines: "The sheer contempt found in Oracle's submission on IT modernization is pretty stunning." Why? Because Oracle contradicts much that it publicly states in other forums about open source and innovation. More than this, Oracle contradicts much of what we now know is essential to competitive differentiation in an increasingly software and data-driven world.
|
||||
|
||||
Take, for example, Oracle's contention that "significant IT development expertise is not... central to successful modernization efforts".
|
||||
|
||||
What? In our "software is eating the world" existence Oracle clearly believes that CIOs are buyers, not doers: "The most important skill set of CIOs today is to critically compete and evaluate commercial alternatives to capture the benefits of innovation conducted at scale, and then to manage the implementation of those technologies efficiently."
|
||||
|
||||
While there is some truth to Oracle's claim – every project shouldn't be a custom one-off that must be supported forever – it's crazy to think that a CIO – government or otherwise – is doing their job effectively by simply shovelling cash into vendors' bank accounts.
|
||||
|
||||
Indeed, as Masnick points out: "If it weren't for Oracle's failures, there might not even be a USDS [the US Digital Service created in 2014 to modernise federal IT]. USDS really grew out of the emergency hiring of some top-notch internet engineers in response to the Healthcare.gov rollout debacle. And if you don't recall, a big part of that debacle was blamed on Oracle's technology."
|
||||
|
||||
In short, [blindly giving money to Oracle][7] and other big vendors is the opposite of IT modernisation.
|
||||
|
||||
In its letter to Liddell, Oracle proceeded to make the fantastic (by which I mean "silly and false") claim that "the fact is that the use of open-source software has been declining rapidly in the private sector". What?!? This is so incredibly untrue that Oracle should score points for being willing to say it out loud. Take a stroll through the most prominent software in big data (Hadoop, Spark, Kafka, etc.), mobile (Android), application development (Kubernetes, Docker), machine learning/AI (TensorFlow, MxNet), and compare it to Oracle's statement. One conclusion must be that Oracle believes its CIO audience is incredibly stupid.
|
||||
|
||||
Oracle then tells a half-truth by declaring: "There is no math that can justify open source from a cost perspective." How so? Because "the cost of support plus the opportunity cost of forgoing features, functions, automation and security overwhelm any presumed cost savings." Which I guess is why Oracle doesn't use any open source like Linux, Kubernetes, etc. in its services.
|
||||
|
||||
Oops.
|
||||
|
||||
### The Vendor Formerly Known As Satan
|
||||
|
||||
The thing is, Oracle doesn't need to do this and, for its own good, shouldn't do this. After all, we already know how this plays out. We need only look at what happened with Microsoft.
|
||||
|
||||
Remember when Microsoft wanted us to "[get the facts][8]" about Linux? Now it's a big-time contributor to Linux. Remember when it told us open source was anti-American and a cancer? Now it aggressively contributes to a huge variety of open-source projects, some of them homegrown in Redmond, and tells the world that "Microsoft [loves][9] open source." Of course, Microsoft loves open source for the same reason any corporation does: it drives revenue as developers look to build applications filled with open-source components on Azure. There's nothing wrong with that.
|
||||
|
||||
Would Microsoft prefer government IT to purchase SQL Server instead of open-source-licensed PostgreSQL? Sure. But look for a [single line][10] in its response to the Trump executive order that signals "open source is bad". You won't find it. Why? Because Microsoft understands that open source is a friend, not foe, and has learned how to monetise it.
|
||||
|
||||
Microsoft, in short, is no longer conflicted about open source. It can compete at the product level while embracing open source at the project level, which helps fuel its overall product and business strategy. Oracle isn't there yet, and is still stuck where Microsoft was a decade ago.
|
||||
|
||||
It's time to grow up, Oracle. For a company that builds great software and understands that it increasingly needs to depend on open source to build that software, it's disingenuous at best to lobby the US government to put the freeze on open source. Oracle needs to learn from Microsoft, stop worrying and love the open-source bomb. It was a key ingredient in Microsoft's resurgence. Maybe it could help Oracle get a cloud clue, too.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.theregister.co.uk/2017/10/12/oracle_must_grow_up_on_open_source/
|
||||
|
||||
作者:[ Matt Asay ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.theregister.co.uk/Author/2905
|
||||
[1]:https://www.theregister.co.uk/Author/2905
|
||||
[2]:https://forums.theregister.co.uk/forum/1/2017/10/12/oracle_must_grow_up_on_open_source/
|
||||
[3]:https://www.oracle.com/corporate/pressrelease/oracle-joins-cncf-091317.html
|
||||
[4]:https://www.whitehouse.gov/the-press-office/2017/05/11/presidential-executive-order-strengthening-cybersecurity-federal
|
||||
[5]:https://github.com/GSA/modernization/issues/41
|
||||
[6]:https://www.techdirt.com/articles/20170930/00522238319/oracle-tells-white-house-stop-hiring-silicon-valley-people-ditch-open-source.shtml
|
||||
[7]:http://www.nytimes.com/2013/12/01/us/politics/inside-the-race-to-rescue-a-health-site-and-obama.html?pagewanted=all
|
||||
[8]:http://www.zdnet.com/article/microsoft-kills-its-get-the-facts-anti-linux-site/
|
||||
[9]:https://channel9.msdn.com/Events/Ignite/2016/BRK2158
|
||||
[10]:https://github.com/GSA/modernization/issues/98
|
||||
@ -0,0 +1,79 @@
|
||||
6 reasons open source is good for business
|
||||
============================================================
|
||||
|
||||
### Here's why businesses should choose the open source model.
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
At a fundamental level, open source solutions are better than proprietary ones. Want to know why? Here are six reasons why businesses and government organizations benefit from using open source technology.
|
||||
|
||||
### 1\. Easier vendor vetting
|
||||
|
||||
Before you invest engineering and financial resources in integrating a product into your infrastructure, you need to know you picked the right one. You want a product that is actively developed, one that brings regular security updates and bugfixes as well as innovations when your business needs them. This last point is more important than you might think: yes, a solution has to fit your requirements. But requirements change as the market matures and your business evolves. If the product doesn't change with them, you have a costly migration ahead.
|
||||
|
||||
How do you know you're not putting your time and money into a product that is dying? In open source, you don't have to take a vendor at its word. You can compare vendors by looking at the [development velocity and health of the community][3] that's developing it. A more active, diverse, and healthy community will result in a better product one or two years down the line—an important thing to consider. Of course, as this [blog about enterprise open source][4] points out, the vendor must be capable of handling the instability that comes from innovation within the development project. Look for a vendor with a long support cycle to avoid that upgrade mill.
|
||||
|
||||
### 2\. Longevity from independence
|
||||
|
||||
Forbes notes that [90% of all startups fail][5] and less than half of small and midsize businesses survive beyond five years. Whenever you have to migrate to a new vendor, you incur huge costs, so it's best to avoid products that only one vendor can sustain.
|
||||
|
||||
Open source enables communities to build software collaboratively. For example, OpenStack is [built by dozens of companies and individual volunteers][6], providing customers certainty that, no matter what happens to any individual vendor, there will always be a vendor available to provide support. With open source, a business makes a long-term investment in the development team's efforts to implement the product. Access to the source code ensures that you will always be able to hire someone from the pool of contributors to keep your deployment alive as long as you need it. Of course, without a big, active community there are few contributors to hire from, so the number of people actively contributing is important.
|
||||
|
||||
### 3\. Security
|
||||
|
||||
Security is a complicated thing, which is why open development is a key factor and a precondition for creating secure solutions. And security is getting more important every day. When development happens in the open, you can directly verify if a vendor is actively pursuing security and watch how it treats security issues. The ability to study the source and perform independent code audits makes it possible to find and fix security issues early. Some vendors offer [bug bounties][7] of thousands of dollars as extra incentive for the community to uncover security flaws and to show confidence in their products.
|
||||
|
||||
Beyond code, open development also means open processes, so you can check and see whether a vendor follows baseline industry-standard development processes recommended by ISO27001, [Cloud Security Principles][8] and others. Of course, an external review by a trusted party, like we at Nextcloud did with [the NCC Group][9], offers additional assurance.
|
||||
|
||||
### 4\. More customer focus
|
||||
|
||||
Because users and customers can directly see and get involved in development, open source projects are typically more aligned with their users' needs than closed source software, which often focuses on ticking checkboxes for the marketing team. You will also notice that open source projects tend to develop in a "wider" way. Whereas a commercial vendor might focus on one specific thing, a community has many "irons in the fire" and is working on a wide range of features, all of interest to an individual or small group of contributing companies or individuals. This leads to fewer easily marketable releases, as it isn't all about one thing, rather a mix-and-match of various improvements. But it creates a far more valuable product for the users.
|
||||
|
||||
### 5\. Better support
|
||||
|
||||
A proprietary vendor is often the one and only party who can help you if there are problems. If they don't offer support the way you need it or charge a huge premium for adjustments your business needs, tough luck. Support for proprietary software is a typical "[lemon market][10]." With open source, the vendor either provides great support or others will fill the gap—it's the free market at its finest, ensuring you get the very best support possible.
|
||||
|
||||
### 6\. Better licensing
|
||||
|
||||
Typical software licenses are [full of nasty clauses][11], usually topped off with forced arbitrage so you won't even have a chance to sue if the vendor misbehaves. Part of the problem is that you merely license a right to use the software, often entirely at the vendor's discretion. You get no ownership, nor any rights if the software doesn't work or stops working, or if the vendor demands more payments. Open source licenses like the GPL are specifically designed to protect the customer rather than the vendor, ensuring you get to use the software however you need and without arbitrary limitations, for as long as you like.
|
||||
|
||||
Thanks to their wide usage, the implications of the GPL and its derivative licenses are widely understood. For example, you can be assured that the license allows your existing (open or closed) infrastructure to connect with it through well-defined APIs, has no restrictions on time or number of users, and won't force you to open configurations or intellectual property (e.g., company logos).
|
||||
|
||||
This also makes compliance easier; with proprietary software, you have harsh compliance clauses with large fines. Worse is what happens with some open core products that ship as a mix of GPL and proprietary software; these [can breach a license][12] and put customers at risk. And, as Gartner points out, an open core model means you get [none of the benefits of open source][13]. A pure open source licensed product avoids all these issues. Instead, you have just one compliance rule: If you make modifications to the code (not configuration, logos, or anything like that), you have to share them with those you distribute the software to _if_ they ask.
|
||||
|
||||
Clearly open sou
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jos Poortvliet - People person, technology enthusiast and all-things-open evangelist. Head of marketing at Nextcloud, previously community manager at ownCloud and SUSE and a long time KDE marketing veteran, loves biking through Berlin and cooking for friends and family. Find my [personal blog here][16].
|
||||
|
||||
-----------------
|
||||
|
||||
via: https://opensource.com/article/17/10/6-reasons-choose-open-source-software
|
||||
|
||||
作者:[Jos Poortvliet Feed ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jospoortvliet
|
||||
[1]:https://opensource.com/article/17/10/6-reasons-choose-open-source-software?rate=um7KfpRlV5lROQDtqJVlU4y8lBa9rsZ0-yr2aUd8fXY
|
||||
[2]:https://opensource.com/user/27446/feed
|
||||
[3]:https://nextcloud.com/blog/nextcloud-the-most-active-open-source-file-sync-and-share-project/
|
||||
[4]:http://www.redhat-cloudstrategy.com/open-source-for-business-people/
|
||||
[5]:http://www.forbes.com/sites/neilpatel/2015/01/16/90-of-startups-will-fail-heres-what-you-need-to-know-about-the-10/
|
||||
[6]:http://stackalytics.com/
|
||||
[7]:https://hackerone.com/nextcloud
|
||||
[8]:https://www.ncsc.gov.uk/guidance/implementing-cloud-security-principles
|
||||
[9]:https://nextcloud.com/secure
|
||||
[10]:https://en.wikipedia.org/wiki/The_Market_for_Lemons
|
||||
[11]:http://boingboing.net/2016/11/01/why-are-license-agreements.html
|
||||
[12]:https://www.gnu.org/licenses/gpl-faq.en.html#GPLPluginsInNF
|
||||
[13]:http://blogs.gartner.com/brian_prentice/2010/03/31/open-core-the-emperors-new-clothes/
|
||||
[14]:https://opensource.com/users/jospoortvliet
|
||||
[15]:https://opensource.com/users/jospoortvliet
|
||||
[16]:http://blog.jospoortvliet.com/
|
||||
@ -0,0 +1,166 @@
|
||||
Martin translating
|
||||
|
||||
NixOS Linux Lets You Configure Your OS Before Installing
|
||||
============================================================
|
||||
|
||||

|
||||
Configuration is key to a successful installation of NixOS.[Creative Commons Zero][4]Pixabay
|
||||
|
||||
I’ve been using Linux for a very long time. Over the years, I’ve been incredibly happy with how the open source landscape has evolved. One particular area that has come quite a long way is the installation of various distributions. Once upon a time, installing Linux was a task best left to those who had considerable tech skills. Now, if you can install an app, you can install Linux. It’s that simple. And that, my friends, is a very good thing—especially when it comes to drawing in new users. The fact that you can install the entire Linux operating system faster than a Windows user can run an update says quite a bit.
|
||||
|
||||
But every so often, I like to see something different—something that might remind me from where I came. That’s exactly what happened when I came into [NixOS][9]. To be quite honest, I had assumed this would be just another Linux distribution that offered the standard features, with the KDE Plasma 5 interface.
|
||||
|
||||
Boy was I wrong.
|
||||
|
||||
After [downloading the ISO image][10], I figured up [VirtualBox][11] and created a new virtual machine, using the downloaded image. Once the VM booted, I found myself at a Bash login instructing me that the root account had an empty password and how to start a GUI display manager (Figure 1).
|
||||
|
||||
### [nixos_1.jpg][5]
|
||||
|
||||

|
||||
|
||||
Figure 1: The first contact with NIXOS might be a bit jarring for some.[Used with permission][1]
|
||||
|
||||
“Okay,” I thought, “let’s fire this up and see what happens.”
|
||||
|
||||
Once the GUI was up and running (KDE Plasma 5), I didn’t see the usual “Install” button. Turns out, NixOS is one of those fascinating distributions that has you configure your OS before you install it. Let’s take a look at how that is done.
|
||||
|
||||
### Pre-install configuration
|
||||
|
||||
The first thing you must do is create a partition. Since the NixOS installer doesn’t include a partition tool, you can fire up the included GParted application (Figure 2) and create an EXT4 partition.
|
||||
|
||||
### [nixos_2.jpg][6]
|
||||
|
||||

|
||||
|
||||
Figure 2: Partitioning the drive before installation.[Used with permission][2]
|
||||
|
||||
With your partition created, mount it with the command _mount /dev/sdX /mnt _ (Where sdX is the location of your newly created partition).
|
||||
|
||||
You now must generate a configuration file. To do this, issue the command:
|
||||
|
||||
```
|
||||
nixos-generate-config --root /mnt
|
||||
```
|
||||
|
||||
The above command will create two files (found in the _/mnt/etc/nixos_ directory):
|
||||
|
||||
* configuration.nix — The default configuration file.
|
||||
|
||||
* hardware-configuration.nix — The hardware configuration (this is not to be edited).
|
||||
|
||||
Issue the command _nano /mnt/etc/nixos/configuration.nix_ . Within this file, we need to take care of a few edits. The first change is to set the option for the boot loader. Look for the line:
|
||||
|
||||
```
|
||||
# boot.loader.grub.device = “/dev/sda”; # or “nodev” for efi only
|
||||
```
|
||||
|
||||
Remove the # sign at the beginning of the line to uncomment this option (making sure /dev/sda is the name of your newly created partition).
|
||||
|
||||
Within the configuration file, you can also set your timezone and add packages to be installed. You will see a commented out sample for package installation that looks like:
|
||||
|
||||
```
|
||||
# List packages installed in system profile. To search by name, run:
|
||||
|
||||
# nix-env -aqP | grep wget
|
||||
|
||||
# environment.systemPackages = with pkgs; [
|
||||
|
||||
# wget vim
|
||||
|
||||
# ];
|
||||
```
|
||||
|
||||
If you want to add packages, during installation, comment out that section and add the packages you like. Say, for instance, you want to add LibreOffice into the mix. You could uncomment the above section to reflect:
|
||||
|
||||
```
|
||||
# List packages installed in system profile. To search by name, run:
|
||||
|
||||
nix-env -aqP | grep wget
|
||||
|
||||
environment.systemPackages = with pkgs; [
|
||||
|
||||
libreoffice wget vim
|
||||
|
||||
];
|
||||
```
|
||||
|
||||
You can find the exact name of the package by issuing the command _nix-env -aqP | grep PACKAGENAME _ (where PACKAGENAME is the name of the package you’re looking for). If you don’t want to issue the command, you can always search the [NixOS packages database.][12]
|
||||
|
||||
After you’ve added all the necessary packages, there is one more thing you must do (if you want to be able to log into the desktop. I will assume you’re going to stick with the KDE Plasma 5 desktop. Go to the bottom of the configuration file and add the following before the final } bracket:
|
||||
|
||||
```
|
||||
services.xserver = {
|
||||
|
||||
enable = true;
|
||||
|
||||
displayManager.sddm.enable = true;
|
||||
|
||||
desktopManager.plasma5.enable = true;
|
||||
|
||||
};
|
||||
```
|
||||
|
||||
You can find out more options for the configuration file, within the [NixOS official documentation][13]. Save and close the configuration file.
|
||||
|
||||
### Installation
|
||||
|
||||
Once you have your configuration exactly how you like it, issue the command (as the root user) nixos-install. Depending upon how many packages you’ve included for installation, the time it takes to complete this task will vary. When it does complete, you can then issue the command reboot and you will (when the reboot completes) be greeted by the KDE Plasma 5 login manager (Figure 3).
|
||||
|
||||
### [nixos_3.jpg][7]
|
||||
|
||||

|
||||
|
||||
Figure 3: The KDE Plasma 5 login manager.[Used with permission][3]
|
||||
|
||||
### Post-install
|
||||
|
||||
One of the first two things you’ll need to do is give the root user a password (issue the command _passwd_ to change the default) and add a standard user. This is done as you would with any Linux distribution. Log in as the root user and then, at a terminal window, issue the command:
|
||||
|
||||
```
|
||||
useradd -m USER
|
||||
```
|
||||
|
||||
Where USER is the name of the user you want to add. Next give the user a password with the command:
|
||||
|
||||
```
|
||||
passwd USER
|
||||
```
|
||||
|
||||
Where USER is the name of the user just added. You will be prompted to type and verify the new password. You can then log into NixOS as that standard user.
|
||||
|
||||
Once you have NixOS installed and running, you can then add new packages to the system, but not via the standard means. If you find you need to install something new, you have to go back to the configuration file (which is now located in _/etc/nixos/_ ), add the packages in the same location you did prior to installation, and then issue the command (as root):
|
||||
|
||||
```
|
||||
nixos-rebuild switch
|
||||
```
|
||||
|
||||
Once the command completes, you can then use the newly installed packages.
|
||||
|
||||
### Enjoy NixOS
|
||||
|
||||
At this point, NixOS is up and running, with all the software you need and the KDE Plasma 5 desktop interface. Not only have you installed Linux, but you’ve installed a Linux distribution customized to meet your exact needs. Enjoy the experience and enjoy NixOS.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/10/nixos-linux-lets-you-configure-your-os-installing
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[5]:https://www.linux.com/files/images/nixos1jpg
|
||||
[6]:https://www.linux.com/files/images/nixos2jpg
|
||||
[7]:https://www.linux.com/files/images/nixos3jpg
|
||||
[8]:https://www.linux.com/files/images/configurationjpg
|
||||
[9]:https://nixos.org/
|
||||
[10]:https://nixos.org/nixos/download.html
|
||||
[11]:https://www.virtualbox.org/wiki/Downloads
|
||||
[12]:https://nixos.org/nixos/packages.html
|
||||
[13]:https://nixos.org/nixos/manual/index.html#ch-configuration
|
||||
@ -0,0 +1,62 @@
|
||||
translating---geekpi
|
||||
|
||||
What is Grafeas? Better auditing for containers
|
||||
============================================================
|
||||
|
||||
### Google's Grafeas provides a common API for metadata about containers, from image and build details to security vulnerabilities
|
||||
|
||||

|
||||
Thinkstock
|
||||
|
||||
The software we run has never been more difficult to vouchsafe than it is today. It is scattered between local deployments and cloud services, built with open source components that aren’t always a known quantity, and delivered on a fast-moving schedule, making it a challenge to guarantee safety or quality.
|
||||
|
||||
The end result is software that is hard to audit, reason about, secure, and manage. It is difficult not just to know what a VM or container was built with, but what has been added or removed or changed and by whom. [Grafeas][5], originally devised by Google, is intended to make these questions easier to answer.
|
||||
|
||||
|
||||
### What is Grafeas?
|
||||
|
||||
Grafeas is an open source project that defines a metadata API for software components. It is meant to provide a uniform metadata schema that allows VMs, containers, JAR files, and other software artifacts to describe themselves to the environments they run in and to the users that manage them. The goal is to allow processes like auditing the software used in a given environment, and auditing the changes made to that software, to be done in a consistent and reliable way.
|
||||
|
||||
Grafeas provides APIs for two kinds of metadata, notes and occurrences:
|
||||
|
||||
|
||||
* Notesare details about some aspect of the software artifact in question. This can be a description of a known software vulnerability, details about how the software was built (the builder version, its checksum, etc.), a history of its deployment, and so on.
|
||||
|
||||
* Occurrences are instances of notes, with details about where and how they were created. Details of a known software vulnerability, for instance, could have occurrence information describing which vulnerability scanner detected it, when it was detected, and whether or not the vulnerability has been addressed.
|
||||
|
||||
Both notes and occurrences are stored in a repository. Each note and occurrence is tracked using an identifier that distinguishes it and makes it unique.
|
||||
|
||||
The Grafeas spec includes several basic schemas for types of notes. The package vulnerability schema, for instance, describes how to store note information for a CVE or vulnerability description. Right now there is no formal process for accepting new schema types, but [plans are on the table][6] for creating such a process.
|
||||
|
||||
### Grafeas clients and third-party support
|
||||
|
||||
Right now, Grafeas exists mainly as a spec and a reference implementation, [available on GitHub][7]. Clients for [Go][8], [Python][9], and [Java ][10]are all available, [generated by Swagger][11], so clients for other languages shouldn’t be hard to produce.
|
||||
|
||||
One key way Google plans to allow Grafeas to be widely used is through Kubernetes. A policy engine for Kubernetes, called Kritis, allows actions to be taken on containers based on their Grafeas metadata.
|
||||
|
||||
Several companies in addition to Google have announced plans for adding Grafeas support to existing products. CoreOS, for instance, is looking at how Grafeas can be integrated with Tectonic, and both [Red Hat][12] and [IBM][13] are planning to add Grafeas integrations to their container products and services.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.infoworld.com/article/3230462/security/what-is-grafeas-better-auditing-for-containers.html
|
||||
|
||||
作者:[Serdar Yegulalp ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.infoworld.com/author/Serdar-Yegulalp/
|
||||
[1]:https://www.infoworld.com/author/Serdar-Yegulalp/
|
||||
[2]:https://www.infoworld.com/author/Serdar-Yegulalp/
|
||||
[3]:https://www.infoworld.com/article/3207686/cloud-computing/how-to-get-started-with-kubernetes.html#tk.ifw-infsb
|
||||
[4]:https://www.infoworld.com/newsletters/signup.html#tk.ifw-infsb
|
||||
[5]:http://grafeas.io/
|
||||
[6]:https://github.com/Grafeas/Grafeas/issues/38
|
||||
[7]:https://github.com/grafeas/grafeas
|
||||
[8]:https://github.com/Grafeas/client-go
|
||||
[9]:https://github.com/Grafeas/client-python
|
||||
[10]:https://github.com/Grafeas/client-java
|
||||
[11]:https://www.infoworld.com/article/2902750/application-development/manage-apis-with-swagger.html
|
||||
[12]:https://www.redhat.com/en/blog/red-hat-google-cloud-and-other-industry-leaders-join-together-standardize-kubernetes-service-component-auditing-and-policy-enforcement
|
||||
[13]:https://developer.ibm.com/dwblog/2017/grafeas/
|
||||
@ -1,67 +0,0 @@
|
||||
# 为什么 DevOps 是我们所知道的安全的终结
|
||||
|
||||

|
||||
|
||||
安全可能是一个艰难的销售。在企业管理者迫使开发团队尽快发布程序的环境下,很难说服他们花费有限的周期来修补安全漏洞。但是鉴于所有网络攻击中有 84% 发生在应用层,组织无法承担其开发团队不包括安全性带来的后果。
|
||||
|
||||
DevOps 的崛起为许多安全领导者带来了困境。Sonatype 的前 CTO [Josh Corman][2] 说:“这是对安全的威胁,但这是安全变得更好的机会。” Corman 是一个坚定的[整合安全和 DevOps 实践来创建 “坚固的 DevOps”][3]的倡导者。_Business Insights_ 与 Corman 谈论了安全和 DevOps 共同的价值,以及这些共同价值如何帮助组织受到更少受到中断和攻击的影响。
|
||||
|
||||
DevOps 中真正的安全状态是什么?[获取报告][1]
|
||||
|
||||
### 安全和 DevOps 实践如何互惠互利?
|
||||
|
||||
** Josh Corman:** 一个主要的例子是 DevOps 团队对所有可测量的东西进行检测的倾向。安全性一直在寻找更多的情报和遥测。你可以采纳许多 DevOps 团队正在测量的内容, 并将这些信息输入到你的日志管理或 SIEM (安全信息和事件管理系统)。
|
||||
|
||||
一个 OODA 循环(观察、定向、决定、行为)的前提是有足够普遍的眼睛和耳朵, 以注意到窃窃私语和回声。DevOps 为你提供无处不在的仪器。
|
||||
|
||||
### 他们有分享的其他文化态度吗?
|
||||
|
||||
** JC:** “严肃对待你的代码”是一个共同的价值。例如,由 Netflix 编写的软件工具 Chaos Monkey 是 DevOps 团队的分水岭。它是为了测试亚马逊网络服务的弹性和可恢复性,Chaos Monkey 使得 Netflix 团队更加强大,更容易为中断做好准备。
|
||||
|
||||
所以现在有个想法是我们的系统需要测试,因此,James Wickett 和我和其他人决定做一个邪恶的、武装的 Chaos Monkey,这就是 GAUNTLT 项目的来由。它基本上是一堆安全测试, 可以在 DevOps 周期和 DevOps 工具链中使用。它也有非常 DevOps 友好的API。
|
||||
|
||||
### 企业安全和 DevOps 价值在哪里相交?
|
||||
|
||||
** JC:** 两个团队都认为复杂性是一切事情的敌人。例如,[安全人员和坚固 DevOps 人员][4]实际上可以说:“看,我们在我们的项目中使用了 11 个日志框架 - 也许我们不需要那么多,也许攻击面和复杂性可能会让我们受到伤害或者损害产品的质量或可用性。”
|
||||
|
||||
复杂性往往是许多事情的敌人。通常情况下,你不会很难说服 DevOps 团队在架构层面使用更好的建筑材料:使用最新的,最不易受攻击的版本,并使用较少的。
|
||||
|
||||
### “更好的建筑材料”是什么意思?
|
||||
|
||||
** JC:** 我是世界上最大的开源仓库的保管人,所以我能看到他们在使用哪些版本,里面有哪些漏洞,何时不为漏洞进行修复, 以及多久。例如,某些日志记录框架不会修复任何错误。其中一些在 90 天内修复了大部分的安全漏洞。人们越来越多地遭到破坏,因为他们使用了一个没有安全的框架。
|
||||
|
||||
除此之外,即使你不知道日志框架的质量,拥有 11 个不同的框架会变得非常笨重、出现 bug,还有额外的工作和复杂性。你暴露在漏洞中的风险要大得多。你想花时间在修复大量的缺陷上,还是在制造下一个大的破坏性的事情上?
|
||||
|
||||
[坚固的 DevOps 的关键是软件供应链管理][5],其中包含三个原则:使用更少和更好的供应商、使用这些供应商的最高质量的部分、并跟踪这些部分,以便在发生错误时,你可以有一个及时和敏捷的响应。
|
||||
|
||||
### 所以改变管理也很重要。
|
||||
|
||||
** JC:** 是的,这是另一个共同的价值。我发现,当一家公司想要执行诸如异常检测或净流量分析等安全测试时,他们需要知道“正常”的样子。让人们失误的许多基本事情与仓库和补丁管理有关。
|
||||
|
||||
我在 _Verizon 数据泄露调查报告中看到_,去年成功利用 97% 的漏洞追踪后只有 10 个 CVE(常见漏洞和风险),而这 10 个已经被修复了十多年。所以,我们羞于谈论高级间谍活动。我们没有做基本的补丁。现在,我不是说如果你修复这 10 个CVE,那么你就没有被利用,而这占据了人们实际失误的最大份额。
|
||||
|
||||
[DevOps 自动化工具][6]的好处是它们已经成为一个意外的变更管理数据库。这真实反应了谁在哪里什么时候做了更改。这是一个巨大的胜利,因为我们经常对安全性有最大影响的因素无法控制。你承受了 CIO 和 CTO 做出的选择的后果。随着 IT 通过自动化变得更加严格和可重复,你可以减少人为错误的机会,并可在哪里发生变化更加可追溯。
|
||||
|
||||
### 你说什么是最重要的共同价值?
|
||||
|
||||
** JC:** DevOps 涉及过程和工具链,但我认为定义属性是文化,特别是移情。 DevOps 有用是因为开发人员和运维团队更好地了解彼此,并能做出更明智的决策。不是在解决孤岛中的问题,而是为了活动流程和目标解决。如果你向 DevOps 的团队展示安全如何能使他们变得更好,那么作为回馈他们往往会问:“那么, 我们是否有任何选择让你的生活更轻松?”因为他们通常不知道他们做的 X、Y 或 Z 的选择使它无法包含安全性。
|
||||
|
||||
对于安全团队,驱动价值的方法之一是在寻求帮助之前变得更有所帮助,在我们告诉 DevOps 团队要做什么之前提供定性和定量的价值。你必须获得 DevOps 团队的信任,并获得发挥的权利,然后才能得到回报。它通常比你想象的快很多。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://techbeacon.com/why-devops-end-security-we-know-it
|
||||
|
||||
作者:[Mike Barton][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/intent/follow?original_referer=https%3A%2F%2Ftechbeacon.com%2Fwhy-devops-end-security-we-know-it%3Fimm_mid%3D0ee8c5%26cmp%3Dem-webops-na-na-newsltr_20170310&ref_src=twsrc%5Etfw®ion=follow_link&screen_name=mikebarton&tw_p=followbutton
|
||||
[1]:https://techbeacon.com/resources/application-security-devops-true-state?utm_source=tb&utm_medium=article&utm_campaign=inline-cta
|
||||
[2]:https://twitter.com/joshcorman
|
||||
[3]:https://techbeacon.com/want-rugged-devops-team-your-release-security-engineers
|
||||
[4]:https://techbeacon.com/rugged-devops-rsa-6-takeaways-security-ops-pros
|
||||
[5]:https://techbeacon.com/josh-corman-security-devops-how-shared-team-values-can-reduce-threats
|
||||
[6]:https://techbeacon.com/devops-automation-best-practices-how-much-too-much
|
||||
@ -1,95 +0,0 @@
|
||||
LEDE 和 OpenWrt
|
||||
===================
|
||||
|
||||
[OpenWrt][1] 项目可能是最广为人知的 Linux 发行版,对于家用 WiFi 路由器和接入点; 12 年多以前,它产自现在有名的 Linksys WRT54G 路由器的源代码。五月初,OpenWrt 用户社区陷入一片巨大的混乱中,当一群 OpenWrt 代码开发者 [宣布][2] 他们将开始着手 OpenWrt 的一个副产品 (或,可能,一个分支)叫 [Linux 嵌入开发环境][3] (LEDE)时。为什么产生分裂对公众来说并不明朗,而且 LEDE 宣言惊到了一些其他 OpenWrt 开发者也暗示这团队的内部矛盾。
|
||||
|
||||
LEDE 宣言被 Jo-Philipp Wich 于五月三日发往所有 OpenWrt 开发者列表和新 LEDE 开发者列表。它描述 LEDE 为"OpenWrt 社区的一次重启" 和 "OpenWrt 项目的一个副产品" 希望产生一个 Linux 嵌入式开发社区 "注重透明性、合作和权利分散。"
|
||||
|
||||
给出的重启的原因是 OpenWrt 遭受着长期以来存在且不能从内部解决的问题——换句话说,关于内部处理方式和政策。例如,宣言称,开发者的数目在不断减少,却没有接纳新开发者的方式(而且貌似没有授权委托访问给新开发者的方法)。项目架构不可靠(例如,这么多年来服务器挂掉在这个项目中也引发了相当多的矛盾),宣言说到,但是内部不合和单点错误阻止了修复它。内部和从这个项目到外面世界也存在着"交流、透明度和合作"的普遍缺失。最后,一些技术缺陷被引用:不充分的测试、缺乏常规维护,和窘迫的稳固性与文档。
|
||||
|
||||
该宣言继续描述 LEDE 重启将解决这些问题。所有交流频道都会打开供公众使用,决策将在项目范围内投票决出,合并政策将放宽等等。更详细的说明可以在 LEDE 站点的 [rules][4] 页找到。其他特别之处中,它说将贡献者将只有一个阶级(也就是,没有“代码开发者”这样拥有额外权利的群体),简单的少数服从多数投票作出决定,并且任何被这个项目管理的架构必须有三个以上管理员账户。在 LEDE 邮件列表, Hauke Mehrtens [补充][5] 到项目将会努力修补发送上游消息——过去 OpenWrt 被批判的一点,尤其是有关内核。
|
||||
|
||||
除了 Wich,这个宣言被 OpenWrt 贡献者 John Crispin、 Daniel Golle、 Felix Fietkau、 Mehrtens、 Matthias Schiffer 和 Steven Barth 共同创作。以给其他有兴趣参与的人访问 LEDE 站点的邀请为结尾。
|
||||
|
||||
#### 回应和问题
|
||||
|
||||
有人可能会猜想 LEDE 组织者预期他们的宣言会有或积极或消极的反响。毕竟,细读宣言中批判 OpenWrt 项目暗示了有一些 OpenWrt 项目成员 LEDE 阵营发现难以共事(“单点错误” 或 “内部不和”阻止了架构修复,例如)
|
||||
|
||||
并且,确实,有很多消极回应。创立者之一 Mike Baker [回应][6] 了一些警告,反驳所有 LEDE 宣言中的结论并称“短语像‘重启’都是含糊不清且具有误导性的而且 LEDE 项目定义它的真实本质失败了。”与此同时,有人关闭了那些在 LEDE 上署名的开发者在 @openwrt.org 的邮件入口;当 Fietkau [提出反对][7], Baker [回复][8]账户“暂时停用”因为“还不确定 LEDE 代表 OpenWrt。” Imre Kaloz, 另一个 OpenWrt 核心成员,[写][9]到“ LEDE 团队生出了大多数 [破] 事儿”在 OpenWrt 里这就是现在所抱怨的。
|
||||
|
||||
但是大多数 OpenWrt 列表的回应对该宣言表示疑惑。列表成员不明确 LEDE 团队是否将为 OpenWrt [继续贡献][10],或导致了这个分支的机构的[确切本质][11]和内部问题是什么。 Baker的第一反应是后悔在宣言中引用的那些问题缺乏公开讨论:“我们意识到当前的 OpenWrt 项目遭受着许多的问题,”但“我们希望有机会去讨论并尝试着解决”它们。 Baker 作出结论:
|
||||
|
||||
我们强调我们确实希望有一个公开的讨论和解决即将到来的事情。我们的目标是与所有能够且希望对 OpenWrt 作出贡献的参与者共事,包括 LEDE 团队。
|
||||
|
||||
除了有关新项目的初心的问题之外,一些列表贡献者提出 LEDE 是否与 OpenWrt 有相同的使用场景定位,给新项目取一个听起来更一般的名字的疑惑。此外,许多人,像 Roman Yeryomin,[表示疑惑][12]为什么这些问题需要 LEDE 团队的离开(来解决),特别是,与此同时, LEDE 团队由大部分活跃核心 OpenWrt 开发者构成。一些列表贡献者,像 Michael Richardson,甚至不清楚[谁还会开发][13] OpenWrt。
|
||||
|
||||
#### 澄清
|
||||
|
||||
LEDE 团队尝试着深入阐释他们的境况。在 Fietkau 给 Baker 的回复中,他说在 OpenWrt 内部关于有目的地改变的讨论会很快变得“有毒,”因此导致没有进展。而且:
|
||||
|
||||
这些讨论的要点在于那些掌握着框架关键部分的人精力有限却拒绝他人的加入和帮助,甚至是面对无法及时解决的重要问题时。
|
||||
|
||||
这种像单点错误一样的事已经持续了很多年了,没有任何有意义的进展来解决它。
|
||||
|
||||
Wich 和 Fietkau 都没有明显指出特别的个体,虽然其他在列表的人可能会想这个基础建设和内部讨论——在 OpenWrt 找出问题针对某些人。 Daniel Dickinson [陈述][14]到:
|
||||
|
||||
我的印象是 Kaloz (至少) 以基础建设为胁来保持控制,并且基本问题是 OpenWrt 是*不*民主的,而且忽视那些真正在 openwrt 工作的人想要的是什么无视他们的愿望,因为他/他们把握着要害。
|
||||
|
||||
另一方面, Luka Perkov [指出][15] 很多 OpemWrt 开发者想从 Subversion 转移到 Git,但 Fietkau 负责块修改。
|
||||
|
||||
清晰的是 OpenWrt 的管理结构并非如预期应用,结果导致,个人冲突爆发而且能够自立门户或者块有预谋地变更,因为没有规定好的程序。明显,这不是一个能长期持续的模式。
|
||||
|
||||
五月6日, Crispin 以新思路[写给][16] OpenWrt 列表成员,尝试着重构 LEDE 项目宣言。这不是,他说,意味着“敌对或分裂”行为,只是与性能不良的 OpenWrt 结构做个清晰的划分并以新的方式开始。问题在于“不要局限于一次单独的时间,一个人或者一次口水战,”他说。“我们想与过去自己造成的错误和作出过很多次的错误管理决定分开” Crispin 也承认宣言没有把握好,说 LEDE 团队 “弄糟了开始的政纲。”
|
||||
|
||||
Crispin 的邮件似乎没能使 Kaloz 满意, 她[坚持认为][17] Crispin (作为发行经理)和 Fietkau (作为领头开发者)可以轻易地在 OpenWrt 内部作出想要的改变。 但是讨论的线索后来变得沉寂;之后 LEDE 或者 OpenWrt 哪边会发生什么还有待观察。
|
||||
|
||||
#### 目的
|
||||
|
||||
对于那些仍在寻找 LEDE 认为有问题的事情更多的细节的 OpenWrt 成员,有更多的信息来源可以为这个问题提供线索。在公众宣言之前,LEDE 组织花了几周谈论他们的计划,会议的 IRC 日志现已[推出][18]。特别有趣的是3月30日[会议][19],包含了这个项目目标的细节讨论。
|
||||
|
||||
有些关于 OpenWrt 的架构特定的抱怨包含在内,像项目的 Trac issue 追踪者的缺点。它充斥着不完整的漏洞报告和“我也是”评论, Wich 说,结果,几乎没有贡献者使用它。此外,人们对这件事感到困惑,漏洞在 Github 上也正被追踪,使得问题应该在哪里被讨论不明了。
|
||||
|
||||
IRC 讨论也定下了开发流程本身。LEDE 团队想作出些改变,以合并到主干的 staging trees 的使用为开端,与 OpenWrt 使用的 commit-directly-to-master 方式不同。项目也将提供基于时间的发行版并鼓励用户测试通过只发行已被成功测试的二进制模块,由社区而不是核心开发者,在实际的硬件上。
|
||||
|
||||
最后,IRC 讨论确定了 LEDE 团队的目的不是用它的宣言吓唬 OpenWrt 。 Crispin 提到 LEDE 首先是“半公开的”并渐渐做得更公开。 Wich 解释说他希望 LEDE 是“中立的、专业的并打开大门欢迎 OpenWrt 以便将来的合并”不幸的是,前期发起并不是做得很好。
|
||||
|
||||
在邮件中, Fietkau 补充道核心 OpenWrt 开发者确实在任务中遇到了像补丁复审和维护这些让他们完成不了其他工作——比如配置下载镜像和改良架构系统的瓶颈。在 LEDE 宣言之后短短几天内,他说,团队成功解决了镜像和建设系统任务,而这些已被搁置多年。
|
||||
|
||||
很多我们在 LEDE 所做是基于移动到 Github 分散包的开发和放开包应如何被维护的控制的经验。这样最终有效减少了我们的工作量而且我们有了很多更活跃的开发者。
|
||||
|
||||
我们真的希望为核心开发做一些类似的事,但是根据我们想作出更大改变的经验,我们觉得在 OpenWrt 项目内做不到。
|
||||
|
||||
修复架构也将收获其他好处,他说,就比如为管理用于同意发行的密码。团队正在考虑附加一些没有上游补丁的情况,像需要补丁的描述和为什么没有发送到上游的解释。他也提到很多留下的 OpenWrt 开发者表示有兴趣加入 LEDE,相关当事人正试图弄清楚他们是否会重新合并项目。
|
||||
|
||||
有人希望 LEDE 更为干脆的管理模式和更为透明的分工会在 OpenWrt 困扰的方面取得成功。解决最初的宣言中诟病的沟通方面的问题会是最大的障碍。如果那个过程处理得好,那么,未来 LEDE 和 OpenWrt 可能找到共同之处并协作。否则,之后两个团队可能一起被逼到拥有比以前更少资源,这是开发者或用户不想看到的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://lwn.net/Articles/686767/
|
||||
|
||||
作者:[Nathan Willis ][a]
|
||||
译者:[XYenChi](https://github.com/XYenChi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://lwn.net/Articles/686767/
|
||||
[1]:https://openwrt.org/
|
||||
[2]:https://lwn.net/Articles/686180/
|
||||
[3]:https://www.lede-project.org/
|
||||
[4]:https://www.lede-project.org/rules.html
|
||||
[5]:http://lists.infradead.org/pipermail/lede-dev/2016-May/000080.html
|
||||
[6]:https://lwn.net/Articles/686988/
|
||||
[7]:https://lwn.net/Articles/686989/
|
||||
[8]:https://lwn.net/Articles/686990/
|
||||
[9]:https://lwn.net/Articles/686991/
|
||||
[10]:https://lwn.net/Articles/686995/
|
||||
[11]:https://lwn.net/Articles/686996/
|
||||
[12]:https://lwn.net/Articles/686992/
|
||||
[13]:https://lwn.net/Articles/686993/
|
||||
[14]:https://lwn.net/Articles/686998/
|
||||
[15]:https://lwn.net/Articles/687001/
|
||||
[16]:https://lwn.net/Articles/687003/
|
||||
[17]:https://lwn.net/Articles/687004/
|
||||
[18]:http://meetings.lede-project.org/lede-adm/2016/?C=M;O=A
|
||||
[19]:http://meetings.lede-project.org/lede-adm/2016/lede-adm.2016-03-30-11.05.log.html
|
||||
@ -1,272 +0,0 @@
|
||||
你需要了解的关于 HTML5 的所有信息
|
||||
============================================================
|
||||
|
||||
|
||||
__
|
||||
|
||||
_HTML5 是 HTML 的第五版且是当前的版本,它是用于在万维网上构建和呈现内容的标记语言。本文将帮助读者了解它。_
|
||||
|
||||
HTML5 通过 W3C 和 Web 超文本应用技术工作组之间的合作发展起来。它是一个更高版本的 HTML,它的许多新元素使你的页面更加语义化和动态。它是为所有人提供更好的 Web 体验而开发的。HTML5 提供了很多的功能,使 Web 更加动态和交互。
|
||||
|
||||
HTML5 的新功能是:
|
||||
|
||||
* 新标签,如 <header> 和 <section>
|
||||
|
||||
* 用于 2D 绘图的 <canvas> 元素
|
||||
|
||||
* 本地存储
|
||||
|
||||
* 新的表单控件, 如日历、日期和时间
|
||||
|
||||
* 新媒体功能
|
||||
|
||||
* 地理位置
|
||||
|
||||
HTML5 还不是官方标准。因此,并不是所有的浏览器都支持它或其中一些功能。开发 HTML5 背后最重要的原因之一是防止用户下载并安装多个插件,如 Silverlight 和 Flash。
|
||||
|
||||
**新标签和元素**
|
||||
|
||||
**语义化元素:** 图 1 展示了一些有用的语义化元素。
|
||||
**表单元素:** HTML5 中的表单元素如图 2 所示。
|
||||
**图形元素:** HTML5 中的图形元素如图 3 所示。
|
||||
**媒体元素:** HTML5 中的新媒体元素如图 4 所示。
|
||||
|
||||
[][3]
|
||||
|
||||
图1:语义化元素
|
||||
|
||||
[][4]
|
||||
|
||||
图2:表单元素
|
||||
|
||||
**HTML5 的高级功能**
|
||||
|
||||
**地理位置**
|
||||
|
||||
这是一个 HTML5 API,用于获取网站用户的地理位置,用户必须首先允许网站获取他或她的位置。这通常通过按钮和/或浏览器弹出窗口来实现。所有最新版本的 Chrome、Firefox、IE、Safari 和 Opera 都可以使用 HTML5 的地理位置功能。
|
||||
|
||||
地理位置的一些用途是:
|
||||
|
||||
* 公共交通网站
|
||||
|
||||
* 出租车及其他运输网站
|
||||
|
||||
* 电子商务网站计算运费
|
||||
|
||||
* 旅行社网站
|
||||
|
||||
* 房地产网站
|
||||
|
||||
* 在附近播放的电影的电影院网站
|
||||
|
||||
* 在线游戏
|
||||
|
||||
* 网站首页提供本地标题和天气
|
||||
|
||||
* 工作职位可以自动计算通勤时间
|
||||
|
||||
**工作原理:** 地理位置通过扫描位置信息的常见源进行工作,其中包括以下内容:
|
||||
|
||||
* 全球定位系统(GPS)是最准确的
|
||||
|
||||
* 网络信号 - IP地址、RFID、Wi-Fi 和蓝牙 MAC地址
|
||||
|
||||
* GSM/CDMA 蜂窝 ID
|
||||
|
||||
* 用户输入
|
||||
|
||||
该 API 提供了非常方便的函数来检测浏览器中的地理位置支持:
|
||||
|
||||
| `if` `(navigator.geolocation) {``//` `do` `stuff``}` |
|
||||
|
||||
_getCurrentPosition_ API 是使用地理位置的主要方法。它检索用户设备的当前地理位置。该位置被描述为一组地理坐标以及航向和速度。位置信息作为位置对象返回。
|
||||
|
||||
语法是:
|
||||
|
||||
`getCurrentPosition(showLocation, ErrorHandler, options);`
|
||||
|
||||
* _showLocation:_ 定义了检索位置信息的回调方法。
|
||||
|
||||
* _ErrorHandler(可选):_ 定义了在处理异步调用时发生错误时调用的回调方法。
|
||||
|
||||
* _options (可选):_ 定义了一组用于检索位置信息的选项。
|
||||
|
||||
[][5]
|
||||
|
||||
图3:图形元素
|
||||
|
||||
[][6]
|
||||
|
||||
图4:媒体元素
|
||||
|
||||
图 5 包含了一个位置对象返回的属性集。
|
||||
|
||||
我们可以通过两种方式向用户提供位置信息:测地和民用:
|
||||
|
||||
1\. 描述位置的测地方式直接指向纬度和经度。
|
||||
2\. 位置信息的民用表示法是可读的且容易被人类理解
|
||||
|
||||
如表 1 所示,每个属性/参数都具测地和民用表示。
|
||||
|
||||
[][7]
|
||||
|
||||
**网络存储**
|
||||
|
||||
在 HTML 中,为了在本机存储用户数据,我们使用 JavaScript cookie。为了避免这种情况,HTML5 已经引入了 Web 存储,网站利用它在本机上存储用户数据。
|
||||
|
||||
与 Cookie 相比,Web 存储的优点是:
|
||||
|
||||
* 更安全
|
||||
|
||||
* 更快
|
||||
|
||||
* 存储更多的数据
|
||||
|
||||
* 存储的数据不会随每个服务器请求一起发送。只有在被要求时才包括在内。这是 HTML5 Web 存储超过 Cookie 的一大优势。
|
||||
|
||||
有两种类型的Web存储对象:
|
||||
|
||||
1) 本地 - 存储没有到期日期的数据。
|
||||
2) 会话 - 仅存储一个会话的数据。
|
||||
|
||||
**如何工作:** _localStorage_ 和 _sessionStorage_ 对象创建一个 _key=value_ 对。
|
||||
|
||||
比如: _ key=“Name”,_ _value=“Palak”_
|
||||
|
||||
这些存储为字符串,但如果需要,可以使用 JavaScript 函数(如 _parseInt()_ 和 _parseFloat()_)进行转换。
|
||||
|
||||
下面给出了使用 Web 存储对象的语法:
|
||||
|
||||
`存储一个值:``• localStorage.setItem(“key1”, “value1”);``• localStorage[“key1”] = “value1”;``得到一个值:``• alert(localStorage.getItem(“key1”));``• alert(localStorage[“key1”]);``删除一个值:``• removeItem(“key1”);``删除所有值:``• localStorage.``clear``();`
|
||||
|
||||
[][8]
|
||||
|
||||
图5:位置对象属性
|
||||
|
||||
**应用缓存 (AppCache)**
|
||||
|
||||
使用 HTML5 AppCache,我们可以使 Web 应用程序在没有 Internet 连接的情况下脱机工作。除 IE 之外,所有浏览器都可以使用 _AppCache_(此时)。
|
||||
|
||||
Application Cache 的优点是:
|
||||
|
||||
* 网页浏览可以脱机
|
||||
|
||||
* 页面加载速度更快
|
||||
|
||||
* 服务器负载更小
|
||||
|
||||
_cache manifest_ 是一个简单的文本文件,其中列出了浏览器应缓存的资源以进行脱机访问。 _manifest_ 属性可以包含在文档的 HTML 标签中,如下所示:
|
||||
|
||||
`<html manifest=”``test``.appcache”>``...``<``/html``>`
|
||||
|
||||
它应该在你要缓存的所有页面上。
|
||||
|
||||
缓存的应用程序页面将保留,除非:
|
||||
|
||||
1\. 用户清除它们
|
||||
2\. manifest 被修改
|
||||
3\. 缓存更新
|
||||
|
||||
**视频**
|
||||
|
||||
在 HTML5 发布之前,没有统一的标准来显示网页上的视频。大多数视频都是通过 Flash 等不同的插件显示的。但 HTML5 规定了使用 video 元素在网页上显示视频的标准方式。
|
||||
|
||||
目前,video 元素支持三种视频格式,如表 2 所示。
|
||||
|
||||
[][9]
|
||||
下面的例子展示了 video 元素的使用:
|
||||
`<! DOCTYPE HTML>``<html>``<body>``<video src=” vdeo.ogg” width=”320” height=”240” controls=”controls”>``This browser does not support the video element.``<``/video``>``<``/body``>``<``/html``>`
|
||||
|
||||
例子使用了 Ogg 文件,并且可以在 Firefox、Opera 和 Chrome 中使用。要使视频在 Safari 和未来版本的 Chrome 中工作,我们必须添加一个 MPEG4 和 WebM 文件。
|
||||
|
||||
video 元素允许多个 source 元素。source 元素可以链接到不同的视频文件。浏览器将使用第一个识别的格式,如下所示:
|
||||
|
||||
`<video width=”320” height=”240” controls=”controls”>``<``source` `src=”vdeo.ogg” ``type``=”video``/ogg``” />``<``source` `src=” vdeo.mp4” ``type``=”video``/mp4``” />``<``source` `src=” vdeo.webm” ``type``=”video``/webm``” />``This browser does not support the video element.``<``/video``>`
|
||||
|
||||
[][10]
|
||||
|
||||
图6:Canvas 的输出
|
||||
|
||||
**音频**
|
||||
|
||||
对于音频,情况类似于视频。在 HTML5 发布之前,在网页上播放音频没有统一的标准。大多数音频也通过 Flash 等不同的插件播放。但 HTML5 规定了通过使用音频元素在网页上播放音频的标准方式。音频元素用于播放声音文件和音频流。
|
||||
|
||||
目前,HTML5 audio 元素支持三种音频格式,如表 3 所示。
|
||||
|
||||
[][11]
|
||||
audio 元素的使用如下所示:
|
||||
|
||||
`<! DOCTYPE HTML>``<html>``<body>``<audio src=” song.ogg” controls=”controls”>``This browser does not support the audio element.``<``/video``>``<``/body``>``<``/html``>`
|
||||
|
||||
此例使用 Ogg 文件,并且可以在 Firefox、Opera 和 Chrome 中使用。要在 Safari 和 Chrome 的未来版本中使 audio 工作,我们必须添加一个 MP3 和 Wav 文件。
|
||||
|
||||
audio 元素允许多个 source 元素,它可以链接到不同的音频文件。浏览器将使用第一个识别的格式,如下所示:
|
||||
|
||||
`<audio controls=”controls”>``<``source` `src=”song.ogg” ``type``=”audio``/ogg``” />``<``source` `src=”song.mp3” ``type``=”audio``/mpeg``” />``This browser does not support the audio element.``<``/audio``>`
|
||||
|
||||
**Canvas**
|
||||
|
||||
要在网页上创建图形,HTML5 使用 Canvas API。我们可以用它绘制任何东西,并且它使用 JavaScript。它通过避免从网络下载图像而提高网站性能。使用 Canvas,我们可以绘制形状和线条、弧线和文本、渐变和图案。此外,Canvas 可以让我们操作图像中甚至视频中的像素。你可以将 Canvas 元素添加到 HTML 页面,如下所示:
|
||||
|
||||
`<canvas ``id``=”myCanvas” width=”200” height=”100”><``/canvas``>`
|
||||
|
||||
Canvas 元素不具有绘制元素的功能。我们可以通过使用 JavaScript 来实现。所有绘画应在 JavaScript 中。
|
||||
|
||||
`<script ``type``=”text``/javascript``”>``var c=document.getElementById(“myCanvas”);``var cxt=c.getContext(“2d”);``cxt.fillStyle=”blue”;``cxt.storkeStyle = “red”;``cxt.fillRect(10,10,100,100);``cxt.storkeRect(10,10,100,100);``<``/script``>`
|
||||
|
||||
以上脚本的输出如图 6 所示。
|
||||
|
||||
你可以绘制许多对象,如弧、圆、线/垂直梯度等。
|
||||
|
||||
**HTML5 工具**
|
||||
|
||||
为了有效操作,所有熟练的或业余的 Web 开发人员/设计人员都应该使用 HTML5 工具,当需要设置工作流/网站或执行重复任务时,这些工具非常有帮助。它们提高了网页设计的可用性。
|
||||
|
||||
以下是一些帮助创建很棒的网站的必要工具。
|
||||
|
||||
_**HTML5 Maker:**_ 用来在 HTML、JavaScript 和 CSS 的帮助下与网站内容交互。非常容易使用。它还允许我们开发幻灯片、滑块、HTML5 动画等。
|
||||
|
||||
_**Liveweave:** _ 用来测试代码。它减少了保存代码并将其加载到屏幕上所花费的时间。在编辑器中粘贴代码即可得到结果。它非常易于使用,并为一些代码提供自动完成功能,这使得开发和测试更快更容易。
|
||||
|
||||
_**Font dragr:**_ 开放字体和矢量图形,以便立即对其进行测试。
|
||||
|
||||
_**HTML5 Please:**_ 允许我们找到与 HTML5 相关的任何内容。如果你想知道如何使用任何一个功能,你可以在 HTML 中搜索。它提供了有关支持浏览器和设备的有用资源的列表、语法,如何使用元素的一般建议等。
|
||||
|
||||
_**Modernizr:** _ 这是一个开源工具,用于给访问者浏览器提供最佳体验。使用此工具,你可以检测访问者的浏览器是否支持 HTML5 功能,并加载相应的脚本。
|
||||
|
||||
_**Adobe Edge Animate:**_ 这是必须处理交互式 HTML 动画的 HTML5 开发人员的有用工具。它用于数字出版、网络和广告领域。此工具允许用户创建无瑕疵的动画,可以跨多个设备运行。
|
||||
|
||||
_**Video.js:**_ 这是一款基于 JavaScript 的 HTML5 视频播放器。如果要将视频添加到你的网站,你应该使用此工具。它使视频看起来不错,并且是网站的一部分。
|
||||
|
||||
_**The W3 Validator:**_ W3 验证工具测试 HTML、XHTML、SMIL、MathML 等中的网站标记的有效性。要测试任何网站的标记有效性,你必须选择文档类型为 HTML5 并输入你网页的 URL。这样做之后,你的代码将被检查,并将提供所有错误和警告。
|
||||
|
||||
_**HTML5 Reset:** _ 此工具允许开发人员在 HTML5 中重写旧网站的代码。
|
||||
你可以使用这些工具为你网站的访问者提供一个良好的网络体验。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
Palak Shah
|
||||
|
||||
作者是高级软件工程师。她喜欢探索新技术,学习创新概念。她也喜欢哲学。你可以通过 palak311@gmail.com 联系她。
|
||||
|
||||
--------------------
|
||||
via: http://opensourceforu.com/2017/06/introduction-to-html5/
|
||||
|
||||
作者:[Palak Shah ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://opensourceforu.com/author/palak-shah/
|
||||
[1]:http://opensourceforu.com/2017/06/introduction-to-html5/#disqus_thread
|
||||
[2]:http://opensourceforu.com/author/palak-shah/
|
||||
[3]:http://opensourceforu.com/wp-content/uploads/2017/05/Figure-1-7.jpg
|
||||
[4]:http://opensourceforu.com/wp-content/uploads/2017/05/Figure-2-5.jpg
|
||||
[5]:http://opensourceforu.com/wp-content/uploads/2017/05/Figure-3-2.jpg
|
||||
[6]:http://opensourceforu.com/wp-content/uploads/2017/05/Figure-4-2.jpg
|
||||
[7]:http://opensourceforu.com/wp-content/uploads/2017/05/table-1.jpg
|
||||
[8]:http://opensourceforu.com/wp-content/uploads/2017/05/Figure5-1.jpg
|
||||
[9]:http://opensourceforu.com/wp-content/uploads/2017/05/table-2.jpg
|
||||
[10]:http://opensourceforu.com/wp-content/uploads/2017/05/Figure6-1.jpg
|
||||
[11]:http://opensourceforu.com/wp-content/uploads/2017/05/table-3.jpg
|
||||
@ -1,164 +0,0 @@
|
||||
动态端口转发:安装带有SSH的SOCKS服务器
|
||||
=================
|
||||
|
||||
在上一篇文章中([Creating TCP / IP (port forwarding) tunnels with SSH: The 8 scenarios possible using OpenSSH][17]),我们看到了处理端口转发的所有可能情况。但是对于静态端口转发,我们只介绍了通过 SSH 连接来访问另一个系统的端口的情况。
|
||||
|
||||
在这篇文章中,我们脱离动态端口转发的前端,而尝试补充它。
|
||||
|
||||
当我们谈论使用 SSH 进行动态端口转发时,我们谈论的是将 SSH 服务器 转换为 [SOCKS][2] 服务器。那么什么是 SOCKS 服务器?
|
||||
|
||||
你知道 [Web 代理][3]是用来做什么的吗?答案可能是肯定的,因为很多公司都在使用它。它是一个直接连接到互联网的系统,允许没有互联网访问的[内部网][4]客户端通过配置浏览器的代理来请求(尽管也有[透明代理][5])浏览网页。Web 代理除了允许输出到 Internet 之外,还可以缓存页面,图像等。资源已经由某些客户端下载,所以您不必为另一个客户端而下载它们。此外,它允许过滤内容并监视用户的活动。当然了,它的基本功能是转发 HTTP 和 HTTPS 流量。
|
||||
|
||||
一个 SOCKS 服务器提供的服务类似于公司内部网络提供的代理服务器服务,但不限于 HTTP/HTTPS,它还允许转发任何 TCP/IP 流量(SOCKS 5 也是 UDP)。
|
||||
|
||||
例如,假设我们希望在一个没有直接连接到互联网的内部网上使用基于 POP3 或 ICMP 的邮件服务和 Thunderbird 的 SMTP 服务。如果我们只有一个 web 代理可以用,我们可以使用的唯一的简单方式是使用一些 webmail(也可以使用 [Thunderbird 的 Webmail 扩展][6])。我们还可以[通过 HTTP 进行隧道传递][7]来利用代理。但最简单的方式是在网络中设置一个可用的 SOCKS 服务器,它可以让我们使用 POP3、ICMP 和 SMTP,而不会造成任何的不便。
|
||||
|
||||
虽然有很多软件可以配置非常专业的 SOCKS 服务器,我们这里使用 OpenSSH 简单地设置一个:
|
||||
|
||||
> ```
|
||||
> Clientessh $ ssh -D 1080 user @ servidorssh
|
||||
> ```
|
||||
|
||||
或者我们可以改进一下:
|
||||
|
||||
> ```
|
||||
> Clientessh $ ssh -fN -D 0.0.0.0:1080 user @ servidorssh
|
||||
> ```
|
||||
|
||||
其中:
|
||||
|
||||
* 选项 `-D` 类似于选项为 `-L` 和 `-R` 的静态端口转发。像这样,我们就可以让客户端只监听本地请求或从其他节点到达的请求,具体的取决于我们将请求关联到哪个地址:
|
||||
|
||||
> ```
|
||||
> -D [bind_address:] port
|
||||
> ```
|
||||
|
||||
在静态端口转发中可以看到,我们使用选项 `-R` 进行反向端口转发,而动态转发是不可能的。我们只能在 SSH 客户端创建 SOCKS 服务器,而不能在 SSH 服务器端创建。
|
||||
|
||||
* 1080 是 SOCKS 服务器的典型端口,正如 8080 是 Web 代理服务器的典型端口一样。
|
||||
|
||||
* 选项 `-N` 防止了远程 shell 交互式会话的实际启动。当我们只使用 `ssh` 来建立隧道时很有用。
|
||||
|
||||
* 选项 `-f` 会使 `ssh` 停留在后台并将其与当前 `shell` 分离,以便使进程成为守护进程。如果没有选项 `-N`(或不指定命令),则不起作用,否则交互式 shell 将与后台进程不兼容。
|
||||
|
||||
使用 [PuTTY][8] 也可以非常简单地进行端口重定向。相当于 `ssh -D 0.0.0.0:1080` 使用此配置:
|
||||
|
||||

|
||||
|
||||
对于通过 SOCKS 服务器访问另一个网络的应用程序,如果应用程序提供了特殊的支持,就会非常方便(虽然不是必需的),就像浏览器支持使用代理服务器一样。浏览器(如 Firefox 或 Internet Explorer)是使用 SOCKS 服务器访问另一个网络的应用程序示例:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
注意:使用 [IEs 4 Linux][1] 进行捕获:如果您需要 Internet Explorer 并使用 Linux,强烈推荐!
|
||||
|
||||
然而,最常见的浏览器并不要求 SOCKS 服务器,因为它们通常与代理服务器配合得更好。
|
||||
|
||||
Thunderbird 也允许这样做,而且很有用:
|
||||
|
||||

|
||||
|
||||
另一个例子:[Spotify][9] 客户端同样支持 SOCKS:
|
||||
|
||||

|
||||
|
||||
我们需要记住的是名称解析。有时我们会发现,在目前的网络中,我们无法解析 SOCKS 服务器另一端所要访问的系统的名称。SOCKS 5 还允许我们传播 DNS 请求(UDP 允许我们使用 SOCKS 5)并将它们发送到另一端:可以指定是否要本地或远程解析(或者也可以测试两者)。支持这一点的应用程序也必须考虑到这一点。例如,Firefox 具有参数 `network.proxy.socks_remote_dns`(在 `about:config` 中),允许我们指定远程解析。默认情况下,它在本地解析。
|
||||
|
||||
Thunderbird 也支持参数 `network.proxy.socks_remote_dns`,但由于没有地址栏来放置 `about:config`,我们需要改变它,就像在 [MozillaZine:about:config][10] 中读到的,依次点击工具→选项→高级→常规→配置编辑器(按钮)。
|
||||
|
||||
没有对 SOCKS 特殊支持的应用程序可以被 “socksified”。这对于使用 TCP/IP 的许多应用程序都没有问题,但并不是全部,这将很好地工作。“Socksifier” 包括加载一个额外的库,它可以检测对 TCP/IP 堆栈的请求,并修改它们以通过 SOCKS 服务器重定向它们,以便通信中不需要使用 SOCKS 支持进行特殊的编程。
|
||||
|
||||
在 Windows 和 [Linux.][18] 上都有 “Socksifiers”。
|
||||
|
||||
对于 Windows,我们举个例子,SocksCap 是一种非商业用途的闭源但免费的产品,我使用了很长时间都十分满意。SocksCap 由一家名为 Permeo 的公司制造,该公司是创建 SOCKS 参考技术的公司。Permeo 被 [Blue Coat][11] 买下后,它[停止了 SocksCap 项目][12]。现在你仍然可以在互联网上找到 `sc32r240.exe` 文件。[FreeCap][13] 也是面向 Windows 的免费代码项目,外观和使用都非常类似于 SocksCap。然而,它工作起来更加糟糕,多年来一直没有维护。看起来,它的作者倾向于推出需要付款的新产品 [WideCap][14]。
|
||||
|
||||
这是 SocksCap 的一个方面,当我们 “socksified” 了几个应用程序。当我们从这里启动它们时,这些应用程序将通过 SOCKS 服务器访问网络:
|
||||
|
||||

|
||||
|
||||
在配置对话框中可以看到,如果选择了协议 SOCKS 5,我们必须选择在本地或远程解析名称:
|
||||
|
||||

|
||||
|
||||
在 Linux 上,一直以来我们都有许多方案来替换一个单一的远程命令。在 Debian/Ubuntu 中,命令行输出:
|
||||
|
||||
> ```
|
||||
> $ Apt-cache search socks
|
||||
> ```
|
||||
|
||||
输出会告诉我们很多东西
|
||||
|
||||
最著名的是 [tsocks][15] 和 [proxychains][16]。他们的工作方式大致相同:只需启动我们想要与他们 “socksify” 的应用程序,就是这样。使用 `proxychains` 的 `wget` 的例子:
|
||||
|
||||
> ```
|
||||
> $ Proxychains wget http://www.google.com
|
||||
> ProxyChains-3.1 (http://proxychains.sf.net)
|
||||
> --19: 13: 20-- http://www.google.com/
|
||||
> Resolving www.google.com ...
|
||||
> DNS-request | Www.google.com
|
||||
> | S-chain | - <- - 10.23.37.3:1080-<><>-4.2.2.2:53-<><>-OK
|
||||
> | DNS-response | Www.google.com is 72.14.221.147
|
||||
> 72.14.221.147
|
||||
> Connecting to www.google.com | 72.14.221.147 |: 80 ...
|
||||
> | S-chain | - <- - 10.23.37.3:1080-<><>-72.14.221.147:80-<><>-OK
|
||||
> Connected.
|
||||
> HTTP request sent, awaiting response ... 200 OK
|
||||
> Length: unspecified [text / html]
|
||||
> Saving to: `index.html '
|
||||
>
|
||||
> [<=>] 6,016 24.0K / s in 0.2s
|
||||
>
|
||||
> 19:13:21 (24.0 KB / s) - `index.html 'saved [6016]
|
||||
> ```
|
||||
|
||||
为此,我们必须指定要在 `/etc/proxychains.conf` 中使用的代理服务器:
|
||||
|
||||
> ```
|
||||
> [ProxyList]
|
||||
> Socks5 clientessh 1080
|
||||
> ```
|
||||
|
||||
DNS 请求是远程进行的:
|
||||
|
||||
> ```
|
||||
> # Proxy DNS requests - no leak for DNS data
|
||||
> Proxy_dns
|
||||
> ```
|
||||
|
||||
另外,在前面的输出中,我们已经看到了同一个 `proxychains` 的几条信息性的消息,而不是标有字符串 `|DNS-request|`、`|S-chain|` 或 `|DNS-response|` 行中的 `wget`。如果我们不想看到它们,也可以在配置中进行调整:
|
||||
|
||||
> ```
|
||||
> # Quiet mode (no output from library)
|
||||
> Quiet_mode
|
||||
> ```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://wesharethis.com/2017/07/15/dynamic-port-forwarding-mount-socks-server-ssh/
|
||||
|
||||
作者:[Ahmad][a]
|
||||
译者:[firmianay](https://github.com/firmianay)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://wesharethis.com/author/ahmad/
|
||||
[1]:https://wesharethis.com/goto/http://www.tatanka.com.br/ies4linux/page/Main_Page
|
||||
[2]:https://wesharethis.com/goto/http://en.wikipedia.org/wiki/SOCKS
|
||||
[3]:https://wesharethis.com/goto/http://en.wikipedia.org/wiki/Proxy_server
|
||||
[4]:https://wesharethis.com/goto/http://en.wikipedia.org/wiki/Intranet
|
||||
[5]:https://wesharethis.com/goto/http://en.wikipedia.org/wiki/Proxy_server#Transparent_and_non-transparent_proxy_server
|
||||
[6]:https://wesharethis.com/goto/http://webmail.mozdev.org/
|
||||
[7]:https://wesharethis.com/goto/http://en.wikipedia.org/wiki/HTTP_tunnel_(software)
|
||||
[8]:https://wesharethis.com/goto/http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html
|
||||
[9]:https://wesharethis.com/goto/https://www.spotify.com/int/download/linux/
|
||||
[10]:https://wesharethis.com/goto/http://kb.mozillazine.org/About:config
|
||||
[11]:https://wesharethis.com/goto/http://www.bluecoat.com/
|
||||
[12]:https://wesharethis.com/goto/http://www.bluecoat.com/products/sockscap
|
||||
[13]:https://wesharethis.com/goto/http://www.freecap.ru/eng/
|
||||
[14]:https://wesharethis.com/goto/http://widecap.ru/en/support/
|
||||
[15]:https://wesharethis.com/goto/http://tsocks.sourceforge.net/
|
||||
[16]:https://wesharethis.com/goto/http://proxychains.sourceforge.net/
|
||||
[17]:https://wesharethis.com/2017/07/14/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/
|
||||
[18]:https://wesharethis.com/2017/07/10/linux-swap-partition/
|
||||
@ -0,0 +1,538 @@
|
||||
Up - 在几秒钟内部署无服务器应用程序
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
去年,我[为 Up 写了一份蓝图][1],其中描述了大多数构建块是如何以最小的成本在 AWS 上创建一个很棒的无服务器环境。这篇文章则是讨论了 [Up][2] 的初始 alpha 版本。
|
||||
|
||||
为什么专注于<ruby>无服务器<rt>serverless</rt></ruby>?对于初学者来说,它可以节省成本,因为你可以按需付费,且只为你使用的付费。无服务器选项是自我修复的,因为每个请求被隔离并被视作“无状态的”。最后,它可以无限轻松地扩展 —— 没有机器或集群要管理。部署你的代码就完成了。
|
||||
|
||||
大约一个月前,我决定开始在 [apex/up][3] 上开发它,并为动态 SVG 版本的 GitHub 用户投票功能写了第一个小型无服务器示例程序 [tj/gh-polls][4]。它运行良好,成本低于每月 1 美元即可为数百万次投票服务,因此我会继续这个项目,看看我是否可以提供开源版本及商业的变体版本。
|
||||
|
||||
其长期的目标是提供“你自己的 Heroku” 的版本,支持许多平台。虽然平台即服务(PaaS)并不新鲜,但无服务器生态系统正在使这种方案日益萎缩。据说,AWS 和其他的经常因为 UX 提供的灵活性而被人诟病。Up 将复杂性抽象出来,同时为你提供一个几乎无需运维的解决方案。
|
||||
|
||||
### 安装
|
||||
|
||||
你可以使用以下命令安装 Up,查看这篇[临时文档][5]开始使用。或者如果你使用安装脚本,请下载[二进制版本][6]。(请记住,这个项目还在早期。)
|
||||
|
||||
```
|
||||
curl -sfL https://raw.githubusercontent.com/apex/up/master/install.sh | sh
|
||||
```
|
||||
|
||||
只需运行以下命令随时升级到最新版本:
|
||||
|
||||
```
|
||||
up upgrade
|
||||
```
|
||||
|
||||
你也可以通过NPM进行安装:
|
||||
|
||||
```
|
||||
npm install -g up
|
||||
```
|
||||
|
||||
### 功能
|
||||
|
||||
这个早期 alpha 版本提供什么功能?让我们来看看!请记住,Up 不是托管服务,因此你需要一个 AWS 帐户和 [AWS 凭证][8]。如果你对 AWS 不熟悉,你可能需要先停下来,直到熟悉流程。
|
||||
|
||||
我的第一个问题是:up(1) 与 [apex(1)][9] 有何不同?Apex 专注于部署功能,用于管道和事件处理,而 Up 则侧重于应用程序、apis 和静态站点,也就是单个可部署单元。Apex 不为你提供 API 网关、SSL 证书或 DNS,也不提供 URL 重写,脚本注入等。
|
||||
|
||||
#### 单命令无服务器应用程序
|
||||
|
||||
Up 可以让你使用单条命令部署应用程序、API 和静态站点。要创建一个应用程序,你需要的是一个文件,在 Node.js 的情况下,`./app.js` 监听由 Up 提供的 `PORT'。请注意,如果你使用的是 `package.json` ,则会检测并使用 `start`和 `build` 脚本。
|
||||
|
||||
```
|
||||
const http = require('http')
|
||||
const { PORT = 3000 } = process.env
|
||||
```
|
||||
|
||||
```
|
||||
http.createServer((req, res) => {
|
||||
res.end('Hello World\n')
|
||||
}).listen(PORT)
|
||||
```
|
||||
|
||||
额外的[运行时][10]支持也立即可用,例如 Golang 的“main.go”,所以你可以在几秒钟内部署 Golang、Python、Crystal 或 Node.js 应用程序。
|
||||
|
||||
```
|
||||
package main
|
||||
```
|
||||
|
||||
```
|
||||
import (
|
||||
"fmt"
|
||||
"log"
|
||||
"net/http"
|
||||
"os"
|
||||
)
|
||||
```
|
||||
|
||||
```
|
||||
func main() {
|
||||
addr := ":" + os.Getenv("PORT")
|
||||
http.HandleFunc("/", hello)
|
||||
log.Fatal(http.ListenAndServe(addr, nil))
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
func hello(w http.ResponseWriter, r *http.Request) {
|
||||
fmt.Fprintln(w, "Hello World from Go")
|
||||
}
|
||||
```
|
||||
|
||||
要部署应用程序输入 `up` 来创建所需的资源,并部署应用程序本身。这里没有模糊不清的地方,一旦它说“完成”了,你就完成了,该应用程序立即可用 —— 没有远程构建过程。
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||

|
||||
|
||||
后续的部署将会更快,因为栈已被配置:
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||

|
||||
|
||||
使用 `up url --open` 测试你的程序,以在浏览器中浏览它,`up url --copy` 将 URL 保存到剪贴板,或者尝试使用 curl:
|
||||
|
||||
```
|
||||
curl `up url`
|
||||
Hello World
|
||||
```
|
||||
|
||||
要删除应用程序及其资源,只需输入 `up stack delete`:
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||

|
||||
|
||||
例如,使用 `up staging` 或 `up production` 和 `up url --open production` 部署到预发布或生产环境。请注意,自定义域名尚不可用,[它们将很快可用][11]。之后,你还可以将版本“推广”到其他环境。
|
||||
|
||||
#### 反向代理
|
||||
|
||||
一个使 Up 独特的功能是,它不仅仅是简单地部署代码,它将一个 Golang 反向代理放在应用程序的前面。这提供了许多功能,如 URL 重写、重定向、脚本注入等等,我们将在后面进一步介绍。
|
||||
|
||||
#### 基础设施即代码
|
||||
|
||||
在配置方面,Up 遵循现代最佳实践,因此多有对基础设施的更改都可以在部署之前预览,并且 IAM 策略的使用还可以限制开发人员访问以防止事故发生。一个好处是它有助于自动记录你的基础设施。
|
||||
|
||||
以下是使用 LetsEncrypt 通过 AWS ACM 配置一些(虚拟)DNS 记录和免费 SSL 证书的示例。
|
||||
|
||||
```
|
||||
{
|
||||
"name": "app",
|
||||
"dns": {
|
||||
"myapp.com": [
|
||||
{
|
||||
"name": "myapp.com",
|
||||
"type": "A",
|
||||
"ttl": 300,
|
||||
"value": ["35.161.83.243"]
|
||||
},
|
||||
{
|
||||
"name": "blog.myapp.com",
|
||||
"type": "CNAME",
|
||||
"ttl": 300,
|
||||
"value": ["34.209.172.67"]
|
||||
},
|
||||
{
|
||||
"name": "api.myapp.com",
|
||||
"type": "A",
|
||||
"ttl": 300,
|
||||
"value": ["54.187.185.18"]
|
||||
}
|
||||
]
|
||||
},
|
||||
"certs": [
|
||||
{
|
||||
"domains": ["myapp.com", "*.myapp.com"]
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
当你首次通过 `up` 部署应用程序时,需要所有的权限,它为你创建 API 网关、Lambda 函数、ACM 证书、Route53 DNS 记录等。
|
||||
|
||||
[ChangeSets][12] 尚未实现,但你能使用 `up stack plan` 预览进一步的更改,并使用 `up stack apply` 提交,这与 Terraform 非常相似。
|
||||
|
||||
详细信息请参阅[配置文档][13]。
|
||||
|
||||
#### 全球部署
|
||||
|
||||
`regions` 数组可以指定应用程序的目标区域。例如,如果你只对单个地区感兴趣,请使用:
|
||||
|
||||
```
|
||||
{
|
||||
"regions": ["us-west-2"]
|
||||
}
|
||||
```
|
||||
|
||||
如果你的客户集中在北美,你可能需要使用美国和加拿大所有地区:
|
||||
|
||||
```
|
||||
{
|
||||
"regions": ["us-*", "ca-*"]
|
||||
}
|
||||
```
|
||||
|
||||
最后,你可以使用目前支持的所有 14 个地区:
|
||||
|
||||
```
|
||||
{
|
||||
"regions": ["*"]
|
||||
}
|
||||
```
|
||||
|
||||
多区域支持仍然是一个正在进行的工作,因为需要一些新的 AWS 功能来将它们结合在一起。
|
||||
|
||||
#### 静态文件服务
|
||||
|
||||
Up 开箱即支持静态文件服务,支持 HTTP 缓存,因此你可以在应用程序前使用 CloudFront 或任何其他 CDN 来大大减少延迟。
|
||||
|
||||
当 `type` 为 “static” 时,默认情况下的工作目录是(`.`),但是你也可以提供一个`static.dir`:
|
||||
|
||||
```
|
||||
{ "name": "app", "type": "static", "static": { "dir": "public" }}
|
||||
```
|
||||
|
||||
#### 构建钩子
|
||||
|
||||
构建钩子允许你在部署或执行其他操作时定义自定义操作。一个常见的例子是使用 Webpack 或 Browserify 捆绑 Node.js 应用程序,这大大减少了文件大小,因为 node_modules 是_很大_的。
|
||||
|
||||
```
|
||||
{
|
||||
"name": "app",
|
||||
"hooks": {
|
||||
"build": "browserify --node server.js > app.js",
|
||||
"clean": "rm app.js"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 脚本和样式表注入
|
||||
|
||||
Up 允许你插入脚本和样式,它可以内联或声明路径。它甚至支持一些“罐头”脚本,用于 Google Analytics(分析)和 [Segment][14],只需复制并粘贴你的写入密钥即可。
|
||||
|
||||
```
|
||||
{
|
||||
"name": "site",
|
||||
"type": "static",
|
||||
"inject": {
|
||||
"head": [
|
||||
{
|
||||
"type": "segment",
|
||||
"value": "API_KEY"
|
||||
},
|
||||
{
|
||||
"type": "inline style",
|
||||
"file": "/css/primer.css"
|
||||
}
|
||||
],
|
||||
"body": [
|
||||
{
|
||||
"type": "script",
|
||||
"value": "/app.js"
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 重写和重定向
|
||||
|
||||
Up通过 `redirects` 对象支持重定向和 URL 重写,该对象将路径模式映射到新位置。如果省略 `status`(或200),那么它是重写,否则是重定向。
|
||||
|
||||
```
|
||||
{
|
||||
"name": "app",
|
||||
"type": "static",
|
||||
"redirects": {
|
||||
"/blog": {
|
||||
"location": "https://blog.apex.sh/",
|
||||
"status": 301
|
||||
},
|
||||
"/docs/:section/guides/:guide": {
|
||||
"location": "/help/:section/:guide",
|
||||
"status": 302
|
||||
},
|
||||
"/store/*": {
|
||||
"location": "/shop/:splat"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
用于重写的常见情况是 SPA(单页面应用程序),你希望为 `index.html` 提供服务,而不管路径如何。当然除非文件存在。
|
||||
|
||||
```
|
||||
{
|
||||
"name": "app",
|
||||
"type": "static",
|
||||
"redirects": {
|
||||
"/*": {
|
||||
"location": "/",
|
||||
"status": 200
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
如果要强制规则,无论文件是否存在,只需添加 `"force": true` 。
|
||||
|
||||
#### 环境变量
|
||||
|
||||
密码将在下一个版本中有,但是现在支持纯文本环境变量:
|
||||
|
||||
```
|
||||
{
|
||||
"name": "api",
|
||||
"environment": {
|
||||
"API_FEATURE_FOO": "1",
|
||||
"API_FEATURE_BAR": "0"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### CORS 支持
|
||||
|
||||
[CORS][16] 支持允许你指定哪些(如果有的话)域可以从浏览器访问你的 API。如果你希望允许任何网站访问你的 API,只需启用它:
|
||||
|
||||
```
|
||||
{
|
||||
"cors": {
|
||||
"enable": true
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
你还可以自定义访问,例如仅限制 API 访问你的前端或 SPA。
|
||||
|
||||
```
|
||||
{
|
||||
"cors": {
|
||||
"allowed_origins": ["https://myapp.com"],
|
||||
"allowed_methods": ["HEAD", "GET", "POST", "PUT", "DELETE"],
|
||||
"allowed_headers": ["Content-Type", "Authorization"]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 日志
|
||||
|
||||
对于 $0.5/GB 的低价格,你可以使用 CloudWatch 日志进行结构化日志查询和跟踪。Up 实现了一种用于改进 CloudWatch 提供的自定义[查询语言][18],专门用于查询结构化 JSON 日志。
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||

|
||||
|
||||
你可以查询现有日志:
|
||||
|
||||
```
|
||||
up logs
|
||||
```
|
||||
|
||||
跟踪在线日志:
|
||||
|
||||
```
|
||||
up logs -f
|
||||
```
|
||||
|
||||
或者对其中任一个进行过滤,例如只显示耗时超过 5 毫秒的 200 个 GET/HEAD 请求:
|
||||
|
||||
```
|
||||
up logs 'method in ("GET", "HEAD") status = 200 duration >= 5'
|
||||
```
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||

|
||||
|
||||
查询语言是非常灵活的,这里有更多来自于 `up help logs` 的例子
|
||||
|
||||
```
|
||||
Show logs from the past 5 minutes.
|
||||
$ up logs
|
||||
```
|
||||
|
||||
```
|
||||
Show logs from the past 30 minutes.
|
||||
$ up logs -s 30m
|
||||
```
|
||||
|
||||
```
|
||||
Show logs from the past 5 hours.
|
||||
$ up logs -s 5h
|
||||
```
|
||||
|
||||
```
|
||||
Show live log output.
|
||||
$ up logs -f
|
||||
```
|
||||
|
||||
```
|
||||
Show error logs.
|
||||
$ up logs error
|
||||
```
|
||||
|
||||
```
|
||||
Show error and fatal logs.
|
||||
$ up logs 'error or fatal'
|
||||
```
|
||||
|
||||
```
|
||||
Show non-info logs.
|
||||
$ up logs 'not info'
|
||||
```
|
||||
|
||||
```
|
||||
Show logs with a specific message.
|
||||
$ up logs 'message = "user login"'
|
||||
```
|
||||
|
||||
```
|
||||
Show 200 responses with latency above 150ms.
|
||||
$ up logs 'status = 200 duration > 150'
|
||||
```
|
||||
|
||||
```
|
||||
Show 4xx and 5xx responses.
|
||||
$ up logs 'status >= 400'
|
||||
```
|
||||
|
||||
```
|
||||
Show emails containing @apex.sh.
|
||||
$ up logs 'user.email contains "@apex.sh"'
|
||||
```
|
||||
|
||||
```
|
||||
Show emails ending with @apex.sh.
|
||||
$ up logs 'user.email = "*@apex.sh"'
|
||||
```
|
||||
|
||||
```
|
||||
Show emails starting with tj@.
|
||||
$ up logs 'user.email = "tj@*"'
|
||||
```
|
||||
|
||||
```
|
||||
Show errors from /tobi and /loki
|
||||
$ up logs 'error and (path = "/tobi" or path = "/loki")'
|
||||
```
|
||||
|
||||
```
|
||||
Show the same as above with 'in'
|
||||
$ up logs 'error and path in ("/tobi", "/loki")'
|
||||
```
|
||||
|
||||
```
|
||||
Show logs with a more complex query.
|
||||
$ up logs 'method in ("POST", "PUT") ip = "207.*" status = 200 duration >= 50'
|
||||
```
|
||||
|
||||
```
|
||||
Pipe JSON error logs to the jq tool.
|
||||
$ up logs error | jq
|
||||
```
|
||||
|
||||
请注意,`and` 关键字是暗含的,虽然你也可以使用它。
|
||||
|
||||
#### 冷启动时间
|
||||
|
||||
这是 AWS Lambda 平台的特性, 但冷启动时间通常远远低于 1 秒, 在未来, 我计划提供一个选项来保持它们在线。
|
||||
|
||||
#### 配置验证
|
||||
|
||||
The `up config` command outputs the resolved configuration, complete with defaults and inferred runtime settings – it also serves the dual purpose of validating configuration, as any error will result in exit > 0.
|
||||
`up config` 命令输出解析后的配置,有默认值和推断的运行时设置 - 它也起到验证配置的双重目的,因为任何错误都会导致 exit > 0。
|
||||
|
||||
#### 崩溃恢复
|
||||
|
||||
使用 Up 作为反向代理的另一个好处是执行崩溃恢复 - 在崩溃后重新启动服务器,并在响应客户端发生错误之前重新尝试该请求。
|
||||
|
||||
例如,假设你的 Node.js 程序由于间歇性数据库问题而导致未捕获的异常崩溃,Up 可以在响应客户端之前重试该请求。之后这个行为会更加可定制。
|
||||
|
||||
#### 持续集成友好
|
||||
|
||||
很难说这是一个功能,但是感谢 Golang 相对较小和独立的二进制文件,你可以在一两秒中在 CI 中安装 Up。
|
||||
|
||||
#### HTTP/2
|
||||
|
||||
Up 通过 API 网关支持 HTTP/2,对服务有很多资源的应用和站点减少延迟。我将来会对许多平台进行更全面的测试,但是 Up 的延迟已经很好了:
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||

|
||||
|
||||
#### 错误页面
|
||||
|
||||
Up 提供了一个默认错误页面,如果你要提供支持电子邮件或调整颜色,你可以使用 `error_pages` 自定义。
|
||||
|
||||
```
|
||||
{ "name": "site", "type": "static", "error_pages": { "variables": { "support_email": "support@apex.sh", "color": "#228ae6" } }}
|
||||
```
|
||||
|
||||
默认情况下,它看上去像这样:
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||

|
||||
|
||||
如果你想提供自定义模板,你可以创建以下一个或多个文件。特定文件优先。
|
||||
|
||||
* `error.html` – 匹配任何 4xx 或 5xx
|
||||
|
||||
* `5xx.html` – 匹配任何 5xx 错误
|
||||
|
||||
* `4xx.html` – 匹配任何 4xx 错误
|
||||
|
||||
* `CODE.html` – 匹配一个特定的代码,如 404.html
|
||||
|
||||
查看[文档][22]阅读更多有关模板的信息。
|
||||
|
||||
### 伸缩和成本
|
||||
|
||||
你已经做了这么多,但是 Up 规模如何?目前,API 网关和 AWS 是目标平台,因此你无需进行任何更改即可扩展,只需部署代码即可完成。你只需支付实际使用的数量、按需并且无需人工干预。
|
||||
|
||||
AWS 每月免费提供 1,000,000 个请求,但你可以使用 [http://serverlesscalc.com][23] 来插入预期流量。在未来 Up 将提供额外的平台,所以如果一个成本过高,你可以迁移到另一个!
|
||||
|
||||
### 未来
|
||||
|
||||
目前为止就这样了!它可能看起来不是很多,但它已经超过 10,000 行代码,并且我刚刚开始开发。看看这个问题队列,假设项目可持续发展,看看未来会有什么期待。
|
||||
|
||||
如果你发现免费版本有用,请考虑在 [OpenCollective][24] 上捐赠 ,因为我没有任何工作。我将在短期内开发早期专业版,早期用户的年费优惠。专业或企业版也将提供源码,因此可以进行内部修复和自定义。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.freecodecamp.org/up-b3db1ca930ee
|
||||
|
||||
作者:[TJ Holowaychuk][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@tjholowaychuk?source=post_header_lockup
|
||||
[1]:https://medium.com/@tjholowaychuk/blueprints-for-up-1-5f8197179275
|
||||
[2]:https://github.com/apex/up
|
||||
[3]:https://github.com/apex/up
|
||||
[4]:https://github.com/tj/gh-polls
|
||||
[5]:https://github.com/apex/up/tree/master/docs
|
||||
[6]:https://github.com/apex/up/releases
|
||||
[7]:https://raw.githubusercontent.com/apex/up/master/install.sh
|
||||
[8]:https://github.com/apex/up/blob/master/docs/aws-credentials.md
|
||||
[9]:https://github.com/apex/apex
|
||||
[10]:https://github.com/apex/up/blob/master/docs/runtimes.md
|
||||
[11]:https://github.com/apex/up/issues/166
|
||||
[12]:https://github.com/apex/up/issues/115
|
||||
[13]:https://github.com/apex/up/blob/master/docs/configuration.md
|
||||
[14]:https://segment.com/
|
||||
[15]:https://blog.apex.sh/
|
||||
[16]:https://developer.mozilla.org/en-US/docs/Web/HTTP/Access_control_CORS
|
||||
[17]:https://myapp.com/
|
||||
[18]:https://github.com/apex/up/blob/master/internal/logs/parser/grammar.peg
|
||||
[19]:http://twitter.com/apex
|
||||
[20]:http://twitter.com/apex
|
||||
[21]:http://twitter.com/apex
|
||||
[22]:https://github.com/apex/up/blob/master/docs/configuration.md#error-pages
|
||||
[23]:http://serverlesscalc.com/
|
||||
[24]:https://opencollective.com/apex-up
|
||||
140
translated/tech/20170903 Genymotion vs Android Emulator.md
Normal file
140
translated/tech/20170903 Genymotion vs Android Emulator.md
Normal file
@ -0,0 +1,140 @@
|
||||
Genymotion vs Android 模拟器
|
||||
============================================================
|
||||
|
||||
### Android 模拟器是否有足够的改善来取代 Genymotion
|
||||
|
||||
|
||||
一直以来一直有关于选择 android 模拟器或者 Genymotion 的争论,我看到很多讨论最后赞成 Genymotion。
|
||||
我根据我周围最常见的情况收集了一些数据, 基于此, 我将连同 Genymotion 评估所有的 android 模拟器。
|
||||
|
||||
最后结论:配置正确时,Android 模拟器比 Genymotion 快。
|
||||
使用带 Google API 的 x86(32位)镜像、3GB RAM、四核CPU。
|
||||
|
||||
> 哈,很高兴我们跳过了
|
||||
> 现在,让我们深入
|
||||
|
||||
免责声明:我已经测试了我的看到的一般情况,即运行测试。所有的基准测试都是在 2015 年中期的 MacBook Pro 上完成的。
|
||||
无论何时我说 Genymotion 指的都是 Genymotion Desktop。他们还有其他产品,如 Genymotion on Cloud&Genymotion on Demand,这里没有考虑。
|
||||
我不是说 Genymotion 是不合适的,但运行测试比某些 Android 模拟器慢。
|
||||
|
||||
关于这个问题的一点背景,然后我们将跳到好的东西上。
|
||||
|
||||
_过去:我有一些基准测试,继续下去。_
|
||||
|
||||
很久以前,Android 模拟器是唯一的选择。但是它们太慢了,这是架构改变的原因。
|
||||
在 x86 机器上运行的 ARM 模拟器可以期待什么?每个指令都必须从 ARM 转换为 x86 架构,这使得它的速度非常慢。
|
||||
|
||||
随之而来的是 Android 的 x86 镜像,随着它们摆脱了 ARM 到 x86 平台转化,速度更快了。
|
||||
现在,你可以在 x86 机器上运行 x86 Android 模拟器。
|
||||
|
||||
> _问题解决了!!!_
|
||||
>
|
||||
> 没有!
|
||||
|
||||
Android 模拟器仍然比人们想要的慢。
|
||||
随后出现了 Genymotion,这是一个在虚拟机中运行的 Android 虚拟机。但是,与在 qemu 上运行的普通老式 android 模拟器相比,它相当稳定和快速。
|
||||
|
||||
我们来看看今天的情况。
|
||||
|
||||
我的团队在 CI 基础架构和开发机器上使用 Genymotion。手头的任务是摆脱 CI 基础设施和开发机器中使用的所有 Genymotion。
|
||||
|
||||
> 你问为什么?
|
||||
> 授权费钱。
|
||||
|
||||
在快速看了一下以后,这似乎是一个愚蠢的举动,因为 Android 模拟器的速度很慢而且有 bug,但它们看起来适得其反,但是当你深入的时候,你会发现 Android 模拟器是优越的。
|
||||
|
||||
我们的情况是对它们进行集成测试(主要是 espresso)。
|
||||
我们的应用程序中只有 1100 多个测试,Genymotion 需要大约 23 分钟才能运行所有测试。
|
||||
|
||||
在 Genymotion 中我们面临的另一些问题是:
|
||||
|
||||
* 有限的命令行工具([GMTool][1])。
|
||||
|
||||
* 由于内存问题,它们需要定期重新启动。这是一个手动任务,想象在配有许多机器的 CI 基础设施上进行这些会怎样。
|
||||
|
||||
进入 Android 模拟器
|
||||
|
||||
第一次尝试设置其中的一个,它给你这么多的选择,你会觉得你在 Subway 餐厅。
|
||||
最大的问题是 x86 或 x86_64 以及是否有 Google API。
|
||||
|
||||
我用这些组合做了一些研究和基准测试,这是我们想出来的。
|
||||
|
||||
鼓声。。。
|
||||
|
||||
> 比赛的获胜者是带 Google API 的 x86
|
||||
> 但是如何?为什么?
|
||||
|
||||
嗯,我会告诉你每一个的问题。
|
||||
|
||||
x86_64 比 x86 慢
|
||||
|
||||
> 你问慢多少.
|
||||
>
|
||||
> 28.2% 多!!!
|
||||
|
||||
使用 Google API 的模拟器更加稳定,没有它们容易崩溃。
|
||||
|
||||
这使我们得出结论:最好的是带 Google API 的x86。
|
||||
|
||||
在我们抛弃 Genymotion 开始使用模拟器之前。有下面几点重要的细节。
|
||||
|
||||
* 我使用的是带 Google API 的 Nexus 5 镜像。
|
||||
|
||||
* 我注意到,给模拟器较少的 RAM 会造成了很多 Google API 崩溃。所以为模拟器设定了 3GB 的 RAM
|
||||
|
||||
* 模拟器有四核
|
||||
|
||||
* HAXM 安装在主机上。
|
||||
|
||||
基准测试的时候到了
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
从基准测试上你可以看到除了 Geekbench4,Android 模拟器都击败了 Genymotion,Geekbench4 我感觉更像是虚拟机击败 qemu。
|
||||
|
||||
> 欢呼模拟器之王
|
||||
|
||||
We are now having a faster test execution time, better command line tools. Also with the latest [Android Emulator][2], things have gone a notch up. Faster boot time and what not.
|
||||
我们现在有更快的测试执行时间、更好的命令行工具。最新的 [Android Emulator][2] 创下的新的记录。更快的启动时间之类。
|
||||
|
||||
Goolgle 一直努力让
|
||||
|
||||
> Android Emulator 变得更好
|
||||
|
||||
如果你没有在使用 android 模拟器。我建议你重新试下来节省一些钱。
|
||||
|
||||
我尝试的另一个但是没有成功的方案是在 AWS 上运行 [Android-x86][3] 镜像。
|
||||
我能够在 vSphere ESXi Hypervisor 中运行它,但不能在 AWS 或任何其他云平台上运行它。如果有人知道原因,请在下面评论。
|
||||
|
||||
PS:[VMWare 现在可以在 AWS 上使用][4],在 AWS 上使用 [Android-x86][5] 毕竟是有可能的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
嗨,我的名字是 Sumit Gupta。我是来自印度古尔冈的软件/应用/网页开发人员。
|
||||
我做这个是因为我喜欢技术,并且一直迷恋它。我已经工作了 3 年以上,但我还是有很多要学习。他们不是说如果你有只是,让别人点亮他们的蜡烛。
|
||||
|
||||
当在编译时,我阅读很多文章,或者听音乐。
|
||||
|
||||
如果你想联系,下面是我的社交信息和 [email][6]。
|
||||
|
||||
via: https://www.plightofbyte.com/android/2017/09/03/genymotion-vs-android-emulator/
|
||||
|
||||
作者:[Sumit Gupta ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.plightofbyte.com/about-me
|
||||
[1]:https://docs.genymotion.com/Content/04_Tools/GMTool/GMTool.htm
|
||||
[2]:https://developer.android.com/studio/releases/emulator.html
|
||||
[3]:http://www.android-x86.org/
|
||||
[4]:https://aws.amazon.com/vmware/
|
||||
[5]:http://www.android-x86.org/
|
||||
[6]:thesumitgupta@outlook.com
|
||||
@ -1,360 +0,0 @@
|
||||
12 件可以用 GitHub 完成的很酷的事情
|
||||
============================================================
|
||||
|
||||
我不能为我的人生想出一个引子来,所以...
|
||||
|
||||
### #1 在 GitHub.com 上编辑代码
|
||||
|
||||
我想我要开始的第一件事是多数人都已经知道的(尽管一周之前的我并不知道)。
|
||||
|
||||
当你登录到 GitHub ,查看一个文件时(任何文本文件,任何版本库),右上方会有一只小铅笔。点击它,你就可以编辑文件了。 当你编辑完成后,GitHub 会给出文件变更的建议然后为你 fork 你的仓库并创建一个 pull 请求。
|
||||
|
||||
是不是很疯狂?它为你创建了 fork !
|
||||
|
||||
不需要去 fork ,pull ,本地更改,push 然后创建一个 PR。
|
||||
|
||||
|
||||

|
||||
|
||||
不是一个真正的 PR
|
||||
|
||||
这对于修改错误的拼写以及编辑代码时的一些糟糕的想法是很有用的。
|
||||
|
||||
### #2 粘贴图像
|
||||
|
||||
在评论和 issue 的描述中并不仅限于使用文字。你知道你可以直接从剪切板粘贴图像吗? 在你粘贴的时候,你会看到图片被上传 (到云端,这毫无疑问)并转换成 markdown 显示的图片格式。
|
||||
|
||||
整洁。
|
||||
|
||||
### #3 格式化代码
|
||||
|
||||
如果你想写一个代码块的话,你可以用三个反引号作为开始 —— 就像你在浏览 [熟练掌握 Markdown][3] 页面所学的一样 —— 而且 GitHub 会尝试去推测你所写下的语言。
|
||||
|
||||
但如果你张贴像是 Vue ,Typescript 或 JSX 这样的代码,你就需要明确指出才能获得高亮显示。
|
||||
|
||||
在首行注明 ````jsx`:
|
||||
|
||||
|
||||

|
||||
|
||||
…这意味着代码段已经正确的呈现:
|
||||
|
||||
|
||||

|
||||
|
||||
(顺便说一下,这些用法可以扩展到 gists。 如果你在 gist 中给出 `.jsx` 扩展,你的 JSX 语法就会高亮显示。)
|
||||
|
||||
这里是[所有被支持的语法][4]的清单。
|
||||
|
||||
### #4 用 PRs 中的魔法词来关闭 issues
|
||||
|
||||
比方说你已经创建了一个 pull 请求用来修复 issue #234 。那么你就可以把 “fixes #234” 这段文字放在你的 PR 描述中(或者是在 PR 的评论的任何位置)。
|
||||
|
||||
接下来,在合并 PR 时会自动关闭与之对应的问题。这是不是很酷?
|
||||
|
||||
这里是[更详细的学习帮助][5]。
|
||||
|
||||
### #5 链接到评论
|
||||
|
||||
是否你曾经想要链接到一个特定的评论但却不知道该怎么做?这是因为你不知道如何去做到这些。但那都将是过去了我的朋友,因为我在这里告诉你,点击紧挨着名字的日期或时间,这就是如何链接到一个评论。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
嘿,这里有 gaearon 的照片!
|
||||
|
||||
### #6 链接到代码
|
||||
|
||||
那么你想要链接到代码的特定行。我明白。
|
||||
|
||||
试试这个:在查看文件的时候,点击挨着代码的行号。
|
||||
|
||||
哇哦,你看到了么?行号位置更新出了 URL !如果你按下 Shift 键并点击其他的行号,SHAZAAM ,URL 再一次更新并且现在出现了行范围的高亮。
|
||||
|
||||
分享这个 URL 将会链接到这个文件的那些行。但等一下,链接所指向的是当前分支。如果文件发生变更了怎么办?也许一个文件当前状态的永久链接就是你以后需要的。
|
||||
|
||||
我比较懒,所以我已经在一张截图中做完了上面所有的步骤:
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
说起 URLs…
|
||||
|
||||
### #7 像命令行一样使用 GitHub URL
|
||||
|
||||
使用 UI 来浏览 GitHub 有着很好的体验。但有些时候最快到达你想去的地方的方法就是在地址栏输入。举个例子,如果我想要跳转到一个我正在工作的分支然后查看与 master 分支的 diff,我就可以在我的仓库名称的后边输入 `/compare/branch-name` 。
|
||||
|
||||
这样就会登录到指定分支的 diff 页面。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
然而这就是与 master 分支的 diff ,如果我正在 integration 分支工作,我可以输入 `/compare/integration-branch...my-branch`。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
对于键盘上的快捷键,`ctrl`+`L` 或 `cmd`+`L` 将会向上跳转光标进入 URL 那里(至少在 Chrome 中是这样)。这一点 —— 加上你的浏览器会自动补全的事实 —— 能够成为一种在分支间跳转的便捷方式。
|
||||
|
||||
小贴士:使用方向键在 Chrome 的自动完成建议中移动同时按 `shift`+`delete` 来删除历史条目(e.g. 一旦分支被合并)。
|
||||
|
||||
(我真的好奇如果我把快捷键写成 `shift + delete` 这样的话,是不是读起来会更加容易。但严格来说 ‘+’ 并不是快捷键的一部分,所以我并不觉得这很舒服。这一点让 _我_ 整晚难以入睡,Rhonda。)
|
||||
|
||||
### #8 在 issue 中创建列表
|
||||
|
||||
你想要在你的 issue 中看到一个复选框列表吗?
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
想要在查看列表中的 issue 时候显示为一个漂亮的 “2 of 5” bar(译者注:条形码)吗?
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
那很好!你可以使用这些的语法创建交互式的复选框:
|
||||
|
||||
```
|
||||
- [ ] Screen width (integer)
|
||||
- [x] Service worker support
|
||||
- [x] Fetch support
|
||||
- [ ] CSS flexbox support
|
||||
- [ ] Custom elements
|
||||
```
|
||||
|
||||
表示方法是空格,破折号,再空格,左括号,填入空格(或者一个 x ),然后封闭括号 ,接着空格,最后是一些话。
|
||||
|
||||
然后其实你可以选中或取消选中这些框!出于一些原因这些对我来说看上去就像是技术的魔法。你可以 _选中_ 这些框! 同时底层的文本会进行更新。
|
||||
|
||||
他们接下来会想什么?
|
||||
|
||||
噢,如果你在一个 project board 上有这些 issue 的话,它也会在这里显示进度:
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
如果在我提到“在一个 project board 上”时你不知道我在说些什么,那么你会在下面的页面进一步了解。
|
||||
|
||||
比如,在页面下 2 厘米的地方。
|
||||
|
||||
### #9 GitHub 上的 Project boards
|
||||
|
||||
我常常在大项目中使用 Jira 。而对于个人项目我总是会使用 Trello 。我很喜欢他们两个。
|
||||
|
||||
当我学会的几周后 GitHub 有它自己的产品,就在我的仓库上的 Project 标签,我想过我会照搬一套我已经在 Trello 上进行的任务。
|
||||
|
||||
|
||||
|
||||

|
||||
没有一个是有趣的
|
||||
|
||||
这里是在 GitHub project 上相同的内容:
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
你的眼睛会因为缺乏对比而适应。
|
||||
|
||||
出于速度的缘故,我把上面所有的都添加为 “notes” —— 意思是他们不是真正的 GitHub issue 。
|
||||
|
||||
但在 GitHub 上,管理任务的权限被集成在版本库的其他地方 —— 所以你可能想要从仓库添加存在的 issue 到 board 上。
|
||||
|
||||
你可以点击右上角的 Add Cards 然后找你想要添加的东西。这里特殊的[搜索语法][6]就派上用场了,举个例子,输入 `is:pr is:open` 然后现在你可以拖动任何开启的 PRs 到 board 上,或者要是你想清理一些 bug 的话就输入 `label:bug`
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
或者你可以将现有的 notes 转换为 issues 。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
或者最后,从一个现有的 issue 屏幕,把它添加到在右边面板的一个 project 。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
它们将会进入一个 project board 的分类列表,这样你就能减少候选的列表的数量。
|
||||
|
||||
作为实现那些 task 的代码,在同一仓库下你所拥有的 ‘task’ 定义有一个巨大(超大)的好处。这意味着今后的几年你能够用一行代码做一个 git blame 并且找出方法回到最初在这个 task 后面写下那些代码的根据,不需要在 Jira、Trello 或其他地方寻找蛛丝马迹。
|
||||
|
||||
#### 缺点
|
||||
|
||||
在过去的三周我已经对所有的 tasks 使用 GitHub 取代 Jira 进行了测试(在有点看板风格的较小规模的项目上) ,到目前为止我都很喜欢。
|
||||
|
||||
但是我无法想象在 scrum (译者注:迭代式增量软件开发过程)项目上使用,我想要在那里完成正确估算、速度的测算以及所有的好东西。
|
||||
|
||||
好消息是,GitHub Projects 只有很少一些“功能”,并不会让你花很长时间去评估它是否值得让你去切换。因此留下一个悬念,看看你是怎么想的。
|
||||
|
||||
总的来说,我有 _得知_ [ZenHub][7] 并且打开过 10 分钟,这也是有史以来的第一次。它是对 GitHub 高效的延伸,可以让你估计你的 issue 并创建 epics 和 dependencies。它也有速度和燃尽图功能;这看起来 _可能是_ 这地球上最伟大的事情。
|
||||
|
||||
延伸阅读: [GitHub help on Projects][8]。
|
||||
|
||||
### #10 GitHub wiki
|
||||
|
||||
对于非结构化集合类的页面 —— 就像 Wikipedia —— GitHub Wiki 提供的(下文我会称之为 Gwiki )就很优秀。
|
||||
|
||||
对于结构化集合类的页面 —— 举个例子,你的文档 —— 并没那么多。这里没办法说“这个页面是那个页面的子页”,或者有像‘下一节’和‘上一节’这样的按钮。Hansel 和 Gretel 将会完蛋,因为这里没有面包屑(译者注:引自童话故事《糖果屋》)。
|
||||
|
||||
(边注,你有 _读过_ 那个故事吗? 这是个残酷的故事。两个混蛋小子将饥肠辘辘的老巫婆烧死在 _她自己的火炉_ 里。无疑留下她来收拾残局。我想这就是为什么如今的年轻人是如此的敏感 —— 今天的睡前故事没有太多的暴力内容。)
|
||||
|
||||
继续 —— 把 Gwiki 拿出来接着讲,我输入一些 NodeJS 文档中的内容作为 wiki 页面,然后创建一个侧边栏让我能够模拟出一些真实结构。这个侧边栏会一直存在,尽管它无法高亮显示你当前所在的页面。
|
||||
|
||||
链接不得不手动维护,但总的来说,我认为这已经很好了。如果你觉得有需要的话可以[看一下][9]。
|
||||
|
||||
|
||||

|
||||
|
||||
它将不会与像 GitBook(它使用了[Redux 文档][10])或一个定制的网站这样的东西去竞争。但它仍然会占据 80% 的页面而且就在你的仓库里。
|
||||
|
||||
我是一个粉丝。
|
||||
|
||||
我的建议:如果你已经拥有不止一个 `README.md` 文件并且想要一些不同的页面作为用户指南或是更详细的文档,那么下一步你就需要停止使用 Gwiki 了。
|
||||
|
||||
如果你开始觉得缺少的结构或导航非常有必要的话,去切换到其他的产品吧。
|
||||
|
||||
### #11 GitHub Pages (带有 Jekyll)
|
||||
|
||||
你可能已经知道了可以使用 GitHub Pages 来托管静态站点。如果你不知道的话现在就可以去试试。不过这一节确切的说是关于使用 _Jekyll_ 来构建一个站点。
|
||||
|
||||
最简单的就是, GitHub Pages + Jekyll 会将你的 `README.md` 呈现在一个漂亮的主题中。举个例子,从 [关于 github][11] 看看我的 readme 页面:
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
如果我为我的 GitHub 站点点击 ‘settings’ 标签,开启 GitHub Pages,然后挑选一个 Jekyll 主题…
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
我会得到一个[ Jekyll 主题页面][12]:
|
||||
|
||||
|
||||

|
||||
|
||||
根据这一点我可以构建一个主要基于易于编辑的 markdown 文件的静态站点,本质上是把 GitHub 变成一个 CMS(译者注:内容管理系统)。
|
||||
|
||||
我还没有真正的使用过它,但这就是 React 和 Bootstrap 站点构建的过程,所以并不可怕。
|
||||
|
||||
注意,在本地运行需要 Ruby ( Windows 用户就需要交换一下眼色并且转向其他的方向。macOS 用户会像这样 “出什么问题了,你要去哪里?Ruby 是一个通用平台!GEMS!”)。
|
||||
|
||||
(这里也有必要加上“暴力或威胁的内容或活动” 在 GitHub Pages 上是不被允许的,因此你不能去部署重启你的 Hansel 和 Gretel 。)
|
||||
|
||||
#### 我的意见
|
||||
|
||||
我观察的 GitHub Pages + Jekyll 越多(为了这篇文章),整件事情好像越是看起来有一点奇怪。
|
||||
|
||||
‘让所有的复杂性远离你所拥有的属于自己的网站’这样的想法是很棒的。但是你仍然需要在本地生成配置。而且可怕的是需要为这样“简单”的东西使用很多 CLI(译者注:命令行界面)命令。
|
||||
|
||||
我只是略读了[入门部分][13]的七页,给我的感觉像是 _我是_ 这里仅有的简单的事情。此前我甚至从来没有学习过所谓简单的“Front Matter”的语法或者所谓简单的“Liquid 模板引擎”的来龙去脉。
|
||||
|
||||
我宁愿只写一个网站。
|
||||
|
||||
老实说我有点惊讶 Facebook 使用它来写 React 文档,因为他们能够用 React 来构件他们的帮助文档并且在一天之内 [pre-render 预渲染到静态的 HTML 文件][14]。
|
||||
|
||||
他们所需要的就跟使用 CMS 中已有的 Markdown 文件一样。
|
||||
|
||||
我想是这样…
|
||||
|
||||
### #12 使用 GitHub 作为 CMS
|
||||
|
||||
比如说你有一个带有一些文本的网站,但是你并不想在 HTML 的标记中储存那些文本。
|
||||
|
||||
取而代之,你想要存放文本块到一个很容易被非开发者编辑的地方。也许使用一些版本控制的形式。甚至可能是一个审查过程。
|
||||
|
||||
这里是我的建议:在你的版本库中使用 markdown 文件存储文本。然后在你的前端使用插件来获取这些文本块并在页面呈现。
|
||||
|
||||
我是 React 的支持者,因此这里有一个 `<Markdown>` 插件的示例,给出一些 markdown 的路径,它们将被获取,解析,并以 HTML 的形式呈现。
|
||||
|
||||
|
||||
(我正在使用的是 [marked][1] npm 包来将 markdown 解析为 HTML。)
|
||||
|
||||
这里是指向我的示例仓库 [/text-snippets][2],里边有一些 markdown 文件 。
|
||||
|
||||
(你也可以前往[获取内容][15]页面获取 GiHub API 来使用 —— 但我不确定你是否可以。)
|
||||
|
||||
你可以使用像这样的插件:
|
||||
|
||||
所以现在 GitHub 就是你的 CMS,可以说,不管有多少文本块都可以放进去。
|
||||
|
||||
上边的示例只是在浏览器上安装好插件后获取 markdown 。如果你想要一个静态站点那么你需要服务器端渲染(server-render)。
|
||||
|
||||
好消息!没什么能阻止你从服务器中获取所有的 markdown 文件 (配上各种为你服务的缓存策略)。如果你沿着这条路继续走下去的话,你可能会想要去看看使用 GitHub API 去获取目录中的所有 markdown 文件的列表。
|
||||
|
||||
### Bonus round —— GitHub 工具!
|
||||
|
||||
我曾经使用过一段时间的 [Chrome 的扩展 Octotree ][16] 而且现在我推荐它。虽然并非真心诚意,但不管怎样我还是推荐它。
|
||||
|
||||
它会在左侧提供一个带有树视图的面板以显示当前你所查看的仓库。
|
||||
|
||||
|
||||

|
||||
|
||||
从[这个视频][17]中我学会了 [octobox][18] ,到目前为止看起来还不错。它是一个 GitHub issues 的收件箱。这就是我要说的全部。
|
||||
|
||||
说到颜色,在上面所有的截图中我都使用了亮色主题,所以不要吓到你。不过说真的,我看到的其他东西都是在黑色的主题上,为什么我非要忍受 GitHub 这个苍白的主题呐?
|
||||
|
||||
|
||||

|
||||
|
||||
这是由 Chrome 扩展 [Stylish][19](它可以在任何网站使用主题)和 [GitHub Dark][20] 风格的一个组合。同时为了完成这样的外观也需要,黑色主题的 Chrome 开发者工具(这是内建的,在设置中打开) 以及 [Atom One Dark for Chrome 主题][21]。
|
||||
|
||||
### Bitbucket
|
||||
|
||||
这些并不完全适合这篇文章的所有地方,但是如果我不称赞 Bitbucket 的话,那就不对了。
|
||||
|
||||
两年前我开始了一个项目并花了大半天时间评估哪一个 git 托管服务更适合,最终 Bitbucket 赢得了相当不错的成绩。他们的代码审查流程遥遥领先(这甚至比 GitHub 拥有的指派审阅者的概念要早很长时间)。
|
||||
|
||||
GitHub 在后来赶上了比赛,这是非常成功的。但不幸的是在过去的一年里我没有机会使用 Bitbucket —— 也许他们依然在某些方面领先。所以,我会力劝每一个选择 git 托管服务的人也要考虑 Bitbucket 。
|
||||
|
||||
### 结尾
|
||||
|
||||
就是这样!我希望这里至少有三件事是你此前并不知道的,我也希望你拥有愉快的一天。
|
||||
|
||||
编辑:在评论中有更多的建议;随便留下你自己喜欢的。真的,我真的希望你能拥有愉快的一天。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/12-cool-things-you-can-do-with-github-f3e0424cf2f0
|
||||
|
||||
作者:[David Gilbertson][a]
|
||||
译者:[softpaopao](https://github.com/softpaopao)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@david.gilbertson
|
||||
[1]:https://www.npmjs.com/package/marked
|
||||
[2]:https://github.com/davidgilbertson/about-github/tree/master/text-snippets
|
||||
[3]:https://guides.github.com/features/mastering-markdown/
|
||||
[4]:https://github.com/github/linguist/blob/fc1404985abb95d5bc33a0eba518724f1c3c252e/vendor/README.md
|
||||
[5]:https://help.github.com/articles/closing-issues-using-keywords/
|
||||
[6]:https://help.github.com/articles/searching-issues-and-pull-requests/
|
||||
[7]:https://www.zenhub.com/
|
||||
[8]:https://help.github.com/articles/tracking-the-progress-of-your-work-with-project-boards/
|
||||
[9]:https://github.com/davidgilbertson/about-github/wiki
|
||||
[10]:http://redux.js.org/
|
||||
[11]:https://github.com/davidgilbertson/about-github
|
||||
[12]:https://davidgilbertson.github.io/about-github/
|
||||
[13]:https://jekyllrb.com/docs/home/
|
||||
[14]:https://github.com/facebookincubator/create-react-app/blob/master/packages/react-scripts/template/README.md#pre-rendering-into-static-html-files
|
||||
[15]:https://developer.github.com/v3/repos/contents/#get-contents
|
||||
[16]:https://chrome.google.com/webstore/detail/octotree/bkhaagjahfmjljalopjnoealnfndnagc?hl=en-US
|
||||
[17]:https://www.youtube.com/watch?v=NhlzMcSyQek&index=2&list=PLNYkxOF6rcIB3ci6nwNyLYNU6RDOU3YyL
|
||||
[18]:https://octobox.io/
|
||||
[19]:https://chrome.google.com/webstore/detail/stylish-custom-themes-for/fjnbnpbmkenffdnngjfgmeleoegfcffe/related?hl=en
|
||||
[20]:https://userstyles.org/styles/37035/github-dark
|
||||
[21]:https://chrome.google.com/webstore/detail/atom-one-dark-theme/obfjhhknlilnfgfakanjeimidgocmkim?hl=en
|
||||
@ -0,0 +1,214 @@
|
||||
[并发服务器: 第一节 —— 简介][18]
|
||||
============================================================
|
||||
|
||||
这是关于并发网络服务器编程的第一篇教程。我计划测试几个主流的、可以同时处理多个客户端请求的服务器并发模型,基于可扩展性和易实现性对这些模型进行评判。所有的服务器都会监听套接字连接,并且实现一些简单的协议用于与客户端进行通讯。
|
||||
|
||||
该系列的所有文章:
|
||||
|
||||
* [第一节 - 简介][7]
|
||||
|
||||
* [第二节 - 线程][8]
|
||||
|
||||
* [第三节 - 事件驱动][9]
|
||||
|
||||
### 协议
|
||||
|
||||
该系列教程所用的协议都非常简单,但足以展示并发服务器设计的许多有趣层面。而且这个协议是 _有状态的_ —— 服务器根据客户端发送的数据改变内部状态,然后根据内部状态产生相应的行为。并非所有的协议都是有状态的 —— 实际上,基于 HTTP 的许多协议是无状态的,但是有状态的协议对于保证重要会议的可靠很常见。
|
||||
|
||||
在服务器端看来,这个协议的视图是这样的:
|
||||
|
||||
|
||||
|
||||
总之:服务器等待新客户端的连接;当一个客户端连接的时候,服务器会向该客户端发送一个 `*` 字符,进入“等待消息”的状态。在该状态下,服务器会忽略客户端发送的所有字符,除非它看到了一个 `^` 字符,这表示一个新消息的开始。这个时候服务器就会转变为“正在通信”的状态,这时它会向客户端回送数据,把收到的所有字符的每个字节加 1 回送给客户端 [ [1][10] ]。当客户端发送了 `$`字符,服务器就会退回到等待新消息的状态。`^` 和 `$` 字符仅仅用于分隔消息 —— 它们不会被服务器回送。
|
||||
|
||||
每个状态之后都有个隐藏的箭头指向 “等待客户端” 状态,用来防止客户端断开连接。因此,客户端要表示“我已经结束”的方法很简单,关掉它那一端的连接就好。
|
||||
|
||||
显然,这个协议是真实协议的简化版,真实使用的协议一般包含复杂的报文头,转义字符序列(例如让消息体中可以出现 `$` 符号),额外的状态变化。但是我们这个协议足以完成期望。
|
||||
|
||||
另一点:这个系列是引导性的,并假设客户端都工作的很好(虽然可能运行很慢);因此没有设置超时,也没有设置特殊的规则来确保服务器不会因为客户端的恶意行为(或是故障)而出现阻塞,导致不能正常结束。
|
||||
|
||||
### 有序服务器
|
||||
|
||||
这个系列中我们的第一个服务端程序是一个简单的“有序”服务器,用 C 进行编写,除了标准的 POSIX 中用于套接字的内容以外没有使用其它库。服务器程序是有序的,因为它一次只能处理一个客户端的请求;当有客户端连接时,像之前所说的那样,服务器会进入到状态机中,并且不再监听套接字接受新的客户端连接,直到当前的客户端结束连接。显然这不是并发的,而且即便在很少的负载下也不能服务多个客户端,但它对于我们的讨论很有用,因为我们需要的是一个易于理解的基础。
|
||||
|
||||
这个服务器的完整代码在 [这里][11];接下来,我会着重于高亮的部分。`main` 函数里面的外层循环用于监听套接字,以便接受新客户端的连接。一旦有客户端进行连接,就会调用 `serve_connection`,这个函数中的代码会一直运行,直到客户端断开连接。
|
||||
|
||||
有序服务器在循环里调用 `accept` 用来监听套接字,并接受新连接:
|
||||
|
||||
```
|
||||
while (1) {
|
||||
struct sockaddr_in peer_addr;
|
||||
socklen_t peer_addr_len = sizeof(peer_addr);
|
||||
|
||||
int newsockfd =
|
||||
accept(sockfd, (struct sockaddr*)&peer_addr, &peer_addr_len);
|
||||
|
||||
if (newsockfd < 0) {
|
||||
perror_die("ERROR on accept");
|
||||
}
|
||||
|
||||
report_peer_connected(&peer_addr, peer_addr_len);
|
||||
serve_connection(newsockfd);
|
||||
printf("peer done\n");
|
||||
}
|
||||
```
|
||||
|
||||
`accept` 函数每次都会返回一个新的已连接的套接字,然后服务器调用 `serve_connection`;注意这是一个 _阻塞式_ 的调用 —— 在 `serve_connection` 返回前,`accept` 函数都不会再被调用了;服务器会被阻塞,直到客户端结束连接才能接受新的连接。换句话说,客户端按 _顺序_ 得到响应。
|
||||
|
||||
这是 `serve_connection` 函数:
|
||||
|
||||
```
|
||||
typedef enum { WAIT_FOR_MSG, IN_MSG } ProcessingState;
|
||||
|
||||
void serve_connection(int sockfd) {
|
||||
if (send(sockfd, "*", 1, 0) < 1) {
|
||||
perror_die("send");
|
||||
}
|
||||
|
||||
ProcessingState state = WAIT_FOR_MSG;
|
||||
|
||||
while (1) {
|
||||
uint8_t buf[1024];
|
||||
int len = recv(sockfd, buf, sizeof buf, 0);
|
||||
if (len < 0) {
|
||||
perror_die("recv");
|
||||
} else if (len == 0) {
|
||||
break;
|
||||
}
|
||||
|
||||
for (int i = 0; i < len; ++i) {
|
||||
switch (state) {
|
||||
case WAIT_FOR_MSG:
|
||||
if (buf[i] == '^') {
|
||||
state = IN_MSG;
|
||||
}
|
||||
break;
|
||||
case IN_MSG:
|
||||
if (buf[i] == '$') {
|
||||
state = WAIT_FOR_MSG;
|
||||
} else {
|
||||
buf[i] += 1;
|
||||
if (send(sockfd, &buf[i], 1, 0) < 1) {
|
||||
perror("send error");
|
||||
close(sockfd);
|
||||
return;
|
||||
}
|
||||
}
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
close(sockfd);
|
||||
}
|
||||
```
|
||||
|
||||
它完全是按照状态机协议进行编写的。每次循环的时候,服务器尝试接收客户端的数据。收到 0 字节意味着客户端断开连接,然后循环就会退出。否则,会逐字节检查接收缓存,每一个字节都可能会触发一个状态。
|
||||
|
||||
`recv` 函数返回接收到的字节数与客户端发送消息的数量完全无关(`^...$` 闭合序列的字节)。因此,在保持状态的循环中,遍历整个缓冲区很重要。而且,每一个接收到的缓冲中可能包含多条信息,但也有可能开始了一个新消息,却没有显式的结束字符;而这个结束字符可能在下一个缓冲中才能收到,这就是处理状态在循环迭代中进行维护的原因。
|
||||
|
||||
例如,试想主循环中的 `recv` 函数在某次连接中返回了三个非空的缓冲:
|
||||
|
||||
1. `^abc$de^abte$f`
|
||||
|
||||
2. `xyz^123`
|
||||
|
||||
3. `25$^ab$abab`
|
||||
|
||||
服务端返回的是哪些数据?追踪代码对于理解状态转变很有用。(答案见 [ [2][12] ])
|
||||
|
||||
### 多个并发客户端
|
||||
|
||||
如果多个客户端在同一时刻向有序服务器发起连接会发生什么事情?
|
||||
|
||||
服务器端的代码(以及它的名字 `有序的服务器`)已经说的很清楚了,一次只能处理 _一个_ 客户端的请求。只要服务器在 `serve_connection` 函数中忙于处理客户端的请求,就不会接受别的客户端的连接。只有当前的客户端断开了连接,`serve_connection` 才会返回,然后最外层的循环才能继续执行接受其他客户端的连接。
|
||||
|
||||
为了演示这个行为,[该系列教程的示例代码][13] 包含了一个 Python 脚本,用于模拟几个想要同时连接服务器的客户端。每一个客户端发送类似之前那样的三个数据缓冲 [ [3][14] ],不过每次发送数据之间会有一定延迟。
|
||||
|
||||
客户端脚本在不同的线程中并发地模拟客户端行为。这是我们的序列化服务器与客户端交互的信息记录:
|
||||
|
||||
```
|
||||
$ python3.6 simple-client.py -n 3 localhost 9090
|
||||
INFO:2017-09-16 14:14:17,763:conn1 connected...
|
||||
INFO:2017-09-16 14:14:17,763:conn1 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-16 14:14:17,763:conn1 received b'b'
|
||||
INFO:2017-09-16 14:14:17,802:conn1 received b'cdbcuf'
|
||||
INFO:2017-09-16 14:14:18,764:conn1 sending b'xyz^123'
|
||||
INFO:2017-09-16 14:14:18,764:conn1 received b'234'
|
||||
INFO:2017-09-16 14:14:19,764:conn1 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-16 14:14:19,765:conn1 received b'36bc1111'
|
||||
INFO:2017-09-16 14:14:19,965:conn1 disconnecting
|
||||
INFO:2017-09-16 14:14:19,966:conn2 connected...
|
||||
INFO:2017-09-16 14:14:19,967:conn2 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-16 14:14:19,967:conn2 received b'b'
|
||||
INFO:2017-09-16 14:14:20,006:conn2 received b'cdbcuf'
|
||||
INFO:2017-09-16 14:14:20,968:conn2 sending b'xyz^123'
|
||||
INFO:2017-09-16 14:14:20,969:conn2 received b'234'
|
||||
INFO:2017-09-16 14:14:21,970:conn2 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-16 14:14:21,970:conn2 received b'36bc1111'
|
||||
INFO:2017-09-16 14:14:22,171:conn2 disconnecting
|
||||
INFO:2017-09-16 14:14:22,171:conn0 connected...
|
||||
INFO:2017-09-16 14:14:22,172:conn0 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-16 14:14:22,172:conn0 received b'b'
|
||||
INFO:2017-09-16 14:14:22,210:conn0 received b'cdbcuf'
|
||||
INFO:2017-09-16 14:14:23,173:conn0 sending b'xyz^123'
|
||||
INFO:2017-09-16 14:14:23,174:conn0 received b'234'
|
||||
INFO:2017-09-16 14:14:24,175:conn0 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-16 14:14:24,176:conn0 received b'36bc1111'
|
||||
INFO:2017-09-16 14:14:24,376:conn0 disconnecting
|
||||
```
|
||||
|
||||
这里要注意连接名:`conn1` 是第一个连接到服务器的,先跟服务器交互了一段时间。接下来的连接 `conn2` —— 在第一个断开连接后,连接到了服务器,然后第三个连接也是一样。就像日志显示的那样,每一个连接让服务器变得繁忙,保持大约 2.2 秒的时间(这实际上是人为地在客户端代码中加入的延迟),在这段时间里别的客户端都不能连接。
|
||||
|
||||
显然,这不是一个可扩展的策略。这个例子中,客户端中加入了延迟,让服务器不能处理别的交互动作。一个智能服务器应该能处理一堆客户端的请求,而这个原始的服务器在结束连接之前一直繁忙(我们将会在之后的章节中看到如何实现智能的服务器)。尽管服务端有延迟,但这不会过度占用CPU;例如,从数据库中查找信息(时间基本上是花在连接到数据库服务器上,或者是花在硬盘中的本地数据库)。
|
||||
|
||||
### 总结及期望
|
||||
|
||||
这个示例服务器达成了两个预期目标:
|
||||
|
||||
1. 首先是介绍了问题范畴和贯彻该系列文章的套接字编程基础。
|
||||
|
||||
2. 对于并发服务器编程的抛砖引玉 —— 就像之前的部分所说,有序服务器还不能在几个轻微的负载下进行扩展,而且没有高效的利用资源。
|
||||
|
||||
在看下一篇文章前,确保你已经理解了这里所讲的服务器/客户端协议,还有有序服务器的代码。我之前介绍过了这个简单的协议;例如 [串行通信分帧][15] 和 [协同运行,作为状态机的替代][16]。要学习套接字网络编程的基础,[Beej's 教程][17] 用来入门很不错,但是要深入理解我推荐你还是看本书。
|
||||
|
||||
如果有什么不清楚的,请在评论区下进行评论或者向我发送邮件。深入理解并发服务器!
|
||||
|
||||
***
|
||||
|
||||
|
||||
[ [1][1] ] 状态转变中的 In/Out 记号是指 [Mealy machine][2]。
|
||||
|
||||
[ [2][3] ] 回应的是 `bcdbcuf23436bc`。
|
||||
|
||||
[ [3][4] ] 这里在结尾处有一点小区别,加了字符串 `0000` —— 服务器回应这个序列,告诉客户端让其断开连接;这是一个简单的握手协议,确保客户端有足够的时间接收到服务器发送的所有回复。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://eli.thegreenplace.net/pages/about
|
||||
[1]:https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/#id1
|
||||
[2]:https://en.wikipedia.org/wiki/Mealy_machine
|
||||
[3]:https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/#id2
|
||||
[4]:https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/#id3
|
||||
[5]:https://eli.thegreenplace.net/tag/concurrency
|
||||
[6]:https://eli.thegreenplace.net/tag/c-c
|
||||
[7]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
[8]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[9]:http://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
[10]:https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/#id4
|
||||
[11]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/sequential-server.c
|
||||
[12]:https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/#id5
|
||||
[13]:https://github.com/eliben/code-for-blog/tree/master/2017/async-socket-server
|
||||
[14]:https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/#id6
|
||||
[15]:http://eli.thegreenplace.net/2009/08/12/framing-in-serial-communications/
|
||||
[16]:http://eli.thegreenplace.net/2009/08/29/co-routines-as-an-alternative-to-state-machines
|
||||
[17]:http://beej.us/guide/bgnet/
|
||||
[18]:https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
Loading…
Reference in New Issue
Block a user