mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
translated
This commit is contained in:
parent
050ee45a8c
commit
dd6942a949
@ -1,140 +0,0 @@
|
||||
[translating by KayGuoWhu]
|
||||
How to set up RAID 10 for high performance and fault tolerant disk I/O on Linux
|
||||
================================================================================
|
||||
A RAID 10 (aka RAID 1+0 or stripe of mirrors) array provides high performance and fault-tolerant disk I/O operations by combining features of RAID 0 (where read/write operations are performed in parallel across multiple drives) and RAID 1 (where data is written identically to two or more drives).
|
||||
|
||||
In this tutorial, I'll show you how to set up a software RAID 10 array using five identical 8 GiB disks. While the minimum number of disks for setting up a RAID 10 array is four (e.g., a striped set of two mirrors), we will add an extra spare drive should one of the main drives become faulty. We will also share some tools that you can later use to analyze the performance of your RAID array.
|
||||
|
||||
Please note that going through all the pros and cons of RAID 10 and other partitioning schemes (with different-sized drives and filesystems) is beyond the scope of this post.
|
||||
|
||||
### How Does a Raid 10 Array Work? ###
|
||||
|
||||
If you need to implement a storage solution that supports I/O-intensive operations (such as database, email, and web servers), RAID 10 is the way to go. Let me show you why. Let's refer to the below image.
|
||||
|
||||
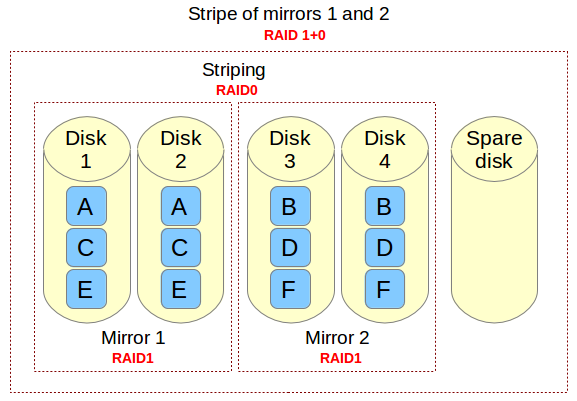
|
||||
|
||||
Imagine a file that is composed of blocks A, B, C, D, E, and F in the above diagram. Each RAID 1 mirror set (e.g., Mirror 1 or 2) replicates blocks on each of its two devices. Because of this configuration, write performance is reduced because every block has to be written twice, once for each disk, whereas read performance remains unchanged compared to reading from single disks. The bright side is that this setup provides redundancy in that unless more than one of the disks in each mirror fail, normal disk I/O operations can be maintained.
|
||||
|
||||
The RAID 0 stripe works by dividing data into blocks and writing block A to Mirror 1, block B to Mirror 2 (and so on) simultaneously, thereby improving the overall read and write performance. On the other hand, none of the mirrors contains the entire information for any piece of data committed to the main set. This means that if one of the mirrors fail, the entire RAID 0 component (and therefore the RAID 10 set) is rendered inoperable, with unrecoverable loss of data.
|
||||
|
||||
### Setting up a RAID 10 Array ###
|
||||
|
||||
There are two possible setups for a RAID 10 array: complex (built in one step) or nested (built by creating two or more RAID 1 arrays, and then using them as component devices in a RAID 0). In this tutorial, we will cover the creation of a complex RAID 10 array due to the fact that it allows us to create an array using either an even or odd number of disks, and can be managed as a single RAID device, as opposed to the nested setup (which only permits an even number of drives, and must be managed as a nested device, dealing with RAID 1 and RAID 0 separately).
|
||||
|
||||
It is assumed that you have mdadm installed, and the daemon running on your system. Refer to [this tutorial][1] for details. It is also assumed that a primary partition sd[bcdef]1 has been created on each disk. Thus, the output of:
|
||||
|
||||
ls -l /dev | grep sd[bcdef]
|
||||
|
||||
should be like:
|
||||
|
||||

|
||||
|
||||
Let's go ahead and create a RAID 10 array with the following command:
|
||||
|
||||
# mdadm --create --verbose /dev/md0 --level=10 --raid-devices=4 /dev/sd[bcde]1 --spare-devices=1 /dev/sdf1
|
||||
|
||||

|
||||
|
||||
When the array has been created (it should not take more than a few minutes), the output of:
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||
should look like:
|
||||
|
||||

|
||||
|
||||
A couple of things to note before we proceed further.
|
||||
|
||||
1. **Used Dev Space** indicates the capacity of each member device used by the array.
|
||||
|
||||
2. **Array Size** is the total size of the array. For a RAID 10 array, this is equal to (N*C)/M, where N: number of active devices, C: capacity of active devices, M: number of devices in each mirror. So in this case, (N*C)/M equals to (4*8GiB)/2 = 16GiB.
|
||||
|
||||
3. **Layout** refers to the fine details of data layout. The possible layout values are as follows.
|
||||
|
||||
----------
|
||||
|
||||
- **n** (default option): means near copies. Multiple copies of one data block are at similar offsets in different devices. This layout yields similar read and write performance than that of a RAID 0 array.
|
||||
|
||||

|
||||
|
||||
- **o** indicates offset copies. Rather than the chunks being duplicated within a stripe, whole stripes are duplicated, but are rotated by one device so duplicate blocks are on different devices. Thus subsequent copies of a block are in the next drive, one chunk further down. To use this layout for your RAID 10 array, add --layout=o2 to the command that is used to create the array.
|
||||
|
||||

|
||||
|
||||
- **f** represents far copies (multiple copies with very different offsets). This layout provides better read performance but worse write performance. Thus, it is the best option for systems that will need to support far more reads than writes. To use this layout for your RAID 10 array, add --layout=f2 to the command that is used to create the array.
|
||||
|
||||

|
||||
|
||||
The number that follows the **n**, **f**, and **o** in the --layout option indicates the number of replicas of each data block that are required. The default value is 2, but it can be 2 to the number of devices in the array. By providing an adequate number of replicas, you can minimize I/O impact on individual drives.
|
||||
|
||||
4. **Chunk Size**, as per the [Linux RAID wiki][2], is the smallest unit of data that can be written to the devices. The optimal chunk size depends on the rate of I/O operations and the size of the files involved. For large writes, you may see lower overhead by having fairly large chunks, whereas arrays that are primarily holding small files may benefit more from a smaller chunk size. To specify a certain chunk size for your RAID 10 array, add **--chunk=desired_chunk_size** to the command that is used to create the array.
|
||||
|
||||
Unfortunately, there is no one-size-fits-all formula to improve performance. Here are a few guidelines to consider.
|
||||
|
||||
- Filesystem: overall, [XFS][3] is said to be the best, while EXT4 remains a good choice.
|
||||
- Optimal layout: far layout improves read performance, but worsens write performance.
|
||||
- Number of replicas: more replicas minimize I/O impact, but increase costs as more disks will be needed.
|
||||
- Hardware: SSDs are more likely to show increased performance (under the same context) than traditional (spinning) disks.
|
||||
|
||||
### RAID Performance Tests using DD ###
|
||||
|
||||
The following benchmarking tests can be used to check on the performance of our RAID 10 array (/dev/md0).
|
||||
|
||||
#### 1. Write operation ####
|
||||
|
||||
A single file of 256MB is written to the device:
|
||||
|
||||
# dd if=/dev/zero of=/dev/md0 bs=256M count=1 oflag=dsync
|
||||
|
||||
512 bytes are written 1000 times:
|
||||
|
||||
# dd if=/dev/zero of=/dev/md0 bs=512 count=1000 oflag=dsync
|
||||
|
||||
With dsync flag, dd bypasses filesystem cache, and performs synchronized write to a RAID array. This option is used to eliminate caching effect during RAID performance tests.
|
||||
|
||||
#### 2. Read operation ####
|
||||
|
||||
256KiB*15000 (3.9 GB) are copied from the array to /dev/null:
|
||||
|
||||
# dd if=/dev/md0 of=/dev/null bs=256K count=15000
|
||||
|
||||
### RAID Performance Tests Using Iozone ###
|
||||
|
||||
[Iozone][4] is a filesystem benchmark tool that allows us to measure a variety of disk I/O operations, including random read/write, sequential read/write, and re-read/re-write. It can export the results to a Microsoft Excel or LibreOffice Calc file.
|
||||
|
||||
#### Installing Iozone on CentOS/RHEL 7 ####
|
||||
|
||||
Enable [Repoforge][5]. Then:
|
||||
|
||||
# yum install iozone
|
||||
|
||||
#### Installing Iozone on Debian 7 ####
|
||||
|
||||
# aptitude install iozone3
|
||||
|
||||
The iozone command below will perform all tests in the RAID-10 array:
|
||||
|
||||
# iozone -Ra /dev/md0 -b /tmp/md0.xls
|
||||
|
||||
- **-R**: generates an Excel-compatible report to standard out.
|
||||
- **-a**: runs iozone in a full automatic mode with all tests and possible record/file sizes. Record sizes: 4k-16M and file sizes: 64k-512M.
|
||||
- **-b /tmp/md0.xls**: stores test results in a specified file.
|
||||
|
||||
Hope this helps. Feel free to add your thoughts or add tips to consider on how to improve performance of RAID 10.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/setup-raid10-linux.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
[1]:http://xmodulo.com/create-software-raid1-array-mdadm-linux.html
|
||||
[2]:https://raid.wiki.kernel.org/
|
||||
[3]:http://ask.xmodulo.com/create-mount-xfs-file-system-linux.html
|
||||
[4]:http://www.iozone.org/
|
||||
[5]:http://xmodulo.com/how-to-set-up-rpmforge-repoforge-repository-on-centos.html
|
||||
@ -0,0 +1,139 @@
|
||||
在Linux上组成RAID 10阵列以实现高性能和高容错性的磁盘I/O
|
||||
================================================================================
|
||||
RAID 10阵列 (又名RAID 1+0 或先镜像后分区)通过结合RAID 0 (读写操作并行在多个磁盘上同时执行)和RAID 1 (数据被完全相同地写入到两个或更多的磁盘)两者的特点实现高性能和高容错性的磁盘I/O。
|
||||
|
||||
这篇文章会指导你如何使用五块相同的8GB磁盘来组成一个软件RAID 10阵列。因为组成一个RAID 10阵列至少需要4块磁盘(比如,两个镜像各有一对分区组合),而且需要添加一块额外的备用磁盘以防某块主要的磁盘出错。本文也会分享一些工具,在稍后用来分析RAID阵列的性能。
|
||||
|
||||
注意RAID 10的优缺点和其它分区方法(在不同大小的磁盘和文件系统上)的内容不在本文讨论范围内。
|
||||
|
||||
### Raid 10 阵列如何工作? ###
|
||||
|
||||
如果你需要实现一种支持I/O密集操作(比如数据库、电子邮件或web服务器)的存储解决方案,RAID 10就是你需要的。来看看为什么这么说,请看下图。
|
||||
|
||||

|
||||
|
||||
上图中的文件由A、B、C、D、E和F六种块组成,每一个RAID 1镜像对(如镜像1和2)在两个磁盘上复制相同的块。因为需要这样配置,写操作性能会因为每个块需要写入两次而下降,每个磁盘各一次;而读操作与从单块磁盘中读取相比并未发生改变。不过这种配置的好处是除非一个镜像中有超过一块的磁盘故障,否则都能保持冗余以维持正常的磁盘I/O操作。
|
||||
|
||||
RAID 0的分区通过将数据划分到不同的块,然后执行同时将块A写入镜像1、将块B写入镜像2(以此类推)的并行操作以提高整体的读写性能。在另一方面,没有任何一个镜像包含构成主存的数据片的全部信息。这就意味着如果其中一个镜像故障,那么整个RAID 0组件将无法正常工作,数据将遭受不可恢复的损失。
|
||||
|
||||
### 建立RAID 10阵列 ###
|
||||
|
||||
有两种建立RAID 10阵列的可行方案:复杂法(一步完成)和嵌套法(先创建两个或更多的RAID 1阵列,然后使用它们组成RAID 0)。本文会关注复杂法创建RAID 10阵列,因为这种方法能够使用偶数或奇数个磁盘去创建阵列,而且能以单个RAID设备的形式被管理,而嵌套法则恰恰相反(只允许偶数个磁盘,必须以嵌套设备的形式被管理,即分开管理RAID 1和RAID 0)。
|
||||
|
||||
假设你的机器已经安装mdadm,并运行着相应的守护进程,细节参见[这篇文章][1]。也假设每个磁盘上已经划分出一个主分区sd[bcdef]1。使用命令
|
||||
|
||||
ls -l /dev | grep sd[bcdef]
|
||||
|
||||
查看到的输出应该如下所示:
|
||||
|
||||

|
||||
|
||||
然后使用下面的命令创建一个RAID 10阵列:
|
||||
|
||||
# mdadm --create --verbose /dev/md0 --level=10 --raid-devices=4 /dev/sd[bcde]1 --spare-devices=1 /dev/sdf1
|
||||
|
||||

|
||||
|
||||
当阵列创建完毕后(最多花费几分钟),执行命令
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||
的输出应如下所示:
|
||||
|
||||

|
||||
|
||||
在更进一步之前需要注意以下事项。
|
||||
|
||||
1. **Used Dev Space**表示阵列所使用的每一块磁盘的容量。
|
||||
|
||||
2. **Array Size**表示阵列的整体大小。RAID 10阵列的大小通过(N*C)/M计算,其中N是活跃磁盘的数目,C是活跃磁盘的总容量,M是每一个镜像中磁盘的数目。在本文的情形下,这个值等于(4*8GiB)/2 = 16GiB。
|
||||
|
||||
3. **Layout**是整个数据布局的详细信息。可能的布局数值如下所示。
|
||||
|
||||
----------
|
||||
|
||||
- **n**(默认选项):代表就近拷贝。一个数据块的多个拷贝在不同磁盘里有相同的偏移量。这种布局提供和RAID 0阵列相似的读写性能。
|
||||
|
||||

|
||||
|
||||
- **o**代表偏移量拷贝。不是复制一个分区里的块,所有的分区都被复制,但会被循环打乱,所以同一个分区中复制的块会出现在不同的磁盘。因此,一个块的后续拷贝会出现在下一个磁盘中,一个块接着一个块。为了在RAID 10阵列中使用这种布局,在创建阵列的命令中添加--layout=o2选项。
|
||||
|
||||

|
||||
|
||||
- **f**代表远端拷贝(多个拷贝在不同的磁盘中具有不同的偏移量)。这种布局提供更好的读性能但带来更差的写性能。因此,对于读远远多于写的系统来说是最好的选择。为了在RAID 10阵列中使用这种布局,在创建阵列的命令中添加--layout=f2。
|
||||
|
||||

|
||||
|
||||
跟在布局选项**n**、**f**和**o**后面的数字代表所需的每一个数据块的副本数目。默认值是2,但可以是2到阵列中磁盘数目之间的某个值。提供足够的副本数目可以最小化单个磁盘上的I/O影响。
|
||||
|
||||
4. **Chunk Size**,以[Linux RAID wiki][2]为准,是写入磁盘的最小数据单元。最佳的chunk大小取决于I/O操作的速率和相关的文件大小。对于大量的写操作,通过设置相对较大的chunks可以得到更低的开销,但对于主要存储小文件的阵列来说更小的chunk性能更好。为了给RAID 10指定一个chunk大小,在创建阵列的命令中添加**--chunk=desired_chunk_size**。
|
||||
|
||||
不幸的是,并没有设置一个大小就能适合全局的策略用来提高性能,但可以参考下面的一些方案。
|
||||
|
||||
- 文件系统:就整体而言,[XFS][3]据说是最好的,当然EXT4也是不错的选择。
|
||||
- 最佳布局:远端布局能提高读性能,但会降低写性能。
|
||||
- 副本数目:更多的副本能最小化I/O影响,但更多的磁盘需要更大的花费。
|
||||
- 硬件:在相同的环境下,SSD比传统(机械旋转)磁盘更能带来出性能提升
|
||||
|
||||
### 使用DD进行RAID性能测试 ###
|
||||
|
||||
下面的基准测试用于检测RAID 10阵列(/dev/md0)的性能。
|
||||
|
||||
#### 1. 写操作 ####
|
||||
|
||||
往磁盘中写入大小为256MB的单个文件:
|
||||
|
||||
# dd if=/dev/zero of=/dev/md0 bs=256M count=1 oflag=dsync
|
||||
|
||||
写入1000次512字节:
|
||||
|
||||
# dd if=/dev/zero of=/dev/md0 bs=512 count=1000 oflag=dsync
|
||||
|
||||
使用dsync标记,dd可以绕过文件系统缓存,在RAID阵列上执行同步写。这个选项用于减少RAID性能测试中缓存的影响。
|
||||
|
||||
#### 2. 读操作 ####
|
||||
|
||||
从阵列中拷贝256KiB*15000(3.9 GB)大小内容到/dev/null:
|
||||
|
||||
# dd if=/dev/md0 of=/dev/null bs=256K count=15000
|
||||
|
||||
### 使用Iozone进行RAID性能测试 ###
|
||||
|
||||
[Iozone][4]是一款文件系统基准测试工具,用来测试各种磁盘I/O操作,包括随机读写、顺序读写和重读重写。它支持将结果导出为微软的Excel或LibreOffice的Calc文件。
|
||||
|
||||
#### 在CentOS/RHEL 7上安装Iozone ####
|
||||
|
||||
先保证[Repoforge][5]可用,然后输入:
|
||||
|
||||
# yum install iozone
|
||||
|
||||
#### 在Debian 7上安装Iozone ####
|
||||
|
||||
# aptitude install iozone3
|
||||
|
||||
下面的iozone命令会在RAID-10阵列中执行所有测试:
|
||||
|
||||
# iozone -Ra /dev/md0 -b /tmp/md0.xls
|
||||
|
||||
- **-R**:往标准输出生成兼容Excel的报告
|
||||
- **-a**:以全自动模式运行所有的测试,并测试各种记录/文件大小。记录大小范围:4K-16M,文件大小范围:64K-512M。
|
||||
- **-b /tmp/md0.xls**: 把测试结果存储到一个指定的文件中
|
||||
|
||||
希望这篇文章对你有所帮助,如果想到任何想法或建议可能会提升RAID 10的性能,请讲出来。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/setup-raid10-linux.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[KayGuoWhu](https://github.com/KayGuoWhu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
[1]:http://xmodulo.com/create-software-raid1-array-mdadm-linux.html
|
||||
[2]:https://raid.wiki.kernel.org/
|
||||
[3]:http://ask.xmodulo.com/create-mount-xfs-file-system-linux.html
|
||||
[4]:http://www.iozone.org/
|
||||
[5]:http://xmodulo.com/how-to-set-up-rpmforge-repoforge-repository-on-centos.html
|
||||
Loading…
Reference in New Issue
Block a user