mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-28 23:20:10 +08:00
commit
dcad6d3941
@ -1,35 +1,43 @@
|
||||
Linux / Unix / Mac OS X 中的 30 个方便的 Bash shell 别名
|
||||
30 个方便的 Bash shell 别名
|
||||
======
|
||||
bash 别名不是把别的,只不过是指向命令的快捷方式而已。`alias` 命令允许用户只输入一个单词就运行任意一个命令或一组命令(包括命令选项和文件名)。执行 `alias` 命令会显示一个所有已定义别名的列表。你可以在 [~/.bashrc][1] 文件中自定义别名。使用别名可以在命令行中减少输入的时间,使工作更流畅,同时增加生产率。
|
||||
|
||||
bash <ruby>别名<rt>alias</rt></ruby>只不过是指向命令的快捷方式而已。`alias` 命令允许用户只输入一个单词就运行任意一个命令或一组命令(包括命令选项和文件名)。执行 `alias` 命令会显示一个所有已定义别名的列表。你可以在 [~/.bashrc][1] 文件中自定义别名。使用别名可以在命令行中减少输入的时间,使工作更流畅,同时增加生产率。
|
||||
|
||||
本文通过 30 个 bash shell 别名的实际案例演示了如何创建和使用别名。
|
||||
|
||||
![30 Useful Bash Shell Aliase For Linux/Unix Users][2]
|
||||
|
||||
## bash alias 的那些事
|
||||
### bash alias 的那些事
|
||||
|
||||
bash shell 中的 alias 命令的语法是这样的:
|
||||
|
||||
### 如何列出 bash 别名
|
||||
```
|
||||
alias [alias-name[=string]...]
|
||||
```
|
||||
|
||||
#### 如何列出 bash 别名
|
||||
|
||||
输入下面的 [alias 命令][3]:
|
||||
|
||||
输入下面的 [alias 命令 ][3]:
|
||||
```
|
||||
alias
|
||||
```
|
||||
|
||||
结果为:
|
||||
|
||||
```
|
||||
alias ..='cd ..'
|
||||
alias amazonbackup='s3backup'
|
||||
alias apt-get='sudo apt-get'
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
默认 alias 命令会列出当前用户定义好的别名。
|
||||
`alias` 命令默认会列出当前用户定义好的别名。
|
||||
|
||||
### 如何定义或者说创建一个 bash shell 别名
|
||||
#### 如何定义或者创建一个 bash shell 别名
|
||||
|
||||
使用下面语法 [创建别名][4]:
|
||||
|
||||
使用下面语法 [创建别名 ][4]:
|
||||
```
|
||||
alias name =value
|
||||
alias name = 'command'
|
||||
@ -38,19 +46,22 @@ alias name = '/path/to/script'
|
||||
alias name = '/path/to/script.pl arg1'
|
||||
```
|
||||
|
||||
举个例子,输入下面命令并回车就会为常用的 `clear`( 清除屏幕)命令创建一个别名 **c**:
|
||||
举个例子,输入下面命令并回车就会为常用的 `clear`(清除屏幕)命令创建一个别名 `c`:
|
||||
|
||||
```
|
||||
alias c = 'clear'
|
||||
```
|
||||
|
||||
然后输入字母 `c` 而不是 `clear` 后回车就会清除屏幕了:
|
||||
|
||||
```
|
||||
c
|
||||
```
|
||||
|
||||
### 如何临时性地禁用 bash 别名
|
||||
#### 如何临时性地禁用 bash 别名
|
||||
|
||||
下面语法可以[临时性地禁用别名][5]:
|
||||
|
||||
下面语法可以[临时性地禁用别名 ][5]:
|
||||
```
|
||||
## path/to/full/command
|
||||
/usr/bin/clear
|
||||
@ -60,37 +71,43 @@ c
|
||||
command ls
|
||||
```
|
||||
|
||||
### 如何删除 bash 别名
|
||||
#### 如何删除 bash 别名
|
||||
|
||||
使用 [unalias 命令来删除别名][6]。其语法为:
|
||||
|
||||
使用 [unalias 命令来删除别名 ][6]。其语法为:
|
||||
```
|
||||
unalias aliasname
|
||||
unalias foo
|
||||
```
|
||||
|
||||
例如,删除我们之前创建的别名 `c`:
|
||||
|
||||
```
|
||||
unalias c
|
||||
```
|
||||
|
||||
你还需要用文本编辑器删掉 [~/.bashrc 文件 ][1] 中的别名定义(参见下一部分内容)。
|
||||
你还需要用文本编辑器删掉 [~/.bashrc 文件][1] 中的别名定义(参见下一部分内容)。
|
||||
|
||||
### 如何让 bash shell 别名永久生效
|
||||
#### 如何让 bash shell 别名永久生效
|
||||
|
||||
别名 `c` 在当前登录会话中依然有效。但当你登出或重启系统后,别名 `c` 就没有了。为了防止出现这个问题,将别名定义写入 [~/.bashrc file][1] 中,输入:
|
||||
|
||||
```
|
||||
vi ~/.bashrc
|
||||
```
|
||||
|
||||
输入下行内容让别名 `c` 对当前用户永久有效:
|
||||
|
||||
```
|
||||
alias c = 'clear'
|
||||
```
|
||||
|
||||
保存并关闭文件就行了。系统级的别名(也就是对所有用户都生效的别名) 可以放在 `/etc/bashrc` 文件中。请注意,alias 命令内建于各种 shell 中,包括 ksh,tcsh/csh,ash,bash 以及其他 shell。
|
||||
保存并关闭文件就行了。系统级的别名(也就是对所有用户都生效的别名)可以放在 `/etc/bashrc` 文件中。请注意,`alias` 命令内建于各种 shell 中,包括 ksh,tcsh/csh,ash,bash 以及其他 shell。
|
||||
|
||||
### 关于特权权限判断
|
||||
#### 关于特权权限判断
|
||||
|
||||
可以将下面代码加入 `~/.bashrc`:
|
||||
|
||||
```
|
||||
# if user is not root, pass all commands via sudo #
|
||||
if [ $UID -ne 0 ]; then
|
||||
@ -99,9 +116,10 @@ if [ $UID -ne 0 ]; then
|
||||
fi
|
||||
```
|
||||
|
||||
### 定义与操作系统类型相关的别名
|
||||
#### 定义与操作系统类型相关的别名
|
||||
|
||||
可以将下面代码加入 `~/.bashrc` [使用 case 语句][7]:
|
||||
|
||||
可以将下面代码加入 `~/.bashrc` [使用 case 语句 ][7]:
|
||||
```
|
||||
### Get os name via uname ###
|
||||
_myos="$(uname)"
|
||||
@ -115,13 +133,14 @@ case $_myos in
|
||||
esac
|
||||
```
|
||||
|
||||
## 30 个 bash shell 别名的案例
|
||||
### 30 个 bash shell 别名的案例
|
||||
|
||||
你可以定义各种类型的别名来节省时间并提高生产率。
|
||||
|
||||
### #1:控制 ls 命令的输出
|
||||
#### #1:控制 ls 命令的输出
|
||||
|
||||
[ls 命令列出目录中的内容][8] 而你可以对输出进行着色:
|
||||
|
||||
[ls 命令列出目录中的内容 ][8] 而你可以对输出进行着色:
|
||||
```
|
||||
## Colorize the ls output ##
|
||||
alias ls = 'ls --color=auto'
|
||||
@ -133,7 +152,8 @@ alias ll = 'ls -la'
|
||||
alias l.= 'ls -d . .. .git .gitignore .gitmodules .travis.yml --color=auto'
|
||||
```
|
||||
|
||||
### #2:控制 cd 命令的行为
|
||||
#### #2:控制 cd 命令的行为
|
||||
|
||||
```
|
||||
## get rid of command not found ##
|
||||
alias cd..= 'cd ..'
|
||||
@ -147,9 +167,10 @@ alias .4= 'cd ../../../../'
|
||||
alias .5= 'cd ../../../../..'
|
||||
```
|
||||
|
||||
### #3:控制 grep 命令的输出
|
||||
#### #3:控制 grep 命令的输出
|
||||
|
||||
[grep 命令是一个用于在纯文本文件中搜索匹配正则表达式的行的命令行工具][9]:
|
||||
|
||||
[grep 命令是一个用于在纯文本文件中搜索匹配正则表达式的行的命令行工具 ][9]:
|
||||
```
|
||||
## Colorize the grep command output for ease of use (good for log files)##
|
||||
alias grep = 'grep --color=auto'
|
||||
@ -157,44 +178,51 @@ alias egrep = 'egrep --color=auto'
|
||||
alias fgrep = 'fgrep --color=auto'
|
||||
```
|
||||
|
||||
### #4:让计算器默认开启 math 库
|
||||
#### #4:让计算器默认开启 math 库
|
||||
|
||||
```
|
||||
alias bc = 'bc -l'
|
||||
```
|
||||
|
||||
### #4:生成 sha1 数字签名
|
||||
#### #4:生成 sha1 数字签名
|
||||
|
||||
```
|
||||
alias sha1 = 'openssl sha1'
|
||||
```
|
||||
|
||||
### #5:自动创建父目录
|
||||
#### #5:自动创建父目录
|
||||
|
||||
[mkdir 命令][10] 用于创建目录:
|
||||
|
||||
[mkdir 命令 ][10] 用于创建目录:
|
||||
```
|
||||
alias mkdir = 'mkdir -pv'
|
||||
```
|
||||
|
||||
### #6:为 diff 输出着色
|
||||
#### #6:为 diff 输出着色
|
||||
|
||||
你可以[使用 diff 来一行行第比较文件][11] 而一个名为 `colordiff` 的工具可以为 diff 输出着色:
|
||||
|
||||
你可以[使用 diff 来一行行第比较文件 ][11] 而一个名为 colordiff 的工具可以为 diff 输出着色:
|
||||
```
|
||||
# install colordiff package :)
|
||||
alias diff = 'colordiff'
|
||||
```
|
||||
|
||||
### #7:让 mount 命令的输出更漂亮,更方便人类阅读
|
||||
#### #7:让 mount 命令的输出更漂亮,更方便人类阅读
|
||||
|
||||
```
|
||||
alias mount = 'mount |column -t'
|
||||
```
|
||||
|
||||
### #8:简化命令以节省时间
|
||||
#### #8:简化命令以节省时间
|
||||
|
||||
```
|
||||
# handy short cuts #
|
||||
alias h = 'history'
|
||||
alias j = 'jobs -l'
|
||||
```
|
||||
|
||||
### #9:创建一系列新命令
|
||||
#### #9:创建一系列新命令
|
||||
|
||||
```
|
||||
alias path = 'echo -e ${PATH//:/\\n}'
|
||||
alias now = 'date +"%T"'
|
||||
@ -202,7 +230,8 @@ alias nowtime =now
|
||||
alias nowdate = 'date +"%d-%m-%Y"'
|
||||
```
|
||||
|
||||
### #10:设置 vim 为默认编辑器
|
||||
#### #10:设置 vim 为默认编辑器
|
||||
|
||||
```
|
||||
alias vi = vim
|
||||
alias svi = 'sudo vi'
|
||||
@ -210,7 +239,8 @@ alias vis = 'vim "+set si"'
|
||||
alias edit = 'vim'
|
||||
```
|
||||
|
||||
### #11:控制网络工具 ping 的输出
|
||||
#### #11:控制网络工具 ping 的输出
|
||||
|
||||
```
|
||||
# Stop after sending count ECHO_REQUEST packets #
|
||||
alias ping = 'ping -c 5'
|
||||
@ -219,16 +249,18 @@ alias ping = 'ping -c 5'
|
||||
alias fastping = 'ping -c 100 -s.2'
|
||||
```
|
||||
|
||||
### #12:显示打开的端口
|
||||
#### #12:显示打开的端口
|
||||
|
||||
使用 [netstat 命令][12] 可以快速列出服务区中所有的 TCP/UDP 端口:
|
||||
|
||||
使用 [netstat 命令 ][12] 可以快速列出服务区中所有的 TCP/UDP 端口:
|
||||
```
|
||||
alias ports = 'netstat -tulanp'
|
||||
```
|
||||
|
||||
### #13:唤醒休眠额服务器
|
||||
#### #13:唤醒休眠的服务器
|
||||
|
||||
[Wake-on-LAN (WOL) 是一个以太网标准][13],可以通过网络消息来开启服务器。你可以使用下面别名来[快速激活 nas 设备][14] 以及服务器:
|
||||
|
||||
[Wake-on-LAN (WOL) 是一个以太网标准 ][13],可以通过网络消息来开启服务器。你可以使用下面别名来[快速激活 nas 设备 ][14] 以及服务器:
|
||||
```
|
||||
## replace mac with your actual server mac address #
|
||||
alias wakeupnas01 = '/usr/bin/wakeonlan 00:11:32:11:15:FC'
|
||||
@ -236,9 +268,10 @@ alias wakeupnas02 = '/usr/bin/wakeonlan 00:11:32:11:15:FD'
|
||||
alias wakeupnas03 = '/usr/bin/wakeonlan 00:11:32:11:15:FE'
|
||||
```
|
||||
|
||||
### #14:控制防火墙 (iptables) 的输出
|
||||
#### #14:控制防火墙 (iptables) 的输出
|
||||
|
||||
[Netfilter 是一款 Linux 操作系统上的主机防火墙][15]。它是 Linux 发行版中的一部分,且默认情况下是激活状态。[这里列出了大多数 Liux 新手防护入侵者最常用的 iptables 方法][16]。
|
||||
|
||||
[Netfilter 是一款 Linux 操作系统上的主机防火墙 ][15]。它是 Linux 发行版中的一部分,且默认情况下是激活状态。[这里列出了大多数 Liux 新手防护入侵者最常用的 iptables 方法 ][16]。
|
||||
```
|
||||
## shortcut for iptables and pass it via sudo#
|
||||
alias ipt = 'sudo /sbin/iptables'
|
||||
@ -251,7 +284,8 @@ alias iptlistfw = 'sudo /sbin/iptables -L FORWARD -n -v --line-numbers'
|
||||
alias firewall =iptlist
|
||||
```
|
||||
|
||||
### #15:使用 curl 调试 web 服务器 /cdn 上的问题
|
||||
#### #15:使用 curl 调试 web 服务器 / CDN 上的问题
|
||||
|
||||
```
|
||||
# get web server headers #
|
||||
alias header = 'curl -I'
|
||||
@ -260,7 +294,8 @@ alias header = 'curl -I'
|
||||
alias headerc = 'curl -I --compress'
|
||||
```
|
||||
|
||||
### #16:增加安全性
|
||||
#### #16:增加安全性
|
||||
|
||||
```
|
||||
# do not delete / or prompt if deleting more than 3 files at a time #
|
||||
alias rm = 'rm -I --preserve-root'
|
||||
@ -276,9 +311,10 @@ alias chmod = 'chmod --preserve-root'
|
||||
alias chgrp = 'chgrp --preserve-root'
|
||||
```
|
||||
|
||||
### #17:更新 Debian Linux 服务器
|
||||
#### #17:更新 Debian Linux 服务器
|
||||
|
||||
[apt-get 命令][17] 用于通过因特网安装软件包 (ftp 或 http)。你也可以一次性升级所有软件包:
|
||||
|
||||
[apt-get 命令 ][17] 用于通过因特网安装软件包 (ftp 或 http)。你也可以一次性升级所有软件包:
|
||||
```
|
||||
# distro specific - Debian / Ubuntu and friends #
|
||||
# install with apt-get
|
||||
@ -289,25 +325,27 @@ alias updatey = "sudo apt-get --yes"
|
||||
alias update = 'sudo apt-get update && sudo apt-get upgrade'
|
||||
```
|
||||
|
||||
### #18:更新 RHEL / CentOS / Fedora Linux 服务器
|
||||
#### #18:更新 RHEL / CentOS / Fedora Linux 服务器
|
||||
|
||||
[yum 命令][18] 是 RHEL / CentOS / Fedora Linux 以及其他基于这些发行版的 Linux 上的软件包管理工具:
|
||||
|
||||
[yum 命令 ][18] 是 RHEL / CentOS / Fedora Linux 以及其他基于这些发行版的 Linux 上的软件包管理工具:
|
||||
```
|
||||
## distrp specifc RHEL/CentOS ##
|
||||
alias update = 'yum update'
|
||||
alias updatey = 'yum -y update'
|
||||
```
|
||||
|
||||
### #19:优化 sudo 和 su 命令
|
||||
#### #19:优化 sudo 和 su 命令
|
||||
|
||||
```
|
||||
# become root #
|
||||
alias root = 'sudo -i'
|
||||
alias su = 'sudo -i'
|
||||
```
|
||||
|
||||
### #20:使用 sudo 执行 halt/reboot 命令
|
||||
#### #20:使用 sudo 执行 halt/reboot 命令
|
||||
|
||||
[shutdown 命令 ][19] 会让 Linux / Unix 系统关机:
|
||||
[shutdown 命令][19] 会让 Linux / Unix 系统关机:
|
||||
```
|
||||
# reboot / halt / poweroff
|
||||
alias reboot = 'sudo /sbin/reboot'
|
||||
@ -316,7 +354,8 @@ alias halt = 'sudo /sbin/halt'
|
||||
alias shutdown = 'sudo /sbin/shutdown'
|
||||
```
|
||||
|
||||
### #21:控制 web 服务器
|
||||
#### #21:控制 web 服务器
|
||||
|
||||
```
|
||||
# also pass it via sudo so whoever is admin can reload it without calling you #
|
||||
alias nginxreload = 'sudo /usr/local/nginx/sbin/nginx -s reload'
|
||||
@ -327,7 +366,8 @@ alias httpdreload = 'sudo /usr/sbin/apachectl -k graceful'
|
||||
alias httpdtest = 'sudo /usr/sbin/apachectl -t && /usr/sbin/apachectl -t -D DUMP_VHOSTS'
|
||||
```
|
||||
|
||||
### #22:与备份相关的别名
|
||||
#### #22:与备份相关的别名
|
||||
|
||||
```
|
||||
# if cron fails or if you want backup on demand just run these commands #
|
||||
# again pass it via sudo so whoever is in admin group can start the job #
|
||||
@ -342,7 +382,8 @@ alias rsnapshotmonthly = 'sudo /home/scripts/admin/scripts/backup/wrapper.rsnaps
|
||||
alias amazonbackup =s3backup
|
||||
```
|
||||
|
||||
### #23:桌面应用相关的别名 - 按需播放的 avi/mp3 文件
|
||||
#### #23:桌面应用相关的别名 - 按需播放的 avi/mp3 文件
|
||||
|
||||
```
|
||||
## play video files in a current directory ##
|
||||
# cd ~/Download/movie-name
|
||||
@ -364,10 +405,10 @@ alias nplaymp3 = 'for i in /nas/multimedia/mp3/*.mp3; do mplayer "$i"; done'
|
||||
alias music = 'mplayer --shuffle *'
|
||||
```
|
||||
|
||||
#### #24:设置系统管理相关命令的默认网卡
|
||||
|
||||
### #24:设置系统管理相关命令的默认网卡
|
||||
[vnstat 一款基于终端的网络流量检测器][20]。[dnstop 是一款分析 DNS 流量的终端工具][21]。[tcptrack 和 iftop 命令显示][22] TCP/UDP 连接方面的信息,它监控网卡并显示其消耗的带宽。
|
||||
|
||||
[vnstat 一款基于终端的网络流量检测器 ][20]。[dnstop 是一款分析 DNS 流量的终端工具 ][21]。[tcptrack 和 iftop 命令显示 ][22] TCP/UDP 连接方面的信息,它监控网卡并显示其消耗的带宽。
|
||||
```
|
||||
## All of our servers eth1 is connected to the Internets via vlan / router etc ##
|
||||
alias dnstop = 'dnstop -l 5 eth1'
|
||||
@ -381,7 +422,8 @@ alias ethtool = 'ethtool eth1'
|
||||
alias iwconfig = 'iwconfig wlan0'
|
||||
```
|
||||
|
||||
### #25:快速获取系统内存,cpu 使用,和 gpu 内存相关信息
|
||||
#### #25:快速获取系统内存,cpu 使用,和 gpu 内存相关信息
|
||||
|
||||
```
|
||||
## pass options to free ##
|
||||
alias meminfo = 'free -m -l -t'
|
||||
@ -404,9 +446,10 @@ alias cpuinfo = 'lscpu'
|
||||
alias gpumeminfo = 'grep -i --color memory /var/log/Xorg.0.log'
|
||||
```
|
||||
|
||||
### #26:控制家用路由器
|
||||
#### #26:控制家用路由器
|
||||
|
||||
`curl` 命令可以用来 [重启 Linksys 路由器][23]。
|
||||
|
||||
curl 命令可以用来 [重启 Linksys 路由器 ][23]。
|
||||
```
|
||||
# Reboot my home Linksys WAG160N / WAG54 / WAG320 / WAG120N Router / Gateway from *nix.
|
||||
alias rebootlinksys = "curl -u 'admin:my-super-password' 'http://192.168.1.2/setup.cgi?todo=reboot'"
|
||||
@ -415,15 +458,17 @@ alias rebootlinksys = "curl -u 'admin:my-super-password' 'http://192.168.1.2/set
|
||||
alias reboottomato = "ssh admin@192.168.1.1 /sbin/reboot"
|
||||
```
|
||||
|
||||
### #27 wget 默认断点续传
|
||||
#### #27 wget 默认断点续传
|
||||
|
||||
[GNU wget 是一款用来从 web 下载文件的自由软件][25]。它支持 HTTP,HTTPS,以及 FTP 协议,而且它也支持断点续传:
|
||||
|
||||
[GNU Wget 是一款用来从 web 下载文件的自由软件 ][25]。它支持 HTTP,HTTPS,以及 FTP 协议,而且它页支持断点续传:
|
||||
```
|
||||
## this one saved by butt so many times ##
|
||||
alias wget = 'wget -c'
|
||||
```
|
||||
|
||||
### #28 使用不同浏览器来测试网站
|
||||
#### #28 使用不同浏览器来测试网站
|
||||
|
||||
```
|
||||
## this one saved by butt so many times ##
|
||||
alias ff4 = '/opt/firefox4/firefox'
|
||||
@ -438,9 +483,10 @@ alias ff =ff13
|
||||
alias browser =chrome
|
||||
```
|
||||
|
||||
### #29:关于 ssh 别名的注意事项
|
||||
#### #29:关于 ssh 别名的注意事项
|
||||
|
||||
不要创建 ssh 别名,代之以 `~/.ssh/config` 这个 OpenSSH SSH 客户端配置文件。它的选项更加丰富。下面是一个例子:
|
||||
|
||||
```
|
||||
Host server10
|
||||
Hostname 1.2.3.4
|
||||
@ -451,12 +497,13 @@ Host server10
|
||||
TCPKeepAlive yes
|
||||
```
|
||||
|
||||
然后你就可以使用下面语句连接 peer1 了:
|
||||
然后你就可以使用下面语句连接 server10 了:
|
||||
|
||||
```
|
||||
$ ssh server10
|
||||
```
|
||||
|
||||
### #30:现在该分享你的别名了
|
||||
#### #30:现在该分享你的别名了
|
||||
|
||||
```
|
||||
## set some other defaults ##
|
||||
@ -486,27 +533,26 @@ alias cdnmdel = '/home/scripts/admin/cdn/purge_cdn_cache --profile akamai --stdi
|
||||
alias amzcdnmdel = '/home/scripts/admin/cdn/purge_cdn_cache --profile amazon --stdin'
|
||||
```
|
||||
|
||||
## 结论
|
||||
### 总结
|
||||
|
||||
本文总结了 *nix bash 别名的多种用法:
|
||||
|
||||
1。为命令设置默认的参数(例如通过 `alias ethtool='ethtool eth0'` 设置 ethtool 命令的默认参数为 eth0)。
|
||||
2。修正错误的拼写(通过 `alias cd。.='cd .。'`让 `cd。.` 变成 `cd .。`)。
|
||||
3。缩减输入。
|
||||
4。设置系统中多版本命令的默认路径(例如 GNU/grep 位于 /usr/local/bin/grep 中而 Unix grep 位于 /bin/grep 中。若想默认使用 GNU grep 则设置别名 `grep='/usr/local/bin/grep'` )。
|
||||
5。通过默认开启命令(例如 rm,mv 等其他命令)的交互参数来增加 Unix 的安全性。
|
||||
6。为老旧的操作系统(比如 MS-DOS 或者其他类似 Unix 的操作系统)创建命令以增加兼容性(比如 `alias del=rm` )。
|
||||
1. 为命令设置默认的参数(例如通过 `alias ethtool='ethtool eth0'` 设置 ethtool 命令的默认参数为 eth0)。
|
||||
2. 修正错误的拼写(通过 `alias cd..='cd ..'`让 `cd..` 变成 `cd ..`)。
|
||||
3. 缩减输入。
|
||||
4. 设置系统中多版本命令的默认路径(例如 GNU/grep 位于 `/usr/local/bin/grep` 中而 Unix grep 位于 `/bin/grep` 中。若想默认使用 GNU grep 则设置别名 `grep='/usr/local/bin/grep'` )。
|
||||
5. 通过默认开启命令(例如 `rm`,`mv` 等其他命令)的交互参数来增加 Unix 的安全性。
|
||||
6. 为老旧的操作系统(比如 MS-DOS 或者其他类似 Unix 的操作系统)创建命令以增加兼容性(比如 `alias del=rm`)。
|
||||
|
||||
我已经分享了多年来为了减少重复输入命令而使用的别名。若你知道或使用的哪些 bash/ksh/csh 别名能够减少输入,请在留言框中分享。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/bash-aliases-mac-centos-linux-unix.html
|
||||
|
||||
作者:[nixCraft][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,103 +1,115 @@
|
||||
一个树莓派 3 的新手指南
|
||||
树莓派 3 的新手指南
|
||||
======
|
||||
> 这个教程将帮助你入门<ruby>树莓派 3<rt>Raspberry Pi 3</rt></ruby>。
|
||||
|
||||

|
||||
|
||||
这篇文章是我的使用树莓派 3 创建新项目的每周系列文章的一部分。该系列的第一篇文章专注于入门,它主要讲使用 PIXEL 桌面去安装树莓派、设置网络以及其它的基本组件。
|
||||
这篇文章是我的使用树莓派 3 创建新项目的每周系列文章的一部分。该系列的这个第一篇文章专注于入门,它主要讲安装 Raspbian 和 PIXEL 桌面,以及设置网络和其它的基本组件。
|
||||
|
||||
### 你需要:
|
||||
|
||||
* 一台树莓派 3
|
||||
* 一个 5v 2mAh 带 USB 接口的电源适配器
|
||||
* 至少 8GB 容量的 Micro SD 卡
|
||||
* Wi-Fi 或者以太网线
|
||||
* 散热片
|
||||
* 键盘和鼠标
|
||||
* 一台 PC 显示器
|
||||
* 一台用于准备 microSD 卡的 Mac 或者 PC
|
||||
* 一台树莓派 3
|
||||
* 一个 5v 2mAh 带 USB 接口的电源适配器
|
||||
* 至少 8GB 容量的 Micro SD 卡
|
||||
* Wi-Fi 或者以太网线
|
||||
* 散热片
|
||||
* 键盘和鼠标
|
||||
* 一台 PC 显示器
|
||||
* 一台用于准备 microSD 卡的 Mac 或者 PC
|
||||
|
||||
|
||||
|
||||
现在市面上有很多基于 Linux 操作系统的树莓派,这种树莓派你可以直接安装它,但是,如果你是第一次接触树莓派,我推荐使用 NOOBS,它是树莓派官方的操作系统安装器,它安装操作系统到设备的过程非常简单。
|
||||
现在有很多基于 Linux 操作系统可用于树莓派,你可以直接安装它,但是,如果你是第一次接触树莓派,我推荐使用 NOOBS,它是树莓派官方的操作系统安装器,它安装操作系统到该设备的过程非常简单。
|
||||
|
||||
在你的电脑上从 [这个链接][1] 下载 NOOBS。它是一个 zip 压缩文件。如果你使用的是 MacOS,可以直接双击它,MacOS 会自动解压这个文件。如果你使用的是 Windows,右键单击它,选择“解压到这里”。
|
||||
|
||||
如果你运行的是 Linux,如何去解压 zip 文件取决于你的桌面环境,因为,不同的桌面环境下解压文件的方法不一样,但是,使用命令行可以很容易地完成解压工作。
|
||||
如果你运行的是 Linux 桌面,如何去解压 zip 文件取决于你的桌面环境,因为,不同的桌面环境下解压文件的方法不一样,但是,使用命令行可以很容易地完成解压工作。
|
||||
|
||||
`$ unzip NOOBS.zip`
|
||||
```
|
||||
$ unzip NOOBS.zip
|
||||
```
|
||||
|
||||
不管它是什么操作系统,打开解压后的文件,你看到的应该是如下图所示的样子:
|
||||
|
||||
![content][3] Swapnil Bhartiya
|
||||
![content][3]
|
||||
|
||||
现在,在你的 PC 上插入 Micro SD 卡,将它格式化成 FAT32 格式的文件系统。在 MacOS 上,使用磁盘实用工具去格式化 Micro SD 卡:
|
||||
|
||||
![format][4] Swapnil Bhartiya
|
||||
![format][4]
|
||||
|
||||
在 Windows 上,只需要右键单击这个卡,然后选择“格式化”选项。如果是在 Linux 上,不同的桌面环境使用不同的工具,就不一一去讲解了。在这里我写了一个教程,[在 Linux 上使用命令行接口][5] 去格式化 SD 卡为 Fat32 文件系统。
|
||||
在 Windows 上,只需要右键单击这个卡,然后选择“格式化”选项。如果是在 Linux 上,不同的桌面环境使用不同的工具,就不一一去讲解了。在这里我写了一个教程,[在 Linux 上使用命令行界面][5] 去格式化 SD 卡为 Fat32 文件系统。
|
||||
|
||||
在你拥有了 FAT32 格式的文件系统后,就可以去拷贝下载的 NOOBS 目录的内容到这个卡的根目录下。如果你使用的是 MacOS 或者 Linux,可以使用 rsync 将 NOOBS 的内容传到 SD 卡的根目录中。在 MacOS 或者 Linux 中打开终端应用,然后运行如下的 rsync 命令:
|
||||
在你的卡格式成了 FAT32 格式的文件系统后,就可以去拷贝下载的 NOOBS 目录的内容到这个卡的根目录下。如果你使用的是 MacOS 或者 Linux,可以使用 `rsync` 将 NOOBS 的内容传到 SD 卡的根目录中。在 MacOS 或者 Linux 中打开终端应用,然后运行如下的 rsync 命令:
|
||||
|
||||
`rsync -avzP /path_of_NOOBS /path_of_sdcard`
|
||||
```
|
||||
rsync -avzP /path_of_NOOBS /path_of_sdcard
|
||||
```
|
||||
|
||||
一定要确保选择了 SD 卡的根目录,在我的案例中(在 MacOS 上),它是:
|
||||
|
||||
`rsync -avzP /Users/swapnil/Downloads/NOOBS_v2_2_0/ /Volumes/U/`
|
||||
```
|
||||
rsync -avzP /Users/swapnil/Downloads/NOOBS_v2_2_0/ /Volumes/U/
|
||||
```
|
||||
|
||||
或者你也可以拷贝粘贴 NOOBS 目录中的内容。一定要确保将 NOOBS 目录中的内容全部拷贝到 Micro SD 卡的根目录下,千万不能放到任何的子目录中。
|
||||
|
||||
现在可以插入这张 Micro SD 卡到树莓派 3 中,连接好显示器、键盘鼠标和电源适配器。如果你拥有有线网络,我建议你使用它,因为有线网络下载和安装操作系统更快。树莓派将引导到 NOOBS,它将提供一个供你去选择安装的分发版列表。从第一个选项中选择树莓派,紧接着会出现如下图的画面。
|
||||
现在可以插入这张 MicroSD 卡到树莓派 3 中,连接好显示器、键盘鼠标和电源适配器。如果你拥有有线网络,我建议你使用它,因为有线网络下载和安装操作系统更快。树莓派将引导到 NOOBS,它将提供一个供你去选择安装的分发版列表。从第一个选项中选择 Raspbian,紧接着会出现如下图的画面。
|
||||
|
||||
![raspi config][6] Swapnil Bhartiya
|
||||
![raspi config][6]
|
||||
|
||||
在你安装完成后,树莓派将重新启动,你将会看到一个欢迎使用树莓派的画面。现在可以去配置它,并且去运行系统更新。大多数情况下,我们都是在没有外设的情况下使用树莓派的,都是使用 SSH 基于网络远程去管理它。这意味着你不需要为了管理树莓派而去为它接上鼠标键盘和显示器。
|
||||
在你安装完成后,树莓派将重新启动,你将会看到一个欢迎使用树莓派的画面。现在可以去配置它,并且去运行系统更新。大多数情况下,我们都是在没有外设的情况下使用树莓派的,都是使用 SSH 基于网络远程去管理它。这意味着你不需要为了管理树莓派而去为它接上鼠标、键盘和显示器。
|
||||
|
||||
开始使用它的第一步是,配置网络(假如你使用的是 Wi-Fi)。点击顶部面板上的网络图标,然后在出现的网络列表中,选择你要配置的网络并为它输入正确的密码。
|
||||
|
||||
![wireless][7] Swapnil Bhartiya
|
||||
![wireless][7]
|
||||
|
||||
恭喜您,无线网络的连接配置完成了。在进入下一步的配置之前,你需要找到你的网络为树莓派分配的 IP 地址,因为远程管理会用到它。
|
||||
|
||||
打开一个终端,运行如下的命令:
|
||||
|
||||
`ifconfig`
|
||||
```
|
||||
ifconfig
|
||||
```
|
||||
|
||||
现在,记下这个设备的 wlan0 部分的 IP 地址。它一般显示为 “inet addr”
|
||||
现在,记下这个设备的 `wlan0` 部分的 IP 地址。它一般显示为 “inet addr”。
|
||||
|
||||
现在,可以去启用 SSH 了,在树莓派上打开一个终端,然后打开 raspi-config 工具。
|
||||
现在,可以去启用 SSH 了,在树莓派上打开一个终端,然后打开 `raspi-config` 工具。
|
||||
|
||||
`sudo raspi-config`
|
||||
```
|
||||
sudo raspi-config
|
||||
```
|
||||
|
||||
树莓派的默认用户名和密码分别是 “pi” 和 “raspberry”。在上面的命令中你会被要求输入密码。树莓派配置工具的第一个选项是去修改默认密码,我强烈推荐你修改默认密码,尤其是你基于网络去使用它的时候。
|
||||
|
||||
第二个选项是去修改主机名,如果在你的网络中有多个树莓派时,主机名用于区分它们。一个有意义的主机名可以很容易在网络上识别每个设备。
|
||||
|
||||
然后进入到接口选项,去启用摄像头、SSH、以及 VNC。如果你在树莓派上使用了一个涉及到多媒体的应用程序,比如,家庭影院系统或者 PC,你也可以去改变音频输出选项。缺省情况下,它的默认输出到 HDMI 接口,但是,如果你使用外部音响,你需要去改变音频输出设置。转到树莓派配置工具的高级配置选项,选择音频,然后选择 3.5mm 作为默认输出。
|
||||
然后进入到接口选项,去启用摄像头、SSH、以及 VNC。如果你在树莓派上使用了一个涉及到多媒体的应用程序,比如,家庭影院系统或者 PC,你也可以去改变音频输出选项。缺省情况下,它的默认输出到 HDMI 接口,但是,如果你使用外部音响,你需要去改变音频输出设置。转到树莓派配置工具的高级配置选项,选择音频,然后选择 “3.5mm” 作为默认输出。
|
||||
|
||||
[小提示:使用箭头键去导航,使用回车键去选择]
|
||||
|
||||
一旦所有的改变被应用, 树莓派将要求重新启动。你可以从树莓派上拔出显示器、鼠标键盘,以后可以通过网络来管理它。现在可以在你的本地电脑上打开终端。如果你使用的是 Windows,你可以使用 Putty 或者去读我的文章 - 怎么在 Windows 10 上安装 Ubuntu Bash。
|
||||
一旦应用了所有的改变, 树莓派将要求重新启动。你可以从树莓派上拔出显示器、鼠标键盘,以后可以通过网络来管理它。现在可以在你的本地电脑上打开终端。如果你使用的是 Windows,你可以使用 Putty 或者去读我的文章 - 怎么在 Windows 10 上安装 Ubuntu Bash。
|
||||
|
||||
在你的本地电脑上输入如下的 SSH 命令:
|
||||
|
||||
`ssh pi@IP_ADDRESS_OF_Pi`
|
||||
```
|
||||
ssh pi@IP_ADDRESS_OF_Pi
|
||||
```
|
||||
|
||||
在我的电脑上,这个命令是这样的:
|
||||
|
||||
`ssh pi@10.0.0.161`
|
||||
```
|
||||
ssh pi@10.0.0.161
|
||||
```
|
||||
|
||||
输入它的密码,你登入到树莓派了!现在你可以从一台远程电脑上去管理你的树莓派。如果你希望通过因特网去管理树莓派,可以去阅读我的文章 - [如何在你的计算机上启用 RealVNC][8]。
|
||||
|
||||
在该系列的下一篇文章中,我将讲解使用你的树莓派去远程管理你的 3D 打印机。
|
||||
|
||||
**这篇文章是作为 IDG 投稿网络的一部分发表的。[想加入吗?][9]**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.infoworld.com/article/3176488/linux/a-beginner-s-guide-to-raspberry-pi-3.html
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
使用 fdisk 和 fallocate 命令创建交换分区
|
||||
======
|
||||
|
||||
交换分区在物理内存(RAM)被填满时用来保持内存中的内容。当 RAM 被耗尽,Linux 会将内存中不活动的页移动到交换空间中,从而空出内存给系统使用。虽然如此,但交换空间不应被认为是物理内存的替代品。
|
||||
|
||||
大多数情况下,建议交换内存的大小为物理内存的 1 到 2 倍。也就是说如果你有 8GB 内存, 那么交换空间大小应该介于8-16 GB。
|
||||
|
||||
若系统中没有配置交换分区,当内存耗尽后,系统可能会杀掉正在运行中的进程/应用,从而导致系统崩溃。在本文中,我们将学会如何为 Linux 系统添加交换分区,我们有两个办法:
|
||||
|
||||
- 使用 fdisk 命令
|
||||
- 使用 fallocate 命令
|
||||
|
||||
### 第一个方法(使用 fdisk 命令)
|
||||
|
||||
通常,系统的第一块硬盘会被命名为 `/dev/sda`,而其中的分区会命名为 `/dev/sda1` 、 `/dev/sda2`。 本文我们使用的是一块有两个主分区的硬盘,两个分区分别为 `/dev/sda1`、 `/dev/sda2`,而我们使用 `/dev/sda3` 来做交换分区。
|
||||
|
||||
首先创建一个新分区,
|
||||
|
||||
```
|
||||
$ fdisk /dev/sda
|
||||
```
|
||||
|
||||
按 `n` 来创建新分区。系统会询问你从哪个柱面开始,直接按回车键使用默认值即可。然后系统询问你到哪个柱面结束, 这里我们输入交换分区的大小(比如 1000MB)。这里我们输入 `+1000M`。
|
||||
|
||||
![swap][2]
|
||||
|
||||
现在我们创建了一个大小为 1000MB 的磁盘了。但是我们并没有设置该分区的类型,我们按下 `t` 然后回车,来设置分区类型。
|
||||
|
||||
现在我们要输入分区编号,这里我们输入 `3`,然后输入磁盘分类号,交换分区的分区类型为 `82` (要显示所有可用的分区类型,按下 `l` ) ,然后再按下 `w` 保存磁盘分区表。
|
||||
|
||||
![swap][4]
|
||||
|
||||
再下一步使用 `mkswap` 命令来格式化交换分区:
|
||||
|
||||
```
|
||||
$ mkswap /dev/sda3
|
||||
```
|
||||
|
||||
然后激活新建的交换分区:
|
||||
|
||||
```
|
||||
$ swapon /dev/sda3
|
||||
```
|
||||
|
||||
然而我们的交换分区在重启后并不会自动挂载。要做到永久挂载,我们需要添加内容到 `/etc/fstab` 文件中。打开 `/etc/fstab` 文件并输入下面行:
|
||||
|
||||
```
|
||||
$ vi /etc/fstab
|
||||
|
||||
/dev/sda3 swap swap default 0 0
|
||||
```
|
||||
|
||||
保存并关闭文件。现在每次重启后都能使用我们的交换分区了。
|
||||
|
||||
### 第二种方法(使用 fallocate 命令)
|
||||
|
||||
我推荐用这种方法因为这个是最简单、最快速的创建交换空间的方法了。`fallocate` 是最被低估和使用最少的命令之一了。 `fallocate` 命令用于为文件预分配块/大小。
|
||||
|
||||
使用 `fallocate` 创建交换空间,我们首先在 `/` 目录下创建一个名为 `swap_space` 的文件。然后分配 2GB 到 `swap_space` 文件:
|
||||
|
||||
```
|
||||
$ fallocate -l 2G /swap_space
|
||||
```
|
||||
|
||||
我们运行下面命令来验证文件大小:
|
||||
|
||||
```
|
||||
$ ls -lh /swap_space
|
||||
```
|
||||
|
||||
然后更改文件权限,让 `/swap_space` 更安全:
|
||||
|
||||
```
|
||||
$ chmod 600 /swap_space
|
||||
```
|
||||
|
||||
这样只有 root 可以读写该文件了。我们再来格式化交换分区(LCTT 译注:虽然这个 `swap_space` 是个文件,但是我们把它当成是分区来挂载):
|
||||
|
||||
```
|
||||
$ mkswap /swap_space
|
||||
```
|
||||
|
||||
然后启用交换空间:
|
||||
|
||||
```
|
||||
$ swapon -s
|
||||
```
|
||||
|
||||
每次重启后都要重新挂载磁盘分区。因此为了使之持久化,就像上面一样,我们编辑 `/etc/fstab` 并输入下面行:
|
||||
|
||||
```
|
||||
/swap_space swap swap sw 0 0
|
||||
```
|
||||
|
||||
保存并退出文件。现在我们的交换分区会一直被挂载了。我们重启后可以在终端运行 `free -m` 来检查交换分区是否生效。
|
||||
|
||||
我们的教程至此就结束了,希望本文足够容易理解和学习,如果有任何疑问欢迎提出。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/create-swap-using-fdisk-fallocate/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=668%2C211
|
||||
[2]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/fidsk.jpg?resize=668%2C211
|
||||
[3]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=620%2C157
|
||||
[4]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/fidsk-swap-select.jpg?resize=620%2C157
|
||||
@ -1,23 +1,26 @@
|
||||
在 RHEL/CentOS 系统上使用 YUM History 命令回滚升级操作
|
||||
在 RHEL/CentOS 系统上使用 YUM history 命令回滚升级操作
|
||||
======
|
||||
|
||||
为服务器打补丁是 Linux 系统管理员的一项重要任务,为的是让系统更加稳定,性能更加优化。厂商经常会发布一些安全/高危的补丁包,相关软件需要升级以防范潜在的安全风险。
|
||||
|
||||
Yum (Yellowdog Update Modified) 是 CentOS 和 RedHat 系统上用的 RPM 包管理工具,Yum history 命令允许系统管理员将系统回滚到上一个状态,但由于某些限制,回滚不是在所有情况下都能成功,有时 yum 命令可能什么都不做,有时可能会删掉一些其他的包。
|
||||
Yum (Yellowdog Update Modified) 是 CentOS 和 RedHat 系统上用的 RPM 包管理工具,`yum history` 命令允许系统管理员将系统回滚到上一个状态,但由于某些限制,回滚不是在所有情况下都能成功,有时 `yum` 命令可能什么都不做,有时可能会删掉一些其他的包。
|
||||
|
||||
我建议你在升级之前还是要做一个完整的系统备份,而 yum history 并不能用来替代系统备份的。系统备份能让你将系统还原到任意时候的节点状态。
|
||||
我建议你在升级之前还是要做一个完整的系统备份,而 `yum history` 并不能用来替代系统备份的。系统备份能让你将系统还原到任意时候的节点状态。
|
||||
|
||||
**推荐阅读:**
|
||||
**(#)** [在 RHEL/CentOS 系统上使用 YUM 命令管理软件包 ][1]
|
||||
**(#)** [在 Fedora 系统上使用 DNF (YUM 的一个分支) 命令管理软件包 ][2]
|
||||
**(#)** [如何让 History 命令显示日期和时间 ][3]
|
||||
|
||||
某些情况下,安装的应用程序在升级了补丁之后不能正常工作或者出现一些错误(可能是由于库不兼容或者软件包升级导致的),那该怎么办呢?
|
||||
- [在 RHEL/CentOS 系统上使用 YUM 命令管理软件包][1]
|
||||
- [在 Fedora 系统上使用 DNF (YUM 的一个分支)命令管理软件包 ][2]
|
||||
- [如何让 history 命令显示日期和时间][3]
|
||||
|
||||
某些情况下,安装的应用程序在升级了补丁之后不能正常工作或者出现一些错误(可能是由于库不兼容或者软件包升级导致的),那该怎么办呢?
|
||||
|
||||
与应用开发团队沟通,并找出导致库和软件包的问题所在,然后使用 `yum history` 命令进行回滚。
|
||||
|
||||
与应用开发团队沟通,并找出导致库和软件包的问题所在,然后使用 yum history 命令进行回滚。
|
||||
**注意:**
|
||||
|
||||
* 它不支持回滚 selinux,selinux-policy-*,kernel,glibc (以及依赖 glibc 的包,比如 gcc)。
|
||||
* 不建议将系统降级到更低的版本(比如 CentOS 6.9 降到 CentOS 6.8),这回导致系统处于不稳定的状态
|
||||
* 它不支持回滚 selinux,selinux-policy-*,kernel,glibc (以及依赖 glibc 的包,比如 gcc)。
|
||||
* 不建议将系统降级到更低的版本(比如 CentOS 6.9 降到 CentOS 6.8),这会导致系统处于不稳定的状态
|
||||
|
||||
让我们先来看看系统上有哪些包可以升级,然后挑选出一些包来做实验。
|
||||
|
||||
@ -66,10 +69,10 @@ Upgrade 4 Package(s)
|
||||
|
||||
Total download size: 5.5 M
|
||||
Is this ok [y/N]: n
|
||||
|
||||
```
|
||||
|
||||
你会发现 `git` 包可以被升级,那我们就用它来实验吧。运行下面命令获得软件包的版本信息(当前安装的版本和可以升级的版本)。
|
||||
你会发现 `git` 包可以被升级,那我们就用它来实验吧。运行下面命令获得软件包的版本信息(当前安装的版本和可以升级的版本)。
|
||||
|
||||
```
|
||||
# yum list git
|
||||
Loaded plugins: fastestmirror, security
|
||||
@ -80,10 +83,10 @@ Installed Packages
|
||||
git.x86_64 1.7.1-8.el6 @base
|
||||
Available Packages
|
||||
git.x86_64 1.7.1-9.el6_9 updates
|
||||
|
||||
```
|
||||
|
||||
运行下面命令来将 `git` 从 `1.7.1-8` 升级到 `1.7.1-9`。
|
||||
|
||||
```
|
||||
# yum update git
|
||||
Loaded plugins: fastestmirror, presto
|
||||
@ -147,27 +150,29 @@ Dependency Updated:
|
||||
perl-Git.noarch 0:1.7.1-9.el6_9
|
||||
|
||||
Complete!
|
||||
|
||||
```
|
||||
|
||||
验证升级后的 `git` 版本.
|
||||
|
||||
```
|
||||
# yum list git
|
||||
Installed Packages
|
||||
git.x86_64 1.7.1-9.el6_9 @updates
|
||||
|
||||
or
|
||||
或
|
||||
# rpm -q git
|
||||
git-1.7.1-9.el6_9.x86_64
|
||||
|
||||
```
|
||||
|
||||
现在我们成功升级这个软件包,可以对它进行回滚了. 步骤如下.
|
||||
现在我们成功升级这个软件包,可以对它进行回滚了。步骤如下。
|
||||
|
||||
### 使用 YUM history 命令回滚升级操作
|
||||
|
||||
首先,使用下面命令获取 yum 操作的 id。下面的输出很清晰地列出了所有需要的信息,例如操作 id、谁做的这个操作(用户名)、操作日期和时间、操作的动作(安装还是升级)、操作影响的包数量。
|
||||
|
||||
首先,使用下面命令获取yum操作id. 下面的输出很清晰地列出了所有需要的信息,例如操作 id, 谁做的这个操作(用户名), 操作日期和时间, 操作的动作(安装还是升级), 操作影响的包数量.
|
||||
```
|
||||
# yum history
|
||||
or
|
||||
或
|
||||
# yum history list all
|
||||
Loaded plugins: fastestmirror, presto
|
||||
ID | Login user | Date and time | Action(s) | Altered
|
||||
@ -185,10 +190,10 @@ ID | Login user | Date and time | Action(s) | Altered
|
||||
3 | root | 2016-10-18 12:53 | Install | 1
|
||||
2 | root | 2016-09-30 10:28 | E, I, U | 31 EE
|
||||
1 | root | 2016-07-26 11:40 | E, I, U | 160 EE
|
||||
|
||||
```
|
||||
|
||||
上面命令现实有两个包受到了影响,因为 git 还升级了它的依赖包 **perl-Git**. 运行下面命令来查看关于操作的详细信息.
|
||||
上面命令显示有两个包受到了影响,因为 `git` 还升级了它的依赖包 `perl-Git`。 运行下面命令来查看关于操作的详细信息。
|
||||
|
||||
```
|
||||
# yum history info 13
|
||||
Loaded plugins: fastestmirror, presto
|
||||
@ -214,7 +219,8 @@ history info
|
||||
|
||||
```
|
||||
|
||||
运行下面命令来回滚 `git` 包到上一个版本.
|
||||
运行下面命令来回滚 `git` 包到上一个版本。
|
||||
|
||||
```
|
||||
# yum history undo 13
|
||||
Loaded plugins: fastestmirror, presto
|
||||
@ -279,21 +285,21 @@ Installed:
|
||||
git.x86_64 0:1.7.1-8.el6 perl-Git.noarch 0:1.7.1-8.el6
|
||||
|
||||
Complete!
|
||||
|
||||
```
|
||||
|
||||
回滚后, 使用下面命令来检查降级包的版本.
|
||||
回滚后,使用下面命令来检查降级包的版本。
|
||||
|
||||
```
|
||||
# yum list git
|
||||
or
|
||||
或
|
||||
# rpm -q git
|
||||
git-1.7.1-8.el6.x86_64
|
||||
|
||||
```
|
||||
|
||||
### 使用YUM downgrade 命令回滚升级
|
||||
|
||||
此外,我们也可以使用 YUM downgrade 命令回滚升级.
|
||||
此外,我们也可以使用 YUM `downgrade` 命令回滚升级。
|
||||
|
||||
```
|
||||
# yum downgrade git-1.7.1-8.el6 perl-Git-1.7.1-8.el6
|
||||
Loaded plugins: search-disabled-repos, security, ulninfo
|
||||
@ -346,14 +352,14 @@ Installed:
|
||||
git.x86_64 0:1.7.1-8.el6 perl-Git.noarch 0:1.7.1-8.el6
|
||||
|
||||
Complete!
|
||||
|
||||
```
|
||||
|
||||
**注意 :** 你也需要降级依赖包, 否则它会删掉当前版本的依赖包而不是对依赖包做降级,因为downgrade命令无法处理依赖关系.
|
||||
注意: 你也需要降级依赖包,否则它会删掉当前版本的依赖包而不是对依赖包做降级,因为 `downgrade` 命令无法处理依赖关系。
|
||||
|
||||
### 至于 Fedora 用户
|
||||
|
||||
命令是一样的,只需要将包管理器名称从YUM改成DNF就行了.
|
||||
命令是一样的,只需要将包管理器名称从 `yum` 改成 `dnf` 就行了。
|
||||
|
||||
```
|
||||
# dnf list git
|
||||
# dnf history
|
||||
@ -361,7 +367,6 @@ Complete!
|
||||
# dnf history undo
|
||||
# dnf list git
|
||||
# dnf downgrade git-1.7.1-8.el6 perl-Git-1.7.1-8.el6
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -370,7 +375,7 @@ via: https://www.2daygeek.com/rollback-fallback-updates-downgrade-packages-cento
|
||||
|
||||
作者:[2daygeek][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
如何在 Linux 上让一段时间不活动的用户自动登出
|
||||
======
|
||||
|
||||

|
||||

|
||||
|
||||
让我们想象这么一个场景。你有一台服务器经常被网络中各系统的很多个用户访问。有可能出现某些用户忘记登出会话让会话保持会话处于连接状态。我们都知道留下一个处于连接状态的用户会话是一件多么危险的事情。有些用户可能会借此故意做一些损坏系统的事情。而你,作为一名系统管理员,会去每个系统上都检查一遍用户是否有登出吗?其实这完全没必要的。而且若网络中有成百上千台机器,这也太耗时了。不过,你可以让用户在本机或 SSH 会话上超过一定时间不活跃的情况下自动登出。本教程就将教你如何在类 Unix 系统上实现这一点。一点都不难。跟我做。
|
||||
|
||||
@ -11,32 +11,40 @@
|
||||
|
||||
#### 方法 1:
|
||||
|
||||
编辑 **~/.bashrc** 或 **~/.bash_profile** 文件:
|
||||
编辑 `~/.bashrc` 或 `~/.bash_profile` 文件:
|
||||
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
```
|
||||
|
||||
或,
|
||||
|
||||
```
|
||||
$ vi ~/.bash_profile
|
||||
```
|
||||
|
||||
将下面行加入其中。
|
||||
将下面行加入其中:
|
||||
|
||||
```
|
||||
TMOUT=100
|
||||
```
|
||||
|
||||
这回让用户在停止动作 100 秒后自动登出。你可以根据需要定义这个值。保存并关闭文件。
|
||||
这会让用户在停止动作 100 秒后自动登出。你可以根据需要定义这个值。保存并关闭文件。
|
||||
|
||||
运行下面命令让更改生效:
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
或,
|
||||
|
||||
```
|
||||
$ source ~/.bash_profile
|
||||
```
|
||||
|
||||
现在让会话闲置 100 秒。100 秒不活动后,你会看到下面这段信息,并且用户会自动退出会话。
|
||||
|
||||
```
|
||||
timed out waiting for input: auto-logout
|
||||
Connection to 192.168.43.2 closed.
|
||||
@ -44,13 +52,16 @@ Connection to 192.168.43.2 closed.
|
||||
|
||||
该设置可以轻易地被用户所修改。因为,`~/.bashrc` 文件被用户自己所拥有。
|
||||
|
||||
要修改或者删除超时设置,只需要删掉上面添加的行然后执行 "source ~/.bashrc" 命令让修改生效。
|
||||
要修改或者删除超时设置,只需要删掉上面添加的行然后执行 `source ~/.bashrc` 命令让修改生效。
|
||||
|
||||
此外,用户也可以运行下面命令来禁止超时:
|
||||
|
||||
此啊玩 i,用户也可以运行下面命令来禁止超时:
|
||||
```
|
||||
$ export TMOUT=0
|
||||
```
|
||||
|
||||
或,
|
||||
|
||||
```
|
||||
$ unset TMOUT
|
||||
```
|
||||
@ -59,14 +70,16 @@ $ unset TMOUT
|
||||
|
||||
#### 方法 2:
|
||||
|
||||
以 root 用户登陆
|
||||
以 root 用户登录。
|
||||
|
||||
创建一个名为 `autologout.sh` 的新文件。
|
||||
|
||||
```
|
||||
# vi /etc/profile.d/autologout.sh
|
||||
```
|
||||
|
||||
加入下面内容:
|
||||
|
||||
```
|
||||
TMOUT=100
|
||||
readonly TMOUT
|
||||
@ -76,55 +89,58 @@ export TMOUT
|
||||
保存并退出该文件。
|
||||
|
||||
为它添加可执行权限:
|
||||
|
||||
```
|
||||
# chmod +x /etc/profile.d/autologout.sh
|
||||
```
|
||||
|
||||
现在,登出或者重启系统。非活动用户就会在 100 秒后自动登出了。普通用户即使想保留会话连接但也无法修改该配置了。他们会在 100 秒后强制退出。
|
||||
|
||||
这两种方法对本地会话和远程会话都适用(即本地登陆的用户和远程系统上通过 SSH 登陆的用户)。下面让我们来看看如何实现只自动登出非活动的 SSH 会话,而不自动登出本地会话。
|
||||
这两种方法对本地会话和远程会话都适用(即本地登录的用户和远程系统上通过 SSH 登录的用户)。下面让我们来看看如何实现只自动登出非活动的 SSH 会话,而不自动登出本地会话。
|
||||
|
||||
#### 方法 3:
|
||||
|
||||
这种方法,我们智慧让 SSH 会话用户在一段时间不活动后自动登出。
|
||||
这种方法,我们只会让 SSH 会话用户在一段时间不活动后自动登出。
|
||||
|
||||
编辑 `/etc/ssh/sshd_config` 文件:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/ssh/sshd_config
|
||||
```
|
||||
|
||||
添加/修改下面行:
|
||||
|
||||
```
|
||||
ClientAliveInterval 100
|
||||
ClientAliveCountMax 0
|
||||
```
|
||||
|
||||
保存并退出该文件。重启 sshd 服务让改动生效。
|
||||
|
||||
```
|
||||
$ sudo systemctl restart sshd
|
||||
```
|
||||
|
||||
现在,在远程系统通过 ssh 登陆该系统。100 秒后,ssh 会话就会自动关闭了,你也会看到下面消息:
|
||||
现在,在远程系统通过 ssh 登录该系统。100 秒后,ssh 会话就会自动关闭了,你也会看到下面消息:
|
||||
|
||||
```
|
||||
$ Connection to 192.168.43.2 closed by remote host.
|
||||
Connection to 192.168.43.2 closed.
|
||||
```
|
||||
|
||||
现在,任何人从远程系统通过 SSH 登陆本系统,都会在 100 秒不活动后自动登出了。
|
||||
现在,任何人从远程系统通过 SSH 登录本系统,都会在 100 秒不活动后自动登出了。
|
||||
|
||||
希望本文能对你有所帮助。我马上还会写另一篇实用指南。如果你觉得我们的指南有用,请在您的社交网络上分享,支持 OSTechNix!
|
||||
希望本文能对你有所帮助。我马上还会写另一篇实用指南。如果你觉得我们的指南有用,请在您的社交网络上分享,支持 我们!
|
||||
|
||||
祝您好运!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/auto-logout-inactive-users-period-time-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,13 +1,13 @@
|
||||
Linux fmt 命令 - 用法与案例
|
||||
Linux 的 fmt 命令用法与案例
|
||||
======
|
||||
|
||||
有时你会发现需要格式化某个文本文件中的内容。比如,该文本文件每行一个单词,而人物是把所有的单词都放在同一行。当然,你可以手工来做,但没人喜欢手工做这么耗时的工作。而且,这只是一个例子 - 事实上的任务可能千奇百怪。
|
||||
有时你会发现需要格式化某个文本文件中的内容。比如,该文本文件每行一个单词,而任务是把所有的单词都放在同一行。当然,你可以手工来做,但没人喜欢手工做这么耗时的工作。而且,这只是一个例子 - 事实上的任务可能千奇百怪。
|
||||
|
||||
好在,有一个命令可以满足至少一部分的文本格式化的需求。这个工具就是 `fmt`。本教程将会讨论 `fmt` 的基本用法以及它提供的一些主要功能。文中所有的命令和指令都在 Ubuntu 16.04LTS 下经过了测试。
|
||||
|
||||
### Linux fmt 命令
|
||||
|
||||
fmt 命令是一个简单的文本格式化工具,任何人都能在命令行下运行它。它的基本语法为:
|
||||
`fmt` 命令是一个简单的文本格式化工具,任何人都能在命令行下运行它。它的基本语法为:
|
||||
|
||||
```
|
||||
fmt [-WIDTH] [OPTION]... [FILE]...
|
||||
@ -15,15 +15,13 @@ fmt [-WIDTH] [OPTION]... [FILE]...
|
||||
|
||||
它的 man 页是这么说的:
|
||||
|
||||
```
|
||||
重新格式化文件FILE(s)中的每一个段落,将结果写到标准输出. 选项 -WIDTH 是 --width=DIGITS 形式的缩写
|
||||
```
|
||||
> 重新格式化文件中的每一个段落,将结果写到标准输出。选项 `-WIDTH` 是 `--width=DIGITS` 形式的缩写。
|
||||
|
||||
下面这些问答方式的例子应该能让你对 fmt 的用法有很好的了解。
|
||||
下面这些问答方式的例子应该能让你对 `fmt` 的用法有很好的了解。
|
||||
|
||||
### Q1。如何使用 fmt 来将文本内容格式成同一行?
|
||||
### Q1、如何使用 fmt 来将文本内容格式成同一行?
|
||||
|
||||
使用 `fmt` 命令的基本格式(省略任何选项)就能做到这一点。你只需要将文件名作为参数传递给它。
|
||||
使用 `fmt` 命令的基本形式(省略任何选项)就能做到这一点。你只需要将文件名作为参数传递给它。
|
||||
|
||||
```
|
||||
fmt [file-name]
|
||||
@ -33,9 +31,9 @@ fmt [file-name]
|
||||
|
||||
[![format contents of file in single line][1]][2]
|
||||
|
||||
你可以看到文件中多行内容都被格式化成同一行了。请注意,这并不会修改原文件(也就是 file1)。
|
||||
你可以看到文件中多行内容都被格式化成同一行了。请注意,这并不会修改原文件(file1)。
|
||||
|
||||
### Q2。如何修改最大行宽?
|
||||
### Q2、如何修改最大行宽?
|
||||
|
||||
默认情况下,`fmt` 命令产生的输出中的最大行宽为 75。然而,如果你想的话,可以用 `-w` 选项进行修改,它接受一个表示新行宽的数字作为参数值。
|
||||
|
||||
@ -47,7 +45,7 @@ fmt -w [n] [file-name]
|
||||
|
||||
[![change maximum line width][3]][4]
|
||||
|
||||
### Q3。如何让 fmt 突出显示第一行?
|
||||
### Q3、如何让 fmt 突出显示第一行?
|
||||
|
||||
这是通过让第一行的缩进与众不同来实现的,你可以使用 `-t` 选项来实现。
|
||||
|
||||
@ -57,7 +55,7 @@ fmt -t [file-name]
|
||||
|
||||
[![make fmt highlight the first line][5]][6]
|
||||
|
||||
### Q4。如何使用 fmt 拆分长行?
|
||||
### Q4、如何使用 fmt 拆分长行?
|
||||
|
||||
fmt 命令也能用来对长行进行拆分,你可以使用 `-s` 选项来应用该功能。
|
||||
|
||||
@ -69,9 +67,9 @@ fmt -s [file-name]
|
||||
|
||||
[![make fmt split long lines][7]][8]
|
||||
|
||||
### Q5。如何在单词与单词之间,行与行之间用空格分开?
|
||||
### Q5、如何在单词与单词之间,句子之间用空格分开?
|
||||
|
||||
fmt 命令提供了一个 `-u` 选项,这会在单词与单词之间用单个空格分开,行与行之间用两个空格分开。你可以这样用:
|
||||
fmt 命令提供了一个 `-u` 选项,这会在单词与单词之间用单个空格分开,句子之间用两个空格分开。你可以这样用:
|
||||
|
||||
```
|
||||
fmt -u [file-name]
|
||||
@ -81,7 +79,7 @@ fmt -u [file-name]
|
||||
|
||||
### 总结
|
||||
|
||||
没错,fmt 提供的功能不多,但不代表它的应用就不广泛。因为你永远不知道什么时候会用到它。在本教程中,我们已经讲解了 `fmt` 提供的主要选项。若想了解更多细节,请查看该工具的 [man 页 ][9]。
|
||||
没错,`fmt` 提供的功能不多,但不代表它的应用就不广泛。因为你永远不知道什么时候会用到它。在本教程中,我们已经讲解了 `fmt` 提供的主要选项。若想了解更多细节,请查看该工具的 [man 页][9]。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -90,7 +88,7 @@ via: https://www.howtoforge.com/linux-fmt-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
76
published/20170919 What Are Bitcoins.md
Normal file
76
published/20170919 What Are Bitcoins.md
Normal file
@ -0,0 +1,76 @@
|
||||
比特币是什么?
|
||||
======
|
||||
|
||||

|
||||
|
||||
<ruby>[比特币][1]<rt>Bitcoin</rt></ruby> 是一种数字货币或者说是电子现金,依靠点对点技术来完成交易。 由于使用点对点技术作为主要网络,比特币提供了一个类似于<ruby>管制经济<rt>managed economy</rt></ruby>的社区。 这就是说,比特币消除了货币管理的集中式管理方式,促进了货币的社区管理。 大部分比特币数字现金的挖掘和管理软件也是开源的。
|
||||
|
||||
第一个比特币软件是由<ruby>中本聪<rt>Satoshi Nakamoto</rt></ruby>开发的,基于开源的密码协议。 比特币最小单位被称为<ruby>聪<rt>Satoshi</rt></ruby>,它基本上是一个比特币的百万分之一(0.00000001 BTC)。
|
||||
|
||||
人们不能低估比特币在数字经济中消除的界限。 例如,比特币消除了由中央机构对货币进行的管理控制,并将控制和管理提供给整个社区。 此外,比特币基于开放源代码密码协议的事实使其成为一个开放的领域,其中存在价值波动、通货紧缩和通货膨胀等严格的活动。 当许多互联网用户正在意识到他们在网上完成交易的隐私性时,比特币正在变得比以往更受欢迎。 但是,对于那些了解暗网及其工作原理的人们,可以确认有些人早就开始使用它了。
|
||||
|
||||
不利的一面是,比特币在匿名支付方面也非常安全,可能会对安全或个人健康构成威胁。 例如,暗网市场是进口药物甚至武器的主要供应商和零售商。 在暗网中使用比特币有助于这种犯罪活动。 尽管如此,如果使用得当,比特币有许多的好处,可以消除一些由于集中的货币代理管理导致的经济上的谬误。 另外,比特币允许在世界任何地方交换现金。 比特币的使用也可以减少货币假冒、印刷或贬值。 同时,依托对等网络作为骨干网络,促进交易记录的分布式权限,交易会更加安全。
|
||||
|
||||
比特币的其他优点包括:
|
||||
|
||||
- 在网上商业世界里,比特币促进资金安全和完全控制。这是因为买家受到保护,以免商家可能想要为较低成本的服务额外收取钱财。买家也可以选择在交易后不分享个人信息。此外,由于隐藏了个人信息,也就保护了身份不被盗窃。
|
||||
- 对于主要的常见货币灾难,比如如丢失、冻结或损坏,比特币是一种替代品。但是,始终都建议对比特币进行备份并使用密码加密。
|
||||
- 使用比特币进行网上购物和付款时,收取的费用少或者不收取。这就提高了使用时的可承受性。
|
||||
- 与其他电子货币不同,商家也面临较少的欺诈风险,因为比特币交易是无法逆转的。即使在高犯罪率和高欺诈的时刻,比特币也是有用的,因为在公开的公共总账(区块链)上难以对付某个人。
|
||||
- 比特币货币也很难被操纵,因为它是开源的,密码协议是非常安全的。
|
||||
- 交易也可以随时随地进行验证和批准。这是数字货币提供的灵活性水准。
|
||||
|
||||
还可以阅读 - [Bitkey:专用于比特币交易的 Linux 发行版][2]
|
||||
|
||||
### 如何挖掘比特币和完成必要的比特币管理任务的应用程序
|
||||
|
||||
在数字货币中,比特币挖矿和管理需要额外的软件。有许多开源的比特币管理软件,便于进行支付,接收付款,加密和备份比特币,还有很多的比特币挖掘软件。有些网站,比如:通过查看广告赚取免费比特币的 [Freebitcoin][4],MoonBitcoin 是另一个可以免费注册并获得比特币的网站。但是,如果有空闲时间和相当多的人脉圈参与,会很方便。有很多提供比特币挖矿的网站,可以轻松注册然后开始挖矿。其中一个主要秘诀就是尽可能引入更多的人构建成一个大型的网络。
|
||||
|
||||
与比特币一起使用时需要的应用程序包括比特币钱包,使得人们可以安全的持有比特币。这就像使用实物钱包来保存硬通货币一样,而这里是以数字形式存在的。钱包可以在这里下载 —— [比特币-钱包][6]。其他类似的应用包括:与比特币钱包类似的[区块链][7]。
|
||||
|
||||
下面的屏幕截图分别显示了 Freebitco 和 MoonBitco 这两个挖矿网站。
|
||||
|
||||
[][8]
|
||||
|
||||
[][9]
|
||||
|
||||
获得比特币的方式多种多样。其中一些包括比特币挖矿机的使用,比特币在交易市场的购买以及免费的比特币在线采矿。比特币可以在 [MtGox][10](LCTT 译注:本文比较陈旧,此交易所已经倒闭),[bitNZ][11],[Bitstamp][12],[BTC-E][13],[VertEx][14] 等等这些网站买到,这些网站都提供了开源开源应用程序。这些应用包括:Bitminter、[5OMiner][15],[BFG Miner][16] 等等。这些应用程序使用一些图形卡和处理器功能来生成比特币。在个人电脑上开采比特币的效率在很大程度上取决于显卡的类型和采矿设备的处理器。(LCTT 译注:目前个人挖矿已经几乎毫无意义了)此外,还有很多安全的在线存储用于备份比特币。这些网站免费提供比特币存储服务。比特币管理网站的例子包括:[xapo][17] , [BlockChain][18] 等。在这些网站上注册需要有效的电子邮件和电话号码进行验证。 Xapo 通过电话应用程序提供额外的安全性,无论何时进行新的登录都需要做请求验证。
|
||||
|
||||
### 比特币的缺点
|
||||
|
||||
使用比特币数字货币所带来的众多优势不容忽视。 但是,由于比特币还处于起步阶段,因此遇到了几个阻力点。 例如,大多数人没有完全意识到比特币数字货币及其工作方式。 缺乏意识可以通过教育和意识的创造来缓解。 比特币用户也面临波动,因为比特币的需求量高于可用的货币数量。 但是,考虑到更长的时间,很多人开始使用比特币的时候,波动性会降低。
|
||||
|
||||
### 改进点
|
||||
|
||||
基于[比特币技术][19]的起步,仍然有变化的余地使其更安全更可靠。 考虑到更长的时间,比特币货币将会发展到足以提供作为普通货币的灵活性。 为了让比特币成功,除了给出有关比特币如何工作及其好处的信息之外,还需要更多人了解比特币。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/things-you-need-to-know-about-bitcoins
|
||||
|
||||
作者:[LINUXANDUBUNTU][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com/
|
||||
[1]:http://www.linuxandubuntu.com/home/bitkey-a-linux-distribution-dedicated-for-conducting-bitcoin-transactions
|
||||
[2]:http://www.linuxandubuntu.com/home/bitkey-a-linux-distribution-dedicated-for-conducting-bitcoin-transactions
|
||||
[3]:http://www.linuxandubuntu.com/home/things-you-need-to-know-about-bitcoins
|
||||
[4]:https://freebitco.in/?r=2167375
|
||||
[5]:http://moonbit.co.in/?ref=c637809a5051
|
||||
[6]:https://bitcoin.org/en/choose-your-wallet
|
||||
[7]:https://blockchain.info/wallet/
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/freebitco-bitcoin-mining-site_orig.jpg
|
||||
[9]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/moonbitcoin-bitcoin-mining-site_orig.png
|
||||
[10]:http://mtgox.com/
|
||||
[11]:https://en.bitcoin.it/wiki/BitNZ
|
||||
[12]:https://www.bitstamp.net/
|
||||
[13]:https://btc-e.com/
|
||||
[14]:https://www.vertexinc.com/
|
||||
[15]:https://www.downloadcloud.com/bitcoin-miner-software.html
|
||||
[16]:https://github.com/luke-jr/bfgminer
|
||||
[17]:https://xapo.com/
|
||||
[18]:https://www.blockchain.com/
|
||||
[19]:https://en.wikipedia.org/wiki/Bitcoin
|
||||
@ -1,14 +1,14 @@
|
||||
在 Ubuntu 16.04 上安装并使用 YouTube-DL
|
||||
======
|
||||
|
||||
Youtube-dl 是一个免费而开源的命令行视频下载工具,可以用来从 Youtube 等类似的网站上下载视频,目前它支持的网站除了 Youtube 还有 Facebook,Dailymotion,Google Video,Yahoo 等等。它构架于 pygtk 之上,需要 Python 的支持来运行。它支持很多操作系统,包括 Windows,Mac 以及 Unix。Youtube-dl 还有断点续传,下载整个频道或者整个播放清单中的视频,添加自定义的标题,代理,等等其他功能。
|
||||
Youtube-dl 是一个自由开源的命令行视频下载工具,可以用来从 Youtube 等类似的网站上下载视频,目前它支持的网站除了 Youtube 还有 Facebook、Dailymotion、Google Video、Yahoo 等等。它构架于 pygtk 之上,需要 Python 的支持来运行。它支持很多操作系统,包括 Windows、Mac 以及 Unix。Youtube-dl 还有断点续传、下载整个频道或者整个播放清单中的视频、添加自定义的标题、代理等等其他功能。
|
||||
|
||||
本文中,我们将来学习如何在 Ubuntu16.04 上安装并使用 Youtube-dl 和 Youtube-dlg。我们还会学习如何以不同质量,不同格式来下载 Youtube 中的视频。
|
||||
本文中,我们将来学习如何在 Ubuntu 16.04 上安装并使用 Youtube-dl 和 Youtube-dlg。我们还会学习如何以不同质量,不同格式来下载 Youtube 中的视频。
|
||||
|
||||
### 前置需求
|
||||
|
||||
* 一台运行 Ubuntu 16.04 的服务器。
|
||||
* 非 root 用户但拥有 sudo 特权。
|
||||
* 一台运行 Ubuntu 16.04 的服务器。
|
||||
* 非 root 用户但拥有 sudo 特权。
|
||||
|
||||
让我们首先用下面命令升级系统到最新版:
|
||||
|
||||
@ -21,37 +21,37 @@ sudo apt-get upgrade -y
|
||||
|
||||
### 安装 Youtube-dl
|
||||
|
||||
默认情况下,Youtube-dl 并不在 Ubuntu-16.04 仓库中。你需要从官网上来下载它。使用 curl 命令可以进行下载:
|
||||
默认情况下,Youtube-dl 并不在 Ubuntu-16.04 仓库中。你需要从官网上来下载它。使用 `curl` 命令可以进行下载:
|
||||
|
||||
首先,使用下面命令安装 curl:
|
||||
首先,使用下面命令安装 `curl`:
|
||||
|
||||
```
|
||||
sudo apt-get install curl -y
|
||||
```
|
||||
|
||||
然后,下载 youtube-dl 的二进制包:
|
||||
然后,下载 `youtube-dl` 的二进制包:
|
||||
|
||||
```
|
||||
curl -L https://yt-dl.org/latest/youtube-dl -o /usr/bin/youtube-dl
|
||||
```
|
||||
|
||||
接着,用下面命令更改 youtube-dl 二进制包的权限:
|
||||
接着,用下面命令更改 `youtube-dl` 二进制包的权限:
|
||||
|
||||
```
|
||||
sudo chmod 755 /usr/bin/youtube-dl
|
||||
```
|
||||
|
||||
youtube-dl 有算是安装好了,现在可以进行下一步了。
|
||||
`youtube-dl` 算是安装好了,现在可以进行下一步了。
|
||||
|
||||
### 使用 Youtube-dl
|
||||
|
||||
运行下面命令会列出 youtube-dl 的所有可选项:
|
||||
运行下面命令会列出 `youtube-dl` 的所有可选项:
|
||||
|
||||
```
|
||||
youtube-dl --h
|
||||
```
|
||||
|
||||
Youtube-dl 支持多种视频格式,像 Mp4,WebM,3gp,以及 FLV 都支持。你可以使用下面命令列出指定视频所支持的所有格式:
|
||||
`youtube-dl` 支持多种视频格式,像 Mp4,WebM,3gp,以及 FLV 都支持。你可以使用下面命令列出指定视频所支持的所有格式:
|
||||
|
||||
```
|
||||
youtube-dl -F https://www.youtube.com/watch?v=j_JgXJ-apXs
|
||||
@ -94,6 +94,7 @@ youtube-dl -f 18 https://www.youtube.com/watch?v=j_JgXJ-apXs
|
||||
```
|
||||
|
||||
该命令会下载 640x360 分辨率的 mp4 格式的视频:
|
||||
|
||||
```
|
||||
[youtube] j_JgXJ-apXs: Downloading webpage
|
||||
[youtube] j_JgXJ-apXs: Downloading video info webpage
|
||||
@ -101,7 +102,6 @@ youtube-dl -f 18 https://www.youtube.com/watch?v=j_JgXJ-apXs
|
||||
[youtube] j_JgXJ-apXs: Downloading MPD manifest
|
||||
[download] Destination: B.A. PASS 2 Trailer no 2 _ Filmybox-j_JgXJ-apXs.mp4
|
||||
[download] 100% of 6.90MiB in 00:47
|
||||
|
||||
```
|
||||
|
||||
如果你想以 mp3 音频的格式下载 Youtube 视频,也可以做到:
|
||||
@ -122,7 +122,7 @@ youtube-dl -citw https://www.youtube.com/channel/UCatfiM69M9ZnNhOzy0jZ41A
|
||||
youtube-dl --proxy http://proxy-ip:port https://www.youtube.com/watch?v=j_JgXJ-apXs
|
||||
```
|
||||
|
||||
若想一条命令下载多个 Youtube 视频,那么首先把所有要下载的 Youtube 视频 URL 存在一个文件中(假设这个文件叫 youtube-list.txt),然后运行下面命令:
|
||||
若想一条命令下载多个 Youtube 视频,那么首先把所有要下载的 Youtube 视频 URL 存在一个文件中(假设这个文件叫 `youtube-list.txt`),然后运行下面命令:
|
||||
|
||||
```
|
||||
youtube-dl -a youtube-list.txt
|
||||
@ -130,7 +130,7 @@ youtube-dl -a youtube-list.txt
|
||||
|
||||
### 安装 Youtube-dl GUI
|
||||
|
||||
若你想要图形化的界面,那么 youtube-dlg 是你最好的选择。youtube-dlg 是一款由 wxPython 所写的免费而开源的 youtube-dl 界面。
|
||||
若你想要图形化的界面,那么 `youtube-dlg` 是你最好的选择。`youtube-dlg` 是一款由 wxPython 所写的免费而开源的 `youtube-dl` 界面。
|
||||
|
||||
该工具默认也不在 Ubuntu 16.04 仓库中。因此你需要为它添加 PPA。
|
||||
|
||||
@ -138,14 +138,14 @@ youtube-dl -a youtube-list.txt
|
||||
sudo add-apt-repository ppa:nilarimogard/webupd8
|
||||
```
|
||||
|
||||
下一步,更新软件包仓库并安装 youtube-dlg:
|
||||
下一步,更新软件包仓库并安装 `youtube-dlg`:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
sudo apt-get install youtube-dlg -y
|
||||
```
|
||||
|
||||
安装好 Youtube-dl 后,就能在 `Unity Dash` 中启动它了:
|
||||
安装好 Youtube-dl 后,就能在 Unity Dash 中启动它了:
|
||||
|
||||
[![][2]][3]
|
||||
|
||||
@ -157,14 +157,13 @@ sudo apt-get install youtube-dlg -y
|
||||
|
||||
恭喜你!你已经成功地在 Ubuntu 16.04 服务器上安装好了 youtube-dl 和 youtube-dlg。你可以很方便地从 Youtube 及任何 youtube-dl 支持的网站上以任何格式和任何大小下载视频了。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/install-and-use-youtube-dl-on-ubuntu-1604/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
144
published/20171119 10 Best LaTeX Editors For Linux.md
Normal file
144
published/20171119 10 Best LaTeX Editors For Linux.md
Normal file
@ -0,0 +1,144 @@
|
||||
10 款 Linux 平台上最好的 LaTeX 编辑器
|
||||
======
|
||||
|
||||
**简介:一旦你克服了 LaTeX 的学习曲线,就没有什么比 LaTeX 更棒了。下面介绍的是针对 Linux 和其他平台的最好的 LaTeX 编辑器。**
|
||||
|
||||
### LaTeX 是什么?
|
||||
|
||||
[LaTeX][1] 是一个文档制作系统。与纯文本编辑器不同,在 LaTeX 编辑器中你不能只写纯文本,为了组织文档的内容,你还必须使用一些 LaTeX 命令。
|
||||
|
||||
![LaTeX 示例][3]
|
||||
|
||||
LaTeX 编辑器一般用在出于学术目的的科学研究文档或书籍的出版,最重要的是,当你需要处理包含众多复杂数学符号的文档时,它能够为你带来方便。当然,使用 LaTeX 编辑器是很有趣的,但它也并非总是很有用,除非你对所要编写的文档有一些特别的需求。
|
||||
|
||||
### 为什么你应当使用 LaTeX?
|
||||
|
||||
好吧,正如我前面所提到的那样,使用 LaTeX 编辑器便意味着你有着特定的需求。为了捣腾 LaTeX 编辑器,并不需要你有一颗极客的头脑。但对于那些使用一般文本编辑器的用户来说,它并不是一个很有效率的解决方法。
|
||||
|
||||
假如你正在寻找一款工具来精心制作一篇文档,同时你对花费时间在格式化文本上没有任何兴趣,那么 LaTeX 编辑器或许正是你所寻找的那款工具。在 LaTeX 编辑器中,你只需要指定文档的类型,它便会相应地为你设置好文档的字体种类和大小尺寸。正是基于这个原因,难怪它会被认为是 [给作家的最好开源工具][4] 之一。
|
||||
|
||||
但请务必注意: LaTeX 编辑器并不是自动化的工具,你必须首先学会一些 LaTeX 命令来让它能够精确地处理文本的格式。
|
||||
|
||||
### 针对 Linux 平台的 10 款最好 LaTeX 编辑器
|
||||
|
||||
事先说明一下,以下列表并没有一个明确的先后顺序,序号为 3 的编辑器并不一定比序号为 7 的编辑器优秀。
|
||||
|
||||
#### 1、 LyX
|
||||
|
||||
![][5]
|
||||
|
||||
[LyX][6] 是一个开源的 LaTeX 编辑器,即是说它是网络上可获取到的最好的文档处理引擎之一。LyX 帮助你集中于你的文章,并忘记对单词的格式化,而这些正是每个 LaTeX 编辑器应当做的。LyX 能够让你根据文档的不同,管理不同的文档内容。一旦安装了它,你就可以控制文档中的很多东西了,例如页边距、页眉、页脚、空白、缩进、表格等等。
|
||||
|
||||
假如你正忙着精心撰写科学类文档、研究论文或类似的文档,你将会很高兴能够体验到 LyX 的公式编辑器,这也是其特色之一。 LyX 还包括一系列的教程来入门,使得入门没有那么多的麻烦。
|
||||
|
||||
#### 2、 Texmaker
|
||||
|
||||
![][7]
|
||||
|
||||
[Texmaker][8] 被认为是 GNOME 桌面环境下最好的 LaTeX 编辑器之一。它呈现出一个非常好的用户界面,带来了极好的用户体验。它也被称之为最实用的 LaTeX 编辑器之一。假如你经常进行 PDF 的转换,你将发现 TeXmaker 相比其他编辑器更加快速。在你书写的同时,你也可以预览你的文档最终将是什么样子的。同时,你也可以观察到可以很容易地找到所需要的符号。
|
||||
|
||||
Texmaker 也提供一个扩展的快捷键支持。你有什么理由不试着使用它呢?
|
||||
|
||||
#### 3、 TeXstudio
|
||||
|
||||
![][9]
|
||||
|
||||
假如你想要一个这样的 LaTeX 编辑器:它既能为你提供相当不错的自定义功能,又带有一个易用的界面,那么 [TeXstudio][10] 便是一个完美的选择。它的 UI 确实很简单,但是不粗糙。 TeXstudio 带有语法高亮,自带一个集成的阅读器,可以让你检查参考文献,同时还带有一些其他的辅助工具。
|
||||
|
||||
它同时还支持某些酷炫的功能,例如自动补全,链接覆盖,书签,多游标等等,这使得书写 LaTeX 文档变得比以前更加简单。
|
||||
|
||||
TeXstudio 的维护很活跃,对于新手或者高级写作者来说,这使得它成为一个引人注目的选择。
|
||||
|
||||
#### 4、 Gummi
|
||||
|
||||
![][11]
|
||||
|
||||
[Gummi][12] 是一个非常简单的 LaTeX 编辑器,它基于 GTK+ 工具箱。当然,在这个编辑器中你找不到许多华丽的选项,但如果你只想能够立刻着手写作, 那么 Gummi 便是我们给你的推荐。它支持将文档输出为 PDF 格式,支持语法高亮,并帮助你进行某些基础的错误检查。尽管在 GitHub 上它已经不再被活跃地维护,但它仍然工作地很好。
|
||||
|
||||
#### 5、 TeXpen
|
||||
|
||||
![][13]
|
||||
|
||||
[TeXpen][14] 是另一个简洁的 LaTeX 编辑器。它为你提供了自动补全功能。但其用户界面或许不会让你感到印象深刻。假如你对用户界面不在意,又想要一个超级容易的 LaTeX 编辑器,那么 TeXpen 将满足你的需求。同时 TeXpen 还能为你校正或提高在文档中使用的英语语法和表达式。
|
||||
|
||||
#### 6、 ShareLaTeX
|
||||
|
||||
![][15]
|
||||
|
||||
[ShareLaTeX][16] 是一款在线 LaTeX 编辑器。假如你想与某人或某组朋友一同协作进行文档的书写,那么这便是你所需要的。
|
||||
|
||||
它提供一个免费方案和几种付费方案。甚至来自哈佛大学和牛津大学的学生也都使用它来进行个人的项目。其免费方案还允许你添加一位协作者。
|
||||
|
||||
其付费方案允许你与 GitHub 和 Dropbox 进行同步,并且能够记录完整的文档修改历史。你可以为你的每个方案选择多个协作者。对于学生,它还提供单独的计费方案。
|
||||
|
||||
#### 7、 Overleaf
|
||||
|
||||
![][17]
|
||||
|
||||
[Overleaf][18] 是另一款在线的 LaTeX 编辑器。它与 ShareLaTeX 类似,它为专家和学生提供了不同的计费方案。它也提供了一个免费方案,使用它你可以与 GitHub 同步,检查你的修订历史,或添加多个合作者。
|
||||
|
||||
在每个项目中,它对文件的数目有所限制。所以在大多数情况下如果你对 LaTeX 文件非常熟悉,这并不会为你带来不便。
|
||||
|
||||
#### 8、 Authorea
|
||||
|
||||
![][19]
|
||||
|
||||
[Authorea][20] 是一个美妙的在线 LaTeX 编辑器。当然,如果考虑到价格,它可能不是最好的一款。对于免费方案,它有 100 MB 的数据上传限制和每次只能创建一个私有文档。而付费方案则提供更多的额外好处,但如果考虑到价格,它可能不是最便宜的。你应该选择 Authorea 的唯一原因应该是因为其用户界面。假如你喜爱使用一款提供令人印象深刻的用户界面的工具,那就不要错过它。
|
||||
|
||||
#### 9、 Papeeria
|
||||
|
||||
![][21]
|
||||
|
||||
[Papeeria][22] 是在网络上你能够找到的最为便宜的 LaTeX 在线编辑器,如果考虑到它和其他的编辑器一样可信赖的话。假如你想免费地使用它,则你不能使用它开展私有项目。但是,如果你更偏爱公共项目,它允许你创建不限数目的项目,添加不限数目的协作者。它的特色功能是有一个非常简便的画图构造器,并且在无需额外费用的情况下使用 Git 同步。假如你偏爱付费方案,它赋予你创建 10 个私有项目的能力。
|
||||
|
||||
#### 10、 Kile
|
||||
|
||||
![Kile LaTeX 编辑器][23]
|
||||
|
||||
位于我们最好 LaTeX 编辑器清单的最后一位是 [Kile][24] 编辑器。有些朋友对 Kile 推崇备至,很大程度上是因为其提供某些特色功能。
|
||||
|
||||
Kile 不仅仅是一款编辑器,它还是一款类似 Eclipse 的 IDE 工具,提供了针对文档和项目的一整套环境。除了快速编译和预览功能,你还可以使用诸如命令的自动补全 、插入引用,按照章节来组织文档等功能。你真的应该使用 Kile 来见识其潜力。
|
||||
|
||||
Kile 在 Linux 和 Windows 平台下都可获取到。
|
||||
|
||||
### 总结
|
||||
|
||||
所以上面便是我们推荐的 LaTeX 编辑器,你可以在 Ubuntu 或其他 Linux 发行版本中使用它们。
|
||||
|
||||
当然,我们可能还遗漏了某些可以在 Linux 上使用并且有趣的 LaTeX 编辑器。如若你正好知道它们,请在下面的评论中让我们知晓。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/LaTeX-editors-linux/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ankush/
|
||||
[1]:https://www.LaTeX-project.org/
|
||||
[3]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/latex-sample-example.jpeg
|
||||
[4]:https://itsfoss.com/open-source-tools-writers/
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/lyx_latex_editor.jpg
|
||||
[6]:https://www.LyX.org/
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/texmaker_latex_editor.jpg
|
||||
[8]:http://www.xm1math.net/texmaker/
|
||||
[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/tex_studio_latex_editor.jpg
|
||||
[10]:https://www.texstudio.org/
|
||||
[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/gummi_latex_editor.jpg
|
||||
[12]:https://github.com/alexandervdm/gummi
|
||||
[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/texpen_latex_editor.jpg
|
||||
[14]:https://sourceforge.net/projects/texpen/
|
||||
[15]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/sharelatex.jpg
|
||||
[16]:https://www.shareLaTeX.com/
|
||||
[17]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/overleaf.jpg
|
||||
[18]:https://www.overleaf.com/
|
||||
[19]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/authorea.jpg
|
||||
[20]:https://www.authorea.com/
|
||||
[21]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/papeeria_latex_editor.jpg
|
||||
[22]:https://www.papeeria.com/
|
||||
[23]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/kile-latex-800x621.png
|
||||
[24]:https://kile.sourceforge.io/
|
||||
@ -0,0 +1,71 @@
|
||||
如何使用 pdfgrep 从终端搜索 PDF 文件
|
||||
======
|
||||
|
||||

|
||||
|
||||
诸如 [grep][1] 和 [ack-grep][2] 之类的命令行工具对于搜索匹配指定[正则表达式][3]的纯文本非常有用。但是你有没有试过使用这些工具在 PDF 中搜索?不要这么做!由于这些工具无法读取PDF文件,因此你不会得到任何结果。它们只能读取纯文本文件。
|
||||
|
||||
顾名思义,[pdfgrep][4] 是一个可以在不打开文件的情况下搜索 PDF 中的文本的小命令行程序。它非常快速 —— 比几乎所有 PDF 浏览器提供的搜索更快。`grep` 和 `pdfgrep` 的最大区别在于 `pdfgrep` 对页进行操作,而 `grep` 对行操作。`grep` 如果在一行上找到多个匹配项,它也会多次打印单行。让我们看看如何使用该工具。
|
||||
|
||||
### 安装
|
||||
|
||||
对于 Ubuntu 和其他基于 Ubuntu 的 Linux 发行版来说,这非常简单:
|
||||
|
||||
```
|
||||
sudo apt install pdfgrep
|
||||
```
|
||||
|
||||
对于其他发行版,只要在[包管理器][5]里输入 “pdfgrep” 查找,它就应该能够安装它。万一你想浏览其代码,你也可以查看项目的 [GitLab 页面][6]。
|
||||
|
||||
### 测试运行
|
||||
|
||||
现在你已经安装了这个工具,让我们去测试一下。`pdfgrep` 命令采用以下格式:
|
||||
|
||||
```
|
||||
pdfgrep [OPTION...] PATTERN [FILE...]
|
||||
```
|
||||
|
||||
- `OPTION` 是一个额外的属性列表,给出诸如 `-i` 或 `--ignore-case` 这样的命令,这两者都会忽略匹配正则中的大小写。
|
||||
- `PATTERN` 是一个扩展正则表达式。
|
||||
|
||||
- `FILE` 如果它在相同的工作目录就是文件的名称,或文件的路径。
|
||||
|
||||
我对 Python 3.6 官方文档运行该命令。下图是结果。
|
||||
|
||||
![pdfgrep search][7]
|
||||
|
||||
红色高亮显示所有遇到单词 “queue” 的地方。在命令中加入 `-i` 选项将会匹配单词 “Queue”。请记住,当加入 `-i` 时,大小写并不重要。
|
||||
|
||||
### 其它
|
||||
|
||||
`pdfgrep` 有相当多的有趣的选项。不过,我只会在这里介绍几个。
|
||||
|
||||
* `-c` 或者 `--count`:这会抑制匹配的正常输出。它只显示在文件中遇到该单词的次数,而不是显示匹配的长输出。
|
||||
* `-p` 或者 `--page-count`:这个选项打印页面上匹配的页码和页面上的该匹配模式出现次数。
|
||||
* `-m` 或者 `--max-count` [number]:指定匹配的最大数目。这意味着当达到匹配次数时,该命令停止读取文件。
|
||||
|
||||
所支持的选项的完整列表可以在 man 页面或者 `pdfgrep` 在线[文档][8]中找到。如果你在批量处理一些文件,不要忘记,`pdfgrep` 可以同时搜索多个文件。可以通过更改 `GREP_COLORS` 环境变量来更改默认的匹配高亮颜色。
|
||||
|
||||
### 总结
|
||||
|
||||
下一次你想在 PDF 中搜索一些东西。请考虑使用 `pdfgrep`。该工具会派上用场,并且节省你的时间。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/search-pdf-files-pdfgrep/
|
||||
|
||||
作者:[Bruno Edoh][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com
|
||||
[1]:https://www.maketecheasier.com/what-is-grep-and-uses/
|
||||
[2]: https://www.maketecheasier.com/ack-a-better-grep/
|
||||
[3]: https://www.maketecheasier.com/the-beginner-guide-to-regular-expressions/
|
||||
[4]: https://pdfgrep.org/
|
||||
[5]: https://www.maketecheasier.com/install-software-in-various-linux-distros/
|
||||
[6]: https://gitlab.com/pdfgrep/pdfgrep
|
||||
[7]: https://www.maketecheasier.com/assets/uploads/2017/11/pdfgrep-screenshot.png (pdfgrep search)
|
||||
[8]: https://pdfgrep.org/doc.html
|
||||
@ -0,0 +1,48 @@
|
||||
手把手教你构建开放式文化
|
||||
======
|
||||
|
||||
> 这本开放式组织的最新著作是大规模体验开方的手册。
|
||||
|
||||

|
||||
|
||||
我们于 2015 年发表<ruby>开放组织<rt>Open Organization</rt></ruby> 后,很多各种类型、各种规模的公司都对“开放式”文化究竟意味着什么感到好奇。甚至当我跟别的公司谈论我们产品和服务的优势时,也总是很快就从谈论技术转移到人和文化上去了。几乎所有对推动创新和保持行业竞争优势有兴趣的人都在思考这个问题。
|
||||
|
||||
不是只有<ruby>高层领导团队<rt>senior leadership teams<rt></ruby>才对开放式工作感兴趣。[红帽公司最近一次调查 ][1] 发现 [81% 的受访者 ][2] 同意这样一种说法:“拥有开放式的组织文化对我们公司非常重要。”
|
||||
|
||||
然而要注意的是。同时只有 [67% 的受访者 ][3] 认为:“我们的组织有足够的资源来构建开放式文化。”
|
||||
|
||||
这个结果与我从其他公司那交流所听到的相吻合:人们希望在开放式文化中工作,他们只是不知道该怎么做。对此我表示同情,因为组织的行事风格是很难捕捉、评估和理解的。在 [Catalyst-In-Chief][4] 中,我将其称之为“组织中最神秘莫测的部分。”
|
||||
|
||||
《开放式组织》认为, 在数字转型有望改变我们工作的许多传统方式的时代,拥抱开放文化是创造持续创新的最可靠途径。当我们在书写这本书的时候,我们所关注的是描述在红帽公司中兴起的那种文化--而不是编写一本如何操作的书。我们并不会制定出一步步的流程来让其他组织采用。
|
||||
|
||||
这也是为什么与其他领导者和高管谈论他们是如何开始构建开放式文化的会那么有趣。在创建开放组织时,很多高管会说我们要“改变我们的文化”。但是文化并不是一项输入。它是一项输出——它是人们互动和日常行为的副产品。
|
||||
|
||||
告诉组织成员“更加透明地工作”,“更多地合作”,以及“更加包容地行动”并没有什么作用。因为像“透明”,“合作”和“包容”这一类的文化特质并不是行动。他们只是组织内指导行为的价值观而已。
|
||||
|
||||
要如何才能构建开放式文化呢?
|
||||
|
||||
在过去的两年里,Opensource.com 社区收集了各种以开放的精神来进行工作、管理和领导的最佳实践方法。现在我们在新书 《[The Open Organization Workbook][5]》 中将之分享出来,这是一本更加规范的引发文化变革的指引。
|
||||
|
||||
要记住,任何改变,尤其是巨大的改变,都需要承诺、耐心,以及努力的工作。我推荐你在通往伟大成功的大道上先使用这本工作手册来实现一些微小的,有意义的成果。
|
||||
|
||||
通过阅读这本书,你将能够构建一个开放而又富有创新的文化氛围,使你们的人能够茁壮成长。我已經迫不及待想听听你的故事了。
|
||||
|
||||
本文摘自 《[Open Organization Workbook project][6]》。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/17/12/whitehurst-workbook-introduction
|
||||
|
||||
作者:[Jim Whitehurst][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jwhitehurst
|
||||
[1]:https://www.redhat.com/en/blog/red-hat-releases-2017-open-source-culture-survey-results
|
||||
[2]:https://www.techvalidate.com/tvid/923-06D-74C
|
||||
[3]:https://www.techvalidate.com/tvid/D30-09E-B52
|
||||
[4]:https://opensource.com/open-organization/resources/catalyst-in-chief
|
||||
[5]:https://opensource.com/open-organization/resources/workbook
|
||||
[6]:https://opensource.com/open-organization/17/8/workbook-project-announcement
|
||||
@ -1,70 +1,89 @@
|
||||
匿名上网:学习在 Linux 上安装 TOR 网络
|
||||
======
|
||||
Tor 网络是一个匿名网络来保护你的互联网以及隐私。Tor 网络是一组志愿者运营的服务器。Tor 通过在由志愿者运营的分布式中继系统之间跳转来保护互联网通信。这避免了人们窥探我们的网络,他们无法了解我们访问的网站或者用户身在何处,并且也可以让我们访问被屏蔽的网站。
|
||||
|
||||
Tor 网络是一个用来保护你的互联网以及隐私的匿名网络。Tor 网络是一组志愿者运营的服务器。Tor 通过在由志愿者运营的分布式中继系统之间跳转来保护互联网通信。这避免了人们窥探我们的网络,他们无法了解我们访问的网站或者用户身在何处,并且也可以让我们访问被屏蔽的网站。
|
||||
|
||||
在本教程中,我们将学习在各种 Linux 操作系统上安装 Tor 网络,以及如何使用它来配置我们的程序来保护通信。
|
||||
|
||||
**(推荐阅读:[如何在 Linux 上安装 Tor 浏览器(Ubuntu、Mint、RHEL、Fedora、CentOS)][1])**
|
||||
推荐阅读:[如何在 Linux 上安装 Tor 浏览器(Ubuntu、Mint、RHEL、Fedora、CentOS)][1]
|
||||
|
||||
### CentOS/RHEL/Fedora
|
||||
|
||||
Tor 包是 EPEL 仓库的一部分,所以如果我们安装了 EPEL 仓库,我们可以直接使用 yum 来安装 Tor。如果你需要在您的系统上安装 EPEL 仓库,请使用下列适当的命令(基于操作系统和体系结构):
|
||||
Tor 包是 EPEL 仓库的一部分,所以如果我们安装了 EPEL 仓库,我们可以直接使用 `yum` 来安装 Tor。如果你需要在您的系统上安装 EPEL 仓库,请使用下列适当的命令(基于操作系统和体系结构):
|
||||
|
||||
**RHEL/CentOS 7**
|
||||
RHEL/CentOS 7:
|
||||
|
||||
**$ sudo rpm -Uvh https://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-11.noarch.rpm**
|
||||
```
|
||||
$ sudo rpm -Uvh https://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-11.noarch.rpm
|
||||
```
|
||||
|
||||
**RHEL/CentOS 6 (64 位)**
|
||||
RHEL/CentOS 6 (64 位):
|
||||
|
||||
**$ sudo rpm -Uvh http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm**
|
||||
```
|
||||
$ sudo rpm -Uvh http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
|
||||
```
|
||||
|
||||
**RHEL/CentOS 6 (32 位)**
|
||||
RHEL/CentOS 6 (32 位):
|
||||
|
||||
**$ sudo rpm -Uvh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm**
|
||||
```
|
||||
$ sudo rpm -Uvh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm
|
||||
```
|
||||
|
||||
安装完成后,我们可以用下面的命令安装 Tor 浏览器:
|
||||
|
||||
**$ sudo yum install tor**
|
||||
```
|
||||
$ sudo yum install tor
|
||||
```
|
||||
|
||||
### Ubuntu
|
||||
|
||||
为了在 Ubuntu 机器上安装 Tor 网络,我们需要添加官方 Tor 仓库。我们需要将仓库信息添加到 “/etc/apt/sources.list” 中。
|
||||
为了在 Ubuntu 机器上安装 Tor 网络,我们需要添加官方 Tor 仓库。我们需要将仓库信息添加到 `/etc/apt/sources.list` 中。
|
||||
|
||||
**$ sudo nano /etc/apt/sources.list**
|
||||
```
|
||||
$ sudo nano /etc/apt/sources.list
|
||||
```
|
||||
|
||||
现在根据你的操作系统添加下面的仓库信息:
|
||||
|
||||
**Ubuntu 16.04**
|
||||
Ubuntu 16.04:
|
||||
|
||||
**deb http://deb.torproject.org/torproject.org xenial main**
|
||||
**deb-src http://deb.torproject.org/torproject.org xenial main**
|
||||
```
|
||||
deb http://deb.torproject.org/torproject.org xenial main
|
||||
deb-src http://deb.torproject.org/torproject.org xenial main
|
||||
```
|
||||
|
||||
**Ubuntu 14.04**
|
||||
Ubuntu 14.04
|
||||
|
||||
**deb http://deb.torproject.org/torproject.org trusty main**
|
||||
**deb-src http://deb.torproject.org/torproject.org trusty main**
|
||||
```
|
||||
deb http://deb.torproject.org/torproject.org trusty main
|
||||
deb-src http://deb.torproject.org/torproject.org trusty main
|
||||
```
|
||||
|
||||
接下来打开终端并执行以下两个命令添加用于签名软件包的 gpg 密钥:
|
||||
|
||||
**$ gpg -keyserver keys.gnupg.net -recv A3C4F0F979CAA22CDBA8F512EE8CBC9E886DDD89**
|
||||
**$ gpg -export A3C4F0F979CAA22CDBA8F512EE8CBC9E886DDD89 | sudo apt-key add -**
|
||||
```
|
||||
$ gpg -keyserver keys.gnupg.net -recv A3C4F0F979CAA22CDBA8F512EE8CBC9E886DDD89
|
||||
$ gpg -export A3C4F0F979CAA22CDBA8F512EE8CBC9E886DDD89 | sudo apt-key add -
|
||||
```
|
||||
|
||||
现在运行更新并安装 Tor 网络:
|
||||
|
||||
**$ sudo apt-get update**
|
||||
**$ sudo apt-get install tor deb.torproject.org-keyring**
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install tor deb.torproject.org-keyring
|
||||
```
|
||||
|
||||
### Debian
|
||||
|
||||
我们可以无需添加任何仓库在 Debian 上安装 Tor 网络。只要打开终端并以 root 身份执行以下命令:
|
||||
|
||||
**$ apt install tor**
|
||||
|
||||
###
|
||||
```
|
||||
$ apt install tor
|
||||
```
|
||||
|
||||
### Tor 配置
|
||||
|
||||
如果你最终目的只是为了保护互联网浏览,而没有其他要求,直接使用 Tor 更好,但是如果你需要保护即时通信、IRC、Jabber 等程序,则需要配置这些应用程序进行安全通信。但在做之前,让我们先看看**[Tor 网站上提到的警告][2]**。
|
||||
如果你最终目的只是为了保护互联网浏览,而没有其他要求,直接使用 Tor 更好,但是如果你需要保护即时通信、IRC、Jabber 等程序,则需要配置这些应用程序进行安全通信。但在做之前,让我们先看看[Tor 网站上提到的警告][2]。
|
||||
|
||||
- 不要大流量使用 Tor
|
||||
- 不要在 Tor 中使用任何浏览器插件
|
||||
@ -72,7 +91,7 @@ Tor 包是 EPEL 仓库的一部分,所以如果我们安装了 EPEL 仓库,
|
||||
- 不要在线打开通过 Tor 下载的任何文档。
|
||||
- 尽可能使用 Tor 桥
|
||||
|
||||
现在配置程序来使用 Tor,例如 jabber。首先选择 “SOCKS代理” 而不是使用 HTTP 代理,并使用端口号 9050,或者也可以使用端口 9150(Tor 浏览器使用)。
|
||||
现在配置程序来使用 Tor,例如 jabber。首先选择 “SOCKS代理” 而不是使用 HTTP 代理,并使用端口号 `9050`,或者也可以使用端口 9150(Tor 浏览器使用)。
|
||||
|
||||
![install tor network][4]
|
||||
|
||||
@ -90,7 +109,7 @@ via: http://linuxtechlab.com/learn-install-tor-network-linux/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,15 @@
|
||||
解决 Linux 和 Windows 双启动带来的时间同步问题
|
||||
======
|
||||
想在保留 windows 系统的前提下尝试其他 Linux 发行版,双启动是个常用的做法。这种方法如此风行是因为实现双启动是一件很容易的事情。然而这也带来了一个大问题,那就是 **时间**。
|
||||
|
||||

|
||||
|
||||
想在保留 Windows 系统的前提下尝试其他 Linux 发行版,双启动是个常用的做法。这种方法如此风行是因为实现双启动是一件很容易的事情。然而这也带来了一个大问题,那就是 **时间**。
|
||||
|
||||
是的,你没有看错。若你只是用一个操作系统,时间同步不会有什么问题。但若有 Windows 和 Linux 两个系统,则可能出现时间同步上的问题。Linux 使用的是格林威治时间而 Windows 使用的是本地时间。当你从 Linux 切换到 Windows 或者从 Windows 切换到 Linux 时,就可能显示错误的时间了。
|
||||
|
||||
不过不要担心,这个问题很好解决。
|
||||
|
||||
点击 windows 系统中的开始菜单,然后搜索 regedit。
|
||||
点击 Windows 系统中的开始菜单,然后搜索 regedit。
|
||||
|
||||
[![open regedit in windows 10][1]][1]
|
||||
|
||||
@ -14,15 +17,13 @@
|
||||
|
||||
[![windows 10 registry editor][2]][2]
|
||||
|
||||
在左边的导航菜单,导航到 -
|
||||
在左边的导航菜单,导航到 `HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\TimeZoneInformation`。
|
||||
|
||||
**`HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\TimeZoneInformation`**
|
||||
|
||||
在右边窗口,右键点击空白位置,然后选择 **`New>> DWORD(32 bit) Value`**。
|
||||
在右边窗口,右键点击空白位置,然后选择 `New >> DWORD(32 bit) Value`。
|
||||
|
||||
[![change time format utc from windows registry][3]][3]
|
||||
|
||||
之后,会有新生成一个条目,而且这个条目默认是高亮的。将这个条目重命名为 `**RealTimeIsUniversal**` 并设置值为 **1。**
|
||||
之后,你会新生成一个条目,而且这个条目默认是高亮的。将这个条目重命名为 `RealTimeIsUniversal` 并设置值为 `1`。
|
||||
|
||||
[![set universal time utc in windows][4]][4]
|
||||
|
||||
@ -34,7 +35,7 @@ via: http://www.theitstuff.com/how-to-sync-time-between-linux-and-windows-dual-b
|
||||
|
||||
作者:[Rishabh Kandari][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,139 @@
|
||||
关于 Linux 页面表隔离补丁的神秘情况
|
||||
=====
|
||||
|
||||
**[本文勘误与补充][1]**
|
||||
|
||||
_长文预警:_ 这是一个目前严格限制的、禁止披露的安全 bug(LCTT 译注:目前已经部分披露),它影响到目前几乎所有实现虚拟内存的 CPU 架构,需要硬件的改变才能完全解决这个 bug。通过软件来缓解这种影响的紧急开发工作正在进行中,并且最近在 Linux 内核中已经得以实现,并且,在 11 月份,在 NT 内核中也开始了一个类似的紧急开发。在最糟糕的情况下,软件修复会导致一般工作负载出现巨大的减速(LCTT 译注:外在表现为 CPU 性能下降)。这里有一个提示,攻击会影响虚拟化环境,包括 Amazon EC2 和 Google 计算引擎,以及另外的提示是,这种精确的攻击可能涉及一个新的 Rowhammer 变种(LCTT 译注:一个由 Google 安全团队提出的 DRAM 的安全漏洞,在文章的后面部分会简单介绍)。
|
||||
|
||||
我一般不太关心安全问题,但是,对于这个 bug 我有点好奇,而一般会去写这个主题的人似乎都很忙,要么就是知道这个主题细节的人会保持沉默。这让我在新年的第一天(元旦那天)花了几个小时深入去挖掘关于这个谜团的更多信息,并且我将这些信息片断拼凑到了一起。
|
||||
|
||||
注意,这是一件相互之间高度相关的事件,因此,它的主要描述都是猜测,除非过一段时间,它的限制禁令被取消。我所看到的,包括涉及到的供应商、许多争论和这种戏剧性场面,将在限制禁令取消的那一天出现。
|
||||
|
||||
### LWN
|
||||
|
||||
这个事件的线索出现于 12 月 20 日 LWN 上的 [内核页面表的当前状况:页面隔离][2]这篇文章。从文章语气上明显可以看到这项工作的紧急程度,内核的核心开发者紧急加入了 [KAISER 补丁系列][3]的开发——它由奥地利的 [TU Graz][4] 的一组研究人员首次发表于去年 10 月份。
|
||||
|
||||
这一系列的补丁的用途从概念上说很简单:为了阻止运行在用户空间的进程在进程页面表中通过映射得到内核空间页面的各种攻击方式,它可以很好地阻止了从非特权的用户空间代码中识别到内核虚拟地址的攻击企图。
|
||||
|
||||
这个小组在描述 KAISER 的论文《[KASLR 已死:KASLR 永存][5]》摘要中特别指出,当用户代码在 CPU 上处于活动状态的时候,在内存管理硬件中删除所有内核地址空间的信息。
|
||||
|
||||
这个补丁集的魅力在于它触及到了核心,内核的全部基柱(以及与用户空间的接口),显然,它应该被最优先考虑。遍观 Linux 中内存管理方面的变化,通常某个变化的首次引入会发生在该改变被合并的很久之前,并且,通常会进行多次的评估、拒绝、以及因各种原因爆发争论的一系列过程。
|
||||
|
||||
而 KAISER(就是现在的 KPTI)系列(从引入到)被合并还不足三个月。
|
||||
|
||||
### ASLR 概述
|
||||
|
||||
从表面上看,这些补丁设计以确保<ruby>地址空间布局随机化<rt>Address Space Layout Randomization</rt></ruby>(ASLR)仍然有效:这是一个现代操作系统的安全特性,它试图将更多的随机位引入到公共映射对象的地址空间中。
|
||||
|
||||
例如,在引用 `/usr/bin/python` 时,动态链接将对系统的 C 库、堆、线程栈、以及主要的可执行文件进行排布,去接受随机分配的地址范围:
|
||||
|
||||
```
|
||||
$ bash -c ‘grep heap /proc/$$/maps’
|
||||
019de000-01acb000 rw-p 00000000 00:00 0 [heap]
|
||||
$ bash -c 'grep heap /proc/$$/maps’
|
||||
023ac000-02499000 rw-p 00000000 00:00 0 [heap]
|
||||
```
|
||||
注意两次运行的 bash 进程的堆(heap)的开始和结束偏移量上的变化。
|
||||
|
||||
如果一个缓存区管理的 bug 将导致攻击者可以去覆写一些程序代码指向的内存地址,而那个地址之后将在程序控制流中使用,这样这种攻击者就可以使控制流转向到一个包含他们所选择的内容的缓冲区上。而这个特性的作用是,对于攻击者来说,使用机器代码来填充缓冲区做他们想做的事情(例如,调用 `system()` C 库函数)将更困难,因为那个函数的地址在不同的运行进程上不同的。
|
||||
|
||||
这是一个简单的示例,ASLR 被设计用于去保护类似这样的许多场景,包括阻止攻击者了解有可能被用来修改控制流的程序数据的地址或者实现一个攻击。
|
||||
|
||||
KASLR 是应用到内核本身的一个 “简化的” ASLR:在每个重新引导的系统上,属于内核的地址范围是随机的,这样就使得,虽然被攻击者操控的控制流运行在内核模式上,但是,他们不能猜测到为实现他们的攻击目的所需要的函数和结构的地址,比如,定位当前进程的数据段,将活动的 UID 从一个非特权用户提升到 root 用户,等等。
|
||||
|
||||
### 坏消息:缓减这种攻击的软件运行成本过于贵重
|
||||
|
||||
之前的方式,Linux 将内核的内存映射到用户内存的同一个页面表中的主要原因是,当用户的代码触发一个系统调用、故障、或者产生中断时,就不需要改变正在运行的进程的虚拟内存布局。
|
||||
|
||||
因为它不需要去改变虚拟内存布局,进而也就不需要去清洗掉(flush)依赖于该布局的与 CPU 性能高度相关的缓存(LCTT 译注:意即如果清掉这些高速缓存,CPU 性能就会下降),而主要是通过 <ruby>[转换查找缓冲器][6]<rt>Translation Lookaside Buffer</rt></ruby>(TLB)(LCTT 译注:TLB ,将虚拟地址转换为物理地址)。
|
||||
|
||||
随着页面表分割补丁的合并,内核每次开始运行时,需要将内核的缓存清掉,并且,每次用户代码恢复运行时都会这样。对于大多数工作负载,在每个系统调用中,TLB 的实际总损失将导致明显的变慢:[@grsecurity 测量的一个简单的案例][7],在一个最新的 AMD CPU 上,Linux `du -s` 命令变慢了 50%。
|
||||
|
||||
### 34C3
|
||||
|
||||
在今年的 CCC 大会上,你可以找到 TU Graz 的另外一位研究人员,《[描述了一个纯 Javascript 的 ASLR 攻击][8]》,通过仔细地掌握 CPU 内存管理单元的操作时机,遍历了描述虚拟内存布局的页面表,来实现 ASLR 攻击。它通过高度精确的时间掌握和选择性回收的 CPU 缓存行的组合方式来实现这种结果,一个运行在 web 浏览器的 Javascript 程序可以找回一个 Javascript 对象的虚拟地址,使得可以利用浏览器内存管理 bug 进行接下来的攻击。(LCTT 译注:本文作者勘误说,上述链接 CCC 的讲演与 KAISER 补丁完全无关,是作者弄错了)
|
||||
|
||||
因此,从表面上看,我们有一组 KAISER 补丁,也展示了解除 ASLR 化地址的技术,并且,这个展示使用的是 Javascript,它很快就可以在一个操作系统内核上进行重新部署。
|
||||
|
||||
### 虚拟内存概述
|
||||
|
||||
在通常情况下,当一些机器码尝试去加载、存储、或者跳转到一个内存地址时,现代的 CPU 必须首先去转换这个 _虚拟地址_ 到一个 _物理地址_ ,这是通过遍历一系列操作系统托管的数组(被称为页面表)的方式进行的,这些数组描述了虚拟地址和安装在这台机器上的物理内存之间的映射。
|
||||
|
||||
在现代操作系统中,虚拟内存可能是最重要的强大特性:它可以避免什么发生呢?例如,一个濒临死亡的进程崩溃了操作系统、一个 web 浏览器 bug 崩溃了你的桌面环境、或者一个运行在 Amazon EC2 中的虚拟机的变化影响了同一台主机上的另一个虚拟机。
|
||||
|
||||
这种攻击的原理是,利用 CPU 上维护的大量的缓存,通过仔细地操纵这些缓存的内容,它可以去推测内存管理单元的地址,以去访问页面表的不同层级,因为一个未缓存的访问将比一个缓存的访问花费更长的时间(以实时而言)。通过检测页面表上可访问的元素,它可能能够恢复在 MMU(LCTT 译注:存储器管理单元)忙于解决的虚拟地址中的大部分比特(bits)。
|
||||
|
||||
### 这种动机的证据,但是不用恐慌
|
||||
|
||||
我们找到了动机,但是到目前为止,我们并没有看到这项工作引进任何恐慌。总的来说,ASLR 并不能完全缓减这种风险,并且也是一道最后的防线:仅在这 6 个月的周期内,即便是一个没有安全意识的人也能看到一些关于解除(unmasking) ASLR 化的指针的新闻,并且,实际上这种事从 ASLR 出现时就有了。
|
||||
|
||||
单独的修复 ASLR 并不足于去描述这项工作高优先级背后的动机。
|
||||
|
||||
### 它是硬件安全 bug 的证据
|
||||
|
||||
通过阅读这一系列补丁,可以明确许多事情。
|
||||
|
||||
第一,正如 [@grsecurity 指出][9] 的,代码中的一些注释已经被编辑掉了(redacted),并且,描述这项工作的附加的主文档文件已经在 Linux 源代码树中看不到了。
|
||||
|
||||
通过检查代码,它以运行时补丁的方式构建,在系统引导时仅当内核检测到是受影响的系统时才会被应用,与对臭名昭著的 [Pentium F00F bug][10] 的缓解措施,使用完全相同的机制:
|
||||
|
||||
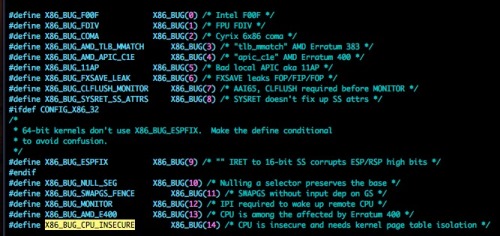
|
||||
|
||||
### 更多的线索:Microsoft 也已经实现了页面表的分割
|
||||
|
||||
通过对 FreeBSD 源代码的一个简单挖掘可以看出,目前,其它的自由操作系统没有实现页面表分割,但是,通过 [Alex Ioniscu 在 Twitter][11] 上的提示,这项工作已经不局限于 Linux 了:从 11 月起,公开的 NT 内核也已经实现了同样的技术。
|
||||
|
||||
### 猜测:Rowhammer
|
||||
|
||||
对 TU Graz 研究人员的工作的进一步挖掘,我们找到这篇 《[当 rowhammer 仅敲一次][12]》,这是 12 月 4 日通告的一个 [新的 Rowhammer 攻击的变种][13]:
|
||||
|
||||
> 在这篇论文中,我们提出了新的 Rowhammer 攻击和漏洞的原始利用方式,表明即便是组合了所有防御也没有效果。我们的新攻击技术,对一个位置的反复 “敲打”(hammering),打破了以前假定的触发 Rowhammer bug 的前提条件。
|
||||
|
||||
快速回顾一下,Rowhammer 是多数(全部?)种类的商业 DRAM 的一类根本性问题,比如,在普通的计算机中的内存上。通过精确操作内存中的一个区域,这可能会导致内存该区域存储的相关(但是逻辑上是独立的)内容被毁坏。效果是,Rowhammer 可能被用于去反转内存中的比特(bits),使未经授权的用户代码可以访问到,比如,这个比特位描述了系统中的其它代码的访问权限。
|
||||
|
||||
我发现在 Rowhammer 上,这项工作很有意思,尤其是它反转的位接近页面表分割补丁时,但是,因为 Rowhammer 攻击要求一个目标:你必须知道你尝试去反转的比特在内存中的物理地址,并且,第一步是得到的物理地址可能是一个虚拟地址,就像在 KASLR 中的解除(unmasking)工作。
|
||||
|
||||
### 猜测:它影响主要的云供应商
|
||||
|
||||
在我能看到的内核邮件列表中,除了该子系统维护者的名字之外,e-mail 地址属于 Intel、Amazon 和 Google 的雇员,这表示这两个大的云计算供应商对此特别感兴趣,这为我们提供了一个强大的线索,这项工作很大的可能是受虚拟化安全驱动的。
|
||||
|
||||
它可能会导致产生更多的猜测:虚拟机 RAM 和由这些虚拟机所使用的虚拟内存地址,最终表示为在主机上大量的相邻的数组,那些数组,尤其是在一个主机上只有两个租户的情况下,在 Xen 和 Linux 内核中是通过内存分配来确定的,这样可能会有(准确性)非常高的可预测行为。
|
||||
|
||||
### 最喜欢的猜测:这是一个提升特权的攻击
|
||||
|
||||
把这些综合到一起,我并不难预测,可能是我们在 2018 年会使用的这些存在提升特权的 bug 的发行版,或者类似的系统推动了如此紧急的进展,并且在补丁集的抄送列表中出现如此多的感兴趣者的名字。
|
||||
|
||||
最后的一个趣闻,虽然我在阅读补丁集的时候没有找到我要的东西,但是,在一些代码中标记,paravirtual 或者 HVM Xen 是不受此影响的。
|
||||
|
||||
### 吃瓜群众表示 2018 将很有趣
|
||||
|
||||
这些猜想是完全有可能的,它离实现很近,但是可以肯定的是,当这些事情被公开后,那将是一个非常令人激动的几个星期。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://pythonsweetness.tumblr.com/post/169166980422/the-mysterious-case-of-the-linux-page-table
|
||||
|
||||
作者:[python sweetness][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://pythonsweetness.tumblr.com/
|
||||
[1]:http://pythonsweetness.tumblr.com/post/169217189597/quiet-in-the-peanut-gallery
|
||||
[2]:https://linux.cn/article-9201-1.html
|
||||
[3]:https://lwn.net/Articles/738975/
|
||||
[4]:https://www.iaik.tugraz.at/content/research/sesys/
|
||||
[5]:https://gruss.cc/files/kaiser.pdf
|
||||
[6]:https://en.wikipedia.org/wiki/Translation_lookaside_buffer
|
||||
[7]:https://twitter.com/grsecurity/status/947439275460702208
|
||||
[8]:https://www.youtube.com/watch?v=ewe3-mUku94
|
||||
[9]:https://twitter.com/grsecurity/status/947147105684123649
|
||||
[10]:https://en.wikipedia.org/wiki/Pentium_F00F_bug
|
||||
[11]:https://twitter.com/aionescu/status/930412525111296000
|
||||
[12]:https://www.tugraz.at/en/tu-graz/services/news-stories/planet-research/singleview/article/wenn-rowhammer-nur-noch-einmal-klopft/
|
||||
[13]:https://arxiv.org/abs/1710.00551
|
||||
[14]:http://pythonsweetness.tumblr.com/post/169166980422/the-mysterious-case-of-the-linux-page-table
|
||||
[15]:http://pythonsweetness.tumblr.com/
|
||||
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
AI and machine learning bias has dangerous implications
|
||||
======
|
||||
translating
|
||||
|
||||

|
||||
|
||||
|
||||
104
sources/talk/20180117 Some thoughts on Spectre and Meltdown.md
Normal file
104
sources/talk/20180117 Some thoughts on Spectre and Meltdown.md
Normal file
@ -0,0 +1,104 @@
|
||||
### Some thoughts on Spectre and Meltdown
|
||||
|
||||
By now I imagine that all of my regular readers, and a large proportion of the rest of the world, have heard of the security issues dubbed "Spectre" and "Meltdown". While there have been some excellent technical explanations of these issues from several sources — I particularly recommend the [Project Zero][3] blog post — I have yet to see anyone really put these into a broader perspective; nor have I seen anyone make a serious attempt to explain these at a level suited for a wide audience. While I have not been involved with handling these issues directly, I think it's time for me to step up and provide both a wider context and a more broadly understandable explanation.
|
||||
|
||||
The story of these attacks starts in late 2004\. I had submitted my doctoral thesis and had a few months before flying back to Oxford for my defense, so I turned to some light reading: Intel's latest "Optimization Manual", full of tips on how to write faster code. (Eking out every last nanosecond of performance has long been an interest of mine.) Here I found an interesting piece of advice: On Intel CPUs with "Hyper-Threading", a common design choice (aligning the top of thread stacks on page boundaries) should be avoided because it would result in some resources being overused and others being underused, with a resulting drop in performance. This started me thinking: If two programs can hurt each others' performance by accident, one should be able to _measure_ whether its performance is being hurt by the other; if it can measure whether its performance is being hurt by people not following Intel's optimization guidelines, it should be able to measure whether its performance is being hurt by other patterns of resource usage; and if it can measure that, it should be able to make deductions about what the other program is doing.
|
||||
|
||||
It took me a few days to convince myself that information could be stolen in this manner, but within a few weeks I was able to steal an [RSA][4] private key from [OpenSSL][5]. Then started the lengthy process of quietly notifying Intel and all the major operating system vendors; and on Friday the 13th of May 2005 I presented [my paper][6] describing this new attack at [BSDCan][7] 2005 — the first attack of this type exploiting how a running program causes changes to the microarchitectural state of a CPU. Three months later, the team of Osvik, Shamir, and Tromer published [their work][8], which showed how the same problem could be exploited to steal [AES][9] keys.
|
||||
|
||||
Over the years there have been many attacks which expoit different aspects of CPU design — exploiting L1 data cache collisions, exploiting L1 code cache collisions, exploiting L2 cache collisions, exploiting the TLB, exploiting branch prediction, etc. — but they have all followed the same basic mechanism: A program does something which interacts with the internal state of a CPU, and either we can measure that internal state (the more common case) or we can set up that internal state before the program runs in a way which makes the program faster or slower. These new attacks use the same basic mechanism, but exploit an entirely new angle. But before I go into details, let me go back to basics for a moment.
|
||||
|
||||
#### Understanding the attacks
|
||||
|
||||
These attacks exploit something called a "side channel". What's a side channel? It's when information is revealed as an inadvertant side effect of what you're doing. For example, in the movie [2001][10], Bowman and Poole enter a pod to ensure that the HAL 9000 computer cannot hear their conversation — but fail to block the _optical_ channel which allows Hal to read their lips. Side channels are related to a concept called "covert channels": Where side channels are about stealing information which was not intended to be conveyed, covert channels are about conveying information which someone is trying to prevent you from sending. The famous case of a [Prisoner of War][11] blinking the word "TORTURE" in Morse code is an example of using a covert channel to convey information.
|
||||
|
||||
Another example of a side channel — and I'll be elaborating on this example later, so please bear with me if it seems odd — is as follows: I want to know when my girlfriend's passport expires, but she won't show me her passport (she complains that it has a horrible photo) and refuses to tell me the expiry date. I tell her that I'm going to take her to Europe on vacation in August and watch what happens: If she runs out to renew her passport, I know that it will expire before August; while if she doesn't get her passport renewed, I know that it will remain valid beyond that date. Her desire to ensure that her passport would be valid inadvertantly revealed to me some information: Whether its expiry date was before or after August.
|
||||
|
||||
Over the past 12 years, people have gotten reasonably good at writing programs which avoid leaking information via side channels; but as the saying goes, if you make something idiot-proof, the world will come up with a better idiot; in this case, the better idiot is newer and faster CPUs. The Spectre and Meltdown attacks make use of something called "speculative execution". This is a mechanism whereby, if a CPU isn't sure what you want it to do next, it will _speculatively_ perform some action. The idea here is that if it guessed right, it will save time later — and if it guessed wrong, it can throw away the work it did and go back to doing what you asked for. As long as it sometimes guesses right, this saves time compared to waiting until it's absolutely certain about what it should be doing next. Unfortunately, as several researchers recently discovered, it can accidentally leak some information during this speculative execution.
|
||||
|
||||
Going back to my analogy: I tell my girlfriend that I'm going to take her on vacation in June, but I don't tell her where yet; however, she knows that it will either be somewhere within Canada (for which she doesn't need a passport, since we live in Vancouver) or somewhere in Europe. She knows that it takes time to get a passport renewed, so she checks her passport and (if it was about to expire) gets it renewed just in case I later reveal that I'm going to take her to Europe. If I tell her later that I'm only taking her to Ottawa — well, she didn't need to renew her passport after all, but in the mean time her behaviour has already revealed to me whether her passport was about to expire. This is what Google refers to "variant 1" of the Spectre vulnerability: Even though she didn't need her passport, she made sure it was still valid _just in case_ she was going to need it.
|
||||
|
||||
"Variant 2" of the Spectre vulnerability also relies on speculative execution but in a more subtle way. Here, instead of the CPU knowing that there are two possible execution paths and choosing one (or potentially both!) to speculatively execute, the CPU has no idea what code it will need to execute next. However, it has been keeping track and knows what it did the last few times it was in the same position, and it makes a guess — after all, there's no harm in guessing since if it guesses wrong it can just throw away the unneeded work. Continuing our analogy, a "Spectre version 2" attack on my girlfriend would be as follows: I spend a week talking about how Oxford is a wonderful place to visit and I really enjoyed the years I spent there, and then I tell her that I want to take her on vacation. She very reasonably assumes that — since I've been talking about Oxford so much — I must be planning on taking her to England, and runs off to check her passport and potentially renew it... but in fact I tricked her and I'm only planning on taking her to Ottawa.
|
||||
|
||||
This "version 2" attack is far more powerful than "version 1" because it can be used to exploit side channels present in many different locations; but it is also much harder to exploit and depends intimately on details of CPU design, since the attacker needs to make the CPU guess the correct (wrong) location to anticipate that it will be visiting next.
|
||||
|
||||
Now we get to the third attack, dubbed "Meltdown". This one is a bit weird, so I'm going to start with the analogy here: I tell my girlfriend that I want to take her to the Korean peninsula. She knows that her passport is valid for long enough; but she immediately runs off to check that her North Korean visa hasn't expired. Why does she have a North Korean visa, you ask? Good question. She doesn't — but she runs off to check its expiry date anyway! Because she doesn't have a North Korean visa, she (somehow) checks the expiry date on _someone else's_ North Korean visa, and then (if it is about to expire) runs out to renew it — and so by telling her that I want to take her to Korea for a vacation _I find out something she couldn't have told me even if she wanted to_ . If this sounds like we're falling down a [Dodgsonian][12] rabbit hole... well, we are. The most common reaction I've heard from security people about this is "Intel CPUs are doing _what???_ ", and it's not by coincidence that one of the names suggested for an early Linux patch was Forcefully Unmap Complete Kernel With Interrupt Trampolines (FUCKWIT). (For the technically-inclined: Intel CPUs continue speculative execution through faults, so the fact that a page of memory cannot be accessed does not prevent it from, well, being accessed.)
|
||||
|
||||
#### How users can protect themselves
|
||||
|
||||
So that's what these vulnerabilities are all about; but what can regular users do to protect themselves? To start with, apply the damn patches. For the next few months there are going to be patches to operating systems; patches to individual applications; patches to phones; patches to routers; patches to smart televisions... if you see a notification saying "there are updates which need to be installed", **install the updates**. (However, this doesn't mean that you should be stupid: If you get an email saying "click here to update your system", it's probably malware.) These attacks are complicated, and need to be fixed in many ways in many different places, so _each individual piece of software_ may have many patches as the authors work their way through from fixing the most easily exploited vulnerabilities to the more obscure theoretical weaknesses.
|
||||
|
||||
What else can you do? Understand the implications of these vulnerabilities. Intel caught some undeserved flak for stating that they believe "these exploits do not have the potential to corrupt, modify or delete data"; in fact, they're quite correct in a direct sense, and this distinction is very relevant. A side channel attack inherently _reveals information_ , but it does not by itself allow someone to take control of a system. (In some cases side channels may make it easier to take advantage of other bugs, however.) As such, it's important to consider what information could be revealed: Even if you're not working on top secret plans for responding to a ballistic missile attack, you've probably accessed password-protected websites (Facebook, Twitter, Gmail, perhaps your online banking...) and possibly entered your credit card details somewhere today. Those passwords and credit card numbers are what you should worry about.
|
||||
|
||||
Now, in order for you to be attacked, some code needs to run on your computer. The most likely vector for such an attack is through a website — and the more shady the website the more likely you'll be attacked. (Why? Because if the owners of a website are already doing something which is illegal — say, selling fake prescription drugs — they're far more likely to agree if someone offers to pay them to add some "harmless" extra code to their site.) You're not likely to get attacked by visiting your bank's website; but if you make a practice of visiting the less reputable parts of the World Wide Web, it's probably best to not log in to your bank's website at the same time. Remember, this attack won't allow someone to take over your computer — all they can do is get access to information which is in your computer's memory _at the time they carry out the attack_ .
|
||||
|
||||
For greater paranoia, avoid accessing suspicious websites _after_ you handle any sensitive information (including accessing password-protected websites or entering your credit card details). It's possible for this information to linger in your computer's memory even after it isn't needed — it will stay there until it's overwritten, usually because the memory is needed for something else — so if you want to be safe you should reboot your computer in between.
|
||||
|
||||
For maximum paranoia: Don't connect to the internet from systems you care about. In the industry we refer to "airgapped" systems; this is a reference back to the days when connecting to a network required wires, so if there was a literal gap with just air between two systems, there was no way they could communicate. These days, with ubiquitous wifi (and in many devices, access to mobile phone networks) the terminology is in need of updating; but if you place devices into "airplane" mode it's unlikely that they'll be at any risk. Mind you, they won't be nearly as useful — there's almost always a tradeoff between security and usability, but if you're handling something really sensitive, you may want to consider this option. (For my [Tarsnap online backup service][13] I compile and cryptographically sign the packages on a system which has never been connected to the Internet. Before I turned it on for the first time, I opened up the case and pulled out the wifi card; and I copy files on and off the system on a USB stick. Tarsnap's slogan, by the way, is "Online backups _for the truly paranoid_ ".)
|
||||
|
||||
#### How developers can protect everyone
|
||||
|
||||
The patches being developed and distributed by operating systems — including microcode updates from Intel — will help a lot, but there are still steps individual developers can take to reduce the risk of their code being exploited.
|
||||
|
||||
First, practice good "cryptographic hygiene": Information which isn't in memory can't be stolen this way. If you have a set of cryptographic keys, load only the keys you need for the operations you will be performing. If you take a password, use it as quickly as possible and then immediately wipe it from memory. This [isn't always possible][14], especially if you're using a high level language which doesn't give you access to low level details of pointers and memory allocation; but there's at least a chance that it will help.
|
||||
|
||||
Second, offload sensitive operations — especially cryptographic operations — to other processes. The security community has become more aware of [privilege separation][15] over the past two decades; but we need to go further than this, to separation of _information_ — even if two processes need exactly the same operating system permissions, it can be valuable to keep them separate in order to avoid information from one process leaking via a side channel attack against the other.
|
||||
|
||||
One common design paradigm I've seen recently is to "[TLS][16] all the things", with a wide range of applications gaining understanding of the TLS protocol layer. This is something I've objected to in the past as it results in unnecessary exposure of applications to vulnerabilities in the TLS stacks they use; side channel attacks provide another reason, namely the unnecessary exposure of the TLS stack to side channels in the application. If you want to add TLS to your application, don't add it to the application itself; rather, use a separate process to wrap and unwrap connections with TLS, and have your application take unencrypted connections over a local (unix) socket or a loopback TCP/IP connection.
|
||||
|
||||
Separating code into multiple processes isn't always practical, however, for reasons of both performance and practical matters of code design. I've been considering (since long before these issues became public) another form of mitigation: Userland page unmapping. In many cases programs have data structures which are "private" to a small number of source files; for example, a random number generator will have internal state which is only accessed from within a single file (with appropriate functions for inputting entropy and outputting random numbers), and a hash table library would have a data structure which is allocated, modified, accessed, and finally freed only by that library via appropriate accessor functions. If these memory allocations can be corralled into a subset of the system address space, and the pages in question only mapped upon entering those specific routines, it could dramatically reduce the risk of information being revealed as a result of vulnerabilities which — like these side channel attacks — are limited to leaking information but cannot be (directly) used to execute arbitrary code.
|
||||
|
||||
Finally, developers need to get better at providing patches: Not just to get patches out promptly, but also to get them into users' hands _and to convince users to install them_ . That last part requires building up trust; as I wrote last year, one of the worst problems facing the industry is the [mixing of security and non-security updates][17]. If users are worried that they'll lose features (or gain "features" they don't want), they won't install the updates you recommend; it's essential to give users the option of getting security patches without worrying about whether anything else they rely upon will change.
|
||||
|
||||
#### What's next?
|
||||
|
||||
So far we've seen three attacks demonstrated: Two variants of Spectre and one form of Meltdown. Get ready to see more over the coming months and years. Off the top of my head, there are four vulnerability classes I expect to see demonstrated before long:
|
||||
|
||||
* Attacks on [p-code][1] interpreters. Google's "Variant 1" demonstrated an attack where a conditional branch was mispredicted resulting in a bounds check being bypassed; but the same problem could easily occur with mispredicted branches in a<tt>switch</tt> statement resulting in the wrong _operation_ being performed on a valid address. On p-code machines which have an opcode for "jump to this address, which contains machine code" (not entirely unlikely in the case of bytecode machines which automatically transpile "hot spots" into host machine code), this could very easily be exploited as a "speculatively execute attacker-provided code" mechanism.
|
||||
|
||||
* Structure deserializing. This sort of code handles attacker-provided inputs which often include the lengths or numbers of fields in a structure, along with bounds checks to ensure the validity of the serialized structure. This is prime territory for a CPU to speculatively reach past the end of the input provided if it mispredicts the layout of the structure.
|
||||
|
||||
* Decompressors, especially in HTTP(S) stacks. Data decompression inherently involves a large number of steps of "look up X in a table to get the length of a symbol, then adjust pointers and perform more memory accesses" — exactly the sort of behaviour which can leak information via cache side channels if a branch mispredict results in X being speculatively looked up in the wrong table. Add attacker-controlled inputs to HTTP stacks and the fact that services speaking HTTP are often required to perform request authentication and/or include TLS stacks, and you have all the conditions needed for sensitive information to be leaked.
|
||||
|
||||
* Remote attacks. As far as I'm aware, all of the microarchitectural side channels demonstrated over the past 14 years have made use of "attack code" running on the system in question to observe the state of the caches or other microarchitectural details in order to extract the desired data. This makes attacks far easier, but should not be considered to be a prerequisite! Remote timing attacks are feasible, and I am confident that we will see a demonstration of "innocent" code being used for the task of extracting the microarchitectural state information before long. (Indeed, I think it is very likely that [certain people][2] are already making use of such remote microarchitectural side channel attacks.)
|
||||
|
||||
#### Final thoughts on vulnerability disclosure
|
||||
|
||||
The way these issues were handled was a mess; frankly, I expected better of Google, I expected better of Intel, and I expected better of the Linux community. When I found that Hyper-Threading was easily exploitable, I spent five months notifying the security community and preparing everyone for my announcement of the vulnerability; but when the embargo ended at midnight UTC and FreeBSD published its advisory a few minutes later, the broader world was taken entirely by surprise. Nobody knew what was coming aside from the people who needed to know; and the people who needed to know had months of warning.
|
||||
|
||||
Contrast that with what happened this time around. Google discovered a problem and reported it to Intel, AMD, and ARM on June 1st. Did they then go around contacting all of the operating systems which would need to work on fixes for this? Not even close. FreeBSD was notified _the week before Christmas_ , over six months after the vulnerabilities were discovered. Now, FreeBSD can occasionally respond very quickly to security vulnerabilities, even when they arise at inconvenient times — on November 30th 2009 a [vulnerability was reported][18] at 22:12 UTC, and on December 1st I [provided a patch][19] at 01:20 UTC, barely over 3 hours later — but that was an extremely simple bug which needed only a few lines of code to fix; the Spectre and Meltdown issues are orders of magnitude more complex.
|
||||
|
||||
To make things worse, the Linux community was notified _and couldn't keep their mouths shut_ . Standard practice for multi-vendor advisories like this is that an embargo date is set, and **nobody does anything publicly prior to that date**. People don't publish advisories; they don't commit patches into their public source code repositories; and they _definitely_ don't engage in arguments on public mailing lists about whether the patches are needed for different CPUs. As a result, despite an embargo date being set for January 9th, by January 4th anyone who cared knew about the issues and there was code being passed around on Twitter for exploiting them.
|
||||
|
||||
This is not the first time I've seen people get sloppy with embargoes recently, but it's by far the worst case. As an industry we pride ourselves on the concept of responsible disclosure — ensuring that people are notified in time to prepare fixes before an issue is disclosed publicly — but in this case there was far too much disclosure and nowhere near enough responsibility. We can do better, and I sincerely hope that next time we do.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.daemonology.net/blog/2018-01-17-some-thoughts-on-spectre-and-meltdown.html
|
||||
|
||||
作者:[ Daemonic Dispatches][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.daemonology.net/blog/
|
||||
[1]:https://en.wikipedia.org/wiki/P-code_machine
|
||||
[2]:https://en.wikipedia.org/wiki/National_Security_Agency
|
||||
[3]:https://googleprojectzero.blogspot.ca/2018/01/reading-privileged-memory-with-side.html
|
||||
[4]:https://en.wikipedia.org/wiki/RSA_(cryptosystem)
|
||||
[5]:https://www.openssl.org/
|
||||
[6]:http://www.daemonology.net/papers/cachemissing.pdf
|
||||
[7]:http://www.bsdcan.org/
|
||||
[8]:https://eprint.iacr.org/2005/271.pdf
|
||||
[9]:https://en.wikipedia.org/wiki/Advanced_Encryption_Standard
|
||||
[10]:https://en.wikipedia.org/wiki/2001:_A_Space_Odyssey_(film)
|
||||
[11]:https://en.wikipedia.org/wiki/Jeremiah_Denton
|
||||
[12]:https://en.wikipedia.org/wiki/Lewis_Carroll
|
||||
[13]:https://www.tarsnap.com/
|
||||
[14]:http://www.daemonology.net/blog/2014-09-06-zeroing-buffers-is-insufficient.html
|
||||
[15]:https://en.wikipedia.org/wiki/Privilege_separation
|
||||
[16]:https://en.wikipedia.org/wiki/Transport_Layer_Security
|
||||
[17]:http://www.daemonology.net/blog/2017-06-14-oil-changes-safety-recalls-software-patches.html
|
||||
[18]:http://seclists.org/fulldisclosure/2009/Nov/371
|
||||
[19]:https://lists.freebsd.org/pipermail/freebsd-security/2009-December/005369.html
|
||||
@ -1,76 +0,0 @@
|
||||
Translating by qhwdw [20090211 Page Cache, the Affair Between Memory and Files][1]
|
||||
============================================================
|
||||
|
||||
|
||||
Previously we looked at how the kernel [manages virtual memory][2] for a user process, but files and I/O were left out. This post covers the important and often misunderstood relationship between files and memory and its consequences for performance.
|
||||
|
||||
Two serious problems must be solved by the OS when it comes to files. The first one is the mind-blowing slowness of hard drives, and [disk seeks in particular][3], relative to memory. The second is the need to load file contents in physical memory once and share the contents among programs. If you use [Process Explorer][4] to poke at Windows processes, you'll see there are ~15MB worth of common DLLs loaded in every process. My Windows box right now is running 100 processes, so without sharing I'd be using up to ~1.5 GB of physical RAM just for common DLLs. No good. Likewise, nearly all Linux programs need [ld.so][5] and libc, plus other common libraries.
|
||||
|
||||
Happily, both problems can be dealt with in one shot: the page cache, where the kernel stores page-sized chunks of files. To illustrate the page cache, I'll conjure a Linux program named render, which opens file scene.dat and reads it 512 bytes at a time, storing the file contents into a heap-allocated block. The first read goes like this:
|
||||
|
||||
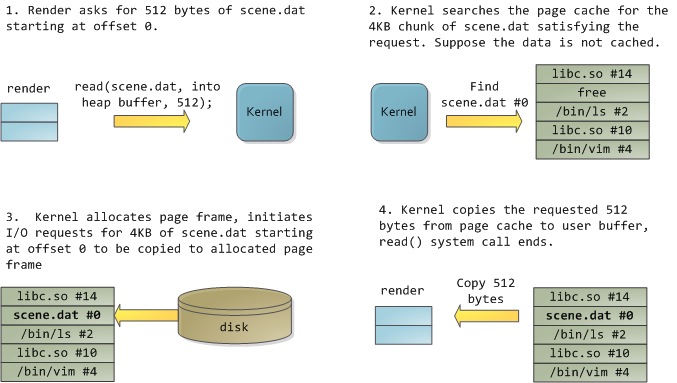
|
||||
|
||||
After 12KB have been read, render's heap and the relevant page frames look thus:
|
||||
|
||||
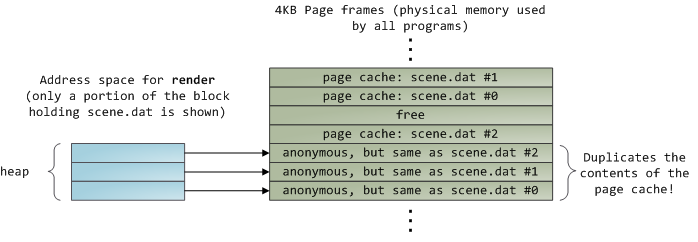
|
||||
|
||||
This looks innocent enough, but there's a lot going on. First, even though this program uses regular read calls, three 4KB page frames are now in the page cache storing part of scene.dat. People are sometimes surprised by this, but all regular file I/O happens through the page cache. In x86 Linux, the kernel thinks of a file as a sequence of 4KB chunks. If you read a single byte from a file, the whole 4KB chunk containing the byte you asked for is read from disk and placed into the page cache. This makes sense because sustained disk throughput is pretty good and programs normally read more than just a few bytes from a file region. The page cache knows the position of each 4KB chunk within the file, depicted above as #0, #1, etc. Windows uses 256KB views analogous to pages in the Linux page cache.
|
||||
|
||||
Sadly, in a regular file read the kernel must copy the contents of the page cache into a user buffer, which not only takes cpu time and hurts the [cpu caches][6], but also wastes physical memory with duplicate data. As per the diagram above, the scene.dat contents are stored twice, and each instance of the program would store the contents an additional time. We've mitigated the disk latency problem but failed miserably at everything else. Memory-mapped files are the way out of this madness:
|
||||
|
||||
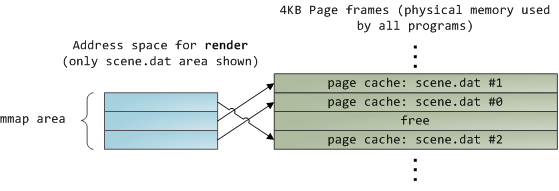
|
||||
|
||||
When you use file mapping, the kernel maps your program's virtual pages directly onto the page cache. This can deliver a significant performance boost: [Windows System Programming][7] reports run time improvements of 30% and up relative to regular file reads, while similar figures are reported for Linux and Solaris in [Advanced Programming in the Unix Environment][8]. You might also save large amounts of physical memory, depending on the nature of your application.
|
||||
|
||||
As always with performance, [measurement is everything][9], but memory mapping earns its keep in a programmer's toolbox. The API is pretty nice too, it allows you to access a file as bytes in memory and does not require your soul and code readability in exchange for its benefits. Mind your [address space][10] and experiment with [mmap][11] in Unix-like systems, [CreateFileMapping][12] in Windows, or the many wrappers available in high level languages. When you map a file its contents are not brought into memory all at once, but rather on demand via [page faults][13]. The fault handler [maps your virtual pages][14] onto the page cache after [obtaining][15] a page frame with the needed file contents. This involves disk I/O if the contents weren't cached to begin with.
|
||||
|
||||
Now for a pop quiz. Imagine that the last instance of our render program exits. Would the pages storing scene.dat in the page cache be freed immediately? People often think so, but that would be a bad idea. When you think about it, it is very common for us to create a file in one program, exit, then use the file in a second program. The page cache must handle that case. When you think more about it, why should the kernel ever get rid of page cache contents? Remember that disk is 5 orders of magnitude slower than RAM, hence a page cache hit is a huge win. So long as there's enough free physical memory, the cache should be kept full. It is therefore not dependent on a particular process, but rather it's a system-wide resource. If you run render a week from now and scene.dat is still cached, bonus! This is why the kernel cache size climbs steadily until it hits a ceiling. It's not because the OS is garbage and hogs your RAM, it's actually good behavior because in a way free physical memory is a waste. Better use as much of the stuff for caching as possible.
|
||||
|
||||
Due to the page cache architecture, when a program calls [write()][16] bytes are simply copied to the page cache and the page is marked dirty. Disk I/O normally does not happen immediately, thus your program doesn't block waiting for the disk. On the downside, if the computer crashes your writes will never make it, hence critical files like database transaction logs must be [fsync()][17]ed (though one must still worry about drive controller caches, oy!). Reads, on the other hand, normally block your program until the data is available. Kernels employ eager loading to mitigate this problem, an example of which is read ahead where the kernel preloads a few pages into the page cache in anticipation of your reads. You can help the kernel tune its eager loading behavior by providing hints on whether you plan to read a file sequentially or randomly (see [madvise()][18], [readahead()][19], [Windows cache hints][20] ). Linux [does read-ahead][21] for memory-mapped files, but I'm not sure about Windows. Finally, it's possible to bypass the page cache using [O_DIRECT][22] in Linux or [NO_BUFFERING][23] in Windows, something database software often does.
|
||||
|
||||
A file mapping may be private or shared. This refers only to updates made to the contents in memory: in a private mapping the updates are not committed to disk or made visible to other processes, whereas in a shared mapping they are. Kernels use the copy on write mechanism, enabled by page table entries, to implement private mappings. In the example below, both render and another program called render3d (am I creative or what?) have mapped scene.dat privately. Render then writes to its virtual memory area that maps the file:
|
||||
|
||||
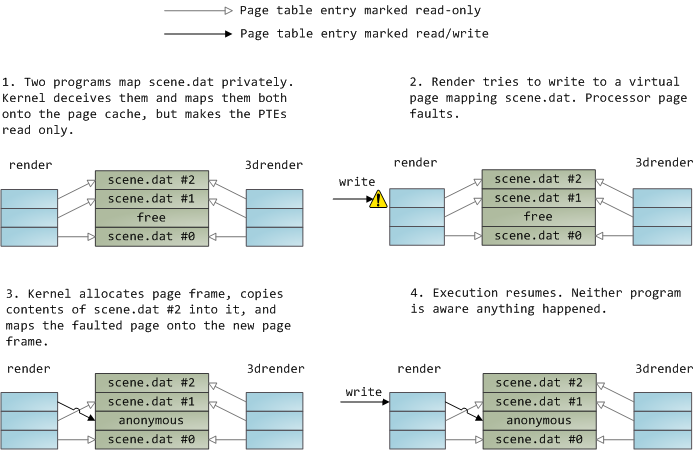
|
||||
|
||||
The read-only page table entries shown above do not mean the mapping is read only, they're merely a kernel trick to share physical memory until the last possible moment. You can see how 'private' is a bit of a misnomer until you remember it only applies to updates. A consequence of this design is that a virtual page that maps a file privately sees changes done to the file by other programs as long as the page has only been read from. Once copy-on-write is done, changes by others are no longer seen. This behavior is not guaranteed by the kernel, but it's what you get in x86 and makes sense from an API perspective. By contrast, a shared mapping is simply mapped onto the page cache and that's it. Updates are visible to other processes and end up in the disk. Finally, if the mapping above were read-only, page faults would trigger a segmentation fault instead of copy on write.
|
||||
|
||||
Dynamically loaded libraries are brought into your program's address space via file mapping. There's nothing magical about it, it's the same private file mapping available to you via regular APIs. Below is an example showing part of the address spaces from two running instances of the file-mapping render program, along with physical memory, to tie together many of the concepts we've seen.
|
||||
|
||||
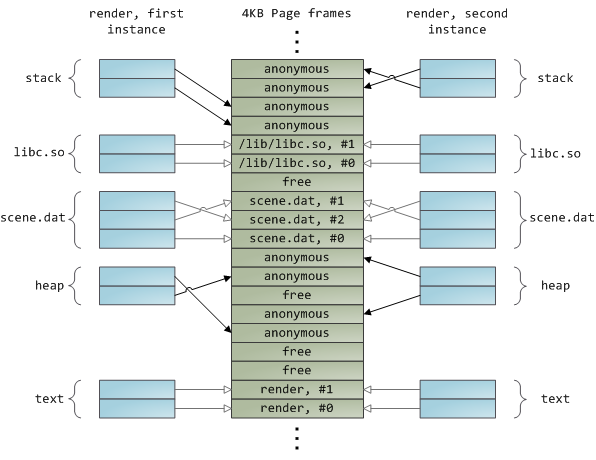
|
||||
|
||||
This concludes our 3-part series on memory fundamentals. I hope the series was useful and provided you with a good mental model of these OS topics.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
[2]:https://manybutfinite.com/post/how-the-kernel-manages-your-memory
|
||||
[3]:https://manybutfinite.com/post/what-your-computer-does-while-you-wait
|
||||
[4]:http://technet.microsoft.com/en-us/sysinternals/bb896653.aspx
|
||||
[5]:http://ld.so
|
||||
[6]:https://manybutfinite.com/post/intel-cpu-caches
|
||||
[7]:http://www.amazon.com/Windows-Programming-Addison-Wesley-Microsoft-Technology/dp/0321256190/
|
||||
[8]:http://www.amazon.com/Programming-Environment-Addison-Wesley-Professional-Computing/dp/0321525949/
|
||||
[9]:https://manybutfinite.com/post/performance-is-a-science
|
||||
[10]:https://manybutfinite.com/post/anatomy-of-a-program-in-memory
|
||||
[11]:http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html
|
||||
[12]:http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx
|
||||
[13]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2678
|
||||
[14]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2436
|
||||
[15]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
|
||||
[16]:http://www.kernel.org/doc/man-pages/online/pages/man2/write.2.html
|
||||
[17]:http://www.kernel.org/doc/man-pages/online/pages/man2/fsync.2.html
|
||||
[18]:http://www.kernel.org/doc/man-pages/online/pages/man2/madvise.2.html
|
||||
[19]:http://www.kernel.org/doc/man-pages/online/pages/man2/readahead.2.html
|
||||
[20]:http://msdn.microsoft.com/en-us/library/aa363858(VS.85).aspx#caching_behavior
|
||||
[21]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
|
||||
[22]:http://www.kernel.org/doc/man-pages/online/pages/man2/open.2.html
|
||||
[23]:http://msdn.microsoft.com/en-us/library/cc644950(VS.85).aspx
|
||||
@ -0,0 +1,383 @@
|
||||
10 Tools To Add Some Spice To Your UNIX/Linux Shell Scripts
|
||||
======
|
||||
There are some misconceptions that shell scripts are only for a CLI environment. You can efficiently use various tools to write GUI and network (socket) scripts under KDE or Gnome desktops. Shell scripts can make use of some of the GUI widget (menus, warning boxes, progress bars, etc.). You can always control the final output, cursor position on the screen, various output effects, and more. With the following tools, you can build powerful, interactive, user-friendly UNIX / Linux bash shell scripts.
|
||||
|
||||
Creating GUI application is not an expensive task but a task that takes time and patience. Luckily, both UNIX and Linux ships with plenty of tools to write beautiful GUI scripts. The following tools are tested on FreeBSD and Linux operating systems but should work under other UNIX like operating systems.
|
||||
|
||||
### 1. notify-send Command
|
||||
|
||||
The notify-send command allows you to send desktop notifications to the user via a notification daemon from the command line. This is useful to inform the desktop user about an event or display some form of information without getting in the user's way. You need to install the following package on a Debian/Ubuntu Linux using [apt command][1]/[apt-get command][2]:
|
||||
`$ sudo apt-get install libnotify-bin`
|
||||
CentOS/RHEL user try the following [yum command][3]:
|
||||
`$ sudo yum install libnotify`
|
||||
Fedora Linux user type the following dnf command:
|
||||
`$ sudo dnf install libnotify`
|
||||
In this example, send simple desktop notification from the command line, enter:
|
||||
```
|
||||
### send some notification ##
|
||||
notify-send "rsnapshot done :)"
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
![Fig:01: notify-send in action ][4]
|
||||
Here is another code with additional options:
|
||||
```
|
||||
....
|
||||
alert=18000
|
||||
live=$(lynx --dump http://money.rediff.com/ | grep 'BSE LIVE' | awk '{ print $5}' | sed 's/,//g;s/\.[0-9]*//g')
|
||||
[ $notify_counter -eq 0 ] && [ $live -ge $alert ] && { notify-send -t 5000 -u low -i "BSE Sensex touched 18k"; notify_counter=1; }
|
||||
...
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
![Fig.02: notify-send with timeouts and other options][5]
|
||||
Where,
|
||||
|
||||
* -t 5000: Specifies the timeout in milliseconds ( 5000 milliseconds = 5 seconds)
|
||||
* -u low : Set the urgency level (i.e. low, normal, or critical).
|
||||
* -i gtk-dialog-info : Set an icon filename or stock icon to display (you can set path as -i /path/to/your-icon.png).
|
||||
|
||||
|
||||
|
||||
For more information on use of the notify-send utility, please refer to the notify-send man page, viewable by typing man notify-send from the command line:
|
||||
```
|
||||
man notify-send
|
||||
```
|
||||
|
||||
### #2: tput Command
|
||||
|
||||
The tput command is used to set terminal features. With tput you can set:
|
||||
|
||||
* Move the cursor around the screen.
|
||||
* Get information about terminal.
|
||||
* Set colors (background and foreground).
|
||||
* Set bold mode.
|
||||
* Set reverse mode and much more.
|
||||
|
||||
|
||||
|
||||
Here is a sample code:
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
# clear the screen
|
||||
tput clear
|
||||
|
||||
# Move cursor to screen location X,Y (top left is 0,0)
|
||||
tput cup 3 15
|
||||
|
||||
# Set a foreground colour using ANSI escape
|
||||
tput setaf 3
|
||||
echo "XYX Corp LTD."
|
||||
tput sgr0
|
||||
|
||||
tput cup 5 17
|
||||
# Set reverse video mode
|
||||
tput rev
|
||||
echo "M A I N - M E N U"
|
||||
tput sgr0
|
||||
|
||||
tput cup 7 15
|
||||
echo "1. User Management"
|
||||
|
||||
tput cup 8 15
|
||||
echo "2. Service Management"
|
||||
|
||||
tput cup 9 15
|
||||
echo "3. Process Management"
|
||||
|
||||
tput cup 10 15
|
||||
echo "4. Backup"
|
||||
|
||||
# Set bold mode
|
||||
tput bold
|
||||
tput cup 12 15
|
||||
read -p "Enter your choice [1-4] " choice
|
||||
|
||||
tput clear
|
||||
tput sgr0
|
||||
tput rc
|
||||
```
|
||||
|
||||
|
||||
Sample outputs:
|
||||
![Fig.03: tput in action][6]
|
||||
For more detail concerning the tput command, see the following man page:
|
||||
```
|
||||
man 5 terminfo
|
||||
man tput
|
||||
```
|
||||
|
||||
### #3: setleds Command
|
||||
|
||||
The setleds command allows you to set the keyboard leds. In this example, set NumLock on:
|
||||
```
|
||||
setleds -D +num
|
||||
```
|
||||
|
||||
To turn it off NumLock, enter:
|
||||
```
|
||||
setleds -D -num
|
||||
```
|
||||
|
||||
* -caps : Clear CapsLock.
|
||||
* +caps : Set CapsLock.
|
||||
* -scroll : Clear ScrollLock.
|
||||
* +scroll : Set ScrollLock.
|
||||
|
||||
|
||||
|
||||
See setleds command man page for more information and options:
|
||||
`man setleds`
|
||||
|
||||
### #4: zenity Command
|
||||
|
||||
The [zenity commadn will display GTK+ dialogs box][7], and return the users input. This allows you to present information, and ask for information from the user, from all manner of shell scripts. Here is a sample GUI client for the whois directory service for given domain name:
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
# Get domain name
|
||||
_zenity="/usr/bin/zenity"
|
||||
_out="/tmp/whois.output.$$"
|
||||
domain=$(${_zenity} --title "Enter domain" \
|
||||
--entry --text "Enter the domain you would like to see whois info" )
|
||||
|
||||
if [ $? -eq 0 ]
|
||||
then
|
||||
# Display a progress dialog while searching whois database
|
||||
whois $domain | tee >(${_zenity} --width=200 --height=100 \
|
||||
--title="whois" --progress \
|
||||
--pulsate --text="Searching domain info..." \
|
||||
--auto-kill --auto-close \
|
||||
--percentage=10) >${_out}
|
||||
|
||||
# Display back output
|
||||
${_zenity} --width=800 --height=600 \
|
||||
--title "Whois info for $domain" \
|
||||
--text-info --filename="${_out}"
|
||||
else
|
||||
${_zenity} --error \
|
||||
--text="No input provided"
|
||||
fi
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
![Fig.04: zenity in Action][8]
|
||||
See the zenity man page for more information and all other supports GTK+ widgets:
|
||||
```
|
||||
zenity --help
|
||||
man zenity
|
||||
```
|
||||
|
||||
### #5: kdialog Command
|
||||
|
||||
kdialog is just like zenity but it is designed for KDE desktop / qt apps. You can display dialogs using kdialog. The following will display message on screen:
|
||||
```
|
||||
kdialog --dontagain myscript:nofilemsg --msgbox "File: '~/.backup/config' not found."
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
![Fig.05: Suppressing the display of a dialog ][9]
|
||||
|
||||
See [shell scripting with KDE Dialogs][10] tutorial for more information.
|
||||
|
||||
### #6: Dialog
|
||||
|
||||
[Dialog is an application used in shell scripts][11] which displays text user interface widgets. It uses the curses or ncurses library. Here is a sample code:
|
||||
```
|
||||
#!/bin/bash
|
||||
dialog --title "Delete file" \
|
||||
--backtitle "Linux Shell Script Tutorial Example" \
|
||||
--yesno "Are you sure you want to permanently delete \"/tmp/foo.txt\"?" 7 60
|
||||
|
||||
# Get exit status
|
||||
# 0 means user hit [yes] button.
|
||||
# 1 means user hit [no] button.
|
||||
# 255 means user hit [Esc] key.
|
||||
response=$?
|
||||
case $response in
|
||||
0) echo "File deleted.";;
|
||||
1) echo "File not deleted.";;
|
||||
255) echo "[ESC] key pressed.";;
|
||||
esac
|
||||
```
|
||||
|
||||
See the dialog man page for details:
|
||||
`man dialog`
|
||||
|
||||
#### A Note About Other User Interface Widgets Tools
|
||||
|
||||
UNIX and Linux comes with lots of other tools to display and control apps from the command line, and shell scripts can make use of some of the KDE / Gnome / X widget set:
|
||||
|
||||
* **gmessage** - a GTK-based xmessage clone.
|
||||
* **xmessage** - display a message or query in a window (X-based /bin/echo)
|
||||
* **whiptail** - display dialog boxes from shell scripts
|
||||
* **python-dialog** - Python module for making simple Text/Console-mode user interfaces
|
||||
|
||||
|
||||
|
||||
### #7: logger command
|
||||
|
||||
The logger command writes entries in the system log file such as /var/log/messages. It provides a shell command interface to the syslog system log module:
|
||||
```
|
||||
logger "MySQL database backup failed."
|
||||
tail -f /var/log/messages
|
||||
logger -t mysqld -p daemon.error "Database Server failed"
|
||||
tail -f /var/log/syslog
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
```
|
||||
Apr 20 00:11:45 vivek-desktop kernel: [38600.515354] CPU0: Temperature/speed normal
|
||||
Apr 20 00:12:20 vivek-desktop mysqld: Database Server failed
|
||||
```
|
||||
|
||||
See howto [write message to a syslog / log file][12] for more information. Alternatively, you can see the logger man page for details:
|
||||
`man logger`
|
||||
|
||||
### #8: setterm Command
|
||||
|
||||
The setterm command can set various terminal attributes. In this example, force screen to turn black in 15 minutes. Monitor standby will occur at 60 minutes:
|
||||
```
|
||||
setterm -blank 15 -powersave powerdown -powerdown 60
|
||||
```
|
||||
|
||||
In this example show underlined text for xterm window:
|
||||
```
|
||||
setterm -underline on;
|
||||
echo "Add Your Important Message Here"
|
||||
setterm -underline off
|
||||
```
|
||||
|
||||
Another useful option is to turn on or off cursor:
|
||||
```
|
||||
setterm -cursor off
|
||||
```
|
||||
|
||||
Turn it on:
|
||||
```
|
||||
setterm -cursor on
|
||||
```
|
||||
|
||||
See the setterm command man page for details:
|
||||
`man setterm`
|
||||
|
||||
### #9: smbclient: Sending Messages To MS-Windows Workstations
|
||||
|
||||
The smbclient command can talk to an SMB/CIFS server. It can send a message to selected users or all users on MS-Windows systems:
|
||||
```
|
||||
smbclient -M WinXPPro <<eof
|
||||
Message 1
|
||||
Message 2
|
||||
...
|
||||
..
|
||||
EOF
|
||||
```
|
||||
|
||||
OR
|
||||
```
|
||||
echo "${Message}" | smbclient -M salesguy2
|
||||
```
|
||||
|
||||
|
||||
See smbclient man page or read our previous post about "[sending a message to Windows Workstation"][13] with smbclient command:
|
||||
`man smbclient`
|
||||
|
||||
### #10: Bash Socket Programming
|
||||
|
||||
Under bash you can open a socket to pass some data through it. You don't have to use curl or lynx commands to just grab data from remote server. Bash comes with two special device files which can be used to open network sockets. From the bash man page:
|
||||
|
||||
1. **/dev/tcp/host/port** - If host is a valid hostname or Internet address, and port is an integer port number or service name, bash attempts to open a TCP connection to the corresponding socket.
|
||||
2. **/dev/udp/host/port** - If host is a valid hostname or Internet address, and port is an integer port number or service name, bash attempts to open a UDP connection to the corresponding socket.
|
||||
|
||||
|
||||
You can use this technquie to dermine if port is open or closed on local or remote server without using nmap or other port scanner:
|
||||
```
|
||||
# find out if TCP port 25 open or not
|
||||
(echo >/dev/tcp/localhost/25) &>/dev/null && echo "TCP port 25 open" || echo "TCP port 25 close"
|
||||
```
|
||||
|
||||
You can use [bash loop and find out open ports][14] with the snippets:
|
||||
```
|
||||
echo "Scanning TCP ports..."
|
||||
for p in {1..1023}
|
||||
do
|
||||
(echo >/dev/tcp/localhost/$p) >/dev/null 2>&1 && echo "$p open"
|
||||
done
|
||||
```
|
||||
|
||||
|
||||
Sample outputs:
|
||||
```
|
||||
Scanning TCP ports...
|
||||
22 open
|
||||
53 open
|
||||
80 open
|
||||
139 open
|
||||
445 open
|
||||
631 open
|
||||
```
|
||||
|
||||
In this example, your bash script act as an HTTP client:
|
||||
```
|
||||
#!/bin/bash
|
||||
exec 3<> /dev/tcp/${1:-www.cyberciti.biz}/80
|
||||
|
||||
printf "GET / HTTP/1.0\r\n" >&3
|
||||
printf "Accept: text/html, text/plain\r\n" >&3
|
||||
printf "Accept-Language: en\r\n" >&3
|
||||
printf "User-Agent: nixCraft_BashScript v.%s\r\n" "${BASH_VERSION}" >&3
|
||||
printf "\r\n" >&3
|
||||
|
||||
while read LINE <&3
|
||||
do
|
||||
# do something on $LINE
|
||||
# or send $LINE to grep or awk for grabbing data
|
||||
# or simply display back data with echo command
|
||||
echo $LINE
|
||||
done
|
||||
```
|
||||
|
||||
See the bash man page for more information:
|
||||
`man bash`
|
||||
|
||||
### A Note About GUI Tools and Cronjob
|
||||
|
||||
You need to request local display/input service using export DISPLAY=[user's machine]:0 command if you are [using cronjob][15] to call your scripts. For example, call /home/vivek/scripts/monitor.stock.sh as follows which uses zenity tool:
|
||||
`@hourly DISPLAY=:0.0 /home/vivek/scripts/monitor.stock.sh`
|
||||
|
||||
Have a favorite UNIX tool to spice up shell script? Share it in the comments below.
|
||||
|
||||
### about the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][16], [Facebook][17], [Google+][18].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/spice-up-your-unix-linux-shell-scripts.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ (See Linux/Unix apt command examples for more info)
|
||||
[2]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html (See Linux/Unix apt-get command examples for more info)
|
||||
[3]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[4]:https://www.cyberciti.biz/media/new/tips/2010/04/notify-send.png (notify-send: Shell Script Get Or Send Desktop Notifications )
|
||||
[5]:https://www.cyberciti.biz/media/new/tips/2010/04/notify-send-with-icons-timeout.png (Linux / UNIX: Display Notifications From Your Shell Scripts With notify-send)
|
||||
[6]:https://www.cyberciti.biz/media/new/tips/2010/04/tput-options.png (Linux / UNIX Script Colours and Cursor Movement With tput)
|
||||
[7]:https://bash.cyberciti.biz/guide/Zenity:_Shell_Scripting_with_Gnome
|
||||
[8]:https://www.cyberciti.biz/media/new/tips/2010/04/zenity-outputs.png (zenity: Linux / UNIX display Dialogs Boxes From The Shell Scripts)
|
||||
[9]:https://www.cyberciti.biz/media/new/tips/2010/04/KDialog.png (Kdialog: Suppressing the display of a dialog )
|
||||
[10]:http://techbase.kde.org/Development/Tutorials/Shell_Scripting_with_KDE_Dialogs
|
||||
[11]:https://bash.cyberciti.biz/guide/Bash_display_dialog_boxes
|
||||
[12]:https://www.cyberciti.biz/tips/howto-linux-unix-write-to-syslog.html
|
||||
[13]:https://www.cyberciti.biz/tips/freebsd-sending-a-message-to-windows-workstation.html
|
||||
[14]:https://www.cyberciti.biz/faq/bash-for-loop/
|
||||
[15]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses/
|
||||
[16]:https://twitter.com/nixcraft
|
||||
[17]:https://facebook.com/nixcraft
|
||||
[18]:https://plus.google.com/+CybercitiBiz
|
||||
@ -1,3 +1,5 @@
|
||||
BriFuture is translating this article.
|
||||
|
||||
Let’s Build A Simple Interpreter. Part 2.
|
||||
======
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
ftrace: trace your kernel functions!
|
||||
Translating by qhwdw ftrace: trace your kernel functions!
|
||||
============================================================
|
||||
|
||||
Hello! Today we’re going to talk about a debugging tool we haven’t talked about much before on this blog: ftrace. What could be more exciting than a new debugging tool?!
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Creating a YUM repository from ISO & Online repo
|
||||
======
|
||||
|
||||
|
||||
@ -1,152 +0,0 @@
|
||||
Notes on BPF & eBPF
|
||||
============================================================
|
||||
|
||||
Today it was Papers We Love, my favorite meetup! Today [Suchakra Sharma][6]([@tuxology][7] on twitter/github) gave a GREAT talk about the original BPF paper and recent work in Linux on eBPF. It really made me want to go write eBPF programs!
|
||||
|
||||
The paper is [The BSD Packet Filter: A New Architecture for User-level Packet Capture][8]
|
||||
|
||||
I wanted to write some notes on the talk here because I thought it was super super good.
|
||||
|
||||
To start, here are the [slides][9] and a [pdf][10]. The pdf is good because there are links at the end and in the PDF you can click the links.
|
||||
|
||||
### what’s BPF?
|
||||
|
||||
Before BPF, if you wanted to do packet filtering you had to copy all the packets into userspace and then filter them there (with “tap”).
|
||||
|
||||
this had 2 problems:
|
||||
|
||||
1. if you filter in userspace, it means you have to copy all the packets into userspace, copying data is expensive
|
||||
|
||||
2. the filtering algorithms people were using were inefficient
|
||||
|
||||
The solution to problem #1 seems sort of obvious, move the filtering logic into the kernel somehow. Okay. (though the details of how that’s done isn’t obvious, we’ll talk about that in a second)
|
||||
|
||||
But why were the filtering algorithms inefficient! Well!!
|
||||
|
||||
If you run `tcpdump host foo` it actually runs a relatively complicated query, which you could represent with this tree:
|
||||
|
||||
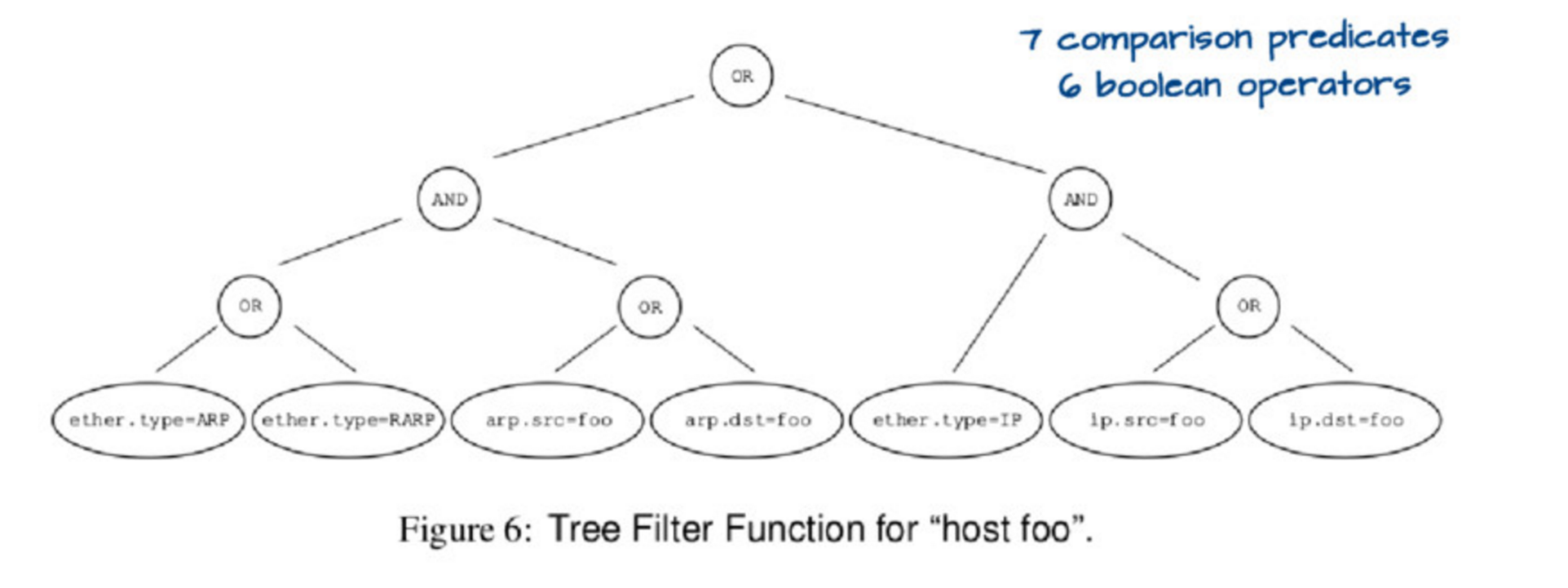
|
||||
|
||||
Evaluating this tree is kind of expensive. so the first insight is that you can actually represent this tree in a simpler way, like this:
|
||||
|
||||
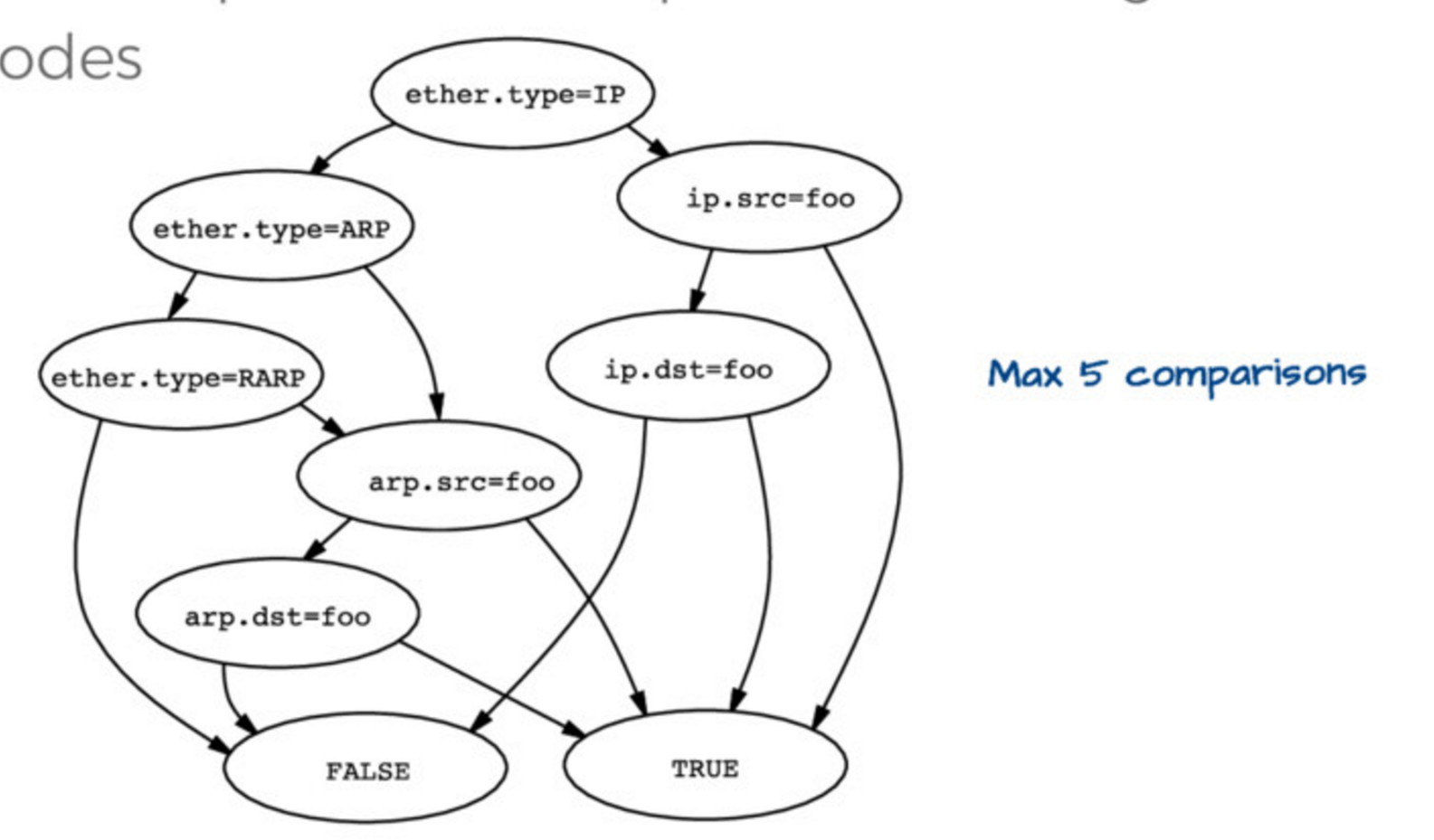
|
||||
|
||||
Then if you have `ether.type = IP` and `ip.src = foo` you automatically know that the packet matches `host foo`, you don’t need to check anything else. So this data structure (they call it a “control flow graph” or “CFG”) is a way better representation of the program you actually want to execute to check matches than the tree we started with.
|
||||
|
||||
### How BPF works in the kernel
|
||||
|
||||
The main important here is that packets are just arrays of bytes. BPF programs run on these arrays of bytes. They’re not allowed to have loops but they _can_ have smart stuff to figure out the length of the IP header (IPv6 & IPv4 are different lengths!) and then find the TCP port based on that length
|
||||
|
||||
```
|
||||
x = ip_header_length
|
||||
port = *(packet_start + x + port_offset)
|
||||
|
||||
```
|
||||
|
||||
(it looks different from that but it’s basically the same). There’s a nice description of the virtual machine in the paper/slides so I won’t explain it.
|
||||
|
||||
When you run `tcpdump host foo` this is what happens, as far as I understand
|
||||
|
||||
1. convert `host foo` into an efficient DAG of the rules
|
||||
|
||||
2. convert that DAG into a BPF program (in BPF bytecode) for the BPF virtual machine
|
||||
|
||||
3. Send the BPF bytecode to the Linux kernel, which verifies it
|
||||
|
||||
4. compile the BPF bytecode program into native code. For example [here’s the JIT code for ARM][1] and for [x86][2]
|
||||
|
||||
5. when packets come in, Linux runs the native code to decide if that packet should be filtered or not. It’l often run only 100-200 CPU instructions for each packet that needs to be processed, which is super fast!
|
||||
|
||||
### the present: eBPF
|
||||
|
||||
But BPF has been around for a long time! Now we live in the EXCITING FUTURE which is eBPF. I’d heard about eBPF a bunch before but I felt like this helped me put the pieces together a little better. (i wrote this [XDP & eBPF post][11]back in April when I was at netdev)
|
||||
|
||||
some facts about eBPF:
|
||||
|
||||
* eBPF programs have their own bytecode language, and are compiled from that bytecode language into native code in the kernel, just like BPF programs
|
||||
|
||||
* eBPF programs run in the kernel
|
||||
|
||||
* eBPF programs can’t access arbitrary kernel memory. Instead the kernel provides functions to get at some restricted subset of things.
|
||||
|
||||
* they _can_ communicate with userspace programs through BPF maps
|
||||
|
||||
* there’s a `bpf` syscall as of Linux 3.18
|
||||
|
||||
### kprobes & eBPF
|
||||
|
||||
You can pick a function (any function!) in the Linux kernel and execute a program that you write every time that function happens. This seems really amazing and magical.
|
||||
|
||||
For example! There’s this [BPF program called disksnoop][12] which tracks when you start/finish writing a block to disk. Here’s a snippet from the code:
|
||||
|
||||
```
|
||||
BPF_HASH(start, struct request *);
|
||||
void trace_start(struct pt_regs *ctx, struct request *req) {
|
||||
// stash start timestamp by request ptr
|
||||
u64 ts = bpf_ktime_get_ns();
|
||||
start.update(&req, &ts);
|
||||
}
|
||||
...
|
||||
b.attach_kprobe(event="blk_start_request", fn_name="trace_start")
|
||||
b.attach_kprobe(event="blk_mq_start_request", fn_name="trace_start")
|
||||
|
||||
```
|
||||
|
||||
This basically declares a BPF hash (which the program uses to keep track of when the request starts / finishes), a function called `trace_start` which is going to be compiled into BPF bytecode, and attaches `trace_start` to the `blk_start_request` kernel function.
|
||||
|
||||
This is all using the `bcc` framework which lets you write Python-ish programs that generate BPF code. You can find it (it has tons of example programs) at[https://github.com/iovisor/bcc][13]
|
||||
|
||||
### uprobes & eBPF
|
||||
|
||||
So I sort of knew you could attach eBPF programs to kernel functions, but I didn’t realize you could attach eBPF programs to userspace functions! That’s really exciting. Here’s [an example of counting malloc calls in Python using an eBPF program][14].
|
||||
|
||||
### things you can attach eBPF programs to
|
||||
|
||||
* network cards, with XDP (which I wrote about a while back)
|
||||
|
||||
* tc egress/ingress (in the network stack)
|
||||
|
||||
* kprobes (any kernel function)
|
||||
|
||||
* uprobes (any userspace function apparently ?? like in any C program with symbols.)
|
||||
|
||||
* probes that were built for dtrace called “USDT probes” (like [these mysql probes][3]). Here’s an [example program using dtrace probes][4]
|
||||
|
||||
* [the JVM][5]
|
||||
|
||||
* tracepoints (not sure what that is yet)
|
||||
|
||||
* seccomp / landlock security things
|
||||
|
||||
* a bunch more things
|
||||
|
||||
### this talk was super cool
|
||||
|
||||
There are a bunch of great links in the slides and in [LINKS.md][15] in the iovisor repository. It is late now but soon I want to actually write my first eBPF program!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/06/28/notes-on-bpf---ebpf/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/
|
||||
[1]:https://github.com/torvalds/linux/blob/v4.10/arch/arm/net/bpf_jit_32.c#L512
|
||||
[2]:https://github.com/torvalds/linux/blob/v3.18/arch/x86/net/bpf_jit_comp.c#L189
|
||||
[3]:https://dev.mysql.com/doc/refman/5.7/en/dba-dtrace-ref-query.html
|
||||
[4]:https://github.com/iovisor/bcc/blob/master/examples/tracing/mysqld_query.py
|
||||
[5]:http://blogs.microsoft.co.il/sasha/2016/03/31/probing-the-jvm-with-bpfbcc/
|
||||
[6]:http://suchakra.in/
|
||||
[7]:https://twitter.com/tuxology
|
||||
[8]:http://www.vodun.org/papers/net-papers/van_jacobson_the_bpf_packet_filter.pdf
|
||||
[9]:https://speakerdeck.com/tuxology/the-bsd-packet-filter
|
||||
[10]:http://step.polymtl.ca/~suchakra/PWL-Jun28-MTL.pdf
|
||||
[11]:https://jvns.ca/blog/2017/04/07/xdp-bpf-tutorial/
|
||||
[12]:https://github.com/iovisor/bcc/blob/0c8c179fc1283600887efa46fe428022efc4151b/examples/tracing/disksnoop.py
|
||||
[13]:https://github.com/iovisor/bcc
|
||||
[14]:https://github.com/iovisor/bcc/blob/00f662dbea87a071714913e5c7382687fef6a508/tests/lua/test_uprobes.lua
|
||||
[15]:https://github.com/iovisor/bcc/blob/master/LINKS.md
|
||||
@ -0,0 +1,333 @@
|
||||
How To Set Up PF Firewall on FreeBSD to Protect a Web Server
|
||||
======
|
||||
|
||||
I am a new FreeBSD server user and moved from netfilter on Linux. How do I setup a firewall with PF on FreeBSD server to protect a web server with single public IP address and interface?
|
||||
|
||||
|
||||
PF is an acronym for packet filter. It was created for OpenBSD but has been ported to FreeBSD and other operating systems. It is a stateful packet filtering engine. This tutorial will show you how to set up a firewall with PF on FreeBSD 10.x and 11.x server to protect your web server.
|
||||
|
||||
|
||||
## Step 1 - Turn on PF firewall
|
||||
|
||||
You need to add the following three lines to /etc/rc.conf file:
|
||||
```
|
||||
# echo 'pf_enable="YES"' >> /etc/rc.conf
|
||||
# echo 'pf_rules="/usr/local/etc/pf.conf"' >> /etc/rc.conf
|
||||
# echo 'pflog_enable="YES"' >> /etc/rc.conf
|
||||
# echo 'pflog_logfile="/var/log/pflog"' >> /etc/rc.conf
|
||||
```
|
||||
Where,
|
||||
|
||||
1. **pf_enable="YES"** - Turn on PF service.
|
||||
2. **pf_rules="/usr/local/etc/pf.conf"** - Read PF rules from this file.
|
||||
3. **pflog_enable="YES"** - Turn on logging support for PF.
|
||||
4. **pflog_logfile="/var/log/pflog"** - File where pflogd should store the logfile i.e. store logs in /var/log/pflog file.
|
||||
|
||||
|
||||
|
||||
[![How To Set Up a Firewall with PF on FreeBSD to Protect a Web Server][1]][1]
|
||||
|
||||
## Step 2 - Creating firewall rules in /usr/local/etc/pf.conf
|
||||
|
||||
Type the following command:
|
||||
```
|
||||
# vi /usr/local/etc/pf.conf
|
||||
```
|
||||
Append the following PF rulesets :
|
||||
```
|
||||
# vim: set ft=pf
|
||||
# /usr/local/etc/pf.conf
|
||||
|
||||
## Set your public interface ##
|
||||
ext_if="vtnet0"
|
||||
|
||||
## Set your server public IP address ##
|
||||
ext_if_ip="172.xxx.yyy.zzz"
|
||||
|
||||
## Set and drop these IP ranges on public interface ##
|
||||
martians = "{ 127.0.0.0/8, 192.168.0.0/16, 172.16.0.0/12, \
|
||||
10.0.0.0/8, 169.254.0.0/16, 192.0.2.0/24, \
|
||||
0.0.0.0/8, 240.0.0.0/4 }"
|
||||
|
||||
## Set http(80)/https (443) port here ##
|
||||
webports = "{http, https}"
|
||||
|
||||
## enable these services ##
|
||||
int_tcp_services = "{domain, ntp, smtp, www, https, ftp, ssh}"
|
||||
int_udp_services = "{domain, ntp}"
|
||||
|
||||
## Skip loop back interface - Skip all PF processing on interface ##
|
||||
set skip on lo
|
||||
|
||||
## Sets the interface for which PF should gather statistics such as bytes in/out and packets passed/blocked ##
|
||||
set loginterface $ext_if
|
||||
|
||||
## Set default policy ##
|
||||
block return in log all
|
||||
block out all
|
||||
|
||||
# Deal with attacks based on incorrect handling of packet fragments
|
||||
scrub in all
|
||||
|
||||
# Drop all Non-Routable Addresses
|
||||
block drop in quick on $ext_if from $martians to any
|
||||
block drop out quick on $ext_if from any to $martians
|
||||
|
||||
## Blocking spoofed packets
|
||||
antispoof quick for $ext_if
|
||||
|
||||
# Open SSH port which is listening on port 22 from VPN 139.xx.yy.zz Ip only
|
||||
# I do not allow or accept ssh traffic from ALL for security reasons
|
||||
pass in quick on $ext_if inet proto tcp from 139.xxx.yyy.zzz to $ext_if_ip port = ssh flags S/SA keep state label "USER_RULE: Allow SSH from 139.xxx.yyy.zzz"
|
||||
## Use the following rule to enable ssh for ALL users from any IP address #
|
||||
## pass in inet proto tcp to $ext_if port ssh
|
||||
### [ OR ] ###
|
||||
## pass in inet proto tcp to $ext_if port 22
|
||||
|
||||
# Allow Ping-Pong stuff. Be a good sysadmin
|
||||
pass inet proto icmp icmp-type echoreq
|
||||
|
||||
# All access to our Nginx/Apache/Lighttpd Webserver ports
|
||||
pass proto tcp from any to $ext_if port $webports
|
||||
|
||||
# Allow essential outgoing traffic
|
||||
pass out quick on $ext_if proto tcp to any port $int_tcp_services
|
||||
pass out quick on $ext_if proto udp to any port $int_udp_services
|
||||
|
||||
# Add custom rules below
|
||||
```
|
||||
|
||||
Save and close the file. PR [welcome here to improve rulesets][2]. To check for syntax error, run:
|
||||
`# service pf check`
|
||||
OR
|
||||
`/etc/rc.d/pf check`
|
||||
OR
|
||||
`# pfctl -n -f /usr/local/etc/pf.conf `
|
||||
|
||||
## Step 3 - Start PF firewall
|
||||
|
||||
The commands are as follows. Be careful you might be disconnected from your server over ssh based session:
|
||||
|
||||
### Start PF
|
||||
|
||||
`# service pf start`
|
||||
|
||||
### Stop PF
|
||||
|
||||
`# service pf stop`
|
||||
|
||||
### Check PF for syntax error
|
||||
|
||||
`# service pf check`
|
||||
|
||||
### Restart PF
|
||||
|
||||
`# service pf restart`
|
||||
|
||||
### See PF status
|
||||
|
||||
`# service pf status`
|
||||
Sample outputs:
|
||||
```
|
||||
Status: Enabled for 0 days 00:02:18 Debug: Urgent
|
||||
|
||||
Interface Stats for vtnet0 IPv4 IPv6
|
||||
Bytes In 19463 0
|
||||
Bytes Out 18541 0
|
||||
Packets In
|
||||
Passed 244 0
|
||||
Blocked 3 0
|
||||
Packets Out
|
||||
Passed 136 0
|
||||
Blocked 12 0
|
||||
|
||||
State Table Total Rate
|
||||
current entries 1
|
||||
searches 395 2.9/s
|
||||
inserts 4 0.0/s
|
||||
removals 3 0.0/s
|
||||
Counters
|
||||
match 19 0.1/s
|
||||
bad-offset 0 0.0/s
|
||||
fragment 0 0.0/s
|
||||
short 0 0.0/s
|
||||
normalize 0 0.0/s
|
||||
memory 0 0.0/s
|
||||
bad-timestamp 0 0.0/s
|
||||
congestion 0 0.0/s
|
||||
ip-option 0 0.0/s
|
||||
proto-cksum 0 0.0/s
|
||||
state-mismatch 0 0.0/s
|
||||
state-insert 0 0.0/s
|
||||
state-limit 0 0.0/s
|
||||
src-limit 0 0.0/s
|
||||
synproxy 0 0.0/s
|
||||
map-failed 0 0.0/s
|
||||
```
|
||||
|
||||
|
||||
### Command to start/stop/restart pflog service
|
||||
|
||||
Type the following commands:
|
||||
```
|
||||
# service pflog start
|
||||
# service pflog stop
|
||||
# service pflog restart
|
||||
```
|
||||
|
||||
## Step 4 - A quick introduction to pfctl command
|
||||
|
||||
You need to use the pfctl command to see PF ruleset and parameter configuration including status information from the packet filter. Let us see all common commands:
|
||||
|
||||
### Show PF rules information
|
||||
|
||||
`# pfctl -s rules`
|
||||
Sample outputs:
|
||||
```
|
||||
block return in log all
|
||||
block drop out all
|
||||
block drop in quick on ! vtnet0 inet from 172.xxx.yyy.zzz/24 to any
|
||||
block drop in quick inet from 172.xxx.yyy.zzz/24 to any
|
||||
pass in quick on vtnet0 inet proto tcp from 139.aaa.ccc.ddd to 172.xxx.yyy.zzz/24 port = ssh flags S/SA keep state label "USER_RULE: Allow SSH from 139.aaa.ccc.ddd"
|
||||
pass inet proto icmp all icmp-type echoreq keep state
|
||||
pass out quick on vtnet0 proto tcp from any to any port = domain flags S/SA keep state
|
||||
pass out quick on vtnet0 proto tcp from any to any port = ntp flags S/SA keep state
|
||||
pass out quick on vtnet0 proto tcp from any to any port = smtp flags S/SA keep state
|
||||
pass out quick on vtnet0 proto tcp from any to any port = http flags S/SA keep state
|
||||
pass out quick on vtnet0 proto tcp from any to any port = https flags S/SA keep state
|
||||
pass out quick on vtnet0 proto tcp from any to any port = ftp flags S/SA keep state
|
||||
pass out quick on vtnet0 proto tcp from any to any port = ssh flags S/SA keep state
|
||||
pass out quick on vtnet0 proto udp from any to any port = domain keep state
|
||||
pass out quick on vtnet0 proto udp from any to any port = ntp keep state
|
||||
```
|
||||
|
||||
#### Show verbose output for each rule
|
||||
|
||||
`# pfctl -v -s rules`
|
||||
|
||||
#### Add rule numbers with verbose output for each rule
|
||||
|
||||
`# pfctl -vvsr show`
|
||||
|
||||
#### Show state
|
||||
|
||||
```
|
||||
# pfctl -s state
|
||||
# pfctl -s state | more
|
||||
# pfctl -s state | grep 'something'
|
||||
```
|
||||
|
||||
### How to disable PF from the CLI
|
||||
|
||||
`# pfctl -d `
|
||||
|
||||
### How to enable PF from the CLI
|
||||
|
||||
`# pfctl -e `
|
||||
|
||||
### How to flush ALL PF rules/nat/tables from the CLI
|
||||
|
||||
`# pfctl -F all`
|
||||
Sample outputs:
|
||||
```
|
||||
rules cleared
|
||||
nat cleared
|
||||
0 tables deleted.
|
||||
2 states cleared
|
||||
source tracking entries cleared
|
||||
pf: statistics cleared
|
||||
pf: interface flags reset
|
||||
```
|
||||
|
||||
#### How to flush only the PF RULES from the CLI
|
||||
|
||||
`# pfctl -F rules `
|
||||
|
||||
#### How to flush only queue's from the CLI
|
||||
|
||||
`# pfctl -F queue `
|
||||
|
||||
#### How to flush all stats that are not part of any rule from the CLI
|
||||
|
||||
`# pfctl -F info`
|
||||
|
||||
#### How to clear all counters from the CLI
|
||||
|
||||
`# pfctl -z clear `
|
||||
|
||||
## Step 5 - See PF log
|
||||
|
||||
PF logs are in binary format. To see them type:
|
||||
`# tcpdump -n -e -ttt -r /var/log/pflog`
|
||||
Sample outputs:
|
||||
```
|
||||
Aug 29 15:41:11.757829 rule 0/(match) block in on vio0: 86.47.225.151.55806 > 45.FOO.BAR.IP.23: S 757158343:757158343(0) win 52206 [tos 0x28]
|
||||
Aug 29 15:41:44.193309 rule 0/(match) block in on vio0: 5.196.83.88.25461 > 45.FOO.BAR.IP.26941: S 2224505792:2224505792(0) ack 4252565505 win 17520 (DF) [tos 0x24]
|
||||
Aug 29 15:41:54.628027 rule 0/(match) block in on vio0: 45.55.13.94.50217 > 45.FOO.BAR.IP.465: S 3941123632:3941123632(0) win 65535
|
||||
Aug 29 15:42:11.126427 rule 0/(match) block in on vio0: 87.250.224.127.59862 > 45.FOO.BAR.IP.80: S 248176545:248176545(0) win 28200 <mss 1410,sackOK,timestamp 1044055305 0,nop,wscale 8> (DF)
|
||||
Aug 29 15:43:04.953537 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.7475: S 1164335542:1164335542(0) win 1024
|
||||
Aug 29 15:43:05.122156 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.7475: R 1164335543:1164335543(0) win 1200
|
||||
Aug 29 15:43:37.302410 rule 0/(match) block in on vio0: 94.130.12.27.18080 > 45.FOO.BAR.IP.64857: S 683904905:683904905(0) ack 4000841729 win 16384 <mss 1460>
|
||||
Aug 29 15:44:46.574863 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.7677: S 3451987887:3451987887(0) win 1024
|
||||
Aug 29 15:44:46.819754 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.7677: R 3451987888:3451987888(0) win 1200
|
||||
Aug 29 15:45:21.194752 rule 0/(match) block in on vio0: 185.40.4.130.55910 > 45.FOO.BAR.IP.80: S 3106068642:3106068642(0) win 1024
|
||||
Aug 29 15:45:32.999219 rule 0/(match) block in on vio0: 185.40.4.130.55910 > 45.FOO.BAR.IP.808: S 322591763:322591763(0) win 1024
|
||||
Aug 29 15:46:30.157884 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.6511: S 2412580953:2412580953(0) win 1024 [tos 0x28]
|
||||
Aug 29 15:46:30.252023 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.6511: R 2412580954:2412580954(0) win 1200 [tos 0x28]
|
||||
Aug 29 15:49:44.337015 rule 0/(match) block in on vio0: 189.219.226.213.22640 > 45.FOO.BAR.IP.23: S 14807:14807(0) win 14600 [tos 0x28]
|
||||
Aug 29 15:49:55.161572 rule 0/(match) block in on vio0: 5.196.83.88.25461 > 45.FOO.BAR.IP.40321: S 1297217585:1297217585(0) ack 1051525121 win 17520 (DF) [tos 0x24]
|
||||
Aug 29 15:49:59.735391 rule 0/(match) block in on vio0: 36.7.147.209.2545 > 45.FOO.BAR.IP.3389: SWE 3577047469:3577047469(0) win 8192 <mss 1460,nop,wscale 8,nop,nop,sackOK> (DF) [tos 0x2 (E)]
|
||||
Aug 29 15:50:00.703229 rule 0/(match) block in on vio0: 36.7.147.209.2546 > 45.FOO.BAR.IP.3389: SWE 1539382950:1539382950(0) win 8192 <mss 1460,nop,wscale 8,nop,nop,sackOK> (DF) [tos 0x2 (E)]
|
||||
Aug 29 15:51:33.880334 rule 0/(match) block in on vio0: 45.55.22.21.53510 > 45.FOO.BAR.IP.2362: udp 14
|
||||
Aug 29 15:51:34.006656 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.6491: S 151489102:151489102(0) win 1024 [tos 0x28]
|
||||
Aug 29 15:51:34.274654 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.6491: R 151489103:151489103(0) win 1200 [tos 0x28]
|
||||
Aug 29 15:51:36.393019 rule 0/(match) block in on vio0: 60.191.38.78.4249 > 45.FOO.BAR.IP.8000: S 3746478095:3746478095(0) win 29200 (DF)
|
||||
Aug 29 15:51:57.213051 rule 0/(match) block in on vio0: 24.137.245.138.7343 > 45.FOO.BAR.IP.5358: S 14134:14134(0) win 14600
|
||||
Aug 29 15:52:37.852219 rule 0/(match) block in on vio0: 122.226.185.125.51128 > 45.FOO.BAR.IP.23: S 1715745381:1715745381(0) win 5840 <mss 1420,sackOK,timestamp 13511417 0,nop,wscale 2> (DF)
|
||||
Aug 29 15:53:31.309325 rule 0/(match) block in on vio0: 189.218.148.69.377 > 45.FOO.BAR.IP5358: S 65340:65340(0) win 14600 [tos 0x28]
|
||||
Aug 29 15:53:31.809570 rule 0/(match) block in on vio0: 13.93.104.140.53184 > 45.FOO.BAR.IP.1433: S 39854048:39854048(0) win 1024
|
||||
Aug 29 15:53:32.138231 rule 0/(match) block in on vio0: 13.93.104.140.53184 > 45.FOO.BAR.IP.1433: R 39854049:39854049(0) win 1200
|
||||
Aug 29 15:53:41.459088 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.6028: S 168338703:168338703(0) win 1024
|
||||
Aug 29 15:53:41.789732 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.6028: R 168338704:168338704(0) win 1200
|
||||
Aug 29 15:54:34.993594 rule 0/(match) block in on vio0: 212.47.234.50.5102 > 45.FOO.BAR.IP.5060: udp 408 (DF) [tos 0x28]
|
||||
Aug 29 15:54:57.987449 rule 0/(match) block in on vio0: 51.15.69.145.5100 > 45.FOO.BAR.IP.5060: udp 406 (DF) [tos 0x28]
|
||||
Aug 29 15:55:07.001743 rule 0/(match) block in on vio0: 190.83.174.214.58863 > 45.FOO.BAR.IP.23: S 757158343:757158343(0) win 27420
|
||||
Aug 29 15:55:51.269549 rule 0/(match) block in on vio0: 142.217.201.69.26112 > 45.FOO.BAR.IP.22: S 757158343:757158343(0) win 22840 <mss 1460>
|
||||
Aug 29 15:58:41.346028 rule 0/(match) block in on vio0: 169.1.29.111.29765 > 45.FOO.BAR.IP.23: S 757158343:757158343(0) win 28509
|
||||
Aug 29 15:59:11.575927 rule 0/(match) block in on vio0: 187.160.235.162.32427 > 45.FOO.BAR.IP.5358: S 22445:22445(0) win 14600 [tos 0x28]
|
||||
Aug 29 15:59:37.826598 rule 0/(match) block in on vio0: 94.74.81.97.54656 > 45.FOO.BAR.IP.3128: S 2720157526:2720157526(0) win 1024 [tos 0x28]
|
||||
Aug 29 15:59:37.991171 rule 0/(match) block in on vio0: 94.74.81.97.54656 > 45.FOO.BAR.IP.3128: R 2720157527:2720157527(0) win 1200 [tos 0x28]
|
||||
Aug 29 16:01:36.990050 rule 0/(match) block in on vio0: 182.18.8.28.23299 > 45.FOO.BAR.IP.445: S 1510146048:1510146048(0) win 16384
|
||||
```
|
||||
|
||||
To see live log run:
|
||||
`# tcpdump -n -e -ttt -i pflog0`
|
||||
For more info the [PF FAQ][3], [FreeBSD HANDBOOK][4] and the following man pages:
|
||||
```
|
||||
# man tcpdump
|
||||
# man pfctl
|
||||
# man pf
|
||||
```
|
||||
|
||||
## about the author:
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][5], [Facebook][6], [Google+][7].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-set-up-a-firewall-with-pf-on-freebsd-to-protect-a-web-server/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2017/08/howto-setup-a-firewall-with-pf-on-freebsd.001.jpeg
|
||||
[2]:https://github.com/nixcraft/pf.conf/blob/master/pf.conf
|
||||
[3]:https://www.openbsd.org/faq/pf/
|
||||
[4]:https://www.freebsd.org/doc/handbook/firewalls.html
|
||||
[5]:https://twitter.com/nixcraft
|
||||
[6]:https://facebook.com/nixcraft
|
||||
[7]:https://plus.google.com/+CybercitiBiz
|
||||
@ -1,82 +0,0 @@
|
||||
translating by Flowsnow
|
||||
|
||||
What Are Bitcoins?
|
||||
======
|
||||
|
||||

|
||||
|
||||
**[Bitcoin][1]** is a digital currency or electronic cash the relies on peer to peer technology for completing transactions. Since peer to peer technology is used as the major network, bitcoins provide a community like managed economy. This is to mean, bitcoins eliminate the centralized authority way of managing currency and promotes community management of currency. Most Also of the software related to bitcoin mining and managing of bitcoin digital cash is open source.
|
||||
|
||||
The first Bitcoin software was developed by Satoshi Nakamoto and it's based on open source cryptographic protocol. Bitcoins smallest unit is known as the Satoshi which is basically one-hundredth millionth of a single bitcoin (0.00000001 BTC).
|
||||
|
||||
One cannot underestimate the boundaries BITCOINS eliminate in the digital economy. For instance, the BITCOIN eliminates governed controls over currency by a centralised agency and offers control and management to the community as a whole. Furthermore, the fact that the BITCOIN is based on an open source cryptographic protocol makes it an open place where there are scrupulous activities such as fluctuating value, deflation and inflation among others. While many internet users are becoming aware of the privacy they should exercise to complete some online transactions, bitcoin is gaining more popularity than ever before. However, for those who know about the dark web and how it works can acknowledge that some people began using it long ago.
|
||||
|
||||
On the downside, the bitcoin is also very secure in making anonymous payments which may be a threat to security or personal health. For instance, the dark web markets are the major suppliers and retailers of imported drugs and even weapons. The use of BITCOINs in the dark web facilitates a safe network for such criminal activities. Despite that, if put to good use, bitcoin has many benefits that can eliminate some of the economic fallacy as a result of centralized agency management of currency. In addition, the bitcoin allows for instance exchange of cash anywhere in the world. The use of bitcoins also mitigates counterfeiting, printing, or devaluation over time. Also, while relying on peer to peer network as its backbone, it promotes the distributed authority of transaction records making it safe to make exchanges.
|
||||
|
||||
Other advantages of the bitcoin include;
|
||||
|
||||
* In the online business world, bitcoin promotes money security and total control. This is because buyers are protected against merchants who may want to charge extra for a lower cost service. The buyer can also choose not to share personal information after making a transaction. Besides, identity theft protection is achieved as a result of backed up hiding personal information.
|
||||
|
||||
* Bitcoins are provided alternatives to major common currency catastrophes such as getting lost, frozen or damaged. However, it is recommended to always make a backup of your bitcoins and encrypt them with a password.
|
||||
|
||||
* In making online purchases and payments using bitcoins, there is a small fee or zero transaction fee charged. This promotes affordability of use.
|
||||
|
||||
* Merchants also face fewer risks that could result from fraud as bitcoin transactions cannot be reversed, unlike other currencies in electronic form. Bitcoins also prove useful even in moments of high crime rate and fraud since it is difficult to con someone over an open public ledger (Blockchain).
|
||||
|
||||
* Bitcoin currency is also hard to be manipulated as it is open source and the cryptographic protocol is very secure.
|
||||
|
||||
* Transactions can also be verified and approved, anywhere, anytime. This is the level of flexibility offered by this digital currency.
|
||||
|
||||
Also Read - [Bitkey A Linux Distribution Dedicated To Bitcoin Transactions][2]
|
||||
|
||||
### How To Mine Bitcoins and The Applications to Accomplish Necessary Bitcoin Management Tasks
|
||||
|
||||
In the digital currency, BITCOIN mining and management requires additional software. There are numerous open source bitcoin management software that make it easy to make payments, receive payments, encrypt and backup of your bitcoins and also bitcoin mining software. There are sites such as; [Freebitcoin][4] where one earns free bitcoins by viewing ads, [MoonBitcoin][5] is another site that one can sign up for free and earn bitcoins. However, it is convenient if one has spare time and a sizable network of friends participating in the same. There are many sites offering bitcoin mining and one can easily sign up and start mining. One of the major secrets is referring as many people as you can to create a large network.
|
||||
|
||||
Applications required for use with bitcoins include the bitcoin wallet which allows one to safely keep bitcoins. This is just like the physical wallet using to keep hard cash but in a digital form. The wallet can be downloaded here - [Bitcoin - Wallet][6] . Other similar applications include; the [Blockchain][7] which works similar to the Bitcoin Wallet.
|
||||
|
||||
The screenshots below show the Freebitco and MoonBitco mining sites respectively.
|
||||
|
||||
[][8]
|
||||
[][9]
|
||||
|
||||
There are various ways of acquiring the bitcoin currency. Some of them include the use of bitcoin mining rigs, purchasing of bitcoins in exchange markets and doing free bitcoin mining online. Purchasing of bitcoins can be done at; [MtGox][10] , [bitNZ][11] , [Bitstamp][12] , [BTC-E][13] , [VertEx][14] , etc.. Several mining open source applications are available online. These applications include; Bitminter, [5OMiner][15] , [BFG Miner][16] among others. These applications make use of some graphics card and processor features to generate bitcoins. The efficiency of mining bitcoins on a pc largely depends on the type of graphics card and the processor of the mining rig. Besides, there are many secure online storages for backing up bitcoins. These sites provide bitcoin storage services free of charge. Examples of bitcoin managing sites include; [xapo][17] , [BlockChain][18] etc. signing up on these sites require a valid email and phone number for verification. Xapo offers additional security through the phone application by requesting for verification whenever a new sign in is made.
|
||||
|
||||
### Disadvantages Of Bitcoins
|
||||
|
||||
The numerous advantages ripped from using bitcoins digital currency cannot be overlooked. However, as it is still in its infancy stage, the bitcoin currency meets several points of resistance. For instance, the majority of individual are not fully aware of the bitcoin digital currency and how it works. The lack of awareness can be mitigated through education and creation of awareness. Bitcoin users also face volatility as the demand for bitcoins is higher than the available amount of coins. However, given more time, volatility will be lowered as when many people will start using bitcoins.
|
||||
|
||||
### Improvements Can be Made
|
||||
|
||||
Based on the infancy of the [bitcoin technology][19] , there is still room for changes to make it more secure and reliable. Given more time, the bitcoin currency will be developed enough to provide flexibility as a common currency. For the bitcoin to succeed, many people need to be made aware of it besides being given information on how it works and its benefits.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/things-you-need-to-know-about-bitcoins
|
||||
|
||||
作者:[LINUXANDUBUNTU][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com/
|
||||
[1]:http://www.linuxandubuntu.com/home/bitkey-a-linux-distribution-dedicated-for-conducting-bitcoin-transactions
|
||||
[2]:http://www.linuxandubuntu.com/home/bitkey-a-linux-distribution-dedicated-for-conducting-bitcoin-transactions
|
||||
[3]:http://www.linuxandubuntu.com/home/things-you-need-to-know-about-bitcoins
|
||||
[4]:https://freebitco.in/?r=2167375
|
||||
[5]:http://moonbit.co.in/?ref=c637809a5051
|
||||
[6]:https://bitcoin.org/en/choose-your-wallet
|
||||
[7]:https://blockchain.info/wallet/
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/freebitco-bitcoin-mining-site_orig.jpg
|
||||
[9]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/moonbitcoin-bitcoin-mining-site_orig.png
|
||||
[10]:http://mtgox.com/
|
||||
[11]:https://en.bitcoin.it/wiki/BitNZ
|
||||
[12]:https://www.bitstamp.net/
|
||||
[13]:https://btc-e.com/
|
||||
[14]:https://www.vertexinc.com/
|
||||
[15]:https://www.downloadcloud.com/bitcoin-miner-software.html
|
||||
[16]:https://github.com/luke-jr/bfgminer
|
||||
[17]:https://xapo.com/
|
||||
[18]:https://www.blockchain.com/
|
||||
[19]:https://en.wikipedia.org/wiki/Bitcoin
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Easy APT Repository · Iain R. Learmonth
|
||||
======
|
||||
|
||||
|
||||
@ -1,61 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Reset Linux Desktop To Default Settings With A Single Command
|
||||
======
|
||||

|
||||
|
||||
A while ago, we shared an article about [**Resetter**][1] - an useful piece of software which is used to reset Ubuntu to factory defaults within few minutes. Using Resetter, anyone can easily reset their Ubuntu system to the state when you installed it in the first time. Today, I stumbled upon a similar thing. No, It's not an application, but a single-line command to reset your Linux desktop settings, tweaks and customization to default state.
|
||||
|
||||
### Reset Linux Desktop To Default Settings
|
||||
|
||||
This command will reset Ubuntu Unity, Gnome and MATE desktops to the default state. I tested this command on both my **Arch Linux MATE** desktop and **Ubuntu 16.04 Unity** desktop. It worked on both systems. I hope it will work on other desktops as well. I don't have any Linux desktop with GNOME as of writing this, so I couldn't confirm it. But, I believe it will work on Gnome DE as well.
|
||||
|
||||
**A word of caution:** Please be mindful that this command will reset all customization and tweaks you made in your system, including the pinned applications in the Unity launcher or Dock, desktop panel applets, desktop indicators, your system fonts, GTK themes, Icon themes, monitor resolution, keyboard shortcuts, window button placement, menu and launcher behaviour etc.
|
||||
|
||||
Good thing is it will only reset the desktop settings. It won't affect the other applications that doesn't use dconf. Also, it won't delete your personal data.
|
||||
|
||||
Now, let us do this. To reset Ubuntu Unity or any other Linux desktop with GNOME/MATE DEs to its default settings, run:
|
||||
```
|
||||
dconf reset -f /
|
||||
```
|
||||
|
||||
This is my Ubuntu 16.04 LTS desktop before running the above command:
|
||||
|
||||
[![][2]][3]
|
||||
|
||||
As you see, I have changed the desktop wallpaper and themes.
|
||||
|
||||
This is how my Ubuntu 16.04 LTS desktop looks like after running that command:
|
||||
|
||||
[![][2]][4]
|
||||
|
||||
Look? Now, my Ubuntu desktop has gone to the factory settings.
|
||||
|
||||
For more details about "dconf" command, refer man pages.
|
||||
```
|
||||
man dconf
|
||||
```
|
||||
|
||||
I personally prefer to use "Resetter" over "dconf" command for this purpose. Because, Resetter provides more options to the users. The users can decide which applications to remove, which applications to keep, whether to keep existing user account or create a new user and many. If you're too lazy to install Resetter, you can just use this "dconf" command to reset your Linux system to default settings within few minutes.
|
||||
|
||||
And, that's all. Hope this helps. I will be soon here with another useful guide. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/reset-linux-desktop-default-settings-single-command/
|
||||
|
||||
作者:[Edwin Arteaga][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com
|
||||
[1]:https://www.ostechnix.com/reset-ubuntu-factory-defaults/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Before-resetting-Ubuntu-to-default-1.png ()
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/After-resetting-Ubuntu-to-default-1.png ()
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Create A Video From PDF Files In Linux
|
||||
======
|
||||

|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
10 layers of Linux container security | Opensource.com
|
||||
Translating by qhwdw 10 layers of Linux container security | Opensource.com
|
||||
======
|
||||

|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
translateing by singledo
|
||||
Processors - Everything You Need to Know
|
||||
======
|
||||

|
||||
|
||||
@ -1,5 +1,8 @@
|
||||
Translating by Drshu
|
||||
|
||||
How to bind ntpd to specific IP addresses on Linux/Unix
|
||||
======
|
||||
|
||||
By default, my ntpd/NTP server listens on all interfaces or IP address i.e 0.0.0.0:123. How do I make sure ntpd only listen on a specific IP address such as localhost or 192.168.1.1:123 on a Linux or FreeBSD Unix server?
|
||||
|
||||
NTP is an acronym for Network Time Protocol. It is used for clock synchronization between computers. The ntpd program is an operating system daemon which sets and maintains the system time of day in synchronism with Internet standard time servers.
|
||||
|
||||
@ -1,185 +0,0 @@
|
||||
Step by Step guide for creating Master Slave replication in MariaDB
|
||||
======
|
||||
In our earlier tutorials,we have already learned [**to install & configure MariaDB**][1] & also [**learned some basic administration commands for managing MariaDB**][2]. We are now going to learn to setup a MASTER SLAVE replication for MariaDB server.
|
||||
|
||||
Replication is used to create multiple copies of our database & these copies then can either be used as another database to run our queries on, queries that might otherwise affect performance of master server like running some heavy analytics queries or we can just use them for data redundancy purposes or for both. We can automate the whole process i.e. data replication occurs automatically from master to slave. Backups are be done without affecting the write operations of the master
|
||||
|
||||
So we will now setup our **master-slave** replication, for this we need two machines with Mariadb installed. IP addresses for the both the machines are mentioned below,
|
||||
|
||||
**Master -** 192.168.1.120 **Hostname-** master.ltechlab.com
|
||||
|
||||
**Slave -** 192.168.1.130 **Hostname -** slave.ltechlab.com
|
||||
|
||||
Once MariaDB has been installed in those machines, we will move on with the tutorial. If you need help installing and configuring maridb, have a[ **look at our tutorial HERE.**][1]
|
||||
|
||||
|
||||
### **Step 1- Master Server Configuration**
|
||||
|
||||
We are going to take a database named ' **important '** in MariaDB, that will be replicated to our slave server. To start the process, we will edit the files ' **/etc/my.cnf** ' , it's the configuration file for mariadb,
|
||||
|
||||
```
|
||||
$ vi /etc/my.cnf
|
||||
```
|
||||
|
||||
& look for section with [mysqld] & then enter the following details,
|
||||
|
||||
```
|
||||
[mysqld]
|
||||
log-bin
|
||||
server_id=1
|
||||
replicate-do-db=important
|
||||
bind-address=192.168.1.120
|
||||
```
|
||||
|
||||
Save & exit the file. Once done, restart the mariadb services,
|
||||
|
||||
```
|
||||
$ systemctl restart mariadb
|
||||
```
|
||||
|
||||
Next, we will login to our mariadb instance on master server,
|
||||
|
||||
```
|
||||
$ mysql -u root -p
|
||||
```
|
||||
|
||||
& then will create a new user for slave named 'slaveuser' & assign it necessary privileges by running the following command
|
||||
|
||||
```
|
||||
STOP SLAVE;
|
||||
GRANT REPLICATION SLAVE ON *.* TO 'slaveuser'@'%' IDENTIFIED BY 'iamslave';
|
||||
FLUSH PRIVILEGES;
|
||||
FLUSH TABLES WITH READ LOCK;
|
||||
SHOW MASTER STATUS;
|
||||
```
|
||||
|
||||
**Note:- ** We need values from **MASTER_LOG_FILE and MASTER_LOG_POS ** from out of 'show master status' for configuring replication, so make sure that you have those.
|
||||
|
||||
Once these commands run successfully, exit from the session by typing 'exit'.
|
||||
|
||||
### Step2 - Create a backup of the database & move it slave
|
||||
|
||||
Now we need to create backup of our database 'important' , which can be done using 'mysqldump' command,
|
||||
|
||||
```
|
||||
$ mysqldump -u root -p important > important_backup.sql
|
||||
```
|
||||
|
||||
Once the backup is complete, we need to log back into the mariadb & unlock our tables,
|
||||
|
||||
```
|
||||
$ mysql -u root -p
|
||||
$ UNLOCK TABLES;
|
||||
```
|
||||
|
||||
& exit the session. Now we will move the database backup to our slave server which has a IPaddress of 192.168.1.130,
|
||||
|
||||
This completes our configuration on Master server, we will now move onto configuring our slave server.
|
||||
|
||||
### Step 3 Configuring Slave server
|
||||
|
||||
We will again start with editing '/etc/my.cnf' file & look for section [mysqld] & enter the following details,
|
||||
|
||||
```
|
||||
[mysqld]
|
||||
server-id = 2
|
||||
replicate-do-db=important
|
||||
[ …]
|
||||
```
|
||||
|
||||
We will now restore our database to mariadb, by running
|
||||
|
||||
```
|
||||
$ mysql -u root -p < /data/ important_backup.sql
|
||||
```
|
||||
|
||||
When the process completes, we will provide the privileges to 'slaveuser' on db 'important' by logging into mariadb on slave server,
|
||||
|
||||
```
|
||||
$ mysql -u root -p
|
||||
```
|
||||
|
||||
```
|
||||
GRANT ALL PRIVILEGES ON important.* TO 'slaveuser'@'localhost' WITH GRANT OPTION;
|
||||
FLUSH PRIVILEGES;
|
||||
```
|
||||
|
||||
Next restart mariadb for implementing the changes.
|
||||
|
||||
```
|
||||
$ systemctl restart mariadb
|
||||
```
|
||||
|
||||
### **Step 4 Start the replication**
|
||||
|
||||
Remember, we need **MASTER_LOG_FILE and MASTER_LOG_POS** variables which we got from running 'SHOW MASTER STATUS' on mariadb on master server. Now login to mariadb on slave server & we will tell our slave server where to look for the master by running the following commands,
|
||||
|
||||
```
|
||||
STOP SLAVE;
|
||||
CHANGE MASTER TO MASTER_HOST= '192.168.1.110′, MASTER_USER='slaveuser', MASTER_PASSWORD='iamslave', MASTER_LOG_FILE='mariadb-bin.000001′, MASTER_LOG_POS=460;
|
||||
SLAVE START;
|
||||
SHOW SLAVE STATUS\G;
|
||||
```
|
||||
|
||||
**Note:-** Change details of your master as necessary.
|
||||
|
||||
### Step 5 Testing the replication
|
||||
|
||||
We will now create a new tables in our database on master to make sure if the replication is working or not. So, login to mariadb on master server,
|
||||
|
||||
```
|
||||
$ mysql -u root -p
|
||||
```
|
||||
|
||||
select the database 'important',
|
||||
|
||||
```
|
||||
use important;
|
||||
```
|
||||
|
||||
and create a table named test in the db,
|
||||
|
||||
```
|
||||
create table test (c int);
|
||||
```
|
||||
|
||||
then insert some value into it,
|
||||
|
||||
```
|
||||
insert into test (c) value (1);
|
||||
```
|
||||
|
||||
To check the added value,
|
||||
|
||||
```
|
||||
select * from test;
|
||||
```
|
||||
|
||||
& you will find that your db has a table has the value you inserted.
|
||||
|
||||
Now let's login to our slave database to make sure if our data replication is working,
|
||||
|
||||
```
|
||||
$ mysql -u root -p
|
||||
$ use important;
|
||||
$ select * from test;
|
||||
```
|
||||
|
||||
You will see that the output shows the same value that we inserted on the master server, hence our replication is working fine without any issues.
|
||||
|
||||
This concludes our tutorial, please send your queries/questions through the comment box below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/creating-master-slave-replication-mariadb/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/installing-configuring-mariadb-rhelcentos/
|
||||
[2]:http://linuxtechlab.com/mariadb-administration-commands-beginners/
|
||||
@ -1,172 +0,0 @@
|
||||
translated by cyleft
|
||||
How To Find Files Based On their Permissions
|
||||
======
|
||||
Finding files in Linux is not a big deal. There are plenty of free and open source graphical utilities available on the market. In my opinion, finding files from command line is much easier and faster. We already knew how to [**find and sort files based on access and modification date and time**][1]. Today, we will see how to find files based on their permissions in Unix-like operating systems.
|
||||
|
||||
For the purpose of this guide, I am going to create three files namely **file1** , **file2** and **file3** with permissions **777** , **766** , **655** respectively in a folder named **ostechnix**.
|
||||
```
|
||||
mkdir ostechnix && cd ostechnix/
|
||||
```
|
||||
```
|
||||
install -b -m 777 /dev/null file1
|
||||
```
|
||||
```
|
||||
install -b -m 766 /dev/null file2
|
||||
```
|
||||
```
|
||||
install -b -m 655 /dev/null file3
|
||||
```
|
||||
|
||||
[![][2]][3]
|
||||
|
||||
Now let us find the files based on their permissions.
|
||||
|
||||
### Find files Based On their Permissions
|
||||
|
||||
The typical syntax to find files based on their permissions is:
|
||||
```
|
||||
find -perm mode
|
||||
```
|
||||
|
||||
The MODE can be either with numeric or octal permission (like 777, 666.. etc) or symbolic permission (like u=x, a=r+x).
|
||||
|
||||
Before going further, we can specify the MODE in three different ways.
|
||||
|
||||
1. If we specify the mode without any prefixes, it will find files of **exact** permissions.
|
||||
2. If we use **" -"** prefix with mode, at least the files should have the given permission, not the exact permission.
|
||||
3. If we use **" /"** prefix, either the owner, the group, or other should have permission to the file.
|
||||
|
||||
|
||||
|
||||
Allow me to explain with some examples, so you can understand better.
|
||||
|
||||
First, we will see finding files based on numeric permissions.
|
||||
|
||||
### Find Files Based On their Numeric (octal) Permissions
|
||||
|
||||
Now let me run the following command:
|
||||
```
|
||||
find -perm 777
|
||||
```
|
||||
|
||||
This command will find the files with permission of **exactly 777** in the current directory.
|
||||
|
||||
[![][2]][4]
|
||||
|
||||
As you see in the above output, file1 is the only one that has **exact 777 permission**.
|
||||
|
||||
Now, let us use "-" prefix and see what happens.
|
||||
```
|
||||
find -perm -766
|
||||
```
|
||||
|
||||
[![][2]][5]
|
||||
|
||||
As you see, the above command displays two files. We have set 766 permission to file2, but this command displays two files, why? Because, here we have used "-" prefix". It means that this command will find all files where the file owner has read/write/execute permissions, file group members have read/write permissions and everything else has also read/write permission. In our case, file1 and file2 have met this criteria. In other words, the files need not to have exact 766 permission. It will display any files that falls under this 766 permission.
|
||||
|
||||
Next, we will use "/" prefix and see what happens.
|
||||
```
|
||||
find -perm /222
|
||||
```
|
||||
|
||||
[![][2]][6]
|
||||
|
||||
The above command will find files which are writable by somebody (either their owner, or their group, or anybody else). Here is another example.
|
||||
```
|
||||
find -perm /220
|
||||
```
|
||||
|
||||
This command will find files which are writable by either their owner or their group. That means the files **don 't have to be writable** by **both the owner and group** to be matched; **either** will do.
|
||||
|
||||
But if you run the same command with "-" prefix, you will only see the files only which are writable by both owner and group.
|
||||
```
|
||||
find -perm -220
|
||||
```
|
||||
|
||||
The following screenshot will show you the difference between these two prefixes.
|
||||
|
||||
[![][2]][7]
|
||||
|
||||
Like I already said, we can also use symbolic notation to represent the file permissions.
|
||||
|
||||
Also read:
|
||||
|
||||
### Find Files Based On their Permissions using symbolic notation
|
||||
|
||||
In the following examples, we use symbolic notations such as **u** ( for user), **g** (group), **o** (others). We can also use the letter **a** to represent all three of these categories. The permissions can be specified using letters **r** (read), **w** (write), **x** (executable).
|
||||
|
||||
For instance, to find any file with group **write** permission, run:
|
||||
```
|
||||
find -perm -g=w
|
||||
```
|
||||
|
||||
[![][2]][8]
|
||||
|
||||
As you see in the above example, file1 and file2 have group **write** permission. Please note that you can use either "=" or "+" for symbolic notation. It doesn't matter. For example, the following two commands do the same thing.
|
||||
```
|
||||
find -perm -g=w
|
||||
find -perm -g+w
|
||||
```
|
||||
|
||||
To find any file which are writable by the file owner, run:
|
||||
```
|
||||
find -perm -u=w
|
||||
```
|
||||
|
||||
To find any file which are writable by all (the file owner, group and everyone else), run:
|
||||
```
|
||||
find -perm -a=w
|
||||
```
|
||||
|
||||
To find files which are writable by **both** their **owner** and their **group** , use this command:
|
||||
```
|
||||
find -perm -g+w,u+w
|
||||
```
|
||||
|
||||
The above command is equivalent of "find -perm -220" command.
|
||||
|
||||
To find files which are writable by **either** their **owner** or their **group** , run:
|
||||
```
|
||||
find -perm /u+w,g+w
|
||||
```
|
||||
|
||||
Or,
|
||||
```
|
||||
find -perm /u=w,g=w
|
||||
```
|
||||
|
||||
These two commands does the same job as "find -perm /220" command.
|
||||
|
||||
For more details, refer the man pages.
|
||||
```
|
||||
man find
|
||||
```
|
||||
|
||||
Also, check the [**man pages alternatives**][9] to learn more simplified examples of any Linux command.
|
||||
|
||||
And, that's all for now folks. I hope this guide was useful. More good stuffs to come. Stay tuned.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/find-files-based-permissions/
|
||||
|
||||
作者:[][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com
|
||||
[1] https://www.ostechnix.com/find-sort-files-based-access-modification-date-time-linux/
|
||||
[2] data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3] http://www.ostechnix.com/wp-content/uploads/2017/12/find-files-1-1.png ()
|
||||
[4] http://www.ostechnix.com/wp-content/uploads/2017/12/find-files-2.png ()
|
||||
[5] http://www.ostechnix.com/wp-content/uploads/2017/12/find-files-3.png ()
|
||||
[6] http://www.ostechnix.com/wp-content/uploads/2017/12/find-files-6.png ()
|
||||
[7] http://www.ostechnix.com/wp-content/uploads/2017/12/find-files-7.png ()
|
||||
[8] http://www.ostechnix.com/wp-content/uploads/2017/12/find-files-8.png ()
|
||||
[9] https://www.ostechnix.com/3-good-alternatives-man-pages-every-linux-user-know/
|
||||
@ -1,179 +0,0 @@
|
||||
How To Count The Number Of Files And Folders/Directories In Linux
|
||||
======
|
||||
Hi folks, today again we came with set of tricky commands that help you in many ways. It's kind of manipulation commands which help you to count files and directories in the current directory, recursive count, list of files created by particular user, etc,.
|
||||
|
||||
In this tutorial, we are going to show you, how to use more than one command like, all together to perform some advanced actions using ls, egrep, wc and find command. The below set of commands which helps you in many ways.
|
||||
|
||||
To experiment this, i'm going to create totally 7 files and 2 folders (5 regular files & 2 hidden files). See the below tree command output which clearly shows the files and folder lists.
|
||||
|
||||
**Suggested Read :** [File Manipulation Commands][1]
|
||||
```
|
||||
# tree -a /opt
|
||||
/opt
|
||||
├── magi
|
||||
│ └── 2g
|
||||
│ ├── test5.txt
|
||||
│ └── .test6.txt
|
||||
├── test1.txt
|
||||
├── test2.txt
|
||||
├── test3.txt
|
||||
├── .test4.txt
|
||||
└── test.txt
|
||||
|
||||
2 directories, 7 files
|
||||
|
||||
```
|
||||
|
||||
**Example-1 :** To count current directory files (excluded hidden files). Run the following command to determine how many files there are in the current directory and it doesn't count dotfiles.
|
||||
```
|
||||
# ls -l . | egrep -c '^-'
|
||||
4
|
||||
|
||||
```
|
||||
|
||||
**Details :**
|
||||
|
||||
* `ls` : list directory contents
|
||||
* `-l` : Use a long listing format
|
||||
* `.` : List information about the FILEs (the current directory by default).
|
||||
* `|` : control operator that send the output of one program to another program for further processing.
|
||||
* `egrep` : print lines matching a pattern
|
||||
* `-c` : General Output Control
|
||||
* `'^-'` : This respectively match the empty string at the beginning and end of a line.
|
||||
|
||||
|
||||
|
||||
**Example-2 :** To count current directory files which includes hidden files. This will include dotfiles as well in the current directory.
|
||||
```
|
||||
# ls -la . | egrep -c '^-'
|
||||
5
|
||||
|
||||
```
|
||||
|
||||
**Example-3 :** Run the following command to count current directory files & folders. It will count all together at once.
|
||||
```
|
||||
# ls -1 | wc -l
|
||||
5
|
||||
|
||||
```
|
||||
|
||||
**Details :**
|
||||
|
||||
* `ls` : list directory contents
|
||||
* `-l` : Use a long listing format
|
||||
* `|` : control operator that send the output of one program to another program for further processing.
|
||||
* `wc` : It's a command to print newline, word, and byte counts for each file
|
||||
* `-l` : print the newline counts
|
||||
|
||||
|
||||
|
||||
**Example-4 :** To count current directory files & folders which includes hidden files & directory.
|
||||
```
|
||||
# ls -1a | wc -l
|
||||
8
|
||||
|
||||
```
|
||||
|
||||
**Example-5 :** To count current directory files recursively which includes hidden files.
|
||||
```
|
||||
# find . -type f | wc -l
|
||||
7
|
||||
|
||||
```
|
||||
|
||||
**Details :**
|
||||
|
||||
* `find` : search for files in a directory hierarchy
|
||||
* `-type` : File is of type
|
||||
* `f` : regular file
|
||||
* `wc` : It's a command to print newline, word, and byte counts for each file
|
||||
* `-l` : print the newline counts
|
||||
|
||||
|
||||
|
||||
**Example-6 :** To print directories & files count using tree command (excluded hidden files).
|
||||
```
|
||||
# tree | tail -1
|
||||
2 directories, 5 files
|
||||
|
||||
```
|
||||
|
||||
**Example-7 :** To print directories & files count using tree command which includes hidden files.
|
||||
```
|
||||
# tree -a | tail -1
|
||||
2 directories, 7 files
|
||||
|
||||
```
|
||||
|
||||
**Example-8 :** Run the below command to count directory recursively which includes hidden directory.
|
||||
```
|
||||
# find . -type d | wc -l
|
||||
3
|
||||
|
||||
```
|
||||
|
||||
**Example-9 :** To count the number of files based on file extension. Here we are going to count `.txt` files.
|
||||
```
|
||||
# find . -name "*.txt" | wc -l
|
||||
7
|
||||
|
||||
```
|
||||
|
||||
**Example-10 :** Count all files in the current directory by using the echo command in combination with the wc command. `4` indicates the amount of files in the current directory.
|
||||
```
|
||||
# echo * | wc
|
||||
1 4 39
|
||||
|
||||
```
|
||||
|
||||
**Example-11 :** Count all directories in the current directory by using the echo command in combination with the wc command. `1` indicates the amount of directories in the current directory.
|
||||
```
|
||||
# echo comic/ published/ sources/ translated/ | wc
|
||||
1 1 6
|
||||
|
||||
```
|
||||
|
||||
**Example-12 :** Count all files and directories in the current directory by using the echo command in combination with the wc command. `5` indicates the amount of directories and files in the current directory.
|
||||
```
|
||||
# echo * | wc
|
||||
1 5 44
|
||||
|
||||
```
|
||||
|
||||
**Example-13 :** To count number of files in the system (Entire system)
|
||||
```
|
||||
# find / -type f | wc -l
|
||||
69769
|
||||
|
||||
```
|
||||
|
||||
**Example-14 :** To count number of folders in the system (Entire system)
|
||||
```
|
||||
# find / -type d | wc -l
|
||||
8819
|
||||
|
||||
```
|
||||
|
||||
**Example-15 :** Run the following command to count number of files, folders, hardlinks, and symlinks in the system (Entire system)
|
||||
```
|
||||
# find / -type d -exec echo dirs \; -o -type l -exec echo symlinks \; -o -type f -links +1 -exec echo hardlinks \; -o -type f -exec echo files \; | sort | uniq -c
|
||||
8779 dirs
|
||||
69343 files
|
||||
20 hardlinks
|
||||
11646 symlinks
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-count-the-number-of-files-and-folders-directories-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
[1]:https://www.2daygeek.com/empty-a-file-delete-contents-lines-from-a-file-remove-matching-string-from-a-file-remove-empty-blank-lines-from-a-file/
|
||||
@ -1,82 +0,0 @@
|
||||
Best open source tutorials in 2017
|
||||
======
|
||||

|
||||
|
||||
A well-written tutorial is a great supplement to any software's official documentation. It can also be an effective alternative if that official documentation is poorly written, incomplete, or non-existent.
|
||||
|
||||
In 2017, Opensource.com published a number of excellent tutorials on a variety of topics. Those tutorials weren't just for experts. We aimed them at users of all levels of skill and experience.
|
||||
|
||||
Let's take a look at the best of those tutorials.
|
||||
|
||||
### It's all about the code
|
||||
|
||||
For many, their first foray into open source involved contributing code to one project or another. Where do you go to learn to code or program? The following two articles are great starting points.
|
||||
|
||||
While not a tutorial in the strictest sense of the word, VM Brasseur's [How to get started learning to program][1] is a good starting point for the neophyte coder. It doesn't merely point out some excellent resources that will help you get started, but also offers important advice about understanding your learning style and how to pick a language.
|
||||
|
||||
If you've logged a more than a few hours in an [IDE][2] or a text editor, you'll probably want to learn a bit more about different approaches to coding. Fraser Tweedale's [Introduction to functional programming][3] does a fine job of introducing a paradigm that you can apply to many widely used programming languages.
|
||||
|
||||
### Going Linux
|
||||
|
||||
Linux is arguably the poster child of open source. It runs a good chunk of the web and powers the world's top supercomputers. And it gives anyone an alternative to proprietary operating systems on their desktops.
|
||||
|
||||
If you're interested in diving deeper into Linux, here are a trio of tutorials for you.
|
||||
|
||||
Jason Baker looks at [setting the Linux $PATH variable][4]. He guides you through this "important skill for any beginning Linux user," which enables you to point the system to directories containing programs and scripts.
|
||||
|
||||
Embrace your inner techie with David Both's guide to [building a DNS name server][5]. He documents, in considerable detail, how to set up and run the server, including what configuration files to edit and how to edit them.
|
||||
|
||||
Want to go a bit more retro in your computing? Jim Hall shows you how to [run DOS programs in Linux][6] using [FreeDOS][7] and [QEMU][8]. Hall's article focuses on running DOS productivity tools, but it's not all serious--he talks about running his favorite DOS games, too.
|
||||
|
||||
### Three slices of Pi
|
||||
|
||||
It's no secret that inexpensive single-board computers have made hardware hacking fun again. Not only that, but they've made it more accessible to more people, regardless of their age or their level of technical proficiency.
|
||||
|
||||
The [Raspberry Pi][9] is probably the most widely used single-board computer out there. Ben Nuttall walks us through how to install and set up [a Postgres database on a Raspberry Pi][10]. From there, you're ready to use it in whatever project you have in mind.
|
||||
|
||||
If your tastes include both the literary and technical, you might be interested in Don Watkins' [How to turn a Raspberry Pi into an eBook server][11]. With a little work and a copy of the [Calibre eBook management software][12], you'll be able to get to your favorite eBooks anywhere you are.
|
||||
|
||||
Raspberry isn't the only flavor of Pi out there. There's also the [Orange Pi Pc Plus][13], an open-source single-board computer. David Egts looks at [getting started with this hackable mini-computer][14].
|
||||
|
||||
### Day-to-day computing
|
||||
|
||||
Open source isn't just for techies. Mere mortals use it to do their daily work and be more productive. Here are a trio of articles for those of us who have 10 thumbs when it comes to anything technical (and for those who don't).
|
||||
|
||||
When you think of microblogging, you probably think Twitter. But Twitter has more than its share of problems. [Mastodon][15] is an open alternative to Twitter that debuted in 2016. Since then, Mastodon has gained a sizeable base of users. Seth Kenlon explains [how to join and use Mastodon][16], and even shows you how to cross-post between Mastodon and Twitter.
|
||||
|
||||
Do you need a little help staying on top of your expenses? All you need is a spreadsheet and the right template. My article on [getting control of your finances][17] shows you how to create a simple, attractive finance-tracking spreadsheet with [LibreOffice Calc][18] (or any other spreadsheet editor).
|
||||
|
||||
ImageMagick is a powerful tool for manipulating graphics. It's one, though, that many people don't use as often as they should. That means they forget the commands just when they need them the most. If that's you, then keep Greg Pittman's [introductory tutorial to ImageMagick][19] handy for those times you need some help.
|
||||
|
||||
Do you have a favorite tutorial published by Opensource.com in 2017? Feel free to share it with the community by leaving a comment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/best-tutorials
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/article/17/4/how-get-started-learning-program
|
||||
[2]:https://en.wikipedia.org/wiki/Integrated_development_environment
|
||||
[3]:https://opensource.com/article/17/4/introduction-functional-programming
|
||||
[4]:https://opensource.com/article/17/6/set-path-linux
|
||||
[5]:https://opensource.com/article/17/4/build-your-own-name-server
|
||||
[6]:https://opensource.com/article/17/10/run-dos-applications-linux
|
||||
[7]:http://www.freedos.org/
|
||||
[8]:https://www.qemu.org
|
||||
[9]:https://en.wikipedia.org/wiki/Raspberry_Pi
|
||||
[10]:https://opensource.com/article/17/10/set-postgres-database-your-raspberry-pi
|
||||
[11]:https://opensource.com/article/17/6/raspberrypi-ebook-server
|
||||
[12]:https://calibre-ebook.com/
|
||||
[13]:http://www.orangepi.org/
|
||||
[14]:https://opensource.com/article/17/1/how-to-orange-pi
|
||||
[15]:https://joinmastodon.org/
|
||||
[16]:https://opensource.com/article/17/4/guide-to-mastodon
|
||||
[17]:https://opensource.com/article/17/8/budget-libreoffice-calc
|
||||
[18]:https://www.libreoffice.org/discover/calc/
|
||||
[19]:https://opensource.com/article/17/8/imagemagick
|
||||
@ -1,166 +0,0 @@
|
||||
translating by wenwensnow
|
||||
HTTP errors in WordPress
|
||||
======
|
||||
![http error wordpress][1]
|
||||
|
||||
We'll show you, how to fix HTTP errors in WordPress, on a Linux VPS. Listed below are the most common HTTP errors in WordPress, experienced by WordPress users, and our suggestions on how to investigate and fix them.
|
||||
|
||||
### 1\. Fix HTTP error in WordPress when uploading images
|
||||
|
||||
If you get an error when uploading an image to your WordPress based site, it may be due to PHP configuration settings on your server, like insufficient memory limit or so.
|
||||
|
||||
Locate the php configuration file using the following command:
|
||||
```
|
||||
#php -i | grep php.ini
|
||||
Configuration File (php.ini) Path => /etc
|
||||
Loaded Configuration File => /etc/php.ini
|
||||
```
|
||||
|
||||
According to the output, the PHP configuration file is located in the '/etc' directory, so edit the '/etc/php.ini' file, find the lines below and modify them with these values:
|
||||
```
|
||||
vi /etc/php.ini
|
||||
```
|
||||
```
|
||||
upload_max_filesize = 64M
|
||||
post_max_size = 32M
|
||||
max_execution_time = 300
|
||||
max_input_time 300
|
||||
memory_limit = 128M
|
||||
```
|
||||
|
||||
Of course if you are unfamiliar with the vi text editor, use your favorite one.
|
||||
|
||||
Do not forget to restart your web server for the changes to take effect.
|
||||
|
||||
If the web server installed on your server is Apache, you may use .htaccess. First, locate the .htaccess file. It should be in the document root directory of the WordPress installation. If there is no .htaccess file, create one, then add the following content:
|
||||
```
|
||||
vi /www/html/path_to_wordpress/.htaccess
|
||||
```
|
||||
```
|
||||
php_value upload_max_filesize 64M
|
||||
php_value post_max_size 32M
|
||||
php_value max_execution_time 180
|
||||
php_value max_input_time 180
|
||||
|
||||
# BEGIN WordPress
|
||||
<IfModule mod_rewrite.c>
|
||||
RewriteEngine On
|
||||
RewriteBase /
|
||||
RewriteRule ^index\.php$ - [L]
|
||||
RewriteCond %{REQUEST_FILENAME} !-f
|
||||
RewriteCond %{REQUEST_FILENAME} !-d
|
||||
RewriteRule . /index.php [L]
|
||||
</IfModule>
|
||||
# END WordPress
|
||||
```
|
||||
|
||||
If you are using nginx, configure the nginx server block about your WordPress instance. It should look something like the example below:
|
||||
```
|
||||
server {
|
||||
|
||||
listen 80;
|
||||
client_max_body_size 128m;
|
||||
client_body_timeout 300;
|
||||
|
||||
server_name your-domain.com www.your-domain.com;
|
||||
|
||||
root /var/www/html/wordpress;
|
||||
index index.php;
|
||||
|
||||
location = /favicon.ico {
|
||||
log_not_found off;
|
||||
access_log off;
|
||||
}
|
||||
|
||||
location = /robots.txt {
|
||||
allow all;
|
||||
log_not_found off;
|
||||
access_log off;
|
||||
}
|
||||
|
||||
location / {
|
||||
try_files $uri $uri/ /index.php?$args;
|
||||
}
|
||||
|
||||
location ~ \.php$ {
|
||||
include fastcgi_params;
|
||||
fastcgi_pass 127.0.0.1:9000;
|
||||
fastcgi_index index.php;
|
||||
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
|
||||
}
|
||||
|
||||
location ~* \.(js|css|png|jpg|jpeg|gif|ico)$ {
|
||||
expires max;
|
||||
log_not_found off;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Depending on the PHP configuration, you may need to replace 'fastcgi_pass 127.0.0.1:9000;' with 'fastcgi_pass unix:/var/run/php7-fpm.sock;' or so.
|
||||
|
||||
Restart nginx service for the changes to take effect.
|
||||
|
||||
### 2\. Fix HTTP error in WordPress due to incorrect file permissions
|
||||
|
||||
If you get an unexpected HTTP error in WordPress, it may be due to incorrect file permissions, so set a proper ownership of your WordPress files and directories:
|
||||
```
|
||||
chown www-data:www-data -R /var/www/html/path_to_wordpress/
|
||||
```
|
||||
|
||||
Replace 'www-data' with the actual web server user, and '/var/www/html/path_to_wordpress' with the actual path of the WordPress installation.
|
||||
|
||||
### 3\. Fix HTTP error in WordPress due to memory limit
|
||||
|
||||
The PHP memory_limit value can be set by adding this to your wp-config.php file:
|
||||
```
|
||||
define('WP_MEMORY_LIMIT', '128MB');
|
||||
```
|
||||
|
||||
### 4\. Fix HTTP error in WordPress due to misconfiguration of PHP.INI
|
||||
|
||||
Edit the main PHP configuration file and locate the line with the content 'cgi.fix_pathinfo' . This will be commented by default and set to 1. Uncomment the line (remove the semi-colon) and change the value from 1 to 0. You may also want to change the 'date.timezone' PHP setting, so edit the PHP configuration file and modify this setting to 'date.timezone = US/Central' (or whatever your timezone is).
|
||||
```
|
||||
vi /etc/php.ini
|
||||
```
|
||||
```
|
||||
cgi.fix_pathinfo=0
|
||||
date.timezone = America/New_York
|
||||
```
|
||||
|
||||
### 5. Fix HTTP error in WordPress due to Apache mod_security modul
|
||||
|
||||
If you are using the Apache mod_security module, it might be causing problems. Try to disable it to see if that is the problem by adding the following lines in .htaccess:
|
||||
```
|
||||
<IfModule mod_security.c>
|
||||
SecFilterEngine Off
|
||||
SecFilterScanPOST Off
|
||||
</IfModule>
|
||||
```
|
||||
|
||||
### 6. Fix HTTP error in WordPress due to problematic plugin or theme
|
||||
|
||||
Some plugins and/or themes may cause HTTP errors and other problems in WordPress. You can try to disable the problematic plugins/themes, or temporarily disable all the plugins. If you have phpMyAdmin, use it to deactivate all plugins:
|
||||
Locate the table wp_options, under the option_name column (field) find the 'active_plugins' row and change the option_value field to: a:0:{}
|
||||
|
||||
Or, temporarily rename your plugins directory via SSH using the following command:
|
||||
```
|
||||
mv /www/html/path_to_wordpress/wp-content/plugins /www/html/path_to_wordpress/wp-content/plugins.old
|
||||
```
|
||||
|
||||
In general, HTTP errors are logged in the web server log files, so a good starting point is to check the web server error log on your server.
|
||||
|
||||
You don't have to Fix HTTP errors in WordPress, if you use one of our [WordPress VPS Hosting][2] services, in which case you can simply ask our expert Linux admins to **fix HTTP errors in WordPress** for you. They are available 24 ×7 and will take care of your request immediately.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.rosehosting.com/blog/http-error-wordpress/
|
||||
|
||||
作者:[rosehosting][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.rosehosting.com
|
||||
[1]:https://www.rosehosting.com/blog/wp-content/uploads/2018/01/http-error-wordpress.jpg
|
||||
[2]:https://www.rosehosting.com/wordpress-hosting.html
|
||||
@ -1,88 +0,0 @@
|
||||
translating by lujun9972
|
||||
How to Change Your Linux Console Fonts
|
||||
======
|
||||

|
||||
|
||||
I try to be a peaceful soul, but some things make that difficult, like tiny console fonts. Mark my words, friends, someday your eyes will be decrepit and you won't be able to read those tiny fonts you coded into everything, and then you'll be sorry, and I will laugh.
|
||||
|
||||
Fortunately, Linux fans, you can change your console fonts. As always, the ever-changing Linux landscape makes this less than straightforward, and font management on Linux is non-existent, so we'll muddle along as best we can. In this article, I'll show what I've found to be the easiest approach.
|
||||
|
||||
### What is the Linux Console?
|
||||
|
||||
Let us first clarify what we're talking about. When I say Linux console, I mean TTY1-6, the virtual terminals that you access from your graphical desktop with Ctrl+Alt+F1 through F6. To get back to your graphical environment, press Alt+F7. (This is no longer universal, however, and your Linux distribution may have it mapped differently. You may have more or fewer TTYs, and your graphical session may not be at F7. For example, Fedora puts the default graphical session at F2, and an extra one at F1.) I think it is amazingly cool that we can have both X and console sessions running at the same time.
|
||||
|
||||
The Linux console is part of the kernel, and does not run in an X session. This is the same console you use on headless servers that have no graphical environments. I call the terminals in a graphical session X terminals, and terminal emulators is my catch-all name for both console and X terminals.
|
||||
|
||||
But that's not all. The Linux console has come a long way from the early ANSI days, and thanks to the Linux framebuffer, it has Unicode and limited graphics support. There are also a number of console multimedia applications that we will talk about in a future article.
|
||||
|
||||
### Console Screenshots
|
||||
|
||||
The easy way to get console screenshots is from inside a virtual machine. Then you can use your favorite graphical screen capture program from the host system. You may also make screen captures from your console with [fbcat][1] or [fbgrab][2]. `fbcat` creates a portable pixmap format (PPM) image; this is a highly portable uncompressed image format that should be readable on any operating system, and of course you can convert it to whatever format you want. `fbgrab` is a wrapper script to `fbcat` that creates a PNG file. There are multiple versions of `fbgrab` written by different people floating around. Both have limited options and make only a full-screen capture.
|
||||
|
||||
`fbcat` needs root permissions, and must redirect to a file. Do not specify a file extension, but only the filename:
|
||||
```
|
||||
$ sudo fbcat > Pictures/myfile
|
||||
|
||||
```
|
||||
|
||||
After cropping in GIMP, I get Figure 1.
|
||||
|
||||
It would be nice to have a little padding on the left margin, so if any of you excellent readers know how to do this, please tell us in the comments.
|
||||
|
||||
`fbgrab` has a few more options that you can read about in `man fbgrab`, such as capturing a different console, and time delay. This example makes a screen grab just like `fbcat`, except you don't have to explicitly redirect:
|
||||
```
|
||||
$ sudo fbgrab Pictures/myOtherfile
|
||||
|
||||
```
|
||||
|
||||
### Finding Fonts
|
||||
|
||||
As far as I know, there is no way to list your installed kernel fonts other than looking in the directories they are stored in: `/usr/share/consolefonts/` (Debian/etc.), `/lib/kbd/consolefonts/` (Fedora), `/usr/share/kbd/consolefonts` (openSUSE)...you get the idea.
|
||||
|
||||
### Changing Fonts
|
||||
|
||||
Readable fonts are not a new concept. Embrace the old! Readability matters. And so does configurability, which sometimes gets lost in the rush to the new-shiny.
|
||||
|
||||
On Debian/Ubuntu/etc. systems you can run `sudo dpkg-reconfigure console-setup` to set your console font, then run the `setupcon` command in your console to activate the changes. `setupcon` is part of the `console-setup` package. If your Linux distribution doesn't include it, there might be a package for you at [openSUSE][3].
|
||||
|
||||
You can also edit `/etc/default/console-setup` directly. This example sets the Terminus Bold font at 32 points, which is my favorite, and restricts the width to 80 columns.
|
||||
```
|
||||
ACTIVE_CONSOLES="/dev/tty[1-6]"
|
||||
CHARMAP="UTF-8"
|
||||
CODESET="guess"
|
||||
FONTFACE="TerminusBold"
|
||||
FONTSIZE="16x32"
|
||||
SCREEN_WIDTH="80"
|
||||
|
||||
```
|
||||
|
||||
The FONTFACE and FONTSIZE values come from the font's filename, `TerminusBold32x16.psf.gz`. Yes, you have to know to reverse the order for FONTSIZE. Computers are so much fun. Run `setupcon` to apply the new configuration. You can see the whole character set for your active font with `showconsolefont`. Refer to `man console-setup` for complete options.
|
||||
|
||||
### Systemd
|
||||
|
||||
Systemd is different from `console-setup`, and you don't need to install anything, except maybe some extra font packages. All you do is edit `/etc/vconsole.conf` and then reboot. On my Fedora and openSUSE systems I had to install some extra Terminus packages to get the larger sizes as the installed fonts only went up to 16 points, and I wanted 32. This is the contents of `/etc/vconsole.conf` on both systems:
|
||||
```
|
||||
KEYMAP="us"
|
||||
FONT="ter-v32b"
|
||||
|
||||
```
|
||||
|
||||
Come back next week to learn some more cool console hacks, and some multimedia console applications.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][4]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/1/how-change-your-linux-console-fonts
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:http://jwilk.net/software/fbcat
|
||||
[2]:https://github.com/jwilk/fbcat/blob/master/fbgrab
|
||||
[3]:https://software.opensuse.org/package/console-setup
|
||||
[4]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,3 +1,5 @@
|
||||
translating by Flowsnow
|
||||
|
||||
Ansible: the Automation Framework That Thinks Like a Sysadmin
|
||||
======
|
||||
|
||||
@ -185,7 +187,6 @@ You should see the results of the uptime command for each host in the webservers
|
||||
|
||||
In a future article, I plan start to dig in to Ansible's ability to manage the remote computers. I'll look at various modules and how you can use the ad-hoc mode to accomplish in a few keystrokes what would take a long time to handle individually on the command line. If you didn't get the results you expected from the sample Ansible commands above, take this time to make sure authentication is working. Check out [the Ansible docs][1] for more help if you get stuck.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/ansible-automation-framework-thinks-sysadmin
|
||||
|
||||
@ -1,72 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Display Asterisks When You Type Password In terminal
|
||||
======
|
||||
|
||||

|
||||
|
||||
When you type passwords in a web browser login or any GUI login, the passwords will be masked as asterisks like 0_sync_master.sh 1_add_new_article_manual.sh 1_add_new_article_newspaper.sh 2_start_translating.sh 3_continue_the_work.sh 4_finish.sh 5_pause.sh base.sh env format.test lctt.cfg parse_url_by_manual.sh parse_url_by_newspaper.py parse_url_by_newspaper.sh README.org reedit.sh reformat.sh or bullets like •••••••••••••. This is the built-in security mechanism to prevent the users near you to view your password. But when you type the password in Terminal to perform any administrative task with **sudo** or **su** , you won't even the see the asterisks or bullets as you type the password. There won't be any visual indication of entering passwords, there won't be any cursor movement, nothing at all. You will not know whether you entered all characters or not. All you will see just a blank screen!
|
||||
|
||||
Look at the following screenshot.
|
||||
|
||||
![][2]
|
||||
|
||||
As you see in the above image, I've already entered the password, but there was no indication (either asterisks or bullets). Now, I am not sure whether I entered all characters in my password or not. This security mechanism also prevents the person near you to guess the password length. Of course, this behavior can be changed. This is what this guide all about. It is not that difficult. Read on!
|
||||
|
||||
#### Display Asterisks When You Type Password In terminal
|
||||
|
||||
To display asterisks as you type password in Terminal, we need to make a small modification in **" /etc/sudoers"** file. Before making any changes, it is better to backup this file. To do so, just run:
|
||||
```
|
||||
sudo cp /etc/sudoers{,.bak}
|
||||
```
|
||||
|
||||
The above command will backup /etc/sudoers file to a new file named /etc/sudoers.bak. You can restore it, just in case something went wrong after editing the file.
|
||||
|
||||
Next, edit **" /etc/sudoers"** file using command:
|
||||
```
|
||||
sudo visudo
|
||||
```
|
||||
|
||||
Find the following line:
|
||||
```
|
||||
Defaults env_reset
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
Add an extra word **" ,pwfeedback"** to the end of that line as shown below.
|
||||
```
|
||||
Defaults env_reset,pwfeedback
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
Then, press **" CTRL+x"** and **" y"** to save and close the file. Restart your Terminal to take effect the changes.
|
||||
|
||||
Now, you will see asterisks when you enter password in Terminal.
|
||||
|
||||
![][5]
|
||||
|
||||
If you're not comfortable to see a blank screen when you type passwords in Terminal, the small tweak will help. Please be aware that the other users can predict the password length if they see the password when you type it. If you don't mind it, go ahead make the changes as described above to make your password visible (masked as asterisks, of course!).
|
||||
|
||||
And, that's all for now. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/display-asterisks-type-password-terminal/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/password-1.png ()
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-1.png ()
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-1-1.png ()
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-2.png ()
|
||||
@ -0,0 +1,147 @@
|
||||
Best Linux Screenshot and Screencasting Tools
|
||||
======
|
||||

|
||||
|
||||
There comes a time you want to capture an error on your screen and send it to the developers or want help from _Stack Overflow,_ you need the right tools to take that screenshot and save it or send it. There are tools in the form of programs and others as shell extensions for GNOME. Not to worry, here are the best Linux Screenshot taking tools that you can use to take those screenshots or make a screencast.
|
||||
|
||||
## Best Linux Screenshot Or Screencasting Tools
|
||||
|
||||
### 1\. Shutter
|
||||
|
||||
[][2]
|
||||
|
||||
[Shutter][3] is one of the best Linux screenshot taking tools. It has the advantage of taking different screenshots depending on what you want to take on your screen. After you take the screenshot, it allows you to see the screenshot before saving it after you take the screenshot. It also includes an extension menu that shows up on your top panel for GNOME. That makes accessing the app much easier and much convenient for anyone to use.
|
||||
|
||||
You can take screenshots of a selection, a window, desktop, window under cursor, section, menu, tooltip or web. Shutter allows you to upload the screenshots directly to the cloud using the preferred cloud services provider. This Linux tool also allows you to edit your screenshots before you save them. It also comes with plugins that you can add or remove.
|
||||
|
||||
To install it, you will have to type the following in the terminal:
|
||||
|
||||
```
|
||||
sudo add-apt-repository -y ppa:shutter/ppa
|
||||
sudo apt-get update && sudo apt-get install shutter
|
||||
```
|
||||
|
||||
### 2. Vokoscreen
|
||||
|
||||
[][4]
|
||||
|
||||
|
||||
[Vokoscreen][5] is an app that allows you to record your screen as you show around and narrate what you are doing on the screen. It is easy to use, has a simple interface and includes a top panel menu for easy access when you are recording your screen.
|
||||
|
||||
|
||||
|
||||
You can choose to record the whole screen, a window or just a selection of an area. Customizing the recording is easy to get the type of screen recording you want to achieve. Vokoscreen even allows you to create a gif as a screen recording. You can also record yourself using the webcam in case you were narrating as tutorials so that you can engage the learners. Once you are done, you can playback the recording right from the application so that you don’t have to keep navigating to find the recording.
|
||||
|
||||
[][6]
|
||||
|
||||
You can install Vocoscreen from your distro repository. Or download the package from [pkgs.org][7] , select the Linux distro you are using.
|
||||
|
||||
```
|
||||
sudo dpkg -i vokoscreen_2.5.0-1_amd64.deb
|
||||
```
|
||||
|
||||
### 3. OBS
|
||||
|
||||
[][8]
|
||||
|
||||
[OBS][9] can be used to record your screen as well as record streams from the internet. It allows you to see whatever you are recording as you stream or as you narrate your screen recording. It allows you to choose the quality of your recording according to your preferences. It also allows you to choose the type of file you want your recording to save to. In addition to the feature of recording, you can switch to Studio mode allowing you to edit your recording to make a complete video without having to use any other external editing software. To install OBS in your Linux distribution, you must have FFmpeg installed on your machine. To install FFmpeg type the following in the terminal for ubuntu 14.04 and earlier:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:kirillshkrogalev/ffmpeg-next
|
||||
|
||||
sudo apt-get update && sudo apt-get install ffmpeg
|
||||
```
|
||||
|
||||
For ubuntu 15.04 and later you can just type the following in the terminal to install FFmpeg:
|
||||
|
||||
```
|
||||
sudo apt-get install ffmpeg
|
||||
```
|
||||
|
||||
If you have already installed FFmpeg, type the following in the terminal to install OBS:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:obsproject/obs-studio
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install obs-studio
|
||||
```
|
||||
|
||||
### 4. Green Recorder
|
||||
|
||||
[][10]
|
||||
|
||||
[Green recorder][11] is a simple interface based program that allows you to record the screen. You can choose what to record including video or just audio and allow you to show the mouse pointer and even follow it as you record your screen. You can record a window or just a selected area on your screen so that only what you want to record shows up in your recording. You can customize the number of frames to record in your final video. In case you want to start recording after a delay, you have the option to configure the delay you wish to set. You have the option to run a command after the recording is done that will run on your machine immediately after you stop recording.
|
||||
|
||||
|
||||
|
||||
To install green recorder, type the following in the terminal:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:fossproject/ppa
|
||||
|
||||
sudo apt update && sudo apt install green-recorder
|
||||
```
|
||||
|
||||
### 5. Kazam
|
||||
|
||||
[][12]
|
||||
|
||||
[Kazam][13] Linux screenshot tool is very popular amongst Linux users. It is an intuitive simple to use app that allows you to take a screencast or a screenshot allowing you to customise the delay before taking a screencast or screenshot. It allows you to select the area, window or fullscreen you want to capture. Kazam’s interface is well laid out and not as complicated as other apps. Its features will leave you happy about taking your screenshots. Kazam also includes a system tray icon and menu that allows you to take the screenshot without going to the application itself.
|
||||
|
||||
|
||||
|
||||
To install Kazam, type the following in the terminal:
|
||||
|
||||
```
|
||||
sudo apt-get install kazam
|
||||
```
|
||||
|
||||
If the PPA is not found, you can install it manually using the following commands:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:kazam-team/stable-series
|
||||
|
||||
sudo apt-get update && sudo apt-get install kazam
|
||||
```
|
||||
|
||||
### 6. Screenshot tool GNOME extension
|
||||
|
||||
[][1]
|
||||
|
||||
There is a GNOME extension just named screenshot tool that always shows up on the system panel until you disable it. It is convenient since it just sits on the system panel until you will trigger it to take a screenshot. The main advantage of this tool is that it is the quickest to access since it is always in your system panel unless you deactivate it in the tweak utility tool. The tool also has a preferences window allowing you to tweak it to your preferences. To install it on your GNOME desktop, head to extensions.gnome.org and search for “_Screenshot Tool”._
|
||||
|
||||
You must have the gnome extensions chrome extension installed as well as GNOME tweaks tool installed to use the tool.
|
||||
|
||||
[][14]
|
||||
|
||||
The **Linux screenshot tools** are quite helpful especially when you don’t know what to do when you come across a problem and want to share the error with [the Linux community][15] or the developers of a program that you are using. Learning developers or programmers or anyone else need it will find these tools useful to share your screenshots. Youtubers and tutorial makers will find the screencasting tools even more useful when they use them to record their tutorials and post them.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/best-linux-screenshot-screencasting-tools
|
||||
|
||||
作者:[linuxandubuntu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-screenshot-extension-compressed_orig.jpg
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/shutter-linux-screenshot-taking-tools_orig.jpg
|
||||
[3]:http://shutter-project.org/
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vokoscreen-screencasting-tool-for-linux_orig.jpg
|
||||
[5]:https://github.com/vkohaupt/vokoscreen
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vokoscreen-preferences_orig.jpg
|
||||
[7]:https://pkgs.org/download/vokoscreen
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/obs-linux-screencasting-tool_orig.jpg
|
||||
[9]:https://obsproject.com/
|
||||
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/green-recording-linux-tool_orig.jpg
|
||||
[11]:https://github.com/foss-project/green-recorder
|
||||
[12]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/kazam-screencasting-tool-for-linux_orig.jpg
|
||||
[13]:https://launchpad.net/kazam
|
||||
[14]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-screenshot-extension-preferences_orig.jpg
|
||||
[15]:http://www.linuxandubuntu.com/home/top-10-communities-to-help-you-learn-linux
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by Yinr
|
||||
|
||||
Multimedia Apps for the Linux Console
|
||||
======
|
||||
|
||||
|
||||
@ -1,112 +0,0 @@
|
||||
The Fold Command Tutorial With Examples For Beginners
|
||||
======
|
||||
|
||||

|
||||
|
||||
Have you ever found yourself in a situation where you want to fold or break the output of a command to fit within a specific width? I have find myself in this situation few times while running VMs, especially the servers with no GUI. Just in case, if you ever wanted to limit the output of a command to a particular width, look nowhere! Here is where **fold** command comes in handy! The fold command wraps each line in an input file to fit a specified width and prints it to the standard output.
|
||||
|
||||
In this brief tutorial, we are going to see the usage of fold command with practical examples.
|
||||
|
||||
### The Fold Command Tutorial With Examples
|
||||
|
||||
Fold command is the part of GNU coreutils package, so let us not bother about installation.
|
||||
|
||||
The typical syntax of fold command:
|
||||
```
|
||||
fold [OPTION]... [FILE]...
|
||||
```
|
||||
|
||||
Allow me to show you some examples, so you can get a better idea about fold command. I have a file named **linux.txt** with some random lines.
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
To wrap each line in the above file to default width, run:
|
||||
```
|
||||
fold linux.txt
|
||||
```
|
||||
|
||||
**80** columns per line is the default width. Here is the output of above command:
|
||||
|
||||
[![][1]][3]
|
||||
|
||||
As you can see in the above output, fold command has limited the output to a width of 80 characters.
|
||||
|
||||
Of course, we can specify your preferred width, for example 50, like below:
|
||||
```
|
||||
fold -w50 linux.txt
|
||||
```
|
||||
|
||||
Sample output would be:
|
||||
|
||||
[![][1]][4]
|
||||
|
||||
Instead of just displaying output, we can also write the output to a new file as shown below:
|
||||
```
|
||||
fold -w50 linux.txt > linux1.txt
|
||||
```
|
||||
|
||||
The above command will wrap the lines of **linux.txt** to a width of 50 characters, and writes the output to new file named **linux1.txt**.
|
||||
|
||||
Let us check the contents of the new file:
|
||||
```
|
||||
cat linux1.txt
|
||||
```
|
||||
|
||||
[![][1]][5]
|
||||
|
||||
Did you closely notice the output of the previous commands? Some words are broken between lines. To overcome this issue, we can use -s flag to break the lines at spaces.
|
||||
|
||||
The following command wraps each line in a given file to width "50" and breaks the line at spaces:
|
||||
```
|
||||
fold -w50 -s linux.txt
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
[![][1]][6]
|
||||
|
||||
See? Now, the output is much clear. This command puts each space separated word in a new line and words with length > 50 are wrapped.
|
||||
|
||||
In all above examples, we limited the output width by columns. However, we can enforce the width of the output to the number of bytes specified using **-b** option. The following command breaks the output at 20 bytes.
|
||||
```
|
||||
fold -b20 linux.txt
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
[![][1]][7]
|
||||
|
||||
**Also read:**
|
||||
|
||||
+ [The Uniq Command Tutorial With Examples For Beginners][8]
|
||||
|
||||
For more details, refer the man pages.
|
||||
```
|
||||
man fold
|
||||
```
|
||||
|
||||
And, that's for now folks. You know now how to use fold command to limit the output of a command to fit in a specific width. I hope this was useful. We will be posting more useful guides everyday. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/fold-command-tutorial-examples-beginners/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-1.png ()
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-2.png ()
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-3-1.png ()
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-4.png ()
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-5-1.png ()
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-6-1.png ()
|
||||
[8]:https://www.ostechnix.com/uniq-command-tutorial-examples-beginners/
|
||||
@ -0,0 +1,121 @@
|
||||
The open organization and inner sourcing movements can share knowledge
|
||||
======
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
Red Hat is a company with roughly 11,000 employees. The IT department consists of roughly 500 members. Though it makes up just a fraction of the entire organization, the IT department is still sufficiently staffed to have many application service, infrastructure, and operational teams within it. Our purpose is "to enable Red Hatters in all functions to be effective, productive, innovative, and collaborative, so that they feel they can make a difference,"--and, more specifically, to do that by providing technologies and related services in a fashion that is as open as possible.
|
||||
|
||||
Being open like this takes time, attention, and effort. While we always strive to be as open as possible, it can be difficult. For a variety of reasons, we don't always succeed.
|
||||
|
||||
In this story, I'll explain a time when, in the rush to innovate, the Red Hat IT organization lost sight of its open ideals. But I'll also explore how returning to those ideals--and using the collaborative tactics of "inner source"--helped us to recover and greatly improve the way we deliver services.
|
||||
|
||||
### About inner source
|
||||
|
||||
Before I explain how inner source helped our team, let me offer some background on the concept.
|
||||
|
||||
Inner source is the adoption of open source development practices between teams within an organization to promote better and faster delivery without requiring project resources be exposed to the world or openly licensed. It allows an organization to receive many of the benefits of open source development methods within its own walls.
|
||||
|
||||
In this way, inner source aligns well with open organization strategies and principles; it provides a path for open, collaborative development. While the open organization defines its principles of openness broadly as transparency, inclusivity, adaptability, collaboration, and community--and covers how to use these open principles for communication, decision making, and many other topics--inner source is about the adoption of specific and tactical practices, processes, and patterns from open source communities to improve delivery.
|
||||
|
||||
For instance, [the Open Organization Maturity Model][1] suggests that in order to be transparent, teams should, at minimum, share all project resources with the project team (though it suggests that it's generally better to share these resources with the entire organization). The common pattern in both inner source and open source development is to host all resources in a publicly available version control system, for source control management, which achieves the open organization goal of high transparency.
|
||||
|
||||
Inner source aligns well with open organization strategies and principles.
|
||||
|
||||
Another example of value alignment appears in the way open source communities accept contributions. In open source communities, source code is transparently available. Community contributions in the form of patches or merge requests are commonly accepted practices (even expected ones). This provides one example of how to meet the open organization's goal of promoting inclusivity and collaboration.
|
||||
|
||||
### The challenge
|
||||
|
||||
Early in 2014, Red Hat IT began its first steps toward making Amazon Web Services (AWS) a standard hosting offering for business critical systems. While teams within Red Hat IT had built several systems and services in AWS by this time, these were bespoke creations, and we desired to make deploying services to IT standards in AWS both simple and standardized.
|
||||
|
||||
In order to make AWS cloud hosting meet our operational standards (while being scalable), the Cloud Enablement team within Red Hat IT decided that all infrastructure in AWS would be configured through code, rather than manually, and that everyone would use a standard set of tools. The Cloud Enablement team designed and built these standard tools; a separate group, the Platform Operations team, was responsible for provisioning and hosting systems and services in AWS using the tools.
|
||||
|
||||
The Cloud Enablement team built a toolset, obtusely named "Template Util," based on AWS Cloud Formations configurations wrapped in a management layer to enforce certain configuration requirements and make stamping out multiple copies of services across environments easier. While the Template Util toolset technically met all our initial requirements, and we eventually provisioned the infrastructure for more than a dozen services with it, engineers in every team working with the tool found using it to be painful. Michael Johnson, one engineer using the tool, said "It made doing something relatively straightforward really complicated."
|
||||
|
||||
Among the issues Template Util exhibited were:
|
||||
|
||||
* Underlying cloud formations technologies implied constraints on application stack management at odds with how we managed our application systems.
|
||||
* The tooling was needlessly complex and brittle in places, using multiple layered templating technologies and languages making syntax issues hard to debug.
|
||||
* The code for the tool--and some of the data users needed to manipulate the tool--were kept in a repository that was difficult for most users to access.
|
||||
* There was no standard process to contributing or accepting changes.
|
||||
* The documentation was poor.
|
||||
|
||||
|
||||
|
||||
As more engineers attempted to use the Template Util toolset, they found even more issues and limitations with the tools. Unhappiness continued to grow. To make matters worse, the Cloud Enablement team then shifted priorities to other deliverables without relinquishing ownership of the tool, so bug fixes and improvements to the tools were further delayed.
|
||||
|
||||
The real, core issues here were our inability to build an inclusive community to collaboratively build shared tooling that met everyone's needs. Fear of losing "ownership," fear of changing requirements, and fear of seeing hard work abandoned all contributed to chronic conflict, which in turn led to poorer outcomes.
|
||||
|
||||
### Crisis point
|
||||
|
||||
By September 2015, more than a year after launching our first major service in AWS with the Template Util tool, we hit a crisis point.
|
||||
|
||||
Many engineers refused to use the tools. That forced all of the related service provisioning work on a small set of engineers, further fracturing the community and disrupting service delivery roadmaps as these engineers struggled to deal with unexpected work. We called an emergency meeting and invited all the teams involved to find a solution.
|
||||
|
||||
During the emergency meeting, we found that people generally thought we needed immediate change and should start the tooling effort over, but even the decision to start over wasn't unanimous. Many solutions emerged--sometimes multiple solutions from within a single team--all of which would require significant work to implement. While we couldn't reach a consensus on which solution to use during this meeting, we did reach an agreement to give proponents of different technologies two weeks to work together, across teams, to build their case with a prototype, which the community could then review.
|
||||
|
||||
While we didn't reach a final and definitive decision, this agreement was the first point where we started to return to the open source ideals that guide our mission. By inviting all involved parties, we were able to be transparent and inclusive, and we could begin rebuilding our internal community. By making clear that we wanted to improve things and were open to new options, we showed our commitment to adaptability and meritocracy. Most importantly, the plan for building prototypes gave people a clear, return path to collaboration.
|
||||
|
||||
When the community reviewed the prototypes, it determined that the clear leader was an Ansible-based toolset that would eventually become known, internally, as Ansicloud. (At the time, no one involved with this work had any idea that Red Hat would acquire Ansible the following month. It should also be noted that other teams within Red Hat have found tools based on Cloud Formation extremely useful, even when our specific Template Util tool did not find success.)
|
||||
|
||||
This prototyping and testing phase didn't fix things overnight, though. While we had consensus on the general direction we needed to head, we still needed to improve the new prototype to the point at which engineers could use it reliably for production services.
|
||||
|
||||
So over the next several months, a handful of engineers worked to further build and extend the Ansicloud toolset. We built three new production services. While we were sharing code, that sharing activity occurred at a low level of maturity. Some engineers had trouble getting access due to older processes. Other engineers headed in slightly different directions, with each engineer having to rediscover some of the core design issues themselves.
|
||||
|
||||
### Returning to openness
|
||||
|
||||
This led to a turning point: Building on top of the previous agreement, we focused on developing a unified vision and providing easier access. To do this, we:
|
||||
|
||||
1. created a list of specific goals for the project (both "must-haves" and "nice-to-haves"),
|
||||
2. created an open issue log for the project to avoid solving the same problem repeatedly,
|
||||
3. opened our code base so anyone in Red Hat could read or clone it, and
|
||||
4. made it easy for engineers to get trusted committer access
|
||||
|
||||
|
||||
|
||||
Our agreement to collaborate, our finally unified vision, and our improved tool development methods spurred the growth of our community. Ansicloud adoption spread throughout the involved organizations, but this led to a new problem: The tool started changing more quickly than users could adapt to it, and improvements that different groups submitted were beginning to affect other groups in unanticipated ways.
|
||||
|
||||
These issues resulted in our recent turn to inner source practices. While every open source project operates differently, we focused on adopting some best practices that seemed common to many of them. In particular:
|
||||
|
||||
* We identified the business owner of the project and the core-contributor group of developers who would govern the development of the tools and decide what contributions to accept. While we want to keep things open, we can't have people working against each other or breaking each other's functionality.
|
||||
* We developed a project README clarifying the purpose of the tool and specifying how to use it. We also created a CONTRIBUTING document explaining how to contribute, what sort of contributions would be useful, and what sort of tests a contribution would need to pass to be accepted.
|
||||
* We began building continuous integration and testing services for the Ansicloud tool itself. This helped us ensure we could quickly and efficiently validate contributions technically, before the project accepted and merged them.
|
||||
|
||||
|
||||
|
||||
With these basic agreements, documents, and tools available, we were back onto the path of open collaboration and successful inner sourcing.
|
||||
|
||||
### Why it matters
|
||||
|
||||
Why does inner source matter?
|
||||
|
||||
From a developer community point of view, shifting from a traditional siloed development model to the inner source model has produced significant, quantifiable improvements:
|
||||
|
||||
* Contributions to our tooling have grown 72% per week (by number of commits).
|
||||
* The percentage of contributions from non-core committers has grown from 27% to 78%; the users of the toolset are driving its development.
|
||||
* The contributor list has grown by 15%, primarily from new users of the tool set, rather than core committers, increasing our internal community.
|
||||
|
||||
|
||||
|
||||
And the tools we've delivered through this project have allowed us to see dramatic improvements in our business outcomes. Using the Ansicloud tools, 54 new multi-environment application service deployments were created in 385 days (compared to 20 services in 1,013 days with the Template Util tools). We've gone from one new service deployment in a 50-day period to one every week--a seven-fold increase in the velocity of our delivery.
|
||||
|
||||
What really matters here is that the improvements we saw were not aberrations. Inner source provides common, easily understood patterns that organizations can adopt to effectively promote collaboration (not to mention other open organization principles). By mirroring open source production practices, inner source can also mirror the benefits of open source code, which have been seen time and time again: higher quality code, faster development, and more engaged communities.
|
||||
|
||||
This article is part of the [Open Organization Workbook project][2].
|
||||
|
||||
### about the author
|
||||
Tom Benninger - Tom Benninger is a Solutions Architect, Systems Engineer, and continual tinkerer at Red Hat, Inc. Having worked with startups, small businesses, and larger enterprises, he has experience within a broad set of IT disciplines. His current area of focus is improving Application Lifecycle Management in the enterprise. He has a particular interest in how open source, inner source, and collaboration can help support modern application development practices and the adoption of DevOps, CI/CD, Agile,...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/1/open-orgs-and-inner-source-it
|
||||
|
||||
作者:[Tom Benninger][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tomben
|
||||
[1]:https://opensource.com/open-organization/resources/open-org-maturity-model
|
||||
[2]:https://opensource.com/open-organization/17/8/workbook-project-announcement
|
||||
80
sources/tech/20180114 Playing Quake 4 on Linux in 2018.md
Normal file
80
sources/tech/20180114 Playing Quake 4 on Linux in 2018.md
Normal file
@ -0,0 +1,80 @@
|
||||
Playing Quake 4 on Linux in 2018
|
||||
======
|
||||
A few months back [I wrote an article][1] outlining the various options Linux users now have for playing Doom 3, as well as stating which of the three contenders I felt to be the best option in 2017. Having already gone to the trouble of getting the original Doom 3 binary working on my modern Arch Linux system, it made me wonder just how much effort it would take to get the closed source Quake 4 port up and running again as well.
|
||||
|
||||
### Getting it running
|
||||
|
||||
[![][2]][3] [![][4]][5]
|
||||
|
||||
Quake 4 was ported to Linux by Timothee Besset in 2005, although the binaries themselves were later taken down along with the rest of the id Software FTP server by ZeniMax. The original [Linux FAQ page][6] is still online though, and mirrors hosting the Linux installer still exist, such as [this one][7] ran by the fan website [Quaddicted][8]. Once downloaded this will give you a graphical installer which will install the game binary without any of the game assets.
|
||||
|
||||
These will need to be taken from either the game discs of a retail Windows version as I did, or taken from an already installed Windows version of the game such as from [Steam][9]. Follow the steps in the Linux FAQ to the letter for best results. Please note that the [GOG.com][10] release of Quake 4 is unique in not supplying a valid CD key, something which is still required for the Linux port to launch. There are [ways to get around this][11], but we only condone these methods for legitimate purchasers.
|
||||
|
||||
Like with Doom 3 I had to remove the libgcc_s.so.1, libSDL-1.2.id.so.0, and libstdc++.so.6 libraries that the game came with in the install directory in order to get it to run. I also ran into the same sound issue I had with Doom 3, meaning I had to modify the Quake4Config.cfg file located in the hidden ~/.quake4/q4base directory in the same fashion as before. However, this time I ran into a whole host of other issues that made me have to modify the configuration file as well.
|
||||
|
||||
First off the language the game wanted to use would always default to Spanish, meaning I had to manually tell the game to use English instead. I also ran into a known issue on all platforms wherein the game would not properly recognize the available VRAM on modern graphics cards, and as such would force the game to use lower image quality settings. Quake 4 will also not render see-through surfaces unless anti-aliasing is enabled, although going beyond 8x caused the game not to load for me.
|
||||
|
||||
Appending the following to the end of the Quake4Config.cfg file resolved all of my issues:
|
||||
|
||||
```
|
||||
seta image_downSize "0"
|
||||
seta image_downSizeBump "0"
|
||||
seta image_downSizeSpecular "0"
|
||||
seta image_filter "GL_LINEAR_MIPMAP_LINEAR"
|
||||
seta image_ignoreHighQuality "0"
|
||||
seta image_roundDown "0"
|
||||
seta image_useCompression "0"
|
||||
seta image_useNormalCompression "0"
|
||||
seta image_anisotropy "16"
|
||||
seta image_lodbias "0"
|
||||
seta r_renderer "best"
|
||||
seta r_multiSamples "8"
|
||||
seta sys_lang "english"
|
||||
seta s_alsa_pcm "hw:0,0"
|
||||
seta com_allowConsole "1"
|
||||
```
|
||||
|
||||
Please note that this will also set the game to use 8x anti-aliasing and restore the drop down console to how it worked in all of the previous Quake games. Similar to the Linux port of Doom 3 the Linux version of Quake 4 also does not support Creative EAX ADVANCED HD audio technology. Unlike Doom 3 though Quake 4 does seem to also feature an alternate method for surround sound, and widescreen support was thankfully patched into the game soon after its release.
|
||||
|
||||
### Playing the game
|
||||
|
||||
[![][12]][13] [![][14]][15]
|
||||
|
||||
Over the years Quake 4 has gained something of a reputation as the black sheep of the Quake family, with many people complaining that the game's vehicle sections, squad mechanics, and general aesthetic made it feel too close to contemporary military shooters of the time. In the game's heart of hearts though it really does feel like a concerted sequel to Quake II, with some of developer Raven Software's own Star Trek: Voyager - Elite Force title thrown in for good measure.
|
||||
|
||||
To me at least Quake 4 does stand as being one of the "Last of the Romans" in terms of being a first person shooter that embraced classic design ideals at a time when similar titles were not getting the support of major publishers. Most of the game still features the player moving between levels featuring fixed enemy placements, a wide variety of available weapons, traditional health packs, and an array of enemies each sporting unique attributes and skills.
|
||||
|
||||
Quake 4 also offers a well made campaign that I found myself going back to on a higher skill level not long after I had already finished my first try at the game. Certain aspects like the vehicle sections do indeed drag the game down a bit, and the multiplayer aspect pails in comparison to its predecessor Quake III Arena, but overall I am quite pleased with what Raven Software was able to accomplish with the Doom 3 engine, especially when so few others tried.
|
||||
|
||||
### Final thoughts
|
||||
|
||||
If anyone ever needed a reason to be reminded of the value of video game source code releases, this is it. Most of the problems I encountered could have been easily sidestepped if Quake 4 source ports were available, but with the likes of John Carmack and Timothee Besset gone from id Software and the current climate at ZeniMax not looking too promising, it is doubtful that any such creations will ever materialize. Doom 3 source ports look to be the end of the road.
|
||||
|
||||
Instead we are stuck using this cranky 32 bit binary with an obstructive CD Key check and a graphics system that freaks out at the sight of any modern video card sporting more than 512 MB of VRAM. The game itself has aged well, with graphics that still look great and dynamic lighting that is better than what is included with many modern titles. It is just a shame that it is now such a pain to get running, not just on Linux, but on any platform.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.gamingonlinux.com/articles/playing-quake-4-on-linux-in-2018.11017
|
||||
|
||||
作者:[Hamish][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.gamingonlinux.com/profiles/6
|
||||
[1]:https://www.gamingonlinux.com/articles/playing-doom-3-on-linux-in-2017.10561
|
||||
[2]:https://www.gamingonlinux.com/uploads/articles/article_images/thumbs/20458196191515697921gol6.jpg
|
||||
[3]:https://www.gamingonlinux.com/uploads/articles/article_images/20458196191515697921gol6.jpg
|
||||
[4]:https://www.gamingonlinux.com/uploads/articles/article_images/thumbs/9405540721515697921gol6.jpg
|
||||
[5]:https://www.gamingonlinux.com/uploads/articles/article_images/9405540721515697921gol6.jpg
|
||||
[6]:http://zerowing.idsoftware.com/linux/quake4/Quake4FrontPage/
|
||||
[7]:https://www.quaddicted.com/files/idgames2/idstuff/quake4/linux/
|
||||
[8]:https://www.quaddicted.com/
|
||||
[9]:http://store.steampowered.com/app/2210/Quake_IV/
|
||||
[10]:https://www.gog.com/game/quake_4
|
||||
[11]:https://www.gog.com/forum/quake_series/quake_4_on_linux_no_cd_key/post31
|
||||
[12]:https://www.gamingonlinux.com/uploads/articles/article_images/thumbs/5043571471515951537gol6.jpg
|
||||
[13]:https://www.gamingonlinux.com/uploads/articles/article_images/5043571471515951537gol6.jpg
|
||||
[14]:https://www.gamingonlinux.com/uploads/articles/article_images/thumbs/6922853731515697921gol6.jpg
|
||||
[15]:https://www.gamingonlinux.com/uploads/articles/article_images/6922853731515697921gol6.jpg
|
||||
@ -0,0 +1,77 @@
|
||||
What a GNU C Compiler Bug looks like
|
||||
======
|
||||
Back in December a Linux Mint user sent a [strange bug report][1] to the darktable mailing list. Apparently the GNU C Compiler (GCC) on his system exited with the following error message, breaking the build process:
|
||||
```
|
||||
cc1: error: unrecognized command line option '-Wno-format-truncation' [-Werror]
|
||||
cc1: all warnings being treated as errors
|
||||
src/iop/CMakeFiles/colortransfer.dir/build.make:67: recipe for target 'src/iop/CMakeFiles/colortransfer.dir/introspection_colortransfer.c.o' failed make[2]: 0_sync_master.sh 1_add_new_article_manual.sh 1_add_new_article_newspaper.sh 2_start_translating.sh 3_continue_the_work.sh 4_finish.sh 5_pause.sh base.sh env format.test lctt.cfg parse_url_by_manual.sh parse_url_by_newspaper.py parse_url_by_newspaper.sh README.org reformat.sh [src/iop/CMakeFiles/colortransfer.dir/introspection_colortransfer.c.o] Error 1 CMakeFiles/Makefile2:6323: recipe for target 'src/iop/CMakeFiles/colortransfer.dir/all' failed
|
||||
|
||||
make[1]: 0_sync_master.sh 1_add_new_article_manual.sh 1_add_new_article_newspaper.sh 2_start_translating.sh 3_continue_the_work.sh 4_finish.sh 5_pause.sh base.sh env format.test lctt.cfg parse_url_by_manual.sh parse_url_by_newspaper.py parse_url_by_newspaper.sh README.org reformat.sh [src/iop/CMakeFiles/colortransfer.dir/all] Error 2
|
||||
|
||||
```
|
||||
|
||||
`-Wno-format-truncation` is a rather new GCC feature which instructs the compiler to issue a warning if it can already deduce at compile time that calls to formatted I/O functions like `snprintf()` or `vsnprintf()` might result in truncated output.
|
||||
|
||||
That's definitely neat, but Linux Mint 18.3 (just like Ubuntu 16.04 LTS) uses GCC 5.4.0, which doesn't support this feature. And darktable relies on a chain of CMake macros to make sure it doesn't use any flags the compiler doesn't know about:
|
||||
```
|
||||
CHECK_COMPILER_FLAG_AND_ENABLE_IT(-Wno-format-truncation)
|
||||
|
||||
```
|
||||
|
||||
So why did this even happen? I logged into one of my Ubuntu 16.04 installations and tried to reproduce the problem. Which wasn't hard, I just had to check out the git tree in question and build it. Boom, same error.
|
||||
|
||||
### The solution
|
||||
|
||||
It turns out that while `-Wformat-truncation` isn't a valid option for GCC 5.4.0 (it's not documented), this version silently accepts the negation under some circumstances (!):
|
||||
```
|
||||
|
||||
sturmflut@hogsmeade:/tmp$ gcc -Wformat-truncation -o test test.c
|
||||
gcc: error: unrecognized command line option '-Wformat-truncation'
|
||||
sturmflut@hogsmeade:/tmp$ gcc -Wno-format-truncation -o test test.c
|
||||
sturmflut@hogsmeade:/tmp$
|
||||
|
||||
```
|
||||
|
||||
(test.c just contains an empty main() method).
|
||||
|
||||
Because darktable uses `CHECK_COMPILER_FLAG_AND_ENABLE_IT(-Wno-format-truncation)`, it is fooled into thinking this compiler version actually supports `-Wno-format-truncation` at all times. The simple test case used by the CMake macro doesn't fail, but the compiler later decides to no longer silently accept the invalid command line option for some reason.
|
||||
|
||||
One of the cases which triggered this was when the source file under compilation had already generated some other warnings before. If I forced a serialized build using `make -j1` on a clean darktable checkout on this machine, `./src/iop/colortransfer.c` actually was the first file which caused any
|
||||
compiler warnings at all, so this is why the process failed exactly there.
|
||||
|
||||
The minimum test case to trigger this behavior in GCC 5.4.0 is a C file with a `main()` function with a parameter which has the wrong type, like this one:
|
||||
```
|
||||
|
||||
int main(int argc, int argv)
|
||||
{
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Then add `-Wall` to make sure the compiler will treat this as a warning, and it fails:
|
||||
```
|
||||
|
||||
sturmflut@hogsmeade:/tmp$ gcc -Wall -Wno-format-truncation -o test test.c
|
||||
test.c:1:5: warning: second argument of 'main' should be 'char **' [-Wmain]
|
||||
int main(int argc, int argv)
|
||||
^
|
||||
cc1: warning: unrecognized command line option '-Wno-format-truncation'
|
||||
|
||||
```
|
||||
|
||||
If you omit `-Wall`, the compiler will not generate the first warning and also not complain about `-Wno-format-truncation`.
|
||||
|
||||
I've never run into this before, but I guess Ubuntu 16.04 is going to stay with us for a while since it is the current LTS release until May 2018, and even after that it will still be supported until 2021. So this buggy GCC version will most likely also stay alive for quite a while. Which is why the check for this flag has been removed from the
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.lieberbiber.de/2018/01/14/what-a-gnu-compiler-bug-looks-like/
|
||||
|
||||
作者:[sturmflut][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.lieberbiber.de/author/sturmflut/
|
||||
[1]:https://www.mail-archive.com/darktable-dev@lists.darktable.org/msg02760.html
|
||||
@ -1,47 +1,47 @@
|
||||
剖析内存中的程序
|
||||
剖析内存中的程序之秘
|
||||
============================================================
|
||||
|
||||
内存管理是一个操作系统的核心任务;它对程序员和系统管理员来说也是至关重要的。在接下来的几篇文章中,我将从实践出发着眼于内存管理,并深入到它的内部结构。尽管这些概念很普通,示例也大都来自于 32 位 x86 架构的 Linux 和 Windows 上。第一篇文章描述了在内存中程序如何分布。
|
||||
内存管理是操作系统的核心任务;它对程序员和系统管理员来说也是至关重要的。在接下来的几篇文章中,我将从实践出发着眼于内存管理,并深入到它的内部结构。虽然这些概念很通用,但示例大都来自于 32 位 x86 架构的 Linux 和 Windows 上。这第一篇文章描述了在内存中程序如何分布。
|
||||
|
||||
在一个多任务操作系统中的每个进程都运行在它自己的内存“沙箱”中。这个沙箱是一个虚拟地址空间,它在 32 位的模式中它总共有 4GB 的内存地址块。这些虚拟地址是通过内核页表映射到物理地址的,并且这些虚拟地址是由操作系统内核来维护,进而被进程所消费的。每个进程都有它自己的一组页表,但是在它这里仅是一个钩子。一旦虚拟地址被启用,这些虚拟地址将被应用到这台电脑上的 _所有软件_,_包括内核本身_。因此,一部分虚拟地址空间必须保留给内核使用:
|
||||
在一个多任务操作系统中的每个进程都运行在它自己的内存“沙箱”中。这个沙箱是一个<ruby>虚拟地址空间<rt>virtual address space</rt></ruby>,在 32 位的模式中它总共有 4GB 的内存地址块。这些虚拟地址是通过内核<ruby>页表<rt>page table</rt></ruby>映射到物理地址的,并且这些虚拟地址是由操作系统内核来维护,进而被进程所消费的。每个进程都有它自己的一组页表,但是这里有点玄机。一旦虚拟地址被启用,这些虚拟地址将被应用到这台电脑上的 _所有软件_,_包括内核本身_。因此,一部分虚拟地址空间必须保留给内核使用:
|
||||
|
||||
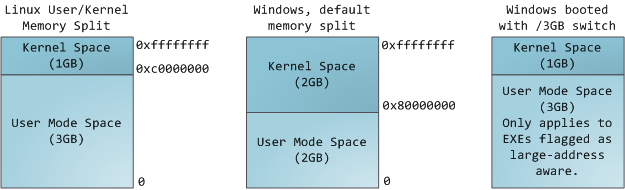
|
||||
|
||||
但是,这并不说内核就使用了很多的物理内存,恰恰相反,它只使用了很少一部分用于去做地址映射。内核空间在内核页表中被标记为仅 [特权代码][1] (ring 2 或更低)独占使用,因此,如果一个用户模式的程序尝试去访问它,将触发一个页面故障错误。在 Linux 中,内核空间是始终存在的,并且在所有进程中都映射相同的物理内存。内核代码和数据总是可寻址的,准备随时去处理中断或者系统调用。相比之下,用户模式中的地址空间,在每次进程切换时都会发生变化:
|
||||
但是,这并**不是**说内核就使用了很多的物理内存,恰恰相反,它只使用了很少一部分可用的地址空间映射到其所需要的物理内存。内核空间在内核页表中被标记为独占使用于 [特权代码][1] (ring 2 或更低),因此,如果一个用户模式的程序尝试去访问它,将触发一个页面故障错误。在 Linux 中,内核空间是始终存在的,并且在所有进程中都映射相同的物理内存。内核代码和数据总是可寻址的,准备随时去处理中断或者系统调用。相比之下,用户模式中的地址空间,在每次进程切换时都会发生变化:
|
||||
|
||||
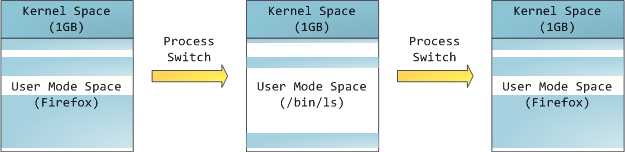
|
||||
|
||||
蓝色的区域代表映射到物理地址的虚拟地址空间,白色的区域是尚未映射的部分。在上面的示例中,Firefox 因它令人惊奇的“狂吃”内存而使用了大量的虚拟内存空间。在地址空间中不同的组合对应了不同的内存段,像堆、栈、等等。请注意,这些段只是一系列内存地址的简化表示,它与 [Intel 类型的段][2] _并没有任何关系_ 。不过,这是一个在 Linux 中的标准的段布局:
|
||||
蓝色的区域代表映射到物理地址的虚拟地址空间,白色的区域是尚未映射的部分。在上面的示例中,众所周知的内存“饕餮” Firefox 使用了大量的虚拟内存空间。在地址空间中不同的条带对应了不同的内存段,像<ruby>堆<rt>heap</rt></ruby>、<ruby>栈<rt>stack</rt></ruby>等等。请注意,这些段只是一系列内存地址的简化表示,它与 [Intel 类型的段][2] _并没有任何关系_ 。不过,这是一个在 Linux 进程的标准段布局:
|
||||
|
||||
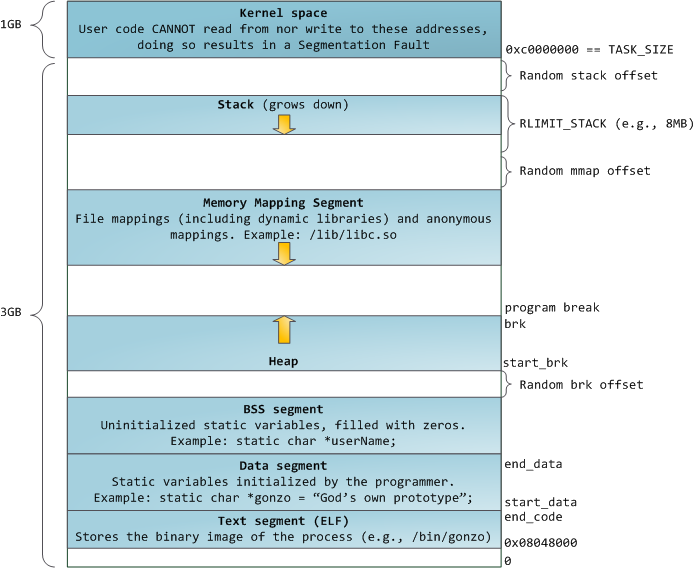
|
||||
|
||||
当计算是快乐、安全、讨人喜欢的时候,在机器中的几乎每个进程上,它们的起始虚拟地址段都是完全相同的。这将使远程挖掘安全漏洞变得容易。一个漏洞利用经常需要去引用绝对内存位置:在栈中的一个地址,这个地址可能是一个库的函数,等等。远程攻击必须要“盲选”这个地址,因为地址空间都是相同的。当攻击者们这样做的时候,人们就会受到伤害。因此,地址空间随机化开始流行起来。Linux 随机化栈、内存映射段、以及在堆上增加起始地址偏移量。不幸的是,32 位的地址空间是非常拥挤的,为地址空间随机化留下的空间不多,因此 [妨碍了地址空间随机化的效果][6]。
|
||||
当计算机还是快乐、安全的时代时,在机器中的几乎每个进程上,那些段的起始虚拟地址都是**完全相同**的。这将使远程挖掘安全漏洞变得容易。漏洞利用经常需要去引用绝对内存位置:比如在栈中的一个地址,一个库函数的地址,等等。远程攻击闭着眼睛也会选择这个地址,因为地址空间都是相同的。当攻击者们这样做的时候,人们就会受到伤害。因此,地址空间随机化开始流行起来。Linux 会通过在其起始地址上增加偏移量来随机化[栈][3]、[内存映射段][4]、以及[堆][5]。不幸的是,32 位的地址空间是非常拥挤的,为地址空间随机化留下的空间不多,因此 [妨碍了地址空间随机化的效果][6]。
|
||||
|
||||
在进程地址空间中最高的段是栈,在大多数编程语言中它存储本地变量和函数参数。调用一个方法或者函数将推送一个新的栈帧到这个栈。当函数返回时这个栈帧被删除。这个简单的设计,可能是因为数据严格遵循 [后进先出(LIFO)][7] 的次序,这意味着跟踪栈内容时不需要复杂的数据结构 – 一个指向栈顶的简单指针就可以做到。推送和弹出也因此而非常快且准确。也可能是,持续的栈区重用倾向于在 [CPU 缓存][8] 中保持活跃的栈内存,这样可以加快访问速度。进程中的每个线程都有它自己的栈。
|
||||
在进程地址空间中最高的段是栈,在大多数编程语言中它存储本地变量和函数参数。调用一个方法或者函数将推送一个新的<ruby>栈帧<rt>stack frame</rt></ruby>到这个栈。当函数返回时这个栈帧被删除。这个简单的设计,可能是因为数据严格遵循 [后进先出(LIFO)][7] 的次序,这意味着跟踪栈内容时不需要复杂的数据结构 —— 一个指向栈顶的简单指针就可以做到。推入和弹出也因此而非常快且准确。也可能是,持续的栈区重用往往会在 [CPU 缓存][8] 中保持活跃的栈内存,这样可以加快访问速度。进程中的每个线程都有它自己的栈。
|
||||
|
||||
向栈中推送更多的而不是刚合适的数据可能会耗尽栈的映射区域。这将触发一个页面故障,在 Linux 中它是通过 [expand_stack()][9] 来处理的,它会去调用 [acct_stack_growth()][10] 来检查栈的增长是否正常。如果栈的大小低于 <tt>RLIMIT_STACK</tt> 的值(一般是 8MB 大小),那么这是一个正常的栈增长和程序的合理使用,否则可能是发生了未知问题。这是一个栈大小按需调节的常见机制。但是,栈的大小达到了上述限制,将会发生一个栈溢出,并且,程序将会收到一个段故障错误。当映射的栈为满足需要而扩展后,在栈缩小时,映射区域并不会收缩。就像美国联邦政府的预算一样,它只会扩张。
|
||||
向栈中推送更多的而不是刚合适的数据可能会耗尽栈的映射区域。这将触发一个页面故障,在 Linux 中它是通过 [`expand_stack()`][9] 来处理的,它会去调用 [`acct_stack_growth()`][10] 来检查栈的增长是否正常。如果栈的大小低于 `RLIMIT_STACK` 的值(一般是 8MB 大小),那么这是一个正常的栈增长和程序的合理使用,否则可能是发生了未知问题。这是一个栈大小按需调节的常见机制。但是,栈的大小达到了上述限制,将会发生一个栈溢出,并且,程序将会收到一个<ruby>段故障<rt>Segmentation Fault</rt></ruby>错误。当映射的栈区为满足需要而扩展后,在栈缩小时,映射区域并不会收缩。就像美国联邦政府的预算一样,它只会扩张。
|
||||
|
||||
动态栈增长是 [唯一例外的情况][11] ,当它去访问一个未映射的内存区域,如上图中白色部分,是允许的。除此之外的任何其它访问未映射的内存区域将在段故障中触发一个页面故障。一些映射区域是只读的,因此,尝试去写入到这些区域也将触发一个段故障。
|
||||
动态栈增长是 [唯一例外的情况][11] ,当它去访问一个未映射的内存区域,如上图中白色部分,是允许的。除此之外的任何其它访问未映射的内存区域将触发一个页面故障,导致段故障。一些映射区域是只读的,因此,尝试去写入到这些区域也将触发一个段故障。
|
||||
|
||||
在栈的下面,有内存映射段。在这里,内核将文件内容直接映射到内存。任何应用程序都可以通过 Linux 的 [mmap()][12] 系统调用( [实现][13])或者 Windows 的 [CreateFileMapping()][14] / [MapViewOfFile()][15] 来请求一个映射。内存映射是实现文件 I/O 的方便高效的方式。因此,它经常被用于加载动态库。有时候,也被用于去创建一个并不匹配任何文件的匿名内存映射,这种映射经常被用做程序数据的替代。在 Linux 中,如果你通过 [malloc()][16] 去请求一个大的内存块,C 库将会创建这样一个匿名映射而不是使用堆内存。这里的‘大’ 表示是超过了<tt>MMAP_THRESHOLD</tt> 设置的字节数,它的缺省值是 128 kB,可以通过 [mallopt()][17] 去调整这个设置值。
|
||||
在栈的下面,有内存映射段。在这里,内核将文件内容直接映射到内存。任何应用程序都可以通过 Linux 的 [`mmap()`][12] 系统调用( [代码实现][13])或者 Windows 的 [`CreateFileMapping()`][14] / [`MapViewOfFile()`][15] 来请求一个映射。内存映射是实现文件 I/O 的方便高效的方式。因此,它经常被用于加载动态库。有时候,也被用于去创建一个并不匹配任何文件的匿名内存映射,这种映射经常被用做程序数据的替代。在 Linux 中,如果你通过 [`malloc()`][16] 去请求一个大的内存块,C 库将会创建这样一个匿名映射而不是使用堆内存。这里所谓的“大”表示是超过了`MMAP_THRESHOLD` 设置的字节数,它的缺省值是 128 kB,可以通过 [`mallopt()`][17] 去调整这个设置值。
|
||||
|
||||
接下来讲的是“堆”,就在我们接下来的地址空间中,堆提供运行时内存分配,像栈一样,但又不同于栈的是,它分配的数据生存期要长于分配它的函数。大多数编程语言都为程序去提供堆管理支持。因此,满足内存需要是编程语言运行时和内核共同来做的事情。在 C 中,堆分配的接口是 [malloc()][18] ,它是个用户友好的接口,然而在编程语言的垃圾回收中,像 C# 中,这个接口使用 <tt>new</tt> 关键字。
|
||||
接下来讲的是“堆”,就在我们接下来的地址空间中,堆提供运行时内存分配,像栈一样,但又不同于栈的是,它分配的数据生存期要长于分配它的函数。大多数编程语言都为程序提供了堆管理支持。因此,满足内存需要是编程语言运行时和内核共同来做的事情。在 C 中,堆分配的接口是 [`malloc()`][18] 一族,然而在垃圾回收式编程语言中,像 C#,这个接口使用 `new` 关键字。
|
||||
|
||||
如果在堆中有足够的空间去满足内存请求,它可以由编程语言运行时来处理内存分配请求,而无需内核参与。否则将通过 [brk()][19] 系统调用([实现][20])来扩大堆以满足内存请求所需的大小。堆的管理是比较 [复杂的][21],在面对我们程序的混乱分配模式时,它通过复杂的算法,努力在速度和内存使用效率之间取得一种平衡。服务一个堆请求所需要的时间可能是非常可观的。实时系统有一个 [特定用途的分配器][22] 去处理这个问题。堆也会出现 _碎片化_ ,如下图所示:
|
||||
如果在堆中有足够的空间可以满足内存请求,它可以由编程语言运行时来处理内存分配请求,而无需内核参与。否则将通过 [`brk()`][19] 系统调用([代码实现][20])来扩大堆以满足内存请求所需的大小。堆管理是比较 [复杂的][21],在面对我们程序的混乱分配模式时,它通过复杂的算法,努力在速度和内存使用效率之间取得一种平衡。服务一个堆请求所需要的时间可能是非常可观的。实时系统有一个 [特定用途的分配器][22] 去处理这个问题。堆也会出现 _碎片化_ ,如下图所示:
|
||||
|
||||

|
||||
|
||||
最后,我们取得了内存的低位段:BSS、数据、以及程序文本。在 C 中,静态(全局)变量的内容都保存在 BSS 和数据中。它们之间的不同之处在于,BSS 保存 _未初始化的_ 静态变量的内容,它的值在源代码中并没有被程序员设置。BSS 内存区域是_匿名_的:它没有映射到任何文件上。如果你在程序中写这样的语句 <tt>static int cntActiveUsers</tt>,<tt>cntActiveUsers</tt> 的内容就保存在 BSS 中。
|
||||
最后,我们抵达了内存的低位段:BSS、数据、以及程序文本。在 C 中,静态(全局)变量的内容都保存在 BSS 和数据中。它们之间的不同之处在于,BSS 保存 _未初始化的_ 静态变量的内容,它的值在源代码中并没有被程序员设置。BSS 内存区域是 _匿名_ 的:它没有映射到任何文件上。如果你在程序中写这样的语句 `static int cntActiveUsers`,`cntActiveUsers` 的内容就保存在 BSS 中。
|
||||
|
||||
反过来,数据段,用于保存在源代码中静态变量_初始化后_的内容。这个内存区域是_非匿名_的。它映射到程序的二进值镜像上的一部分,这个二进制镜像包含在源代码中给定初始化值的静态变量内容。因此,如果你在程序中写这样的语句 <tt>static int cntWorkerBees = 10</tt>,那么,cntWorkerBees 的内容就保存在数据段中,并且初始值为 10。尽管可以通过数据段映射到一个文件,但是这是一个私有内存映射,意味着,如果在内存中这个文件发生了变化,它并不会将这种变化反映到底层的文件上。必须是这样的,否则,分配的全局变量将会改变你磁盘上的二进制文件镜像,这种做法就太不可思议了!
|
||||
反过来,数据段,用于保存在源代码中静态变量 _初始化后_ 的内容。这个内存区域是 _非匿名_ 的。它映射了程序的二进值镜像上的一部分,包含了在源代码中给定初始化值的静态变量内容。因此,如果你在程序中写这样的语句 `static int cntWorkerBees = 10`,那么,`cntWorkerBees` 的内容就保存在数据段中,并且初始值为 `10`。尽管可以通过数据段映射到一个文件,但是这是一个私有内存映射,意味着,如果改变内存,它并不会将这种变化反映到底层的文件上。必须是这样的,否则,分配的全局变量将会改变你磁盘上的二进制文件镜像,这种做法就太不可思议了!
|
||||
|
||||
用图去展示一个数据段是很困难的,因为它使用一个指针。在那种情况下,指针 <tt>gonzo</tt> 的_内容_ – 保存在数据段上的一个 4 字节的内存地址。它并没有指向一个真实的字符串。而这个字符串存在于文本段中,文本段是只读的,它用于保存你的代码中的类似于字符串常量这样的内容。文本段也映射你的内存中的库,但是,如果你的程序写入到这个区域,将会触发一个段故障错误。尽管在 C 中,它比不上从一开始就避免这种指针错误那么有效,但是,这种机制也有助于避免指针错误。这里有一个展示这些段和示例变量的图:
|
||||
用图去展示一个数据段是很困难的,因为它使用一个指针。在那种情况下,指针 `gonzo` 的_内容_(一个 4 字节的内存地址)保存在数据段上。然而,它并没有指向一个真实的字符串。而这个字符串存在于文本段中,文本段是只读的,它用于保存你的代码中的类似于字符串常量这样的内容。文本段也会在内存中映射你的二进制文件,但是,如果你的程序写入到这个区域,将会触发一个段故障错误。尽管在 C 中,它比不上从一开始就避免这种指针错误那么有效,但是,这种机制也有助于避免指针错误。这里有一个展示这些段和示例变量的图:
|
||||
|
||||
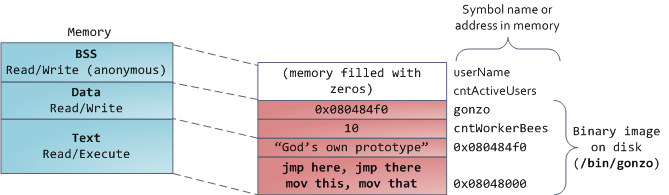
|
||||
|
||||
你可以通过读取 <tt>/proc/pid_of_process/maps</tt> 文件来检查 Linux 进程中的内存区域。请记住,一个段可以包含很多的区域。例如,每个内存映射的文件一般都在 mmap 段中的它自己的区域中,而动态库有类似于BSS 和数据一样的额外的区域。下一篇文章中我们将详细说明“区域(area)”的真正含义是什么。此外,有时候人们所说的“数据段(data segment)”是指“数据 + BSS + 堆”。
|
||||
你可以通过读取 `/proc/pid_of_process/maps` 文件来检查 Linux 进程中的内存区域。请记住,一个段可以包含很多的区域。例如,每个内存映射的文件一般都在 mmap 段中的它自己的区域中,而动态库有类似于 BSS 和数据一样的额外的区域。下一篇文章中我们将详细说明“<ruby>区域<rt>area</rt></ruby>”的真正含义是什么。此外,有时候人们所说的“<ruby>数据段<rt>data segment</rt></ruby>”是指“<ruby>数据<rt>data</rt></ruby> + BSS + 堆”。
|
||||
|
||||
你可以使用 [nm][23] 和 [objdump][24] 命令去检查二进制镜像,去显示它们的符号、地址、段、等等。最终,在 Linux 中上面描述的虚拟地址布局是一个“弹性的”布局,这就是这几年来的缺省情况。它假设 <tt>RLIMIT_STACK</tt> 有一个值。如果没有值的话,Linux 将恢复到如下所示的“经典” 布局:
|
||||
你可以使用 [nm][23] 和 [objdump][24] 命令去检查二进制镜像,去显示它们的符号、地址、段等等。最终,在 Linux 中上面描述的虚拟地址布局是一个“弹性的”布局,这就是这几年来的缺省情况。它假设 `RLIMIT_STACK` 有一个值。如果没有值的话,Linux 将恢复到如下所示的“经典” 布局:
|
||||
|
||||
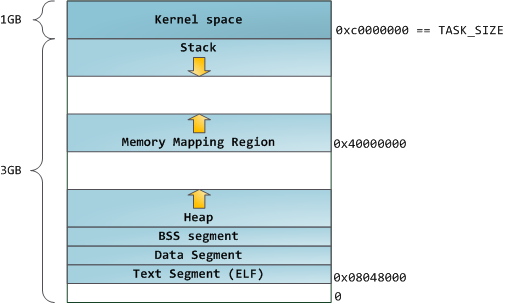
|
||||
|
||||
@ -51,9 +51,9 @@
|
||||
|
||||
via: http://duartes.org/gustavo/blog/post/anatomy-of-a-program-in-memory/
|
||||
|
||||
作者:[gustavo ][a]
|
||||
作者:[gustavo][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,76 @@
|
||||
[页面缓存,内存和文件之间的那些事][1]
|
||||
============================================================
|
||||
|
||||
|
||||
上一篇文章中我们学习了内核怎么为一个用户进程 [管理虚拟内存][2],而忽略了文件和 I/O。这一篇文章我们将专门去讲这个重要的主题 —— 页面缓存。文件和内存之间的关系常常很不好去理解,而它们对系统性能的影响却是非常大的。
|
||||
|
||||
在面对文件时,有两个很重要的问题需要操作系统去解决。第一个是相对内存而言,慢的让人发狂的硬盘驱动器,[尤其是磁盘查找][3]。第二个是需要将文件内容一次性地加载到物理内存中,以便程序间共享文件内容。如果你在 Windows 中使用 [进程浏览器][4] 去查看它的进程,你将会看到每个进程中加载了大约 ~15MB 的公共 DLLs。我的 Windows 机器上现在大约运行着 100 个进程,因此,如果不共享的话,仅这些公共的 DLLs 就要使用高达 ~1.5 GB 的物理内存。如果是那样的话,那就太糟糕了。同样的,几乎所有的 Linux 进程都需要 [ld.so][5] 和 libc,加上其它的公共库,它们占用的内存数量也不是一个小数目。
|
||||
|
||||
幸运的是,所有的这些问题都用一个办法解决了:页面缓存 —— 保存在内存中的页面大小的文件块。为了用图去说明页面缓存,我捏造出一个名为 Render 的 Linux 程序,它打开了文件 scene.dat,并且一次读取 512 字节,并将文件内容存储到一个分配的堆块中。第一次读取的过程如下:
|
||||
|
||||

|
||||
|
||||
读取完 12KB 的文件内容以后,Render 程序的堆和相关的页面帧如下图所示:
|
||||
|
||||

|
||||
|
||||
它看起来很简单,其实这一过程做了很多的事情。首先,虽然这个程序使用了普通的读取调用,但是,已经有三个 4KB 的页面帧将文件 scene.dat 的一部分内容保存在了页面缓存中。虽然有时让人觉得很惊奇,但是,普通的文件 I/O 就是这样通过页面缓存来进行的。在 x86 架构的 Linux 中,内核将文件认为是一系列的 4KB 大小的块。如果你从文件中读取单个字节,包含这个字节的整个 4KB 块将被从磁盘中读入到页面缓存中。这是可以理解的,因为磁盘通常是持续吞吐的,并且程序读取的磁盘区域也不仅仅只保存几个字节。页面缓存知道文件中的每个 4KB 块的位置,在上图中用 #0、#1、等等来描述。Windows 也是类似的,使用 256KB 大小的页面缓存。
|
||||
|
||||
不幸的是,在一个普通的文件读取中,内核必须拷贝页面缓存中的内容到一个用户缓存中,它不仅花费 CPU 时间和影响 [CPU 缓存][6],在复制数据时也浪费物理内存。如前面的图示,scene.dat 的内存被保存了两次,并且,程序中的每个实例都在另外的时间中去保存了内容。我们虽然解决了从磁盘中读取文件缓慢的问题,但是在其它的方面带来了更痛苦的问题。内存映射文件是解决这种痛苦的一个方法:
|
||||
|
||||

|
||||
|
||||
当你使用文件映射时,内核直接在页面缓存上映射你的程序的虚拟页面。这样可以显著提升性能:[Windows 系统编程][7] 的报告指出,在相关的普通文件读取上运行时性能有多达 30% 的提升,在 [Unix 环境中的高级编程][8] 的报告中,文件映射在 Linux 和 Solaris 也有类似的效果。取决于你的应用程序类型的不同,通过使用文件映射,可以节约大量的物理内存。
|
||||
|
||||
对高性能的追求是永衡不变的目标,[测量是很重要的事情][9],内存映射应该是程序员始终要使用的工具。而 API 提供了非常好用的实现方式,它允许你通过内存中的字节去访问一个文件,而不需要为了这种好处而牺牲代码可读性。在一个类 Unix 的系统中,可以使用 [mmap][11] 查看你的 [地址空间][10],在 Windows 中,可以使用 [CreateFileMapping][12],或者在高级编程语言中还有更多的可用封装。当你映射一个文件内容时,它并不是一次性将全部内容都映射到内存中,而是通过 [页面故障][13] 来按需映射的。在 [获取][15] 需要的文件内容的页面帧后,页面故障句柄在页面缓存上 [映射你的虚拟页面][14] 。如果一开始文件内容没有缓存,这还将涉及到磁盘 I/O。
|
||||
|
||||
假设我们的 Reader 程序是持续存在的实例,现在出现一个突发的状况。在页面缓存中保存着 scene.dat 内容的页面要立刻释放掉吗?这是一个人们经常要考虑的问题,但是,那样做并不是个好主意。你应该想到,我们经常在一个程序中创建一个文件,退出程序,然后,在第二个程序去使用这个文件。页面缓存正好可以处理这种情况。如果考虑更多的情况,内核为什么要清除页面缓存的内容?请记住,磁盘读取的速度要慢于内存 5 个数量级,因此,命中一个页面缓存是一件有非常大收益的事情。因此,只要有足够大的物理内存,缓存就应该始终完整保存。并且,这一原则适用于所有的进程。如果你现在运行 Render,一周后 scene.dat 的内容还在缓存中,那么应该恭喜你!这就是什么内核缓存越来越大,直至达到最大限制的原因。它并不是因为操作系统设计的太“垃圾”而浪费你的内存,其实这是一个非常好的行为,因为,释放物理内存才是一种“浪费”。(译者注:释放物理内存会导致页面缓存被清除,下次运行程序需要的相关数据,需要再次从磁盘上进行读取,会“浪费” CPU 和 I/O 资源)最好的做法是尽可能多的使用缓存。
|
||||
|
||||
由于页面缓存架构的原因,当程序调用 [write()][16] 时,字节只是被简单地拷贝到页面缓存中,并将这个页面标记为“赃”页面。磁盘 I/O 通常并不会立即发生,因此,你的程序并不会被阻塞在等待磁盘写入上。如果这时候发生了电脑死机,你的写入将不会被标记,因此,对于至关重要的文件,像数据库事务日志,必须要求 [fsync()][17]ed(仍然还需要去担心磁盘控制器的缓存失败问题),另一方面,读取将被你的程序阻塞,走到数据可用为止。内核采取预加载的方式来缓解这个矛盾,它一般提前预读取几个页面并将它加载到页面缓存中,以备你后来的读取。在你计划进行一个顺序或者随机读取时(请查看 [madvise()][18]、[readahead()][19]、[Windows cache hints][20] ),你可以通过提示(hint)帮助内核去调整这个预加载行为。Linux 会对内存映射的文件进行 [预读取][21],但是,在 Windows 上并不能确保被内存映射的文件也会预读。当然,在 Linux 中它可能会使用 [O_DIRECT][22] 跳过预读取,或者,在 Windows 中使用 [NO_BUFFERING][23] 去跳过预读,一些数据库软件就经常这么做。
|
||||
|
||||
一个内存映射的文件可以是私有的,也可以是共享的。当然,这只是针对内存中内容的更新而言:在一个私有的内存映射文件上,更新并不会提交到磁盘或者被其它进程可见,然而,共享的内存映射文件,则正好相反,它的任何更新都会提交到磁盘上,并且对其它的进程可见。内核在写机制上使用拷贝,这是通过页面表条目来实现这种私有的映射。在下面的例子中,Render 和另一个被称为 render3d 都私有映射到 scene.dat 上。然后 Render 去写入映射的文件的虚拟内存区域:
|
||||
|
||||

|
||||
|
||||
上面展示的只读页面表条目并不意味着映射是只读的,它只是内核的一个用于去共享物理内存的技巧,直到尽可能的最后一刻之前。你可以认为“私有”一词用的有点不太恰当,你只需要记住,这个“私有”仅用于更新的情况。这种设计的重要性在于,要想看到被映射的文件的变化,其它程序只能读取它的虚拟页面。一旦“写时复制”发生,从其它地方是看不到这种变化的。但是,内核并不能保证这种行为,因为它是在 x86 中实现的,从 API 的角度来看,这是有意义的。相比之下,一个共享的映射只是将它简单地映射到页面缓存上。更新会被所有的进程看到并被写入到磁盘上。最终,如果上面的映射是只读的,页面故障将触发一个内存段失败而不是写到一个副本。
|
||||
|
||||
动态加载库是通过文件映射融入到你的程序的地址空间中的。这没有什么可奇怪的,它通过普通的 APIs 为你提供与私有文件映射相同的效果。下面的示例展示了 Reader 程序映射的文件的两个实例运行的地址空间的一部分,以及物理内存,尝试将我们看到的许多概念综合到一起。
|
||||
|
||||

|
||||
|
||||
这是内存架构系列的第三部分的结论。我希望这个系列文章对你有帮助,对理解操作系统的这些主题提供一个很好的思维模型。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
[2]:https://manybutfinite.com/post/how-the-kernel-manages-your-memory
|
||||
[3]:https://manybutfinite.com/post/what-your-computer-does-while-you-wait
|
||||
[4]:http://technet.microsoft.com/en-us/sysinternals/bb896653.aspx
|
||||
[5]:http://ld.so
|
||||
[6]:https://manybutfinite.com/post/intel-cpu-caches
|
||||
[7]:http://www.amazon.com/Windows-Programming-Addison-Wesley-Microsoft-Technology/dp/0321256190/
|
||||
[8]:http://www.amazon.com/Programming-Environment-Addison-Wesley-Professional-Computing/dp/0321525949/
|
||||
[9]:https://manybutfinite.com/post/performance-is-a-science
|
||||
[10]:https://manybutfinite.com/post/anatomy-of-a-program-in-memory
|
||||
[11]:http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html
|
||||
[12]:http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx
|
||||
[13]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2678
|
||||
[14]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2436
|
||||
[15]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
|
||||
[16]:http://www.kernel.org/doc/man-pages/online/pages/man2/write.2.html
|
||||
[17]:http://www.kernel.org/doc/man-pages/online/pages/man2/fsync.2.html
|
||||
[18]:http://www.kernel.org/doc/man-pages/online/pages/man2/madvise.2.html
|
||||
[19]:http://www.kernel.org/doc/man-pages/online/pages/man2/readahead.2.html
|
||||
[20]:http://msdn.microsoft.com/en-us/library/aa363858(VS.85).aspx#caching_behavior
|
||||
[21]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
|
||||
[22]:http://www.kernel.org/doc/man-pages/online/pages/man2/open.2.html
|
||||
[23]:http://msdn.microsoft.com/en-us/library/cc644950(VS.85).aspx
|
||||
164
translated/tech/20141106 System Calls Make the World Go Round.md
Normal file
164
translated/tech/20141106 System Calls Make the World Go Round.md
Normal file
@ -0,0 +1,164 @@
|
||||
# 系统调用,让世界转起来!
|
||||
|
||||
我其实不想将它分解开给你看,一个用户应用程序在整个系统中就像一个可怜的孤儿一样无依无靠:
|
||||
|
||||
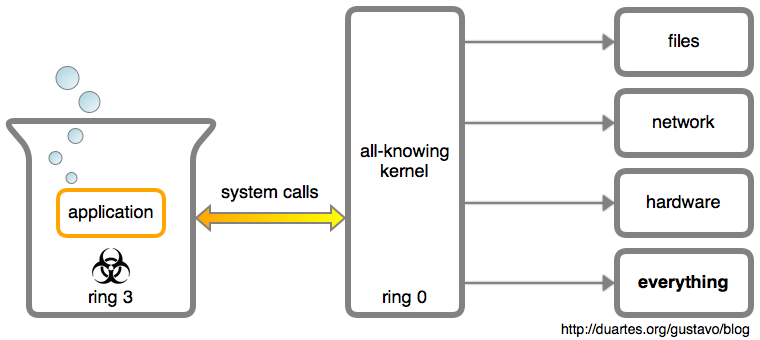
|
||||
|
||||
它与外部世界的每个交流都要在内核的帮助下通过系统调用才能完成。一个应用程序要想保存一个文件、写到终端、或者打开一个 TCP 连接,内核都要参与。应用程序是被内核高度怀疑的:认为它到处充斥着 bugs,而最糟糕的是那些充满邪恶想法的天才大脑(写的恶意程序)。
|
||||
|
||||
这些系统调用是从一个应用程序到内核的函数调用。它们因为安全考虑使用一个特定的机制,实际上你只是调用了内核的 API。“系统调用”这个术语指的是调用由内核提供的特定功能(比如,系统调用 open())或者是调用途径。你也可以简称为:syscall。
|
||||
|
||||
这篇文章讲解系统调用,系统调用与调用一个库有何区别,以及在操作系统/应用程序接口上的刺探工具。如果想彻底了解应用程序借助操作系统都发生的哪些事情?那么就可以将一个不可能解决的问题转变成一个快速而有趣的难题。
|
||||
|
||||
因此,下图是一个运行着的应用程序,一个用户进程:
|
||||
|
||||
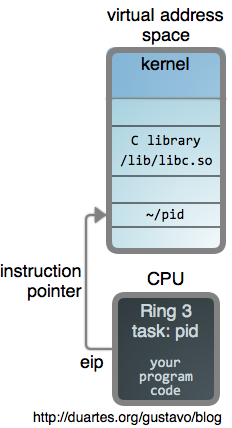
|
||||
|
||||
它有一个私有的 [虚拟地址空间][2]—— 它自己的内存沙箱。整个系统都在地址空间中,程序的二进制文件加上它所需要的库全部都 [被映射到内存中][3]。内核自身也映射为地址空间的一部分。
|
||||
|
||||
下面是我们程序的代码和 PID,进程的 PID 可以通过 [getpid(2)][4]:
|
||||
|
||||
pid.c [download][1]
|
||||
|
||||
|
|
||||
```
|
||||
123456789
|
||||
```
|
||||
|
|
||||
```
|
||||
#include #include #include int main(){ pid_t p = getpid(); printf("%d\n", p);}
|
||||
```
|
||||
|
|
||||
|
||||
**(致校对:本文的所有代码部分都出现了排版错误,请与原文核对确认!!)**
|
||||
|
||||
在 Linux 中,一个进程并不是一出生就知道它的 PID。要想知道它的 PID,它必须去询问内核,因此,这个询问请求也是一个系统调用:
|
||||
|
||||
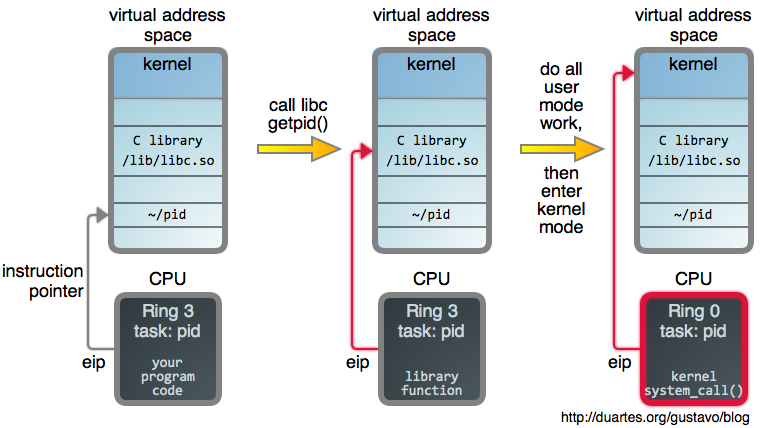
|
||||
|
||||
它的第一步是开始于调用一个 C 库的 [getpid()][5],它是系统调用的一个封装。当你调用一些功能时,比如,open(2)、read(2)、以及相关的一些支持时,你就调用了这些封装。其实,对于大多数编程语言在这一块的原生方法,最终都是在 libc 中完成的。
|
||||
|
||||
极简设计的操作系统都提供了方便的 API 封装,这样可以保持内核的简洁。所有的内核代码运行在特权模式下,有 bugs 的内核代码行将会产生致命的后果。在用户模式下做的任何事情都是在用户模式中完成的。由库来提供友好的方法和想要的参数处理,像 printf(3) 这样。
|
||||
|
||||
我们拿一个 web APIs 进行比较,内核的封装方式与构建一个简单易行的 HTTP 接口去提供服务是类似的,然后使用特定语言的守护方法去提供特定语言的库。或者也可能有一些缓存,它是库的 getpid() 完成的内容:首次调用时,它真实地去执行了一个系统调用,然后,它缓存了 PID,这样就可以避免后续调用时的系统调用开销。
|
||||
|
||||
一旦封装完成,它做的第一件事就是进入了超空间(hyperspace)的内核(译者注:一个快速而安全的计算环境,独立于操作系统而存在)。这种转换机制因处理器架构设计不同而不同。(译者注:就是前一段时间爆出的存在于处理器硬件中的运行于 Ring -3 的操作系统,比如,Intel 的 ME)在 Intel 处理器中,参数和 [系统调用号][6] 是 [加载到寄存器中的][7],然后,运行一个 [指令][8] 将 CPU 置于 [特权模式][9] 中,并立即将控制权转移到内核中的全局系统调用 [入口][10]。如果你对这些细节感兴趣,David Drysdale 在 LWN 上有两篇非常好的文章([第一篇][11],[第二篇][12])。
|
||||
|
||||
内核然后使用这个系统调用号作为进入 [sys_call_table][14] 的一个 [索引][13],它是一个函数指针到每个系统调用实现的数组。在这里,调用 了 [sys_getpid][15]:
|
||||
|
||||
|
||||
|
||||
在 Linux 中,系统调用大多数都实现为独立的 C 函数,有时候这样做 [很琐碎][16],但是通过内核优秀的设计,系统调用被严格隔离。它们是工作在一般数据结构中的普通代码。关于这些争论的验证除了完全偏执的以外,其它的还是非常好的。
|
||||
|
||||
一旦它们的工作完成,它们就会正常返回,然后,根据特定代码转回到用户模式,封装将在那里继续做一些后续处理工作。在我们的例子中,[getpid(2)][17] 现在缓存了由内核返回的 PID。如果内核返回了一个错误,另外的封装可以去设置全局 errno 变量。让你知道 GNU 所关心的一些小事。
|
||||
|
||||
如果你想看未处理的原生内容,glibc 提供了 [syscall(2)][18] 函数,它可以不通过封装来产生一个系统调用。你也可以通过它来做一个你自己的封装。这对一个 C 库来说,并不神奇,也不是保密的。
|
||||
|
||||
这种系统调用的设计影响是很深远的。我们从一个非常有用的 [strace(1)][19] 开始,这个工具可以用来监视 Linux 进程的系统调用(在 Mac 上,看 [dtruss(1m)][20] 和神奇的 [dtrace][21];在 Windows 中,看 [sysinternals][22])。这里在 pid 上的跟踪:
|
||||
|
||||
|
|
||||
```
|
||||
1234567891011121314151617181920
|
||||
```
|
||||
|
|
||||
```
|
||||
~/code/x86-os$ strace ./pidexecve("./pid", ["./pid"], [/* 20 vars */]) = 0brk(0) = 0x9aa0000access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)mmap2(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7767000access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3fstat64(3, {st_mode=S_IFREG|0644, st_size=18056, ...}) = 0mmap2(NULL, 18056, PROT_READ, MAP_PRIVATE, 3, 0) = 0xb7762000close(3) = 0[...snip...]getpid() = 14678fstat64(1, {st_mode=S_IFCHR|0600, st_rdev=makedev(136, 1), ...}) = 0mmap2(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7766000write(1, "14678\n", 614678) = 6exit_group(6) = ?
|
||||
```
|
||||
|
|
||||
|
||||
输出的每一行都显示了一个系统调用 、它的参数、以及返回值。如果你在一个循环中将 getpid(2) 运行 1000 次,你就会发现始终只有一个 getpid() 系统调用,因为,它的 PID 已经被缓存了。我们也可以看到在格式化输出字符串之后,printf(3) 调用了 write(2)。
|
||||
|
||||
strace 可以开始一个新进程,也可以附加到一个已经运行的进程上。你可以通过不同程序的系统调用学到很多的东西。例如,sshd 守护进程一天都干了什么?
|
||||
|
||||
|
|
||||
```
|
||||
1234567891011121314151617181920212223242526272829
|
||||
```
|
||||
|
|
||||
```
|
||||
~/code/x86-os$ ps ax | grep sshd12218 ? Ss 0:00 /usr/sbin/sshd -D~/code/x86-os$ sudo strace -p 12218Process 12218 attached - interrupt to quitselect(7, [3 4], NULL, NULL, NULL[ ... nothing happens ... No fun, it's just waiting for a connection using select(2) If we wait long enough, we might see new keys being generated and so on, but let's attach again, tell strace to follow forks (-f), and connect via SSH]~/code/x86-os$ sudo strace -p 12218 -f[lots of calls happen during an SSH login, only a few shown][pid 14692] read(3, "-----BEGIN RSA PRIVATE KEY-----\n"..., 1024) = 1024[pid 14692] open("/usr/share/ssh/blacklist.RSA-2048", O_RDONLY|O_LARGEFILE) = -1 ENOENT (No such file or directory)[pid 14692] open("/etc/ssh/blacklist.RSA-2048", O_RDONLY|O_LARGEFILE) = -1 ENOENT (No such file or directory)[pid 14692] open("/etc/ssh/ssh_host_dsa_key", O_RDONLY|O_LARGEFILE) = 3[pid 14692] open("/etc/protocols", O_RDONLY|O_CLOEXEC) = 4[pid 14692] read(4, "# Internet (IP) protocols\n#\n# Up"..., 4096) = 2933[pid 14692] open("/etc/hosts.allow", O_RDONLY) = 4[pid 14692] open("/lib/i386-linux-gnu/libnss_dns.so.2", O_RDONLY|O_CLOEXEC) = 4[pid 14692] stat64("/etc/pam.d", {st_mode=S_IFDIR|0755, st_size=4096, ...}) = 0[pid 14692] open("/etc/pam.d/common-password", O_RDONLY|O_LARGEFILE) = 8[pid 14692] open("/etc/pam.d/other", O_RDONLY|O_LARGEFILE) = 4
|
||||
```
|
||||
|
|
||||
|
||||
看懂 SSH 的调用是块难啃的骨头,但是,如果搞懂它你就学会了跟踪。也可以用它去看一个应用程序打开的哪个文件是有用的(“这个配置是从哪里来的?”)。如果你有一个出现错误的进程,你可以跟踪它,然后去看它通过系统调用做了什么?当一些应用程序没有提供适当的错误信息而意外退出时,你可以去检查它是否是一个系统调用失败。你也可以使用过滤器,查看每个调用的次数,等等:
|
||||
|
||||
|
|
||||
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
123456789
|
||||
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
|
|
||||
```
|
||||
~/code/x86-os$ strace -T -e trace=recv curl -silent www.google.com. > /dev/nullrecv(3, "HTTP/1.1 200 OK\r\nDate: Wed, 05 N"..., 16384, 0) = 4164 <0.000007>recv(3, "fl a{color:#36c}a:visited{color:"..., 16384, 0) = 2776 <0.000005>recv(3, "adient(top,#4d90fe,#4787ed);filt"..., 16384, 0) = 4164 <0.000007>recv(3, "gbar.up.spd(b,d,1,!0);break;case"..., 16384, 0) = 2776 <0.000006>recv(3, "$),a.i.G(!0)),window.gbar.up.sl("..., 16384, 0) = 1388 <0.000004>recv(3, "margin:0;padding:5px 8px 0 6px;v"..., 16384, 0) = 1388 <0.000007>recv(3, "){window.setTimeout(function(){v"..., 16384, 0) = 1484 <0.000006>
|
||||
```
|
||||
|
|
||||
|
||||
我鼓励你去浏览在你的操作系统中的这些工具。使用它们会让你觉得自己像个超人一样强大。
|
||||
|
||||
但是,足够有用的东西,往往要让我们深入到它的设计中。我们可以看到那些用户空间中的应用程序是被严格限制在它自己的虚拟地址空间中,它的虚拟地址空间运行在 Ring 3(非特权模式)中。一般来说,只涉及到计算和内存访问的任务是不需要请求系统调用的。例如,像 [strlen(3)][23] 和 [memcpy(3)][24] 这样的 C 库函数并不需要内核去做什么。这些都是在应用程序内部发生的事。
|
||||
|
||||
一个 C 库函数的 man 页面节上(在圆括号 2 和 3 中)也提供了线索。节 2 是用于系统调用封装,而节 3 包含了其它 C 库函数。但是,正如我们在 printf(3) 中所看到的,一个库函数可以最终产生一个或者多个系统调用。
|
||||
|
||||
如果你对此感到好奇,这里是 [Linux][25] ( [Filippo's list][26])和 [Windows][27] 的全部系统调用列表。它们各自有 ~310 和 ~460 个系统调用。看这些系统调用是非常有趣的,因为,它们代表了软件在现代的计算机上能够做什么。另外,你还可能在这里找到与进程间通讯和性能相关的“宝藏”。这是一个“不懂 Unix 的人注定最终还要重新发明一个蹩脚的 Unix ” 的地方。(译者注:“Those who do not understand Unix are condemned to reinvent it,poorly。”这句话是 [Henry Spencer][35] 的名言,反映了 Unix 的设计哲学,它的一些理念和文化是一种技术发展的必须结果,看似糟糕却无法超越。)
|
||||
|
||||
与 CPU 周期相比,许多系统调用花很长的时间去执行任务,例如,从一个硬盘驱动器中读取内容。在这种情况下,调用进程在底层的工作完成之前一直处于休眠状态。因为,CPUs 运行的非常快,一般的程序都因为 I/O 的限制在它的生命周期的大部分时间处于休眠状态,等待系统的调用。相反,如果你跟踪一个计算密集型任务,你经常会看到没有任何的系统调用参与其中。在这种情况下,[top(1)][29] 将显示大量的 CPU 使用。
|
||||
|
||||
在一个系统调用中的开销可能会是一个问题。例如,固态硬盘比普通硬盘要快很多,但是,操作系统的开销可能比 I/O 操作本身的开销 [更加昂贵][30]。执行大量读写操作的程序可能就是操作系统开销的瓶颈所在。[向量化 I/O][31] 对此有一些帮助。因此要做 [文件的内存映射][32],它允许一个程序仅访问内存就可以读或写磁盘文件。类似的映射也存在于像视频卡这样的地方。最终,经济性俱佳的云计算可能导致内核在用户模式/内核模式的切换消失或者最小化。
|
||||
|
||||
最终,系统调用还有益于系统安全。一是,无论看起来多么模糊的一个二进制程序,你都可以通过观察它的系统调用来检查它的行为。这种方式可能用于去检测恶意程序。例如,我们可以记录一个未知程序的系统调用的策略,并对它的偏差进行报警,或者对程序调用指定一个白名单,这样就可以让漏洞利用变得更加困难。在这个领域,我们有大量的研究,和许多工具,但是没有“杀手级”的解决方案。
|
||||
|
||||
这就是系统调用。很抱歉这篇文章有点长,我希望它对你有用。接下来的时间,我将写更多(短的)文章,也可以在 [RSS][33] 和 [Twitter][34] 关注我。这篇文章献给 glorious Clube Atlético Mineiro。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/system-calls/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/code/x86-os/pid.c
|
||||
[2]:https://manybutfinite.com/post/anatomy-of-a-program-in-memory
|
||||
[3]:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
[4]:http://linux.die.net/man/2/getpid
|
||||
[5]:https://sourceware.org/git/?p=glibc.git;a=blob;f=sysdeps/unix/sysv/linux/getpid.c;h=937b1d4e113b1cff4a5c698f83d662e130d596af;hb=4c6da7da9fb1f0f94e668e6d2966a4f50a7f0d85#l49
|
||||
[6]:https://github.com/torvalds/linux/blob/v3.17/arch/x86/syscalls/syscall_64.tbl#L48
|
||||
[7]:https://sourceware.org/git/?p=glibc.git;a=blob;f=sysdeps/unix/sysv/linux/x86_64/sysdep.h;h=4a619dafebd180426bf32ab6b6cb0e5e560b718a;hb=4c6da7da9fb1f0f94e668e6d2966a4f50a7f0d85#l139
|
||||
[8]:https://sourceware.org/git/?p=glibc.git;a=blob;f=sysdeps/unix/sysv/linux/x86_64/sysdep.h;h=4a619dafebd180426bf32ab6b6cb0e5e560b718a;hb=4c6da7da9fb1f0f94e668e6d2966a4f50a7f0d85#l179
|
||||
[9]:https://manybutfinite.com/post/cpu-rings-privilege-and-protection
|
||||
[10]:https://github.com/torvalds/linux/blob/v3.17/arch/x86/kernel/entry_64.S#L354-L386
|
||||
[11]:http://lwn.net/Articles/604287/
|
||||
[12]:http://lwn.net/Articles/604515/
|
||||
[13]:https://github.com/torvalds/linux/blob/v3.17/arch/x86/kernel/entry_64.S#L422
|
||||
[14]:https://github.com/torvalds/linux/blob/v3.17/arch/x86/kernel/syscall_64.c#L25
|
||||
[15]:https://github.com/torvalds/linux/blob/v3.17/kernel/sys.c#L800-L809
|
||||
[16]:https://github.com/torvalds/linux/blob/v3.17/kernel/sys.c#L800-L859
|
||||
[17]:http://linux.die.net/man/2/getpid
|
||||
[18]:http://linux.die.net/man/2/syscall
|
||||
[19]:http://linux.die.net/man/1/strace
|
||||
[20]:https://developer.apple.com/library/mac/documentation/Darwin/Reference/ManPages/man1/dtruss.1m.html
|
||||
[21]:http://dtrace.org/blogs/brendan/2011/10/10/top-10-dtrace-scripts-for-mac-os-x/
|
||||
[22]:http://technet.microsoft.com/en-us/sysinternals/bb842062.aspx
|
||||
[23]:http://linux.die.net/man/3/strlen
|
||||
[24]:http://linux.die.net/man/3/memcpy
|
||||
[25]:https://github.com/torvalds/linux/blob/v3.17/arch/x86/syscalls/syscall_64.tbl
|
||||
[26]:https://filippo.io/linux-syscall-table/
|
||||
[27]:http://j00ru.vexillium.org/ntapi/
|
||||
[28]:https://manybutfinite.com/post/what-your-computer-does-while-you-wait/
|
||||
[29]:http://linux.die.net/man/1/top
|
||||
[30]:http://danluu.com/clwb-pcommit/
|
||||
[31]:http://en.wikipedia.org/wiki/Vectored_I/O
|
||||
[32]:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
[33]:http://feeds.feedburner.com/GustavoDuarte
|
||||
[34]:http://twitter.com/food4hackers
|
||||
[35]:https://en.wikipedia.org/wiki/Henry_Spencer
|
||||
152
translated/tech/20170628 Notes on BPF and eBPF.md
Normal file
152
translated/tech/20170628 Notes on BPF and eBPF.md
Normal file
@ -0,0 +1,152 @@
|
||||
关于 BPF 和 eBPF 的笔记
|
||||
============================================================
|
||||
|
||||
今天,我喜欢的 meetup 网站上有一篇我超爱的文章![Suchakra Sharma][6]([@tuxology][7] 在 twitter/github)的一篇非常棒的关于传统 BPF 和在 Linux 中最新加入的 eBPF 的讨论文章,正是它促使我想去写一个 eBPF 的程序!
|
||||
|
||||
这篇文章就是 —— [BSD 包过滤器:一个新的用户级包捕获架构][8]
|
||||
|
||||
我想在讨论的基础上去写一些笔记,因为,我觉得它超级棒!
|
||||
|
||||
这是 [幻灯片][9] 和一个 [pdf][10]。这个 pdf 非常好,结束的位置有一些链接,在 PDF 中你可以直接点击这个链接。
|
||||
|
||||
### 什么是 BPF?
|
||||
|
||||
在 BPF 出现之前,如果你想去做包过滤,你必须拷贝所有进入用户空间的包,然后才能去过滤它们(使用 “tap”)。
|
||||
|
||||
这样做存在两个问题:
|
||||
|
||||
1. 如果你在用户空间中过滤,意味着你将拷贝所有进入用户空间的包,拷贝数据的代价是很昂贵的。
|
||||
|
||||
2. 使用的过滤算法很低效
|
||||
|
||||
问题 #1 的解决方法似乎很明显,就是将过滤逻辑移到内核中。(虽然具体实现的细节并没有明确,我们将在稍后讨论)
|
||||
|
||||
但是,为什么过滤算法会很低效?
|
||||
|
||||
如果你运行 `tcpdump host foo`,它实际上运行了一个相当复杂的查询,用下图的这个树来描述它:
|
||||
|
||||

|
||||
|
||||
评估这个树有点复杂。因此,可以用一种更简单的方式来表示这个树,像这样:
|
||||
|
||||

|
||||
|
||||
然后,如果你设置 `ether.type = IP` 和 `ip.src = foo`,你必然明白匹配的包是 `host foo`,你也不用去检查任何其它的东西了。因此,这个数据结构(它们称为“控制流图” ,或者 “CFG”)是表示你真实希望去执行匹配检查的程序的最佳方法,而不是用前面的树。
|
||||
|
||||
### 为什么 BPF 要工作在内核中
|
||||
|
||||
这里的关键点是,包仅仅是个字节的数组。BPF 程序是运行在这些字节的数组上。它们不允许有循环(loops),但是,它们 _可以_ 有聪明的办法知道 IP 包头(IPv6 和 IPv4 长度是不同的)以及基于它们的长度来找到 TCP 端口
|
||||
|
||||
```
|
||||
x = ip_header_length
|
||||
port = *(packet_start + x + port_offset)
|
||||
|
||||
```
|
||||
|
||||
(看起来不一样,其实它们基本上都相同)。在这个论文/幻灯片上有一个非常详细的虚拟机的描述,因此,我不打算解释它。
|
||||
|
||||
当你运行 `tcpdump host foo` 后,这时发生了什么?就我的理解,应该是如下的过程。
|
||||
|
||||
1. 转换 `host foo` 为一个高效的 DAG 规则
|
||||
|
||||
2. 转换那个 DAG 规则为 BPF 虚拟机的一个 BPF 程序(BPF 字节码)
|
||||
|
||||
3. 发送 BPF 字节码到 Linux 内核,由 Linux 内核验证它
|
||||
|
||||
4. 编译这个 BPF 字节码程序为一个原生(native)代码。例如, [在 ARM 上是 JIT 代码][1] 以及为 [x86][2] 的机器码
|
||||
|
||||
5. 当包进入时,Linux 运行原生代码去决定是否过滤这个包。对于每个需要去处理的包,它通常仅需运行 100 - 200 个 CPU 指令就可以完成,这个速度是非常快的!
|
||||
|
||||
### 现状:eBPF
|
||||
|
||||
毕竟 BPF 出现已经有很长的时间了!现在,我们可以拥有一个更加令人激动的东西,它就是 eBPF。我以前听说过 eBPF,但是,我觉得像这样把这些片断拼在一起更好(我在 4 月份的 netdev 上我写了这篇 [XDP & eBPF 的文章][11]回复)
|
||||
|
||||
关于 eBPF 的一些事实是:
|
||||
|
||||
* eBPF 程序有它们自己的字节码语言,并且从那个字节码语言编译成内核原生代码,就像 BPF 程序
|
||||
|
||||
* eBPF 运行在内核中
|
||||
|
||||
* eBPF 程序不能随心所欲的访问内核内存。而是通过内核提供的函数去取得一些受严格限制的所需要的内容的子集。
|
||||
|
||||
* 它们 _可以_ 与用户空间的程序通过 BPF 映射进行通讯
|
||||
|
||||
* 这是 Linux 3.18 的 `bpf` 系统调用
|
||||
|
||||
### kprobes 和 eBPF
|
||||
|
||||
你可以在 Linux 内核中挑选一个函数(任意函数),然后运行一个你写的每次函数被调用时都运行的程序。这样看起来是不是很神奇。
|
||||
|
||||
例如:这里有一个 [名为 disksnoop 的 BPF 程序][12],它的功能是当你开始/完成写入一个块到磁盘时,触发它执行跟踪。下图是它的代码片断:
|
||||
|
||||
```
|
||||
BPF_HASH(start, struct request *);
|
||||
void trace_start(struct pt_regs *ctx, struct request *req) {
|
||||
// stash start timestamp by request ptr
|
||||
u64 ts = bpf_ktime_get_ns();
|
||||
start.update(&req, &ts);
|
||||
}
|
||||
...
|
||||
b.attach_kprobe(event="blk_start_request", fn_name="trace_start")
|
||||
b.attach_kprobe(event="blk_mq_start_request", fn_name="trace_start")
|
||||
|
||||
```
|
||||
|
||||
从根本上来说,它声明一个 BPF 哈希(它的作用是当请求开始/完成时,这个程序去触发跟踪),一个名为 `trace_start` 的函数将被编译进 BPF 字节码,然后附加 `trace_start` 到内核函数 `blk_start_request` 上。
|
||||
|
||||
这里使用的是 `bcc` 框架,它可以使你写的 Python 化的程序去生成 BPF 代码。你可以在 [https://github.com/iovisor/bcc][13] 找到它(那里有非常多的示例程序)。
|
||||
|
||||
### uprobes 和 eBPF
|
||||
|
||||
因为我知道你可以附加 eBPF 程序到内核函数上,但是,我不知道你能否将 eBPF 程序附加到用户空间函数上!那会有更多令人激动的事情。这是 [在 Python 中使用一个 eBPF 程序去计数 malloc 调用的示例][14]。
|
||||
|
||||
### 附加 eBPF 程序时应该考虑的事情
|
||||
|
||||
* 带 XDP 的网卡(我之前写过关于这方面的文章)
|
||||
|
||||
* tc egress/ingress (在网络栈上)
|
||||
|
||||
* kprobes(任意内核函数)
|
||||
|
||||
* uprobes(很明显,任意用户空间函数??像带符号的任意 C 程序)
|
||||
|
||||
* probes 是为 dtrace 构建的名为 “USDT probes” 的探针(像 [这些 mysql 探针][3])。这是一个 [使用 dtrace 探针的示例程序][4]
|
||||
|
||||
* [JVM][5]
|
||||
|
||||
* 跟踪点
|
||||
|
||||
* seccomp / landlock 安全相关的事情
|
||||
|
||||
* 更多的事情
|
||||
|
||||
### 这个讨论超级棒
|
||||
|
||||
在幻灯片里有很多非常好的链接,并且在 iovisor 仓库里有个 [LINKS.md][15]。现在已经很晚了,但是,很快我将写我的第一个 eBPF 程序了!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/06/28/notes-on-bpf---ebpf/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/
|
||||
[1]:https://github.com/torvalds/linux/blob/v4.10/arch/arm/net/bpf_jit_32.c#L512
|
||||
[2]:https://github.com/torvalds/linux/blob/v3.18/arch/x86/net/bpf_jit_comp.c#L189
|
||||
[3]:https://dev.mysql.com/doc/refman/5.7/en/dba-dtrace-ref-query.html
|
||||
[4]:https://github.com/iovisor/bcc/blob/master/examples/tracing/mysqld_query.py
|
||||
[5]:http://blogs.microsoft.co.il/sasha/2016/03/31/probing-the-jvm-with-bpfbcc/
|
||||
[6]:http://suchakra.in/
|
||||
[7]:https://twitter.com/tuxology
|
||||
[8]:http://www.vodun.org/papers/net-papers/van_jacobson_the_bpf_packet_filter.pdf
|
||||
[9]:https://speakerdeck.com/tuxology/the-bsd-packet-filter
|
||||
[10]:http://step.polymtl.ca/~suchakra/PWL-Jun28-MTL.pdf
|
||||
[11]:https://jvns.ca/blog/2017/04/07/xdp-bpf-tutorial/
|
||||
[12]:https://github.com/iovisor/bcc/blob/0c8c179fc1283600887efa46fe428022efc4151b/examples/tracing/disksnoop.py
|
||||
[13]:https://github.com/iovisor/bcc
|
||||
[14]:https://github.com/iovisor/bcc/blob/00f662dbea87a071714913e5c7382687fef6a508/tests/lua/test_uprobes.lua
|
||||
[15]:https://github.com/iovisor/bcc/blob/master/LINKS.md
|
||||
@ -1,117 +0,0 @@
|
||||
使用 FDISK 和 FALLOCATE 命令创建交换分区
|
||||
======
|
||||
交换分区在物理内存(RAM)被填满时用来保持内存中的内容. 当 RAM 被耗尽, Linux 会将内存中不活动的页移动到交换空间中,从而空出内存给系统使用. 虽然如此, 但交换空间不应被认为是可以用来替代物理内存/RAM的.
|
||||
|
||||
大多数情况下, 建议交换内存的大小为物理内存的1到2倍. 也就是说如果你有8GB内存, 那么交换空间大小应该介于8-16 GB.
|
||||
|
||||
若系统中没有配置交换分区, 当内存耗尽后,系统可能会杀掉正在运行中哦该的进程/应哟该从而导致系统崩溃. 在本文中, 我们将学会如何为Linux系统添加交换分区,我们有两个办法:
|
||||
|
||||
+ **使用 fdisk 命令**
|
||||
+ **使用 fallocate 命令**
|
||||
|
||||
|
||||
|
||||
### 第一个方法(使用 Fdisk 命令)
|
||||
|
||||
通常, 系统的第一块硬盘会被命名为 **/dev/sda** 而其中的分区会命名为 **/dev/sda1** , **/dev/sda2**. 本文我们使用的石块有两个主分区的硬盘,两个分区分别为 /dev/sda1, /dev/sda2,而我们使用 /dev/sda3 来做交换分区.
|
||||
|
||||
首先创建一个新分区,
|
||||
|
||||
```
|
||||
$ fdisk /dev/sda
|
||||
```
|
||||
|
||||
按 **' n'** 来创建新分区. 系统会询问你从哪个柱面开始, 直接按回车键使用默认值即可。然后系统询问你到哪个柱面结束, 这里我们输入交换分区的大小(比如1000MB). 这里我们输入 +1000M.
|
||||
|
||||
![swap][2]
|
||||
|
||||
现在我们创建了一个大小为 1000MB 的磁盘了。但是我们并没有设个分区的类型, 我们按下 **" t"** 然后回车来设置分区类型.
|
||||
|
||||
现在我们要输入分区编号, 这里我们输入 **3**,然后输入磁盘分类id,交换分区的磁盘类型为 **82** (要显示所有可用的磁盘类型, 按下 **" l"** ) 然后再按下 " **w "** 保存磁盘分区表.
|
||||
|
||||
![swap][4]
|
||||
|
||||
再下一步使用 `mkswap` 命令来格式化交换分区
|
||||
|
||||
```
|
||||
$ mkswap /dev/sda3
|
||||
```
|
||||
|
||||
然后激活新建的交换分区
|
||||
|
||||
```
|
||||
$ swapon /dev/sda3
|
||||
```
|
||||
|
||||
然而我们的交换分区在重启后并不会自动挂载. 要做到永久挂载,我们需要添加内容道 `/etc/fstab` 文件中. 打开 `/etc/fstab` 文件并输入下面行
|
||||
|
||||
```
|
||||
$ vi /etc/fstab
|
||||
```
|
||||
|
||||
```
|
||||
/dev/sda3 swap swap default 0 0
|
||||
```
|
||||
|
||||
保存并关闭文件. 现在每次重启后都能使用我们的交换分区了.
|
||||
|
||||
### 第二种方法(使用 fallocate 命令)
|
||||
|
||||
我推荐用这种方法因为这个是最简单,最快速的创建交换空间的方法了. Fallocate 是最被低估和使用最少的命令之一了. Fallocate 用于为文件预分配块/大小.
|
||||
|
||||
使用 fallocate 创建交换空间, 我们首先在 ** '/'** 目录下创建一个名为 **swap_space** 的文件. 然后分配2GB道 swap_space 文件,
|
||||
|
||||
```
|
||||
$ fallocate -l 2G /swap_space
|
||||
```
|
||||
|
||||
我们运行下面命令来验证文件大小
|
||||
|
||||
```
|
||||
ls-lh /swap_space.
|
||||
```
|
||||
|
||||
然后更改文件权限,让 `/swap_space` 更安全
|
||||
|
||||
```
|
||||
$ chmod 600 /swap_space**
|
||||
```
|
||||
|
||||
这样只有 root 可以读写该文件了. 我们再来格式化交换分区(译者注:虽然这个swap_space应该是文件,但是我们把它当成是分区来挂载),
|
||||
|
||||
```
|
||||
$ mkswap /swap_space
|
||||
```
|
||||
|
||||
然后启用交换空间
|
||||
|
||||
```
|
||||
$ swapon -s
|
||||
```
|
||||
|
||||
每次重启后都要重现挂载磁盘分区. 因此为了使之持久话,就像上面一样,我们编辑 `/etc/fstab` 并输入下面行
|
||||
|
||||
```
|
||||
/swap_space swap swap sw 0 0
|
||||
```
|
||||
|
||||
保存并退出文件. 现在我们的交换分区会一直被挂载了. 我们重启后可以在终端运行 **free -m** 来检查交换分区是否生效.
|
||||
|
||||
我们的教程至此就结束了, 希望本文足够容易理解和学习. 如果有任何疑问欢迎提出.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/create-swap-using-fdisk-fallocate/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=668%2C211
|
||||
[2]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/fidsk.jpg?resize=668%2C211
|
||||
[3]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=620%2C157
|
||||
[4]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/fidsk-swap-select.jpg?resize=620%2C157
|
||||
@ -0,0 +1,59 @@
|
||||
使用一个命令重置 Linux 桌面到默认设置
|
||||
======
|
||||

|
||||
|
||||
前段时间,我们分享了一篇关于 [**Resetter**][1] 的文章 - 这是一个有用的软件,可以在几分钟内将 Ubuntu 重置为出厂默认设置。使用 Resetter,任何人都可以轻松地将 Ubuntu 重置为第一次安装时的状态。今天,我偶然发现了一个类似的东西。不,它不是一个应用程序,而是一个单行的命令来重置你的 Linux 桌面设置、调整和定制到默认状态。
|
||||
|
||||
### 将 Linux 桌面重置为默认设置
|
||||
|
||||
这个命令会将 Ubuntu Unity、Gnome 和 MATE 桌面重置为默认状态。我在我的 **Arch Linux MATE** 和 **Ubuntu 16.04 Unity** 上测试了这个命令。它可以在两个系统上工作。我希望它也能在其他桌面上运行。在写这篇文章的时候,我还没有安装 GNOME 的 Linux 桌面,因此我无法确认。但是,我相信它也可以在 Gnome 桌面环境中使用。
|
||||
|
||||
**一句忠告:**请注意,此命令将重置你在系统中所做的所有定制和调整,包括 Unity 启动器或 Dock 中的固定应用程序、桌面小程序、桌面指示器、系统字体、GTK主题、图标主题、显示器分辨率、键盘快捷键、窗口按钮位置、菜单和启动器行为等。
|
||||
|
||||
好的是它只会重置桌面设置。它不会影响其他不使用 dconf 的程序。此外,它不会删除你的个人资料。
|
||||
|
||||
现在,让我们开始。要将 Ubuntu Unity 或其他带有 GNOME/MATE 环境的 Linux 桌面重置,运行下面的命令:
|
||||
```
|
||||
dconf reset -f /
|
||||
```
|
||||
|
||||
在运行上述命令之前,这是我的 Ubuntu 16.04 LTS 桌面:
|
||||
|
||||
[![][2]][3]
|
||||
|
||||
如你所见,我已经改变了桌面壁纸和主题。
|
||||
|
||||
这是运行该命令后,我的 Ubuntu 16.04 LTS 桌面的样子:
|
||||
|
||||
[![][2]][4]
|
||||
|
||||
看见了么?现在,我的 Ubuntu 桌面已经回到了出厂设置。
|
||||
|
||||
有关 “dconf” 命令的更多详细信息,请参阅手册页。
|
||||
```
|
||||
man dconf
|
||||
```
|
||||
|
||||
在重置桌面上我个人更喜欢 “Resetter” 而不是 “dconf” 命令。因为,Resetter 给用户提供了更多的选择。用户可以决定删除哪些应用程序、保留哪些应用程序、是保留现有用户帐户还是创建新用户等等。如果你懒得安装 Resetter,你可以使用这个 “dconf” 命令在几分钟内将你的 Linux 系统重置为默认设置。
|
||||
|
||||
就是这样了。希望这个有帮助。我将很快发布另一篇有用的指导。敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/reset-linux-desktop-default-settings-single-command/
|
||||
|
||||
作者:[Edwin Arteaga][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com
|
||||
[1]:https://www.ostechnix.com/reset-ubuntu-factory-defaults/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Before-resetting-Ubuntu-to-default-1.png ()
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/After-resetting-Ubuntu-to-default-1.png ()
|
||||
@ -1,19 +1,18 @@
|
||||
translating---geekpi
|
||||
|
||||
Fixing vim in Debian – There and back again
|
||||
在 Debian 中修复 vim - 去而复得
|
||||
======
|
||||
I was wondering for quite some time why on my server vim behaves so stupid with respect to the mouse: Jumping around, copy and paste wasn't possible the usual way. All this despite having
|
||||
我一直在想,为什么我服务器上 vim 为什么在鼠标方面表现得如此愚蠢:不能像平时那样跳转、复制、粘贴。尽管在 `/etc/vim/vimrc.local` 中已经设置了
|
||||
```
|
||||
set mouse=
|
||||
```
|
||||
|
||||
in my `/etc/vim/vimrc.local`. Finally I found out why, thanks to bug [#864074][1] and fixed it.
|
||||
最后我终于知道为什么了,多谢 bug [#864074][1] 并且修复了它。
|
||||
|
||||
![][2]
|
||||
|
||||
The whole mess comes from the fact that, when there is no `~/.vimrc`, vim loads `defaults.vim` **after** ` vimrc.local` and thus overwriting several settings put in there.
|
||||
原因是,当没有 `~/.vimrc` 的时候,vim在 `vimrc.local` **之后**加载 `defaults.vim`,从而覆盖了几个设置。
|
||||
|
||||
There is a comment (I didn't see, though) in `/etc/vim/vimrc` explaining this:
|
||||
在 `/etc/vim/vimrc` 中有一个注释(虽然我没有看到)解释了这一点:
|
||||
```
|
||||
" Vim will load $VIMRUNTIME/defaults.vim if the user does not have a vimrc.
|
||||
" This happens after /etc/vim/vimrc(.local) are loaded, so it will override
|
||||
@ -24,11 +23,11 @@ There is a comment (I didn't see, though) in `/etc/vim/vimrc` explaining this:
|
||||
```
|
||||
|
||||
|
||||
I agree that this is a good way to setup vim on a normal installation of Vim, but the Debian package could do better. The problem is laid out clearly in the bug report: If there is no `~/.vimrc`, settings in `/etc/vim/vimrc.local` are overwritten.
|
||||
我同意这是在正常安装 vim 后设置 vim 的好方法,但 Debian 包可以做得更好。在错误报告中清楚地说明了这个问题:如果没有 `~/.vimrc`,`/etc/vim/vimrc.local` 中的设置被覆盖。
|
||||
|
||||
This is as counterintuitive as it can be in Debian - and I don't know any other package that does it in a similar way.
|
||||
这在Debian中是违反直觉的 - 而且我也不知道其他包中是否采用类似的方法。
|
||||
|
||||
Since the settings in `defaults.vim` are quite reasonable, I want to have them, but only fix a few of the items I disagree with, like the mouse. At the end what I did is the following in my `/etc/vim/vimrc.local`:
|
||||
由于 `defaults.vim` 中的设置非常合理,所以我希望使用它,但只修改了一些我不同意的项目,比如鼠标。最后,我在 `/etc/vim/vimrc.local` 中做了以下操作:
|
||||
```
|
||||
if filereadable("/usr/share/vim/vim80/defaults.vim")
|
||||
source /usr/share/vim/vim80/defaults.vim
|
||||
@ -42,14 +41,14 @@ set mouse=
|
||||
```
|
||||
|
||||
|
||||
There is probably a better way to get a generic load statement that does not depend on the Vim version, but for now I am fine with that.
|
||||
可能有更好的方式来获得一个不依赖于 vim 版本的通用加载语句, 但现在我对此很满意。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.preining.info/blog/2017/10/fixing-vim-in-debian/
|
||||
|
||||
作者:[Norbert Preining][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,13 +1,12 @@
|
||||
translating by kimii
|
||||
More ways to examine network connections on Linux
|
||||
检查 linux 上网络连接的更多方法
|
||||
======
|
||||
The ifconfig and netstat commands are incredibly useful, but there are many other commands that can help you see what's up with you network on Linux systems. Today's post explores some very handy commands for examining network connections.
|
||||
ifconfig 和 netstat 命令当然非常有用,但还有很多其他命令能帮你查看 linux 系统上的网络状况。本文探索了一些检查网络连接的非常简便的命令。
|
||||
|
||||
### ip command
|
||||
### ip 命令
|
||||
|
||||
The **ip** command shows a lot of the same kind of information that you'll get when you use **ifconfig**. Some of the information is in a different format - e.g., "192.168.0.6/24" instead of "inet addr:192.168.0.6 Bcast:192.168.0.255" and ifconfig is better for packet counts, but the ip command has many useful options.
|
||||
**ip** 命令显示了许多与你使用 **ifconfig** 命令时的一样信息。其中一些信息以不同的格式呈现,比如使用“192.168.0.6/24”,而不是“inet addr:192.168.0.6 Bcast:192.168.0.255”,尽管 ifconfig 更适合数据包计数,但 ip 命令有许多有用的选项。
|
||||
|
||||
First, here's the **ip a** command listing information on all network interfaces.
|
||||
首先,这里是 **ip a** 命令列出的所有网络接口的信息。
|
||||
```
|
||||
$ ip a
|
||||
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
|
||||
@ -25,7 +24,7 @@ $ ip a
|
||||
|
||||
```
|
||||
|
||||
If you want only to see a simple list of network interfaces, you can limit its output with **grep**.
|
||||
如果你只想看到简单的网络接口列表,你可以用 **grep** 限制它的输出。
|
||||
```
|
||||
$ ip a | grep inet
|
||||
inet 127.0.0.1/8 scope host lo
|
||||
@ -35,7 +34,7 @@ $ ip a | grep inet
|
||||
|
||||
```
|
||||
|
||||
You can get a glimpse of your default route using a command like this:
|
||||
使用如下面的命令,你可以看到你的默认路由:
|
||||
```
|
||||
$ ip route show
|
||||
default via 192.168.0.1 dev eth0
|
||||
@ -43,18 +42,18 @@ default via 192.168.0.1 dev eth0
|
||||
|
||||
```
|
||||
|
||||
In this output, you can see that the default gateway is 192.168.0.1 through eth0 and that the local network is the fairly standard 192.168.0.0/24.
|
||||
在这个输出中,你可以看到通过 eth0 的默认网关是 192.168.0.1,并且本地网络是相当标准的 192.168.0.0/24。
|
||||
|
||||
You can also use the **ip** command to bring network interfaces up and shut them down.
|
||||
你也可以使用 **ip** 命令来启用和禁用网络接口。
|
||||
```
|
||||
$ sudo ip link set eth1 up
|
||||
$ sudo ip link set eth1 down
|
||||
|
||||
```
|
||||
|
||||
### ethtool command
|
||||
### ethtool 命令
|
||||
|
||||
Another very useful tool for examining networks is **ethtool**. This command provides a lot of descriptive data on network interfaces.
|
||||
另一个检查网络非常有用的工具是 **ethtool**。这个命令提供了网络接口上的许多描述性的数据。
|
||||
```
|
||||
$ ethtool eth0
|
||||
Settings for eth0:
|
||||
@ -83,7 +82,7 @@ Cannot get wake-on-lan settings: Operation not permitted
|
||||
|
||||
```
|
||||
|
||||
You can also use the **ethtool** command to examine ethernet driver settings.
|
||||
你也可以使用 **ethtool** 命令来检查以太网驱动设置。
|
||||
```
|
||||
$ ethtool -i eth0
|
||||
driver: e1000e
|
||||
@ -99,7 +98,7 @@ supports-priv-flags: no
|
||||
|
||||
```
|
||||
|
||||
The autonegotiation details can be displayed with a command like this:
|
||||
自动协商的详细信息可以用这样的命令来显示:
|
||||
```
|
||||
$ ethtool -a eth0
|
||||
Pause parameters for eth0:
|
||||
@ -109,9 +108,10 @@ TX: on
|
||||
|
||||
```
|
||||
|
||||
### traceroute command
|
||||
### traceroute 命令
|
||||
|
||||
The **traceroute** command displays routing pathways. It works by using the TTL (time to live) field in the packet header in a series of packets to capture the path that packets take and how long they take to get from one hop to the next. Traceroute's output helps to gauge the health of network connections, since some routes might take much longer to reach the eventual destination.
|
||||
|
||||
**traceroute** 命令显示路由路径。它通过在一系列数据包中设置数据包头的TTL(生存时间)字段来捕获数据包所经过的路径,以及数据包从一跳到下一跳需要的时间。Traceroute 的输出有助于评估网络连接的健康状况,因为某些路由可能需要花费更长的时间才能到达最终的目的地。
|
||||
```
|
||||
$ sudo traceroute world.std.com
|
||||
traceroute to world.std.com (192.74.137.5), 30 hops max, 60 byte packets
|
||||
@ -133,13 +133,13 @@ traceroute to world.std.com (192.74.137.5), 30 hops max, 60 byte packets
|
||||
|
||||
```
|
||||
|
||||
### tcptraceroute command
|
||||
### tcptraceroute 命令
|
||||
|
||||
The **tcptraceroute** command does basically the same thing as traceroute except that it is able to bypass the most common firewall filters. As the command's man page explains, tcptraceroute sends out TCP SYN packets instead of UDP or ICMP ECHO packets, thus making it less susceptible to being blocked.
|
||||
**tcptraceroute** 命令与 traceroute 基本上是一样的,只是它能够绕过最常见的防火墙的过滤。正如该命令的手册页所述,tcptraceroute 发送 TCP SYN 数据包而不是 UDP 或 ICMP ECHO 数据包,所以其不易被阻塞。
|
||||
|
||||
### tcpdump command
|
||||
### tcpdump 命令
|
||||
|
||||
The **tcpdump** command allows you to capture network packets for later analysis. With the -D option, it lists available interfaces.
|
||||
**tcpdump** 命令允许你捕获网络数据包来进一步分析。使用 -D 选项列出可用的网络接口。
|
||||
```
|
||||
$ tcpdump -D
|
||||
1.eth0 [Up, Running]
|
||||
@ -157,7 +157,7 @@ $ tcpdump -D
|
||||
|
||||
```
|
||||
|
||||
The -v (verbose) option controls how much detail you will see -- more v's, more details, but more than three v's doesn't add anything more.
|
||||
-v(verbose)选项控制你看到的细节程度--越多的 v,越详细,但超过 3 个 v 不会有更多意义。
|
||||
```
|
||||
$ sudo tcpdump -vv host 192.168.0.32
|
||||
tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
@ -172,9 +172,10 @@ tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 262144 byt
|
||||
|
||||
```
|
||||
|
||||
Expect to see a _lot_ of output when you run commands like this one.
|
||||
当你运行像这样的命令时,会看到非常多的输出。
|
||||
|
||||
这个命令捕获来自特定主机和 eth0 上的 11 个数据包。-w 选项标识保存捕获包的文件。在这个示例命令中,我们只要求捕获 11 个数据包。
|
||||
|
||||
This command captures 11 packets from a specific host and over eth0. The -w option identifies the file that will contain the capture packets. In this example command, we've only asked to capture 11 packets.
|
||||
```
|
||||
$ sudo tcpdump -c 11 -i eth0 src 192.168.0.32 -w packets.pcap
|
||||
tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
@ -184,9 +185,10 @@ tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 262144 byt
|
||||
|
||||
```
|
||||
|
||||
### arp command
|
||||
### arp 命令
|
||||
|
||||
arp 命令将 IPv4 地址映射到硬件地址。它所提供的信息也可以在一定程度上用于识别系统,因为网络适配器可以告诉你使用它们的系统的一些信息。下面的第二个MAC 地址,从 f8:8e:85 开始,很容易被识别为 Comtrend 路由器。
|
||||
|
||||
The arp command maps IPv4 addresses to hardware addresses. The information provided can also be used to identify the systems to some extent, since the network adaptors in use can tell you something about the systems using them. The second MAC address below, starting with f8:8e:85, is easily identified as a Comtrend router.
|
||||
```
|
||||
$ arp -a
|
||||
? (192.168.0.12) at b0:c0:90:3f:10:15 [ether] on eth0
|
||||
@ -194,15 +196,14 @@ $ arp -a
|
||||
|
||||
```
|
||||
|
||||
The first line above shows the MAC address for the network adaptor on the system itself. This network adaptor appears to have been manufactured by Chicony Electronics in Taiwan. You can look up MAC address associations fairly easily on the web with tools such as this one from Wireshark -- https://www.wireshark.org/tools/oui-lookup.html
|
||||
|
||||
上面的第一行显示了系统本身的网络适配器的 MAC 地址。该网络适配器似乎已由台湾 Chicony 电子公司制造。你可以很容易地在网上查找 MAC 地址关联,例如来自 Wireshark 的这个工具 -- https://www.wireshark.org/tools/oui-lookup.html
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3233306/linux/more-ways-to-examine-network-connections-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[kimii](https://github.com/kimii)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,184 @@
|
||||
一步一步学习如何在 MariaDB 中配置主从复制
|
||||
======
|
||||
在我们前面的教程中,我们已经学习了 [**如何安装和配置 MariaDB**][1],也学习了 [**管理 MariaDB 的一些基础命令**][2]。现在我们来学习,如何在 MariaDB 服务器上配置一个主从复制。
|
||||
|
||||
复制是用于为我们的数据库去创建多个副本,这些副本可以在其它数据库上用于运行查询,像一些非常繁重的查询可能会影响主数据库服务器的性能,或者我们可以使用它来做数据冗余,或者兼具以上两个目的。我们可以将这个过程自动化,即主服务器到从服务器的复制过程自动进行。执行备份而不影响在主服务器上的写操作。
|
||||
|
||||
因此,我们现在去配置我们的主-从复制,它需要两台安装了 MariaDB 的机器。它们的 IP 地址如下:
|
||||
|
||||
**主服务器 -** 192.168.1.120 **主机名** master.ltechlab.com
|
||||
|
||||
**从服务器 -** 192.168.1.130 **主机名 -** slave.ltechlab.com
|
||||
|
||||
MariaDB 安装到这些机器上之后,我们继续进行本教程。如果你需要安装和配置 MariaDB 的教程,请查看[ **这个教程**][1]。
|
||||
|
||||
|
||||
### **第 1 步 - 主服务器配置**
|
||||
|
||||
我们现在进入到 MariaDB 中的一个命名为 ' **important '** 的数据库,它将被复制到我们的从服务器。为开始这个过程,我们编辑名为 ' **/etc/my.cnf** ' 的文件,它是 MariaDB 的配置文件。
|
||||
|
||||
```
|
||||
$ vi /etc/my.cnf
|
||||
```
|
||||
|
||||
在这个文件中找到 [mysqld] 节,然后输入如下内容:
|
||||
|
||||
```
|
||||
[mysqld]
|
||||
log-bin
|
||||
server_id=1
|
||||
replicate-do-db=important
|
||||
bind-address=192.168.1.120
|
||||
```
|
||||
|
||||
保存并退出这个文件。完成之后,需要重启 MariaDB 服务。
|
||||
|
||||
```
|
||||
$ systemctl restart mariadb
|
||||
```
|
||||
|
||||
接下来,我们登入我们的主服务器上的 Mariadb 实例。
|
||||
|
||||
```
|
||||
$ mysql -u root -p
|
||||
```
|
||||
|
||||
在它上面创建一个命名为 'slaveuser' 的为主从复制使用的新用户,然后运行如下的命令为它分配所需要的权限:
|
||||
|
||||
```
|
||||
STOP SLAVE;
|
||||
GRANT REPLICATION SLAVE ON *.* TO 'slaveuser'@'%' IDENTIFIED BY 'iamslave';
|
||||
FLUSH PRIVILEGES;
|
||||
FLUSH TABLES WITH READ LOCK;
|
||||
SHOW MASTER STATUS;
|
||||
```
|
||||
|
||||
**注意: ** 我们配置主从复制需要 **MASTER_LOG_FILE 和 MASTER_LOG_POS ** 的值,它可以通过 'show master status' 来获得,因此,你一定要确保你记下了它们的值。
|
||||
|
||||
这些命令运行完成之后,输入 'exit' 退出这个会话。
|
||||
|
||||
### 第 2 步 - 创建一个数据库备份,并将它移动到从服务器上
|
||||
|
||||
现在,我们需要去为我们的数据库 'important' 创建一个备份,可以使用 'mysqldump' 命令去备份。
|
||||
|
||||
```
|
||||
$ mysqldump -u root -p important > important_backup.sql
|
||||
```
|
||||
|
||||
备份完成后,我们需要重新登陆到 MariaDB 数据库,并解锁我们的表。
|
||||
|
||||
```
|
||||
$ mysql -u root -p
|
||||
$ UNLOCK TABLES;
|
||||
```
|
||||
|
||||
然后退出这个会话。现在,我们移动我们刚才的备份到从服务器上,它的 IP 地址是:192.168.1.130。
|
||||
|
||||
在主服务器上的配置已经完成了,现在,我们开始配置从服务器。
|
||||
|
||||
### 第 3 步:配置从服务器
|
||||
|
||||
我们再次去编辑 '/etc/my.cnf' 文件,找到配置文件中的 [mysqld] 节,然后输入如下内容:
|
||||
|
||||
```
|
||||
[mysqld]
|
||||
server-id = 2
|
||||
replicate-do-db=important
|
||||
[ …]
|
||||
```
|
||||
|
||||
现在,我们恢复我们主数据库的备份到从服务器的 MariaDB 上,运行如下命令:
|
||||
|
||||
```
|
||||
$ mysql -u root -p < /data/ important_backup.sql
|
||||
```
|
||||
|
||||
当这个恢复过程结束之后,我们将通过登入到从服务器上的 MariaDB,为数据库 'important' 上的用户 'slaveuser' 授权。
|
||||
|
||||
```
|
||||
$ mysql -u root -p
|
||||
```
|
||||
|
||||
```
|
||||
GRANT ALL PRIVILEGES ON important.* TO 'slaveuser'@'localhost' WITH GRANT OPTION;
|
||||
FLUSH PRIVILEGES;
|
||||
```
|
||||
|
||||
接下来,为了这个变化生效,重启 MariaDB。
|
||||
|
||||
```
|
||||
$ systemctl restart mariadb
|
||||
```
|
||||
|
||||
### **第 4 步:启动复制**
|
||||
|
||||
记住,我们需要 **MASTER_LOG_FILE 和 MASTER_LOG_POS** 变量的值,它可以通过在主服务器上运行 'SHOW MASTER STATUS' 获得。现在登入到从服务器上的 MariaDB,然后通过运行下列命令,告诉我们的从服务器它应该去哪里找主服务器。
|
||||
|
||||
```
|
||||
STOP SLAVE;
|
||||
CHANGE MASTER TO MASTER_HOST= '192.168.1.110′, MASTER_USER='slaveuser', MASTER_PASSWORD='iamslave', MASTER_LOG_FILE='mariadb-bin.000001′, MASTER_LOG_POS=460;
|
||||
SLAVE START;
|
||||
SHOW SLAVE STATUS\G;
|
||||
```
|
||||
|
||||
**注意:** 请根据你的机器的具体情况来改变主服务器的配置。
|
||||
|
||||
### 第 5 步:测试复制
|
||||
|
||||
我们将在我们的主服务器上创建一个新表来测试主从复制是否正常工作。因此,登入到主服务器上的 MariaDB。
|
||||
|
||||
```
|
||||
$ mysql -u root -p
|
||||
```
|
||||
|
||||
选择数据库为 'important':
|
||||
|
||||
```
|
||||
use important;
|
||||
```
|
||||
|
||||
在这个数据库上创建一个名为 ‘test’ 的表:
|
||||
|
||||
```
|
||||
create table test (c int);
|
||||
```
|
||||
|
||||
然后在这个表中插入一些数据:
|
||||
|
||||
```
|
||||
insert into test (c) value (1);
|
||||
```
|
||||
|
||||
检索刚才插入的值是否存在:
|
||||
|
||||
```
|
||||
select * from test;
|
||||
```
|
||||
|
||||
你将会看到刚才你插入的值已经在这个新建的表中了。
|
||||
|
||||
现在,我们登入到从服务器的数据库中,查看主从复制是否正常工作。
|
||||
|
||||
```
|
||||
$ mysql -u root -p
|
||||
$ use important;
|
||||
$ select * from test;
|
||||
```
|
||||
|
||||
你可以看到与前面在主服务器上的命令输出是一样的。因此,说明我们的主从服务工作正常,没有发生任何问题。
|
||||
|
||||
我们的教程结束了,请在下面的评论框中留下你的查询/问题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/creating-master-slave-replication-mariadb/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/installing-configuring-mariadb-rhelcentos/
|
||||
[2]:http://linuxtechlab.com/mariadb-administration-commands-beginners/
|
||||
@ -1,184 +0,0 @@
|
||||
针对 Linux 平台的 10 款最好 LaTeX 编辑器
|
||||
======
|
||||
**简介:一旦你克服了 LaTeX 的学习曲线,就没有什么比得上 LaTeX 了。下面介绍的是针对 Linux 和其他平台的最好的 LaTeX 编辑器。**
|
||||
|
||||
## LaTeX 是什么?
|
||||
|
||||
[LaTeX][1] 是一个文档制作系统。与纯文本编辑器不同,在 LaTeX 编辑器中你不能只写纯文本,为了组织文档的内容,你还必须使用一些 LaTeX 命令。
|
||||
|
||||
![LaTeX 示例][2]![LaTeX 示例][3]
|
||||
|
||||
LaTeX 编辑器一般用在出于学术目的的科学研究文档或书籍的出版,最重要的是,当你需要处理包含众多复杂数学符号的文档时,它能够为你带来方便。当然,使用 LaTeX 编辑器是很有趣的,但它也并非总是很有用,除非你对所要编写的文档有一些特别的需求。
|
||||
|
||||
## 为什么你应当使用 LaTeX?
|
||||
|
||||
好吧,正如我前面所提到的那样,使用 LaTeX 编辑器便意味着你有着特定的需求。为了捣腾 LaTeX 编辑器,并不需要你有一颗极客的头脑。但对于那些使用一般文本编辑器的用户来说,它并不是一个很有效率的解决方法。
|
||||
|
||||
假如你正在寻找一款工具来精心制作一篇文档,同时你对花费时间在格式化文本上没有任何兴趣,那么 LaTeX 编辑器或许正是你所寻找的那款工具。在 LaTeX 编辑器中,你只需要指定文档的类型,它便会相应地为你设置好文档的字体种类和大小尺寸。正是基于这个原因,难怪它会被认为是 [给作家的最好开源工具][4] 之一。
|
||||
|
||||
但请务必注意: LaTeX 编辑器并不是自动化的工具,你必须首先学会一些 LaTeX 命令来让它能够精确地处理文本的格式。
|
||||
|
||||
## 针对 Linux 平台的 10 款最好 LaTeX 编辑器
|
||||
|
||||
事先说明一下,以下列表并没有一个明确的先后顺序,序号为 3 的编辑器并不一定比序号为 7 的编辑器优秀。
|
||||
|
||||
### 1\. LyX
|
||||
|
||||
![][2]
|
||||
|
||||
![][5]
|
||||
|
||||
LyX 是一个开源的 LaTeX 编辑器,即是说它是网络上可获取到的最好的文档处理引擎之一。LyX 帮助你集中于你的文章,并忘记对单词的格式化,而这些正是每个 LaTeX 编辑器应当做的。LyX 能够让你根据文档的不同,管理不同的文档内容。一旦安装了它,你就可以控制文档中的很多东西了,例如页边距,页眉,页脚,空白,缩进,表格等等。
|
||||
|
||||
假如你正忙着精心撰写科学性的文档,研究论文或类似的文档,你将会很高兴能够体验到 LyX 的公式编辑器,这也是其特色之一。 LyX 还包括一系列的教程来入门,使得入门没有那么多的麻烦。
|
||||
|
||||
[LyX][6]
|
||||
|
||||
### 2\. Texmaker
|
||||
|
||||
![][2]
|
||||
|
||||
![][7]
|
||||
|
||||
Texmaker 被认为是 GNOME 桌面环境下最好的 LaTeX 编辑器之一。它呈现出一个非常好的用户界面,带来了极好的用户体验。它也被冠以最实用的 LaTeX 编辑器之一。假如你经常进行 PDF 的转换,你将发现 TeXmaker 相比其他编辑器更加快速。在你书写的同时,你也可以预览你的文档最终将是什么样子的。同时,你也可以观察到可以很容易地找到所需要的符号。
|
||||
|
||||
Texmaker 也提供一个扩展的快捷键支持。你有什么理由不试着使用它呢?
|
||||
|
||||
[Texmaker][8]
|
||||
|
||||
### 3\. TeXstudio
|
||||
|
||||
![][2]
|
||||
|
||||
![][9]
|
||||
|
||||
假如你想要一个这样的 LaTeX 编辑器:它既能为你提供相当不错的自定义功能,又带有一个易用的界面,那么 TeXstudio 便是一个完美的选择。它的 UI 确实很简单,但是不粗糙。 TeXstudio 带有语法高亮,自带一个集成的阅读器,可以让你检查参考文献,同时还带有一些其他的辅助工具。
|
||||
|
||||
它同时还支持某些酷炫的功能,例如自动补全,链接覆盖,书签,多游标等等,这使得书写 LaTeX 文档变得比以前更加简单。
|
||||
|
||||
TeXstudio 的维护很活跃,对于新手或者高级写作者来说,这使得它成为一个引人注目的选择。
|
||||
|
||||
[TeXstudio][10]
|
||||
|
||||
### 4\. Gummi
|
||||
|
||||
![][2]
|
||||
|
||||
![][11]
|
||||
|
||||
Gummi 是一个非常简单的 LaTeX 编辑器,它基于 GTK+ 工具箱。当然,在这个编辑器中你找不到许多华丽的选项,但如果你只想能够立刻着手写作, 那么 Gummi 便是我们给你的推荐。它支持将文档输出为 PDF 格式,支持语法高亮,并帮助你进行某些基础的错误检查。尽管在 GitHub 上它已经不再被活跃地维护,但它仍然工作地很好。
|
||||
|
||||
[Gummi][12]
|
||||
|
||||
### 5\. TeXpen
|
||||
|
||||
![][2]
|
||||
|
||||
![][13]
|
||||
|
||||
TeXpen 是另一个简洁的 LaTeX 编辑器。它为你提供了自动补全功能。但其用户界面或许不会让你感到印象深刻。假如你对用户界面不在意,又想要一个超级容易的 LaTeX 编辑器,那么 TeXpen 将满足你的需求。同时 TeXpen 还能为你校正或提高在文档中使用的英语语法和表达式。
|
||||
|
||||
[TeXpen][14]
|
||||
|
||||
### 6\. ShareLaTeX
|
||||
|
||||
![][2]
|
||||
|
||||
![][15]
|
||||
|
||||
ShareLaTeX 是一款在线 LaTeX 编辑器。假如你想与某人或某组朋友一同协作进行文档的书写,那么这便是你所需要的。
|
||||
|
||||
它提供一个免费方案和几种付费方案。甚至来自哈佛大学和牛津大学的学生也都使用它来进行个人的项目。其免费方案还允许你添加一位协作者。
|
||||
|
||||
其付费方案允许你与 GitHub 和 Dropbox 进行同步,并且能够记录完整的文档修改历史。你可以为你的每个方案选择多个协作者。对于学生,它还提供单独的计费方案。
|
||||
|
||||
[ShareLaTeX][16]
|
||||
|
||||
### 7\. Overleaf
|
||||
|
||||
![][2]
|
||||
|
||||
![][17]
|
||||
|
||||
Overleaf 是另一款在线的 LaTeX 编辑器。它与 ShareLaTeX 类似,它为专家和学生提供了不同的计费方案。它也提供了一个免费方案,使用它你可以与 GitHub 同步,检查你的修订历史,或添加多个合作者。
|
||||
|
||||
在每个项目中,它对文件的数目有所限制。所以在大多数情况下如果你对 LaTeX 文件非常熟悉,这并不会为你带来不便。
|
||||
|
||||
[Overleaf][18]
|
||||
|
||||
### 8\. Authorea
|
||||
|
||||
![][2]
|
||||
|
||||
![][19]
|
||||
|
||||
Authorea 是一个美妙的在线 LaTeX 编辑器。当然,如果考虑到价格,它可能不是最好的一款。对于免费方案,它有 100 MB 的数据上传限制和每次只能创建一个私有文档。而付费方案则提供更多的额外好处,但如果考虑到价格,它可能不是最便宜的。你应该选择 Authorea 的唯一原因应该是因为其用户界面。假如你喜爱使用一款提供令人印象深刻的用户界面的工具,那就不要错过它。
|
||||
|
||||
[Authorea][20]
|
||||
|
||||
### 9\. Papeeria
|
||||
|
||||
![][2]
|
||||
|
||||
![][21]
|
||||
|
||||
Papeeria 是在网络上你能够找到的最为便宜的 LaTeX 在线编辑器,如果考虑到它和其他的编辑器一样可信赖的话。假如你想免费地使用它,则你不能使用它开展私有项目。但是,如果你更偏爱公共项目,它允许你创建不限数目的项目,添加不限数目的协作者。它的特色功能是有一个非常简便的画图构造器,并且在无需额外费用的情况下使用 Git 同步。假如你偏爱付费方案,它赋予你创建 10 个私有项目的能力。
|
||||
|
||||
[Papeeria][22]
|
||||
|
||||
### 10\. Kile
|
||||
|
||||
![Kile LaTeX 编辑器][2]
|
||||
|
||||
![Kile LaTeX 编辑器][23]
|
||||
|
||||
位于我们最好 LaTeX 编辑器清单的最后一位是 Kile 编辑器。有些朋友对 Kile 推崇备至,很大程度上是因为其提供某些特色功能。
|
||||
|
||||
Kile 不仅仅是一款编辑器,它还是一款类似 Eclipse 的 IDE 工具,提供了针对文档和项目的一整套环境。除了快速编译和预览功能,你还可以使用诸如命令的自动补全,插入引用,按照章节来组织文档等功能。你真的应该使用 Kile 来见识其潜力。
|
||||
|
||||
Kile 在 Linux 和 Windows 平台下都可获取到。
|
||||
|
||||
[Kile][24]
|
||||
|
||||
### 总结
|
||||
|
||||
所以上面便是我们推荐的 LaTeX 编辑器,你可以在 Ubuntu 或其他 Linux 发行版本中使用它们。
|
||||
|
||||
当然,我们可能还遗漏了某些可以在 Linux 上使用并且有趣的 LaTeX 编辑器。如若你正好知道它们,请在下面的评论中让我们知晓。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/LaTeX-editors-linux/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ankush/
|
||||
[1]:https://www.LaTeX-project.org/
|
||||
[2]:data:image/gif;base64,R0lGODdhAQABAPAAAP///wAAACwAAAAAAQABAEACAkQBADs=
|
||||
[3]:https://itsfoss.com/wp-content/uploads/2017/11/LaTeX-sample-example.jpeg
|
||||
[4]:https://itsfoss.com/open-source-tools-writers/
|
||||
[5]:https://itsfoss.com/wp-content/uploads/2017/10/LyX_LaTeX_editor.jpg
|
||||
[6]:https://www.LyX.org/
|
||||
[7]:https://itsfoss.com/wp-content/uploads/2017/10/texmaker_LaTeX_editor.jpg
|
||||
[8]:http://www.xm1math.net/texmaker/
|
||||
[9]:https://itsfoss.com/wp-content/uploads/2017/10/tex_studio_LaTeX_editor.jpg
|
||||
[10]:https://www.texstudio.org/
|
||||
[11]:https://itsfoss.com/wp-content/uploads/2017/10/gummi_LaTeX_editor.jpg
|
||||
[12]:https://github.com/alexandervdm/gummi
|
||||
[13]:https://itsfoss.com/wp-content/uploads/2017/10/texpen_LaTeX_editor.jpg
|
||||
[14]:https://sourceforge.net/projects/texpen/
|
||||
[15]:https://itsfoss.com/wp-content/uploads/2017/10/shareLaTeX.jpg
|
||||
[16]:https://www.shareLaTeX.com/
|
||||
[17]:https://itsfoss.com/wp-content/uploads/2017/10/overleaf.jpg
|
||||
[18]:https://www.overleaf.com/
|
||||
[19]:https://itsfoss.com/wp-content/uploads/2017/10/authorea.jpg
|
||||
[20]:https://www.authorea.com/
|
||||
[21]:https://itsfoss.com/wp-content/uploads/2017/10/papeeria_LaTeX_editor.jpg
|
||||
[22]:https://www.papeeria.com/
|
||||
[23]:https://itsfoss.com/wp-content/uploads/2017/11/kile-LaTeX-800x621.png
|
||||
[24]:https://kile.sourceforge.io/
|
||||
@ -0,0 +1,170 @@
|
||||
根据权限查找文件
|
||||
======
|
||||
|
||||
在 Linux 中查找文件并不是什么大问题。市面上也有很多可靠的免费开源可视化的查询工具。但对我而言,查询文件,用命令行的方式会更快更简单。我们已经知道 [ 如何根据访问、修改文件时间寻找或整理文件 ][1]。今天,在基于 Unix 的操作系统中,我们将见识如何通过权限查询文件。
|
||||
|
||||
本段教程中,我将创建三个文件名为 **file1**,**file2** 和 **file3** 分别赋予 **777**,**766** 和 **655** 文件权限,并分别置于名为 **ostechnix** 的文件夹中。
|
||||
```
|
||||
mkdir ostechnix && cd ostechnix/
|
||||
```
|
||||
```
|
||||
install -b -m 777 /dev/null file1
|
||||
```
|
||||
```
|
||||
install -b -m 766 /dev/null file2
|
||||
```
|
||||
```
|
||||
install -b -m 655 /dev/null file3
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
现在,让我们通过权限来查询一下文件。
|
||||
|
||||
### 根据权限查询文件
|
||||
|
||||
根据权限查询文件最具代表性的语法:
|
||||
```
|
||||
find -perm mode
|
||||
```
|
||||
|
||||
MODE 可以是代表权限的八进制数字(777,666…)也可以是权限符号(u=x,a=r+x)。
|
||||
|
||||
在深入之前,我们就以下三点详细说明 MODE 参数。
|
||||
|
||||
1. 如果我们不指定任何参数前缀,它将会寻找 **具体** 权限的文件。
|
||||
2. 如果我们使用 **“-”** 参数前缀, 寻找到的文件至少拥有 mode 所述的权限,而不是具体的权限(大于或等于此权限的文件都会被查找出来)。
|
||||
3. 如果我们使用 **“/”** 参数前缀,那么所有者、组或者其他人任意一个应当享有此文件的权限。
|
||||
|
||||
为了让你更好的理解,让我举些例子。
|
||||
|
||||
首先,我们将要看到基于数字权限查询文件。
|
||||
|
||||
### 基于数字(八进制)权限查询文件
|
||||
|
||||
让我们运行下列命令:
|
||||
```
|
||||
find -perm 777
|
||||
```
|
||||
|
||||
这条命令将会查询到当前目录权限为 **确切为 777** 权限的文件。
|
||||
|
||||
![1][4]
|
||||
|
||||
当你看见屏幕输出行时,file1 是唯一一个拥有 **确切为 777 权限** 的文件。
|
||||
|
||||
现在,让我们使用 “-” 参数前缀,看看会发生什么。
|
||||
```
|
||||
find -perm -766
|
||||
```
|
||||
|
||||
![][5]
|
||||
|
||||
如你所见,命令行上显示两个文件。我们给 file2 设置了 766 权限,但是命令行显示两个文件,什么鬼?因为,我们设置了 “-” 参数前缀。它意味着这条命令将在所有文件中查询文件所有者的 读/写/执行 权限,文件用户组的 读/写权限和其他用户的 读/写 全西安。本例中,file1 和 file2 都符合要求。换句话说,文件并不一样要求时确切的 766 权限。它将会显示任何属于(高于)此权限的文件 。
|
||||
|
||||
然后,让我们使用 “/” 参数前置,看看会发生什么。
|
||||
```
|
||||
find -perm /222
|
||||
```
|
||||
|
||||
![][6]
|
||||
|
||||
上述命令将会查询所有者、用户组或其他拥有写权限的文件。这里有另外一个例子
|
||||
|
||||
```
|
||||
find -perm /220
|
||||
```
|
||||
|
||||
这条命令会查询所有者或用户组中拥有写权限的文件。这意味着 **所有者和用户组** 中匹配 **不全拥有写权限**。
|
||||
|
||||
如果你使用 “-” 前缀运行相同的命令,你只会看到所有者和用户组都拥有写权限的文件。
|
||||
```
|
||||
find -perm -220
|
||||
```
|
||||
|
||||
下面的截图会告诉你这两个参数前缀的不同。
|
||||
|
||||
![][7]
|
||||
|
||||
如我之前说过的一样,我们可以使用符号表示文件权限。
|
||||
|
||||
请阅读:
|
||||
|
||||
### 基于符号的文件权限查询文件
|
||||
|
||||
在下面的例子中,我们使用例如 **u**(所有者),**g**(用户组) 和 **o**(其他) 的符号表示法。我们也可以使用字母 **a** 代表上述三种类型。我们可以通过特指的 **r** (读), **w** (写), **x** (执行) 分别代表它们的权限。
|
||||
|
||||
例如,寻找用户组中拥有 **写** 权限的文件,执行:
|
||||
```
|
||||
find -perm -g=w
|
||||
```
|
||||
|
||||
![][8]
|
||||
|
||||
上面的例子中,file1 和 file2 都拥有 **写** 权限。请注意,你可以等效使用 “=”或“+”两种符号标识。例如,下列两行相同效果的代码。
|
||||
```
|
||||
find -perm -g=w
|
||||
find -perm -g+w
|
||||
```
|
||||
|
||||
查询文件所有者中拥有写权限的文件,执行:
|
||||
```
|
||||
find -perm -u=w
|
||||
```
|
||||
|
||||
查询所有用户中拥有写权限的文件,执行:
|
||||
```
|
||||
find -perm -a=w
|
||||
```
|
||||
|
||||
查询 **所有者** 和 **用户组** 中同时拥有写权限的文件,执行:
|
||||
```
|
||||
find -perm -g+w,u+w
|
||||
```
|
||||
|
||||
上述命令等效与“find -perm -220”。
|
||||
|
||||
查询 **所有者** 或 **用户组** 中拥有写权限的文件,执行:
|
||||
```
|
||||
find -perm /u+w,g+w
|
||||
```
|
||||
|
||||
或者,
|
||||
```
|
||||
find -perm /u=w,g=w
|
||||
```
|
||||
|
||||
上述命令等效于 “find -perm /220”。
|
||||
更多详情,参照 man 手册。
|
||||
```
|
||||
man find
|
||||
```
|
||||
|
||||
了解更多简化案例或其他 Linux 命令,查看[**man 手册**][9]。
|
||||
|
||||
然后,这就是所有的内容。希望这个教程有用。更多干货,敬请关注。
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/find-files-based-permissions/
|
||||
|
||||
作者:[][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com
|
||||
[1]:https://www.ostechnix.com/find-sort-files-based-access-modification-date-time-linux/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7/
|
||||
[3]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-1-1.png
|
||||
[4]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-2.png
|
||||
[5]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-3.png
|
||||
|
||||
[6]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-6.png
|
||||
[7]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-7.png
|
||||
[8]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-8.png
|
||||
[9]:https://www.ostechnix.com/3-good-alternatives-man-pages-every-linux-user-know/
|
||||
@ -0,0 +1,163 @@
|
||||
如何统计Linux中文件和文件夹/目录的数量
|
||||
======
|
||||
嗨,伙计们,今天我们又来了一系列棘手的命令,会多方面帮助你。 这是一种操作命令,它可以帮助您计算当前目录中的文件和目录,递归计数,特定用户创建的文件列表等。
|
||||
|
||||
在本教程中,我们将向您展示如何使用多个命令,并使用ls,egrep,wc和find命令执行一些高级操作。 下面的命令很有帮助。
|
||||
|
||||
为了实验,我打算总共创建7个文件和2个文件夹(5个常规文件和2个隐藏文件)。 看到下面的tree命令的输出清楚的展示文件和文件夹列表。
|
||||
|
||||
**推荐阅读** [文件操作命令][1]
|
||||
```
|
||||
# tree -a /opt
|
||||
/opt
|
||||
├── magi
|
||||
│ └── 2g
|
||||
│ ├── test5.txt
|
||||
│ └── .test6.txt
|
||||
├── test1.txt
|
||||
├── test2.txt
|
||||
├── test3.txt
|
||||
├── .test4.txt
|
||||
└── test.txt
|
||||
|
||||
2 directories, 7 files
|
||||
|
||||
```
|
||||
|
||||
**示例-1 :** 统计当前目录文件(排除隐藏文件)。 运行以下命令以确定当前目录中有多少个文件,并且不计算点文件(LCTT译者注:点文件即当前目录文件和上级目录文件)。
|
||||
```
|
||||
# ls -l . | egrep -c '^-'
|
||||
4
|
||||
```
|
||||
|
||||
**细节:**
|
||||
|
||||
* `ls` : 列出目录内容
|
||||
* `-l` : 使用长列表格式
|
||||
* `.` : 列出有关文件的信息(默认为当前目录)
|
||||
* `|` : 控制操作器将一个程序的输出发送到另一个程序进行进一步处理
|
||||
* `egrep` : 打印符合模式的行
|
||||
* `-c` : 通用输出控制
|
||||
* `'^-'` : 它们分别匹配一行的开头和结尾的空字符串
|
||||
|
||||
|
||||
|
||||
**示例-2 :** 统计包含隐藏文件的当前目录文件。 包括当前目录中的点文件。
|
||||
```
|
||||
# ls -la . | egrep -c '^-'
|
||||
5
|
||||
```
|
||||
|
||||
**示例-3 :** 运行以下命令来计算当前目录文件和文件夹。 它会一次计算所有的。
|
||||
```
|
||||
# ls -1 | wc -l
|
||||
5
|
||||
```
|
||||
|
||||
**细节:**
|
||||
|
||||
* `ls` : 列出目录内容
|
||||
* `-l` : 使用长列表格式
|
||||
* `|` : 控制操作器将一个程序的输出发送到另一个程序进行进一步处理
|
||||
* `wc` : 这是一个为每个文件打印换行符,字和字节数的命令
|
||||
* `-l` : 打印换行符数
|
||||
|
||||
|
||||
|
||||
**示例-4 :** 统计包含隐藏文件和目录的当前目录文件和文件夹。
|
||||
```
|
||||
# ls -1a | wc -l
|
||||
8
|
||||
```
|
||||
|
||||
**示例-5 :** 递归计算当前目录文件,其中包括隐藏文件。
|
||||
```
|
||||
# find . -type f | wc -l
|
||||
7
|
||||
```
|
||||
|
||||
**细节 :**
|
||||
|
||||
* `find` : 搜索目录层次结构中的文件
|
||||
* `-type` : 文件类型
|
||||
* `f` : 常规文件
|
||||
* `wc` : 这是一个为每个文件打印换行符,字和字节数的命令
|
||||
* `-l` : 打印换行符数
|
||||
|
||||
|
||||
|
||||
**示例-6 :** 使用tree命令打印目录和文件数(排除隐藏文件)。
|
||||
```
|
||||
# tree | tail -1
|
||||
2 directories, 5 files
|
||||
```
|
||||
|
||||
**示例-7 :** 使用包含隐藏文件的树命令打印目录和文件数。
|
||||
```
|
||||
# tree -a | tail -1
|
||||
2 directories, 7 files
|
||||
```
|
||||
|
||||
**示例-8 :** 运行下面的命令递归计算包含隐藏目录的目录。
|
||||
```
|
||||
# find . -type d | wc -l
|
||||
3
|
||||
```
|
||||
|
||||
**示例-9 :** 根据文件扩展名计算文件数量。 这里我们要计算 `.txt` 文件。
|
||||
```
|
||||
# find . -name "*.txt" | wc -l
|
||||
7
|
||||
```
|
||||
|
||||
**示例-10 :** 使用echo命令和wc命令统计当前目录中的所有文件。 `4`表示当前目录中的文件数量。
|
||||
```
|
||||
# echo * | wc
|
||||
1 4 39
|
||||
```
|
||||
|
||||
**示例-11 :** 通过使用echo命令和wc命令来统计当前目录中的所有目录。 `1`表示当前目录中的目录数量。
|
||||
```
|
||||
# echo comic/ published/ sources/ translated/ | wc
|
||||
1 1 6
|
||||
```
|
||||
|
||||
**示例-12 :** 通过使用echo命令和wc命令来统计当前目录中的所有文件和目录。 `5`表示当前目录中的目录和文件的数量。
|
||||
```
|
||||
# echo * | wc
|
||||
1 5 44
|
||||
```
|
||||
|
||||
**示例-13 :** 统计系统(整个系统)中的文件数。
|
||||
```
|
||||
# find / -type f | wc -l
|
||||
69769
|
||||
```
|
||||
|
||||
**示例-14 :** 统计系统(整个系统)中的文件夹数。
|
||||
```
|
||||
# find / -type d | wc -l
|
||||
8819
|
||||
```
|
||||
|
||||
**示例-15 :** 运行以下命令来计算系统(整个系统)中的文件,文件夹,硬链接和符号链接数。
|
||||
```
|
||||
# find / -type d -exec echo dirs \; -o -type l -exec echo symlinks \; -o -type f -links +1 -exec echo hardlinks \; -o -type f -exec echo files \; | sort | uniq -c
|
||||
8779 dirs
|
||||
69343 files
|
||||
20 hardlinks
|
||||
11646 symlinks
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-count-the-number-of-files-and-folders-directories-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
[1]:https://www.2daygeek.com/empty-a-file-delete-contents-lines-from-a-file-remove-matching-string-from-a-file-remove-empty-blank-lines-from-a-file/
|
||||
@ -1,64 +0,0 @@
|
||||
如何使用 pdfgrep 从终端搜索 PDF 文件
|
||||
======
|
||||
诸如 [grep][1] 和 [ack-grep][2] 之类的命令行工具对于搜索匹配指定[正则表达式][3]的纯文本非常有用。但是你有没有试过使用这些工具在 PDF 中搜索模板?不要这么做!由于这些工具无法读取PDF文件,因此你不会得到任何结果。他们只能读取纯文本文件。
|
||||
|
||||
顾名思义,[pdfgrep][4] 是一个小的命令行程序,可以在不打开文件的情况下搜索 PDF 中的文本。它非常快速 - 比几乎所有 PDF 浏览器提供的搜索更快。grep 和 pdfgrep 的区别在于 pdfgrep 对页进行操作,而 grep 对行操作。grep 如果在一行上找到多个匹配项,它也会多次打印单行。让我们看看如何使用该工具。
|
||||
|
||||
对于 Ubuntu 和其他基于 Ubuntu 的 Linux 发行版来说,这非常简单:
|
||||
```
|
||||
sudo apt install pdfgrep
|
||||
```
|
||||
|
||||
对于其他发行版,只要将 `pdfgrep` 作为[包管理器][5]的输入,它就应该能够安装。万一你想浏览代码,你也可以查看项目的[ GitLab 页面][6]。
|
||||
|
||||
现在你已经安装了这个工具,让我们去测试一下。pdfgrep 命令采用以下格式:
|
||||
```
|
||||
pdfgrep [OPTION...] PATTERN [FILE...]
|
||||
```
|
||||
|
||||
**OPTION** 是一个额外的属性列表,给出诸如 `-i` 或 `--ignore-case` 这样的命令,这两者都会忽略匹配正则中的大小写。
|
||||
|
||||
**PATTERN** 是一个扩展的正则表达式。
|
||||
|
||||
**FILE** 如果它在相同的工作目录或文件的路径,这是文件的名称。
|
||||
|
||||
我根据官方文档用 Python 3.6 运行命令。下图是结果。
|
||||
|
||||
![pdfgrep search][7]
|
||||
|
||||
![pdfgrep search][7]
|
||||
|
||||
红色高亮显示所有遇到单词 “queue” 的地方。在命令中加入 `-i` 选项将会匹配单词 “Queue”。请记住,当加入 `-i` 时,大小写并不重要。
|
||||
|
||||
pdfgrep 有相当多的有趣的选项。不过,我只会在这里介绍几个。
|
||||
|
||||
|
||||
* `-c` 或者 `--count`:这会抑制匹配的正常输出。它只显示在文件中遇到该单词的次数,而不是显示匹配的长输出,
|
||||
* `-p` 或者 `--page-count`:这个选项打印页面上匹配的页码和页面上的模式出现次数
|
||||
* `-m` 或者 `--max-count` [number]:指定匹配的最大数目。这意味着当达到匹配次数时,该命令停止读取文件。
|
||||
|
||||
|
||||
|
||||
支持的选项的完整列表可以在 man 页面或者 pdfgrep 在线[文档][8]中找到。以防你在处理一些批量文件,不要忘记,pdfgrep 可以同时搜索多个文件。可以通过更改 GREP_COLORS 环境变量来更改默认的匹配高亮颜色。
|
||||
|
||||
下一次你想在 PDF 中搜索一些东西。请考虑使用 pdfgrep。该工具会派上用场,并且节省你的时间。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/search-pdf-files-pdfgrep/
|
||||
|
||||
作者:[Bruno Edoh][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com
|
||||
[1] https://www.maketecheasier.com/what-is-grep-and-uses/
|
||||
[2] https://www.maketecheasier.com/ack-a-better-grep/
|
||||
[3] https://www.maketecheasier.com/the-beginner-guide-to-regular-expressions/
|
||||
[4] https://pdfgrep.org/
|
||||
[5] https://www.maketecheasier.com/install-software-in-various-linux-distros/
|
||||
[6] https://gitlab.com/pdfgrep/pdfgrep
|
||||
[7] https://www.maketecheasier.com/assets/uploads/2017/11/pdfgrep-screenshot.png (pdfgrep search)
|
||||
[8] https://pdfgrep.org/doc.html
|
||||
@ -1,43 +0,0 @@
|
||||
手把手教你构建开放式文化
|
||||
======
|
||||
我们于 2015 年发表 `开放组织 (Open Organization)` 后,很对各种类型不同大小的公司都对“开放式”文化究竟意味着什么感到好奇。甚至当我跟别的公司谈论我们产品和服务的优势时,也总是很快就从谈论技术转移到人和文化上去了。几乎所有对推动创新和保持行业竞争优势有兴趣的人都在思考这个问题。
|
||||
|
||||
不是只有高级领导团队 (Senior leadership teams) 才对开放式工作感兴趣。[红帽公司最近一次调查 ][1] 发现 [81% 的受访者 ][2] 同意这样一种说法:"拥有开放式的组织文化对我们公司非常重要。"
|
||||
|
||||
然而要注意的是。同时只有 [67% 的受访者 ][3] 认为:"我们的组织有足够的资源来构建开放式文化。"
|
||||
|
||||
这个结果与我从其他公司那交流所听到的相吻合:人们希望在开放式文化中工作,他们只是不知道该怎么做。对此我表示同情,因为组织的行事风格是很难捕捉,评估,和理解的。在 [Catalyst-In-Chief][4] 中,我将其称之为 "组织中最神秘莫测的部分。"
|
||||
|
||||
开放式组织之所以让人神往是因为在这个数字化转型有望改变传统工作方式的时代,拥抱开放文化是保持持续创新的最可靠的途径。当我们在书写本文的时候,我们所关注的是描述在红帽公司中兴起的那种文化--而不是编写一本如何操作的书。我们并不会制定出一步步的流程来让其他组织采用。
|
||||
|
||||
这也是为什么与其他领导者和高管谈论他们是如何开始构建开放式文化的会那么有趣。在创建开发组织时,很多高管会说我们要"改变我们的文化"。但是文化并不是一项输入。它是一项输出--它是人们互动和日常行为的副产品。
|
||||
|
||||
告诉组织成员"更加透明地工作","更多地合作",以及 "更加包容地行动" 并没有什么作用。因为像 "透明," "合作," and "包容" 这一类的文化特质并不是行动。他们只是组织内指导行为的价值观而已。
|
||||
|
||||
纳入要如何才能构建开放式文化呢?
|
||||
|
||||
在过去的两年里,Opensource.com 设计收集了各种以开放的精神来进行工作,管理和领导的最佳实践方法。现在我们在新书 [The Open Organization Workbook][5] 中将之分享出来,这是一本更加规范的引发文化变革的指引。
|
||||
|
||||
要记住,任何改变,尤其是巨大的改变,都需要许诺 (commitment),耐心,以及努力的工作。我推荐你在通往伟大成功的大道上先使用这本工作手册来实现一些微小的,有意义的成果。
|
||||
|
||||
通过阅读这本书,你将能够构建一个开放而又富有创新的文化氛围,使你们的人能够茁壮成长。我已經迫不及待想听听你的故事了。
|
||||
|
||||
本文摘自 [Open Organization Workbook project][6]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/17/12/whitehurst-workbook-introduction
|
||||
|
||||
作者:[Jim Whitehurst][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jwhitehurst
|
||||
[1]:https://www.redhat.com/en/blog/red-hat-releases-2017-open-source-culture-survey-results
|
||||
[2]:https://www.techvalidate.com/tvid/923-06D-74C
|
||||
[3]:https://www.techvalidate.com/tvid/D30-09E-B52
|
||||
[4]:https://opensource.com/open-organization/resources/catalyst-in-chief
|
||||
[5]:https://opensource.com/open-organization/resources/workbook
|
||||
[6]:https://opensource.com/open-organization/17/8/workbook-project-announcement
|
||||
@ -1,139 +0,0 @@
|
||||
# [关于 Linux 页面表隔离补丁的神秘情况][14]
|
||||
|
||||
* * *
|
||||
|
||||
_长文预警:_ 这是一个目前严格限制的、禁止披露的安全 bug,它影响到目前几乎所有实现虚拟内存的 CPU 架构,需要硬件的改变才能完全解决这个 bug。通过软件来缓解这种影响的紧急开发工作正在进行中,并且最近在 Linux 内核中已经得以实现,并且,在 11 月份,在 NT 内核中也开始了一个类似的紧急开发。在最糟糕的情况下,软件修复会导致一般工作负载出现巨大的减速(译者注:外在表现为 CPU 性能下降)。这里有一个提示,攻击会影响虚拟化环境,包括 Amazon EC2 和 Google 计算引擎,以及另外的提示是,这种精确的攻击可能涉及一个新的 Rowhammer 变种(译者注:一个由 Google 安全团队提出的 DRAM 的安全漏洞,在文章的后面部分会简单介绍)。
|
||||
|
||||
* * *
|
||||
|
||||
我一般不太关心安全问题,但是,对于这个 bug 我有点好奇,而一般会去写这个主题的人似乎都很忙,要么就是知道这个主题细节的人会保持沉默。这让我在新年的第一天(元旦那天)花了几个小时深入去挖掘关于这个谜团的更多信息,并且我将这些信息片断拼凑到了一起。
|
||||
|
||||
注意,这是一件相互之间高度相关的事件,因此,它的主要描述都是猜测,除非过一段时间,它的限制禁令被取消。我所看到的,包括涉及到的供应商、许多争论和这种戏剧性场面,将在限制禁令取消的那一天出现。
|
||||
|
||||
**LWN**
|
||||
|
||||
这个事件的线索出现于 12 月 20 日 LWN 上的 [内核页面表的当前状况:页面隔离][2](致校对:就是昨天我翻译的那篇) 这篇文章。它在 10 月份被奥地利的 [TU Graz][4] 的一组研究人员第一次发表。从文章语气上明显可以看到这项工作的紧急程度,内核的核心开发者紧急加入了 [KAISER 补丁系列][3]。
|
||||
|
||||
这一系列的补丁的用途从概念上说很简单:为了阻止运行在用户空间的进程在进程页面表中,通过映射得到内核空间页面的各种攻击方式,可以很好地阻止了从非特权的用户空间代码中识别到内核虚拟地址的攻击企图。
|
||||
|
||||
这组论文描述的 KAISER,[KASLR 已死:KASLR 永存][5](致校对:这里我觉得是[ASLR 已死:KASLR 永存],请查看原文出处。),在它的抽象中,通过特定的引用,在内存管理硬件中去删除所有内核地址空间的信息,即便是用户代码在这个 CPU 上处于活动状态的时候。
|
||||
|
||||
这个补丁集的魅力在于它触及到了核心,内核的全部基础核心(和与用户空间的接口),显然,它应该被最优先考虑。在 Linux 中当我读到关于内存管理的变化时,通常,第一个引用发生在变化被合并的很久之前,并且,通常会进行多次的评估、拒绝、以及因各种原因爆发争论的一系列过程。
|
||||
|
||||
KAISER(就是现在的 KPTI)系列被合并还不足三个月。
|
||||
|
||||
**ASLR 概述**
|
||||
|
||||
从表面上看,设计的这些补丁可以确保地址空间布局随机化仍然有效:这是一个现代操作系统的安全特性,它企图去将更多的随机位,引入到公共映射对象的地址空间中。
|
||||
|
||||
例如,在引用 /usr/bin/python 时,动态链接将对系统的 C 库、堆、线程栈、以及主要的可执行文件进行排布,去接受随机分配的地址范围:
|
||||
|
||||
> $ bash -c ‘grep heap /proc/$$/maps’
|
||||
> 019de000-01acb000 rw-p 00000000 00:00 0 [heap]
|
||||
> $ bash -c 'grep heap /proc/$$/maps’
|
||||
> 023ac000-02499000 rw-p 00000000 00:00 0 [heap]
|
||||
|
||||
注意跨 bash 进程的开始和结束偏移量上的堆的变化。
|
||||
|
||||
这个特性的效果是,一个 buffer 管理的 bug 导致一个攻击者可以去覆写一些程序代码指向的内存地址,并且,那个地址将在程序控制流中被使用,诸如这种攻击者可以使控制流转向到一个包含他们选择的内容的 buffer 上,对于攻击者来说,使用机器代码来填充 buffer 将更困难。例如,system() C 库函数将被引用,因为,那个函数的地址在不同的运行进程上不同的。
|
||||
|
||||
这是一个简单的示例,ASLR 被设计用于去保护类似这样的许多场景,包括阻止攻击者从有可能被用来修改控制流或者实现一个攻击的程序数据的地址内容。
|
||||
|
||||
KASLR 是 “简化的” 应用到内核本身的 ASLR:在每个重新引导的系统上,属于内核的地址范围是随机的,这样就使得,虽然被攻击者转向的控制流运行在内核模式上,但是,不能猜测到为实现他们的攻击目的所需要的函数和结构的地址,比如,定位当前进程数据,将活动的 UID 从一个非特权用户提升到 root 用户,等等。
|
||||
|
||||
**坏消息:缓减这种攻击的软件运行成本过于贵重**
|
||||
|
||||
老的 Linux 将内核内存映射在同一个页面表中的这个行为的主要原因是,当用户的代码触发一个系统调用、故障、或者产生中断时,用户内存也是这种行为,这样就不需要改变正在运行的进程的虚拟内存布局。
|
||||
|
||||
因为在那样,它不需要去改变虚拟内存布局,进而也就不需要去清洗掉(flush)与 CPU 性能高度依赖的缓存(致校对:意思是如果清掉这些缓存,CPU 性能就会下降),主要是通过 [转换查找缓冲器][6](译者注:Translation Lookaside Buffer(TLB)(将虚拟地址转换为物理地址)。
|
||||
|
||||
使用已合并的页面表分割补丁后变成,内核每次开始运行时,需要将内核的缓存清掉,并且,每次用户代码恢复运行时都会这样。对于大多数工作负载,在每个系统调用中,TLB 的实际总损失将导致明显的变慢:[@grsecurity 测量的一个简单的案例][7],在一个最新的 AMD CPU 上,Linux “du -s” 变慢了 50%。
|
||||
|
||||
**34C3**
|
||||
|
||||
在今年的 CCC 上,你可以找到 TU Graz 的研究人员的另一篇,[一个纯 Javascript 的 ASLR 攻击描述][8] ,通过仔细地掌握 CPU 内存管理单元的操作时机,遍历了描述虚拟内存布局的页面表,来实现 ASLR 攻击。它通过高度精确的时间掌握和选择性回收的 CPU 缓存行的组合方式来实现这种结果,一个运行在 web 浏览器的 Javascript 程序可以找回一个 Javascript 对象的虚拟地址,使得利用浏览器内存管理 bugs 被允许进行接下来的攻击。
|
||||
|
||||
因此,从表面上看,我们有一组 KAISER 补丁,也展示了解除 ASLR 的地址的技术,并且,这个展示使用的是 Javascript,很快就可以在一个操作系统内核上进行重新部署。
|
||||
|
||||
**虚拟内存概述**
|
||||
|
||||
在通常情况下,当一些机器码尝试去加载、存储、或者跳转到一个内存地址时,现代的 CPUs 必须首先去转换这个 _虚拟地址_ 到一个 _物理地址_ ,通过使用一系列操作系统托管的数组(被称为页面表),来描述一个虚拟地址和安装在这台机器上的物理内存之间的映射。
|
||||
|
||||
在现代操作系统中,虚拟内存可能是仅有的一个非常重要的强大特性:它都阻止了什么呢?例如,一个濒临死亡的进程崩溃了操作系统、一个 web 浏览器 bugs 崩溃了你的桌面环境、或者,一个运行在 Amazon EC2 中的虚拟机的变化影响了同一台主机上的另一个虚拟机。
|
||||
|
||||
这种攻击的原理是,利用 CPU 上维护的大量的缓存,通过仔细地操纵这些缓存的内存,它可以去推测内存管理单元的地址,以去访问页面表的不同层级,因为一个未缓存的访问将比一个缓存的访问花费更长的时间。通过检测页面表上可访问的元素,它可能去恢复在 MMU(译者注:存储器管理单元)忙于解决的虚拟地址中的大部分比特(bits)。
|
||||
|
||||
**这种动机的证据,但是不用恐慌**
|
||||
|
||||
我们找到了动机,但是到目前为止,我们并没有看到这项工作引进任何恐慌。总的来说,ASLR 并不能完全缓减这种风险,并且也是一道最后的防线:仅在这 6 个月的周期内,即便是一个没有安全意识的人也能看到一些关于解除(unmasking) ASLR 的指针的新闻,并且,实际上 ASLR 已经存在了。
|
||||
|
||||
单独的修复 ASLR 并不足于去描述这项工作高优先级背后的动机。
|
||||
|
||||
**它是硬件安全 bug 的证据**
|
||||
|
||||
通过阅读这一系列补丁,可以明确许多事情。
|
||||
|
||||
第一,正如 [@grsecurity 指出][9] 的,代码中的一些注释已经被编辑(redacted),并且,描述这项工作的额外的主文档文件已经在 Linux 源代码树中看不到了。
|
||||
|
||||
测试代码已经以运行时补丁的方式构建,在系统引导时仅当内核检测到是受影响的系统时才会被应用,与对臭名昭著的 [Pentium F00F bug][10] 的缓解措施,使用完全相同的机制:
|
||||
|
||||

|
||||
|
||||
**更多的线索:Microsoft 也已经实现了页面表的分割**
|
||||
|
||||
通过对 FreeBSD 源代码的一个小挖掘可以看出,目前,其它的免费操作系统没有实现页面表分割,但是,通过 [Alex Ioniscu on Twitter][11] 的启示,这项工作已经不局限于 Linux 了:从 11 月起,公开的 NT 内核也已经实现了同样的技术。
|
||||
|
||||
**猜测的结果:Rowhammer**
|
||||
|
||||
在 TU Graz 上进一步挖掘对这项工作的研究,我们找到 [When rowhammer only knocks once][12],12 月 4 日通告的一个 [新的 Rowhammer 攻击的变种][13]:
|
||||
|
||||
> 在这篇论文中,我们提出了新的 Rowhammer 攻击和原始的漏洞利用,表明即便是所有防御的组合也没有效果。我们的新攻击技术,对一个位置的反复 “敲打”(hammering),打破了以前假定的触发 Rowhammer bug 的前提条件。
|
||||
|
||||
作一个快速回顾,Rowhammer 是一个对主要(全部?)种类的商品 DRAMs 的基础问题的一个类别,比如,在普通的计算机中的内存上。通过精确操作内存中的一个区域,这可能会导致内存该区域存储的相关(但是逻辑上是独立的)内容被毁坏。效果是,Rowhammer 可能被用于去反转内存中的比特(bits),使未经授权的用户代码可以访问到,比如,这个比特位描述了系统中的其它代码的访问权限。
|
||||
|
||||
我发现在 Rowhammer 上,这项工作很有意思,尤其是它反转的位接近页面表分割补丁时,但是,因为 Rowhammer 攻击要求一个目标:你必须知道你尝试去反转的比特在内存中的物理地址,并且,第一步是得到的物理地址可能是一个虚拟地址,比如,在 KASLR 中的解除(unmasking)工作。
|
||||
|
||||
**猜测的结果:它影响主要的云供应商**
|
||||
|
||||
在我能看到的内核邮件列表中,除了子系统维护者的名字之外,e-mail 地址是属于 Intel、Amazon、和 Google 的雇员,这表示这两个大的云计算供应商对此特别感兴趣,这为我们提供了一个强大的线索,这项工作很大的可能是受虚拟化安全驱动的。
|
||||
|
||||
它可能会导致产生更多的猜测:虚拟机 RAM 和由这些虚拟机所使用的虚拟内存地址,最终表示为在主机上大量的相邻的数组,那些数组,尤其是在一个主机上只有两个租户的情况下,在 Xen 和 Linux 内核中是通过内存分配来确定的,这样可能会有(准确性)非常高的可预测行为。
|
||||
|
||||
**最喜欢的猜测:这是一个提升特权的攻击**
|
||||
|
||||
把这些综合到一起,我并不难预测,如果我们在 2018 年使用这些存在提升特权的 bug 的发行版,或者类似的系统去驱动如此紧急的情况,并且在补丁集的抄送列表中出现如此多的感兴趣者的名字。
|
||||
|
||||
最后的一个趣闻,虽然我在阅读补丁集的时候没有找到我要的东西,但是,在一些代码中标记,paravirtual 或者 HVM Xen 是不受此影响的。
|
||||
|
||||
**Invest in popcorn, 2018 将很有趣**
|
||||
|
||||
这些猜想是完全有可能的,它离实现很近,但是可以肯定的是,当这些事情被公开后,那将是一个非常令人激动的几个星期。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://pythonsweetness.tumblr.com/post/169166980422/the-mysterious-case-of-the-linux-page-table
|
||||
|
||||
作者:[python sweetness][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://pythonsweetness.tumblr.com/
|
||||
[1]:http://pythonsweetness.tumblr.com/post/169217189597/quiet-in-the-peanut-gallery
|
||||
[2]:http://t.umblr.com/redirect?z=https%3A%2F%2Flwn.net%2FArticles%2F741878%2F&t=ODY1YTM4MjYyYzU2NzNmM2VmYzEyMGIzODJkY2IxNDg0MDhkZDM1MSxXRG55eVpXNw%3D%3D&b=t%3AqBH2b-yWL63V8acbuG-EUQ&p=http%3A%2F%2Fpythonsweetness.tumblr.com%2Fpost%2F169166980422%2Fthe-mysterious-case-of-the-linux-page-table&m=1
|
||||
[3]:http://t.umblr.com/redirect?z=https%3A%2F%2Flwn.net%2FArticles%2F738975%2F&t=MzQxMmMyYThhNDdiMGJkZmRmZWI5NDkzZmQ3ZTM4ZDcwYzFhMjU5OSxXRG55eVpXNw%3D%3D&b=t%3AqBH2b-yWL63V8acbuG-EUQ&p=http%3A%2F%2Fpythonsweetness.tumblr.com%2Fpost%2F169166980422%2Fthe-mysterious-case-of-the-linux-page-table&m=1
|
||||
[4]:http://t.umblr.com/redirect?z=https%3A%2F%2Fwww.iaik.tugraz.at%2Fcontent%2Fresearch%2Fsesys%2F&t=NzEwZjg5YmQ1ZTNlZWIyYWE0YzgzZmZjN2ZmM2E2YjMzNDk5YTk4YixXRG55eVpXNw%3D%3D&b=t%3AqBH2b-yWL63V8acbuG-EUQ&p=http%3A%2F%2Fpythonsweetness.tumblr.com%2Fpost%2F169166980422%2Fthe-mysterious-case-of-the-linux-page-table&m=1
|
||||
[5]:http://t.umblr.com/redirect?z=https%3A%2F%2Fgruss.cc%2Ffiles%2Fkaiser.pdf&t=OTk4NGQwZTQ1NTdlNzE1ZGEyZTdlY2ExMTY1MTJhNzk2ODIzYWY1OSxXRG55eVpXNw%3D%3D&b=t%3AqBH2b-yWL63V8acbuG-EUQ&p=http%3A%2F%2Fpythonsweetness.tumblr.com%2Fpost%2F169166980422%2Fthe-mysterious-case-of-the-linux-page-table&m=1
|
||||
[6]:http://t.umblr.com/redirect?z=https%3A%2F%2Fen.wikipedia.org%2Fwiki%2FTranslation_lookaside_buffer&t=NjEyNGUzNTk2MGY3ODY3ODIxZjQ1Yjc4YWZjMGNmNmI1OWU1M2U0YyxXRG55eVpXNw%3D%3D&b=t%3AqBH2b-yWL63V8acbuG-EUQ&p=http%3A%2F%2Fpythonsweetness.tumblr.com%2Fpost%2F169166980422%2Fthe-mysterious-case-of-the-linux-page-table&m=1
|
||||
[7]:https://twitter.com/grsecurity/status/947439275460702208
|
||||
[8]:http://t.umblr.com/redirect?z=https%3A%2F%2Fwww.youtube.com%2Fwatch%3Fv%3Dewe3-mUku94&t=NjczZmIzNWY3YTA2NGFiZDJmYThlMjlhMWM1YTE3NThhNzY0OGJlMSxXRG55eVpXNw%3D%3D&b=t%3AqBH2b-yWL63V8acbuG-EUQ&p=http%3A%2F%2Fpythonsweetness.tumblr.com%2Fpost%2F169166980422%2Fthe-mysterious-case-of-the-linux-page-table&m=1
|
||||
[9]:https://twitter.com/grsecurity/status/947147105684123649
|
||||
[10]:http://t.umblr.com/redirect?z=https%3A%2F%2Fen.wikipedia.org%2Fwiki%2FPentium_F00F_bug&t=Yjc4MDZhNDZjZDdiYWNkNmJkNjQ3ZDNjZmVlZmRkMGM2NDYwN2I2YSxXRG55eVpXNw%3D%3D&b=t%3AqBH2b-yWL63V8acbuG-EUQ&p=http%3A%2F%2Fpythonsweetness.tumblr.com%2Fpost%2F169166980422%2Fthe-mysterious-case-of-the-linux-page-table&m=1
|
||||
[11]:https://twitter.com/aionescu/status/930412525111296000
|
||||
[12]:http://t.umblr.com/redirect?z=https%3A%2F%2Fwww.tugraz.at%2Fen%2Ftu-graz%2Fservices%2Fnews-stories%2Fplanet-research%2Fsingleview%2Farticle%2Fwenn-rowhammer-nur-noch-einmal-klopft%2F&t=NWM1ZjZlZWU2NzFlMWIyNmI5MGZlNjJlZmM2YTlhOTIzNGY3Yjk4NyxXRG55eVpXNw%3D%3D&b=t%3AqBH2b-yWL63V8acbuG-EUQ&p=http%3A%2F%2Fpythonsweetness.tumblr.com%2Fpost%2F169166980422%2Fthe-mysterious-case-of-the-linux-page-table&m=1
|
||||
[13]:http://t.umblr.com/redirect?z=https%3A%2F%2Farxiv.org%2Fabs%2F1710.00551&t=ZjAyMDUzZWRmYjExNGNlYzRlMjE1NTliMTI2M2Y4YjkxMTFhMjI0OCxXRG55eVpXNw%3D%3D&b=t%3AqBH2b-yWL63V8acbuG-EUQ&p=http%3A%2F%2Fpythonsweetness.tumblr.com%2Fpost%2F169166980422%2Fthe-mysterious-case-of-the-linux-page-table&m=1
|
||||
[14]:http://pythonsweetness.tumblr.com/post/169166980422/the-mysterious-case-of-the-linux-page-table
|
||||
[15]:http://pythonsweetness.tumblr.com/
|
||||
|
||||
|
||||
@ -0,0 +1,85 @@
|
||||
Translating zjon
|
||||
2017最佳开源教程
|
||||
======
|
||||

|
||||
|
||||
一个精心编写的教程是任何软件的官方文档的一个很好的补充。 如果官方文件写得不好,不完整或不存在,它也可能是一个有效的选择。
|
||||
|
||||
2017、Opensource.com 发布一些有关各种主题的优秀教程。这些教程不只是针对专家们的。我们把他们针对各种技能水平和经验的用户。
|
||||
|
||||
让我们来看看最好的教程。
|
||||
|
||||
### 关于代码
|
||||
|
||||
对许多人来说,他们对开源的第一次涉足涉及为一个项目或另一个项目提供代码。你在哪里学习编码或编程?以下两篇文章是很好的起点。
|
||||
|
||||
严格来说,VM Brasseur 的[如何开始学习编程][1]是为新手程序员的一个很好的起点,而不是一个教程。它不仅指出了一些有助于你开始学习的优秀资源,而且还提供了了解你的学习方式和如何选择语言的重要建议。
|
||||
|
||||
如果您已经在一个 [IDE][2] 或文本编辑器中记录了几个小时,那么您可能需要学习更多关于编码的不同方法。Fraser Tweedale 的[功能编程的简介][3]很好地引入范式可以应用到许多广泛使用的编程语言。
|
||||
|
||||
### 流行的 Linux
|
||||
|
||||
Linux 是开源的典范。它运行了大量的网络,为世界顶级超级计算机提供动力。它让任何人都可以在台式机上使用专有的操作系统。
|
||||
|
||||
如果你有兴趣深入Linux,这里有三个教程供你参考。
|
||||
|
||||
Jason Baker 查看[设置 Linux $PATH 变量][4]。他引导你通过这一“任何Linux初学者的重要技巧”,使您能够将系统指向包含程序和脚本的目录。
|
||||
|
||||
拥抱你的核心技师 David Both 指南[建立一个 DNS 域名服务器][5]。他详细地记录了如何设置和运行服务器,包括要编辑的配置文件以及如何编辑它们。
|
||||
|
||||
想在你的电脑上更复古一点吗?Jim Hall 告诉你如何[在 Linux 下运行 DOS 程序][6]使用 [FreeDOS][7]和 [qemu][8]。Hall 的文章着重于运行 DOS 生产力工具,但并不全是严肃的——他也谈到了运行他最喜欢的 DOS 游戏。
|
||||
|
||||
### 3 个 Pi
|
||||
|
||||
廉价的单板机使硬件再次变得有趣,这并不是秘密。不仅如此,它们使更多的人更容易接近,无论他们的年龄或技术水平如何。
|
||||
|
||||
其中,[树莓派][9]可能是最广泛使用的单板计算机。Ben Nuttall 带我们通过如何安装和设置 [Postgres 数据库在树莓派上][10]。从那里,你可以在任何你想要的项目中使用它。
|
||||
|
||||
如果你的品味包括文学和技术,你可能会对 Don Watkins 的[如何将树莓派变成电子书服务器][11]感兴趣。有一点工作和一个 [Calibre 电子书管理软件][12]的副本,你就可以得到你最喜欢的电子书,无论你在哪里。
|
||||
|
||||
树莓派并不是其中唯一有特点的。还有 [Orange Pi Pc Plus][13],一种开源的单板机。David Egts 看着[开始使用这个可编程迷你电脑][14]。
|
||||
|
||||
### 日常计算学
|
||||
|
||||
开源并不仅针对技术专家,更多的凡人用它来做日常工作,而且更加效率。这里有三篇文章,使我们这些笨手笨脚的人做任何事情变得优雅(或者不是)。
|
||||
|
||||
当你想到微博的时候,你可能会想到 Twitter。但是 Twitter 的问题多于它的问题。[Mastodon][15] 是 Twitter 的开放的替代方案,它在 2016 年首次亮相。从此, Mastodon 就获得相当大的用户基数。Seth Kenlon 说明[如何加入和使用 Mastodon][16],甚至告诉你如何在 Mastodon 和 Twitter 间交替使用。
|
||||
|
||||
你需要一点帮助来维持开支吗?你所需要的只是一个电子表格和正确的模板。我的文章[要控制你的财政状况] [17],向你展示了如何用[LibreOffice Calc][18] (或任何其他电子表格编辑器)创建一个简单而有吸引力的财务跟踪。
|
||||
|
||||
ImageMagick 是强大的图形处理工具。但是,很多人不经常使用。这意味着他们在最需要它们时忘记了命令。如果是你,Greg Pittman 的 [ImageMagick 入门教程][19]在你需要一些帮助时候能派上用场。
|
||||
|
||||
你有最喜欢的 2017 Opensource.com 公布的教程吗?请随意留言与社区分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/best-tutorials
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[zjon](https://github.com/zjon)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/article/17/4/how-get-started-learning-program
|
||||
[2]:https://en.wikipedia.org/wiki/Integrated_development_environment
|
||||
[3]:https://opensource.com/article/17/4/introduction-functional-programming
|
||||
[4]:https://opensource.com/article/17/6/set-path-linux
|
||||
[5]:https://opensource.com/article/17/4/build-your-own-name-server
|
||||
[6]:https://opensource.com/article/17/10/run-dos-applications-linux
|
||||
[7]:http://www.freedos.org/
|
||||
[8]:https://www.qemu.org
|
||||
[9]:https://en.wikipedia.org/wiki/Raspberry_Pi
|
||||
[10]:https://opensource.com/article/17/10/set-postgres-database-your-raspberry-pi
|
||||
[11]:https://opensource.com/article/17/6/raspberrypi-ebook-server
|
||||
[12]:https://calibre-ebook.com/
|
||||
[13]:http://www.orangepi.org/
|
||||
[14]:https://opensource.com/article/17/1/how-to-orange-pi
|
||||
[15]:https://joinmastodon.org/
|
||||
[16]:https://opensource.com/article/17/4/guide-to-mastodon
|
||||
[17]:https://opensource.com/article/17/8/budget-libreoffice-calc
|
||||
[18]:https://www.libreoffice.org/discover/calc/
|
||||
[19]:https://opensource.com/article/17/8/imagemagick
|
||||
|
||||
|
||||
189
translated/tech/20180102 HTTP errors in WordPress.md
Normal file
189
translated/tech/20180102 HTTP errors in WordPress.md
Normal file
@ -0,0 +1,189 @@
|
||||
WordPress 中的HTTP错误
|
||||
======
|
||||
![http error wordpress][1]
|
||||
|
||||
我们会向你介绍,如何修复WordPress中的HTTP错误(在Linux VPS上)。 下面列出了WordPress用户遇到的最常见的HTTP错误,我们的建议侧重于如何发现错误原因以及解决方法。
|
||||
|
||||
|
||||
|
||||
|
||||
### 1\. 修复在上传图像时出现的HTTP错误
|
||||
|
||||
如果你在基于WordPress的网页中上传图像时出现错误,这也许是因为服务器上PHP配置,例如存储空间不足或者其他配置问题造成的。
|
||||
|
||||
|
||||
用如下命令查找php配置文件:
|
||||
|
||||
|
||||
```
|
||||
#php -i | grep php.ini
|
||||
Configuration File (php.ini) Path => /etc
|
||||
Loaded Configuration File => /etc/php.ini
|
||||
```
|
||||
|
||||
根据输出结果,php配置文件位于 '/etc'文件夹下。编辑 '/etc/php.ini'文件,找出下列行,并按照下面的例子修改其中相对应的值:
|
||||
|
||||
|
||||
```
|
||||
vi /etc/php.ini
|
||||
```
|
||||
```
|
||||
upload_max_filesize = 64M
|
||||
post_max_size = 32M
|
||||
max_execution_time = 300
|
||||
max_input_time 300
|
||||
memory_limit = 128M
|
||||
```
|
||||
|
||||
当然,如果你不习惯使用vi文本编辑器,你可以选用自己喜欢的。
|
||||
|
||||
|
||||
不要忘记重启你的网页服务器来让改动生效。
|
||||
|
||||
|
||||
如果你安装的网页服务器是Apache,你需要使用 .htaccess文件。首先,找到 .htaccess 文件。它位于WordPress安装路径的根文件夹下。如果没有找到 .htaccess文件,需要自己手动创建一个,然后加入如下内容:
|
||||
|
||||
|
||||
```
|
||||
vi /www/html/path_to_wordpress/.htaccess
|
||||
```
|
||||
```
|
||||
php_value upload_max_filesize 64M
|
||||
php_value post_max_size 32M
|
||||
php_value max_execution_time 180
|
||||
php_value max_input_time 180
|
||||
|
||||
# BEGIN WordPress
|
||||
<IfModule mod_rewrite.c>
|
||||
RewriteEngine On
|
||||
RewriteBase /
|
||||
RewriteRule ^index\.php$ - [L]
|
||||
RewriteCond %{REQUEST_FILENAME} !-f
|
||||
RewriteCond %{REQUEST_FILENAME} !-d
|
||||
RewriteRule . /index.php [L]
|
||||
</IfModule>
|
||||
# END WordPress
|
||||
```
|
||||
如果你使用的网页服务器是nginx,在WordPress实例中具体配置nginx服务器的设置。详细配置和下面的例子相似:
|
||||
|
||||
```
|
||||
server {
|
||||
|
||||
listen 80;
|
||||
client_max_body_size 128m;
|
||||
client_body_timeout 300;
|
||||
|
||||
server_name your-domain.com www.your-domain.com;
|
||||
|
||||
root /var/www/html/wordpress;
|
||||
index index.php;
|
||||
|
||||
location = /favicon.ico {
|
||||
log_not_found off;
|
||||
access_log off;
|
||||
}
|
||||
|
||||
location = /robots.txt {
|
||||
allow all;
|
||||
log_not_found off;
|
||||
access_log off;
|
||||
}
|
||||
|
||||
location / {
|
||||
try_files $uri $uri/ /index.php?$args;
|
||||
}
|
||||
|
||||
location ~ \.php$ {
|
||||
include fastcgi_params;
|
||||
fastcgi_pass 127.0.0.1:9000;
|
||||
fastcgi_index index.php;
|
||||
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
|
||||
}
|
||||
|
||||
location ~* \.(js|css|png|jpg|jpeg|gif|ico)$ {
|
||||
expires max;
|
||||
log_not_found off;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
根据自己的PHP配置,你需要将 'fastcgi_pass 127.0.0.1:9000;' 用类似于 'fastcgi_pass unix:/var/run/php7-fpm.sock;' 替换掉(依照实际连接方式)
|
||||
|
||||
|
||||
重启nginx服务来使改动生效。
|
||||
|
||||
|
||||
|
||||
### 2\. 修复因为不恰当的文件权限而产生的HTTP错误
|
||||
|
||||
如果你在WordPress中出现一个意外错误,也许是因为不恰当的文件权限导致的,所以需要给WordPress文件和文件夹设置一个正确的权限:
|
||||
|
||||
```
|
||||
chown www-data:www-data -R /var/www/html/path_to_wordpress/
|
||||
```
|
||||
|
||||
将 'www-data' 替换成实际的网页服务器用户,将 '/var/www/html/path_to_wordpress' 换成WordPress的实际安装路径。
|
||||
|
||||
|
||||
### 3\. 修复因为内存不足而产生的HTTP错误
|
||||
|
||||
你可以通过在wp-config.php中添加如下内容来设置PHP的最大内存限制:
|
||||
|
||||
```
|
||||
define('WP_MEMORY_LIMIT', '128MB');
|
||||
```
|
||||
|
||||
### 4\. 修复因为PHP.INI文件错误配置而产生的HTTP错误
|
||||
|
||||
编辑PHP配置主文件,然后找到 'cgi.fix_pathinfo' 这一行。 这一行内容默认情况下是被注释掉的,默认值为1。取消这一行的注释(删掉这一行最前面的分号),然后将1改为0.同时需要修改 'date.timezone' 这一PHP设置,再次编辑 PHP 配置文件并将这一选项改成 'date.timezone = US/Central' (或者将等号后内容改为你所在的时区)
|
||||
|
||||
```
|
||||
vi /etc/php.ini
|
||||
```
|
||||
```
|
||||
cgi.fix_pathinfo=0
|
||||
date.timezone = America/New_York
|
||||
```
|
||||
|
||||
### 5. 修复因为Apache mod_security模块而产生的HTTP错误
|
||||
|
||||
如果你在使用 Apache mod_security 模块,这可能也会引起问题。试着禁用这一模块,确认是否因为在 .htaccess 文件中加入如下内容而引起了问题:
|
||||
|
||||
```
|
||||
<IfModule mod_security.c>
|
||||
SecFilterEngine Off
|
||||
SecFilterScanPOST Off
|
||||
</IfModule>
|
||||
```
|
||||
|
||||
### 6. 修复因为有问题的插件/主题而产生的HTTP错误
|
||||
|
||||
一些插件或主题也会导致HTTP错误以及其他问题。你可以首先禁用有问题的插件/主题,或暂时禁用所有WordPress插件。如果你有phpMyAdmin,使用它来禁用所有插件:在其中找到 wp_options这一表格,在 option_name 这一列中找到 'active_plugins' 这一行,然后将 option_value 改为 :a:0:{}
|
||||
|
||||
|
||||
或者用以下命令通过SSH重命名插件所在文件夹:
|
||||
|
||||
```
|
||||
mv /www/html/path_to_wordpress/wp-content/plugins /www/html/path_to_wordpress/wp-content/plugins.old
|
||||
```
|
||||
|
||||
通常情况下,HTTP错误会被记录在网页服务器的日志文件中,所以寻找错误时一个很好的切入点就是查看服务器日志。
|
||||
|
||||
|
||||
如果你在使用WordPress VPS主机服务的话,你不需要自己去修复WordPress中出现的HTTP错误。你只要让你的Linux管理员来处理它们,他们24小时在线并且会立刻开始着手解决你的问题。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.rosehosting.com/blog/http-error-wordpress/
|
||||
|
||||
作者:[rosehosting][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.rosehosting.com
|
||||
[1]:https://www.rosehosting.com/blog/wp-content/uploads/2018/01/http-error-wordpress.jpg
|
||||
[2]:https://www.rosehosting.com/wordpress-hosting.html
|
||||
@ -0,0 +1,88 @@
|
||||
如何更改 Linux 控制台上的字体
|
||||
======
|
||||

|
||||
|
||||
我尝试尽可能的保持心灵祥和,然而总有一些事情让我意难平,比如控制台字体太小了。记住我的话,朋友,有一天你的眼睛会退化,无法再看清你编码时用的那些细小字体,到那时你就后悔莫及了。
|
||||
|
||||
幸好,Linux 死忠们,你可以更改控制台的字体。按照 Linux 一贯的尿性,不断变化的 Linux 环境使得这个问题变得不太简单明了,而 Linux 上也没有字体管理这么个东西,这使得我们很容易就被搞晕了。本文,我将会向你展示,我找到的更改字体的最简方法。
|
||||
|
||||
### Linux 控制台是个什么鬼?
|
||||
|
||||
首先让我们来澄清一下我们说的到底是个什么东西。当我提到 Linux 控制台,我指的是 TTY1-6,即你从图形环境用 `Ctrl-Alt-F1` 到 `F6` 切换到的虚拟终端。按下 `Ctrl+Alt+F7` 会切回图形环境。(不过这些热键已经不再通用,你的 Linux 发行版可能有不同的键映射。你的 TTY 的数量也可能不同,你图形环境会话也可能不在 `F7`。比如,Fedora 的默认图形会话是 `F2`,它只有一个额外的终端在 `F1`。) 我觉得能同时拥有 X 会话和终端绘画实在是太酷了。
|
||||
|
||||
Linux 控制台是内核的一部分,而且并不运行在 X 会话中。它和你在没有图形环境的无头服务器中用的控制台是一样的。我称呼在图形会话中的 X 终端为终端,而将控制台和 X 终端统称为终端模拟器。
|
||||
|
||||
但这还没完。Linux 终端从早期的 ANSI 时代开始已经经历了长久的发展,多亏了 Linux framebuffer,它现在支持 Unicode 并且对图形也有了有限的一些支持。而且出现了很多在控制台下运行的多媒体应用,这些我们在以后的文章中会提到。
|
||||
|
||||
### 控制台截屏
|
||||
|
||||
获取控制台截屏的最简单方法是让控制台跑在虚拟机内部。然后你可以在宿主系统上使用中意的截屏软件来抓取。不过借助 [fbcat][1] 和 [fbgrab][2] 你也可以直接在控制台上截屏。`fbcat` 会创建一个可移植的像素映射格式 (PPM) 图像; 这是一个高度可移植的未压缩图像格式,可以在所有的操作系统上读取,当然你也可以把它转换成任何喜欢的其他格式。`fbgrab` 则是 `fbcat` 的一个封装脚本,用来生成一个 PNG 文件。不同的人写过多个版本的 `fbgrab`。每个版本的选项都有限而且只能创建截取全屏。
|
||||
|
||||
`fbcat` 的执行需要 root 权限,而且它的输出需要重定向到文件中。你无需指定文件扩展名,只需要输入文件名就行了:
|
||||
```
|
||||
$ sudo fbcat > Pictures/myfile
|
||||
|
||||
```
|
||||
|
||||
在 GIMP 中裁剪后,就得到了图 1。
|
||||
|
||||

|
||||
Figure 1:View after cropping。
|
||||
|
||||
如果能在左边空白处有一点填充就好了,如果有读者知道如何实现请在留言框中告诉我。
|
||||
|
||||
`fbgrab` 还有一些选项,你可以通过 `man fbgrab` 来查看,这些选项包括对另一个控制台进行截屏,以及延时截屏。在下面的例子中可以看到,`fbgrab` 截屏跟 `fbcat` 截屏类似,只是你无需明确进行输出重定性了:
|
||||
```
|
||||
$ sudo fbgrab Pictures/myOtherfile
|
||||
|
||||
```
|
||||
|
||||
### 查找字体
|
||||
|
||||
就我所知,除了查看字体存储目录 `/usr/share/consolefonts/`(Debian/etc。),`/lib/kbd/consolefonts/` (Fedora),`/usr/share/kbd/consolefonts` (openSUSE),外没有其他方法可以列出已安装的字体了。
|
||||
|
||||
### 更改字体
|
||||
|
||||
可读字体不是什么新概念。我们应该尊重以前的经验!可读性是很重要的。可配置性也很重要,然而现如今却不怎么看重了。
|
||||
|
||||
在 Debian/Ubuntu/ 等系统上,可以运行 `sudo dpkg-reconfigure console-setup` 来设置控制台字体,然后在控制台运行 `setupcon` 命令来让变更生效。`setupcon` 属于 `console-setup` 软件包中的一部分。若你的 Linux 发行版中不包含该工具,可以在 [openSUSE][3] 中下载到它。
|
||||
|
||||
你也可以直接编辑 `/etc/default/console-setup` 文件。下面这个例子中设置字体为 32 点大小的 Terminus Bold 字体,这是我的最爱,并且严格限制控制台宽度为 80 列。
|
||||
```
|
||||
ACTIVE_CONSOLES="/dev/tty[1-6]"
|
||||
CHARMAP="UTF-8"
|
||||
CODESET="guess"
|
||||
FONTFACE="TerminusBold"
|
||||
FONTSIZE="16x32"
|
||||
SCREEN_WIDTH="80"
|
||||
|
||||
```
|
||||
|
||||
这里的 FONTFACE 和 FONTSIZE 的值来自于字体的文件名,`TerminusBold32x16.psf.gz`。是的,你需要反转 FONTSIZE 中值的顺序。计算机就是这么搞笑。然后再运行 `setupcon` 来让新配置生效。可以使用 `showconsolefont` 来查看当前所用字体的所有字符集。要查看完整的选项说明请参考 `man console-setup`。
|
||||
|
||||
### Systemd
|
||||
|
||||
Systemd 与 `console-setup` 不太一样,除了字体之外,你无需安装任何东西。你只需要编辑 `/etc/vconsole.conf` 然后重启就行了。我在 Fedora 和 openSUSE 系统中安装了一些额外的大型号的 Terminus 字体包,因为默认安装的字体最大只有 16 点而我想要的是 32 点。然后将 `/etc/vconsole.conf` 的内容修改为:
|
||||
```
|
||||
KEYMAP="us"
|
||||
FONT="ter-v32b"
|
||||
|
||||
```
|
||||
|
||||
下周我们还将学习一些更加酷的控制台小技巧,以及一些在控制台上运行的多媒体应用。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/1/how-change-your-linux-console-fonts
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:http://jwilk.net/software/fbcat
|
||||
[2]:https://github.com/jwilk/fbcat/blob/master/fbgrab
|
||||
[3]:https://software.opensuse.org/package/console-setup
|
||||
@ -0,0 +1,70 @@
|
||||
如何在终端输入密码时显示星号
|
||||
======
|
||||
|
||||

|
||||
|
||||
当你在 Web 浏览器或任何 GUI 登录中输入密码时,密码会被标记成星号 ******** 或圆形符号 ••••••••••••• 。这是内置的安全机制,以防止你附近的用户看到你的密码。但是当你在终端输入密码来执行任何 **sudo** 或 **su** 的管理任务时,你不会在输入密码的时候看见星号或者圆形符号。它不会有任何输入密码的视觉指示,也不会有任何光标移动,什么也没有。你不知道你是否输入了所有的字符。你只会看到一个空白的屏幕!
|
||||
|
||||
看看下面的截图。
|
||||
|
||||
![][2]
|
||||
|
||||
正如你在上面的图片中看到的,我已经输入了密码,但没有任何指示(星号或圆形符号)。现在,我不确定我是否输入了所有密码。这个安全机制也可以防止你附近的人猜测密码长度。当然,这种行为可以改变。这是本指南要说的。这并不困难。请继续阅读。
|
||||
|
||||
#### 当你在终端输入密码时显示星号
|
||||
|
||||
要在终端输入密码时显示星号,我们需要在 **“/etc/sudoers”** 中做一些小修改。在做任何更改之前,最好备份这个文件。为此,只需运行:
|
||||
```
|
||||
sudo cp /etc/sudoers{,.bak}
|
||||
```
|
||||
|
||||
上述命令将 /etc/sudoers 备份成名为 /etc/sudoers.bak。你可以恢复它,以防万一在编辑文件后出错。
|
||||
|
||||
接下来,使用下面的命令编辑 **“/etc/sudoers”**:
|
||||
```
|
||||
sudo visudo
|
||||
```
|
||||
|
||||
找到下面这行:
|
||||
```
|
||||
Defaults env_reset
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
在该行的末尾添加一个额外的单词 **“,pwfeedback”**,如下所示。
|
||||
```
|
||||
Defaults env_reset,pwfeedback
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
然后,按下 **“CTRL + x”** 和 **“y”** 保存并关闭文件。重新启动终端以使更改生效。
|
||||
|
||||
现在,当你在终端输入密码时,你会看到星号。
|
||||
|
||||
![][5]
|
||||
|
||||
如果你对在终端输入密码时看不到密码感到不舒服,那么这个小技巧会有帮助。请注意,当你输入输入密码时其他用户就可以预测你的密码长度。如果你不介意,请按照上述方法进行更改,以使你的密码可见(当然,标记为星号!)。
|
||||
|
||||
现在就是这样了。还有更好的东西。敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/display-asterisks-type-password-terminal/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/password-1.png ()
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-1.png ()
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-1-1.png ()
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-2.png ()
|
||||
@ -0,0 +1,118 @@
|
||||
Fold命令入门级示例教程
|
||||
======
|
||||
|
||||

|
||||
|
||||
你有没有发现自己在某种情况下想要折叠或打破命令的输出用于适应特定的宽度? 在运行虚拟机的时候,我遇到了几次这种的情况,特别是没有GUI的服务器。 以防万一,如果你想限制一个命令的输出为一个特定的宽度,现在看看这里! **fold**命令在这里就能派的上用场了! fold命令以适合指定的宽度调整输入文件中的每一行并将其打印到标准输出。
|
||||
|
||||
在这个简短的教程中,我们将看到fold命令的用法,带有实例哦。
|
||||
|
||||
### fold命令示例教程
|
||||
|
||||
fold命令是GNU coreutils包的一部分,所以我们不用为安装的事情烦恼。
|
||||
|
||||
fold命令的典型语法:
|
||||
```
|
||||
fold [OPTION]... [FILE]...
|
||||
```
|
||||
|
||||
请允许我向您展示一些示例,以便您更好地了解fold命令。 我有一个名为linux.txt文件,内容是随机的。
|
||||
|
||||
Allow me to show you some examples, so you can get a better idea about fold command. I have a file named **linux.txt** with some random lines.
|
||||
|
||||
![][2]
|
||||
|
||||
要将上述文件中的每一行换行为默认宽度,请运行:
|
||||
|
||||
```
|
||||
fold linux.txt
|
||||
```
|
||||
|
||||
每行**80**列是默认的宽度。 这里是上述命令的输出:
|
||||
|
||||
![][3]
|
||||
|
||||
正如你在上面的输出中看到的,fold命令已经将输出限制为80个字符的宽度。
|
||||
|
||||
当然,我们可以指定您的首选宽度,例如50,如下所示:
|
||||
|
||||
```
|
||||
fold -w50 linux.txt
|
||||
```
|
||||
|
||||
Sample output would be:
|
||||
|
||||
![][4]
|
||||
|
||||
我们也可以将输出写入一个新的文件,如下所示:
|
||||
|
||||
```
|
||||
fold -w50 linux.txt > linux1.txt
|
||||
```
|
||||
|
||||
以上命令将把**linux.txt**的行宽度改为50个字符,并将输出写入到名为**linux1.txt**的新文件中。
|
||||
|
||||
让我们检查一下新文件的内容:
|
||||
|
||||
```
|
||||
cat linux1.txt
|
||||
```
|
||||
|
||||
![][5]
|
||||
|
||||
你有没有注意到前面的命令的输出? 有些词在行之间被打破。 为了解决这个问题,我们可以使用-s标志来在空格处换行。
|
||||
|
||||
以下命令将给定文件中的每行调整为宽度“50”,并在空格处换到新行:
|
||||
|
||||
```
|
||||
fold -w50 -s linux.txt
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![][6]
|
||||
|
||||
看清楚了吗? 现在,输出很清楚。 换到新行中的单词都是用空格隔开的,所在行单词的长度大于50的时候就会被调整到下一行。
|
||||
|
||||
在所有上面的例子中,我们用列来限制输出宽度。 但是,我们可以使用**-b**选项将输出的宽度强制为指定的字节数。 以下命令以20个字节中断输出。
|
||||
|
||||
```
|
||||
fold -b20 linux.txt
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
![][7]
|
||||
|
||||
**另请阅读:**
|
||||
|
||||
+ [Unix命令入门级示例教程][8]
|
||||
|
||||
有关更多详细信息,请参阅man手册页。
|
||||
```
|
||||
man fold
|
||||
```
|
||||
|
||||
而且,这些就是所有的内容了。 您现在知道如何使用fold命令以适应特定的宽度来限制命令的输出。 我希望这是有用的。 我们将每天发布更多有用的指南。 敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/fold-command-tutorial-examples-beginners/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-2.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-3-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-4.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-5-1.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-6-1.png
|
||||
[8]:https://www.ostechnix.com/uniq-command-tutorial-examples-beginners/
|
||||
Loading…
Reference in New Issue
Block a user