mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-28 23:20:10 +08:00
commit
dbafca2535
@ -1,25 +1,25 @@
|
||||
Linux版EPUB阅读器
|
||||
================================================================================
|
||||
|
||||
如果说用平板电脑看书尚属主流的话,那么在电脑上读书就非常少见了。专注阅读16世纪的书是非常困难的了,没人希望后台蹦出Facebook聊天窗口。但是如果你非要在电脑上打开电子书的话,那么你需要一个电子书阅读软件。大多数编辑支持使用EPUB格式来存放电子书(电子出版物)。幸运的书,linux上从不缺乏此类软件。以下书一些Linux上比较好的EPUB阅读软件。
|
||||
如果说用平板电脑看书尚属主流的话,那么在电脑上读书就非常少见了。专注阅读16世纪的书是非常困难的了,没人希望后台蹦出QQ聊天窗口。但是如果你非要在电脑上打开电子书的话,那么你需要一个电子书阅读软件。大多数出版物支持使用EPUB格式的电子书(电子出版物)。幸运的是,linux上从不缺乏EPUB阅读器类的软件。以下是一些Linux上不错的EPUB阅读软件。
|
||||
|
||||
### 1. Calibre ###
|
||||
|
||||
|
||||
|
||||
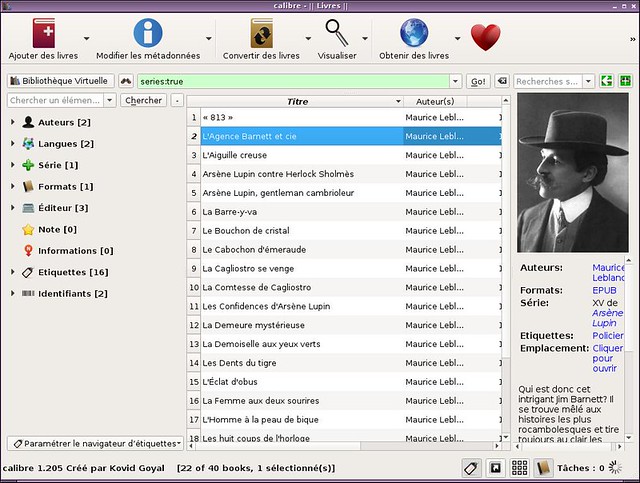
先从列表中最有名的软件开始: [Calibre][1]。Calibre 不仅仅是个阅读器,他还是个电子图书馆。软件支持几乎所有的格式,集成了阅读器,管理器,一个可以从互联网下载书籍封面的元数据编辑器,一个EPUB编辑器,新闻阅读器和一个用来下载电子书的搜索引擎。可喜的是,界面丝毫不逊色专业的阅读软件。唯一的缺点书如果你只想要一个EPUB阅读器的话,这个软件还是太大了。
|
||||
先从列表中最有名的软件开始: [Calibre][1]。Calibre 不仅仅是个阅读器,它还是个电子图书馆。软件支持几乎所有的格式,集成了阅读器、管理器、一个可以从互联网下载书籍封面的元数据编辑器、一个EPUB编辑器、新闻阅读器和一个用来下载电子书的搜索引擎。可喜的是,界面丝毫不逊色专业的阅读软件。唯一的缺点是如果你只想要一个EPUB阅读器的话,这个软件还是太大了。
|
||||
|
||||
### 2. FBReader ###
|
||||
|
||||
|
||||
|
||||
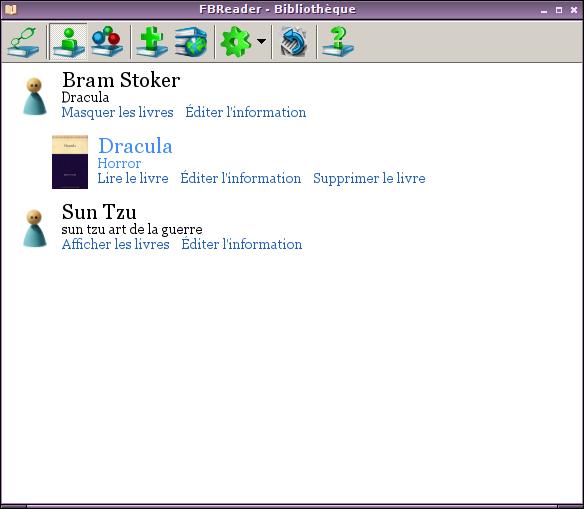
[FBReader][2] 也是一个图书馆管理软件,但是比Calibre小。界面简洁分为两个部分:左边书文件管理、元数据编辑、和下载新书等功能;右边书阅读区。如果你喜欢简洁,这个软件挺不错。我个人非常喜欢这类直观标记书籍和分类的做法。
|
||||
[FBReader][2] 也是一个图书馆管理软件,但是比Calibre小。界面简洁分为两个部分:左边是文件管理、元数据编辑和下载新书等功能;右边是阅读区。如果你喜欢简洁,这个软件挺不错。我个人非常喜欢这类直观标记书籍和分类的做法。
|
||||
|
||||
### 3. Cool Reader ###
|
||||
|
||||

|
||||
|
||||
对于那些只想想看EPUB书内容的用户,我推荐 [Cool Reader][5]。遵循Linux应用程序的规则,Cool Reader 做了优化,每次只打开一个EPUB文件,可以使用简单的快捷键进行阅读和导航。由于程序书基于Qt开发的,所以他也遵循Qt的规则,需要大量的设置项。
|
||||
对于那些只想想看EPUB书内容的用户,我推荐 [Cool Reader][5]。遵循Linux应用程序的文化,Cool Reader 做了优化,每次只打开一个EPUB文件,可以使用简单的快捷键进行阅读和导航。由于程序书基于Qt开发的,所以他也遵循Qt的风格,需要大量的设置项。
|
||||
|
||||
### 4. Okular ###
|
||||
|
||||
@ -31,19 +31,19 @@ Linux版EPUB阅读器
|
||||
|
||||

|
||||
|
||||
[pPub][4]是个老项目,Github上可以找到这个项目,他最后的更新已经是在两年前了。尽管如此,这个软件还是值得使用的,pPub是用Python编写的,基于GTK3和WebKit,是个简单轻量的软件。界面可能需要一些更新,不够简洁,但是内部却非常好。软件支持JavaScript。所以,谁来捡起这个项目呢?
|
||||
[pPub][4]是个老项目,Github上可以找到这个项目,它最后的更新已经是在两年前了。尽管如此,这个软件还是值得使用的,pPub是用Python编写的,基于GTK3和WebKit,是个简单轻量的软件。界面可能需要一些更新,不够简洁,但是内部却非常好。软件支持JavaScript。所以,谁来捡起这个项目呢?
|
||||
|
||||
### 6. epub ###
|
||||
|
||||
|
||||
|
||||
如果你只是想快速简单的查看EPUB文件的内容,不关心任何图形化界面功能的话,最好使用命令行模式打开EPUB。[epub][6] 是一个用Python编写的阅读器,可以在终端环境读取EPUB文件的内容。软件可以在章节、页面见切换,没有其他的功能。这是最简洁的EPUB阅读器了。
|
||||
如果你只是想快速简单的查看EPUB文件的内容,不关心任何图形化界面功能的话,最好使用命令行模式打开EPUB。[epub][6] 是一个用Python编写的阅读器,可以在终端环境读取EPUB文件的内容。软件可以在章节、页面间切换,没有其他的功能。这是最简洁的EPUB阅读器了。
|
||||
|
||||
### 7. Sigil ###
|
||||
|
||||
|
||||
|
||||
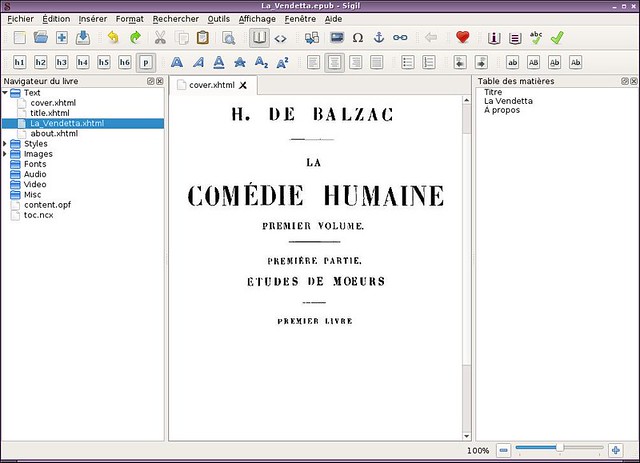
最后介绍的这个实际上不是个EPUB阅读器,应该是个独立的编辑器。[Sigil][7] 可以提取EPUB文件的内容并转换成其他格式:xhtml文本,图像,格式,还有其他的内容,比如音频等。界面比基本的阅读器复杂,但是功能还是比较丰富的。我很喜欢他的标签体系,如果你对网页比较熟悉的话,这个软件书很好使用的。
|
||||
最后介绍的这个实际上不是个EPUB阅读器,应该是个独立的编辑器。[Sigil][7] 可以提取EPUB文件的内容并将其分离成其他格式:xhtml文本、图像、css,及其他的内容比如音频等。界面比基本的阅读器复杂,但是功能还是比较丰富的。我很喜它的标签体系,如果你对网页比较熟悉的话,这个软件是很好使用的。
|
||||
|
||||
总结,有很多的开源的EPUB阅读器,有一些只有最基本的功能, 另外一些功能却太多了。一般来说,我建议你选择一个最合适的使用。如果你有更好的EPUB阅读器,请在评论里告诉我们!
|
||||
|
||||
@ -53,7 +53,7 @@ via: http://xmodulo.com/2014/08/good-epub-reader-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[shipsw](https://github.com/shipsw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,36 +1,36 @@
|
||||
怎样通过 Twitter 的开源库来随处使用 Emoji 表情符号
|
||||
怎样通过 Twitter 的开源库来随处使用 Emoji 表情符号
|
||||
================================================================================
|
||||
> 通过 GitHub 将它们嵌入到网页和其他项目中。
|
||||
|
||||

|
||||
|
||||
Emoji, 来自日本的小巧符号,通过图像表达感情,已经征服了手机文字信息的世界。
|
||||
Emoji, 来自日本的小巧符号,通过图像表达感情,已经征服了移动互联网的信息世界。
|
||||
|
||||
现在,你可以在虚拟世界中随处使用它们了。 Twitter 最近[开源了][1]他们的 emoji 符号库,使得你可以在你自己的网站,应用,和项目中使用它们。
|
||||
|
||||
但这需要一点体力活。 Unicode 已经识别甚至标准化了 emoji 字母表, 然而 emoji 仍然[不能完全与所有的网络浏览器相兼容][2],这意味着大多数情况下,它们将呈现为 “豆腐块”或 空白盒子。当 Twitter 想使得 emoji 可用时,社交网络联合一家名为[Icon Factory][3]的公司共同渲染浏览器以模仿 文本信息符号的效果。结果,Twiter 说道 人们对他们的 emoji 库有很大的需求。
|
||||
但这需要一点体力活。 Unicode 已经识别甚至标准化了 emoji 字母表, 然而 emoji 仍然[不能完全与所有的网络浏览器相兼容][2],这意味着大多数情况下,它们将呈现为 “豆腐块”或“空白盒子”。当 Twitter 想使得 emoji 到处可用时,这家社交网络联合了一家名为[Icon Factory][3]的公司来渲染浏览器以模仿文本信息符号的效果。Twiter 认为人们对他们的 emoji 库有很大的需求。
|
||||
|
||||
现在, 你可以从 [GitHub][4] 上克隆 Twitter 的整个库,从而在你的开发项目中使用它们。 下面将为你介绍如何达到上面的目的以及如何使得 emoji 更容易被使用。
|
||||
|
||||
### 为 Emoji 得到 Unicode 支持 ###
|
||||
|
||||
Unicode 是国际编码标准,它为任意的符号,字母或人们想在网络上使用的数字配置了一串符号。换句话说,它是 你如何在计算机上阅读文本 与 计算机如何读取文本 之间的缺失环节。例如,对于你正看到的位于这些句子中的`空白`,计算机读取为 “&mbsp”。
|
||||
Unicode 是国际编码标准,它为任意的符号、字母或人们想在网络上使用的数字配置了一串编码。换句话说,它是你如何在计算机上阅读文本与计算机如何读取文本之间的缺失环节。例如,对于你正看到的位于这些句子中的`空格`(LCTT 译注:英文分词中间的空格),计算机读取为 “ ”。
|
||||
|
||||
Unicode 甚至拥有其自己的 [原始 emoji][5],它们可以 在没有你的任何努力的情况下在浏览器中被阅读。例如,当你看到了 一个 ❤ 符号,你的计算机正在解码字符串 “2665” 。
|
||||
Unicode 甚至拥有其自己的[原始 emoji][5],它们可以在没有你的任何努力的情况下在浏览器中被阅读。例如,当你看到了 一个 ❤ 符号,你的计算机正在解码字符串 “2665” 。
|
||||
|
||||
要在大多数情况下使用 Twitter 的 emoji 库,你只需在你的 HTML 网页中的 `<head>`块中添加如下脚本:
|
||||
|
||||
<script src="//twemoji.maxcdn.com/twemoji.min.js"></script>
|
||||
|
||||
这样就使得你的项目可以访问 包含有已经在 Twitter 中可使用的数以百计的 Emoji 符号的 JavaScript 库。然而,创建一个仅仅包含这个脚本的文档并不能使得在你的网站中呈现出 emoji 符号,实际上,你仍需要嵌入一些 emoji 符号!
|
||||
这样就使得你的项目可以访问包含有已经在 Twitter 中可使用的数以百计的 Emoji 符号的 JavaScript 库。然而,创建一个仅仅包含这个脚本的文档并不能使得在你的网站中呈现出 emoji 符号,实际上,你仍需要嵌入这些 emoji 符号!
|
||||
|
||||
在 `<body>`块中,粘贴一些可以在 Twitter 的[preview.html 文件源代码][6] 中找到的 emoji 字符串。我使用了 🎹 和 🏁,当然我并不知道在浏览器窗口中它们的样子。是的,你必须粘贴并猜测它们。你已经看出了问题,我们将在 第二小节中予以解决。
|
||||
在 `<body>`块中,粘贴一些可以在 Twitter 的[preview.html 文件源代码][6] 中找到的 emoji 字符串。我使用了 🎹 和 🏁,当然我并不知道在浏览器窗口中它们的样子。是的,你必须粘贴并猜测它们。你已经看出了问题,我们将在第二小节中予以解决。
|
||||
|
||||
无论如何,通过一些尝试,你可以将一个如下图的原始 HTML 文件---
|
||||
|
||||

|
||||
|
||||
---转变成如下图的网页:
|
||||
---显示为如下图的网页:
|
||||
|
||||

|
||||
|
||||
@ -52,11 +52,11 @@ Unicode 甚至拥有其自己的 [原始 emoji][5],它们可以 在没有你
|
||||
|
||||
<link rel="stylesheet" href="twemoji-awesome.css">
|
||||
|
||||
一旦你将上面的代码添加了进去,你便可以删除先前添加的 Twitter 的脚本链接。
|
||||
一旦你将上面的代码添加了进去,你便可以删除先前添加的 Twitter 的脚本链接。
|
||||
|
||||
现在,找到 `body` 块部分的代码,然后添加一些 emoji 符号。我使用了 `<i class="twa twa-sparkling-heart"></i>`, `<i class="twa twa-exclamation"></i>`, `<i class="twa twa-lg twa-sparkles"></i>` 和 `<i class="twa twa-beer"></i>`。
|
||||
现在,找到 `body` 块部分的代码,然后添加一些 emoji 符号。我使用了 `<i class="twa twa-sparkling-heart"></i>`, `<i class="twa twa-exclamation"></i>`, `<i class="twa twa-lg twa-sparkles"></i>` 和 `<i class="twa twa-beer"></i>`。
|
||||
|
||||
最终,你将得到如下的代码:
|
||||
最终,你将得到如下的代码:
|
||||
|
||||

|
||||
|
||||
@ -64,9 +64,9 @@ Unicode 甚至拥有其自己的 [原始 emoji][5],它们可以 在没有你
|
||||
|
||||

|
||||
|
||||
当当!这样你不仅得到了一个可以在浏览器中支持 emoji 符号的基本网页,而且还知道了如何简单地实现它。你可以随意的在[我的 GitHub][9] 中查看这个教程,并且可以克隆这些实际的文件而不只是看看这些截图。
|
||||
Duang!这样你不仅得到了一个可以在浏览器中支持 emoji 符号的基本网页,而且还知道了如何简单地实现它。你可以随意的在[我的 GitHub][9] 中查看这个教程,并且可以克隆这些实际的文件而不只是看看这些截图。
|
||||
|
||||
来自于[得到 Emoji][10]的引导图像; Lauren Orsini 截图。
|
||||
题图来自于[得到 Emoji][10]; Lauren Orsini 截图。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -74,7 +74,7 @@ via: http://readwrite.com/2014/11/12/how-to-use-emoji-in-the-browser-window
|
||||
|
||||
作者:[Lauren Orsini][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
127
published/20141203 Undelete Files on Linux Systems.md
Normal file
127
published/20141203 Undelete Files on Linux Systems.md
Normal file
@ -0,0 +1,127 @@
|
||||
怎样在 Linux 系统中恢复已删除文件
|
||||
================================================================================
|
||||
|
||||
当用户意外地删除了一个仍然需要的文件时,大多数情况下,是没有简便的方法可以重新找回或重建这个文件。不过,幸运的是文件是可以通过一些方法恢复的。当用户删除了一个文件,该文件并没有消失,只是被隐藏了一段时间。
|
||||
|
||||
这里将解释它是如何工作的。在一个文件系统中,有一个叫做 `文件分配表` 的东西,这个表跟踪文件在存储单元(如硬盘, MicroSD 卡,闪存驱动器等等)中的位置。当一个文件被删除,文件系统将会在`文件分配表`中执行以下两个任务之一:这个文件在`文件分配表`上的条目被标记为 “自由空间” 或删除`文件分配表`里这个文件的条目,且将相应的空间被标记为自由空间 。现在,如果有一个新的文件需要被放置在一个存储单元上,操作系统将会把这个文件放置到标记为空位的地方。在新文件被写入到这个空位后,被删除的文件就彻底消失了。当需要恢复一个已经删除的文件时,用户绝对不能再对任何文件进行操作,因为假如该文件对应的“空位”被占用,这个文件就永远也不能恢复了。
|
||||
|
||||
### 恢复软件是如何工作的? ###
|
||||
|
||||
大多数的文件系统(在删除文件时)只是标记空间为空白。在这些文件系统下,恢复软件查看`文件分配表`这个文件,然后复制被删除的文件到另外的存储单元中。假如该文件被复制到其它需要恢复的被删除的存储单元中,那么用户将有可能会失去那个所需的删除文件。
|
||||
|
||||
文件系统很少会擦除`文件分配表`中的条目。假如文件系统真的这样做了, 这便是恢复软件在恢复文件了。恢复软件在存储单元中扫描文件头,所有文件都拥有一个特殊的编码字符串,它们位于文件的最前面,也被叫做 `魔法数字`。例如,一个编译的 JAVA 类文件的魔法数字在十六进制中是“CAFEBABE”。所以,假如要恢复该类型的文件,恢复软件会查找 “CAFEBABE” 然后复制文件到另一个存储单元。一些恢复软件可以查找某种特殊的文件类型。若用户想恢复一个 PDF 文件,则恢复软件将会查找十六进制的魔法数字 “25504446”,这恰恰是 ASCII 编码中的 “%PDF”。恢复软件将会查找所有的魔法数字,然后用户可以选择恢复哪个已删除的文件。
|
||||
|
||||
假如一个文件的部分被覆写了,则整个文件就会被损坏。通常这个文件可以被恢复,但是其中的内容可能已经没有什么用处。例如,恢复一个已损坏的 JPEG 文件将会是无意义的,因为图片查看器不能从这个损坏的文件产生一幅图片。因此,即使用户拥有了这个文件,该文件也将毫无用处。
|
||||
|
||||
### 设备的位置:###
|
||||
|
||||
在我们继续之前,下面的一些信息将会对指引恢复软件找到正确的存储单元起到一定的帮助。所有的设备均挂载在 `/dev/` 目录下。操作系统赋予每个设备的名称(并不是管理员给予每个分区或设备的名称)遵循一定的命名规律。
|
||||
|
||||
第一个 SATA 硬盘的第二个分区的名称将会是 sda2。名称的第一个字母暗示了存储类型,在这里指的是 SATA,但字母 “s” 也可能指的是 SCSI、 FireWire(火线端口)或 USB。第二个字母 “d” 指的是 disk(硬盘)。第三个字母指的是设备序数,即字母 “a” 指的是第一个 SATA 而 “b” 指的是第二个。最后的数字代表分区。没有分区数字的设备名代表该设置的所有分区。对于上面的例子,对应的名称为 sda 。作为命名的第一个字母还可能是 “h” ,这对应 PATA 硬盘(IDE)。
|
||||
|
||||
以下为命名规律的一些例子。假如一个用户有一个 SATA 硬盘(sda),这个设备有 4 个分区- sda1、 sda2、 sda3 和 sda4 。该用户删除了第三个分区,但直到格式化第四个分区之前,第四个分区名 sda4 都将保留不变。然后该用户插入了一个带有一个分区 - 即sdb1- 的 usb 存储卡(sdb),又增加了一个带有一个分区 -hda1- 的 IDE 硬盘 ,接着该用户又增加了一个 SCSI 硬盘 - sdc1 。接着用户移除了 USB 存储卡(sdb)。现在,SCSI 硬盘的名称仍然为 sdc,但如果这个 SCSI 被移除接着再被插入,则它的名称将变为 sdb。虽然还有其他的存储设备存在, 那个 IDE 硬盘的名称仍会有一个 “a”, 因为它是第一个 IDE 硬盘,IDE 设备的命名与 SCSI、 SATA、 FireWire 和 USB 设备要分开计数。
|
||||
|
||||
### 使用 TestDisk 进行恢复:###
|
||||
|
||||
每个恢复软件有其不同的功能,特征及支持的不同文件系统。下面是一些关于 使用 TestDisk 在各种文件系统中恢复文件的指南。
|
||||
|
||||
####FAT16、 FAT32、 exFAT (FAT64)、 NTFS 以及 ext2/3/4:####
|
||||
|
||||
TestDisk 是一个运行在 Linux、 *BSD、 SunOS、 Mac OS X、 DOS 和 Windows 等操作系统下的开源的自由软件。 TestDisk 可以从下面的链接中找到 :[http://www.cgsecurity.org/wiki/TestDisk][1]。TestDisk 也可以通过键入 `sudo apt-get install testdisk` 来安装。TestDisk 有着许多的功能,但这篇文章将只关注恢复文件这个功能。
|
||||
|
||||
使用 root 权限从终端中打开 TestDisk 可以通过键入 `sudo testdisk` 命令。
|
||||
|
||||
现在, TestDisk 命令行应用将会被执行。终端的显示将会改变。TestDisk 询问用户它是否可以保留日志,这完全由用户决定。假如一个用户正从系统存储中恢复文件,则不必保留日志。可选择的选项有“生成”、 “追加” 和 “无日志”。假如用户想保留日志,则日志将会保留在该用户的主目录。
|
||||
|
||||

|
||||
|
||||
在接着的屏幕中,存储设备以 `/dev/*`的方式被罗列出来。对于我的系统,系统的存储单元为 `/dev/sda`,这意味着我的存储单元为 一个 SATA硬盘(sd)且它是第一个硬盘(a)。每个存储单元的容量以 Gigabyte(千兆字节)为单位显示的。使用上下键来选择一个存储设备然后点击进入。
|
||||
|
||||

|
||||
|
||||
下一屏显示出一个列有分区表(也叫做分区映射表)的清单。正如文件有`文件配置表`,分区有着分区表。分区是存储设备上的分段。例如在几乎所有的 Linux 系统中,至少存在两种分区类型 - EXT3/4 和 Swap 。每一个分区表将会在下面被简要地描述。TestDisk 并不支持所有类型的分区表,所以这并不是完整的列表。
|
||||
|
||||

|
||||
|
||||
- **Intel** - 这类分区表在 Windows 系统和许多的 Linux 系统中非常普遍,它也常常称作 MBR 分区表。
|
||||
- **EFI GPT** - 这种类型的分区表通常用在 Linux 系统中。对于 Linux 系统,这种分区表是最为推荐的, 因为逻辑分区或扩展分区的概念并不适用于 GPT (GUID Partition Table) 分区表。 这意味着,如果每个分区中有一个 Linux 系统,一个 Linux 用户可以从多种类型的 Linux 系统中进行多重启动。当然使用 GPT 分区表还有其他的优势,但那些已超出了本文的讨论范围。
|
||||
- **Humax** - Humax 分区映射表适用于韩国公司 Humax 生产的设备。
|
||||
- **Mac** - Apple 分区映射表 (APM) 适用于 Apple 的设备。
|
||||
- **None** - 某些设备并没有分区表。例如,许多 Subor 游戏控制台不使用分区映射表。如果一个用户试图以其它分区表类型从这类设备中恢复文件,用户就会困扰 TestDisk 为何找卟到任何的文件系统或者文件。
|
||||
- **Sun** - Sun 分区表适用于 Sun 系统。
|
||||
- **Xbox** -Xbox 适用于使用 Xbox 分区映射表的存储设备。
|
||||
|
||||
假如用户选择了 “Xbox” ,尽管他的系统使用了 GPT 分区表, 那么 TestDisk 将不能找到任何分区或文件系统。假如 TestDisk 按照用户的选择执行,则它可能猜测错误。(下面的图片显示的是当分区表类型错误时的输出)
|
||||
|
||||

|
||||
|
||||
当用户为他们的设备选择了正确的选项,则在下一屏中,选择 “高级” 选项。
|
||||
|
||||

|
||||
|
||||
现在,用户将看到一个列有用户存储设备中所有的文件系统或分区的列表。假如用户选择了错误的分区映射表,则在这一步中用户就将会知道他们做出了错误的选择。假如没有错误,通过移动文字光标来高亮选择含有被删除文件的分区。使用 左右键来高亮位于终端底部的 “列表”。接着,按下回车确认。
|
||||
|
||||

|
||||
|
||||
新的一屏便会呈现出列有文件和目录的列表。那些白色的文件名就是未被删除的文件,而红色的文件名是那些已被删除的文件。最右边的一列是文件的名称,从右到左方向的接着一列是文件的创建日期,再往左的一列是文件的大小(以 byte/ 比特为单位),最左边带有“-”,“d” ,“r”, “w” 和"x"的一列则代表的是文件的权限情况。“d” 表示该文件为一个目录,其他的权限术语与本文关系不大。在列表的最顶端以“.”代表的一项表示当前目录,第二行以".."代表的一项表示当前目录的上级目录,所以用户可以通过选择目录所在行到达该目录。
|
||||
|
||||

|
||||
|
||||
举个例子,我想进入"Xaiml\_Dataset" 目录,该目录基本上由被删除的文件组成。通过按键盘上的 "c"键,我将恢复文件 "computers.xaiml",接着我被询问选择一个目标目录,当然,我应该放置该文件到另一个分区中。现在,当我在我的家目录时,按下了“c”键。(选择目标目录时)哪个目录被高亮并没有什么影响,当前目录就是目标目录,在屏幕的上方,将会显示“复制完成”的消息。在我的家目录中便会有一个名为"Xaiml_Dataset"的目录,里面里有一个 Xaiml 文件。 假如我在更多的已删除文件上按“c” 键,则这些文件将会被放置到新的文件夹中而无需再向我询问目标目录。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
当这些步骤完成后,重复按“q”键直到看到正常的终端模样。目录"Xaiml_Dataset" 只能被 root 用户访问。为了解决这个问题,使用 root 权限改变该目录及其子目录的权限。做完这些后,文件便被恢复了且用户可以访问它们。
|
||||
|
||||
### 特别的 ReiserFS:###
|
||||
|
||||
为了从 ReiserFS 文件系统中恢复一个文件,首先需将分区中的所有文件做一个备份。因为如果发生某些错误, 这个方法可能会引起文件丢失。接着执行下面的命令,其中 `DEVICE`指的是那些以 sda2 形式命名的设备。一些文件将被放入 lost+found 目录而其他则会保存到原先被删除的位置。
|
||||
|
||||
reiserfsck --rebuild-tree --scan-whole-partition /dev/DEVICE
|
||||
|
||||
### 恢复被某个程序打开的删除文件: ###
|
||||
|
||||
假设用户意外地删除了一个文件,且该文件被某个程序打开。虽然在硬盘中该文件被删除了,但这个程序正使用着位于 RAM 中的该文件的副本。幸好,我们有两种简单的解决方法来恢复该文件。
|
||||
|
||||
假如这个软件有保存功能,如文本编辑器,则用户可以重新保存该文件,这样,文本编辑器可以将该文件写入硬盘中。
|
||||
|
||||
假设在音乐播放器中有一个 MP3 文件,而该音乐播放器并不能保存该 MP3 文件,则这种情形下需要比先前花更多的时间来恢复文件。不幸的是,这种方法并不能保证在所有的系统和应用中有效。首先,键入下面的命令。
|
||||
|
||||
lsof -c smplayer | grep mp3
|
||||
|
||||
上面的命令会列出所有由 smplayer 使用的文件,这个列表由 `grep` 命令通过管道搜索 mp3 。命令的输入类似于下面:
|
||||
|
||||
smplayer 10037 collier mp3 169r 8,1 676376 1704294 /usr/bin/smplayer
|
||||
|
||||
现在,键入下面的命令来直接从 RAM(在 Linux 系统中,`/proc/`映射到 RAM)中恢复文件,并复制该文件到选定的文件夹中。其中 `cp` 指的是复制命令,输出中的数字 10037 来自于进程数,输出中的数字 169 指的是文件描述符,"~/Music/"为目标目录,最后的 "music.mp3" 为用户想恢复的文件的名称。
|
||||
|
||||
cp /proc/10037/fd/169 ~/Music/music.mp3
|
||||
|
||||
### 真正的删除: ###
|
||||
|
||||
为确保一个文件不能被恢复,可以使用一个命令来 “擦除” 硬盘。擦除硬盘实际上是向硬盘中写入无意义的数据。例如,许多擦除程序向硬盘中写入零,随机字母或随机数据。不会有空间被占用或丢失,擦除程序只是对空位进行重写覆盖。假如存储单元被文件占满而没有空余空间,则所有先前被删除的文件将会消失而不能恢复。
|
||||
|
||||
擦除硬盘的目的是确保隐私数据不被他人看见。举个例子,一个公司可能预订了一些新的电脑,总经理决定将旧的电脑卖掉,然而,新的电脑拥有者可能会看到公司的一些机密或诸如信用卡号码,地址等顾客信息。幸好,公司的电脑技术人员可以在卖掉这些旧电脑之前,擦除这些硬盘。
|
||||
|
||||
为了安装擦除程序 secure-delete,键入 `sudo apt-get install secure-delete`,这个命令将会安装一个包含 4 个程序的程序集,用以确保被删除的文件不能被恢复。
|
||||
|
||||
- srm - 永久删除一个文件。使用方法: `srm -f ./secret_file.txt`
|
||||
- sfill - 擦除空白空间。使用方法: `sfill -f /mount/point/of/partition`
|
||||
- sswap - 擦除 swap 空间。使用方法: `sswap -f /dev/SWAP_DEVICE`
|
||||
|
||||
假如电脑实际去清除那些删除的文件,那么就需要花费更长的时间去执行删除任务。将某些空间标记为空位是快速且容易的,但使得文件永远消失需要花费一定的时间。例如,擦除一个存储单元,可能需要花费几个小时的时间(根据磁盘容量大小)。总之,现在的系统工作的就挺好,因为即便用户清空了垃圾箱,他们仍然有另一次机会来改变他们当初的想法(或错误)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.org/threads/undelete-files-on-linux-systems.4316/
|
||||
|
||||
作者:[DevynCJohnson][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.org/members/devyncjohnson.4843/
|
||||
[1]:http://www.cgsecurity.org/wiki/TestDisk
|
||||
@ -28,7 +28,7 @@ Btrfs文件系统在Linux中的创建及其特性
|
||||
|
||||
### 转换到Btrfs ###
|
||||
|
||||
**警告:在尝试转换文件系统前,请务必备份数据。虽然此操作很稳定,也很安全,但它仍然可能导致数据丢失,而防止此情况发生的唯一途径就是进行数据备份。**
|
||||
**警告:在尝试转换文件系统前,请务必备份数据!虽然此操作很稳定,也很安全,但它仍然可能导致数据丢失,而防止此情况发生的唯一途径就是进行数据备份。**
|
||||
|
||||
将现存的ext4文件系统转换到btrfs是相当简单而易懂的。你首先需要使用fsck来检查你现存分区上是否存在错误,然后使用btrfs-convert命令进行转换。如果你想要对/dev/sda3分区进行转换,你可以进行以下操作:
|
||||
|
||||
@ -41,7 +41,7 @@ Btrfs文件系统在Linux中的创建及其特性
|
||||
|
||||
### 转换根分区 ###
|
||||
|
||||
如果你想要对你系统上的根分区进行转换,你首先需要使用Live CD启动。对于Ubuntu,你可以使用Ubuntu安装CD来完成此操作,在启动后第一个屏幕选择“尝试Ubuntu”。对于其它系统,你同样可以使用Live CD镜像,操作类似。
|
||||
如果你想要对你系统上的根分区进行转换,你首先需要使用Live CD启动。对于Ubuntu,你可以使用Ubuntu安装盘来完成此操作,在启动后第一个屏幕选择“尝试Ubuntu”。对于其它系统,你同样可以使用Live CD镜像,操作类似。
|
||||
|
||||
在启动后,打开终端,使用下面的命令来转换文件系统。
|
||||
|
||||
@ -57,7 +57,7 @@ Btrfs文件系统在Linux中的创建及其特性
|
||||
|
||||

|
||||
|
||||
现在来编辑fstab,并根据blkid输出的结果来修改当前/文件系统的UUID,并将它的文件系统类型修改为btrfs,修改后的行如下:
|
||||
现在来编辑fstab,并根据blkid输出的结果来修改当前“/”文件系统的UUID,并将它的文件系统类型修改为btrfs,修改后的行如下:
|
||||
|
||||
UUID=8e7e80aa-337e-4179-966d-d60128bd3714 / btrfs defaults 0 1
|
||||
|
||||
@ -74,7 +74,7 @@ via: http://linoxide.com/file-system/create-btrfs-features/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
实例展示Ubuntu中apt-get和apt-cache命令的使用
|
||||
apt-get 和 apt-cache 命令实例展示
|
||||
================================================================================
|
||||
apt-get和apt-cache是**Ubuntu Linux**中的命令行下的**包管理**工具。 apt-get的GUI版本是Synaptic包管理器,本篇中我们会讨论apt-get和apt-cache命令的不同。
|
||||
apt-get和apt-cache是**Ubuntu Linux**中的命令行下的**包管理**工具。 apt-get的GUI版本是Synaptic包管理器。本篇中我们会展示apt-get和apt-cache命令的15个不同例子。
|
||||
|
||||
### 示例:1 列出所有可用包 ###
|
||||
|
||||
@ -16,7 +16,7 @@ apt-get和apt-cache是**Ubuntu Linux**中的命令行下的**包管理**工具
|
||||
|
||||
### 示例:2 用关键字搜索包 ###
|
||||
|
||||
这个命令在你不确定包名时很有用,只要在apt-cache(这里原文是apt-get,应为笔误)后面输入与包相关的关键字即可/
|
||||
这个命令在你不确定包名时很有用,只要在apt-cache(LCTT 译注:这里原文是apt-get,应为笔误)后面输入与包相关的关键字即可。
|
||||
|
||||
linuxtechi@localhost:~$ apt-cache search "web server"
|
||||
apache2 - Apache HTTP Server
|
||||
@ -37,7 +37,7 @@ apt-get和apt-cache是**Ubuntu Linux**中的命令行下的**包管理**工具
|
||||
pnp4nagios-bin: /etc/pnp4nagios/nagios.cfg
|
||||
pnp4nagios-bin: /usr/share/doc/pnp4nagios/examples/nagios.cfg
|
||||
|
||||
### 示例:3 显示特定包的基本信息 ###
|
||||
### 示例:3 显示特定包的基本信息 ###
|
||||
|
||||
linuxtechi@localhost:~$ apt-cache show postfix
|
||||
Package: postfix
|
||||
@ -92,7 +92,7 @@ apt-get和apt-cache是**Ubuntu Linux**中的命令行下的**包管理**工具
|
||||
|
||||
### 示例:6 使用 “apt-get update” 更新仓库 ###
|
||||
|
||||
使用命令“apt-get update”, 我们可以重新从源仓库中同步文件索引。包的索引从“/etc/apt/sources.list”中检索
|
||||
使用命令“apt-get update”, 我们可以重新从源仓库中同步文件索引。包的索引从“/etc/apt/sources.list”中检索。
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get update
|
||||
Ign http://extras.ubuntu.com utopic InRelease
|
||||
@ -106,7 +106,7 @@ apt-get和apt-cache是**Ubuntu Linux**中的命令行下的**包管理**工具
|
||||
Ign http://in.archive.ubuntu.com utopic-backports InRelease
|
||||
................................................................
|
||||
|
||||
### 示例:7 使用apt-get安装包 ###
|
||||
### 示例:7 使用apt-get安装包 ###
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get install icinga
|
||||
|
||||
@ -140,15 +140,15 @@ apt-get和apt-cache是**Ubuntu Linux**中的命令行下的**包管理**工具
|
||||
Get:1 http://in.archive.ubuntu.com/ubuntu/ utopic/universe icinga amd64 1.11.6-1build1 [1,474 B]
|
||||
Fetched 1,474 B in 1s (1,363 B/s)
|
||||
|
||||
上面的目录会从你当前的目录下载icinga包。
|
||||
上面的目录会把icinga包下载到你的当前工作目录。
|
||||
|
||||
### 示例:12 清理本地包占用的磁盘空间 ###
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get clean
|
||||
|
||||
上面的命令会清零apt-get在下载包时占用的磁盘空间。
|
||||
上面的命令会清空apt-get所下载的包占用的磁盘空间。
|
||||
|
||||
我们也可以使用“**autoclean**”选项来代替“**clean**“,两者之间主要的区别是autoclean清理不再使用且没用的下载。
|
||||
我们也可以使用“**autoclean**”选项来代替“**clean**”,两者之间主要的区别是autoclean清理不再使用且没用的下载。
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get autoclean
|
||||
Reading package lists... Done
|
||||
@ -167,9 +167,9 @@ apt-get和apt-cache是**Ubuntu Linux**中的命令行下的**包管理**工具
|
||||
Get:1 Changelog for apache2 (http://changelogs.ubuntu.com/changelogs/pool/main/a/apache2/apache2_2.4.10-1ubuntu1/changelog) [195 kB]
|
||||
Fetched 195 kB in 3s (60.9 kB/s)
|
||||
|
||||
上面的命令会下载apache2的更新日志,并在你屏幕上显示。
|
||||
上面的命令会下载apache2的更新日志,并在你屏幕上分页显示。
|
||||
|
||||
### 示例15 使用 “check” 选项显示损坏的依赖 ###
|
||||
### 示例:15 使用 “check” 选项显示损坏的依赖关系 ###
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get check
|
||||
Reading package lists... Done
|
||||
@ -182,7 +182,7 @@ via: http://www.linuxtechi.com/ubuntu-apt-get-apt-cache-commands-examples/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
================================================================================
|
||||
你可能会有很多理由想要把一个应用、一个用户或者一个环境与你的 linux 系统隔离开来。不同的操作系统有不同的实现方式,而在 linux 中,一个典型的方式就是 chroot 环境。
|
||||
|
||||
在这份教程中,我会一步一步指导你怎么使用 chroot 命令去配置一个与真实系统分离出来的独立环境。这个功能主要可以用于测试项目,这些步骤都在 **Ubuntu 14.04** 虚拟专用服务器(VPS)上执行。
|
||||
在这份教程中,我会一步一步指导你怎么使用 chroot 命令去配置一个与真实系统分离出来的独立环境。这个功能主要可以用于测试项目,以下这些步骤都在 **Ubuntu 14.04** 虚拟专用服务器(VPS)上执行。
|
||||
|
||||
学会快速搭建一个简单的 chroot 环境是一项非常实用的技能,绝大多数系统管理员都能从中受益。
|
||||
|
||||
@ -22,7 +22,7 @@
|
||||
|
||||
举个例子,你可以在 chroot 环境中编译、安装、测试软件,而不去动真实的系统。你也可以**在64位环境下使用 chroot 创建一个32位环境,然后运行一个32位的程序**(LCTT泽注:如果你的真实环境是32位的,那就不能 chroot 一个64位的环境了)。
|
||||
|
||||
但是 为了安全考虑,chroot 环境为非特权用户设立了非常严格的限制,而不是提供完整的安全策略。如果你需要的是有完善的安全策略的隔离方案,可以考虑下 LXC、Docker、vservers等等。
|
||||
但是为了安全考虑,chroot 环境为非特权用户设立了非常严格的限制,而不是提供完整的安全策略。如果你需要的是有完善的安全策略的隔离方案,可以考虑下 LXC、Docker、vservers等等。
|
||||
|
||||
### Debootstrap 和 Schroot ###
|
||||
|
||||
@ -138,7 +138,7 @@ via: http://linoxide.com/ubuntu-how-to/configure-chroot-environment-ubuntu-14-04
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
================================================================================
|
||||
今天我们将会在Ubuntu Server 14.04 LTS (Trusty)上安装一个博客平台Ghost。
|
||||
|
||||
Ghost是一款设计优美的发布平台,很容易使用且对任何人都免费。它是免费的开源软件(FOSS),它的源码在Github上。截至2014年1月,它的界面很简单还有分析面板。编辑使用的是分屏显示。
|
||||
Ghost是一款设计优美的发布平台,很容易使用且对任何人都免费。它是免费的开源软件(FOSS),它的源码在Github上。截至2015年1月(LCTT 译注:原文为2014,应为2015),它的界面很简单还有分析面板。编辑使用的是很便利的分屏显示。
|
||||
|
||||
因此有了这篇步骤明确的在Ubuntu Server上安装Ghost的教程:
|
||||
|
||||
@ -52,12 +52,12 @@ Ghost是一款设计优美的发布平台,很容易使用且对任何人都免
|
||||
sudo adduser --shell /bin/bash --gecos 'Ghost application' ghost
|
||||
sudo chown -R ghost:ghost /var/www/ghost/
|
||||
|
||||
现在启动Ghost,你需要以“ghsot”用户登录。
|
||||
现在启动Ghost,你需要以“ghost”用户登录。
|
||||
|
||||
su - ghost
|
||||
cd /var/www/ghost/
|
||||
|
||||
现在,你已经以“ghsot”用户登录,并可启动Ghost:
|
||||
现在,你已经以“ghost”用户登录,并可启动Ghost:
|
||||
|
||||
npm start --production
|
||||
|
||||
@ -67,7 +67,7 @@ via: http://linoxide.com/ubuntu-how-to/install-ghost-ubuntu-server-14-04/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -65,7 +65,7 @@
|
||||
|
||||
vi /etc/sysconfig/iptables
|
||||
|
||||
加入红色显示的行:
|
||||
加入如下行“-A INPUT -p tcp -m state --state NEW --dport 23 -j ACCEPT”:
|
||||
|
||||
# Firewall configuration written by system-config-firewall
|
||||
# Manual customization of this file is not recommended.
|
||||
@ -151,7 +151,7 @@ via: http://www.unixmen.com/installing-telnet-centosrhelscientific-linux-6-7/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -5,17 +5,17 @@
|
||||
|
||||

|
||||
|
||||
这个教程会一步一步的教你如何安装Xubuntu Linux。
|
||||
这个教程会一步步教你如何安装Xubuntu Linux。
|
||||
|
||||
为什么你会想要安装Xubuntu呢?这里有三个原因:
|
||||
|
||||
1. 你有一台安装Windows XP的计算机,但是微软已经不再对Windows XP提供支持
|
||||
2. 你的[电脑运行很慢][1],并且你想要一个轻量级并且跟得上时代潮流的操作系统
|
||||
3. 你想要增加一些DIY经验
|
||||
2. 你的[电脑运行很慢][1],你想要一个轻量级并且跟得上时代潮流的操作系统
|
||||
3. 你想要自定义你的电脑使用体验
|
||||
|
||||
首先,你需要[下载Xubuntu,并且创建一个启动优盘][2]。
|
||||
首先,你需要[下载Xubuntu,并且创建一个可启动的USB驱动器][2]。
|
||||
|
||||
完成以后,用优盘启动到Xubuntu,然后点击安装Xubuntu图标。
|
||||
完成以后,用优盘启动到当前版本的Xubuntu,然后点击安装Xubuntu图标。
|
||||
|
||||
### 选择你的安装语言 ###
|
||||
|
||||
@ -29,9 +29,9 @@
|
||||
|
||||

|
||||
|
||||
第二步,需要你来选择你的网络链接。这个步骤不是必须的。
|
||||
第二步,需要你来选择你的网络链接。这个步骤不是必须的,你在这个阶段可能会选择不设置网络链接是有原因的。
|
||||
|
||||
如果你[网络状况十分糟糕][3],直接跳过是一个明智的选择,因为安装程序会在安装过程中从网络上下载一些更新包。那么可想而知,你的安装过程就会花费很长的时间。
|
||||
如果你的[网络状况十分糟糕][3],不选无线网络是一个明智的选择,因为安装程序会在安装过程中从网络上下载一些更新包。那么可想而知,你的安装过程就会花费很长的时间。
|
||||
|
||||
当然,如果你的[网速很快][4],选择一个无线网,然后输入密码就行了。
|
||||
|
||||
@ -51,17 +51,19 @@
|
||||
|
||||
安装过程中,如果电池电量耗完的话,你才必须要链接到到电源。
|
||||
|
||||
请注意,如果你连网了,这里有一个关闭安装过程中下载更新包的复选框。
|
||||
|
||||
这里还有一个复选框,提示你是否安装用于[播放MP3][5]或者[Flash视频][6]的第三方软件,当然,这些内容也可以在安装完成以后进行。
|
||||
|
||||
### 选择安装类型 ###
|
||||
|
||||

|
||||
|
||||
接下来的步骤是选择安装类型。显示那些选项,取决于之前电脑上安装了什么系统。
|
||||
接下来的步骤是选择安装类型。显示哪些选项,取决于之前电脑上安装了什么系统。
|
||||
|
||||
在我的示例中,我已经安装了[Ubuntu MATE][7],所以,我的选项是重装Ubuntu、删除并且重装、Xubuntu和Ubuntu双系统、以及其他。
|
||||
在我的示例中,我已经安装了[Ubuntu MATE][7],所以,我的选项是重装Ubuntu、删除并且重装、安装Xubuntu和Ubuntu双系统,或者其它。
|
||||
|
||||
如果你的计算机上安装了Windows,那么你得到的选项就是,安装双系统、使用Xubuntu替换Windows以及其他。
|
||||
如果你的计算机上安装了Windows,那么你得到的选项就是,安装双系统,使用Xubuntu替换Windows或者其他。
|
||||
|
||||
这个教程只是用来说明如何在计算机上安装Xubuntu,而不是怎么安装双系统,那将是一个完全不同的教程。
|
||||
|
||||
@ -73,11 +75,11 @@
|
||||
|
||||

|
||||
|
||||
选择你要在那个磁盘上安装的Xubuntu。
|
||||
选择你要安装Xubuntu的磁盘。
|
||||
|
||||
点击“Install Now”。
|
||||
|
||||
这时候会弹出一个警告窗口,会提示你,选择的磁盘驱动器会被完全清除,然后会显示一个新创建的分区列表。
|
||||
这时候会弹出一个警告窗口,会提示你选择的磁盘驱动器会被完全清除,然后会显示一个新创建的分区列表。
|
||||
|
||||
> 备注:这是你改变主意的最后一个机会,如果你点击继续,磁盘就会被完全清除,然后开始安装Xubuntu。
|
||||
|
||||
@ -103,7 +105,7 @@
|
||||
|
||||
如果你需要确认键盘布局是否正确,可以在“Type here to test your keyboard”输入字符。你需要特别注意fn键和一些符号,例如英镑和美元符号。
|
||||
|
||||
如果在安装过程中没有设对也没关系,安装完成以后在Xubuntu系统设置中也可以进行调整。
|
||||
如果在安装过程中没有设置正确也没关系,安装完成以后在Xubuntu系统设置中也可以进行调整。
|
||||
|
||||
### 新增用户 ###
|
||||
|
||||
@ -115,9 +117,9 @@
|
||||
|
||||
为用户选择一个用户名并且[创建一个密码][8]。为了保证你的密码输入正确,你需要输入两遍。
|
||||
|
||||
如果你想要系统自动登入,而不是在每次启动的时候输入密码,选择“Log in automatically”。尽管对于我来说,我肯定不会选择这个选项。
|
||||
如果你想要系统自动登入,而不是在每次启动的时候输入密码,选择“Log in automatically”。对于我来说,我肯定不会选择这个选项。
|
||||
|
||||
更好的选项是“Require my password to log in”,并且如果你想要更高的安全等级,勾选“Encrypt my home fodler”选项。
|
||||
更好的选项是“Require my password to log in”,并且如果你想要更高的安全等级,勾选“Encrypt my home folder”选项。
|
||||
|
||||
点击“Continue”然后继续。
|
||||
|
||||
@ -125,9 +127,9 @@
|
||||
|
||||

|
||||
|
||||
这个步骤中,将会会拷贝文件到你的电脑,并且安装Xubuntu。
|
||||
这个步骤中,将会拷贝文件到你的电脑,并且安装Xubuntu。
|
||||
|
||||
在这个过程中,你会看到一个简短的幻灯片。在这个时候你可以去[泡一杯咖啡][9]或者放松一下什么的。
|
||||
在这个过程中,你会看到一个简短的幻灯片。在这个时候你可以去[泡一杯咖啡][9]或者放松一下。
|
||||
|
||||
安装完成以后,会弹出提示告诉你是否重新启动,并且开始体验一下新安装的Xubuntu系统。
|
||||
|
||||
@ -139,7 +141,7 @@ via : http://linux.about.com/od/howtos/ss/A-Step-By-Step-Guide-To-Installing-Xu
|
||||
|
||||
作者:[Gary Newell][a]
|
||||
译者:[zhouj-sh](https://github.com/zhouj-sh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -152,4 +154,4 @@ via : http://linux.about.com/od/howtos/ss/A-Step-By-Step-Guide-To-Installing-Xu
|
||||
[6]:http://animation.about.com/od/2danimationtutorials/ss/2d_fla_lesson1.htm
|
||||
[7]:http://www.everydaylinuxuser.com/2014/11/ubuntu-mate-vs-lubuntu-on-old-netbook.html
|
||||
[8]:http://netsecurity.about.com/cs/generalsecurity/a/aa112103b.htm
|
||||
[9]:http://coffeetea.about.com/od/preparationandrecipes/
|
||||
[9]:http://coffeetea.about.com/od/preparationandrecipes/
|
||||
@ -1,4 +1,4 @@
|
||||
3种创建轻量、持久化的Xubuntu Linux USB系统盘的方法
|
||||
3种方法来创建轻量、持久化的Xubuntu Linux USB系统盘
|
||||
================================================================================
|
||||
|
||||
### 使用Universal USB Install创建持久化USB Xubuntu系统盘 ###
|
||||
@ -9,13 +9,13 @@
|
||||
|
||||
> 译者注:持久化Linux USB系统盘(Persistent Linux USB drive),安装在优盘的Linux系统,允许用户保存数据到优盘而不是仅仅将这些修改留在内存中。这些数据可以在重启后恢复并且重新使用,甚至是在其他的机器上面启动也没有关系。一般情况下,持久化系统盘会安装一个压缩过的Linux操作系统。
|
||||
|
||||
为什么你需要做这些事情呢,这里有5个很好的理由:
|
||||
为什么要这样做呢,这里有5个很好的理由:
|
||||
|
||||
1. 你想要在你的电脑上安装一个轻量的并且功能完善的Linux版本。
|
||||
1. 你想要在你的电脑上安装一个轻量并且功能完善的Linux版本。
|
||||
2. 你的电脑没有硬盘,那么一个Linux USB系统盘就可以让这台电脑摆脱被扔到垃圾堆的命运。
|
||||
3. 你想体验一下Linux,但是你却不想花太多的时间去准备。
|
||||
4. 你想创建一个USB系统恢复盘,并且在优盘上安装一些特定的应用程序。
|
||||
5. 你想要一个可以装在屁股口袋或者可以挂在钥匙圈上面的可定制的Linux版本。
|
||||
5. 你想要一个可定制的Linux版本,能装在后兜或者挂在钥匙圈上。
|
||||
|
||||
现在,我们有了充足的理由,那么开始做一些准备工作吧。
|
||||
|
||||
@ -51,7 +51,7 @@
|
||||
|
||||
14.04版是一个长期维护的版本,维护周期会持续3年。14.10是最新版本,但是只提供9个月的维护。
|
||||
|
||||
你选择了下载站点以后,会提示你选择32位版本或者64位版本。如果你的电脑是32位,就选32位版本,同样,如果你的电脑是64位选64位版本就行了。
|
||||
你选择了下载站点以后,会提示你选择32位版本或者64位版本。如果你的电脑是32位,就选32位版本,同样,如果你的电脑是64位,那就选64位版本。
|
||||
|
||||
[点击这里,有一个教程来教你辨别你的电脑是32位还是64位][5]。
|
||||
|
||||
@ -105,7 +105,7 @@ Universal USB Installer主界面出现以后,从下拉列表中选择你想要
|
||||
|
||||
Startup Disk Creator使用起来很简单。
|
||||
|
||||
界面被划分成两个部分。在上面部分指定下载的系统盘路径,在下面指定安装的优盘。
|
||||
界面被划分成两个部分。上部分指定下载的系统盘路径,下部分指定安装的优盘。
|
||||
|
||||
首先,点击“Other”按钮,第二步,选择你所下载的Xubuntu ISO文件。
|
||||
|
||||
@ -119,7 +119,7 @@ Startup Disk Creator使用起来很简单。
|
||||
|
||||
你创建的过程中,你可能需要输入几次你的系统密码,USB系统盘创建完成以后,你就可以使用它启动到Xubuntu了。
|
||||
|
||||
### 使用UNetbootin创建持久化Xubuntu系统盘 ###
|
||||
### 使用UNetbootin创建持久化的Xubuntu系统盘 ###
|
||||
|
||||

|
||||
|
||||
@ -127,7 +127,7 @@ Startup Disk Creator使用起来很简单。
|
||||
|
||||
个人来说,在Windows系统上面我喜欢用Universal USB Installer,但Linux的话,UNetbootin更合适一些。
|
||||
|
||||
> 注:UNetbootin并不是100%完美的,它并不支持所有的Linux发行版。
|
||||
> 注:UNetbootin并不是100%完美的,不是所有的Linux发行版都支持。
|
||||
|
||||
Windows平台可以点击[这里][8]下载UNetbootin。
|
||||
|
||||
@ -141,11 +141,11 @@ Linux平台可以使用package manager安装UNetbootin。
|
||||
|
||||
> sudo unetbootin
|
||||
|
||||
UNetbootin的界面分为两个部分。你可以在上面的部分选择一个Linux发行版,然后下载它,如果已经下载了某个发行版,可以在下半部分选择已经下载的系统盘。
|
||||
UNetbootin的界面分为两个部分。你可以在上半部分选择一个Linux发行版,然后下载它,如果已经下载了某个发行版,可以在下半部分选择已经下载的系统盘。
|
||||
|
||||
点击“Diskimage”单选框,然后点击三个点的按钮。找到已经下载的Xubuntu ISO文件。路径会显示到按钮旁边的文本框里面。
|
||||
|
||||
修改“Space used to preserve files across reboots”的值,来指定你想要用来存储“持久化”数据的空间大小。
|
||||
设置“Space used to preserve files across reboots”的值,来指定你想要用来存储“持久化”数据的空间大小。
|
||||
|
||||
类型选择USB drive,然后选择优盘的盘符。
|
||||
|
||||
@ -159,7 +159,7 @@ via : http://linux.about.com/od/howtos/ss/How-To-Create-A-Persistent-Bootable-Xu
|
||||
|
||||
作者:[Gary Newell][a]
|
||||
译者:[zhouj-sh](https://github.com/Zhouj-sh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -171,4 +171,4 @@ via : http://linux.about.com/od/howtos/ss/How-To-Create-A-Persistent-Bootable-Xu
|
||||
[5]:http://pcsupport.about.com/od/fixtheproblem/f/32-bit-64-bit-windows.htm
|
||||
[6]:http://www.pendrivelinux.com/universal-usb-installer-easy-as-1-2-3/
|
||||
[7]:http://linux.about.com/od/howtos/fl/Learn-Ubuntu-The-Unity-Dash.htm
|
||||
[8]:http://linux.about.com/od/howtos/ss/How-To-Create-A-UEFI-Bootable-Ubuntu-USB-Drive-Using-Windows.htm
|
||||
[8]:http://linux.about.com/od/howtos/ss/How-To-Create-A-UEFI-Bootable-Ubuntu-USB-Drive-Using-Windows.htm
|
||||
@ -1,6 +1,6 @@
|
||||
如何在CentOS 7中禁止IPv6
|
||||
================================================================================
|
||||
最近,我的一位朋友问我该如何禁止IPv6。在搜索了一番之后,我找到了下面的方案。下面就是我在CentOS 7迷你版中禁止IPv6的方法。
|
||||
最近,我的一位朋友问我该如何禁止IPv6。在搜索了一番之后,我找到了下面的方案。下面就是在我的CentOS 7 迷你服务器禁止IPv6的方法。
|
||||
|
||||
你可以用两个方法做到这个。
|
||||
|
||||
@ -41,7 +41,6 @@
|
||||
|
||||
### 我在禁止IPv6后遇到问题怎么办 ###
|
||||
|
||||
You may get problems after disabling IPv6.
|
||||
你可能在禁止IPv6后遇到一些问题
|
||||
|
||||
#### 问题1: ####
|
||||
@ -60,9 +59,7 @@ vi /etc/ssh/sshd_config
|
||||
|
||||
AddressFamily inet
|
||||
|
||||
或者,
|
||||
|
||||
在这行的前面去掉注释**(#)**:
|
||||
或者,在这行的前面去掉注释**(#)**:
|
||||
|
||||
#ListenAddress 0.0.0.0
|
||||
|
||||
@ -89,7 +86,7 @@ via: http://www.unixmen.com/disable-ipv6-centos-7/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
如何在崩溃后重启Cinnamon
|
||||
================================================================================
|
||||
Cinnamon是一个提供了高级创新特性和传统用户体验的Linux桌面环境。桌面布局和Gnome 2相似。底层的技术与Gnome Shell相似。它的重点是让用户有宾至如归的感觉并提供一个简单和舒适的桌面体验。
|
||||
Cinnamon是一个提供了高级创新特性和传统用户体验的Linux桌面环境。桌面布局和Gnome 2相似。底层的技术与Gnome Shell相似。它的重点是让用户以熟悉的方式得到简单和舒适的桌面体验。
|
||||
|
||||
本篇中我们会展示一个快速的方法来重启Cinnamon而不用在崩溃后登出或者重启。
|
||||
|
||||
@ -18,15 +18,15 @@ Cinnamon应该会重新在面板和菜单中显示图标和文本了。
|
||||
|
||||

|
||||
|
||||
享受吧!
|
||||
试试吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/quick-tip-restart-cinnamon-crash/
|
||||
|
||||
作者:[Enock Seth Nyamador][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -6,7 +6,7 @@ curl是一个强大的命令行工具,它可以通过网络将信息传递给
|
||||
|
||||
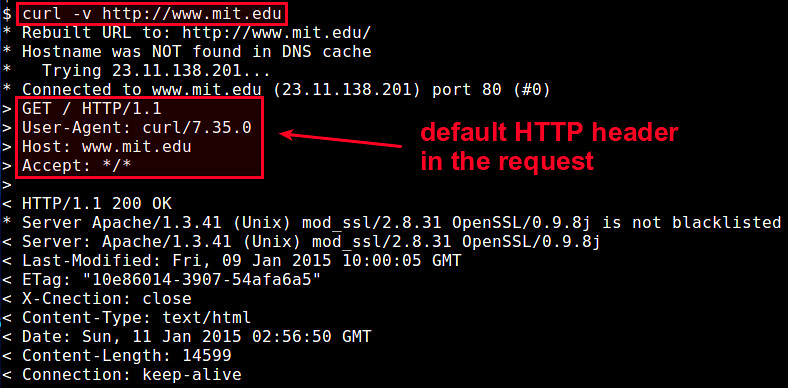
|
||||
|
||||
在一些个例中,或许你想要在一个HTTP请求中覆盖掉默认的HTTP头或者添加一个新的自定义头部字段。例如,你或许想要重写“HOST”字段来测试一个[负载均衡][1],或者通过重写"User-Agent"字符串来欺骗特定浏览器以解决其访问限制的问题。
|
||||
在一些个例中,或许你想要在一个HTTP请求中覆盖掉默认的HTTP头或者添加一个新的自定义头部字段。例如,你或许想要重写“HOST”字段来测试一个[负载均衡][1],或者通过重写"User-Agent"字符串来假冒特定浏览器以解决一些访问限制的问题。
|
||||
|
||||
为了解决所有这些问题,curl提供了一个简单的方法来完全控制传出HTTP请求的HTTP头。你需要的这个参数是“-H” 或者 “--header”。
|
||||
|
||||
@ -36,7 +36,7 @@ wget是另外一个类似于curl,可以用来获取URL的命令行工具。并
|
||||
via: http://ask.xmodulo.com/custom-http-header-curl.html
|
||||
|
||||
译者:[Ping](http://mr-ping.com)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
Linux有问必答--如果修复Google Chrome 的 ‘Your profile could not be opened correctly’错误
|
||||
Linux有问必答——如何修复Google Chrome 的“Your profile could not be opened correctly”错误
|
||||
================================================================================
|
||||
> **提问**:当我在linux打开Google Chrome 浏览器时,我已经几次收到弹出窗口,提示我的档案文件没有被正确打开(Your profile could not be opened correctly.)。每次我打开Chrome都要弹出来,我应该如何修复这个问题?
|
||||
|
||||
当你在你的Chrome上看见"Your profile could not be opened correctly"错误信息时,那是因为你的Chrome档案数据已经损坏。这个问题经常发生在手动升级Google Chrome时候。
|
||||
当你在你的Chrome上看见"Your profile could not be opened correctly"错误信息时,从某种程度上讲,那是因为你的Chrome配置文件数据已经损坏。这个问题经常发生在手动升级Google Chrome的时候。
|
||||
|
||||
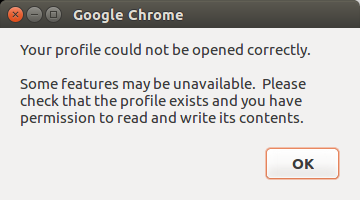
|
||||
|
||||
@ -10,7 +10,7 @@ Linux有问必答--如果修复Google Chrome 的 ‘Your profile could not be op
|
||||
|
||||
### 方法一 ###
|
||||
|
||||
关掉所有Chrome窗口和子窗口。
|
||||
关掉所有Chrome窗口和标签页。
|
||||
|
||||
进入~/.config/google-chrome/Default,移除或者重命名"Web Data"文件。
|
||||
|
||||
@ -21,9 +21,9 @@ Linux有问必答--如果修复Google Chrome 的 ‘Your profile could not be op
|
||||
|
||||
### 方法二 ###
|
||||
|
||||
关掉所有Chrome窗口和子窗口。
|
||||
关掉所有Chrome窗口和标签页。
|
||||
|
||||
进入~/.config/google-chrome/"Profile 1", 并重命名"History"文件。
|
||||
进入~/.config/google-chrome/"Profile 1",并重命名"History"文件。
|
||||
|
||||
$ cd ~/.config/google-chrome/"Profile 1"
|
||||
$ mv History History.bak
|
||||
@ -32,9 +32,9 @@ Linux有问必答--如果修复Google Chrome 的 ‘Your profile could not be op
|
||||
|
||||
### 方法三 ###
|
||||
|
||||
如果依然没有解决,你可以试试移除所有默认档案文件夹(~/.config/google-chrome/Default)。注意:如果这样做,你将会遗失所有之前打开的Google子窗口,导入的书签,浏览记录和登录数据等。
|
||||
如果依然没有解决,你可以试试移除所有默认配置文件夹(~/.config/google-chrome/Default)。注意:如果这样做,你将会遗失所有之前打开的Google标签、导入的书签,浏览记录和登录数据等。
|
||||
|
||||
在移除之前,先关掉所有Chrome窗口和子窗口
|
||||
在移除之前,先关掉所有Chrome窗口和标签页
|
||||
|
||||
$ rm -rf ~/.config/google-chrome/Default
|
||||
|
||||
@ -45,6 +45,6 @@ Linux有问必答--如果修复Google Chrome 的 ‘Your profile could not be op
|
||||
via: http://ask.xmodulo.com/your-profile-could-not-be-opened-correctly-google-chrome.html
|
||||
|
||||
译者:[VicYu/Vic020](http://vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -1,14 +1,14 @@
|
||||
非Linux的免费开源软件:Homebrew
|
||||
非Linux的自由开源软件:Homebrew
|
||||
================================================================================
|
||||
我日常工作中使用的是OS X。我能容忍它很大程序上是因为它的终端。如果我不能在黑色背景绿色文字的终端下工作,我想我会疯了。不幸的是,OS Xmei没有我需要的全部命令行工具。Homebrew的到来拯救了这。
|
||||
我日常工作中使用的是OS X。我能容忍它很大程序上是因为它的终端。如果我不能在黑色背景绿色文字的终端下工作,我想我会疯了。不幸的是,OS X 没有我需要的全部命令行工具。Homebrew的到来拯救了我。
|
||||
|
||||

|
||||
|
||||
Homebrew扮演了OS X中缺乏的包管理器的角色。命令的使用很像apt-get,它能够安装无数的应用。一个最好的例子是wget。我很惊讶OS X中没有包含wget,但是homebrew中有,这是最简单的一套了
|
||||
Homebrew扮演了OS X中所缺乏的包管理器的角色。命令的使用很像apt-get,它能够安装无数的应用。一个最好的例子是wget。我很惊讶OS X中没有包含wget,但是homebrew中有,很简单就安装上了。
|
||||
|
||||
最棒的是homebrew在/usr/local文件夹下安装软件。你不必担心homebrew会破坏你的系统,因为它不会访问/usr/local之外的其他文件。OSX系统更新不会覆盖你的程序,并且/usr/local/bin已经在PATH中,使用homebrew安装的程序可以直接工作。
|
||||
|
||||
homebrew使用ruby管理它的包和功能,但是使用它不需要任何编程知识。并且安装过程只需要在命令行中复制粘贴就好了。如果你使用的是OS X,但是你希望像在Linux中那样方便地安装熬,就试一试homrbrew吧:[http://brew.sh][1]。
|
||||
homebrew使用ruby管理它的包和功能,但是使用它不需要任何编程知识。并且安装过程只需要在命令行中复制粘贴就好了。如果你使用的是OS X,但是你希望像在Linux中那样方便地安装,就试一试homrbrew吧:[http://brew.sh][1]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -16,7 +16,7 @@ via: http://www.linuxjournal.com/content/non-linux-foss-homebrew
|
||||
|
||||
作者:[Shawn Powers][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,12 @@
|
||||
如何避免在ELemetary OS Freya中出现两个Google Chrome 图标[快速提示]
|
||||
如何避免在ELemetary OS Freya中出现两个Google Chrome 图标
|
||||
================================================================================
|
||||

|
||||
|
||||
这篇文章会教你**如何避免在ELemetary OS Freya中出现两个Google Chrome 图标**。
|
||||
|
||||
Chrome才是我在所有系统中使用的主浏览器。而[Modori][2]默认在dock中,你不得不每次在使用Chrome时在Slingshot中搜索Google Chrome。为了节省时间,我假设你选择的是“保持在dock”中。
|
||||
Chrome才是我在所有系统中使用的主浏览器。[Modori][2] 是默认放在dock中的浏览器,所以你每次使用Chrome时都需要在Slingshot中搜索Google Chrome,而为了节省时间,我通常会将它“保持在dock”中。
|
||||
|
||||
这里的问题是当你点击dock中的Chrome图标时,它会创建另外一个Google Chrome的实例。这就在dock中留下两个Chrome图标,这个或许可以被忽略但是很显然这是设计上的一个干扰。如果你有相同的感受,让我们看下如何移除这第二个Google Chrome图标。
|
||||
这里的问题是当你点击dock中的Chrome图标时,它会创建另外一个Google Chrome的实例。这就在dock中留下两个Chrome图标,这或许你可以不在意,但是很显然处女座不能忍!如果你有相同的感受,让我们看下如何移除这第二个Google Chrome图标。
|
||||
|
||||
### 在Elementary OS Freya的dock中删除第二个Google Chrome 图标 ###
|
||||
|
||||
@ -37,7 +37,7 @@ Chrome才是我在所有系统中使用的主浏览器。而[Modori][2]默认在
|
||||
|
||||
#### 第四步: ####
|
||||
|
||||
进入Slingshot并且再次打开Google Chrome。再次选择“keep in dock”。关闭并重启来验证它是否在dock中打开了另外一个新的Chrome实例。这里不需要重启系统。
|
||||
进入Slingshot并且再次打开Google Chrome。再次选择“keep in dock”。关闭并重新打开它来验证它是否在dock中打开了另外一个新的Chrome图标。这里不需要重启系统。
|
||||
|
||||
我希望这篇提示能够帮助你删除Elementary OS Freya中多出的Chrome图标。有任何问题或建议让我在评论区中知道。
|
||||
|
||||
@ -47,7 +47,7 @@ via: http://itsfoss.com/rid-google-chrome-icons-dock-elementary-os-freya/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,40 @@
|
||||
Italian Region Emilia-Romagna Is Switching To OpenOffice
|
||||
================================================================================
|
||||

|
||||
|
||||
Italy seems to be winning the race to Open Source adoption, it seems. We have learned about how various Italian cities like [Udine][1], [Turin][2], [Todi and Turni][3] opted for [open source alternatives of Microsoft office][4] in the past. Now the news comes that [Emilia-Romagna][5] region in northern Italy is about to complete its switch to [Apache OpenOffice][6] next month.
|
||||
|
||||
### Switching to OpenOffice ###
|
||||
|
||||
The migration to OpenOffice will be complete by next month and will cover 4200 workstations, across 10 departments and 5 agencies. In addition, Open Document Format (ODF) will be the default document format. The initiative to switch to OpenOffice was approved in late 2013 and was originally planned to be completed by end of 2014. The move to OpenOffice from proprietary office product is believed to [save around 2 million euro][8] in licensing fee.
|
||||
|
||||
To ease this migration and improve interoperability, several custom tools and plugins are also being developed by the team in charge of the migration.
|
||||
|
||||
Head of the project, Giovanni Grazia is enthusiastic about the migration but he is prepared for the brickbats as well.
|
||||
|
||||
> “Changing office suite is hard work, and we use the occasion to advocate for free and open source software. Some of the region’s civil servants are keen to switch, and some are very annoyed, as they have been using the proprietary alternative for 20 years. To deal with any issues during the transition, a team of five support staffers is backed up by three IT specialists. Department by department, one at a time, we’re completing the switch. Step by step, change is coming.”
|
||||
|
||||
#### Best wishes ####
|
||||
|
||||
I wish good luck to Grazia and hope that other administrative regions in Italy will follow the suit. I also hope that neighboring countries like [France will also speed up the open source adoption process][8].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/emiliaromagna-completes-switch-openoffice/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/udine-open-source/
|
||||
[2]:http://itsfoss.com/italian-city-turin-open-source/
|
||||
[3]:http://itsfoss.com/italian-cities-switch-libreoffice/
|
||||
[4]:http://itsfoss.com/best-free-open-source-alternatives-microsoft-office/
|
||||
[5]:http://en.wikipedia.org/wiki/Emilia-Romagna
|
||||
[6]:https://www.openoffice.org/
|
||||
[7]:http://www.slwoods.co.uk/?p=2886
|
||||
[8]:http://itsfoss.com/french-city-toulouse-saved-1-million-euro-libreoffice/
|
||||
@ -0,0 +1,67 @@
|
||||
Install Google’s Material Design Inspired GTK And Icon Theme Paper in Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
[Paper][1] is a new upcoming GTK and icon theme inspired by Google’s [Material design][2] guidelines. It is developed by Sam Hewitt, the man behind [Moka Project][3]. Moka has always been in the list of [best themes for Ubuntu][4] and looking at Paper, I can say that once it is developed completely, it will surely be listed as one of the [best GTK themes][5].
|
||||
|
||||
Yes, you heard it right. The theme is still under development. Therefore I suggest that if you want to install Paper theme in Ubuntu or any other Linux distributions, do it only for experimentation purpose. You may see some broken icons here and there but the over all experience is nice.
|
||||
|
||||
### Install Paper theme in Ubuntu based distributions via PPA ###
|
||||
|
||||
Sam has a dedicated PPA for Ubuntu based distributions. I recommend that you use this PPA instead of downloading the theme because you’ll be getting the updates on the themes regularly. This PPA is available for Ubuntu 15.04, Ubuntu 14.10, Ubuntu 14.04, Elementary OS Freya, Elementary OS Luna, Linux Mint 17, Linux Mint 16 and other Linux distributions based on Ubuntu.
|
||||
|
||||
Open a terminal and use the following commands:
|
||||
|
||||
sudo add-apt-repository ppa:snwh/pulp
|
||||
sudo apt-get update
|
||||
sudo apt-get install paper-gtk-theme paper-icon-theme
|
||||
|
||||
### Download Paper GTK and icon theme ###
|
||||
|
||||
If you do not want to use the PPA, you can download the themes and icons manually. As I said previously, you won’t get the updates automatically this way.
|
||||
|
||||
- [Download Paper icon themes][6]
|
||||
- [Download Paper GTK themes][7]
|
||||
|
||||
#### Using Paper themes and icons ####
|
||||
|
||||
I hope that you know how to change or install themes in your respective Linux distributions. If you are not unaware of it, below are few tutorials that could help you to install new themes:
|
||||
|
||||
- [How to change themes in Ubuntu Unity][8]
|
||||
- [How to change themes in GNOME Shell][9]
|
||||
- [How to change themes in Linux Mint][10]
|
||||
- [How to change theme in Elementary OS Freya][11]
|
||||
|
||||
#### Here is what Paper theme looks like ####
|
||||
|
||||
Since I am using [Elementary OS Freya][12] these days, here are some of the screenshots of how Paper theme and icons look like in Elementary OS Freya. I have used a wallpaper with Material design look so that it blends well with the icon and themes.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
How do you find this Material design inspired theme? If you did use it, do share the screenshot of your desktop with rest of us here.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/install-paper-theme-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://snwh.org/paper/
|
||||
[2]:http://www.google.fr/design/spec/material-design/introduction.html
|
||||
[3]:http://mokaproject.com/moka-icon-theme/
|
||||
[4]:http://itsfoss.com/best-icon-themes-ubuntu-1404/
|
||||
[5]:http://itsfoss.com/gnome-shell-themes-ubuntu-1404/
|
||||
[6]:https://github.com/snwh/paper-icon-theme
|
||||
[7]:https://github.com/snwh/paper-gtk-theme
|
||||
[8]:http://itsfoss.com/how-to-install-themes-in-ubuntu-13-10/
|
||||
[9]:http://itsfoss.com/install-switch-themes-gnome-shell/
|
||||
[10]:http://itsfoss.com/install-icon-linux-mint/
|
||||
[11]:http://itsfoss.com/install-themes-icons-elementary-os-freya/
|
||||
[12]:http://itsfoss.com/tag/elementary-os-freya/
|
||||
114
sources/share/20150227 Chess in a Few Bytes.md
Normal file
114
sources/share/20150227 Chess in a Few Bytes.md
Normal file
@ -0,0 +1,114 @@
|
||||
Chess in a Few Bytes
|
||||
================================================================================
|
||||
I am showing my age by mentioning that my introduction to computing was a ZX81, a home computer produced by a UK developer (Sinclair Research) which had a whopping 1KB of RAM. The 1KB is not a typographical error, the home computer really shipped with a mere 1KB of onboard memory. But this memory limitation did not prevent enthusiasts producing a huge variety of software. In fact the machine sparked a generation of programming wizards who were forced to get to grips with its workings. The machine was upgradable with a 16KB RAM pack which offered so many more coding possibilities. But the unexpanded 1KB machine still inspired programmers to release remarkable software.
|
||||
|
||||

|
||||
|
||||
My favourite ZX81 games were Flight Simulation, 3D Monster Maze, Galaxians, and above all 1K ZX Chess. Only the latter was written for the unexpanded ZX81. In fact, David Horne's 1K ZX Chess was coded in a mere 672 bytes of RAM. However, the game managed to implement most chess rules, and offer a computer opponent. While some important rules were omitted (castling, pawn promotion, and en passant capture), it was still amazing to be able to play against artificial intelligence. The game took up a fair chunk of my misspent youth.
|
||||
|
||||
1K ZX Chess remained the smallest implementation of chess on any computer for 33 years until the record was broken by BootChess this year, and subsequently by Toledo AtomChess. These three games do not implement all of the chess rules, so for completeness I have included my favourite small implementation of chess that implements a complete set of chess rules.
|
||||
|
||||
Linux has a good range of extremely strong chess engines such as Stockfish, Critter, Togo II, Crafty, GNU Chess, and Komodo. The chess engines featured in this article offer no match to a good chess engine, but they show how much can be achieved with a minuscule codebase.
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
You may have seen a considerable amount of press coverage about BootChess, a chess program written in 487 bytes of code, smashing the record of the then smallest chess program, 1K ZX Chess. Óscar Toledo Gutiérrez took up the mantle and decided to code an even more compact chess game. Toledo Atomchess is a mere 481 bytes of x86 assembly code which fits in a boot sector. The engine plays a reasonable game of chess given the limitations of its incredibly small codebase.
|
||||
|
||||
Features include:
|
||||
|
||||
- Basic chess movements
|
||||
- ASCII text representation of chess board
|
||||
- Moves are entered in algebraic form
|
||||
- Search depth of 3-ply
|
||||
|
||||
Obviously, to fit the chess of game into 481 bytes, the author had to make some sacrifices. These limitations include:
|
||||
|
||||
- No promotion of pawns
|
||||
- No castling
|
||||
- No en passant
|
||||
- No move validation
|
||||
|
||||
The author has also written chess programs in C, JavaScript and Java; each are very small implementations of chess.
|
||||
|
||||
- Website: [nanochess.org/chess6.html][1]
|
||||
- Developer: Óscar Toledo Gutiérrez
|
||||
- License: Free for non-commercial use
|
||||
- Version Number: -
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
BootChess is an extremely small computer implementation of chess. The game is crammed into a mere 487 bytes and runs on Windows, Mac OS X and Linux operating systems. The board and pieces of BootChess are represented by text alone, with P representing pawns, Q used for the queens and full stops entered for empty squares.
|
||||
|
||||
Features include:
|
||||
|
||||
- Graphic text representation of chess board and use input
|
||||
- Bootsector sized (512 bytes) with a playable chess game
|
||||
- x86 bios hardware only bootstrap (no software dependencies)
|
||||
- All main legal moves including double square pawn start
|
||||
- Pawn promotion to queen (contrary to 1k ZX Chess)
|
||||
- CPU artificial intelligence called taxiMax > minMax half-ply
|
||||
- Hard-coded Spanish white pieces opening
|
||||
|
||||
Again, there are some important limitations. Omissions include:
|
||||
|
||||
- Under-promotion
|
||||
- En passant pawn capture
|
||||
- No castling
|
||||
- 3-repetition rule
|
||||
- 50 move draw rule
|
||||
- No opening or closing books
|
||||
- One or more minMax/negaMax full plies for artificial intelligence
|
||||
|
||||
- Website: [www.pouet.net/prod.php?which=64962][2]
|
||||
- Developer: Olivier "Baudsurfer/RSi" Poudade
|
||||
- License: WTFPL v2
|
||||
- Version Number: .02
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Micro-Max is a 133-line chess source which is written in C
|
||||
|
||||
The author has implemented a (hash) transposition table, the engine checks the legality of the input moves, and full FIDE rules except for for under-promotions.
|
||||
|
||||
Features include:
|
||||
|
||||
- Recursive negamax search
|
||||
- Quiescence search with recaptures
|
||||
- Recapture extensions
|
||||
- Iterative deepening
|
||||
- Best-move-first 'sorting'
|
||||
- Hash table storing score and best move
|
||||
- Full FIDE rules (except under promotion) and move-legality checking
|
||||
|
||||
There is also a stripped-down 1433-character version, but allowing you to play under-promotions for full FIDE-rule compliance.
|
||||
|
||||
- Website: [home.hccnet.nl/h.g.muller/max-src2.html][3]
|
||||
- Developer: Harm Geert Muller
|
||||
- License: The MIT License
|
||||
- Version Number: 3.2
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20150222033906262/ChessBytes.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://nanochess.org/chess6.html
|
||||
[2]:http://www.pouet.net/prod.php?which=64962
|
||||
[3]:http://home.hccnet.nl/h.g.muller/max-src2.html
|
||||
@ -0,0 +1,31 @@
|
||||
Torvalds: 'People who start writing kernel code get hired really quickly'
|
||||
================================================================================
|
||||
Now more than ever, the development of the Linux kernel is a matter for the professionals, as unpaid volunteer contributions to the project reached their lowest recorded levels in the latest "Who Writes Linux" report, which was released today.
|
||||
|
||||
According to the report, which is compiled by the Linux Foundation, just 11.8 percent of kernel development last year was done by unpaid volunteers -- a 19 percent downturn from the 2012 figure of 14.6 percent. The foundation says that the downward trend in volunteer contributions has been present for years.
|
||||
|
||||

|
||||
|
||||
Even so, unpaid contributors were still the single biggest source of commits in the latest Who Writes Linux, at 11,968 total changes -- good for 12.4 percent of the whole. However, corporate contributors collectively account for much, much more. The Linux Foundation said that more than 80 percent of all work on the kernel is done by paid professional developers.
|
||||
|
||||
According to Linus Torvalds, the shift towards paid developers hasn't changed much about kernel development on its own.
|
||||
|
||||
"I think one reason it hasn't changed things all that much is that it's not so much 'unpaid volunteers are going away' as 'people who start writing kernel code get hired really quickly,'" he told Network World.
|
||||
|
||||
Torvalds said that, while Linux development has changed for plenty of other reasons -- and that, naturally, new contributors pop up all the time -- many of the original developers, with decades of experience, have simply been snapped up by companies with an interest in Linux.
|
||||
|
||||
"We may have started as volunteers, but we're happily employed doing Linux these days," he said.
|
||||
|
||||
Torvalds' own role in development has become increasingly hands-off, according to the report -- he has personally signed off on 329 patches since version 3.10 of kernel was released, or 0.4 percent. Increasingly, subsystem maintainers do their own reviews and merges of code.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2885339/application-development/torvalds-people-who-start-writing-kernel-code-get-hired-really-quickly.html
|
||||
|
||||
作者:[Jon Gold][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Jon-Gold/
|
||||
@ -0,0 +1,187 @@
|
||||
10 quick tar command examples to create/extract archives in Linux
|
||||
================================================================================
|
||||
### Tar command on Linux ###
|
||||
|
||||
The tar (tape archive) command is a frequently used command on linux that allows you to store files into an archive.
|
||||
|
||||
The commonly seen file extensions are .tar.gz and .tar.bz2 which is a tar archive further compressed using gzip or bzip algorithms respectively.
|
||||
|
||||
In this tutorial we shall take a look at simple examples of using the tar command to do daily jobs of creating and extracting archives on linux desktops or servers.
|
||||
|
||||
### Using the tar command ###
|
||||
|
||||
The tar command is available by default on most linux systems and you do not need to install it separately.
|
||||
|
||||
> With tar there are 2 compression formats, gzip and bzip. The "z" option specifies gzip and "j" option specifies bzip. It is also possible to create uncompressed archives.
|
||||
|
||||
#### 1. Extract a tar.gz archive ####
|
||||
|
||||
Well, the more common use is to extract tar archives. The following command shall extract the files out a tar.gz archive
|
||||
|
||||
$ tar -xvzf tarfile.tar.gz
|
||||
|
||||
Here is a quick explanation of the parameters used -
|
||||
|
||||
> x - Extract files
|
||||
>
|
||||
> v - verbose, print the file names as they are extracted one by one
|
||||
>
|
||||
> z - The file is a "gzipped" file
|
||||
>
|
||||
> f - Use the following tar archive for the operation
|
||||
|
||||
Those are some of the important options to memorise
|
||||
|
||||
**Extract tar.bz2/bzip archives**
|
||||
|
||||
Files with extension bz2 are compressed with the bzip algorithm and tar command can deal with them as well. Use the j option instead of the z option.
|
||||
|
||||
$ tar -xvjf archivefile.tar.bz2
|
||||
|
||||
#### 2. Extract files to a specific directory or path ####
|
||||
|
||||
To extract out the files to a specific directory, specify the path using the "-C" option. Note that its a capital C.
|
||||
|
||||
$ tar -xvzf abc.tar.gz -C /opt/folder/
|
||||
|
||||
However first make sure that the destination directory exists, since tar is not going to create the directory for you and will fail if it does not exist.
|
||||
|
||||
#### 3. Extract a single file ####
|
||||
|
||||
To extract a single file out of an archive just add the file name after the command like this
|
||||
|
||||
$ tar -xz -f abc.tar.gz "./new/abc.txt"
|
||||
|
||||
More than once file can be specified in the above command like this
|
||||
|
||||
$ tar -xv -f abc.tar.gz "./new/cde.txt" "./new/abc.txt"
|
||||
|
||||
#### 4. Extract multiple files using wildcards ####
|
||||
|
||||
Wildcards can be used to extract out a bunch of files matching the given wildcards. For example all files with ".txt" extension.
|
||||
|
||||
$ tar -xv -f abc.tar.gz --wildcards "*.txt"
|
||||
|
||||
#### 5. List and search contents of the tar archive ####
|
||||
|
||||
If you want to just list out the contents of the tar archive and not extract them, use the "-t" option. The following command prints the contents of a gzipped tar archive,
|
||||
|
||||
$ tar -tz -f abc.tar.gz
|
||||
./new/
|
||||
./new/cde.txt
|
||||
./new/subdir/
|
||||
./new/subdir/in.txt
|
||||
./new/abc.txt
|
||||
...
|
||||
|
||||
Pipe the output to grep to search a file or less command to browse the list. Using the "v" verbose option shall print additional details about each file.
|
||||
|
||||
For tar.bz2/bzip files use the "j" option
|
||||
|
||||
Use the above command in combination with the grep command to search the archive. Simple!
|
||||
|
||||
$ tar -tvz -f abc.tar.gz | grep abc.txt
|
||||
-rw-rw-r-- enlightened/enlightened 0 2015-01-13 11:40 ./new/abc.txt
|
||||
|
||||
#### 6. Create a tar/tar.gz archive ####
|
||||
|
||||
Now that we have learnt how to extract existing tar archives, its time to start creating new ones. The tar command can be told to put selected files in an archive or an entire directory. Here are some examples.
|
||||
|
||||
The following command creates a tar archive using a directory, adding all files in it and sub directories as well.
|
||||
|
||||
$ tar -cvf abc.tar ./new/
|
||||
./new/
|
||||
./new/cde.txt
|
||||
./new/abc.txt
|
||||
|
||||
The above example does not create a compressed archive. Just a plain archive, that puts multiple files together without any real compression.
|
||||
|
||||
In order to compress, use the "z" or "j" option for gzip or bzip respectively.
|
||||
|
||||
$ tar -cvzf abc.tar.gz ./new/
|
||||
|
||||
> The extension of the file name does not really matter. "tar.gz" and tgz are common extensions for files compressed with gzip. ".tar.bz2" and ".tbz" are commonly used extensions for bzip compressed files.
|
||||
|
||||
#### 7. Ask confirmation before adding files ####
|
||||
|
||||
A useful option is "w" which makes tar ask for confirmation for every file before adding it to the archive. This can be sometimes useful.
|
||||
|
||||
Only those files would be added which are given a yes answer. If you do not enter anything, the default answer would be a "No".
|
||||
|
||||
# Add specific files
|
||||
|
||||
$ tar -czw -f abc.tar.gz ./new/*
|
||||
add ‘./new/abc.txt’?y
|
||||
add ‘./new/cde.txt’?y
|
||||
add ‘./new/newfile.txt’?n
|
||||
add ‘./new/subdir’?y
|
||||
add ‘./new/subdir/in.txt’?n
|
||||
|
||||
# Now list the files added
|
||||
$ tar -t -f abc.tar.gz
|
||||
./new/abc.txt
|
||||
./new/cde.txt
|
||||
./new/subdir/
|
||||
|
||||
#### 8. Add files to existing archives ####
|
||||
|
||||
The r option can be used to add files to existing archives, without having to create new ones. Here is a quick example
|
||||
|
||||
$ tar -rv -f abc.tar abc.txt
|
||||
|
||||
> Files cannot be added to compressed archives (gz or bzip). Files can only be added to plain tar archives.
|
||||
|
||||
#### 9. Add files to compressed archives (tar.gz/tar.bz2) ####
|
||||
|
||||
Its already mentioned that its not possible to add files to compressed archives. However it can still be done with a simple trick. Use the gunzip command to uncompress the archive, add file to archive and compress it again.
|
||||
|
||||
$ gunzip archive.tar.gz
|
||||
$ tar -rf archive.tar ./path/to/file
|
||||
$ gzip archive.tar
|
||||
|
||||
For bzip files use the bzip2 and bunzip2 commands respectively.
|
||||
|
||||
#### 10. Backup with tar ####
|
||||
|
||||
A real scenario is to backup directories at regular intervals. The tar command can be scheduled to take such backups via cron. Here is an example -
|
||||
|
||||
$ tar -cvz -f archive-$(date +%Y%m%d).tar.gz ./new/
|
||||
|
||||
Run the above command via cron and it would keep creating backup files with names like -
|
||||
'archive-20150218.tar.gz'.
|
||||
|
||||
Ofcourse make sure that the disk space is not overflown with larger and larger archives.
|
||||
|
||||
#### 11. Verify archive files while creation ####
|
||||
|
||||
The "W" option can be used to verify the files after creating archives. Here is a quick example.
|
||||
|
||||
$ tar -cvW -f abc.tar ./new/
|
||||
./new/
|
||||
./new/cde.txt
|
||||
./new/subdir/
|
||||
./new/subdir/in.txt
|
||||
./new/newfile.txt
|
||||
./new/abc.txt
|
||||
Verify ./new/
|
||||
Verify ./new/cde.txt
|
||||
Verify ./new/subdir/
|
||||
Verify ./new/subdir/in.txt
|
||||
Verify ./new/newfile.txt
|
||||
Verify ./new/abc.txt
|
||||
|
||||
Note that the verification cannot be done on compressed archives. It works only with uncompressed tar archives.
|
||||
|
||||
Thats all for now. For more check out the man page for tar command, with "man tar".
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.binarytides.com/linux-tar-command/
|
||||
|
||||
作者:[Silver Moon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117145272367995638274/posts
|
||||
@ -0,0 +1,80 @@
|
||||
How to make remote incremental backup of LUKS-encrypted disk/partition
|
||||
================================================================================
|
||||
Some of us have our hard drives at home or on a [VPS][1] encrypted by [Linux Unified Key Setup (LUKS)][2] for security reasons, and these drives can quickly grow to tens or hundreds of GBs in size. So while we enjoy the security of our LUKS device, we may start to think about a possible remote backup solution. For secure off-site backup, we will need something that operates at the block level of the encrypted LUKS device, and not at the un-encrypted file system level. So in the end we find ourselves in a situation where we will need to transfer the entire LUKS device (let's say 200GB for example) each time we want to make a backup. Clearly not feasible. How can we deal with this problem?
|
||||
|
||||
### A Solution: Bdsync ###
|
||||
|
||||
This is when a brilliant open-source tool called [Bdsync][3] (thanks to Rolf Fokkens) comes to our rescue. As the name implies, Bdsync can synchronize "block devices" over network. For fast synchronization, Bdsync generates and compares MD5 checksums of blocks in the local/remote block devices, and sync only the differences. What rsync can do at the file system level, Bdsync can do it at the block device level. Naturally, it works with encrypted LUKS devices as well. Pretty neat!
|
||||
|
||||
Using Bdsync, the first-time backup will copy the entire LUKS block device to a remote host, so it will take a lot of time to finish. However, after that initial backup, if we make some new files on the LUKS device, the second backup will be finished quickly because we will need to copy only that blocks which have been changed. Classic incremental backup at play!
|
||||
|
||||
### Install Bdsync on Linux ###
|
||||
|
||||
Bdsync is not included in the standard repositories of [Linux][4] distributions. Thus you need to build it from the source. Use the following distro-specific instructions to install Bdsync and its man page on your system.
|
||||
|
||||
#### Debian, Ubuntu or Linux Mint ####
|
||||
|
||||
$ sudo apt-get install git gcc libssl-dev
|
||||
$ git clone https://github.com/TargetHolding/bdsync.git
|
||||
$ cd bdsync
|
||||
$ make
|
||||
$ sudo cp bdsync /usr/local/sbin
|
||||
$ sudo mkdir -p /usr/local/man/man1
|
||||
$ sudo sh -c 'gzip -c bdsync.1 > /usr/local/man/man1/bdsync.1.gz'
|
||||
|
||||
#### Fedora or CentOS/RHEL ####
|
||||
|
||||
$ sudo yum install git gcc openssl-devel
|
||||
$ git clone https://github.com/TargetHolding/bdsync.git
|
||||
$ cd bdsync
|
||||
$ make
|
||||
$ sudo cp bdsync /usr/local/sbin
|
||||
$ sudo mkdir -p /usr/local/man/man1
|
||||
$ sudo sh -c 'gzip -c bdsync.1 > /usr/local/man/man1/bdsync.1.gz'
|
||||
|
||||
### Perform Off-site Incremental Backup of LUKS-Encrypted Device ###
|
||||
|
||||
I assume that you have already provisioned a LUKS-encrypted block device as a backup source (e.g., /dev/LOCDEV). I also assume that you have a remote host where the source device will be backed up (e.g., as /dev/REMDEV).
|
||||
|
||||
You need to access the root account on both systems, and set up [password-less SSH access][5] from the local host to a remote host. Finally, you need to install Bdsync on both hosts.
|
||||
|
||||
To initiate a remote backup process on the local host, we execute the following command as the root:
|
||||
|
||||
# bdsync "ssh root@remote_host bdsync --server" /dev/LOCDEV /dev/REMDEV | gzip > /some_local_path/DEV.bdsync.gz
|
||||
|
||||
Some explanations are needed here. Bdsync client will open an SSH connection to the remote host as the root, and execute Bdsync client with --server option. As clarified, /dev/LOCDEV is our source LUKS block device on the local host, and /dev/REMDEV is the target block device on the remote host. They could be /dev/sda (for an entire disk) or /dev/sda2 (for a single partition). The output of the local Bdsync client is then piped to gzip, which creates DEV.bdsync.gz (so-called binary patch file) in the local host.
|
||||
|
||||
The first time you run the above command, it will take very long time, depending on your Internet/LAN speed and the size of /dev/LOCDEV. Remember that you must have two block devices (/dev/LOCDEV and /dev/REMDEV) with the same size.
|
||||
|
||||
The next step is to copy the generated patch file from the local host to the remote host. Using scp is one possibility:
|
||||
|
||||
# scp /some_local_path/DEV.bdsync.gz root@remote_host:/remote_path
|
||||
|
||||
The final step is to execute the following command on the remote host, which will apply the patch file to /dev/REMDEV:
|
||||
|
||||
# gzip -d < /remote_path/DEV.bdsync.gz | bdsync --patch=/dev/DSTDEV
|
||||
|
||||
I recommend doing some tests with small partitions (without any important data) before deploying Bdsync with real data. After you fully understand how the entire setup works, you can start backing up real data.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In conclusion, we showed how to use Bdsync to perform incremental backups for LUKS devices. Like rsync, only a fraction of data, not the entire LUKS device, is needed to be pushed to an off-site backup site at each backup, which saves bandwidth and backup time. Rest assured that all the data transfer is secured by SSH or SCP, on top of the fact that the device itself is encrypted by LUKS. It is also possible to improve this setup by using a dedicated user (instead of the root) who can run bdsync. We can also use bdsync for ANY block device, such as LVM volumes or RAID disks, and can easily set up Bdsync to back up local disks on to USB drives as well. As you can see, its possibility is limitless!
|
||||
|
||||
Feel free to share your thought.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/remote-incremental-backup-luks-encrypted-disk-partition.html
|
||||
|
||||
作者:[Iulian Murgulet][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/iulian
|
||||
[1]:http://xmodulo.com/go/digitalocean
|
||||
[2]:http://xmodulo.com/how-to-create-encrypted-disk-partition-on-linux.html
|
||||
[3]:http://bdsync.rolf-fokkens.nl/
|
||||
[4]:http://xmodulo.com/recommend/linuxbook
|
||||
[5]:http://xmodulo.com/how-to-enable-ssh-login-without.html
|
||||
@ -0,0 +1,258 @@
|
||||
How to set up IPv6 BGP peering and filtering in Quagga BGP router
|
||||
================================================================================
|
||||
In the previous tutorials, we demonstrated how we can set up a [full-fledged BGP router][1] and configure [prefix filtering][2] with Quagga. In this tutorial, we are going to show you how we can set up IPv6 BGP peering and advertise IPv6 prefixes through BGP. We will also demonstrate how we can filter IPv6 prefixes advertised or received by using prefix-list and route-map features.
|
||||
|
||||
### Topology ###
|
||||
|
||||
For this tutorial, we will be considering the following topology.
|
||||
|
||||

|
||||
|
||||
Service providers A and B want to establish an IPv6 BGP peering between them. Their IPv6 and AS information is as follows.
|
||||
|
||||
- Peering IP block: 2001:DB8:3::/64
|
||||
- Service provider A: AS 100, 2001:DB8:1::/48
|
||||
- Service provider B: AS 200, 2001:DB8:2::/48
|
||||
|
||||
### Installing Quagga on CentOS/RHEL ###
|
||||
|
||||
If Quagga has not already been installed, we can install it using yum.
|
||||
|
||||
# yum install quagga
|
||||
|
||||
On CentOS/RHEL 7, the default SELinux policy, which prevents /usr/sbin/zebra from writing to its configuration directory, can interfere with the setup procedure we are going to describe. Thus we want to disable this policy as follows. Skip this step if you are using CentOS/RHEL 6.
|
||||
|
||||
# setsebool -P zebra_write_config 1
|
||||
|
||||
### Creating Configuration Files ###
|
||||
|
||||
After installation, we start the configuration process by creating the zebra/bgpd configuration files.
|
||||
|
||||
# cp /usr/share/doc/quagga-XXXXX/zebra.conf.sample /etc/quagga/zebra.conf
|
||||
# cp /usr/share/doc/quagga-XXXXX/bgpd.conf.sample /etc/quagga/bgpd.conf
|
||||
|
||||
Next, enable auto-start of these services.
|
||||
|
||||
**On CentOS/RHEL 6:**
|
||||
|
||||
# service zebra start; service bgpd start
|
||||
# chkconfig zebra on; chkconfig bgpd on
|
||||
|
||||
**On CentOS/RHEL 7:**
|
||||
|
||||
# systemctl start zebra; systemctl start bgpd
|
||||
# systemctl enable zebra; systmectl enable bgpd
|
||||
|
||||
Quagga provides a built-in shell called vtysh, whose interface is similar to those of major router vendors such as Cisco or Juniper. Launch vtysh command shell:
|
||||
|
||||
# vtysh
|
||||
|
||||
The prompt will be changed to:
|
||||
|
||||
router-a#
|
||||
|
||||
or
|
||||
|
||||
router-b#
|
||||
|
||||
In the rest of the tutorials, these prompts indicate that you are inside vtysh shell of either router.
|
||||
|
||||
### Specifying Log File for Zebra ###
|
||||
|
||||
Let's configure the log file for Zebra, which will be helpful for debugging.
|
||||
|
||||
First, enter the global configuration mode by typing:
|
||||
|
||||
router-a# configure terminal
|
||||
|
||||
The prompt will be changed to:
|
||||
|
||||
router-a(config)#
|
||||
|
||||
Now specify log file location. Then exit the configuration mode:
|
||||
|
||||
router-a(config)# log file /var/log/quagga/quagga.log
|
||||
router-a(config)# exit
|
||||
|
||||
Save configuration permanently by:
|
||||
|
||||
router-a# write
|
||||
|
||||
### Configuring Interface IP Addresses ###
|
||||
|
||||
Let's now configure the IP addresses for Quagga's physical interfaces.
|
||||
|
||||
First, we check the available interfaces from inside vtysh.
|
||||
|
||||
router-a# show interfaces
|
||||
|
||||
----------
|
||||
|
||||
Interface eth0 is up, line protocol detection is disabled
|
||||
## OUTPUT TRUNCATED ###
|
||||
Interface eth1 is up, line protocol detection is disabled
|
||||
## OUTPUT TRUNCATED ##
|
||||
|
||||
Now we assign necessary IPv6 addresses.
|
||||
|
||||
router-a# conf terminal
|
||||
router-a(config)# interface eth0
|
||||
router-a(config-if)# ipv6 address 2001:db8:3::1/64
|
||||
router-a(config-if)# interface eth1
|
||||
router-a(config-if)# ipv6 address 2001:db8:1::1/64
|
||||
|
||||
We use the same method to assign IPv6 addresses to router-B. I am summarizing the configuration below.
|
||||
|
||||
router-b# show running-config
|
||||
|
||||
----------
|
||||
|
||||
interface eth0
|
||||
ipv6 address 2001:db8:3::2/64
|
||||
|
||||
interface eth1
|
||||
ipv6 address 2001:db8:2::1/64
|
||||
|
||||
Since the eth0 interface of both routers are in the same subnet, i.e., 2001:DB8:3::/64, you should be able to ping from one router to another. Make sure that you can ping successfully before moving on to the next step.
|
||||
|
||||
router-a# ping ipv6 2001:db8:3::2
|
||||
|
||||
----------
|
||||
|
||||
PING 2001:db8:3::2(2001:db8:3::2) 56 data bytes
|
||||
64 bytes from 2001:db8:3::2: icmp_seq=1 ttl=64 time=3.20 ms
|
||||
64 bytes from 2001:db8:3::2: icmp_seq=2 ttl=64 time=1.05 ms
|
||||
|
||||
### Phase 1: IPv6 BGP Peering ###
|
||||
|
||||
In this section, we will configure IPv6 BGP between the two routers. We start by specifying BGP neighbors in router-A.
|
||||
|
||||
router-a# conf t
|
||||
router-a(config)# router bgp 100
|
||||
router-a(config-router)# no auto-summary
|
||||
router-a(config-router)# no synchronization
|
||||
router-a(config-router)# neighbor 2001:DB8:3::2 remote-as 200
|
||||
|
||||
Next, we define the address family for IPv6. Within the address family section, we will define the network to be advertised, and activate the neighbors as well.
|
||||
|
||||
router-a(config-router)# address-family ipv6
|
||||
router-a(config-router-af)# network 2001:DB8:1::/48
|
||||
router-a(config-router-af)# neighbor 2001:DB8:3::2 activate
|
||||
|
||||
We will go through the same configuration for router-B. I'm providing the summary of the configuration.
|
||||
|
||||
router-b# conf t
|
||||
router-b(config)# router bgp 200
|
||||
router-b(config-router)# no auto-summary
|
||||
router-b(config-router)# no synchronization
|
||||
router-b(config-router)# neighbor 2001:DB8:3::1 remote-as 100
|
||||
router-b(config-router)# address-family ipv6
|
||||
router-b(config-router-af)# network 2001:DB8:2::/48
|
||||
router-b(config-router-af)# neighbor 2001:DB8:3::1 activate
|
||||
|
||||
If all goes well, an IPv6 BGP session should be up between the two routers. If not already done, please make sure that necessary ports (TCP 179) are [open in your firewall][3].
|
||||
|
||||
We can check IPv6 BGP session information using the following commands.
|
||||
|
||||
**For BGP summary:**
|
||||
|
||||
router-a# show bgp ipv6 unicast summary
|
||||
|
||||
**For BGP advertised routes:**
|
||||
|
||||
router-a# show bgp ipv6 neighbors <neighbor-IPv6-address> advertised-routes
|
||||
|
||||
**For BGP received routes:**
|
||||
|
||||
router-a# show bgp ipv6 neighbors <neighbor-IPv6-address> routes
|
||||
|
||||

|
||||
|
||||
### Phase 2: Filtering IPv6 Prefixes ###
|
||||
|
||||
As we can see from the above output, the routers are advertising their full /48 IPv6 prefix. For demonstration purposes, we will consider the following requirements.
|
||||
|
||||
- Router-B will advertise one /64 prefix, one /56 prefix, as well as one full /48 prefix.
|
||||
- Router-A will accept any IPv6 prefix owned by service provider B, which has a netmask length between /56 and /64.
|
||||
|
||||
We are going to filter the prefix as required, using prefix-list and route-map in router-A.
|
||||
|
||||

|
||||
|
||||
#### Modifying prefix advertisement for Router-B ####
|
||||
|
||||
Currently, router-B is advertising only one /48 prefix. We will modify router-B's BGP configuration so that it advertises additional /56 and /64 prefixes as well.
|
||||
|
||||
router-b# conf t
|
||||
router-b(config)# router bgp 200
|
||||
router-b(config-router)# address-family ipv6
|
||||
router-b(config-router-af)# network 2001:DB8:2::/56
|
||||
router-b(config-router-af)# network 2001:DB8:2::/64
|
||||
|
||||
We will verify that all prefixes are received at router-A.
|
||||
|
||||
|
||||
|
||||
Great! As we are receiving all prefixes in router-A, we will move forward and create prefix-list and route-map entries to filter these prefixes.
|
||||
|
||||
#### Creating Prefix-List ####
|
||||
|
||||
As described in the [previous tutorial][4], prefix-list is a mechanism that is used to match an IP address prefix with a subnet length. Once a matched prefix is found, we can apply filtering or other actions to the matched prefix. To meet our requirements, we will go ahead and create a necessary prefix-list entry in router-A.
|
||||
|
||||
router-a# conf t
|
||||
router-a(config)# ipv6 prefix-list FILTER-IPV6-PRFX permit 2001:DB8:2::/56 le 64
|
||||
|
||||
The above commands will create a prefix-list entry named 'FILTER-IPV6-PRFX' which will match any prefix in the 2001:DB8:2:: pool with a netmask between 56 and 64.
|
||||
|
||||
#### Creating and Applying Route-Map ####
|
||||
|
||||
Now that the prefix-list entry is created, we will create a corresponding route-map rule which uses the prefix-list entry.
|
||||
|
||||
router-a# conf t
|
||||
router-a(config)# route-map FILTER-IPV6-RMAP permit 10
|
||||
router-a(config-route-map)# match ipv6 address prefix-list FILTER-IPV6-PRFX
|
||||
|
||||
The above commands will create a route-map rule named 'FILTER-IPV6-RMAP'. This rule will permit IPv6 addresses matched by the prefix-list 'FILTER-IPV6-PRFX' that we have created earlier.
|
||||
|
||||
Remember that a route-map rule is only effective when it is applied to a neighbor or an interface in a certain direction. We will apply the route-map in the BGP neighbor configuration. As the filter is meant for inbound prefixes, we apply the route-map in the inbound direction.
|
||||
|
||||
router-a# conf t
|
||||
router-a(config)# router bgp 100
|
||||
router-a(config-router)# address-family ipv6
|
||||
router-a(config-router-af)# neighbor 2001:DB8:3::2 route-map FILTER-IPV6-RMAP in
|
||||
|
||||
Now when we check the routes received at router-A, we should see only two prefixes that are allowed.
|
||||
|
||||

|
||||
|
||||
**Note**: You may need to reset the BGP session for the route-map to take effect.
|
||||
|
||||
All IPv6 BGP sessions can be restarted using the following command:
|
||||
|
||||
router-a# clear bgp ipv6 *
|
||||
|
||||
I am summarizing the configuration of both routers so you get a clear picture at a glance.
|
||||
|
||||
|
||||
|
||||
### Summary ###
|
||||
|
||||
To sum up, this tutorial focused on how to set up BGP peering and filtering using IPv6. We showed how to advertise IPv6 prefixes to a neighboring BGP router, and how to filter the prefixes advertised or received are advertised. Note that the process described in this tutorial may affect production networks of a service provider, so please use caution.
|
||||
|
||||
Hope this helps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/ipv6-bgp-peering-filtering-quagga-bgp-router.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/centos-bgp-router-quagga.html
|
||||
[2]:http://xmodulo.com/filter-bgp-routes-quagga-bgp-router.html
|
||||
[3]:http://ask.xmodulo.com/open-port-firewall-centos-rhel.html
|
||||
[4]:http://xmodulo.com/filter-bgp-routes-quagga-bgp-router.html
|
||||
@ -0,0 +1,148 @@
|
||||
Linux FAQs with Answers--How to disable IPv6 on Linux
|
||||
================================================================================
|
||||
> **Question**: I notice that one of my applications is trying to establish a connection over IPv6. But since our local network is not able to route IPv6 traffic, the IPv6 connection times out, and the application falls back to IPv4, which causes unnecessary delay. As I don't have any need for IPv6 at the moment, I would like to disable IPv6 on my Linux box. What is a proper way to turn off IPv6 on Linux?
|
||||
|
||||
IPv6 has been introduced as a replacement of IPv4, the traditional 32-bit address space used in the Internet, to solve the imminent exhaustion of available IPv4 address space. However, since IPv4 has been used by every host or device connected to the Internet, it is practically impossible to switch every one of them to IPv6 overnight. Numerous IPv4 to IPv6 transition mechanisms (e.g., dual IP stack, tunneling, proxying) have been proposed to facilitate the adoption of IPv6, and many applications are being rewritten, as we speak, to add support for IPv6. One thing for sure is that IPv4 and IPv6 will inevitably coexist for the forseeable future.
|
||||
|
||||
Ideally the [ongoing IPv6 transition process][1] should not be visible to end users, but the mixed IPv4/IPv6 environment might sometimes cause you to encounter various hiccups originating from unintended interaction between IPv4 and IPv6. For example, you may experience timeouts from applications such as apt-get or ssh trying to unsuccessfully connecting via IPv6, DNS server accidentally dropping AAAA DNS records for IPv6, or your IPv6-capable device not compatible with your ISP's legacy IPv4 network, etc.
|
||||
|
||||
Of course this doesn't mean that you should blindly disable IPv6 on you Linux box. With all the benefits promised by IPv6, we as a society want to fully embrace it eventually, but as part of troubleshooting process for end-user experienced hiccups, you may try turning off IPv6 to see if indeed IPv6 is a culprit.
|
||||
|
||||
Here are a few techniques allowing you to disable IPv6 partially (e.g., for a certain network interface) or completely on Linux. These tips should be applicable to all major Linux distributions including Ubuntu, Debian, Linux Mint, CentOS, Fedora, RHEL, and Arch Linux.
|
||||
|
||||
### Check if IPv6 is Enabled on Linux ###
|
||||
|
||||
All modern Linux distributions have IPv6 automatically enabled by default. To see IPv6 is activated on your Linux, use ifconfig or ip commands. If you see "inet6" in the output of these commands, this means your Linux has IPv6 enabled.
|
||||
|
||||
$ ifconfig
|
||||
|
||||
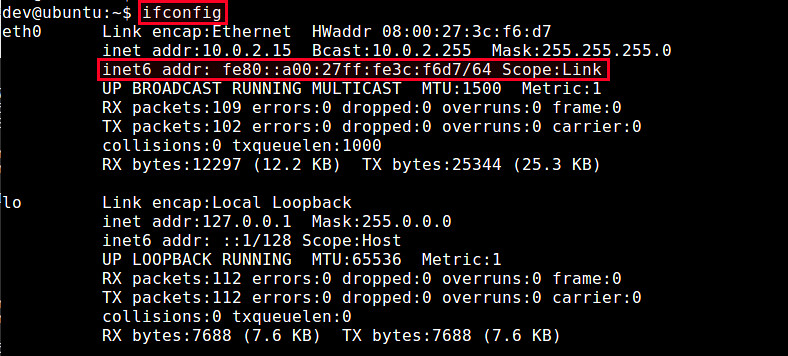
|
||||
|
||||
$ ip addr
|
||||
|
||||
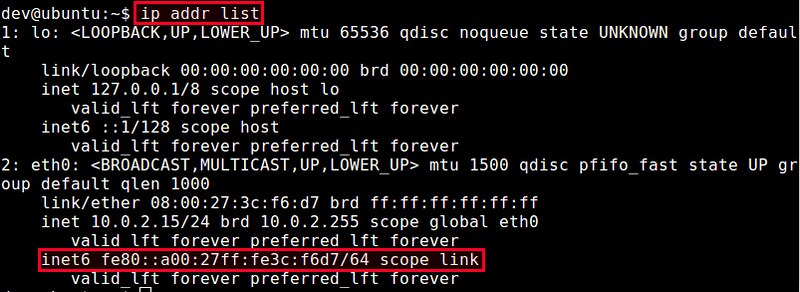
|
||||
|
||||
### Disable IPv6 Temporarily ###
|
||||
|
||||
If you want to turn off IPv6 temporarily on your Linux system, you can use /proc file system. By "temporarily", we mean that the change we make to disable IPv6 will not be preserved across reboots. IPv6 will be enabled back again after you reboot your Linux box.
|
||||
|
||||
To disable IPv6 for a particular network interface, use the following command.
|
||||
|
||||
$ sudo sh -c 'echo 1 > /proc/sys/net/ipv6/conf/<interface-name>/disable_ipv6'
|
||||
|
||||
For example, to disable IPv6 for eth0 interface:
|
||||
|
||||
$ sudo sh -c 'echo 1 > /proc/sys/net/ipv6/conf/eth0/disable_ipv6'
|
||||
|
||||
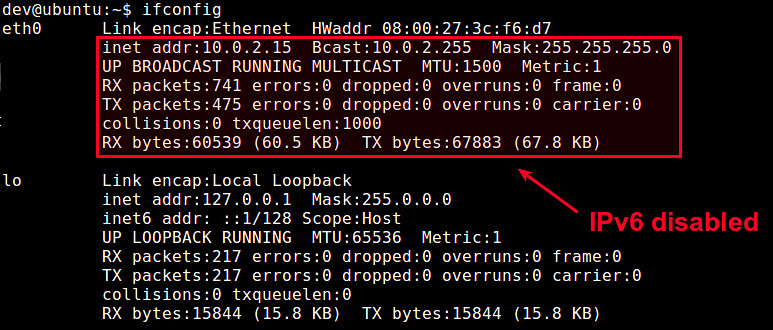
|
||||
|
||||
To enable IPv6 back on eth0 interface:
|
||||
|
||||
$ sudo sh -c 'echo 0 > /proc/sys/net/ipv6/conf/eth0/disable_ipv6'
|
||||
|
||||
If you want to disable IPv6 system-wide for all interfaces including loopback interface, use this command:
|
||||
|
||||
$ sudo sh -c 'echo 1 > /proc/sys/net/ipv6/conf/all/disable_ipv6'
|
||||
|
||||
### Disable IPv6 Permanently across Reboots ###
|
||||
|
||||
The above method does not permanently disable IPv6 across reboots. IPv6 will be activated again once you reboot your system. If you want to turn off IPv6 for good, there are several ways you can do it.
|
||||
|
||||
#### Method One ####
|
||||
|
||||
The first method is to apply the above /proc changes persistently in /etc/sysctl.conf file.
|
||||
|
||||
That is, open /etc/sysctl.conf with a text editor, and add the following lines.
|
||||
|
||||
# to disable IPv6 on all interfaces system wide
|
||||
net.ipv6.conf.all.disable_ipv6 = 1
|
||||
|
||||
# to disable IPv6 on a specific interface (e.g., eth0, lo)
|
||||
net.ipv6.conf.lo.disable_ipv6 = 1
|
||||
net.ipv6.conf.eth0.disable_ipv6 = 1
|
||||
|
||||
To activate these changes in /etc/sysctl.conf, run:
|
||||
|
||||
$ sudo sysctl -p /etc/sysctl.conf
|
||||
|
||||
or simply reboot.
|
||||
|
||||
#### Method Two ####
|
||||
|
||||
An alternative way to disable IPv6 permanently is to pass a necessary kernel parameter via GRUB/GRUB2 during boot time.
|
||||
|
||||
Open /etc/default/grub with a text editor, and add "ipv6.disable=1" to GRUB_CMDLINE_LINUX variable.
|
||||
|
||||
$ sudo vi /etc/default/grub
|
||||
|
||||
----------
|
||||
|
||||
GRUB_CMDLINE_LINUX="xxxxx ipv6.disable=1"
|
||||
|
||||
In the above, "xxxxx" denotes any existing kernel parameter(s). Add "ipv6.disable=1" after them.
|
||||
|
||||

|
||||
|
||||
Finally, don't forget to apply the modified GRUB/GRUB2 settings by running:
|
||||
|
||||
On Debian, Ubuntu or Linux Mint:
|
||||
|
||||
$ sudo update-grub
|
||||
|
||||
On Fedora, CentOS/RHEL:
|
||||
|
||||
$ sudo grub2-mkconfig -o /boot/grub2/grub.cfg
|
||||
|
||||
Now IPv6 will be completely disabled once you reboot your Linux system.
|
||||
|
||||
### Other Optional Steps after Disabling IPv6 ###
|
||||
|
||||
Here are a few optional steps you can consider after disabling IPv6. This is because while you disable IPv6 in the kernel, other programs may still try to use IPv6. In most cases, such application behaviors will not break things, but you want to disable IPv6 for them for efficiency or safety reason.
|
||||
|
||||
#### /etc/hosts ####
|
||||
|
||||
Depending on your setup, /etc/hosts may contain one or more IPv6 hosts and their addresses. Open /etc/hosts with a text editor, and comment out all lines which contain IPv6 hosts.
|
||||
|
||||
$ sudo vi /etc/hosts
|
||||
|
||||
----------
|
||||
|
||||
# comment these IPv6 hosts
|
||||
# ::1 ip6-localhost ip6-loopback
|
||||
# fe00::0 ip6-localnet
|
||||
# ff00::0 ip6-mcastprefix
|
||||
# ff02::1 ip6-allnodes
|
||||
# ff02::2 ip6-allrouters
|
||||
|
||||
#### Network Manager ####
|
||||
|
||||
If you are using NetworkManager to manage your network settings, you can disable IPv6 on NetworkManager as follows. Open the wired connection on NetworkManager, click on "IPv6 Settings" tab, and choose "Ignore" in "Method" field. Save the change and exit.
|
||||
|
||||
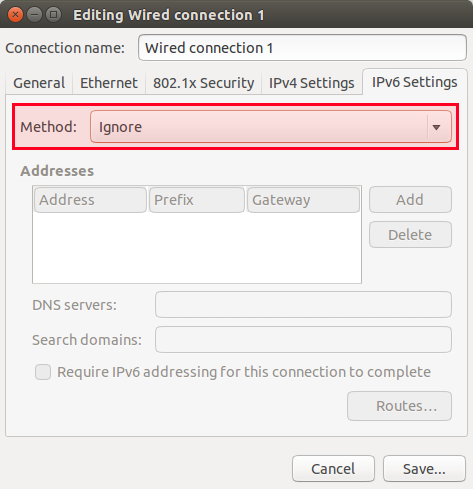
|
||||
|
||||
#### SSH server ####
|
||||
|
||||
By default, OpenSSH server (sshd) tries to bind on both IPv4 and IPv6 addresses.
|
||||
|
||||
To force sshd to bind only on IPv4 address, open /etc/ssh/sshd_config with a text editor, and add the following line. inet is for IPv4 only, and inet6 is for IPv6 only.
|
||||
|
||||
$ sudo vi /etc/ssh/sshd_config
|
||||
|
||||
----------
|
||||
|
||||
AddressFamily inet
|
||||
|
||||
and restart sshd server.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/disable-ipv6-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://www.google.com/intl/en/ipv6/statistics.html
|
||||
@ -0,0 +1,63 @@
|
||||
Linux FAQs with Answers--How to install a USB webcam in Raspberry Pi
|
||||
================================================================================
|
||||
> **Question**: Can I use a standard USB-based webcam on Raspberry Pi? How can I check if my USB webcam is compatible with Raspberry Pi, and how can I install it on Raspberry Pi?
|
||||
|
||||
If you want to take pictures or record videos using Raspberry Pi board, you can install [Raspberry Pi camera board][1]. If you do not want to shell out money just for the camera board module, there is yet another way, which is to utilize a commonly found [USB web camera][2]. You may already have one for your PC.
|
||||
|
||||
In this tutorial, we show how to set up a USB web camera on Raspberry Pi board. We assume that you are using Raspbian operation system.
|
||||
|
||||
Before we start, it is better to check if your USB web camera is [one of those][3] which are known to be compatible with Raspberry Pi. If your USB webcam is not found in the compatibility list, don't be discouraged, as there is still a chance that your USB web camera may be detected by Raspberry Pi.
|
||||
|
||||
### Check if a USB Webcam is Compatible with Raspberry Pi ###
|
||||
|
||||
To check whether your USB web camera is detected on Raspberry Pi or not, plug it into the USB port of your Raspberry Pi, and type lsusb command in the terminal.
|
||||
|
||||
$ lsusb
|
||||
|
||||
If the output of the command does not list your webcam, there is a possibility that this is because your Raspberry Pi doesn't supply enough power needed for your USB web camera. In this case, you can try using a separate power line for the USB web camera, such as [USB power hub][4], and then repeat the lsusb command. If the USB webcam is still not recognized, we can only suggest you buy another USB web camera which is supported by Raspberry Pi.
|
||||
|
||||
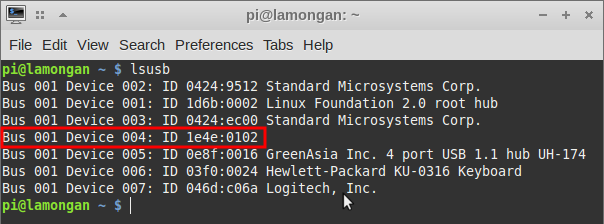
|
||||
|
||||
In the above screenshot, the USB web camera is detected as "1e4e:0102", but it doesn't show the maker or the name of the web camera. When we try it with Fedora 20 in a laptop, it is successfully detected as "1e4e:0102 Cubeternet GL-UPC822 UVC WebCam."
|
||||
|
||||
Another way to check if your USB web camera is supported by Raspberry Pi is by checking the /dev directory. If there is /dev/video0, this implies that your USB webcam is recognized by Raspberry Pi.
|
||||
|
||||
### Take a Picture with USB Webcam ###
|
||||
|
||||
After your USB webcam is successfully hooked up with Raspberry Pi, the next thing to do is to take some pictures to verify its functionality.
|
||||
|
||||
For this, you can install fswebcam, which is a small webcam application. You can install fswebcam directly from the Raspbian repository as follows.
|
||||
|
||||
$ sudo apt-get install fswebcam
|
||||
|
||||
Once fswebcam is installed, run the following command in a terminal to capture a picture from the USB webcam:
|
||||
|
||||
$ fswebcam --no-banner -r 640x480 image.jpg
|
||||
|
||||
This command will capture a picture with 640x480 resolution, and save it as image.jpg. It will not put any banner in the bottom part of the picture.
|
||||
|
||||
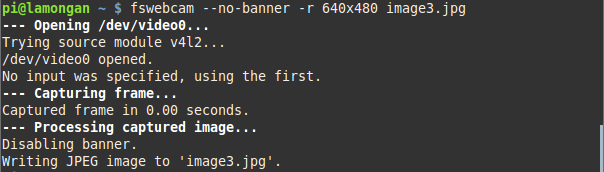
|
||||
|
||||
Here is the result from the fswebcam command with 640x480 resolution.
|
||||
|
||||

|
||||
|
||||
The next example picture is captured without defining the resolution. The picture color is blueish, and the default resolution is only 358x288.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/install-usb-webcam-raspberry-pi.html
|
||||
|
||||
作者:[Kristophorus Hadiono][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/kristophorus
|
||||
[1]:http://xmodulo.com/install-raspberry-pi-camera-board.html
|
||||
[2]:http://xmodulo.com/go/usb_webcam
|
||||
[3]:http://elinux.org/RPi_USB_Webcams
|
||||
[4]:http://xmodulo.com/go/usb_powerhub
|
||||
@ -0,0 +1,60 @@
|
||||
translating by martin.
|
||||
|
||||
Linux FAQs with Answers--How to install full kernel source on Debian or Ubuntu
|
||||
================================================================================
|
||||
> **Question**: I need to download and install a full kernel source tree to compile a custom kernel for my Debian or Ubuntu system. What is a proper way to download full kernel source on Debian or Ubuntu?
|
||||
|
||||
Before installing full kernel source on your Linux system, ask yourself whether you really need the full kernel source. If you are trying to compile a kernel module or a custom driver for your kernel, you do not need the full kernel source. You only need to install [matching kernel header files][1], and that's it.
|
||||
|
||||
You need the full kernel source tree only if you want to build a custom kernel after modifying the kernel code in any way and/or tweaking default kernel options.
|
||||
|
||||
Here is how to **download and install full kernel source tree from Debian or Ubuntu repositories**. While you can download the official kernel source code from [https://www.kernel.org/pub/linux/kernel/][2], using distro's repositories allows you to download a kernel source with the maintainer's patches applied to it.
|
||||
|
||||
### Install Full Kernel Source on Debian ###
|
||||
|
||||
Before downloading kernel source, install dpkg-dev, which contains a suite of development tools needed to build Debian source packages. Among other things, dpkg-dev contains dpgk-source tool which can extract a Debian source package and automatically apply patches.
|
||||
|
||||
$ sudo apt-get install dpkg-dev
|
||||
|
||||
Next, run the following command to download full kernel source.
|
||||
|
||||
$ apt-get source linux-image-$(uname -r)
|
||||
|
||||
Along with the full kernel source (linux_X.X.XX.orig.tar.xz), any available kernel patches (linux_X.X.X+XXX.debian.tar.xz) and source control file (linux_XXXX.dsc) will also be downloaded and stored in the current directory. The .dsc file instructs how the patches are applied to the kernel sources.
|
||||
|
||||
Upon the completion of download, the above command will automatically invoke dpkg-source tool, which will unpack the downloaded kernel source in the current directory, and apply downloaded patches according to .dsc file.
|
||||
|
||||
The final full kernel source tree will be available in the current directory as "linux-X.X.XX".
|
||||
|
||||
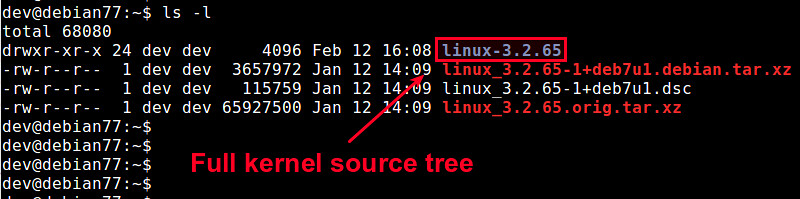
|
||||
|
||||
### Install Full Kernel Source on Ubuntu ###
|
||||
|
||||
If you want to install full kernel source, the Debian way described above should work on Ubuntu as well.
|
||||
|
||||
There is another way to download full kernel source on Ubuntu. You can actually check out the kernel source tree maintained by Canonical for different Ubuntu releases.
|
||||
|
||||
$ sudo apt-get install git
|
||||
$ git clone git://kernel.ubuntu.com/ubuntu/ubuntu-$(lsb_release --codename | cut -f2).git
|
||||
|
||||
For example, if you are using Ubuntu 14.04, the above command will check out code from "ubuntu-trusty" Git repository.
|
||||
|
||||

|
||||
|
||||
Once you check out the Git repository, use the following command to install necessary development packages to meet the build dependencies for the kernel source tree.
|
||||
|
||||
$ sudo apt-get build-dep linux-image-$(uname -r)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/install-full-kernel-source-debian-ubuntu.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://ask.xmodulo.com/install-kernel-headers-linux.html
|
||||
[2]:https://www.kernel.org/pub/linux/kernel/
|
||||
@ -0,0 +1,444 @@
|
||||
Bringing a Bunch of Best Known Linux Network Tools
|
||||
================================================================================
|
||||
It is very useful to use command line tools to monitor the network on your system and there are a tons of them out there available for the linux user such as nethogs, ntopng, nload, iftop, iptraf, bmon, slurm, tcptrack, cbm, netwatch, collectl, trafshow, cacti, etherape, ipband, jnettop, netspeed and speedometer.
|
||||
|
||||
Since there are many linux gurus and developers out there it is obvious that other network monitoring tools exist but I am not going to cover all of them in this tutorial.
|
||||
|
||||
Each one of the above tools has its own specifics but at the end all they do is monitor network traffic and there is not really only one way to do the job. For example nethogs can be used to show bandwidth per process in case you want to know the application which is consuming your entire network resources, iftop can be used to show bandwidth per socket connection and tools like nload help to get information about the overall bandwidth.
|
||||
|
||||
### 1) nethogs ###
|
||||
|
||||
nethogs is a free tool that is very handy when it comes to find out which PID is causing the trouble with your network traffic as it groups bandwidth by process instead of breaking the traffic down per protocol or per subnet, like most tools do. It is feature rich, supports both IPv4 and IPv6 and in my opinion is the best utility when you want to identify programs that are consuming all your bandwidth on your linux machine.
|
||||
|
||||
A linux user can use **nethogs** to show TCP download and upload-speed per process, monitor a specific device by using the command **nethogs eth0** where eth0 is the name of the device you want to get information from and also get information on the speed at which the data is currently being transferred.
|
||||
|
||||
To me nethogs is very easy to use, maybe because I like it so much that I use it all the time to monitor network bandwidth on my Ubuntu 12.04 LTS machine.
|
||||
|
||||
For example to sniff in promiscious the option -p is used like shown in the following command.
|
||||
|
||||
nethogs -p wlan0
|
||||
|
||||
If you like to learn more about nethogs and explore it in a very deep way than don't hesitate to read our full tutorial on this network bandwidth monitoring tool.
|
||||
|
||||
### 2) nload ###
|
||||
|
||||
nload is a console application which can be used to monitor network traffic and bandwidth usage in real time and it also visualizes the traffic by providing two easy to understand graphs. This cool network monitoring tool can also be used to switch between devices while monitoring and this can be done by pressing the left and right arrow keys.
|
||||
|
||||

|
||||
|
||||
As you can see from the above screenshot graphs provided by the nload tool are very easy to understand, provide useful information and also display additional info like total amount of transferred data and min/max network usage.
|
||||
|
||||
And what is even cooler is the fact that you can run the tool nload with the help of the following command which seems to be very short and easy to remember.
|
||||
|
||||
nload
|
||||
|
||||
I am very sure that our detailed tutorial on how to use nload will help new linux users and even experienced ones that are looking for more information on it.
|
||||
|
||||
### 3) slurm ###
|
||||
|
||||
slurm is another network load monitoring tool for linux which shows results in a nice ascii grap and it also supports many keys for interaction such as c to switch to classic mode, s to switch to split graph mode, **r** to redraw the screen, **L** to enable TX/RX led, **m** to switch between classic split and large view, and **q** to quit slurm.
|
||||
|
||||

|
||||
|
||||
There are also some other keys available in the network load monitoring tool slurm and you can easily study them in the manual page by using the following command.
|
||||
|
||||
man slurm
|
||||
|
||||
slurm is available in the official repos of Ubuntu and Debian so users of these distros can easy download it by using the apt-get install command like shown below.
|
||||
|
||||
sudo apt-get install slurm
|
||||
|
||||
We have covered slurm usage on a tutorial so please visit it and do not forget to share the knowledge with other linux friends.
|
||||
|
||||
### 4) iftop ###
|
||||
|
||||
iftop is a very useful tool when you want to display bandwidth usage on an interface by host. According to the manual page **iftop** listens to network traffic on a named interface, or on the first
|
||||
interface it can find which looks like an external interface if none is specified, and displays a table of current bandwidth usage by pairs of hosts.
|
||||
|
||||
Ubuntu and Debian users can easily install iftop on their machines by using the following command on a terminal.
|
||||
|
||||
sudo apt-get install iftop
|
||||
|
||||
Use the following command to install iftop on your machine using yum
|
||||
|
||||
yum -y install iftop
|
||||
|
||||
### 5) collectl ###
|
||||
|
||||
collectl can be used to collect data that describes the current system status and it supports the following modes:
|
||||
|
||||
- Record Mode
|
||||
- Playback Mode
|
||||
|
||||
**Record Mode** allows to take data from a live system and either display it on a terminal or writte to one or more files or a socket.
|
||||
|
||||
**Playback Mode**
|
||||
|
||||
According to the manual pages in this mode data is read from one or more data files that were generated in Record Mode.
|
||||
|
||||
Ubuntu and Debian users can use their default package manager to install collectl on their machines. The following command will do the job for them.
|
||||
|
||||
sudo apt-get install collectl
|
||||
|
||||
Use the following command because these distros have collectl in their official repos too.
|
||||
|
||||
yum install collectl
|
||||
|
||||
### 6) Netstat ###
|
||||
|
||||
Netstat is a command line tool for **monitoring incoming** and **outgoing network packets statistics** as well as interface statistics. It displays network connections for the Transmission Control Protocol (both incoming and outgoing),routing tables, and a number of network interface (network interface controller or software-defined network interface) and network protocol statistics.
|
||||
|
||||
Ubuntu and Debian users can use the default package manager to install netstat on their box. Netstat software includes inside the package net-tools. And can be installed by running the below commands in a shell or terminal:
|
||||
|
||||
sudo apt-get install net-tools
|
||||
|
||||
CentOS, Fedora, RHEL users can use the default package manager to install netstat on their box. Netstat software includes inside the package net-tools. And can be installed by running the below commands in a shell or terminal:
|
||||
|
||||
yum install net-tools
|
||||
|
||||
Simply, run the following to monitor the network packet statistic with Netstat:
|
||||
|
||||
netstat
|
||||
|
||||

|
||||
|
||||
For more information or manual about netstat, we can simply type man netstat in a shell or terminal:
|
||||
|
||||
man netstat
|
||||
|
||||

|
||||
|
||||
### 7) Netload ###
|
||||
|
||||
The netload command just displays a small report on the current traffic load, and the total number of bytes transferred since the program start. No more features are there. Its part of the netdiag.
|
||||
|
||||
We can install Netload using yum in fedora as it is in the default repository. But if you're running CentOS or RHEL, we'll need to install [rpmforge repository][1] .
|
||||
|
||||
# yum install netdiag
|
||||
|
||||
Netload is available in the default repository as a part of netdiag so, we can easily install **netdiag** using **apt** manager using the command below.
|
||||
|
||||
$ sudo install netdiag
|
||||
|
||||
To run netload, we must make sure to choose a working network interface name like eth0, eh1, wlan0, mon0, etc. And run the following command accordingly in a shell or a terminal.
|
||||
|
||||
$ netload wlan2
|
||||
|
||||
Note: Please replace wlan2 with the network interface name you wanna use. If you wanna scan for your network interface name run ip link show in a terminal or shell.
|
||||
|
||||
### 8) Nagios ###
|
||||
|
||||
Nagios is a leading open source powerful monitoring system that enables network/system administrators to identify and resolve server related problems before they affect major business processes. With the Nagios system, administrators can able to monitor remote Linux, Windows, Switches, Routers and Printers on a single window. It shows critical warnings and indicates if something went wrong in your network/server which indirectly helps you to begin remediation processes before they occur.
|
||||
|
||||
Nagios has a web interface in which there is a graphical monitor of activities. One can login to the web interface by browsing to the url http://localhost/nagios/ or http://localhost/nagios3/ . Please replace localhost with your IP-address if on remote machine. Then enter the username and pass then, we'll get to see the information like shown below.
|
||||
|
||||

|
||||
|
||||
### 9) EtherApe ###
|
||||
|
||||
EtherApe is a graphical network monitor for Unix modeled after etherman. Featuring link layer, IP and TCP modes and support interfaces Ethernet, FDDI, Token Ring, ISDN, PPP, SLIP and WLAN devices, plus several encapsulation formats. Hosts and links change in size with traffic and color coded protocols display. It can filter traffic to be shown, and can read packets from a file as well as live from the network.
|
||||
|
||||
It is easy to install etherape in CentOS, Fedora, RHEL distributions of Linux cause they are available default on their official repository. We can use yum manager to install it with the command shown below:
|
||||
|
||||
yum install etherape
|
||||
|
||||
We can install EtherApe on Ubuntu, Debian and their derivatives using **apt** manager with the below command.
|
||||
|
||||
sudo apt-get install etherape
|
||||
|
||||
After EtherApe is installed on the system, we'll need to run etherape in root permission as:
|
||||
|
||||
sudo etherape
|
||||
|
||||
Then, the **GUI** of **etherape** will be executed. Then, up in the menu we can select the **Mode** (IP, Link Layer, TCP) and **Interface** under **Capture**. After everything are set, we'll need to click **Start** button. Then, we'll gonna see something like this.
|
||||
|
||||

|
||||
|
||||
### 10) tcpflow ###
|
||||
|
||||
tcpflow is a command line utility that captures data transmitted as part of TCP connections (flows), and stores the data in a way that is convenient for protocol analysis or debugging. It reconstructs the actual data streams and stores each flow in a separate file for later analysis. It understands TCP sequence numbers and will correctly reconstruct data streams regardless of retransmissions or out-of-order delivery .
|
||||
|
||||
Installing tcpflow in Ubuntu, Debian system is easy via **apt** manager as it is available by default in the official repository.
|
||||
|
||||
$ sudo apt-get install tcpflow
|
||||
|
||||
We can install tcpflow in Fedora, CentOS, RHEL and their derivatives from repository using **yum** manager as shown below.
|
||||
|
||||
# yum install tcpflow
|
||||
|
||||
If it is not available in the repository or can't be installed via yum manager, we need to install manually from **http://pkgs.repoforge.org/tcpflow/** as shown below.
|
||||
|
||||
If you are running 64 bit PC:
|
||||
|
||||
# yum install --nogpgcheck http://pkgs.repoforge.org/tcpflow/tcpflow-0.21-1.2.el6.rf.x86_64.rpm
|
||||
|
||||
If you are running 32 bit PC:
|
||||
|
||||
# yum install --nogpgcheck http://pkgs.repoforge.org/tcpflow/tcpflow-0.21-1.2.el6.rf.i686.rpm
|
||||
|
||||
We can use tcpflow to capture all/some tcp traffic and put it in an easy to read file. The below command does what we want but we'll need to run that command in an empty directory as it creates files of the format x.x.x.x.y-a.a.a.a.z and after done, just press Control-C that command to stop it.
|
||||
|
||||
$ sudo tcpflow -i eth0 port 8000
|
||||
|
||||
Note: Please replace eth0 with the interface of the card you are trying to capture.
|
||||
|
||||
### 11) IPTraf ###
|
||||
|
||||
[IPTraf][2] is a console-based network statistics utility for Linux. It gathers a variety of figures such as TCP connection packet and byte counts, interface statistics and activity indicators, TCP/UDP traffic breakdowns, and LAN station packet and byte counts.
|
||||
|
||||
IPTraf is available in the default repository so, we can easily install IPTraf using **apt** manager using the command below.
|
||||
|
||||
$ sudo apt-get install iptraf
|
||||
|
||||
IPTraf is available in the default repository so, we can easily install IPTraf using yum manager using the command below.
|
||||
|
||||
# yum install iptraf
|
||||
|
||||
We need to run TPTraf in administration permission with a valid network interface name. Here, we have wlan2 so, we'll be using wlan2 as interface name.
|
||||
|
||||
$ sudo iptraf
|
||||
|
||||

|
||||
|
||||
To start the general interface statistics, enter:
|
||||
|
||||
# iptraf -g
|
||||
|
||||
To see the detailed statistics facility on an interface called eth0
|
||||
|
||||
# iptraf -d wlan2
|
||||
|
||||
To see the TCP and UDP monitor on an interface called eth0
|
||||
|
||||
# iptraf -z wlan2
|
||||
|
||||
To displays the packet size counts on an interface called eth0
|
||||
|
||||
# iptraf -z wlan2
|
||||
|
||||
Note: Please replace wlan2 with your interface name. You can check your interface by running command ip link show .
|
||||
|
||||
### 12) Speedometer ###
|
||||
|
||||
Speedometer is a small and simple tool that just draws out good looking graphs of incoming and outgoing traffic through a given interface.
|
||||
|
||||
Speedometer is available in the default repository so, we can easily install Speedometer using yum manager using the command below.
|
||||
|
||||
# yum install speedometer
|
||||
|
||||
Speedometer is available in the default repository so, we can easily install Speedometer using apt manager using the command below.
|
||||
|
||||
$ sudo apt-get install speedometer
|
||||
|
||||
Speedometer can simply be run by executing the following command in a shell or a terminal.
|
||||
|
||||
$ speedometer -r wlan2 -t wlan2
|
||||
|
||||

|
||||
|
||||
Note: Please replace wlan2 with the network interface name you would like to use.
|
||||
|
||||
### 13) Netwatch ###
|
||||
|
||||
Netwatch is part of the netdiag collection of tools, and it too displays the connections between local host and other remote hosts, and the speed at which data is transferring on each connection.
|
||||
|
||||
We can install Netwatch using yum in fedora as it is in the default repository. But if you're running CentOS or RHEL, we'll need to install [rpmforge repository][3] .
|
||||
|
||||
# yum install netwatch
|
||||
|
||||
Netwatch is available in the default repository as a part of netdiag so, we can easily install **netdiag** using **apt** manager using the command below.
|
||||
|
||||
$ sudo install netdiag
|
||||
|
||||
To run netwatch, we'll need to execute the following command in a terminal or shell.
|
||||
|
||||
$ sudo netwatch -e wlan2 -nt
|
||||
|
||||

|
||||
|
||||
Note: Please replace wlan2 with the network interface name you wanna use. If you wanna scan for your network interface name run ip link show in a terminal or shell.
|
||||
|
||||
### 14) Trafshow ###
|
||||
|
||||
Trafshow reports the current active connections like netwatch and pktstat, trafshow, their protocol and the data transfer speed on each connection. It can filter out connections using pcap type filters.
|
||||
|
||||
We can install Netwatch using yum in fedora as it is in the default repository. But if you're running CentOS or RHEL, we'll need to install [rpmforge repository][4] .
|
||||
|
||||
# yum install trafshow
|
||||
|
||||
Trafshow is available in the default repository so, we can easily install it using **apt** manager using the command below.
|
||||
|
||||
$ sudo install trafshow
|
||||
|
||||
To monitor using trafshow, we'll need to run the following command in a shell or terminal.
|
||||
|
||||
$ sudo trafshow -i wlan2
|
||||
|
||||

|
||||
|
||||
To monitor specifically tcp connections add tcp as shown below.
|
||||
|
||||
$ sudo trafshow -i wlan2 tcp
|
||||
|
||||

|
||||
|
||||
Note: Please replace wlan2 with the network interface name you wanna use. If you wanna scan for your network interface name run ip link show in a terminal or shell.
|
||||
|
||||
### 15) Vnstat ###
|
||||
|
||||
Vnstat is bit different from most of the other tools. It actually runs a background service/daemon and keeps recording the size of data transfer all the time. Next it can be used to generate a report of the history of network usage.
|
||||
|
||||
We'll need to turn on EPEL Repository then run **yum** manager to install vnstat.
|
||||
|
||||
# yum install vnstat
|
||||
|
||||
Vnstat is available in the default repository. So, we can run **apt** manager to install it using the following command.
|
||||
|
||||
$ sudo apt-get install vnstat
|
||||
|
||||
Running vnstat without any options would simply show the total amount of data transfer that took place since the date the daemon is running.
|
||||
|
||||
$ vnstat
|
||||
|
||||

|
||||
|
||||
To monitor the bandwidth usage in realtime, use the '-l' option (live mode). It would then show the total bandwidth used by incoming and outgoing data, but in a very precise manner without any internal details about host connections or processes.
|
||||
|
||||
$ vnstat -l
|
||||
|
||||

|
||||
|
||||
After done, press Ctrl-C to stop which will result the following type of output
|
||||
|
||||

|
||||
|
||||
### 16) tcptrack ###
|
||||
|
||||
[tcptrack][5] displays the status of TCP connections that it sees on a given network interface. tcptrack monitors their state and displays information such as state, source/destination addresses and bandwidth usage in a sorted, updated list very much like the **top** command.
|
||||
|
||||
As tcptrack is in the repository , we can simply install tcptrack in Debian, Ubuntu from their repository using apt manager. To do so, we'll need to execute the following command in a shell or terminal:
|
||||
|
||||
$ sudo apt-get install tcptrack
|
||||
|
||||
We can install it using yum in fedora as it is in the default repository. But if you're running CentOS or RHEL, we'll need to install [rpmforge repository][6] . To do so, we'll need to run the following commands.
|
||||
|
||||
# wget http://apt.sw.be/redhat/el6/en/x86_64/rpmforge/RPMS/rpmforge-release-0.5.3-1.el6.rf.x86_64.rpm
|
||||
|
||||
# rpm -Uvh rpmforge-release*rpm
|
||||
|
||||
# yum install tcptrack
|
||||
|
||||
Note: Here, we have downloaded current latest version of rpmforge-release ie 0.5.3-1 . You can always get the latest version from rpmforge repository and do replace with that you downloaded in the above command.
|
||||
|
||||
**tcptrack** needs to be run in root permission or superuser. We'll need to execute tcptrack with the network interface name we wanna monitor the TCP connections of. Here, we've wlan2 so will be using that as:
|
||||
|
||||
sudo tcptrack -i wlan2
|
||||
|
||||

|
||||
|
||||
If you wanna monitor of specific ports then:
|
||||
|
||||
# tcptrack -i wlan2 port 80
|
||||
|
||||

|
||||
|
||||
Please replace 80 with the port number you wanna monitor .Note: Please replace wlan2 with the network interface name you wanna use. If you wanna scan for your network interface name run ip link show in a terminal or shell.
|
||||
|
||||
### 17) CBM ###
|
||||
|
||||
The CBM or Color Bandwidth Meter displays current traffic of all network device. This program is so simple that is should be self-explanatory. Source code and newer versions of CBM are available at [http://www.isotton.com/utils/cbm/][7] .
|
||||
|
||||
As CBM is in the repository , we can simply install CBM in Debian, Ubuntu from their repository using **apt** manager. To do so, we'll need to execute the following command in a shell or terminal:
|
||||
|
||||
$ sudo apt-get install cbm
|
||||
|
||||
We simply need to run cbm in a shell or terminal as shown below:
|
||||
|
||||
$ cbm
|
||||
|
||||

|
||||
|
||||
### 18) bmon ###
|
||||
|
||||
[Bmon][8] or Bandwidth Monitoring is a tool that intended for debugging and monitor bandwidth in real-time access. This tool is capable to retrieving statistics from various input modules. It provides various output methods including a curses based interface,lightweight HTML output but also formatable ASCII output.
|
||||
|
||||
bmon is available in the repository, so we can install it in Debian, Ubuntu from their repository using apt manager. To do so, we'll need to run the following command in a shell or terminal.
|
||||
|
||||
$ sudo apt-get install bmon
|
||||
|
||||
We can run bmon and monitor our bandwidth status using the command below.
|
||||
|
||||
$ bmon
|
||||
|
||||

|
||||
|
||||
### 19) tcpdump ###
|
||||
|
||||
[TCPDump][9] is a tool for network monitoring and data acquisition. It can save lots of time and can be used for debugging network or server related problems. It prints out a description of the contents of packets on a network interface that match the boolean expression.
|
||||
|
||||
tcpdump is available in the default repository of Debian, Ubuntu so, we can simply use apt manager to install it under sudo privilege . To do so, we'll need to run the following command in a shell or terminal.
|
||||
|
||||
$ sudo apt -get install tcpdump
|
||||
|
||||
tcpdump is also available in the repository of Fedora, CentOS, RHEL so, we can install it via yum manager as:
|
||||
|
||||
# yum install tcpdump
|
||||
|
||||
tcpdump needs to be run in root permission or superuser. We'll need to execute tcpdump with the network interface name we wanna monitor the TCP connections of. Here, we've wlan2 so will be using it as:
|
||||
|
||||
$ sudo tcpdump -i wlan2
|
||||
|
||||

|
||||
|
||||
If you want to monitor to a specific port only, then can run the command as follows. Here is the example for port 80 (webserver).
|
||||
|
||||
$ sudo tcpdump -i wlan2 'port 80'
|
||||
|
||||

|
||||
|
||||
### 20) ntopng ###
|
||||
|
||||
[ntopng][20] is the next generation version of the original ntop. It is a network probe that shows network usage in a way similar to what top does for processes. ntopng is based on libpcap and it has been written in a portable way in order to virtually run on every Unix platform, MacOSX and on Win32 as well.
|
||||
|
||||
To install ntopng in Debian, Ubuntu system, we'll first need to install the required **dependencies packages to compile ntopng**. You can install them all by running the below command in a shell or a terminal.
|
||||
|
||||
$ sudo apt-get install libpcap-dev libglib2.0-dev libgeoip-dev redis-server wget libxml2-dev build-essential checkinstall
|
||||
|
||||
Now, we'll need to manually compile ntopng for our system as:
|
||||
|
||||
$ sudo wget http://sourceforge.net/projects/ntop/files/ntopng/ntopng-1.1_6932.tgz/download
|
||||
$ sudo tar zxfv ntopng-1.1_6932.tgz
|
||||
$ sudo cd ntopng-1.1_6932
|
||||
$ sudo ./configure
|
||||
$ sudo make
|
||||
$ sudo make install
|
||||
|
||||
Now, you should have your ntopng installed in your Debian or Ubuntu system.
|
||||
|
||||
We have already covered tutorial on ntopng usages. It is available in both command line and web interface. We can go ahead to get knowledge on it.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this first part we covered some network load monitoring tools for linux that are very helpful to a sysadmin and even a novice user. Each one of the tools covered in this article has its own specifics, different options but at the end they all help you to monitor your network traffic.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/monitoring-2/network-monitoring-tools-linux/
|
||||
|
||||
作者:[Bobbin Zachariah][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/bobbin/
|
||||
[1]:http://pkgs.org/centos-7/repoforge-x86_64/netwatch-1.0c-1.el7.rf.x86_64.rpm.html
|
||||
[2]:http://iptraf.seul.org/
|
||||
[3]:http://pkgs.org/centos-7/repoforge-x86_64/netwatch-1.0c-1.el7.rf.x86_64.rpm.html
|
||||
[4]:http://pkgs.org/centos-6/epel-x86_64/trafshow-5.2.3-6.el6.x86_64.rpm.html
|
||||
[5]:http://linux.die.net/man/1/tcptrack
|
||||
[6]:http://pkgs.org/centos-6/repoforge-x86_64/tcptrack-1.4.0-1.el6.rf.x86_64.rpm.html
|
||||
[7]:http://www.isotton.com/utils/cbm/
|
||||
[8]:https://github.com/tgraf/bmon/
|
||||
[9]:http://www.tcpdump.org/
|
||||
[10]:http://www.ntop.org/
|
||||
@ -0,0 +1,114 @@
|
||||
Enjoy Android Apps on Ubuntu using ARChon Runtime
|
||||
================================================================================
|
||||
Before, we gave try to many android app emulating tools like Genymotion, Virtualbox, Android SDK, etc to try to run android apps on it. But, with this new Chrome Android Runtime, we are able to run Android Apps on our Chrome Browser. So, here are the steps we'll need to follow to install Android Apps on Ubuntu using ARChon Runtime.
|
||||
|
||||
Google had [announced the first set of Android apps is ready to run natively on Chrome OS][1], a feature made possible using a new ‘**Android Runtime**’ extension. Now, a developer named Vlad Filippov has figured out a way to bring Android Apps to Chrome on the desktop. His chromeos-apk script and ARChon Android Runtime extension work hand-in-hand to bring Android apps to Chrome browser on the Windows, Mac and Linux desktop.
|
||||
|
||||
Performance of this apps through the runtime is not pretty good. Similarly, as its both an unofficial repackaging of the official runtime and running outside of Google's Chrome OS, system integration like webcam, speakers, etc. may be patchy or non-existent.
|
||||
|
||||
### Installing Chrome ###
|
||||
|
||||
First of all, we'll need Chrome installed in our machine, Chrome version 37 or higher is required. We can download them from the [download page of Chrome Browser][2].
|
||||
|
||||
If you wanna install a Dev Channel version you'll need to follow below procedure.
|
||||
|
||||
We'll need to add repository source list for Google Chrome which can be done my using the following command.
|
||||
|
||||
$ wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | sudo apt-key add -
|
||||
$ sudo sh -c 'echo "deb http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google-chrome.list'
|
||||
|
||||

|
||||
|
||||
After adding the repository source list, we'll need to update the local repository index by the command below.
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
Now, we'll gonna install google chrome unstable which is dev version.
|
||||
|
||||
$ sudo apt-get install google-chrome-unstable
|
||||
|
||||

|
||||
|
||||
### Installing Archon Runtime ###
|
||||
|
||||
Next we'll need to download the custom-made ergo officially not endorsed by Google or Chromium Android Runtime created by Vlad Filippov. This differs from the official version in a number of ways, the chief being it can be used on desktop versions of the browser. Here below is the runtime we need to download, please select anyone of the following according to your bit of Ubuntu installed.
|
||||
|
||||
For **32-bit** Ubuntu Distributions:
|
||||
|
||||
- [Download Archron for 32-bit Ubuntu][3]
|
||||
|
||||
For **64-bit** Ubuntu Distributions:
|
||||
|
||||
- [Download Archron for 64-bit Ubuntu][4]
|
||||
|
||||
Once the runtime has fully downloaded you will need to extract the contents from the .zip files and move the resulting directory to Home. Here is the gist commands for this steps to download and extract the contents.
|
||||
|
||||
$ wget https://github.com/vladikoff/chromeos-apk/releases/download/v3.0.0/ARChon-v1.1-x86_32.zip
|
||||
|
||||

|
||||
|
||||
$ unzip ARChon-v1.1-x86_32.zip ~/
|
||||
|
||||
Now to install the runtime, we'll gonna Open our latest Google Chrome and goto the url **chrome://extensions/** then, we'll need to check ‘**Enable developer mode**’. Finally, we'll gonna click on the ‘**load unpacked extension**’ button and select the folder which was placed into **~/Home**.
|
||||
|
||||
### Installing ChromeOS-APK ###
|
||||
|
||||
To convert APKs manually is something you really don’t need to do any more if you use one of the apps mentioned above — you will need to install the ‘[chromeos-apk][5]’ command line JavaScript utility. This is available to install through the Node Packaged Modules (npm) manager. To install nmp and chromeos-apk, we'll need to run the following command in a shell or terminal.
|
||||
|
||||
$ sudo apt-get install npm nodejs nodejs-legacy
|
||||
|
||||
**If you are running 64 bit OS**, you should grab the following library, to do so run the below commands in a shell or terminal.
|
||||
|
||||
$ sudo apt-get install lib32stdc++6
|
||||
|
||||
Now run the command to install the the latest chromeos-apk is:
|
||||
|
||||
$ npm install -g chromeos-apk@latest
|
||||
|
||||

|
||||
|
||||
Depending on your system configuration you may need to need to run this latter command as sudo.
|
||||
|
||||
Now, we'll gonna for Google to find an APK of an app to give it a try, bearing in mind **not all Android apps will work**, and those that do may be unstable or lack features. Most of the messenger out of the box are not working.
|
||||
|
||||
### Converting APK ###
|
||||
|
||||
Place your **Android APK in ~/Home**, then return to **Terminal** to convert it using the following command:
|
||||
|
||||
$ chromeos-apk myapp.apk --archon
|
||||
|
||||
If you want the app in fullscreen mode then run the following instead:
|
||||
|
||||
$ chromeos-apk myapp.apk --archon --tablet
|
||||
|
||||
Note: Please replace myapp.apk to the Android APK app filename you want to convert.
|
||||
|
||||
For our ease, we can also use [Twerk][6] for the conversion process if we want to skip this step.
|
||||
|
||||
### Running Android Apk ###
|
||||
|
||||
Finally, we'll need to open our chrome browser and then goto chrome://extensions page and enable developer mode then tap the ‘load unpacked extension’ button and select the folder the script above created.
|
||||
|
||||
Now, we can Open the Chrome App Launcher to run it.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Hurray! We have successfully installed Android Apk App in our favorite desktop browser ie Chrome Browser. This article is all about the popular Chrome Android Runtime called Archon created by Vlad Filippov. This runtime allows us to run converted Apk files in our Chrome browser. It has not yet supported messaging apps like Whatsapp, etc. So, if you have any questions, suggestions, feedback please write them in the comment box below. Thank you ! Enjoy Archon :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/android-apps-ubuntu-archon-runtime/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://chrome.blogspot.com/2014/09/first-set-of-android-apps-coming-to.html
|
||||
[2]:https://www.google.com/chrome/browser
|
||||
[3]:https://github.com/vladikoff/chromeos-apk/releases/download/v3.0.0/ARChon-v1.1-x86_32.zip
|
||||
[4]:https://github.com/vladikoff/chromeos-apk/releases/download/v3.0.0/ARChon-v1.1-x86_64.zip
|
||||
[5]:https://github.com/vladikoff/chromeos-apk/blob/master/README.md
|
||||
[6]:https://chrome.google.com/webstore/detail/twerk/jhdnjmjhmfihbfjdgmnappnoaehnhiaf
|
||||
@ -0,0 +1,86 @@
|
||||
Fix Minimal BASH like line editing is supported GRUB Error In Linux
|
||||
================================================================================
|
||||
The other day when I [installed Elementary OS in dual boot with Windows][1], I encountered a Grub error at the reboot time. I was presented with command line with error message:
|
||||
|
||||
**Minimal BASH like line editing is supported. For the first word, TAB lists possible command completions. anywhere else TAB lists possible device or file completions.**
|
||||
|
||||

|
||||
|
||||
Indeed this is not an error specific to Elementary OS. It is a common [Grub][2] error that could occur with any Linux OS be it Ubuntu, Fedora, Linux Mint etc.
|
||||
|
||||
In this post we shall see **how to fix this “minimal BASH like line editing is supported” Grub error in Ubuntu** based Linux systems.
|
||||
|
||||
> You can read this tutorial to fix similar and more frequent issue, [error: no such partition grub rescue in Linux][3].
|
||||
|
||||
### Prerequisites ###
|
||||
|
||||
To fix this issue, you would need the followings:
|
||||
|
||||
- A live USB or disk of the same OS and same version
|
||||
- A working internet connection in the live session
|
||||
|
||||
Once you make sure that you have the prerequisites, let’s see how to fix the black screen of death for Linux (if I can call it that ;)).
|
||||
|
||||
### How to fix this “minimal BASH like line editing is supported” Grub error in Ubuntu based Linux ###
|
||||
|
||||
I know that you might point out that this Grub error is not exclusive to Ubuntu or Ubuntu based Linux distributions, then why am I putting emphasis on the world Ubuntu? The reason is, here we will take an easy way out and use a tool called **Boot Repair** to fix our problem. I am not sure if this tool is available for other distributions like Fedora. Without wasting anymore time, let’s see how to solve minimal BASH like line editing is supported Grub error.
|
||||
|
||||
### Step 1: Boot in lives session ###
|
||||
|
||||
Plug in the live USB and boot in to the live session.
|
||||
|
||||
### Step 2: Install Boot Repair ###
|
||||
|
||||
Once you are in the lives session, open the terminal and use the following commands to install Boot Repair:
|
||||
|
||||
sudo add-apt-repository ppa:yannubuntu/boot-repair
|
||||
sudo apt-get update
|
||||
sudo apt-get install boot-repair
|
||||
|
||||
Note: Follow this tutorial to [fix failed to fetch cdrom apt-get update cannot be used to add new CD-ROMs error][4], if you encounter it while running the above command.
|
||||
|
||||
### Step 3: Repair boot with Boot Repair ###
|
||||
|
||||
Once you installed Boot Repair, run it from the command line using the following command:
|
||||
|
||||
boot-repair &
|
||||
|
||||
Actually things are pretty straight forward from here. You just need to follow the instructions provided by Boot Repair tool. First, click on **Recommended repair** option in the Boot Repair.
|
||||
|
||||

|
||||
|
||||
It will take couple of minutes for Boot Repair to analyze the problem with boot and Grub. Afterwards, it will provide you some commands to use in the command line. Copy the commands one by one in terminal. For me it showed me a screen like this:
|
||||
|
||||

|
||||
|
||||
It will do some processes after you enter these commands:
|
||||
|
||||

|
||||
|
||||
Once the process finishes, it will provide you a URL which consists of the logs of the boot repair. If your boot issue is not fixed even now, you can go to the forum or mail to the dev team and provide them the URL as a reference. Cool, isn’t it?
|
||||
|
||||

|
||||
|
||||
After the boot repair finishes successfully, shutdown your computer, remove the USB and boot again. For me it booted successfully but added two additional lines in the Grub screen. Something which was not of importance to me as I was happy to see the system booting normally again.
|
||||
|
||||

|
||||
|
||||
### Did it work for you? ###
|
||||
|
||||
So this is how I fixed **minimal BASH like line editing is supported Grub error in Elementary OS Freya**. How about you? Did it work for you? Feel free to ask a question or drop a suggestion in the comment box below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/fix-minimal-bash-line-editing-supported-grub-error-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/guide-install-elementary-os-luna/
|
||||
[2]:http://www.gnu.org/software/grub/
|
||||
[3]:http://itsfoss.com/solve-error-partition-grub-rescue-ubuntu-linux/
|
||||
[4]:http://itsfoss.com/fix-failed-fetch-cdrom-aptget-update-add-cdroms/
|
||||
@ -0,0 +1,72 @@
|
||||
How To Fix: Failed to fetch cdrom apt-get update cannot be used to add new CD-ROMs
|
||||
================================================================================
|
||||

|
||||
|
||||
These days I am experimenting with Elementary OS Freya and during this, I encountered a very common updater error: **Failed to fetch cdrom Please use apt-cdrom to make this CD-ROM recognized by APT. apt-get update cannot be used to add new CD-ROMs**. The complete error looked like this after running the apt-get update command:
|
||||
|
||||
> W: Failed to fetch cdrom://elementary OS 0.3 _Freya_ – Daily amd64 (20150208)/dists/trusty/main/binary-amd64/Packages Please use apt-cdrom to make this CD-ROM recognized by APT. apt-get update cannot be used to add new CD-ROMs
|
||||
>
|
||||
> W: Failed to fetch cdrom://elementary OS 0.3 _Freya_ – Daily amd64 (20150208)/dists/trusty/restricted/binary-amd64/Packages Please use apt-cdrom to make this CD-ROM recognized by APT. apt-get update cannot be used to add new CD-ROMs
|
||||
>
|
||||
> E: Some index files failed to download. They have been ignored, or old ones used instead.
|
||||
|
||||
In this post, we shall see how to fix this error.
|
||||
|
||||
### Fix Failed to fetch cdrom apt-get update cannot be used to add new CD-ROMs error ###
|
||||
|
||||
The reason for this error is that cdrom has been included as one of the the sources here. And to fix this issue, we need to remove this from the list of software sources.
|
||||
|
||||
In Ubuntu, look for Software & Updates:
|
||||
|
||||

|
||||
|
||||
In the first tab Ubuntu Software, look for the cdrom, if it’s checked, uncheck it.
|
||||
|
||||

|
||||
|
||||
Close the Software Sources and run the update again. It should work fine now.
|
||||
|
||||
### Further troubleshoot: ###
|
||||
|
||||
The method described above should have fixed this **apt-get update cannot be used to add new CD-ROMs** error. But this was not the case for me because the option of cdrom was already grayed out as I was using live session.
|
||||
|
||||

|
||||
|
||||
Now to fix our error, we shall take the command line route. Open a terminal and use the following line to see what is included in sources list:
|
||||
|
||||
cat /etc/apt/sources.list
|
||||
|
||||
The output for me was as following:
|
||||
|
||||
deb cdrom:[elementary OS 0.3 _Freya_ – Daily amd64 (20150208)]/ trusty main restricted
|
||||
deb http://archive.ubuntu.com/ubuntu/ trusty main restricted universe multiverse
|
||||
deb-src http://archive.ubuntu.com/ubuntu/ trusty main restricted universe multiverse
|
||||
deb http://security.ubuntu.com/ubuntu/ trusty-security main restricted universe multiverse
|
||||
deb-src http://security.ubuntu.com/ubuntu/ trusty-security main restricted universe multiverse
|
||||
deb http://archive.ubuntu.com/ubuntu/ trusty-updates main restricted universe multiverse
|
||||
deb-src http://archive.ubuntu.com/ubuntu/ trusty-updates main restricted universe multiverse
|
||||
|
||||
Look at the first line in the above list. It includes cdrom. We need to comment out this line by adding # in front of it to make it look like this:
|
||||
|
||||
#deb cdrom:[elementary OS 0.3 _Freya_ – Daily amd64 (20150208)]/ trusty main restricted
|
||||
|
||||
To do that use the command below:
|
||||
|
||||
sudo gedit /etc/apt/sources.list
|
||||
|
||||
Once you have edited the sources.list, run the apt-get update once again. The error apt-get update cannot be used to add new CD-ROMs should have been fixed. If you are facing any other update issue, do look at this article which is a collection of most [common Ubuntu update error fixes][1].
|
||||
|
||||
I hope you found this tutorial helpful. If you have any questions or suggestions, feel free to drop a comment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/fix-failed-fetch-cdrom-aptget-update-add-cdroms/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/fix-update-errors-ubuntu-1404/
|
||||
@ -0,0 +1,99 @@
|
||||
johnhoow translating...
|
||||
How to Install Lightweight Budgie ( v8) Desktop in Ubuntu 14.04
|
||||
================================================================================
|
||||
Budgie is the flagship desktop of the Evolve OS Linux Distribution, and is an Evolve OS project. Designed with the modern user in mind, it focuses on simplicity and elegance. A huge advantage for the Budgie desktop is that it is not a fork of another project, but rather one written from scratch with integration in mind.
|
||||
|
||||
The [Budgie Desktop][1] tightly integrates with the GNOME stack, employing underlying technologies to offer an alternative desktop experience. In the spirit of open source, the project is compatible with and available for other Linux distributions.
|
||||
|
||||
Also note that Budgie can now emulate the look and feel of the GNOME 2 desktop, optionally, via a setting in the panel preferences.
|
||||
|
||||
### Features in the 0.8 release ###
|
||||
|
||||
- IconTasklist: Add pinning support
|
||||
- IconTasklist: Use .desktop files for quicklists
|
||||
- IconTasklist: Use .desktop files for icon resolution
|
||||
- IconTasklist: Support “attention” hint (blue blink)
|
||||
- Panel: Support dark theme (used by default)
|
||||
- Add Menubar applet
|
||||
- Panel: Initial autohide support (manual, not automatic)
|
||||
- Panel: Support shadow onall screen edges
|
||||
- Panel: Dynamic support for gnome panel theming
|
||||
- RunDialog: Complete visual refresh (bootiful)
|
||||
- BudgieMenu: Add compact mode, use by default
|
||||
- BudgieMenu: Sort items by usage
|
||||
- BudgieMenu: Remove old power option
|
||||
- Editor: Add all menu options to UI
|
||||
- Support from GNOME 3.10 up to 3.16 (unreleased, git)
|
||||
- wm: Kill workspace animation (resolve after v8)
|
||||
- wm: Better animations for changing of wallpapers
|
||||
|
||||
### Important information ###
|
||||
|
||||
- Budgie [released version 0.8][2] so it is still in development and a beta.
|
||||
- No nnative network management; can be fixed by using Ubuntu's applet.
|
||||
- Budgie is intended for the Evolve OS so even with this PPA it might be buggy.
|
||||
- GNOME themes work better than the native Ubuntu themes.
|
||||
- Ubuntu’s overlay scrollbars are not working.
|
||||
- If you want to read more visit the Evolve OS website.
|
||||
|
||||
### Installation ###
|
||||
|
||||
Now, we'll install our Lightweight Budgie Desktop in our Ubuntu 14.04 LTS "Trusty" distribution of Linux Operating System. First of all, we'll need to add ppa repository to our Ubuntu PC. To do so, we'll need to execute the below command in a shell or terminal.
|
||||
|
||||
$ sudo add-apt-repository ppa:evolve-os/ppa
|
||||
|
||||

|
||||
|
||||
Now, after we finish adding PPA to our Ubuntu Computer, we'll need to update the local repository index in it. It can be done by running the following command in the same terminal or shell after above is done.
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
Then, finally, we'll install the one and only Budgie Desktop Environment in our Ubuntu machine running the latest version 14.04 LTS.
|
||||
|
||||
$ sudo apt-get install budgie-desktop
|
||||
|
||||

|
||||
|
||||
**Notes**
|
||||
|
||||
It is in active development and features remain missing, including, but not limited to: no network management support, no volume control applet (keyboard keys will work fine), no notification system and no way to ‘pin’ apps to the task bar.
|
||||
|
||||
As a workaround you can disable overlay scrollbars, set a different default theme and quit a session from the terminal using the following command:
|
||||
|
||||
$ gnome-session-quit
|
||||
|
||||

|
||||
|
||||
### Log into the Budgie Session ###
|
||||
|
||||
After installation is completed, we’ll be able to select ‘Budgie’ from the session selector of the Unity Greeter. For that, we'll need to logout the current user and get back to the login screen. Then, we'll be able to switch to Budgie Desktop Environment.
|
||||
|
||||

|
||||
|
||||
### Budgie Desktop Environment ###
|
||||
|
||||

|
||||
|
||||
### Logging Out ###
|
||||
|
||||
You can simply execute **budgie-session --logout** in a shell or terminal to logout it.
|
||||
|
||||
$ budgie-sessioon --logout
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Hurray! We have successfully installed our Lightweight Budgie Desktop Environment in our Ubuntu 14.04 LTS "Trusty" box. As we know, Budgie Desktop is still underdevelopment which makes it a lot of stuffs missing. Though it’s based on Gnome’s GTK3, it’s not a fork. The desktop is written completely from scratch, and the design is elegant and well thought out. If you have any questions, comments, feedback please do write on the comment box below and let us know what stuffs needs to be added or improved. Thank You! Enjoy Budgie Desktop 0.8 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/install-lightweight-budgie-v8-desktop-ubuntu/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://evolve-os.com/budgie/
|
||||
[2]:https://evolve-os.com/2014/11/16/courageous-budgie-v8-released/
|
||||
@ -1,118 +0,0 @@
|
||||
怎样在 Linux 系统中恢复已删除文件
|
||||
================================================================================
|
||||
大多数情况下,一个电脑用户可能意外地删除了一个仍然需要的文件,但没有一个简便的方法来重新找回或重建这个文件。幸好,文件可以被恢复。当用户删除了一个文件,该文件并没有消失,只是被隐藏了一段时间。这里将解释它是如何工作的。在一个文件系统中,有一个叫做 `文件分配表` 的文件,这个表跟踪文件在存储单元(硬盘, MicroSD 卡,闪存驱动器 等等)中的位置。当一个文件被删除,文件系统将会在`文件分配表`中执行以下 两个任务中的一个:这个文件在`文件分配表`上的条目被标记为 “空白空间” 或 这个文件在`文件分配表`的条目被擦除,且相应的空间被标记为 空白空间 。现在,如果一个文件需要被放置在一个存储单元上,操作系统将会把这个文件放置到标记为 空白 的空间中。在新文件被写入到这个空白空间后,被删除的文件就彻底消失了。当需要恢复一个已经删除的文件时,用户绝对不能再对任何文件进行操作,因为假如 该文件对应的 空白空间 被占用,这个文件就永远也不能恢复了。
|
||||
|
||||
### 恢复软件是如何工作的? ###
|
||||
|
||||
大多数的文件系统只是标记空间为空白,在这些文件系统下,恢复软件查看`文件分配表`这个文件,然后复制被删除的文件到另外的存储单元中。假如该文件被复制到原来所处的存储单元中,那么用户将有可能会失去那个所需的删除文件。
|
||||
|
||||
文件系统很少会擦除`文件配置表`中的条目。假如文件系统真的这样做了, 这便是恢复软件在恢复文件了。恢复软件在存储单元中扫描文件头,所有文件都拥有一个特殊的编码字符串,它们位于文件的最前面,也被叫做 `魔法数字`。例如,一个编译的 JAVA 类文件的魔法数字在十六进制中是“CAFEBABE”。所以,假如要恢复该类型的文件,恢复软件会查找 “CAFEBABE” 然后复制文件到另一个存储单元。一些恢复软件可以查找某种特殊的文件类型。若用户想恢复一个 PDF 文件,则恢复软件将会查找十六进制的魔法数字 “25504446”,这恰恰是 ASCII 编码中的 “%PDF”。其他的恢复软件将查找所有的魔法数字。然后,用户可以选择恢复哪个已删除的文件。
|
||||
|
||||
假如一个文件的部分被重写了,则整个文件就会被损坏。通常这个文件可以被恢复,但是其中的内容可能已经没有什么用处。例如,恢复一个已损坏的 JPEG 文件将会是无意义的,因为 图片查看器不能从这个损坏的文件产生一幅图片。因此,即使用户拥有了这个文件,该文件也将毫无用处。
|
||||
|
||||
### 设备的位置: ###
|
||||
|
||||
在我们继续之前,下面的一些信息将会对 指引恢复软件找到正确的存储单元 起到一定的帮助。所有的设备均挂载在 `/dev/` 目录下。操作系统赋予每个设备的名称(并不是管理员给予每个分区或设备的名称) 遵循一定的命名规律。第一个 SATA 硬盘的第二个分区的名称将会是 sda2。名称的第一个字母暗示了存储类型,在这里指的是 SATA,但字母 “s” 也可能指的是 SCSI, FireWire(火线端口), 或 USB。第二个字母 “d” 指的是 disk(硬盘)。第三个字母指的是设备序数,即字母 “a” 指的是第一个 SATA 而 “b” 指的是第二个。最后的数字代表分区。一个带有所有分区的设备的命名将只有字母而没有数字。对于上面的例子,对应的名称为 sda 。作为命名的第一个字母还可能是 “h” ,这对应 PATA 硬盘(IDE)。以下为命名规律的一些例子。假如一个用户有一个 SATA 硬盘(sda),这个设备有 4 个分区- sda1, sda2, sda3, 和 sda4 。该用户删除了第三个分区,但直到格式化第四个分区之前,将第四个分区保留。然后该用户插入了一个带有一个分区 - 即sdb1- 的 usb 存储卡(sdb),又增加了一个 带有一个分区 -hda1- 的 IDE 硬盘 ,接着该用户又增加了一个 SCSI 硬盘 - sdc1 。接着用户移除了 USB 存储卡(sdb)。现在,SCSI 硬盘的名称仍然为 sdc,但如果这个 SCSI 被移除接着再被插入,则它的名称将变为 sdb。即使其他的存储设备仍然存在, 那个 IDE 硬盘的名称仍会有一个 “a”, 因为它是第一个 IDE 硬盘,IDE 设备的命名与 SCSI, SATA, FireWire, 和 USB 设备要分开计数。
|
||||
|
||||
### 恢复: ###
|
||||
|
||||
每个恢复软件有其不同的功能,特征及支持的不同文件系统。下面是一些关于 使用 TestDisk 在一系列的文件系统中恢复文件的指南。
|
||||
|
||||
**FAT16, FAT32, exFAT (FAT64), NTFS, 以及 ext2/3/4:**
|
||||
|
||||
TestDisk 是一个运行在 Linux, *BSD, SunOS, Mac OS X, DOS, 和 Windows 等操作系统下的开源,免费软件。 TestDisk 可以从下面的链接中找到 :[http://www.cgsecurity.org/wiki/TestDisk][1]。TestDisk 也可以通过键入 `sudo apt-get install testdisk` 来安装。TestDisk 有着许多的功能,但这篇文章将只关注 恢复文件 这个功能。
|
||||
|
||||
使用 root 权限从终端中打开 TestDisk 可以通过键入 `sudo testdisk` 命令。
|
||||
|
||||
现在, TestDisk 命令行应用将会被执行。终端的外观将会改变。TestDisk 询问用户 它是否可以保留日志,这完全由用户决定。假如一个用户正从系统存储中恢复文件,则 TestDisk 不会保留日志。可选择的选项有 "生成", "追加", 和 "无 log"。假如用户想保留日志,则日志将会保留在该用户的主目录。
|
||||
|
||||

|
||||
|
||||
在接着的屏幕中,存储设备以 `/dev/*`的方式被罗列出来。对于我的系统,系统的存储单元为 `/dev/sda`,这意味着我的存储单元为 一个 SATA硬盘(sd) 且它是第一个硬盘(a)。每个存储单元的容量以 Gigabyte(千兆字节)为单位显示的。使用上下键来选择一个存储设备然后点击进入。
|
||||
|
||||

|
||||
|
||||
下一屏显示出一个列有分区表(也叫做 分区映射表)的清单。正如文件有`文件配置表`,分区有着分区表。分区是存储设备上的划分部分。例如在几乎所有的 Linux 系统中,至少存在两种分区类型 - EXT3/4 和 Swap 。每一个分区表将会在下面被简要地描述。TestDisk 并不支持所有类型的分区表,所以下面的列表不是完整的。
|
||||
|
||||

|
||||
|
||||
- **Intel** - 这类分区表在 Windows 系统和许多的 Linux 系统中非常普遍,它也以 MBR 的名称为人们熟知。
|
||||
- **EFI GPT** - 这种类型的分区表通常用在 Linux 系统中。对于 Linux系统,这种分区表是最为推荐的, 因为逻辑分区或扩展分区的概念并不适用于 GPT (GUID Partition Table) 分区表。 这意味着,如果每个分区中有一个 Linux 系统,一个 Linux 用户可以从多种类型的 Linux 系统中进行多重启动。当然使用 GPT 分区表还有其他的优势,但那些已超出了本文的讨论范围。
|
||||
- **Humax** - Humax 分区映射表适用于韩国公司 Humax 生产的设备。
|
||||
- **Mac** - Apple 分区映射表 (APM) 适用于 Apple 的设备。
|
||||
- **None** - 某些设备并没有分区表。例如,许多 Subor 游戏控制台不使用分区映射表。如果一个用户试图从这类设备中恢复文件, 并且认为分区表不是其他的类型,则实际上 TestDisk 并不能找到任何的文件系统或者文件,这将给用户带来困扰。
|
||||
- **Sun** - Sun 分区表适用于 Sun 系统。
|
||||
- **Xbox** -Xbox 适用于使用 Xbox 分区映射表的自家存储设备。
|
||||
|
||||
假如用户选择了 “Xbox” ,尽管他的系统使用了 GPT 分区表, 那么 TestDisk 将不能找到任何分区或文件系统。假如 TestDisk 按照用户的选择执行,则它将不正确地进行猜测。(下面的图片显示的是当分区表类型错误时的输出)
|
||||
|
||||

|
||||
|
||||
一旦用户为他们的设备选择了正确的选项,则在下一屏中,选择 “高级” 选项。
|
||||
|
||||

|
||||
|
||||
现在,用户将看到一个列有 在用户的存储设备中所有的文件系统或分区 的列表。假如用户选择了错误的分区映射表,则在这一步中用户就将会知道他们做出了错误的选择。假如没有错误,通过放置文字类型的光标来高亮含有被删除文件的分区。使用 左右键 来高亮位于终端底部的 “列表”。接着,点击确认。
|
||||
|
||||

|
||||
|
||||
新的一屏便会呈现出列有文件和目录的列表。那些发白的文件就是还没有被删除的文件,而红色的文件就是那些已经被删除了的文件。最右边的一列是文件的名称,从右到左方向的接着一列是文件的创建日期,再往左的一列是文件的大小(以 byte(比特) 为单位),最左边带有虚线, “d” ,“r”, “w” 和"x"的一列则代表的是文件的权限情况。“d” 表示该文件为一个目录,其他的权限术语与本文关系不大。在列表的最顶端以“.”代表的一项表示当前目录,第二行以".."代表的一项表示当前目录的上级目录,通过选择这一行,用户可以到达上级目录。举个例子,我想进入"Xaiml_Dataset" 目录,该目录基本上由被删除的文件组成。通过按键盘上的 "c"键,我将恢复文件 "computers.xaiml",接着我被询问选择一个目标目录,当然,我将放置该文件到另一个分区中。现在,我在我的家目录中,并按下了“c”键。哪个目录被高亮并没有什么影响。当前目录就是目标目录,在屏幕的上方,将会显示“复制完成”的消息。在我的家目录中便会有一个名为"Xaiml_Dataset"的目录,里面里有名为 Xaiml 的文件。 假如我在更多的 已删除文件上按“c” 键,则这些文件将会被放置到新的文件夹中而无需再向我询问目标目录。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
当这些步骤完成后,重复按“q”键直到看到正常的终端模样。目录"Xaiml_Dataset" 只能被 root 用户访问。为了修复这个问题,使用 root 权限改变该目录及其子目录的权限。做完这些后,文件便被恢复了且用户可以访问它们。
|
||||
|
||||
### ReiserFS: ###
|
||||
|
||||
为了从 ReiserFS 文件系统中恢复一个文件,首先需将分区中的所有文件做一个备份。因为如果发生某些错误, 这个方法可能会引起文件丢失。接着执行下面的命令,其中 `DEVICE`指的是那些以 sda2 形式命名的设备。一些文件将被放入 lost+found 目录而其他则会保存到原先被删除的位置。
|
||||
|
||||
reiserfsck --rebuild-tree --scan-whole-partition /dev/DEVICE
|
||||
|
||||
### 恢复被某个程序打开的删除文件: ###
|
||||
|
||||
假设用户意外地删除了一个文件,且该文件被某个程序打开。虽然在硬盘中该文件被删除了,但这个程序正使用着位于 RAM 中的该文件的副本。幸好,我们有两种简单的解决方法来恢复该文件。
|
||||
|
||||
假如这个软件有自动保存功能,如文本编辑器,则用户可以重新保存该文件,这样,文本编辑器可以将该文件写入硬盘中。
|
||||
|
||||
假设在音乐播放器中有一个 MP3 文件,而该音乐播放器并不能保存该 MP3 文件,则这种情形下需要比先前花更多的时间来恢复文件。不幸的是,这种方法并不能保证在所有的系统和应用中有效。首先,键入下面的命令。
|
||||
|
||||
lsof -c smplayer | grep mp3
|
||||
|
||||
上面的命令会列出所有由 smplayer 使用的文件,这个列表由 `grep` 命令通过管道搜索 mp3 。命令的输入类似于下面:
|
||||
|
||||
smplayer 10037 collier mp3 169r 8,1 676376 1704294 /usr/bin/smplayer
|
||||
|
||||
现在,键入下面的命令来直接从 RAM(在 Linux 系统中,`/proc/`代表 RAM) 中恢复文件,并复制该文件到选定的文件夹中。其中 `cp` 指的是复制命令,输出中的数字 10037 来自于进程数,输出中的数字 169 指的是文件描述符,"~/Music/"为目标目录,最后的 "music.mp3" 为用户想恢复的文件的名称。
|
||||
|
||||
cp /proc/10037/fd/169 ~/Music/music.mp3
|
||||
|
||||
### 真正的删除: ###
|
||||
|
||||
为确保一个文件不能被恢复,可以使用一个命令来 “擦除” 硬盘。擦除硬盘意味着向硬盘中写入无意义的数据。例如,许多擦除程序向硬盘中写入零,随机字母或随机数据,没有空间将会被占用或丢失,擦除程序只是对空白空间进行重写覆盖。假如存储单元被文件占满而没有空余空间,则所有先前被删除的文件将会消失。
|
||||
|
||||
擦除硬盘的目的是确保隐私数据不被他人看见。举个例子,一个公司可能预订了一些新的电脑,总经理决定将旧的电脑卖掉,然而,新的电脑拥有者可能会看到公司的一些机密或诸如信用卡号码,地址等顾客信息。幸好,公司的电脑技术人员可以在卖掉这些旧电脑之前,擦除这些硬盘。
|
||||
|
||||
为了安装擦除程序 secure-delete,键入 `sudo apt-get install secure-delete`,这个命令将会安装一个包含 4 个程序的程序集,用以确保被删除的文件不能被恢复。
|
||||
|
||||
- srm - 永久删除一个文件。使用方法: `srm -f ./secret_file.txt`
|
||||
- sfill - 擦除空白空间。使用方法: `sfill -f /mount/point/of/partition`
|
||||
- sswap - 擦除 swap 空间。使用方法: `sswap -f /dev/SWAP_DEVICE`
|
||||
|
||||
假如电脑真的要去删除打算删除的文件,那么需要花费更长的时间去执行删除任务。将某些空间标记为空白空间是快速且容易的,但使得文件永远消失需要花费一定的时间。例如,擦除一个存储单元,可能需要花费几个小时的时间(根据磁盘容量大小)。总之,当前的系统工作良好,因为即便用户清空了垃圾箱,他们仍然有另一次机会来改变他们当初的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.org/threads/undelete-files-on-linux-systems.4316/
|
||||
|
||||
作者:[DevynCJohnson][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.org/members/devyncjohnson.4843/
|
||||
[1]:http://www.cgsecurity.org/wiki/TestDisk
|
||||
@ -0,0 +1,98 @@
|
||||
Linux 有问必答:如何在Linux中修复“fatal error: lame/lame.h: No such file or directory”
|
||||
================================================================================
|
||||
> **提问**: 我尝试着在Linux中编译视频编码器,但是编译提示出错:“fatal error: lame/lame.h: No such file or directory”, 我该如何修复这个错误?
|
||||
|
||||
下面的编译错误说明你的系统没有安装LAME库和它的开发文件。
|
||||
|
||||
fatal error: lame/lame.h: No such file or directory
|
||||
|
||||
[LAME][1]("LAME Ain't an MP3 Encoder")是一个流行的LPGL授权的MP3编码器。许多视频编码工具使用或者支持LAME。这其中有[FFmpeg][2]、 VLC、 [Audacity][3]、 K3b、 RipperX等。
|
||||
|
||||
要修复这个编译错误,你需要安装LAME库和开发文件,按照下面的来。
|
||||
|
||||
### 在Debian、Ubuntu或者Linux Mint上安装LAME库和安装文件 ###
|
||||
|
||||
Debian和它的衍生版在基础库中已经提供了LAME库,因此可以用apt-get直接安装。
|
||||
|
||||
$ sudo apt-get install libmp3lame-dev
|
||||
|
||||
### 在Fedora、CentOS/RHEL上安装LAME库和安装文件 ###
|
||||
|
||||
在基于RED HAT的版本中,LAME在RPM Fusion的免费仓库中就有,那么你需要先设置[RPM Fusion (免费)仓库][4]。
|
||||
|
||||
RPM Fusion设置完成后,如下安装LAME开发文件。
|
||||
|
||||
$ sudo yum --enablerepo=rpmfusion-free-updates install lame-devel
|
||||
|
||||
在2015年1月,RPM Fusion仓库已经不可以在CentOS/RHEL 7中可用了。因此,这个方法不能用在CentOS/RHEL 7 中。这时你就要从源码安装LAME库了(下面会描述)。
|
||||
|
||||
### 在Debian、Ubuntu或者Linux Mint中从源码编译LAME库 ###
|
||||
|
||||
如果你希望用不同的编译选项安装自定义的LAME库,你需要自己编译。下面是怎样在基于Debian的系统中编译和安装LAME库(和它的头文件)。
|
||||
|
||||
$ sudo apt-get install gcc git
|
||||
$ wget http://downloads.sourceforge.net/project/lame/lame/3.99/lame-3.99.5.tar.gz
|
||||
$ tar -xzf lame-3.99.5.tar.gz
|
||||
$ cd lame-3.99.5
|
||||
$ ./configure --enable-static --enable-shared
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
注意当你运行上面的配置步骤时,你可以根据你的需求启用会禁止不同的选项。运行下面的命令查看不同的编译选项。
|
||||
|
||||
$ ./configure --help
|
||||
|
||||
共享/静态LAME默认安装在 /usr/local/lib。要让共享库可以被其他程序使用,完成最后一步:
|
||||
|
||||
用编辑器打开 /etc/ld.so.conf,加入下面这行。
|
||||
|
||||
/usr/local/lib
|
||||
|
||||
接着运行下面的命令,这会将/usr/local/lib中的共享库添加到动态加载缓存中,因此LAME库就可以被其他程序调用了。
|
||||
|
||||
$ sudo ldconfig
|
||||
|
||||
### 在Fedora或者CentOS/RHEL中从源码编译LAME库 ###
|
||||
|
||||
如果你的发行版(比如 CentOS 7)没有提供预编译的LAME库,或者你想要自定义LAME库,你需要从源码自己编译。下面是在基于Red Hat的系统中编译安装LAME库的方法。
|
||||
|
||||
|
||||
$ sudo yum install gcc git
|
||||
$ wget http://downloads.sourceforge.net/project/lame/lame/3.99/lame-3.99.5.tar.gz
|
||||
$ tar -xzf lame-3.99.5.tar.gz
|
||||
$ cd lame-3.99.5
|
||||
$ ./configure --enable-static --enable-shared
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
运行make之前,你可以在configure中带上合适的选项自定义编译选项。你可以用下面的命令检查可用的选项:
|
||||
|
||||
$ ./configure --help
|
||||
|
||||
最后你需要完成最后一步,因为安装在/usr/local/lib的LAME共享库可能在其他程序中不可用。
|
||||
|
||||
在/etc/ld.so.conf中添加下面这行:
|
||||
|
||||
/usr/local/lib
|
||||
|
||||
接着运行下面的命令。这会添加 /usr/local/lib中的共享库(包括LAME)到动态加载缓存中,让其他程序可以访问到。
|
||||
|
||||
$ sudo ldconfig
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/fatal-error-lame-no-such-file-or-directory.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://lame.sourceforge.net/
|
||||
[2]:http://ask.xmodulo.com/compile-ffmpeg-ubuntu-debian.html
|
||||
[3]:http://xmodulo.com/how-to-cut-split-or-edit-mp3-file-on-linux.html
|
||||
[4]:http://xmodulo.com/how-to-install-rpm-fusion-on-fedora.html
|
||||
Loading…
Reference in New Issue
Block a user