mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject into new
This commit is contained in:
commit
db7d476bfc
@ -4,7 +4,7 @@
|
||||

|
||||

|
||||
|
||||
[](https://travis-ci.org/LCTT/TranslateProject)
|
||||
[](https://travis-ci.com/LCTT/TranslateProject)
|
||||
[](https://github.com/LCTT/TranslateProject/graphs/contributors)
|
||||
[](https://github.com/LCTT/TranslateProject/pulls?q=is%3Apr+is%3Aclosed)
|
||||
|
||||
|
||||
@ -0,0 +1,447 @@
|
||||
17 种查看 Linux 物理内存的方法
|
||||
=======
|
||||
|
||||
大多数系统管理员在遇到性能问题时会检查 CPU 和内存利用率。Linux 中有许多实用程序可以用于检查物理内存。这些命令有助于我们检查系统中存在的物理内存,还允许用户检查各种方面的内存利用率。
|
||||
|
||||
我们大多数人只知道很少的命令,在本文中我们试图包含所有可能的命令。
|
||||
|
||||
你可能会想,为什么我想知道所有这些命令,而不是知道一些特定的和例行的命令呢。
|
||||
|
||||
不要觉得没用或对此有负面的看法,因为每个人都有不同的需求和看法,所以,对于那些在寻找其它目的的人,这对于他们非常有帮助。
|
||||
|
||||
### 什么是 RAM
|
||||
|
||||
计算机内存是能够临时或永久存储信息的物理设备。RAM 代表随机存取存储器,它是一种易失性存储器,用于存储操作系统,软件和硬件使用的信息。
|
||||
|
||||
有两种类型的内存可供选择:
|
||||
|
||||
* 主存
|
||||
* 辅助内存
|
||||
|
||||
主存是计算机的主存储器。CPU 可以直接读取或写入此内存。它固定在电脑的主板上。
|
||||
|
||||
* **RAM**:随机存取存储器是临时存储。关闭计算机后,此信息将消失。
|
||||
* **ROM**: 只读存储器是永久存储,即使系统关闭也能保存数据。
|
||||
|
||||
### 方法-1:使用 free 命令
|
||||
|
||||
`free` 显示系统中空闲和已用的物理内存和交换内存的总量,以及内核使用的缓冲区和缓存。它通过解析 `/proc/meminfo` 来收集信息。
|
||||
|
||||
**建议阅读:** [free – 在 Linux 系统中检查内存使用情况统计(空闲和已用)的标准命令][1]
|
||||
|
||||
```
|
||||
$ free -m
|
||||
total used free shared buff/cache available
|
||||
Mem: 1993 1681 82 81 228 153
|
||||
Swap: 12689 1213 11475
|
||||
|
||||
$ free -g
|
||||
total used free shared buff/cache available
|
||||
Mem: 1 1 0 0 0 0
|
||||
Swap: 12 1 11
|
||||
```
|
||||
|
||||
### 方法-2:使用 /proc/meminfo 文件
|
||||
|
||||
`/proc/meminfo` 是一个虚拟文本文件,它包含有关系统 RAM 使用情况的大量有价值的信息。
|
||||
|
||||
它报告系统上的空闲和已用内存(物理和交换)的数量。
|
||||
|
||||
```
|
||||
$ grep MemTotal /proc/meminfo
|
||||
MemTotal: 2041396 kB
|
||||
|
||||
$ grep MemTotal /proc/meminfo | awk '{print $2 / 1024}'
|
||||
1993.55
|
||||
|
||||
$ grep MemTotal /proc/meminfo | awk '{print $2 / 1024 / 1024}'
|
||||
1.94683
|
||||
```
|
||||
|
||||
### 方法-3:使用 top 命令
|
||||
|
||||
`top` 命令是 Linux 中监视实时系统进程的基本命令之一。它显示系统信息和运行的进程信息,如正常运行时间、平均负载、正在运行的任务、登录的用户数、CPU 数量和 CPU 利用率,以及内存和交换信息。运行 `top` 命令,然后按下 `E` 来使内存利用率以 MB 为单位显示。
|
||||
|
||||
**建议阅读:** [TOP 命令示例监视服务器性能][2]
|
||||
|
||||
```
|
||||
$ top
|
||||
|
||||
top - 14:38:36 up 1:59, 1 user, load average: 1.83, 1.60, 1.52
|
||||
Tasks: 223 total, 2 running, 221 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu(s): 48.6 us, 11.2 sy, 0.0 ni, 39.3 id, 0.3 wa, 0.0 hi, 0.5 si, 0.0 st
|
||||
MiB Mem : 1993.551 total, 94.184 free, 1647.367 used, 252.000 buff/cache
|
||||
MiB Swap: 12689.58+total, 11196.83+free, 1492.750 used. 306.465 avail Mem
|
||||
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
9908 daygeek 20 0 2971440 649324 39700 S 55.8 31.8 11:45.74 Web Content
|
||||
21942 daygeek 20 0 2013760 308700 69272 S 35.0 15.1 4:13.75 Web Content
|
||||
4782 daygeek 20 0 3687116 227336 39156 R 14.5 11.1 16:47.45 gnome-shell
|
||||
```
|
||||
|
||||
### 方法-4:使用 vmstat 命令
|
||||
|
||||
`vmstat` 是一个漂亮的标准工具,它报告 Linux 系统的虚拟内存统计信息。`vmstat` 报告有关进程、内存、分页、块 IO、陷阱和 CPU 活动的信息。它有助于 Linux 管理员在故障检修时识别系统瓶颈。
|
||||
|
||||
**建议阅读:** [vmstat – 一个报告虚拟内存统计信息的标准且漂亮的工具][3]
|
||||
|
||||
```
|
||||
$ vmstat -s | grep "total memory"
|
||||
2041396 K total memory
|
||||
|
||||
$ vmstat -s -S M | egrep -ie 'total memory'
|
||||
1993 M total memory
|
||||
|
||||
$ vmstat -s | awk '{print $1 / 1024 / 1024}' | head -1
|
||||
1.94683
|
||||
|
||||
```
|
||||
|
||||
### 方法-5:使用 nmon 命令
|
||||
|
||||
`nmon` 是另一个很棒的工具,用于在 Linux 终端上监视各种系统资源,如 CPU、内存、网络、磁盘、文件系统、NFS、top 进程、Power 的微分区和资源(Linux 版本和处理器)。
|
||||
|
||||
只需按下 `m` 键,即可查看内存利用率统计数据(缓存、活动、非活动、缓冲、空闲,以 MB 和百分比为单位)。
|
||||
|
||||
**建议阅读:** [nmon – Linux 中一个监视系统资源的漂亮的工具][4]
|
||||
|
||||
```
|
||||
┌nmon─14g──────[H for help]───Hostname=2daygeek──Refresh= 2secs ───07:24.44─────────────────┐
|
||||
│ Memory Stats ─────────────────────────────────────────────────────────────────────────────│
|
||||
│ RAM High Low Swap Page Size=4 KB │
|
||||
│ Total MB 32079.5 -0.0 -0.0 20479.0 │
|
||||
│ Free MB 11205.0 -0.0 -0.0 20479.0 │
|
||||
│ Free Percent 34.9% 100.0% 100.0% 100.0% │
|
||||
│ MB MB MB │
|
||||
│ Cached= 19763.4 Active= 9617.7 │
|
||||
│ Buffers= 172.5 Swapcached= 0.0 Inactive = 10339.6 │
|
||||
│ Dirty = 0.0 Writeback = 0.0 Mapped = 11.0 │
|
||||
│ Slab = 636.6 Commit_AS = 118.2 PageTables= 3.5 │
|
||||
│───────────────────────────────────────────────────────────────────────────────────────────│
|
||||
│ │
|
||||
│ │
|
||||
│ │
|
||||
│ │
|
||||
│ │
|
||||
│ │
|
||||
└───────────────────────────────────────────────────────────────────────────────────────────┘
|
||||
```
|
||||
|
||||
### 方法-6:使用 dmidecode 命令
|
||||
|
||||
`dmidecode` 是一个读取计算机 DMI 表内容的工具,它以人类可读的格式显示系统硬件信息。(DMI 意即桌面管理接口,也有人说是读取的是 SMBIOS —— 系统管理 BIOS)
|
||||
|
||||
此表包含系统硬件组件的描述,以及其它有用信息,如序列号、制造商信息、发布日期和 BIOS 修改等。
|
||||
|
||||
**建议阅读:** [Dmidecode – 获取 Linux 系统硬件信息的简便方法][5]
|
||||
|
||||
```
|
||||
# dmidecode -t memory | grep Size:
|
||||
Size: 8192 MB
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: 8192 MB
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: 8192 MB
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: 8192 MB
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
```
|
||||
|
||||
只打印已安装的 RAM 模块。
|
||||
|
||||
```
|
||||
# dmidecode -t memory | grep Size: | grep -v "No Module Installed"
|
||||
Size: 8192 MB
|
||||
Size: 8192 MB
|
||||
Size: 8192 MB
|
||||
Size: 8192 MB
|
||||
```
|
||||
|
||||
汇总所有已安装的 RAM 模块。
|
||||
|
||||
```
|
||||
# dmidecode -t memory | grep Size: | grep -v "No Module Installed" | awk '{sum+=$2}END{print sum}'
|
||||
32768
|
||||
```
|
||||
|
||||
### 方法-7:使用 hwinfo 命令
|
||||
|
||||
`hwinfo` 意即硬件信息,它是另一个很棒的实用工具,用于探测系统中存在的硬件,并以人类可读的格式显示有关各种硬件组件的详细信息。
|
||||
|
||||
它报告有关 CPU、RAM、键盘、鼠标、图形卡、声音、存储、网络接口、磁盘、分区、BIOS 和网桥等的信息。
|
||||
|
||||
**建议阅读:** [hwinfo(硬件信息)– 一个在 Linux 系统上检测系统硬件信息的好工具][6]
|
||||
|
||||
```
|
||||
$ hwinfo --memory
|
||||
01: None 00.0: 10102 Main Memory
|
||||
[Created at memory.74]
|
||||
Unique ID: rdCR.CxwsZFjVASF
|
||||
Hardware Class: memory
|
||||
Model: "Main Memory"
|
||||
Memory Range: 0x00000000-0x7a4abfff (rw)
|
||||
Memory Size: 1 GB + 896 MB
|
||||
Config Status: cfg=new, avail=yes, need=no, active=unknown
|
||||
```
|
||||
|
||||
### 方法-8:使用 lshw 命令
|
||||
|
||||
`lshw`(代表 Hardware Lister)是一个小巧的工具,可以生成机器上各种硬件组件的详细报告,如内存配置、固件版本、主板配置、CPU 版本和速度、缓存配置、USB、网卡、显卡、多媒体、打印机、总线速度等。
|
||||
|
||||
它通过读取 `/proc` 目录和 DMI 表中的各种文件来生成硬件信息。
|
||||
|
||||
**建议阅读:** [LSHW (Hardware Lister) – 一个在 Linux 上获取硬件信息的好工具][7]
|
||||
|
||||
```
|
||||
$ sudo lshw -short -class memory
|
||||
[sudo] password for daygeek:
|
||||
H/W path Device Class Description
|
||||
==================================================
|
||||
/0/0 memory 128KiB BIOS
|
||||
/0/1 memory 1993MiB System memory
|
||||
```
|
||||
|
||||
### 方法-9:使用 inxi 命令
|
||||
|
||||
`inxi` 是一个很棒的工具,它可以检查 Linux 上的硬件信息,并提供了大量的选项来获取 Linux 系统上的所有硬件信息,这些特性是我在 Linux 上的其它工具中从未发现的。它是从 locsmif 编写的古老的但至今看来都异常灵活的 infobash 演化而来的。
|
||||
|
||||
`inxi` 是一个脚本,它可以快速显示系统硬件、CPU、驱动程序、Xorg、桌面、内核、GCC 版本、进程、RAM 使用情况以及各种其它有用的信息,还可以用于论坛技术支持和调试工具。
|
||||
|
||||
**建议阅读:** [inxi – 一个检查 Linux 上硬件信息的好工具][8]
|
||||
|
||||
```
|
||||
$ inxi -F | grep "Memory"
|
||||
Info: Processes: 234 Uptime: 3:10 Memory: 1497.3/1993.6MB Client: Shell (bash) inxi: 2.3.37
|
||||
```
|
||||
|
||||
### 方法-10:使用 screenfetch 命令
|
||||
|
||||
`screenfetch` 是一个 bash 脚本。它将自动检测你的发行版,并在右侧显示该发行版标识的 ASCII 艺术版本和一些有价值的信息。
|
||||
|
||||
**建议阅读:** [ScreenFetch – 以 ASCII 艺术标志在终端显示 Linux 系统信息][9]
|
||||
|
||||
```
|
||||
$ screenfetch
|
||||
./+o+- daygeek@ubuntu
|
||||
yyyyy- -yyyyyy+ OS: Ubuntu 17.10 artful
|
||||
://+//////-yyyyyyo Kernel: x86_64 Linux 4.13.0-37-generic
|
||||
.++ .:/++++++/-.+sss/` Uptime: 44m
|
||||
.:++o: /++++++++/:--:/- Packages: 1831
|
||||
o:+o+:++.`..`` `.-/oo+++++/ Shell: bash 4.4.12
|
||||
.:+o:+o/. `+sssoo+/ Resolution: 1920x955
|
||||
.++/+:+oo+o:` /sssooo. DE: GNOME
|
||||
/+++//+:`oo+o /::--:. WM: GNOME Shell
|
||||
\+/+o+++`o++o ++////. WM Theme: Adwaita
|
||||
.++.o+++oo+:` /dddhhh. GTK Theme: Azure [GTK2/3]
|
||||
.+.o+oo:. `oddhhhh+ Icon Theme: Papirus-Dark
|
||||
\+.++o+o``-````.:ohdhhhhh+ Font: Ubuntu 11
|
||||
`:o+++ `ohhhhhhhhyo++os: CPU: Intel Core i7-6700HQ @ 2x 2.592GHz
|
||||
.o:`.syhhhhhhh/.oo++o` GPU: llvmpipe (LLVM 5.0, 256 bits)
|
||||
/osyyyyyyo++ooo+++/ RAM: 1521MiB / 1993MiB
|
||||
````` +oo+++o\:
|
||||
`oo++.
|
||||
```
|
||||
|
||||
### 方法-11:使用 neofetch 命令
|
||||
|
||||
`neofetch` 是一个跨平台且易于使用的命令行(CLI)脚本,它收集你的 Linux 系统信息,并将其作为一张图片显示在终端上,也可以是你的发行版徽标,或者是你选择的任何 ascii 艺术。
|
||||
|
||||
**建议阅读:** [Neofetch – 以 ASCII 分发标志来显示 Linux 系统信息][10]
|
||||
|
||||
```
|
||||
$ neofetch
|
||||
.-/+oossssoo+/-. daygeek@ubuntu
|
||||
`:+ssssssssssssssssss+:` --------------
|
||||
-+ssssssssssssssssssyyssss+- OS: Ubuntu 17.10 x86_64
|
||||
.ossssssssssssssssssdMMMNysssso. Host: VirtualBox 1.2
|
||||
/ssssssssssshdmmNNmmyNMMMMhssssss/ Kernel: 4.13.0-37-generic
|
||||
+ssssssssshmydMMMMMMMNddddyssssssss+ Uptime: 47 mins
|
||||
/sssssssshNMMMyhhyyyyhmNMMMNhssssssss/ Packages: 1832
|
||||
.ssssssssdMMMNhsssssssssshNMMMdssssssss. Shell: bash 4.4.12
|
||||
+sssshhhyNMMNyssssssssssssyNMMMysssssss+ Resolution: 1920x955
|
||||
ossyNMMMNyMMhsssssssssssssshmmmhssssssso DE: ubuntu:GNOME
|
||||
ossyNMMMNyMMhsssssssssssssshmmmhssssssso WM: GNOME Shell
|
||||
+sssshhhyNMMNyssssssssssssyNMMMysssssss+ WM Theme: Adwaita
|
||||
.ssssssssdMMMNhsssssssssshNMMMdssssssss. Theme: Azure [GTK3]
|
||||
/sssssssshNMMMyhhyyyyhdNMMMNhssssssss/ Icons: Papirus-Dark [GTK3]
|
||||
+sssssssssdmydMMMMMMMMddddyssssssss+ Terminal: gnome-terminal
|
||||
/ssssssssssshdmNNNNmyNMMMMhssssss/ CPU: Intel i7-6700HQ (2) @ 2.591GHz
|
||||
.ossssssssssssssssssdMMMNysssso. GPU: VirtualBox Graphics Adapter
|
||||
-+sssssssssssssssssyyyssss+- Memory: 1620MiB / 1993MiB
|
||||
`:+ssssssssssssssssss+:`
|
||||
.-/+oossssoo+/-.
|
||||
```
|
||||
|
||||
### 方法-12:使用 dmesg 命令
|
||||
|
||||
`dmesg`(代表显示消息或驱动消息)是大多数类 Unix 操作系统上的命令,用于打印内核的消息缓冲区。
|
||||
|
||||
```
|
||||
$ dmesg | grep "Memory"
|
||||
[ 0.000000] Memory: 1985916K/2096696K available (12300K kernel code, 2482K rwdata, 4000K rodata, 2372K init, 2368K bss, 110780K reserved, 0K cma-reserved)
|
||||
[ 0.012044] x86/mm: Memory block size: 128MB
|
||||
```
|
||||
|
||||
### 方法-13:使用 atop 命令
|
||||
|
||||
`atop` 是一个用于 Linux 的 ASCII 全屏系统性能监视工具,它能报告所有服务器进程的活动(即使进程在间隔期间已经完成)。
|
||||
|
||||
它记录系统和进程活动以进行长期分析(默认情况下,日志文件保存 28 天),通过使用颜色等来突出显示过载的系统资源。它结合可选的内核模块 netatop 显示每个进程或线程的网络活动。
|
||||
|
||||
**建议阅读:** [Atop – 实时监控系统性能,资源,进程和检查资源利用历史][11]
|
||||
|
||||
```
|
||||
$ atop -m
|
||||
|
||||
ATOP - ubuntu 2018/03/31 19:34:08 ------------- 10s elapsed
|
||||
PRC | sys 0.47s | user 2.75s | | | #proc 219 | #trun 1 | #tslpi 802 | #tslpu 0 | #zombie 0 | clones 7 | | | #exit 4 |
|
||||
CPU | sys 7% | user 22% | irq 0% | | | idle 170% | wait 0% | | steal 0% | guest 0% | | curf 2.59GHz | curscal ?% |
|
||||
cpu | sys 3% | user 11% | irq 0% | | | idle 85% | cpu001 w 0% | | steal 0% | guest 0% | | curf 2.59GHz | curscal ?% |
|
||||
cpu | sys 4% | user 11% | irq 0% | | | idle 85% | cpu000 w 0% | | steal 0% | guest 0% | | curf 2.59GHz | curscal ?% |
|
||||
CPL | avg1 1.98 | | avg5 3.56 | avg15 3.20 | | | csw 14894 | | intr 6610 | | | numcpu 2 | |
|
||||
MEM | tot 1.9G | free 101.7M | cache 244.2M | dirty 0.2M | buff 6.9M | slab 92.9M | slrec 35.6M | shmem 97.8M | shrss 21.0M | shswp 3.2M | vmbal 0.0M | hptot 0.0M | hpuse 0.0M |
|
||||
SWP | tot 12.4G | free 11.6G | | | | | | | | | vmcom 7.9G | | vmlim 13.4G |
|
||||
PAG | scan 0 | steal 0 | | stall 0 | | | | | | | swin 3 | | swout 0 |
|
||||
DSK | sda | busy 0% | | read 114 | write 37 | KiB/r 21 | KiB/w 6 | | MBr/s 0.2 | MBw/s 0.0 | avq 6.50 | | avio 0.26 ms |
|
||||
NET | transport | tcpi 11 | tcpo 17 | udpi 4 | udpo 8 | tcpao 3 | tcppo 0 | | tcprs 3 | tcpie 0 | tcpor 0 | udpnp 0 | udpie 0 |
|
||||
NET | network | ipi 20 | | ipo 33 | ipfrw 0 | deliv 20 | | | | | icmpi 5 | | icmpo 0 |
|
||||
NET | enp0s3 0% | pcki 11 | pcko 28 | sp 1000 Mbps | si 1 Kbps | so 1 Kbps | | coll 0 | mlti 0 | erri 0 | erro 0 | drpi 0 | drpo 0 |
|
||||
NET | lo ---- | pcki 9 | pcko 9 | sp 0 Mbps | si 0 Kbps | so 0 Kbps | | coll 0 | mlti 0 | erri 0 | erro 0 | drpi 0 | drpo 0 |
|
||||
|
||||
PID TID MINFLT MAJFLT VSTEXT VSLIBS VDATA VSTACK VSIZE RSIZE PSIZE VGROW RGROW SWAPSZ RUID EUID MEM CMD 1/1
|
||||
2536 - 941 0 188K 127.3M 551.2M 144K 2.3G 281.2M 0K 0K 344K 6556K daygeek daygeek 14% Web Content
|
||||
2464 - 75 0 188K 187.7M 680.6M 132K 2.3G 226.6M 0K 0K 212K 42088K daygeek daygeek 11% firefox
|
||||
2039 - 4199 6 16K 163.6M 423.0M 132K 3.5G 220.2M 0K 0K 2936K 109.6M daygeek daygeek 11% gnome-shell
|
||||
10822 - 1 0 4K 16680K 377.0M 132K 3.4G 193.4M 0K 0K 0K 0K root root 10% java
|
||||
```
|
||||
|
||||
### 方法-14:使用 htop 命令
|
||||
|
||||
`htop` 是由 Hisham 用 ncurses 库开发的用于 Linux 的交互式进程查看器。与 `top` 命令相比,`htop` 有许多特性和选项。
|
||||
|
||||
**建议阅读:** [使用 Htop 命令监视系统资源][12]
|
||||
|
||||
```
|
||||
$ htop
|
||||
|
||||
1 [||||||||||||| 13.0%] Tasks: 152, 587 thr; 1 running
|
||||
2 [||||||||||||||||||||||||| 25.0%] Load average: 0.91 2.03 2.66
|
||||
Mem[||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||1.66G/1.95G] Uptime: 01:14:53
|
||||
Swp[|||||| 782M/12.4G]
|
||||
|
||||
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
|
||||
2039 daygeek 20 0 3541M 214M 46728 S 36.6 10.8 22:36.77 /usr/bin/gnome-shell
|
||||
2045 daygeek 20 0 3541M 214M 46728 S 10.3 10.8 3:02.92 /usr/bin/gnome-shell
|
||||
2046 daygeek 20 0 3541M 214M 46728 S 8.3 10.8 3:04.96 /usr/bin/gnome-shell
|
||||
6080 daygeek 20 0 807M 37228 24352 S 2.1 1.8 0:11.99 /usr/lib/gnome-terminal/gnome-terminal-server
|
||||
2880 daygeek 20 0 2205M 164M 17048 S 2.1 8.3 7:16.50 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51:0|57:128|58:10000|63:0|65:400|66
|
||||
6125 daygeek 20 0 1916M 159M 92352 S 2.1 8.0 2:09.14 /usr/lib/firefox/firefox -contentproc -childID 7 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51:0|57:128|58:10000|63:0|65:400|66
|
||||
2536 daygeek 20 0 2335M 243M 26792 S 2.1 12.2 6:25.77 /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51:0|57:128|58:10000|63:0|65:400|66
|
||||
2653 daygeek 20 0 2237M 185M 20788 S 1.4 9.3 3:01.76 /usr/lib/firefox/firefox -contentproc -childID 4 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51:0|57:128|58:10000|63:0|65:400|66
|
||||
```
|
||||
|
||||
### 方法-15:使用 corefreq 实用程序
|
||||
|
||||
CoreFreq 是为 Intel 64 位处理器设计的 CPU 监控软件,支持的架构有 Atom、Core2、Nehalem、SandyBridge 和 superior,AMD 家族 0F。
|
||||
|
||||
CoreFreq 提供了一个框架来以高精确度检索 CPU 数据。
|
||||
|
||||
**建议阅读:** [CoreFreq – 一个用于 Linux 系统的强大的 CPU 监控工具][13]
|
||||
|
||||
```
|
||||
$ ./corefreq-cli -k
|
||||
Linux:
|
||||
|- Release [4.13.0-37-generic]
|
||||
|- Version [#42-Ubuntu SMP Wed Mar 7 14:13:23 UTC 2018]
|
||||
|- Machine [x86_64]
|
||||
Memory:
|
||||
|- Total RAM 2041396 KB
|
||||
|- Shared RAM 99620 KB
|
||||
|- Free RAM 108428 KB
|
||||
|- Buffer RAM 8108 KB
|
||||
|- Total High 0 KB
|
||||
|- Free High 0 KB
|
||||
```
|
||||
|
||||
### 方法-16:使用 glances 命令
|
||||
|
||||
Glances 是用 Python 编写的跨平台基于 curses(LCTT 译注:curses 是一个 Linux/Unix 下的图形函数库)的系统监控工具。我们可以说它一应俱全,就像在最小的空间含有最大的信息。它使用 psutil 库从系统中获取信息。
|
||||
|
||||
Glances 可以监视 CPU、内存、负载、进程列表、网络接口、磁盘 I/O、Raid、传感器、文件系统(和文件夹)、Docker、监视器、警报、系统信息、正常运行时间、快速预览(CPU、内存、负载)等。
|
||||
|
||||
**建议阅读:** [Glances (一应俱全)– 一个 Linux 的高级的实时系
|
||||
统性能监控工具][14]
|
||||
|
||||
```
|
||||
$ glances
|
||||
|
||||
ubuntu (Ubuntu 17.10 64bit / Linux 4.13.0-37-generic) - IP 192.168.1.6/24 Uptime: 1:08:40
|
||||
|
||||
CPU [|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 90.6%] CPU - 90.6% nice: 0.0% ctx_sw: 4K MEM \ 78.4% active: 942M SWAP - 5.9% LOAD 2-core
|
||||
MEM [||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 78.0%] user: 55.1% irq: 0.0% inter: 1797 total: 1.95G inactive: 562M total: 12.4G 1 min: 4.35
|
||||
SWAP [|||| 5.9%] system: 32.4% iowait: 1.8% sw_int: 897 used: 1.53G buffers: 14.8M used: 749M 5 min: 4.38
|
||||
idle: 7.6% steal: 0.0% free: 431M cached: 273M free: 11.7G 15 min: 3.38
|
||||
|
||||
NETWORK Rx/s Tx/s TASKS 211 (735 thr), 4 run, 207 slp, 0 oth sorted automatically by memory_percent, flat view
|
||||
docker0 0b 232b
|
||||
enp0s3 12Kb 4Kb Systemd 7 Services loaded: 197 active: 196 failed: 1
|
||||
lo 616b 616b
|
||||
_h478e48e 0b 232b CPU% MEM% VIRT RES PID USER NI S TIME+ R/s W/s Command
|
||||
63.8 18.9 2.33G 377M 2536 daygeek 0 R 5:57.78 0 0 /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
DefaultGateway 83ms 78.5 10.9 3.46G 217M 2039 daygeek 0 S 21:07.46 0 0 /usr/bin/gnome-shell
|
||||
8.5 10.1 2.32G 201M 2464 daygeek 0 S 8:45.69 0 0 /usr/lib/firefox/firefox -new-window
|
||||
DISK I/O R/s W/s 1.1 8.5 2.19G 170M 2653 daygeek 0 S 2:56.29 0 0 /usr/lib/firefox/firefox -contentproc -childID 4 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
dm-0 0 0 1.7 7.2 2.15G 143M 2880 daygeek 0 S 7:10.46 0 0 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
sda1 9.46M 12K 0.0 4.9 1.78G 97.2M 6125 daygeek 0 S 1:36.57 0 0 /usr/lib/firefox/firefox -contentproc -childID 7 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
```
|
||||
|
||||
### 方法-17 : 使用 Gnome 系统监视器
|
||||
|
||||
Gnome 系统监视器是一个管理正在运行的进程和监视系统资源的工具。它向你显示正在运行的程序以及耗费的处理器时间,内存和磁盘空间。
|
||||
|
||||
![][16]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/easy-ways-to-check-size-of-physical-memory-ram-in-linux/
|
||||
|
||||
作者:[Ramya Nuvvula][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/ramya/
|
||||
[1]:https://www.2daygeek.com/free-command-to-check-memory-usage-statistics-in-linux/
|
||||
[2]:https://www.2daygeek.com/top-command-examples-to-monitor-server-performance/
|
||||
[3]:https://www.2daygeek.com/linux-vmstat-command-examples-tool-report-virtual-memory-statistics/
|
||||
[4]:https://www.2daygeek.com/nmon-system-performance-monitor-system-resources-on-linux/
|
||||
[5]:https://www.2daygeek.com/dmidecode-get-print-display-check-linux-system-hardware-information/
|
||||
[6]:https://www.2daygeek.com/hwinfo-check-display-detect-system-hardware-information-linux/
|
||||
[7]:https://www.2daygeek.com/lshw-find-check-system-hardware-information-details-linux/
|
||||
[8]:https://www.2daygeek.com/inxi-system-hardware-information-on-linux/
|
||||
[9]:https://www.2daygeek.com/screenfetch-display-linux-systems-information-ascii-distribution-logo-terminal/
|
||||
[10]:https://www.2daygeek.com/neofetch-display-linux-systems-information-ascii-distribution-logo-terminal/
|
||||
[11]:https://www.2daygeek.com/atop-system-process-performance-monitoring-tool/
|
||||
[12]:https://www.2daygeek.com/htop-command-examples-to-monitor-system-resources/
|
||||
[13]:https://www.2daygeek.com/corefreq-linux-cpu-monitoring-tool/
|
||||
[14]:https://www.2daygeek.com/install-glances-advanced-real-time-linux-system-performance-monitoring-tool-on-centos-fedora-ubuntu-debian-opensuse-arch-linux/
|
||||
[15]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[16]:https://www.2daygeek.com/wp-content/uploads/2018/03/check-memory-information-using-gnome-system-monitor.png
|
||||
@ -1,86 +1,76 @@
|
||||
6.828 中使用的工具
|
||||
Caffeinated 6.828:使用的工具
|
||||
======
|
||||
### 6.828 中使用的工具
|
||||
|
||||
在这个课程中你将使用两套工具:一个是 x86 模拟器 QEMU,它用来运行你的内核;另一个是编译器工具链,包括汇编器、链接器、C 编译器、以及调试器,它们用来编译和测试你的内核。本文有你需要去下载和安装你自己的副本相关信息。本课程假定你熟悉所有出现的 Unix 命令的用法。
|
||||
在这个课程中你将使用两套工具:一个是 x86 模拟器 QEMU,它用来运行你的内核;另一个是编译器工具链,包括汇编器、链接器、C 编译器,以及调试器,它们用来编译和测试你的内核。本文有你需要去下载和安装你自己的副本相关信息。本课程假定你熟悉所有出现的 Unix 命令的用法。
|
||||
|
||||
我们强烈推荐你使用一个 Debathena 机器,比如 athena.dialup.mit.edu,去做你的实验。如果你使用 MIT 的运行在 Linux 上的 Athena 机器,那么本课程所需要的所有软件工具都在 6.828 的存储中:只需要输入 'add -f 6.828' 就可以访问它们。
|
||||
我们强烈推荐你使用一个 Debathena 机器去做你的实验,比如 athena.dialup.mit.edu。如果你使用运行在 Linux 上的 MIT Athena 机器,那么本课程所需要的所有软件工具都在 6.828 的存储中:只需要输入 `add -f 6.828` 就可以访问它们。
|
||||
|
||||
如果你不使用一个 Debathena 机器,我们建议你使用一台 Linux 虚拟机。如果是这样,你可以在你的 Linux 虚拟机上构建和安装工具。我们将在下面介绍如何在 Linux 和 MacOS 计算上来构建和安装工具。
|
||||
如果你不使用 Debathena 机器,我们建议你使用一台 Linux 虚拟机。如果是这样,你可以在你的 Linux 虚拟机上构建和安装工具。我们将在下面介绍如何在 Linux 和 MacOS 计算上来构建和安装工具。
|
||||
|
||||
在 [Cygwin][1] 的帮助下,在窗口中运行这个开发环境也是可行的。安装 cygwin,并确保安装了 flex 和 bison 包(它们在开发头下面)。
|
||||
在 [Cygwin][1] 的帮助下,在 Windows 中运行这个开发环境也是可行的。安装 cygwin,并确保安装了 flex 和 bison 包(它们在开发 header 软件包分类下面)。
|
||||
|
||||
对于 6.828 中使用的工具中的有用的命令,请参考[实验工具指南][2]。
|
||||
|
||||
#### 编译器工具链
|
||||
### 编译器工具链
|
||||
|
||||
一个 “编译器工具链“ 是一套程序,包括一个 C 编译器、汇编器、和链接器,使用它们来将代码转换成可运行的二进制文件。你需要一个能够生成在 32 位 Intel 架构(x86 架构)上运行的 ELF 二进制格式程序的编译器工具链。
|
||||
“编译器工具链“ 是一套程序,包括一个 C 编译器、汇编器和链接器,使用它们来将代码转换成可运行的二进制文件。你需要一个能够生成在 32 位 Intel 架构(x86 架构)上运行的 ELF 二进制格式程序的编译器工具链。
|
||||
|
||||
##### 测试你的编译器工具链
|
||||
#### 测试你的编译器工具链
|
||||
|
||||
现代的 Linux 和 BSD UNIX 发行版已经为 6.828 提供了一个合适的工具链。去测试你的发行版,可以输入如下的命令:
|
||||
|
||||
```
|
||||
% objdump -i
|
||||
|
||||
```
|
||||
|
||||
第二行应该是 `elf32-i386`。
|
||||
|
||||
```
|
||||
% gcc -m32 -print-libgcc-file-name
|
||||
|
||||
```
|
||||
|
||||
这个命令应该会输出如 `/usr/lib/gcc/i486-linux-gnu/version/libgcc.a` 或 `/usr/lib/gcc/x86_64-linux-gnu/version/32/libgcc.a` 这样的东西。
|
||||
|
||||
如果这些命令都运行成功,说明你的工具链都已安装,你不需要去编译你自己的工具链。
|
||||
|
||||
如果 gcc 命令失败,你可能需要去安装一个开发环境。在 Ubuntu Linux 上,输入如下的命令:
|
||||
如果 `gcc` 命令失败,你可能需要去安装一个开发环境。在 Ubuntu Linux 上,输入如下的命令:
|
||||
|
||||
```
|
||||
% sudo apt-get install -y build-essential gdb
|
||||
|
||||
```
|
||||
|
||||
在 64 位的机器上,你可能需要去安装一个 32 位的支持库。链接失败的表现是有一个类似于 "`__udivdi3` not found" 和 "`__muldi3` not found” 的错误信息。在 Ubuntu Linux 上,输入如下的命令去尝试修复这个问题:
|
||||
在 64 位的机器上,你可能需要去安装一个 32 位的支持库。链接失败的表现是有一个类似于 “`__udivdi3` not found” 和 “`__muldi3` not found” 的错误信息。在 Ubuntu Linux 上,输入如下的命令去尝试修复这个问题:
|
||||
|
||||
```
|
||||
% sudo apt-get install gcc-multilib
|
||||
|
||||
```
|
||||
|
||||
##### 使用一个虚拟机
|
||||
#### 使用一个虚拟机
|
||||
|
||||
获得一个兼容的工具链的最容易的另外的方法是,在你的计算机上安装一个现代的 Linux 发行版。使用虚拟化平台,Linux 可以与你正常的计算环境和平共处。安装一个 Linux 虚拟机共有两步。首先,去下载一个虚拟化平台。
|
||||
|
||||
* [**VirtualBox**][3](对 Mac、Linux、Windows 免费)— [下载地址][3]
|
||||
* [VirtualBox][3](对 Mac、Linux、Windows 免费)— [下载地址][3]
|
||||
* [VMware Player][4](对 Linux 和 Windows 免费,但要求注册)
|
||||
* [VMware Fusion][5](可以从 IS&T 免费下载)。
|
||||
|
||||
|
||||
|
||||
VirtualBox 有点慢并且灵活性欠佳,但它免费!
|
||||
|
||||
虚拟化平台安装完成后,下载一个你选择的 Linux 发行版的引导磁盘镜像。
|
||||
|
||||
* 我们使用的是 [Ubuntu 桌面版][6]。
|
||||
|
||||
|
||||
|
||||
这将下载一个命名类似于 `ubuntu-10.04.1-desktop-i386.iso` 的文件。启动你的虚拟化平台并创建一个新(32 位)的虚拟机。使用下载的 Ubuntu 镜像作为一个引导磁盘;安装过程在不同的虚拟机上有所不同,但都很简单。就像上面一样输入 `objdump -i`,去验证你的工具是否已安装。你将在虚拟机中完成你的工作。
|
||||
|
||||
##### 构建你自己的编译器工具链
|
||||
#### 构建你自己的编译器工具链
|
||||
|
||||
在设置上你将花一些时间,但是比起一个虚拟机来说,它的性能要稍好一些,并且让你工作在你熟悉的环境中(Unix/MacOS)。对于 MacOS 命令,你可以快进到文章的末尾部分去看。
|
||||
你需要花一些时间来设置,但是比起一个虚拟机来说,它的性能要稍好一些,并且让你工作在你熟悉的环境中(Unix/MacOS)。对于 MacOS 命令,你可以快进到文章的末尾部分去看。
|
||||
|
||||
###### Linux
|
||||
##### Linux
|
||||
|
||||
通过将下列行添加到 `conf/env.mk` 中去使用你自己的工具链:
|
||||
|
||||
```
|
||||
GCCPREFIX=
|
||||
|
||||
```
|
||||
|
||||
我们假设你将工具链安装到了 `/usr/local` 中。你将需要大量的空间(大约 1 GB)去编译工具。如果你空间不足,在它的 `make install` 步骤之后删除它们的目录。
|
||||
@ -94,7 +84,7 @@ GCCPREFIX=
|
||||
+ http://ftpmirror.gnu.org/gcc/gcc-4.6.4/gcc-core-4.6.4.tar.bz2
|
||||
+ http://ftpmirror.gnu.org/gdb/gdb-7.3.1.tar.bz2
|
||||
|
||||
(你可能也在使用这些包的最新版本。)解包并构建。绿色粗体文本显示如何安装到 `/usr/local` 中,它是我们建议的。要安装到不同的目录,$PFX,注意高亮输入处的不同。如果有问题,可以看下面。
|
||||
(你可能也在使用这些包的最新版本。)解包并构建。安装到 `/usr/local` 中,它是我们建议的。要安装到不同的目录,如 `$PFX`,注意相应修改。如果有问题,可以看下面。
|
||||
|
||||
```c
|
||||
export PATH=$PFX/bin:$PATH
|
||||
@ -166,39 +156,40 @@ cd gdb-7.3.1
|
||||
make all
|
||||
make install # This step may require privilege (sudo make install)
|
||||
cd ..
|
||||
|
||||
```
|
||||
|
||||
###### Linux 排错
|
||||
**Linux 排错:**
|
||||
|
||||
Q:我不能运行 `make install`,因为我在这台机器上没有 root 权限。
|
||||
|
||||
A:我们的指令假定你是安装到了 `/usr/local` 目录中。但是,在你的环境中可能并不是这样做的。如果你仅能够在你的家目录中安装代码。那么在上面的命令中,使用 `--prefix=$HOME` 去替换 `--prefix=/usr/local`。你也需要修改你的 `PATH` 和 `LD_LIBRARY_PATH` 环境变量,以通知你的 shell 这个工具的位置。例如:
|
||||
|
||||
* Q:我不能运行 `make install`,因为我在这台机器上没有 root 权限。
|
||||
A:我们的指令假定你是安装到了 `/usr/local` 目录中。但是,在你的环境中可能并不是这样做的。如果你仅能够在你的 home 目录中安装代码。那么在上面的命令中,使用 `--prefix=$HOME`(并[点击这里][7] 去更新后面的命令)去替换 `--prefix=/usr/local`。你也需要修改你的 `PATH` 和 `LD_LIBRARY_PATH` 环境变量,以通知你的 shell 这个工具的位置。例如:
|
||||
```
|
||||
export PATH=$HOME/bin:$PATH
|
||||
export LD_LIBRARY_PATH=$HOME/lib:$LD_LIBRARY_PATH
|
||||
export PATH=$HOME/bin:$PATH
|
||||
export LD_LIBRARY_PATH=$HOME/lib:$LD_LIBRARY_PATH
|
||||
```
|
||||
|
||||
在你的 `~/.bashrc` 文件中输入这些行,以便于你登入后不需要每次都输入它们。
|
||||
|
||||
Q:我构建失败了,错误信息是 “library not found”。
|
||||
|
||||
|
||||
* Q:我构建失败了,错误信息是 "library not found”。
|
||||
A:你需要去设置你的 `LD_LIBRARY_PATH`。环境变量必须包含 `PREFIX/lib` 目录(例如 `/usr/local/lib`)。
|
||||
|
||||
##### MacOS
|
||||
|
||||
|
||||
#### MacOS
|
||||
|
||||
首先从 Mac OSX 上安装开发工具开始:
|
||||
`xcode-select --install`
|
||||
首先从 Mac OSX 上安装开发工具开始:`xcode-select --install` 。
|
||||
|
||||
你可以从 homebrew 上安装 qemu 的依赖,但是不能去安装 qemu,因为我们需要安装打了 6.828 补丁的 qemu。
|
||||
|
||||
`brew install $(brew deps qemu)`
|
||||
```
|
||||
brew install $(brew deps qemu)
|
||||
```
|
||||
|
||||
gettext 工具并不能把已安装的二进制文件添加到路径中,因此你需要去运行:
|
||||
gettext 工具并不能把它已安装的二进制文件添加到路径中,因此你需要去运行:
|
||||
|
||||
`PATH=${PATH}:/usr/local/opt/gettext/bin make install`
|
||||
```
|
||||
PATH=${PATH}:/usr/local/opt/gettext/bin make install
|
||||
```
|
||||
|
||||
完成后,开始安装 qemu。
|
||||
|
||||
@ -208,13 +199,12 @@ gettext 工具并不能把已安装的二进制文件添加到路径中,因此
|
||||
|
||||
不幸的是,QEMU 的调试功能虽然很强大,但是有点不成熟,因此我们强烈建议你使用我们打过 6.828 补丁的版本,而不是发行版自带的版本。这个安装在 Athena 上的 QEMU 版本已经打过补丁了。构建你自己的、打 6.828 补丁的 QEMU 版本的过程如下:
|
||||
|
||||
1. 克隆 IAP 6.828 QEMU 的 git 仓库:`git clone https://github.com/mit-pdos/6.828-qemu.git qemu`。
|
||||
2. 在 Linux 上,你或许需要安装几个库。我们成功地在 Debian/Ubuntu 16.04 上构建 6.828 版的 QEMU 需要安装下列的库:libsdl1.2-dev、libtool-bin、libglib2.0-dev、libz-dev、和 libpixman-1-dev。
|
||||
3. 配置源代码(方括号中是可选参考;用你自己的真实路径替换 PFX)
|
||||
1. 克隆 IAP 6.828 QEMU 的 git 仓库:`git clone https://github.com/mit-pdos/6.828-qemu.git qemu`。
|
||||
2. 在 Linux 上,你或许需要安装几个库。我们成功地在 Debian/Ubuntu 16.04 上构建 6.828 版的 QEMU 需要安装下列的库:libsdl1.2-dev、libtool-bin、libglib2.0-dev、libz-dev 和 libpixman-1-dev。
|
||||
3. 配置源代码(方括号中是可选参数;用你自己的真实路径替换 `PFX`)
|
||||
1. Linux:`./configure --disable-kvm --disable-werror [--prefix=PFX] [--target-list="i386-softmmu x86_64-softmmu"]`。
|
||||
2. OS X:`./configure --disable-kvm --disable-werror --disable-sdl [--prefix=PFX] [--target-list="i386-softmmu x86_64-softmmu"]`。`prefix` 参数指定安装 QEMU 的位置;如果不指定,将缺省安装 QEMU 到 `/usr/local` 目录中。`target-list` 参数将简单地简化 QEMU 所支持的架构。
|
||||
4. 运行 `make && make install`。
|
||||
|
||||
4. 运行 `make && make install`。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -224,7 +214,7 @@ via: https://pdos.csail.mit.edu/6.828/2018/tools.html
|
||||
作者:[csail.mit][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,159 @@
|
||||
Terminalizer:一个记录您终端活动并且生成 Gif 图像的工具
|
||||
====
|
||||
|
||||
今天我们要讨论一个广为人知的主题,我们也围绕这个主题写过许多的文章,因此我不会针对这个如何记录终端会话流程给出太多具体的资料。
|
||||
|
||||
我们可以使用脚本命令来记录 Linux 的终端会话,这也是大家公认的一种办法。不过今天我们将来介绍一个能起到相同作用的工具 —— Terminalizer。
|
||||
|
||||
这个工具可以帮助我们记录用户的终端活动,以帮助我们从输出的文件中找到有用的信息。
|
||||
|
||||
### 什么是 Terminlizer
|
||||
|
||||
用户可以用 Terminlizer 记录他们的终端活动并且生成一个 Gif 图像。它是一个允许高度定制的 CLI 工具。用户可以在网络播放器、在线播放器上用链接分享他们记录下的文件。
|
||||
|
||||
**推荐阅读:**
|
||||
|
||||
- [Script – 一个记录您终端对话的简单工具][1]
|
||||
- [在 Linux 上自动记录/捕捉所有用户的终端对话][2]
|
||||
- [Teleconsole – 一个能立即与任何人分享您终端对话的工具][3]
|
||||
- [tmate – 立即与任何人分享您的终端对话][4]
|
||||
- [Peek – 在 Linux 里制造一个 Gif 记录器][5]
|
||||
- [Kgif – 一个能生成 Gif 图片,以记录窗口活动的简单 Shell 脚本][6]
|
||||
- [Gifine – 在 Ubuntu/Debian 里快速制造一个 Gif 视频][7]
|
||||
|
||||
目前没有发行版拥有官方软件包来安装此实用程序,不过我们可以用 Node.js 来安装它。
|
||||
|
||||
### 如何在 Linux 上安装 Node.js
|
||||
|
||||
安装 Node.js 有许多种方法。我们在这里将会教您一个常用的方法。
|
||||
|
||||
在 Ubuntu/LinuxMint 上可以使用 [APT-GET 命令][8] 或者 [APT 命令][9] 来安装 Node.js。
|
||||
|
||||
```
|
||||
$ curl -sL https://deb.nodesource.com/setup_8.x | sudo -E bash -
|
||||
$ sudo apt-get install -y nodejs
|
||||
```
|
||||
|
||||
在 Debian 上使用 [APT-GET 命令][8] 或者 [APT 命令][9] 来安装 Node.js。
|
||||
|
||||
```
|
||||
# curl -sL https://deb.nodesource.com/setup_8.x | bash -
|
||||
# apt-get install -y nodejs
|
||||
```
|
||||
|
||||
在 RHEL/CentOS 上,使用 [YUM 命令][10] 来安装。
|
||||
|
||||
```
|
||||
$ sudo curl --silent --location https://rpm.nodesource.com/setup_8.x | sudo bash -
|
||||
$ sudo yum install epel-release
|
||||
$ sudo yum -y install nodejs
|
||||
```
|
||||
|
||||
在 Fedora 上,用 [DNF 命令][11] 来安装 tmux。
|
||||
|
||||
```
|
||||
$ sudo dnf install nodejs
|
||||
```
|
||||
|
||||
在 Arch Linux 上,用 [Pacman 命令][12] 来安装 tmux。
|
||||
|
||||
```
|
||||
$ sudo pacman -S nodejs npm
|
||||
```
|
||||
|
||||
在 openSUSE 上,用 [Zypper Command][13] 来安装 tmux。
|
||||
|
||||
```
|
||||
$ sudo zypper in nodejs6
|
||||
```
|
||||
|
||||
### 如何安装 Terminalizer
|
||||
|
||||
您已经安装了 Node.js 这个先决软件包,现在是时候在您的系统上安装 Terminalizer 了。简单执行如下的 `npm` 命令即可安装。
|
||||
|
||||
```
|
||||
$ sudo npm install -g terminalizer
|
||||
```
|
||||
|
||||
### 如何使用 Terminalizer
|
||||
|
||||
您只需要执行如下的命令,即可使用 Terminalizer 记录您的终端会话活动。您可以敲击 `CTRL+D` 来结束并且保存记录。
|
||||
|
||||
```
|
||||
# terminalizer record 2g-session
|
||||
|
||||
defaultConfigPath
|
||||
The recording session is started
|
||||
Press CTRL+D to exit and save the recording
|
||||
```
|
||||
|
||||
这将会将您记录的会话保存成一个 YAML 文件,在这个例子里,我的文件名将会是 2g-session-activity.yml。
|
||||
|
||||
![][15]
|
||||
|
||||
```
|
||||
# logout
|
||||
Successfully Recorded
|
||||
The recording data is saved into the file:
|
||||
/home/daygeek/2g-session.yml
|
||||
You can edit the file and even change the configurations.
|
||||
```
|
||||
|
||||
![][16]
|
||||
|
||||
### 如何播放记录下来的文件
|
||||
|
||||
使用以下命令来播放您记录的 YAML 文件。在以下操作中,请确保您已经用了您的文件名来替换 “2g-session”。
|
||||
|
||||
```
|
||||
# terminalizer play 2g-session
|
||||
```
|
||||
|
||||
将记录的文件渲染成 Gif 图像。
|
||||
|
||||
```
|
||||
# terminalizer render 2g-session
|
||||
```
|
||||
|
||||
注意: 以下的两个命令在此版本尚且不可用,或许在下一版本这两个命令将会付诸使用。
|
||||
|
||||
如果您想要将记录的文件分享给其他人,您可以将您的文件上传到在线播放器,并且将链接分享给对方。
|
||||
|
||||
```
|
||||
terminalizer share 2g-session
|
||||
```
|
||||
|
||||
为记录的文件生成一个网络播放器。
|
||||
|
||||
```
|
||||
# terminalizer generate 2g-session
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/terminalizer-a-tool-to-record-your-terminal-and-generate-animated-gif-images/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[thecyanbird](https://github.com/thecyanbird)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[1]: https://www.2daygeek.com/script-command-record-save-your-terminal-session-activity-linux/
|
||||
[2]: https://www.2daygeek.com/automatically-record-all-users-terminal-sessions-activity-linux-script-command/
|
||||
[3]: https://www.2daygeek.com/teleconsole-share-terminal-session-instantly-to-anyone-in-seconds/
|
||||
[4]: https://www.2daygeek.com/tmate-instantly-share-your-terminal-session-to-anyone-in-seconds/
|
||||
[5]: https://www.2daygeek.com/peek-create-animated-gif-screen-recorder-capture-arch-linux-mint-fedora-ubuntu/
|
||||
[6]: https://www.2daygeek.com/kgif-create-animated-gif-file-active-window-screen-recorder-capture-arch-linux-mint-fedora-ubuntu-debian-opensuse-centos/
|
||||
[7]: https://www.2daygeek.com/gifine-create-animated-gif-vedio-recorder-linux-mint-debian-ubuntu/
|
||||
[8]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[9]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[10]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[11]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[12]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[13]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[14]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[15]: https://www.2daygeek.com/wp-content/uploads/2018/10/terminalizer-record-2g-session-1.gif
|
||||
[16]: https://www.2daygeek.com/wp-content/uploads/2018/10/terminalizer-play-2g-session.gif
|
||||
@ -1,7 +1,7 @@
|
||||
使用Python的toolz库开始函数式编程
|
||||
使用 Python 的 toolz 库开始函数式编程
|
||||
======
|
||||
|
||||
toolz库允许你操作函数,使其更容易理解,更容易测试代码。
|
||||
> toolz 库允许你操作函数,使其更容易理解,更容易测试代码。
|
||||
|
||||

|
||||
|
||||
@ -20,7 +20,11 @@ def add_one_word(words, word):
|
||||
|
||||
这个函数假设它的第一个参数是一个不可变的类似字典的对象,它返回一个新的类似字典的在相关位置递增的对象:这就是一个简单的频率计数器。
|
||||
|
||||
但是,只有将它应用于单词流并做归纳时才有用。 我们可以使用内置模块 `functools` 中的归纳器。 `functools.reduce(function, stream, initializer)`
|
||||
但是,只有将它应用于单词流并做*归纳*时才有用。 我们可以使用内置模块 `functools` 中的归纳器。
|
||||
|
||||
```
|
||||
functools.reduce(function, stream, initializer)
|
||||
```
|
||||
|
||||
我们想要一个函数,应用于流,并且能能返回频率计数。
|
||||
|
||||
@ -30,14 +34,12 @@ def add_one_word(words, word):
|
||||
add_all_words = curry(functools.reduce, add_one_word)
|
||||
```
|
||||
|
||||
使用此版本,我们需要提供初始化程序。 但是,我们不能只将 `pyrsistent.m` 函数添加到 `curry` 函数中中; 因为这个顺序是错误的。
|
||||
使用此版本,我们需要提供初始化程序。但是,我们不能只将 `pyrsistent.m` 函数添加到 `curry` 函数中; 因为这个顺序是错误的。
|
||||
|
||||
```
|
||||
add_all_words_flipped = flip(add_all_words)
|
||||
```
|
||||
|
||||
The `flip` higher-level function returns a function that calls the original, with arguments flipped.
|
||||
|
||||
`flip` 这个高阶函数返回一个调用原始函数的函数,并且翻转参数顺序。
|
||||
|
||||
```
|
||||
@ -46,7 +48,7 @@ get_all_words = add_all_words_flipped(pyrsistent.m())
|
||||
|
||||
我们利用 `flip` 自动调整其参数的特性给它一个初始值:一个空字典。
|
||||
|
||||
现在我们可以执行 `get_all_words(word_stream)` 这个函数来获取频率字典。 但是,我们如何获得一个单词流呢? Python文件是行流的。
|
||||
现在我们可以执行 `get_all_words(word_stream)` 这个函数来获取频率字典。 但是,我们如何获得一个单词流呢? Python 文件是按行供流的。
|
||||
|
||||
```
|
||||
def to_words(lines):
|
||||
@ -60,9 +62,9 @@ def to_words(lines):
|
||||
words_from_file = toolz.compose(get_all_words, to_words)
|
||||
```
|
||||
|
||||
在这种情况下,组合只是使两个函数很容易阅读:首先将文件的行流应用于 `to_words`,然后将 `get_all_words` 应用于 `to_words` 的结果。 散文似乎与代码相反。
|
||||
在这种情况下,组合只是使两个函数很容易阅读:首先将文件的行流应用于 `to_words`,然后将 `get_all_words` 应用于 `to_words` 的结果。 但是文字上读起来似乎与代码执行相反。
|
||||
|
||||
当我们开始认真对待可组合性时,这很重要。 有时可以将代码编写为一个单元序列,单独测试每个单元,最后将它们全部组合。 如果有几个组合元素时,组合的顺序可能就很难理解。
|
||||
当我们开始认真对待可组合性时,这很重要。有时可以将代码编写为一个单元序列,单独测试每个单元,最后将它们全部组合。如果有几个组合元素时,组合的顺序可能就很难理解。
|
||||
|
||||
`toolz` 库借用了 Unix 命令行的做法,并使用 `pipe` 作为执行相同操作的函数,但顺序相反。
|
||||
|
||||
@ -70,17 +72,13 @@ words_from_file = toolz.compose(get_all_words, to_words)
|
||||
words_from_file = toolz.pipe(to_words, get_all_words)
|
||||
```
|
||||
|
||||
Now it reads more intuitively: Pipe the input into `to_words`, and pipe the results into `get_all_words`. On a command line, the equivalent would look like this:
|
||||
|
||||
现在读起来更直观了:将输入传递到 `to_words`,并将结果传递给 `get_all_words`。 在命令行上,等效写法如下所示:
|
||||
|
||||
```
|
||||
$ cat files | to_words | get_all_words
|
||||
```
|
||||
|
||||
The `toolz` library allows us to manipulate functions, slicing, dicing, and composing them to make our code easier to understand and to test.
|
||||
|
||||
`toolz` 库允许我们操作函数,切片,分割和组合,以使我们的代码更容易理解和测试。
|
||||
`toolz` 库允许我们操作函数,切片、分割和组合,以使我们的代码更容易理解和测试。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -89,10 +87,10 @@ via: https://opensource.com/article/18/10/functional-programming-python-toolz
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/18/10/functional-programming-python-immutable-data-structures
|
||||
[1]: https://linux.cn/article-10222-1.html
|
||||
41
published/20181109 7 reasons I love open source.md
Normal file
41
published/20181109 7 reasons I love open source.md
Normal file
@ -0,0 +1,41 @@
|
||||
我爱开源的 7 个理由
|
||||
======
|
||||
|
||||
> 成为开源社区的一员绝对是一个明智之举,原因有很多。
|
||||
|
||||

|
||||
|
||||
这就是我为什么包括晚上和周末在内花费非常多的时间待在 [GitHub][1] 上,成为开源社区的一个活跃成员。
|
||||
|
||||
我参加过各种规模的项目,从个人项目到几个人的协作项目,乃至有数百位贡献者的项目,每一个项目都让我有新的受益。
|
||||
|
||||
|
||||
|
||||
也就是说,这里有七个原因让我为开源做出贡献:
|
||||
|
||||
* **它让我的技能与时俱进。** 在咨询公司的管理职位工作,有时我觉得自己与创建软件的实际过程越来越远。参与开源项目使我可以重新回到我最热爱的编程之中。也使我能够体验新技术,学习新技术和语言,并且使我不被酷酷的孩子们落下。
|
||||
* **它教我如何与人打交道。** 与一群素未谋面的人合作开源项目在与人交往方面能够教会你很多。你很快会发现每个人有他们自己的压力,他们自己的义务,以及不同的时间表。学习如何与一群陌生人合作是一种很好的生活技能。
|
||||
* **它使我成为一个更好的沟通者。** 开源项目的维护者的时间有限。你很快就知道,要成功地贡献,你必须能够清楚、简明地表达你所做的改变、添加或修复,最重要的是,你为什么要这么做。
|
||||
* **它使我成为一个更好的开发者。** 没有什么能像成百上千的其他开发者依赖你的代码一样 —— 它敦促你更加专注软件设计、测试和文档。
|
||||
* **它使我的造物变得更好。** 可能开源背后最强大的观念是它允许你驾驭一个由有创造力、有智慧、有知识的个人组成的全球网络。我知道我自己一个人的能力是有限的,我不可能什么都知道,但与开源社区的合作有助于我改进我的创作。
|
||||
* **它告诉我小事物的价值。** 如果一个项目的文档不清楚或不完整,我会毫不犹豫地把它做得更好。一个小小的更新或修复可能只节省开发人员几分钟的时间,但是随着用户数量的增加,您一个小小的更改可能产生巨大的价值。
|
||||
* **它使我更好的营销。** 好的,这是一个奇怪的例子。有这么多伟大的开源项目在那里,感觉像一场争夺关注的拼搏。从事于开源让我学到了很多营销的价值。这不是关于讲述或创建一个华丽的网站。而是关于如何清楚地传达你所创造的,它是如何使用的,以及它带来的好处。
|
||||
|
||||
我可以继续讨论开源是如何帮助你发展伙伴、关系和朋友的,不过你应该都知道了。有许多原因让我乐于成为开源社区的一员。
|
||||
|
||||
你可能想知道这些如何用于大型金融服务机构的 IT 战略。简单来说:谁不想要一个擅长与人交流和工作,具有尖端的技能,并能够推销他们的成果的开发团队呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/reasons-love-open-source
|
||||
|
||||
作者:[Colin Eberhardt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[ChiZelin](https://github.com/ChiZelin)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/colineberhardt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/ColinEberhardt/
|
||||
@ -1,3 +1,7 @@
|
||||
translating by belitex
|
||||
translating by belitex
|
||||
translating by belitex
|
||||
translating by belitex
|
||||
Directing traffic: Demystifying internet-scale load balancing
|
||||
======
|
||||
Common techniques used to balance network traffic come with advantages and trade-offs.
|
||||
|
||||
@ -1,41 +0,0 @@
|
||||
7 reasons I love open source
|
||||
======
|
||||
Being a part of the open source community is a huge win for many reasons.
|
||||

|
||||
|
||||
Here's why I spend so much of my time—including evenings and weekends—[on GitHub][1], as an active member of the open source community.
|
||||
|
||||
I’ve worked on everything from solo projects to small collaborative group efforts to projects with hundreds of contributors. With each project, I’ve learned something new.
|
||||
|
||||

|
||||
|
||||
* **It keeps my skills fresh.** As someone in a management position at a consultancy, I sometimes feel like I am becoming more and more distant from the physical process of creating software. Working on open source projects allows me to get back to what I love best: writing code. It also allows me to experiment with new technologies, learn new techniques and languages—and keep up with the cool kids!
|
||||
* **It teaches me about people.** Working on an open source project with a group of people you’ve never met teaches you a lot about how to interact with people. You quickly discover that everyone has their own pressures, their own commitments, and differing timescales. Learning how to work collaboratively with a group of strangers is a great life skill.
|
||||
* **It makes me a better communicator.** Maintainers of open source projects have a limited amount of time. You quickly learn that to successfully contribute, you must be able to communicate clearly and concisely what you are changing, adding, or fixing, and most importantly, why you are doing it.
|
||||
* **It makes me a better developer**. There is nothing quite like having hundreds—or thousands—of other developers depend on your code. It motivates you to pay a lot more attention to software design, testing, and documentation.
|
||||
* **It makes my own creations better**. Possibly the most powerful concept behind open source is that it allows you to harness a global network of creative, intelligent, and knowledgeable individuals. I know I have my limits, and I don’t know everything, but engaging with the open source community helps me improve my creations.
|
||||
* **It teaches me the value of small things**. If the documentation for a project is unclear or incomplete, I don’t hesitate to make it better. One small update or fix might save a developer only a few minutes, but multiplied across all the users, your one small change can have a significant impact.
|
||||
* **It makes me better at marketing**. Ok, this is an odd one. There are so many great open source projects out there that it can feel like a struggle to get noticed. Working in open source has taught me a lot about the value of marketing your creations. This isn’t about spin or creating a flashy website. It is about clearly communicating what you have created, how it is used, and the benefits it brings.
|
||||
|
||||
|
||||
|
||||
That said, here are seven reasons why I contribute to open source:
|
||||
|
||||
I could go on about how open source helps you build partnerships, connections, and friends, but you get the idea. There are a great many reasons why I thoroughly enjoy being part of the open source community.
|
||||
|
||||
You might be wondering how all this applies to the IT strategy for large financial services organizations. Simple: Who wouldn’t want a team of developers who are great at communicating and working with people, have cutting-edge skills, and are able to market their creations?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/reasons-love-open-source
|
||||
|
||||
作者:[Colin Eberhardt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/colineberhardt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/ColinEberhardt/
|
||||
@ -0,0 +1,93 @@
|
||||
Have you seen these personalities in open source?
|
||||
======
|
||||
An inclusive community is a more creative and effective community. But how can you make sure you're accommodating the various personalities that call your community "home"?
|
||||

|
||||
|
||||
When I worked with the Mozilla Foundation, long before the organization boasted more than a hundred and fifty staff members, we conducted a foundation-wide Myers-Briggs indicator. The [Myers-Briggs][1] is a popular personality assessment, one used widely in [career planning and the business world][2]. Created in the early twentieth century, it's the product of two women: Katharine Cook Briggs and her daughter Isabel Briggs Myers, who built the tool on Carl Jung's Theory of Psychological Types (which was itself based on clinical observations, as opposed to "controlled" scientific studies). Each of my co-workers (53 at the time) answered the questions. We were curious about what kind of insights we would gain into our individual personalities, and, by extension, about how we'd best work together.
|
||||
|
||||
Our team's report showed that the people working for the Mozilla Foundation, one of the biggest and oldest open source projects on the web, were people with the least common personality types. Where about 77% of the general population fit into the top 8 most common Myers-Briggs types, only 23% of the Mozilla Foundation team did. Our team was mostly composed of the rarer Myers-Briggs types. For example, 23% of the team shared my own individual personality type ("ENTP"), which is interesting to me, since people with that personality type only make up 3.2% of the general population. And 9% of the team were ENTJ, the second rarest personality type, at just 1.8% of the population.
|
||||
|
||||
I began to wonder: Do open source projects attract a certain type of personality? Or is this one assessment of full-time open sourcers just a fluke?
|
||||
|
||||
And if it's true, which aspects of personality can we tug on when encouraging community participation? How can we use our knowledge of personality and psychology to push our open source projects towards success?
|
||||
|
||||
### The personalities of open source
|
||||
|
||||
Thinking about personality types and open source communities is tricky. In short, when we're talking about personality, we see lots speculation.
|
||||
|
||||
Personality assessments and, indeed, the entire field of psychology are often considered "soft science." Academics in the field have long struggled to be seen as scientifically relevant. Other subjects, like physics and mathematics, can prove hard truths—this is the way it is, and if it's not like this, then it's not true.
|
||||
|
||||
Thinking about personality types and open source communities is tricky. In short, when we're talking about personality, we see lots speculation.
|
||||
|
||||
But people and their brains are fascinatingly complicated, and definitively proving a theory is impossible. Conducting controlled studies with human beings is difficult; there are ethical implications, physical needs, and no two people are alike—so there is no way to have a truly stable control group. Plus, there's always an outlier of some sort, because our backgrounds and experiences structure our personalities and the way we think. In psychology, the closest we can get to a "hard truth" is something like "This is mostly the way it is, except when it's not." Only in recent years (and with recent advancements in technology) have links between psychology and neurology provided us with some psychological "hard truths." For example, we know, definitively, which parts of the brain are responsible for certain functions.
|
||||
|
||||
Emotion and personality, however, are more elusive subjects; generalizations remain difficult and face relevant intellectual criticism. But when we're thinking about designing communities around personality types, we can work with some useful archetypes.
|
||||
|
||||
After all, anyone can find a place in open source. Millions of people participate in various projects and communities. Open source isn't just for engineers anymore; we've gone global. And while open source might not be as mainstream as, say, eggs, I'm confident that every personality type, gender identity, sexual orientation, age, and background is represented in the global open source community.
|
||||
|
||||
When designing open source projects, you want to ensure that you build [architectures of participation][3] for everyone. Successful projects have communities, and community-building happens intentionally. Community management takes time and effort, so if you're hoping to lead a successful open source project, don't spend all your resources on the product. Care for your people, and your people will help you with the rest of it.
|
||||
|
||||
Here's what to consider as you begin architecting an inclusive community.
|
||||
|
||||
#### Introverted versus extraverted
|
||||
|
||||
An introvert is someone who gains energy from solitude, while an extravert gains energy from being around other people. We all have a little of both. For example, an introvert teaching might be using his extravert mode of operation all day. To recharge after a day at work, he'd likely need to go into quiet mode, thinking internally. An extravert teacher would be just as tired from the same day, but to recharge he'd want to talk about the day. An extravert might happily have a dinner party and use that as a mode of recharging.
|
||||
|
||||
Another important difference is that those with an extravert preference tend to do a lot of their thinking out loud, whereas introverts think carefully before speaking. Thinking out loud can be difficult for an introvert to understand, as she might expect the things being said to have already been thought about. But for an extravert, verbalizing is a way of figuring stuff out. They don't mind saying things that are incorrect, because doing so helps them process information.
|
||||
|
||||
Introverts and extraverts have different comfort levels with regard to participation; they may need different pathways for getting involved in your project or community.
|
||||
|
||||
Some communities are accustomed to being marginalized, so being welcoming and encouraging becomes even more important if you want to have a diverse and inclusive project. Remember, diversity is also intentional, and inclusivity is one of [the principles of an open organization][4].
|
||||
|
||||
Not everyone feels comfortable speaking in a community call or posting to a public forum. Not everyone will respond to a public list. Personal outreach and communication strategies that are more private are important for ensuring inclusivity. In addition to transparent and public communication mechanisms, a well-designed open source project will point contributors to specific people they can reach directly.
|
||||
|
||||
#### Strict versus flexible
|
||||
|
||||
Did you know that some people need highly structured environments or workflows to be productive, while others would become incapacitated by such structures? For many creative types, an adaptive and flexible environment or workflow is essential. For a truly inclusive project, you'll need to provide for both. I recommend that you always document and detail your processes. Write up your approaches, make an overview, and share the process with your community. [I've done this][5] while working on Greenpeace's open source project, [Planet 4][6].
|
||||
|
||||
As a leader or community manager, you need to be flexible and kind when people don't follow your carefully planned processes. The approach might make sense to you and your team—it might make sense to a lot of people in the community—but it might be too strict for others. You should gently remind people of your processes, but you'll find that some people just won't follow it. Instead of creating a secondary process for those who need less structure, just be responsive to whatever the request might be. People will tell you what they need; they will ask the question they need answered. And then you can generate even greater participation by demonstrating your own adaptability.
|
||||
|
||||
#### Certainty versus ambiguity
|
||||
|
||||
Openly documenting everything, including meeting notes, is a common practice for open source projects and communities. I am, indeed, in the habit of making charts and slides to pair with written documentation. Different brains process information differently: For some, a drawing is more easily digestible than a document, and vice versa! A leader in this space needs to understand that when people read the notes, some will read the lines and others will read between them.
|
||||
|
||||
The preference for taking things at face value is not more correct than a preference for exploring the murky possibilities of differing kinds of information. People remember meetings and events in different ways, and their varying perspectives can cause uncertainty around decisions that have been made. In short, just because something is a "fact" doesn't mean that there aren't multiple perspectives of it.
|
||||
|
||||
Documenting decisions is an important practice in open source, but so is [helping people understand the context around those decisions][7]. Having to go back to something that's already finished can be frustrating, but being a leader in open source means being flexible and understanding the neurodiversity at work in your community.
|
||||
|
||||
#### Objective versus subjective
|
||||
|
||||
Nothing in the universe is certain—indeed, even gravity didn't always exist. Humans define the world around them; it's part of our nature. We're wonderful at rationalizing occurrences so things make sense to us.
|
||||
|
||||
And when it comes to personality, this means some people might see an objective reality (the facts defined and unshakeable, "gravity exists") while others might see a subjective world (facts are merely stories we tell ourselves to make sense of our reality, "we wanted a reason that we stick to the Earth"). One common personality conflict stems from how we view the concept of truth. While some people rely on objective fact to guide their perceptions of the ways they should be interacting with the world, others prefer to let their subjective feelings guide how they judge the facts. In any industry, conflicts between varying ways of thinking can be difficult to reconcile.
|
||||
|
||||
Open leaders need to ensure a healthy and sustainable environment for all community members. When conflict arises, be ready to "believe" everyone—because from each of their perspectives, they're most likely right. Note that "believing" everyone doesn't mean putting up with destructive behavior (there should never be room in your community for racism, sexism, ageism or outright trolling, no matter how people might frame these behaviors). It means creating a place that allows people to respectfully discuss and debate their perspectives. Be sure you put a code of conduct in place to help with this.
|
||||
|
||||
### Inclusivity at the fore
|
||||
|
||||
In open source, practicing inclusivity means seeking to bend your mind towards ways of thinking that might not come naturally to you. We can all become more empathetic towards other people, helping our communities grow to be more diverse. Learn to recognize your own preferences and understand how your brain works—but also remember that everyone's neural networks work a bit differently. Then, as a leader, make sure you're creating space for everyone by championing inclusivity, fairness, open-mindedness, and neurodiversity.
|
||||
|
||||
(Special thanks to [Adam Procter][8].)
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/11/design-communities-personality-types
|
||||
|
||||
作者:[Laura Hilliger][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/laurahilliger
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Myers%E2%80%93Briggs_Type_Indicator
|
||||
[2]: https://opensource.com/open-organization/16/7/personality-test-for-teams
|
||||
[3]: https://opensource.com/business/12/6/architecture-participation
|
||||
[4]: https://opensource.com/open-organization/resources/open-org-definition
|
||||
[5]: https://medium.com/planet4/improving-p4-in-tandem-774a0d306fbc
|
||||
[6]: https://medium.com/planet4
|
||||
[7]: https://opensource.com/open-organization/16/3/what-it-means-be-open-source-leader
|
||||
[8]: http://adamprocter.co.uk
|
||||
@ -0,0 +1,54 @@
|
||||
What you need to know about the GPL Cooperation Commitment
|
||||
======
|
||||
|
||||
The GPL Cooperation Commitment fosters innovation by freeing developers from fear of license termination.
|
||||
|
||||

|
||||
|
||||
Imagine what the world would look like if growth, innovation, and development were free from fear. Innovation without fear is fostered by consistent, predictable, and fair license enforcement. That is what the [GPL Cooperation Commitment][1] aims to accomplish.
|
||||
|
||||
Last year, I wrote an article about licensing effects on downstream users of open source software. As I was conducting research for that article, it became apparent that license enforcement is infrequent and often unpredictable. In that article, I offered potential solutions to the need to make open source license enforcement consistent and predictable. However, I only considered "traditional" methods (e.g., through the court system or some form of legislative action) that a law student might consider.
|
||||
|
||||
In November 2017, Red Hat, IBM, Google, and Facebook proposed the the "non-traditional" solution I had not considered: the GPL Cooperation Commitment, which provides for fair and consistent enforcement of the GPL. I believe the GPL Cooperation Commitment is critical for two reasons: First, consistent and fair license enforcement is crucial for growth in the open source community; second, unpredictability is undesirable in the legal community.
|
||||
|
||||
### Understanding the GPL
|
||||
|
||||
To understand the GPL Cooperation Commitment, you must first understand the GPL's history. GPL is short for [GNU General Public License][2]. The GPL is a "copyleft" open source license, meaning that a software's distributor must make the source code available to downstream users. The GPL also prohibits placing restrictions on downstream use. These requirements keep individual users from denying freedoms (to use, study, share, and improve the software) to others. Under the GPL, a license to use the code is granted to all downstream users, provided they meet the requirements and conditions of the license. If a licensee does not meet the license's requirements, they are non-compliant.
|
||||
|
||||
Under the second version of the GPL (GPLv2), a license automatically terminates upon any non-compliance, which causes some software developers to shy away from using the GPL. However, the third version of the GPL (GPLv3) [added a "cure provision"][3] that gives a 30-day period for a licensee to remediate any GPL violation. If the violation is cured within 30 days following notification of non-compliance, the license is not terminated.
|
||||
|
||||
This provision eliminates the fear of termination due to an innocent mistake, thus fostering development and innovation by bringing peace of mind to users and distributors of the software.
|
||||
|
||||
### What the GPL Cooperation Commitment does
|
||||
|
||||
The GPL Cooperation Commitment applies the GPLv3's cure provisions to GPLv2-licensed software, thereby protecting licensees of GPLv2 code from the automatic termination of their license, consistent with the protections afforded by the GPLv3.
|
||||
|
||||
The GPL Cooperation Commitment is important because, while software engineers typically want to do the right thing and maintain compliance, they sometimes misunderstand how to do so. This agreement enables developers to avoid termination when they are non-compliant due to confusion or simple mistakes.
|
||||
|
||||
The GPL Cooperation Commitment spawned from an announcement in 2017 by the Linux Foundation Technical Advisory Board that the Linux kernel project would [adopt the cure provision from GPLv3][4]. With the GPL Cooperation Commitment, many major technology companies and individual developers made the same commitment and expanded it by applying the cure period to all of their software licensed under GPLv2 (and LGPLv2.1), not only to contributions to the Linux kernel.
|
||||
|
||||
Broad adoption of the GPL Cooperation Commitment will have a positive impact on the open source community because a significant amount of software is licensed under GPLv2. An increasing number of companies and individuals are expected to adopt the GPL Cooperation Commitment, which will lead to a significant amount of GPLv2 (and LGPLv2.1) code under license terms that promote fair and predictable approaches to license enforcement.
|
||||
|
||||
In fact, as of November 2018, more than 40 companies, including industry leaders IBM, Google, Amazon, Microsoft, Tencent, Intel, and Red Hat, have [signed onto the GPL Cooperation Commitment][5] and are working collaboratively to create a standard of fair and predictable enforcement within the open source community. The GPL Cooperation Commitment is just one example of how the community comes together to ensure the future of open source.
|
||||
|
||||
The GPL Cooperation Commitment tells downstream licensees that you respect their good intentions and that your GPLv2 code is safe for them to use. More information, including about how you can add your name to the commitment, is available on the [GPL Cooperation Commitment website][6].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/gpl-cooperation-commitment
|
||||
|
||||
作者:[Brooke Driver][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bdriver
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://gplcc.github.io/gplcc/
|
||||
[2]: https://www.gnu.org/licenses/licenses.en.html
|
||||
[3]: https://opensource.com/article/18/6/gplv3-anniversary
|
||||
[4]: https://www.kernel.org/doc/html/v4.16/process/kernel-enforcement-statement.html
|
||||
[5]: https://gplcc.github.io/gplcc/Company/Company-List.html
|
||||
[6]: http://gplcc.github.io/gplcc
|
||||
@ -1,173 +0,0 @@
|
||||
thecyanbird translating
|
||||
|
||||
Terminalizer – A Tool To Record Your Terminal And Generate Animated Gif Images
|
||||
======
|
||||
This is know topic for most of us and i don’t want to give you the detailed information about this flow. Also, we had written many article under this topics.
|
||||
|
||||
Script command is the one of the standard command to record Linux terminal sessions. Today we are going to discuss about same kind of tool called Terminalizer.
|
||||
|
||||
This tool will help us to record the users terminal activity, also will help us to identify other useful information from the output.
|
||||
|
||||
### What Is Terminalizer
|
||||
|
||||
Terminalizer allow users to record their terminal activity and allow them to generate animated gif images. It’s highly customizable CLI tool that user can share a link for an online player, web player for a recording file.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [Script – A Simple Command To Record Your Terminal Session Activity][1]
|
||||
**(#)** [Automatically Record/Capture All Users Terminal Sessions Activity In Linux][2]
|
||||
**(#)** [Teleconsole – A Tool To Share Your Terminal Session Instantly To Anyone In Seconds][3]
|
||||
**(#)** [tmate – Instantly Share Your Terminal Session To Anyone In Seconds][4]
|
||||
**(#)** [Peek – Create a Animated GIF Recorder in Linux][5]
|
||||
**(#)** [Kgif – A Simple Shell Script to Create a Gif File from Active Window][6]
|
||||
**(#)** [Gifine – Quickly Create An Animated GIF Video In Ubuntu/Debian][7]
|
||||
|
||||
There is no distribution official package to install this utility and we can easily install it by using Node.js.
|
||||
|
||||
### How To Install Noje.js in Linux
|
||||
|
||||
Node.js can be installed in multiple ways. Here, we are going to teach you the standard method.
|
||||
|
||||
For Ubuntu/LinuxMint use [APT-GET Command][8] or [APT Command][9] to install Node.js
|
||||
|
||||
```
|
||||
$ curl -sL https://deb.nodesource.com/setup_8.x | sudo -E bash -
|
||||
$ sudo apt-get install -y nodejs
|
||||
|
||||
```
|
||||
|
||||
For Debian use [APT-GET Command][8] or [APT Command][9] to install Node.js
|
||||
|
||||
```
|
||||
# curl -sL https://deb.nodesource.com/setup_8.x | bash -
|
||||
# apt-get install -y nodejs
|
||||
|
||||
```
|
||||
|
||||
For **`RHEL/CentOS`** , use [YUM Command][10] to install tmux.
|
||||
|
||||
```
|
||||
$ sudo curl --silent --location https://rpm.nodesource.com/setup_8.x | sudo bash -
|
||||
$ sudo yum install epel-release
|
||||
$ sudo yum -y install nodejs
|
||||
|
||||
```
|
||||
|
||||
For **`Fedora`** , use [DNF Command][11] to install tmux.
|
||||
|
||||
```
|
||||
$ sudo dnf install nodejs
|
||||
|
||||
```
|
||||
|
||||
For **`Arch Linux`** , use [Pacman Command][12] to install tmux.
|
||||
|
||||
```
|
||||
$ sudo pacman -S nodejs npm
|
||||
|
||||
```
|
||||
|
||||
For **`openSUSE`** , use [Zypper Command][13] to install tmux.
|
||||
|
||||
```
|
||||
$ sudo zypper in nodejs6
|
||||
|
||||
```
|
||||
|
||||
### How to Install Terminalizer
|
||||
|
||||
As you have already installed prerequisite package called Node.js, now it’s time to install Terminalizer on your system. Simple run the below npm command to install Terminalizer.
|
||||
|
||||
```
|
||||
$ sudo npm install -g terminalizer
|
||||
|
||||
```
|
||||
|
||||
### How to Use Terminalizer
|
||||
|
||||
To record your session activity using Terminalizer, just run the following Terminalizer command. Once you started the recording then play around it and finally hit `CTRL+D` to exit and save the recording.
|
||||
|
||||
```
|
||||
# terminalizer record 2g-session
|
||||
|
||||
defaultConfigPath
|
||||
The recording session is started
|
||||
Press CTRL+D to exit and save the recording
|
||||
|
||||
```
|
||||
|
||||
This will save your recording session as a YAML file, in this case my filename would be 2g-session-activity.yml.
|
||||
![][15]
|
||||
|
||||
Just type few commands to verify this and finally hit `CTRL+D` to exit the current capture. When you hit `CTRL+D` on the terminal and you will be getting the below output.
|
||||
|
||||
```
|
||||
# logout
|
||||
Successfully Recorded
|
||||
The recording data is saved into the file:
|
||||
/home/daygeek/2g-session.yml
|
||||
You can edit the file and even change the configurations.
|
||||
|
||||
```
|
||||
|
||||
![][16]
|
||||
|
||||
### How to Play the Recorded File
|
||||
|
||||
Use the below command format to paly your recorded YAML file. Make sure, you have to input your recorded file instead of us.
|
||||
|
||||
```
|
||||
# terminalizer play 2g-session
|
||||
|
||||
```
|
||||
|
||||
Render a recording file as an animated gif image.
|
||||
|
||||
```
|
||||
# terminalizer render 2g-session
|
||||
|
||||
```
|
||||
|
||||
`Note:` Below two commands are not implemented yet in the current version and will be available in the next version.
|
||||
|
||||
If you would like to share your recording to others then upload a recording file and get a link for an online player and share it.
|
||||
|
||||
```
|
||||
terminalizer share 2g-session
|
||||
|
||||
```
|
||||
|
||||
Generate a web player for a recording file
|
||||
|
||||
```
|
||||
# terminalizer generate 2g-session
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/terminalizer-a-tool-to-record-your-terminal-and-generate-animated-gif-images/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[1]: https://www.2daygeek.com/script-command-record-save-your-terminal-session-activity-linux/
|
||||
[2]: https://www.2daygeek.com/automatically-record-all-users-terminal-sessions-activity-linux-script-command/
|
||||
[3]: https://www.2daygeek.com/teleconsole-share-terminal-session-instantly-to-anyone-in-seconds/
|
||||
[4]: https://www.2daygeek.com/tmate-instantly-share-your-terminal-session-to-anyone-in-seconds/
|
||||
[5]: https://www.2daygeek.com/peek-create-animated-gif-screen-recorder-capture-arch-linux-mint-fedora-ubuntu/
|
||||
[6]: https://www.2daygeek.com/kgif-create-animated-gif-file-active-window-screen-recorder-capture-arch-linux-mint-fedora-ubuntu-debian-opensuse-centos/
|
||||
[7]: https://www.2daygeek.com/gifine-create-animated-gif-vedio-recorder-linux-mint-debian-ubuntu/
|
||||
[8]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[9]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[10]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[11]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[12]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[13]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[14]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[15]: https://www.2daygeek.com/wp-content/uploads/2018/10/terminalizer-record-2g-session-1.gif
|
||||
[16]: https://www.2daygeek.com/wp-content/uploads/2018/10/terminalizer-play-2g-session.gif
|
||||
@ -1,125 +0,0 @@
|
||||
Translating by qhwdw
|
||||
LinuxBoot for Servers: Enter Open Source, Goodbye Proprietary UEFI
|
||||
============================================================
|
||||
|
||||
[LinuxBoot][13] is an Open Source [alternative][14] to Proprietary [UEFI][15] firmware. It was released last year and is now being increasingly preferred by leading hardware manufacturers as default firmware. Last year, LinuxBoot was warmly [welcomed][16]into the Open Source family by The Linux Foundation.
|
||||
|
||||
This project was an initiative by Ron Minnich, author of LinuxBIOS and lead of [coreboot][17] at Google, in January 2017.
|
||||
|
||||
Google, Facebook, [Horizon Computing Solutions][18], and [Two Sigma][19] collaborated together to develop the [LinuxBoot project][20] (formerly called [NERF][21]) for server machines based on Linux.
|
||||
|
||||
Its openness allows Server users to easily customize their own boot scripts, fix issues, build their own [runtimes][22] and [reflash their firmware][23] with their own keys. They do not need to wait for vendor updates.
|
||||
|
||||
Following is a video of [Ubuntu Xenial][24] booting for the first time with NERF BIOS:
|
||||
|
||||
[视频](https://youtu.be/HBkZAN3xkJg)
|
||||
|
||||
Let’s talk about some other advantages by comparing it to UEFI in terms of Server hardware.
|
||||
|
||||
### Advantages of LinuxBoot over UEFI
|
||||
|
||||

|
||||
|
||||
Here are some of the major advantages of LinuxBoot over UEFI:
|
||||
|
||||
### Significantly faster startup
|
||||
|
||||
It can boot up Server boards in less than twenty seconds, versus multiple minutes on UEFI.
|
||||
|
||||
### Significantly more flexible
|
||||
|
||||
LinuxBoot can make use of any devices, filesystems and protocols that Linux supports.
|
||||
|
||||
### Potentially more secure
|
||||
|
||||
Linux device drivers and filesystems have significantly more scrutiny than through UEFI.
|
||||
|
||||
We can argue that UEFI is partly open with [EDK II][25] and LinuxBoot is partly closed. But it has been [addressed][26] that even such EDK II code does not have the proper level of inspection and correctness as the [Linux Kernel][27] goes through, while there is a huge amount of other Closed Source components within UEFI development.
|
||||
|
||||
On the other hand, LinuxBoot has a significantly smaller amount of binaries with only a few hundred KB, compared to the 32 MB of UEFI binaries.
|
||||
|
||||
To be precise, LinuxBoot fits a whole lot better into the [Trusted Computing Base][28], unlike UEFI.
|
||||
|
||||
[Suggested readBest Free and Open Source Alternatives to Adobe Products for Linux][29]
|
||||
|
||||
LinuxBoot has a [kexec][30] based bootloader which does not support startup on Windows/non-Linux kernels, but that is insignificant since most clouds are Linux-based Servers.
|
||||
|
||||
### LinuxBoot adoption
|
||||
|
||||
In 2011, the [Open Compute Project][31] was started by [Facebook][32] who [open-sourced][33] designs of some of their Servers, built to make its data centers more efficient. LinuxBoot has been tested on a few Open Compute Hardware listed as under:
|
||||
|
||||
* Winterfell
|
||||
|
||||
* Leopard
|
||||
|
||||
* Tioga Pass
|
||||
|
||||
More [OCP][34] hardware are described [here][35] in brief. The OCP Foundation runs a dedicated project on firmware through [Open System Firmware][36].
|
||||
|
||||
Some other devices that support LinuxBoot are:
|
||||
|
||||
* [QEMU][9] emulated [Q35][10] systems
|
||||
|
||||
* [Intel S2600wf][11]
|
||||
|
||||
* [Dell R630][12]
|
||||
|
||||
Last month end, [Equus Compute Solutions][37] [announced][38] the release of its [WHITEBOX OPEN™][39] M2660 and M2760 Servers, as a part of their custom, cost-optimized Open-Hardware Servers and storage platforms. Both of them support LinuxBoot to customize the Server BIOS for flexibility, improved security, and create a blazingly fast booting experience.
|
||||
|
||||
### What do you think of LinuxBoot?
|
||||
|
||||
LinuxBoot is quite well documented [on GitHub][40]. Do you like the features that set it apart from UEFI? Would you prefer using LinuxBoot rather than UEFI for starting up Servers, owing to the former’s open-ended development and future? Let us know in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/linuxboot-uefi/
|
||||
|
||||
作者:[ Avimanyu Bandyopadhyay][a]
|
||||
选题:[oska874][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/avimanyu/
|
||||
[b]:https://github.com/oska874
|
||||
[1]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[2]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[3]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[4]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[5]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[6]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[7]:https://itsfoss.com/author/avimanyu/
|
||||
[8]:https://itsfoss.com/linuxboot-uefi/#comments
|
||||
[9]:https://en.wikipedia.org/wiki/QEMU
|
||||
[10]:https://wiki.qemu.org/Features/Q35
|
||||
[11]:https://trmm.net/S2600
|
||||
[12]:https://trmm.net/NERF#Installing_on_a_Dell_R630
|
||||
[13]:https://www.linuxboot.org/
|
||||
[14]:https://www.phoronix.com/scan.php?page=news_item&px=LinuxBoot-OSFC-2018-State
|
||||
[15]:https://itsfoss.com/check-uefi-or-bios/
|
||||
[16]:https://www.linuxfoundation.org/blog/2018/01/system-startup-gets-a-boost-with-new-linuxboot-project/
|
||||
[17]:https://en.wikipedia.org/wiki/Coreboot
|
||||
[18]:http://www.horizon-computing.com/
|
||||
[19]:https://www.twosigma.com/
|
||||
[20]:https://trmm.net/LinuxBoot_34c3
|
||||
[21]:https://trmm.net/NERF
|
||||
[22]:https://trmm.net/LinuxBoot_34c3#Runtimes
|
||||
[23]:http://www.tech-faq.com/flashing-firmware.html
|
||||
[24]:https://itsfoss.com/features-ubuntu-1604/
|
||||
[25]:https://www.tianocore.org/
|
||||
[26]:https://media.ccc.de/v/34c3-9056-bringing_linux_back_to_server_boot_roms_with_nerf_and_heads
|
||||
[27]:https://medium.com/@bhumikagoyal/linux-kernel-development-cycle-52b4c55be06e
|
||||
[28]:https://en.wikipedia.org/wiki/Trusted_computing_base
|
||||
[29]:https://itsfoss.com/adobe-alternatives-linux/
|
||||
[30]:https://en.wikipedia.org/wiki/Kexec
|
||||
[31]:https://en.wikipedia.org/wiki/Open_Compute_Project
|
||||
[32]:https://github.com/facebook
|
||||
[33]:https://github.com/opencomputeproject
|
||||
[34]:https://www.networkworld.com/article/3266293/lan-wan/what-is-the-open-compute-project.html
|
||||
[35]:http://hyperscaleit.com/ocp-server-hardware/
|
||||
[36]:https://www.opencompute.org/projects/open-system-firmware
|
||||
[37]:https://www.equuscs.com/
|
||||
[38]:http://www.dcvelocity.com/products/Software_-_Systems/20180924-equus-compute-solutions-introduces-whitebox-open-m2660-and-m2760-servers/
|
||||
[39]:https://www.equuscs.com/servers/whitebox-open/
|
||||
[40]:https://github.com/linuxboot/linuxboot
|
||||
@ -1,106 +0,0 @@
|
||||
Translating by Jamkr
|
||||
|
||||
Revisiting the Unix philosophy in 2018
|
||||
======
|
||||
The old strategy of building small, focused applications is new again in the modern microservices environment.
|
||||

|
||||
|
||||
In 1984, Rob Pike and Brian W. Kernighan published an article called "[Program Design in the Unix Environment][1]" in the AT&T Bell Laboratories Technical Journal, in which they argued the Unix philosophy, using the example of BSD's **cat -v** implementation. In a nutshell that philosophy is: Build small, focused programs—in whatever language—that do only one thing but do this thing well, communicate via **stdin** / **stdout** , and are connected through pipes.
|
||||
|
||||
Sound familiar?
|
||||
|
||||
Yeah, I thought so. That's pretty much the [definition of microservices][2] offered by James Lewis and Martin Fowler:
|
||||
|
||||
> In short, the microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API.
|
||||
|
||||
While one *nix program or one microservice may be very limited or not even very interesting on its own, it's the combination of such independently working units that reveals their true benefit and, therefore, their power.
|
||||
|
||||
### *nix vs. microservices
|
||||
|
||||
The following table compares programs (such as **cat** or **lsof** ) in a *nix environment against programs in a microservices environment.
|
||||
|
||||
| | *nix | Microservices |
|
||||
| ----------------------------------- | -------------------------- | ----------------------------------- |
|
||||
| Unit of execution | program using stdin/stdout | service with HTTP or gRPC API |
|
||||
| Data flow | Pipes | ? |
|
||||
| Configuration & parameterization | Command-line arguments, | |
|
||||
| environment variables, config files | JSON/YAML docs | |
|
||||
| Discovery | Package manager, man, make | DNS, environment variables, OpenAPI |
|
||||
|
||||
Let's explore each line in slightly greater detail.
|
||||
|
||||
#### Unit of execution
|
||||
|
||||
**stdin** and writes output to **stdout**. A microservices setup deals with a service that exposes one or more communication interfaces, such as HTTP or gRPC APIs. In both cases, you'll find stateless examples (essentially a purely functional behavior) and stateful examples, where, in addition to the input, some internal (persisted) state decides what happens.
|
||||
|
||||
#### Data flow
|
||||
|
||||
The unit of execution in *nix (such as Linux) is an executable file (binary or interpreted script) that, ideally, reads input fromand writes output to. A microservices setup deals with a service that exposes one or more communication interfaces, such as HTTP or gRPC APIs. In both cases, you'll find stateless examples (essentially a purely functional behavior) and stateful examples, where, in addition to the input, some internal (persisted) state decides what happens.
|
||||
|
||||
Traditionally, *nix programs could communicate via pipes. In other words, thanks to [Doug McIlroy][3], you don't need to create temporary files to pass around and each can process virtually endless streams of data between processes. To my knowledge, there is nothing comparable to a pipe standardized in microservices, besides my little [Apache Kafka-based experiment from 2017][4].
|
||||
|
||||
#### Configuration and parameterization
|
||||
|
||||
How do you configure a program or service—either on a permanent or a by-call basis? Well, with *nix programs you essentially have three options: command-line arguments, environment variables, or full-blown config files. In microservices, you typically deal with YAML (or even worse, JSON) documents, defining the layout and configuration of a single microservice as well as dependencies and communication, storage, and runtime settings. Examples include [Kubernetes resource definitions][5], [Nomad job specifications][6], or [Docker Compose][7] files. These may or may not be parameterized; that is, either you have some templating language, such as [Helm][8] in Kubernetes, or you find yourself doing an awful lot of **sed -i** commands.
|
||||
|
||||
#### Discovery
|
||||
|
||||
How do you know what programs or services are available and how they are supposed to be used? Well, in *nix, you typically have a package manager as well as good old man; between them, they should be able to answer all the questions you might have. In a microservices setup, there's a bit more automation in finding a service. In addition to bespoke approaches like [Airbnb's SmartStack][9] or [Netflix's Eureka][10], there usually are environment variable-based or DNS-based [approaches][11] that allow you to discover services dynamically. Equally important, [OpenAPI][12] provides a de-facto standard for HTTP API documentation and design, and [gRPC][13] does the same for more tightly coupled high-performance cases. Last but not least, take developer experience (DX) into account, starting with writing good [Makefiles][14] and ending with writing your docs with (or in?) [**style**][15].
|
||||
|
||||
### Pros and cons
|
||||
|
||||
Both *nix and microservices offer a number of challenges and opportunities
|
||||
|
||||
#### Composability
|
||||
|
||||
It's hard to design something that has a clear, sharp focus and can also play well with others. It's even harder to get it right across different versions and to introduce respective error case handling capabilities. In microservices, this could mean retry logic and timeouts—maybe it's a better option to outsource these features into a service mesh? It's hard, but if you get it right, its reusability can be enormous.
|
||||
|
||||
#### Observability
|
||||
|
||||
In a monolith (in 2018) or a big program that tries to do it all (in 1984), it's rather straightforward to find the culprit when things go south. But, in a
|
||||
|
||||
```
|
||||
yes | tr \\n x | head -c 450m | grep n
|
||||
```
|
||||
|
||||
or a request path in a microservices setup that involves, say, 20 services, how do you even start to figure out which one is behaving badly? Luckily we have standards, notably [OpenCensus][16] and [OpenTracing][17]. Observability still might be the biggest single blocker if you are looking to move to microservices.
|
||||
|
||||
#### Global state
|
||||
|
||||
While it may not be such a big issue for *nix programs, in microservices, global state remains something of a discussion. Namely, how to make sure the local (persistent) state is managed effectively and how to make the global state consistent with as little effort as possible.
|
||||
|
||||
### Wrapping up
|
||||
|
||||
In the end, the question remains: Are you using the right tool for a given task? That is, in the same way a specialized *nix program implementing a range of functions might be the better choice for certain use cases or phases, it might be that a monolith [is the best option][18] for your organization or workload. Regardless, I hope this article helps you see the many, strong parallels between the Unix philosophy and microservices—maybe we can learn something from the former to benefit the latter.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/revisiting-unix-philosophy-2018
|
||||
|
||||
作者:[Michael Hausenblas][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mhausenblas
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://harmful.cat-v.org/cat-v/
|
||||
[2]: https://martinfowler.com/articles/microservices.html
|
||||
[3]: https://en.wikipedia.org/wiki/Douglas_McIlroy
|
||||
[4]: https://speakerdeck.com/mhausenblas/distributed-named-pipes-and-other-inter-services-communication
|
||||
[5]: http://kubernetesbyexample.com/
|
||||
[6]: https://www.nomadproject.io/docs/job-specification/index.html
|
||||
[7]: https://docs.docker.com/compose/overview/
|
||||
[8]: https://helm.sh/
|
||||
[9]: https://github.com/airbnb/smartstack-cookbook
|
||||
[10]: https://github.com/Netflix/eureka
|
||||
[11]: https://kubernetes.io/docs/concepts/services-networking/service/#discovering-services
|
||||
[12]: https://www.openapis.org/
|
||||
[13]: https://grpc.io/
|
||||
[14]: https://suva.sh/posts/well-documented-makefiles/
|
||||
[15]: https://www.linux.com/news/improve-your-writing-gnu-style-checkers
|
||||
[16]: https://opencensus.io/
|
||||
[17]: https://opentracing.io/
|
||||
[18]: https://robertnorthard.com/devops-days-well-architected-monoliths-are-okay/
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by Jamkr
|
||||
|
||||
How to partition and format a drive on Linux
|
||||
======
|
||||
Everything you wanted to know about setting up storage but were afraid to ask.
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
HankChow translating
|
||||
|
||||
Gitbase: Exploring git repos with SQL
|
||||
======
|
||||
Gitbase is a Go-powered open source project that allows SQL queries to be run on Git repositories.
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
translating by caixiangyue
|
||||
How To Find The Execution Time Of A Command Or Process In Linux
|
||||
======
|
||||

|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Choosing a printer for Linux
|
||||
======
|
||||
Linux offers widespread support for printers. Learn how to take advantage of it.
|
||||
|
||||
@ -1,234 +0,0 @@
|
||||
HankChow translating
|
||||
|
||||
The Difference Between more, less And most Commands
|
||||
======
|
||||

|
||||
If you’re a newbie Linux user, you might be confused with these three command like utilities, namely **more** , **less** and **most**. No problem! In this brief guide, I will explain the differences between these three commands, with some examples in Linux. To be precise, they are more or less same with slight differences. All these commands comes preinstalled in most Linux distributions.
|
||||
|
||||
First, we will discuss about ‘more’ command.
|
||||
|
||||
### The ‘more’ program
|
||||
|
||||
The **‘more’** is an old and basic terminal pager or paging program that is used to open a given file for interactive reading. If the content of the file is too large to fit in one screen, it displays the contents page by page. You can scroll through the contents of the file by pressing **ENTER** or **SPACE BAR** keys. But one limitation is you can scroll in **forward direction only** , not backwards. That means, you can scroll down, but can’t go up.
|
||||
|
||||

|
||||
|
||||
**Update:**
|
||||
|
||||
A fellow Linux user has pointed out that more command do allow backward scrolling. The original version allowed only the forward scrolling. However, the newer implementations allows limited backward movement. To scroll backwards, just press **b**. The only limitation is that it doesn’t work for pipes (ls|more for example).
|
||||
|
||||
To quit, press **q**.
|
||||
|
||||
**more command examples:**
|
||||
|
||||
Open a file, for example ostechnix.txt, for interactive reading:
|
||||
|
||||
```
|
||||
$ more ostechnix.txt
|
||||
```
|
||||
|
||||
To search for a string, type search query after the forward slash (/) like below:
|
||||
|
||||
```
|
||||
/linux
|
||||
```
|
||||
|
||||
To go to then next matching string, press **‘n’**.
|
||||
|
||||
To open the file start at line number 10, simply type:
|
||||
|
||||
```
|
||||
$ more +10 file
|
||||
```
|
||||
|
||||
The above command show the contents of ostechnix.txt starting from 10th line.
|
||||
|
||||
If you want the ‘more’ utility to prompt you to continue reading file by pressing the space bar key, just use **-d** flag:
|
||||
|
||||
```
|
||||
$ more -d ostechnix.txt
|
||||
```
|
||||
|
||||
![][2]
|
||||
|
||||
As you see in the above screenshot, the more command prompts you to press SPACE to continue.
|
||||
|
||||
To view the summary of all options and keybindings in the help section, press **h**.
|
||||
|
||||
For more details about **‘more’** command, refer man pages.
|
||||
|
||||
```
|
||||
$ man more
|
||||
```
|
||||
|
||||
### The ‘less’ program
|
||||
|
||||
The **‘less** ‘ command is also used to open a given file for interactive reading, allowing scrolling and search. If the content of the file is too large, it pages the output and so you can scroll page by page. Unlike the ‘more’ command, it allows scrolling on both directions. That means, you can scroll up and down through a file.
|
||||
|
||||
|
||||
|
||||
So, feature-wise, ‘less’ has more advantages than ‘more’ command. Here are some notable advantages of ‘less’ command:
|
||||
|
||||
* Allows forward and backward scrolling,
|
||||
* Search in forward and backward directions,
|
||||
* Go to the end and start of the file immediately,
|
||||
* Open the given file in an editor.
|
||||
|
||||
|
||||
|
||||
**less command examples:**
|
||||
|
||||
Open a file:
|
||||
|
||||
```
|
||||
$ less ostechnix.txt
|
||||
```
|
||||
|
||||
Press **SPACE BAR** or **ENTER** key to go down and press **‘b’** to go up.
|
||||
|
||||
To perform a forward search, type search query after the forward slash ( **/** ) like below:
|
||||
|
||||
```
|
||||
/linux
|
||||
```
|
||||
|
||||
To go to then next matching string, press **‘n’**. To go back to the previous matching string, press **N** (shift+n).
|
||||
|
||||
To perform a backward search, type search query after the question mark ( **?** ) like below:
|
||||
|
||||
```
|
||||
?linux
|
||||
```
|
||||
|
||||
Press **n/N** to go to **next/previous** match.
|
||||
|
||||
To open the currently opened file in an editor, press **v**. It will open your file in your default text editor. You can now edit, remove, rename the text in the file.
|
||||
|
||||
To view the summary of less commands, options, keybindings, press **h**.
|
||||
|
||||
To quit, press **q**.
|
||||
|
||||
For more details about ‘less’ command, refer the man pages.
|
||||
|
||||
```
|
||||
$ man less
|
||||
```
|
||||
|
||||
### The ‘most’ program
|
||||
|
||||
The ‘most’ terminal pager has more features than ‘more’ and ‘less’ programs. Unlike the previous utilities, the ‘most’ command can able to open more than one file at a time. You can easily switch between the opened files, edit the current file, jump to the **N** th line in the opened file, split the current window in half, lock and scroll windows together and so on. By default, it won’t wrap the long lines, but truncates them and provides a left/right scrolling option.
|
||||
|
||||
**most command examples:**
|
||||
|
||||
Open a single file:
|
||||
|
||||
```
|
||||
$ most ostechnix1.txt
|
||||
```
|
||||
|
||||
To edit the current file, press **e**.
|
||||
|
||||
To perform a forward search, press **/** or **S** or **f** and type the search query. Press **n** to find the next matching string in the current direction.
|
||||
|
||||
![][3]
|
||||
|
||||
To perform a backward search, press **?** and type the search query. Similarly, press **n** to find the next matching string in the current direction.
|
||||
|
||||
Open multiple files at once:
|
||||
|
||||
```
|
||||
$ most ostechnix1.txt ostechnix2.txt ostechnix3.txt
|
||||
```
|
||||
|
||||
If you have opened multiple files, you can switch to next file by typing **:n**. Use **UP/DOWN** arrow keys to select next file and hit **ENTER** key to view the chosen file.
|
||||

|
||||
|
||||
To open a file at the first occurrence of given string, for example **linux** :
|
||||
|
||||
```
|
||||
$ most file +/linux
|
||||
```
|
||||
|
||||
To view the help section, press **h** at any time.
|
||||
|
||||
**List of all keybindings:**
|
||||
|
||||
Navigation:
|
||||
|
||||
* **SPACE, D** – Scroll down one screen.
|
||||
* **DELETE, U** – Scroll Up one screen.
|
||||
* **DOWN arrow** – Move Down one line.
|
||||
* **UP arrow** – Move Up one line.
|
||||
* **T** – Goto Top of File.
|
||||
* **B** – Goto Bottom of file.
|
||||
* **> , TAB** – Scroll Window right.
|
||||
* **<** – Scroll Window left.
|
||||
* **RIGHT arrow** – Scroll Window left by 1 column.
|
||||
* **LEFT arrow** – Scroll Window right by 1 column.
|
||||
* **J, G** – Goto nth line. For example, to jump to the 10th line, simply type **“100j”** (without quotes).
|
||||
* **%** – Goto percent.
|
||||
|
||||
|
||||
|
||||
Window Commands:
|
||||
|
||||
* **Ctrl-X 2, Ctrl-W 2** – Split window.
|
||||
* **Ctrl-X 1, Ctrl-W 1** – Make only one window.
|
||||
* **O, Ctrl-X O** – Move to other window.
|
||||
* **Ctrl-X 0 (zero)** – Delete Window.
|
||||
|
||||
|
||||
|
||||
Search through files:
|
||||
|
||||
* **S, f, /** – Search forward.
|
||||
* **?** – Search Backward.
|
||||
* **N** – Find next match in current search direction.
|
||||
|
||||
|
||||
|
||||
Exit:
|
||||
|
||||
* **q** – Quit MOST program. All opened files will be closed.
|
||||
* **:N, :n** – Quit this file and view next (Use UP/DOWN arrow keys to select next file).
|
||||
|
||||
|
||||
|
||||
For more details about ‘most’ command, refer the man pages.
|
||||
|
||||
```
|
||||
$ man most
|
||||
```
|
||||
|
||||
### TL;DR
|
||||
|
||||
**more** – An old, very basic paging program. Allows only forward navigation and limited backward navigation.
|
||||
|
||||
**less** – It has more features than ‘more’ utility. Allows both forward and backward navigation and search functionalities. It starts faster than text editors like **vi** when you open large text files.
|
||||
|
||||
**most** – It has all features of above programs including additional features, like opening multiple files at a time, locking and scrolling all windows together, splitting the windows and more.
|
||||
|
||||
And, that’s all for now. Hope you got the basic idea about these three paging programs. I’ve covered only the basics. You can learn more advanced options and functionalities of these programs by looking into the respective program’s man pages.
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/the-difference-between-more-less-and-most-commands/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: http://www.ostechnix.com/wp-content/uploads/2018/11/more-1.png
|
||||
[3]: http://www.ostechnix.com/wp-content/uploads/2018/11/most-1-1.gif
|
||||
@ -1,154 +0,0 @@
|
||||
The alias And unalias Commands Explained With Examples
|
||||
======
|
||||

|
||||
|
||||
You may forget the complex and lengthy Linux commands after certain period of time unless you’re a heavy command line user. Sure, there are a few ways to [**recall the forgotten commands**][1]. You could simply [**save the frequently used commands**][2] and use them on demand. Also, you can [**bookmark the important commands**][3] in your Terminal and use whenever you want. And, of course there is already a built-in **“history”** command available to help you to remember the commands. Another easiest way to remember such long commands is to simply create an alias (shortcut) to them. Not just long commands, you can create alias to any frequently used Linux commands for easier repeated invocation. By this approach, you don’t need to memorize those commands anymore. In this guide, we are going to learn about **alias** and **unalias** commands with examples in Linux.
|
||||
|
||||
### The alias command
|
||||
|
||||
The **alias** command is used to run any command or set of commands (inclusive of many options, arguments) with a user-defined string. The string could be a simple name or abbreviations for the commands regardless of how complex the original commands are. You can use the aliases as the way you use the normal Linux commands. The alias command comes preinstalled in shells, including BASH, Csh, Ksh and Zsh etc.
|
||||
|
||||
The general syntax of alias command is:
|
||||
|
||||
```
|
||||
alias [alias-name[=string]...]
|
||||
```
|
||||
|
||||
Let us go ahead and see some examples.
|
||||
|
||||
**List aliases**
|
||||
|
||||
You might already have aliases in your system. Some applications may create the aliases automatically when you install them. To view the list of existing aliases, run:
|
||||
|
||||
```
|
||||
$ alias
|
||||
```
|
||||
|
||||
or,
|
||||
|
||||
```
|
||||
$ alias -p
|
||||
```
|
||||
|
||||
I have the following aliases in my Arch Linux system.
|
||||
|
||||
```
|
||||
alias betty='/home/sk/betty/main.rb'
|
||||
alias ls='ls --color=auto'
|
||||
alias pbcopy='xclip -selection clipboard'
|
||||
alias pbpaste='xclip -selection clipboard -o'
|
||||
alias update='newsbeuter -r && sudo pacman -Syu'
|
||||
```
|
||||
|
||||
**Create a new alias**
|
||||
|
||||
Like I already said, you don’t need to memorize the lengthy and complex commands. You don’t even need to run long commands over and over. Just create an alias to the command with easily recognizable name and run it whenever you want. Let us say, you want to use this command often.
|
||||
|
||||
```
|
||||
$ du -h --max-depth=1 | sort -hr
|
||||
```
|
||||
|
||||
This command finds which sub-directories consume how much disk size in the current working directory. This command is bit long. Instead of remembering the whole command, we can easily create an alias like below:
|
||||
|
||||
```
|
||||
$ alias du='du -h --max-depth=1 | sort -hr'
|
||||
```
|
||||
|
||||
Here, **du** is the alias name. You can use any name to the alias to easily remember it later.
|
||||
|
||||
You can either use single or double quotes when creating an alias. It makes no difference.
|
||||
|
||||
Now you can just run the alias (i.e **du** in our case) instead of the full command. Both will produce the same result.
|
||||
|
||||
The aliases will expire with the current shell session. They will be gone once you log out of the current session. In order to make the aliases permanent, you need to add them in your shell’s configuration file.
|
||||
|
||||
On BASH shell, edit **~/.bashrc** file:
|
||||
|
||||
```
|
||||
$ nano ~/.bashrc
|
||||
```
|
||||
|
||||
Add the aliases one by one:
|
||||

|
||||
|
||||
Save and quit the file. Then, update the changes by running the following command:
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
Now, the aliases are persistent across sessions.
|
||||
|
||||
On ZSH, you need to add the aliases in **~/.zshrc** file. Similarly, add your aliases in **~/.config/fish/config.fish** file if you use Fish shell.
|
||||
|
||||
**Viewing a specific aliased command**
|
||||
|
||||
As I mentioned earlier, you can view the list of all aliases in your system using ‘alias’ command. If you want to view the command associated with a given alias, for example ‘du’, just run:
|
||||
|
||||
```
|
||||
$ alias du
|
||||
alias du='du -h --max-depth=1 | sort -hr'
|
||||
```
|
||||
|
||||
As you can see, the above command display the command associated with the word ‘du’.
|
||||
|
||||
For more details about alias command, refer the man pages:
|
||||
|
||||
```
|
||||
$ man alias
|
||||
```
|
||||
|
||||
### The unalias command
|
||||
|
||||
As the name says, the **unalias** command simply removes the aliases in your system. The typical syntax of unalias command is:
|
||||
|
||||
```
|
||||
unalias <alias-name>
|
||||
```
|
||||
|
||||
To remove an aliased command, for example ‘du’ which we created earlier, simply run:
|
||||
|
||||
```
|
||||
$ unalias du
|
||||
```
|
||||
|
||||
The unalias command not only removes the alias from the current session, but also remove them permanently from your shell’s configuration file.
|
||||
|
||||
Another way to remove an alias is to create a new alias with same name.
|
||||
|
||||
To remove all aliases from the current session, use **-a** flag:
|
||||
|
||||
```
|
||||
$ unalias -a
|
||||
```
|
||||
|
||||
For more details, refer man pages.
|
||||
|
||||
```
|
||||
$ man unalias
|
||||
```
|
||||
|
||||
Creating aliases to complex and lengthy commands will save you some time if you run those commands over and over. Now it is your time to create aliases the frequently used commands.
|
||||
|
||||
And, that’s all for now. Hope this helps. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/the-alias-and-unalias-commands-explained-with-examples/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/easily-recall-forgotten-linux-commands/
|
||||
[2]: https://www.ostechnix.com/save-commands-terminal-use-demand/
|
||||
[3]: https://www.ostechnix.com/bookmark-linux-commands-easier-repeated-invocation/
|
||||
@ -0,0 +1,101 @@
|
||||
Meet TiDB: An open source NewSQL database
|
||||
======
|
||||
5 key differences between MySQL and TiDB for scaling in the cloud
|
||||
|
||||

|
||||
|
||||
As businesses adopt cloud-native architectures, conversations will naturally lead to what we can do to make the database horizontally scalable. The answer will likely be to take a closer look at [TiDB][1].
|
||||
|
||||
TiDB is an open source [NewSQL][2] database released under the Apache 2.0 License. Because it speaks the [MySQL][3] protocol, your existing applications will be able to connect to it using any MySQL connector, and [most SQL functionality][4] remains identical (joins, subqueries, transactions, etc.).
|
||||
|
||||
Step under the covers, however, and there are differences. If your architecture is based on MySQL with Read Replicas, you'll see things work a little bit differently with TiDB. In this post, I'll go through the top five key differences I've found between TiDB and MySQL.
|
||||
|
||||
### 1. TiDB natively distributes query execution and storage
|
||||
|
||||
With MySQL, it is common to scale-out via replication. Typically you will have one MySQL master with many slaves, each with a complete copy of the data. Using either application logic or technology like [ProxySQL][5], queries are routed to the appropriate server (offloading queries from the master to slaves whenever it is safe to do so).
|
||||
|
||||
Scale-out replication works very well for read-heavy workloads, as the query execution can be divided between replication slaves. However, it becomes a bottleneck for write-heavy workloads, since each replica must have a full copy of the data. Another way to look at this is that MySQL Replication scales out SQL processing, but it does not scale out the storage. (By the way, this is true for traditional replication as well as newer solutions such as Galera Cluster and Group Replication.)
|
||||
|
||||
TiDB works a little bit differently:
|
||||
|
||||
* Query execution is handled via a layer of TiDB servers. Scaling out SQL processing is possible by adding new TiDB servers, which is very easy to do using Kubernetes [ReplicaSets][6]. This is because TiDB servers are [stateless][7]; its [TiKV][8] storage layer is responsible for all of the data persistence.
|
||||
|
||||
* The data for tables is automatically sharded into small chunks and distributed among TiKV servers. Three copies of each data region (the TiKV name for a shard) are kept in the TiKV cluster, but no TiKV server requires a full copy of the data. To use MySQL terminology: Each TiKV server is both a master and a slave at the same time, since for some data regions it will contain the primary copy, and for others, it will be secondary.
|
||||
|
||||
* TiDB supports queries across data regions or, in MySQL terminology, cross-shard queries. The metadata about where the different regions are located is maintained by the Placement Driver, the management server component of any TiDB Cluster. All operations are fully [ACID][9] compliant, and an operation that modifies data across two regions uses a [two-phase commit][10].
|
||||
|
||||
|
||||
|
||||
|
||||
For MySQL users learning TiDB, a simpler explanation is the TiDB servers are like an intelligent proxy that translates SQL into batched key-value requests to be sent to TiKV. TiKV servers store your tables with range-based partitioning. The ranges automatically balance to keep each partition at 96MB (by default, but configurable), and each range can be stored on a different TiKV server. The Placement Driver server keeps track of which ranges are located where and automatically rebalances a range if it becomes too large or too hot.
|
||||
|
||||
This design has several advantages of scale-out replication:
|
||||
|
||||
* It independently scales the SQL Processing and Data Storage tiers. For many workloads, you will hit one bottleneck before the other.
|
||||
|
||||
* It incrementally scales by adding nodes (for both SQL and Data Storage).
|
||||
|
||||
* It utilizes hardware better. To scale out MySQL to one master and four replicas, you would have five copies of the data. TiDB would use only three replicas, with hotspots automatically rebalanced via the Placement Driver.
|
||||
|
||||
|
||||
|
||||
|
||||
### 2. TiDB's storage engine is RocksDB
|
||||
|
||||
MySQL's default storage engine has been InnoDB since 2010. Internally, InnoDB uses a [B+tree][11] data structure, which is similar to what traditional commercial databases use.
|
||||
|
||||
By contrast, TiDB uses RocksDB as the storage engine with TiKV. RocksDB has advantages for large datasets because it can compress data more effectively and insert performance does not degrade when indexes can no longer fit in memory.
|
||||
|
||||
Note that both MySQL and TiDB support an API that allows new storage engines to be made available. For example, Percona Server and MariaDB both support RocksDB as an option.
|
||||
|
||||
### 3. TiDB gathers metrics in Prometheus/Grafana
|
||||
|
||||
Tracking key metrics is an important part of maintaining database health. MySQL centralizes these fast-changing metrics in Performance Schema. Performance Schema is a set of in-memory tables that can be queried via regular SQL queries.
|
||||
|
||||
With TiDB, rather than retaining the metrics inside the server, a strategic choice was made to ship the information to a best-of-breed service. Prometheus+Grafana is a common technology stack among operations teams today, and the included graphs make it easy to create your own or configure thresholds for alarms.
|
||||
|
||||
|
||||
|
||||
### 4. TiDB handles DDL significantly better
|
||||
|
||||
If we ignore for a second that not all data definition language (DDL) changes in MySQL are online, a larger challenge when running a distributed MySQL system is externalizing schema changes on all nodes at the same time. Think about a scenario where you have 10 shards and add a column, but each shard takes a different length of time to complete the modification. This challenge still exists without sharding, since replicas will process DDL after a master.
|
||||
|
||||
TiDB implements online DDL using the [protocol introduced by the Google F1 paper][12]. In short, DDL changes are broken up into smaller transition stages so they can prevent data corruption scenarios, and the system tolerates an individual node being behind up to one DDL version at a time.
|
||||
|
||||
### 5. TiDB is designed for HTAP workloads
|
||||
|
||||
The MySQL team has traditionally focused its attention on optimizing performance for online transaction processing ([OLTP][13]) queries. That is, the MySQL team spends more time making simpler queries perform better instead of making all or complex queries perform better. There is nothing wrong with this approach since many applications only use simple queries.
|
||||
|
||||
TiDB is designed to perform well across hybrid transaction/analytical processing ([HTAP][14]) queries. This is a major selling point for those who want real-time analytics on their data because it eliminates the need for batch loads between their MySQL database and an analytics database.
|
||||
|
||||
### Conclusion
|
||||
|
||||
These are my top five observations based on 15 years in the MySQL world and coming to TiDB. While many of them refer to internal differences, I recommend checking out the TiDB documentation on [MySQL Compatibility][4]. It describes some of the finer points about any differences that may affect your applications.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/key-differences-between-mysql-and-tidb
|
||||
|
||||
作者:[Morgan Tocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/morgo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.pingcap.com/docs/
|
||||
[2]: https://en.wikipedia.org/wiki/NewSQL
|
||||
[3]: https://en.wikipedia.org/wiki/MySQL
|
||||
[4]: https://www.pingcap.com/docs/sql/mysql-compatibility/
|
||||
[5]: https://proxysql.com/
|
||||
[6]: https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/
|
||||
[7]: https://en.wikipedia.org/wiki/State_(computer_science)
|
||||
[8]: https://github.com/tikv/tikv/wiki
|
||||
[9]: https://en.wikipedia.org/wiki/ACID_(computer_science)
|
||||
[10]: https://en.wikipedia.org/wiki/Two-phase_commit_protocol
|
||||
[11]: https://en.wikipedia.org/wiki/B%2B_tree
|
||||
[12]: https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/41344.pdf
|
||||
[13]: https://en.wikipedia.org/wiki/Online_transaction_processing
|
||||
[14]: https://en.wikipedia.org/wiki/Hybrid_transactional/analytical_processing_(HTAP)
|
||||
@ -0,0 +1,85 @@
|
||||
ProtectedText – A Free Encrypted Notepad To Save Your Notes Online
|
||||
======
|
||||

|
||||
Note taking is an important skill to have for all of us. It will help us to remember and maintain permanent record of what we have read, learned and listened to. There are so many apps, tools and utilities available out there for note taking purpose. Today I am going to talk about one such application. Say hello to **ProtectedText** , a free, encrypted notepad to save the notes online. It is a free web service where you can write down your texts, encrypt them and access them from anywhere from any device. It is that simple. All you need is a web browser in an Internet-enabled device.
|
||||
|
||||
ProtectedText site doesn’t require any personal information and doesn’t store the passwords. There is no ads, no cookies, no user tracking and no registration. No one can view the notes except those who have the password to decrypt the text. Since there is no user registration required, you don’t need to create any accounts on this site. Once you done typing the notes, just close the web browser and you’re good to go!
|
||||
|
||||
### Let us save the notes in the encrypted notepad
|
||||
|
||||
Open ProtectedText site by clicking on the following button:
|
||||
|
||||
You will be landed in the home page where you can type your “site name” in the white box given at the center of the page. Alternatively, just write the site name directly in the address bar. Site name is just a custom name (E.g **<https://www.protectedtext.com/mysite>** ) you choose to access your private portal where you keep your notes.
|
||||
|
||||
|
||||
|
||||
If the site you chosen doesn’t exist, you will see the following message. Click on the button says **“Create”** to create your notepad page.
|
||||
|
||||
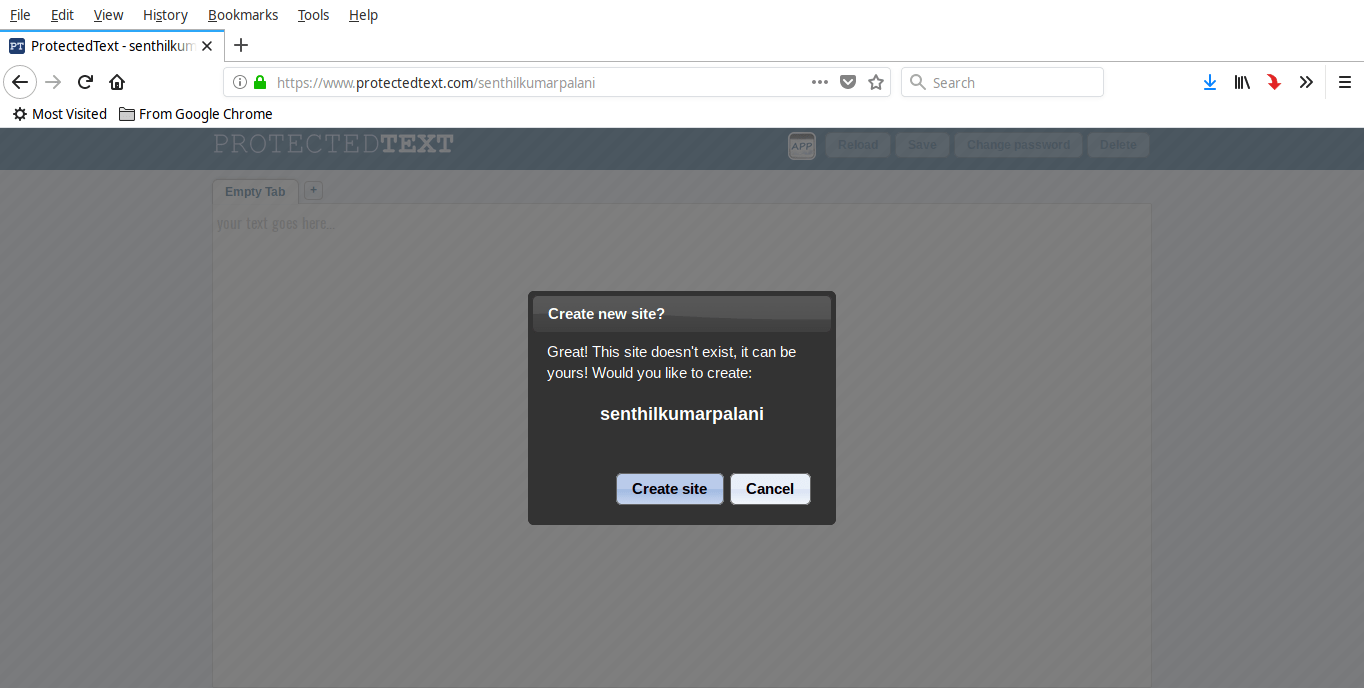
|
||||
|
||||
That’s it. A dedicated private page has been created for you. Now, start typing the notes. The current maximum length is a bit more then 750,000 chars per page.
|
||||
|
||||
ProtectedText site uses **AES algorithm** to encrypt and decrypt your content and **SHA512 algorithm** for hashing.
|
||||
|
||||
Once you’re done, click **Save** button on the top.
|
||||
|
||||
|
||||
|
||||
After you hit the Save button, you will be prompted to enter a password to protect your site. Enter the password twice and click **Save**.
|
||||
|
||||
|
||||
|
||||
You can use any password of your choice. However, it is recommended to use a long and complex password (inclusive of numbers, special characters) to prevent brute-force attacks. The longer the password, the better! Since ProtectedText servers won’t save your password, **there is no way to recover the lost password**. So, please remember the password or use any password managers like [**Buttercup**][3] and [**KeeWeb**][4] to store your credentials.
|
||||
|
||||
You can access your notepad at anytime by visiting its URL from any device. When you access the URL, you will see the following message. Just type your password and start adding and/or updating the notes.
|
||||
|
||||
|
||||
|
||||
The site can be accessed only by you and others who know the password. If you want to make your site public, just add the password of your site like this: **ProtectedText.com/yourSite?yourPassword** which will automatically decrypt **yourSite** with **yourPassword**.
|
||||
|
||||
There is also an [**Android app**][6] available, which allows you to sync notes across all your devices, work offline, backup notes and lock/unlock your site.
|
||||
|
||||
**Pros**
|
||||
|
||||
* Simple, easy to use, fast and free!
|
||||
* ProtectedText.com client side code is freely available [**here**][7]. You can analyze and check the code yourself to understand what is under the hood.
|
||||
* There is no expiration date to your stored content. You can just leave them there as long as you want.
|
||||
* It is possible to make your data both private (only you can view the data) and public (Data can be viewed by all).
|
||||
|
||||
|
||||
|
||||
**Cons**
|
||||
|
||||
* The client side code is open to everyone, however the server side code is not. So, you **can’t self-host the service yourself**. You got to trust them. If you don’t trust them, it is better to stay away from this site.
|
||||
* Since the site doesn’t store anything about yourself including the password, there is no way to recover your data if you forget the password. They claims that they don’t even know who owns which data. So, don’t lose the password.
|
||||
|
||||
|
||||
|
||||
If you ever wanted a simple way to store your notes online and access them wherever you go without installing any additional tools, ProtectedText service might be a good choice. If you know any similar services and applications, let me know them in the comment section below. I will check them out as well.
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/protectedtext-a-free-encrypted-notepad-to-save-your-notes-online/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: http://www.ostechnix.com/wp-content/uploads/2018/11/Protected-Text-4.png
|
||||
[3]: https://www.ostechnix.com/buttercup-a-free-secure-and-cross-platform-password-manager/
|
||||
[4]: https://www.ostechnix.com/keeweb-an-open-source-cross-platform-password-manager/
|
||||
[5]: http://www.ostechnix.com/wp-content/uploads/2018/11/Protected-Text-5.png
|
||||
[6]: https://play.google.com/store/apps/details?id=com.protectedtext.android
|
||||
[7]: https://www.protectedtext.com/js/main.js
|
||||
@ -1,456 +0,0 @@
|
||||
在 Linux 中 17 种方法来查看物理内存(RAM)
|
||||
=======
|
||||
|
||||
大多数系统管理员在遇到性能问题时会检查 CPU 和内存利用率。
|
||||
|
||||
Linux 中有许多实用程序可以用于检查物理内存。
|
||||
|
||||
这些命令有助于我们检查系统中存在的物理 RAM,还允许用户检查各种方面的内存利用率。
|
||||
|
||||
我们大多数人只知道很少的命令,在本文中我们试图包含所有可能的命令。
|
||||
|
||||
你可能会想,为什么我想知道所有这些命令,而不是知道一些特定的和例行的命令。
|
||||
|
||||
不要认为不好或采取负面的方式,因为每个人都有不同的需求和看法,所以,对于那些在寻找其它目的的人,这对于他们非常有帮助。
|
||||
|
||||
### 什么是 RAM
|
||||
|
||||
计算机内存是能够临时或永久存储信息的物理设备。RAM 代表随机存取存储器,它是一种易失性存储器,用于存储操作系统,软件和硬件使用的信息。
|
||||
|
||||
有两种类型的内存可供选择:
|
||||
* 主存
|
||||
* 辅助内存
|
||||
|
||||
主存是计算机的主存储器。CPU 可以直接读取或写入此内存。它固定在电脑的主板上。
|
||||
|
||||
* **`RAM:`** 随机存取存储器是临时存储。关闭计算机后,此信息将消失。
|
||||
* **`ROM:`** 只读存储器是永久存储,即使系统关闭也能保存数据。
|
||||
|
||||
### 方法-1 : 使用 free 命令
|
||||
|
||||
free 显示系统中空闲和已用的物理内存和交换内存的总量,以及内核使用的缓冲区和缓存。它通过解析 /proc/meminfo 来收集信息。
|
||||
|
||||
**建议阅读:** [free – 在 Linux 系统中检查内存使用情况统计(空闲和已用)的标准命令][1]
|
||||
```
|
||||
$ free -m
|
||||
total used free shared buff/cache available
|
||||
Mem: 1993 1681 82 81 228 153
|
||||
Swap: 12689 1213 11475
|
||||
|
||||
$ free -g
|
||||
total used free shared buff/cache available
|
||||
Mem: 1 1 0 0 0 0
|
||||
Swap: 12 1 11
|
||||
|
||||
```
|
||||
|
||||
### 方法-2 : 使用 /proc/meminfo 文件
|
||||
|
||||
/proc/meminfo 是一个虚拟文本文件,它包含有关系统 RAM 使用情况的大量有价值的信息。
|
||||
|
||||
它报告系统上的空闲和已用内存(物理和交换)的数量。
|
||||
```
|
||||
$ grep MemTotal /proc/meminfo
|
||||
MemTotal: 2041396 kB
|
||||
|
||||
$ grep MemTotal /proc/meminfo | awk '{print $2 / 1024}'
|
||||
1993.55
|
||||
|
||||
$ grep MemTotal /proc/meminfo | awk '{print $2 / 1024 / 1024}'
|
||||
1.94683
|
||||
|
||||
```
|
||||
|
||||
### 方法-3 : 使用 top 命令
|
||||
|
||||
Top 命令是 Linux 中监视实时系统进程的基本命令之一。它显示系统信息和运行的进程信息,如正常运行时间,平均负载,正在运行的任务,登录的用户数,CPU 数量和 CPU 利用率,以及内存和交换信息。运行 top 命令,然后按下 `E` 来使内存利用率以 MB 为单位。
|
||||
|
||||
**建议阅读:** [TOP 命令示例监视服务器性能][2]
|
||||
```
|
||||
$ top
|
||||
|
||||
top - 14:38:36 up 1:59, 1 user, load average: 1.83, 1.60, 1.52
|
||||
Tasks: 223 total, 2 running, 221 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu(s): 48.6 us, 11.2 sy, 0.0 ni, 39.3 id, 0.3 wa, 0.0 hi, 0.5 si, 0.0 st
|
||||
MiB Mem : 1993.551 total, 94.184 free, 1647.367 used, 252.000 buff/cache
|
||||
MiB Swap: 12689.58+total, 11196.83+free, 1492.750 used. 306.465 avail Mem
|
||||
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
9908 daygeek 20 0 2971440 649324 39700 S 55.8 31.8 11:45.74 Web Content
|
||||
21942 daygeek 20 0 2013760 308700 69272 S 35.0 15.1 4:13.75 Web Content
|
||||
4782 daygeek 20 0 3687116 227336 39156 R 14.5 11.1 16:47.45 gnome-shell
|
||||
|
||||
```
|
||||
|
||||
### 方法-4 : 使用 vmstat 命令
|
||||
|
||||
vmstat 是一个标准且漂亮的工具,它报告 Linux 系统的虚拟内存统计信息。vmstat 报告有关进程,内存,分页,块 IO,陷阱和 CPU 活动的信息。它有助于 Linux 管理员在故障检修时识别系统瓶颈。
|
||||
|
||||
**建议阅读:** [vmstat – 一个报告虚拟内存统计信息的标准且漂亮的工具][3]
|
||||
```
|
||||
$ vmstat -s | grep "total memory"
|
||||
2041396 K total memory
|
||||
|
||||
$ vmstat -s -S M | egrep -ie 'total memory'
|
||||
1993 M total memory
|
||||
|
||||
$ vmstat -s | awk '{print $1 / 1024 / 1024}' | head -1
|
||||
1.94683
|
||||
|
||||
```
|
||||
|
||||
### 方法-5 : 使用 nmon 命令
|
||||
|
||||
nmon 是另一个很棒的工具,用于监视各种系统资源,如 CPU,内存,网络,磁盘,文件系统,NFS,top 进程,Power 微分区和 Linux 终端上的资源(Linux 版本和处理器)。
|
||||
|
||||
只需按下 `m` 键,即可查看内存利用率统计数据(缓存,活动,非活动,缓冲,空闲,以 MB 和百分比为单位)。
|
||||
|
||||
**建议阅读:** [nmon – Linux 中一个监视系统资源的漂亮的工具][4]
|
||||
```
|
||||
┌nmon─14g──────[H for help]───Hostname=2daygeek──Refresh= 2secs ───07:24.44─────────────────┐
|
||||
│ Memory Stats ─────────────────────────────────────────────────────────────────────────────│
|
||||
│ RAM High Low Swap Page Size=4 KB │
|
||||
│ Total MB 32079.5 -0.0 -0.0 20479.0 │
|
||||
│ Free MB 11205.0 -0.0 -0.0 20479.0 │
|
||||
│ Free Percent 34.9% 100.0% 100.0% 100.0% │
|
||||
│ MB MB MB │
|
||||
│ Cached= 19763.4 Active= 9617.7 │
|
||||
│ Buffers= 172.5 Swapcached= 0.0 Inactive = 10339.6 │
|
||||
│ Dirty = 0.0 Writeback = 0.0 Mapped = 11.0 │
|
||||
│ Slab = 636.6 Commit_AS = 118.2 PageTables= 3.5 │
|
||||
│───────────────────────────────────────────────────────────────────────────────────────────│
|
||||
│ │
|
||||
│ │
|
||||
│ │
|
||||
│ │
|
||||
│ │
|
||||
│ │
|
||||
└───────────────────────────────────────────────────────────────────────────────────────────┘
|
||||
|
||||
```
|
||||
|
||||
### 方法-6 : 使用 dmidecode 命令
|
||||
|
||||
Dmidecode 是一个读取计算机 DMI表内容的工具,它以人类可读的格式显示系统硬件信息。(DMI 代表桌面管理接口,有人说 SMBIOS 代表系统管理 BIOS)
|
||||
|
||||
此表包含系统硬件组件的描述,以及其它有用信息,如序列号,制造商信息,发布日期和 BIOS 修改等。
|
||||
|
||||
**建议阅读:**
|
||||
[Dmidecode – 获取 Linux 系统硬件信息的简便方法][5]
|
||||
```
|
||||
# dmidecode -t memory | grep Size:
|
||||
Size: 8192 MB
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: 8192 MB
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: 8192 MB
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: 8192 MB
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
|
||||
```
|
||||
|
||||
只打印已安装的 RAM 模块。
|
||||
```
|
||||
|
||||
# dmidecode -t memory | grep Size: | grep -v "No Module Installed"
|
||||
Size: 8192 MB
|
||||
Size: 8192 MB
|
||||
Size: 8192 MB
|
||||
Size: 8192 MB
|
||||
|
||||
```
|
||||
|
||||
汇总所有已安装的 RAM 模块。
|
||||
```
|
||||
# dmidecode -t memory | grep Size: | grep -v "No Module Installed" | awk '{sum+=$2}END{print sum}'
|
||||
32768
|
||||
|
||||
```
|
||||
|
||||
### 方法-7 : 使用 hwinfo 命令
|
||||
|
||||
hwinfo 代表硬件信息,它是另一个很棒的实用工具,用于探测系统中存在的硬件,并以人类可读的格式显示有关各种硬件组件的详细信息。
|
||||
|
||||
它报告有关 CPU,RAM,键盘,鼠标,图形卡,声音,存储,网络接口,磁盘,分区,BIOS 和网桥等的信息。
|
||||
|
||||
**建议阅读:** [hwinfo(硬件信息)– 一个在 Linux 系统上检测系统硬件信息的好工具][6]
|
||||
```
|
||||
$ hwinfo --memory
|
||||
01: None 00.0: 10102 Main Memory
|
||||
[Created at memory.74]
|
||||
Unique ID: rdCR.CxwsZFjVASF
|
||||
Hardware Class: memory
|
||||
Model: "Main Memory"
|
||||
Memory Range: 0x00000000-0x7a4abfff (rw)
|
||||
Memory Size: 1 GB + 896 MB
|
||||
Config Status: cfg=new, avail=yes, need=no, active=unknown
|
||||
|
||||
```
|
||||
|
||||
### 方法-8 : 使用 lshw 命令
|
||||
|
||||
lshw(代表 Hardware Lister)是一个小巧的工具,可以生成机器上各种硬件组件的详细报告,如内存配置,固件版本,主板配置,CPU 版本和速度,缓存配置,USB,网卡,显卡,多媒体,打印机,总线速度等。
|
||||
|
||||
它通过读取 /proc 目录和 DMI 表中的各种文件来生成硬件信息。
|
||||
|
||||
**建议阅读:** [LSHW (Hardware Lister) – 一个在 Linux 上获取硬件信息的好工具][7]
|
||||
```
|
||||
$ sudo lshw -short -class memory
|
||||
[sudo] password for daygeek:
|
||||
H/W path Device Class Description
|
||||
==================================================
|
||||
/0/0 memory 128KiB BIOS
|
||||
/0/1 memory 1993MiB System memory
|
||||
|
||||
```
|
||||
|
||||
### 方法-9 : 使用 inxi 命令
|
||||
|
||||
inxi 是一个很棒的工具,它可以检查 Linux 上的硬件信息,并提供了大量的选项来获取 Linux 系统上的所有硬件信息,这些特性是我在 Linux 上的其它工具中从未发现的。它是从 locsmif 编写的古老的但至今看来都异常灵活的 infobash 演化而来的。
|
||||
|
||||
inxi 是一个脚本,它可以快速显示系统硬件,CPU,驱动程序,Xorg,桌面,内核,GCC 版本,进程,RAM 使用情况以及各种其它有用的信息,还可以用于论坛技术支持和调试工具。
|
||||
|
||||
**建议阅读:** [inxi – 一个检查 Linux 上硬件信息的好工具][8]
|
||||
```
|
||||
$ inxi -F | grep "Memory"
|
||||
Info: Processes: 234 Uptime: 3:10 Memory: 1497.3/1993.6MB Client: Shell (bash) inxi: 2.3.37
|
||||
|
||||
```
|
||||
|
||||
### 方法-10 : 使用 screenfetch 命令
|
||||
|
||||
screenFetch 是一个 bash 脚本。它将自动检测你的发行版,并在右侧显示该发行版标识的 ASCII 艺术版本和一些有价值的信息。
|
||||
|
||||
**建议阅读:** [ScreenFetch – 以 ASCII 艺术标志在终端显示 Linux 系统信息][9]
|
||||
```
|
||||
$ screenfetch
|
||||
./+o+- [email protected]
|
||||
yyyyy- -yyyyyy+ OS: Ubuntu 17.10 artful
|
||||
://+//////-yyyyyyo Kernel: x86_64 Linux 4.13.0-37-generic
|
||||
.++ .:/++++++/-.+sss/` Uptime: 44m
|
||||
.:++o: /++++++++/:--:/- Packages: 1831
|
||||
o:+o+:++.`..```.-/oo+++++/ Shell: bash 4.4.12
|
||||
.:+o:+o/. `+sssoo+/ Resolution: 1920x955
|
||||
.++/+:+oo+o:` /sssooo. DE: GNOME
|
||||
/+++//+:`oo+o /::--:. WM: GNOME Shell
|
||||
\+/+o+++`o++o ++////. WM Theme: Adwaita
|
||||
.++.o+++oo+:` /dddhhh. GTK Theme: Azure [GTK2/3]
|
||||
.+.o+oo:. `oddhhhh+ Icon Theme: Papirus-Dark
|
||||
\+.++o+o``-````.:ohdhhhhh+ Font: Ubuntu 11
|
||||
`:o+++ `ohhhhhhhhyo++os: CPU: Intel Core i7-6700HQ @ 2x 2.592GHz
|
||||
.o:`.syhhhhhhh/.oo++o` GPU: llvmpipe (LLVM 5.0, 256 bits)
|
||||
/osyyyyyyo++ooo+++/ RAM: 1521MiB / 1993MiB
|
||||
````` +oo+++o\:
|
||||
`oo++.
|
||||
|
||||
```
|
||||
|
||||
### 方法-11 : 使用 neofetch 命令
|
||||
|
||||
Neofetch 是一个跨平台且易于使用的命令行(CLI)脚本,它收集你的 Linux 系统信息,并将其作为一张图片显示在终端上,也可以是你的发行版徽标,或者是你选择的任何 ascii 艺术。
|
||||
|
||||
**建议阅读:** [Neofetch – 以 ASCII 分发标志来显示 Linux 系统信息][10]
|
||||
```
|
||||
$ neofetch
|
||||
.-/+oossssoo+/-. [email protected]
|
||||
`:+ssssssssssssssssss+:` --------------
|
||||
-+ssssssssssssssssssyyssss+- OS: Ubuntu 17.10 x86_64
|
||||
.ossssssssssssssssssdMMMNysssso. Host: VirtualBox 1.2
|
||||
/ssssssssssshdmmNNmmyNMMMMhssssss/ Kernel: 4.13.0-37-generic
|
||||
+ssssssssshmydMMMMMMMNddddyssssssss+ Uptime: 47 mins
|
||||
/sssssssshNMMMyhhyyyyhmNMMMNhssssssss/ Packages: 1832
|
||||
.ssssssssdMMMNhsssssssssshNMMMdssssssss. Shell: bash 4.4.12
|
||||
+sssshhhyNMMNyssssssssssssyNMMMysssssss+ Resolution: 1920x955
|
||||
ossyNMMMNyMMhsssssssssssssshmmmhssssssso DE: ubuntu:GNOME
|
||||
ossyNMMMNyMMhsssssssssssssshmmmhssssssso WM: GNOME Shell
|
||||
+sssshhhyNMMNyssssssssssssyNMMMysssssss+ WM Theme: Adwaita
|
||||
.ssssssssdMMMNhsssssssssshNMMMdssssssss. Theme: Azure [GTK3]
|
||||
/sssssssshNMMMyhhyyyyhdNMMMNhssssssss/ Icons: Papirus-Dark [GTK3]
|
||||
+sssssssssdmydMMMMMMMMddddyssssssss+ Terminal: gnome-terminal
|
||||
/ssssssssssshdmNNNNmyNMMMMhssssss/ CPU: Intel i7-6700HQ (2) @ 2.591GHz
|
||||
.ossssssssssssssssssdMMMNysssso. GPU: VirtualBox Graphics Adapter
|
||||
-+sssssssssssssssssyyyssss+- Memory: 1620MiB / 1993MiB
|
||||
`:+ssssssssssssssssss+:`
|
||||
.-/+oossssoo+/-.
|
||||
|
||||
```
|
||||
|
||||
### 方法-12 : 使用 dmesg 命令
|
||||
|
||||
dmesg(代表显示消息或驱动消息)是大多数类 unix 操作系统上的命令,用于打印内核的消息缓冲区。
|
||||
```
|
||||
$ dmesg | grep "Memory"
|
||||
[ 0.000000] Memory: 1985916K/2096696K available (12300K kernel code, 2482K rwdata, 4000K rodata, 2372K init, 2368K bss, 110780K reserved, 0K cma-reserved)
|
||||
[ 0.012044] x86/mm: Memory block size: 128MB
|
||||
|
||||
```
|
||||
|
||||
### 方法-13 : 使用 atop 命令
|
||||
|
||||
Atop 是一个用于 Linux 的 ASCII 全屏系统性能监视工具,它能报告所有服务器进程的活动(即使进程在间隔期间已经完成)。
|
||||
|
||||
它记录系统和进程活动以进行长期分析(默认情况下,日志文件保存 28 天),通过使用颜色等来突出显示过载的系统资源。它结合可选的内核模块 netatop 显示每个进程或线程的网络活动。
|
||||
|
||||
**建议阅读:** [Atop – 实时监控系统性能,资源,进程和检查资源利用历史][11]
|
||||
```
|
||||
$ atop -m
|
||||
|
||||
ATOP - ubuntu 2018/03/31 19:34:08 ------------- 10s elapsed
|
||||
PRC | sys 0.47s | user 2.75s | | | #proc 219 | #trun 1 | #tslpi 802 | #tslpu 0 | #zombie 0 | clones 7 | | | #exit 4 |
|
||||
CPU | sys 7% | user 22% | irq 0% | | | idle 170% | wait 0% | | steal 0% | guest 0% | | curf 2.59GHz | curscal ?% |
|
||||
cpu | sys 3% | user 11% | irq 0% | | | idle 85% | cpu001 w 0% | | steal 0% | guest 0% | | curf 2.59GHz | curscal ?% |
|
||||
cpu | sys 4% | user 11% | irq 0% | | | idle 85% | cpu000 w 0% | | steal 0% | guest 0% | | curf 2.59GHz | curscal ?% |
|
||||
CPL | avg1 1.98 | | avg5 3.56 | avg15 3.20 | | | csw 14894 | | intr 6610 | | | numcpu 2 | |
|
||||
MEM | tot 1.9G | free 101.7M | cache 244.2M | dirty 0.2M | buff 6.9M | slab 92.9M | slrec 35.6M | shmem 97.8M | shrss 21.0M | shswp 3.2M | vmbal 0.0M | hptot 0.0M | hpuse 0.0M |
|
||||
SWP | tot 12.4G | free 11.6G | | | | | | | | | vmcom 7.9G | | vmlim 13.4G |
|
||||
PAG | scan 0 | steal 0 | | stall 0 | | | | | | | swin 3 | | swout 0 |
|
||||
DSK | sda | busy 0% | | read 114 | write 37 | KiB/r 21 | KiB/w 6 | | MBr/s 0.2 | MBw/s 0.0 | avq 6.50 | | avio 0.26 ms |
|
||||
NET | transport | tcpi 11 | tcpo 17 | udpi 4 | udpo 8 | tcpao 3 | tcppo 0 | | tcprs 3 | tcpie 0 | tcpor 0 | udpnp 0 | udpie 0 |
|
||||
NET | network | ipi 20 | | ipo 33 | ipfrw 0 | deliv 20 | | | | | icmpi 5 | | icmpo 0 |
|
||||
NET | enp0s3 0% | pcki 11 | pcko 28 | sp 1000 Mbps | si 1 Kbps | so 1 Kbps | | coll 0 | mlti 0 | erri 0 | erro 0 | drpi 0 | drpo 0 |
|
||||
NET | lo ---- | pcki 9 | pcko 9 | sp 0 Mbps | si 0 Kbps | so 0 Kbps | | coll 0 | mlti 0 | erri 0 | erro 0 | drpi 0 | drpo 0 |
|
||||
|
||||
PID TID MINFLT MAJFLT VSTEXT VSLIBS VDATA VSTACK VSIZE RSIZE PSIZE VGROW RGROW SWAPSZ RUID EUID MEM CMD 1/1
|
||||
2536 - 941 0 188K 127.3M 551.2M 144K 2.3G 281.2M 0K 0K 344K 6556K daygeek daygeek 14% Web Content
|
||||
2464 - 75 0 188K 187.7M 680.6M 132K 2.3G 226.6M 0K 0K 212K 42088K daygeek daygeek 11% firefox
|
||||
2039 - 4199 6 16K 163.6M 423.0M 132K 3.5G 220.2M 0K 0K 2936K 109.6M daygeek daygeek 11% gnome-shell
|
||||
10822 - 1 0 4K 16680K 377.0M 132K 3.4G 193.4M 0K 0K 0K 0K root root 10% java
|
||||
|
||||
```
|
||||
|
||||
### 方法-14 : 使用 htop 命令
|
||||
|
||||
htop 是由 Hisham 用 ncurses 库开发的用于 Linux 的交互式进程查看器。与 top 命令相比,htop 有许多特性和选项。
|
||||
|
||||
**建议阅读:** [使用 Htop 命令监视系统资源][12]
|
||||
```
|
||||
$ htop
|
||||
|
||||
1 [||||||||||||| 13.0%] Tasks: 152, 587 thr; 1 running
|
||||
2 [||||||||||||||||||||||||| 25.0%] Load average: 0.91 2.03 2.66
|
||||
Mem[||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||1.66G/1.95G] Uptime: 01:14:53
|
||||
Swp[|||||| 782M/12.4G]
|
||||
|
||||
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
|
||||
2039 daygeek 20 0 3541M 214M 46728 S 36.6 10.8 22:36.77 /usr/bin/gnome-shell
|
||||
2045 daygeek 20 0 3541M 214M 46728 S 10.3 10.8 3:02.92 /usr/bin/gnome-shell
|
||||
2046 daygeek 20 0 3541M 214M 46728 S 8.3 10.8 3:04.96 /usr/bin/gnome-shell
|
||||
6080 daygeek 20 0 807M 37228 24352 S 2.1 1.8 0:11.99 /usr/lib/gnome-terminal/gnome-terminal-server
|
||||
2880 daygeek 20 0 2205M 164M 17048 S 2.1 8.3 7:16.50 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51:0|57:128|58:10000|63:0|65:400|66
|
||||
6125 daygeek 20 0 1916M 159M 92352 S 2.1 8.0 2:09.14 /usr/lib/firefox/firefox -contentproc -childID 7 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51:0|57:128|58:10000|63:0|65:400|66
|
||||
2536 daygeek 20 0 2335M 243M 26792 S 2.1 12.2 6:25.77 /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51:0|57:128|58:10000|63:0|65:400|66
|
||||
2653 daygeek 20 0 2237M 185M 20788 S 1.4 9.3 3:01.76 /usr/lib/firefox/firefox -contentproc -childID 4 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51:0|57:128|58:10000|63:0|65:400|66
|
||||
|
||||
```
|
||||
|
||||
### 方法-15 : 使用 corefreq 实用程序
|
||||
|
||||
CoreFreq 是为 Intel 64 位处理器设计的 CPU 监控软件,支持的架构有 Atom,Core2,Nehalem,SandyBridge 和 superior,AMD 家族。(to 校正:这里 OF 最后什么意思)
|
||||
|
||||
CoreFreq 提供了一个框架来以高精确度检索 CPU 数据。
|
||||
|
||||
**建议阅读:** [CoreFreq – 一个用于 Linux 系统的强大的 CPU 监控工具][13]
|
||||
```
|
||||
$ ./corefreq-cli -k
|
||||
Linux:
|
||||
|- Release [4.13.0-37-generic]
|
||||
|- Version [#42-Ubuntu SMP Wed Mar 7 14:13:23 UTC 2018]
|
||||
|- Machine [x86_64]
|
||||
Memory:
|
||||
|- Total RAM 2041396 KB
|
||||
|- Shared RAM 99620 KB
|
||||
|- Free RAM 108428 KB
|
||||
|- Buffer RAM 8108 KB
|
||||
|- Total High 0 KB
|
||||
|- Free High 0 KB
|
||||
|
||||
$ ./corefreq-cli -k | grep "Total RAM" | awk '{print $4 / 1024 }'
|
||||
1993.55
|
||||
|
||||
$ ./corefreq-cli -k | grep "Total RAM" | awk '{print $4 / 1024 / 1024}'
|
||||
1.94683
|
||||
|
||||
```
|
||||
|
||||
### 方法-16 : 使用 glances 命令
|
||||
|
||||
Glances 是用 Python 编写的跨平台基于 curses(LCTT 译注:curses 是一个 Linux/Unix 下的图形函数库)的系统监控工具。我们可以说一物俱全,就像在最小的空间含有最大的信息。它使用 psutil 库从系统中获取信息。
|
||||
|
||||
Glances 可以监视 CPU,内存,负载,进程列表,网络接口,磁盘 I/O,Raid,传感器,文件系统(和文件夹),Docker,监视器,警报,系统信息,正常运行时间,快速预览(CPU,内存,负载)等。
|
||||
|
||||
**建议阅读:** [Glances (一物俱全)– 一个 Linux 的高级的实时系统性能监控工具][14]
|
||||
```
|
||||
$ glances
|
||||
|
||||
ubuntu (Ubuntu 17.10 64bit / Linux 4.13.0-37-generic) - IP 192.168.1.6/24 Uptime: 1:08:40
|
||||
|
||||
CPU [|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 90.6%] CPU - 90.6% nice: 0.0% ctx_sw: 4K MEM \ 78.4% active: 942M SWAP - 5.9% LOAD 2-core
|
||||
MEM [||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 78.0%] user: 55.1% irq: 0.0% inter: 1797 total: 1.95G inactive: 562M total: 12.4G 1 min: 4.35
|
||||
SWAP [|||| 5.9%] system: 32.4% iowait: 1.8% sw_int: 897 used: 1.53G buffers: 14.8M used: 749M 5 min: 4.38
|
||||
idle: 7.6% steal: 0.0% free: 431M cached: 273M free: 11.7G 15 min: 3.38
|
||||
|
||||
NETWORK Rx/s Tx/s TASKS 211 (735 thr), 4 run, 207 slp, 0 oth sorted automatically by memory_percent, flat view
|
||||
docker0 0b 232b
|
||||
enp0s3 12Kb 4Kb Systemd 7 Services loaded: 197 active: 196 failed: 1
|
||||
lo 616b 616b
|
||||
_h478e48e 0b 232b CPU% MEM% VIRT RES PID USER NI S TIME+ R/s W/s Command
|
||||
63.8 18.9 2.33G 377M 2536 daygeek 0 R 5:57.78 0 0 /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
DefaultGateway 83ms 78.5 10.9 3.46G 217M 2039 daygeek 0 S 21:07.46 0 0 /usr/bin/gnome-shell
|
||||
8.5 10.1 2.32G 201M 2464 daygeek 0 S 8:45.69 0 0 /usr/lib/firefox/firefox -new-window
|
||||
DISK I/O R/s W/s 1.1 8.5 2.19G 170M 2653 daygeek 0 S 2:56.29 0 0 /usr/lib/firefox/firefox -contentproc -childID 4 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
dm-0 0 0 1.7 7.2 2.15G 143M 2880 daygeek 0 S 7:10.46 0 0 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
sda1 9.46M 12K 0.0 4.9 1.78G 97.2M 6125 daygeek 0 S 1:36.57 0 0 /usr/lib/firefox/firefox -contentproc -childID 7 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
|
||||
```
|
||||
|
||||
### 方法-17 : 使用 gnome-system-monitor
|
||||
|
||||
系统监视器是一个管理正在运行的进程和监视系统资源的工具。它向你显示正在运行的程序以及耗费的处理器时间,内存和磁盘空间。
|
||||
![][16]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/easy-ways-to-check-size-of-physical-memory-ram-in-linux/
|
||||
|
||||
作者:[Ramya Nuvvula][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/ramya/
|
||||
[1]:https://www.2daygeek.com/free-command-to-check-memory-usage-statistics-in-linux/
|
||||
[2]:https://www.2daygeek.com/top-command-examples-to-monitor-server-performance/
|
||||
[3]:https://www.2daygeek.com/linux-vmstat-command-examples-tool-report-virtual-memory-statistics/
|
||||
[4]:https://www.2daygeek.com/nmon-system-performance-monitor-system-resources-on-linux/
|
||||
[5]:https://www.2daygeek.com/dmidecode-get-print-display-check-linux-system-hardware-information/
|
||||
[6]:https://www.2daygeek.com/hwinfo-check-display-detect-system-hardware-information-linux/
|
||||
[7]:https://www.2daygeek.com/lshw-find-check-system-hardware-information-details-linux/
|
||||
[8]:https://www.2daygeek.com/inxi-system-hardware-information-on-linux/
|
||||
[9]:https://www.2daygeek.com/screenfetch-display-linux-systems-information-ascii-distribution-logo-terminal/
|
||||
[10]:https://www.2daygeek.com/neofetch-display-linux-systems-information-ascii-distribution-logo-terminal/
|
||||
[11]:https://www.2daygeek.com/atop-system-process-performance-monitoring-tool/
|
||||
[12]:https://www.2daygeek.com/htop-command-examples-to-monitor-system-resources/
|
||||
[13]:https://www.2daygeek.com/corefreq-linux-cpu-monitoring-tool/
|
||||
[14]:https://www.2daygeek.com/install-glances-advanced-real-time-linux-system-performance-monitoring-tool-on-centos-fedora-ubuntu-debian-opensuse-arch-linux/
|
||||
[15]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[16]:https://www.2daygeek.com/wp-content/uploads/2018/03/check-memory-information-using-gnome-system-monitor.png
|
||||
@ -0,0 +1,124 @@
|
||||
服务器的 LinuxBoot:告别 UEFI、拥抱开源
|
||||
============================================================
|
||||
|
||||
[LinuxBoot][13] 是私有的 [UEFI][15] 固件的 [替代者][14]。它发布于去年,并且现在已经得到主流的硬件生产商的认可成为他们产品的默认固件。去年,LinuxBoot 已经被 Linux 基金会接受并[纳入][16]开源家族。
|
||||
|
||||
这个项目最初是由 Ron Minnich 在 2017 年 1 月提出,它是 LinuxBIOS 的创造人,并且在 Google 领导 [coreboot][17] 的工作。
|
||||
|
||||
Google、Facebook、[Horizon 计算解决方案][18]、和 [Two Sigma][19] 共同合作,在运行 Linux 的服务器上开发 [LinuxBoot 项目][20](以前叫 [NERF][21])。
|
||||
|
||||
它开放允许服务器用户去很容易地定制他们自己的引导脚本、修复问题、构建他们自己的[运行时][22] 和用他们自己的密钥去 [刷入固件][23]。他们不需要等待供应商的更新。
|
||||
|
||||
下面是第一次使用 NERF BIOS 去引导 [Ubuntu Xenial][24] 的视频:
|
||||
|
||||
[点击看视频](https://youtu.be/HBkZAN3xkJg)
|
||||
|
||||
我们来讨论一下它与 UEFI 相比在服务器硬件方面的其它优势。
|
||||
|
||||
### LinuxBoot 超越 UEFI 的优势
|
||||
|
||||

|
||||
|
||||
下面是一些 LinuxBoot 超越 UEFI 的主要优势:
|
||||
|
||||
### 启动速度显著加快
|
||||
|
||||
它能在 20 秒钟以内完成服务器启动,而 UEFI 需要几分钟的时间。
|
||||
|
||||
### 显著的灵活性
|
||||
|
||||
LinuxBoot 可以用在各种设备、文件系统和 Linux 支持的协议上。
|
||||
|
||||
### 更加安全
|
||||
|
||||
相比 UEFI 而言,LinuxBoot 在设备驱动程序和文件系统方面进行更加严格的检查。
|
||||
|
||||
我们可能主张 UEFI 是使用 [EDK II][25] 而部分开源的,而 LinuxBoot 是部分闭源的。但有人[提出][26],即便有像 EDK II 这样的代码,但也没有做适当的审查级别和像 [Linux 内核][27] 那样的正确性检查,并且在 UEFI 的开发中还大量使用闭源组件。
|
||||
|
||||
其它方面,LinuxBoot 有非常少的二进制文件,它仅用了大约一百多 KB,相比而言,UEFI 的二进制文件有 32 MB。
|
||||
|
||||
严格来说,LinuxBoot 与 UEFI 不一样,更适合于[可信计算基础][28]。
|
||||
|
||||
[建议阅读 Linux 上最好的自由开源的 Adobe 产品的替代者][29]
|
||||
|
||||
LinuxBoot 有一个基于 [kexec][30] 的引导加载器,它不支持启动 Windows/非 Linux 内核,但这影响并不大,因为主流的云都是基于 Linux 的服务器。
|
||||
|
||||
### LinuxBoot 的采用者
|
||||
|
||||
自 2011 年, [Facebook][32] 发起了[开源计算项目][31],它的一些服务器是基于[开源][33]设计的,目的是构建的数据中心更加高效。LinuxBoot 已经在下面列出的几个开源计算硬件上做了测试:
|
||||
|
||||
* Winterfell
|
||||
|
||||
* Leopard
|
||||
|
||||
* Tioga Pass
|
||||
|
||||
更多 [OCP][34] 硬件在[这里][35]有一个简短的描述。OCP 基金会通过[开源系统固件][36]运行一个专门的固件项目。
|
||||
|
||||
支持 LinuxBoot 的其它一些设备有:
|
||||
|
||||
* [QEMU][9] 仿真的 [Q35][10] 系统
|
||||
|
||||
* [Intel S2600wf][11]
|
||||
|
||||
* [Dell R630][12]
|
||||
|
||||
上个月底(2018 年 9 月 24 日),[Equus 计算解决方案][37] [宣布][38] 发行它的 [白盒开放式™][39] M2660 和 M2760 服务器,作为它们的定制的、成本优化的、开放硬件服务器和存储平台的一部分。它们都支持 LinuxBoot 灵活定制服务器的 BIOS,以提升安全性和设计一个非常快的纯净的引导体验。
|
||||
|
||||
### 你认为 LinuxBoot 怎么样?
|
||||
|
||||
LinuxBoot 在 [GitHub][40] 上有很丰富的文档。你喜欢它与 UEFI 不同的特性吗?由于 LinuxBoot 的开放式开发和未来,你愿意使用 LinuxBoot 而不是 UEFI 去启动你的服务器吗?请在下面的评论区告诉我们吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/linuxboot-uefi/
|
||||
|
||||
作者:[ Avimanyu Bandyopadhyay][a]
|
||||
选题:[oska874][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/avimanyu/
|
||||
[b]:https://github.com/oska874
|
||||
[1]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[2]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[3]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[4]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[5]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[6]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[7]:https://itsfoss.com/author/avimanyu/
|
||||
[8]:https://itsfoss.com/linuxboot-uefi/#comments
|
||||
[9]:https://en.wikipedia.org/wiki/QEMU
|
||||
[10]:https://wiki.qemu.org/Features/Q35
|
||||
[11]:https://trmm.net/S2600
|
||||
[12]:https://trmm.net/NERF#Installing_on_a_Dell_R630
|
||||
[13]:https://www.linuxboot.org/
|
||||
[14]:https://www.phoronix.com/scan.php?page=news_item&px=LinuxBoot-OSFC-2018-State
|
||||
[15]:https://itsfoss.com/check-uefi-or-bios/
|
||||
[16]:https://www.linuxfoundation.org/blog/2018/01/system-startup-gets-a-boost-with-new-linuxboot-project/
|
||||
[17]:https://en.wikipedia.org/wiki/Coreboot
|
||||
[18]:http://www.horizon-computing.com/
|
||||
[19]:https://www.twosigma.com/
|
||||
[20]:https://trmm.net/LinuxBoot_34c3
|
||||
[21]:https://trmm.net/NERF
|
||||
[22]:https://trmm.net/LinuxBoot_34c3#Runtimes
|
||||
[23]:http://www.tech-faq.com/flashing-firmware.html
|
||||
[24]:https://itsfoss.com/features-ubuntu-1604/
|
||||
[25]:https://www.tianocore.org/
|
||||
[26]:https://media.ccc.de/v/34c3-9056-bringing_linux_back_to_server_boot_roms_with_nerf_and_heads
|
||||
[27]:https://medium.com/@bhumikagoyal/linux-kernel-development-cycle-52b4c55be06e
|
||||
[28]:https://en.wikipedia.org/wiki/Trusted_computing_base
|
||||
[29]:https://itsfoss.com/adobe-alternatives-linux/
|
||||
[30]:https://en.wikipedia.org/wiki/Kexec
|
||||
[31]:https://en.wikipedia.org/wiki/Open_Compute_Project
|
||||
[32]:https://github.com/facebook
|
||||
[33]:https://github.com/opencomputeproject
|
||||
[34]:https://www.networkworld.com/article/3266293/lan-wan/what-is-the-open-compute-project.html
|
||||
[35]:http://hyperscaleit.com/ocp-server-hardware/
|
||||
[36]:https://www.opencompute.org/projects/open-system-firmware
|
||||
[37]:https://www.equuscs.com/
|
||||
[38]:http://www.dcvelocity.com/products/Software_-_Systems/20180924-equus-compute-solutions-introduces-whitebox-open-m2660-and-m2760-servers/
|
||||
[39]:https://www.equuscs.com/servers/whitebox-open/
|
||||
[40]:https://github.com/linuxboot/linuxboot
|
||||
@ -0,0 +1,104 @@
|
||||
2018 重温 Unix 哲学
|
||||
======
|
||||
在现代微服务环境中,构建小型,集中应用程序的旧策略又再一次流行了起来。
|
||||

|
||||
|
||||
1984年,Rob Pike 和 Brian W 在 AT&T 贝尔实验室技术期刊上发表了名为 “[Unix 环境编程][1]” 的文章,其中他们使用 BSD 的 **cat -v** 例子来认证 Unix 哲学。简而言之,Unix 哲学是:构建小型,单一的应用程序——不管用什么语言——只做一件小而美的事情,用 **stdin** / **stdout** 进行通信,并通过管道进行连接。
|
||||
|
||||
听起来是不是有点耳熟?
|
||||
|
||||
是的,我也这么认为。这就是 James Lewis 和 Martin Fowler 给出的 [微服务的定义][2] 。
|
||||
|
||||
> 简单来说,微服务架构的风格是将应用程序开发为一套单一,小型服务的方法,每个服务都运行在它的进程中,并用轻量级机制进行通信,通常是 HTTP 资源 API 。
|
||||
|
||||
虽然一个 *nix 程序或者是一个微服务本身可能非常局限甚至不是很有趣,但是当这些独立工作的单元组合在一起的时候就显示出了它们真正的好处和强大。
|
||||
|
||||
### *nix程序 vs 微服务
|
||||
|
||||
下面的表格对比了 *nix 环境中的程序(例如 **cat** 或 **lsof**)与微服务环境中的程序。
|
||||
|
||||
| | *nix 程序 | 微服务 |
|
||||
| ----------------------------------- | -------------------------- | ---------------------------------- |
|
||||
| 执行单元 | 程序使用 `stdin/stdout` | 使用 HTTP 或 gRPC API |
|
||||
| 数据流 | 管道 | ? |
|
||||
| 可配置和参数化 | 命令行参数 | |
|
||||
| 环境变量和配置文件 | JSON/YAML 文档 | |
|
||||
| 发现 | 包管理器, man, make | DNS, 环境变量, OpenAPI |
|
||||
|
||||
让我们详细的看看每一行。
|
||||
|
||||
#### 执行单元
|
||||
|
||||
*nix 系统(像 Linux)中的执行单元是一个可执行的文件(二进制或者是脚本),理想情况下,它们从 `stdin` 读取输入并将输出写入 `stdout`。而微服务通过暴露一个或多个通信接口来提供服务,比如 HTTP 和 gRPC APIs。在这两种情况下,你都会发现无状态示例(本质上是纯函数行为)和有状态示例,除了输入之外,还有一些内部(持久)状态决定发生了什么。
|
||||
|
||||
#### 数据流
|
||||
|
||||
传统的,*nix 程序能够通过管道进行通信。换名话说,我们要感谢 [Doug McIlroy][3],你不需要创建临时文件来传递,而可以在每个进程之间处理无穷无尽的数据流。据我所知,除了 [2017 年做的基于 `Apache Kafka` 小实验][4],没有什么能比得上管道化的微服务了。
|
||||
|
||||
#### 可配置和参数化
|
||||
|
||||
你是如何配置程序或者服务的,无论是永久性的服务还是即时的服务?是的,在 *nix 系统上,你通常有三种方法:命令行参数,环境变量,或全面化的配置文件。在微服务架构中,典型的做法是用 YAML ( 或者甚至是worse,JSON ) 文档,定制好一个服务的布局和配置以及依赖的组件和通信,存储,和运行时配置。例如 [ Kubernetes 资源定义][5],[Nomad 工作规范][6],或 [Docker 组件][7] 文档。这些可能参数化也可能不参数化;也就是说,除非你知道一些模板语言,像 Kubernetes 中的 [Helm][8],否则你会发现你使用了很多 **sed -i** 这样的命令。
|
||||
|
||||
#### 发现
|
||||
|
||||
你怎么知道有哪些程序和服务可用,以及如何使用它们?在 *nix 系统中通常都有一个包管理器和一个很好用的 man 页面;使用他们,应该能够回答你所有的问题。在微服务的设置中,在寻找一个服务的时候会相对更自动化一些。除了像 [Airbnb 的 SmartStack][9] 或 [Netflix 的 Eureka][10] 等可以定制以外,通常还有基于环境变量或基于 DNS 的[方法][11],允许您动态的发现服务。同样重要的是,事实上 [OpenAPI][12] 为 HTTP API 提供了一套标准文档和设计模式,[gRPC][13] 为一些耦合性强的高性能项目也做了同样的事情。最后非常重要的一点是,考虑到开发人员的经验(DX),应该从写一份好的 [Makefiles][14] 开始,并以编写符合 [**风格**][15] 的文档结束。
|
||||
|
||||
### 优点和缺点
|
||||
|
||||
*nix 系统和微服务都提供了许多挑战和机遇
|
||||
|
||||
#### 模块性
|
||||
|
||||
设计一个简洁,有清晰的目的并且能够很好的和其它模块配合是很困难的。甚至是在不同版本中实现并引入相应的异常处理流程都很困难的。在微服务中,这意味着重试逻辑和超时机制,或者将这些功能外包到服务网格( service mesh )是不是一个更好的选择呢?这确实比较难,可如果你做好了,那它的可重用性是巨大的。
|
||||
|
||||
#### Observability
|
||||
|
||||
#### 预测
|
||||
|
||||
在一个巨型(2018年)或是一个试图做任何事情的大型程序(1984)年,当事情开始变坏的时候,应当能够直接的找到问题的根源。但是在一个
|
||||
|
||||
```
|
||||
yes | tr \\n x | head -c 450m | grep n
|
||||
```
|
||||
|
||||
或者在一个微服务设置中请求一个路径,例如,涉及20个服务,你怎么弄清楚是哪个服务的问题?幸运的是,我们有很多标准,特别是 [OpenCensus][16] 和 [OpenTracing][17]。如果您希望转向微服务,可预测性仍然可能是最大的问题。
|
||||
|
||||
#### 全局状态
|
||||
|
||||
对于 *nix 程序来说可能不是一个大问题,但在微服务中,全局状态仍然是一个需要讨论的问题。也就是说,如何确保有效的管理本地化(持久性)的状态以及尽可能在少做变更的情况下使全局保持一致。
|
||||
|
||||
### 总结一下
|
||||
|
||||
最后,问题仍然是:你是否在使用合适的工具来完成特定的工作?也就是说,以同样的方式实现一个特定的 *nix 程序在某些时候或者阶段会是一个更好的选择,它是可能在你的组织或工作过程中的一个[最好的选择][18]。无论如何,我希望这篇文章可以让你看到 Unix 哲学和微服务之间许多强有力的相似之处。也许我们可以从前者那里学到一些东西使后者受益。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/revisiting-unix-philosophy-2018
|
||||
|
||||
作者:[Michael Hausenblas][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Jamkr](https://github.com/Jamkr)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mhausenblas
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://harmful.cat-v.org/cat-v/
|
||||
[2]: https://martinfowler.com/articles/microservices.html
|
||||
[3]: https://en.wikipedia.org/wiki/Douglas_McIlroy
|
||||
[4]: https://speakerdeck.com/mhausenblas/distributed-named-pipes-and-other-inter-services-communication
|
||||
[5]: http://kubernetesbyexample.com/
|
||||
[6]: https://www.nomadproject.io/docs/job-specification/index.html
|
||||
[7]: https://docs.docker.com/compose/overview/
|
||||
[8]: https://helm.sh/
|
||||
[9]: https://github.com/airbnb/smartstack-cookbook
|
||||
[10]: https://github.com/Netflix/eureka
|
||||
[11]: https://kubernetes.io/docs/concepts/services-networking/service/#discovering-services
|
||||
[12]: https://www.openapis.org/
|
||||
[13]: https://grpc.io/
|
||||
[14]: https://suva.sh/posts/well-documented-makefiles/
|
||||
[15]: https://www.linux.com/news/improve-your-writing-gnu-style-checkers
|
||||
[16]: https://opencensus.io/
|
||||
[17]: https://opentracing.io/
|
||||
[18]: https://robertnorthard.com/devops-days-well-architected-monoliths-are-okay/
|
||||
@ -0,0 +1,230 @@
|
||||
more、less 和 most 的区别
|
||||
======
|
||||

|
||||
|
||||
如果你是一个 Linux 方面的新手,你可能会在 `more`、`less`、`most` 这三个命令行工具之间产生疑惑。在本文当中,我会对这三个命令行工具进行对比,以及展示它们各自在 Linux 中的一些使用例子。总的来说,这几个命令行工具之间都有相通和差异,而且它们在大部分 Linux 发行版上都有自带。
|
||||
|
||||
我们首先来看看 `more` 命令。
|
||||
|
||||
### more 命令
|
||||
|
||||
`more` 是一个较为传统的终端阅读工具,它可以用于打开指定的文件并进行交互式阅读。如果文件的内容太长,在一屏以内无法完整显示,就会逐页显示文件内容。使用回车键或者空格键可以滚动浏览文件的内容,但有一个限制,就是只能够单向滚动。也就是说只能按顺序往下翻页,而不能进行回看。
|
||||
|
||||

|
||||
|
||||
**更新**
|
||||
|
||||
有的 Linux 用户向我指出,在 `more` 当中是可以向上翻页的。不过,最原始版本的 `more` 确实只允许向下翻页,在后续出现的较新的版本中也允许了有限次数的向上翻页,只需要在浏览过程中按 `b` 键即可向上翻页。唯一的限制是 `more` 不能搭配管道使用。(我使用 more 是可以搭配管道使用的,不知道原作者为什么要这样写,麻烦校对确认一下这一句是否需要去掉)
|
||||
|
||||
按 `q` 即可退出 `more`。
|
||||
|
||||
**更多示例**
|
||||
|
||||
打开 ostechnix.txt 文件进行交互式阅读,可以执行以下命令:
|
||||
|
||||
```
|
||||
$ more ostechnix.txt
|
||||
```
|
||||
|
||||
在阅读过程中,如果需要查找某个字符串,只需要像下面这样在斜杠(/)之后输入需要查找的内容:
|
||||
|
||||
```
|
||||
/linux
|
||||
```
|
||||
|
||||
按 `n` 键可以跳转到下一个匹配的字符串。
|
||||
|
||||
如果需要在文件的第 10 行开始阅读,只需要执行:
|
||||
|
||||
```
|
||||
$ more +10 file
|
||||
```
|
||||
|
||||
就可以从文件的第 10 行开始显示文件的内容了。
|
||||
|
||||
如果你需要让 `more` 提示你按空格键来翻页,可以加上 `-d` 参数:
|
||||
|
||||
```
|
||||
$ more -d ostechnix.txt
|
||||
```
|
||||
|
||||
![][2]
|
||||
|
||||
如上图所示,`more` 会提示你可以按空格键翻页。
|
||||
|
||||
如果需要查看所有选项以及对应的按键,可以按 `h` 键。
|
||||
|
||||
要查看 `more` 的更多详细信息,可以参考手册:
|
||||
|
||||
```
|
||||
$ man more
|
||||
```
|
||||
|
||||
### less 命令
|
||||
|
||||
`less` 命令也是用于打开指定的文件并进行交互式阅读,它也支持翻页和搜索。如果文件的内容太长,也会对输出进行分页,因此也可以翻页阅读。比 `more` 命令更好的一点是,`less` 支持向上翻页和向下翻页,也就是可以在整个文件中任意阅读。
|
||||
|
||||

|
||||
|
||||
在使用功能方面,`less` 比 `more` 命令具有更多优点,以下列出其中几个:
|
||||
|
||||
* 支持向上翻页和向下翻页
|
||||
* 支持向上搜索和向下搜索
|
||||
* 可以跳转到文件的末尾并立即从文件的开头开始阅读
|
||||
* 在编辑器中打开指定的文件
|
||||
|
||||
|
||||
|
||||
**更多示例**
|
||||
|
||||
打开文件:
|
||||
|
||||
```
|
||||
$ less ostechnix.txt
|
||||
```
|
||||
|
||||
按空格键或回车键可以向下翻页,按 `b` 键可以向上翻页。
|
||||
|
||||
如果需要向下搜索,在斜杠(/)之后输入需要搜索的内容:
|
||||
|
||||
```
|
||||
/linux
|
||||
```
|
||||
|
||||
按 `n` 键可以跳转到下一个匹配的字符串,如果需要跳转到上一个匹配的字符串,可以按 `N` 键。
|
||||
|
||||
如果需要向上搜索,在问号(?)之后输入需要搜索的内容:
|
||||
|
||||
```
|
||||
?linux
|
||||
```
|
||||
|
||||
同样是按 `n` 键或 `N` 键跳转到下一个或上一个匹配的字符串。
|
||||
|
||||
只需要按 `v` 键,就会将正在阅读的文件在默认编辑器中打开,然后就可以对文件进行各种编辑操作了。
|
||||
|
||||
按 `h` 键可以查看 `less` 工具的选项和对应的按键。
|
||||
|
||||
按 `q` 键可以退出阅读。
|
||||
|
||||
要查看 `less` 的更多详细信息,可以参考手册:
|
||||
|
||||
```
|
||||
$ man less
|
||||
```
|
||||
|
||||
### most 命令
|
||||
|
||||
`most` 同样是一个终端阅读工具,而且比 `more` 和 `less` 的功能更为丰富。`most` 支持同时打开多个文件、编辑当前打开的文件、迅速跳转到文件中的某一行、分屏阅读、同时锁定或滚动多个屏幕等等功能。在默认情况下,对于较长的行,`most` 不会将其截断成多行显示,而是提供了左右滚动功能在同一行内显示。
|
||||
|
||||
**更多示例**
|
||||
|
||||
打开文件:
|
||||
|
||||
```
|
||||
$ most ostechnix1.txt
|
||||
```
|
||||

|
||||
按 `e` 键可以编辑当前文件。
|
||||
|
||||
如果需要向下搜索,在斜杠(/)或 S 或 f 之后输入需要搜索的内容,按 `n` 键就可以跳转到下一个匹配的字符串。
|
||||
|
||||
![][3]
|
||||
|
||||
如果需要向上搜索,在问号(?)之后输入需要搜索的内容,也是通过按 `n` 键跳转到下一个匹配的字符串。
|
||||
|
||||
同时打开多个文件:
|
||||
|
||||
```
|
||||
$ most ostechnix1.txt ostechnix2.txt ostechnix3.txt
|
||||
```
|
||||
|
||||
在打开了多个文件的状态下,可以输入 `:n` 切换到其它文件,使用`↑` 或 `↓` 键选择需要切换到的文件,按回车键就可以查看对应的文件。
|
||||

|
||||
|
||||
要打开文件并跳转到某个字符串首次出现的位置(例如 linux),可以执行以下命令:
|
||||
|
||||
```
|
||||
$ most file +/linux
|
||||
```
|
||||
|
||||
按 `h` 键可以查看帮助。
|
||||
|
||||
**按键操作列表**
|
||||
|
||||
移动:
|
||||
|
||||
* **空格键或 `D` 键** – 向下滚动一屏
|
||||
* **DELETE 键或 `U` 键** – 向上滚动一屏
|
||||
* **`↓` 键** – 向下移动一行
|
||||
* **`↑` 键** – 向上移动一行
|
||||
* **`T` 键** – 移动到文件开头
|
||||
* **`B` 键** – 移动到文件末尾
|
||||
* **`>` 键或 TAB 键** – 向右滚动屏幕
|
||||
* **`<` 键** – 向左滚动屏幕
|
||||
* **`→` 键** – 向右移动一列
|
||||
* **`←` 键** – 向左移动一列
|
||||
* **`J` 键或 `G` 键** – 移动到某一行,例如 `10j` 可以移动到第 10 行
|
||||
* **`%` 键** – 移动到文件长度某个百分比的位置
|
||||
|
||||
|
||||
|
||||
窗口命令:
|
||||
|
||||
* **`Ctrl-X 2`、`Ctrl-W 2`** – 分屏
|
||||
* **`Ctrl-X 1`、`Ctrl-W 1`** – 只显示一个窗口
|
||||
* **`O` 键、`Ctrl-X O`** – 切换到另一个窗口
|
||||
* **`Ctrl-X 0`** – 删除窗口
|
||||
|
||||
|
||||
|
||||
文件内搜索:
|
||||
|
||||
* **`S` 键或 `f` 键或 `/` 键** – 向下搜索
|
||||
* **`?` 键** – 向上搜索
|
||||
* **`n` 键** – 跳转到下一个匹配的字符串
|
||||
|
||||
|
||||
|
||||
退出:
|
||||
|
||||
* **`q` 键** – 退出 `most` ,且所有打开的文件都会被关闭
|
||||
* **`:N`、`:n`** – 退出当前文件并查看下一个文件(使用`↑` 键、`↓` 键选择下一个文件)
|
||||
|
||||
|
||||
|
||||
要查看 `most` 的更多详细信息,可以参考手册:
|
||||
|
||||
```
|
||||
$ man most
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
**`more`** – 传统且基础的文件阅读工具,仅支持向下翻页和有限次数的向上翻页。
|
||||
|
||||
**`less`** – 比 `more` 功能丰富,支持向下翻页和向上翻页,也支持文本搜索。在打开大文件的时候,比 `vi` 这类文本编辑器启动得更快。
|
||||
|
||||
**`most`** – 在上述两个工具功能的基础上,还加入了同时打开多个文件、同时锁定或滚动多个屏幕、分屏等等大量功能。
|
||||
|
||||
以上就是我的介绍,希望能让你通过我的文章对这三个工具有一定的认识。如果想了解这篇文章以外的关于这几个工具的详细功能,请参阅它们的 `man` 手册。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/the-difference-between-more-less-and-most-commands/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: http://www.ostechnix.com/wp-content/uploads/2018/11/more-1.png
|
||||
[3]: http://www.ostechnix.com/wp-content/uploads/2018/11/most-1-1.gif
|
||||
|
||||
@ -0,0 +1,155 @@
|
||||
举例说明 alias 和 unalias 命令
|
||||
======
|
||||

|
||||
|
||||
如果不是一个深度的命令行用户的话,你可能已经忘记了这些复杂且冗长的 Linux 命令了。当然,有很多方法可以让你 [**回想起遗忘的命令**][1]。你可以简单的 [**保存常用的命令**][2] 然后按需使用。也可以在终端里 [**标记重要的命令**][3],然后在任何时候你想要的时间使用它们。而且,Linux 有一个内建命令 **history** 可以帮助你记忆这些命令。另外一个最简便的方式就是为这些命令创建一个别名。你可以为任何经常重复调用的常用命令创建别名,而不仅仅是长命令。通过这种方法,你不必再过多地记忆这些命令。这篇文章中,我们将会在 Linux 环境下举例说明 **alias** 和 **unalias** 命令。
|
||||
|
||||
### alias 命令
|
||||
|
||||
**alias** 使用一个用户自定义的字符串来代替一个或者一串命令(包括多个选项,参数)。这个字符串可以是一个简单的名字或者缩写,不管这个命令原来多么复杂。alias 命令已经预装在 shell(包括 BASH,Csh,Ksh 和 Zsh 等) 当中。
|
||||
|
||||
|
||||
alias 的通用语法是:
|
||||
|
||||
```
|
||||
alias [alias-name[=string]...]
|
||||
```
|
||||
接下来看几个例子。
|
||||
|
||||
**列出别名**
|
||||
|
||||
可能在你的系统中已经设置了一些别名。有些应用在你安装它们的时候可能已经自动创建了别名。要查看已经存在的别名,运行:
|
||||
|
||||
```
|
||||
$ alias
|
||||
```
|
||||
|
||||
或者,
|
||||
|
||||
```
|
||||
$ alias -p
|
||||
```
|
||||
|
||||
在我的 Arch Linux 系统中已经设置了下面这些别名。
|
||||
|
||||
```
|
||||
alias betty='/home/sk/betty/main.rb'
|
||||
alias ls='ls --color=auto'
|
||||
alias pbcopy='xclip -selection clipboard'
|
||||
alias pbpaste='xclip -selection clipboard -o'
|
||||
alias update='newsbeuter -r && sudo pacman -Syu'
|
||||
```
|
||||
|
||||
**创建一个新的别名**
|
||||
|
||||
像我之前说的,你不必去记忆这些又臭又长的命令。你甚至不必一遍一遍的运行长命令。只需要为这些命令创建一个简单易懂的别名,然后在任何你想使用的时候运行这些别名就可以了。这种方式会让你爱上命令行。
|
||||
|
||||
```
|
||||
$ du -h --max-depth=1 | sort -hr
|
||||
```
|
||||
|
||||
这个命令将会查找当前工作目录下的各个子目录占用的磁盘大小,并按照从大到小的顺序进行排序。这个命令有点长。我们可以像下面这样轻易地为其创建一个 别名:
|
||||
|
||||
```
|
||||
$ alias du='du -h --max-depth=1 | sort -hr'
|
||||
```
|
||||
|
||||
这里的 **du** 就是这条命令的别名。这个别名可以被设置为任何名字,主要便于记忆和区别。
|
||||
|
||||
在创建一个别名的时候,使用单引号或者双引号都是可以的。这两种方法最后的结果没有任何区别。
|
||||
|
||||
现在你可以运行这个别名(例如我们这个例子中的 **du** )。它和上面的原命令将会产生相同的结果。
|
||||
|
||||
这个别名仅限于当前 shell 会话中。一旦你退出了当前 shell 会话,别名也就失效了。为了让这些别名长久有效,你需要把它们添加到你 shell 的配置文件当中。
|
||||
|
||||
BASH,编辑 **~/.bashrc** 文件:
|
||||
|
||||
```
|
||||
$ nano ~/.bashrc
|
||||
```
|
||||
|
||||
一行添加一个别名:
|
||||

|
||||
|
||||
保存并退出这个文件。然后运行以下命令更新修改:
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
现在,这些别名在所有会话中都可以永久使用了。
|
||||
|
||||
ZSH,你需要添加这些别名到 **~/.zshrc**文件中。
|
||||
Fish,跟上面的类似,添加这些别名到 **~/.config/fish/config.fish** 文件中。
|
||||
|
||||
**查看某个特定的命令别名**
|
||||
|
||||
像我上面提到的,你可以使用 ‘alias’ 命令列出你系统中所有的别名。如果你想查看跟给定的别名有关的命令,例如 ‘du’,只需要运行:
|
||||
|
||||
```
|
||||
$ alias du
|
||||
alias du='du -h --max-depth=1 | sort -hr'
|
||||
```
|
||||
|
||||
像你看到的那样,上面的命令可以显示与单词 ‘du’ 有关的命令。
|
||||
|
||||
关于 别名 命令更多的细节,参阅 man 手册页:
|
||||
|
||||
```
|
||||
$ man alias
|
||||
```
|
||||
|
||||
### unalias 命令
|
||||
|
||||
跟它的名字说的一样,**unalias** 命令可以很轻松地从你的系统当中移除别名。unalias 命令的通用语法是:
|
||||
|
||||
```
|
||||
unalias <alias-name>
|
||||
```
|
||||
|
||||
要移除命令的别名,像我们之前创建的 ‘du’,只需要运行:
|
||||
|
||||
```
|
||||
$ unalias du
|
||||
```
|
||||
|
||||
unalias 命令不仅会从当前会话中移除别名,也会从你的 shell 配置文件中永久地移除别名。
|
||||
|
||||
还有一种移除别名的方法,是创建具有相同名称的新别名。
|
||||
|
||||
要从当前会话中移除所有的别名,使用 **-a** 选项:
|
||||
|
||||
```
|
||||
$ unalias -a
|
||||
```
|
||||
|
||||
更多细节,参阅 man 手册页。
|
||||
|
||||
```
|
||||
$ man unalias
|
||||
```
|
||||
|
||||
如果你经常一遍又一遍的运行这些繁杂又冗长的命令,给它们创建别名可以节省你的时间。现在是你为常用命令创建别名的时候了。
|
||||
|
||||
这就是所有的内容了。希望可以帮到你。还有更多的干货即将到来,敬请期待!
|
||||
|
||||
祝近祺!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/the-alias-and-unalias-commands-explained-with-examples/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/easily-recall-forgotten-linux-commands/
|
||||
[2]: https://www.ostechnix.com/save-commands-terminal-use-demand/
|
||||
[3]: https://www.ostechnix.com/bookmark-linux-commands-easier-repeated-invocation/
|
||||
Loading…
Reference in New Issue
Block a user