mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
commit
da64aa1c49
@ -0,0 +1,100 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (oska874)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10530-1.html)
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 5 OK05)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok05.html)
|
||||
[#]: author: (Robert Mullins http://www.cl.cam.ac.uk/~rdm34)
|
||||
|
||||
计算机实验室之树莓派:课程 5 OK05
|
||||
======
|
||||
|
||||
OK05 课程构建于课程 OK04 的基础,使用它来闪烁摩尔斯电码的 SOS 序列(`...---...`)。这里假设你已经有了 [课程 4:OK04][1] 操作系统的代码作为基础。
|
||||
|
||||
### 1、数据
|
||||
|
||||
到目前为止,我们与操作系统有关的所有内容提供的都是指令。然而有时候,指令只是完成了一半的工作。我们的操作系统可能还需要数据。
|
||||
|
||||
> 一些早期的操作系统确实只允许特定文件中的特定类型的数据,但是这通常被认为限制太多了。现代方法确实可以使程序变得复杂的多。
|
||||
|
||||
通常,数据就是些很重要的值。你可能接受过培训,认为数据就是某种类型的,比如,文本文件包含文本,图像文件包含图片,等等。说实话,这只是你的想法而已。计算机上的全部数据都是二进制数字,重要的是我们选择用什么来解释这些数据。在这个例子中,我们会用一个闪灯序列作为数据保存下来。
|
||||
|
||||
在 `main.s` 结束处复制下面的代码:
|
||||
|
||||
```
|
||||
.section .data %定义 .data 段
|
||||
.align 2 %对齐
|
||||
pattern: %定义整形变量
|
||||
.int 0b11111111101010100010001000101010
|
||||
```
|
||||
|
||||
> `.align num` 确保下一行代码的地址是 2^num 的整数倍。
|
||||
|
||||
> `.int val` 输出数值 `val`。
|
||||
|
||||
要区分数据和代码,我们将数据都放在 `.data` 区域。我已经将该区域包含在操作系统的内存布局图。我选择将数据放到代码后面。将我们的指令和数据分开保存的原因是,如果最后我们在自己的操作系统上实现一些安全措施,我们就需要知道代码的那些部分是可以执行的,而那些部分是不行的。
|
||||
|
||||
我在这里使用了两个新命令 `.align` 和 `.int`。`.align` 保证接下来的数据是按照 2 的乘方对齐的。在这个里,我使用 `.align 2` ,意味着数据最终存放的地址是 2^2=4 的整数倍。这个操作是很重要的,因为我们用来读取内存的指令 `ldr` 要求内存地址是 4 的倍数。
|
||||
|
||||
命令 `.int` 直接复制它后面的常量到输出。这意味着 11111111101010100010001000101010<sub>2</sub> 将会被存放到输出,所以该标签模式实际是将这段数据标识为模式。
|
||||
|
||||
> 关于数据的一个挑战是寻找一个高效和有用的展示形式。这种保存一个开、关的时间单元的序列的方式,运行起来很容易,但是将很难编辑,因为摩尔斯电码的 `-` 或 `.` 样式丢失了。
|
||||
|
||||
如我提到的,数据可以代表你想要的所有东西。在这里我编码了摩尔斯电码的 SOS 序列,对于不熟悉的人,就是 `...---...`。我使用 0 表示一个时间单元的 LED 灭灯,而 1 表示一个时间单元的 LED 亮。这样,我们可以像这样编写一些代码在数据中显示一个序列,然后要显示不同序列,我们所有需要做的就是修改这段数据。下面是一个非常简单的例子,操作系统必须一直执行这段程序,解释和展示数据。
|
||||
|
||||
复制下面几行到 `main.s` 中的标记 `loop$` 之前。
|
||||
|
||||
```
|
||||
ptrn .req r4 %重命名 r4 为 ptrn
|
||||
ldr ptrn,=pattern %加载 pattern 的地址到 ptrn
|
||||
ldr ptrn,[ptrn] %加载地址 ptrn 所在内存的值
|
||||
seq .req r5 %重命名 r5 为 seq
|
||||
mov seq,#0 %seq 赋值为 0
|
||||
```
|
||||
|
||||
这段代码加载 `pattrern` 到寄存器 `r4`,并加载 0 到寄存器 `r5`。`r5` 将是我们的序列位置,所以我们可以追踪我们已经展示了多少个 `pattern`。
|
||||
|
||||
如果 `pattern` 的当前位置是 1 且仅有一个 1,下面的代码将非零值放入 `r1`。
|
||||
|
||||
```
|
||||
mov r1,#1 %加载1到 r1
|
||||
lsl r1,seq %对r1 的值逻辑左移 seq 次
|
||||
and r1,ptrn %按位与
|
||||
```
|
||||
|
||||
这段代码对你调用 `SetGpio` 很有用,它必须有一个非零值来关掉 LED,而一个 0 值会打开 LED。
|
||||
|
||||
现在修改 `main.s` 中你的全部代码,这样代码中每次循环会根据当前的序列数设置 LED,等待 250000 毫秒(或者其他合适的延时),然后增加序列数。当这个序列数到达 32 就需要返回 0。看看你是否能实现这个功能,作为额外的挑战,也可以试着只使用一条指令。
|
||||
|
||||
### 2、当你玩得开心时,时间过得很快
|
||||
|
||||
你现在准备好在树莓派上实验。应该闪烁一串包含 3 个短脉冲,3 个长脉冲,然后 3 个短脉冲的序列。在一次延时之后,这种模式应该重复。如果这不工作,请查看我们的问题页。
|
||||
|
||||
一旦它工作,祝贺你已经抵达 OK 系列教程的结束点。
|
||||
|
||||
在这个系列我们学习了汇编代码,GPIO 控制器和系统定时器。我们已经学习了函数和 ABI,以及几个基础的操作系统原理,已经关于数据的知识。
|
||||
|
||||
你现在已经可以准备学习下面几个更高级的课程的某一个。
|
||||
|
||||
* [Screen][2] 系列是接下来的,会教你如何通过汇编代码使用屏幕。
|
||||
* [Input][3] 系列教授你如何使用键盘和鼠标。
|
||||
|
||||
到现在,你已经有了足够的信息来制作操作系统,用其它方法和 GPIO 交互。如果你有任何机器人工具,你可能会想尝试编写一个通过 GPIO 管脚控制的机器人操作系统。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok05.html
|
||||
|
||||
作者:[Robert Mullins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[ezio](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cl.cam.ac.uk/~rdm34
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-10526-1.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html
|
||||
@ -1,14 +1,15 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10527-1.html)
|
||||
[#]: subject: (Hacking math education with Python)
|
||||
[#]: via: (https://opensource.com/article/19/1/hacking-math)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
将 Python 结合到数学教育中
|
||||
======
|
||||
|
||||
> 身兼教师、开发者、作家数职的 Peter Farrell 来讲述为什么使用 Python 来讲数学课会比传统方法更加好。
|
||||
|
||||

|
||||
@ -19,11 +20,11 @@
|
||||
|
||||
Peter 的灵感来源于 Logo 语言之父 [Seymour Papert][2],他的 Logo 语言现在还存在于 Python 的 [Turtle 模块][3]中。Logo 语言中的海龟形象让 Peter 喜欢上了 Python,并且进一步将 Python 应用到数学教学中。
|
||||
|
||||
Peter 在他的新书《[<ruby>Python 数学奇遇记<rt>Math Adventures with Python</rt></ruby>][5]》中分享了他的方法:“图文并茂地指导如何用代码探索数学”。因此我最近对他进行了一次采访,向他了解更多这方面的情况。
|
||||
Peter 在他的新书《<ruby>[Python 数学奇遇记][5]<rt>Math Adventures with Python</rt></ruby>》中分享了他的方法:“图文并茂地指导如何用代码探索数学”。因此我最近对他进行了一次采访,向他了解更多这方面的情况。
|
||||
|
||||
**Don Watkins(译者注:本文作者):** 你的教学背景是什么?
|
||||
**Don Watkins(LCTT 译注:本文作者):** 你的教学背景是什么?
|
||||
|
||||
**Peter Farrell:** 我曾经当过八年的数学老师,之后又教了十年的数学。我还在当老师的时候,就阅读过 Papert 的 《[<ruby>头脑风暴<rt>Mindstorms</rt></ruby>][6]》并从中受到了启发,将 Logo 语言和海龟引入到了我所有的数学课上。
|
||||
**Peter Farrell:** 我曾经当过八年的数学老师,之后又做了十年的数学私教。我还在当老师的时候,就阅读过 Papert 的 《<ruby>[头脑风暴][6]<rt>Mindstorms</rt></ruby>》并从中受到了启发,将 Logo 语言和海龟引入到了我所有的数学课上。
|
||||
|
||||
**DW:** 你为什么开始使用 Python 呢?
|
||||
|
||||
@ -68,7 +69,7 @@ via: https://opensource.com/article/19/1/hacking-math
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,14 +1,15 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10529-1.html)
|
||||
[#]: subject: (More About Angle Brackets in Bash)
|
||||
[#]: via: (https://www.linux.com/blog/learn/2019/1/more-about-angle-brackets-bash)
|
||||
[#]: author: (Paul Brown https://www.linux.com/users/bro66)
|
||||
|
||||
Bash 中尖括号的更多用法
|
||||
======
|
||||
> 在这篇文章,我们继续来深入探讨尖括号的更多其它用法。
|
||||
|
||||

|
||||
|
||||
@ -22,19 +23,20 @@ Bash 中尖括号的更多用法
|
||||
diff <(ls /original/dir/) <(ls /backup/dir/)
|
||||
```
|
||||
|
||||
[`diff`][2] 命令是一个逐行比较两个文件之间差异的工具。在上面的例子中,就使用了 `<` 让 `diff` 认为两个 `ls` 命令输出的结果都是文件,从而能够比较它们之间的差异。
|
||||
[diff][2] 命令是一个逐行比较两个文件之间差异的工具。在上面的例子中,就使用了 `<` 让 `diff` 认为两个 `ls` 命令输出的结果都是文件,从而能够比较它们之间的差异。
|
||||
|
||||
要注意,在 `<` 和 `(...)` 之间是没有空格的。
|
||||
|
||||
我尝试在我的图片目录和它的备份目录执行上面的命令,输出的是以下结果:
|
||||
|
||||
```
|
||||
diff <(ls /My/Pictures/) <(ls /My/backup/Pictures/) 5d4 < Dv7bIIeUUAAD1Fc.jpg:large.jpg
|
||||
diff <(ls /My/Pictures/) <(ls /My/backup/Pictures/)
|
||||
5d4 < Dv7bIIeUUAAD1Fc.jpg:large.jpg
|
||||
```
|
||||
|
||||
输出结果中的 `<` 表示 `Dv7bIIeUUAAD1Fc.jpg:large.jpg` 这个文件存在于左边的目录(`/My/Pictures`)但不存在于右边的目录(`/My/backup/Pictures`)中。也就是说,在备份过程中可能发生了问题,导致这个文件没有被成功备份。如果 `diff` 没有显示出任何输出结果,就表明两个目录中的文件是一致的。
|
||||
|
||||
看到这里你可能会想到,既然可以通过 `<` 将一些命令行的输出内容作为一个文件,提供给一个需要接受文件格式的命令,那么在上一篇文章的“最喜欢的演员排序”例子中,就可以省去中间的一些步骤,直接对输出内容执行 `sort` 操作了。
|
||||
看到这里你可能会想到,既然可以通过 `<` 将一些命令行的输出内容作为一个文件提供给一个需要接受文件格式的命令,那么在上一篇文章的“最喜欢的演员排序”例子中,就可以省去中间的一些步骤,直接对输出内容执行 `sort` 操作了。
|
||||
|
||||
确实如此,这个例子可以简化成这样:
|
||||
|
||||
@ -42,7 +44,7 @@ diff <(ls /My/Pictures/) <(ls /My/backup/Pictures/) 5d4 < Dv7bIIeUUAAD1Fc.jpg:la
|
||||
sort -r <(while read -r name surname films;do echo $films $name $surname ; done < CBactors)
|
||||
```
|
||||
|
||||
### Here string
|
||||
### Here 字符串
|
||||
|
||||
除此以外,尖括号的重定向功能还有另一种使用方式。
|
||||
|
||||
@ -52,9 +54,9 @@ sort -r <(while read -r name surname films;do echo $films $name $surname ; done
|
||||
myvar="Hello World" echo $myvar | tr '[:lower:]' '[:upper:]' HELLO WORLD
|
||||
```
|
||||
|
||||
[`tr`][3] 命令可以将一个字符串转换为某种格式。在上面的例子中,就使用了 `tr` 将字符串中的所有小写字母都转换为大写字母。
|
||||
[tr][3] 命令可以将一个字符串转换为某种格式。在上面的例子中,就使用了 `tr` 将字符串中的所有小写字母都转换为大写字母。
|
||||
|
||||
要理解的是,这个传递过程的重点不是变量,而是变量的值,也就是字符串 `Hello World`。这样的字符串叫做 here string,含义是“这就是我们要处理的字符串”。但对于上面的例子,还可以用更直观的方式的处理,就像下面这样:
|
||||
要理解的是,这个传递过程的重点不是变量,而是变量的值,也就是字符串 `Hello World`。这样的字符串叫做 HERE 字符串,含义是“这就是我们要处理的字符串”。但对于上面的例子,还可以用更直观的方式的处理,就像下面这样:
|
||||
|
||||
```
|
||||
tr '[:lower:]' '[:upper:]' <<< $myvar
|
||||
@ -75,13 +77,13 @@ via: https://www.linux.com/blog/learn/2019/1/more-about-angle-brackets-bash
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/blog/learn/2019/1/understanding-angle-brackets-bash
|
||||
[1]: https://linux.cn/article-10502-1.html
|
||||
[2]: https://linux.die.net/man/1/diff
|
||||
[3]: https://linux.die.net/man/1/tr
|
||||
|
||||
@ -0,0 +1,59 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (4 confusing open source license scenarios and how to navigate them)
|
||||
[#]: via: (https://opensource.com/article/19/1/open-source-license-scenarios)
|
||||
[#]: author: (P.Kevin Nelson https://opensource.com/users/pkn4645)
|
||||
|
||||
4 confusing open source license scenarios and how to navigate them
|
||||
======
|
||||
|
||||
Before you begin using a piece of software, make sure you fully understand the terms of its license.
|
||||
|
||||

|
||||
|
||||
As an attorney running an open source program office for a Fortune 500 corporation, I am often asked to look into a product or component where there seems to be confusion as to the licensing model. Under what terms can the code be used, and what obligations run with such use? This often happens when the code or the associated project community does not clearly indicate availability under a [commonly accepted open source license][1]. The confusion is understandable as copyright owners often evolve their products and services in different directions in response to market demands. Here are some of the scenarios I commonly discover and how you can approach each situation.
|
||||
|
||||
### Multiple licenses
|
||||
|
||||
The product is truly open source with an [Open Source Initiative][2] (OSI) open source-approved license, but has changed licensing models at least once if not multiple times throughout its lifespan. This scenario is fairly easy to address; the user simply has to decide if the latest version with its attendant features and bug fixes is worth the conditions to be compliant with the current license. If so, great. If not, then the user can move back in time to a version released under a more palatable license and start from that fork, understanding that there may not be an active community for support and continued development.
|
||||
|
||||
### Old open source
|
||||
|
||||
This is a variation on the multiple licenses model with the twist that current licensing is proprietary only. You have to use an older version to take advantage of open source terms and conditions. Most often, the product was released under a valid open source license up to a certain point in its development, but then the copyright holder chose to evolve the code in a proprietary fashion and offer new releases only under proprietary commercial licensing terms. So, if you want the newest capabilities, you have to purchase a proprietary license, and you most likely will not get a copy of the underlying source code. Most often the open source community that grew up around the original code line falls away once the members understand there will be no further commitment from the copyright holder to the open source branch. While this scenario is understandable from the copyright holder's perspective, it can be seen as "burning a bridge" to the open source community. It would be very difficult to again leverage the benefits of the open source contribution models once a project owner follows this path.
|
||||
|
||||
### Open core
|
||||
|
||||
By far the most common discovery is that a product has both an open source-licensed "community edition" and a proprietary-licensed commercial offering, commonly referred to as open core. This is often encouraging to potential consumers, as it gives them a "try before you buy" option or even a chance to influence both versions of the product by becoming an active member of the community. I usually encourage clients to begin with the community version, get involved, and see what they can achieve. Then, if the product becomes a crucial part of their business plan, they have the option to upgrade to the proprietary level at any time.
|
||||
|
||||
### Freemium
|
||||
|
||||
The component is not open source at all, but instead it is released under some version of the "freemium" model. A version with restricted or time-limited functionality can be downloaded with no immediate purchase required. However, since the source code is usually not provided and its accompanying license does not allow perpetual use, the creation of derivative works, nor further distribution, it is definitely not open source. In this scenario, it is usually best to pass unless you are prepared to purchase a proprietary license and accept all attendant terms and conditions of use. Users are often the most disappointed in this outcome as it has somewhat of a deceptive feel.
|
||||
|
||||
### OSI compliant
|
||||
|
||||
Of course, the happy path I haven't mentioned is to discover the project has a single, clear, OSI-compliant license. In those situations, open source software is as easy as downloading and going forward within appropriate use.
|
||||
|
||||
Each of the more complex scenarios described above can present problems to potential development projects, but consultation with skilled procurement or intellectual property professionals with regard to licensing lineage can reveal excellent opportunities.
|
||||
|
||||
An earlier version of this article was published on [OSS Law][3] and is republished with the author's permission.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/open-source-license-scenarios
|
||||
|
||||
作者:[P.Kevin Nelson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/pkn4645
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.org/licenses
|
||||
[2]: https://opensource.org/licenses/category
|
||||
[3]: http://www.pknlaw.com/2017/06/i-thought-that-was-open-source.html
|
||||
@ -0,0 +1,118 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Config management is dead: Long live Config Management Camp)
|
||||
[#]: via: (https://opensource.com/article/19/2/configuration-management-camp)
|
||||
[#]: author: (Matthew Broberg https://opensource.com/users/mbbroberg)
|
||||
|
||||
Config management is dead: Long live Config Management Camp
|
||||
======
|
||||
|
||||
CfgMgmtCamp '19 co-organizers share their take on ops, DevOps, observability, and the rise of YoloOps and YAML engineers.
|
||||
|
||||

|
||||
|
||||
Everyone goes to [FOSDEM][1] in Brussels to learn from its massive collection of talk tracks, colloquially known as developer rooms, that run the gauntlet of curiosities, covering programming languages like Rust, Go, and Python, to special topics ranging from community, to legal, to privacy. After two days of nonstop activity, many FOSDEM attendees move on to Ghent, Belgium, to join hundreds for Configuration Management Camp ([CfgMgmtCamp][2]).
|
||||
|
||||
Kris Buytaert and Toshaan Bharvani run the popular post-FOSDEM show centered around infrastructure management, featuring hackerspaces, training, workshops, and keynotes. It's a deeply technical exploration of the who, what, and how of building resilient infrastructure. It started in 2013 as a PuppetCamp but expanded to include more communities and tools in 2014.
|
||||
|
||||
I spoke with Kris and Toshaan, who both have a healthy sense of humor, about CfgMgmtCamp's past, present, and future. Our interview has been edited for length and clarity.
|
||||
|
||||
**Matthew: Your opening[keynote][3] is called "CfgMgmtCamp is dead." Is config management dead? Will it live on, or will something take its place?**
|
||||
|
||||
**Kris:** We've noticed people are jumping on the hype of containers, trying to solve the same problems in a different way. But they are still managing config, only in different ways and with other tools. Over the past couple of years, we've evolved from a conference with a focus on infrastructure-as-code tooling, such as Puppet, Chef, CFEngine, Ansible, Juju, and Salt, to a more open source infrastructure automation conference in general. So, config management is definitely not dead. Infrastructure-as-code is also not dead, but it all is evolving.
|
||||
|
||||
**Toshaan:** We see people changing tools, jumping on hype, and communities changing; however, the basic ideas and concepts remain the same.
|
||||
|
||||
**Matthew: It's great to see[observability as the topic][4] of one of your keynotes. Why should those who care about configuration management also care about monitoring and observability?**
|
||||
|
||||
**Kris:** While the name of the conference hasn't changed, the tools have evolved and we have expanded our horizon. Ten years ago, [Devopsdays][5] was just #devopsdays, but it evolved to focus on culture—the C of [CAMS][6] in the DevOps' core principles of Culture, Automation, Measurement, and Sharing.
|
||||
|
||||

|
||||
|
||||
[Monitorama][7] filled the gap on monitoring and metrics (tackling the M in CAMS). Config Management Camp is about open source Automation, the A. Since they are all open source conferences, they fulfill the Sharing part, completing the CAMS concept.
|
||||
|
||||
Observability sits on the line between Automation and Measurement. To go one step further, in some of my talks about open source monitoring, I describe the evolution of monitoring tools from #monitoringsucks to #monitoringlove; for lots of people (including me), the love for monitoring returned because we tied it to automation. We started to provision a service and automatically adapted the monitoring of that service to its state. Gone were the days where the monitoring tool was out of sync with reality.
|
||||
|
||||
Looking at it from the other side, when you have an infrastructure or application so complex that you need observability in it, you'd better not be deploying manually; you will need some form of automation at that level of complexity. So, observability and infrastructure automation are tied together.
|
||||
|
||||
**Toshaan:** Yes, while in the past we focused on configuration management, we will be looking to expand that into all types of infrastructure management. Last year, we played with this idea, and we were able to have a lot of cross-tool presentations. This year, we've taken this a step further by having more differentiated content.
|
||||
|
||||
**Matthew: Some of my virtualization and Linux admin friends push back, saying observability is a developer's responsibility. How would you respond without just saying "DevOps?"**
|
||||
|
||||
**Kris:** What you describe is what I call "Ooops Devs." This is a trend where the people who run the platform don't really care what they run; as long as port 80 is listening and the node pings, they are happy. It's equally bad as "Dev Ooops." "Ooops Devs" is where the devs rant about the ops folks because they are slow, not agile, and not responsive. But, to me, your job as an ops person or as a Linux admin is to keep a service running, and the only way to do that is to take on that task is as a team—with your colleagues who have different roles and insights, people who write code, people who design, etc. It is a shared responsibility. And hiding behind "that is someone else's responsibility," doesn't smell like collaboration going on.
|
||||
|
||||
**Toshaan:** Even in the dark ages of silos, I believe a true sysadmin should have cared about observability, monitoring, and automation. I believe that the DevOps movement has made this much more widespread, and that it has become easier to get this information and expose it. On the other hand, I believe that pure operators or sysadmins have learned to be team players (or, they may have died out). I like the analogy of an army unit composed of different specialty soldiers who work together to complete a mission; we have engineers who work to deliver products or services.
|
||||
|
||||
**Matthew: In a[Devopsdays Zurich talk][8], Kris offered an opinion that Americans build software for acquisition and Europeans build for resilience. In that light, what are the best skills for someone who wants to build meaningful infrastructure?**
|
||||
|
||||
**Toshaan:** I believe still some people don't understand the complexity of code sprawl, and they believe that some new hype will solve this magically.
|
||||
|
||||
**Kris:** This year, we invited [Steve Traugott][9], co-author of the 1998 USENIX paper "[Bootstrapping an Infrastructure][10]" that helped kickstart our community. So many people never read [Infrastructures.org][11], never experienced the pain of building images and image sprawl, and don't understand the evolution we went through that led us to build things the way we build them from source code.
|
||||
|
||||
People should study topics such as idempotence, resilience, reproducibility, and surviving the tenth floor test. (As explained in "Bootstrapping an Infrastructure": "The test we used when designing infrastructures was 'Can I grab a random machine and throw it out the tenth-floor window without adversely impacting users for more than 10 minutes?' If the answer to this was 'yes,' then we knew we were doing things right.") But only after they understand the service they are building—the service is the absolute priority—can they begin working on things like: how can we run this, how can we make sure it keeps running, how can it fail and how can we prevent that, and if it disappears, how can we spin it up again fast, unnoticed by the end user.
|
||||
|
||||
**Toshaan:** 100% uptime.
|
||||
|
||||
**Kris:** The challenge we have is that lots of people don't have that experience yet. We've seen the rise of [YoloOps][12]—just spin it up once, fire, and forget—which results in security problems, stability problems, data loss, etc., and they often grasp onto the solutions in YoloOps, the easy way to do something quickly and move on. But understanding how things will eventually fail takes time, it's called experience.
|
||||
|
||||
**Toshaan:** Well, when I was a student and manned the CentOS stand at FOSDEM, I remember a guy coming up to the stand and complaining that he couldn't do consulting because of the "fire once and forgot" policy of CentOS, and that it just worked too well. I like to call this ZombieOps, but YoloOps works also.
|
||||
|
||||
**Matthew: I see you're leading the second year of YamlCamp as well. Why does a markup language need its own camp?**
|
||||
|
||||
**Kris:** [YamlCamp][13] is a parody, it's a joke. Last year, Bob Walker ([@rjw1][14]) gave a talk titled "Are we all YAML engineers now?" that led to more jokes. We've had a discussion for years about rebranding CfgMgmtCamp; the problem is that people know our name, we have a large enough audience to keep going, and changing the name would mean effort spent on logos, website, DNS, etc. We won't change the name, but we joked that we could rebrand to YamlCamp, because for some weird reason, a lot of the talks are about YAML. :)
|
||||
|
||||
**Matthew: Do you think systems engineers should list YAML as a skill or a language on their CV? Should companies be hiring YAML engineers, or do you have "Long live all YAML engineers" on the website in jest?**
|
||||
|
||||
**Toshaan:** Well, the real question is whether people are willing to call themselves YAML engineers proudly, because we already have enough DevOps engineers.
|
||||
|
||||
**Matthew: What FOSS software helps you manage the event?**
|
||||
|
||||
**Toshaan:** I re-did the website in Hugo CMS because we were spending too much time maintaining the website manually. I chose Hugo, because I was learning Golang, and because it has been successfully used for other conferences and my own website. I also wanted a static website and iCalendar output, so we could use calendar tooling such as Giggity to have a good scheduling tool.
|
||||
|
||||
The website now builds quite nicely, and while I still have some ideas on improvements, maintenance is now much easier.
|
||||
|
||||
For the call for proposals (CFP), we now use [OpenCFP][15]. We want to optimize the submission, voting, selection, and extraction to be as automated as possible, while being easy and comfortable for potential speakers, reviewers, and ourselves to use. OpenCFP seems to be the tool that works; while we still have some feature requirements, I believe that, once we have some time to contribute back to OpenCFP, we'll have a fully functional and easy tool to run CFPs with.
|
||||
|
||||
Last, we switched from EventBrite to Pretix because I wanted to be GDPR compliant and have the ability to run our questions, vouchers, and extra features. Pretix allows us to control registration of attendees, speakers, sponsors, and organizers and have a single overview of all the people coming to the event.
|
||||
|
||||
### Wrapping up
|
||||
|
||||
The beauty of Configuration Management Camp to me is that it continues to evolve with its audience. Configuration management is certainly at the heart of the work, but it's in service to resilient infrastructure. Keep your eyes open for the talk recordings to learn from the [line up of incredible speakers][16], and thank you to the team for running this (free) show!
|
||||
|
||||
You can follow Kris [@KrisBuytaert][17] and Toshaan [@toshywoshy][18]. You can also see Kris' past articles [on his blog][19].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/configuration-management-camp
|
||||
|
||||
作者:[Matthew Broberg][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mbbroberg
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fosdem.org/2019/
|
||||
[2]: https://cfgmgmtcamp.eu/
|
||||
[3]: https://cfgmgmtcamp.eu/schedule/monday/intro00/
|
||||
[4]: https://cfgmgmtcamp.eu/schedule/monday/keynote0/
|
||||
[5]: https://www.devopsdays.org/
|
||||
[6]: http://devopsdictionary.com/wiki/CAMS
|
||||
[7]: http://monitorama.com/
|
||||
[8]: https://vimeo.com/272519813
|
||||
[9]: https://cfgmgmtcamp.eu/schedule/tuesday/keynote1/
|
||||
[10]: http://www.infrastructures.org/papers/bootstrap/bootstrap.html
|
||||
[11]: http://www.infrastructures.org/
|
||||
[12]: https://gist.githubusercontent.com/mariozig/5025613/raw/yolo
|
||||
[13]: https://twitter.com/yamlcamp
|
||||
[14]: https://twitter.com/rjw1
|
||||
[15]: https://github.com/opencfp/opencfp
|
||||
[16]: https://cfgmgmtcamp.eu/speaker/
|
||||
[17]: https://twitter.com/KrisBuytaert
|
||||
[18]: https://twitter.com/toshywoshy
|
||||
[19]: https://krisbuytaert.be/index.shtml
|
||||
@ -0,0 +1,91 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (7 predictions for artificial intelligence in 2019)
|
||||
[#]: via: (https://opensource.com/article/19/2/predictions-artificial-intelligence)
|
||||
[#]: author: (Salil Sethi https://opensource.com/users/salilsethi)
|
||||
|
||||
7 predictions for artificial intelligence in 2019
|
||||
======
|
||||
|
||||
While 2018 was a big year for AI, the stage is set for it to make an even deeper impact in 2019.
|
||||
|
||||

|
||||
|
||||
Without question, 2018 was a big year for artificial intelligence (AI) as it pushed even further into the mainstream, successfully automating more functionality than ever before. Companies are increasingly exploring applications for AI, and the general public has grown accustomed to interacting with the technology on a daily basis.
|
||||
|
||||
The stage is set for AI to continue transforming the world as we know it. In 2019, not only will the technology continue growing in global prevalence, but it will also spawn deeper conversations around important topics, fuel innovative business models, and impact society in new ways, including the following seven.
|
||||
|
||||
### 1\. Machine learning as a service (MLaaS) will be deployed more broadly
|
||||
|
||||
In 2018, we witnessed major strides in MLaaS with technology powerhouses like Google, Microsoft, and Amazon leading the way. Prebuilt machine learning solutions and capabilities are becoming more attractive in the market, especially to smaller companies that don't have the necessary in-house resources or talent. For those that have the technical know-how and experience, there is a significant opportunity to sell and deploy packaged solutions that can be easily implemented by others.
|
||||
|
||||
Today, MLaaS is sold primarily on a subscription or usage basis by cloud-computing providers. For example, Microsoft Azure's ML Studio provides developers with a drag-and-drop environment to develop powerful machine learning models. Google Cloud's Machine Learning Engine also helps developers build large, sophisticated algorithms for a variety of applications. In 2017, Amazon jumped into the realm of AI and launched Amazon SageMaker, another platform that developers can use to build, train, and deploy custom machine learning models.
|
||||
|
||||
In 2019 and beyond, be prepared to see MLaaS offered on a much broader scale. Transparency Market Research predicts it will grow to US$20 billion at an alarming 40% CAGR by 2025.
|
||||
|
||||
### 2\. More explainable or "transparent" AI will be developed
|
||||
|
||||
Although there are already many examples of how AI is impacting our world, explaining the outputs and rationale of complex machine learning models remains a challenge.
|
||||
|
||||
Unfortunately, AI continues to carry the "black box" burden, posing a significant limitation in situations where humans want to understand the rationale behind AI-supported decision making.
|
||||
|
||||
AI democratization has been led by a plethora of open source tools and libraries, such as Scikit Learn, TensorFlow, PyTorch, and more. The open source community will lead the charge to build explainable, or "transparent," AI that can clearly document its logic, expose biases in data sets, and provide answers to follow-up questions.
|
||||
|
||||
Before AI is widely adopted, humans need to know that the technology can perform effectively and explain its reasoning under any circumstance.
|
||||
|
||||
### 3\. AI will impact the global political landscape
|
||||
|
||||
In 2019, AI will play a bigger role on the global stage, impacting relationships between international superpowers that are investing in the technology. Early adopters of AI, such as the US and [China][1], will struggle to balance self-interest with collaborative R&D. Countries that have AI talent and machine learning capabilities will experience tremendous growth in areas like predictive analytics, creating a wider global technology gap.
|
||||
|
||||
Additionally, more conversations will take place around the ethical use of AI. Naturally, different countries will approach this topic differently, which will affect political relationships. Overall, AI's impact will be small relative to other international issues, but more noticeable than before.
|
||||
|
||||
### 4\. AI will create more jobs than it eliminates
|
||||
|
||||
Over the long term, many jobs will be eliminated as a result of AI-enabled automation. Roles characterized by repetitive, manual tasks are being outsourced to AI more and more every day. However, in 2019, AI will create more jobs than it replaces.
|
||||
|
||||
Rather than eliminating the need for humans entirely, AI is augmenting existing systems and processes. As a result, a new type of role is emerging. Humans are needed to support AI implementation and oversee its application. Next year, more manual labor will transition to management-type jobs that work alongside AI, a trend that will continue to 2020. Gartner predicts that in two years, [AI will create 2.3 million jobs while only eliminating 1.8 million.][2]
|
||||
|
||||
### 5\. AI assistants will become more pervasive and useful
|
||||
|
||||
AI assistants are nothing new to the modern world. Apple's Siri and Amazon's Alexa have been supporting humans on the road and in their homes for years. In 2019, we will see AI assistants continue to grow in their sophistication and capabilities. As they collect more behavioral data, AI assistants will become better at responding to requests and completing tasks. With advances in natural language processing and speech recognition, humans will have smoother and more useful interactions with AI assistants.
|
||||
|
||||
In 2018, we saw companies launch promising new AI assistants. Recently, Google began rolling out its voice-enabled reservation booking service, Duplex, which can call and book appointments on behalf of users. Technology company X.ai has built two AI personal assistants, Amy and Andrew, who can interact with humans and schedule meetings for their employers. Amazon also recently announced Echo Auto, a device that enables drivers to integrate Alexa into their vehicles. However, humans will continue to place expectations ahead of reality and be disappointed at the technology's limitations.
|
||||
|
||||
### 6\. AI/ML governance will gain importance
|
||||
|
||||
With so many companies investing in AI, much more energy will be put towards developing effective AI governance structures. Frameworks are needed to guide data collection and management, appropriate AI use, and ethical applications. Successful and appropriate AI use involves many different stakeholders, highlighting the need for reliable and consistent governing bodies.
|
||||
|
||||
In 2019, more organizations will create governance structures and more clearly define how AI progress and implementation are managed. Given the current gap in explainability, these structures will be tremendously important as humans continue to turn to AI to support decision-making.
|
||||
|
||||
### 7\. AI will help companies solve AI talent shortages
|
||||
|
||||
A [shortage of AI and machine learning talent][3] is creating an innovation bottleneck. A [survey][4] released last year from O'Reilly revealed that the biggest challenge companies are facing related to using AI is a lack of available talent. And as technological advancement continues to accelerate, it is becoming harder for companies to develop talent that can lead large-scale enterprise AI efforts.
|
||||
|
||||
To combat this, organizations will—ironically—use AI and machine learning to help address the talent gap in 2019. For example, Google Cloud's AutoML includes machine learning products that help developers train machine learning models without having any prior AI coding experience. Amazon Personalize is another machine learning service that helps developers build sophisticated personalization systems that can be implemented in many ways by different kinds of companies. In addition, companies will use AI to find talent and fill job vacancies and propel innovation forward.
|
||||
|
||||
### AI In 2019: bigger and better with a tighter leash
|
||||
|
||||
Over the next year, AI will grow more prevalent and powerful than ever. Expect to see new applications and challenges and be ready for an increased emphasis on checks and balances.
|
||||
|
||||
What do you think? How might AI impact the world in 2019? Please share your thoughts in the comments below!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/predictions-artificial-intelligence
|
||||
|
||||
作者:[Salil Sethi][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/salilsethi
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.turingtribe.com/story/china-is-achieving-ai-dominance-by-relying-on-young-blue-collar-workers-rLMsmWqLG4fGFwisQ
|
||||
[2]: https://www.gartner.com/en/newsroom/press-releases/2017-12-13-gartner-says-by-2020-artificial-intelligence-will-create-more-jobs-than-it-eliminates
|
||||
[3]: https://www.turingtribe.com/story/tencent-says-there-are-only-bTpNm9HKaADd4DrEi
|
||||
[4]: https://www.forbes.com/sites/bernardmarr/2018/06/25/the-ai-skills-crisis-and-how-to-close-the-gap/#19bafcf631f3
|
||||
@ -0,0 +1,82 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (4 steps to becoming an awesome agile developer)
|
||||
[#]: via: (https://opensource.com/article/19/2/steps-agile-developer)
|
||||
[#]: author: (Daniel Oh https://opensource.com/users/daniel-oh)
|
||||
|
||||
4 steps to becoming an awesome agile developer
|
||||
======
|
||||
There's no magical way to do it, but these practices will put you well on your way to embracing agile in application development, testing, and debugging.
|
||||

|
||||
|
||||
Enterprises are rushing into their DevOps journey through [agile][1] software development with cloud-native technologies such as [Linux containers][2], [Kubernetes][3], and [serverless][4]. Continuous integration helps enterprise developers reduce bugs, unexpected errors, and improve the quality of their code deployed in production.
|
||||
|
||||
However, this doesn't mean all developers in DevOps automatically embrace agile for their daily work in application development, testing, and debugging. There is no magical way to do it, but the following four practical steps and best practices will put you well on your way to becoming an awesome agile developer.
|
||||
|
||||
### Start with design thinking agile practices
|
||||
|
||||
There are many opportunities to learn about using agile software development practices in your DevOps initiatives. Agile practices inspire people with new ideas and experiences for improving their daily work in application development with team collaboration. More importantly, those practices will help you discover the answers to questions such as: Why am I doing this? What kind of problems am I trying to solve? How do I measure the outcomes?
|
||||
|
||||
A [domain-driven design][5] approach will help you start discovery sooner and easier. For example, the [Start At The End][6] practice helps you redesign your application and explore potential business outcomes—such as, what would happen if your application fails in production? You might also be interested in [Event Storming][7] for interactive and rapid discovery or [Impact Mapping][8] for graphical and strategic design as part of domain-driven design practices.
|
||||
|
||||
### Use a predictive approach first
|
||||
|
||||
In agile software development projects, enterprise developers are mainly focused on adapting to rapidly changing app development environments such as reactive runtimes, cloud-native frameworks, Linux container packaging, and the Kubernetes platform. They believe this is the best way to become an agile developer in their organization. However, this type of adaptive approach typically makes it harder for developers to understand and report what they will do in the next sprint. Developers might know the ultimate goal and, at best, the app features for a release about four months from the current sprint.
|
||||
|
||||
In contrast, the predictive approach places more emphasis on analyzing known risks and planning future sprints in detail. For example, predictive developers can accurately report the functions and tasks planned for the entire development process. But it's not a magical way to make your agile projects succeed all the time because the predictive team depends totally on effective early-stage analysis. If the analysis does not work very well, it may be difficult for the project to change direction once it gets started.
|
||||
|
||||
To mitigate this risk, I recommend that senior agile developers increase the predictive capabilities with a plan-driven method, and junior agile developers start with the adaptive methods for value-driven development.
|
||||
|
||||
### Continuously improve code quality
|
||||
|
||||
Don't hesitate to engage in [continuous integration][9] (CI) practices for improving your application before deploying code into production. To adopt modern application frameworks, such as cloud-native architecture, Linux container packaging, and hybrid cloud workloads, you have to learn about automated tools to address complex CI procedures.
|
||||
|
||||
[Jenkins][10] is the standard CI tool for many organizations; it allows developers to build and test applications in many projects in an automated fashion. Its most important function is detecting unexpected errors during CI to prevent them from happening in production. This should increase business outcomes through better customer satisfaction.
|
||||
|
||||
Automated CI enables agile developers to not only improve the quality of their code but their also application development agility through learning and using open source tools and patterns such as [behavior-driven development][11], [test-driven development][12], [automated unit testing][13], [pair programming][14], [code review][15], and [design pattern][16].
|
||||
|
||||
### Never stop exploring communities
|
||||
|
||||
Never settle, even if you already have a great reputation as an agile developer. You have to continuously take on bigger challenges to make great software in an agile way.
|
||||
|
||||
By participating in the very active and growing open source community, you will not only improve your skills as an agile developer, but your actions can also inspire other developers who want to learn agile practices.
|
||||
|
||||
How do you get involved in specific communities? It depends on your interests and what you want to learn. It might mean presenting specific topics at conferences or local meetups, writing technical blog posts, publishing practical guidebooks, committing code, or creating pull requests to open source projects' Git repositories. It's worth exploring open source communities for agile software development, as I've found it is a great way to share your expertise, knowledge, and practices with other brilliant developers and, along the way, help each other.
|
||||
|
||||
### Get started
|
||||
|
||||
These practical steps can give you a shorter path to becoming an awesome agile developer. Then you can lead junior developers in your team and organization to become more flexible, valuable, and predictive using agile principles.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/steps-agile-developer
|
||||
|
||||
作者:[Daniel Oh][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/daniel-oh
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/18/10/what-agile
|
||||
[2]: https://opensource.com/resources/what-are-linux-containers
|
||||
[3]: https://opensource.com/resources/what-is-kubernetes
|
||||
[4]: https://opensource.com/article/18/11/open-source-serverless-platforms
|
||||
[5]: https://en.wikipedia.org/wiki/Domain-driven_design
|
||||
[6]: https://openpracticelibrary.com/practice/start-at-the-end/
|
||||
[7]: https://openpracticelibrary.com/practice/event-storming/
|
||||
[8]: https://openpracticelibrary.com/practice/impact-mapping/
|
||||
[9]: https://en.wikipedia.org/wiki/Continuous_integration
|
||||
[10]: https://jenkins.io/
|
||||
[11]: https://en.wikipedia.org/wiki/Behavior-driven_development
|
||||
[12]: https://en.wikipedia.org/wiki/Test-driven_development
|
||||
[13]: https://en.wikipedia.org/wiki/Unit_testing
|
||||
[14]: https://en.wikipedia.org/wiki/Pair_programming
|
||||
[15]: https://en.wikipedia.org/wiki/Code_review
|
||||
[16]: https://en.wikipedia.org/wiki/Design_pattern
|
||||
@ -0,0 +1,69 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Introducing kids to computational thinking with Python)
|
||||
[#]: via: (https://opensource.com/article/19/2/break-down-stereotypes-python)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
Introducing kids to computational thinking with Python
|
||||
======
|
||||
Coding program gives low-income students the skills, confidence, and knowledge to break free from economic and societal disadvantages.
|
||||
|
||||

|
||||
|
||||
When the [Parkman Branch][1] of the Detroit Public Library was flooded with bored children taking up all the computers during summer break, the library saw it not as a problem, rather an opportunity. They started a coding club, the [Parkman Coders][2], led by [Qumisha Goss][3], a librarian who is leveraging the power of Python to introduce disadvantaged children to computational thinking.
|
||||
|
||||
When she started the Parkman Coders program about four years ago, "Q" (as she is known) didn't know much about coding. Since then, she's become a specialist in library instruction and technology and a certified Raspberry Pi instructor.
|
||||
|
||||
The program began by using [Scratch][4], but the students got bored with the block coding interface, which they regarded as "baby stuff." She says, "I knew we need to make a change to something that was still beginner friendly, but that would be more challenging for them to continue to hold their attention." At this point, she started teaching them Python.
|
||||
|
||||
Q first saw Python while playing a game with dungeons and skeleton monsters on [Code.org][5]. She began to learn Python by reading books like [Python Programming: An Introduction to Computer Science][6] and [Python for Kids][7]. She also recommends [Automate the Boring Stuff with Python][8] and [Lauren Ipsum: A Story about Computer Science and Other Improbable Things][9].
|
||||
|
||||
### Setting up a Raspberry Pi makerspace
|
||||
|
||||
Q decided to use [Raspberry Pi][10] computers to avoid the possibility that the students might be able to hack into the library system's computers, which weren't arranged in a way conducive to a makerspace anyway. The Pi's affordability, plus its flexibility and the included free software, lent more credibility to her decision.
|
||||
|
||||
While the coder program was the library's effort keep the peace and create a learning space that would engage the children, it quickly grew so popular that it ran out of space, computers, and adequate electrical outlets in a building built in 1921. They started with 10 Raspberry Pi computers shared among 20 children, but the library obtained funding from individuals, companies including Microsoft, the 4H, and the Detroit Public Library Foundation to get more equipment and expand the program.
|
||||
|
||||
Currently, about 40 children participate in each session and they have enough Raspberry Pi's for one device per child and some to give away. Many of the Parkman Coders come from low socio-economic backgrounds and don't have a computer at home, so the library provides them with donated Chromebooks.
|
||||
|
||||
Q says, "when kids demonstrate that they have a good understanding of how to use a Raspberry Pi or a [Microbit][11] and have been coming to programs regularly, we give them equipment to take home with them. This process is very challenging, however, because [they may not] have internet access at home [or] all the peripheral things they need like monitors, keyboards, and mice."
|
||||
|
||||
### Learning life skills and breaking stereotypes with Python
|
||||
|
||||
Q says, "I believe that the mainstays of learning computer science are learning critical thinking and problem-solving skills. My hope is that these lessons will stay with the kids as they grow and pursue futures in whatever field they choose. In addition, I'm hoping to inspire some pride in creatorship. It's a very powerful feeling to know 'I made this thing,' and once they've had these successes early, I hope they will approach new challenges with zeal."
|
||||
|
||||
She also says, "in learning to program, you have to learn to be hyper-vigilant about spelling and capitalization, and for some of our kids, reading is an issue. To make sure that the program is inclusive, we spell aloud during our lessons, and we encourage kids to speak up if they don't know a word or can't spell it correctly."
|
||||
|
||||
Q also tries to give extra attention to children who need it. She says, "if I recognize that someone has a more severe problem, we try to get them paired with a tutor at our library outside of program time, but still allow them to come to the program. We want to help them without discouraging them from participating."
|
||||
|
||||
Most importantly, the Parkman Coders program seeks to help every child realize that each has a unique skill set and abilities. Most of the children are African-American and half are girls. Q says, "we live in a world where we grow up with societal stigmas that frequently limit our own belief of what we can accomplish." She believes that children need a nonjudgmental space where "they can try new things, mess up, and discover."
|
||||
|
||||
The environment Q and the Parkman Coders program creates helps the participants break away from economic and societal disadvantages. She says that the secret sauce is to "make sure you have a welcoming space so anyone can come and that your space is forgiving and understanding. Let people come as they are, and be prepared to teach and to learn; when people feel comfortable and engaged, they want to stay."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/break-down-stereotypes-python
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://detroitpubliclibrary.org/locations/parkman
|
||||
[2]: https://www.dplfound.org/single-post/2016/05/15/Parkman-Branch-Coders
|
||||
[3]: https://www.linkedin.com/in/qumisha-goss-b3bb5470
|
||||
[4]: https://scratch.mit.edu/
|
||||
[5]: http://Code.org
|
||||
[6]: https://www.amazon.com/Python-Programming-Introduction-Computer-Science/dp/1887902996
|
||||
[7]: https://nostarch.com/pythonforkids
|
||||
[8]: https://automatetheboringstuff.com/
|
||||
[9]: https://nostarch.com/laurenipsum
|
||||
[10]: https://www.raspberrypi.org/
|
||||
[11]: https://microbit.org/guide/
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (Guevaraya)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
106
sources/tech/20190131 Will quantum computing break security.md
Normal file
106
sources/tech/20190131 Will quantum computing break security.md
Normal file
@ -0,0 +1,106 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Will quantum computing break security?)
|
||||
[#]: via: (https://opensource.com/article/19/1/will-quantum-computing-break-security)
|
||||
[#]: author: (Mike Bursell https://opensource.com/users/mikecamel)
|
||||
|
||||
Will quantum computing break security?
|
||||
======
|
||||
|
||||
Do you want J. Random Hacker to be able to pretend they're your bank?
|
||||
|
||||

|
||||
|
||||
Over the past few years, a new type of computer has arrived on the block: the quantum computer. It's arguably the sixth type of computer:
|
||||
|
||||
1. **Humans:** Before there were artificial computers, people used, well, people. And people with this job were called "computers."
|
||||
|
||||
2. **Mechanical analogue:** These are devices such as the [Antikythera mechanism][1], astrolabes, or slide rules.
|
||||
|
||||
3. **Mechanical digital:** In this category, I'd count anything that allowed discrete mathematics but didn't use electronics for the actual calculation: the abacus, Babbage's Difference Engine, etc.
|
||||
|
||||
4. **Electronic analogue:** Many of these were invented for military uses such as bomb sights, gun aiming, etc.
|
||||
|
||||
5. **Electronic digital:** I'm going to go out on a limb here and characterise Colossus as the first electronic digital computer1: these are basically what we use today for anything from mobile phones to supercomputers.
|
||||
|
||||
6. **Quantum computers:** These are coming and are fundamentally different from all of the previous generations.
|
||||
|
||||
|
||||
|
||||
|
||||
### What is quantum computing?
|
||||
|
||||
Quantum computing uses concepts from quantum mechanics to allow very different types of calculations from what we're used to in "classical computing." I'm not even going to try to explain, because I know I'd do a terrible job, so I suggest you try something like [Wikipedia's definition][2] as a starting point. What's important for our purposes is to understand that quantum computers use qubits to do calculations, and for quite a few types of mathematical algorithms—and therefore computing operations––they can solve problems much faster than classical computers.
|
||||
|
||||
What's "much faster"? Much, much faster: orders of magnitude faster. A calculation that might take years or decades with a classical computer could, in certain circumstances, take seconds. Impressive, yes? And scary. Because one of the types of problems that quantum computers should be good at solving is decrypting encrypted messages, even without the keys.
|
||||
|
||||
This means that someone with a sufficiently powerful quantum computer should be able to read all of your current and past messages, decrypt any stored data, and maybe fake digital signatures. Is this a big thing? Yes. Do you want J. Random Hacker to be able to pretend they're your bank?2 Do you want that transaction on the blockchain where you were sold a 10 bedroom mansion in Mayfair to be "corrected" to be a bedsit in Weston-super-Mare?3
|
||||
|
||||
### Some good news
|
||||
|
||||
This is all scary stuff, but there's good news of various types.
|
||||
|
||||
The first is that, in order to make any of this work at all, you need a quantum computer with a good number of qubits operating, and this is turning out to be hard.4 The general consensus is that we've got a few years before anybody has a "big" enough quantum computer to do serious damage to classical encryption algorithms.
|
||||
|
||||
The second is that, even with a sufficient number of qubits to attacks our existing algorithms, you still need even more to allow for error correction.
|
||||
|
||||
The third is that, although there are theoretical models to show how to attack some of our existing algorithms, actually making them work is significantly harder than you or I5 might expect. In fact, some of the attacks may turn out to be infeasible or just take more years to perfect than we worry about.
|
||||
|
||||
The fourth is that there are clever people out there who are designing quantum-computation-resistant algorithms (sometimes referred to as "post-quantum algorithms") that we can use, at least for new encryption, once they've been tested and become widely available.
|
||||
|
||||
All in all, in fact, there's a strong body of expert opinion that says we shouldn't be overly worried about quantum computing breaking our encryption in the next five or even 10 years.
|
||||
|
||||
### And some bad news
|
||||
|
||||
It's not all rosy, however. Two issues stick out to me as areas of concern.
|
||||
|
||||
1. People are still designing and rolling out systems that don't consider the issue. If you're coming up with a system that is likely to be in use for 10 or more years or will be encrypting or signing data that must remain confidential or attributable over those sorts of periods, then you should be considering the possible impact of quantum computing on your system.
|
||||
|
||||
2. Some of the new, quantum-computing-resistant algorithms are proprietary. This means that when you and I want to start implementing systems that are designed to be quantum-computing resistant, we'll have to pay to do so. I'm a big proponent of open source, and particularly of [open source cryptography][3], and my big worry is that we just won't be able to open source these things, and worse, that when new protocol standards are created––either de-facto or through standards bodies––they will choose proprietary algorithms that exclude the use of open source, whether on purpose, through ignorance, or because few good alternatives are available.
|
||||
|
||||
|
||||
|
||||
|
||||
### What to do?
|
||||
|
||||
Luckily, there are things you can do to address both of the issues above. The first is to think and plan when designing a system about what the impact of quantum computing might be on it. Often—very often—you won't need to implement anything explicit now (and it could be hard to, given the current state of the art), but you should at least embrace [the concept of crypto-agility][4]: designing protocols and systems so you can swap out algorithms if required.7
|
||||
|
||||
The second is a call to arms: Get involved in the open source movement and encourage everybody you know who has anything to do with cryptography to rally for open standards and for research into non-proprietary, quantum-computing-resistant algorithms. This is something that's very much on my to-do list, and an area where pressure and lobbying is just as important as the research itself.
|
||||
|
||||
1\. I think it's fair to call it the first electronic, programmable computer. I know there were earlier non-programmable ones, and that some claim ENIAC, but I don't have the space or the energy to argue the case here.
|
||||
|
||||
2\. No.
|
||||
|
||||
3\. See 2. Don't get me wrong, by the way—I grew up near Weston-super-Mare, and it's got things going for it, but it's not Mayfair.
|
||||
|
||||
4\. And if a quantum physicist says something's hard, then to my mind, it's hard.
|
||||
|
||||
5\. And I'm assuming that neither of us is a quantum physicist or mathematician.6
|
||||
|
||||
6\. I'm definitely not.
|
||||
|
||||
7\. And not just for quantum-computing reasons: There's a good chance that some of our existing classical algorithms may just fall to other, non-quantum attacks such as new mathematical approaches.
|
||||
|
||||
This article was originally published on [Alice, Eve, and Bob][5] and is reprinted with the author's permission.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/will-quantum-computing-break-security
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mikecamel
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Antikythera_mechanism
|
||||
[2]: https://en.wikipedia.org/wiki/Quantum_computing
|
||||
[3]: https://opensource.com/article/17/10/many-eyes
|
||||
[4]: https://aliceevebob.com/2017/04/04/disbelieving-the-many-eyes-hypothesis/
|
||||
[5]: https://aliceevebob.com/2019/01/08/will-quantum-computing-break-security/
|
||||
121
sources/tech/20190201 Top 5 Linux Distributions for New Users.md
Normal file
121
sources/tech/20190201 Top 5 Linux Distributions for New Users.md
Normal file
@ -0,0 +1,121 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Top 5 Linux Distributions for New Users)
|
||||
[#]: via: (https://www.linux.com/blog/learn/2019/2/top-5-linux-distributions-new-users)
|
||||
[#]: author: (Jack Wallen https://www.linux.com/users/jlwallen)
|
||||
|
||||
Top 5 Linux Distributions for New Users
|
||||
======
|
||||
|
||||

|
||||
|
||||
Linux has come a long way from its original offering. But, no matter how often you hear how easy Linux is now, there are still skeptics. To back up this claim, the desktop must be simple enough for those unfamiliar with Linux to be able to make use of it. And, the truth is that plenty of desktop distributions make this a reality.
|
||||
|
||||
### No Linux knowledge required
|
||||
|
||||
It might be simple to misconstrue this as yet another “best user-friendly Linux distributions” list. That is not what we’re looking at here. What’s the difference? For my purposes, the defining line is whether or not Linux actually plays into the usage. In other words, could you set a user in front of a desktop operating system and have them be instantly at home with its usage? No Linux knowledge required.
|
||||
|
||||
Believe it or not, some distributions do just that. I have five I’d like to present to you here. You’ve probably heard of all of them. They might not be your distribution of choice, but you can guarantee that they slide Linux out of the spotlight and place the user front and center.
|
||||
|
||||
Let’s take a look at the chosen few.
|
||||
|
||||
### Elementary OS
|
||||
|
||||
The very philosophy of Elementary OS is centered around how people actually use their desktops. The developers and designers have gone out of their way to create a desktop that is as simple as possible. In the process, they’ve de-Linux’d Linux. That is not to say they’ve removed Linux from the equation. No. Instead, what they’ve done is create an operating system that is about as neutral as you’ll find. Elementary OS is streamlined in such a way as to make sure everything is perfectly logical. From the single Dock to the clear-to-anyone Applications menu, this is a desktop that doesn’t say to the user, “You’re using Linux!” In fact, the layout itself is reminiscent of Mac, but with the addition of a simple app menu (Figure 1).
|
||||
|
||||
![Elementary OS Juno][2]
|
||||
|
||||
Figure 1: The Elementary OS Juno Application menu in action.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
Another important aspect of Elementary OS that places it on this list is that it’s not nearly as flexible as some other desktop distributions. Sure, some users would balk at that, but having a desktop that doesn’t throw every bell and whistle at the user makes for a very familiar environment -- one that neither requires or allows a lot of tinkering. That aspect of the OS goes a long way to make the platform familiar to new users.
|
||||
|
||||
And like any modern Linux desktop distribution, Elementary OS includes and App Store, called AppCenter, where users can install all the applications they need, without ever having to touch the command line.
|
||||
|
||||
### Deepin
|
||||
|
||||
Deepin not only gets my nod for one of the most beautiful desktops on the market, it’s also just as easy to adopt as any desktop operating system available. With a very simplistic take on the desktop interface, there’s very little in the way of users with zero Linux experience getting up to speed on its usage. In fact, you’d be hard-pressed to find a user who couldn’t instantly start using the Deepin desktop. The only possible hitch in that works might be the sidebar control center (Figure 2).
|
||||
|
||||
![][5]
|
||||
|
||||
Figure 2: The Deepin sidebar control panel.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
But even that sidebar control panel is as intuitive as any other configuration tool on the market. And anyone that has used a mobile device will be instantly at home with the layout. As for opening applications, Deepin takes a macOS Launchpad approach with the Launcher. This button is in the usual far right position on the desktop dock, so users will immediately gravitate to that, understanding that it is probably akin to the standard “Start” menu.
|
||||
|
||||
In similar fashion as Elementary OS (and most every Linux distribution on the market), Deepin includes an app store (simply called “Store”), where plenty of apps can be installed with ease.
|
||||
|
||||
### Ubuntu
|
||||
|
||||
You knew it was coming. Ubuntu is most often ranked at the top of most user-friendly Linux lists. Why? Because it’s one of the chosen few where a knowledge of Linux simply isn’t necessary to get by on the desktop. Prior to the adoption of GNOME (and the ousting of Unity), that wouldn’t have been the case. Why? Because Unity often needed a bit of tweaking to get it to the point where a tiny bit of Linux knowledge wasn’t necessary (Figure 3). Now that Ubuntu has adopted GNOME, and tweaked it to the point where an understanding of GNOME isn’t even necessary, this desktop makes Linux take a back seat to simplicity and usability.
|
||||
|
||||
![Ubuntu 18.04][7]
|
||||
|
||||
Figure 3: The Ubuntu 18.04 desktop is instantly familiar.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
Unlike Elementary OS, Ubuntu doesn’t hold the user back. So anyone who wants more from their desktop, can have it. However, the out of the box experience is enough for just about any user type. Anyone looking for a desktop that makes the user unaware as to just how much power they have at their fingertips, could certainly do worse than Ubuntu.
|
||||
|
||||
### Linux Mint
|
||||
|
||||
I will preface this by saying I’ve never been the biggest fan of Linux Mint. It’s not that I don’t respect what the developers are doing, it’s more an aesthetic. I prefer modern-looking desktop environments. But that old school desktop metaphor (found in the default Cinnamon desktop) is perfectly familiar to nearly anyone who uses it. With a taskbar, start button, system tray, and desktop icons (Figure 4), Linux Mint offers an interface that requires zero learning curve. In fact, some users might be initially fooled into thinking they are working with a Windows 7 clone. Even the updates warning icon will look instantly familiar to users.
|
||||
|
||||
![Linux Mint ][9]
|
||||
|
||||
Figure 4: The Linux Mint Cinnamon desktop is very Windows 7-ish.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
Because Linux Mint benefits from being based on Ubuntu, it’ll not only enjoy an immediate familiarity, but a high usability. No matter if you have even the slightest understanding of the underlying platform, users will feel instantly at home on Linux Mint.
|
||||
|
||||
### Ubuntu Budgie
|
||||
|
||||
Our list concludes with a distribution that also does a fantastic job of making the user forget they are using Linux, and makes working with the usual tools a simple, beautiful thing. Melding the Budgie Desktop with Ubuntu makes for an impressively easy to use distribution. And although the layout of the desktop (Figure 5) might not be the standard fare, there is no doubt the acclimation takes no time. In fact, outside of the Dock defaulting to the left side of the desktop, Ubuntu Budgie has a decidedly Elementary OS look to it.
|
||||
|
||||
![Budgie][11]
|
||||
|
||||
Figure 5: The Budgie desktop is as beautiful as it is simple.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
The System Tray/Notification area in Ubuntu Budgie offers a few more features than the usual fare: Features such as quick access to Caffeine (a tool to keep your desktop awake), a Quick Notes tool (for taking simple notes), Night Lite switch, a Places drop-down menu (for quick access to folders), and of course the Raven applet/notification sidebar (which is similar to, but not quite as elegant as, the Control Center sidebar in Deepin). Budgie also includes an application menu (top left corner), which gives users access to all of their installed applications. Open an app and the icon will appear in the Dock. Right-click that app icon and select Keep in Dock for even quicker access.
|
||||
|
||||
Everything about Ubuntu Budgie is intuitive, so there’s practically zero learning curve involved. It doesn’t hurt that this distribution is as elegant as it is easy to use.
|
||||
|
||||
### Give One A Chance
|
||||
|
||||
And there you have it, five Linux distributions that, each in their own way, offer a desktop experience that any user would be instantly familiar with. Although none of these might be your choice for top distribution, it’s hard to argue their value when it comes to users who have no familiarity with Linux.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][12]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2019/2/top-5-linux-distributions-new-users
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/jlwallen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/files/images/elementaryosjpg-2
|
||||
[2]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/elementaryos_0.jpg?itok=KxgNUvMW (Elementary OS Juno)
|
||||
[3]: https://www.linux.com/licenses/category/used-permission
|
||||
[4]: https://www.linux.com/files/images/deepinjpg
|
||||
[5]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/deepin.jpg?itok=VV381a9f
|
||||
[6]: https://www.linux.com/files/images/ubuntujpg-1
|
||||
[7]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/ubuntu_1.jpg?itok=bax-_Tsg (Ubuntu 18.04)
|
||||
[8]: https://www.linux.com/files/images/linuxmintjpg
|
||||
[9]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/linuxmint.jpg?itok=8sPon0Cq (Linux Mint )
|
||||
[10]: https://www.linux.com/files/images/budgiejpg-0
|
||||
[11]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/budgie_0.jpg?itok=zcf-AHmj (Budgie)
|
||||
[12]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
77
sources/tech/20190204 7 Best VPN Services For 2019.md
Normal file
77
sources/tech/20190204 7 Best VPN Services For 2019.md
Normal file
@ -0,0 +1,77 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (7 Best VPN Services For 2019)
|
||||
[#]: via: (https://www.ostechnix.com/7-best-opensource-vpn-services-for-2019/)
|
||||
[#]: author: (Editor https://www.ostechnix.com/author/editor/)
|
||||
|
||||
7 Best VPN Services For 2019
|
||||
======
|
||||
|
||||
At least 67 percent of global businesses in the past three years have faced data breaching. The breaching has been reported to expose hundreds of millions of customers. Studies show that an estimated 93 percent of these breaches would have been avoided had data security fundamentals been considered beforehand.
|
||||
|
||||
Understand that poor data security can be extremely costly, especially to a business and could quickly lead to widespread disruption and possible harm to your brand reputation. Although some businesses can pick up the pieces the hard way, there are still those that fail to recover. Today however, you are fortunate to have access to data and network security software.
|
||||
|
||||

|
||||
|
||||
As you start 2019, keep off cyber-attacks by investing in a **V** irtual **P** rivate **N** etwork commonly known as **VPN**. When it comes to online privacy and security, there are many uncertainties. There are hundreds of different VPN providers, and picking the right one means striking just the right balance between pricing, services, and ease of use.
|
||||
|
||||
If you are looking for a solid 100 percent tested and secure VPN, you might want to do your due diligence and identify the best match. Here are the top 7 Best tried and tested VPN services For 2019.
|
||||
|
||||
### 1. Vpnunlimitedapp
|
||||
|
||||
With VPN Unlimited, you have total security. This VPN allows you to use any WIFI without worrying that your personal data can be leaked. With AES-256, your data is encrypted and protected against prying third-parties and hackers. This VPN ensures you stay anonymous and untracked on all websites no matter the location. It offers a 7-day trial and a variety of protocol options: OpenVPN, IKEv2, and KeepSolid Wise. Demanding users are entitled to special extras such as a personal server, lifetime VPN subscription, and personal IP options.
|
||||
|
||||
### 2. VPN Lite
|
||||
|
||||
VPN Lite is an easy-to-use and **free VPN service** that allows you to browse the internet at no charges. You remain anonymous and your privacy is protected. It obscures your IP and encrypts your data meaning third parties are not able to track your activities on all online platforms. You also get to access all online content. With VPN Lite, you get to access blocked sites in your state. You can also gain access to public WIFI without the worry of having sensitive information tracked and hacked by spyware and hackers.
|
||||
|
||||
### 3. HotSpot Shield
|
||||
|
||||
Launched in 2005, this is a popular VPN embraced by the majority of users. The VPN protocol here is integrated by at least 70 percent of the largest security companies globally. It is also known to have thousands of servers across the globe. It comes with two free options. One is completely free but supported by online advertisements, and the second one is a 7-day trial which is the flagship product. It contains military grade data encryption and protects against malware. HotSpot Shield guaranteed secure browsing and offers lightning-fast speeds.
|
||||
|
||||
### 4. TunnelBear
|
||||
|
||||
This is the best way to start if you are new to VPNs. It comes to you with a user-friendly interface complete with animated bears. With the help of TunnelBear, users are able to connect to servers in at least 22 countries at great speeds. It uses **AES 256-bit encryption** guaranteeing no data logging meaning your data stays protected. You also get unlimited data for up to five devices.
|
||||
|
||||
### 5. ProtonVPN
|
||||
|
||||
This VPN offers you a strong premium service. You may suffer from reduced connection speeds, but you also get to enjoy its unlimited data. It features an intuitive interface easy to use, and comes with a multi-platform compatibility. Proton’s servers are said to be specifically optimized for torrenting and thus cannot give access to Netflix. You get strong security features such as protocols and encryptions meaning your browsing activities remain secure.
|
||||
|
||||
### 6. ExpressVPN
|
||||
|
||||
This is known as the best offshore VPN for unblocking and privacy. It has gained recognition for being the top VPN service globally resulting from solid customer support and fast speeds. It offers routers that come with browser extensions and custom firmware. ExpressVPN also has an admirable scope of quality apps, plenty of servers, and can only support up to three devices.
|
||||
|
||||
It’s not entirely free, and happens to be one of the most expensive VPNs on the market today because it is fully packed with the most advanced features. With it comes a 30-day money-back guarantee, meaning you can freely test this VPN for a month. Good thing is; it is completely risk-free. If you need a VPN for a short duration to bypass online censorship for instance, this could, be your go-to solution. You don’t want to give trials to a spammy, slow, free program.
|
||||
|
||||
It is also one of the best ways to enjoy online streaming as well as outdoor security. Should you need to continue using it, you only have to renew or cancel your free trial if need be. Express VPN has over 2000 servers across 90 countries, unblocks Netflix, gives lightning fast connections, and gives users total privacy.
|
||||
|
||||
### 7. PureVPN
|
||||
|
||||
While this VPN may not be completely free, it falls under the most budget-friendly services on this list. Users can sign up for a free seven days trial and later choose one of its paid plans. With this VPN, you get to access 750-plus servers in at least 140 countries. There is also access to easy installation on almost all devices. All its paid features can still be accessed within the free trial window. That includes unlimited data transfers, IP leakage protection, and ISP invisibility. The supproted operating systems are iOS, Android, Windows, Linux, and macOS.
|
||||
|
||||
### Summary
|
||||
|
||||
With the large variety of available freemium VPN services today, why not take that opportunity to protect yourself and your customers? Understand that there are some great VPN services. Even the most secure free service however, cannot be touted as risk free. You might want to upgrade to a premium one for increased protection. Premium VPN allows you to test freely offering risk-free money-back guarantee. Whether you plan to sign up for a paid VPN or commit to a free one, it is highly advisable to have a VPN.
|
||||
|
||||
**About the author:**
|
||||
|
||||
**Renetta K. Molina** is a tech enthusiast and fitness enthusiast. She writes about technology, apps, WordPress and a variety of other topics. In her free time, she likes to play golf and read books. She loves to learn and try new things.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/7-best-opensource-vpn-services-for-2019/
|
||||
|
||||
作者:[Editor][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -0,0 +1,125 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Top 5 open source network monitoring tools)
|
||||
[#]: via: (https://opensource.com/article/19/2/network-monitoring-tools)
|
||||
[#]: author: (Paul Bischoff https://opensource.com/users/paulbischoff)
|
||||
|
||||
Top 5 open source network monitoring tools
|
||||
======
|
||||
Keep an eye on your network to avoid downtime with these monitoring tools.
|
||||

|
||||
|
||||
Maintaining a live network is one of a system administrator's most essential tasks, and keeping a watchful eye over connected systems is essential to keeping a network functioning at its best.
|
||||
|
||||
There are many different ways to keep tabs on a modern network. Network monitoring tools are designed for the specific purpose of monitoring network traffic and response times, while application performance management solutions use agents to pull performance data from the application stack. If you have a live network, you need network monitoring to make sure you aren't vulnerable to an attacker. Likewise, if you rely on lots of different applications to run your daily operations, you will need an [application performance management][1] solution as well.
|
||||
|
||||
This article will focus on open source network monitoring tools. These tools help monitor individual nodes and applications for signs of poor performance. Through one window, you can view the performance of an entire network and even get alerts to keep you in the loop if you're away from your desk.
|
||||
|
||||
Before we get into the top five network monitoring tools, let's look more closely at the reasons you need to use one.
|
||||
|
||||
### Why do I need a network monitoring tool?
|
||||
|
||||
Network monitoring tools are vital to maintaining networks because they allow you to keep an eye on devices connected to the network from a central location. These tools help flag devices with subpar performance so you can step in and run troubleshooting to get to the root of the problem.
|
||||
|
||||
Running in-depth troubleshooting can minimize performance problems and prevent security breaches. In practical terms, this keeps the network online and eliminates the risk of falling victim to unnecessary downtime. Regular network maintenance can also help prevent outages that could take thousands of users offline.
|
||||
|
||||
A network monitoring tool enables you to:
|
||||
|
||||
* Autodiscover devices connected to your network
|
||||
* View live and historic performance data for a range of devices and applications
|
||||
* Configure alerts to notify you of unusual activity
|
||||
* Generate graphs and reports to analyze network activity in greater depth
|
||||
|
||||
### The top 5 open source network monitoring tools
|
||||
|
||||
Now, that you know why you need a network monitoring tool, take a look at the top 5 open source tools to see which might best meet your needs.
|
||||
|
||||
#### Cacti
|
||||
|
||||
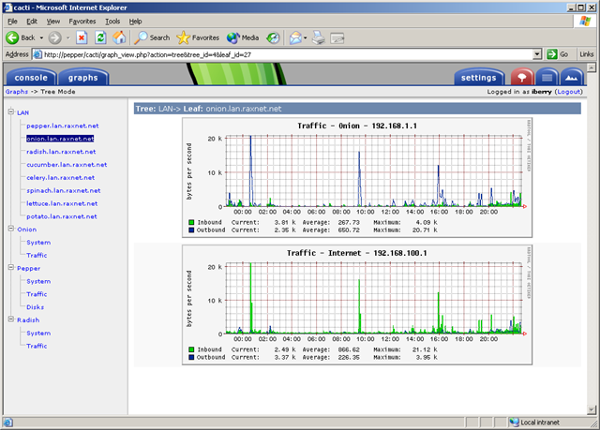
|
||||
|
||||
If you know anything about open source network monitoring tools, you've probably heard of [Cacti][2]. It's a graphing solution that acts as an addition to [RRDTool][3] and is used by many network administrators to collect performance data in LANs. Cacti comes with Simple Network Management Protocol (SNMP) support on Windows and Linux to create graphs of traffic data.
|
||||
|
||||
Cacti typically works by using data sourced from user-created scripts that ping hosts on a network. The values returned by the scripts are stored in a MySQL database, and this data is used to generate graphs.
|
||||
|
||||
This sounds complicated, but Cacti has templates to help speed the process along. You can also create a graph or data source template that can be used for future monitoring activity. If you'd like to try it out, [download Cacti][4] for free on Linux and Windows.
|
||||
|
||||
#### Nagios Core
|
||||
|
||||
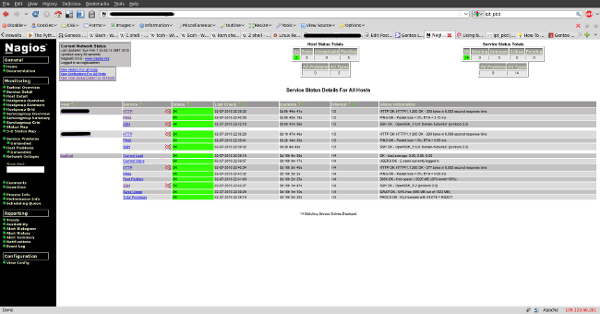
|
||||
|
||||
[Nagios Core][5] is one of the most well-known open source monitoring tools. It provides a network monitoring experience that combines open source extensibility with a top-of-the-line user interface. With Nagios Core, you can auto-discover devices, monitor connected systems, and generate sophisticated performance graphs.
|
||||
|
||||
Support for customization is one of the main reasons Nagios Core has become so popular. For example, [Nagios V-Shell][6] was added as a PHP web interface built in AngularJS, searchable tables and a RESTful API designed with CodeIgniter.
|
||||
|
||||
If you need more versatility, you can check the Nagios Exchange, which features a range of add-ons that can incorporate additional features into your network monitoring. These range from the strictly cosmetic to monitoring enhancements like [nagiosgraph][7]. You can try it out by [downloading Nagios Core][8] for free.
|
||||
|
||||
#### Icinga 2
|
||||
|
||||
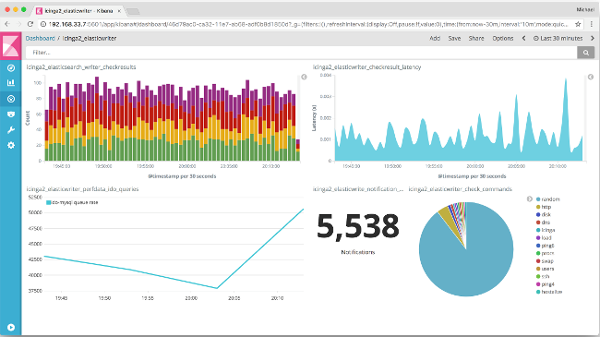
|
||||
|
||||
[Icinga 2][9] is another widely used open source network monitoring tool. It builds on the groundwork laid by Nagios Core. It has a flexible RESTful API that allows you to enter your own configurations and view live performance data through the dashboard. Dashboards are customizable, so you can choose exactly what information you want to monitor in your network.
|
||||
|
||||
Visualization is an area where Icinga 2 performs particularly well. It has native support for Graphite and InfluxDB, which can turn performance data into full-featured graphs for deeper performance analysis.
|
||||
|
||||
Icinga2 also allows you to monitor both live and historical performance data. It offers excellent alerts capabilities for live monitoring, and you can configure it to send notifications of performance problems by email or text. You can [download Icinga 2][10] for free for Windows, Debian, DHEL, SLES, Ubuntu, Fedora, and OpenSUSE.
|
||||
|
||||
#### Zabbix
|
||||
|
||||
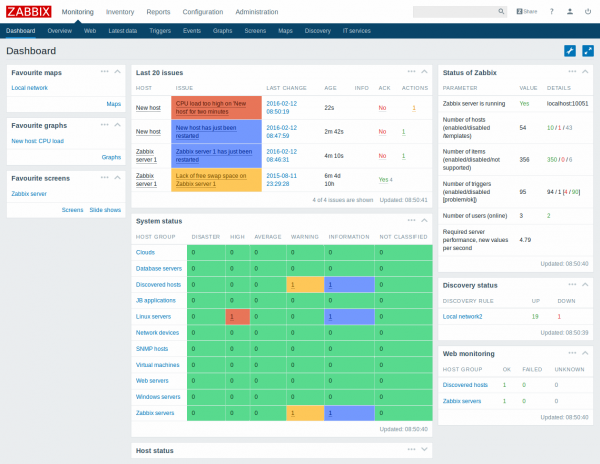
|
||||
|
||||
[Zabbix][11] is another industry-leading open source network monitoring tool, used by companies from Dell to Salesforce on account of its malleable network monitoring experience. Zabbix does network, server, cloud, application, and services monitoring very well.
|
||||
|
||||
You can track network information such as network bandwidth usage, network health, and configuration changes, and weed out problems that need to be addressed. Performance data in Zabbix is connected through SNMP, Intelligent Platform Management Interface (IPMI), and IPv6.
|
||||
|
||||
Zabbix offers a high level of convenience compared to other open source monitoring tools. For instance, you can automatically detect devices connected to your network before using an out-of-the-box template to begin monitoring your network. You can [download Zabbix][12] for free for CentOS, Debian, Oracle Linux, Red Hat Enterprise Linux, Ubuntu, and Raspbian.
|
||||
|
||||
#### Prometheus
|
||||
|
||||
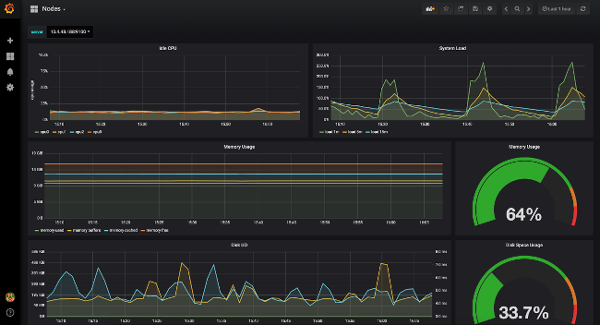
|
||||
|
||||
[Prometheus][13] is an open source network monitoring tool with a large community following. It was built specifically for monitoring time-series data. You can identify time-series data by metric name or key-value pairs. Time-series data is stored on local disks so that it's easy to access in an emergency.
|
||||
|
||||
Prometheus' [Alertmanager][14] allows you to view notifications every time it raises an event. Alertmanager can send notifications via email, PagerDuty, or OpsGenie, and you can silence alerts if necessary.
|
||||
|
||||
Prometheus' visual elements are excellent and allow you to switch from the browser to the template language and Grafana integration. You can also integrate various third-party data sources into Prometheus from Docker, StatsD, and JMX to customize your Prometheus experience.
|
||||
|
||||
As a network monitoring tool, Prometheus is suitable for organizations of all sizes. The onboard integrations and the easy-to-use Alertmanager make it capable of handling any workload, regardless of its size. You can [download Prometheus][15] for free.
|
||||
|
||||
### Which are best?
|
||||
|
||||
No matter what industry you're working in, if you rely on a network to do business, you need to implement some form of network monitoring. Network monitoring tools are an invaluable resource that help provide you with the visibility to keep your systems online. Monitoring your systems will give you the best chance to keep your equipment in working order.
|
||||
|
||||
As the tools on this list show, you don't need to spend an exorbitant amount of money to reap the rewards of network monitoring. Of the five, I believe Icinga 2 and Zabbix are the best options for providing you with everything you need to start monitoring your network to keep it online. Staying vigilant will help to minimize the change of being caught off-guard by performance issues.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/network-monitoring-tools
|
||||
|
||||
作者:[Paul Bischoff][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/paulbischoff
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.comparitech.com/net-admin/application-performance-management/
|
||||
[2]: https://www.cacti.net/index.php
|
||||
[3]: https://en.wikipedia.org/wiki/RRDtool
|
||||
[4]: https://www.cacti.net/download_cacti.php
|
||||
[5]: https://www.nagios.org/projects/nagios-core/
|
||||
[6]: https://exchange.nagios.org/directory/Addons/Frontends-%28GUIs-and-CLIs%29/Web-Interfaces/Nagios-V-2DShell/details
|
||||
[7]: https://exchange.nagios.org/directory/Addons/Graphing-and-Trending/nagiosgraph/details#_ga=2.79847774.890594951.1545045715-2010747642.1545045715
|
||||
[8]: https://www.nagios.org/downloads/nagios-core/
|
||||
[9]: https://icinga.com/products/icinga-2/
|
||||
[10]: https://icinga.com/download/
|
||||
[11]: https://www.zabbix.com/
|
||||
[12]: https://www.zabbix.com/download
|
||||
[13]: https://prometheus.io/
|
||||
[14]: https://prometheus.io/docs/alerting/alertmanager/
|
||||
[15]: https://prometheus.io/download/
|
||||
@ -0,0 +1,435 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (12 Methods To Check The Hard Disk And Hard Drive Partition On Linux)
|
||||
[#]: via: (https://www.2daygeek.com/linux-command-check-hard-disks-partitions/)
|
||||
[#]: author: (Vinoth Kumar https://www.2daygeek.com/author/vinoth/)
|
||||
|
||||
12 Methods To Check The Hard Disk And Hard Drive Partition On Linux
|
||||
======
|
||||
|
||||
Usually Linux admins check the available hard disk and it’s partitions whenever they want to add a new disks or additional partition in the system.
|
||||
|
||||
We used to check the partition table of our hard disk to view the disk partitions.
|
||||
|
||||
This will help you to view how many partitions were already created on the disk. Also, it allow us to verify whether we have any free space or not.
|
||||
|
||||
In general hard disks can be divided into one or more logical disks called partitions.
|
||||
|
||||
Each partitions can be used as a separate disk with its own file system and partition information is stored in a partition table.
|
||||
|
||||
It’s a 64-byte data structure. The partition table is part of the master boot record (MBR), which is a small program that is executed when a computer boots.
|
||||
|
||||
The partition information are saved in the 0 the sector of the disk. Make a note, all the partitions must be formatted with an appropriate file system before files can be written to it.
|
||||
|
||||
This can be verified using the following 12 methods.
|
||||
|
||||
* **`fdisk:`** manipulate disk partition table
|
||||
* **`sfdisk:`** display or manipulate a disk partition table
|
||||
* **`cfdisk:`** display or manipulate a disk partition table
|
||||
* **`parted:`** a partition manipulation program
|
||||
* **`lsblk:`** lsblk lists information about all available or the specified block devices.
|
||||
* **`blkid:`** locate/print block device attributes.
|
||||
* **`hwinfo:`** hwinfo stands for hardware information tool is another great utility that used to probe for the hardware present in the system.
|
||||
* **`lshw:`** lshw is a small tool to extract detailed information on the hardware configuration of the machine.
|
||||
* **`inxi:`** inxi is a command line system information script built for for console and IRC.
|
||||
* **`lsscsi:`** list SCSI devices (or hosts) and their attributes
|
||||
* **`cat /proc/partitions:`**
|
||||
* **`ls -lh /dev/disk/:`** The directory contains Disk manufacturer name, serial number, partition ID and real block device files, Those were symlink with real block device files.
|
||||
|
||||
|
||||
|
||||
### How To Check Hard Disk And Hard Drive Partition In Linux Using fdisk Command?
|
||||
|
||||
**[fdisk][1]** stands for fixed disk or format disk is a cli utility that allow users to perform following actions on disks. It allows us to view, create, resize, delete, move and copy the partitions.
|
||||
|
||||
```
|
||||
# fdisk -l
|
||||
|
||||
Disk /dev/sda: 30 GiB, 32212254720 bytes, 62914560 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0xeab59449
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sda1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 20973568 62914559 41940992 20G 83 Linux
|
||||
|
||||
|
||||
Disk /dev/sdb: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
|
||||
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0x8cc8f9e5
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sdc1 2048 2099199 2097152 1G 83 Linux
|
||||
/dev/sdc3 4196352 6293503 2097152 1G 83 Linux
|
||||
/dev/sdc4 6293504 20971519 14678016 7G 5 Extended
|
||||
/dev/sdc5 6295552 8392703 2097152 1G 83 Linux
|
||||
|
||||
|
||||
Disk /dev/sdd: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
|
||||
Disk /dev/sde: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
```
|
||||
|
||||
### How To Check Hard Disk And Hard Drive Partition In Linux Using sfdisk Command?
|
||||
|
||||
sfdisk is a script-oriented tool for partitioning any block device. sfdisk supports MBR (DOS), GPT, SUN and SGI disk labels, but no longer provides any functionality for CHS (Cylinder-Head-Sector) addressing.
|
||||
|
||||
```
|
||||
# sfdisk -l
|
||||
|
||||
Disk /dev/sda: 30 GiB, 32212254720 bytes, 62914560 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0xeab59449
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sda1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 20973568 62914559 41940992 20G 83 Linux
|
||||
|
||||
|
||||
Disk /dev/sdb: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
|
||||
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0x8cc8f9e5
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sdc1 2048 2099199 2097152 1G 83 Linux
|
||||
/dev/sdc3 4196352 6293503 2097152 1G 83 Linux
|
||||
/dev/sdc4 6293504 20971519 14678016 7G 5 Extended
|
||||
/dev/sdc5 6295552 8392703 2097152 1G 83 Linux
|
||||
|
||||
|
||||
Disk /dev/sdd: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
|
||||
Disk /dev/sde: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
```
|
||||
|
||||
### How To Check Hard Disk And Hard Drive Partition In Linux Using cfdisk Command?
|
||||
|
||||
cfdisk is a curses-based program for partitioning any block device. The default device is /dev/sda. It provides basic partitioning functionality with a user-friendly interface.
|
||||
|
||||
```
|
||||
# cfdisk /dev/sdc
|
||||
Disk: /dev/sdc
|
||||
Size: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Label: dos, identifier: 0x8cc8f9e5
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
>> /dev/sdc1 2048 2099199 2097152 1G 83 Linux
|
||||
Free space 2099200 4196351 2097152 1G
|
||||
/dev/sdc3 4196352 6293503 2097152 1G 83 Linux
|
||||
/dev/sdc4 6293504 20971519 14678016 7G 5 Extended
|
||||
├─/dev/sdc5 6295552 8392703 2097152 1G 83 Linux
|
||||
└─Free space 8394752 20971519 12576768 6G
|
||||
|
||||
|
||||
|
||||
┌───────────────────────────────────────────────────────────────────────────────┐
|
||||
│ Partition type: Linux (83) │
|
||||
│Filesystem UUID: d17e3c31-e2c9-4f11-809c-94a549bc43b7 │
|
||||
│ Filesystem: ext2 │
|
||||
│ Mountpoint: /part1 (mounted) │
|
||||
└───────────────────────────────────────────────────────────────────────────────┘
|
||||
[Bootable] [ Delete ] [ Quit ] [ Type ] [ Help ] [ Write ]
|
||||
[ Dump ]
|
||||
|
||||
Quit program without writing changes
|
||||
```
|
||||
|
||||
### How To Check Hard Disk And Hard Drive Partition In Linux Using parted Command?
|
||||
|
||||
**[parted][2]** is a program to manipulate disk partitions. It supports multiple partition table formats, including MS-DOS and GPT. It is useful for creating space for new operating systems, reorganising disk usage, and copying data to new hard disks.
|
||||
|
||||
```
|
||||
# parted -l
|
||||
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sda: 32.2GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
|
||||
Number Start End Size Type File system Flags
|
||||
1 10.7GB 32.2GB 21.5GB primary ext4 boot
|
||||
|
||||
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sdb: 10.7GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sdc: 10.7GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
|
||||
Number Start End Size Type File system Flags
|
||||
1 1049kB 1075MB 1074MB primary ext2
|
||||
3 2149MB 3222MB 1074MB primary ext4
|
||||
4 3222MB 10.7GB 7515MB extended
|
||||
5 3223MB 4297MB 1074MB logical
|
||||
|
||||
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sdd: 10.7GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sde: 10.7GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
```
|
||||
|
||||
### How To Check Hard Disk And Hard Drive Partition In Linux Using lsblk Command?
|
||||
|
||||
lsblk lists information about all available or the specified block devices. The lsblk command reads the sysfs filesystem and udev db to gather information.
|
||||
|
||||
If the udev db is not available or lsblk is compiled without udev support than it tries to read LABELs, UUIDs and filesystem types from the block device. In this case root permissions are necessary. The command prints all block devices (except RAM disks) in a tree-like format by default.
|
||||
|
||||
```
|
||||
# lsblk
|
||||
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
|
||||
sda 8:0 0 30G 0 disk
|
||||
└─sda1 8:1 0 20G 0 part /
|
||||
sdb 8:16 0 10G 0 disk
|
||||
sdc 8:32 0 10G 0 disk
|
||||
├─sdc1 8:33 0 1G 0 part /part1
|
||||
├─sdc3 8:35 0 1G 0 part /part2
|
||||
├─sdc4 8:36 0 1K 0 part
|
||||
└─sdc5 8:37 0 1G 0 part
|
||||
sdd 8:48 0 10G 0 disk
|
||||
sde 8:64 0 10G 0 disk
|
||||
sr0 11:0 1 1024M 0 rom
|
||||
```
|
||||
|
||||
### How To Check Hard Disk And Hard Drive Partition In Linux Using blkid Command?
|
||||
|
||||
blkid is a command-line utility to locate/print block device attributes. It uses libblkid library to get disk partition UUID in Linux system.
|
||||
|
||||
```
|
||||
# blkid
|
||||
/dev/sda1: UUID="d92fa769-e00f-4fd7-b6ed-ecf7224af7fa" TYPE="ext4" PARTUUID="eab59449-01"
|
||||
/dev/sdc1: UUID="d17e3c31-e2c9-4f11-809c-94a549bc43b7" TYPE="ext2" PARTUUID="8cc8f9e5-01"
|
||||
/dev/sdc3: UUID="ca307aa4-0866-49b1-8184-004025789e63" TYPE="ext4" PARTUUID="8cc8f9e5-03"
|
||||
/dev/sdc5: PARTUUID="8cc8f9e5-05"
|
||||
```
|
||||
|
||||
### How To Check Hard Disk And Hard Drive Partition In Linux Using hwinfo Command?
|
||||
|
||||
**[hwinfo][3]** stands for hardware information tool is another great utility that used to probe for the hardware present in the system and display detailed information about varies hardware components in human readable format.
|
||||
|
||||
```
|
||||
# hwinfo --block --short
|
||||
disk:
|
||||
/dev/sdd VBOX HARDDISK
|
||||
/dev/sdb VBOX HARDDISK
|
||||
/dev/sde VBOX HARDDISK
|
||||
/dev/sdc VBOX HARDDISK
|
||||
/dev/sda VBOX HARDDISK
|
||||
partition:
|
||||
/dev/sdc1 Partition
|
||||
/dev/sdc3 Partition
|
||||
/dev/sdc4 Partition
|
||||
/dev/sdc5 Partition
|
||||
/dev/sda1 Partition
|
||||
cdrom:
|
||||
/dev/sr0 VBOX CD-ROM
|
||||
```
|
||||
|
||||
### How To Check Hard Disk And Hard Drive Partition In Linux Using lshw Command?
|
||||
|
||||
**[lshw][4]** (stands for Hardware Lister) is a small nifty tool that generates detailed reports about various hardware components on the machine such as memory configuration, firmware version, mainboard configuration, CPU version and speed, cache configuration, usb, network card, graphics cards, multimedia, printers, bus speed, etc.
|
||||
|
||||
```
|
||||
# lshw -short -class disk -class volume
|
||||
H/W path Device Class Description
|
||||
===================================================
|
||||
/0/3/0.0.0 /dev/cdrom disk CD-ROM
|
||||
/0/4/0.0.0 /dev/sda disk 32GB VBOX HARDDISK
|
||||
/0/4/0.0.0/1 /dev/sda1 volume 19GiB EXT4 volume
|
||||
/0/5/0.0.0 /dev/sdb disk 10GB VBOX HARDDISK
|
||||
/0/6/0.0.0 /dev/sdc disk 10GB VBOX HARDDISK
|
||||
/0/6/0.0.0/1 /dev/sdc1 volume 1GiB Linux filesystem partition
|
||||
/0/6/0.0.0/3 /dev/sdc3 volume 1GiB EXT4 volume
|
||||
/0/6/0.0.0/4 /dev/sdc4 volume 7167MiB Extended partition
|
||||
/0/6/0.0.0/4/5 /dev/sdc5 volume 1GiB Linux filesystem partition
|
||||
/0/7/0.0.0 /dev/sdd disk 10GB VBOX HARDDISK
|
||||
/0/8/0.0.0 /dev/sde disk 10GB VBOX HARDDISK
|
||||
```
|
||||
|
||||
### How To Check Hard Disk And Hard Drive Partition In Linux Using inxi Command?
|
||||
|
||||
**[inxi][5]** is a nifty tool to check hardware information on Linux and offers wide range of option to get all the hardware information on Linux system that i never found in any other utility which are available in Linux. It was forked from the ancient and mindbendingly perverse yet ingenius infobash, by locsmif.
|
||||
|
||||
```
|
||||
# inxi -Dp
|
||||
Drives: HDD Total Size: 75.2GB (22.3% used)
|
||||
ID-1: /dev/sda model: VBOX_HARDDISK size: 32.2GB
|
||||
ID-2: /dev/sdb model: VBOX_HARDDISK size: 10.7GB
|
||||
ID-3: /dev/sdc model: VBOX_HARDDISK size: 10.7GB
|
||||
ID-4: /dev/sdd model: VBOX_HARDDISK size: 10.7GB
|
||||
ID-5: /dev/sde model: VBOX_HARDDISK size: 10.7GB
|
||||
Partition: ID-1: / size: 20G used: 16G (85%) fs: ext4 dev: /dev/sda1
|
||||
ID-3: /part1 size: 1008M used: 1.3M (1%) fs: ext2 dev: /dev/sdc1
|
||||
ID-4: /part2 size: 976M used: 2.6M (1%) fs: ext4 dev: /dev/sdc3
|
||||
```
|
||||
|
||||
### How To Check Hard Disk And Hard Drive Partition In Linux Using lsscsi Command?
|
||||
|
||||
Uses information in sysfs (Linux kernel series 2.6 and later) to list SCSI devices (or hosts) currently attached to the system. Options can be used to control the amount and form of information provided for each device.
|
||||
|
||||
By default in this utility device node names (e.g. “/dev/sda” or “/dev/root_disk”) are obtained by noting the major and minor numbers for the listed device obtained from sysfs
|
||||
|
||||
```
|
||||
# lsscsi
|
||||
[0:0:0:0] cd/dvd VBOX CD-ROM 1.0 /dev/sr0
|
||||
[2:0:0:0] disk ATA VBOX HARDDISK 1.0 /dev/sda
|
||||
[3:0:0:0] disk ATA VBOX HARDDISK 1.0 /dev/sdb
|
||||
[4:0:0:0] disk ATA VBOX HARDDISK 1.0 /dev/sdc
|
||||
[5:0:0:0] disk ATA VBOX HARDDISK 1.0 /dev/sdd
|
||||
[6:0:0:0] disk ATA VBOX HARDDISK 1.0 /dev/sde
|
||||
```
|
||||
|
||||
### How To Check Hard Disk And Hard Drive Partition In Linux Using ProcFS?
|
||||
|
||||
The proc filesystem (procfs) is a special filesystem in Unix-like operating systems that presents information about processes and other system information.
|
||||
|
||||
It’s sometimes referred to as a process information pseudo-file system. It doesn’t contain ‘real’ files but runtime system information (e.g. system memory, devices mounted, hardware configuration, etc).
|
||||
|
||||
```
|
||||
# cat /proc/partitions
|
||||
major minor #blocks name
|
||||
|
||||
11 0 1048575 sr0
|
||||
8 0 31457280 sda
|
||||
8 1 20970496 sda1
|
||||
8 16 10485760 sdb
|
||||
8 32 10485760 sdc
|
||||
8 33 1048576 sdc1
|
||||
8 35 1048576 sdc3
|
||||
8 36 1 sdc4
|
||||
8 37 1048576 sdc5
|
||||
8 48 10485760 sdd
|
||||
8 64 10485760 sde
|
||||
```
|
||||
|
||||
### How To Check Hard Disk And Hard Drive Partition In Linux Using /dev/disk Path?
|
||||
|
||||
This directory contains four directories, it’s by-id, by-uuid, by-path and by-partuuid. Each directory contains some useful information and it’s symlinked with real block device files.
|
||||
|
||||
```
|
||||
# ls -lh /dev/disk/by-id
|
||||
total 0
|
||||
lrwxrwxrwx 1 root root 9 Feb 2 23:08 ata-VBOX_CD-ROM_VB0-01f003f6 -> ../../sr0
|
||||
lrwxrwxrwx 1 root root 9 Feb 3 00:14 ata-VBOX_HARDDISK_VB26e827b5-668ab9f4 -> ../../sda
|
||||
lrwxrwxrwx 1 root root 10 Feb 3 00:14 ata-VBOX_HARDDISK_VB26e827b5-668ab9f4-part1 -> ../../sda1
|
||||
lrwxrwxrwx 1 root root 9 Feb 2 23:39 ata-VBOX_HARDDISK_VB3774c742-fb2b3e4e -> ../../sdd
|
||||
lrwxrwxrwx 1 root root 9 Feb 2 23:39 ata-VBOX_HARDDISK_VBe72672e5-029a918e -> ../../sdc
|
||||
lrwxrwxrwx 1 root root 10 Feb 2 23:39 ata-VBOX_HARDDISK_VBe72672e5-029a918e-part1 -> ../../sdc1
|
||||
lrwxrwxrwx 1 root root 10 Feb 2 23:39 ata-VBOX_HARDDISK_VBe72672e5-029a918e-part3 -> ../../sdc3
|
||||
lrwxrwxrwx 1 root root 10 Feb 2 23:39 ata-VBOX_HARDDISK_VBe72672e5-029a918e-part4 -> ../../sdc4
|
||||
lrwxrwxrwx 1 root root 10 Feb 2 23:39 ata-VBOX_HARDDISK_VBe72672e5-029a918e-part5 -> ../../sdc5
|
||||
lrwxrwxrwx 1 root root 9 Feb 2 23:39 ata-VBOX_HARDDISK_VBed1cf451-9f51c5f6 -> ../../sdb
|
||||
lrwxrwxrwx 1 root root 9 Feb 2 23:39 ata-VBOX_HARDDISK_VBf242dbdd-49a982eb -> ../../sde
|
||||
```
|
||||
|
||||
Output of by-uuid
|
||||
|
||||
```
|
||||
# ls -lh /dev/disk/by-uuid
|
||||
total 0
|
||||
lrwxrwxrwx 1 root root 10 Feb 2 23:39 ca307aa4-0866-49b1-8184-004025789e63 -> ../../sdc3
|
||||
lrwxrwxrwx 1 root root 10 Feb 2 23:39 d17e3c31-e2c9-4f11-809c-94a549bc43b7 -> ../../sdc1
|
||||
lrwxrwxrwx 1 root root 10 Feb 3 00:14 d92fa769-e00f-4fd7-b6ed-ecf7224af7fa -> ../../sda1
|
||||
```
|
||||
|
||||
Output of by-path
|
||||
|
||||
```
|
||||
# ls -lh /dev/disk/by-path
|
||||
total 0
|
||||
lrwxrwxrwx 1 root root 9 Feb 2 23:08 pci-0000:00:01.1-ata-1 -> ../../sr0
|
||||
lrwxrwxrwx 1 root root 9 Feb 3 00:14 pci-0000:00:0d.0-ata-1 -> ../../sda
|
||||
lrwxrwxrwx 1 root root 10 Feb 3 00:14 pci-0000:00:0d.0-ata-1-part1 -> ../../sda1
|
||||
lrwxrwxrwx 1 root root 9 Feb 2 23:39 pci-0000:00:0d.0-ata-2 -> ../../sdb
|
||||
lrwxrwxrwx 1 root root 9 Feb 2 23:39 pci-0000:00:0d.0-ata-3 -> ../../sdc
|
||||
lrwxrwxrwx 1 root root 10 Feb 2 23:39 pci-0000:00:0d.0-ata-3-part1 -> ../../sdc1
|
||||
lrwxrwxrwx 1 root root 10 Feb 2 23:39 pci-0000:00:0d.0-ata-3-part3 -> ../../sdc3
|
||||
lrwxrwxrwx 1 root root 10 Feb 2 23:39 pci-0000:00:0d.0-ata-3-part4 -> ../../sdc4
|
||||
lrwxrwxrwx 1 root root 10 Feb 2 23:39 pci-0000:00:0d.0-ata-3-part5 -> ../../sdc5
|
||||
lrwxrwxrwx 1 root root 9 Feb 2 23:39 pci-0000:00:0d.0-ata-4 -> ../../sdd
|
||||
lrwxrwxrwx 1 root root 9 Feb 2 23:39 pci-0000:00:0d.0-ata-5 -> ../../sde
|
||||
```
|
||||
|
||||
Output of by-partuuid
|
||||
|
||||
```
|
||||
# ls -lh /dev/disk/by-partuuid
|
||||
total 0
|
||||
lrwxrwxrwx 1 root root 10 Feb 2 23:39 8cc8f9e5-01 -> ../../sdc1
|
||||
lrwxrwxrwx 1 root root 10 Feb 2 23:39 8cc8f9e5-03 -> ../../sdc3
|
||||
lrwxrwxrwx 1 root root 10 Feb 2 23:39 8cc8f9e5-04 -> ../../sdc4
|
||||
lrwxrwxrwx 1 root root 10 Feb 2 23:39 8cc8f9e5-05 -> ../../sdc5
|
||||
lrwxrwxrwx 1 root root 10 Feb 3 00:14 eab59449-01 -> ../../sda1
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-command-check-hard-disks-partitions/
|
||||
|
||||
作者:[Vinoth Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/vinoth/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/linux-fdisk-command-to-manage-disk-partitions/
|
||||
[2]: https://www.2daygeek.com/how-to-manage-disk-partitions-using-parted-command/
|
||||
[3]: https://www.2daygeek.com/hwinfo-check-display-detect-system-hardware-information-linux/
|
||||
[4]: https://www.2daygeek.com/lshw-find-check-system-hardware-information-details-linux/
|
||||
[5]: https://www.2daygeek.com/inxi-system-hardware-information-on-linux/
|
||||
172
sources/tech/20190205 5 Streaming Audio Players for Linux.md
Normal file
172
sources/tech/20190205 5 Streaming Audio Players for Linux.md
Normal file
@ -0,0 +1,172 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 Streaming Audio Players for Linux)
|
||||
[#]: via: (https://www.linux.com/blog/2019/2/5-streaming-audio-players-linux)
|
||||
[#]: author: (Jack Wallen https://www.linux.com/users/jlwallen)
|
||||
|
||||
5 Streaming Audio Players for Linux
|
||||
======
|
||||

|
||||
|
||||
As I work, throughout the day, music is always playing in the background. Most often, that music is in the form of vinyl spinning on a turntable. But when I’m not in purist mode, I’ll opt to listen to audio by way of a streaming app. Naturally, I’m on the Linux platform, so the only tools I have at my disposal are those that play well on my operating system of choice. Fortunately, plenty of options exist for those who want to stream audio to their Linux desktops.
|
||||
|
||||
In fact, Linux offers a number of solid offerings for music streaming, and I’ll highlight five of my favorite tools for this task. A word of warning, not all of these players are open source. But if you’re okay running a proprietary app on your open source desktop, you have some really powerful options. Let’s take a look at what’s available.
|
||||
|
||||
### Spotify
|
||||
|
||||
Spotify for Linux isn’t some dumb-downed, half-baked app that crashes every other time you open it, and doesn’t offer the full-range of features found on the macOS and Windows equivalent. In fact, the Linux version of Spotify is exactly the same as you’ll find on other platforms. With the Spotify streaming client you can listen to music and podcasts, create playlists, discover new artists, and so much more. And the Spotify interface (Figure 1) is quite easy to navigate and use.
|
||||
|
||||
![Spotify][2]
|
||||
|
||||
Figure 1: The Spotify interface makes it easy to find new music and old favorites.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
You can install Spotify either using snap (with the command sudo snap install spotify), or from the official repository, with the following commands:
|
||||
|
||||
* sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys 931FF8E79F0876134EDDBDCCA87FF9DF48BF1C90
|
||||
|
||||
* sudo echo deb <http://repository.spotify.com> stable non-free | sudo tee /etc/apt/sources.list.d/spotify.list
|
||||
|
||||
* sudo apt-get update
|
||||
|
||||
* sudo apt-get install spotify-client
|
||||
|
||||
|
||||
|
||||
|
||||
Once installed, you’ll want to log into your Spotify account, so you can start streaming all of the great music to help motivate you to get your work done. If you have Spotify installed on other devices (and logged into the same account), you can dictate to which device the music should stream (by clicking the Devices Available icon near the bottom right corner of the Spotify window).
|
||||
|
||||
### Clementine
|
||||
|
||||
Clementine one of the best music players available to the Linux platform. Clementine not only allows user to play locally stored music, but to connect to numerous streaming audio services, such as:
|
||||
|
||||
* Amazon Cloud Drive
|
||||
|
||||
* Box
|
||||
|
||||
* Dropbox
|
||||
|
||||
* Icecast
|
||||
|
||||
* Jamendo
|
||||
|
||||
* Magnatune
|
||||
|
||||
* RockRadio.com
|
||||
|
||||
* Radiotunes.com
|
||||
|
||||
* SomaFM
|
||||
|
||||
* SoundCloud
|
||||
|
||||
* Spotify
|
||||
|
||||
* Subsonic
|
||||
|
||||
* Vk.com
|
||||
|
||||
* Or internet radio streams
|
||||
|
||||
|
||||
|
||||
|
||||
There are two caveats to using Clementine. The first is you must be using the most recent version (as the build available in some repositories is out of date and won’t install the necessary streaming plugins). Second, even with the most recent build, some streaming services won’t function as expected. For example, with Spotify, you’ll only have available to you the Top Tracks (and not your playlist … or the ability to search for songs).
|
||||
|
||||
With Clementine Internet radio streaming, you’ll find musicians and bands you’ve never heard of (Figure 2), and plenty of them to tune into.
|
||||
|
||||
![Clementine][5]
|
||||
|
||||
Figure 2: Clementine Internet radio is a great way to find new music.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
### Odio
|
||||
|
||||
Odio is a cross-platform, proprietary app (available for Linux, MacOS, and Windows) that allows you to stream internet music stations of all genres. Radio stations are curated from [www.radio-browser.info][6] and the app itself does an incredible job of presenting the streams for you (Figure 3).
|
||||
|
||||
|
||||
![Odio][8]
|
||||
|
||||
Figure 3: The Odio interface is one of the best you’ll find.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
Odio makes it very easy to find unique Internet radio stations and even add those you find and enjoy to your library. Currently, the only way to install Odio on Linux is via Snap. If your distribution supports snap packages, install this streaming app with the command:
|
||||
|
||||
sudo snap install odio
|
||||
|
||||
Once installed, you can open the app and start using it. There is no need to log into (or create) an account. Odio is very limited in its settings. In fact, it only offers the choice between a dark or light theme in the settings window. However, as limited as it might be, Odio is one of your best bets for playing Internet radio on Linux.
|
||||
|
||||
Streamtuner2 is an outstanding Internet radio station GUI tool. With it you can stream music from the likes of:
|
||||
|
||||
* Internet radio stations
|
||||
|
||||
* Jameno
|
||||
|
||||
* MyOggRadio
|
||||
|
||||
* Shoutcast.com
|
||||
|
||||
* SurfMusic
|
||||
|
||||
* TuneIn
|
||||
|
||||
* Xiph.org
|
||||
|
||||
* YouTube
|
||||
|
||||
|
||||
### StreamTuner2
|
||||
|
||||
Streamtuner2 offers a nice (if not slightly outdated) interface, that makes it quite easy to find and stream your favorite music. The one caveat with StreamTuner2 is that it’s really just a GUI for finding the streams you want to hear. When you find a station, double-click on it to open the app associated with the stream. That means you must have the necessary apps installed, in order for the streams to play. If you don’t have the proper apps, you can’t play the streams. Because of this, you’ll spend a good amount of time figuring out what apps to install for certain streams (Figure 4).
|
||||
|
||||
![Streamtuner2][10]
|
||||
|
||||
Figure 4: Configuring Streamtuner2 isn’t for the faint of heart.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
### VLC
|
||||
|
||||
VLC has been, for a very long time, dubbed the best media playback tool for Linux. That’s with good reason, as it can play just about anything you throw at it. Included in that list is streaming radio stations. Although you won’t find VLC connecting to the likes of Spotify, you can head over to Internet-Radio, click on a playlist and have VLC open it without a problem. And considering how many internet radio stations are available at the moment, you won’t have any problem finding music to suit your tastes. VLC also includes tools like visualizers, equalizers (Figure 5), and more.
|
||||
|
||||
![VLC ][12]
|
||||
|
||||
Figure 5: The VLC visualizer and equalizer features in action.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
The only caveat to VLC is that you do have to have a URL for the Internet Radio you wish you hear, as the tool itself doesn’t curate. But with those links in hand, you won’t find a better media player than VLC.
|
||||
|
||||
### Always More Where That Came From
|
||||
|
||||
If one of these five tools doesn’t fit your needs, I suggest you open your distribution’s app store and search for one that will. There are plenty of tools to make streaming music, podcasts, and more not only possible on Linux, but easy.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][13] course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2019/2/5-streaming-audio-players-linux
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/jlwallen
|
||||
[b]: https://github.com/lujun9972
|
||||
[2]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/spotify_0.jpg?itok=8-Ym-R61 (Spotify)
|
||||
[3]: https://www.linux.com/licenses/category/used-permission
|
||||
[5]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/clementine_0.jpg?itok=5oODJO3b (Clementine)
|
||||
[6]: http://www.radio-browser.info
|
||||
[8]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/odio.jpg?itok=sNPTSS3c (Odio)
|
||||
[10]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/streamtuner2.jpg?itok=1MSbafWj (Streamtuner2)
|
||||
[12]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/vlc_0.jpg?itok=QEOsq7Ii (VLC )
|
||||
[13]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,122 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (CFS: Completely fair process scheduling in Linux)
|
||||
[#]: via: (https://opensource.com/article/19/2/fair-scheduling-linux)
|
||||
[#]: author: (Marty kalin https://opensource.com/users/mkalindepauledu)
|
||||
|
||||
CFS: Completely fair process scheduling in Linux
|
||||
======
|
||||
CFS gives every task a fair share of processor resources in a low-fuss but highly efficient way.
|
||||

|
||||
|
||||
Linux takes a modular approach to processor scheduling in that different algorithms can be used to schedule different process types. A scheduling class specifies which scheduling policy applies to which type of process. Completely fair scheduling (CFS), which became part of the Linux 2.6.23 kernel in 2007, is the scheduling class for normal (as opposed to real-time) processes and therefore is named **SCHED_NORMAL**.
|
||||
|
||||
CFS is geared for the interactive applications typical in a desktop environment, but it can be configured as **SCHED_BATCH** to favor the batch workloads common, for example, on a high-volume web server. In any case, CFS breaks dramatically with what might be called "classic preemptive scheduling." Also, the "completely fair" claim has to be seen with a technical eye; otherwise, the claim might seem like an empty boast.
|
||||
|
||||
Let's dig into the details of what sets CFS apart from—indeed, above—other process schedulers. Let's start with a quick review of some core technical terms.
|
||||
|
||||
### Some core concepts
|
||||
|
||||
Linux inherits the Unix view of a process as a program in execution. As such, a process must contend with other processes for shared system resources: memory to hold instructions and data, at least one processor to execute instructions, and I/O devices to interact with the external world. Process scheduling is how the operating system (OS) assigns tasks (e.g., crunching some numbers, copying a file) to processors—a running process then performs the task. A process has one or more threads of execution, which are sequences of machine-level instructions. To schedule a process is to schedule one of its threads on a processor.
|
||||
|
||||
In a simplifying move, Linux turns process scheduling into thread scheduling by treating a scheduled process as if it were single-threaded. If a process is multi-threaded with N threads, then N scheduling actions would be required to cover the threads. Threads within a multi-threaded process remain related in that they share resources such as memory address space. Linux threads are sometimes described as lightweight processes, with the lightweight underscoring the sharing of resources among the threads within a process.
|
||||
|
||||
Although a process can be in various states, two are of particular interest in scheduling. A blocked process is awaiting the completion of some event such as an I/O event. The process can resume execution only after the event completes. A runnable process is one that is not currently blocked.
|
||||
|
||||
A process is processor-bound (aka compute-bound) if it consumes mostly processor as opposed to I/O resources, and I/O-bound in the opposite case; hence, a processor-bound process is mostly runnable, whereas an I/O-bound process is mostly blocked. As examples, crunching numbers is processor-bound, and accessing files is I/O-bound. Although an entire process might be characterized as either processor-bound or I/O-bound, a given process may be one or the other during different stages of its execution. Interactive desktop applications, such as browsers, tend to be I/O-bound.
|
||||
|
||||
A good process scheduler has to balance the needs of processor-bound and I/O-bound tasks, especially in an operating system such as Linux that thrives on so many hardware platforms: desktop machines, embedded devices, mobile devices, server clusters, supercomputers, and more.
|
||||
|
||||
### Classic preemptive scheduling versus CFS
|
||||
|
||||
Unix popularized classic preemptive scheduling, which other operating systems including VAX/VMS, Windows NT, and Linux later adopted. At the center of this scheduling model is a fixed timeslice, the amount of time (e.g., 50ms) that a task is allowed to hold a processor until preempted in favor of some other task. If a preempted process has not finished its work, the process must be rescheduled. This model is powerful in that it supports multitasking (concurrency) through processor time-sharing, even on the single-CPU machines of yesteryear.
|
||||
|
||||
The classic model typically includes multiple scheduling queues, one per process priority: Every process in a higher-priority queue gets scheduled before any process in a lower-priority queue. As an example, VAX/VMS uses 32 priority queues for scheduling.
|
||||
|
||||
CFS dispenses with fixed timeslices and explicit priorities. The amount of time for a given task on a processor is computed dynamically as the scheduling context changes over the system's lifetime. Here is a sketch of the motivating ideas and technical details:
|
||||
|
||||
* Imagine a processor, P, which is idealized in that it can execute multiple tasks simultaneously. For example, tasks T1 and T2 can execute on P at the same time, with each receiving 50% of P's magical processing power. This idealization describes perfect multitasking, which CFS strives to achieve on actual as opposed to idealized processors. CFS is designed to approximate perfect multitasking.
|
||||
|
||||
* The CFS scheduler has a target latency, which is the minimum amount of time—idealized to an infinitely small duration—required for every runnable task to get at least one turn on the processor. If such a duration could be infinitely small, then each runnable task would have had a turn on the processor during any given timespan, however small (e.g., 10ms, 5ns, etc.). Of course, an idealized infinitely small duration must be approximated in the real world, and the default approximation is 20ms. Each runnable task then gets a 1/N slice of the target latency, where N is the number of tasks. For example, if the target latency is 20ms and there are four contending tasks, then each task gets a timeslice of 5ms. By the way, if there is only a single task during a scheduling event, this lucky task gets the entire target latency as its slice. The fair in CFS comes to the fore in the 1/N slice given to each task contending for a processor.
|
||||
|
||||
* The 1/N slice is, indeed, a timeslice—but not a fixed one because such a slice depends on N, the number of tasks currently contending for the processor. The system changes over time. Some processes terminate and new ones are spawned; runnable processes block and blocked processes become runnable. The value of N is dynamic and so, therefore, is the 1/N timeslice computed for each runnable task contending for a processor. The traditional **nice** value is used to weight the 1/N slice: a low-priority **nice** value means that only some fraction of the 1/N slice is given to a task, whereas a high-priority **nice** value means that a proportionately greater fraction of the 1/N slice is given to a task. In summary, **nice** values do not determine the slice, but only modify the 1/N slice that represents fairness among the contending tasks.
|
||||
|
||||
* The operating system incurs overhead whenever a context switch occurs; that is, when one process is preempted in favor of another. To keep this overhead from becoming unduly large, there is a minimum amount of time (with a typical setting of 1ms to 4ms) that any scheduled process must run before being preempted. This minimum is known as the minimum granularity. If many tasks (e.g., 20) are contending for the processor, then the minimum granularity (assume 4ms) might be more than the 1/N slice (in this case, 1ms). If the minimum granularity turns out to be larger than the 1/N slice, the system is overloaded because there are too many tasks contending for the processor—and fairness goes out the window.
|
||||
|
||||
* When does preemption occur? CFS tries to minimize context switches, given their overhead: time spent on a context switch is time unavailable for other tasks. Accordingly, once a task gets the processor, it runs for its entire weighted 1/N slice before being preempted in favor of some other task. Suppose task T1 has run for its weighted 1/N slice, and runnable task T2 currently has the lowest virtual runtime (vruntime) among the tasks contending for the processor. The vruntime records, in nanoseconds, how long a task has run on the processor. In this case, T1 would be preempted in favor of T2.
|
||||
|
||||
* The scheduler tracks the vruntime for all tasks, runnable and blocked. The lower a task's vruntime, the more deserving the task is for time on the processor. CFS accordingly moves low-vruntime tasks towards the front of the scheduling line. Details are forthcoming because the line is implemented as a tree, not a list.
|
||||
|
||||
* How often should the CFS scheduler reschedule? There is a simple way to determine the scheduling period. Suppose that the target latency (TL) is 20ms and the minimum granularity (MG) is 4ms:
|
||||
|
||||
`TL / MG = (20 / 4) = 5 ## five or fewer tasks are ok`
|
||||
|
||||
In this case, five or fewer tasks would allow each task a turn on the processor during the target latency. For example, if the task number is five, each runnable task has a 1/N slice of 4ms, which happens to equal the minimum granularity; if the task number is three, each task gets a 1/N slice of almost 7ms. In either case, the scheduler would reschedule in 20ms, the duration of the target latency.
|
||||
|
||||
Trouble occurs if the number of tasks (e.g., 10) exceeds TL / MG because now each task must get the minimum time of 4ms instead of the computed 1/N slice, which is 2ms. In this case, the scheduler would reschedule in 40ms:
|
||||
|
||||
`(number of tasks) core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated MG = (10 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 4) = 40ms ## period = 40ms`
|
||||
|
||||
|
||||
|
||||
|
||||
Linux schedulers that predate CFS use heuristics to promote the fair treatment of interactive tasks with respect to scheduling. CFS takes a quite different approach by letting the vruntime facts speak mostly for themselves, which happens to support sleeper fairness. An interactive task, by its very nature, tends to sleep a lot in the sense that it awaits user inputs and so becomes I/O-bound; hence, such a task tends to have a relatively low vruntime, which tends to move the task towards the front of the scheduling line.
|
||||
|
||||
### Special features
|
||||
|
||||
CFS supports symmetrical multiprocessing (SMP) in which any process (whether kernel or user) can execute on any processor. Yet configurable scheduling domains can be used to group processors for load balancing or even segregation. If several processors share the same scheduling policy, then load balancing among them is an option; if a particular processor has a scheduling policy different from the others, then this processor would be segregated from the others with respect to scheduling.
|
||||
|
||||
Configurable scheduling groups are another CFS feature. As an example, consider the Nginx web server that's running on my desktop machine. At startup, this server has a master process and four worker processes, which act as HTTP request handlers. For any HTTP request, the particular worker that handles the request is irrelevant; it matters only that the request is handled in a timely manner, and so the four workers together provide a pool from which to draw a task-handler as requests come in. It thus seems fair to treat the four Nginx workers as a group rather than as individuals for scheduling purposes, and a scheduling group can be used to do just that. The four Nginx workers could be configured to have a single vruntime among them rather than individual vruntimes. Configuration is done in the traditional Linux way, through files. For vruntime-sharing, a file named **cpu.shares** , with the details given through familiar shell commands, would be created.
|
||||
|
||||
As noted earlier, Linux supports scheduling classes so that different scheduling policies, together with their implementing algorithms, can coexist on the same platform. A scheduling class is implemented as a code module in C. CFS, the scheduling class described so far, is **SCHED_NORMAL**. There are also scheduling classes specifically for real-time tasks, **SCHED_FIFO** (first in, first out) and **SCHED_RR** (round robin). Under **SCHED_FIFO** , tasks run to completion; under **SCHED_RR** , tasks run until they exhaust a fixed timeslice and are preempted.
|
||||
|
||||
### CFS implementation
|
||||
|
||||
CFS requires efficient data structures to track task information and high-performance code to generate the schedules. Let's begin with a central term in scheduling, the runqueue. This is a data structure that represents a timeline for scheduled tasks. Despite the name, the runqueue need not be implemented in the traditional way, as a FIFO list. CFS breaks with tradition by using a time-ordered red-black tree as a runqueue. The data structure is well-suited for the job because it is a self-balancing binary search tree, with efficient **insert** and **remove** operations that execute in **O(log N)** time, where N is the number of nodes in the tree. Also, a tree is an excellent data structure for organizing entities into a hierarchy based on a particular property, in this case a vruntime.
|
||||
|
||||
In CFS, the tree's internal nodes represent tasks to be scheduled, and the tree as a whole, like any runqueue, represents a timeline for task execution. Red-black trees are in wide use beyond scheduling; for example, Java uses this data structure to implement its **TreeMap**.
|
||||
|
||||
Under CFS, every processor has a specific runqueue of tasks, and no task occurs at the same time in more than one runqueue. Each runqueue is a red-black tree. The tree's internal nodes represent tasks or task groups, and these nodes are indexed by their vruntime values so that (in the tree as a whole or in any subtree) the internal nodes to the left have lower vruntime values than the ones to the right:
|
||||
|
||||
```
|
||||
25 ## 25 is a task vruntime
|
||||
/\
|
||||
17 29 ## 17 roots the left subtree, 29 the right one
|
||||
/\ ...
|
||||
5 19 ## and so on
|
||||
... \
|
||||
nil ## leaf nodes are nil
|
||||
```
|
||||
|
||||
In summary, tasks with the lowest vruntime—and, therefore, the greatest need for a processor—reside somewhere in the left subtree; tasks with relatively high vruntimes congregate in the right subtree. A preempted task would go into the right subtree, thus giving other tasks a chance to move leftwards in the tree. A task with the smallest vruntime winds up in the tree's leftmost (internal) node, which is thus the front of the runqueue.
|
||||
|
||||
The CFS scheduler has an instance, the C **task_struct** , to track detailed information about each task to be scheduled. This structure embeds a **sched_entity** structure, which in turn has scheduling-specific information, in particular, the vruntime per task or task group:
|
||||
|
||||
```
|
||||
struct task_struct { /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var info on a task **/
|
||||
...
|
||||
struct sched_entity se; /** vruntime, etc. **/
|
||||
...
|
||||
};
|
||||
```
|
||||
|
||||
The red-black tree is implemented in familiar C fashion, with a premium on pointers for efficiency. A **cfs_rq** structure instance embeds a **rb_root** field named **tasks_timeline** , which points to the root of a red-black tree. Each of the tree's internal nodes has pointers to the parent and the two child nodes; the leaf nodes have nil as their value.
|
||||
|
||||
CFS illustrates how a straightforward idea—give every task a fair share of processor resources—can be implemented in a low-fuss but highly efficient way. It's worth repeating that CFS achieves fair and efficient scheduling without traditional artifacts such as fixed timeslices and explicit task priorities. The pursuit of even better schedulers goes on, of course; for the moment, however, CFS is as good as it gets for general-purpose processor scheduling.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/fair-scheduling-linux
|
||||
|
||||
作者:[Marty kalin][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mkalindepauledu
|
||||
[b]: https://github.com/lujun9972
|
||||
142
sources/tech/20190205 DNS and Root Certificates.md
Normal file
142
sources/tech/20190205 DNS and Root Certificates.md
Normal file
@ -0,0 +1,142 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (DNS and Root Certificates)
|
||||
[#]: via: (https://lushka.al/dns-and-certificates/)
|
||||
[#]: author: (Anxhelo Lushka https://lushka.al/)
|
||||
|
||||
DNS and Root Certificates
|
||||
======
|
||||
|
||||
Due to recent events we (as in we from the Privacy Today group) felt compelled to write an impromptu article on this matter. It’s intended for all audiences so it will be kept simple - technical details may be posted later.
|
||||
|
||||
### What Is DNS And Why Does It Concern You?
|
||||
|
||||
DNS stands for Domain Name System and you encounter it daily. Whenever your web browser or any other application connects to the internet, it will most likely do so using a domain. A domain is simply the address you type: i.e. [duckduckgo.com][1]. Your computer needs to know where this leads to and will ask a DNS resolver for help. It will return an IP like [176.34.155.23][2]; the public network address you need to know to connect. This process is called a DNS lookup.
|
||||
|
||||
There are certain implications for both your privacy and your security as well as your liberty:
|
||||
|
||||
#### Privacy
|
||||
|
||||
Since you ask the resolver for an IP for a domain name, it knows exactly which sites you’re visiting and, thanks to the “Internet Of Things”, often abbreviated as IoT, even which appliances you use at home.
|
||||
|
||||
#### Security
|
||||
|
||||
You’re trusting the resolver that the IP it returns is correct. There are certain checks to ensure it is so, under normal circumstances, that is not a common source of issues. These can be undermined though and that’s why this article is important. If the IP is not correct, you can be fooled into connecting to malicious 3rd parties - even without ever noticing any difference. In this case, your privacy is in much greater danger because, not only are the sites you visit tracked, but the contents as well. 3rd parties can see exactly what you’re looking at, collect personal information you enter (such as passwords), and a lot more. Your whole identity can be taken over with ease.
|
||||
|
||||
#### Liberty
|
||||
|
||||
Censorship is commonly enforced via DNS. It’s not the most effective way to do so but it is extremely widespread. Even in western countries, it’s routinely used by corporations and governments. They use the same methods as potential attackers; they will not return the correct IP when you ask. They could act as if the domain doesn’t exist or direct you elsewhere entirely.
|
||||
|
||||
### Ways DNS lookups can happen
|
||||
|
||||
#### 3rd Party DNS Resolvers Hosted By Your ISP
|
||||
|
||||
Most people are using 3rd party resolvers hosted by their Internet Service Provider. When you connect your modem, they will automatically be fetched and you might never bother with it at all.
|
||||
|
||||
#### 3rd Party DNS Resolver Of Your Choice
|
||||
|
||||
If you already knew what DNS means then you might have decided to use another DNS resolver of your choice. This might improve the situation since it makes it harder for your ISP to track you and you can avoid some forms of censorship. Both are still possible though, but the methods required are not as widely used.
|
||||
|
||||
#### Your Own (local) DNS Resolver
|
||||
|
||||
You can run your own and avoid some of the possible perils of using others’. If you’re interested in more information drop us a line.
|
||||
|
||||
### Root Certificates
|
||||
|
||||
#### What Is A Root Certificate?
|
||||
|
||||
Whenever you visit a website starting with https, you communicate with it using a certificate it sends. It enables your browser to encrypt the communication and ensures that nobody listening in can snoop. That’s why everybody has been told to look out for the https (rather than http) when logging into websites. The certificate itself only verifies that it has been generated for a certain domain. There’s more though:
|
||||
|
||||
That’s where the root certificate comes in. Think of it as the next higher level that makes sure the levels below are correct. It verifies that the certificate sent to you has been authorized by a certificate authority. This authority ensures that the person creating the certificate is actually the real operator.
|
||||
|
||||
This is also referred to as the chain of trust. Your operating system includes a set of these root certificates by default so that the chain of trust can be guaranteed.
|
||||
|
||||
#### Abuse
|
||||
|
||||
We now know that:
|
||||
|
||||
* DNS resolvers send you an IP address when you send a domain name
|
||||
* Certificates allow encrypting your communication and verify they have been generated for the domain you visit
|
||||
* Root certificates verify that the certificate is legitimate and has been created by the real site operator
|
||||
|
||||
|
||||
|
||||
**How can it be abused?**
|
||||
|
||||
* A malicious DNS resolver can send you a wrong IP for the purpose of censorship as said before. They can also send you to a completely different site.
|
||||
* This site can send you a fake certificate.
|
||||
* A malicious root certificate can “verify” this fake certificate.
|
||||
|
||||
|
||||
|
||||
This site will look absolutely fine to you; it has https in the URL and, if you click it, it will say verified. All just like you learned, right? **No!**
|
||||
|
||||
It now receives all the communication you intended to send to the original. This bypasses the checks created to avoid it. You won’t receive error messages, your browser won’t complain.
|
||||
|
||||
**All your data is compromised!**
|
||||
|
||||
### Conclusion
|
||||
|
||||
#### Risks
|
||||
|
||||
* Using a malicious DNS resolver can always compromise your privacy but your security will be unharmed as long as you look out for the https.
|
||||
* Using a malicious DNS resolver and a malicious root certificate, your privacy and security are fully compromised.
|
||||
|
||||
|
||||
|
||||
#### Actions To Take
|
||||
|
||||
**Do not ever install a 3rd party root certificate!** There are very few exceptions why you would want to do so and none of them are applicable to general end users.
|
||||
|
||||
**Do not fall for clever marketing that ensures “ad blocking”, “military grade security”, or something similar**. There are methods of using DNS resolvers on their own to enhance your privacy but installing a 3rd party root certificate never makes sense. You are opening yourself up to extreme abuse.
|
||||
|
||||
### Seeing It Live
|
||||
|
||||
**WARNING**
|
||||
|
||||
A friendly sysadmin provided a live demo so you can see for yourself in realtime. This is real.
|
||||
|
||||
**DO NOT ENTER PRIVATE DATA! REMOVE THE CERT AND DNS AFTERWARDS!**
|
||||
|
||||
If you do not know how to, don’t install it in the first place. While we trust our friend you still wouldn’t want to have the root certificate of a random and unknown 3rd party installed.
|
||||
|
||||
#### Live Demo
|
||||
|
||||
Here is the link: <http://https-interception.info.tm/>
|
||||
|
||||
* Set the provided DNS resolver
|
||||
* Install the provided root certificate
|
||||
* Visit <https://paypal.com> and enter random login data
|
||||
* Your data will show up on the website
|
||||
|
||||
|
||||
|
||||
### Further Information
|
||||
|
||||
If you are interested in more technical details, let us know. If there is enough interest, we might write an article but, for now, the important part is sharing the basics so you can make an informed decision and not fall for marketing and straight up fraud. Feel free to suggest other topics that are important to you.
|
||||
|
||||
This post is mirrored from [Privacy Today channel][3]. [Privacy Today][4] is a group about all things privacy, open source, libre philosophy and more!
|
||||
|
||||
All content is licensed under CC BY-NC-SA 4.0. ([Attribution-NonCommercial-ShareAlike 4.0 International][5]).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://lushka.al/dns-and-certificates/
|
||||
|
||||
作者:[Anxhelo Lushka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://lushka.al/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://duckduckgo.com
|
||||
[2]: http://176.34.155.23
|
||||
[3]: https://t.me/privacytoday
|
||||
[4]: https://t.me/joinchat/Awg5A0UW-tzOLX7zMoTDog
|
||||
[5]: https://creativecommons.org/licenses/by-nc-sa/4.0/
|
||||
@ -0,0 +1,443 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Install Apache, MySQL, PHP (LAMP) Stack On Ubuntu 18.04 LTS)
|
||||
[#]: via: (https://www.ostechnix.com/install-apache-mysql-php-lamp-stack-on-ubuntu-18-04-lts/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
|
||||
Install Apache, MySQL, PHP (LAMP) Stack On Ubuntu 18.04 LTS
|
||||
======
|
||||
|
||||

|
||||
|
||||
**LAMP** stack is a popular, open source web development platform that can be used to run and deploy dynamic websites and web-based applications. Typically, LAMP stack consists of Apache webserver, MariaDB/MySQL databases, PHP/Python/Perl programming languages. LAMP is the acronym of **L** inux, **M** ariaDB/ **M** YSQL, **P** HP/ **P** ython/ **P** erl. This tutorial describes how to install Apache, MySQL, PHP (LAMP stack) in Ubuntu 18.04 LTS server.
|
||||
|
||||
### Install Apache, MySQL, PHP (LAMP) Stack On Ubuntu 18.04 LTS
|
||||
|
||||
For the purpose of this tutorial, we will be using the following Ubuntu testbox.
|
||||
|
||||
* **Operating System** : Ubuntu 18.04.1 LTS Server Edition
|
||||
* **IP address** : 192.168.225.22/24
|
||||
|
||||
|
||||
|
||||
#### 1. Install Apache web server
|
||||
|
||||
First of all, update Ubuntu server using commands:
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
|
||||
$ sudo apt upgrade
|
||||
```
|
||||
|
||||
Next, install Apache web server:
|
||||
|
||||
```
|
||||
$ sudo apt install apache2
|
||||
```
|
||||
|
||||
Check if Apache web server is running or not:
|
||||
|
||||
```
|
||||
$ sudo systemctl status apache2
|
||||
```
|
||||
|
||||
Sample output would be:
|
||||
|
||||
```
|
||||
● apache2.service - The Apache HTTP Server
|
||||
Loaded: loaded (/lib/systemd/system/apache2.service; enabled; vendor preset: en
|
||||
Drop-In: /lib/systemd/system/apache2.service.d
|
||||
└─apache2-systemd.conf
|
||||
Active: active (running) since Tue 2019-02-05 10:48:03 UTC; 1min 5s ago
|
||||
Main PID: 2025 (apache2)
|
||||
Tasks: 55 (limit: 2320)
|
||||
CGroup: /system.slice/apache2.service
|
||||
├─2025 /usr/sbin/apache2 -k start
|
||||
├─2027 /usr/sbin/apache2 -k start
|
||||
└─2028 /usr/sbin/apache2 -k start
|
||||
|
||||
Feb 05 10:48:02 ubuntuserver systemd[1]: Starting The Apache HTTP Server...
|
||||
Feb 05 10:48:03 ubuntuserver apachectl[2003]: AH00558: apache2: Could not reliably
|
||||
Feb 05 10:48:03 ubuntuserver systemd[1]: Started The Apache HTTP Server.
|
||||
```
|
||||
|
||||
Congratulations! Apache service is up and running!!
|
||||
|
||||
##### 1.1 Adjust firewall to allow Apache web server
|
||||
|
||||
By default, the apache web browser can’t be accessed from remote systems if you have enabled the UFW firewall in Ubuntu 18.04 LTS. You must allow the http and https ports by following the below steps.
|
||||
|
||||
First, list out the application profiles available on your Ubuntu system using command:
|
||||
|
||||
```
|
||||
$ sudo ufw app list
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
```
|
||||
Available applications:
|
||||
Apache
|
||||
Apache Full
|
||||
Apache Secure
|
||||
OpenSSH
|
||||
```
|
||||
|
||||
As you can see, Apache and OpenSSH applications have installed UFW profiles. You can list out information about each profile and its included rules using “ **ufw app info “Profile Name”** command.
|
||||
|
||||
Let us look into the **“Apache Full”** profile. To do so, run:
|
||||
|
||||
```
|
||||
$ sudo ufw app info "Apache Full"
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
```
|
||||
Profile: Apache Full
|
||||
Title: Web Server (HTTP,HTTPS)
|
||||
Description: Apache v2 is the next generation of the omnipresent Apache web
|
||||
server.
|
||||
|
||||
Ports:
|
||||
80,443/tcp
|
||||
```
|
||||
|
||||
As you see, “Apache Full” profile has included the rules to enable traffic to the ports **80** and **443** :
|
||||
|
||||
Now, run the following command to allow incoming HTTP and HTTPS traffic for this profile:
|
||||
|
||||
```
|
||||
$ sudo ufw allow in "Apache Full"
|
||||
Rules updated
|
||||
Rules updated (v6)
|
||||
```
|
||||
|
||||
If you don’t want to allow https traffic, but only http (80) traffic, run:
|
||||
|
||||
```
|
||||
$ sudo ufw app info "Apache"
|
||||
```
|
||||
|
||||
##### 1.2 Test Apache Web server
|
||||
|
||||
Now, open your web browser and access Apache test page by navigating to **<http://localhost/>** or **<http://IP-Address/>**.
|
||||
|
||||
|
||||
|
||||
If you are see a screen something like above, you are good to go. Apache server is working!
|
||||
|
||||
#### 2. Install MySQL
|
||||
|
||||
To install MySQL On Ubuntu, run:
|
||||
|
||||
```
|
||||
$ sudo apt install mysql-server
|
||||
```
|
||||
|
||||
Verify if MySQL service is running or not using command:
|
||||
|
||||
```
|
||||
$ sudo systemctl status mysql
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||
```
|
||||
● mysql.service - MySQL Community Server
|
||||
Loaded: loaded (/lib/systemd/system/mysql.service; enabled; vendor preset: enab
|
||||
Active: active (running) since Tue 2019-02-05 11:07:50 UTC; 17s ago
|
||||
Main PID: 3423 (mysqld)
|
||||
Tasks: 27 (limit: 2320)
|
||||
CGroup: /system.slice/mysql.service
|
||||
└─3423 /usr/sbin/mysqld --daemonize --pid-file=/run/mysqld/mysqld.pid
|
||||
|
||||
Feb 05 11:07:49 ubuntuserver systemd[1]: Starting MySQL Community Server...
|
||||
Feb 05 11:07:50 ubuntuserver systemd[1]: Started MySQL Community Server.
|
||||
```
|
||||
|
||||
Mysql is running!
|
||||
|
||||
##### 2.1 Setup database administrative user (root) password
|
||||
|
||||
By default, MySQL **root** user password is blank. You need to secure your MySQL server by running the following script:
|
||||
|
||||
```
|
||||
$ sudo mysql_secure_installation
|
||||
```
|
||||
|
||||
You will be asked whether you want to setup **VALIDATE PASSWORD plugin** or not. This plugin allows the users to configure strong password for database credentials. If enabled, It will automatically check the strength of the password and enforces the users to set only those passwords which are secure enough. **It is safe to leave this plugin disabled**. However, you must use a strong and unique password for database credentials. If don’t want to enable this plugin, just press any key to skip the password validation part and continue the rest of the steps.
|
||||
|
||||
If your answer is **Yes** , you will be asked to choose the level of password validation.
|
||||
|
||||
```
|
||||
Securing the MySQL server deployment.
|
||||
|
||||
Connecting to MySQL using a blank password.
|
||||
|
||||
VALIDATE PASSWORD PLUGIN can be used to test passwords
|
||||
and improve security. It checks the strength of password
|
||||
and allows the users to set only those passwords which are
|
||||
secure enough. Would you like to setup VALIDATE PASSWORD plugin?
|
||||
|
||||
Press y|Y for Yes, any other key for No y
|
||||
```
|
||||
|
||||
The available password validations are **low** , **medium** and **strong**. Just enter the appropriate number (0 for low, 1 for medium and 2 for strong password) and hit ENTER key.
|
||||
|
||||
```
|
||||
There are three levels of password validation policy:
|
||||
|
||||
LOW Length >= 8
|
||||
MEDIUM Length >= 8, numeric, mixed case, and special characters
|
||||
STRONG Length >= 8, numeric, mixed case, special characters and dictionary file
|
||||
|
||||
Please enter 0 = LOW, 1 = MEDIUM and 2 = STRONG:
|
||||
```
|
||||
|
||||
Now, enter the password for MySQL root user. Please be mindful that you must use password for mysql root user depending upon the password policy you choose in the previous step. If you didn’t enable the plugin, just use any strong and unique password of your choice.
|
||||
|
||||
```
|
||||
Please set the password for root here.
|
||||
|
||||
New password:
|
||||
|
||||
Re-enter new password:
|
||||
|
||||
Estimated strength of the password: 50
|
||||
Do you wish to continue with the password provided?(Press y|Y for Yes, any other key for No) : y
|
||||
```
|
||||
|
||||
Once you entered the password twice, you will see the password strength (In our case it is **50** ). If it is OK for you, press Y to continue with the provided password. If not satisfied with password length, press any other key and set a strong password. I am OK with my current password, so I chose **y**.
|
||||
|
||||
For the rest of questions, just type **y** and hit ENTER. This will remove anonymous user, disallow root user login remotely and remove test database.
|
||||
|
||||
```
|
||||
Remove anonymous users? (Press y|Y for Yes, any other key for No) : y
|
||||
Success.
|
||||
|
||||
Normally, root should only be allowed to connect from
|
||||
'localhost'. This ensures that someone cannot guess at
|
||||
the root password from the network.
|
||||
|
||||
Disallow root login remotely? (Press y|Y for Yes, any other key for No) : y
|
||||
Success.
|
||||
|
||||
By default, MySQL comes with a database named 'test' that
|
||||
anyone can access. This is also intended only for testing,
|
||||
and should be removed before moving into a production
|
||||
environment.
|
||||
|
||||
Remove test database and access to it? (Press y|Y for Yes, any other key for No) : y
|
||||
- Dropping test database...
|
||||
Success.
|
||||
|
||||
- Removing privileges on test database...
|
||||
Success.
|
||||
|
||||
Reloading the privilege tables will ensure that all changes
|
||||
made so far will take effect immediately.
|
||||
|
||||
Reload privilege tables now? (Press y|Y for Yes, any other key for No) : y
|
||||
Success.
|
||||
|
||||
All done!
|
||||
```
|
||||
|
||||
That’s it. Password for MySQL root user has been set.
|
||||
|
||||
##### 2.2 Change authentication method for MySQL root user
|
||||
|
||||
By default, MySQL root user is set to authenticate using the **auth_socket** plugin in MySQL 5.7 and newer versions on Ubuntu. Even though it enhances the security, it will also complicate things when you access your database server using any external programs, for example phpMyAdmin. To fix this issue, you need to change authentication method from **auth_socket** to **mysql_native_password**. To do so, login to your MySQL prompt using command:
|
||||
|
||||
```
|
||||
$ sudo mysql
|
||||
```
|
||||
|
||||
Run the following command at the mysql prompt to find the current authentication method for all mysql user accounts:
|
||||
|
||||
```
|
||||
SELECT user,authentication_string,plugin,host FROM mysql.user;
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||
```
|
||||
+------------------|-------------------------------------------|-----------------------|-----------+
|
||||
| user | authentication_string | plugin | host |
|
||||
+------------------|-------------------------------------------|-----------------------|-----------+
|
||||
| root | | auth_socket | localhost |
|
||||
| mysql.session | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE | mysql_native_password | localhost |
|
||||
| mysql.sys | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE | mysql_native_password | localhost |
|
||||
| debian-sys-maint | *F126737722832701DD3979741508F05FA71E5BA0 | mysql_native_password | localhost |
|
||||
+------------------|-------------------------------------------|-----------------------|-----------+
|
||||
4 rows in set (0.00 sec)
|
||||
```
|
||||
|
||||
![][2]
|
||||
|
||||
As you see, mysql root user uses `auth_socket` plugin for authentication.
|
||||
|
||||
To change this authentication to **mysql_native_password** method, run the following command at mysql prompt. Don’t forget to replace **“password”** with a strong and unique password of your choice. If you have enabled VALIDATION plugin, make sure you have used a strong password based on the current policy requirements.
|
||||
|
||||
```
|
||||
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'password';
|
||||
```
|
||||
|
||||
Update the changes using command:
|
||||
|
||||
```
|
||||
FLUSH PRIVILEGES;
|
||||
```
|
||||
|
||||
Now check again if the authentication method is changed or not using command:
|
||||
|
||||
```
|
||||
SELECT user,authentication_string,plugin,host FROM mysql.user;
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
![][3]
|
||||
|
||||
Good! Now the myql root user can authenticate using password to access mysql shell.
|
||||
|
||||
Exit from the mysql prompt:
|
||||
|
||||
```
|
||||
exit
|
||||
```
|
||||
|
||||
#### 3\. Install PHP
|
||||
|
||||
To install PHP, run:
|
||||
|
||||
```
|
||||
$ sudo apt install php libapache2-mod-php php-mysql
|
||||
```
|
||||
|
||||
After installing PHP, create **info.php** file in the Apache root document folder. Usually, the apache root document folder will be **/var/www/html/** or **/var/www/** in most Debian based Linux distributions. In Ubuntu 18.04 LTS, it is **/var/www/html/**.
|
||||
|
||||
Let us create **info.php** file in the apache root folder:
|
||||
|
||||
```
|
||||
$ sudo vi /var/www/html/info.php
|
||||
```
|
||||
|
||||
Add the following lines:
|
||||
|
||||
```
|
||||
<?php
|
||||
phpinfo();
|
||||
?>
|
||||
```
|
||||
|
||||
Press ESC key and type **:wq** to save and quit the file. Restart apache service to take effect the changes.
|
||||
|
||||
```
|
||||
$ sudo systemctl restart apache2
|
||||
```
|
||||
|
||||
##### 3.1 Test PHP
|
||||
|
||||
Open up your web browser and navigate to **<http://IP-address/info.php>** URL.
|
||||
|
||||
You will see the php test page now.
|
||||
|
||||

|
||||
|
||||
Usually, when a user requests a directory from the web server, Apache will first look for a file named **index.html**. If you want to change Apache to serve php files rather than others, move **index.php** to first position in the **dir.conf** file as shown below
|
||||
|
||||
```
|
||||
$ sudo vi /etc/apache2/mods-enabled/dir.conf
|
||||
```
|
||||
|
||||
Here is the contents of the above file.
|
||||
|
||||
```
|
||||
<IfModule mod_dir.c>
|
||||
DirectoryIndex index.html index.cgi index.pl index.php index.xhtml index.htm
|
||||
</IfModule>
|
||||
|
||||
# vim: syntax=apache ts=4 sw=4 sts=4 sr noet
|
||||
```
|
||||
|
||||
Move the “index.php” file to first. Once you made the changes, your **dir.conf** file will look like below.
|
||||
|
||||
```
|
||||
<IfModule mod_dir.c>
|
||||
DirectoryIndex index.php index.html index.cgi index.pl index.xhtml index.htm
|
||||
</IfModule>
|
||||
|
||||
# vim: syntax=apache ts=4 sw=4 sts=4 sr noet
|
||||
```
|
||||
|
||||
Press **ESC** key and type **:wq** to save and close the file. Restart Apache service to take effect the changes.
|
||||
|
||||
```
|
||||
$ sudo systemctl restart apache2
|
||||
```
|
||||
|
||||
##### 3.2 Install PHP modules
|
||||
|
||||
To improve the functionality of PHP, you can install some additional PHP modules.
|
||||
|
||||
To list the available PHP modules, run:
|
||||
|
||||
```
|
||||
$ sudo apt-cache search php- | less
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||
![][4]
|
||||
|
||||
Use the arrow keys to go through the result. To exit, type **q** and hit ENTER key.
|
||||
|
||||
To find the details of any particular php module, for example **php-gd** , run:
|
||||
|
||||
```
|
||||
$ sudo apt-cache show php-gd
|
||||
```
|
||||
|
||||
To install a php module run:
|
||||
|
||||
```
|
||||
$ sudo apt install php-gd
|
||||
```
|
||||
|
||||
To install all modules (not necessary though), run:
|
||||
|
||||
```
|
||||
$ sudo apt-get install php*
|
||||
```
|
||||
|
||||
Do not forget to restart Apache service after installing any php module. To check if the module is loaded or not, open info.php file in your browser and check if it is present.
|
||||
|
||||
Next, you might want to install any database management tools to easily manage databases via a web browser. If so, install phpMyAdmin as described in the following link.
|
||||
|
||||
Congratulations! We have successfully setup LAMP stack in Ubuntu 18.04 LTS server.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/install-apache-mysql-php-lamp-stack-on-ubuntu-18-04-lts/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: http://www.ostechnix.com/wp-content/uploads/2019/02/mysql-1.png
|
||||
[3]: http://www.ostechnix.com/wp-content/uploads/2019/02/mysql-2.png
|
||||
[4]: http://www.ostechnix.com/wp-content/uploads/2016/06/php-modules.png
|
||||
@ -0,0 +1,133 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Installing Kali Linux on VirtualBox: Quickest & Safest Way)
|
||||
[#]: via: (https://itsfoss.com/install-kali-linux-virtualbox)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Installing Kali Linux on VirtualBox: Quickest & Safest Way
|
||||
======
|
||||
|
||||
**This tutorial shows you how to install Kali Linux on Virtual Box in Windows and Linux in the quickest way possible.**
|
||||
|
||||
[Kali Linux][1] is one of the [best Linux distributions for hacking][2] and security enthusiasts.
|
||||
|
||||
Since it deals with a sensitive topic like hacking, it’s like a double-edged sword. We have discussed it in the detailed Kali Linux review in the past so I am not going to bore you with the same stuff again.
|
||||
|
||||
While you can install Kali Linux by replacing the existing operating system, using it via a virtual machine would be a better and safer option.
|
||||
|
||||
With Virtual Box, you can use Kali Linux as a regular application in your Windows/Linux system. It’s almost the same as running VLC or a game in your system.
|
||||
|
||||
Using Kali Linux in a virtual machine is also safe. Whatever you do inside Kali Linux will NOT impact your ‘host system’ (i.e. your original Windows or Linux operating system). Your actual operating system will be untouched and your data in the host system will be safe.
|
||||
|
||||
![Kali Linux on Virtual Box][3]
|
||||
|
||||
### How to install Kali Linux on VirtualBox
|
||||
|
||||
I’ll be using [VirtualBox][4] here. It is a wonderful open source virtualization solution for just about anyone (professional or personal use). It’s available free of cost.
|
||||
|
||||
In this tutorial, we will talk about Kali Linux in particular but you can install almost any other OS whose ISO file exists or a pre-built virtual machine save file is available.
|
||||
|
||||
**Note:** The same steps apply for Windows/Linux running VirtualBox.
|
||||
|
||||
As I already mentioned, you can have either Windows or Linux installed as your host. But, in this case, I have Windows 10 installed (don’t hate me!) where I try to install Kali Linux in VirtualBox step by step.
|
||||
|
||||
And, the best part is – even if you happen to use a Linux distro as your primary OS, the same steps will be applicable!
|
||||
|
||||
Wondering, how? Let’s see…
|
||||
|
||||
### Step by Step Guide to install Kali Linux on VirtualBox
|
||||
|
||||
We are going to use a custom Kali Linux image made for VirtualBox specifically. You can also download the ISO file for Kali Linux and create a new virtual machine – but why do that when you have an easy alternative?
|
||||
|
||||
#### 1\. Download and install VirtualBox
|
||||
|
||||
The first thing you need to do is to download and install VirtualBox from Oracle’s official website.
|
||||
|
||||
[Download VirtualBox](https://www.virtualbox.org/wiki/Downloads)
|
||||
|
||||
Once you download the installer, just double click on it to install VirtualBox. It’s the same for installing VirtualBox on Ubuntu/Fedora Linux as well.
|
||||
|
||||
#### 2\. Download ready-to-use virtual image of Kali Linux
|
||||
|
||||
After installing it successfully, head to [Offensive Security’s download page][5] to download the VM image for VirtualBox. If you change your mind to utilize [VMware][6], that is available too.
|
||||
|
||||
![Kali Linux Virtual Box Image][7]
|
||||
|
||||
As you can see the file size is well over 3 GB, you should either use the torrent option or download it using a [download manager][8].
|
||||
|
||||
#### 3\. Install Kali Linux on Virtual Box
|
||||
|
||||
Once you have installed VirtualBox and downloaded the Kali Linux image, you just need to import it to VirtualBox in order to make it work.
|
||||
|
||||
Here’s how to import the VirtualBox image for Kali Linux:
|
||||
|
||||
**Step 1** : Launch VirtualBox. You will notice an **Import** button – click on it
|
||||
|
||||
![virtualbox import][9] Click on Import button
|
||||
|
||||
**Step 2:** Next, browse the file you just downloaded and choose it to be imported (as you can see in the image below). The file name should start with ‘kali linux‘ and end with . **ova** extension.
|
||||
|
||||
![virtualbox import file][10] Importing Kali Linux image
|
||||
|
||||
**S** Once selected, proceed by clicking on **Next**.
|
||||
|
||||
**Step 3** : Now, you will be shown the settings for the virtual machine you are about to import. So, you can customize them or not – that is your choice. It is okay if you go with the default settings.
|
||||
|
||||
You need to select a path where you have sufficient storage available. I would never recommend the **C:** drive on Windows.
|
||||
|
||||
![virtualbox kali linux settings][11] Import hard drives as VDI
|
||||
|
||||
Here, the hard drives as VDI refer to virtually mount the hard drives by allocating the storage space set.
|
||||
|
||||
After you are done with the settings, hit **Import** and wait for a while.
|
||||
|
||||
**Step 4:** You will now see it listed. So, just hit **Start** to launch it.
|
||||
|
||||
You might get an error at first for USB port 2.0 controller support, you can disable it to resolve it or just follow the on-screen instruction of installing an additional package to fix it. And, you are done!
|
||||
|
||||
![kali linux on windows virtual box][12]Kali Linux running in VirtualBox
|
||||
|
||||
I hope this guide helps you easily install Kali Linux on Virtual Box. Of course, Kali Linux has a lot of useful tools in it for penetration testing – good luck with that!
|
||||
|
||||
**Tip** : Both Kali Linux and Ubuntu are Debian-based. If you face any issues or error with Kali Linux, you may follow the tutorials intended for Ubuntu or Debian on the internet.
|
||||
|
||||
### Bonus: Free Kali Linux Guide Book
|
||||
|
||||
If you are just starting with Kali Linux, it will be a good idea to know how to use Kali Linux.
|
||||
|
||||
Offensive Security, the company behind Kali Linux, has created a guide book that explains the basics of Linux, basics of Kali Linux, configuration, setups. It also has a few chapters on penetration testing and security tools.
|
||||
|
||||
Basically, it has everything you need to get started with Kali Linux. And the best thing is that the book is available to download for free.
|
||||
|
||||
Let us know in the comments below if you face an issue or simply share your experience with Kali Linux on VirtualBox.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-kali-linux-virtualbox
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.kali.org/
|
||||
[2]: https://itsfoss.com/linux-hacking-penetration-testing/
|
||||
[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/kali-linux-virtual-box.png?resize=800%2C450&ssl=1
|
||||
[4]: https://www.virtualbox.org/
|
||||
[5]: https://www.offensive-security.com/kali-linux-vm-vmware-virtualbox-image-download/
|
||||
[6]: https://itsfoss.com/install-vmware-player-ubuntu-1310/
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/kali-linux-virtual-box-image.jpg?resize=800%2C347&ssl=1
|
||||
[8]: https://itsfoss.com/4-best-download-managers-for-linux/
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmbox-import-kali-linux.jpg?ssl=1
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmbox-linux-next.jpg?ssl=1
|
||||
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmbox-kali-linux-settings.jpg?ssl=1
|
||||
[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/kali-linux-on-windows-virtualbox.jpg?resize=800%2C429&ssl=1
|
||||
[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/kali-linux-virtual-box.png?fit=800%2C450&ssl=1
|
||||
@ -0,0 +1,95 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (4 cool new projects to try in COPR for February 2019)
|
||||
[#]: via: (https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-february-2019/)
|
||||
[#]: author: (Dominik Turecek https://fedoramagazine.org)
|
||||
|
||||
4 cool new projects to try in COPR for February 2019
|
||||
======
|
||||
|
||||

|
||||
|
||||
COPR is a [collection][1] of personal repositories for software that isn’t carried in Fedora. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
|
||||
|
||||
Here’s a set of new and interesting projects in COPR.
|
||||
|
||||
### CryFS
|
||||
|
||||
[CryFS][2] is a cryptographic filesystem. It is designed for use with cloud storage, mainly Dropbox, although it works with other storage providers as well. CryFS encrypts not only the files in the filesystem, but also metadata, file sizes and directory structure.
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides CryFS for Fedora 28 and 29, and for EPEL 7. To install CryFS, use these commands:
|
||||
|
||||
```
|
||||
sudo dnf copr enable fcsm/cryfs
|
||||
sudo dnf install cryfs
|
||||
```
|
||||
|
||||
### Cheat
|
||||
|
||||
[Cheat][3] is a utility for viewing various cheatsheets in command-line, aiming to help remind usage of programs that are used only occasionally. For many Linux utilities, cheat provides cheatsheets containing condensed information from man pages, focusing mainly on the most used examples. In addition to the built-in cheatsheets, cheat allows you to edit the existing ones or creating new ones from scratch.
|
||||
|
||||
![][4]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides cheat for Fedora 28, 29 and Rawhide, and for EPEL 7. To install cheat, use these commands:
|
||||
|
||||
```
|
||||
sudo dnf copr enable tkorbar/cheat
|
||||
sudo dnf install cheat
|
||||
```
|
||||
|
||||
### Setconf
|
||||
|
||||
[Setconf][5] is a simple program for making changes in configuration files, serving as an alternative for sed. The only thing setconf does is that it finds the key in the specified file and changes its value. Setconf provides only a few options to change its behavior — for example, uncommenting the line that is being changed.
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides setconf for Fedora 27, 28 and 29. To install setconf, use these commands:
|
||||
|
||||
```
|
||||
sudo dnf copr enable jamacku/setconf
|
||||
sudo dnf install setconf
|
||||
```
|
||||
|
||||
### Reddit Terminal Viewer
|
||||
|
||||
[Reddit Terminal Viewer][6], or rtv, is an interface for browsing Reddit from terminal. It provides the basic functionality of Reddit, so you can log in to your account, view subreddits, comment, upvote and discover new topics. Rtv currently doesn’t, however, support Reddit tags.
|
||||
|
||||
![][7]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides Reddit Terminal Viewer for Fedora 29 and Rawhide. To install Reddit Terminal Viewer, use these commands:
|
||||
|
||||
```
|
||||
sudo dnf copr enable tc01/rtv
|
||||
sudo dnf install rtv
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-february-2019/
|
||||
|
||||
作者:[Dominik Turecek][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://copr.fedorainfracloud.org/
|
||||
[2]: https://www.cryfs.org/
|
||||
[3]: https://github.com/chrisallenlane/cheat
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/01/cheat.png
|
||||
[5]: https://setconf.roboticoverlords.org/
|
||||
[6]: https://github.com/michael-lazar/rtv
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2019/01/rtv.png
|
||||
211
sources/tech/20190206 And, Ampersand, and - in Linux.md
Normal file
211
sources/tech/20190206 And, Ampersand, and - in Linux.md
Normal file
@ -0,0 +1,211 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (And, Ampersand, and & in Linux)
|
||||
[#]: via: (https://www.linux.com/blog/learn/2019/2/and-ampersand-and-linux)
|
||||
[#]: author: (Paul Brown https://www.linux.com/users/bro66)
|
||||
|
||||
And, Ampersand, and & in Linux
|
||||
======
|
||||

|
||||
|
||||
Take a look at the tools covered in the [three][1] [previous][2] [articles][3], and you will see that understanding the glue that joins them together is as important as recognizing the tools themselves. Indeed, tools tend to be simple, and understanding what _mkdir_ , _touch_ , and _find_ do (make a new directory, update a file, and find a file in the directory tree, respectively) in isolation is easy.
|
||||
|
||||
But understanding what
|
||||
|
||||
```
|
||||
mkdir test_dir 2>/dev/null || touch images.txt && find . -iname "*jpg" > backup/dir/images.txt &
|
||||
```
|
||||
|
||||
does, and why we would write a command line like that is a whole different story.
|
||||
|
||||
It pays to look more closely at the sign and symbols that live between the commands. It will not only help you better understand how things work, but will also make you more proficient in chaining commands together to create compound instructions that will help you work more efficiently.
|
||||
|
||||
In this article and the next, we'll be looking at the the ampersand (`&`) and its close friend, the pipe (`|`), and see how they can mean different things in different contexts.
|
||||
|
||||
### Behind the Scenes
|
||||
|
||||
Let's start simple and see how you can use `&` as a way of pushing a command to the background. The instruction:
|
||||
|
||||
```
|
||||
cp -R original/dir/ backup/dir/
|
||||
```
|
||||
|
||||
Copies all the files and subdirectories in _original/dir/_ into _backup/dir/_. So far so simple. But if that turns out to be a lot of data, it could tie up your terminal for hours.
|
||||
|
||||
However, using:
|
||||
|
||||
```
|
||||
cp -R original/dir/ backup/dir/ &
|
||||
```
|
||||
|
||||
pushes the process to the background courtesy of the final `&`. This frees you to continue working on the same terminal or even to close the terminal and still let the process finish up. Do note, however, that if the process is asked to print stuff out to the standard output (like in the case of `echo` or `ls`), it will continue to do so, even though it is being executed in the background.
|
||||
|
||||
When you push a process into the background, Bash will print out a number. This number is the PID or the _Process' ID_. Every process running on your Linux system has a unique process ID and you can use this ID to pause, resume, and terminate the process it refers to. This will become useful later.
|
||||
|
||||
In the meantime, there are a few tools you can use to manage your processes as long as you remain in the terminal from which you launched them:
|
||||
|
||||
* `jobs` shows you the processes running in your current terminal, whether be it in the background or foreground. It also shows you a number associated with each job (different from the PID) that you can use to refer to each process:
|
||||
|
||||
```
|
||||
$ jobs
|
||||
[1]- Running cp -i -R original/dir/* backup/dir/ &
|
||||
[2]+ Running find . -iname "*jpg" > backup/dir/images.txt &
|
||||
```
|
||||
|
||||
* `fg` brings a job from the background to the foreground so you can interact with it. You tell `fg` which process you want to bring to the foreground with a percentage symbol (`%`) followed by the number associated with the job that `jobs` gave you:
|
||||
|
||||
```
|
||||
$ fg %1 # brings the cp job to the foreground
|
||||
cp -i -R original/dir/* backup/dir/
|
||||
```
|
||||
|
||||
If the job was stopped (see below), `fg` will start it again.
|
||||
|
||||
* You can stop a job in the foreground by holding down [Ctrl] and pressing [Z]. This doesn't abort the action, it pauses it. When you start it again with (`fg` or `bg`) it will continue from where it left off...
|
||||
|
||||
...Except for [`sleep`][4]: the time a `sleep` job is paused still counts once `sleep` is resumed. This is because `sleep` takes note of the clock time when it was started, not how long it was running. This means that if you run `sleep 30` and pause it for more than 30 seconds, once you resume, `sleep` will exit immediately.
|
||||
|
||||
* The `bg` command pushes a job to the background and resumes it again if it was paused:
|
||||
|
||||
```
|
||||
$ bg %1
|
||||
[1]+ cp -i -R original/dir/* backup/dir/ &
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
As mentioned above, you won't be able to use any of these commands if you close the terminal from which you launched the process or if you change to another terminal, even though the process will still continue working.
|
||||
|
||||
To manage background processes from another terminal you need another set of tools. For example, you can tell a process to stop from a a different terminal with the [`kill`][5] command:
|
||||
|
||||
```
|
||||
kill -s STOP <PID>
|
||||
```
|
||||
|
||||
And you know the PID because that is the number Bash gave you when you started the process with `&`, remember? Oh! You didn't write it down? No problem. You can get the PID of any running process with the `ps` (short for _processes_ ) command. So, using
|
||||
|
||||
```
|
||||
ps | grep cp
|
||||
```
|
||||
|
||||
will show you all the processes containing the string " _cp_ ", including the copying job we are using for our example. It will also show you the PID:
|
||||
|
||||
```
|
||||
$ ps | grep cp
|
||||
14444 pts/3 00:00:13 cp
|
||||
```
|
||||
|
||||
In this case, the PID is _14444_. and it means you can stop the background copying with:
|
||||
|
||||
```
|
||||
kill -s STOP 14444
|
||||
```
|
||||
|
||||
Note that `STOP` here does the same thing as [Ctrl] + [Z] above, that is, it pauses the execution of the process.
|
||||
|
||||
To start the paused process again, you can use the `CONT` signal:
|
||||
|
||||
```
|
||||
kill -s CONT 14444
|
||||
```
|
||||
|
||||
There is a good list of many of [the main signals you can send a process here][6]. According to that, if you wanted to terminate the process, not just pause it, you could do this:
|
||||
|
||||
```
|
||||
kill -s TERM 14444
|
||||
```
|
||||
|
||||
If the process refuses to exit, you can force it with:
|
||||
|
||||
```
|
||||
kill -s KILL 14444
|
||||
```
|
||||
|
||||
This is a bit dangerous, but very useful if a process has gone crazy and is eating up all your resources.
|
||||
|
||||
In any case, if you are not sure you have the correct PID, add the `x` option to `ps`:
|
||||
|
||||
```
|
||||
$ ps x| grep cp
|
||||
14444 pts/3 D 0:14 cp -i -R original/dir/Hols_2014.mp4
|
||||
original/dir/Hols_2015.mp4 original/dir/Hols_2016.mp4
|
||||
original/dir/Hols_2017.mp4 original/dir/Hols_2018.mp4 backup/dir/
|
||||
```
|
||||
|
||||
And you should be able to see what process you need.
|
||||
|
||||
Finally, there is nifty tool that combines `ps` and `grep` all into one:
|
||||
|
||||
```
|
||||
$ pgrep cp
|
||||
8
|
||||
18
|
||||
19
|
||||
26
|
||||
33
|
||||
40
|
||||
47
|
||||
54
|
||||
61
|
||||
72
|
||||
88
|
||||
96
|
||||
136
|
||||
339
|
||||
6680
|
||||
13735
|
||||
14444
|
||||
```
|
||||
|
||||
Lists all the PIDs of processes that contain the string " _cp_ ".
|
||||
|
||||
In this case, it isn't very helpful, but this...
|
||||
|
||||
```
|
||||
$ pgrep -lx cp
|
||||
14444 cp
|
||||
```
|
||||
|
||||
... is much better.
|
||||
|
||||
In this case, `-l` tells `pgrep` to show you the name of the process and `-x` tells `pgrep` you want an exact match for the name of the command. If you want even more details, try `pgrep -ax command`.
|
||||
|
||||
### Next time
|
||||
|
||||
Putting an `&` at the end of commands has helped us explain the rather useful concept of processes working in the background and foreground and how to manage them.
|
||||
|
||||
One last thing before we leave: processes running in the background are what are known as _daemons_ in UNIX/Linux parlance. So, if you had heard the term before and wondered what they were, there you go.
|
||||
|
||||
As usual, there are more ways to use the ampersand within a command line, many of which have nothing to do with pushing processes into the background. To see what those uses are, we'll be back next week with more on the matter.
|
||||
|
||||
Read more:
|
||||
|
||||
[Linux Tools: The Meaning of Dot][1]
|
||||
|
||||
[Understanding Angle Brackets in Bash][2]
|
||||
|
||||
[More About Angle Brackets in Bash][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2019/2/and-ampersand-and-linux
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/blog/learn/2019/1/linux-tools-meaning-dot
|
||||
[2]: https://www.linux.com/blog/learn/2019/1/understanding-angle-brackets-bash
|
||||
[3]: https://www.linux.com/blog/learn/2019/1/more-about-angle-brackets-bash
|
||||
[4]: https://ss64.com/bash/sleep.html
|
||||
[5]: https://bash.cyberciti.biz/guide/Sending_signal_to_Processes
|
||||
[6]: https://www.computerhope.com/unix/signals.htm
|
||||
126
sources/tech/20190206 Getting started with Vim visual mode.md
Normal file
126
sources/tech/20190206 Getting started with Vim visual mode.md
Normal file
@ -0,0 +1,126 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Getting started with Vim visual mode)
|
||||
[#]: via: (https://opensource.com/article/19/2/getting-started-vim-visual-mode)
|
||||
[#]: author: (Susan Lauber https://opensource.com/users/susanlauber)
|
||||
|
||||
Getting started with Vim visual mode
|
||||
======
|
||||
Visual mode makes it easier to highlight and manipulate text in Vim.
|
||||

|
||||
|
||||
Ansible playbook files are text files in a YAML format. People who work regularly with them have their favorite editors and plugin extensions to make the formatting easier.
|
||||
|
||||
When I teach Ansible with the default editor available in most Linux distributions, I use Vim's visual mode a lot. It allows me to highlight my actions on the screen—what I am about to edit and the text manipulation task I'm doing—to make it easier for my students to learn.
|
||||
|
||||
### Vim's visual mode
|
||||
|
||||
When editing text with Vim, visual mode can be extremely useful for identifying chunks of text to be manipulated.
|
||||
|
||||
Vim's visual mode has three versions: character, line, and block. The keystrokes to enter each mode are:
|
||||
|
||||
* Character mode: **v** (lower-case)
|
||||
* Line mode: **V** (upper-case)
|
||||
* Block mode: **Ctrl+v**
|
||||
|
||||
|
||||
|
||||
Here are some ways to use each mode to simplify your work.
|
||||
|
||||
### Character mode
|
||||
|
||||
Character mode can highlight a sentence in a paragraph or a phrase in a sentence. Then the visually identified text can be deleted, copied, changed, or modified with any other Vim editing command.
|
||||
|
||||
#### Move a sentence
|
||||
|
||||
To move a sentence from one place to another, start by opening the file and moving the cursor to the first character in the sentence you want to move.
|
||||
|
||||
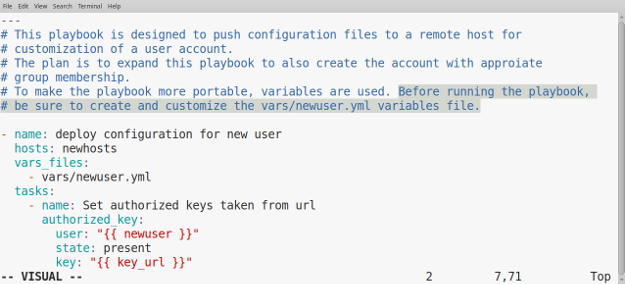
|
||||
|
||||
* Press the **v** key to enter visual character mode. The word **VISUAL** will appear at the bottom of the screen.
|
||||
* Use the Arrow keys to highlight the desired text. You can use other navigation commands, such as **w** to highlight to the beginning of the next word or **$** to include the rest of the line.
|
||||
* Once the text is highlighted, press the **d** key to delete the text.
|
||||
* If you deleted too much or not enough, press **u** to undo and start again.
|
||||
* Move your cursor to the new location and press **p** to paste the text.
|
||||
|
||||
|
||||
|
||||
#### Change a phrase
|
||||
|
||||
You can also highlight a chunk of text that you want to replace.
|
||||
|
||||
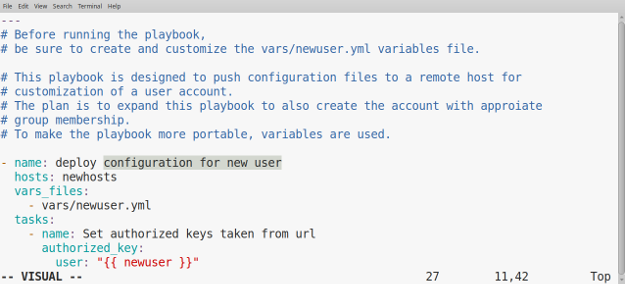
|
||||
|
||||
* Place the cursor at the first character you want to change.
|
||||
* Press **v** to enter visual character mode.
|
||||
* Use navigation commands, such as the Arrow keys, to highlight the phrase.
|
||||
* Press **c** to change the highlighted text.
|
||||
* The highlighted text will disappear, and you will be in Insert mode where you can add new text.
|
||||
* After you finish typing the new text, press **Esc** to return to command mode and save your work.
|
||||
|
||||
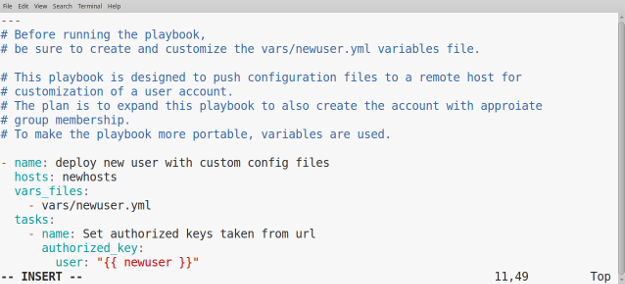
|
||||
|
||||
### Line mode
|
||||
|
||||
When working with Ansible playbooks, the order of tasks can matter. Use visual line mode to move a task to a different location in the playbook.
|
||||
|
||||
#### Manipulate multiple lines of text
|
||||
|
||||
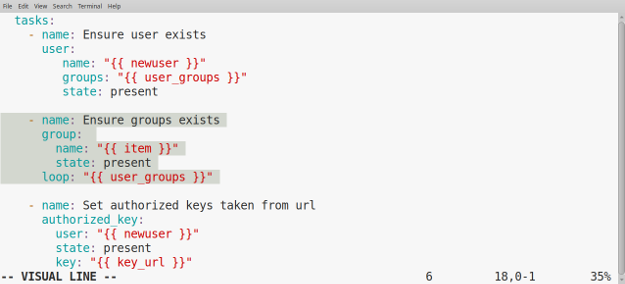
|
||||
|
||||
* Place your cursor anywhere on the first or last line of the text you want to manipulate.
|
||||
* Press **Shift+V** to enter line mode. The words **VISUAL LINE** will appear at the bottom of the screen.
|
||||
* Use navigation commands, such as the Arrow keys, to highlight multiple lines of text.
|
||||
* Once the desired text is highlighted, use commands to manipulate it. Press **d** to delete, then move the cursor to the new location, and press **p** to paste the text.
|
||||
* **y** (yank) can be used instead of **d** (delete) if you want to copy the task.
|
||||
|
||||
|
||||
|
||||
#### Indent a set of lines
|
||||
|
||||
When working with Ansible playbooks or YAML files, indentation matters. A highlighted block can be shifted right or left with the **>** and **<** keys.
|
||||
|
||||
![]9https://opensource.com/sites/default/files/uploads/vim-visual-line2.png
|
||||
|
||||
* Press **>** to increase the indentation of all the lines.
|
||||
* Press **<** to decrease the indentation of all the lines.
|
||||
|
||||
|
||||
|
||||
Try other Vim commands to apply them to the highlighted text.
|
||||
|
||||
### Block mode
|
||||
|
||||
The visual block mode is useful for manipulation of specific tabular data files, but it can also be extremely helpful as a tool to verify indentation of an Ansible playbook.
|
||||
|
||||
Tasks are a list of items and in YAML each list item starts with a dash followed by a space. The dashes must line up in the same column to be at the same indentation level. This can be difficult to see with just the human eye. Indentation of other lines within the task is also important.
|
||||
|
||||
#### Verify tasks lists are indented the same
|
||||
|
||||
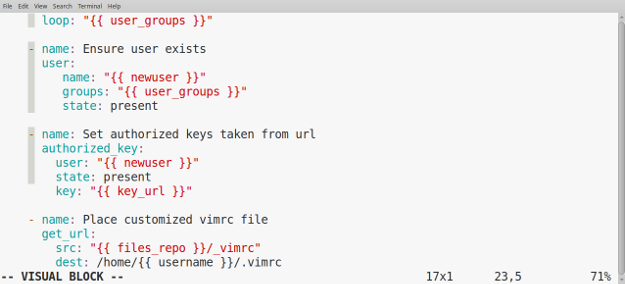
|
||||
|
||||
* Place your cursor on the first character of the list item.
|
||||
* Press **Ctrl+v** to enter visual block mode. The words **VISUAL BLOCK** will appear at the bottom of the screen.
|
||||
* Use the Arrow keys to highlight the single character column. You can verify that each task is indented the same amount.
|
||||
* Use the Arrow keys to expand the block right or left to check whether the other indentation is correct.
|
||||
|
||||
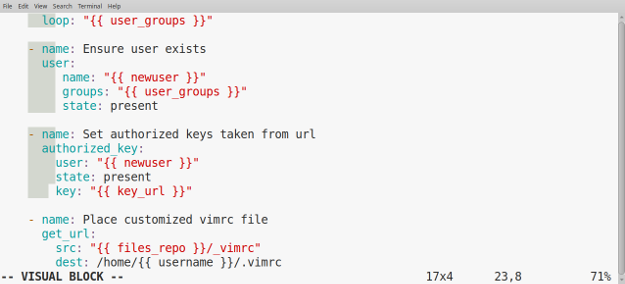
|
||||
|
||||
Even though I am comfortable with other Vim editing shortcuts, I still like to use visual mode to sort out what text I want to manipulate. When I demo other concepts during a presentation, my students see a tool to highlight text and hit delete in this "new to them" text only editor.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/getting-started-vim-visual-mode
|
||||
|
||||
作者:[Susan Lauber][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/susanlauber
|
||||
[b]: https://github.com/lujun9972
|
||||
325
sources/tech/20190207 10 Methods To Create A File In Linux.md
Normal file
325
sources/tech/20190207 10 Methods To Create A File In Linux.md
Normal file
@ -0,0 +1,325 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (10 Methods To Create A File In Linux)
|
||||
[#]: via: (https://www.2daygeek.com/linux-command-to-create-a-file/)
|
||||
[#]: author: (Vinoth Kumar https://www.2daygeek.com/author/vinoth/)
|
||||
|
||||
10 Methods To Create A File In Linux
|
||||
======
|
||||
|
||||
As we already know that everything is a file in Linux, that includes device as well.
|
||||
|
||||
Linux admin should be performing the file creation activity multiple times (It may 20 times or 50 times or more than that, it’s depends upon their environment) in a day.
|
||||
|
||||
Navigate to the following URL, if you would like to **[create a file in a specific size in Linux][1]**.
|
||||
|
||||
It’s very important. how efficiently are we creating a file. Why i’m saying efficient? there is a lot of benefit if you know the efficient way to perform an activity.
|
||||
|
||||
It will save you a lot of time. You can spend those valuable time on other important or major tasks, where you want to spend some more time instead of doing that in hurry.
|
||||
|
||||
Here i’m including multiple ways to create a file in Linux. I advise you to choose few which is easy and efficient for you to perform your activity.
|
||||
|
||||
You no need to install any of the following commands because all these commands has been installed as part of Linux core utilities except nano command.
|
||||
|
||||
It can be done using the following 6 methods.
|
||||
|
||||
* **`Redirect Symbol (>):`** Standard redirect symbol allow us to create a 0KB empty file in Linux.
|
||||
* **`touch:`** touch command can create a 0KB empty file if does not exist.
|
||||
* **`echo:`** echo command is used to display line of text that are passed as an argument.
|
||||
* **`printf:`** printf command is used to display the given text on the terminal window.
|
||||
* **`cat:`** It concatenate files and print on the standard output.
|
||||
* **`vi/vim:`** Vim is a text editor that is upwards compatible to Vi. It can be used to edit all kinds of plain text.
|
||||
* **`nano:`** nano is a small and friendly editor. It copies the look and feel of Pico, but is free software.
|
||||
* **`head:`** head is used to print the first part of files..
|
||||
* **`tail:`** tail is used to print the last part of files..
|
||||
* **`truncate:`** truncate is used to shrink or extend the size of a file to the specified size.
|
||||
|
||||
|
||||
|
||||
### How To Create A File In Linux Using Redirect Symbol (>)?
|
||||
|
||||
Standard redirect symbol allow us to create a 0KB empty file in Linux. Basically it used to redirect the output of a command to a new file. When you use redirect symbol without a command then it’s create a file.
|
||||
|
||||
But it won’t allow you to input any text while creating a file. However, it’s very simple and will be useful for lazy admins. To do so, simple enter the redirect symbol followed by the filename which you want.
|
||||
|
||||
```
|
||||
$ > daygeek.txt
|
||||
```
|
||||
|
||||
Use the ls command to check the created file.
|
||||
|
||||
```
|
||||
$ ls -lh daygeek.txt
|
||||
-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:00 daygeek.txt
|
||||
```
|
||||
|
||||
### How To Create A File In Linux Using touch Command?
|
||||
|
||||
touch command is used to update the access and modification times of each FILE to the current time.
|
||||
|
||||
It’s create a new file if does not exist. Also, touch command doesn’t allow us to enter any text while creating a file. By default it creates a 0KB empty file.
|
||||
|
||||
```
|
||||
$ touch daygeek1.txt
|
||||
```
|
||||
|
||||
Use the ls command to check the created file.
|
||||
|
||||
```
|
||||
$ ls -lh daygeek1.txt
|
||||
-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:02 daygeek1.txt
|
||||
```
|
||||
|
||||
### How To Create A File In Linux Using echo Command?
|
||||
|
||||
echo is a built-in command found in most operating systems. It is frequently used in scripts, batch files, and as part of individual commands to insert a text.
|
||||
|
||||
This is nice command that allow users to input a text while creating a file. Also, it allow us to append the text in the next time.
|
||||
|
||||
```
|
||||
$ echo "2daygeek.com is a best Linux blog to learn Linux" > daygeek2.txt
|
||||
```
|
||||
|
||||
Use the ls command to check the created file.
|
||||
|
||||
```
|
||||
$ ls -lh daygeek2.txt
|
||||
-rw-rw-r-- 1 daygeek daygeek 49 Feb 4 02:04 daygeek2.txt
|
||||
```
|
||||
|
||||
To view the content from the file, use the cat command.
|
||||
|
||||
```
|
||||
$ cat daygeek2.txt
|
||||
2daygeek.com is a best Linux blog to learn Linux
|
||||
```
|
||||
|
||||
If you would like to append the content in the same file, use the double redirect Symbol (>>).
|
||||
|
||||
```
|
||||
$ echo "It's FIVE years old blog" >> daygeek2.txt
|
||||
```
|
||||
|
||||
You can view the appended content from the file using cat command.
|
||||
|
||||
```
|
||||
$ cat daygeek2.txt
|
||||
2daygeek.com is a best Linux blog to learn Linux
|
||||
It's FIVE years old blog
|
||||
```
|
||||
|
||||
### How To Create A File In Linux Using printf Command?
|
||||
|
||||
printf command also works in the same way like how echo command works.
|
||||
|
||||
printf command in Linux is used to display the given string on the terminal window. printf can have format specifiers, escape sequences or ordinary characters.
|
||||
|
||||
```
|
||||
$ printf "2daygeek.com is a best Linux blog to learn Linux\n" > daygeek3.txt
|
||||
```
|
||||
|
||||
Use the ls command to check the created file.
|
||||
|
||||
```
|
||||
$ ls -lh daygeek3.txt
|
||||
-rw-rw-r-- 1 daygeek daygeek 48 Feb 4 02:12 daygeek3.txt
|
||||
```
|
||||
|
||||
To view the content from the file, use the cat command.
|
||||
|
||||
```
|
||||
$ cat daygeek3.txt
|
||||
2daygeek.com is a best Linux blog to learn Linux
|
||||
```
|
||||
|
||||
If you would like to append the content in the same file, use the double redirect Symbol (>>).
|
||||
|
||||
```
|
||||
$ printf "It's FIVE years old blog\n" >> daygeek3.txt
|
||||
```
|
||||
|
||||
You can view the appended content from the file using cat command.
|
||||
|
||||
```
|
||||
$ cat daygeek3.txt
|
||||
2daygeek.com is a best Linux blog to learn Linux
|
||||
It's FIVE years old blog
|
||||
```
|
||||
|
||||
### How To Create A File In Linux Using cat Command?
|
||||
|
||||
cat stands for concatenate. It is very frequently used in Linux to reads data from a file.
|
||||
|
||||
cat is one of the most frequently used commands on Unix-like operating systems. It’s offer three functions which is related to text file such as display content of a file, combine multiple files into the single output and create a new file.
|
||||
|
||||
```
|
||||
$ cat > daygeek4.txt
|
||||
2daygeek.com is a best Linux blog to learn Linux
|
||||
It's FIVE years old blog
|
||||
```
|
||||
|
||||
Use the ls command to check the created file.
|
||||
|
||||
```
|
||||
$ ls -lh daygeek4.txt
|
||||
-rw-rw-r-- 1 daygeek daygeek 74 Feb 4 02:18 daygeek4.txt
|
||||
```
|
||||
|
||||
To view the content from the file, use the cat command.
|
||||
|
||||
```
|
||||
$ cat daygeek4.txt
|
||||
2daygeek.com is a best Linux blog to learn Linux
|
||||
It's FIVE years old blog
|
||||
```
|
||||
|
||||
If you would like to append the content in the same file, use the double redirect Symbol (>>).
|
||||
|
||||
```
|
||||
$ cat >> daygeek4.txt
|
||||
This website is maintained by Magesh M, It's licensed under CC BY-NC 4.0.
|
||||
```
|
||||
|
||||
You can view the appended content from the file using cat command.
|
||||
|
||||
```
|
||||
$ cat daygeek4.txt
|
||||
2daygeek.com is a best Linux blog to learn Linux
|
||||
It's FIVE years old blog
|
||||
This website is maintained by Magesh M, It's licensed under CC BY-NC 4.0.
|
||||
```
|
||||
|
||||
### How To Create A File In Linux Using vi/vim Command?
|
||||
|
||||
Vim is a text editor that is upwards compatible to Vi. It can be used to edit all kinds of plain text. It is especially useful for editing programs.
|
||||
|
||||
There are a lot of features are available in vim to edit a single file with the command.
|
||||
|
||||
```
|
||||
$ vi daygeek5.txt
|
||||
|
||||
2daygeek.com is a best Linux blog to learn Linux
|
||||
It's FIVE years old blog
|
||||
```
|
||||
|
||||
Use the ls command to check the created file.
|
||||
|
||||
```
|
||||
$ ls -lh daygeek5.txt
|
||||
-rw-rw-r-- 1 daygeek daygeek 75 Feb 4 02:23 daygeek5.txt
|
||||
```
|
||||
|
||||
To view the content from the file, use the cat command.
|
||||
|
||||
```
|
||||
$ cat daygeek5.txt
|
||||
2daygeek.com is a best Linux blog to learn Linux
|
||||
It's FIVE years old blog
|
||||
```
|
||||
|
||||
### How To Create A File In Linux Using nano Command?
|
||||
|
||||
Nano’s is a another editor, an enhanced free Pico clone. nano is a small and friendly editor. It copies the look and feel of Pico, but is free software, and implements several features that Pico lacks, such as: opening multiple files, scrolling per line, undo/redo, syntax coloring, line numbering, and soft-wrapping overlong lines.
|
||||
|
||||
```
|
||||
$ nano daygeek6.txt
|
||||
|
||||
2daygeek.com is a best Linux blog to learn Linux
|
||||
It's FIVE years old blog
|
||||
This website is maintained by Magesh M, It's licensed under CC BY-NC 4.0.
|
||||
```
|
||||
|
||||
Use the ls command to check the created file.
|
||||
|
||||
```
|
||||
$ ls -lh daygeek6.txt
|
||||
-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:26 daygeek6.txt
|
||||
```
|
||||
|
||||
To view the content from the file, use the cat command.
|
||||
|
||||
```
|
||||
$ cat daygeek6.txt
|
||||
2daygeek.com is a best Linux blog to learn Linux
|
||||
It's FIVE years old blog
|
||||
This website is maintained by Magesh M, It's licensed under CC BY-NC 4.0.
|
||||
```
|
||||
|
||||
### How To Create A File In Linux Using head Command?
|
||||
|
||||
head command is used to output the first part of files. By default it prints the first 10 lines of each FILE to standard output. With more than one FILE, precede each with a header giving the file name.
|
||||
|
||||
```
|
||||
$ head -c 0K /dev/zero > daygeek7.txt
|
||||
```
|
||||
|
||||
Use the ls command to check the created file.
|
||||
|
||||
```
|
||||
$ ls -lh daygeek7.txt
|
||||
-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:30 daygeek7.txt
|
||||
```
|
||||
|
||||
### How To Create A File In Linux Using tail Command?
|
||||
|
||||
tail command is used to output the last part of files. By default it prints the first 10 lines of each FILE to standard output. With more than one FILE, precede each with a header giving the file name.
|
||||
|
||||
```
|
||||
$ tail -c 0K /dev/zero > daygeek8.txt
|
||||
```
|
||||
|
||||
Use the ls command to check the created file.
|
||||
|
||||
```
|
||||
$ ls -lh daygeek8.txt
|
||||
-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:31 daygeek8.txt
|
||||
```
|
||||
|
||||
### How To Create A File In Linux Using truncate Command?
|
||||
|
||||
truncate command is used to shrink or extend the size of a file to the specified size.
|
||||
|
||||
```
|
||||
$ truncate -s 0K daygeek9.txt
|
||||
```
|
||||
|
||||
Use the ls command to check the created file.
|
||||
|
||||
```
|
||||
$ ls -lh daygeek9.txt
|
||||
-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:37 daygeek9.txt
|
||||
```
|
||||
|
||||
I have performed totally 10 commands in this article to test this. All together in the single output.
|
||||
|
||||
```
|
||||
$ ls -lh daygeek*
|
||||
-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:02 daygeek1.txt
|
||||
-rw-rw-r-- 1 daygeek daygeek 74 Feb 4 02:07 daygeek2.txt
|
||||
-rw-rw-r-- 1 daygeek daygeek 74 Feb 4 02:15 daygeek3.txt
|
||||
-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:20 daygeek4.txt
|
||||
-rw-rw-r-- 1 daygeek daygeek 75 Feb 4 02:23 daygeek5.txt
|
||||
-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:26 daygeek6.txt
|
||||
-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:32 daygeek7.txt
|
||||
-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:32 daygeek8.txt
|
||||
-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:38 daygeek9.txt
|
||||
-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:00 daygeek.txt
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-command-to-create-a-file/
|
||||
|
||||
作者:[Vinoth Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/vinoth/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/create-a-file-in-specific-certain-size-linux/
|
||||
@ -0,0 +1,227 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to determine how much memory is installed, used on Linux systems)
|
||||
[#]: via: (https://www.networkworld.com/article/3336174/linux/how-much-memory-is-installed-and-being-used-on-your-linux-systems.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
How to determine how much memory is installed, used on Linux systems
|
||||
======
|
||||

|
||||
|
||||
There are numerous ways to get information on the memory installed on Linux systems and view how much of that memory is being used. Some commands provide an overwhelming amount of detail, while others provide succinct, though not necessarily easy-to-digest, answers. In this post, we'll look at some of the more useful tools for checking on memory and its usage.
|
||||
|
||||
Before we get into the details, however, let's review a few details. Physical memory and virtual memory are not the same. The latter includes disk space that configured to be used as swap. Swap may include partitions set aside for this usage or files that are created to add to the available swap space when creating a new partition may not be practical. Some Linux commands provide information on both.
|
||||
|
||||
Swap expands memory by providing disk space that can be used to house inactive pages in memory that are moved to disk when physical memory fills up.
|
||||
|
||||
One file that plays a role in memory management is **/proc/kcore**. This file looks like a normal (though extremely large) file, but it does not occupy disk space at all. Instead, it is a virtual file like all of the files in /proc.
|
||||
|
||||
```
|
||||
$ ls -l /proc/kcore
|
||||
-r--------. 1 root root 140737477881856 Jan 28 12:59 /proc/kcore
|
||||
```
|
||||
|
||||
Interestingly, the two systems queried below do _not_ have the same amount of memory installed, yet the size of /proc/kcore is the same on both. The first of these two systems has 4 GB of memory installed; the second has 6 GB.
|
||||
|
||||
```
|
||||
system1$ ls -l /proc/kcore
|
||||
-r--------. 1 root root 140737477881856 Jan 28 12:59 /proc/kcore
|
||||
system2$ ls -l /proc/kcore
|
||||
-r-------- 1 root root 140737477881856 Feb 5 13:00 /proc/kcore
|
||||
```
|
||||
|
||||
Explanations that claim the size of this file represents the amount of available virtual memory (maybe plus 4K) don't hold much weight. This number would suggest that the virtual memory on these systems is 128 terrabytes! That number seems to represent instead how much memory a 64-bit systems might be capable of addressing — not how much is available on the system. Calculations of what 128 terrabytes and that number, plus 4K would look like are fairly easy to make on the command line:
|
||||
|
||||
```
|
||||
$ expr 1024 \* 1024 \* 1024 \* 1024 \* 128
|
||||
140737488355328
|
||||
$ expr 1024 \* 1024 \* 1024 \* 1024 \* 128 + 4096
|
||||
140737488359424
|
||||
```
|
||||
|
||||
Another and more human-friendly command for examining memory is the **free** command. It gives you an easy-to-understand report on memory.
|
||||
|
||||
```
|
||||
$ free
|
||||
total used free shared buff/cache available
|
||||
Mem: 6102476 812244 4090752 13112 1199480 4984140
|
||||
Swap: 2097148 0 2097148
|
||||
```
|
||||
|
||||
With the **-g** option, free reports the values in gigabytes.
|
||||
|
||||
```
|
||||
$ free -g
|
||||
total used free shared buff/cache available
|
||||
Mem: 5 0 3 0 1 4
|
||||
Swap: 1 0 1
|
||||
```
|
||||
|
||||
With the **-t** option, free shows the same values as it does with no options (don't confuse -t with terrabytes!) but by adding a total line at the bottom of its output.
|
||||
|
||||
```
|
||||
$ free -t
|
||||
total used free shared buff/cache available
|
||||
Mem: 6102476 812408 4090612 13112 1199456 4983984
|
||||
Swap: 2097148 0 2097148
|
||||
Total: 8199624 812408 6187760
|
||||
```
|
||||
|
||||
And, of course, you can choose to use both options.
|
||||
|
||||
```
|
||||
$ free -tg
|
||||
total used free shared buff/cache available
|
||||
Mem: 5 0 3 0 1 4
|
||||
Swap: 1 0 1
|
||||
Total: 7 0 5
|
||||
```
|
||||
|
||||
You might be disappointed in this report if you're trying to answer the question "How much RAM is installed on this system?" This is the same system shown in the example above that was described as having 6GB of RAM. That doesn't mean this report is wrong, but that it's the system's view of the memory it has at its disposal.
|
||||
|
||||
The free command also provides an option to update the display every X seconds (10 in the example below).
|
||||
|
||||
```
|
||||
$ free -s 10
|
||||
total used free shared buff/cache available
|
||||
Mem: 6102476 812280 4090704 13112 1199492 4984108
|
||||
Swap: 2097148 0 2097148
|
||||
|
||||
total used free shared buff/cache available
|
||||
Mem: 6102476 812260 4090712 13112 1199504 4984120
|
||||
Swap: 2097148 0 2097148
|
||||
```
|
||||
|
||||
With **-l** , the free command provides high and low memory usage.
|
||||
|
||||
```
|
||||
$ free -l
|
||||
total used free shared buff/cache available
|
||||
Mem: 6102476 812376 4090588 13112 1199512 4984000
|
||||
Low: 6102476 2011888 4090588
|
||||
High: 0 0 0
|
||||
Swap: 2097148 0 2097148
|
||||
```
|
||||
|
||||
Another option for looking at memory is the **/proc/meminfo** file. Like /proc/kcore, this is a virtual file and one that gives a useful report showing how much memory is installed, free and available. Clearly, free and available do not represent the same thing. MemFree seems to represent unused RAM. MemAvailable is an estimate of how much memory is available for starting new applications.
|
||||
|
||||
```
|
||||
$ head -3 /proc/meminfo
|
||||
MemTotal: 6102476 kB
|
||||
MemFree: 4090596 kB
|
||||
MemAvailable: 4984040 kB
|
||||
```
|
||||
|
||||
If you only want to see total memory, you can use one of these commands:
|
||||
|
||||
```
|
||||
$ awk '/MemTotal/ {print $2}' /proc/meminfo
|
||||
6102476
|
||||
$ grep MemTotal /proc/meminfo
|
||||
MemTotal: 6102476 kB
|
||||
```
|
||||
|
||||
The **DirectMap** entries break information on memory into categories.
|
||||
|
||||
```
|
||||
$ grep DirectMap /proc/meminfo
|
||||
DirectMap4k: 213568 kB
|
||||
DirectMap2M: 6076416 kB
|
||||
```
|
||||
|
||||
DirectMap4k represents the amount of memory being mapped to standard 4k pages, while DirectMap2M shows the amount of memory being mapped to 2MB pages.
|
||||
|
||||
The **getconf** command is one that will provide quite a bit more information than most of us want to contemplate.
|
||||
|
||||
```
|
||||
$ getconf -a | more
|
||||
LINK_MAX 65000
|
||||
_POSIX_LINK_MAX 65000
|
||||
MAX_CANON 255
|
||||
_POSIX_MAX_CANON 255
|
||||
MAX_INPUT 255
|
||||
_POSIX_MAX_INPUT 255
|
||||
NAME_MAX 255
|
||||
_POSIX_NAME_MAX 255
|
||||
PATH_MAX 4096
|
||||
_POSIX_PATH_MAX 4096
|
||||
PIPE_BUF 4096
|
||||
_POSIX_PIPE_BUF 4096
|
||||
SOCK_MAXBUF
|
||||
_POSIX_ASYNC_IO
|
||||
_POSIX_CHOWN_RESTRICTED 1
|
||||
_POSIX_NO_TRUNC 1
|
||||
_POSIX_PRIO_IO
|
||||
_POSIX_SYNC_IO
|
||||
_POSIX_VDISABLE 0
|
||||
ARG_MAX 2097152
|
||||
ATEXIT_MAX 2147483647
|
||||
CHAR_BIT 8
|
||||
CHAR_MAX 127
|
||||
--More--
|
||||
```
|
||||
|
||||
Pare that output down to something specific with a command like the one shown below, and you'll get the same kind of information provided by some of the commands above.
|
||||
|
||||
```
|
||||
$ getconf -a | grep PAGES | awk 'BEGIN {total = 1} {if (NR == 1 || NR == 3) total *=$NF} END {print total / 1024" kB"}'
|
||||
6102476 kB
|
||||
```
|
||||
|
||||
That command calculates memory by multiplying the values in the first and last lines of output like this:
|
||||
|
||||
```
|
||||
PAGESIZE 4096 <==
|
||||
_AVPHYS_PAGES 1022511
|
||||
_PHYS_PAGES 1525619 <==
|
||||
```
|
||||
|
||||
Calculating that independently, we can see how that value is derived.
|
||||
|
||||
```
|
||||
$ expr 4096 \* 1525619 / 1024
|
||||
6102476
|
||||
```
|
||||
|
||||
Clearly that's one of those commands that deserves to be turned into an alias!
|
||||
|
||||
Another command with very digestible output is **top**. In the first five lines of top's output, you'll see some numbers that show how memory is being used.
|
||||
|
||||
```
|
||||
$ top
|
||||
top - 15:36:38 up 8 days, 2:37, 2 users, load average: 0.00, 0.00, 0.00
|
||||
Tasks: 266 total, 1 running, 265 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu(s): 0.2 us, 0.4 sy, 0.0 ni, 99.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
MiB Mem : 3244.8 total, 377.9 free, 1826.2 used, 1040.7 buff/cache
|
||||
MiB Swap: 3536.0 total, 3535.7 free, 0.3 used. 1126.1 avail Mem
|
||||
```
|
||||
|
||||
And finally a command that will answer the question "So, how much RAM is installed on this system?" in a succinct fashion:
|
||||
|
||||
```
|
||||
$ sudo dmidecode -t 17 | grep "Size.*MB" | awk '{s+=$2} END {print s / 1024 "GB"}'
|
||||
6GB
|
||||
```
|
||||
|
||||
Depending on how much detail you want to see, Linux systems provide a lot of options for seeing how much memory is installed on your systems and how much is used and available.
|
||||
|
||||
Join the Network World communities on [Facebook][1] and [LinkedIn][2] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3336174/linux/how-much-memory-is-installed-and-being-used-on-your-linux-systems.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.facebook.com/NetworkWorld/
|
||||
[2]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,185 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (3 Ways to Install Deb Files on Ubuntu Linux)
|
||||
[#]: via: (https://itsfoss.com/install-deb-files-ubuntu)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
3 Ways to Install Deb Files on Ubuntu Linux
|
||||
======
|
||||
|
||||
**This beginner article explains how to install deb packages in Ubuntu. It also shows you how to remove those deb packages afterwards.**
|
||||
|
||||
This is another article in the Ubuntu beginner series. If you are absolutely new to Ubuntu, you might wonder about [how to install applications][1].
|
||||
|
||||
The easiest way is to use the Ubuntu Software Center. Search for an application by its name and install it from there.
|
||||
|
||||
Life would be too simple if you could find all the applications in the Software Center. But that does not happen, unfortunately.
|
||||
|
||||
Some software are available via DEB packages. These are archived files that end with .deb extension.
|
||||
|
||||
You can think of .deb files as the .exe files in Windows. You double click on the .exe file and it starts the installation procedure in Windows. DEB packages are pretty much the same.
|
||||
|
||||
You can find these DEB packages from the download section of the software provider’s website. For example, if you want to [install Google Chrome on Ubuntu][2], you can download the DEB package of Chrome from its website.
|
||||
|
||||
Now the question arises, how do you install deb files? There are multiple ways of installing DEB packages in Ubuntu. I’ll show them to you one by one in this tutorial.
|
||||
|
||||
![Install deb files in Ubuntu][3]
|
||||
|
||||
### Installing .deb files in Ubuntu and Debian-based Linux Distributions
|
||||
|
||||
You can choose a GUI tool or a command line tool for installing a deb package. The choice is yours.
|
||||
|
||||
Let’s go on and see how to install deb files.
|
||||
|
||||
#### Method 1: Use the default Software Center
|
||||
|
||||
The simplest method is to use the default software center in Ubuntu. You have to do nothing special here. Simply go to the folder where you have downloaded the .deb file (it should be the Downloads folder) and double click on this file.
|
||||
|
||||
![Google Chrome deb file on Ubuntu][4]Double click on the downloaded .deb file to start installation
|
||||
|
||||
It will open the software center and you should see the option to install the software. All you have to do is to hit the install button and enter your login password.
|
||||
|
||||
![Install Google Chrome in Ubuntu Software Center][5]The installation of deb file will be carried out via Software Center
|
||||
|
||||
See, it’s even simple than installing from a .exe files on Windows, isn’t it?
|
||||
|
||||
#### Method 2: Use Gdebi application for installing deb packages with dependencies
|
||||
|
||||
Again, life would be a lot simpler if things always go smooth. But that’s not life as we know it.
|
||||
|
||||
Now that you know that .deb files can be easily installed via Software Center, let me tell you about the dependency error that you may encounter with some packages.
|
||||
|
||||
What happens is that a program may be dependent on another piece of software (libraries). When the developer is preparing the DEB package for you, he/she may assume that your system already has that piece of software on your system.
|
||||
|
||||
But if that’s not the case and your system doesn’t have those required pieces of software, you’ll encounter the infamous ‘dependency error’.
|
||||
|
||||
The Software Center cannot handle such errors on its own so you have to use another tool called [gdebi][6].
|
||||
|
||||
gdebi is a lightweight GUI application that has the sole purpose of installing deb packages.
|
||||
|
||||
It identifies the dependencies and tries to install these dependencies along with installing the .deb files.
|
||||
|
||||
![gdebi handling dependency while installing deb package][7]Image Credit: [Xmodulo][8]
|
||||
|
||||
Personally, I prefer gdebi over software center for installing deb files. It is a lightweight application so the installation seems quicker. You can read in detail about [using gDebi and making it the default for installing DEB packages][6].
|
||||
|
||||
You can install gdebi from the software center or using the command below:
|
||||
|
||||
```
|
||||
sudo apt install gdebi
|
||||
```
|
||||
|
||||
#### Method 3: Install .deb files in command line using dpkg
|
||||
|
||||
If you want to install deb packages in command lime, you can use either apt command or dpkg command. Apt command actually uses [dpkg command][9] underneath it but apt is more popular and easy to use.
|
||||
|
||||
If you want to use the apt command for deb files, use it like this:
|
||||
|
||||
```
|
||||
sudo apt install path_to_deb_file
|
||||
```
|
||||
|
||||
If you want to use dpkg command for installing deb packages, here’s how to do it:
|
||||
|
||||
```
|
||||
sudo dpkg -i path_to_deb_file
|
||||
```
|
||||
|
||||
In both commands, you should replace the path_to_deb_file with the path and name of the deb file you have downloaded.
|
||||
|
||||
![Install deb files using dpkg command in Ubuntu][10]Installing deb files using dpkg command in Ubuntu
|
||||
|
||||
If you get a dependency error while installing the deb packages, you may use the following command to fix the dependency issues:
|
||||
|
||||
```
|
||||
sudo apt install -f
|
||||
```
|
||||
|
||||
### How to remove deb packages
|
||||
|
||||
Removing a deb package is not a big deal as well. And no, you don’t need the original deb file that you had used for installing the program.
|
||||
|
||||
#### Method 1: Remove deb packages using apt commands
|
||||
|
||||
All you need is the name of the program that you have installed and then you can use apt or dpkg to remove that program.
|
||||
|
||||
```
|
||||
sudo apt remove program_name
|
||||
```
|
||||
|
||||
Now the question comes, how do you find the exact program name that you need to use in the remove command? The apt command has a solution for that as well.
|
||||
|
||||
You can find the list of all installed files with apt command but manually going through this will be a pain. So you can use the grep command to search for your package.
|
||||
|
||||
For example, I installed AppGrid application in the previous section but if I want to know the exact program name, I can use something like this:
|
||||
|
||||
```
|
||||
sudo apt list --installed | grep grid
|
||||
```
|
||||
|
||||
This will give me all the packages that have grid in their name and from there, I can get the exact program name.
|
||||
|
||||
```
|
||||
apt list --installed | grep grid
|
||||
WARNING: apt does not have a stable CLI interface. Use with caution in scripts.
|
||||
appgrid/now 0.298 all [installed,local]
|
||||
```
|
||||
|
||||
As you can see, a program called appgrid has been installed. Now you can use this program name with the apt remove command.
|
||||
|
||||
#### Method 2: Remove deb packages using dpkg commands
|
||||
|
||||
You can use dpkg to find the installed program’s name:
|
||||
|
||||
```
|
||||
dpkg -l | grep grid
|
||||
```
|
||||
|
||||
The output will give all the packages installed that has grid in its name.
|
||||
|
||||
```
|
||||
dpkg -l | grep grid
|
||||
|
||||
ii appgrid 0.298 all Discover and install apps for Ubuntu
|
||||
```
|
||||
|
||||
ii in the above command output means package has been correctly installed.
|
||||
|
||||
Now that you have the program name, you can use dpkg command to remove it:
|
||||
|
||||
```
|
||||
dpkg -r program_name
|
||||
```
|
||||
|
||||
**Tip: Updating deb packages**
|
||||
Some deb packages (like Chrome) provide updates through system updates but for most other programs, you’ll have to remove the existing program and install the newer version.
|
||||
|
||||
I hope this beginner guide helped you to install deb packages on Ubuntu. I added the remove part so that you’ll have better control over the programs you installed.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-deb-files-ubuntu
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/remove-install-software-ubuntu/
|
||||
[2]: https://itsfoss.com/install-chrome-ubuntu/
|
||||
[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/deb-packages-ubuntu.png?resize=800%2C450&ssl=1
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/install-google-chrome-ubuntu-4.jpeg?resize=800%2C347&ssl=1
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/install-google-chrome-ubuntu-5.jpeg?resize=800%2C516&ssl=1
|
||||
[6]: https://itsfoss.com/gdebi-default-ubuntu-software-center/
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/gdebi-handling-dependency.jpg?ssl=1
|
||||
[8]: http://xmodulo.com
|
||||
[9]: https://help.ubuntu.com/lts/serverguide/dpkg.html.en
|
||||
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/install-deb-file-with-dpkg.png?ssl=1
|
||||
[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/deb-packages-ubuntu.png?fit=800%2C450&ssl=1
|
||||
153
sources/tech/20190208 How To Install And Use PuTTY On Linux.md
Normal file
153
sources/tech/20190208 How To Install And Use PuTTY On Linux.md
Normal file
@ -0,0 +1,153 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Install And Use PuTTY On Linux)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-install-and-use-putty-on-linux/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
|
||||
How To Install And Use PuTTY On Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
**PuTTY** is a free and open source GUI client that supports wide range of protocols including SSH, Telnet, Rlogin and serial for Windows and Unix-like operating systems. Generally, Windows admins use PuTTY as a SSH and telnet client to access the remote Linux servers from their local Windows systems. However, PuTTY is not limited to Windows. It is also popular among Linux users as well. This guide explains how to install PuTTY on Linux and how to access and manage the remote Linux servers using PuTTY.
|
||||
|
||||
### Install PuTTY on Linux
|
||||
|
||||
PuTTY is available in the official repositories of most Linux distributions. For instance, you can install PuTTY on Arch Linux and its variants using the following command:
|
||||
|
||||
```
|
||||
$ sudo pacman -S putty
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
|
||||
```
|
||||
$ sudo apt install putty
|
||||
```
|
||||
|
||||
### How to use PuTTY to access remote Linux systems
|
||||
|
||||
Once PuTTY is installed, launch it from the menu or from your application launcher. Alternatively, you can launch it from the Terminal by running the following command:
|
||||
|
||||
```
|
||||
$ putty
|
||||
```
|
||||
|
||||
This is how PuTTY default interface looks like.
|
||||
|
||||
|
||||
|
||||
As you can see, most of the options are self-explanatory. On the left pane of the PuTTY interface, you can do/edit/modify various configurations such as,
|
||||
|
||||
1. PuTTY session logging,
|
||||
2. Options for controlling the terminal emulation, control and change effects of keys,
|
||||
3. Control terminal bell sounds,
|
||||
4. Enable/disable Terminal advanced features,
|
||||
5. Set the size of PuTTY window,
|
||||
6. Control the scrollback in PuTTY window (Default is 2000 lines),
|
||||
7. Change appearance of PuTTY window and cursor,
|
||||
8. Adjust windows border,
|
||||
9. Change fonts for texts in PuTTY window,
|
||||
10. Save login details,
|
||||
11. Set proxy details,
|
||||
12. Options to control various protocols such as SSH, Telnet, Rlogin, Serial etc.
|
||||
13. And more.
|
||||
|
||||
|
||||
|
||||
All options are categorized under a distinct name for ease of understanding.
|
||||
|
||||
### Access a remote Linux server using PuTTY
|
||||
|
||||
Click on the **Session** tab on the left pane. Enter the hostname (or IP address) of your remote system you want to connect to. Next choose the connection type, for example Telnet, Rlogin, SSH etc. The default port number will be automatically selected depending upon the connection type you choose. For example if you choose SSH, port number 22 will be selected. For Telnet, port number 23 will be selected and so on. If you have changed the default port number, don’t forget to mention it in the **Port** section. I am going to access my remote via SSH, hence I choose SSH connection type. After entering the Hostname or IP address of the system, click **Open**.
|
||||
|
||||
|
||||
|
||||
If this is the first time you have connected to this remote system, PuTTY will display a security alert dialog box that asks whether you trust the host you are connecting to. Click **Accept** to add the remote system’s host key to the PuTTY’s cache:
|
||||
|
||||
![][2]
|
||||
|
||||
Next enter your remote system’s user name and password. Congratulations! You’ve successfully connected to your remote system via SSH using PuTTY.
|
||||
|
||||
|
||||
|
||||
**Access remote systems configured with key-based authentication**
|
||||
|
||||
Some Linux administrators might have configured their remote servers with key-based authentication. For example, when accessing AMS instances from PuTTY, you need to specify the key file’s location. PuTTY supports public key authentication and uses its own key format ( **.ppk** files).
|
||||
|
||||
Enter the hostname or IP address in the Session section. Next, In the **Category** pane, expand **Connection** , expand **SSH** , and then choose **Auth**. Browse the location of the **.ppk** key file and click **Open**.
|
||||
|
||||
![][3]
|
||||
|
||||
Click Accept to add the host key if it is the first time you are connecting to the remote system. Finally, enter the remote system’s passphrase (if the key is protected with a passphrase while generating it) to connect.
|
||||
|
||||
**Save PuTTY sessions**
|
||||
|
||||
Sometimes, you want to connect to the remote system multiple times. If so, you can save the session and load it whenever you want without having to type the hostname or ip address, port number every time.
|
||||
|
||||
Enter the hostname (or IP address) and provide a session name and click **Save**. If you have key file, make sure you have already given the location before hitting the Save button.
|
||||
|
||||
![][4]
|
||||
|
||||
Now, choose session name under the **Saved sessions** tab and click **Load** and click **Open** to launch it.
|
||||
|
||||
**Transferring files to remote systems using the PuTTY Secure Copy Client (pscp)
|
||||
**
|
||||
|
||||
Usually, the Linux users and admins use **‘scp’** command line tool to transfer files from local Linux system to the remote Linux servers. PuTTY does have a dedicated client named **PuTTY Secure Copy Clinet** ( **PSCP** in short) to do this job. If you’re using windows os in your local system, you may need this tool to transfer files from local system to remote systems. PSCP can be used in both Linux and Windows systems.
|
||||
|
||||
The following command will copy **file.txt** to my remote Ubuntu system from Arch Linux.
|
||||
|
||||
```
|
||||
pscp -i test.ppk file.txt sk@192.168.225.22:/home/sk/
|
||||
```
|
||||
|
||||
Here,
|
||||
|
||||
* **-i test.ppk** : Key file to access remote system,
|
||||
* **file.txt** : file to be copied to remote system,
|
||||
* **sk@192.168.225.22** : username and ip address of remote system,
|
||||
* **/home/sk/** : Destination path.
|
||||
|
||||
|
||||
|
||||
To copy a directory. use **-r** (recursive) option like below:
|
||||
|
||||
```
|
||||
pscp -i test.ppk -r dir/ sk@192.168.225.22:/home/sk/
|
||||
```
|
||||
|
||||
To transfer files from Windows to remote Linux server using pscp, run the following command from command prompt:
|
||||
|
||||
```
|
||||
pscp -i test.ppk c:\documents\file.txt.txt sk@192.168.225.22:/home/sk/
|
||||
```
|
||||
|
||||
You know now what is PuTTY, how to install and use it to access remote systems. Also, you have learned how to transfer files to the remote systems from the local system using pscp program.
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-install-and-use-putty-on-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: http://www.ostechnix.com/wp-content/uploads/2019/02/putty-2.png
|
||||
[3]: http://www.ostechnix.com/wp-content/uploads/2019/02/putty-4.png
|
||||
[4]: http://www.ostechnix.com/wp-content/uploads/2019/02/putty-5.png
|
||||
@ -0,0 +1,192 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Remove/Delete The Empty Lines In A File In Linux)
|
||||
[#]: via: (https://www.2daygeek.com/remove-delete-empty-lines-in-a-file-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
How To Remove/Delete The Empty Lines In A File In Linux
|
||||
======
|
||||
|
||||
Some times you may wants to remove or delete the empty lines in a file in Linux.
|
||||
|
||||
If so, you can use the one of the below method to achieve it.
|
||||
|
||||
It can be done in many ways but i have listed simple methods in the article.
|
||||
|
||||
You may aware of that grep, awk and sed commands are specialized for textual data manipulation.
|
||||
|
||||
Navigate to the following URL, if you would like to read more about these kind of topics. For **[creating a file in specific size in Linux][1]** multiple ways, for **[creating a file in Linux][2]** multiple ways and for **[removing a matching string from a file in Linux][3]**.
|
||||
|
||||
These are fall in advanced commands category because these are used in most of the shell script to do required things.
|
||||
|
||||
It can be done using the following 5 methods.
|
||||
|
||||
* **`sed Command:`** Stream editor for filtering and transforming text.
|
||||
* **`grep Command:`** Print lines that match patterns.
|
||||
* **`cat Command:`** It concatenate files and print on the standard output.
|
||||
* **`tr Command:`** Translate or delete characters.
|
||||
* **`awk Command:`** The awk utility shall execute programs written in the awk programming language, which is specialized for textual data manipulation.
|
||||
* **`perl Command:`** Perl is a programming language specially designed for text editing.
|
||||
|
||||
|
||||
|
||||
To test this, i had already created the file called `2daygeek.txt` with some texts and empty lines. The details are below.
|
||||
|
||||
```
|
||||
$ cat 2daygeek.txt
|
||||
2daygeek.com is a best Linux blog to learn Linux.
|
||||
|
||||
It's FIVE years old blog.
|
||||
|
||||
This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
|
||||
|
||||
He got two GIRL babys.
|
||||
|
||||
Her names are Tanisha & Renusha.
|
||||
```
|
||||
|
||||
Now everything is ready and i’m going to test this in multiple ways.
|
||||
|
||||
### How To Remove/Delete The Empty Lines In A File In Linux Using sed Command?
|
||||
|
||||
Sed is a stream editor. A stream editor is used to perform basic text transformations on an input stream (a file or input from a pipeline).
|
||||
|
||||
```
|
||||
$ sed '/^$/d' 2daygeek.txt
|
||||
2daygeek.com is a best Linux blog to learn Linux.
|
||||
It's FIVE years old blog.
|
||||
This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
|
||||
He got two GIRL babes.
|
||||
Her names are Tanisha & Renusha.
|
||||
```
|
||||
|
||||
Details are follow:
|
||||
|
||||
* **`sed:`** It’s a command
|
||||
* **`//:`** It holds the searching string.
|
||||
* **`^:`** Matches start of string.
|
||||
* **`$:`** Matches end of string.
|
||||
* **`d:`** Delete the matched string.
|
||||
* **`2daygeek.txt:`** Source file name.
|
||||
|
||||
|
||||
|
||||
### How To Remove/Delete The Empty Lines In A File In Linux Using grep Command?
|
||||
|
||||
grep searches for PATTERNS in each FILE. PATTERNS is one or patterns separated by newline characters, and grep prints each line that matches a pattern.
|
||||
|
||||
```
|
||||
$ grep . 2daygeek.txt
|
||||
or
|
||||
$ grep -Ev "^$" 2daygeek.txt
|
||||
or
|
||||
$ grep -v -e '^$' 2daygeek.txt
|
||||
2daygeek.com is a best Linux blog to learn Linux.
|
||||
It's FIVE years old blog.
|
||||
This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
|
||||
He got two GIRL babes.
|
||||
Her names are Tanisha & Renusha.
|
||||
```
|
||||
|
||||
Details are follow:
|
||||
|
||||
* **`grep:`** It’s a command
|
||||
* **`.:`** Replaces any character.
|
||||
* **`^:`** matches start of string.
|
||||
* **`$:`** matches end of string.
|
||||
* **`E:`** For extended regular expressions pattern matching.
|
||||
* **`e:`** For regular expressions pattern matching.
|
||||
* **`v:`** To select non-matching lines from the file.
|
||||
* **`2daygeek.txt:`** Source file name.
|
||||
|
||||
|
||||
|
||||
### How To Remove/Delete The Empty Lines In A File In Linux Using awk Command?
|
||||
|
||||
The awk utility shall execute programs written in the awk programming language, which is specialized for textual data manipulation. An awk program is a sequence of patterns and corresponding actions.
|
||||
|
||||
```
|
||||
$ awk NF 2daygeek.txt
|
||||
or
|
||||
$ awk '!/^$/' 2daygeek.txt
|
||||
or
|
||||
$ awk '/./' 2daygeek.txt
|
||||
2daygeek.com is a best Linux blog to learn Linux.
|
||||
It's FIVE years old blog.
|
||||
This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
|
||||
He got two GIRL babes.
|
||||
Her names are Tanisha & Renusha.
|
||||
```
|
||||
|
||||
Details are follow:
|
||||
|
||||
* **`awk:`** It’s a command
|
||||
* **`//:`** It holds the searching string.
|
||||
* **`^:`** matches start of string.
|
||||
* **`$:`** matches end of string.
|
||||
* **`.:`** Replaces any character.
|
||||
* **`!:`** Delete the matched string.
|
||||
* **`2daygeek.txt:`** Source file name.
|
||||
|
||||
|
||||
|
||||
### How To Delete The Empty Lines In A File In Linux using Combination of cat And tr Command?
|
||||
|
||||
cat stands for concatenate. It is very frequently used in Linux to reads data from a file.
|
||||
|
||||
cat is one of the most frequently used commands on Unix-like operating systems. It’s offer three functions which is related to text file such as display content of a file, combine multiple files into the single output and create a new file.
|
||||
|
||||
Translate, squeeze, and/or delete characters from standard input, writing to standard output.
|
||||
|
||||
```
|
||||
$ cat 2daygeek.txt | tr -s '\n'
|
||||
2daygeek.com is a best Linux blog to learn Linux.
|
||||
It's FIVE years old blog.
|
||||
This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
|
||||
He got two GIRL babes.
|
||||
Her names are Tanisha & Renusha.
|
||||
```
|
||||
|
||||
Details are follow:
|
||||
|
||||
* **`cat:`** It’s a command
|
||||
* **`tr:`** It’s a command
|
||||
* **`|:`** Pipe symbol. It pass first command output as a input to another command.
|
||||
* **`s:`** Replace each sequence of a repeated character that is listed in the last specified SET.
|
||||
* **`\n:`** To add a new line.
|
||||
* **`2daygeek.txt:`** Source file name.
|
||||
|
||||
|
||||
|
||||
### How To Remove/Delete The Empty Lines In A File In Linux Using perl Command?
|
||||
|
||||
Perl stands in for “Practical Extraction and Reporting Language”. Perl is a programming language specially designed for text editing. It is now widely used for a variety of purposes including Linux system administration, network programming, web development, etc.
|
||||
|
||||
```
|
||||
$ perl -ne 'print if /\S/' 2daygeek.txt
|
||||
2daygeek.com is a best Linux blog to learn Linux.
|
||||
It's FIVE years old blog.
|
||||
This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
|
||||
He got two GIRL babes.
|
||||
Her names are Tanisha & Renusha.
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/remove-delete-empty-lines-in-a-file-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/create-a-file-in-specific-certain-size-linux/
|
||||
[2]: https://www.2daygeek.com/linux-command-to-create-a-file/
|
||||
[3]: https://www.2daygeek.com/empty-a-file-delete-contents-lines-from-a-file-remove-matching-string-from-a-file-remove-empty-blank-lines-from-a-file/
|
||||
107
sources/tech/20190211 How does rootless Podman work.md
Normal file
107
sources/tech/20190211 How does rootless Podman work.md
Normal file
@ -0,0 +1,107 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How does rootless Podman work?)
|
||||
[#]: via: (https://opensource.com/article/19/2/how-does-rootless-podman-work)
|
||||
[#]: author: (Daniel J Walsh https://opensource.com/users/rhatdan)
|
||||
|
||||
How does rootless Podman work?
|
||||
======
|
||||
Learn how Podman takes advantage of user namespaces to run in rootless mode.
|
||||

|
||||
|
||||
In my [previous article][1] on user namespace and [Podman][2], I discussed how you can use Podman commands to launch different containers with different user namespaces giving you better separation between containers. Podman also takes advantage of user namespaces to be able to run in rootless mode. Basically, when a non-privileged user runs Podman, the tool sets up and joins a user namespace. After Podman becomes root inside of the user namespace, Podman is allowed to mount certain filesystems and set up the container. Note there is no privilege escalation here other then additional UIDs available to the user, explained below.
|
||||
|
||||
### How does Podman create the user namespace?
|
||||
|
||||
#### shadow-utils
|
||||
|
||||
Most current Linux distributions include a version of shadow-utils that uses the **/etc/subuid** and **/etc/subgid** files to determine what UIDs and GIDs are available for a user in a user namespace.
|
||||
|
||||
```
|
||||
$ cat /etc/subuid
|
||||
dwalsh:100000:65536
|
||||
test:165536:65536
|
||||
$ cat /etc/subgid
|
||||
dwalsh:100000:65536
|
||||
test:165536:65536
|
||||
```
|
||||
|
||||
The useradd program automatically allocates 65536 UIDs for each user added to the system. If you have existing users on a system, you would need to allocate the UIDs yourself. The format of these files is **username:STARTUID:TOTALUIDS**. Meaning in my case, dwalsh is allocated UIDs 100000 through 165535 along with my default UID, which happens to be 3265 defined in /etc/passwd. You need to be careful when allocating these UID ranges that they don't overlap with any **real** UID on the system. If you had a user listed as UID 100001, now I (dwalsh) would be able to become this UID and potentially read/write/execute files owned by the UID.
|
||||
|
||||
Shadow-utils also adds two setuid programs (or setfilecap). On Fedora I have:
|
||||
|
||||
```
|
||||
$ getcap /usr/bin/newuidmap
|
||||
/usr/bin/newuidmap = cap_setuid+ep
|
||||
$ getcap /usr/bin/newgidmap
|
||||
/usr/bin/newgidmap = cap_setgid+ep
|
||||
```
|
||||
|
||||
Podman executes these files to set up the user namespace. You can see the mappings by examining /proc/self/uid_map and /proc/self/gid_map from inside of the rootless container.
|
||||
|
||||
```
|
||||
$ podman run alpine cat /proc/self/uid_map /proc/self/gid_map
|
||||
0 3267 1
|
||||
1 100000 65536
|
||||
0 3267 1
|
||||
1 100000 65536
|
||||
```
|
||||
|
||||
As seen above, Podman defaults to mapping root in the container to your current UID (3267) and then maps ranges of allocated UIDs/GIDs in /etc/subuid and /etc/subgid starting at 1. Meaning in my example, UID=1 in the container is UID 100000, UID=2 is UID 100001, all the way up to 65536, which is 165535.
|
||||
|
||||
Any item from outside of the user namespace that is owned by a UID or GID that is not mapped into the user namespace appears to belong to the user configured in the **kernel.overflowuid** sysctl, which by default is 35534, which my /etc/passwd file says has the name **nobody**. Since your process can't run as an ID that isn't mapped, the owner and group permissions don't apply, so you can only access these files based on their "other" permissions. This includes all files owned by **real** root on the system running the container, since root is not mapped into the user namespace.
|
||||
|
||||
The [Buildah][3] command has a cool feature, [**buildah unshare**][4]. This puts you in the same user namespace that Podman runs in, but without entering the container's filesystem, so you can list the contents of your home directory.
|
||||
|
||||
```
|
||||
$ ls -ild /home/dwalsh
|
||||
8193 drwx--x--x. 290 dwalsh dwalsh 20480 Jan 29 07:58 /home/dwalsh
|
||||
$ buildah unshare ls -ld /home/dwalsh
|
||||
drwx--x--x. 290 root root 20480 Jan 29 07:58 /home/dwalsh
|
||||
```
|
||||
|
||||
Notice that when listing the home dir attributes outside the user namespace, the kernel reports the ownership as dwalsh, while inside the user namespace it reports the directory as owned by root. This is because the home directory is owned by 3267, and inside the user namespace we are treating that UID as root.
|
||||
|
||||
### What happens next in Podman after the user namespace is set up?
|
||||
|
||||
Podman uses [containers/storage][5] to pull the container image, and containers/storage is smart enough to map all files owned by root in the image to the root of the user namespace, and any other files owned by different UIDs to their user namespace UIDs. By default, this content gets written to ~/.local/share/containers/storage. Container storage works in rootless mode with either the vfs mode or with Overlay. Note: Overlay is supported only if the [fuse-overlayfs][6] executable is installed.
|
||||
|
||||
The kernel only allows user namespace root to mount certain types of filesystems; at this time it allows mounting of procfs, sysfs, tmpfs, fusefs, and bind mounts (as long as the source and destination are owned by the user running Podman. OverlayFS is not supported yet, although the kernel teams are working on allowing it).
|
||||
|
||||
Podman then mounts the container's storage if it is using fuse-overlayfs; if the storage driver is using vfs, then no mounting is required. Podman on vfs requires a lot of space though, since each container copies the entire underlying filesystem.
|
||||
|
||||
Podman then mounts /proc and /sys along with a few tmpfs and creates the devices in the container.
|
||||
|
||||
In order to use networking other than the host networking, Podman uses the [slirp4netns][7] program to set up **User mode networking for unprivileged network namespace**. Slirp4netns allows Podman to expose ports within the container to the host. Note that the kernel still will not allow a non-privileged process to bind to ports less than 1024. Podman-1.1 or later is required for binding to ports.
|
||||
|
||||
Rootless Podman can use user namespace for container separation, but you only have access to the UIDs defined in the /etc/subuid file.
|
||||
|
||||
### Conclusion
|
||||
|
||||
The Podman tool is enabling people to build and use containers without sacrificing the security of the system; you can give your developers the access they need without giving them root.
|
||||
|
||||
And when you put your containers into production, you can take advantage of the extra security provided by the user namespace to keep the workloads isolated from each other.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/how-does-rootless-podman-work
|
||||
|
||||
作者:[Daniel J Walsh][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rhatdan
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/18/12/podman-and-user-namespaces
|
||||
[2]: https://podman.io/
|
||||
[3]: https://buildah.io/
|
||||
[4]: https://github.com/containers/buildah/blob/master/docs/buildah-unshare.md
|
||||
[5]: https://github.com/containers/storage
|
||||
[6]: https://github.com/containers/fuse-overlayfs
|
||||
[7]: https://github.com/rootless-containers/slirp4netns
|
||||
@ -0,0 +1,68 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What's the right amount of swap space for a modern Linux system?)
|
||||
[#]: via: (https://opensource.com/article/19/2/swap-space-poll)
|
||||
[#]: author: (David Both https://opensource.com/users/dboth)
|
||||
|
||||
What's the right amount of swap space for a modern Linux system?
|
||||
======
|
||||
Complete our survey and voice your opinion on how much swap space to allocate.
|
||||

|
||||
|
||||
Swap space is one of those things that everyone seems to have an idea about, and I am no exception. All my sysadmin friends have their opinions, and most distributions make recommendations too.
|
||||
|
||||
Many years ago, the rule of thumb for the amount of swap space that should be allocated was 2X the amount of RAM installed in the computer. Of course that was when a typical computer's RAM was measured in KB or MB. So if a computer had 64KB of RAM, a swap partition of 128KB would be an optimum size.
|
||||
|
||||
This took into account the fact that RAM memory sizes were typically quite small, and allocating more than 2X RAM for swap space did not improve performance. With more than twice RAM for swap, most systems spent more time thrashing than performing useful work.
|
||||
|
||||
RAM memory has become quite inexpensive and many computers now have RAM in the tens of gigabytes. Most of my newer computers have at least 4GB or 8GB of RAM, two have 32GB, and my main workstation has 64GB. When dealing with computers with huge amounts of RAM, the limiting performance factor for swap space is far lower than the 2X multiplier. As a consequence, recommended swap space is considered a function of system memory workload, not system memory.
|
||||
|
||||
Table 1 provides the Fedora Project's recommended size for a swap partition, depending on the amount of RAM in your system and whether you want enough memory for your system to hibernate. To allow for hibernation, you need to edit the swap space in the custom partitioning stage. The "recommended" swap partition size is established automatically during a default installation, but I usually find it's either too large or too small for my needs.
|
||||
|
||||
The [Fedora 28 Installation Guide][1] defines current thinking about swap space allocation. Note that other versions of Fedora and other Linux distributions may differ slightly, but this is the same table Red Hat Enterprise Linux uses for its recommendations. These recommendations have not changed since Fedora 19.
|
||||
|
||||
| Amount of RAM installed in system | Recommended swap space | Recommended swap space with hibernation |
|
||||
| --------------------------------- | ---------------------- | --------------------------------------- |
|
||||
| ≤ 2GB | 2X RAM | 3X RAM |
|
||||
| 2GB – 8GB | = RAM | 2X RAM |
|
||||
| 8GB – 64GB | 4G to 0.5X RAM | 1.5X RAM |
|
||||
| >64GB | Minimum 4GB | Hibernation not recommended |
|
||||
|
||||
Table 1: Recommended system swap space in Fedora 28's documentation.
|
||||
|
||||
Table 2 contains my recommendations based on my experiences in multiple environments over the years.
|
||||
| Amount of RAM installed in system | Recommended swap space |
|
||||
| --------------------------------- | ---------------------- |
|
||||
| ≤ 2GB | 2X RAM |
|
||||
| 2GB – 8GB | = RAM |
|
||||
| > 8GB | 8GB |
|
||||
|
||||
Table 2: My recommended system swap space.
|
||||
|
||||
It's possible that neither of these tables will work for your environment, but they will give you a place to start. The main consideration is that as the amount of RAM increases, adding more swap space simply leads to thrashing well before the swap space comes close to being filled. If you have too little virtual memory, you should add more RAM, if possible, rather than more swap space.
|
||||
|
||||
In order to test the Fedora (and RHEL) swap space recommendations, I used its recommendation of **0.5*RAM** on my two largest systems (the ones with 32GB and 64GB of RAM). Even when running four or five VMs, multiple documents in LibreOffice, Thunderbird, the Chrome web browser, several terminal emulator sessions, the Xfe file manager, and a number of other background applications, the only time I see any use of swap is during backups I have scheduled for every morning at about 2am. Even then, swap usage is no more than 16MB—yes megabytes. These results are for my system with my loads and do not necessarily apply to your real-world environment.
|
||||
|
||||
I recently had a conversation about swap space with some of the other Community Moderators here at [Opensource.com][2], and Chris Short, one of my friends in that illustrious and talented group, pointed me to an old [article][3] where he recommended using 1GB for swap space. This article was written in 2003, and he told me later that he now recommends zero swap space.
|
||||
|
||||
So, we wondered, what you think? What do you recommend or use on your systems for swap space?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/swap-space-poll
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://docs.fedoraproject.org/en-US/fedora/f28/install-guide/
|
||||
[2]: http://Opensource.com
|
||||
[3]: https://chrisshort.net/moving-to-linux-partitioning/
|
||||
@ -1,103 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (oska874)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 5 OK05)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok05.html)
|
||||
[#]: author: (Robert Mullins http://www.cl.cam.ac.uk/~rdm34)
|
||||
|
||||
translating by ezio
|
||||
|
||||
树莓派计算机实验室 课程 5 OK05
|
||||
======
|
||||
|
||||
OK05 课程构建于课程 OK04 的基础,使用更多代码方式烧、保存写莫尔斯码的 SOS 序列(`...---...`)。这里假设你已经有了 [课程 4: OK04][1] 操作系统的代码基础。
|
||||
|
||||
### 1 数据
|
||||
|
||||
到目前为止,我们与操作系统有关的所有内容都提供了遵循的说明。然而有时候,说明只是一半。我们的操作系统可能需要数据
|
||||
|
||||
> 一些早期的操作系统确实只允许特定文件中的特定类型的数据,但是这通常被认为太严格了。现代方法确实使程序变得复杂的多。
|
||||
|
||||
通常,只是数据的值很重要。你可能经过训练,认为数据是指定类型,比如,一个文本文件包含文章,一个图像文件包含一幅图片,等等。说实话,这只是一个理想罢了。计算机上的全部数据都是二进制数字,重要的是我们选择用什么来解释这些数据。在这个例子中,我们会将一个闪灯序列作为数据保存下来。
|
||||
|
||||
在 `main.s` 结束处复制下面的代码:
|
||||
|
||||
```
|
||||
.section .data %定义 .data 段
|
||||
.align 2 %对齐
|
||||
pattern: %定义整形变量
|
||||
.int 0b11111111101010100010001000101010
|
||||
```
|
||||
|
||||
>`.align num` 保证下一行代码的地址是 `2^num` 的整数倍。
|
||||
|
||||
>`.int val` 输出数值 `val`。
|
||||
|
||||
要区分数据和代码,我们将数据都放在 `.data` 区域。我已经将该区域包含在操作系统的内存布局图。我已经选择将数据放到代码后面。将我们的指令和数据分开保存的原因是,如果最后我们在自己的操作系统上实现一些安全措施,我们就需要知道代码的那些部分是可以执行的,而那些部分是不行的。
|
||||
|
||||
我在这里使用了两个新命令 `.align` 和 `.int`。`.align` 保证下来的数据是按照 2 的乘方对齐的。在这个里,我使用 `.align 2` ,意味着数据最终存放的地址是 `2^2=4` 的整数倍。这个操作是很重要的,因为我们用来读取内寸的指令 `ldr` 要求内存地址是 4 的倍数。
|
||||
|
||||
The .int command copies the constant after it into the output directly. That means that 111111111010101000100010001010102 will be placed into the output, and so the label pattern actually labels this piece of data as pattern.
|
||||
|
||||
命令 `.int` 直接复制它后面的常量到输出。这意味着 `11111111101010100010001000101010`(二进制数) 将会被存放到输出,所以标签模式实际将标记这段数据作为模式。
|
||||
|
||||
> 关于数据的一个挑战是寻找一个高效和有用的展示形式。这种保存一个开、关的时间单元的序列的方式,运行起来很容易,但是将很难编辑,因为摩尔斯的原理 `-` 或 `.` 丢失了。
|
||||
|
||||
如我提到的,数据可以意味这你想要的所有东西。在这里我编码了摩尔斯代码 SOS 序列,对于不熟悉的人,就是 `...---...`。我使用 0 表示一个时间单元的 LED 灭灯,而 1 表示一个时间单元的 LED 亮。这样,我们可以像这样编写一些代码在数据中显示一个序列,然后要显示不同序列,我们所有需要做的就是修改这段数据。下面是一个非常简单的例子,操作系统必须一直执行这段程序,解释和展示数据。
|
||||
|
||||
复制下面几行到 `main.s` 中的标记 `loop$` 之前。
|
||||
|
||||
```
|
||||
ptrn .req r4 %重命名 r4 为 ptrn
|
||||
ldr ptrn,=pattern %加载 pattern 的地址到 ptrn
|
||||
ldr ptrn,[ptrn] %加载地址 ptrn 所在内存的值
|
||||
seq .req r5 %重命名 r5 为 seq
|
||||
mov seq,#0 %seq 赋值为 0
|
||||
```
|
||||
|
||||
这段代码加载 `pattrern` 到寄存器 `r4`,并加载 0 到寄存器 `r5`。`r5` 将是我们的序列位置,所以我们可以追踪有多少 `pattern` 我们已经展示了。
|
||||
|
||||
下面的代码将非零值放入 `r1` ,如果仅仅是如果,这里有个 1 在当前位置的 `pattern`。
|
||||
|
||||
```
|
||||
mov r1,#1 %加载1到 r1
|
||||
lsl r1,seq %对r1 的值逻辑左移 seq 次
|
||||
and r1,ptrn %按位与
|
||||
```
|
||||
|
||||
这段代码对你调用 `SetGpio` 很有用,它必须有一个非零值来关掉 LED,而一个0值会打开 LED。
|
||||
|
||||
现在修改 `main.s` 中全部你的代码,这样代码中每次循环会根据当前的序列数设置 LED,等待 250000 毫秒(或者其他合适的延时),然后增加序列数。当这个序列数到达 32 就需要返回 0.看看你是否能实现这个功能,作为额外的挑战,也可以试着只使用一条指令。
|
||||
|
||||
### 2 Time Flies When You're Having Fun... 当你玩得开心时,过得很快
|
||||
|
||||
你现在准备好在树莓派上实验。应该闪烁一串包含 3 个短脉冲,3 个长脉冲,然后 3 个更短脉冲的序列。在一次延时之后,这种模式应该重复。如果这部工作,请查看我们的问题页。
|
||||
|
||||
一旦它工作,祝贺你已经达到 OK 系列教程的结束。
|
||||
|
||||
在这个谢列我们学习了汇编代码,GPIO 控制器和系统定时器。我们已经学习了函数和 ABI,以及几个基础的操作系统原理,和关于数据的知识。
|
||||
|
||||
你现在已经准备好下面几个更高级的课程的某一个。
|
||||
* [Screen][2] 系列是接下来的,会教你如何通过汇编代码使用屏幕。
|
||||
* [Input][3] 系列教授你如何使用键盘和鼠标。
|
||||
|
||||
到现在,你已经有了足够的信息来制作操作系统,用其它方法和 GPIO 交互。如果你有任何机器人工具,你可能会想尝试编写一个通过 GPIO 管教控制的机器人操作系统。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok05.html
|
||||
|
||||
作者:[Robert Mullins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[ezio](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cl.cam.ac.uk/~rdm34
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok04.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html
|
||||
@ -7,57 +7,56 @@
|
||||
[#]: via: (https://fedoramagazine.org/3-simple-and-useful-gnome-shell-extensions/)
|
||||
[#]: author: (Ryan Lerch https://fedoramagazine.org/introducing-flatpak/)
|
||||
|
||||
3 simple and useful GNOME Shell extensions
|
||||
3 个简单实用的 GNOME Shell 扩展
|
||||
======
|
||||
|
||||

|
||||
|
||||
The default desktop of Fedora Workstation — GNOME Shell — is known and loved by many users for its minimal, clutter-free user interface. It is also known for the ability to add to the stock interface using extensions. In this article, we cover 3 simple, and useful extensions for GNOME Shell. These three extensions provide a simple extra behaviour to your desktop; simple tasks that you might do every day.
|
||||
Fedora Workstation 的默认桌面 GNOME Shell,因其最小化,整洁的用户界面而闻名并深受许多用户的喜爱。它还以可使用扩展添加到 stock 界面的能力而闻名。在本文中,我们将介绍 GNOME Shell 的 3 个简单且有用的扩展。这三个扩展为你的桌面提供了简单的,你可能每天都会做的行为。
|
||||
|
||||
### 安装扩展程序
|
||||
|
||||
### Installing Extensions
|
||||
|
||||
The quickest and easiest way to install GNOME Shell extensions is with the Software Application. Check out the previous post here on the Magazine for more details:
|
||||
安装 GNOME Shell 扩展的最快捷最简单的方法是使用软件应用。有关详细信息,请查看 Magazine 中的上一篇文章:
|
||||
|
||||

|
||||
|
||||
### Removable Drive Menu
|
||||
|
||||
![][1]
|
||||
Removable Drive Menu extension on Fedora 29
|
||||
|
||||
First up is the [Removable Drive Menu][2] extension. It is a simple tool that adds a small widget in the system tray if you have a removable drive inserted into your computer. This allows you easy access to open Files for your removable drive, or quickly and easily eject the drive for safe removal of the device.
|
||||
Fedora 29 中的 Removable Drive Menu 扩展
|
||||
|
||||
首先是 [Removable Drive Menu][2] 扩展。如果你的计算机中有可移动驱动器,那么它是一个可在系统托盘中添加一个 widget 的简单工具。它可以使你轻松打开可移动驱动器中的文件,或者快速方便地弹出驱动器以安全移除设备。
|
||||
|
||||
![][3]
|
||||
Removable Drive Menu in the Software application
|
||||
|
||||
### Extensions Extension.
|
||||
软件应用中的 Removable Drive Menu
|
||||
|
||||
### Extensions 扩展
|
||||
|
||||
![][4]
|
||||
|
||||
The [Extensions][5] extension is super useful if you are always installing and trying out new extensions. It provides a list of all the installed extensions, allowing you to enable or disable them. Additionally, if an extension has settings, it allows quick access to the settings dialog for each one.
|
||||
如果你一直在安装和尝试新扩展,那么 [Extensions][5] 扩展非常有用。它提供了所有已安装扩展的列表,允许你启用或禁用它们。此外,如果扩展有设置,那么可以快速打开每个扩展的设置对话框。
|
||||
|
||||
![][6]
|
||||
the Extensions extension in the Software application
|
||||
|
||||
软件中的 Extensions 扩展
|
||||
|
||||
### Frippery Move Clock
|
||||
|
||||
![][7]
|
||||
|
||||
Finally, there is the simplest extension in the list. [Frippery Move Clock][8], simply moves the position of the clock from the center of the top bar to the right, next to the status area.
|
||||
最后的是列表中最简单的扩展。[Frippery Move Clock][8],只是将时钟位置从顶部栏的中心向右移动,位于状态区旁边。
|
||||
|
||||
![][9]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/3-simple-and-useful-gnome-shell-extensions/
|
||||
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/introducing-flatpak/
|
||||
Loading…
Reference in New Issue
Block a user