mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
Merge branch 'master' of https://github.com/runningwater/TranslateProject
This commit is contained in:
commit
da09e5286c
published
20140611 Little Known Apache Mesos Project Helps Mesosphere Raise $10M From Andreessen Horowitz.md20140624 Super Pi Brothers.md20140701 Get OpenVPN up and running, enjoy your privacy.md20140702 Wine 1.7.21 (Development Version) Released--Install in RedHat and Debian Based Systems.md20140709 How to set up two-factor authentication for SSH login on Linux.md20140711 How to Install Lightweight Budgie Desktop in Ubuntu 14.04.md20140711 How to simulate key press and mouse movement in Linux.md20140714 Linux slabtop command--Display Kernel Slab Cache Information.md20140714 Test read or write speed of usb and ssd drives with dd command on Linux.md20140718 Linux Kernel Testing and Debugging 4.md20140718 Linux Kernel Testing and Debugging 5.md20140718 Linux Kernel Testing and Debugging 6.md20140722 Budgie Desktop 5.1 Is a Superb New Desktop Environment for Conservative Users.md20140723 How to configure chroot SFTP in Linux.md20140729 Linux FAQs with Answers--How to check which fonts are used in a PDF document.md20140731 Top 10 Free Linux Games.md20140807 Linux FAQs with Answers--How to fix 'fatal error--jsoncpp or json or json.h--No such file or directory'.md20140811 StuntRally 2.4 Is the Most Advanced Free Racing Game on Linux.md20140818 How To Schedule A Shutdown In Ubuntu 14.04 [Quick Tip].md
sources
news
20140811 StuntRally 2.4 Is the Most Advanced Free Racing Game on Linux.md20140826 Munich Council--LiMux Demise Has Been Greatly Exaggerated.md20140828 GIMP 2.8.12 Released--Here' s How to Install it on Ubuntu.md20140829 Red Hat Shake-up, Desktop Users, and Outta Time.mdMunich Council- LiMux Demise Has Been Greatly Exaggerated.md
talk
20140610 How does the cloud affect the everyday linux user.md20140819 KDE Plasma 5--For those Linux users undecided on the kernel' s future.md20140826 Linus Torvalds Promotes Linux for Desktops, Embedded Computing.md20140826 Linus Torvalds Started a Revolution on August 25 1991 Happy Birthday Linux.md20140828 Interesting facts about Linux.md20140829 Linux Doesn't Need to Own the Desktop.md
tech
20140722 How to manage DigitalOcean VPS droplets from the command line on Linux.md20140808 How to install Puppet server and client on CentOS and RHEL.md20140811 Disable or Password Protect Single User Mode or RHEL ro CentOS ro 5.x ro 6.x.md20140813 How to remove file metadata on Linux.md20140818 How to configure Access Control Lists (ACLs) on Linux.md20140819 How to Encrypt Email in Linux.md20140825 Linux FAQs with Answers--How to enable Nux Dextop repository on CentOS or RHEL.md20140826 20 Postfix Interview Questions and Answers.md20140826 How to configure SNMPv3 on ubuntu 14.04 server.md20140826 Linux Tutorial--Install Ansible Configuration Management And IT Automation Tool.md20140828 How to create a site-to-site IPsec VPN tunnel using Openswan in Linux.md20140828 Setup Thin Provisioning Volumes in Logical Volume Management (LVM)--Part IV.md20140829 6 Interesting Funny Commands of Linux (Fun in Terminal) – Part II.md20140829 Fun in Linux Terminal--Play with Word and Character Counts.md
translated
talk
20140611 Little Known Apache Mesos Project Helps Mesosphere Raise $10M From Andreessen Horowitz.md20140825 China Will Change The Way All Software Is Bought And Sold.md20140826 Linus Torvalds is my hero, says 13 year old Zachary DuPont.md
tech
20140716 Linux FAQs with Answers--How to define PATH environment variable for sudo commands.md20140722 How to manage DigitalOcean VPS droplets from the command line on Linux.md20140808 How to install Puppet server and client on CentOS and RHEL.md20140811 Disable or Password Protect Single User Mode or RHEL ro CentOS ro 5.x ro 6.x.md20140813 How to remove file metadata on Linux.md20140815 How to manage a WiFi connection from the command line.md20140818 How to configure Access Control Lists (ACLs) on Linux.md20140819 Linux Systemd--Start or Stop or Restart Services in RHEL or CentOS 7.md20140825 Linux FAQs with Answers--How to fix 'failed to run aclocal--No such file or directory'.md20140825 Linux FAQs with Answers--How to install Shutter on CentOS.md20140825 Linux FAQs with Answers--How to show a MAC learning table of Linux bridge.md20140825 Linux Terminal--speedtest_cli checks your real bandwidth speed.mdHow to listen to Internet radio from the command line on Linux.md
@ -0,0 +1,50 @@
|
||||
鲜为人知的 Apache Mesos 项目帮助 Mesosphere 公司得到了千万美元投资
|
||||
================================================================================
|
||||

|
||||
|
||||
[Mesosphere][1],一家试图围绕鲜为人知的 Apache Mesos 项目开展商业活动的公司,刚刚从 Andreessen Horowitz 那里获得了 1000 万美元投资。以下是为什么这个项目能够吸引如此巨款的原因。
|
||||
|
||||
事实上 Mesos 这款自动扩放软件已经出现了五年了。据 Mesosphere 的CEO及联合创始人 Florian Leibert 所述,Mesos 已经在 Twitter 内已经管理了超过 50,000 个以上的CPU。此外, EBay, AirBnB, Netflix 还有 HubSpot 也是这款软件的使用者。
|
||||
|
||||
当那些互联网巨头发现 Mesos 的时候,这项技术却并不为大多数企业所知。但它确实可以满足一些公司在他们内部的数据中心上应用公共云的一些技术的需求。
|
||||
|
||||
Mesos 管理集群机器,根据需要自动扩放应用。它在每台机器上只依赖很少的软件,它由一个主调度程序协调。据 Leibert 所说,其CPU 占用为 0 并且几乎不消耗任何内存。在其工作的每台机器上的该软件会向调度程序报告关于虚拟机或者服务器的容量信息,接着调度程序向目标机器分派任务。
|
||||
|
||||
“如果一项任务终断并且没有返回任何结果,主调度程序知道如何重新调度它和它所用的资源在哪里。” Mesosphere 的资深副总裁 Matt Trifiro 说。
|
||||
|
||||
Mesos 能自动扩放一系列的任务,包括 Hadoop 数据库,Ruby on Rails 节点,以及 Cassandra 。
|
||||
|
||||
使用 Mesos 使得 Hubspot 削减了一半的 AWS(Amazon Web Services) 的费用支出,Liebert 说道。这是因为 Mesos 能够在目标机器之间有效地分配作业量的原因。
|
||||
|
||||
然而,Mesos 更有可能应用到那些试图真正地在内部创建一个类 AWS 环境的企业,一位来自 451 Research 的分析员 Jay Lyman 说。AWS 提供一些[自动扩放工具][3],但大多数公司对于在公共云基础设施上运行所有东西还是感到不安。与此同时,他们并不想着反对他们的开发者采用 AWS 那样的公共云中可用的优异性能。他们希望他们的私有云能集成这些可用的优点。
|
||||
|
||||
“如你所见,类似 AWS 风格的界面风格,与监控、命令、操控以及稳定性相融合,” Liebert 继续说道。
|
||||
|
||||
Mesos 既可以在一个私有云上也可以在 AWS 上运行,向企业提供最有效率地使用其内部云的方法,并在需要扩放时自动切换到 AWS 去。
|
||||
|
||||
但是,从另外的方面说 Mesos 也是有一些缺点的。它[并不能运行][4]任何 Windows 操作系统或者比较古老的应用比如说 SAP 软件。
|
||||
|
||||
不过,Lyman 说,“假如一个团队拥有长时期使用云的经历,他们大概早就对 Linux 操作系统情有独钟了。”
|
||||
|
||||
在将来,Mesosphere 能够支持 Windows 操作系统是很有可能的。最初,像 Puppet 和 Chef 这样的技术也只支持 Linux 操作系统,Lyman 表示。“这只是早期 Mesosphere 的特性。现在它还是不太成熟,” 他又说道。
|
||||
|
||||
Mesosphere 正瞄向大部分使用现代编程技术构建了越来越多的运行于 Linux 的应用的企业,以及 Twitter 和 Netflix 这种在初创时还没有 Mesos 类似技术的第一代 Web 2.0 公司。“这是早期两类最常见的客户概况,” Trifiro 说。
|
||||
|
||||
年终之前,Mesosphere 希望发布包含文档的商业产品,通过技术支持与颁发许可证来获得营收。Mesosphere 已开发一款名为 Marathon 的大规模扩放编制工具,并且支持 Docker 集成。它现在免费提供打包好的 Mesos 发行版,希望以此占有未来的市场。
|
||||
|
||||
Mesosphere 同时也正在为少数早期的顾客工作。它帮助 HubSpot 实施有关 Mesos 的搭建。
|
||||
|
||||
Mesosphere 在这个领域并不唯一。Rightscale,Scalr 以及现在归 Dell 所有的 Enstratius,全都提供了一些各种版本的扩放或云管理技术。Mesosphere 强调说,Mesos 及其公司自己开发的技术在单独机器中创建服务器集群方面的表现远胜于市场上的其他同类软件。来自 Andreessen 的新投资一定会帮助 Meos 获得更大的动力。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thenewstack.io/little-known-apache-mesos-project-helps-mesosphere-raise-10m-from-andreessen/
|
||||
|
||||
译者:[SteveArcher](https://github.com/SteveArcher) 校对:[ wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://mesosphere.io/
|
||||
[2]:http://mesos.apache.org/
|
||||
[3]:http://aws.amazon.com/autoscaling/
|
||||
[4]:http://mesosphere.io/learn/
|
||||
@ -1,23 +1,27 @@
|
||||
超级树莓派兄弟
|
||||
================================================================================
|
||||
我已经不象以前那样玩那么多游戏了。虽然之前我当然花费了生命里的无数时间在任天堂,SNES,或是之后在我电脑上的第一人称射击游戏(只在Linux下,谢谢),如今,我更愿意把空余时间花在我累积起来的许多其他非游戏爱好上。但是最近,我发现自己又抹掉了Wii手柄上的灰尘,这样就可以玩一玩我重新购买的NES和SNES游戏了。不过问题是,这些游戏需要用到一些特别的控制器,而且我已经有一个修改过的SNES控制器可以通过USB连接。这已经有足够的理由让我去寻找一个更合适的方案。当然,我也可以简单地接上三个甚至四个手柄,然后在客厅里面堆满游戏。但是我已经习惯于把我的CD和DVD都提取成文件,然后在中心媒体服务器上挑选着听或是看。所以如果每次我想换游戏的时候,不用起身去翻游戏卡带,那就完美了。当然,这意味着得使用模拟器。尽管之前我在一个改动过的Xbox上成功过,不过可惜它已经不在我手上了。然后我觉得一定有什么人已经在树莓派上实现过这种平台,结果是肯定的,在简单地搜索和一些命令之后,我在一个剩下的树莓派上搭起来一个完美的怀旧游戏中心。
|
||||
我已经不象以前那样玩那么多游戏了。虽然之前我当然花费了生命里的无数时间在任天堂,SNES,或是之后在我电脑上的第一人称射击游戏(只在Linux下,谢谢),如今,我更愿意把空余时间花在我累积起来的许多其他非游戏爱好上。
|
||||
|
||||
但是最近,我发现自己又抹掉了Wii手柄上的灰尘,这样就可以玩一玩我重新购买的NES和SNES游戏了。不过问题是,这些游戏需要用到一些特别的控制器,而且我已经有一个修改过的SNES控制器可以通过USB连接。这已经有足够的理由让我去寻找一个更合适的方案。
|
||||
|
||||
当然,我也可以简单地接上三个甚至四个手柄,然后在客厅里面堆满游戏。但是我已经习惯于把我的CD和DVD都提取成文件,然后在中心媒体服务器上挑选着听或是看。所以如果每次我想换游戏的时候,不用起身去翻游戏卡带,那就完美了。
|
||||
|
||||
当然,这意味着得使用模拟器。尽管之前我在一个改动过的Xbox上成功过,不过可惜它已经不在我手上了。然后我觉得一定有什么人已经在树莓派上实现过这种平台,结果是肯定的,在简单地搜索和一些命令之后,我在一个剩下的树莓派上搭起来一个完美的怀旧游戏中心。
|
||||
|
||||
树莓派项目的一个优点是,有大量的用户在使用相同的硬件。对我来说,这意味着我不用完整地参考别人的指引再根据自己的需求做出必要的改动,而只需要简单地完全按照别人的指导做就行了。在我这件事情上,我找到了RetroPie项目,它把你安装时需要用到的所有命令都包到了一个单一的大脚本中。在执行完后,你就完整地安装并配置好了RetroArch,它集成了所有的主流模拟器以及一个统一的配置方式,再加上一个在树莓派上开机启动的EmulationStation图形界面,通过它可以只用手柄就能方便地定位到你想玩的游戏。
|
||||
|
||||
### 安装RetroPie ###
|
||||
|
||||
在安装RetroPie之前,你可能需要确认一下你的Raspbian版本(树莓派默认的Linux发行版,这也是这个项目假设你在用的)是不是最新的,包括有没有新的固件。这只需要几个通用的`apt`命令。虽然,在这一步里你当然可以接个键盘到树莓派上,不过我觉得用`ssh`登录到树莓派上更方便。之后直接复制和粘贴下面的命令:
|
||||
在安装RetroPie之前,你可能需要确认一下你的Raspbian版本(树莓派默认的Linux发行版,这也是这个项目假设你在用的)是不是最新的,包括有没有新的固件。这只需要几个通用的`apt`命令。虽然,在这一步里你可以接个键盘到树莓派上,不过我觉得用`ssh`登录到树莓派上更方便。之后直接复制和粘贴下面的命令:
|
||||
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get -y upgrade
|
||||
|
||||
现在树莓派已经更新到最新了,再确认一下是否安装了git和dialog,然后可以通过git来下载RetroPie:
|
||||
|
||||
|
||||
$ sudo apt-get -y install git dialog
|
||||
$ cd
|
||||
$ git clone --depth=0
|
||||
↪git://github.com/petrockblog/RetroPie-Setup.git
|
||||
$ git clone --depth=0 git://github.com/petrockblog/RetroPie-Setup.git
|
||||
|
||||
执行完上边的命令后会创建一个RetroPie-Setup目录,里面有主要的安装脚本。之后你只需要进去这个目录,并运行安装脚本:
|
||||
|
||||
@ -29,9 +33,9 @@
|
||||
|
||||

|
||||
|
||||
#### 图1. RetroPie安装菜单 ####
|
||||
*图1. RetroPie安装菜单*
|
||||
|
||||
在vanilla Raspbian固件版本中,这一步会需要很长时间,因为有大量不同的包需要下载和安装。在安装完成之后,返回在RetroPie安装主界面中,在主菜单里选择SETUP,在之后的二级菜单里,你可以调整设置,例如是否开机启动EmulationStation(推荐打开)以及是否允许欢迎界面。在我这里,我两个都允许了,因为我希望这个设备是一个独立的模拟游戏机。不过你需要了解的是,如果你确实允许了EmulationStation开机自动启动,你仍然可以ssh登录到机器上然后执行原始的RetroPie安装配置脚本来改变这个设置。
|
||||
在vanilla Raspbian固件版本中,这一步会需要很长时间,因为有大量不同的包需要下载和安装。在安装完成之后,返回在RetroPie安装主界面中,在主菜单里选择SETUP,在之后的二级菜单里,你可以调整设置,例如是否开机启动EmulationStation(推荐打开)以及是否允许欢迎界面。在我这里,我两个都允许了,因为我希望这个设备是一个独立的模拟游戏机。不过你需要了解的是,即便你打开了EmulationStation开机自动启动,你仍然可以ssh登录到机器上然后执行原始的RetroPie安装配置脚本来改变这个设置。
|
||||
|
||||
### 添加ROM ###
|
||||
|
||||
@ -46,11 +50,11 @@
|
||||
|
||||
### EmulationStation ###
|
||||
|
||||
重启完之后,当看到EmulationStation界面时应该会很高兴,之后它会提示你设定控制杆,游戏手柄,或键盘按键,这样就可以控制EmulationStation菜单了。不过注意一下,这并不会影响手柄在游戏里的按键定义,只是用于控制EmulationStation菜单的。在设定完手柄后,你应该可以按下向右或向左方向键来切换不同的模拟器菜单了。在我这里,我将会在游戏里用到手柄上的所有按钮,所以我特别将另一个键盘上的键映射到菜单功能,这样在我玩完一个游戏后,不用重启树莓派就可以退出来。
|
||||
重启完之后,你会很高兴地看到EmulationStation界面,之后它会提示你设定控制杆,游戏手柄,或键盘按键,这样就可以控制EmulationStation菜单了。不过注意一下,这并不会影响手柄在游戏里的按键定义,只是用于控制EmulationStation菜单的。在设定完手柄后,你应该可以按下向右或向左方向键来切换不同的模拟器菜单了。在我这里,我将会在游戏里用到手柄上的所有按钮,所以我特别将另一个键盘上的键映射到菜单功能,这样在我玩完一个游戏后,不用重启树莓派就可以退出来。
|
||||
|
||||
EmulationStation只会显示已经侦测到ROM的模拟器,所以,如果你还没有拷贝ROM的话,得先做这件事情,然后可能还得重启一下才会有效果。而且,默认情况下,你的手柄没有为任何游戏做配置,但是,如果你在EmulationStation里一直按向右键足够多次以后,会弹出输入设定界面,你可以在里面映射手柄按键。有一个亮点是,当你设定好按键后,它会相应地应用到其他模拟器中。
|
||||
|
||||
就是这些了。在这之后,你可以浏览你收藏的各种游戏,然后按下绑定到确定的那个按键开始游戏。一开始我还担心树莓派可能不够强劲来玩我的游戏,但是直到现在,我试过地所有游戏都可以完美地运行。
|
||||
就是这些了。在这之后,你可以浏览你收藏的各种游戏,然后按下绑定到“确定”的那个按键开始游戏。一开始我还担心树莓派可能不够强劲来玩我的游戏,但是直到现在,我试过地所有游戏都可以完美地运行。
|
||||
|
||||
### 资源 ###
|
||||
|
||||
@ -62,7 +66,7 @@ RetroPie安装文档:[https://github.com/petrockblog/RetroPie-Setup][2]
|
||||
|
||||
via: http://www.linuxjournal.com/content/super-pi-brothers
|
||||
|
||||
译者:[zpl1025](https://github.com/zpl1025) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[zpl1025](https://github.com/zpl1025) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,43 +1,42 @@
|
||||
2q1w2007翻译中
|
||||
搭建并运行OpenVPN,享受你的隐私生活
|
||||
十步搭建 OpenVPN,享受你的隐私生活
|
||||
================================================================================
|
||||

|
||||
|
||||
> 我们支持保护隐私,不为我们有自己的秘密需要保护,只是我们认为保护隐私应该成为一项基本人权。所以我们坚信无论谁在什么时候行使这项权利,都应该不受拘束的获取必须的工具和服务。OpenVPN就是这样一种服务并且有多种工具(客户端) 来让我们利用并享受这种服务。
|
||||
> 我们支持保护隐私,不为我们有自己的秘密需要保护,只是我们认为保护隐私应该成为一项基本人权。所以我们坚信无论谁在什么时候行使这项权利,都应该不受拘束的获取必须的工具和服务。OpenVPN就是这样一种服务并且有多种工具(客户端) 来让我们利用并享受这种服务。
|
||||
|
||||
通过与一个[OpenVPN][1]服务器建立连接,我们基本上在我们的设备和远端运行OpenVPN的主机之间建立了一个安全的通信通道。尽管在两个端点之间的通信可能被截获,但是信息是经过高强度加密的所以实际上它对于攻击者没什么用。OpenVPN除了扮演加密通信通道的调解人,我们也可以通过设置使服务器扮演因特网网管的角色。通过这种方式,我们可以连接任何不安全的Wifi,然后迅速的链接到远程的OpenVPN服务器并在不需要考虑偷窥的人或者无聊的管理员的情况下运行需要上网的程序。(注意:OpenVPN服务器旁还是需要信任的管理员的。)
|
||||
通过与一个[OpenVPN][1]服务器建立连接,我们基本上在我们的设备和远端运行OpenVPN的主机之间建立了一个安全的通信通道。尽管在两个端点之间的通信可能被截获,但是信息是经过高强度加密的所以实际上它对于攻击者没什么用。OpenVPN除了扮演加密通信通道的调解人,我们也可以通过设置使服务器扮演互联网网关的角色。通过这种方式,我们可以**连接任何不安全的Wifi**,然后迅速的链接到远程的OpenVPN服务器,然后在不需要考虑偷窥的人或者无聊的管理员的情况下运行需要上网的程序。(注意:OpenVPN服务器旁还是需要信任的管理员的。)
|
||||
|
||||
这篇文章将一步一步的教会你如何在[Ubuntu Server 14.04 LTS][2]上安装OpenVPN。OpenVPN所在的主机可能是云上的一台VPS,一台在我们家里某台电脑上运行的虚拟机,或者是一个老到你都快忘了的设备。
|
||||
这篇文章将一步一步的教会你如何在[Ubuntu Server 14.04 LTS][2]上安装OpenVPN。OpenVPN所在的主机可能是云上的一台VPS,一台在我们家里某台电脑上运行的虚拟机,或者是一个老到你都快忘了的设备。
|
||||
|
||||
### 第一步 -- 准备系统 ###
|
||||
### 第一步 准备系统 ###
|
||||
|
||||
我们需要Ubuntu Server主机的一个命令行终端,比如通过SSH从远程访问它。首先需要更新它的本地仓库数据:
|
||||
我们需要Ubuntu Server主机的一个命令行终端,比如通过SSH从远程访问它。首先需要更新它的本地仓库数据:
|
||||
|
||||
sub0@delta:~$ sudo apt-get update
|
||||
|
||||
进行操作系统和已安装的包的升级,输入:
|
||||
进行操作系统和已安装的包的升级,输入:
|
||||
|
||||
sub0@delta:~$ sudo apt-get dist-upgrade
|
||||
|
||||
如果升级了新内核,那就需要重启。当更新完成后,就该安装OpenVPN了:
|
||||
如果升级了新内核,那就需要重启。当更新完成后,就该安装OpenVPN了:
|
||||
|
||||
sub0@delta:~$ sudo apt-get -y install openvpn easy-rsa dnsmasq
|
||||
|
||||
注意,我们用apt-get安装了三个包:
|
||||
注意,我们用apt-get安装了三个包:
|
||||
|
||||
- openvpn提供了OpenVPN的核心
|
||||
- easy-rsa包含了一些有用的密钥管理脚本
|
||||
- dnsmasq是当我们的OpenVPN所在的主机将扮演客户端的路由器时会用到的域名服务器
|
||||
|
||||
### 第二步 -- 生成证书和私钥 ###
|
||||
### 第二步 生成证书和私钥 ###
|
||||
|
||||
这是安装OpenVPN中最重要和最关键的一步,目的是建立公钥基础设施(PKI)。包括如下内容:
|
||||
这是安装OpenVPN中最重要和最关键的一步,目的是建立公钥基础设施(PKI)。包括如下内容:
|
||||
|
||||
- 为OpenVPN服务器创建一个证书(公钥)和一个私钥
|
||||
- 为每个OpenVPN客户端创建证书和私钥
|
||||
- 建立一个证书颁发机构(CA)并创建证书和私钥。这个私钥用来给OpenVPN服务器和客户端的证书签名
|
||||
|
||||
从最后一个做起,我们先建立一个目录:
|
||||
从最后一个做起,我们先建立一个目录:
|
||||
|
||||
sub0@delta:~$ sudo mkdir /etc/openvpn/easy-rsa
|
||||
|
||||
@ -45,11 +44,11 @@
|
||||
|
||||
sub0@delta:~$ sudo cp -r /usr/share/easy-rsa/* /etc/openvpn/easy-rsa
|
||||
|
||||
在我们创建CA的私钥之前,我们先编辑/etc/openvpn/easy-rsa/vars(我们喜欢用nano,不过这只是我们的喜好,你爱用什么用什么):
|
||||
在我们创建CA的私钥之前,我们先编辑/etc/openvpn/easy-rsa/vars(我们喜欢用nano编辑器,不过这只是我们的喜好,你爱用什么用什么):
|
||||
|
||||
sub0@delta:~$ sudo nano /etc/openvpn/easy-rsa/vars
|
||||
|
||||
在文件的尾部,我们设置主证书和密钥的信息:
|
||||
在文件的尾部,我们设置主证书和密钥的信息:
|
||||
|
||||
export KEY_COUNTRY="GR"
|
||||
export KEY_PROVINCE="Central Macedonia"
|
||||
@ -61,9 +60,9 @@
|
||||
export KEY_OU="Parabing"
|
||||
export KEY_ALTNAMES="VPNsRUS"
|
||||
|
||||
你可以根据自己的情况设置不同的值。特别注意最后KEY_ALTNAMES这一行,尽管这不是原本vars文件中有的但是我们还是把它加到文件的尾部,不然build-ca脚本会运行失败。
|
||||
你可以根据自己的情况设置不同的值。特别注意最后KEY_ALTNAMES这一行,尽管这不是原本vars文件中有的但是我们还是把它加到文件的尾部,不然build-ca脚本会运行失败。
|
||||
|
||||
保存更改,我们得按[CTRL+O]然后按[Enter]。想退出nano,请按[CTRL+X]。现在,我们要获得root访问权限,继续生成主证书和私钥(LCTT译注:请注意命令行账户发生了改变):
|
||||
保存更改,我们得按[CTRL+O]然后按[Enter]。想退出nano,请按[CTRL+X]。现在,我们要获得root访问权限,继续生成主证书和私钥(LCTT译注:请注意命令行账户发生了改变):
|
||||
|
||||
sub0@delta:~$ sudo su
|
||||
root@delta:/home/sub0# cd /etc/openvpn/easy-rsa
|
||||
@ -93,11 +92,11 @@
|
||||
Email Address [nobody@parabing.com]:
|
||||
root@delta:/etc/openvpn/easy-rsa#
|
||||
|
||||
在我们的实例中,所有问题的答案都选择了默认的。在运行了build-ca脚本后,我们就获得了主证书文件(keys/ca.crt)和对应的私钥(keys/ca.key)。私钥必须不计代价的保密。
|
||||
在我们的例子中,所有问题的答案都选择了默认的。在运行了build-ca脚本后,我们就获得了主证书文件(keys/ca.crt)和对应的私钥(keys/ca.key)。私钥必须不计代价的保密。
|
||||
|
||||
### 第三步 -- 生成OpenVPN服务器的证书和私钥 ###
|
||||
### 第三步 生成OpenVPN服务器的证书和私钥 ###
|
||||
|
||||
在我们为OpenVPN服务器生成证书和密钥之前,我们得给他起个名。我决定把它叫"delta",然后运行build-key-server脚本来获取证书和密钥:
|
||||
在我们为OpenVPN服务器生成证书和密钥之前,我们得给他起个名。我决定把它叫"delta",然后运行build-key-server脚本来获取证书和密钥:
|
||||
|
||||
root@delta:/etc/openvpn/easy-rsa# sh build-key-server delta
|
||||
Generating a 1024 bit RSA private key
|
||||
@ -145,11 +144,11 @@
|
||||
Data Base Updated
|
||||
root@delta:/etc/openvpn/easy-rsa#
|
||||
|
||||
当脚本成功运行完的时候,我们就得到了服务器的证书(keys/delta.crt)和私钥(keys/delta.key)。注意服务器证书被CA的私钥签名了。
|
||||
当脚本成功运行完的时候,我们就得到了服务器的证书(keys/delta.crt)和私钥(keys/delta.key)。注意服务器证书被CA的私钥签名了。
|
||||
|
||||
### 第四步 -- 生成Diffie-Hellman参数 ###
|
||||
### 第四步 生成Diffie-Hellman参数 ###
|
||||
|
||||
幸亏有了Diffie-Hellman参数,我们才能在不安全的通信通道里安全的交换密钥。为了生成它我们需要键入:
|
||||
幸亏有了Diffie-Hellman参数,我们才能在不安全的通信通道里安全的交换密钥。为了生成它我们需要键入:
|
||||
|
||||
root@delta:/etc/openvpn/easy-rsa# sh build-dh
|
||||
Generating DH parameters, 2048 bit long safe prime, generator 2
|
||||
@ -162,7 +161,7 @@
|
||||
.......................................++*++*++*
|
||||
root@delta:/etc/openvpn/easy-rsa#
|
||||
|
||||
证书,私钥和包含Diffie-Hellman参数的文件已生成,它们都储存在/etc/openvpn/easy-rsa/keys,所以我们到现在为止已经有如下五个文件了:
|
||||
证书,私钥和包含Diffie-Hellman参数的文件已生成,它们都储存在/etc/openvpn/easy-rsa/keys,所以我们到现在为止已经有如下五个文件了:
|
||||
|
||||
1. **ca.crt** – 证书颁发机构(CA)的证书
|
||||
2. **ca.key** – CA的私钥
|
||||
@ -177,9 +176,9 @@
|
||||
root@delta:/etc/openvpn/easy-rsa/keys# cd ..
|
||||
root@delta:/etc/openvpn/easy-rsa#
|
||||
|
||||
### 第五步 -- 为OpenVPN客户端生成证书和私钥 ###
|
||||
### 第五步 为OpenVPN客户端生成证书和私钥 ###
|
||||
|
||||
试想我们的笔记本要连接OpenVPN服务器。为了实现这个很常见的情况,我们首先需要为客户端(比如:我们的笔记本)生成证书和私钥,在/etc/openvpn/easy-rsa有一个脚本帮我们完成这项工作:
|
||||
试想我们的笔记本要连接OpenVPN服务器。为了实现这个很常见的情况,我们首先需要为客户端(比如:我们的笔记本)生成证书和私钥,在/etc/openvpn/easy-rsa有一个脚本帮我们完成这项工作:
|
||||
|
||||
root@delta:/etc/openvpn/easy-rsa# source vars
|
||||
NOTE: If you run ./clean-all, I will be doing a rm -rf on /etc/openvpn/easy-rsa/keys
|
||||
@ -229,7 +228,7 @@
|
||||
Data Base Updated
|
||||
root@delta:/etc/openvpn/easy-rsa#
|
||||
|
||||
我们为密钥选取的名字是"laptop",当build-key脚本运行完之后,我们就得到了在keys/laptop.crt的证书和在keys/laptop.key的私钥。有了这两个文件和CA的证书,我们得把这三个文件拷贝到用户有(比如用户sub0)权访问的地方。比如我们可以在用户的home目录中新建一个目录并把三个文件拷贝过去:
|
||||
我们为密钥选取的名字是"laptop",当build-key脚本运行完之后,我们就得到了在keys/laptop.crt的证书和在keys/laptop.key的私钥。有了这两个文件和CA的证书,我们得把这三个文件拷贝到用户有(比如用户sub0)权访问的地方。比如我们可以在用户的home目录中新建一个目录并把三个文件拷贝过去:
|
||||
|
||||
root@delta:/etc/openvpn/easy-rsa# mkdir /home/sub0/ovpn-client
|
||||
root@delta:/etc/openvpn/easy-rsa# cd keys
|
||||
@ -238,11 +237,11 @@
|
||||
root@delta:/etc/openvpn/easy-rsa/keys# cd ..
|
||||
root@delta:/etc/openvpn/easy-rsa#
|
||||
|
||||
ovpn-client文件夹必须安全的拷贝到我们的笔记本电脑上。我们可以给多个客户端分发这三个文件。当然了,等我们需要一个不一样的证书-私钥对的时候只要再次运行build-key脚本即可。
|
||||
ovpn-client文件夹必须安全的拷贝到我们的笔记本电脑上。我们可以给多个客户端分发这三个文件。当然了,等我们需要一个不一样的证书-私钥对的时候只要再次运行build-key脚本即可。
|
||||
|
||||
### 第六步 -- OpenVPN服务器设置 ###
|
||||
|
||||
等会我们的OpenVPN服务器就要启动并运行了。但是开始的时候,我们需要更改一些设置。在/usr/share/doc/openvpn/examples/sample-config-files中有一个示例配置文件,它很适合我们的教程,这个文件叫server.conf.gz:
|
||||
等会我们的OpenVPN服务器就要启动并运行了。但是开始的时候,我们需要更改一些设置。在/usr/share/doc/openvpn/examples/sample-config-files中有一个示例配置文件,它很适合我们的教程,这个文件叫server.conf.gz:
|
||||
|
||||
root@delta:/etc/openvpn/easy-rsa# cd /etc/openvpn
|
||||
root@delta:/etc/openvpn# cp /usr/share/doc/openvpn/examples/sample-config-files/server.conf.gz .
|
||||
@ -250,18 +249,18 @@ ovpn-client文件夹必须安全的拷贝到我们的笔记本电脑上。我们
|
||||
root@delta:/etc/openvpn# mv server.conf delta.conf
|
||||
root@delta:/etc/openvpn#
|
||||
|
||||
如你所见,我们把server.conf.gz拷贝到/etc/openvpn,解压并重命名到delta.conf。你可以按个人喜好给OpenVPN服务器配置文件取名字,但是它必须有".conf"扩展名。我们现在用nano打开配置文件:
|
||||
如你所见,我们把server.conf.gz拷贝到/etc/openvpn,解压并重命名到delta.conf。你可以按个人喜好给OpenVPN服务器配置文件取名字,但是它必须有".conf"扩展名。我们现在用nano打开配置文件:
|
||||
|
||||
root@delta:/etc/openvpn# nano delta.conf
|
||||
|
||||
下面是我们应该做出的更改。
|
||||
|
||||
- 首先,定位到这一行
|
||||
- 首先,定位到这一行
|
||||
|
||||
cert server.crt
|
||||
key server.key
|
||||
|
||||
确认OpenVPN服务器证书和私钥的位置和名称,在我们的例子中,这两行要改成
|
||||
确认OpenVPN服务器证书和私钥的位置和名称,在我们的例子中,这两行要改成
|
||||
|
||||
cert delta.crt
|
||||
key delta.key
|
||||
@ -274,18 +273,18 @@ ovpn-client文件夹必须安全的拷贝到我们的笔记本电脑上。我们
|
||||
|
||||
dh dh2048.pem
|
||||
|
||||
- 在配置文件的末尾,我们添加下面这两行:
|
||||
- 在配置文件的末尾,我们添加下面这两行:
|
||||
|
||||
push "redirect-gateway def1"
|
||||
push "dhcp-option DNS 10.8.0.1"
|
||||
|
||||
最后这两行指示客户端用OpenVPN作为默认的网关,并用10.8.0.1作为DNS服务器。注意10.8.0.1是OpenVPN启动时自动创建的隧道接口的IP。如果客户用别的域名解析服务,那么我们就得提防不安全的DNS服务器。为了避免这种泄露,我们建议所有OpenVPN客户端使用10.8.0.1作为DNS服务器。
|
||||
最后这两行指示客户端用OpenVPN作为默认的网关,并用10.8.0.1作为DNS服务器。注意10.8.0.1是OpenVPN启动时自动创建的隧道接口的IP。如果客户用别的域名解析服务,那么我们就得提防不安全的DNS服务器。为了避免这种泄露,我们建议所有OpenVPN客户端使用10.8.0.1作为DNS服务器。
|
||||
|
||||
我们以这种方式来开始运行OpenVPN服务器:
|
||||
|
||||
root@delta:/etc/openvpn# service openvpn start
|
||||
|
||||
默认的,OpenVPN服务器监听1194/UDP端口。一种查看的方法是使用netstat工具:
|
||||
默认的,OpenVPN服务器监听1194/UDP端口。一种查看的方法是使用netstat工具:
|
||||
|
||||
root@delta:/etc/openvpn# netstat -anup
|
||||
Active Internet connections (servers and established)
|
||||
@ -297,11 +296,11 @@ ovpn-client文件夹必须安全的拷贝到我们的笔记本电脑上。我们
|
||||
udp6 0 0 :::60622 :::* 555/dhclient
|
||||
udp6 0 0 :::53 :::* 2756/dnsmasq
|
||||
|
||||
看起来一切运行的不错,但是我们还没设置DNS服务器呢。
|
||||
看起来一切运行的不错,但是我们还没设置DNS服务器呢。
|
||||
|
||||
### 第七步 -- 为OpenVPN客户端搭建DNS ###
|
||||
### 第七步 为OpenVPN客户端搭建DNS ###
|
||||
|
||||
这就是为什么我们要安装dnsmasq,打开它的配置文件。
|
||||
这就是为什么我们要安装dnsmasq的原因,打开它的配置文件。
|
||||
|
||||
root@delta:/etc/openvpn# nano /etc/dnsmasq.conf
|
||||
|
||||
@ -321,13 +320,13 @@ ovpn-client文件夹必须安全的拷贝到我们的笔记本电脑上。我们
|
||||
|
||||
bind-interfaces
|
||||
|
||||
为了让dnsmasq应用这些更改,我们重启它:
|
||||
为了让dnsmasq应用这些更改,我们重启它:
|
||||
|
||||
root@delta:/etc/openvpn# service dnsmasq restart
|
||||
* Restarting DNS forwarder and DHCP server dnsmasq [ OK ]
|
||||
root@delta:/etc/openvpn#
|
||||
|
||||
现在,dnamasq在本地回环(lo)和隧道(tun0)接口监听DNS请求。netstat的输出看起来是这个样子的:
|
||||
现在,dnamasq在本地回环(lo)和隧道(tun0)接口监听DNS请求。netstat的输出看起来是这个样子的:
|
||||
|
||||
root@delta:/etc/openvpn# netstat -anup
|
||||
Active Internet connections (servers and established)
|
||||
@ -339,13 +338,13 @@ ovpn-client文件夹必须安全的拷贝到我们的笔记本电脑上。我们
|
||||
udp 0 0 0.0.0.0:68 0.0.0.0:* 638/dhclient
|
||||
udp6 0 0 :::39148 :::* 638/dhclient
|
||||
|
||||
### 第八步 -- 路由功能 ###
|
||||
### 第八步 路由功能 ###
|
||||
|
||||
我们希望在一些"盒子"或虚拟机上运行的OpneVPN有路由的功能,这意味着要开启IP转发.为了打开它,我们用root账户键入:
|
||||
我们希望在一些机器或虚拟机上运行的OpneVPN有路由的功能,这意味着要开启IP转发。为了打开它,我们用root账户键入:
|
||||
|
||||
root@delta:/etc/openvpn# echo "1" > /proc/sys/net/ipv4/ip_forward
|
||||
|
||||
为了让这个设置重启也好用,我们编辑 /etc/sysctl.conf:
|
||||
为了让这个设置重启也好用,我们编辑 /etc/sysctl.conf:
|
||||
|
||||
root@delta:/etc/openvpn# nano /etc/sysctl.conf
|
||||
|
||||
@ -365,7 +364,7 @@ ovpn-client文件夹必须安全的拷贝到我们的笔记本电脑上。我们
|
||||
root@delta:/etc/openvpn# iptables -t nat -A POSTROUTING -s 10.8.0.0/24 -o eth0 -j MASQUERADE
|
||||
root@delta:/etc/openvpn#
|
||||
|
||||
当然了,我们希望每次Ubuntu启动的时候,这些规则都好用。所以我们得把它们加到/etc/rc.local里:
|
||||
当然了,我们希望每次Ubuntu启动的时候,这些规则都好用。所以我们得把它们加到/etc/rc.local里:
|
||||
|
||||
#!/bin/sh -e
|
||||
#
|
||||
@ -393,11 +392,11 @@ ovpn-client文件夹必须安全的拷贝到我们的笔记本电脑上。我们
|
||||
|
||||
service dnsmasq restart
|
||||
|
||||
> 这非常重要:在系统启动时,dnsmasq会尝试在OpenVPN之前启动。但是OpenVPN启动之前是没有隧道(tun0)接口的,所以dnsmasq自然就挂了。过了一阵,当/etc/rc.local读到隧道(tun0)接口出现时,它会在这时重启dnsmasq然后就一切如你所愿了。
|
||||
> 这非常重要:在系统启动时,dnsmasq会尝试在OpenVPN之前启动。但是OpenVPN启动之前是没有隧道(tun0)接口的,所以dnsmasq自然就挂了。过了一阵,当/etc/rc.local读到隧道(tun0)接口出现时,它会在这时重启dnsmasq然后就一切如你所愿了。
|
||||
|
||||
### 第九步 -- 客户端设置 ###
|
||||
### 第九步 客户端设置 ###
|
||||
|
||||
在第五步,我们在用户的home目录里我们建立了ovpn-client文件夹(在我们的例子里是/home/sub0)。在哪里有CA的证书和客户端证书和私钥。现在只缺客户端配置文件了,在/usr/share/doc/openvpn/examples/sample-config-files有一个示例配置文件:
|
||||
在第五步,我们在用户的home目录里我们建立了ovpn-client文件夹(在我们的例子里是/home/sub0)。在哪里有CA的证书和客户端证书和私钥。现在只缺客户端配置文件了,在/usr/share/doc/openvpn/examples/sample-config-files有一个示例配置文件:
|
||||
|
||||
root@delta:/etc/openvpn# exit
|
||||
exit
|
||||
@ -405,19 +404,19 @@ service dnsmasq restart
|
||||
sub0@delta:~/ovpn-client$ cp /usr/share/doc/openvpn/examples/sample-config-files/client.conf .
|
||||
sub0@delta:~/ovpn-client$
|
||||
|
||||
我们编需要辑client.conf,定位到这一行:
|
||||
我们需要编辑client.conf,定位到这一行:
|
||||
|
||||
remote my-server-1 1194
|
||||
|
||||
"my-server-1"是一个占位符,现在我们要把它换成我们自己服务器的公网域名或IP。如果我们已经给服务器分配域名了,那只要把它填到my-server-1的位置。如果没有域名,那么得获取公网IP。如何获取呢?一种方式是键入下列命令:
|
||||
"my-server-1"是一个占位符,现在我们要把它换成我们自己服务器的公网域名或IP。如果我们已经给服务器分配域名了,那只要把它填到my-server-1的位置。如果没有域名,那么得获取公网IP。如何获取呢?一种方式是键入下列命令:
|
||||
|
||||
sub0@delta:~/ovpn-client$ curl ipecho.net/plain ; echo
|
||||
|
||||
(如果不是一个数字的IP地址, 或是发生错误,那就等会再试。)所以我们现在知道我们的服务器公网IP了,但是它是动态的还是静态的呢?当我们把服务器架设在家或者办公室的时候,极有可能就是动态IP。如果是动态IP的话,可以用免费的动态域名服务(DDNS),比如[No-IP](http://www.noip.com)的服务。如果使用No-IP,假设我们选择了免费的域名dnsalias.net,那么这一行应该像这样填写:
|
||||
(如果不是一个数字的IP地址, 或是发生错误,那就等会再试。)所以我们现在知道我们的服务器公网IP了,但是它是动态的还是静态的呢?当我们把服务器架设在家或者办公室的时候,极有可能就是动态IP。如果是动态IP的话,可以用免费的动态域名服务(DDNS),比如[No-IP](http://www.noip.com)的服务。如果使用No-IP,假设我们选择了免费的域名dnsalias.net,那么这一行应该像这样填写:
|
||||
|
||||
remote ovpn.dnsalias.net 1194
|
||||
|
||||
"ovpn"是我们给服务器起的主机名。如果我们的服务器在云上,那么它可能有一个静态IP。如果有静态IP的话,那么这一行应该是这样的:
|
||||
"ovpn"是我们给服务器起的主机名。如果我们的服务器在云上,那么它可能有一个静态IP。如果有静态IP的话,那么这一行应该是这样的:
|
||||
|
||||
remote 1.2.3.4 1194
|
||||
|
||||
@ -426,56 +425,56 @@ service dnsmasq restart
|
||||
cert client.crt
|
||||
key client.key
|
||||
|
||||
在我们的例子里,客户端的证书和密钥的名字分别是laptop.crt和laptop.key所以我们的client.conf要包含下面这两行:
|
||||
在我们的例子里,客户端的证书和密钥的名字分别是laptop.crt和laptop.key所以我们的client.conf要包含下面这两行:
|
||||
|
||||
cert laptop.crt
|
||||
key laptop.key
|
||||
|
||||
在确认保存client.conf的修改之后,我们需要安全的把整个ovpn-client文件夹传输到客户端。一种方式是使用scp命令(安全拷贝或在SSH上拷贝)。另一种方式由优秀而免费的软件FileZilla提供,使用在SSH上运行的FTP(SFTP)。
|
||||
在确认保存client.conf的修改之后,我们需要安全的把整个ovpn-client文件夹传输到客户端。一种方式是使用scp命令(安全拷贝或在SSH上拷贝)。另一种方式由优秀而免费的软件FileZilla提供,使用在SSH上运行的FTP(SFTP)。
|
||||
|
||||
### 第十步 -- 连接并测试 ###
|
||||
### 第十步 连接并测试 ###
|
||||
|
||||

|
||||
|
||||
|
||||
所以我们到底怎么样才能链接到远程的OpenVPN服务器的呢?它完全取决于我们手中现有的设备类型,当然也取决于所运行的操作系统。我们将在四种不同类别的操作系统上运行,Linux, Windows, OS X和iOS/Android。注意,无论在什么设备和系统上,我们都得在OpenVPN服务器的本地网络外才能连接成功。此外,如果在服务器前有防火墙,我们需要增加一条这样的规则:
|
||||
所以我们到底怎么样才能链接到远程的OpenVPN服务器的呢?它完全取决于我们手中现有的设备类型,当然也取决于所运行的操作系统。我们将在四种不同类别的操作系统上运行,Linux, Windows, OS X和iOS/Android。注意,无论在什么设备和系统上,我们都得在OpenVPN服务器的本地网络外才能连接成功。此外,如果在服务器前有防火墙,我们需要增加一条这样的规则:
|
||||
|
||||
*把所有从1194/UDP端口收到的包转发到服务器公网接口的1194/UDP端口。*
|
||||
|
||||
这是一个简单的防火墙规则。事不宜迟,让我们与我们难以置信的OpenVPN服务器建立第一个连接吧。
|
||||
这是一个简单的防火墙规则。事不宜迟,让我们与我们难以置信的OpenVPN服务器建立第一个连接吧。
|
||||
|
||||
**Linux**: 我们只需安装openvpn包。一种连接远程OpenVPN服务器的方式是新建一个终端,切换到ovpn-client文件夹并以root身份或使用sudo来键入下列命令:
|
||||
**Linux**: 我们只需安装openvpn包。一种连接远程OpenVPN服务器的方式是新建一个终端,切换到ovpn-client文件夹并以root身份或使用sudo来键入下列命令:
|
||||
|
||||
/usr/sbin/openvpn --config client.conf
|
||||
|
||||
任何时候,如果我们需要终止OpenVPN,按[CTRL+C]就行了。
|
||||
任何时候如果我们需要终止OpenVPN,按[CTRL+C]就行了。
|
||||
|
||||
**Windows**: 有一个免费的OpenVPN客户端软件叫做[OpenVPN Desktop Client][3]。 配置文件client.conf需要重命名成client.ovpn,这就是我们需要提供给OpenVPN Desktop Client的文件。程序会读取client.ovpn并给OpenVPN服务器生成一个新的连接配置。
|
||||
**Windows**: 有一个免费的OpenVPN客户端软件叫做[OpenVPN Desktop Client][3]。 配置文件client.conf需要重命名成client.ovpn,这就是我们需要提供给OpenVPN Desktop Client的文件。程序会读取client.ovpn并给OpenVPN服务器生成一个新的连接配置。
|
||||
|
||||

|
||||
|
||||
**OS X**: [tunnelblick][4]是一款可以连接OpenVPN的免费开源OS X软件。[Viscosity][5]也可以但它是商业软件,不过我们喜欢。Viscosity会读取client.conf并给OpenVPN服务器生成一个新的连接配置。
|
||||
**OS X**: [tunnelblick][4]是一款可以连接OpenVPN的免费开源OS X软件。[Viscosity][5]也可以但它是商业软件,不过我们喜欢。Viscosity会读取client.conf并给OpenVPN服务器生成一个新的连接配置。
|
||||
|
||||
**iOS/Android**: OpenVPN connect是绝佳的选择。它是免费的且可以从[App Store][6]和[Google Play store][7]获得
|
||||
|
||||
不管是什么平台,有时我们想检验我们是否真的使用OpenVPN连接了。一种检验方法是完成下面这简单的4步:
|
||||
不管是什么平台,有时我们想检验我们是否真的使用OpenVPN连接了。一种检验方法是完成下面这简单的4步:
|
||||
|
||||
在连接到OpenVPN服务器前我们需要…
|
||||
|
||||
- 打开[whatip.com][8]记录我们的公网IP
|
||||
- 打开[dnsleaktest.com][10],运行标准测试(standard test),记录我们的域名解析服务器
|
||||
- 打开[dnsleaktest.com][10],运行标准测试(standard test),记录我们的域名解析服务器
|
||||
|
||||

|
||||
|
||||
在连接到OpenVPN服务器后重复这两部。如果我们获取到两个不同的公网IP,这意味着我们的网络出口已在远端OpenVPN服务器那。此外,如果获取了两个不同的域名解析服务器,那么就不存在DNS泄露的问题了。
|
||||
在连接到OpenVPN服务器后重复这两部。如果我们获取到两个不同的公网IP,这意味着我们的网络出口已在远端OpenVPN服务器那。此外,如果获取了两个不同的域名解析服务器,那么就不存在DNS泄露的问题了。
|
||||
|
||||
### 感言 ###
|
||||
|
||||
我用三个不同的OpenVPN服务器,都是定制的。 一个运行在希腊Thessaloniki的家庭办公室的pfSense路由。当我不在办公室时,我用这个服务器安全的连接到局域网。剩下的两个服务器在两个不同的VPS上,一个在冰岛雷克雅未克,另一个在美国纽泽西州。当我在外且需要任意用一个WiFi热点的时候,我不必考虑安全问题:我只需简单的连接到雷克雅未克的服务器然后正常上网。有时我想看看限制用户地理位置在美国的服务。在这种不太常见的情况下,新泽西的服务器就派上用场了,当我连接时,我就获得了美国的一个公网IP,这样就可以访问有地理位置限制的服务了。值得注意的是,一些服务会把一些知名的VPN公司的IP列入黑名单。这是在你选的VPS提供商建立自己的OpenVPN*十分重要*的一个优点:这不大可能被列入黑名单.
|
||||
我用了三个不同的OpenVPN服务器,都是定制的。 一个运行在希腊Thessaloniki的家庭办公室的pfSense路由。当我不在办公室时,我用这个服务器安全的连接到局域网。剩下的两个服务器在两个不同的VPS上,一个在冰岛雷克雅未克,另一个在美国纽泽西州。当我在外面且需要任意用一个WiFi热点的时候,我不必考虑安全问题:我只需简单的连接到雷克雅未克的服务器然后正常上网。有时我想看看那些限制用户地理位置在美国的服务。在这种不太常见的情况下,新泽西的服务器就派上用场了,当我连接时,我就获得了美国的一个公网IP,这样就可以访问有地理位置限制的服务了。值得注意的是,一些服务会把一些知名的VPN公司的IP列入黑名单。这是在你选的VPS提供商建立自己的OpenVPN*十分重要*的一个优点:这不大可能被列入黑名单。
|
||||
|
||||
无论你的物理位置在哪, OpenVPN确保客户端和服务器之间的数据流是高度加密的。没有OpenVPN的数据则是另一种情况。 取决于不同的应用层协议,它可能仍然是加密的,但它也可能是未加密的。所以除非你对OpenVPN服务器和它的本地网络有绝对的控制权,你不能完全相信另一端的管理员。这种精神是显而易见的:如果你真的在乎你自己的隐私,那么你需要注意你的行为可能在破坏它。
|
||||
无论你的物理位置在哪, OpenVPN确保客户端和服务器之间的数据流是高度加密的。没有OpenVPN的数据则是另一种情况。 取决于不同的应用层协议,它可能仍然是加密的,但它也可能是未加密的。所以除非你对OpenVPN服务器和它的本地网络有绝对的控制权,你不能完全相信另一端的管理员。这种精神是显而易见的:如果你真的在乎你自己的隐私,那么你需要注意你的行为可能在破坏它。
|
||||
|
||||
一个例子是我们有希望点对点传输。我们有一个在云上配置好的OpenVPN服务器。当需要任意用一个WiFi热点的时候,你没有丝毫的担心,因为你连在OpenVPN服务器上。然后你打开你最喜欢的电子邮件客户端从一个依然使用SMTP的老服务器收信。你猜会发生什么?你的用户名和密码以未加密的纯文本格式离开OpenVPN服务器。与此同时一个在你OpenVPN服务器附近的带宽管理员很容易就嗅探出你的证书并记录到他们越来越长的名叫"random happy people.txt"的列表。
|
||||
一个例子是我们希望点对点传输。我们有一个在云上配置好的OpenVPN服务器。当需要任意用一个WiFi热点的时候,你没有丝毫的担心,因为你连在OpenVPN服务器上。然后你打开你最喜欢的电子邮件客户端从一个依然使用SMTP的老服务器收信。你猜会发生什么?你的用户名和密码以未加密的纯文本格式离开OpenVPN服务器。与此同时一个在你OpenVPN服务器附近的鬼鬼祟祟的管理员很容易就嗅探出你的证书并记录到他们越来越长的名叫"random happy people.txt"的列表。
|
||||
|
||||
所以你该做什么?很简单。你应该继续使用OpenVPN服务器,但不要使用应用了旧的或不安全的协议的应用程序。
|
||||
|
||||
@ -485,7 +484,7 @@ service dnsmasq restart
|
||||
|
||||
via: http://parabing.com/2014/06/openvpn-on-ubuntu/
|
||||
|
||||
译者:[2q1w2007](https://github.com/2q1w2007) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[2q1w2007](https://github.com/2q1w2007) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,45 +1,27 @@
|
||||
2q1w2007翻译中
|
||||
Wine 1.7.21 (开发者版本) 发布 – 在基于RedHat或Debian的系统上安装
|
||||
在基于RedHat或Debian的系统上安装 Wine 1.7
|
||||
================================================================================
|
||||
Wine,Linux上最流行也是最有力的软件, 用来不出问题的在Linux平台上运行Windows程序和游戏。
|
||||
Wine,Linux上最流行也是最有力的软件, 可以顺利地在Linux平台上运行Windows程序和游戏。
|
||||
|
||||

|
||||

|
||||
|
||||
在Linux上安装Wine(开发者版本)
|
||||
这篇文章教你怎么在像CentOS, Fedora, Ubuntu, Linux Mint一样基于**Red Hat**和**Debian**的系统上安装最新的**Wine 1.7**。
|
||||
|
||||
**WineHQ** 团队, 最近发布了一个新的开发者版本**Wine 1.7.21**,带来了许多新特性和几个修正。
|
||||
### 在Linux安装 Wine 1.7 ###
|
||||
|
||||
Wine的团队, 坚持每周更新开发者版本并带来了许多新特性和修正。 每个新版本都带来对新程序和游戏的支持,这让Wine成为最流行的也是想在Linux平台运行基于Windows的软件的用户的必备工具.
|
||||
|
||||
根据changelog, 该版本有如下关键的新特性:
|
||||
|
||||
- C runtime中添加临界区的支持.
|
||||
- Unicode 升级到 Unicode 7.
|
||||
- 新增交错 PNG 编码支持.
|
||||
- Packager 库初始化 stub
|
||||
- 修改了几个bug.
|
||||
|
||||
更多深度的改变信息在 [changelog][1] .
|
||||
|
||||
这篇文章教你怎么在像CentOS, Fedora, Ubuntu, Linux Mint一样基于**Red Hat**和**Debian**的系统上安装最新的**Wine 1.7.21**。
|
||||
|
||||
### 在Linux安装 Wine 1.7.21 开发者版本 ###
|
||||
|
||||
不幸的, 在基于**Red Hat**的系统上没有官方的 Wine 仓库,所以唯一的安装方式是从源码编译。你需要安装一些依赖的包比如gcc, flex, bison, libX11-devel freetype-devel 和 Development Tools,这些包用来从源码编译Wine。我们可以用**YUM**命令安装他们。
|
||||
不幸的, 在基于**Red Hat**的系统上没有官方的 Wine 仓库,所以唯一的安装方式是从源码编译。你需要安装一些依赖的包比如gcc, flex, bison, libX11-devel freetype-devel 和 Development Tools,这些包用来从源码编译Wine。我们可以用**yum**命令安装他们。
|
||||
|
||||
#### 在 RedHat, Fedora 和 CentOS 上 ####
|
||||
|
||||
# yum -y groupinstall 'Development Tools'
|
||||
# yum -y install flex bison libX11-devel freetype-devel
|
||||
|
||||
接下来,下载最新的开发者版本(即**1.7.21**)并用下面的命令提取出来。
|
||||
接下来,下载最新的开发版本(如**1.7.21**)并用下面的命令解压。
|
||||
|
||||
$ cd /tmp
|
||||
$ wget http://citylan.dl.sourceforge.net/project/wine/Source/wine-1.7.21.tar.bz2
|
||||
$ tar -xvf wine-1.7.21.tar.bz2 -C /tmp/
|
||||
|
||||
现在,是时候以普通用户身份编译并搭建Wine的安装程序了。(**注意**: 根据机器性能和网络速度的不同,安装过程需要 **15-20** 分钟,安装过程中会要求输入 **root** 密码。)
|
||||
|
||||
现在,要以普通用户身份编译并搭建Wine的安装程序。(**注意**: 根据机器性能和网络速度的不同,安装过程需要 **15-20** 分钟,安装过程中会要求输入 **root** 密码。)
|
||||
|
||||
**32位系统上**
|
||||
|
||||
@ -61,15 +43,13 @@ Wine的团队, 坚持每周更新开发者版本并带来了许多新特性和
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install wine 1.7 winetricks
|
||||
|
||||
**注意**: 写这篇文章的时候版本是 **1.7.20** 新版本还没上传到仓库,但当新版本可用时上面的命令将安装 **1.7.21** 。
|
||||
|
||||
一旦装完了,你可以以如下方式运行基于Windows的软件和游戏。
|
||||
|
||||
$ wine notepad
|
||||
$ wine notepad.exe
|
||||
$ wine c:\\windows\\notepad.exe
|
||||
|
||||
**注意**: 请记住,这是个开发者版本,不要用在生产环境。 建议此版本只用在测试用途
|
||||
**注意**: 请记住,如果是开发版本不要用在生产环境。 建议只用在测试用途
|
||||
|
||||
如果你想安装最近的稳定版Wine, 请看下面的文章, 在文章里介绍了在几乎所以Linux系统中安装Wine的方法
|
||||
|
||||
@ -80,21 +60,11 @@ Wine的团队, 坚持每周更新开发者版本并带来了许多新特性和
|
||||
|
||||
- [WineHQ Homepage][4]
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
#### Ravi Saive ####
|
||||
|
||||
Owner at [TecMint.com][5]
|
||||
|
||||
Simple Word a Computer Geek and Linux Guru who loves to share tricks and tips on Internet. Most Of My Servers runs on Open Source Platform called Linux.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-wine-in-linux/
|
||||
|
||||
译者:[2q1w2007](https://github.com/2q1w2007) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[2q1w2007](https://github.com/2q1w2007) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,37 +1,111 @@
|
||||
如何为Linux系统中的SSH添加双重认证
|
||||
================================================================================
|
||||
近来很多知名企业都出现了密码泄露,业内对多重认证的呼声也越来越高。在这种多重认证的系统中,用户需要通过两种不同的认证程序:提供他们知道的信息(如 用户名/密码),再借助其他工具提供用户所不知道的信息(如 用手机生成的一次性密码)。这种组合方式常叫做双因子认证或者两阶段验证。
|
||||
|
||||
为了鼓励广泛采用双因子认证的方式,Google公司发布了[Google Authenticator][1],一款开源的,可基于开放规则(如 HMAP/基于时间)生成一次性密码的软件。这是一款跨平台软件,可运行在Linux, [Android][2], [iOS][3]。Google公司同时也支持插件式鉴别模块PAM(pluggable authentication module),使其能和其他也适用PAM进行验证的工具(如OpenSSH)协同工作。
|
||||
在本教程中,我们将叙述集成OpenSSH和Google提供的认证器实现**如何为SSH服务设置双因子认证**。我将使用一款[Android][4]设备来生成一次性密码,本教程中需要两样兵器:(1)一台运行着OpenSSH服务的Linux终端,(2)一台安卓设备。
|
||||
|
||||
在本教程中,我们将叙述集成OpenSSH和Google提供的认证器实现**如何为SSH服务设置双因子认证**。我将使用一款[Android][4]设备来生成一次性密码,本教程中需要两样武器:(1)一台运行着OpenSSH服务的Linux终端,(2)一台安卓设备。
|
||||
|
||||
### 在Linux系统中安装Google Authenticator ###
|
||||
|
||||
第一步需要在运行着OpenSSH服务的Linux主机上安装Google认证器。按照[安装指南] [5]的步骤安装Google认证器及其PAM模块。
|
||||
第一步需要在运行着OpenSSH服务的Linux主机上安装Google认证器。按照如下步骤安装Google认证器及其PAM模块。
|
||||
|
||||
#### 用安装包安装 Google Authenticator ####
|
||||
|
||||
如果你不想自己构建 Google Authenticator,在几个 Linux 发行版上有已经编译好的安装包。安装包里面包含 Google Authenticator 二进制程序和 PAM 模块。
|
||||
|
||||
在 Ubuntu 上安装 Google Authenticator:
|
||||
|
||||
$ sudo apt-get install libpam-google-authenticator
|
||||
|
||||
在 Fedora 上安装 Google Authenticator:
|
||||
|
||||
$ sudo yum install google-authenticator
|
||||
|
||||
在 CentOS 上安装 Google Authenticator ,需要首先启用 EPEL 软件库,然后运行如下命令:
|
||||
|
||||
$ sudo yum install google-authenticator
|
||||
|
||||
如果不想使用已经编译好的安装包,或者你的 Linux 发行版不在此列,可以自行编译:
|
||||
|
||||
#### 在 Linux 上 Google Authenticator ####
|
||||
|
||||
首先,安装构建 Google Authenticator 所需的软件包。
|
||||
|
||||
在 Debian、 Ubuntu 或 Linux Mint 上:
|
||||
|
||||
$ sudo apt-get install wget make gcc libpam0g-dev
|
||||
|
||||
在 CentOS、 Fedora 或 RHEL上:
|
||||
|
||||
$ sudo yum install wget make gcc pam-devel
|
||||
|
||||
然后下载 Google Authenticator 的源代码,并按如下命令编译。
|
||||
|
||||
$ wget https://google-authenticator.googlecode.com/files/libpam-google-authenticator-1.0-source.tar.bz2
|
||||
$ tar xvfvj libpam-google-authenticator-1.0-source.tar.bz2
|
||||
$ cd libpam-google-authenticator-1.0
|
||||
$ make
|
||||
|
||||
如果构建成功,你会在目录中看到 pam_google_authenticator.so 和 google-authenticator 两个文件。
|
||||
|
||||
最后,将 Google Authenticator 安装到合适位置
|
||||
|
||||
$ sudo make install
|
||||
|
||||
|
||||
#### 排错 ####
|
||||
|
||||
当编译 Google Authenticator 时出现如下错误:
|
||||
|
||||
fatal error: security/pam_appl.h: No such file or directory
|
||||
|
||||
要修复这个问题,请安装如下依赖包。
|
||||
|
||||
在 Debian、 Ubuntu 或 Linux Mint 上:
|
||||
|
||||
$ sudo apt-get install libpam0g-dev
|
||||
|
||||
在 CentOS、 Fedora 或 RHEL 上:
|
||||
|
||||
$ sudo yum install pam-devel
|
||||
|
||||
|
||||
当Google认证器安装好后,你需要在Linux主机上创建验证密钥,并且在安卓设备上注册,注意这项配置操作是一次性的。我们将详细叙述如何完成这些操作:
|
||||
|
||||
### 生成验证密钥 ###
|
||||
|
||||
在Linux主机上运行Google认证器
|
||||
|
||||
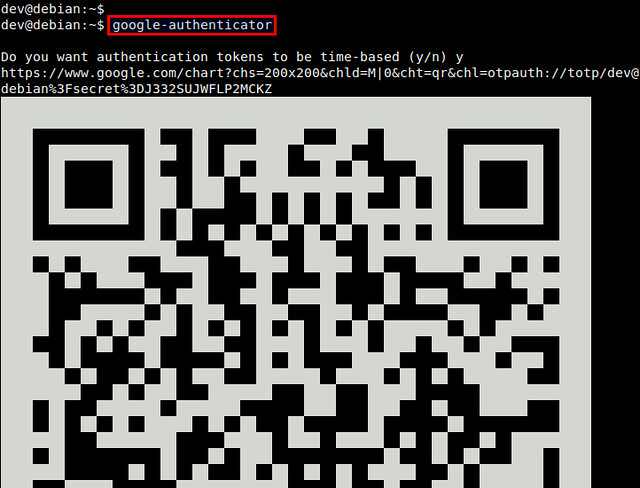
$ google-authenticator
|
||||
|
||||
你将看到一个QR码,它使用图形保存了我们数字形态的密钥。一会我们要用到它在安卓设备上完成配置。
|
||||
你将看到一个QR码,它使用如下图形表示我们数字形态的密钥。一会我们要用到它在安卓设备上完成配置。
|
||||
|
||||
|
||||
|
||||
|
||||
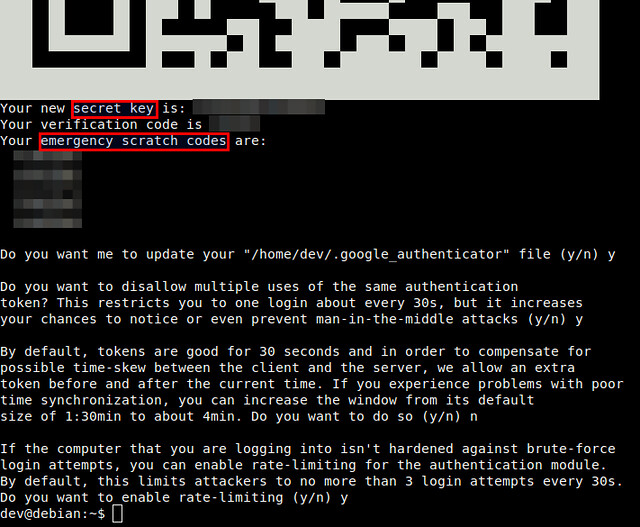
Google认证器会问一些问题,如果你不确定,就回答"Yes"。这个应急备用验证码(图中 emergency scratch codes)可以在你丢失被绑定的安卓设备的情况下恢复访问,并且设备也不再生成一次性密码。所以最好将应急备用验证码妥善保存。
|
||||
Google认证器会问一些问题,如果你不确定,就回答"Yes"。这个应急备用验证码(图中 emergency scratch codes)可以在你由于丢失了绑定的安卓设备的情况下(所以不能得到生成的一次性密码)恢复访问。最好将应急备用验证码妥善保存。
|
||||
|
||||
### 在安卓设备上运行Google认证器 ###
|
||||
|
||||
我们需要在安卓设备上安装[Google Authenticator app][6]才能完成双因子认证,到Google Play下载并安装一个。在安卓设备上运行Google认证器,找到下图所示中的配置菜单。
|
||||
|
||||
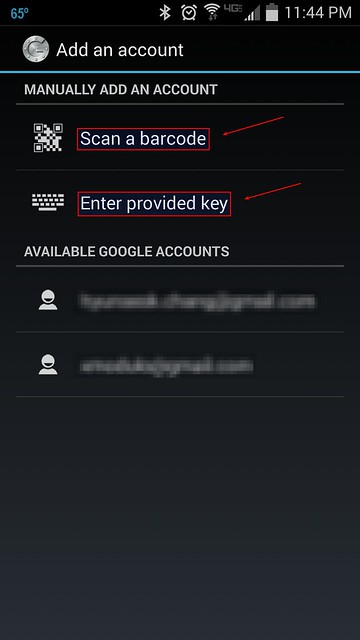
|
||||
|
||||
你可以选择"Scan a barcode" 或者"Enter provided key"选项。"Scan a barcode"允许你扫描QR码来完成密钥的输入,在此可能需要先安装扫描软件[Barcode Scanner app][7]。如果选择"Enter provided key"选项,你可以使用键盘输入验证密钥,如下图所示:
|
||||
|
||||
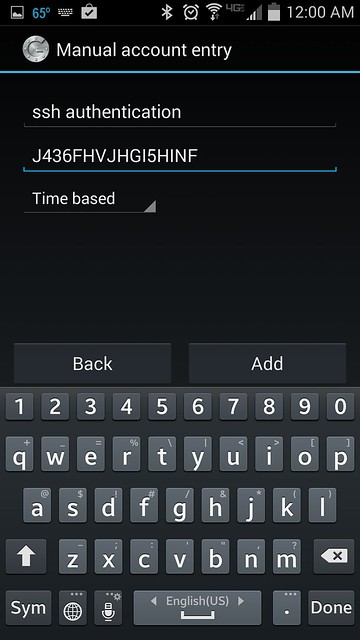
|
||||
|
||||
无论采用上述两种选项的任何方式,一旦成功,你将看到注册成功提示和一次性密码,如下图所示:
|
||||
|
||||
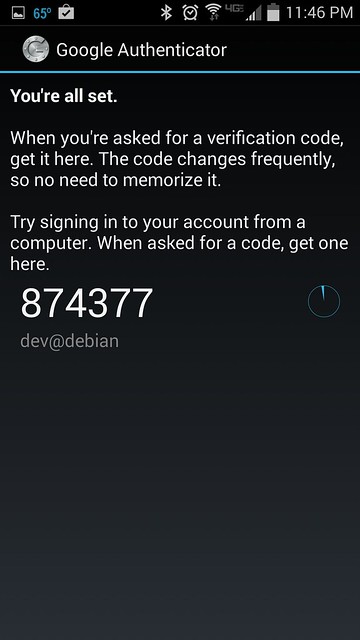
|
||||
|
||||
### 为SSH服务器用Google认证器 ###
|
||||
|
||||
最终我们需要修改两个文件来完成集成Google认证器和OpenSSH服务这临门一脚。
|
||||
|
||||
首先,修改PAM配置文件,命令和需添加的内容如下:
|
||||
|
||||
$ sudo vi /etc/pam.d/sshd
|
||||
|
||||
----------
|
||||
@ -39,6 +113,7 @@ Google认证器会问一些问题,如果你不确定,就回答"Yes"。这个
|
||||
auth required pam_google_authenticator.so
|
||||
|
||||
然后打开SSH配置文件,找到参数ChallengeResponseAuthentication,并启用它。
|
||||
|
||||
$ sudo vi /etc/ssh/sshd_config
|
||||
|
||||
----------
|
||||
@ -47,35 +122,40 @@ ChallengeResponseAuthentication yes
|
||||
|
||||
|
||||
最后,重启SSH服务。
|
||||
在 Ubuntu, Debian, Linux Mint:
|
||||
|
||||
在 Ubuntu、 Debian 和 Linux Mint 上:
|
||||
|
||||
$ sudo service ssh restart
|
||||
|
||||
在Fedora:
|
||||
在Fedora (或 CentOS/RHEL 7)上:
|
||||
|
||||
$ sudo systemctl restart sshd
|
||||
|
||||
在CentOS 或 RHEL:
|
||||
在CentOS 6.x或 RHEL 6.x上:
|
||||
|
||||
$ sudo service sshd restart
|
||||
|
||||
### 验证双因子认证 ###
|
||||
|
||||
在绑定的安卓设备上运行Google认证器,获得一个一次性验证码,该验证码30秒内有效,一旦过期,将重新生成一个新的验证码。
|
||||
|
||||
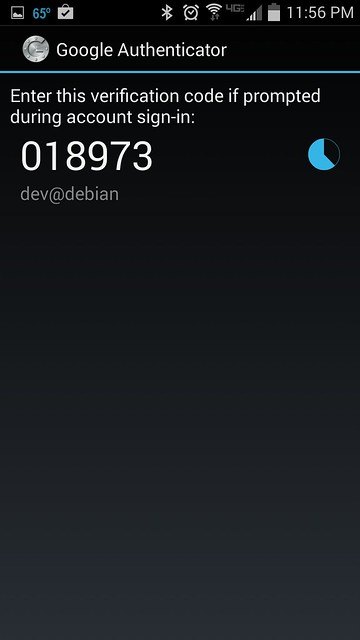
|
||||
|
||||
现在和往常一样,使用SSH登录终端
|
||||
|
||||
$ ssh user@ssh_server
|
||||
|
||||
当提示你输入验证码的时候,输入我们刚获得的验证码。验证成功后,再输入SSH的登录密码。
|
||||
|
||||
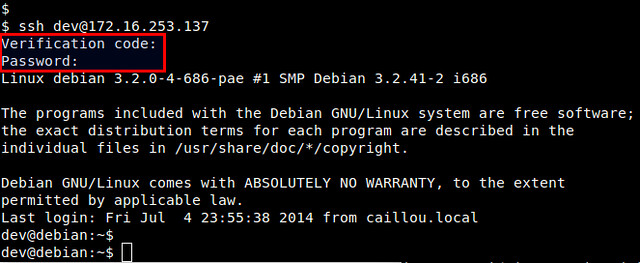
|
||||
|
||||
双因子认证通过在用户密码前新增一层来有效的保护我们脆弱的用户密码。你可以使用Google认证器来保护我们其他的密码,如Google账户, WordPress.com, Dropbox.com, Outlook.com等等。是否使用这项技术,取决于我们自己,但采用双因子认证已经是行业的大趋势了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/07/two-factor-authentication-ssh-login-linux.html
|
||||
|
||||
译者:[nd0104](https://github.com/nd0104) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[nd0104](https://github.com/nd0104) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,16 +1,17 @@
|
||||
怎样在ubuntu 14.04上安装轻量级的Budgie桌面
|
||||
================================================================================
|
||||
**如果你在推特上关注了我们,你可能看见了我们最近分享的一张截图,和这张截图一起的还有对它所展示的桌面进行命名的邀请。 **
|
||||
|
||||
你猜对了吗? 答案就是budgie —— 一种为基于openSUSE 的linux发行版Evolve OS所设计,但不仅仅只能用于 Evolve OS的简易桌面环境。
|
||||
**如果你在推特上关注了我们,你可能看见了我们最近分享的一张截图,和这张截图一起的还有对它所展示的桌面进行命名的邀请。**
|
||||
|
||||
你猜对了吗? 答案就是[Budgie][1] —— 一种为基于openSUSE 的linux发行版Evolve OS所设计、但不仅仅只能用于 Evolve OS的简易桌面环境。
|
||||
|
||||
|
||||
|
||||
我们第一次描写Budgie是在三月份,当时我们被它的整洁,小巧的美感,灵活的架构,还有重复使用在当今大多数发行版中所使用的GNOME 3.10 成熟技术中的公共部分和标堆栈的决定所折服。
|
||||
我们第一次提到Budgie是在三月份,当时我们被它的整洁、小巧的美感、灵活的架构,还有再次使用在当今大多数发行版中所使用的GNOME 3.10 成熟技术中的公共部分和标堆栈的决定所折服。
|
||||
|
||||
我对此项目的领导者LKey Doherty所作出的开发选择非常佩服。无可否认另起炉灶有它的优点,但决定从上游的项目获取帮助将可以整个项目进展得更快,无论是在发展方面(更轻的技术负担)还是在用户可使用方面(更容易在其它发行版上运行)。
|
||||
我对此项目的领导者Ikey Doherty所作出的开发选择非常佩服。无可否认另起炉灶有它的优点,但决定从上游的项目获取帮助将可以整个项目进展得更快,无论是在发展方面(更轻的技术负担)还是在用户可使用方面(更容易在其它发行版上运行)。
|
||||
|
||||
政治因素选择除外,这款桌面以干净,小巧向谷歌Chrome OS的Ash桌面表示敬意。如果你不介意有些许粗糙的边缘,那它值得你玩玩。那么怎样在Ubuntu安装Budgie呢?
|
||||
除了政治因素选择以外,这款桌面干净、小巧,向谷歌Chrome OS的Ash桌面致敬。如果你不介意有些许粗糙的边缘,那它值得你玩玩。那么怎样在Ubuntu安装Budgie呢?
|
||||
|
||||
###非官方的PPA是不正式的 ###
|
||||
|
||||
@ -18,37 +19,38 @@
|
||||
|
||||
但如果你很懒,想不费周折就在Ubuntu 14.04 LTS(或者一个基于它的发行版)运行Budgie,那么你可以通过比较容易的途径来实现。
|
||||
|
||||
添加一个非官方的Unofficial PPA,刷新你的软件源然后进行安装。几分钟后在这个家庭中你将有一位名叫Bob的新叔叔,并且有一个新的桌面可以玩耍。
|
||||
只要添加一个**非官方的PPA**,刷新你的软件源然后进行安装。几分钟后在这个家庭中你将有一位[名叫Bob][2]的新叔叔,并且有一个新的桌面可以玩耍。
|
||||
|
||||
###添加Budgie PPA ###
|
||||
|
||||
将以下命令复制进一个打开的终端窗口,在提示过后输入你的密码(如果需要的话)
|
||||
将以下命令复制进一个打开的终端窗口,在提示过后输入你的密码(如果需要的话):
|
||||
|
||||
sudo add-apt-repository ppa:sukso96100/budgie-desktop
|
||||
sudo apt-get update && sudo apt-get install budgie-desktop
|
||||
|
||||
### 登入Budgie会话 ###
|
||||
|
||||
安装完成后你就可以在Unity欢迎界面的会话选择器中选择Budgie会话了。(别忘了以后要把选择项改回到稳定的桌面环境)
|
||||
安装完成后你就可以在Unity欢迎界面的会话选择器中选择“Budgie”了。(别忘了以后要把选择项改回到稳定的桌面环境)
|
||||
|
||||
### 注意 ###
|
||||
|
||||
**budgie是不稳定,不完善的,它在Ubuntu上也没有被正式支持。它正在积极开发中,缺少一些特性,包括(但不仅仅只有这些):不支持网络管理,没有音量控制小程序(键盘工作良好),没有通知系统,无法将应用程序“固定”在任务栏。**
|
||||
**budgie是不稳定、不完善的,并且它在Ubuntu上也没有被正式支持。**它正在积极开发中,功能还仍然有些缺失,包括但不仅限于:不支持网络管理,没有音量控制小程序(键盘按键工作良好),没有通知系统,无法将应用程序“固定”在任务栏。
|
||||
|
||||
它对UBUNTU的叠加滚动条和一些GTK主题的支持也不是很好,而且在使用upstart的发行版(例如ubuntu,即使它正在改变之中)中会话管理器(例如,注销,重启等等)将无法工作。
|
||||
它对UBUNTU的叠加滚动条、一些GTK主题的支持也不是很好,而且在使用upstart的发行版(例如ubuntu,[即使它正在改变之中][3])中会话管理器(例如,注销,重启等等)将无法工作。
|
||||
|
||||
一个应变方法是:禁用叠加滚动条,设置一个默认主题,通过在终端中使用以下命名来退出会话。
|
||||
一个应变方法是:禁用叠加滚动条,设置一个默认主题,通过在终端中使用以下命名来退出会话:
|
||||
|
||||
gnome-session-quit
|
||||
|
||||
想着脑海中所有的这些警告,我建议想使用稳定的,可靠的系统的人现在暂时不要使用它。
|
||||
脑海中有了上述这些警告后,我得建议那些自己的理智倾向于使用稳定、可靠的系统的人现在暂时不要使用它。
|
||||
|
||||
**而剩下那些狂热的业余爱好者们呢?好吧,请在下面留言告诉我们你觉得它如何。我给Bob让路。**
|
||||
|
||||
而作为狂热一族的业余体验呢?请在下面评论,让我们了解你的想法。我将退出而让Bob来接手。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/07/install-budgie-evolve-os-desktop-ubuntu-14-04
|
||||
|
||||
译者:[Love-xuan](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[Love-xuan](https://github.com/Love-xuan) 校对:[reinoir](https://github.com/reinoi)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,8 @@
|
||||
在Linux中模拟击键和鼠标移动
|
||||
================================================================================
|
||||
<pre><code>
|
||||
你是否曾经拥有一个梦
|
||||
——你的计算机
|
||||
——你的计算机`
|
||||
可以自动为你干活?
|
||||
或许,并非因为
|
||||
你刚看了终结者。
|
||||
@ -27,9 +28,10 @@
|
||||
xdotool可以通过读取文本文件
|
||||
模拟击键的旋律
|
||||
以及鼠标的曼舞
|
||||
|
||||
</code></pre>
|
||||
|
||||
### 让Xdotool在Linux定居 ###
|
||||
|
||||
对于Ubuntu,Debian或者Linux Mint,你能够只做:
|
||||
|
||||
$ sudo apt-get install xdotool
|
||||
@ -64,7 +66,7 @@
|
||||
|
||||
$ xdotool type ''
|
||||
|
||||
这些对于基本的击键而言已经足够了。但是,xdotool的众多长处之一,就是它可以获取特定窗口的焦点。它可以获取右边的窗口,然后在里面输入,同时阻止所有你记录的按键,让那些动作随风而逝吧。要获得该功能,一个简单的命令可以搞定:
|
||||
这些对于基本的击键而言已经足够了。但是,xdotool的众多长处之一,就是它可以获取特定窗口的焦点。它可以获取右边的窗口,然后在里面输入,所有你记录下的按键都不会人间蒸发,而是老老实实的如你所愿的出现在那里。要获得该功能,一个简单的命令可以搞定:
|
||||
|
||||
$ xdotool search --name [name of the window] key [keys to press]
|
||||
|
||||
@ -80,7 +82,7 @@
|
||||
|
||||
这会让鼠标移动到(x,y),然后点击鼠标左键。“1”代表鼠标左键,“2”则是滚轮,“3”则是右键。
|
||||
|
||||
最后,一旦你这些命令根植于你脑海,你也许想要实际转储于文件来编辑并试着玩玩。鉴于此,就会有超过一个语句以上的内容了。你可以写的就是一个bash脚本了:
|
||||
最后,一旦你这些命令根植于你脑海,你也许想要实际转储于文件来编辑并试着玩玩。鉴于此,就会有超过一个语句以上的内容了。你需要的就是写一个bash脚本了:
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
@ -96,7 +98,7 @@
|
||||
|
||||
### 意外收获 ###
|
||||
|
||||
作为本文的一个意外收获,这里是xdotool的一个具体实例。你可能听说过,也可能没听说过Bing,微软的搜索引擎。在后面的实例中,你从没听过Bing奖励吧:一个程序,可以让你用Bing积分兑取亚马逊的礼物卡和其它的一些礼物卡。要赚取这些积分,你可以每天在Bing上搜索累计达30次,每次搜索你都会获得0.5个积分。换句话说,你必须把Bing设为默认搜索引擎,并每天使用它。
|
||||
作为本文的一个意外收获,这里是xdotool的一个具体实例。你可能听说过,也可能没听说过Bing —— 微软的搜索引擎。在后面的实例中,你会看到你可能从没听过Bing奖励:一个程序,可以让你用Bing积分兑取亚马逊的礼物卡和其它的一些礼物卡。要赚取这些积分,你可以每天在Bing上搜索累计达30次,每次搜索你都会获得0.5个积分。换句话说,你必须把Bing设为默认搜索引擎,并每天使用它。
|
||||
|
||||
或者,你可以使用xdotool脚本,在这个脚本中,会自动聚焦到Firefox(你可以用你喜欢的浏览器来取代它),并使用fortune命令生成一些随机单词来实施搜索。大约30秒之内,你的日常搜索任务就完成了。
|
||||
|
||||
@ -115,7 +117,7 @@
|
||||
done
|
||||
|
||||
|
||||
下面来个小结吧:我真的很喜欢xdotool,即便它完整功能超越了本文涵盖的范围。这对于脚本和任务自动化而言,确实是种平易的方式。负面的问题是,它可能不是最有效率的一个。但我要再说一遍,它忠于职守了,而且学习起来也不是那么麻烦。
|
||||
下面来个小结吧:我真的很喜欢xdotool,即便它的完整功能超越了本文涵盖的范围。这对于脚本和任务自动化而言,确实是种平易的方式。负面的问题是,它可能不是最有效率的一个。但我要再说一遍,它忠于职守了,而且学习起来也不是那么麻烦。
|
||||
|
||||
你对xdotool怎么看呢?你是否更喜欢另外一个自动化工具,而不是它呢?为什么呢?请在评论中告诉我们吧。
|
||||
|
||||
@ -123,7 +125,7 @@
|
||||
|
||||
via: http://xmodulo.com/2014/07/simulate-key-press-mouse-movement-linux.html
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[GOLinux](https://github.com/GOLinux) 校对:[ wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
Linux slabtop命令——显示内核片缓存信息
|
||||
================================================================================
|
||||
|
||||
Linux内核需要为临时对象如任务或者设备结构和节点分配内存,缓存分配器管理着这些对象类型的缓存。现代Linux内核部署了该缓存分配器以持有缓存,称之为片。不同类型的片缓存由片分配器维护。本文集中讨论slabtop命令,该命令显示了实时内核片缓存信息。
|
||||
Linux内核需要为临时对象如任务或者设备结构和节点分配内存,缓存分配器管理着这些类型对象的缓存。现代Linux内核部署了该缓存分配器以持有缓存,称之为片。不同类型的片缓存由片分配器维护。本文集中讨论slabtop命令,该命令显示了实时内核片缓存信息。
|
||||
|
||||
### 1. 命令用法: ###
|
||||
|
||||
@ -12,7 +12,7 @@ Linux内核需要为临时对象如任务或者设备结构和节点分配内存
|
||||
你可以在前面设置“sudo”来运行该命令,默认输出见下图:
|
||||
|
||||

|
||||
|
||||
|
||||
要退出slabtop,只需敲‘q’,就像在top命令中那样。
|
||||
|
||||
### 2. Slabtop选项: ###
|
||||
@ -31,7 +31,7 @@ Linux内核需要为临时对象如任务或者设备结构和节点分配内存
|
||||
|
||||
#### 2.3 输出一次: ####
|
||||
|
||||
-o或--once选项不会刷新输出,它仅仅将一次输出结果丢给STDOUT,然后退出。
|
||||
-o或--once选项不会刷新输出,它仅仅将一次输出结果丢给STDOUT,然后退出。
|
||||
|
||||

|
||||
|
||||
@ -2,17 +2,17 @@ Linux系统中使用 DD 命令测试 USB 和 SSD 硬盘的读写速度
|
||||
================================================================================
|
||||
### 磁盘驱动器速度 ###
|
||||
|
||||
磁盘驱动器的速度是以在一个单位时间内能读写数据量的多少来衡量的。DD 命令是一个简单的命令行工具,它可用对磁盘进行任意数据块的读取和写入,同时可以度量读取写入的速度。
|
||||
磁盘驱动器的速度是以一个单位时间内读写数据量的多少来衡量的。DD 命令是一个简单的命令行工具,它可用对磁盘进行任意数据块的读取和写入,同时可以度量读取写入的速度。
|
||||
|
||||
在这篇文章中,我们将会使用 DD 命令来测试 USB 和 SSD 磁盘的读取和写入速度。
|
||||
|
||||
数据传输速度不但取决于驱动盘本身,而且还与连接的接口有关。比如, USB 2.0 端口的最大传输速度是 35 兆字节/秒,所以如果您把一个支持高速传输的 USB 3.0 驱动盘插入 USB 2.0 端口的话,它实际的传输速度将是 2.0 端口的上下限。
|
||||
数据传输速度不但取决于驱动盘本身,而且还与连接的接口有关。比如, USB 2.0 端口的最大传输速度是 35 兆字节/秒,所以如果您把一个支持高速传输的 USB 3.0 驱动盘插入 USB 2.0 端口的话,它实际的传输速度将是 2.0 端口的下限。
|
||||
|
||||
这对于 SSD 也是一样的。 SSD 连接的 SATA 端口有不同的类型。平均是 375 兆字节/秒的 SATA 2.0 端口理论上最大传输速度是 3 Gbit/秒,而 SATA 3.0 是这个速度的两倍。
|
||||
|
||||
### 测试方法 ###
|
||||
|
||||
挂载上驱动盘,终端上进入此盘目录下。然后使用 DD 命令,首先写入固定大小块的一个文件,接着读取这个文件。
|
||||
挂载上驱动盘,从终端进入此盘目录下。然后使用 DD 命令,首先写入固定大小块的一个文件,接着读取这个文件。
|
||||
|
||||
DD 命令通用语法格式如下:
|
||||
|
||||
@ -22,11 +22,11 @@ DD 命令通用语法格式如下:
|
||||
|
||||
### 固态硬盘 ###
|
||||
|
||||
我们使用的是一块“三星 Evo 120G” 的固态硬盘。它性价比很高,很适合刚开始用固态硬盘的用户,也是我的第一块固态硬盘,并且在市场上表现的也非常不错。
|
||||
我们使用的是一块“三星 Evo 120G” 的固态硬盘。它性价比很高,很适合刚开始用固态硬盘的用户,也是我的第一块固态硬盘,并且也是市场上效果最好的固态硬盘之一。
|
||||
|
||||
这次实验中,我们把硬盘接在 SATA 2.0 端口上。
|
||||
|
||||
#### 写入速度 ####
|
||||
|
||||
#### 写入速度 ####
|
||||
|
||||
首先让我们写入固态硬盘
|
||||
|
||||
@ -35,7 +35,7 @@ DD 命令通用语法格式如下:
|
||||
1024+0 records out
|
||||
1073741824 bytes (1.1 GB) copied, 4.82364 s, 223 MB/s
|
||||
|
||||
的大小实际上是相当大的。你可以尝试用更小的尺寸如 64 K甚至是 4K 的。
|
||||
的大小实际上是相当大的。你可以尝试用更小的尺寸如 64K 甚至是 4K 的。
|
||||
|
||||
#### 读取速度 ####
|
||||
|
||||
@ -52,7 +52,7 @@ DD 命令通用语法格式如下:
|
||||
165118+0 records out
|
||||
676323328 bytes (676 MB) copied, 3.0114 s, 225 MB/s
|
||||
|
||||
在 Arch Linux 的维基页上有一整页的关于从同的厂商,如英特尔、三星、Sandisk 等提供的各类固态硬盘的读/写速度的信息。点击如下的 url 可得到得到想着信息。
|
||||
在 Arch Linux 的维基页上有一整页的关于不同的厂商,如英特尔、三星、Sandisk 等提供的各类固态硬盘 读/写速度的信息。点击如下的 url 可以查看相关信息。
|
||||
|
||||
[https://wiki.archlinux.org/index.php/SSD_Benchmarking][1]
|
||||
|
||||
@ -60,7 +60,7 @@ DD 命令通用语法格式如下:
|
||||
|
||||
此次实验我们会测量普通的 USB/随身笔的读写速度。驱动盘都是接入标准的 USB 2.0 端口的。首先用的是一个 4GB 大小的 sony USB 驱动盘,随后用的是一个 16GB 大小的 strontium 驱动盘。
|
||||
|
||||
首先把驱动盘插入端口,并挂载上,使其可读的。然后从命令行下面进入挂载的文件目录下。
|
||||
首先把驱动盘插入端口,并挂载上,使其可读。然后从命令行下面进入挂载的文件目录下。
|
||||
|
||||
#### Sony 4GB - 写入 ####
|
||||
|
||||
@ -75,11 +75,11 @@ DD 命令通用语法格式如下:
|
||||
|
||||
#### Sony 4GB - 读取 ####
|
||||
|
||||
把相同的文件读取回来,测试速度。首先运行如下命令清除内存缓存
|
||||
把相同的文件读取回来,测试速度。首先运行如下命令清除内存缓存。
|
||||
|
||||
$ sudo sh -c "sync && echo 3 > /proc/sys/vm/drop_caches"
|
||||
|
||||
现在就可以使用 DD 命令来读取文件了
|
||||
现在就可以使用 DD 命令来读取文件了。
|
||||
|
||||
# dd if=./largefile of=/dev/null bs=8k
|
||||
8000+0 records in
|
||||
@ -92,7 +92,7 @@ DD 命令通用语法格式如下:
|
||||
|
||||
上面实验中, USB 驱动盘插入USB 2.0 端口,读取的速度达到了 24.7兆字节/秒,这是很不错的读速度。但写入速度就不敢恭维了。
|
||||
|
||||
下面让我们用 Strontium 的 16GB 的驱动盘来做相同的实验。虽然 Strontium 的 USB 驱动盘很稳定,但它也是一款很便宜的品牌。
|
||||
下面让我们用 16GB 的 Strontium 驱动盘来做相同的实验。虽然 Strontium 的 USB 驱动盘很稳定,但它也是一款很便宜的品牌。
|
||||
|
||||
#### Strontium 16gb 盘写入速度 ####
|
||||
|
||||
@ -136,4 +136,4 @@ via: http://www.binarytides.com/linux-test-drive-speed/
|
||||
[1]:http://wiki.archlinux.org/index.php/SSD_Benchmarking
|
||||
[2]:http://en.wikipedia.org/wiki/USB
|
||||
[e]:m00n.silv3r@gmail.com
|
||||
[g]:http://plus.google.com/117145272367995638274/posts
|
||||
[g]:http://plus.google.com/117145272367995638274/posts
|
||||
@ -1,4 +1,4 @@
|
||||
Linux 内核测试和调试 - 4
|
||||
Linux 内核测试和调试(4)
|
||||
================================================================================
|
||||
### 自动测试工具 ###
|
||||
|
||||
@ -38,11 +38,11 @@ Linux 内核本身包含很多调试功能,比如 kmemcheck 和 kmemleak。
|
||||
|
||||
#### kmemcheck ####
|
||||
|
||||
> kmemcheck 是一个动态检查工具,可以检测出一些未被初始化的内存(LCTT:内核态使用这些内存可能会造成系统崩溃)并发出警告。它的功能与 Valgrind 类似,只是 Valgrind 运行在用户态,而 kmemchecke 运行在内核态。编译内核时加上 CONFIG_KMEMCHECK 选项打开 kmemcheck 调试功能。你可以阅读 Documentation/kmemcheck.txt 来学习如何配置使用这个功能,以及如何看懂调试结果。
|
||||
> kmemcheck 是一个动态检查工具,可以检测出一些未被初始化的内存(LCTT:内核态使用这些内存可能会造成系统崩溃)并发出警告。它的功能与 Valgrind 类似,只是 Valgrind 运行在用户态,而 kmemchecke 运行在内核态。编译内核时加上 `CONFIG_KMEMCHECK` 选项打开 kmemcheck 调试功能。你可以阅读 Documentation/kmemcheck.txt 来学习如何配置使用这个功能,以及如何看懂调试结果。
|
||||
|
||||
#### kmemleak ####
|
||||
|
||||
> kmemleak 通过类似于垃圾收集器的功能来检测内核是否有内存泄漏问题。而 kmemleak 与垃圾收集器的不同之处在于前者不会释放孤儿目标(LCTT:不会再被使用的、应该被释放而没被释放的内存区域),而是将它们打印到 /sys/kernel/debug/kmemleak 文件中。用户态的 Valgrind 也有一个类似的功能,使用 --leak-check 选项可以检测并报错内存泄漏问题,但并不释放这个孤儿内存。编译内核时使用 CONFIG_DEBUG_KMEMLEAK 选项打开 kmemcleak 调试功能。阅读 Documentation/kmemleak.txt 来学习怎么使用这个工具并读懂调试结果。
|
||||
> kmemleak 通过类似于垃圾收集器的功能来检测内核是否有内存泄漏问题。而 kmemleak 与垃圾收集器的不同之处在于前者不会释放孤儿目标(LCTT:不会再被使用的、应该被释放而没被释放的内存区域),而是将它们打印到 /sys/kernel/debug/kmemleak 文件中。用户态的 Valgrind 也有一个类似的功能,使用 --leak-check 选项可以检测并报错内存泄漏问题,但并不释放这个孤儿内存。编译内核时使用 `CONFIG_DEBUG_KMEMLEAK` 选项打开 kmemcleak 调试功能。阅读 Documentation/kmemleak.txt 来学习怎么使用这个工具并读懂调试结果。
|
||||
|
||||
### 内核调试接口 ###
|
||||
|
||||
@ -54,13 +54,13 @@ Linux 内核通过配置选项、调试用的 API、接口和框架来支持动
|
||||
|
||||
### 调试的 API ###
|
||||
|
||||
调试 API 的一个很好的例子是 DMA-debug,用来调试驱动是否错误使用了 DMA 提供的 API。它会跟踪每个设备的映射关系,检测程序有没有试图为一些根本不存在的映射执行“取消映射”操作,检测代码建立 DMA 映射后可能产生的“映射丢失”的错误。内核配置选项 CONFIG_HAVE_DMA_APT_DEBUG 和 CONFIG_DMA_API_DEBUG 可以为内核提供这个功能。其中,CONFIG_DMA_API_DEBUG 选项启用后,内核调用 DMA 的 API 的同时也会调用 Debug-dma 接口。举例来说,当一个驱动调用 dma_map_page() 函数来映射一个 DMA 缓存时,dma_map_page() 会调用debug_dma_map_page() 函数来跟踪这个缓存,直到驱动调用 dma_unmap_page() 来取消映射。详细内容请参考[使用 DMA 调试 API 检测潜在的数据污染和内存泄漏问题][3]。
|
||||
调试 API 的一个很好的例子是 DMA-debug,用来调试驱动是否错误使用了 DMA 提供的 API。它会跟踪每个设备的映射关系,检测程序有没有试图为一些根本不存在的映射执行“取消映射”操作,检测代码建立 DMA 映射后可能产生的“映射丢失”的错误。内核配置选项 `CONFIG_HAVE_DMA_APT_DEBUG` 和 `CONFIG_DMA_API_DEBUG` 可以为内核提供这个功能。其中,`CONFIG_DMA_API_DEBUG` 选项启用后,内核调用 DMA 的 API 的同时也会调用 Debug-dma 接口。举例来说,当一个驱动调用 `dma_map_page()` 函数来映射一个 DMA 缓存时,`dma_map_page()` 会调用`debug_dma_map_page()` 函数来跟踪这个缓存,直到驱动调用 `dma_unmap_page()` 来取消映射。详细内容请参考[使用 DMA 调试 API 检测潜在的数据污染和内存泄漏问题][3]。
|
||||
|
||||
### 动态调试 ###
|
||||
|
||||
动态调试功能就是你可以决定在程序运行过程中是否要 pr_debug(), dev_dbg(), print_hex_dump_debug(), print_hex_dump_bytes() 这些函数正常运行起来。什么意思?当程序运行过程中出现错误时,你可以指定程序打印有针对性的、详细的调试信息。这功能牛逼极了,我们不再需要为了添加调试代码定位一个问题,而重新编译安装内核。你可以指定 CONDIF_DYNAMIC_DEBUG 选项打开动态调试功能,然后通过 /sys/kernel/debug/dynamic_debug/control 接口指定要打印哪些调试日志。下面分别列出代码级别和模块级别打印日志的操作方法:
|
||||
动态调试功能就是你可以决定在程序运行过程中是否要 `pr_debug()`, `dev_dbg()`, `print_hex_dump_debug()`, `print_hex_dump_bytes()` 这些函数正常运行起来。什么意思?当程序运行过程中出现错误时,你可以指定程序打印有针对性的、详细的调试信息。这功能牛逼极了,我们不再需要为了添加调试代码定位一个问题,而重新编译安装内核。你可以指定 `CONDIF_DYNAMIC_DEBUG` 选项打开动态调试功能,然后通过 `/sys/kernel/debug/dynamic_debug/control` 接口指定要打印哪些调试日志。下面分别列出代码级别和模块级别打印日志的操作方法:
|
||||
|
||||
让 kernel/power/suspend.c 源码第340行的 pr_debug() 函数打印日志:
|
||||
让 kernel/power/suspend.c 源码第340行的 `pr_debug()` 函数打印日志:
|
||||
|
||||
echo 'file suspend.c line 340 +p' > /sys/kernel/debug/dynamic_debug/control
|
||||
|
||||
@ -72,7 +72,7 @@ Linux 内核通过配置选项、调试用的 API、接口和框架来支持动
|
||||
|
||||
> 编辑 /etc/modprobe.d/modname.conf 文件(没有这个文件就创建一个),添加 dyndbg='plmft' 选项。然而对于哪些通过 initramfs 加载的驱动来说,这个配置基本无效(LCTT:免费奉送点比较高级的知识哈。系统启动时,需要先让 initramfs 挂载一个虚拟的文件系统,然后再挂载启动盘上的真实文件系统。这个虚拟文件系统里面的文件是 initramfs 自己提供的,也就是说你在真实的文件系统下面配置了 /etc/modprobe.d/modname.conf 这个文件,initramfs 是压根不去理会的。站在内核驱动的角度看:如果内核驱动在 initramfs 过程中被加载到内核,这个驱动读取到的 /etc/modprobe.d/modname.conf 是 initramfs 提供的,而不是你编辑的那个。所以会有上述“写了配置文件后重启依然无效”的结论)。对于这种刁民,呃,刁驱动,我们需要修改 grub 配置文件,在 kernel 那一行添加 module.dyndbg='plmft' 参数,这样你的驱动就可以开机启动动态调试功能了。
|
||||
|
||||
想打印更详细的调试信息,可以使用 dynamic_debug.verbose=1 选项。参考 Documentation/dynamic-debug-howto.txt 文件获取更多信息。
|
||||
想打印更详细的调试信息,可以使用 `dynamic_debug.verbose=1` 选项。参考 Documentation/dynamic-debug-howto.txt 文件获取更多信息。
|
||||
|
||||
### 设置追踪点 ###
|
||||
|
||||
@ -135,7 +135,7 @@ Linux 内核通过配置选项、调试用的 API、接口和框架来支持动
|
||||
|
||||
via:http://www.linuxjournal.com/content/linux-kernel-testing-and-debugging?page=0,3
|
||||
|
||||
译者:[bazz2](https://github.com/bazz2) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[bazz2](https://github.com/bazz2) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Linux 内核测试和调试 - 5
|
||||
Linux 内核测试和调试(5)
|
||||
================================================================================
|
||||
### 仿真环境下进行 Linux 电源管理子系统测试 ###
|
||||
|
||||
@ -85,6 +85,6 @@ git bisect 是一个非常有用非常强大的工具,用于将 git 上的一
|
||||
|
||||
via: http://www.linuxjournal.com/content/linux-kernel-testing-and-debugging?page=0,4
|
||||
|
||||
译者:[bazz2](https://github.com/bazz2) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[bazz2](https://github.com/bazz2) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -1,4 +1,4 @@
|
||||
Linux 内核的测试和调试 - 6
|
||||
Linux 内核的测试和调试(6)
|
||||
================================================================================
|
||||
### Linux 内核补丁测试 ###
|
||||
|
||||
@ -12,7 +12,7 @@ Linux 内核的测试和调试 - 6
|
||||
|
||||
如果你对你的补丁测试结果感到很满意,你就可以提交补丁了。请确保提交 commit 的信息要描述得非常清楚。要让内核维护者和其他开发者看懂补丁所修改的内容,这一点非常重要。生成补丁后,执行 scripts/checkpatch.pl 脚本,找到 checkpatch 是产生的错误或警告(如果有的话),修复它们。重新生成补丁,直到补丁通过这个脚本的测试。重新测试这个补丁。将本补丁用于其他的内核源码上,保证不会有冲突产生。
|
||||
|
||||
现在你做好提交补丁的准备了。先运行 scriptst/get_maintainer.pl 来确认你应该把补丁发给哪个内核维护者。注意不要以附件形式发送补丁,而是以纯文本形式粘贴在邮件里面。确保你的邮件客户端可以发送纯文本信息,你可以试试给自己发送一份补丁邮件来测试你的邮件客户端的功能。收到自己的邮件后,运行 checkpatch 命令并给自己的内核源码打上你的补丁。如果这两部都能通过,你就可以给 Linux 邮箱列表发送补丁了。使用 git send-email 命令是提交补丁最安全的方式,可以避免你的邮箱的兼容性问题。你的 .gitconfig 文件里面需要配置好有效的 smtp 服务器,详细操作参考 git 的帮助文档。
|
||||
现在你做好提交补丁的准备了。先运行 `scriptst/get_maintainer.pl` 来确认你应该把补丁发给哪个内核维护者。注意不要以附件形式发送补丁,而是以纯文本形式粘贴在邮件里面。确保你的邮件客户端可以发送纯文本信息,你可以试试给自己发送一份补丁邮件来测试你的邮件客户端的功能。收到自己的邮件后,运行 checkpatch 命令并给自己的内核源码打上你的补丁。如果这两部都能通过,你就可以给 Linux 邮箱列表发送补丁了。使用 git send-email 命令是提交补丁最安全的方式,可以避免你的邮箱的兼容性问题。你的 .gitconfig 文件里面需要配置好有效的 smtp 服务器,详细操作参考 git 的帮助文档。
|
||||
|
||||
更多提交补丁的规矩,请参考下面的资料:
|
||||
|
||||
@ -111,7 +111,7 @@ Shuah Khan 是三星公司开源组的高级 Linux 内核开发工程师。
|
||||
|
||||
via: http://www.linuxjournal.com/content/linux-kernel-testing-and-debugging?page=0,5
|
||||
|
||||
译者:[bazz2](https://github.com/bazz2) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[bazz2](https://github.com/bazz2) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,14 +1,14 @@
|
||||
Budgie桌面5.1 对保守的用户来说是一个极好的新桌面环境
|
||||
Budgie桌面5.1 :给保守用户的超好桌面环境
|
||||
================================================================================
|
||||

|
||||
|
||||
**Evolve OS的开发者Ikey Doherty,制作了这款叫做Budgie Desktop的新桌面环境并且发布了它的新版本。**
|
||||
|
||||
Evolve OS还没有发布,但开发者正积极地进行关于它的工作。系统中并没有采用一个现有的桌面环境,他决定最好还是制作一个自己的。这个桌面基于GNOME并用了不少GNOME的包,但它看起来却截然不同。事实上,它使用了与MATE和Cinnamon桌面相同的模式,尽管Budgie似乎更有现代感更优美一些。
|
||||
Evolve OS还没有发布,但开发者正积极地进行关于它的工作。系统中并没有采用任何现有的桌面环境,他们决定最好还是制作一个自己的。这个桌面基于GNOME并用了不少GNOME的包,但它看起来却截然不同。事实上,它使用了与MATE和Cinnamon桌面相同的模式,尽管Budgie似乎更有现代感更优美一些。
|
||||
|
||||
有趣的是,桌面这个关键的技术部分却先于其将要服务的操作系统发布了,但是潜在的用户完全不必惊讶。由此也出现了可用于Ubuntu 14.04 LTS 和Ubuntu 14.10的[PPA][1],但这不是官方的。Arch Linux用户也将还会在AUR库中发现新的桌面环境。
|
||||
有趣的是,桌面这个关键的技术部分却先于其将要服务的操作系统发布了,但是对此感兴趣的用户完全不必惊讶。由此也出现了可用于Ubuntu 14.04 LTS 和Ubuntu 14.10的[PPA][1],但这不是官方的。Arch Linux用户也将还会在AUR库中发现新的桌面环境。
|
||||
|
||||
“从V4版本以来,几乎所有的改变都与面板有关。它已被使用Vala语言重写,这降低了维护开销也大大降低了新贡献者进入的门槛。所以,如果你使用OBS的话,当你于(希望是)今天在OBS上获取到更新,或者对Evolve OS用户,你已经安装了更新,你将只能感觉到很小的视觉差异。我的想法是不去改变外观,而是重写代码来使它更好些。”
|
||||
“从V4版本以来,几乎所有的改变都与面板有关。它已被使用Vala语言重写,这降低了维护开销也大大降低了新贡献者进入的门槛。所以,如果你使用OBS的话,当你(希望是)今天在OBS上获取到更新,或者对Evolve OS用户,你已经安装了更新,你将只能感觉到很小的视觉差异。我的想法是不去改变外观,而是重写代码来使它更好些。”
|
||||
|
||||
“将它重写成Vala语言的程序付出了很多努力,但马上就会见到成效。将来桌面整个都将会用Vala重写,成为‘第二次写’——第二次我们会做的更好”Ikey Doherty在发布[公告][2]中这样说。
|
||||
|
||||
@ -30,7 +30,7 @@ via: http://news.softpedia.com/news/Budgie-Desktop-5-1-Is-a-Superb-New-Desktop-E
|
||||
|
||||
原文作者:[Silviu Stahie][a]
|
||||
|
||||
译者:[linuhap](https://github.com/linuhap) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[linuhap](https://github.com/linuhap) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,12 @@
|
||||
在Linux中为SFTP配置chroot环境
|
||||
在 Linux 中为非 SSH 用户配置 SFTP 环境
|
||||
================================================================================
|
||||
在**某些环境**中,系统管理员想要允许极少数用户传输文件到Linux盒子中,而非ssh。要实现这一目的,我们可以使用**SFTP**,并为其构建chroot环境。
|
||||
在**某些环境**中,系统管理员想要允许极少数用户在可以传输文件到Linux机器中,但是不允许使用 SSH。要实现这一目的,我们可以使用**SFTP**,并为其构建chroot环境。
|
||||
|
||||
### SFTP & chroot背景: ###
|
||||
|
||||
**SFTP**是值**SSH文件传输协议(SSH File Transfer protocol)或安全文件传输协议(Secure File Transfer Protocol)**,它提供了任何可信数据流下的文件访问、文件传输以及文件管理功能。当我们为SFTP配置chroot环境后,只有被许可的用户可以访问,并被限制到它们的**家目录**中,或者我们可以这么说:被许可的用户将处于牢笼环境中,在此环境中它们甚至不能切换它们的目录。
|
||||
**SFTP**是指**SSH文件传输协议(SSH File Transfer protocol)或安全文件传输协议(Secure File Transfer Protocol)**,它提供了可信数据流下的文件访问、文件传输以及文件管理功能。当我们为SFTP配置chroot环境后,只有被许可的用户可以访问,并被限制到他们的**家目录**中,换言之:被许可的用户将处于牢笼环境中,在此环境中它们甚至不能切换它们的目录。
|
||||
|
||||
在本文中,我们将配置**RHEL 6.X** & **CentOS 6.X中的SFTP Chroot环境**。我们开启一个用户帐号‘**Jack**’,该用户将被允许在Linux盒子上传输文件,但没有ssh访问权限。
|
||||
在本文中,我们将配置**RHEL 6.X** 和 **CentOS 6.X中的SFTP Chroot环境**。我们开启一个用户帐号‘**Jack**’,该用户将被允许在Linux机器上传输文件,但没有ssh访问权限。
|
||||
|
||||
### 步骤:1 创建组 ###
|
||||
|
||||
@ -14,7 +14,7 @@
|
||||
|
||||
### 步骤:2 分配附属组(sftp_users)给用户 ###
|
||||
|
||||
如果用户在系统上不存在,使用以下命令创建:
|
||||
如果用户在系统上不存在,使用以下命令创建( LCTT 译注:这里给用户指定了一个不能登录的 shell,以防止通过 ssh 登录):
|
||||
|
||||
[root@localhost ~]# useradd -G sftp_users -s /sbin/nologin jack
|
||||
[root@localhost ~]# passwd jack
|
||||
@ -23,7 +23,7 @@
|
||||
|
||||
[root@localhost ~]# usermod –G sftp_users -s /sbin/nologin jack
|
||||
|
||||
**注意**:如果你想要修改用户的**默认家目录**,那么在useradd和usermod命令中使用‘**-d**’选项,并设置**合适的权限**。
|
||||
**注意**:如果你想要修改用户的**默认家目录**,那么可以在useradd和usermod命令中使用‘**-d**’选项,并设置**合适的权限**。
|
||||
|
||||
### 步骤:3 现在编辑配置文件 “/etc/ssh/sshd_config” ###
|
||||
|
||||
@ -33,7 +33,7 @@
|
||||
Subsystem sftp internal-sftp
|
||||
|
||||
# add Below lines at the end of file
|
||||
Match Group sftp_users
|
||||
Match Group sftp_users
|
||||
X11Forwarding no
|
||||
AllowTcpForwarding no
|
||||
ChrootDirectory %h
|
||||
@ -42,7 +42,7 @@
|
||||
#### 此处: ####
|
||||
|
||||
- **Match Group sftp_users** – 该参数指定以下的行将仅仅匹配sftp_users组中的用户
|
||||
- **ChrootDirectory %h** – 该参数指定用户验证后用于chroot环境的路径(默认的用户家目录)。对于Jack,该路径就是/home/jack。
|
||||
- **ChrootDirectory %h** – 该参数指定用户验证后用于chroot环境的路径(默认的用户家目录)。对于用户 Jack,该路径就是/home/jack。
|
||||
- **ForceCommand internal-sftp** – 该参数强制执行内部sftp,并忽略任何~/.ssh/rc文件中的命令。
|
||||
|
||||
重启ssh服务
|
||||
@ -82,7 +82,7 @@ via: http://www.linuxtechi.com/configure-chroot-sftp-in-linux/
|
||||
|
||||
原文作者:[Pradeep Kumar][a]
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[GOLinux](https://github.com/GOLinux) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Linux常见问题及答案——如何检查PDF文档中使用了哪种字体
|
||||
Linux有问必答:如何检查PDF中使用了哪种字体
|
||||
================================================================================
|
||||
|
||||
>**问题**:我想要知道PDF文件中使用了什么字体,或者嵌入了什么字体。Linux中有工具可以检查PDF文档中使用了哪种字体吗?
|
||||
@ -34,6 +34,6 @@ Linux常见问题及答案——如何检查PDF文档中使用了哪种字体
|
||||
via: http://ask.xmodulo.com/check-which-fonts-are-used-pdf-document.html
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -1,4 +1,4 @@
|
||||
排名前十的 Linux 免费游戏
|
||||
10大 Linux 免费游戏
|
||||
================================================================================
|
||||
假如当你考虑从 Windows 平台迁移至 Linux 平台时,“我能在 Linux 平台上游戏吗?”这类疑问正困扰着你,那么对此这有一个答案就是 ———— “快去 Linux 平台吧!”。感谢开源组织一直以来坚持不懈为 Linux 操作系统开发不同类型的游戏,还有从不缺乏好的商业游戏,并且在 Linux 平台下游戏时的乐趣完全不亚于其他几个平台(比如 Windows 平台)的在线数字发行平台 ———— Steam。
|
||||
|
||||
@ -15,6 +15,7 @@
|
||||
《军团要塞 2》已经收到了许多称赞性评论与大奖,这主要跟它充满艺术的表现手法、游戏的平衡性、幽默感,以及图像风格有关。与其他游戏,如使命召唤、半条命,采取极度真实的画面不同,这款游戏的设定看起来像是把卡通元素带进了世界中。
|
||||
|
||||
** 游戏介绍 **:和原版游戏一样,《军团要塞 2》围绕两支相互对立的队伍进行;红队(可信赖的拆迁队)与蓝队(建筑者联合团体),两队都为了以战斗为基础的主要目标相互竞争。
|
||||
|
||||
玩家可以选择九种角色,分别是侦察兵、士兵、火焰兵、爆破兵、重装兵、工程师、医疗兵、狙击手和间谍,每一个角色都有其独特的武器、优势与弱点。
|
||||
|
||||
#### 系统需求: ####
|
||||
@ -61,7 +62,7 @@
|
||||
|
||||

|
||||
|
||||
《Dota 2》,《Dota》的续作,是一款由 Valve 公司开发的多人在线战术竞技类(Multiplayer Online Battle Arena,MOBA)电子游戏。《DOTA 2》发行时就完全免费,于 2013 年 7 月 9 日发行 Windows 版,于 2013 年 7 月 18 日发行 Linux 版,并且只能通过 Valve 的在线数字发行平台 Steam 进行游戏。Dota 2 因为其令人愉悦的游戏体验和大幅提高的游戏品质得到了电子游戏评论家的热烈称赞。尽管 Dota 2 也因为其陡峭的学习曲线受到批评。
|
||||
《Dota 2》,是《Dota》的续作,是一款由 Valve 公司开发的多人在线战术竞技类(Multiplayer Online Battle Arena,MOBA)电子游戏。《DOTA 2》发行时就完全免费,于 2013 年 7 月 9 日发行 Windows 版,于 2013 年 7 月 18 日发行 Linux 版,并且只能通过 Valve 的在线数字发行平台 Steam 进行游戏。Dota 2 因为其令人愉悦的游戏体验和大幅提高的游戏品质得到了电子游戏评论家的热烈称赞。尽管 Dota 2 也因为其陡峭的学习曲线受到批评。
|
||||
|
||||
** 游戏介绍 **:每一场标准的 Dota 2 比赛都是独立的,同时由 2 支相互敌对的团体参与,天辉和夜魇,每个团队均由 5 名玩家组成。每个团队占据地图的一角作为大本营,每个团队的大本营上均有一座被称作“远古神迹”的建筑存在。为了赢得游戏,任意一方团队必须摧毁对方的远古神迹。Dota 2 中有 9 种游戏模式与 107 个英雄可供挑选。每名玩家控制一位英雄,通过升级、获取物品、收集金币还有击败敌对团队以获取胜利。
|
||||
|
||||
@ -113,7 +114,7 @@
|
||||
|
||||
《Urban Terror》,缩写作 UrT,是一款由 FrozenSand 开发的免费多人 FPS 电子游戏。游戏于 2007 年作为免费独立游戏发行,使用 ioquake3(某游戏引擎项目,作为一个纯净基础包向更多的图像和音频特性提供改进支持)作为引擎。
|
||||
|
||||
正如这款官方游戏格言‘现实的乐趣’所述,它是一个打包很好的产品,同时安装简便、画质优良、依赖需求少,并且游戏非常平衡,这些特色使这款游戏成为了独一无二的、令人享受并且吸引人的游戏。2007 年的 Mod DB 上,Urban Terror 被提名为年度 Mod 奖。
|
||||
正如这款官方游戏格言‘现实的乐趣’所述,它是一个封包很好的产品,同时安装简便、画质优良、依赖需求少,并且游戏非常平衡,这些特色使这款游戏成为了独一无二的、令人享受并且吸引人的游戏。2007 年的 Mod DB 上,Urban Terror 被提名为年度 Mod 奖。
|
||||
|
||||
** 游戏介绍 **:这款游戏被标为“好莱坞战术射击游戏”,具有多种游戏的混合元素,例如:《雷神之锤 III 竞技场》、《虚幻竞技场》以及《反恐精英》。这款 Mod 通过一系列改变使得游戏更加真实,比如武器和现实中的类似,具有后坐力,射击时精准度会下降,并且当弹药库用完时需要重新填装。伤害同样现实化了,比如伤口需要包扎,腿伤或脚伤会拖慢玩家的速度。
|
||||
|
||||
@ -262,9 +263,9 @@
|
||||
|
||||
《Tremulous》是一款免费开源的游戏,包含有团队 FPS 模式与即时战略元素。游戏由 Dark Legion Development 在 ioquake2 游戏引擎的基础上开发,于 2005 年 8 月 11 日发行。尽管游戏的起源是雷神 3 的一个 mod,但最后却独立出来了。
|
||||
|
||||
《Tremulous》荣获了 Mod Database 举办的 2006 年 “年度 Mod” 颁奖典礼中的 “玩家评选的年度最佳独立游戏” 奖项,同时也获得了 Planet Quake 网站玩家投票的第一个“以雷神引擎开的基于 GPL 协议的最佳免费游戏”。
|
||||
《Tremulous》荣获了 Mod Database 举办的 2006 年 “年度 Mod” 颁奖典礼中的 “玩家评选的年度最佳独立游戏” 奖项,同时也获得了 Planet Quake 网站玩家投票的第一个“以雷神引擎开发的基于 GPL 协议的最佳免费游戏”。
|
||||
|
||||
** 游戏介绍 **:游戏背景可推测设定在未来,在那个时代人类与蜘蛛外形的外星人进行战斗。玩家可以在两个仅有的种族,人类与外星人,中选择自己的种族,每个种族的玩家都可以像即时战略游戏一样在游戏中进行建筑。其中最重要的建筑是重生点,重生点允许死亡的队友重新加入游戏。
|
||||
** 游戏介绍 **:游戏背景可推测设定在未来,在那个时代人类与蜘蛛外形的外星人进行战斗。玩家可以在两个仅有的种族——人类与外星人——中选择自己的种族,每个种族的玩家都可以像即时战略游戏一样在游戏中进行建筑。其中最重要的建筑是重生点,重生点允许死亡的队友重新加入游戏。
|
||||
|
||||
#### 系统需求: ####
|
||||
|
||||
@ -349,9 +350,9 @@
|
||||
|
||||

|
||||
|
||||
《开放竞技场》是一款开源的多人 FPS 类游戏,基于由 id tech 3 引擎 fork 的 ioquake3 开发而来。游戏由 OpenArena 团队开发,并且遵守 GPLv2(GNU General Public License V2.0)协议。游戏官方网站的下载版本包括 GNU/Linux,Microsoft Windows 以及 Mac OS X 操作系统的对应版,同样支持诸如 Debian、Gentoo、Fedora、Arch、Mandriva 还有 Ubuntu 等 Linux 发行版。开放竞技场是一款可以离线或者在线进行的免费游戏,玩家也可以自己架设局域网或者 Internet 服务器。
|
||||
《开放竞技场》是一款开源的多人 FPS 类游戏,基于由 id tech 3 引擎 fork 的 ioquake3 开发而来。游戏由 OpenArena 团队开发,并且遵守 GPLv2协议。游戏官方网站的下载版本包括 GNU/Linux,Microsoft Windows 以及 Mac OS X 操作系统的对应版,同样支持诸如 Debian、Gentoo、Fedora、Arch、Mandriva 还有 Ubuntu 等 Linux 发行版。开放竞技场是一款可以离线或者在线进行的免费游戏,玩家也可以自己架设局域网或者 Internet 服务器。
|
||||
|
||||
** 游戏介绍 **:《开放竞技场》几乎和《雷神 III 竞技场》一样:通过杀敌得分获得游戏胜利,在不同的场景下可以使用一系列为平衡游戏所设计的武器。每场竞赛都有其独特的“竞技场”,地图上玩家们互相残杀;游戏包含多种游戏类型:死亡竞赛、锦标赛、团队死亡竞赛,还有夺旗模式。由于暴力以及成人因素,这款游戏并不适于 17 岁以下的孩子。
|
||||
** 游戏介绍 **:《开放竞技场》几乎和《雷神 III 竞技场》一样:通过杀敌得分获得游戏胜利,在不同的场景下可以使用一系列为平衡游戏所设计的武器。每场竞赛都有其独特的“竞技场”,地图上玩家们互相残杀;游戏包含多种游戏类型:死亡竞赛、锦标赛、团队死亡竞赛,还有夺旗模式。由于暴力以及成人因素,这款游戏由于其暴力程度并不适于 17 岁以下的孩子。
|
||||
|
||||
#### 系统需求: ####
|
||||
|
||||
@ -478,7 +479,7 @@ via: http://mylinuxbook.com/top-10-free-linux-games/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[SteveArcher](https://github.com/SteveArcher)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[ wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,38 @@
|
||||
Linux上最先进的免费赛车游戏:StuntRally 2.4
|
||||
================================================================================
|
||||

|
||||
StuntRally
|
||||
|
||||
**StuntRally,免费的赛车游戏,拥有超过150个赛道和大量的车型,刚刚发布2.4版本,并带来大量的更新和新功能。**
|
||||
|
||||
这个游戏使用了多项技术, 例如 Vdrift、物理引擎 bullet、面向对象图形渲染引擎 OGRE、 网格的渲染优化 PagedGeometry 和 MyGUI 等等,不一一列举,开发者将其全部整合在一起构造了一个非常复杂和有趣的赛车游戏.
|
||||
|
||||
玩家可以在147个赛道和26个不同的场景中游戏,总计有四个小时的车程时间。在如此多的选择下,你要知道,而StuntRally是完全免费的!
|
||||
|
||||
其他功能包括在幽灵驾驶(可以跟踪你的车子在赛道上的最佳瞬间),赛道幽灵(赛道上的最佳驾驶,一个绿幽灵赛车,可以出现在所有轨道),回放(记录你的驾驶过程,并可以从其它的摄像头角度查看),许多的教程,几个总冠军杯赛,一些挑战赛,分屏赛车,和多人游戏。
|
||||
|
||||
最重要的是,开发商还提供了一个轨道编辑器,允许用户实时编辑道路节点及其参数,改变所有的赛道参数,调整地形生成器,甚至修改驾驶中的汽车的属性。
|
||||
|
||||
根据更新日志,添加了6个新的地图,删除了12个旧关卡,更新了一些赛道,增加了两个名为Crystals 和 GreeceWhite的场景,实现了太空飞船式气垫船,一半的赛道添加了新的天空纹理贴图,一些赛道上的静态景物现在可以用了,汽车属性页有了状态条、速度图,并添加了一个短列表视图。
|
||||
|
||||
同时,字体现在他们已重新调整得更大了,增加了包括胜利、失败、过圈最佳时间和故障检测排除等声音,已修复了多人游戏中用户昵称出现两次的问题,在一些赛道实现了地形、浓雾、水体的影响,关卡编辑器已经做了一些改进,汽车转向控制进行了改进,修复了游戏中的汽车表面调整窗口。
|
||||
|
||||
关于StuntRally更多最新消息可以参考 [通告][1]。
|
||||
|
||||
下载 StuntRally 2.4:
|
||||
|
||||
- [Stunt Rally 2.4 tar.xz][2][binary] [735 MB]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/StuntRally-2-4-Is-the-Most-Advance-Free-Racing-Game-on-Linux-454345.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[fbigun](https://github.com/fbigun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:https://code.google.com/p/vdrift-ogre/wiki/VersionHistory
|
||||
[2]:http://sourceforge.net/projects/stuntrally/files/2.4/StuntRally-2.4-linux64.tar.xz/download
|
||||
@ -1,40 +0,0 @@
|
||||
StuntRally 2.4 Is the Most Advanced Free Racing Game on Linux
|
||||
================================================================================
|
||||

|
||||
StuntRally
|
||||
|
||||
**StuntRally, a free racing game that features over 150 tracks and lots of cars, has just reached version 2.4 and and it bring numerous updates and new features.**
|
||||
|
||||
The game is built with the help of several technologies, such as Vdrift, bullet, OGRE, PagedGeometry, and MyGUI, just to name a few, but the developers have manged to put together a very complex and interesting racing title.
|
||||
|
||||
The players can play on 147 track and in 26 different scenarios, which totals four hours of drive time. This is quite a lot, if we keep in mind that StuntRally is completely free.
|
||||
|
||||
Other features included in the are ghost drive (chase your best time car on track), track's ghost (best drive for track, a green ghost car ES, on all tracks), replays (save your drive and watch it from other cameras later), numerous tutorial, a few championships, a few challenges, split-screen racing, and multiplayer.
|
||||
|
||||
To top it all off, the developers also implemented a Track Editor that should allow users to edit road points and their parameters in real time, to change all of the track parameters, to tweak the terrain generator, and even to modify elements of the cars while driving.
|
||||
|
||||
According to the changelog, 6 new maps have been added, 12 old levels have been deleted, a number of tracks have been renewed, a couple of new sceneries named Crystals and GreeceWhite have been added, spaceship hovercrafts have been implemented, new sky textures have been added on half of tracks, new static objects on few tracks are now available, and car tab with bars for stats, speed graph, and a short list view has been added.
|
||||
|
||||
Also, fonts are now bigger and they have been resized, sounds for win, loose, lap, best time, and wrong checkpoint resolution have been added, the multiplayer has been repaired and the nick can no longer appear twice, damage from terrain, height fog, fluids has been implemented on a few tracks, the level editor has received a number of improvements, the steering has been improved, and the surfaces in the game's car tweak window have been fixed.
|
||||
|
||||
Users need to remember that the developers only provide the source package for the game and that means that it needs compiling. This might take a little bit longer, but StuntRally is totally worth it.
|
||||
|
||||
More details about this new release of StuntRally can be found in the [announcement][1].
|
||||
|
||||
Download StuntRally 2.4:
|
||||
|
||||
- [Stunt Rally 2.4 tar.xz][1][binary] [735 MB]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/StuntRally-2-4-Is-the-Most-Advance-Free-Racing-Game-on-Linux-454345.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:https://code.google.com/p/vdrift-ogre/wiki/VersionHistory
|
||||
[2]:http://sourceforge.net/projects/stuntrally/files/2.4/StuntRally-2.4-linux64.tar.xz/download
|
||||
@ -0,0 +1,41 @@
|
||||
[sailing]
|
||||
Munich Council: LiMux Demise Has Been Greatly Exaggerated
|
||||
================================================================================
|
||||

|
||||
LiMux – Munich City Council’s Official OS
|
||||
|
||||
A Munich city council spokesman has attempted to clarify the reasons behind its [plan to re-examine the role of open-source][1] software in local government IT systems.
|
||||
|
||||
The response comes after numerous German media outlets revealed that the city’s incoming mayor has asked for a report into the use of LiMux, the open-source Linux distribution used by more than 80% of municipalities.
|
||||
|
||||
Reports quoted an unnamed city official, who claimed employees were ‘suffering’ from having to use open-source software. Others called it an ‘expensive failure’, with the deputy mayor, Josef Schmid, saying the move was ‘driven by ideology’, not financial prudence.
|
||||
|
||||
With Munich often viewed as the poster child for large Linux migrations, news of the potential renege quickly went viral. Now council spokesman Stefan Hauf has attempted to bring clarity to the situation.
|
||||
|
||||
### ‘Plans for the future’ ###
|
||||
|
||||
Hauf confirms that the city’s new mayor has requested a review of the city’s IT systems, including its choice of operating systems. But the report is not, as implied in earlier reports, solely tasked with deciding whether to return to using Microsoft Windows.
|
||||
|
||||
**“It’s about the organisation, the costs, performance and the usability and satisfaction of the users,”** [Techrepublic][2] quote him as saying.
|
||||
|
||||
**“[It's about gathering the] facts so we can decide and make a proposal for the city council how to proceed in future.”**
|
||||
|
||||
Hauf also confirms that council staff have, and do, complain about LiMux, but that the majority of issues stem from compatibility issues in OpenOffice, something a potential switch to LibreOffice could solve.
|
||||
|
||||
So is Munich about to switch back to Windows? As we said in our original coverage: it’s just too early to say, but it’s not being ruled out.
|
||||
|
||||
No final date for the report’s recommendations is yet set, and any binding decision on Munich’s IT infrastructure will need to be made by its elected members, the majority of whom are said to ‘support’ the LiMux initiative.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/08/munich-council-say-talk-limux-demise-greatly-exaggerated
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://www.omgubuntu.co.uk/2014/08/munich-city-linux-switching-back-windows
|
||||
[2]:http://www.techrepublic.com/article/no-munich-isnt-about-to-ditch-free-software-and-move-back-to-windows/
|
||||
@ -0,0 +1,46 @@
|
||||
linuhap翻译中
|
||||
GIMP 2.8.12 Released — Here’s How to Install it on Ubuntu
|
||||
================================================================================
|
||||
**A [new update][1] to the popular open-source Photoshop alternative The GIMP is now available for download.**
|
||||
|
||||

|
||||
GIMP is a Free Photoshop Alternative
|
||||
|
||||
As the latest entry in the GIMP 2.8.x series — [released back in 2012][2] and notable for introducing the long-sought ‘single window mode’ — version 2.8.12 continues to refine rather than reinvent. As such there are no new user-facing features to be found.
|
||||
|
||||
Instead, developers bring a fresh batch of bug fixes to the table aimed at improving the overall stability, security and style of the famous app.
|
||||
|
||||
- Brush sizes from plugins are no longer distorted
|
||||
- ‘More robust’ loading of .XCF files
|
||||
- Widget direction now matches interface language (e.g. RTL)
|
||||
- Security improvements to the script-fu-server
|
||||
|
||||
Documentation, help and translation updates are also included. For a complete change log of everything fixed between 2.8.10 and 2.8.12, see [the GNOME Git notes][2].
|
||||
|
||||
### Install Latest GIMP in Ubuntu ###
|
||||
|
||||
Source for the latest release can be downloaded from the official website or via [an official torrent][3].
|
||||
|
||||
On Ubuntu? You can install GIMP 2.8.12 in Ubuntu 12.04 LTS and 14.04 LTS by adding the [following third-party PPA][4] to Software Sources:
|
||||
|
||||
sudo add-apt-repository ppa:otto-kesselgulasch/gimp
|
||||
|
||||
sudo apt-get update && sudo apt-get install gimp
|
||||
|
||||
After installation has complete you can proceed to open GIMP 2.8.12 from the Unity Dash (or equivalent).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/08/whats-new-in-gimp-2-8-12-plus-install-ubuntu
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://www.omgubuntu.co.uk/2012/05/gimp-2-8-released
|
||||
[2]:https://git.gnome.org/browse/gimp/plain/NEWS?h=gimp-2-8
|
||||
[3]:http://download.gimp.org/pub/gimp/v2.8/gimp-2.8.12.tar.bz2.torrent
|
||||
[4]:https://launchpad.net/~otto-kesselgulasch/+archive/ubuntu/gimp
|
||||
@ -0,0 +1,31 @@
|
||||
Red Hat Shake-up, Desktop Users, and Outta Time
|
||||
================================================================================
|
||||

|
||||
|
||||
Our top story tonight is the seemingly sudden resignation of Red Hat CTO Brian Stevens. In other news, John C. Dvorak says "Linux has run out of time" and Infoworld.com says there may be problems with Red Hat Enterprise 7. OpenSource.com has a couple of interesting interviews and Nick Heath has five big names that use Linux on the desktop.
|
||||
|
||||
**In a late afternoon** [press release][1], Red Hat announced the resignation of long-time CTO Brian Stevens. Paul Cormier will be handling CTO duties until Stevens' replacement is named. No reason for the sudden resignation was given although CEO Whitehurst said, "We want to thank Brian for his years of service and numerous contributions to Red Hat’s business. We wish him well in his future endeavors." However, Steven J. Vaughan-Nichols says some rumors are flying. One says friction between Stevens and Cormier caused the resignation and others say Stevens had higher ambitions than Red Hat could provide. He'd been with Red Hat since 2001 and had been CTO at Mission Critical Linux before that [according to Vaughan-Nichols][2] who also said Stevens' Red Hat page was gone within seconds of the announcement.
|
||||
|
||||
**Speaking of Red Hat**, InfoWorld.com has a review of RHEL 7 available to the general public today. Reviewer Paul Venezia runs down the new features, but soon mentions systemd as one of the many new features "certain to cause consternation." After offering his opinion on several other key features and even throwing in a tip or two, [Venezia concludes][3], "RHEL 7 is a fairly significant departure from the expected full-revision release from Red Hat. This is not merely a reskinning of the previous release with updated packages, a more modern kernel, and some new toolkits and widgets. This is a very different release than RHEL 6 in any form, mostly due to the move to Systemd."
|
||||
|
||||
**Our own Sam Dean** [today said][4] that Linux doesn't need to own the desktop because of its success in many other key areas. While that may be true, Nick Heath today listed "five big names that use Linux on the desktop." He said besides Munich, there's Google for one and they even have their own Ubuntu derivative. He lists a couple of US government agencies and then mentions CERN and others. See that [full story][5] for more.
|
||||
|
||||
Despite that feel-good report, John C. Dvorak said he's tired of waiting for someone to develop that one "killer app" that would bring in the masses or satisfy his needs. [He says][6] he has to make podcasts and "photographic art" and he just can't do that with Linux. Our native applications "do not cut it in the end."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ostatic.com/blog/red-hat-shake-up-desktop-users-and-outta-time
|
||||
|
||||
作者:[Susan Linton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ostatic.com/member/susan-linton
|
||||
[1]:http://www.businesswire.com/news/home/20140827006134/en/Brian-Stevens-Step-CTO-Red-Hat#.U_5AlvFdX0p
|
||||
[2]:http://www.zdnet.com/red-hat-chief-technology-officer-resigns-7000033058/
|
||||
[3]:http://www.infoworld.com/d/data-center/review-rhel-7-lands-jolt-249219
|
||||
[4]:http://ostatic.com/blog/linux-doesnt-need-to-own-the-desktop
|
||||
[5]:http://www.techrepublic.com/article/five-big-names-that-use-linux-on-the-desktop/
|
||||
[6]:http://www.pcmag.com/article2/0,2817,2465125,00.asp
|
||||
@ -0,0 +1,41 @@
|
||||
慕尼黑市议会称: LiMux 项目的死讯被过分夸大了
|
||||
================================================================================
|
||||

|
||||
|
||||
LiMux - 慕尼黑市议会的官方操作系统
|
||||
|
||||
慕尼黑市议会的新闻发言人试图澄清其[计划重新审视当地政府 IT 系统使用的所有开源软件][1]的背后原因。
|
||||
|
||||
大量德国媒体披露,“慕尼黑市新任市长要求提交一份关于 LiMux 使用率的报告”,LiMux是一个在该市超过 80% 的市政府部门中使用的开源 Linux 发行版 ,慕尼黑市议会新闻发言人正是针对这条新闻所做的反应。
|
||||
|
||||
该报告引用了一位不愿透露姓名的市政府官员的话,他声称政府雇员在使用开源软件时“非常痛苦”,还有人人称其为“昂贵的失败”。副市长 Josef Schmid 说,(更换到开源系统)这件事是“意识形态驱使的”,并非理性的财务行为。
|
||||
|
||||
过去被看成是大规模迁移 Linux 的典范的慕尼黑市,如今这个背道而驰的新闻迅速像病毒一样扩散开来。现在市议会的新闻发言人 Stefan Hauf 正试着澄清这件事。
|
||||
|
||||
### “未来计划” ###
|
||||
|
||||
Hauf 确认了新任市长要求重新审查城市 IT 系统以及操作系统选择的事,但这份报告的目的并不像之前报道中暗示的那样仅仅是为了决定什么时候退回到 Microsoft Windows。
|
||||
|
||||
**“这是有关机构、经费、性能和可用性以及用户满意度的事,”** [Techrepublic][2] 引用了他的言辞。
|
||||
|
||||
**“(这仅仅是在收集)现实情况,为我们决定市议会今后该如何处理提供依据。”**
|
||||
|
||||
Hauf 同时也确认了市议会员工的确抱怨过 LiMux,但是主要集中在 OpenOffice 的兼容性问题上,有些问题只要换到 LibreOffice 就能解决。
|
||||
|
||||
那么,慕尼黑市会用回 Windows 吗?正如我们在之前的报道中所说:不能排除这种可能,但是现在下结论还太早。
|
||||
|
||||
目前该报告所建议的截止日期还没定,任何和慕尼黑 IT 基础设施相关的决定都需要由他们自己投票决定,主流选民目前抱有“支持” LiMux 的态度。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/08/munich-council-say-talk-limux-demise-greatly-exaggerated
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[sailing](https://github.com/sailing)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://www.omgubuntu.co.uk/2014/08/munich-city-linux-switching-back-windows
|
||||
[2]:http://www.techrepublic.com/article/no-munich-isnt-about-to-ditch-free-software-and-move-back-to-windows/
|
||||
@ -1,3 +1,5 @@
|
||||
barney-ro translating
|
||||
|
||||
How does the cloud affect the everyday linux user?
|
||||
================================================================================
|
||||
### Introduction ###
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
[Translating by SteveArcher]
|
||||
KDE Plasma 5—For those Linux users undecided on the kernel’s future
|
||||
================================================================================
|
||||
> Review—new release straddles traditional desktop needs, long term multi-device plans.
|
||||
|
||||
@ -0,0 +1,31 @@
|
||||
Linus Torvalds Promotes Linux for Desktops, Embedded Computing
|
||||
================================================================================
|
||||
> Linux kernel developer and open source leader Linus Torvalds spoke recently about the future of desktop Linux and Linux for embedded devices.
|
||||
|
||||

|
||||
|
||||
What's the future of Linux for desktop computers and embedded devices? That's a question up for debate, but Linux founder and open source superstar Linus Torvalds provided some intriguing viewpoints in a discussion at the [Linux Foundation's][1] recent LinuxCon event.
|
||||
|
||||
As the guy who wrote the first Linux kernel code and shared it publicly over the Internet back in 1991, Torvalds is without doubt among the most famous developers of open source software—or any software, really—alive today. And while Torvalds is only one individual among many thousands of people and organizations guiding the development of Linux, his opinions tend to be influential with the open source community, and his role as a lead kernel developer places him in a powerful position for deciding which features and code make it into the operating system.
|
||||
|
||||
So it's worth paying attention when Torvalds says, "I still want the desktop," as he [did last week][2] at LinuxCon. It's a sign that he still sees a future for Linux as an operating system for powering personal PCs, even though desktop Linux market share has remained minuscule and relatively flat for more than a decade, and most of the commercial activity around Linux these days involves servers or Android-powered mobile hardware.
|
||||
|
||||
But, Torvalds added, ensuring a strong future for desktop Linux means solving an "infrastructure problem" that stems, he seems to believe, from the broader open source software ecosystem and the hardware world. It's not the core Linux code itself that's at issue, and making the channel friendly for desktop Linux is a feat Torvalds and his fellow kernel developers probably have little power to achieve on their own. That's up to app developers, hardware manufacturers and other parties who have the power to deliver computing platforms based on Linux that people will readily use.
|
||||
|
||||
On the other hand, Torvalds also mentioned a hope that kernel developers might streamline the Linux code for embedded devices—a task that might be at odds in some ways with making the kernel more desktop-friendly. But that's not necessarily the case, and at any rate, given that Linux is designed to be so modular, there's no reason a single kernel code base can't meet the needs of desktop users and embedded developers equally well, depending on which chunks they choose to use.
|
||||
|
||||
As a longtime desktop Linux user who would also like to see more Linux-powered embedded devices, I'm hoping Torvalds's aspirations in both regards will be realized, and that I will one day be able to do everything I need using only Linux, whether it's on a desktop computer, a mobile phone, the car or anywhere else.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/082514/linus-torvalds-promotes-linux-desktops-and-embedded-compu
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:http://linuxfoundation.org/
|
||||
[2]:http://www.eweek.com/enterprise-apps/linux-founder-linus-torvalds-still-wants-the-desktop.html
|
||||
@ -0,0 +1,41 @@
|
||||
Linus Torvalds Started a Revolution on August 25, 1991. Happy Birthday, Linux!
|
||||
================================================================================
|
||||

|
||||
Linus Torvalds
|
||||
|
||||
**The Linux project has just turned 23 and it's now the biggest collaborative endeavor in the world, with thousands of people working on it.**
|
||||
|
||||
Back in 1991, a young programmer called Linus Torvalds wanted to make a free operating system that wasn't going to be as big as the GNU project and that was just a hobby. He started something that would turn out to be the most successful operating system on the planet, but no one would have been able to guess it back then.
|
||||
|
||||
Linus Torvalds sent an email on August 25, 1991, asking for help in testing his new operating system. Things haven't changed all that much in the meantime and he still sends emails about new Linux releases, although back then it wasn't called like that.
|
||||
|
||||
"I'm doing a (free) operating system (just a hobby, won't be big and professional like gnu) for 386(486) AT clones. This has been brewing since april, and is starting to get ready. I'd like any feedback on things people like/dislike in minix, as my OS resembles it somewhat (same physical layout of the file-system (due to practical reasons) among other things). I've currently ported bash(1.08) and gcc(1.40), and things seem to work."
|
||||
|
||||
"This implies that I'll get something practical within a few months, and I'd like to know what features most people would want. Any suggestions are welcome, but I won't promise I'll implement them :-) PS. Yes - it's free of any minix code, and it has a multi-threaded fs. It is NOT protable (uses 386 task switching etc), and it probably never will support anything other than AT-harddisks, as that's all I have :-(. " [wrote][1] Linus Torvalds.
|
||||
|
||||
This is the entire mails that started it all, although it's interesting to see how things have evolved since then. The Linux operating system caught on, especially on the server market, but the power of Linux also extended in other areas.
|
||||
|
||||
In fact, it's hard to find any technology that hasn't been influenced by a Linus OS. Phones, TVs, fridges, minicomputers, consoles, tablets, and basically everything that has a chip in it is capable of running Linux or it already has some sort of Linux-based OS installed on it.
|
||||
|
||||
Linux is omnipresent on billions of devices and its influence is growing each year on an exponential basis. You might think that Linus is also the wealthiest man on the planet, but remember, Linux is free software and anyone can use it, modify it, and make money of it. He didn't do it for the money.
|
||||
|
||||
Linus Torvalds started a revolution in 1991, but it hasn't ended. In fact, you could say that it's just getting started.
|
||||
|
||||
> Happy Anniversary, Linux! Please join us in celebrating 23 years of the free OS that has changed the world. [pic.twitter.com/mTVApV85gD][2]
|
||||
>
|
||||
> — The Linux Foundation (@linuxfoundation) [August 25, 2014][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Linus-Torvalds-Started-a-Revolution-on-August-25-1991-Happy-Birthday-Linux-456212.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:https://groups.google.com/forum/#!original/comp.os.minix/dlNtH7RRrGA/SwRavCzVE7gJ
|
||||
[2]:http://t.co/mTVApV85gD
|
||||
[3]:https://twitter.com/linuxfoundation/statuses/503799441900314624
|
||||
85
sources/talk/20140828 Interesting facts about Linux.md
Normal file
85
sources/talk/20140828 Interesting facts about Linux.md
Normal file
@ -0,0 +1,85 @@
|
||||
Interesting facts about Linux
|
||||
================================================================================
|
||||
Today, August, 25th, is the 23rd birthday of Linux. The modest [Usenet post][1] made by a 21 year old student at the University of Helsinki on August 25th, 1991, marks the birth of the venerable Linux as we know it today.
|
||||
|
||||
Fast forward 23 years, and now Linux is everywhere, not only installed on end user desktops, [smartphones][2] and embedded systems, but also fulfilling the needs of [leading enterprises][3] and powering mission-critical systems such as [US Navy's nuclear submarines][4] and [FAA's air traffic control][5]. Entering the era of ubiquitous cloud computing, Linux is continuing [its dominance][6] as by far the most popular platform for the cloud.
|
||||
|
||||
Celebrating the 23rd birthday of Linux today, let me show you **some interesting facts and history you may not know about Linux**. If there is anything to add, feel free to share it in the comments. In this article, I will use the terms "Linux", "kernel" or "Linux kernel" interchangeably to mean the same thing.
|
||||
|
||||
1. There is a never-ending debate on whether or not Linux is an operating system. Technically, the term "Linux" refers to the kernel, a core component of an operating system. Folks who argue that Linux is not an operating system are operating system purists who think that the kernel alone does not make the whole operating system, or free software ideologists who believe that the largest free operating system should be named "[GNU/Linux][7]" to give credit where credit is due (i.e., [GNU project][8]). On the other hand, some developers and programmers have a view that Linux qualifies as an operating system in a sense that it implements the [POSIX standard][9].
|
||||
|
||||
2. According to openhub.net, the majority (95%) of Linux is written in C language. The second popular language for Linux is assembly language (2.8%). The dominance of C lanaguage over C++ is no surprise given Linus's stance on C++. Here is the programming language breakdown for Linux.
|
||||
|
||||

|
||||
|
||||
3. Linux has been built by a total of [13,036 contributors][10] worldwide. The most prolific contributor is, of course, Linus Torvalds himself, who has committed code more than 20,000 times over the course of the lifetime of Linux. The following figures show the all-time top-10 contributors of Linux in terms of commit counts.
|
||||
|
||||

|
||||
|
||||
4. The total source lines of code (SLOC) of Linux is over 17 million. The estimated cost for the entire code base is 5,526 person-years, or over 300M USD according to [basic COCOMO model][11].
|
||||
|
||||
5. Enterprises have not been simply consumers of Linux. Their employees have been [actively participated][12] in the development of Linux. The figure below shows the top-10 corporate sponsors of Linux kernel development, in terms of total commit counts from their employees, as of year 2013. They include commercial Linux distributors (Red Hat, SUSE), chip/embedded system makers (Intel, Texas Instruments, Wolfson), non-profits (Linaro), and other IT power houses (IBM, Samsung, Google).
|
||||
|
||||
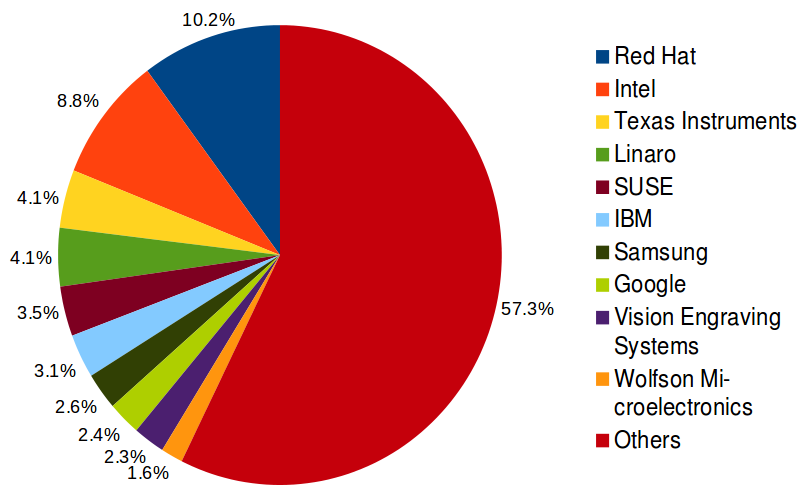
|
||||
|
||||
6. The official mascot of Linux is "Tux", a friendly penguin character. The idea of using a cuddly penguin as a mascot/logo was in fact [first conceived and asserted][13] by Linus himself. Why penguin? Personally Linus is fond of penguins, despite the fact that he once was bitten by a ferocious penguin, causing him infected with a disease.
|
||||
|
||||
7. A Linux "distribution" contains the Linux kernel, supporting GNU utilities/libraries, and other third-party applications. According to [distrowatch.com][14], there are a total of 286 actively maintained Linux distrutions. The oldest among them is [Slackware][15] whose very first release 1.0 became available in 1993.
|
||||
|
||||
8. Kernel.org, which is the main repository of Linux source code, was [compromised][16] by an unknown attacker in August, 2011, who managed to tamper with several kernel.org's servers. In an effort to tighten up access policies of the Linux kernel, Linux foundation recently [turned on][17] two-factor authentication at the official Git repositories hosting the Linux kernel.
|
||||
|
||||
9. The dominance of Linux on top 500 supercomputers [continues to rise][18]. As of June 2014, 97% of the world-fastest computers are powered by Linux.
|
||||
|
||||
10. Spacewatch, a research group of Lunar and Planetary Laboratory at the University of Arizona, named several asteroids ([9793 Torvalds][19], [9882 Stallman][20], [9885 Linux][21] and [9965 GNU][22]) after GNU/Linux and their creators, in recognition of the free operating system which was instrumental in their asteroid survey activities.
|
||||
|
||||
11. In the modern history of Linux kernel development, there was a big jump in kernel version: from 2.6 to 3.0. The [renumbering to version 3][23] actually did not signify any major restructuring in kernel code, but was simply to celebrate the 20 year milestone of the Linux kernel.
|
||||
|
||||
12. In 2000, Steve Jobs at Apple Inc. [tried to hire][24] Linus Torvalds to have him drop Linux development and instead work on "Unix for the biggest user base," which was OS X back then. Linus declined the offer.
|
||||
|
||||
13. The [reboot()][25] system call in the Linux kernel requires two magic numbers. The second magic number comes from the [birth dates][26] of Linus Torvalds and his three daughters.
|
||||
|
||||
14. With so many fans of Linux around the world, there are [criticisms][27] on current Linux distributions (mainly desktops), such as limited hardware support, lack of standardization, instability due to short upgrade/release cycles, etc. During the [Linux kernel panel][28] at LinuxCon 2014, Linus was quoted as saying "I still want the desktop" when asked where he thinks Linux should go next.
|
||||
|
||||
If you know any interesting facts about Linux, feel free to share them in the comments.
|
||||
|
||||
Happy birthday, Linux!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/interesting-facts-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://groups.google.com/forum/message/raw?msg=comp.os.minix/dlNtH7RRrGA/SwRavCzVE7gJ
|
||||
[2]:http://developer.android.com/about/index.html
|
||||
[3]:http://fortune.com/2013/05/06/how-linux-conquered-the-fortune-500/
|
||||
[4]:http://www.linuxjournal.com/article/7789
|
||||
[5]:http://fcw.com/Articles/2006/05/01/FAA-manages-air-traffic-with-Linux.aspx
|
||||
[6]:http://thecloudmarket.com/stats
|
||||
[7]:http://www.gnu.org/gnu/why-gnu-linux.html
|
||||
[8]:http://www.gnu.org/gnu/gnu-history.html
|
||||
[9]:http://en.wikipedia.org/wiki/POSIX
|
||||
[10]:https://www.openhub.net/p/linux/contributors/summary
|
||||
[11]:https://www.openhub.net/p/linux/estimated_cost
|
||||
[12]:http://www.linuxfoundation.org/publications/linux-foundation/who-writes-linux-2013
|
||||
[13]:http://www.sjbaker.org/wiki/index.php?title=The_History_of_Tux_the_Linux_Penguin
|
||||
[14]:http://distrowatch.com/search.php?ostype=All&category=All&origin=All&basedon=All¬basedon=None&desktop=All&architecture=All&status=Active
|
||||
[15]:http://www.slackware.com/info/
|
||||
[16]:http://pastebin.com/BKcmMd47
|
||||
[17]:http://www.linux.com/news/featured-blogs/203-konstantin-ryabitsev/784544-linux-kernel-git-repositories-add-2-factor-authentication
|
||||
[18]:http://www.top500.org/statistics/details/osfam/1
|
||||
[19]:http://ssd.jpl.nasa.gov/sbdb.cgi?sstr=9793
|
||||
[20]:http://ssd.jpl.nasa.gov/sbdb.cgi?sstr=9882
|
||||
[21]:http://ssd.jpl.nasa.gov/sbdb.cgi?sstr=9885
|
||||
[22]:http://ssd.jpl.nasa.gov/sbdb.cgi?sstr=9965
|
||||
[23]:https://lkml.org/lkml/2011/5/29/204
|
||||
[24]:http://www.wired.com/2012/03/mr-linux/2/
|
||||
[25]:http://lxr.free-electrons.com/source/kernel/reboot.c#L199
|
||||
[26]:http://www.nndb.com/people/444/000022378/
|
||||
[27]:http://linuxfonts.narod.ru/why.linux.is.not.ready.for.the.desktop.current.html
|
||||
[28]:https://www.youtube.com/watch?v=8myENKt8bD0
|
||||
@ -0,0 +1,32 @@
|
||||
Linux Doesn't Need to Own the Desktop
|
||||
================================================================================
|
||||
Linus Torvalds issued Linux 3.17 rc-2 on Monday of this week, and [he deviated from his normal schedule][1] in doing so, because August 25 happens to mark the 23rd anniversary of the original Linux announcement. "Hello everybody out there using minix," Torvalds wrote.
|
||||
|
||||
Meanwhile, PCMag.com has proclaimed that [Linux has run out of time][2]. But isn't it true that the endless discussions of whether Linux is a success on the desktop are moot? Linux is in supercomputers and cars, it formed the basis for Android and is the most popular platform to run emerging cloud platforms like OpenStack on--just to name a few of its successes. The desktop is not the only battleground for Linux.
|
||||
|
||||
Jon Buys took note of specialization and the Linux desktop [in a recent post][3], where he wrote:
|
||||
|
||||
> "Recently, IT World asked “[Does it still make sense for Linus to want the desktop for Linux?][4]”, and Matt Asay from Tech Repubic asked “[Can we please stop talking about the Linux desktop?][5]”. Both publishers are critical of the claim that there is still room for Linux on Personal Computers, and point to Android as a Linux success story...What both articles miss though is that the flexibility of Linux, and the permissiveness of its open source license may be the things that save Linux on the desktop."
|
||||
|
||||
That may be true, but Linux is so much to so many people beyond the desktop. Linux's opportunity for great market share on the desktop has come and gone.
|
||||
|
||||
The simple fact is that Linux has changed the world and been a tremendous success outside the desktop, and there is nothing wrong with that. Android is hardly the only Linux-based platform that has made a big mark. Linux is huge on servers, in embedded technology, and is a constant prompt for innovation on emerging platforms. Ubuntu is the most popular platform for building OpenStack deployments on. Supercomputers all over the world run Linux, and Chrome OS is based on it.
|
||||
|
||||
So Linux is making a huge difference globally, and it is time for detractors to stop focusing exclusively on its status on the desktop.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ostatic.com/blog/linux-doesnt-need-to-own-the-desktop
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ostatic.com/member/samdean
|
||||
[1]:http://www.theregister.co.uk/2014/08/26/linux_turns_23_and_linus_torvalds_celebrates_as_only_he_can/
|
||||
[2]:http://www.pcmag.com/article2/0,2817,2465125,00.asp
|
||||
[3]:http://ostatic.com/blog/specialization-and-the-linux-desktop
|
||||
[4]:http://www.itworld.com/open-source/432816/does-it-still-make-sense-linus-want-desktop-linux
|
||||
[5]:http://www.techrepublic.com/article/can-we-please-stop-talking-about-the-linux-desktop/
|
||||
@ -1,185 +0,0 @@
|
||||
How to manage DigitalOcean VPS droplets from the command line on Linux
|
||||
================================================================================
|
||||
[DigitalOcean][1] is one of the [hottest][2] new kids in the block in the cloud VPS hosting market. While not offering as comprehensive service portfolio as Amazon Web Services and the likes, DigitalOcean is already a strong contender for the best Linux-based cloud VPS service targeted at small businesses and developers, thanks to their competitive pricing and user-friendly management interface.
|
||||
|
||||

|
||||
|
||||
Whenever you need a web-facing server for your personal project, you can quickly spin up a "droplet" (nickname for a VPS instance at [DigitalOcean][3]). And kill it when it's not needed. No need to burn a hole in your pocket as you are charged for its up time. While DigitalOcean's web-based management interface is streamlined already, for those of you who are die-hard fans of command-line interface (CLI), there is a CLI-based droplet management tool called [Tugboat][4]. Thanks to this CLI tool, any complex droplet management task can easily be turned into a script.
|
||||
|
||||
In this tutorial, I am going to describe **how to use Tugboat to manage DigitalOcean dropets from the command line**.
|
||||
|
||||
### Install Tugboat on Linux ###
|
||||
|
||||
To install Tugboat on Debian, Ubuntu or Linux Mint:
|
||||
|
||||
$ sudo apt-get install ruby-dev
|
||||
$ sudo gem install tugboat
|
||||
|
||||
To install Tugboat on Fedora:
|
||||
|
||||
$ sudo yum install ruby-devel
|
||||
$ sudo gem install tugboat
|
||||
|
||||
To install Tugboat on CentOS, first [install or upgrade to the latest Ruby][5], because on CentOS 6.5 and earlier, the default Ruby does not meet the minimum version requirement (1.9 and higher) for Tugboat. Once you install Ruby 1.9 and higher, install Tugboat as follows.
|
||||
|
||||
$ sudo gem install tugboat
|
||||
|
||||
### Configure Tugboat for the First Time ###
|
||||
|
||||
After installation, it's time to go through one-time configuration, which involves authorizing Tugboat to access your DigitalOcean account.
|
||||
|
||||
Go to [https://cloud.digitalocean.com/api_access][6], and create a new API key. Make a note of client ID and API key.
|
||||
|
||||

|
||||
|
||||
Start authorization process by running:
|
||||
|
||||
$ tugboat authorize
|
||||
|
||||
When prompted, enter your client ID and API key. It will ask you several other questions. You can accept default answers for now. We are going to customize the default settings later anyway.
|
||||
|
||||
[][7]
|
||||
|
||||
Now let's customize default droplet settings to reflect your typical use cases. For that, first check available droplet offerings (e.g., available images, regions, sizes).
|
||||
|
||||
Running the command below will show you a list of available droplet images. Pick a default image to use, and make a note of the corresponding ID.
|
||||
|
||||
$ tugboat images --global
|
||||
|
||||

|
||||
|
||||
Similarly, pick a default geographic location from available regions:
|
||||
|
||||
$ tugboat regions
|
||||
|
||||
Also, choose a default droplet size from available RAM sizes:
|
||||
|
||||
$ tugboat sizes
|
||||
|
||||

|
||||
|
||||
Now put your default choices in ~/.tugboat. For example, here I customize my default settings to 512MB Ubuntu 14.04 x64 to be created in New York region. Set "ssh_user" to root if you want to enable SSH via key authentication, which will be described shortly.
|
||||
|
||||
$ vi ~/.tugboat
|
||||
|
||||
----------
|
||||
|
||||
---
|
||||
authentication:
|
||||
client_key: XXXXXXXXXXXXXXXXXXX
|
||||
api_key: XXXXXXXXXXXXXXXXXXXX
|
||||
ssh:
|
||||
ssh_user: root
|
||||
ssh_key_path: /home/dev/.ssh/id_rsa
|
||||
ssh_port: '22'
|
||||
defaults:
|
||||
region: '4'
|
||||
image: '3240036'
|
||||
size: '66'
|
||||
ssh_key: ''
|
||||
private_networking: 'false'
|
||||
backups_enabled: 'false'
|
||||
|
||||
### Create and Add SSH Key to DigitalOcean ###
|
||||
|
||||
A secure way to access your droplet instance is to SSH to the instance via [key authentication][8].
|
||||
|
||||
In fact, you can automatically enable key authentication for your droplets by registering your SSH public key with [DigitalOcean][9]. Here is how to do it.
|
||||
|
||||
First, generate a private/public SSH key pair (if you don't have one).
|
||||
|
||||
$ ssh-keygen -t rsa -C "your@emailaddress.com"
|
||||
|
||||
Assuming that the generated key pair consists of: ~/.ssh/id_rsa (private key) and ~/.ssh/id_rsa.pub (public key), go ahead and upload your public key by running:
|
||||
|
||||
$ tugboat add-key [name-of-your-key]
|
||||
|
||||
You can give your key any name you like (e.g., "my-default-key"). When prompted, enter the path to your public key (e.g., /home/user/.ssh/id_rsa.pub). After key uploading is completed, verify the key is successfully added by running:
|
||||
|
||||
$ tugboat keys
|
||||
|
||||

|
||||
|
||||
The key should also appear in DigitalOcean's [SSH key page][10]. If you want the key to be automatically used for your droplets, add the ID of your key to ~/.tugboat.
|
||||
|
||||
ssh_key: '182710'
|
||||
|
||||
### Basic Usage of Tugboat ###
|
||||
|
||||
Here are a few basic use cases of tugboat command line.
|
||||
|
||||
1. Create a new droplet with default settings.
|
||||
|
||||
$ tugboat create <name-of-droplet>
|
||||
|
||||
2. Show a list of all active droplets.
|
||||
|
||||
$ tugboat droplets
|
||||
|
||||
3. Display information about a droplet.
|
||||
|
||||
$ tugboat info <name-of-droplet>
|
||||
|
||||
[][11]
|
||||
|
||||
4. Shutdown a droplet, and remove its image.
|
||||
|
||||
$ tugboat destroy <name-of-droplet>
|
||||
|
||||
5. Shutdown a droplet, but keep its image
|
||||
|
||||
$ tugboat halt <name-of-droplet>
|
||||
|
||||
6. Take a snapshot of a droplet. The droplet must be turned off first.
|
||||
|
||||
$ tugboat snapshot <snapshot-name> <name-of-droplet>
|
||||
|
||||
7. Resize (increase or decrease the RAM size of) a droplet. The droplet must be shutdown first.
|
||||
|
||||
$ tugboat resize <name-of-droplet> -s <image-id>
|
||||
|
||||
If you want to know more about a particular command option, run:
|
||||
|
||||
$ tugboat help <command>
|
||||
|
||||

|
||||
|
||||
### Troubleshooting ###
|
||||
|
||||
1. When I run tugboat command, it fails with the following error.
|
||||
|
||||
/usr/lib/ruby/site_ruby/1.8/rubygems/custom_require.rb:31:in `gem_original_require': /usr/lib/ruby/gems/1.8/gems/tugboat-0.2.0/lib/tugboat/cli.rb:12: syntax error, unexpected ':', expecting kEND (SyntaxError)
|
||||
|
||||
Tugboat requires Ruby 1.9 and higher. You need to upgrade Ruby to solve this problem. For CentOS, refer to [this tutorial][12].
|
||||
|
||||
2. When I try to install Tugboat with gem, I get the following error.
|
||||
|
||||
/usr/local/share/ruby/site_ruby/rubygems/core_ext/kernel_require.rb:55:in `require': cannot load such file -- json/pure (LoadError)
|
||||
|
||||
Install the following gem to fix the problem.
|
||||
|
||||
$ sudo gem install json_pure
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/07/manage-digitalocean-vps-droplets-command-line-linux.html
|
||||
|
||||
原文作者:[Dan Nanni][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/go/digitalocean
|
||||
[2]:http://news.netcraft.com/archives/2013/12/11/digitalocean-now-growing-faster-than-amazon.html
|
||||
[3]:http://xmodulo.com/go/digitalocean
|
||||
[4]:https://github.com/pearkes/tugboat
|
||||
[5]:http://ask.xmodulo.com/upgrade-ruby-centos.html
|
||||
[6]:https://cloud.digitalocean.com/api_access
|
||||
[7]:https://www.flickr.com/photos/xmodulo/14685122101/
|
||||
[8]:http://xmodulo.com/2012/04/how-to-enable-ssh-login-without.html
|
||||
[9]:http://xmodulo.com/go/digitalocean
|
||||
[10]:https://cloud.digitalocean.com/ssh_keys
|
||||
[11]:https://www.flickr.com/photos/xmodulo/14501627440/
|
||||
[12]:http://ask.xmodulo.com/upgrade-ruby-centos.html
|
||||
@ -1,198 +0,0 @@
|
||||
[sailing]
|
||||
How to install Puppet server and client on CentOS and RHEL
|
||||
================================================================================
|
||||
As a system administrator acquires more and more systems to manage, automation of mundane tasks gets quite important. Many administrators adopted the way of writing custom scripts, that are simulating complex orchestration software. Unfortunately, scripts get obsolete, people who developed them leave, and without an enormous level of maintenance, after some time these scripts will end up unusable. It is certainly more desirable to share a system that everyone can use, and invest in tools that can be used regardless of one's employer. For that we have several systems available, and in this howto you will learn how to use one of them - Puppet.
|
||||
|
||||
### What is Puppet? ###
|
||||
|
||||
Puppet is an automation software for IT system administrators and consultants. It allows you to automate repetitive tasks such as the installation of applications and services, patch management, and deployments. Configuration for all resources are stored in so called "manifests", that can be applied to multiple machines or just a single server. If you would like to know more information, The Puppet Labs site has a more complete description of [what Puppet is and how it works][1].
|
||||
|
||||
### What are we going to achieve in this tutorial? ###
|
||||
|
||||
We will install and configure a Puppet server, and set up some basic configuration for our client servers. You will discover how to write and manage Puppet manifests and how to push it into your servers.
|
||||
|
||||
### Prerequisites ###
|
||||
|
||||
Since Puppet is not in basic CentOS or RHEL distribution repositories, we have to add a custom repository provided by Puppet Labs. On all servers in which you want to use Puppet, install the repository by executing following command (RPM file name can change with new release):
|
||||
|
||||
**On CentOS/RHEL 6.5:**
|
||||
|
||||
# rpm -ivh https://yum.puppetlabs.com/el/6.5/products/x86_64/puppetlabs-release-6-10.noarch.rpm
|
||||
|
||||
**On CentOS/RHEL 7:**
|
||||
|
||||
# rpm -ivh https://yum.puppetlabs.com/el/7/products/x86_64/puppetlabs-release-7-10.noarch.rpm
|
||||
|
||||
### Server Installation ###
|
||||
|
||||
Install the package "puppet-server" on the server you want to use as a master.
|
||||
|
||||
# yum install puppet-server
|
||||
|
||||
When the installation is done, set the Puppet server to automatically start on boot and turn it on.
|
||||
|
||||
# chkconfig puppetmaster on
|
||||
# service puppetmaster start
|
||||
|
||||
Now when we have the server working, we need to make sure that it is reachable from our network.
|
||||
|
||||
On CentOS/RHEL 6, where iptables is used as firewall, add following line into section ":OUTPUT ACCEPT" of /etc/sysconfig/iptables.
|
||||
|
||||
> -A INPUT -m state --state NEW -m tcp -p tcp --dport 8140 -j ACCEPT
|
||||
|
||||
To apply this change, it's necessary to restart iptables.
|
||||
|
||||
# service iptables restart
|
||||
|
||||
On CentOS/RHEL 7, where firewalld is used, the same thing can be achieved by:
|
||||
|
||||
# firewall-cmd --permanent --zone=public --add-port=8140/tcp
|
||||
# firewall-cmd --reload
|
||||
|
||||
### Client Installation ###
|
||||
|
||||
Install the Puppet client package on your client nodes by executing the following:
|
||||
|
||||
# yum install puppet
|
||||
|
||||
When the installation finishes, make sure that Puppet will start after boot.
|
||||
|
||||
# chkconfig puppet on
|
||||
|
||||
Your Puppet client nodes have to know where the Puppet master server is located. The best practice for this is to use a DNS server, where you can configure the Puppet domain name. If you don't have a DNS server running, you can use the /etc/hosts file, by simply adding the following line:
|
||||
|
||||
> 1.2.3.4 server.your.domain
|
||||
|
||||
> 2.3.4.5 client-node.your.domain
|
||||
|
||||
1.2.3.4 corresponds to the IP address of your Puppet master server, "server.your.domain" is the domain name of your master server (the default is usually the server's hostname), "client-node.your.domain" is your client node. This hosts file should be configured accordingly on all involved servers (both Puppet master and clients).
|
||||
|
||||
When you are done with these settings, we need to show the Puppet client what is its master. By default Puppet looks for a server called "puppet", but this setting is usually inappropriate for your network configuration, therefore we will exchange it for the proper FQDN of the Puppet master server. Open the file /etc/sysconfig/puppet and change the "PUPPET_SERVER" value to your Puppet master server domain name specified in /etc/hosts:
|
||||
|
||||
> PUPPET_SERVER=server.your.domain
|
||||
|
||||
The master server name also has to be defined in the section "[agent]" of /etc/puppet/puppet.conf:
|
||||
|
||||
> server=server.your.domain
|
||||
|
||||
Now you can start your Puppet client:
|
||||
|
||||
# service puppet start
|
||||
|
||||
We need to force our client to check in with the Puppet master by using:
|
||||
|
||||
# puppet agent --test
|
||||
|
||||
You should see something like the following output. Don't panic, this is desired as the server is still not verified on the Puppet master server.
|
||||
|
||||
> Exiting; no certificate found and waitforcert is disabled
|
||||
|
||||
Go back to your puppet master server and check certificate verification requests:
|
||||
|
||||
# puppet cert list
|
||||
|
||||
You should see a list of all the servers that requested a certificate signing from your puppet master. Find the hostname of your client server and sign it using the following command (client-node is the domain name of your client node):
|
||||
|
||||
# puppet cert sign client-node
|
||||
|
||||
At this point you have a working Puppet client and server. Congratulations! However, right now there is nothing for the Puppet master to instruct the client to do. So, let's create some basic manifest and set our client node to install basic utilities.
|
||||
|
||||
Connect back to your Puppet server and make sure the directory /etc/puppet/manifests exists.
|
||||
|
||||
# mkdir -p /etc/puppet/manifests
|
||||
|
||||
Now create the manifest file /etc/puppet/manifests/site.pp with the following content
|
||||
|
||||
node 'client-node' {
|
||||
include custom_utils
|
||||
}
|
||||
|
||||
class custom_utils {
|
||||
package { ["nmap","telnet","vim-enhanced","traceroute"]:
|
||||
ensure => latest,
|
||||
allow_virtual => false,
|
||||
}
|
||||
}
|
||||
|
||||
and restart the puppetmaster service.
|
||||
|
||||
# service puppetmaster restart
|
||||
|
||||
The default refresh interval of the client configuration is 30 minutes, if you want to force the application of your changes manually, execute the following command on your client node:
|
||||
|
||||
# puppet agent -t
|
||||
|
||||
If you would like to change the default client refresh interval, add:
|
||||
|
||||
> runinterval = <yourtime>
|
||||
|
||||
to the "[agent]" section of /etc/puppet/puppet.conf on your client node. This setting can be a time interval in seconds (30 or 30s), minutes (30m), hours (6h), days (2d), or years (5y). Note that a runinterval of 0 means "run continuously" rather than "never run".
|
||||
|
||||
### Tips & Tricks ###
|
||||
|
||||
#### 1. Debugging ####
|
||||
|
||||
It can happen from time to time that you will submit a wrong configuration and you have to debug where the Puppet failed. For that you will always start with either checking logs in /var/log/puppet/ or running the agent manually to see the output:
|
||||
|
||||
# puppet agent -t
|
||||
|
||||
By default "-t" activates verbose mode, so it allows you to see the output of Puppet. This command also has several parameters that might help you identify your problem a bit more. The first useful option is:
|
||||
|
||||
# puppet agent -t --debug
|
||||
|
||||
Debug shows you basically all steps that Puppet goes through during its runtime. It can be really useful during debug of really complicated rules. Another parameter you might find really useful is:
|
||||
|
||||
# puppet agent -t --noop
|
||||
|
||||
This option sets puppet in so called dry-run mode, where no changes are performed. Puppet only writes what it would do on the screen but nothing is written on the disk.
|
||||
|
||||
#### 2. Modules ####
|
||||
|
||||
After some time you find yourself in the situation where you will want to have more complicated manifests. But before you will sit down and start to program them, you should invest some time and browse [https://forge.puppetlabs.com][2]. Forge is a repository of the Puppet community modules and it's very likely that you find the solution for your problem already made there. If not, feel free to write your own and submit it, so other people can benefit from the Puppet modularity.
|
||||
|
||||
Now, let's assume that you have already found a module that would fix your problem. How to install it into the system? It is actually quite easy, because Puppet already contains an interface to download modules directly. Simply type the following command:
|
||||
|
||||
# puppet module install <module_name> --version 0.0.0
|
||||
|
||||
<module_name> is the name of your chosen module, the version is optional (if not specified then the latest release is taken). If you don't remember the name of the module you want to install, you can try to find it by using module search:
|
||||
|
||||
# puppet module search <search_string>
|
||||
|
||||
As a result you will get a list of all modules that contain your search string.
|
||||
|
||||
# puppet module search apache
|
||||
|
||||
----------
|
||||
|
||||
Notice: Searching https://forgeapi.puppetlabs.com ...
|
||||
NAME DESCRIPTION AUTHOR KEYWORDS
|
||||
example42-apache Puppet module for apache @example42 example42, apache
|
||||
puppetlabs-apache Puppet module for Apache @puppetlabs apache web httpd centos rhel ssl wsgi proxy
|
||||
theforeman-apache Apache HTTP server configuration @theforeman foreman apache httpd DEPRECATED
|
||||
|
||||
And if you would like to see what modules you already installed, type:
|
||||
|
||||
# puppet module list
|
||||
|
||||
### Summary ###
|
||||
|
||||
By now, you should have a fully functional Puppet master that is delivering basic configuration to one or more client servers. At this point feel free to add more settings into your configuration to adapt it to your infrastructure. Don't worry about experimenting with Puppet and you will see that it can be a genuine lifesaver.
|
||||
|
||||
Puppet labs is trying to maintain a top quality documentation for their projects, so if you would like to learn more about Puppet and its configuration, I strongly recommend visiting the Puppet project page at [http://docs.puppetlabs.com][3].
|
||||
|
||||
If you have any questions feel free to post them in the comments and I will do my best to answer and advise.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/install-puppet-server-client-centos-rhel.html
|
||||
|
||||
作者:[Jaroslav Štěpánek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/jaroslav
|
||||
[1]:https://puppetlabs.com/puppet/what-is-puppet/
|
||||
[2]:https://forge.puppetlabs.com/
|
||||
[3]:http://docs.puppetlabs.com/
|
||||
@ -1,68 +0,0 @@
|
||||
Disable / Password Protect Single User Mode / RHEL / CentOS / 5.x / 6.x
|
||||
================================================================================
|
||||
Hello All,
|
||||
|
||||
If you have not protected Single User Mode with Password then it is big risk for your Linux Server, So protecting Single User Mode with Password is very important when it comes to security,
|
||||
|
||||
Today in this article i will show you how you can protect Single User Mode with Password on RHEL / CentOS 5.x and RHEL / CentOS 6.x.
|
||||
|
||||
Please execute given commands carefully else your system will not boot properly. First i would request you to read full procedure and then try to follow. Do it at your own risk :-)
|
||||
|
||||

|
||||
Password Protect
|
||||
|
||||
### 1. For RHEL / CentOS 5.x ###
|
||||
|
||||
#### 1.1 Before doing anything please take backup of your /etc/inittab ####
|
||||
|
||||
cp /etc/inittab /etc/inittab.backup
|
||||
|
||||
**To Disable and Make Single User Mode Password Protected, Execute below command as root :-**
|
||||
|
||||
[root@tejas-barot-linux ~]$ sed -i '1i su:S:wait:/sbin/sulogin'
|
||||
|
||||
**So It will look like below**
|
||||
|
||||
su:S:wait:/sbin/sulogin
|
||||
# Default runlevel. The runlevels used by RHS are:
|
||||
# 0 - halt (Do NOT set initdefault to this)
|
||||
# 1 - Single user mode
|
||||
# 2 - Multiuser, without NFS (The same as 3, if you do not have networking)
|
||||
# 3 - Full multiuser mode
|
||||
# 4 - unused
|
||||
# 5 - X11
|
||||
# 6 - reboot (Do NOT set initdefault to this)
|
||||
#
|
||||
id:3:initdefault:
|
||||
|
||||
*NOTE: If you do not want to use sed command then You can always add “su:S:wait:/sbin/sulogin” at top in /etc/inittab*
|
||||
|
||||
### 2. For RHEL / CentOS 6.x ###
|
||||
|
||||
#### 2.1 Before doing anything please take backup of your /etc/inittab ####
|
||||
|
||||
cp /etc/sysconfig/init /etc/sysconfig/init.backup
|
||||
|
||||
#### 2.2 To Disable and Make Single User Mode Password Protected, Execute below command as root :- ####
|
||||
|
||||
[root@tejas-barot-linux ~]$#sed -i 's/SINGLE=\/sbin\/sushell/SINGLE=\/sbin\/sulogin/' /etc/sysconfig/init
|
||||
|
||||
**So It will look like below**
|
||||
|
||||
SINGLE=/sbin/sulogin
|
||||
|
||||
*NOTE :- If you do not want to use sed command then You can always change to “SINGLE=/sbin/sulogin” in /etc/sysconfig/init*
|
||||
|
||||
Enjoy Linux :) Enjoy Open Source
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tejasbarot.com/2014/05/05/disable-password-protect-single-user-mode-rhel-centos-5-x-6-x/#axzz39oGCBRuX
|
||||
|
||||
作者:[Tejas Barot][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/+TejasBarot
|
||||
@ -1,111 +0,0 @@
|
||||
How to remove file metadata on Linux
|
||||
================================================================================
|
||||
A typical data file often has associated "metadata" which is descriptive information about the file, represented in the form of a set of name-value pairs. Common metadata include creator's name, tools used to generate the file, file creation/update date, location of creation, editing history, etc. EXIF (images), RDF (web resources), DOI (digital documents) are some of popular metadata standards.
|
||||
|
||||
While metadata has its own merits in data management fields, it can actually affect your privacy [adversely][1]. EXIF data in photo images can reveal personally identifiable information such as your camera model, GPS coordinate of shooting, your favorite photo editor software, etc. Metadata in documents and spreadsheets contain author/affiliation information and other editing history. Not to be paranoid, but metadata gathering tools such as [metagoofil][2] are often exploited during information gathering stage as part of penetration testing.
|
||||
|
||||
For those of you who want to strip any personalizing metadata from any shared data, there are ways to remove metadata from data files. You can use existing document or image editor software which typically have built-in metadata editing capability. In this tutorial, let me introduce a nice standalone **metadata cleaner tool** which is developed for a single goal: **anonymize all metadata for your privacy**.
|
||||
|
||||
[MAT][3] (Metadata Anonymisation Toolkit) is a dedicated metadata cleaner written in Python. It was developed under the umbrella of the Tor project, and comes standard on [Tails][4], privacy-enhanced live OS.
|
||||
|
||||
Compared to other tools such as [exiftool][5] which can write to only a limited number of file types, MAT can eliminate metadata from all kinds of files: images (png, jpg), documents (odt, docx, pptx, xlsx, pdf), archives (tar, tar.bz2), audio (mp3, ogg, flac), etc.
|
||||
|
||||
### Install MAT on Linux ###
|
||||
|
||||
On Debian-based systems (Ubuntu or Linux Mint), MAT comes packaged, so installation is straightforward:
|
||||
|
||||
$ sudo apt-get install mat
|
||||
|
||||
On Fedora, MAT does not come as a pre-built package, so you need to build it from the source. Here is how I built MAT on Fedora (with some limited success; see the bottom of the tutorial):
|
||||
|
||||
$ sudo yum install python-devel intltool python-pdfrw perl-Image-ExifTool python-mutagen
|
||||
$ sudo pip install hachoir-core hachoir-parser
|
||||
$ wget https://mat.boum.org/files/mat-0.5.tar.xz
|
||||
$ tar xf mat-0.5.tar.xz
|
||||
$ cd mat-0.5
|
||||
$ python setup.py install
|
||||
|
||||
### Anonymize Metadata with MAT-GUI ###
|
||||
|
||||
Once installed, MAT can be accessible via GUI as well as from the command line. To launch MAT's GUI, simply type:
|
||||
|
||||
$ mat-gui
|
||||
|
||||
Let's clean up a sample document file (e.g., private.odt) which has the following metadata embedded.
|
||||
|
||||
|
||||
|
||||
To add the file to MAT for cleanup, click on "Add" icon. Once the file is loaded, click on "Check" icon to scan for any hidden metadata information.
|
||||
|
||||
|
||||
|
||||
Once any metadata is detected by MAT, "State" will be marked as "Dirty". You can double click the file to see detected metadata.
|
||||
|
||||
|
||||
|
||||
To clean up metadata from the file, click on "Clean" icon. MAT will automatically empty all private metadata fields from the file.
|
||||
|
||||
|
||||
|
||||
The cleaned up state is without any personally identifiable traces:
|
||||
|
||||
|
||||
|
||||
### Anonymize Metadata from the Command Line ###
|
||||
|
||||
As mentioned before, another way to invoke MAT is from the command line, and for that, use mat command.
|
||||
|
||||
To check for any sensitive metadata, first go to the directory where your files are located, and then run:
|
||||
|
||||
$ mat -c .
|
||||
|
||||
It will scan all files in the current directory and its sub directories, and report their state (clean or unclean).
|
||||
|
||||
|
||||
|
||||
You can check actual metadata detected by using '-d' option:
|
||||
|
||||
$ mat -d <input_file>
|
||||
|
||||
|
||||
|
||||
If you don't supply any option with mat command, the default action is to remove metadata from files. If you want to keep a backup of original files during cleanup, use '-b' option. The following command cleans up all files, and stores original files as '*.bak" files.
|
||||
|
||||
$ mat -b .
|
||||
|
||||
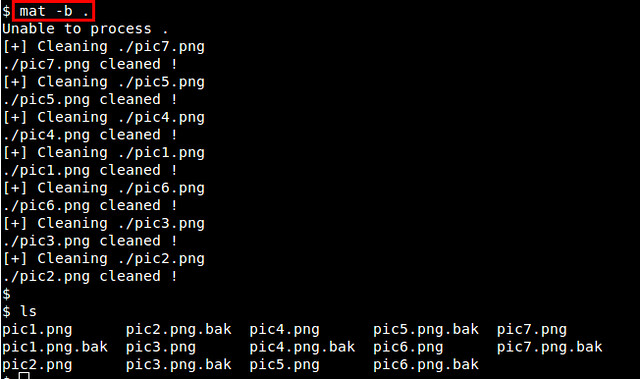
|
||||
|
||||
To see a list of all supported file types, run:
|
||||
|
||||
$ mat -l
|
||||
|
||||
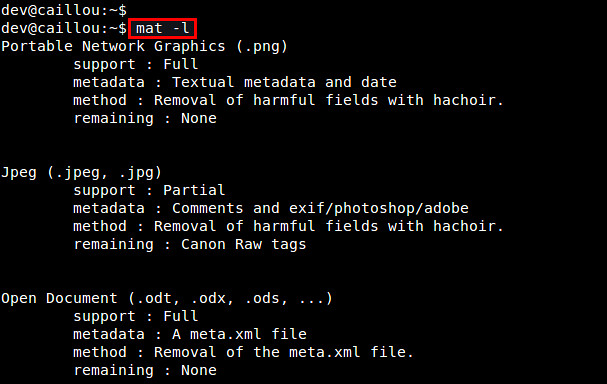
|
||||
|
||||
### Troubleshooting ###
|
||||
|
||||
Currently I have the following issue with a compiled version of MAT on Fedora. When I attempt to clean up archive/document files (e.g., *.gz, *.odt, *.docx) on Fedora, MAT fails with the following error. If you know how to fix this problem, let me know in the comment.
|
||||
|
||||
File "/usr/lib64/python2.7/zipfile.py", line 305, in __init__
|
||||
raise ValueError('ZIP does not support timestamps before 1980')
|
||||
ValueError: ZIP does not support timestamps before 1980
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
MAT is a simple, yet extremely useful tool to prevent any inadvertent privacy leaks from metadata. Note that it is still your responsibility to anonymize file content, if necessary. All MAT does is to eliminate metadata associated with your files, but does nothing with the files themselves. In short, MAT can be a life saver as it can handle most common metadata removal, but you shouldn't rely solely on it to guarantee your privacy.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/remove-file-metadata-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://www.theguardian.com/world/2013/sep/30/nsa-americans-metadata-year-documents
|
||||
[2]:http://code.google.com/p/metagoofil/
|
||||
[3]:https://mat.boum.org/
|
||||
[4]:https://tails.boum.org/
|
||||
[5]:http://xmodulo.com/2013/08/view-or-edit-pdf-and-image-metadata-from-command-line-on-linux.html
|
||||
@ -1,120 +0,0 @@
|
||||
How to configure Access Control Lists (ACLs) on Linux
|
||||
================================================================================
|
||||
Working with permissions on Linux is rather a simple task. You can define permissions for users, groups or others. This works really well when you work on a desktop PC or a virtual Linux instance which typically doesn't have a lot of users, or when users don't share files among themselves. However, what if you are a big organization where you operate NFS or Samba servers for diverse users. Then you will need to be neat picky and set up more complex configurations and permissions to meet the requirements of your organization.
|
||||
|
||||
Linux (and other Unixes, that are POSIX compliant) has so-called Access Control Lists (ACLs), which are a way to assign permissions beyond the common paradigm. For example, by default you apply three permission groups: owner, group, and others. With ACLs, you can add permissions for other users or groups that are not simple "others" or any other group that the owner is not part of it. You can allow particular users A, B and C to have write permissions without letting their whole group to have writing permission.
|
||||
|
||||
ACLs are available for a variety of Linux filesystems including ext2, ext3, ext4, XFS, Btfrs, etc. If you are not sure if the filesystem you are using supports ACLs, just read the documentation.
|
||||
|
||||
### Enable ACLs on your Filesystem ###
|
||||
|
||||
First of all, we need to install the tools to manage ACLs.
|
||||
|
||||
On Ubuntu/Debian:
|
||||
|
||||
$ sudo apt-get install acl
|
||||
|
||||
On CentOS/Fedora/RHEL:
|
||||
|
||||
# yum -y install acl
|
||||
|
||||
On Archlinux:
|
||||
|
||||
# pacman -S acl
|
||||
|
||||
For demonstration purpose, I will use Ubuntu server, but other distributions should work the same.
|
||||
|
||||
After installing ACL tools, it is necessary to enable ACL feature on our disk partitions so that we can start using it.
|
||||
|
||||
First, we can check if ACL feature is already enabled:
|
||||
|
||||
$ mount
|
||||
|
||||
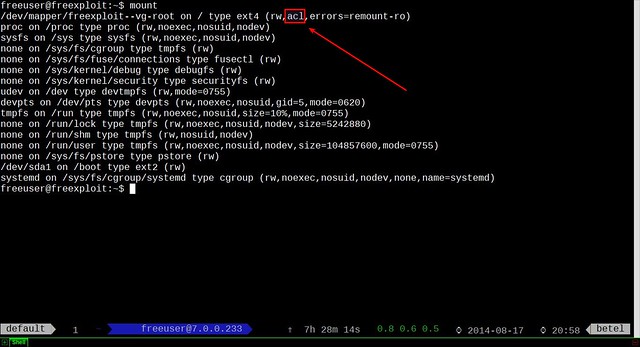
|
||||
|
||||
As you noticed, my root partition has the ACL attribute enabled. In case yours doesn't, you need to edit your /etc/fstab file. Add acl flag in front of your options for the partition you want to enable ACL.
|
||||
|
||||
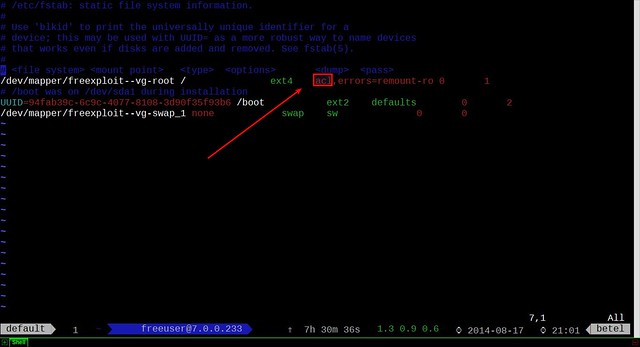
|
||||
|
||||
Now we need to re-mount the partition (I prefer to reboot completely, because I don't like losing data). If you enabled ACL for any other partitions, you have to remount them as well.
|
||||
|
||||
$ sudo mount / -o remount
|
||||
|
||||
Awesome! Now that we have enable ACL in our system, let's start to work with it.
|
||||
|
||||
### ACL Examples ###
|
||||
|
||||
Basically ACLs are managed by two commands: **setfacl** which is used to add or modify ACLs, and getfacl which shows assigned ACLs. Let's do some testing.
|
||||
|
||||
I created a directory /shared owned by a hypothetical user named freeuser.
|
||||
|
||||
$ ls -lh /
|
||||
|
||||
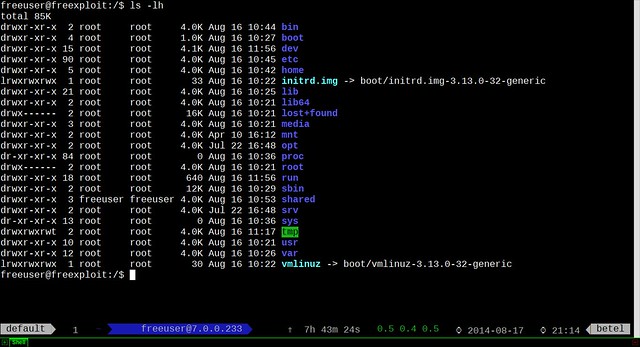
|
||||
|
||||
I want to share this directory with two other users test and test2, one with full permissions and the other with just read permission.
|
||||
|
||||
First, to set ACLs for user test:
|
||||
|
||||
$ sudo setfacl -m u:test:rwx /shared
|
||||
|
||||
Now user test can create directories, files, and access anything under /shared directory.
|
||||
|
||||
|
||||
|
||||
Now we will add read-only permission for user test2:
|
||||
|
||||
$ sudo setfacl -m u:test2:rx /shared
|
||||
|
||||
Note that execution permission is necessary so test2 can read directories.
|
||||
|
||||
|
||||
|
||||
Let me explain the syntax of setfacl command:
|
||||
|
||||
- **-m** means modify ACL. You can add new, or modify existing ACLs.
|
||||
- **u:** means user. You can use **g** to set group permissions.
|
||||
- **test** is the name of the user.
|
||||
- **:rwx** represents permissions you want to set.
|
||||
|
||||
Now let me show you how to read ACLs.
|
||||
|
||||
$ ls -lh /shared
|
||||
|
||||

|
||||
|
||||
As you noticed, there is a + (plus) sign after normal permissions. It means that there are ACLs set up. To actually read ACLs, we need to run:
|
||||
|
||||
$ sudo getfacl /shared
|
||||
|
||||
|
||||
|
||||
Finally if you want to remove ACL:
|
||||
|
||||
$ sudo setfacl -x u:test /shared
|
||||
|
||||
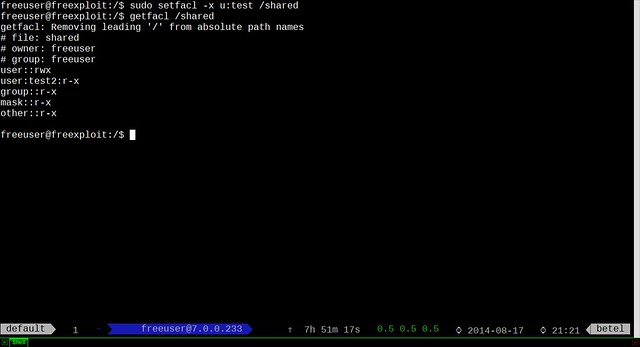
|
||||
|
||||
If you want to wipe out all ACL entries at once:
|
||||
|
||||
$ sudo setfacl -b /shared
|
||||
|
||||

|
||||
|
||||
One last thing. The commands cp and mv can change their behavior when they work over files or directories with ACLs. In the case of cp, you need to add the '-p' parameter to copy ACLs. If this is not posible, it will show you a warning. mv will always move the ACLs, and also if it is not posible, it will show you a warning.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Using ACLs gives you a tremendous power and control over files you want to share, especially on NFS/Samba servers. Moreover, if you administer shared hosting, this tool is a must have.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/configure-access-control-lists-acls-linux.html
|
||||
|
||||
作者:[Christopher Valerio][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/valerio
|
||||
@ -1,3 +1,4 @@
|
||||
[translating by KayGuoWhu]
|
||||
How to Encrypt Email in Linux
|
||||
================================================================================
|
||||
|
||||
|
||||
@ -0,0 +1,49 @@
|
||||
Linux FAQs with Answers--How to enable Nux Dextop repository on CentOS or RHEL
|
||||
================================================================================
|
||||
> **Question**: I would like to install a RPM package which is available only in Nux Dextop repository. How can I set up Nux Dextop repository on CentOS or RHEL?
|
||||
|
||||
[Nux Dextop][1] is a third-party RPM repository which contains many popular desktop and multimedia related packages (e.g., Ardour, Shutter, etc) for CentOS, RHEL and ScientificLinux. Currently, Nux Dextop repository is available for CentOS/RHEL 6 and 7.
|
||||
|
||||
To enable Nux Dextop repository on CentOS or RHEL, follow the instructions below.
|
||||
|
||||
First of all, understand that Nux Dextop is designed to coexist with EPEL repository. So you need to [enable EPEL][2] in order to use Nux Dextop repo.
|
||||
|
||||
After enabling EPEL, go ahead and install Nux Dextop repository with rpm command as follows.
|
||||
|
||||
On CentOS/RHEL 6.*:
|
||||
|
||||
$ sudo rpm -Uvh http://li.nux.ro/download/nux/dextop/el6/x86_64/nux-dextop-release-0-2.el6.nux.noarch.rpm
|
||||
|
||||
On CentOS/RHEL 7:
|
||||
|
||||
$ sudo rpm -Uvh http://li.nux.ro/download/nux/dextop/el7/x86_64/nux-dextop-release-0-1.el7.nux.noarch.rpm
|
||||
|
||||
Now verify that Nux Dextop repository is successfully installed:
|
||||
|
||||
$ yum repolist
|
||||
|
||||
|
||||
|
||||
### For Repoforge/RPMforge Users ###
|
||||
|
||||
According to the author, Nux Dextop is known to cause conflicts with other third-party RPM repos such as Repoforge and ATrpms. Therefore, if you enabled any third-party repos other than EPEL, it is highly recommend you set Nux Dextop repository to "default off" state. That is, open /etc/yum.repos.d/nux-dextop.repo with a text editor, and change "enabled=1" to "enabled=0" under nux-desktop.
|
||||
|
||||
$ sudo vi /etc/yum.repos.d/nux-dextop.repo
|
||||
|
||||
|
||||
|
||||
Then whenever you want to install a package from Nux Dextop repo, explicitly enable the repo as follows.
|
||||
|
||||
$ sudo yum --enablerepo=nux-dextop install <package-name>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/enable-nux-dextop-repository-centos-rhel.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://li.nux.ro/download/nux/dextop/
|
||||
[2]:http://xmodulo.com/2013/03/how-to-set-up-epel-repository-on-centos.html
|
||||
@ -0,0 +1,122 @@
|
||||
20 Postfix Interview Questions & Answers
|
||||
================================================================================
|
||||
### Q:1 What is postfix and default port used for postfix ? ###
|
||||
|
||||
Ans: Postfix is a open source MTA (Mail Transfer agent) which is used to route & deliver emails. Postfix is the alternate of widely used Sendmail MTA. Default port for postfix is 25.
|
||||
|
||||
### Q:2 What is the difference between Postfix & Sendmail ? ###
|
||||
|
||||
Ans: Postfix uses a modular approach and is composed of multiple independent executables. Sendmail has a more monolithic design utilizing a single always running daemon.
|
||||
|
||||
### Q:3 What is MTA and it’s role in mailing system ? ###
|
||||
|
||||
Ans: MTA Stands for Mail Transfer Agent.MTA receives and delivers email. Determines message routing and possible address rewriting. Locally delivered messages are handed off to an MDA for final delivery. Examples Qmail, Postfix, Sendmail
|
||||
|
||||
### Q:4 What is MDA ? ###
|
||||
|
||||
Ans: MDA stands for Mail Delivery Agent. MDA is a Program that handles final delivery of messages for a system's local recipients. MDAs can often filter or categorize messages upon delivery. An MDA might also determine that a message must be forwarded to another email address. Example Procmail
|
||||
|
||||
### Q:5 What is MUA ? ###
|
||||
|
||||
Ans: MUA stands for Mail User Agent. MUA is aEmail client software used to compose, send, and retrieve email messages. Sends messages through an MTA. Retrieves messages from a mail store either directly or through a POP/ IMAP server. Examples Outlook, Thunderbird, Evolution.
|
||||
|
||||
### Q:6 What is the use of postmaster account in Mailserver ? ###
|
||||
|
||||
Ans: An email administrator is commonly referred to as a postmaster. An individual with postmaster responsibilities makes sure that the mail system is working correctly, makes configuration changes, and adds/removes email accounts, among other things. You must have a postmaster alias at all domains for which you handle email that directs messages to the correct person or persons .
|
||||
|
||||
### Q:7 What are the important daemons in postfix ? ###
|
||||
|
||||
Ans : Below are the lists of impportant daemons in postfix mail server :
|
||||
|
||||
- **master** :The master daemon is the brain of the Postfix mail system. It spawns all other daemons.
|
||||
- **smtpd**: The smtpd daemon (server) handles incoming connections.
|
||||
- **smtp** :The smtp client handles outgoing connections.
|
||||
- **qmgr** :The qmgr-Daemon is the heart of the Postfix mail system. It processes and controls all messages in the mail queues.
|
||||
- **local** : The local program is Postfix’ own local delivery agent. It stores messages in mailboxes.
|
||||
|
||||
### Q:8 What are the configuration files of postfix server ? ###
|
||||
|
||||
Ans: There are two main Configuration files of postfix :
|
||||
|
||||
- **/etc/postfix/main.cf** : This file holds global configuration options. They will be applied to all instances of a daemon, unless they are overridden in master.cf
|
||||
- **/etc/postfix/master.cf** : This file defines runtime environment for daemons attached to services. Runtime behavior defined in main.cf may be overridden by setting service specific options.
|
||||
|
||||
### Q:9 How to restart the postfix service & make it enable across reboot ? ###
|
||||
|
||||
Ans: Use this command to restart service “ Service postfix restart” and to make the service persist across the reboot, use the command “ chkconfig postfix on”
|
||||
|
||||
### Q:10 How to check the mail's queue in postfix ? ###
|
||||
|
||||
Ans: Postfix maintains two queues, the pending mails queue, and the deferred mail queue,the deferred mail queue has the mail that has soft-fail and should be retried (Temporary failure), Postfix retries the deferred queue on set intervals (configurable, and by default 5 minutes)
|
||||
|
||||
To display the list of queued mails :
|
||||
|
||||
# postqueue -p
|
||||
|
||||
To Save the output of above command :
|
||||
|
||||
# postqueue -p > /mnt/queue-backup.txt
|
||||
|
||||
Tell Postfix to process the Queue now
|
||||
|
||||
# postqueue -f
|
||||
|
||||
### Q:11 How to delete mails from the queue in postfix ? ###
|
||||
|
||||
Ans: Use below command to delete all queued mails
|
||||
|
||||
# postsuper -d ALL
|
||||
|
||||
To delete only deferred mails from queue , use below command
|
||||
|
||||
# postsuper -d ALL deferred
|
||||
|
||||
### Q:12 How to check postfix configuration from the command line ? ###
|
||||
|
||||
Ans: Using the command 'postconf -n' we can see current configuration of postfix excluding the lines which are commented.
|
||||
|
||||
### Q:13 Which command is used to see live mail logs in postfix ? ###
|
||||
|
||||
Ans: Use the command 'tail -f /var/log/maillog' or 'tailf /var/log/maillog'
|
||||
|
||||
### Q:14 How to send a test mail from command line ? ###
|
||||
|
||||
Ans: Use the below command to send a test mail from postfix itself :
|
||||
|
||||
# echo "Test mail from postfix" | mail -s "Plz ignore" info@something.com
|
||||
|
||||
### Q:15 What is an Open mail relay ? ###
|
||||
|
||||
Ans: An open mail relay is an SMTP server configured in such a way that it allows anyone on the Internet to send e-mail through it, not just mail destined to or originating from known users.This used to be the default configuration in many mail servers; indeed, it was the way the Internet was initially set up, but open mail relays have become unpopular because of their exploitation by spammers and worms.
|
||||
|
||||
### Q:16 What is relay host in postfix ? ###
|
||||
|
||||
Ans: Relay host is the smtp address , if mentioned in postfix config file , then all the incoming mails be relayed through smtp server.
|
||||
|
||||
### Q:17 What is Greylisting ? ###
|
||||
|
||||
Ans: Greylisting is a method of defending e-mail users against spam. A mail transfer agent (MTA) using greylisting will "temporarily reject" any email from a sender it does not recognize. If the mail is legitimate the originating server will, after a delay, try again and, if sufficient time has elapsed, the email will be accepted.
|
||||
|
||||
### Q:18 What is the importance of SPF records in mail servers ? ###
|
||||
|
||||
Ans: SPF (Sender Policy Framework) is a system to help domain owners specify the servers which are supposed to send mail from their domain. The aim is that other mail systems can then check to make sure the server sending email from that domain is authorized to do so – reducing the chance of email 'spoofing', phishing schemes and spam!
|
||||
|
||||
### Q:19 What is the use of Domain Keys(DKIM) in mail servers ? ###
|
||||
|
||||
Ans: DomainKeys is an e-mail authentication system designed to verify the DNS domain of an e-mail sender and the message integrity. The DomainKeys specification has adopted aspects of Identified Internet Mail to create an enhanced protocol called DomainKeys Identified Mail (DKIM).
|
||||
|
||||
### Q:20 What is the role of Anti-Spam SMTP Proxy (ASSP) in mail server ? ###
|
||||
|
||||
Ans: ASSP is a gateway server which is install in front of your MTA and implements auto-whitelists, self learning Bayesian, Greylisting, DNSBL, DNSWL, URIBL, SPF, SRS, Backscatter, Virus scanning, attachment blocking, Senderbase and multiple other filter methods
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/postfix-interview-questions-answers/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
@ -0,0 +1,99 @@
|
||||
How to configure SNMPv3 on ubuntu 14.04 server
|
||||
================================================================================
|
||||
Simple Network Management Protocol (SNMP) is an "Internet-standard protocol for managing devices on IP networks". Devices that typically support SNMP include routers, switches, servers, workstations, printers, modem racks and more.It is used mostly in network management systems to monitor network-attached devices for conditions that warrant administrative attention. SNMP is a component of the Internet Protocol Suite as defined by the Internet Engineering Task Force (IETF). It consists of a set of standards for network management, including an application layer protocol, a database schema, and a set of data objects.[2]
|
||||
|
||||
SNMP exposes management data in the form of variables on the managed systems, which describe the system configuration. These variables can then be queried (and sometimes set) by managing applications.
|
||||
|
||||
### Why you want to use SNMPv3 ###
|
||||
|
||||
Although SNMPv3 makes no changes to the protocol aside from the addition of cryptographic security, it looks much different due to new textual conventions, concepts, and terminology.
|
||||
|
||||
SNMPv3 primarily added security and remote configuration enhancements to SNMP.
|
||||
|
||||
Security has been the biggest weakness of SNMP since the beginning. Authentication in SNMP Versions 1 and 2 amounts to nothing more than a password (community string) sent in clear text between a manager and agent.[1] Each SNMPv3 message contains security parameters which are encoded as an octet string. The meaning of these security parameters depends on the security model being used.
|
||||
|
||||
SNMPv3 provides important security features:
|
||||
|
||||
Confidentiality -- Encryption of packets to prevent snooping by an unauthorized source.
|
||||
|
||||
Integrity -- Message integrity to ensure that a packet has not been tampered while in transit including an optional packet replay protection mechanism.
|
||||
|
||||
Authentication -- to verify that the message is from a valid source.
|
||||
|
||||
### Install SNMP server and client in ubuntu ###
|
||||
|
||||
Open the terminal and run the following command
|
||||
|
||||
sudo apt-get install snmpd snmp
|
||||
|
||||
After installation you need to do the following changes.
|
||||
|
||||
### Configuring SNMPv3 in Ubuntu ###
|
||||
|
||||
Get access to the daemon from the outside.
|
||||
|
||||
The default installation only provides access to the daemon for localhost. In order to get access from the outside open the file /etc/default/snmpd in your favorite editor
|
||||
|
||||
sudo vi /etc/default/snmpd
|
||||
|
||||
Change the following line
|
||||
|
||||
From
|
||||
|
||||
SNMPDOPTS='-Lsd -Lf /dev/null -u snmp -g snmp -I -smux,mteTrigger,mteTriggerConf -p /var/run/snmpd.pid'
|
||||
|
||||
to
|
||||
|
||||
SNMPDOPTS='-Lsd -Lf /dev/null -u snmp -I -smux -p /var/run/snmpd.pid -c /etc/snmp/snmpd.conf'
|
||||
|
||||
and restart snmpd
|
||||
|
||||
sudo /etc/init.d/snmpd restart
|
||||
|
||||
### Define SNMPv3 users, authentication and encryption parameters ###
|
||||
|
||||
SNMPv3 can be used in a number of ways depending on the “securityLevel” configuration parameter:
|
||||
|
||||
noAuthNoPriv -- No authorisation and no encryption, basically no security at all!
|
||||
authNoPriv -- Authorisation is required but collected data sent over the network is not encrypted.
|
||||
authPriv -- The strongest form. Authorisation required and everything sent over the network is encrypted.
|
||||
|
||||
The snmpd configuration settings are all saved in a file called /etc/snmp/snmpd.conf. Open this file in your editor as in:
|
||||
|
||||
sudo vi /etc/snmp/snmpd.conf
|
||||
|
||||
Add the following lines to the end of the file:
|
||||
|
||||
#
|
||||
createUser user1
|
||||
createUser user2 MD5 user2password
|
||||
createUser user3 MD5 user3password DES user3encryption
|
||||
#
|
||||
rouser user1 noauth 1.3.6.1.2.1.1
|
||||
rouser user2 auth 1.3.6.1.2.1
|
||||
rwuser user3 priv 1.3.6.1.2.1
|
||||
|
||||
Note:- If you want to use your own username/password combinations you need to note that the password and encryption phrases should have a length of at least 8 characters
|
||||
|
||||
Also you need to do the following change so that snmp can listen for connections on all interfaces
|
||||
|
||||
From
|
||||
|
||||
#agentAddress udp:161,udp6:[::1]:161
|
||||
|
||||
to
|
||||
|
||||
agentAddress udp:161,udp6:[::1]:161
|
||||
|
||||
Save your modified snmpd.conf file and restart the daemon with:
|
||||
|
||||
sudo /etc/init.d/snmpd restart
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/how-to-configure-snmpv3-on-ubuntu-14-04-server.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,466 @@
|
||||
Linux Tutorial: Install Ansible Configuration Management And IT Automation Tool
|
||||
================================================================================
|
||||
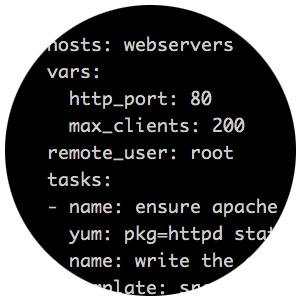
|
||||
|
||||
Today I will be talking about ansible, a powerful configuration management solution written in python. There are many configuration management solutions available, all with pros and cons, ansible stands apart from many of them for its simplicity. What makes ansible different than many of the most popular configuration management systems is that its agent-less, no need to setup agents on every node you want to control. Plus, this has the benefit of being able to control you entire infrastructure from more than one place, if needed. That last point's validity, of being a benefit, may be debatable but I find it as a positive in most cases. Enough talk, lets get started with Ansible installation and configuration on a RHEL/CentOS, and Debian/Ubuntu based systems.
|
||||
|
||||
### Prerequisites ###
|
||||
|
||||
1. Distro: RHEL/CentOS/Debian/Ubuntu Linux
|
||||
1. Jinja2: A modern and designer friendly templating language for Python.
|
||||
1. PyYAML: A YAML parser and emitter for the Python programming language.
|
||||
1. parmiko: Native Python SSHv2 protocol library.
|
||||
1. httplib2: A comprehensive HTTP client library.
|
||||
1. Most of the actions listed in this post are written with the assumption that they will be executed by the root user running the bash or any other modern shell.
|
||||
|
||||
How Ansible works
|
||||
|
||||
Ansible tool uses no agents. It requires no additional custom security infrastructure, so it’s easy to deploy. All you need is ssh client and server:
|
||||
|
||||
+----------------------+ +---------------+
|
||||
|Linux/Unix workstation| SSH | file_server1 |
|
||||
|with Ansible |<------------------>| db_server2 | Unix/Linux servers
|
||||
+----------------------+ Modules | proxy_server3 | in local/remote
|
||||
192.168.1.100 +---------------+ data centers
|
||||
|
||||
Where,
|
||||
|
||||
1. 192.168.1.100 - Install Ansible on your local workstation/server.
|
||||
1. file_server1..proxy_server3 - Use 192.168.1.100 and Ansible to automates configuration management of all servers.
|
||||
1. SSH - Setup ssh keys between 192.168.1.100 and local/remote servers.
|
||||
|
||||
### Ansible Installation Tutorial ###
|
||||
|
||||
Installation of ansible is a breeze, many distributions have a package available in their 3rd party repos which can easily be installed, a quick alternative is to just pip install it or grab the latest copy from github. To install using your package manager, on [RHEL/CentOS Linux based systems you will most likely need the EPEL repo][1] then:
|
||||
|
||||
#### Install ansible on a RHEL/CentOS Linux based system ####
|
||||
|
||||
Type the following [yum command][2]:
|
||||
|
||||
$ sudo yum install ansible
|
||||
|
||||
#### Install ansible on a Debian/Ubuntu Linux based system ####
|
||||
|
||||
Type the following [apt-get command][3]:
|
||||
|
||||
$ sudo apt-get install software-properties-common
|
||||
$ sudo apt-add-repository ppa:ansible/ansible
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install ansible
|
||||
|
||||
#### Install ansible using pip ####
|
||||
|
||||
The [pip command is a tool for installing and managing Python packages][4], such as those found in the Python Package Index. The following method works on Linux and Unix-like systems:
|
||||
|
||||
$ sudo pip install ansible
|
||||
|
||||
#### Install the latest version of ansible using source code ####
|
||||
|
||||
You can install the latest version from github as follows:
|
||||
|
||||
$ cd ~
|
||||
$ git clone git://github.com/ansible/ansible.git
|
||||
$ cd ./ansible
|
||||
$ source ./hacking/env-setup
|
||||
|
||||
When running ansible from a git checkout, one thing to remember is that you will need to setup your environment everytime you want to use it, or you can add it to your bash rc file:
|
||||
|
||||
# ADD TO BASH RC
|
||||
$ echo "export ANSIBLE_HOSTS=~/ansible_hosts" >> ~/.bashrc
|
||||
$ echo "source ~/ansible/hacking/env-setup" >> ~/.bashrc
|
||||
|
||||
The hosts file for ansible is basically a list of hosts that ansible is able to perform work on. By default ansible looks for the hosts file at /etc/ansible/hosts, but there are ways to override that which can be handy if you are working with multiple installs or have several different clients for whose datacenters you are responsible for. You can pass the hosts file on the command line using the -i option:
|
||||
|
||||
$ ansible all -m shell -a "hostname" --ask-pass -i /etc/some/other/dir/ansible_hosts
|
||||
|
||||
My preference however is to use and environment variable, this can be useful if source a different file when starting work for a specific client. The environment variable is $ANSIBLE_HOSTS, and can be set as follows:
|
||||
|
||||
$ export ANSIBLE_HOSTS=~/ansible_hosts
|
||||
|
||||
Once all requirements are installed and you have you hosts file setup you can give it a test run. For a quick test I put 127.0.0.1 into the ansible hosts file as follow:
|
||||
|
||||
$ echo "127.0.0.1" > ~/ansible_hosts
|
||||
|
||||
Now lets test with a quick ping:
|
||||
|
||||
$ ansible all -m ping
|
||||
|
||||
OR ask for the ssh password:
|
||||
|
||||
$ ansible all -m ping --ask-pass
|
||||
|
||||
I have run across a problem a few times regarding initial setup, it is highly recommended you setup keys for ansible to use but in the previous test we used --ask-pass, on some machines you will need [to install sshpass][5] or add a -c paramiko like so:
|
||||
|
||||
$ ansible all -m ping --ask-pass -c paramiko
|
||||
|
||||
Or you [can install sshpass][6], however sshpass is not always available in the standard repos so paramiko can be easier.
|
||||
|
||||
### Setup SSH Keys ###
|
||||
|
||||
Now that we have gotten the configuration, and other simple stuff, out of the way lets move onto doing something productive. Alot of the power of ansible lies in playbooks, which are basically scripted ansible runs (for the most part), but we will start with some one liners before we build out a playbook. Lets start with creating and configuring keys so we can avoid the -c and --ask-pass options:
|
||||
|
||||
$ ssh-keygen -t rsa
|
||||
|
||||
Sample outputs:
|
||||
|
||||
Generating public/private rsa key pair.
|
||||
Enter file in which to save the key (/home/mike/.ssh/id_rsa):
|
||||
Enter passphrase (empty for no passphrase):
|
||||
Enter same passphrase again:
|
||||
Your identification has been saved in /home/mike/.ssh/id_rsa.
|
||||
Your public key has been saved in /home/mike/.ssh/id_rsa.pub.
|
||||
The key fingerprint is:
|
||||
94:a0:19:02:ba:25:23:7f:ee:6c:fb:e8:38:b4:f2:42 mike@ultrabook.linuxdork.com
|
||||
The key's randomart image is:
|
||||
+--[ RSA 2048]----+
|
||||
|... . . |
|
||||
|. . + . . |
|
||||
|= . o o |
|
||||
|.* . |
|
||||
|. . . S |
|
||||
| E.o |
|
||||
|.. .. |
|
||||
|o o+.. |
|
||||
| +o+*o. |
|
||||
+-----------------+
|
||||
|
||||
Now obviously there are plenty of ways to put this in place on the remote machine but since we are using ansible, lets use that:
|
||||
|
||||
$ ansible all -m copy -a "src=/home/mike/.ssh/id_rsa.pub dest=/tmp/id_rsa.pub" --ask-pass -c paramiko
|
||||
|
||||
Sample outputs:
|
||||
|
||||
SSH password:
|
||||
127.0.0.1 | success >> {
|
||||
"changed": true,
|
||||
"dest": "/tmp/id_rsa.pub",
|
||||
"gid": 100,
|
||||
"group": "users",
|
||||
"md5sum": "bafd3fce6b8a33cf1de415af432774b4",
|
||||
"mode": "0644",
|
||||
"owner": "mike",
|
||||
"size": 410,
|
||||
"src": "/home/mike/.ansible/tmp/ansible-tmp-1407008170.46-208759459189201/source",
|
||||
"state": "file",
|
||||
"uid": 1000
|
||||
}
|
||||
|
||||
Next, add the public key in remote server, enter:
|
||||
|
||||
$ ansible all -m shell -a "cat /tmp/id_rsa.pub >> /root/.ssh/authorized_keys" --ask-pass -c paramiko
|
||||
|
||||
Sample outputs:
|
||||
|
||||
SSH password:
|
||||
127.0.0.1 | FAILED | rc=1 >>
|
||||
/bin/sh: /root/.ssh/authorized_keys: Permission denied
|
||||
|
||||
Whoops, we want to be able to run things as root, so lets add a -u option:
|
||||
|
||||
$ ansible all -m shell -a "cat /tmp/id_rsa.pub >> /root/.ssh/authorized_keys" --ask-pass -c paramiko -u root
|
||||
|
||||
Sample outputs:
|
||||
|
||||
SSH password:
|
||||
127.0.0.1 | success | rc=0 >>
|
||||
|
||||
Please note, I wanted to demonstrate a file transfer using ansible, there is however a more built in way for managing keys using ansible:
|
||||
|
||||
$ ansible all -m authorized_key -a "user=mike key='{{ lookup('file', '/home/mike/.ssh/id_rsa.pub') }}' path=/home/mike/.ssh/authorized_keys manage_dir=no" --ask-pass -c paramiko
|
||||
|
||||
Sample outputs:
|
||||
|
||||
SSH password:
|
||||
127.0.0.1 | success >> {
|
||||
"changed": true,
|
||||
"gid": 100,
|
||||
"group": "users",
|
||||
"key": "ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCq+Z8/usprXk0aCAPyP0TGylm2MKbmEsHePUOd7p5DO1QQTHak+9gwdoJJavy0yoUdi+C+autKjvuuS+vGb8+I+8mFNu5CvKiZzIpMjZvrZMhHRdNud7GuEanusTEJfi1pUd3NA2iXhl4a6S9a/4G2mKyf7QQSzI4Z5ddudUXd9yHmo9Yt48/ASOJLHIcYfSsswOm8ux1UnyeHqgpdIVONVFsKKuSNSvZBVl3bXzhkhjxz8RMiBGIubJDBuKwZqNSJkOlPWYN76btxMCDVm07O7vNChpf0cmWEfM3pXKPBq/UBxyG2MgoCGkIRGOtJ8UjC/daadBUuxg92/u01VNEB mike@ultrabook.linuxdork.com",
|
||||
"key_options": null,
|
||||
"keyfile": "/home/mike/.ssh/authorized_keys",
|
||||
"manage_dir": false,
|
||||
"mode": "0600",
|
||||
"owner": "mike",
|
||||
"path": "/home/mike/.ssh/authorized_keys",
|
||||
"size": 410,
|
||||
"state": "file",
|
||||
"uid": 1000,
|
||||
"unique": false,
|
||||
"user": "mike"
|
||||
}
|
||||
|
||||
Now that the keys are in place lets try running an arbitrary command like hostname and hope we don't get prompted for a password
|
||||
|
||||
$ ansible all -m shell -a "hostname" -u root
|
||||
|
||||
Sample outputs:
|
||||
|
||||
127.0.0.1 | success | rc=0 >>
|
||||
|
||||
Success!!! Now that we can run commands as root and not be bothered by using a password we are in a good place to easily configure any and all hosts in the ansible hosts file. Let's remove the key from /tmp:
|
||||
|
||||
$ ansible all -m file -a "dest=/tmp/id_rsa.pub state=absent" -u root
|
||||
|
||||
Sample outputs:
|
||||
|
||||
127.0.0.1 | success >> {
|
||||
"changed": true,
|
||||
"path": "/tmp/id_rsa.pub",
|
||||
"state": "absent"
|
||||
}
|
||||
|
||||
Next, I'm going to make sure we have a few packages installed and on the latest version and we will move on to something a little more complicated:
|
||||
|
||||
$ ansible all -m zypper -a "name=apache2 state=latest" -u root
|
||||
|
||||
Sample outputs:
|
||||
|
||||
127.0.0.1 | success >> {
|
||||
"changed": false,
|
||||
"name": "apache2",
|
||||
"state": "latest"
|
||||
}
|
||||
|
||||
Alright, the key we placed in /tmp is now absent and we have the latest version of apache installed. This brings me to the next point, something that makes ansible very flexible and gives more power to playbooks, many may have noticed the -m zypper in the previous commands. Now unless you use openSuse or Suse enterpise you may not be familiar with zypper, it is basically the equivalent of yum in the suse world. In all of the examples above I have only had one machine in my hosts file, and while everything but the last command should work on any standard *nix systems with standard ssh configs, this leads to a problem. What if we had multiple machine types that we wanted to manage? Well this is where playbooks, and the configurability of ansible really shines. First lets modify our hosts file a little, here goes:
|
||||
|
||||
$ cat ~/ansible_hosts
|
||||
|
||||
Sample outputs:
|
||||
|
||||
[RHELBased]
|
||||
10.50.1.33
|
||||
10.50.1.47
|
||||
|
||||
[SUSEBased]
|
||||
127.0.0.1
|
||||
|
||||
First, we create some groups of servers, and give them some meaningful tags. Then we create a playbook that will do different things for the different kinds of servers. You might notice the similarity between the yaml data structures and the command line instructions we ran earlier. Basically the -m is a module, and -a is for module args. In the YAML representation you put the module then :, and finally the args.
|
||||
|
||||
---
|
||||
- hosts: SUSEBased
|
||||
remote_user: root
|
||||
tasks:
|
||||
- zypper: name=apache2 state=latest
|
||||
- hosts: RHELBased
|
||||
remote_user: root
|
||||
tasks:
|
||||
- yum: name=httpd state=latest
|
||||
|
||||
Now that we have a simple playbook, we can run it as follows:
|
||||
|
||||
$ ansible-playbook testPlaybook.yaml -f 10
|
||||
|
||||
Sample outputs:
|
||||
|
||||
PLAY [SUSEBased] **************************************************************
|
||||
|
||||
GATHERING FACTS ***************************************************************
|
||||
ok: [127.0.0.1]
|
||||
|
||||
TASK: [zypper name=apache2 state=latest] **************************************
|
||||
ok: [127.0.0.1]
|
||||
|
||||
PLAY [RHELBased] **************************************************************
|
||||
|
||||
GATHERING FACTS ***************************************************************
|
||||
ok: [10.50.1.33]
|
||||
ok: [10.50.1.47]
|
||||
|
||||
TASK: [yum name=httpd state=latest] *******************************************
|
||||
changed: [10.50.1.33]
|
||||
changed: [10.50.1.47]
|
||||
|
||||
PLAY RECAP ********************************************************************
|
||||
10.50.1.33 : ok=2 changed=1 unreachable=0 failed=0
|
||||
10.50.1.47 : ok=2 changed=1 unreachable=0 failed=0
|
||||
127.0.0.1 : ok=2 changed=0 unreachable=0 failed=0
|
||||
|
||||
Now you will notice that you will see output from each machine that ansible contacted. The -f is what lets ansible run on multiple hosts in parallel. Instead of using all, or a name of a host group, on the command line you can put this passwords for the ask-pass prompt into the playbook. While we no longer need the --ask-pass since we have ssh keys setup, it comes in handy when setting up new machines, and even new machines can run from a playbook. To demonstrate this lets convert our earlier key example into a playbook:
|
||||
|
||||
---
|
||||
- hosts: SUSEBased
|
||||
remote_user: mike
|
||||
sudo: yes
|
||||
tasks:
|
||||
- authorized_key: user=root key="{{ lookup('file', '/home/mike/.ssh/id_rsa.pub') }}" path=/root/.ssh/authorized_keys manage_dir=no
|
||||
- hosts: RHELBased
|
||||
remote_user: mdonlon
|
||||
sudo: yes
|
||||
tasks:
|
||||
- authorized_key: user=root key="{{ lookup('file', '/home/mike/.ssh/id_rsa.pub') }}" path=/root/.ssh/authorized_keys manage_dir=no
|
||||
|
||||
Now there are plenty of other options here that could be done, for example having the keys dropped during a kickstart, or via some other kind of process involved with bringing up machines on the hosting of your choice, but this can be used in pretty much any situation assuming ssh is setup to accept a password. One thing to think about before writing out too many playbooks, version control can save you a lot of time. Machines need to change over time, you don't need to re-write a playbook every time a machine changes, just update the pertinent bits and commit the changes. Another benefit of this ties into what I said earlier about being able to manage the entire infrastructure from multiple places. You can easily git clone your playbook repo onto a new machine and be completely setup to manage everything in a repetitive manner.
|
||||
|
||||
#### Real world ansible example ####
|
||||
|
||||
I know a lot of people make great use of services like pastebin, and a lot of companies for obvious reasons setup their own internal instance of something similar. Recently, I came across a newish application called showterm and coincidentally I was asked to setup an internal instance of it for a client. I will spare you the details of this app, but you can google showterm if interested. So for a reasonable real world example I will attempt to setup a showterm server, and configure the needed app on the client to use it. In the process we will need a database server as well. So here goes, lets start with the client configuration.
|
||||
|
||||
---
|
||||
- hosts: showtermClients
|
||||
remote_user: root
|
||||
tasks:
|
||||
- yum: name=rubygems state=latest
|
||||
- yum: name=ruby-devel state=latest
|
||||
- yum: name=gcc state=latest
|
||||
- gem: name=showterm state=latest user_install=no
|
||||
|
||||
That was easy, lets move on to the main server:
|
||||
|
||||
---
|
||||
- hosts: showtermServers
|
||||
remote_user: root
|
||||
tasks:
|
||||
- name: ensure packages are installed
|
||||
yum: name={{item}} state=latest
|
||||
with_items:
|
||||
- postgresql
|
||||
- postgresql-server
|
||||
- postgresql-devel
|
||||
- python-psycopg2
|
||||
- git
|
||||
- ruby21
|
||||
- ruby21-passenger
|
||||
- name: showterm server from github
|
||||
git: repo=https://github.com/ConradIrwin/showterm.io dest=/root/showterm
|
||||
- name: Initdb
|
||||
command: service postgresql initdb
|
||||
creates=/var/lib/pgsql/data/postgresql.conf
|
||||
|
||||
- name: Start PostgreSQL and enable at boot
|
||||
service: name=postgresql
|
||||
enabled=yes
|
||||
state=started
|
||||
- gem: name=pg state=latest user_install=no
|
||||
handlers:
|
||||
- name: restart postgresql
|
||||
service: name=postgresql state=restarted
|
||||
|
||||
- hosts: showtermServers
|
||||
remote_user: root
|
||||
sudo: yes
|
||||
sudo_user: postgres
|
||||
vars:
|
||||
dbname: showterm
|
||||
dbuser: showterm
|
||||
dbpassword: showtermpassword
|
||||
tasks:
|
||||
- name: create db
|
||||
postgresql_db: name={{dbname}}
|
||||
|
||||
- name: create user with ALL priv
|
||||
postgresql_user: db={{dbname}} name={{dbuser}} password={{dbpassword}} priv=ALL
|
||||
- hosts: showtermServers
|
||||
remote_user: root
|
||||
tasks:
|
||||
- name: database.yml
|
||||
template: src=database.yml dest=/root/showterm/config/database.yml
|
||||
- hosts: showtermServers
|
||||
remote_user: root
|
||||
tasks:
|
||||
- name: run bundle install
|
||||
shell: bundle install
|
||||
args:
|
||||
chdir: /root/showterm
|
||||
- hosts: showtermServers
|
||||
remote_user: root
|
||||
tasks:
|
||||
- name: run rake db tasks
|
||||
shell: 'bundle exec rake db:create db:migrate db:seed'
|
||||
args:
|
||||
chdir: /root/showterm
|
||||
- hosts: showtermServers
|
||||
remote_user: root
|
||||
tasks:
|
||||
- name: apache config
|
||||
template: src=showterm.conf dest=/etc/httpd/conf.d/showterm.conf
|
||||
|
||||
Not so bad, now keeping in mind that this is a somewhat random and obscure app that we can now install in a consistent fashion on any number of machines, this is where the benefits of configuration management really come to light. Also, in most cases the declarative syntax almost speaks for itself and wiki pages need not go into as much detail, although a wiki page with too much detail is never a bad thing in my opinion.
|
||||
|
||||
### Expanding Configuration ###
|
||||
|
||||
We have not touched on everything here, Ansible has many options for configuring you setup. You can do things like embedding variables in your hosts file, so that Ansible will interpolate them on the remote nodes, eg.
|
||||
|
||||
[RHELBased]
|
||||
10.50.1.33 http_port=443
|
||||
10.50.1.47 http_port=80 ansible_ssh_user=mdonlon
|
||||
|
||||
[SUSEBased]
|
||||
127.0.0.1 http_port=443
|
||||
|
||||
While this is really handy for quick configurations, you can also layer variables across multiple files in yaml format. In you hosts file path you can make two sub directories named group_vars and host_vars. Any files in those paths that match the name of the group of hosts, or a host name in your hosts file will be interpolated at run time. So the previous example would look like this:
|
||||
|
||||
ultrabook:/etc/ansible # pwd
|
||||
/etc/ansible
|
||||
ultrabook:/etc/ansible # tree
|
||||
.
|
||||
├── group_vars
|
||||
│ ├── RHELBased
|
||||
│ └── SUSEBased
|
||||
├── hosts
|
||||
└── host_vars
|
||||
├── 10.50.1.33
|
||||
└── 10.50.1.47
|
||||
|
||||
----------
|
||||
|
||||
2 directories, 5 files
|
||||
ultrabook:/etc/ansible # cat hosts
|
||||
[RHELBased]
|
||||
10.50.1.33
|
||||
10.50.1.47
|
||||
|
||||
----------
|
||||
|
||||
[SUSEBased]
|
||||
127.0.0.1
|
||||
ultrabook:/etc/ansible # cat group_vars/RHELBased
|
||||
ultrabook:/etc/ansible # cat group_vars/SUSEBased
|
||||
---
|
||||
http_port: 443
|
||||
ultrabook:/etc/ansible # cat host_vars/10.50.1.33
|
||||
---
|
||||
http_port: 443
|
||||
ultrabook:/etc/ansible # cat host_vars/10.50.1.47
|
||||
---
|
||||
http_port:80
|
||||
ansible_ssh_user: mdonlon
|
||||
|
||||
### Refining Playbooks ###
|
||||
|
||||
There are many ways to organize playbooks as well. In the previous examples we used a single file, and everything is really simplified. One way of organizing things that is commonly used is creating roles. Basically you load a main file as your playbook, and that then imports all the data from the extra files, the extra files are organized as roles. For example if you have a wordpress site, you need a web head, and a database. The web head will have a web server, the app code, and any needed modules. The database is sometimes ran on the same host and some times ran on remote hosts, and this is where roles really shine. You make a directory, and small playbook for each role. In this case we can have an apache role, mysql role, wordpress role, mod_php, and php roles. The big advantage to this is that not every role has to be applied on one server, in this case mysql could be applied to a separate machine. This also allows for code re-use, for example you apache role could be used with python apps and php apps alike. Demonstrating this is a little beyond the scope of this article, and there are many different ways of doing thing, I would recommend searching for ansible playbook examples. There are many people contributing code on github, and I am sure various other sites.
|
||||
|
||||
### Modules ###
|
||||
|
||||
All of the work being done behind the scenes in ansible is driven by modules. Ansible has an excellent library of built in modules that do things like package installation, transferring files, and everything we have done in this article. But for some people this will not be suitable for their setup, ansible has a means of adding your own modules. One great thing about the API provided by Ansible is that you are not restricted to the language it was written in, Python, you can use any language really. Ansible modules work by passing around JSON data structures, so as long as you can build a JSON data structure in your language of choice, which I am pretty sure any scripting language can do, you can begin coding something right away. There is much documentation on the Ansible site, about how the module interface works, and many examples of modules on github as well. Keep in mind that some obscure languages may not have great support, but that would only be because not enough people are contributing code in that language, try it out and publish your results somewhere!
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In conclusion, there are many systems around for configuration management, I hope this article shows the ease of setup for ansible which I believe is one of its strongest points. Please keep in mind that I was trying to show a lot of different ways to do things, and not everything above may be considered best practice in your private infrastructure, or the coding world abroad. Here are some more links to take you knowledge of ansible to the next level:
|
||||
|
||||
- [Ansible project][7] home page.
|
||||
- [Ansible project documentation][8].
|
||||
- [Multistage environments with Ansible][9].
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/python-tutorials/linux-tutorial-install-ansible-configuration-management-and-it-automation-tool/
|
||||
|
||||
作者:[Nix Craft][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.cyberciti.biz/tips/about-us
|
||||
[1]:http://www.cyberciti.biz/faq/fedora-sl-centos-redhat6-enable-epel-repo/
|
||||
[2]:http://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/
|
||||
[3]:http://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html
|
||||
[4]:http://www.cyberciti.biz/faq/debian-ubuntu-centos-rhel-linux-install-pipclient/
|
||||
[5]:http://www.cyberciti.biz/faq/noninteractive-shell-script-ssh-password-provider/
|
||||
[6]:http://www.cyberciti.biz/faq/noninteractive-shell-script-ssh-password-provider/
|
||||
[7]:http://www.ansible.com/
|
||||
[8]:http://docs.ansible.com/
|
||||
[9]:http://rosstuck.com/multistage-environments-with-ansible/
|
||||
@ -0,0 +1,218 @@
|
||||
How to create a site-to-site IPsec VPN tunnel using Openswan in Linux
|
||||
================================================================================
|
||||
A virtual private network (VPN) tunnel is used to securely interconnect two physically separate networks through a tunnel over the Internet. Tunneling is needed when the separate networks are private LAN subnets with globally non-routable private IP addresses, which are not reachable to each other via traditional routing over the Internet. For example, VPN tunnels are often deployed to connect different NATed branch office networks belonging to the same institution.
|
||||
|
||||
Sometimes VPN tunneling may be used simply for its security benefit as well. Service providers or private companies may design their networks in such a way that vital servers (e.g., database, VoIP, banking servers) are placed in a subnet that is accessible to trusted personnel through a VPN tunnel only. When a secure VPN tunnel is required, [IPsec][1] is often a preferred choice because an IPsec VPN tunnel is secured with multiple layers of security.
|
||||
|
||||
This tutorial will show how we can easily create a site-to-site VPN tunnel using [Openswan][2] in Linux.
|
||||
|
||||
### Topology ###
|
||||
|
||||
This tutorial will focus on the following topologies for creating an IPsec tunnel.
|
||||
|
||||
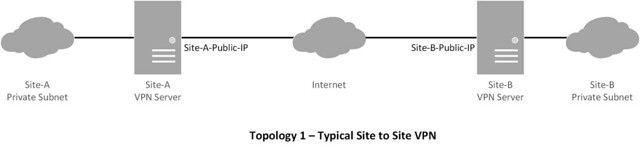
|
||||
|
||||
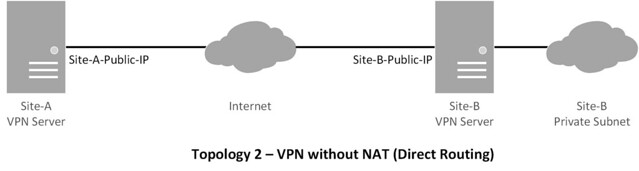
|
||||
|
||||
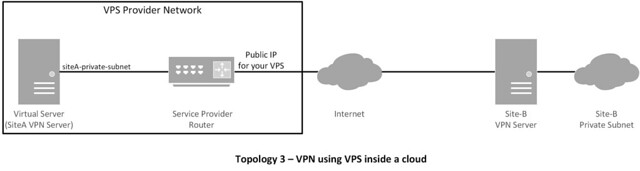
|
||||
|
||||
### Installing Packages and Preparing VPN Servers ###
|
||||
|
||||
Usually, you will be managing site-A only, but based on the requirements, you could be managing both site-A and site-B. We start the process by installing Openswan.
|
||||
|
||||
On Red Hat based Systems (CentOS, Fedora or RHEL):
|
||||
|
||||
# yum install openswan lsof
|
||||
|
||||
On Debian based Systems (Debian, Ubuntu or Linux Mint):
|
||||
|
||||
# apt-get install openswan
|
||||
|
||||
Now we disable VPN redirects, if any, in the server using these commands:
|
||||
|
||||
# for vpn in /proc/sys/net/ipv4/conf/*;
|
||||
# do echo 0 > $vpn/accept_redirects;
|
||||
# echo 0 > $vpn/send_redirects;
|
||||
# done
|
||||
|
||||
Next, we modify the kernel parameters to allow IP forwarding and disable redirects permanently.
|
||||
|
||||
# vim /etc/sysctl.conf
|
||||
|
||||
----------
|
||||
|
||||
net.ipv4.ip_forward = 1
|
||||
net.ipv4.conf.all.accept_redirects = 0
|
||||
net.ipv4.conf.all.send_redirects = 0
|
||||
|
||||
Reload /etc/sysctl.conf:
|
||||
|
||||
# sysctl -p
|
||||
|
||||
We allow necessary ports in the firewall. Please make sure that the rules are not conflicting with existing firewall rules.
|
||||
|
||||
# iptables -A INPUT -p udp --dport 500 -j ACCEPT
|
||||
# iptables -A INPUT -p tcp --dport 4500 -j ACCEPT
|
||||
# iptables -A INPUT -p udp --dport 4500 -j ACCEPT
|
||||
|
||||
Finally, we create firewall rules for NAT.
|
||||
|
||||
# iptables -t nat -A POSTROUTING -s site-A-private-subnet -d site-B-private-subnet -j SNAT --to site-A-Public-IP
|
||||
|
||||
Please make sure that the firewall rules are persistent.
|
||||
|
||||
#### Note: ####
|
||||
|
||||
- You could use MASQUERADE instead of SNAT. Logically it should work, but it caused me to have issues with virtual private servers (VPS) in the past. So I would use SNAT if I were you.
|
||||
- If you are managing site-B as well, create similar rules in site-B server.
|
||||
- Direct routing does not need SNAT.
|
||||
|
||||
### Preparing Configuration Files ###
|
||||
|
||||
The first configuration file that we will work with is ipsec.conf. Regardless of which server you are configuring, always consider your site as 'left' and remote site as 'right'. The following configuration is done in siteA's VPN server.
|
||||
|
||||
# vim /etc/ipsec.conf
|
||||
|
||||
----------
|
||||
|
||||
## general configuration parameters ##
|
||||
|
||||
config setup
|
||||
plutodebug=all
|
||||
plutostderrlog=/var/log/pluto.log
|
||||
protostack=netkey
|
||||
nat_traversal=yes
|
||||
virtual_private=%v4:10.0.0.0/8,%v4:192.168.0.0/16,%v4:172.16.0.0/16
|
||||
## disable opportunistic encryption in Red Hat ##
|
||||
oe=off
|
||||
|
||||
## disable opportunistic encryption in Debian ##
|
||||
## Note: this is a separate declaration statement ##
|
||||
include /etc/ipsec.d/examples/no_oe.conf
|
||||
|
||||
## connection definition in Red Hat ##
|
||||
conn demo-connection-redhat
|
||||
authby=secret
|
||||
auto=start
|
||||
ike=3des-md5
|
||||
## phase 1 ##
|
||||
keyexchange=ike
|
||||
## phase 2 ##
|
||||
phase2=esp
|
||||
phase2alg=3des-md5
|
||||
compress=no
|
||||
pfs=yes
|
||||
type=tunnel
|
||||
left=<siteA-public-IP>
|
||||
leftsourceip=<siteA-public-IP>
|
||||
leftsubnet=<siteA-private-subnet>/netmask
|
||||
## for direct routing ##
|
||||
leftsubnet=<siteA-public-IP>/32
|
||||
leftnexthop=%defaultroute
|
||||
right=<siteB-public-IP>
|
||||
rightsubnet=<siteB-private-subnet>/netmask
|
||||
|
||||
## connection definition in Debian ##
|
||||
conn demo-connection-debian
|
||||
authby=secret
|
||||
auto=start
|
||||
## phase 1 ##
|
||||
keyexchange=ike
|
||||
## phase 2 ##
|
||||
esp=3des-md5
|
||||
pfs=yes
|
||||
type=tunnel
|
||||
left=<siteA-public-IP>
|
||||
leftsourceip=<siteA-public-IP>
|
||||
leftsubnet=<siteA-private-subnet>/netmask
|
||||
## for direct routing ##
|
||||
leftsubnet=<siteA-public-IP>/32
|
||||
leftnexthop=%defaultroute
|
||||
right=<siteB-public-IP>
|
||||
rightsubnet=<siteB-private-subnet>/netmask
|
||||
|
||||
Authentication can be done in several different ways. This tutorial will cover the use of pre-shared key, which is added to the file /etc/ipsec.secrets.
|
||||
|
||||
# vim /etc/ipsec.secrets
|
||||
|
||||
----------
|
||||
|
||||
siteA-public-IP siteB-public-IP: PSK "pre-shared-key"
|
||||
## in case of multiple sites ##
|
||||
siteA-public-IP siteC-public-IP: PSK "corresponding-pre-shared-key"
|
||||
|
||||
### Starting the Service and Troubleshooting ###
|
||||
|
||||
The server should now be ready to create a site-to-site VPN tunnel. If you are managing siteB as well, please make sure that you have configured the siteB server with necessary parameters. For Red Hat based systems, please make sure that you add the service into startup using chkconfig command.
|
||||
|
||||
# /etc/init.d/ipsec restart
|
||||
|
||||
If there are no errors in both end servers, the tunnel should be up now. Taking the following into consideration, you can test the tunnel with ping command.
|
||||
|
||||
1. The siteB-private subnet should not be reachable from site A, i.e., ping should not work if the tunnel is not up.
|
||||
1. After the tunnel is up, try ping to siteB-private-subnet from siteA. This should work.
|
||||
|
||||
Also, the routes to the destination's private subnet should appear in the server's routing table.
|
||||
|
||||
# ip route
|
||||
|
||||
----------
|
||||
|
||||
[siteB-private-subnet] via [siteA-gateway] dev eth0 src [siteA-public-IP]
|
||||
default via [siteA-gateway] dev eth0
|
||||
|
||||
Additionally, we can check the status of the tunnel using the following useful commands.
|
||||
|
||||
# service ipsec status
|
||||
|
||||
----------
|
||||
|
||||
IPsec running - pluto pid: 20754
|
||||
pluto pid 20754
|
||||
1 tunnels up
|
||||
some eroutes exist
|
||||
|
||||
----------
|
||||
|
||||
# ipsec auto --status
|
||||
|
||||
----------
|
||||
|
||||
## output truncated ##
|
||||
000 "demo-connection-debian": myip=<siteA-public-IP>; hisip=unset;
|
||||
000 "demo-connection-debian": ike_life: 3600s; ipsec_life: 28800s; rekey_margin: 540s; rekey_fuzz: 100%; keyingtries: 0; nat_keepalive: yes
|
||||
000 "demo-connection-debian": policy: PSK+ENCRYPT+TUNNEL+PFS+UP+IKEv2ALLOW+SAREFTRACK+lKOD+rKOD; prio: 32,28; interface: eth0;
|
||||
|
||||
## output truncated ##
|
||||
000 #184: "demo-connection-debian":500 STATE_QUICK_R2 (IPsec SA established); EVENT_SA_REPLACE in 1653s; newest IPSEC; eroute owner; isakmp#183; idle; import:not set
|
||||
|
||||
## output truncated ##
|
||||
000 #183: "demo-connection-debian":500 STATE_MAIN_I4 (ISAKMP SA established); EVENT_SA_REPLACE in 1093s; newest ISAKMP; lastdpd=-1s(seq in:0 out:0); idle; import:not set
|
||||
|
||||
The log file /var/log/pluto.log should also contain useful information regarding authentication, key exchanges and information on different phases of the tunnel. If your tunnel doesn't come up, you could check there as well.
|
||||
|
||||
If you are sure that all the configuration is correct, and if your tunnel is still not coming up, you should check the following things.
|
||||
|
||||
1. Many ISPs filter IPsec ports. Make sure that UDP 500, TCP/UDP 4500 ports are allowed by your ISP. You could try connecting to your server IPsec ports from a remote location by telnet.
|
||||
1. Make sure that necessary ports are allowed in the firewall of the server/s.
|
||||
1. Make sure that the pre-shared keys are identical in both end servers.
|
||||
1. The left and right parameters should be properly configured on both end servers.
|
||||
1. If you are facing problems with NAT, try using SNAT instead of MASQUERADING.
|
||||
|
||||
To sum up, this tutorial focused on the procedure of creating a site-to-site IPSec VPN tunnel in Linux using Openswan. VPN tunnels are very useful in enhancing security as they allow admins to make critical resources available only through the tunnels. Also VPN tunnels ensure that the data in transit is secured from eavesdropping or interception.
|
||||
|
||||
Hope this helps. Let me know what you think.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/create-site-to-site-ipsec-vpn-tunnel-openswan-linux.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://en.wikipedia.org/wiki/IPsec
|
||||
[2]:https://www.openswan.org/
|
||||
@ -0,0 +1,213 @@
|
||||
Setup Thin Provisioning Volumes in Logical Volume Management (LVM) – Part IV
|
||||
================================================================================
|
||||
Logical Volume management has great features such as snapshots and Thin Provisioning. Previously in (Part – III) we have seen how to snapshot the logical volume. Here in this article, we will going to see how to setup thin Provisioning volumes in LVM.
|
||||
|
||||

|
||||
Setup Thin Provisioning in LVM
|
||||
|
||||
### What is Thin Provisioning? ###
|
||||
|
||||
Thin Provisioning is used in lvm for creating virtual disks inside a thin pool. Let us assume that I have a **15GB** storage capacity in my server. I already have 2 clients who has 5GB storage each. You are the third client, you asked for 5GB storage. Back then we use to provide the whole 5GB (Thick Volume) but you may use 2GB from that 5GB storage and 3GB will be free which you can fill it up later.
|
||||
|
||||
But what we do in thin Provisioning is, we use to define a thin pool inside one of the large volume group and define the thin volumes inside that thin pool. So, that whatever files you write will be stored and your storage will be shown as 5GB. But the full 5GB will not allocate the entire disk. The same process will be done for other clients as well. Like I said there are 2 clients and you are my 3rd client.
|
||||
|
||||
So, let us assume how much total GB I have assigned for clients? Totally 15GB was already completed, If someone comes to me and ask for 5GB can I give? The answer is “**Yes**“, here in thin Provisioning I can give 5GB for 4th Client even though I have assigned 15GB.
|
||||
|
||||
**Warning**: From 15GB, if we are Provisioning more than 15GB it is called Over Provisioning.
|
||||
|
||||
### How it Works? and How we provide storage to new Clients? ###
|
||||
|
||||
I have provided you 5GB but you may used only 2GB and other 3GB will be free. In Thick Provisioning we can’t do this, because it will allocate the whole space at first itself.
|
||||
|
||||
In thin Provisioning if I’m defining 5GB for you it won’t allocate the whole disk space while defining a volume, it will grow till 5GB according to your data write, Hope you got it! same like you, other clients too won’t use the full volumes so there will be a chance to add 5GB to a new client, This is called over Provisioning.
|
||||
|
||||
But it’s compulsory to monitored each and every volume growth, if not it will end-up in a disaster. While over Provisioning is done if the all 4 clients write the data’s badly to disk you may face an issue because it will fill up your 15GB and overflow to get drop the volumes.
|
||||
|
||||
### Requirements ###
|
||||
|
||||
注:此三篇文章如果发布后可换成发布后链接,原文在前几天更新中
|
||||
|
||||
- [Create Disk Storage with LVM in Linux – PART 1][1]
|
||||
- [How to Extend/Reduce LVM’s in Linux – Part II][2]
|
||||
- [How to Create/Restore Snapshot of Logical Volume in LVM – Part III][3]
|
||||
|
||||
#### My Server Setup ####
|
||||
|
||||
Operating System – CentOS 6.5 with LVM Installation
|
||||
Server IP – 192.168.0.200
|
||||
|
||||
### Step 1: Setup Thin Pool and Volumes ###
|
||||
|
||||
Let’s do it practically how to setup the thin pool and thin volumes. First we need a large size of Volume group. Here I’m creating Volume group with **15GB** for demonstration purpose. Now, list the volume group using the below command.
|
||||
|
||||
# vgcreate -s 32M vg_thin /dev/sdb1
|
||||
|
||||

|
||||
Listing Volume Group
|
||||
|
||||
Next, check for the size of Logical volume availability, before creating the thin pool and volumes.
|
||||
|
||||
# vgs
|
||||
# lvs
|
||||
|
||||

|
||||
Check Logical Volume
|
||||
|
||||
We can see there is only default logical volumes for file-system and swap is present in the above lvs output.
|
||||
|
||||
### Creating a Thin Pool ###
|
||||
|
||||
To create a Thin pool for 15GB in volume group (vg_thin) use the following command.
|
||||
|
||||
# lvcreate -L 15G --thinpool tp_tecmint_pool vg_thin
|
||||
|
||||
- **-L** – Size of volume group
|
||||
- **–thinpool** – To o create a thinpool
|
||||
- **tp_tecmint_poolThin** - pool name
|
||||
- **vg_thin** – Volume group name were we need to create the pool
|
||||
|
||||

|
||||
Create Thin Pool
|
||||
|
||||
To get more detail we can use the command ‘lvdisplay’.
|
||||
|
||||
# lvdisplay vg_thin/tp_tecmint_pool
|
||||
|
||||

|
||||
Logical Volume Information
|
||||
|
||||
Here we haven’t created Virtual thin volumes in this thin-pool. In the image we can see Allocated pool data showing **0.00%**.
|
||||
|
||||
### Creating Thin Volumes ###
|
||||
|
||||
Now we can define thin volumes inside the thin pool with the help of ‘lvcreate’ command with option -V (Virtual).
|
||||
|
||||
# lvcreate -V 5G --thin -n thin_vol_client1 vg_thin/tp_tecmint_pool
|
||||
|
||||
I have created a Thin virtual volume with the name of **thin_vol_client1** inside the **tp_tecmint_pool** in my **vg_thin** volume group. Now, list the logical volumes using below command.
|
||||
|
||||
# lvs
|
||||
|
||||

|
||||
List Logical Volumes
|
||||
|
||||
Just now, we have created the thin volume above, that’s why there is no data showing i.e. **0.00%M**.
|
||||
|
||||
Fine, let me create 2 more Thin volumes for other 2 clients. Here you can see now there are 3 thin volumes created under the pool (**tp_tecmint_pool**). So, from this point, we came to know that I have used all 15GB pool.
|
||||
|
||||

|
||||
|
||||
### Creating File System ###
|
||||
|
||||
Now, create mount points and mount these three thin volumes and copy some files in it using below commands.
|
||||
|
||||
# mkdir -p /mnt/client1 /mnt/client2 /mnt/client3
|
||||
|
||||
List the created directories.
|
||||
|
||||
# ls -l /mnt/
|
||||
|
||||
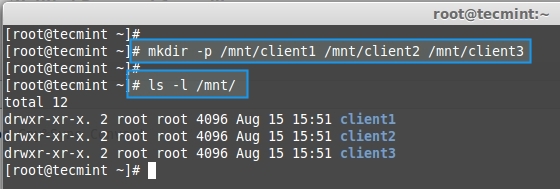
|
||||
Creating Mount Points
|
||||
|
||||
Create the file system for these created thin volumes using ‘mkfs’ command.
|
||||
|
||||
# mkfs.ext4 /dev/vg_thin/thin_vol_client1 && mkfs.ext4 /dev/vg_thin/thin_vol_client2 && mkfs.ext4 /dev/vg_thin/thin_vol_client3
|
||||
|
||||

|
||||
Create File System
|
||||
|
||||
Mount all three client volumes to the created mount point using ‘mount’ command.
|
||||
|
||||
# mount /dev/vg_thin/thin_vol_client1 /mnt/client1/ && mount /dev/vg_thin/thin_vol_client2 /mnt/client2/ && mount /dev/vg_thin/thin_vol_client3 /mnt/client3/
|
||||
|
||||
List the mount points using ‘df’ command.
|
||||
|
||||
# df -h
|
||||
|
||||

|
||||
Print Mount Points
|
||||
|
||||
Here, we can see all the 3 clients volumes are mounted and therefore only 3% of data are used in every clients volumes. So, let’s add some more files to all 3 mount points from my desktop to fill up some space.
|
||||
|
||||

|
||||
Add Files To Volumes
|
||||
|
||||
Now list the mount point and see the space used in every thin volumes & list the thin pool to see the size used in pool.
|
||||
|
||||
# df -h
|
||||
# lvdisplay vg_thin/tp_tecmint_pool
|
||||
|
||||

|
||||
Check Mount Point Size
|
||||
|
||||

|
||||
Check Thin Pool Size
|
||||
|
||||
The above command shows, the three mount pints along with their sizes in percentage.
|
||||
|
||||
13% of datas used out of 5GB for client1
|
||||
29% of datas used out of 5GB for client2
|
||||
49% of datas used out of 5GB for client3
|
||||
|
||||
While looking into the thin-pool we can see only **30%** of data is written totally. This is the total of above three clients virtual volumes.
|
||||
|
||||
### Over Provisioning ###
|
||||
|
||||
Now the **4th** client came to me and asked for 5GB storage space. Can I give? Because I had already given 15GB Pool to 3 clients. Is it possible to give 5GB more to another client? Yes it is possible to give. This is when we use **Over Provisioning**, which means giving the space more than what I have.
|
||||
|
||||
Let me create 5GB for the 4th Client and verify the size.
|
||||
|
||||
# lvcreate -V 5G --thin -n thin_vol_client4 vg_thin/tp_tecmint_pool
|
||||
# lvs
|
||||
|
||||

|
||||
Create thin Storage
|
||||
|
||||
I have only 15GB size in pool, but I have created 4 volumes inside thin-pool up-to 20GB. If all four clients start to write data to their volumes to fill up the pace, at that time, we will face critical situation, if not there will no issue.
|
||||
|
||||
Now I have created file system in **thin_vol_client4**, then mounted under **/mnt/client4** and copy some files in it.
|
||||
|
||||
# lvs
|
||||
|
||||

|
||||
Verify Thin Storage
|
||||
|
||||
We can see in the above picture, that the total used size in newly created client 4 up-to **89.34%** and size of thin pool as **59.19%** used. If all these users are not writing badly to volume it will be free from overflow, drop. To avoid the overflow we need to extend the thin-pool size.
|
||||
|
||||
**Important**: Thin-pools are just a logical volume, so if we need to extend the size of thin-pool we can use the same command like, we’ve used for logical volumes extend, but we can’t reduce the size of thin-pool.
|
||||
|
||||
# lvextend
|
||||
|
||||
Here we can see how to extend the logical thin-pool (**tp_tecmint_pool**).
|
||||
|
||||
# lvextend -L +15G /dev/vg_thin/tp_tecmint_pool
|
||||
|
||||

|
||||
Extend Thin Storage
|
||||
|
||||
Next, list the thin-pool size.
|
||||
|
||||
# lvs
|
||||
|
||||

|
||||
Verify Thin Storage
|
||||
|
||||
Earlier our **tp_tecmint_pool** size was 15GB and 4 thin volumes which was over Provision by 20GB. Now it has extended to 30GB so our over Provisioning has been normalized and thin volumes are free from overflow, drop. This way you can add ever more thin volumes to the pool.
|
||||
|
||||
Here, we have seen how to create a thin-pool using a large size of volume group and create thin-volumes inside a thin-pool using Over-Provisioning and extending the pool. In the next article we will see how to setup a lvm Striping.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/setup-thin-provisioning-volumes-in-lvm/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:http://www.tecmint.com/create-lvm-storage-in-linux/
|
||||
[2]:http://www.tecmint.com/extend-and-reduce-lvms-in-linux/
|
||||
[3]:http://www.tecmint.com/take-snapshot-of-logical-volume-and-restore-in-lvm/
|
||||
@ -0,0 +1,106 @@
|
||||
6 Interesting Funny Commands of Linux (Fun in Terminal) – Part II
|
||||
================================================================================
|
||||
In our past following articles, we’ve shown some useful articles on some funny commands of Linux, which shows that Linux is not as complex as it seems and can be fun if we know how to use it. Linux command line can perform any complex task very easily and with perfection and can be interesting and joyful.
|
||||
|
||||
- [20 Funny Commands of Linux – Part I][1]注,此篇的原文应该翻译过,文件名应该是:20 Funny Commands of Linux or Linux is Fun in Terminal
|
||||
- [Fun in Linux Terminal – Play with Word and Character Counts][2]注:这篇文章刚刚补充上
|
||||
|
||||

|
||||
Funny Linux Commands
|
||||
|
||||
The former Post comprises of 20 funny Linux Commands/Script (and subcommands) which was highly appreciated by our readers. The other post, though not that much popular as former comprises of Commands/ Scripts and Tweaks which lets you play with text files, words and strings.
|
||||
|
||||
This post aims at bringing some new fun commands and one-liner scripts which is going to rejoice you.
|
||||
|
||||
### 1. pv Command ###
|
||||
|
||||
You might have seen simulating text in movies. It appears as, it is being typed in real time. Won’t it be nice, if you can have such an effect in terminal?
|
||||
|
||||
This can be achieved, by installing ‘**pv**‘ command in your Linux system by using ‘**apt**‘ or ‘**yum**‘ tool. Let’s install ‘**pv**‘ command as shown.
|
||||
|
||||
# yum install pv [On RedHat based Systems]
|
||||
|
||||
# sudo apt-get install pv [On Debian based Systems]
|
||||
|
||||
Once, ‘**pv**‘ command installed successfully on your system, let’s try to run the following one liner command to see the real time text effect on the screen.
|
||||
|
||||
$ echo "Tecmint[dot]com is a community of Linux Nerds and Geeks" | pv -qL 10
|
||||
|
||||

|
||||
pv command in action
|
||||
|
||||
**Note**: The ‘**q**‘ option means ‘quite’, no output information and option ‘**L**‘ means the Limit of Transfer of bytes per second. The number value can be adjusted in either direction (must be integer) to get desired simulation of text.
|
||||
|
||||
### 2. toilet Command ###
|
||||
|
||||
How about printing text with border in terminal, using an one-liner script command ‘**toilet**‘. Again, you must have ‘**toilet**‘ command installed on your system, if not use apt or yum to install it.
|
||||
|
||||
$ while true; do echo “$(date | toilet -f term -F border –Tecmint)”; sleep 1; done
|
||||
|
||||

|
||||
toilet command in action
|
||||
|
||||
**Note**: The above script needs to be suspended using **ctrl+z** key.
|
||||
|
||||
### 3. rig Command ###
|
||||
|
||||
This command generates a random identity and address, every time. To run, this command you need to install ‘**rig**‘ using apt or yum.
|
||||
|
||||
# rig
|
||||
|
||||

|
||||
rig command in action
|
||||
|
||||
### 4. aview Command ###
|
||||
|
||||
How about viewing an image in ASCII format on the terminal? We must have a package ‘**aview**‘ installed, just apt or yum it. I’ve an image named ‘**elephant.jpg**‘ in my current working directory and I want view it on terminal as ASCII format.
|
||||
|
||||
$ asciiview elephant.jpg -driver curses
|
||||
|
||||

|
||||
aview command in action
|
||||
|
||||
### 5. xeyes Command ###
|
||||
|
||||
In last article we introduced a command ‘**oneko**‘ which attaches jerry with mouse pointer and keeps on chasing it. A similar program ‘**xeyes**‘ which is a graphical programs and as soon as you fire the command you will see two monster eyes chasing your movement.
|
||||
|
||||
$ xeyes
|
||||
|
||||

|
||||
xeyes command in action
|
||||
|
||||
### 6. cowsay Command ###
|
||||
|
||||
Do you remember last time we introduced command, which is useful in output of desired text with animated character cow. What if you want other animal in place of cow? Check a list of available animals.
|
||||
|
||||
$ cowsay -l
|
||||
|
||||
How about Elephant inside ASCII Snake?
|
||||
|
||||
$ cowsay -f elephant-in-snake Tecmint is Best
|
||||
|
||||

|
||||
cowsay command in action
|
||||
|
||||
How about Elephant inside ASCII goat?
|
||||
|
||||
$ cowsay -f gnu Tecmint is Best
|
||||
|
||||

|
||||
cowsay goat in action
|
||||
|
||||
That’s all for now. I’ll be here again with another interesting article. Till then stay update and connected to Tecmint. Don’t forget to provide us with your valuable feedback in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-funny-commands/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/20-funny-commands-of-linux-or-linux-is-fun-in-terminal/
|
||||
[2]:http://www.tecmint.com/play-with-word-and-character-counts-in-linux/
|
||||
@ -0,0 +1,176 @@
|
||||
Fun in Linux Terminal – Play with Word and Character Counts
|
||||
================================================================================
|
||||
Linux command line has a lot of fun around itself and many tedious task can be performed very easily yet with perfection. Playing with words and characters, their frequency in a text file, etc is what we are going to see in this article.
|
||||
|
||||
The only command that comes to our mind, for tweaking Linux command line to manipulate words and characters from a text file is [wc command][1].
|
||||
|
||||

|
||||
|
||||
A ‘**wc**‘ command which stands for word count is capable of Printing Newline, word & byte counts from a text file.
|
||||
|
||||
To work with the small scripts to analyze text file, we must have a text file. To maintain uniformity, we are creating a text file with the output of man command, as described below.
|
||||
|
||||
$ man man > man.txt
|
||||
|
||||
The above command creates a text file ‘**man.txt**‘ with the content of ‘**manual page**‘ for ‘man‘ command.
|
||||
|
||||
We want to check the most common words, in the above created ‘**Text File**‘ by running the below script.
|
||||
|
||||
$ cat man.txt | tr ' ' '\012' | tr '[:upper:]' '[:lower:]' | tr -d '[:punct:]' | grep -v '[^a-z]' | sort | uniq -c | sort -rn | head
|
||||
|
||||
### Sample Output ###
|
||||
|
||||
7557
|
||||
262 the
|
||||
163 to
|
||||
112 is
|
||||
112 a
|
||||
78 of
|
||||
78 manual
|
||||
76 and
|
||||
64 if
|
||||
63 be
|
||||
|
||||
The above one liner simple script shows, ten most frequently appearing words and their frequency of appearance, in the text file.
|
||||
|
||||
How about breaking down a word into individual using following command.
|
||||
|
||||
$ echo 'tecmint team' | fold -w1
|
||||
|
||||
### Sample Output ###
|
||||
|
||||
t
|
||||
e
|
||||
c
|
||||
m
|
||||
i
|
||||
n
|
||||
t
|
||||
t
|
||||
e
|
||||
a
|
||||
m
|
||||
|
||||
**Note**: Here, ‘-w1′ is for width.
|
||||
|
||||
Now we will be breaking down every single word in a text file, sort the result and get the desired output with the frequency of ten most frequent characters.
|
||||
|
||||
$ fold -w1 < man.txt | sort | uniq -c | sort -rn | head
|
||||
|
||||
### Sample Output ###
|
||||
|
||||
8579
|
||||
2413 e
|
||||
1987 a
|
||||
1875 t
|
||||
1644 i
|
||||
1553 n
|
||||
1522 o
|
||||
1514 s
|
||||
1224 r
|
||||
1021 l
|
||||
|
||||
How about getting most frequent characters in the text file with uppercase and lowercase differently along with their occurrence frequency.
|
||||
|
||||
$ fold -w1 < man.txt | sort | tr '[:lower:]' '[:upper:]' | uniq -c | sort -rn | head -20
|
||||
|
||||
### Sample Output ###
|
||||
|
||||
11636
|
||||
2504 E
|
||||
2079 A
|
||||
2005 T
|
||||
1729 I
|
||||
1645 N
|
||||
1632 S
|
||||
1580 o
|
||||
1269 R
|
||||
1055 L
|
||||
836 H
|
||||
791 P
|
||||
766 D
|
||||
753 C
|
||||
725 M
|
||||
690 U
|
||||
605 F
|
||||
504 G
|
||||
352 Y
|
||||
344 .
|
||||
|
||||
Check the above output, where punctuation mark is included. Lets strip out punctuation, with ‘**tr**‘ command. Here we go:
|
||||
|
||||
$ fold -w1 < man.txt | tr '[:lower:]' '[:upper:]' | sort | tr -d '[:punct:]' | uniq -c | sort -rn | head -20
|
||||
|
||||
### Sample Output ###
|
||||
|
||||
11636
|
||||
2504 E
|
||||
2079 A
|
||||
2005 T
|
||||
1729 I
|
||||
1645 N
|
||||
1632 S
|
||||
1580 O
|
||||
1550
|
||||
1269 R
|
||||
1055 L
|
||||
836 H
|
||||
791 P
|
||||
766 D
|
||||
753 C
|
||||
725 M
|
||||
690 U
|
||||
605 F
|
||||
504 G
|
||||
352 Y
|
||||
|
||||
Now I have three text files, lets run the above one liner script to see the output.
|
||||
|
||||
$ cat *.txt | fold -w1 | tr '[:lower:]' '[:upper:]' | sort | tr -d '[:punct:]' | uniq -c | sort -rn | head -8
|
||||
|
||||
### Sample Output ###
|
||||
|
||||
11636
|
||||
2504 E
|
||||
2079 A
|
||||
2005 T
|
||||
1729 I
|
||||
1645 N
|
||||
1632 S
|
||||
1580 O
|
||||
|
||||
Next we will be generating those infrequent letters that are at least ten letters long. Here is the simple script.
|
||||
|
||||
$ cat man.txt | tr '' '\012' | tr '[:upper:]' '[:lower:]' | tr -d '[:punct:]' | tr -d '[0-9]' | sort | uniq -c | sort -n | grep -E '..................' | head
|
||||
|
||||
### Sample Output ###
|
||||
|
||||
1 ──────────────────────────────────────────
|
||||
1 a all
|
||||
1 abc any or all arguments within are optional
|
||||
1 able see setlocale for precise details
|
||||
1 ab options delimited by cannot be used together
|
||||
1 achieved by using the less environment variable
|
||||
1 a child process returned a nonzero exit status
|
||||
1 act as if this option was supplied using the name as a filename
|
||||
1 activate local mode format and display local manual files
|
||||
1 acute accent
|
||||
|
||||
**Note**: The more and more dots in the above script till all the results are generated. We can use .{10} to get ten character matches.
|
||||
|
||||
These simple scripts, also make us know most frequent appearing words and characters in English.
|
||||
|
||||
That’s all for now. I’ll be here again with another interesting and off the beat topic worth knowing, which you people will love to read. Don’t forget to provide us with your valuable feedback in comment section, below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/play-with-word-and-character-counts-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/wc-command-examples/
|
||||
@ -1,50 +0,0 @@
|
||||
有人知道 Apache Mesos 项目帮助 Mesosphere 公司从 Andreessen Horowitz 那里筹集了 1000 万美元吗?
|
||||
================================================================================
|
||||

|
||||
|
||||
[Mesosphere][1],一家试图以鲜为人知的 Apache Mesos 项目为中心开展商业活动的公司,刚刚从 Andreessen Horowitz 那里获得了 1000 万美元投资。以下是为什么这个项目能够吸引如此巨款的原因。
|
||||
|
||||
事实上 Mesos 这款自动扩放软件在五年前就开发出来了。据 Mesosphere 的首席执行官及联合创始人 Florian Leibert 所述,Mesos 已经在 Twitter 上被超过 50,000 的核心使用。同时 EBay, AirBnB, Netflix 还有 HubSpot 也是这款软件的使用者。
|
||||
|
||||
当那些互联网巨头发现发现 Mesos 的时候,这项技术却并不为大多数企业所知。但它确实可以满足一些公司试图在公共云采取技术措施,使得他们自己可以访问内部数据中心的需求。
|
||||
|
||||
Mesos 管理集群机器,根据需要自动扩放应用。它在每台机器上只依赖很少的软件 ———— 据 Leibert 所说,其处理器的占用为 0 并且几乎不消耗任何内存 ———— 会与一个主调度程序相协调。在其工作的每台机器上的该软件会向调度程序报告关于虚拟机或者服务器的容量信息,接着调度程序向目标机器分派任务。
|
||||
|
||||
“如果一项任务终断并且没有返回任何结果,在 Mesos 的协助下,管理员将重启该任务并能知道该任务在何处终断,” Mesosphere 的资深副总裁 Matt Trifiro 说。
|
||||
|
||||
Mesos 能自动扩放一系列的工作包括 Hadoop 数据库,Ruby 运行干线上的节点,以及 Cassandra 。
|
||||
|
||||
使用 Mesos 使得 Hubspot 在 AWS(Amazon Web Services) 的账单上削减了一半的支出,Liebert 说道。这是因为 Mesos 能够在目标机器之间有效地分配作业量的原因。
|
||||
|
||||
然而,Mesos 更有可能应用于企业中去,这些企业试图实质地内部创建一个类 AWS 环境,一位来自 451 Research 的分析员 Jay Lyman 说。AWS 提供一些[自动扩放工具][3]。但大多数公司对于在公共云基础设施上运行所有东西还是感到不安。与此同时,他们并不企图阻止他们的开发者采用 AWS 那样的公共云中可用的优异性能。他们希望他们的私有云能集成这些可用的优点。
|
||||
|
||||
“如你所见,AWS 风格的界面风格与守旧主义、命令、操控以及稳定性相融合,” Liebert 继续说道。
|
||||
|
||||
Mesos 既可以在一个私有云上也可以在 AWS 上运行,向企业提供最有效率地使用其内部云的方法,并在需要扩放时自动切换到 AWS 去。
|
||||
|
||||
但是,以某种角度观察 Mesos 也是有一些缺点的。它[并不能运行][4]任何 Windows 操作系统或者比较古老的应用比如说 SAP 软件。
|
||||
|
||||
不过,Lyman 说,“假如一个团队拥有长时期使用云的经历,他们大概早就对 Linux 操作系统情有独钟了。”
|
||||
|
||||
在将来,Mesosphere 能够支持 Windows 操作系统是很有可能的。最初,像 Puppet 和 Chef 这样的技术也只支持 Linux 操作系统,Lyman 表示。“这预示了早期 Mesosphere 的特性。现在它还是不太成熟,” 他又说道。
|
||||
|
||||
Mesosphere 正瞄向大部分构建了与日俱增的运行于 Linux 操作系统的应用的企业,以及使用现代编程语言如同 Twitter 和 Netflix 这类刚成立不久还未具备 Mesos 这种技术的初代 Web 2.0 公司。“这是早期两类最常见的客户概况,” Trifiro 说。
|
||||
|
||||
年终之前,Mesosphere 希望发布包含文档的商务产品,通过技术支持与颁发许可证来获得收入。Mesosphere 已开发一款名为 Marathon 的大规模扩放编制工具,并且支持融入 Docker 中。它现在免费提供打包过的 Mesos 分发,希望以此占有未来的市场。
|
||||
|
||||
Mesosphere 同时也正在为少数早期的顾客工作。它帮助 HubSpot 实施有关 Mesos 的搭建。
|
||||
|
||||
Mesosphere 在这个领域并不唯一。Rightscale,Scalr 以及现在归 Dell 所有的 Enstratius,全都提供了一些扩放或云管理技术的版本实例。Mesosphere 强调说其开发的技术 Mesos 在单独机器中创建服务器集群方面的表现远胜于市场上的其他同类软件。来自 Andreessen 的新投资一定会帮助 Meos 获得新生。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thenewstack.io/little-known-apache-mesos-project-helps-mesosphere-raise-10m-from-andreessen/
|
||||
|
||||
译者:[SteveArcher](https://github.com/SteveArcher) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://mesosphere.io/
|
||||
[2]:http://mesos.apache.org/
|
||||
[3]:http://aws.amazon.com/autoscaling/
|
||||
[4]:http://mesosphere.io/learn/
|
||||
@ -0,0 +1,67 @@
|
||||
中国将要改变软件购买和销售的方式
|
||||
================================================================================
|
||||

|
||||
|
||||
> 这一切都是关于“开源”.
|
||||
|
||||
**中国并不需要开源,也不需要你的软件。具体说来,中国市场并不需要你的工程师日以继夜的工作,也不需要你提供的任何东西。
|
||||
|
||||
中国每年会产生超过100000名新软件工程师们,这些工程师会写出一大批令人惊叹的奇妙软件。如果有中国市场上尚未出现的软件,中国的工程师们就会从国外“借鉴”。在2012年,这样的软件掠夺达到了77%之多。对于那些已经面对着开源和云服务的挑战的软件卖家来说,中国无疑让他们的日子更苦难了。
|
||||
|
||||
不止是更困难,简直是举步维艰。
|
||||
|
||||
中国正在挑战西方公司在中国或者其他地方赚钱的模式。对于那些已经明白如何在中国运营的公司来说,他们的未来看起来一片光明。
|
||||
|
||||
### 抵制中国模式 ###
|
||||
|
||||
当然,并非每家公司都会坐以待毙。以微软为例,微软通用美国的国家司法权力来禁止中国公司做生意——除非他们像微软购买许可证。这是一种很聪明的做法,而且它可能会为微软创造数以十亿计的价值。但是最终这一做法看起来与中国市场格格不入。
|
||||
|
||||
原因很简单,中国与微软对待知识产权的态度十分不同。
|
||||
|
||||
正如 [我所提到的][2],“中国的企业更倾向于购买复杂的,面向企业的软件。因为这种软件比服务大众的公司设计出来的软件更先进,就像同在亚洲的印度。”但这种形势不会持续太久,因为中国的软件产业正在以一种惊人的速度前进,并毫无颓势。中国一定会坚持向西方国家“借鉴”代码直到有一天有足够的能力可以创造出有创新能力的软件。
|
||||
|
||||
但是即使这样,中国的软件公司与美国软件的运营模式还是有所不同,美国的软件大多都已经捆绑在设备、架构在云端或者公司只因为提供软件支持而要价。而这些运营模式中国是无法克隆的。
|
||||
|
||||
不出所料的,每一个收费模式是公司门使用“开源”进行盈利。
|
||||
|
||||
### 开源化中国 ###
|
||||
|
||||
正如CCID的分析师在 [J. Aaron Farr 的关于中国开源化报告][3] 中指出的,中国的开源社区规模很小而且没什么影响力。开源社区们没有大项目、参与者稀少而且资金匮乏。
|
||||
|
||||
这真是个坏消息。
|
||||
|
||||
好消息是,像华为这样的公司就把开源作为一种战略前景。具体而言,当华为的开源项目过时或者不是很强势的时候,这种现象就证明了他们的科技步伐是错误的。在与参与了开源项目的华为公司内部顾问的谈话中,虽然华为对如何参与到开源社区还处于摸索阶段,但他们总是对华为的开源项目赞不绝口。
|
||||
|
||||
这种无人关注开源的现象不会长久地持续下去。
|
||||
|
||||
从一件事就可以看出端倪。中国最大的互联网公司们都纷纷以积极地姿态拥抱开源,这意味着中国开源时代的到来。你若是和任意一位在百度、阿里巴巴、微博的员工谈话,你会发现他们的软件项目都是彻底开源的。这些开源的软件都是运行在这些公司自己研发的硬件上而不是西方的硬件上。
|
||||
|
||||
换句话说,这样的模式已经和西方的运营模式如出一辙了。
|
||||
|
||||
抬头看看 [现金软件行业内最炙手可热的新公司][5], 你就会知道中国的互联网公司未来的主流趋势,正如发生在西方世界的一样。不出意料的,许多都是关于“开源”。
|
||||
|
||||
### 销售给中国 ###
|
||||
|
||||
所有的一切都表明中国的软件行业不会像美国的软件行业发展历史一般发展。中国不会产生在柜台上卖卖软件就赚上亿美元的公司。因为西方对于知识产权的观念就是不适于中国的科技经济。
|
||||
|
||||
所以,软件卖家们需要售卖币软件更丰富的产品。云服务是一大前景。硬件设施看起来也是前途璀璨。软件支持和咨询服务(虽然有一些非主流)也很被公司门看好。总而言之,中国的软件行业会充满了开源味道,而不能靠着简单的售卖专柜软件的形式赚钱。
|
||||
|
||||
图片由 [hackNY.org][6] 提供。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
原文: http://readwrite.com/2014/08/12/china-opensource-software-ip-programmers-united-states
|
||||
|
||||
作者:[Matt Asay][a]
|
||||
译者:[chi1shi2](https://github.com/chi1shi2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://readwrite.com/author/matt-asay
|
||||
[1]:http://readwrite.com/2014/03/17/microsoft-anti-piracy-strategy-china
|
||||
[2]:http://readwrite.com/2014/04/11/india-starts-paying-for-software-china-it
|
||||
[3]:http://cdn.oreillystatic.com/en/assets/1/event/12/Open%20Source%20in%20China%20Presentation%201.pdf
|
||||
[4]:http://huawei.com/en/about-huawei/Partner/openathuawei/index.htm
|
||||
[5]:http://codingvc.com/which-technologies-do-startups-use-an-exploration-of-angellist-data
|
||||
[6]:https://www.flickr.com/photos/hackny/8675057448/
|
||||
@ -0,0 +1,54 @@
|
||||
“Linux之父——莱纳斯•托瓦德斯是我的英雄”说这话的是13岁的扎卡里杜邦
|
||||
================================================================================
|
||||

|
||||
|
||||
Zachary DuPon是一个6年级学生他马上满13岁。他是使用Arch liunx的用户并期待着安装Gentoo Linux
|
||||
|
||||
Zachary DuPon的故事是这样的-他的学校组织了一个计划给哪里的学生,要求他们写一封信给他们的英雄,大多数孩子写给名人,而Zachary DuPon写了现代科技世界的“真”英雄-莱纳斯•托瓦德斯
|
||||
|
||||
由于莱纳斯在家工作,他没有透露工作的地点,Zach的信来到了Linux基金会,在浏览的信件之前,发送给了莱纳斯。当基金会看到了这封信,他们联系了扎克的学校然后,being as generous as they are,邀请他到LinuxCon,以便他能遇到他的英雄。
|
||||
|
||||
linux的执行董事长Jim Zemlin,引领Zach到讨论小组的人群之后。Zach遇到了莱纳斯并得到了经过linux之父签名的linux圣经;他也收到了莱纳自己书的签名 [只为了好玩:一个意外的革命][1]
|
||||
|
||||

|
||||
莱纳斯•托沃兹为扎克里杜邦签名书
|
||||
|
||||

|
||||
扎克里杜邦的家人
|
||||
|
||||

|
||||
Swapnil Bhartiya和扎克里杜邦
|
||||
|
||||
我不想失去这个机会,所以我走近了杜邦家族,他们已经和莱纳斯开始谈话,于是安排了这个采访视频。
|
||||
|
||||
我是一个两岁孩子的父亲,而作为一名父亲,我是真正的惊讶怎样的信心,在善于表达和聪明的扎克的思想里
|
||||
|
||||
相反我告诉你我们谈论什么,我提供给你这个视屏采访
|
||||
|
||||
注:Youtube 视频,发布的时候不行改成一个链接吧
|
||||
<iframe scrolling="no" frameborder="0" allowfullscreen="" mozallowfullscreen="" webkitallowfullscreen="" src="//www.youtube-nocookie.com/embed/pHK5mfLdmRs?autoplay=0" class="arve-inner"></iframe>
|
||||
|
||||
这是一些采访的事件:
|
||||
|
||||
- 他使用Arch linux
|
||||
他计划他一旦变成好的程序员做出的贡献
|
||||
他没有提交任何漏洞报告,并认为他应该。他也表示他没有出现任何漏
|
||||
(这行未翻译)
|
||||
他喜欢KDE的原始桌面,但是它在他的网关机器上工作不时很好
|
||||
他是一个Debian GNU/linux用户和XFCE桌面环境
|
||||
|
||||
|
||||
莱纳斯也是扎克英雄,但是扎克是整个GNU/linux和自由软件社区的英雄,谁不断地提醒我们,我们的未来是在伟大的支持里。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.themukt.com/2014/08/24/linus-torvalds-hero-says-13-years-old-zachary-dupont/
|
||||
|
||||
作者:[wapnil Bhartiya][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.themukt.com/author/swapnil_bhartiya/
|
||||
[1]:http://www.amazon.com/gp/product/0066620732/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=0066620732&linkCode=as2&tag=muktware-20&linkId=HBKEBIFVZQC35GGK
|
||||
@ -1,23 +1,23 @@
|
||||
|
||||
Linux 常见问题(有答案的哦)-- 如何为sudo命令定义PATH环境变量
|
||||
Linux有问必答——如何为sudo命令定义PATH环境变量
|
||||
================================================================================
|
||||
>**问题**:我安装了一个程序到/usr/local/bin目录下,这个程序需要root权限才能执行,当我用sudo去执行它时,收到"sudo: XXXXX: command not found"的错误提示,不知道为什么/usr/local/bin没有被包含到PATH环境变量下面来,我该如何解决这个问题?
|
||||
|
||||
当你使用sudo去执行一个程序时,处于安全的考虑,这个程序将在一个新的、最小化的环境中执行,也就是说,诸如PATH这样的环境变量,在sudo命令下已经被重置成默认状态了。
|
||||
所以当一个刚初始化的PATH变量中不包含你所要运行的程序所在的目录,你就会得到"command not found"的错误提示。
|
||||
当你使用sudo去执行一个程序时,处于安全的考虑,这个程序将在一个新的、最小化的环境中执行,也就是说,诸如PATH这样的环境变量,在sudo命令下已经被重置成默认状态了。所以当一个刚初始化的PATH变量中不包含你所要运行的程序所在的目录,用sudo去执行,你就会得到"command not found"的错误提示。
|
||||
|
||||
为了改变PATH在sudo会话中的初始值,打开/etc/sudoers文件并编辑,找到"secure_path"一行,"secure_path"中包含的路径就将在sudo会话中的PATH变量中生效。
|
||||
要想改变PATH在sudo会话中的初始值,用文本编辑器打开/etc/sudoers文件,找到"secure_path"一行,当你执行sudo 命令时,"secure_path"中包含的路径将被当做默认PATH变量使用。
|
||||
|
||||
添加所需要的路径(如 /usr/local/bin)到"secure_path"下,在开篇所遇见的问题就将迎刃而解。
|
||||
|
||||
添加所需要的路径(如 /usr/local/bin)到"secure_path"下,在开篇所遇见的问题就将迎刃而解。
|
||||
Defaults secure_path = /sbin:/bin:/usr/sbin:/usr/bin:/usr/local/bin
|
||||
|
||||
|
||||
这个修改会即刻生效。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/define-path-environment-variable-sudo-commands.html
|
||||
|
||||
译者:[nd0104](https://github.com/nd0104) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[nd0104](https://github.com/nd0104) 校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,185 @@
|
||||
使用Linux命令行管理DigitalOcean VPS水滴
|
||||
================================================================================
|
||||
[DigitalOcean][1]是云VPS主机市场中最炙手可热的新生儿。虽然没有提供像Amazon之类一样的综合服务业务,DigitalOcean已经成为定位于中小型企业和开发者的基于Linux的最佳云VPS服务的强有力的竞争者,这都得归功于他们具有竞争力的价格和对用户友好的管理界面。
|
||||
|
||||

|
||||
|
||||
不管什么时候,当你需要一个面向网络的服务器用于你的个人项目,你都可以全速开动一个“水滴”([DigitalOcean][3]中VPS实例的昵称),也可以在你不需要时杀掉它,没必要为了让你的VPS保持运作而烧光了你的钱袋。尽管DigitalOcean基于网络的管理界面已经十分高效,但对于那些命令行界面的死忠派,它还是提供了基于命令行界面的水滴管理工具,它叫[tugboat][4]。多亏了这个命令行工具,所有复杂的水滴管理任务都可以简单地转变成一个脚本来完成。
|
||||
|
||||
在本文中,我打算讲述**怎样使用tugboat来从命令行对DigitalOcean水滴进行管理**。
|
||||
|
||||
### 在Linux上安装tugboat ###
|
||||
|
||||
在Debian,Ubuntu或者Linux Mint上安装tugboat:
|
||||
|
||||
$ sudo apt-get install ruby-dev
|
||||
$ sudo gem install tugboat
|
||||
|
||||
在Fedora上安装tugboat:
|
||||
|
||||
$ sudo yum install ruby-devel
|
||||
$ sudo gem install tugboat
|
||||
|
||||
要在CentOS上安装tugboat,首先[安装或升级到最新的Ruby][5],因为在CentOS 6.5以及更早的版本上,默认的Ruby不满足拖船所需的最小版本(1.9及更高版本)。安装Ruby 1.9及更高版本后,请按如下方式安装tugboat。
|
||||
|
||||
$ sudo gem install tugboat
|
||||
|
||||
### tugboat首次使用配置 ###
|
||||
|
||||
在安装完后,就该实行一次配置,配置涉及了授权tugboat访问DigitalOcean帐号。
|
||||
|
||||
转到[https://cloud.digitalocean.com/api_access][6],并创建新的API密钥,记录客户ID和API密钥。
|
||||
|
||||

|
||||
|
||||
通过运行以下命令来启动授权过程:
|
||||
|
||||
$ tugboat authorize
|
||||
|
||||
在提示你输入客户ID和API密钥时,请输入。它会询问几个其它问题,目前你可以接受默认的回答。我们打算在今后自定义默认设置。
|
||||
|
||||
[][7]
|
||||
|
||||
现在,让我们自定义默认水滴设置,以反映你典型的使用状况。要那么做,首先检查水滴提供的可用的东西(如,可用的镜像、区域、大小)。
|
||||
|
||||
运行以下命令,它会列出可用的水滴镜像。选取使用一个默认镜像,并记录相关的ID。
|
||||
|
||||
$ tugboat images --global
|
||||
|
||||

|
||||
|
||||
类似,从可用区域中选取一个默认的地理位置:
|
||||
|
||||
$ tugboat regions
|
||||
|
||||
同时,从可用的RAM大小中选择一个默认的水滴大小:
|
||||
|
||||
$ tugboat sizes
|
||||
|
||||

|
||||
|
||||
现在,把你的默认选择放到~/.tugboat中。例如,我在这里自定义了默认设置:区域在纽约,系统是Ubuntu 14.04,内存512MB。如果你想要通过密钥验证启用SSH,设置“ssh_user”为root,这个我很快会讲到。
|
||||
|
||||
$ vi ~/.tugboat
|
||||
|
||||
----------
|
||||
|
||||
---
|
||||
authentication:
|
||||
client_key: XXXXXXXXXXXXXXXXXXX
|
||||
api_key: XXXXXXXXXXXXXXXXXXXX
|
||||
ssh:
|
||||
ssh_user: root
|
||||
ssh_key_path: /home/dev/.ssh/id_rsa
|
||||
ssh_port: '22'
|
||||
defaults:
|
||||
region: '4'
|
||||
image: '3240036'
|
||||
size: '66'
|
||||
ssh_key: ''
|
||||
private_networking: 'false'
|
||||
backups_enabled: 'false'
|
||||
|
||||
### 创建并添加SSH密钥到数字海洋 ###
|
||||
|
||||
要访问水滴实例,一个安全的方式是通过[密钥验证][8]的SSH连接到该实例。
|
||||
|
||||
事实上,你可以通过使用[DigitalOcean][9]来注册SSH公钥,为你的水滴实现自动启用密钥验证。下面告诉你怎么做。
|
||||
|
||||
首先,生成一个公/私密钥对(如果你还没有)。
|
||||
|
||||
$ ssh-keygen -t rsa -C "your@emailaddress.com"
|
||||
|
||||
假设生成的密钥对由~/.ssh/id_rsa(私钥)和~/.ssh/id_rsa.pub(公钥)构成,去将你的公钥上传吧,命令如下:
|
||||
|
||||
$ tugboat add-key [name-of-your-key]
|
||||
|
||||
你可以任意给你的密钥命名(如,“my-default-key”)。当出现提示时,输入公钥路径(如,/home/user/.ssh/id_rsa.pub)。在密钥上传完成后,运行以下命令来验证密钥是否正确添加:
|
||||
|
||||
$ tugboat keys
|
||||
|
||||

|
||||
|
||||
密钥也应该出现在DigitalOcean的[SSH密钥页][10]。如果你想要密钥自动使用到水滴中,添加密钥ID到~/.tugboat中。
|
||||
|
||||
ssh_key: '182710'
|
||||
|
||||
### 拖船的基本用法 ###
|
||||
|
||||
这里列出了tugboat命令行的一些基本使用情况。
|
||||
|
||||
1. 使用默认设置创建新水滴。
|
||||
|
||||
$ tugboat create <name-of-droplet>
|
||||
|
||||
2. 列出所有活动水滴。
|
||||
|
||||
$ tugboat droplets
|
||||
|
||||
3. 显示水滴的信息。
|
||||
|
||||
$ tugboat info <name-of-droplet>
|
||||
|
||||
[][11]
|
||||
|
||||
4. 关闭水滴,并移除镜像。
|
||||
|
||||
$ tugboat destroy <name-of-droplet>
|
||||
|
||||
5. 关闭水滴,但保持镜像
|
||||
|
||||
$ tugboat halt <name-of-droplet>
|
||||
|
||||
6. 为水滴创建快照,水滴必须先关闭。
|
||||
|
||||
$ tugboat snapshot <snapshot-name> <name-of-droplet>
|
||||
|
||||
7. 调整水滴大小(增加或减少RAM大小),水滴必须先关闭。
|
||||
|
||||
$ tugboat resize <name-of-droplet> -s <image-id>
|
||||
|
||||
如果你想要知道特定命令的更多选项,运行:
|
||||
|
||||
$ tugboat help <command>
|
||||
|
||||

|
||||
|
||||
### 排障 ###
|
||||
|
||||
1. 当我运行tugboat命令时,它出错了,并出现以下错误。
|
||||
|
||||
/usr/lib/ruby/site_ruby/1.8/rubygems/custom_require.rb:31:in `gem_original_require': /usr/lib/ruby/gems/1.8/gems/tugboat-0.2.0/lib/tugboat/cli.rb:12: syntax error, unexpected ':', expecting kEND (SyntaxError)
|
||||
|
||||
Tugboat要求Ruby 1.9及更高版本,你需要升级Ruby来解决该问题。对于CentOS,请参考[此教程][12]
|
||||
|
||||
2. 当我试着用gem来安装Tugboat时,出现了下面的错误。
|
||||
|
||||
/usr/local/share/ruby/site_ruby/rubygems/core_ext/kernel_require.rb:55:in `require': cannot load such file -- json/pure (LoadError)
|
||||
|
||||
安装以下gem来修复该问题。
|
||||
|
||||
$ sudo gem install json_pure
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/07/manage-digitalocean-vps-droplets-command-line-linux.html
|
||||
|
||||
原文作者:[Dan Nanni][a]
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/go/digitalocean
|
||||
[2]:http://news.netcraft.com/archives/2013/12/11/digitalocean-now-growing-faster-than-amazon.html
|
||||
[3]:http://xmodulo.com/go/digitalocean
|
||||
[4]:https://github.com/pearkes/tugboat
|
||||
[5]:http://ask.xmodulo.com/upgrade-ruby-centos.html
|
||||
[6]:https://cloud.digitalocean.com/api_access
|
||||
[7]:https://www.flickr.com/photos/xmodulo/14685122101/
|
||||
[8]:http://xmodulo.com/2012/04/how-to-enable-ssh-login-without.html
|
||||
[9]:http://xmodulo.com/go/digitalocean
|
||||
[10]:https://cloud.digitalocean.com/ssh_keys
|
||||
[11]:https://www.flickr.com/photos/xmodulo/14501627440/
|
||||
[12]:http://ask.xmodulo.com/upgrade-ruby-centos.html
|
||||
@ -0,0 +1,197 @@
|
||||
在 CentOS 和 RHEL 上安装 Puppet 服务器和客户端
|
||||
================================================================================
|
||||
当手中有相当多的机器需要管理的时候,自动化处理冗余又无聊的任务对系统管理员来说就很重要了。很多管理员习惯了自己写脚本模拟复杂软件之间的调度。不幸的是,脚本会过时,脚本的作者会离职,如果不花费巨大精力来维护这些脚本的话,它们早晚会一点儿用也没有。如果能有一个系统,任何人都可以使用、安装工具,不论其受雇于何人,那真是太期待了。目前已有几种系统可以解决这类需求,这篇教程将介绍其中之一——Puppet——的使用方法。
|
||||
|
||||
### Puppet 是什么? ###
|
||||
|
||||
Puppet 是一款为 IT 系统管理员和顾问设计的自动化软件,你可以用它自动化地完成诸如安装应用程序和服务、补丁管理和部署等工作。所有资源的相关配置都以“manifests”的方式保存,单台机器或者多台机器都可以使用。如果你想了解更多内容,Puppet 实验室的网站上有关于 [Puppet 及其工作原理][1]的更详细的介绍。
|
||||
|
||||
### 本教程要做些什么? ###
|
||||
|
||||
在这篇教程里,我们将一起安装配置一个 Puppet 服务器,然后在我们的客户端服务器(译注:这里的“客户端服务器”指需要部署业务逻辑的服务器)上完成一些基本配置。
|
||||
|
||||
### 准备工作 ###
|
||||
|
||||
由于 Puppet 不是 CentOS 或 RHEL 发行版的基本仓库,所以我们得手动添加 Puppet 实验室提供的自定义仓库。在所有你想使用 Puppet 的地方执行以下命令安装这个仓库(版本不同,对应的 RPM 文件名可能略有不同)。
|
||||
|
||||
**对于 CentOS/RHEL 6.5:**
|
||||
|
||||
# rpm -ivh https://yum.puppetlabs.com/el/6.5/products/x86_64/puppetlabs-release-6-10.noarch.rpm
|
||||
|
||||
**对于 CentOS/RHEL 7:**
|
||||
|
||||
# rpm -ivh https://yum.puppetlabs.com/el/7/products/x86_64/puppetlabs-release-7-10.noarch.rpm
|
||||
|
||||
### 安装服务器端 ###
|
||||
|
||||
在你打算用作 master 的服务器上安装 "puppet-server" 包。
|
||||
|
||||
# yum install puppet-server
|
||||
|
||||
安装完成后,设置 Puppet 服务器开机自动启动,然后启动它。
|
||||
|
||||
# chkconfig puppetmaster on
|
||||
# service puppetmaster start
|
||||
|
||||
现在服务器已经运行起来了,我们试试看我们的网络能不能访问到它。
|
||||
|
||||
对于使用 iptables 当做防火墙的 CentOS/RHEL 6,在 `/etc/sysconfig/iptables` 文件的 `OUTPUT ACCEPT` 小节里添加下面这一行。
|
||||
|
||||
> -A INPUT -m state --state NEW -m tcp -p tcp --dport 8140 -j ACCEPT
|
||||
|
||||
重新启动 iptables 服务让刚才的修改生效。
|
||||
|
||||
# service iptables restart
|
||||
|
||||
在安装了防火墙的 CentOS/RHEL 7 上,我们这么做:
|
||||
|
||||
# firewall-cmd --permanent --zone=public --add-port=8140/tcp
|
||||
# firewall-cmd --reload
|
||||
|
||||
### 安装客户端 ###
|
||||
|
||||
执行下面的命令,在客户端节点安装 Puppet 客户端。
|
||||
|
||||
# yum install puppet
|
||||
|
||||
安装完成后,确保 Puppet 会随开机自动启动。
|
||||
|
||||
# chkconfig puppet on
|
||||
|
||||
Puppet 客户端需要知道 Puppet master 服务器的地址。最佳方案是使用 DNS 服务器解析 Puppet master 服务器地址。如果你没有 DNS 服务器,在 `/etc/hosts` 里添加下面这几行也可以:
|
||||
|
||||
> 1.2.3.4 server.your.domain
|
||||
|
||||
> 2.3.4.5 client-node.your.domain
|
||||
|
||||
1.2.3.4 对应你的 Puppet master 服务器 IP 地址,“server.your.domain”是你的 master 服务器域名(默认通常是服务器的 hostname),“client-node.your.domain”是你的客户端节点。包括 Puppet master 和客户端,所有相关的服务器都要在 hosts 文件里配置。
|
||||
|
||||
完成这些设置之后,我们要让 Puppet 客户端知道它的 master 是谁。默认情况下,Puppet 会查找名为“puppet”的服务器,但通常这并不符合你网络环境的真实情况,所以我们要改成 Pupper master 服务器的完整域名。打开文件 `/etc/sysconfig/puppet`,把 `PUPPET_SERVER` 变量的值改成你在 `/etc/hosts` 文件里指定的 Puppet master 服务器的域名。
|
||||
|
||||
> PUPPET_SERVER=server.your.domain
|
||||
|
||||
master 服务器名也要在 `/etc/puppet/puppet.conf` 文件的“[agent]”小节里事先定义好。
|
||||
|
||||
> server=server.your.domain
|
||||
|
||||
现在可以启动 Puppet 客户端了:
|
||||
|
||||
# service puppet start
|
||||
|
||||
强制我们的客户端在 Puppet master 服务器上登记:
|
||||
|
||||
# puppet agent --test
|
||||
|
||||
你会看到类似于下面的输出。别怕,这是正常现象,因为服务器还没有在 Puppet master 服务器上验证过。
|
||||
|
||||
> Exiting; no certificate found and waitforcert is disabled
|
||||
|
||||
返回 Puppet master 服务器,检查证书验证请求:
|
||||
|
||||
# puppet cert list
|
||||
|
||||
你应该能看到一个列出了所有向 Puppet master 服务器发起证书签名请求的服务器。找到你客户端服务器的 hostname 然后使用下面的命令签名(client-node 是你客户端节点的域名):
|
||||
|
||||
# puppet cert sign client-node
|
||||
|
||||
到此为止 Puppet 客户端和服务器都正常工作了。恭喜你!但是,现在 Puppet master 没有任何要客户端做的事儿。好吧,我们来创建一些基本的 manifest 文件然后让我们的客户端节点安装一些基本工具。
|
||||
|
||||
回到你的 Puppet 服务器,确保目录 `/etc/puppet/manifests` 存在。
|
||||
|
||||
# mkdir -p /etc/puppet/manifests
|
||||
|
||||
创建 manifest 文件 `/etc/puppet/manifests/site.pp`,内容如下
|
||||
|
||||
node 'client-node' {
|
||||
include custom_utils
|
||||
}
|
||||
|
||||
class custom_utils {
|
||||
package { ["nmap","telnet","vim-enhanced","traceroute"]:
|
||||
ensure => latest,
|
||||
allow_virtual => false,
|
||||
}
|
||||
}
|
||||
|
||||
然后重新启动 puppetmaster 服务。
|
||||
|
||||
# service puppetmaster restart
|
||||
|
||||
客户端默认每 30 分钟更新一次配置,如果你希望你的修改能强制生效,就在客户端执行如下命令:
|
||||
|
||||
# puppet agent -t
|
||||
|
||||
如果你需要修改客户端的默认刷新时间,编辑客户端节点的 `/etc/puppet/puppet.conf` 文件中“[agent]”小节,增加下面这一行:
|
||||
|
||||
> runinterval = <yourtime>
|
||||
|
||||
这个选项的值可以是秒(格式比如 30 或者 30s),分钟(30m),小时(6h),天(2d)以及年(5y)。值得注意的是,0 意味着“立即执行”而不是“从不执行”。
|
||||
|
||||
### 提示和技巧 ###
|
||||
|
||||
#### 1. 调试 ####
|
||||
|
||||
你免不了会提交错误的配置,然后不得不通过调试判断问题出现在哪儿。一般来说,你要么通过查看日志文件 `/var/log/puppet` 着手解决问题,要么手动执行查看输出:
|
||||
|
||||
# puppet agent -t
|
||||
|
||||
使用“-t”选项,你可以看到 Puppet 的详细输出。这条命令还有额外的选项可以帮你定位问题。首先要介绍的选项是:
|
||||
|
||||
# puppet agent -t --debug
|
||||
|
||||
Debug 选项会显示 Puppet 本次运行时的差不多每一个步骤,这在调试非常复杂的问题时很有用。另一个很有用的选项是:
|
||||
|
||||
# puppet agent -t --noop
|
||||
|
||||
这个选项让 puppet 工作在 dry-run(译注:空转模式,不会对真实环境产生影响)模式下,不会应用任何修改。Puppet 只会把其工作内容输出到屏幕上,不会写到磁盘里去。
|
||||
|
||||
#### 2. 模块 ####
|
||||
|
||||
有时候你需要更复杂的 manifest 文件,在你着手编写它们之前,你有必要花点儿时间浏览一下 [https://forge.puppetlabs.com][2]。Forge 是一个集合了 Puppet 模块的社区,你的问题很可能已经有人解答过了,你能在那儿找到解决问题的模块。如果找不到,那就自己写一个然后提交上去,其他人也能从中获益。
|
||||
|
||||
现在,假设你已经找到了一个模块能解决你的问题。怎么把它安装到你的系统中去呢?非常简单,因为 Puppet 已经有了可以直接下载模块的用户界面,只需要执行下面的命令:
|
||||
|
||||
# puppet module install <module_name> --version 0.0.0
|
||||
|
||||
<module_name> 是你选择的模块的名字,版本号可选(如果没有指定版本号,默认使用最新的版本)。如果你不记得想安装的模块的名字了,试试下面的命令搜索模块:
|
||||
|
||||
# puppet module search <search_string>
|
||||
|
||||
你会得到一个包含 search_string 的列表。
|
||||
|
||||
# puppet module search apache
|
||||
|
||||
----------
|
||||
|
||||
Notice: Searching https://forgeapi.puppetlabs.com ...
|
||||
NAME DESCRIPTION AUTHOR KEYWORDS
|
||||
example42-apache Puppet module for apache @example42 example42, apache
|
||||
puppetlabs-apache Puppet module for Apache @puppetlabs apache web httpd centos rhel ssl wsgi proxy
|
||||
theforeman-apache Apache HTTP server configuration @theforeman foreman apache httpd DEPRECATED
|
||||
|
||||
如果你想查看已经安装了哪些模块,键入:
|
||||
|
||||
# puppet module list
|
||||
|
||||
### 总结 ###
|
||||
|
||||
到目前为止,你应该有了功能完整的可以向一个或多个客户端服务器推送基本配置的 Puppet master 服务器。你可以自己随便加点儿配置适配你自己的网络环境。不必为试用 Puppet 担心,你会发现,它会拯救你的生活。
|
||||
|
||||
Puppet 实验室正在试着维护一个质量上乘的项目文档,所以如果你想学点儿关于 Puppet 相关的配置,我强烈推荐你访问 Puppet 项目的主页 [http://docs.puppetlabs.com][3]。
|
||||
|
||||
如果你有任何问题,敬请在文章下方评论,我会尽我所能回答你并给你建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/install-puppet-server-client-centos-rhel.html
|
||||
|
||||
作者:[Jaroslav Štěpánek][a]
|
||||
译者:[sailing](https://github.com/sailing)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/jaroslav
|
||||
[1]:https://puppetlabs.com/puppet/what-is-puppet/
|
||||
[2]:https://forge.puppetlabs.com/
|
||||
[3]:http://docs.puppetlabs.com/
|
||||
@ -0,0 +1,68 @@
|
||||
在RHEL / CentOS / 5.x / 6.x上禁用并使单用户模式受到密码保护
|
||||
================================================================================
|
||||
大家好,
|
||||
|
||||
如果您还没有使用密码保护单用户模式,这对你的Linux服务器会是一个很大的风险,所以在涉及到安全性时,使用密码保护单用户模式是非常重要的。
|
||||
|
||||
今天这篇文章我会向你展示如何在RHEL / CentOS 5.x 和 RHEL / CentOS 6.x上使用密码保护你的单用户模式。
|
||||
|
||||
请仔细地执行所给出的命令,不然你的系统将会无法正常启动。首先,我会请你先完整地读完,然后在尝试。请自己承担相应的后果:-)
|
||||
|
||||

|
||||
Password Protect
|
||||
|
||||
### 1. 对于 RHEL / CentOS 5.x ###
|
||||
|
||||
#### 1.1 开始之前请先备份你的 /etc/inittab ####
|
||||
|
||||
cp /etc/inittab /etc/inittab.backup
|
||||
|
||||
** 禁用并使单用户模式受到密码保护,用root执行下面的命令 :-**
|
||||
|
||||
[root@tejas-barot-linux ~]$ sed -i '1i su:S:wait:/sbin/sulogin'
|
||||
|
||||
** 这样你会看到像下面这样的 **
|
||||
|
||||
su:S:wait:/sbin/sulogin
|
||||
# Default runlevel. The runlevels used by RHS are:
|
||||
# 0 - halt (Do NOT set initdefault to this)
|
||||
# 1 - Single user mode
|
||||
# 2 - Multiuser, without NFS (The same as 3, if you do not have networking)
|
||||
# 3 - Full multiuser mode
|
||||
# 4 - unused
|
||||
# 5 - X11
|
||||
# 6 - reboot (Do NOT set initdefault to this)
|
||||
#
|
||||
id:3:initdefault:
|
||||
|
||||
*NOTE: 如果你不想使用sed命令你可以在/etc/inittab 顶部加入 “su:S:wait:/sbin/sulogin” *
|
||||
|
||||
### 2. 对于 RHEL / CentOS 6.x ###
|
||||
|
||||
#### 2.1 开始之前请先备份你的 /etc/inittab####
|
||||
|
||||
cp /etc/sysconfig/init /etc/sysconfig/init.backup
|
||||
|
||||
#### 2.2 禁用并使单用户模式受到密码保护,用root执行下面的命令 :- ####
|
||||
|
||||
[root@tejas-barot-linux ~]$#sed -i 's/SINGLE=\/sbin\/sushell/SINGLE=\/sbin\/sulogin/' /etc/sysconfig/init
|
||||
|
||||
**这样你会看到像下面这样的**
|
||||
|
||||
SINGLE=/sbin/sulogin
|
||||
|
||||
*注意 :- 如果你不想使用sed你可以在 /etc/sysconfig/init 中直接改成 “SINGLE=/sbin/sulogin”*
|
||||
|
||||
E享受Linux :) 享受开源
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tejasbarot.com/2014/05/05/disable-password-protect-single-user-mode-rhel-centos-5-x-6-x/#axzz39oGCBRuX
|
||||
|
||||
作者:[Tejas Barot][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/+TejasBarot
|
||||
115
translated/tech/20140813 How to remove file metadata on Linux.md
Normal file
115
translated/tech/20140813 How to remove file metadata on Linux.md
Normal file
@ -0,0 +1,115 @@
|
||||
移除Linux系统上的文件元数据
|
||||
================================================================================
|
||||
|
||||
典型的数据文件通常关联着“元数据”,其包含这个文件的描述信息,表现为一系列属性-值的集合。元数据一般包括创建者名称、生成文件的工具、文件创建/修改时期、创建位置和编辑历史等等。EXIF(镜像标准)、RDF(web资源)和DOI(数字文档)是几种流行的元数据标准。
|
||||
|
||||
|
||||
虽然元数据在数据管理领域有它的优点,但事实上它会[危害][1]你的隐私。相机图片中的EXIF格式数据会泄露出可识别的个人信息,比如相机型号、拍摄相关的GPS坐标和用户偏爱的照片编辑软件等。在文档和电子表格中的元数据包含作者/所属单位信息和相关的编辑历史。不一定这么绝对,但诸如[metagoofil][2]一类的元数据收集工具在信息收集的过程中常最作为入侵测试的一部分被利用。
|
||||
|
||||
对那些想要从共享数据中擦除一切个人元数据的用户来说,有一些方法从数据文件中移除元数据。你可以使用已有的文档或图片编辑软件,通常有自带的元数据编辑功能。在这个教程里,我会介绍一种不错的、单独的**元数据清理工具**,其目标只有一个:**匿名一切私有元数据**。
|
||||
|
||||
[MAT][3](元数据匿名工具箱)是一款专业的元数据清理器,使用Python编写。它在Tor工程旗下开发而成,在[Trails][4]上衍生出标准,后者是一种私人增强的live操作系统。【翻译得别扭,麻烦修正:)】
|
||||
|
||||
与诸如[exiftool][5]等只能对有限数量的文件类型进行写入的工具相比,MAT支持从各种各样的文件中消除元数据:图片(png、jpg)、文档(odt、docx、pptx、xlsx和pdf)、归档文件(tar、tar.bz2)和音频(mp3、ogg、flac)等。
|
||||
|
||||
### 在Linux上安装MAT ###
|
||||
|
||||
在基于Debian的系统(Ubuntu或Linux Mint)上,已经打包好MAT,所以安装很直接:
|
||||
|
||||
$ sudo apt-get install mat
|
||||
|
||||
在Fedora上,并没有预先生成的MAT包,所以你需要从源码生成。这是我在Fedora上生成MAT的步骤(不成功的话,请查看教程底部):
|
||||
|
||||
$ sudo yum install python-devel intltool python-pdfrw perl-Image-ExifTool python-mutagen
|
||||
$ sudo pip install hachoir-core hachoir-parser
|
||||
$ wget https://mat.boum.org/files/mat-0.5.tar.xz
|
||||
$ tar xf mat-0.5.tar.xz
|
||||
$ cd mat-0.5
|
||||
$ python setup.py install
|
||||
|
||||
### 使用MAT-GUI匿名元数据 ###
|
||||
|
||||
一旦安装好,通过GUI和命令行都可以使用MAT。输入这个命令启动MAT的GUI:
|
||||
|
||||
$ mat-gui
|
||||
|
||||
尝试清理一个包含如下内置元数据的实例文档文件(如private.odt)。
|
||||
|
||||

|
||||
|
||||
点击“添加”按钮来添加需要清理的文件到MAT中。一旦载入文件,点击“确认”按钮对所有隐藏的元数据信息进行扫描。
|
||||
|
||||

|
||||
|
||||
只要元数据被MAT检测到,“State”状态就会被标记成“Dirty”。双击文件可以查看检测到的元数据。
|
||||
|
||||

|
||||
|
||||
点击“清理”按钮来清除文件中的元数据。MAT会自动清空文件中的所有私有元数据字段。
|
||||
|
||||

|
||||
|
||||
清除后的状态中不包含任何私有可辨识的痕迹:
|
||||
|
||||

|
||||
|
||||
### 从命令行匿名元数据 ###
|
||||
|
||||
$ mat -c .
|
||||
|
||||
正如前面提到的,另一种调用MAT的方式是从命令行,使用mat命令可达到。
|
||||
|
||||
为了检查任何敏感的元数据,先前往文件所在的目录,然后运行:
|
||||
|
||||
$ mat -c .
|
||||
|
||||
这样会扫描当前目录和其子目录下的所有文件,并报告它们的状态(已清理或未清理)。
|
||||
|
||||

|
||||
|
||||
你可以使用“-d”选项来查看检测到的真实元数据:
|
||||
|
||||
$ mat -d <input_file>
|
||||
|
||||

|
||||
|
||||
如果不为mat命令提供任何选项,默认操作会移除文件的元数据。如果要在清理的过程中保留原始文件的备份,使用“-b”选项。下面命令会清除所有文件的元数据,并将原始文件存储为“*.bak”文件。
|
||||
|
||||
$ mat -b .
|
||||
|
||||

|
||||
|
||||
查看所支持的文件类型,请运行:
|
||||
|
||||
$ mat -l
|
||||
|
||||

|
||||
|
||||
### 故障排除 ###
|
||||
|
||||
当前我在Fedora上使用编译版本的MAT遇到了下列问题。当我尝试在Fedora清除归档/文档文件的元数据时(如*.gz、*.odt、*.docx),MAT因为下列错误失败。如果你知道如何解决这个问题,请在评论里回复我。
|
||||
|
||||
File "/usr/lib64/python2.7/zipfile.py", line 305, in __init__
|
||||
raise ValueError('ZIP does not support timestamps before 1980')
|
||||
ValueError: ZIP does not support timestamps before 1980
|
||||
|
||||
### 总结 ###
|
||||
|
||||
MAT是一款简单但非常好用的工具,用来预防从元数据中无意泄露私人数据。请注意如果有必要,还是需要你去隐藏文件内容。MAT能做的是消除与文件相关的元数据,但并不会对文件本身进行任何操作。简而言之,MAT是一名救生员,因为它可以处理大多数常见的元数据移除,但不应该只指望它来保证你的隐私。[译者注:养成良好的隐私保护意识和习惯才是最好的方法]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/remove-file-metadata-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[KayGuoWhu](https://github.com/KayGuoWhu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://www.theguardian.com/world/2013/sep/30/nsa-americans-metadata-year-documents
|
||||
[2]:http://code.google.com/p/metagoofil/
|
||||
[3]:https://mat.boum.org/
|
||||
[4]:https://tails.boum.org/
|
||||
[5]:http://xmodulo.com/2013/08/view-or-edit-pdf-and-image-metadata-from-command-line-on-linux.html
|
||||
@ -0,0 +1,78 @@
|
||||
在命令行中管理 Wifi 连接
|
||||
================================================================================
|
||||
无论何时要安装一款新的 Linux 发行系统,一般的建议都是让您通过有线连接来接到互联网的。这主要的原因有两条:第一,您的无线网卡也许安装的驱动不正确而不能用;第二,如果您是从命令行中来安装系统的,管理 WiFi 就非常可怕。我总是试图避免在命令行中处理 WiFi 。但 Linux 的世界,应具有无所畏惧的精神。如果您不知道怎样操作,您需要继续往下来学习之,这就是写这篇文章的唯一原因。所以我强迫自己学习如何在命令行中管理 WiFi 连接。
|
||||
|
||||
There are of course multiple ways to connect to a WiFi from the command line. But for the sake of this post, and as an advice, I will try to use the most basic way: the one that uses programs and utilities included in the "default packages" of any distribution. Or at least I will try. An obvious reason for this choice is that the process can potentially be reproduced on any Linux computer. The downside is its relative complexity.通过命令行来设置连接到 WiFi 当然有很多种方法,但在这篇文章里,也是一个建议,我将会作用最基本的方法:那就是使用在任何发布版本中都有的包含在“默认包”里的程序和工具。
|
||||
|
||||
First, I will assume that you have the correct drivers loaded for your wireless LAN card. There is no way to start anything without that. And if you don't, you should take a look at the Wiki and documentation for your distribution.
|
||||
|
||||
Then you can check which interface supports wireless connections with the command
|
||||
|
||||
$ iwconfig
|
||||
|
||||
|
||||
|
||||
In general, the wireless interface is called wlan0. There are of course exceptions, but for the rest of this tutorial, I will call it that way.
|
||||
|
||||
Just in case, you should make sure that the interface is up with:
|
||||
|
||||
$ sudo ip link set wlan0 up
|
||||
|
||||
Once you know that your interface is operational, you should scan for nearby wireless networks with:
|
||||
|
||||
$ sudo iw dev wlan0 scan | less
|
||||
|
||||
|
||||
|
||||
From the output, you can extract the name of the network (its SSID), its signal power, and which type of security it uses (e.g., WEP, WPA/WPA2). From there, the road splits into two: the nice and easy, and the slightly more complicated case.
|
||||
|
||||
If the network you want to connect to is not encrypted, you can connect straight to it with:
|
||||
|
||||
$ sudo iw dev wlan0 connect [network SSID]
|
||||
|
||||
If the network uses WEP encryption, it is also quite easy:
|
||||
|
||||
$ sudo iw dev wlan0 connect [network SSID] key 0:[WEP key]
|
||||
|
||||
But everything gets worse if the network uses WPA or WPA2 protocols. In this case, you have to use the utility called wpa_supplicant, which is not always included by default. You then have to modify the file at /etc/wpa_supplicant/wpa_supplicant.conf to add the lines:
|
||||
|
||||
network={
|
||||
ssid="[network ssid]"
|
||||
psk="[the passphrase]"
|
||||
priority=1
|
||||
}
|
||||
|
||||
I recommend that you append it at the end of the file, and make sure that the other configurations are commented out. Be careful that both the ssid and the passphrase are case sensitive. You can also technically put the name of the access point as the ssid, and wpa_supplicant will replace it with the proper ssid.
|
||||
|
||||
Once the configuration file is completed, launch this command in the background:
|
||||
|
||||
$ sudo wpa_supplicant -i wlan0 -c /etc/wpa_supplicant/wpa_supplicant.conf
|
||||
|
||||
Finally, whether you connected to an open or a secure network, you have to get an IP address. Simply use:
|
||||
|
||||
$ sudo dhcpcd wlan0
|
||||
|
||||
If everything goes well, you should get a brand new local IP via DHCP, and the process will fork in the background. If you want to be sure that you are connected, you can always check again with:
|
||||
|
||||
$ iwconfig
|
||||
|
||||
|
||||
|
||||
To conclude, I think that getting over the first step is completely worth it. You never know when your GUI will be down, or when you cannot access a wired connection, so getting ready now seems very important. Also, as mentioned before, there are a lot of ways (e.g., NetworkManager, [wicd][1], [netcfg][2], [wifi][3]) to manage a wireless connection. If I try to stick to the most basic way, I know that in some cases, the utilities that I used may not even be available to you, and that you would have to download them prior to that. On the other side of the balance, there are some more advanced programs, which are definitely not included in the "default packages," which will greatly simplify the whole process. But as a general advice, it is good to stick to the basics at first.
|
||||
|
||||
What other ways would you recommend to connect via WiFi from the command line? Please let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/manage-wifi-connection-command-line.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://wicd.sourceforge.net/
|
||||
[2]:https://www.archlinux.org/netcfg/
|
||||
[3]:https://github.com/rockymeza/wifi
|
||||
@ -0,0 +1,121 @@
|
||||
配置Linux访问控制列表(ACL)
|
||||
================================================================================
|
||||
使用拥有权限控制的Liunx,工作是一件轻松的任务。它可以定义任何user,group和other的权限。无论是在桌面电脑或者不会有很多用户的虚拟Linux实例,或者当用户不愿意分享他们之间的文件时,这样的工作是很棒的。然而,如果你是在一个大型组织,你运行了NFS或者Samba服务给不同的用户。然后你将会需要灵活的挑选并设置很多复杂的配置和权限去满足你的组织不同的需求。
|
||||
|
||||
Linux(和其他Unix,兼容POSIX的)所以拥有访问控制列表(ACL),它是一种分配权限之外的普遍范式。例如,默认情况下你需要确认3个权限组:owner,group和other。使用ACL,你可以增加权限给其他用户或组别,而不单只是简单的"other"或者是拥有者不存在的组别。可以允许指定的用户A、B、C拥有写权限而不再是让他们整个组拥有写权限。
|
||||
|
||||
ACL支持多种Linux文件系统,包括ext2, ext3, ext4, XFS, Btfrs, 等。如果你不确定你的文件系统是否支持ACL,请参考文档。
|
||||
|
||||
### 在文件系统使ACL生效 ###
|
||||
|
||||
首先,我们需要安装工具来管理ACL。
|
||||
|
||||
Ubuntu/Debian 中:
|
||||
|
||||
$ sudo apt-get install acl
|
||||
|
||||
CentOS/Fedora/RHEL 中:
|
||||
|
||||
# yum -y install acl
|
||||
|
||||
Archlinux 中:
|
||||
|
||||
# pacman -S acl
|
||||
|
||||
出于演示目的,我将使用ubuntu server版本,其他版本类似。
|
||||
|
||||
安装ACL完成后,需要激活我们磁盘分区的ACL功能,这样我们才能使用它。
|
||||
|
||||
首先,我们检查ACL功能是否已经开启。
|
||||
|
||||
$ mount
|
||||
|
||||

|
||||
|
||||
你可以注意到,我的root分区中ACL属性已经开启。万一你没有开启,你需要编辑/etc/fstab文件。增加acl标记,在你需要开启ACL的分区之前。
|
||||
|
||||

|
||||
|
||||
现在我们需要重新挂载分区(我喜欢完全重启,因为我不想丢掉数据),如果你对任何分区开启ACL,你必须也重新挂载它。
|
||||
|
||||
$ sudo mount / -o remount
|
||||
|
||||
令人敬佩!现在我们已经在我们的系统中开启ACL,让我们开始和它一起工作。
|
||||
|
||||
### ACL 范例 ###
|
||||
|
||||
基础ACL通过两条命令管理:**setfacl**用于增加或者修改ACL,**getfacl**用于显示分配完的ACL。让我们来做一些测试。
|
||||
|
||||
我创建一个目录/shared给一个假设的用户,名叫freeuser
|
||||
|
||||
$ ls -lh /
|
||||
|
||||

|
||||
|
||||
我想要分享这个目录给其他两个用户test和test2,一个拥有完整权限,另一个只有读权限。
|
||||
|
||||
First, to set ACLs for user test:
|
||||
首先,为用户test设置ACL:
|
||||
|
||||
$ sudo setfacl -m u:test:rwx /shared
|
||||
|
||||
现在用户test可以随意创建文件夹,文件和访问在/shared目录下的任何地方。
|
||||
|
||||

|
||||
|
||||
现在我们增加只读权限给用户test2:
|
||||
|
||||
$ sudo setfacl -m u:test2:rx /shared
|
||||
|
||||
注意test2读取目录需要执行(x)权限
|
||||
|
||||

|
||||
|
||||
让我来解释下setfacl命令格式:
|
||||
|
||||
- **-m** 表示修改ACL。你可以增加新的,或修改存在的ACL
|
||||
- **u:** 表示用户。你可以使用 **g** 来设置组权限
|
||||
- **test** 用户名
|
||||
- **:rwx** 需要设置的权限。
|
||||
|
||||
现在让我向你展示如何读取ACL:
|
||||
|
||||
$ ls -lh /shared
|
||||
|
||||

|
||||
|
||||
你可以注意到,正常权限后多一个+标记。这表示ACL已经设置成功。为了真正读取ACL,我们需要运行:
|
||||
|
||||
$ sudo getfacl /shared
|
||||
|
||||

|
||||
|
||||
最后,如果你需要移除ACL:
|
||||
|
||||
$ sudo setfacl -x u:test /shared
|
||||
|
||||

|
||||
|
||||
如果你想要立即擦除所有ACL条目:
|
||||
|
||||
$ sudo setfacl -b /shared
|
||||
|
||||

|
||||
|
||||
最后一件事。在设置了ACL文件或目录工作时,cp和mv命令会改变这些设置。在cp的情况下,需要添加“p”参数来复制ACL设置。如果这不可行,它将会展示一个警告。mv默认移动ACL设置,如果这也不可行,它也会向您展示一个警告。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
使用ACL给了在你想要分享的文件上巨大的权利和控制,特别是在NFS/Samba服务。此外,如果你的主管共享主机,这个工具是必备的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/configure-access-control-lists-acls-linux.html
|
||||
|
||||
作者:[Christopher Valerio][a]
|
||||
译者:[VicYu](http://www.vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/valerio
|
||||
@ -1,27 +1,27 @@
|
||||
Linux Systemd —— 在RHEL/CentOS 7中启动/停止/重启服务
|
||||
================================================================================
|
||||
|
||||
RHEL/CentOS 7.0中一个最主要的改变,就是切换到了**systemd**。它用于替代红帽企业版Linux的前任版本中的SysV和Upstart,对系统和服务进行管理。systemd兼容SysV和Linux标准组的启动脚本。
|
||||
RHEL/CentOS 7.0中一个最主要的改变,就是切换到了**systemd**。它用于替代红帽企业版Linux前任版本中的SysV和Upstart,对系统和服务进行管理。systemd兼容SysV和Linux标准组的启动脚本。
|
||||
|
||||
**Systemd**是一个Linux操作系统下的系统和服务管理器。它被设计成向后兼容SysV启动脚本,并提供了大量的特性,如开机时平行启动系统服务,按需启动守护进程,支持系统状态快照,或者基于依赖的服务控制逻辑。
|
||||
|
||||
先前的使用SysV初始化或Upstart的红帽企业版Linux版本中,使用位于/etc/rc.d/init.d/目录中的bash初始化脚本进行管理。而在RHEL 7/CentOS 7中,这些启动脚本被服务单元取代了。服务单元以.service扩展结束,提供了与初始化脚本同样的用途。要查看、启动、停止、重启、启用或者禁用系统服务,你要使用systemctl来代替旧的service命令。
|
||||
先前的使用SysV初始化或Upstart的红帽企业版Linux版本中,使用位于/etc/rc.d/init.d/目录中的bash初始化脚本进行管理。而在RHEL 7/CentOS 7中,这些启动脚本被服务单元取代了。服务单元以.service文件扩展结束,提供了与初始化脚本同样的用途。要查看、启动、停止、重启、启用或者禁用系统服务,你要使用systemctl来代替旧的service命令。
|
||||
|
||||
> 注:为了向后兼容,旧的service命令在CentOS 7中仍然可用,它会重定向所有命令到新的systemctl工具。
|
||||
>
|
||||
|
||||
### 使用systemctl来启动/停止/重启服务 ###
|
||||
|
||||
要启动一个服务,你需要使用像这样的命令:
|
||||
要启动一个服务,你需要使用如下命令:
|
||||
|
||||
# systemctl start httpd.service
|
||||
|
||||
这会启动httpd服务,就我们而言,Apache HTTP服务器。
|
||||
|
||||
要停掉它,可以以root身份使用该命令:
|
||||
要停掉它,需要以root身份使用该命令:
|
||||
|
||||
# systemctl stop httpd.service
|
||||
|
||||
要重启,你可以使用restart选项,如果服务在运行中,它将重启服务;或者使用start,如果服务不在运行。你也可以使用try-start选项,它只会在服务已经在运行中的时候重启服务。同时,reload选项你也可以有,它会重新加载配置文件。
|
||||
要重启,你可以使用restart选项,如果服务在运行中,它将重启服务;如果服务不在运行中,它将会启动。你也可以使用try-start选项,它只会在服务已经在运行中的时候重启服务。同时,reload选项你也可以有,它会重新加载配置文件。
|
||||
|
||||
# systemctl restart httpd.service
|
||||
# systemctl try-restart httpd.service
|
||||
@ -54,7 +54,7 @@ RHEL/CentOS 7.0中一个最主要的改变,就是切换到了**systemd**。它
|
||||
|
||||

|
||||
|
||||
虽然在过去的几年中,对systemd的采用饱受争议,然而大多数主流发行版都已经逐渐采用或打算在下一个发行版中采用它。所以,它是一个有用的工具,我们需要好好熟悉它。
|
||||
虽然在过去的几年中,对systemd的采用饱受争议,然而大多数主流发行版都已经逐渐采用或打算在下一个发行版中采用它。所以,它是一个有用的工具,我们需要好好熟悉它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -62,7 +62,7 @@ via: http://linoxide.com/linux-command/start-stop-services-systemd/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,50 @@
|
||||
Linux有问必答——如何修复“运行aclocal失败:没有该文件或目录”
|
||||
================================================================================
|
||||
> **问题**:我试着在Linux上构建一个程序,该程序的开发版本是使用“autogen.sh”脚本进行的。当我运行它来创建配置脚本时,却发生了下面的错误:
|
||||
>
|
||||
> Can't exec "aclocal": No such file or directory at /usr/share/autoconf/Autom4te/FileUtils.pm line 326.
|
||||
> autoreconf: failed to run aclocal: No such file or directory
|
||||
>
|
||||
> 我怎样才能修复这个程序?
|
||||
|
||||
开发版本常常是通过autogen.sh使用程序源代码生成的,构建过程包括验证程序功能和生成配置脚本。autogen.sh脚本依赖于autoreconf来调用autoconf,automake,aclocal和其它相关工具。
|
||||
|
||||
丢失的aclocal是automake包的一部分,因此,要修复该错误,请安装以下包。
|
||||
|
||||
在Debian,Ubuntu或Linux Mint上:
|
||||
|
||||
$ sudo apt-get install automake
|
||||
|
||||
在CentOS,Fedora或RHEL上:
|
||||
|
||||
$ sudo yum install automake
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/fix-failed-to-run-aclocal.html
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:
|
||||
[2]:
|
||||
[3]:
|
||||
[4]:
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
@ -0,0 +1,22 @@
|
||||
Linux有问必答——如何在CentOS上安装Shutter
|
||||
================================================================================
|
||||
> **问题**:我想要在我的CentOS桌面上试试Shutter屏幕截图程序,但是,当我试着用yum来安装Shutter时,它总是告诉我“没有shutter包可用”。我怎样才能在CentOS上安装Shutter啊?
|
||||
|
||||
[Shutter][1]是一个用于Linux桌面的开源(GPLv3)屏幕截图工具。它打包有大量用户友好的功能,这让它成为Linux中功能最强大的屏幕截图程序之一。你可以用Shutter来捕捉一个规则区域、一个窗口、整个桌面屏幕、或者甚至是来自任意专用地址的一个网页的截图。除此之外,你也可以用它内建的图像编辑器来对捕获的截图进行编辑,应用不同的效果,将图像导出为不同的图像格式(svg,pdf,ps),或者上传图片到公共图像主机或者FTP站点。
|
||||
Shutter is not available as a pre-built package on CentOS (as of version 7). Fortunately, there exists a third-party RPM repository called Nux Dextop, which offers Shutter package. So [enable Nux Dextop repository][2] on CentOS. Then use the following command to install Shutter.
|
||||
|
||||
$ sudo yum --enablerepo=nux-dextop install shutter
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/install-shutter-centos.html
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://shutter-project.org/
|
||||
[2]:http://ask.xmodulo.com/enable-nux-dextop-repository-centos-rhel.html
|
||||
@ -0,0 +1,23 @@
|
||||
Linux有问必答——如何显示Linux网桥的MAC学习表
|
||||
================================================================================
|
||||
|
||||
> **问题**:我想要检查一下我用brctl工具创建的Linux网桥的MAC地址学习状态。请问,我要怎样才能查看Linux网桥的MAC学习表(或者转发表)?
|
||||
|
||||
Linux网桥是网桥的软件实现,这是Linux内核的内核部分。与硬件网桥相类似,Linux网桥维护了一个2层转发表(也称为MAC学习表,转发数据库,或者仅仅称为FDB),它跟踪记录了MAC地址与端口的对应关系。当一个网桥在端口N收到一个包时(源MAC地址为X),它在FDB中记录为MAC地址X可以从端口N到达。这样的话,以后当网桥需要转发一个包到地址X时,它就可以从FDB查询知道转发到哪里。构建一个FDB常常称之为“MAC学习”或仅仅称为“学习”过程。
|
||||
|
||||
你可以使用以下命令来检查Linux网桥当前转发表或MAC学习表。
|
||||
|
||||
$ sudo brctl showmacs <bridge-name>
|
||||
|
||||

|
||||
|
||||
该命令将显示一个学习到的MAC地址与关联端口的列表。各个条目都有一个相关的附于其上的老化计时器,因此转发条目可以在一定时间后刷新,以使MAC学习表更新到最新。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/show-mac-learning-table-linux-bridge.html
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,152 @@
|
||||
Linux终端:speedtest_cli检测你的实时带宽速度
|
||||
===
|
||||
|
||||

|
||||
|
||||
什么是你在家(或者办公室)的上传和下载速度?你能保证,你支付费用给ISP的同时,你得到了等价的回报?
|
||||
|
||||
为了测试我们因特网连接的速度,当下存在着一些因特网服务,比如说SpeedTest,这是一种可以通过Web浏览器和手机应用程序浏览的web服务
|
||||
|
||||
现在,你可以很容易地检测你的网速,使用speedtest_cli同样很简单,它是一个使用[speedtest.net][2]来测试因特网[带宽][1]的命令行界面。通过这种方式,你也可以在没有浏览器或者图形化界面的服务器上做带宽测试
|
||||
|
||||
### 安装 ###
|
||||
|
||||
speedtest_cli是一个python脚本,所以它真的很容易安装和使用,你拥有许多方式安装它:
|
||||
|
||||
#### 1)pip / easy_install ####
|
||||
|
||||
打开一个终端,输入下面的命令:
|
||||
|
||||
pip install speedtest_cli
|
||||
|
||||
或者
|
||||
|
||||
easy_install speedtest_cli
|
||||
|
||||
#### 2)Github ####
|
||||
|
||||
想要直接从github安装,你得这么做:
|
||||
|
||||
pip install git+https://github.com/sivel/speedtest-cli.git
|
||||
|
||||
或者
|
||||
|
||||
git clone https://github.com/sivel/speedtest-cli.git
|
||||
python speedtest-cli/setup.py install
|
||||
|
||||
#### 3)作为Ubuntu/Debian或者Mint包 ####
|
||||
|
||||
getdeb仓库给我们提供了[安装包][3],按照下面的步骤,就可以轻松安装:
|
||||
|
||||
- 安装[getdeb包][4]
|
||||
或者
|
||||
- 手动地配置仓库:
|
||||
进入系统管理软件源,第三方软件选项,加上:
|
||||
|
||||
deb http://archive.getdeb.net/ubuntu trusty-getdeb apps
|
||||
|
||||
增加仓库GPG钥匙,打开终端窗口,然后输入:
|
||||
|
||||
wget -q -O- http://archive.getdeb.net/getdeb-archive.key | sudo apt-key add -
|
||||
|
||||
现在,你就可以使用下面的命令安装speedtest_cli包了:
|
||||
|
||||
sudo apt-get update
|
||||
sudo apt-get install python-speedtest-cli
|
||||
|
||||
#### 4)下载(和以前的方式一样) ####
|
||||
|
||||
作为最后的选择,只需要下载python脚本,然后在你想运行的地方运行脚本:
|
||||
|
||||
wget -O speedtest-cli https://raw.github.com/sivel/speedtest-cli/master/speedtest_cli.py
|
||||
chmod +x speedtest-cli
|
||||
|
||||
或者
|
||||
|
||||
curl -o speedtest-cli https://raw.github.com/sivel/speedtest-cli/master/speedtest_cli.py
|
||||
chmod +x speedtest-cli
|
||||
|
||||
### 基本用法 ###
|
||||
|
||||
你可以不带任何选项地运行speedtest_cli.py,然后你会在终端获得关于你带宽速度的报告,这就是我蹩脚的意大利Adsl输出:
|
||||
|
||||
$ ./speedtest_cli.py
|
||||
Retrieving speedtest.net configuration...
|
||||
Retrieving speedtest.net server list...
|
||||
Testing from Telecom Italia (87.13.73.66)...
|
||||
Selecting best server based on latency...
|
||||
Hosted by LepidaSpA (Bologna) [12.20 km]: 104.347 ms
|
||||
Testing download speed........................................
|
||||
Download: 6.35 Mbits/s
|
||||
Testing upload speed...............................................
|
||||
Upload: 0.34 Mbits/s
|
||||
|
||||
这就是简简单单的基本用法,这足以让你知道你因特网连接的好坏,但是有可能,你需要和朋友分享这条信息,为了到达此目的,只需要-share选项
|
||||
|
||||
./speedtest_cli.py --share
|
||||
Retrieving speedtest.net configuration...
|
||||
Retrieving speedtest.net server list...
|
||||
Testing from Telecom Italia (87.13.73.66)...
|
||||
Selecting best server based on latency...
|
||||
Hosted by LepidaSpA (Bologna) [12.20 km]: 93.778 ms
|
||||
Testing download speed........................................
|
||||
Download: 6.20 Mbits/s
|
||||
Testing upload speed...............................................
|
||||
Upload: 0.33 Mbits/s
|
||||
Share results: http://www.speedtest.net/result/3700218352.png
|
||||
|
||||
这将会产生一个类似于下面的图像(但是我希望你图像里面的值更好):
|
||||
|
||||

|
||||
|
||||
另一个有趣的选项是-list,它会按照距离列出所有speedtest.net服务器,下面是我运行的结果:
|
||||
|
||||
Retrieving speedtest.net configuration...
|
||||
Retrieving speedtest.net server list...
|
||||
2872) LepidaSpA (Bologna, Italy) [12.20 km]
|
||||
1561) MYNETWAY S.R.L. (Cesena, Italy) [80.97 km]
|
||||
2710) ReteIVO by D.t.s. Srl (Florence, Italy) [90.90 km]
|
||||
4826) Inteplanet Srl (Verona, Italy) [100.45 km]
|
||||
3998) Wolnext srl (Verona, Italy) [100.45 km]
|
||||
2957) Wifiweb s.r.l. (Altavilla Vicentina, Italy) [103.11 km]
|
||||
3103) E4A s.r.l. (Vicenza, Italy) [107.17 km]
|
||||
3804) Interplanet Srl (Vicenza, Italy) [107.17 km]
|
||||
1014) NTRnet (Vicenza, Italy) [107.17 km]
|
||||
3679) Hynet s r l (Vicenza, Italy) [107.17 km]
|
||||
3745) Comeser Srl (Fidenza, Italy) [114.00 km]
|
||||
5011) Welcomeitalia spa (Massarosa, Italy) [119.26 km]
|
||||
2864) ReteIVO by D.t.s. Srl (Massa, Italy) [120.92 km]
|
||||
2918) ReteIVO by D.t.s. Srl (Arezzo, Italy) [129.79 km]
|
||||
...
|
||||
|
||||
现在,我知道围绕在我周围的服务器的ID,我可以使用-server选项选择一个特定的服务器,所以,为了选择位于Florence(ID 2710)的服务器,我使用下面的命令:
|
||||
|
||||
./speedtest_cli.py --server 2710
|
||||
Retrieving speedtest.net configuration...
|
||||
Retrieving speedtest.net server list...
|
||||
Testing from Telecom Italia (87.13.73.66)...
|
||||
Hosted by ReteIVO by D.t.s. Srl (Florence) [90.90 km]: 106.505 ms
|
||||
Testing download speed........................................
|
||||
Download: 6.18 Mbits/s
|
||||
Testing upload speed..............................................
|
||||
Upload: 0.35 Mbits/s
|
||||
|
||||
文章由[Asapy Programming Company][5]发表
|
||||
|
||||
---
|
||||
|
||||
via: http://linuxaria.com/howto/linux-terminal-speedtest_cli-checks-you
|
||||
r-real-bandwidth-speed
|
||||
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://linuxaria.com/article/tool-command-line-bandwidth-linux
|
||||
[2]:http://linuxaria.com/howto/speedtest.net
|
||||
[3]:http://www.getdeb.net/
|
||||
[4]:http://archive.getdeb.net/install_deb/getdeb-repository_0.1-1~getde
|
||||
b1_all.deb
|
||||
[5]:http://www.asapy.com/
|
||||
|
||||
@ -0,0 +1,136 @@
|
||||
如何在Linux命令行下收听网络电台
|
||||
========================================================================
|
||||
对于系统管理员和Linux爱好者来说,我们花大量的时间在Linux屏幕前,但是你们知道网络/本地电台上的音乐可以极大的提高我们的生产力吗?不管你相信与否,在工作环境中有适当的声音,如音乐或者喋喋不休的声音都可以提高我们的创造力。如果你喜欢在音乐环境中工作,这个教程也许会对你有用。我将会向你展示**如何在命令行中收听潘多拉(Pandora)在线电台**(LCTT译注:Pandora Internet Radio是一个仅为美国、澳大利亚和新西兰提供自动音乐推荐的系统。详细介绍[Prandoea电台][1])
|
||||
|
||||
正如你已经知道的,Pandora是最有名的在线电台服务之一,它包含无数的不同种类的免费音乐流,同时它还有一个强大的音乐推荐引擎。Pandora可以通过不同的方法访问,如:浏览器,桌面客户端或者手机Apps,开源社区还给出了另一种访问Pandora音乐服务的方法:Linux命令行。
|
||||
|
||||
[pianobar][2]是一个播放Pandora在线电台音乐的开源命令行音乐播放器。它有一个简单的人机接口,用于播放和管理音乐电台。同时还有其他包括歌曲评价,即将上线音乐列表,播放历史,自定义快捷键绑定,远程控制等功能。对于那些居住在不可访问Pandora音乐服务区域的用户(即美国、澳大利亚和新西兰以外的用户)。Pianobar还配置了代理服务的支持。
|
||||
|
||||
###在Linux中安装Pianobar###
|
||||
在Debian或者其他Debian的衍生品,如Ubuntu或LinuxMint中,Pianobar是一个已经编译好的软件包,因此安装Pianobar只是简单的输入如下命令:
|
||||
|
||||
$ sudo apt-get install pianobar
|
||||
|
||||
在Fedora中,Pianobar并不包含在基础的软件库中。因此,你需要通过源代码编译安装Pianobar。整个安装过程会有点麻烦,但是下面的教程将会实现Pianobar在Frdora系统中编译安装。该教程在Fedora20版本中测试通过。
|
||||
|
||||
首先,根据[FFmpeg安装教程][3]编译并安装FFmpeg。
|
||||
|
||||
然后,[启用RPM Fusion源][4],并安装其他依赖软件:
|
||||
|
||||
$ sudo yum install wget gcc-c++ pkgconfig gnutls-devel json-c-devel libgcrypt-devel make libao-devel faad2-devel libmad-devel libao faad2-libs
|
||||
|
||||
编译并安装Pianobar
|
||||
|
||||
$ wget http://6xq.net/projects/pianobar/pianobar-2014.06.08.tar.bz2
|
||||
$ tar xvfvj pianobar-2014.06.08.tar.bz2
|
||||
$ cd pianobar-2014.06.08
|
||||
$ PKG_CONFIG_PATH=/usr/local/lib/pkgconfig:$PKG_CONFIG_PATH make
|
||||
$ sudo make install
|
||||
|
||||
最后允许Paniobar加载安装在/usr/local/lib目录下的FFmpeg共享库,在/etc/ld.so.conf配置文件中添加下面一行:
|
||||
|
||||
>/usr/local/lib
|
||||
|
||||
重载所有的共享库
|
||||
|
||||
就这样,Pianobar已经在Fedora系统中安装完成。
|
||||
|
||||
###在命令行中收听Pandora音乐###
|
||||
|
||||
paniobar的基本用法是输入如下命令:
|
||||
|
||||
> $ pianobar
|
||||
|
||||
该命令将会要求你登录到Pandora并从你的个性化电台列表中选择要收听的电台。在你选择电台后,音乐就开始自动播放。
|
||||
|
||||

|
||||
|
||||
按‘?’按键pianobar会列出一系列可用个命令,其中一些如下:
|
||||
>- s: 更换电台
|
||||
- u: 查看即将上线音乐列表
|
||||
- h: 查看播放历史
|
||||
- n: 播放下一首
|
||||
- b: 收藏歌曲或艺术家
|
||||
- ( 或者 ): 减少或增加播放音量
|
||||
- S: 暂停播放
|
||||
- P: 恢复播放
|
||||
- V:为当前收听的歌曲或者艺术家创建一个电台
|
||||
- +或者-:查看上一首或者下一首歌曲
|
||||
- a:添加音乐到电台
|
||||
- q:退出pianobar
|
||||
|
||||
|
||||
|
||||
###将Pianobar配置为自动登录###
|
||||
你可以再一个单独的配置文件中配置Pianobar的各项默认配置。例如:你可以将你的登录信息配置到配置文件中,这样你就不用每次都要手动输入。下面是如何创建一个配置文件的示例:
|
||||
|
||||
> $ mkdir -p ~/.config/pianobar
|
||||
|
||||
----------
|
||||
|
||||
> $ vi ~/.config/pianobar/config
|
||||
|
||||
----------
|
||||
|
||||
> # Example pianobar configuration file
|
||||
>
|
||||
> # Pandora login info
|
||||
user = your@email_address
|
||||
password = plaintext_password
|
||||
>
|
||||
> # Users who cannot access Pandora in their region can set a proxy.
|
||||
control_proxy = http://user:password@host:port/
|
||||
>
|
||||
> # Initial volume in dB: between -30 and +5
|
||||
volume = 0
|
||||
>
|
||||
> # Audio quality: high, medium or low
|
||||
audio_quality = high
|
||||
|
||||
如需了解完整的配置选项,请参阅其man手册页。
|
||||
|
||||
$ man pianobar
|
||||
|
||||
###远程控制Pianobar###
|
||||
|
||||
Pianobar的另一个优秀的特性是支持远程控制,你可以通过命令管道(FIFO)为Pianobar的一个运行实例发送命令。下面是远程控制Pianobar的示例:
|
||||
|
||||
首先在目录~/.config/pianobar下创建一个FIFO命令管道
|
||||
|
||||
> $ mkfifo ~/.config/pianobar/ctl
|
||||
|
||||
然后运行Pianobar
|
||||
|
||||
现在,你可以通过使用echo命令发送任何的单字符命令键到Pianobar中,例如:播放下一首歌曲:
|
||||
|
||||
> $ echo -n 'n' > ~/.config/pianobar/ctl
|
||||
|
||||
你可以很容易的将此配置扩展到远程计算机中,当Pianobar在主机X上运行,你可以从远程主机Y中通过SSH控制Pianobar,如下所示:
|
||||
|
||||
在主机Y中,运行:
|
||||
|
||||
> $ ssh user@host_X "echo -n 'n' > ~/.config/pianobar/ctl"
|
||||
|
||||
当然,你希望为登录到主机X的SSH登录认证[启用秘钥认证][5],这样你就不用每次都输入SSH密码。
|
||||
|
||||
当你想在[树莓PI][6]上设置一个可以远程控制的在线电台播放器时,Pianobar的远程控制特性将会让你非常方便的实现该需求。
|
||||
|
||||
希望你像我一样喜欢Pianobar,若有什么想法,请在评论中告诉我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/listen-to-internet-radio-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[cvsher](https://github.com/cvsher)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://zh.wikipedia.org/wiki/Pandora%E7%94%B5%E5%8F%B0
|
||||
[2]:http://6xq.net/projects/pianobar/
|
||||
[3]:http://ask.xmodulo.com/compile-ffmpeg-centos-fedora-rhel.html
|
||||
[4]:http://xmodulo.com/2013/06/how-to-install-rpm-fusion-on-fedora.html
|
||||
[5]:http://xmodulo.com/2012/04/how-to-enable-ssh-login-without.html
|
||||
[6]:http://xmodulo.com/go/raspberrypi
|
||||
Loading…
Reference in New Issue
Block a user