mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
Merge remote-tracking branch 'LCTT/master' into 20190811-How-to-measure-the-health-of-an-open-source-community
This commit is contained in:
commit
d8d9ff3fe0
@ -0,0 +1,69 @@
|
||||
使用 MacSVG 创建 SVG 动画
|
||||
======
|
||||
|
||||
> 开源 SVG:墙上的魔法字。
|
||||
|
||||

|
||||
|
||||
新巴比伦的摄政王[伯沙撒][1]没有注意到他在盛宴期间神奇地[书写在墙上的文字][2]。但是,如果他在公元前 539 年有一台笔记本电脑和良好的互联网连接,他可能会通过在浏览器上阅读 SVG 来避开那些讨厌的波斯人。
|
||||
|
||||
出现在网页上的动画文本和对象是建立用户兴趣和参与度的好方法。有几种方法可以实现这一点,例如视频嵌入、动画 GIF 或幻灯片 —— 但你也可以使用[可缩放矢量图形(SVG)][3]。
|
||||
|
||||
SVG 图像与 JPG 不同,因为它可以缩放而不会丢失其分辨率。矢量图像是由点而不是像素创建的,所以无论它放大到多大,它都不会失去分辨率或像素化。充分利用可缩放的静态图像的一个例子是网站的徽标。
|
||||
|
||||
### 动起来,动起来
|
||||
|
||||
你可以使用多种绘图程序创建 SVG 图像,包括开源的 [Inkscape][4] 和 Adobe Illustrator。让你的图像“能动起来”需要更多的努力。幸运的是,有一些开源解决方案甚至可以引起伯沙撒的注意。
|
||||
|
||||
[MacSVG][5] 是一款可以让你的图像动起来的工具。你可以在 [GitHub][6] 上找到源代码。
|
||||
|
||||
根据其[官网][5]说,MacSVG 由阿肯色州康威的 Douglas Ward 开发,是一个“用于设计 HTML5 SVG 艺术和动画的开源 Mac OS 应用程序”。
|
||||
|
||||
我想使用 MacSVG 来创建一个动画签名。我承认我发现这个过程有点令人困惑,并且在我第一次尝试创建一个实际的动画 SVG 图像时失败了。
|
||||
|
||||
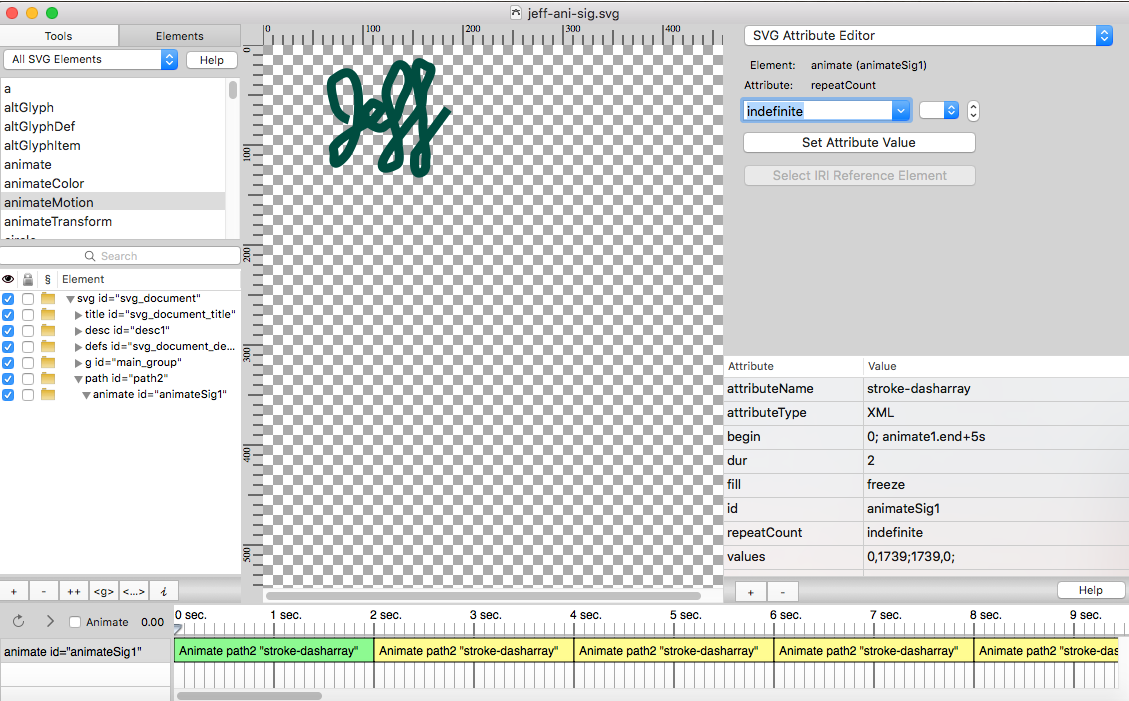
|
||||
|
||||
重要的是首先要了解要展示的书法内容实际写的是什么。
|
||||
|
||||
动画文字背后的属性是 [stroke-dasharray][7]。将该术语分成三个单词有助于解释正在发生的事情:“stroke” 是指用笔(无论是物理的笔还是数字化笔)制作的线条或笔画。“dash” 意味着将笔划分解为一系列折线。“array” 意味着将整个东西生成为数组。这是一个简单的概述,但它可以帮助我理解应该发生什么以及为什么。
|
||||
|
||||
使用 MacSVG,你可以导入图形(.PNG)并使用钢笔工具描绘书写路径。我使用了草书来表示我的名字。然后,只需应用该属性来让书法动画起来、增加和减少笔划的粗细、改变其颜色等等。完成后,动画的书法将导出为 .SVG 文件,并可以在网络上使用。除书写外,MacSVG 还可用于许多不同类型的 SVG 动画。
|
||||
|
||||
### 在 WordPress 中书写
|
||||
|
||||
我准备在我的 [WordPress][8] 网站上传和分享我的 SVG 示例,但我发现 WordPress 不允许进行 SVG 媒体导入。幸运的是,我找到了一个方便的插件:Benbodhi 的 [SVG 支持][9]插件允许快速、轻松地导入我的 SVG,就像我将 JPG 导入媒体库一样。我能够在世界各地向巴比伦人展示我[写在墙上的魔法字][10]。
|
||||
|
||||
我在 [Brackets][11] 中开源了 SVG 的源代码,结果如下:
|
||||
|
||||
```
|
||||
<?xml version="1.0" encoding="utf-8" standalone="yes"?>
|
||||
<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.1//EN" "http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd">
|
||||
<svg xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:cc="http://web.resource.org/cc/" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:sodipodi="http://sodipodi.sourceforge.net/DTD/sodipodi-0.dtd" xmlns:inkscape="http://www.inkscape.org/namespaces/inkscape" height="360px" style="zoom: 1;" cursor="default" id="svg_document" width="480px" baseProfile="full" version="1.1" preserveAspectRatio="xMidYMid meet" viewBox="0 0 480 360"><title id="svg_document_title">Path animation with stroke-dasharray</title><desc id="desc1">This example demonstrates the use of a path element, an animate element, and the stroke-dasharray attribute to simulate drawing.</desc><defs id="svg_document_defs"></defs><g id="main_group"></g><path stroke="#004d40" id="path2" stroke-width="9px" d="M86,75 C86,75 75,72 72,61 C69,50 66,37 71,34 C76,31 86,21 92,35 C98,49 95,73 94,82 C93,91 87,105 83,110 C79,115 70,124 71,113 C72,102 67,105 75,97 C83,89 111,74 111,74 C111,74 119,64 119,63 C119,62 110,57 109,58 C108,59 102,65 102,66 C102,67 101,75 107,79 C113,83 118,85 122,81 C126,77 133,78 136,64 C139,50 147,45 146,33 C145,21 136,15 132,24 C128,33 123,40 123,49 C123,58 135,87 135,96 C135,105 139,117 133,120 C127,123 116,127 120,116 C124,105 144,82 144,81 C144,80 158,66 159,58 C160,50 159,48 161,43 C163,38 172,23 166,22 C160,21 155,12 153,23 C151,34 161,68 160,78 C159,88 164,108 163,113 C162,118 165,126 157,128 C149,130 152,109 152,109 C152,109 185,64 185,64 " fill="none" transform=""><animate values="0,1739;1739,0;" attributeType="XML" begin="0; animate1.end+5s" id="animateSig1" repeatCount="indefinite" attributeName="stroke-dasharray" fill="freeze" dur="2"></animate></path></svg>
|
||||
```
|
||||
|
||||
你会使用 MacSVG 做什么?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/macsvg-open-source-tool-animation
|
||||
|
||||
作者:[Jeff Macharyas][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rikki-endsley
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Belshazzar
|
||||
[2]: https://en.wikipedia.org/wiki/Belshazzar%27s_feast
|
||||
[3]: https://en.wikipedia.org/wiki/Scalable_Vector_Graphics
|
||||
[4]: https://inkscape.org/
|
||||
[5]: https://macsvg.org/
|
||||
[6]: https://github.com/dsward2/macSVG
|
||||
[7]: https://gist.github.com/mbostock/5649592
|
||||
[8]: https://macharyas.com/
|
||||
[9]: https://wordpress.org/plugins/svg-support/
|
||||
[10]: https://macharyas.com/index.php/2018/10/14/open-source-svg/
|
||||
[11]: http://brackets.io/
|
||||
167
published/20181220 Getting started with Prometheus.md
Normal file
167
published/20181220 Getting started with Prometheus.md
Normal file
@ -0,0 +1,167 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11234-1.html)
|
||||
[#]: subject: (Getting started with Prometheus)
|
||||
[#]: via: (https://opensource.com/article/18/12/introduction-prometheus)
|
||||
[#]: author: (Michael Zamot https://opensource.com/users/mzamot)
|
||||
|
||||
Prometheus 入门
|
||||
======
|
||||
|
||||
> 学习安装 Prometheus 监控和警报系统并编写它的查询。
|
||||
|
||||

|
||||
|
||||
[Prometheus][1] 是一个开源的监控和警报系统,它直接从目标主机上运行的代理程序中抓取指标,并将收集的样本集中存储在其服务器上。也可以使用像 `collectd_exporter` 这样的插件推送指标,尽管这不是 Promethius 的默认行为,但在主机位于防火墙后面或位于安全策略禁止打开端口的某些环境中它可能很有用。
|
||||
|
||||
Prometheus 是[云原生计算基金会(CNCF)][2]的一个项目。它使用<ruby>联合模型<rt>federation model</rt></ruby>进行扩展,该模型使得一个 Prometheus 服务器能够抓取另一个 Prometheus 服务器的数据。这允许创建分层拓扑,其中中央系统或更高级别的 Prometheus 服务器可以抓取已从下级实例收集的聚合数据。
|
||||
|
||||
除 Prometheus 服务器外,其最常见的组件是[警报管理器][3]及其输出器。
|
||||
|
||||
警报规则可以在 Prometheus 中创建,并配置为向警报管理器发送自定义警报。然后,警报管理器处理和管理这些警报,包括通过电子邮件或第三方服务(如 [PagerDuty][4])等不同机制发送通知。
|
||||
|
||||
Prometheus 的输出器可以是库、进程、设备或任何其他能将 Prometheus 抓取的指标公开出去的东西。 这些指标可在端点 `/metrics` 中获得,它允许 Prometheus 无需代理直接抓取它们。本文中的教程使用 `node_exporter` 来公开目标主机的硬件和操作系统指标。输出器的输出是明文的、高度可读的,这是 Prometheus 的优势之一。
|
||||
|
||||
此外,你可以将 Prometheus 作为后端,配置 [Grafana][5] 来提供数据可视化和仪表板功能。
|
||||
|
||||
### 理解 Prometheus 的配置文件
|
||||
|
||||
抓取 `/metrics` 的间隔秒数控制了时间序列数据库的粒度。这在配置文件中定义为 `scrape_interval` 参数,默认情况下设置为 60 秒。
|
||||
|
||||
在 `scrape_configs` 部分中为每个抓取作业设置了目标。每个作业都有自己的名称和一组标签,可以帮助你过滤、分类并更轻松地识别目标。一项作业可以有很多目标。
|
||||
|
||||
### 安装 Prometheus
|
||||
|
||||
在本教程中,为简单起见,我们将使用 Docker 安装 Prometheus 服务器和 `node_exporter`。Docker 应该已经在你的系统上正确安装和配置。对于更深入、自动化的方法,我推荐 Steve Ovens 的文章《[如何使用 Ansible 与 Prometheus 建立系统监控][6]》。
|
||||
|
||||
在开始之前,在工作目录中创建 Prometheus 配置文件 `prometheus.yml`,如下所示:
|
||||
|
||||
```
|
||||
global:
|
||||
scrape_interval: 15s
|
||||
evaluation_interval: 15s
|
||||
|
||||
scrape_configs:
|
||||
- job_name: 'prometheus'
|
||||
|
||||
static_configs:
|
||||
- targets: ['localhost:9090']
|
||||
|
||||
- job_name: 'webservers'
|
||||
|
||||
static_configs:
|
||||
- targets: ['<node exporter node IP>:9100']
|
||||
```
|
||||
|
||||
通过运行以下命令用 Docker 启动 Prometheus:
|
||||
|
||||
```
|
||||
$ sudo docker run -d -p 9090:9090 -v
|
||||
/path/to/prometheus.yml:/etc/prometheus/prometheus.yml
|
||||
prom/prometheus
|
||||
```
|
||||
|
||||
默认情况下,Prometheus 服务器将使用端口 9090。如果此端口已在使用,你可以通过在上一个命令的后面添加参数 `--web.listen-address="<IP of machine>:<port>"` 来更改它。
|
||||
|
||||
在要监视的计算机中,使用以下命令下载并运行 `node_exporter` 容器:
|
||||
|
||||
```
|
||||
$ sudo docker run -d -v "/proc:/host/proc" -v "/sys:/host/sys" -v
|
||||
"/:/rootfs" --net="host" prom/node-exporter --path.procfs
|
||||
/host/proc --path.sysfs /host/sys --collector.filesystem.ignored-
|
||||
mount-points "^/(sys|proc|dev|host|etc)($|/)"
|
||||
```
|
||||
|
||||
出于本文练习的目的,你可以在同一台机器上安装 `node_exporter` 和 Prometheus。请注意,生产环境中在 Docker 下运行 `node_exporter` 是不明智的 —— 这仅用于测试目的。
|
||||
|
||||
要验证 `node_exporter` 是否正在运行,请打开浏览器并导航到 `http://<IP of Node exporter host>:9100/metrics`,这将显示收集到的所有指标;也即是 Prometheus 将要抓取的相同指标。
|
||||
|
||||
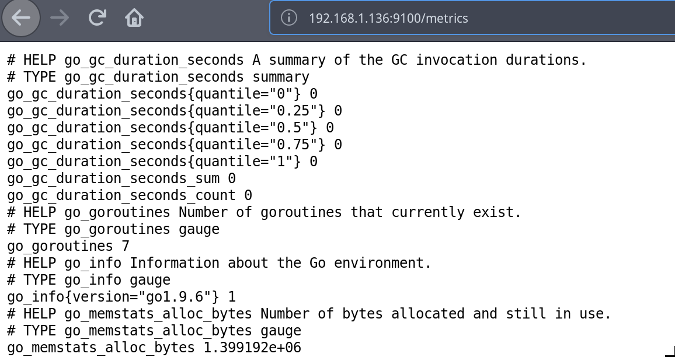
|
||||
|
||||
要确认 Prometheus 服务器安装成功,打开浏览器并导航至:<http://localhost:9090>。
|
||||
|
||||
你应该看到了 Prometheus 的界面。单击“Status”,然后单击“Targets”。在 “Status” 下,你应该看到你的机器被列为 “UP”。
|
||||
|
||||
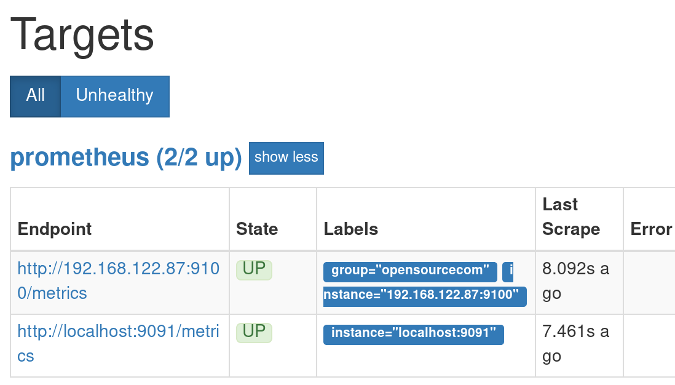
|
||||
|
||||
### 使用 Prometheus 查询
|
||||
|
||||
现在是时候熟悉一下 [PromQL][7](Prometheus 的查询语法)及其图形化 Web 界面了。转到 Prometheus 服务器上的 `http://localhost:9090/graph`。你将看到一个查询编辑器和两个选项卡:“Graph” 和 “Console”。
|
||||
|
||||
Prometheus 将所有数据存储为时间序列,使用指标名称标识每个数据。例如,指标 `node_filesystem_avail_bytes` 显示可用的文件系统空间。指标的名称可以在表达式框中使用,以选择具有此名称的所有时间序列并生成即时向量。如果需要,可以使用选择器和标签(一组键值对)过滤这些时间序列,例如:
|
||||
|
||||
```
|
||||
node_filesystem_avail_bytes{fstype="ext4"}
|
||||
```
|
||||
|
||||
过滤时,你可以匹配“完全相等”(`=`)、“不等于”(`!=`),“正则匹配”(`=~`)和“正则排除匹配”(`!~`)。以下示例说明了这一点:
|
||||
|
||||
要过滤 `node_filesystem_avail_bytes` 以显示 ext4 和 XFS 文件系统:
|
||||
|
||||
```
|
||||
node_filesystem_avail_bytes{fstype=~"ext4|xfs"}
|
||||
```
|
||||
|
||||
要排除匹配:
|
||||
|
||||
```
|
||||
node_filesystem_avail_bytes{fstype!="xfs"}
|
||||
```
|
||||
|
||||
你还可以使用方括号得到从当前时间往回的一系列样本。你可以使用 `s` 表示秒,`m` 表示分钟,`h` 表示小时,`d` 表示天,`w` 表示周,而 `y` 表示年。使用时间范围时,返回的向量将是范围向量。
|
||||
|
||||
例如,以下命令生成从五分钟前到现在的样本:
|
||||
|
||||
```
|
||||
node_memory_MemAvailable_bytes[5m]
|
||||
```
|
||||
|
||||
Prometheus 还包括了高级查询的功能,例如:
|
||||
|
||||
```
|
||||
100 * (1 - avg by(instance)(irate(node_cpu_seconds_total{job='webservers',mode='idle'}[5m])))
|
||||
```
|
||||
|
||||
请注意标签如何用于过滤作业和模式。指标 `node_cpu_seconds_total` 返回一个计数器,`irate()`函数根据范围间隔的最后两个数据点计算每秒的变化率(意味着该范围可以小于五分钟)。要计算 CPU 总体使用率,可以使用 `node_cpu_seconds_total` 指标的空闲(`idle`)模式。处理器的空闲比例与繁忙比例相反,因此从 1 中减去 `irate` 值。要使其为百分比,请将其乘以 100。
|
||||
|
||||
|
||||
|
||||
### 了解更多
|
||||
|
||||
Prometheus 是一个功能强大、可扩展、轻量级、易于使用和部署的监视工具,对于每个系统管理员和开发人员来说都是必不可少的。出于这些原因和其他原因,许多公司正在将 Prometheus 作为其基础设施的一部分。
|
||||
|
||||
要了解有关 Prometheus 及其功能的更多信息,我建议使用以下资源:
|
||||
|
||||
+ 关于 [PromQL][8]
|
||||
+ 什么是 [node_exporters 集合][9]
|
||||
+ [Prometheus 函数][10]
|
||||
+ [4 个开源监控工具] [11]
|
||||
+ [现已推出:DevOps 监控工具的开源指南] [12]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/introduction-prometheus
|
||||
|
||||
作者:[Michael Zamot][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mzamot
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://prometheus.io/
|
||||
[2]: https://www.cncf.io/
|
||||
[3]: https://prometheus.io/docs/alerting/alertmanager/
|
||||
[4]: https://en.wikipedia.org/wiki/PagerDuty
|
||||
[5]: https://grafana.com/
|
||||
[6]: https://opensource.com/article/18/3/how-use-ansible-set-system-monitoring-prometheus
|
||||
[7]: https://prometheus.io/docs/prometheus/latest/querying/basics/
|
||||
[8]: https://prometheus.io/docs/prometheus/latest/querying/basics/
|
||||
[9]: https://github.com/prometheus/node_exporter#collectors
|
||||
[10]: https://prometheus.io/docs/prometheus/latest/querying/functions/
|
||||
[11]: https://opensource.com/article/18/8/open-source-monitoring-tools
|
||||
[12]: https://opensource.com/article/18/8/now-available-open-source-guide-devops-monitoring-tools
|
||||
150
published/20190318 Let-s try dwm - dynamic window manager.md
Normal file
150
published/20190318 Let-s try dwm - dynamic window manager.md
Normal file
@ -0,0 +1,150 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11235-1.html)
|
||||
[#]: subject: (Let’s try dwm — dynamic window manager)
|
||||
[#]: via: (https://fedoramagazine.org/lets-try-dwm-dynamic-window-manger/)
|
||||
[#]: author: (Adam Šamalík https://fedoramagazine.org/author/asamalik/)
|
||||
|
||||
试试动态窗口管理器 dwm 吧
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
如果你崇尚效率和极简主义,并且正在为你的 Linux 桌面寻找新的窗口管理器,那么你应该尝试一下<ruby>动态窗口管理器<rt>dynamic window manager</rt></ruby> dwm。以不到 2000 标准行的代码写就的 dwm,是一个速度极快而功能强大,且可高度定制的窗口管理器。
|
||||
|
||||
你可以在平铺、单片和浮动布局之间动态选择,使用标签将窗口组织到多个工作区,并使用键盘快捷键快速导航。本文将帮助你开始使用 dwm。
|
||||
|
||||
### 安装
|
||||
|
||||
要在 Fedora 上安装 dwm,运行:
|
||||
|
||||
```
|
||||
$ sudo dnf install dwm dwm-user
|
||||
```
|
||||
|
||||
`dwm` 包会安装窗口管理器本身,`dwm-user` 包显著简化了配置,本文稍后将对此进行说明。
|
||||
|
||||
此外,为了能够在需要时锁定屏幕,我们还将安装 `slock`,这是一个简单的 X 显示锁屏。
|
||||
|
||||
```
|
||||
$ sudo dnf install slock
|
||||
```
|
||||
|
||||
当然,你可以根据你的个人喜好使用其它的锁屏。
|
||||
|
||||
### 快速入门
|
||||
|
||||
要启动 dwm,在登录屏选择 “dwm-user” 选项。
|
||||
|
||||
![][2]
|
||||
|
||||
登录后,你将看到一个非常简单的桌面。事实上,顶部唯一的一个面板列出了代表工作空间的 9 个标签和一个代表窗户布局的 `[]=` 符号。
|
||||
|
||||
#### 启动应用
|
||||
|
||||
在查看布局之前,首先启动一些应用程序,以便你可以随时使用布局。可以通过按 `Alt+p` 并键入应用程序的名称,然后回车来启动应用程序。还有一个快捷键 `Alt+Shift+Enter` 用于打开终端。
|
||||
|
||||
现在有一些应用程序正在运行了,请查看布局。
|
||||
|
||||
#### 布局
|
||||
|
||||
默认情况下有三种布局:平铺布局,单片布局和浮动布局。
|
||||
|
||||
平铺布局由条形图上的 `[]=` 表示,它将窗口组织为两个主要区域:左侧为主区域,右侧为堆叠区。你可以按 `Alt+t` 激活平铺布局。
|
||||
|
||||
![][3]
|
||||
|
||||
平铺布局背后的想法是,主窗口放在主区域中,同时仍然可以看到堆叠区中的其他窗口。你可以根据需要在它们之间快速切换。
|
||||
|
||||
要在两个区域之间交换窗口,请将鼠标悬停在堆叠区中的一个窗口上,然后按 `Alt+Enter` 将其与主区域中的窗口交换。
|
||||
|
||||
![][4]
|
||||
|
||||
单片布局由顶部栏上的 `[N]` 表示,可以使你的主窗口占据整个屏幕。你可以按 `Alt+m` 切换到它。
|
||||
|
||||
最后,浮动布局可让你自由移动和调整窗口大小。它的快捷方式是 `Alt+f`,顶栏上的符号是 `><>`。
|
||||
|
||||
#### 工作区和标签
|
||||
|
||||
每个窗口都分配了一个顶部栏中列出的标签(1-9)。要查看特定标签,请使用鼠标单击其编号或按 `Alt+1..9`。你甚至可以使用鼠标右键单击其编号,一次查看多个标签。
|
||||
|
||||
通过使用鼠标突出显示后,并按 `Alt+Shift+1..9`,窗口可以在不同标签之间移动。
|
||||
|
||||
### 配置
|
||||
|
||||
为了使 dwm 尽可能简约,它不使用典型的配置文件。而是你需要修改代表配置的 C 语言头文件,并重新编译它。但是不要担心,在 Fedora 中你只需要简单地编辑主目录中的一个文件,而其他一切都会在后台发生,这要归功于 Fedora 的维护者提供的 `dwm-user` 包。
|
||||
|
||||
首先,你需要使用类似于以下的命令将文件复制到主目录中:
|
||||
|
||||
```
|
||||
$ mkdir ~/.dwm
|
||||
$ cp /usr/src/dwm-VERSION-RELEASE/config.def.h ~/.dwm/config.h
|
||||
```
|
||||
|
||||
你可以通过运行 `man dwm-start` 来获取确切的路径。
|
||||
|
||||
其次,只需编辑 `~/.dwm/config.h` 文件。例如,让我们配置一个新的快捷方式:通过按 `Alt+Shift+L` 来锁定屏幕。
|
||||
|
||||
考虑到我们已经安装了本文前面提到的 `slock` 包,我们需要在文件中添加以下两行以使其工作:
|
||||
|
||||
在 `/* commands */` 注释下,添加:
|
||||
|
||||
```
|
||||
static const char *slockcmd[] = { "slock", NULL };
|
||||
```
|
||||
|
||||
添加下列行到 `static Key keys[]` 中:
|
||||
|
||||
```
|
||||
{ MODKEY|ShiftMask, XK_l, spawn, {.v = slockcmd } },
|
||||
```
|
||||
|
||||
最终,它应该看起来如下:
|
||||
|
||||
```
|
||||
...
|
||||
/* commands */
|
||||
static char dmenumon[2] = "0"; /* component of dmenucmd, manipulated in spawn() */
|
||||
static const char *dmenucmd[] = { "dmenu_run", "-m", dmenumon, "-fn", dmenufont, "-nb", normbgcolor, "-nf", normfgcolor, "-sb", selbgcolor, "-sf", selfgcolor, NULL };
|
||||
static const char *termcmd[] = { "st", NULL };
|
||||
static const char *slockcmd[] = { "slock", NULL };
|
||||
|
||||
static Key keys[] = {
|
||||
/* modifier key function argument */
|
||||
{ MODKEY|ShiftMask, XK_l, spawn, {.v = slockcmd } },
|
||||
{ MODKEY, XK_p, spawn, {.v = dmenucmd } },
|
||||
{ MODKEY|ShiftMask, XK_Return, spawn, {.v = termcmd } },
|
||||
...
|
||||
```
|
||||
|
||||
保存文件。
|
||||
|
||||
最后,按 `Alt+Shift+q` 注销,然后重新登录。`dwm-user` 包提供的脚本将识别你已更改主目录中的`config.h` 文件,并会在登录时重新编译 dwm。因为 dwm 非常小,它快到你甚至都不会注意到它重新编译了。
|
||||
|
||||
你现在可以尝试按 `Alt+Shift+L` 锁定屏幕,然后输入密码并按回车键再次登录。
|
||||
|
||||
### 总结
|
||||
|
||||
如果你崇尚极简主义并想要一个非常快速而功能强大的窗口管理器,dwm 可能正是你一直在寻找的。但是,它可能不适合初学者,你可能需要做许多其他配置才能按照你的喜好进行配置。
|
||||
|
||||
要了解有关 dwm 的更多信息,请参阅该项目的主页: <https://dwm.suckless.org/>。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/lets-try-dwm-dynamic-window-manger/
|
||||
|
||||
作者:[Adam Šamalík][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/asamalik/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/03/dwm-magazine-image-816x345.png
|
||||
[2]: https://fedoramagazine.org/wp-content/uploads/2019/03/choosing-dwm-1024x469.png
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2019/03/dwm-desktop-1024x593.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/03/Screenshot-2019-03-15-at-11.12.32-1024x592.png
|
||||
@ -1,38 +1,38 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11243-1.html)
|
||||
[#]: subject: (How To Check Linux Package Version Before Installing It)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-check-linux-package-version-before-installing-it/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
How To Check Linux Package Version Before Installing It
|
||||
如何在安装之前检查 Linux 软件包的版本?
|
||||
======
|
||||
|
||||
![Check Linux Package Version][1]
|
||||
|
||||
Most of you will know how to [**find the version of an installed package**][2] in Linux. But, what would you do to find the packages’ version which are not installed in the first place? No problem! This guide describes how to check Linux package version before installing it in Debian and its derivatives like Ubuntu. This small tip might be helpful for those wondering what version they would get before installing a package.
|
||||
大多数人都知道如何在 Linux 中[查找已安装软件包的版本][2],但是,你会如何查找那些还没有安装的软件包的版本呢?很简单!本文将介绍在 Debian 及其衍生品(如 Ubuntu)中,如何在软件包安装之前检查它的版本。对于那些想在安装之前知道软件包版本的人来说,这个小技巧可能会有所帮助。
|
||||
|
||||
### Check Linux Package Version Before Installing It
|
||||
### 在安装之前检查 Linux 软件包版本
|
||||
|
||||
There are many ways to find a package’s version even if it is not installed already in DEB-based systems. Here I have given a few methods.
|
||||
在基于 DEB 的系统中,即使软件包还没有安装,也有很多方法可以查看他的版本。接下来,我将一一介绍。
|
||||
|
||||
##### Method 1 – Using Apt
|
||||
#### 方法 1 – 使用 Apt
|
||||
|
||||
The quick and dirty way to check a package version, simply run:
|
||||
检查软件包的版本的懒人方法:
|
||||
|
||||
```
|
||||
$ apt show <package-name>
|
||||
```
|
||||
|
||||
**Example:**
|
||||
**示例:**
|
||||
|
||||
```
|
||||
$ apt show vim
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
**示例输出:**
|
||||
|
||||
```
|
||||
Package: vim
|
||||
@ -67,23 +67,21 @@ Description: Vi IMproved - enhanced vi editor
|
||||
N: There is 1 additional record. Please use the '-a' switch to see it
|
||||
```
|
||||
|
||||
As you can see in the above output, “apt show” command displays, many important details of the package such as,
|
||||
正如你在上面的输出中看到的,`apt show` 命令显示了软件包许多重要的细节,例如:
|
||||
|
||||
1. package name,
|
||||
2. version,
|
||||
3. origin (from where the vim comes from),
|
||||
4. maintainer,
|
||||
5. home page of the package,
|
||||
6. dependencies,
|
||||
7. download size,
|
||||
8. description,
|
||||
9. and many.
|
||||
1. 包名称,
|
||||
2. 版本,
|
||||
3. 来源(vim 来自哪里),
|
||||
4. 维护者,
|
||||
5. 包的主页,
|
||||
6. 依赖,
|
||||
7. 下载大小,
|
||||
8. 简介,
|
||||
9. 其他。
|
||||
|
||||
因此,Ubuntu 仓库中可用的 Vim 版本是 **8.0.1453**。如果我把它安装到我的 Ubuntu 系统上,就会得到这个版本。
|
||||
|
||||
|
||||
So, the available version of Vim package in the Ubuntu repositories is **8.0.1453**. This is the version I get if I install it on my Ubuntu system.
|
||||
|
||||
Alternatively, use **“apt policy”** command if you prefer short output:
|
||||
或者,如果你不想看那么多的内容,那么可以使用 `apt policy` 这个命令:
|
||||
|
||||
```
|
||||
$ apt policy vim
|
||||
@ -98,7 +96,7 @@ vim:
|
||||
500 http://archive.ubuntu.com/ubuntu bionic/main amd64 Packages
|
||||
```
|
||||
|
||||
Or even shorter:
|
||||
甚至更短:
|
||||
|
||||
```
|
||||
$ apt list vim
|
||||
@ -107,17 +105,17 @@ vim/bionic-updates,bionic-security 2:8.0.1453-1ubuntu1.1 amd64
|
||||
N: There is 1 additional version. Please use the '-a' switch to see it
|
||||
```
|
||||
|
||||
**Apt** is the default package manager in recent Ubuntu versions. So, this command is just enough to find the detailed information of a package. It doesn’t matter whether given package is installed or not. This command will simply list the given package’s version along with all other details.
|
||||
`apt` 是 Ubuntu 最新版本的默认包管理器。因此,这个命令足以找到一个软件包的详细信息,给定的软件包是否安装并不重要。这个命令将简单地列出给定包的版本以及其他详细信息。
|
||||
|
||||
##### Method 2 – Using Apt-get
|
||||
#### 方法 2 – 使用 Apt-get
|
||||
|
||||
To find a package version without installing it, we can use **apt-get** command with **-s** option.
|
||||
要查看软件包的版本而不安装它,我们可以使用 `apt-get` 命令和 `-s` 选项。
|
||||
|
||||
```
|
||||
$ apt-get -s install vim
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
**示例输出:**
|
||||
|
||||
```
|
||||
NOTE: This is only a simulation!
|
||||
@ -136,19 +134,19 @@ Inst vim (2:8.0.1453-1ubuntu1.1 Ubuntu:18.04/bionic-updates, Ubuntu:18.04/bionic
|
||||
Conf vim (2:8.0.1453-1ubuntu1.1 Ubuntu:18.04/bionic-updates, Ubuntu:18.04/bionic-security [amd64])
|
||||
```
|
||||
|
||||
Here, -s option indicates **simulation**. As you can see in the output, It performs no action. Instead, It simply performs a simulation to let you know what is going to happen when you install the Vim package.
|
||||
这里,`-s` 选项代表 **模拟**。正如你在输出中看到的,它不执行任何操作。相反,它只是模拟执行,好让你知道在安装 Vim 时会发生什么。
|
||||
|
||||
You can substitute “install” option with “upgrade” option to see what will happen when you upgrade a package.
|
||||
你可以将 `install` 选项替换为 `upgrade`,以查看升级包时会发生什么。
|
||||
|
||||
```
|
||||
$ apt-get -s upgrade vim
|
||||
```
|
||||
|
||||
##### Method 3 – Using Aptitude
|
||||
#### 方法 3 – 使用 Aptitude
|
||||
|
||||
**Aptitude** is an ncurses and commandline-based front-end to APT package manger in Debian and its derivatives.
|
||||
在 Debian 及其衍生品中,`aptitude` 是一个基于 ncurses(LCTT 译注:ncurses 是终端基于文本的字符处理的库)和命令行的前端 APT 包管理器。
|
||||
|
||||
To find the package version with Aptitude, simply run:
|
||||
使用 aptitude 来查看软件包的版本,只需运行:
|
||||
|
||||
```
|
||||
$ aptitude versions vim
|
||||
@ -156,7 +154,7 @@ p 2:8.0.1453-1ubuntu1
|
||||
p 2:8.0.1453-1ubuntu1.1 bionic-security,bionic-updates 500
|
||||
```
|
||||
|
||||
You can also use simulation option ( **-s** ) to see what would happen if you install or upgrade package.
|
||||
你还可以使用模拟选项(`-s`)来查看安装或升级包时会发生什么。
|
||||
|
||||
```
|
||||
$ aptitude -V -s install vim
|
||||
@ -167,33 +165,29 @@ Need to get 1,152 kB of archives. After unpacking 2,852 kB will be used.
|
||||
Would download/install/remove packages.
|
||||
```
|
||||
|
||||
Here, **-V** flag is used to display detailed information of the package version.
|
||||
|
||||
Similarly, just substitute “install” with “upgrade” option to see what would happen if you upgrade a package.
|
||||
这里,`-V` 标志用于显示软件包的详细信息。
|
||||
|
||||
```
|
||||
$ aptitude -V -s upgrade vim
|
||||
```
|
||||
|
||||
Another way to find the non-installed package’s version using Aptitude command is:
|
||||
类似的,只需将 `install` 替换为 `upgrade` 选项,即可查看升级包会发生什么。
|
||||
|
||||
```
|
||||
$ aptitude search vim -F "%c %p %d %V"
|
||||
```
|
||||
|
||||
Here,
|
||||
这里,
|
||||
|
||||
* **-F** is used to specify which format should be used to display the output,
|
||||
* **%c** – status of the given package (installed or not installed),
|
||||
* **%p** – name of the package,
|
||||
* **%d** – description of the package,
|
||||
* **%V** – version of the package.
|
||||
* `-F` 用于指定应使用哪种格式来显示输出,
|
||||
* `%c` – 包的状态(已安装或未安装),
|
||||
* `%p` – 包的名称,
|
||||
* `%d` – 包的简介,
|
||||
* `%V` – 包的版本。
|
||||
|
||||
当你不知道完整的软件包名称时,这非常有用。这个命令将列出包含给定字符串(即 vim)的所有软件包。
|
||||
|
||||
|
||||
This is helpful when you don’t know the full package name. This command will list all packages that contains the given string (i.e vim).
|
||||
|
||||
Here is the sample output of the above command:
|
||||
以下是上述命令的示例输出:
|
||||
|
||||
```
|
||||
[...]
|
||||
@ -207,17 +201,17 @@ p vim-voom Vim two-pane out
|
||||
p vim-youcompleteme fast, as-you-type, fuzzy-search code completion engine for Vim 0+20161219+git
|
||||
```
|
||||
|
||||
##### Method 4 – Using Apt-cache
|
||||
#### 方法 4 – 使用 Apt-cache
|
||||
|
||||
**Apt-cache** command is used to query APT cache in Debian-based systems. It is useful for performing many operations on APT’s package cache. One fine example is we can [**list installed applications from a certain repository/ppa**][3].
|
||||
`apt-cache` 命令用于查询基于 Debian 的系统中的 APT 缓存。对于要在 APT 的包缓存上执行很多操作时,它很有用。一个很好的例子是我们可以从[某个仓库或 ppa 中列出已安装的应用程序][3]。
|
||||
|
||||
Not just installed applications, we can also find the version of a package even if it is not installed. For instance, the following command will find the version of Vim package:
|
||||
不仅是已安装的应用程序,我们还可以找到软件包的版本,即使它没有被安装。例如,以下命令将找到 Vim 的版本:
|
||||
|
||||
```
|
||||
$ apt-cache policy vim
|
||||
```
|
||||
|
||||
Sample output:
|
||||
示例输出:
|
||||
|
||||
```
|
||||
vim:
|
||||
@ -231,19 +225,19 @@ vim:
|
||||
500 http://archive.ubuntu.com/ubuntu bionic/main amd64 Packages
|
||||
```
|
||||
|
||||
As you can see in the above output, Vim is not installed. If you wanted to install it, you would get version **8.0.1453**. It also displays from which repository the vim package is coming from.
|
||||
正如你在上面的输出中所看到的,Vim 并没有安装。如果你想安装它,你会知道它的版本是 **8.0.1453**。它还显示 vim 包来自哪个仓库。
|
||||
|
||||
##### Method 5 – Using Apt-show-versions
|
||||
#### 方法 5 – 使用 Apt-show-versions
|
||||
|
||||
**Apt-show-versions** command is used to list installed and available package versions in Debian and Debian-based systems. It also displays the list of all upgradeable packages. It is quite handy if you have a mixed stable/testing environment. For instance, if you have enabled both stable and testing repositories, you can easily find the list of applications from testing and also you can upgrade all packages in testing.
|
||||
在 Debian 和基于 Debian 的系统中,`apt-show-versions` 命令用于列出已安装和可用软件包的版本。它还显示所有可升级软件包的列表。如果你有一个混合的稳定或测试环境,这是非常方便的。例如,如果你同时启用了稳定和测试仓库,那么你可以轻松地从测试库找到应用程序列表,还可以升级测试库中的所有软件包。
|
||||
|
||||
Apt-show-versions is not installed by default. You need to install it using command:
|
||||
默认情况下系统没有安装 `apt-show-versions`,你需要使用以下命令来安装它:
|
||||
|
||||
```
|
||||
$ sudo apt-get install apt-show-versions
|
||||
```
|
||||
|
||||
Once installed, run the following command to find the version of a package,for example Vim:
|
||||
安装后,运行以下命令查找软件包的版本,例如 Vim:
|
||||
|
||||
```
|
||||
$ apt-show-versions -a vim
|
||||
@ -253,15 +247,15 @@ vim:amd64 2:8.0.1453-1ubuntu1.1 bionic-updates archive.ubuntu.com
|
||||
vim:amd64 not installed
|
||||
```
|
||||
|
||||
Here, **-a** switch prints all available versions of the given package.
|
||||
这里,`-a` 选项打印给定软件包的所有可用版本。
|
||||
|
||||
If the given package is already installed, you need not to use **-a** option. In that case, simply run:
|
||||
如果已经安装了给定的软件包,那么就不需要使用 `-a` 选项。在这种情况下,只需运行:
|
||||
|
||||
```
|
||||
$ apt-show-versions vim
|
||||
```
|
||||
|
||||
And, that’s all. If you know any other methods, please share them in the comment section below. I will check and update this guide.
|
||||
差不多完了。如果你还了解其他方法,在下面的评论中分享,我将检查并更新本指南。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -269,8 +263,8 @@ via: https://www.ostechnix.com/how-to-check-linux-package-version-before-install
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -69,17 +69,17 @@ package org.opensource.demo.singleton;
|
||||
|
||||
public class OpensourceSingleton {
|
||||
|
||||
private static OpensourceSingleton uniqueInstance;
|
||||
private static OpensourceSingleton uniqueInstance;
|
||||
|
||||
private OpensourceSingleton() {
|
||||
}
|
||||
private OpensourceSingleton() {
|
||||
}
|
||||
|
||||
public static OpensourceSingleton getInstance() {
|
||||
if (uniqueInstance == null) {
|
||||
uniqueInstance = new OpensourceSingleton();
|
||||
}
|
||||
return uniqueInstance;
|
||||
}
|
||||
public static OpensourceSingleton getInstance() {
|
||||
if (uniqueInstance == null) {
|
||||
uniqueInstance = new OpensourceSingleton();
|
||||
}
|
||||
return uniqueInstance;
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
@ -102,20 +102,20 @@ package org.opensource.demo.singleton;
|
||||
|
||||
public class ImprovedOpensourceSingleton {
|
||||
|
||||
private volatile static ImprovedOpensourceSingleton uniqueInstance;
|
||||
private volatile static ImprovedOpensourceSingleton uniqueInstance;
|
||||
|
||||
private ImprovedOpensourceSingleton() {}
|
||||
private ImprovedOpensourceSingleton() {}
|
||||
|
||||
public static ImprovedOpensourceSingleton getInstance() {
|
||||
if (uniqueInstance == null) {
|
||||
synchronized (ImprovedOpensourceSingleton.class) {
|
||||
if (uniqueInstance == null) {
|
||||
uniqueInstance = new ImprovedOpensourceSingleton();
|
||||
}
|
||||
}
|
||||
}
|
||||
return uniqueInstance;
|
||||
}
|
||||
public static ImprovedOpensourceSingleton getInstance() {
|
||||
if (uniqueInstance == null) {
|
||||
synchronized (ImprovedOpensourceSingleton.class) {
|
||||
if (uniqueInstance == null) {
|
||||
uniqueInstance = new ImprovedOpensourceSingleton();
|
||||
}
|
||||
}
|
||||
}
|
||||
return uniqueInstance;
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
@ -141,20 +141,20 @@ package org.opensource.demo.factory;
|
||||
|
||||
public class OpensourceFactory {
|
||||
|
||||
public OpensourceJVMServers getServerByVendor([String][18] name) {
|
||||
if(name.equals("Apache")) {
|
||||
return new Tomcat();
|
||||
}
|
||||
else if(name.equals("Eclipse")) {
|
||||
return new Jetty();
|
||||
}
|
||||
else if (name.equals("RedHat")) {
|
||||
return new WildFly();
|
||||
}
|
||||
else {
|
||||
return null;
|
||||
}
|
||||
}
|
||||
public OpensourceJVMServers getServerByVendor(String name) {
|
||||
if(name.equals("Apache")) {
|
||||
return new Tomcat();
|
||||
}
|
||||
else if(name.equals("Eclipse")) {
|
||||
return new Jetty();
|
||||
}
|
||||
else if (name.equals("RedHat")) {
|
||||
return new WildFly();
|
||||
}
|
||||
else {
|
||||
return null;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
@ -164,9 +164,9 @@ public class OpensourceFactory {
|
||||
package org.opensource.demo.factory;
|
||||
|
||||
public interface OpensourceJVMServers {
|
||||
public void startServer();
|
||||
public void stopServer();
|
||||
public [String][18] getName();
|
||||
public void startServer();
|
||||
public void stopServer();
|
||||
public String getName();
|
||||
}
|
||||
```
|
||||
|
||||
@ -176,17 +176,17 @@ public interface OpensourceJVMServers {
|
||||
package org.opensource.demo.factory;
|
||||
|
||||
public class WildFly implements OpensourceJVMServers {
|
||||
public void startServer() {
|
||||
[System][19].out.println("Starting WildFly Server...");
|
||||
}
|
||||
public void startServer() {
|
||||
System.out.println("Starting WildFly Server...");
|
||||
}
|
||||
|
||||
public void stopServer() {
|
||||
[System][19].out.println("Shutting Down WildFly Server...");
|
||||
}
|
||||
public void stopServer() {
|
||||
System.out.println("Shutting Down WildFly Server...");
|
||||
}
|
||||
|
||||
public [String][18] getName() {
|
||||
return "WildFly";
|
||||
}
|
||||
public String getName() {
|
||||
return "WildFly";
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
@ -209,9 +209,9 @@ package org.opensource.demo.observer;
|
||||
|
||||
public interface Topic {
|
||||
|
||||
public void addObserver([Observer][22] observer);
|
||||
public void deleteObserver([Observer][22] observer);
|
||||
public void notifyObservers();
|
||||
public void addObserver(Observer observer);
|
||||
public void deleteObserver(Observer observer);
|
||||
public void notifyObservers();
|
||||
}
|
||||
```
|
||||
|
||||
@ -226,39 +226,39 @@ import java.util.List;
|
||||
import java.util.ArrayList;
|
||||
|
||||
public class Conference implements Topic {
|
||||
private List<Observer> listObservers;
|
||||
private int totalAttendees;
|
||||
private int totalSpeakers;
|
||||
private [String][18] nameEvent;
|
||||
private List<Observer> listObservers;
|
||||
private int totalAttendees;
|
||||
private int totalSpeakers;
|
||||
private String nameEvent;
|
||||
|
||||
public Conference() {
|
||||
listObservers = new ArrayList<Observer>();
|
||||
}
|
||||
public Conference() {
|
||||
listObservers = new ArrayList<Observer>();
|
||||
}
|
||||
|
||||
public void addObserver([Observer][22] observer) {
|
||||
listObservers.add(observer);
|
||||
}
|
||||
public void addObserver(Observer observer) {
|
||||
listObservers.add(observer);
|
||||
}
|
||||
|
||||
public void deleteObserver([Observer][22] observer) {
|
||||
int i = listObservers.indexOf(observer);
|
||||
if (i >= 0) {
|
||||
listObservers.remove(i);
|
||||
}
|
||||
}
|
||||
public void deleteObserver(Observer observer) {
|
||||
int i = listObservers.indexOf(observer);
|
||||
if (i >= 0) {
|
||||
listObservers.remove(i);
|
||||
}
|
||||
}
|
||||
|
||||
public void notifyObservers() {
|
||||
for (int i=0, nObservers = listObservers.size(); i < nObservers; ++ i) {
|
||||
[Observer][22] observer = listObservers.get(i);
|
||||
observer.update(totalAttendees,totalSpeakers,nameEvent);
|
||||
}
|
||||
}
|
||||
public void notifyObservers() {
|
||||
for (int i=0, nObservers = listObservers.size(); i < nObservers; ++ i) {
|
||||
Observer observer = listObservers.get(i);
|
||||
observer.update(totalAttendees,totalSpeakers,nameEvent);
|
||||
}
|
||||
}
|
||||
|
||||
public void setConferenceDetails(int totalAttendees, int totalSpeakers, [String][18] nameEvent) {
|
||||
this.totalAttendees = totalAttendees;
|
||||
this.totalSpeakers = totalSpeakers;
|
||||
this.nameEvent = nameEvent;
|
||||
notifyObservers();
|
||||
}
|
||||
public void setConferenceDetails(int totalAttendees, int totalSpeakers, String nameEvent) {
|
||||
this.totalAttendees = totalAttendees;
|
||||
this.totalSpeakers = totalSpeakers;
|
||||
this.nameEvent = nameEvent;
|
||||
notifyObservers();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
@ -269,8 +269,8 @@ public class Conference implements Topic {
|
||||
```
|
||||
package org.opensource.demo.observer;
|
||||
|
||||
public interface [Observer][22] {
|
||||
public void update(int totalAttendees, int totalSpeakers, [String][18] nameEvent);
|
||||
public interface Observer {
|
||||
public void update(int totalAttendees, int totalSpeakers, String nameEvent);
|
||||
}
|
||||
```
|
||||
|
||||
@ -281,27 +281,27 @@ public interface [Observer][22] {
|
||||
```
|
||||
package org.opensource.demo.observer;
|
||||
|
||||
public class MonitorConferenceAttendees implements [Observer][22] {
|
||||
private int totalAttendees;
|
||||
private int totalSpeakers;
|
||||
private [String][18] nameEvent;
|
||||
private Topic topic;
|
||||
public class MonitorConferenceAttendees implements Observer {
|
||||
private int totalAttendees;
|
||||
private int totalSpeakers;
|
||||
private String nameEvent;
|
||||
private Topic topic;
|
||||
|
||||
public MonitorConferenceAttendees(Topic topic) {
|
||||
this.topic = topic;
|
||||
topic.addObserver(this);
|
||||
}
|
||||
public MonitorConferenceAttendees(Topic topic) {
|
||||
this.topic = topic;
|
||||
topic.addObserver(this);
|
||||
}
|
||||
|
||||
public void update(int totalAttendees, int totalSpeakers, [String][18] nameEvent) {
|
||||
this.totalAttendees = totalAttendees;
|
||||
this.totalSpeakers = totalSpeakers;
|
||||
this.nameEvent = nameEvent;
|
||||
printConferenceInfo();
|
||||
}
|
||||
public void update(int totalAttendees, int totalSpeakers, String nameEvent) {
|
||||
this.totalAttendees = totalAttendees;
|
||||
this.totalSpeakers = totalSpeakers;
|
||||
this.nameEvent = nameEvent;
|
||||
printConferenceInfo();
|
||||
}
|
||||
|
||||
public void printConferenceInfo() {
|
||||
[System][19].out.println(this.nameEvent + " has " + totalSpeakers + " speakers and " + totalAttendees + " attendees");
|
||||
}
|
||||
public void printConferenceInfo() {
|
||||
System.out.println(this.nameEvent + " has " + totalSpeakers + " speakers and " + totalAttendees + " attendees");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Scvoet)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: translator: (scvoet)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11232-1.html)
|
||||
[#]: subject: (How To Add ‘New Document’ Option In Right Click Context Menu In Ubuntu 18.04)
|
||||
[#]: via: ((https://www.ostechnix.com/how-to-add-new-document-option-in-right-click-context-menu-in-ubuntu-18-04/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
@ -12,25 +12,25 @@
|
||||
|
||||
![Add 'New Document' Option In Right Click Context Menu In Ubuntu 18.04 GNOME desktop][1]
|
||||
|
||||
前几天,我在各种在线资源站点上收集关于 [**Linux 包管理**][2] 的参考资料。在我想创建一个用于保存笔记的文件,我突然发现我的 Ubuntu 18.04 LTS 桌面并没有“创建文件”的按钮了,它好像离奇失踪了。在谷歌一下后,我发现原来“新建文档”按钮不再被集成在 Ubuntu GNOME 版本中了。庆幸的是,我找到了一个在 Ubuntu 18.04 LTS 桌面的右键单击菜单中添加“新建文档”按钮的简易解决方案。
|
||||
前几天,我在各种在线资源站点上收集关于 [Linux 包管理器][2] 的参考资料。在我想创建一个用于保存笔记的文件,我突然发现我的 Ubuntu 18.04 LTS 桌面并没有“新建文件”的按钮了,它好像离奇失踪了。在谷歌一下后,我发现原来“新建文档”按钮不再被集成在 Ubuntu GNOME 版本中了。庆幸的是,我找到了一个在 Ubuntu 18.04 LTS 桌面的右键单击菜单中添加“新建文档”按钮的简易解决方案。
|
||||
|
||||
就像你在下方截图中看到的一样,Nautilus 文件管理器的右键单击菜单中并没有“新建文件”按钮。
|
||||
|
||||
![][3]
|
||||
|
||||
Ubuntu 18.04 移除了右键点击菜单中的“新建文件”的选项。
|
||||
*Ubuntu 18.04 移除了右键点击菜单中的“新建文件”的选项。*
|
||||
|
||||
如果你想添加此一按钮,请按照以下步骤进行操作。
|
||||
如果你想添加此按钮,请按照以下步骤进行操作。
|
||||
|
||||
### 在 Ubuntu 的右键单击菜单中添加“新建文件”按钮
|
||||
|
||||
首先,你需要确保您的系统中有 **~/Templates** 文件夹。如果没有的话,可以按照下面的命令进行创建。
|
||||
首先,你需要确保你的系统中有 `~/Templates` 文件夹。如果没有的话,可以按照下面的命令进行创建。
|
||||
|
||||
```
|
||||
$ mkdir ~/Templates
|
||||
```
|
||||
|
||||
然后打开终端应用并使用 cd 命令进入 **~/Templates** 文件夹:
|
||||
然后打开终端应用并使用 `cd` 命令进入 `~/Templates` 文件夹:
|
||||
|
||||
```
|
||||
$ cd ~/Templates
|
||||
@ -50,11 +50,11 @@ $ touch "Empty Document"
|
||||
|
||||
![][4]
|
||||
|
||||
新开一个 Nautilus 文件管理器,然后检查一下右键单击菜单中是否成功添加了“新建文档”按钮。
|
||||
新打开一个 Nautilus 文件管理器,然后检查一下右键单击菜单中是否成功添加了“新建文档”按钮。
|
||||
|
||||
![][5]
|
||||
|
||||
在 Ubuntu 18.04 的右键单击菜单中添加“新建文件”按钮
|
||||
*在 Ubuntu 18.04 的右键单击菜单中添加“新建文件”按钮*
|
||||
|
||||
如上图所示,我们重新启用了“新建文件”的按钮。
|
||||
|
||||
@ -73,7 +73,7 @@ $ touch New\ PyScript.py
|
||||
|
||||
在“新建文件”子菜单中给不同的文件类型添加按钮
|
||||
|
||||
注意,所有文件都应该创建在 **~/Templates** 文件夹下。
|
||||
注意,所有文件都应该创建在 `~/Templates` 文件夹下。
|
||||
|
||||
现在,打开 Nautilus 并检查“新建文件” 菜单中是否有相应的新建文件按钮。
|
||||
|
||||
@ -93,14 +93,13 @@ via: https://www.ostechnix.com/how-to-add-new-document-option-in-right-click-con
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID][c]
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[scvoet](https://github.com/scvoet)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux 中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[c]: https://github.com/scvoet
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/07/Add-New-Document-Option-In-Right-Click-Context-Menu-1-720x340.png
|
||||
[2]: https://www.ostechnix.com/linux-package-managers-compared-appimage-vs-snap-vs-flatpak/
|
||||
[3]: https://www.ostechnix.com/wp-content/uploads/2019/07/new-document-option-missing.png
|
||||
@ -0,0 +1,113 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11238-1.html)
|
||||
[#]: subject: (Find Out How Long Does it Take To Boot Your Linux System)
|
||||
[#]: via: (https://itsfoss.com/check-boot-time-linux/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
你的 Linux 系统开机时间已经击败了 99% 的电脑
|
||||
======
|
||||
|
||||
当你打开系统电源时,你会等待制造商的徽标出现,屏幕上可能会显示一些消息(以非安全模式启动),然后是 [Grub][1] 屏幕、操作系统加载屏幕以及最后的登录屏。
|
||||
|
||||
你检查过这花费了多长时间么?也许没有。除非你真的需要知道,否则你不会在意开机时间。
|
||||
|
||||
但是如果你很想知道你的 Linux 系统需要很长时间才能启动完成呢?使用秒表是一种方法,但在 Linux 中,你有一种更好、更轻松地了解系统启动时间的方法。
|
||||
|
||||
### 在 Linux 中使用 systemd-analyze 检查启动时间
|
||||
|
||||

|
||||
|
||||
无论你是否喜欢,[systemd][3] 运行在大多数流行的 Linux 发行版中。systemd 有许多管理 Linux 系统的工具。其中一个就是 `systemd-analyze`。
|
||||
|
||||
`systemd-analyze` 命令为你提供最近一次启动时运行的服务数量以及消耗时间的详细信息。
|
||||
|
||||
如果在终端中运行以下命令:
|
||||
|
||||
```
|
||||
systemd-analyze
|
||||
```
|
||||
|
||||
你将获得总启动时间以及固件、引导加载程序、内核和用户空间所消耗的时间:
|
||||
|
||||
```
|
||||
Startup finished in 7.275s (firmware) + 13.136s (loader) + 2.803s (kernel) + 12.488s (userspace) = 35.704s
|
||||
|
||||
graphical.target reached after 12.408s in userspace
|
||||
```
|
||||
|
||||
正如你在上面的输出中所看到的,我的系统花了大约 35 秒才进入可以输入密码的页面。我正在使用戴尔 XPS Ubuntu。它使用 SSD 存储,尽管如此,它还需要很长时间才能启动。
|
||||
|
||||
不是那么令人印象深刻,是吗?为什么不共享你们系统的启动时间?我们来比较吧。
|
||||
|
||||
你可以使用以下命令将启动时间进一步细分为每个单元:
|
||||
|
||||
```
|
||||
systemd-analyze blame
|
||||
```
|
||||
|
||||
这将生成大量输出,所有服务按所用时间的降序列出。
|
||||
|
||||
```
|
||||
7.347s plymouth-quit-wait.service
|
||||
6.198s NetworkManager-wait-online.service
|
||||
3.602s plymouth-start.service
|
||||
3.271s plymouth-read-write.service
|
||||
2.120s apparmor.service
|
||||
1.503s [email protected]
|
||||
1.213s motd-news.service
|
||||
908ms snapd.service
|
||||
861ms keyboard-setup.service
|
||||
739ms fwupd.service
|
||||
702ms bolt.service
|
||||
672ms dev-nvme0n1p3.device
|
||||
608ms [email protected]:intel_backlight.service
|
||||
539ms snap-core-7270.mount
|
||||
504ms snap-midori-451.mount
|
||||
463ms snap-screencloud-1.mount
|
||||
446ms snapd.seeded.service
|
||||
440ms snap-gtk\x2dcommon\x2dthemes-1313.mount
|
||||
420ms snap-core18-1066.mount
|
||||
416ms snap-scrcpy-133.mount
|
||||
412ms snap-gnome\x2dcharacters-296.mount
|
||||
```
|
||||
|
||||
#### 额外提示:改善启动时间
|
||||
|
||||
如果查看此输出,你可以看到网络管理器和 [plymouth][4] 都消耗了大量的启动时间。
|
||||
|
||||
Plymouth 负责你在 Ubuntu 和其他发行版中在登录页面出现之前的引导页面。网络管理器负责互联网连接,可以关闭它来加快启动时间。不要担心,在你登录后,你可以正常使用 wifi。
|
||||
|
||||
```
|
||||
sudo systemctl disable NetworkManager-wait-online.service
|
||||
```
|
||||
|
||||
如果要还原更改,可以使用以下命令:
|
||||
|
||||
```
|
||||
sudo systemctl enable NetworkManager-wait-online.service
|
||||
```
|
||||
|
||||
请不要在不知道用途的情况下自行禁用各种服务。这可能会产生危险的后果。
|
||||
|
||||
现在你知道了如何检查 Linux 系统的启动时间,为什么不在评论栏分享你的系统的启动时间?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/check-boot-time-linux/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.gnu.org/software/grub/
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/linux-boot-time.jpg?resize=800%2C450&ssl=1
|
||||
[3]: https://en.wikipedia.org/wiki/Systemd
|
||||
[4]: https://wiki.archlinux.org/index.php/Plymouth
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11236-1.html)
|
||||
[#]: subject: (How to Get Linux Kernel 5.0 in Ubuntu 18.04 LTS)
|
||||
[#]: via: (https://itsfoss.com/ubuntu-hwe-kernel/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
@ -10,31 +10,31 @@
|
||||
如何在 Ubuntu 18.04 LTS 中获取 Linux 5.0 内核
|
||||
======
|
||||
|
||||
_ **最近发布的 Ubuntu 18.04.3 包括 Linux 5.0 内核中的几个新功能和改进,但默认情况下没有安装。本教程演示了如何在 Ubuntu 18.04 LTS 中获取 Linux 5 内核。** _
|
||||
> 最近发布的 Ubuntu 18.04.3 包括 Linux 5.0 内核中的几个新功能和改进,但默认情况下没有安装。本教程演示了如何在 Ubuntu 18.04 LTS 中获取 Linux 5 内核。
|
||||
|
||||
[Subscribe to It’s FOSS YouTube Channel for More Videos][1]
|
||||

|
||||
|
||||
[Ubuntu 18.04 的第三个“点发布版”在这里][2],它带来了新的稳定版本的 GNOME 组件、livepatch 桌面集成和内核 5.0。
|
||||
[Ubuntu 18.04 的第三个“点发布版”已经发布][2],它带来了新的稳定版本的 GNOME 组件、livepatch 桌面集成和内核 5.0。
|
||||
|
||||
可是等等!什么是“点发布版”(point release)?让我先解释一下。
|
||||
可是等等!什么是“<ruby>小数点版本<rt>point release</rt></ruby>”?让我先解释一下。
|
||||
|
||||
### Ubuntu LTS 点发布版
|
||||
### Ubuntu LTS 小数点版本
|
||||
|
||||
Ubuntu 18.04 于 2018 年 4 月发布,由于它是一个长期支持 (LTS) 版本,它将一直支持到 2023 年。从那时起,已经有许多 bug 修复,安全更新和软件升级。如果你今天下载 Ubuntu 18.04,你需要在[在安装 Ubuntu 后首先安装这些更新][3]。
|
||||
Ubuntu 18.04 于 2018 年 4 月发布,由于它是一个长期支持 (LTS) 版本,它将一直支持到 2023 年。从那时起,已经有许多 bug 修复、安全更新和软件升级。如果你今天下载 Ubuntu 18.04,你需要在[在安装 Ubuntu 后首先安装这些更新][3]。
|
||||
|
||||
当然,这不是一种理想情况。这就是 Ubuntu 提供这些“点发布版”的原因。点发布版包含所有功能和安全更新以及自 LTS 版本首次发布以来添加的 bug 修复。如果你今天下载 Ubuntu,你会得到 Ubuntu 18.04.3 而不是 Ubuntu 18.04。这节省了在新安装的 Ubuntu 系统上下载和安装数百个更新的麻烦。
|
||||
当然,这不是一种理想情况。这就是 Ubuntu 提供这些“小数点版本”的原因。点发布版包含所有功能和安全更新以及自 LTS 版本首次发布以来添加的 bug 修复。如果你今天下载 Ubuntu,你会得到 Ubuntu 18.04.3 而不是 Ubuntu 18.04。这节省了在新安装的 Ubuntu 系统上下载和安装数百个更新的麻烦。
|
||||
|
||||
好了!现在你知道“点发布版”的概念了。你如何升级到这些点发布版?答案很简单。只需要像平时一样[更新你的 Ubuntu 系统][4],这样你将在最新的点发布版上了。
|
||||
好了!现在你知道“小数点版本”的概念了。你如何升级到这些小数点版本?答案很简单。只需要像平时一样[更新你的 Ubuntu 系统][4],这样你将在最新的小数点版本上了。
|
||||
|
||||
你可以[查看 Ubuntu 版本][5]来了解正在使用的版本。我检查了一下,因为我用的是 Ubuntu 18.04.3,我以为我的内核会是 5。当我[查看 Linux 内核版本][6]时,它仍然是基本内核 4.15。
|
||||
|
||||
![Ubuntu Version And Linux Kernel Version Check][7]
|
||||
|
||||
这是为什么?如果 Ubuntu 18.04.3 有 Linux 5.0 内核,为什么它仍然使用 Linux 4.15 内核?这是因为你必须通过选择 LTS 支持栈(通常称为 HWE)手动请求在 Ubuntu LTS 中安装新内核。
|
||||
这是为什么?如果 Ubuntu 18.04.3 有 Linux 5.0 内核,为什么它仍然使用 Linux 4.15 内核?这是因为你必须通过选择 LTS <ruby>支持栈<rt>Enablement Stack</rt></ruby>(通常称为 HWE)手动请求在 Ubuntu LTS 中安装新内核。
|
||||
|
||||
### 使用 HWE 在Ubuntu 18.04 中获取 Linux 5.0 内核
|
||||
|
||||
默认情况下,Ubuntu LTS 将保持在最初发布的 Linux 内核上。 [硬件支持栈][9](HWE)为现有的 Ubuntu LTS 版本提供了更新的内核和 xorg 支持。
|
||||
默认情况下,Ubuntu LTS 将保持在最初发布的 Linux 内核上。<ruby>[硬件支持栈][9]<rt>hardware enablement stack</rt></ruby>(HWE)为现有的 Ubuntu LTS 版本提供了更新的内核和 xorg 支持。
|
||||
|
||||
最近发生了一些变化。如果你下载了 Ubuntu 18.04.2 或更新的桌面版本,那么就会为你启用 HWE,默认情况下你将获得新内核以及常规更新。
|
||||
|
||||
@ -54,7 +54,7 @@ sudo apt-get install --install-recommends linux-generic-hwe-18.04
|
||||
|
||||
完成 HWE 内核的安装后,重启系统。现在你应该拥有更新的 Linux 内核了。
|
||||
|
||||
**你在 Ubuntu 18.04 中获取 5.0 内核了么?**
|
||||
### 你在 Ubuntu 18.04 中获取 5.0 内核了么?
|
||||
|
||||
请注意,下载并安装了 Ubuntu 18.04.2 的用户已经启用了 HWE。所以这些用户将能轻松获取 5.0 内核。
|
||||
|
||||
@ -69,7 +69,7 @@ via: https://itsfoss.com/ubuntu-hwe-kernel/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,81 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11241-1.html)
|
||||
[#]: subject: (GNOME and KDE team up on the Linux desktop, docs for Nvidia GPUs open up, a powerful new way to scan for firmware vulnerabilities, and more news)
|
||||
[#]: via: (https://opensource.com/article/19/8/news-august-17)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||
|
||||
开源新闻综述:GNOME 和 KDE 达成合作、Nvidia 开源 GPU 文档
|
||||
======
|
||||
|
||||
> 不要错过两周以来最大的开源头条新闻。
|
||||
|
||||
![Weekly news roundup with TV][1]
|
||||
|
||||
在本期开源新闻综述中,我们将介绍两种新的强大数据可视化工具、Nvidia 开源其 GPU 文档、激动人心的新工具、确保自动驾驶汽车的固件安全等等!
|
||||
|
||||
### GNOME 和 KDE 在 Linux 桌面上达成合作伙伴
|
||||
|
||||
Linux 在桌面计算机上一直处于分裂状态。在最近的一篇[公告][2]中称,“两个主要的 Linux 桌面竞争对手,[GNOME 基金会][3] 和 [KDE][4] 已经同意合作。”
|
||||
|
||||
这两个组织将成为今年 11 月在巴塞罗那举办的 [Linux App Summit(LAS)2019][5] 的赞助商。这一举措在某种程度上似乎是对桌面计算不再是争夺支配地位的最佳场所的回应。无论是什么原因,Linux 桌面的粉丝们都有新的理由希望未来出现一个标准化的 GUI 环境。
|
||||
|
||||
### 新的开源数据可视化工具
|
||||
|
||||
这个世界上很少有不是由数据驱动的。除非数据以人们可以互动的形式出现,否则它并不是很好使用。最近开源的两个数据可视化项目正在尝试使数据更有用。
|
||||
|
||||
第一个工具名为 **Neuroglancer**,由 [Google 的研究团队][6]创建。它“使神经科医生能够在交互式可视化中建立大脑神经通路的 3D 模型。”Neuroglancer 通过使用神经网络追踪大脑中的神经元路径并构建完整的可视化来实现这一点。科学家已经使用了 Neuroglancer(你可以[从 GitHub 取得][7])通过扫描果蝇的大脑来建立一个交互式地图。
|
||||
|
||||
第二个工具来自一个不太能想到的的来源:澳大利亚信号理事会。这是该国家类似 NSA 的机构,它“开源了[内部数据可视化和分析工具][8]之一。”这个被称为 **[Constellation][9]** 的工具可以“识别复杂数据集中的趋势和模式,并且能够扩展到‘数十亿输入’。”该机构总干事迈克•伯吉斯表示,他希望“这一工具将有助于产生有利于所有澳大利亚人的科学和其他方面的突破。”鉴于它是开源的,它可以使整个世界受益。
|
||||
|
||||
### Nvidia 开始发布 GPU 文档
|
||||
|
||||
多年来,图形处理单元(GPU)制造商 Nvidia 并没有做出什么让开源项目轻松开发其产品的驱动程序的努力。现在,该公司通过[发布 GPU 硬件文档][10]向这些项目迈出了一大步。
|
||||
|
||||
该公司根据 MIT 许可证发布的文档[可在 GitHub 上获取][11]。它涵盖了几个关键领域,如设备初始化、内存时钟/调整和电源状态。据硬件新闻网站 Phoronix 称,开发了 Nvidia GPU 的开源驱动程序的 Nouveau 项目将是率先使用该文档来推动其开发工作的项目之一。
|
||||
|
||||
### 用于保护固件的新工具
|
||||
|
||||
似乎每周都有的消息称,移动设备或连接互联网的小设备中出现新漏洞。通常,这些漏洞存在于控制设备的固件中。自动驾驶汽车服务 Cruise [发布了一个开源工具][12],用于在这些漏洞成为问题之前捕获这些漏洞。
|
||||
|
||||
该工具被称为 [FwAnalzyer][13]。它检查固件代码中是否存在许多潜在问题,包括“识别潜在危险的可执行文件”,并查明“任何错误遗留的调试代码”。Cruise 的工程师 Collin Mulliner 曾帮助开发该工具,他说通过在代码上运行 FwAnalyzer,固件开发人员“现在能够检测并防止各种安全问题。”
|
||||
|
||||
### 其它新闻
|
||||
|
||||
* [为什么洛杉矶决定将未来寄予开源][14]
|
||||
* [麻省理工学院出版社发布了关于开源出版软件的综合报告][15]
|
||||
* [华为推出鸿蒙操作系统,不会放弃 Android 智能手机][16]
|
||||
|
||||
*一如既往地感谢 Opensource.com 的工作人员和主持人本周的帮助。*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/news-august-17
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/weekly_news_roundup_tv.png?itok=B6PM4S1i (Weekly news roundup with TV)
|
||||
[2]: https://www.zdnet.com/article/gnome-and-kde-work-together-on-the-linux-desktop/
|
||||
[3]: https://www.gnome.org/
|
||||
[4]: https://kde.org/
|
||||
[5]: https://linuxappsummit.org/
|
||||
[6]: https://www.cbronline.com/news/brain-mapping-google-ai
|
||||
[7]: https://github.com/google/neuroglancer
|
||||
[8]: https://www.computerworld.com.au/article/665286/australian-signals-directorate-open-sources-data-analysis-tool/
|
||||
[9]: https://www.constellation-app.com/
|
||||
[10]: https://www.phoronix.com/scan.php?page=news_item&px=NVIDIA-Open-GPU-Docs
|
||||
[11]: https://github.com/nvidia/open-gpu-doc
|
||||
[12]: https://arstechnica.com/information-technology/2019/08/self-driving-car-service-open-sources-new-tool-for-securing-firmware/
|
||||
[13]: https://github.com/cruise-automation/fwanalyzer
|
||||
[14]: https://www.techrepublic.com/article/why-la-decided-to-open-source-its-future/
|
||||
[15]: https://news.mit.edu/2019/mit-press-report-open-source-publishing-software-0808
|
||||
[16]: https://www.itnews.com.au/news/huawei-unveils-harmony-operating-system-wont-ditch-android-for-smartphones-529432
|
||||
@ -0,0 +1,105 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (LiVES Video Editor 3.0 is Here With Significant Improvements)
|
||||
[#]: via: (https://itsfoss.com/lives-video-editor/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
LiVES Video Editor 3.0 is Here With Significant Improvements
|
||||
======
|
||||
|
||||
We recently covered a list of [best open source video editors][1]. LiVES is one of those open source video editors, available for free.
|
||||
|
||||
Even though a lot of users are still waiting for the release on Windows, a major update just popped up for LiVES Video Editor (i.e v3.0.1 as the latest package) on Linux. The new upgrade includes some new features and improvements.
|
||||
|
||||
In this article, I’ll cover the key improvements in the new version and I’ll also mention the steps to install it on your Linux system.
|
||||
|
||||
### LiVES Video Editor 3.0: New Changes
|
||||
|
||||
![Lives Video Editor Loading in Zorin OS][2]
|
||||
|
||||
Overall, with this major update – LiVES Video Editor aims to have a smoother playback, prevent unwanted crashes, optimized video recording, and making the online video downloader more useful.
|
||||
|
||||
The list of changes are:
|
||||
|
||||
* Render silence to end of video if necessary during rendering.
|
||||
* Improvements to openGL playback plugin, including much smoother playback.
|
||||
* Re-enable Advanced options for the openGL playback plugin.
|
||||
* Allow “Enough” in VJ / Pre-decode all frames
|
||||
* Refactor code for timebase calculations during playback (better a/v synch).
|
||||
* Overhaul external audio and audio recording to improve accuracy and use fewer CPU cycles.
|
||||
* Auto switch to internal audio when entering multitack mode.
|
||||
* Show correct effects state (on / off) when reshowing effect mapper window.
|
||||
* Eliminate some race conditions between the audio and video threads.
|
||||
* Improvements to online video downloader, clip size and format can now be selected, added an update option.
|
||||
* Implemented reference counting for realtime effect instances.
|
||||
* Extensively rewrote the main interface, cleaning up the code and making many visual improvements.
|
||||
* Optimized recording when video generators are running.
|
||||
* Improvements to the projectM filter wrapper, including SDL2 support.
|
||||
* Added an option to invert the Z-order in multitrack compositor (rear layers can now overlay front ones).
|
||||
* Added support for musl libc
|
||||
* Updated translations for Ukranian
|
||||
|
||||
|
||||
|
||||
While some of the points listed can just go over your head if you are not an advanced video editor. But, in a nutshell, all of these things make ‘LiVES Video Editor’ a better open source video editing software.
|
||||
|
||||
[][3]
|
||||
|
||||
Suggested read VidCutter Lets You Easily Trim And Merge Videos In Linux
|
||||
|
||||
### Installing LiVES Video Editor on Linux
|
||||
|
||||
LiVES is normally available in the repository of all major Linux distributions. However, you may not find the latest version on your software center yet. So, if you want to install it that way – you’ll have to wait.
|
||||
|
||||
If you want to install it manually, you can get the RPM packages for Fedora/Open SUSE from its download page. The source is also available for Linux distros.
|
||||
|
||||
[Download LiVES Video Editor][4]
|
||||
|
||||
For Ubuntu (or Ubuntu-based distros), you can add the [unofficial PPA][5] maintained by [Ubuntuhandbook][6]. Here’s how to do it:
|
||||
|
||||
**1.** Launch the terminal and enter the following command:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:ubuntuhandbook1/lives
|
||||
```
|
||||
|
||||
You will be prompted for the password to authenticate the addition of PPA.
|
||||
|
||||
**2.** Once done, you can now easily proceed to update the list of packages and get LiVES Video Editor installed. Here’s the set of commands that you need to enter next:
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt install lives lives-plugins
|
||||
```
|
||||
|
||||
**3.** Now, it will start downloading and installing the video editor. You should be good to go in a minute.
|
||||
|
||||
**Wrapping Up**
|
||||
|
||||
There are a handful of [video editors available on Linux][7]. But they are not often considered good enough for professional editing. I am not a professional but I do manage simple editing with such freely available video editors like LiVES.
|
||||
|
||||
How about you? How’s your experience with LiVES or other video editors on Linux? Let us know your thoughts in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/lives-video-editor/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/open-source-video-editors/
|
||||
[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/lives-video-editor-loading.jpg?ssl=1
|
||||
[3]: https://itsfoss.com/vidcutter-video-editor-linux/
|
||||
[4]: http://lives-video.com/index.php?do=downloads#binaries
|
||||
[5]: https://itsfoss.com/ppa-guide/
|
||||
[6]: http://ubuntuhandbook.org/index.php/2019/08/lives-video-editor-3-0-released-install-ubuntu/
|
||||
[7]: https://itsfoss.com/best-video-editing-software-linux/
|
||||
@ -1,317 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Command Line Heroes: Season 1: OS Wars)
|
||||
[#]: via: (https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-1)
|
||||
[#]: author: (redhat https://www.redhat.com)
|
||||
|
||||
Command Line Heroes: Season 1: OS Wars
|
||||
======
|
||||
Saron Yitbarek:
|
||||
|
||||
Some stories are so epic, with such high stakes , that in my head, it's like that crawling text at the start of a Star Wars movie. You know, like-
|
||||
|
||||
Voice Actor:
|
||||
|
||||
Episode One, The OS Wars.
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
Yeah, like that.
|
||||
|
||||
Voice Actor:
|
||||
|
||||
[00:00:30]
|
||||
|
||||
It is a period of mounting tensions. The empires of Bill Gates and Steve Jobs careen toward an inevitable battle over proprietary software. Gates has formed a powerful alliance with IBM, while Jobs refuses to license his hardware or operating system. Their battle for dominance threatens to engulf the galaxy in an OS war. Meanwhile, in distant lands, and unbeknownst to the emperors, open source rebels have begun to gather.
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:01:00]
|
||||
|
||||
Okay. Maybe that's a bit dramatic, but when we're talking about the OS wars of the 1980s, '90s, and 2000s, it's hard to overstate things. There really was an epic battle for dominance. Steve Jobs and Bill Gates really did hold the fate of billions in their hands. Control the operating system, and you control how the vast majority of people use computers, how we communicate with each other, how we source information. I could go on, but you know all this. Control the OS, and you would be an emperor.
|
||||
|
||||
[00:01:30]
|
||||
|
||||
[00:02:00]
|
||||
|
||||
I'm Saron Yitbarek [00:01:24], and you're listening to Command Line Heroes, an original podcast from Red Hat. What is a Command Line Hero, you ask? Well, if you would rather make something than just use it, if you believe developers have the power to build a better future, if you want a world where we all get a say in how our technologies shape our lives, then you, my friend, are a command line hero. In this series, we bring you stories from the developers among us who are transforming tech from the command line up. And who am I to be guiding you on this trek? Who is Saron Yitbarek? Well, actually I'm guessing I'm a lot like you. I'm a developer for starters, and everything I do depends on open source software. It's my world. The stories we tell on this podcast are a way for me to get above the daily grind of my work, and see that big picture. I hope it does the same thing for you , too.
|
||||
|
||||
[00:02:30]
|
||||
|
||||
[00:03:00]
|
||||
|
||||
What I wanted to know right off the bat was, where did open source technology even come from? I mean, I know a fair bit about Linus Torvalds and the glories of L inux ® , as I'm sure you do , too, but really, there was life before open source, right? And if I want to truly appreciate the latest and greatest of things like DevOps and containers, and on and on, well, I feel like I owe it to all those earlier developers to know where this stuff came from. So, let's take a short break from worrying about memory leaks and buffer overflows. Our journey begins with the OS wars, the epic battle for control of the desktop. It was like nothing the world had ever seen, and I'll tell you why. First, in the age of computing, you've got exponentially scaling advantages for the big fish ; and second, there's never been such a battle for control on ground that's constantly shifting. Bill Gates and Steve Jobs? They don't know it yet, but by the time this story is halfway done, everything they're fighting for is going to change, evolve, and even ascend into the cloud.
|
||||
|
||||
[00:03:30]
|
||||
|
||||
[00:04:00]
|
||||
|
||||
Okay, it's the fall of 1983. I was negative six years old. Ronald Reagan was president, and the U . S . and the Soviet Union are threatening to drag the planet into nuclear war. Over at the Civic Center in Honolulu, it's the annual Apple sales conference. An exclusive bunch of Apple employees are waiting for Steve Jobs to get onstage. He's this super bright-eyed 28-year-old, and he's looking pretty confident. In a very serious voice, Jobs speaks into the mic and says that he's invited three industry experts to have a panel discussion on software. But the next thing that happens is not what you'd expect. Super cheesy '80s music fills the room. A bunch of multi-colored tube lights light up the stage, and then an announcer voice says-
|
||||
|
||||
Voice Actor:
|
||||
|
||||
And now, ladies and gentlemen, the Macintosh software dating game.
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:04:30]
|
||||
|
||||
[00:05:00]
|
||||
|
||||
Jobs has this big grin on his face as he reveals that the three CEOs on stage have to take turns wooing him. It's essentially an '80s version of The Bachelor, but for tech love. Two of the software bigwigs say their bit, and then it's over to contestant number three. Is that? Yup. A fresh - faced Bill Gates with large square glasses that cover half his face. He proclaims that during 1984, half of Microsoft's revenue is going to come from Macintosh software. The audience loves it, and gives him a big round of applause. What they don't know is that one month after this event, Bill Gates will announce his plans to release Windows 1.0. You'd never guess Jobs is flirting with someone who'd end up as Apple's biggest rival. But Microsoft and Apple are about to live through the worst marriage in tech history. They're going to betray each other, they're going to try and destroy each other, and they're going to be deeply, painfully bound to each other.
|
||||
|
||||
James Allworth:
|
||||
|
||||
[00:05:30]
|
||||
|
||||
I guess philosophically, one was more idealistic and focused on the user experience above all else, and was an integrated organization, whereas Microsoft much more pragmatic, a modular focus-
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
That's James Allworth. He's a prolific tech writer who worked inside the corporate team of Apple Retail. Notice that definition of Apple he gives. An integrated organization. That sense of a company beholden only to itself. A company that doesn't want to rely on others. That's key.
|
||||
|
||||
James Allworth:
|
||||
|
||||
[00:06:00]
|
||||
|
||||
Apple was the integrated player, and it wanted to focus on a delightful user experience, and that meant that it wanted to control the entire stack and everything that was delivered, from the hardware to the operating system, to even some of the applications that ran on top of the operating system. That always served it well in periods where new innovations, important innovations, were coming to market where you needed to be across both hardware and software, and where being able to change the hardware based on what you wanted to do and what t was new in software was an advantage. For example-
|
||||
|
||||
[00:06:30]
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:07:00]
|
||||
|
||||
A lot of people loved that integration, and became die hard Apple fans. Plenty of others stuck with Microsoft. Back to that sales conference in Honolulu. At that very same event, Jobs gave his audience a sneak peek at the Superbowl ad he was about to release. You might have seen it for yourself. Think George Orwell's 1984. In this cold and gray world, mindless automatons are shuffling along under a dictator's projected gaze. They represent IBM users. Then, beautiful, athletic Anya Major, representing Apple, comes running through the hall in full color. She hurls her sledgehammer at Big Brother's screen, smashing it to bits. Big Brother's spell is broken, and a booming voice tells us that Apple is about to introduce the Macintosh.
|
||||
|
||||
Voice Actor:
|
||||
|
||||
And you'll see why 1984 will not be like 1984.
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:07:30]
|
||||
|
||||
And yeah, looking back at that commercial, the idea that Apple was a freedom fighter working to set the masses free is a bit much. But the thing hit a nerve. Ken Segal worked at the advertising firm that made the commercial for Apple. He was Steve Jobs' advertising guy for more than a decade in the early days.
|
||||
|
||||
Ken Segal:
|
||||
|
||||
[00:08:00]
|
||||
|
||||
Well, the 1984 commercial came with a lot of risk. In fact, it was so risky that Apple didn't want to run it when they saw it. You've probably heard stories that Steve liked it, but the Apple board did not like it. In fact, they were so outraged that so much money had been spent on such a thing that they wanted to fire the ad agency. Steve was the one sticking up for the agency.
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
Jobs, as usual, knew a good mythology when he saw one.
|
||||
|
||||
Ken Segal:
|
||||
|
||||
That commercial struck such a chord within the company, within the industry, that it became this thing for Apple. Whether or not people were buying computers that day, it had a sort of an aura that stayed around for years and years and years, and helped define the character of the company. We're the rebels. We're the guys with the sledgehammer.
|
||||
|
||||
[00:08:30]
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
So in their battle for the hearts and minds of literally billions of potential consumers, the emperors of Apple and Microsoft were learning to frame themselves as redeemers. As singular heroes. As lifestyle choices. But Bill Gates knew something that Apple had trouble understanding. This idea that in a wired world, nobody, not even an emperor, can really go it alone.
|
||||
|
||||
[00:09:00]
|
||||
|
||||
[00:09:30]
|
||||
|
||||
June 25th, 1985. Gates sends a memo to Apple's then CEO John Scully. This was during the wilderness years. Jobs had just been excommunicated, and wouldn't return to Apple until 1996. Maybe it was because Jobs was out that Gates felt confident enough to write what he wrote. In the memo, he encourages Apple to license their OS to clone makers. I want to read a bit from the end of the memo, just to give you a sense of how perceptive it was. Gates writes, "It is now impossible for Apple to create a standard out of their innovative technology without support from other personal computer manufacturers. Apple must open the Macintosh architecture to have the independent support required to gain momentum and establish a standard." In other words, no more operating in a silo, you guys. You've got to be willing to partner with others. You have to work with developers.
|
||||
|
||||
[00:10:00]
|
||||
|
||||
[00:10:30]
|
||||
|
||||
You see this philosophy years later, when Microsoft CEO Steve Ballmer gets up on stage to give a keynote and he starts shouting, "Developers, developers, developers, developers, developers, developers. Developers, developers, developers, developers, developers, developers, developers, developers." You get the idea. Microsoft likes developers. Now, they're not about to share source code with them, but they do want to build this whole ecosystem of partners. And when Bill Gates suggests that Apple do the same, as you might have guessed, the idea is tossed out the window. Apple had drawn a line in the sand, and five months after they trashed Gates' memo, Microsoft released Windows 1.0. The war was on.
|
||||
|
||||
Developers, developers, developers, developers, developers, developers, developers, developers, developers, developers, developers, developers, developers, developers, developers, developers, developers, developers.
|
||||
|
||||
[00:11:00]
|
||||
|
||||
You're listening to Command Line Heroes, an original podcast from Red Hat. In this inaugural episode, we go back in time to relive the epic story of the OS wars, and we're going to find out, how did a war between tech giants clear the way for the open source world we all live in today?
|
||||
|
||||
[00:11:30]
|
||||
|
||||
Okay, a little backstory. Forgive me if you've heard this one, but it's a classic. It's 1979, and Steve Jobs drives up to the Xerox Park research center in Palo Alto. The engineers there have been developing this whole fleet of elements for what they call a graphical user interface. Maybe you've heard of it. They've got menus, they've got scroll bars, they've got buttons and folders and overlapping windows. It was a beautiful new vision of what a computer interface could look like. And nobody had any of this stuff. Author and journalist Steven Levy talks about its potential.
|
||||
|
||||
Steven Levy:
|
||||
|
||||
[00:12:00]
|
||||
|
||||
There was a lot of excitement about this new interface that was going to be much friendlier than what we had before, which used what was called the command line, where there was really no interaction between you and the computer in the way you'd interact with something in real life. The mouse and the graphics on the computer gave you a way to do that, to point to something just like you'd point to something in real life. It made it a lot easier. You didn't have to memorize all these codes.
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:12:30]
|
||||
|
||||
[00:13:00]
|
||||
|
||||
Except, the Xerox executives did not get that they were sitting on top of a platinum mine. The engineers were more aware than the execs. Typical. So those engineers were, yeah, a little stressed out that they were instructed to show Jobs how everything worked. But the executives were calling the shots. Jobs felt, quote, "The product genius that brought them to that monopolistic position gets rotted out by people running these companies that have no conception of a good product versus a bad product." That's sort of harsh, but hey, Jobs walked out of that meeting with a truckload of ideas that Xerox executives had missed. Pretty much everything he needed to revolutionize the desktop computing experience. Apple releases the Lisa in 1983, and then the Mac in 1984. These devices are made by the ideas swiped from Xerox.
|
||||
|
||||
[00:13:30]
|
||||
|
||||
What's interesting to me is Jobs' reaction to the claim that he stole the GUI. He's pretty philosophical about it. He quotes Picasso, saying, "Good artists copy, great artists steal." He tells one reporter, "We have always been shameless about stealing great ideas." Great artists steal. Okay. I mean, we're not talking about stealing in a hard sense. Nobody's obtaining proprietary source code and blatantly incorporating it into their operating system. This is softer, more like idea borrowing. And that's much more difficult to control, as Jobs himself was about to learn. Legendary software wizard, and true command line hero, Andy Hertzfeld, was an original member of the Macintosh development team.
|
||||
|
||||
[00:14:00]
|
||||
|
||||
Andy Hertzfeld:
|
||||
|
||||
[00:14:30]
|
||||
|
||||
[00:15:00]
|
||||
|
||||
Yeah, Microsoft was our first software partner with the Macintosh. At the time, we didn't really consider them a competitor. They were the very first company outside of Apple that we gave Macintosh prototypes to. I talked with the technical lead at Microsoft usually once a week. They were the first outside party trying out the software that we wrote. They gave us very important feedback, and in general I would say the relationship was pretty good. But I also noticed in my conversations with the technical lead, he started asking questions that he didn't really need to know about how the system was implemented, and I got the idea that they were trying to copy the Macintosh. I t old Steve Jobs about it pretty early on, but it really came to a head in the fall of 1983. We discovered that they actually, without telling us ahead of time, they announced Windows at the COMDEX in November 1983 and Steve Jobs hit the roof. He really considered that a betrayal.
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:15:30]
|
||||
|
||||
[00:16:00]
|
||||
|
||||
As newer versions of Windows were released, it became pretty clear that Microsoft had lifted from Apple all the ideas that Apple had lifted from Xerox. Jobs was apoplectic. His Picasso line about how great artists steal. Yeah. That goes out the window. Though maybe Gates was using it now. Reportedly, when Jobs screamed at Gates that he'd stolen from them, Gates responded, "Well Steve, I think it's more like we both had this rich neighbor named Xerox, and I broke into his house to steal the TV set, and found out that you'd already stolen it." Apple ends up suing Microsoft for stealing the look and feel of their GUI. The case goes on for years, but in 1993, a judge from the 9th Circuit Court of Appeals finally sides with Microsoft. Judge Vaughn Walker declares that look and feel are not covered by copyright. This is super important. That decision prevented Apple from creating a monopoly with the interface that would dominate desktop computing. Soon enough, Apple's brief lead had vanished. Here's Steven Levy's take.
|
||||
|
||||
Steven Levy:
|
||||
|
||||
[00:16:30]
|
||||
|
||||
[00:17:00]
|
||||
|
||||
They lost the lead not because of intellectual property theft on Microsoft's part, but because they were unable to consolidate their advantage in having a better operating system during the 1980s. They overcharged for their computers, quite frankly. So Microsoft had been developing Windows, starting with the mid-1980s, but it wasn't until Windows 3 in 1990, I believe, where they really came across with a version that was ready for prime time. Ready for masses of people to use. At that point is where Microsoft was able to migrate huge numbers of people, hundreds of millions, over to the graphical interface in a way that Apple had not been able to do. Even though they had a really good operating system, they used it since 1984.
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:17:30]
|
||||
|
||||
[00:18:00]
|
||||
|
||||
Microsoft now dominated the OS battlefield. They held 90% of the market, and standardized their OS across a whole variety of PCs. The future of the OS looked like it'd be controlled by Microsoft. And then? Well, at the 1997 Macworld Expo in Boston, you have an almost bankrupt Apple. A more humble Steve Jobs gets on stage, and starts talking about the importance of partnerships, and one in particular, he says, has become very, very meaningful. Their new partnership with Microsoft. Steve Jobs is calling for a détente, a ceasefire. Microsoft could have their enormous market share. If we didn't know better, we might think we were entering a period of peace in the kingdom. But when stakes are this high, it's never that simple. Just as Apple and Microsoft were finally retreating to their corners, pretty bruised from decades of fighting, along came a 21-year-old Finnish computer science student who, almost by accident, changed absolutely everything.
|
||||
|
||||
I'm Saron Yitbarek, and this is Command Line Heroes.
|
||||
|
||||
[00:18:30]
|
||||
|
||||
While certain tech giants were busy bashing each other over proprietary software, there were new champions of free and open source software popping up like mushrooms. One of these champions was Richard Stallman. You're probably familiar with his work. He wanted free software and a free society. That's free as in free speech, not free as in free beer. Back in the '80s, Stallman saw that there was no viable alternative to pricey, proprietary OSs, like UNIX . So, he decided to make his own. Stallman's Free Software Foundation developed GNU, which stood for GNU's not UNIX , of course. It'd be an OS like UNIX, but free of all UNIX code, and free for users to share.
|
||||
|
||||
[00:19:00]
|
||||
|
||||
[00:19:30]
|
||||
|
||||
Just to give you a sense of how important that idea of free software was in the 1980s, the companies that owned the UNIX code at different points, AT&T Bell Laboratories and then UNIX System Laboratories, they threatened lawsuits on anyone making their own OS after looking at UNIX source code. These guys were next - level proprietary. All those programmers were, in the words of the two companies, "mentally contaminated," because they'd seen UNIX code. In a famous court case between UNIX System Laboratories and Berkeley Software Design, it was argued that any functionally similar system, even though it didn't use the UNIX code itself, was a bre a ch of copyright. Paul Jones was a developer at that time. He's now the director of the digital library ibiblio.org.
|
||||
|
||||
Paul Jones:
|
||||
|
||||
[00:20:00]
|
||||
|
||||
Anyone who has seen any of the code is mentally contaminated was their argument. That would have made almost anyone who had worked on a computer operating system that involved UNIX , in any computer science department, was mentally contaminated. So in one year at USENIX, we all got little white bar pin s with red letters that say mentally contaminated, and we all wear those around to our own great pleasure, to show that we were sticking it to Bell because we were mentally contaminated.
|
||||
|
||||
[00:20:30]
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:21:00]
|
||||
|
||||
The whole world was getting mentally contaminated. Staying pure, keeping things nice and proprietary, that old philosophy was getting less and less realistic. It was into this contaminated reality that one of history's biggest command line heroes was born, a boy in Finland named Linus Torvalds. If this is Star Wars, then Linus Torvalds is our Luke Skywalker. He was a mild-mannered grad student at the University of Helsinki. Talented, but lacking in grand visions. The classic reluctant hero. And, like any young hero, he was also frustrated. He wanted to incorporate the 386 processor into his new PC's functions. He wasn't impressed by the MS-DOS running on his IBM clone, and he couldn't afford the $5,000 price tag on the UNIX software that would have given him some programming freedom. The solution, which Torvalds crafted on MINIX in the spring of 1991, was an OS kernel called Linux. The kernel of an OS of his very own.
|
||||
|
||||
[00:21:30]
|
||||
|
||||
Steven Vaughan-Nichols:
|
||||
|
||||
Linus Torvalds really just wanted to have something to play with.
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
Steven Vaughan-Nichols is a contributing editor at ZDNet.com, and he's been writing about the business of technology since there was a business of technology.
|
||||
|
||||
Steven Vaughan-Nichols:
|
||||
|
||||
[00:22:00]
|
||||
|
||||
[00:22:30]
|
||||
|
||||
There were a couple of operating systems like it at the time. The main one that he was concerned about was called MINIX. That was an operating system that was meant for students to learn how to build operating systems. Linus looked at that, and thought that it was interesting, but he wanted to build his own. So it really started as a do-it-yourself project at Helsinki. That's how it all started, is just basically a big kid playing around and learning how to do things. But what was different in his case is that he was both bright enough and persistent enough, and also friendly enough to get all these other people working on it, and then he started seeing the project through. 27 years later, it is much, much bigger than he ever dreamed it would be.
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:23:00]
|
||||
|
||||
By the fall of 1991, Torvalds releases 10,000 lines of code, and people around the world start offering comments, then tweaks, additions, edits. That might seem totally normal to you as a developer today, but remember, at that time, open collaboration like that was a moral affront to the whole proprietary system that Microsoft, Apple, and IBM had done so well by. Then that openness gets enshrined. Torvalds places Linux under the GNU general public license. The license that had kept Stallman's GNU system free was now going to keep Linux free , too. The importance of that move to incorporate GPL, basically preserving the freedom and openness of the software forever, cannot be overstated. Vaughan-Nichols explains.
|
||||
|
||||
[00:23:30]
|
||||
|
||||
Steven Vaughan-Nichols:
|
||||
|
||||
In fact, by the license that it's under, which is called GPL version 2, you have to share the code if you're going to try to sell it or present it to the world, so that if you make an improvement, it's not enough just to give someone the improvement. You actually have to share with them the nuts and bolts of all those changes. Then they are adapted into Linux if they're good enough.
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:24:00]
|
||||
|
||||
That public approach proved massively attractive. Eric Raymond, one of the early evangelists of the movement wrote in his famous essay that, "Corporations like Microsoft and Apple have been trying to build software cathedrals, while Linux and its kind were offering a great babbling bazaar of different agendas and approaches. The bazaar was a lot more fun than the cathedral."
|
||||
|
||||
Stormy Peters:
|
||||
|
||||
I think at the time, what attracted people is that they were going to be in control of their own world.
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
Stormy Peters is an industry analyst, and an advocate for free and open source software.
|
||||
|
||||
[00:24:30]
|
||||
|
||||
Stormy Peters:
|
||||
|
||||
[00:25:00]
|
||||
|
||||
When open source software first came out, the OS was all proprietary. You couldn't even add a printer without going through proprietary software. You couldn't add a headset. You couldn't develop a small hardware device of your own, and make it work with your laptop. You couldn't even put in a DVD and copy it, because you couldn't change the software. Even if you owned the DVD, you couldn't copy it. You had no control over this hardware/software system that you'd bought. You couldn't create anything new and bigger and better out of it. That's why an open source operating system was so important at the beginning. We needed an open source collaborative environment where we could build bigger and better things.
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:25:30]
|
||||
|
||||
Mind you, Linux isn't a purely egalitarian utopia. Linus Torvalds doesn't approve everything that goes into the kernel, but he does preside over its changes. He's installed a dozen or so people below him to manage different parts of the kernel. They, in turn, trust people under themselves, and so on, in a pyramid of trust. Changes might come from anywhere, but they're all judged and curated.
|
||||
|
||||
[00:26:00]
|
||||
|
||||
It is amazing, though, to think how humble, and kind of random, Linus' DIY project was to begin with. He didn't have a clue he was the Luke Skywalker figure in all this. He was just 21, and had been programming half his life. But this was the first time the silo opened up, and people started giving him feedback. Dozens, then hundreds, and thousands of contributors. With crowdsourcing like that, it doesn't take long before Linux starts growing. Really growing. It even finally gets noticed by Microsoft. Their CEO, Steve Ballmer, called Linux, and I quote, "A cancer that attaches itself in an intellectual property sense to everything it touches." Steven Levy describes where Ballmer was coming from.
|
||||
|
||||
Steven Levy:
|
||||
|
||||
[00:26:30]
|
||||
|
||||
Once Microsoft really solidified its monopoly, and indeed it was judged in federal court as a monopoly, anything that could be a threat to that, they reacted very strongly to. So of course, the idea that free software would be emerging, when they were charging for software, they saw as a cancer. They tried to come up with an intellectual property theory about why this was going to be bad for consumers.
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:27:00]
|
||||
|
||||
Linux was spreading, and Microsoft was worried. By 2006, Linux would become the second most widely used operating system after Windows, with about 5,000 developers working on it worldwide. Five thousand. Remember that memo that Bill Gates sent to Apple, the one where he's lecturing them about the importance of partnering with other people? Turns out, open source would take that idea of partnerships to a whole new level, in a way Bill Gates would have never foreseen.
|
||||
|
||||
[00:27:30]
|
||||
|
||||
[00:28:00]
|
||||
|
||||
We've been talking about these huge battles for the OS, but so far, the unsung heroes, the developers, haven't fully made it onto the battlefield. That changes next time, on Command Line Heroes. In episode two, part two of the OS wars, it's the rise of Linux. Businesses wake up, and realize the importance of developers. These open source rebels grow stronger, and the battlefield shifts from the desktop to the server room. There's corporate espionage, new heroes, and the unlikeliest change of heart in tech history. It all comes to a head in the concluding half of the OS wars.
|
||||
|
||||
[00:28:30]
|
||||
|
||||
To get new episodes of Command Line Heroes delivered automatically for free, make sure you hit subscribe on Apple podcasts, Spotify, Google Play, or however you get your podcasts. Over the rest of the season, we're visiting the latest battlefields, the up-for-grab territories where the next generation of Command Line Heroes are making their mark. For more info, check us out at redhat.com/commandlineheroes. I'm Saron Yitbarek. Until next time, keep on coding.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-1
|
||||
|
||||
作者:[redhat][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.redhat.com
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -1,3 +1,12 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (cycoe)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (A brief history of text-based games and open source)
|
||||
[#]: via: (https://opensource.com/article/18/7/interactive-fiction-tools)
|
||||
[#]: author: (Jason Mclntosh https://opensource.com/users/jmac)
|
||||
|
||||
A brief history of text-based games and open source
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,64 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Extreme's acquisitions have prepped it to better battle Cisco, Arista, HPE, others)
|
||||
[#]: via: (https://www.networkworld.com/article/3432173/extremes-acquisitions-have-prepped-it-to-better-battle-cisco-arista-hpe-others.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
Extreme's acquisitions have prepped it to better battle Cisco, Arista, HPE, others
|
||||
======
|
||||
Extreme has bought cloud, SD-WAN and data center technologies that make it more prepared to take on its toughest competitors.
|
||||
Extreme Networks has in recent months restyled the company with data-center networking technology acquisitions and upgrades, but now comes the hard part – executing with enterprise customers and effectively competing with the likes of Cisco, VMware, Arista, Juniper, HPE and others.
|
||||
|
||||
The company’s latest and perhaps most significant long-term move was closing the [acquisition of wireless-networking vendor Aerohive][1] for about $210 million. The deal brings Extreme Aerohive’s wireless-networking technology – including its WiFi 6 gear, SD-WAN software and cloud-management services.
|
||||
|
||||
**More about edge networking**
|
||||
|
||||
* [How edge networking and IoT will reshape data centers][2]
|
||||
* [Edge computing best practices][3]
|
||||
* [How edge computing can help secure the IoT][4]
|
||||
|
||||
|
||||
|
||||
With the Aerohive technology, Extreme says customers and partners will be able to mix and match a broader array of software, hardware, and services to create networks that support their unique needs, and that can be managed and automated from the enterprise edge to the cloud.
|
||||
|
||||
The Aerohive buy is just the latest in a string of acquisitions that have reshaped the company. In the past few years the company has acquired networking and data-center technology from Avaya and Brocade, and it bought wireless player Zebra Technologies in 2016 for $55 million.
|
||||
|
||||
While it has been a battle to integrate and get solid sales footing for those acquisitions – particularly Brocade and Avaya, the company says those challenges are behind it and that the Aerohive integration will be much smoother.
|
||||
|
||||
“After scaling Extreme’s business to $1B in revenue [for FY 2019, which ended in June] and expanding our portfolio to include end-to-end enterprise networking solutions, we are now taking the next step to transform our business to add sustainable, subscription-oriented cloud-based solutions that will enable us to drive recurring revenue and improved cash-flow generation,” said Extreme CEO Ed Meyercord at the firm’s [FY 19 financial analysts][5] call.
|
||||
|
||||
The strategy to move more toward a software-oriented, cloud-based revenue generation and technology development is brand new for Extreme. The company says it expects to generate as much as 30 percent of revenues from recurring charges in the near future. The tactic was enabled in large part by the Aerohive buy, which doubled Extreme’s customer based to 60,000 and its sales partners to 11,000 and whose revenues are recurring and cloud-based. The acquisition also created the number-three enterprise Wireless LAN company behind Cisco and HPE/Aruba.
|
||||
|
||||
“We are going to take this Aerohive system and expand across our entire portfolio and use it to deliver common, simplified software with feature packages for on-premises or in-cloud based on customers' use case,” added Norman Rice, Extreme’s Chief Marketing, Development and Product Operations Officer. “We have never really been in any cloud conversations before so for us this will be a major add.”
|
||||
|
||||
Indeed, the Aerohive move is key for the company’s future, analysts say.
|
||||
|
||||
To continue reading this article register now
|
||||
|
||||
[Get Free Access][6]
|
||||
|
||||
[Learn More][7] Existing Users [Sign In][6]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3432173/extremes-acquisitions-have-prepped-it-to-better-battle-cisco-arista-hpe-others.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3405440/extreme-targets-cloud-services-sd-wan-wifi-6-with-210m-aerohive-grab.html
|
||||
[2]: https://www.networkworld.com/article/3291790/data-center/how-edge-networking-and-iot-will-reshape-data-centers.html
|
||||
[3]: https://www.networkworld.com/article/3331978/lan-wan/edge-computing-best-practices.html
|
||||
[4]: https://www.networkworld.com/article/3331905/internet-of-things/how-edge-computing-can-help-secure-the-iot.html
|
||||
[5]: https://seekingalpha.com/article/4279527-extreme-networks-inc-extr-ceo-ed-meyercord-q4-2019-results-earnings-call-transcript
|
||||
[6]: javascript://
|
||||
[7]: https://www.networkworld.com/learn-about-insider/
|
||||
@ -0,0 +1,71 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Nvidia rises to the need for natural language processing)
|
||||
[#]: via: (https://www.networkworld.com/article/3432203/nvidia-rises-to-the-need-for-natural-language-processing.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Nvidia rises to the need for natural language processing
|
||||
======
|
||||
As the demand for natural language processing grows for chatbots and AI-powered interactions, more companies will need systems that can provide it. Nvidia says its platform can handle it.
|
||||
![andy.brandon50 \(CC BY-SA 2.0\)][1]
|
||||
|
||||
Nvidia is boasting of a breakthrough in conversation natural language processing (NLP) training and inference, enabling more complex interchanges between customers and chatbots with immediate responses.
|
||||
|
||||
The need for such technology is expected to grow, as digital voice assistants alone are expected to climb from 2.5 billion to 8 billion within the next four years, according to Juniper Research, while Gartner predicts that by 2021, 15% of all customer service interactions will be completely handled by AI, an increase of 400% from 2017.
|
||||
|
||||
The company said its DGX-2 AI platform trained the BERT-Large AI language model in less than an hour and performed AI inference in 2+ milliseconds, making it possible “for developers to use state-of-the-art language understanding for large-scale applications.”
|
||||
|
||||
**[ Also read: [What is quantum computing (and why enterprises should care)][2] ]**
|
||||
|
||||
BERT, or Bidirectional Encoder Representations from Transformers, is a Google-powered AI language model that many developers say has better accuracy than humans in some performance evaluations. It’s all discussed [here][3].
|
||||
|
||||
### Nvidia sets natural language processing records
|
||||
|
||||
All told, Nvidia is claiming three NLP records:
|
||||
|
||||
**1\. Training:** Running the largest version of the BERT language model, a Nvidia DGX SuperPOD with 92 Nvidia DGX-2H systems running 1,472 V100 GPUs cut training from several days to 53 minutes. A single DGX-2 system, which is about the size of a tower PC, trained BERT-Large in 2.8 days.
|
||||
|
||||
“The quicker we can train a model, the more models we can train, the more we learn about the problem, and the better the results get,” said Bryan Catanzaro, vice president of applied deep learning research, in a statement.
|
||||
|
||||
**2\. Inference**: Using Nvidia T4 GPUs on its TensorRT deep learning inference platform, Nvidia performed inference on the BERT-Base SQuAD dataset in 2.2 milliseconds, well under the 10 millisecond processing threshold for many real-time applications, and far ahead of the 40 milliseconds measured with highly optimized CPU code.
|
||||
|
||||
**3\. Model:** Nvidia said its new custom model, called Megatron, has 8.3 billion parameters, making it 24 times larger than the BERT-Large and the world's largest language model based on Transformers, the building block used for BERT and other natural language AI models.
|
||||
|
||||
In a move sure to make FOSS advocates happy, Nvidia is also making a ton of source code available via [GitHub][4].
|
||||
|
||||
* NVIDIA GitHub BERT training code with PyTorch
|
||||
* NGC model scripts and check-points for TensorFlow
|
||||
* TensorRT optimized BERT Sample on GitHub
|
||||
* Faster Transformer: C++ API, TensorRT plugin, and TensorFlow OP
|
||||
* MXNet Gluon-NLP with AMP support for BERT (training and inference)
|
||||
* TensorRT optimized BERT Jupyter notebook on AI Hub
|
||||
* Megatron-LM: PyTorch code for training massive Transformer models
|
||||
|
||||
|
||||
|
||||
Not that any of this is easily consumed. We’re talking very advanced AI code. Very few people will be able to make heads or tails of it. But the gesture is a positive one.
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3432203/nvidia-rises-to-the-need-for-natural-language-processing.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/04/alphabetic_letters_characters_language_by_andybrandon50_cc_by-sa_2-0_1500x1000-100794409-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3275367/what-s-quantum-computing-and-why-enterprises-need-to-care.html
|
||||
[3]: https://medium.com/ai-network/state-of-the-art-ai-solutions-1-google-bert-an-ai-model-that-understands-language-better-than-92c74bb64c
|
||||
[4]: https://github.com/NVIDIA/TensorRT/tree/release/5.1/demo/BERT/
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,73 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Get ready for the convergence of IT and OT networking and security)
|
||||
[#]: via: (https://www.networkworld.com/article/3432132/get-ready-for-the-convergence-of-it-and-ot-networking-and-security.html)
|
||||
[#]: author: (Linda Musthaler https://www.networkworld.com/author/Linda-Musthaler/)
|
||||
|
||||
Get ready for the convergence of IT and OT networking and security
|
||||
======
|
||||
Collecting telemetry data from operational networks and passing it to information networks for analysis has its benefits. But this convergence presents big cultural and technology challenges.
|
||||
![Thinkstock][1]
|
||||
|
||||
Most IT networking professionals are so busy with their day-to-day responsibilities that they don’t have time to consider taking on more work. But for companies with an industrial component, there’s an elephant in the room that is clamoring for attention. I’m talking about the increasingly common convergence of IT and operational technology (OT) networking and security.
|
||||
|
||||
Traditionally, IT and OT have had very separate roles in an organization. IT is typically tasked with moving data between computers and humans, whereas OT is tasked with moving data between “things,” such as sensors, actuators, smart machines, and other devices to enhance manufacturing and industrial processes. Not only were the roles for IT and OT completely separate, but their technologies and networks were, too.
|
||||
|
||||
That’s changing, however, as companies want to collect telemetry data from the OT side to drive analytics and business processes on the IT side. The lines between the two sides are blurring, and this has big implications for IT networking and security teams.
|
||||
|
||||
“This convergence of IT and OT systems is absolutely on the increase, and it's especially affecting the industries that are in the business of producing things, whatever those things happen to be,” according to Jeff Hussey, CEO of [Tempered Networks][2], which is working to help bridge the gap between the two. “There are devices on the OT side that are increasingly networked but without any security to those networks. Their operators historically relied on an air gap between the networks of devices, but those gaps no longer exist. The complexity of the environment and the expansive attack surface that is created as a result of connecting all of these devices to corporate networks massively increases the tasks needed to secure even the traditional networks, much less the expanded converged networks.”
|
||||
|
||||
**[ Also read: [Is your enterprise software committing security malpractice?][3] | Get regularly scheduled insights: [Sign up for Network World newsletters][4] ]**
|
||||
|
||||
Hussey is well versed on the cultural and technology issues in this arena. When asked if IT and OT people are working together to integrate their networks, he says, “That would be ideal, but it’s not really what we see in the marketplace. Typically, we see some acrimony between these two groups.”
|
||||
|
||||
Hussey explains that the groups move at different paces.
|
||||
|
||||
“The OT groups think in terms of 10-plus year cycles, whereas the IT groups think in terms of three-plus years cycles,” he says. “There's a lot more change and iteration in IT environments than there is OT environments, which are traditionally extremely static. But now companies want to bring telemetry data that is produced by OT devices back to some workload in a data center or in a cloud. That forces a requirement for secure connectivity because of corporate governance or regulatory requirements, and this is when we most often see the two groups clash.”
|
||||
|
||||
**[ [Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][5] ]**
|
||||
|
||||
Based on the situations Hussey has observed so far, the onus to connect and secure the disparate networks falls to the IT side of the house. This is a big challenge because the tools that have traditionally been used for security in IT environments aren’t necessarily appropriate or applicable in OT environments. IT and OT systems have very different protocols and operating systems. It’s not practical to try to create network segmentation using firewall rules, access control lists, VLANs, or VPNs because those things can’t scale to the workloads presented in OT environments.
|
||||
|
||||
### OT practices create IT security concerns
|
||||
|
||||
Steve Fey, CEO of [Totem Building Cybersecurity][6], concurs with Hussey and points out another significant issue in trying to integrate the networking and security aspects of IT and OT systems. In the OT world, it’s often the device vendors or their local contractors who manage and maintain all aspects of the device, typically through remote access. These vendors even install the remote access capabilities and set up the users. “This is completely opposite to how it should be done from a cybersecurity policy perspective,” says Fey. And yet, it’s common today in many industrial environments.
|
||||
|
||||
Fey’s company is in the building controls industry, which automates control of everything from elevators and HVAC systems to lighting and life safety systems in commercial buildings.
|
||||
|
||||
“The building controls industry, in particular, is one that's characterized by a completely different buying and decision-making culture than in enterprise IT. Everything from how the systems are engineered, purchased, installed, and supported is very different than the equivalent world of enterprise IT. Even the suppliers are largely different,” says Fey. “This is another aspect of the cultural challenge between IT and OT teams. They are two worlds that are having to figure each other out because of the cyber threats that pose a risk to these control systems.”
|
||||
|
||||
Fey says major corporate entities are just waking up to the reality of this massive threat surface, whether it’s in their buildings or their manufacturing processes.
|
||||
|
||||
“There’s a dire need to overcome decades of installed OT systems that have been incorrectly configured and incorrectly operated without the security policies and safeguards that are normal to enterprise IT. But the toolsets for these environments are incompatible, and the cultural differences are great,” he says.
|
||||
|
||||
Totem’s goal is to bridge this gap with a specific focus on cyber and to provide a toolset that is recognizable to the enterprise IT world.
|
||||
|
||||
Both Hussey and Fey say it’s likely that IT groups will be charged with leading the convergence of IT and OT networks, but they must include their OT counterparts in the efforts. There are big cultural and technical gaps to bridge to deliver the results that industrial companies are hoping to achieve.
|
||||
|
||||
Join the Network World communities on [Facebook][7] and [LinkedIn][8] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3432132/get-ready-for-the-convergence-of-it-and-ot-networking-and-security.html
|
||||
|
||||
作者:[Linda Musthaler][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Linda-Musthaler/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/02/abstract_networks_thinkstock_881604844-100749945-large.jpg
|
||||
[2]: https://www.temperednetworks.com/
|
||||
[3]: https://www.networkworld.com/article/3429559/is-your-enterprise-software-committing-security-malpractice.html
|
||||
[4]: https://www.networkworld.com/newsletters/signup.html
|
||||
[5]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
|
||||
[6]: https://totembuildings.com/
|
||||
[7]: https://www.facebook.com/NetworkWorld/
|
||||
[8]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,73 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Powering edge data centers: Blue energy might be the perfect solution)
|
||||
[#]: via: (https://www.networkworld.com/article/3432116/powering-edge-data-centers-blue-energy-might-be-the-perfect-solution.html)
|
||||
[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
|
||||
|
||||
Powering edge data centers: Blue energy might be the perfect solution
|
||||
======
|
||||
Blue energy, created by mixing seawater and fresh water, could be the perfect solution for providing cheap and eco-friendly power to edge data centers.
|
||||
![Benkrut / Getty Images][1]
|
||||
|
||||
About a cubic yard of freshwater mixed with seawater provides almost two-thirds of a kilowatt-hour of energy. And scientists say a revolutionary new battery chemistry based on that theme could power edge data centers.
|
||||
|
||||
The idea is to harness power from wastewater treatment plants located along coasts, which happen to be ideal locations for edge data centers and are heavy electricity users.
|
||||
|
||||
“Places where salty ocean water and freshwater mingle could provide a massive source of renewable power,” [writes Rob Jordan in a Stanford University article][2].
|
||||
|
||||
**[ Read also: [Data centers may soon recycle heat into electricity][3] | Get regularly scheduled insights: [Sign up for Network World newsletters][4] ]**
|
||||
|
||||
The chemical process harnesses a mix of sodium and chloride ions. They’re squirted from battery electrodes into a solution and cause current to flow. That initial infusion is then followed by seawater being exchanged with wastewater effluent. It reverses the current flow and creates the energy, the researchers explain.
|
||||
|
||||
“Energy is recovered during both the freshwater and seawater flushes, with no upfront energy investment and no need for charging,” the article says.
|
||||
|
||||
In other words, the battery is continually recharging and discharging with no added input—such as electricity from the grid. The Stanford researchers say the technology could be ideal for making coastal wastewater plants energy independent.
|
||||
|
||||
### Coastal edge data centers
|
||||
|
||||
But edge data centers, also taking up location on the coasts, could also benefit. Those data centers are already exploring kinetic wave-energy to harvest power, as well as using seawater to cool data centers.
|
||||
|
||||
I’ve written about [Ocean Energy’s offshore, power platform using kinetic wave energy][5]. That 125-feet-long, wave converter solution, not only uses ocean water for power generation, but its sea-environment implementation means the same body of water can be used for cooling, too.
|
||||
|
||||
“Ocean cooling and ocean energy in the one device” is a seductive solution, the head of that company said at the time.
|
||||
|
||||
[Microsoft, too, has an underwater data center][6] that proffers the same kinds of power benefits.
|
||||
|
||||
Locating data centers on coasts or in the sea rather than inland doesn’t just provide virtually free-of-cost, power and cooling advantages, plus the associated eco-emissions advantages. The coasts tend to be where the populous is, and locating data center operations near to where the actual calculations, data stores, and other activities need to take place fits neatly into low-latency edge computing, conceptually.
|
||||
|
||||
Other advantages to placing a data center actually in the ocean, although close to land, include the fact that there’s no rent in open waters. And in international waters, one could imagine regulatory advantages—there isn’t a country’s official hovering around.
|
||||
|
||||
However, by placing the installation on terra firma (as the seawater-saltwater mix power solution would be designed for) but close to water at a coast, one can use the necessary seawater and gain an advantage of ease of access to the real estate, connections, and so on.
|
||||
|
||||
The Stanford University engineers, in their seawater/wastewater mix tests, flushed a battery prototype 180 times with wastewater from the Palo Alto Regional Water Quality Control Plant and seawater from nearby Half Moon Bay. The group says they obtained 97% “capturing [of] the salinity gradient energy,” or the blue energy, as it’s sometimes called.
|
||||
|
||||
“Surplus power production could even be diverted to nearby industrial operations,” the article continues.
|
||||
|
||||
“Tapping blue energy at the global scale: rivers running into the ocean” is yet to be solved. “But it is a good starting point,” says Stanford scholar Kristian Dubrawski in the article.
|
||||
|
||||
Join the Network World communities on [Facebook][7] and [LinkedIn][8] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3432116/powering-edge-data-centers-blue-energy-might-be-the-perfect-solution.html
|
||||
|
||||
作者:[Patrick Nelson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Patrick-Nelson/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/08/uk_united_kingdom_northern_ireland_belfast_river_lagan_waterfront_architecture_by_benkrut_gettyimages-530205844_2400x1600-100807934-large.jpg
|
||||
[2]: https://news.stanford.edu/2019/07/29/generating-energy-wastewater/
|
||||
[3]: https://www.networkworld.com/article/3410578/data-centers-may-soon-recycle-heat-into-electricity.html
|
||||
[4]: https://www.networkworld.com/newsletters/signup.html
|
||||
[5]: https://www.networkworld.com/article/3314597/wave-energy-to-power-undersea-data-centers.html
|
||||
[6]: https://www.networkworld.com/article/3283332/microsoft-launches-undersea-free-cooling-data-center.html
|
||||
[7]: https://www.facebook.com/NetworkWorld/
|
||||
[8]: https://www.linkedin.com/company/network-world
|
||||
@ -1,4 +1,3 @@
|
||||
leemeans translating
|
||||
7 deadly sins of documentation
|
||||
======
|
||||

|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
bestony is translating.
|
||||
|
||||
Create a Clean-Code App with Kotlin Coroutines and Android Architecture Components
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,215 +0,0 @@
|
||||
Use LVM to Upgrade Fedora
|
||||
======
|
||||
|
||||

|
||||
|
||||
Most users find it simple to upgrade [from one Fedora release to the next][1] with the standard process. However, there are inevitably many special cases that Fedora can also handle. This article shows one way to upgrade using DNF along with Logical Volume Management (LVM) to keep a bootable backup in case of problems. This example upgrades a Fedora 26 system to Fedora 28.
|
||||
|
||||
The process shown here is more complex than the standard upgrade process. You should have a strong grasp of how LVM works before you use this process. Without proper skill and care, you could **lose data and/or be forced to reinstall your system!** If you don’t know what you’re doing, it is **highly recommended** you stick to the supported upgrade methods only.
|
||||
|
||||
### Preparing the system
|
||||
|
||||
Before you start, ensure your existing system is fully updated.
|
||||
```
|
||||
$ sudo dnf update
|
||||
$ sudo systemctl reboot # or GUI equivalent
|
||||
|
||||
```
|
||||
|
||||
Check that your root filesystem is mounted via LVM.
|
||||
```
|
||||
$ df /
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
/dev/mapper/vg_sdg-f26 20511312 14879816 4566536 77% /
|
||||
|
||||
$ sudo lvs
|
||||
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
|
||||
f22 vg_sdg -wi-ao---- 15.00g
|
||||
f24_64 vg_sdg -wi-ao---- 20.00g
|
||||
f26 vg_sdg -wi-ao---- 20.00g
|
||||
home vg_sdg -wi-ao---- 100.00g
|
||||
mockcache vg_sdg -wi-ao---- 10.00g
|
||||
swap vg_sdg -wi-ao---- 4.00g
|
||||
test vg_sdg -wi-a----- 1.00g
|
||||
vg_vm vg_sdg -wi-ao---- 20.00g
|
||||
|
||||
```
|
||||
|
||||
If you used the defaults when you installed Fedora, you may find the root filesystem is mounted on a LV named root. The name of your volume group will likely be different. Look at the total size of the root volume. In the example, the root filesystem is named f26 and is 20G in size.
|
||||
|
||||
Next, ensure you have enough free space in LVM.
|
||||
```
|
||||
$ sudo vgs
|
||||
VG #PV #LV #SN Attr VSize VFree
|
||||
vg_sdg 1 8 0 wz--n- 232.39g 42.39g
|
||||
|
||||
```
|
||||
|
||||
This system has enough free space to allocate a 20G logical volume for the upgraded Fedora 28 root. If you used the default install, there will be no free space in LVM. Managing LVM in general is beyond the scope of this article, but here are some possibilities:
|
||||
|
||||
1\. /home on its own LV, and lots of free space in /home
|
||||
|
||||
You can logout of the GUI and switch to a text console, logging in as root. Then you can unmount /home, and use lvreduce -r to resize and reallocate the /home LV. You might also boot from a Live image (so as not to use /home) and use the gparted GUI utility.
|
||||
|
||||
2\. Most of the LVM space allocated to a root LV, with lots of free space in the filesystem
|
||||
|
||||
You can boot from a Live image and use the gparted GUI utility to reduce the root LV. Consider moving /home to its own filesystem at this point, but that is beyond the scope of this article.
|
||||
|
||||
3\. Most of the file systems are full, but you have LVs you no longer need
|
||||
|
||||
You can delete the unneeded LVs, freeing space in the volume group for this operation.
|
||||
|
||||
### Creating a backup
|
||||
|
||||
First, allocate a new LV for the upgraded system. Make sure to use the correct name for your system’s volume group (VG). In this example it’s vg_sdg.
|
||||
```
|
||||
$ sudo lvcreate -L20G -n f28 vg_sdg
|
||||
Logical volume "f28" created.
|
||||
|
||||
```
|
||||
|
||||
Next, make a snapshot of your current root filesystem. This example creates a snapshot volume named f26_s.
|
||||
```
|
||||
$ sync
|
||||
$ sudo lvcreate -s -L1G -n f26_s vg_sdg/f26
|
||||
Using default stripesize 64.00 KiB.
|
||||
Logical volume "f26_s" created.
|
||||
|
||||
```
|
||||
|
||||
The snapshot can now be copied to the new LV. **Make sure you have the destination correct** when you substitute your own volume names. If you are not careful you could delete data irrevocably. Also, make sure you are copying from the snapshot of your root, **not** your live root.
|
||||
```
|
||||
$ sudo dd if=/dev/vg_sdg/f26_s of=/dev/vg_sdg/f28 bs=256k
|
||||
81920+0 records in
|
||||
81920+0 records out
|
||||
21474836480 bytes (21 GB, 20 GiB) copied, 149.179 s, 144 MB/s
|
||||
|
||||
```
|
||||
|
||||
Give the new filesystem copy a unique UUID. This is not strictly necessary, but UUIDs are supposed to be unique, so this avoids future confusion. Here is how for an ext4 root filesystem:
|
||||
```
|
||||
$ sudo e2fsck -f /dev/vg_sdg/f28
|
||||
$ sudo tune2fs -U random /dev/vg_sdg/f28
|
||||
|
||||
```
|
||||
|
||||
Then remove the snapshot volume which is no longer needed:
|
||||
```
|
||||
$ sudo lvremove vg_sdg/f26_s
|
||||
Do you really want to remove active logical volume vg_sdg/f26_s? [y/n]: y
|
||||
Logical volume "f26_s" successfully removed
|
||||
|
||||
```
|
||||
|
||||
You may wish to make a snapshot of /home at this point if you have it mounted separately. Sometimes, upgraded applications make changes that are incompatible with a much older Fedora version. If needed, edit the /etc/fstab file on the **old** root filesystem to mount the snapshot on /home. Remember that when the snapshot is full, it will disappear! You may also wish to make a normal backup of /home for good measure.
|
||||
|
||||
### Configuring to use the new root
|
||||
|
||||
First, mount the new LV and backup your existing GRUB settings:
|
||||
```
|
||||
$ sudo mkdir /mnt/f28
|
||||
$ sudo mount /dev/vg_sdg/f28 /mnt/f28
|
||||
$ sudo mkdir /mnt/f28/f26
|
||||
$ cd /boot/grub2
|
||||
$ sudo cp -p grub.cfg grub.cfg.old
|
||||
|
||||
```
|
||||
|
||||
Edit grub.conf and add this before the first menuentry, unless you already have it:
|
||||
```
|
||||
menuentry 'Old boot menu' {
|
||||
configfile /grub2/grub.cfg.old
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Edit grub.conf and change the default menuentry to activate and mount the new root filesystem. Change this line:
|
||||
```
|
||||
linux16 /vmlinuz-4.16.11-100.fc26.x86_64 root=/dev/mapper/vg_sdg-f26 ro rd.lvm.lv=vg_sdg/f26 rd.lvm.lv=vg_sdg/swap rhgb quiet LANG=en_US.UTF-8
|
||||
|
||||
```
|
||||
|
||||
So that it reads like this. Remember to use the correct names for your system’s VG and LV entries!
|
||||
```
|
||||
linux16 /vmlinuz-4.16.11-100.fc26.x86_64 root=/dev/mapper/vg_sdg-f28 ro rd.lvm.lv=vg_sdg/f28 rd.lvm.lv=vg_sdg/swap rhgb quiet LANG=en_US.UTF-8
|
||||
|
||||
```
|
||||
|
||||
Edit /mnt/f28/etc/default/grub and change the default root LV activated at boot:
|
||||
```
|
||||
GRUB_CMDLINE_LINUX="rd.lvm.lv=vg_sdg/f28 rd.lvm.lv=vg_sdg/swap rhgb quiet"
|
||||
|
||||
```
|
||||
|
||||
Edit /mnt/f28/etc/fstab to change the mounting of the root filesystem from the old volume:
|
||||
```
|
||||
/dev/mapper/vg_sdg-f26 / ext4 defaults 1 1
|
||||
|
||||
```
|
||||
|
||||
to the new one:
|
||||
```
|
||||
/dev/mapper/vg_sdg-f28 / ext4 defaults 1 1
|
||||
|
||||
```
|
||||
|
||||
Then, add a read-only mount of the old system for reference purposes:
|
||||
```
|
||||
/dev/mapper/vg_sdg-f26 /f26 ext4 ro,nodev,noexec 0 0
|
||||
|
||||
```
|
||||
|
||||
If your root filesystem is mounted by UUID, you will need to change this. Here is how if your root is an ext4 filesystem:
|
||||
```
|
||||
$ sudo e2label /dev/vg_sdg/f28 F28
|
||||
|
||||
```
|
||||
|
||||
Now edit /mnt/f28/etc/fstab to use the label. Change the mount line for the root file system so it reads like this:
|
||||
```
|
||||
LABEL=F28 / ext4 defaults 1 1
|
||||
|
||||
```
|
||||
|
||||
### Rebooting and upgrading
|
||||
|
||||
Reboot, and your system will be using the new root filesystem. It is still Fedora 26, but a copy with a new LV name, and ready for dnf system-upgrade! If anything goes wrong, use the Old Boot Menu to boot back into your working system, which this procedure avoids touching.
|
||||
```
|
||||
$ sudo systemctl reboot # or GUI equivalent
|
||||
...
|
||||
$ df / /f26
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
/dev/mapper/vg_sdg-f28 20511312 14903196 4543156 77% /
|
||||
/dev/mapper/vg_sdg-f26 20511312 14866412 4579940 77% /f26
|
||||
|
||||
```
|
||||
|
||||
You may wish to verify that using the Old Boot Menu does indeed get you back to having root mounted on the old root filesystem.
|
||||
|
||||
Now follow the instructions at [this wiki page][2]. If anything goes wrong with the system upgrade, you have a working system to boot back into.
|
||||
|
||||
### Future ideas
|
||||
|
||||
The steps to create a new LV and copy a snapshot of root to it could be automated with a generic script. It needs only the name of the new LV, since the size and device of the existing root are easy to determine. For example, one would be able to type this command:
|
||||
```
|
||||
$ sudo copyfs / f28
|
||||
|
||||
```
|
||||
|
||||
Supplying the mount-point to copy makes it clearer what is happening, and copying other mount-points like /home could be useful.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/use-lvm-upgrade-fedora/
|
||||
|
||||
作者:[Stuart D Gathman][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/sdgathman/
|
||||
[1]:https://fedoramagazine.org/upgrading-fedora-27-fedora-28/
|
||||
[2]:https://fedoraproject.org/wiki/DNF_system_upgrade
|
||||
@ -1,69 +0,0 @@
|
||||
Create animated, scalable vector graphic images with MacSVG
|
||||
======
|
||||
|
||||
Open source SVG: The writing is on the wall
|
||||
|
||||

|
||||
|
||||
The Neo-Babylonian regent [Belshazzar][1] did not heed [the writing on the wall][2] that magically appeared during his great feast. However, if he had had a laptop and a good internet connection in 539 BC, he might have staved off those pesky Persians by reading the SVG on the browser.
|
||||
|
||||
Animating text and objects on web pages is a great way to build user interest and engagement. There are several ways to achieve this, such as a video embed, an animated GIF, or a slideshow—but you can also use [scalable vector graphics][3] (SVG).
|
||||
|
||||
An SVG image is different from, say, a JPG, because it is scalable without losing its resolution. A vector image is created by points, not dots, so no matter how large it gets, it will not lose its resolution or pixelate. An example of a good use of scalable, static images would be logos on websites.
|
||||
|
||||
### Move it, move it
|
||||
|
||||
You can create SVG images with several drawing programs, including open source [Inkscape][4] and Adobe Illustrator. Getting your images to “do something” requires a bit more effort. Fortunately, there are open source solutions that would get even Belshazzar’s attention.
|
||||
|
||||
[MacSVG][5] is one tool that will get your images moving. You can find the source code on [GitHub][6].
|
||||
|
||||
Developed by Douglas Ward of Conway, Arkansas, MacSVG is an “open source Mac OS app for designing HTML5 SVG art and animation,” according to its [website][5].
|
||||
|
||||
I was interested in using MacSVG to create an animated signature. I admit that I found the process a bit confusing and failed at my first attempts to create an actual animated SVG image.
|
||||
|
||||

|
||||
|
||||
It is important to first learn what makes “the writing on the wall” actually write.
|
||||
|
||||
The attribute behind the animated writing is [stroke-dasharray][7]. Breaking the term into three words helps explain what is happening: Stroke refers to the line or stroke you would make with a pen, whether physical or digital. Dash means breaking the stroke down into a series of dashes. Array means producing the whole thing into an array. That’s a simple overview, but it helped me understand what was supposed to happen and why.
|
||||
|
||||
With MacSVG, you can import a graphic (.PNG) and use the pen tool to trace the path of the writing. I used a cursive representation of my first name. Then it was just a matter of applying the attributes to animate the writing, increase and decrease the thickness of the stroke, change its color, and so on. Once completed, the animated writing was exported as an .SVG file and was ready for use on the web. MacSVG can be used for many different types of SVG animation in addition to handwriting.
|
||||
|
||||
### The writing is on the WordPress
|
||||
|
||||
I was ready to upload and share my SVG example on my [WordPress][8] site, but I discovered that WordPress does not allow for SVG media imports. Fortunately, I found a handy plugin: Benbodhi’s [SVG Support][9] allowed a quick, easy import of my SVG the same way I would import a JPG to my Media Library. I was able to showcase my [writing on the wall][10] to Babylonians everywhere.
|
||||
|
||||
I opened the source code of my SVG in [Brackets][11], and here are the results:
|
||||
|
||||
```
|
||||
<?xml version="1.0" encoding="utf-8" standalone="yes"?>
|
||||
<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.1//EN" "http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd">
|
||||
<svg xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:cc="http://web.resource.org/cc/" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:sodipodi="http://sodipodi.sourceforge.net/DTD/sodipodi-0.dtd" xmlns:inkscape="http://www.inkscape.org/namespaces/inkscape" height="360px" style="zoom: 1;" cursor="default" id="svg_document" width="480px" baseProfile="full" version="1.1" preserveAspectRatio="xMidYMid meet" viewBox="0 0 480 360"><title id="svg_document_title">Path animation with stroke-dasharray</title><desc id="desc1">This example demonstrates the use of a path element, an animate element, and the stroke-dasharray attribute to simulate drawing.</desc><defs id="svg_document_defs"></defs><g id="main_group"></g><path stroke="#004d40" id="path2" stroke-width="9px" d="M86,75 C86,75 75,72 72,61 C69,50 66,37 71,34 C76,31 86,21 92,35 C98,49 95,73 94,82 C93,91 87,105 83,110 C79,115 70,124 71,113 C72,102 67,105 75,97 C83,89 111,74 111,74 C111,74 119,64 119,63 C119,62 110,57 109,58 C108,59 102,65 102,66 C102,67 101,75 107,79 C113,83 118,85 122,81 C126,77 133,78 136,64 C139,50 147,45 146,33 C145,21 136,15 132,24 C128,33 123,40 123,49 C123,58 135,87 135,96 C135,105 139,117 133,120 C127,123 116,127 120,116 C124,105 144,82 144,81 C144,80 158,66 159,58 C160,50 159,48 161,43 C163,38 172,23 166,22 C160,21 155,12 153,23 C151,34 161,68 160,78 C159,88 164,108 163,113 C162,118 165,126 157,128 C149,130 152,109 152,109 C152,109 185,64 185,64 " fill="none" transform=""><animate values="0,1739;1739,0;" attributeType="XML" begin="0; animate1.end+5s" id="animateSig1" repeatCount="indefinite" attributeName="stroke-dasharray" fill="freeze" dur="2"></animate></path></svg>
|
||||
```
|
||||
|
||||
What would you use MacSVG for?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/macsvg-open-source-tool-animation
|
||||
|
||||
作者:[Jeff Macharyas][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rikki-endsley
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Belshazzar
|
||||
[2]: https://en.wikipedia.org/wiki/Belshazzar%27s_feast
|
||||
[3]: https://en.wikipedia.org/wiki/Scalable_Vector_Graphics
|
||||
[4]: https://inkscape.org/
|
||||
[5]: https://macsvg.org/
|
||||
[6]: https://github.com/dsward2/macSVG
|
||||
[7]: https://gist.github.com/mbostock/5649592
|
||||
[8]: https://macharyas.com/
|
||||
[9]: https://wordpress.org/plugins/svg-support/
|
||||
[10]: https://macharyas.com/index.php/2018/10/14/open-source-svg/
|
||||
[11]: http://brackets.io/
|
||||
@ -1,166 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Getting started with Prometheus)
|
||||
[#]: via: (https://opensource.com/article/18/12/introduction-prometheus)
|
||||
[#]: author: (Michael Zamot https://opensource.com/users/mzamot)
|
||||
|
||||
Getting started with Prometheus
|
||||
======
|
||||
Learn to install and write queries for the Prometheus monitoring and alerting system.
|
||||

|
||||
|
||||
[Prometheus][1] is an open source monitoring and alerting system that directly scrapes metrics from agents running on the target hosts and stores the collected samples centrally on its server. Metrics can also be pushed using plugins like **collectd_exporter** —although this is not Promethius' default behavior, it may be useful in some environments where hosts are behind a firewall or prohibited from opening ports by security policy.
|
||||
|
||||
Prometheus, a project of the [Cloud Native Computing Foundation][2], scales up using a federation model, which enables one Prometheus server to scrape another Prometheus server. This allows creation of a hierarchical topology, where a central system or higher-level Prometheus server can scrape aggregated data already collected from subordinate instances.
|
||||
|
||||
Besides the Prometheus server, its most common components are its [Alertmanager][3] and its exporters.
|
||||
|
||||
Alerting rules can be created within Prometheus and configured to send custom alerts to Alertmanager. Alertmanager then processes and handles these alerts, including sending notifications through different mechanisms like email or third-party services like [PagerDuty][4].
|
||||
|
||||
Prometheus' exporters can be libraries, processes, devices, or anything else that exposes the metrics that will be scraped by Prometheus. The metrics are available at the endpoint **/metrics** , which allows Prometheus to scrape them directly without needing an agent. The tutorial in this article uses **node_exporter** to expose the target hosts' hardware and operating system metrics. Exporters' outputs are plaintext and highly readable, which is one of Prometheus' strengths.
|
||||
|
||||
In addition, you can configure [Grafana][5] to use Prometheus as a backend to provide data visualization and dashboarding functions.
|
||||
|
||||
### Making sense of Prometheus' configuration file
|
||||
|
||||
The number of seconds between when **/metrics** is scraped controls the granularity of the time-series database. This is defined in the configuration file as the **scrape_interval** parameter, which by default is set to 60 seconds.
|
||||
|
||||
Targets are set for each scrape job in the **scrape_configs** section. Each job has its own name and a set of labels that can help filter, categorize, and make it easier to identify the target. One job can have many targets.
|
||||
|
||||
### Installing Prometheus
|
||||
|
||||
In this tutorial, for simplicity, we will install a Prometheus server and **node_exporter** with docker. Docker should already be installed and configured properly on your system. For a more in-depth, automated method, I recommend Steve Ovens' article [How to use Ansible to set up system monitoring with Prometheus][6].
|
||||
|
||||
Before starting, create the Prometheus configuration file **prometheus.yml** in your work directory as follows:
|
||||
|
||||
```
|
||||
global:
|
||||
scrape_interval: 15s
|
||||
evaluation_interval: 15s
|
||||
|
||||
scrape_configs:
|
||||
- job_name: 'prometheus'
|
||||
|
||||
static_configs:
|
||||
- targets: ['localhost:9090']
|
||||
|
||||
- job_name: 'webservers'
|
||||
|
||||
static_configs:
|
||||
- targets: ['<node exporter node IP>:9100']
|
||||
```
|
||||
|
||||
Start Prometheus with Docker by running the following command:
|
||||
|
||||
```
|
||||
$ sudo docker run -d -p 9090:9090 -v
|
||||
/path/to/prometheus.yml:/etc/prometheus/prometheus.yml
|
||||
prom/prometheus
|
||||
```
|
||||
|
||||
By default, the Prometheus server will use port 9090. If this port is already in use, you can change it by adding the parameter **\--web.listen-address=" <IP of machine>:<port>"** at the end of the previous command.
|
||||
|
||||
In the machine you want to monitor, download and run the **node_exporter** container by using the following command:
|
||||
|
||||
```
|
||||
$ sudo docker run -d -v "/proc:/host/proc" -v "/sys:/host/sys" -v
|
||||
"/:/rootfs" --net="host" prom/node-exporter --path.procfs
|
||||
/host/proc --path.sysfs /host/sys --collector.filesystem.ignored-
|
||||
mount-points "^/(sys|proc|dev|host|etc)($|/)"
|
||||
```
|
||||
|
||||
For the purposes of this learning exercise, you can install **node_exporter** and Prometheus on the same machine. Please note that it's not wise to run **node_exporter** under Docker in production—this is for testing purposes only.
|
||||
|
||||
To verify that **node_exporter** is running, open your browser and navigate to **http:// <IP of Node exporter host>:9100/metrics**. All the metrics collected will be displayed; these are the same metrics Prometheus will scrape.
|
||||
|
||||

|
||||
|
||||
To verify the Prometheus server installation, open your browser and navigate to <http://localhost:9090>.
|
||||
|
||||
You should see the Prometheus interface. Click on **Status** and then **Targets**. Under State, you should see your machines listed as **UP**.
|
||||
|
||||

|
||||
|
||||
### Using Prometheus queries
|
||||
|
||||
It's time to get familiar with [PromQL][7], Prometheus' query syntax, and its graphing web interface. Go to **<http://localhost:9090/graph>** on your Prometheus server. You will see a query editor and two tabs: Graph and Console.
|
||||
|
||||
Prometheus stores all data as time series, identifying each one with a metric name. For example, the metric **node_filesystem_avail_bytes** shows the available filesystem space. The metric's name can be used in the expression box to select all of the time series with this name and produce an instant vector. If desired, these time series can be filtered using selectors and labels—a set of key-value pairs—for example:
|
||||
|
||||
```
|
||||
node_filesystem_avail_bytes{fstype="ext4"}
|
||||
```
|
||||
|
||||
When filtering, you can match "exactly equal" ( **=** ), "not equal" ( **!=** ), "regex-match" ( **=~** ), and "do not regex-match" ( **!~** ). The following examples illustrate this:
|
||||
|
||||
To filter **node_filesystem_avail_bytes** to show both ext4 and XFS filesystems:
|
||||
|
||||
```
|
||||
node_filesystem_avail_bytes{fstype=~"ext4|xfs"}
|
||||
```
|
||||
|
||||
To exclude a match:
|
||||
|
||||
```
|
||||
node_filesystem_avail_bytes{fstype!="xfs"}
|
||||
```
|
||||
|
||||
You can also get a range of samples back from the current time by using square brackets. You can use **s** to represent seconds, **m** for minutes, **h** for hours, **d** for days, **w** for weeks, and **y** for years. When using time ranges, the vector returned will be a range vector.
|
||||
|
||||
For example, the following command produces the samples from five minutes to the present:
|
||||
|
||||
```
|
||||
node_memory_MemAvailable_bytes[5m]
|
||||
```
|
||||
|
||||
Prometheus also includes functions to allow advanced queries, such as this:
|
||||
|
||||
```
|
||||
100 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated (1 - avg by(instance)(irate(node_cpu_seconds_total{job='webservers',mode='idle'}[5m])))
|
||||
```
|
||||
|
||||
Notice how the labels are used to filter the job and the mode. The metric **node_cpu_seconds_total** returns a counter, and the **irate()** function calculates the per-second rate of change based on the last two data points of the range interval (meaning the range can be smaller than five minutes). To calculate the overall CPU usage, you can use the idle mode of the **node_cpu_seconds_total** metric. The idle percent of a processor is the opposite of a busy processor, so the **irate** value is subtracted from 1. To make it a percentage, multiply it by 100.
|
||||
|
||||

|
||||
|
||||
### Learn more
|
||||
|
||||
Prometheus is a powerful, scalable, lightweight, and easy to use and deploy monitoring tool that is indispensable for every system administrator and developer. For these and other reasons, many companies are implementing Prometheus as part of their infrastructure.
|
||||
|
||||
To learn more about Prometheus and its functions, I recommend the following resources:
|
||||
|
||||
+ About [PromQL][8]
|
||||
+ What [node_exporters collects][9]
|
||||
+ [Prometheus functions][10]
|
||||
+ [4 open source monitoring tools][11]
|
||||
+ [Now available: The open source guide to DevOps monitoring tools][12]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/introduction-prometheus
|
||||
|
||||
作者:[Michael Zamot][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mzamot
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://prometheus.io/
|
||||
[2]: https://www.cncf.io/
|
||||
[3]: https://prometheus.io/docs/alerting/alertmanager/
|
||||
[4]: https://en.wikipedia.org/wiki/PagerDuty
|
||||
[5]: https://grafana.com/
|
||||
[6]: https://opensource.com/article/18/3/how-use-ansible-set-system-monitoring-prometheus
|
||||
[7]: https://prometheus.io/docs/prometheus/latest/querying/basics/
|
||||
[8]: https://prometheus.io/docs/prometheus/latest/querying/basics/
|
||||
[9]: https://github.com/prometheus/node_exporter#collectors
|
||||
[10]: https://prometheus.io/docs/prometheus/latest/querying/functions/
|
||||
[11]: https://opensource.com/article/18/8/open-source-monitoring-tools
|
||||
[12]: https://opensource.com/article/18/8/now-available-open-source-guide-devops-monitoring-tools
|
||||
@ -1,150 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Let’s try dwm — dynamic window manager)
|
||||
[#]: via: (https://fedoramagazine.org/lets-try-dwm-dynamic-window-manger/)
|
||||
[#]: author: (Adam Šamalík https://fedoramagazine.org/author/asamalik/)
|
||||
|
||||
Let’s try dwm — dynamic window manager
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
If you like efficiency and minimalism, and are looking for a new window manager for your Linux desktop, you should try _dwm_ — dynamic window manager. Written in under 2000 standard lines of code, dwm is extremely fast yet powerful and highly customizable window manager.
|
||||
|
||||
You can dynamically choose between tiling, monocle and floating layouts, organize your windows into multiple workspaces using tags, and quickly navigate through using keyboard shortcuts. This article helps you get started using dwm.
|
||||
|
||||
## **Installation**
|
||||
|
||||
To install dwm on Fedora, run:
|
||||
|
||||
```
|
||||
$ sudo dnf install dwm dwm-user
|
||||
```
|
||||
|
||||
The _dwm_ package installs the window manager itself, and the _dwm-user_ package significantly simplifies configuration which will be explained later in this article.
|
||||
|
||||
Additionally, to be able to lock the screen when needed, we’ll also install _slock_ — a simple X display locker.
|
||||
|
||||
```
|
||||
$ sudo dnf install slock
|
||||
```
|
||||
|
||||
However, you can use a different one based on your personal preference.
|
||||
|
||||
## **Quick start**
|
||||
|
||||
To start dwm, choose the _dwm-user_ option on the login screen.
|
||||
|
||||
![][2]
|
||||
|
||||
After you log in, you’ll see a very simple desktop. In fact, the only thing there will be a bar at the top listing our nine tags that represent workspaces and a _[]=_ symbol that represents the layout of your windows.
|
||||
|
||||
### Launching applications
|
||||
|
||||
Before looking into the layouts, first launch some applications so you can play with the layouts as you go. Apps can be started by pressing _Alt+p_ and typing the name of the app followed by _Enter_. There’s also a shortcut _Alt+Shift+Enter_ for opening a terminal.
|
||||
|
||||
Now that some apps are running, have a look at the layouts.
|
||||
|
||||
### Layouts
|
||||
|
||||
There are three layouts available by default: the tiling layout, the monocle layout, and the floating layout.
|
||||
|
||||
The tiling layout, represented by _[]=_ on the bar, organizes windows into two main areas: master on the left, and stack on the right. You can activate the tiling layout by pressing _Alt+t._
|
||||
|
||||
![][3]
|
||||
|
||||
The idea behind the tiling layout is that you have your primary window in the master area while still seeing the other ones in the stack. You can quickly switch between them as needed.
|
||||
|
||||
To swap windows between the two areas, hover your mouse over one in the stack area and press _Alt+Enter_ to swap it with the one in the master area.
|
||||
|
||||
![][4]
|
||||
|
||||
The monocle layout, represented by _[N]_ on the top bar, makes your primary window take the whole screen. You can switch to it by pressing _Alt+m_.
|
||||
|
||||
Finally, the floating layout lets you move and resize your windows freely. The shortcut for it is _Alt+f_ and the symbol on the top bar is _> <>_.
|
||||
|
||||
### Workspaces and tags
|
||||
|
||||
Each window is assigned to a tag (1-9) listed at the top bar. To view a specific tag, either click on its number using your mouse or press _Alt+1..9._ You can even view multiple tags at once by clicking on their number using the secondary mouse button.
|
||||
|
||||
Windows can be moved between different tags by highlighting them using your mouse, and pressing _Alt+Shift+1..9._
|
||||
|
||||
## **Configuration**
|
||||
|
||||
To make dwm as minimalistic as possible, it doesn’t use typical configuration files. Instead, you modify a C header file representing the configuration, and recompile it. But don’t worry, in Fedora it’s as simple as just editing one file in your home directory and everything else happens in the background thanks to the _dwm-user_ package provided by the maintainer in Fedora.
|
||||
|
||||
First, you need to copy the file into your home directory using a command similar to the following:
|
||||
|
||||
```
|
||||
$ mkdir ~/.dwm
|
||||
$ cp /usr/src/dwm-VERSION-RELEASE/config.def.h ~/.dwm/config.h
|
||||
```
|
||||
|
||||
You can get the exact path by running _man dwm-start._
|
||||
|
||||
Second, just edit the _~/.dwm/config.h_ file. As an example, let’s configure a new shortcut to lock the screen by pressing _Alt+Shift+L_.
|
||||
|
||||
Considering we’ve installed the _slock_ package mentioned earlier in this post, we need to add the following two lines into the file to make it work:
|
||||
|
||||
Under the _/* commands */_ comment, add:
|
||||
|
||||
```
|
||||
static const char *slockcmd[] = { "slock", NULL };
|
||||
```
|
||||
|
||||
And the following line into _static Key keys[]_ :
|
||||
|
||||
```
|
||||
{ MODKEY|ShiftMask, XK_l, spawn, {.v = slockcmd } },
|
||||
```
|
||||
|
||||
In the end, it should look like as follows: (added lines are highlighted)
|
||||
|
||||
```
|
||||
...
|
||||
/* commands */
|
||||
static char dmenumon[2] = "0"; /* component of dmenucmd, manipulated in spawn() */
|
||||
static const char *dmenucmd[] = { "dmenu_run", "-m", dmenumon, "-fn", dmenufont, "-nb", normbgcolor, "-nf", normfgcolor, "-sb", selbgcolor, "-sf", selfgcolor, NULL };
|
||||
static const char *termcmd[] = { "st", NULL };
|
||||
static const char *slockcmd[] = { "slock", NULL };
|
||||
|
||||
static Key keys[] = {
|
||||
/* modifier key function argument */
|
||||
{ MODKEY|ShiftMask, XK_l, spawn, {.v = slockcmd } },
|
||||
{ MODKEY, XK_p, spawn, {.v = dmenucmd } },
|
||||
{ MODKEY|ShiftMask, XK_Return, spawn, {.v = termcmd } },
|
||||
...
|
||||
```
|
||||
|
||||
Save the file.
|
||||
|
||||
Finally, just log out by pressing _Alt+Shift+q_ and log in again. The scripts provided by the _dwm-user_ package will recognize that you have changed the _config.h_ file in your home directory and recompile dwm on login. And becuse dwm is so tiny, it’s fast enough you won’t even notice it.
|
||||
|
||||
You can try locking your screen now by pressing _Alt+Shift+L_ , and then logging back in again by typing your password and pressing enter.
|
||||
|
||||
## **Conclusion**
|
||||
|
||||
If you like minimalism and want a very fast yet powerful window manager, dwm might be just what you’ve been looking for. However, it probably isn’t for beginners. There might be a lot of additional configuration you’ll need to do in order to make it just as you like it.
|
||||
|
||||
To learn more about dwm, see the project’s homepage at <https://dwm.suckless.org/>.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/lets-try-dwm-dynamic-window-manger/
|
||||
|
||||
作者:[Adam Šamalík][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/asamalik/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/03/dwm-magazine-image-816x345.png
|
||||
[2]: https://fedoramagazine.org/wp-content/uploads/2019/03/choosing-dwm-1024x469.png
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2019/03/dwm-desktop-1024x593.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/03/Screenshot-2019-03-15-at-11.12.32-1024x592.png
|
||||
@ -1,111 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Turn On And Shutdown The Raspberry Pi [Absolute Beginner Tip])
|
||||
[#]: via: (https://itsfoss.com/turn-on-raspberry-pi/)
|
||||
[#]: author: (Chinmay https://itsfoss.com/author/chinmay/)
|
||||
|
||||
How To Turn On And Shutdown The Raspberry Pi [Absolute Beginner Tip]
|
||||
======
|
||||
|
||||
_**Brief: This quick tip teaches you how to turn on Raspberry Pi and how to shut it down properly afterwards.**_
|
||||
|
||||
The [Raspberry Pi][1] is one of the [most popular SBC (Single-Board-Computer)][2]. If you are interested in this topic, I believe that you’ve finally got a Pi device. I also advise to get all the [additional Raspberry Pi accessories][3] to get started with your device.
|
||||
|
||||
You’re ready to turn it on and start to tinker around with it. It has it’s own similarities and differences compared to traditional computers like desktops and laptops.
|
||||
|
||||
Today, let’s go ahead and learn how to turn on and shutdown a Raspberry Pi as it doesn’t really feature a ‘power button’ of sorts.
|
||||
|
||||
For this article I’m using a Raspberry Pi 3B+, but it’s the same for all the Raspberry Pi variants.
|
||||
|
||||
Bestseller No. 1
|
||||
|
||||
[][4]
|
||||
|
||||
[CanaKit Raspberry Pi 3 B+ (B Plus) Starter Kit (32 GB EVO+ Edition, Premium Black Case)][4]
|
||||
|
||||
CanaKit - Personal Computers
|
||||
|
||||
$79.99 [][5]
|
||||
|
||||
Bestseller No. 2
|
||||
|
||||
[][6]
|
||||
|
||||
[CanaKit Raspberry Pi 3 B+ (B Plus) with Premium Clear Case and 2.5A Power Supply][6]
|
||||
|
||||
CanaKit - Personal Computers
|
||||
|
||||
$54.99 [][5]
|
||||
|
||||
### Turn on Raspberry Pi
|
||||
|
||||
![Micro USB port for Power][7]
|
||||
|
||||
The micro USB port powers the Raspberry Pi, the way you turn it on is by plugging in the power cable into the micro USB port. But, before you do that you should make sure that you have done the following things.
|
||||
|
||||
* Preparing the micro SD card with Raspbian according to the official [guide][8] and inserting into the micro SD card slot.
|
||||
* Plugging in the HDMI cable, USB keyboard and a Mouse.
|
||||
* Plugging in the Ethernet Cable(Optional).
|
||||
|
||||
|
||||
|
||||
Once you have done the above, plug in the power cable. This turns on the Raspberry Pi and the display will light up and load the Operating System.
|
||||
|
||||
Bestseller No. 1
|
||||
|
||||
[][4]
|
||||
|
||||
[CanaKit Raspberry Pi 3 B+ (B Plus) Starter Kit (32 GB EVO+ Edition, Premium Black Case)][4]
|
||||
|
||||
CanaKit - Personal Computers
|
||||
|
||||
$79.99 [][5]
|
||||
|
||||
### Shutting Down the Pi
|
||||
|
||||
Shutting down the Pi is pretty straight forward, click the menu button and choose shutdown.
|
||||
|
||||
![Turn off Raspberry Pi graphically][9]
|
||||
|
||||
Alternatively, you can use the [shutdown command][10] in the terminal:
|
||||
|
||||
```
|
||||
sudo shutdown now
|
||||
```
|
||||
|
||||
Once the shutdown process has started **wait** till it completely finishes and then you can cut the power to it. Once the Pi shuts down, there is no real way to turn the Pi back on without turning off and turning on the power. You could the GPIO’s to turn on the Pi from the shutdown state but it’ll require additional modding.
|
||||
|
||||
[][2]
|
||||
|
||||
Suggested read 12 Single Board Computers: Alternative to Raspberry Pi
|
||||
|
||||
_Note: Micro USB ports tend to be fragile, hence turn-off/on the power at source instead of frequently unplugging and plugging into the micro USB port._
|
||||
|
||||
Well, that’s about all you should know about turning on and shutting down the Pi, what do you plan to use it for? Let me know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/turn-on-raspberry-pi/
|
||||
|
||||
作者:[Chinmay][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/chinmay/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.raspberrypi.org/
|
||||
[2]: https://itsfoss.com/raspberry-pi-alternatives/
|
||||
[3]: https://itsfoss.com/things-you-need-to-get-your-raspberry-pi-working/
|
||||
[4]: https://www.amazon.com/CanaKit-Raspberry-Starter-Premium-Black/dp/B07BCC8PK7?SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B07BCC8PK7&keywords=raspberry%20pi%20kit (CanaKit Raspberry Pi 3 B+ (B Plus) Starter Kit (32 GB EVO+ Edition, Premium Black Case))
|
||||
[5]: https://www.amazon.com/gp/prime/?tag=chmod7mediate-20 (Amazon Prime)
|
||||
[6]: https://www.amazon.com/CanaKit-Raspberry-Premium-Clear-Supply/dp/B07BC7BMHY?SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B07BC7BMHY&keywords=raspberry%20pi%20kit (CanaKit Raspberry Pi 3 B+ (B Plus) with Premium Clear Case and 2.5A Power Supply)
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/04/raspberry-pi-3-microusb.png?fit=800%2C532&ssl=1
|
||||
[8]: https://www.raspberrypi.org/documentation/installation/installing-images/README.md
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/04/Raspbian-ui-menu.jpg?fit=800%2C492&ssl=1
|
||||
[10]: https://linuxhandbook.com/linux-shutdown-command/
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Flowsnow)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,118 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Find Out How Long Does it Take To Boot Your Linux System)
|
||||
[#]: via: (https://itsfoss.com/check-boot-time-linux/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Find Out How Long Does it Take To Boot Your Linux System
|
||||
======
|
||||
|
||||
When you power on your system, you wait for the manufacturer’s logo to come up, a few messages on the screen perhaps (booting in insecure mode), [Grub][1] screen, operating system loading screen and finally the login screen.
|
||||
|
||||
Did you check how long did it take? Perhaps not. Unless you really need to know, you won’t bother with the boot time details.
|
||||
|
||||
But what if you are curious to know long long your Linux system takes to boot? Running a stopwatch is one way to find that but in Linux, you have better and easier ways to find out your system’s start up time.
|
||||
|
||||
### Checking boot time in Linux with systemd-analyze
|
||||
|
||||
![][2]
|
||||
|
||||
Like it or not, [systemd][3] is running on most of the popular Linux distributions. The systemd has a number of utilities to manage your Linux system. One of those utilities is systemd-analyze.
|
||||
|
||||
The systemd-analyze command gives you a detail of how many services ran at the last start up and how long they took.
|
||||
|
||||
If you run the following command in the terminal:
|
||||
|
||||
```
|
||||
systemd-analyze
|
||||
```
|
||||
|
||||
You’ll get the total boot time along with the time taken by firmware, boot loader, kernel and the userspace:
|
||||
|
||||
```
|
||||
Startup finished in 7.275s (firmware) + 13.136s (loader) + 2.803s (kernel) + 12.488s (userspace) = 35.704s
|
||||
|
||||
graphical.target reached after 12.408s in userspace
|
||||
```
|
||||
|
||||
As you can see in the output above, it took about 35 seconds for my system to reach the screen where I could enter my password. I am using Dell XPS Ubuntu edition. It uses SSD storage and despite of that it takes this much time to start.
|
||||
|
||||
Not that impressive, is it? Why don’t you share your system’s boot time? Let’s compare.
|
||||
|
||||
You can further breakdown the boot time into each unit with the following command:
|
||||
|
||||
```
|
||||
systemd-analyze blame
|
||||
```
|
||||
|
||||
This will produce a huge output with all the services listed in the descending order of the time taken.
|
||||
|
||||
```
|
||||
7.347s plymouth-quit-wait.service
|
||||
6.198s NetworkManager-wait-online.service
|
||||
3.602s plymouth-start.service
|
||||
3.271s plymouth-read-write.service
|
||||
2.120s apparmor.service
|
||||
1.503s [email protected]
|
||||
1.213s motd-news.service
|
||||
908ms snapd.service
|
||||
861ms keyboard-setup.service
|
||||
739ms fwupd.service
|
||||
702ms bolt.service
|
||||
672ms dev-nvme0n1p3.device
|
||||
608ms [email protected]:intel_backlight.service
|
||||
539ms snap-core-7270.mount
|
||||
504ms snap-midori-451.mount
|
||||
463ms snap-screencloud-1.mount
|
||||
446ms snapd.seeded.service
|
||||
440ms snap-gtk\x2dcommon\x2dthemes-1313.mount
|
||||
420ms snap-core18-1066.mount
|
||||
416ms snap-scrcpy-133.mount
|
||||
412ms snap-gnome\x2dcharacters-296.mount
|
||||
```
|
||||
|
||||
#### Bonus Tip: Improving boot time
|
||||
|
||||
If you look at this output, you can see that both network manager and [plymouth][4] take a huge bunch of boot time.
|
||||
|
||||
[][5]
|
||||
|
||||
Suggested read How To Fix: No Unity, No Launcher, No Dash In Ubuntu Linux
|
||||
|
||||
Plymouth is responsible for that boot splash screen you see before the login screen in Ubuntu and other distributions. Network manager is responsible for the internet connection and may be turned off to speed up boot time. Don’t worry, once you log in, you’ll have wifi working normally.
|
||||
|
||||
```
|
||||
sudo systemctl disable NetworkManager-wait-online.service
|
||||
```
|
||||
|
||||
If you want to revert the change, you can use this command:
|
||||
|
||||
```
|
||||
sudo systemctl enable NetworkManager-wait-online.service
|
||||
```
|
||||
|
||||
Now, please don’t go disabling various services on your own without knowing what it is used for. It may have dangerous consequences.
|
||||
|
||||
_**Now that you know how to check the boot time of your Linux system, why not share your system’s boot time in the comment section?**_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/check-boot-time-linux/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.gnu.org/software/grub/
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/linux-boot-time.jpg?resize=800%2C450&ssl=1
|
||||
[3]: https://en.wikipedia.org/wiki/Systemd
|
||||
[4]: https://wiki.archlinux.org/index.php/Plymouth
|
||||
[5]: https://itsfoss.com/how-to-fix-no-unity-no-launcher-no-dash-in-ubuntu-12-10-quick-tip/
|
||||
130
sources/tech/20190815 12 extensions for your GNOME desktop.md
Normal file
130
sources/tech/20190815 12 extensions for your GNOME desktop.md
Normal file
@ -0,0 +1,130 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (12 extensions for your GNOME desktop)
|
||||
[#]: via: (https://opensource.com/article/19/8/extensions-gnome-desktop)
|
||||
[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdosshttps://opensource.com/users/erezhttps://opensource.com/users/alanfdosshttps://opensource.com/users/patrickhttps://opensource.com/users/liamnairn)
|
||||
|
||||
12 extensions for your GNOME desktop
|
||||
======
|
||||
Add functionality and features to your Linux desktop with these add-ons.
|
||||
![A person working.][1]
|
||||
|
||||
The GNOME desktop is the default graphical user interface for most of the popular Linux distributions and some of the BSD and Solaris operating systems. Currently at version 3, GNOME provides a sleek user experience, and extensions are available for additional functionality.
|
||||
|
||||
We've covered [GNOME extensions][2] at Opensource.com before, but to celebrate GNOME's 22nd anniversary, I decided to revisit the topic. Some of these extensions may already be installed, depending on your Linux distribution; if not, check your package manager.
|
||||
|
||||
### How to add extensions from the package manager
|
||||
|
||||
To install extensions that aren't in your distro, open the package manager and click **Add-ons**. Then click **Shell Extensions** at the top-right of the Add-ons screen, and you will see a button for **Extension Settings** and a list of available extensions.
|
||||
|
||||
![Package Manager Add-ons Extensions view][3]
|
||||
|
||||
Use the Extension Settings button to enable, disable, or configure the extensions you have installed.
|
||||
|
||||
Now that you know how to add and enable extensions, here are some good ones to try.
|
||||
|
||||
## 1\. GNOME Clocks
|
||||
|
||||
[GNOME Clocks][4] is an application that includes a world clock, alarm, stopwatch, and timer. You can configure clocks for different geographic locations. For example, if you regularly work with colleagues in another time zone, you can set up a clock for their location. You can access the World Clocks section in the top panel's drop-down menu by clicking the system clock. It shows your configured world clocks (not including your local time), so you can quickly check the time in other parts of the world.
|
||||
|
||||
## 2\. GNOME Weather
|
||||
|
||||
[GNOME Weather][5] displays the weather conditions and forecast for your current location. You can access local weather conditions from the top panel's drop-down menu. You can also check the weather in other geographic locations using Weather's Places menu.
|
||||
|
||||
GNOME Clocks and Weather are small applications that have extension-like functionality. Both are installed by default on Fedora 30 (which is what I'm using). If you're using another distribution and don't see them, check the package manager.
|
||||
|
||||
You can see both extensions in action in the image below.
|
||||
|
||||
![Clocks and Weather shown in the drop-down][6]
|
||||
|
||||
## 3\. Applications Menu
|
||||
|
||||
I think the GNOME 3 interface is perfectly enjoyable in its stock form, but you may prefer a traditional application menu. In GNOME 30, the [Applications Menu][7] extension was installed by default but not enabled. To enable it, click the Extensions Settings button in the Add-ons section of the package manager and enable the Applications Menu extension.
|
||||
|
||||
![Extension Settings][8]
|
||||
|
||||
Now you can see the Applications Menu in the top-left corner of the top panel.
|
||||
|
||||
![Applications Menu][9]
|
||||
|
||||
## 4\. More columns in applications view
|
||||
|
||||
The Applications view is set by default to six columns of icons, probably because GNOME needs to accommodate a wide array of displays. If you're using a wide-screen display, you can use the [More columns in applications menu][10] extension to increase the columns. I find that setting it to eight makes better use of my screen by eliminating the empty columns on either side of the icons when I launch the Applications view.
|
||||
|
||||
## Add system info to the top panel
|
||||
|
||||
The next three extensions provide basic system information to the top panel.
|
||||
|
||||
* 5. [Harddisk LED][11] shows a small hard drive icon with input/output (I/O) activity.
|
||||
* 6. [Load Average][12] indicates Linux load averages taken over three time intervals.
|
||||
* 7. [Uptime Indicator][13] shows system uptime; when it's clicked, it shows the date and time the system was started.
|
||||
|
||||
|
||||
|
||||
## 8\. Sound Input and Output Device Chooser
|
||||
|
||||
Your system may have more than one audio device for input and output. For example, my laptop has internal speakers and sometimes I use a wireless Bluetooth speaker. The [Sound Input and Output Device Chooser][14] extension adds a list of your sound devices to the System Menu so you can quickly select which one you want to use.
|
||||
|
||||
## 9\. Drop Down Terminal
|
||||
|
||||
Fellow Opensource.com writer [Scott Nesbitt][15] recommended the next two extensions. The first, [Drop Down Terminal][16], enables a terminal window to drop down from the top panel by pressing a certain key; the default is the key above Tab; on my keyboard, that's the tilde (~) character. Drop Down Terminal has a settings menu for customizing transparency, height, the activation keystroke, and other configurations.
|
||||
|
||||
## 10\. Todo.txt
|
||||
|
||||
[Todo.txt][17] adds a menu to the top panel for maintaining a file for Todo.txt task tracking. You can add or delete a task from the menu or mark it as completed.
|
||||
|
||||
![Drop-down menu for Todo.txt][18]
|
||||
|
||||
## 11\. Removable Drive Menu
|
||||
|
||||
Opensource.com editor [Seth Kenlon][19] suggested [Removable Drive Menu][20]. It provides a drop-down menu for managing removable media, such as USB thumb drives. From the extension's menu, you can access a drive's files and eject it. The menu only appears when removable media is inserted.
|
||||
|
||||
![Removable Drive Menu][21]
|
||||
|
||||
## 12\. GNOME Internet Radio
|
||||
|
||||
I enjoy listening to internet radio streams with the [GNOME Internet Radio][22] extension, which I wrote about in [How to Stream Music with GNOME Internet Radio][23].
|
||||
|
||||
* * *
|
||||
|
||||
What are your favorite GNOME extensions? Please share them in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/extensions-gnome-desktop
|
||||
|
||||
作者:[Alan Formy-Duval][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/alanfdosshttps://opensource.com/users/erezhttps://opensource.com/users/alanfdosshttps://opensource.com/users/patrickhttps://opensource.com/users/liamnairn
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003784_02_os.comcareers_os_rh2x.png?itok=jbRfXinl (A person working.)
|
||||
[2]: https://opensource.com/article/17/2/top-gnome-shell-extensions
|
||||
[3]: https://opensource.com/sites/default/files/uploads/add-onsextensions_6.png (Package Manager Add-ons Extensions view)
|
||||
[4]: https://wiki.gnome.org/Apps/Clocks
|
||||
[5]: https://wiki.gnome.org/Apps/Weather
|
||||
[6]: https://opensource.com/sites/default/files/uploads/clocksweatherdropdown_6.png (Clocks and Weather shown in the drop-down)
|
||||
[7]: https://extensions.gnome.org/extension/6/applications-menu/
|
||||
[8]: https://opensource.com/sites/default/files/uploads/add-onsextensionsettings_6.png (Extension Settings)
|
||||
[9]: https://opensource.com/sites/default/files/uploads/applicationsmenuextension_5.png (Applications Menu)
|
||||
[10]: https://extensions.gnome.org/extension/1305/more-columns-in-applications-view/
|
||||
[11]: https://extensions.gnome.org/extension/988/harddisk-led/
|
||||
[12]: https://extensions.gnome.org/extension/1381/load-average/
|
||||
[13]: https://extensions.gnome.org/extension/508/uptime-indicator/
|
||||
[14]: https://extensions.gnome.org/extension/906/sound-output-device-chooser/
|
||||
[15]: https://opensource.com/users/scottnesbitt
|
||||
[16]: https://extensions.gnome.org/extension/442/drop-down-terminal/
|
||||
[17]: https://extensions.gnome.org/extension/570/todotxt/
|
||||
[18]: https://opensource.com/sites/default/files/uploads/todo.txtmenu_3.png (Drop-down menu for Todo.txt)
|
||||
[19]: https://opensource.com/users/seth
|
||||
[20]: https://extensions.gnome.org/extension/7/removable-drive-menu/
|
||||
[21]: https://opensource.com/sites/default/files/uploads/removabledrivemenu_3.png (Removable Drive Menu)
|
||||
[22]: https://extensions.gnome.org/extension/836/internet-radio/
|
||||
[23]: https://opensource.com/article/19/6/gnome-internet-radio
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -0,0 +1,282 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to create a vanity Tor .onion web address)
|
||||
[#]: via: (https://opensource.com/article/19/8/how-create-vanity-tor-onion-address)
|
||||
[#]: author: (Kc Nwaezuoke https://opensource.com/users/areahintshttps://opensource.com/users/sethhttps://opensource.com/users/bexelbiehttps://opensource.com/users/bcotton)
|
||||
|
||||
How to create a vanity Tor .onion web address
|
||||
======
|
||||
Generate a vanity .onion website to protect your anonymity—and your
|
||||
visitors' privacy, too.
|
||||
![Password security with a mask][1]
|
||||
|
||||
[Tor][2] is a powerful, open source network that enables anonymous and non-trackable (or difficult to track) browsing of the internet. It's able to achieve this because of users running Tor nodes, which serve as intentional detours between two otherwise direct paths. For instance, if you are in New Zealand and visit python.nz, instead of being routed next door to the data center running python.nz, your traffic might be routed to Pittsburgh and then Berlin and then Vanuatu and finally to python.nz. The Tor network, being built upon opt-in participant nodes, has an ever-changing structure. Only within this dynamic network space can there exist an exciting, transient top-level domain identifier: the .onion address.
|
||||
|
||||
If you own or are looking to create a website, you can generate a vanity .onion site to protect your and your visitors' anonymity.
|
||||
|
||||
### What are onion addresses?
|
||||
|
||||
Because Tor is dynamic and intentionally re-routes traffic in unpredictable ways, an onion address makes both the information provider (you) and the person accessing the information (your traffic) difficult to trace by one another, by intermediate network hosts, or by an outsider. Generally, an onion address is unattractive, with 16-character names like 8zd335ae47dp89pd.onion. Not memorable, and difficult to identify when spoofed, but a few projects that culminated with Shallot (forked as eschalot) provides "vanity" onion addresses to solve those issues.
|
||||
|
||||
Creating a vanity onion URL on your own is possible but computationally expensive. Getting the exact 16 characters you want could take a single computer billions of years to achieve.
|
||||
|
||||
Here's a rough example (courtesy of [Shallot][3]) of how much time it takes to generate certain lengths of characters on a 1.5GHz processor:
|
||||
|
||||
Characters | Time
|
||||
---|---
|
||||
1 | Less than 1 second
|
||||
2 | Less than 1 second
|
||||
3 | Less than 1 second
|
||||
4 | 2 seconds
|
||||
5 | 1 minute
|
||||
6 | 30 minutes
|
||||
7 | 1 day
|
||||
8 | 25 days
|
||||
9 | 2.5 years
|
||||
10 | 40 years
|
||||
11 | 640 years
|
||||
12 | 10 millennia
|
||||
13 | 160 millennia
|
||||
14 | 2.6 million years
|
||||
|
||||
I love how this table goes from 25 days to 2.5 years. If you wanted to generate 56 characters, it would take 1078 years.
|
||||
|
||||
An onion address with 16 characters is referred to as a version 2 onion address, and one with 56 characters is a version 3 onion address. If you're using the Tor browser, you can check out this [v2 address][4] or this [v3 address][5].
|
||||
|
||||
A v3 address has several advantages over v2:
|
||||
|
||||
* Better crypto (v3 replaced SHA1/DH/RSA1024 with SHA3/ed25519/curve25519)
|
||||
* Improved directory protocol that leaks much less information to directory servers
|
||||
* Improved directory protocol with a smaller surface for targeted attacks
|
||||
* Better onion address security against impersonation
|
||||
|
||||
|
||||
|
||||
However, the downside (supposedly) of v3 is the marketing effort you might need to get netizens to type that marathon-length URL in their browser.
|
||||
|
||||
You can [learn more about v3][6] in the Tor docs.
|
||||
|
||||
### Why you might need an onion address
|
||||
|
||||
A .onion domain has a few key advantages. Its key feature is that it can be accessed only with a Tor browser. Many people don't even know Tor exists, so you shouldn't expect massive traffic on your .onion site. However, the Tor browser provides numerous layers of anonymity not available on more popular browsers. If you want to ensure near-total anonymity for both you and your visitors, onion addresses are built for it.
|
||||
|
||||
With Tor, you do not need to register with ICANN to create your own domain. You don't need to hide your details from Whois searches, and your ICANN account won't be vulnerable to malicious takeovers. You are completely in control of your privacy and your domain.
|
||||
|
||||
An onion address is also an effective way to bypass censorship restrictions imposed by a government or regime. Its privacy helps protect you if your site may be viewed as a threat to the interests of the political class. Sites like Wikileaks are the best examples.
|
||||
|
||||
### What you need to generate a vanity URL
|
||||
|
||||
To configure a vanity onion address, you need to generate a new private key to match a custom hostname.
|
||||
|
||||
Two applications that you can use for generating .onion addresses are [eschalot][7] for v2 addresses and [mkp224o][8] for v3 addresses.
|
||||
|
||||
Eschalot is a Tor hidden service name generator. It allows you to produce a (partially) customized vanity .onion address using a brute-force method. Eschalot is distributed in source form under the BSD license and should compile on any Unix or Linux system.
|
||||
|
||||
mkp224o is a vanity address generator for ed25519 .onion services that's available on GitHub with the CC0 1.0 Universal license. It generates vanity 56-character onion addresses.
|
||||
|
||||
Here's a simple explanation of how these applications work. (This assumes you are comfortable with Git.)
|
||||
|
||||
#### Eschalot
|
||||
|
||||
Eschalot requires [OpenSSL][9] 0.9.7 or later libraries with source headers. Confirm your version with this command:
|
||||
|
||||
|
||||
```
|
||||
$ openssl version
|
||||
OpenSSL 1.1.1c FIPS 28 May 2019
|
||||
```
|
||||
|
||||
You also need a [Make][10] utility (either BSD or GNU Make will do) and a C compiler (GCC, PCC, or LLVM/Clang).
|
||||
|
||||
Clone the eschalot repo to your system, and then compile:
|
||||
|
||||
|
||||
```
|
||||
$ git clone <https://github.com/ReclaimYourPrivacy/eschalot.git>
|
||||
$ cd eschalot-1.2.0
|
||||
$ make
|
||||
```
|
||||
|
||||
If you're not using GCC, you must set the **CC** environment variable. For example, to use PCC instead:
|
||||
|
||||
|
||||
```
|
||||
$ make clean
|
||||
$ env CC=pcc make
|
||||
```
|
||||
|
||||
##### Using eschalot
|
||||
|
||||
To see Echalot's Help pages, type **./eschalot** in the terminal:
|
||||
|
||||
|
||||
```
|
||||
$ ./eschalot
|
||||
Version: 1.2.0
|
||||
|
||||
usage:
|
||||
eschalot [-c] [-v] [-t count] ([-n] [-l min-max] -f filename) | (-r regex) | (-p prefix)
|
||||
-v : verbose mode - print extra information to STDERR
|
||||
-c : continue searching after the hash is found
|
||||
-t count : number of threads to spawn default is one)
|
||||
-l min-max : look for prefixes that are from 'min' to 'max' characters long
|
||||
-n : Allow digits to be part of the prefix (affects wordlist mode only)
|
||||
-f filename: name of the text file with a list of prefixes
|
||||
-p prefix : single prefix to look for (1-16 characters long)
|
||||
-r regex : search for a POSIX-style regular expression
|
||||
|
||||
Examples:
|
||||
eschalot -cvt4 -l8-12 -f wordlist.txt >> results.txt
|
||||
eschalot -v -r '^test|^exam'
|
||||
eschalot -ct5 -p test
|
||||
|
||||
base32 alphabet allows letters [a-z] and digits [2-7]
|
||||
Regex pattern examples:
|
||||
xxx must contain 'xxx'
|
||||
^foo must begin with 'foo'
|
||||
bar$ must end with 'bar'
|
||||
b[aoeiu]r must have a vowel between 'b' and 'r'
|
||||
'^ab|^cd' must begin with 'ab' or 'cd'
|
||||
[a-z]{16} must contain letters only, no digits
|
||||
^dusk.*dawn$ must begin with 'dusk' and end with 'dawn'
|
||||
[a-z2-7]{16} any name - will succeed after one iteration
|
||||
```
|
||||
|
||||
You can use eschalot to generate an address using the prefix **-p** for _privacy_. Assuming your system has multiple CPU cores, use _multi-threading_ (**-t**) to speed up the URL generation. To _get verbose output_, use the **-v** option. Write the results of your calculation to a file named **newonion.txt**:
|
||||
|
||||
|
||||
```
|
||||
`./eschalot -v -t4 -p privacy >> newonion.txt`
|
||||
```
|
||||
|
||||
The script executes until it finds a suitable match:
|
||||
|
||||
|
||||
```
|
||||
$ ./eschalot -v -t4 -p privacy >> newonion.txt
|
||||
Verbose, single result, no digits, 4 threads, prefixes 7-7 characters long.
|
||||
Thread #1 started.
|
||||
Thread #2 started.
|
||||
Thread #3 started.
|
||||
Thread #4 started.
|
||||
Running, collecting performance data...
|
||||
Found a key for privacy (7) - privacyzofgsihx2.onion
|
||||
```
|
||||
|
||||
To access the public and private keys eschalot generates, locate **newonion.txt** in the eschalot folder.
|
||||
|
||||
#### mkp224o
|
||||
|
||||
mkp224o requires a C99 compatible compiler, Libsodium, GNU Make, GNU Autoconf, and a Unix-like platform. It has been tested on Linux and OpenBSD.
|
||||
|
||||
To get started, clone the mkp224o repo onto your system, generate the required [Autotools infrastructure][11], configure, and compile:
|
||||
|
||||
|
||||
```
|
||||
$ git clone <https://github.com/cathugger/mkp224o.git>
|
||||
$ cd mkp224o
|
||||
$ ./autogen.sh
|
||||
$ ./configure
|
||||
$ make
|
||||
```
|
||||
|
||||
##### Using mkp224o
|
||||
|
||||
Type **./mkp224o -h** to view Help:
|
||||
|
||||
|
||||
```
|
||||
$ ./mkp224o -h
|
||||
Usage: ./mkp224o filter [filter...] [options]
|
||||
./mkp224o -f filterfile [options]
|
||||
Options:
|
||||
-h - print help to stdout and quit
|
||||
-f - specify filter file which contains filters separated by newlines
|
||||
-D - deduplicate filters
|
||||
-q - do not print diagnostic output to stderr
|
||||
-x - do not print onion names
|
||||
-v - print more diagnostic data
|
||||
-o filename - output onion names to specified file (append)
|
||||
-O filename - output onion names to specified file (overwrite)
|
||||
-F - include directory names in onion names output
|
||||
-d dirname - output directory
|
||||
-t numthreads - specify number of threads to utilise (default - CPU core count or 1)
|
||||
-j numthreads - same as -t
|
||||
-n numkeys - specify number of keys (default - 0 - unlimited)
|
||||
-N numwords - specify number of words per key (default - 1)
|
||||
-z - use faster key generation method; this is now default
|
||||
-Z - use slower key generation method
|
||||
-B - use batching key generation method (>10x faster than -z, experimental)
|
||||
-s - print statistics each 10 seconds
|
||||
-S t - print statistics every specified ammount of seconds
|
||||
-T - do not reset statistics counters when printing
|
||||
-y - output generated keys in YAML format instead of dumping them to filesystem
|
||||
-Y [filename [host.onion]] - parse YAML encoded input and extract key(s) to filesystem
|
||||
```
|
||||
|
||||
One or more filters are required for mkp224o to work. When executed, mkp224o creates a directory with secret and public keys, plus a hostname for each discovered service. By default, **root** is the current directory, but that can be overridden with the **-d** switch.
|
||||
|
||||
Use the **-t numthreads** option to define how many threads you want to use during processing, and **-v** to see verbose output. Use the **fast** filter, and generate four keys by setting the **-n** option:
|
||||
|
||||
|
||||
```
|
||||
$ ./mkp224o filter fast -t 4 -v -n 4 -d ~/Extracts
|
||||
set workdir: /home/areahints/Extracts/
|
||||
sorting filters... done.
|
||||
filters:
|
||||
fast
|
||||
filter
|
||||
in total, 2 filters
|
||||
using 4 threads
|
||||
fastrcl5totos3vekjbqcmgpnias5qytxnaj7gpxtxhubdcnfrkapqad.onion
|
||||
fastz7zvpzic6dp6pvwpmrlc43b45usm2itkn4bssrklcjj5ax74kaad.onion
|
||||
fastqfj44b66mqffbdfsl46tg3c3xcccbg5lfuhr73k7odfmw44uhdqd.onion
|
||||
fast4xwqdhuphvglwic5dfcxoysz2kvblluinr4ubak5pluunduy7qqd.onion
|
||||
waiting for threads to finish... done.
|
||||
```
|
||||
|
||||
In the directory path set with **-d**, mkp224o creates a folder with the v3 address name it has generated, and within it you see your hostname, secret, and public files.
|
||||
|
||||
Use the **-s** switch to enable printing statistics, which may be useful when benchmarking different ed25519 implementations on your machine. Also, read the **OPTIMISATION.txt** file in mkp224o for performance-related tips.
|
||||
|
||||
### Notes about security
|
||||
|
||||
If you're wondering about the security of v2 generated keys, [Shallot][3] provides an interesting take:
|
||||
|
||||
> It is sometimes claimed that private keys generated by Shallot are less secure than those generated by Tor. This is false. Although Shallot generates a keypair with an unusually large public exponent **e**, it performs all of the sanity checks specified by PKCS #1 v2.1 (directly in **sane_key**), and then performs all of the sanity checks that Tor does when it generates an RSA keypair (by calling the OpenSSL function **RSA_check_key**).
|
||||
|
||||
"[Zooko's Triangle][12]" (which is discussed in [Stiegler's Petname Systems][13]) argues that names cannot be global, secure, and memorable at the same time. This means while .onion names are unique and secure, they have the disadvantage that they cannot be meaningful to humans.
|
||||
|
||||
Imagine that an attacker creates an .onion name that looks similar to the .onion of a different onion service and replaces its hyperlink on the onion wiki. How long would it take for someone to recognize it?
|
||||
|
||||
The onion address system has trade-offs, but vanity addresses may be a reasonable balance among them.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/how-create-vanity-tor-onion-address
|
||||
|
||||
作者:[Kc Nwaezuoke][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/areahintshttps://opensource.com/users/sethhttps://opensource.com/users/bexelbiehttps://opensource.com/users/bcotton
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/security_password_mask_secret.png?itok=EjqwosxY (Password security with a mask)
|
||||
[2]: https://www.torproject.org/
|
||||
[3]: https://github.com/katmagic/Shallot
|
||||
[4]: http://6zdgh5a5e6zpchdz.onion/
|
||||
[5]: http://vww6ybal4bd7szmgncyruucpgfkqahzddi37ktceo3ah7ngmcopnpyyd.onion/
|
||||
[6]: https://www.torproject.org/docs/tor-onion-service.html.en#four
|
||||
[7]: https://github.com/ReclaimYourPrivacy/eschalot
|
||||
[8]: https://github.com/cathugger/mkp224o
|
||||
[9]: https://www.openssl.org/
|
||||
[10]: https://en.wikipedia.org/wiki/Make_(software)
|
||||
[11]: https://opensource.com/article/19/7/introduction-gnu-autotools
|
||||
[12]: https://en.wikipedia.org/wiki/Zooko%27s_triangle
|
||||
[13]: http://www.skyhunter.com/marcs/petnames/IntroPetNames.html
|
||||
@ -0,0 +1,195 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Keeping track of Linux users: When do they log in and for how long?)
|
||||
[#]: via: (https://www.networkworld.com/article/3431864/keeping-track-of-linux-users-when-do-they-log-in-and-for-how-long.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
Keeping track of Linux users: When do they log in and for how long?
|
||||
======
|
||||
Getting an idea how often your users are logging in and how much time they spend on a Linux server is pretty easy with a couple commands and maybe a script or two.
|
||||
![Adikos \(CC BY 2.0\)][1]
|
||||
|
||||
The Linux command line provides some excellent tools for determining how frequently users log in and how much time they spend on a system. Pulling information from the **/var/log/wtmp** file that maintains details on user logins can be time-consuming, but with a couple easy commands, you can extract a lot of useful information on user logins.
|
||||
|
||||
One of the commands that helps with this is the **last** command. It provides a list of user logins that can go quite far back. The output looks like this:
|
||||
|
||||
```
|
||||
$ last | head -5 | tr -s " "
|
||||
shs pts/0 192.168.0.14 Wed Aug 14 09:44 still logged in
|
||||
shs pts/0 192.168.0.14 Wed Aug 14 09:41 - 09:41 (00:00)
|
||||
shs pts/0 192.168.0.14 Wed Aug 14 09:40 - 09:41 (00:00)
|
||||
nemo pts/1 192.168.0.18 Wed Aug 14 09:38 still logged in
|
||||
shs pts/0 192.168.0.14 Tue Aug 13 06:15 - 18:18 (00:24)
|
||||
```
|
||||
|
||||
Note that the **tr -s " "** portion of the command above reduces strings of blanks to single blanks, and in this case, it keeps the output shown from being so wide that it would be wrapped around on this web page. Without the **tr** command, that output would look like this:
|
||||
|
||||
```
|
||||
$ last | head -5
|
||||
shs pts/0 192.168.0.14 Wed Aug 14 09:44 still logged in
|
||||
shs pts/0 192.168.0.14 Wed Aug 14 09:41 - 09:41 (00:00)
|
||||
shs pts/0 192.168.0.14 Wed Aug 14 09:40 - 09:41 (00:00)
|
||||
nemo pts/1 192.168.0.18 Wed Aug 14 09:38 still logged in
|
||||
shs pts/0 192.168.0.14 Wed Aug 14 09:15 - 09:40 (00:24)
|
||||
```
|
||||
|
||||
**[ Two-Minute Linux Tips: [Learn how to master a host of Linux commands in these 2-minute video tutorials][2] ]**
|
||||
|
||||
While it’s easy to generate and review login activity records like these for all users with the **last** command or for some particular user with a **last username** command, without the pipe to **head**, these commands will generally result in a _lot_ of data. In this case, a listing for all users would have 908 lines.
|
||||
|
||||
```
|
||||
$ last | wc -l
|
||||
908
|
||||
```
|
||||
|
||||
### Counting logins with last
|
||||
|
||||
If you don't need all of the login detail, you can view user login sessions as a simple count of logins for all users on the system with a command like this:
|
||||
|
||||
```
|
||||
$ for user in `ls /home`; do echo -ne "$user\t"; last $user | wc -l; done
|
||||
dorothy 21
|
||||
dory 13
|
||||
eel 29
|
||||
jadep 124
|
||||
jdoe 27
|
||||
jimp 42
|
||||
nemo 9
|
||||
shark 17
|
||||
shs 423
|
||||
test 2
|
||||
waynek 201
|
||||
```
|
||||
|
||||
The list above shows how many times each user has logged since the current **/var/log/wtmp** file was initiated. Notice, however, that the command to generate it does depend on user accounts being set up in the default /home directory.
|
||||
|
||||
Depending on how much data has been accumulated in your current **wtmp** file, you may see a lot of logins or relatively few. To get a little more insight into how relevant the number of logins are, you could turn this command into a script, adding a command that shows when the first login in the current file occurred to provide a little perspective.
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
echo -n "Logins since "
|
||||
who /var/log/wtmp | head -1 | awk '{print $3}'
|
||||
echo "======================="
|
||||
|
||||
for user in `ls /home`
|
||||
do
|
||||
echo -ne "$user\t"
|
||||
last $user | wc -l
|
||||
done
|
||||
```
|
||||
|
||||
When you run the script, the "Logins since" line will let you know how to interpret the stats shown.
|
||||
|
||||
```
|
||||
$ ./show_user_logins
|
||||
Logins since 2018-10-05
|
||||
=======================
|
||||
dorothy 21
|
||||
dory 13
|
||||
eel 29
|
||||
jadep 124
|
||||
jdoe 27
|
||||
jimp 42
|
||||
nemo 9
|
||||
shark 17
|
||||
shs 423
|
||||
test 2
|
||||
waynek 201
|
||||
```
|
||||
|
||||
### Looking at accumulated login time with **ac**
|
||||
|
||||
The **ac** command provides a report on user login time — hours spent logged in. As with the **last** command, **ac** reports on user logins since the last rollover of the **wtmp** file since **ac**, like **last**, gets its details from **/var/log/wtmp**. The **ac** command, however, provides a much different view of user activity than the number of logins. For a single user, we might use a command like this one:
|
||||
|
||||
```
|
||||
$ ac nemo
|
||||
total 31.61
|
||||
```
|
||||
|
||||
This tells us that nemo has spent nearly 32 hours logged in. To use the command to generate a listing of the login times for all users, you might use a command like this:
|
||||
|
||||
```
|
||||
$ for user in `ls /home`; do ac $user | sed "s/total/$user\t/" ; done
|
||||
dorothy 9.12
|
||||
dory 1.67
|
||||
eel 4.32
|
||||
…
|
||||
```
|
||||
|
||||
In this command, we are replacing the word “total” in each line with the relevant username. And, as long as usernames are fewer than 8 characters, the output will line up nicely. To left justify the output, you can modify that command to this:
|
||||
|
||||
```
|
||||
$ for user in `ls /home`; do ac $user | sed "s/^\t//" | sed "s/total/$user\t/" ; done
|
||||
dorothy 9.12
|
||||
dory 1.67
|
||||
eel 4.32
|
||||
...
|
||||
```
|
||||
|
||||
The first used of **sed** in that string of commands strips off the initial tabs.
|
||||
|
||||
To turn this command into a script and display the initial date for the **wtmp** file to add more relevance to the hour counts, you could use a script like this:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
echo -n "hours online since "
|
||||
who /var/log/wtmp | head -1 | awk '{print $3}'
|
||||
echo "============================="
|
||||
|
||||
for user in `ls /home`
|
||||
do
|
||||
ac $user | sed "s/^\t//" | sed "s/total/$user\t/"
|
||||
done
|
||||
```
|
||||
|
||||
If you run the script, you'll see the hours spent by each user over the lifespan of the **wtmp** file:
|
||||
|
||||
```
|
||||
$ ./show_user_hours
|
||||
hours online since 2018-10-05
|
||||
=============================
|
||||
dorothy 70.34
|
||||
dory 4.67
|
||||
eel 17.05
|
||||
jadep 186.04
|
||||
jdoe 28.20
|
||||
jimp 11.49
|
||||
nemo 11.61
|
||||
shark 13.04
|
||||
shs 3563.60
|
||||
test 1.00
|
||||
waynek 312.00
|
||||
```
|
||||
|
||||
The difference between the user activity levels in this example is pretty obvious with one user spending only one hour on the system since October and another dominating the system.
|
||||
|
||||
### Wrap-up
|
||||
|
||||
Reviewing how often users log into a system and how many hours they spend online can both give you an overview of how a system is being used and who are likely the heaviest users. Of course, login time does not necessarily correspond to how much work each user is getting done, but it's likely close and commands such as **last** and **ac **can help you identify the most active users.
|
||||
|
||||
### More Linux advice: Sandra Henry-Stocker explains how to use the rev command in this 2-Minute Linux Tip video
|
||||
|
||||
Join the Network World communities on [Facebook][3] and [LinkedIn][4] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3431864/keeping-track-of-linux-users-when-do-they-log-in-and-for-how-long.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/08/keyboard-adikos-100808324-large.jpg
|
||||
[2]: https://www.youtube.com/playlist?list=PL7D2RMSmRO9J8OTpjFECi8DJiTQdd4hua
|
||||
[3]: https://www.facebook.com/NetworkWorld/
|
||||
[4]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,169 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Cockpit and the evolution of the Web User Interface)
|
||||
[#]: via: (https://fedoramagazine.org/cockpit-and-the-evolution-of-the-web-user-interface/)
|
||||
[#]: author: (Shaun Assam https://fedoramagazine.org/author/sassam/)
|
||||
|
||||
Cockpit and the evolution of the Web User Interface
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Over 3 years ago the Fedora Magazine published an article entitled [Cockpit: an overview][2]. Since then, the interface has see some eye-catching changes. Today’s Cockpit is cleaner and the larger fonts makes better use of screen real-estate.
|
||||
|
||||
This article will go over some of the changes made to the UI. It will also explore some of the general tools available in the web interface to simplify those monotonous sysadmin tasks.
|
||||
|
||||
### Cockpit installation
|
||||
|
||||
Cockpit can be installed using the **dnf install cockpit** command. This provides a minimal setup providing the basic tools required to use the interface.
|
||||
|
||||
Another option is to install the Headless Management group. This will install additional packages used to extend the usability of Cockpit. It includes extensions for NetworkManager, software packages, disk, and SELinux management.
|
||||
|
||||
Run the following commands to enable the web service on boot and open the firewall port:
|
||||
|
||||
```
|
||||
$ sudo systemctl enable --now cockpit.socket
|
||||
Created symlink /etc/systemd/system/sockets.target.wants/cockpit.socket -> /usr/lib/systemd/system/cockpit.socket
|
||||
|
||||
$ sudo firewall-cmd --permanent --add-service cockpit
|
||||
success
|
||||
$ sudo firewall-cmd --reload
|
||||
success
|
||||
```
|
||||
|
||||
### Logging into the web interface
|
||||
|
||||
To access the web interface, open your favourite browser and enter the server’s domain name or IP in the address bar followed by the service port (9090). Because Cockpit uses HTTPS, the installation will create a self-signed certificate to encrypt passwords and other sensitive data. You can safely accept this certificate, or request a CA certificate from your sysadmin or a trusted source.
|
||||
|
||||
Once the certificate is accepted, the new and improved login screen will appear. Long-time users will notice the username and password fields have been moved to the top. In addition, the white background behind the credential fields immediately grabs the user’s attention.
|
||||
|
||||
![][3]
|
||||
|
||||
A feature added to the login screen since the previous article is logging in with **sudo** privileges — if your account is a member of the wheel group. Check the box beside _Reuse my password for privileged tasks_ to elevate your rights.
|
||||
|
||||
Another edition to the login screen is the option to connect to remote servers also running the Cockpit web service. Click _Other Options_ and enter the host name or IP address of the remote machine to manage it from your local browser.
|
||||
|
||||
### Home view
|
||||
|
||||
Right off the bat we get a basic overview of common system information. This includes the make and model of the machine, the operating system, if the system is up-to-date, and more.
|
||||
|
||||
![][4]
|
||||
|
||||
Clicking the make/model of the system displays hardware information such as the BIOS/Firmware. It also includes details about the components as seen with **lspci**.
|
||||
|
||||
![][5]
|
||||
|
||||
Clicking on any of the options to the right will display the details of that device. For example, the _% of CPU cores_ option reveals details on how much is used by the user and the kernel. In addition, the _Memory & Swap_ graph displays how much of the system’s memory is used, how much is cached, and how much of the swap partition active. The _Disk I/O_ and _Network Traffic_ graphs are linked to the Storage and Networking sections of Cockpit. These topics will be revisited in an upcoming article that explores the system tools in detail.
|
||||
|
||||
#### Secure Shell Keys and authentication
|
||||
|
||||
Because security is a key factor for sysadmins, Cockpit now has the option to view the machine’s MD5 and SHA256 key fingerprints. Clicking the **Show fingerprints** options reveals the server’s ECDSA, ED25519, and RSA fingerprint keys.
|
||||
|
||||
![][6]
|
||||
|
||||
You can also add your own keys by clicking on your username in the top-right corner and selecting **Authentication**. Click on **Add keys** to validate the machine on other systems. You can also revoke your privileges in the Cockpit web service by clicking on the **X** button to the right.
|
||||
|
||||
![][7]
|
||||
|
||||
#### Changing the host name and joining a domain
|
||||
|
||||
Changing the host name is a one-click solution from the home page. Click the host name currently displayed, and enter the new name in the _Change Host Name_ box. One of the latest features is the option to provide a _Pretty name_.
|
||||
|
||||
Another feature added to Cockpit is the ability to connect to a directory server. Click _Join a domain_ and a pop-up will appear requesting the domain address or name, organization unit (optional), and the domain admin’s credentials. The Domain Membership group provides all the packages required to join an LDAP server including FreeIPA, and the popular Active Directory.
|
||||
|
||||
To opt-out, click on the domain name followed by _Leave Domain_. A warning will appear explaining the changes that will occur once the system is no longer on the domain. To confirm click the red _Leave Domain_ button.
|
||||
|
||||
![][8]
|
||||
|
||||
#### Configuring NTP and system date and time
|
||||
|
||||
Using the command-line and editing config files definitely takes the cake when it comes to maximum tweaking. However, there are times when something more straightforward would suffice. With Cockpit, you have the option to set the system’s date and time manually or automatically using NTP. Once synchronized, the information icon on the right turns from red to blue. The icon will disappear if you manually set the date and time.
|
||||
|
||||
To change the timezone, type the continent and a list of cities will populate beneath.
|
||||
|
||||
![][9]
|
||||
|
||||
#### Shutting down and restarting
|
||||
|
||||
You can easily shutdown and restart the server right from home screen in Cockpit. You can also delay the shutdown/reboot and send a message to warn users.
|
||||
|
||||
![][10]
|
||||
|
||||
#### Configuring the performance profile
|
||||
|
||||
If the _tuned_ and _tuned-utils_ packages are installed, performance profiles can be changed from the main screen. By default it is set to a recommended profile. However, if the purpose of the server requires more performance, we can change the profile from Cockpit to suit those needs.
|
||||
|
||||
![][11]
|
||||
|
||||
### Terminal web console
|
||||
|
||||
A Linux sysadmin’s toolbox would be useless without access to a terminal. This allows admins to fine-tune the server beyond what’s available in Cockpit. With the addition of themes, admins can quickly adjust the text and background colours to suit their preference.
|
||||
|
||||
Also, if you type **exit** by mistake, click the _Reset_ button in the top-right corner*.* This will provide a fresh screen with a flashing cursor.
|
||||
|
||||
![][12]
|
||||
|
||||
### Adding a remote server and the Dashboard overlay
|
||||
|
||||
The Headless Management group includes the Dashboard module (**cockpit-dashboard**). This provides an overview the of the CPU, memory, network, and disk performance in a real-time graph. Remote servers can also be added and managed through the same interface.
|
||||
|
||||
For example, to add a remote computer in Dashboard, click the **+** button. Enter the name or IP address of the server and select the colour of your choice. This helps to differentiate the stats of the servers in the graph. To switch between servers, click on the host name (as seen in the screen-cast below). To remove a server from the list, click the check-mark icon, then click the red trash icon. The example below demonstrates how Cockpit manages a remote machine named _server02.local.lan_.
|
||||
|
||||
![][13]
|
||||
|
||||
### Documentation and finding help
|
||||
|
||||
As always, the _man_ pages are a great place to find documentation. A simple search in the command-line results with pages pertaining to different aspects of using and configuring the web service.
|
||||
|
||||
```
|
||||
$ man -k cockpit
|
||||
cockpit (1) - Cockpit
|
||||
cockpit-bridge (1) - Cockpit Host Bridge
|
||||
cockpit-desktop (1) - Cockpit Desktop integration
|
||||
cockpit-ws (8) - Cockpit web service
|
||||
cockpit.conf (5) - Cockpit configuration file
|
||||
```
|
||||
|
||||
The Fedora repository also has a package called **cockpit-doc**. The package’s description explains it best:
|
||||
|
||||
> The Cockpit Deployment and Developer Guide shows sysadmins how to deploy Cockpit on their machines as well as helps developers who want to embed or extend Cockpit.
|
||||
|
||||
For more documentation visit <https://cockpit-project.org/external/source/HACKING>
|
||||
|
||||
### Conclusion
|
||||
|
||||
This article only touches upon some of the main functions available in Cockpit. Managing storage devices, networking, user account, and software control will be covered in an upcoming article. In addition, optional extensions such as the 389 directory service, and the _cockpit-ostree_ module used to handle packages in Fedora Silverblue.
|
||||
|
||||
The options continue to grow as more users adopt Cockpit. The interface is ideal for admins who want a light-weight interface to control their server(s).
|
||||
|
||||
What do you think about Cockpit? Share your experience and ideas in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/cockpit-and-the-evolution-of-the-web-user-interface/
|
||||
|
||||
作者:[Shaun Assam][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/sassam/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/08/cockpit-816x345.jpg
|
||||
[2]: https://fedoramagazine.org/cockpit-overview/
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2019/08/cockpit-login-screen.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/08/cockpit-home-screen.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2019/08/cockpit-system-info.gif
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2019/08/cockpit-ssh-key-fingerprints.png
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2019/08/cockpit-authentication.png
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2019/08/cockpit-hostname-domain.gif
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2019/08/cockpit-date-time.png
|
||||
[10]: https://fedoramagazine.org/wp-content/uploads/2019/08/cockpit-power-options.gif
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2019/08/cockpit-tuned.gif
|
||||
[12]: https://fedoramagazine.org/wp-content/uploads/2019/08/cockpit-terminal.gif
|
||||
[13]: https://fedoramagazine.org/wp-content/uploads/2019/08/cockpit-add-remote-servers.gif
|
||||
@ -0,0 +1,208 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Designing open audio hardware as DIY kits)
|
||||
[#]: via: (https://opensource.com/article/19/8/open-audio-kit-developer)
|
||||
[#]: author: (Chris Hermansen https://opensource.com/users/clhermansenhttps://opensource.com/users/alanfdosshttps://opensource.com/users/clhermansen)
|
||||
|
||||
Designing open audio hardware as DIY kits
|
||||
======
|
||||
Did you know you can build your own speaker systems? Muffsy creator
|
||||
shares how he got into making open audio hardware and why he started
|
||||
selling his designs to other DIYers.
|
||||
![Colorful sound wave graph][1]
|
||||
|
||||
Previously in this series about people who are developing audio technology in the open, I interviewed [Juan Rios, developer and maintainer of Guayadeque][2] and [Sander Jansen, developer and maintainer of Goggles Music Manager][3]. These conversations have broadened my thinking and helped me enjoy their software even more than before.
|
||||
|
||||
For this article, I contacted Håvard Skrödahl, founder of [Muffsy][4]. His hobby is designing open source audio hardware, and he offers his designs as kits for those of us who can't wait to wind up the soldering iron for another adventure.
|
||||
|
||||
I've built two of Håvard's kits: a [moving coil (MC) cartridge preamp][5] and a [moving magnet (MM) cartridge phono preamp][6]. Both were a lot of fun to build and sound great. They were also a bit of a stroll down memory lane for me. In my 20s, I built some other audio kits, including a [Hafler DH-200 power amplifier][7] and a [DH-110 preamplifier][8]. Before that, I built a power amplifier using a Motorola circuit design; both the design and the amplifier were lost along the way, but they were a lot of fun!
|
||||
|
||||
### Meet Håvard Skrödahl, open audio hardware maker
|
||||
|
||||
**Q: How did you get started designing music playback hardware?**
|
||||
|
||||
**A:** I was a teenager in the mid-'80, and listening to records and cassettes were the only options we had. Vinyl was, of course, the best quality, while cassettes were more portable. About five years ago, I was getting back into vinyl and found myself lacking the equipment I needed. So, I decided to make my own phono stage (also called a phono preamp). The first iteration was bulky and had a relatively bad [RIAA filter][9], but I improved it during the first few months.
|
||||
|
||||
The first version was completely homemade. I was messing about with toner transfer and chemicals and constantly breaking drill bits to create this board.
|
||||
|
||||
![Phono stage board top][10]
|
||||
|
||||
Top of the phono stage board
|
||||
|
||||
![Bottom of the phono stage board][11]
|
||||
|
||||
Bottom of the phono stage board
|
||||
|
||||
I was over the moon with this phono stage. It worked perfectly, even though the RIAA curve was out by quite a bit. It also had variable input impedance (greatly inspired by the [Audiokarma CNC phono stage][12]).
|
||||
|
||||
When I moved on to getting boards professionally made, I found that the impedance settings could be improved quite a bit. My setup needed adjustable gain, so I added it. The RIAA filter was completely redesigned, and it is (to my knowledge) the only accurate RIAA filter circuit that uses [standard E24 component values][13].
|
||||
|
||||
![Muffsy audio hardware boards][14]
|
||||
|
||||
Various iterations of boards in development.
|
||||
|
||||
**Q: How did you decide to offer your work as kits? And how did you go from kits to open source?**
|
||||
|
||||
**A:** The component values being E24 came from a lack of decent, component providers in my area (or so I thought, as it turned out I have a great provider nearby), so I had to go for standard values. This meant my circuit was well suited for DIY, and I started selling blank printed circuit boards on [Tindie][15].
|
||||
|
||||
What really made the phono stage suitable as a kit was a power supply that didn't require messing about with [mains electricity][16]. It's basically an AC adapter, a voltage doubler, and a couple of three-pin voltage regulators.
|
||||
|
||||
So there I was; I had a phono stage, a power supply, and the right (and relatively easy to source) components. The boards fit straight into the enclosure I'd selected, and I made a suitable back panel. I could now sell a DIY kit that turns into a working device once it is assembled. This is pretty unique; you won't see many kit suppliers provide everything that's needed to make a functional product.
|
||||
|
||||
![Phono stage kit with the power supply and back panel][17]
|
||||
|
||||
The assembled current phono stage kit with the power supply and back panel.
|
||||
|
||||
As a bonus, since this is just my hobby, I'm not even aiming for profit. This is also partly why my designs are open source. Not revealing who is using the designs, but you'll find them in more than one professional vinyl mastering studio, in governmental digitization projects, and even at a vinyl player manufacturer that you will have heard of.
|
||||
|
||||
**Q: Tell us a bit about your educational background. Are you an electrical engineer? Where did your interest in circuits come from?**
|
||||
|
||||
**A:** I went to a military school of electrical engineering (EE). My career has been pretty void of EE though, apart from a few years as a telephony switch technician. The music interest has stayed with me, though, and I've been dreaming of making something all my life. I would rather avoid mains electricity though, so signal level and below is where I'm happy.
|
||||
|
||||
**Q: In your day job, do you do hardware stuff as well? Or software? What about open source—does it matter to your day job?**
|
||||
|
||||
**A:** My profession is IT management, system architecture, and security. So I'm not doing any hardware designs at work. I wouldn't be where I am today without open source, so that is the other part of the reason why my designs are openly available.
|
||||
|
||||
**Q: Can you tell us a bit about what it takes to go from a design, to a circuit board, to producing a kit?**
|
||||
|
||||
**A:** I am motivated by my own needs when it comes to starting a new project. Or if I get inspired, like I was when I made a constant current [LED][18] tester. The LED tester required a very specific sub-milliampere meter, and it was kind of hard to find an enclosure for it. So the LED tester wasn't suited for a kit.
|
||||
|
||||
![LED tester][19]
|
||||
|
||||
LED tester
|
||||
|
||||
I made a [notch filter][20] that requires matched precision capacitors, and the potentiometers are quite hard to fine-tune. Besides, I don't see people lining up to buy this product, so it's not suited to be a kit.
|
||||
|
||||
![Notch filter][21]
|
||||
|
||||
Notch filter
|
||||
|
||||
I made an inverse RIAA filter using only surface-mount device [(SMD) components][22]—not something I would offer as a kit. I built an SMD vacuum pickup tool for this project, so it wasn't all for nothing.
|
||||
|
||||
![SMD vacuum pickup tool][23]
|
||||
|
||||
SMD vacuum pickup tool
|
||||
|
||||
I've made various PSU/transformer breakout boards, which are not suitable as kits because they require mains electricity.
|
||||
|
||||
![PSU/transformer breakout board][24]
|
||||
|
||||
PSU/transformer breakout boards
|
||||
|
||||
I designed and built the [MC Head Amp][25] without even owning an [MC cartridge][26]. I even built the [O2 headphone amp][27] without owning a pair of headphones, although people much smarter than me suspect it was a clever excuse for buying a pair of Sennheisers.
|
||||
|
||||
Kits need to be something I think people need, they must be easy to assemble (or rather difficult to assemble incorrectly), not too expensive nor require exotic components, and can't weigh too much because of the very expensive postage from Sweden.
|
||||
|
||||
Most importantly, I need to have time and space for another kit. This picture shows pretty much all the space I have available for my kits, two boxes deep, IKEA all the way.
|
||||
|
||||
![A shelf filled with boxed of Muffsy kits][28]
|
||||
|
||||
**Q: Are you a musician or audiophile? What kind of equipment do you have?**
|
||||
|
||||
**A:** I'm not a musician, and I am not an audiophile in the way most people would define such a person. I do know, from education and experience, that good sound doesn't have to cost a whole lot. It can be quite cheap, actually. A lot of the cost is in transformers, enclosures, and licenses (the stickers on the front of your gear). Stay away from those, and you're back at signal level audio that can be really affordable.
|
||||
|
||||
Don't get me wrong; there are a lot of gifted designers who spend an awful lot of time and creativity making the next great piece of equipment. They deserve to get paid for their work. What I mean is that the components that go into this equipment can be bought for not much money at all.
|
||||
|
||||
My equipment is a simple [op-amp][29]-based preamp with a rotational input-switch and a sub-$25 class-D amp based on the TPA3116 chip (which I will be upgrading to an IcePower 125ASX2). I'm using both the Muffsy Phono Preamp and the Muffsy MC Head Amp. Then I've got some really nice Dynaco A25 loudspeakers that I managed to refurbish through nothing more than good old dumb luck. I went for the cheapest Pro-Ject turntable that's still a "real" turntable. That's it. No surround, no remote control (yet), unless you count the Chromecast Audio that's connected to the back of my amp.
|
||||
|
||||
![Håvard Skrödahl's A/V setup][30]
|
||||
|
||||
Håvard's A/V setup
|
||||
|
||||
I'll happily shell out for quality components, good connectors, and shielded signal cables. But, to be diplomatic, I'd rather use the correct component for the job instead of the most expensive one. I do get questions about specific resistors and expensive "boutique" components now and then. I keep my answer short and remind people that my own builds are identical to what I sell on Tindie.
|
||||
|
||||
My preamp uses my MC Head Amp as a building block.
|
||||
|
||||
![Preamp internals][31]
|
||||
|
||||
Preamp internals
|
||||
|
||||
**Q: What kind of software do you use for hardware design?**
|
||||
|
||||
**A:** I've been using [Eagle][32] for many years. Getting into a different workflow takes a lot of time and requires a whole lot of mistakes, so no [KiCad][33] yet.
|
||||
|
||||
**Q: Can you tell us a bit about where your kits are going? Is there a new head amplifier? A new phono amplifier? What about a line-level pre-amp or power amp?**
|
||||
|
||||
**A:** If I were to do a power amp, I wouldn't dream of selling it because of what I said about mains electricity. Chip amps and [Class-D][34] seem to have taken over the DIY segment anyway, and I'm really happy with Class-D.
|
||||
|
||||
My latest kit is an input selector. It's something that's a cross between hardware and software as it uses an [ESP32][35] system on a chip microcontroller. And it's something that I want for myself.
|
||||
|
||||
The kit includes everything you need. It's got a rotational encoder, an infrared receiver, and I'm even adding a remote control to the kit. The software and hardware are available on GitHub, also under a permissive open source license, and will soon include Alexa voice support and [MQTT][36] for app or command line remote control.
|
||||
|
||||
![Input selector][37]
|
||||
|
||||
Input selector kit
|
||||
|
||||
My lineup now consists of preamps for MC and MM cartridges, a power supply and a back panel for them, and the input selector. I'm even selling bare circuit boards for a tube preamp and accompanying power supply.
|
||||
|
||||
These components make up pretty much all the internals of a complete preamplifier, which has become one of my main motivational factors.
|
||||
|
||||
I have nothing new or significantly better to provide in terms of an ordinary preamplifier, so I'm using a modified version of a well-known circuit. I cannot, and would not, sell this circuit, as it's proprietary.
|
||||
|
||||
Anyhow, here's my personal goal. It's still a work in progress, using an S3207 enclosure and a front panel made at Frontpanel Express.
|
||||
|
||||
![Muffsy preamp][38]
|
||||
|
||||
New Muffsy preamp prototype
|
||||
|
||||
* * *
|
||||
|
||||
Thanks, Håvard, that looks pretty great! I'd be happy to have something like that sitting on my Hi-Fi shelf.
|
||||
|
||||
I hope there are people out there just waiting to try their hand at audio kit building or even board layout from proven open source schematics, and they find Håvard's story motivating. As for me, I think my next project could be an [active crossover][39].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/open-audio-kit-developer
|
||||
|
||||
作者:[Chris Hermansen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/clhermansenhttps://opensource.com/users/alanfdosshttps://opensource.com/users/clhermansen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/colorful_sound_wave.png?itok=jlUJG0bM (Colorful sound wave graph)
|
||||
[2]: https://opensource.com/article/19/6/creator-guayadeque-music-player
|
||||
[3]: https://opensource.com/article/19/6/gogglesmm-developer-sander-jansen
|
||||
[4]: https://www.muffsy.com/
|
||||
[5]: https://opensource.com/article/18/5/building-muffsy-phono-head-amplifier-kit
|
||||
[6]: https://opensource.com/article/18/7/diy-amplifier-vinyl-records
|
||||
[7]: https://kenrockwell.com/audio/hafler/dh-200.htm
|
||||
[8]: https://www.hifiengine.com/manual_library/hafler/dh-110.shtml
|
||||
[9]: https://en.wikipedia.org/wiki/RIAA_equalization
|
||||
[10]: https://opensource.com/sites/default/files/uploads/phono-stagetop.png (Phono stage board top)
|
||||
[11]: https://opensource.com/sites/default/files/uploads/phono-stagebottom.png (Bottom of the phono stage board)
|
||||
[12]: https://forum.psaudio.com/t/the-cnc-phono-stage-diy/3613
|
||||
[13]: https://en.wikipedia.org/wiki/E_series_of_preferred_numbers
|
||||
[14]: https://opensource.com/sites/default/files/uploads/boards.png (Muffsy audio hardware boards)
|
||||
[15]: https://www.tindie.com/stores/skrodahl/
|
||||
[16]: https://en.wikipedia.org/wiki/Mains_electricity
|
||||
[17]: https://opensource.com/sites/default/files/uploads/phonostage-kit.png (Phono stage kit with the power supply and back panel)
|
||||
[18]: https://en.wikipedia.org/wiki/Light-emitting_diode
|
||||
[19]: https://opensource.com/sites/default/files/uploads/led-tester.png (LED tester)
|
||||
[20]: https://en.wikipedia.org/wiki/Band-stop_filter
|
||||
[21]: https://opensource.com/sites/default/files/uploads/notch-filter.png (Notch filter)
|
||||
[22]: https://en.wikipedia.org/wiki/Surface-mount_technology
|
||||
[23]: https://opensource.com/sites/default/files/uploads/smd-vacuum-pick-tool.png (SMD vacuum pickup tool)
|
||||
[24]: https://opensource.com/sites/default/files/uploads/psu-transformer-breakout-board.png (PSU/transformer breakout board)
|
||||
[25]: https://leachlegacy.ece.gatech.edu/headamp/
|
||||
[26]: https://blog.audio-technica.com/audio-solutions-question-week-differences-moving-magnet-moving-coil-phono-cartridges/
|
||||
[27]: http://nwavguy.blogspot.com/2011/07/o2-headphone-amp.html
|
||||
[28]: https://opensource.com/sites/default/files/uploads/kit-shelves.png (Muffsy kits on shelves)
|
||||
[29]: https://en.wikipedia.org/wiki/Operational_amplifier
|
||||
[30]: https://opensource.com/sites/default/files/uploads/av-setup.png (Håvard Skrödahl's A/V setup)
|
||||
[31]: https://opensource.com/sites/default/files/uploads/preamp-internals.png (Preamp internals)
|
||||
[32]: https://en.wikipedia.org/wiki/EAGLE_(program)
|
||||
[33]: https://en.wikipedia.org/wiki/KiCad
|
||||
[34]: https://en.wikipedia.org/wiki/Class-D_amplifier
|
||||
[35]: https://en.wikipedia.org/wiki/ESP32
|
||||
[36]: http://mqtt.org/
|
||||
[37]: https://opensource.com/sites/default/files/uploads/input-selector.png (Input selector)
|
||||
[38]: https://opensource.com/sites/default/files/uploads/muffsy-preamp.png (Muffsy preamp)
|
||||
[39]: https://www.youtube.com/watch?v=7u9OKPL1ezA&feature=youtu.be
|
||||
@ -0,0 +1,150 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to encrypt files with gocryptfs on Linux)
|
||||
[#]: via: (https://opensource.com/article/19/8/how-encrypt-files-gocryptfs)
|
||||
[#]: author: (Brian "bex" Exelbierd https://opensource.com/users/bexelbiehttps://opensource.com/users/sethhttps://opensource.com/users/marcobravo)
|
||||
|
||||
How to encrypt files with gocryptfs on Linux
|
||||
======
|
||||
Gocryptfs encrypts at the file level, so synchronization operations can
|
||||
work efficiently on each file.
|
||||
![Filing papers and documents][1]
|
||||
|
||||
[Gocryptfs][2] is a Filesystem in Userspace (FUSE)-mounted file-level encryption program. FUSE-mounted means that the encrypted files are stored in a single directory tree that is mounted, like a USB key, using the [FUSE][3] interface. This allows any user to do the mount—you don't need to be root. Because gocryptfs encrypts at the file level, synchronization operations that copy your files can work efficiently on each file. This contrasts with disk-level encryption, where the whole disk is encrypted as a single, large binary blob.
|
||||
|
||||
When you use gocryptfs in its normal mode, your files are stored on your disk in an encrypted format. However, when you mount the encrypted files, you get unencrypted access to your files, just like any other file on your computer. This means all your regular tools and programs can use your unencrypted files. Changes, new files, and deletions are reflected in real-time in the encrypted version of the files stored on your disk.
|
||||
|
||||
### Install gocryptfs
|
||||
|
||||
Installing gocryptfs is easy on [Fedora][4] because it is packaged for Fedora 30 and Rawhide. Therefore, **sudo dnf install gocryptfs** does all the required installation work. If you're not using Fedora, you can find details on installing from source, on Debian, or via Homebrew in the [Quickstart][5].
|
||||
|
||||
### Initialize your encrypted filesystem
|
||||
|
||||
To get started, you need to decide where you want to store your encrypted files. This example will keep the files in **~/.sekrit_files** so that they don't show up when doing a normal **ls**.
|
||||
|
||||
Start by initializing the filesystem. This will require you to choose a password. You are strongly encouraged to use a unique password you've never used anywhere else, as this is your key to unlocking your files. The project's authors recommend a password with between 64 and 128 bits of entropy. Assuming you use upper and lower case letters and numbers, this means your password should be between [11 and 22 characters long][6]. If you're using a password manager, this should be easy to accomplish with a generated password.
|
||||
|
||||
When you initialize the filesystem, you will see a unique key. Store this key somewhere securely, as it will allow you to access your files if you need to recover your files but have forgotten your password. The key works without your password, so keep it private!
|
||||
|
||||
The initialization routine looks like this:
|
||||
|
||||
|
||||
```
|
||||
$ mkdir ~/.sekrit_files
|
||||
$ gocryptfs -init ~/.sekrit_files
|
||||
Choose a password for protecting your files.
|
||||
Password:
|
||||
Repeat:
|
||||
|
||||
Your master key is:
|
||||
|
||||
XXXXXXXX-XXXXXXXX-XXXXXXXX-XXXXXXXX-
|
||||
XXXXXXXX-XXXXXXXX-XXXXXXXX-XXXXXXXX
|
||||
|
||||
If the gocryptfs.conf file becomes corrupted or you ever forget your password,
|
||||
there is only one hope for recovery: The master key. Print it to a piece of
|
||||
paper and store it in a drawer. This message is only printed once.
|
||||
The gocryptfs filesystem has been created successfully.
|
||||
You can now mount it using: gocryptfs .sekrit_files MOUNTPOINT
|
||||
```
|
||||
|
||||
If you look in the **~/.sekrit_files** directory, you will see two files: a configuration file and a unique directory-level initialization vector. You will not need to edit these two files by hand. Make sure you do not delete these files.
|
||||
|
||||
### Use your encrypted filesystem
|
||||
|
||||
To use your encrypted filesystem, you need to mount it. This requires an empty directory where you can mount the filesystem. For example, use the **~/my_files** directory. As you can see from the initialization, mounting is easy:
|
||||
|
||||
|
||||
```
|
||||
$ gocryptfs ~/.sekrit_files ~/my_files
|
||||
Password:
|
||||
Decrypting master key
|
||||
Filesystem mounted and ready.
|
||||
```
|
||||
|
||||
If you check out the **~/my_files** directory, you'll see it is empty. The configuration and initialization vector files aren't data, so they don't show up. Let's put some data in the filesystem and see what happens:
|
||||
|
||||
|
||||
```
|
||||
$ cp /usr/share/dict/words ~/my_files/
|
||||
$ ls -la ~/my_files/ ~/.sekrit_files/
|
||||
~/my_files/:
|
||||
.rw-r--r-- 5.0M bexelbie 19 Jul 17:48 words
|
||||
|
||||
~/.sekrit_files/:
|
||||
.r--------@ 402 bexelbie 19 Jul 17:39 gocryptfs.conf
|
||||
.r--------@ 16 bexelbie 19 Jul 17:39 gocryptfs.diriv
|
||||
.rw-r--r--@ 5.0M bexelbie 19 Jul 17:48 xAQrtlyYSFeCN5w7O3-9zg
|
||||
```
|
||||
|
||||
Notice that there is a new file in the **~/.sekrit_files** directory. This is the encrypted copy of the dictionary you copied in (the file name will vary). Feel free to use **cat** and other tools to examine these files and experiment with adding, deleting, and modifying files. Make sure to test with a few applications, such as LibreOffice.
|
||||
|
||||
Remember, this a filesystem mount, so the contents of **~/my_files** aren't saved to disk. You can verify this by running **mount | grep my_files** and observing the output. Only the encrypted files are written to your disk. The FUSE interface is doing real-time encryption and decryption of the files and presenting them to your applications and shell as a filesystem.
|
||||
|
||||
### Unmount the filesystem
|
||||
|
||||
When you're done with your files, you can unmount them. This causes the unencrypted filesystem to no longer be available. The encrypted files in **~/.sekrit_files** are unaffected. Unmount the filesystem using the FUSE mounter program with **fusermount -u ~/my_files** .
|
||||
|
||||
### Back up your data
|
||||
|
||||
One of the cool benefits of gocryptfs using file-level encryption is that it makes backing up your encrypted data easier. The files are safe to store on a synchronizing system, such as OwnCloud or Dropbox. The standard disclaimer about not modifying the same file at the same time applies. However, the files can be backed up even if they are mounted. You can also save your data any other way you would typically back up files. You don't need anything special.
|
||||
|
||||
When you do backups, make sure to include the **gocryptfs.diriv** file. This file is not a secret and can be saved with the backup. However, your **gocryptfs.conf** is a secret. When you control the entirety of the backup chain, such as with tape, you can back it up with the rest of the files. However, when the files are backed up to the cloud or publicly, you may wish to omit this file. In theory, if someone gets this file, the only thing protecting your files is the strength of your password. If you have chosen a [strong password][6], that may be enough; however, you need to consider your situation carefully. More details are in this gocryptfs [upstream issue][7].
|
||||
|
||||
### Bonus: Reverse mode
|
||||
|
||||
A neat feature of gocryptfs is the reverse mode function. In reverse mode, point gocryptfs at your unencrypted data, and it will create a mount point with an encrypted view of this data. This is useful for things such as creating encrypted backups. This is easy to do:
|
||||
|
||||
|
||||
```
|
||||
$ gocryptfs -reverse -init my_files
|
||||
Choose a password for protecting your files.
|
||||
Password:
|
||||
Repeat:
|
||||
|
||||
Your master key is:
|
||||
|
||||
XXXXXXXX-XXXXXXXX-XXXXXXXX-XXXXXXXX-
|
||||
XXXXXXXX-XXXXXXXX-XXXXXXXX-XXXXXXXX
|
||||
|
||||
If the gocryptfs.conf file becomes corrupted or you ever forget your password,
|
||||
there is only one hope for recovery: The master key. Print it to a piece of
|
||||
paper and store it in a drawer. This message is only printed once.
|
||||
The gocryptfs-reverse filesystem has been created successfully.
|
||||
You can now mount it using: gocryptfs -reverse my_files MOUNTPOINT
|
||||
|
||||
$ gocryptfs -reverse my_files sekrit_files
|
||||
Password:
|
||||
Decrypting master key
|
||||
Filesystem mounted and ready.
|
||||
```
|
||||
|
||||
Now **sekrit_files** contains an encrypted view of your unencrypted data from **my_files**. This can be backed up, shared, or handled as needed. The directory is read-only, as there is nothing useful you can do with those files except back them up.
|
||||
|
||||
A new file, **.gocryptfs.reverse.conf**, has been added to **my_files** to provide a stable encrypted view. This configuration file will ensure that each reverse mount will use the same encryption key. This way you could, for example, back up only changed files.
|
||||
|
||||
Gocryptfs is a flexible file encryption tool that allows you to store your data in an encrypted manner without changing your workflow or processes significantly. The design has undergone a security audit, and the developers have experience with other systems, such as **encfs**. I encourage you to add gocryptfs to your system today and start protecting your data.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/how-encrypt-files-gocryptfs
|
||||
|
||||
作者:[Brian "bex" Exelbierd][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bexelbiehttps://opensource.com/users/sethhttps://opensource.com/users/marcobravo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/documents_papers_file_storage_work.png?itok=YlXpAqAJ (Filing papers and documents)
|
||||
[2]: https://nuetzlich.net/gocryptfs/
|
||||
[3]: https://en.wikipedia.org/wiki/Filesystem_in_Userspace
|
||||
[4]: https://getfedora.org
|
||||
[5]: https://nuetzlich.net/gocryptfs/quickstart/
|
||||
[6]: https://github.com/rfjakob/gocryptfs/wiki/Password-Strength
|
||||
[7]: https://github.com/rfjakob/gocryptfs/issues/50
|
||||
147
sources/tech/20190816 How to plan your next IT career move.md
Normal file
147
sources/tech/20190816 How to plan your next IT career move.md
Normal file
@ -0,0 +1,147 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to plan your next IT career move)
|
||||
[#]: via: (https://opensource.com/article/19/8/plan-next-IT-career-move)
|
||||
[#]: author: (Matthew Broberg https://opensource.com/users/mbbroberghttps://opensource.com/users/marcobravo)
|
||||
|
||||
How to plan your next IT career move
|
||||
======
|
||||
Ask yourself these essential career questions about cloud, DevOps,
|
||||
coding, and where you're going next in IT.
|
||||
![Two hands holding a resume with computer, clock, and desk chair ][1]
|
||||
|
||||
Being part of technology-oriented communities has been an essential part of my career development. The first community that made a difference for me was focused on virtualization. Less than a year into my first career-related job, I met a group of friends who were significant contributors to this "vCommunity," and I found their enthusiasm to be contagious. That began our daily "nerd herd," where a handful of us met nearly every day for coffee before our shifts in tech support. We often discussed the latest software releases or hardware specs of a related storage array, and other times we strategized about how we could help each other grow in our careers.
|
||||
|
||||
> Any community worth being a part of will lift you up as you lift others up in the process.
|
||||
|
||||
In those years, I learned a foundational truth that's as true for me today as it was then: Any community worth being a part of will lift you up as you lift others up in the process.
|
||||
|
||||
![me with friends at New England VTUG meeting][2]
|
||||
|
||||
Matthew with friends [Jonathan][3] and [Paul][4] (L-R) at a New England VTUG meeting.
|
||||
|
||||
We began going to conferences together, with the first major effort by being the volunteer social team for a user group out of New England. We set up a Twitter account, sending play-by-plays as the event happened, but we also were there, in person, to welcome new members into our community of practice. While it wasn't my intention, finding that intersection of community and technology taught me the skills that led to my next job offer. And my story wasn't unique; many of us supported each other, and many of us advanced in our careers along the way.
|
||||
|
||||
While I remained connected to the vCommunity, I haven't kept up with the (mostly proprietary) technology stack we used to talk about.
|
||||
|
||||
My preferred technology shifted direction drastically when I fell in love with open source. It's been about five years since I knew virtualization deeply and two years since I spoke at an event centered on the topic. So it was a surprise and honor to be invited to give the opening keynote to the last edition of the [New England Virtualization Technology User Group][5]'s (VTUG) Summer Slam in July. Here's what I spoke about.
|
||||
|
||||
### Technology and, more importantly, employment
|
||||
|
||||
When I heard the user group was hosting its last-ever event, I said I'd love to be part of it. The challenge was that I didn't know how I would. While there is plenty of open source virtualization technology, I had shifted further up the stack toward applications and programming languages of late, so my technical angle wouldn't make for a good talk. The organizer said, "Good, that's what people need to hear."
|
||||
|
||||
Being further away from the vCommunity meant I had missed some of the context of the last few years. A noticeable amount of the community was facing unemployment. When they went to apply for a new job, there were new titles like [DevOps Engineer][6] and [SRE][7]. Not only that, I was told that the deep focus on a single vendor of proprietary virtualization technology is no longer enough. Virtualization and storage administration (my first area of expertise) appear to be the hardest hit by this shift. One story I heard at the event was that over 50% of a local user group's attendees were looking, and there was a gap in awareness of how to move forward.
|
||||
|
||||
So while I enjoy having lighthearted conversations with people learning to contribute to open source, this talk was different. It had more to do with people's lives than usual. The stakes were higher.
|
||||
|
||||
### 3 trends worth exploring
|
||||
|
||||
There are a thousand ways to summarize the huge waves of change that are taking place in the tech industry. In my talk, I offered the idea that cloud, DevOps, and coding are three distinct trends making some of those waves and worth considering as you plan the next steps in your IT-oriented career.
|
||||
|
||||
* Cloud, including the new operational model of IT that is often Kubernetes-based
|
||||
* DevOps, which rejects the silos, ticket systems, and blame of legacy IT departments
|
||||
* Coding, including the practice of infrastructure as code (accompanied by a ton of YAML)
|
||||
|
||||
|
||||
|
||||
I imagine them as literal waves, crashing down upon the ships of the old way to make way for the new.
|
||||
|
||||
![Adaption of The Great Wave Off Kanagawa][8]
|
||||
|
||||
Adaption of [The Great Wave Off Kanagawa][9]
|
||||
|
||||
We have two mutually exclusive options as we consider how to respond to these shifts. We can paddle hard, feeling like we're going against the current, or we can stay put and be crushed by the wave. One is uncomfortable in the short term, while the other is more comfortable for now. Only one option is survivable. It sounds scary, and I'm okay with that. The stakes are real.
|
||||
|
||||
![Adaption of The Great Wave Off Kanagawa][10]
|
||||
|
||||
Adaption of [The Great Wave Off Kanagawa][9]
|
||||
|
||||
Cloud, DevOps, and coding are each massive topics with a ton of nuance to unpack. But if want to retool your skills for the future, I'm confident that focusing on **any** of them will set you up for a successful next step.
|
||||
|
||||
### Finding the right adoption timeline
|
||||
|
||||
One of the most challenging aspects of this is the sheer onslaught of information. It's reasonable to ask what you should learn, specifically, and when. I'm reminded of the work of [Nassim Taleb][11] who, among his deeply thoughtful insights into risk, makes note of a powerful concept:
|
||||
|
||||
> "The longer a technology lives, the longer it can be expected to live."
|
||||
> – Nassim Taleb, [_Antifragile_][12] (2012)
|
||||
|
||||
This sticking power of technology may offer insight into the right time to jump on a wave of newness. It doesn't have to be right away, given that early adopters may find their efforts don't have enough stick-to-it-ness to linger beyond a passing trend. That aligns well with my style: I'm rarely an early adopter, and I'm comfortable with that fact. I leave a lot of the early testing and debugging of new projects to those who are excited by the uncertainty of it all, and I'll be around for the phase when the brilliant idea needs to be refined (or, as [Simon Wardley][13] puts it, I prefer the [Settling phase over the Pioneer one][14]). That also aligns well with the perspective of most admin-centric professionals I know. They're wary of new things because they know saying yes to something in production is easier than supporting it after it gets there.
|
||||
|
||||
![One theory on when to adopt technology as its being displaced][15]
|
||||
|
||||
What I also love about Taleb's words is they offer a reasonable equation to make sure you're not the last to adopt a technology. Why not be last? Because you'll be so far behind that no one will want to hire you.
|
||||
|
||||
So what does that equation look like? I think it's taking Taleb's theory, more broadly called the [Lindy effect][16], and doing the math: you can expect that any technology will be in existence at least as long as it was before a competitor came into play. So if X technology excited for 30 years before Y threatened its dominance, you can expect X to be in existence for another 30 years (even if Y is way more popular, powerful, and trendy). It takes a long time for technology to "die."
|
||||
|
||||
My observation is more of a half-life of that concept: you can expect broad adoption of Y technology halfway through the adoption curve. By that point, companies hiring will start to signal they want this knowledge on their team, and it's reasonable for even the most skeptical of Sysadmins to learn said technology. In practice, that may look like this, where ETOA is the estimated time of mass adoption:
|
||||
|
||||
![IP4 to IP6 estimated time of mass adoption][17]
|
||||
|
||||
Many would love for IPv6 to be widely adopted sooner than 2027, and this theory offers a potential reason why it takes so long. Change is going somewhere, but the pace more aligned with the Lindy effect than to those people's expectations.
|
||||
|
||||
To paraphrase statistician [George Box][18], "all models are wrong, but some are more useful than others." Taleb's adaptation of the Lindy effect helps me think about how I need to prioritize my learning relative to the larger waves of change happening in the industry.
|
||||
|
||||
### Asking the right questions
|
||||
|
||||
The thing I cannot say often enough is that _people who have IT admin skills have a ton of options when they look at the industry_.
|
||||
|
||||
Every person who has been an admin has had to learn new technology. They excel at it. And while mastery takes time, a decent amount of familiarity and a willingness to learn are very hirable skills. Learning a new technology and inspecting its operational model to anticipate its failures in production are hugely valuable to any project. I look at open source software projects on GitHub and GitLab regularly, and many are looking for feedback on how to get their projects ready for production environments. Admins are experts at operational improvement.
|
||||
|
||||
All that said, it can still be paralyzing to decide what to learn. When people are feeling stuck, I recommend asking yourself these questions to jumpstart your thinking:
|
||||
|
||||
1. What technology do you want to know?
|
||||
2. What's your next career?
|
||||
|
||||
|
||||
|
||||
The first question is full of important reminders. First off, many of us in IT have the privilege of choosing to study the things that bring us joy to learn. It's a wonderful feeling to be excited by our work, and I love when I see that in someone I'm mentoring.
|
||||
|
||||
Another favorite takeaway is that no one is born knowing any specific technology. All technology skills are learned skills. So, your back-of-the-mind thought that "I don't understand that" is often masking the worry that "I can't learn it." Investigate further, and you'll find that your nagging sense of impossibility is easily disproven by everything you've accomplished until this point. I find a gentle and regular reminder that all technology is learned is a great place to start. You've done this before; you will do so again.
|
||||
|
||||
Here's one more piece of advice: stick with one thing and go deep. Skills—and the stories we tell about them to potential employers—are more interesting the deeper we can go. Therefore, when you're learning to code in your language of choice, find a way to build something that you can talk about at length in a job interview. Maybe it's an Ansible module in Python or a Go module for Terraform. Either one is a lot more powerful than saying you can code Hello World in seven languages.
|
||||
|
||||
There is also power in asking yourself what your next career will be. It's a reminder that you have one and, to survive and advance, you have to continue learning. What got you here will not get you where you're going next.
|
||||
|
||||
It's freeing to find that your next career can be an evolution of what you know now or a doubling-down on something much larger. I advocate for evolutionary, not revolutionary. There is a lot of foundational knowledge in everything we know, and it can be powerful to us and the story we tell others when we stay connected to our past.
|
||||
|
||||
### Community is key
|
||||
|
||||
All careers evolve and skills develop. Many of us are drawn to IT because it requires continual learning. Know that you can do it, and stick with your community to help you along the way.
|
||||
|
||||
If you're looking for a way to apply your background in IT administration and you have an open source story to tell, we would love to help you share it. Read our [information for writers][19] to learn how.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/plan-next-IT-career-move
|
||||
|
||||
作者:[Matthew Broberg][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mbbroberghttps://opensource.com/users/marcobravo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/resume_career_document_general.png?itok=JEaFL2XI (Two hands holding a resume with computer, clock, and desk chair )
|
||||
[2]: https://opensource.com/sites/default/files/uploads/vtug.png (Matthew with friends at New England VTUG meeting)
|
||||
[3]: https://twitter.com/jfrappier
|
||||
[4]: https://twitter.com/paulbraren
|
||||
[5]: https://vtug.com/
|
||||
[6]: https://opensource.com/article/19/7/how-transition-career-devops-engineer
|
||||
[7]: https://opensource.com/article/19/7/sysadmins-vs-sres
|
||||
[8]: https://opensource.com/sites/default/files/uploads/greatwave.png (Adaption of The Great Wave Off Kanagawa)
|
||||
[9]: https://en.wikipedia.org/wiki/The_Great_Wave_off_Kanagawa
|
||||
[10]: https://opensource.com/sites/default/files/uploads/greatwave2.png (Adaption of The Great Wave Off Kanagawa)
|
||||
[11]: https://en.wikipedia.org/wiki/Nassim_Nicholas_Taleb
|
||||
[12]: https://en.wikipedia.org/wiki/Antifragile
|
||||
[13]: https://twitter.com/swardley
|
||||
[14]: https://blog.gardeviance.org/2015/03/on-pioneers-settlers-town-planners-and.html
|
||||
[15]: https://opensource.com/sites/default/files/articles/displacing-technology-lindy-effect-opensource.com_.png (One theory on when to adopt technology as its being displaced)
|
||||
[16]: https://en.wikipedia.org/wiki/Lindy_effect
|
||||
[17]: https://opensource.com/sites/default/files/uploads/ip4-to-etoa.png (IP4 to IP6 estimated time of mass adoption)
|
||||
[18]: https://en.wikipedia.org/wiki/George_E._P._Box
|
||||
[19]: https://opensource.com/how-submit-article
|
||||
@ -0,0 +1,209 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Share Your Keyboard and Mouse Between Linux and Raspberry Pi)
|
||||
[#]: via: (https://itsfoss.com/keyboard-mouse-sharing-between-computers/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Share Your Keyboard and Mouse Between Linux and Raspberry Pi
|
||||
======
|
||||
|
||||
_**This DIY tutorial teaches you to share mouse and keyboard between multiple computers using open source software Barrier.**_
|
||||
|
||||
I have a multi-monitor setup where my [Dell XPS running Ubuntu][1] is connected to two external monitors. I recently got a [Raspberry Pi 4][2] that has the capability to double up as a desktop. I bought a new screen so that I could set it up for monitoring the performance of my cloud servers.
|
||||
|
||||
Now the problem is that I have fours screens and one pair of keyboard and mouse. I could use a new keyboard-mouse pair but my desk doesn’t have enough free space and it’s not very convenient to switch keyboards and mouse all the time.
|
||||
|
||||
One way to tackle this problem would be to buy a kvm switch. This is a handy gadget that allows you to use same display screen, keyboard and mouse between several computers running various operating systems. You can easily find one for around $30 on Amazon.
|
||||
|
||||
Bestseller No. 1
|
||||
|
||||
[][3]
|
||||
|
||||
[UGREEN USB Switch Selector 2 Computers Sharing 4 USB Devices USB 2.0 Peripheral Switcher Box Hub for Mouse, Keyboard, Scanner, Printer, PCs with One-Button Swapping and 2 Pack USB A to A Cable][3]
|
||||
|
||||
Ugreen Group Limited - Electronics
|
||||
|
||||
$18.99 [][4]
|
||||
|
||||
But I didn’t go for the hardware solution. I opted for a software based approach to share the keyboard and mouse between computers.
|
||||
|
||||
I used [Barrier][5], an open source fork of the now proprietary software [Synergy][6]. Synergy Core is still open source but you can’t get encryption option in its GUI. With all its limitation, Barrier works fine for me.
|
||||
|
||||
Let’s see how you can use Barrier to share mouse and keyboard with multiple computers. Did I mention that you can even share clipboard and thus copy paste text between the computers?
|
||||
|
||||
### Set up Barrier to share keyboard and mouse between Linux and Raspberry Pi or other devices
|
||||
|
||||
![][7]
|
||||
|
||||
I have prepared this tutorial with Ubuntu 18.04.3 and Raspbian 10. Some installation instructions may differ based on your distribution and version but you’ll get the idea of what you need to do here.
|
||||
|
||||
#### Step 1: Install Barrier
|
||||
|
||||
The first step is obvious. You need to install Barrier in your computer.
|
||||
|
||||
Barrier is available in the universe repository starting Ubuntu 19.04 so you can easily install it using apt command.
|
||||
|
||||
You’ll have to use the snap version of Barrier in Ubuntu 18.04. Open Software Center and search for Barrier. I recommend using barrier-maxiberta
|
||||
|
||||
![Install this Barrier version][8]
|
||||
|
||||
On other distributions, you should [enable Snap][9] first and then use this command:
|
||||
|
||||
```
|
||||
sudo snap install barrier-maxiberta
|
||||
```
|
||||
|
||||
Barrier is available in Debian 10 repositories. So installing barrier on Raspbian was easy with the [apt command][10]:
|
||||
|
||||
```
|
||||
sudo apt install barrier
|
||||
```
|
||||
|
||||
Once you have installed the software, it’s time to configure it.
|
||||
|
||||
[][11]
|
||||
|
||||
Suggested read Fix Application Installation Issues In elementary OS
|
||||
|
||||
#### Step 2: Configure Barrier server
|
||||
|
||||
Barrier works on server-client model. You should configure your main computer as server and the secondary computer as client.
|
||||
|
||||
In my case, my Ubuntu 18.04 is my main system so I set it up as the server. Search for Barrier in menu and start it.
|
||||
|
||||
![Setup Barrier as server][12]
|
||||
|
||||
You should see an IP address and an SSL fingerprint. It’s not entirely done because you have to configure the server a little. Click on Configure Server option.
|
||||
|
||||
![Configure the Barrier server][13]
|
||||
|
||||
In here, you should see your own system in the center. Now you have to drag and drop the computer icon from the top right to a suitable position. The position is important because that’s how your mouse pointer will move between screens.
|
||||
|
||||
![Setup Barrier server with client screens][14]
|
||||
|
||||
Do note that you should provide the [hostname][15] of the client computer. In my case, it was raspberrypi. It won’t work if the hostname is not correct. Don’t know the client’s hostname? Don’t worry, you can get it from the client system.
|
||||
|
||||
#### Step 3: Setup barrier client
|
||||
|
||||
On the second computer, start Barrier and choose to use it as client.
|
||||
|
||||
![Setup Barrier Client on Raspberry Pi][16]
|
||||
|
||||
You need to provide the IP address of Barrier server. You can find this IP address on the Barrier application running on the main system (see the screenshots in previous section).
|
||||
|
||||
![Setup Barrier Client on Raspberry Pi][17]
|
||||
|
||||
If you see an option to accept secure connection from another computer, accept it.
|
||||
|
||||
You should be now able to move your mouse pointer between the screens connected to two different computers running two different operating systems. How cool is that!
|
||||
|
||||
### Optional: Autostart Barrier [Intermediate to Advanced Users]
|
||||
|
||||
Now that you have setup Barrier and enjoying by using the same mouse and keyboard for more than one computers, what happens when you reboot your system? You need to start Barrier in both the systems again, right? This means that you need to connect keyboard-mouse to the second computer as well.
|
||||
|
||||
[][18]
|
||||
|
||||
Suggested read How To Fix Windows Updates Stuck At 0%
|
||||
|
||||
Since I use Wireless mouse and keyboard, this is still easier as all I need to do is to take the adapter from my laptop and plug it in the Raspberry Pi. This works but I don’t want to do this extra step. This is why I made Barrier running at the start on both systems so that I could use the same mouse and keyboard without any additional step.
|
||||
|
||||
There is no autostart option in the Barrier application. But it’s easy to [add an application to autostart in Ubuntu][19]. Just open the Startup Applications program and add the command _**barrier-maxiberta.barrier**_ here.
|
||||
|
||||
![Adding Barrier To Startup applications in Ubuntu][20]
|
||||
|
||||
That was the easy part. It’s not the same in Raspberry Pi though. Since Raspbian uses systemd, you can use it to create a new service that will run at the boot time.
|
||||
|
||||
Open a terminal and create a new file named barrier.service in /etc/systemd/system directory. If this directory doesn’t exist, create it. You can use your favorite command line text editor for this task. I used Vim here.
|
||||
|
||||
```
|
||||
sudo vim /etc/systemd/system/barrier.service
|
||||
```
|
||||
|
||||
Now add lines like these to your file. _**You must replace 192.168.0.109 with your barrier server’s IP address.**_
|
||||
|
||||
```
|
||||
[Unit]
|
||||
Description=Barrier Client mouse/keyboard share
|
||||
Requires=display-manager.service
|
||||
After=display-manager.service
|
||||
StartLimitIntervalSec=0
|
||||
|
||||
[Service]
|
||||
Type=forking
|
||||
ExecStart=/usr/bin/barrierc --no-restart --name raspberrypi --enable-crypto 192.168.0.109
|
||||
Restart=always
|
||||
RestartSec=10
|
||||
User=pi
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
```
|
||||
|
||||
Save your file. I would advise to run the command mentioned in ExecStart line manually to see if it works or not. This will save you some headache later.
|
||||
|
||||
Reload the systemd daemon:
|
||||
|
||||
```
|
||||
sudo systemctl daemon-reload
|
||||
```
|
||||
|
||||
Now start this new service
|
||||
|
||||
```
|
||||
systemctl start barrier.service
|
||||
```
|
||||
|
||||
Check its status to see if its running fine:
|
||||
|
||||
```
|
||||
systemctl status barrier.service
|
||||
```
|
||||
|
||||
If it works, add it to startup services:
|
||||
|
||||
```
|
||||
systemctl enable barrier.service
|
||||
```
|
||||
|
||||
This should take care of things for you. Now you should be able to control the Raspberry Pi (or any other second computer) with a single keyboard mouse pair.
|
||||
|
||||
I know that these DIY stuff may not work straightforward for everyone so if you face issues, let me know in the comments and I’ll try to help you out.
|
||||
|
||||
If it worked for you or if you use some other solution to share the mouse and keyboard between the computers, do mention it in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/keyboard-mouse-sharing-between-computers/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/dell-xps-13-ubuntu-review/
|
||||
[2]: https://itsfoss.com/raspberry-pi-4/
|
||||
[3]: https://www.amazon.com/UGREEN-Selector-Computers-Peripheral-One-Button/dp/B01MXXQKGM?SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B01MXXQKGM&keywords=kvm%20switch (UGREEN USB Switch Selector 2 Computers Sharing 4 USB Devices USB 2.0 Peripheral Switcher Box Hub for Mouse, Keyboard, Scanner, Printer, PCs with One-Button Swapping and 2 Pack USB A to A Cable)
|
||||
[4]: https://www.amazon.com/gp/prime/?tag=chmod7mediate-20 (Amazon Prime)
|
||||
[5]: https://github.com/debauchee/barrier
|
||||
[6]: https://symless.com/synergy
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/Share-Keyboard-and-Mouse.jpg?resize=800%2C450&ssl=1
|
||||
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/barrier-ubuntu-snap.jpg?ssl=1
|
||||
[9]: https://itsfoss.com/install-snap-linux/
|
||||
[10]: https://itsfoss.com/apt-command-guide/
|
||||
[11]: https://itsfoss.com/fix-application-installation-issues-elementary-os-loki/
|
||||
[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/barrier-2.jpg?resize=800%2C512&ssl=1
|
||||
[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/barrier-server-ubuntu.png?resize=800%2C450&ssl=1
|
||||
[14]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/barrier-server-configuration.png?ssl=1
|
||||
[15]: https://itsfoss.com/change-hostname-ubuntu/
|
||||
[16]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/setup-barrier-client.jpg?resize=800%2C400&ssl=1
|
||||
[17]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/setup-barrier-client-2.jpg?resize=800%2C400&ssl=1
|
||||
[18]: https://itsfoss.com/fix-windows-updates-stuck-0/
|
||||
[19]: https://itsfoss.com/manage-startup-applications-ubuntu/
|
||||
[20]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/adding-barrier-to-startup-apps-ubuntu.jpg?ssl=1
|
||||
@ -0,0 +1,321 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Create Availability Zones in OpenStack from Command Line)
|
||||
[#]: via: (https://www.linuxtechi.com/create-availability-zones-openstack-command-line/)
|
||||
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
|
||||
|
||||
How to Create Availability Zones in OpenStack from Command Line
|
||||
======
|
||||
|
||||
In **OpenStack** terminology, **Availability Zones (AZ**) is defined as a logical partition of compute(nova), block storage (cinder) and network Service (neutron). Availability zones are required to segregate the work load of environments like production and non-production, let me elaborate this statement.
|
||||
|
||||
[![Availability-Zones-OpenStack-Command-Line][1]][2]
|
||||
|
||||
let’s suppose we have a tenant in OpenStack who wants to deploy their VMs in Production and Non-Production, so to create this type of setup in openstack , first we have to identify which computes will be considered as Production and Non-production then we have to create host-aggregate group where we will add the computes to the host-aggregate group and then we will map th host aggregate group to the Availability Zone.
|
||||
|
||||
In this tutorial we will demonstrate how to create and use computes availability zones in openstack via command line.
|
||||
|
||||
### Creating compute availability zones
|
||||
|
||||
Whenever OpenStack is deployed, Nova is the default Availability Zone(AZ) created automatically and all the compute nodes belongs to Nova AZ. Run the below openstack command from the controller node to list Availability zones,
|
||||
|
||||
```
|
||||
~# source openrc
|
||||
~# openstack availability zone list
|
||||
+-----------+-------------+
|
||||
| Zone Name | Zone Status |
|
||||
+-----------+-------------+
|
||||
| internal | available |
|
||||
| nova | available |
|
||||
| nova | available |
|
||||
| nova | available |
|
||||
+-----------+-------------+
|
||||
~#
|
||||
```
|
||||
|
||||
To list only compute’s availability zones, run the beneath openstack command,
|
||||
|
||||
```
|
||||
~# openstack availability zone list --compute
|
||||
+-----------+-------------+
|
||||
| Zone Name | Zone Status |
|
||||
+-----------+-------------+
|
||||
| internal | available |
|
||||
| nova | available |
|
||||
+-----------+-------------+
|
||||
~#
|
||||
```
|
||||
|
||||
To list all compute hosts which are mapped to nova availability zone execute the below command,
|
||||
|
||||
```
|
||||
~# openstack host list | grep -E "Zone|nova"
|
||||
| Host Name | Service | Zone |
|
||||
| compute-0-1 | compute | nova |
|
||||
| compute-0-2 | compute | nova |
|
||||
| compute-0-4 | compute | nova |
|
||||
| compute-0-3 | compute | nova |
|
||||
| compute-0-8 | compute | nova |
|
||||
| compute-0-6 | compute | nova |
|
||||
| compute-0-9 | compute | nova |
|
||||
| compute-0-5 | compute | nova |
|
||||
| compute-0-7 | compute | nova |
|
||||
~#
|
||||
```
|
||||
|
||||
Let’s create a two host-aggregate group with name **production** and **non-production**, add compute-4,5 & 6 to production host aggregate group and compute-7,8 & 9 to non-production host aggregate group.
|
||||
|
||||
Create Production and Non-Production Host aggregate using following OpenStack commands,
|
||||
|
||||
```
|
||||
~# openstack aggregate create production
|
||||
+-------------------+----------------------------+
|
||||
| Field | Value |
|
||||
+-------------------+----------------------------+
|
||||
| availability_zone | None |
|
||||
| created_at | 2019-08-17T03:02:41.561259 |
|
||||
| deleted | False |
|
||||
| deleted_at | None |
|
||||
| id | 7 |
|
||||
| name | production |
|
||||
| updated_at | None |
|
||||
+-------------------+----------------------------+
|
||||
|
||||
~# openstack aggregate create non-production
|
||||
+-------------------+----------------------------+
|
||||
| Field | Value |
|
||||
+-------------------+----------------------------+
|
||||
| availability_zone | None |
|
||||
| created_at | 2019-08-17T03:02:53.806713 |
|
||||
| deleted | False |
|
||||
| deleted_at | None |
|
||||
| id | 10 |
|
||||
| name | non-production |
|
||||
| updated_at | None |
|
||||
+-------------------+----------------------------+
|
||||
~#
|
||||
```
|
||||
|
||||
Now create the availability zones and associate it to its respective host aggregate groups
|
||||
|
||||
**Syntax:**
|
||||
|
||||
# openstack aggregate set –zone <az_name> <host_aggregate_name>
|
||||
|
||||
```
|
||||
~# openstack aggregate set --zone production-az production
|
||||
~# openstack aggregate set --zone non-production-az non-production
|
||||
```
|
||||
|
||||
Finally add the compute host to its host-aggregate group
|
||||
|
||||
**Syntax:**
|
||||
|
||||
# openstack aggregate add host <host_aggregate_name> <compute_host>
|
||||
|
||||
```
|
||||
~# openstack aggregate add host production compute-0-4
|
||||
~# openstack aggregate add host production compute-0-5
|
||||
~# openstack aggregate add host production compute-0-6
|
||||
```
|
||||
|
||||
Similarly add compute host to non-production host aggregation group,
|
||||
|
||||
```
|
||||
~# openstack aggregate add host non-production compute-0-7
|
||||
~# openstack aggregate add host non-production compute-0-8
|
||||
~# openstack aggregate add host non-production compute-0-9
|
||||
```
|
||||
|
||||
Execute the beneath openstack commands to verify Host aggregate group and its availability zone
|
||||
|
||||
```
|
||||
~# openstack aggregate list
|
||||
+----+----------------+-------------------+
|
||||
| ID | Name | Availability Zone |
|
||||
+----+----------------+-------------------+
|
||||
| 7 | production | production-az |
|
||||
| 10 | non-production | non-production-az |
|
||||
+----+----------------+-------------------+
|
||||
~#
|
||||
```
|
||||
|
||||
Run below commands to list computes associated to AZ and host aggregate group
|
||||
|
||||
```
|
||||
~# openstack aggregate show production
|
||||
+-------------------+--------------------------------------------+
|
||||
| Field | Value |
|
||||
+-------------------+--------------------------------------------+
|
||||
| availability_zone | production-az |
|
||||
| created_at | 2019-08-17T03:02:42.000000 |
|
||||
| deleted | False |
|
||||
| deleted_at | None |
|
||||
| hosts | [u'compute-0-4', u'compute-0-5', u'compute-0-6'] |
|
||||
| id | 7 |
|
||||
| name | production |
|
||||
| properties | |
|
||||
| updated_at | None |
|
||||
+-------------------+--------------------------------------------+
|
||||
|
||||
~# openstack aggregate show non-production
|
||||
+-------------------+---------------------------------------------+
|
||||
| Field | Value |
|
||||
+-------------------+---------------------------------------------+
|
||||
| availability_zone | non-production-az |
|
||||
| created_at | 2019-08-17T03:02:54.000000 |
|
||||
| deleted | False |
|
||||
| deleted_at | None |
|
||||
| hosts | [u'compute-0-7', u'compute-0-8', u'compute-0-9'] |
|
||||
| id | 10 |
|
||||
| name | non-production |
|
||||
| properties | |
|
||||
| updated_at | None |
|
||||
+-------------------+---------------------------------------------+
|
||||
~#
|
||||
```
|
||||
|
||||
Above command’s output confirm that we have successfully create host aggregate group and availability zones.
|
||||
|
||||
### Launch Virtual Machines in Availability Zones
|
||||
|
||||
Now let’s create couple virtual machines in these two availability zones, to create a vm in particular availability zone use below command,
|
||||
|
||||
**Syntax:**
|
||||
|
||||
# openstack server create –flavor <flavor-name> –image <Image-Name-Or-Image-ID> –nic net-id=<Network-ID> –security-group <Security-Group-ID> –key-name <Keypair-Name> –availability-zone <AZ-Name> <VM-Name>
|
||||
|
||||
Example is shown below:
|
||||
|
||||
```
|
||||
~# openstack server create --flavor m1.small --image Cirros --nic net-id=37b9ab9a-f198-4db1-a5d6-5789b05bfb4c --security-group f8dda7c3-f7c3-423b-923a-2b21fe0bbf3c --key-name mykey --availability-zone production-az test-vm-prod-az
|
||||
```
|
||||
|
||||
Run below command to verify virtual machine details:
|
||||
|
||||
```
|
||||
~# openstack server show test-vm-prod-az
|
||||
```
|
||||
|
||||
![Openstack-Server-AZ-command][1]
|
||||
|
||||
To create a virtual machine in a specific compute node under availability zone, use the below command,
|
||||
|
||||
**Syntax:**
|
||||
|
||||
# openstack server create –flavor <flavor-name> –image <Image-Name-Or-Image-ID> –nic net-id=<Network-ID> –security-group <Security-Group-ID> –key-name {Keypair-Name} –availability-zone <AZ-Name>:<Compute-Host> <VM-Name>
|
||||
|
||||
Let suppose we want to spin a vm under production AZ on specific compute (compute-0-6), so to accomplish this, run the beneath command,
|
||||
|
||||
```
|
||||
~# openstack server create --flavor m1.small --image Cirros --nic net-id=37b9ab9a-f198-4db1-a5d6-5789b05bfb4c --security-group f8dda7c3-f7c3-423b-923a-2b21fe0bbf3c --key-name mykey --availability-zone production-az:compute-0-6 test-vm-prod-az-host
|
||||
```
|
||||
|
||||
Execute following command to verify the VM details:
|
||||
|
||||
```
|
||||
~# openstack server show test-vm-prod-az-host
|
||||
```
|
||||
|
||||
Output above command would be something like below:
|
||||
|
||||
![OpenStack-VM-AZ-Specific-Host][1]
|
||||
|
||||
Similarly, we can create virtual machines in non-production AZ, example is shown below
|
||||
|
||||
```
|
||||
~# openstack server create --flavor m1.small --image Cirros --nic net-id=37b9ab9a-f198-4db1-a5d6-5789b05bfb4c --security-group f8dda7c3-f7c3-423b-923a-2b21fe0bbf3c --key-name mykey --availability-zone non-production-az vm-nonprod-az
|
||||
```
|
||||
|
||||
Use below command verify the VM details,
|
||||
|
||||
```
|
||||
~# openstack server show vm-nonprod-az
|
||||
```
|
||||
|
||||
Output of above command would be something like below,
|
||||
|
||||
![OpenStack-Non-Production-AZ-VM][1]
|
||||
|
||||
### Removing Host aggregate group and Availability Zones
|
||||
|
||||
Let’s suppose we want to remove /delete above created host aggregate group and availability zones, for that first we must remove host from the host aggregate group, use the below command,
|
||||
|
||||
```
|
||||
~# openstack aggregate show production
|
||||
```
|
||||
|
||||
Above command will give u the list of compute host which are added to production host aggregate group.
|
||||
|
||||
Use below command to remove host from the host aggregate group
|
||||
|
||||
**Syntax:**
|
||||
|
||||
# openstack aggregate remove host <host-aggregate-name> <compute-name>
|
||||
|
||||
```
|
||||
~# openstack aggregate remove host production compute-0-4
|
||||
~# openstack aggregate remove host production compute-0-5
|
||||
~# openstack aggregate remove host production compute-0-6
|
||||
```
|
||||
|
||||
Once you remove all host from the group, then re-run the below command,
|
||||
|
||||
```
|
||||
~# openstack aggregate show production
|
||||
+-------------------+----------------------------+
|
||||
| Field | Value |
|
||||
+-------------------+----------------------------+
|
||||
| availability_zone | production-az |
|
||||
| created_at | 2019-08-17T03:02:42.000000 |
|
||||
| deleted | False |
|
||||
| deleted_at | None |
|
||||
| hosts | [] |
|
||||
| id | 7 |
|
||||
| name | production |
|
||||
| properties | |
|
||||
| updated_at | None |
|
||||
+-------------------+----------------------------+
|
||||
~#
|
||||
```
|
||||
|
||||
As we can see in above output there is no compute host associated to production host aggregate group, now we are good to remove the group
|
||||
|
||||
Use below command to delete host aggregate group and its associated availability zone
|
||||
|
||||
```
|
||||
~# openstack aggregate delete production
|
||||
```
|
||||
|
||||
Run the following command to check whether availability zone has been removed or not,
|
||||
|
||||
```
|
||||
~# openstack availability zone list | grep -i production-az
|
||||
~#
|
||||
```
|
||||
|
||||
Similarly, you can refer the above steps to remove or delete non-production host aggregate and its availability zone.
|
||||
|
||||
That’s all from this tutorial, in case above content helps you to understand OpenStack host aggregate and availability zones then please do share your feedback and comments.
|
||||
|
||||
**Read Also: [Top 30 OpenStack Interview Questions and Answers][3]**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/create-availability-zones-openstack-command-line/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linuxtechi.com/author/pradeep/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: https://www.linuxtechi.com/wp-content/uploads/2019/08/Availability-Zones-OpenStack-Command-Line.jpg
|
||||
[3]: https://www.linuxtechi.com/openstack-interview-questions-answers/
|
||||
@ -0,0 +1,316 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Command Line Heroes: Season 1: OS Wars)
|
||||
[#]: via: (https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-1)
|
||||
[#]: author: (redhat https://www.redhat.com)
|
||||
|
||||
Command Line Heroes: Season 1: OS Wars
|
||||
======
|
||||
Saron Yitbarek:
|
||||
|
||||
有些故事如史诗般,惊险万分,在我脑海中似乎出现了星球大战电影开头的爬行文字。你知道的,就像-
|
||||
|
||||
Voice Actor:
|
||||
|
||||
第一集,操作系统大战。
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
是的,就像那样子。
|
||||
|
||||
Voice Actor:
|
||||
|
||||
[00:00:30]
|
||||
|
||||
当前形势比较紧张。Bill Gates 与 Steve Jobs 的帝国发起了一场无可避免的专有软件之战。Gates 与 IBM 结成了强大的联盟,而 Jobs 拒绝对它的硬件和操作系统开放授权。他们争夺统治地位的争斗在一场操作系统战争中席卷了整个银河系。与此同时,帝王所不知道的是,在偏远之地,开源的反叛者们开始集聚。
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:01:00]
|
||||
|
||||
好吧。这也许有点戏剧性,但当我们谈论 80 年代,90 年代和 00 年代的操作系统之争时,这也不算言过其实。确实曾经发生过一场史诗级的通知之战。Steve Jobs 和 Bill Gates 确实掌握着数十亿美元的命运。掌控了操作系统,你就掌握了绝大多数人使用计算机的方式,我们互相通讯的方式,我们获取信息的方式。我可以一直罗列下去,不过你知道我的意思。掌握了操作系统,你就是帝王。
|
||||
|
||||
[00:01:30]
|
||||
|
||||
我是 Saron Yitbarek,你现在收听的是代码英雄,一款红帽公司原创的博客节目。你问,什么是代码英雄?嗯,如果你创造而不仅仅是使用,如果你相信开发者拥有构建美好未来的能力,如果你希望拥有一个大家都有权利表达科技如何塑造生活的世界,那么你,我的朋友,就是代码英雄。在本系列节目中,我们将为你带来那些"白码起家(原文是 from the command line up,应该是改编自 from the ground up)" 改变技术的程序员故事。那么我是谁,凭什么指导你踏上这段艰苦的旅程?Saron Yitbarek 是哪根葱?嗯,事实上我觉得我跟你差不多。我是一名面向初学者的开发人员,我做的任何事都依赖于开源软件。这是我的世界。通过在博客中讲故事,我可以跳出无聊的日常工作,看清大局。希望它对你也一样有用。
|
||||
|
||||
[00:02:00]
|
||||
|
||||
|
||||
[00:02:30]
|
||||
|
||||
[00:03:00]
|
||||
|
||||
我迫不及待地想直到,开源技术从何而来?我的意思时,我对 Linus Torvalds 和 Linux ® 的荣耀有一些了解,我相信你也一样,但是说真的,开源并不是一开始就有的对吗?如果我像发至内心的感激最新最棒的技术,比如 DevOps 和 containers 之类的,我感觉我对那些早期的开发者有所亏欠,我有必要了解这些东西来自何处。所以,让我们暂时先不用担心内存泄露和缓冲溢出。我们的旅程从操作系统之战开始,这是一场波澜壮阔的桌面控制之战。这场战争亘古未有,因为。首先,在计算机时代,大公司拥有指数级的规模优势; 其次,从未有过这么一场控制争夺战是如此变化多端。Bill Gates 和 Steve Jobs? 他们也不知道结果会如何,但是到目前为止,这个故事进行到一半的时候,他们所争夺的所有东西都将发声改变,进化,最终上升到云端。
|
||||
|
||||
[00:03:30]
|
||||
|
||||
[00:04:00]
|
||||
|
||||
好的,让我们回到 1983 年的秋季。还有六年我才出生。那时候的总统还是 Ronald Reagan,美国和苏联扬言要把星球拖入核战争中。在 Honolulu 的公民中心正在举办一年一度的苹果公司销售会议。一群苹果公司的员工正在等待 Steve Jobs 上台。他 28 岁,热情洋溢,看起来非常自信。Jobs 很严肃地对着麦克风说他邀请了三个行业专家来软件进行了一次小组讨论。然而随后发生的事情你肯定想不到。超级俗气的 80 年代音乐响彻整个房间。一堆多彩灯管照亮了舞台,然后一个播音员的声音响起-
|
||||
|
||||
Voice Actor:
|
||||
|
||||
女士们,先生们,现在是麦金塔软件的约会游戏。
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:04:30]
|
||||
|
||||
[00:05:00]
|
||||
|
||||
Jobs 的脸上露出一个大大的笑容,台上有三个 CEO 都需要轮流向他示好。这基本上就是 80 年代科技界的钻石王老五。两个软件大佬讲完话后,然后就轮到第三个人讲话了。仅此而已不是吗?是得。新面孔 Bill Gates 带着一个大大的方框眼镜遮住了半个脸。他宣称在 1984 年,微软的一半收入将来至于麦金塔软件。他的这番话引来了观众热情的掌声。但是他们不知道的是,在一个月后,Bill Gates 将会宣布发布 Windows 1.0 的计划。你永远也猜不到 Jobs 正在跟未来苹果最大的敌人打情骂俏。但微软和苹果即将经历科技史上最糟糕的婚礼。他们会彼此背叛,相互毁灭,但又深深地、痛苦地捆绑在一起。
|
||||
|
||||
James Allworth:
|
||||
|
||||
[00:05:30]
|
||||
|
||||
我猜从哲学上来讲,一个更理想化,注重用户体验高于一切,是一个集成的组织,而微软则更务实,更模块化-
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
这是 James Allworth。他是一位多产的科技作家,曾在苹果零售团队工作。注意他给出的苹果的定义。一个集成的组织。那种只对自己负责的公司。一个不想依赖别人的公司。这是关键。
|
||||
|
||||
James Allworth:
|
||||
|
||||
[00:06:00]
|
||||
|
||||
苹果是一家集成的公司,它专注于愉悦的用户体验,这意味着它希望控制整技术栈以及交付的一切内容,从硬件到操作系统,甚至运行在操作系统上的应用程序。
|
||||
当新的创新,重要的创新刚刚进入市场,而你需要横跨软硬件,并且能够根据自己意愿和软件的革新来改变硬件时,这是一个优势。例如-,
|
||||
|
||||
[00:06:30]
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:07:00]
|
||||
很多人喜欢这种整合的模式,并因此成为了苹果的铁杆粉丝。还有很多人则选择了微软。回到 Honolulu 的销售会议上。在同一场活动中,乔布斯向观众展示了他即将发布的超级碗广告。你可能已经亲眼见过这则广告了。想想 George Orwell 的 1984。在这个冰冷、灰暗的世界里,在独裁者投射的目光下,没有头脑的机器人正在缓慢移动。这些机器人代表着 IBM 的用户们。然后,代表苹果公司的美丽而健壮的 Anya Major 穿着鲜艳的衣服跑过大厅。她向着老大哥的屏幕猛地透出大锤,将它砸成一片一片的。老大哥的咒语解除了,一个低沉的声音响起,苹果公司要开始介绍麦金塔了。
|
||||
|
||||
Voice Actor:
|
||||
|
||||
这就是为什么现实中的 1984 跟小说 1984 不一样了。
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:07:30]
|
||||
|
||||
是的,现在回顾这则广告,认为苹果是一个致力于解放大众的自由斗士的想法有点过分了。但这件事触动了我的神经。Ken Segal 曾在为苹果制作这则广告的广告公司工作过。在早期,他为 Steve Jobs 做了十多年的广告。
|
||||
|
||||
Ken Segal:
|
||||
|
||||
[00:08:00]
|
||||
|
||||
1984 这则广告的风险很大。事实上,它的风险太大,以至于苹果公司在看到它的时候都不想播出它。你可能听说了 Steve 喜欢它,但苹果公司董事会的人并不喜欢它。事实上,他们很愤怒,这么多钱被花在这么一件事情上,以至于他们想解雇广告代理商。Steve 则为我们公司辩护。
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
Jobs,一如既往地,慧眼识英雄。
|
||||
|
||||
Ken Segal:
|
||||
|
||||
这则广告在公司内,在业界内都引起了共鸣,成为了苹果产品的代表。无论人们那天是否有在购买电脑,它都带来了一种持续多年的影响,帮助定义了这家公司的品质。我们是叛军。我们是拿着大锤的人。
|
||||
|
||||
[00:08:30]
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
因此,在争夺数十亿潜在消费者偏好的过程中,苹果公司和微软公司的帝王们正在学着把自己塑造成救世主,非凡的英雄,一种对生活方式的选择。但 Bill Gates 知道一些苹果难以理解的事情。那就是在一个相互连接的世界里,没有人,甚至是皇帝,能独自完成任务。
|
||||
|
||||
[00:09:00]
|
||||
|
||||
[00:09:30]
|
||||
|
||||
1985 年 6 月 25 日。盖茨给当时的苹果 CEO 发了一份备忘录。那是一个迷失的年代。乔布斯刚刚被逐出公司,直到 1996 年才回到苹果。也许正是因为乔布斯离开了,盖茨才敢写这份东西。在备忘录中,他鼓励苹果授权制造商分发他们的操作系统。我想读一下备忘录的最后部分,让你们知道这份备忘录是多么的有洞察力。盖茨写道:“如果没有其他个人电脑制造商的支持,苹果现在不可能让他们的创新技术成为标准。苹果必须开放麦金塔的架构,以获得获得快速发展和建立标准所需的支持”。换句话说,你们不要再自己玩自己的了。你们必须有与他人合作的意愿。你们必须与开发者合作。
|
||||
|
||||
[00:10:00]
|
||||
|
||||
[00:10:30]
|
||||
|
||||
多年后你依然可以看到这条哲学思想,当微软首席执行官 Steve Ballmer 上台做主题演讲时,他开始大喊:“开发者,开发者,开发者,开发者,开发者,开发者,开发者,开发者,开发者。” 你懂我的意思了吧。微软喜欢开发人员。虽然目前他们不打算与这些开发人员共享源代码,但是他们确实想建立起整个合作伙伴生态系统。而当 Bill Gates 建议苹果公司也这么做时(你可能已经猜到了),这个想法就被抛到了九霄云外。他们的关系产生了间隙,五个月后,微软发布了 Windows 1.0。战争开始了。
|
||||
|
||||
开发者,开发者,开发者,开发者,开发者,开发者,开发者,开发者,开发者,开发者,开发者,开发者,开发者,开发者,开发者,开发者,开发者,开发者。
|
||||
|
||||
[00:11:00]
|
||||
|
||||
您正在收听的是来自红帽公司的原创播客《代码英雄》。本集是第一集,我们将回到过去,重温操作系统战争的史诗故事,我们将会找出,科技巨头之间的战争是如何为我们今天所生活的开源世界扫清道路的?
|
||||
|
||||
[00:11:30]
|
||||
|
||||
好的,让我们先来个背景故事吧。如果你已经听过了,那么请原谅我,但它很经典。当时是 1979 年,Steve Jobs 开车去 Palo Alto 的 Xerox Park 研究中心。那里的工程师一直在为他们所称之为的"图形用户界面"开发一系列的元素。也许你听说过。它们有菜单,滚动条,按钮,文件夹和重叠的窗口。这是对计算机界面的一个美丽的新设想。这是前所未有的。作家兼记者 Steve Levy 会谈到它的潜力。
|
||||
|
||||
Steven Levy:
|
||||
|
||||
[00:12:00]
|
||||
新界面要前所未有地有好的多,这让我们无比兴奋,以前我们用的是所谓的命令行,它的让你和电脑之间的交互方式跟现实生活中的交互方式完全不同。
|
||||
电脑上的鼠标和图像让你可以可以像现实生活中的交互一样实现与电脑的交互,你可以像指向现实生活中的东西一样指向电脑上的东西。这让事情变得简单多了。你无需要记住所有代码。
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:12:30]
|
||||
|
||||
[00:13:00]
|
||||
|
||||
不过,施乐的高管们并没有意识到他们正坐在金矿上。一如既往地,工程师比主管们更清楚它的价值。因此那些工程师,当被要求向 Jobs 展示所有这些东西是如何工作时,有点紧张。然而这是毕竟是高管的命令。Jobs 觉得,用他的话来说,“这个产品天才本来能够让施乐公司垄断整个行业,可是他最终会被公司的经营者毁掉,因为他们对产品的好坏没有概念”。这话有些苛刻,但是,Jobs 带着一卡车施乐高管错过的想法离开了会议。这几乎包含了他需要革新桌面计算体验的所有东西。1983 年,苹果发布了 Lisa 电脑,1984 年又发布了 Mac 电脑。这些设备的创意是抄袭自施乐公司的。
|
||||
|
||||
[00:13:30]
|
||||
|
||||
让我感兴趣的是,乔布斯对控诉他偷了图形用户界面的反应。他对此很冷静。他引用毕加索的话:“好的艺术家复制,伟大的艺术家偷窃。”他告诉一位记者,“我们总是无耻地窃取伟大的创意”。伟大的艺术家偷窃。好吧。我的意思是,我们说的并不是严格意义上的偷窃。没有人获得专有的源代码并公然将其集成到他们自己的操作系统中去。这要更温和些,更像是创意的借用。这就难控制的多了,就像 Jobs 自己即将学到的那样。传奇的软件向导、真正的代码英雄 Andy Hertzfeld 就是麦金塔开发团队的最初成员。
|
||||
|
||||
[00:14:00]
|
||||
|
||||
Andy Hertzfeld:
|
||||
|
||||
[00:14:30]
|
||||
|
||||
[00:15:00]
|
||||
|
||||
是的,微软是我们与麦金塔电脑的第一个软件合作伙伴。当时,我们并没有把他们当成是竞争对手。他们是苹果之外,第一家我们交付麦金塔原型的公司。我通常每周都会和微软的技术主管聊一次。他们是尝试我们所编写软件的第一个外部团队。他们给了我们非常重要的反馈,总的来说,我认为我们的关系非常好。但我也注意到,在我与技术主管的交谈中,他开始问一些系统实现方面的问题,而他本无需知道这些,我觉得,他们想要复制麦金塔电脑。我很早以前就像史蒂夫·乔布斯反馈过这件事,但在 1983 年秋天,这件事达到了高潮。我们发现,他们在 1983 年 11 月的 COMDEX 上发布了 Windows,但却没有提前告诉我们。对此史蒂夫·乔布斯勃然大怒。他认为那是一种背叛。
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:15:30]
|
||||
|
||||
[00:16:00]
|
||||
|
||||
随着新版 Windows 的发布,很明显,微软从苹果那里学到了苹果从施乐那里学来的所有想法。乔布斯很易怒。他的关于伟大艺术家如何偷窃的毕加索名言被别人学去了。而且恐怕盖茨也正是这么做的。据报道,当乔布斯怒斥盖茨偷了他们的东西时,盖茨回应道:“史蒂夫,我觉得这更像是我们都有一个叫施乐的富有邻居,我闯进他家偷电视机,却发现你已经偷过了”。苹果最终以窃取 GUI 的外观和风格为名起诉了微软。这个案子持续了好几年,但是在 1993 年,第九次巡回上诉法院的一名法官最终站在了微软一边。Vaughn Walker 法官宣布外观和风格不受版权保护。这是非常重要的。这一决定让苹果在无法垄断桌面计算的界面。很快,苹果短暂的领先优势消失了。以下是 Steven Levy 的观点。
|
||||
|
||||
Steven Levy:
|
||||
|
||||
[00:16:30]
|
||||
|
||||
[00:17:00]
|
||||
|
||||
他们之所以失去领先地位,不是因为微软方面窃取了知识产权,而是因为在上世纪 80 年代,他们无法通过更好的操作系统来巩固自己的优势。坦率地说,他们的电脑索价过高。因此微软从 20 世纪 80 年代中期开始开发 Windows 系统,但直到 1990 年开发出的 Windows 3,我想,他才真正算是一个为黄金时期做好准备的版本,才真正可供大众使用。从此以后,微软能够将数以亿计的用户迁移到图形界面,而这是苹果无法做到的。虽然苹果公司有一个非常好的操作系统,但是那已经是 1984 年的产品了。
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:17:30]
|
||||
|
||||
[00:18:00]
|
||||
现在微软主导着操作系统的战场。他们占据了 90% 的市场份额,并且针对各种各样的个人电脑进行了标准化。操作系统的未来看起来会由微软掌控。此后发生了什么 ?1997 年,波士顿 Macworld 博览会上,你看到了一个几近破产的苹果。一个谦逊的多的史蒂夫·乔布斯走上舞台,开始谈论伙伴关系的重要性。特别是他们与微软的新型合作伙伴关系。史蒂夫·乔布斯呼吁双方缓和关系,停止火拼。微软将拥有巨大的市场份额。从表面看,我们可能会认为世界和平了。但当利益如此巨大时,事情就没那么简单了。就在苹果和微软在数十年的争斗中伤痕累累、最终走向死角之际,一名 21 岁的芬兰计算机科学专业学生出现了。几乎是偶然地,他彻底改变了一切。
|
||||
|
||||
我是 Saron Yitbarek,这里是代码英雄。
|
||||
|
||||
[00:18:30]
|
||||
正当某些科技巨头正忙着就专有软件相互攻击时,自由软件和开源软件的新领军者如雨后春笋般涌现。其中一位优胜者就是理查德·斯托尔曼。你也许对他的工作很熟悉。他想要有自由软件和自由社会。这就像言论自由一样的自由,而不是像免费啤酒一样的免费。早在 80 年代,斯托尔曼就发现,除了昂贵的专有操作系统(如 UNIX) 外,就没有其他可行的替代品。因此他决定自己做一个。斯托尔曼的自由软件基金会发明了 GNU,它的意思是 "GNU's not UNIX"。它将是一个像 UNIX 一样的操作系统,但不包含所有 UNIX 代码,而且用户可以自由共享。
|
||||
|
||||
[00:19:00]
|
||||
|
||||
[00:19:30]
|
||||
|
||||
为了让你体会到 80 年代自由软件概念的重要性,从不同角度来说拥有 UNIX 代码的两家公司,AT&T 贝尔实验室 以及 UNIX 系统实验室威胁将会起诉任何看过 UNIX 源代码后又创建自己操作系统的人。
|
||||
这些人是次一级的专利所属。用这两家公司的话来说,所有这些程序员都在“精神上受到了污染”,因为他们都见过 UNIX 代码。在 UNIX 系统实验室和 Berkeley 软件设计之间的一个著名的法庭案例中,有人认为任何功能类似的系统,即使它本身没有使用 UNIX 代码,也归版权所有。Paul Jones 当时是一名开发人员。他现在是数字图书馆 ibiblio.org 的主任。
|
||||
|
||||
Paul Jones:
|
||||
|
||||
[00:20:00]
|
||||
|
||||
他们认为,任何看过代码的人都受到了精神污染。因此几乎所有在安装有与 UNIX 相关操作系统的电脑上工作过的人以及任何在计算机科学部门工作的人都受到精神上的污染。因此,在 USENIX 的一年里,我们都 a 发有带有红字的白色小别针,上面写着“精神受到了污染”。我们很喜欢带着这些别针到处走,以表达我们力挺 Bell,因为我们的精神受到了污染。
|
||||
|
||||
[00:20:30]
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:21:00]
|
||||
|
||||
整个世界都被精神污染了。想要保持纯粹,保持事物的美好和专有的旧哲学正变得越来越不现实。正是在这被污染的现实中,历史上最伟大其中一个的代码英雄诞生了,他是一个芬兰男孩,名叫 Linus Torvalds。如果这是《星球大战》,那么 Linus Torvalds 就是我们的卢克·天行者。他是赫尔辛基大学一名温文尔雅的研究生。有才华,但缺乏宏伟的愿景。典型的被逼上梁山的英雄。和其他年轻的英雄一样,他也感到沮丧。他想把 386 处理器整合到他的新电脑中。他对自己的 IBM 主机上运行的 MS-DOS 操作系统并不感冒,也负担不起 UNIX 软件 5000 美元的价格,而只有 UNIX 才能让他自由地编程。解决方案是 Torvalds 在 1991 年春天基于 MINIX 开发了一个名为 Linux 的操作系统内核。他自己的操作系统内核。
|
||||
|
||||
[00:21:30]
|
||||
|
||||
Steven Vaughan-Nichols:
|
||||
|
||||
Linus Torvalds 真的只想找点乐子。
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
Steven Vaughan-Nichols 是 ZDNet.com 的特约编辑,而且他从科技行业出现以来就一直在写科技行业相关的内容。
|
||||
|
||||
Steven Vaughan-Nichols:
|
||||
|
||||
[00:22:00]
|
||||
|
||||
[00:22:30]
|
||||
|
||||
当时有几个类似的操作系统。他最关心的是一个名叫 MINIX 的操作系统,MINIX 旨在让学生学习如何构建操作系统。莱纳斯着到这些,觉得很有趣,但他想建立自己的操作系统。因此它始于赫尔辛基的一个 DIY 项目。一切就这样开始了,基本上就是一个大孩子在玩耍,学习如何做事。但不同之处在于,他足够聪明,足够执着,也足够友好,让所有其他人都参与进来,然后他开始把这个项目进行到底。27 年后,这个项目变得比他想象的要大得多。
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:23:00]
|
||||
|
||||
到 1991 年秋季,Torvalds 发布了 10,000 行代码,世界各地的人们开始提供注释,然后进行优化、添加和修改代码。对于今天的开发人员来说,这似乎很正常,但请记住,在那个时候,像这样的开放协作是对整个专有系统(微软、苹果和 IBM 在这方面做的非常好)道德上的侮辱。随后这种开放性被奉若神明。Torvalds 将 Linux 置于 GNU 通用公共许可证之下。曾经保障斯托尔曼的 GNU 系统自由的许可证现在也将保障 Linux 的自由。Vaughan-Nichols 解释道,迁移到 incorporate GPL 的重要性怎么强调都不过分,它基本上能永远保证软件的自由和开放性。
|
||||
|
||||
[00:23:30]
|
||||
|
||||
Steven Vaughan-Nichols:
|
||||
|
||||
事实上,根据 Linux 所遵循的许可协议,即 GPL 第 2 版,如果你想把贩卖 Linux 或者向全世界展示它,你必须与它人共享代码,所以如果你对其做了一些改进,仅仅给别人使用是不够的。事实上你必须和他们分享所有这些变化的具体细节。然后,如果这些改进足够好,就会被 Linux 所吸收。
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:24:00]
|
||||
|
||||
事实证明,这种公开的方式极具吸引力。Eric Raymond 是这场运动的早期传道者之一,他在他那篇著名的文章中写道:“微软和苹果这样的公司一直在试图建造软件大教堂,而 Linux 及类似的软件则提供了一个由不同日程和方法组成的巨大集市”集市比大教堂有趣多了。
|
||||
|
||||
tormy Peters:
|
||||
|
||||
我认为在那个时候,真正吸引人的是人们终于可以把控自己的世界了。
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
Stormy Peters 是一位行业分析师,也是自由和开源软件的倡导者。
|
||||
|
||||
[00:24:30]
|
||||
|
||||
Stormy Peters:
|
||||
|
||||
[00:25:00]
|
||||
|
||||
开源软件第一次出现的时候,所有的操作系统都是专有的。如果不使用专有软件,你甚至不能添加打印机。您不能添加耳机。你不能自己开发一个小型硬件设备,然后让它在你的笔记本电脑上运行。你甚至不能放入 DVD 并复制它,因为你不能改变软件。即使你拥有这张 DVD,你也无法复制它。你无法控制你购买的硬件/软件系统。你不能从中创造出任何新的、更大的、更好的东西。这就是为什么开源操作系统在一开始是如此重要的原因。我们需要一个开源协作环境,在那里我们可以构建更大更好的东西。
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:25:30]
|
||||
|
||||
请注意,Linux 并不是一个纯粹的平等主义乌托邦。Linus Torvalds 不会批准所有对内核的修改,但是他确实主持内核的变更。他安排了十几个人来管理内核的不同部分。这些人也会信任自己下面的人,以此类推,形成信任金字塔。变化可能来自任何地方,但它们都是经过判断和策划的。
|
||||
|
||||
[00:26:00]
|
||||
|
||||
然而,考虑到到 Linus 的 DIY 项目一开始是多么的简陋和随意,这项成就令人十分惊讶。他完全不知道自己就是卢克·天行者。当时他只有 21 岁,一半的时间都在编程。但是当魔盒第一次被打开,人们开始给他反馈。几十个,然后几百个,成千上万的贡献者。有了这样的众包基础,Linux 很快就开始成长。真的成长得很快。甚至最终引起了微软的注意。他们的首席执行官 Steve Ballmer 将 Linux 称为是“一种癌症,从知识产权得角度来看,它传染了接触到得任何东西 ”。Steven Levy 将会描述 Ballmer 的由来。
|
||||
|
||||
Steven Levy:
|
||||
|
||||
[00:26:30]
|
||||
一旦微软真正巩固了它的垄断地位,而且它也确实被联邦法院判定为垄断,他们将会对任何可能对其构成威胁的事情做出强烈反应。因此,既然他们对软件收费,很自然得,他们将自由软件得出现看成是一种癌症。他们试图提出一个知识产权理论,来解释为什么这对消费者不利。
|
||||
|
||||
Saron Yitbarek:
|
||||
|
||||
[00:27:00]
|
||||
|
||||
Linux 在不断传播,微软也开始担心起来。到了 2006 年,Linux 成为仅次于 Windows 的第二大常用操作系统,全球约有 5000 名开发人员在使用它。5000 名开发者。还记得比尔·盖茨给苹果公司的备忘录吗?在那份备忘录中,他向苹果公司的员工们论述了与他人合作的重要性。事实证明,开源将把伙伴关系的概念提升到一个全新的水平,这是 Bill Gates 从未预见到的。
|
||||
|
||||
[00:27:30]
|
||||
|
||||
[00:28:00]
|
||||
|
||||
我们一直在谈论操作系统之间的巨型战斗,但是到目前为止,并没有怎么提到无名英雄和开发者们。在下次得代码英雄中,情况就不同了。第二集讲的是操作系统大战的第二部分,是关于 Linux 崛起的。业界醒悟过来,认识到了开发人员的重要性。这些开源反叛者变得越来越强大,战场从桌面转移到了服务器领域。这里有商业间谍活动、新的英雄人物,还有科技史上最不可能改变的想法。这一切都在操作系统大战的后半集内达到了高潮。
|
||||
|
||||
[00:28:30]
|
||||
|
||||
要想自动免费获得新一集的代码英雄,请点击订阅苹果播客 、Spotify、 谷歌播放器等其他应用获取播客。在这一季剩下的时间里,我们将参观最新的战场,相互争斗的版图,这里是下一代代码英雄留下印记的地方。更多信息,请访问 redhat.com/commandlineheroes。我是 Saron Yitbarek。下次之前,继续编码。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-1
|
||||
|
||||
作者:[redhat][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.redhat.com
|
||||
[b]: https://github.com/lujun9972
|
||||
214
translated/tech/20180622 Use LVM to Upgrade Fedora.md
Normal file
214
translated/tech/20180622 Use LVM to Upgrade Fedora.md
Normal file
@ -0,0 +1,214 @@
|
||||
使用 LVM 升级 Fedora
|
||||
======
|
||||
|
||||

|
||||
|
||||
大多数用户发现使用标准流程升级[从一个 Fedora 版本升级到下一个][1]很简单。但是,Fedora 升级也不可避免地会遇到许多特殊情况。本文介绍了使用 DNF 和逻辑卷管理(LVM)进行升级的一种方法,以便在出现问题时保留可引导备份。这个例子是将 Fedora 26 系统升级到 Fedora 28。
|
||||
|
||||
此处展示的过程比标准升级过程更复杂。在使用此过程之前,你应该充分掌握 LVM 的工作原理。如果没有适当的技能和细心,你可能会丢失数据和/或被迫重新安装系统!如果你不知道自己在做什么,那么**强烈建议**你坚持只使用受支持的升级方法。
|
||||
|
||||
### 准备系统
|
||||
|
||||
在开始之前,请确保你的现有系统已完全更新。
|
||||
|
||||
```
|
||||
$ sudo dnf update
|
||||
$ sudo systemctl reboot # 或采用 GUI 方式
|
||||
```
|
||||
|
||||
检查你的根文件系统是否是通过 LVM 挂载的。
|
||||
|
||||
```
|
||||
$ df /
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
/dev/mapper/vg_sdg-f26 20511312 14879816 4566536 77% /
|
||||
|
||||
$ sudo lvs
|
||||
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
|
||||
f22 vg_sdg -wi-ao---- 15.00g
|
||||
f24_64 vg_sdg -wi-ao---- 20.00g
|
||||
f26 vg_sdg -wi-ao---- 20.00g
|
||||
home vg_sdg -wi-ao---- 100.00g
|
||||
mockcache vg_sdg -wi-ao---- 10.00g
|
||||
swap vg_sdg -wi-ao---- 4.00g
|
||||
test vg_sdg -wi-a----- 1.00g
|
||||
vg_vm vg_sdg -wi-ao---- 20.00g
|
||||
```
|
||||
|
||||
如果你在安装 Fedora 时使用了默认值,你可能会发现根文件系统挂载在名为 `root` 的逻辑卷(LV)上。卷组(VG)的名称可能会有所不同。看看根卷的总大小。在该示例中,根文件系统名为 `f26`,大小为 `20G`。
|
||||
|
||||
接下来,确保 LVM 中有足够的可用空间。
|
||||
|
||||
```
|
||||
$ sudo vgs
|
||||
VG #PV #LV #SN Attr VSize VFree
|
||||
vg_sdg 1 8 0 wz--n- 232.39g 42.39g
|
||||
```
|
||||
|
||||
该系统有足够的可用空间,可以为升级后的 Fedora 28 的根卷分配 20G 的逻辑卷。如果你使用的是默认安装,则你的 LVM 中将没有可用空间。对 LVM 的一般性管理超出了本文的范围,但这里有一些可能采取的方法:
|
||||
|
||||
1、`/home` 在自己的逻辑卷,而且 `/home` 中有大量空闲空间。
|
||||
|
||||
你可以从图形界面中注销并切换到文本控制台,以 `root` 用户身份登录。然后你可以卸载 `/home`,并使用`lvreduce -r` 调整大小并重新分配 `/home` 逻辑卷。你也可以从<ruby>现场镜像<rt>Live image</rt></ruby>启动(以便不使用 `/home`)并使用 gparted GUI 实用程序进行分区调整。
|
||||
|
||||
2、大多数 LVM 空间被分配给根卷,该文件系统中有大量可用空间。
|
||||
|
||||
你可以从现场镜像启动并使用 gparted GUI 实用程序来减少根卷的大小。此时也可以考虑将 `/home` 移动到另外的文件系统,但这超出了本文的范围。
|
||||
|
||||
3、大多数文件系统已满,但你有个已经不再需要逻辑卷。
|
||||
|
||||
你可以删除不需要的逻辑卷,释放卷组中的空间以进行此操作。
|
||||
|
||||
### 创建备份
|
||||
|
||||
首先,为升级后的系统分配新的逻辑卷。确保为系统的卷组(VG)使用正确的名称。在这个例子中它是 `vg_sdg`。
|
||||
|
||||
```
|
||||
$ sudo lvcreate -L20G -n f28 vg_sdg
|
||||
Logical volume "f28" created.
|
||||
```
|
||||
|
||||
接下来,创建当前根文件系统的快照。此示例创建名为 `f26_s` 的快照卷。
|
||||
|
||||
```
|
||||
$ sync
|
||||
$ sudo lvcreate -s -L1G -n f26_s vg_sdg/f26
|
||||
Using default stripesize 64.00 KiB.
|
||||
Logical volume "f26_s" created.
|
||||
```
|
||||
|
||||
现在可以将快照复制到新逻辑卷。当你替换自己的卷名时,**请确保目标正确**。如果不小心,就会不可撤销地删除了数据。此外,请确保你从根卷的快照复制,**而不是**你的现在的根卷。
|
||||
|
||||
```
|
||||
$ sudo dd if=/dev/vg_sdg/f26_s of=/dev/vg_sdg/f28 bs=256k
|
||||
81920+0 records in
|
||||
81920+0 records out
|
||||
21474836480 bytes (21 GB, 20 GiB) copied, 149.179 s, 144 MB/s
|
||||
```
|
||||
|
||||
给新文件系统一个唯一的 UUID。这不是绝对必要的,但 UUID 应该是唯一的,因此这避免了未来的混淆。以下是在 ext4 根文件系统上的方法:
|
||||
|
||||
```
|
||||
$ sudo e2fsck -f /dev/vg_sdg/f28
|
||||
$ sudo tune2fs -U random /dev/vg_sdg/f28
|
||||
```
|
||||
|
||||
然后删除不再需要的快照卷:
|
||||
|
||||
```
|
||||
$ sudo lvremove vg_sdg/f26_s
|
||||
Do you really want to remove active logical volume vg_sdg/f26_s? [y/n]: y
|
||||
Logical volume "f26_s" successfully removed
|
||||
```
|
||||
|
||||
如果你单独挂载了 `/home`,你可能希望在此处制作 `/home` 的快照。有时,升级的应用程序会进行与旧版 Fedora 版本不兼容的更改。如果需要,编辑**旧**根文件系统上的 `/etc/fstab` 文件以在 `/home` 上挂载快照。请记住,当快照已满时,它将消失!另外,你可能还希望给 `/home` 做个正常备份。
|
||||
|
||||
### 配置以使用新的根
|
||||
|
||||
首先,安装新的逻辑卷并备份现有的 GRUB 设置:
|
||||
|
||||
```
|
||||
$ sudo mkdir /mnt/f28
|
||||
$ sudo mount /dev/vg_sdg/f28 /mnt/f28
|
||||
$ sudo mkdir /mnt/f28/f26
|
||||
$ cd /boot/grub2
|
||||
$ sudo cp -p grub.cfg grub.cfg.old
|
||||
```
|
||||
|
||||
编辑 `grub.conf` 并在第一个菜单项 `menuentry` 之前添加这些,除非你已经有了:
|
||||
|
||||
```
|
||||
menuentry 'Old boot menu' {
|
||||
configfile /grub2/grub.cfg.old
|
||||
}
|
||||
```
|
||||
|
||||
编辑 `grub.conf` 并更改默认菜单项以激活并挂载新的根文件系统。改变这一行:
|
||||
|
||||
```
|
||||
linux16 /vmlinuz-4.16.11-100.fc26.x86_64 root=/dev/mapper/vg_sdg-f26 ro rd.lvm.lv=vg_sdg/f26 rd.lvm.lv=vg_sdg/swap rhgb quiet LANG=en_US.UTF-8
|
||||
```
|
||||
|
||||
如你看到的这样。请记住使用你系统上的正确的卷组和逻辑卷条目名称!
|
||||
|
||||
```
|
||||
linux16 /vmlinuz-4.16.11-100.fc26.x86_64 root=/dev/mapper/vg_sdg-f28 ro rd.lvm.lv=vg_sdg/f28 rd.lvm.lv=vg_sdg/swap rhgb quiet LANG=en_US.UTF-8
|
||||
```
|
||||
|
||||
编辑 `/mnt/f28/etc/default/grub` 并改变在启动时激活的默认根卷:
|
||||
|
||||
```
|
||||
GRUB_CMDLINE_LINUX="rd.lvm.lv=vg_sdg/f28 rd.lvm.lv=vg_sdg/swap rhgb quiet"
|
||||
```
|
||||
|
||||
编辑 `/mnt/f28/etc/fstab`,将挂载的根文件系统从旧的逻辑卷:
|
||||
|
||||
```
|
||||
/dev/mapper/vg_sdg-f26 / ext4 defaults 1 1
|
||||
```
|
||||
|
||||
改为新的:
|
||||
|
||||
```
|
||||
/dev/mapper/vg_sdg-f28 / ext4 defaults 1 1
|
||||
```
|
||||
|
||||
然后,出于参考的用途,只读挂载旧的根卷:
|
||||
|
||||
```
|
||||
/dev/mapper/vg_sdg-f26 /f26 ext4 ro,nodev,noexec 0 0
|
||||
```
|
||||
|
||||
如果你的根文件系统是通过 UUID 挂载的,你需要改变这个方式。如果你的根文件系统是 ext4 你可以这样做:
|
||||
|
||||
```
|
||||
$ sudo e2label /dev/vg_sdg/f28 F28
|
||||
```
|
||||
|
||||
现在编辑 `/mnt/f28/etc/fstab` 使用该卷标。改变该根文件系统的挂载行,像这样:
|
||||
|
||||
```
|
||||
LABEL=F28 / ext4 defaults 1 1
|
||||
```
|
||||
|
||||
### 重启与升级
|
||||
|
||||
重新启动,你的系统将使用新的根文件系统。它仍然是 Fedora 26,但是带有新的逻辑卷名称的副本,并可以进行 `dnf` 系统升级!如果出现任何问题,请使用旧引导菜单引导回到你的工作系统,此过程可避免触及旧系统。
|
||||
|
||||
```
|
||||
$ sudo systemctl reboot # or GUI equivalent
|
||||
...
|
||||
$ df / /f26
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
/dev/mapper/vg_sdg-f28 20511312 14903196 4543156 77% /
|
||||
/dev/mapper/vg_sdg-f26 20511312 14866412 4579940 77% /f26
|
||||
```
|
||||
|
||||
你可能希望验证使用旧的引导菜单确实可以让你回到挂载在旧的根文件系统上的根。
|
||||
|
||||
现在按照[此维基页面][2]中的说明进行操作。如果系统升级出现任何问题,你还会有一个可以重启回去的工作系统。
|
||||
|
||||
### 进一步的考虑
|
||||
|
||||
创建新的逻辑卷并将根卷的快照复制到其中的步骤可以使用通用脚本自动完成。它只需要新的逻辑卷的名称,因为现有根的大小和设备很容易确定。例如,可以输入以下命令:
|
||||
|
||||
```
|
||||
$ sudo copyfs / f28
|
||||
```
|
||||
|
||||
提供挂载点以进行复制可以更清楚地了解发生了什么,并且复制其他挂载点(例如 `/home`)可能很有用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/use-lvm-upgrade-fedora/
|
||||
|
||||
作者:[Stuart D Gathman][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/sdgathman/
|
||||
[1]:https://fedoramagazine.org/upgrading-fedora-27-fedora-28/
|
||||
[2]:https://fedoraproject.org/wiki/DNF_system_upgrade
|
||||
@ -0,0 +1,71 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Turn On And Shutdown The Raspberry Pi [Absolute Beginner Tip])
|
||||
[#]: via: (https://itsfoss.com/turn-on-raspberry-pi/)
|
||||
[#]: author: (Chinmay https://itsfoss.com/author/chinmay/)
|
||||
|
||||
如何打开和关闭树莓派(新手教程)
|
||||
======
|
||||
|
||||
_ **简介:这个贴士教你如何打开树莓派以及如何在之后正确关闭它。** _
|
||||
|
||||
[树莓派][1]是[最流行的 SBC(单板计算机)][2]之一。如果你对这个话题感兴趣,我相信你已经有了一个树莓派。我还建议你使用[其他树莓派配件][3]来开始使用你的设备。
|
||||
|
||||
你已经准备好打开并开始使用。与桌面和笔记本电脑等传统电脑相比,它有相似以及不同之处。
|
||||
|
||||
今天,让我们继续学习如何打开和关闭树莓派,因为它并没有真正的“电源按钮”。
|
||||
|
||||
在本文中,我使用的是树莓派 3B+,但对于所有树莓派变体都是如此。
|
||||
|
||||
### 如何打开树莓派
|
||||
|
||||
![Micro USB port for Power][7]
|
||||
|
||||
micro USB 口为树莓派供电,打开它的方式是将电源线插入 micro USB 口。但是开始之前,你应该确保做了以下事情。
|
||||
|
||||
* 根据官方[指南][8]准备带有 Raspbian 的 micro SD 卡并插入 micro SD 卡插槽。
|
||||
* 插入 HDMI 线、USB 键盘和鼠标。
|
||||
* 插入以太网线(可选)。
|
||||
|
||||
成上述操作后,请插入电源线。这会打开树莓派,显示屏将亮起并加载操作系统。
|
||||
|
||||
### 关闭树莓派
|
||||
|
||||
关闭树莓派非常简单,单击菜单按钮并选择关闭。
|
||||
|
||||
![Turn off Raspberry Pi graphically][9]
|
||||
|
||||
或者你可以在终端使用 [shutdown 命令][10]
|
||||
|
||||
```
|
||||
sudo shutdown now
|
||||
```
|
||||
|
||||
shutdown 执行后**等待**它完成,接着你可以关闭电源。树莓派关闭后,没有真正的办法可以在不重新打开电源的情况下打开树莓派。你可以使用 GPIO 打开树莓派,但这需要额外的改装。
|
||||
|
||||
_注意:Micro USB 口往往是脆弱的,因此请关闭/打开电源,而不是经常拔出插入 micro USB 口。_
|
||||
|
||||
好吧,这就是关于打开和关闭树莓派的所有内容,你打算用它做什么?请在评论中告诉我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/turn-on-raspberry-pi/
|
||||
|
||||
作者:[Chinmay][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/chinmay/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.raspberrypi.org/
|
||||
[3]: https://itsfoss.com/things-you-need-to-get-your-raspberry-pi-working/
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/04/raspberry-pi-3-microusb.png?fit=800%2C532&ssl=1
|
||||
[8]: https://www.raspberrypi.org/documentation/installation/installing-images/README.md
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/04/Raspbian-ui-menu.jpg?fit=800%2C492&ssl=1
|
||||
[10]: https://linuxhandbook.com/linux-shutdown-command/
|
||||
Loading…
Reference in New Issue
Block a user