mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
commit
d72ffea8b8
71
README.md
71
README.md
@ -38,7 +38,7 @@ LCTT 的组成
|
||||
* 2013/09/16 公开发布了翻译组成立消息后,又有新的成员申请加入了。并从此建立见习成员制度。
|
||||
* 2013/09/24 鉴于大家使用 GitHub 的水平不一,容易导致主仓库的一些错误,因此换成了常规的 fork+PR 的模式来进行翻译流程。
|
||||
* 2013/10/11 根据对 LCTT 的贡献,划分了 Core Translators 组,最先的加入成员是 vito-L 和 tinyeyeser。
|
||||
* 2013/10/12 取消对 LINUX.CN 注册用户的依赖,在 QQ 群内、文章内都采用 GitHub 的注册 ID。
|
||||
* 2013/10/12 取消对 LINUX.CN 注册用户的关联,在 QQ 群内、文章内都采用 GitHub 的注册 ID。
|
||||
* 2013/10/18 正式启动 man 翻译计划。
|
||||
* 2013/11/10 举行第一次北京线下聚会。
|
||||
* 2014/01/02 增加了 Core Translators 成员: geekpi。
|
||||
@ -52,7 +52,10 @@ LCTT 的组成
|
||||
* 2015/04/19 发起 LFS-BOOK-7.7-systemd 项目。
|
||||
* 2015/06/09 提升 ictlyh 和 dongfengweixiao 为 Core Translators 成员。
|
||||
* 2015/11/10 提升 strugglingyouth、FSSlc、Vic020、alim0x 为 Core Translators 成员。
|
||||
* 2016/02/18 由于选题 DeadFire 重病,任命 oska874 接手选题工作。
|
||||
* 2016/02/29 选题 DeadFire 病逝。
|
||||
* 2016/05/09 提升 PurlingNayuki 为校对。
|
||||
* 2016/09/10 LCTT 三周年。
|
||||
|
||||
活跃成员
|
||||
-------------------------------
|
||||
@ -61,25 +64,26 @@ LCTT 的组成
|
||||
- Leader @wxy,
|
||||
- Source @oska874,
|
||||
- Proofreader @PurlingNayuki,
|
||||
- Proofreader @carolinewuyan,
|
||||
- CORE @geekpi,
|
||||
- CORE @GOLinux,
|
||||
- CORE @ictlyh,
|
||||
- CORE @carolinewuyan,
|
||||
- CORE @strugglingyouth,
|
||||
- CORE @FSSlc
|
||||
- CORE @zpl1025,
|
||||
- CORE @runningwater,
|
||||
- CORE @bazz2,
|
||||
- CORE @Vic020,
|
||||
- CORE @dongfengweixiao,
|
||||
- CORE @alim0x,
|
||||
- CORE @tinyeyeser,
|
||||
- CORE @Locez,
|
||||
- Senior @DeadFire,
|
||||
- Senior @reinoir222,
|
||||
- Senior @tinyeyeser,
|
||||
- Senior @vito-L,
|
||||
- Senior @jasminepeng,
|
||||
- Senior @willqian,
|
||||
- Senior @vizv,
|
||||
- Senior @dongfengweixiao,
|
||||
- ZTinoZ,
|
||||
- martin2011qi,
|
||||
- theo-l,
|
||||
@ -87,94 +91,81 @@ LCTT 的组成
|
||||
- wi-cuckoo,
|
||||
- disylee,
|
||||
- haimingfg,
|
||||
- KayGuoWhu,
|
||||
- wwy-hust,
|
||||
- felixonmars,
|
||||
- KayGuoWhu,
|
||||
- mr-ping,
|
||||
- su-kaiyao,
|
||||
- GHLandy,
|
||||
- ivo-wang,
|
||||
- cvsher,
|
||||
- StdioA,
|
||||
- wyangsun,
|
||||
- ivo-wang,
|
||||
- GHLandy,
|
||||
- cvsher,
|
||||
- DongShuaike,
|
||||
- flsf,
|
||||
- SPccman,
|
||||
- Stevearzh
|
||||
- mr-ping,
|
||||
- Linchenguang,
|
||||
- Linux-pdz,
|
||||
- 2q1w2007,
|
||||
- H-mudcup,
|
||||
- cposture,
|
||||
- MikeCoder,
|
||||
- NearTan,
|
||||
- goreliu,
|
||||
- xiqingongzi,
|
||||
- goreliu,
|
||||
- NearTan,
|
||||
- TxmszLou,
|
||||
- ZhouJ-sh,
|
||||
- wangjiezhe,
|
||||
- icybreaker,
|
||||
- vim-kakali,
|
||||
- shipsw,
|
||||
- Moelf,
|
||||
- name1e5s,
|
||||
- johnhoow,
|
||||
- soooogreen,
|
||||
- kokialoves,
|
||||
- linuhap,
|
||||
- GitFuture,
|
||||
- ChrisLeeGit,
|
||||
- blueabysm,
|
||||
- boredivan,
|
||||
- name1e5s,
|
||||
- StdioA,
|
||||
- yechunxiao19,
|
||||
- l3b2w1,
|
||||
- XLCYun,
|
||||
- KevinSJ,
|
||||
- zky001,
|
||||
- l3b2w1,
|
||||
- tenght,
|
||||
- coloka,
|
||||
- luoyutiantang,
|
||||
- sonofelice,
|
||||
- jiajia9linuxer,
|
||||
- scusjs,
|
||||
- tnuoccalanosrep,
|
||||
- woodboow,
|
||||
- 1w2b3l,
|
||||
- JonathanKang,
|
||||
- bestony,
|
||||
- crowner,
|
||||
- dingdongnigetou,
|
||||
- mtunique,
|
||||
- CNprober,
|
||||
- Rekii008,
|
||||
- hyaocuk,
|
||||
- szrlee,
|
||||
- KnightJoker,
|
||||
- Xuanwo,
|
||||
- nd0104,
|
||||
- Moelf,
|
||||
- xiaoyu33,
|
||||
- guodongxiaren,
|
||||
- ynmlml,
|
||||
- vim-kakali,
|
||||
- Flowsnow,
|
||||
- ggaaooppeenngg,
|
||||
- Ricky-Gong,
|
||||
- zky001,
|
||||
- lfzark,
|
||||
- 213edu,
|
||||
- bestony,
|
||||
- mudongliang,
|
||||
- Tanete,
|
||||
- lfzark,
|
||||
- liuaiping,
|
||||
- Timeszoro,
|
||||
- rogetfan,
|
||||
- JeffDing,
|
||||
- Yuking-net,
|
||||
|
||||
|
||||
(按增加行数排名前百)
|
||||
|
||||
LFS 项目活跃成员有:
|
||||
|
||||
- @ictlyh
|
||||
- @dongfengweixiao
|
||||
- @wxy
|
||||
- @H-mudcup
|
||||
- @zpl1025
|
||||
- @KevinSJ
|
||||
- @Yuking-net
|
||||
|
||||
(更新于2016/06/20)
|
||||
(按增加行数排名前百,更新于2016/09/10)
|
||||
|
||||
谢谢大家的支持!
|
||||
|
||||
|
||||
42
lctt2016.md
Normal file
42
lctt2016.md
Normal file
@ -0,0 +1,42 @@
|
||||
LCTT 2016:LCTT 成立三周年了!
|
||||
===========================
|
||||
|
||||
不知不觉,LCTT 已经成立三年了,对于我这样已经迈过四张的人来说,愈发的感觉时间过得真快。
|
||||
|
||||
这三年来,我们 LCTT 经历了很多事情,有些事情想起来仍恍如昨日。
|
||||
|
||||
三年前的这一天,我的一个偶发的想法促使我在 Linux 中国的 QQ 群里面发了一则消息,具体的消息内容已经不可考了,大意是鉴于英文 man 手册的中文翻译太差,想组织一些人来重新翻译。不料发出去之后很快赢得一些有热情、有理想的小伙伴们的响应。于是我匆匆建了一个群,拉了一些人进来,甚至当时连翻译组的名称都没有确定。LCTT (Linux.Cn Translation Team)这个名称都是后来逐步定下来的。
|
||||
|
||||
关于 LCTT 的早期发展情况,可以参考 LCTT 2014 年周年[总结](http://linux.cn/article-3784-1.html)。
|
||||
|
||||
虽然说“翻译 man 手册”这个最初建群的目标因为种种原因搁浅而一直未能重启,但是,这三年来,我们组织了 [213 位志愿者](https://github.com/LCTT/TranslateProject/graphs/contributors)翻译了 2155 篇文章,接受了 [4263 个 PR](https://github.com/LCTT/TranslateProject/pulls?q=is%3Apr+is%3Aclosed),得到了 476 个星。
|
||||
|
||||
这三年来,我们经历了 man 项目的流产、 LFS 手册的翻译发布、选题 DeadFire 的离去。得益于 Linux 中国的网站和微博,乃至微信的兴起后的传播,志愿者们的译文传播很广,切实的为国内的开源社区做出了贡献(当然,与此同时,Linux 中国社区也随之更加壮大)。
|
||||
|
||||
这些年间,LCTT 来了很多人,也有人慢慢淡出,这里面涌现了不少做出了卓越贡献的人,比如:
|
||||
|
||||
- geekpi,作为整个 LCTT 项目中翻译量最大贡献者,却鲜少在群内说话,偶尔露面,被戏称为“鸡排兄”。
|
||||
- GOLinux,紧追“鸡排兄”的第二位强人,嗯,群内大部分人的昵称都是他起的,包括楼上。
|
||||
- tinyeyeser,“小眼儿”以翻译风趣幽默著称,是 LCTT 早期初创成员之一。
|
||||
- Vito-L,早期成员,LCTT 的多数 Wiki 出自于其手。
|
||||
- DeadFire,创始成员,从最开始到其离世,一直负责 LCTT 的所有选题工作。
|
||||
- oska874,在接过选题工作的重任后,全面主持 LCTT 的工作。
|
||||
- carolinewuyan,承担了相当多的校对工作。
|
||||
- alim0x,独立完成了 Android 编年史系列的翻译(多达 26 篇,现在还没发布完)等等。
|
||||
|
||||
其它还有 ictlyh、strugglingyouth、FSSlc、zpl1025、runningwater、bazz2、Vic020、dongfengweixiao、jasminepeng、willqian、vizv、ZTinoZ、martin2011qi、felixonmars、su-kaiyao、GHLandy、flsf、H-mudcup、StdioA、crowner、vim-kakali 等等,以及还有很多这里没有提到名字的人,都对 LCTT 做出不可磨灭的贡献。
|
||||
|
||||
具体的贡献排行榜,可以看[这里](https://github.com/LCTT/TranslateProject/graphs/contributors)。
|
||||
|
||||
每年写总结时,我都需要和 gource 以及 ffmpeg 搏斗半天,今年,我又用 gource 重新制作了一份 LCTT 的 GitHub 版本仓库的变迁视频,以飨众人。
|
||||
|
||||
本来想写很多,或许 LCTT 和 Linux 中国已经成了我的生活的一部分,竟然不知道该写点什么了,那就此搁笔罢。
|
||||
|
||||
另外,为 LCTT 的诸位兄弟姐妹们献上我及管理团队的祝福,也欢迎更多的志愿者加入 LCTT ,传送门在此:
|
||||
|
||||
- 项目网站:https://lctt.github.io/ ,请先访问此处了解情况。
|
||||
- “Linux中国”开源社区:https://linux.cn/ ,所有翻译的文章都在这里以及它的同名微博、微信发布。
|
||||
|
||||
LCTT 组长 wxy
|
||||
|
||||
2016/9/10
|
||||
@ -1,21 +1,15 @@
|
||||
|
||||
|
||||
【flankershen翻译中】
|
||||
|
||||
|
||||
|
||||
How to Set Nginx as Reverse Proxy on Centos7 CPanel
|
||||
如何在 CentOS 7 用 cPanel 配置 Nginx 反向代理
|
||||
================================================================================
|
||||
|
||||
Nginx is one of the fastest and most powerful web-server. It is known for its high performance and low resource utilization. It can be installed as both a standalone and a Reverse Proxy Web-server. In this article, I'm discussing about the installation of Nginx as a reverse proxy along with Apache on a CPanel server with latest CentOS 7 installed.
|
||||
Nginx 是最快和最强大的 Web 服务器之一,以其高性能和低资源占用率而闻名。它既可以被安装为一个独立的 Web 服务器,也可以安装成反向代理 Web 服务器。在这篇文章,我将讨论在安装了 cPanel 管理系统的 Centos 7 服务器上安装 Nginx 作为 Apache 的反向代理服务器。
|
||||
|
||||
Nginx as a reverse proxy will work as a frontend webserver serving static contents along with Apache serving the dynamic files in backend. This setup will boost up the overall server performance.
|
||||
Nginx 作为前端服务器用反向代理为静态文件提供服务,Apache 作为后端为动态文件提供服务。这个设置将整体提高服务器的性能。
|
||||
|
||||
Let's walk through the installation steps for Nginx as reverse proxy in CentOS7 x86_64 bit server with cPanel 11.52 installed.
|
||||
让我们过一遍在已经安装好 cPanel 11.52 的 CentOS 7 x86_64 服务器上配置 Nginx 作为反向代理的安装过程。
|
||||
|
||||
First of all, we need to install the EPEL repo to start-up with the process.
|
||||
首先,我们需要安装 EPEL 库来启动这个进程
|
||||
|
||||
### Step 1: Install the EPEL repo. ###
|
||||
### 第一步: 安装 EPEL 库###
|
||||
|
||||
root@server1 [/usr]# yum -y install epel-release
|
||||
Loaded plugins: fastestmirror, tsflags, universal-hooks
|
||||
@ -31,13 +25,13 @@ First of all, we need to install the EPEL repo to start-up with the process.
|
||||
|
||||
Dependencies Resolved
|
||||
|
||||
===============================================================================================================================================
|
||||
Package Arch Version Repository Size
|
||||
===============================================================================================================================================
|
||||
========================================================================================
|
||||
Package Arch Version Repository Size
|
||||
========================================================================================
|
||||
Installing:
|
||||
epel-release noarch 7-5 extras 14 k
|
||||
|
||||
### Step 2: After installing the repo, we can start with the installation of the nDeploy RPM repo for CentOS to install our required nDeploy Webstack and Nginx plugin. ###
|
||||
### 第二步: 可以安装 nDeploy 的 CentOS RPM 库来安装我们所需的 nDeploy Web 类软件和 Nginx 插件 ###
|
||||
|
||||
root@server1 [/usr]# yum -y install http://rpm.piserve.com/nDeploy-release-centos-1.0-1.noarch.rpm
|
||||
Loaded plugins: fastestmirror, tsflags, universal-hooks
|
||||
@ -51,13 +45,13 @@ First of all, we need to install the EPEL repo to start-up with the process.
|
||||
|
||||
Dependencies Resolved
|
||||
|
||||
===============================================================================================================================================
|
||||
========================================================================================
|
||||
Package Arch Version Repository Size
|
||||
===============================================================================================================================================
|
||||
========================================================================================
|
||||
Installing:
|
||||
nDeploy-release-centos noarch 1.0-1 /nDeploy-release-centos-1.0-1.noarch 110
|
||||
|
||||
### Step 3: Install the nDeploy and Nginx nDeploy plugins. ###
|
||||
### 第三步:安装 nDeploy 和 Nginx nDeploy 插件 ###
|
||||
|
||||
root@server1 [/usr]# yum --enablerepo=ndeploy install nginx-nDeploy nDeploy
|
||||
Loaded plugins: fastestmirror, tsflags, universal-hooks
|
||||
@ -70,9 +64,9 @@ First of all, we need to install the EPEL repo to start-up with the process.
|
||||
|
||||
Dependencies Resolved
|
||||
|
||||
===============================================================================================================================================
|
||||
========================================================================================
|
||||
Package Arch Version Repository Size
|
||||
===============================================================================================================================================
|
||||
========================================================================================
|
||||
Installing:
|
||||
nDeploy noarch 2.0-11.el7 ndeploy 80 k
|
||||
nginx-nDeploy x86_64 1.8.0-34.el7 ndeploy 36 M
|
||||
@ -84,12 +78,12 @@ First of all, we need to install the EPEL repo to start-up with the process.
|
||||
python-lxml x86_64 3.2.1-4.el7 base 758 k
|
||||
|
||||
Transaction Summary
|
||||
===============================================================================================================================================
|
||||
========================================================================================
|
||||
Install 2 Packages (+5 Dependent packages)
|
||||
|
||||
With these steps, we've completed with the installation of Nginx plugin in our server. Now we need to configure Nginx as reverse proxy and create the virtualhost for the existing cPanel user accounts. For that we can run the following script.
|
||||
通过以上这些步骤,我们完成了在我们的服务器上 Nginx 插件的安装。现在我们可以配置 Nginx 作为反向代理和为已有的 cPanel 用户账户创建虚拟主机,为此我们可以运行如下脚本。
|
||||
|
||||
### Step 4: To enable Nginx as a front end Web Server and create the default configuration files. ###
|
||||
### 第四步:启动 Nginx 作为默认的前端 Web 服务器,并创建默认的配置文件###
|
||||
|
||||
root@server1 [/usr]# /opt/nDeploy/scripts/cpanel-nDeploy-setup.sh enable
|
||||
Modifying apache http and https port in cpanel
|
||||
@ -101,9 +95,9 @@ With these steps, we've completed with the installation of Nginx plugin in our s
|
||||
ConfGen:: saheetha
|
||||
ConfGen:: satest
|
||||
|
||||
As you can see these script will modify the Apache port from 80 to another port to make Nginx run as a front end web server and create the virtual host configuration files for the existing cPanel accounts. Once it is done, confirm the status of both Apache and Nginx.
|
||||
你可以看到这个脚本将修改 Apache 的端口从 80 到另一个端口来让 Nginx 作为前端 Web 服务器,并为现有的 cPanel 用户创建虚拟主机配置文件。一旦完成,确认 Apache 和 Nginx 的状态。
|
||||
|
||||
### Apache Status: ###
|
||||
#### Apache 状态:####
|
||||
|
||||
root@server1 [/var/run/httpd]# systemctl status httpd
|
||||
● httpd.service - Apache Web Server
|
||||
@ -118,7 +112,7 @@ As you can see these script will modify the Apache port from 80 to another port
|
||||
Jan 18 06:34:23 server1.centos7-test.com apachectl[25606]: httpd (pid 24760) already running
|
||||
Jan 18 06:34:23 server1.centos7-test.com systemd[1]: Started Apache Web Server.
|
||||
|
||||
### Nginx Status: ###
|
||||
#### Nginx 状态:####
|
||||
|
||||
root@server1 [~]# systemctl status nginx
|
||||
● nginx.service - nginx-nDeploy - high performance web server
|
||||
@ -137,7 +131,7 @@ As you can see these script will modify the Apache port from 80 to another port
|
||||
Jan 17 17:18:29 server1.centos7-test.com nginx[3804]: nginx: configuration file /etc/nginx/nginx.conf test is successful
|
||||
Jan 17 17:18:29 server1.centos7-test.com systemd[1]: Started nginx-nDeploy - high performance web server.
|
||||
|
||||
Nginx act as a frontend webserver running on port 80 and Apache configuration is modified to listen on http port 9999 and https port 4430. Please see their status below:
|
||||
Nginx 作为前端服务器运行在 80 端口,Apache 配置被更改为监听 http 端口 9999 和 https 端口 4430。请看他们的情况:
|
||||
|
||||
root@server1 [/usr/local/src]# netstat -plan | grep httpd
|
||||
tcp 0 0 0.0.0.0:4430 0.0.0.0:* LISTEN 17270/httpd
|
||||
@ -151,13 +145,13 @@ Nginx act as a frontend webserver running on port 80 and Apache configuration is
|
||||
tcp 0 0 127.0.0.1:80 0.0.0.0:* LISTEN 17802/nginx: master
|
||||
tcp 0 0 45.79.183.73:80 0.0.0.0:* LISTEN 17802/nginx: master
|
||||
|
||||
The virtualhost entries created for the existing users as located in the folder "**/etc/nginx/sites-enabled**". This file path is included in the Nginx main configuration file.
|
||||
为已有用户创建的虚拟主机的配置文件在 "**/etc/nginx/sites-enabled**"。 这个文件路径包含了 Nginx 主要配置文件。
|
||||
|
||||
root@server1 [/etc/nginx/sites-enabled]# ll | grep .conf
|
||||
-rw-r--r-- 1 root root 311 Jan 17 09:02 saheetha.com.conf
|
||||
-rw-r--r-- 1 root root 336 Jan 17 09:02 saheethastest.com.conf
|
||||
|
||||
### Sample Vhost for a domain: ###
|
||||
#### 一个域名的示例虚拟主机:###
|
||||
|
||||
server {
|
||||
|
||||
@ -173,7 +167,7 @@ The virtualhost entries created for the existing users as located in the folder
|
||||
|
||||
}
|
||||
|
||||
We can confirm the working of the web server status by calling a website in the browser. Please see the web server information on my server after the installation.
|
||||
我们可以启动浏览器查看网站来确定 Web 服务器的工作状态。安装后,请阅读服务器上的 web 服务信息。
|
||||
|
||||
root@server1 [/home]# ip a | grep -i eth0
|
||||
3: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
|
||||
@ -183,24 +177,24 @@ We can confirm the working of the web server status by calling a website in the
|
||||
|
||||

|
||||
|
||||
Nginx will create the virtual host automatically for any newly created accounts in cPanel. With these simple steps we can configure Nginx as reverse proxy on a CentOS 7/CPanel server.
|
||||
Nginx 将会为任何最新在 cPanel 中创建的账户创建虚拟主机。通过这些简单的的步骤,我们能够在一台 CentOS 7 / cPanel 的服务器上配置 Nginx 作为反向代理。
|
||||
|
||||
### Advantages of Nginx as Reverse Proxy: ###
|
||||
### Nginx 作为反向代理的优势###
|
||||
|
||||
1. Easy to install and configure
|
||||
2. Performance and efficiency
|
||||
3. Prevent DDOS attacks
|
||||
4. Allows .htaccess PHP rewrite rules
|
||||
1. 便于安装和配置。
|
||||
2. 效率高、性能好。
|
||||
3. 防止 Ddos 攻击。
|
||||
4. 支持使用 .htaccess 作为 PHP 的重写规则。
|
||||
|
||||
I hope this article is useful for you guys. Thank you for referring to this. I would appreciate your valuable comments and suggestions on this for further improvements.
|
||||
我希望这篇文章对你们有用。感谢你看它。我非常高兴收到你的宝贵意见和建议,并进一步改善。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/set-nginx-reverse-proxy-centos-7-cpanel/
|
||||
|
||||
作者:[Saheetha Shameer][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[bestony](https://github.com/bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,73 @@
|
||||
一位跨平台开发者的自白
|
||||
=============================================
|
||||
|
||||

|
||||
|
||||
[Andreia Gaita][1] 在 OSCON 开源大会上发表了一个题为[跨平台开发者的自白][2]的演讲。她长期从事于开源工作,并且为 [Mono][3] 工程(LCTT 译注:一个致力于开创 .NET 在 Linux 上使用的开源工程)做着贡献,主要以 C#/C++ 开发。Andreia 任职于 GitHub,她的工作是专注构建 Visual Studio 的 GitHub 扩展管理器。
|
||||
|
||||
我在她发表演讲前就迫不及待的想要问她一些关于跨平台开发的事,问问她作为一名跨平台开发者在这 16 年之中学习到了什么。
|
||||
|
||||

|
||||
|
||||
**在你开发跨平台代码中,你使用过的最简单的和最难的代码语言是什么?**
|
||||
|
||||
我很少讨论某种语言的好坏,更多是讨论是那些语言有哪些库和工具。语言的编译器、解释器以及构建系统决定了用它们做跨平台开发的难易程度(或者它们是否可能做跨平台开发),可用的 UI 库和对本地系统的访问能力决定了与该操作系统集成的紧密程度。按照我的观点,我认为 C# 最适合完成跨平台开发工作。这种语言自身包括了允许快速的本地调用和精确的内存映射的功能,如果你希望你的代码能够与系统和本地函数库进行交互就需要这些功能。而当我需要非常特殊的系统功能时,我就会切换到 C 或者 C++。
|
||||
|
||||
**你使用的跨平台开发工具或者抽象层有哪些?**
|
||||
|
||||
我的大部分跨平台工作都是为其它需要开发跨平台应用的人开发工具、库和绑定(binding),一般是用 MONO/C# 和 C/C++。在抽象的层面我用的不多,更多是在 glib 库和友元(friends)方面。大多数时候,我用 Mono 去完成各种跨平台应用的,包括 UI,或者偶然在游戏开发中用到 Unity3D 的部分。我经常使用 Electron(LCTT 译注:Atom 编辑器的兄弟项目,可以用 Electron 开发桌面应用)。
|
||||
|
||||
**你接触过哪些构建系统?它们之间的区别是由于语言还是平台的不同?**
|
||||
|
||||
我试着选择适合我使用的语言的构建系统。那样,就会很少遇到让我头疼的问题(希望如此)。它需要支持平台和体系结构间的选择、构建输出结果位置可以智能些(多个并行构建),以及易配置性等。大多数时候,我的项目会结合使用 C/C++ 和 C#,我要从同一源代码同时构建不同的配置环境(调试、发布、Windows、OSX、Linux、Android、iOS 等等),这通常需要为每个构建的输出结果选择带有不同参数的不同编译器。构建系统可以帮我做到这一切而不用让我(太)费心。我时常尝试着用不同的构建系统,看看有些什么新的变化,但是最终,我还是回到了使用 makefile 的情况,并结合使用 shell 和批处理脚本或 Perl 脚本来完成工作(因为如果我希望用户来构建我的软件,我还是最好选择一种到处都可以用的命令行脚本语言)。
|
||||
|
||||
**你怎样平衡在这种使用统一的用户界面下提供原生的外观和体验的需求呢?**
|
||||
|
||||
跨平台的用户界面的实现很困难。在过去几年中我已经使用了一些跨平台 GUI,并且我认为这些事情上并没有最优解。基本上有两种选择。你可以选择一个跨平台工具去做一个并不是完全适合你所有支持的平台的 UI,但是代码库比较小,维护成本比较低。或者你可以选择去开发针对平台的 UI,那样看起来更原生,集成的也更好,但是需要更大的代码库和更高的维护成本。这种决定完全取决于 APP 的类型、它有多少功能、你有多少资源,以及你要把它运行在多少平台上?
|
||||
|
||||
最后,我认为用户比较接受这种“一个 UI 打通关”了,就比如 Electron 框架。我有个 Chromium+C+C# 的框架侧项目,有一天我希望可以用 C# 构建 Electron 型的 app,这样的话我就可以做到两全其美了。
|
||||
|
||||
**构建/打包系统的依赖性对你有影响吗 ?**
|
||||
|
||||
我依赖的使用方面很保守,我被崩溃的 ABI(LCTT 译注:应用程序二进制接口)、冲突的符号、以及丢失的包等问题困扰了太多次。我决定我要针对的操作系统版本,并选择最低的公有部分来使问题最小化。通常这就意味着有五种不同的 Xcode 和 OSX 框架库,要在同样的机器上相应安装五种不同的 Visual Studio 版本,多种 clang(LCTT 译注:C语言、C++、Object-C、C++ 语言的轻量级编译器)和 gcc 版本,一系列的运行着各种发行版的虚拟机。如果我不能确定我要使用的操作系统的包的状态,我有时就会静态连接库,有时会子模块化依赖以确保它们一直可用。大多时候,我会避免这些很棘手的问题,除非我非常需要使用他们。
|
||||
|
||||
**你使用持续集成(CI)、代码审查以及相关的工具吗?**
|
||||
|
||||
基本每天都用。这是保持高效的唯一方式。我在一个项目中做的第一件事情是配置跨平台构建脚本,保证每件事尽可能自动化完成。当你面向多平台开发的时候,持续集成是至关重要的。没有人能在一个机器上构建各种平台的不同组合,并且一旦你的构建过程没有包含所有的平台,你就不会注意到你搞砸的事情。在一个共享式的多平台代码库中,不同的人拥有不同的平台和功能,所以保证质量的唯一的方法是跨团队代码审查结合持续集成和其他分析工具。这不同于其他的软件项目,如果不使用相关的工具就会面临失败。
|
||||
|
||||
**你依赖于自动构建测试,或者倾向于在每个平台上构建并且进行本地测试吗?**
|
||||
|
||||
对于不包括 UI 的工具和库,我通常使用自动构建测试。如果有 UI,两种方法我都会用到——针对已有的 GUI 工具的可靠的、可脚本化的 UI 自动化少到几乎没有,所以我要么我去针对我要跨我所支持的平台创建 UI 自动化工具,要么手动进行测试。如果一个项目使用了定制的 UI 库(比如说一个类似 Unity3D 的 OpenGL UI),开发可编程的自动化工具并自动化大多数工作就相当容易。不过,没有什么东西会像人一样双击就测试出问题。
|
||||
|
||||
**如果你要做跨平台开发,你喜欢用跨编辑器的构建系统,比如在 Windows 上使用 Visual Studio,在 Linux 上使用 Qt Creator,在 Mac 上使用 XCode 吗?还是你更趋向于使用 Eclipse 这样的可以在所有平台上使用的单一平台?**
|
||||
|
||||
我喜欢使用跨编辑器的构建系统。我更喜欢在不同的IDE上保存项目文件(这样可以使增加 IDE 变得更容易),通过使用构建脚本让 IDE 在它们支持的平台上去构建。对于一个开发者来说编辑器是最重要的工具,学习它们是需要花费时间和精力的,而它们是不可相互替代的。我有我自己喜欢的编辑器和工具,每个人也可以使用他们最喜爱的工具。
|
||||
|
||||
**在跨平台开发的时候,你更喜欢使用什么样的编辑器、开发环境和 IDE 呢?**
|
||||
|
||||
跨平台开发者被限制在只能选择可以在多数平台上工作的所共有的不多选择之一。我爱用 Visual Studio,但是我不能依赖它完成除 Windows 平台之外的工作(你可能不想让 Windows 成为你的主要的交叉编译平台),所以我不会使用它作为我的主要 IDE。即使可以,跨平台开发者的核心技能也是尽可能的了解和使用大量的平台。这就意味着必须很熟悉它们——使用该平台上的编辑器和库,了解这种操作系统及其适用场景、运行方式以及它的局限性等。做这些事情就需要头脑清醒(我的捷径是加强记忆),我必须依赖跨平台的编辑器。所以我使用 Emacs 和 Sublime。
|
||||
|
||||
**你之前和现在最喜欢的跨平台项目是什么?**
|
||||
|
||||
我一直很喜欢 Mono,并且得心应手,其它的项目大部分都是以某种方式围绕着它进行的。Gluezilla 是我在多年前开发的一个 Mozilla 绑定(binding),可以把 C# 开发的应用嵌入到 Web 浏览器页面中,并且看起来很有特色。我开发过一个 Winform 应用,它是在 linux 上开发的,它可以在 Windows 上运行在一个 Mozilla 浏览器页面里嵌入的 GTK 视图中。CppSharp 项目(以前叫做 Cxxi,更早时叫做 CppInterop)是一个我开始为 C++ 库生成 C# 绑定(binding)的项目,这样就可以在 C# 中调用、创建实例、子类化 C++ 类。这样,它在运行的时候就能够检测到所使用的平台,以及用来创建本地运行库的是什么编译器,并为它生成正确的 C# 绑定(binding)。这多么有趣啊。
|
||||
|
||||
**你怎样看跨平台开发的未来趋势呢?**
|
||||
|
||||
我们构建本地应用程序的方式已经改变了,我感觉在各种桌面操作系统的明显差异在慢慢变得模糊;所以构建跨平台的应用程序将会更加容易,而且对系统的集成也不需要完全本地化。不好的是,这可能意味着应用程序易用性更糟,并且在发挥操作系统特性方面所能做的更少。库、工具以及运行环境的跨平台开发是一种我们知道怎样做的更好,但是跨平台应用程序的开发仍然需要我们的努力。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/5/oscon-interview-andreia-gaita
|
||||
|
||||
作者:[Marcus D. Hanwell][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mhanwell
|
||||
[1]: https://twitter.com/sh4na
|
||||
[2]: http://conferences.oreilly.com/oscon/open-source-us/public/schedule/detail/48702
|
||||
[3]: http://www.mono-project.com/
|
||||
|
||||
89
published/20160509 Android vs. iPhone Pros and Cons.md
Normal file
89
published/20160509 Android vs. iPhone Pros and Cons.md
Normal file
@ -0,0 +1,89 @@
|
||||
对比 Android 和 iPhone 的优缺点
|
||||
===================================
|
||||
|
||||
>当我们比较 Android 与 iPhone 的时候,很显然 Android 具有一定的优势,而 iPhone 则在一些关键方面更好。但是,究竟哪个比较好呢?
|
||||
|
||||
对 Android 与 iPhone 比较是个个人的问题。
|
||||
|
||||
就好比我来说,我两个都用。我深知这两个平台的优缺点。所以,我决定分享我关于这两个移动平台的观点。另外,然后谈谈我对新的 Ubuntu 移动平台的印象和它的优势。
|
||||
|
||||
### iPhone 的优点
|
||||
|
||||
虽然这些天我是个十足的 Android 用户,但我必须承认 iPhone 在某些方面做的是不错。首先,苹果公司在他们的设备更新方面有更好的成绩。这对于运行着 iOS 的旧设备来说尤其是这样。反观 Android ,如果不是谷歌亲生的 Nexus,它最好也不过是一个更高端的运营商支持的手机,你将发现它们的更新少的可怜或者根本没有。
|
||||
|
||||
其中 iPhone 做得很好的另一个领域是应用程序的可用性。展开来说,iPhone 应用程序几乎总是有一个简洁的外观。这并不是说 Android 应用程序就是丑陋的,而是,它们可能只是没有像 iOS 上一样的保持不变的操控习惯和一以贯之的用户体验。两个典型的例子, [Dark Sky][1] (天气)和 [Facebook Paper][2] 很好表现了 iOS 独有的布局。
|
||||
|
||||
再有就是备份过程。 Android 可以备份,默认情况下是备份到谷歌。但是对应用数据起不了太大作用。对比 iPhone ,iCloud 基本上可以对你的 iOS 设备进行了完整备份。
|
||||
|
||||
### iPhone 令我失望的地方
|
||||
|
||||
对 iPhone 来说,最无可争辩的问题是它的硬件限制要比软件限制更大,换句话来说,就是存储容量问题。
|
||||
|
||||
你看,对于大多数 Android 手机,我可以买一个容量较小的手机,然后以后可以添加 SD 卡。这意味着两件事:第一,我可以使用 SD 卡来存储大量的媒体文件。其次,我甚至可以用 SD 卡来存储“一些”我的应用程序。而苹果完全不能这么做。
|
||||
|
||||
另一个 iPhone 让我失望的地方是它提供的选择很少。备份您的设备?希望你喜欢 iTunes 或 iCloud 吧。但对一些像我一样用 Linux 的人,那就意味着,我唯一的选择便是使用 iCloud。
|
||||
|
||||
要公平的说,如果你愿意越狱,你的 iPhone 还有一些其他解决方案的,但这并不是这篇文章所讲的。 Android 的 解锁 root 也一样。本文章针对的是两个平台的原生设置。
|
||||
|
||||
最后,让我们不要忘记这件看起来很小的事—— [iTunes 会删掉用户的音乐][3],因为它认为和苹果音乐的内容重复了……或者因为一些其它的类似规定。这不是 iPhone 特有的情况?我不同意,因为那些音乐最终就是在 iPhone 上没有了。我能十分肯定地这么说,是因为不管在哪里我都不会说这种谎话。
|
||||
|
||||

|
||||
|
||||
*Android 和 iPhone 的对决取决于什么功能对你来说最重要。*
|
||||
|
||||
### Android 的优点
|
||||
|
||||
Android 给我最大的好处就是 iPhone 所提供不了的:选择。这包括对应用程序、设备以及手机是整体如何工作的选择。
|
||||
|
||||
我爱桌面小工具!对于 iPhone 用户来说,它们也许看上去很蠢。但我可以告诉你,它们可以让我不用打开应用程序就可以看到所需的数据,而无需额外的麻烦。另一个类似的功能,我喜欢安装定制的桌面界面,而不是我的手机默认的那个!
|
||||
|
||||
最后,我可以通过像 [Airdroid][4] 和 [Tasker][5] 这样的工具给我的智能手机添加计算机级的完整功能。AirDroid 可以让我把我的 Android 手机当成带有一个文件管理和通信功能的计算机——这可以让我可以轻而易举的使用鼠标和键盘。Tasker 更厉害,我可以用它让我手机根据环境变得可联系或不可联系,当我设置好了之后,当我到会议室之后我的手机就会自己进入会议模式,甚至变成省电模式。我还可以设置它当我到达特定的目的地时自动启动某个应用程序。
|
||||
|
||||
### Android 让我失望的地方
|
||||
|
||||
Android 备份选项仅限于特定的用户数据,而不是手机的完整克隆。如果不解锁 root,要么你只能听之任之,要么你必须用 Android SDK 来解决。期望普通用户会解锁 root 或运行 SDK 来完成备份(我的意思是一切都备份)显然是一个笑话。
|
||||
|
||||
是的,谷歌的备份服务会备份谷歌应用程序的数据、以及其他相关的自定义设置。但它是远不及我们所看到的苹果服务一样完整。为了完成类似于苹果那样的功能,我发现你就要么必须解锁 root ,要么将其连接到一个在 PC 机上使用一些不知道是什么的软件来干这个。
|
||||
|
||||
不过,公平的说,我知道使用 Nexus 的人能从该设备特有的[完整备份服务][6]中得到帮助。对不起,但是谷歌的默认备份方案是不行的。对于通过在 PC 上使用 adb (Android Debug Bridge) 来备份也是一样的——不会总是如预期般的恢复。
|
||||
|
||||
等吧,它会变好的。经过了很多失败的失望和挫折之后,我发现有一个应用程序,看起来它“可能”提供了一点点微小的希望,它叫 Helium 。它不像我发现的其他应用程序那样拥有误导性的和令人沮丧的局限性,[Helium][7] 最初看起来像是谷歌应该一直提供的备份应用程序——注意,只是“看起来像”。可悲的是,它绊了我一跤。第一次运行时,我不仅需要将它连接到我的计算机上,甚至使用他们提供的 Linux 脚本都不工作。在删除他们的脚本后,我弄了一个很好的老式 adb 来备份到我的 Linux PC 上。你可能要知道的是:你需要在开发工具里打开一箩筐东西,而且如果你运行 Twilight 应用的话还要关闭它。当 adb 的备份选项在我的手机上不起作用时,我花了一点时间把这个搞好了。
|
||||
|
||||
最后,Android 为非 root 用户也提供了可以轻松备份一些如联系人、短信等简单东西的选择。但是,要深度手机备份的话,以我经验还是通过有线连接和 adb。
|
||||
|
||||
### Ubuntu 能拯救我们吗?
|
||||
|
||||
在手机领域,通过对这两大玩家之间的优劣比较,我们很期望从 Ubuntu 看到更好的表现。但是,迄今为止,它的表现相当低迷。
|
||||
|
||||
我喜欢开发人员基于这个操作系统正在做的那些努力,我当然想在 iPhone 和 Android 手机之外有第三种选择。但是不幸的是,它在手机和平板上并不受欢迎,而且由于硬件的低端以及在 YouTube 上的糟糕的演示,有很多不好的传闻。
|
||||
|
||||
公平来说,我在以前也用过 iPhone 和 Android 的低端机,所以这不是对 Ubuntu 的挖苦。但是它要表现出准备与 iPhone 和 Android 相竞争的功能生态时,那就另说了,这还不是我现在特别感兴趣的东西。在以后的日子里,也许吧,我会觉得 Ubuntu 手机可以满足我的需要了。
|
||||
|
||||
###Android 与 iPhone 之争:为什么 Android 将终究赢得胜利
|
||||
|
||||
忽视 Android 那些痛苦的缺点,它起码给我了选择。它并没有把我限制在只有两种备份数据的方式上。是的,一些 Android 的限制事实上是由于它的关注点在于让我选择如何处理我的数据。但是,我可以选择我自己的设备,想加内存就加内存。Android 可以我让做很多很酷的东西,而 iPhone 根本就没有能力这些事情。
|
||||
|
||||
从根本上来说, Android 给非 root 用户提供了访问手机功能的更大自由。无论是好是坏,这是人们想要的一种自由。现在你们其中有很多 iPhone 的粉丝应该感谢像 [libimobiledevice][8] 这样项目带来的影响。看看苹果阻止 Linux 用户所做的事情……然后问问你自己:作为一个 Linux 用户这真的值得吗?
|
||||
|
||||
发表下评论吧,分享你对 iPhone 、Android 或 Ubuntu 的看法。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/mobile-wireless/android-vs.-iphone-pros-and-cons.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[jovov](https://github.com/jovov)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]: http://darkskyapp.com/
|
||||
[2]: https://www.facebook.com/paper/
|
||||
[3]: https://blog.vellumatlanta.com/2016/05/04/apple-stole-my-music-no-seriously/
|
||||
[4]: https://www.airdroid.com/
|
||||
[5]: http://tasker.dinglisch.net/
|
||||
[6]: https://support.google.com/nexus/answer/2819582?hl=en
|
||||
[7]: https://play.google.com/store/apps/details?id=com.koushikdutta.backup&hl=en
|
||||
[8]: http://www.libimobiledevice.org/
|
||||
|
||||
@ -0,0 +1,39 @@
|
||||
Linux 将成为 21 世纪汽车的主要操作系统
|
||||
===============================================================
|
||||
|
||||
> 汽车可不单单是由引擎和华丽外壳组成的,汽车里还有许许多多的计算部件,而 Linux 就在它们里面跑着。
|
||||
|
||||
Linux 不只运行在你的服务器和手机(安卓)上。它还运行在你的车里。当然了,没人会因为某个车载系统而去买辆车。但是 Linux 已经为像丰田、日产、捷豹路虎这些大型汽车制造商提供了信息娱乐系统、平视显示以及其联网汽车(connected car)的 4G 与 Wi-Fi 系统,而且 [Linux 即将登陆福特汽车][1]、马自达、三菱、斯巴鲁。
|
||||
|
||||

|
||||
|
||||
*如今,所有的 Linux 和开源汽车软件的成果都已经在 Linux 基金会的 Automotive Grade Linux (AGL)项目下统一标准化了。*
|
||||
|
||||
传统软件公司也进入了移动物联网领域。 Movimento、甲骨文、高通、Texas Instruments、UIEvolution 和 VeriSilicon 都已经[加入 Automotive Grade Linux(AGL)项目][2]。 [AGL][3] 是一个相互协作的开源项目,志在于为联网汽车打造一个基于 Linux 的通用软件栈。
|
||||
|
||||
“随着联网汽车技术和信息娱乐系统需求的快速增长,AGL 过去几年中得到了极大的发展,” Linux 基金会汽车总经理 Dan Cauchy 如是说。
|
||||
|
||||
Cauchy 又补充道,“我们的会员基础不单单只是迅速壮大,而且通过横跨不同的业界实现了多元化,从半导体和车载软件到 IoT 和连接云服务。这是一个明显的迹象,即联网汽车的革命已经间接影响到许多行业纵向市场。”
|
||||
|
||||
这些公司在 AGL 发布了新的 AGL Unified Code Base (UCB) 之后加入了 AGL 项目。这个新的 Linux 发行版基于 AGL 和另外两个汽车开源项目: [Tizen][4] 和 [GENIVI Alliance][5] 。 UCB 是第二代 Linux 汽车系统。它从底层开始开发,一直到特定的汽车应用软件。它能处理导航、通信、安全、安保和信息娱乐系统。
|
||||
|
||||
“汽车行业需要一个标准的开源系统和框架来让汽车制造商和供应商能够快速地将类似智能手机的功能带入到汽车中来。” Cauchy 说。“这个新的发行版将 AGL、Tizen、GENIVI 项目和相关开源代码中的精华部分整合进 AGL Unified Code Base (UCB)中,使得汽车制造商能够利用一个通用平台进行快速创新。 在汽车中采用基于 Linux 的系统来实现所有功能时, AGL 的 UCB 发行版将扮演一个重大的角色。”
|
||||
|
||||
他说得对。自从 2016 年 1 月发布以来,已有四个汽车公司和十个新的软件厂商加入了 AGL。Esso,如今的 Exxon, 曾让 “把老虎装入油箱” 这条广告语出了名。我怀疑 “把企鹅装到引擎盖下” 这样的广告语是否也会变得家喻户晓,但是它却道出了事实。 Linux 正在慢慢成为 21 世纪汽车的主要操作系统。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/the-linux-in-your-car-movement-gains-momentum/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]: https://www.automotivelinux.org/news/announcement/2016/01/ford-mazda-mitsubishi-motors-and-subaru-join-linux-foundation-and
|
||||
[2]: https://www.automotivelinux.org/news/announcement/2016/05/oracle-qualcomm-innovation-center-texas-instruments-and-others-support
|
||||
[3]: https://www.automotivelinux.org/
|
||||
[4]: https://www.tizen.org/
|
||||
[5]: http://www.genivi.org/
|
||||
@ -0,0 +1,74 @@
|
||||
使用 Python 和 Asyncio 编写在线多人游戏(一)
|
||||
===================================================================
|
||||
|
||||
你在 Python 中用过异步编程吗?本文中我会告诉你怎样做,而且用一个[能工作的例子][1]来展示它:这是一个流行的贪吃蛇游戏,而且是为多人游戏而设计的。
|
||||
|
||||
- [游戏入口在此,点此体验][2]。
|
||||
|
||||
###1、简介
|
||||
|
||||
在技术和文化领域,大规模多人在线游戏(MMO)毋庸置疑是我们当今世界的潮流之一。很长时间以来,为一个 MMO 游戏写一个服务器这件事总是会涉及到大量的预算与复杂的底层编程技术,不过在最近这几年,事情迅速发生了变化。基于动态语言的现代框架允许在中档的硬件上面处理大量并发的用户连接。同时,HTML5 和 WebSockets 标准使得创建基于实时图形的游戏的直接运行至浏览器上的客户端成为可能,而不需要任何的扩展。
|
||||
|
||||
对于创建可扩展的非堵塞性的服务器来说,Python 可能不是最受欢迎的工具,尤其是和在这个领域里最受欢迎的 Node.js 相比而言。但是最近版本的 Python 正在改变这种现状。[asyncio][3] 的引入和一个特别的 [async/await][4] 语法使得异步代码看起来像常规的阻塞代码一样,这使得 Python 成为了一个值得信赖的异步编程语言,所以我将尝试利用这些新特点来创建一个多人在线游戏。
|
||||
|
||||
###2、异步
|
||||
|
||||
一个游戏服务器应该可以接受尽可能多的用户并发连接,并实时处理这些连接。一个典型的解决方案是创建线程,然而在这种情况下并不能解决这个问题。运行上千的线程需要 CPU 在它们之间不停的切换(这叫做上下文切换),这将导致开销非常大,效率很低下。更糟糕的是使用进程来实现,因为,不但如此,它们还会占用大量的内存。在 Python 中,甚至还有一个问题,Python 的解释器(CPython)并不是针对多线程设计的,相反它主要针对于单线程应用实现最大的性能。这就是为什么它使用 GIL(global interpreter lock),这是一个不允许同时运行多线程 Python 代码的架构,以防止同一个共享对象出现使用不可控。正常情况下,在当前线程正在等待的时候,解释器会转换到另一个线程,通常是等待一个 I/O 的响应(举例说,比如等待 Web 服务器的响应)。这就允许在你的应用中实现非阻塞 I/O 操作,因为每一个操作仅仅阻塞一个线程而不是阻塞整个服务器。然而,这也使得通常的多线程方案变得几近无用,因为它不允许你并发执行 Python 代码,即使是在多核心的 CPU 上也是这样。而与此同时,在一个单一线程中拥有非阻塞 I/O 是完全有可能的,因而消除了经常切换上下文的需要。
|
||||
|
||||
实际上,你可以用纯 Python 代码来实现一个单线程的非阻塞 I/O。你所需要的只是标准的 [select][5] 模块,这个模块可以让你写一个事件循环来等待未阻塞的 socket 的 I/O。然而,这个方法需要你在一个地方定义所有 app 的逻辑,用不了多久,你的 app 就会变成非常复杂的状态机。有一些框架可以简化这个任务,比较流行的是 [tornade][6] 和 [twisted][7]。它们被用来使用回调方法实现复杂的协议(这和 Node.js 比较相似)。这种框架运行在它自己的事件循环中,按照定义的事件调用你的回调函数。并且,这或许是一些情况的解决方案,但是它仍然需要使用回调的方式编程,这使你的代码变得碎片化。与写同步代码并且并发地执行多个副本相比,这就像我们在普通的线程上做的一样。在单个线程上这为什么是不可能的呢?
|
||||
|
||||
这就是为什么出现微线程(microthread)概念的原因。这个想法是为了在一个线程上并发执行任务。当你在一个任务中调用阻塞的方法时,有一个叫做“manager” (或者“scheduler”)的东西在执行事件循环。当有一些事件准备处理的时候,一个 manager 会转移执行权给一个任务,并等着它执行完毕。任务将一直执行,直到它遇到一个阻塞调用,然后它就会将执行权返还给 manager。
|
||||
|
||||
> 微线程也称为轻量级线程(lightweight threads)或绿色线程(green threads)(来自于 Java 中的一个术语)。在伪线程中并发执行的任务叫做 tasklets、greenlets 或者协程(coroutines)。
|
||||
|
||||
Python 中的微线程最早的实现之一是 [Stackless Python][8]。它之所以这么知名是因为它被用在了一个叫 [EVE online][9] 的非常有名的在线游戏中。这个 MMO 游戏自称说在一个持久的“宇宙”中,有上千个玩家在做不同的活动,这些都是实时发生的。Stackless 是一个独立的 Python 解释器,它代替了标准的函数栈调用,并且直接控制程序运行流程来减少上下文切换的开销。尽管这非常有效,这个解决方案不如在标准解释器中使用“软”库更流行,像 [eventlet][10] 和 [gevent][11] 的软件包配备了修补过的标准 I/O 库,I/O 函数会将执行权传递到内部事件循环。这使得将正常的阻塞代码转变成非阻塞的代码变得简单。这种方法的一个缺点是从代码上看这并不分明,它的调用是非阻塞的。新版本的 Python 引入了本地协程作为生成器的高级形式。在 Python 的 3.4 版本之后,引入了 asyncio 库,这个库依赖于本地协程来提供单线程并发。但是仅仅到了 Python 3.5 ,协程就变成了 Python 语言的一部分,使用新的关键字 async 和 await 来描述。这是一个简单的例子,演示了使用 asyncio 来运行并发任务。
|
||||
|
||||
```
|
||||
import asyncio
|
||||
|
||||
async def my_task(seconds):
|
||||
print("start sleeping for {} seconds".format(seconds))
|
||||
await asyncio.sleep(seconds)
|
||||
print("end sleeping for {} seconds".format(seconds))
|
||||
|
||||
all_tasks = asyncio.gather(my_task(1), my_task(2))
|
||||
loop = asyncio.get_event_loop()
|
||||
loop.run_until_complete(all_tasks)
|
||||
loop.close()
|
||||
```
|
||||
|
||||
我们启动了两个任务,一个睡眠 1 秒钟,另一个睡眠 2 秒钟,输出如下:
|
||||
|
||||
```
|
||||
start sleeping for 1 seconds
|
||||
start sleeping for 2 seconds
|
||||
end sleeping for 1 seconds
|
||||
end sleeping for 2 seconds
|
||||
```
|
||||
|
||||
正如你所看到的,协程不会阻塞彼此——第二个任务在第一个结束之前启动。这发生的原因是 asyncio.sleep 是协程,它会返回执行权给调度器,直到时间到了。
|
||||
|
||||
在下一节中,我们将会使用基于协程的任务来创建一个游戏循环。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-asyncio-getting-asynchronous/
|
||||
|
||||
作者:[Kyrylo Subbotin][a]
|
||||
译者:[xinglianfly](https://github.com/xinglianfly)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-asyncio-getting-asynchronous/
|
||||
[1]: http://snakepit-game.com/
|
||||
[2]: http://snakepit-game.com/
|
||||
[3]: https://docs.python.org/3/library/asyncio.html
|
||||
[4]: https://docs.python.org/3/whatsnew/3.5.html#whatsnew-pep-492
|
||||
[5]: https://docs.python.org/2/library/select.html
|
||||
[6]: http://www.tornadoweb.org/
|
||||
[7]: http://twistedmatrix.com/
|
||||
[8]: http://www.stackless.com/
|
||||
[9]: http://www.eveonline.com/
|
||||
[10]: http://eventlet.net/
|
||||
[11]: http://www.gevent.org/
|
||||
@ -1,37 +1,37 @@
|
||||
用Python实现Python解释器
|
||||
用 Python 实现 Python 解释器
|
||||
===
|
||||
|
||||
_Allison是Dropbox的工程师,在那里她维护着世界上最大的由Python客户组成的网络。在Dropbox之前,她是Recurse Center的导师, 曾在纽约写作。在北美的PyCon做过关于Python内部机制的演讲,并且她喜欢奇怪的bugs。她的博客地址是[akaptur.com](http://akaptur.com)._
|
||||
_Allison 是 Dropbox 的工程师,在那里她维护着这个世界上最大的 Python 客户端网络之一。在去 Dropbox 之前,她是 Recurse Center 的协调人, 是这个位于纽约的程序员深造机构的作者。她在北美的 PyCon 做过关于 Python 内部机制的演讲,并且她喜欢研究奇怪的 bug。她的博客地址是 [akaptur.com](http://akaptur.com)。_
|
||||
|
||||
## Introduction
|
||||
### 介绍
|
||||
|
||||
Byterun是一个用Python实现的Python解释器。随着我在Byterun上的工作,我惊讶并很高兴地的发现,这个Python解释器的基础结构可以满足500行的限制。在这一章我们会搞清楚这个解释器的结构,给你足够的知识探索下去。我们的目标不是向你展示解释器的每个细节---像编程和计算机科学其他有趣的领域一样,你可能会投入几年的时间去搞清楚这个主题。
|
||||
Byterun 是一个用 Python 实现的 Python 解释器。随着我对 Byterun 的开发,我惊喜地的发现,这个 Python 解释器的基础结构用 500 行代码就能实现。在这一章我们会搞清楚这个解释器的结构,给你足够探索下去的背景知识。我们的目标不是向你展示解释器的每个细节---像编程和计算机科学其他有趣的领域一样,你可能会投入几年的时间去深入了解这个主题。
|
||||
|
||||
Byterun是Ned Batchelder和我完成的,建立在Paul Swartz的工作之上。它的结构和主要的Python实现(CPython)差不多,所以理解Byterun会帮助你理解大多数解释器特别是CPython解释器。(如果你不知道你用的是什么Python,那么很可能它就是CPython)。尽管Byterun很小,但它能执行大多数简单的Python程序。
|
||||
Byterun 是 Ned Batchelder 和我完成的,建立在 Paul Swartz 的工作之上。它的结构和主要的 Python 实现(CPython)差不多,所以理解 Byterun 会帮助你理解大多数解释器,特别是 CPython 解释器。(如果你不知道你用的是什么 Python,那么很可能它就是 CPython)。尽管 Byterun 很小,但它能执行大多数简单的 Python 程序(这一章是基于 Python 3.5 及其之前版本生成的字节码的,在 Python 3.6 中生成的字节码有一些改变)。
|
||||
|
||||
### A Python Interpreter
|
||||
#### Python 解释器
|
||||
|
||||
在开始之前,让我们缩小一下“Pyhton解释器”的意思。在讨论Python的时候,“解释器”这个词可以用在很多不同的地方。有的时候解释器指的是REPL,当你在命令行下敲下`python`时所得到的交互式环境。有时候人们会相互替代的使用Python解释器和Python来说明执行Python代码的这一过程。在本章,“解释器”有一个更精确的意思:执行Python程序过程中的最后一步。
|
||||
在开始之前,让我们限定一下“Pyhton 解释器”的意思。在讨论 Python 的时候,“解释器”这个词可以用在很多不同的地方。有的时候解释器指的是 Python REPL,即当你在命令行下敲下 `python` 时所得到的交互式环境。有时候人们会或多或少的互换使用 “Python 解释器”和“Python”来说明从头到尾执行 Python 代码的这一过程。在本章中,“解释器”有一个更精确的意思:Python 程序的执行过程中的最后一步。
|
||||
|
||||
在解释器接手之前,Python会执行其他3个步骤:词法分析,语法解析和编译。这三步合起来把源代码转换成_code object_,它包含着解释器可以理解的指令。而解释器的工作就是解释code object中的指令。
|
||||
在解释器接手之前,Python 会执行其他 3 个步骤:词法分析,语法解析和编译。这三步合起来把源代码转换成代码对象(code object),它包含着解释器可以理解的指令。而解释器的工作就是解释代码对象中的指令。
|
||||
|
||||
你可能很奇怪执行Python代码会有编译这一步。Python通常被称为解释型语言,就像Ruby,Perl一样,它们和编译型语言相对,比如C,Rust。然而,这里的术语并不是它看起来的那样精确。大多数解释型语言包括Python,确实会有编译这一步。而Python被称为解释型的原因是相对于编译型语言,它在编译这一步的工作相对较少(解释器做相对多的工作)。在这章后面你会看到,Python的编译器比C语言编译器需要更少的关于程序行为的信息。
|
||||
你可能很奇怪执行 Python 代码会有编译这一步。Python 通常被称为解释型语言,就像 Ruby,Perl 一样,它们和像 C,Rust 这样的编译型语言相对。然而,这个术语并不是它看起来的那样精确。大多数解释型语言包括 Python 在内,确实会有编译这一步。而 Python 被称为解释型的原因是相对于编译型语言,它在编译这一步的工作相对较少(解释器做相对多的工作)。在这章后面你会看到,Python 的编译器比 C 语言编译器需要更少的关于程序行为的信息。
|
||||
|
||||
### A Python Python Interpreter
|
||||
#### Python 的 Python 解释器
|
||||
|
||||
Byterun是一个用Python写的Python解释器,这点可能让你感到奇怪,但没有比用C语言写C语言编译器更奇怪。(事实上,广泛使用的gcc编译器就是用C语言本身写的)你可以用几乎的任何语言写一个Python解释器。
|
||||
Byterun 是一个用 Python 写的 Python 解释器,这点可能让你感到奇怪,但没有比用 C 语言写 C 语言编译器更奇怪的了。(事实上,广泛使用的 gcc 编译器就是用 C 语言本身写的)你可以用几乎任何语言写一个 Python 解释器。
|
||||
|
||||
用Python写Python既有优点又有缺点。最大的缺点就是速度:用Byterun执行代码要比用CPython执行慢的多,CPython解释器是用C语言实现的并做了优化。然而Byterun是为了学习而设计的,所以速度对我们不重要。使用Python最大优点是我们可以*仅仅*实现解释器,而不用担心Python运行时的部分,特别是对象系统。比如当Byterun需要创建一个类时,它就会回退到“真正”的Python。另外一个优势是Byterun很容易理解,部分原因是它是用高级语言写的(Python!)(另外我们不会对解释器做优化 --- 再一次,清晰和简单比速度更重要)
|
||||
用 Python 写 Python 既有优点又有缺点。最大的缺点就是速度:用 Byterun 执行代码要比用 CPython 执行慢的多,CPython 解释器是用 C 语言实现的,并做了认真优化。然而 Byterun 是为了学习而设计的,所以速度对我们不重要。使用 Python 最大优势是我们可以*仅仅*实现解释器,而不用担心 Python 运行时部分,特别是对象系统。比如当 Byterun 需要创建一个类时,它就会回退到“真正”的 Python。另外一个优势是 Byterun 很容易理解,部分原因是它是用人们很容易理解的高级语言写的(Python !)(另外我们不会对解释器做优化 --- 再一次,清晰和简单比速度更重要)
|
||||
|
||||
## Building an Interpreter
|
||||
### 构建一个解释器
|
||||
|
||||
在我们考察Byterun代码之前,我们需要一些对解释器结构的高层次视角。Python解释器是如何工作的?
|
||||
在我们考察 Byterun 代码之前,我们需要从高层次对解释器结构有一些了解。Python 解释器是如何工作的?
|
||||
|
||||
Python解释器是一个_虚拟机_,模拟真实计算机的软件。我们这个虚拟机是栈机器,它用几个栈来完成操作(与之相对的是寄存器机器,它从特定的内存地址读写数据)。
|
||||
Python 解释器是一个虚拟机(virtual machine),是一个模拟真实计算机的软件。我们这个虚拟机是栈机器(stack machine),它用几个栈来完成操作(与之相对的是寄存器机器(register machine),它从特定的内存地址读写数据)。
|
||||
|
||||
Python解释器是一个_字节码解释器_:它的输入是一些命令集合称作_字节码_。当你写Python代码时,词法分析器,语法解析器和编译器生成code object让解释器去操作。每个code object都包含一个要被执行的指令集合 --- 它就是字节码 --- 另外还有一些解释器需要的信息。字节码是Python代码的一个_中间层表示_:它以一种解释器可以理解的方式来表示源代码。这和汇编语言作为C语言和机器语言的中间表示很类似。
|
||||
Python 解释器是一个字节码解释器(bytecode interpreter):它的输入是一些称作字节码(bytecode)的指令集。当你写 Python 代码时,词法分析器、语法解析器和编译器会生成代码对象(code object)让解释器去操作。每个代码对象都包含一个要被执行的指令集 —— 它就是字节码 —— 以及还有一些解释器需要的信息。字节码是 Python 代码的一个中间层表示( intermediate representation):它以一种解释器可以理解的方式来表示源代码。这和汇编语言作为 C 语言和机器语言的中间表示很类似。
|
||||
|
||||
### A Tiny Interpreter
|
||||
#### 微型解释器
|
||||
|
||||
为了让说明更具体,让我们从一个非常小的解释器开始。它只能计算两个数的和,只能理解三个指令。它执行的所有代码只是这三个指令的不同组合。下面就是这三个指令:
|
||||
|
||||
@ -39,7 +39,7 @@ Python解释器是一个_字节码解释器_:它的输入是一些命令集合
|
||||
- `ADD_TWO_VALUES`
|
||||
- `PRINT_ANSWER`
|
||||
|
||||
我们不关心词法,语法和编译,所以我们也不在乎这些指令是如何产生的。你可以想象,你写下`7 + 5`,然后一个编译器为你生成那三个指令的组合。如果你有一个合适的编译器,你甚至可以用Lisp的语法来写,只要它能生成相同的指令。
|
||||
我们不关心词法、语法和编译,所以我们也不在乎这些指令集是如何产生的。你可以想象,当你写下 `7 + 5`,然后一个编译器为你生成那三个指令的组合。如果你有一个合适的编译器,你甚至可以用 Lisp 的语法来写,只要它能生成相同的指令。
|
||||
|
||||
假设
|
||||
|
||||
@ -58,13 +58,13 @@ what_to_execute = {
|
||||
"numbers": [7, 5] }
|
||||
```
|
||||
|
||||
Python解释器是一个_栈机器_,所以它必须通过操作栈来完成这个加法。(\aosafigref{500l.interpreter.stackmachine}.)解释器先执行第一条指令,`LOAD_VALUE`,把第一个数压到栈中。接着它把第二个数也压到栈中。然后,第三条指令,`ADD_TWO_VALUES`,先把两个数从栈中弹出,加起来,再把结果压入栈中。最后一步,把结果弹出并输出。
|
||||
Python 解释器是一个栈机器(stack machine),所以它必须通过操作栈来完成这个加法(见下图)。解释器先执行第一条指令,`LOAD_VALUE`,把第一个数压到栈中。接着它把第二个数也压到栈中。然后,第三条指令,`ADD_TWO_VALUES`,先把两个数从栈中弹出,加起来,再把结果压入栈中。最后一步,把结果弹出并输出。
|
||||
|
||||
\aosafigure[240pt]{interpreter-images/interpreter-stack.png}{A stack machine}{500l.interpreter.stackmachine}
|
||||

|
||||
|
||||
`LOAD_VALUE`这条指令告诉解释器把一个数压入栈中,但指令本身并没有指明这个数是多少。指令需要一个额外的信息告诉解释器去哪里找到这个数。所以我们的指令集有两个部分:指令本身和一个常量列表。(在Python中,字节码就是我们称为的“指令”,而解释器执行的是_code object_。)
|
||||
`LOAD_VALUE`这条指令告诉解释器把一个数压入栈中,但指令本身并没有指明这个数是多少。指令需要一个额外的信息告诉解释器去哪里找到这个数。所以我们的指令集有两个部分:指令本身和一个常量列表。(在 Python 中,字节码就是我们所称的“指令”,而解释器“执行”的是代码对象。)
|
||||
|
||||
为什么不把数字直接嵌入指令之中?想象一下,如果我们加的不是数字,而是字符串。我们可不想把字符串这样的东西加到指令中,因为它可以有任意的长度。另外,我们这种设计也意味着我们只需要对象的一份拷贝,比如这个加法 `7 + 7`, 现在常量表 `"numbers"`只需包含一个`7`。
|
||||
为什么不把数字直接嵌入指令之中?想象一下,如果我们加的不是数字,而是字符串。我们可不想把字符串这样的东西加到指令中,因为它可以有任意的长度。另外,我们这种设计也意味着我们只需要对象的一份拷贝,比如这个加法 `7 + 7`, 现在常量表 `"numbers"`只需包含一个`[7]`。
|
||||
|
||||
你可能会想为什么会需要除了`ADD_TWO_VALUES`之外的指令。的确,对于我们两个数加法,这个例子是有点人为制作的意思。然而,这个指令却是建造更复杂程序的轮子。比如,就我们目前定义的三个指令,只要给出正确的指令组合,我们可以做三个数的加法,或者任意个数的加法。同时,栈提供了一个清晰的方法去跟踪解释器的状态,这为我们增长的复杂性提供了支持。
|
||||
|
||||
@ -89,7 +89,7 @@ class Interpreter:
|
||||
self.stack.append(total)
|
||||
```
|
||||
|
||||
这三个方法完成了解释器所理解的三条指令。但解释器还需要一样东西:一个能把所有东西结合在一起并执行的方法。这个方法就叫做`run_code`, 它把我们前面定义的字典结构`what-to-execute`作为参数,循环执行里面的每条指令,如何指令有参数,处理参数,然后调用解释器对象中相应的方法。
|
||||
这三个方法完成了解释器所理解的三条指令。但解释器还需要一样东西:一个能把所有东西结合在一起并执行的方法。这个方法就叫做 `run_code`,它把我们前面定义的字典结构 `what-to-execute` 作为参数,循环执行里面的每条指令,如果指令有参数就处理参数,然后调用解释器对象中相应的方法。
|
||||
|
||||
```python
|
||||
def run_code(self, what_to_execute):
|
||||
@ -106,20 +106,20 @@ class Interpreter:
|
||||
self.PRINT_ANSWER()
|
||||
```
|
||||
|
||||
为了测试,我们创建一个解释器对象,然后用前面定义的 7 + 5 的指令集来调用`run_code`。
|
||||
为了测试,我们创建一个解释器对象,然后用前面定义的 7 + 5 的指令集来调用 `run_code`。
|
||||
|
||||
```python
|
||||
interpreter = Interpreter()
|
||||
interpreter.run_code(what_to_execute)
|
||||
```
|
||||
|
||||
显然,它会输出12
|
||||
显然,它会输出12。
|
||||
|
||||
尽管我们的解释器功能受限,但这个加法过程几乎和真正的Python解释器是一样的。这里,我们还有几点要注意。
|
||||
尽管我们的解释器功能十分受限,但这个过程几乎和真正的 Python 解释器处理加法是一样的。这里,我们还有几点要注意。
|
||||
|
||||
首先,一些指令需要参数。在真正的Python bytecode中,大概有一半的指令有参数。像我们的例子一样,参数和指令打包在一起。注意_指令_的参数和传递给对应方法的参数是不同的。
|
||||
首先,一些指令需要参数。在真正的 Python 字节码当中,大概有一半的指令有参数。像我们的例子一样,参数和指令打包在一起。注意指令的参数和传递给对应方法的参数是不同的。
|
||||
|
||||
第二,指令`ADD_TWO_VALUES`不需要任何参数,它从解释器栈中弹出所需的值。这正是以栈为基础的解释器的特点。
|
||||
第二,指令`ADD_TWO_VALUES`不需要任何参数,它从解释器栈中弹出所需的值。这正是以基于栈的解释器的特点。
|
||||
|
||||
记得我们说过只要给出合适的指令集,不需要对解释器做任何改变,我们就能做多个数的加法。考虑下面的指令集,你觉得会发生什么?如果你有一个合适的编译器,什么代码才能编译出下面的指令集?
|
||||
|
||||
@ -134,11 +134,11 @@ class Interpreter:
|
||||
"numbers": [7, 5, 8] }
|
||||
```
|
||||
|
||||
从这点出发,我们开始看到这种结构的可扩展性:我们可以通过向解释器对象增加方法来描述更多的操作(只要有一个编译器能为我们生成组织良好的指令集)。
|
||||
从这点出发,我们开始看到这种结构的可扩展性:我们可以通过向解释器对象增加方法来描述更多的操作(只要有一个编译器能为我们生成组织良好的指令集就行)。
|
||||
|
||||
#### Variables
|
||||
##### 变量
|
||||
|
||||
接下来给我们的解释器增加变量的支持。我们需要一个保存变量值的指令,`STORE_NAME`;一个取变量值的指令`LOAD_NAME`;和一个变量到值的映射关系。目前,我们会忽略命名空间和作用域,所以我们可以把变量和值的映射直接存储在解释器对象中。最后,我们要保证`what_to_execute`除了一个常量列表,还要有个变量名字的列表。
|
||||
接下来给我们的解释器增加变量的支持。我们需要一个保存变量值的指令 `STORE_NAME`;一个取变量值的指令`LOAD_NAME`;和一个变量到值的映射关系。目前,我们会忽略命名空间和作用域,所以我们可以把变量和值的映射直接存储在解释器对象中。最后,我们要保证`what_to_execute`除了一个常量列表,还要有个变量名字的列表。
|
||||
|
||||
```python
|
||||
>>> def s():
|
||||
@ -159,9 +159,9 @@ class Interpreter:
|
||||
"names": ["a", "b"] }
|
||||
```
|
||||
|
||||
我们的新的的实现在下面。为了跟踪哪名字绑定到那个值,我们在`__init__`方法中增加一个`environment`字典。我们也增加了`STORE_NAME`和`LOAD_NAME`方法,它们获得变量名,然后从`environment`字典中设置或取出这个变量值。
|
||||
我们的新的实现在下面。为了跟踪哪个名字绑定到哪个值,我们在`__init__`方法中增加一个`environment`字典。我们也增加了`STORE_NAME`和`LOAD_NAME`方法,它们获得变量名,然后从`environment`字典中设置或取出这个变量值。
|
||||
|
||||
现在指令参数就有两个不同的意思,它可能是`numbers`列表的索引,也可能是`names`列表的索引。解释器通过检查所执行的指令就能知道是那种参数。而我们打破这种逻辑 ,把指令和它所用何种参数的映射关系放在另一个单独的方法中。
|
||||
现在指令的参数就有两个不同的意思,它可能是`numbers`列表的索引,也可能是`names`列表的索引。解释器通过检查所执行的指令就能知道是那种参数。而我们打破这种逻辑 ,把指令和它所用何种参数的映射关系放在另一个单独的方法中。
|
||||
|
||||
```python
|
||||
class Interpreter:
|
||||
@ -207,7 +207,7 @@ class Interpreter:
|
||||
self.LOAD_NAME(argument)
|
||||
```
|
||||
|
||||
仅仅五个指令,`run_code`这个方法已经开始变得冗长了。如果保持这种结构,那么每条指令都需要一个`if`分支。这里,我们要利用Python的动态方法查找。我们总会给一个称为`FOO`的指令定义一个名为`FOO`的方法,这样我们就可用Python的`getattr`函数在运行时动态查找方法,而不用这个大大的分支结构。`run_code`方法现在是这样:
|
||||
仅仅五个指令,`run_code`这个方法已经开始变得冗长了。如果保持这种结构,那么每条指令都需要一个`if`分支。这里,我们要利用 Python 的动态方法查找。我们总会给一个称为`FOO`的指令定义一个名为`FOO`的方法,这样我们就可用 Python 的`getattr`函数在运行时动态查找方法,而不用这个大大的分支结构。`run_code`方法现在是这样:
|
||||
|
||||
```python
|
||||
def execute(self, what_to_execute):
|
||||
@ -222,9 +222,9 @@ class Interpreter:
|
||||
bytecode_method(argument)
|
||||
```
|
||||
|
||||
## Real Python Bytecode
|
||||
### 真实的 Python 字节码
|
||||
|
||||
现在,放弃我们的小指令集,去看看真正的Python字节码。字节码的结构和我们的小解释器的指令集差不多,除了字节码用一个字节而不是一个名字来指示这条指令。为了理解它的结构,我们将考察一个函数的字节码。考虑下面这个例子:
|
||||
现在,放弃我们的小指令集,去看看真正的 Python 字节码。字节码的结构和我们的小解释器的指令集差不多,除了字节码用一个字节而不是一个名字来代表这条指令。为了理解它的结构,我们将考察一个函数的字节码。考虑下面这个例子:
|
||||
|
||||
```python
|
||||
>>> def cond():
|
||||
@ -236,7 +236,7 @@ class Interpreter:
|
||||
...
|
||||
```
|
||||
|
||||
Python在运行时会暴露一大批内部信息,并且我们可以通过REPL直接访问这些信息。对于函数对象`cond`,`cond.__code__`是与其关联的code object,而`cond.__code__.co_code`就是它的字节码。当你写Python代码时,你永远也不会想直接使用这些属性,但是这可以让我们做出各种恶作剧,同时也可以看看内部机制。
|
||||
Python 在运行时会暴露一大批内部信息,并且我们可以通过 REPL 直接访问这些信息。对于函数对象`cond`,`cond.__code__`是与其关联的代码对象,而`cond.__code__.co_code`就是它的字节码。当你写 Python 代码时,你永远也不会想直接使用这些属性,但是这可以让我们做出各种恶作剧,同时也可以看看内部机制。
|
||||
|
||||
```python
|
||||
>>> cond.__code__.co_code # the bytecode as raw bytes
|
||||
@ -247,9 +247,9 @@ b'd\x01\x00}\x00\x00|\x00\x00d\x02\x00k\x00\x00r\x16\x00d\x03\x00Sd\x04\x00Sd\x0
|
||||
100, 4, 0, 83, 100, 0, 0, 83]
|
||||
```
|
||||
|
||||
当我们直接输出这个字节码,它看起来完全无法理解 --- 唯一我们了解的是它是一串字节。很幸运,我们有一个很强大的工具可以用:Python标准库中的`dis`模块。
|
||||
当我们直接输出这个字节码,它看起来完全无法理解 —— 唯一我们了解的是它是一串字节。很幸运,我们有一个很强大的工具可以用:Python 标准库中的`dis`模块。
|
||||
|
||||
`dis`是一个字节码反汇编器。反汇编器以为机器而写的底层代码作为输入,比如汇编代码和字节码,然后以人类可读的方式输出。当我们运行`dis.dis`, 它输出每个字节码的解释。
|
||||
`dis`是一个字节码反汇编器。反汇编器以为机器而写的底层代码作为输入,比如汇编代码和字节码,然后以人类可读的方式输出。当我们运行`dis.dis`,它输出每个字节码的解释。
|
||||
|
||||
```python
|
||||
>>> dis.dis(cond)
|
||||
@ -270,9 +270,9 @@ b'd\x01\x00}\x00\x00|\x00\x00d\x02\x00k\x00\x00r\x16\x00d\x03\x00Sd\x04\x00Sd\x0
|
||||
29 RETURN_VALUE
|
||||
```
|
||||
|
||||
这些都是什么意思?让我们以第一条指令`LOAD_CONST`为例子。第一列的数字(`2`)表示对应源代码的行数。第二列的数字是字节码的索引,告诉我们指令`LOAD_CONST`在0位置。第三列是指令本身对应的人类可读的名字。如果第四列存在,它表示指令的参数。如果第5列存在,它是一个关于参数是什么的提示。
|
||||
这些都是什么意思?让我们以第一条指令`LOAD_CONST`为例子。第一列的数字(`2`)表示对应源代码的行数。第二列的数字是字节码的索引,告诉我们指令`LOAD_CONST`在位置 0 。第三列是指令本身对应的人类可读的名字。如果第四列存在,它表示指令的参数。如果第五列存在,它是一个关于参数是什么的提示。
|
||||
|
||||
考虑这个字节码的前几个字节:[100, 1, 0, 125, 0, 0]。这6个字节表示两条带参数的指令。我们可以使用`dis.opname`,一个字节到可读字符串的映射,来找到指令100和指令125代表是什么:
|
||||
考虑这个字节码的前几个字节:[100, 1, 0, 125, 0, 0]。这 6 个字节表示两条带参数的指令。我们可以使用`dis.opname`,一个字节到可读字符串的映射,来找到指令 100 和指令 125 代表的是什么:
|
||||
|
||||
```python
|
||||
>>> dis.opname[100]
|
||||
@ -281,11 +281,11 @@ b'd\x01\x00}\x00\x00|\x00\x00d\x02\x00k\x00\x00r\x16\x00d\x03\x00Sd\x04\x00Sd\x0
|
||||
'STORE_FAST'
|
||||
```
|
||||
|
||||
第二和第三个字节 --- 1 ,0 ---是`LOAD_CONST`的参数,第五和第六个字节 --- 0,0 --- 是`STORE_FAST`的参数。就像我们前面的小例子,`LOAD_CONST`需要知道的到哪去找常量,`STORE_FAST`需要找到名字。(Python的`LOAD_CONST`和我们小例子中的`LOAD_VALUE`一样,`LOAD_FAST`和`LOAD_NAME`一样)。所以这六个字节代表第一行源代码`x = 3`.(为什么用两个字节表示指令的参数?如果Python使用一个字节,每个code object你只能有256个常量/名字,而用两个字节,就增加到了256的平方,65536个)。
|
||||
第二和第三个字节 —— 1 、0 ——是`LOAD_CONST`的参数,第五和第六个字节 —— 0、0 —— 是`STORE_FAST`的参数。就像我们前面的小例子,`LOAD_CONST`需要知道的到哪去找常量,`STORE_FAST`需要知道要存储的名字。(Python 的`LOAD_CONST`和我们小例子中的`LOAD_VALUE`一样,`LOAD_FAST`和`LOAD_NAME`一样)。所以这六个字节代表第一行源代码`x = 3` (为什么用两个字节表示指令的参数?如果 Python 使用一个字节,每个代码对象你只能有 256 个常量/名字,而用两个字节,就增加到了 256 的平方,65536个)。
|
||||
|
||||
### Conditionals and Loops
|
||||
#### 条件语句与循环语句
|
||||
|
||||
到目前为止,我们的解释器只能一条接着一条的执行指令。这有个问题,我们经常会想多次执行某个指令,或者在特定的条件下跳过它们。为了可以写循环和分支结构,解释器必须能够在指令中跳转。在某种程度上,Python在字节码中使用`GOTO`语句来处理循环和分支!让我们再看一个`cond`函数的反汇编结果:
|
||||
到目前为止,我们的解释器只能一条接着一条的执行指令。这有个问题,我们经常会想多次执行某个指令,或者在特定的条件下跳过它们。为了可以写循环和分支结构,解释器必须能够在指令中跳转。在某种程度上,Python 在字节码中使用`GOTO`语句来处理循环和分支!让我们再看一个`cond`函数的反汇编结果:
|
||||
|
||||
```python
|
||||
>>> dis.dis(cond)
|
||||
@ -306,11 +306,11 @@ b'd\x01\x00}\x00\x00|\x00\x00d\x02\x00k\x00\x00r\x16\x00d\x03\x00Sd\x04\x00Sd\x0
|
||||
29 RETURN_VALUE
|
||||
```
|
||||
|
||||
第三行的条件表达式`if x < 5`被编译成四条指令:`LOAD_FAST`, `LOAD_CONST`, `COMPARE_OP`和 `POP_JUMP_IF_FALSE`。`x < 5`对应加载`x`,加载5,比较这两个值。指令`POP_JUMP_IF_FALSE`完成`if`语句。这条指令把栈顶的值弹出,如果值为真,什么都不发生。如果值为假,解释器会跳转到另一条指令。
|
||||
第三行的条件表达式`if x < 5`被编译成四条指令:`LOAD_FAST`、 `LOAD_CONST`、 `COMPARE_OP`和 `POP_JUMP_IF_FALSE`。`x < 5`对应加载`x`、加载 5、比较这两个值。指令`POP_JUMP_IF_FALSE`完成这个`if`语句。这条指令把栈顶的值弹出,如果值为真,什么都不发生。如果值为假,解释器会跳转到另一条指令。
|
||||
|
||||
这条将被加载的指令称为跳转目标,它作为指令`POP_JUMP`的参数。这里,跳转目标是22,索引为22的指令是`LOAD_CONST`,对应源码的第6行。(`dis`用`>>`标记跳转目标。)如果`X < 5`为假,解释器会忽略第四行(`return yes`),直接跳转到第6行(`return "no"`)。因此解释器通过跳转指令选择性的执行指令。
|
||||
这条将被加载的指令称为跳转目标,它作为指令`POP_JUMP`的参数。这里,跳转目标是 22,索引为 22 的指令是`LOAD_CONST`,对应源码的第 6 行。(`dis`用`>>`标记跳转目标。)如果`X < 5`为假,解释器会忽略第四行(`return yes`),直接跳转到第6行(`return "no"`)。因此解释器通过跳转指令选择性的执行指令。
|
||||
|
||||
Python的循环也依赖于跳转。在下面的字节码中,`while x < 5`这一行产生了和`if x < 10`几乎一样的字节码。在这两种情况下,解释器都是先执行比较,然后执行`POP_JUMP_IF_FALSE`来控制下一条执行哪个指令。第四行的最后一条字节码`JUMP_ABSOLUT`(循环体结束的地方),让解释器返回到循环开始的第9条指令处。当 `x < 10`变为假,`POP_JUMP_IF_FALSE`会让解释器跳到循环的终止处,第34条指令。
|
||||
Python 的循环也依赖于跳转。在下面的字节码中,`while x < 5`这一行产生了和`if x < 10`几乎一样的字节码。在这两种情况下,解释器都是先执行比较,然后执行`POP_JUMP_IF_FALSE`来控制下一条执行哪个指令。第四行的最后一条字节码`JUMP_ABSOLUT`(循环体结束的地方),让解释器返回到循环开始的第 9 条指令处。当 `x < 10`变为假,`POP_JUMP_IF_FALSE`会让解释器跳到循环的终止处,第 34 条指令。
|
||||
|
||||
```python
|
||||
>>> def loop():
|
||||
@ -340,23 +340,23 @@ Python的循环也依赖于跳转。在下面的字节码中,`while x < 5`这
|
||||
38 RETURN_VALUE
|
||||
```
|
||||
|
||||
### Explore Bytecode
|
||||
#### 探索字节码
|
||||
|
||||
我希望你用`dis.dis`来试试你自己写的函数。一些有趣的问题值得探索:
|
||||
|
||||
- 对解释器而言for循环和while循环有什么不同?
|
||||
- 对解释器而言 for 循环和 while 循环有什么不同?
|
||||
- 能不能写出两个不同函数,却能产生相同的字节码?
|
||||
- `elif`是怎么工作的?列表推导呢?
|
||||
|
||||
## Frames
|
||||
### 帧
|
||||
|
||||
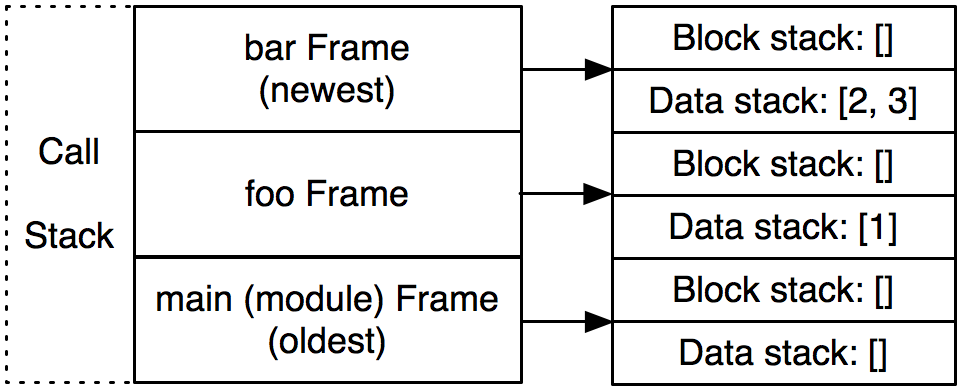
到目前为止,我们已经知道了Python虚拟机是一个栈机器。它能顺序执行指令,在指令间跳转,压入或弹出栈值。但是这和我们期望的解释器还有一定距离。在前面的那个例子中,最后一条指令是`RETURN_VALUE`,它和`return`语句相对应。但是它返回到哪里去呢?
|
||||
到目前为止,我们已经知道了 Python 虚拟机是一个栈机器。它能顺序执行指令,在指令间跳转,压入或弹出栈值。但是这和我们期望的解释器还有一定距离。在前面的那个例子中,最后一条指令是`RETURN_VALUE`,它和`return`语句相对应。但是它返回到哪里去呢?
|
||||
|
||||
为了回答这个问题,我们必须再增加一层复杂性:frame。一个frame是一些信息的集合和代码的执行上下文。frames在Python代码执行时动态的创建和销毁。每个frame对应函数的一次调用。--- 所以每个frame只有一个code object与之关联,而一个code object可以有多个frame。比如你有一个函数递归的调用自己10次,这会产生11个frame,每次调用对应一个,再加上启动模块对应的一个frame。总的来说,Python程序的每个作用域有一个frame,比如,模块,函数,类。
|
||||
为了回答这个问题,我们必须再增加一层复杂性:帧(frame)。一个帧是一些信息的集合和代码的执行上下文。帧在 Python 代码执行时动态地创建和销毁。每个帧对应函数的一次调用 —— 所以每个帧只有一个代码对象与之关联,而一个代码对象可以有多个帧。比如你有一个函数递归的调用自己 10 次,这会产生 11 个帧,每次调用对应一个,再加上启动模块对应的一个帧。总的来说,Python 程序的每个作用域都有一个帧,比如,模块、函数、类定义。
|
||||
|
||||
Frame存在于_调用栈_中,一个和我们之前讨论的完全不同的栈。(你最熟悉的栈就是调用栈,就是你经常看到的异常回溯,每个以"File 'program.py'"开始的回溯对应一个frame。)解释器在执行字节码时操作的栈,我们叫它_数据栈_。其实还有第三个栈,叫做_块栈_,用于特定的控制流块,比如循环和异常处理。调用栈中的每个frame都有它自己的数据栈和块栈。
|
||||
帧存在于调用栈(call stack)中,一个和我们之前讨论的完全不同的栈。(你最熟悉的栈就是调用栈,就是你经常看到的异常回溯,每个以"File 'program.py'"开始的回溯对应一个帧。)解释器在执行字节码时操作的栈,我们叫它数据栈(data stack)。其实还有第三个栈,叫做块栈(block stack),用于特定的控制流块,比如循环和异常处理。调用栈中的每个帧都有它自己的数据栈和块栈。
|
||||
|
||||
让我们用一个具体的例子来说明。假设Python解释器执行到标记为3的地方。解释器正在`foo`函数的调用中,它接着调用`bar`。下面是frame调用栈,块栈和数据栈的示意图。我们感兴趣的是解释器先从最底下的`foo()`开始,接着执行`foo`的函数体,然后到达`bar`。
|
||||
让我们用一个具体的例子来说明一下。假设 Python 解释器执行到下面标记为 3 的地方。解释器正处于`foo`函数的调用中,它接着调用`bar`。下面是帧调用栈、块栈和数据栈的示意图。我们感兴趣的是解释器先从最底下的`foo()`开始,接着执行`foo`的函数体,然后到达`bar`。
|
||||
|
||||
```python
|
||||
>>> def bar(y):
|
||||
@ -372,32 +372,30 @@ Frame存在于_调用栈_中,一个和我们之前讨论的完全不同的栈
|
||||
3
|
||||
```
|
||||
|
||||
\aosafigure[240pt]{interpreter-images/interpreter-callstack.png}{The call stack}{500l.interpreter.callstack}
|
||||
|
||||
|
||||
现在,解释器在`bar`函数的调用中。调用栈中有3个frame:一个对应于模块层,一个对应函数`foo`,别一个对应函数`bar`。(\aosafigref{500l.interpreter.callstack}.)一旦`bar`返回,与它对应的frame就会从调用栈中弹出并丢弃。
|
||||
现在,解释器处于`bar`函数的调用中。调用栈中有 3 个帧:一个对应于模块层,一个对应函数`foo`,另一个对应函数`bar`。(见上图)一旦`bar`返回,与它对应的帧就会从调用栈中弹出并丢弃。
|
||||
|
||||
字节码指令`RETURN_VALUE`告诉解释器在frame间传递一个值。首先,它把位于调用栈栈顶的frame中的数据栈的栈顶值弹出。然后把整个frame弹出丢弃。最后把这个值压到下一个frame的数据栈中。
|
||||
字节码指令`RETURN_VALUE`告诉解释器在帧之间传递一个值。首先,它把位于调用栈栈顶的帧中的数据栈的栈顶值弹出。然后把整个帧弹出丢弃。最后把这个值压到下一个帧的数据栈中。
|
||||
|
||||
当Ned Batchelder和我在写Byterun时,很长一段时间我们的实现中一直有个重大的错误。我们整个虚拟机中只有一个数据栈,而不是每个frame都有一个。我们写了很多测试代码,同时在Byterun和真正的Python上运行,希望得到一致结果。我们几乎通过了所有测试,只有一样东西不能通过,那就是生成器。最后,通过仔细的阅读CPython的源码,我们发现了错误所在[^thanks]。把数据栈移到每个frame就解决了这个问题。
|
||||
当 Ned Batchelder 和我在写 Byterun 时,很长一段时间我们的实现中一直有个重大的错误。我们整个虚拟机中只有一个数据栈,而不是每个帧都有一个。我们写了很多测试代码,同时在 Byterun 和真正的 Python 上运行,希望得到一致结果。我们几乎通过了所有测试,只有一样东西不能通过,那就是生成器(generators)。最后,通过仔细的阅读 CPython 的源码,我们发现了错误所在(感谢 Michael Arntzenius 对这个 bug 的洞悉)。把数据栈移到每个帧就解决了这个问题。
|
||||
|
||||
[^thanks]: 感谢 Michael Arntzenius 对这个bug的洞悉。
|
||||
回头在看看这个 bug,我惊讶的发现 Python 真的很少依赖于每个帧有一个数据栈这个特性。在 Python 中几乎所有的操作都会清空数据栈,所以所有的帧公用一个数据栈是没问题的。在上面的例子中,当`bar`执行完后,它的数据栈为空。即使`foo`公用这一个栈,它的值也不会受影响。然而,对应生成器,它的一个关键的特点是它能暂停一个帧的执行,返回到其他的帧,一段时间后它能返回到原来的帧,并以它离开时的相同状态继续执行。
|
||||
|
||||
回头在看看这个bug,我惊讶的发现Python真的很少依赖于每个frame有一个数据栈这个特性。在Python中几乎所有的操作都会清空数据栈,所以所有的frame公用一个数据栈是没问题的。在上面的例子中,当`bar`执行完后,它的数据栈为空。即使`foo`公用这一个栈,它的值也不会受影响。然而,对应生成器,一个关键的特点是它能暂停一个frame的执行,返回到其他的frame,一段时间后它能返回到原来的frame,并以它离开时的相同状态继续执行。
|
||||
### Byterun
|
||||
|
||||
## Byterun
|
||||
现在我们有足够的 Python 解释器的知识背景去考察 Byterun。
|
||||
|
||||
现在我们有足够的Python解释器的知识背景去考察Byterun。
|
||||
Byterun 中有四种对象。
|
||||
|
||||
Byterun中有四种对象。
|
||||
- `VirtualMachine`类,它管理高层结构,尤其是帧调用栈,并包含了指令到操作的映射。这是一个比前面`Inteprter`对象更复杂的版本。
|
||||
- `Frame`类,每个`Frame`类都有一个代码对象,并且管理着其他一些必要的状态位,尤其是全局和局部命名空间、指向调用它的整的指针和最后执行的字节码指令。
|
||||
- `Function`类,它被用来代替真正的 Python 函数。回想一下,调用函数时会创建一个新的帧。我们自己实现了`Function`,以便我们控制新的`Frame`的创建。
|
||||
- `Block`类,它只是包装了块的 3 个属性。(块的细节不是解释器的核心,我们不会花时间在它身上,把它列在这里,是因为 Byterun 需要它。)
|
||||
|
||||
- `VirtualMachine`类,它管理高层结构,frame调用栈,指令到操作的映射。这是一个比前面`Inteprter`对象更复杂的版本。
|
||||
- `Frame`类,每个`Frame`类都有一个code object,并且管理者其他一些必要的状态信息,全局和局部命名空间,指向调用它的frame的指针和最后执行的字节码指令。
|
||||
- `Function`类,它被用来代替真正的Python函数。回想一下,调用函数时会创建一个新的frame。我们自己实现`Function`,所以我们控制新frame的创建。
|
||||
- `Block`类,它只是包装了block的3个属性。(block的细节不是解释器的核心,我们不会花时间在它身上,把它列在这里,是因为Byterun需要它。)
|
||||
#### `VirtualMachine` 类
|
||||
|
||||
### The `VirtualMachine` Class
|
||||
|
||||
程序运行时只有一个`VirtualMachine`被创建,因为我们只有一个解释器。`VirtualMachine`保存调用栈,异常状态,在frame中传递的返回值。它的入口点是`run_code`方法,它以编译后的code object为参数,以创建一个frame为开始,然后运行这个frame。这个frame可能再创建出新的frame;调用栈随着程序的运行增长缩短。当第一个frame返回时,执行结束。
|
||||
每次程序运行时只会创建一个`VirtualMachine`实例,因为我们只有一个 Python 解释器。`VirtualMachine` 保存调用栈、异常状态、在帧之间传递的返回值。它的入口点是`run_code`方法,它以编译后的代码对象为参数,以创建一个帧为开始,然后运行这个帧。这个帧可能再创建出新的帧;调用栈随着程序的运行而增长和缩短。当第一个帧返回时,执行结束。
|
||||
|
||||
```python
|
||||
class VirtualMachineError(Exception):
|
||||
@ -418,9 +416,9 @@ class VirtualMachine(object):
|
||||
|
||||
```
|
||||
|
||||
### The `Frame` Class
|
||||
#### `Frame` 类
|
||||
|
||||
接下来,我们来写`Frame`对象。frame是一个属性的集合,它没有任何方法。前面提到过,这些属性包括由编译器生成的code object;局部,全局和内置命名空间;前一个frame的引用;一个数据栈;一个块栈;最后执行的指令指针。(对于内置命名空间我们需要多做一点工作,Python在不同模块中对这个命名空间有不同的处理;但这个细节对我们的虚拟机不重要。)
|
||||
接下来,我们来写`Frame`对象。帧是一个属性的集合,它没有任何方法。前面提到过,这些属性包括由编译器生成的代码对象;局部、全局和内置命名空间;前一个帧的引用;一个数据栈;一个块栈;最后执行的指令指针。(对于内置命名空间我们需要多做一点工作,Python 在不同模块中对这个命名空间有不同的处理;但这个细节对我们的虚拟机不重要。)
|
||||
|
||||
```python
|
||||
class Frame(object):
|
||||
@ -441,7 +439,7 @@ class Frame(object):
|
||||
self.block_stack = []
|
||||
```
|
||||
|
||||
接着,我们在虚拟机中增加对frame的操作。这有3个帮助函数:一个创建新的frame的方法,和压栈和出栈的方法。第四个函数,`run_frame`,完成执行frame的主要工作,待会我们再讨论这个方法。
|
||||
接着,我们在虚拟机中增加对帧的操作。这有 3 个帮助函数:一个创建新的帧的方法(它负责为新的帧找到名字空间),和压栈和出栈的方法。第四个函数,`run_frame`,完成执行帧的主要工作,待会我们再讨论这个方法。
|
||||
|
||||
```python
|
||||
class VirtualMachine(object):
|
||||
@ -481,9 +479,9 @@ class VirtualMachine(object):
|
||||
# we'll come back to this shortly
|
||||
```
|
||||
|
||||
### The `Function` Class
|
||||
#### `Function` 类
|
||||
|
||||
`Function`的实现有点扭曲,但是大部分的细节对理解解释器不重要。重要的是当调用函数时 --- `__call__`方法被调用 --- 它创建一个新的`Frame`并运行它。
|
||||
`Function`的实现有点曲折,但是大部分的细节对理解解释器不重要。重要的是当调用函数时 —— 即调用 `__call__`方法 —— 它创建一个新的`Frame`并运行它。
|
||||
|
||||
```python
|
||||
class Function(object):
|
||||
@ -534,7 +532,7 @@ def make_cell(value):
|
||||
return fn.__closure__[0]
|
||||
```
|
||||
|
||||
接着,回到`VirtualMachine`对象,我们对数据栈的操作也增加一些帮助方法。字节码操作的栈总是在当前frame的数据栈。这些帮助函数让我们能实现`POP_TOP`,`LOAD_FAST`字节码,并且让其他操作栈的指令可读性更高。
|
||||
接着,回到`VirtualMachine`对象,我们对数据栈的操作也增加一些帮助方法。字节码操作的栈总是在当前帧的数据栈。这些帮助函数让我们的`POP_TOP`、`LOAD_FAST`以及其他操作栈的指令的实现可读性更高。
|
||||
|
||||
```python
|
||||
class VirtualMachine(object):
|
||||
@ -562,11 +560,11 @@ class VirtualMachine(object):
|
||||
return []
|
||||
```
|
||||
|
||||
在我们运行frame之前,我们还需两个方法。
|
||||
在我们运行帧之前,我们还需两个方法。
|
||||
|
||||
第一个方法,`parse_byte_and_args`,以一个字节码为输入,先检查它是否有参数,如果有,就解析它的参数。这个方法同时也更新frame的`last_instruction`属性,它指向最后执行的指令。一条没有参数的指令只有一个字节长度,而有参数的字节有3个字节长。参数的意义依赖于指令是什么。比如,前面说过,指令`POP_JUMP_IF_FALSE`,它的参数指的是跳转目标。`BUILD_LIST`, 它的参数是列表的个数。`LOAD_CONST`,它的参数是常量的索引。
|
||||
第一个方法,`parse_byte_and_args` 以一个字节码为输入,先检查它是否有参数,如果有,就解析它的参数。这个方法同时也更新帧的`last_instruction`属性,它指向最后执行的指令。一条没有参数的指令只有一个字节长度,而有参数的字节有3个字节长。参数的意义依赖于指令是什么。比如,前面说过,指令`POP_JUMP_IF_FALSE`,它的参数指的是跳转目标。`BUILD_LIST`,它的参数是列表的个数。`LOAD_CONST`,它的参数是常量的索引。
|
||||
|
||||
一些指令用简单的数字作为参数。对于另一些,虚拟机需要一点努力去发现它含意。标准库中的`dis`模块中有一个备忘单,它解释什么参数有什么意思,这让我们的代码更加简洁。比如,列表`dis.hasname`告诉我们`LOAD_NAME`, `IMPORT_NAME`,`LOAD_GLOBAL`,以及另外的9个指令都有同样的意思:名字列表的索引。
|
||||
一些指令用简单的数字作为参数。对于另一些,虚拟机需要一点努力去发现它含意。标准库中的`dis`模块中有一个备忘单,它解释什么参数有什么意思,这让我们的代码更加简洁。比如,列表`dis.hasname`告诉我们`LOAD_NAME`、 `IMPORT_NAME`、`LOAD_GLOBAL`,以及另外的 9 个指令的参数都有同样的意义:对于这些指令,它们的参数代表了代码对象中的名字列表的索引。
|
||||
|
||||
```python
|
||||
class VirtualMachine(object):
|
||||
@ -600,8 +598,7 @@ class VirtualMachine(object):
|
||||
return byte_name, argument
|
||||
```
|
||||
|
||||
下一个方法是`dispatch`,它查看给定的指令并执行相应的操作。在CPython中,这个分派函数用一个巨大的switch语句实现,有超过1500行的代码。幸运的是,我们用的是Python,我们的代码会简洁的多。我们会为每一个字节码名字定义一个方法,然后用`getattr`来查找。就像我们前面的小解释器一样,如果一条指令叫做`FOO_BAR`,那么它对应的方法就是`byte_FOO_BAR`。现在,我们先把这些方法当做一个黑盒子。每个指令方法都会返回`None`或者一个字符串`why`,有些情况下虚拟机需要这个额外`why`信息。这些指令方法的返回值,仅作为解释器状态的内部指示,千万不要和执行frame的返回值相混淆。
|
||||
|
||||
下一个方法是`dispatch`,它查找给定的指令并执行相应的操作。在 CPython 中,这个分派函数用一个巨大的 switch 语句实现,有超过 1500 行的代码。幸运的是,我们用的是 Python,我们的代码会简洁的多。我们会为每一个字节码名字定义一个方法,然后用`getattr`来查找。就像我们前面的小解释器一样,如果一条指令叫做`FOO_BAR`,那么它对应的方法就是`byte_FOO_BAR`。现在,我们先把这些方法当做一个黑盒子。每个指令方法都会返回`None`或者一个字符串`why`,有些情况下虚拟机需要这个额外`why`信息。这些指令方法的返回值,仅作为解释器状态的内部指示,千万不要和执行帧的返回值相混淆。
|
||||
|
||||
```python
|
||||
class VirtualMachine(object):
|
||||
@ -662,13 +659,13 @@ class VirtualMachine(object):
|
||||
return self.return_value
|
||||
```
|
||||
|
||||
### The `Block` Class
|
||||
#### `Block` 类
|
||||
|
||||
在我们完成每个字节码方法前,我们简单的讨论一下块。一个块被用于某种控制流,特别是异常处理和循环。它负责保证当操作完成后数据栈处于正确的状态。比如,在一个循环中,一个特殊的迭代器会存在栈中,当循环完成时它从栈中弹出。解释器需要检查循环仍在继续还是已经停止。
|
||||
|
||||
为了跟踪这些额外的信息,解释器设置了一个标志来指示它的状态。我们用一个变量`why`实现这个标志,它可以是`None`或者是下面几个字符串这一,`"continue"`, `"break"`,`"excption"`,`return`。他们指示对块栈和数据栈进行什么操作。回到我们迭代器的例子,如果块栈的栈顶是一个`loop`块,`why`是`continue`,迭代器就因该保存在数据栈上,不是如果`why`是`break`,迭代器就会被弹出。
|
||||
为了跟踪这些额外的信息,解释器设置了一个标志来指示它的状态。我们用一个变量`why`实现这个标志,它可以是`None`或者是下面几个字符串之一:`"continue"`、`"break"`、`"excption"`、`return`。它们指示对块栈和数据栈进行什么操作。回到我们迭代器的例子,如果块栈的栈顶是一个`loop`块,`why`的代码是`continue`,迭代器就应该保存在数据栈上,而如果`why`是`break`,迭代器就会被弹出。
|
||||
|
||||
块操作的细节比较精细,我们不会花时间在这上面,但是有兴趣的读者值得仔细的看看。
|
||||
块操作的细节比这个还要繁琐,我们不会花时间在这上面,但是有兴趣的读者值得仔细的看看。
|
||||
|
||||
```python
|
||||
Block = collections.namedtuple("Block", "type, handler, stack_height")
|
||||
@ -737,9 +734,9 @@ class VirtualMachine(object):
|
||||
return why
|
||||
```
|
||||
|
||||
## The Instructions
|
||||
### 指令
|
||||
|
||||
剩下了的就是完成那些指令方法了:`byte_LOAD_FAST`,`byte_BINARY_MODULO`等等。而这些指令的实现并不是很有趣,这里我们只展示了一小部分,完整的实现在这儿https://github.com/nedbat/byterun。(足够执行我们前面所述的所有代码了。)
|
||||
剩下了的就是完成那些指令方法了:`byte_LOAD_FAST`、`byte_BINARY_MODULO`等等。而这些指令的实现并不是很有趣,这里我们只展示了一小部分,完整的实现[在 GitHub 上](https://github.com/nedbat/byterun)。(这里包括的指令足够执行我们前面所述的所有代码了。)
|
||||
|
||||
```python
|
||||
class VirtualMachine(object):
|
||||
@ -926,11 +923,11 @@ class VirtualMachine(object):
|
||||
return "return"
|
||||
```
|
||||
|
||||
## Dynamic Typing: What the Compiler Doesn't Know
|
||||
### 动态类型:编译器不知道它是什么
|
||||
|
||||
你可能听过Python是一种动态语言 --- 是它是动态类型的。在我们建造解释器的过程中,已经透露出这样的信息。
|
||||
你可能听过 Python 是一种动态语言 —— 它是动态类型的。在我们建造解释器的过程中,已经透露出这样的信息。
|
||||
|
||||
动态的一个意思是很多工作在运行时完成。前面我们看到Python的编译器没有很多关于代码真正做什么的信息。举个例子,考虑下面这个简单的函数`mod`。它取两个参数,返回它们的模运算值。从它的字节码中,我们看到变量`a`和`b`首先被加载,然后字节码`BINAY_MODULO`完成这个模运算。
|
||||
动态的一个意思是很多工作是在运行时完成的。前面我们看到 Python 的编译器没有很多关于代码真正做什么的信息。举个例子,考虑下面这个简单的函数`mod`。它取两个参数,返回它们的模运算值。从它的字节码中,我们看到变量`a`和`b`首先被加载,然后字节码`BINAY_MODULO`完成这个模运算。
|
||||
|
||||
```python
|
||||
>>> def mod(a, b):
|
||||
@ -944,25 +941,25 @@ class VirtualMachine(object):
|
||||
4
|
||||
```
|
||||
|
||||
计算19 % 5得4,--- 一点也不奇怪。如果我们用不同类的参数呢?
|
||||
计算 19 % 5 得4,—— 一点也不奇怪。如果我们用不同类的参数呢?
|
||||
|
||||
```python
|
||||
>>> mod("by%sde", "teco")
|
||||
'bytecode'
|
||||
```
|
||||
|
||||
刚才发生了什么?你可能见过这样的语法,格式化字符串。
|
||||
刚才发生了什么?你可能在其它地方见过这样的语法,格式化字符串。
|
||||
|
||||
```
|
||||
>>> print("by%sde" % "teco")
|
||||
bytecode
|
||||
```
|
||||
|
||||
用符号`%`去格式化字符串会调用字节码`BUNARY_MODULO`.它取栈顶的两个值求模,不管这两个值是字符串,数字或是你自己定义的类的实例。字节码在函数编译时生成(或者说,函数定义时)相同的字节码会用于不同类的参数。
|
||||
用符号`%`去格式化字符串会调用字节码`BUNARY_MODULO`。它取栈顶的两个值求模,不管这两个值是字符串、数字或是你自己定义的类的实例。字节码在函数编译时生成(或者说,函数定义时)相同的字节码会用于不同类的参数。
|
||||
|
||||
Python的编译器关于字节码的功能知道的很少。而取决于解释器来决定`BINAYR_MODULO`应用于什么类型的对象并完成正确的操作。这就是为什么Python被描述为_动态类型_:直到运行前你不必知道这个函数参数的类型。相反,在一个静态类型语言中,程序员需要告诉编译器参数的类型是什么(或者编译器自己推断出参数的类型。)
|
||||
Python 的编译器关于字节码的功能知道的很少,而取决于解释器来决定`BINAYR_MODULO`应用于什么类型的对象并完成正确的操作。这就是为什么 Python 被描述为动态类型(dynamically typed):直到运行前你不必知道这个函数参数的类型。相反,在一个静态类型语言中,程序员需要告诉编译器参数的类型是什么(或者编译器自己推断出参数的类型。)
|
||||
|
||||
编译器的无知是优化Python的一个挑战 --- 只看字节码,而不真正运行它,你就不知道每条字节码在干什么!你可以定义一个类,实现`__mod__`方法,当你对这个类的实例使用`%`时,Python就会自动调用这个方法。所以,`BINARY_MODULO`其实可以运行任何代码。
|
||||
编译器的无知是优化 Python 的一个挑战 —— 只看字节码,而不真正运行它,你就不知道每条字节码在干什么!你可以定义一个类,实现`__mod__`方法,当你对这个类的实例使用`%`时,Python 就会自动调用这个方法。所以,`BINARY_MODULO`其实可以运行任何代码。
|
||||
|
||||
看看下面的代码,第一个`a % b`看起来没有用。
|
||||
|
||||
@ -972,25 +969,23 @@ def mod(a,b):
|
||||
return a %b
|
||||
```
|
||||
|
||||
不幸的是,对这段代码进行静态分析 --- 不运行它 --- 不能确定第一个`a % b`没有做任何事。用 `%`调用`__mod__`可能会写一个文件,或是和程序的其他部分交互,或者其他任何可以在Python中完成的事。很难优化一个你不知道它会做什么的函数。在Russell Power和Alex Rubinsteyn的优秀论文中写道,“我们可以用多快的速度解释Python?”,他们说,“在普遍缺乏类型信息下,每条指令必须被看作一个`INVOKE_ARBITRARY_METHOD`。”
|
||||
不幸的是,对这段代码进行静态分析 —— 不运行它 —— 不能确定第一个`a % b`没有做任何事。用 `%`调用`__mod__`可能会写一个文件,或是和程序的其他部分交互,或者其他任何可以在 Python 中完成的事。很难优化一个你不知道它会做什么的函数。在 Russell Power 和 Alex Rubinsteyn 的优秀论文中写道,“我们可以用多快的速度解释 Python?”,他们说,“在普遍缺乏类型信息下,每条指令必须被看作一个`INVOKE_ARBITRARY_METHOD`。”
|
||||
|
||||
## Conclusion
|
||||
### 总结
|
||||
|
||||
Byterun是一个比CPython容易理解的简洁的Python解释器。Byterun复制了CPython的主要结构:一个基于栈的指令集称为字节码,它们顺序执行或在指令间跳转,向栈中压入和从中弹出数据。解释器随着函数和生成器的调用和返回,动态的创建,销毁frame,并在frame间跳转。Byterun也有着和真正解释器一样的限制:因为Python使用动态类型,解释器必须在运行时决定指令的正确行为。
|
||||
Byterun 是一个比 CPython 容易理解的简洁的 Python 解释器。Byterun 复制了 CPython 的主要结构:一个基于栈的解释器对称之为字节码的指令集进行操作,它们顺序执行或在指令间跳转,向栈中压入和从中弹出数据。解释器随着函数和生成器的调用和返回,动态的创建、销毁帧,并在帧之间跳转。Byterun 也有着和真正解释器一样的限制:因为 Python 使用动态类型,解释器必须在运行时决定指令的正确行为。
|
||||
|
||||
我鼓励你去反汇编你的程序,然后用Byterun来运行。你很快会发现这个缩短版的Byterun所没有实现的指令。完整的实现在https://github.com/nedbat/byterun,或者仔细阅读真正的CPython解释器`ceval.c`,你也可以实现自己的解释器!
|
||||
我鼓励你去反汇编你的程序,然后用 Byterun 来运行。你很快会发现这个缩短版的 Byterun 所没有实现的指令。完整的实现在 https://github.com/nedbat/byterun ,或者你可以仔细阅读真正的 CPython 解释器`ceval.c`,你也可以实现自己的解释器!
|
||||
|
||||
## Acknowledgements
|
||||
### 致谢
|
||||
|
||||
Thanks to Ned Batchelder for originating this project and guiding my contributions, Michael Arntzenius for his help debugging the code and editing the prose, Leta Montopoli for her edits, and the entire Recurse Center community for their support and interest. Any errors are my own.
|
||||
感谢 Ned Batchelder 发起这个项目并引导我的贡献,感谢 Michael Arntzenius 帮助调试代码和这篇文章的修订,感谢 Leta Montopoli 的修订,以及感谢整个 Recurse Center 社区的支持和鼓励。所有的不足全是我自己没搞好。
|
||||
|
||||
--------------------------------------
|
||||
via:http://aosabook.org/en/500L/a-python-interpreter-written-in-python.html
|
||||
|
||||
作者: Allison Kaptur Allison
|
||||
via: http://aosabook.org/en/500L/a-python-interpreter-written-in-python.html
|
||||
|
||||
作者: Allison Kaptur
|
||||
译者:[qingyunha](https://github.com/qingyunha)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,236 @@
|
||||
使用 Python 和 Asyncio 编写在线多用人游戏(二)
|
||||
==================================================================
|
||||
|
||||

|
||||
|
||||
> 你在 Python 中用过异步编程吗?本文中我会告诉你怎样做,而且用一个[能工作的例子][1]来展示它:这是一个流行的贪吃蛇游戏,而且是为多人游戏而设计的。
|
||||
|
||||
介绍和理论部分参见“[第一部分 异步化][2]”。
|
||||
|
||||
- [游戏入口在此,点此体验][1]。
|
||||
|
||||
### 3、编写游戏循环主体
|
||||
|
||||
游戏循环是每一个游戏的核心。它持续地运行以读取玩家的输入、更新游戏的状态,并且在屏幕上渲染游戏结果。在在线游戏中,游戏循环分为客户端和服务端两部分,所以一般有两个循环通过网络通信。通常客户端的角色是获取玩家输入,比如按键或者鼠标移动,将数据传输给服务端,然后接收需要渲染的数据。服务端处理来自玩家的所有数据,更新游戏的状态,执行渲染下一帧的必要计算,然后将结果传回客户端,例如游戏中对象的新位置。如果没有可靠的理由,不混淆客户端和服务端的角色是一件很重要的事。如果你在客户端执行游戏逻辑的计算,很容易就会和其它客户端失去同步,其实你的游戏也可以通过简单地传递客户端的数据来创建。
|
||||
|
||||
> 游戏循环的一次迭代称为一个嘀嗒(tick)。嘀嗒是一个事件,表示当前游戏循环的迭代已经结束,下一帧(或者多帧)的数据已经就绪。
|
||||
|
||||
在后面的例子中,我们使用相同的客户端,它使用 WebSocket 从一个网页上连接到服务端。它执行一个简单的循环,将按键码发送给服务端,并显示来自服务端的所有信息。[客户端代码戳这里][4]。
|
||||
|
||||
### 例子 3.1:基本游戏循环
|
||||
|
||||
> [例子 3.1 源码][5]。
|
||||
|
||||
我们使用 [aiohttp][6] 库来创建游戏服务器。它可以通过 asyncio 创建网页服务器和客户端。这个库的一个优势是它同时支持普通 http 请求和 websocket。所以我们不用其他网页服务器来渲染游戏的 html 页面。
|
||||
|
||||
下面是启动服务器的方法:
|
||||
|
||||
```
|
||||
app = web.Application()
|
||||
app["sockets"] = []
|
||||
|
||||
asyncio.ensure_future(game_loop(app))
|
||||
|
||||
app.router.add_route('GET', '/connect', wshandler)
|
||||
app.router.add_route('GET', '/', handle)
|
||||
|
||||
web.run_app(app)
|
||||
```
|
||||
|
||||
`web.run_app` 是创建服务主任务的快捷方法,通过它的 `run_forever()` 方法来执行 `asyncio` 事件循环。建议你查看这个方法的源码,弄清楚服务器到底是如何创建和结束的。
|
||||
|
||||
`app` 变量就是一个类似于字典的对象,它用于在所连接的客户端之间共享数据。我们使用它来存储连接的套接字的列表。随后会用这个列表来给所有连接的客户端发送消息。`asyncio.ensure_future()` 调用会启动主游戏循环的任务,每隔2 秒向客户端发送嘀嗒消息。这个任务会在同样的 asyncio 事件循环中和网页服务器并行执行。
|
||||
|
||||
有两个网页请求处理器:`handle` 是提供 html 页面的处理器;`wshandler` 是主要的 websocket 服务器任务,处理和客户端之间的交互。在事件循环中,每一个连接的客户端都会创建一个新的 `wshandler` 任务。这个任务会添加客户端的套接字到列表中,以便 `game_loop` 任务可以给所有的客户端发送消息。然后它将随同消息回显客户端的每个击键。
|
||||
|
||||
在启动的任务中,我们在 `asyncio` 的主事件循环中启动 worker 循环。任务之间的切换发生在它们之间任何一个使用 `await`语句来等待某个协程结束时。例如 `asyncio.sleep` 仅仅是将程序执行权交给调度器一段指定的时间;`ws.receive` 等待 websocket 的消息,此时调度器可能切换到其它任务。
|
||||
|
||||
在浏览器中打开主页,连接上服务器后,试试随便按下键。它们的键值会从服务端返回,每隔 2 秒这个数字会被游戏循环中发给所有客户端的嘀嗒消息所覆盖。
|
||||
|
||||
我们刚刚创建了一个处理客户端按键的服务器,主游戏循环在后台做一些处理,周期性地同时更新所有的客户端。
|
||||
|
||||
### 例子 3.2: 根据请求启动游戏
|
||||
|
||||
> [例子 3.2 的源码][7]
|
||||
|
||||
在前一个例子中,在服务器的生命周期内,游戏循环一直运行着。但是现实中,如果没有一个人连接服务器,空运行游戏循环通常是不合理的。而且,同一个服务器上可能有不同的“游戏房间”。在这种假设下,每一个玩家“创建”一个游戏会话(比如说,多人游戏中的一个比赛或者大型多人游戏中的副本),这样其他用户可以加入其中。当游戏会话开始时,游戏循环才开始执行。
|
||||
|
||||
在这个例子中,我们使用一个全局标记来检测游戏循环是否在执行。当第一个用户发起连接时,启动它。最开始,游戏循环没有执行,标记设置为 `False`。游戏循环是通过客户端的处理方法启动的。
|
||||
|
||||
```
|
||||
if app["game_is_running"] == False:
|
||||
asyncio.ensure_future(game_loop(app))
|
||||
```
|
||||
|
||||
当 `game_loop()` 运行时,这个标记设置为 `True`;当所有客户端都断开连接时,其又被设置为 `False`。
|
||||
|
||||
### 例子 3.3:管理任务
|
||||
|
||||
> [例子3.3源码][8]
|
||||
|
||||
这个例子用来解释如何和任务对象协同工作。我们把游戏循环的任务直接存储在游戏循环的全局字典中,代替标记的使用。在像这样的一个简单例子中并不一定是最优的,但是有时候你可能需要控制所有已经启动的任务。
|
||||
|
||||
```
|
||||
if app["game_loop"] is None or \
|
||||
app["game_loop"].cancelled():
|
||||
app["game_loop"] = asyncio.ensure_future(game_loop(app))
|
||||
```
|
||||
|
||||
这里 `ensure_future()` 返回我们存放在全局字典中的任务对象,当所有用户都断开连接时,我们使用下面方式取消任务:
|
||||
|
||||
```
|
||||
app["game_loop"].cancel()
|
||||
```
|
||||
|
||||
这个 `cancel()` 调用将通知调度器不要向这个协程传递执行权,而且将它的状态设置为已取消:`cancelled`,之后可以通过 `cancelled()` 方法来检查是否已取消。这里有一个值得一提的小注意点:当你持有一个任务对象的外部引用时,而这个任务执行中发生了异常,这个异常不会抛出。取而代之的是为这个任务设置一个异常状态,可以通过 `exception()` 方法来检查是否出现了异常。这种悄无声息地失败在调试时不是很有用。所以,你可能想用抛出所有异常来取代这种做法。你可以对所有未完成的任务显式地调用 `result()` 来实现。可以通过如下的回调来实现:
|
||||
|
||||
```
|
||||
app["game_loop"].add_done_callback(lambda t: t.result())
|
||||
```
|
||||
|
||||
如果我们打算在我们代码中取消这个任务,但是又不想产生 `CancelError` 异常,有一个检查 `cancelled` 状态的点:
|
||||
|
||||
```
|
||||
app["game_loop"].add_done_callback(lambda t: t.result()
|
||||
if not t.cancelled() else None)
|
||||
```
|
||||
|
||||
注意仅当你持有任务对象的引用时才需要这么做。在前一个例子,所有的异常都是没有额外的回调,直接抛出所有异常。
|
||||
|
||||
### 例子 3.4:等待多个事件
|
||||
|
||||
> [例子 3.4 源码][9]
|
||||
|
||||
在许多场景下,在客户端的处理方法中你需要等待多个事件的发生。除了来自客户端的消息,你可能需要等待不同类型事件的发生。比如,如果你的游戏时间有限制,那么你可能需要等一个来自定时器的信号。或者你需要使用管道来等待来自其它进程的消息。亦或者是使用分布式消息系统的网络中其它服务器的信息。
|
||||
|
||||
为了简单起见,这个例子是基于例子 3.1。但是这个例子中我们使用 `Condition` 对象来与已连接的客户端保持游戏循环的同步。我们不保存套接字的全局列表,因为只在该处理方法中使用套接字。当游戏循环停止迭代时,我们使用 `Condition.notify_all()` 方法来通知所有的客户端。这个方法允许在 `asyncio` 的事件循环中使用发布/订阅的模式。
|
||||
|
||||
为了等待这两个事件,首先我们使用 `ensure_future()` 来封装任务中这个可等待对象。
|
||||
|
||||
```
|
||||
if not recv_task:
|
||||
recv_task = asyncio.ensure_future(ws.receive())
|
||||
if not tick_task:
|
||||
await tick.acquire()
|
||||
tick_task = asyncio.ensure_future(tick.wait())
|
||||
```
|
||||
|
||||
在我们调用 `Condition.wait()` 之前,我们需要在它后面获取一把锁。这就是我们为什么先调用 `tick.acquire()` 的原因。在调用 `tick.wait()` 之后,锁会被释放,这样其他的协程也可以使用它。但是当我们收到通知时,会重新获取锁,所以在收到通知后需要调用 `tick.release()` 来释放它。
|
||||
|
||||
我们使用 `asyncio.wait()` 协程来等待两个任务。
|
||||
|
||||
```
|
||||
done, pending = await asyncio.wait(
|
||||
[recv_task,
|
||||
tick_task],
|
||||
return_when=asyncio.FIRST_COMPLETED)
|
||||
```
|
||||
|
||||
程序会阻塞,直到列表中的任意一个任务完成。然后它返回两个列表:执行完成的任务列表和仍然在执行的任务列表。如果任务执行完成了,其对应变量赋值为 `None`,所以在下一个迭代时,它可能会被再次创建。
|
||||
|
||||
### 例子 3.5: 结合多个线程
|
||||
|
||||
> [例子 3.5 源码][10]
|
||||
|
||||
在这个例子中,我们结合 `asyncio` 循环和线程,在一个单独的线程中执行主游戏循环。我之前提到过,由于 `GIL` 的存在,Python 代码的真正并行执行是不可能的。所以使用其它线程来执行复杂计算并不是一个好主意。然而,在使用 `asyncio` 时结合线程有原因的:当我们使用的其它库不支持 `asyncio` 时就需要。在主线程中调用这些库会阻塞循环的执行,所以异步使用他们的唯一方法是在不同的线程中使用他们。
|
||||
|
||||
我们使用 `asyncio` 循环的`run_in_executor()` 方法和 `ThreadPoolExecutor` 来执行游戏循环。注意 `game_loop()` 已经不再是一个协程了。它是一个由其它线程执行的函数。然而我们需要和主线程交互,在游戏事件到来时通知客户端。`asyncio` 本身不是线程安全的,它提供了可以在其它线程中执行你的代码的方法。普通函数有 `call_soon_threadsafe()`,协程有 `run_coroutine_threadsafe()`。我们在 `notify()` 协程中增加了通知客户端游戏的嘀嗒的代码,然后通过另外一个线程执行主事件循环。
|
||||
|
||||
```
|
||||
def game_loop(asyncio_loop):
|
||||
print("Game loop thread id {}".format(threading.get_ident()))
|
||||
async def notify():
|
||||
print("Notify thread id {}".format(threading.get_ident()))
|
||||
await tick.acquire()
|
||||
tick.notify_all()
|
||||
tick.release()
|
||||
|
||||
while 1:
|
||||
task = asyncio.run_coroutine_threadsafe(notify(), asyncio_loop)
|
||||
# blocking the thread
|
||||
sleep(1)
|
||||
# make sure the task has finished
|
||||
task.result()
|
||||
```
|
||||
|
||||
当你执行这个例子时,你会看到 “Notify thread id” 和 “Main thread id” 相等,因为 `notify()` 协程在主线程中执行。与此同时 `sleep(1)` 在另外一个线程中执行,因此它不会阻塞主事件循环。
|
||||
|
||||
### 例子 3.6:多进程和扩展
|
||||
|
||||
> [例子 3.6 源码][11]
|
||||
|
||||
单线程的服务器可能运行得很好,但是它只能使用一个 CPU 核。为了将服务扩展到多核,我们需要执行多个进程,每个进程执行各自的事件循环。这样我们需要在进程间交互信息或者共享游戏的数据。而且在一个游戏中经常需要进行复杂的计算,例如路径查找之类。这些任务有时候在一个游戏嘀嗒中没法快速完成。在协程中不推荐进行费时的计算,因为它会阻塞事件的处理。在这种情况下,将这个复杂任务交给其它并行执行的进程可能更合理。
|
||||
|
||||
最简单的使用多个核的方法是启动多个使用单核的服务器,就像之前的例子中一样,每个服务器占用不同的端口。你可以使用 `supervisord` 或者其它进程控制的系统。这个时候你需要一个像 `HAProxy` 这样的负载均衡器,使得连接的客户端分布在多个进程间。已经有一些可以连接 asyncio 和一些流行的消息及存储系统的适配系统。例如:
|
||||
|
||||
- [aiomcache][12] 用于 memcached 客户端
|
||||
- [aiozmq][13] 用于 zeroMQ
|
||||
- [aioredis][14] 用于 Redis 存储,支持发布/订阅
|
||||
|
||||
你可以在 github 或者 pypi 上找到其它的软件包,大部分以 `aio` 开头。
|
||||
|
||||
使用网络服务在存储持久状态和交换某些信息时可能比较有效。但是如果你需要进行进程间通信的实时处理,它的性能可能不足。此时,使用标准的 unix 管道可能更合适。`asyncio` 支持管道,在`aiohttp`仓库有个 [使用管道的服务器的非常底层的例子][15]。
|
||||
|
||||
在当前的例子中,我们使用 Python 的高层类库 [multiprocessing][16] 来在不同的核上启动复杂的计算,使用 `multiprocessing.Queue` 来进行进程间的消息交互。不幸的是,当前的 `multiprocessing` 实现与 `asyncio` 不兼容。所以每一个阻塞方法的调用都会阻塞事件循环。但是此时线程正好可以起到帮助作用,因为如果在不同线程里面执行 `multiprocessing` 的代码,它就不会阻塞主线程。所有我们需要做的就是把所有进程间的通信放到另外一个线程中去。这个例子会解释如何使用这个方法。和上面的多线程例子非常类似,但是我们从线程中创建的是一个新的进程。
|
||||
|
||||
```
|
||||
def game_loop(asyncio_loop):
|
||||
# coroutine to run in main thread
|
||||
async def notify():
|
||||
await tick.acquire()
|
||||
tick.notify_all()
|
||||
tick.release()
|
||||
|
||||
queue = Queue()
|
||||
|
||||
# function to run in a different process
|
||||
def worker():
|
||||
while 1:
|
||||
print("doing heavy calculation in process {}".format(os.getpid()))
|
||||
sleep(1)
|
||||
queue.put("calculation result")
|
||||
|
||||
Process(target=worker).start()
|
||||
|
||||
while 1:
|
||||
# blocks this thread but not main thread with event loop
|
||||
result = queue.get()
|
||||
print("getting {} in process {}".format(result, os.getpid()))
|
||||
task = asyncio.run_coroutine_threadsafe(notify(), asyncio_loop)
|
||||
task.result()
|
||||
```
|
||||
|
||||
这里我们在另外一个进程中运行 `worker()` 函数。它包括一个执行复杂计算并把计算结果放到 `queue` 中的循环,这个 `queue` 是 `multiprocessing.Queue` 的实例。然后我们就可以在另外一个线程的主事件循环中获取结果并通知客户端,就和例子 3.5 一样。这个例子已经非常简化了,它没有合理的结束进程。而且在真实的游戏中,我们可能需要另外一个队列来将数据传递给 `worker`。
|
||||
|
||||
有一个项目叫 [aioprocessing][17],它封装了 `multiprocessing`,使得它可以和 `asyncio` 兼容。但是实际上它只是和上面例子使用了完全一样的方法:从线程中创建进程。它并没有给你带来任何方便,除了它使用了简单的接口隐藏了后面的这些技巧。希望在 Python 的下一个版本中,我们能有一个基于协程且支持 `asyncio` 的 `multiprocessing` 库。
|
||||
|
||||
> 注意!如果你从主线程或者主进程中创建了一个不同的线程或者子进程来运行另外一个 `asyncio` 事件循环,你需要显式地使用 `asyncio.new_event_loop()` 来创建循环,不然的话可能程序不会正常工作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-writing-game-loop/
|
||||
|
||||
作者:[Kyrylo Subbotin][a]
|
||||
译者:[chunyang-wen](https://github.com/chunyang-wen)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-writing-game-loop/
|
||||
[1]: http://snakepit-game.com/
|
||||
[2]: https://linux.cn/article-7767-1.html
|
||||
[3]: http://snakepit-game.com/
|
||||
[4]: https://github.com/7WebPages/snakepit-game/blob/master/simple/index.html
|
||||
[5]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_basic.py
|
||||
[6]: http://aiohttp.readthedocs.org/
|
||||
[7]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_handler.py
|
||||
[8]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_global.py
|
||||
[9]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_wait.py
|
||||
[10]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_thread.py
|
||||
[11]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_process.py
|
||||
[12]: https://github.com/aio-libs/aiomcache
|
||||
[13]: https://github.com/aio-libs/aiozmq
|
||||
[14]: https://github.com/aio-libs/aioredis
|
||||
[15]: https://github.com/KeepSafe/aiohttp/blob/master/examples/mpsrv.py
|
||||
[16]: https://docs.python.org/3.5/library/multiprocessing.html
|
||||
[17]: https://github.com/dano/aioprocessing
|
||||
464
published/20160608 Simple Python Framework from Scratch.md
Normal file
464
published/20160608 Simple Python Framework from Scratch.md
Normal file
@ -0,0 +1,464 @@
|
||||
从零构建一个简单的 Python 框架
|
||||
===================================
|
||||
|
||||
为什么你想要自己构建一个 web 框架呢?我想,原因有以下几点:
|
||||
|
||||
- 你有一个新奇的想法,觉得将会取代其他的框架
|
||||
- 你想要获得一些名气
|
||||
- 你遇到的问题很独特,以至于现有的框架不太合适
|
||||
- 你对 web 框架是如何工作的很感兴趣,因为你想要成为一位更好的 web 开发者。
|
||||
|
||||
接下来的笔墨将着重于最后一点。这篇文章旨在通过对设计和实现过程一步一步的阐述告诉读者,我在完成一个小型的服务器和框架之后学到了什么。你可以在这个[代码仓库][1]中找到这个项目的完整代码。
|
||||
|
||||
我希望这篇文章可以鼓励更多的人来尝试,因为这确实很有趣。它让我知道了 web 应用是如何工作的,而且这比我想的要容易的多!
|
||||
|
||||
### 范围
|
||||
|
||||
框架可以处理请求-响应周期、身份认证、数据库访问、模板生成等部分工作。Web 开发者使用框架是因为,大多数的 web 应用拥有大量相同的功能,而对每个项目都重新实现同样的功能意义不大。
|
||||
|
||||
比较大的的框架如 Rails 和 Django 实现了高层次的抽象,或者说“自备电池”(“batteries-included”,这是 Python 的口号之一,意即所有功能都自足。)。而实现所有的这些功能可能要花费数千小时,因此在这个项目上,我们重点完成其中的一小部分。在开始写代码前,我先列举一下所需的功能以及限制。
|
||||
|
||||
功能:
|
||||
|
||||
- 处理 HTTP 的 GET 和 POST 请求。你可以在[这篇 wiki][2] 中对 HTTP 有个大致的了解。
|
||||
- 实现异步操作(我*喜欢* Python 3 的 asyncio 模块)。
|
||||
- 简单的路由逻辑以及参数撷取。
|
||||
- 像其他微型框架一样,提供一个简单的用户级 API 。
|
||||
- 支持身份认证,因为学会这个很酷啊(微笑)。
|
||||
|
||||
限制:
|
||||
|
||||
- 将只支持 HTTP 1.1 的一个小子集,不支持传输编码(transfer-encoding)、HTTP 认证(http-auth)、内容编码(content-encoding,如 gzip)以及[持久化连接][3]等功能。
|
||||
- 不支持对响应内容的 MIME 判断 - 用户需要手动指定。
|
||||
- 不支持 WSGI - 仅能处理简单的 TCP 连接。
|
||||
- 不支持数据库。
|
||||
|
||||
我觉得一个小的用例可以让上述内容更加具体,也可以用来演示这个框架的 API:
|
||||
|
||||
```
|
||||
from diy_framework import App, Router
|
||||
from diy_framework.http_utils import Response
|
||||
|
||||
|
||||
# GET simple route
|
||||
async def home(r):
|
||||
rsp = Response()
|
||||
rsp.set_header('Content-Type', 'text/html')
|
||||
rsp.body = '<html><body><b>test</b></body></html>'
|
||||
return rsp
|
||||
|
||||
|
||||
# GET route + params
|
||||
async def welcome(r, name):
|
||||
return "Welcome {}".format(name)
|
||||
|
||||
# POST route + body param
|
||||
async def parse_form(r):
|
||||
if r.method == 'GET':
|
||||
return 'form'
|
||||
else:
|
||||
name = r.body.get('name', '')[0]
|
||||
password = r.body.get('password', '')[0]
|
||||
|
||||
return "{0}:{1}".format(name, password)
|
||||
|
||||
# application = router + http server
|
||||
router = Router()
|
||||
router.add_routes({
|
||||
r'/welcome/{name}': welcome,
|
||||
r'/': home,
|
||||
r'/login': parse_form,})
|
||||
|
||||
app = App(router)
|
||||
app.start_server()
|
||||
```
|
||||
'
|
||||
用户需要定义一些能够返回字符串或 `Response` 对象的异步函数,然后将这些函数与表示路由的字符串配对,最后通过一个函数调用(`start_server`)开始处理请求。
|
||||
|
||||
完成设计之后,我将它抽象为几个我需要编码的部分:
|
||||
|
||||
- 接受 TCP 连接以及调度一个异步函数来处理这些连接的部分
|
||||
- 将原始文本解析成某种抽象容器的部分
|
||||
- 对于每个请求,用来决定调用哪个函数的部分
|
||||
- 将上述部分集中到一起,并为开发者提供一个简单接口的部分
|
||||
|
||||
我先编写一些测试,这些测试被用来描述每个部分的功能。几次重构后,整个设计被分成若干部分,每个部分之间是相对解耦的。这样就非常好,因为每个部分可以被独立地研究学习。以下是我上文列出的抽象的具体体现:
|
||||
|
||||
- 一个 HTTPServer 对象,需要一个 Router 对象和一个 http_parser 模块,并使用它们来初始化。
|
||||
- HTTPConnection 对象,每一个对象表示一个单独的客户端 HTTP 连接,并且处理其请求-响应周期:使用 http_parser 模块将收到的字节流解析为一个 Request 对象;使用一个 Router 实例寻找并调用正确的函数来生成一个响应;最后将这个响应发送回客户端。
|
||||
- 一对 Request 和 Response 对象为用户提供了一种友好的方式,来处理实质上是字节流的字符串。用户不需要知道正确的消息格式和分隔符是怎样的。
|
||||
- 一个包含“路由:函数”对应关系的 Router 对象。它提供一个添加配对的方法,可以根据 URL 路径查找到相应的函数。
|
||||
- 最后,一个 App 对象。它包含配置信息,并使用它们实例化一个 HTTPServer 实例。
|
||||
|
||||
让我们从 `HTTPConnection` 开始来讲解各个部分。
|
||||
|
||||
### 模拟异步连接
|
||||
|
||||
为了满足上述约束条件,每一个 HTTP 请求都是一个单独的 TCP 连接。这使得处理请求的速度变慢了,因为建立多个 TCP 连接需要相对高的花销(DNS 查询,TCP 三次握手,[慢启动][4]等等的花销),不过这样更加容易模拟。对于这一任务,我选择相对高级的 [asyncio-stream][5] 模块,它建立在 [asyncio 的传输和协议][6]的基础之上。我强烈推荐你读一读标准库中的相应代码,很有意思!
|
||||
|
||||
一个 `HTTPConnection` 的实例能够处理多个任务。首先,它使用 `asyncio.StreamReader` 对象以增量的方式从 TCP 连接中读取数据,并存储在缓存中。每一个读取操作完成后,它会尝试解析缓存中的数据,并生成一个 `Request` 对象。一旦收到了这个完整的请求,它就生成一个回复,并通过 `asyncio.StreamWriter` 对象发送回客户端。当然,它还有两个任务:超时连接以及错误处理。
|
||||
|
||||
你可以在[这里][7]浏览这个类的完整代码。我将分别介绍代码的每一部分。为了简单起见,我移除了代码文档。
|
||||
|
||||
```
|
||||
class HTTPConnection(object):
|
||||
def init(self, http_server, reader, writer):
|
||||
self.router = http_server.router
|
||||
self.http_parser = http_server.http_parser
|
||||
self.loop = http_server.loop
|
||||
|
||||
self._reader = reader
|
||||
self._writer = writer
|
||||
self._buffer = bytearray()
|
||||
self._conn_timeout = None
|
||||
self.request = Request()
|
||||
```
|
||||
|
||||
这个 `init` 方法没啥意思,它仅仅是收集了一些对象以供后面使用。它存储了一个 `router` 对象、一个 `http_parser` 对象以及 `loop` 对象,分别用来生成响应、解析请求以及在事件循环中调度任务。
|
||||
|
||||
然后,它存储了代表一个 TCP 连接的读写对,和一个充当原始字节缓冲区的空[字节数组][8]。`_conn_timeout` 存储了一个 [asyncio.Handle][9] 的实例,用来管理超时逻辑。最后,它还存储了 `Request` 对象的一个单一实例。
|
||||
|
||||
下面的代码是用来接受和发送数据的核心功能:
|
||||
|
||||
```
|
||||
async def handle_request(self):
|
||||
try:
|
||||
while not self.request.finished and not self._reader.at_eof():
|
||||
data = await self._reader.read(1024)
|
||||
if data:
|
||||
self._reset_conn_timeout()
|
||||
await self.process_data(data)
|
||||
if self.request.finished:
|
||||
await self.reply()
|
||||
elif self._reader.at_eof():
|
||||
raise BadRequestException()
|
||||
except (NotFoundException,
|
||||
BadRequestException) as e:
|
||||
self.error_reply(e.code, body=Response.reason_phrases[e.code])
|
||||
except Exception as e:
|
||||
self.error_reply(500, body=Response.reason_phrases[500])
|
||||
|
||||
self.close_connection()
|
||||
```
|
||||
|
||||
所有内容被包含在 `try-except` 代码块中,这样在解析请求或响应期间抛出的异常可以被捕获到,然后一个错误响应会发送回客户端。
|
||||
|
||||
在 `while` 循环中不断读取请求,直到解析器将 `self.request.finished` 设置为 True ,或者客户端关闭连接所触发的信号使得 `self._reader_at_eof()` 函数返回值为 True 为止。这段代码尝试在每次循环迭代中从 `StreamReader` 中读取数据,并通过调用 `self.process_data(data)` 函数以增量方式生成 `self.request`。每次循环读取数据时,连接超时计数器被重置。
|
||||
|
||||
这儿有个错误,你发现了吗?稍后我们会再讨论这个。需要注意的是,这个循环可能会耗尽 CPU 资源,因为如果没有读取到东西 `self._reader.read()` 函数将会返回一个空的字节对象 `b''`。这就意味着循环将会不断运行,却什么也不做。一个可能的解决方法是,用非阻塞的方式等待一小段时间:`await asyncio.sleep(0.1)`。我们暂且不对它做优化。
|
||||
|
||||
还记得上一段我提到的那个错误吗?只有从 `StreamReader` 读取数据时,`self._reset_conn_timeout()` 函数才会被调用。这就意味着,**直到第一个字节到达时**,`timeout` 才被初始化。如果有一个客户端建立了与服务器的连接却不发送任何数据,那就永远不会超时。这可能被用来消耗系统资源,从而导致拒绝服务式攻击(DoS)。修复方法就是在 `init` 函数中调用 `self._reset_conn_timeout()` 函数。
|
||||
|
||||
当请求接受完成或连接中断时,程序将运行到 `if-else` 代码块。这部分代码会判断解析器收到完整的数据后是否完成了解析。如果是,好,生成一个回复并发送回客户端。如果不是,那么请求信息可能有错误,抛出一个异常!最后,我们调用 `self.close_connection` 执行清理工作。
|
||||
|
||||
解析请求的部分在 `self.process_data` 方法中。这个方法非常简短,也易于测试:
|
||||
|
||||
```
|
||||
async def process_data(self, data):
|
||||
self._buffer.extend(data)
|
||||
|
||||
self._buffer = self.http_parser.parse_into(
|
||||
self.request, self._buffer)
|
||||
```
|
||||
|
||||
每一次调用都将数据累积到 `self._buffer` 中,然后试着用 `self.http_parser` 来解析已经收集的数据。这里需要指出的是,这段代码展示了一种称为[依赖注入(Dependency Injection)][10]的模式。如果你还记得 `init` 函数的话,应该知道我们传入了一个包含 `http_parser` 对象的 `http_server` 对象。在这个例子里,`http_parser` 对象是 `diy_framework` 包中的一个模块。不过它也可以是任何含有 `parse_into` 函数的类,这个 `parse_into` 函数接受一个 `Request` 对象以及字节数组作为参数。这很有用,原因有二:一是,这意味着这段代码更易扩展。如果有人想通过一个不同的解析器来使用 `HTTPConnection`,没问题,只需将它作为参数传入即可。二是,这使得测试更加容易,因为 `http_parser` 不是硬编码的,所以使用虚假数据或者 [mock][11] 对象来替代是很容易的。
|
||||
|
||||
下一段有趣的部分就是 `reply` 方法了:
|
||||
|
||||
```
|
||||
async def reply(self):
|
||||
request = self.request
|
||||
handler = self.router.get_handler(request.path)
|
||||
|
||||
response = await handler.handle(request)
|
||||
|
||||
if not isinstance(response, Response):
|
||||
response = Response(code=200, body=response)
|
||||
|
||||
self._writer.write(response.to_bytes())
|
||||
await self._writer.drain()
|
||||
```
|
||||
|
||||
这里,一个 `HTTPConnection` 的实例使用了 `HTTPServer` 中的 `router` 对象来得到一个生成响应的对象。一个路由可以是任何一个拥有 `get_handler` 方法的对象,这个方法接收一个字符串作为参数,返回一个可调用的对象或者抛出 `NotFoundException` 异常。而这个可调用的对象被用来处理请求以及生成响应。处理程序由框架的使用者编写,如上文所说的那样,应该返回字符串或者 `Response` 对象。`Response` 对象提供了一个友好的接口,因此这个简单的 if 语句保证了无论处理程序返回什么,代码最终都得到一个统一的 `Response` 对象。
|
||||
|
||||
接下来,被赋值给 `self._writer` 的 `StreamWriter` 实例被调用,将字节字符串发送回客户端。函数返回前,程序在 `await self._writer.drain()` 处等待,以确保所有的数据被发送给客户端。只要缓存中还有未发送的数据,`self._writer.close()` 方法就不会执行。
|
||||
|
||||
`HTTPConnection` 类还有两个更加有趣的部分:一个用于关闭连接的方法,以及一组用来处理超时机制的方法。首先,关闭一条连接由下面这个小函数完成:
|
||||
|
||||
```
|
||||
def close_connection(self):
|
||||
self._cancel_conn_timeout()
|
||||
self._writer.close()
|
||||
```
|
||||
|
||||
每当一条连接将被关闭时,这段代码首先取消超时,然后把连接从事件循环中清除。
|
||||
|
||||
超时机制由三个相关的函数组成:第一个函数在超时后给客户端发送错误消息并关闭连接;第二个函数用于取消当前的超时;第三个函数调度超时功能。前两个函数比较简单,我将详细解释第三个函数 `_reset_cpmm_timeout()` 。
|
||||
|
||||
```
|
||||
def _conn_timeout_close(self):
|
||||
self.error_reply(500, 'timeout')
|
||||
self.close_connection()
|
||||
|
||||
def _cancel_conn_timeout(self):
|
||||
if self._conn_timeout:
|
||||
self._conn_timeout.cancel()
|
||||
|
||||
def _reset_conn_timeout(self, timeout=TIMEOUT):
|
||||
self._cancel_conn_timeout()
|
||||
self._conn_timeout = self.loop.call_later(
|
||||
timeout, self._conn_timeout_close)
|
||||
```
|
||||
|
||||
每当 `_reset_conn_timeout` 函数被调用时,它会先取消之前所有赋值给 `self._conn_timeout` 的 `asyncio.Handle` 对象。然后,使用 [BaseEventLoop.call_later][12] 函数让 `_conn_timeout_close` 函数在超时数秒(`timeout`)后执行。如果你还记得 `handle_request` 函数的内容,就知道每当接收到数据时,这个函数就会被调用。这就取消了当前的超时并且重新安排 `_conn_timeout_close` 函数在超时数秒(`timeout`)后执行。只要接收到数据,这个循环就会不断地重置超时回调。如果在超时时间内没有接收到数据,最后函数 `_conn_timeout_close` 就会被调用。
|
||||
|
||||
### 创建连接
|
||||
|
||||
我们需要创建 `HTTPConnection` 对象,并且正确地使用它们。这一任务由 `HTTPServer` 类完成。`HTTPServer` 类是一个简单的容器,可以存储着一些配置信息(解析器,路由和事件循环实例),并使用这些配置来创建 `HTTPConnection` 实例:
|
||||
|
||||
```
|
||||
class HTTPServer(object):
|
||||
def init(self, router, http_parser, loop):
|
||||
self.router = router
|
||||
self.http_parser = http_parser
|
||||
self.loop = loop
|
||||
|
||||
async def handle_connection(self, reader, writer):
|
||||
connection = HTTPConnection(self, reader, writer)
|
||||
asyncio.ensure_future(connection.handle_request(), loop=self.loop)
|
||||
```
|
||||
|
||||
`HTTPServer` 的每一个实例能够监听一个端口。它有一个 `handle_connection` 的异步方法来创建 `HTTPConnection` 的实例,并安排它们在事件循环中运行。这个方法被传递给 [asyncio.start_server][13] 作为一个回调函数。也就是说,每当一个 TCP 连接初始化时(以 `StreamReader` 和 `StreamWriter` 为参数),它就会被调用。
|
||||
|
||||
```
|
||||
self._server = HTTPServer(self.router, self.http_parser, self.loop)
|
||||
self._connection_handler = asyncio.start_server(
|
||||
self._server.handle_connection,
|
||||
host=self.host,
|
||||
port=self.port,
|
||||
reuse_address=True,
|
||||
reuse_port=True,
|
||||
loop=self.loop)
|
||||
```
|
||||
|
||||
这就是构成整个应用程序工作原理的核心:`asyncio.start_server` 接受 TCP 连接,然后在一个预配置的 `HTTPServer` 对象上调用一个方法。这个方法将处理一条 TCP 连接的所有逻辑:读取、解析、生成响应并发送回客户端、以及关闭连接。它的重点是 IO 逻辑、解析和生成响应。
|
||||
|
||||
讲解了核心的 IO 部分,让我们继续。
|
||||
|
||||
### 解析请求
|
||||
|
||||
这个微型框架的使用者被宠坏了,不愿意和字节打交道。它们想要一个更高层次的抽象 —— 一种更加简单的方法来处理请求。这个微型框架就包含了一个简单的 HTTP 解析器,能够将字节流转化为 Request 对象。
|
||||
|
||||
这些 Request 对象是像这样的容器:
|
||||
|
||||
```
|
||||
class Request(object):
|
||||
def init(self):
|
||||
self.method = None
|
||||
self.path = None
|
||||
self.query_params = {}
|
||||
self.path_params = {}
|
||||
self.headers = {}
|
||||
self.body = None
|
||||
self.body_raw = None
|
||||
self.finished = False
|
||||
```
|
||||
|
||||
它包含了所有需要的数据,可以用一种容易理解的方法从客户端接受数据。哦,不包括 cookie ,它对身份认证是非常重要的,我会将它留在第二部分。
|
||||
|
||||
每一个 HTTP 请求都包含了一些必需的内容,如请求路径和请求方法。它们也包含了一些可选的内容,如请求体、请求头,或是 URL 参数。随着 REST 的流行,除了 URL 参数,URL 本身会包含一些信息。比如,"/user/1/edit" 包含了用户的 id 。
|
||||
|
||||
一个请求的每个部分都必须被识别、解析,并正确地赋值给 Request 对象的对应属性。HTTP/1.1 是一个文本协议,事实上这简化了很多东西。(HTTP/2 是一个二进制协议,这又是另一种乐趣了)
|
||||
|
||||
解析器不需要跟踪状态,因此 `http_parser` 模块其实就是一组函数。调用函数需要用到 `Request` 对象,并将它连同一个包含原始请求信息的字节数组传递给 `parse_into` 函数。然后解析器会修改 `Request` 对象以及充当缓存的字节数组。字节数组的信息被逐渐地解析到 request 对象中。
|
||||
|
||||
`http_parser` 模块的核心功能就是下面这个 `parse_into` 函数:
|
||||
|
||||
```
|
||||
def parse_into(request, buffer):
|
||||
_buffer = buffer[:]
|
||||
if not request.method and can_parse_request_line(_buffer):
|
||||
(request.method, request.path,
|
||||
request.query_params) = parse_request_line(_buffer)
|
||||
remove_request_line(_buffer)
|
||||
|
||||
if not request.headers and can_parse_headers(_buffer):
|
||||
request.headers = parse_headers(_buffer)
|
||||
if not has_body(request.headers):
|
||||
request.finished = True
|
||||
|
||||
remove_intro(_buffer)
|
||||
|
||||
if not request.finished and can_parse_body(request.headers, _buffer):
|
||||
request.body_raw, request.body = parse_body(request.headers, _buffer)
|
||||
clear_buffer(_buffer)
|
||||
request.finished = True
|
||||
return _buffer
|
||||
```
|
||||
|
||||
从上面的代码中可以看到,我把解析的过程分为三个部分:解析请求行(这行像这样:GET /resource HTTP/1.1),解析请求头以及解析请求体。
|
||||
|
||||
请求行包含了 HTTP 请求方法以及 URL 地址。而 URL 地址则包含了更多的信息:路径、url 参数和开发者自定义的 url 参数。解析请求方法和 URL 还是很容易的 - 合适地分割字符串就好了。函数 `urlparse.parse` 可以用来解析 URL 参数。开发者自定义的 URL 参数可以通过正则表达式来解析。
|
||||
|
||||
接下来是 HTTP 头部。它们是一行行由键值对组成的简单文本。问题在于,可能有多个 HTTP 头有相同的名字,却有不同的值。一个值得关注的 HTTP 头部是 `Content-Length`,它描述了请求体的字节长度(不是整个请求,仅仅是请求体)。这对于决定是否解析请求体有很重要的作用。
|
||||
|
||||
最后,解析器根据 HTTP 方法和头部来决定是否解析请求体。
|
||||
|
||||
### 路由!
|
||||
|
||||
在某种意义上,路由就像是连接框架和用户的桥梁,用户用合适的方法创建 `Router` 对象并为其设置路径/函数对,然后将它赋值给 App 对象。而 App 对象依次调用 `get_handler` 函数生成相应的回调函数。简单来说,路由就负责两件事,一是存储路径/函数对,二是返回需要的路径/函数对
|
||||
|
||||
`Router` 类中有两个允许最终开发者添加路由的方法,分别是 `add_routes` 和 `add_route`。因为 `add_routes` 就是 `add_route` 函数的一层封装,我们将主要讲解 `add_route` 函数:
|
||||
|
||||
```
|
||||
def add_route(self, path, handler):
|
||||
compiled_route = self.class.build_route_regexp(path)
|
||||
if compiled_route not in self.routes:
|
||||
self.routes[compiled_route] = handler
|
||||
else:
|
||||
raise DuplicateRoute
|
||||
```
|
||||
|
||||
首先,这个函数使用 `Router.build_router_regexp` 的类方法,将一条路由规则(如 '/cars/{id}' 这样的字符串),“编译”到一个已编译的正则表达式对象。这些已编译的正则表达式用来匹配请求路径,以及解析开发者自定义的 URL 参数。如果已经存在一个相同的路由,程序就会抛出一个异常。最后,这个路由/处理程序对被添加到一个简单的字典`self.routes`中。
|
||||
|
||||
下面展示 Router 是如何“编译”路由的:
|
||||
|
||||
```
|
||||
@classmethod
|
||||
def build_route_regexp(cls, regexp_str):
|
||||
"""
|
||||
Turns a string into a compiled regular expression. Parses '{}' into
|
||||
named groups ie. '/path/{variable}' is turned into
|
||||
'/path/(?P<variable>[a-zA-Z0-9_-]+)'.
|
||||
|
||||
:param regexp_str: a string representing a URL path.
|
||||
:return: a compiled regular expression.
|
||||
"""
|
||||
def named_groups(matchobj):
|
||||
return '(?P<{0}>[a-zA-Z0-9_-]+)'.format(matchobj.group(1))
|
||||
|
||||
re_str = re.sub(r'{([a-zA-Z0-9_-]+)}', named_groups, regexp_str)
|
||||
re_str = ''.join(('^', re_str, '$',))
|
||||
return re.compile(re_str)
|
||||
```
|
||||
|
||||
这个方法使用正则表达式将所有出现的 `{variable}` 替换为 `(?P<variable>)`。然后在字符串头尾分别添加 `^` 和 `$` 标记,最后编译正则表达式对象。
|
||||
|
||||
完成了路由存储仅成功了一半,下面是如何得到路由对应的函数:
|
||||
|
||||
```
|
||||
def get_handler(self, path):
|
||||
logger.debug('Getting handler for: {0}'.format(path))
|
||||
for route, handler in self.routes.items():
|
||||
path_params = self.class.match_path(route, path)
|
||||
if path_params is not None:
|
||||
logger.debug('Got handler for: {0}'.format(path))
|
||||
wrapped_handler = HandlerWrapper(handler, path_params)
|
||||
return wrapped_handler
|
||||
|
||||
raise NotFoundException()
|
||||
```
|
||||
|
||||
一旦 `App` 对象获得一个 `Request` 对象,也就获得了 URL 的路径部分(如 /users/15/edit)。然后,我们需要匹配函数来生成一个响应或者 404 错误。`get_handler` 函数将路径作为参数,循环遍历路由,对每条路由调用 `Router.match_path` 类方法检查是否有已编译的正则对象与这个请求路径匹配。如果存在,我们就调用 `HandleWrapper` 来包装路由对应的函数。`path_params` 字典包含了路径变量(如 '/users/15/edit' 中的 '15'),若路由没有指定变量,字典就为空。最后,我们将包装好的函数返回给 `App` 对象。
|
||||
|
||||
如果遍历了所有的路由都找不到与路径匹配的,函数就会抛出 `NotFoundException` 异常。
|
||||
|
||||
这个 `Route.match` 类方法挺简单:
|
||||
|
||||
```
|
||||
def match_path(cls, route, path):
|
||||
match = route.match(path)
|
||||
try:
|
||||
return match.groupdict()
|
||||
except AttributeError:
|
||||
return None
|
||||
```
|
||||
|
||||
它使用正则对象的 [match 方法][14]来检查路由是否与路径匹配。若果不匹配,则返回 None 。
|
||||
|
||||
最后,我们有 `HandleWraapper` 类。它的唯一任务就是封装一个异步函数,存储 `path_params` 字典,并通过 `handle` 方法对外提供一个统一的接口。
|
||||
|
||||
```
|
||||
class HandlerWrapper(object):
|
||||
def init(self, handler, path_params):
|
||||
self.handler = handler
|
||||
self.path_params = path_params
|
||||
self.request = None
|
||||
|
||||
async def handle(self, request):
|
||||
return await self.handler(request, **self.path_params)
|
||||
```
|
||||
|
||||
### 组合到一起
|
||||
|
||||
框架的最后部分就是用 `App` 类把所有的部分联系起来。
|
||||
|
||||
`App` 类用于集中所有的配置细节。一个 `App` 对象通过其 `start_server` 方法,使用一些配置数据创建一个 `HTTPServer` 的实例,然后将它传递给 [asyncio.start_server 函数][15]。`asyncio.start_server` 函数会对每一个 TCP 连接调用 `HTTPServer` 对象的 `handle_connection` 方法。
|
||||
|
||||
```
|
||||
def start_server(self):
|
||||
if not self._server:
|
||||
self.loop = asyncio.get_event_loop()
|
||||
self._server = HTTPServer(self.router, self.http_parser, self.loop)
|
||||
self._connection_handler = asyncio.start_server(
|
||||
self._server.handle_connection,
|
||||
host=self.host,
|
||||
port=self.port,
|
||||
reuse_address=True,
|
||||
reuse_port=True,
|
||||
loop=self.loop)
|
||||
|
||||
logger.info('Starting server on {0}:{1}'.format(
|
||||
self.host, self.port))
|
||||
self.loop.run_until_complete(self._connection_handler)
|
||||
|
||||
try:
|
||||
self.loop.run_forever()
|
||||
except KeyboardInterrupt:
|
||||
logger.info('Got signal, killing server')
|
||||
except DiyFrameworkException as e:
|
||||
logger.error('Critical framework failure:')
|
||||
logger.error(e.traceback)
|
||||
finally:
|
||||
self.loop.close()
|
||||
else:
|
||||
logger.info('Server already started - {0}'.format(self))
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
如果你查看源码,就会发现所有的代码仅 320 余行(包括测试代码的话共 540 余行)。这么少的代码实现了这么多的功能,让我有点惊讶。这个框架没有提供模板、身份认证以及数据库访问等功能(这些内容也很有趣哦)。这也让我知道,像 Django 和 Tornado 这样的框架是如何工作的,而且我能够快速地调试它们了。
|
||||
|
||||
这也是我按照测试驱动开发完成的第一个项目,整个过程有趣而有意义。先编写测试用例迫使我思考设计和架构,而不仅仅是把代码放到一起,让它们可以运行。不要误解我的意思,有很多时候,后者的方式更好。不过如果你想给确保这些不怎么维护的代码在之后的几周甚至几个月依然工作,那么测试驱动开发正是你需要的。
|
||||
|
||||
我研究了下[整洁架构][16]以及依赖注入模式,这些充分体现在 `Router` 类是如何作为一个更高层次的抽象的(实体?)。`Router` 类是比较接近核心的,像 `http_parser` 和 `App` 的内容比较边缘化,因为它们只是完成了极小的字符串和字节流、或是中层 IO 的工作。测试驱动开发(TDD)迫使我独立思考每个小部分,这使我问自己这样的问题:方法调用的组合是否易于理解?类名是否准确地反映了我正在解决的问题?我的代码中是否很容易区分出不同的抽象层?
|
||||
|
||||
来吧,写个小框架,真的很有趣:)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://mattscodecave.com/posts/simple-python-framework-from-scratch.html
|
||||
|
||||
作者:[Matt][a]
|
||||
译者:[Cathon](https://github.com/Cathon)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://mattscodecave.com/hire-me.html
|
||||
[1]: https://github.com/sirMackk/diy_framework
|
||||
[2]:https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
|
||||
[3]: https://en.wikipedia.org/wiki/HTTP_persistent_connection
|
||||
[4]: https://en.wikipedia.org/wiki/TCP_congestion-avoidance_algorithm#Slow_start
|
||||
[5]: https://docs.python.org/3/library/asyncio-stream.html
|
||||
[6]: https://docs.python.org/3/library/asyncio-protocol.html
|
||||
[7]: https://github.com/sirMackk/diy_framework/blob/88968e6b30e59504251c0c7cd80abe88f51adb79/diy_framework/http_server.py#L46
|
||||
[8]: https://docs.python.org/3/library/functions.html#bytearray
|
||||
[9]: https://docs.python.org/3/library/asyncio-eventloop.html#asyncio.Handle
|
||||
[10]: https://en.wikipedia.org/wiki/Dependency_injection
|
||||
[11]: https://docs.python.org/3/library/unittest.mock.html
|
||||
[12]: https://docs.python.org/3/library/asyncio-eventloop.html#asyncio.BaseEventLoop.call_later
|
||||
[13]: https://docs.python.org/3/library/asyncio-stream.html#asyncio.start_server
|
||||
[14]: https://docs.python.org/3/library/re.html#re.match
|
||||
[15]: https://docs.python.org/3/library/asyncio-stream.html?highlight=start_server#asyncio.start_server
|
||||
[16]: https://blog.8thlight.com/uncle-bob/2012/08/13/the-clean-architecture.html
|
||||
@ -0,0 +1,141 @@
|
||||
科学音频处理(一):怎样使用 Octave 对音频文件进行读写操作
|
||||
================
|
||||
|
||||
Octave 是一个类似于 Linux 上的 Matlab 的软件,它拥有数量众多的函数和命令,支持声音采集、记录、回放以及音频信号的数字化处理,用于娱乐应用、研究、医学以及其它科学领域。在本教程中,我们会在 Ubuntu 上使用 Octave 的 4.0.0 版本读取音频文件,然后通过生成信号并且播放来模仿在各种情况下对音频信号的使用。
|
||||
|
||||
本教程中关注的不是安装和学习使用安装好的音频处理软件,而是从设计和音频工程的角度理解它是如何工作的。
|
||||
|
||||
### 环境准备
|
||||
|
||||
首先是安装 octave,在 Ubuntu 终端运行下面的命令添加 Octave PPA,然后安装 Octave 。
|
||||
|
||||
```
|
||||
sudo apt-add-repository ppa:octave/stable
|
||||
sudo apt-get update
|
||||
sudo apt-get install octave
|
||||
```
|
||||
|
||||
### 步骤1:打开 Octave
|
||||
|
||||
在这一步中我们单击软件图标打开 Octave,可以通过单击下拉式按钮选择工作路径。
|
||||
|
||||
|
||||
|
||||
### 步骤2:音频信息
|
||||
|
||||
使用`audioinfo`命令查看要处理的音频文件的相关信息。
|
||||
|
||||
```
|
||||
>> info = audioinfo ('testing.ogg')
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
### 步骤3:读取音频文件
|
||||
|
||||
在本教程中我会使用 ogg 文件来读取这种文件的属性,比如采样、音频类型(stereo 和 mono)、信道数量等。必须声明的一点是教程中使用的所有的命令都是在 Octave 终端窗口中执行的。首先,我们必须要把这个 ogg 文件赋给一个变量。注意:**文件必须在 Octave 的工作路径中。**
|
||||
|
||||
```
|
||||
>> file='yourfile.ogg'
|
||||
```
|
||||
|
||||
```
|
||||
>> [M, fs] = audioread(file)
|
||||
```
|
||||
|
||||
这里的 M 是一个一列或两列的矩阵,取决于信道的数量,fs 是采样率。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
下面的操作都可以读取音频文件:
|
||||
|
||||
```
|
||||
>> [y, fs] = audioread (filename, samples)
|
||||
|
||||
>> [y, fs] = audioread (filename, datatype)
|
||||
|
||||
>> [y, fs] = audioread (filename, samples, datatype)
|
||||
```
|
||||
|
||||
samples 指定开始帧和结束帧,datatype 指定返回的数据类型。可以为所有变量设置值:
|
||||
|
||||
```
|
||||
>> samples = [1, fs)
|
||||
|
||||
>> [y, fs] = audioread (filename, samples)
|
||||
```
|
||||
|
||||
数据类型:
|
||||
|
||||
```
|
||||
>> [y,Fs] = audioread(filename,'native')
|
||||
```
|
||||
|
||||
如果值是“native”,那么它的数据类型就依数据在音频文件中的存储情况而定。
|
||||
|
||||
### 步骤4:音频文件的写操作
|
||||
|
||||
新建一个 ogg 文件:
|
||||
|
||||
我们会从一个余弦值创建一个 ogg 文件。采样率是每秒 44100 次,这个文件最少进行 10 秒的采样。余弦信号的频率是 440 Hz。
|
||||
|
||||
```
|
||||
>> filename='cosine.ogg';
|
||||
>> fs=44100;
|
||||
>> t=0:1/fs:10;
|
||||
>> w=2*pi*440*t;
|
||||
>> signal=cos(w);
|
||||
>> audiowrite(filename, signal, fs);
|
||||
```
|
||||
|
||||
这就在工作路径中创建了一个 'cosine.ogg' 文件,这个文件中包含余弦信号。
|
||||
|
||||
|
||||
|
||||
播放这个 'cosine.ogg' 文件就会产生一个 440Hz 的 音调,这个音调正好是乐理中的 'A' 调。如果需要查看保存在文件中的值就必须使用 'audioread' 函数读取文件。在后续的教程中,我们会看到怎样在两个信道中读取一个音频文件。
|
||||
|
||||
### 步骤5:播放音频文件
|
||||
|
||||
Octave 有一个默认的音频播放器,可以用这个音频播放器进行测试。使用下面的函数:
|
||||
|
||||
```
|
||||
>> [y,fs]=audioread('yourfile.ogg');
|
||||
>> player=audioplayer(y, fs, 8)
|
||||
|
||||
scalar structure containing the fields:
|
||||
|
||||
BitsPerSample = 8
|
||||
CurrentSample = 0
|
||||
DeviceID = -1
|
||||
NumberOfChannels = 1
|
||||
Running = off
|
||||
SampleRate = 44100
|
||||
TotalSamples = 236473
|
||||
Tag =
|
||||
Type = audioplayer
|
||||
UserData = [](0x0)
|
||||
>> play(player);
|
||||
```
|
||||
|
||||
|
||||
在这个教程的续篇,我们会进入音频处理的高级特性部分,可能会接触到一些科学和商业应用中的实例。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-read-and-write-audio-files-with-octave-4-in-ubuntu/
|
||||
|
||||
作者:[David Duarte][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twitter.com/intent/follow?original_referer=https%3A%2F%2Fwww.howtoforge.com%2Ftutorial%2Fhow-to-read-and-write-audio-files-with-octave-4-in-ubuntu%2F&ref_src=twsrc%5Etfw®ion=follow_link&screen_name=howtoforgecom&tw_p=followbutton
|
||||
|
||||
|
||||
@ -0,0 +1,114 @@
|
||||
5 个给 Linux 新手的最佳包管理器
|
||||
=====================================================
|
||||
|
||||
一个 Linux 新用户应该知道他或她的进步源自于对 Linux 发行版的使用,而 Linux 发行版有好几种,并以不同的方式管理软件包。
|
||||
|
||||
在 Linux 中,包管理器非常重要,知道如何使用多种包管理器可以让你像一个高手一样活得很舒适,从在仓库下载软件、安装软件,到更新软件、处理依赖和删除软件是非常重要的,这也是Linux 系统管理的一个重要部分。
|
||||
|
||||

|
||||
|
||||
*最好的Linux包管理器*
|
||||
|
||||
成为一个 Linux 高手的一个标志是了解主要的 Linux 发行版如何处理包,在这篇文章中,我们应该看一些你在 Linux 上能找到的最佳的包管理器,
|
||||
|
||||
在这里,我们的主要重点是关于一些最佳包管理器的相关信息,但不是如何使用它们,这些留给你亲自发现。但我会提供一些有意义的链接,使用指南或更多。
|
||||
|
||||
### 1. DPKG - Debian 包管理系统(Debian Package Management System)
|
||||
|
||||
Dpkg 是 Debian Linux 家族的基础包管理系统,它用于安装、删除、存储和提供`.deb`包的信息。
|
||||
|
||||
这是一个低层面的工具,并且有多个前端工具可以帮助用户从远程的仓库获取包,或处理复杂的包关系的工具,包括如下:
|
||||
|
||||
- 参考:[15 个用于基于 Debian 的发行版的 “dpkg” 命令实例][1]
|
||||
|
||||
#### APT (高级打包工具(Advanced Packaging Tool))
|
||||
|
||||
这个是一个 dpkg 包管理系统的前端工具,它是一个非常受欢迎的、自由而强大的,有用的命令行包管理器系统。
|
||||
|
||||
Debian 及其衍生版,例如 Ubuntu 和 Linux Mint 的用户应该非常熟悉这个包管理工具。
|
||||
|
||||
想要了解它是如何工作的,你可以去看看下面这些 HOW TO 指南:
|
||||
|
||||
- 参考:[15 个怎样在 Ubuntu/Debian 上使用新的 APT 工具的例子][2]
|
||||
- 参考:[25 个用于包管理的有用的 APT-GET 和 APT-CACHE 的基础命令][3]
|
||||
|
||||
#### Aptitude 包管理器
|
||||
|
||||
这个也是 Debian Linux 家族一个非常出名的命令行前端包管理工具,它工作方式类似 APT ,它们之间有很多可以比较的地方,不过,你应该两个都试试才知道哪个工作的更好。
|
||||
|
||||
它最初为 Debian 及其衍生版设计的,但是现在它的功能延伸到 RHEL 家族。你可以参考这个指南了解更多关于 APT 和 Aptitude。
|
||||
|
||||
- 参考:[APT 和 Aptitude 是什么?它们知道到底有什么不同?][4]
|
||||
|
||||
#### Synaptic 包管理器
|
||||
|
||||
Synaptic是一个基于GTK+的APT的可视化包管理器,对于一些不想使用命令行的用户,它非常好用。
|
||||
|
||||
### 2. RPM 红帽包管理器(Red Hat Package Manager)
|
||||
|
||||
这个是红帽创建的 Linux 基本标准(LSB)打包格式和基础包管理系统。基于这个底层系统,有多个前端包管理工具可供你使用,但我们应该只看那些最好的,那就是:
|
||||
|
||||
#### YUM (黄狗更新器,修改版(Yellowdog Updater, Modified))
|
||||
|
||||
这个是一个开源、流行的命令行包管理器,它是用户使用 RPM 的界面(之一)。你可以把它和 Debian Linux 系统中的 APT 进行对比,它和 APT 拥有相同的功能。你可以从这个 HOW TO 指南中的例子更加清晰的理解YUM:
|
||||
|
||||
- 参考:[20 个用于包管理的 YUM 命令][5]
|
||||
|
||||
#### DNF(优美的 Yum(Dandified Yum))
|
||||
|
||||
这个也是一个用于基于 RPM 的发行版的包管理器,Fedora 18 引入了它,它是下一代 YUM。
|
||||
|
||||
如果你用 Fedora 22 及更新版本,你肯定知道它是默认的包管理器。这里有一些链接,将为你提供更多关于 DNF 的信息和如何使用它。
|
||||
|
||||
- 参考:[DNF - 基于 RPM 的发行版的下一代通用包管理软件][6]
|
||||
- 参考: [27 个管理 Fedora 软件包的 ‘DNF’ 命令例子][7]
|
||||
|
||||
### 3. Pacman 包管理器 – Arch Linux
|
||||
|
||||
这个是一个流行的、强大而易用的包管理器,它用于 Arch Linux 和其他的一些小众发行版。它提供了一些其他包管理器提供的基本功能,包括安装、自动解决依赖关系、升级、卸载和降级软件。
|
||||
|
||||
但是最大的用处是,它为 Arch 用户创建了一个简单易用的包管理方式。你可以阅读 [Pacman 概览][8],它会解释上面提到的一些功能。
|
||||
|
||||
### 4. Zypper 包管理器 – openSUSE
|
||||
|
||||
这个是一个使用 libzypp 库制作的用于 OpenSUSE 系统上的命令行包管理器,它的常用功能包括访问仓库、安装包、解决依赖问题和其他功能。
|
||||
|
||||
更重要的是,它也可以支持存储库扩展功能,如模式、补丁和产品。新的 OpenSUSE 用户可以参考下面的链接来掌控它。
|
||||
|
||||
- 参考:[45 个让你精通 openSUSE 包管理的 Zypper 命令][9]
|
||||
|
||||
### 5. Portage 包管理器 – Gentoo
|
||||
|
||||
这个是 Gentoo 的包管理器,当下不怎么流行的一个发行版,但是这并不阻止它成为 Linux 下最好的软件包管理器之一。
|
||||
|
||||
Portage 项目的主要目标是创建一个简单、无故障的包管理系统,包含向后兼容、自动化等功能。
|
||||
|
||||
如果希望理解的更清晰,可以看下: [Portage 项目页][10]。
|
||||
|
||||
### 结束语
|
||||
|
||||
正如我在开始时提到的,这个指南的主要意图是给 Linux 用户提供一个最佳软件包管理器的列表,但知道如何使用它们可以通过其后提供的重要的链接,并实际去试试它们。
|
||||
|
||||
各个发行版的用户需要学习超出他们的发行版之外的一些东西,才能更好理解上述提到的这些不同的包管理器。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-package-managers/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[Bestony](https://github.com/bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/admin/
|
||||
[1]: http://www.tecmint.com/dpkg-command-examples/
|
||||
[2]: http://www.tecmint.com/apt-advanced-package-command-examples-in-ubuntu/
|
||||
[3]: http://www.tecmint.com/useful-basic-commands-of-apt-get-and-apt-cache-for-package-management/
|
||||
[4]: http://www.tecmint.com/difference-between-apt-and-aptitude/
|
||||
[5]: http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[6]: http://www.tecmint.com/dnf-next-generation-package-management-utility-for-linux/
|
||||
[7]: http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
[8]: https://wiki.archlinux.org/index.php/Pacman
|
||||
[9]: http://www.tecmint.com/zypper-commands-to-manage-suse-linux-package-management/
|
||||
[10]: https://wiki.gentoo.org/wiki/Project:Portage
|
||||
@ -0,0 +1,110 @@
|
||||
Ubuntu 的 Snap、Red Hat 的 Flatpak 这种通吃所有发行版的打包方式真的有用吗?
|
||||
=================================================================================
|
||||
|
||||

|
||||
|
||||
**对新一代的打包格式开始渗透到 Linux 生态系统中的深入观察**
|
||||
|
||||
最近我们听到越来越多的有关于 Ubuntu 的 Snap 包和由 Red Hat 员工 Alexander Larsson 创造的 Flatpak (曾经叫做 xdg-app)的消息。
|
||||
|
||||
这两种下一代打包方法在本质上拥有相同的目标和特点:即不依赖于第三方系统功能库的独立包装。
|
||||
|
||||
这种 Linux 新技术方向似乎自然会让人脑海中浮现这样的问题:独立包的优点/缺点是什么?这是否让我们拥有更好的 Linux 系统?其背后的动机是什么?
|
||||
|
||||
为了回答这些问题,让我们先深入了解一下 Snap 和 Flatpak。
|
||||
|
||||
### 动机
|
||||
|
||||
根据 [Flatpak][1] 和 [Snap][2] 的声明,背后的主要动机是使同一版本的应用程序能够运行在多个 Linux 发行版。
|
||||
|
||||
> “从一开始它的主要目标是允许相同的应用程序运行在各种 Linux 发行版和操作系统上。” —— Flatpak
|
||||
|
||||
> “……‘snap’ 通用 Linux 包格式,使简单的二进制包能够完美的、安全的运行在任何 Linux 桌面、服务器、云和设备上。” —— Snap
|
||||
|
||||
说得更具体一点,站在 Snap 和 Flatpak (以下称之为 S&F)背后的人认为,Linux 平台存在碎片化的问题。
|
||||
|
||||
这个问题导致了开发者们需要做许多不必要的工作来使他的软件能够运行在各种不同的发行版上,这影响了整个平台的前进。
|
||||
|
||||
所以,作为 Linux 发行版(Ubuntu 和 Red Hat)的领导者,他们希望消除这个障碍,推动平台发展。
|
||||
|
||||
但是,是否是更多的个人收益刺激了 S&F 的开发?
|
||||
|
||||
#### 个人收益?
|
||||
|
||||
虽然没有任何官方声明,但是试想一下,如果能够创造这种可能会被大多数发行版(即便不是全部)所采用的打包方式,那么这个项目的领导者将可能成为一个能够决定 Linux 大船航向的重要人物。
|
||||
|
||||
### 优势
|
||||
|
||||
这种独立包的好处多多,并且取决于不同的因素。
|
||||
|
||||
这些因素基本上可以归为两类:
|
||||
|
||||
#### 用户角度
|
||||
|
||||
**+** 从 Liunx 用户的观点来看:Snap 和 Flatpak 带来了将任何软件包(软件或应用)安装在用户使用的任何发行版上的可能性。
|
||||
|
||||
例如你在使用一个不是很流行的发行版,由于开发工作的缺乏,它的软件仓库只有很稀少的包。现在,通过 S&F 你就可以显著的增加包的数量,这是一个多么美好的事情。
|
||||
|
||||
**+** 同样,对于使用流行的发行版的用户,即使该发行版的软件仓库上有很多的包,他也可以在不改变它现有的功能库的同时安装一个新的包。
|
||||
|
||||
比方说, 一个 Debian 的用户想要安装一个 “测试分支” 的包,但是他又不想将他的整个系统变成测试版(来让该包运行在更新的功能库上)。现在,他就可以简单的想安装哪个版本就安装哪个版本,而不需要考虑库的问题。
|
||||
|
||||
对于持后者观点的人,可能基本上都是使用源文件编译他们的包的人,然而,除非你使用类似 Gentoo 这样基于源代码的发行版,否则大多数用户将从头编译视为是一个恶心到吐的事情。
|
||||
|
||||
**+** 高级用户,或者称之为 “拥有安全意识的用户” 可能会觉得更容易接受这种类型的包,只要它们来自可靠来源,这种包倾向于提供另一层隔离,因为它们通常是与系统包想隔离的。
|
||||
|
||||
\* 不论是 Snap 还是 Flatpak 都在不断努力增强它们的安全性,通常他们都使用 “沙盒化” 来隔离,以防止它们可能携带病毒感染整个系统,就像微软 Windows 系统中的 .exe 程序一样。(关于微软和 S&F 后面还会谈到)
|
||||
|
||||
#### 开发者角度
|
||||
|
||||
与普通用户相比,对于开发者来说,开发 S&F 包的优点可能更加清楚。这一点已经在上一节有所提示。
|
||||
|
||||
尽管如此,这些优点有:
|
||||
|
||||
**+** S&F 通过统一开发的过程,将多发行版的开发变得简单了起来。对于需要将他的应用运行在多个发行版的开发者来说,这大大的减少了他们的工作量。
|
||||
|
||||
**++** 因此,开发者能够更容易的使他的应用运行在更多的发行版上。
|
||||
|
||||
**+** S&F 允许开发者私自发布他的包,不需要依靠发行版维护者在每一个/每一次发行版中发布他的包。
|
||||
|
||||
**++** 通过上述方法,开发者可以不依赖发行版而直接获取到用户安装和卸载其软件的统计数据。
|
||||
|
||||
**++** 同样是通过上述方法,开发者可以更好的直接与用户互动,而不需要通过中间媒介,比如发行版这种中间媒介。
|
||||
|
||||
### 缺点
|
||||
|
||||
**–** 膨胀。就是这么简单。Flatpak 和 Snap 并不是凭空变出来它的依赖关系。相反,它是通过将依赖关系预构建在其中来代替使用系统中的依赖关系。
|
||||
|
||||
就像谚语说的:“山不来就我,我就去就山”。
|
||||
|
||||
**–** 之前提到安全意识强的用户会喜欢 S&F 提供的额外的一层隔离,只要该应用来自一个受信任的来源。但是从另外一个角度看,对这方面了解较少的用户,可能会从一个不靠谱的地方弄来一个包含恶意软件的包从而导致危害。
|
||||
|
||||
上面提到的观点可以说是有很有意义的,虽说今天的流行方法,像 PPA、overlay 等也可能是来自不受信任的来源。
|
||||
|
||||
但是,S&F 包更加增加这个风险,因为恶意软件开发者只需要开发一个版本就可以感染各种发行版。相反,如果没有 S&F,恶意软件的开发者就需要创建不同的版本以适应不同的发行版。
|
||||
|
||||
### 原来微软一直是正确的吗?
|
||||
|
||||
考虑到上面提到的,很显然,在大多数情况下,使用 S&F 包的优点超过缺点。
|
||||
|
||||
至少对于二进制发行版的用户,或者重点不是轻量级的发行版的用户来说是这样的。
|
||||
|
||||
这促使我问出这个问题,可能微软一直是正确的吗?如果是的,那么当 S&F 变成 Linux 的标准后,你还会一如既往的使用 Linux 或者类 Unix 系统吗?
|
||||
|
||||
很显然,时间会是这个问题的最好答案。
|
||||
|
||||
不过,我认为,即使不完全正确,但是微软有些地方也是值得赞扬的,并且以我的观点来看,所有这些方式在 Linux 上都立马能用也确实是一个亮点。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.iwillfolo.com/ubuntus-snap-red-hats-flatpack-and-is-one-fits-all-linux-packages-useful/
|
||||
|
||||
作者:[Editorials][a]
|
||||
译者:[Chao-zhi](https://github.com/Chao-zhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.iwillfolo.com/category/editorials/
|
||||
[1]: http://flatpak.org/press/2016-06-21-flatpak-released.html
|
||||
[2]: https://insights.ubuntu.com/2016/06/14/universal-snap-packages-launch-on-multiple-linux-distros
|
||||
@ -0,0 +1,111 @@
|
||||
JStock:Linux 上不错的股票投资组合管理软件
|
||||
================================================================================
|
||||
|
||||
如果你在股票市场做投资,那么你可能非常清楚投资组合管理计划有多重要。管理投资组合的目标是依据你能承受的风险,时间层面的长短和资金盈利的目标去为你量身打造的一种投资计划。鉴于这类软件的重要性,因此从来不会缺乏商业性的 app 和股票行情检测软件,每一个都可以兜售复杂的投资组合以及跟踪报告功能。
|
||||
|
||||
对于我们这些 Linux 爱好者们,我也找到了一些**好用的开源投资组合管理工具**,用来在 Linux 上管理和跟踪股票的投资组合,这里高度推荐一个基于 java 编写的管理软件 [JStock][1]。如果你不是一个 java 粉,也许你会放弃它,JStock 需要运行在沉重的 JVM 环境上。但同时,在每一个安装了 JRE 的环境中它都可以马上运行起来,在你的 Linux 环境中它会运行的很顺畅。
|
||||
|
||||
“开源”就意味着免费或标准低下的时代已经过去了。鉴于 JStock 只是一个个人完成的产物,作为一个投资组合管理软件它最令人印象深刻的是包含了非常多实用的功能,以上所有的荣誉属于它的作者 Yan Cheng Cheok!例如,JStock 支持通过监视列表去监控价格,多种投资组合,自选/内置的股票指标与相关监测,支持27个不同的股票市场和跨平台的云端备份/还原。JStock 支持多平台部署(Linux, OS X, Android 和 Windows),你可以通过云端保存你的 JStock 投资组合,并通过云平台无缝的备份/还原到其他的不同平台上面。
|
||||
|
||||
现在我将向你展示如何安装以及使用过程的一些具体细节。
|
||||
|
||||
### 在 Linux 上安装 JStock ###
|
||||
|
||||
因为 JStock 使用Java编写,所以必须[安装 JRE][2]才能让它运行起来。小提示,JStock 需要 JRE1.7 或更高版本。如你的 JRE 版本不能满足这个需求,JStock 将会运行失败然后出现下面的报错。
|
||||
|
||||
Exception in thread "main" java.lang.UnsupportedClassVersionError: org/yccheok/jstock/gui/JStock : Unsupported major.minor version 51.0
|
||||
|
||||
|
||||
在你的 Linux 上安装好了 JRE 之后,从其官网下载最新的发布的 JStock,然后加载启动它。
|
||||
|
||||
$ wget https://github.com/yccheok/jstock/releases/download/release_1-0-7-13/jstock-1.0.7.13-bin.zip
|
||||
$ unzip jstock-1.0.7.13-bin.zip
|
||||
$ cd jstock
|
||||
$ chmod +x jstock.sh
|
||||
$ ./jstock.sh
|
||||
|
||||
教程的其他部分,让我来给大家展示一些 JStock 的实用功能
|
||||
|
||||
### 监视监控列表中股票价格的波动 ###
|
||||
|
||||
使用 JStock 你可以创建一个或多个监视列表,它可以自动的监视股票价格的波动并给你提供相应的通知。在每一个监视列表里面你可以添加多个感兴趣的股票进去。之后在“Fall Below”和“Rise Above”的表格里添加你的警戒值,分别设定该股票的最低价格和最高价格。
|
||||
|
||||
|
||||
|
||||
例如你设置了 AAPL 股票的最低/最高价格分别是 $102 和 $115.50,只要在价格低于 $102 或高于 $115.50 时你就得到桌面通知。
|
||||
|
||||
你也可以设置邮件通知,这样你将收到一些价格信息的邮件通知。设置邮件通知在“Options”菜单里,在“Alert”标签中国,打开“Send message to email(s)”,填入你的 Gmail 账户。一旦完成 Gmail 认证步骤,JStock 就会开始发送邮件通知到你的 Gmail 账户(也可以设置其他的第三方邮件地址)。
|
||||
|
||||
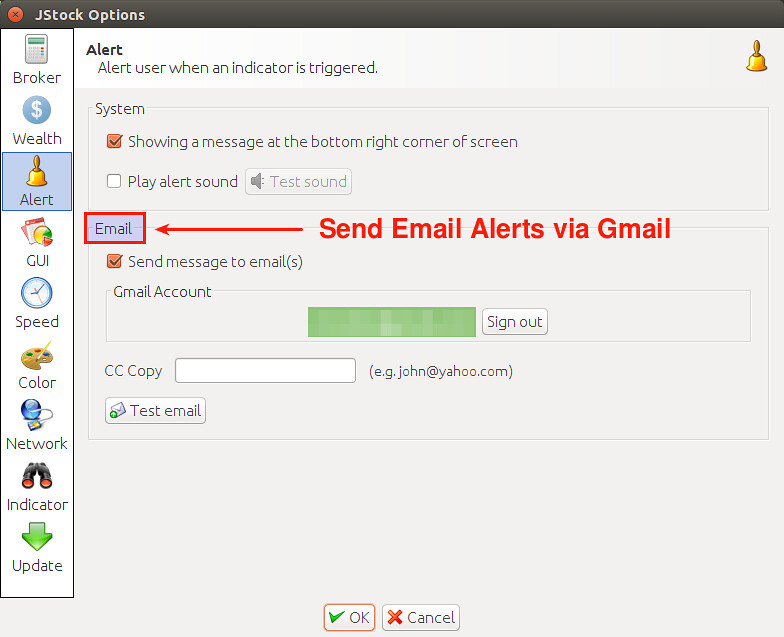
|
||||
|
||||
### 管理多个投资组合 ###
|
||||
|
||||
JStock 允许你管理多个投资组合。这个功能对于你使用多个股票经纪人时是非常实用的。你可以为每个经纪人创建一个投资组合去管理你的“买入/卖出/红利”用来了解每一个经纪人的业务情况。你也可以在“Portfolio”菜单里面选择特定的投资组合来切换不同的组合项目。下面是一张截图用来展示一个假设的投资组合。
|
||||
|
||||
|
||||
|
||||
你也可以设置付给中介费,你可以为每个买卖交易设置中介费、印花税以及结算费。如果你比较懒,你也可以在选项菜单里面启用自动费用计算,并提前为每一家经济事务所设置费用方案。当你为你的投资组合增加交易之后,JStock 将自动的计算并计入费用。
|
||||
|
||||
|
||||
|
||||
### 使用内置/自选股票指标来监控 ###
|
||||
|
||||
如果你要做一些股票的技术分析,你可能需要基于各种不同的标准来监控股票(这里叫做“股票指标”)。对于股票的跟踪,JStock提供多个[预设的技术指示器][3] 去获得股票上涨/下跌/逆转指数的趋势。下面的列表里面是一些可用的指标。
|
||||
|
||||
- 平滑异同移动平均线(MACD)
|
||||
- 相对强弱指标 (RSI)
|
||||
- 资金流向指标 (MFI)
|
||||
- 顺势指标 (CCI)
|
||||
- 十字线
|
||||
- 黄金交叉线,死亡交叉线
|
||||
- 涨幅/跌幅
|
||||
|
||||
开启预设指示器能需要在 JStock 中点击“Stock Indicator Editor”标签。之后点击右侧面板中的安装按钮。选择“Install from JStock server”选项,之后安装你想要的指示器。
|
||||
|
||||

|
||||
|
||||
一旦安装了一个或多个指示器,你可以用他们来扫描股票。选择“Stock Indicator Scanner”标签,点击底部的“Scan”按钮,选择需要的指示器。
|
||||
|
||||

|
||||
|
||||
当你选择完需要扫描的股票(例如, NYSE, NASDAQ)以后,JStock 将执行该扫描,并将该指示器捕获的结果通过列表展现。
|
||||
|
||||

|
||||
|
||||
除了预设指示器以外,你也可以使用一个图形化的工具来定义自己的指示器。下面这张图例用于监控当前价格小于或等于60天平均价格的股票。
|
||||
|
||||

|
||||
|
||||
### 通过云在 Linux 和 Android JStock 之间备份/恢复###
|
||||
|
||||
另一个非常棒的功能是 JStock 支持云备份恢复。Jstock 可以通过 Google Drive 把你的投资组合/监视列表在云上备份和恢复,这个功能可以实现在不同平台上无缝穿梭。如果你在两个不同的平台之间来回切换使用 Jstock,这种跨平台备份和还原非常有用。我在 Linux 桌面和 Android 手机上测试过我的 Jstock 投资组合,工作的非常漂亮。我在 Android 上将 Jstock 投资组合信息保存到 Google Drive 上,然后我可以在我的 Linux 版的 Jstock 上恢复它。如果能够自动同步到云上,而不用我手动地触发云备份/恢复就更好了,十分期望这个功能出现。
|
||||
|
||||

|
||||
|
||||
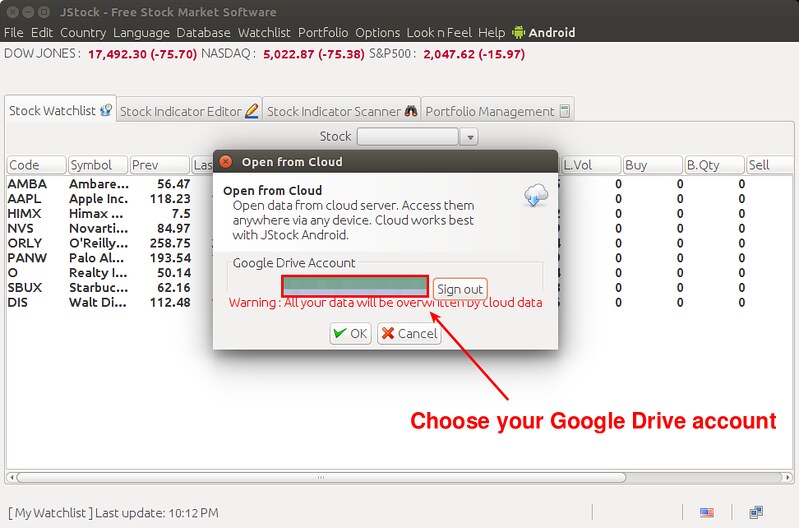
|
||||
|
||||
如果你在从 Google Drive 还原之后不能看到你的投资信息以及监视列表,请确认你的国家信息与“Country”菜单里面设置的保持一致。
|
||||
|
||||
JStock 的安卓免费版可以从 [Google Play Store][4] 获取到。如果你需要完整的功能(比如云备份,通知,图表等),你需要一次性支付费用升级到高级版。我认为高级版物有所值。
|
||||
|
||||
|
||||
|
||||
写在最后,我应该说一下它的作者,Yan Cheng Cheok,他是一个十分活跃的开发者,有bug及时反馈给他。这一切都要感谢他!!!
|
||||
|
||||
关于 JStock 这个投资组合跟踪软件你有什么想法呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/stock-portfolio-management-software-Linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[ivo-wang](https://github.com/ivo-wang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://Linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://jstock.org/
|
||||
[2]:http://ask.xmodulo.com/install-java-runtime-Linux.html
|
||||
[3]:http://jstock.org/ma_indicator.html
|
||||
[4]:https://play.google.com/store/apps/details?id=org.yccheok.jstock.gui
|
||||
@ -0,0 +1,65 @@
|
||||
共享的未来:Pydio 与 ownCloud 的联合
|
||||
=========================================================
|
||||
|
||||

|
||||
|
||||
*图片来源 : opensource.com*
|
||||
|
||||
开源共享生态圈内容纳了许多各异的项目,它们每一个都给出了自己的解决方案,且每一个都不按套路来。有很多原因导致你选择开源的解决方案,而非 Dropbox、Google Drive、iCloud 或 OneDrive 这些商业的解决方案。这些商业的解决方案虽然能让你不必为如何管理数据担心,但也理所应当的带着种种限制,其中就包括对于原有基础结构的控制和整合不足。
|
||||
|
||||
对于用户而言仍有相当一部分可供选择的文件分享和同步的替代品,其中就包括了 Pydio 和 ownCloud。
|
||||
|
||||
### Pydio
|
||||
|
||||
Pydio (Put your data in orbit 把你的数据放上轨道) 项目由一位作曲家 Charles du Jeu 发起,起初他只是需要一种与乐队成员分享大型音频文件的方法。[Pydio][1] 是一种文件分享与同步的解决方案,综合了多存储后端,设计时还同时考虑了开发者和系统管理员两方面。在世界各地有逾百万的下载量,已被翻译成 27 种语言。
|
||||
|
||||
项目在刚开始的时候便开源了,先是在 [SourceForge][2] 上茁壮的成长,现在已在 [GitHub][3] 上安了家。
|
||||
|
||||
用户界面基于 Google 的 [Material 设计风格][4]。用户可以使用现有的传统文件基础结构或是根据预估的需求部署 Pydio,并通过 web、桌面和移动端应用随时随地地管理自己的东西。对于管理员来说,细粒度的访问权限绝对是配置访问时的利器。
|
||||
|
||||
在 [Pydio 社区][5],你可以找到许多让你增速的资源。Pydio 网站 [对于如何为 Pydio GitHub 仓库贡献][6] 给出了明确的指导方案。[论坛][7]中也包含了开发者板块和社区。
|
||||
|
||||
### ownCloud
|
||||
|
||||
[ownCloud][8] 在世界各地拥有逾 8 百万的用户,它是一个开源、自行管理的文件同步共享技术。同步客户端支持所有主流平台并支持 WebDAV 通过 web 界面实现。ownCloud 拥有简单的使用界面,强大的管理工具,和大规模的共享及协作功能——以满足用户管理数据时的需求。
|
||||
|
||||
ownCloud 的开放式架构是通过 API 和为应用提供平台来实现可扩展性的。迄今已有逾 300 款应用,功能包括处理像日历、联系人、邮件、音乐、密码、笔记等诸多数据类型。ownCloud 由一个数百位贡献者的国际化的社区开发,安全,并且能做到为小到一个树莓派大到好几百万用户的 PB 级存储集群量身定制。
|
||||
|
||||
### 联合共享 (Federated sharing)
|
||||
|
||||
文件共享开始转向团队合作时代,而标准化为合作提供了坚实的土壤。
|
||||
|
||||
联合共享(Federated sharing)——一个由 [OpenCloudMesh][9] 项目提供的新的开放标准,就是在这个方向迈出的一步。先不说别的,在支持该标准的服务器之间分享文件和文件夹,比如说 Pydio 和 ownCloud。
|
||||
|
||||
ownCloud 7 率先引入该标准,这种服务器到服务器的分享方式可以让你挂载远程服务器上共享的文件,实际上就是创建你自己的云上之云。你可以直接为其它支持联合共享的服务器上的用户创建共享链接。
|
||||
|
||||
实现这个新的 API 允许存储解决方案之间更深层次的集成,同时保留了原有平台的安全,控制和特性。
|
||||
|
||||
“交换和共享文件是当下和未来不可或缺的东西。”ownCloud 的创始人 Frank Karlitschek 说道:“正因如此,采用联合和分布的方式而非集中的数据孤岛就显得至关重要。联合共享的设计初衷便是在保证安全和用户隐私的同时追求分享的无缝、至简之道。”
|
||||
|
||||
### 下一步是什么呢?
|
||||
|
||||
正如 OpenCloudMesh 做的那样,将会通过像 Pydio 和 ownCloud 这样的机构和公司,合作推广这一文件共享的新开放标准。ownCloud 9 已经引入联合的服务器之间交换用户列表的功能,让你的用户们在你的服务器上享有和你同样的无缝体验。将来,一个中央地址簿服务(联合的)集合,用以检索其他联合云 ID 的构想可能会把云间合作推向一个新的高度。
|
||||
|
||||
这一举措无疑有助于日益开放的技术社区中的那些成员方便地讨论,开发,并推动“OCM 分享 API”作为一个厂商中立协议。所有领导 OCM 项目的合作伙伴都全心致力于开放 API 的设计原则,并欢迎其他开源的文件分享和同步社区参与并加入其中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/5/sharing-files-pydio-owncloud
|
||||
|
||||
作者:[ben van 't ende][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/benvantende
|
||||
[1]: https://pydio.com/
|
||||
[2]: https://sourceforge.net/projects/ajaxplorer/
|
||||
[3]: https://github.com/pydio/
|
||||
[4]: https://www.google.com/design/spec/material-design/introduction.html
|
||||
[5]: https://pydio.com/en/community
|
||||
[6]: https://pydio.com/en/community/contribute
|
||||
[7]: https://pydio.com/forum/f
|
||||
[8]: https://owncloud.org/
|
||||
[9]: https://wiki.geant.org/display/OCM/Open+Cloud+Mesh
|
||||
@ -0,0 +1,64 @@
|
||||
教你用 google-drive-ocamlfuse 在 Linux 上挂载 Google Drive
|
||||
=====================
|
||||
|
||||
> 如果你在找一个方便的方式在 Linux 机器上挂载你的 Google Drive 文件夹, Jack Wallen 将教你怎么使用 google-drive-ocamlfuse 来挂载 Google Drive。
|
||||
|
||||

|
||||
|
||||
*图片来源: Jack Wallen*
|
||||
|
||||
Google 还没有发行 Linux 版本的 Google Drive 应用,尽管现在有很多方法从 Linux 中访问你的 Drive 文件。
|
||||
|
||||
如果你喜欢界面化的工具,你可以选择 Insync。如果你喜欢用命令行,有很多像 Grive2 这样的工具,和更容易使用的以 Ocaml 语言编写的基于 FUSE 的文件系统。我将会用后面这种方式演示如何在 Linux 桌面上挂载你的 Google Drive。尽管这是通过命令行完成的,但是它的用法会简单到让你吃惊。它太简单了以至于谁都能做到。
|
||||
|
||||
这个系统的特点:
|
||||
|
||||
- 对普通文件/文件夹有完全的读写权限
|
||||
- 对于 Google Docs,sheets,slides 这三个应用只读
|
||||
- 能够访问 Drive 回收站(.trash)
|
||||
- 处理重复文件功能
|
||||
- 支持多个帐号
|
||||
|
||||
让我们接下来完成 google-drive-ocamlfuse 在 Ubuntu 16.04 桌面的安装,然后你就能够访问云盘上的文件了。
|
||||
|
||||
### 安装
|
||||
|
||||
1. 打开终端。
|
||||
2. 用 `sudo add-apt-repository ppa:alessandro-strada/ppa` 命令添加必要的 PPA
|
||||
3. 出现提示的时候,输入你的 root 密码并按下回车。
|
||||
4. 用 `sudo apt-get update` 命令更新应用。
|
||||
5. 输入 `sudo apt-get install google-drive-ocamlfuse` 命令安装软件。
|
||||
|
||||
### 授权
|
||||
|
||||
接下来就是授权 google-drive-ocamlfuse,让它有权限访问你的 Google 账户。先回到终端窗口敲下命令 `google-drive-ocamlfuse`,这个命令将会打开一个浏览器窗口,它会提示你登陆你的 Google 帐号或者如果你已经登陆了 Google 帐号,它会询问是否允许 google-drive-ocamlfuse 访问 Google 账户。如果你还没有登录,先登录然后点击“允许”。接下来的窗口(在 Ubuntu 16.04 桌面上会出现,但不会出现在 Elementary OS Freya 桌面上)将会询问你是否授给 gdfuse 和 OAuth2 Endpoint 访问你的 Google 账户的权限,再次点击“允许”。然后出现的窗口就会告诉你等待授权令牌下载完成,这个时候就能最小化浏览器了。当你的终端提示如下图一样的内容,你就能知道令牌下载完了,并且你已经可以挂载 Google Drive 了。
|
||||
|
||||

|
||||
|
||||
*应用已经得到授权,你可以进行后面的工作。*
|
||||
|
||||
### 挂载 Google Drive
|
||||
|
||||
在挂载 Google Drive 之前,你得先创建一个文件夹,作为挂载点。在终端里,敲下`mkdir ~/google-drive`命令在你的家目录下创建一个新的文件夹。最后敲下命令`google-drive-ocamlfuse ~/google-drive`将你的 Google Drive 挂载到 google-drive 文件夹中。
|
||||
|
||||
这时你可以查看本地 google-drive 文件夹中包含的 Google Drive 文件/文件夹。你可以把 Google Drive 当作本地文件系统来进行工作。
|
||||
|
||||
当你想卸载 google-drive 文件夹,输入命令 `fusermount -u ~/google-drive`。
|
||||
|
||||
### 没有 GUI,但它特别好用
|
||||
|
||||
我发现这个特别的系统非常容易使用,在同步 Google Drive 时它出奇的快,并且这可以作为一种本地备份你的 Google Drive 账户的巧妙方式。(LCTT 译注:然而首先你得能使用……)
|
||||
|
||||
试试 google-drive-ocamlfuse,看看你能用它做出什么有趣的事。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.techrepublic.com/article/how-to-mount-your-google-drive-on-linux-with-google-drive-ocamlfuse/
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.techrepublic.com/search/?a=jack+wallen
|
||||
@ -0,0 +1,227 @@
|
||||
使用 OpenCV 识别图片中的猫咪
|
||||
=======================================
|
||||
|
||||

|
||||
|
||||
你知道 OpenCV 可以识别在图片中小猫的脸吗?而且是拿来就能用,不需要其它的库之类的。
|
||||
|
||||
之前我也不知道。
|
||||
|
||||
但是在 [Kendrick Tan 曝出这个功能][1]后,我需要亲自体验一下……去看看到 OpenCV 是如何在我没有察觉到的情况下,将这一个功能添加进了他的软件库(就像一只悄悄溜进空盒子的猫咪一样,等待别人发觉)。
|
||||
|
||||
下面,我将会展示如何使用 OpenCV 的猫咪检测器在图片中识别小猫的脸。同样的,该技术也可以用在视频流中。
|
||||
|
||||
### 使用 OpenCV 在图片中检测猫咪
|
||||
|
||||
如果你查找过 [OpenCV 的代码仓库][3],尤其是在 [haarcascades 目录][4]里(OpenCV 在这里保存处理它预先训练好的 Haar 分类器,以检测各种物体、身体部位等), 你会看到这两个文件:
|
||||
|
||||
- haarcascade_frontalcatface.xml
|
||||
- haarcascade\_frontalcatface\_extended.xml
|
||||
|
||||
这两个 Haar Cascade 文件都将被用来在图片中检测小猫的脸。实际上,我使用了相同的 cascades 分类器来生成这篇博文顶端的图片。
|
||||
|
||||
在做了一些调查工作之后,我发现这些 cascades 分类器是由鼎鼎大名的 [Joseph Howse][5]训练和贡献给 OpenCV 仓库的,他写了很多很棒的教程和书籍,在计算机视觉领域有着很高的声望。
|
||||
|
||||
下面,我将会展示给你如何使用 Howse 的 Haar cascades 分类器来检测图片中的小猫。
|
||||
|
||||
### 猫咪检测代码
|
||||
|
||||
让我们开始使用 OpenCV 来检测图片中的猫咪。新建一个叫 cat_detector.py 的文件,并且输入如下的代码:
|
||||
|
||||
```
|
||||
# import the necessary packages
|
||||
import argparse
|
||||
import cv2
|
||||
|
||||
# construct the argument parse and parse the arguments
|
||||
ap = argparse.ArgumentParser()
|
||||
ap.add_argument("-i", "--image", required=True,
|
||||
help="path to the input image")
|
||||
ap.add_argument("-c", "--cascade",
|
||||
default="haarcascade_frontalcatface.xml",
|
||||
help="path to cat detector haar cascade")
|
||||
args = vars(ap.parse_args())
|
||||
```
|
||||
|
||||
第 2 和第 3 行主要是导入了必要的 python 包。6-12 行用于解析我们的命令行参数。我们仅要求一个必需的参数 `--image` ,它是我们要使用 OpenCV 检测猫咪的图片。
|
||||
|
||||
我们也可以(可选的)通过 `--cascade` 参数指定我们的 Haar cascade 分类器的路径。默认使用 `haarcascades_frontalcatface.xml`,假定这个文件和你的 `cat_detector.py` 在同一目录下。
|
||||
|
||||
注意:我已经打包了猫咪的检测代码,还有在这个教程里的样本图片。你可以在博文原文的 “下载” 部分下载到。如果你是刚刚接触 Python+OpenCV(或者 Haar cascade),我建议你下载这个 zip 压缩包,这个会方便你跟着教程学习。
|
||||
|
||||
接下来,就是检测猫的时刻了:
|
||||
|
||||
```
|
||||
# load the input image and convert it to grayscale
|
||||
image = cv2.imread(args["image"])
|
||||
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
|
||||
|
||||
# load the cat detector Haar cascade, then detect cat faces
|
||||
# in the input image
|
||||
detector = cv2.CascadeClassifier(args["cascade"])
|
||||
rects = detector.detectMultiScale(gray, scaleFactor=1.3,
|
||||
minNeighbors=10, minSize=(75, 75))
|
||||
```
|
||||
|
||||
在 15、16 行,我们从硬盘上读取了图片,并且进行灰度化(这是一个在将图片传给 Haar cascade 分类器之前的常用的图片预处理步骤,尽管不是必须的)
|
||||
|
||||
20 行,从硬盘加载 Haar casacade 分类器,即猫咪检测器,并且实例化 `cv2.CascadeClassifier` 对象。
|
||||
|
||||
在 21、22 行通过调用 `detector` 的 `detectMultiScale` 方法使用 OpenCV 完成猫脸检测。我们给 `detectMultiScale` 方法传递了四个参数。包括:
|
||||
|
||||
1. 图片 `gray`,我们要在该图片中检测猫脸。
|
||||
2. 检测猫脸时的[图片金字塔][6] 的检测粒度 `scaleFactor` 。更大的粒度将会加快检测的速度,但是会对检测准确性( true-positive)产生影响。相反的,一个更小的粒度将会影响检测的时间,但是会增加准确性( true-positive)。但是,细粒度也会增加误报率(false-positive)。你可以看这篇博文的“ Haar cascades 注意事项”部分来获得更多的信息。
|
||||
3. `minNeighbors` 参数控制了检定框的最少数量,即在给定区域内被判断为猫脸的最少数量。这个参数可以很好的排除误报(false-positive)结果。
|
||||
4. 最后,`minSize` 参数不言自明。这个值描述每个检定框的最小宽高尺寸(单位是像素),这个例子中就是 75\*75
|
||||
|
||||
`detectMultiScale` 函数会返回 `rects`,这是一个 4 元组列表。这些元组包含了每个检测到的猫脸的 (x,y) 坐标值,还有宽度、高度。
|
||||
|
||||
最后,让我们在图片上画下这些矩形来标识猫脸:
|
||||
|
||||
```
|
||||
# loop over the cat faces and draw a rectangle surrounding each
|
||||
for (i, (x, y, w, h)) in enumerate(rects):
|
||||
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2)
|
||||
cv2.putText(image, "Cat #{}".format(i + 1), (x, y - 10),
|
||||
cv2.FONT_HERSHEY_SIMPLEX, 0.55, (0, 0, 255), 2)
|
||||
|
||||
# show the detected cat faces
|
||||
cv2.imshow("Cat Faces", image)
|
||||
cv2.waitKey(0)
|
||||
```
|
||||
|
||||
给我们这些框(比如,rects)的数据,我们在 25 行依次遍历它。
|
||||
|
||||
在 26 行,我们在每张猫脸的周围画上一个矩形。27、28 行展示了一个整数,即图片中猫咪的数量。
|
||||
|
||||
最后,31,32 行在屏幕上展示了输出的图片。
|
||||
|
||||
### 猫咪检测结果
|
||||
|
||||
为了测试我们的 OpenCV 猫咪检测器,可以在原文的最后,下载教程的源码。
|
||||
|
||||
然后,在你解压缩之后,你将会得到如下的三个文件/目录:
|
||||
|
||||
1. cat_detector.py:我们的主程序
|
||||
2. haarcascade_frontalcatface.xml: 猫咪检测器 Haar cascade
|
||||
3. images:我们将会使用的检测图片目录。
|
||||
|
||||
到这一步,执行以下的命令:
|
||||
|
||||
```
|
||||
$ python cat_detector.py --image images/cat_01.jpg
|
||||
```
|
||||
|
||||
|
||||
|
||||
*图 1. 在图片中检测猫脸,甚至是猫咪部分被遮挡了。*
|
||||
|
||||
注意,我们已经可以检测猫脸了,即使它的其余部分是被遮挡的。
|
||||
|
||||
试下另外的一张图片:
|
||||
|
||||
```
|
||||
python cat_detector.py --image images/cat_02.jpg
|
||||
```
|
||||
|
||||

|
||||
|
||||
*图 2. 使用 OpenCV 检测猫脸的第二个例子,这次猫脸稍有不同。*
|
||||
|
||||
这次的猫脸和第一次的明显不同,因为它正在发出“喵呜”叫声的当中。这种情况下,我们依旧能检测到正确的猫脸。
|
||||
|
||||
在下面这张图片的结果也是正确的:
|
||||
|
||||
```
|
||||
$ python cat_detector.py --image images/cat_03.jpg
|
||||
```
|
||||
|
||||
|
||||
|
||||
*图 3. 使用 OpenCV 和 python 检测猫脸*
|
||||
|
||||
我们最后的一个样例就是在一张图中检测多张猫脸:
|
||||
|
||||
```
|
||||
$ python cat_detector.py --image images/cat_04.jpg
|
||||
```
|
||||
|
||||

|
||||
|
||||
*图 4. 在同一张图片中使用 OpenCV 检测多只猫*
|
||||
|
||||
注意,Haar cascade 返回的检定框不一定是以你预期的顺序。这种情况下,中间的那只猫会被标记成第三只。你可以通过判断他们的 (x, y) 坐标来自己排序这些检定框。
|
||||
|
||||
#### 关于精度的说明
|
||||
|
||||
在这个 xml 文件中的注释非常重要,Joseph Hower 提到了这个猫脸检测器有可能会将人脸识别成猫脸。
|
||||
|
||||
这种情况下,他推荐使用两种检测器(人脸 & 猫脸),然后将出现在人脸识别结果中的结果剔除掉。
|
||||
|
||||
#### Haar cascades 注意事项
|
||||
|
||||
这个方法首先出现在 Paul Viola 和 Michael Jones 2001 年出版的 [Rapid Object Detection using a Boosted Cascade of Simple Features][7] 论文中。现在它已经成为了计算机识别领域引用最多的论文之一。
|
||||
|
||||
这个算法能够识别图片中的对象,无论它们的位置和比例。而且最令人感兴趣的或许是它能在现有的硬件条件下实现实时检测。
|
||||
|
||||
在他们的论文中,Viola 和 Jones 关注在训练人脸检测器;但是,这个框架也能用来检测各类事物,如汽车、香蕉、路标等等。
|
||||
|
||||
#### 问题是?
|
||||
|
||||
Haar cascades 最大的问题就是如何确定 `detectMultiScale` 方法的参数正确。特别是 `scaleFactor` 和 `minNeighbors` 参数。你很容易陷入一张一张图片调参数的坑,这个就是该对象检测器很难被实用化的原因。
|
||||
|
||||
这个 `scaleFactor` 变量控制了用来检测对象的图片的各种比例的[图像金字塔][8]。如果 `scaleFactor` 参数过大,你就只需要检测图像金字塔中较少的层,这可能会导致你丢失一些在图像金字塔层之间缩放时少了的对象。
|
||||
|
||||
换句话说,如果 `scaleFactor` 参数过低,你会检测过多的金字塔图层。这虽然可以能帮助你检测到更多的对象。但是他会造成计算速度的降低,还会**明显**提高误报率。Haar cascades 分类器就是这样。
|
||||
|
||||
为了避免这个,我们通常使用 [Histogram of Oriented Gradients + 线性 SVM 检测][9] 替代。
|
||||
|
||||
上述的 HOG + 线性 SVM 框架的参数更容易调优。而且更好的误报率也更低,但是唯一不好的地方是无法实时运算。
|
||||
|
||||
### 对对象识别感兴趣?并且希望了解更多?
|
||||
|
||||

|
||||
|
||||
*图 5. 在 PyImageSearch Gurus 课程中学习如何构建自定义的对象识别器。*
|
||||
|
||||
如果你对学习如何训练自己的自定义对象识别器感兴趣,请务必要去了解下 PyImageSearch Gurus 课程。
|
||||
|
||||
在这个课程中,我提供了 15 节课,覆盖了超过 168 页的教程,来教你如何从 0 开始构建自定义的对象识别器。你会掌握如何应用 HOG + 线性 SVM 框架来构建自己的对象识别器来识别路标、面孔、汽车(以及附近的其它东西)。
|
||||
|
||||
要学习 PyImageSearch Gurus 课程(有 10 节示例免费课程),点此:https://www.pyimagesearch.com/pyimagesearch-gurus/?src=post-cat-detection
|
||||
|
||||
### 总结
|
||||
|
||||
在这篇博文里,我们学习了如何使用 OpenCV 默认就有的 Haar cascades 分类器来识别图片中的猫脸。这些 Haar casacades 是由 [Joseph Howse][9] 训练兵贡献给 OpenCV 项目的。我是在 Kendrick Tan 的[这篇文章][10]中开始注意到这个。
|
||||
|
||||
尽管 Haar cascades 相当有用,但是我们也经常用 HOG + 线性 SVM 替代。因为后者相对而言更容易使用,并且可以有效地降低误报率。
|
||||
|
||||
我也会[在 PyImageSearch Gurus 课程中][11]详细的讲述如何构建定制的 HOG + 线性 SVM 对象识别器,来识别包括汽车、路标在内的各种事物。
|
||||
|
||||
不管怎样,我希望你喜欢这篇博文。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.pyimagesearch.com/2016/06/20/detecting-cats-in-images-with-opencv/
|
||||
|
||||
作者:[Adrian Rosebrock][a]
|
||||
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.pyimagesearch.com/author/adrian/
|
||||
[1]: http://kendricktan.github.io/find-cats-in-photos-using-computer-vision.html
|
||||
[2]: http://www.pyimagesearch.com/2016/06/20/detecting-cats-in-images-with-opencv/#
|
||||
[3]: https://github.com/Itseez/opencv
|
||||
[4]: https://github.com/Itseez/opencv/tree/master/data/haarcascades
|
||||
[5]: http://nummist.com/
|
||||
[6]: http://www.pyimagesearch.com/2015/03/16/image-pyramids-with-python-and-opencv/
|
||||
[7]: https://www.cs.cmu.edu/~efros/courses/LBMV07/Papers/viola-cvpr-01.pdf
|
||||
[8]: http://www.pyimagesearch.com/2015/03/16/image-pyramids-with-python-and-opencv/
|
||||
[9]: http://www.pyimagesearch.com/2014/11/10/histogram-oriented-gradients-object-detection/
|
||||
[10]: http://kendricktan.github.io/find-cats-in-photos-using-computer-vision.html
|
||||
[11]: https://www.pyimagesearch.com/pyimagesearch-gurus/
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,105 @@
|
||||
Fedora 中的容器技术:systemd-nspawn
|
||||
===
|
||||
|
||||
欢迎来到“Fedora 中的容器技术”系列!本文是该系列文章中的第一篇,它将说明你可以怎样使用 Fedora 中各种可用的容器技术。本文将学习 `systemd-nspawn` 的相关知识。
|
||||
|
||||
### 容器是什么?
|
||||
|
||||
一个容器就是一个用户空间实例,它能够在与托管容器的系统(叫做宿主系统)相隔离的环境中运行一个程序或者一个操作系统。这和 `chroot` 或 [虚拟机][1] 的思想非常类似。运行在容器中的进程是由与宿主操作系统相同的内核来管理的,但它们是与宿主文件系统以及其它进程隔离开的。
|
||||
|
||||
### 什么是 systemd-nspawn?
|
||||
|
||||
systemd 项目认为应当将容器技术变成桌面的基础部分,并且应当和用户的其余系统集成在一起。为此,systemd 提供了 `systemd-nspawn`,这款工具能够使用多种 Linux 技术创建容器。它也提供了一些容器管理工具。
|
||||
|
||||
`systemd-nspawn` 和 `chroot` 在许多方面都是类似的,但是前者更加强大。它虚拟化了文件系统、进程树以及客户系统中的进程间通信。它的吸引力在于它提供了很多用于管理容器的工具,例如用来管理容器的 `machinectl`。由 `systemd-nspawn` 运行的容器将会与 systemd 组件一同运行在宿主系统上。举例来说,一个容器的日志可以输出到宿主系统的日志中。
|
||||
|
||||
在 Fedora 24 上,`systemd-nspawn` 已经从 systemd 软件包分离出来了,所以你需要安装 `systemd-container` 软件包。一如往常,你可以使用 `dnf install systemd-container` 进行安装。
|
||||
|
||||
### 创建容器
|
||||
|
||||
使用 `systemd-nspawn` 创建一个容器是很容易的。假设你有一个专门为 Debian 创造的应用,并且无法在其它发行版中正常运行。那并不是一个问题,我们可以创造一个容器!为了设置容器使用最新版本的 Debian(现在是 Jessie),你需要挑选一个目录来放置你的系统。我暂时将使用目录 `~/DebianJessie`。
|
||||
|
||||
一旦你创建完目录,你需要运行 `debootstrap`,你可以从 Fedora 仓库中安装它。对于 Debian Jessie,你运行下面的命令来初始化一个 Debian 文件系统。
|
||||
|
||||
```
|
||||
$ debootstrap --arch=amd64 stable ~/DebianJessie
|
||||
```
|
||||
|
||||
以上默认你的架构是 x86_64。如果不是的话,你必须将架构的名称改为 `amd64`。你可以使用 `uname -m` 得知你的机器架构。
|
||||
|
||||
一旦设置好你的根目录,你就可以使用下面的命令来启动你的容器。
|
||||
|
||||
```
|
||||
$ systemd-nspawn -bD ~/DebianJessie
|
||||
```
|
||||
|
||||
容器将会在数秒后准备好并运行,当你试图登录时就会注意到:你无法使用你的系统上任何账户。这是因为 `systemd-nspawn` 虚拟化了用户。修复的方法很简单:将之前的命令中的 `-b` 移除即可。你将直接进入容器的 root 用户的 shell。此时,你只能使用 `passwd` 命令为 root 设置密码,或者使用 `adduser` 命令添加一个新用户。一旦设置好密码或添加好用户,你就可以把 `-b` 标志添加回去然后继续了。你会进入到熟悉的登录控制台,然后你使用设置好的认证信息登录进去。
|
||||
|
||||
以上对于任意你想在容器中运行的发行版都适用,但前提是你需要使用正确的包管理器创建系统。对于 Fedora,你应使用 DNF 而非 `debootstrap`。想要设置一个最小化的 Fedora 系统,你可以运行下面的命令,要将“/absolute/path/”替换成任何你希望容器存放的位置。
|
||||
|
||||
```
|
||||
$ sudo dnf --releasever=24 --installroot=/absolute/path/ install systemd passwd dnf fedora-release
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 设置网络
|
||||
|
||||
如果你尝试启动一个服务,但它绑定了你宿主机正在使用的端口,你将会注意到这个问题:你的容器正在使用和宿主机相同的网络接口。幸运的是,`systemd-nspawn` 提供了几种可以将网络从宿主机分开的方法。
|
||||
|
||||
#### 本地网络
|
||||
|
||||
第一种方法是使用 `--private-network` 标志,它默认仅创建一个回环设备。这对于你不需要使用网络的环境是非常理想的,例如构建系统和其它持续集成系统。
|
||||
|
||||
#### 多个网络接口
|
||||
|
||||
如果你有多个网络接口设备,你可以使用 `--network-interface` 标志给容器分配一个接口。想要给我的容器分配 `eno1`,我会添加选项 `--network-interface=eno1`。当某个接口分配给一个容器后,宿主机就不能同时使用那个接口了。只有当容器彻底关闭后,宿主机才可以使用那个接口。
|
||||
|
||||
#### 共享网络接口
|
||||
|
||||
对于我们中那些并没有额外的网络设备的人来说,还有其它方法可以访问容器。一种就是使用 `--port` 选项。这会将容器中的一个端口定向到宿主机。使用格式是 `协议:宿主机端口:容器端口`,这里的协议可以是 `tcp` 或者 `udp`,`宿主机端口` 是宿主机的一个合法端口,`容器端口` 则是容器中的一个合法端口。你可以省略协议,只指定 `宿主机端口:容器端口`。我通常的用法类似 `--port=2222:22`。
|
||||
|
||||
你可以使用 `--network-veth` 启用完全的、仅宿主机模式的网络,这会在宿主机和容器之间创建一个虚拟的网络接口。你也可以使用 `--network-bridge` 桥接二者的连接。
|
||||
|
||||
### 使用 systemd 组件
|
||||
|
||||
如果你容器中的系统含有 D-Bus,你可以使用 systemd 提供的实用工具来控制并监视你的容器。基础安装的 Debian 并不包含 `dbus`。如果你想在 Debian Jessie 中使用 `dbus`,你需要运行命令 `apt install dbus`。
|
||||
|
||||
#### machinectl
|
||||
|
||||
为了能够轻松地管理容器,systemd 提供了 `machinectl` 实用工具。使用 `machinectl`,你可以使用 `machinectl login name` 登录到一个容器中、使用 `machinectl status name`检查状态、使用 `machinectl reboot name` 启动容器或者使用 `machinectl poweroff name` 关闭容器。
|
||||
|
||||
### 其它 systemd 命令
|
||||
|
||||
多数 systemd 命令,例如 `journalctl`, `systemd-analyze` 和 `systemctl`,都支持使用 `--machine` 选项来指定容器。例如,如果你想查看一个名为 “foobar” 的容器的日志,你可以使用 `journalctl --machine=foobar`。你也可以使用 `systemctl --machine=foobar status service` 来查看运行在这个容器中的服务状态。
|
||||
|
||||
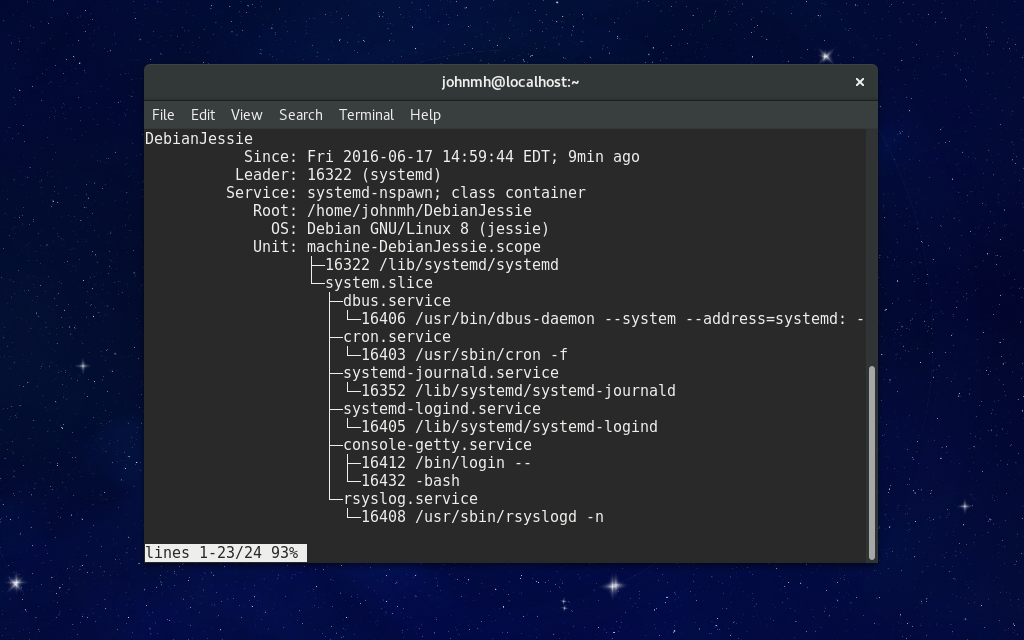
|
||||
|
||||
### 和 SELinux 一起工作
|
||||
|
||||
如果你要使用 SELinux 强制模式(Fedora 默认模式),你需要为你的容器设置 SELinux 环境。想要那样的话,你需要在宿主系统上运行下面两行命令。
|
||||
|
||||
```
|
||||
$ semanage fcontext -a -t svirt_sandbox_file_t "/path/to/container(/.*)?"
|
||||
$ restorecon -R /path/to/container/
|
||||
```
|
||||
|
||||
确保使用你的容器路径替换 “/path/to/container”。对于我的容器 "DebianJessie",我会运行下面的命令:
|
||||
|
||||
```
|
||||
$ semanage fcontext -a -t svirt_sandbox_file_t "/home/johnmh/DebianJessie(/.*)?"
|
||||
$ restorecon -R /home/johnmh/DebianJessie/
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/container-technologies-fedora-systemd-nspawn/
|
||||
|
||||
作者:[John M. Harris, Jr.][a]
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/container-technologies-fedora-systemd-nspawn/
|
||||
[1]: https://en.wikipedia.org/wiki/Virtual_machine
|
||||
@ -0,0 +1,101 @@
|
||||
如何在 Ubuntu Linux 16.04上安装开源的 Discourse 论坛
|
||||
===============================================================================
|
||||
|
||||
Discourse 是一个开源的论坛,它可以以邮件列表、聊天室或者论坛等多种形式工作。它是一个广受欢迎的现代的论坛工具。在服务端,它使用 Ruby on Rails 和 Postgres 搭建, 并且使用 Redis 缓存来减少读取时间 , 在客户端,它使用支持 Java Script 的浏览器。它非常容易定制,结构良好,并且它提供了转换插件,可以对你现存的论坛、公告板进行转换,例如: vBulletin、phpBB、Drupal、SMF 等等。在这篇文章中,我们将学习在 Ubuntu 操作系统下安装 Discourse。
|
||||
|
||||
它以安全作为设计思想,所以发垃圾信息的人和黑客们不能轻易的实现其企图。它能很好的支持各种现代设备,并可以相应的调整以手机和平板的显示。
|
||||
|
||||
### 在 Ubuntu 16.04 上安装 Discourse
|
||||
|
||||
让我们开始吧 ! 最少需要 1G 的内存,并且官方支持的安装过程需要已经安装了 docker。 说到 docker,它还需要安装Git。要满足以上的两点要求我们只需要运行下面的命令:
|
||||
|
||||
```
|
||||
wget -qO- https://get.docker.com/ | sh
|
||||
```
|
||||
|
||||

|
||||
|
||||
用不了多久就安装好了 docker 和 Git,安装结束以后,在你的系统上的 /var 分区创建一个 Discourse 文件夹(当然你也可以选择其他的分区)。
|
||||
|
||||
```
|
||||
mkdir /var/discourse
|
||||
```
|
||||
|
||||
现在我们来克隆 Discourse 的 Github 仓库到这个新建的文件夹。
|
||||
|
||||
```
|
||||
git clone https://github.com/discourse/discourse_docker.git /var/discourse
|
||||
```
|
||||
|
||||
进入这个克隆的文件夹。
|
||||
|
||||
```
|
||||
cd /var/discourse
|
||||
```
|
||||
|
||||

|
||||
|
||||
你将看到“discourse-setup” 脚本文件,运行这个脚本文件进行 Discourse 的初始化。
|
||||
|
||||
```
|
||||
./discourse-setup
|
||||
```
|
||||
|
||||
**备注: 在安装 discourse 之前请确保你已经安装好了邮件服务器。**
|
||||
|
||||
安装向导将会问你以下六个问题:
|
||||
|
||||
```
|
||||
Hostname for your Discourse?
|
||||
Email address for admin account?
|
||||
SMTP server address?
|
||||
SMTP user name?
|
||||
SMTP port [587]:
|
||||
SMTP password? []:
|
||||
```
|
||||
|
||||

|
||||
|
||||
当你提交了以上信息以后, 它会让你提交确认, 如果一切都很正常,点击回车以后安装开始。
|
||||
|
||||

|
||||
|
||||
现在“坐等放宽”,需要花费一些时间来完成安装,倒杯咖啡,看看有什么错误信息没有。
|
||||
|
||||

|
||||
|
||||
安装成功以后看起来应该像这样。
|
||||
|
||||

|
||||
|
||||
现在打开浏览器,如果已经做了域名解析,你可以使用你的域名来连接 Discourse 页面 ,否则你只能使用IP地址了。你将看到如下信息:
|
||||
|
||||

|
||||
|
||||
就是这个,点击 “Sign Up” 选项创建一个新的账户,然后进行你的 Discourse 设置。
|
||||
|
||||

|
||||
|
||||
### 结论
|
||||
|
||||
它安装简便,运行完美。 它拥有现代论坛所有必备功能。它以 GPL 发布,是完全开源的产品。简单、易用、以及特性丰富是它的最大特点。希望你喜欢这篇文章,如果有问题,你可以给我们留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxpitstop.com/install-discourse-on-ubuntu-linux-16-04/
|
||||
|
||||
作者:[Aun][a]
|
||||
译者:[kokialoves](https://github.com/kokialoves)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://linuxpitstop.com/author/aun/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
31
published/201607/20160630 What makes up the Fedora kernel.md
Normal file
31
published/201607/20160630 What makes up the Fedora kernel.md
Normal file
@ -0,0 +1,31 @@
|
||||
Fedora 内核是由什么构成的?
|
||||
====================================
|
||||
|
||||

|
||||
|
||||
每个 Fedora 系统都运行着一个内核。许多代码片段组合在一起使之成为现实。
|
||||
|
||||
每个 Fedora 内核都起始于一个来自于[上游社区][1]的基线版本——通常称之为 vanilla 内核。上游内核就是标准。(Fedora 的)目标是包含尽可能多的上游代码,这样使得 bug 修复和 API 更新更加容易,同时也会有更多的人审查代码。理想情况下,Fedora 能够直接获取 kernel.org 的内核,然后发送给所有用户。
|
||||
|
||||
现实情况是,使用 vanilla 内核并不能完全满足 Fedora。Vanilla 内核可能并不支持一些 Fedora 用户希望拥有的功能。用户接收的 [Fedora 内核] 是在 vanilla 内核之上打了很多补丁的内核。这些补丁被认为“不在树上(out of tree)”。许多这些位于补丁树之外的补丁都不会存在太久。如果某补丁能够修复一个问题,那么该补丁可能会被合并到 Fedora 树,以便用户能够更快地收到修复。当内核变基到一个新版本时,在新版本中的补丁都将被清除。
|
||||
|
||||
一些补丁会在 Fedora 内核树上存在很长时间。一个很好的例子是,安全启动补丁就是这类补丁。这些补丁提供了 Fedora 希望支持的功能,即使上游社区还没有接受它们。保持这些补丁更新是需要付出很多努力的,所以 Fedora 尝试减少不被上游内核维护者接受的补丁数量。
|
||||
|
||||
通常来说,想要在 Fedora 内核中获得一个补丁的最佳方法是先给 [Linux 内核邮件列表(LKML)][3] 发送补丁,然后请求将该补丁包含到 Fedora 中。如果某个维护者接受了补丁,就意味着 Fedora 内核树中将来很有可能会包含该补丁。一些来自于 GitHub 等地方的还没有提交给 LKML 的补丁是不可能进入内核树的。首先向 LKML 发送补丁是非常重要的,它能确保 Fedora 内核树中携带的补丁是功能正常的。如果没有社区审查,Fedora 最终携带的补丁将会充满 bug 并会导致问题。
|
||||
|
||||
Fedora 内核中包含的代码来自许多地方。一切都需要提供最佳的体验。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/makes-fedora-kernel/
|
||||
|
||||
作者:[Laura Abbott][a]
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/makes-fedora-kernel/
|
||||
[1]: http://www.kernel.org/
|
||||
[2]: http://pkgs.fedoraproject.org/cgit/rpms/kernel.git/
|
||||
[3]: http://www.labbott.name/blog/2015/10/02/the-art-of-communicating-with-lkml/
|
||||
@ -1,23 +1,21 @@
|
||||
如何在 Ubuntu 14.04 和 16.04 上建立网桥(br0)
|
||||
如何在 Ubuntu 上建立网桥
|
||||
=======================================================================
|
||||
|
||||
> 作为一个 Ubuntu 16.04 LTS 的初学者。如何在 Ubuntu 14.04 和 16.04 的主机上建立网桥呢?
|
||||
|
||||

|
||||
顾名思义,网桥的作用是通过物理接口连接内部和外部网络。对于虚拟端口或者 LXC/KVM/Xen/容器来说,这非常有用。网桥虚拟端口看起来是网络上的一个常规设备。在这个教程中,我将会介绍如何在 Ubuntu 服务器上通过 bridge-utils (brctl) 命令行来配置 Linux 网桥。
|
||||
|
||||
顾名思义,网桥的作用是通过物理接口连接内部和外部网络。对于虚拟端口或者 LXC/KVM/Xen/容器来说,这非常有用。通过网桥虚拟端口看起来是网络上的一个常规设备。在这个教程中,我将会介绍如何在 Ubuntu 服务器上通过 bridge-utils(brctl) 命令行来配置 Linux 网桥。
|
||||
|
||||
### 网桥网络示例
|
||||
### 网桥化的网络示例
|
||||
|
||||
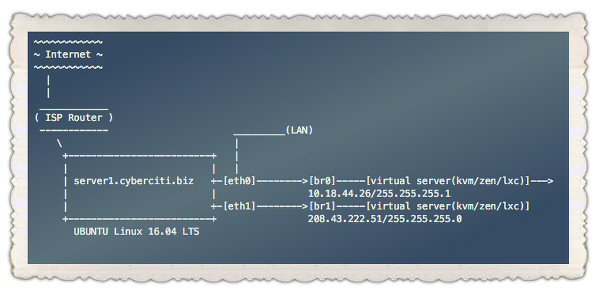
|
||||
>Fig.01: Kvm/Xen/LXC 容器网桥实例 (br0)
|
||||
|
||||
In this example eth0 and eth1 is the physical network interface. eth0 connected to the LAN and eth1 is attached to the upstream ISP router/Internet.
|
||||
在这个例子中,eth0 和 eth1 是物理网络接口。eth0 连接着局域网,eth1 连接着上游路由器/网络。
|
||||
*图 01: Kvm/Xen/LXC 容器网桥示例 (br0)*
|
||||
|
||||
在这个例子中,eth0 和 eth1 是物理网络接口。eth0 连接着局域网,eth1 连接着上游路由器和互联网。
|
||||
|
||||
### 安装 bridge-utils
|
||||
|
||||
使用[apt-get 命令][1] 安装 bridge-utils:
|
||||
使用 [apt-get 命令][1] 安装 bridge-utils:
|
||||
|
||||
```
|
||||
$ sudo apt-get install bridge-utils
|
||||
@ -32,7 +30,8 @@ $ sudo apt install bridge-utils
|
||||
样例输出:
|
||||
|
||||
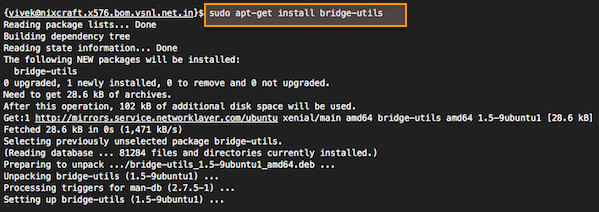
|
||||
>Fig.02: Ubuntu 安装 bridge-utils 包
|
||||
|
||||
*图 02: Ubuntu 安装 bridge-utils 包*
|
||||
|
||||
### 在 Ubuntu 服务器上创建网桥
|
||||
|
||||
@ -43,10 +42,10 @@ $ sudo cp /etc/network/interfaces /etc/network/interfaces.bakup-1-july-2016
|
||||
$ sudo vi /etc/network/interfaces
|
||||
```
|
||||
|
||||
接下来设置 eth1 并且将他绑定到 br1 ,输入(删除或者注释所有 eth1 相关配置):
|
||||
接下来设置 eth1 并且将它映射到 br1 ,输入如下(删除或者注释所有 eth1 相关配置):
|
||||
|
||||
```
|
||||
# br1 setup with static wan IPv4 with ISP router as gateway
|
||||
# br1 使用静态公网 IP 地址,并以 ISP 的路由器作为网关
|
||||
auto br1
|
||||
iface br1 inet static
|
||||
address 208.43.222.51
|
||||
@ -60,7 +59,7 @@ iface br1 inet static
|
||||
bridge_maxwait 0
|
||||
```
|
||||
|
||||
接下来设置 eth0 并将它绑定到 br0,输入(删除或者注释所有 eth1 相关配置):
|
||||
接下来设置 eth0 并将它映射到 br0,输入如下(删除或者注释所有 eth0 相关配置):
|
||||
|
||||
```
|
||||
auto br0
|
||||
@ -70,8 +69,8 @@ iface br0 inet static
|
||||
broadcast 10.18.44.63
|
||||
dns-nameservers 10.0.80.11 10.0.80.12
|
||||
# set static route for LAN
|
||||
post-up route add -net 10.0.0.0 netmask 255.0.0.0 gw 10.18.44.1
|
||||
post-up route add -net 161.26.0.0 netmask 255.255.0.0 gw 10.18.44.1
|
||||
post-up route add -net 10.0.0.0 netmask 255.0.0.0 gw 10.18.44.1
|
||||
post-up route add -net 161.26.0.0 netmask 255.255.0.0 gw 10.18.44.1
|
||||
bridge_ports eth0
|
||||
bridge_stp off
|
||||
bridge_fd 0
|
||||
@ -80,7 +79,7 @@ iface br0 inet static
|
||||
|
||||
### 关于 br0 和 DHCP 的一点说明
|
||||
|
||||
DHCP 的配置选项:
|
||||
如果使用 DHCP ,配置选项是这样的:
|
||||
|
||||
```
|
||||
auto br0
|
||||
@ -95,7 +94,7 @@ iface br0 inet dhcp
|
||||
|
||||
### 重启服务器或者网络服务
|
||||
|
||||
你需要重启服务器或者输入下列命令来重启网络服务(在 SSH 登陆的会话中这可能不管用):
|
||||
你需要重启服务器或者输入下列命令来重启网络服务(在 SSH 登录的会话中这可能不管用):
|
||||
|
||||
```
|
||||
$ sudo systemctl restart networking
|
||||
@ -111,20 +110,21 @@ $ sudo /etc/init.d/restart networking
|
||||
|
||||
使用 ping/ip 命令来验证 LAN 和 WAN 网络接口运行正常:
|
||||
```
|
||||
# See br0 and br1
|
||||
# 查看 br0 和 br1
|
||||
ip a show
|
||||
# See routing info
|
||||
# 查看路由信息
|
||||
ip r
|
||||
# ping public site
|
||||
# ping 外部站点
|
||||
ping -c 2 cyberciti.biz
|
||||
# ping lan server
|
||||
# ping 局域网服务器
|
||||
ping -c 2 10.0.80.12
|
||||
```
|
||||
|
||||
样例输出:
|
||||
|
||||
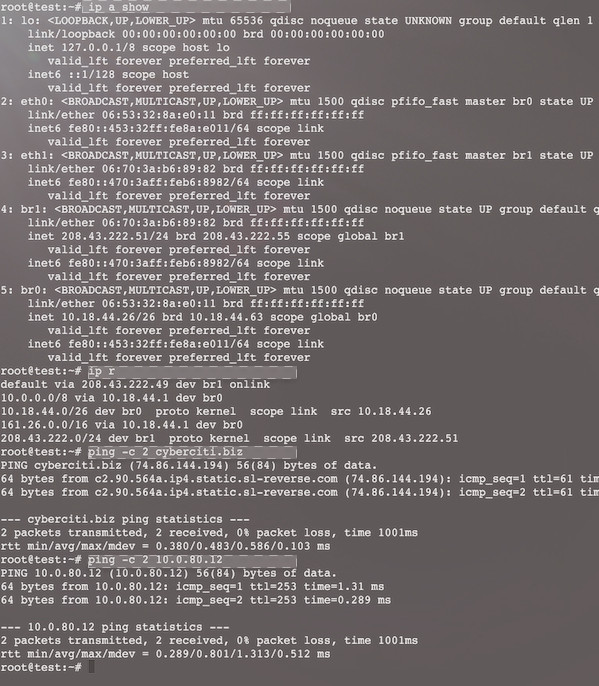
|
||||
>Fig.03: 验证网桥的以太网连接
|
||||
|
||||
*图 03: 验证网桥的以太网连接*
|
||||
|
||||
现在,你就可以配置 br0 和 br1 来让 XEN/KVM/LXC 容器访问因特网或者私有局域网了。再也没有必要去设置特定路由或者 iptables 的 SNAT 规则了。
|
||||
|
||||
@ -134,8 +134,8 @@ ping -c 2 10.0.80.12
|
||||
via: http://www.cyberciti.biz/faq/how-to-create-bridge-interface-ubuntu-linux/
|
||||
|
||||
作者:[VIVEK GITE][a]
|
||||
译者:[译者ID](https://github.com/MikeCoder)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
使用 Python 创建你自己的 Shell:Part I
|
||||
使用 Python 创建你自己的 Shell (一)
|
||||
==========================================
|
||||
|
||||
我很想知道一个 shell (像 bash,csh 等)内部是如何工作的。为了满足自己的好奇心,我使用 Python 实现了一个名为 **yosh** (Your Own Shell)的 Shell。本文章所介绍的概念也可以应用于其他编程语言。
|
||||
我很想知道一个 shell (像 bash,csh 等)内部是如何工作的。于是为了满足自己的好奇心,我使用 Python 实现了一个名为 **yosh** (Your Own Shell)的 Shell。本文章所介绍的概念也可以应用于其他编程语言。
|
||||
|
||||
(提示:你可以在[这里](https://github.com/supasate/yosh)查找本博文使用的源代码,代码以 MIT 许可证发布。在 Mac OS X 10.11.5 上,我使用 Python 2.7.10 和 3.4.3 进行了测试。它应该可以运行在其他类 Unix 环境,比如 Linux 和 Windows 上的 Cygwin。)
|
||||
|
||||
@ -20,15 +20,15 @@ yosh_project
|
||||
|
||||
`yosh_project` 为项目根目录(你也可以把它简单命名为 `yosh`)。
|
||||
|
||||
`yosh` 为包目录,且 `__init__.py` 可以使它成为与包目录名字相同的包(如果你不写 Python,可以忽略它。)
|
||||
`yosh` 为包目录,且 `__init__.py` 可以使它成为与包的目录名字相同的包(如果你不用 Python 编写的话,可以忽略它。)
|
||||
|
||||
`shell.py` 是我们主要的脚本文件。
|
||||
|
||||
### 步骤 1:Shell 循环
|
||||
|
||||
当启动一个 shell,它会显示一个命令提示符并等待你的命令输入。在接收了输入的命令并执行它之后(稍后文章会进行详细解释),你的 shell 会重新回到循环,等待下一条指令。
|
||||
当启动一个 shell,它会显示一个命令提示符并等待你的命令输入。在接收了输入的命令并执行它之后(稍后文章会进行详细解释),你的 shell 会重新回到这里,并循环等待下一条指令。
|
||||
|
||||
在 `shell.py`,我们会以一个简单的 mian 函数开始,该函数调用了 shell_loop() 函数,如下:
|
||||
在 `shell.py` 中,我们会以一个简单的 main 函数开始,该函数调用了 shell_loop() 函数,如下:
|
||||
|
||||
```
|
||||
def shell_loop():
|
||||
@ -43,7 +43,7 @@ if __name__ == "__main__":
|
||||
main()
|
||||
```
|
||||
|
||||
接着,在 `shell_loop()`,为了指示循环是否继续或停止,我们使用了一个状态标志。在循环的开始,我们的 shell 将显示一个命令提示符,并等待读取命令输入。
|
||||
接着,在 `shell_loop()` 中,为了指示循环是否继续或停止,我们使用了一个状态标志。在循环的开始,我们的 shell 将显示一个命令提示符,并等待读取命令输入。
|
||||
|
||||
```
|
||||
import sys
|
||||
@ -56,15 +56,15 @@ def shell_loop():
|
||||
status = SHELL_STATUS_RUN
|
||||
|
||||
while status == SHELL_STATUS_RUN:
|
||||
# Display a command prompt
|
||||
### 显示命令提示符
|
||||
sys.stdout.write('> ')
|
||||
sys.stdout.flush()
|
||||
|
||||
# Read command input
|
||||
### 读取命令输入
|
||||
cmd = sys.stdin.readline()
|
||||
```
|
||||
|
||||
之后,我们切分命令输入并进行执行(我们即将实现`命令切分`和`执行`函数)。
|
||||
之后,我们切分命令(tokenize)输入并进行执行(execute)(我们即将实现 `tokenize` 和 `execute` 函数)。
|
||||
|
||||
因此,我们的 shell_loop() 会是如下这样:
|
||||
|
||||
@ -79,33 +79,33 @@ def shell_loop():
|
||||
status = SHELL_STATUS_RUN
|
||||
|
||||
while status == SHELL_STATUS_RUN:
|
||||
# Display a command prompt
|
||||
### 显示命令提示符
|
||||
sys.stdout.write('> ')
|
||||
sys.stdout.flush()
|
||||
|
||||
# Read command input
|
||||
### 读取命令输入
|
||||
cmd = sys.stdin.readline()
|
||||
|
||||
# Tokenize the command input
|
||||
### 切分命令输入
|
||||
cmd_tokens = tokenize(cmd)
|
||||
|
||||
# Execute the command and retrieve new status
|
||||
### 执行该命令并获取新的状态
|
||||
status = execute(cmd_tokens)
|
||||
```
|
||||
|
||||
这就是我们整个 shell 循环。如果我们使用 `python shell.py` 启动我们的 shell,它会显示命令提示符。然而如果我们输入命令并按回车,它会抛出错误,因为我们还没定义`命令切分`函数。
|
||||
这就是我们整个 shell 循环。如果我们使用 `python shell.py` 启动我们的 shell,它会显示命令提示符。然而如果我们输入命令并按回车,它会抛出错误,因为我们还没定义 `tokenize` 函数。
|
||||
|
||||
为了退出 shell,可以尝试输入 ctrl-c。稍后我将解释如何以优雅的形式退出 shell。
|
||||
|
||||
### 步骤 2:命令切分
|
||||
### 步骤 2:命令切分(tokenize)
|
||||
|
||||
当用户在我们的 shell 中输入命令并按下回车键,该命令将会是一个包含命令名称及其参数的很长的字符串。因此,我们必须切分该字符串(分割一个字符串为多个标记)。
|
||||
当用户在我们的 shell 中输入命令并按下回车键,该命令将会是一个包含命令名称及其参数的长字符串。因此,我们必须切分该字符串(分割一个字符串为多个元组)。
|
||||
|
||||
咋一看似乎很简单。我们或许可以使用 `cmd.split()`,以空格分割输入。它对类似 `ls -a my_folder` 的命令起作用,因为它能够将命令分割为一个列表 `['ls', '-a', 'my_folder']`,这样我们便能轻易处理它们了。
|
||||
|
||||
然而,也有一些类似 `echo "Hello World"` 或 `echo 'Hello World'` 以单引号或双引号引用参数的情况。如果我们使用 cmd.spilt,我们将会得到一个存有 3 个标记的列表 `['echo', '"Hello', 'World"']` 而不是 2 个标记的列表 `['echo', 'Hello World']`。
|
||||
|
||||
幸运的是,Python 提供了一个名为 `shlex` 的库,它能够帮助我们效验如神地分割命令。(提示:我们也可以使用正则表达式,但它不是本文的重点。)
|
||||
幸运的是,Python 提供了一个名为 `shlex` 的库,它能够帮助我们如魔法般地分割命令。(提示:我们也可以使用正则表达式,但它不是本文的重点。)
|
||||
|
||||
|
||||
```
|
||||
@ -120,23 +120,23 @@ def tokenize(string):
|
||||
...
|
||||
```
|
||||
|
||||
然后我们将这些标记发送到执行进程。
|
||||
然后我们将这些元组发送到执行进程。
|
||||
|
||||
### 步骤 3:执行
|
||||
|
||||
这是 shell 中核心和有趣的一部分。当 shell 执行 `mkdir test_dir` 时,到底发生了什么?(提示: `mkdir` 是一个带有 `test_dir` 参数的执行程序,用于创建一个名为 `test_dir` 的目录。)
|
||||
这是 shell 中核心而有趣的一部分。当 shell 执行 `mkdir test_dir` 时,到底发生了什么?(提示: `mkdir` 是一个带有 `test_dir` 参数的执行程序,用于创建一个名为 `test_dir` 的目录。)
|
||||
|
||||
`execvp` 是涉及这一步的首个函数。在我们解释 `execvp` 所做的事之前,让我们看看它的实际效果。
|
||||
`execvp` 是这一步的首先需要的函数。在我们解释 `execvp` 所做的事之前,让我们看看它的实际效果。
|
||||
|
||||
```
|
||||
import os
|
||||
...
|
||||
|
||||
def execute(cmd_tokens):
|
||||
# Execute command
|
||||
### 执行命令
|
||||
os.execvp(cmd_tokens[0], cmd_tokens)
|
||||
|
||||
# Return status indicating to wait for next command in shell_loop
|
||||
### 返回状态以告知在 shell_loop 中等待下一个命令
|
||||
return SHELL_STATUS_RUN
|
||||
|
||||
...
|
||||
@ -144,11 +144,11 @@ def execute(cmd_tokens):
|
||||
|
||||
再次尝试运行我们的 shell,并输入 `mkdir test_dir` 命令,接着按下回车键。
|
||||
|
||||
在我们敲下回车键之后,问题是我们的 shell 会直接退出而不是等待下一个命令。然而,目标正确地被创建。
|
||||
在我们敲下回车键之后,问题是我们的 shell 会直接退出而不是等待下一个命令。然而,目录正确地创建了。
|
||||
|
||||
因此,`execvp` 实际上做了什么?
|
||||
|
||||
`execvp` 是系统调用 `exec` 的一个变体。第一个参数是程序名字。`v` 表示第二个参数是一个程序参数列表(可变参数)。`p` 表示环境变量 `PATH` 会被用于搜索给定的程序名字。在我们上一次的尝试中,它将会基于我们的 `PATH` 环境变量查找`mkdir` 程序。
|
||||
`execvp` 是系统调用 `exec` 的一个变体。第一个参数是程序名字。`v` 表示第二个参数是一个程序参数列表(参数数量可变)。`p` 表示将会使用环境变量 `PATH` 搜索给定的程序名字。在我们上一次的尝试中,它将会基于我们的 `PATH` 环境变量查找`mkdir` 程序。
|
||||
|
||||
(还有其他 `exec` 变体,比如 execv、execvpe、execl、execlp、execlpe;你可以 google 它们获取更多的信息。)
|
||||
|
||||
@ -158,7 +158,7 @@ def execute(cmd_tokens):
|
||||
|
||||
因此,我们需要其他的系统调用来解决问题:`fork`。
|
||||
|
||||
`fork` 会开辟新的内存并拷贝当前进程到一个新的进程。我们称这个新的进程为**子进程**,调用者进程为**父进程**。然后,子进程内存会被替换为被执行的程序。因此,我们的 shell,也就是父进程,可以免受内存替换的危险。
|
||||
`fork` 会分配新的内存并拷贝当前进程到一个新的进程。我们称这个新的进程为**子进程**,调用者进程为**父进程**。然后,子进程内存会被替换为被执行的程序。因此,我们的 shell,也就是父进程,可以免受内存替换的危险。
|
||||
|
||||
让我们看看修改的代码。
|
||||
|
||||
@ -166,34 +166,34 @@ def execute(cmd_tokens):
|
||||
...
|
||||
|
||||
def execute(cmd_tokens):
|
||||
# Fork a child shell process
|
||||
# If the current process is a child process, its `pid` is set to `0`
|
||||
# else the current process is a parent process and the value of `pid`
|
||||
# is the process id of its child process.
|
||||
### 分叉一个子 shell 进程
|
||||
### 如果当前进程是子进程,其 `pid` 被设置为 `0`
|
||||
### 否则当前进程是父进程的话,`pid` 的值
|
||||
### 是其子进程的进程 ID。
|
||||
pid = os.fork()
|
||||
|
||||
if pid == 0:
|
||||
# Child process
|
||||
# Replace the child shell process with the program called with exec
|
||||
### 子进程
|
||||
### 用被 exec 调用的程序替换该子进程
|
||||
os.execvp(cmd_tokens[0], cmd_tokens)
|
||||
elif pid > 0:
|
||||
# Parent process
|
||||
### 父进程
|
||||
while True:
|
||||
# Wait response status from its child process (identified with pid)
|
||||
### 等待其子进程的响应状态(以进程 ID 来查找)
|
||||
wpid, status = os.waitpid(pid, 0)
|
||||
|
||||
# Finish waiting if its child process exits normally
|
||||
# or is terminated by a signal
|
||||
### 当其子进程正常退出时
|
||||
### 或者其被信号中断时,结束等待状态
|
||||
if os.WIFEXITED(status) or os.WIFSIGNALED(status):
|
||||
break
|
||||
|
||||
# Return status indicating to wait for next command in shell_loop
|
||||
### 返回状态以告知在 shell_loop 中等待下一个命令
|
||||
return SHELL_STATUS_RUN
|
||||
|
||||
...
|
||||
```
|
||||
|
||||
当我们的父进程调用 `os.fork()`时,你可以想象所有的源代码被拷贝到了新的子进程。此时此刻,父进程和子进程看到的是相同的代码,且并行运行着。
|
||||
当我们的父进程调用 `os.fork()` 时,你可以想象所有的源代码被拷贝到了新的子进程。此时此刻,父进程和子进程看到的是相同的代码,且并行运行着。
|
||||
|
||||
如果运行的代码属于子进程,`pid` 将为 `0`。否则,如果运行的代码属于父进程,`pid` 将会是子进程的进程 id。
|
||||
|
||||
@ -205,13 +205,13 @@ def execute(cmd_tokens):
|
||||
|
||||
现在,你可以尝试运行我们的 shell 并输入 `mkdir test_dir2`。它应该可以正确执行。我们的主 shell 进程仍然存在并等待下一条命令。尝试执行 `ls`,你可以看到已创建的目录。
|
||||
|
||||
但是,这里仍有许多问题。
|
||||
但是,这里仍有一些问题。
|
||||
|
||||
第一,尝试执行 `cd test_dir2`,接着执行 `ls`。它应该会进入到一个空的 `test_dir2` 目录。然而,你将会看到目录并没有变为 `test_dir2`。
|
||||
|
||||
第二,我们仍然没有办法优雅地退出我们的 shell。
|
||||
|
||||
我们将会在 [Part 2][1] 解决诸如此类的问题。
|
||||
我们将会在 [第二部分][1] 解决诸如此类的问题。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -219,8 +219,8 @@ def execute(cmd_tokens):
|
||||
via: https://hackercollider.com/articles/2016/07/05/create-your-own-shell-in-python-part-1/
|
||||
|
||||
作者:[Supasate Choochaisri][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,17 +1,17 @@
|
||||
使用 Python 创建你自己的 Shell:Part II
|
||||
使用 Python 创建你自己的 Shell(下)
|
||||
===========================================
|
||||
|
||||
在[part 1][1] 中,我们已经创建了一个主要的 shell 循环、切分了的命令输入,以及通过 `fork` 和 `exec` 执行命令。在这部分,我们将会解决剩下的问题。首先,`cd test_dir2` 命令无法修改我们的当前目录。其次,我们仍无法优雅地从 shell 中退出。
|
||||
在[上篇][1]中,我们已经创建了一个 shell 主循环、切分了命令输入,以及通过 `fork` 和 `exec` 执行命令。在这部分,我们将会解决剩下的问题。首先,`cd test_dir2` 命令无法修改我们的当前目录。其次,我们仍无法优雅地从 shell 中退出。
|
||||
|
||||
### 步骤 4:内置命令
|
||||
|
||||
“cd test_dir2 无法修改我们的当前目录” 这句话是对的,但在某种意义上也是错的。在执行完该命令之后,我们仍然处在同一目录,从这个意义上讲,它是对的。然而,目录实际上已经被修改,只不过它是在子进程中被修改。
|
||||
“`cd test_dir2` 无法修改我们的当前目录” 这句话是对的,但在某种意义上也是错的。在执行完该命令之后,我们仍然处在同一目录,从这个意义上讲,它是对的。然而,目录实际上已经被修改,只不过它是在子进程中被修改。
|
||||
|
||||
还记得我们 fork 了一个子进程,然后执行命令,执行命令的过程没有发生在父进程上。结果是我们只是改变了子进程的当前目录,而不是父进程的目录。
|
||||
还记得我们分叉(fork)了一个子进程,然后执行命令,执行命令的过程没有发生在父进程上。结果是我们只是改变了子进程的当前目录,而不是父进程的目录。
|
||||
|
||||
然后子进程退出,而父进程在原封不动的目录下继续运行。
|
||||
|
||||
因此,这类与 shell 自己相关的命令必须是内置命令。它必须在 shell 进程中执行而没有分叉(forking)。
|
||||
因此,这类与 shell 自己相关的命令必须是内置命令。它必须在 shell 进程中执行而不是在分叉中(forking)。
|
||||
|
||||
#### cd
|
||||
|
||||
@ -35,7 +35,6 @@ yosh_project
|
||||
import os
|
||||
from yosh.constants import *
|
||||
|
||||
|
||||
def cd(args):
|
||||
os.chdir(args[0])
|
||||
|
||||
@ -66,23 +65,21 @@ SHELL_STATUS_RUN = 1
|
||||
|
||||
```python
|
||||
...
|
||||
# Import constants
|
||||
### 导入常量
|
||||
from yosh.constants import *
|
||||
|
||||
# Hash map to store built-in function name and reference as key and value
|
||||
### 使用哈希映射来存储内建的函数名及其引用
|
||||
built_in_cmds = {}
|
||||
|
||||
|
||||
def tokenize(string):
|
||||
return shlex.split(string)
|
||||
|
||||
|
||||
def execute(cmd_tokens):
|
||||
# Extract command name and arguments from tokens
|
||||
### 从元组中分拆命令名称与参数
|
||||
cmd_name = cmd_tokens[0]
|
||||
cmd_args = cmd_tokens[1:]
|
||||
|
||||
# If the command is a built-in command, invoke its function with arguments
|
||||
### 如果该命令是一个内建命令,使用参数调用该函数
|
||||
if cmd_name in built_in_cmds:
|
||||
return built_in_cmds[cmd_name](cmd_args)
|
||||
|
||||
@ -91,29 +88,29 @@ def execute(cmd_tokens):
|
||||
|
||||
我们使用一个 python 字典变量 `built_in_cmds` 作为哈希映射(hash map),以存储我们的内置函数。我们在 `execute` 函数中提取命令的名字和参数。如果该命令在我们的哈希映射中,则调用对应的内置函数。
|
||||
|
||||
(提示:`built_in_cmds[cmd_name]` 返回能直接使用参数调用的函数引用的。)
|
||||
(提示:`built_in_cmds[cmd_name]` 返回能直接使用参数调用的函数引用。)
|
||||
|
||||
我们差不多准备好使用内置的 `cd` 函数了。最后一步是将 `cd` 函数添加到 `built_in_cmds` 映射中。
|
||||
|
||||
```
|
||||
...
|
||||
# Import all built-in function references
|
||||
### 导入所有内建函数引用
|
||||
from yosh.builtins import *
|
||||
|
||||
...
|
||||
|
||||
# Register a built-in function to built-in command hash map
|
||||
### 注册内建函数到内建命令的哈希映射中
|
||||
def register_command(name, func):
|
||||
built_in_cmds[name] = func
|
||||
|
||||
|
||||
# Register all built-in commands here
|
||||
### 在此注册所有的内建命令
|
||||
def init():
|
||||
register_command("cd", cd)
|
||||
|
||||
|
||||
def main():
|
||||
# Init shell before starting the main loop
|
||||
###在开始主循环之前初始化 shell
|
||||
init()
|
||||
shell_loop()
|
||||
```
|
||||
@ -138,7 +135,7 @@ from yosh.builtins.cd import *
|
||||
|
||||
我们需要一个可以修改 shell 状态为 `SHELL_STATUS_STOP` 的函数。这样,shell 循环可以自然地结束,shell 将到达终点而退出。
|
||||
|
||||
和 `cd` 一样,如果我们在子进程中 fork 和执行 `exit` 函数,其对父进程是不起作用的。因此,`exit` 函数需要成为一个 shell 内置函数。
|
||||
和 `cd` 一样,如果我们在子进程中分叉并执行 `exit` 函数,其对父进程是不起作用的。因此,`exit` 函数需要成为一个 shell 内置函数。
|
||||
|
||||
让我们从这开始:在 `builtins` 目录下创建一个名为 `exit.py` 的新文件。
|
||||
|
||||
@ -159,7 +156,6 @@ yosh_project
|
||||
```
|
||||
from yosh.constants import *
|
||||
|
||||
|
||||
def exit(args):
|
||||
return SHELL_STATUS_STOP
|
||||
```
|
||||
@ -173,11 +169,10 @@ from yosh.builtins.exit import *
|
||||
|
||||
最后,我们在 `shell.py` 中的 `init()` 函数注册 `exit` 命令。
|
||||
|
||||
|
||||
```
|
||||
...
|
||||
|
||||
# Register all built-in commands here
|
||||
### 在此注册所有的内建命令
|
||||
def init():
|
||||
register_command("cd", cd)
|
||||
register_command("exit", exit)
|
||||
@ -193,7 +188,7 @@ def init():
|
||||
|
||||
我希望你能像我一样享受创建 `yosh` (**y**our **o**wn **sh**ell)的过程。但我的 `yosh` 版本仍处于早期阶段。我没有处理一些会使 shell 崩溃的极端状况。还有很多我没有覆盖的内置命令。为了提高性能,一些非内置命令也可以实现为内置命令(避免新进程创建时间)。同时,大量的功能还没有实现(请看 [公共特性](http://tldp.org/LDP/Bash-Beginners-Guide/html/x7243.html) 和 [不同特性](http://www.tldp.org/LDP/intro-linux/html/x12249.html))
|
||||
|
||||
我已经在 github.com/supasate/yosh 中提供了源代码。请随意 fork 和尝试。
|
||||
我已经在 https://github.com/supasate/yosh 中提供了源代码。请随意 fork 和尝试。
|
||||
|
||||
现在该是创建你真正自己拥有的 Shell 的时候了。
|
||||
|
||||
@ -205,12 +200,12 @@ via: https://hackercollider.com/articles/2016/07/06/create-your-own-shell-in-pyt
|
||||
|
||||
作者:[Supasate Choochaisri][a]
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://disqus.com/by/supasate_choochaisri/
|
||||
[1]: https://hackercollider.com/articles/2016/07/05/create-your-own-shell-in-python-part-1/
|
||||
[1]: https://linux.cn/article-7624-1.html
|
||||
[2]: http://tldp.org/LDP/Bash-Beginners-Guide/html/x7243.html
|
||||
[3]: http://www.tldp.org/LDP/intro-linux/html/x12249.html
|
||||
[4]: https://github.com/supasate/yosh
|
||||
80
published/201607/20160718 OPEN SOURCE ACCOUNTING SOFTWARE.md
Normal file
80
published/201607/20160718 OPEN SOURCE ACCOUNTING SOFTWARE.md
Normal file
@ -0,0 +1,80 @@
|
||||
GNU KHATA:开源的会计管理软件
|
||||
============================================
|
||||
|
||||
作为一个活跃的 Linux 爱好者,我经常向我的朋友们介绍 Linux,帮助他们选择最适合他们的发行版本,同时也会帮助他们安装一些适用于他们工作的开源软件。
|
||||
|
||||
但是在这一次,我就变得很无奈。我的叔叔,他是一个自由职业的会计师。他会有一系列的为了会计工作的漂亮而成熟的付费软件。我不那么确定我能在在开源软件中找到这么一款可以替代的软件——直到昨天。
|
||||
|
||||
Abhishek 给我推荐了一些[很酷的软件][1],而其中 GNU Khata 脱颖而出。
|
||||
|
||||
[GNU Khata][2] 是一个会计工具。 或者,我应该说成是一系列的会计工具集合?它就像经济管理方面的 [Evernote][3] 一样。它的应用是如此之广,以至于它不但可以用于个人的财务管理,也可以用于大型公司的管理,从店铺存货管理到税率计算,都可以有效处理。
|
||||
|
||||
有个有趣的地方,Khata 这个词在印度或者是其他的印度语国家中意味着账户,所以这个会计软件叫做 GNU Khata。
|
||||
|
||||
### 安装
|
||||
|
||||
互联网上有很多关于旧的 Web 版本的 Khata 安装介绍。现在,GNU Khata 只能用在 Debian/Ubuntu 和它们的衍生版本中。我建议你按照 GNU Khata 官网给出的如下步骤来安装。我们来快速过一下。
|
||||
|
||||
- 从[这里][4]下载安装器。
|
||||
- 在下载目录打开终端。
|
||||
- 粘贴复制以下的代码到终端,并且执行。
|
||||
|
||||
```
|
||||
sudo chmod 755 GNUKhatasetup.run
|
||||
sudo ./GNUKhatasetup.run
|
||||
```
|
||||
|
||||
这就结束了,从你的 Dash 或者是应用菜单中启动 GNU Khata 吧。
|
||||
|
||||
### 第一次启动
|
||||
|
||||
GNU Khata 在浏览器中打开,并且展现以下的画面。
|
||||
|
||||

|
||||
|
||||
填写组织的名字、组织形式,财务年度并且点击 proceed 按钮进入管理设置页面。
|
||||
|
||||

|
||||
|
||||
仔细填写你的用户名、密码、安全问题及其答案,并且点击“create and login”。
|
||||
|
||||

|
||||
|
||||
你已经全部设置完成了。使用菜单栏来开始使用 GNU Khata 来管理你的财务吧。这很容易。
|
||||
|
||||
### 移除 GNU KHATA
|
||||
|
||||
如果你不想使用 GNU Khata 了,你可以执行如下命令移除:
|
||||
|
||||
```
|
||||
sudo apt-get remove --auto-remove gnukhata-core-engine
|
||||
```
|
||||
|
||||
你也可以通过新立得软件管理来删除它。
|
||||
|
||||
### GNU KHATA 真的是市面上付费会计应用的竞争对手吗?
|
||||
|
||||
首先,GNU Khata 以简化为设计原则。顶部的菜单栏组织的很方便,可以帮助你有效的进行工作。你可以选择管理不同的账户和项目,并且切换非常容易。[它们的官网][5]表明,GNU Khata 可以“像说印度语一样方便”(LCTT 译注:原谅我,这个软件作者和本文作者是印度人……)。同时,你知道 GNU Khata 也可以在云端使用吗?
|
||||
|
||||
所有的主流的账户管理工具,比如分类账簿、项目报表、财务报表等等都用专业的方式整理,并且支持自定义格式和即时展示。这让会计和仓储管理看起来如此的简单。
|
||||
|
||||
这个项目正在积极的发展,正在寻求实操中的反馈以帮助这个软件更加进步。考虑到软件的成熟性、使用的便利性还有免费的情况,GNU Khata 可能会成为你最好的账簿助手。
|
||||
|
||||
请在评论框里留言吧,让我们知道你是如何看待 GNU Khata 的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/using-gnu-khata/
|
||||
|
||||
作者:[Aquil Roshan][a]
|
||||
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/aquil/
|
||||
[1]: https://itsfoss.com/category/apps/
|
||||
[2]: http://www.gnukhata.in/
|
||||
[3]: https://evernote.com/
|
||||
[4]: https://cloud.openmailbox.org/index.php/s/L8ppsxtsFq1345E/download
|
||||
[5]: http://www.gnukhata.in/
|
||||
@ -0,0 +1,36 @@
|
||||
在浏览器中体验 Ubuntu
|
||||
=====================================================
|
||||
|
||||
[Ubuntu][2] 的背后的公司 [Canonical][1] 为 Linux 推广做了很多努力。无论你有多么不喜欢 Ubuntu,你必须承认它对 “Linux 易用性”的影响。Ubuntu 以及其衍生是使用最多的 Linux 版本。
|
||||
|
||||
为了进一步推广 Ubuntu Linux,Canonical 把它放到了浏览器里,你可以在任何地方使用这个 [Ubuntu 演示版][0]。 它将帮你更好的体验 Ubuntu,以便让新人更容易决定是否使用它。
|
||||
|
||||
你可能争辩说 USB 版的 Linux 更好。我同意,但是你要知道你要下载 ISO,创建 USB 启动盘,修改配置文件,然后才能使用这个 USB 启动盘来体验。这么乏味并不是每个人都乐意这么干的。 在线体验是一个更好的选择。
|
||||
|
||||
那么,你能在 Ubuntu 在线看到什么。实际上并不多。
|
||||
|
||||
你可以浏览文件,你可以使用 Unity Dash,浏览 Ubuntu 软件中心,甚至装几个应用(当然它们不会真的安装),看一看文件浏览器和其它一些东西。以上就是全部了。但是在我看来,这已经做的很好了,让你知道它是个什么,对这个流行的操作系统有个直接感受。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
如果你的朋友或者家人对试试 Linux 抱有兴趣,但是想在安装前想体验一下 Linux 。你可以给他们以下链接:[Ubuntu 在线导览][0] 。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-online-demo/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[kokialoves](https://github.com/kokialoves)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[0]: http://tour.ubuntu.com/en/
|
||||
[1]: http://www.canonical.com/
|
||||
[2]: http://www.ubuntu.com/
|
||||
200
published/201607/20160722 7 Best Markdown Editors for Linux.md
Normal file
200
published/201607/20160722 7 Best Markdown Editors for Linux.md
Normal file
@ -0,0 +1,200 @@
|
||||
Linux 上 10 个最好的 Markdown 编辑器
|
||||
======================================
|
||||
|
||||
在这篇文章中,我们会点评一些可以在 Linux 上安装使用的最好的 Markdown 编辑器。 你可以找到非常多的 Linux 平台上的 Markdown 编辑器,但是在这里我们将尽可能地为您推荐那些最好的。
|
||||
|
||||
|
||||
|
||||
*Best Linux Markdown Editors*
|
||||
|
||||
对于不了解 Markdown 的人做个简单介绍,Markdown 是由著名的 Aaron Swartz 和 John Gruber 发明的标记语言,其最初的解析器是一个用 Perl 写的简单、轻量的[同名工具][1]。它可以将用户写的纯文本转为可用的 HTML(或 XHTML)。它实际上是一门易读,易写的纯文本语言,以及一个用于将文本转为 HTML 的转换工具。
|
||||
|
||||
希望你先对 Markdown 有一个稍微的了解,接下来让我们逐一列出这些编辑器。
|
||||
|
||||
### 1. Atom
|
||||
|
||||
Atom 是一个现代的、跨平台、开源且强大的文本编辑器,它可以运行在 Linux、Windows 和 MAC OS X 等操作系统上。用户可以在它的基础上进行定制,删减修改任何配置文件。
|
||||
|
||||
它包含了一些非常杰出的特性:
|
||||
|
||||
- 内置软件包管理器
|
||||
- 智能自动补全功能
|
||||
- 提供多窗口操作
|
||||
- 支持查找替换功能
|
||||
- 包含一个文件系统浏览器
|
||||
- 轻松自定义主题
|
||||
- 开源、高度扩展性的软件包等
|
||||
|
||||
|
||||
|
||||
*Atom Markdown Editor for Linux*
|
||||
|
||||
访问主页: <https://atom.io/>
|
||||
|
||||
### 2. GNU Emacs
|
||||
|
||||
Emacs 是 Linux 平台上一款的流行文本编辑器。它是一个非常棒的、具备高扩展性和定制性的 Markdown 语言编辑器。
|
||||
|
||||
它综合了以下这些神奇的特性:
|
||||
|
||||
- 带有丰富的内置文档,包括适合初学者的教程
|
||||
- 有完整的 Unicode 支持,可显示所有的人类符号
|
||||
- 支持内容识别的文本编辑模式
|
||||
- 包括多种文件类型的语法高亮
|
||||
- 可用 Emacs Lisp 或 GUI 对其进行高度定制
|
||||
- 提供了一个包系统可用来下载安装各种扩展等
|
||||
|
||||

|
||||
|
||||
*Emacs Markdown Editor for Linux*
|
||||
|
||||
访问主页: <https://www.gnu.org/software/emacs/>
|
||||
|
||||
### 3. Remarkable
|
||||
|
||||
Remarkable 可能是 Linux 上最好的 Markdown 编辑器了,它也适用于 Windows 操作系统。它的确是是一个卓越且功能齐全的 Markdown 编辑器,为用户提供了一些令人激动的特性。
|
||||
|
||||
一些卓越的特性:
|
||||
|
||||
- 支持实时预览
|
||||
- 支持导出 PDF 和 HTML
|
||||
- 支持 Github Markdown 语法
|
||||
- 支持定制 CSS
|
||||
- 支持语法高亮
|
||||
- 提供键盘快捷键
|
||||
- 高可定制性和其他
|
||||
|
||||
|
||||
|
||||
*Remarkable Markdown Editor for Linux*
|
||||
|
||||
访问主页: <https://remarkableapp.github.io>
|
||||
|
||||
### 4. Haroopad
|
||||
|
||||
Haroopad 是为 Linux,Windows 和 Mac OS X 构建的跨平台 Markdown 文档处理程序。用户可以用它来书写许多专家级格式的文档,包括电子邮件、报告、博客、演示文稿和博客文章等等。
|
||||
|
||||
功能齐全且具备以下的亮点:
|
||||
|
||||
- 轻松导入内容
|
||||
- 支持导出多种格式
|
||||
- 广泛支持博客和邮件
|
||||
- 支持许多数学表达式
|
||||
- 支持 Github Markdown 扩展
|
||||
- 为用户提供了一些令人兴奋的主题、皮肤和 UI 组件等等
|
||||
|
||||

|
||||
|
||||
*Haroopad Markdown Editor for Linux*
|
||||
|
||||
访问主页: <http://pad.haroopress.com/>
|
||||
|
||||
### 5. ReText
|
||||
|
||||
ReText 是为 Linux 和其它几个 POSIX 兼容操作系统提供的简单、轻量、强大的 Markdown 编辑器。它还可以作为一个 reStructuredText 编辑器,并且具有以下的特性:
|
||||
|
||||
- 简单直观的 GUI
|
||||
- 具备高定制性,用户可以自定义语法文件和配置选项
|
||||
- 支持多种配色方案
|
||||
- 支持使用多种数学公式
|
||||
- 启用导出扩展等等
|
||||
|
||||
|
||||
|
||||
*ReText Markdown Editor for Linux*
|
||||
|
||||
访问主页: <https://github.com/retext-project/retext>
|
||||
|
||||
### 6. UberWriter
|
||||
|
||||
UberWriter 是一个简单、易用的 Linux Markdown 编辑器。它的开发受 Mac OS X 上的 iA writer 影响很大,同样它也具备这些卓越的特性:
|
||||
|
||||
- 使用 pandoc 进行所有的文本到 HTML 的转换
|
||||
- 提供了一个简洁的 UI 界面
|
||||
- 提供了一种专心(distraction free)模式,高亮用户最后的句子
|
||||
- 支持拼写检查
|
||||
- 支持全屏模式
|
||||
- 支持用 pandoc 导出 PDF、HTML 和 RTF
|
||||
- 启用语法高亮和数学函数等等
|
||||
|
||||
|
||||
|
||||
*UberWriter Markdown Editor for Linux*
|
||||
|
||||
访问主页: <http://uberwriter.wolfvollprecht.de/>
|
||||
|
||||
### 7. Mark My Words
|
||||
|
||||
Mark My Words 同样也是一个轻量、强大的 Markdown 编辑器。它是一个相对比较新的编辑器,因此提供了包含语法高亮在内的大量的功能,简单和直观的 UI。
|
||||
|
||||
下面是一些棒极了,但还未捆绑到应用中的功能:
|
||||
|
||||
- 实时预览
|
||||
- Markdown 解析和文件 IO
|
||||
- 状态管理
|
||||
- 支持导出 PDF 和 HTML
|
||||
- 监测文件的修改
|
||||
- 支持首选项设置
|
||||
|
||||
|
||||
|
||||
*MarkMyWords Markdown Editor for-Linux*
|
||||
|
||||
访问主页: <https://github.com/voldyman/MarkMyWords>
|
||||
|
||||
### 8. Vim-Instant-Markdown 插件
|
||||
|
||||
Vim 是 Linux 上的一个久经考验的强大、流行而开源的文本编辑器。它用于编程极棒。它也高度支持插件功能,可以让用户为其增加一些其它功能,包括 Markdown 预览。
|
||||
|
||||
有好几种 Vim 的 Markdown 预览插件,但是 [Vim-Instant-Markdown][2] 的表现最佳。
|
||||
|
||||
###9. Bracket-MarkdownPreview 插件
|
||||
|
||||
Brackets 是一个现代、轻量、开源且跨平台的文本编辑器。它特别为 Web 设计和开发而构建。它的一些重要功能包括:支持内联编辑器、实时预览、预处理支持及更多。
|
||||
|
||||
它也是通过插件高度可扩展的,你可以使用 [Bracket-MarkdownPreview][3] 插件来编写和预览 Markdown 文档。
|
||||
|
||||

|
||||
|
||||
*Brackets Markdown Plugin Preview*
|
||||
|
||||
### 10. SublimeText-Markdown 插件
|
||||
|
||||
Sublime Text 是一个精心打造的、流行的、跨平台文本编辑器,用于代码、markdown 和普通文本。它的表现极佳,包括如下令人兴奋的功能:
|
||||
|
||||
- 简洁而美观的 GUI
|
||||
- 支持多重选择
|
||||
- 提供专心模式
|
||||
- 支持窗体分割编辑
|
||||
- 通过 Python 插件 API 支持高度插件化
|
||||
- 完全可定制化,提供命令查找模式
|
||||
|
||||
[SublimeText-Markdown][4] 插件是一个支持格式高亮的软件包,带有一些漂亮的颜色方案。
|
||||
|
||||
|
||||
|
||||
*SublimeText Markdown Plugin Preview*
|
||||
|
||||
### 结论
|
||||
|
||||
通过上面的列表,你大概已经知道要为你的 Linux 桌面下载、安装什么样的 Markdown 编辑器和文档处理程序了。
|
||||
|
||||
请注意,这里提到的最好的 Markdown 编辑器可能对你来说并不是最好的选择。因此你可以通过下面的反馈部分,为我们展示你认为列表中未提及的,并且具备足够的资格的,令人兴奋的 Markdown 编辑器。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/best-markdown-editors-for-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[Locez](https://github.com/locez)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
[1]: https://daringfireball.net/projects/markdown/
|
||||
[2]: https://github.com/suan/vim-instant-markdown
|
||||
[3]: https://github.com/gruehle/MarkdownPreview
|
||||
[4]: https://github.com/SublimeText-Markdown/MarkdownEditing
|
||||
|
||||
@ -0,0 +1,69 @@
|
||||
怎样在 Ubuntu 中修改默认程序
|
||||
==============================================
|
||||
|
||||

|
||||
|
||||
> 简介: 这个新手指南会向你展示如何在 Ubuntu Linux 中修改默认程序
|
||||
|
||||
对于我来说,安装 [VLC 多媒体播放器][1]是[安装完 Ubuntu 16.04 该做的事][2]中最先做的几件事之一。为了能够使我双击一个视频就用 VLC 打开,在我安装完 VLC 之后我会设置它为默认程序。
|
||||
|
||||
作为一个新手,你需要知道如何在 Ubuntu 中修改任何默认程序,这也是我今天在这篇指南中所要讲的。
|
||||
|
||||
### 在 UBUNTU 中修改默认程序
|
||||
|
||||
这里提及的方法适用于所有的 Ubuntu 12.04,Ubuntu 14.04 和Ubuntu 16.04。在 Ubuntu 中,这里有两种基本的方法可以修改默认程序:
|
||||
|
||||
- 通过系统设置
|
||||
- 通过右键菜单
|
||||
|
||||
#### 1.通过系统设置修改 Ubuntu 的默认程序
|
||||
|
||||
进入 Unity 面板并且搜索系统设置(System Settings):
|
||||
|
||||

|
||||
|
||||
在系统设置(System Settings)中,选择详细选项(Details):
|
||||
|
||||

|
||||
|
||||
在左边的面板中选择默认程序(Default Applications),你会发现在右边的面板中可以修改默认程序。
|
||||
|
||||

|
||||
|
||||
正如看到的那样,这里只有少数几类的默认程序可以被改变。你可以在这里改变浏览器、邮箱客户端、日历、音乐、视频和相册的默认程序。那其他类型的默认程序怎么修改?
|
||||
|
||||
不要担心,为了修改其他类型的默认程序,我们会用到右键菜单。
|
||||
|
||||
#### 2.通过右键菜单修改默认程序
|
||||
|
||||
如果你使用过 Windows 系统,你应该看见过右键菜单的“打开方式”,可以通过这个来修改默认程序。我们在 Ubuntu 中也有相似的方法。
|
||||
|
||||
右键一个还没有设置默认打开程序的文件,选择“属性(properties)”
|
||||
|
||||

|
||||
|
||||
*从右键菜单中选择属性*
|
||||
|
||||
在这里,你可以选择使用什么程序打开,并且设置为默认程序。
|
||||
|
||||

|
||||
|
||||
*在 Ubuntu 中设置打开 WebP 图片的默认程序为 gThumb*
|
||||
|
||||
小菜一碟不是么?一旦你做完这些,所有同样类型的文件都会用你选择的默认程序打开。
|
||||
|
||||
我很希望这个新手指南对你在修改 Ubuntu 的默认程序时有帮助。如果你有任何的疑问或者建议,可以随时在下面评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/change-default-applications-ubuntu/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[Locez](https://github.com/locez)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: http://www.videolan.org/vlc/index.html
|
||||
[2]: https://linux.cn/article-7453-1.html
|
||||
@ -0,0 +1,136 @@
|
||||
Terminix:一个很赞的基于 GTK3 的平铺式 Linux 终端模拟器
|
||||
============================================================
|
||||
|
||||
现在,你可以很容易的找到[大量的 Linux 终端模拟器][1],每一个都可以给用户留下深刻的印象。
|
||||
|
||||
但是,很多时候,我们会很难根据我们的喜好来找到一款心仪的日常使用的终端模拟器。这篇文章中,我们将会推荐一款叫做 Terminix 的令人激动的终端模拟机。
|
||||
|
||||
|
||||
|
||||
*Terminix Linux 终端模拟器*
|
||||
|
||||
Terminix 是一个使用 VTE GTK+ 3 组件的平铺式终端模拟器。使用 GTK 3 开发的原因主要是为了符合 GNOME HIG(人机接口 Human Interface Guidelines) 标准。另外,Terminix 已经在 GNOME 和 Unity 桌面环境下测试过了,也有用户在其他的 Linux 桌面环境下测试成功。
|
||||
|
||||
和其他的终端模拟器一样,Terminix 有着很多知名的特征,列表如下:
|
||||
|
||||
- 允许用户进行任意的垂直或者水平分屏
|
||||
- 支持拖拽功能来进行重新排布终端
|
||||
- 支持使用拖拽的方式终端从窗口中将脱离出来
|
||||
- 支持终端之间的输入同步,因此,可以在一个终端输入命令,而在另一个终端同步复现
|
||||
- 终端的分组配置可以保存在硬盘,并再次加载
|
||||
- 支持透明背景
|
||||
- 允许使用背景图片
|
||||
- 基于主机和目录来自动切换配置
|
||||
- 支持进程完成的通知信息
|
||||
- 配色方案采用文件存储,同时支持自定义配色方案
|
||||
|
||||
### 如何在 Linux 系统上安装 Terminix
|
||||
|
||||
现在来详细说明一下在不同的 Linux 发行版本上安装 Terminix 的步骤。首先,在此列出 Terminix 在 Linux 所需要的环境需求。
|
||||
|
||||
#### 依赖组件
|
||||
|
||||
为了正常运行,该应用需要使用如下库:
|
||||
|
||||
- GTK 3.14 或者以上版本
|
||||
- GTK VTE 0.42 或者以上版本
|
||||
- Dconf
|
||||
- GSettings
|
||||
- Nautilus 的 iNautilus-Python 插件
|
||||
|
||||
如果你已经满足了如上的系统要求,接下来就是安装 Terminix 的步骤。
|
||||
|
||||
#### 在 RHEL/CentOS 7 或者 Fedora 22-24 上
|
||||
|
||||
首先,你需要通过新建文件 `/etc/yum.repos.d/terminix.repo` 来增加软件仓库,使用你最喜欢的文本编辑器来进行编辑:
|
||||
|
||||
```
|
||||
# vi /etc/yum.repos.d/terminix.repo
|
||||
```
|
||||
|
||||
然后拷贝如下的文字到我们刚新建的文件中:
|
||||
|
||||
```
|
||||
[heikoada-terminix]
|
||||
name=Copr repo for terminix owned by heikoada
|
||||
baseurl=https://copr-be.cloud.fedoraproject.org/results/heikoada/terminix/fedora-$releasever-$basearch/
|
||||
skip_if_unavailable=True
|
||||
gpgcheck=1
|
||||
gpgkey=https://copr-be.cloud.fedoraproject.org/results/heikoada/terminix/pubkey.gpg
|
||||
enabled=1
|
||||
enabled_metadata=1
|
||||
```
|
||||
|
||||
保存文件并退出。
|
||||
|
||||
然后更新你的系统,并且安装 Terminix,步骤如下:
|
||||
|
||||
```
|
||||
---------------- On RHEL/CentOS 7 ----------------
|
||||
# yum update
|
||||
# yum install terminix
|
||||
|
||||
---------------- On Fedora 22-24 ----------------
|
||||
# dnf update
|
||||
# dnf install terminix
|
||||
```
|
||||
|
||||
#### 在 Ubuntu 16.04-14.04 和 Linux Mint 18-17
|
||||
|
||||
虽然没有基于 Debian/Ubuntu 发行版本的官方的软件包,但是你依旧可以通过如下的命令手动安装。
|
||||
|
||||
```
|
||||
$ wget -c https://github.com/gnunn1/terminix/releases/download/1.1.1/terminix.zip
|
||||
$ sudo unzip terminix.zip -d /
|
||||
$ sudo glib-compile-schemas /usr/share/glib-2.0/schemas/
|
||||
```
|
||||
|
||||
#### 其它 Linux 发行版
|
||||
|
||||
OpenSUSE 用户可以从默认仓库中安装 Terminix,Arch Linux 用户也可以安装 [AUR Terminix 软件包][2]。
|
||||
|
||||
### Terminix 截图教程
|
||||
|
||||

|
||||
|
||||
*Terminix 终端*
|
||||
|
||||

|
||||
|
||||
*Terminix 终端设置*
|
||||
|
||||

|
||||
|
||||
*Terminix 多终端界面*
|
||||
|
||||
### 如何卸载删除 Terminix
|
||||
|
||||
|
||||
如果你是手动安装的 Terminix 并且想要删除它,那么你可以参照如下的步骤来卸载它。从 [Github 仓库][3]上下载 uninstall.sh,并且给它可执行权限并且执行它:
|
||||
|
||||
```
|
||||
$ wget -c https://github.com/gnunn1/terminix/blob/master/uninstall.sh
|
||||
$ chmod +x uninstall.sh
|
||||
$ sudo sh uninstall.sh
|
||||
```
|
||||
|
||||
但是如果你是通过包管理器安装的 Terminix,你可以使用包管理器来卸载它。
|
||||
|
||||
在这篇介绍中,我们在众多优秀的终端模拟器中发现了一个重要的 Linux 终端模拟器。你可以尝试着去体验下它的新特性,并且可以将它和你现在使用的终端进行比较。
|
||||
|
||||
重要的一点,如果你想得到更多信息或者有疑问,请使用评论区,而且不要忘了,给我一个关于你使用体验的反馈。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/terminix-tiling-terminal-emulator-for-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
[1]: http://www.tecmint.com/linux-terminal-emulators/
|
||||
[2]: https://aur.archlinux.org/packages/terminix
|
||||
[3]: https://github.com/gnunn1/terminix
|
||||
@ -0,0 +1,90 @@
|
||||
为你的 Linux 桌面设置一张实时的地球照片
|
||||
=================================================================
|
||||
|
||||
|
||||
|
||||
厌倦了看同样的桌面背景了么?这里有一个(可能是)世界上最棒的东西。
|
||||
|
||||
‘[Himawaripy][1]’ 是一个 Python 3 小脚本,它会抓取由[日本 Himawari 8 气象卫星][2]拍摄的接近实时的地球照片,并将它设置成你的桌面背景。
|
||||
|
||||
安装完成后,你可以将它设置成每 10 分钟运行的定时任务(自然,它要在后台运行),这样它就可以实时地取回地球的照片并设置成背景了。
|
||||
|
||||
因为 Himawari-8 是一颗同步轨道卫星,你只能看到澳大利亚上空的地球的图片——但是它实时的天气形态、云团和光线仍使它很壮丽,对我而言要是看到英国上方的就更好了!
|
||||
|
||||
高级设置允许你配置从卫星取回的图片质量,但是要记住增加图片质量会增加文件大小及更长的下载等待!
|
||||
|
||||
最后,虽然这个脚本与其他我们提到过的其他脚本类似,它还仍保持更新及可用。
|
||||
|
||||
###获取 Himawaripy
|
||||
|
||||
Himawaripy 已经在一系列的桌面环境中都测试过了,包括 Unity、LXDE、i3、MATE 和其他桌面环境。它是自由开源软件,但是整体来说安装及配置不太简单。
|
||||
|
||||
在该项目的 [Github 主页][0]上可以找到安装和设置该应用程序的所有指导(提示:没有一键安装功能)。
|
||||
|
||||
- [实时地球壁纸脚本的 GitHub 主页][0]
|
||||
|
||||
### 安装及使用
|
||||
|
||||

|
||||
|
||||
一些读者请我在本文中补充一下一步步安装该应用的步骤。以下所有步骤都在其 GitHub 主页上,这里再贴一遍。
|
||||
|
||||
1、下载及解压 Himawaripy
|
||||
|
||||
这是最容易的步骤。点击下面的下载链接,然后下载最新版本,并解压到你的下载目录里面。
|
||||
|
||||
- [下载 Himawaripy 主干文件(.zip 格式)][3]
|
||||
|
||||
2、安装 python3-setuptools
|
||||
|
||||
你需要手工来安装主干软件包,Ubuntu 里面默认没有安装它:
|
||||
|
||||
```
|
||||
sudo apt install python3-setuptools
|
||||
```
|
||||
|
||||
3、安装 Himawaripy
|
||||
|
||||
在终端中,你需要切换到之前解压的目录中,并运行如下安装命令:
|
||||
|
||||
```
|
||||
cd ~/Downloads/himawaripy-master
|
||||
sudo python3 setup.py install
|
||||
```
|
||||
|
||||
4、 看看它是否可以运行并下载最新的实时图片:
|
||||
```
|
||||
himawaripy
|
||||
```
|
||||
5、 设置定时任务
|
||||
|
||||
如果你希望该脚本可以在后台自动运行并更新(如果你需要手动更新,只需要运行 ‘himarwaripy’ 即可)
|
||||
|
||||
在终端中运行:
|
||||
```
|
||||
crontab -e
|
||||
```
|
||||
在其中新加一行(默认每10分钟运行一次)
|
||||
```
|
||||
*/10 * * * * /usr/local/bin/himawaripy
|
||||
```
|
||||
关于[配置定时任务][4]可以在 Ubuntu Wiki 上找到更多信息。
|
||||
|
||||
该脚本安装后你不需要不断运行它,它会自动的每十分钟在后台运行一次。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2016/07/set-real-time-earth-wallpaper-ubuntu-desktop
|
||||
|
||||
作者:[JOEY-ELIJAH SNEDDON][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]: https://github.com/boramalper/himawaripy
|
||||
[2]: https://en.wikipedia.org/wiki/Himawari_8
|
||||
[0]: https://github.com/boramalper/himawaripy
|
||||
[3]: https://github.com/boramalper/himawaripy/archive/master.zip
|
||||
[4]: https://help.ubuntu.com/community/CronHowto
|
||||
@ -0,0 +1,257 @@
|
||||
Fabric - 通过 SSH 来自动化管理 Linux 任务和布署应用
|
||||
===========================
|
||||
|
||||
当要管理远程机器或者要布署应用时,虽然你有多种命令行工具可以选择,但是其中很多工具都缺少详细的使用文档。
|
||||
|
||||
在这篇教程中,我们将会一步一步地向你介绍如何使用 fabric 来帮助你更好得管理多台服务器。
|
||||
|
||||

|
||||
|
||||
*使用 Fabric 来自动化地管理 Linux 任务*
|
||||
|
||||
Fabric 是一个用 Python 编写的命令行工具库,它可以帮助系统管理员高效地执行某些任务,比如通过 SSH 到多台机器上执行某些命令,远程布署应用等。
|
||||
|
||||
在使用之前,如果你拥有使用 Python 的经验能帮你更好的使用 Fabric。当然,如果没有那也不影响使用 Fabric。
|
||||
|
||||
我们为什么要选择 Fabric:
|
||||
|
||||
- 简单
|
||||
- 完备的文档
|
||||
- 如果你会 Python,不用增加学习其他语言的成本
|
||||
- 易于安装使用
|
||||
- 使用便捷
|
||||
- 支持多台机器并行操作
|
||||
|
||||
### 在 Linux 上如何安装 Fabric
|
||||
|
||||
Fabric 有一个特点就是要远程操作的机器只需要支持标准的 OpenSSH 服务即可。只要保证在机器上安装并开启了这个服务就能使用 Fabric 来管理机器。
|
||||
|
||||
#### 依赖
|
||||
|
||||
- Python 2.5 或更新版本,以及对应的开发组件
|
||||
- Python-setuptools 和 pip(可选,但是非常推荐)gcc
|
||||
|
||||
我们推荐使用 pip 安装 Fabric,但是你也可以使用系统自带的包管理器如 `yum`, `dnf` 或 `apt-get` 来安装,包名一般是 `fabric` 或 `python-fabric`。
|
||||
|
||||
如果是基于 RHEL/CentOS 的发行版本的系统,你可以使用系统自带的 [EPEL 源][1] 来安装 fabric。
|
||||
|
||||
```
|
||||
# yum install fabric [适用于基于 RedHat 系统]
|
||||
# dnf install fabric [适用于 Fedora 22+ 版本]
|
||||
```
|
||||
|
||||
如果你是 Debian 或者其派生的系统如 Ubuntu 和 Mint 的用户,你可以使用 apt-get 来安装,如下所示:
|
||||
|
||||
```
|
||||
# apt-get install fabric
|
||||
```
|
||||
|
||||
如果你要安装开发版的 Fabric,你需要安装 pip 来安装 master 分支上最新版本。
|
||||
|
||||
```
|
||||
# yum install python-pip [适用于基于 RedHat 系统]
|
||||
# dnf install python-pip [适用于Fedora 22+ 版本]
|
||||
# apt-get install python-pip [适用于基于 Debian 系统]
|
||||
```
|
||||
|
||||
安装好 pip 后,你可以使用 pip 获取最新版本的 Fabric。
|
||||
|
||||
```
|
||||
# pip install fabric
|
||||
```
|
||||
|
||||
### 如何使用 Fabric 来自动化管理 Linux 任务
|
||||
|
||||
现在我们来开始使用 Fabric,在之前的安装的过程中,Fabric Python 脚本已经被放到我们的系统目录,当我们要运行 Fabric 时输入 `fab` 命令即可。
|
||||
|
||||
#### 在本地 Linux 机器上运行命令行
|
||||
|
||||
按照惯例,先用你喜欢的编辑器创建一个名为 fabfile.py 的 Python 脚本。你可以使用其他名字来命名脚本,但是就需要指定这个脚本的路径,如下所示:
|
||||
|
||||
```
|
||||
# fabric --fabfile /path/to/the/file.py
|
||||
```
|
||||
|
||||
Fabric 使用 `fabfile.py` 来执行任务,这个文件应该放在你执行 Fabric 命令的目录里面。
|
||||
|
||||
**例子 1**:创建入门的 `Hello World` 任务:
|
||||
|
||||
```
|
||||
# vi fabfile.py
|
||||
```
|
||||
|
||||
在文件内输入如下内容:
|
||||
|
||||
```
|
||||
def hello():
|
||||
print('Hello world, Tecmint community')
|
||||
```
|
||||
|
||||
保存文件并执行以下命令:
|
||||
|
||||
```
|
||||
# fab hello
|
||||
```
|
||||
|
||||
|
||||
|
||||
*Fabric 工具使用说明*
|
||||
|
||||
**例子 2**:新建一个名为 fabfile.py 的文件并打开:
|
||||
|
||||
粘贴以下代码至文件:
|
||||
|
||||
```
|
||||
#! /usr/bin/env python
|
||||
from fabric.api import local
|
||||
def uptime():
|
||||
local('uptime')
|
||||
```
|
||||
|
||||
保存文件并执行以下命令:
|
||||
|
||||
```
|
||||
# fab uptime
|
||||
```
|
||||
|
||||

|
||||
|
||||
*Fabric: 检查系统运行时间*
|
||||
|
||||
让我们看看这个例子,fabfile.py 文件在本机执行了 uptime 这个命令。
|
||||
|
||||
#### 在远程 Linux 机器上运行命令来执行自动化任务
|
||||
|
||||
Fabric API 使用了一个名为 `env` 的关联数组(Python 中的词典)作为配置目录,来储存 Fabric 要控制的机器的相关信息。
|
||||
|
||||
`env.hosts` 是一个用来存储你要执行 Fabric 任务的机器的列表,如果你的 IP 地址是 192.168.0.0,想要用 Fabric 来管理地址为 192.168.0.2 和 192.168.0.6 的机器,需要的配置如下所示:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
from fabric.api import env
|
||||
env.hosts = [ '192.168.0.2', '192.168.0.6' ]
|
||||
```
|
||||
|
||||
上面这几行代码只是声明了你要执行 Fabric 任务的主机地址,但是实际上并没有执行任何任务,下面我们就来定义一些任务。Fabric 提供了一系列可以与远程服务器交互的方法。
|
||||
|
||||
Fabric 提供了众多的方法,这里列出几个经常会用到的:
|
||||
|
||||
- run - 可以在远程机器上运行的 shell 命令
|
||||
- local - 可以在本机上运行的 shell 命令
|
||||
- sudo - 使用 root 权限在远程机器上运行的 shell 命令
|
||||
- get - 从远程机器上下载一个或多个文件
|
||||
- put - 上传一个或多个文件到远程机器
|
||||
|
||||
**例子 3**:在多台机子上输出信息,新建新的 fabfile.py 文件如下所示
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
from fabric.api import env, run
|
||||
env.hosts = ['192.168.0.2','192.168.0.6']
|
||||
def echo():
|
||||
run("echo -n 'Hello, you are tuned to Tecmint ' ")
|
||||
```
|
||||
|
||||
运行以下命令执行 Fabric 任务
|
||||
|
||||
```
|
||||
# fab echo
|
||||
```
|
||||
|
||||

|
||||
|
||||
*fabric: 自动在远程 Linux 机器上执行任务*
|
||||
|
||||
**例子 4**:你可以继续改进之前创建的执行 uptime 任务的 fabfile.py 文件,让它可以在多台服务器上运行 uptime 命令,也可以检查其磁盘使用情况,如下所示:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
from fabric.api import env, run
|
||||
env.hosts = ['192.168.0.2','192.168.0.6']
|
||||
def uptime():
|
||||
run('uptime')
|
||||
def disk_space():
|
||||
run('df -h')
|
||||
```
|
||||
|
||||
保存并执行以下命令
|
||||
|
||||
```
|
||||
# fab uptime
|
||||
# fab disk_space
|
||||
```
|
||||
|
||||
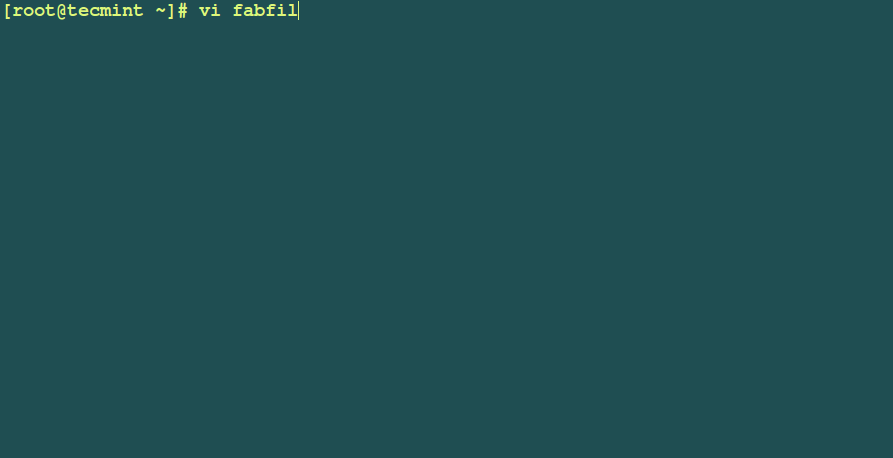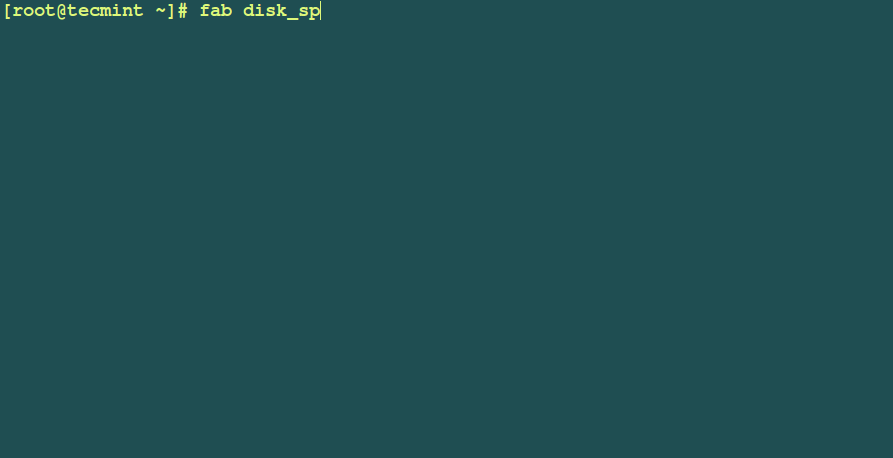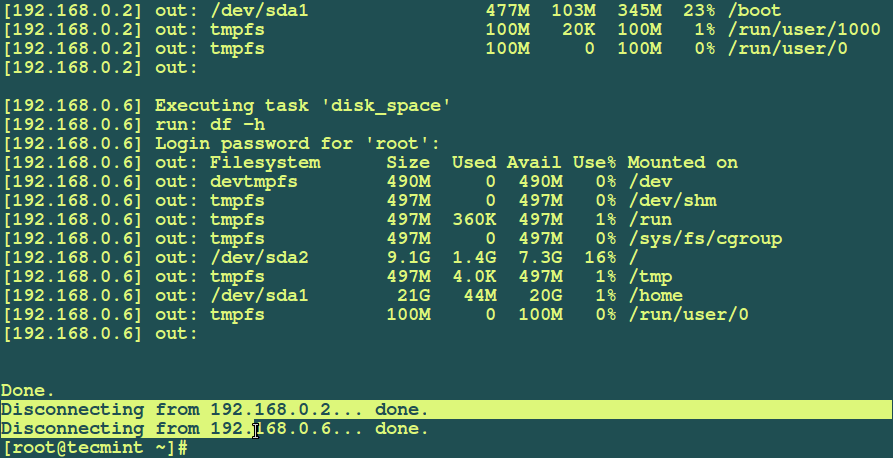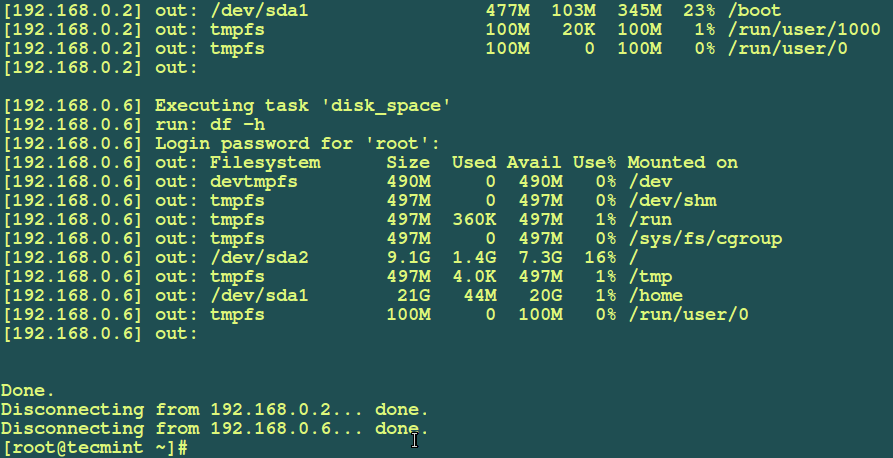
|
||||
|
||||
*Fabric:自动在多台服务器上执行任务*
|
||||
|
||||
#### 在远程服务器上自动化布署 LAMP
|
||||
|
||||
**例子 5**:我们来尝试一下在远程服务器上布署 LAMP(Linux, Apache, MySQL/MariaDB and PHP)
|
||||
|
||||
我们要写个函数在远程使用 root 权限安装 LAMP。
|
||||
|
||||
##### 在 RHEL/CentOS 或 Fedora 上
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
from fabric.api import env, run
|
||||
env.hosts = ['192.168.0.2','192.168.0.6']
|
||||
def deploy_lamp():
|
||||
run ("yum install -y httpd mariadb-server php php-mysql")
|
||||
```
|
||||
|
||||
##### 在 Debian/Ubuntu 或 Linux Mint 上
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
from fabric.api import env, run
|
||||
env.hosts = ['192.168.0.2','192.168.0.6']
|
||||
def deploy_lamp():
|
||||
sudo("apt-get install -q apache2 mysql-server libapache2-mod-php5 php5-mysql")
|
||||
```
|
||||
|
||||
保存并执行以下命令:
|
||||
|
||||
```
|
||||
# fab deploy_lamp
|
||||
```
|
||||
|
||||
注:由于安装时会输出大量信息,这个例子我们就不提供屏幕 gif 图了
|
||||
|
||||
现在你可以使用 Fabric 和上文例子所示的功能来[自动化的管理 Linux 服务器上的任务][2]了。
|
||||
|
||||
#### 一些 Fabric 有用的选项
|
||||
|
||||
- 你可以运行 `fab -help` 输出帮助信息,里面列出了所有可以使用的命令行信息
|
||||
- `–fabfile=PATH` 选项可以让你定义除了名为 fabfile.py 之外的模块
|
||||
- 如果你想用指定的用户名登录远程主机,请使用 `-user=USER` 选项
|
||||
- 如果你需要密码进行验证或者 sudo 提权,请使用 `–password=PASSWORD` 选项
|
||||
- 如果需要输出某个命令的详细信息,请使用 `–display=命令名` 选项
|
||||
- 使用 `--list` 输出所有可用的任务
|
||||
- 使用 `--list-format=FORMAT` 选项能格式化 `-list` 选项输出的信息,可选的有 short、normal、 nested
|
||||
- `--config=PATH` 选项可以指定读取配置文件的地址
|
||||
- `-–colorize-errors` 能显示彩色的错误输出信息
|
||||
- `--version` 输出当前版本
|
||||
|
||||
### 总结
|
||||
|
||||
Fabric 是一个强大并且文档完备的工具,对于新手来说也能很快上手,阅读提供的文档能帮助你更好的了解它。如果你在安装和使用 Fabric 时发现什么问题可以在评论区留言,我们会及时回复。
|
||||
|
||||
参考:[Fabric 文档][3]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/automating-linux-system-administration-tasks/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[NearTan](https://github.com/NearTan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
[1]: https://linux.cn/article-2324-1.html
|
||||
[2]: http://www.tecmint.com/use-ansible-playbooks-to-automate-complex-tasks-on-multiple-linux-servers/
|
||||
[3]: http://docs.fabfile.org/en/1.4.0/usage/env.html
|
||||
96
published/201608/20151208 6 creative ways to use ownCloud.md
Normal file
96
published/201608/20151208 6 creative ways to use ownCloud.md
Normal file
@ -0,0 +1,96 @@
|
||||
ownCloud 的六大神奇用法
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
(图片来源:Opensource.com)
|
||||
|
||||
[ownCloud][1] 是一个自行托管的开源文件同步和共享服务器。就像“行业老大” Dropbox、Google Drive、Box 和其他的同类服务一样,ownCloud 也可以让你访问自己的文件、日历、联系人和其他数据。你可以在自己设备之间同步任意数据(或部分数据)并分享给其他人。然而,ownCloud 要比其它的商业解决方案更棒,可以[将 ownCloud 运行在自己的服务器][2]而不是其它人的服务器上。
|
||||
|
||||
现在,让我们一起来看看在 ownCloud 上的六个创造性的应用方式。其中一些是由于 ownCloud 的开源才得以完成,而另外的则是 ownCloud 自身特有的功能。
|
||||
|
||||
### 1. 可扩展的 ownCloud “派”集群 ###
|
||||
|
||||
由于 ownCloud 是开源的,你可以选择将它运行在自己的服务器中,或者从你信任的服务商那里获取空间——没必要将你的文件存储在那些大公司的服务器中,谁知他们将你的文件存储到哪里去。[点击此处查看部分 ownCloud 服务商][3],或者下载该服务软件到你的虚拟主机中[搭建自己的服务器][4].
|
||||
|
||||

|
||||
|
||||
*拍摄: Jörn Friedrich Dreyer. [CC BY-SA 4.0.][5]*
|
||||
|
||||
我们见过最具创意的事情就是架设[香蕉派集群][6]和[树莓派集群][7]。ownCloud 的扩展性通常用于支持成千上万的用户,但有些人则将它往不同方向发展,通过将多个微型系统集群在一起,就可以创建出运行速度超快的 ownCloud。酷毙了!
|
||||
|
||||
### 2. 密码同步 ###
|
||||
|
||||
为了让 ownCloud 更容易扩展,我们将它变得超级的模块化,甚至还有一个 [ownCloud 应用商店][8]。你可以在里边找到音乐和视频播放器、日历、联系人、生产力应用、游戏、应用模板(sketching app)等等。
|
||||
|
||||
从近 200 多个应用中仅挑选一个是一件非常困难的事,但密码管理则是一个很独特的功能。只有不超过三个应用提供这个功能:[Passwords][9]、[Secure Container][10] 和 [Passman][11]。
|
||||
|
||||
|
||||
|
||||
### 3. 随心所欲地存储文件 ###
|
||||
|
||||
外部存储可以让你将现有数据挂载到 ownCloud 上,让你通过一个界面来访问存储在 FTP、WebDAV、Amazon S3,甚至 Dropbox 和 Google Drive 的文件。
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="520" height="315" frameborder="0" allowfullscreen="" src="https://www.youtube.com/embed/uezzFDRnoPY"></iframe>
|
||||
|
||||
行业老大们喜欢创建自己的 “藩篱花园”,Box 的用户只能和其它的 Box 用户协作;假如你想从 Google Drive 分享你的文件,你的同伴也必须要有一个 Google 账号才可以访问的分享。通过 ownCloud 的外部存储功能,你可以轻松打破这些。
|
||||
|
||||
最有创意的就是把 Google Drive 和 Dropbox 添加为外部存储。这样你就可以无缝连接它们,通过一个简单的链接即可分享给其它人——并不需要账户。
|
||||
|
||||
### 4. 获取上传的文件 ###
|
||||
|
||||
由于 ownCloud 是开源开,人们可以不受公司需求的制约而向它贡献感兴趣的功能。我们的贡献者总是很在意安全和隐私,所以 ownCloud 引入的通过密码保护公共链接并[设置失效期限][12]的功能要比其它人早很多。
|
||||
|
||||
现在,ownCloud 可以配置分享链接的读写权限了,这就是说链接的访问者可以无缝的编辑你分享给他们的文件(可以有密码保护,也可以没有),或者将文件上传到服务器前不用强制他们提供私人信息来注册服务。
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="520" height="315" frameborder="0" allowfullscreen="" src="https://www.youtube.com/embed/3GSppxEhmZY"></iframe>
|
||||
|
||||
对于有人想给你分享大体积的文件时,这个特性就非常有用了。相比于上传到第三方站点、然后给你发送一个连接、你再去下载文件(通常需要登录),ownCloud 仅需要上传文件到你提供的分享文件夹,你就可以马上获取到文件了。
|
||||
|
||||
### 5. 免费却又安全的存储空间 ###
|
||||
|
||||
之前就强调过,我们的代码贡献者最关注的就是安全和隐私,这就是 ownCloud 中有用于加密和解密存储数据的应用的原因。
|
||||
|
||||
通过使用 ownCloud 将你的文件存储到 Dropbox 或者 Google Drive,则会违背夺回数据的控制权并保持数据隐私的初衷。但是加密应用则可以改变这个状况。在发送数据给这些提供商前进行数据加密,并在取回数据的时候进行解密,你的数据就会变得很安全。
|
||||
|
||||
### 6. 在你的可控范围内分享文件 ###
|
||||
|
||||
作为开源项目,ownCloud 没有必要自建 “藩篱花园”。通过“联邦云共享(Federated Cloud Sharing)”:这个[由 ownCloud 开发和发布的][13]协议使不同的文件同步和共享服务器可以彼此之间进行通信,并能够安全地传输文件。联邦云共享本身来自一个有趣的事情:有 [22 所德国大学][14] 想要为自身的 50 万名学生建立一个庞大的云服务,但是每个大学都想控制自己学生的数据。于是乎,我们需要一个创造性的解决方案:也就是联邦云服务。该解决方案可以连接全部的大学,使得学生们可以无缝的协同工作。同时,每个大学的系统管理员保持着对自己学生创建的文件的控制权,并可采用自己的策略,如限制限额,或者限制什么人、什么文件以及如何共享。
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="520" height="315" frameborder="0" allowfullscreen="" src="https://www.youtube.com/embed/9-JEmlH2DEg"></iframe>
|
||||
|
||||
并且,这项神奇的技术并没有限制于德国的大学之间,每个 ownCloud 用户都能在自己的用户设置中找到自己的[联邦云 ID][15],并将之分享给同伴。
|
||||
|
||||
现在你明白了吧。通过这六个方式,ownCloud 就能让人们做一些特殊而独特的事。而使这一切成为可能的,就是 ownCloud 是开源的,其设计目标就是让你的数据自由。
|
||||
|
||||
你有其它的 ownCloud 的创意用法吗?请发表评论让我们知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/15/12/6-creative-ways-use-owncloud
|
||||
|
||||
作者:[Jos Poortvliet][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jospoortvliet
|
||||
[1]:https://owncloud.com/
|
||||
[2]:https://blogs.fsfe.org/mk/new-stickers-and-leaflets-no-cloud-and-e-mail-self-defense/
|
||||
[3]:https://owncloud.org/providers
|
||||
[4]:https://owncloud.org/install/#instructions-server
|
||||
[5]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[6]:http://www.owncluster.de/
|
||||
[7]:https://christopherjcoleman.wordpress.com/2013/01/05/host-your-owncloud-on-a-raspberry-pi-cluster/
|
||||
[8]:https://apps.owncloud.com/
|
||||
[9]:https://apps.owncloud.com/content/show.php/Passwords?content=170480
|
||||
[10]:https://apps.owncloud.com/content/show.php/Secure+Container?content=167268
|
||||
[11]:https://apps.owncloud.com/content/show.php/Passman?content=166285
|
||||
[12]:https://owncloud.com/owncloud45-community/
|
||||
[13]:http://karlitschek.de/2015/08/announcing-the-draft-federated-cloud-sharing-api/
|
||||
[14]:https://owncloud.com/customer/sciebo/
|
||||
[15]:https://owncloud.org/federation/
|
||||
498
published/201608/20151220 GCC-Inline-Assembly-HOWTO.md
Normal file
498
published/201608/20151220 GCC-Inline-Assembly-HOWTO.md
Normal file
@ -0,0 +1,498 @@
|
||||
* * *
|
||||
|
||||
# GCC 内联汇编 HOWTO
|
||||
|
||||
v0.1, 01 March 2003.
|
||||
* * *
|
||||
|
||||
_本 HOWTO 文档将讲解 GCC 提供的内联汇编特性的用途和用法。对于阅读这篇文章,这里只有两个前提要求,很明显,就是 x86 汇编语言和 C 语言的基本认识。_
|
||||
|
||||
* * *
|
||||
|
||||
## 1. 简介
|
||||
|
||||
### 1.1 版权许可
|
||||
|
||||
Copyright (C)2003 Sandeep S.
|
||||
|
||||
本文档自由共享;你可以重新发布它,并且/或者在遵循自由软件基金会发布的 GNU 通用公共许可证下修改它;也可以是该许可证的版本 2 或者(按照你的需求)更晚的版本。
|
||||
|
||||
发布这篇文档是希望它能够帮助别人,但是没有任何担保;甚至不包括可售性和适用于任何特定目的的担保。关于更详细的信息,可以查看 GNU 通用许可证。
|
||||
|
||||
### 1.2 反馈校正
|
||||
|
||||
请将反馈和批评一起提交给 [Sandeep.S](mailto:busybox@sancharnet.in) 。我将感谢任何一个指出本文档中错误和不准确之处的人;一被告知,我会马上改正它们。
|
||||
|
||||
### 1.3 致谢
|
||||
|
||||
我对提供如此棒的特性的 GNU 人们表示真诚的感谢。感谢 Mr.Pramode C E 所做的所有帮助。感谢在 Govt Engineering College 和 Trichur 的朋友们的精神支持和合作,尤其是 Nisha Kurur 和 Sakeeb S 。 感谢在 Gvot Engineering College 和 Trichur 的老师们的合作。
|
||||
|
||||
另外,感谢 Phillip , Brennan Underwood 和 colin@nyx.net ;这里的许多东西都厚颜地直接取自他们的工作成果。
|
||||
|
||||
* * *
|
||||
|
||||
## 2. 概览
|
||||
|
||||
在这里,我们将学习 GCC 内联汇编。这里内联(inline)表示的是什么呢?
|
||||
|
||||
我们可以要求编译器将一个函数的代码插入到调用者代码中函数被实际调用的地方。这样的函数就是内联函数。这听起来和宏差不多?这两者确实有相似之处。
|
||||
|
||||
内联函数的优点是什么呢?
|
||||
|
||||
这种内联方法可以减少函数调用开销。同时如果所有实参的值为常量,它们的已知值可以在编译期允许简化,因此并非所有的内联函数代码都需要被包含进去。代码大小的影响是不可预测的,这取决于特定的情况。为了声明一个内联函数,我们必须在函数声明中使用 `inline` 关键字。
|
||||
|
||||
现在我们正处于一个猜测内联汇编到底是什么的点上。它只不过是一些写为内联函数的汇编程序。在系统编程上,它们方便、快速并且极其有用。我们主要集中学习(GCC)内联汇编函数的基本格式和用法。为了声明内联汇编函数,我们使用 `asm` 关键词。
|
||||
|
||||
内联汇编之所以重要,主要是因为它可以操作并且使其输出通过 C 变量显示出来。正是因为此能力, "asm" 可以用作汇编指令和包含它的 C 程序之间的接口。
|
||||
|
||||
* * *
|
||||
|
||||
## 3. GCC 汇编语法
|
||||
|
||||
Linux上的 GNU C 编译器 GCC ,使用 **AT&T** / **UNIX** 汇编语法。在这里,我们将使用 AT&T 语法 进行汇编编码。如果你对 AT&T 语法不熟悉的话,请不要紧张,我会教你的。AT&T 语法和 Intel 语法的差别很大。我会给出主要的区别。
|
||||
|
||||
1. 源操作数和目的操作数顺序
|
||||
|
||||
AT&T 语法的操作数方向和 Intel 语法的刚好相反。在Intel 语法中,第一操作数为目的操作数,第二操作数为源操作数,然而在 AT&T 语法中,第一操作数为源操作数,第二操作数为目的操作数。也就是说,
|
||||
|
||||
Intel 语法中的 `Op-code dst src` 变为
|
||||
|
||||
AT&T 语法中的 `Op-code src dst`。
|
||||
|
||||
2. 寄存器命名
|
||||
|
||||
寄存器名称有 `%` 前缀,即如果必须使用 `eax`,它应该用作 `%eax`。
|
||||
|
||||
3. 立即数
|
||||
|
||||
AT&T 立即数以 `$` 为前缀。静态 "C" 变量也使用 `$` 前缀。在 Intel 语法中,十六进制常量以 `h` 为后缀,然而 AT&T 不使用这种语法,这里我们给常量添加前缀 `0x`。所以,对于十六进制,我们首先看到一个 `$`,然后是 `0x`,最后才是常量。
|
||||
|
||||
4. 操作数大小
|
||||
|
||||
在 AT&T 语法中,存储器操作数的大小取决于操作码名字的最后一个字符。操作码后缀 ’b’ 、’w’、’l’ 分别指明了字节(byte)(8位)、字(word)(16位)、长型(long)(32位)存储器引用。Intel 语法通过给存储器操作数添加 `byte ptr`、 `word ptr` 和 `dword ptr` 前缀来实现这一功能。
|
||||
|
||||
因此,Intel的 `mov al, byte ptr foo` 在 AT&T 语法中为 `movb foo, %al`。
|
||||
|
||||
5. 存储器操作数
|
||||
|
||||
在 Intel 语法中,基址寄存器包含在 `[` 和 `]` 中,然而在 AT&T 中,它们变为 `(` 和 `)`。另外,在 Intel 语法中, 间接内存引用为
|
||||
|
||||
`section:[base + index*scale + disp]`,在 AT&T中变为 `section:disp(base, index, scale)`。
|
||||
|
||||
需要牢记的一点是,当一个常量用于 disp 或 scale,不能添加 `$` 前缀。
|
||||
|
||||
现在我们看到了 Intel 语法和 AT&T 语法之间的一些主要差别。我仅仅写了它们差别的一部分而已。关于更完整的信息,请参考 GNU 汇编文档。现在为了更好地理解,我们可以看一些示例。
|
||||
|
||||
```
|
||||
+------------------------------+------------------------------------+
|
||||
| Intel Code | AT&T Code |
|
||||
+------------------------------+------------------------------------+
|
||||
| mov eax,1 | movl $1,%eax |
|
||||
| mov ebx,0ffh | movl $0xff,%ebx |
|
||||
| int 80h | int $0x80 |
|
||||
| mov ebx, eax | movl %eax, %ebx |
|
||||
| mov eax,[ecx] | movl (%ecx),%eax |
|
||||
| mov eax,[ebx+3] | movl 3(%ebx),%eax |
|
||||
| mov eax,[ebx+20h] | movl 0x20(%ebx),%eax |
|
||||
| add eax,[ebx+ecx*2h] | addl (%ebx,%ecx,0x2),%eax |
|
||||
| lea eax,[ebx+ecx] | leal (%ebx,%ecx),%eax |
|
||||
| sub eax,[ebx+ecx*4h-20h] | subl -0x20(%ebx,%ecx,0x4),%eax |
|
||||
+------------------------------+------------------------------------+
|
||||
```
|
||||
* * *
|
||||
|
||||
## 4. 基本内联
|
||||
|
||||
基本内联汇编的格式非常直接了当。它的基本格式为
|
||||
|
||||
`asm("汇编代码");`
|
||||
|
||||
示例
|
||||
|
||||
```
|
||||
asm("movl %ecx %eax"); /* 将 ecx 寄存器的内容移至 eax */
|
||||
__asm__("movb %bh (%eax)"); /* 将 bh 的一个字节数据 移至 eax 寄存器指向的内存 */
|
||||
```
|
||||
|
||||
你可能注意到了这里我使用了 `asm ` 和 `__asm__`。这两者都是有效的。如果关键词 `asm` 和我们程序的一些标识符冲突了,我们可以使用 `__asm__`。如果我们的指令多于一条,我们可以每个一行,并用双引号圈起,同时为每条指令添加 ’\n’ 和 ’\t’ 后缀。这是因为 gcc 将每一条当作字符串发送给 **as**(GAS)(LCTT 译注: GAS 即 GNU 汇编器),并且通过使用换行符/制表符发送正确格式化后的行给汇编器。
|
||||
|
||||
示例
|
||||
|
||||
```
|
||||
__asm__ ("movl %eax, %ebx\n\t"
|
||||
"movl $56, %esi\n\t"
|
||||
"movl %ecx, $label(%edx,%ebx,$4)\n\t"
|
||||
"movb %ah, (%ebx)");
|
||||
```
|
||||
|
||||
如果在代码中,我们涉及到一些寄存器(即改变其内容),但在没有恢复这些变化的情况下从汇编中返回,这将会导致一些意想不到的事情。这是因为 GCC 并不知道寄存器内容的变化,这会导致问题,特别是当编译器做了某些优化。在没有告知 GCC 的情况下,它将会假设一些寄存器存储了一些值——而我们可能已经改变却没有告知 GCC——它会像什么事都没发生一样继续运行(LCTT 译注:什么事都没发生一样是指GCC不会假设寄存器装入的值是有效的,当退出改变了寄存器值的内联汇编后,寄存器的值不会保存到相应的变量或内存空间)。我们所可以做的是使用那些没有副作用的指令,或者当我们退出时恢复这些寄存器,要不就等着程序崩溃吧。这是为什么我们需要一些扩展功能,扩展汇编给我们提供了那些功能。
|
||||
|
||||
* * *
|
||||
|
||||
## 5. 扩展汇编
|
||||
|
||||
在基本内联汇编中,我们只有指令。然而在扩展汇编中,我们可以同时指定操作数。它允许我们指定输入寄存器、输出寄存器以及修饰寄存器列表。GCC 不强制用户必须指定使用的寄存器。我们可以把头疼的事留给 GCC ,这可能可以更好地适应 GCC 的优化。不管怎么说,基本格式为:
|
||||
|
||||
```
|
||||
asm ( 汇编程序模板
|
||||
: 输出操作数 /* 可选的 */
|
||||
: 输入操作数 /* 可选的 */
|
||||
: 修饰寄存器列表 /* 可选的 */
|
||||
);
|
||||
```
|
||||
|
||||
汇编程序模板由汇编指令组成。每一个操作数由一个操作数约束字符串所描述,其后紧接一个括弧括起的 C 表达式。冒号用于将汇编程序模板和第一个输出操作数分开,另一个(冒号)用于将最后一个输出操作数和第一个输入操作数分开(如果存在的话)。逗号用于分离每一个组内的操作数。总操作数的数目限制在 10 个,或者机器描述中的任何指令格式中的最大操作数数目,以较大者为准。
|
||||
|
||||
如果没有输出操作数但存在输入操作数,你必须将两个连续的冒号放置于输出操作数原本会放置的地方周围。
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
asm ("cld\n\t"
|
||||
"rep\n\t"
|
||||
"stosl"
|
||||
: /* 无输出寄存器 */
|
||||
: "c" (count), "a" (fill_value), "D" (dest)
|
||||
: "%ecx", "%edi"
|
||||
);
|
||||
```
|
||||
|
||||
现在来看看这段代码是干什么的?以上的内联汇编是将 `fill_value` 值连续 `count` 次拷贝到寄存器 `edi` 所指位置(LCTT 译注:每执行 stosl 一次,寄存器 edi 的值会递增或递减,这取决于是否设置了 direction 标志,因此以上代码实则初始化一个内存块)。 它也告诉 gcc 寄存器 `ecx` 和 `edi` 一直无效(LCTT 译注:原文为 eax ,但代码修饰寄存器列表中为 ecx,因此这可能为作者的纰漏。)。为了更加清晰地说明,让我们再看一个示例。
|
||||
|
||||
```
|
||||
int a=10, b;
|
||||
asm ("movl %1, %%eax;
|
||||
movl %%eax, %0;"
|
||||
:"=r"(b) /* 输出 */
|
||||
:"r"(a) /* 输入 */
|
||||
:"%eax" /* 修饰寄存器 */
|
||||
);
|
||||
```
|
||||
|
||||
这里我们所做的是使用汇编指令使 ’b’ 变量的值等于 ’a’ 变量的值。一些有意思的地方是:
|
||||
|
||||
* "b" 为输出操作数,用 %0 引用,并且 "a" 为输入操作数,用 %1 引用。
|
||||
* "r" 为操作数约束。之后我们会更详细地了解约束(字符串)。目前,"r" 告诉 GCC 可以使用任一寄存器存储操作数。输出操作数约束应该有一个约束修饰符 "=" 。这修饰符表明它是一个只读的输出操作数。
|
||||
* 寄存器名字以两个 % 为前缀。这有利于 GCC 区分操作数和寄存器。操作数以一个 % 为前缀。
|
||||
* 第三个冒号之后的修饰寄存器 %eax 用于告诉 GCC %eax 的值将会在 "asm" 内部被修改,所以 GCC 将不会使用此寄存器存储任何其他值。
|
||||
|
||||
当 “asm” 执行完毕, "b" 变量会映射到更新的值,因为它被指定为输出操作数。换句话说, “asm” 内 "b" 变量的修改应该会被映射到 “asm” 外部。
|
||||
|
||||
现在,我们可以更详细地看看每一个域。
|
||||
|
||||
### 5.1 汇编程序模板
|
||||
|
||||
汇编程序模板包含了被插入到 C 程序的汇编指令集。其格式为:每条指令用双引号圈起,或者整个指令组用双引号圈起。同时每条指令应以分界符结尾。有效的分界符有换行符(`\n`)和分号(`;`)。`\n` 可以紧随一个制表符(`\t`)。我们应该都明白使用换行符或制表符的原因了吧(LCTT 译注:就是为了排版和分隔)?和 C 表达式对应的操作数使用 %0、%1 ... 等等表示。
|
||||
|
||||
### 5.2 操作数
|
||||
|
||||
C 表达式用作 “asm” 内的汇编指令操作数。每个操作数前面是以双引号圈起的操作数约束。对于输出操作数,在引号内还有一个约束修饰符,其后紧随一个用于表示操作数的 C 表达式。即,“操作数约束”(C 表达式)是一个通用格式。对于输出操作数,还有一个额外的修饰符。约束字符串主要用于决定操作数的寻址方式,同时也用于指定使用的寄存器。
|
||||
|
||||
如果我们使用的操作数多于一个,那么每一个操作数用逗号隔开。
|
||||
|
||||
在汇编程序模板中,每个操作数用数字引用。编号方式如下。如果总共有 n 个操作数(包括输入和输出操作数),那么第一个输出操作数编号为 0 ,逐项递增,并且最后一个输入操作数编号为 n - 1 。操作数的最大数目在前一节我们讲过。
|
||||
|
||||
输出操作数表达式必须为左值。输入操作数的要求不像这样严格。它们可以为表达式。扩展汇编特性常常用于编译器所不知道的机器指令 ;-)。如果输出表达式无法直接寻址(即,它是一个位域),我们的约束字符串必须给定一个寄存器。在这种情况下,GCC 将会使用该寄存器作为汇编的输出,然后存储该寄存器的内容到输出。
|
||||
|
||||
正如前面所陈述的一样,普通的输出操作数必须为只写的; GCC 将会假设指令前的操作数值是死的,并且不需要被(提前)生成。扩展汇编也支持输入-输出或者读-写操作数。
|
||||
|
||||
所以现在我们来关注一些示例。我们想要求一个数的5次方结果。为了计算该值,我们使用 `lea` 指令。
|
||||
|
||||
```
|
||||
asm ("leal (%1,%1,4), %0"
|
||||
: "=r" (five_times_x)
|
||||
: "r" (x)
|
||||
);
|
||||
```
|
||||
|
||||
这里我们的输入为 x。我们不指定使用的寄存器。 GCC 将会选择一些输入寄存器,一个输出寄存器,来做我们预期的工作。如果我们想要输入和输出放在同一个寄存器里,我们也可以要求 GCC 这样做。这里我们使用那些读-写操作数类型。这里我们通过指定合适的约束来实现它。
|
||||
|
||||
```
|
||||
asm ("leal (%0,%0,4), %0"
|
||||
: "=r" (five_times_x)
|
||||
: "0" (x)
|
||||
);
|
||||
```
|
||||
|
||||
现在输出和输出操作数位于同一个寄存器。但是我们无法得知是哪一个寄存器。现在假如我们也想要指定操作数所在的寄存器,这里有一种方法。
|
||||
|
||||
```
|
||||
asm ("leal (%%ecx,%%ecx,4), %%ecx"
|
||||
: "=c" (x)
|
||||
: "c" (x)
|
||||
);
|
||||
```
|
||||
|
||||
在以上三个示例中,我们并没有在修饰寄存器列表里添加任何寄存器,为什么?在头两个示例, GCC 决定了寄存器并且它知道发生了什么改变。在最后一个示例,我们不必将 'ecx' 添加到修饰寄存器列表(LCTT 译注: 原文修饰寄存器列表这个单词拼写有错,这里已修正),gcc 知道它表示 x。因此,因为它可以知道 `ecx` 的值,它就不被当作修饰的(寄存器)了。
|
||||
|
||||
### 5.3 修饰寄存器列表
|
||||
|
||||
一些指令会破坏一些硬件寄存器内容。我们不得不在修饰寄存器中列出这些寄存器,即汇编函数内第三个 ’**:**’ 之后的域。这可以通知 gcc 我们将会自己使用和修改这些寄存器,这样 gcc 就不会假设存入这些寄存器的值是有效的。我们不用在这个列表里列出输入、输出寄存器。因为 gcc 知道 “asm” 使用了它们(因为它们被显式地指定为约束了)。如果指令隐式或显式地使用了任何其他寄存器,(并且寄存器没有出现在输出或者输出约束列表里),那么就需要在修饰寄存器列表中指定这些寄存器。
|
||||
|
||||
如果我们的指令可以修改条件码寄存器(cc),我们必须将 "cc" 添加进修饰寄存器列表。
|
||||
|
||||
如果我们的指令以不可预测的方式修改了内存,那么需要将 "memory" 添加进修饰寄存器列表。这可以使 GCC 不会在汇编指令间保持缓存于寄存器的内存值。如果被影响的内存不在汇编的输入或输出列表中,我们也必须添加 **volatile** 关键词。
|
||||
|
||||
我们可以按我们的需求多次读写修饰寄存器。参考一下模板内的多指令示例;它假设子例程 _foo 接受寄存器 `eax` 和 `ecx` 里的参数。
|
||||
|
||||
```
|
||||
asm ("movl %0,%%eax;
|
||||
movl %1,%%ecx;
|
||||
call _foo"
|
||||
: /* no outputs */
|
||||
: "g" (from), "g" (to)
|
||||
: "eax", "ecx"
|
||||
);
|
||||
```
|
||||
|
||||
### 5.4 Volatile ...?
|
||||
|
||||
如果你熟悉内核源码或者类似漂亮的代码,你一定见过许多声明为 `volatile` 或者 `__volatile__`的函数,其跟着一个 `asm` 或者 `__asm__`。我之前提到过关键词 `asm` 和 `__asm__`。那么什么是 `volatile` 呢?
|
||||
|
||||
如果我们的汇编语句必须在我们放置它的地方执行(例如,不能为了优化而被移出循环语句),将关键词 `volatile` 放置在 asm 后面、()的前面。以防止它被移动、删除或者其他操作,我们将其声明为 `asm volatile ( ... : ... : ... : ...);`
|
||||
|
||||
如果担心发生冲突,请使用 `__volatile__`。
|
||||
|
||||
如果我们的汇编只是用于一些计算并且没有任何副作用,不使用 `volatile` 关键词会更好。不使用 `volatile` 可以帮助 gcc 优化代码并使代码更漂亮。
|
||||
|
||||
|
||||
在“一些实用的诀窍”一节中,我提供了多个内联汇编函数的例子。那里我们可以了解到修饰寄存器列表的细节。
|
||||
|
||||
* * *
|
||||
|
||||
## 6. 更多关于约束
|
||||
|
||||
到这个时候,你可能已经了解到约束和内联汇编有很大的关联。但我们对约束讲的还不多。约束用于表明一个操作数是否可以位于寄存器和位于哪种寄存器;操作数是否可以为一个内存引用和哪种地址;操作数是否可以为一个立即数和它可能的取值范围(即值的范围),等等。
|
||||
|
||||
### 6.1 常用约束
|
||||
|
||||
在许多约束中,只有小部分是常用的。我们来看看这些约束。
|
||||
|
||||
1. **寄存器操作数约束(r)**
|
||||
|
||||
当使用这种约束指定操作数时,它们存储在通用寄存器(GPR)中。请看下面示例:
|
||||
|
||||
`asm ("movl %%eax, %0\n" :"=r"(myval));`
|
||||
|
||||
这里,变量 myval 保存在寄存器中,寄存器 eax 的值被复制到该寄存器中,并且 myval 的值从寄存器更新到了内存。当指定 "r" 约束时, gcc 可以将变量保存在任何可用的 GPR 中。要指定寄存器,你必须使用特定寄存器约束直接地指定寄存器的名字。它们为:
|
||||
|
||||
```
|
||||
+---+--------------------+
|
||||
| r | Register(s) |
|
||||
+---+--------------------+
|
||||
| a | %eax, %ax, %al |
|
||||
| b | %ebx, %bx, %bl |
|
||||
| c | %ecx, %cx, %cl |
|
||||
| d | %edx, %dx, %dl |
|
||||
| S | %esi, %si |
|
||||
| D | %edi, %di |
|
||||
+---+--------------------+
|
||||
```
|
||||
|
||||
2. **内存操作数约束(m)**
|
||||
|
||||
当操作数位于内存时,任何对它们的操作将直接发生在内存位置,这与寄存器约束相反,后者首先将值存储在要修改的寄存器中,然后将它写回到内存位置。但寄存器约束通常用于一个指令必须使用它们或者它们可以大大提高处理速度的地方。当需要在 “asm” 内更新一个 C 变量,而又不想使用寄存器去保存它的值,使用内存最为有效。例如,IDTR 寄存器的值存储于内存位置 loc 处:
|
||||
|
||||
`asm("sidt %0\n" : :"m"(loc));`
|
||||
|
||||
3. **匹配(数字)约束**
|
||||
|
||||
在某些情况下,一个变量可能既充当输入操作数,也充当输出操作数。可以通过使用匹配约束在 "asm" 中指定这种情况。
|
||||
|
||||
`asm ("incl %0" :"=a"(var):"0"(var));`
|
||||
|
||||
在操作数那一节中,我们也看到了一些类似的示例。在这个匹配约束的示例中,寄存器 "%eax" 既用作输入变量,也用作输出变量。 var 输入被读进 %eax,并且等递增后更新的 %eax 再次被存储进 var。这里的 "0" 用于指定与第 0 个输出变量相同的约束。也就是,它指定 var 输出实例应只被存储在 "%eax" 中。该约束可用于:
|
||||
- 在输入从变量读取或变量修改后且修改被写回同一变量的情况
|
||||
- 在不需要将输入操作数实例和输出操作数实例分开的情况
|
||||
|
||||
使用匹配约束最重要的意义在于它们可以有效地使用可用寄存器。
|
||||
|
||||
其他一些约束:
|
||||
|
||||
1. "m" : 允许一个内存操作数,可以使用机器普遍支持的任一种地址。
|
||||
2. "o" : 允许一个内存操作数,但只有当地址是可偏移的。即,该地址加上一个小的偏移量可以得到一个有效地址。
|
||||
3. "V" : 一个不允许偏移的内存操作数。换言之,任何适合 "m" 约束而不适合 "o" 约束的操作数。
|
||||
4. "i" : 允许一个(带有常量)的立即整形操作数。这包括其值仅在汇编时期知道的符号常量。
|
||||
5. "n" : 允许一个带有已知数字的立即整形操作数。许多系统不支持汇编时期的常量,因为操作数少于一个字宽。对于此种操作数,约束应该使用 'n' 而不是'i'。
|
||||
6. "g" : 允许任一寄存器、内存或者立即整形操作数,不包括通用寄存器之外的寄存器。
|
||||
|
||||
以下约束为 x86 特有。
|
||||
|
||||
1. "r" : 寄存器操作数约束,查看上面给定的表格。
|
||||
2. "q" : 寄存器 a、b、c 或者 d。
|
||||
3. "I" : 范围从 0 到 31 的常量(对于 32 位移位)。
|
||||
4. "J" : 范围从 0 到 63 的常量(对于 64 位移位)。
|
||||
5. "K" : 0xff。
|
||||
6. "L" : 0xffff。
|
||||
7. "M" : 0、1、2 或 3 (lea 指令的移位)。
|
||||
8. "N" : 范围从 0 到 255 的常量(对于 out 指令)。
|
||||
9. "f" : 浮点寄存器
|
||||
10. "t" : 第一个(栈顶)浮点寄存器
|
||||
11. "u" : 第二个浮点寄存器
|
||||
12. "A" : 指定 `a` 或 `d` 寄存器。这主要用于想要返回 64 位整形数,使用 `d` 寄存器保存最高有效位和 `a` 寄存器保存最低有效位。
|
||||
|
||||
### 6.2 约束修饰符
|
||||
|
||||
当使用约束时,对于更精确的控制超过了对约束作用的需求,GCC 给我们提供了约束修饰符。最常用的约束修饰符为:
|
||||
|
||||
1. "=" : 意味着对于这条指令,操作数为只写的;旧值会被忽略并被输出数据所替换。
|
||||
2. "&" : 意味着这个操作数为一个早期改动的操作数,其在该指令完成前通过使用输入操作数被修改了。因此,这个操作数不可以位于一个被用作输出操作数或任何内存地址部分的寄存器。如果在旧值被写入之前它仅用作输入而已,一个输入操作数可以为一个早期改动操作数。
|
||||
|
||||
上述的约束列表和解释并不完整。示例可以让我们对内联汇编的用途和用法更好的理解。在下一节,我们会看到一些示例,在那里我们会发现更多关于修饰寄存器列表的东西。
|
||||
|
||||
* * *
|
||||
|
||||
## 7. 一些实用的诀窍
|
||||
|
||||
现在我们已经介绍了关于 GCC 内联汇编的基础理论,现在我们将专注于一些简单的例子。将内联汇编函数写成宏的形式总是非常方便的。我们可以在 Linux 内核代码里看到许多汇编函数。(usr/src/linux/include/asm/*.h)。
|
||||
|
||||
1. 首先我们从一个简单的例子入手。我们将写一个两个数相加的程序。
|
||||
|
||||
```
|
||||
int main(void)
|
||||
{
|
||||
int foo = 10, bar = 15;
|
||||
__asm__ __volatile__("addl %%ebx,%%eax"
|
||||
:"=a"(foo)
|
||||
:"a"(foo), "b"(bar)
|
||||
);
|
||||
printf("foo+bar=%d\n", foo);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
这里我们要求 GCC 将 foo 存放于 %eax,将 bar 存放于 %ebx,同时我们也想要在 %eax 中存放结果。'=' 符号表示它是一个输出寄存器。现在我们可以以其他方式将一个整数加到一个变量。
|
||||
|
||||
```
|
||||
__asm__ __volatile__(
|
||||
" lock ;\n"
|
||||
" addl %1,%0 ;\n"
|
||||
: "=m" (my_var)
|
||||
: "ir" (my_int), "m" (my_var)
|
||||
: /* 无修饰寄存器列表 */
|
||||
);
|
||||
```
|
||||
|
||||
这是一个原子加法。为了移除原子性,我们可以移除指令 'lock'。在输出域中,"=m" 表明 my_var 是一个输出且位于内存。类似地,"ir" 表明 my_int 是一个整型,并应该存在于其他寄存器(回想我们上面看到的表格)。没有寄存器位于修饰寄存器列表中。
|
||||
|
||||
2. 现在我们将在一些寄存器/变量上展示一些操作,并比较值。
|
||||
|
||||
```
|
||||
__asm__ __volatile__( "decl %0; sete %1"
|
||||
: "=m" (my_var), "=q" (cond)
|
||||
: "m" (my_var)
|
||||
: "memory"
|
||||
);
|
||||
```
|
||||
|
||||
这里,my_var 的值减 1 ,并且如果结果的值为 0,则变量 cond 置 1。我们可以通过将指令 "lock;\n\t" 添加为汇编模板的第一条指令以增加原子性。
|
||||
|
||||
以类似的方式,为了增加 my_var,我们可以使用 "incl %0" 而不是 "decl %0"。
|
||||
|
||||
这里需要注意的地方是(i)my_var 是一个存储于内存的变量。(ii)cond 位于寄存器 eax、ebx、ecx、edx 中的任何一个。约束 "=q" 保证了这一点。(iii)同时我们可以看到 memory 位于修饰寄存器列表中。也就是说,代码将改变内存中的内容。
|
||||
|
||||
3. 如何置 1 或清 0 寄存器中的一个比特位。作为下一个诀窍,我们将会看到它。
|
||||
|
||||
```
|
||||
__asm__ __volatile__( "btsl %1,%0"
|
||||
: "=m" (ADDR)
|
||||
: "Ir" (pos)
|
||||
: "cc"
|
||||
);
|
||||
```
|
||||
|
||||
这里,ADDR 变量(一个内存变量)的 'pos' 位置上的比特被设置为 1。我们可以使用 'btrl' 来清除由 'btsl' 设置的比特位。pos 的约束 "Ir" 表明 pos 位于寄存器,并且它的值为 0-31(x86 相关约束)。也就是说,我们可以设置/清除 ADDR 变量上第 0 到 31 位的任一比特位。因为条件码会被改变,所以我们将 "cc" 添加进修饰寄存器列表。
|
||||
|
||||
4. 现在我们看看一些更为复杂而有用的函数。字符串拷贝。
|
||||
|
||||
```
|
||||
static inline char * strcpy(char * dest,const char *src)
|
||||
{
|
||||
int d0, d1, d2;
|
||||
__asm__ __volatile__( "1:\tlodsb\n\t"
|
||||
"stosb\n\t"
|
||||
"testb %%al,%%al\n\t"
|
||||
"jne 1b"
|
||||
: "=&S" (d0), "=&D" (d1), "=&a" (d2)
|
||||
: "0" (src),"1" (dest)
|
||||
: "memory");
|
||||
return dest;
|
||||
}
|
||||
```
|
||||
|
||||
源地址存放于 esi,目标地址存放于 edi,同时开始拷贝,当我们到达 **0** 时,拷贝完成。约束 "&S"、"&D"、"&a" 表明寄存器 esi、edi 和 eax 早期修饰寄存器,也就是说,它们的内容在函数完成前会被改变。这里很明显可以知道为什么 "memory" 会放在修饰寄存器列表。
|
||||
|
||||
我们可以看到一个类似的函数,它能移动双字块数据。注意函数被声明为一个宏。
|
||||
|
||||
```
|
||||
#define mov_blk(src, dest, numwords) \
|
||||
__asm__ __volatile__ ( \
|
||||
"cld\n\t" \
|
||||
"rep\n\t" \
|
||||
"movsl" \
|
||||
: \
|
||||
: "S" (src), "D" (dest), "c" (numwords) \
|
||||
: "%ecx", "%esi", "%edi" \
|
||||
)
|
||||
```
|
||||
|
||||
这里我们没有输出,寄存器 ecx、esi和 edi 的内容发生了改变,这是块移动的副作用。因此我们必须将它们添加进修饰寄存器列表。
|
||||
|
||||
5. 在 Linux 中,系统调用使用 GCC 内联汇编实现。让我们看看如何实现一个系统调用。所有的系统调用被写成宏(linux/unistd.h)。例如,带有三个参数的系统调用被定义为如下所示的宏。
|
||||
|
||||
```
|
||||
type name(type1 arg1,type2 arg2,type3 arg3) \
|
||||
{ \
|
||||
long __res; \
|
||||
__asm__ volatile ( "int $0x80" \
|
||||
: "=a" (__res) \
|
||||
: "0" (__NR_##name),"b" ((long)(arg1)),"c" ((long)(arg2)), \
|
||||
"d" ((long)(arg3))); \
|
||||
__syscall_return(type,__res); \
|
||||
}
|
||||
```
|
||||
|
||||
无论何时调用带有三个参数的系统调用,以上展示的宏就会用于执行调用。系统调用号位于 eax 中,每个参数位于 ebx、ecx、edx 中。最后 "int 0x80" 是一条用于执行系统调用的指令。返回值被存储于 eax 中。
|
||||
|
||||
每个系统调用都以类似的方式实现。Exit 是一个单一参数的系统调用,让我们看看它的代码看起来会是怎样。它如下所示。
|
||||
|
||||
```
|
||||
{
|
||||
asm("movl $1,%%eax; /* SYS_exit is 1 */
|
||||
xorl %%ebx,%%ebx; /* Argument is in ebx, it is 0 */
|
||||
int $0x80" /* Enter kernel mode */
|
||||
);
|
||||
}
|
||||
```
|
||||
|
||||
Exit 的系统调用号是 1,同时它的参数是 0。因此我们分配 eax 包含 1,ebx 包含 0,同时通过 `int $0x80` 执行 `exit(0)`。这就是 exit 的工作原理。
|
||||
|
||||
* * *
|
||||
|
||||
## 8. 结束语
|
||||
|
||||
这篇文档已经将 GCC 内联汇编过了一遍。一旦你理解了基本概念,你就可以按照自己的需求去使用它们了。我们看了许多例子,它们有助于理解 GCC 内联汇编的常用特性。
|
||||
|
||||
GCC 内联是一个极大的主题,这篇文章是不完整的。更多关于我们讨论过的语法细节可以在 GNU 汇编器的官方文档上获取。类似地,要获取完整的约束列表,可以参考 GCC 的官方文档。
|
||||
|
||||
当然,Linux 内核大量地使用了 GCC 内联。因此我们可以在内核源码中发现许多各种各样的例子。它们可以帮助我们很多。
|
||||
|
||||
如果你发现任何的错别字,或者本文中的信息已经过时,请告诉我们。
|
||||
|
||||
* * *
|
||||
|
||||
## 9. 参考
|
||||
|
||||
1. [Brennan’s Guide to Inline Assembly](http://www.delorie.com/djgpp/doc/brennan/brennan_att_inline_djgpp.html)
|
||||
2. [Using Assembly Language in Linux](http://linuxassembly.org/articles/linasm.html)
|
||||
3. [Using as, The GNU Assembler](http://www.gnu.org/manual/gas-2.9.1/html_mono/as.html)
|
||||
4. [Using and Porting the GNU Compiler Collection (GCC)](http://gcc.gnu.org/onlinedocs/gcc_toc.html)
|
||||
5. [Linux Kernel Source](http://ftp.kernel.org/)
|
||||
|
||||
* * *
|
||||
|
||||
via: http://www.ibiblio.org/gferg/ldp/GCC-Inline-Assembly-HOWTO.html
|
||||
|
||||
作者:[Sandeep.S](mailto:busybox@sancharnet.in) 译者:[cposture](https://github.com/cposture) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,161 @@
|
||||
5 个最受人喜爱的开源 Django 包
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
图片来源:Opensource.com
|
||||
|
||||
_Jacob Kaplan-Moss 和 Frank Wiles 也参与了本文的写作。_
|
||||
|
||||
Django 围绕“[可重用应用][1]”的思想建立:自包含的包提供了可重复使用的特性。你可以将这些可重用应用组装起来,在加上适用于你的网站的特定代码,来搭建你自己的网站。Django 具有一个丰富多样的、由可供你使用的可重用应用组建起来的生态系统——PyPI 列出了[超过 8000个 Django 应用][2]——可你该如何知道哪些是最好的呢?
|
||||
|
||||
为了节省你的时间,我们总结了五个最受喜爱的 Django 应用。它们是:
|
||||
|
||||
- [Cookiecutter][3]: 建立 Django 网站的最佳方式。
|
||||
- [Whitenoise][4]: 最棒的静态资源服务器。
|
||||
- [Django Rest Framework][5]: 使用 Django 开发 REST API 的最佳方式。
|
||||
- [Wagtail][6]: 基于 Django 的最佳内容管理系统(CMS)。
|
||||
- [django-allauth][7]: 提供社交账户登录的最佳应用(如 Twitter, Facebook, GitHub 等)。
|
||||
|
||||
我们同样推荐你看看 [Django Packages][8],这是一个可重用 Django 应用的目录。Django Packages 将 Django 应用组织成“表格”,你可以在功能相似的不同应用之间进行比较并做出选择。你可以查看每个包中提供的特性和使用统计情况。(比如:这是[ REST 工具的表格][9],也许可以帮助你理解我们为何推荐 Django REST Framework。
|
||||
|
||||
### 为什么你应该相信我们?
|
||||
|
||||
我们使用 Django 的时间几乎比任何人都长。在 Django 发布之前,我们当中的两个人(Frank 和 Jacob)就在 [Lawrence Journal-World][10] (Django 的发源地)工作(事实上,是他们两人推动了 Django 开源发布的进程)。我们在过去的八年当中运行着一个咨询公司,来建议公司怎样最好地应用 Django。
|
||||
|
||||
所以,我们见证了 Django 项目和社群的完整历史,我们见证了那些流行的软件包的兴起和没落。在我们三个之中,我们个人可能试用了 8000 个应用中至少一半以上,或者我们知道谁试用过这些。我们对如何使应用变得坚实可靠有着深刻的理解,并且我们对给予这些应用持久力量的来源也有着深入的了解。
|
||||
|
||||
### 建立 Django 网站的最佳方式:[Cookiecutter][3]
|
||||
|
||||
建立一个新项目或应用总是有些痛苦。你可以用 Django 内建的 `startproject`。不过,如果你像我们一样,对如何做事比较挑剔。Cookiecutter 为你提供了一个快捷简单的方式来构建项目或易于重用的应用模板,从而解决了这个问题。一个简单的例子:键入 `pip install cookiecutter`,然后在命令行中运行以下命令:
|
||||
|
||||
```bash
|
||||
$ cookiecutter https://github.com/marcofucci/cookiecutter-simple-django
|
||||
```
|
||||
|
||||
接下来你需要回答几个简单的问题,比如你的项目名称、目录(repo)、作者名字、E-Mail 和其他几个关于配置的小问题。这些能够帮你补充项目相关的细节。我们使用最最原始的 “_foo_” 作为我们的目录名称。所以 cokkiecutter 在子目录 “_foo_” 下建立了一个简单的 Django 项目。
|
||||
|
||||
如果你在 “_foo_” 项目中闲逛,你会看见你刚刚选择的其它设置已通过模板,连同所需的子目录一同嵌入到文件当中。这个“模板”在我们刚刚在执行 `cookiecutter` 命令时输入的唯一一个参数 Github 仓库 URL 中定义。这个样例工程使用了一个 Github 远程仓库作为模板;不过你也可以使用本地的模板,这在建立非重用项目时非常有用。
|
||||
|
||||
我们认为 cookiecutter 是一个极棒的 Django 包,但是,事实上其实它在面对纯 Python 甚至非 Python 相关需求时也极为有用。你能够将所有文件以一种可重复的方式精确地摆放在任何位置上,使得 cookiecutter 成为了一个简化(DRY)工作流程的极佳工具。
|
||||
|
||||
### 最棒的静态资源服务器:[Whitenoise][4]
|
||||
|
||||
多年来,托管网站的静态资源——图片、Javascript、CSS——都是一件很痛苦的事情。Django 内建的 [django.views.static.serve][11] 视图,就像 Django 文章所述的那样,“在生产环境中不可靠,所以只应为开发环境的提供辅助功能。”但使用一个“真正的” Web 服务器,如 NGINX 或者借助 CDN 来托管媒体资源,配置起来会比较困难。
|
||||
|
||||
Whitenoice 很简洁地解决了这个问题。它可以像在开发环境那样轻易地在生产环境中设置静态服务器,并且针对生产环境进行了加固和优化。它的设置方法极为简单:
|
||||
|
||||
1. 确保你在使用 Django 的 [contrib.staticfiles][12] 应用,并确认你在配置文件中正确设置了 `STATIC_ROOT` 变量。
|
||||
|
||||
2. 在 `wsgi.py` 文件中启用 Whitenoise:
|
||||
|
||||
```python
|
||||
from django.core.wsgi import get_wsgi_application
|
||||
from whitenoise.django import DjangoWhiteNoise
|
||||
|
||||
application = get_wsgi_application()
|
||||
application = DjangoWhiteNoise(application)
|
||||
```
|
||||
|
||||
配置它真的就这么简单!对于大型应用,你可能想要使用一个专用的媒体服务器和/或一个 CDN,但对于大多数小型或中型 Django 网站,Whitenoise 已经足够强大。
|
||||
|
||||
如需查看更多关于 Whitenoise 的信息,[请查看文档][13]。
|
||||
|
||||
### 开发 REST API 的最佳工具:[Django REST Framework][5]
|
||||
|
||||
REST API 正在迅速成为现代 Web 应用的标准功能。 API 就是简单的使用 JSON 对话而不是 HTML,当然你可以只用 Django 做到这些。你可以制作自己的视图,设置合适的 `Content-Type`,然后返回 JSON 而不是渲染后的 HTML 响应。这是在像 [Django Rest Framework][14](下称 DRF)这样的 API 框架发布之前,大多数人所做的。
|
||||
|
||||
如果你对 Django 的视图类很熟悉,你会觉得使用 DRF 构建 REST API 与使用它们很相似,不过 DRF 只针对特定 API 使用场景而设计。一般的 API 设置只需要一点代码,所以我们没有提供一份让你兴奋的示例代码,而是强调了一些可以让你生活的更舒适的 DRF 特性:
|
||||
|
||||
* 可自动预览的 API 可以使你的开发和人工测试轻而易举。你可以查看 DRF 的[示例代码][15]。你可以查看 API 响应,并且不需要你做任何事就可以支持 POST/PUT/DELETE 类型的操作。
|
||||
* 便于集成各种认证方式,如 OAuth, Basic Auth, 或API Tokens。
|
||||
* 内建请求速率限制。
|
||||
* 当与 [django-rest-swagger][16] 组合使用时,API 文档几乎可以自动生成。
|
||||
* 广泛的第三方库生态。
|
||||
|
||||
当然,你可以不依赖 DRF 来构建 API,但我们无法想象你不去使用 DRF 的原因。就算你不使用 DRF 的全部特性,使用一个成熟的视图库来构建你自己的 API 也会使你的 API 更加一致、完全,更能提高你的开发速度。如果你还没有开始使用 DRF, 你应该找点时间去体验一下。
|
||||
|
||||
### 基于 Django 的最佳 CMS:[Wagtail][6]
|
||||
|
||||
Wagtail 是当下 Django CMS(内容管理系统)世界中最受人青睐的应用,并且它的热门有足够的理由。就像大多数的 CMS 一样,它具有极佳的灵活性,可以通过简单的 Django 模型来定义不同类型的页面及其内容。使用它,你可以从零开始在几个小时而不是几天之内来和建造一个基本可以运行的内容管理系统。举一个小例子,为你公司的员工定义一个员工页面类型可以像下面一样简单:
|
||||
|
||||
```python
|
||||
from wagtail.wagtailcore.models import Page
|
||||
from wagtail.wagtailcore.fields import RichTextField
|
||||
from wagtail.wagtailadmin.edit_handlers import FieldPanel, MultiFieldPanel
|
||||
from wagtail.wagtailimages.edit_handlers import ImageChooserPanel
|
||||
|
||||
class StaffPage(Page):
|
||||
name = models.CharField(max_length=100)
|
||||
hire_date = models.DateField()
|
||||
bio = models.RichTextField()
|
||||
email = models.EmailField()
|
||||
headshot = models.ForeignKey('wagtailimages.Image', null=True, blank=True)
|
||||
content_panels = Page.content_panels + [
|
||||
FieldPanel('name'),
|
||||
FieldPanel('hire_date'),
|
||||
FieldPanel('email'),
|
||||
FieldPanel('bio',classname="full"),
|
||||
ImageChoosePanel('headshot'),
|
||||
]
|
||||
```
|
||||
|
||||
然而,Wagtail 真正出彩的地方在于它的灵活性及其易于使用的现代化管理页面。你可以控制不同类型的页面在哪网站的哪些区域可以访问,为页面添加复杂的附加逻辑,还天生就支持标准的适应/审批工作流。在大多数 CMS 系统中,你会在开发时在某些点上遇到困难。而使用 Wagtail 时,我们经过不懈努力找到了一个突破口,使得让我们轻易地开发出一套简洁稳定的系统,使得程序完全依照我们的想法运行。如果你对此感兴趣,我们写了一篇[深入理解 Wagtail][17。
|
||||
|
||||
### 提供社交账户登录的最佳工具:[django-allauth][7]
|
||||
|
||||
django-allauth 是一个能够解决你的注册和认证需求的、可重用的 Django 应用。无论你需要构建本地注册系统还是社交账户注册系统,django-allauth 都能够帮你做到。
|
||||
|
||||
这个应用支持多种认证体系,比如用户名或电子邮件。一旦用户注册成功,它还可以提供从无需认证到电子邮件认证的多种账户验证的策略。同时,它也支持多种社交账户和电子邮件账户。它还支持插拔式注册表单,可让用户在注册时回答一些附加问题。
|
||||
|
||||
django-allauth 支持多于 20 种认证提供者,包括 Facebook、Github、Google 和 Twitter。如果你发现了一个它不支持的社交网站,很有可能通过第三方插件提供该网站的接入支持。这个项目还支持自定义后端,可以支持自定义的认证方式,对每个有定制认证需求的人来说这都很棒。
|
||||
|
||||
django-allauth 易于配置,且有[完善的文档][18]。该项目通过了很多测试,所以你可以相信它的所有部件都会正常运作。
|
||||
|
||||
你有最喜爱的 Django 包吗?请在评论中告诉我们。
|
||||
|
||||
### 关于作者
|
||||
|
||||

|
||||
|
||||
*Jeff Triplett 劳伦斯,堪萨斯州 <http://www.jefftriplett.com/>*
|
||||
|
||||
我在 2007 年搬到了堪萨斯州的劳伦斯,在 Django 的发源地—— Lawrence Journal-World 工作。我现在在劳伦斯市的 [Revolution Systems (Revsys)][19] 工作,做一位开发者兼顾问。
|
||||
|
||||
我是[北美 Django 运动基金会(DEFNA)][20]的联合创始人,2015 和 2016 年 [DjangoCon US][21] 的会议主席,而且我在 Django 的发源地劳伦斯参与组织了 [Django Birthday][22] 来庆祝 Django 的 10 岁生日。
|
||||
|
||||
我是当地越野跑小组的成员,我喜欢篮球,我还喜欢梦见自己随着一道气流游遍美国。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/15/12/5-favorite-open-source-django-packages
|
||||
|
||||
作者:[Jeff Triplett][a]
|
||||
译者:[StdioA](https://github.com/StdioA)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jefftriplett
|
||||
[1]:https://docs.djangoproject.com/en/1.8/intro/reusable-apps/
|
||||
[2]:https://pypi.python.org/pypi?:action=browse&c=523
|
||||
[3]:https://github.com/audreyr/cookiecutter
|
||||
[4]:http://whitenoise.evans.io/en/latest/base.html
|
||||
[5]:http://www.django-rest-framework.org/
|
||||
[6]:https://wagtail.io/
|
||||
[7]:http://www.intenct.nl/projects/django-allauth/
|
||||
[8]:https://www.djangopackages.com/
|
||||
[9]:https://www.djangopackages.com/grids/g/rest/
|
||||
[10]:http://www2.ljworld.com/news/2015/jul/09/happy-birthday-django/
|
||||
[11]:https://docs.djangoproject.com/en/1.8/ref/views/#django.views.static.serve
|
||||
[12]:https://docs.djangoproject.com/en/1.8/ref/contrib/staticfiles/
|
||||
[13]:http://whitenoise.evans.io/en/latest/index.html
|
||||
[14]:http://www.django-rest-framework.org/
|
||||
[15]:http://restframework.herokuapp.com/
|
||||
[16]:http://django-rest-swagger.readthedocs.org/en/latest/index.html
|
||||
[17]:https://opensource.com/business/15/5/wagtail-cms
|
||||
[18]:http://django-allauth.readthedocs.org/en/latest/
|
||||
[19]:http://www.revsys.com/
|
||||
[20]:http://defna.org/
|
||||
[21]:https://2015.djangocon.us/
|
||||
[22]:https://djangobirthday.com/
|
||||
150
published/201608/20160309 Let’s Build A Web Server. Part 1.md
Normal file
150
published/201608/20160309 Let’s Build A Web Server. Part 1.md
Normal file
@ -0,0 +1,150 @@
|
||||
搭个 Web 服务器(一)
|
||||
=====================================
|
||||
|
||||
一天,有一个正在散步的妇人恰好路过一个建筑工地,看到三个正在工作的工人。她问第一个人:“你在做什么?”第一个人没好气地喊道:“你没看到我在砌砖吗?”妇人对这个答案不满意,于是问第二个人:“你在做什么?”第二个人回答说:“我在建一堵砖墙。”说完,他转向第一个人,跟他说:“嗨,你把墙砌过头了。去把刚刚那块砖弄下来!”然而,妇人对这个答案依然不满意,于是又问了第三个人相同的问题。第三个人仰头看着天,对她说:“我在建造世界上最大的教堂。”当他回答时,第一个人和第二个人在为刚刚砌错的砖而争吵。他转向那两个人,说:“不用管那块砖了。这堵墙在室内,它会被水泥填平,没人会看见它的。去砌下一层吧。”
|
||||
|
||||
这个故事告诉我们:如果你能够理解整个系统的构造,了解系统的各个部件如何相互结合(如砖、墙还有整个教堂),你就能够更快地定位及修复问题(那块砌错的砖)。
|
||||
|
||||
如果你想从头开始创造一个 Web 服务器,那么你需要做些什么呢?
|
||||
|
||||
我相信,如果你想成为一个更好的开发者,你**必须**对日常使用的软件系统的内部结构有更深的理解,包括编程语言、编译器与解释器、数据库及操作系统、Web 服务器及 Web 框架。而且,为了更好更深入地理解这些系统,你**必须**从头开始,用一砖一瓦来重新构建这个系统。
|
||||
|
||||
荀子曾经用这几句话来表达这种思想:
|
||||
|
||||
>“不闻不若闻之。(I hear and I forget.)”
|
||||
|
||||
|
||||
|
||||
>“闻之不若见之。(I see and I remember.)”
|
||||
|
||||
|
||||
|
||||
>“知之不若行之。(I do and I understand.)”
|
||||
|
||||
|
||||
|
||||
我希望你现在能够意识到,重新建造一个软件系统来了解它的工作方式是一个好主意。
|
||||
|
||||
在这个由三篇文章组成的系列中,我将会教你构建你自己的 Web 服务器。我们开始吧~
|
||||
|
||||
先说首要问题:Web 服务器是什么?
|
||||
|
||||
|
||||
|
||||
简而言之,它是一个运行在一个物理服务器上的网络服务器(啊呀,服务器套服务器),等待客户端向其发送请求。当它接收请求后,会生成一个响应,并回送至客户端。客户端和服务端之间通过 HTTP 协议来实现相互交流。客户端可以是你的浏览器,也可以是使用 HTTP 协议的其它任何软件。
|
||||
|
||||
最简单的 Web 服务器实现应该是什么样的呢?这里我给出我的实现。这个例子由 Python 写成,即使你没听说过 Python(它是一门超级容易上手的语言,快去试试看!),你也应该能够从代码及注释中理解其中的理念:
|
||||
|
||||
```
|
||||
import socket
|
||||
|
||||
HOST, PORT = '', 8888
|
||||
|
||||
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||||
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||||
listen_socket.bind((HOST, PORT))
|
||||
listen_socket.listen(1)
|
||||
print 'Serving HTTP on port %s ...' % PORT
|
||||
while True:
|
||||
client_connection, client_address = listen_socket.accept()
|
||||
request = client_connection.recv(1024)
|
||||
print request
|
||||
|
||||
http_response = """\
|
||||
HTTP/1.1 200 OK
|
||||
|
||||
Hello, World!
|
||||
"""
|
||||
client_connection.sendall(http_response)
|
||||
client_connection.close()
|
||||
```
|
||||
|
||||
将以上代码保存为 webserver1.py,或者直接从 [GitHub][1] 上下载这个文件。然后,在命令行中运行这个程序。像这样:
|
||||
|
||||
```
|
||||
$ python webserver1.py
|
||||
Serving HTTP on port 8888 …
|
||||
```
|
||||
|
||||
现在,在你的网页浏览器的地址栏中输入 URL:http://localhost:8888/hello ,敲一下回车,然后来见证奇迹。你应该看到“Hello, World!”显示在你的浏览器中,就像下图那样:
|
||||
|
||||
|
||||
|
||||
说真的,快去试一试。你做实验的时候,我会等着你的。
|
||||
|
||||
完成了?不错!现在我们来讨论一下它实际上是怎么工作的。
|
||||
|
||||
首先我们从你刚刚输入的 Web 地址开始。它叫 [URL][2],这是它的基本结构:
|
||||
|
||||
|
||||
|
||||
URL 是一个 Web 服务器的地址,浏览器用这个地址来寻找并连接 Web 服务器,并将上面的内容返回给你。在你的浏览器能够发送 HTTP 请求之前,它需要与 Web 服务器建立一个 TCP 连接。然后会在 TCP 连接中发送 HTTP 请求,并等待服务器返回 HTTP 响应。当你的浏览器收到响应后,就会显示其内容,在上面的例子中,它显示了“Hello, World!”。
|
||||
|
||||
我们来进一步探索在发送 HTTP 请求之前,客户端与服务器建立 TCP 连接的过程。为了建立链接,它们使用了所谓“套接字(socket)”。我们现在不直接使用浏览器发送请求,而在命令行中使用 `telnet` 来人工模拟这个过程。
|
||||
|
||||
在你运行 Web 服务器的电脑上,在命令行中建立一个 telnet 会话,指定一个本地域名,使用端口 8888,然后按下回车:
|
||||
|
||||
```
|
||||
$ telnet localhost 8888
|
||||
Trying 127.0.0.1 …
|
||||
Connected to localhost.
|
||||
```
|
||||
|
||||
这个时候,你已经与运行在你本地主机的服务器建立了一个 TCP 连接。在下图中,你可以看到一个服务器从头开始,到能够建立 TCP 连接的基本过程。
|
||||
|
||||
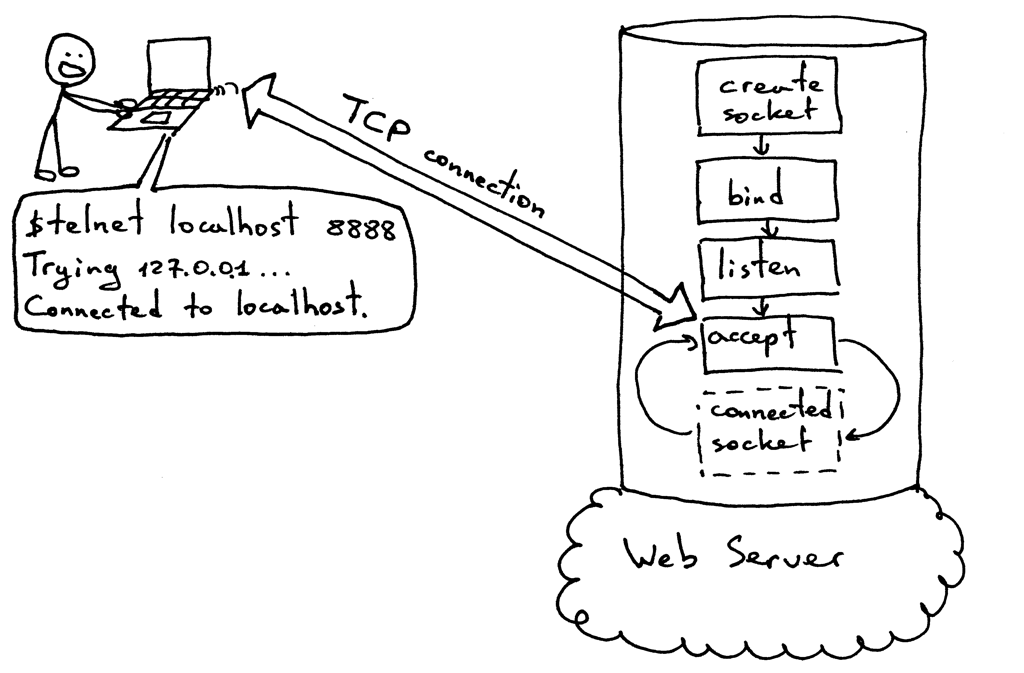
|
||||
|
||||
在同一个 telnet 会话中,输入 `GET /hello HTTP/1.1`,然后输入回车:
|
||||
|
||||
```
|
||||
$ telnet localhost 8888
|
||||
Trying 127.0.0.1 …
|
||||
Connected to localhost.
|
||||
GET /hello HTTP/1.1
|
||||
|
||||
HTTP/1.1 200 OK
|
||||
Hello, World!
|
||||
```
|
||||
|
||||
你刚刚手动模拟了你的浏览器(的工作)!你发送了 HTTP 请求,并且收到了一个 HTTP 应答。下面是一个 HTTP 请求的基本结构:
|
||||
|
||||
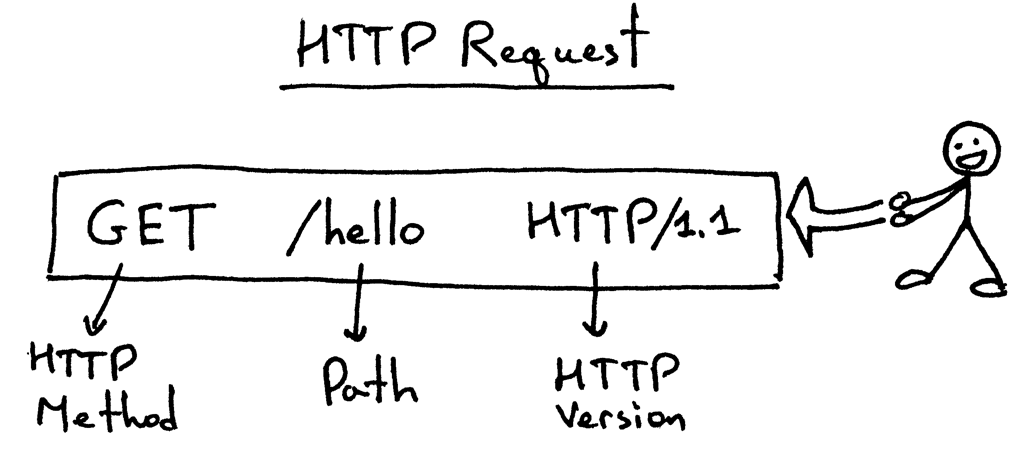
|
||||
|
||||
HTTP 请求的第一行由三部分组成:HTTP 方法(`GET`,因为我们想让我们的服务器返回一些内容),以及标明所需页面的路径 `/hello`,还有协议版本。
|
||||
|
||||
为了简单一些,我们刚刚构建的 Web 服务器完全忽略了上面的请求内容。你也可以试着输入一些无用内容而不是“GET /hello HTTP/1.1”,但你仍然会收到一个“Hello, World!”响应。
|
||||
|
||||
一旦你输入了请求行并敲了回车,客户端就会将请求发送至服务器;服务器读取请求行,就会返回相应的 HTTP 响应。
|
||||
|
||||
下面是服务器返回客户端(在上面的例子里是 telnet)的响应内容:
|
||||
|
||||
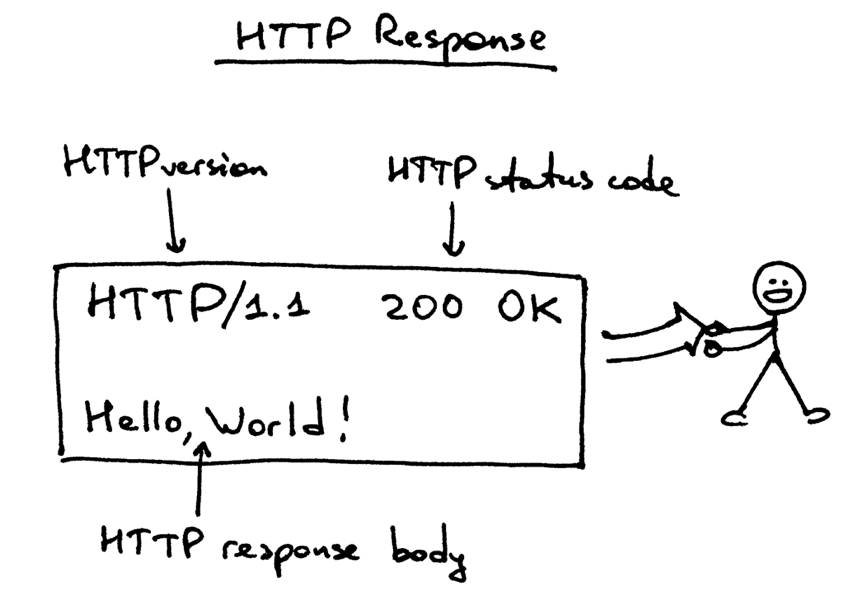
|
||||
|
||||
我们来解析它。这个响应由三部分组成:一个状态行 `HTTP/1.1 200 OK`,后面跟着一个空行,再下面是响应正文。
|
||||
|
||||
HTTP 响应的状态行 HTTP/1.1 200 OK 包含了 HTTP 版本号,HTTP 状态码以及 HTTP 状态短语“OK”。当浏览器收到响应后,它会将响应正文显示出来,这也就是为什么你会在浏览器中看到“Hello, World!”。
|
||||
|
||||
以上就是 Web 服务器的基本工作模型。总结一下:Web 服务器创建一个处于监听状态的套接字,循环接收新的连接。客户端建立 TCP 连接成功后,会向服务器发送 HTTP 请求,然后服务器会以一个 HTTP 响应做应答,客户端会将 HTTP 的响应内容显示给用户。为了建立 TCP 连接,客户端和服务端均会使用套接字。
|
||||
|
||||
现在,你应该了解了 Web 服务器的基本工作方式,你可以使用浏览器或其它 HTTP 客户端进行试验。如果你尝试过、观察过,你应该也能够使用 telnet,人工编写 HTTP 请求,成为一个“人形” HTTP 客户端。
|
||||
|
||||
现在留一个小问题:“你要如何在不对程序做任何改动的情况下,在你刚刚搭建起来的 Web 服务器上适配 Django, Flask 或 Pyramid 应用呢?”
|
||||
|
||||
我会在本系列的第二部分中来详细讲解。敬请期待。
|
||||
|
||||
顺便,我在撰写一本名为《搭个 Web 服务器:从头开始》的书。这本书讲解了如何从头开始编写一个基本的 Web 服务器,里面包含本文中没有的更多细节。订阅邮件列表,你就可以获取到这本书的最新进展,以及发布日期。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ruslanspivak.com/lsbaws-part1/
|
||||
|
||||
作者:[Ruslan][a]
|
||||
译者:[StdioA](https://github.com/StdioA)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://linkedin.com/in/ruslanspivak/
|
||||
[1]: https://github.com/rspivak/lsbaws/blob/master/part1/webserver1.py
|
||||
[2]: http://en.wikipedia.org/wiki/Uniform_resource_locator
|
||||
|
||||
@ -0,0 +1,49 @@
|
||||
伴随 Linux 成长的职业生涯
|
||||
==================================
|
||||
|
||||

|
||||
|
||||
我与 Linux 的故事开始于 1998 年,一直延续到今天。 当时我在 Gap 公司工作,管理着成千台运行着 [OS/2][1] 系统的台式机 ( 在随后的几年里变成了 [Warp 3.0][2])。 作为一个 OS/2 的粉丝,那时我非常喜欢那个时候。 随着这些台式机的嗡鸣,我们使用 Gap 开发的工具轻而易举地就能支撑起对成千的用户的服务支持。 然而,一切都将改变了。
|
||||
|
||||
在 1998 年的 11 月, 我收到邀请加入一个新成立的公司,这家公司将专注于企业级 Linux 上。 这就是后来非常出名的 [Linuxcare][2]。
|
||||
|
||||
### 我在 Linuxcare 的时光
|
||||
|
||||
我曾经接触过一些 Linux , 但我从未想过要把它提供给企业客户。仅仅几个月后 ( 从这里开始成为了空间和时间上的转折点 ), 我就在管理一整条线的业务,让企业获得他们的软件,硬件,甚至是证书认证等各种在当时非常盛行的 Linux 服务。
|
||||
|
||||
我支持的客户包括像 IBM ,Dell ,HP 这样的厂商以确保他们的硬件能够成功的运行 Linux 。 今天你们应该都听过许多关于在硬件上预装 Linux 的事, 但当时 Dell 邀请我去讨论为即将到来的贸易展上将 Linux 运行在认证的笔记本电脑上。 这是多么激动人心的时刻 !同时我们在之后几年内也支持了 IBM 和 HP 等多项认证工作。
|
||||
|
||||
Linux 变化得非常快,并且它总是这样。 它也获得了更多的关键设备的支持,比如声音,网络和图形。在这段时间, 我把个人使用的系统从基于 RPM 的系统换成了 [Debian][3] 。
|
||||
|
||||
### 使用 Linux 的这些年
|
||||
|
||||
几年前我在一些做 Linux 硬件设备、Linux 定制软件以及 Linux 数据中心的公司工作。而在二十世纪中期的时候,那时我正在忙为那些在雷蒙德附近(微软公司所在地)的大一些的软件公司做咨询工作,为他们对比 Linux 解决方案及其自己的解决方案做分析和验证。 我个人使用的系统一直没有改变,我仍会在尽可能的情况下运行 Debian 测试系统。
|
||||
|
||||
我真的非常欣赏发行版的灵活性和永久更新状态。 Debian 是我所使用过的最有趣且拥有良好支持的发行版,并且它拥有最好的社区,而我是社区的一份子。
|
||||
|
||||
当我回首我使用 Linux 的这几年,我仍记得大约在二十世纪前期和中期的时候在圣何塞,旧金山,波士顿和纽约召开的那些 Linux Expo 大会。在 Linuxcare 时我们总是会摆一些有趣而且时髦的展位,在那边逛的时候总会碰到一些老朋友。这一切工作都是需要付出代价的,所有的这一切都是在努力地强调使用 Linux 的乐趣。
|
||||
|
||||
随着虚拟化和云的崛起也让 Linux 变得更加有趣。 当我在 Linuxcare 的时候, 我们常和斯坦福大学附近的帕洛阿尔托的一个约 30 人左右的小公司在一块。我们会开车到他们的办公处,然后帮他们准备和我们一起参加展览的东西。 谁会想得到这个小小的初创公司会成就后来的 VMware ?
|
||||
|
||||
我还有许多的故事,能认识这些人并和他们一起工作我感到很幸运。 Linux 在各方面都不断发展且变得尤为重要。 并且甚至随着它重要性的提升,它使用起来仍然非常有趣。 我认为它的开放性和可定制能力给它带来了大量的新用户,这也是让我感到非常震惊的一点。
|
||||
|
||||
### 现在
|
||||
|
||||
在过去的五年里我的工作重心逐渐离开 Linux。 我所管理的大规模基础设施项目中包含着许多不同的操作系统 ( 包括非开源的和开源的 ), 但我的心一直以来都是和 Linux 在一起的。
|
||||
|
||||
在使用 Linux 过程中的乐趣和不断进步是在过去的 18 年里一直驱动我的动力。我从 Linux 2.0 内核开始看着它变成现在的这样。 Linux 是一个卓越的、生机勃勃的且非常酷的东西。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/3/my-linux-story-michael-perry
|
||||
|
||||
作者:[Michael Perry][a]
|
||||
译者:[chenxinlong](https://github.com/chenxinlong)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
[a]: https://opensource.com/users/mpmilestogo
|
||||
[1]: https://en.wikipedia.org/wiki/OS/2
|
||||
[2]: https://archive.org/details/IBMOS2Warp3Collection
|
||||
[3]: https://en.wikipedia.org/wiki/Linuxcare
|
||||
[4]: https://www.debian.org/
|
||||
[5]:
|
||||
430
published/201608/20160406 Let’s Build A Web Server. Part 2.md
Normal file
430
published/201608/20160406 Let’s Build A Web Server. Part 2.md
Normal file
@ -0,0 +1,430 @@
|
||||
搭个 Web 服务器(二)
|
||||
===================================
|
||||
|
||||
在[第一部分][1]中,我提出了一个问题:“如何在你刚刚搭建起来的 Web 服务器上适配 Django, Flask 或 Pyramid 应用,而不用单独对 Web 服务器做做出改动以适应各种不同的 Web 框架呢?”我们可以从这一篇中找到答案。
|
||||
|
||||
曾几何时,你所选择的 Python Web 框架会限制你所可选择的 Web 服务器,反之亦然。如果某个框架及服务器设计用来协同工作的,那么一切正常:
|
||||
|
||||
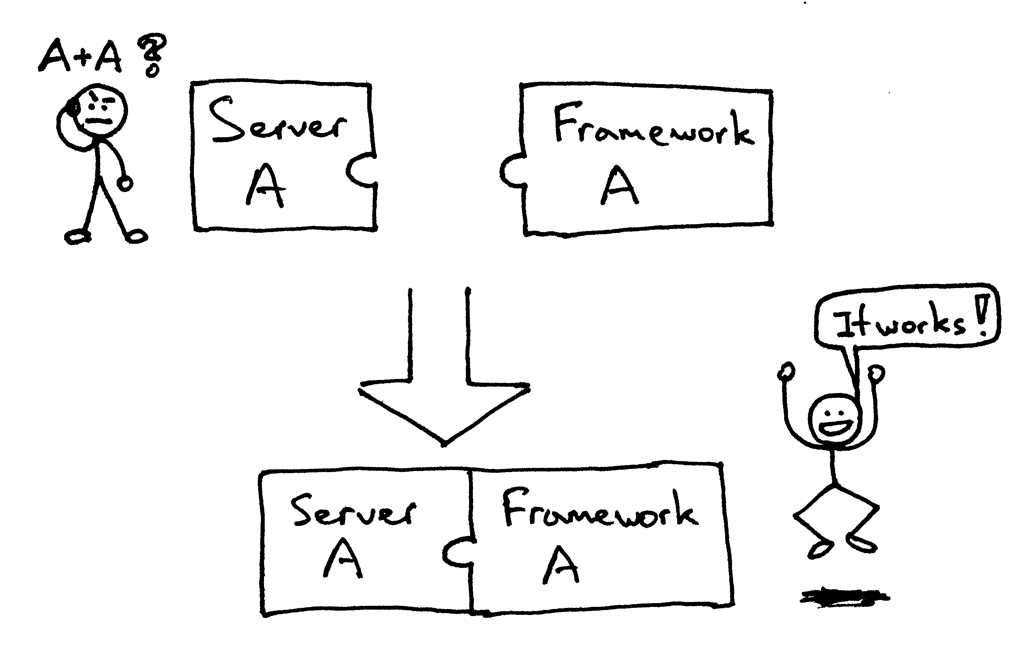
|
||||
|
||||
但你可能正面对着(或者曾经面对过)尝试将一对无法适配的框架和服务器搭配在一起的问题:
|
||||
|
||||
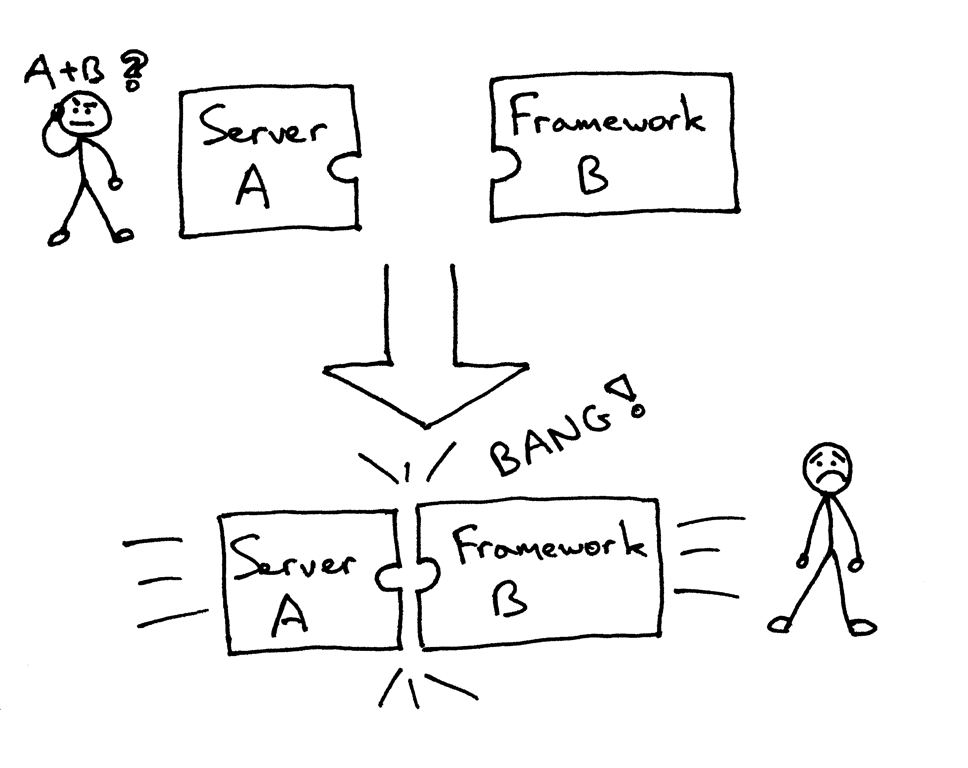
|
||||
|
||||
基本上,你需要选择那些能够一起工作的框架和服务器,而不能选择你想用的那些。
|
||||
|
||||
所以,你该如何确保在不对 Web 服务器或框架的代码做任何更改的情况下,让你的 Web 服务器和多个不同的 Web 框架一同工作呢?这个问题的答案,就是 Python Web 服务器网关接口(Web Server Gateway Interface )(缩写为 [WSGI][2],念做“wizgy”)。
|
||||
|
||||

|
||||
|
||||
WSGI 允许开发者互不干扰地选择 Web 框架及 Web 服务器的类型。现在,你可以真正将 Web 服务器及框架任意搭配,然后选出你最中意的那对组合。比如,你可以使用 [Django][3],[Flask][4] 或者 [Pyramid][5],与 [Gunicorn][6],[Nginx/uWSGI][7] 或 [Waitress][8] 进行结合。感谢 WSGI 同时对服务器与框架的支持,我们可以真正随意选择它们的搭配了。
|
||||
|
||||
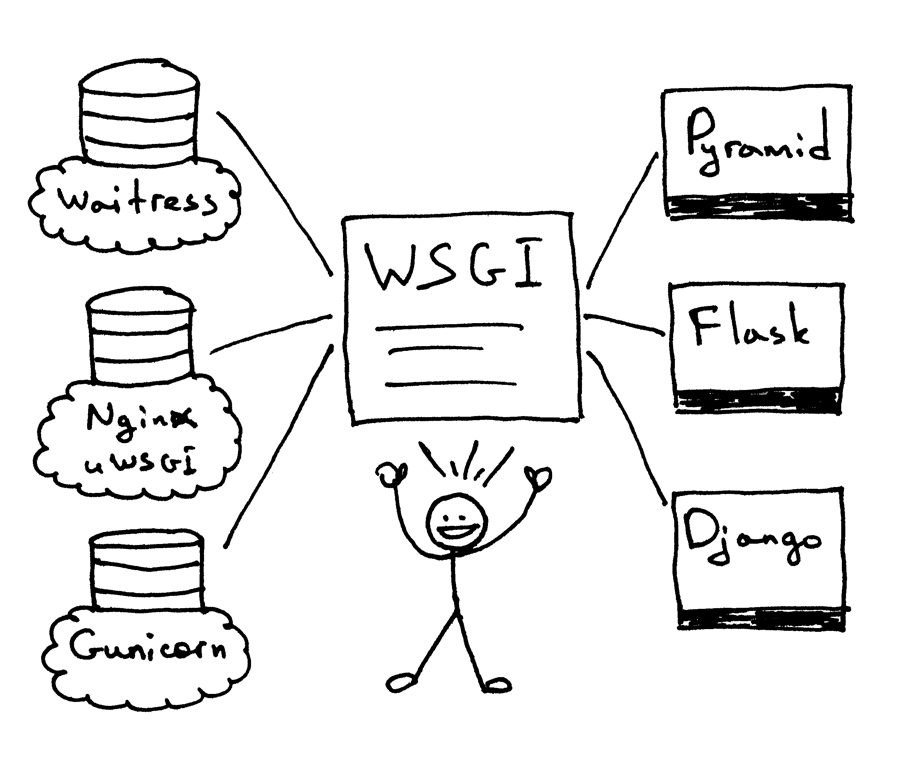
|
||||
|
||||
所以,WSGI 就是我在第一部分中提出,又在本文开头重复了一遍的那个问题的答案。你的 Web 服务器必须实现 WSGI 接口的服务器部分,而现代的 Python Web 框架均已实现了 WSGI 接口的框架部分,这使得你可以直接在 Web 服务器中使用任意框架,而不需要更改任何服务器代码,以对特定的 Web 框架实现兼容。
|
||||
|
||||
现在,你已经知道 Web 服务器及 Web 框架对 WSGI 的支持使得你可以选择最合适的一对来使用,而且它也有利于服务器和框架的开发者,这样他们只需专注于其擅长的部分来进行开发,而不需要触及另一部分的代码。其它语言也拥有类似的接口,比如:Java 拥有 Servlet API,而 Ruby 拥有 Rack。
|
||||
|
||||
这些理论都不错,但是我打赌你在说:“Show me the code!” 那好,我们来看看下面这个很小的 WSGI 服务器实现:
|
||||
|
||||
```
|
||||
### 使用 Python 2.7.9,在 Linux 及 Mac OS X 下测试通过
|
||||
import socket
|
||||
import StringIO
|
||||
import sys
|
||||
|
||||
|
||||
class WSGIServer(object):
|
||||
|
||||
address_family = socket.AF_INET
|
||||
socket_type = socket.SOCK_STREAM
|
||||
request_queue_size = 1
|
||||
|
||||
def __init__(self, server_address):
|
||||
### 创建一个监听的套接字
|
||||
self.listen_socket = listen_socket = socket.socket(
|
||||
self.address_family,
|
||||
self.socket_type
|
||||
)
|
||||
### 允许复用同一地址
|
||||
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||||
### 绑定地址
|
||||
listen_socket.bind(server_address)
|
||||
### 激活套接字
|
||||
listen_socket.listen(self.request_queue_size)
|
||||
### 获取主机的名称及端口
|
||||
host, port = self.listen_socket.getsockname()[:2]
|
||||
self.server_name = socket.getfqdn(host)
|
||||
self.server_port = port
|
||||
### 返回由 Web 框架/应用设定的响应头部字段
|
||||
self.headers_set = []
|
||||
|
||||
def set_app(self, application):
|
||||
self.application = application
|
||||
|
||||
def serve_forever(self):
|
||||
listen_socket = self.listen_socket
|
||||
while True:
|
||||
### 获取新的客户端连接
|
||||
self.client_connection, client_address = listen_socket.accept()
|
||||
### 处理一条请求后关闭连接,然后循环等待另一个连接建立
|
||||
self.handle_one_request()
|
||||
|
||||
def handle_one_request(self):
|
||||
self.request_data = request_data = self.client_connection.recv(1024)
|
||||
### 以 'curl -v' 的风格输出格式化请求数据
|
||||
print(''.join(
|
||||
'< {line}\n'.format(line=line)
|
||||
for line in request_data.splitlines()
|
||||
))
|
||||
|
||||
self.parse_request(request_data)
|
||||
|
||||
### 根据请求数据构建环境变量字典
|
||||
env = self.get_environ()
|
||||
|
||||
### 此时需要调用 Web 应用来获取结果,
|
||||
### 取回的结果将成为 HTTP 响应体
|
||||
result = self.application(env, self.start_response)
|
||||
|
||||
### 构造一个响应,回送至客户端
|
||||
self.finish_response(result)
|
||||
|
||||
def parse_request(self, text):
|
||||
request_line = text.splitlines()[0]
|
||||
request_line = request_line.rstrip('\r\n')
|
||||
### 将请求行分成几个部分
|
||||
(self.request_method, # GET
|
||||
self.path, # /hello
|
||||
self.request_version # HTTP/1.1
|
||||
) = request_line.split()
|
||||
|
||||
def get_environ(self):
|
||||
env = {}
|
||||
### 以下代码段没有遵循 PEP8 规则,但这样排版,是为了通过强调
|
||||
### 所需变量及它们的值,来达到其展示目的。
|
||||
###
|
||||
### WSGI 必需变量
|
||||
env['wsgi.version'] = (1, 0)
|
||||
env['wsgi.url_scheme'] = 'http'
|
||||
env['wsgi.input'] = StringIO.StringIO(self.request_data)
|
||||
env['wsgi.errors'] = sys.stderr
|
||||
env['wsgi.multithread'] = False
|
||||
env['wsgi.multiprocess'] = False
|
||||
env['wsgi.run_once'] = False
|
||||
### CGI 必需变量
|
||||
env['REQUEST_METHOD'] = self.request_method # GET
|
||||
env['PATH_INFO'] = self.path # /hello
|
||||
env['SERVER_NAME'] = self.server_name # localhost
|
||||
env['SERVER_PORT'] = str(self.server_port) # 8888
|
||||
return env
|
||||
|
||||
def start_response(self, status, response_headers, exc_info=None):
|
||||
### 添加必要的服务器头部字段
|
||||
server_headers = [
|
||||
('Date', 'Tue, 31 Mar 2015 12:54:48 GMT'),
|
||||
('Server', 'WSGIServer 0.2'),
|
||||
]
|
||||
self.headers_set = [status, response_headers + server_headers]
|
||||
### 为了遵循 WSGI 协议,start_response 函数必须返回一个 'write'
|
||||
### 可调用对象(返回值.write 可以作为函数调用)。为了简便,我们
|
||||
### 在这里无视这个细节。
|
||||
### return self.finish_response
|
||||
|
||||
def finish_response(self, result):
|
||||
try:
|
||||
status, response_headers = self.headers_set
|
||||
response = 'HTTP/1.1 {status}\r\n'.format(status=status)
|
||||
for header in response_headers:
|
||||
response += '{0}: {1}\r\n'.format(*header)
|
||||
response += '\r\n'
|
||||
for data in result:
|
||||
response += data
|
||||
### 以 'curl -v' 的风格输出格式化请求数据
|
||||
print(''.join(
|
||||
'> {line}\n'.format(line=line)
|
||||
for line in response.splitlines()
|
||||
))
|
||||
self.client_connection.sendall(response)
|
||||
finally:
|
||||
self.client_connection.close()
|
||||
|
||||
SERVER_ADDRESS = (HOST, PORT) = '', 8888
|
||||
|
||||
def make_server(server_address, application):
|
||||
server = WSGIServer(server_address)
|
||||
server.set_app(application)
|
||||
return server
|
||||
|
||||
if __name__ == '__main__':
|
||||
if len(sys.argv) < 2:
|
||||
sys.exit('Provide a WSGI application object as module:callable')
|
||||
app_path = sys.argv[1]
|
||||
module, application = app_path.split(':')
|
||||
module = __import__(module)
|
||||
application = getattr(module, application)
|
||||
httpd = make_server(SERVER_ADDRESS, application)
|
||||
print('WSGIServer: Serving HTTP on port {port} ...\n'.format(port=PORT))
|
||||
httpd.serve_forever()
|
||||
```
|
||||
|
||||
当然,这段代码要比第一部分的服务器代码长不少,但它仍然很短(只有不到 150 行),你可以轻松理解它,而不需要深究细节。上面的服务器代码还可以做更多——它可以用来运行一些你喜欢的框架写出的 Web 应用,可以是 Pyramid,Flask,Django 或其它 Python WSGI 框架。
|
||||
|
||||
不相信吗?自己来试试看吧。把以上的代码保存为 `webserver2.py`,或直接从 [Github][9] 上下载它。如果你打算不加任何参数而直接运行它,它会抱怨一句,然后退出。
|
||||
|
||||
```
|
||||
$ python webserver2.py
|
||||
Provide a WSGI application object as module:callable
|
||||
```
|
||||
|
||||
它想做的其实是为你的 Web 应用服务,而这才是重头戏。为了运行这个服务器,你唯一需要的就是安装好 Python。不过,如果你希望运行 Pyramid,Flask 或 Django 应用,你还需要先安装那些框架。那我们把这三个都装上吧。我推荐的安装方式是通过 `virtualenv` 安装。按照以下几步来做,你就可以创建并激活一个虚拟环境,并在其中安装以上三个 Web 框架。
|
||||
|
||||
```
|
||||
$ [sudo] pip install virtualenv
|
||||
$ mkdir ~/envs
|
||||
$ virtualenv ~/envs/lsbaws/
|
||||
$ cd ~/envs/lsbaws/
|
||||
$ ls
|
||||
bin include lib
|
||||
$ source bin/activate
|
||||
(lsbaws) $ pip install pyramid
|
||||
(lsbaws) $ pip install flask
|
||||
(lsbaws) $ pip install django
|
||||
```
|
||||
|
||||
现在,你需要创建一个 Web 应用。我们先从 Pyramid 开始吧。把以下代码保存为 `pyramidapp.py`,并与刚刚的 `webserver2.py` 放置在同一目录,或直接从 [Github][10] 下载该文件:
|
||||
|
||||
```
|
||||
from pyramid.config import Configurator
|
||||
from pyramid.response import Response
|
||||
|
||||
|
||||
def hello_world(request):
|
||||
return Response(
|
||||
'Hello world from Pyramid!\n',
|
||||
content_type='text/plain',
|
||||
)
|
||||
|
||||
config = Configurator()
|
||||
config.add_route('hello', '/hello')
|
||||
config.add_view(hello_world, route_name='hello')
|
||||
app = config.make_wsgi_app()
|
||||
```
|
||||
|
||||
现在,你可以用你自己的 Web 服务器来运行你的 Pyramid 应用了:
|
||||
|
||||
```
|
||||
(lsbaws) $ python webserver2.py pyramidapp:app
|
||||
WSGIServer: Serving HTTP on port 8888 ...
|
||||
```
|
||||
|
||||
你刚刚让你的服务器去加载 Python 模块 `pyramidapp` 中的可执行对象 `app`。现在你的服务器可以接收请求,并将它们转发到你的 Pyramid 应用中了。在浏览器中输入 http://localhost:8888/hello ,敲一下回车,然后看看结果:
|
||||
|
||||
|
||||
|
||||
你也可以使用命令行工具 `curl` 来测试服务器:
|
||||
|
||||
```
|
||||
$ curl -v http://localhost:8888/hello
|
||||
...
|
||||
```
|
||||
|
||||
看看服务器和 `curl` 向标准输出流打印的内容吧。
|
||||
|
||||
现在来试试 `Flask`。运行步骤跟上面的一样。
|
||||
|
||||
```
|
||||
from flask import Flask
|
||||
from flask import Response
|
||||
flask_app = Flask('flaskapp')
|
||||
|
||||
|
||||
@flask_app.route('/hello')
|
||||
def hello_world():
|
||||
return Response(
|
||||
'Hello world from Flask!\n',
|
||||
mimetype='text/plain'
|
||||
)
|
||||
|
||||
app = flask_app.wsgi_app
|
||||
```
|
||||
|
||||
将以上代码保存为 `flaskapp.py`,或者直接从 [Github][11] 下载,然后输入以下命令运行服务器:
|
||||
|
||||
```
|
||||
(lsbaws) $ python webserver2.py flaskapp:app
|
||||
WSGIServer: Serving HTTP on port 8888 ...
|
||||
```
|
||||
|
||||
现在在浏览器中输入 http://localhost:8888/hello ,敲一下回车:
|
||||
|
||||
|
||||
|
||||
同样,尝试一下 `curl`,然后你会看到服务器返回了一条 `Flask` 应用生成的信息:
|
||||
|
||||
```
|
||||
$ curl -v http://localhost:8888/hello
|
||||
...
|
||||
```
|
||||
|
||||
这个服务器能处理 Django 应用吗?试试看吧!不过这个任务可能有点复杂,所以我建议你将整个仓库克隆下来,然后使用 [Github][13] 仓库中的 [djangoapp.py][12] 来完成这个实验。这里的源代码主要是将 Django 的 helloworld 工程(已使用 `Django` 的 `django-admin.py startproject` 命令创建完毕)添加到了当前的 Python 路径中,然后导入了这个工程的 WSGI 应用。(LCTT 译注:除了这里展示的代码,还需要一个配合的 helloworld 工程才能工作,代码可以参见 [Github][13] 仓库。)
|
||||
|
||||
```
|
||||
import sys
|
||||
sys.path.insert(0, './helloworld')
|
||||
from helloworld import wsgi
|
||||
|
||||
|
||||
app = wsgi.application
|
||||
```
|
||||
|
||||
将以上代码保存为 `djangoapp.py`,然后用你的 Web 服务器运行这个 Django 应用:
|
||||
|
||||
```
|
||||
(lsbaws) $ python webserver2.py djangoapp:app
|
||||
WSGIServer: Serving HTTP on port 8888 ...
|
||||
```
|
||||
|
||||
输入以下链接,敲回车:
|
||||
|
||||
|
||||
|
||||
你这次也可以在命令行中测试——你之前应该已经做过两次了——来确认 Django 应用处理了你的请求:
|
||||
|
||||
```
|
||||
$ curl -v http://localhost:8888/hello
|
||||
...
|
||||
```
|
||||
|
||||
你试过了吗?你确定这个服务器可以与那三个框架搭配工作吗?如果没试,请去试一下。阅读固然重要,但这个系列的内容是**重新搭建**,这意味着你需要亲自动手干点活。去试一下吧。别担心,我等着你呢。不开玩笑,你真的需要试一下,亲自尝试每一步,并确保它像预期的那样工作。
|
||||
|
||||
好,你已经体验到了 WSGI 的威力:它可以使 Web 服务器及 Web 框架随意搭配。WSGI 在 Python Web 服务器及框架之间提供了一个微型接口。它非常简单,而且在服务器和框架端均可以轻易实现。下面的代码片段展示了 WSGI 接口的服务器及框架端实现:
|
||||
|
||||
```
|
||||
def run_application(application):
|
||||
"""服务器端代码。"""
|
||||
### Web 应用/框架在这里存储 HTTP 状态码以及 HTTP 响应头部,
|
||||
### 服务器会将这些信息传递给客户端
|
||||
headers_set = []
|
||||
### 用于存储 WSGI/CGI 环境变量的字典
|
||||
environ = {}
|
||||
|
||||
def start_response(status, response_headers, exc_info=None):
|
||||
headers_set[:] = [status, response_headers]
|
||||
|
||||
### 服务器唤醒可执行变量“application”,获得响应头部
|
||||
result = application(environ, start_response)
|
||||
### 服务器组装一个 HTTP 响应,将其传送至客户端
|
||||
…
|
||||
|
||||
def app(environ, start_response):
|
||||
"""一个空的 WSGI 应用"""
|
||||
start_response('200 OK', [('Content-Type', 'text/plain')])
|
||||
return ['Hello world!']
|
||||
|
||||
run_application(app)
|
||||
```
|
||||
|
||||
这是它的工作原理:
|
||||
|
||||
1. Web 框架提供一个可调用对象 `application` (WSGI 规范没有规定它的实现方式)。
|
||||
2. Web 服务器每次收到来自客户端的 HTTP 请求后,会唤醒可调用对象 `applition`。它会向该对象传递一个包含 WSGI/CGI 变量的环境变量字典 `environ`,以及一个可调用对象 `start_response`。
|
||||
3. Web 框架或应用生成 HTTP 状态码和 HTTP 响应头部,然后将它传给 `start_response` 函数,服务器会将其存储起来。同时,Web 框架或应用也会返回 HTTP 响应正文。
|
||||
4. 服务器将状态码、响应头部及响应正文组装成一个 HTTP 响应,然后将其传送至客户端(这一步并不在 WSGI 规范中,但从逻辑上讲,这一步应该包含在工作流程之中。所以为了明确这个过程,我把它写了出来)
|
||||
|
||||
这是这个接口规范的图形化表达:
|
||||
|
||||
|
||||
|
||||
到现在为止,你已经看过了用 Pyramid、Flask 和 Django 写出的 Web 应用的代码,你也看到了一个 Web 服务器如何用代码来实现另一半(服务器端的) WSGI 规范。你甚至还看到了我们如何在不使用任何框架的情况下,使用一段代码来实现一个最简单的 WSGI Web 应用。
|
||||
|
||||
其实,当你使用上面的框架编写一个 Web 应用时,你只是在较高的层面工作,而不需要直接与 WSGI 打交道。但是我知道你一定也对 WSGI 接口的框架部分感兴趣,因为你在看这篇文章呀。所以,我们不用 Pyramid、Flask 或 Django,而是自己动手来创造一个最朴素的 WSGI Web 应用(或 Web 框架),然后将它和你的服务器一起运行:
|
||||
|
||||
```
|
||||
def app(environ, start_response):
|
||||
"""一个最简单的 WSGI 应用。
|
||||
|
||||
这是你自己的 Web 框架的起点 ^_^
|
||||
"""
|
||||
status = '200 OK'
|
||||
response_headers = [('Content-Type', 'text/plain')]
|
||||
start_response(status, response_headers)
|
||||
return ['Hello world from a simple WSGI application!\n']
|
||||
```
|
||||
|
||||
同样,将上面的代码保存为 `wsgiapp.py` 或直接从 [Github][14] 上下载该文件,然后在 Web 服务器上运行这个应用,像这样:
|
||||
|
||||
```
|
||||
(lsbaws) $ python webserver2.py wsgiapp:app
|
||||
WSGIServer: Serving HTTP on port 8888 ...
|
||||
```
|
||||
|
||||
在浏览器中输入下面的地址,然后按下回车。这是你应该看到的结果:
|
||||
|
||||
|
||||
|
||||
你刚刚在学习如何创建一个 Web 服务器的过程中自己编写了一个最朴素的 WSGI Web 框架!棒极了!
|
||||
|
||||
现在,我们再回来看看服务器传给客户端的那些东西。这是在使用 HTTP 客户端调用你的 Pyramid 应用时,服务器生成的 HTTP 响应内容:
|
||||
|
||||

|
||||
|
||||
这个响应和你在本系列第一部分中看到的 HTTP 响应有一部分共同点,但它还多出来了一些内容。比如说,它拥有四个你曾经没见过的 [HTTP 头部][15]:`Content-Type`, `Content-Length`, `Date` 以及 `Server`。这些头部内容基本上在每个 Web 服务器返回的响应中都会出现。不过,它们都不是被严格要求出现的。这些 HTTP 请求/响应头部字段的目的在于它可以向你传递一些关于 HTTP 请求/响应的额外信息。
|
||||
|
||||
既然你对 WSGI 接口了解的更深了一些,那我再来展示一下上面那个 HTTP 响应中的各个部分的信息来源:
|
||||
|
||||
|
||||
|
||||
我现在还没有对上面那个 `environ` 字典做任何解释,不过基本上这个字典必须包含那些被 WSGI 规范事先定义好的 WSGI 及 CGI 变量值。服务器在解析 HTTP 请求时,会从请求中获取这些变量的值。这是 `environ` 字典应该有的样子:
|
||||
|
||||
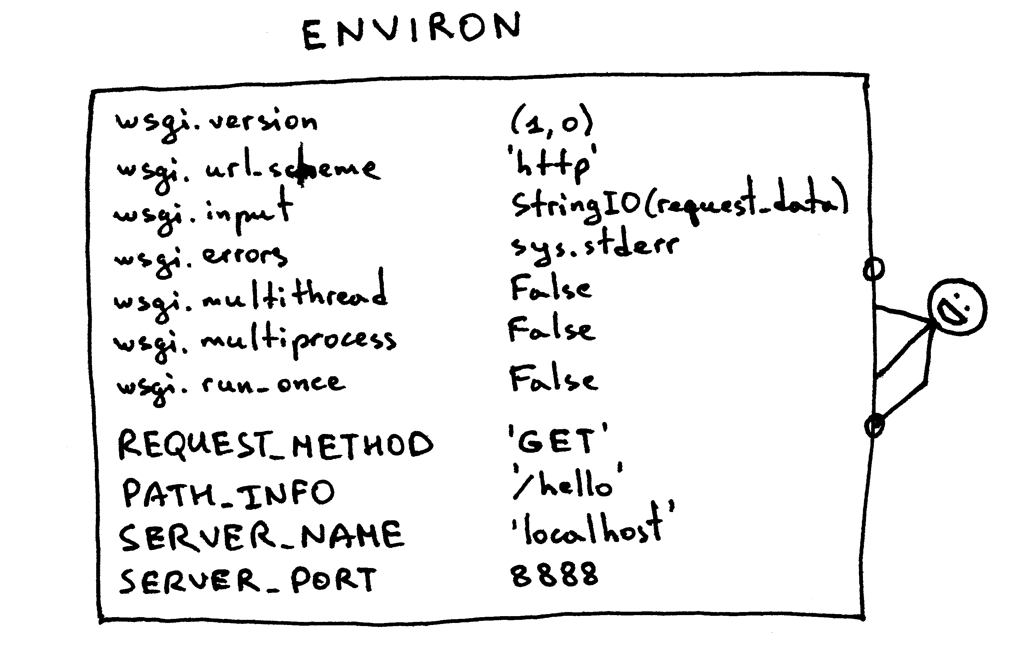
|
||||
|
||||
Web 框架会利用以上字典中包含的信息,通过字典中的请求路径、请求动作等等来决定使用哪个视图来处理响应、在哪里读取请求正文、在哪里输出错误信息(如果有的话)。
|
||||
|
||||
现在,你已经创造了属于你自己的 WSGI Web 服务器,你也使用不同 Web 框架做了几个 Web 应用。而且,你在这个过程中也自己创造出了一个朴素的 Web 应用及框架。这个过程真是累人。现在我们来回顾一下,你的 WSGI Web 服务器在服务请求时,需要针对 WSGI 应用做些什么:
|
||||
|
||||
- 首先,服务器开始工作,然后会加载一个可调用对象 `application`,这个对象由你的 Web 框架或应用提供
|
||||
- 然后,服务器读取一个请求
|
||||
- 然后,服务器会解析这个请求
|
||||
- 然后,服务器会使用请求数据来构建一个 `environ` 字典
|
||||
- 然后,它会用 `environ` 字典及一个可调用对象 `start_response` 作为参数,来调用 `application`,并获取响应体内容。
|
||||
- 然后,服务器会使用 `application` 返回的响应体,和 `start_response` 函数设置的状态码及响应头部内容,来构建一个 HTTP 响应。
|
||||
- 最终,服务器将 HTTP 响应回送给客户端。
|
||||
|
||||
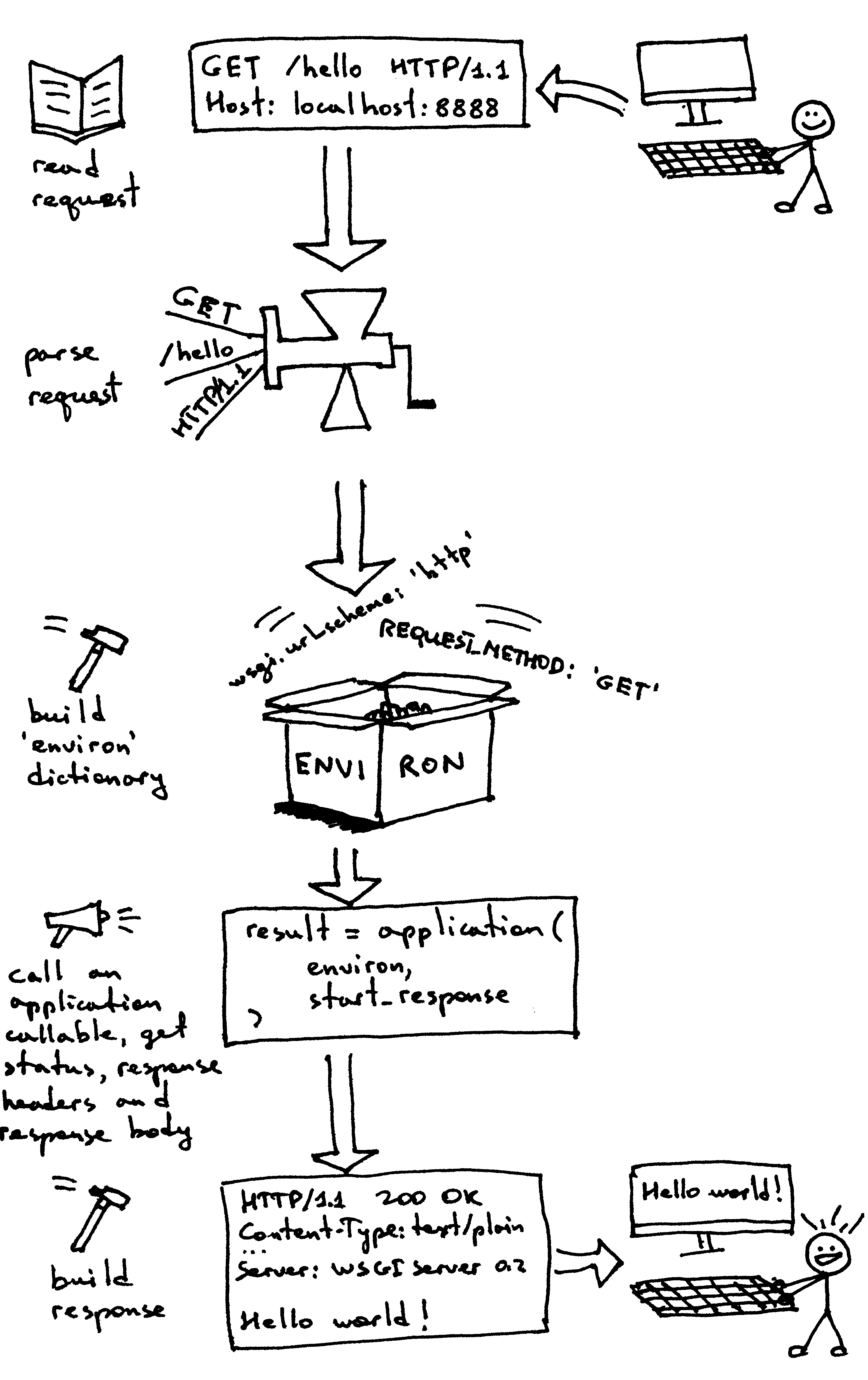
|
||||
|
||||
这基本上是服务器要做的全部内容了。你现在有了一个可以正常工作的 WSGI 服务器,它可以为使用任何遵循 WSGI 规范的 Web 框架(如 Django、Flask、Pyramid,还有你刚刚自己写的那个框架)构建出的 Web 应用服务。最棒的部分在于,它可以在不用更改任何服务器代码的情况下,与多个不同的 Web 框架一起工作。真不错。
|
||||
|
||||
在结束之前,你可以想想这个问题:“你该如何让你的服务器在同一时间处理多个请求呢?”
|
||||
|
||||
敬请期待,我会在第三部分向你展示一种解决这个问题的方法。干杯!
|
||||
|
||||
顺便,我在撰写一本名为《搭个 Web 服务器:从头开始》的书。这本书讲解了如何从头开始编写一个基本的 Web 服务器,里面包含本文中没有的更多细节。[订阅邮件列表][16],你就可以获取到这本书的最新进展,以及发布日期。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ruslanspivak.com/lsbaws-part2/
|
||||
|
||||
作者:[Ruslan][a]
|
||||
译者:[StdioA](https://github.com/StdioA)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://github.com/rspivak/
|
||||
[1]: https://linux.cn/article-7662-1.html
|
||||
[2]: https://www.python.org/dev/peps/pep-0333/
|
||||
[3]: https://www.djangoproject.com/
|
||||
[4]: http://flask.pocoo.org/
|
||||
[5]: http://trypyramid.com/
|
||||
[6]: http://gunicorn.org/
|
||||
[7]: http://uwsgi-docs.readthedocs.org/
|
||||
[8]: http://waitress.readthedocs.org/
|
||||
[9]: https://github.com/rspivak/lsbaws/blob/master/part2/webserver2.py
|
||||
[10]: https://github.com/rspivak/lsbaws/blob/master/part2/pyramidapp.py
|
||||
[11]: https://github.com/rspivak/lsbaws/blob/master/part2/flaskapp.py
|
||||
[12]: https://github.com/rspivak/lsbaws/blob/master/part2/flaskapp.py
|
||||
[13]: https://github.com/rspivak/lsbaws/
|
||||
[14]: https://github.com/rspivak/lsbaws/blob/master/part2/wsgiapp.py
|
||||
[15]: http://en.wikipedia.org/wiki/List_of_HTTP_header_fields
|
||||
[16]: https://ruslanspivak.com/lsbaws-part2/
|
||||
@ -0,0 +1,94 @@
|
||||
给学习 OpenStack 架构的新手入门指南
|
||||
===========================================================
|
||||
|
||||
OpenStack 欢迎新成员的到来,但是,对于这个发展趋近成熟并且快速迭代的开源社区而言,能够拥有一个新手指南并不是件坏事。在奥斯汀举办的 OpenStack 峰会上,[Paul Belanger][1] (来自红帽公司)、 [Elizabeth K. Joseph][2] (来自 HPE 公司)和 [Christopher Aedo][3] (来自 IBM 公司)就[针对新人的 OpenStack 架构][4]作了一场专门的讲演。在这次采访中,他们提供了一些建议和资源来帮助新人成为 OpenStack 贡献者中的一员。
|
||||
|
||||

|
||||
|
||||
**你的讲演介绍中说你将“深入架构核心,并解释你需要知道的关于让 OpenStack 工作起来的每一件事情”。这对于 40 分钟的讲演来说是一个艰巨的任务。那么,对于学习 OpenStack 架构的新手来说最需要知道那些事情呢?**
|
||||
|
||||
**Elizabeth K. Joseph (EKJ)**: 我们没有为 OpenStack 使用 GitHub 这种提交补丁的方式,这是因为这样做会对新手造成巨大的困扰,尽管由于历史原因我们还是在 GitHub 上维护了所有库的一个镜像。相反,我们使用了一种完全开源的评审形式,而且持续集成(CI)是由 OpenStack 架构团队维护的。与之有关的,自从我们使用了 CI 系统,每一个提交给 OpenStack 的改变都会在被合并之前进行测试。
|
||||
|
||||
**Paul Belanger (PB)**: 这个项目中的大多数都是富有激情的人,因此当你提交的补丁被某个人否定时不要感到沮丧。
|
||||
|
||||
**Christopher Aedo (CA)**:社区会帮助你取得成功,因此不要害怕提问或者寻求更多的那些能够促进你理解某些事物的引导者。
|
||||
|
||||
**在你的讲话中,对于一些你无法涉及到的方面,你会向新手推荐哪些在线资源来让他们更加容易入门?**
|
||||
|
||||
**PB**:当然是我们的 [OpenStack 项目架构文档][5]。我们已经花了足够大的努力来尽可能让这些文档能够随时保持最新状态。在 OpenStack 运行中使用的每个系统都作为一个项目,都制作了专门的页面来进行说明。甚至于连 OpenStack 云这种架构团队也会放到线上。
|
||||
|
||||
**EKJ**:我对于架构文档这件事上的观点和 Paul 是一致的,另外,我们十分乐意看到来自那些正在学习项目的人们提交上来的补丁。我们通常不会意识到我们忽略了文档中的某些内容,除非它们恰好被人问起。因此,阅读、学习,会帮助我们修补这些知识上的漏洞。你可以在 [OpenStack 架构邮件清单]提出你的问题,或者在我们位于 FreeNode 上的 #OpenStack-infra 的 IRC 专栏发起你的提问。
|
||||
|
||||
**CA**:我喜欢[这个详细的帖子][7],它是由 Ian Wienand 写的一篇关于构建镜像的文章。
|
||||
|
||||
**"gotchas" 会是 OpenStack 新的贡献者们所寻找的吗?**
|
||||
|
||||
**EKJ**:向项目作出贡献并不仅仅是提交新的代码和新的特性;OpenStack 社区高度重视代码评审。如果你想要别人查看你的补丁,那你最好先看看其他人是如何做的,然后参考他们的风格,最后一步步做到你也能够向其他人一样提交清晰且结构分明的代码补丁。你越是能让你的同伴了解你的工作并知道你正在做的评审,那他们也就越有可能及时评审你的代码。
|
||||
|
||||
**CA**:我看到过大量的新手在面对 [Gerrit][8] 时受挫,阅读开发者引导中的[开发者工作步骤][9],有可能的话多读几遍。如果你没有用过 Gerrit,那你最初对它的感觉可能是困惑和无力的。但是,如果你随后做了一些代码评审的工作,那么你就能轻松应对它。此外,我是 IRC 的忠实粉丝,它可能是一个获得帮助的好地方,但是,你最好保持一个长期在线的状态,这样,尽管你在某个时候没有出现,人们也可以回答你的问题。(阅读 [IRC,开源成功的秘诀][10])你不必总是在线,但是你最好能够轻松的在一个频道中回溯之前信息,以此来跟上最新的动态,这种能力非常重要。
|
||||
|
||||
**PB**:我同意 Elizabeth 和 Chris 的观点, Gerrit 是需要花点精力的,它将汇聚你的开发方面的努力。你不仅仅要提交代码给别人去评审,同时,你也要能够评审其他人的代码。看到 Gerrit 的界面,你可能一时会变的很困惑。我推荐新手去尝试 [Gertty][11],它是一个基于控制台的终端界面,用于 Gerrit 代码评审系统,而它恰好也是 OpenStack 架构所驱动的一个项目。
|
||||
|
||||
**你对于 OpenStack 新手如何通过网络与其他贡献者交流方面有什么好的建议?**
|
||||
|
||||
**PB**:对我来说,是通过 IRC 并在 Freenode 上参加 #OpenStack-infra 频道([IRC 日志][12])。这频道上面有很多对新手来说很有价值的资源。你可以看到 OpenStack 项目日复一日的运作情况,同时,一旦你知道了 OpenStack 项目的工作原理,你将更好的知道如何为 OpenStack 的未来发展作出贡献。
|
||||
|
||||
**CA**:我想要为 IRC 再次说明一点,在 IRC 上保持全天在线记录对我来说有非常重大的意义,因为我会时刻保持连接并随时接到提醒。这也是一种非常好的获得帮助的方式,特别是当你和某人卡在了项目中出现的某一个难题的时候,而在一个活跃的 IRC 频道中,总会有一些人很乐意为你解决问题。
|
||||
|
||||
**EKJ**:[OpenStack 开发邮件列表][13]对于能够时刻查看到你所致力于的 OpenStack 项目的最新情况是非常重要的。因此,我推荐一定要订阅它。邮件列表使用主题标签来区分项目,因此你可以设置你的邮件客户端来使用它来专注于你所关心的项目。除了在线资源之外,全世界范围内也成立了一些 OpenStack 小组,他们被用来为 OpenStack 的用户和贡献者提供服务。这些小组可能会定期要求 OpenStack 主要贡献者们举办座谈和活动。你可以在 MeetUp.com 上搜素你所在地域的贡献者活动聚会,或者在 [groups.openstack.org][14] 上查看你所在的地域是否存在 OpenStack 小组。最后,还有一个每六个月举办一次的 [OpenStack 峰会][15],这个峰会上会作一些关于架构的演说。当前状态下,这个峰会包含了用户会议和开发者会议,会议内容都是和 OpenStack 相关的东西,包括它的过去,现在和未来。
|
||||
|
||||
**OpenStack 需要在那些方面得到提升来让新手更加容易学会并掌握?**
|
||||
|
||||
**PB**: 我认为我们的 [account-setup][16] 环节对于新的贡献者已经做的比较容易了,特别是教他们如何提交他们的第一个补丁。真正参与到 OpenStack 开发者模式中是需要花费很大的努力的,相比贡献者来说已经显得非常多了;然而,一旦融入进去了,这个模式将会运转的十分高效和令人满意。
|
||||
|
||||
**CA**: 我们拥有一个由专业开发者组成的社区,而且我们的关注点都是发展 OpenStack 本身,同时,我们致力于让用户付出更小的代价去使用 OpenStack 云架构平台。我们需要发掘更多的应用开发者,并且鼓励更多的人去开发能在 OpenStack 云上完美运行的云应用程序,我们还鼓励他们在[社区 App 目录][17]上去贡献那些由他们开发的应用。我们可以通过不断提升我们的 API 标准和保证我们不同的库(比如 libcloud,phpopencloud 以及其他一些库)持续地为开发者提供可信赖的支持来实现这一目标。还有一点就是通过举办更多的 OpenStack 黑客比赛。所有的这些事情都可以降低新人的学习门槛,这样也能引导他们与这个社区之间的关系更加紧密。
|
||||
|
||||
**EKJ**: 我已经致力于开源软件很多年了。但是,对于大量的 OpenStack 开发者而言,这是一个他们自己所从事的第一个开源项目。我发现他们之前使用私有软件的背景并没有为他们塑造开源的观念、方法论,以及在开源项目中需要具备的合作技巧。我乐于看到我们能够让那些曾经一直在使用私有软件工作的人能够真正的明白他们在开源如软件社区所从事的事情的巨大价值。
|
||||
|
||||
**我想把 2016 年打造成开源俳句之年。请用俳句来向新手解释 OpenStack 一下。**
|
||||
|
||||
(LCTT 译注:俳句(Haiku)是一种日本古典短诗,以5-7-5音节为三句,校对者不揣浅陋,诌了几句歪诗,勿笑 :D,另外 OpenStack 本身音节太长,就捏造了一个中文译名“开栈”——明白就好。)
|
||||
|
||||
**PB**: 开栈在云上//倘钟情自由软件//先当造补丁(OpenStack runs clouds
|
||||
If you enjoy free software
|
||||
Submit your first patch)
|
||||
|
||||
**CA**:时光不必久//开栈将支配世界//协力早来到(In the near future
|
||||
OpenStack will rule the world
|
||||
Help make it happen!)
|
||||
|
||||
**EKJ**:开栈有自由//放在自家服务器//运行你的云(OpenStack is free
|
||||
Deploy on your own servers
|
||||
And run your own cloud!)
|
||||
|
||||
*Paul、Elizabeth 和 Christopher 在 4 月 25 号星期一上午 11:15 于奥斯汀举办的 OpenStack 峰会发表了[演说][18]。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/4/interview-openstack-infrastructure-beginners
|
||||
|
||||
作者:[Rikki Endsley][a]
|
||||
译者:[kylepeng93](https://github.com/kylepeng93)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://rikkiendsley.com/
|
||||
[1]: https://twitter.com/pabelanger
|
||||
[2]: https://twitter.com/pleia2
|
||||
[3]: https://twitter.com/docaedo
|
||||
[4]: https://www.openstack.org/summit/austin-2016/summit-schedule/events/7337
|
||||
[5]: http://docs.openstack.org/infra/system-config/
|
||||
[6]: http://lists.openstack.org/cgi-bin/mailman/listinfo/openstack-infra
|
||||
[7]: https://www.technovelty.org/openstack/image-building-in-openstack-ci.html
|
||||
[8]: https://code.google.com/p/gerrit/
|
||||
[9]: http://docs.openstack.org/infra/manual/developers.html#development-workflow
|
||||
[10]: https://developer.ibm.com/opentech/2015/12/20/irc-the-secret-to-success-in-open-source/
|
||||
[11]: https://pypi.python.org/pypi/gertty
|
||||
[12]: http://eavesdrop.openstack.org/irclogs/%23openstack-infra/
|
||||
[13]: http://lists.openstack.org/cgi-bin/mailman/listinfo/openstack-dev
|
||||
[14]: https://groups.openstack.org/
|
||||
[15]: https://www.openstack.org/summit/
|
||||
[16]: http://docs.openstack.org/infra/manual/developers.html#account-setup
|
||||
[17]: https://apps.openstack.org/
|
||||
[18]: https://www.openstack.org/summit/austin-2016/summit-schedule/events/7337
|
||||
@ -0,0 +1,61 @@
|
||||
Drupal、IoT 和开源硬件之间的交集
|
||||
=======================================================
|
||||
|
||||

|
||||
|
||||
|
||||
来认识一下 [Amber Matz][1],她是来自 Lullabot Education 旗下的 [Drupalize.Me][3] 的产品经理以及培训师。当她没有倒腾 Arduino、Raspberry Pi 以及电子穿戴设备时,通常会在波特兰 Drupal 用户组里担任辩论主持人。
|
||||
|
||||
在即将举行的 [DrupalCon NOLA][3] 大会上,Amber 将主持一个关于 Drupal 和 IoT 的主题。如果你会去参加,也想了解下开源硬件,IoT 和 Drupal 之间的交集,那这个将很合适。如果你去不了新奥尔良的现场也没关系,Amber 还分享了许多很酷的事情。在这次采访中,她讲述了自己参与 Drupal 的原因,一些她自己喜欢的开源硬件项目,以及 IoT 和 Drupal 的未来。
|
||||
|
||||

|
||||
|
||||
**你是怎么加入 Drupal 社区的?**
|
||||
|
||||
在这之前,我在一家大型非盈利性机构市场部的“网站管理部”工作,飞快地批量生产出各种定制 PHP/MySQL 表单。最终我厌烦了这一切,并开始在网上寻找更好的方式。然后我找到了 Drupal 6 并开始沉迷进去。过了几年,在一次跳槽之后,我发现了波特兰 Drupal 用户组,然后在里面找了一份全职的 Drupal 开发者工作。我一直经常参加在波特兰的聚会,在那里我找到了大量的社区、朋友和专业方面的发展。一个偶然的机会,我在 Lullabot 找了一份培训师的工作,为 Drupalize.Me 提供内容。现在,我管理着 Drupalize.Me 的内容输出,负责编撰 Drupal 8 相关的内容,还很大程度地参与到波特兰 Drupal 社区中。我是今年的协调员,寻找并安排演讲者们。
|
||||
|
||||
**我们想知道:什么是 Arduino 原型,你是怎么找到它的,以及你用 Arduino 做过的最酷的事是什么?**
|
||||
|
||||
Arduino,Raspberry Pi,以及可穿戴电子设备,这些年到处都能听到这些术语。我在几年前通过 Becky Stern 的 YouTube 秀(最近由 Becky 继续主持,每周三播出)发现了 [Adafruit 的可穿戴电子设备][4]。我被那些可穿戴设备迷住了,还订了一套 LED 缝制工具,不过没做出任何东西。我不太适合它。我没有任何电子相关的背景,而且在我被那些项目吸引的时候,我根本不知道怎么做出那样的东西,它似乎看上去太遥远了。
|
||||
|
||||
后来,我在 Coursera 上找到了一个“物联网”专题。(很时髦,对吧?)我很快就喜欢上了。我最终找到了 Arduino 是什么的解释,以及所有这些其他的重要术语和概念。我订了一套推荐的 Arduino 初学者套件,还附带了一本如何上手的小册子。当我第一次让 LED 闪烁的时候,开心极了。我在圣诞节以及之后有两个星期的假期,然而我什么都没干,就一直根据初学者小册子给 Arduino 电路编程。很奇怪我觉得很放松!我太喜欢了。
|
||||
|
||||
在一月份的时候,我开始构思我自己的原型设备。在知道我需要主持公司培训的开场白时,我用五个 LED 灯和 Arduino 搭建了一个开场白视觉计时器的原型。
|
||||
|
||||

|
||||
|
||||
这是一次巨大的成功。我还做了我的第一个可穿戴项目,一件会发光的连帽衫,使用了和 Arduino IDE 兼容的 Gemma 微控制器,一个小的圆形可缝制部件,然后用可导电的线缝起来,将一个滑动可变电阻和衣服帽口的收缩绳连在一起,用来控制缝到帽子里的五个 NeoPixel 灯的颜色。这就是我对原型设计的看法:做一些很好玩也可能会有点实际用途的疯狂项目。
|
||||
|
||||
**Drupal 和 IoT 带来的最大机遇是什么??**
|
||||
|
||||
IoT 与 Web Service 以及 Drupal 分层趋势实际并没有太大差别。就是将数据从一个东西传送到另一个东西,然后将数据转换成一些有用的东西。但数据是如何送达?能用来做点什么?你觉得现在就有一大堆现成的解决方案、应用、中间层,以及 API 吗?采用 IoT,这只会继续成几何指数级的增长。我觉得,给我任何一个设备或“东西”,总有办法来将它连接到互联网上,有很多办法。而且有大量现成的代码库来帮助创客们将他们的数据从一个东西传到另一个东西。
|
||||
|
||||
那么 Drupal 在这里处于什么位置?首先,Web services 将是第一个明显的地方。但作为一个创客,我不希望将时间花在编写 Drupal 的订制模块上。我想要的是即插即用!所以我很高兴出现这样的模块能连接 IoT 云端 API 和服务,比如 ThingSpeak,Adafruit.io,IFTTT,以及其他的。我觉得也有一个很好的商业机会,在 Drupal 里构建一套 IoT 云服务,允许用户发送和存储他们的传感器数据,并可以制成表格和图像,还可以写一些插件可以响应特定数据或阙值。每一个 IoT 云 API 服务都是一个细分的机会,所以能留下很大空间给其他人。
|
||||
|
||||
**这次 DrupalCon 你有哪些期待?**
|
||||
|
||||
我喜欢与 Drupal 上的朋友重逢,认识一些新的人,还能见到 Lullabot 和 Drupalize.Me 的同事(我们是分布式的公司)!Drupal 8 有太多东西可以去探索了,我们给我们的客户们提供了海量的培训资料。所以,我很期待参与一些 Drupal 8 相关的主题,以及跟上最新的开发进度。最后,我对新奥尔良也很感兴趣!我曾经在 2004 年去过,很期待将这次将看到哪些改变。
|
||||
|
||||
**谈一谈你这次 DrupalCon 上的演讲:“超越闪烁:将 Drupal 加到你的 IoT 游乐场中”。别人为什么要参加?他们最重要的收获会是什么?**
|
||||
|
||||
我的主题的标题是,“超越闪烁:将 Drupal 加到你的 IoT 游乐场中”,假设我们所有人都处在同一进度和层次,你不需要了解任何关于 Arduino、物联网、甚至是 Drupal,都能跟上。我将从用 Arduino 让 LED 灯闪烁开始,然后我会谈一下我自己在这里面的最大收获:玩、学、教和做。我会列出一些曾经激励过我的例子,它们也很有希望能激发和鼓励其他听众去尝试一下。然后,就是展示时间!
|
||||
|
||||
首先,第一个东西。它是一个建筑提醒信号灯。在这个展示里,我会说明如何将信号灯连到互联网上,以及如何响应从云 API 服务收到的数据。然后,第二个东西。它是一个蒸汽朋克风格 iPhone 外壳形式的“天气手表”。有一个小型 LED 矩阵用来显示我的天气的图标,一个气压和温度传感器,一个 GPS 模块,以及一个 Bluetooth LE 模块,都连接到一个 Adafruit Flora 微控制器上。第二个东西能通过蓝牙连接到我的 iPhone 上的一个应用,并将天气和位置数据通过 MQTT 协议发到 Adafruit.io 的服务器!然后,在 Drupal 这边,我会从云端下载这些数据,更新天气信息,然后更新地图。所以大家也能体验一下通过web service、地图和 Drupal 8 的功能块所能做的事情。
|
||||
|
||||
学习和制作这些展示原型是一次烧脑的探险,我也希望有人能参与这个主题并感染一点我对这种技术交叉的传染性热情!我很兴奋能分享一些我的发现。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/5/drupalcon-interview-amber-matz
|
||||
|
||||
作者:[Jason Hibbets][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jhibbets
|
||||
[1]: https://www.drupal.org/u/amber-himes-matz
|
||||
[2]: https://drupalize.me/
|
||||
[3]: https://events.drupal.org/neworleans2016/
|
||||
[4]: https://www.adafruit.com/beckystern
|
||||
@ -0,0 +1,49 @@
|
||||
Linus Torvalds 谈及物联网、智能设备、安全连接等问题
|
||||
===========================================================================
|
||||
|
||||

|
||||
|
||||
*Dirk Hohndel 在嵌入式大会上采访 Linus Torvalds 。*
|
||||
|
||||
|
||||
4 月 4 日到 6 日,在圣迭戈召开的[嵌入式 Linux 大会(Embedded Linux Conference)][0](ELC) 从首次举办到现在已经有 11 年了,该会议包括了与 Linus Torvalds 的主题讨论。作为 Linux 内核的缔造者和最高决策者——用采访他的英特尔 Linux 和开源技术总监 Dirk Hohndel 的话说,“(他是)我们聚在一起的理由”——他对 Linux 在嵌入式和物联网应用程序领域的发展表示乐观。Torvalds 很明确地力挺了嵌入式 Linux,它被 Linux 桌面、服务器和云技术这些掩去光芒已经很多年了。
|
||||
|
||||

|
||||
|
||||
*Linus Torvalds 在嵌入式 Linux 大会上的演讲。*
|
||||
|
||||
物联网是嵌入式大会的主题,在 OpenIoT 峰会讲演中谈到了,在 Torvalds 的访谈中也是主要话题。
|
||||
|
||||
Torvalds 对 Hohndel 说到,“或许你不会在物联网末端设备上看到 Linux 的影子,但是在你有一个中心设备的时候,你就会需要它。尤其是物联网标准都有 23 个的时候,你就更需要智能设备了。如果你全部使用的是低级设备,它们没必要一定运行 Linux;如果它们采用的标准稍有差异,你就需要很多的智能设备。我们将来也不会有一个完全开放的标准来将这些物联网设备统一到一起,但是我们会有 3/4 的主要协议是一样的,然后那些智能的中心设备就可以对它们进行互相转换。”
|
||||
|
||||
当 Hohndel 问及在物联网的巨大安全漏洞的时候,Torvalds 神情如常。他说:“我不担心安全问题因为我们能做的不是很多,物联网(设备)是不能更新的,这是我们面对的事实。"
|
||||
|
||||
Linux 缔造者看起来更关心的是一次性嵌入式项目缺少对上游的及时贡献,尽管他注意到近年来这些有了一些显著改善,特别是在硬件整合方面。
|
||||
|
||||
“嵌入式领域历来就很难与开源开发者有所联系,但是我认为这些都在发生改变。”Torvalds 说:“ARM 社区变得越来越好了。内核维护者实际上现在也能跟上了一些硬件的更新换代。一切都在变好,但是还不够。”
|
||||
|
||||
Torvalds 承认他在家经常使用桌面系统而不是嵌入式系统,并且对硬件不是很熟悉。
|
||||
|
||||
“我已经用电烙铁弄坏了很多东西。”他说到。“我真的不适合搞硬件开发。”另一方面,Torvalds 设想如果他现在是个年轻人,他可能也在摆弄 Raspberry Pi 和 BeagleBone(猎兔犬板)。“最棒的是你不需要精通焊接,你只需要买个新的板子就行。”
|
||||
|
||||
同时,Torvalds 也承诺他要为 Linux 桌面再奋斗一个 25 年。他笑着说:“我要为它工作一生。”
|
||||
|
||||
下面,请看完整[视频](https://youtu.be/tQKUWkR-wtM)。
|
||||
|
||||
|
||||
要获取关于嵌入式 Linux 和物联网的最新信息,请访问 2016 年嵌入式 Linux 大会 150+ 分钟的会议全程。[现在观看][1]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/linus-torvalds-talks-iot-smart-devices-security-concerns-and-more-video
|
||||
|
||||
作者:[ERIC BROWN][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/ericstephenbrown
|
||||
[0]: http://events.linuxfoundation.org/events/embedded-linux-conference
|
||||
[1]: http://go.linuxfoundation.org/elc-openiot-summit-2016-videos?utm_source=lf&utm_medium=blog&utm_campaign=linuxcom
|
||||
|
||||
@ -1,16 +1,10 @@
|
||||
---
|
||||
date: 2016-07-09 14:42
|
||||
status: public
|
||||
title: 20160512 Bitmap in Linux Kernel
|
||||
---
|
||||
|
||||
Linux 内核里的数据结构
|
||||
Linux 内核里的数据结构——位数组
|
||||
================================================================================
|
||||
|
||||
Linux 内核中的位数组和位操作
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
除了不同的基于[链式](https://en.wikipedia.org/wiki/Linked_data_structure)和[树](https://en.wikipedia.org/wiki/Tree_%28data_structure%29)的数据结构以外,Linux 内核也为[位数组](https://en.wikipedia.org/wiki/Bit_array)或`位图`提供了 [API](https://en.wikipedia.org/wiki/Application_programming_interface)。位数组在 Linux 内核里被广泛使用,并且在以下的源代码文件中包含了与这样的结构搭配使用的通用 `API`:
|
||||
除了不同的基于[链式](https://en.wikipedia.org/wiki/Linked_data_structure)和[树](https://en.wikipedia.org/wiki/Tree_%28data_structure%29)的数据结构以外,Linux 内核也为[位数组](https://en.wikipedia.org/wiki/Bit_array)(或称为位图(bitmap))提供了 [API](https://en.wikipedia.org/wiki/Application_programming_interface)。位数组在 Linux 内核里被广泛使用,并且在以下的源代码文件中包含了与这样的结构搭配使用的通用 `API`:
|
||||
|
||||
* [lib/bitmap.c](https://github.com/torvalds/linux/blob/master/lib/bitmap.c)
|
||||
* [include/linux/bitmap.h](https://github.com/torvalds/linux/blob/master/include/linux/bitmap.h)
|
||||
@ -19,14 +13,14 @@ Linux 内核中的位数组和位操作
|
||||
|
||||
* [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h)
|
||||
|
||||
头文件。正如我上面所写的,`位图`在 Linux 内核中被广泛地使用。例如,`位数组`常常用于保存一组在线/离线处理器,以便系统支持[热插拔](https://www.kernel.org/doc/Documentation/cpu-hotplug.txt)的 CPU(你可以在 [cpumasks](https://0xax.gitbooks.io/linux-insides/content/Concepts/cpumask.html) 部分阅读更多相关知识 ),一个`位数组`可以在 Linux 内核初始化等期间保存一组已分配的中断处理。
|
||||
头文件。正如我上面所写的,`位图`在 Linux 内核中被广泛地使用。例如,`位数组`常常用于保存一组在线/离线处理器,以便系统支持[热插拔](https://www.kernel.org/doc/Documentation/cpu-hotplug.txt)的 CPU(你可以在 [cpumasks](https://0xax.gitbooks.io/linux-insides/content/Concepts/cpumask.html) 部分阅读更多相关知识 ),一个位数组(bit array)可以在 Linux 内核初始化等期间保存一组已分配的[中断处理](https://en.wikipedia.org/wiki/Interrupt_request_%28PC_architecture%29)。
|
||||
|
||||
因此,本部分的主要目的是了解位数组是如何在 Linux 内核中实现的。让我们现在开始吧。
|
||||
因此,本部分的主要目的是了解位数组(bit array)是如何在 Linux 内核中实现的。让我们现在开始吧。
|
||||
|
||||
位数组声明
|
||||
================================================================================
|
||||
|
||||
在我们开始查看位图操作的 `API` 之前,我们必须知道如何在 Linux 内核中声明它。有两中通用的方法声明位数组。第一种简单的声明一个位数组的方法是,定义一个 unsigned long 的数组,例如:
|
||||
在我们开始查看`位图`操作的 `API` 之前,我们必须知道如何在 Linux 内核中声明它。有两种声明位数组的通用方法。第一种简单的声明一个位数组的方法是,定义一个 `unsigned long` 的数组,例如:
|
||||
|
||||
```C
|
||||
unsigned long my_bitmap[8]
|
||||
@ -44,7 +38,7 @@ unsigned long my_bitmap[8]
|
||||
* `name` - 位图名称;
|
||||
* `bits` - 位图中位数;
|
||||
|
||||
并且只是使用 `BITS_TO_LONGS(bits)` 元素展开 `unsigned long` 数组的定义。 `BITS_TO_LONGS` 宏将一个给定的位数转换为 `longs` 的个数,换言之,就是计算 `bits` 中有多少个 `8` 字节元素:
|
||||
并且只是使用 `BITS_TO_LONGS(bits)` 元素展开 `unsigned long` 数组的定义。 `BITS_TO_LONGS` 宏将一个给定的位数转换为 `long` 的个数,换言之,就是计算 `bits` 中有多少个 `8` 字节元素:
|
||||
|
||||
```C
|
||||
#define BITS_PER_BYTE 8
|
||||
@ -70,18 +64,18 @@ unsigned long my_bitmap[1];
|
||||
体系结构特定的位操作
|
||||
================================================================================
|
||||
|
||||
我们已经看了以上一对源文件和头文件,它们提供了位数组操作的 [API](https://en.wikipedia.org/wiki/Application_programming_interface)。其中重要且广泛使用的位数组 API 是体系结构特定的且位于已提及的头文件中 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h)。
|
||||
我们已经看了上面提及的一对源文件和头文件,它们提供了位数组操作的 [API](https://en.wikipedia.org/wiki/Application_programming_interface)。其中重要且广泛使用的位数组 API 是体系结构特定的且位于已提及的头文件中 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h)。
|
||||
|
||||
首先让我们查看两个最重要的函数:
|
||||
|
||||
* `set_bit`;
|
||||
* `clear_bit`.
|
||||
|
||||
我认为没有必要解释这些函数的作用。从它们的名字来看,这已经很清楚了。让我们直接查看它们的实现。如果你浏览 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 头文件,你将会注意到这些函数中的每一个都有[原子性](https://en.wikipedia.org/wiki/Linearizability)和非原子性两种变体。在我们开始深入这些函数的实现之前,首先,我们必须了解一些有关原子操作的知识。
|
||||
我认为没有必要解释这些函数的作用。从它们的名字来看,这已经很清楚了。让我们直接查看它们的实现。如果你浏览 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 头文件,你将会注意到这些函数中的每一个都有[原子性](https://en.wikipedia.org/wiki/Linearizability)和非原子性两种变体。在我们开始深入这些函数的实现之前,首先,我们必须了解一些有关原子(atomic)操作的知识。
|
||||
|
||||
简而言之,原子操作保证两个或以上的操作不会并发地执行同一数据。`x86` 体系结构提供了一系列原子指令,例如, [xchg](http://x86.renejeschke.de/html/file_module_x86_id_328.html)、[cmpxchg](http://x86.renejeschke.de/html/file_module_x86_id_41.html) 等指令。除了原子指令,一些非原子指令可以在 [lock](http://x86.renejeschke.de/html/file_module_x86_id_159.html) 指令的帮助下具有原子性。目前已经对原子操作有了充分的理解,我们可以接着探讨 `set_bit` 和 `clear_bit` 函数的实现。
|
||||
简而言之,原子操作保证两个或以上的操作不会并发地执行同一数据。`x86` 体系结构提供了一系列原子指令,例如, [xchg](http://x86.renejeschke.de/html/file_module_x86_id_328.html)、[cmpxchg](http://x86.renejeschke.de/html/file_module_x86_id_41.html) 等指令。除了原子指令,一些非原子指令可以在 [lock](http://x86.renejeschke.de/html/file_module_x86_id_159.html) 指令的帮助下具有原子性。现在你已经对原子操作有了足够的了解,我们可以接着探讨 `set_bit` 和 `clear_bit` 函数的实现。
|
||||
|
||||
我们先考虑函数的非原子性变体。非原子性的 `set_bit` 和 `clear_bit` 的名字以双下划线开始。正如我们所知道的,所有这些函数都定义于 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 头文件,并且第一个函数就是 `__set_bit`:
|
||||
我们先考虑函数的非原子性(non-atomic)变体。非原子性的 `set_bit` 和 `clear_bit` 的名字以双下划线开始。正如我们所知道的,所有这些函数都定义于 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 头文件,并且第一个函数就是 `__set_bit`:
|
||||
|
||||
```C
|
||||
static inline void __set_bit(long nr, volatile unsigned long *addr)
|
||||
@ -92,25 +86,25 @@ static inline void __set_bit(long nr, volatile unsigned long *addr)
|
||||
|
||||
正如我们所看到的,它使用了两个参数:
|
||||
|
||||
* `nr` - 位数组中的位号(从0开始,译者注)
|
||||
* `nr` - 位数组中的位号(LCTT 译注:从 0开始)
|
||||
* `addr` - 我们需要置位的位数组地址
|
||||
|
||||
注意,`addr` 参数使用 `volatile` 关键字定义,以告诉编译器给定地址指向的变量可能会被修改。 `__set_bit` 的实现相当简单。正如我们所看到的,它仅包含一行[内联汇编代码](https://en.wikipedia.org/wiki/Inline_assembler)。在我们的例子中,我们使用 [bts](http://x86.renejeschke.de/html/file_module_x86_id_25.html) 指令,从位数组中选出一个第一操作数(我们的例子中的 `nr`),存储选出的位的值到 [CF](https://en.wikipedia.org/wiki/FLAGS_register) 标志寄存器并设置该位(即 `nr` 指定的位置为1,译者注)。
|
||||
注意,`addr` 参数使用 `volatile` 关键字定义,以告诉编译器给定地址指向的变量可能会被修改。 `__set_bit` 的实现相当简单。正如我们所看到的,它仅包含一行[内联汇编代码](https://en.wikipedia.org/wiki/Inline_assembler)。在我们的例子中,我们使用 [bts](http://x86.renejeschke.de/html/file_module_x86_id_25.html) 指令,从位数组中选出一个第一操作数(我们的例子中的 `nr`)所指定的位,存储选出的位的值到 [CF](https://en.wikipedia.org/wiki/FLAGS_register) 标志寄存器并设置该位(LCTT 译注:即 `nr` 指定的位置为 1)。
|
||||
|
||||
注意,我们了解了 `nr` 的用法,但这里还有一个参数 `addr` 呢!你或许已经猜到秘密就在 `ADDR`。 `ADDR` 是一个定义在同一头文件的宏,它展开为一个包含给定地址和 `+m` 约束的字符串:
|
||||
注意,我们了解了 `nr` 的用法,但这里还有一个参数 `addr` 呢!你或许已经猜到秘密就在 `ADDR`。 `ADDR` 是一个定义在同一个头文件中的宏,它展开为一个包含给定地址和 `+m` 约束的字符串:
|
||||
|
||||
```C
|
||||
#define ADDR BITOP_ADDR(addr)
|
||||
#define BITOP_ADDR(x) "+m" (*(volatile long *) (x))
|
||||
```
|
||||
|
||||
除了 `+m` 之外,在 `__set_bit` 函数中我们可以看到其他约束。让我们查看并试图理解它们所表示的意义:
|
||||
除了 `+m` 之外,在 `__set_bit` 函数中我们可以看到其他约束。让我们查看并试着理解它们所表示的意义:
|
||||
|
||||
* `+m` - 表示内存操作数,这里的 `+` 表明给定的操作数为输入输出操作数;
|
||||
* `I` - 表示整型常量;
|
||||
* `+m` - 表示内存操作数,这里的 `+` 表明给定的操作数为输入输出操作数;
|
||||
* `I` - 表示整型常量;
|
||||
* `r` - 表示寄存器操作数
|
||||
|
||||
除了这些约束之外,我们也能看到 `memory` 关键字,其告诉编译器这段代码会修改内存中的变量。到此为止,现在我们看看相同的原子性变体函数。它看起来比非原子性变体更加复杂:
|
||||
除了这些约束之外,我们也能看到 `memory` 关键字,其告诉编译器这段代码会修改内存中的变量。到此为止,现在我们看看相同的原子性(atomic)变体函数。它看起来比非原子性(non-atomic)变体更加复杂:
|
||||
|
||||
```C
|
||||
static __always_inline void
|
||||
@ -128,7 +122,7 @@ set_bit(long nr, volatile unsigned long *addr)
|
||||
}
|
||||
```
|
||||
|
||||
(BITOP_ADDR 的定义为:`#define BITOP_ADDR(x) "=m" (*(volatile long *) (x))`,ORB 为字节按位或,译者注)
|
||||
(LCTT 译注:BITOP_ADDR 的定义为:`#define BITOP_ADDR(x) "=m" (*(volatile long *) (x))`,ORB 为字节按位或。)
|
||||
|
||||
首先注意,这个函数使用了与 `__set_bit` 相同的参数集合,但额外地使用了 `__always_inline` 属性标记。 `__always_inline` 是一个定义于 [include/linux/compiler-gcc.h](https://github.com/torvalds/linux/blob/master/include/linux/compiler-gcc.h) 的宏,并且只是展开为 `always_inline` 属性:
|
||||
|
||||
@ -136,19 +130,19 @@ set_bit(long nr, volatile unsigned long *addr)
|
||||
#define __always_inline inline __attribute__((always_inline))
|
||||
```
|
||||
|
||||
其意味着这个函数总是内联的,以减少 Linux 内核映像的大小。现在我们试着了解 `set_bit` 函数的实现。首先我们在 `set_bit` 函数的开头检查给定的位数量。`IS_IMMEDIATE` 宏定义于相同[头文件](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h),并展开为 gcc 内置函数的调用:
|
||||
其意味着这个函数总是内联的,以减少 Linux 内核映像的大小。现在让我们试着了解下 `set_bit` 函数的实现。首先我们在 `set_bit` 函数的开头检查给定的位的数量。`IS_IMMEDIATE` 宏定义于相同的[头文件](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h),并展开为 [gcc](https://en.wikipedia.org/wiki/GNU_Compiler_Collection) 内置函数的调用:
|
||||
|
||||
```C
|
||||
#define IS_IMMEDIATE(nr) (__builtin_constant_p(nr))
|
||||
```
|
||||
|
||||
如果给定的参数是编译期已知的常量,`__builtin_constant_p` 内置函数则返回 `1`,其他情况返回 `0`。假若给定的位数是编译期已知的常量,我们便无须使用效率低下的 `bts` 指令去设置位。我们可以只需在给定地址指向的字节和和掩码上执行 [按位或](https://en.wikipedia.org/wiki/Bitwise_operation#OR) 操作,其字节包含给定的位,而掩码为位号高位 `1`,其他位为 0。在其他情况下,如果给定的位号不是编译期已知常量,我们便做和 `__set_bit` 函数一样的事。`CONST_MASK_ADDR` 宏:
|
||||
如果给定的参数是编译期已知的常量,`__builtin_constant_p` 内置函数则返回 `1`,其他情况返回 `0`。假若给定的位数是编译期已知的常量,我们便无须使用效率低下的 `bts` 指令去设置位。我们可以只需在给定地址指向的字节上执行 [按位或](https://en.wikipedia.org/wiki/Bitwise_operation#OR) 操作,其字节包含给定的位,掩码位数表示高位为 `1`,其他位为 0 的掩码。在其他情况下,如果给定的位号不是编译期已知常量,我们便做和 `__set_bit` 函数一样的事。`CONST_MASK_ADDR` 宏:
|
||||
|
||||
```C
|
||||
#define CONST_MASK_ADDR(nr, addr) BITOP_ADDR((void *)(addr) + ((nr)>>3))
|
||||
```
|
||||
|
||||
展开为带有到包含给定位的字节偏移的给定地址,例如,我们拥有地址 `0x1000` 和 位号是 `0x9`。因为 `0x9` 是 `一个字节 + 一位`,所以我们的地址是 `addr + 1`:
|
||||
展开为带有到包含给定位的字节偏移的给定地址,例如,我们拥有地址 `0x1000` 和位号 `0x9`。因为 `0x9` 代表 `一个字节 + 一位`,所以我们的地址是 `addr + 1`:
|
||||
|
||||
```python
|
||||
>>> hex(0x1000 + (0x9 >> 3))
|
||||
@ -166,7 +160,7 @@ set_bit(long nr, volatile unsigned long *addr)
|
||||
'0b10'
|
||||
```
|
||||
|
||||
最后,我们应用 `按位或` 运算到这些变量上面,因此,假如我们的地址是 `0x4097` ,并且我们需要置位号为 `9` 的位 为 1:
|
||||
最后,我们应用 `按位或` 运算到这些变量上面,因此,假如我们的地址是 `0x4097` ,并且我们需要置位号为 `9` 的位为 1:
|
||||
|
||||
```python
|
||||
>>> bin(0x4097)
|
||||
@ -175,11 +169,11 @@ set_bit(long nr, volatile unsigned long *addr)
|
||||
'0b100010'
|
||||
```
|
||||
|
||||
`第 9 位` 将会被置位。(这里的 9 是从 0 开始计数的,比如0010,按照作者的意思,其中的 1 是第 1 位,译者注)
|
||||
`第 9 位` 将会被置位。(LCTT 译注:这里的 9 是从 0 开始计数的,比如0010,按照作者的意思,其中的 1 是第 1 位)
|
||||
|
||||
注意,所有这些操作使用 `LOCK_PREFIX` 标记,其展开为 [lock](http://x86.renejeschke.de/html/file_module_x86_id_159.html) 指令,保证该操作的原子性。
|
||||
|
||||
正如我们所知,除了 `set_bit` 和 `__set_bit` 操作之外,Linux 内核还提供了两个功能相反的函数,在原子性和非原子性的上下文中清位。它们为 `clear_bit` 和 `__clear_bit`。这两个函数都定义于同一个[头文件](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 并且使用相同的参数集合。不仅参数相似,一般而言,这些函数与 `set_bit` 和 `__set_bit` 也非常相似。让我们查看非原子性 `__clear_bit` 的实现吧:
|
||||
正如我们所知,除了 `set_bit` 和 `__set_bit` 操作之外,Linux 内核还提供了两个功能相反的函数,在原子性和非原子性的上下文中清位。它们是 `clear_bit` 和 `__clear_bit`。这两个函数都定义于同一个[头文件](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 并且使用相同的参数集合。不仅参数相似,一般而言,这些函数与 `set_bit` 和 `__set_bit` 也非常相似。让我们查看非原子性 `__clear_bit` 的实现吧:
|
||||
|
||||
```C
|
||||
static inline void __clear_bit(long nr, volatile unsigned long *addr)
|
||||
@ -188,7 +182,7 @@ static inline void __clear_bit(long nr, volatile unsigned long *addr)
|
||||
}
|
||||
```
|
||||
|
||||
没错,正如我们所见,`__clear_bit` 使用相同的参数集合,并包含极其相似的内联汇编代码块。它仅仅使用 [btr](http://x86.renejeschke.de/html/file_module_x86_id_24.html) 指令替换 `bts`。正如我们从函数名所理解的一样,通过给定地址,它清除了给定的位。`btr` 指令表现得像 `bts`(原文这里为 btr,可能为笔误,修正为 bts,译者注)。该指令选出第一操作数指定的位,存储它的值到 `CF` 标志寄存器,并且清楚第二操作数指定的位数组中的对应位。
|
||||
没错,正如我们所见,`__clear_bit` 使用相同的参数集合,并包含极其相似的内联汇编代码块。它只是使用 [btr](http://x86.renejeschke.de/html/file_module_x86_id_24.html) 指令替换了 `bts`。正如我们从函数名所理解的一样,通过给定地址,它清除了给定的位。`btr` 指令表现得像 `bts`(LCTT 译注:原文这里为 btr,可能为笔误,修正为 bts)。该指令选出第一操作数所指定的位,存储它的值到 `CF` 标志寄存器,并且清除第二操作数指定的位数组中的对应位。
|
||||
|
||||
`__clear_bit` 的原子性变体为 `clear_bit`:
|
||||
|
||||
@ -208,11 +202,11 @@ clear_bit(long nr, volatile unsigned long *addr)
|
||||
}
|
||||
```
|
||||
|
||||
并且正如我们所看到的,它与 `set_bit` 非常相似,同时只包含了两处差异。第一处差异为 `clear_bit` 使用 `btr` 指令来清位,而 `set_bit` 使用 `bts` 指令来置位。第二处差异为 `clear_bit` 使用否定的位掩码和 `按位与` 在给定的字节上置位,而 `set_bit` 使用 `按位或` 指令。
|
||||
并且正如我们所看到的,它与 `set_bit` 非常相似,只有两处不同。第一处差异为 `clear_bit` 使用 `btr` 指令来清位,而 `set_bit` 使用 `bts` 指令来置位。第二处差异为 `clear_bit` 使用否定的位掩码和 `按位与` 在给定的字节上置位,而 `set_bit` 使用 `按位或` 指令。
|
||||
|
||||
到此为止,我们可以在任何位数组置位和清位了,并且能够转到位掩码上的其他操作。
|
||||
到此为止,我们可以在任意位数组置位和清位了,我们将看看位掩码上的其他操作。
|
||||
|
||||
在 Linux 内核位数组上最广泛使用的操作是设置和清除位,但是除了这两个操作外,位数组上其他操作也是非常有用的。Linux 内核里另一种广泛使用的操作是知晓位数组中一个给定的位是否被置位。我们能够通过 `test_bit` 宏的帮助实现这一功能。这个宏定义于 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 头文件,并展开为 `constant_test_bit` 或 `variable_test_bit` 的调用,这要取决于位号。
|
||||
在 Linux 内核中对位数组最广泛使用的操作是设置和清除位,但是除了这两个操作外,位数组上其他操作也是非常有用的。Linux 内核里另一种广泛使用的操作是知晓位数组中一个给定的位是否被置位。我们能够通过 `test_bit` 宏的帮助实现这一功能。这个宏定义于 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 头文件,并根据位号分别展开为 `constant_test_bit` 或 `variable_test_bit` 调用。
|
||||
|
||||
```C
|
||||
#define test_bit(nr, addr) \
|
||||
@ -221,7 +215,7 @@ clear_bit(long nr, volatile unsigned long *addr)
|
||||
: variable_test_bit((nr), (addr)))
|
||||
```
|
||||
|
||||
因此,如果 `nr` 是编译期已知常量,`test_bit` 将展开为 `constant_test_bit` 函数的调用,而其他情况则为 `variable_test_bit`。现在让我们看看这些函数的实现,我们从 `variable_test_bit` 开始看起:
|
||||
因此,如果 `nr` 是编译期已知常量,`test_bit` 将展开为 `constant_test_bit` 函数的调用,而其他情况则为 `variable_test_bit`。现在让我们看看这些函数的实现,让我们从 `variable_test_bit` 开始看起:
|
||||
|
||||
```C
|
||||
static inline int variable_test_bit(long nr, volatile const unsigned long *addr)
|
||||
@ -237,7 +231,7 @@ static inline int variable_test_bit(long nr, volatile const unsigned long *addr)
|
||||
}
|
||||
```
|
||||
|
||||
`variable_test_bit` 函数调用了与 `set_bit` 及其他函数使用的相似的参数集合。我们也可以看到执行 [bt](http://x86.renejeschke.de/html/file_module_x86_id_22.html) 和 [sbb](http://x86.renejeschke.de/html/file_module_x86_id_286.html) 指令的内联汇编代码。`bt` 或 `bit test` 指令从第二操作数指定的位数组选出第一操作数指定的一个指定位,并且将该位的值存进标志寄存器的 [CF](https://en.wikipedia.org/wiki/FLAGS_register) 位。第二个指令 `sbb` 从第二操作数中减去第一操作数,再减去 `CF` 的值。因此,这里将一个从给定位数组中的给定位号的值写进标志寄存器的 `CF` 位,并且执行 `sbb` 指令计算: `00000000 - CF`,并将结果写进 `oldbit` 变量。
|
||||
`variable_test_bit` 函数使用了与 `set_bit` 及其他函数使用的相似的参数集合。我们也可以看到执行 [bt](http://x86.renejeschke.de/html/file_module_x86_id_22.html) 和 [sbb](http://x86.renejeschke.de/html/file_module_x86_id_286.html) 指令的内联汇编代码。`bt` (或称 `bit test`)指令从第二操作数指定的位数组选出第一操作数指定的一个指定位,并且将该位的值存进标志寄存器的 [CF](https://en.wikipedia.org/wiki/FLAGS_register) 位。第二个指令 `sbb` 从第二操作数中减去第一操作数,再减去 `CF` 的值。因此,这里将一个从给定位数组中的给定位号的值写进标志寄存器的 `CF` 位,并且执行 `sbb` 指令计算: `00000000 - CF`,并将结果写进 `oldbit` 变量。
|
||||
|
||||
`constant_test_bit` 函数做了和我们在 `set_bit` 所看到的一样的事:
|
||||
|
||||
@ -251,7 +245,7 @@ static __always_inline int constant_test_bit(long nr, const volatile unsigned lo
|
||||
|
||||
它生成了一个位号对应位为高位 `1`,而其他位为 `0` 的字节(正如我们在 `CONST_MASK` 所看到的),并将 [按位与](https://en.wikipedia.org/wiki/Bitwise_operation#AND) 应用于包含给定位号的字节。
|
||||
|
||||
下一广泛使用的位数组相关操作是改变一个位数组中的位。为此,Linux 内核提供了两个辅助函数:
|
||||
下一个被广泛使用的位数组相关操作是改变一个位数组中的位。为此,Linux 内核提供了两个辅助函数:
|
||||
|
||||
* `__change_bit`;
|
||||
* `change_bit`.
|
||||
@ -274,7 +268,7 @@ static inline void __change_bit(long nr, volatile unsigned long *addr)
|
||||
1
|
||||
```
|
||||
|
||||
`__change_bit` 的原子版本为 `change_bit` 函数:
|
||||
`__change_bit` 的原子版本为 `change_bit` 函数:
|
||||
|
||||
```C
|
||||
static inline void change_bit(long nr, volatile unsigned long *addr)
|
||||
@ -291,14 +285,14 @@ static inline void change_bit(long nr, volatile unsigned long *addr)
|
||||
}
|
||||
```
|
||||
|
||||
它和 `set_bit` 函数很相似,但也存在两点差异。第一处差异为 `xor` 操作而不是 `or`。第二处差异为 `btc`(原文为 `bts`,为作者笔误,译者注) 而不是 `bts`。
|
||||
它和 `set_bit` 函数很相似,但也存在两点不同。第一处差异为 `xor` 操作而不是 `or`。第二处差异为 `btc`( LCTT 译注:原文为 `bts`,为作者笔误) 而不是 `bts`。
|
||||
|
||||
目前,我们了解了最重要的体系特定的位数组操作,是时候看看一般的位图 API 了。
|
||||
|
||||
通用位操作
|
||||
================================================================================
|
||||
|
||||
除了 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 中体系特定的 API 外,Linux 内核提供了操作位数组的通用 API。正如我们本部分开头所了解的一样,我们可以在 [include/linux/bitmap.h](https://github.com/torvalds/linux/blob/master/include/linux/bitmap.h) 头文件和* [lib/bitmap.c](https://github.com/torvalds/linux/blob/master/lib/bitmap.c) 源文件中找到它。但在查看这些源文件之前,我们先看看 [include/linux/bitops.h](https://github.com/torvalds/linux/blob/master/include/linux/bitops.h) 头文件,其提供了一系列有用的宏,让我们看看它们当中一部分。
|
||||
除了 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 中体系特定的 API 外,Linux 内核提供了操作位数组的通用 API。正如我们本部分开头所了解的一样,我们可以在 [include/linux/bitmap.h](https://github.com/torvalds/linux/blob/master/include/linux/bitmap.h) 头文件和 [lib/bitmap.c](https://github.com/torvalds/linux/blob/master/lib/bitmap.c) 源文件中找到它。但在查看这些源文件之前,我们先看看 [include/linux/bitops.h](https://github.com/torvalds/linux/blob/master/include/linux/bitops.h) 头文件,其提供了一系列有用的宏,让我们看看它们当中一部分。
|
||||
|
||||
首先我们看看以下 4 个 宏:
|
||||
|
||||
@ -307,7 +301,7 @@ static inline void change_bit(long nr, volatile unsigned long *addr)
|
||||
* `for_each_clear_bit`
|
||||
* `for_each_clear_bit_from`
|
||||
|
||||
所有这些宏都提供了遍历位数组中某些位集合的迭代器。第一个红迭代那些被置位的位。第二个宏也是一样,但它是从某一确定位开始。最后两个宏做的一样,但是迭代那些被清位的位。让我们看看 `for_each_set_bit` 宏:
|
||||
所有这些宏都提供了遍历位数组中某些位集合的迭代器。第一个宏迭代那些被置位的位。第二个宏也是一样,但它是从某一个确定的位开始。最后两个宏做的一样,但是迭代那些被清位的位。让我们看看 `for_each_set_bit` 宏:
|
||||
|
||||
```C
|
||||
#define for_each_set_bit(bit, addr, size) \
|
||||
@ -316,7 +310,7 @@ static inline void change_bit(long nr, volatile unsigned long *addr)
|
||||
(bit) = find_next_bit((addr), (size), (bit) + 1))
|
||||
```
|
||||
|
||||
正如我们所看到的,它使用了三个参数,并展开为一个循环,该循环从作为 `find_first_bit` 函数返回结果的第一个置位开始到最后一个置位且小于给定大小为止。
|
||||
正如我们所看到的,它使用了三个参数,并展开为一个循环,该循环从作为 `find_first_bit` 函数返回结果的第一个置位开始,到小于给定大小的最后一个置位为止。
|
||||
|
||||
除了这四个宏, [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 也提供了 `64-bit` 或 `32-bit` 变量循环的 API 等等。
|
||||
|
||||
@ -339,7 +333,7 @@ static inline void bitmap_zero(unsigned long *dst, unsigned int nbits)
|
||||
}
|
||||
```
|
||||
|
||||
首先我们可以看到对 `nbits` 的检查。 `small_const_nbits` 是一个定义在同一[头文件](https://github.com/torvalds/linux/blob/master/include/linux/bitmap.h) 的宏:
|
||||
首先我们可以看到对 `nbits` 的检查。 `small_const_nbits` 是一个定义在同一个[头文件](https://github.com/torvalds/linux/blob/master/include/linux/bitmap.h) 的宏:
|
||||
|
||||
```C
|
||||
#define small_const_nbits(nbits) \
|
||||
@ -398,7 +392,7 @@ via: https://github.com/0xAX/linux-insides/blob/master/DataStructures/bitmap.md
|
||||
|
||||
作者:[0xAX][a]
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
66
published/201608/20160516 Scaling Collaboration in DevOps.md
Normal file
66
published/201608/20160516 Scaling Collaboration in DevOps.md
Normal file
@ -0,0 +1,66 @@
|
||||
DevOps 的弹性合作
|
||||
=================================
|
||||
|
||||

|
||||
|
||||
那些熟悉 DevOps 的人通常认为与其说 DevOps 是一种技术不如说是一种文化。在 DevOps 的有效实践上需要一些特定的工具和经验,但是 DevOps 成功的基础在于企业内如何做好[团队和个体协作][1],从而可以让事情更快、更高效而有效的完成。
|
||||
|
||||
大多数的 DevOps 平台和工具都是以可扩展性为设计理念的。DevOps 环境通常运行在云端,并且容易发生变化。对于DevOps 软件来说,支持实时伸缩以解决冲突和摩擦是重要的。这同样对于人的因素也是一样的,但弹性合作却是完全不同的。
|
||||
|
||||
跨企业协同是 DevOps 成功的关键。好的代码和开发最终需要形成产品才能给用户带来价值。公司所面临的挑战是如何做到无缝衔接和尽可能的提高速度及自动化水平,而不是牺牲质量或性能。企业如何才能流水线化代码的开发和部署,同时保持维护工作的明晰、可控和合规?
|
||||
|
||||
### 新兴趋势
|
||||
|
||||
首先,我先提供一些背景,分享一些 [451 Research][2] 在 DevOps 及其常规应用方面获取的数据。云、敏捷和Devops 的能力在今天是非常重要的,不管是理念还是现实。451 研究公司发现采用这些东西以及容器技术的企业在不断增多,包括在生产环境中的大量使用。
|
||||
|
||||
拥抱这些技术和方式有许多优点,比如提高灵活性和速度,降低成本,提高适应能力和可靠性,适应新的或新兴的应用。据 451 Research 称,团队也面临着一些障碍,包括缺乏熟悉其中所需的技能的人、这些新兴技术的不成熟、成本和安全问题等。
|
||||
|
||||
在 “[Voice of the Enterprise: SDI Q4 2015 survey][2]” 报告中,451 Research 发现超过一半的受访者(57.1%)考虑他们稍晚些再采用,甚至会最后才采用这些新技术。另一方面,近半受访者(48.3 %)认为自己是率先或早期的采用者。
|
||||
|
||||
这些普遍性的情绪也表现在对其他问题的调查中。当问起容器的执行情况时,50.3% 的人表示这根本不在他们的计划中。剩下 49.7% 的人则是在计划、试点或积极使用容器技术。近 2/3(65.1%)的人表示,他们用敏捷开发方式来开发应用,但是只有 39.6% 的人回应称他们正在积极拥抱 DevOps。然而,敏捷软件开发已经在行业内存在了多年,451 Research 注意到容器和 Devops 的采用率显著提升,这是一个新的趋势。
|
||||
|
||||
当被问及首要的三个 IT 痛点是什么,被提及最多的是成本或预算、人员不足和遗留软件问题。随着企业向云、DevOps、和容器等转型,这些问题都需要加以解决,以及如何规划技术和有效协作。
|
||||
|
||||
### 当前状况
|
||||
|
||||
软件行业正处于急剧变化之中,这很大程度是由 DevOps 所推动的,它使得软件开发变得越来越横跨整个业务高度集成。软件的开发变得不再闭门造车,而越来越体现协作和社交化的功能。
|
||||
|
||||
几年还是在小说和展板中的理念和方法迅速成熟,成为了今天推动价值的主流技术和框架。企业依靠如敏捷、精益、虚拟化、云计算、自动化和微服务等概念来简化开发,同时使工作更加有效和高效。
|
||||
|
||||
为了适应和发展,企业需要完成一系列的关键任务。当今面临的挑战是如何加快发展的同时降低成本。团队需要消除 IT 和其他业务之间存在的障碍,并在一个由技术驱动的竞争环境中提供更多有效的战略合作。
|
||||
|
||||
敏捷、云计算、DevOps 和容器在这个过程中起着重要的作用,而将它们连接在一起的是有效的合作。每一种技术和方法都提供了独特的优势,但真正的价值来自于团队作为一个整体能够进行规模协同,以及团队所使用的工具和平台。成功的 DevOps 的实现也需要开发和 IT 运营团队之外其他利益相关者的参与,包括安全、数据库、存储和业务队伍。
|
||||
|
||||
### 合作即平台
|
||||
|
||||
有一些在线的服务和平台,比如 Github 促进和增进了协作。这个在线平台的功能是一个在线代码库,但是所产生的价值远超乎存储代码。
|
||||
|
||||
这样一个[协作平台][4]之所以有助于开发人员和团队合作,是因为它提供了一个可以分享和讨论代码和流程的社区。管理者可以监视进度和跟踪将要发布的代码。开发人员在将实验性的想法放到实际的产品环境中之前,可以在一个安全的环境中进行实验,新的想法和实验可以有效地与适当的团队进行沟通。
|
||||
|
||||
更加敏捷的开发和 DevOps 的关键之一是允许开发人员测试一些东西并快速收集相关的反馈。目标是生产高质量的代码和功能,而不是浪费时间建立和管理基础设施或者安排更多的会议来讨论这个问题。比如 GitHub 平台,能够更有效的和可扩展的协作是因为当参与者想要进行代码审查时很方便。不需要尝试协调和安排代码审查会议,所以开发人员可以继续工作而不被打断,从而产生更大的生产力和工作满意度。
|
||||
|
||||
Sendachi 的 Steven Anderson 指出,Github 是一个协作平台,但它也是一个和你一起工作的工具。这样意味着它不仅可以帮助协作和持续集成,还影响了代码质量。
|
||||
|
||||
合作平台的好处之一是,大型团队的开发人员可以分解成更小的团队,可以更有效地专注于特定的组件。它还提供了诸如文件共享这样的代码之外的功能,模糊了技术和非技术的贡献,增加了协作和可见性。
|
||||
|
||||
### 合作是关键
|
||||
|
||||
合作的重要性不言而喻。合作是 DevOps 文化的关键,也是在当今世界能够进行敏捷开发并保持竞争优势的决定因素。执行或管理支持以及内部传道是很重要的。团队还需要拥抱文化的转变---迈向共同目标的跨职能部门的技能融合。
|
||||
|
||||
要建立起来这样的文化,有效的合作是至关重要的。一个合作平台是弹性合作的必要组件,因为简化了生产活动,并且减少了冗余和尝试,同时还产生了更高质量的结果。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://devops.com/2016/05/16/scaling-collaboration-devops/
|
||||
|
||||
作者:[TONY BRADLEY][a]
|
||||
译者:[Bestony](https://github.com/Bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://devops.com/author/tonybsg/
|
||||
[1]: http://devops.com/2014/12/15/four-strategies-supporting-devops-collaboration/
|
||||
[2]: https://451research.com/
|
||||
[3]: https://451research.com/customer-insight-voice-of-the-enterprise-overview
|
||||
[4]: http://devops.com/events/analytics-of-collaboration-on-github/
|
||||
@ -1,15 +1,13 @@
|
||||
Python 3: 加密简介
|
||||
===================================
|
||||
|
||||
Python 3 的标准库中没什么用来解决加密的,不过却有用于处理哈希的库。在这里我们会对其进行一个简单的介绍,但重点会放在两个第三方的软件包: PyCrypto 和 cryptography 上。我们将学习如何使用这两个库,来加密和解密字符串。
|
||||
|
||||
---
|
||||
Python 3 的标准库中没多少用来解决加密的,不过却有用于处理哈希的库。在这里我们会对其进行一个简单的介绍,但重点会放在两个第三方的软件包:PyCrypto 和 cryptography 上。我们将学习如何使用这两个库,来加密和解密字符串。
|
||||
|
||||
### 哈希
|
||||
|
||||
如果需要用到安全哈希算法或是消息摘要算法,那么你可以使用标准库中的 **hashlib** 模块。这个模块包含了标准的安全哈希算法,包括 SHA1,SHA224,SHA256,SHA384,SHA512 以及 RSA 的 MD5 算法。Python 的 **zlib** 模块也提供 adler32 以及 crc32 哈希函数。
|
||||
如果需要用到安全哈希算法或是消息摘要算法,那么你可以使用标准库中的 **hashlib** 模块。这个模块包含了符合 FIPS(美国联邦信息处理标准)的安全哈希算法,包括 SHA1,SHA224,SHA256,SHA384,SHA512 以及 RSA 的 MD5 算法。Python 也支持 adler32 以及 crc32 哈希函数,不过它们在 **zlib** 模块中。
|
||||
|
||||
一个哈希最常见的用法是,存储密码的哈希值而非密码本身。当然了,使用的哈希函数需要稳健一点,否则容易被破解。另一个常见的用法是,计算一个文件的哈希值,然后将这个文件和它的哈希值分别发送。接受到文件的人可以计算文件的哈希值,检验是否与接受到的哈希值相符。如果两者相符,就说明文件在传送的过程中未经篡改。
|
||||
哈希的一个最常见的用法是,存储密码的哈希值而非密码本身。当然了,使用的哈希函数需要稳健一点,否则容易被破解。另一个常见的用法是,计算一个文件的哈希值,然后将这个文件和它的哈希值分别发送。接收到文件的人可以计算文件的哈希值,检验是否与接受到的哈希值相符。如果两者相符,就说明文件在传送的过程中未经篡改。
|
||||
|
||||
让我们试着创建一个 md5 哈希:
|
||||
|
||||
@ -26,8 +24,6 @@ TypeError: Unicode-objects must be encoded before hashing
|
||||
b'\x14\x82\xec\x1b#d\xf6N}\x16*+[\x16\xf4w'
|
||||
```
|
||||
|
||||
Let’s take a moment to break this down a bit. First off, we import **hashlib** and then we create an instance of an md5 HASH object. Next we add some text to the hash object and we get a traceback. It turns out that to use the md5 hash, you have to pass it a byte string instead of a regular string. So we try that and then call it’s **digest** method to get our hash. If you prefer the hex digest, we can do that too:
|
||||
|
||||
让我们花点时间一行一行来讲解。首先,我们导入 **hashlib** ,然后创建一个 md5 哈希对象的实例。接着,我们向这个实例中添加一个字符串后,却得到了报错信息。原来,计算 md5 哈希时,需要使用字节形式的字符串而非普通字符串。正确添加字符串后,我们调用它的 **digest** 函数来得到哈希值。如果你想要十六进制的哈希值,也可以用以下方法:
|
||||
|
||||
```
|
||||
@ -35,7 +31,7 @@ Let’s take a moment to break this down a bit. First off, we import **hashlib**
|
||||
'1482ec1b2364f64e7d162a2b5b16f477'
|
||||
```
|
||||
|
||||
实际上,有一种精简的方法来创建哈希,下面我们看一下用这种方法创建一个 sha512 哈希:
|
||||
实际上,有一种精简的方法来创建哈希,下面我们看一下用这种方法创建一个 sha1 哈希:
|
||||
|
||||
```
|
||||
>>> sha = hashlib.sha1(b'Hello Python').hexdigest()
|
||||
@ -45,14 +41,11 @@ Let’s take a moment to break this down a bit. First off, we import **hashlib**
|
||||
|
||||
可以看到,我们可以同时创建一个哈希实例并且调用其 digest 函数。然后,我们打印出这个哈希值看一下。这里我使用 sha1 哈希函数作为例子,但它不是特别安全,读者可以随意尝试其他的哈希函数。
|
||||
|
||||
|
||||
---
|
||||
|
||||
### 密钥导出
|
||||
|
||||
Python 的标准库对密钥导出支持较弱。实际上,hashlib 函数库提供的唯一方法就是 **pbkdf2_hmac** 函数。它是基于口令的密钥导出函数 PKCS#5 ,并使用 HMAC 作为伪随机函数。因为它支持加盐和迭代操作,你可以使用类似的方法来哈希你的密码。例如,如果你打算使用 SHA-256 加密方法,你将需要至少 16 个字节的盐,以及最少 100000 次的迭代操作。
|
||||
Python 的标准库对密钥导出支持较弱。实际上,hashlib 函数库提供的唯一方法就是 **pbkdf2_hmac** 函数。它是 PKCS#5 的基于口令的第二个密钥导出函数,并使用 HMAC 作为伪随机函数。因为它支持“加盐(salt)”和迭代操作,你可以使用类似的方法来哈希你的密码。例如,如果你打算使用 SHA-256 加密方法,你将需要至少 16 个字节的“盐”,以及最少 100000 次的迭代操作。
|
||||
|
||||
简单来说,盐就是随机的数据,被用来加入到哈希的过程中,以加大破解的难度。这基本可以保护你的密码免受字典和彩虹表的攻击。
|
||||
简单来说,“盐”就是随机的数据,被用来加入到哈希的过程中,以加大破解的难度。这基本可以保护你的密码免受字典和彩虹表(rainbow table)的攻击。
|
||||
|
||||
让我们看一个简单的例子:
|
||||
|
||||
@ -66,9 +59,7 @@ Python 的标准库对密钥导出支持较弱。实际上,hashlib 函数库
|
||||
b'6e97bad21f6200f9087036a71e7ca9fa01a59e1d697f7e0284cd7f9b897d7c02'
|
||||
```
|
||||
|
||||
这里,我们用 SHA256 对一个密码进行哈希,使用了一个糟糕的盐,但经过了 100000 次迭代操作。当然,SHA 实际上并不被推荐用来创建密码的密钥。你应该使用类似 **scrypt** 的算法来替代。另一个不错的选择是使用一个叫 **bcrypt** 的第三方库。它是被专门设计出来哈希密码的。
|
||||
|
||||
---
|
||||
这里,我们用 SHA256 对一个密码进行哈希,使用了一个糟糕的盐,但经过了 100000 次迭代操作。当然,SHA 实际上并不被推荐用来创建密码的密钥。你应该使用类似 **scrypt** 的算法来替代。另一个不错的选择是使用一个叫 **bcrypt** 的第三方库,它是被专门设计出来哈希密码的。
|
||||
|
||||
### PyCryptodome
|
||||
|
||||
@ -86,11 +77,11 @@ pip install pycryptodome
|
||||
pip install pycryptodomex
|
||||
```
|
||||
|
||||
如果你遇到了问题,可能是因为你没有安装正确的依赖包(译者注:如 python-devel),或者你的 Windows 系统需要一个编译器。如果你需要安装上的帮助或技术支持,可以访问 PyCryptodome 的[网站][1]。
|
||||
如果你遇到了问题,可能是因为你没有安装正确的依赖包(LCTT 译注:如 python-devel),或者你的 Windows 系统需要一个编译器。如果你需要安装上的帮助或技术支持,可以访问 PyCryptodome 的[网站][1]。
|
||||
|
||||
还值得注意的是,PyCryptodome 在 PyCrypto 最后版本的基础上有很多改进。非常值得去访问它们的主页,看看有什么新的特性。
|
||||
|
||||
### 加密字符串
|
||||
#### 加密字符串
|
||||
|
||||
访问了他们的主页之后,我们可以看一些例子。在第一个例子中,我们将使用 DES 算法来加密一个字符串:
|
||||
|
||||
@ -116,8 +107,7 @@ ValueError: Input strings must be a multiple of 8 in length
|
||||
b'>\xfc\x1f\x16x\x87\xb2\x93\x0e\xfcH\x02\xd59VQ'
|
||||
```
|
||||
|
||||
这段代码稍有些复杂,让我们一点点来看。首先需要注意的是,DES 加密使用的密钥长度为 8 个字节,这也是我们将密钥变量设置为 8 个字符的原因。而我们需要加密的字符串的长度必须是 8 的倍数,所以我们创建了一个名为 **pad** 的函数,来给一个字符串末尾添加空格,直到它的长度是 8 的倍数。然后,我们创建了一个 DES 的实例,以及我们需要加密的文本。我们还创建了一个经过填充处理的文本。我们尝试这对未经填充处理的文本进行加密,啊欧,报错了!我们需要对经过填充处理的文本进行加密,然后得到加密的字符串。
|
||||
(译者注:encrypt 函数的参数应为 byte 类型字符串,代码为:`encrypted_text = des.encrypt(padded_textpadded_text.encode('uf-8'))`)
|
||||
这段代码稍有些复杂,让我们一点点来看。首先需要注意的是,DES 加密使用的密钥长度为 8 个字节,这也是我们将密钥变量设置为 8 个字符的原因。而我们需要加密的字符串的长度必须是 8 的倍数,所以我们创建了一个名为 **pad** 的函数,来给一个字符串末尾填充空格,直到它的长度是 8 的倍数。然后,我们创建了一个 DES 的实例,以及我们需要加密的文本。我们还创建了一个经过填充处理的文本。我们尝试着对未经填充处理的文本进行加密,啊欧,报了一个 ValueError 错误!我们需要对经过填充处理的文本进行加密,然后得到加密的字符串。(LCTT 译注:encrypt 函数的参数应为 byte 类型字符串,代码为:`encrypted_text = des.encrypt(padded_text.encode('utf-8'))`)
|
||||
|
||||
知道了如何加密,还要知道如何解密:
|
||||
|
||||
@ -128,7 +118,7 @@ b'Python rocks! '
|
||||
|
||||
幸运的是,解密非常容易,我们只需要调用 des 对象的 **decrypt** 方法就可以得到我们原来的 byte 类型字符串了。下一个任务是学习如何用 RSA 算法加密和解密一个文件。首先,我们需要创建一些 RSA 密钥。
|
||||
|
||||
### 创建 RSA 密钥
|
||||
#### 创建 RSA 密钥
|
||||
|
||||
如果你希望使用 RSA 算法加密数据,那么你需要拥有访问 RAS 公钥和私钥的权限,否则你需要生成一组自己的密钥对。在这个例子中,我们将生成自己的密钥对。创建 RSA 密钥非常容易,所以我们将在 Python 解释器中完成。
|
||||
|
||||
@ -148,9 +138,9 @@ b'Python rocks! '
|
||||
|
||||
接下来,我们通过 RSA 密钥实例的 **publickey** 方法创建我们的公钥。我们使用方法链调用 publickey 和 exportKey 方法生成公钥,同样将它写入磁盘上的文件。
|
||||
|
||||
### 加密文件
|
||||
#### 加密文件
|
||||
|
||||
有了私钥和公钥之后,我们就可以加密一些数据,并写入文件了。这儿有个比较标准的例子:
|
||||
有了私钥和公钥之后,我们就可以加密一些数据,并写入文件了。这里有个比较标准的例子:
|
||||
|
||||
```
|
||||
from Crypto.PublicKey import RSA
|
||||
@ -204,17 +194,15 @@ with open('/path/to/encrypted_data.bin', 'rb') as fobj:
|
||||
print(data)
|
||||
```
|
||||
|
||||
如果你认真看了上一个例子,这段代码应该很容易解析。在这里,我们先读取二进制的加密文件,然后导入私钥。注意,当你导入私钥时,需要提供一个密码,否则会出现错误。然后,我们文件中读取数据,首先是加密的会话密钥,然后是 16 字节的随机数和 16 字节的消息认证码,最后是剩下的加密的数据。
|
||||
如果你认真看了上一个例子,这段代码应该很容易解析。在这里,我们先以二进制模式读取我们的加密文件,然后导入私钥。注意,当你导入私钥时,需要提供一个密码,否则会出现错误。然后,我们文件中读取数据,首先是加密的会话密钥,然后是 16 字节的随机数和 16 字节的消息认证码,最后是剩下的加密的数据。
|
||||
|
||||
接下来我们需要解密出会话密钥,重新创建 AES 密钥,然后解密出数据。
|
||||
|
||||
你还可以用 PyCryptodome 库做更多的事。不过我们要接着讨论在 Python 中还可以用什么来满足我们加密解密的需求。
|
||||
|
||||
---
|
||||
|
||||
### cryptography 包
|
||||
|
||||
**cryptography** 的目标是成为人类易于使用的密码学包,就像 **requests** 是人类易于使用的 HTTP 库一样。这个想法使你能够创建简单安全,易于使用的加密方案。如果有需要的话,你也可以使用一些底层的密码学基元,但这也需要你知道更多的细节,否则创建的东西将是不安全的。
|
||||
**cryptography** 的目标是成为“人类易于使用的密码学包(cryptography for humans)”,就像 **requests** 是“人类易于使用的 HTTP 库(HTTP for Humans)”一样。这个想法使你能够创建简单安全、易于使用的加密方案。如果有需要的话,你也可以使用一些底层的密码学基元,但这也需要你知道更多的细节,否则创建的东西将是不安全的。
|
||||
|
||||
如果你使用的 Python 版本是 3.5, 你可以使用 pip 安装,如下:
|
||||
|
||||
@ -222,7 +210,7 @@ print(data)
|
||||
pip install cryptography
|
||||
```
|
||||
|
||||
你会看到 cryptography 包还安装了一些依赖包(译者注:如 libopenssl-devel)。如果安装都顺利,我们就可以试着加密一些文本了。让我们使用 **Fernet** 对称加密算法,它保证了你加密的任何信息在不知道密码的情况下不能被篡改或读取。Fernet 还通过 **MultiFernet** 支持密钥轮换。下面让我们看一个简单的例子:
|
||||
你会看到 cryptography 包还安装了一些依赖包(LCTT 译注:如 libopenssl-devel)。如果安装都顺利,我们就可以试着加密一些文本了。让我们使用 **Fernet** 对称加密算法,它保证了你加密的任何信息在不知道密码的情况下不能被篡改或读取。Fernet 还通过 **MultiFernet** 支持密钥轮换。下面让我们看一个简单的例子:
|
||||
|
||||
```
|
||||
>>> from cryptography.fernet import Fernet
|
||||
@ -242,9 +230,8 @@ b'My super secret message'
|
||||
|
||||
首先我们需要导入 Fernet,然后生成一个密钥。我们输出密钥看看它是什么样儿。如你所见,它是一个随机的字节串。如果你愿意的话,可以试着多运行 **generate_key** 方法几次,生成的密钥会是不同的。然后我们使用这个密钥生成 Fernet 密码实例。
|
||||
|
||||
现在我们有了用来加密和解密消息的密码。下一步是创建一个需要加密的消息,然后使用 **encrypt** 方法对它加密。我打印出加密的文本,然后你可以看到你不再能够读懂它。为了**解密**出我们的秘密消息,我们只需调用 decrypt 方法,并传入加密的文本作为参数。结果就是我们得到了消息字节串形式的纯文本。
|
||||
现在我们有了用来加密和解密消息的密码。下一步是创建一个需要加密的消息,然后使用 **encrypt** 方法对它加密。我打印出加密的文本,然后你可以看到你再也读不懂它了。为了解密出我们的秘密消息,我们只需调用 **decrypt** 方法,并传入加密的文本作为参数。结果就是我们得到了消息字节串形式的纯文本。
|
||||
|
||||
---
|
||||
|
||||
### 小结
|
||||
|
||||
@ -268,7 +255,7 @@ via: http://www.blog.pythonlibrary.org/2016/05/18/python-3-an-intro-to-encryptio
|
||||
|
||||
作者:[Mike][a]
|
||||
译者:[Cathon](https://github.com/Cathon)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,21 +1,19 @@
|
||||
Linux 平台下 Python 脚本编程入门 – Part 1
|
||||
Linux 平台下 Python 脚本编程入门(一)
|
||||
===============================================================================
|
||||
|
||||
|
||||
众所周知,系统管理员需要精通一门脚本语言,而且招聘机构列出的职位需求上也会这么写。大多数人会认为 Bash (或者其他的 shell 语言)用起来很方便,但一些强大的语言(比如 Python)会给你带来一些其它的好处。
|
||||
|
||||

|
||||
> 在 Linux 中学习 Python 脚本编程
|
||||
|
||||
*在 Linux 中学习 Python 脚本编程*
|
||||
|
||||
首先,我们会使用 Python 的命令行工具,还会接触到 Python 的面向对象特性(这篇文章的后半部分会谈到它)。
|
||||
|
||||
最后,学习 Python
|
||||
可以助力于你在[桌面应用开发][2]及[数据科学领域][3]的事业。
|
||||
学习 Python 可以助力于你在[桌面应用开发][2]及[数据科学领域][3]的职业发展。
|
||||
|
||||
容易上手,广泛使用,拥有海量“开箱即用”的模块(它是一组包含 Python 声明的外部文件),Python 理所当然地成为了美国计算机专业大学生在一年级时所上的程序设计课所用语言的不二之选。
|
||||
容易上手,广泛使用,拥有海量“开箱即用”的模块(它是一组包含 Python 语句的外部文件),Python 理所当然地成为了美国计算机专业大学生在一年级时所上的程序设计课所用语言的不二之选。
|
||||
|
||||
在这个由两篇文章构成的系列中,我们将回顾 Python
|
||||
的基础部分,希望初学编程的你能够将这篇实用的文章作为一个编程入门的跳板,和日后使用 Python 时的一篇快速指引。
|
||||
在这个由两篇文章构成的系列中,我们将回顾 Python 的基础部分,希望初学编程的你能够将这篇实用的文章作为一个编程入门的跳板,和日后使用 Python 时的一篇快速指引。
|
||||
|
||||
### Linux 中的 Python
|
||||
|
||||
@ -33,7 +31,8 @@ $ python3
|
||||
```
|
||||
|
||||
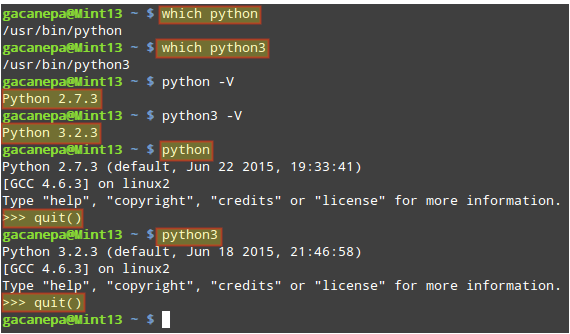
|
||||
> 在 Linux 中运行 Python 命令
|
||||
|
||||
*在 Linux 中运行 Python 命令*
|
||||
|
||||
如果你希望在键入 `python` 时使用 Python 3.x 而不是 2.x,你可以像下面一样更改对应的符号链接:
|
||||
|
||||
@ -44,11 +43,12 @@ $ ln -s python3.2 python # Choose the Python 3.x binary here
|
||||
```
|
||||
|
||||
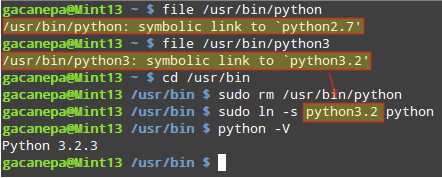
|
||||
> 删除 Python 2,使用 Python 3
|
||||
|
||||
*删除 Python 2,使用 Python 3*
|
||||
|
||||
顺便一提,有一点需要注意:尽管 Python 2.x 仍旧被使用,但它并不会被积极维护。因此,你可能要考虑像上面指示的那样来切换到 3.x。2.x 和 3.x 的语法有一些不同,我们会在这个系列文章中使用后者。
|
||||
|
||||
另一个在 Linux 中使用 Python 的方法是通过 IDLE (the Python Integrated Development Environment),一个为编写 Python 代码而生的图形用户界面。在安装它之前,你最好查看一下适用于你的 Linux 发行版的 IDLE 可用版本。
|
||||
另一个在 Linux 中使用 Python 的方法是通过 IDLE (the Python Integrated Development Environment),这是一个为编写 Python 代码而生的图形用户界面。在安装它之前,你最好查看一下适用于你的 Linux 发行版的 IDLE 可用版本。
|
||||
|
||||
```
|
||||
# aptitude search idle [Debian 及其衍生发行版]
|
||||
@ -68,23 +68,24 @@ $ sudo aptitude install idle-python3.2 # I'm using Linux Mint 13
|
||||
|
||||
1. 轻松打开外部文件 (File → Open);
|
||||
|
||||
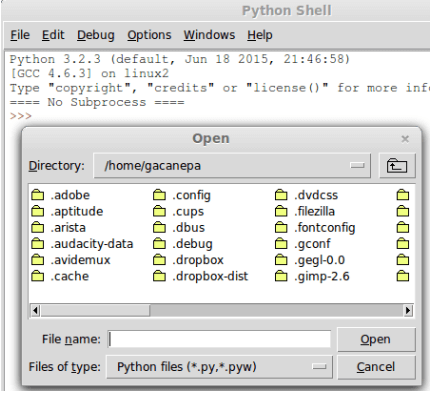
|
||||
> Python Shell
|
||||

|
||||
|
||||
*Python Shell*
|
||||
|
||||
2. 复制 (`Ctrl + C`) 和粘贴 (`Ctrl + V`) 文本;
|
||||
3. 查找和替换文本;
|
||||
4. 显示可能的代码补全(一个在其他 IDE 里可能叫做 Intellisense 或者 Autocompletion 的功能);
|
||||
4. 显示可能的代码补全(一个在其他 IDE 里可能叫做“智能感知”或者“自动补完”的功能);
|
||||
5. 更改字体和字号,等等。
|
||||
|
||||
最厉害的是,你可以用 IDLE 创建桌面工程。
|
||||
最厉害的是,你可以用 IDLE 创建桌面应用。
|
||||
|
||||
我们在这两篇文章中不会开发桌面应用,所以你可以根据喜好来选择 IDLE 或 Python shell 去运行下面的例子。
|
||||
|
||||
### Python 中的基本运算
|
||||
|
||||
就像你预料的那样,你能够直接进行算术操作(你可以在所有操作中使用足够多的括号!),还可以轻松地使用 Python 拼接字符串。
|
||||
就像你预料的那样,你能够直接进行算术操作(你可以在你的所有运算中使用足够多的括号!),还可以轻松地使用 Python 拼接字符串。
|
||||
|
||||
你还可以将运算结果赋给一个变量,然后在屏幕上显示它。Python 有一个叫做输出 (concatenation) 的实用功能——把一串变量和/或字符串用逗号分隔,然后在 print 函数中插入,它会返回一个由你刚才提供的变量依序构成的句子:
|
||||
你还可以将运算结果赋给一个变量,然后在屏幕上显示它。Python 有一个叫做拼接 (concatenation) 的实用功能——给 print 函数提供一串用逗号分隔的变量和/或字符串,它会返回一个由你刚才提供的变量依序构成的句子:
|
||||
|
||||
```
|
||||
>>> a = 5
|
||||
@ -100,15 +101,16 @@ $ sudo aptitude install idle-python3.2 # I'm using Linux Mint 13
|
||||
如果你尝试在静态类型语言中(如 Java 或 C#)做这件事,它将抛出一个错误。
|
||||
|
||||
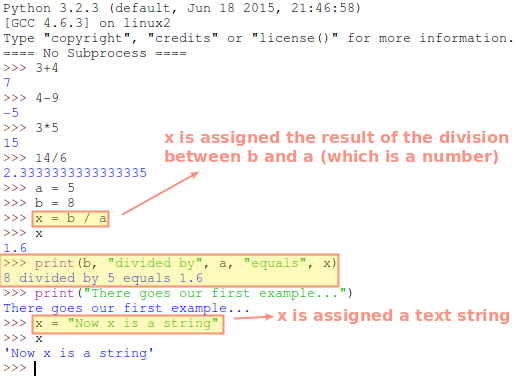
|
||||
> 学习 Python 的基本操作
|
||||
|
||||
*学习 Python 的基本操作*
|
||||
|
||||
### 面向对象编程的简单介绍
|
||||
|
||||
在面向对象编程(OOP)中,程序中的所有实体都会由对象的形式呈现,所以它们可以与其他对象交互。因此,对象拥有属性,而且大多数对象可以完成动作(这被称为对象的方法)。
|
||||
在面向对象编程(OOP)中,程序中的所有实体都会由对象的形式呈现,并且它们可以与其他对象交互。因此,对象拥有属性,而且大多数对象可以执行动作(这被称为对象的方法)。
|
||||
|
||||
举个例子:我们来想象一下,创建一个对象“狗”。它可能拥有的一些属性有`颜色`、`品种`、`年龄`等等,而它可以完成的动作有 `叫()`、`吃()`、`睡觉()`,诸如此类。
|
||||
|
||||
你可以看到,方法名后面会跟着一对括号,他们当中可能会包含一个或多个参数(向方法中传递的值),也有可能什么都不包含。
|
||||
你可以看到,方法名后面会跟着一对括号,括号当中可能会包含一个或多个参数(向方法中传递的值),也有可能什么都不包含。
|
||||
|
||||
我们用 Python 的基本对象类型之一——列表来解释这些概念。
|
||||
|
||||
@ -139,19 +141,21 @@ $ sudo aptitude install idle-python3.2 # I'm using Linux Mint 13
|
||||
>>> rockBands.pop(0)
|
||||
```
|
||||
|
||||
如果你输入了对象的名字,然后在后面输入了一个点,你可以按 Ctrl + 空格来显示这个对象的可用方法列表。
|
||||
如果你输入了对象的名字,然后在后面输入了一个点,你可以按 `Ctrl + space` 来显示这个对象的可用方法列表。
|
||||
|
||||
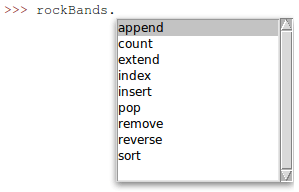
|
||||
> 列出可用的 Python 方法
|
||||
|
||||
*列出可用的 Python 方法*
|
||||
|
||||
列表中含有的元素个数是它的一个属性。它通常被叫做“长度”,你可以通过向内建函数 `len` 传递一个列表作为它的参数来显示该列表的长度(顺便一提,之前的例子中提到的 print 语句,是 Python 的另一个内建函数)。
|
||||
|
||||
如果你在 IDLE 中输入 `len`,然后跟上一个不闭合的括号,你会看到这个函数的默认语法:
|
||||
|
||||
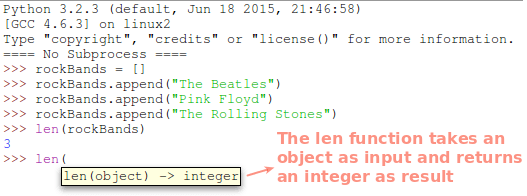
|
||||
> Python 的 len 函数
|
||||
|
||||
现在我们来看看列表中的特定条目。他们也有属性和方法吗?答案是肯定的。比如,你可以将一个字符串条目装换为大写形式,并获取这个字符串所包含的字符数量。像下面这样做:
|
||||
*Python 的 len 函数*
|
||||
|
||||
现在我们来看看列表中的特定条目。它们也有属性和方法吗?答案是肯定的。比如,你可以将一个字符串条目转换为大写形式,并获取这个字符串所包含的字符数量。像下面这样做:
|
||||
|
||||
```
|
||||
>>> rockBands[0].upper()
|
||||
@ -162,11 +166,11 @@ $ sudo aptitude install idle-python3.2 # I'm using Linux Mint 13
|
||||
|
||||
### 总结
|
||||
|
||||
在这篇文章中,我们简要介绍了 Python,它的命令行 shell,IDLE,展示了如何执行算术运算,如何在变量中存储数据,如何使用 `print` 函数在屏幕上重新显示那些数据(无论是它们本身还是它们的一部分),还通过一个实际的例子解释了对象的属性和方法。
|
||||
在这篇文章中,我们简要介绍了 Python、它的命令行 shell、IDLE,展示了如何执行算术运算,如何在变量中存储数据,如何使用 `print` 函数在屏幕上重新显示那些数据(无论是它们本身还是它们的一部分),还通过一个实际的例子解释了对象的属性和方法。
|
||||
|
||||
下一篇文章中,我们会展示如何使用条件语句和循环语句来实现流程控制。我们也会解释如何编写一个脚本来帮助我们完成系统管理任务。
|
||||
|
||||
你是不是想继续学习一些有关 Python 的知识呢?敬请期待本系列的第二部分(我们会将 Python 的慷慨、脚本中的命令行工具与其他部分结合在一起),你还可以考虑购买我们的《终极 Python 编程》系列教程([这里][4]有详细信息)。
|
||||
你是不是想继续学习一些有关 Python 的知识呢?敬请期待本系列的第二部分(我们会在脚本中将 Python 和命令行工具的优点结合在一起),你还可以考虑购买我们的《终极 Python 编程》系列教程([这里][4]有详细信息)。
|
||||
|
||||
像往常一样,如果你对这篇文章有什么问题,可以向我们寻求帮助。你可以使用下面的联系表单向我们发送留言,我们会尽快回复你。
|
||||
|
||||
@ -176,7 +180,7 @@ via: http://www.tecmint.com/learn-python-programming-and-scripting-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[StdioA](https://github.com/StdioA)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
54
published/201608/20160531 The Anatomy of a Linux User.md
Normal file
54
published/201608/20160531 The Anatomy of a Linux User.md
Normal file
@ -0,0 +1,54 @@
|
||||
深入理解 Linux 用戶
|
||||
================================
|
||||
|
||||
**一些新的 GNU/Linux 用户很清楚 Linux 不是 Windows,但其他人对此则不甚了解,而最好的发行版设计者们则会谨记着这两种人的存在。**
|
||||
|
||||
### Linux 的核心
|
||||
|
||||
不管怎么说,Nicky 看起来都不太引人注目。她已经三十岁了,却决定在离开学校多年后回到学校学习。她在海军待了六年,后来接受了一份老友给她的新工作,想试试这份工作会不会比她在军队的工作更有前途。这种换工作的事情在战后的军事后勤处非常常见。我正是因此而认识的她。她那时是一个八个州的货车运输业中介组织的区域经理,而那会我在达拉斯跑肉品包装工具的运输。
|
||||
|
||||

|
||||
|
||||
Nicky 和我在 2006 年成为了好朋友。她很外向,几乎每一个途经她负责的线路上的人她都乐于接触。我们经常星期五晚上相约去一家室内激光枪战中心打真人 CS。像这样一次就打三个的半小时战役对我们来说并不鲜见。或许这并不像彩弹游戏(LCTT 译注:一种军事游戏,双方以汽枪互射彩色染料弹丸,对方被击中后衣服上会留下彩色印渍即表示“被消灭”——必应词典)一样便宜,但是它很有临场感,还稍微有点恐怖游戏的感觉。某次活动的时候,她问我能否帮她维修电脑。
|
||||
|
||||
她知道我在为了让一些贫穷的孩子能拥有他们自己的电脑而奔走,当她抱怨她的电脑很慢的时候,我开玩笑地说她可以给比尔盖茨的 401k 计划交钱了(LCTT 译注:401k 计划始于20世纪80年代初,是一种由雇员、雇主共同缴费建立起来的完全基金式的养老保险制度。此处隐喻需要购买新电脑而向比尔盖茨的微软公司付费软件费用。)。Nicky 却说这是了解 Linux 的最佳时间。
|
||||
|
||||
她的电脑是品牌机,是个带有 Dell 19'' 显示器的 2005 年中款的华硕电脑。不幸的是,这台电脑没有好好照料,上面充斥着所能找到的各种关都关不掉的工具栏和弹窗软件。我们把电脑上的文件都做了备份之后就开始安装 Linux 了。我们一起完成了安装,并且确信她知道了如何分区。不到一个小时,她的电脑上就有了一个“金闪闪”的 PCLinuxOS 桌面。
|
||||
|
||||
在她操作新系统时,她经常评论这个系统看起来多么漂亮。她并非随口一说;她为眼前光鲜亮丽的桌面着了魔。她说她的桌面漂亮的就像化了“彩妆”一样。这是我在安装系统期间特意设置的,我每次安装 Linux 的时候都会把它打扮的漂漂亮亮的。我希望这些桌面让每个人看起来都觉得漂亮。
|
||||
|
||||
大概第一周左右,她通过电话和邮件问了我一些常规问题,而最主要的问题还是她想知道如何保存她 OpenOffice 文件才可以让她的同事也可以打开这些文件。教一个人使用 Linux 或者 Open/LibreOffice 的时候最重要的就是教她保存文件。大多数用户在弹出的对话框中直接点了保存,结果就用默认的开放文档格式(Open Document Format)保存了,这让他们吃了不少苦头。
|
||||
|
||||
曾经有过这么一件事,大约一年前或者更久,一个高中生说他没有通过期末考试,因为教授不能打开包含他的论文的文件。这引来了一些读者的激烈评论,大家都不知道这件事该怪谁,这孩子没错,而他的教授,似乎也没错。
|
||||
|
||||
我认识的一些大学教授他们每一个人都知道怎么打开 ODF 文件。另外,那个该死的微软在这方面做得真 XX 的不错,我觉得微软 Office 现在已经能打开 ODT 或者 ODF 文件了。不过我也不确定,毕竟我从 2005 年就没用过 Microsoft Office 了。
|
||||
|
||||
甚至在过去糟糕的日子里,微软公开而悍然地通过产品绑架的方式来在企业桌面领域推行他们的软件时,我和一些微软 Office 的用户在开展业务和洽谈合作时从来没有出现过问题,因为我会提前想到可能出现的问题并且不会有侥幸心理。我会发邮件给他们询问他们正在使用的 Office 版本。这样,我就可以确保以他们能够读写的格式保存文件。
|
||||
|
||||
说回 Nicky ,她花了很多时间学习她的 Linux 系统。我很惊奇于她的热情。
|
||||
|
||||
当人们意识到需要抛弃所有的 Windows 的使用习惯和工具的时候,学习 Linux 系统就会很容易。甚至在告诉那些淘气的孩子们如何使用之后,再次回来检查的时候,他们都不会试图把 .exe 文件下载到桌面上或某个下载文件夹。
|
||||
|
||||
在我们通常讨论这些文件的时候,我们也会提及关于更新的问题。长久以来我一直反对在一台机器上有多个软件安装系统和更新管理软件。以 Mint 来说,它完全禁用了 Synaptic 中的更新功能,这让我失去兴趣。但是即便对于我们这些仍然在使用 dpkg 和 apt 的老家伙们来说,睿智的脑袋也已经开始意识到命令行对新用户来说并不那么温馨而友好。
|
||||
|
||||
我曾严正抗议并强烈谴责 Synaptic 功能上的削弱,直到它说服了我。你记得什么时候第一次使用的新打造的 Linux 发行版,并拥有了最高管理权限吗? 你记得什么时候对 Synaptic 中列出的大量软件进行过梳理吗?你记得怎样开始安装每个你发现的很酷的程序吗?你记得有多少这样的程序都是以字母"lib"开头的吗?
|
||||
|
||||
我也曾做过那样的事。我安装又弄坏了好几次 Linux,后来我才发现那些库(lib)文件是应用程序的螺母和螺栓,而不是应用程序本身。这就是 Linux Mint 和 Ubuntu 幕后那些聪明的开发者创造了智能、漂亮和易用的应用安装器的原因。Synaptic 仍然是我们这些老玩家爱用的工具,但是对于那些在我们之后才来的新手来说,有太多的方式可以让他们安装库文件和其他类似的包。在新的安装程序中,这些文件的显示会被折叠起来,不会展示给用户。真的,这才是它应该做的。
|
||||
|
||||
除非你要准备好了打很多支持电话。
|
||||
|
||||
现在的 Linux 发行版中藏了很多智慧的结晶,我也很感谢这些开发者们,因为他们,我的工作变得更容易。不是每一个 Linux 新用户都像 Nicky 这样富有学习能力和热情。她对我来说就是一个“装好就行”的项目,只需要为她解答一些问题,其它的她会自己研究解决。像她这样极具学习能力和热情的用户的毕竟是少数。这样的 Linux 新人任何时候都是珍稀物种。
|
||||
|
||||
很不错,他们都是要教自己的孩子使用 Linux 的人。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://fossforce.com/2016/05/anatomy-linux-user/
|
||||
|
||||
作者:[Ken Starks][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[PurlingNayuki](https://github.com/PurlingNayuki), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://linuxlock.blogspot.com/
|
||||
@ -0,0 +1,292 @@
|
||||
Linux 平台下 Python 脚本编程入门(二)
|
||||
======================================================================================
|
||||
|
||||
在“[Linux 平台下 Python 脚本编程入门][1]”系列之前的文章里,我们向你介绍了 Python 的简介,它的命令行 shell 和 IDLE(LCTT 译注:python 自带的一个 IDE)。我们也演示了如何进行算术运算、如何在变量中存储值、还有如何打印那些值到屏幕上。最后,我们通过一个练习示例讲解了面向对象编程中方法和属性概念。
|
||||
|
||||

|
||||
|
||||
*在 Python 编程中写 Linux Shell 脚本*
|
||||
|
||||
本篇中,我们会讨论控制流(根据用户输入的信息、计算的结果,或者一个变量的当前值选择不同的动作行为)和循环(自动重复执行任务),接着应用我们目前所学东西来编写一个简单的 shell 脚本,这个脚本会显示操作系统类型、主机名、内核版本、版本号和机器硬件架构。
|
||||
|
||||
这个例子尽管很基础,但是会帮助我们证明,比起使用一般的 bash 工具,我们通过发挥 Python 面向对象的特性来编写 shell 脚本会更简单些。
|
||||
|
||||
换句话说,我们想从这里出发:
|
||||
|
||||
```
|
||||
# uname -snrvm
|
||||
```
|
||||
|
||||

|
||||
|
||||
*检查 Linux 的主机名*
|
||||
|
||||
到
|
||||
|
||||

|
||||
|
||||
*用 Python 脚本来检查 Linux 的主机名*
|
||||
|
||||
或者
|
||||
|
||||

|
||||
|
||||
*用脚本检查 Linux 系统信息*
|
||||
|
||||
看着不错,不是吗?那我们就挽起袖子,开干吧。
|
||||
|
||||
### Python 中的控制流
|
||||
|
||||
如我们刚说那样,控制流允许我们根据一个给定的条件,选择不同的输出结果。在 Python 中最简单的实现就是一个 `if`/`else` 语句。
|
||||
|
||||
基本语法是这样的:
|
||||
|
||||
```
|
||||
if 条件:
|
||||
# 动作 1
|
||||
else:
|
||||
# 动作 2
|
||||
```
|
||||
|
||||
当“条件”求值为真(true),下面的代码块就会被执行(`# 动作 1`代表的部分)。否则,else 下面的代码就会运行。
|
||||
“条件”可以是任何表达式,只要可以求得值为真或者假。
|
||||
|
||||
举个例子:
|
||||
|
||||
1. `1 < 3` # 真
|
||||
2. `firstName == "Gabriel"` # 对 firstName 为 Gabriel 的人是真,对其他不叫 Gabriel 的人为假
|
||||
|
||||
- 在第一个例子中,我们比较了两个值,判断 1 是否小于 3。
|
||||
- 在第二个例子中,我们比较了 firstName(一个变量)与字符串 “Gabriel”,看在当前执行的位置,firstName 的值是否等于该字符串。
|
||||
- 条件和 else 表达式都必须跟着一个冒号(`:`)。
|
||||
- **缩进在 Python 中非常重要**。同样缩进下的行被认为是相同的代码块。
|
||||
|
||||
请注意,`if`/`else` 表达式只是 Python 中许多控制流工具的一个而已。我们先在这里了解以下,后面会用在我们的脚本中。你可以在[官方文档][2]中学到更多工具。
|
||||
|
||||
### Python 中的循环
|
||||
|
||||
简单来说,一个循环就是一组指令或者表达式序列,可以按顺序一直执行,只要条件为真,或者对列表里每个项目执行一一次。
|
||||
|
||||
Python 中最简单的循环,就是用 for 循环迭代一个给定列表的元素,或者对一个字符串从第一个字符开始到执行到最后一个字符结束。
|
||||
|
||||
基本语句:
|
||||
|
||||
```
|
||||
for x in example:
|
||||
# do this
|
||||
```
|
||||
|
||||
这里的 example 可以是一个列表或者一个字符串。如果是列表,变量 x 就代表列表中每个元素;如果是字符串,x 就代表字符串中每个字符。
|
||||
|
||||
```
|
||||
>>> rockBands = []
|
||||
>>> rockBands.append("Roxette")
|
||||
>>> rockBands.append("Guns N' Roses")
|
||||
>>> rockBands.append("U2")
|
||||
>>> for x in rockBands:
|
||||
print(x)
|
||||
或
|
||||
>>> firstName = "Gabriel"
|
||||
>>> for x in firstName:
|
||||
print(x)
|
||||
```
|
||||
|
||||
上面例子的输出如下图所示:
|
||||
|
||||

|
||||
|
||||
*学习 Python 中的循环*
|
||||
|
||||
### Python 模块
|
||||
|
||||
很明显,必须有个办法将一系列的 Python 指令和表达式保存到文件里,然后在需要的时候取出来。
|
||||
|
||||
准确来说模块就是这样的。比如,os 模块提供了一个到操作系统的底层的接口,可以允许我们做许多通常在命令行下执行的操作。
|
||||
|
||||
没错,os 模块包含了许多可以用来调用的方法和属性,就如我们之前文章里讲解的那样。不过,我们需要使用 `import` 关键词导入(或者叫包含)模块到运行环境里来:
|
||||
|
||||
```
|
||||
>>> import os
|
||||
```
|
||||
|
||||
我们来打印出当前的工作目录:
|
||||
|
||||
```
|
||||
>>> os.getcwd()
|
||||
```
|
||||
|
||||
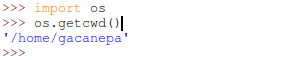
|
||||
|
||||
*学习 Python 模块*
|
||||
|
||||
现在,让我们把这些结合在一起(包括之前文章里讨论的概念),编写需要的脚本。
|
||||
|
||||
### Python 脚本
|
||||
|
||||
以一段声明文字开始一个脚本是个不错的想法,它可以表明脚本的目的、发布所依据的许可证,以及一个列出做出的修改的修订历史。尽管这主要是个人喜好,但这会让我们的工作看起来比较专业。
|
||||
|
||||
这里有个脚本,可以输出这篇文章最前面展示的那样。脚本做了大量的注释,可以让大家可以理解发生了什么。
|
||||
|
||||
在进行下一步之前,花点时间来理解它。注意,我们是如何使用一个 `if`/`else` 结构,判断每个字段标题的长度是否比字段本身的值还大。
|
||||
|
||||
基于比较结果,我们用空字符去填充一个字段标题和下一个之间的空格。同时,我们使用一定数量的短线作为字段标题与其值之间的分割符。
|
||||
|
||||
```
|
||||
#!/usr/bin/python3
|
||||
# 如果你没有安装 Python 3 ,那么修改这一行为 #!/usr/bin/python
|
||||
|
||||
# Script name: uname.py
|
||||
# Purpose: Illustrate Python's OOP capabilities to write shell scripts more easily
|
||||
# License: GPL v3 (http://www.gnu.org/licenses/gpl.html)
|
||||
|
||||
# Copyright (C) 2016 Gabriel Alejandro Cánepa
|
||||
# Facebook / Skype / G+ / Twitter / Github: gacanepa
|
||||
# Email: gacanepa (at) gmail (dot) com
|
||||
|
||||
# This program is free software: you can redistribute it and/or modify
|
||||
# it under the terms of the GNU General Public License as published by
|
||||
# the Free Software Foundation, either version 3 of the License, or
|
||||
# (at your option) any later version.
|
||||
|
||||
# This program is distributed in the hope that it will be useful,
|
||||
# but WITHOUT ANY WARRANTY; without even the implied warranty of
|
||||
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
||||
# GNU General Public License for more details.
|
||||
|
||||
# You should have received a copy of the GNU General Public License
|
||||
# along with this program. If not, see .
|
||||
|
||||
# REVISION HISTORY
|
||||
# DATE VERSION AUTHOR CHANGE DESCRIPTION
|
||||
# ---------- ------- --------------
|
||||
# 2016-05-28 1.0 Gabriel Cánepa Initial version
|
||||
|
||||
### 导入 os 模块
|
||||
import os
|
||||
|
||||
### 将 os.uname() 的输出赋值给 systemInfo 变量
|
||||
### os.uname() 会返回五个字符串元组(sysname, nodename, release, version, machine)
|
||||
### 参见文档:https://docs.python.org/3.2/library/os.html#module-os
|
||||
systemInfo = os.uname()
|
||||
|
||||
### 这是一个固定的数组,用于描述脚本输出的字段标题
|
||||
headers = ["Operating system","Hostname","Release","Version","Machine"]
|
||||
|
||||
### 初始化索引值,用于定义每一步迭代中
|
||||
### systemInfo 和字段标题的索引
|
||||
index = 0
|
||||
|
||||
### 字段标题变量的初始值
|
||||
caption = ""
|
||||
|
||||
### 值变量的初始值
|
||||
values = ""
|
||||
|
||||
### 分隔线变量的初始值
|
||||
separators = ""
|
||||
|
||||
### 开始循环
|
||||
for item in systemInfo:
|
||||
if len(item) < len(headers[index]):
|
||||
### 一个包含横线的字符串,横线长度等于item[index] 或 headers[index]
|
||||
### 要重复一个字符,用引号圈起来并用星号(*)乘以所需的重复次数
|
||||
separators = separators + "-" * len(headers[index]) + " "
|
||||
caption = caption + headers[index] + " "
|
||||
values = values + systemInfo[index] + " " * (len(headers[index]) - len(item)) + " "
|
||||
else:
|
||||
separators = separators + "-" * len(item) + " "
|
||||
caption = caption + headers[index] + " " * (len(item) - len(headers[index]) + 1)
|
||||
values = values + item + " "
|
||||
### 索引加 1
|
||||
index = index + 1
|
||||
### 终止循环
|
||||
|
||||
### 输出转换为大写的变量(字段标题)名
|
||||
print(caption.upper())
|
||||
|
||||
### 输出分隔线
|
||||
print(separators)
|
||||
|
||||
# 输出值(systemInfo 中的项目)
|
||||
print(values)
|
||||
|
||||
### 步骤:
|
||||
### 1) 保持该脚本为 uname.py (或任何你想要的名字)
|
||||
### 并通过如下命令给其执行权限:
|
||||
### chmod +x uname.py
|
||||
### 2) 执行它;
|
||||
### ./uname.py
|
||||
```
|
||||
|
||||
如果你已经按照上述描述将上面的脚本保存到一个文件里,并给文件增加了执行权限,那么运行它:
|
||||
|
||||
```
|
||||
# chmod +x uname.py
|
||||
# ./uname.py
|
||||
```
|
||||
|
||||
如果试图运行脚本时你得到了如下的错误:
|
||||
|
||||
```
|
||||
-bash: ./uname.py: /usr/bin/python3: bad interpreter: No such file or directory
|
||||
```
|
||||
|
||||
这意味着你没有安装 Python3。如果那样的话,你要么安装 Python3 的包,要么替换解释器那行(如果如之前文章里概述的那样,跟着下面的步骤去更新 Python 执行文件的软连接,要特别注意并且非常小心):
|
||||
|
||||
```
|
||||
#!/usr/bin/python3
|
||||
```
|
||||
|
||||
为
|
||||
|
||||
```
|
||||
#!/usr/bin/python
|
||||
```
|
||||
|
||||
这样会通过使用已经安装好的 Python 2 去执行该脚本。
|
||||
|
||||
**注意**:该脚本在 Python 2.x 与 Pyton 3.x 上都测试成功过了。
|
||||
|
||||
尽管比较粗糙,你可以认为该脚本就是一个 Python 模块。这意味着你可以在 IDLE 中打开它(File → Open… → Select file):
|
||||
|
||||
|
||||
|
||||
*在 IDLE 中打开 Python*
|
||||
|
||||
一个包含有文件内容的新窗口就会打开。然后执行 Run → Run module(或者按 F5)。脚本的输出就会在原始的 Shell 里显示出来:
|
||||
|
||||
|
||||
|
||||
*执行 Python 脚本*
|
||||
|
||||
如果你想纯粹用 bash 写一个脚本,也获得同样的结果,你可能需要结合使用 [awk][3]、[sed][4],并且借助复杂的方法来存储与获得列表中的元素(不要忘了使用 tr 命令将小写字母转为大写)。
|
||||
|
||||
另外,在所有的 Linux 系统版本中都至少集成了一个 Python 版本(2.x 或者 3.x,或者两者都有)。你还需要依赖 shell 去完成同样的目标吗?那样你可能需要为不同的 shell 编写不同的版本。
|
||||
|
||||
这里演示了面向对象编程的特性,它会成为一个系统管理员得力的助手。
|
||||
|
||||
**注意**:你可以在我的 Github 仓库里获得 [这个 python 脚本][5](或者其他的)。
|
||||
|
||||
### 总结
|
||||
|
||||
这篇文章里,我们讲解了 Python 中控制流、循环/迭代、和模块的概念。我们也演示了如何利用 Python 中面向对象编程的方法和属性来简化复杂的 shell 脚本。
|
||||
|
||||
你有任何其他希望去验证的想法吗?开始吧,写出自己的 Python 脚本,如果有任何问题可以咨询我们。不必犹豫,在分割线下面留下评论,我们会尽快回复你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/learn-python-programming-to-write-linux-shell-scripts/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/gacanepa/
|
||||
[1]: http://www.tecmint.com/learn-python-programming-and-scripting-in-linux/
|
||||
[2]: http://please%20note%20that%20the%20if%20/%20else%20statement%20is%20only%20one%20of%20the%20many%20control%20flow%20tools%20available%20in%20Python.%20We%20reviewed%20it%20here%20since%20we%20will%20use%20it%20in%20our%20script%20later.%20You%20can%20learn%20more%20about%20the%20rest%20of%20the%20tools%20in%20the%20official%20docs.
|
||||
[3]: http://www.tecmint.com/use-linux-awk-command-to-filter-text-string-in-files/
|
||||
[4]: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[5]: https://github.com/gacanepa/scripts/blob/master/python/uname.py
|
||||
|
||||
@ -0,0 +1,392 @@
|
||||
如何用 Python 和 Flask 建立部署一个 Facebook Messenger 机器人
|
||||
==========================================================================
|
||||
|
||||
这是我建立一个简单的 Facebook Messenger 机器人的记录。功能很简单,它是一个回显机器人,只是打印回用户写了什么。
|
||||
|
||||
回显服务器类似于服务器的“Hello World”例子。
|
||||
|
||||
这个项目的目的不是建立最好的 Messenger 机器人,而是让你了解如何建立一个小型机器人和每个事物是如何整合起来的。
|
||||
|
||||
- [技术栈][1]
|
||||
- [机器人架构][2]
|
||||
- [机器人服务器][3]
|
||||
- [部署到 Heroku][4]
|
||||
- [创建 Facebook 应用][5]
|
||||
- [结论][6]
|
||||
|
||||
### 技术栈
|
||||
|
||||
使用到的技术栈:
|
||||
|
||||
- [Heroku][7] 做后端主机。免费级足够这个等级的教程。回显机器人不需要任何种类的数据持久,所以不需要数据库。
|
||||
- [Python][8] 是我们选择的语言。版本选择 2.7,虽然它移植到 Pyhton 3 很容易,只需要很少的改动。
|
||||
- [Flask][9] 作为网站开发框架。它是非常轻量的框架,用在小型工程或微服务是非常完美的。
|
||||
- 最后 [Git][10] 版本控制系统用来维护代码和部署到 Heroku。
|
||||
- 值得一提:[Virtualenv][11]。这个 python 工具是用来创建清洁的 python 库“环境”的,这样你可以只安装必要的需求和最小化应用的大小。
|
||||
|
||||
### 机器人架构
|
||||
|
||||
Messenger 机器人是由一个响应两种请求的服务器组成的:
|
||||
|
||||
- GET 请求被用来认证。他们与你注册的 FaceBook 认证码一同被 Messenger 发出。
|
||||
- POST 请求被用来实际的通信。典型的工作流是,机器人将通过用户发送带有消息数据的 POST 请求而建立通信,然后我们将处理这些数据,并发回我们的 POST 请求。如果这个请求完全成功(返回一个 200 OK 状态码),我们也将响应一个 200 OK 状态码给初始的 Messenger请求。
|
||||
|
||||
这个教程应用将托管到 Heroku,它提供了一个优雅而简单的部署应用的接口。如前所述,免费级可以满足这个教程。
|
||||
|
||||
在应用已经部署并且运行后,我们将创建一个 Facebook 应用然后连接它到我们的应用,以便 Messenger 知道发送请求到哪,这就是我们的机器人。
|
||||
|
||||
### 机器人服务器
|
||||
|
||||
基本的服务器代码可以在 Github 用户 [hult(Magnus Hult)][13] 的 [Chatbot][12] 项目上获取,做了一些只回显消息的代码修改和修正了一些我遇到的错误。最终版本的服务器代码如下:
|
||||
|
||||
```
|
||||
from flask import Flask, request
|
||||
import json
|
||||
import requests
|
||||
|
||||
app = Flask(__name__)
|
||||
|
||||
### 这需要填写被授予的页面通行令牌(PAT)
|
||||
### 它由将要创建的 Facebook 应用提供。
|
||||
PAT = ''
|
||||
|
||||
@app.route('/', methods=['GET'])
|
||||
def handle_verification():
|
||||
print "Handling Verification."
|
||||
if request.args.get('hub.verify_token', '') == 'my_voice_is_my_password_verify_me':
|
||||
print "Verification successful!"
|
||||
return request.args.get('hub.challenge', '')
|
||||
else:
|
||||
print "Verification failed!"
|
||||
return 'Error, wrong validation token'
|
||||
|
||||
@app.route('/', methods=['POST'])
|
||||
def handle_messages():
|
||||
print "Handling Messages"
|
||||
payload = request.get_data()
|
||||
print payload
|
||||
for sender, message in messaging_events(payload):
|
||||
print "Incoming from %s: %s" % (sender, message)
|
||||
send_message(PAT, sender, message)
|
||||
return "ok"
|
||||
|
||||
def messaging_events(payload):
|
||||
"""Generate tuples of (sender_id, message_text) from the
|
||||
provided payload.
|
||||
"""
|
||||
data = json.loads(payload)
|
||||
messaging_events = data["entry"][0]["messaging"]
|
||||
for event in messaging_events:
|
||||
if "message" in event and "text" in event["message"]:
|
||||
yield event["sender"]["id"], event["message"]["text"].encode('unicode_escape')
|
||||
else:
|
||||
yield event["sender"]["id"], "I can't echo this"
|
||||
|
||||
|
||||
def send_message(token, recipient, text):
|
||||
"""Send the message text to recipient with id recipient.
|
||||
"""
|
||||
|
||||
r = requests.post("https://graph.facebook.com/v2.6/me/messages",
|
||||
params={"access_token": token},
|
||||
data=json.dumps({
|
||||
"recipient": {"id": recipient},
|
||||
"message": {"text": text.decode('unicode_escape')}
|
||||
}),
|
||||
headers={'Content-type': 'application/json'})
|
||||
if r.status_code != requests.codes.ok:
|
||||
print r.text
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run()
|
||||
```
|
||||
|
||||
让我们分解代码。第一部分是引入所需的依赖:
|
||||
|
||||
```
|
||||
from flask import Flask, request
|
||||
import json
|
||||
import requests
|
||||
```
|
||||
|
||||
接下来我们定义两个函数(使用 Flask 特定的 app.route 装饰器),用来处理到我们的机器人的 GET 和 POST 请求。
|
||||
|
||||
```
|
||||
@app.route('/', methods=['GET'])
|
||||
def handle_verification():
|
||||
print "Handling Verification."
|
||||
if request.args.get('hub.verify_token', '') == 'my_voice_is_my_password_verify_me':
|
||||
print "Verification successful!"
|
||||
return request.args.get('hub.challenge', '')
|
||||
else:
|
||||
print "Verification failed!"
|
||||
return 'Error, wrong validation token'
|
||||
```
|
||||
|
||||
当我们创建 Facebook 应用时,verify_token 对象将由我们声明的 Messenger 发送。我们必须自己来校验它。最后我们返回“hub.challenge”给 Messenger。
|
||||
|
||||
处理 POST 请求的函数更有意思一些:
|
||||
|
||||
```
|
||||
@app.route('/', methods=['POST'])
|
||||
def handle_messages():
|
||||
print "Handling Messages"
|
||||
payload = request.get_data()
|
||||
print payload
|
||||
for sender, message in messaging_events(payload):
|
||||
print "Incoming from %s: %s" % (sender, message)
|
||||
send_message(PAT, sender, message)
|
||||
return "ok"
|
||||
```
|
||||
|
||||
当被调用时,我们抓取消息载荷,使用函数 messaging_events 来拆解它,并且提取发件人身份和实际发送的消息,生成一个可以循环处理的 python 迭代器。请注意 Messenger 发送的每个请求有可能多于一个消息。
|
||||
|
||||
```
|
||||
def messaging_events(payload):
|
||||
"""Generate tuples of (sender_id, message_text) from the
|
||||
provided payload.
|
||||
"""
|
||||
data = json.loads(payload)
|
||||
messaging_events = data["entry"][0]["messaging"]
|
||||
for event in messaging_events:
|
||||
if "message" in event and "text" in event["message"]:
|
||||
yield event["sender"]["id"], event["message"]["text"].encode('unicode_escape')
|
||||
else:
|
||||
yield event["sender"]["id"], "I can't echo this"
|
||||
```
|
||||
|
||||
对每个消息迭代时,我们会调用 send_message 函数,然后我们使用 Facebook Graph messages API 对 Messenger 发回 POST 请求。在这期间我们一直没有回应我们阻塞的原始 Messenger请求。这会导致超时和 5XX 错误。
|
||||
|
||||
上述情况是我在解决遇到错误时发现的,当用户发送表情时实际上是发送的 unicode 标识符,但是被 Python 错误的编码了,最终我们发回了一些乱码。
|
||||
|
||||
这个发回 Messenger 的 POST 请求将永远不会完成,这会导致给初始请求返回 5xx 状态码,显示服务不可用。
|
||||
|
||||
通过使用 `encode('unicode_escape')` 封装消息,然后在我们发送回消息前用 `decode('unicode_escape')` 解码消息就可以解决。
|
||||
|
||||
```
|
||||
def send_message(token, recipient, text):
|
||||
"""Send the message text to recipient with id recipient.
|
||||
"""
|
||||
|
||||
r = requests.post("https://graph.facebook.com/v2.6/me/messages",
|
||||
params={"access_token": token},
|
||||
data=json.dumps({
|
||||
"recipient": {"id": recipient},
|
||||
"message": {"text": text.decode('unicode_escape')}
|
||||
}),
|
||||
headers={'Content-type': 'application/json'})
|
||||
if r.status_code != requests.codes.ok:
|
||||
print r.text
|
||||
```
|
||||
|
||||
### 部署到 Heroku
|
||||
|
||||
一旦代码已经建立成我想要的样子时就可以进行下一步。部署应用。
|
||||
|
||||
那么,该怎么做?
|
||||
|
||||
我之前在 Heroku 上部署过应用(主要是 Rails),然而我总是遵循某种教程做的,所用的配置是创建好了的。而在本文的情况下,我就需要从头开始。
|
||||
|
||||
幸运的是有官方 [Heroku 文档][14]来帮忙。这篇文档很好地说明了运行应用程序所需的最低限度。
|
||||
|
||||
长话短说,我们需要的除了我们的代码还有两个文件。第一个文件是“requirements.txt”,它列出了运行应用所依赖的库。
|
||||
|
||||
需要的第二个文件是“Procfile”。这个文件通知 Heroku 如何运行我们的服务。此外这个文件只需要一点点内容:
|
||||
|
||||
```
|
||||
web: gunicorn echoserver:app
|
||||
```
|
||||
|
||||
Heroku 对它的解读是,我们的应用通过运行 echoserver.py 启动,并且应用将使用 gunicorn 作为 Web 服务器。我们使用一个额外的网站服务器是因为与性能相关,在上面的 Heroku 文档里对此解释了:
|
||||
|
||||
> Web 应用程序并发处理传入的 HTTP 请求比一次只处理一个请求的 Web 应用程序会更有效利地用测试机的资源。由于这个原因,我们建议使用支持并发请求的 Web 服务器来部署和运行产品级服务。
|
||||
|
||||
> Django 和 Flask web 框架提供了一个方便的内建 Web 服务器,但是这些阻塞式服务器一个时刻只能处理一个请求。如果你部署这种服务到 Heroku 上,你的测试机就会资源利用率低下,应用会感觉反应迟钝。
|
||||
|
||||
> Gunicorn 是一个纯 Python 的 HTTP 服务器,用于 WSGI 应用。允许你在单独一个测试机内通过运行多 Python 进程的方式来并发的运行各种 Python 应用。它在性能、灵活性和配置简易性方面取得了完美的平衡。
|
||||
|
||||
回到我们之前提到过的“requirements.txt”文件,让我们看看它如何结合 Virtualenv 工具。
|
||||
|
||||
很多情况下,你的开发机器也许已经安装了很多 python 库。当部署应用时你不想全部加载那些库,但是辨认出你实际使用哪些库很困难。
|
||||
|
||||
Virtualenv 可以创建一个新的空白虚拟环境,以便你可以只安装你应用所需要的库。
|
||||
|
||||
你可以运行如下命令来检查当前安装了哪些库:
|
||||
|
||||
```
|
||||
kostis@KostisMBP ~ $ pip freeze
|
||||
cycler==0.10.0
|
||||
Flask==0.10.1
|
||||
gunicorn==19.6.0
|
||||
itsdangerous==0.24
|
||||
Jinja2==2.8
|
||||
MarkupSafe==0.23
|
||||
matplotlib==1.5.1
|
||||
numpy==1.10.4
|
||||
pyparsing==2.1.0
|
||||
python-dateutil==2.5.0
|
||||
pytz==2015.7
|
||||
requests==2.10.0
|
||||
scipy==0.17.0
|
||||
six==1.10.0
|
||||
virtualenv==15.0.1
|
||||
Werkzeug==0.11.10
|
||||
```
|
||||
|
||||
注意:pip 工具应该已经与 Python 一起安装在你的机器上。如果没有,查看[官方网站][15]如何安装它。
|
||||
|
||||
现在让我们使用 Virtualenv 来创建一个新的空白环境。首先我们给我们的项目创建一个新文件夹,然后进到目录下:
|
||||
|
||||
```
|
||||
kostis@KostisMBP projects $ mkdir echoserver
|
||||
kostis@KostisMBP projects $ cd echoserver/
|
||||
kostis@KostisMBP echoserver $
|
||||
```
|
||||
|
||||
现在来创建一个叫做 echobot 的新环境。运行下面的 source 命令激活它,然后使用 pip freeze 检查,我们能看到现在是空的。
|
||||
|
||||
```
|
||||
kostis@KostisMBP echoserver $ virtualenv echobot
|
||||
kostis@KostisMBP echoserver $ source echobot/bin/activate
|
||||
(echobot) kostis@KostisMBP echoserver $ pip freeze
|
||||
(echobot) kostis@KostisMBP echoserver $
|
||||
```
|
||||
|
||||
我们可以安装需要的库。我们需要是 flask、gunicorn 和 requests,它们被安装后我们就创建 requirements.txt 文件:
|
||||
|
||||
```
|
||||
(echobot) kostis@KostisMBP echoserver $ pip install flask
|
||||
(echobot) kostis@KostisMBP echoserver $ pip install gunicorn
|
||||
(echobot) kostis@KostisMBP echoserver $ pip install requests
|
||||
(echobot) kostis@KostisMBP echoserver $ pip freeze
|
||||
click==6.6
|
||||
Flask==0.11
|
||||
gunicorn==19.6.0
|
||||
itsdangerous==0.24
|
||||
Jinja2==2.8
|
||||
MarkupSafe==0.23
|
||||
requests==2.10.0
|
||||
Werkzeug==0.11.10
|
||||
(echobot) kostis@KostisMBP echoserver $ pip freeze > requirements.txt
|
||||
```
|
||||
|
||||
上述完成之后,我们用 python 代码创建 echoserver.py 文件,然后用之前提到的命令创建 Procfile,我们最终的文件/文件夹如下:
|
||||
|
||||
```
|
||||
(echobot) kostis@KostisMBP echoserver $ ls
|
||||
Procfile echobot echoserver.py requirements.txt
|
||||
```
|
||||
|
||||
我们现在准备上传到 Heroku。我们需要做两件事。第一是如果还没有安装 Heroku toolbet,就安装它(详见 [Heroku][16])。第二是通过 Heroku [网页界面][17]创建一个新的 Heroku 应用。
|
||||
|
||||
点击右上的大加号然后选择“Create new app”。
|
||||
|
||||

|
||||
|
||||
为你的应用选择一个名字,然后点击“Create App”。
|
||||
|
||||

|
||||
|
||||
你将会重定向到你的应用的控制面板,在那里你可以找到如何部署你的应用到 Heroku 的细节说明。
|
||||
|
||||
```
|
||||
(echobot) kostis@KostisMBP echoserver $ heroku login
|
||||
(echobot) kostis@KostisMBP echoserver $ git init
|
||||
(echobot) kostis@KostisMBP echoserver $ heroku git:remote -a <myappname>
|
||||
(echobot) kostis@KostisMBP echoserver $ git add .
|
||||
(echobot) kostis@KostisMBP echoserver $ git commit -m "Initial commit"
|
||||
(echobot) kostis@KostisMBP echoserver (master) $ git push heroku master
|
||||
...
|
||||
remote: https://<myappname>.herokuapp.com/ deployed to Heroku
|
||||
...
|
||||
(echobot) kostis@KostisMBP echoserver (master) $ heroku config:set WEB_CONCURRENCY=3
|
||||
```
|
||||
|
||||
如上,当你推送你的修改到 Heroku 之后,你会得到一个用于公开访问你新创建的应用的 URL。保存该 URL,下一步需要它。
|
||||
|
||||
### 创建这个 Facebook 应用
|
||||
|
||||
让我们的机器人可以工作的最后一步是创建这个我们将连接到其上的 Facebook 应用。Facebook 通常要求每个应用都有一个相关页面,所以我们来[创建一个][18]。
|
||||
|
||||
接下来我们去 [Facebook 开发者专页][19],点击右上角的“My Apps”按钮并选择“Add a New App”。不要选择建议的那个,而是点击“basic setup”。填入需要的信息并点击“Create App Id”,然后你会重定向到新的应用页面。
|
||||
|
||||

|
||||
|
||||
|
||||
在 “Products” 菜单之下,点击“+ Add Product” ,然后在“Messenger”下点击“Get Started”。跟随这些步骤设置 Messenger,当完成后你就可以设置你的 webhooks 了。Webhooks 简单的来说是你的服务所用的 URL 的名称。点击 “Setup Webhooks” 按钮,并添加该 Heroku 应用的 URL (你之前保存的那个)。在校验元组中写入 ‘my_voice_is_my_password_verify_me’。你可以写入任何你要的内容,但是不管你在这里写入的是什么内容,要确保同时修改代码中 handle_verification 函数。然后勾选 “messages” 选项。
|
||||
|
||||

|
||||
|
||||
点击“Verify and Save” 就完成了。Facebook 将访问该 Heroku 应用并校验它。如果不工作,可以试试运行:
|
||||
|
||||
```
|
||||
(echobot) kostis@KostisMBP heroku logs -t
|
||||
```
|
||||
|
||||
然后看看日志中是否有错误。如果发现错误, Google 搜索一下可能是最快的解决方法。
|
||||
|
||||
最后一步是取得页面访问元组(PAT),它可以将该 Facebook 应用于你创建好的页面连接起来。
|
||||
|
||||

|
||||
|
||||
从下拉列表中选择你创建好的页面。这会在“Page Access Token”(PAT)下面生成一个字符串。点击复制它,然后编辑 echoserver.py 文件,将其贴入 PAT 变量中。然后在 Git 中添加、提交并推送该修改。
|
||||
|
||||
```
|
||||
(echobot) kostis@KostisMBP echoserver (master) $ git add .
|
||||
(echobot) kostis@KostisMBP echoserver (master) $ git commit -m "Initial commit"
|
||||
(echobot) kostis@KostisMBP echoserver (master) $ git push heroku master
|
||||
```
|
||||
|
||||
最后,在 Webhooks 菜单下再次选择你的页面并点击“Subscribe”。
|
||||
|
||||

|
||||
|
||||
现在去访问你的页面并建立会话:
|
||||
|
||||

|
||||
|
||||
成功了,机器人回显了!
|
||||
|
||||
注意:除非你要将这个机器人用在 Messenger 上测试,否则你就是机器人唯一响应的那个人。如果你想让其他人也试试它,到 [Facebook 开发者专页][19]中,选择你的应用、角色,然后添加你要添加的测试者。
|
||||
|
||||
###总结
|
||||
|
||||
这对于我来说是一个非常有用的项目,希望它可以指引你找到开始的正确方向。[官方的 Facebook 指南][20]有更多的资料可以帮你学到更多。
|
||||
|
||||
你可以在 [Github][21] 上找到该项目的代码。
|
||||
|
||||
如果你有任何评论、勘误和建议,请随时联系我。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/
|
||||
|
||||
作者:[Konstantinos Tsaprailis][a]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://github.com/kostistsaprailis
|
||||
[1]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#tech-stack
|
||||
[2]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#bot-architecture
|
||||
[3]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#the-bot-server
|
||||
[4]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#deploying-to-heroku
|
||||
[5]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#creating-the-facebook-app
|
||||
[6]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#conclusion
|
||||
[7]: https://www.heroku.com
|
||||
[8]: https://www.python.org
|
||||
[9]: http://flask.pocoo.org
|
||||
[10]: https://git-scm.com
|
||||
[11]: https://virtualenv.pypa.io/en/stable
|
||||
[12]: https://github.com/hult/facebook-chatbot-python
|
||||
[13]: https://github.com/hult
|
||||
[14]: https://devcenter.heroku.com/articles/python-gunicorn
|
||||
[15]: https://pip.pypa.io/en/stable/installing
|
||||
[16]: https://toolbelt.heroku.com
|
||||
[17]: https://dashboard.heroku.com/apps
|
||||
[18]: https://www.facebook.com/pages/create
|
||||
[19]: https://developers.facebook.com/
|
||||
[20]: https://developers.facebook.com/docs/messenger-platform/implementation
|
||||
[21]: https://github.com/kostistsaprailis/messenger-bot-tutorial
|
||||
@ -1,45 +1,45 @@
|
||||
Smem – Linux 下基于进程和用户的内存占用报告程序
|
||||
Smem – Linux 下基于进程和用户的内存占用报告
|
||||
===========================================================================
|
||||
|
||||
Linux 系统的内存管理工作中,内存使用情况的监控是十分重要的,在各种 Linux 发行版上你会找到许多这种工具。它们的工作方式多种多样,在这里,我们将会介绍如何安装和使用这样的一个名为 SMEM 的工具软件。
|
||||
|
||||
Linux 系统的内存管理工作中,内存使用情况的监控是十分重要的,不同的 Linux 发行版可能会提供不同的工具。但是它们的工作方式多种多样,这里,我们将会介绍如何安装和使用这样的一个名为 SMEM 的工具软件。
|
||||
|
||||
Smem 是一款命令行下的内存使用情况报告工具。和其它传统的内存报告工具不同个,它仅做这一件事情——报告 PPS(实际使用的物理内存[比例分配共享库占用的内存]),这种内存使用量表示方法对于那些在虚拟内存中的应用和库更有意义。
|
||||
Smem 是一款命令行下的内存使用情况报告工具,它能够给用户提供 Linux 系统下的内存使用的多种报告。和其它传统的内存报告工具不同的是,它有个独特的功能,可以报告 PSS(按比例占用大小:Proportional Set Size),这种内存使用量表示方法对于那些在虚拟内存中的应用和库更有意义。
|
||||
|
||||

|
||||
>Smem – Linux 内存报告工具
|
||||
|
||||
已有的传统工具会将目光主要集中于读取 RSS(实际使用物理内存[包含共享库占用的内存]),这种方法对于恒量那些使用物理内存方案的使用情况来说是标准方法,但是应用程序往往会高估内存的使用情况。
|
||||
*Smem – Linux 内存报告工具*
|
||||
|
||||
PSS 从另一个侧面,为那些使用虚拟内存方案的应用和库提供了给出了确定内存“公评分担”的合理措施。
|
||||
已有的传统工具会将目光主要集中于读取 RSS(实际占用大小:Resident Set Size),这种方法是以物理内存方案来衡量使用情况的标准方法,但是往往高估了应用程序的内存的使用情况。
|
||||
|
||||
你可以 [阅读此指南了解 (关于内存的 RSS 和 PSS)][1] Linux 系统中的内存占用。
|
||||
PSS 从另一个侧面,通过判定在虚拟内存中的应用和库所使用的“合理分享”的内存,来给出更可信的衡量结果。
|
||||
|
||||
你可以阅读此[指南 (关于内存的 RSS 和 PSS)][1]了解 Linux 系统中的内存占用,不过现在让我们继续看看 smem 的特点。
|
||||
|
||||
### Smem 这一工具的特点
|
||||
|
||||
- 系统概览列表
|
||||
- 以进程,映射和用户来显示或者是过滤
|
||||
- 以进程、映射和用户来显示或者是过滤
|
||||
- 从 /proc 文件系统中得到数据
|
||||
- 从多个数据源配置显示条目
|
||||
- 可配置输出单元和百分比
|
||||
- 易于配置列表标题和汇总
|
||||
- 从多个数据源配置显示的条目
|
||||
- 可配置输出单位和百分比
|
||||
- 易于配置列表表头和汇总
|
||||
- 从镜像文件夹或者是压缩的 tar 文件中获得数据快照
|
||||
- 内置的图表生成机制
|
||||
- 在嵌入式系统中使用轻量级的捕获工具
|
||||
- 轻量级的捕获工具,可用于嵌入式系统
|
||||
|
||||
### 如何安装 Smem - Linux 下的内存使用情况报告工具
|
||||
|
||||
安装之前,需要确保满足以下的条件:
|
||||
|
||||
- 现代内存 (版本号高于 2.6.27)
|
||||
- 现代内核 (版本号高于 2.6.27)
|
||||
- 较新的 Python 版本 (2.4 及以后版本)
|
||||
- 可选的 [matplotlib][2] 库用于生成图表
|
||||
|
||||
对于当今的大多数的 Linux 发行版而言,内核版本和 Python 的版本都能够 满足需要,所以仅需要为生成良好的图表安装 matplotlib 库。
|
||||
对于当今的大多数的 Linux 发行版而言,内核版本和 Python 的版本都能够满足需要,所以仅需要为生成良好的图表安装 matplotlib 库。
|
||||
|
||||
#### RHEL, CentOS 和 Fedora
|
||||
|
||||
首先启用 [EPEL (Extra Packages for Enterprise Linux)][3] 软件源然后按照下列步骤操作:
|
||||
首先启用 [EPEL (Extra Packages for Enterprise Linux)][3] 软件源,然后按照下列步骤操作:
|
||||
|
||||
```
|
||||
# yum install smem python-matplotlib python-tk
|
||||
@ -59,7 +59,7 @@ $ sudo apt-get install smem python-matplotlib python-tk
|
||||
|
||||
#### Arch Linux
|
||||
|
||||
使用此 [AUR repository][4]。
|
||||
使用此 [AUR 仓库][4]。
|
||||
|
||||
### 如何使用 Smem – Linux 下的内存使用情况报告工具
|
||||
|
||||
@ -69,7 +69,7 @@ $ sudo apt-get install smem python-matplotlib python-tk
|
||||
$ sudo smem
|
||||
```
|
||||
|
||||
监视 Linux 系统中的内存使用情况
|
||||
*监视 Linux 系统中的内存使用情况*
|
||||
|
||||
```
|
||||
PID User Command Swap USS PSS RSS
|
||||
@ -108,7 +108,7 @@ $ sudo smem
|
||||
....
|
||||
```
|
||||
|
||||
当常规用户运行 smem,将会显示由用户启用的进程的占用情况,其中进程按照 PSS 的值升序排列。
|
||||
当普通用户运行 smem,将会显示由该用户启用的进程的占用情况,其中进程按照 PSS 的值升序排列。
|
||||
|
||||
下面的输出为用户 “aaronkilik” 启用的进程的使用情况:
|
||||
|
||||
@ -116,7 +116,7 @@ $ sudo smem
|
||||
$ smem
|
||||
```
|
||||
|
||||
监视 Linux 系统中的内存使用情况
|
||||
*监视 Linux 系统中的内存使用情况*
|
||||
|
||||
```
|
||||
PID User Command Swap USS PSS RSS
|
||||
@ -156,12 +156,13 @@ $ smem
|
||||
...
|
||||
```
|
||||
|
||||
使用 smem 是还有一些参数可以选用,例如当参看整个系统的内存占用情况,运行以下的命令:
|
||||
使用 smem 时还有一些参数可以选用,例如当查看整个系统的内存占用情况,运行以下的命令:
|
||||
|
||||
```
|
||||
$ sudo smem -w
|
||||
```
|
||||
监视 Linux 系统中的内存使用情况
|
||||
|
||||
*监视 Linux 系统中的内存使用情况*
|
||||
|
||||
```
|
||||
Area Used Cache Noncache
|
||||
@ -178,7 +179,7 @@ free memory 4424936 4424936 0
|
||||
$ sudo smem -u
|
||||
```
|
||||
|
||||
Linux 下以用户为单位监控内存占用情况
|
||||
*Linux 下以用户为单位监控内存占用情况*
|
||||
|
||||
```
|
||||
User Count Swap USS PSS RSS
|
||||
@ -201,7 +202,7 @@ tecmint 64 0 1652888 1815699 2763112
|
||||
$ sudo smem -m
|
||||
```
|
||||
|
||||
Linux 下以映射为单位监控内存占用情况
|
||||
*Linux 下以映射为单位监控内存占用情况*
|
||||
|
||||
```
|
||||
Map PIDs AVGPSS PSS
|
||||
@ -231,15 +232,15 @@ Map PIDs AVGPSS PSS
|
||||
....
|
||||
```
|
||||
|
||||
还有其它的选项用于 smem 的输出,下面将会举两个例子。
|
||||
还有其它的选项可以筛选 smem 的输出,下面将会举两个例子。
|
||||
|
||||
要按照用户名筛选输出的信息,调用 -u 或者是 --userfilter="regex" 选项,就像下面的命令这样:
|
||||
要按照用户名筛选输出的信息,使用 -u 或者是 --userfilter="regex" 选项,就像下面的命令这样:
|
||||
|
||||
```
|
||||
$ sudo smem -u
|
||||
```
|
||||
|
||||
按照用户报告内存使用情况
|
||||
*按照用户报告内存使用情况*
|
||||
|
||||
```
|
||||
User Count Swap USS PSS RSS
|
||||
@ -256,13 +257,13 @@ root 39 0 323804 353374 496552
|
||||
tecmint 64 0 1708900 1871766 2819212
|
||||
```
|
||||
|
||||
要按照进程名称筛选输出信息,调用 -P 或者是 --processfilter="regex" 选项,就像下面的命令这样:
|
||||
要按照进程名称筛选输出信息,使用 -P 或者是 --processfilter="regex" 选项,就像下面的命令这样:
|
||||
|
||||
```
|
||||
$ sudo smem --processfilter="firefox"
|
||||
```
|
||||
|
||||
按照进程名称报告内存使用情况
|
||||
*按照进程名称报告内存使用情况*
|
||||
|
||||
```
|
||||
PID User Command Swap USS PSS RSS
|
||||
@ -271,7 +272,7 @@ PID User Command Swap USS PSS RSS
|
||||
4424 tecmint /usr/lib/firefox/firefox 0 931732 937590 961504
|
||||
```
|
||||
|
||||
输出的格式有时候也很重要,smem 提供了一些参数帮助您格式化内存使用报告,我们将举出几个例子。
|
||||
输出的格式有时候也很重要,smem 提供了一些帮助您格式化内存使用报告的参数,我们将举出几个例子。
|
||||
|
||||
设置哪些列在报告中,使用 -c 或者是 --columns选项,就像下面的命令这样:
|
||||
|
||||
@ -279,7 +280,7 @@ PID User Command Swap USS PSS RSS
|
||||
$ sudo smem -c "name user pss rss"
|
||||
```
|
||||
|
||||
按列报告内存使用情况
|
||||
*按列报告内存使用情况*
|
||||
|
||||
```
|
||||
Name User PSS RSS
|
||||
@ -317,7 +318,7 @@ ssh-agent tecmint 485 992
|
||||
$ sudo smem -p
|
||||
```
|
||||
|
||||
按百分比报告内存使用情况
|
||||
*按百分比报告内存使用情况*
|
||||
|
||||
```
|
||||
PID User Command Swap USS PSS RSS
|
||||
@ -345,13 +346,13 @@ $ sudo smem -p
|
||||
....
|
||||
```
|
||||
|
||||
下面的额命令将会在输出的最后输出一行汇总信息:
|
||||
下面的命令将会在输出的最后输出一行汇总信息:
|
||||
|
||||
```
|
||||
$ sudo smem -t
|
||||
```
|
||||
|
||||
报告内存占用合计
|
||||
*报告内存占用合计*
|
||||
|
||||
```
|
||||
PID User Command Swap USS PSS RSS
|
||||
@ -389,27 +390,29 @@ PID User Command Swap USS PSS RSS
|
||||
|
||||
比如,你可以生成一张进程的 PSS 和 RSS 值的条状图。在下面的例子中,我们会生成属于 root 用户的进程的内存占用图。
|
||||
|
||||
纵坐标为每一个进程的 PSS 和 RSS 值,横坐标为 root 用户的所有进程:
|
||||
纵坐标为每一个进程的 PSS 和 RSS 值,横坐标为 root 用户的所有进程(的 ID):
|
||||
|
||||
```
|
||||
$ sudo smem --userfilter="root" --bar pid -c"pss rss"
|
||||
```
|
||||
|
||||
|
||||
>Linux Memory Usage in PSS and RSS Values
|
||||
|
||||
也可以生成进程及其 PSS 和 RSS 占用量的饼状图。以下的命令将会输出一张 root 用户的所有进程的饼状。
|
||||
*Linux Memory Usage in PSS and RSS Values*
|
||||
|
||||
`--pie` name 意思为以各个进程名字为标签,`-s` 选项帮助以 PSS 的值排序。
|
||||
也可以生成进程及其 PSS 和 RSS 占用量的饼状图。以下的命令将会输出一张 root 用户的所有进程的饼状图。
|
||||
|
||||
`--pie` name 意思为以各个进程名字为标签,`-s` 选项用来以 PSS 的值排序。
|
||||
|
||||
```
|
||||
$ sudo smem --userfilter="root" --pie name -s pss
|
||||
```
|
||||
|
||||
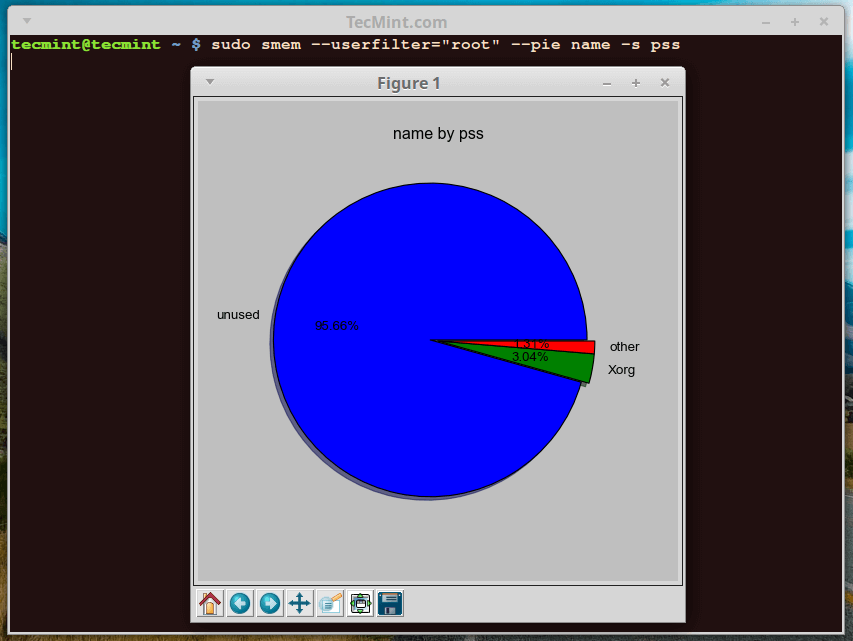
|
||||
>Linux Memory Consumption by Processes
|
||||
|
||||
它们还提供了一些其它与 PSS 和 RSS 相关的字段用于图表的标签:
|
||||
*Linux Memory Consumption by Processes*
|
||||
|
||||
除了 PSS 和 RSS ,其它的字段也可以用于图表的标签:
|
||||
|
||||
假如需要获得帮助,非常简单,仅需要输入 `smem -h` 或者是浏览帮助页面。
|
||||
|
||||
@ -420,16 +423,16 @@ $ sudo smem --userfilter="root" --pie name -s pss
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/smem-linux-memory-usage-per-process-per-user/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+tecmint+%28Tecmint%3A+Linux+Howto%27s+Guide%29
|
||||
via: http://www.tecmint.com/smem-linux-memory-usage-per-process-per-user/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[dongfengweixiao](https://github.com/dongfengweixiao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
[1]: https://emilics.com/notebook/enblog/p871.html
|
||||
[2]: http://matplotlib.org/index.html
|
||||
[3]: http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[3]: https://linux.cn/article-2324-1.html
|
||||
[4]: https://www.archlinux.org/packages/community/i686/smem/
|
||||
@ -0,0 +1,255 @@
|
||||
在 Linux 上用 SELinux 或 AppArmor 实现强制访问控制(MAC)
|
||||
===========================================================================
|
||||
|
||||
为了解决标准的“用户-组-其他/读-写-执行”权限以及[访问控制列表][1]的限制以及加强安全机制,美国国家安全局(NSA)设计出一个灵活的强制访问控制(Mandatory Access Control:MAC)方法 SELinux(Security Enhanced Linux 的缩写),来限制标准的权限之外的种种权限,在仍然允许对这个控制模型后续修改的情况下,让进程尽可能以最小权限访问或在系统对象(如文件,文件夹,网络端口等)上执行其他操作。
|
||||
|
||||

|
||||
|
||||
*SELinux 和 AppArmor 加固 Linux 安全*
|
||||
|
||||
另一个流行并且被广泛使用的 MAC 是 AppArmor,相比于 SELinux 它提供更多的特性,包括一个学习模式,可以让系统“学习”一个特定应用的行为,以及通过配置文件设置限制实现安全的应用使用。
|
||||
|
||||
在 CentOS 7 中,SELinux 合并进了内核并且默认启用强制(Enforcing)模式(下一节会介绍这方面更多的内容),与之不同的是,openSUSE 和 Ubuntu 使用的是 AppArmor 。
|
||||
|
||||
在这篇文章中我们会解释 SELinux 和 AppArmor 的本质,以及如何在你选择的发行版上使用这两个工具之一并从中获益。
|
||||
|
||||
### SELinux 介绍以及如何在 CentOS 7 中使用
|
||||
|
||||
Security Enhanced Linux 可以以两种不同模式运行:
|
||||
|
||||
- 强制(Enforcing):这种情况下,SELinux 基于 SELinux 策略规则拒绝访问,策略规则是一套控制安全引擎的规则。
|
||||
- 宽容(Permissive):这种情况下,SELinux 不拒绝访问,但如果在强制模式下会被拒绝的操作会被记录下来。
|
||||
|
||||
SELinux 也能被禁用。尽管这不是它的一个操作模式,不过也是一种选择。但学习如何使用这个工具强过只是忽略它。时刻牢记这一点!
|
||||
|
||||
使用 `getenforce` 命令来显示 SELinux 的当前模式。如果你想要更改模式,使用 `setenforce 0`(设置为宽容模式)或 `setenforce 1`(强制模式)。
|
||||
|
||||
因为这些设置重启后就失效了,你需要编辑 `/etc/selinux/config` 配置文件并设置 `SELINUX` 变量为 `enforcing`、`permissive` 或 `disabled` ,保存设置让其重启后也有效:
|
||||
|
||||
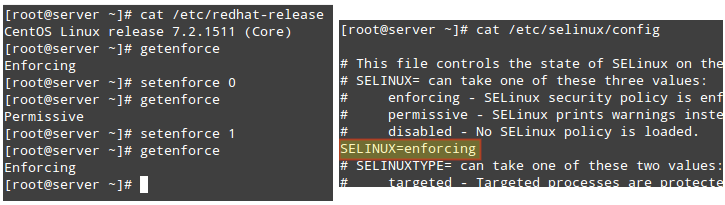
|
||||
|
||||
*如何启用和禁用 SELinux 模式*
|
||||
|
||||
还有一点要注意,如果 `getenforce` 返回 Disabled,你得编辑 `/etc/selinux/config` 配置文件为你想要的操作模式并重启。否则你无法利用 `setenforce` 设置(或切换)操作模式。
|
||||
|
||||
`setenforce` 的典型用法之一包括在 SELinux 模式之间切换(从强制到宽容或相反)来定位一个应用是否行为不端或没有像预期一样工作。如果它在你将 SELinux 设置为宽容模式正常工作,你就可以确定你遇到的是 SELinux 权限问题。
|
||||
|
||||
有两种我们使用 SELinux 可能需要解决的典型案例:
|
||||
|
||||
- 改变一个守护进程监听的默认端口。
|
||||
- 给一个虚拟主机设置 /var/www/html 以外的文档根路径值。
|
||||
|
||||
让我们用以下例子来看看这两种情况。
|
||||
|
||||
#### 例 1:更改 sshd 守护进程的默认端口
|
||||
|
||||
大部分系统管理员为了加强服务器安全首先要做的事情之一就是更改 SSH 守护进程监听的端口,主要是为了阻止端口扫描和外部攻击。要达到这个目的,我们要更改 `/etc/ssh/sshd_config` 中的 Port 值为以下值(我们在这里使用端口 9999 为例):
|
||||
|
||||
```
|
||||
Port 9999
|
||||
```
|
||||
|
||||
在尝试重启服务并检查它的状态之后,我们会看到它启动失败:
|
||||
|
||||
```
|
||||
# systemctl restart sshd
|
||||
# systemctl status sshd
|
||||
```
|
||||
|
||||
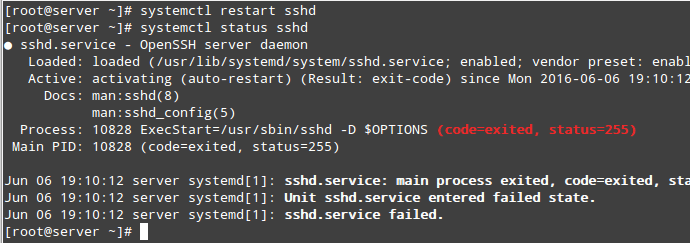
|
||||
|
||||
*检查 SSH 服务状态*
|
||||
|
||||
如果我们看看 `/var/log/audit/audit.log`,就会看到 sshd 被 SELinux 阻止在端口 9999 上启动,因为它是 JBoss 管理服务的保留端口(SELinux 日志信息包含了词语“AVC”,所以应该很容易把它同其他信息区分开来):
|
||||
|
||||
```
|
||||
# cat /var/log/audit/audit.log | grep AVC | tail -1
|
||||
```
|
||||
|
||||

|
||||
|
||||
*检查 Linux 审计日志*
|
||||
|
||||
在这种情况下大部分人可能会禁用 SELinux,但我们不这么做。我们会看到有个让 SELinux 和监听其他端口的 sshd 和谐共处的方法。首先确保你有 `policycoreutils-python` 这个包,执行:
|
||||
|
||||
```
|
||||
# yum install policycoreutils-python
|
||||
```
|
||||
|
||||
查看 SELinux 允许 sshd 监听的端口列表。在接下来的图片中我们还能看到端口 9999 是为其他服务保留的,所以我们暂时无法用它来运行其他服务:
|
||||
|
||||
```
|
||||
# semanage port -l | grep ssh
|
||||
```
|
||||
|
||||
当然我们可以给 SSH 选择其他端口,但如果我们确定我们不会使用这台机器跑任何 JBoss 相关的服务,我们就可以修改 SELinux 已存在的规则,转而给 SSH 分配那个端口:
|
||||
|
||||
```
|
||||
# semanage port -m -t ssh_port_t -p tcp 9999
|
||||
```
|
||||
|
||||
这之后,我们就可以用前一个 `semanage` 命令检查端口是否正确分配了,即使用 `-lC` 参数(list custom 的简称):
|
||||
|
||||
```
|
||||
# semanage port -lC
|
||||
# semanage port -l | grep ssh
|
||||
```
|
||||
|
||||
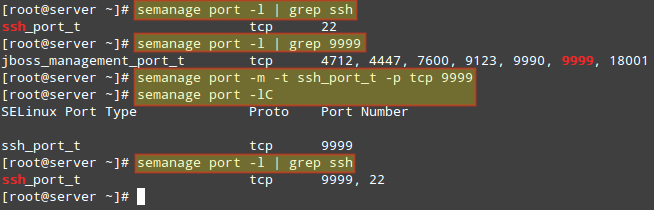
|
||||
|
||||
*给 SSH 分配端口*
|
||||
|
||||
我们现在可以重启 SSH 服务并通过端口 9999 连接了。注意这个更改重启之后依然有效。
|
||||
|
||||
#### 例 2:给一个虚拟主机设置 /var/www/html 以外的文档根路径(DocumentRoot)
|
||||
|
||||
如果你需要用除 `/var/www/html` 以外目录作为文档根目录(DocumentRoot)[设置一个 Apache 虚拟主机][2](也就是说,比如 `/websrv/sites/gabriel/public_html`):
|
||||
|
||||
```
|
||||
DocumentRoot “/websrv/sites/gabriel/public_html”
|
||||
```
|
||||
|
||||
Apache 会拒绝提供内容,因为 `index.html` 已经被标记为了 `default_t SELinux` 类型,Apache 无法访问它:
|
||||
|
||||
```
|
||||
# wget http://localhost/index.html
|
||||
# ls -lZ /websrv/sites/gabriel/public_html/index.html
|
||||
```
|
||||
|
||||

|
||||
|
||||
*被标记为 default_t SELinux 类型*
|
||||
|
||||
和之前的例子一样,你可以用以下命令验证这是不是 SELinux 相关的问题:
|
||||
|
||||
```
|
||||
# cat /var/log/audit/audit.log | grep AVC | tail -1
|
||||
```
|
||||
|
||||

|
||||
|
||||
*检查日志确定是不是 SELinux 的问题*
|
||||
|
||||
要将 `/websrv/sites/gabriel/public_html` 整个目录内容标记为 `httpd_sys_content_t`,执行:
|
||||
|
||||
```
|
||||
# semanage fcontext -a -t httpd_sys_content_t "/websrv/sites/gabriel/public_html(/.*)?"
|
||||
```
|
||||
|
||||
上面这个命令会赋予 Apache 对那个目录以及其内容的读取权限。
|
||||
|
||||
最后,要应用这条策略(并让更改的标记立即生效),执行:
|
||||
|
||||
```
|
||||
# restorecon -R -v /websrv/sites/gabriel/public_html
|
||||
```
|
||||
|
||||
现在你应该可以访问这个目录了:
|
||||
|
||||
```
|
||||
# wget http://localhost/index.html
|
||||
```
|
||||
|
||||
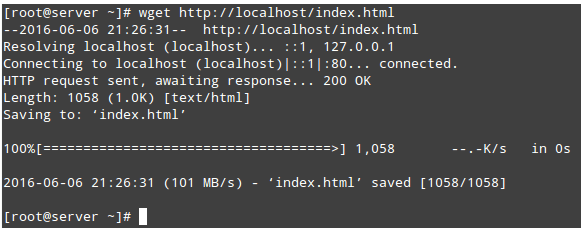
|
||||
|
||||
*访问 Apache 目录*
|
||||
|
||||
要获取关于 SELinux 的更多信息,参阅 Fedora 22 中的 [SELinux 用户及管理员指南][3]。
|
||||
|
||||
### AppArmor 介绍以及如何在 OpenSUSE 和 Ubuntu 上使用它
|
||||
|
||||
AppArmor 的操作是基于写在纯文本文件中的规则定义,该文件中含有允许权限和访问控制规则。安全配置文件用来限制应用程序如何与系统中的进程和文件进行交互。
|
||||
|
||||
系统初始就提供了一系列的配置文件,但其它的也可以由应用程序在安装的时候设置或由系统管理员手动设置。
|
||||
|
||||
像 SELinux 一样,AppArmor 以两种模式运行。在 enforce 模式下,应用被赋予它们运行所需要的最小权限,但在 complain 模式下 AppArmor 允许一个应用执行受限的操作并将操作造成的“抱怨”记录到日志里(`/var/log/kern.log`,`/var/log/audit/audit.log`,和其它放在 `/var/log/apparmor` 中的日志)。
|
||||
|
||||
日志中会显示配置文件在强制模式下运行时会产生错误的记录,它们中带有 `audit` 这个词。因此,你可以在 AppArmor 的 enforce 模式下运行之前,先在 complain 模式下尝试运行一个应用并调整它的行为。
|
||||
|
||||
可以用这个命令显示 AppArmor 的当前状态:
|
||||
|
||||
```
|
||||
$ sudo apparmor_status
|
||||
```
|
||||
|
||||
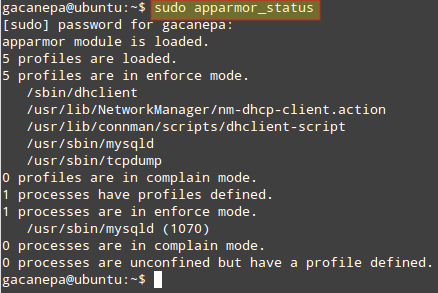
|
||||
|
||||
*查看 AppArmor 的状态*
|
||||
|
||||
上面的图片指明配置 `/sbin/dhclient`,`/usr/sbin/`,和 `/usr/sbin/tcpdump` 等处在 enforce 模式下(在 Ubuntu 下默认就是这样的)。
|
||||
|
||||
因为不是所有的应用都包含相关的 AppArmor 配置,apparmor-profiles 包给其它没有提供限制的包提供了配置。默认它们配置在 complain 模式下运行,以便系统管理员能够测试并选择一个所需要的配置。
|
||||
|
||||
我们将会利用 apparmor-profiles,因为写一份我们自己的配置已经超出了 LFCS [认证][4]的范围了。但是,由于配置都是纯文本文件,你可以查看并学习它们,为以后创建自己的配置做准备。
|
||||
|
||||
AppArmor 配置保存在 `/etc/apparmor.d` 中。让我们来看看这个文件夹在安装 apparmor-profiles 之前和之后有什么不同:
|
||||
|
||||
```
|
||||
$ ls /etc/apparmor.d
|
||||
```
|
||||
|
||||

|
||||
|
||||
*查看 AppArmor 文件夹内容*
|
||||
|
||||
如果你再次执行 `sudo apparmor_status`,你会在 complain 模式看到更长的配置文件列表。你现在可以执行下列操作。
|
||||
|
||||
将当前在 enforce 模式下的配置文件切换到 complain 模式:
|
||||
|
||||
```
|
||||
$ sudo aa-complain /path/to/file
|
||||
```
|
||||
|
||||
以及相反的操作(complain –> enforce):
|
||||
|
||||
```
|
||||
$ sudo aa-enforce /path/to/file
|
||||
```
|
||||
|
||||
上面这些例子是允许使用通配符的。举个例子:
|
||||
|
||||
```
|
||||
$ sudo aa-complain /etc/apparmor.d/*
|
||||
```
|
||||
|
||||
会将 `/etc/apparmor.d` 中的所有配置文件设置为 complain 模式,反之
|
||||
|
||||
```
|
||||
$ sudo aa-enforce /etc/apparmor.d/*
|
||||
```
|
||||
|
||||
会将所有配置文件设置为 enforce 模式。
|
||||
|
||||
要完全禁用一个配置,在 `/etc/apparmor.d/disabled` 目录中创建一个符号链接:
|
||||
|
||||
```
|
||||
$ sudo ln -s /etc/apparmor.d/profile.name /etc/apparmor.d/disable/
|
||||
```
|
||||
|
||||
要获取关于 AppArmor 的更多信息,参阅[官方的 AppArmor wiki][5] 以及 [Ubuntu 提供的][6]文档。
|
||||
|
||||
### 总结
|
||||
|
||||
在这篇文章中我们学习了一些 SELinux 和 AppArmor 这两个著名的强制访问控制系统的基本知识。什么时候使用两者中的一个或是另一个?为了避免提高难度,你可能需要考虑专注于你选择的发行版自带的那一个。不管怎样,它们会帮助你限制进程和系统资源的访问,以提高你服务器的安全性。
|
||||
|
||||
关于本文你有任何的问题,评论,或建议,欢迎在下方发表。不要犹豫,让我们知道你是否有疑问或评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/mandatory-access-control-with-selinux-or-apparmor-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/gacanepa/
|
||||
[1]: http://www.tecmint.com/secure-files-using-acls-in-linux/
|
||||
[2]: http://www.tecmint.com/apache-virtual-hosting-in-centos/
|
||||
[3]: https://docs.fedoraproject.org/en-US/Fedora/22/html/SELinux_Users_and_Administrators_Guide/index.html
|
||||
[4]: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[5]: http://wiki.apparmor.net/index.php/Main_Page
|
||||
[6]: https://help.ubuntu.com/community/AppArmor
|
||||
|
||||
|
||||
@ -0,0 +1,110 @@
|
||||
Ubuntu Snap 软件包接管 Linux 桌面和 IoT 软件的发行
|
||||
===========================================================================
|
||||
|
||||
[Canonical][28] 和 [Ubuntu][29] 创始人 Mark Shuttleworth 在一次采访中说他不准备宣布 Ubuntu 的新 [ Snap 程序包格式][30]。但是就在几个月之后,很多 Linux 发行版的开发者和公司都宣布他们会把 Snap 作为通用 Linux 程序包格式。
|
||||
|
||||

|
||||
|
||||
*Linux 供应商,独立软件开发商和公司门全都采用 Ubuntu Snap 作为多种 Linux 系统的配置和更新程序包。*
|
||||
|
||||
为什么呢?因为 Snap 能使一个单一的二进制程序包可以完美、安全地运行在任何 Linux 台式机、服务器、云或物联网设备上。据 Canonical 的 Ubuntu 客户端产品和版本负责人 Olli Ries 说:
|
||||
|
||||
>[Snap 程序包的安全机制][1]让我们在更快的跨发行版的应用更新中打开了新的局面,因为 Snap 应用是与系统的其它部分想隔离的。用户可以安装一个 Snap 而不用担心是否会影响其他的应用程序和操作系统。
|
||||
|
||||
当然了,如 Linux 内核的早期开发者和 CoreOS 安全维护者 Matthew Garrett 指出的那样:如果你[将 Snap 用在不安全的程序中,比如 X11 窗口系统][2],实际上您并不会获得安全性。(LCTT 译注:X11 也叫做 X Window 系统,X Window 系统 ( X11 或 X )是一种位图显示的视窗系统 。它是在 Unix 和类 Unix 操作系统 ,以及 OpenVMS 上建立图形用户界面的标准工具包和协议,并可用于几乎所有已有的现代操作系统。)
|
||||
|
||||
Shuttleworth 同意 Garrett 的观点,但是他也说你可以控制 Snap 应用是如何与系统的其它部分如何交互的。比如,一个 web 浏览器可以包含在一个安全的 Snap 程序包中,这个 Snap 使用 Ubuntu 打包的 [openssl][3] TLS 和 SSL 库。除此之外,即使有些东西影响到了浏览器实例内部,也不能进入到底层的操作系统。
|
||||
|
||||
很多公司也这样认为。戴尔、三星、Mozilla、[krita][7](LCTT 译注:Krita 是一个位图形编辑软件,KOffice 套装的一部份。包含一个绘画程式和照片编辑器,Krita 是自由软件,并根据GNU通用公共许可证发布)、[Mycroft][8](LCTT 译注:Mycroft 是一个开源AI智能家居平台,配置 Raspberry Pi 2 和 Arduino 控制器),以及 [Horizon Computing][9](LCTT 译注:为客户提供优质的硬件架构为其运行云平台)都将使用 Snap。Arch Linux、Debain、Gentoo 和 OpenWrt 开发团队也已经拥抱了 Snap,也会把 Snap 加入到他们各自的发行版中。
|
||||
|
||||
Snap 包又叫做“Snaps”,现在已经可以原生的运行在 Arch、Debian、Fedora、Kubuntu、Lubuntu、Ubuntu GNOME、Ubuntu Kylin、Ubuntu MATE、Ubuntu Unity 和 Xubuntu 之上。 Snap 也在 CentOS、Elementary、Gentoo、Mint、OpenSUSE 和 Red Hat Enterprise Linux (RHEL) 上取得了验证,并且也很容易运行在其他 Linux 发行版上。
|
||||
|
||||
这些发行版正在使用 Snaps,Shuttleworth 声称:“Snaps 为每个 Linux 台式机、服务器、设备和云机器带来了很多应用程序,在让用户使用最好的应用的同时也给了用户选择发行版的自由。”
|
||||
|
||||
这些发行版共同代表了 Linux 桌面、服务器和云系统发行版的主流。为什么它们从现有的软件包管理系统换了过来呢? Arch Linux 的贡献者 Tim Jester-Pfadt 解释说,“Snaps 最棒的一点是它支持先锐和测试通道,这可以让用户选择使用预发布的开发者版本或跟着最新的稳定版本。”
|
||||
|
||||
除过这些 Linux 分支,独立软件开发商也将会因为 Snap 很好的简化了第三方 Linux 应用程序分发和安全维护问题而拥抱 Snap。例如,[文档基金会][14]也将会让流行的开源办公套件 [LibreOffice][15] 支持 Snap 程序包。
|
||||
|
||||
文档基金会的联合创始人 Thorsten Behrens 这样说:
|
||||
|
||||
> 我们的目标是尽可能的使 LibreOffice 能被大多数人更容易使用。Snap 使我们的用户能够在不同的桌面系统和发行版上更快捷、更容易、持续地获取最新的 LibreOffice 版本。更好的是,它也会帮助我们的发布工程师最终从周而复始的、自产的、陈旧的 Linux 开发解决方案中解放出来,很多东西都可以一同维护了。
|
||||
|
||||
Mozilla 的 Firefix 副总裁 Nick Nguyen 在该声明中提到:
|
||||
|
||||
> 我们力求为用户提供良好的使用体验,并且使火狐浏览器能够在更多平台、设备和操作系统上运行。随着引入 Snaps ,对火狐浏览器的持续优化成为可能,使它可以为 Linux 用户提供最新的特性。
|
||||
|
||||
[Krita 基金会][17] (基于 KDE 的图形程序)项目领导 Boudewijn Rempt 说:
|
||||
|
||||
> 在一个私有仓库中维护 DEB 包是复杂而耗时的。Snaps 更容易维护、打包和分发。把 Snap 放进软件商店也特别容易,这是我发布软件用过的最舒服的软件商店了。[Krita 3.0][18] 刚刚作为一个 snap 程序包发行,新版本出现时它会自动更新。
|
||||
|
||||
不仅 Linux 桌面系统程序为 Snap 而激动。物联网(IoT)和嵌入式开发者也以双手拥抱了 Snap。
|
||||
|
||||
由于 Snaps 彼此隔离,带来了数据安全性,它们还可以自动更新或回滚,这对于硬件设备是极好的。多个厂商都发布了运行着 snappy 的设备(LCTT 译注:Snap 基于 snappy进行构建),这带来了一种新的带有物联网应用商店的“智能新锐”设备。Snappy 设备能够自动接收系统更新,并且连同安装在设备上的应用程序也会得到更新。
|
||||
|
||||
据 Shuttleworth 说,戴尔公司是最早一批认识到 Snap 的巨大潜力的物联网供应商之一,也决定在他们的设备上使用 Snap 了。
|
||||
|
||||
戴尔公司的物联网战略和合作伙伴主管 Jason Shepherd 说:“我们认为,Snaps 能解决在单一物联网网关上部署和运行多个第三方应用程序所带来的安全风险和可管理性挑战。这种可信赖的通用的应用程序格式才是戴尔真正需要的,我们的物联网解决方案合作伙伴和商业客户都对构建一个可扩展的、IT 级的、充满活力的物联网应用生态系统有极大的兴趣。”
|
||||
|
||||
OpenWrt 的开发者 Matteo Croce 说:“这很简单, Snaps 可以在保持核心系统不变的情况下递送新的应用... Snaps 是为 OpenWrt AP 和路由器提供大量软件的最快方式。”
|
||||
|
||||
Shuttleworth 并不认为 Snaps 会取代已经存在的 Linux 程序包比如 [RPM][19] 和 [DEB][20]。相反,他认为它们将会相辅相成。Snaps 将会与现有软件包共存。每个发行版都有其自己提供和更新核心系统及其更新的机制。Snap 为桌面系统带来的是通用的应用程序,这些应用程序不会影响到操作系统的基础。
|
||||
|
||||
每个 Snap 都通过使用大量的内核隔离和安全机制而限制,以满足 Snap 应用的需求。谨慎的审核过程可以确保 Snap 仅仅得到其完成请求操作的权限。用户在安装 Snap 的时候也不必考虑复杂的安全问题。
|
||||
|
||||
Snap 本质上是一个自包容的 zip 文件,能够快速地在包内执行。流行的[优麒麟][21]团队的负责人 Jack Yu 称:“Snaps 比传统的 Linux 包更容易构建,允许我们独立于操作系统解决依赖性,所以我们很容易地跨发行版为所有用户提供最好、最新的中国 Linux 应用。”
|
||||
|
||||
由 Canonical 设计的 Snap 程序包格式由 [snapd][22] 所处理。它的开发工作放在 GitHub 上。将其移植到更多的 Linux 发行版已经被证明是很简单的,社区还在不断增长,吸引了大量具有 Linux 经验的贡献者。
|
||||
|
||||
Snap 程序包使用 snapcraft 工具来构建。项目官网是 [snapcraft.io][24],其上有构建 Snap 的指导和逐步指南,以及给项目开发者和使用者的文档。Snap 能够基于现有的发行版程序包构建,但通常使用源代码来构建,以获得优化和减小软件包大小。
|
||||
|
||||
如果你不是 Ubuntu 的忠实粉丝或者一个专业的 Linux 开发者,你可能还不知道 Snap。未来,在任何平台上需要用 Linux 完成工作的任何人都会知道这个软件。它会成为主流,尤其是在 Linux 应用程序的安装和更新机制方面。
|
||||
|
||||
### 相关内容:
|
||||
|
||||
- [Linux 专家 Matthew Garrett:Ubuntu 16.04 的新 Snap 程序包格式存在安全风险 ][25]
|
||||
- [Ubuntu Linux 16.04 ]
|
||||
- [Microsoft 和 Canonical 合作使 Ubuntu 可以在 Windows 10 上运行 ]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/ubuntu-snap-takes-charge-of-linux-desktop-and-iot-software-distribution/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[28]: http://www.canonical.com/
|
||||
[29]: http://www.ubuntu.com/
|
||||
[30]: https://insights.ubuntu.com/2016/04/13/snaps-for-classic-ubuntu/
|
||||
[1]: https://insights.ubuntu.com/2016/04/13/snaps-for-classic-ubuntu/
|
||||
[2]: http://www.zdnet.com/article/linux-expert-matthew-garrett-ubuntu-16-04s-new-snap-format-is-a-security-risk/
|
||||
[3]: https://www.openssl.org/
|
||||
[4]: http://www.dell.com/en-us/
|
||||
[5]: http://www.samsung.com/us/
|
||||
[6]: http://www.mozilla.com/
|
||||
[7]: https://krita.org/en/
|
||||
[8]: https://mycroft.ai/
|
||||
[9]: http://www.horizon-computing.com/
|
||||
[10]: https://www.archlinux.org/
|
||||
[11]: https://www.debian.org/
|
||||
[12]: https://www.gentoo.org/
|
||||
[13]: https://openwrt.org/
|
||||
[14]: https://www.documentfoundation.org/
|
||||
[15]: https://www.libreoffice.org/download/libreoffice-fresh/
|
||||
[16]: https://www.mozilla.org/en-US/firefox/new/
|
||||
[17]: https://krita.org/en/about/krita-foundation/
|
||||
[18]: https://krita.org/en/item/krita-3-0-released/
|
||||
[19]: http://rpm5.org/
|
||||
[20]: https://www.debian.org/doc/manuals/debian-faq/ch-pkg_basics.en.html
|
||||
[21]: http://www.ubuntu.com/desktop/ubuntu-kylin
|
||||
[22]: https://launchpad.net/ubuntu/+source/snapd
|
||||
[23]: https://github.com/snapcore/snapd
|
||||
[24]: http://snapcraft.io/
|
||||
[25]: http://www.zdnet.com/article/linux-expert-matthew-garrett-ubuntu-16-04s-new-snap-format-is-a-security-risk/
|
||||
[26]: http://www.zdnet.com/article/ubuntu-linux-16-04-is-here/
|
||||
[27]: http://www.zdnet.com/article/microsoft-and-canonical-partner-to-bring-ubuntu-to-windows-10/
|
||||
|
||||
|
||||
@ -2,15 +2,16 @@
|
||||
====================================================================
|
||||
|
||||

|
||||
>Linux 系统中一切都是文件并有相应的文件类型
|
||||
|
||||
*Linux 系统中一切都是文件并有相应的文件类型*
|
||||
|
||||
在 Unix 和它衍生的比如 Linux 系统中,一切都可以看做文件。虽然它仅仅只是一个泛泛的概念,但这是事实。如果有不是文件的,那它一定是正运行的进程。
|
||||
|
||||
要理解这点,可以举个例子,您的根目录(/) 的空间是由不同类型的 Linux 文件所占据的。当您创建一个文件或向系统传一个文件时,它在物理磁盘上占据的一些空间,可以认为是一个特定的格式(文件类型)。
|
||||
要理解这点,可以举个例子,您的根目录(/)的空间充斥着不同类型的 Linux 文件。当您创建一个文件或向系统传输一个文件时,它会在物理磁盘上占据的一些空间,而且是一个特定的格式(文件类型)。
|
||||
|
||||
虽然 Linux 系统中文件和目录没有什么不同,但目录还有一个重要的功能,那就是有结构性的分组存储其它文件,以方便查找访问。所有的硬件部件都表示为文件,系统使用这些文件来与硬件通信。
|
||||
虽然 Linux 系统中文件和目录没有什么不同,但目录还有一个重要的功能,那就是有结构性的分组存储其它文件,以方便查找访问。所有的硬件组件都表示为文件,系统使用这些文件来与硬件通信。
|
||||
|
||||
这些思想是对伟大的 Linux 财产的重要阐述,因此像文档、目录(Mac OS X 和 Windows 系统下是文件夹)、键盘、监视器、硬盘、可移动媒体设备、打印机、调制解调器、虚拟终端,还有进程间通信(IPC)和网络通信等输入/输出资源都在定义在文件系统空间下的字节流。
|
||||
这些思想是对 Linux 中的各种事物的重要阐述,因此像文档、目录(Mac OS X 和 Windows 系统下称之为文件夹)、键盘、监视器、硬盘、可移动媒体设备、打印机、调制解调器、虚拟终端,还有进程间通信(IPC)和网络通信等输入/输出资源都是定义在文件系统空间下的字节流。
|
||||
|
||||
一切都可看作是文件,其最显著的好处是对于上面所列出的输入/输出资源,只需要相同的一套 Linux 工具、实用程序和 API。
|
||||
|
||||
@ -28,7 +29,7 @@ Linux 系统中有三种基本的文件类型:
|
||||
|
||||
它们是包含文本、数据、程序指令等数据的文件,其在 Linux 系统中是最常见的一种。包括如下:
|
||||
|
||||
- 只读文件
|
||||
- 可读文件
|
||||
- 二进制文件
|
||||
- 图像文件
|
||||
- 压缩文件等等
|
||||
@ -37,7 +38,7 @@ Linux 系统中有三种基本的文件类型:
|
||||
|
||||
特殊文件包括以下几种:
|
||||
|
||||
块文件:设备文件,对访问系统硬件部件提供了缓存接口。他们提供了一种使用文件系统与设备驱动通信的方法。
|
||||
块文件(block):设备文件,对访问系统硬件部件提供了缓存接口。它们提供了一种通过文件系统与设备驱动通信的方法。
|
||||
|
||||
有关于块文件一个重要的性能就是它们能在指定时间内传输大块的数据和信息。
|
||||
|
||||
@ -73,7 +74,7 @@ brw-rw---- 1 root disk 1, 5 May 18 10:26 ram5
|
||||
...
|
||||
```
|
||||
|
||||
字符文件: 也是设备文件,对访问系统硬件组件提供了非缓冲串行接口。它们与设备的通信工作方式是一次只传输一个字符的数据。
|
||||
字符文件(Character): 也是设备文件,对访问系统硬件组件提供了非缓冲串行接口。它们与设备的通信工作方式是一次只传输一个字符的数据。
|
||||
|
||||
列出某目录下的字符文件:
|
||||
|
||||
@ -113,7 +114,7 @@ crw-rw-rw- 1 root tty 5, 2 May 18 17:40 ptmx
|
||||
crw-rw-rw- 1 root root 1, 8 May 18 10:26 random
|
||||
```
|
||||
|
||||
符号链接文件 : 符号链接是指向系统上其他文件的引用。因此,符号链接文件是指向其它文件的文件,也可以是目录或常规文件。
|
||||
符号链接文件(Symbolic link) : 符号链接是指向系统上其他文件的引用。因此,符号链接文件是指向其它文件的文件,那些文件可以是目录或常规文件。
|
||||
|
||||
列出某目录下的符号链接文件:
|
||||
|
||||
@ -142,11 +143,11 @@ Linux 中使用 `ln` 工具就可以创建一个符号链接文件,如下所
|
||||
# ls -l /home/tecmint/ | grep "^l" [列出符号链接文件]
|
||||
```
|
||||
|
||||
在上面的例子中,首先我们在 `/tmp` 目录创建了一个名叫 `file1.txt` 的文件,然后创建符号链接文件,所以 `/home/tecmint/file1.txt` 指向 `/tmp/file1.txt` 文件。
|
||||
在上面的例子中,首先我们在 `/tmp` 目录创建了一个名叫 `file1.txt` 的文件,然后创建符号链接文件,将 `/home/tecmint/file1.txt` 指向 `/tmp/file1.txt` 文件。
|
||||
|
||||
套接字和命令管道 : 连接一个进行的输出和另一个进程的输入,允许进程间通信的文件。
|
||||
管道(Pipes)和命令管道(Named pipes) : 将一个进程的输出连接到另一个进程的输入,从而允许进程间通信(IPC)的文件。
|
||||
|
||||
命名管道实际上是一个文件,用来使两个进程彼此通信,就像一个 Linux pipe(管道) 命令一样。
|
||||
命名管道实际上是一个文件,用来使两个进程彼此通信,就像一个 Linux 管道一样。
|
||||
|
||||
列出某目录下的管道文件:
|
||||
|
||||
@ -154,7 +155,7 @@ Linux 中使用 `ln` 工具就可以创建一个符号链接文件,如下所
|
||||
# ls -l | grep "^p"
|
||||
```
|
||||
|
||||
输出例子
|
||||
输出例子:
|
||||
|
||||
```
|
||||
prw-rw-r-- 1 tecmint tecmint 0 May 18 17:47 pipe1
|
||||
@ -171,19 +172,17 @@ prw-rw-r-- 1 tecmint tecmint 0 May 18 17:47 pipe5
|
||||
# echo "This is named pipe1" > pipe1
|
||||
```
|
||||
|
||||
在上的例子中,我们创建了一个名叫 `pipe1` 的命名管道,然后使用 [echo 命令][2] 加入一些数据,在这操作后,要使用这些输入数据就要用非交互的 shell 了。
|
||||
在上的例子中,我们创建了一个名叫 `pipe1` 的命名管道,然后使用 [echo 命令][2] 加入一些数据,这之后在处理输入的数据时 shell 就变成非交互式的了(LCTT 译注:被管道占住了)。
|
||||
|
||||
|
||||
|
||||
然后,我们打开另外的 shell 终端,运行另外的命令来打印出刚加入管道的数据。
|
||||
然后,我们打开另外一个 shell 终端,运行另外的命令来打印出刚加入管道的数据。
|
||||
|
||||
```
|
||||
# while read line ;do echo "This was passed-'$line' "; done<pipe1
|
||||
```
|
||||
|
||||
套接字文件 : 提供进程间通信方法的文件,它们能为运行在不同环境中的进程之间的数据和信息提供传输的能力。
|
||||
套接字文件(sockets) : 提供进程间通信方法的文件,它们能在运行在不同环境中的进程之间传输数据和信息。
|
||||
|
||||
这就是说,套接字 (sockets) 可以对运行网络上不同机器中的进行之间的数据和信息进行传输。
|
||||
这就是说,套接字可以为运行网络上不同机器中的进程提供数据和信息传输。
|
||||
|
||||
一个 socket 运行的例子就是网页浏览器连接到网站服务器的过程。
|
||||
|
||||
@ -191,13 +190,13 @@ prw-rw-r-- 1 tecmint tecmint 0 May 18 17:47 pipe5
|
||||
# ls -l /dev/ | grep "^s"
|
||||
```
|
||||
|
||||
输出例子
|
||||
输出例子:
|
||||
|
||||
```
|
||||
srw-rw-rw- 1 root root 0 May 18 10:26 log
|
||||
```
|
||||
|
||||
下面是使用 C 语言编写的调用 `socket()` 函数的例子。
|
||||
下面是使用 C 语言编写的调用 `socket()` 系统调用的例子。
|
||||
|
||||
```
|
||||
int socket_desc= socket(AF_INET, SOCK_STREAM, 0 );
|
||||
@ -205,15 +204,15 @@ int socket_desc= socket(AF_INET, SOCK_STREAM, 0 );
|
||||
|
||||
上例中:
|
||||
|
||||
- `AF_INET` 指的是地址域(IPv4)
|
||||
- `SOCK_STREAM` 指的是类型 (默认使用 TCP 协议连接)
|
||||
- `0` 指协议(IP 协议)
|
||||
- `AF_INET` 指的是地址域(IPv4)
|
||||
- `SOCK_STREAM` 指的是类型(默认使用 TCP 协议连接)
|
||||
- `0` 指协议(IP 协议)
|
||||
|
||||
使用 `socket_desc` 来引用管道文件,它跟文件描述符是一样的,然后再使用系统函数 `read()` 和 `write()` 来分别从这个管道文件读写数据。
|
||||
|
||||
### 目录文件
|
||||
#### 目录文件
|
||||
|
||||
是一些特殊的文件,既可以包含普通文件又可包含特殊文件,它们在 Linux 文件系统中是以根(/)目录为起点分层组织存在的。
|
||||
这是一些特殊的文件,既可以包含普通文件又可包含其它的特殊文件,它们在 Linux 文件系统中是以根(/)目录为起点分层组织存在的。
|
||||
|
||||
列出某目录下的目录文件:
|
||||
|
||||
@ -221,7 +220,7 @@ int socket_desc= socket(AF_INET, SOCK_STREAM, 0 );
|
||||
# ls -l / | grep "^d"
|
||||
```
|
||||
|
||||
输出例子
|
||||
输出例子:
|
||||
|
||||
```
|
||||
drwxr-xr-x 2 root root 4096 May 5 15:49 bin
|
||||
@ -257,18 +256,17 @@ drwxr-xr-x 12 root root 4096 Nov 12 2015 var
|
||||
|
||||
### 结论
|
||||
|
||||
现在应该有一个清楚的认识为什么 Linux 系统中一切都是文件以及 Linux 系统中可以存在哪些类型的文件了。
|
||||
现在应该对为什么 Linux 系统中一切都是文件以及 Linux 系统中可以存在哪些类型的文件有一个清楚的认识了。
|
||||
|
||||
您可以通过阅读更多有关各个文件类型的文章和对应的创建过程等来增加更多知识。我希望这篇教程对您有所帮助。有任何疑问或有补充的知识,请留下评论,一起来讨论。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/explanation-of-everything-is-a-file-and-types-of-files-in-linux/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+tecmint+%28Tecmint%3A+Linux+Howto%27s+Guide%29
|
||||
via: http://www.tecmint.com/explanation-of-everything-is-a-file-and-types-of-files-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,483 @@
|
||||
Mock 在 Python 单元测试中的使用
|
||||
=====================================
|
||||
|
||||
本文讲述的是 Python 中 Mock 的使用。
|
||||
|
||||
### 如何执行单元测试而不用考验你的耐心
|
||||
|
||||
很多时候,我们编写的软件会直接与那些被标记为“垃圾”的服务交互。用外行人的话说:服务对我们的应用程序很重要,但是我们想要的是交互,而不是那些不想要的副作用,这里的“不想要”是在自动化测试运行的语境中说的。例如:我们正在写一个社交 app,并且想要测试一下 "发布到 Facebook" 的新功能,但是不想每次运行测试集的时候真的发布到 Facebook。
|
||||
|
||||
Python 的 `unittest` 库包含了一个名为 `unittest.mock` 或者可以称之为依赖的子包,简称为
|
||||
`mock` —— 其提供了极其强大和有用的方法,通过它们可以模拟(mock)并去除那些我们不希望的副作用。
|
||||
|
||||

|
||||
|
||||
*注意:`mock` [最近被收录][1]到了 Python 3.3 的标准库中;先前发布的版本必须通过 [PyPI][2] 下载 Mock 库。*
|
||||
|
||||
### 恐惧系统调用
|
||||
|
||||
再举另一个例子,我们在接下来的部分都会用到它,这是就是**系统调用**。不难发现,这些系统调用都是主要的模拟对象:无论你是正在写一个可以弹出 CD 驱动器的脚本,还是一个用来删除 /tmp 下过期的缓存文件的 Web 服务,或者一个绑定到 TCP 端口的 socket 服务器,这些调用都是在你的单元测试上下文中不希望产生的副作用。
|
||||
|
||||
作为一个开发者,你需要更关心你的库是否成功地调用了一个可以弹出 CD 的系统函数(使用了正确的参数等等),而不是切身经历 CD 托盘每次在测试执行的时候都打开了。(或者更糟糕的是,弹出了很多次,在一个单元测试运行期间多个测试都引用了弹出代码!)
|
||||
|
||||
同样,保持单元测试的效率和性能意味着需要让如此多的“缓慢代码”远离自动测试,比如文件系统和网络访问。
|
||||
|
||||
对于第一个例子来说,我们要从原始形式换成使用 `mock` 重构一个标准 Python 测试用例。我们会演示如何使用 mock 写一个测试用例,使我们的测试更加智能、快速,并展示更多关于我们软件的工作原理。
|
||||
|
||||
### 一个简单的删除函数
|
||||
|
||||
我们都有过需要从文件系统中一遍又一遍的删除文件的时候,因此,让我们在 Python 中写一个可以使我们的脚本更加轻易完成此功能的函数。
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import os
|
||||
|
||||
def rm(filename):
|
||||
os.remove(filename)
|
||||
```
|
||||
|
||||
很明显,我们的 `rm` 方法此时无法提供比 `os.remove` 方法更多的相关功能,但我们可以在这里添加更多的功能,使我们的基础代码逐步改善。
|
||||
|
||||
让我们写一个传统的测试用例,即,没有使用 `mock`:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from mymodule import rm
|
||||
|
||||
import os.path
|
||||
import tempfile
|
||||
import unittest
|
||||
|
||||
class RmTestCase(unittest.TestCase):
|
||||
|
||||
tmpfilepath = os.path.join(tempfile.gettempdir(), "tmp-testfile")
|
||||
|
||||
def setUp(self):
|
||||
with open(self.tmpfilepath, "wb") as f:
|
||||
f.write("Delete me!")
|
||||
|
||||
def test_rm(self):
|
||||
# remove the file
|
||||
rm(self.tmpfilepath)
|
||||
# test that it was actually removed
|
||||
self.assertFalse(os.path.isfile(self.tmpfilepath), "Failed to remove the file.")
|
||||
```
|
||||
|
||||
我们的测试用例相当简单,但是在它每次运行的时候,它都会创建一个临时文件并且随后删除。此外,我们没有办法测试我们的 `rm` 方法是否正确地将我们的参数向下传递给 `os.remove` 调用。我们可以基于以上的测试*认为*它做到了,但还有很多需要改进的地方。
|
||||
|
||||
#### 使用 Mock 重构
|
||||
|
||||
让我们使用 mock 重构我们的测试用例:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from mymodule import rm
|
||||
|
||||
import mock
|
||||
import unittest
|
||||
|
||||
class RmTestCase(unittest.TestCase):
|
||||
|
||||
@mock.patch('mymodule.os')
|
||||
def test_rm(self, mock_os):
|
||||
rm("any path")
|
||||
# test that rm called os.remove with the right parameters
|
||||
mock_os.remove.assert_called_with("any path")
|
||||
```
|
||||
|
||||
使用这些重构,我们从根本上改变了测试用例的操作方式。现在,我们有一个可以用于验证其他功能的内部对象。
|
||||
|
||||
##### 潜在陷阱
|
||||
|
||||
第一件需要注意的事情就是,我们使用了 `mock.patch` 方法装饰器,用于模拟位于 `mymodule.os` 的对象,并且将 mock 注入到我们的测试用例方法。那么只是模拟 `os` 本身,而不是 `mymodule.os` 下 `os` 的引用(LCTT 译注:注意 `@mock.patch('mymodule.os')` 便是模拟 `mymodule.os` 下的 `os`),会不会更有意义呢?
|
||||
|
||||
当然,当涉及到导入和管理模块,Python 的用法就像蛇一样灵活。在运行时,`mymodule` 模块有它自己的被导入到本模块局部作用域的 `os`。因此,如果我们模拟 `os`,我们是看不到 mock 在 `mymodule` 模块中的模仿作用的。
|
||||
|
||||
这句话需要深刻地记住:
|
||||
|
||||
> 模拟一个东西要看它用在何处,而不是来自哪里。
|
||||
|
||||
如果你需要为 `myproject.app.MyElaborateClass` 模拟 `tempfile` 模块,你可能需要将 mock 用于 `myproject.app.tempfile`,而其他模块保持自己的导入。
|
||||
|
||||
先将那个陷阱放一边,让我们继续模拟。
|
||||
|
||||
#### 向 ‘rm’ 中加入验证
|
||||
|
||||
之前定义的 rm 方法相当的简单。在盲目地删除之前,我们倾向于验证一个路径是否存在,并验证其是否是一个文件。让我们重构 rm 使其变得更加智能:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import os
|
||||
import os.path
|
||||
|
||||
def rm(filename):
|
||||
if os.path.isfile(filename):
|
||||
os.remove(filename)
|
||||
```
|
||||
|
||||
很好。现在,让我们调整测试用例来保持测试的覆盖率。
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from mymodule import rm
|
||||
|
||||
import mock
|
||||
import unittest
|
||||
|
||||
class RmTestCase(unittest.TestCase):
|
||||
|
||||
@mock.patch('mymodule.os.path')
|
||||
@mock.patch('mymodule.os')
|
||||
def test_rm(self, mock_os, mock_path):
|
||||
# set up the mock
|
||||
mock_path.isfile.return_value = False
|
||||
|
||||
rm("any path")
|
||||
|
||||
# test that the remove call was NOT called.
|
||||
self.assertFalse(mock_os.remove.called, "Failed to not remove the file if not present.")
|
||||
|
||||
# make the file 'exist'
|
||||
mock_path.isfile.return_value = True
|
||||
|
||||
rm("any path")
|
||||
|
||||
mock_os.remove.assert_called_with("any path")
|
||||
```
|
||||
|
||||
我们的测试用例完全改变了。现在我们可以在没有任何副作用的情况下核实并验证方法的内部功能。
|
||||
|
||||
#### 将文件删除作为服务
|
||||
|
||||
到目前为止,我们只是将 mock 应用在函数上,并没应用在需要传递参数的对象和实例的方法上。我们现在开始涵盖对象的方法。
|
||||
|
||||
首先,我们将 `rm` 方法重构成一个服务类。实际上将这样一个简单的函数转换成一个对象,在本质上这不是一个合理的需求,但它能够帮助我们了解 `mock` 的关键概念。让我们开始重构:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import os
|
||||
import os.path
|
||||
|
||||
class RemovalService(object):
|
||||
"""A service for removing objects from the filesystem."""
|
||||
|
||||
def rm(filename):
|
||||
if os.path.isfile(filename):
|
||||
os.remove(filename)
|
||||
```
|
||||
|
||||
你会注意到我们的测试用例没有太大变化:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from mymodule import RemovalService
|
||||
|
||||
import mock
|
||||
import unittest
|
||||
|
||||
class RemovalServiceTestCase(unittest.TestCase):
|
||||
|
||||
@mock.patch('mymodule.os.path')
|
||||
@mock.patch('mymodule.os')
|
||||
def test_rm(self, mock_os, mock_path):
|
||||
# instantiate our service
|
||||
reference = RemovalService()
|
||||
|
||||
# set up the mock
|
||||
mock_path.isfile.return_value = False
|
||||
|
||||
reference.rm("any path")
|
||||
|
||||
# test that the remove call was NOT called.
|
||||
self.assertFalse(mock_os.remove.called, "Failed to not remove the file if not present.")
|
||||
|
||||
# make the file 'exist'
|
||||
mock_path.isfile.return_value = True
|
||||
|
||||
reference.rm("any path")
|
||||
|
||||
mock_os.remove.assert_called_with("any path")
|
||||
```
|
||||
|
||||
很好,我们知道 `RemovalService` 会如预期般的工作。接下来让我们创建另一个服务,将 `RemovalService` 声明为它的一个依赖:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import os
|
||||
import os.path
|
||||
|
||||
class RemovalService(object):
|
||||
"""A service for removing objects from the filesystem."""
|
||||
|
||||
def rm(self, filename):
|
||||
if os.path.isfile(filename):
|
||||
os.remove(filename)
|
||||
|
||||
|
||||
class UploadService(object):
|
||||
|
||||
def __init__(self, removal_service):
|
||||
self.removal_service = removal_service
|
||||
|
||||
def upload_complete(self, filename):
|
||||
self.removal_service.rm(filename)
|
||||
```
|
||||
|
||||
因为我们的测试覆盖了 `RemovalService`,因此我们不会对我们测试用例中 `UploadService` 的内部函数 `rm` 进行验证。相反,我们将调用 `UploadService` 的 `RemovalService.rm` 方法来进行简单测试(当然没有其他副作用),我们通过之前的测试用例便能知道它可以正确地工作。
|
||||
|
||||
这里有两种方法来实现测试:
|
||||
|
||||
1. 模拟 RemovalService.rm 方法本身。
|
||||
2. 在 UploadService 的构造函数中提供一个模拟实例。
|
||||
|
||||
因为这两种方法都是单元测试中非常重要的方法,所以我们将同时对这两种方法进行回顾。
|
||||
|
||||
##### 方法 1:模拟实例的方法
|
||||
|
||||
`mock` 库有一个特殊的方法装饰器,可以模拟对象实例的方法和属性,即 `@mock.patch.object decorator` 装饰器:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from mymodule import RemovalService, UploadService
|
||||
|
||||
import mock
|
||||
import unittest
|
||||
|
||||
class RemovalServiceTestCase(unittest.TestCase):
|
||||
|
||||
@mock.patch('mymodule.os.path')
|
||||
@mock.patch('mymodule.os')
|
||||
def test_rm(self, mock_os, mock_path):
|
||||
# instantiate our service
|
||||
reference = RemovalService()
|
||||
|
||||
# set up the mock
|
||||
mock_path.isfile.return_value = False
|
||||
|
||||
reference.rm("any path")
|
||||
|
||||
# test that the remove call was NOT called.
|
||||
self.assertFalse(mock_os.remove.called, "Failed to not remove the file if not present.")
|
||||
|
||||
# make the file 'exist'
|
||||
mock_path.isfile.return_value = True
|
||||
|
||||
reference.rm("any path")
|
||||
|
||||
mock_os.remove.assert_called_with("any path")
|
||||
|
||||
|
||||
class UploadServiceTestCase(unittest.TestCase):
|
||||
|
||||
@mock.patch.object(RemovalService, 'rm')
|
||||
def test_upload_complete(self, mock_rm):
|
||||
# build our dependencies
|
||||
removal_service = RemovalService()
|
||||
reference = UploadService(removal_service)
|
||||
|
||||
# call upload_complete, which should, in turn, call `rm`:
|
||||
reference.upload_complete("my uploaded file")
|
||||
|
||||
# check that it called the rm method of any RemovalService
|
||||
mock_rm.assert_called_with("my uploaded file")
|
||||
|
||||
# check that it called the rm method of _our_ removal_service
|
||||
removal_service.rm.assert_called_with("my uploaded file")
|
||||
```
|
||||
|
||||
非常棒!我们验证了 `UploadService` 成功调用了我们实例的 `rm` 方法。你是否注意到一些有趣的地方?这种修补机制(patching mechanism)实际上替换了我们测试用例中的所有 `RemovalService` 实例的 `rm` 方法。这意味着我们可以检查实例本身。如果你想要了解更多,可以试着在你模拟的代码下断点,以对这种修补机制的原理获得更好的认识。
|
||||
|
||||
##### 陷阱:装饰顺序
|
||||
|
||||
当我们在测试方法中使用多个装饰器,其顺序是很重要的,并且很容易混乱。基本上,当装饰器被映射到方法参数时,[装饰器的工作顺序是反向的][3]。思考这个例子:
|
||||
|
||||
|
||||
```
|
||||
@mock.patch('mymodule.sys')
|
||||
@mock.patch('mymodule.os')
|
||||
@mock.patch('mymodule.os.path')
|
||||
def test_something(self, mock_os_path, mock_os, mock_sys):
|
||||
pass
|
||||
```
|
||||
|
||||
注意到我们的参数和装饰器的顺序是反向匹配了吗?这部分是由 [Python 的工作方式][4]所导致的。这里是使用多个装饰器的情况下它们执行顺序的伪代码:
|
||||
|
||||
```
|
||||
patch_sys(patch_os(patch_os_path(test_something)))
|
||||
```
|
||||
|
||||
因为 `sys` 补丁位于最外层,所以它最晚执行,使得它成为实际测试方法参数的最后一个参数。请特别注意这一点,并且在运行你的测试用例时,使用调试器来保证正确的参数以正确的顺序注入。
|
||||
|
||||
##### 方法 2:创建 Mock 实例
|
||||
|
||||
我们可以使用构造函数为 `UploadService` 提供一个 Mock 实例,而不是模拟特定的实例方法。我更推荐方法 1,因为它更加精确,但在多数情况,方法 2 或许更加有效和必要。让我们再次重构测试用例:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from mymodule import RemovalService, UploadService
|
||||
|
||||
import mock
|
||||
import unittest
|
||||
|
||||
class RemovalServiceTestCase(unittest.TestCase):
|
||||
|
||||
@mock.patch('mymodule.os.path')
|
||||
@mock.patch('mymodule.os')
|
||||
def test_rm(self, mock_os, mock_path):
|
||||
# instantiate our service
|
||||
reference = RemovalService()
|
||||
|
||||
# set up the mock
|
||||
mock_path.isfile.return_value = False
|
||||
|
||||
reference.rm("any path")
|
||||
|
||||
# test that the remove call was NOT called.
|
||||
self.assertFalse(mock_os.remove.called, "Failed to not remove the file if not present.")
|
||||
|
||||
# make the file 'exist'
|
||||
mock_path.isfile.return_value = True
|
||||
|
||||
reference.rm("any path")
|
||||
|
||||
mock_os.remove.assert_called_with("any path")
|
||||
|
||||
|
||||
class UploadServiceTestCase(unittest.TestCase):
|
||||
|
||||
def test_upload_complete(self, mock_rm):
|
||||
# build our dependencies
|
||||
mock_removal_service = mock.create_autospec(RemovalService)
|
||||
reference = UploadService(mock_removal_service)
|
||||
|
||||
# call upload_complete, which should, in turn, call `rm`:
|
||||
reference.upload_complete("my uploaded file")
|
||||
|
||||
# test that it called the rm method
|
||||
mock_removal_service.rm.assert_called_with("my uploaded file")
|
||||
```
|
||||
|
||||
在这个例子中,我们甚至不需要修补任何功能,只需为 `RemovalService` 类创建一个 auto-spec,然后将实例注入到我们的 `UploadService` 以验证功能。
|
||||
|
||||
`mock.create_autospec` 方法为类提供了一个同等功能实例。实际上来说,这意味着在使用返回的实例进行交互的时候,如果使用了非法的方式将会引发异常。更具体地说,如果一个方法被调用时的参数数目不正确,将引发一个异常。这对于重构来说是非常重要。当一个库发生变化的时候,中断测试正是所期望的。如果不使用 auto-spec,尽管底层的实现已经被破坏,我们的测试仍然会通过。
|
||||
|
||||
##### 陷阱:mock.Mock 和 mock.MagicMock 类
|
||||
|
||||
`mock` 库包含了两个重要的类 [mock.Mock](http://www.voidspace.org.uk/python/mock/mock.html) 和 [mock.MagicMock](http://www.voidspace.org.uk/python/mock/magicmock.html#magic-mock),大多数内部函数都是建立在这两个类之上的。当在选择使用 `mock.Mock` 实例、`mock.MagicMock` 实例还是 auto-spec 的时候,通常倾向于选择使用 auto-spec,因为对于未来的变化,它更能保持测试的健全。这是因为 `mock.Mock` 和 `mock.MagicMock` 会无视底层的 API,接受所有的方法调用和属性赋值。比如下面这个用例:
|
||||
|
||||
```
|
||||
class Target(object):
|
||||
def apply(value):
|
||||
return value
|
||||
|
||||
def method(target, value):
|
||||
return target.apply(value)
|
||||
```
|
||||
|
||||
我们可以像下面这样使用 mock.Mock 实例进行测试:
|
||||
|
||||
```
|
||||
class MethodTestCase(unittest.TestCase):
|
||||
|
||||
def test_method(self):
|
||||
target = mock.Mock()
|
||||
|
||||
method(target, "value")
|
||||
|
||||
target.apply.assert_called_with("value")
|
||||
```
|
||||
|
||||
这个逻辑看似合理,但如果我们修改 `Target.apply` 方法接受更多参数:
|
||||
|
||||
```
|
||||
class Target(object):
|
||||
def apply(value, are_you_sure):
|
||||
if are_you_sure:
|
||||
return value
|
||||
else:
|
||||
return None
|
||||
```
|
||||
|
||||
重新运行你的测试,你会发现它仍能通过。这是因为它不是针对你的 API 创建的。这就是为什么你总是应该使用 `create_autospec` 方法,并且在使用 `@patch`和 `@patch.object` 装饰方法时使用 `autospec` 参数。
|
||||
|
||||
### 现实例子:模拟 Facebook API 调用
|
||||
|
||||
作为这篇文章的结束,我们写一个更加适用的现实例子,一个在介绍中提及的功能:发布消息到 Facebook。我将写一个不错的包装类及其对应的测试用例。
|
||||
|
||||
```
|
||||
import facebook
|
||||
|
||||
class SimpleFacebook(object):
|
||||
|
||||
def __init__(self, oauth_token):
|
||||
self.graph = facebook.GraphAPI(oauth_token)
|
||||
|
||||
def post_message(self, message):
|
||||
"""Posts a message to the Facebook wall."""
|
||||
self.graph.put_object("me", "feed", message=message)
|
||||
```
|
||||
|
||||
这是我们的测试用例,它可以检查我们发布的消息,而不是真正地发布消息:
|
||||
|
||||
```
|
||||
import facebook
|
||||
import simple_facebook
|
||||
import mock
|
||||
import unittest
|
||||
|
||||
class SimpleFacebookTestCase(unittest.TestCase):
|
||||
|
||||
@mock.patch.object(facebook.GraphAPI, 'put_object', autospec=True)
|
||||
def test_post_message(self, mock_put_object):
|
||||
sf = simple_facebook.SimpleFacebook("fake oauth token")
|
||||
sf.post_message("Hello World!")
|
||||
|
||||
# verify
|
||||
mock_put_object.assert_called_with(message="Hello World!")
|
||||
```
|
||||
|
||||
正如我们所看到的,在 Python 中,通过 mock,我们可以非常容易地动手写一个更加智能的测试用例。
|
||||
|
||||
### Python Mock 总结
|
||||
|
||||
即使对它的使用还有点不太熟悉,对[单元测试][7]来说,Python 的 `mock` 库可以说是一个规则改变者。我们已经演示了常见的用例来了解了 `mock` 在单元测试中的使用,希望这篇文章能够帮助 [Python 开发者][8]克服初期的障碍,写出优秀、经受过考验的代码。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.toptal.com/python/an-introduction-to-mocking-in-python
|
||||
|
||||
作者:[NAFTULI TZVI KAY][a]
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.slviki.com/
|
||||
[1]: http://www.python.org/dev/peps/pep-0417/
|
||||
[2]: https://pypi.python.org/pypi/mock
|
||||
[3]: http://www.voidspace.org.uk/python/mock/patch.html#nesting-patch-decorators
|
||||
[4]: http://docs.python.org/2/reference/compound_stmts.html#function-definitions
|
||||
[5]: http://www.voidspace.org.uk/python/mock/helpers.html#autospeccing
|
||||
[6]: http://www.voidspace.org.uk/python/mock/mock.html
|
||||
[7]: http://www.toptal.com/qa/how-to-write-testable-code-and-why-it-matters
|
||||
[8]: http://www.toptal.com/python
|
||||
119
published/201608/20160620 5 SSH Hardening Tips.md
Normal file
119
published/201608/20160620 5 SSH Hardening Tips.md
Normal file
@ -0,0 +1,119 @@
|
||||
五条强化 SSH 安全的建议
|
||||
======================
|
||||
|
||||

|
||||
|
||||
*采用这些简单的建议,使你的 OpenSSH 会话更加安全。*
|
||||
|
||||
当你查看你的 SSH 服务日志,可能你会发现充斥着一些不怀好意的尝试性登录。这里有 5 条常规建议(和一些个别特殊策略)可以让你的 OpenSSH 会话更加安全。
|
||||
|
||||
### 1. 强化密码登录
|
||||
|
||||
密码登录很方便,因为你可以从任何地方的任何机器上登录。但是它们在暴力攻击面前也是脆弱的。尝试以下策略来强化你的密码登录。
|
||||
|
||||
- 使用一个密码生成工具,例如 pwgen。pwgen 有几个选项,最有用的就是密码长度的选项(例如,`pwgen 12` 产生一个12位字符的密码)
|
||||
- 不要重复使用密码。忽略所有那些不要写下你的密码的建议,然后将你的所有登录信息都记在一个本子上。如果你不相信我的建议,那总可以相信安全权威 [Bruce Schneier][1] 吧。如果你足够细心,没有人能够发现你的笔记本,那么这样能够不受到网络上的那些攻击。
|
||||
- 你可以为你的登录记事本增加一些额外的保护措施,例如用字符替换或者增加新的字符来掩盖笔记本上的登录密码。使用一个简单而且好记的规则,比如说给你的密码增加两个额外的随机字符,或者使用单个简单的字符替换,例如 `#` 替换成 `*`。
|
||||
- 为你的 SSH 服务开启一个非默认的监听端口。是的,这是很老套的建议,但是它确实很有效。检查你的登录;很有可能 22 端口是被普遍攻击的端口,其他端口则很少被攻击。
|
||||
- 使用 [Fail2ban][2] 来动态保护你的服务器,是服务器免于被暴力攻击。
|
||||
- 使用不常用的用户名。绝不能让 root 可以远程登录,并避免用户名为“admin”。
|
||||
|
||||
### 2. 解决 `Too Many Authentication Failures` 报错
|
||||
|
||||
当我的 ssh 登录失败,并显示“Too many authentication failures for carla”的报错信息时,我很难过。我知道我应该不介意,但是这报错确实很碍眼。而且,正如我聪慧的奶奶曾经说过,伤痛之感并不能解决问题。解决办法就是在你的(客户端的) `~/.ssh/config` 文件设置强制密码登录。如果这个文件不存在,首先创个 `~/.ssh/` 目录。
|
||||
|
||||
```
|
||||
$ mkdir ~/.ssh
|
||||
$ chmod 700 ~/.ssh
|
||||
```
|
||||
然后在一个文本编辑器创建 `~/.ssh/confg` 文件,输入以下行,使用你自己的远程域名替换 HostName。
|
||||
|
||||
```
|
||||
HostName remote.site.com
|
||||
PubkeyAuthentication=no
|
||||
```
|
||||
|
||||
(LCTT 译注:这种错误发生在你使用一台 Linux 机器使用 ssh 登录另外一台服务器时,你的 .ssh 目录中存储了过多的私钥文件,而 ssh 客户端在你没有指定 -i 选项时,会默认逐一尝试使用这些私钥来登录远程服务器后才会提示密码登录,如果这些私钥并不能匹配远程主机,显然会触发这样的报错,甚至拒绝连接。因此本条是通过禁用本地私钥的方式来强制使用密码登录——显然这并不可取,如果你确实要避免用私钥登录,那你应该用 `-o PubkeyAuthentication=no` 选项登录。显然这条和下两条是互相矛盾的,所以请无视本条即可。)
|
||||
|
||||
### 3. 使用公钥认证
|
||||
|
||||
公钥认证比密码登录安全多了,因为它不受暴力密码攻击的影响,但是并不方便因为它依赖于 RSA 密钥对。首先,你要创建一个公钥/私钥对。下一步,私钥放于你的客户端电脑,并且复制公钥到你想登录的远程服务器。你只能从拥有私钥的电脑登录才能登录到远程服务器。你的私钥就和你的家门钥匙一样敏感;任何人获取到了私钥就可以获取你的账号。你可以给你的私钥加上密码来增加一些强化保护规则。
|
||||
|
||||
使用 RSA 密钥对管理多个用户是一种好的方法。当一个用户离开了,只要从服务器删了他的公钥就能取消他的登录。
|
||||
|
||||
以下例子创建一个新的 3072 位长度的密钥对,它比默认的 2048 位更安全,而且为它起一个独一无二的名字,这样你就可以知道它属于哪个服务器。
|
||||
|
||||
```
|
||||
$ ssh-keygen -t rsa -b 3072 -f id_mailserver
|
||||
```
|
||||
|
||||
以下创建两个新的密钥, `id_mailserver` 和 `id_mailserver.pub`,`id_mailserver` 是你的私钥--不要传播它!现在用 `ssh-copy-id` 命令安全地复制你的公钥到你的远程服务器。你必须确保在远程服务器上有可用的 SSH 登录方式。
|
||||
|
||||
```
|
||||
$ ssh-copy-id -i id_rsa.pub user@remoteserver
|
||||
|
||||
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
|
||||
user@remoteserver's password:
|
||||
|
||||
Number of key(s) added: 1
|
||||
|
||||
Now try logging into the machine, with: "ssh 'user@remoteserver'"
|
||||
and check to make sure that only the key(s) you wanted were added.
|
||||
```
|
||||
|
||||
`ssh-copy-id` 会确保你不会无意间复制了你的私钥。从上述输出中复制登录命令,记得带上其中的单引号,以测试你的新的密钥登录。
|
||||
|
||||
```
|
||||
$ ssh 'user@remoteserver'
|
||||
```
|
||||
|
||||
它将用你的新密钥登录,如果你为你的私钥设置了密码,它会提示你输入。
|
||||
|
||||
### 4. 取消密码登录
|
||||
|
||||
一旦你已经测试并且验证了你的公钥可以登录,就可以取消密码登录,这样你的远程服务器就不会被暴力密码攻击。如下设置**你的远程服务器**的 `/etc/sshd_config` 文件。
|
||||
|
||||
```
|
||||
PasswordAuthentication no
|
||||
```
|
||||
|
||||
然后重启服务器上的 SSH 守护进程。
|
||||
|
||||
### 5. 设置别名 -- 这很快捷而且很有 B 格
|
||||
|
||||
你可以为你的远程登录设置常用的别名,来替代登录时输入的命令,例如 `ssh -u username -p 2222 remote.site.with.long-name`。你可以使用 `ssh remote1`。你的客户端机器上的 `~/.ssh/config` 文件可以参照如下设置
|
||||
|
||||
```
|
||||
Host remote1
|
||||
HostName remote.site.with.long-name
|
||||
Port 2222
|
||||
User username
|
||||
PubkeyAuthentication no
|
||||
```
|
||||
|
||||
如果你正在使用公钥登录,可以参照这个:
|
||||
|
||||
```
|
||||
Host remote1
|
||||
HostName remote.site.with.long-name
|
||||
Port 2222
|
||||
User username
|
||||
IdentityFile ~/.ssh/id_remoteserver
|
||||
```
|
||||
|
||||
[OpenSSH 文档][3] 很长而且详细,但是当你掌握了基础的 SSH 使用规则之后,你会发现它非常的有用,而且包含很多可以通过 OpenSSH 来实现的炫酷效果。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/5-ssh-hardening-tips
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[maywanting](https://github.com/maywanting)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/cschroder
|
||||
[1]: https://www.schneier.com/blog/archives/2005/06/write_down_your.html
|
||||
[2]: http://www.fail2ban.org/wiki/index.php/Main_Page
|
||||
[3]: http://www.openssh.com/
|
||||
@ -0,0 +1,35 @@
|
||||
Flatpak 为 Linux 带来了独立应用
|
||||
================
|
||||
|
||||

|
||||
|
||||
[Flatpak][1] 的开发团队[宣布了][2] Flatpak 桌面应用框架已经可用了。 Flatpak (以前在开发时名为 xdg-app)为应用提供了捆绑为一个 Flatpak 软件包的能力,可以让应用在很多 Linux 发行版上都以轻松而一致的体验来安装和运行。将应用程序捆绑成 Flatpak 为其提供了沙盒安全环境,可以将它们与操作系统和彼此之间相互隔离。查看 [Flatpak 网站][3]上的[发布公告][4]来了解关于 Flatpak 框架技术的更多信息。
|
||||
|
||||
### 在 Fedora 中安装 Flatpak
|
||||
|
||||
如果用户想要运行以 Flatpak 格式打包的应用,在 Fedora 上安装是很容易的,Flatpak 格式已经可以在官方的 Fedora 23 和 Fedora 24 仓库中获得。Flatpak 网站上有[在 Fedora 上安装的完整细节][5],同时也有如何在 Arch、 Debian、Mageia 和 Ubuntu 中安装的方法。[许多的应用][6]已经使用 Flatpak 打包构建了,这包括 LibreOffice、Inkscape 和 GIMP。
|
||||
|
||||
### 对应用开发者
|
||||
|
||||
如果你是一个应用开发者,Flatpak 网站也包含许多有关于[使用 Flatpak 打包和分发应用程序][7]的重要资料。这些资料中包括了使用 Flakpak SDK 构建独立的、沙盒化的 Flakpak 应用程序的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/introducing-flatpak/
|
||||
|
||||
作者:[Ryan Lerch][a]
|
||||
译者:[zky001](https://github.com/zky001)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/introducing-flatpak/
|
||||
[1]: http://flatpak.org/
|
||||
[2]: http://flatpak.org/press/2016-06-21-flatpak-released.html
|
||||
[3]: http://flatpak.org/
|
||||
[4]: http://flatpak.org/press/2016-06-21-flatpak-released.html
|
||||
[5]: http://flatpak.org/getting.html
|
||||
[6]: http://flatpak.org/apps.html
|
||||
[7]: http://flatpak.org/developer.html
|
||||
|
||||
|
||||
@ -0,0 +1,81 @@
|
||||
在推特上我关注的人 72% 都是男性
|
||||
===============================================
|
||||
|
||||

|
||||
|
||||
至少,这是我的估计。推特并不会询问用户的性别,因此我 [写了一个程序][1] ,根据姓名猜测他们的性别。在那些关注我的人当中,性别分布甚至更糟,83% 的是男性。据我所知,其他的还不全都是女性。
|
||||
|
||||
修正第一个数字并不是什么神秘的事:我注意寻找更多支持我兴趣的女性专家,并且关注他们。
|
||||
|
||||
另一方面,第二个数字,我只能只能轻微影响一点,但是我也打算改进下。我在推特上的关系网应该代表的是软件行业的多元化未来,而不是不公平的现状。
|
||||
|
||||
### 我应该怎么估算呢
|
||||
|
||||
我开始估算我关注的人(推特的上的术语是“朋友”)的性别分布,然后发现这格外的难。[推特的分析][2]给我展示了如下的结果, 关于关注我的人的性别估算:
|
||||
|
||||
|
||||
|
||||
因此,推特的分析将我的关注者分成了三类:男性、女性、未知,并且给我们展示了前面两组的比例。(性别二值化现象在这里并不存在——未知性别的人都集中在组织的推特账号上。)但是我关注的人的性别比例,推特并没有告诉我。 [而这就是可以改进的][3],然后我开始搜索能够帮我估算这个数字的服务,最终发现了 [FollowerWonk][4] 。
|
||||
|
||||
FollowerWonk 估算我关注的人里面有 71% 都是男性。这个估算准确吗? 为了评估一下,我把 FollowerWonk 和 Twitter 对我关注的人的进行了估算,结果如下:
|
||||
|
||||
**推特分析**
|
||||
|
||||
| | 男性 | 女性 |
|
||||
| --------- | ---- | ---- |
|
||||
| **我的关注者** | 83% | 17% |
|
||||
|
||||
**FollowerWonk**
|
||||
|
||||
| | 男性 | 女性 |
|
||||
| --------- | ---- | ---- |
|
||||
| **我的关注者** | 81% | 19% |
|
||||
| **我关注的人** | 72% | 28% |
|
||||
|
||||
FollowerWonk 的分析显示我的关注者中 81% 的人都是男性,很接近推特分析的数字。这个结果还说得过去。如果FollowerWonk 和 Twitter 在我的关注者的性别比例上是一致的,这就表明 FollowerWonk 对我关注的人的性别估算也应当是合理的。使用 FollowerWonk 我就能养成估算这些数字的爱好,并且做出改进。
|
||||
|
||||
然而,使用 FollowerWonk 检测我关注的人的性别分布一个月需要 30 美元,这真是一个昂贵的爱好。我并不需要FollowerWonk 的所有的功能。我能很经济的解决只需要性别分布的问题吗?
|
||||
|
||||
因为 FollowerWonk 的估算数字看起来比较合理,我试图做一个自己的 FollowerWonk 。使用 Python 和[一些好心的费城人写的 Twitter API 封装类][5](LCTT 译注:Twitter API 封装类是由 Mike Taylor 等一批费城人在 github 上开源的一个项目),我开始下载我所有关注的人和我所有的关注者的简介。我马上就发现推特的速率限制是很低,因此我随机的采样了一部分用户。
|
||||
|
||||
我写了一个初步的程序,在所有我关注的人的简介中搜索一个和性别相关的代词。例如,如果简介中包含了“she”或者“her”这样的字眼,可能这就属于一个女性,如果简介中包含了“they”或者“them”,那么可能这就是性别未知的。但是大多数简介中不会出现这些代词。对于这种简介,和性别关联最紧密的信息就是姓名了。例如:@gvanrossum 的姓名那一栏是“Guido van Rossum”,第一姓名是“Guido”,这表明 @gvanrossum 是一个女的。当找不到代词的时候,我就使用名字来评估性别估算数字。
|
||||
|
||||
我的脚本把每个名字的一部分传到性别检测机中去检测性别。[性别检测机][6]也有可预见的失败,比如错误的把“Brooklyn Zen Center”当做一个名叫“Brooklyn”的女性,但是它的评估结果与 FollowerWonk 和 Twitter 的相比也是很合理的:
|
||||
|
||||
| | 非男非女 | 男性 | 女性 | 性别未知的 |
|
||||
| ----- | ---- | ---- | ---- | ----- |
|
||||
| 我关注的人 | 1 | 168 | 66 | 173 |
|
||||
| | 0% | 72% | 28% | |
|
||||
| 我的关注者 | 0 | 459 | 108 | 433 |
|
||||
| | 0% | 81% | 19% | |
|
||||
|
||||
(数据基于我所有的408个关注的人和1000个关注者。)
|
||||
|
||||
### 了解你的数字
|
||||
|
||||
我想你们也能检测你们推特关系网的性别分布。所以我将“Proportional”应用发布到 PythonAnywhere 这个便利的服务上,每月仅需 10 美元:
|
||||
|
||||
> <www.proporti.onl>
|
||||
|
||||
这个应用可能会在速率上有限制,超过会失败,因此请温柔的对待它。github 上放了源代码[代码][7] ,也有命令行的工具。
|
||||
|
||||
是谁代表了你的推特关系网?你还在忍受那些在过去几十年里一直在谈论的软件行业的不公平的男女分布吗?或者你的关系网看起来像软件行业的未来吗?让我们了解我们的数字并且改善他们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://emptysqua.re/blog/gender-of-twitter-users-i-follow/
|
||||
|
||||
作者:[A. Jesse Jiryu Davis][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://disqus.com/by/AJesseJiryuDavis/
|
||||
[1]: https://www.proporti.onl/
|
||||
[2]: https://analytics.twitter.com/
|
||||
[3]: http://english.stackexchange.com/questions/14952/that-which-is-measured-improves
|
||||
[4]: https://moz.com/followerwonk/
|
||||
[5]: https://github.com/bear/python-twitter/graphs/contributors
|
||||
[6]: https://pypi.python.org/pypi/SexMachine/
|
||||
[7]: https://github.com/ajdavis/twitter-gender-distribution
|
||||
@ -0,0 +1,113 @@
|
||||
Python 高级图像处理
|
||||
======================================
|
||||
|
||||

|
||||
|
||||
构建图像搜索引擎并不是一件容易的任务。这里有几个概念、工具、想法和技术需要实现。主要的图像处理概念之一是逆图像查询(RIQ:reverse image querying)。Google、Cloudera、Sumo Logic 和 Birst 等公司在使用逆图像搜索中名列前茅。通过分析图像和使用数据挖掘 RIQ 提供了很好的洞察分析能力。
|
||||
|
||||
### 顶级公司与逆图像搜索
|
||||
|
||||
有很多顶级的技术公司使用 RIQ 来取得了不错的收益。例如:在 2014 年 Pinterest 第一次带来了视觉搜索。随后在 2015 年发布了一份白皮书,披露了其架构。逆图像搜索让 Pinterest 获得了时尚品的视觉特征,并可以显示相似产品的推荐。
|
||||
|
||||
众所周知,谷歌图片使用逆图像搜索允许用户上传一张图片然后搜索相关联的图片。通过使用先进的算法对提交的图片进行分析和数学建模,然后和谷歌数据库中无数的其他图片进行比较得到相似的结果。
|
||||
|
||||
**这是 OpenCV 2.4.9 特征比较报告一个图表:**
|
||||
|
||||

|
||||
|
||||
### 算法 & Python库
|
||||
|
||||
在我们使用它工作之前,让我们过一遍构建图像搜索引擎的 Python 库的主要元素:
|
||||
|
||||
### 专利算法
|
||||
|
||||
#### 尺度不变特征变换(SIFT - Scale-Invariant Feature Transform)算法
|
||||
|
||||
1. 带有非自由功能的一个专利技术,利用图像识别符,以识别相似图像,甚至那些来自不同的角度,大小,深度和尺度的图片,也会被包括在搜索结果中。[点击这里][4]查看 SIFT 详细视频。
|
||||
2. SIFT 能与从许多图片中提取了特征的大型数据库正确地匹配搜索条件。
|
||||
3. 能匹配不同视角的相同图像和匹配不变特征来获得搜索结果是 SIFT 的另一个特征。了解更多关于尺度不变[关键点][5]。
|
||||
|
||||
#### 加速鲁棒特征(SURF - Speeded Up Robust Features)算法
|
||||
|
||||
1. [SURF][1] 也是一种带有非自由功能的专利技术,而且还是一种“加速”的 SIFT 版本。不像 SIFT,SURF 接近于带有箱式过滤器(Box Filter)的高斯拉普拉斯算子(Laplacian of Gaussian)。
|
||||
2. SURF 依赖于黑塞矩阵(Hessian Matrix)的位置和尺度。
|
||||
3. 在许多应用中,旋转不变性不是一个必要条件,所以不按这个方向查找加速了处理。
|
||||
4. SURF 包括了几种特性,提升了每一步的速度。SIFT 在旋转和模糊化方面做的很好,比 SIFT 的速度快三倍。然而它不擅长处理照明和变换视角。
|
||||
5. OpenCV 程序功能库提供了 SURF 功能,SURF.compute() 和 SURF.Detect() 可以用来找到描述符和要点。阅读更多关于SURF[点击这里][2]
|
||||
|
||||
### 开源算法
|
||||
|
||||
#### KAZE 算法
|
||||
|
||||
1. KAZE是一个开源的非线性尺度空间的二维多尺度和新的特征检测和描述算法。在加性算子分裂(Additive Operator Splitting, AOS)和可变电导扩散中的有效技术被用来建立非线性尺度空间。
|
||||
2. 多尺度图像处理的基本原理很简单:创建一个图像的尺度空间,同时用正确的函数过滤原始图像,以提高时间或尺度。
|
||||
|
||||
#### 加速的 KAZE(AKAZE - Accelerated-KAZE) 算法
|
||||
|
||||
1. 顾名思义,这是一个更快的图像搜索方式,它会在两幅图像之间找到匹配的关键点。AKAZE 使用二进制描述符和非线性尺度空间来平衡精度和速度。
|
||||
|
||||
#### 二进制鲁棒性不变尺度可变关键点(BRISK - Binary Robust Invariant Scalable Keypoints) 算法
|
||||
|
||||
1. BRISK 非常适合关键点的描述、检测与匹配。
|
||||
2. 是一种高度自适应的算法,基于尺度空间 FAST 的快速检测器和一个位字符串描述符,有助于显著加快搜索。
|
||||
3. 尺度空间关键点检测与关键点描述帮助优化当前相关任务的性能。
|
||||
|
||||
#### 快速视网膜关键点(FREAK - Fast Retina Keypoint)
|
||||
|
||||
1. 这个新的关键点描述的灵感来自人的眼睛。通过图像强度比能有效地计算一个二进制串级联。FREAK 算法相比 BRISK、SURF 和 SIFT 算法可以更快的计算与内存负载较低。
|
||||
|
||||
#### 定向 FAST 和旋转 BRIEF(ORB - Oriented FAST and Rotated BRIEF)
|
||||
|
||||
1. 快速的二进制描述符,ORB 具有抗噪声和旋转不变性。ORB 建立在 FAST 关键点检测器和 BRIEF 描述符之上,有成本低、性能好的元素属性。
|
||||
2. 除了快速和精确的定位元件,有效地计算定向的 BRIEF,分析变动和面向 BRIEF 特点相关,是另一个 ORB 的特征。
|
||||
|
||||
### Python库
|
||||
|
||||
#### OpenCV
|
||||
|
||||
1. OpenCV 支持学术和商业用途,它是一个开源的机器学习和计算机视觉库,OpenCV 便于组织利用和修改代码。
|
||||
2. 超过 2500 个优化的算法,包括当前最先进的机器学习和计算机视觉算法服务与各种图像搜索--人脸检测、目标识别、摄像机目标跟踪,从图像数据库中寻找类似图像、眼球运动跟随、风景识别等。
|
||||
3. 像谷歌,IBM,雅虎,索尼,本田,微软和英特尔这样的大公司广泛的使用 OpenCV。
|
||||
4. OpenCV 拥有 python,java,C,C++ 和 MATLAB 接口,同时支持 Windows,Linux,Mac OS 和 Android。
|
||||
|
||||
#### Python 图像库 (PIL)
|
||||
|
||||
1. Python 图像库(PIL)支持多种文件格式,同时提供图像处理和图形解决方案。开源的 PIL 为你的 Python解释器添加了图像处理能力。
|
||||
2. 标准的图像处理能力包括图像增强、透明和遮罩处理、图像过滤、像素操作等。
|
||||
|
||||
详细的数据和图表,请看[这里][3]的 OpenCV 2.4.9 特征比较报告。
|
||||
|
||||
### 构建图像搜索引擎
|
||||
|
||||
图像搜索引擎可以从预置的图像库选择相似的图像。其中最受欢迎的是谷歌的著名的图像搜索引擎。对于初学者来说,有不同的方法来建立这样的系统。提几个如下:
|
||||
|
||||
1. 采用图像提取、图像描述提取、元数据提取和搜索结果提取,建立图像搜索引擎。
|
||||
2. 定义你的图像描述符,数据集索引,定义你的相似性度量,然后进行搜索和排名。
|
||||
3. 选择要搜索的图像,选择用于进行搜索的目录,搜索所有图片的目录,创建图片特征索引,评估搜索图片的相同特征,匹配搜索的图片并获得匹配的图片。
|
||||
|
||||
我们的方法基本上从比较灰度版本的图像,逐渐演变到复杂的特征匹配算法如 SIFT 和 SURF,最后采用的是开源的解决方案 BRISK 。所有这些算法都提供了有效的结果,但在性能和延迟有细微变化。建立在这些算法上的引擎有许多应用,如分析流行统计的图形数据,在图形内容中识别对象,等等。
|
||||
|
||||
**举例**:一个 IT 公司为其客户建立了一个图像搜索引擎。因此,如果如果搜索一个品牌的标志图像,所有相关的品牌形象也应该显示在搜索结果。所得到的结果也能够被客户用于分析,使他们能够根据地理位置估计品牌知名度。但它还比较年轻,RIQ(反向图像搜索)的潜力尚未被完全挖掘利用。
|
||||
|
||||
这就结束了我们的文章,使用 Python 构建图像搜索引擎。浏览我们的博客部分来查看最新的编程技术。
|
||||
|
||||
数据来源:OpenCV 2.4.9 特征比较报告(computer-vision-talks.com)
|
||||
|
||||
(感谢 Ananthu Nair 的指导与补充)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cuelogic.com/blog/advanced-image-processing-with-python/
|
||||
|
||||
作者:[Snehith Kumbla][a]
|
||||
译者:[Johnny-Liao](https://github.com/Johnny-Liao)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cuelogic.com/blog/author/snehith-kumbla/
|
||||
[1]: http://docs.opencv.org/3.0-beta/doc/py_tutorials/py_feature2d/py_surf_intro/py_surf_intro.html
|
||||
[2]: http://www.vision.ee.ethz.ch/~surf/eccv06.pdf
|
||||
[3]: https://docs.google.com/spreadsheets/d/1gYJsy2ROtqvIVvOKretfxQG_0OsaiFvb7uFRDu5P8hw/edit#gid=10
|
||||
[4]: https://www.youtube.com/watch?v=NPcMS49V5hg
|
||||
[5]: https://www.cs.ubc.ca/~lowe/papers/ijcv04.pdf
|
||||
192
published/201608/20160628 Python 101 An Intro to urllib.md
Normal file
192
published/201608/20160628 Python 101 An Intro to urllib.md
Normal file
@ -0,0 +1,192 @@
|
||||
Python 学习:urllib 简介
|
||||
=================================
|
||||
|
||||
Python 3 的 urllib 模块是一堆可以处理 URL 的组件集合。如果你有 Python 2 的知识,那么你就会注意到 Python 2 中有 urllib 和 urllib2 两个版本的模块。这些现在都是 Python 3 的 urllib 包的一部分。当前版本的 urllib 包括下面几部分:
|
||||
|
||||
- urllib.request
|
||||
- urllib.error
|
||||
- urllib.parse
|
||||
- urllib.rebotparser
|
||||
|
||||
接下来我们会分开讨论除了 urllib.error 以外的几部分。官方文档实际推荐你尝试第三方库, requests,一个高级的 HTTP 客户端接口。然而我依然认为知道如何不依赖第三方库打开 URL 并与之进行交互是很有用的,而且这也可以帮助你理解为什么 requests 包是如此的流行。
|
||||
|
||||
|
||||
### urllib.request
|
||||
|
||||
urllib.request 模块期初是用来打开和获取 URL 的。让我们看看你可以用函数 urlopen 可以做的事:
|
||||
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> url = urllib.request.urlopen('https://www.google.com/')
|
||||
>>> url.geturl()
|
||||
'https://www.google.com/'
|
||||
>>> url.info()
|
||||
<http.client.HTTPMessage object at 0x7fddc2de04e0>
|
||||
>>> header = url.info()
|
||||
>>> header.as_string()
|
||||
('Date: Fri, 24 Jun 2016 18:21:19 GMT\n'
|
||||
'Expires: -1\n'
|
||||
'Cache-Control: private, max-age=0\n'
|
||||
'Content-Type: text/html; charset=ISO-8859-1\n'
|
||||
'P3P: CP="This is not a P3P policy! See '
|
||||
'https://www.google.com/support/accounts/answer/151657?hl=en for more info."\n'
|
||||
'Server: gws\n'
|
||||
'X-XSS-Protection: 1; mode=block\n'
|
||||
'X-Frame-Options: SAMEORIGIN\n'
|
||||
'Set-Cookie: '
|
||||
'NID=80=tYjmy0JY6flsSVj7DPSSZNOuqdvqKfKHDcHsPIGu3xFv41LvH_Jg6LrUsDgkPrtM2hmZ3j9V76pS4K_cBg7pdwueMQfr0DFzw33SwpGex5qzLkXUvUVPfe9g699Qz4cx9ipcbU3HKwrRYA; '
|
||||
'expires=Sat, 24-Dec-2016 18:21:19 GMT; path=/; domain=.google.com; HttpOnly\n'
|
||||
'Alternate-Protocol: 443:quic\n'
|
||||
'Alt-Svc: quic=":443"; ma=2592000; v="34,33,32,31,30,29,28,27,26,25"\n'
|
||||
'Accept-Ranges: none\n'
|
||||
'Vary: Accept-Encoding\n'
|
||||
'Connection: close\n'
|
||||
'\n')
|
||||
>>> url.getcode()
|
||||
200
|
||||
```
|
||||
|
||||
在这里我们包含了需要的模块,然后告诉它打开 Google 的 URL。现在我们就有了一个可以交互的 HTTPResponse 对象。我们要做的第一件事是调用方法 geturl ,它会返回根据 URL 获取的资源。这可以让我们发现 URL 是否进行了重定向。
|
||||
|
||||
接下来调用 info ,它会返回网页的元数据,比如请求头信息。因此,我们可以将结果赋给我们的 headers 变量,然后调用它的方法 as_string 。就可以打印出我们从 Google 收到的头信息。你也可以通过 getcode 得到网页的 HTTP 响应码,当前情况下就是 200,意思是正常工作。
|
||||
|
||||
如果你想看看网页的 HTML 代码,你可以调用变量 url 的方法 read。我不准备再现这个过程,因为输出结果太长了。
|
||||
|
||||
请注意 request 对象默认发起 GET 请求,除非你指定了它的 data 参数。如果你给它传递了 data 参数,这样 request 对象将会变成 POST 请求。
|
||||
|
||||
---
|
||||
|
||||
### 下载文件
|
||||
|
||||
urllib 一个典型的应用场景是下载文件。让我们看看几种可以完成这个任务的方法:
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> url = 'http://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
|
||||
>>> response = urllib.request.urlopen(url)
|
||||
>>> data = response.read()
|
||||
>>> with open('/home/mike/Desktop/test.zip', 'wb') as fobj:
|
||||
... fobj.write(data)
|
||||
...
|
||||
```
|
||||
|
||||
这个例子中我们打开一个保存在我的博客上的 zip 压缩文件的 URL。然后我们读出数据并将数据写到磁盘。一个替代此操作的方案是使用 urlretrieve :
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> url = 'http://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
|
||||
>>> tmp_file, header = urllib.request.urlretrieve(url)
|
||||
>>> with open('/home/mike/Desktop/test.zip', 'wb') as fobj:
|
||||
... with open(tmp_file, 'rb') as tmp:
|
||||
... fobj.write(tmp.read())
|
||||
```
|
||||
|
||||
方法 urlretrieve 会把网络对象拷贝到本地文件。除非你在使用 urlretrieve 的第二个参数指定你要保存文件的路径,否则这个文件将被拷贝到临时文件夹的随机命名的一个文件中。这个可以为你节省一步操作,并且使代码看起来更简单:
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> url = 'http://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
|
||||
>>> urllib.request.urlretrieve(url, '/home/mike/Desktop/blog.zip')
|
||||
('/home/mike/Desktop/blog.zip',
|
||||
<http.client.HTTPMessage object at 0x7fddc21c2470>)
|
||||
```
|
||||
|
||||
如你所见,它返回了文件保存的路径,以及从请求得来的头信息。
|
||||
|
||||
### 设置你的用户代理
|
||||
|
||||
当你使用浏览器访问网页时,浏览器会告诉网站它是谁。这就是所谓的 user-agent (用户代理)字段。Python 的 urllib 会表示它自己为 Python-urllib/x.y , 其中 x 和 y 是你使用的 Python 的主、次版本号。有一些网站不认识这个用户代理字段,然后网站可能会有奇怪的表现或者根本不能正常工作。辛运的是你可以很轻松的设置你自己的 user-agent 字段。
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> user_agent = ' Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0'
|
||||
>>> url = 'http://www.whatsmyua.com/'
|
||||
>>> headers = {'User-Agent': user_agent}
|
||||
>>> request = urllib.request.Request(url, headers=headers)
|
||||
>>> with urllib.request.urlopen(request) as response:
|
||||
... with open('/home/mdriscoll/Desktop/user_agent.html', 'wb') as out:
|
||||
... out.write(response.read())
|
||||
```
|
||||
|
||||
这里设置我们的用户代理为 Mozilla FireFox ,然后我们访问 <http://www.whatsmyua.com/> , 它会告诉我们它识别出的我们的 user-agent 字段。之后我们将 url 和我们的头信息传给 urlopen 创建一个 Request 实例。最后我们保存这个结果。如果你打开这个结果,你会看到我们成功的修改了自己的 user-agent 字段。使用这段代码尽情的尝试不同的值来看看它是如何改变的。
|
||||
|
||||
---
|
||||
|
||||
### urllib.parse
|
||||
|
||||
urllib.parse 库是用来拆分和组合 URL 字符串的标准接口。比如,你可以使用它来转换一个相对的 URL 为绝对的 URL。让我们试试用它来转换一个包含查询的 URL :
|
||||
|
||||
|
||||
```
|
||||
>>> from urllib.parse import urlparse
|
||||
>>> result = urlparse('https://duckduckgo.com/?q=python+stubbing&t=canonical&ia=qa')
|
||||
>>> result
|
||||
ParseResult(scheme='https', netloc='duckduckgo.com', path='/', params='', query='q=python+stubbing&t=canonical&ia=qa', fragment='')
|
||||
>>> result.netloc
|
||||
'duckduckgo.com'
|
||||
>>> result.geturl()
|
||||
'https://duckduckgo.com/?q=python+stubbing&t=canonical&ia=qa'
|
||||
>>> result.port
|
||||
None
|
||||
```
|
||||
|
||||
这里我们导入了函数 urlparse , 并且把一个包含搜索查询字串的 duckduckgo 的 URL 作为参数传给它。我的查询字串是搜索关于 “python stubbing” 的文章。如你所见,它返回了一个 ParseResult 对象,你可以用这个对象了解更多关于 URL 的信息。举个例子,你可以获取到端口信息(本例中没有端口信息)、网络位置、路径和很多其它东西。
|
||||
|
||||
### 提交一个 Web 表单
|
||||
|
||||
这个模块还有一个方法 urlencode 可以向 URL 传输数据。 urllib.parse 的一个典型使用场景是提交 Web 表单。让我们通过搜索引擎 duckduckgo 搜索 Python 来看看这个功能是怎么工作的。
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> import urllib.parse
|
||||
>>> data = urllib.parse.urlencode({'q': 'Python'})
|
||||
>>> data
|
||||
'q=Python'
|
||||
>>> url = 'http://duckduckgo.com/html/'
|
||||
>>> full_url = url + '?' + data
|
||||
>>> response = urllib.request.urlopen(full_url)
|
||||
>>> with open('/home/mike/Desktop/results.html', 'wb') as f:
|
||||
... f.write(response.read())
|
||||
```
|
||||
|
||||
这个例子很直接。基本上我们是使用 Python 而不是浏览器向 duckduckgo 提交了一个查询。要完成这个我们需要使用 urlencode 构建我们的查询字符串。然后我们把这个字符串和网址拼接成一个完整的正确 URL ,然后使用 urllib.request 提交这个表单。最后我们就获取到了结果然后保存到磁盘上。
|
||||
|
||||
---
|
||||
|
||||
### urllib.robotparser
|
||||
|
||||
robotparser 模块是由一个单独的类 RobotFileParser 构成的。这个类会回答诸如一个特定的用户代理是否获取已经设置了 robot.txt 的网站的 URL。 robot.txt 文件会告诉网络爬虫或者机器人当前网站的那些部分是不允许被访问的。让我们看一个简单的例子:
|
||||
|
||||
```
|
||||
>>> import urllib.robotparser
|
||||
>>> robot = urllib.robotparser.RobotFileParser()
|
||||
>>> robot.set_url('http://arstechnica.com/robots.txt')
|
||||
None
|
||||
>>> robot.read()
|
||||
None
|
||||
>>> robot.can_fetch('*', 'http://arstechnica.com/')
|
||||
True
|
||||
>>> robot.can_fetch('*', 'http://arstechnica.com/cgi-bin/')
|
||||
False
|
||||
```
|
||||
|
||||
这里我们导入了 robot 分析器类,然后创建一个实例。然后我们给它传递一个表明网站 robots.txt 位置的 URL 。接下来我们告诉分析器来读取这个文件。完成后,我们给它了一组不同的 URL 让它找出那些我们可以爬取而那些不能爬取。我们很快就看到我们可以访问主站但是不能访问 cgi-bin 路径。
|
||||
|
||||
---
|
||||
|
||||
### 总结一下
|
||||
|
||||
现在你就有能力使用 Python 的 urllib 包了。在这一节里,我们学习了如何下载文件、提交 Web 表单、修改自己的用户代理以及访问 robots.txt。 urllib 还有一大堆附加功能没有在这里提及,比如网站身份认证。你可能会考虑在使用 urllib 进行身份认证之前切换到 requests 库,因为 requests 已经以更易用和易调试的方式实现了这些功能。我同时也希望提醒你 Python 已经通过 http.cookies 模块支持 Cookies 了,虽然在 request 包里也很好的封装了这个功能。你应该可能考虑同时试试两个来决定那个最适合你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.blog.pythonlibrary.org/2016/06/28/python-101-an-intro-to-urllib/
|
||||
|
||||
作者:[Mike][a]
|
||||
译者:[Ezio](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.blog.pythonlibrary.org/author/mld/
|
||||
@ -0,0 +1,322 @@
|
||||
17 个 Linux 下用于 C/C++ 的最好的 IDE /编辑器
|
||||
=======================
|
||||
|
||||
C++,一个众所周知的 C 语言的扩展,是一个优秀的、强大的、通用编程语言,它能够提供现代化的、通用的编程功能,可以用于开发包括视频游戏、搜索引擎、其他计算机软件乃至操作系统等在内的各种大型应用。
|
||||
|
||||
C++,提供高度可靠性的同时还能够允许操作底层内存来满足更高级的编程要求。
|
||||
|
||||

|
||||
|
||||
虽然已经有了一些供程序员用来写 C/C++ 代码的文本编辑器,但 IDE 可以为轻松、完美的编程提供综合的环境和组件。
|
||||
|
||||
在这篇文章里,我们会向你展示一些可以在 Linux 平台上找到的用于 C++ 或者其他编程语言编程的最好的 IDE。
|
||||
|
||||
### 1. 用于 C/C++ 开发的 Netbeans
|
||||
|
||||
Netbeans 是一个自由而开源的、流行的跨平台 IDE ,可用于 C/C++ 以及其他编程语言,可以使用由社区开发的插件展现了其完全的扩展性。
|
||||
|
||||
它包含了用于 C/C++ 开发的项目类型和模版,并且你可以使用静态和动态函数库来构建应用程序。此外,你可以利用现有的代码去创造你的工程,并且也可以通过拖放的方式导入二进制文件来从头构建应用。
|
||||
|
||||
让我们来看看关于它的特性:
|
||||
|
||||
- C/C++ 编辑器很好的整合了多线程的 [GNU GDB 调试工具][1]
|
||||
- 支持代码协助
|
||||
- 支持 C++11 标准
|
||||
- 在里面创建和运行 C/C++ 测试程序
|
||||
- 支持 QT 工具包
|
||||
- 支持将已编译的应用程序自动打包到 .tar,.zip 等归档文件
|
||||
- 支持多个编译器,例如: GNU、Clang/LLVM、Cygwin、Oracle Solaris Studio 和 MinGW
|
||||
- 支持远程开发
|
||||
- 文件导航
|
||||
- 源代码检查
|
||||
|
||||

|
||||
|
||||
主页:<https://netbeans.org/features/cpp/index.html>
|
||||
|
||||
### 2. Code::Blocks
|
||||
|
||||
Code::Blocks 是一个免费的、具有高度扩展性的、并且可以配置的跨平台 C++ IDE,它为用户提供了必备而典范的功能。它具有一致的界面和体验。
|
||||
|
||||
最重要的是,你可以通过用户开发的插件扩展它的功能,一些插件是随同 Code::Blocks 发布的,而另外一些则不是,它们由 Code::Block 开发团队之外的个人用户所编写的。
|
||||
|
||||
其功能分为编译器、调试器、界面功能,它们包括:
|
||||
|
||||
- 支持多种编译器如 GCC、clang、Borland C++ 5.5、digital mars 等等
|
||||
- 非常快,不需要 makefile
|
||||
- 支持多个目标平台的项目
|
||||
- 支持将项目组合起来的工作空间
|
||||
- GNU GDB 接口
|
||||
- 支持完整的断点功能,包括代码断点,数据断点,断点条件等等
|
||||
- 显示本地函数的符号和参数
|
||||
- 用户内存导出和语法高亮显示
|
||||
- 可自定义、可扩展的界面以及许多其他的的功能,包括那些用户开发的插件添加功能
|
||||
|
||||

|
||||
|
||||
主页: <http://www.codeblocks.org>
|
||||
|
||||
### 3. Eclipse CDT (C/C++ Development Tooling)
|
||||
|
||||
Eclipse 在编程界是一款著名的、开源的、跨平台的 IDE。它给用户提供了一个很棒的界面,并支持拖拽功能以方便界面元素的布置。
|
||||
|
||||
Eclipse CDT 是一个基于 Eclipse 主平台的项目,它提供了一个完整功能的 C/C++ IDE,并具有以下功能:
|
||||
|
||||
- 支持项目创建
|
||||
- 管理各种工具链的构建
|
||||
- 标准的 make 构建
|
||||
- 源代码导航
|
||||
- 一些知识工具,如调用图、类型分级结构,内置浏览器,宏定义浏览器
|
||||
- 支持语法高亮的代码编辑器
|
||||
- 支持代码折叠和超链接导航
|
||||
- 代码重构与代码生成
|
||||
- 可视化调试存储器、寄存器的工具
|
||||
- 反汇编查看器以及更多功能
|
||||
|
||||
|
||||
|
||||
主页: <http://www.eclipse.org/cdt/>
|
||||
|
||||
### 4.CodeLite IDE
|
||||
|
||||
CodeLite 也是一款为 C/C++、JavaScript(Node.js)和 PHP 编程专门设计打造的自由而开源的、跨平台的 IDE。
|
||||
|
||||
它的一些主要特点包括:
|
||||
|
||||
- 代码补完,提供了两个代码补完引擎
|
||||
- 支持多种编译器,包括 GCC、clang/VC++
|
||||
- 以代码词汇的方式显示错误
|
||||
- 构建选项卡中的错误消息可点击
|
||||
- 支持下一代 LLDB 调试器
|
||||
- 支持 GDB
|
||||
- 支持重构
|
||||
- 代码导航
|
||||
- 使用内置的 SFTP 进行远程开发
|
||||
- 源代码控制插件
|
||||
- 开发基于 wxWidgets 应用的 RAD(快速应用程序开发)工具,以及更多的特性
|
||||
|
||||
|
||||
|
||||
主页: <http://codelite.org/>
|
||||
|
||||
### 5. Bluefish 编辑器
|
||||
|
||||
Bluefish 不仅仅是一个一般的编辑器,它是一个轻量级的、快捷的编辑器,为程序员提供了如开发网站、编写脚本和软件代码的 IDE 特性。它支持多平台,可以在 Linux、Mac OSX、FreeBSD、OpenBSD、Solaris 和 Windows 上运行,同时支持包括 C/C++ 在内的众多编程语言。
|
||||
|
||||
下面列出的是它众多功能的一部分:
|
||||
|
||||
- 多文档界面
|
||||
- 支持递归打开文件,基于文件名通配模式或者内容模式
|
||||
- 提供一个非常强大的搜索和替换功能
|
||||
- 代码片段边栏
|
||||
- 支持整合个人的外部过滤器,可使用命令如 awk,sed,sort 以及自定义构建脚本组成(过滤器的)管道文件
|
||||
- 支持全屏编辑
|
||||
- 网站上传和下载
|
||||
- 支持多种编码等许多其他功能
|
||||
|
||||

|
||||
|
||||
主页: <http://bluefish.openoffice.nl>
|
||||
|
||||
### 6. Brackets 代码编辑器
|
||||
|
||||
Brackets 是一个现代化风格的、开源的文本编辑器,专为 Web 设计与开发打造。它可以通过插件进行高度扩展,因此 C/C++ 程序员通过安装 C/C++/Objective-C 包来使用它来开发,这个包用来在辅助 C/C++ 代码编写的同时提供了 IDE 之类的特性。
|
||||
|
||||

|
||||
|
||||
主页: <http://brackets.io/>
|
||||
|
||||
### 7. Atom 代码编辑器
|
||||
|
||||
Atom 也是一个现代化风格、开源的多平台文本编辑器,它能运行在 Linux、Windows 或是 Mac OS X 平台。它的定制可深入底层,用户可以自定义它,以便满足各种编写代码的需求。
|
||||
|
||||
它功能完整,主要的功能包括:
|
||||
|
||||
- 内置了包管理器
|
||||
- 智能的自动补完
|
||||
- 内置文件浏览器
|
||||
- 查找、替换以及其他更多的功能
|
||||
|
||||
|
||||
|
||||
主页: <https://atom.io/>
|
||||
|
||||
安装指南: <http://www.tecmint.com/atom-text-and-source-code-editor-for-linux/>
|
||||
|
||||
### 8. Sublime Text 编辑器
|
||||
|
||||
Sublime Text 是一个完善的、跨平台的文本编辑器,可用于代码、标记语言和一般文字。它可以用来编写 C/C++ 代码,并且提供了非常棒的用户界面。
|
||||
|
||||
它的功能列表包括:
|
||||
|
||||
- 多重选择
|
||||
- 按模式搜索命令
|
||||
- 抵达任何一处的功能
|
||||
- 免打扰模式
|
||||
- 窗口分割
|
||||
- 支持项目之间快速的切换
|
||||
- 高度可定制
|
||||
- 支持基于 Python 的 API 插件以及其他特性
|
||||
|
||||

|
||||
|
||||
主页: <https://www.sublimetext.com>
|
||||
|
||||
安装指南: <http://www.tecmint.com/install-sublime-text-editor-in-linux/>
|
||||
|
||||
### 9. JetBrains CLion
|
||||
|
||||
JetBrains CLion 是一个收费的、强大的跨平台 C/C++ IDE。它是一个完全整合的 C/C++ 程序开发环境,并提供 Cmake 项目模型、一个嵌入式终端窗口和一个主要以键盘操作的编码环境。
|
||||
|
||||
它还提供了一个智能而现代化的编辑器,具有许多令人激动的功能,提供了理想的编码环境,这些功能包括:
|
||||
|
||||
- 除了 C/C++ 还支持其他多种语言
|
||||
- 在符号声明和上下文中轻松导航
|
||||
- 代码生成和重构
|
||||
- 可定制的编辑器
|
||||
- 即时代码分析
|
||||
- 集成的代码调试器
|
||||
- 支持 Git、Subversion、Mercurial、CVS、Perforcevia(通过插件)和 TFS
|
||||
- 无缝集成了 Google 测试框架
|
||||
- 通过 Vim 仿真插件支持 Vim 编辑体验
|
||||
|
||||
|
||||
|
||||
主页: <https://www.jetbrains.com/clion/>
|
||||
|
||||
### 10. 微软的 Visual Studio Code 编辑器
|
||||
|
||||
Visual Studio 是一个功能丰富的、完全整合的、跨平台开发环境,运行在 Linux、Windows 和 Mac OS X 上。 最近它向 Linux 用户开源了,它重新定义了代码编辑这件事,为用户提供了在 Windows、Android、iOS 和 Web 等多个平台开发不同应用所需的一切工具。
|
||||
|
||||
它功能完备,功能分类为应用程序开发、应用生命周期管理、扩展和集成特性。你可以从 Visual Studio 官网阅读全面的功能列表。
|
||||
|
||||
|
||||
|
||||
主页: <https://www.visualstudio.com>
|
||||
|
||||
### 11. KDevelop
|
||||
|
||||
KDevelop 是另一个自由而开源的跨平台 IDE,能够运行在 Linux、Solaris、FreeBSD、Windows、Mac OS X 和其他类 Unix 操作系统上。它基于 KDevPlatform、KDE 和 Qt 库。KDevelop 可以通过插件高度扩展,功能丰富且具有以下显著特色:
|
||||
|
||||
- 支持基于 Clang 的 C/C++ 插件
|
||||
- 支持 KDE 4 配置迁移
|
||||
- 支持调用二进制编辑器 Oketa
|
||||
- 支持众多视图插件下的差异行编辑
|
||||
- 支持 Grep 视图,使用窗口小部件节省垂直空间等
|
||||
|
||||
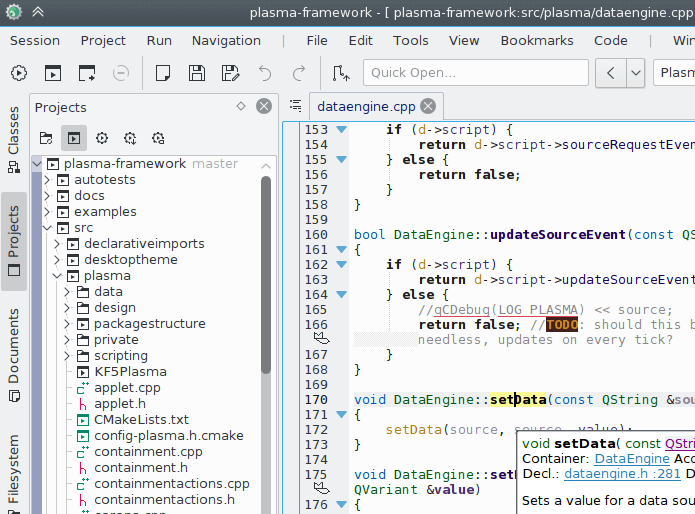
|
||||
|
||||
主页: <https://www.kdevelop.org>
|
||||
|
||||
### 12. Geany IDE
|
||||
|
||||
Geany 是一个免费的、快速的、轻量级跨平台 IDE,只需要很少的依赖包就可以工作,独立于流行的 Linux 桌面环境下,比如 GNOME 和 KDE。它需要 GTK2 库实现功能。
|
||||
|
||||
它的特性包括以下列出的内容:
|
||||
|
||||
- 支持语法高亮显示
|
||||
- 代码折叠
|
||||
- 调用提示
|
||||
- 符号名自动补完
|
||||
- 符号列表
|
||||
- 代码导航
|
||||
- 一个简单的项目管理工具
|
||||
- 可以编译并运行用户代码的内置系统
|
||||
- 可以通过插件扩展
|
||||
|
||||

|
||||
|
||||
主页: <http://www.geany.org/>
|
||||
|
||||
### 13. Ajunta DeveStudio
|
||||
|
||||
Ajunta DevStudio 是一个简单,强大的 GNOME 界面的软件开发工作室,支持包括 C/C++ 在内的几种编程语言。
|
||||
|
||||
它提供了先进的编程工具,比如项目管理、GUI 设计、交互式调试器、应用程序向导、源代码编辑器、版本控制等。此外,除了以上特点,Ajunta DeveStudio 也有其他很多不错的 IDE 功能,包括:
|
||||
|
||||
- 简单的用户界面
|
||||
- 可通过插件扩展
|
||||
- 整合了 Glade 用于所见即所得的 UI 开发
|
||||
- 项目向导和模板
|
||||
- 整合了 GDB 调试器
|
||||
- 内置文件管理器
|
||||
- 使用 DevHelp 提供上下文敏感的编程辅助
|
||||
- 源代码编辑器支持语法高亮显示、智能缩进、自动缩进、代码折叠/隐藏、文本缩放等
|
||||
|
||||

|
||||
|
||||
主页: <http://anjuta.org/>
|
||||
|
||||
### 14. GNAT Programming Studio
|
||||
|
||||
GNAT Programming Studio 是一个免费的、易于使用的 IDE,设计的目的用于统一开发人员与他/她的代码和软件之间的交互。
|
||||
|
||||
它通过高亮程序的重要部分和逻辑从而提升源代码导航体验,打造了一个理想的编程环境。它的设计目标是为你带来更舒适的编程体验,使用户能够从头开始开发全面的系统。
|
||||
|
||||
它丰富的特性包括以下这些:
|
||||
|
||||
- 直观的用户界面
|
||||
- 对开发者的友好性
|
||||
- 支持多种编程语言,跨平台
|
||||
- 灵活的 MDI(多文档界面)
|
||||
- 高度可定制
|
||||
- 使用喜欢的工具获得全面的可扩展性
|
||||
|
||||

|
||||
|
||||
主页: <http://libre.adacore.com/tools/gps/>
|
||||
|
||||
### 15. Qt Creator
|
||||
|
||||
这是一款收费的、跨平台的 IDE,用于创建连接设备、用户界面和应用程序。Qt Creator 可以让用户比应用的编码做到更多的创新。
|
||||
|
||||
它可以用来创建移动和桌面应用程序,也可以连接到嵌入式设备。
|
||||
|
||||
它的优点包含以下几点:
|
||||
|
||||
- 复杂的代码编辑器
|
||||
- 支持版本控制
|
||||
- 项目和构建管理工具
|
||||
- 支持多屏幕和多平台,易于构建目标之间的切换等等
|
||||
|
||||

|
||||
|
||||
主页: <https://www.qt.io/ide/>
|
||||
|
||||
### 16. Emacs 编辑器
|
||||
|
||||
Emacs 是一个自由的、强大的、可高度扩展的、可定制的、跨平台文本编辑器,你可以在 Linux、Solaris、FreeBSD、NetBSD、OpenBSD、Windows 和 Mac OS X 这些系统中使用该编辑器。
|
||||
|
||||
Emacs 的核心也是一个 Emacs Lisp 的解释器,Emacs Lisp 是一种基于 Lisp 的编程语言。在撰写本文时,GNU Emacs 的最新版本是 24.5,Emacs 的基本功能包括:
|
||||
|
||||
- 内容识别编辑模式
|
||||
- Unicode 的完全支持
|
||||
- 可使用 GUI 或 Emacs Lisp 代码高度定制
|
||||
- 下载和安装扩展的打包系统
|
||||
- 超出了正常文本编辑的功能生态系统,包括项目策划、邮件、日历和新闻阅读器等
|
||||
- 完整的内置文档,以及用户指南等等
|
||||
|
||||
|
||||
|
||||
主页: https://www.gnu.org/software/emacs/
|
||||
|
||||
### 17. VI/VIM 编辑器
|
||||
|
||||
Vim,一款 VI 编辑器的改进版本,是一款自由的、强大的、流行的并且高度可配置的文本编辑器。它为有效率地文本编辑而生,并且为 Unix/Linux 使用者提供了激动人心的编辑器特性,因此,它对于撰写和编辑 C/C++ 代码也是一个好的选择。
|
||||
|
||||
总的来说,与传统的文本编辑器相比,IDE 为编程提供了更多的便利,因此使用它们是一个很好的选择。它们带有激动人心的特征并且提供了一个综合性的开发环境,有时候程序员不得不陷入对最好的 C/C++ IDE 的选择。
|
||||
|
||||
在互联网上你还可以找到许多 IDE 来下载,但不妨试试我们推荐的这几款,可以帮助你尽快找到哪一款是你需要的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/best-linux-ide-editors-source-code-editors/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ZenMoore](https://github.com/ZenMoore) ,[LiBrad](https://github.com/LiBrad) ,[WangYueScream](https://github.com/WangYueScream) ,[LemonDemo](https://github.com/LemonDemo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
[1]: http://www.tecmint.com/debug-source-code-in-linux-using-gdb/
|
||||
@ -0,0 +1,100 @@
|
||||
用 VeraCrypt 加密闪存盘
|
||||
============================================
|
||||
|
||||
很多安全专家偏好像 VeraCrypt 这类能够用来加密闪存盘的开源软件,是因为可以获取到它的源代码。
|
||||
|
||||
保护 USB 闪存盘里的数据,加密是一个聪明的方法,正如我们在使用 Microsoft 的 BitLocker [加密闪存盘][1] 一文中提到的。
|
||||
|
||||
但是如果你不想用 BitLocker 呢?
|
||||
|
||||
你可能有顾虑,因为你不能够查看 Microsoft 的程序源码,那么它容易被植入用于政府或其它用途的“后门”。而由于开源软件的源码是公开的,很多安全专家认为开源软件很少藏有后门。
|
||||
|
||||
还好,有几个开源加密软件能作为 BitLocker 的替代。
|
||||
|
||||
要是你需要在 Windows 系统,苹果的 OS X 系统或者 Linux 系统上加密以及访问文件,开源软件 [VeraCrypt][2] 提供绝佳的选择。
|
||||
|
||||
VeraCrypt 源于 TrueCrypt。TrueCrypt 是一个备受好评的开源加密软件,尽管它现在已经停止维护了。但是 TrueCrypt 的代码通过了审核,没有发现什么重要的安全漏洞。另外,在 VeraCrypt 中对它进行了改善。
|
||||
|
||||
Windows,OS X 和 Linux 系统的版本都有。
|
||||
|
||||
用 VeraCrypt 加密 USB 闪存盘不像用 BitLocker 那么简单,但是它也只要几分钟就好了。
|
||||
|
||||
### 用 VeraCrypt 加密闪存盘的 8 个步骤
|
||||
|
||||
对应你的操作系统 [下载 VeraCrypt][3] 之后:
|
||||
|
||||
打开 VeraCrypt,点击 Create Volume,进入 VeraCrypt 的创建卷的向导程序(VeraCrypt Volume Creation Wizard)。
|
||||
|
||||

|
||||
|
||||
VeraCrypt 创建卷向导(VeraCrypt Volume Creation Wizard)允许你在闪存盘里新建一个加密文件容器,这与其它未加密文件是独立的。或者你也可以选择加密整个闪存盘。这个时候你就选加密整个闪存盘就行。
|
||||
|
||||

|
||||
|
||||
然后选择标准模式(Standard VeraCrypt Volume)。
|
||||
|
||||

|
||||
|
||||
选择你想加密的闪存盘的驱动器卷标(这里是 O:)。
|
||||
|
||||

|
||||
|
||||
选择创建卷模式(Volume Creation Mode)。如果你的闪存盘是空的,或者你想要删除它里面的所有东西,选第一个。要么你想保持所有现存的文件,选第二个就好了。
|
||||
|
||||

|
||||
|
||||
这一步允许你选择加密选项。要是你不确定选哪个,就用默认的 AES 和 SHA-512 设置。
|
||||
|
||||

|
||||
|
||||
确定了卷容量后,输入并确认你想要用来加密数据密码。
|
||||
|
||||

|
||||
|
||||
要有效工作,VeraCrypt 要从一个熵或者“随机数”池中取出一个随机数。要初始化这个池,你将被要求随机地移动鼠标一分钟。一旦进度条变绿了,或者更方便的是等到进度条到了屏幕右边足够远的时候,点击 “Format” 来结束创建加密盘。
|
||||
|
||||

|
||||
|
||||
### 用 VeraCrypt 使用加密过的闪存盘
|
||||
|
||||
当你想要使用一个加密了的闪存盘,先插入闪存盘到电脑上,启动 VeraCrypt。
|
||||
|
||||
然后选择一个没有用过的卷标(比如 z:),点击自动挂载设备(Auto-Mount Devices)。
|
||||
|
||||

|
||||
|
||||
输入密码,点击确定。
|
||||
|
||||

|
||||
|
||||
挂载过程需要几分钟,这之后你的解密盘就能通过你先前选择的盘符进行访问了。
|
||||
|
||||
### VeraCrypt 移动硬盘安装步骤
|
||||
|
||||
如果你设置闪存盘的时候,选择的是加密过的容器而不是加密整个盘,你可以选择创建 VeraCrypt 称为移动盘(Traveler Disk)的设备。这会复制安装一个 VeraCrypt 到 USB 闪存盘。当你在别的 Windows 电脑上插入 U 盘时,就能从 U 盘自动运行 VeraCrypt;也就是说没必要在新电脑上安装 VeraCrypt。
|
||||
|
||||
你可以设置闪存盘作为一个移动硬盘(Traveler Disk),在 VeraCrypt 的工具栏(Tools)菜单里选择 Traveler Disk SetUp 就行了。
|
||||
|
||||

|
||||
|
||||
要从移动盘(Traveler Disk)上运行 VeraCrypt,你必须要有那台电脑的管理员权限,这不足为奇。尽管这看起来是个限制,机密文件无法在不受控制的电脑上安全打开,比如在一个商务中心的电脑上。
|
||||
|
||||
> 本文作者 Paul Rubens 从事技术行业已经超过 20 年。这期间他为英国和国际主要的出版社,包括 《The Economist》《The Times》《Financial Times》《The BBC》《Computing》和《ServerWatch》等出版社写过文章,
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.esecurityplanet.com/open-source-security/how-to-encrypt-flash-drive-using-veracrypt.html
|
||||
|
||||
作者:[Paul Rubens][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.esecurityplanet.com/author/3700/Paul-Rubens
|
||||
[1]: http://www.esecurityplanet.com/views/article.php/3880616/How-to-Encrypt-a-USB-Flash-Drive.htm
|
||||
[2]: http://www.esecurityplanet.com/open-source-security/veracrypt-a-worthy-truecrypt-alternative.html
|
||||
[3]: https://veracrypt.codeplex.com/releases/view/619351
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,98 @@
|
||||
在用户空间做我们会在内核空间做的事情
|
||||
=======================================================
|
||||
|
||||
我相信,Linux 最好也是最坏的事情,就是内核空间(kernel space)和用户空间(user space)之间的巨大差别。
|
||||
|
||||
如果没有这个区别,Linux 可能也不会成为世界上影响力最大的操作系统。如今,Linux 的使用范围在世界上是最大的,而这些应用又有着世界上最大的用户群——尽管大多数用户并不知道,当他们进行谷歌搜索或者触摸安卓手机的时候,他们其实正在使用 Linux。如果不是 Linux 的巨大成功,Apple 公司也可能并不会成为现在这样(即在他们的电脑产品中使用 BSD 的技术)(LCTT 译注:Linux 获得成功后,Apple 曾与 Linus 协商使用 Linux 核心作为 Apple 电脑的操作系统并帮助开发的事宜,但遭到拒绝。因此,Apple 转向使用许可证更为宽松的 BSD 。)。
|
||||
|
||||
不(需要)关注用户空间是 Linux 内核开发中的一个特点而非缺陷。正如 Linus 在 2003 年的[极客巡航(Geek Cruise)][18]中提到的那样,“我只做内核相关的东西……我并不知道内核之外发生的事情,而且我也并不关心。我只关注内核部分发生的事情。” 多年之后的[另一次极客巡航][19]上, Andrew Morton 给我上了另外的一课,这之后我写道:
|
||||
|
||||
> 内核空间是Linux 所在的地方,而用户空间是 Linux 与其它的“自然材料”一起使用的地方。内核空间和用户空间的区别,和自然材料与人类用其生产的人造材料的区别很类似。
|
||||
|
||||
这个区别是自然而然的结果,就是尽管外面的世界一刻也离不开 Linux, 但是 Linux 社区还是保持相对较小。所以,为了增加哪怕一点我们社区团体的规模,我希望指出两件事情。第一件已经非常火了,另外一件可能会火起来。
|
||||
|
||||
第一件事情就是 [区块链(blockchain)][1],出自著名的分布式货币——比特币之手。当你正在阅读这篇文章的同时,人们对区块链的[关注度正在直线上升][2]。
|
||||
|
||||

|
||||
|
||||
*图1. 区块链的谷歌搜索趋势*
|
||||
|
||||
第二件事就是自主身份(self-sovereign identity)。为了解释这个概念,让我先来问你:你是谁,你来自哪里?
|
||||
|
||||
如果你从你的老板、你的医生或者车管所,Facebook、Twitter 或者谷歌上得到答案,你就会发现它们都是行政身份(administrative identifiers)——这些机构完全以自己的便利为原因设置这些身份和职位。正如一家区块链技术公司 [Evernym][3] 的 Timothy Ruff 所说,“你并不因组织而存在,但你的身份却因此存在。”身份是个因变量。自变量——即控制着身份的变量——是(你所在的)组织。
|
||||
|
||||
如果你的答案出自你自己,我们就有一个广大空间来发展一个新的领域,在这个领域中,我们完全自由。
|
||||
|
||||
据我所知,第一个解释这个的人是 [Devon Loffreto][4]。在 2012 年 2 月,他在博客 [Moxy Tongue][5] 中写道:“什么是 'Sovereign Source Authority'?”。在发表于 2016 年 2 月的 “[Self-Sovereign Identity][6]” 一文中,他写道:
|
||||
|
||||
> 自主身份必须是独立个人提出的,并且不包含社会因素……自主身份源于每个个体对其自身本源的认识。 一个自主身份可以为个体带来新的社会面貌。每个个体都可能为自己生成一个自主身份,并且这并不会改变固有的人权。使用自主身份机制是所有参与者参与的基石,并且依旧可以同各种形式的人类社会保持联系。
|
||||
|
||||
将这个概念放在 Linux 领域中,只有个人才能为他或她设定一个自己的开源社区身份。这在现实实践中,这只是一个非常正常的事件。举个例子,我自己的身份包括:
|
||||
|
||||
- David Allen Searls,我父母会这样叫我。
|
||||
- David Searls,正式场合下我会这么称呼自己。
|
||||
- Dave,我的亲戚和好朋友会这么叫我。
|
||||
- Doc,大多数人会这么叫我。
|
||||
|
||||
作为承认以上称呼的自主身份来源,我可以在不同的情景中轻易的转换。但是,这只是在现实世界中。在虚拟世界中,这就变得非常困难。除了上述的身份之外,我还可以是 @dsearls (我的 twitter 账号) 和 dsearls (其他的网络账号)。然而为了记住成百上千的不同账号的登录名和密码,我已经不堪重负。
|
||||
|
||||
你可以在你的浏览器上感受到这个糟糕的体验。在火狐上,我有成百上千个用户名密码。很多已经废弃(很多都是从 Netscape 时代遗留下来的),但是我想会有大量的工作账号需要处理。对于这些,我只是被动接受者。没有其他的解决方法。甚至一些安全较低的用户认证,已经成为了现实世界中不可缺少的一环。
|
||||
|
||||
现在,最简单的方式来联系账号,就是通过 “Log in with Facebook” 或者 “Login in with Twitter” 来进行身份认证。在这种情况下,我们中的每一个甚至并不是真正意义上的自己,甚至(如果我们希望被其他人认识的话)缺乏对其他实体如何认识我们的控制。
|
||||
|
||||
我们从一开始就需要的是一个可以实体化我们的自主身份和交流时选择如何保护和展示自身的个人系统。因为缺少这个能力,我们现在陷入混乱。Shoshana Zuboff 称之为 “监视资本主义”,她如此说道:
|
||||
|
||||
>...难以想象,在见证了互联网和获得了的巨大成功的谷歌背后。世界因 Apple 和 FBI 的对决而紧密联系在一起。讲道理,热衷于监视的资本家开发的监视系统是每一个国家安全机构都渴望的。
|
||||
|
||||
然后,她问道,”我们怎样才能保护自己远离他人的影响?“
|
||||
|
||||
我建议使用自主身份。我相信这是我们唯一的既可以保证我们从监视中逃脱、又可以使我们有一个有序的世界的办法。以此为基础,我们才可以完全无顾忌地和社会,政治,商业上的人交流。
|
||||
|
||||
我在五月联合国举行的 [ID2020][7] 会议中总结了这个临时的结论。很高兴,Devon Loffreto 也在那,他于 2013 年推动了自主身份的创立。这是[我那时写的一些文章][8],引用了 Devon 的早期博客(比如上面的原文)。
|
||||
|
||||
这有三篇这个领域的准则:
|
||||
|
||||
- "[Self-Sovereign Identity][9]" - Devon Loffreto.
|
||||
- "[System or Human First][10]" - Devon Loffreto.
|
||||
- "[The Path to Self-Sovereign Identity][11]" - Christopher Allen.
|
||||
|
||||
从 Evernym 的简要说明中,[digi.me][12]、 [iRespond][13] 和 [Respect Network][14] 也被包括在内。自主身份和社会身份 (也被称为“当前模式(current model)”) 的对比结果,显示在图二中。
|
||||
|
||||

|
||||
|
||||
*图 2. 当前模式身份 vs. 自主身份*
|
||||
|
||||
Sovrin 就是为此而生的[平台][15],它阐述自己为一个“依托于先进、专用、经授权、分布式平台的,完全开源、基于标识的身份声明图平台”。同时,这也有一本[白皮书][16]。它的代码名为 [plenum][17],并且公开在 Github 上。
|
||||
|
||||
在这里——或者其他类似的地方——我们就可以在用户空间中重现我们在过去 25 年中在内核空间做过的事情。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxjournal.com/content/doing-user-space-what-we-did-kernel-space
|
||||
|
||||
作者:[Doc Searls][a]
|
||||
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||
校对:[PurlingNayuki](https://github.com/PurlingNayuki)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linuxjournal.com/users/doc-searls
|
||||
[1]: https://en.wikipedia.org/wiki/Block_chain_%28database%29
|
||||
[2]: https://www.google.com/trends/explore#q=blockchain
|
||||
[3]: http://evernym.com/
|
||||
[4]: https://twitter.com/nzn
|
||||
[5]: http://www.moxytongue.com/2012/02/what-is-sovereign-source-authority.html
|
||||
[6]: http://www.moxytongue.com/2016/02/self-sovereign-identity.html
|
||||
[7]: http://www.id2020.org/
|
||||
[8]: http://blogs.harvard.edu/doc/2013/10/14/iiw-challenge-1-sovereign-identity-in-the-great-silo-forest
|
||||
[9]: http://www.moxytongue.com/2016/02/self-sovereign-identity.html
|
||||
[10]: http://www.moxytongue.com/2016/05/system-or-human.html
|
||||
[11]: http://www.lifewithalacrity.com/2016/04/the-path-to-self-soverereign-identity.html
|
||||
[12]: https://get.digi.me/
|
||||
[13]: http://irespond.com/
|
||||
[14]: https://www.respectnetwork.com/
|
||||
[15]: http://evernym.com/technology
|
||||
[16]: http://evernym.com/assets/doc/Identity-System-Essentials.pdf?v=167284fd65
|
||||
[17]: https://github.com/evernym/plenum
|
||||
[18]: http://www.linuxjournal.com/article/6427
|
||||
[19]: http://www.linuxjournal.com/article/8664
|
||||
@ -0,0 +1,279 @@
|
||||
使用 Docker Swarm 部署可扩展的 Python3 应用
|
||||
==============
|
||||
|
||||
[Ben Firshman][2] 最近在 [Dockercon][1] 做了一个关于使用 Docker 构建无服务应用的演讲,你可以在[这里查看详情][3](还有视频)。之后,我写了一篇关于如何使用 [AWS Lambda][5] 构建微服务系统的[文章][4]。
|
||||
|
||||
今天,我想展示给你的就是如何使用 [Docker Swarm][6] 部署一个简单的 Python Falcon REST 应用。这里我不会使用[dockerrun][7] 或者是其他无服务特性,你可能会惊讶,使用 Docker Swarm 部署(复制)一个 Python(Java、Go 都一样)应用是如此的简单。
|
||||
|
||||
注意:这展示的部分步骤是截取自 [Swarm Tutorial][8],我已经修改了部分内容,并且[增加了一个 Vagrant Helper 的仓库][9]来启动一个可以让 Docker Swarm 工作起来的本地测试环境。请确保你使用的是 1.12 或以上版本的 Docker Engine。我写这篇文章的时候,使用的是 1.12RC2 版本。注意的是,这只是一个测试版本,可能还会有修改。
|
||||
|
||||
你要做的第一件事,就是如果你想本地运行的话,你要保证 [Vagrant][10] 已经正确的安装和运行了。你也可以按如下步骤使用你最喜欢的云服务提供商部署 Docker Swarm 虚拟机系统。
|
||||
|
||||
我们将会使用这三台 VM:一个简单的 Docker Swarm 管理平台和两台 worker。
|
||||
|
||||
安全注意事项:Vagrantfile 代码中包含了部分位于 Docker 测试服务器上的 shell 脚本。这是一个潜在的安全问题,它会运行你不能控制的脚本,所以请确保你会在运行代码之前[审查过这部分的脚本][11]。
|
||||
|
||||
```
|
||||
$ git clone https://github.com/chadlung/vagrant-docker-swarm
|
||||
$ cd vagrant-docker-swarm
|
||||
$ vagrant plugin install vagrant-vbguest
|
||||
$ vagrant up
|
||||
```
|
||||
|
||||
Vagrant up 命令需要一些时间才能完成。
|
||||
|
||||
SSH 登陆进入 manager1 虚拟机:
|
||||
|
||||
```
|
||||
$ vagrant ssh manager1
|
||||
```
|
||||
|
||||
在 manager1 的 ssh 终端会话中执行如下命令:
|
||||
|
||||
```
|
||||
$ sudo docker swarm init --listen-addr 192.168.99.100:2377
|
||||
```
|
||||
|
||||
现在还没有 worker 注册上来:
|
||||
|
||||
```
|
||||
$ sudo docker node ls
|
||||
```
|
||||
|
||||
让我们注册两个新的 worker,请打开两个新的终端会话(保持 manager1 会话继续运行):
|
||||
|
||||
```
|
||||
$ vagrant ssh worker1
|
||||
```
|
||||
|
||||
在 worker1 的 ssh 终端会话上执行如下命令:
|
||||
|
||||
```
|
||||
$ sudo docker swarm join 192.168.99.100:2377
|
||||
```
|
||||
|
||||
在 worker2 的 ssh 终端会话上重复这些命令。
|
||||
|
||||
在 manager1 终端上执行如下命令:
|
||||
|
||||
```
|
||||
$ docker node ls
|
||||
```
|
||||
|
||||
你将会看到:
|
||||
|
||||

|
||||
|
||||
在 manager1 的终端里部署一个简单的服务。
|
||||
|
||||
```
|
||||
sudo docker service create --replicas 1 --name pinger alpine ping google.com
|
||||
```
|
||||
|
||||
这个命令将会部署一个服务,它会从 worker 之一 ping google.com。(或者 manager,manager 也可以运行服务,不过如果你只是想 worker 运行容器的话,[也可以禁用这一点][12])。可以使用如下命令,查看哪些节点正在执行服务:
|
||||
|
||||
```
|
||||
$ sudo docker service tasks pinger
|
||||
```
|
||||
|
||||
结果会和这个比较类似:
|
||||
|
||||

|
||||
|
||||
所以,我们知道了服务正跑在 worker1 上。我们可以回到 worker1 的会话里,然后进入正在运行的容器:
|
||||
|
||||
```
|
||||
$ sudo docker ps
|
||||
```
|
||||
|
||||

|
||||
|
||||
你可以看到容器的 id 是: ae56769b9d4d,在我的例子中,我运行如下的代码:
|
||||
|
||||
```
|
||||
$ sudo docker attach ae56769b9d4d
|
||||
```
|
||||
|
||||

|
||||
|
||||
你可以按下 CTRL-C 来停止服务。
|
||||
|
||||
回到 manager1,然后移除这个 pinger 服务。
|
||||
|
||||
```
|
||||
$ sudo docker service rm pinger
|
||||
```
|
||||
|
||||
现在,我们将会部署可复制的 Python 应用。注意,为了保持文章的简洁,而且容易复制,所以部署的是一个简单的应用。
|
||||
|
||||
你需要做的第一件事就是将镜像放到 [Docker Hub][13]上,或者使用我[已经上传的一个][14]。这是一个简单的 Python 3 Falcon REST 应用。它有一个简单的入口: /hello 带一个 value 参数。
|
||||
|
||||
放在 [chadlung/hello-app][15] 上的 Python 代码看起来像这样:
|
||||
|
||||
```
|
||||
import json
|
||||
from wsgiref import simple_server
|
||||
|
||||
import falcon
|
||||
|
||||
|
||||
class HelloResource(object):
|
||||
def on_get(self, req, resp):
|
||||
try:
|
||||
value = req.get_param('value')
|
||||
|
||||
resp.content_type = 'application/json'
|
||||
resp.status = falcon.HTTP_200
|
||||
resp.body = json.dumps({'message': str(value)})
|
||||
except Exception as ex:
|
||||
resp.status = falcon.HTTP_500
|
||||
resp.body = str(ex)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
app = falcon.API()
|
||||
hello_resource = HelloResource()
|
||||
app.add_route('/hello', hello_resource)
|
||||
httpd = simple_server.make_server('0.0.0.0', 8080, app)
|
||||
httpd.serve_forever()
|
||||
```
|
||||
|
||||
Dockerfile 很简单:
|
||||
|
||||
```
|
||||
FROM python:3.4.4
|
||||
|
||||
RUN pip install -U pip
|
||||
RUN pip install -U falcon
|
||||
|
||||
EXPOSE 8080
|
||||
|
||||
COPY . /hello-app
|
||||
WORKDIR /hello-app
|
||||
|
||||
CMD ["python", "app.py"]
|
||||
```
|
||||
|
||||
上面表示的意思很简单,如果你想,你可以在本地运行该进行来访问这个入口: <http://127.0.0.1:8080/hello?value=Fred>
|
||||
|
||||
这将返回如下结果:
|
||||
|
||||
```
|
||||
{"message": "Fred"}
|
||||
```
|
||||
|
||||
在 Docker Hub 上构建和部署这个 hello-app(修改成你自己的 Docker Hub 仓库或者[使用这个][15]):
|
||||
|
||||
```
|
||||
$ sudo docker build . -t chadlung/hello-app:2
|
||||
$ sudo docker push chadlung/hello-app:2
|
||||
```
|
||||
|
||||
现在,我们可以将应用部署到之前的 Docker Swarm 了。登录 manager1 的 ssh 终端会话,并且执行:
|
||||
|
||||
```
|
||||
$ sudo docker service create -p 8080:8080 --replicas 2 --name hello-app chadlung/hello-app:2
|
||||
$ sudo docker service inspect --pretty hello-app
|
||||
$ sudo docker service tasks hello-app
|
||||
```
|
||||
|
||||
现在,我们已经可以测试了。使用任何一个 Swarm 节点的 IP 来访问 /hello 入口。在本例中,我在 manager1 的终端里使用 curl 命令:
|
||||
|
||||
注意,Swarm 中的所有的 IP 都可以,不管这个服务是运行在一台还是更多的节点上。
|
||||
|
||||
```
|
||||
$ curl -v -X GET "http://192.168.99.100:8080/hello?value=Chad"
|
||||
$ curl -v -X GET "http://192.168.99.101:8080/hello?value=Test"
|
||||
$ curl -v -X GET "http://192.168.99.102:8080/hello?value=Docker"
|
||||
```
|
||||
|
||||
结果:
|
||||
|
||||
```
|
||||
* Hostname was NOT found in DNS cache
|
||||
* Trying 192.168.99.101...
|
||||
* Connected to 192.168.99.101 (192.168.99.101) port 8080 (#0)
|
||||
> GET /hello?value=Chad HTTP/1.1
|
||||
> User-Agent: curl/7.35.0
|
||||
> Host: 192.168.99.101:8080
|
||||
> Accept: */*
|
||||
>
|
||||
* HTTP 1.0, assume close after body
|
||||
< HTTP/1.0 200 OK
|
||||
< Date: Tue, 28 Jun 2016 23:52:55 GMT
|
||||
< Server: WSGIServer/0.2 CPython/3.4.4
|
||||
< content-type: application/json
|
||||
< content-length: 19
|
||||
<
|
||||
{"message": "Chad"}
|
||||
```
|
||||
|
||||
从浏览器中访问其他节点:
|
||||
|
||||

|
||||
|
||||
如果你想看运行的所有服务,你可以在 manager1 节点上运行如下代码:
|
||||
|
||||
```
|
||||
$ sudo docker service ls
|
||||
```
|
||||
|
||||
如果你想添加可视化控制平台,你可以安装 [Docker Swarm Visualizer][16](这对于展示非常方便)。在 manager1 的终端中执行如下代码:
|
||||
|
||||
```
|
||||
$ sudo docker run -it -d -p 5000:5000 -e HOST=192.168.99.100 -e PORT=5000 -v /var/run/docker.sock:/var/run/docker.sock manomarks/visualizer)
|
||||
```
|
||||
|
||||
打开你的浏览器,并且访问: <http://192.168.99.100:5000/>
|
||||
|
||||
结果如下(假设已经运行了两个 Docker Swarm 服务):
|
||||
|
||||

|
||||
|
||||
要停止运行 hello-app(已经在两个节点上运行了),可以在 manager1 上执行这个代码:
|
||||
|
||||
```
|
||||
$ sudo docker service rm hello-app
|
||||
```
|
||||
|
||||
如果想停止 Visualizer, 那么在 manager1 的终端中执行:
|
||||
|
||||
```
|
||||
$ sudo docker ps
|
||||
```
|
||||
|
||||
获得容器的 ID,这里是: f71fec0d3ce1,从 manager1 的终端会话中执行这个代码:
|
||||
|
||||
```
|
||||
$ sudo docker stop f71fec0d3ce1
|
||||
```
|
||||
|
||||
祝你成功使用 Docker Swarm。这篇文章主要是以 1.12 版本来进行描述的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.giantflyingsaucer.com/blog/?p=5923
|
||||
|
||||
作者:[Chad Lung][a]
|
||||
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.giantflyingsaucer.com/blog/?author=2
|
||||
[1]: http://dockercon.com/
|
||||
[2]: https://blog.docker.com/author/bfirshman/
|
||||
[3]: https://blog.docker.com/author/bfirshman/
|
||||
[4]: http://www.giantflyingsaucer.com/blog/?p=5730
|
||||
[5]: https://aws.amazon.com/lambda/
|
||||
[6]: https://docs.docker.com/swarm/
|
||||
[7]: https://github.com/bfirsh/dockerrun
|
||||
[8]: https://docs.docker.com/engine/swarm/swarm-tutorial/
|
||||
[9]: https://github.com/chadlung/vagrant-docker-swarm
|
||||
[10]: https://www.vagrantup.com/
|
||||
[11]: https://test.docker.com/
|
||||
[12]: https://docs.docker.com/engine/reference/commandline/swarm_init/
|
||||
[13]: https://hub.docker.com/
|
||||
[14]: https://hub.docker.com/r/chadlung/hello-app/
|
||||
[15]: https://hub.docker.com/r/chadlung/hello-app/
|
||||
[16]: https://github.com/ManoMarks/docker-swarm-visualizer
|
||||
118
published/201608/20160706 What is Git.md
Normal file
118
published/201608/20160706 What is Git.md
Normal file
@ -0,0 +1,118 @@
|
||||
Git 系列(一):什么是 Git
|
||||
===========
|
||||
|
||||
欢迎阅读本系列关于如何使用 Git 版本控制系统的教程!通过本文的介绍,你将会了解到 Git 的用途及谁该使用 Git。
|
||||
|
||||
如果你刚步入开源的世界,你很有可能会遇到一些在 Git 上托管代码或者发布使用版本的开源软件。事实上,不管你知道与否,你都在使用基于 Git 进行版本管理的软件:Linux 内核(就算你没有在手机或者电脑上使用 Linux,你正在访问的网站也是运行在 Linux 系统上的),Firefox、Chrome 等其他很多项目都通过 Git 代码库和世界各地开发者共享他们的代码。
|
||||
|
||||
换个角度来说,你是否仅仅通过 Git 就可以和其他人共享你的代码?你是否可以在家里或者企业里私有化的使用 Git?你必须要通过一个 GitHub 账号来使用 Git 吗?为什么要使用 Git 呢?Git 的优势又是什么?Git 是我唯一的选择吗?这对 Git 所有的疑问都会把我们搞的一脑浆糊。
|
||||
|
||||
因此,忘记你以前所知的 Git,让我们重新走进 Git 世界的大门。
|
||||
|
||||
### 什么是版本控制系统?
|
||||
|
||||
Git 首先是一个版本控制系统。现在市面上有很多不同的版本控制系统:CVS、SVN、Mercurial、Fossil 当然还有 Git。
|
||||
|
||||
很多像 GitHub 和 GitLab 这样的服务是以 Git 为基础的,但是你也可以只使用 Git 而无需使用其他额外的服务。这意味着你可以以私有或者公有的方式来使用 Git。
|
||||
|
||||
如果你曾经和其他人有过任何电子文件方面的合作,你就会知道传统版本管理的工作流程。开始是很简单的:你有一个原始的版本,你把这个版本发送给你的同事,他们在接收到的版本上做了些修改,现在你们有两个版本了,然后他们把他们手上修改过的版本发回来给你。你把他们的修改合并到你手上的版本中,现在两个版本又合并成一个最新的版本了。
|
||||
|
||||
然后,你修改了你手上最新的版本,同时,你的同事也修改了他们手上合并前的版本。现在你们有 3 个不同的版本了,分别是合并后最新的版本,你修改后的版本,你同事手上继续修改过的版本。至此,你们的版本管理工作开始变得越来越混乱了。
|
||||
|
||||
正如 Jason van Gumster 在他的文章中指出 [即使是艺术家也需要版本控制][1],而且已经在个别人那里发现了这种趋势变化。无论是艺术家还是科学家,开发一个某种实验版本是并不鲜见的;在你的项目中,可能有某个版本大获成功,把项目推向一个新的高度,也可能有某个版本惨遭失败。因此,最终你不可避免的会创建出一堆名为project\_justTesting.kdenlive、project\_betterVersion.kdenlive、project\_best\_FINAL.kdenlive、project\_FINAL-alternateVersion.kdenlive 等类似名称的文件。
|
||||
|
||||
不管你是修改一个 for 循环,还是一些简单的文本编辑,一个好的版本控制系统都会让我们的生活更加的轻松。
|
||||
|
||||
### Git 快照
|
||||
|
||||
Git 可以为项目创建快照,并且存储这些快照为唯一的版本。
|
||||
|
||||
如果你将项目带领到了一个错误的方向上,你可以回退到上一个正确的版本,并且开始尝试另一个可行的方向。
|
||||
|
||||
如果你是和别人合作开发,当有人向你发送他们的修改时,你可以将这些修改合并到你的工作分支中,然后你的同事就可以获取到合并后的最新版本,并在此基础上继续工作。
|
||||
|
||||
Git 并不是魔法,因此冲突还是会发生的(“你修改了某文件的最后一行,但是我把这行整行都删除了;我们怎样处理这些冲突呢?”),但是总体而言,Git 会为你保留了所有更改的历史版本,甚至允许并行版本。这为你保留了以任何方式处理冲突的能力。
|
||||
|
||||
### 分布式 Git
|
||||
|
||||
在不同的机器上为同一个项目工作是一件复杂的事情。因为在你开始工作时,你想要获得项目的最新版本,然后此基础上进行修改,最后向你的同事共享这些改动。传统的方法是通过笨重的在线文件共享服务或者老旧的电邮附件,但是这两种方式都是效率低下且容易出错。
|
||||
|
||||
Git 天生是为分布式工作设计的。如果你要参与到某个项目中,你可以克隆(clone)该项目的 Git 仓库,然后就像这个项目只有你本地一个版本一样对项目进行修改。最后使用一些简单的命令你就可以拉取(pull)其他开发者的修改,或者你可以把你的修改推送(push)给别人。现在不用担心谁手上的是最新的版本,或者谁的版本又存放在哪里等这些问题了。全部人都是在本地进行开发,然后向共同的目标推送或者拉取更新。(或者不是共同的目标,这取决于项目的开发方式)。
|
||||
|
||||
### Git 界面
|
||||
|
||||
最原始的 Git 是运行在 Linux 终端上的应用软件。然而,得益于 Git 是开源的,并且拥有良好的设计,世界各地的开发者都可以为 Git 设计不同的访问界面。
|
||||
|
||||
Git 完全是免费的,并且已经打包在 Linux,BSD,Illumos 和其他类 Unix 系统中,Git 命令看起来像这样:
|
||||
|
||||
```
|
||||
$ git --version
|
||||
git version 2.5.3
|
||||
```
|
||||
|
||||
可能最著名的 Git 访问界面是基于网页的,像 GitHub、开源的 GitLab、Savannah、BitBucket 和 SourceForge 这些网站都是基于网页端的 Git 界面。这些站点为面向公众和面向社会的开源软件提供了最大限度的代码托管服务。在一定程度上,基于浏览器的图形界面(GUI)可以尽量的减缓 Git 的学习曲线。下面的 GitLab 界面的截图:
|
||||
|
||||
|
||||
|
||||
再者,第三方 Git 服务提供商或者独立开发者甚至可以在 Git 的基础上开发出不是基于 HTML 的定制化前端界面。此类界面让你可以不用打开浏览器就可以方便的使用 Git 进行版本管理。其中对用户最透明的方式是直接集成到文件管理器中。KDE 文件管理器 Dolphin 可以直接在目录中显示 Git 状态,甚至支持提交,推送和拉取更新操作。
|
||||
|
||||
|
||||
|
||||
[Sparkleshare][2] 使用 Git 作为其 Dropbox 式的文件共享界面的基础。
|
||||
|
||||
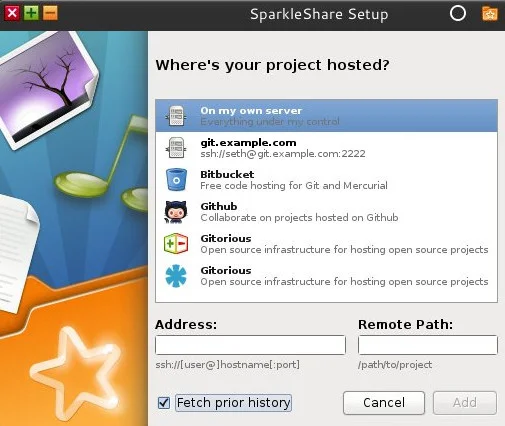
|
||||
|
||||
想了解更多的内容,可以查看 [Git wiki][3],这个(长长的)页面中展示了很多 Git 的图形界面项目。
|
||||
|
||||
### 谁应该使用 Git?
|
||||
|
||||
就是你!我们更应该关心的问题是什么时候使用 Git?和用 Git 来干嘛?
|
||||
|
||||
### 我应该在什么时候使用 Git 呢?我要用 Git 来干嘛呢?
|
||||
|
||||
想更深入的学习 Git,我们必须比平常考虑更多关于文件格式的问题。
|
||||
|
||||
Git 是为了管理源代码而设计的,在大多数编程语言中,源代码就意味者一行行的文本。当然,Git 并不知道你把这些文本当成是源代码还是下一部伟大的美式小说。因此,只要文件内容是以文本构成的,使用 Git 来跟踪和管理其版本就是一个很好的选择了。
|
||||
|
||||
但是什么是文本呢?如果你在像 Libre Office 这类办公软件中编辑一些内容,通常并不会产生纯文本内容。因为通常复杂的应用软件都会对原始的文本内容进行一层封装,就如把原始文本内容用 XML 标记语言包装起来,然后封装在 Zip 包中。这种对原始文本内容进行一层封装的做法可以保证当你把文件发送给其他人时,他们可以看到你在办公软件中编辑的内容及特定的文本效果。奇怪的是,虽然,通常你的需求可能会很复杂,就像保存 [Kdenlive][4] 项目文件,或者保存从 [Inkscape][5] 导出的SVG文件,但是,事实上使用 Git 管理像 XML 文本这样的纯文本类容是最简单的。
|
||||
|
||||
如果你在使用 Unix 系统,你可以使用 `file` 命令来查看文件内容构成:
|
||||
|
||||
```
|
||||
$ file ~/path/to/my-file.blah
|
||||
my-file.blah: ASCII text
|
||||
$ file ~/path/to/different-file.kra: Zip data (MIME type "application/x-krita")
|
||||
```
|
||||
|
||||
如果还是不确定,你可以使用 `head` 命令来查看文件内容:
|
||||
|
||||
```
|
||||
$ head ~/path/to/my-file.blah
|
||||
```
|
||||
|
||||
如果输出的文本你基本能看懂,这个文件就很有可能是文本文件。如果你仅仅在一堆乱码中偶尔看到几个熟悉的字符,那么这个文件就可能不是文本文件了。
|
||||
|
||||
准确的说:Git 可以管理其他格式的文件,但是它会把这些文件当成二进制大对象(blob)。两者的区别是,在文本文件中,Git 可以明确的告诉你在这两个快照(或者说提交)间有 3 行是修改过的。但是如果你在两个提交(commit)之间对一张图片进行的编辑操作,Git 会怎么指出这种修改呢?实际上,因为图片并不是以某种可以增加或删除的有意义的文本构成,因此 Git 并不能明确的描述这种变化。当然我个人是非常希望图片的编辑可以像把文本“\<sky>丑陋的蓝绿色\</sky>”修改成“\<sky>漂浮着蓬松白云的天蓝色\</sky>”一样的简单,但是事实上图片的编辑并没有这么简单。
|
||||
|
||||
经常有人在 Git 上放入 png 图标、电子表格或者流程图这类二进制大型对象(blob)。尽管,我们知道在 Git 上管理此类大型文件并不直观,但是,如果你需要使用 Git 来管理此类文件,你也并不需要过多的担心。如果你参与的项目同时生成文本文件和二进制大文件对象(如视频游戏中常见的场景,这些和源代码同样重要的图像和音频材料),那么你有两条路可以走:要么开发出你自己的解决方案,就如使用指向共享网络驱动器的引用;要么使用 Git 插件,如 Joey Hess 开发的 [git annex][6],以及 [Git-Media][7] 项目。
|
||||
|
||||
你看,Git 真的是一个任何人都可以使用的工具。它是你进行文件版本管理的一个强大而且好用工具,同时它并没有你开始认为的那么可怕。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/resources/what-is-git
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[cvsher](https://github.com/cvsher)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]: https://opensource.com/life/16/2/version-control-isnt-just-programmers
|
||||
[2]: http://sparkleshare.org/
|
||||
[3]: https://git.wiki.kernel.org/index.php/InterfacesFrontendsAndTools#Graphical_Interfaces
|
||||
[4]: https://opensource.com/life/11/11/introduction-kdenlive
|
||||
[5]: http://inkscape.org/
|
||||
[6]: https://git-annex.branchable.com/
|
||||
[7]: https://github.com/alebedev/git-media
|
||||
141
published/201608/20160711 Getting started with Git.md
Normal file
141
published/201608/20160711 Getting started with Git.md
Normal file
@ -0,0 +1,141 @@
|
||||
初步了解 Git
|
||||
=========================
|
||||
|
||||

|
||||
|
||||
*图片来源:opensource.com*
|
||||
|
||||
在这个系列的[介绍篇][4]中,我们学习到了谁应该使用 Git,以及 Git 是用来做什么的。今天,我们将学习如何克隆公共 Git 仓库,以及如何提取出独立的文件而不用克隆整个仓库。
|
||||
|
||||
由于 Git 如此流行,因而如果你能够至少熟悉一些基础的 Git 知识也能为你的生活带来很多便捷。如果你可以掌握 Git 基础(你可以的,我发誓!),那么你将能够下载任何你需要的东西,甚至还可能做一些贡献作为回馈。毕竟,那就是开源的精髓所在:你拥有获取你使用的软件代码的权利,拥有和他人分享的自由,以及只要你愿意就可以修改它的权利。只要你熟悉了 Git,它就可以让这一切都变得很容易。
|
||||
|
||||
那么,让我们一起来熟悉 Git 吧。
|
||||
|
||||
### 读和写
|
||||
|
||||
一般来说,有两种方法可以和 Git 仓库交互:你可以从仓库中读取,或者你也能够向仓库中写入。它就像一个文件:有时候你打开一个文档只是为了阅读它,而其它时候你打开文档是因为你需要做些改动。
|
||||
|
||||
本文仅讲解如何从 Git 仓库读取。我们将会在后面的一篇文章中讲解如何向 Git 仓库写回的主题。
|
||||
|
||||
### Git 还是 GitHub?
|
||||
|
||||
一句话澄清:Git 不同于 GitHub(或 GitLab,或 Bitbucket)。Git 是一个命令行程序,所以它就像下面这样:
|
||||
|
||||
```
|
||||
$ git
|
||||
usage: Git [--version] [--help] [-C <path>]
|
||||
[-p | --paginate | --no-pager] [--bare]
|
||||
[--Git-dir=<path>] <command> [<args>]
|
||||
|
||||
```
|
||||
|
||||
由于 Git 是开源的,所以就有许多聪明人围绕它构建了基础软件;这些基础软件,包括在他们自己身边,都已经变得非常流行了。
|
||||
|
||||
我的文章系列将首先教你纯粹的 Git 知识,因为一旦你理解了 Git 在做什么,那么你就无需关心正在使用的前端工具是什么了。然而,我的文章系列也将涵盖通过流行的 Git 服务完成每项任务的常用方法,因为那些将可能是你首先会遇到的。
|
||||
|
||||
### 安装 Git
|
||||
|
||||
在 Linux 系统上,你可以从所使用的发行版软件仓库中获取并安装 Git。BSD 用户应当在 Ports 树的 devel 部分查找 Git。
|
||||
|
||||
对于闭源的操作系统,请前往其[项目官网][1],并根据说明安装。一旦安装后,在 Linux、BSD 和 Mac OS X 上的命令应当没有任何差别。Windows 用户需要调整 Git 命令,从而和 Windows 文件系统相匹配,或者安装 Cygwin 以原生的方式运行 Git,而不受 Windows 文件系统转换问题的羁绊。
|
||||
|
||||
### Git 下午茶
|
||||
|
||||
并非每个人都需要立刻将 Git 加入到我们的日常生活中。有些时候,你和 Git 最多的交互就是访问一个代码库,下载一两个文件,然后就不用它了。以这样的方式看待 Git,它更像是下午茶而非一次正式的宴会。你进行一些礼节性的交谈,获得了需要的信息,然后你就会离开,至少接下来的三个月你不再想这样说话。
|
||||
|
||||
当然,那是可以的。
|
||||
|
||||
一般来说,有两种方法访问 Git:使用命令行,或者使用一种神奇的因特网技术通过 web 浏览器快速轻松地访问。
|
||||
|
||||
假设你想要给终端安装一个回收站,因为你已经被 rm 命令毁掉太多次了。你可能听说过 Trashy ,它称自己为「理智的 rm 命令中间人」,也许你想在安装它之前阅读它的文档。幸运的是,[Trashy 公开地托管在 GitLab.com][2]。
|
||||
|
||||
### Landgrab
|
||||
|
||||
我们工作的第一步是对这个 Git 仓库使用 landgrab 排序方法:我们会克隆这个完整的仓库,然后会根据内容排序。由于该仓库是托管在公共的 Git 服务平台上,所以有两种方式来完成工作:使用命令行,或者使用 web 界面。
|
||||
|
||||
要想使用 Git 获取整个仓库,就要使用 git clone 命令和 Git 仓库的 URL 作为参数。如果你不清楚正确的 URL 是什么,仓库应该会告诉你的。GitLab 为你提供了 [Trashy][3] 仓库的用于拷贝粘贴的 URL。
|
||||
|
||||
|
||||
|
||||
你也许注意到了,在某些服务平台上,会同时提供 SSH 和 HTTPS 链接。只有当你拥有仓库的写权限时,你才可以使用 SSH。否则的话,你必须使用 HTTPS URL。
|
||||
|
||||
一旦你获得了正确的 URL,克隆仓库是非常容易的。就是 git clone 该 URL 即可,以及一个可选的指定要克隆到的目录。默认情况下会将 git 目录克隆到你当前所在的目录;例如,'trashy.git' 将会克隆到你当前位置的 'trashy' 目录。我使用 .clone 扩展名标记那些只读的仓库,而使用 .git 扩展名标记那些我可以读写的仓库,不过这并不是官方要求的。
|
||||
|
||||
```
|
||||
$ git clone https://gitlab.com/trashy/trashy.git trashy.clone
|
||||
Cloning into 'trashy.clone'...
|
||||
remote: Counting objects: 142, done.
|
||||
remote: Compressing objects: 100% (91/91), done.
|
||||
remote: Total 142 (delta 70), reused 103 (delta 47)
|
||||
Receiving objects: 100% (142/142), 25.99 KiB | 0 bytes/s, done.
|
||||
Resolving deltas: 100% (70/70), done.
|
||||
Checking connectivity... done.
|
||||
```
|
||||
|
||||
一旦成功地克隆了仓库,你就可以像对待你电脑上任何其它目录那样浏览仓库中的文件。
|
||||
|
||||
另外一种获得仓库拷贝的方式是使用 web 界面。GitLab 和 GitHub 都会提供一个 .zip 格式的仓库快照文件。GitHub 有一个大大的绿色下载按钮,但是在 GitLab 中,可以在浏览器的右侧找到并不显眼的下载按钮。
|
||||
|
||||
|
||||
|
||||
### 仔细挑选
|
||||
|
||||
另外一种从 Git 仓库中获取文件的方法是找到你想要的文件,然后把它从仓库中拽出来。只有 web 界面才提供这种方法,本质上来说,你看到的是别人的仓库克隆;你可以把它想象成一个 HTTP 共享目录。
|
||||
|
||||
使用这种方法的问题是,你也许会发现某些文件并不存在于原始仓库中,因为完整形式的文件可能只有在执行 make 命令后才能构建,那只有你下载了完整的仓库,阅读了 README 或者 INSTALL 文件,然后运行相关命令之后才会产生。不过,假如你确信文件存在,而你只想进入仓库,获取那个文件,然后离开的话,你就可以那样做。
|
||||
|
||||
在 GitLab 和 GitHub 中,单击文件链接,并在 Raw 模式下查看,然后使用你的 web 浏览器的保存功能,例如:在 Firefox 中,“文件” \> “保存页面为”。在一个 GitWeb 仓库中(这是一个某些更喜欢自己托管 git 的人使用的私有 git 仓库 web 查看器),Raw 查看链接在文件列表视图中。
|
||||
|
||||
|
||||
|
||||
### 最佳实践
|
||||
|
||||
通常认为,和 Git 交互的正确方式是克隆完整的 Git 仓库。这样认为是有几个原因的。首先,可以使用 git pull 命令轻松地使克隆仓库保持更新,这样你就不必在每次文件改变时就重回 web 站点获得一份全新的拷贝。第二,你碰巧需要做些改进,只要保持仓库整洁,那么你可以非常轻松地向原来的作者提交所做的变更。
|
||||
|
||||
现在,可能是时候练习查找感兴趣的 Git 仓库,然后将它们克隆到你的硬盘中了。只要你了解使用终端的基础知识,那就不会太难做到。还不知道基本的终端使用方式吗?那再给多我 5 分钟时间吧。
|
||||
|
||||
### 终端使用基础
|
||||
|
||||
首先要知道的是,所有的文件都有一个路径。这是有道理的;如果我让你在常规的非终端环境下为我打开一个文件,你就要导航到文件在你硬盘的位置,并且直到你找到那个文件,你要浏览一大堆窗口。例如,你也许要点击你的家目录 > 图片 > InktoberSketches > monkey.kra。
|
||||
|
||||
在那样的场景下,文件 monkeysketch.kra 的路径是:$HOME/图片/InktoberSketches/monkey.kra。
|
||||
|
||||
在终端中,除非你正在处理一些特殊的系统管理员任务,你的文件路径通常是以 $HOME 开头的(或者,如果你很懒,就使用 ~ 字符),后面紧跟着一些列的文件夹直到文件名自身。
|
||||
|
||||
这就和你在 GUI 中点击各种图标直到找到相关的文件或文件夹类似。
|
||||
|
||||
如果你想把 Git 仓库克隆到你的文档目录,那么你可以打开一个终端然后运行下面的命令:
|
||||
|
||||
```
|
||||
$ git clone https://gitlab.com/foo/bar.git
|
||||
$HOME/文档/bar.clone
|
||||
```
|
||||
|
||||
一旦克隆完成,你可以打开一个文件管理器窗口,导航到你的文档文件夹,然后你就会发现 bar.clone 目录正在等待着你访问。
|
||||
|
||||
如果你想要更高级点,你或许会在以后再次访问那个仓库,可以尝试使用 git pull 命令来查看项目有没有更新:
|
||||
|
||||
```
|
||||
$ cd $HOME/文档/bar.clone
|
||||
$ pwd
|
||||
bar.clone
|
||||
$ git pull
|
||||
```
|
||||
|
||||
到目前为止,你需要初步了解的所有终端命令就是那些了,那就去探索吧。你实践得越多,Git 掌握得就越好(熟能生巧),这是重点,也是事情的本质。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/7/stumbling-git
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]: https://git-scm.com/download
|
||||
[2]: https://gitlab.com/trashy/trashy
|
||||
[3]: https://gitlab.com/trashy/trashy.git
|
||||
[4]: https://linux.cn/article-7639-1.html
|
||||
129
published/201608/20160715 bc - Command line calculator.md
Normal file
129
published/201608/20160715 bc - Command line calculator.md
Normal file
@ -0,0 +1,129 @@
|
||||
bc : 一个命令行计算器
|
||||
============================
|
||||
|
||||

|
||||
|
||||
假如你在一个图形桌面环境中需要一个计算器时,你可能只需要一路进行点击便可以找到一个计算器。例如,Fedora 工作站中就已经包含了一个名为 `Calculator` 的工具。它有着几种不同的操作模式,例如,你可以进行复杂的数学运算或者金融运算。但是,你知道吗,命令行也提供了一个与之相似的名为 `bc` 的工具?
|
||||
|
||||
`bc` 工具可以为你提供的功能可以满足你对科学计算器、金融计算器或者是简单计算器的期望。另外,假如需要的话,它还可以从命令行中被脚本化。这使得当你需要做复杂的数学运算时,你可以在 shell 脚本中使用它。
|
||||
|
||||
因为 bc 也被用于其他的系统软件,例如 CUPS 打印服务,所以它可能已经在你的 Fedora 系统中被安装了。你可以使用下面这个命令来进行检查:
|
||||
|
||||
```
|
||||
dnf list installed bc
|
||||
```
|
||||
|
||||
假如因为某些原因你没有在上面命令的输出中看到它,你可以使用下面的这个命令来安装它:
|
||||
|
||||
```
|
||||
sudo dnf install bc
|
||||
```
|
||||
|
||||
### 用 bc 做一些简单的数学运算
|
||||
|
||||
使用 bc 的一种方式是进入它自己的 shell。在那里你可以按行进行许多次计算。当你键入 bc 后,首先出现的是有关这个程序的警告:
|
||||
|
||||
```
|
||||
$ bc
|
||||
bc 1.06.95
|
||||
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006 Free Software Foundation, Inc.
|
||||
This is free software with ABSOLUTELY NO WARRANTY.
|
||||
For details type `warranty'.
|
||||
```
|
||||
|
||||
现在你可以按照每行一个输入运算式或者命令了:
|
||||
|
||||
```
|
||||
1+1
|
||||
```
|
||||
|
||||
bc 会回答上面计算式的答案是:
|
||||
|
||||
```
|
||||
2
|
||||
```
|
||||
|
||||
在这里你还可以执行其他的命令。你可以使用 加(+)、减(-)、乘(*)、除(/)、圆括号、指数符号(\^) 等等。请注意 bc 同样也遵循所有约定俗成的运算规则,例如运算的先后顺序。你可以试试下面的例子:
|
||||
|
||||
```
|
||||
(4+7)*2
|
||||
4+7*2
|
||||
```
|
||||
|
||||
若要退出 bc 可以通过按键组合 `Ctrl+D` 来发送 “输入结束”信号给 bc 。
|
||||
|
||||
使用 bc 的另一种方式是使用 `echo` 命令来传递运算式或命令。下面这个示例就是计算器中的 “Hello, world” 例子,使用 shell 的管道函数(|) 来将 `echo` 的输出传入 `bc` 中:
|
||||
|
||||
```
|
||||
echo '1+1' | bc
|
||||
```
|
||||
|
||||
使用 shell 的管道,你可以发送不止一个运算操作,你需要使用分号来分隔不同的运算。结果将在不同的行中返回。
|
||||
|
||||
```
|
||||
echo '1+1; 2+2' | bc
|
||||
```
|
||||
|
||||
### 精度
|
||||
|
||||
在某些计算中,bc 会使用精度的概念,即小数点后面的数字位数。默认的精度是 0。除法操作总是使用精度的设定。所以,如果你没有设置精度,有可能会带来意想不到的答案:
|
||||
|
||||
```
|
||||
echo '3/2' | bc
|
||||
echo 'scale=3; 3/2' | bc
|
||||
```
|
||||
|
||||
乘法使用一个更复杂的精度选择机制:
|
||||
|
||||
```
|
||||
echo '3*2' | bc
|
||||
echo '3*2.0' | bc
|
||||
```
|
||||
|
||||
同时,加法和减法的相关运算则与之相似:
|
||||
|
||||
```
|
||||
echo '7-4.15' | bc
|
||||
```
|
||||
|
||||
### 其他进制系统
|
||||
|
||||
bc 的另一个有用的功能是可以使用除了十进制以外的其他计数系统。例如,你可以轻松地做十六进制或二进制的数学运算。可以使用 `ibase` 和 `obase` 命令来分别设定输入和输出的进制系统。需要记住的是一旦你使用了 `ibase`,之后你输入的任何数字都将被认为是在新定义的进制系统中。
|
||||
|
||||
要做十六进制数到十进制数的转换或运算,你可以使用类似下面的命令。请注意大于 9 的十六进制数必须是大写的(A-F):
|
||||
|
||||
```
|
||||
echo 'ibase=16; A42F' | bc
|
||||
echo 'ibase=16; 5F72+C39B' | bc
|
||||
```
|
||||
|
||||
若要使得结果是十六进制数,则需要设定 `obase` :
|
||||
|
||||
```
|
||||
echo 'obase=16; ibase=16; 5F72+C39B' | bc
|
||||
```
|
||||
|
||||
下面是一个小技巧。假如你在 shell 中做这些十六进制运算,怎样才能使得输入重新为十进制数呢?答案是使用 `ibase` 命令,但你必须设定它为在当前进制中与十进制中的 10 等价的值。例如,假如 `ibase` 被设定为十六进制,你需要输入:
|
||||
|
||||
```
|
||||
ibase=A
|
||||
```
|
||||
|
||||
一旦你执行了上面的命令,所有输入的数字都将是十进制的了,接着你便可以输入 `obase=10` 来重置输出的进制系统。
|
||||
|
||||
### 结论
|
||||
|
||||
上面所提到的只是 bc 所能做到的基础。它还允许你为某些复杂的运算和程序定义函数、变量和循环结构。你可以在你的系统中将这些程序保存为文本文件以便你在需要的时候使用。你还可以在网上找到更多的资源,它们提供了更多的例子以及额外的函数库。快乐地计算吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/bc-command-line-calculator/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/pfrields/
|
||||
[1]: http://phodd.net/gnu-bc/
|
||||
@ -0,0 +1,94 @@
|
||||
Linux 命令行下的最佳文本编辑器
|
||||
==========================================
|
||||
|
||||

|
||||
|
||||
文本编辑软件在任何操作系统上都是必备的软件。我们在 Linux 上不缺乏[非常现代化的编辑软件][1],但是它们都是基于 GUI(图形界面)的编辑软件。
|
||||
|
||||
正如你所了解的,Linux 真正的魅力在于命令行。当你正在用命令行工作时,你就需要一个可以在控制台窗口运行的文本编辑器。
|
||||
|
||||
正因为这个目的,我们准备了一个基于 Linux 命令行的文本编辑器清单。
|
||||
|
||||
### [VIM][2]
|
||||
|
||||
如果你已经使用 Linux 有一段时间,那么你肯定听到过 Vim 。Vim 是一个高度可配置的、跨平台的、高效率的文本编辑器。
|
||||
|
||||
几乎所有的 Linux 发行版本都已经内置了 Vim ,由于其特性之丰富,它已经变得非常流行了。
|
||||
|
||||

|
||||
|
||||
*Vim 用户界面*
|
||||
|
||||
Vim 可能会让第一次使用它的人感到非常痛苦。我记得我第一次尝试使用 Vim 编辑一个文本文件时,我是非常困惑的。我不能用 Vim 输入一个字母,更有趣的是,我甚至不知道该怎么关闭它。如果你准备使用 Vim ,你需要有决心跨过一个陡峭的学习路线。
|
||||
|
||||
但是一旦你经历过了那些,通过梳理一些文档,记住它的命令和快捷键,你会发现这段学习经历是非常值得的。你可以将 Vim 按照你的意愿进行改造:配置一个让你看起来舒服的界面,通过使用脚本或者插件等来提高工作效率。Vim 支持格式高亮,宏记录和操作记录。
|
||||
|
||||
在Vim官网上,它是这样介绍的:
|
||||
|
||||
>**Vim: The power tool for everyone!**
|
||||
|
||||
如何使用它完全取决于你。你可以仅仅使用它作为文本编辑器,或者你可以将它打造成一个完善的IDE(Integrated Development Environment:集成开发环境)。
|
||||
|
||||
### [GNU EMACS][3]
|
||||
|
||||
GNU Emacs 毫无疑问是非常强大的文本编辑器之一。如果你听说过 Vim 和 Emacs ,你应该知道这两个编辑器都拥有非常忠诚的粉丝基础,并且他们对于文本编辑器的选择非常看重。你也可以在互联网上找到大量关于他们的段子:
|
||||
|
||||

|
||||
|
||||
*Vim vs Emacs*
|
||||
|
||||
Emacs 是一个跨平台的、既有有图形界面也有命令行界面的软件。它也拥有非常多的特性,更重要的是,可扩展!
|
||||
|
||||

|
||||
|
||||
*Emacs 用户界面*
|
||||
|
||||
像 Vim一样,Emacs 也需要经历一个陡峭的学习路线。但是一旦你掌握了它,你就能完全体会到它的强大。Emacs 可以处理几乎所有类型文本文件。它的界面可以定制以适应你的工作流。它也支持宏记录和快捷键。
|
||||
|
||||
Emacs 独特的特性是它可以“变形”成和文本编辑器完全不同的的东西。有大量的模块可使它在不同的场景下成为不同的应用,例如:计算器、新闻阅读器、文字处理器等。你甚至都可以在 Emacs 里面玩游戏。
|
||||
|
||||
### [NANO][5]
|
||||
|
||||
如果说到简易方便的软件,Nano 就是一个。不像 Vim 和 Emacs,nano 的学习曲线是平滑的。
|
||||
|
||||
如果你仅仅是想创建和编辑一个文本文件,不想给自己找太多挑战,Nano 估计是最适合你的了。
|
||||
|
||||

|
||||
|
||||
*Nano 用户界面*
|
||||
|
||||
Nano 可用的快捷键都在用户界面的下方展示出来了。Nano 仅仅拥有最基础的文本编辑软件的功能。
|
||||
|
||||
它是非常小巧的,非常适合编辑系统配置文件。对于那些不需要复杂的命令行编辑功能的人来说,Nano 是完美配备。
|
||||
|
||||
### 其它
|
||||
|
||||
这里还有一些我想要提及其它编辑器:
|
||||
|
||||
[The Nice Editor (ne)][6]: 官网是这样介绍的:
|
||||
|
||||
> 如果你有足够的资料,也有使用 Emacs 的耐心或使用 Vim 的良好心态,那么 ne 可能不适合你。
|
||||
|
||||
基本上 ne 拥有像 Vim 和 Emacs 一样多的高级功能,包括:脚本和宏记录。但是它有更为直观的操作方式和平滑的学习路线。
|
||||
|
||||
### 你认为呢?
|
||||
|
||||
我知道,如果你是一个熟练的 Linux 用户,你可以会说还有很多应该被列入 “Linux 最好的命令行编辑器”清单上。因此我想跟你说,如果你还知道其他的 Linux 命令行文本编辑器,你是否愿意跟我们一同分享?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/command-line-text-editors-linux/
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[chenzhijun](https://github.com/chenzhijun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/munif/
|
||||
[1]: https://linux.cn/article-7468-1.html
|
||||
[2]: http://www.vim.org/
|
||||
[3]: https://www.gnu.org/software/emacs/
|
||||
[4]: https://itsfoss.com/download-linux-wallpapers-cheat-sheets/
|
||||
[5]: http://www.nano-editor.org/
|
||||
[6]: http://ne.di.unimi.it/
|
||||
176
published/201608/20160718 Creating your first Git repository.md
Normal file
176
published/201608/20160718 Creating your first Git repository.md
Normal file
@ -0,0 +1,176 @@
|
||||
Git 系列(三):建立你的第一个 Git 仓库
|
||||
======================================
|
||||
|
||||

|
||||
|
||||
现在是时候学习怎样创建你自己的 Git 仓库了,还有怎样增加文件和完成提交。
|
||||
|
||||
在本系列[前面的文章][4]中,你已经学习了怎样作为一个最终用户与 Git 进行交互;你就像一个漫无目的的流浪者一样偶然发现了一个开源项目网站,克隆了仓库,然后你就可以继续钻研它了。你知道了和 Git 进行交互并不像你想的那样困难,或许你只是需要被说服现在去使用 Git 完成你的工作罢了。
|
||||
|
||||
虽然 Git 确实是被许多重要软件选作版本控制工具,但是并不是仅能用于这些重要软件;它也能管理你购物清单(如果它们对你来说很重要的话,当然可以了!)、你的配置文件、周报或日记、项目进展日志、甚至源代码!
|
||||
|
||||
使用 Git 是很有必要的,毕竟,你肯定有过因为一个备份文件不能够辨认出版本信息而抓狂的时候。
|
||||
|
||||
Git 无法帮助你,除非你开始使用它,而现在就是开始学习和使用它的最好时机。或者,用 Git 的话来说,“没有其他的 `push` 能像 `origin HEAD` 一样有帮助了”(千里之行始于足下的意思)。我保证,你很快就会理解这一点的。
|
||||
|
||||
### 类比于录音
|
||||
|
||||
我们经常用名词“快照”来指代计算机上的镜像,因为很多人都能够对插满了不同时光的照片的相册充满了感受。这很有用,不过,我认为 Git 更像是进行一场录音。
|
||||
|
||||
也许你不太熟悉传统的录音棚卡座式录音机,它包括几个部件:一个可以正转或反转的转轴、保存声音波形的磁带,可以通过拾音头在磁带上记录声音波形,或者检测到磁带上的声音波形并播放给听众。
|
||||
|
||||
除了往前播放磁带,你也可以把磁带倒回到之前的部分,或快进跳过后面的部分。
|
||||
|
||||
想象一下上世纪 70 年代乐队录制磁带的情形。你可以想象到他们一遍遍地练习歌曲,直到所有部分都非常完美,然后记录到音轨上。起初,你会录下鼓声,然后是低音,再然后是吉他声,最后是主唱。每次你录音时,录音棚工作人员都会把磁带倒带,然后进入循环模式,这样它就会播放你之前录制的部分。比如说如果你正在录制低音,你就会在背景音乐里听到鼓声,就像你自己在击鼓一样,然后吉他手在录制时会听到鼓声、低音(和牛铃声)等等。在每个循环中,你都会录制一部分,在接下来的循环中,工作人员就会按下录音按钮将其合并记录到磁带中。
|
||||
|
||||
你也可以拷贝或换下整个磁带,如果你要对你的作品重新混音的话。
|
||||
|
||||
现在我希望对于上述的上世纪 70 年代的录音工作的描述足够生动,这样我们就可以把 Git 的工作想象成一个录音工作了。
|
||||
|
||||
### 新建一个 Git 仓库
|
||||
|
||||
首先得为我们的虚拟的录音机买一些磁带。用 Git 的话说,这些磁带就是*仓库*;它是完成所有工作的基础,也就是说这里是存放 Git 文件的地方(即 Git 工作区)。
|
||||
|
||||
任何目录都可以成为一个 Git 仓库,但是让我们从一个新目录开始。这需要下面三个命令:
|
||||
|
||||
- 创建目录(如果你喜欢的话,你可以在你的图形化的文件管理器里面完成。)
|
||||
- 在终端里切换到目录。
|
||||
- 将其初始化成一个 Git 管理的目录。
|
||||
|
||||
也就是运行如下代码:
|
||||
|
||||
```
|
||||
$ mkdir ~/jupiter # 创建目录
|
||||
$ cd ~/jupiter # 进入目录
|
||||
$ git init . # 初始化你的新 Git 工作区
|
||||
```
|
||||
|
||||
在这个例子中,文件夹 jupiter 是一个空的但是合法的 Git 仓库。
|
||||
|
||||
有了仓库接下来的事情就可以按部就班进行了。你可以克隆该仓库,你可以在一个历史点前后来回穿梭(前提是你有一个历史点),创建交替的时间线,以及做 Git 能做的其它任何事情。
|
||||
|
||||
在 Git 仓库里面工作和在任何目录里面工作都是一样的,可以在仓库中新建文件、复制文件、保存文件。你可以像平常一样做各种事情;Git 并不复杂,除非你把它想复杂了。
|
||||
|
||||
在本地的 Git 仓库中,一个文件可以有以下这三种状态:
|
||||
|
||||
- 未跟踪文件(Untracked):你在仓库里新建了一个文件,但是你没有把文件加入到 Git 的管理之中。
|
||||
- 已跟踪文件(Tracked):已经加入到 Git 管理的文件。
|
||||
- 暂存区文件(Staged):被修改了的已跟踪文件,并加入到 Git 的提交队列中。
|
||||
|
||||
任何你新加入到 Git 仓库中的文件都是未跟踪文件。这些文件保存在你的电脑硬盘上,但是你没有告诉 Git 这是需要管理的文件,用我们的录音机来类比,就是录音机还没打开;乐队就开始在录音棚里忙碌了,但是录音机并没有准备录音。
|
||||
|
||||
不用担心,Git 会在出现这种情况时告诉你:
|
||||
|
||||
```
|
||||
$ echo "hello world" > foo
|
||||
$ git status
|
||||
On branch master
|
||||
Untracked files:
|
||||
(use "git add <file>..." to include in what will be committed)
|
||||
foo
|
||||
nothing added but untracked files present (use "git add" to track)
|
||||
```
|
||||
|
||||
你看到了,Git 会提醒你怎样把文件加入到提交任务中。
|
||||
|
||||
### 不使用 Git 命令进行 Git 操作
|
||||
|
||||
在 GitHub 或 GitLab 上创建一个仓库只需要用鼠标点几下即可。这并不难,你单击“New Repository”这个按钮然后跟着提示做就可以了。
|
||||
|
||||
在仓库中包括一个“README”文件是一个好习惯,这样人们在浏览你的仓库的时候就可以知道你的仓库是干什么的,更有用的是可以让你在克隆一个有东西的仓库前知道它有些什么。
|
||||
|
||||
克隆仓库通常很简单,但是在 GitHub 上获取仓库改动权限就稍微复杂一些,为了通过 GitHub 验证你必须有一个 SSH 密钥。如果你使用 Linux 系统,可以通过下面的命令生成:
|
||||
|
||||
```
|
||||
$ ssh-keygen
|
||||
```
|
||||
|
||||
然后复制你的新密钥的内容,它是纯文本文件,你可以使用一个文本编辑器打开它,也可以使用如下 cat 命令查看:
|
||||
|
||||
```
|
||||
$ cat ~/.ssh/id_rsa.pub
|
||||
```
|
||||
|
||||
现在把你的密钥粘贴到 [GitHub SSH 配置文件][1] 中,或者 [GitLab 配置文件][2]。
|
||||
|
||||
如果你通过使用 SSH 模式克隆了你的项目,你就可以将修改写回到你的仓库了。
|
||||
|
||||
另外,如果你的系统上没有安装 Git 的话也可以使用 GitHub 的文件上传接口来添加文件。
|
||||
|
||||
|
||||
|
||||
### 跟踪文件
|
||||
|
||||
正如命令 `git status` 的输出告诉你的那样,如果你想让 git 跟踪一个文件,你必须使用命令 `git add` 把它加入到提交任务中。这个命令把文件存在了暂存区,这里存放的都是等待提交的文件,或者也可以用在快照中。在将文件包括到快照中,和添加要 Git 管理的新的或临时文件时,`git add` 命令的目的是不同的,不过至少现在,你不用为它们之间的不同之处而费神。
|
||||
|
||||
类比录音机,这个动作就像打开录音机开始准备录音一样。你可以想象为对已经在录音的录音机按下暂停按钮,或者倒回开头等着记录下个音轨。
|
||||
|
||||
当你把文件添加到 Git 管理中,它会标识其为已跟踪文件:
|
||||
|
||||
```
|
||||
$ git add foo
|
||||
$ git status
|
||||
On branch master
|
||||
Changes to be committed:
|
||||
(use "git reset HEAD <file>..." to unstage)
|
||||
new file: foo
|
||||
```
|
||||
|
||||
加入文件到提交任务中并不是“准备录音”。这仅仅是将该文件置于准备录音的状态。在你添加文件后,你仍然可以修改该文件;它只是被标记为**已跟踪**和**处于暂存区**,所以在它被写到“磁带”前你可以将它撤出或修改它(当然你也可以再次将它加入来做些修改)。但是请注意:你还没有在磁带中记录该文件,所以如果弄坏了一个之前还是好的文件,你是没有办法恢复的,因为你没有在“磁带”中记下那个文件还是好着的时刻。
|
||||
|
||||
如果你最后决定不把文件记录到 Git 历史列表中,那么你可以撤销提交任务,在 Git 中是这样做的:
|
||||
|
||||
```
|
||||
$ git reset HEAD foo
|
||||
```
|
||||
|
||||
这实际上就是解除了录音机的准备录音状态,你只是在录音棚中转了一圈而已。
|
||||
|
||||
### 大型提交
|
||||
|
||||
有时候,你想要提交一些内容到仓库;我们以录音机类比,这就好比按下录音键然后记录到磁带中一样。
|
||||
|
||||
在一个项目所经历的不同阶段中,你会按下这个“记录键”无数次。比如,如果你尝试了一个新的 Python 工具包并且最终实现了窗口呈现功能,然后你肯定要进行提交,以便你在实验新的显示选项时搞砸了可以回退到这个阶段。但是如果你在 Inkscape 中画了一些图形草样,在提交前你可能需要等到已经有了一些要开发的内容。尽管你可能提交了很多次,但是 Git 并不会浪费很多,也不会占用太多磁盘空间,所以在我看来,提交的越多越好。
|
||||
|
||||
`commit` 命令会“记录”仓库中所有的暂存区文件。Git 只“记录”已跟踪的文件,即,在过去某个时间点你使用 `git add` 命令加入到暂存区的所有文件,以及从上次提交后被改动的文件。如果之前没有过提交,那么所有跟踪的文件都包含在这次提交中,以 Git 的角度来看,这是一次非常重要的修改,因为它们从没放到仓库中变成了放进去。
|
||||
|
||||
完成一次提交需要运行下面的命令:
|
||||
|
||||
```
|
||||
$ git commit -m 'My great project, first commit.'
|
||||
```
|
||||
|
||||
这就保存了所有提交的文件,之后可以用于其它操作(或者,用英国电视剧《神秘博士》中时间领主所讲的 Gallifreyan 语说,它们成为了“固定的时间点” )。这不仅是一个提交事件,也是一个你在 Git 日志中找到该提交的引用指针:
|
||||
|
||||
```
|
||||
$ git log --oneline
|
||||
55df4c2 My great project, first commit.
|
||||
```
|
||||
|
||||
如果想浏览更多信息,只需要使用不带 `--oneline` 选项的 `git log` 命令。
|
||||
|
||||
在这个例子中提交时的引用号码是 55df4c2。它被叫做“提交哈希(commit hash)”(LCTT 译注:这是一个 SHA-1 算法生成的哈希码,用于表示一个 git 提交对象),它代表着刚才你的提交所包含的所有新改动,覆盖到了先前的记录上。如果你想要“倒回”到你的提交历史点上,就可以用这个哈希作为依据。
|
||||
|
||||
你可以把这个哈希想象成一个声音磁带上的 [SMPTE 时间码][3],或者再形象一点,这就是好比一个黑胶唱片上两首不同的歌之间的空隙,或是一个 CD 上的音轨编号。
|
||||
|
||||
当你改动了文件之后并且把它们加入到提交任务中,最终完成提交,这就会生成新的提交哈希,它们每一个所标示的历史点都代表着你的产品不同的版本。
|
||||
|
||||
这就是 Charlie Brown 这样的音乐家们为什么用 Git 作为版本控制系统的原因。
|
||||
|
||||
在接下来的文章中,我们将会讨论关于 Git HEAD 的各个方面,我们会真正地向你揭示时间旅行的秘密。不用担心,你只需要继续读下去就行了(或许你已经在读了?)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/7/creating-your-first-git-repository
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]: https://github.com/settings/keys
|
||||
[2]: https://gitlab.com/profile/keys
|
||||
[3]: http://slackermedia.ml/handbook/doku.php?id=timecode
|
||||
[4]: https://linux.cn/article-7641-1.html
|
||||
@ -0,0 +1,60 @@
|
||||
Vim 起步的五个技巧
|
||||
=====================================
|
||||
|
||||

|
||||
|
||||
多年来,我一直想学 Vim。如今 Vim 是我最喜欢的 Linux 文本编辑器,也是开发者和系统管理者最喜爱的开源工具。我说的学习,指的是真正意义上的学习。想要精通确实很难,所以我只想要达到熟练的水平。我使用了这么多年的 Linux ,我会的也仅仅只是打开一个文件,使用上下左右箭头按键来移动光标,切换到插入模式,更改一些文本,保存,然后退出。
|
||||
|
||||
但那只是 Vim 的最最基本的操作。我的技能水平只能让我在终端使用 Vim 修改文本,但是它并没有任何一个我想象中强大的文本处理功能。这样我完全无法用 Vim 发挥出胜出 Pico 和 Nano 的能力。
|
||||
|
||||
所以到底为什么要学习 Vim?因为我花费了相当多的时间用于编辑文本,而且我知道还有很大的效率提升空间。为什么不选择 Emacs,或者是更为现代化的编辑器例如 Atom?因为 Vim 适合我,至少我有一丁点的使用经验。而且,很重要的一点就是,在我需要处理的系统上很少碰见没有装 Vim 或者它的弱化版(Vi)。如果你有强烈的欲望想学习对你来说更给力的 Emacs,我希望这些对于 Emacs 同类编辑器的建议能对你有所帮助。
|
||||
|
||||
花了几周的时间专注提高我的 Vim 使用技巧之后,我想分享的第一个建议就是必须使用它。虽然这看起来就是明知故问的回答,但事实上它比我所预想的计划要困难一些。我的大多数工作是在网页浏览器上进行的,而且每次我需要在浏览器之外打开并编辑一段文本时,就需要避免下意识地打开 Gedit。Gedit 已经放在了我的快速启动栏中,所以第一步就是移除这个快捷方式,然后替换成 Vim 的。
|
||||
|
||||
为了更好的学习 Vim,我尝试了很多。如果你也正想学习,以下列举了一些作为推荐。
|
||||
|
||||
### Vimtutor
|
||||
|
||||
通常如何开始学习最好就是使用应用本身。我找到一个小的应用叫 Vimtutor,当你在学习编辑一个文本时它能辅导你一些基础知识,它向我展示了很多我这些年都忽视的基础命令。Vimtutor 一般在有 Vim 的地方都能找到它,如果你的系统上没有 Vimtutor,Vimtutor 可以很容易从你的包管理器上安装。
|
||||
|
||||
### GVim
|
||||
|
||||
我知道并不是每个人都认同这个,但就是它让我从使用终端中的 Vim 转战到使用 GVim 来满足我基本编辑需求。反对者表示 GVim 鼓励使用鼠标,而 Vim 主要是为键盘党设计的。但是我能通过 GVim 的下拉菜单快速找到想找的指令,并且 GVim 可以提醒我正确的指令然后通过敲键盘执行它。努力学习一个新的编辑器然后陷入无法解决的困境,这种感觉并不好受。每隔几分钟读一下 man 出来的文字或者使用搜索引擎来提醒你该用的按键序列也并不是最好的学习新事物的方法。
|
||||
|
||||
### 键盘表
|
||||
|
||||
当我转战 GVim,我发现有一个键盘的“速查表”来提醒我最基础的按键很是便利。网上有很多这种可用的表,你可以下载、打印,然后贴在你身边的某一处地方。但是为了我的笔记本键盘,我选择买一沓便签纸。这些便签纸在美国不到 10 美元,当我使用键盘编辑文本,尝试新的命令的时候,可以随时提醒我。
|
||||
|
||||
### Vimium
|
||||
|
||||
上文提到,我工作都在浏览器上进行。其中一条我觉得很有帮助的建议就是,使用 [Vimium][1] 来用增强使用 Vim 的体验。Vimium 是 Chrome 浏览器上的一个开源插件,能用 Vim 的指令快捷操作 Chrome。我发现我只用了几次使用快捷键切换上下文,就好像比之前更熟悉这些快捷键了。同样的扩展 Firefox 上也有,例如 [Vimerator][2]。
|
||||
|
||||
### 其它人
|
||||
|
||||
毫无疑问,最好的学习方法就是求助于在你之前探索过的人,让他给你建议、反馈和解决方法。
|
||||
|
||||
如果你住在一个大城市,那么附近可能会有一个 Vim meetup 小组,或者还有 Freenode IRC 上的 #vim 频道。#vim 频道是 Freenode 上最活跃的频道之一,那上面可以针对你个人的问题来提供帮助。听上面的人发发牢骚或者看看别人尝试解决自己没有遇到过的问题,仅仅是这样我都觉得很有趣。
|
||||
|
||||
------
|
||||
|
||||
那么,现在怎么样了?到现在为止还不错。为它所花的时间是否值得就在于之后它为你节省了多少时间。但是当我发现一个新的按键序列可以来跳过词,或者一些相似的小技巧,我经常会收获意外的惊喜与快乐。每天我至少可以看见,一点点的回报,正在逐渐配得上当初的付出。
|
||||
|
||||
学习 Vim 并不仅仅只有这些建议,还有很多。我很喜欢指引别人去 [Vim Advantures][3],它是一种使用 Vim 按键方式进行移动的在线游戏。而在另外一天我在 [Vimgifts.com][4] 发现了一个非常神奇的虚拟学习工具,那可能就是你真正想要的:用一个小小的 gif 动图来描述 Vim 操作。
|
||||
|
||||
你有花时间学习 Vim 吗?或者是任何需要大量键盘操作的程序?那些经过你努力后掌握的工具,你认为这些努力值得吗?效率的提高有没有达到你的预期?分享你们的故事在下面的评论区吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/7/tips-getting-started-vim
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[maywanting](https://github.com/maywanting)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[1]: https://github.com/philc/vimium
|
||||
[2]: http://www.vimperator.org/
|
||||
[3]: http://vim-adventures.com/
|
||||
[4]: http://vimgifs.com/
|
||||
61
published/201608/20160722 Keeweb A Linux Password Manager.md
Normal file
61
published/201608/20160722 Keeweb A Linux Password Manager.md
Normal file
@ -0,0 +1,61 @@
|
||||
Linux 下的密码管理器:Keeweb
|
||||
================================
|
||||
|
||||

|
||||
|
||||
如今,我们依赖于越来越多的线上服务。我们每注册一个线上服务,就要设置一个密码;如此,我们就不得不记住数以百计的密码。这样对于每个人来说,都很容易忘记密码。我将在本文中介绍 Keeweb,它是一款 Linux 密码管理器,可以为你离线或在线地安全存储所有的密码。
|
||||
|
||||
当谈及 Linux 密码管理器时,我们会发现有很多这样的软件。我们已经在 LinuxAndUbuntu 上讨论过像 [Keepass][1] 和 [Encryptr,一个基于零知识系统的密码管理器][2] 这样的密码管理器。Keeweb 则是另外一款我们将在本文讲解的 Linux 密码管理器。
|
||||
|
||||
### Keeweb 可以离线或在线存储密码
|
||||
|
||||
Keeweb 是一款跨平台的密码管理器。它可以离线存储你所有的密码,并且能够同步到你自己的云存储服务上,例如 OneDrive、Google Drive、Dropbox 等。Keeweb 并没有它提供它自己的在线数据库来的同步你的密码。
|
||||
|
||||
要使用 Keeweb 连接你的线上存储服务,只需要点击界面中的“more”,然后再点击你想要使用的服务即可。
|
||||
|
||||

|
||||
|
||||
现在,Keeweb 会提示你登录到你的云盘。登录成功后,给 Keeweb 授权使用你的账户。
|
||||
|
||||

|
||||
|
||||
### 使用 Keeweb 存储密码
|
||||
|
||||
使用 Keeweb 存储你的密码是非常容易的。你可以使用一个复杂的密码加密你的密码文件。Keeweb 也允许你使用一个秘钥文件来锁定密码文件,但是我并不推荐这种方式。如果某个家伙拿到了你的秘钥文件,他只需要简单点击一下就可以解锁你的密码文件。
|
||||
|
||||
#### 创建密码
|
||||
|
||||
想要创建一个新的密码,你只需要简单地点击 `+` 号,然后你就会看到所有需要填充的输入框。根据你的需要创建更多的密码记录。
|
||||
|
||||
#### 搜索密码
|
||||
|
||||

|
||||
|
||||
Keeweb 拥有一个图标库,这样你就可以轻松地找到各种特定的密码记录。你可以改变图标的颜色、下载更多的图标,甚至可以直接从你的电脑中导入图标。这对于密码搜索来说,异常好使。
|
||||
|
||||
相似的服务的密码可以分组,这样你就可以在一个文件夹里找到它们。你也可以给密码打上标签并把它们存放在不同分类中。
|
||||
|
||||

|
||||
|
||||
### 主题
|
||||
|
||||

|
||||
|
||||
如果你喜欢类似于白色或者高对比度的亮色主题,你可以在“设置 > 通用 > 主题”中修改。(Keeweb)有四款可供选择的主题,其中两款为暗色,另外两款为亮色。
|
||||
|
||||
### 不喜欢 Linux 密码管理器?没问题!
|
||||
|
||||
我已经发表过文章介绍了另外两款 Linux 密码管理器,它们分别是 Keepass 和 Encryptr,在 Reddit 和其它社交媒体上有些关于它们的争论。有些人反对使用任何密码管理器,也有人持相反意见。在本文中,我想要澄清的是,存放密码文件是我们自己的责任。我认为像 keepass 和 Keeweb 这样的密码管理器是非常好用的,因为它们并没有自己的云来存放你的密码。这些密码管理器会创建一个文件,然后你可以将它存放在你的硬盘上,或者使用像 VeraCrypt 这样的应用给它加密。我个人不使用也不推荐使用那些将密码存储在它们自己数据库的服务。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/keeweb-a-linux-password-manager
|
||||
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.linuxandubuntu.com/home/keeweb-a-linux-password-manager
|
||||
[1]: http://www.linuxandubuntu.com/home/keepass-password-management-tool-creates-strong-passwords-and-keeps-them-secure
|
||||
[2]: http://www.linuxandubuntu.com/home/encryptr-zero-knowledge-system-based-password-manager-for-linux
|
||||
@ -0,0 +1,182 @@
|
||||
Git 系列(四):在 Git 中进行版本回退
|
||||
=============================================
|
||||
|
||||

|
||||
|
||||
在这篇文章中,你将学到如何查看项目中的历史版本,如何进行版本回退,以及如何创建 Git 分支以便你可以大胆尝试而不会出现问题。
|
||||
|
||||
在你的 Git 项目的历史中,你的位置就像是摇滚专辑中的一个片段,由一个被称为 HEAD 的 标记来确定(如磁带录音机或录音播放器的播放头)。要在你的 Git 时间线上前后移动 HEAD ,需要使用 `git checkout` 命令。
|
||||
|
||||
git checkout 命令的使用方式有两种。最常见的用途是从一个以前的提交中恢复文件,你也可以整个倒回磁带,切换到另一个分支。
|
||||
|
||||
|
||||
### 恢复一个文件
|
||||
|
||||
当你意识到一个本来很好文件被你完全改乱了。我们都这么干过:我们把文件放到一个地方,添加并提交,然后我们发现它还需要做点最后的调整,最后这个文件被搞得面目全非了。
|
||||
|
||||
要把它恢复到最后的完好状态,使用 git checkout 从最后的提交(即 HEAD)中恢复:
|
||||
|
||||
```
|
||||
$ git checkout HEAD filename
|
||||
```
|
||||
|
||||
如果你碰巧提交了一个错误的版本,你需要找回更早的版本,使用 git log 查看你更早的提交,然后从合适的提交中找回它:
|
||||
|
||||
```
|
||||
$ git log --oneline
|
||||
79a4e5f bad take
|
||||
f449007 The second commit
|
||||
55df4c2 My great project, first commit.
|
||||
|
||||
$ git checkout 55df4c2 filename
|
||||
|
||||
```
|
||||
|
||||
现在,以前的文件恢复到了你当前的位置。(任何时候你都可以用 git status 命令查看你的当前状态)因为这个文件改变了,你需要添加这个文件,再进行提交:
|
||||
|
||||
```
|
||||
$ git add filename
|
||||
$ git commit -m 'restoring filename from first commit.'
|
||||
```
|
||||
|
||||
使用 Git log 验证你所提交的:
|
||||
|
||||
```
|
||||
$ git log --oneline
|
||||
d512580 restoring filename from first commit
|
||||
79a4e5f bad take
|
||||
f449007 The second commit
|
||||
55df4c2 My great project, first commit.
|
||||
```
|
||||
|
||||
从本质上讲,你已经倒好了磁带并修复了坏的地方,所以你需要重新录制正确的。
|
||||
|
||||
### 回退时间线
|
||||
|
||||
恢复文件的另一种方式是回退整个 Git 项目。这里使用了分支的思想,这是另一种替代方法。
|
||||
|
||||
如果你要回到历史提交,你要将 Git HEAD 回退到以前的版本才行。这个例子将回到最初的提交处:
|
||||
|
||||
```
|
||||
$ git log --oneline
|
||||
d512580 restoring filename from first commit
|
||||
79a4e5f bad take
|
||||
f449007 The second commit
|
||||
55df4c2 My great project, first commit.
|
||||
|
||||
$ git checkout 55df4c2
|
||||
```
|
||||
|
||||
当你以这种方式倒回磁带,如果你按下录音键再次开始,就会丢失以前的工作。Git 默认假定你不想这样做,所以将 HEAD 从项目中分离出来,可以让你如所需的那样工作,而不会因为偶尔的记录而影响之后的工作。
|
||||
|
||||
如果你想看看以前的版本,想要重新做或者尝试不同的方法,那么安全一点的方式就是创建一个新的分支。可以将这个过程想象为尝试同一首歌曲的不同版本,或者创建一个混音的。原始的依然存在,关闭那个分支做你想做的版本吧。
|
||||
|
||||
就像记录到一个空白磁带一样,把你的 Git HEAD 指到一个新的分支处:
|
||||
|
||||
```
|
||||
$ git checkout -b remix
|
||||
Switched to a new branch 'remix'
|
||||
```
|
||||
|
||||
现在你已经切换到了另一个分支,在你面前的是一个替代的干净工作区,准备开始工作吧。
|
||||
|
||||
也可以不用改变时间线来做同样的事情。也许你很想这么做,但切换到一个临时的工作区只是为了尝试一些疯狂的想法。这在工作中完全是可以接受的,请看:
|
||||
|
||||
```
|
||||
$ git status
|
||||
On branch master
|
||||
nothing to commit, working directory clean
|
||||
|
||||
$ git checkout -b crazy_idea
|
||||
Switched to a new branch 'crazy_idea'
|
||||
```
|
||||
|
||||
现在你有一个干净的工作空间,在这里你可以完成一些奇怪的想法。一旦你完成了,可以保留你的改变,或者丢弃他们,并切换回你的主分支。
|
||||
|
||||
若要放弃你的想法,切换到你的主分支,假装新分支不存在:
|
||||
|
||||
```
|
||||
$ git checkout master
|
||||
```
|
||||
|
||||
想要继续使用你的疯狂的想法,需要把它们拉回到主分支,切换到主分支然后合并新分支到主分支:
|
||||
|
||||
```
|
||||
$ git checkout master
|
||||
$ git merge crazy_idea
|
||||
```
|
||||
|
||||
git 的分支功能很强大,开发人员在克隆仓库后马上创建一个新分支是很常见的做法;这样,他们所有的工作都在自己的分支上,可以提交并合并到主分支。Git 是很灵活的,所以没有“正确”或“错误”的方式(甚至一个主分支也可以与其所属的远程仓库分离),但分支易于分离任务和提交贡献。不要太激动,你可以如你所愿的有很多的 Git 分支。完全自由。
|
||||
|
||||
### 远程协作
|
||||
|
||||
到目前为止你已经在自己舒适而私密的家中维护着一个 Git 仓库,但如何与其他人协同工作呢?
|
||||
|
||||
有好几种不同的方式来设置 Git 以便让多人可以同时在一个项目上工作,所以首先我们要克隆仓库,你可能已经从某人的 Git 服务器或 GitHub 主页,或在局域网中的共享存储上克隆了一个仓库。
|
||||
|
||||
工作在私人仓库下和共享仓库下唯一不同的是你需要把你的改变 `push` 到别人的仓库。我们把工作的仓库称之为本地(local)仓库,其他仓库称为远程(remote)仓库。
|
||||
|
||||
当你以读写的方式克隆一个仓库时,克隆的仓库会继承自被称为 origin 的远程库。你可以看看你的克隆仓库的远程仓库:
|
||||
|
||||
```
|
||||
$ git remote --verbose
|
||||
origin seth@example.com:~/myproject.Git (fetch)
|
||||
origin seth@example.com:~/myproject.Git (push)
|
||||
```
|
||||
|
||||
有一个 origin 远程库非常有用,因为它有异地备份的功能,并允许其他人在该项目上工作。
|
||||
|
||||
如果克隆没有继承 origin 远程库,或者如果你选择以后再添加,可以使用 `git remote` 命令:
|
||||
|
||||
```
|
||||
$ git remote add seth@example.com:~/myproject.Git
|
||||
```
|
||||
|
||||
如果你修改了文件,想把它们发到有读写权限的 origin 远程库,使用 `git push`。第一次推送改变,必须也发送分支信息。不直接在主分支上工作是一个很好的做法,除非你被要求这样做:
|
||||
|
||||
```
|
||||
$ git checkout -b seth-dev
|
||||
$ git add exciting-new-file.txt
|
||||
$ git commit -m 'first push to remote'
|
||||
$ git push -u origin HEAD
|
||||
```
|
||||
|
||||
它会推送你当前的位置(HEAD)及其存在的分支到远程。当推送过一次后,以后每次推送可以不使用 -u 选项:
|
||||
|
||||
```
|
||||
$ git add another-file.txt
|
||||
$ git commit -m 'another push to remote'
|
||||
$ git push origin HEAD
|
||||
```
|
||||
|
||||
### 合并分支
|
||||
|
||||
当你工作在一个 Git 仓库时,你可以合并任意测试分支到主分支。当团队协作时,你可能想在将它们合并到主分支之前检查他们的改变:
|
||||
|
||||
```
|
||||
$ git checkout contributor
|
||||
$ git pull
|
||||
$ less blah.txt ### 检查改变的文件
|
||||
$ git checkout master
|
||||
$ git merge contributor
|
||||
```
|
||||
|
||||
如果你正在使用 GitHub 或 GitLab 以及类似的东西,这个过程是不同的。但克隆项目并把它作为你自己的仓库都是相似的。你可以在本地工作,将改变提交到你的 GitHub 或 GitLab 帐户,而不用其它人的许可,因为这些库是你自己的。
|
||||
|
||||
如果你想要让你克隆的仓库接受你的改变,需要创建了一个拉取请求(pull request),它使用 Web 服务的后端发送补丁到真正的拥有者,并允许他们审查和拉取你的改变。
|
||||
|
||||
克隆一个项目通常是在 Web 服务端完成的,它和使用 Git 命令来管理项目是类似的,甚至推送的过程也是。然后它返回到 Web 服务打开一个拉取请求,工作就完成了。
|
||||
|
||||
下一部分我们将整合一些有用的插件到 Git 中来帮你轻松的完成日常工作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/7/how-restore-older-file-versions-git
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
@ -0,0 +1,215 @@
|
||||
如何在 Ubuntu Linux 16.04 LTS 中使用多个连接加速 apt-get/apt
|
||||
=================================================
|
||||
|
||||
我该如何加速在 Ubuntu Linux 16.04 或者 14.04 LTS 上从多个仓库中下载包的 apt-get 或者 apt 命令?
|
||||
|
||||
你需要使用到 apt-fast 这个 shell 封装器。它会通过多个连接同时下载一个包来加速 apt-get/apt 和 aptitude 命令。所有的包都会同时下载。它使用 aria2c 作为默认的下载加速器。
|
||||
|
||||
### 安装 apt-fast 工具
|
||||
|
||||
在 Ubuntu Linux 14.04 或者之后的版本尝试下面的命令:
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:saiarcot895/myppa
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
|
||||
|
||||
更新你的仓库:
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
```
|
||||
|
||||
|
||||
|
||||
安装 apt-fast:
|
||||
|
||||
```
|
||||
$ sudo apt-get -y install apt-fast
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
$ sudo apt -y install apt-fast
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
The following additional packages will be installed:
|
||||
aria2 libc-ares2 libssh2-1
|
||||
Suggested packages:
|
||||
aptitude
|
||||
The following NEW packages will be installed:
|
||||
apt-fast aria2 libc-ares2 libssh2-1
|
||||
0 upgraded, 4 newly installed, 0 to remove and 0 not upgraded.
|
||||
Need to get 1,282 kB of archives.
|
||||
After this operation, 4,786 kB of additional disk space will be used.
|
||||
Do you want to continue? [Y/n] y
|
||||
Get:1 http://01.archive.ubuntu.com/ubuntu xenial/universe amd64 libssh2-1 amd64 1.5.0-2 [70.3 kB]
|
||||
Get:2 http://ppa.launchpad.net/saiarcot895/myppa/ubuntu xenial/main amd64 apt-fast all 1.8.3~137+git7b72bb7-0ubuntu1~ppa3~xenial1 [34.4 kB]
|
||||
Get:3 http://01.archive.ubuntu.com/ubuntu xenial/main amd64 libc-ares2 amd64 1.10.0-3 [33.9 kB]
|
||||
Get:4 http://01.archive.ubuntu.com/ubuntu xenial/universe amd64 aria2 amd64 1.19.0-1build1 [1,143 kB]
|
||||
54% [4 aria2 486 kB/1,143 kB 42%] 20.4 kB/s 32s
|
||||
```
|
||||
|
||||
### 配置 apt-fast
|
||||
|
||||
你将会得到下面的提示(必须输入一个5到16的数值):
|
||||
|
||||
|
||||
|
||||
并且
|
||||
|
||||
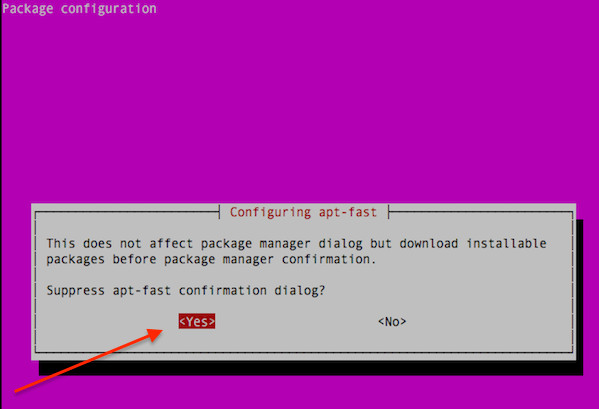
|
||||
|
||||
你也可以直接编辑设置:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/apt-fast.conf
|
||||
```
|
||||
|
||||
> **请注意这个工具并不是给慢速网络连接的,它是给快速网络连接的。如果你的网速慢,那么你将无法从这个工具中得到好处。**
|
||||
|
||||
### 我该怎么使用 apt-fast 命令?
|
||||
|
||||
语法是:
|
||||
|
||||
```
|
||||
apt-fast command
|
||||
apt-fast [options] command
|
||||
```
|
||||
|
||||
#### 使用 apt-fast 取回新的包列表
|
||||
|
||||
```
|
||||
sudo apt-fast update
|
||||
```
|
||||
|
||||
#### 使用 apt-fast 执行升级
|
||||
|
||||
```
|
||||
sudo apt-fast upgrade
|
||||
```
|
||||
|
||||
|
||||
#### 执行发行版升级(发布或者强制内核升级),输入:
|
||||
|
||||
```
|
||||
$ sudo apt-fast dist-upgrade
|
||||
```
|
||||
|
||||
#### 安装新的包
|
||||
|
||||
语法是:
|
||||
|
||||
```
|
||||
sudo apt-fast install pkg
|
||||
```
|
||||
|
||||
比如要安装 nginx,输入:
|
||||
|
||||
```
|
||||
$ sudo apt-fast install nginx
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
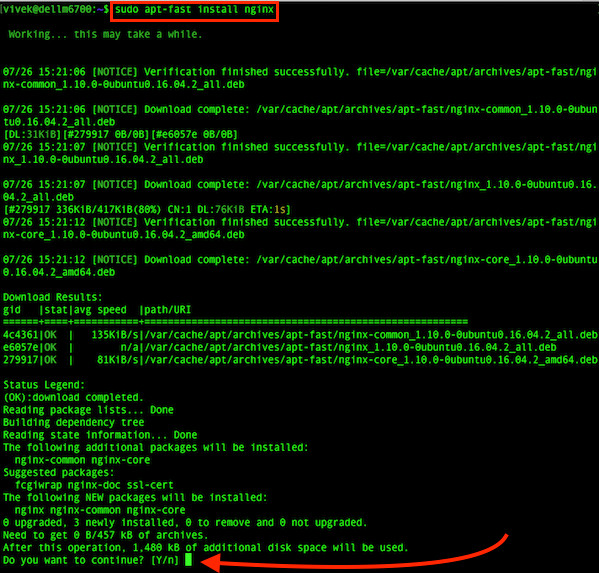
|
||||
|
||||
#### 删除包
|
||||
|
||||
```
|
||||
$ sudo apt-fast remove pkg
|
||||
$ sudo apt-fast remove nginx
|
||||
```
|
||||
|
||||
#### 删除包和它的配置文件
|
||||
|
||||
```
|
||||
$ sudo apt-fast purge pkg
|
||||
$ sudo apt-fast purge nginx
|
||||
```
|
||||
|
||||
#### 删除所有未使用的包
|
||||
|
||||
```
|
||||
$ sudo apt-fast autoremove
|
||||
```
|
||||
|
||||
#### 下载源码包
|
||||
|
||||
```
|
||||
$ sudo apt-fast source pkgNameHere
|
||||
```
|
||||
|
||||
#### 清理下载的文件
|
||||
|
||||
```
|
||||
$ sudo apt-fast clean
|
||||
```
|
||||
|
||||
#### 清理旧的下载文件
|
||||
|
||||
```
|
||||
$ sudo apt-fast autoclean
|
||||
```
|
||||
|
||||
#### 验证没有破坏的依赖
|
||||
|
||||
```
|
||||
$ sudo apt-fast check
|
||||
```
|
||||
|
||||
#### 下载二进制包到当前目录
|
||||
|
||||
```
|
||||
$ sudo apt-fast download pkgNameHere
|
||||
$ sudo apt-fast download nginx
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
[#7bee0c 0B/0B CN:1 DL:0B]
|
||||
07/26 15:35:42 [NOTICE] Verification finished successfully. file=/home/vivek/nginx_1.10.0-0ubuntu0.16.04.2_all.deb
|
||||
07/26 15:35:42 [NOTICE] Download complete: /home/vivek/nginx_1.10.0-0ubuntu0.16.04.2_all.deb
|
||||
Download Results:
|
||||
gid |stat|avg speed |path/URI
|
||||
======+====+===========+=======================================================
|
||||
7bee0c|OK | n/a|/home/vivek/nginx_1.10.0-0ubuntu0.16.04.2_all.deb
|
||||
Status Legend:
|
||||
(OK):download completed.
|
||||
```
|
||||
|
||||
#### 下载并显示指定包的 changelog
|
||||
|
||||
```
|
||||
$ sudo apt-fast changelog pkgNameHere
|
||||
$ sudo apt-fast changelog nginx
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/how-to-speed-up-apt-get-apt-command-ubuntu-linux/
|
||||
|
||||
作者:[VIVEK GITE][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cyberciti.biz/tips/about-us
|
||||
@ -0,0 +1,75 @@
|
||||
在 Linux 下如何查看一个进程的运行时间
|
||||
=====================
|
||||
|
||||

|
||||
|
||||
> 我是一个 Linux 系统的新手。我该如何在我的 Ubuntu 服务器上查看一个进程(或者根据进程 id 查看)已经运行了多久?
|
||||
|
||||
你需要使用 ps 命令来查看关于一组正在运行的进程的信息。ps 命令提供了如下的两种格式化选项。
|
||||
|
||||
1. etime 显示了自从该进程启动以来,经历过的时间,格式为 `[[DD-]hh:]mm:ss`。
|
||||
2. etimes 显示了自该进程启动以来,经历过的时间,以秒的形式。
|
||||
|
||||
### 如何查看一个进程已经运行的时间?
|
||||
|
||||
你需要在 ps 命令之后添加 -o etimes 或者 -o etime 参数。它的语法如下:
|
||||
|
||||
```
|
||||
ps -p {PID-HERE} -o etime
|
||||
ps -p {PID-HERE} -o etimes
|
||||
```
|
||||
|
||||
#### 第一步:找到一个进程的 PID (openvpn 为例)
|
||||
|
||||
```
|
||||
$ pidof openvpn
|
||||
6176
|
||||
```
|
||||
|
||||
#### 第二步:openvpn 进程运行了多长时间?
|
||||
|
||||
```
|
||||
$ ps -p 6176 -o etime
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
$ ps -p 6176 -o etimes
|
||||
```
|
||||
|
||||
隐藏输出头部:
|
||||
|
||||
```
|
||||
$ ps -p 6176 -o etime=
|
||||
$ ps -p 6176 -o etimes=
|
||||
```
|
||||
|
||||
样例输出:
|
||||
|
||||
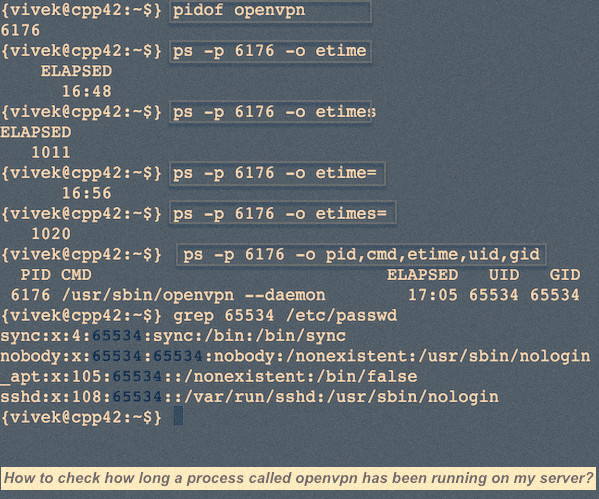
|
||||
|
||||
这个 6176 就是你想查看的进程的 PID。在这个例子中,我查看的是 openvpn 进程。你可以按照你的需求随意的更换 openvpn 进程名或者是 PID。在下面的例子中,我打印了 PID、执行命令、运行时间、用户 ID、和用户组 ID:
|
||||
|
||||
```
|
||||
$ ps -p 6176 -o pid,cmd,etime,uid,gid
|
||||
```
|
||||
|
||||
样例输出:
|
||||
|
||||
```
|
||||
PID CMD ELAPSED UID GID
|
||||
6176 /usr/sbin/openvpn --daemon 15:25 65534 65534
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/how-to-check-how-long-a-process-has-been-running/
|
||||
|
||||
作者:[VIVEK GITE][a]
|
||||
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cyberciti.biz/faq/how-to-check-how-long-a-process-has-been-running/
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user