mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-06 01:20:12 +08:00
commit
d6aa783d44
@ -8,23 +8,23 @@ Linux能够提供消费者想要的东西吗?
|
||||
|
||||
Linux需要深深凝视自己的水晶球,仔细体会那场浏览器大战留下的尘埃,然后留意一下这点建议:
|
||||
|
||||
如果你不能提供他们想要的,他们就会离开。
|
||||
> 如果你不能提供他们想要的,他们就会离开。
|
||||
|
||||
而这种事与愿违的另一个例子是Windows 8。消费者不喜欢那套界面。而微软却坚持使用,因为这是把所有东西搬到Surface平板上所必须的。相同的情况也可能发生在Canonical和Ubuntu Unity身上 -- 尽管它们的目标并不是单一独特地针对平板电脑来设计(所以,整套界面在桌面系统上仍然很实用而且直观)。
|
||||
|
||||
一直以来,Linux开发者和设计者们看上去都按照他们自己的想法来做事情。他们过分在意“吃你自家的狗粮”这句话了。以至于他们忘记了一件非常重要的事情:
|
||||
|
||||
没有新用户,他们的“根基”也仅仅只属于他们自己。
|
||||
> 没有新用户,他们的“根基”也仅仅只属于他们自己。
|
||||
|
||||
换句话说,唱诗班不仅仅是被传道,他们也同时在宣传。让我给你看三个案例来完全掌握这一点。
|
||||
|
||||
- 多年以来,有在Linux系统中替代活动目录(Active Directory)的需求。我很想把这个名称换成LDAP,但是你真的用过LDAP吗?那就是个噩梦。开发者们也努力了想让LDAP能易用一点,但是没一个做到了。而让我很震惊的是这样一个从多用户环境下发展起来的平台居然没有一个能和AD正面较量的功能。这需要一组开发人员,从头开始建立一个AD的开源替代。这对那些寻求从微软产品迁移的中型企业来说是非常大的福利。但是在这个产品做好之前,他们还不能开始迁移。
|
||||
- 多年以来,一直有在Linux系统中替代活动目录(Active Directory)的需求。我很想把这个名称换成LDAP,但是你真的用过LDAP吗?那就是个噩梦。开发者们也努力了想让LDAP能易用一点,但是没一个做到了。而让我很震惊的是这样一个从多用户环境下发展起来的平台居然没有一个能和AD正面较量的功能。这需要一组开发人员,从头开始建立一个AD的开源替代。这对那些寻求从微软产品迁移的中型企业来说是非常大的福利。但是在这个产品做好之前,他们还不能开始迁移。
|
||||
- 另一个从微软激发的需求是Exchange/Outlook。是,我也知道许多人都开始用云。但是,事实上中等和大型规模生意仍然依赖于Exchange/Outlook组合,直到能有更好的产品出现。而这将非常有希望发生在开源社区。整个拼图的一小块已经摆好了(虽然还需要一些工作)- 群件客户端,Evolution。如果有人能够从Zimbra拉出一个分支,然后重新设计成可以配合Evolution(甚至Thunderbird)来提供服务实现Exchange的简单替代,那这个游戏就不是这么玩了,而消费者获得的利益将是巨大的。
|
||||
- 便宜,便宜,还是便宜。这是大多数人都得咽下去的苦药片 - 但是消费者(和生意)就是希望便宜。看看去年一年Chromebook的销量吧。现在,搜索一下Linux笔记本看能不能找到700美元以下的。而只用三分之一的价格,就可以买到一个让你够用的Chromebook(一个使用了Linux内核的平台)。但是因为Linux仍然是一个细分市场,很难降低成本。像红帽那种公司也许可以改变现状。他们也已经推出了服务器硬件。为什么不推出一些和Chromebook有类似定位但是却运行完整Linux环境的低价中档笔记本呢?(请看“[Cloudbook是Linux的未来吗?][1]”)其中的关键是这种设备要低成本并且符合普通消费者的要求。不要站在游戏玩家/开发者的角度去思考了,记住普通消费者真正的需求 - 一个网页浏览器,不会有更多了。这是Chromebook为什么可以这么轻松地成功。Google精确地知道消费者想要什么,然后推出相应的产品。而面对Linux,一些公司仍然认为他们吸引买家的唯一途径是高端昂贵的硬件。而有一点讽刺的是,口水战中最经常听到的却是Linux只能在更慢更旧的硬件上运行。
|
||||
|
||||
最后,Linux需要看一看乔布斯传(Book Of Jobs),搞清楚如何说服消费者们他们真正要的就是Linux。在生意上和在家里 -- 每个人都可以享受到Linux带来的好处。说真的,开源社区怎么可能做不到这点呢?Linux本身就已经带有很多漂亮的时髦术语标签:稳定性,可靠性,安全性,云,免费 -- 再加上Linux实际已经进入到绝大多数人手中了(只是他们自己还不清楚罢了)。现在是时候让他们知道这一点了。如果你是用Android或者Chromebooks,那么你就在用(某种形式上的)Linux。
|
||||
最后,Linux需要看一看乔布斯传(Book Of Jobs),搞清楚如何说服消费者们他们真正要的就是Linux。在公司里和在家里 -- 每个人都可以享受到Linux带来的好处。说真的,开源社区怎么可能做不到这点呢?Linux本身就已经带有很多漂亮的时髦术语标签:稳定性、可靠性、安全性、云、免费 -- 再加上Linux实际已经进入到绝大多数人手中了(只是他们自己还不清楚罢了)。现在是时候让他们知道这一点了。如果你是用Android或者Chromebooks,那么你就在用(某种形式上的)Linux。
|
||||
|
||||
搞清楚消费者需求一直以来都是Linux社区的绊脚石。而且我知道 -- 太多的Linux开发都基于某个开发者有个特殊的想法。这意味着这些开发都针对的“微型市场”。是时候,无论如何,让Linux开发社区能够进行全球性思考了。“一般用户有什么需求,我们怎么满足他们?”让我提几个最基本的点。
|
||||
搞清楚消费者需求一直以来都是Linux社区的绊脚石。而且我知道 -- 太多的Linux开发都基于某个开发者有个特殊的想法。这意味着这些开发都针对的“微型市场”。是时候了,无论如何,让Linux开发社区能够进行全球性思考了。“一般用户有什么需求,我们怎么满足他们?”让我提几个最基本的点。
|
||||
|
||||
一般用户想要:
|
||||
|
||||
@ -43,7 +43,7 @@ via: http://www.techrepublic.com/article/will-linux-ever-be-able-to-give-consume
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,21 +1,20 @@
|
||||
Translating by H-mudcup
|
||||
如何在Ubuntu桌面上使用Steam Music音乐播放器
|
||||
================================================================================
|
||||
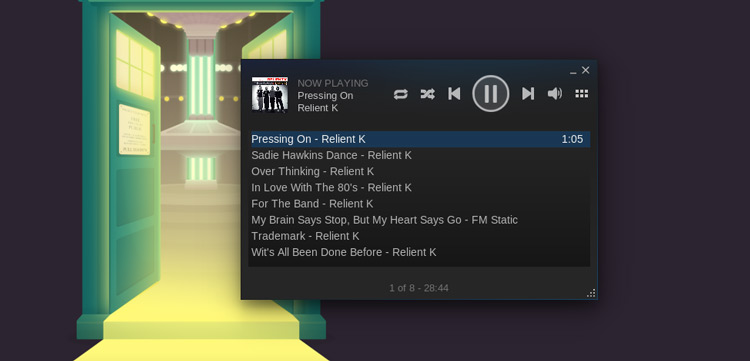
|
||||
|
||||
**‘音乐让人们走到一起’ 麦当娜曾这样唱道。但是Steam的新音乐播放器特性能否很好的混搭小资与叛逆?**
|
||||
|
||||
如果你曾与世隔绝,充耳不闻,你就会错过与Steam Music的相识。播放器的特性并不是全新的。从今年的早些时候开始,它就已经以这样或那样的形式进行了测试。
|
||||
如果你曾与世隔绝,充耳不闻,你就会错过与Steam Music的相识。它的特性并不是全新的。从今年的早些时候开始,它就已经以这样或那样的形式进行了测试。
|
||||
|
||||
但Steam客户端最近一次在Windows、Mac和Linux上的定期更新中,所有的客户端都能使用它了。你会问为什么一个游戏客户端会添加一个音乐播放器呢?当然是为了让你能一边玩游戏一边一边听你最喜欢的音乐了。
|
||||
|
||||
别担心:在游戏的音乐声中再加上你自己的音乐,并没有这句话看起来一样糟(哈哈)。Steam会帮你减少或消除游戏的背景音乐,但在混音器中保持效果音的高音量,以便于你能和平时一样听到那些叮,嘭和各种爆炸声。
|
||||
别担心:在游戏的音乐声中再加上你自己的音乐,听起来并不会像你想象的那么糟(哈哈)。Steam会帮你减少或消除游戏的背景音乐,但在混音器中保持效果音的高音量,以便于你能和平时一样听到那些叮,嘭和各种爆炸声。
|
||||
|
||||
### 使用Steam Music音乐播放器 ###
|
||||
### 使用Steam Music音乐播放器 ###
|
||||
|
||||
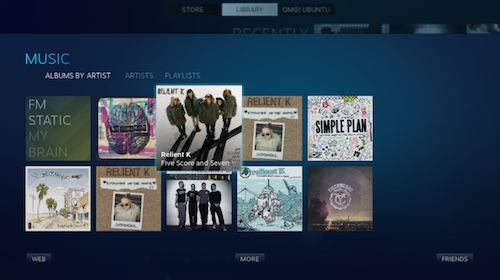
|
||||
|
||||
大图模式
|
||||
*大图模式*
|
||||
|
||||
任何使用最新版客户端的人都能使用Steam Music音乐播放器。它是个相当简单的附加程序:它让你能从你的电脑中添加、浏览并播放音乐。
|
||||
|
||||
@ -27,19 +26,19 @@ Valve说他们“*……计划增加更多的功能以便用户能以新的方
|
||||
|
||||
#### Steam Music的重要特性:####
|
||||
|
||||
- 只播放MP3文件
|
||||
- 只能播放MP3文件
|
||||
- 与游戏中的音乐相融
|
||||
- 在游戏中可以控制音乐
|
||||
- 播放器可以在桌面上或在大图模式下运行
|
||||
- 基于播放列表的播放方式
|
||||
|
||||
**它没有整合到Ubuntu的声音菜单里而且目前也不支持键盘上的多媒体键。**
|
||||
**它没有整合到Ubuntu的声音菜单里,而且目前也不支持键盘上的多媒体键。**
|
||||
|
||||
### 在Ubuntu上使用Steam Music播放器 ###
|
||||
|
||||
添加音乐是你播放音乐前的第一件事。在Ubuntu上,默认设置下,Steam会自动添加两个文件夹:Home下的标准Music目录和它自带的Steam Music文件夹。任何可下载的音轨都保存在其中。
|
||||
显然,添加音乐是你播放音乐前的第一件事。在Ubuntu上,默认设置下,Steam会自动添加两个文件夹:Home下的标准Music目录和它自带的Steam Music文件夹。任何可下载的音轨都保存在其中。
|
||||
|
||||
注意:目前**Steam Music只播放MP3文件**。如果你打大部分音乐都是其他文件格式(比如.acc、.m4a等等),这些文件不会被添加也不能被播放。
|
||||
注意:目前**Steam Music只能播放MP3文件**。如果你的大部分音乐都是其他文件格式(比如.acc、.m4a等等),这些文件不会被添加也不能被播放。
|
||||
|
||||
若想添加其他的文件夹或重新扫描:
|
||||
|
||||
@ -63,7 +62,7 @@ Steam Music是一个以‘队列’方式工作的系统。你可以通过双击
|
||||
|
||||
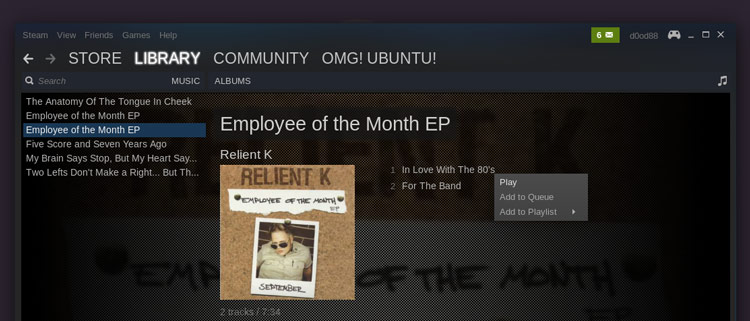
|
||||
|
||||
若想**发送桌面播放器**请点击右上角的音符图标或通过**View > Music Player**菜单。
|
||||
若想**启动桌面播放器**请点击右上角的音符图标或通过**View > Music Player**菜单。
|
||||
|
||||
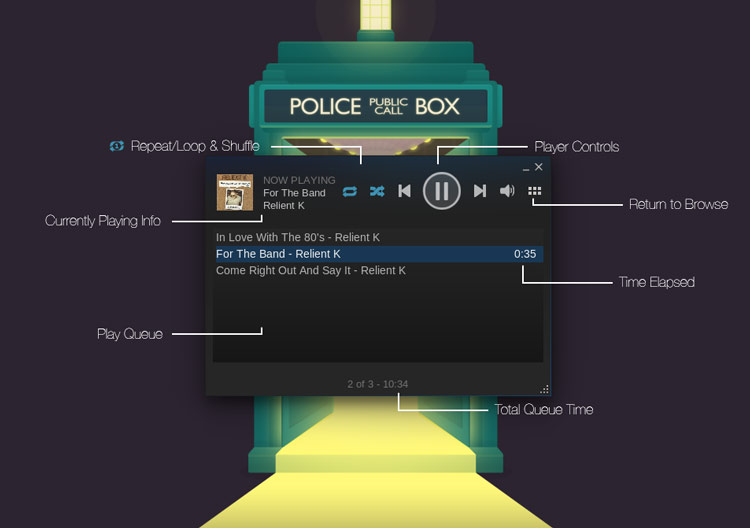
|
||||
|
||||
@ -73,7 +72,7 @@ via: http://www.omgubuntu.co.uk/2014/10/use-steam-music-player-linux
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,44 +1,46 @@
|
||||
2014年会是 "Linux桌面年"吗?
|
||||
================================================================================
|
||||
> 现在谈起Linux桌面终于能头头是道了
|
||||
> Linux桌面现在终于发出最强音!
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
**看来Linux在2014年有很多改变,许多用户都表示今年Linux的确有进步,但是仅凭这个就能断定2014年就是"Linux桌面年"吗?**
|
||||
|
||||
"Linux桌面年"这句话,在过去几年就被传诵得像句颂歌一样,可以说是在试图用一种比较有意义的方式来标记它的发展进程。此类事情目前还没有发生过,在我们的见证下也从无先例,所以这就不难理解为什么Linux用户会用这个角度去看待这句话。
|
||||
|
||||
大多数软件和硬件领域不太会有这种快速的进步,都以较慢的速度发展,但是对于那些在工业领域有更好眼光的人来说,事情就会变得疯狂。即使有可能,针对某一时刻或某一事件还是比较困难的,但是Linux在几年的过程中还是以指数方式迅速发展成长。
|
||||
|
||||

|
||||
|
||||
|
||||
### Linux桌面年这句话不可轻言 ###
|
||||
|
||||
没有一个比较权威的人和机构能判定Linux桌面年已经到来或者已经过去,所以我们只能尝试根据迄今为止我们所看到的和用户所反映的去推断。有一些人比较保守,改变对他们影响不大,还有一些人则比较激进,永远不知满足。这真的要取决于你的见解了。
|
||||
|
||||
点燃这一切的火花似乎就是Linux上的Steam平台,尽管在这变成现实之前我们已经看到了一些Linux游戏已经开始有重要的动作了。在任何情况下,Valve都可能是我们今天所看到的一系列复苏事件的催化剂。
|
||||
|
||||
在过去的十年里,Linux桌面以一种缓慢的速度在发展,并没有什么真正的改变。创新肯定是有的,但是市场份额几乎还是保持不变。无论桌面变得多么酷或Linux相比之前的任何一版多出了多少特点,很大程度上还是在原地踏步,包括那些制作专有软件的公司,他们的参与度一直很小,基本上就忽略掉了Linux。
|
||||

|
||||
|
||||
在过去的十年里,Linux桌面以一种缓慢的速度在发展,并没有什么真正的改变。创新肯定是有的,但是市场份额几乎还是保持不变。无论桌面变得多么酷或Linux相比之前的任何一版多出了多少特点,很大程度上还是在原地踏步,包括那些开发商业软件的公司,他们的参与度一直很小,基本上就忽略掉了Linux。
|
||||
|
||||
|
||||

|
||||
|
||||
现在,相比过去的十年里,更多的公司表现出了对Linux平台的浓厚兴趣。或许这是一种自然地演变,Valve并没有做什么,但是Linux最终还是达到了一个能被普通用户接受并理解的水平,并不只是因为令人着迷的开源技术。
|
||||
|
||||
驱动程序能力强了,游戏工作室就会定期移植游戏,在Linux中我们前所未见的应用和中间件就会开始出现。Linux内核发展达到了难以置信的速度,大多数发行版的安装过程通常都不怎么难,所有这一切都只是冰山一角。
|
||||
|
||||

|
||||
|
||||
所以,当有人问你2014年是不是Linux桌面年时,你可以说“是的!”,因为Linux桌面完全统治了2014年。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Was-2014-The-Year-of-Linux-Desktop-467036.shtml
|
||||
|
||||
作者:[Silviu Stahie ][a]
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,12 @@
|
||||
Attic——重复数据删除备份程序
|
||||
Attic——删除重复数据的备份程序
|
||||
================================================================================
|
||||
Attic是一个Python写的重复数据删除备份程序,其主要目标是提供一种高效安全的数据备份方式。重复数据消除技术的使用使得Attic适用于日常备份,因为它可以只存储那些修改过的数据。
|
||||
Attic是一个Python写的删除重复数据的备份程序,其主要目标是提供一种高效安全的数据备份方式。重复数据消除技术的使用使得Attic适用于日常备份,因为它可以只存储那些修改过的数据。
|
||||
|
||||
### Attic特性 ###
|
||||
|
||||
#### 空间高效存储 ####
|
||||
|
||||
可变块大小重复数据消除技术用于减少检测到的冗余数据存储字节数量。每个文件被分割成若干可变长度组块,只有那些从没见过的组块会被压缩并添加到仓库中。
|
||||
可变块大小重复数据消除技术用于减少检测到的冗余数据存储字节数量。每个文件被分割成若干可变长度组块,只有那些从没见过的组合块会被压缩并添加到仓库中。
|
||||
|
||||
#### 可选数据加密 ####
|
||||
|
||||
@ -44,29 +44,29 @@ Attic可以通过SSH将数据存储到安装有Attic的远程主机上。
|
||||
|
||||
该备份将更快些,也更小些,因为只有之前从没见过的新数据会被存储。--stats选项会让Attic输出关于新创建的归档的统计数据,比如唯一数据(不和其它归档共享)的数量:
|
||||
|
||||
归档名:Tuesday
|
||||
归档指纹:387a5e3f9b0e792e91ce87134b0f4bfe17677d9248cb5337f3fbf3a8e157942a
|
||||
开始时间: Tue Mar 25 12:00:10 2014
|
||||
结束时间: Tue Mar 25 12:00:10 2014
|
||||
持续时间: 0.08 seconds
|
||||
文件数量: 358
|
||||
最初大小 压缩后大小 重复数据删除后大小
|
||||
本归档: 57.16 MB 46.78 MB 151.67 kB
|
||||
所有归档:114.02 MB 93.46 MB 44.81 MB
|
||||
归档名:Tuesday
|
||||
归档指纹:387a5e3f9b0e792e91ce87134b0f4bfe17677d9248cb5337f3fbf3a8e157942a
|
||||
开始时间: Tue Mar 25 12:00:10 2014
|
||||
结束时间: Tue Mar 25 12:00:10 2014
|
||||
持续时间: 0.08 seconds
|
||||
文件数量: 358
|
||||
最初大小 压缩后大小 重复数据删除后大小
|
||||
本归档: 57.16 MB 46.78 MB 151.67 kB
|
||||
所有归档:114.02 MB 93.46 MB 44.81 MB
|
||||
|
||||
列出仓库中所有归档:
|
||||
|
||||
$ attic list /somewhere/my-repository.attic
|
||||
|
||||
Monday Mon Mar 24 11:59:35 2014
|
||||
Tuesday Tue Mar 25 12:00:10 2014
|
||||
Monday Mon Mar 24 11:59:35 2014
|
||||
Tuesday Tue Mar 25 12:00:10 2014
|
||||
|
||||
列出Monday归档的内容:
|
||||
|
||||
$ attic list /somewhere/my-repository.attic::Monday
|
||||
|
||||
drwxr-xr-x user group 0 Jan 06 15:22 home/user/Documents
|
||||
-rw-r--r-- user group 7961 Nov 17 2012 home/user/Documents/Important.doc
|
||||
drwxr-xr-x user group 0 Jan 06 15:22 home/user/Documents
|
||||
-rw-r--r-- user group 7961 Nov 17 2012 home/user/Documents/Important.doc
|
||||
|
||||
恢复Monday归档:
|
||||
|
||||
@ -76,7 +76,7 @@ drwxr-xr-x user group 0 Jan 06 15:22 home/user/Documents
|
||||
|
||||
$ attic delete /somwhere/my-backup.attic::Monday
|
||||
|
||||
详情请查阅[Attic文档][1]
|
||||
详情请查阅[Attic文档][1]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -84,7 +84,7 @@ via: http://www.ubuntugeek.com/attic-deduplicating-backup-program.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
红帽反驳:“grinch”算不上Linux漏洞
|
||||
红帽反驳:“grinch(鬼精灵)”算不上Linux漏洞
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -14,7 +14,7 @@
|
||||
|
||||
Alert Logic 称攻击者可以使用第三方Linux 软件框架Policy Kit (Polkit)达到利用“鬼精灵”漏洞的目的。Polkit旨在帮助用户安装与运行软件包,此开源程序由红帽维护。Alert Logic 声称,允许用户安装软件程序的过程中往往需要超级用户权限,如此一来,Polkit也在不经意间或通过其它形式为恶意程序的运行洞开方便之门。
|
||||
|
||||
红帽对此不以为意,表示系统就是这么设计的,换句话说,“鬼精灵”不是臭虫而是一项特性。
|
||||
红帽对此不以为意,表示系统就是这么设计的,换句话说,**“鬼精灵”不是臭虫而是一项特性。**
|
||||
|
||||
安全监控公司Threat Stack联合创造人 Jen Andre [就此在一篇博客][4]中写道:“如果你任由用户通过使用那些利用了Policykit的软件,无需密码就可以在系统上安装任何软件,实际上也就绕过了Linux内在授权与访问控制。”
|
||||
|
||||
@ -52,7 +52,7 @@ via:http://www.computerworld.com/article/2861392/security0/the-grinch-isnt-a-lin
|
||||
|
||||
作者:[Joab Jackson][a]
|
||||
译者:[yupmoon](https://github.com/yupmoon)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,10 @@
|
||||
Linux有问必答-- 如何在Debian下安装闭源软件包
|
||||
Linux有问必答:如何在Debian下安装闭源软件包
|
||||
================================================================================
|
||||
> **提问**: 我需要在Debian下安装特定的闭源设备驱动。然而, 我无法再Debian中找到并安装包.如何在Debian下安装闭源软件包?
|
||||
> **提问**: 我需要在Debian下安装特定的闭源设备驱动。然而, 我无法在Debian中找到并安装软件包。如何在Debian下安装闭源软件包?
|
||||
|
||||
Debian是一个拥有[48,000][1]软件包的发行版. 这些软件包被分为三类: main, contrib 和 non-free, 主要是根据许可证要求, 例如, [Debian开源软件指南][2] (DFSG).
|
||||
Debian是一个拥有[48,000][1]软件包的发行版. 这些软件包被分为三类: main, contrib 和 non-free, 主要是根据许可证要求, 参照[Debian开源软件指南][2] (DFSG)。
|
||||
|
||||
main软件仓库包括符合DFSG的开源软件。contrib也包括符合DFSG的开源软件,但是依赖闭源软件来编译或者执行。non-free包括不符合DFSG的,可再分发的闭源软件。main仓库被认为是Debian项目的一部分,但是contrib和non-free不是。后两者只是为了用户的方便而维护和提供。
|
||||
main软件仓库包括符合DFSG的开源软件。contrib也包括符合DFSG的开源软件,但是依赖闭源软件来编译或者执行。non-free包括不符合DFSG的、可再分发的闭源软件。main仓库被认为是Debian项目的一部分,但是contrib和non-free不是。后两者只是为了用户的方便而维护和提供。
|
||||
|
||||
如果你想一直能够在Debian上安装闭源软件包,你需要添加contrib和non-free软件仓库。这样做,用文本编辑器打开 /etc/apt/sources.list 添加"contrib non-free""到每个源。
|
||||
|
||||
@ -22,11 +22,11 @@ main软件仓库包括符合DFSG的开源软件。contrib也包括符合DFSG的
|
||||
|
||||
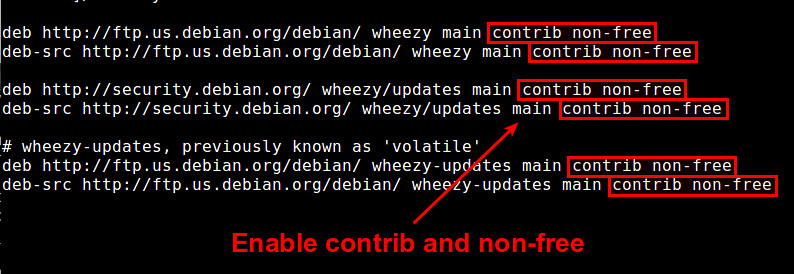
|
||||
|
||||
修改完源后, 运行下面命令去下载contrib和non-free软件仓库的文件索引.
|
||||
修改完源后, 运行下面命令去下载contrib和non-free软件仓库的文件索引。
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
如果你用 aptitude, 运行下面命令.
|
||||
如果你用 aptitude, 运行下面命令。
|
||||
|
||||
$ sudo aptitude update
|
||||
|
||||
@ -39,7 +39,7 @@ main软件仓库包括符合DFSG的开源软件。contrib也包括符合DFSG的
|
||||
via: http://ask.xmodulo.com/install-nonfree-packages-debian.html
|
||||
|
||||
译者:[mtunique](https://github.com/mtunique)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,44 +0,0 @@
|
||||
Linus Torvalds Launches Linux Kernel 3.19 RC1, One of the Biggest So Far
|
||||
================================================================================
|
||||
> new development cycle for Linux kernel has started
|
||||
|
||||

|
||||
|
||||
**The first Linux kernel Release Candidate has been made available in the 3.19 branch and it looks like it's one of the biggest ones so far. Linux Torvalds surprised everyone with an early launch, but it's easy to understand why.**
|
||||
|
||||
The Linux kernel development cycle has been refreshed with a new released, 3.19. Given the fact that the 3.18 branch reached stable status just a couple of weeks ago, today's release was not completely unexpected. The holidays are coming and many of the developers and maintainers will probably take a break. Usually, a new RC is launched on a weekly basis, but users might see a slight delay this time.
|
||||
|
||||
There is no mention of the regression problem that was identified in Linux kernel 3.18, but it's pretty certain that they are still working to fix it. On the other hand, Linux did say that this is a very large released, in fact it's one of the biggest ones made until now. It's likely that many devs wanted to push their patches before the holidays, so the next RC should be a smaller.
|
||||
|
||||
### Linux kernel 3.19 RC1 marks the start of a new cycle ###
|
||||
|
||||
The size of the releases has been increasing, along with the frequency. The development cycle for the kernel usually takes about 8 to 10 weeks and it seldom happens to be more than that, which brings a nice predictability for the project.
|
||||
|
||||
"That said, maybe there aren't any real stragglers - and judging by the size of rc1, there really can't have been much. Not only do I think there are more commits than there were in linux-next, this is one of the bigger rc1's (at least by commits) historically. We've had bigger ones (3.10 and 3.15 both had large merge windows leading up to them), but this was definitely not a small merge window."
|
||||
|
||||
"In the 'big picture', this looks like a fairly normal release. About two thirds driver updates, with about half of the rest being architecture updates (and no, the new nios2 patches are not at all dominant, it's about half ARM, with the new nios2 support being less than 10% of the arch updates by lines overall)," [reads][1] the announcement made by Linus Torvalds.
|
||||
|
||||
More details about this RC can be found on the official mailing list.
|
||||
|
||||
#### Download Linux kernel 3.19 RC1 source package: ####
|
||||
|
||||
- [tar.xz (3.18.1 Stable)][3]File size: 77.2 MB
|
||||
- [tar.xz (3.19 RC1 Unstable)][4]
|
||||
|
||||
It you want to test it, you will need to compile it yourself although it's advisable to not use a production machines.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Linus-Torvalds-Launches-Linux-kernel-3-19-RC1-One-of-the-Biggest-So-Far-468043.shtml
|
||||
|
||||
作者:[Silviu Stahie ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:http://lkml.iu.edu/hypermail/linux/kernel/1412.2/02480.html
|
||||
[2]:http://linux.softpedia.com/get/System/Operating-Systems/Kernels/Linux-Kernel-Development-8069.shtml
|
||||
[3]:https://www.kernel.org/pub/linux/kernel/v3.x/linux-3.18.1.tar.xz
|
||||
[4]:https://www.kernel.org/pub/linux/kernel/v3.x/testing/linux-3.19-rc1.tar.xz
|
||||
@ -0,0 +1,125 @@
|
||||
4 Steps to Setup Local Repository in Ubuntu using APT-mirror
|
||||
================================================================================
|
||||
Today we will show you how to setup a local repository in your Ubuntu PC or Ubuntu Server straight from the official Ubuntu repository. There are a lot benefit of creating a local repository in your computer if you have a lot of computers to install software, security updates and fixes often in all systems, then having a local Ubuntu repository is an efficient way. Because all required packages are downloaded over the fast LAN connection from your local server, so that it will save your Internet bandwidth and reduces the annual cost of Internet..
|
||||
|
||||
You can setup a local repository of Ubuntu in your local PC or server using many tools, but we'll featuring about APT-Mirror in this tutorial. Here, we'll be mirroring packages from the default mirror to our Local Server or PC and we'll need at least **120 GB** or more free space in your local or external hard drive. It can be configured through a **HTTP** or **FTP** server to share its software packages with local system clients.
|
||||
|
||||
We'll need to install Apache Web Server and APT-Mirror to get our stuffs working out of the box. Here are the steps below to configure a working local repository:
|
||||
|
||||
### 1. Installing Required Packages ###
|
||||
|
||||
First of all, we are going to pull whole packages from the public repository of Ubuntu package server and save them in our local Ubuntu server hard disk.
|
||||
|
||||
We'll first install a web server to host our local repository. We'll install Apache web server but you can install any web server you wish, web server are necessary for the http protocol. You can additionally install FTP servers like proftpd, vsftpd,etc if you need to configure for ftp protocols and Rsync for rsync protocols.
|
||||
|
||||
$ sudo apt-get install apache2
|
||||
|
||||
And then we'll need to install apt-mirror:
|
||||
|
||||
$ sudo apt-get install apt-mirror
|
||||
|
||||

|
||||
|
||||
**Note: As I have already mentioned that we'll need at least 120 GBs free space to get all the packages mirrored or download.**
|
||||
|
||||
### 2. Configuring APT-Mirror ###
|
||||
|
||||
Now create a directory on your harddisk to save all packages. For example, let us create a directory called “/linoxide”. We are going to save all packages in this directory:
|
||||
|
||||
$ sudo mkdir /linoxide
|
||||
|
||||

|
||||
|
||||
Now, open the file **/etc/apt/mirror.list** file
|
||||
|
||||
$ sudo nano /etc/apt/mirror.list
|
||||
|
||||

|
||||
|
||||
Copy the below lines of configuration to mirror.list and edit as your requirements.
|
||||
|
||||
############# config ##################
|
||||
#
|
||||
set base_path /linoxide
|
||||
#
|
||||
# set mirror_path $base_path/mirror
|
||||
# set skel_path $base_path/skel
|
||||
# set var_path $base_path/var
|
||||
# set cleanscript $var_path/clean.sh
|
||||
# set defaultarch <running host architecture>
|
||||
# set postmirror_script $var_path/postmirror.sh
|
||||
# set run_postmirror 0
|
||||
set nthreads 20
|
||||
set _tilde 0
|
||||
#
|
||||
############# end config ##############
|
||||
|
||||
deb http://archive.ubuntu.com/ubuntu trusty main restricted universe multiverse
|
||||
deb http://archive.ubuntu.com/ubuntu trusty-security main restricted universe multiverse
|
||||
deb http://archive.ubuntu.com/ubuntu trusty-updates main restricted universe multiverse
|
||||
#deb http://archive.ubuntu.com/ubuntu trusty-proposed main restricted universe multiverse
|
||||
#deb http://archive.ubuntu.com/ubuntu trusty-backports main restricted universe multiverse
|
||||
|
||||
deb-src http://archive.ubuntu.com/ubuntu trusty main restricted universe multiverse
|
||||
deb-src http://archive.ubuntu.com/ubuntu trusty-security main restricted universe multiverse
|
||||
deb-src http://archive.ubuntu.com/ubuntu trusty-updates main restricted universe multiverse
|
||||
#deb-src http://archive.ubuntu.com/ubuntu trusty-proposed main restricted universe multiverse
|
||||
#deb-src http://archive.ubuntu.com/ubuntu trusty-backports main restricted universe multiverse
|
||||
|
||||
clean http://archive.ubuntu.com/ubuntu
|
||||
|
||||

|
||||
|
||||
**Note: You can replace the above official mirror server url by the nearest one, you can get your nearest server by visiting the page [Ubuntu Mirror Server][1]. If you are not in hurry and can wait for the mirroring, you can go with the default official one.**
|
||||
|
||||
Here, we are going to mirror package repository of the latest and greatest LTS release of Ubuntu ie. Ubuntu 14.04 LTS (Trusty Tahr) so, we have configured trusty. If you need to mirror of Saucy or other version of Ubuntu, please edit it as its codename.
|
||||
|
||||
Now, we'll have to run apt-mirror which will now get/mirror all the packages in the repository.
|
||||
|
||||
sudo apt-mirror
|
||||
|
||||
It will take time to download all the packages from the Ubuntu Server which depends upon the connection speed and performance with respect to you and the mirror server. I have interrupted the download as I have already done that...
|
||||
|
||||

|
||||
|
||||
### 3.Configuring Web Server ###
|
||||
|
||||
To be able to access the repo from other computers you need a webserver. You can also do it via ftp but I choose to use a webserver as I mentioned in above step 1. So, we are now gonna configure Apache Server:
|
||||
|
||||
We will create a symlink from our local repo's directory to a directory ubuntu in the hosting directory of Apache ie /var/www/ubuntu
|
||||
|
||||
$ sudo ln -s /linoxide /var/www/ubuntu
|
||||
$ sudo service apache2 start
|
||||
|
||||

|
||||
|
||||
The above command will allow us to browse our Mirrored Repo from our localhost ie http://127.0.0.1 by default.
|
||||
|
||||
### 4. Configuring Client Side ###
|
||||
|
||||
Finally, we need to add repository source in other computers which will fetch the packages and repository from our computer. To do that, we'll need to edit /etc/apt/sources.list and add the following lines.
|
||||
|
||||
$ sudo nano /etc/apt/sources.list
|
||||
|
||||
Add this line in /etc/apt/sources.list and save.
|
||||
|
||||
deb http://192.168.0.100/ubuntu/ trusty main restricted universe
|
||||
|
||||
**Note: here 192.168.0.100 is the LAN IP address of our server computer, you need to replace that with yours.**
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
Finally, we are done. Now you can install the required packages using sudo apt-get install packagename from your local Ubuntu repository with high speed download and with low bandwidth.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/setup-local-repository-ubuntu/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://launchpad.net/ubuntu/+archivemirrors
|
||||
264
sources/tech/20141229 5 User Space Debugging Tools in Linux.md
Normal file
264
sources/tech/20141229 5 User Space Debugging Tools in Linux.md
Normal file
@ -0,0 +1,264 @@
|
||||
5 User Space Debugging Tools in Linux
|
||||
================================================================================
|
||||
By definition, debugging tools are those programs which allow us to monitor ,control and correct errors in other programs while they execute. Why should we use debugging tools? To answer this, there are various situations where we get stuck while running some programs and will have the need to understand what exactly happened. For example, we might be running an application and it produces some error messages. To fix those errors, we should first figure out why and from where did the error messages come from. An application might suddenly hang and we will have to know what other processes were running at that time. We might also have to figure out what was process 'x' doing at the time of hang. In order to dissect such details, we will need the help of debugging tools. There are a few user space debugging tools and techniques in Linux which are quite useful in analysing user space problems. They are:
|
||||
|
||||
- **'print' statements**
|
||||
- **Querying (/proc, /sys etc)**
|
||||
- **Tracing (strace/ltrace)**
|
||||
- **Valgrind (memwatch)**
|
||||
- **GDB**
|
||||
|
||||
Let's go through each of them one by one.
|
||||
|
||||
### 1.'print' statements ###
|
||||
|
||||
This is a basic or primitive way of debugging a problem. We can insert print statements in the middle of a program to understand the control flow and get the value of key variables. Though it is a simple technique, it has some disadvantages to it. Programs need to be edited to add 'print 'statements which then will have to be recompiled and rerun to get the output. This is a time-consuming method if the program to be debugged is quite big.
|
||||
|
||||
### 2. Querying ###
|
||||
|
||||
In some situations, we might want to figure out in what state a running process is in the kernel or what is the memory map that it is occupying there etc. In order to obtain this type of information, we need not insert any code into the kernel. Instead, one can use the /proc filesystem.
|
||||
|
||||
/proc is a pseudo filesystem that gets populated with runtime system information (cpu information, amount of memory etc) once the system is up and running.
|
||||
|
||||

|
||||
output of 'ls /proc'
|
||||
|
||||
As you can see, each process that is running in the system has an entry in the /proc filesystem in the form of its process id . Details about each of these processes can be obtained by looking into the files present in its process id directory
|
||||
|
||||

|
||||
output of 'ls /proc/pid'
|
||||
|
||||
Explaining all the entries inside the /proc filesystem is beyond the scope of this document. Some of the useful ones are listed below:
|
||||
|
||||
- /proc/cmdline -> Kernel command line
|
||||
- /proc/cpuinfo -> information about the processor's make, model etc
|
||||
- /proc/filesystems -> filesystem information supported by the kernel
|
||||
- /proc//cmdline -> command line arguments passed to the current process
|
||||
- /proc//mem -> memory held by the process
|
||||
- /proc//status -> status of the process
|
||||
|
||||
### 3. Tracing ###
|
||||
|
||||
strace and ltrace are two of the tracing tools used in Linux to trace program execution details.
|
||||
|
||||
#### strace: ####
|
||||
|
||||
strace intercepts and records system calls within a process and the signals received by it. To the user, it displays the system calls, arguments passed to them and the return values. strace can be attached to a process that is already running or to a new process. It is useful as a diagnostic and debugging tools for developers and system administrators. It can also be used as a tool to understand how system calls work by tracing different programs. Advantage of this tool is that no source code is needed and programs need not be recompiled.
|
||||
|
||||
The basic syntax for using strace is:
|
||||
|
||||
**strace command**
|
||||
|
||||
There are various options that are available to be used with strace command. One can check out the man page for strace tool to get more details.
|
||||
|
||||
The output of strace can be quite lengthy and we may not be interested in going through each and every line that is displayed. We can use the '-e expr' option to filter the unwanted data.
|
||||
|
||||
Use '-p pid' option to attach it to a running process.
|
||||
|
||||
Output of the command can be redirected to a file using the '-o' option
|
||||
|
||||

|
||||
output of strace filtering only the open system call
|
||||
|
||||
#### ltrace: ####
|
||||
|
||||
ltrace tracks and records the dynamic (runtime) library calls made by a process and the signals received by it. It can also track the system calls made within a process. It's usage is similar to strace
|
||||
|
||||
**ltrace command**
|
||||
|
||||
'-i ' option prints the instruction pointer at the time of library call
|
||||
|
||||
'-S' option is used to display both system calls and library calls
|
||||
|
||||
Refer to the ltrace man page for all the available options.
|
||||
|
||||

|
||||
output of ltrace capturing 'strcmp' library call
|
||||
|
||||
### 4. Valgrind ###
|
||||
|
||||
Valgrind is a suite of debugging and profiling tools. One of the widely used and the default tool is a memory checking tool called 'Memcheck' which intercepts calls made to malloc(), new(), free() and delete(). In other words, it is useful in detecting problems like:
|
||||
|
||||
- memory leaks
|
||||
- double freeing
|
||||
- boundary overruns
|
||||
- using uninitialized memory
|
||||
- using a memory after it has been freed etc.
|
||||
|
||||
It works directly with the executable files.
|
||||
|
||||
Valgrind comes with a few drawbacks as well. It can slow down your program as it increases the memory footprint. It can sometimes produce false positives and false negatives. It cannot detect out-of-range access to statically allocated arrays
|
||||
|
||||
In order to use it, first download it and install it on your system. ([Valgrind's download page][1]). It can be installed using the package manager for the operating system that one is using.
|
||||
|
||||
Installation using command line involves decompressing and untarring the downloaded file.
|
||||
|
||||
tar -xjvf valgring-x.y.z.tar.bz2 (where x.y.z is the version number you are trying to install)
|
||||
|
||||
Get inside the newly created directory (valgrind-x.y.z)and run the following commands:
|
||||
|
||||
./configure
|
||||
make
|
||||
make install
|
||||
|
||||
Let's understand how valgrind works with a small program(test.c):
|
||||
|
||||
#include <stdio.h>
|
||||
|
||||
void f(void)
|
||||
|
||||
{
|
||||
int x = malloc(10 * sizeof(int));
|
||||
|
||||
x[10] = 0;
|
||||
}
|
||||
|
||||
int main()
|
||||
{
|
||||
f();
|
||||
return 0;
|
||||
}
|
||||
|
||||
Compile the program:
|
||||
|
||||
gcc -o test -g test.c
|
||||
|
||||
Now we have an executable file called 'test'. We can now use valgrind to check for memory errors:
|
||||
|
||||
valgrind –tool=memcheck –leak-check=yes test
|
||||
|
||||
Here is the valgrind output showing the errors:
|
||||
|
||||

|
||||
output of valgrind showing heap block overrun and memory leak
|
||||
|
||||
As we can see in the above message, we are trying to access the area beyond what is allocated in function f and the allocated memory is not freed.
|
||||
|
||||
### 5. GDB ###
|
||||
|
||||
GDB is a debugger from Free Software Foundation. It is useful in locating and fixing problems in the code. It gives control to the user to perform various actions when the program to be debugged is running, like:
|
||||
|
||||
- starting the program
|
||||
- stop at specified locations
|
||||
- stop on specified conditions
|
||||
- examine required information
|
||||
- make changes to data in the program etc.
|
||||
|
||||
One can also attach a core dump of a crashed program to GDB and analyse the cause of crash.
|
||||
|
||||
GDB provides a lot of options to debug programs. However, we will cover some important options here so that one can get a feel of how to get started with GDB.
|
||||
|
||||
If you do not already have GDB installed, it can be downloaded from [GDB's official website][2].
|
||||
|
||||
#### Compiling programs: ####
|
||||
|
||||
In order to debug a program using GDB, it has to be compiled using gcc with the'-g' option. This produces debugging information in the operating system's native format and GDB works with this information.
|
||||
|
||||
Here is a simple program (example1.c)performing divide by zero to show the usage of GDB:
|
||||
|
||||
#include
|
||||
int divide()
|
||||
{
|
||||
int x=5, y=0;
|
||||
return x / y;
|
||||
}
|
||||
|
||||
int main()
|
||||
{
|
||||
divide();
|
||||
}
|
||||
|
||||

|
||||
An example showing usage of gdb
|
||||
|
||||
#### Invoking GDB: ####
|
||||
|
||||
GDB can be started by executing 'gdb' in the command-line:
|
||||
|
||||

|
||||
invoking gdb
|
||||
|
||||
Once invoked, it remains there waiting for commands from the terminal and executing them until exited .
|
||||
|
||||
If a process is already running and you need to attach GDB to it, it can be done by specifying the process id Suppose a program has already crashed and one wants to analyse the cause of the problem, then attaching GDB to the core file helps.
|
||||
|
||||
#### Starting the program: ####
|
||||
|
||||
Once you are inside GDB, use the 'run' command to start the program to be debugged
|
||||
|
||||
#### Passing arguments to the program: ####
|
||||
|
||||
Use the 'set args' command to send the arguments to your program when it runs next time 'show args' will show the arguments passed to the program
|
||||
|
||||
#### Verifying the stack: ####
|
||||
|
||||
Whenever a program stops, first thing anyone wants to understand is why it stopped and how it stopped there. This information is called backtrace. Every function call generated by a program gets stored along with the local variables, arguments passed, call location etc in a block of data inside the stack and is called a frame. Using GDB we can examine all this data. GDB identifies these frames by giving them numbers starting from the innermost frame.
|
||||
|
||||
- **bt**: prints the backtrace of the entire stack
|
||||
- **bt <n>** prints the backtrace of n frames
|
||||
- **frame <frame number>**: switches to the specified frame and prints that frame
|
||||
- **up <n>**: move 'n' frames up
|
||||
- **down <n>**: move 'n' frames down. ( n is 1 by default)
|
||||
|
||||
#### Examining data: ####
|
||||
|
||||
Program's data can be examined inside GDB using the 'print' command. For example, if 'x' is a variable inside the debugging program, 'print x' prints the value of x.
|
||||
|
||||
#### Examining source: ####
|
||||
|
||||
Parts of source file can be printed within GDB. 'list' command by default prints 10 lines of code.
|
||||
|
||||
- **list <linenum>**: list the source file around 'linenum'
|
||||
- **list <function>**: list the source from the beginning of 'function'
|
||||
|
||||
- **disas <function>**: displays the machine code for the function
|
||||
|
||||
#### Stopping and resuming the program: ####
|
||||
|
||||
Using GDB, we can set breakpoints, watchpoint etc in order to stop the program wherever required.
|
||||
|
||||
- **break <location>**: Sets up a breakpoint at 'location'. When this is hit while the program is executing, control is given to the user.
|
||||
- **watch <expr>**: GDB stops when the 'expr' is written into by the program and it's value changes
|
||||
- **catch <event>**: GDB stops when the 'event' occurs.
|
||||
- **disable <breakpoint>**: disable the specified breakpoint
|
||||
- **enable <breakpoint>**: enable the specified breakpoint
|
||||
- **delete <breakpoint>**: delete the breakpoint / watchpoint / catch point passed. If no arguments are passed default action is to work on all the breakpoints
|
||||
|
||||
- **step**: execute the program step by step
|
||||
- **continue**: continue with program execution until execution is complete
|
||||
|
||||
#### Exiting GDB: ####
|
||||
|
||||
Use the 'quit' command to exit from GDB
|
||||
|
||||
There are many more options that are available with GDB. Use the help option once you are inside GDB for more details.
|
||||
|
||||

|
||||
getting help within gdb
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this article, we have seen different types of user space debug tools available in Linux. To summarise all of them, here is a quick guideline on when to use what:
|
||||
Basic debugging, getting values of key variables – print statements
|
||||
|
||||
Get information about filesystems supported, available memory, cpus, status of a running program in the kernel etc - querying /proc filesystem
|
||||
|
||||
Initial problem diagnosis, system call or library call related issues , understanding program flow – strace / ltrace
|
||||
|
||||
Application space related memory problems – valgrind
|
||||
|
||||
To examine runtime behaviour of applications, analysing application crashes – gdb.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/user-space-debugging-tools-linux/
|
||||
|
||||
作者:[B N Poornima][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/bnpoornima/
|
||||
[1]:http://valgrind.org/downloads.html
|
||||
[2]:http://www.gnu.org/software/gdb/download/
|
||||
@ -0,0 +1,83 @@
|
||||
How to Create Btrfs Filesystem in Linux and its Features
|
||||
================================================================================
|
||||
**Btrfs** (B-tree file system) is a new CoW (copy-on-write) file system for Linux. It's development began at [Oracle Corporation][1] in 2007 and it was marked as stable in August 2014. The purpose of Btrfs is to address the lack of pooling, snapshots, checksums, and integral multi-device spanning in Linux file systems and its goal was to let Linux scale for the storage that will be available. Scaling is not just about addressing the storage but also means being able to administer and to manage it with a clean interface that lets people see what's being used and makes it more reliable.
|
||||
|
||||
You should note that Btrfs has just become stable so it is recommended to always use the latest available version of the kernel to avoid any problems or bugs.
|
||||
|
||||
### Btrfs Features ###
|
||||
|
||||
Among the most important features of the new file system:
|
||||
|
||||
- Extent based file storage
|
||||
- 16 EiB maximum file size
|
||||
- Space-efficient packing of small files and indexed directories
|
||||
- Dynamic inode allocation
|
||||
- Writable snapshots and read-only snapshots
|
||||
- Subvolumes (separate internal filesystem roots)
|
||||
- Checksums on data and metadata
|
||||
- Compression (gzip and LZO)
|
||||
- Integrated multiple device support
|
||||
- File Striping, File Mirroring, and File Striping+Mirroring implementations
|
||||
- Efficient incremental backup
|
||||
- Background scrub process for finding and fixing errors on files with redundant copies
|
||||
- Online filesystem defragmentation and Offline filesystem check
|
||||
- Btrfs filesystem have much enhancement on RAID 5/ RAID 6 support and many [bug fixes has been added on linux 3.19][2]
|
||||
|
||||
You can [read about the new features][3] on this wiki article covering the subject.
|
||||
|
||||
### Converting to Btrfs ###
|
||||
|
||||
**WARNING: You should always backup your data before atempting to convert a file system. Although this operation is stable and safe it can lead to data loss and the only way to prevent this is to always have a backup of your data.**
|
||||
|
||||
Converting an existing ext4 filesystem to btrfs is quite simple and straightforward, you will first need to use fsck to check if there are any errors on your existing partition and then use the btrfs-convert command to convert it. If the partition you wish to convert is /dev/sda3 you can do it like this:
|
||||
|
||||
# fsck.ext4 /dev/sda4
|
||||
# btrfs-convert /dev/sda4
|
||||
|
||||
You can then use the mount command to mount it where you wish.
|
||||
|
||||

|
||||
|
||||
### Converting the root partition ###
|
||||
|
||||
If you wish to convert the root partition of your system you will first have to boot a live CD, you can do this by using the Ubuntu installation CD and selecting "Try Ubuntu" from the first screen or use any other Live CD image available.
|
||||
|
||||
After you boot open a terminal and use it to convert the filesystem.
|
||||
|
||||
# fsck.ext4 /dev/sda1
|
||||
# btrfs-convert /dev/sda1
|
||||
|
||||
Next chroot to the filesystem so you can change fstab and reinstall grub
|
||||
|
||||
# mount /dev/sda1 /mnt
|
||||
# for i in dev dev/pts proc sys ; do mount --bind /$i /mnt/$i ; done
|
||||
# chroot /mnt
|
||||
# blkid | grep sda1
|
||||
|
||||

|
||||
|
||||
Now edit fstab and replace the current UUID of the / filesystem with the one blkid outputted and the filesystem type with btrfs, the new line should look like this:
|
||||
|
||||
UUID=8e7e80aa-337e-4179-966d-d60128bd3714 / btrfs defaults 0 1
|
||||
|
||||
Then reinstall Grub:
|
||||
|
||||
# grub-install /dev/sda
|
||||
# update-grub
|
||||
|
||||
You can now reboot the machine without using the boot CD and use it with the new filesystem.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/file-system/create-btrfs-features/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/adriand/
|
||||
[1]:http://www.oracle.com/index.html
|
||||
[2]:http://lkml.iu.edu/hypermail/linux/kernel/1412.1/03583.html
|
||||
[3]:https://btrfs.wiki.kernel.org/index.php/Main_Page#Features
|
||||
@ -0,0 +1,202 @@
|
||||
How to Install Bugzilla 4.4 on Ubuntu / CentOS 6.x
|
||||
================================================================================
|
||||
Here, we are gonna show you how we can install Bugzilla in an Ubuntu 14.04 or CentOS 6.5/7. Bugzilla is a Free and Open Source Software(FOSS) which is web based bug tracking tool used to log and track defect database, its Bug-tracking systems allow individual or groups of developers effectively to keep track of outstanding problems with their product. Despite being "free", Bugzilla has many features its expensive counterparts lack. Consequently, Bugzilla has quickly become a favorite of thousands of organizations across the globe.
|
||||
|
||||
Bugzilla is very adaptable to various situations. They are used now a days in different IT support queues, Systems Administration deployment management, chip design and development problem tracking (both pre-and-post fabrication), and software and hardware bug tracking for luminaries such as Redhat, NASA, Linux-Mandrake, and VA Systems.
|
||||
|
||||
### 1. Installing dependencies ###
|
||||
|
||||
Setting up Bugzilla is fairly **easy**. This blog is specific to Ubuntu 14.04 and CentOS 6.5 ( though it might work with older versions too )
|
||||
|
||||
In order to get Bugzilla up and running in Ubuntu or CentOS, we are going to install Apache webserver ( SSL enabled ) , MySQL database server and also some tools that are required to install and configure Bugzilla.
|
||||
|
||||
To install Bugzilla in your server, you'll need to have the following components installed:
|
||||
|
||||
- Per l(5.8.1 or above)
|
||||
- MySQL
|
||||
- Apache2
|
||||
- Bugzilla
|
||||
- Perl modules
|
||||
- Bugzilla using apache
|
||||
|
||||
As we have mentioned that this article explains installation of both Ubuntu 14.04 and CentOS 6.5/7, we will have 2 different sections for them.
|
||||
|
||||
Here are the steps you need to follow to setup Bugzilla in your Ubuntu 14.04 LTS and CentOS 7:
|
||||
|
||||
**Preparing the required dependency packages:**
|
||||
|
||||
You need to install the essential packages by running the following command:
|
||||
|
||||
**For Ubuntu:**
|
||||
|
||||
$ sudo apt-get install apache2 mysql-server libapache2-mod-perl2
|
||||
libapache2-mod-perl2-dev libapache2-mod-perl2-doc perl postfix make gcc g++
|
||||
|
||||
**For CentOS:**
|
||||
|
||||
$ sudo yum install httpd mod_ssl mysql-server mysql php-mysql gcc perl* mod_perl-devel
|
||||
|
||||
**Note: Please run all the commands in a shell or terminal and make sure you have root access (sudo) on the machine.**
|
||||
|
||||
### 2. Running Apache server ###
|
||||
|
||||
As you have already installed the apache server from the above step, we need to now configure apache server and run it. We'll need to go for sudo or root mode to get all the commands working so, we'll gonna switch to root access.
|
||||
|
||||
$ sudo -s
|
||||
|
||||
Now, we need to open port 80 in the firewall and need to save the changes.
|
||||
|
||||
# iptables -I INPUT -p tcp --dport 80 -j ACCEPT
|
||||
# service iptables save
|
||||
|
||||
Now, we need to run the service:
|
||||
|
||||
For CentOS:
|
||||
|
||||
# service httpd start
|
||||
|
||||
Lets make sure that Apache will restart every time you restart the machine:
|
||||
|
||||
# /sbin/chkconfig httpd on
|
||||
|
||||
For Ubuntu:
|
||||
|
||||
# service apache2 start
|
||||
|
||||
Now, as we have started our apache http server, we will be able to open apache server at IP address of 127.0.0.1 by default.
|
||||
|
||||
### 3. Configuring MySQL Server ###
|
||||
|
||||
Now, we need to start our MySQL server:
|
||||
|
||||
For CentOS:
|
||||
|
||||
# chkconfig mysqld on
|
||||
# service start mysqld
|
||||
|
||||
For Ubuntu:
|
||||
|
||||
# service mysql-server start
|
||||
|
||||

|
||||
|
||||
Login with root access to MySQL and create a DB for Bugzilla. Change “mypassword” to anything you want for your mysql password. You will need it later when configuring Bugzilla too.
|
||||
|
||||
For Both CentOS 6.5 and Ubuntu 14.04 Trusty
|
||||
|
||||
# mysql -u root -p
|
||||
|
||||
# password: (You'll need to enter your password)
|
||||
|
||||
# mysql > create database bugs;
|
||||
|
||||
# mysql > grant all on bugs.* to root@localhost identified by "mypassword";
|
||||
|
||||
#mysql > quit
|
||||
|
||||
**Note: Please remember the DB name, passwords for mysql , we'll need it later.**
|
||||
|
||||
### 4. Installing and configuring Bugzilla ###
|
||||
|
||||
Now, as we have all the required packages set and running, we'll want to configure our Bugzilla.
|
||||
|
||||
So, first we'll want to download the latest Bugzilla package, here I am downloading version 4.5.2 .
|
||||
|
||||
To download using wget in a shell or terminal:
|
||||
|
||||
wget http://ftp.mozilla.org/pub/mozilla.org/webtools/bugzilla-4.5.2.tar.gz
|
||||
|
||||
You can also download from their official site ie. [http://www.bugzilla.org/download/][1]
|
||||
|
||||
**Extracting and renaming the downloaded bugzilla tarball:**
|
||||
|
||||
# tar zxvf bugzilla-4.5.2.tar.gz -C /var/www/html/
|
||||
|
||||
# cd /var/www/html/
|
||||
|
||||
# mv -v bugzilla-4.5.2 bugzilla
|
||||
|
||||
|
||||
|
||||
**Note**: Here, **/var/www/html/bugzilla/** is the directory where we're gonna **host Bugzilla**.
|
||||
|
||||
Now, we'll configure buzilla:
|
||||
|
||||
# cd /var/www/html/bugzilla/
|
||||
|
||||
# ./checksetup.pl --check-modules
|
||||
|
||||

|
||||
|
||||
After the check is done, we will see some missing modules that needs to be installed And that can be installed by the command below:
|
||||
|
||||
# cd /var/www/html/bugzilla
|
||||
# perl install-module.pl --all
|
||||
|
||||
This will take a bit time to download and install all dependencies. Run the **checksetup.pl –check-modules** command again to verify there are nothing left to install.
|
||||
|
||||
Now we'll need to run the below command which will automatically generate a file called “localconfig” in the /var/www/html/bugzilla directory.
|
||||
|
||||
# ./checksetup.pl
|
||||
|
||||
Make sure you input the correct database name, user, and password we created earlier in the localconfig file
|
||||
|
||||
# nano ./localconfig
|
||||
|
||||
# checksetup.pl
|
||||
|
||||

|
||||
|
||||
If all is well, checksetup.pl should now successfully configure Bugzilla.
|
||||
|
||||
Now we need to add Bugzilla to our Apache config file. so, we'll need to open /etc/httpd/conf/httpd.conf (For CentOS) or etc/apache2/apache2.conf (For Ubuntu) with a text editor:
|
||||
|
||||
For CentOS:
|
||||
|
||||
# nano /etc/httpd/conf/httpd.conf
|
||||
|
||||
For Ubuntu:
|
||||
|
||||
# nano etc/apache2/apache2.conf
|
||||
|
||||
Now, we'll need to configure Apache server we'll need to add the below configuration in the config file:
|
||||
|
||||
<VirtualHost *:80>
|
||||
DocumentRoot /var/www/html/bugzilla/
|
||||
</VirtualHost>
|
||||
|
||||
<Directory /var/www/html/bugzilla>
|
||||
AddHandler cgi-script .cgi
|
||||
Options +Indexes +ExecCGI
|
||||
DirectoryIndex index.cgi
|
||||
AllowOverride Limit FileInfo Indexes
|
||||
</Directory>
|
||||
|
||||
Lastly, we need to edit .htaccess file and comment out “Options -Indexes” line at the top by adding “#”
|
||||
|
||||
Lets restart our apache server and test our installation.
|
||||
|
||||
For CentOS:
|
||||
|
||||
# service httpd restart
|
||||
|
||||
For Ubuntu:
|
||||
|
||||
# service apache2 restart
|
||||
|
||||

|
||||
|
||||
Finally, our Bugzilla is ready to get bug reports now in our Ubuntu 14.04 LTS and CentOS 6.5 and you can browse to bugzilla by going to the localhost page ie 127.0.0.1 or to your IP address in your web browser .
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/tools/install-bugzilla-ubuntu-centos/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.bugzilla.org/download/
|
||||
@ -0,0 +1,45 @@
|
||||
Linus Torvalds发布了Linux 3.19 RC1,目前为止最大的更新
|
||||
================================================================================
|
||||
> 新的内核开发周期开始了
|
||||
|
||||

|
||||
|
||||
**首个内核候选版本在3.19分支上发布了,它看上去像目前最大的更新。这个早先发布让众人惊喜,但是很容易理解为什么。**
|
||||
|
||||
内核开发周期被新的3.19的发布而刷新了。事实是3.18分支才几周前才发布,今天的发布并不是完全在预期中。假期要来了,很多开发者和维护任何可能会休息。一般来说RC版本每周发布一次,但是用户可能会看到轻微的延误。
|
||||
|
||||
这个版本没有提到在Linux 3.18中确认的回归问题,但是可以确定的是,开发人员仍在努力修复中。另一方面,Linus说这是一个很大的更新,事实上这是目前为止最大的更新。很有可能是许多开发者想要在节日之前推送他们的补丁,因此,下一个RC版本会小一些。
|
||||
|
||||
### Linux 3.19 RC1 标志着新的一个周期的开始 ###
|
||||
|
||||
发布版本的大小随着更新的频率正在增加。内核的开发周期通常大约8到10周,并且很少多于这个,这给项目一个很好的预测。
|
||||
|
||||
[阅读][1] Linus Torvalds的发布声明中说:“也就是说,也许没有真正的落后者,并且从rc1的大小来看,真的已经不多了。我不仅觉得下一个版本有更多的提交,并且比历史上的rc1更多(知道在提交数量上)。我们已经有比较大的版本(3.10和3.15的都有很大的很并窗口导致的),但是这明显不是一个小的合并窗口。”
|
||||
|
||||
“在这个在蓝图下,这看上去只是一个常规发布。大约三分之二的驱动更新,这剩下的一半是架构的更新(新的nios2补丁还没有优势,它只有ARM一半的性能,新的niso2支持小于整体架构更新的10%)。”
|
||||
|
||||
|
||||
具体关于这个RC的细节可以在官方邮件列表中找到。
|
||||
|
||||
#### 下载 Linux 3.19 RC1 源码包: ####
|
||||
|
||||
- [tar.xz (3.18.1 Stable)][3]文件大小 77.2 MB
|
||||
- [tar.xz (3.19 RC1 Unstable)][4]
|
||||
|
||||
如果你想要测试,需要自己编译。并不建议在生产机器上测试。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Linus-Torvalds-Launches-Linux-kernel-3-19-RC1-One-of-the-Biggest-So-Far-468043.shtml
|
||||
|
||||
作者:[Silviu Stahie ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:http://lkml.iu.edu/hypermail/linux/kernel/1412.2/02480.html
|
||||
[2]:http://linux.softpedia.com/get/System/Operating-Systems/Kernels/Linux-Kernel-Development-8069.shtml
|
||||
[3]:https://www.kernel.org/pub/linux/kernel/v3.x/linux-3.18.1.tar.xz
|
||||
[4]:https://www.kernel.org/pub/linux/kernel/v3.x/testing/linux-3.19-rc1.tar.xz
|
||||
Loading…
Reference in New Issue
Block a user