mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-15 01:50:08 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
d6a1515491
@ -1,25 +1,26 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (liujing97)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10698-1.html)
|
||||
[#]: subject: (How To Set Password Policies In Linux)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-set-password-policies-in-linux/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
|
||||
如何在 Linux 系统中设置密码策略
|
||||
如何设置 Linux 系统的密码策略
|
||||
======
|
||||
|
||||

|
||||
|
||||
虽然 Linux 的设计是安全的,但还是存在许多安全漏洞的风险。弱密码就是其中之一。作为系统管理员,你必须为用户提供一个强密码。因为大部分的系统漏洞就是由于弱密码而引发的。本教程描述了在基于 DEB 系统的 Linux,比如 Debian, Ubuntu, Linux Mint 等和基于 RPM 系统的 Linux,比如 RHEL, CentOS, Scientific Linux 等的系统下设置像**密码长度**,**密码复杂度**,**密码有效期**等密码策略。
|
||||
虽然 Linux 的设计是安全的,但还是存在许多安全漏洞的风险,弱密码就是其中之一。作为系统管理员,你必须为用户提供一个强密码。因为大部分的系统漏洞就是由于弱密码而引发的。本教程描述了在基于 DEB 系统的 Linux,比如 Debian、Ubuntu、Linux Mint 等和基于 RPM 系统的 Linux,比如 RHEL、CentOS、Scientific Linux 等的系统下设置像**密码长度**、**密码复杂度**、**密码有效期**等密码策略。
|
||||
|
||||
### 在基于 DEB 的系统中设置密码长度
|
||||
|
||||
默认情况下,所有的 Linux 操作系统要求用户**密码长度最少6个字符**。我强烈建议不要低于这个限制。并且不要使用你的真实名称、父母、配偶、孩子的名字,或者你的生日作为密码。即便是一个黑客新手,也可以很快地破解这类密码。一个好的密码必须是至少 6 个字符,并且包含数字,大写字母和特殊符号。
|
||||
默认情况下,所有的 Linux 操作系统要求用户**密码长度最少 6 个字符**。我强烈建议不要低于这个限制。并且不要使用你的真实名称、父母、配偶、孩子的名字,或者你的生日作为密码。即便是一个黑客新手,也可以很快地破解这类密码。一个好的密码必须是至少 6 个字符,并且包含数字、大写字母和特殊符号。
|
||||
|
||||
通常地,在基于 DEB 的操作系统中,密码和身份认证相关的配置文件被存储在 **/etc/pam.d/** 目录中。
|
||||
通常地,在基于 DEB 的操作系统中,密码和身份认证相关的配置文件被存储在 `/etc/pam.d/` 目录中。
|
||||
|
||||
设置最小密码长度,编辑 **/etc/pam.d/common-password** 文件;
|
||||
设置最小密码长度,编辑 `/etc/pam.d/common-password` 文件;
|
||||
|
||||
```
|
||||
$ sudo nano /etc/pam.d/common-password
|
||||
@ -33,7 +34,7 @@ password [success=2 default=ignore] pam_unix.so obscure sha512
|
||||
|
||||
![][2]
|
||||
|
||||
在末尾添加额外的文字:**minlen=8**。在这里我设置的最小密码长度为 **8**。
|
||||
在末尾添加额外的文字:`minlen=8`。在这里我设置的最小密码长度为 `8`。
|
||||
|
||||
```
|
||||
password [success=2 default=ignore] pam_unix.so obscure sha512 minlen=8
|
||||
@ -43,15 +44,15 @@ password [success=2 default=ignore] pam_unix.so obscure sha512 minlen=8
|
||||
|
||||
保存并关闭该文件。这样一来,用户现在不能设置小于 8 个字符的密码。
|
||||
|
||||
### 在基于RPM的系统中设置密码长度
|
||||
### 在基于 RPM 的系统中设置密码长度
|
||||
|
||||
**在 RHEL, CentOS, Scientific Linux 7.x** 系统中, 以root身份执行下面的命令来设置密码长度。
|
||||
**在 RHEL、CentOS、Scientific Linux 7.x** 系统中, 以 root 身份执行下面的命令来设置密码长度。
|
||||
|
||||
```
|
||||
# authconfig --passminlen=8 --update
|
||||
```
|
||||
|
||||
查看最小密码长度, 执行:
|
||||
查看最小密码长度,执行:
|
||||
|
||||
```
|
||||
# grep "^minlen" /etc/security/pwquality.conf
|
||||
@ -63,7 +64,7 @@ password [success=2 default=ignore] pam_unix.so obscure sha512 minlen=8
|
||||
minlen = 8
|
||||
```
|
||||
|
||||
**在 RHEL, CentOS, Scientific Linux 6.x** 系统中, 编辑 **/etc/pam.d/system-auth** 文件:
|
||||
**在 RHEL、CentOS、Scientific Linux 6.x** 系统中,编辑 `/etc/pam.d/system-auth` 文件:
|
||||
|
||||
```
|
||||
# nano /etc/pam.d/system-auth
|
||||
@ -77,11 +78,11 @@ password requisite pam_cracklib.so try_first_pass retry=3 type= minlen=8
|
||||
|
||||

|
||||
|
||||
在以上所有设置中,最小密码长度是 **8** 个字符。
|
||||
如上设置中,最小密码长度是 `8` 个字符。
|
||||
|
||||
### 在基于DEB的系统中设置密码复杂度
|
||||
### 在基于 DEB 的系统中设置密码复杂度
|
||||
|
||||
此设置会强制要求密码中应该包含多少类型,比如大写字母,小写字母和其他字符。
|
||||
此设置会强制要求密码中应该包含多少类型,比如大写字母、小写字母和其他字符。
|
||||
|
||||
首先,用下面命令安装密码质量检测库:
|
||||
|
||||
@ -89,13 +90,13 @@ password requisite pam_cracklib.so try_first_pass retry=3 type= minlen=8
|
||||
$ sudo apt-get install libpam-pwquality
|
||||
```
|
||||
|
||||
之后,编辑 **/etc/pam.d/common-password** 文件:
|
||||
之后,编辑 `/etc/pam.d/common-password` 文件:
|
||||
|
||||
```
|
||||
$ sudo nano /etc/pam.d/common-password
|
||||
```
|
||||
|
||||
为了设置密码中至少有一个**大写字母**,则在下面这行的末尾添加文字 **‘ucredit=-1’**。
|
||||
为了设置密码中至少有一个**大写字母**,则在下面这行的末尾添加文字 `ucredit=-1`。
|
||||
|
||||
```
|
||||
password requisite pam_pwquality.so retry=3 ucredit=-1
|
||||
@ -115,9 +116,9 @@ password requisite pam_pwquality.so retry=3 dcredit=-1
|
||||
password requisite pam_pwquality.so retry=3 ocredit=-1
|
||||
```
|
||||
|
||||
正如你在上面样例中看到的一样,我们设置了密码中至少含有一个大写字母、一个小写字母和一个特殊字符。你可以设置被最大允许的任意数量的大写字母,小写字母和特殊字符。
|
||||
正如你在上面样例中看到的一样,我们设置了密码中至少含有一个大写字母、一个小写字母和一个特殊字符。你可以设置被最大允许的任意数量的大写字母、小写字母和特殊字符。
|
||||
|
||||
你还可以设置密码中被允许的最大或最小类型的数量。
|
||||
你还可以设置密码中被允许的字符类的最大或最小数量。
|
||||
|
||||
下面的例子展示了设置一个新密码中被要求的字符类的最小数量:
|
||||
|
||||
@ -125,7 +126,7 @@ password requisite pam_pwquality.so retry=3 ocredit=-1
|
||||
password requisite pam_pwquality.so retry=3 minclass=2
|
||||
```
|
||||
|
||||
### 在基于RPM的系统中设置密密码杂度
|
||||
### 在基于 RPM 的系统中设置密码复杂度
|
||||
|
||||
**在 RHEL 7.x / CentOS 7.x / Scientific Linux 7.x 中:**
|
||||
|
||||
@ -201,7 +202,7 @@ dcredit = -1
|
||||
ocredit = -1
|
||||
```
|
||||
|
||||
在 **RHEL 6.x / CentOS 6.x / Scientific Linux 6.x systems** 中,以root身份编辑 **/etc/pam.d/system-auth** 文件:
|
||||
在 **RHEL 6.x / CentOS 6.x / Scientific Linux 6.x systems** 中,以 root 身份编辑 `/etc/pam.d/system-auth` 文件:
|
||||
|
||||
```
|
||||
# nano /etc/pam.d/system-auth
|
||||
@ -212,17 +213,17 @@ ocredit = -1
|
||||
```
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 type= minlen=8 dcredit=-1 ucredit=-1 lcredit=-1 ocredit=-1
|
||||
```
|
||||
在以上每个设置中,密码必须要至少包含 8 个字符。另外,密码必须至少包含一个大写字母、一个小写字母、一个数字和一个其他字符。
|
||||
|
||||
### 在基于DEB的系统中设置密码有效期
|
||||
如上设置中,密码必须要至少包含 `8` 个字符。另外,密码必须至少包含一个大写字母、一个小写字母、一个数字和一个其他字符。
|
||||
|
||||
### 在基于 DEB 的系统中设置密码有效期
|
||||
|
||||
现在,我们将要设置下面的策略。
|
||||
|
||||
1. 密码被使用的最长天数。
|
||||
2. 密码更改允许的最小间隔天数。
|
||||
3. 密码到期之前发出警告的天数。
|
||||
|
||||
|
||||
|
||||
设置这些策略,编辑:
|
||||
|
||||
```
|
||||
@ -239,7 +240,7 @@ PASS_WARN_AGE 7
|
||||
|
||||
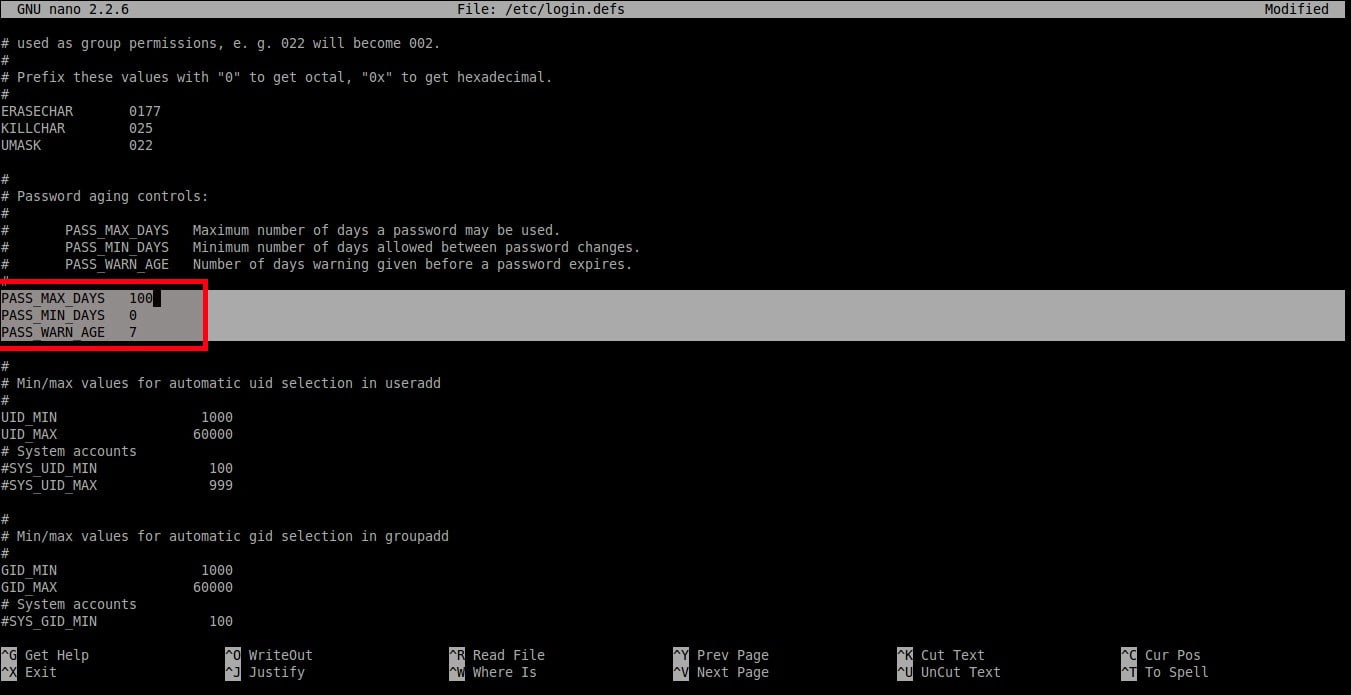
|
||||
|
||||
正如你在上面样例中看到的一样,用户应该每 **100** 天修改一次密码,并且密码到期之前的 **7** 天开始出现警告信息。
|
||||
正如你在上面样例中看到的一样,用户应该每 `100` 天修改一次密码,并且密码到期之前的 `7` 天开始出现警告信息。
|
||||
|
||||
请注意,这些设置将会在新创建的用户中有效。
|
||||
|
||||
@ -280,6 +281,7 @@ Minimum number of days between password change : 0
|
||||
Maximum number of days between password change : 99999
|
||||
Number of days of warning before password expires : 7
|
||||
```
|
||||
|
||||
正如你在上面看到的输出一样,该密码是无限期的。
|
||||
|
||||
修改已存在用户的密码有效期,
|
||||
@ -288,22 +290,23 @@ Number of days of warning before password expires : 7
|
||||
$ sudo chage -E 24/06/2018 -m 5 -M 90 -I 10 -W 10 sk
|
||||
```
|
||||
|
||||
上面的命令将会设置用户 **‘sk’** 的密码期限是 **24/06/2018**。并且修改密码的最小间隔时间为 5 天,最大间隔时间为 **90** 天。用户账号将会在 **10 天**后被自动锁定而且在到期之前的 **10 天**将会显示警告信息。
|
||||
上面的命令将会设置用户 `sk` 的密码期限是 `24/06/2018`。并且修改密码的最小间隔时间为 `5` 天,最大间隔时间为 `90` 天。用户账号将会在 `10` 天后被自动锁定,而且在到期之前的 `10` 天前显示警告信息。
|
||||
|
||||
### 在基于 RPM 的系统中设置密码效期
|
||||
|
||||
这点和基于 DEB 的系统是相同的。
|
||||
|
||||
### 在基于 DEB 的系统中禁止使用近期使用过的密码
|
||||
|
||||
你可以限制用户去设置一个已经使用过的密码。通俗的讲,就是说用户不能再次使用相同的密码。
|
||||
|
||||
为设置这一点,编辑 **/etc/pam.d/common-password** 文件:
|
||||
为设置这一点,编辑 `/etc/pam.d/common-password` 文件:
|
||||
|
||||
```
|
||||
$ sudo nano /etc/pam.d/common-password
|
||||
```
|
||||
|
||||
找到下面这行并且在末尾添加文字 **‘remember=5’**:
|
||||
找到下面这行并且在末尾添加文字 `remember=5`:
|
||||
|
||||
```
|
||||
password [success=2 default=ignore] pam_unix.so obscure use_authtok try_first_pass sha512 remember=5
|
||||
@ -313,27 +316,23 @@ password [success=2 default=ignore] pam_unix.so obscure use_a
|
||||
|
||||
### 在基于 RPM 的系统中禁止使用近期使用过的密码
|
||||
|
||||
这点对于 RHEL 6.x 和 RHEL 7.x 是相同的。他们的克隆系统类似于 CentOS, Scientific Linux。
|
||||
这点对于 RHEL 6.x 和 RHEL 7.x 和它们的衍生系统 CentOS、Scientific Linux 是相同的。
|
||||
|
||||
以root身份编辑 **/etc/pam.d/system-auth** 文件,
|
||||
以 root 身份编辑 `/etc/pam.d/system-auth` 文件,
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
```
|
||||
|
||||
找到下面这行,并且在末尾添加文字 **remember=5**。
|
||||
找到下面这行,并且在末尾添加文字 `remember=5`。
|
||||
|
||||
```
|
||||
password sufficient pam_unix.so sha512 shadow nullok try_first_pass use_authtok remember=5
|
||||
```
|
||||
|
||||
现在你知道了 Linux 中的密码策略是什么,以及如何在基于 DEB 和 RPM 的系统中设置不同的密码策略。
|
||||
|
||||
现在就这样,我很快会在这里发表另外一天有趣而且有用的文章。在此之前会与 OSTechNix 保持联系。如果您觉得本教程对你有帮助,请在您的社交,专业网络上分享并支持我们。
|
||||
|
||||
祝贺!
|
||||
|
||||
现在你了解了 Linux 中的密码策略,以及如何在基于 DEB 和 RPM 的系统中设置不同的密码策略。
|
||||
|
||||
就这样,我很快会在这里发表另外一天有趣而且有用的文章。在此之前请保持关注。如果您觉得本教程对你有帮助,请在您的社交,专业网络上分享并支持我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -342,7 +341,7 @@ via: https://www.ostechnix.com/how-to-set-password-policies-in-linux/
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[liujing97](https://github.com/liujing97)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,115 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Moelf)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (A Look Back at the History of Firefox)
|
||||
[#]: via: (https://itsfoss.com/history-of-firefox)
|
||||
[#]: author: (John Paul https://itsfoss.com/author/john/)
|
||||
|
||||
A Look Back at the History of Firefox
|
||||
======
|
||||
|
||||
The Firefox browser has been a mainstay of the open-source community for a long time. For many years it was the default web browser on (almost) all Linux distros and the lone obstacle to Microsoft’s total dominance of the internet. This browser has roots that go back all the way to the very early days of the internet. Since this week marks the 30th anniversary of the internet, there is no better time to talk about how Firefox became the browser we all know and love.
|
||||
|
||||
### Early Roots
|
||||
|
||||
In the early 1990s, a young man named [Marc Andreessen][1] was working on his bachelor’s degree in computer science at the University of Illinois. While there, he started working for the [National Center for Supercomputing Applications][2]. During that time [Sir Tim Berners-Lee][3] released an early form of the web standards that we know today. Marc [was introduced][4] to a very primitive web browser named [ViolaWWW][5]. Seeing that the technology had potential, Marc and Eric Bina created an easy to install browser for Unix named [NCSA Mosaic][6]). The first alpha was released in June 1993. By September, there were ports to Windows and Macintosh. Mosaic became very popular because it was easier to use than other browsing software.
|
||||
|
||||
In 1994, Marc graduated and moved to California. He was approached by Jim Clark, who had made his money selling computer hardware and software. Clark had used Mosaic and saw the financial possibilities of the internet. Clark recruited Marc and Eric to start an internet software company. The company was originally named Mosaic Communications Corporation, however, the University of Illinois did not like [their use of the name Mosaic][7]. As a result, the company name was changed to Netscape Communications Corporation.
|
||||
|
||||
The company’s first project was an online gaming network for the Nintendo 64, but that fell through. The first product they released was a web browser named Mosaic Netscape 0.9, subsequently renamed Netscape Navigator. Internally, the browser project was codenamed mozilla, which stood for “Mosaic killer”. An employee created a cartoon of a [Godzilla like creature][8]. They wanted to take out the competition.
|
||||
|
||||
![Early Firefox Mascot][9]Early Mozilla mascot at Netscape
|
||||
|
||||
They succeed mightily. At the time, one of the biggest advantages that Netscape had was the fact that its browser looked and functioned the same on every operating system. Netscape described this as giving everyone a level playing field.
|
||||
|
||||
As usage of Netscape Navigator increase, the market share of NCSA Mosaic cratered. In 1995, Netscape went public. [On the first day][10], the stock started at $28, jumped to $75 and ended the day at $58. Netscape was without any rivals.
|
||||
|
||||
But that didn’t last for long. In the summer of 1994, Microsoft released Internet Explorer 1.0, which was based on Spyglass Mosaic which was based on NCSA Mosaic. The [browser wars][11] had begun.
|
||||
|
||||
Over the next few years, Netscape and Microsoft competed for dominance of the internet. Each added features to compete with the other. Unfortunately, Internet Explorer had an advantage because it came bundled with Windows. On top of that, Microsoft had more programmers and money to throw at the problem. Toward the end of 1997, Netscape started to run into financial problems.
|
||||
|
||||
### Going Open Source
|
||||
|
||||
![Mozilla Firefox][12]
|
||||
|
||||
In January 1998, Netscape open-sourced the code of the Netscape Communicator 4.0 suite. The [goal][13] was to “harness the creative power of thousands of programmers on the Internet by incorporating their best enhancements into future versions of Netscape’s software. This strategy is designed to accelerate development and free distribution by Netscape of future high-quality versions of Netscape Communicator to business customers and individuals.”
|
||||
|
||||
The project was to be shepherded by the newly created Mozilla Organization. However, the code from Netscape Communicator 4.0 proved to be very difficult to work with due to its size and complexity. On top of that, several parts could not be open sourced because of licensing agreements with third parties. In the end, it was decided to rewrite the browser from scratch using the new [Gecko][14]) rendering engine.
|
||||
|
||||
In November 1998, Netscape was acquired by AOL for [stock swap valued at $4.2 billion][15].
|
||||
|
||||
Starting from scratch was a major undertaking. Mozilla Firefox (initially nicknamed Phoenix) was created in June 2002 and it worked on multiple operating systems, such as Linux, Mac OS, Microsoft Windows, and Solaris.
|
||||
|
||||
The following year, AOL announced that they would be shutting down browser development. The Mozilla Foundation was subsequently created to handle the Mozilla trademarks and handle the financing of the project. Initially, the Mozilla Foundation received $2 million in donations from AOL, IBM, Sun Microsystems, and Red Hat.
|
||||
|
||||
In March 2003, Mozilla [announced pl][16][a][16][ns][16] to separate the suite into stand-alone applications because of creeping software bloat. The stand-alone browser was initially named Phoenix. However, the name was changed due to a trademark dispute with the BIOS manufacturer Phoenix Technologies, which had a BIOS-based browser named trademark dispute with the BIOS manufacturer Phoenix Technologies. Phoenix was renamed Firebird only to run afoul of the Firebird database server people. The browser was once more renamed to the Firefox that we all know.
|
||||
|
||||
At the time, [Mozilla said][17], “We’ve learned a lot about choosing names in the past year (more than we would have liked to). We have been very careful in researching the name to ensure that we will not have any problems down the road. We have begun the process of registering our new trademark with the US Patent and Trademark office.”
|
||||
|
||||
![Mozilla Firefox 1.0][18]Firefox 1.0 : [Picture Credit][19]
|
||||
|
||||
The first official release of Firefox was [0.8][20] on February 8, 2004. 1.0 followed on November 9, 2004. Version 2.0 and 3.0 followed in October 2006 and June 2008 respectively. Each major release brought with it many new features and improvements. In many respects, Firefox pulled ahead of Internet Explorer in terms of features and technology, but IE still had more users.
|
||||
|
||||
That changed with the release of Google’s Chrome browser. In the months before the release of Chrome in September 2008, Firefox accounted for 30% of all [browser usage][21] and IE had over 60%. According to StatCounter’s [January 2019 report][22], Firefox accounts for less than 10% of all browser usage, while Chrome has over 70%.
|
||||
|
||||
Fun Fact
|
||||
|
||||
Contrary to popular belief, the logo of Firefox doesn’t feature a fox. It’s actually a [Red Panda][23]. In Chinese, “fire fox” is another name for the red panda.
|
||||
|
||||
### The Future
|
||||
|
||||
As noted above, Firefox currently has the lowest market share in its recent history. There was a time when a bunch of browsers were based on Firefox, such as the early version of the [Flock browser][24]). Now most browsers are based on Google technology, such as Opera and Vivaldi. Even Microsoft is giving up on browser development and [joining the Chromium band wagon][25].
|
||||
|
||||
This might seem like quite a downer after the heights of the early Netscape years. But don’t forget what Firefox has accomplished. A group of developers from around the world have created the second most used browser in the world. They clawed 30% market share away from Microsoft’s monopoly, they can do it again. After all, they have us, the open source community, behind them.
|
||||
|
||||
The fight against the monopoly is one of the several reasons [why I use Firefox][26]. Mozilla regained some of its lost market-share with the revamped release of [Firefox Quantum][27] and I believe that it will continue the upward path.
|
||||
|
||||
What event from Linux and open source history would you like us to write about next? Please let us know in the comments below.
|
||||
|
||||
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][28].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/history-of-firefox
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Marc_Andreessen
|
||||
[2]: https://en.wikipedia.org/wiki/National_Center_for_Supercomputing_Applications
|
||||
[3]: https://en.wikipedia.org/wiki/Tim_Berners-Lee
|
||||
[4]: https://www.w3.org/DesignIssues/TimBook-old/History.html
|
||||
[5]: http://viola.org/
|
||||
[6]: https://en.wikipedia.org/wiki/Mosaic_(web_browser
|
||||
[7]: http://www.computinghistory.org.uk/det/1789/Marc-Andreessen/
|
||||
[8]: http://www.davetitus.com/mozilla/
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/Mozilla_boxing.jpg?ssl=1
|
||||
[10]: https://www.marketwatch.com/story/netscape-ipo-ignited-the-boom-taught-some-hard-lessons-20058518550
|
||||
[11]: https://en.wikipedia.org/wiki/Browser_wars
|
||||
[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/mozilla-firefox.jpg?resize=800%2C450&ssl=1
|
||||
[13]: https://web.archive.org/web/20021001071727/wp.netscape.com/newsref/pr/newsrelease558.html
|
||||
[14]: https://en.wikipedia.org/wiki/Gecko_(software)
|
||||
[15]: http://news.cnet.com/2100-1023-218360.html
|
||||
[16]: https://web.archive.org/web/20050618000315/http://www.mozilla.org/roadmap/roadmap-02-Apr-2003.html
|
||||
[17]: https://www-archive.mozilla.org/projects/firefox/firefox-name-faq.html
|
||||
[18]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/firefox-1.jpg?ssl=1
|
||||
[19]: https://www.iceni.com/blog/firefox-1-0-introduced-2004/
|
||||
[20]: https://en.wikipedia.org/wiki/Firefox_version_history
|
||||
[21]: https://en.wikipedia.org/wiki/Usage_share_of_web_browsers
|
||||
[22]: http://gs.statcounter.com/browser-market-share/desktop/worldwide/#monthly-201901-201901-bar
|
||||
[23]: https://en.wikipedia.org/wiki/Red_panda
|
||||
[24]: https://en.wikipedia.org/wiki/Flock_(web_browser
|
||||
[25]: https://www.windowscentral.com/microsoft-building-chromium-powered-web-browser-windows-10
|
||||
[26]: https://itsfoss.com/why-firefox/
|
||||
[27]: https://itsfoss.com/firefox-quantum-ubuntu/
|
||||
[28]: http://reddit.com/r/linuxusersgroup
|
||||
[29]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/mozilla-firefox.jpg?fit=800%2C450&ssl=1
|
||||
@ -1,93 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Take to the virtual skies with FlightGear)
|
||||
[#]: via: (https://opensource.com/article/19/1/flightgear)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
Take to the virtual skies with FlightGear
|
||||
======
|
||||
Dreaming of piloting a plane? Try open source flight simulator FlightGear.
|
||||

|
||||
|
||||
If you've ever dreamed of piloting a plane, you'll love [FlightGear][1]. It's a full-featured, [open source][2] flight simulator that runs on Linux, MacOS, and Windows.
|
||||
|
||||
The FlightGear project began in 1996 due to dissatisfaction with commercial flight simulation programs, which were not scalable. Its goal was to create a sophisticated, robust, extensible, and open flight simulator framework for use in academia and pilot training or by anyone who wants to play with a flight simulation scenario.
|
||||
|
||||
### Getting started
|
||||
|
||||
FlightGear's hardware requirements are fairly modest, including an accelerated 3D video card that supports OpenGL for smooth framerates. It runs well on my Linux laptop with an i5 processor and only 4GB of RAM. Its documentation includes an [online manual][3]; a [wiki][4] with portals for [users][5] and [developers][6]; and extensive tutorials (such as one for its default aircraft, the [Cessna 172p][7]) to teach you how to operate it.
|
||||
|
||||
It's easy to install on both [Fedora][8] and [Ubuntu][9] Linux. Fedora users can consult the [Fedora installation page][10] to get FlightGear running.
|
||||
|
||||
On Ubuntu 18.04, I had to install a repository:
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:saiarcot895/flightgear
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install flightgear
|
||||
```
|
||||
|
||||
Once the installation finished, I launched it from the GUI, but you can also launch the application from a terminal by entering:
|
||||
|
||||
```
|
||||
$ fgfs
|
||||
```
|
||||
|
||||
### Configuring FlightGear
|
||||
|
||||
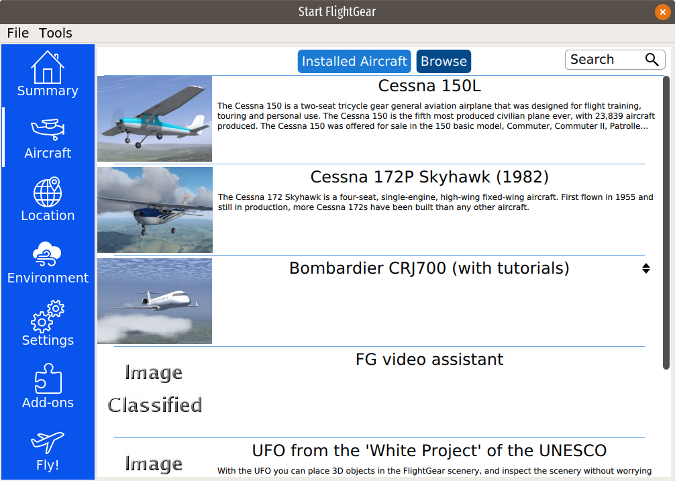
The menu on the left side of the application window provides configuration options.
|
||||
|
||||
|
||||
|
||||
**Summary** returns you to the application's home screen.
|
||||
|
||||
**Aircraft** shows the aircraft you have installed and offers the option to install up to 539 other aircraft available in FlightGear's default "hangar." I installed a Cessna 150L, a Piper J-3 Cub, and a Bombardier CRJ-700. Some of the aircraft (including the CRJ-700) have tutorials to teach you how to fly a commercial jet; I found the tutorials informative and accurate.
|
||||
|
||||
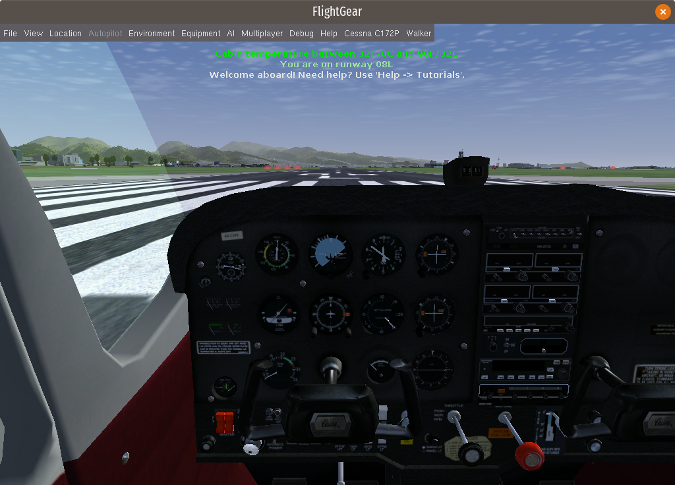
|
||||
|
||||
To select an aircraft to pilot, highlight it and click on **Fly!** at the bottom of the menu. I chose the default Cessna 172p and found the cockpit depiction extremely accurate.
|
||||
|
||||
|
||||
|
||||
The default airport is Honolulu, but you can change it in the **Location** menu by providing your favorite airport's [ICAO airport code][11] identifier. I found some small, local, non-towered airports like Olean and Dunkirk, New York, as well as larger airports including Buffalo, O'Hare, and Raleigh—and could even choose a specific runway.
|
||||
|
||||
Under **Environment** , you can adjust the time of day, the season, and the weather. The simulation includes advance weather modeling and the ability to download current weather from [NOAA][12].
|
||||
|
||||
**Settings** provides an option to start the simulation in Paused mode by default. Also in Settings, you can select multi-player mode, which allows you to "fly" with other players on FlightGear supporters' global network of servers that allow for multiple users. You must have a moderately fast internet connection to support this functionality.
|
||||
|
||||
The **Add-ons** menu allows you to download aircraft and additional scenery.
|
||||
|
||||
### Take flight
|
||||
|
||||
To "fly" my Cessna, I used a Logitech joystick that worked well. You can calibrate your joystick using an option in the **File** menu at the top.
|
||||
|
||||
Overall, I found the simulation very accurate and think the graphics are great. Try FlightGear yourself — I think you will find it a very fun and complete simulation package.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/flightgear
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://home.flightgear.org/
|
||||
[2]: http://wiki.flightgear.org/GNU_General_Public_License
|
||||
[3]: http://flightgear.sourceforge.net/getstart-en/getstart-en.html
|
||||
[4]: http://wiki.flightgear.org/FlightGear_Wiki
|
||||
[5]: http://wiki.flightgear.org/Portal:User
|
||||
[6]: http://wiki.flightgear.org/Portal:Developer
|
||||
[7]: http://wiki.flightgear.org/Cessna_172P
|
||||
[8]: http://rpmfind.net/linux/rpm2html/search.php?query=flightgear
|
||||
[9]: https://launchpad.net/~saiarcot895/+archive/ubuntu/flightgear
|
||||
[10]: https://apps.fedoraproject.org/packages/FlightGear/
|
||||
[11]: https://en.wikipedia.org/wiki/ICAO_airport_code
|
||||
[12]: https://www.noaa.gov/
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (liujing97)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
@ -350,7 +350,7 @@ via: https://www.2daygeek.com/how-to-understand-and-identify-file-types-in-linux
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[liujing97](https://github.com/liujing97)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
@ -100,7 +100,7 @@ via: https://opensource.com/article/19/4/log-analysis-tools
|
||||
|
||||
作者:[Sam Bocetta][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,158 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (9 features developers should know about Selenium IDE)
|
||||
[#]: via: (https://opensource.com/article/19/4/features-selenium-ide)
|
||||
[#]: author: (Al Sargent https://opensource.com/users/alsargent)
|
||||
|
||||
9 features developers should know about Selenium IDE
|
||||
======
|
||||
The new Selenium IDE brings the benefits of functional test automation
|
||||
to many IT professionals—and to frontend developers specifically.
|
||||
![magnifying glass on computer screen][1]
|
||||
|
||||
There has long been a stigma associated with using record-and-playback tools for testing rather than scripted QA automation tools like [Selenium Webdriver][2], [Cypress][3], and [WebdriverIO][4].
|
||||
|
||||
Record-and-playbook tools are perceived to suffer from many issues, including a lack of cross-browser support, no way to run scripts in parallel or from CI build scripts, poor support for responsive web apps, and no way to quickly diagnose frontend bugs.
|
||||
|
||||
Needless to say, it's been somewhat of a rough road for these tools, and after Selenium IDE [went end-of-life][5] in 2017, many thought the road for record and playback would end altogether.
|
||||
|
||||
Well, it turns out this perception was wrong. Not long after the Selenium IDE project was discontinued, my colleagues at [Applitools approached the Selenium open source community][6] to see how they could help.
|
||||
|
||||
Since then, much of Selenium IDE's code has been revamped. The code is now freely available on GitHub under an Apache 2.0 license, managed by the Selenium community, and supported by [two full-time engineers][7], one of whom literally wrote the book on [Selenium testing][8].
|
||||
|
||||
![Selenium IDE's GitHub repository][9]
|
||||
|
||||
The new Selenium IDE brings the benefits of functional test automation to many IT professionals—and to frontend developers specifically. Here are nine things developers should know about the new Selenium IDE.
|
||||
|
||||
### 1\. Selenium IDE is now cross-browser
|
||||
|
||||
When the record-and-playback tool first came out in 2006, Firefox was the shiny new browser it hitched its wagon to, and it remained that way for a decade. No more! Selenium IDE is now available as a [Google Chrome Extension][10] and [Firefox Add-on][11].
|
||||
|
||||
Even better, Selenium IDE can run its tests on Selenium WebDriver servers by using Selenium IDE's new command-line test runner, [SIDE Runner][12]. SIDE Runner blends elements of Selenium IDE and Selenium Webdriver. It takes a Selenium IDE script, saved as a [**.side** file][13], and runs it using browser drivers such as [ChromeDriver][14], [EdgeDriver][15], Firefox's [Geckodriver][16], [IEDriver][17], and [SafariDriver][18].
|
||||
|
||||
SIDE Runner and the other drivers above are available as [straightforward npm installs][12]. Here's what it looks like in action.
|
||||
|
||||
![SIDE Runner][19]
|
||||
|
||||
### 2\. No more brittle functional tests
|
||||
|
||||
For years, brittle tests have been an issue for functional tests—whether you record them or code them by hand. Now that developers are releasing new features more frequently, their user interface (UI) code is constantly changing as well. When a UI changes, object locators often change, too.
|
||||
|
||||
Selenium IDE fixes that by capturing multiple object locators when you record your script. During playback, if Selenium IDE can't find one locator, it tries each of the other locators until it finds one that works. Your test will fail only if none of the locators work. This doesn't guarantee scripts will always play back, but it does insulate scripts against numerous changes. As you can see below, Selenium IDE captures linkText, an xPath expression, and CSS-based locators.
|
||||
|
||||
![Selenium IDE captures linkText, an xPath expression, and CSS-based locators][20]
|
||||
|
||||
### 3\. Conditional logic to handle UI features
|
||||
|
||||
When testing web apps, scripts have to handle intermittent UI elements that can randomly appear in your app. These come in the form of cookie notices, popups for special offers, quote requests, newsletter subscriptions, paywall notifications, adblocker requests, and more.
|
||||
|
||||
Conditional logic is a great way to handle these intermittent UI features. Developers can easily insert conditional logic—also called control flow—into Selenium IDE scripts. [Here are details][21] and how it looks.
|
||||
|
||||
![Selenium IDE's Conditional logic][22]
|
||||
|
||||
### 4\. Support for embedded code
|
||||
|
||||
As broad as the new [Selenium IDE API][23] is, it doesn't do everything. For this reason, Selenium IDE has **[**execute** **script**][24]** and **[execute async script][25]** commands that let your script call a JavaScript snippet.
|
||||
|
||||
This provides developers with a tremendous amount of flexibility to take advantage of JavaScript's flexibility and wide range of libraries. To use it, click on the test step where you want JavaScript to run, choose **Insert New Command** , and enter **execute script** or **execute async script** in the command field, as shown below.
|
||||
|
||||
![Selenium IDE's command line][26]
|
||||
|
||||
### 5\. Selenium IDE runs from CI build scripts
|
||||
|
||||
Because SIDE Runner is called from the command line, you can easily fit it into CI build scripts, so long as the CI server can call **selenium-ide-runner** and upload the **.side** file (the test script) as a build artifact. For example, here's how to upload an input file in [Jenkins][27], [Travis][28], and [CircleCI][29].
|
||||
|
||||
This means Selenium IDE can be better integrated into the software development technology stack. In addition, the scripts created by less-technical QA team members—including business analysts—can run with every build. This helps better align QA with the developer so fewer bugs escape into production.
|
||||
|
||||
### 6\. Support for third-party plugins
|
||||
|
||||
Imagine companies building plugins to have Selenium IDE do all kinds of things, like uploading scripts to a functional testing cloud, a load testing cloud, or a production application monitoring service.
|
||||
|
||||
Plenty of companies have integrated Selenium Webdriver into their offerings, and I bet the same will happen with Selenium IDE. You can also [build your own Selenium IDE plugin][30].
|
||||
|
||||
### 7\. Visual UI testing
|
||||
|
||||
Speaking of new plugins, Applitools introduced a new Selenium IDE plugin to add artificial intelligence-powered visual validations to the equation. Available through the [Chrome][31] and [Firefox][32] stores via a three-second install, just plug in the Applitools API key and go.
|
||||
|
||||
Visual checkpoints are a great way to ensure a UI renders correctly. Rather than a bunch of assert statements on all the UI elements—which would be a pain to maintain—one visual checkpoint checks all your page elements.
|
||||
|
||||
Best of all, visual AI looks at a web app the same way a human does, ignoring minor differences. This means fewer fake bugs to frustrate a development team.
|
||||
|
||||
### 8\. Visually test responsive web apps
|
||||
|
||||
When testing the visual layout of [responsive web apps][33], it's best to do it on a wide range of screen sizes (also called viewports) to ensure nothing appears out of whack. It's all too easy for responsive web bugs to creep in, and when they do, the problems can range from merely cosmetic to business stopping.
|
||||
|
||||
When you use visual UI testing for Selenium IDE, you can visually test your webpages on the Applitools [Visual Grid][34], which has more than 100 combinations of browsers, emulated devices, and viewport sizes.
|
||||
|
||||
Once tests run on the Visual Grid, developers can easily check the test results on all the various combinations.
|
||||
|
||||
![Selenium IDE's Visual Grid][35]
|
||||
|
||||
### 9\. Responsive web bugs have nowhere to hide
|
||||
|
||||
Selenium IDE can help pinpoint the cause of frontend bugs. Every Selenium IDE script that's run with the Visual Grid can be analyzed with Applitools' [Root Cause Analysis][36]. It's no longer enough to find a bug—developers also need to fix it.
|
||||
|
||||
When a visual bug is discovered, it can be clicked on and just the relevant (not all) Document Object Model (DOM) and CSS differences will be displayed.
|
||||
|
||||
![Finding visual bugs][37]
|
||||
|
||||
In summary, much like many emerging technologies in software development, Selenium IDE is part of a larger trend of making life easier and simpler for technical professionals and enabling them to spend more time and effort on creating code for even faster feedback.
|
||||
|
||||
* * *
|
||||
|
||||
_This article is based on[16 reasons why to use Selenium IDE in 2019 (and 2 why not)][38] originally published on the Applitools blog._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/features-selenium-ide
|
||||
|
||||
作者:[Al Sargent][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/alsargent
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/search_find_code_issue_bug_programming.png?itok=XPrh7fa0 (magnifying glass on computer screen)
|
||||
[2]: https://www.seleniumhq.org/projects/webdriver/
|
||||
[3]: https://www.cypress.io/
|
||||
[4]: https://webdriver.io/
|
||||
[5]: https://seleniumhq.wordpress.com/2017/08/09/firefox-55-and-selenium-ide/
|
||||
[6]: https://seleniumhq.wordpress.com/2018/08/06/selenium-ide-tng/
|
||||
[7]: https://github.com/SeleniumHQ/selenium-ide/graphs/contributors
|
||||
[8]: http://davehaeffner.com/
|
||||
[9]: https://opensource.com/sites/default/files/uploads/selenium_ide_github_graphic_1.png (Selenium IDE's GitHub repository)
|
||||
[10]: https://chrome.google.com/webstore/detail/selenium-ide/mooikfkahbdckldjjndioackbalphokd
|
||||
[11]: https://addons.mozilla.org/en-US/firefox/addon/selenium-ide/
|
||||
[12]: https://www.seleniumhq.org/selenium-ide/docs/en/introduction/command-line-runner/
|
||||
[13]: https://www.seleniumhq.org/selenium-ide/docs/en/introduction/command-line-runner/#launching-the-runner
|
||||
[14]: http://chromedriver.chromium.org/
|
||||
[15]: https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
|
||||
[16]: https://github.com/mozilla/geckodriver
|
||||
[17]: https://github.com/SeleniumHQ/selenium/wiki/InternetExplorerDriver
|
||||
[18]: https://developer.apple.com/documentation/webkit/testing_with_webdriver_in_safari
|
||||
[19]: https://opensource.com/sites/default/files/uploads/selenium_ide_side_runner_2.png (SIDE Runner)
|
||||
[20]: https://opensource.com/sites/default/files/uploads/selenium_ide_linktext_3.png (Selenium IDE captures linkText, an xPath expression, and CSS-based locators)
|
||||
[21]: https://www.seleniumhq.org/selenium-ide/docs/en/introduction/control-flow/
|
||||
[22]: https://opensource.com/sites/default/files/uploads/selenium_ide_conditional_logic_4.png (Selenium IDE's Conditional logic)
|
||||
[23]: https://www.seleniumhq.org/selenium-ide/docs/en/api/commands/
|
||||
[24]: https://www.seleniumhq.org/selenium-ide/docs/en/api/commands/#execute-script
|
||||
[25]: https://www.seleniumhq.org/selenium-ide/docs/en/api/commands/#execute-async-script
|
||||
[26]: https://opensource.com/sites/default/files/uploads/selenium_ide_command_line_5.png (Selenium IDE's command line)
|
||||
[27]: https://stackoverflow.com/questions/27491789/how-to-upload-a-generic-file-into-a-jenkins-job
|
||||
[28]: https://docs.travis-ci.com/user/uploading-artifacts/
|
||||
[29]: https://circleci.com/docs/2.0/artifacts/
|
||||
[30]: https://www.seleniumhq.org/selenium-ide/docs/en/plugins/plugins-getting-started/
|
||||
[31]: https://chrome.google.com/webstore/detail/applitools-for-selenium-i/fbnkflkahhlmhdgkddaafgnnokifobik
|
||||
[32]: https://addons.mozilla.org/en-GB/firefox/addon/applitools-for-selenium-ide/
|
||||
[33]: https://en.wikipedia.org/wiki/Responsive_web_design
|
||||
[34]: https://applitools.com/visualgrid
|
||||
[35]: https://opensource.com/sites/default/files/uploads/selenium_ide_visual_grid_6.png (Selenium IDE's Visual Grid)
|
||||
[36]: https://applitools.com/root-cause-analysis
|
||||
[37]: https://opensource.com/sites/default/files/uploads/seleniumice_rootcauseanalysis_7.png (Finding visual bugs)
|
||||
[38]: https://applitools.com/blog/why-selenium-ide-2019
|
||||
@ -0,0 +1,97 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 open source tools for teaching young children to read)
|
||||
[#]: via: (https://opensource.com/article/19/4/early-literacy-tools)
|
||||
[#]: author: (Laura B. Janusek https://opensource.com/users/lbjanusek)
|
||||
|
||||
5 open source tools for teaching young children to read
|
||||
======
|
||||
Early literacy apps give kids a foundation in letter recognition,
|
||||
alphabet sequencing, word finding, and more.
|
||||
![][1]
|
||||
|
||||
Anyone who sees a child using a tablet or smartphone observes their seemingly innate ability to scroll through apps and swipe through screens, flexing those "digital native" muscles. According to [Common Sense Media][2], the percentage of US households in which 0- to 8-year-olds have access to a smartphone has grown from 52% in 2011 to 98% in 2017. While the debates around age guidelines and screen time surge, it's hard to deny that children are developing familiarity and skills with technology at an unprecedented rate.
|
||||
|
||||
This rise in early technical literacy may be astonishing, but what about _traditional_ literacy, the good old-fashioned ability to read? What does the intersection of early literacy development and early tech use look like? Let's explore some open source tools for early learners that may help develop both of these critical skill sets.
|
||||
|
||||
### Balancing risks and rewards
|
||||
|
||||
But first, a disclaimer: Guidelines for technology use, especially for young children, are [constantly changing][3]. Organizations like the American Academy of Pediatrics, Common Sense Media, Zero to Three, and PBS Kids are continually conducting research and publishing recommendations. One position that all of these and other organizations can agree on is that plopping a child in front of a screen with unmonitored content for an unlimited set of time is highly inadvisable.
|
||||
|
||||
Even setting kids up with educational content or tools for extended periods of time may have risks. And on the flip side, research on the benefits of education technologies is often limited or unavailable. In short, there are many cases in which we don't know for certain if educational technology use at a young age is beneficial, detrimental, or simply neutral.
|
||||
|
||||
But if screen time is available to your child or student, it's logical to infer that educational resources would be preferable over simpler pop-the-bubble or slice-the-fruit games or platforms that could house inappropriate content or online predators. While we may not be able to prove that education apps will make a child's test scores soar, we can at least take comfort in their generally being safer and more age-appropriate than the internet at large.
|
||||
|
||||
That said, if you're open to exploring early-education technologies, there are many reasons to look to open source options. Open source technologies are not only free but open to collaborative improvement. In many cases, they are created by developers who are educators or parents themselves, and they're a great way to avoid in-app purchases, advertisements, and paid upgrades. Open source programs can often be downloaded and installed on your device and accessed without an internet connection. Plus, the idea of [open source in education][4] is a growing trend, and there are countless resources to [learn more][5] about the concept.
|
||||
|
||||
But for now, let's check out some open source tools for early literacy in action!
|
||||
|
||||
### Childsplay
|
||||
|
||||
![Childsplay screenshot][6]
|
||||
|
||||
Let's start simple. [Childsplay][7], licensed under the GPLv2, is the most basic of the resources on this list. It's a compilation of just over a dozen educational games for young learners, four of which are specific to letter recognition, including memory games and an activity where the learner identifies a spoken letter.
|
||||
|
||||
### eduActiv8
|
||||
|
||||
![eduActiv8 screenshot][8]
|
||||
|
||||
[eduActiv8][9] started in 2011 as a personal project for the developer's son, "whose thirst for learning and knowledge inspired the creation of this educational program." It includes activities for building basic math and early literacy skills, including a variety of spelling, matching, and listening activities. Games include filling in missing letters in the alphabet, unscrambling letters to form a word, matching words to images, and completing mazes by connecting letters in the correct order. eduActiv8 was written in [Python][10] and is available under the GPLv3.
|
||||
|
||||
### GCompris
|
||||
|
||||
![GCompris screenshot][11]
|
||||
|
||||
[GCompris][12] is an open source behemoth (licensed under the GPLv3) of early educational activities. A French software engineer started it in 2000, and it now includes over 130 educational games in nearly 20 languages. Tailored for learners under age 10, it includes activities for letter recognition and drawing, alphabet sequencing, vocabulary building, and games like hangman to identify missing letters in words, plus activities for learning braille. It also includes games in math and music, plus classics from tic-tac-toe to chess.
|
||||
|
||||
### Feed the Monster
|
||||
|
||||
![Feed the Monster screenshot][13]
|
||||
|
||||
The quality of the playful "monster" graphics in [Feed the Monster][14] definitely sets it apart from the others on this list, plus it supports nearly 40 languages! The app includes activities for sorting letters to form words, memory games to match words to images, and letter-tracing writing activities. The app is developed by Curious Learning, which states: "We create, localize, distribute, and optimize open source mobile software so every child can learn to read." While Feed the Monster's offerings are geared toward early readers, Curious Mind's roadmap suggests it's headed towards a more robust personalized literacy platform growing on a foundation of research with MIT, Tufts, and Georgia State University.
|
||||
|
||||
### Syntax Untangler
|
||||
|
||||
![Syntax Untangler screenshot][15]
|
||||
|
||||
[Syntax Untangler][16] is the outlier of this group. Developed by a technologist at the University of Wisconsin–Madison under the GPLv2, the application is "particularly designed for training language learners to recognize and parse linguistic features." Examples show the software being used for foreign language learning, but anyone can use it to create language identification games, including games for early literacy activities like letter recognition. It could also be applied to later literacy skills, like identifying parts of speech in complex sentences or literary techniques in poetry or fiction.
|
||||
|
||||
### Wrapping up
|
||||
|
||||
Access to [literary environments][17] has been shown to impact literacy and attitudes towards reading. Why not strive to create a digital literary environment for our kids by filling our devices with educational technologies, just like our shelves are filled with books?
|
||||
|
||||
Now it's your turn! What open source literacy tools have you used? Comment below to share.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/early-literacy-tools
|
||||
|
||||
作者:[Laura B. Janusek][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/lbjanusek
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/idea_innovation_kid_education.png?itok=3lRp6gFa
|
||||
[2]: https://www.commonsensemedia.org/research/the-common-sense-census-media-use-by-kids-age-zero-to-eight-2017?action
|
||||
[3]: https://www.businessinsider.com/smartphone-use-young-kids-toddlers-limits-science-2018-3
|
||||
[4]: /article/18/1/best-open-education
|
||||
[5]: https://opensource.com/resources/open-source-education
|
||||
[6]: https://opensource.com/sites/default/files/uploads/cp_flashcards.gif (Childsplay screenshot)
|
||||
[7]: http://www.childsplay.mobi/
|
||||
[8]: https://opensource.com/sites/default/files/uploads/eduactiv8.jpg (eduActiv8 screenshot)
|
||||
[9]: https://www.eduactiv8.org/
|
||||
[10]: /article/17/11/5-approaches-learning-python
|
||||
[11]: https://opensource.com/sites/default/files/uploads/gcompris2.png (GCompris screenshot)
|
||||
[12]: https://gcompris.net/index-en.html
|
||||
[13]: https://opensource.com/sites/default/files/uploads/feedthemonster.png (Feed the Monster screenshot)
|
||||
[14]: https://www.curiouslearning.org/
|
||||
[15]: https://opensource.com/sites/default/files/uploads/syntaxuntangler.png (Syntax Untangler screenshot)
|
||||
[16]: https://courses.dcs.wisc.edu/untangler/
|
||||
[17]: http://www.jstor.org/stable/41386459
|
||||
234
sources/tech/20190405 File sharing with Git.md
Normal file
234
sources/tech/20190405 File sharing with Git.md
Normal file
@ -0,0 +1,234 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (File sharing with Git)
|
||||
[#]: via: (https://opensource.com/article/19/4/file-sharing-git)
|
||||
[#]: author: (Seth Kenlon (Red Hat, Community Moderator) https://opensource.com/users/seth)
|
||||
|
||||
File sharing with Git
|
||||
======
|
||||
SparkleShare is an open source, Git-based, Dropbox-style file sharing
|
||||
application. Learn more in our series about little-known uses of Git.
|
||||
![][1]
|
||||
|
||||
[Git][2] is one of those rare applications that has managed to encapsulate so much of modern computing into one program that it ends up serving as the computational engine for many other applications. While it's best-known for tracking source code changes in software development, it has many other uses that can make your life easier and more organized. In this series leading up to Git's 14th anniversary on April 7, we'll share seven little-known ways to use Git. Today, we'll look at SparkleShare, which uses Git as the backbone for file sharing.
|
||||
|
||||
### Git for file sharing
|
||||
|
||||
One of the nice things about Git is that it's inherently distributed. It's built to share. Even if you're sharing a repository just with other computers on your own network, Git brings transparency to the act of getting files from a shared location.
|
||||
|
||||
As interfaces go, Git is pretty simple. It varies from user to user, but the common incantation when sitting down to get some work done is just **git pull** or maybe the slightly more complex **git pull && git checkout -b my-branch**. Still, for some people, the idea of _entering a command_ into their computer at all is confusing or bothersome. Computers are meant to make life easy, and computers are good at repetitious tasks, and so there are easier ways to share files with Git.
|
||||
|
||||
### SparkleShare
|
||||
|
||||
The [SparkleShare][3] project is a cross-platform, open source, Dropbox-style file sharing application based on Git. It automates all Git commands, triggering the add, commit, push, and pull processes with the simple act of dragging-and-dropping a file into a specially designated SparkleShare directory. Because it is based on Git, you get fast, diff-based pushes and pulls, and you inherit all the benefits of Git version control and backend infrastructure (like Git hooks). It can be entirely self-hosted, or you can use it with Git hosting services like [GitLab][4], GitHub, Bitbucket, and others. Furthermore, because it's basically just a frontend to Git, you can access your SparkleShare files on devices that may not have a SparkleShare client but do have Git clients.
|
||||
|
||||
Just as you get all the benefits of Git, you also get all the usual Git restrictions: It's impractical to use SparkleShare to store hundreds of photos and music and videos because Git is designed and optimized for text. Git certainly has the capability to store large files of binary data but it is designed to track history, so once a file is added to it, it's nearly impossible to completely remove it. This somewhat limits the usefulness of SparkleShare for some people, but it makes it ideal for many workflows, including [calendaring][5].
|
||||
|
||||
#### Installing SparkleShare
|
||||
|
||||
SparkleShare is cross-platform, with installers for Windows and Mac available from its [website][6]. For Linux, there's a [Flatpak][7] in your software installer, or you can run these commands in a terminal:
|
||||
|
||||
|
||||
```
|
||||
$ sudo flatpak remote-add flathub <https://flathub.org/repo/flathub.flatpakrepo>
|
||||
$ sudo flatpak install flathub org.sparkleshare.SparkleShare
|
||||
```
|
||||
|
||||
### Creating a Git repository
|
||||
|
||||
SparkleShare isn't software-as-a-service (SaaS). You run SparkleShare on your computer to communicate with a Git repository—SparkleShare doesn't store your data. If you don't have a Git repository to sync a folder with yet, you must create one before launching SparkleShare. You have three options: hosted Git, self-hosted Git, or self-hosted SparkleShare.
|
||||
|
||||
#### Git hosting
|
||||
|
||||
SparkleShare can use any Git repository you can access for storage, so if you have or create an account with GitLab or any other hosting service, it can become the backend for your SparkleShare. For example, the open source [Notabug.org][8] service is a Git hosting service like GitHub and GitLab, but unique enough to prove SparkleShare's flexibility. Creating a new repository differs from host to host depending on the user interface, but all of the major ones follow the same general model.
|
||||
|
||||
First, locate the button in your hosting service to create a new project or repository and click on it to begin. Then step through the repository creation process, providing a name for your repository, privacy level (repositories often default to being public), and whether or not to initialize the repository with a README file. Whether you need a README or not, enable an initial README file. Starting a repository with a file isn't strictly necessary, but it forces the Git host to instantiate a **master** branch in the repository, which helps ensure that frontend applications like SparkleShare have a branch to commit and push to. It's also useful for you to see a file, even if it's an almost empty README file, to confirm that you have connected.
|
||||
|
||||
![Creating a Git repository][9]
|
||||
|
||||
Once you've created a repository, obtain the URL it uses for SSH clones. You can get this URL the same way anyone gets any URL for a Git project: navigate to the page of the repository and look for the **Clone** button or field.
|
||||
|
||||
![Cloning a URL on GitHub][10]
|
||||
|
||||
Cloning a GitHub URL.
|
||||
|
||||
![Cloning a URL on GitLab][11]
|
||||
|
||||
Cloning a GitLab URL.
|
||||
|
||||
This is the address SparkleShare uses to reach your data, so make note of it. Your Git repository is now configured.
|
||||
|
||||
#### Self-hosted Git
|
||||
|
||||
You can use SparkleShare to access a Git repository on any computer you have access to. No special setup is required, aside from a bare Git repository. However, if you want to give access to your Git repository to anyone else, then you should run a Git manager like [Gitolite][12] or SparkleShare's own Dazzle server to help you manage SSH keys and accounts. At the very least, create a user specific to Git so that users with access to your Git repository don't also automatically gain access to the rest of your server.
|
||||
|
||||
Log into your server as the Git user (or yourself, if you're very good at managing user and group permissions) and create a repository:
|
||||
|
||||
|
||||
```
|
||||
$ mkdir ~/sparkly.git
|
||||
$ cd ~/sparkly.git
|
||||
$ git init --bare .
|
||||
```
|
||||
|
||||
Your Git repository is now configured.
|
||||
|
||||
#### Dazzle
|
||||
|
||||
SparkleShare's developers provide a Git management system called [Dazzle][13] to help you self-host Git repositories.
|
||||
|
||||
On your server, download the Dazzle application to some location in your path:
|
||||
|
||||
|
||||
```
|
||||
$ curl <https://raw.githubusercontent.com/hbons/Dazzle/master/dazzle.sh> \
|
||||
\--output ~/bin/dazzle
|
||||
$ chmod +x ~/bin/dazzle
|
||||
```
|
||||
|
||||
Dazzle sets up a user specific to Git and SparkleShare and also implements access rights based on keys generated by the SparkleShare application. For now, just set up a project:
|
||||
|
||||
|
||||
```
|
||||
`$ dazzle create sparkly`
|
||||
```
|
||||
|
||||
Your server is now configured as a SparkleShare host.
|
||||
|
||||
### Configuring SparkleShare
|
||||
|
||||
When you launch SparkleShare for the first time, you are prompted to configure what server you want SparkleShare to use for storage. This process may feel like a first-run setup wizard, but it's actually the usual process for setting up a new shared location within SparkleShare. Unlike many shared drive applications, with SparkleShare you can have several locations configured at once. The first shared location you configure isn't any more significant than any shared location you may set up later, and you're not signing up with SparkleShare or any other service. You're just pointing SparkleShare at a Git repository so that it knows what to keep your first SparkleShare folder in sync with.
|
||||
|
||||
On the first screen, identify yourself by whatever means you want on record in the Git commits that SparkleShare makes on your behalf. You can use anything, even fake information that resolves to nothing. It's purely for the commit messages, which you may never even see if you have no interest in reviewing the Git backend processes.
|
||||
|
||||
The next screen prompts you to choose your hosting type. If you are using GitLab, GitHub, Planio, or Bitbucket, then select the appropriate one. For anything else, select **Own server**.
|
||||
|
||||
![Choosing a Sparkleshare host][14]
|
||||
|
||||
At the bottom of this screen, you must enter the SSH clone URL. If you're self-hosting, the address is something like **<ssh://username@example.com>** and the remote path is the absolute path to the Git repository you created for this purpose.
|
||||
|
||||
Based on my self-hosted examples above, the address to my imaginary server is **<ssh://git@example.com:22122>** (the **:22122** indicates a nonstandard SSH port) and the remote path is **/home/git/sparkly.git**.
|
||||
|
||||
If I use my Notabug.org account instead, the address from the example above is **[git@notabug.org][15]** and the path is **seth/sparkly.git**.
|
||||
|
||||
SparkleShare will fail the first time it attempts to connect to the host because you have not yet copied the SparkleShare client ID (an SSH key specific to the SparkleShare application) to the Git host. This is expected, so don't cancel the process. Leave the SparkleShare setup window open and obtain the client ID from the SparkleShare icon in your system tray. Then copy the client ID to your clipboard so you can add it to your Git host.
|
||||
|
||||
![Getting the client ID from Sparkleshare][16]
|
||||
|
||||
#### Adding your client ID to a hosted Git account
|
||||
|
||||
Minor UI differences aside, adding an SSH key (which is all the client ID is) is basically the same process on any hosting service. In your Git host's web dashboard, navigate to your user settings and find the **SSH Keys** category. Click the **Add New Key** button (or similar) and paste the contents of your SparkleShare client ID.
|
||||
|
||||
![Adding an SSH key][17]
|
||||
|
||||
Save the key. If you want someone else, such as collaborators or family members, to be able to access this same repository, they must provide you with their SparkleShare client ID so you can add it to your account.
|
||||
|
||||
#### Adding your client ID to a self-hosted Git account
|
||||
|
||||
A SparkleShare client ID is just an SSH key, so copy and paste it into your Git user's **~/.ssh/authorized_keys** file.
|
||||
|
||||
#### Adding your client ID with Dazzle
|
||||
|
||||
If you are using Dazzle to manage your SparkleShare projects, add a client ID with this command:
|
||||
|
||||
|
||||
```
|
||||
`$ dazzle link`
|
||||
```
|
||||
|
||||
When Dazzle prompts you for the ID, paste in the client ID found in the SparkleShare menu.
|
||||
|
||||
### Using SparkleShare
|
||||
|
||||
Once you've added your client ID to your Git host, click the **Retry** button in the SparkleShare window to finish setup. When it's finished cloning your repository, you can close the SparkleShare setup window, and you'll find a new **SparkleShare** folder in your home directory. If you set up a Git repository with a hosting service and chose to include a README or license file, you can see them in your SparkleShare directory.
|
||||
|
||||
![Sparkleshare file manager][18]
|
||||
|
||||
Otherwise, there are some hidden directories, which you can see by revealing hidden directories in your file manager.
|
||||
|
||||
![Showing hidden files in GNOME][19]
|
||||
|
||||
You use SparkleShare the same way you use any directory on your computer: you put files into it. Anytime a file or directory is placed into a SparkleShare folder, it's copied in the background to your Git repository.
|
||||
|
||||
#### Excluding certain files
|
||||
|
||||
Since Git is designed to remember _everything_ , you may want to exclude specific file types from ever being recorded. There are a few reasons to manage excluded files. By defining files that are off limits for SparkleShare, you can avoid accidental copying of large files. You can also design a scheme for yourself that enables you to store files that logically belong together (MIDI files with their **.flac** exports, for instance) in one directory, but manually back up the large files yourself while letting SparkleShare back up the text-based files.
|
||||
|
||||
If you can't see hidden files in your system's file manager, then reveal them. Navigate to your SparkleShare folder, then to the directory representing your repository, locate a file called **.gitignore** , and open it in a text editor. You can enter file extensions or file names, one per line, into **.gitignore** , and any file matching what you list will be (as the file name suggests) ignored.
|
||||
|
||||
|
||||
```
|
||||
Thumbs.db
|
||||
$RECYCLE.BIN/
|
||||
.DS_Store
|
||||
._*
|
||||
.fseventsd
|
||||
.Spotlight-V100
|
||||
.Trashes
|
||||
.directory
|
||||
.Trash-*
|
||||
*.wav
|
||||
*.ogg
|
||||
*.flac
|
||||
*.mp3
|
||||
*.m4a
|
||||
*.opus
|
||||
*.jpg
|
||||
*.png
|
||||
*.mp4
|
||||
*.mov
|
||||
*.mkv
|
||||
*.avi
|
||||
*.pdf
|
||||
*.djvu
|
||||
*.epub
|
||||
*.od{s,t}
|
||||
*.cbz
|
||||
```
|
||||
|
||||
You know the types of files you encounter most often, so concentrate on the ones most likely to sneak their way into your SparkleShare directory. If you want to exercise a little overkill, you can find good collections of **.gitignore** files on Notabug.org and also on the internet at large.
|
||||
|
||||
With those entries in your **.gitignore** file, you can place large files that you don't want sent to your Git host in your SparkleShare directory, and SparkleShare will ignore them entirely. Of course, that means it's up to you to make sure they get onto a backup or distributed to your SparkleShare collaborators through some other means.
|
||||
|
||||
### Automation
|
||||
|
||||
[Automation][20] is part of the silent agreement we have with computers: they do the repetitious, boring stuff that we humans either aren't very good at doing or aren't very good at remembering. SparkleShare is a nice, simple way to automate the routine distribution of data. It isn't right for every Git repository, by any means. It doesn't have an interface for advanced Git functions; it doesn't have a pause button or a manual override. And that's OK because its scope is intentionally limited. SparkleShare does what SparkleShare sets out to do, it does it well, and it's one Git repository you won't have to think about.
|
||||
|
||||
If you have a use for that kind of steady, invisible automation, give SparkleShare a try.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/file-sharing-git
|
||||
|
||||
作者:[Seth Kenlon (Red Hat, Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_cloud21x_cc.png?itok=5UwC92dO
|
||||
[2]: https://git-scm.com/
|
||||
[3]: http://www.sparkleshare.org/
|
||||
[4]: http://gitlab.com
|
||||
[5]: https://opensource.com/article/19/4/calendar-git
|
||||
[6]: http://sparkleshare.org
|
||||
[7]: /business/16/8/flatpak
|
||||
[8]: http://notabug.org
|
||||
[9]: https://opensource.com/sites/default/files/uploads/git-new-repo.jpg (Creating a Git repository)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/github-clone-url.jpg (Cloning a URL on GitHub)
|
||||
[11]: https://opensource.com/sites/default/files/uploads/gitlab-clone-url.jpg (Cloning a URL on GitLab)
|
||||
[12]: http://gitolite.org
|
||||
[13]: https://github.com/hbons/Dazzle
|
||||
[14]: https://opensource.com/sites/default/files/uploads/sparkleshare-host.jpg (Choosing a Sparkleshare host)
|
||||
[15]: mailto:git@notabug.org
|
||||
[16]: https://opensource.com/sites/default/files/uploads/sparkleshare-clientid.jpg (Getting the client ID from Sparkleshare)
|
||||
[17]: https://opensource.com/sites/default/files/uploads/git-ssh-key.jpg (Adding an SSH key)
|
||||
[18]: https://opensource.com/sites/default/files/uploads/sparkleshare-file-manager.jpg (Sparkleshare file manager)
|
||||
[19]: https://opensource.com/sites/default/files/uploads/gnome-show-hidden-files.jpg (Showing hidden files in GNOME)
|
||||
[20]: /downloads/ansible-quickstart
|
||||
@ -0,0 +1,86 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Streaming internet radio with RadioDroid)
|
||||
[#]: via: (https://opensource.com/article/19/4/radiodroid-internet-radio-player)
|
||||
[#]: author: (Chris Hermansen (Community Moderator) https://opensource.com/users/clhermansen)
|
||||
|
||||
Streaming internet radio with RadioDroid
|
||||
======
|
||||
Listen to your favorite internet radio stations over your home stereo
|
||||
with this easy setup.
|
||||
![woman programming][1]
|
||||
|
||||
Online news outlets have recently lamented the [passing of Google's Chromecast Audio device][2]. The device received [favorable reviews][3] in the audio press, so I had already been thinking about acquiring one. Given the news of Chromecast's demise, I decided to look for one at a reasonable price—before they were all snapped up or thrown in the dumpster.
|
||||
|
||||
I found one at [MobileFun][4] and put in my order. The device eventually arrived, packaged in the usual serviceable but minimal Google wrapping, with a very brief Get Started guide printed on the outside.
|
||||
|
||||
![Google Chromecast Audio][5]
|
||||
|
||||
I cabled it to my home stereo via my digital-analog converter's optical S/PDIF connection, hoping that would provide the best sound quality.
|
||||
|
||||
The setup ran flawlessly, and in about five minutes I was ready to play some tunes. I knew that a number of Android applications support Chromecast, so I decided to test it out with Google Play Music; sure enough, it worked just fine and sounded quite good. However, being an open source kind of person, I decided to see what I could find in the way of open source players that work with Chromecast.
|
||||
|
||||
### RadioDroid to the rescue
|
||||
|
||||
The [RadioDroid Android application][6] fit the bill. It is open source and available on [GitHub][7], Google Play, and [F-Droid][8]. According to the documentation, RadioDroid looks up and plays streams from the [Community Radio Browser][9] website. So I decided to install it on my handset and give it a shot.
|
||||
|
||||
![RadioDroid][10]
|
||||
|
||||
The installation was quick and smooth, and RadioDroid opened rapidly to display local stations. You can see the Chromecast button (the icon that looks like a rectangle with wavefronts) near the top-right side of this screenshot.
|
||||
|
||||
I played around with a few of the local stations. The application reliably played music on my handset's speaker, but I had to futz around with the Chromecast button to get the music to stream over the Chromecast. But stream it did!
|
||||
|
||||
I decided to seek out my favorite internet radio station, [Radio Grenouille][11] in Marseille, France. There are various ways to find stations in RadioDroid. One is to use the tabs—Local, Topclick, etc.—located above the list of stations. One of the tabs is Countries; I found France, with some 1,500 stations, on the list and scrolled—and scrolled, and scrolled—down through the list to find Radio Grenouille. Another way is to use the Search button at the top of the screen; the search was rapid and returned that wonderful radio station. I tried a few other searches, and they all returned reasonable info.
|
||||
|
||||
Going back to the Local tab, I scrolled through the listings and learned that "local" seems to be defined as "in the same country." So, even though Seattle, Portland, San Francisco, Los Angeles, and Juneau are closer to my home than Toronto, I didn't see any of them in Local. However, by using Search, I could find all stations with "Seattle" in their name.
|
||||
|
||||
The Languages tab let me find all stations broadcasting in Portugues, Portuguese, Português, Português Brasil, Português do Brasil, Portuguẽs, and Portugês. I quickly found another favorite station, [91 Rock Curitiba][12].
|
||||
|
||||
Then inspiration struck—it's springtime, but who cares? Let's listen to some Christmas music. And sure enough, searching for Christmas led me to [181.FM – Christmas Blender][13]. Well, a minute or two of that was enough for me…
|
||||
|
||||
So, all in all, I recommend the RadioDroid and Chromecast combo as a nice way to play internet radio on a home stereo at a reasonable cost.
|
||||
|
||||
### As for the music…
|
||||
|
||||
Recently I picked up an interesting album of very ambient (even beatless) music called [Continuum One][14] by [Qua Continuum][15] from the [Blue Coast Music][16] store. Blue Coast has a lot to offer the open source music enthusiast: music is available by download (and sometimes physical format) without resorting to those grotesque platform-specific download managers; it typically provides several formats, including WAV, FLAC, and DSD; different word lengths and bitrates are provided for WAV and FLAC, including 16/44.1, 24/96, and 24/192, and for DSD, 2.8, 5.6, and 11.2 MHz; and the music is recorded with great care using wonderful facilities. Unfortunately, I don't find a lot of music there to my taste, though I like a few of the artists available on Blue Coast, including Qua Continuum, [Art Lande][17], and [Alex De Grassi][18].
|
||||
|
||||
Over on [Bandcamp][19], I picked up [Emancipator's Baralku][20] and [Framework's Tides][21], both of which I enjoy. The music created by these two artists hits my sweet spot—it's electronic but not (generally) dance, it's melodic, and it tends to have some great hooks. There are many things for open source aficionados to like about Bandcamp, such as the ability to listen to the work in its entirety before buying; the lack of bloatware downloaders; the amounts shared with the musicians; and its support for [Creative Commons music][22].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/radiodroid-internet-radio-player
|
||||
|
||||
作者:[Chris Hermansen (Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/clhermansen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming-code-keyboard-laptop-music-headphones.png?itok=EQZ2WKzy (woman programming)
|
||||
[2]: https://www.theverge.com/2019/1/11/18178751/google-chromecast-audio-discontinued-sale
|
||||
[3]: https://www.whathifi.com/google/chromecast-audio/review
|
||||
[4]: https://www.mobilefun.com/google-chromecast-audio-black-70476
|
||||
[5]: https://opensource.com/sites/default/files/uploads/internet-radio_chromecast.png (Google Chromecast Audio)
|
||||
[6]: https://play.google.com/store/apps/details?id=net.programmierecke.radiodroid2
|
||||
[7]: https://github.com/segler-alex/RadioDroid
|
||||
[8]: https://f-droid.org/en/packages/net.programmierecke.radiodroid2/
|
||||
[9]: http://www.radio-browser.info/gui/#!/
|
||||
[10]: https://opensource.com/sites/default/files/uploads/internet-radio_radiodroid.png (RadioDroid)
|
||||
[11]: http://www.radiogrenouille.com/
|
||||
[12]: https://91rock.com.br/
|
||||
[13]: http://player.181fm.com/?station=181-xblender
|
||||
[14]: https://www.youtube.com/watch?v=PqLCQXPS8iQ
|
||||
[15]: https://bluecoastmusic.com/artists/qua-continuum
|
||||
[16]: https://bluecoastmusic.com/store
|
||||
[17]: https://bluecoastmusic.com/store?f%5B0%5D=search_api_multi_aggregation_1%3Aart%20lande
|
||||
[18]: https://bluecoastmusic.com/store?f%5B0%5D=search_api_multi_aggregation_1%3Aalex%20de%20grassi
|
||||
[19]: https://bandcamp.com/
|
||||
[20]: https://emancipator.bandcamp.com/album/baralku
|
||||
[21]: https://frameworksuk.bandcamp.com/album/tides
|
||||
[22]: https://bandcamp.com/tag/creative-commons
|
||||
240
sources/tech/20190406 Run a server with Git.md
Normal file
240
sources/tech/20190406 Run a server with Git.md
Normal file
@ -0,0 +1,240 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Run a server with Git)
|
||||
[#]: via: (https://opensource.com/article/19/4/server-administration-git)
|
||||
[#]: author: (Seth Kenlon (Red Hat, Community Moderator) https://opensource.com/users/seth/users/seth)
|
||||
|
||||
Run a server with Git
|
||||
======
|
||||
Thanks to Gitolite, you can manage a Git server with Git. Learn how in
|
||||
our series about little-known Git uses.
|
||||
![computer servers processing data][1]
|
||||
|
||||
As I've tried to demonstrate in this series leading up to Git's 14th anniversary on April 7, [Git][2] can do a wide range of things beyond tracking source code. Believe it or not, Git can even manage your Git server, so you can, more or less, run a Git server with Git itself.
|
||||
|
||||
Of course, this involves a lot of components beyond everyday Git, not the least of which is [Gitolite][3], the backend application managing the fiddly bits that you configure using Git. The great thing about Gitolite is that, because it uses Git as its frontend interface, it's easy to integrate Git server administration within the rest of your Git-based workflow. Gitolite provides precise control over who can access specific repositories on your server and what permissions they have. You can manage that sort of thing yourself with the usual Linux system tools, but it takes a lot of work if you have more than just one or two repos across a half-dozen users.
|
||||
|
||||
Gitolite's developers have done the hard work to make it easy for you to provide many users with access to your Git server without giving them access to your entire environment—and you can do it all with Git.
|
||||
|
||||
What Gitolite is _not_ is a GUI admin and user panel. That sort of experience is available with the excellent [Gitea][4] project, but this article focuses on the simple elegance and comforting familiarity of Gitolite.
|
||||
|
||||
### Install Gitolite
|
||||
|
||||
Assuming your Git server runs Linux, you can install Gitolite with your package manager ( **yum** on CentOS and RHEL, **apt** on Debian and Ubuntu, **zypper** on OpenSUSE, and so on). For example, on RHEL:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo yum install gitolite3`
|
||||
```
|
||||
|
||||
Many repositories still have older versions of Gitolite for legacy support, but the current version is version 3.
|
||||
|
||||
You must have passwordless SSH access to your server. You can use a password to log in if you prefer, but Gitolite relies on SSH keys, so you must configure the option to log in with keys. If you don't know how to configure a server for passwordless SSH access, go learn how to do that first (the [Setting up SSH key authentication][5] section of Steve Ovens's Ansible article explains it well). It's an essential part of secure server administration—as well as of running Gitolite.
|
||||
|
||||
### Configure a Git user
|
||||
|
||||
Without Gitolite, if a person requests access to a Git repository you host on a server, you have to provide that person with a user account. Git provides a special shell, the **git-shell** , which is an ultra-specific shell that performs only Git tasks. This lets you have users who can access your server only through the filter of a very limited shell environment.
|
||||
|
||||
That solution works, but it usually means a user gains access to all repositories on your server unless you have a very good schema for group permissions and maintain those permissions strictly whenever a new repository is created. It also requires a lot of manual configuration at the system level, an area usually reserved for a specific tier of sysadmins and not necessarily the person usually in charge of Git repositories.
|
||||
|
||||
Gitolite sidesteps this issue entirely by designating one username for every person who needs access to any repository. By default, the username is **git** , and because Gitolite's documentation assumes that's what is used, it's a good default to keep when you're learning the tool. It's also a well-known convention for anyone who's ever used GitLab or GitHub or any other Git hosting service.
|
||||
|
||||
Gitolite calls this user the _hosting user_. Create an account on your server to act as the hosting user (I'll stick with **git** because that's the convention):
|
||||
|
||||
|
||||
```
|
||||
` $ sudo adduser --create-home git`
|
||||
```
|
||||
|
||||
For you to control the **git** user account, it must have a valid public SSH key that belongs to you. You should already have this set up, so **cp** your public key ( _not your private key_ ) to the **git** user's home directory:
|
||||
|
||||
|
||||
```
|
||||
$ sudo cp ~/.ssh/id_ed25519.pub /home/git/
|
||||
$ sudo chown git:git /home/git/id_ed25519.pub
|
||||
```
|
||||
|
||||
If your public key doesn't end with the extension **.pub** , Gitolite will not use it, so rename the file accordingly. Change to that user account to run Gitolite's setup:
|
||||
|
||||
|
||||
```
|
||||
$ sudo su - git
|
||||
$ gitolite setup --pubkey id_ed25519.pub
|
||||
```
|
||||
|
||||
After the setup script runs, the **git** home's user directory will have a **repositories** directory, which (for now) contains the files **git-admin.git** and **testing.git**. That's all the setup the server requires, so log out.
|
||||
|
||||
### Use Gitolite
|
||||
|
||||
Managing Gitolite is a matter of editing text files in a Git repository, specifically **gitolite-admin.git**. You won't SSH into your server for Git administration, and Gitolite encourages you not to try. The repositories you and your users store on the Gitolite server are _bare_ repositories, so it's best to stay out of them.
|
||||
|
||||
|
||||
```
|
||||
$ git clone [git@example.com][6]:gitolite-admin.git gitolite-admin.git
|
||||
$ cd gitolite-admin.git
|
||||
$ ls -1
|
||||
conf
|
||||
keydir
|
||||
```
|
||||
|
||||
The **conf** directory in this repository contains a file called **gitolite.conf**. Open it in a text editor or use **cat** to view its contents:
|
||||
|
||||
|
||||
```
|
||||
repo gitolite-admin
|
||||
RW+ = id_ed22519
|
||||
|
||||
repo testing
|
||||
RW+ = @all
|
||||
```
|
||||
|
||||
You may have an idea of what this configuration file does: **gitolite-admin** represents this repository, and the owner of the **id_ed25519** key has read, write, and Git administrative privileges. In other words, rather than mapping users to normal local Unix users (because all your users log in using the **git** hosting user identity), Gitolite maps users to SSH keys listed in the **keydir** directory.
|
||||
|
||||
The **testing.git** repository gives full permissions to everyone with access to the server using special group notation.
|
||||
|
||||
#### Add users
|
||||
|
||||
If you want to add a user called **alice** to your Git server, the person Alice must send you her public SSH key. Gitolite uses whatever is to the left of the **.pub** extension as the identifier for your Git users. Rather than using the default key name values, give keys a name indicative of the key owner. If a user has more than one key (e.g., one for her laptop, one for her desktop), you can use subdirectories to avoid file name collisions. For instance, the key Alice uses from her laptop might come to you as the default **id_rsa.pub** , so rename it **alice.pub** or similar (or let the users name the key according to their local user accounts on their computers), and place it into the **gitolite-admin.git/keydir/work/laptop/** directory. If she sends you another key from her desktop, name it **alice.pub** (the same as the previous one) and add it to **keydir/work/desktop/**. Another key might go into **keydir/home/desktop/** , and so on. Gitolite recursively searches **keydir** for a **.pub** file matching a repository "user" and treats any match as the same identity.
|
||||
|
||||
When you add keys to the **keydir** directory, you must commit them back to your server. This is such an easy thing to forget that there's a real argument here for using an automated Git application like [**Sparkleshare**][7] so any change is committed back to your Gitolite admin immediately. The first time you forget to commit and push—and waste three hours of your time and your user's time troubleshooting—you'll see that Gitolite is the perfect justification for using Sparkleshare.
|
||||
|
||||
|
||||
```
|
||||
$ git add keydir
|
||||
$ git commit -m 'added alice-laptop-0.pub'
|
||||
$ git push origin HEAD
|
||||
```
|
||||
|
||||
Alice, by default, gains access to the **testing.git** directory so she can test connectivity and functionality with that.
|
||||
|
||||
#### Set permissions
|
||||
|
||||
As with users, directory permissions and groups are abstracted away from the normal Unix tools you might be used to (or find information about online). Permissions to projects are granted in the **gitolite.conf** file in **gitolite-admin.git/conf** directory. There are four levels of permissions:
|
||||
|
||||
* **R** allows read-only. A user with **R** permissions on a repository may clone it, and that's all.
|
||||
* **RW** allows a user to perform a fast-forward push of a branch, create new branches, and create new tags. More or less, this one feels like a "normal" Git repository to most users.
|
||||
* **RW+** allows Git actions that are potentially destructive. A user can perform normal fast-forward pushes, as well as rewind pushes, do rebases, and delete branches and tags. This may or may not be something you want to grant to all contributors on a project.
|
||||
* **-** explicitly denies access to a repository. This is essentially the same as a user not being listed in the repository's configuration.
|
||||
|
||||
|
||||
|
||||
Create a new repository or modify an existing repository's permissions by adjusting **gitolite.conf**. For instance, to give Alice permissions to administrate a new repository called **widgets.git** :
|
||||
|
||||
|
||||
```
|
||||
repo gitolite-admin
|
||||
RW+ = id_ed22519
|
||||
|
||||
repo testing
|
||||
RW+ = @all
|
||||
|
||||
repo widgets
|
||||
RW+ = alice
|
||||
```
|
||||
|
||||
Now Alice—and Alice alone—can clone the repo:
|
||||
|
||||
|
||||
```
|
||||
[alice]$ git clone [git@example.com][6]:widgets.git
|
||||
Cloning into 'widgets'...
|
||||
warning: You appear to have cloned an empty repository.
|
||||
```
|
||||
|
||||
On her initial push, Alice must use the **-u** option to send her branch to the empty repository (as she would have to do with any Git host).
|
||||
|
||||
To make user management easier, you can define groups of repositories:
|
||||
|
||||
|
||||
```
|
||||
@qtrepo = widgets
|
||||
@qtrepo = games
|
||||
|
||||
repo gitolite-admin
|
||||
RW+ = id_ed22519
|
||||
|
||||
repo testing
|
||||
RW+ = @all
|
||||
|
||||
repo @qtrepo
|
||||
RW+ = alice
|
||||
```
|
||||
|
||||
Just as you can create group repositories, you can group users. One user group exists by default: **@all**. As you might expect, it includes all users, without exception. You can create your own:
|
||||
|
||||
|
||||
```
|
||||
@qtrepo = widgets
|
||||
@qtrepo = games
|
||||
|
||||
@developers = alice bob
|
||||
|
||||
repo gitolite-admin
|
||||
RW+ = id_ed22519
|
||||
|
||||
repo testing
|
||||
RW+ = @all
|
||||
|
||||
repo @qtrepo
|
||||
RW+ = @developers
|
||||
```
|
||||
|
||||
As with adding or modifying key files, any change to the **gitolite.conf** file must be committed and pushed to take effect.
|
||||
|
||||
### Create a repository
|
||||
|
||||
By default, Gitolite assumes repository creation happens from the top down. For instance, a project manager with access to the Git server creates a project repository and, through the Gitolite administration repo, adds developers.
|
||||
|
||||
In practice, you might prefer to grant users permission to create repositories. Gitolite calls these "wild repos" (I'm not sure whether that's commentary on how the repos come into being or a reference to the wildcard characters required by the configuration file to let it happen). Here's an example:
|
||||
|
||||
|
||||
```
|
||||
@managers = alice bob
|
||||
|
||||
repo foo/CREATOR/[a-z]..*
|
||||
C = @managers
|
||||
RW+ = CREATOR
|
||||
RW = WRITERS
|
||||
R = READERS
|
||||
```
|
||||
|
||||
The first line defines a group of users: the group is called **@managers** and contains users **alice** and **bob**. The next line sets up a wildcard allowing repositories that do not yet exist to be created in a directory called **foo** followed by a subdirectory named for the user creating the repo. For example:
|
||||
|
||||
|
||||
```
|
||||
[alice]$ git clone [git@example.com][6]:foo/alice/cool-app.git
|
||||
Cloning into cool-app'...
|
||||
Initialized empty Git repository in /home/git/repositories/foo/alice/cool-app.git
|
||||
warning: You appear to have cloned an empty repository.
|
||||
```
|
||||
|
||||
There are some mechanisms for the creator of a wild repo to define who can read and write to their repository, but they're limited in scope. For the most part, Gitolite assumes that a specific set of users governs project permission. One solution is to grant all users access to **gitolite-admin** using a Git hook to require manager approval to merge changes into the master branch.
|
||||
|
||||
### Learn more
|
||||
|
||||
Gitolite has many more features than what this introductory article covers, so try it out. The [documentation][8] is excellent, and once you read through it, you can customize your Gitolite server to provide your users whatever level of control you are comfortable with. Gitolite is a low-maintenance, simple system that you can install, set up, and then more or less forget about.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/server-administration-git
|
||||
|
||||
作者:[Seth Kenlon (Red Hat, Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/server_data_system_admin.png?itok=q6HCfNQ8 (computer servers processing data)
|
||||
[2]: https://git-scm.com/
|
||||
[3]: http://gitolite.com
|
||||
[4]: http://gitea.io
|
||||
[5]: Setting%20up%20SSH%20key%20authentication
|
||||
[6]: mailto:git@example.com
|
||||
[7]: https://opensource.com/article/19/4/file-sharing-git
|
||||
[8]: http://gitolite.com/gitolite/quick_install.html
|
||||
@ -0,0 +1,72 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (zhs852)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Happy 14th anniversary Git: What do you love about Git?)
|
||||
[#]: via: (https://opensource.com/article/19/4/what-do-you-love-about-git)
|
||||
[#]: author: (Jen Wike Huger (Red Hat) https://opensource.com/users/jen-wike/users/seth)
|
||||
|
||||
Happy 14th anniversary Git: What do you love about Git?
|
||||
======
|
||||
Git's huge influence on software development practices is hard to match.
|
||||
![arrows cycle symbol for failing faster][1]
|
||||
|
||||
In the 14 years since Linus Torvalds developed Git, its influence on software development practices would be hard to match—in StackOverflow's 2018 developer survey, [87% of respondents][2] said they use Git for version control. Clearly, no other tool is anywhere close to knocking Git off its throne as the king of source control management (SCM).
|
||||
|
||||
In honor of Git's 14th anniversary on April 7, I asked some enthusiasts what they love most about it. Here's what they told me.
|
||||
|
||||
_(Some responses have been lightly edited for grammar and clarity)_
|
||||
|
||||
"I can't stand Git. Incomprehensible terminology, distributed so that truth does not exist, requires add-ons like Gerrit to make it 50% as usable as a nice centralized repository like Subversion or Perforce. But in the spirit of answering 'what do you like about Git?': Git makes arbitrarily abstruse source tree manipulations possible and usually makes it easy to undo them when it takes 20 tries to get them right." — _[Sweet Tea Dorminy][3]_
|
||||
|
||||
"I like that Git doesn't enforce any particular workflow and development teams are free to collaborate in a way that works for them, be it with pull requests or emailed diffs or push permission for all." — _[Andy Price][4]_
|
||||
|
||||
"I've been using Git since 2006 or 2007. What I love about Git is that it works well both for small projects that may never leave my computer and for large, collaborative, distributed projects. Git provides you all the tools to rollback from (almost) every bad commit you make, and as such has significantly reduced my stress when it comes to software management." — _[Jonathan S. Katz][5]_
|
||||
|
||||
"I appreciate Git's principle of ["plumbing" vs. "porcelain" commands][6]. Users can effectively share any kind of information using Git without needing to know how the internals work. That said, the curious have access to commands that peel back the layers, revealing the content-addressable filesystem that powers many code-sharing communities." — _[Matthew Broberg][7]_
|
||||
|
||||
"I love Git because I can do almost anything to explore, develop, build, test, and commit application codes in my own Git repo. It always motivates me to participate in open source projects." — _[Daniel Oh][8]_
|
||||
|
||||
"Git is the first version control tool I used, and it went from being scary to friendly over the years. I love how it empowers you to feel confident about code you are changing while it gives you the assurance that your master branch is safe (obviously unless you force-push half-baked code to the production/master branch). Its ability to reverse changes by checking out older commits is great too." — _[Kedar Vijay Kulkarni][9]_
|
||||
|
||||
"I love Git because it made several other SCM software obsolete. No one uses VS, Subversion can be used with git-svn (if needed at all), BitKeeper is remembered only by elders, it's similar with Monotone. Sure, there is Mercurial, but for me it was kind of 'still a work in progress' when I used it while upstreaming Firefox support for AArch64 (a few years ago). Someone may even mention Perforce, SourceSafe, or some other 'enterprise' solutions, but they are not popular in the FOSS world." — _[Marcin Juszkiewicz][10]_
|
||||
|
||||
"I love the simplicity of the internal model of SHA1ed (commit → tree → blob) objects. And porcelain commands. And that I used it as patching mechanism for JBoss/Red Hat Fuse. And that this mechanism works. And how Git can be explained in the [great tale of three trees][11]." — _[Grzegorz Grzybek][12]_
|
||||
|
||||
"I like the [generated Git man pages][13] which make me humble in front of Git. (This is a page that generates Git-sounding but in reality completely nonsense pages—which often gives the same feeling as real Git pages…)" — _[Marko Myllynen][14]_
|
||||
|
||||
"Git changed my life as a developer going from a world where SCM was a problem to a world where it is a solution." — _[Joel Takvorian][15]_
|
||||
|
||||
* * *
|
||||
|
||||
Now that we've heard from these 10 Git enthusiasts, it's your turn: What do _you_ appreciate about Git? Please share your opinions in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/what-do-you-love-about-git
|
||||
|
||||
作者:[Jen Wike Huger (Red Hat)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jen-wike/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/fail_progress_cycle_momentum_arrow.png?itok=q-ZFa_Eh (arrows cycle symbol for failing faster)
|
||||
[2]: https://insights.stackoverflow.com/survey/2018/#work-_-version-control
|
||||
[3]: https://github.com/sweettea
|
||||
[4]: https://www.linkedin.com/in/andrew-price-8771796/
|
||||
[5]: https://opensource.com/users/jkatz05
|
||||
[6]: https://git-scm.com/book/en/v2/Git-Internals-Plumbing-and-Porcelain
|
||||
[7]: https://opensource.com/users/mbbroberg
|
||||
[8]: https://opensource.com/users/daniel-oh
|
||||
[9]: https://opensource.com/users/kkulkarn
|
||||
[10]: https://github.com/hrw
|
||||
[11]: https://speakerdeck.com/schacon/a-tale-of-three-trees
|
||||
[12]: https://github.com/grgrzybek
|
||||
[13]: https://git-man-page-generator.lokaltog.net/
|
||||
[14]: https://github.com/myllynen
|
||||
[15]: https://github.com/jotak
|
||||
247
sources/tech/20190407 Manage multimedia files with Git.md
Normal file
247
sources/tech/20190407 Manage multimedia files with Git.md
Normal file
@ -0,0 +1,247 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Manage multimedia files with Git)
|
||||
[#]: via: (https://opensource.com/article/19/4/manage-multimedia-files-git)
|
||||
[#]: author: (Seth Kenlon (Red Hat, Community Moderator) https://opensource.com/users/seth)
|
||||
|
||||
Manage multimedia files with Git
|
||||
======
|
||||
Learn how to use Git to track large multimedia files in your projects in
|
||||
the final article in our series on little-known uses of Git.
|
||||
![video editing dashboard][1]
|
||||
|
||||
Git is very specifically designed for source code version control, so it's rarely embraced by projects and industries that don't primarily work in plaintext. However, the advantages of an asynchronous workflow are appealing, especially in the ever-growing number of industries that combine serious computing with seriously artistic ventures, including web design, visual effects, video games, publishing, currency design (yes, that's a real industry), education… the list goes on and on.
|
||||
|
||||
In this series leading up to Git's 14th anniversary, we've shared six little-known ways to use Git. In this final article, we'll look at software that brings the advantages of Git to managing multimedia files.
|
||||
|
||||
### The problem with managing multimedia files with Git
|
||||
|
||||
It seems to be common knowledge that Git doesn't work well with non-text files, but it never hurts to challenge assumptions. Here's an example of copying a photo file using Git:
|
||||
|
||||
|
||||
```
|
||||
$ du -hs
|
||||
108K .
|
||||
$ cp ~/photos/dandelion.tif .
|
||||
$ git add dandelion.tif
|
||||
$ git commit -m 'added a photo'
|
||||
[master (root-commit) fa6caa7] two photos
|
||||
1 file changed, 0 insertions(+), 0 deletions(-)
|
||||
create mode 100644 dandelion.tif
|
||||
$ du -hs
|
||||
1.8M .
|
||||
```
|
||||
|
||||
Nothing unusual so far; adding a 1.8MB photo to a directory results in a directory 1.8MB in size. So, let's try removing the file:
|
||||
|
||||
|
||||
```
|
||||
$ git rm dandelion.tif
|
||||
$ git commit -m 'deleted a photo'
|
||||
$ du -hs
|
||||
828K .
|
||||
```
|
||||
|
||||
You can see the problem here: Removing a large file after it's been committed increases a repository's size roughly eight times its original, barren state (from 108K to 828K). You can perform tests to get a better average, but this simple demonstration is consistent with my experience. The cost of committing files that aren't text-based is minimal at first, but the longer a project stays active, the more changes people make to static content, and the more those fractions start to add up. When a Git repository becomes very large, the major cost is usually speed. The time to perform pulls and pushes goes from being how long it takes to take a sip of coffee to how long it takes to wonder if your computer got kicked off the network.
|
||||
|
||||
The reason static content causes Git to grow in size is that formats based on text allow Git to pull out just the parts that have changed. Raster images and music files make as much sense to Git as they would to you if you looked at the binary data contained in a .png or .wav file. So Git just takes all the data and makes a new copy of it, even if only one pixel changes from one photo to the next.
|
||||
|
||||
### Git-portal
|
||||
|
||||
In practice, many multimedia projects don't need or want to track the media's history. The media part of a project tends to have a different lifecycle than the text or code part of a project. Media assets generally progress in one direction: a picture starts as a pencil sketch, proceeds toward its destination as a digital painting, and, even if the text is rolled back to an earlier version, the art continues its forward progress. It's rare for media to be bound to a specific version of a project. The exceptions are usually graphics that reflect datasets—usually tables or graphs or charts—that can be done in text-based formats such as SVG.
|
||||
|
||||
So, on many projects that involve both media and text (whether it's narrative prose or code), Git is an acceptable solution to file management, as long as there's a playground outside the version control cycle for artists to play in.
|
||||
|
||||
![Graphic showing relationship between art assets and Git][2]
|
||||
|
||||
A simple way to enable that is [Git-portal][3], a Bash script armed with Git hooks that moves your asset files to a directory outside Git's purview and replaces them with symlinks. Git commits the symlinks (sometimes called aliases or shortcuts), which are trivially small, so all you commit are your text files and whatever symlinks represent your media assets. Because the replacement files are symlinks, your project continues to function as expected because your local machine follows the symlinks to their "real" counterparts. Git-portal maintains a project's directory structure when it swaps out a file with a symlink, so it's easy to reverse the process, should you decide that Git-portal isn't right for your project or you need to build a version of your project without symlinks (for distribution, for instance).
|
||||
|
||||
Git-portal also allows remote synchronization of assets over rsync, so you can set up a remote storage location as a centralized source of authority.
|
||||
|
||||
Git-portal is ideal for multimedia projects, including video game and tabletop game design, virtual reality projects with big 3D model renders and textures, [books][4] with graphics and .odt exports, collaborative [blog websites][5], music projects, and much more. It's not uncommon for an artist to perform versioning in their application—in the form of layers (in the graphics world) and tracks (in the music world)—so Git adds nothing to multimedia project files themselves. The power of Git is leveraged for other parts of artistic projects (prose and narrative, project management, subtitle files, credits, marketing copy, documentation, and so on), and the power of structured remote backups is leveraged by the artists.
|
||||
|
||||
#### Install Git-portal
|
||||
|
||||
There are RPM packages for Git-portal located at <https://klaatu.fedorapeople.org/git-portal>, which you can download and install.
|
||||
|
||||
Alternately, you can install Git-portal manually from its home on GitLab. It's just a Bash script and some Git hooks (which are also Bash scripts), but it requires a quick build process so that it knows where to install itself:
|
||||
|
||||
|
||||
```
|
||||
$ git clone <https://gitlab.com/slackermedia/git-portal.git> git-portal.clone
|
||||
$ cd git-portal.clone
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
#### Use Git-portal
|
||||
|
||||
Git-portal is used alongside Git. This means, as with all large-file extensions to Git, there are some added steps to remember. But you only need Git-portal when dealing with your media assets, so it's pretty easy to remember unless you've acclimated yourself to treating large files the same as text files (which is rare for Git users). There's one setup step you must do to use Git-portal in a project:
|
||||
|
||||
|
||||
```
|
||||
$ mkdir bigproject.git
|
||||
$ cd !$
|
||||
$ git init
|
||||
$ git-portal init
|
||||
```
|
||||
|
||||
Git-portal's **init** function creates a **_portal** directory in your Git repository and adds it to your .gitignore file.
|
||||
|
||||
Using Git-portal in a daily routine integrates smoothly with Git. A good example is a MIDI-based music project: the project files produced by the music workstation are text-based, but the MIDI files are binary data:
|
||||
|
||||
|
||||
```
|
||||
$ ls -1
|
||||
_portal
|
||||
song.1.qtr
|
||||
song.qtr
|
||||
song-Track_1-1.mid
|
||||
song-Track_1-3.mid
|
||||
song-Track_2-1.mid
|
||||
$ git add song*qtr
|
||||
$ git-portal song-Track*mid
|
||||
$ git add song-Track*mid
|
||||
```
|
||||
|
||||
If you look into the **_portal** directory, you'll find the original MIDI files. The files in their place are symlinks to **_portal** , which keeps the music workstation working as expected:
|
||||
|
||||
|
||||
```
|
||||
$ ls -lG
|
||||
[...] _portal/
|
||||
[...] song.1.qtr
|
||||
[...] song.qtr
|
||||
[...] song-Track_1-1.mid -> _portal/song-Track_1-1.mid*
|
||||
[...] song-Track_1-3.mid -> _portal/song-Track_1-3.mid*
|
||||
[...] song-Track_2-1.mid -> _portal/song-Track_2-1.mid*
|
||||
```
|
||||
|
||||
As with Git, you can also add a directory of files:
|
||||
|
||||
|
||||
```
|
||||
$ cp -r ~/synth-presets/yoshimi .
|
||||
$ git-portal add yoshimi
|
||||
Directories cannot go through the portal. Sending files instead.
|
||||
$ ls -lG _portal/yoshimi
|
||||
[...] yoshimi.stat -> ../_portal/yoshimi/yoshimi.stat*
|
||||
```
|
||||
|
||||
Removal works as expected, but when removing something in **_portal** , you should use **git-portal rm** instead of **git rm**. Using Git-portal ensures that the file is removed from **_portal** :
|
||||
|
||||
|
||||
```
|
||||
$ ls
|
||||
_portal/ song.qtr song-Track_1-3.mid@ yoshimi/
|
||||
song.1.qtr song-Track_1-1.mid@ song-Track_2-1.mid@
|
||||
$ git-portal rm song-Track_1-3.mid
|
||||
rm 'song-Track_1-3.mid'
|
||||
$ ls _portal/
|
||||
song-Track_1-1.mid* song-Track_2-1.mid* yoshimi/
|
||||
```
|
||||
|
||||
If you forget to use Git-portal, then you have to remove the portal file manually:
|
||||
|
||||
|
||||
```
|
||||
$ git-portal rm song-Track_1-1.mid
|
||||
rm 'song-Track_1-1.mid'
|
||||
$ ls _portal/
|
||||
song-Track_1-1.mid* song-Track_2-1.mid* yoshimi/
|
||||
$ trash _portal/song-Track_1-1.mid
|
||||
```
|
||||
|
||||
Git-portal's only other function is to list all current symlinks and find any that may have become broken, which can sometimes happen if files move around in a project directory:
|
||||
|
||||
|
||||
```
|
||||
$ mkdir foo
|
||||
$ mv yoshimi foo
|
||||
$ git-portal status
|
||||
bigproject.git/song-Track_2-1.mid: symbolic link to _portal/song-Track_2-1.mid
|
||||
bigproject.git/foo/yoshimi/yoshimi.stat: broken symbolic link to ../_portal/yoshimi/yoshimi.stat
|
||||
```
|
||||
|
||||
If you're using Git-portal for a personal project and maintaining your own backups, this is technically all you need to know about Git-portal. If you want to add in collaborators or you want Git-portal to manage backups the way (more or less) Git does, you can a remote.
|
||||
|
||||
#### Add Git-portal remotes
|
||||
|
||||
Adding a remote location for Git-portal is done through Git's existing remote function. Git-portal implements Git hooks, scripts hidden in your repository's .git directory, to look at your remotes for any that begin with **_portal**. If it finds one, it attempts to **rsync** to the remote location and synchronize files. Git-portal performs this action anytime you do a Git push or a Git merge (or pull, which is really just a fetch and an automatic merge).
|
||||
|
||||
If you've only cloned Git repositories, then you may never have added a remote yourself. It's a standard Git procedure:
|
||||
|
||||
|
||||
```
|
||||
$ git remote add origin [git@gitdawg.com][6]:seth/bigproject.git
|
||||
$ git remote -v
|
||||
origin [git@gitdawg.com][6]:seth/bigproject.git (fetch)
|
||||
origin [git@gitdawg.com][6]:seth/bigproject.git (push)
|
||||
```
|
||||
|
||||
The name **origin** is a popular convention for your main Git repository, so it makes sense to use it for your Git data. Your Git-portal data, however, is stored separately, so you must create a second remote to tell Git-portal where to push to and pull from. Depending on your Git host, you may need a separate server because gigabytes of media assets are unlikely to be accepted by a Git host with limited space. Or maybe you're on a server that permits you to access only your Git repository and not external storage directories:
|
||||
|
||||
|
||||
```
|
||||
$ git remote add _portal [seth@example.com][7]:/home/seth/git/bigproject_portal
|
||||
$ git remote -v
|
||||
origin [git@gitdawg.com][6]:seth/bigproject.git (fetch)
|
||||
origin [git@gitdawg.com][6]:seth/bigproject.git (push)
|
||||
_portal [seth@example.com][7]:/home/seth/git/bigproject_portal (fetch)
|
||||
_portal [seth@example.com][7]:/home/seth/git/bigproject_portal (push)
|
||||
```
|
||||
|
||||
You may not want to give all of your users individual accounts on your server, and you don't have to. To provide access to the server hosting a repository's large file assets, you can run a Git frontend like **[Gitolite][8]** , or you can use **rrsync** (i.e., restricted rsync).
|
||||
|
||||
Now you can push your Git data to your remote Git repository and your Git-portal data to your remote portal:
|
||||
|
||||
|
||||
```
|
||||
$ git push origin HEAD
|
||||
master destination detected
|
||||
Syncing _portal content...
|
||||
sending incremental file list
|
||||
sent 9,305 bytes received 18 bytes 1,695.09 bytes/sec
|
||||
total size is 60,358,015 speedup is 6,474.10
|
||||
Syncing _portal content to example.com:/home/seth/git/bigproject_portal
|
||||
```
|
||||
|
||||
If you have Git-portal installed and a **_portal** remote configured, your **_portal** directory will be synchronized, getting new content from the server and sending fresh content with every push. While you don't have to do a Git commit and push to sync with the server (a user could just use rsync directly), I find it useful to require commits for artistic changes. It integrates artists and their digital assets into the rest of the workflow, and it provides useful metadata about project progress and velocity.
|
||||
|
||||
### Other options
|
||||
|
||||
If Git-portal is too simple for you, there are other options for managing large files with Git. [Git Large File Storage][9] (LFS) is a fork of a defunct project called git-media and is maintained and supported by GitHub. It requires special commands (like **git lfs track** to protect large files from being tracked by Git) and requires the user to manage a .gitattributes file to update which files in the repository are tracked by LFS. It supports _only_ HTTP and HTTPS remotes for large files, so your LFS server must be configured so users can authenticate over HTTP rather than SSH or rsync.
|
||||
|
||||
A more flexible option than LFS is [git-annex][10], which you can learn more about in my article about [managing binary blobs in Git][11] (ignore the parts about the deprecated git-media, as its former flexibility doesn't apply to its successor, Git LFS). Git-annex is a flexible and elegant solution with a detailed system for adding, removing, and moving large files within a repository. Because it's flexible and powerful, there are lots of new commands and rules to learn, so take a look at its [documentation][12].
|
||||
|
||||
If, however, your needs are simple and you like a solution that utilizes existing technology to do simple and obvious tasks, Git-portal might be the tool for the job.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/manage-multimedia-files-git
|
||||
|
||||
作者:[Seth Kenlon (Red Hat, Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/video_editing_folder_music_wave_play.png?itok=-J9rs-My (video editing dashboard)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/git-velocity.jpg (Graphic showing relationship between art assets and Git)
|
||||
[3]: http://gitlab.com/slackermedia/git-portal.git
|
||||
[4]: https://www.apress.com/gp/book/9781484241691
|
||||
[5]: http://mixedsignals.ml
|
||||
[6]: mailto:git@gitdawg.com
|
||||
[7]: mailto:seth@example.com
|
||||
[8]: https://opensource.com/article/19/4/file-sharing-git
|
||||
[9]: https://git-lfs.github.com/
|
||||
[10]: https://git-annex.branchable.com/
|
||||
[11]: https://opensource.com/life/16/8/how-manage-binary-blobs-git-part-7
|
||||
[12]: https://git-annex.branchable.com/walkthrough/
|
||||
@ -0,0 +1,352 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (A beginner's guide to building DevOps pipelines with open source tools)
|
||||
[#]: via: (https://opensource.com/article/19/4/devops-pipeline)
|
||||
[#]: author: (Bryant Son (Red Hat, Community Moderator) https://opensource.com/users/brson/users/milindsingh/users/milindsingh/users/dscripter)
|
||||
|
||||
A beginner's guide to building DevOps pipelines with open source tools
|
||||
======
|
||||
If you're new to DevOps, check out this five-step process for building
|
||||
your first pipeline.
|
||||
![Shaking hands, networking][1]
|
||||
|
||||
DevOps has become the default answer to fixing software development processes that are slow, siloed, or otherwise dysfunctional. But that doesn't mean very much when you're new to DevOps and aren't sure where to begin. This article explores what a DevOps pipeline is and offers a five-step process to create one. While this tutorial is not comprehensive, it should give you a foundation to start on and expand later. But first, a story.
|
||||
|
||||
### My DevOps journey
|
||||
|
||||
I used to work for the cloud team at Citi Group, developing an Infrastructure-as-a-Service (IaaS) web application to manage Citi's cloud infrastructure, but I was always interested in figuring out ways to make the development pipeline more efficient and bring positive cultural change to the development team. I found my answer in a book recommended by Greg Lavender, who was the CTO of Citi's cloud architecture and infrastructure engineering, called _[The Phoenix Project][2]_. The book reads like a novel while it explains DevOps principles.
|
||||
|
||||
A table at the back of the book shows how often different companies deploy to the release environment:
|
||||
|
||||
Company | Deployment Frequency
|
||||
---|---
|
||||
Amazon | 23,000 per day
|
||||
Google | 5,500 per day
|
||||
Netflix | 500 per day
|
||||
Facebook | 1 per day
|
||||
Twitter | 3 per week
|
||||
Typical enterprise | 1 every 9 months
|
||||
|
||||
How are the frequency rates of Amazon, Google, and Netflix even possible? It's because these companies have figured out how to make a nearly perfect DevOps pipeline.
|
||||
|
||||
This definitely wasn't the case before we implemented DevOps at Citi. Back then, my team had different staged environments, but deployments to the development server were very manual. All developers had access to just one development server based on IBM WebSphere Application Server Community Edition. The problem was the server went down whenever multiple users simultaneously tried to make deployments, so the developers had to let each other know whenever they were about to make a deployment, which was quite a pain. In addition, there were problems with low code test coverages, cumbersome manual deployment processes, and no way to track code deployments with a defined task or a user story.
|
||||
|
||||
I realized something had to be done, and I found a colleague who felt the same way. We decided to collaborate to build an initial DevOps pipeline—he set up a virtual machine and a Tomcat application server while I worked on Jenkins, integrating with Atlassian Jira and BitBucket, and code testing coverages. This side project was hugely successful: we almost fully automated the development pipeline, we achieved nearly 100% uptime on our development server, we could track and improve code testing coverage, and the Git branch could be associated with the deployment and Jira task. And most of the tools we used to construct our DevOps pipeline were open source.
|
||||
|
||||
I now realize how rudimentary our DevOps pipeline was, as we didn't take advantage of advanced configurations like Jenkins files or Ansible. However, this simple process worked well, maybe due to the [Pareto][3] principle (also known as the 80/20 rule).
|
||||
|
||||
### A brief introduction to DevOps and the CI/CD pipeline
|
||||
|
||||
If you ask several people, "What is DevOps? you'll probably get several different answers. DevOps, like agile, has evolved to encompass many different disciplines, but most people will agree on a few things: DevOps is a software development practice or a software development lifecycle (SDLC) and its central tenet is cultural change, where developers and non-developers all breathe in an environment where formerly manual things are automated; everyone does what they are best at; the number of deployments per period increases; throughput increases; and flexibility improves.
|
||||
|
||||
While having the right software tools is not the only thing you need to achieve a DevOps environment, some tools are necessary. A key one is continuous integration and continuous deployment (CI/CD). This pipeline is where the environments have different stages (e.g., DEV, INT, TST, QA, UAT, STG, PROD), manual things are automated, and developers can achieve high-quality code, flexibility, and numerous deployments.
|
||||
|
||||
This article describes a five-step approach to creating a DevOps pipeline, like the one in the following diagram, using open source tools.
|
||||
|
||||
![Complete DevOps pipeline][4]
|
||||
|
||||
Without further ado, let's get started.
|
||||
|
||||
### Step 1: CI/CD framework
|
||||
|
||||
The first thing you need is a CI/CD tool. Jenkins, an open source, Java-based CI/CD tool based on the MIT License, is the tool that popularized the DevOps movement and has become the de facto standard.
|
||||
|
||||
So, what is Jenkins? Imagine it as some sort of a magical universal remote control that can talk to many many different services and tools and orchestrate them. On its own, a CI/CD tool like Jenkins is useless, but it becomes more powerful as it plugs into different tools and services.
|
||||
|
||||
Jenkins is just one of many open source CI/CD tools that you can leverage to build a DevOps pipeline.
|
||||
|
||||
Name | License
|
||||
---|---
|
||||
[Jenkins][5] | Creative Commons and MIT
|
||||
[Travis CI][6] | MIT
|
||||
[CruiseControl][7] | BSD
|
||||
[Buildbot][8] | GPL
|
||||
[Apache Gump][9] | Apache 2.0
|
||||
[Cabie][10] | GNU
|
||||
|
||||
Here's what a DevOps process looks like with a CI/CD tool.
|
||||
|
||||
![CI/CD tool][11]
|
||||
|
||||
You have a CI/CD tool running in your localhost, but there is not much you can do at the moment. Let's follow the next step of DevOps journey.
|
||||
|
||||
### Step 2: Source control management
|
||||
|
||||
The best (and probably the easiest) way to verify that your CI/CD tool can perform some magic is by integrating with a source control management (SCM) tool. Why do you need source control? Suppose you are developing an application. Whenever you build an application, you are programming—whether you are using Java, Python, C++, Go, Ruby, JavaScript, or any of the gazillion programming languages out there. The programming codes you write are called source codes. In the beginning, especially when you are working alone, it's probably OK to put everything in your local directory. But when the project gets bigger and you invite others to collaborate, you need a way to avoid merge conflicts while effectively sharing the code modifications. You also need a way to recover a previous version—and the process of making a backup and copying-and-pasting gets old. You (and your teammates) want something better.
|
||||
|
||||
This is where SCM becomes almost a necessity. A SCM tool helps by storing your code in repositories, versioning your code, and coordinating among project members.
|
||||
|
||||
Although there are many SCM tools out there, Git is the standard and rightly so. I highly recommend using Git, but there are other open source options if you prefer.
|
||||
|
||||
Name | License
|
||||
---|---
|
||||
[Git][12] | GPLv2 & LGPL v2.1
|
||||
[Subversion][13] | Apache 2.0
|
||||
[Concurrent Versions System][14] (CVS) | GNU
|
||||
[Vesta][15] | LGPL
|
||||
[Mercurial][16] | GNU GPL v2+
|
||||
|
||||
Here's what the DevOps pipeline looks like with the addition of SCM.
|
||||
|
||||
![Source control management][17]
|
||||
|
||||
The CI/CD tool can automate the tasks of checking in and checking out source code and collaborating across members. Not bad? But how can you make this into a working application so billions of people can use and appreciate it?
|
||||
|
||||
### Step 3: Build automation tool
|
||||
|
||||
Excellent! You can check out the code and commit your changes to the source control, and you can invite your friends to collaborate on the source control development. But you haven't yet built an application. To make it a web application, it has to be compiled and put into a deployable package format or run as an executable. (Note that an interpreted programming language like JavaScript or PHP doesn't need to be compiled.)
|
||||
|
||||
Enter the build automation tool. No matter which build tool you decide to use, all build automation tools have a shared goal: to build the source code into some desired format and to automate the task of cleaning, compiling, testing, and deploying to a certain location. The build tools will differ depending on your programming language, but here are some common open source options to consider.
|
||||
|
||||
Name | License | Programming Language
|
||||
---|---|---
|
||||
[Maven][18] | Apache 2.0 | Java
|
||||
[Ant][19] | Apache 2.0 | Java
|
||||
[Gradle][20] | Apache 2.0 | Java
|
||||
[Bazel][21] | Apache 2.0 | Java
|
||||
[Make][22] | GNU | N/A
|
||||
[Grunt][23] | MIT | JavaScript
|
||||
[Gulp][24] | MIT | JavaScript
|
||||
[Buildr][25] | Apache | Ruby
|
||||
[Rake][26] | MIT | Ruby
|
||||
[A-A-P][27] | GNU | Python
|
||||
[SCons][28] | MIT | Python
|
||||
[BitBake][29] | GPLv2 | Python
|
||||
[Cake][30] | MIT | C#
|
||||
[ASDF][31] | Expat (MIT) | LISP
|
||||
[Cabal][32] | BSD | Haskell
|
||||
|
||||
Awesome! You can put your build automation tool configuration files into your source control management and let your CI/CD tool build it.
|
||||
|
||||
![Build automation tool][33]
|
||||
|
||||
Everything is good, right? But where can you deploy it?
|
||||
|
||||
### Step 4: Web application server
|
||||
|
||||
So far, you have a packaged file that might be executable or deployable. For any application to be truly useful, it has to provide some kind of a service or an interface, but you need a vessel to host your application.
|
||||
|
||||
For a web application, a web application server is that vessel. An application server offers an environment where the programming logic inside the deployable package can be detected, render the interface, and offer the web services by opening sockets to the outside world. You need an HTTP server as well as some other environment (like a virtual machine) to install your application server. For now, let's assume you will learn about this along the way (although I will discuss containers below).
|
||||
|
||||
There are a number of open source web application servers available.
|
||||
|
||||
Name | License | Programming Language
|
||||
---|---|---
|
||||
[Tomcat][34] | Apache 2.0 | Java
|
||||
[Jetty][35] | Apache 2.0 | Java
|
||||
[WildFly][36] | GNU Lesser Public | Java
|
||||
[GlassFish][37] | CDDL & GNU Less Public | Java
|
||||
[Django][38] | 3-Clause BSD | Python
|
||||
[Tornado][39] | Apache 2.0 | Python
|
||||
[Gunicorn][40] | MIT | Python
|
||||
[Python Paste][41] | MIT | Python
|
||||
[Rails][42] | MIT | Ruby
|
||||
[Node.js][43] | MIT | Javascript
|
||||
|
||||
Now the DevOps pipeline is almost usable. Good job!
|
||||
|
||||
![Web application server][44]
|
||||
|
||||
Although it's possible to stop here and integrate further on your own, code quality is an important thing for an application developer to be concerned about.
|
||||
|
||||
### Step 5: Code testing coverage
|
||||
|
||||
Implementing code test pieces can be another cumbersome requirement, but developers need to catch any errors in an application early on and improve the code quality to ensure end users are satisfied. Luckily, there are many open source tools available to test your code and suggest ways to improve its quality. Even better, most CI/CD tools can plug into these tools and automate the process.
|
||||
|
||||
There are two parts to code testing: _code testing frameworks_ that help write and run the tests, and _code quality suggestion tools_ that help improve code quality.
|
||||
|
||||
#### Code test frameworks
|
||||
|
||||
Name | License | Programming Language
|
||||
---|---|---
|
||||
[JUnit][45] | Eclipse Public License | Java
|
||||
[EasyMock][46] | Apache | Java
|
||||
[Mockito][47] | MIT | Java
|
||||
[PowerMock][48] | Apache 2.0 | Java
|
||||
[Pytest][49] | MIT | Python
|
||||
[Hypothesis][50] | Mozilla | Python
|
||||
[Tox][51] | MIT | Python
|
||||
|
||||
#### Code quality suggestion tools
|
||||
|
||||
Name | License | Programming Language
|
||||
---|---|---
|
||||
[Cobertura][52] | GNU | Java
|
||||
[CodeCover][53] | Eclipse Public (EPL) | Java
|
||||
[Coverage.py][54] | Apache 2.0 | Python
|
||||
[Emma][55] | Common Public License | Java
|
||||
[JaCoCo][56] | Eclipse Public License | Java
|
||||
[Hypothesis][50] | Mozilla | Python
|
||||
[Tox][51] | MIT | Python
|
||||
[Jasmine][57] | MIT | JavaScript
|
||||
[Karma][58] | MIT | JavaScript
|
||||
[Mocha][59] | MIT | JavaScript
|
||||
[Jest][60] | MIT | JavaScript
|
||||
|
||||
Note that most of the tools and frameworks mentioned above are written for Java, Python, and JavaScript, since C++ and C# are proprietary programming languages (although GCC is open source).
|
||||
|
||||
Now that you've implemented code testing coverage tools, your DevOps pipeline should resemble the DevOps pipeline diagram shown at the beginning of this tutorial.
|
||||
|
||||
### Optional steps
|
||||
|
||||
#### Containers
|
||||
|
||||
As I mentioned above, you can host your application server on a virtual machine or a server, but containers are a popular solution.
|
||||
|
||||
[What are][61] [containers][61]? The short explanation is that a VM needs the huge footprint of an operating system, which overwhelms the application size, while a container just needs a few libraries and configurations to run the application. There are clearly still important uses for a VM, but a container is a lightweight solution for hosting an application, including an application server.
|
||||
|
||||
Although there are other options for containers, Docker and Kubernetes are the most popular.
|
||||
|
||||
Name | License
|
||||
---|---
|
||||
[Docker][62] | Apache 2.0
|
||||
[Kubernetes][63] | Apache 2.0
|
||||
|
||||
To learn more, check out these other [Opensource.com][64] articles about Docker and Kubernetes:
|
||||
|
||||
* [What Is Docker?][65]
|
||||
* [An introduction to Docker][66]
|
||||
* [What is Kubernetes?][67]
|
||||
* [From 0 to Kubernetes][68]
|
||||
|
||||
|
||||
|
||||
#### Middleware automation tools
|
||||
|
||||
Our DevOps pipeline mostly focused on collaboratively building and deploying an application, but there are many other things you can do with DevOps tools. One of them is leveraging Infrastructure as Code (IaC) tools, which are also known as middleware automation tools. These tools help automate the installation, management, and other tasks for middleware software. For example, an automation tool can pull applications, like a web application server, database, and monitoring tool, with the right configurations and deploy them to the application server.
|
||||
|
||||
Here are several open source middleware automation tools to consider:
|
||||
|
||||
Name | License
|
||||
---|---
|
||||
[Ansible][69] | GNU Public
|
||||
[SaltStack][70] | Apache 2.0
|
||||
[Chef][71] | Apache 2.0
|
||||
[Puppet][72] | Apache or GPL
|
||||
|
||||
For more on middleware automation tools, check out these other [Opensource.com][64] articles:
|
||||
|
||||
* [A quickstart guide to Ansible][73]
|
||||
* [Automating deployment strategies with Ansible][74]
|
||||
* [Top 5 configuration management tools][75]
|
||||
|
||||
|
||||
|
||||
### Where can you go from here?
|
||||
|
||||
This is just the tip of the iceberg for what a complete DevOps pipeline can look like. Start with a CI/CD tool and explore what else you can automate to make your team's job easier. Also, look into [open source communication tools][76] that can help your team work better together.
|
||||
|
||||
For more insight, here are some very good introductory articles about DevOps:
|
||||
|
||||
* [What is DevOps][77]
|
||||
* [5 things to master to be a DevOps engineer][78]
|
||||
* [DevOps is for everyone][79]
|
||||
* [Getting started with predictive analytics in DevOps][80]
|
||||
|
||||
|
||||
|
||||
Integrating DevOps with open source agile tools is also a good idea:
|
||||
|
||||
* [What is agile?][81]
|
||||
* [4 steps to becoming an awesome agile developer][82]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/devops-pipeline
|
||||
|
||||
作者:[Bryant Son (Red Hat, Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/brson/users/milindsingh/users/milindsingh/users/dscripter
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/network_team_career_hand.png?itok=_ztl2lk_ (Shaking hands, networking)
|
||||
[2]: https://www.amazon.com/dp/B078Y98RG8/
|
||||
[3]: https://en.wikipedia.org/wiki/Pareto_principle
|
||||
[4]: https://opensource.com/sites/default/files/uploads/1_finaldevopspipeline.jpg (Complete DevOps pipeline)
|
||||
[5]: https://github.com/jenkinsci/jenkins
|
||||
[6]: https://github.com/travis-ci/travis-ci
|
||||
[7]: http://cruisecontrol.sourceforge.net
|
||||
[8]: https://github.com/buildbot/buildbot
|
||||
[9]: https://gump.apache.org
|
||||
[10]: http://cabie.tigris.org
|
||||
[11]: https://opensource.com/sites/default/files/uploads/2_runningjenkins.jpg (CI/CD tool)
|
||||
[12]: https://git-scm.com
|
||||
[13]: https://subversion.apache.org
|
||||
[14]: http://savannah.nongnu.org/projects/cvs
|
||||
[15]: http://www.vestasys.org
|
||||
[16]: https://www.mercurial-scm.org
|
||||
[17]: https://opensource.com/sites/default/files/uploads/3_sourcecontrolmanagement.jpg (Source control management)
|
||||
[18]: https://maven.apache.org
|
||||
[19]: https://ant.apache.org
|
||||
[20]: https://gradle.org/
|
||||
[21]: https://bazel.build
|
||||
[22]: https://www.gnu.org/software/make
|
||||
[23]: https://gruntjs.com
|
||||
[24]: https://gulpjs.com
|
||||
[25]: http://buildr.apache.org
|
||||
[26]: https://github.com/ruby/rake
|
||||
[27]: http://www.a-a-p.org
|
||||
[28]: https://www.scons.org
|
||||
[29]: https://www.yoctoproject.org/software-item/bitbake
|
||||
[30]: https://github.com/cake-build/cake
|
||||
[31]: https://common-lisp.net/project/asdf
|
||||
[32]: https://www.haskell.org/cabal
|
||||
[33]: https://opensource.com/sites/default/files/uploads/4_buildtools.jpg (Build automation tool)
|
||||
[34]: https://tomcat.apache.org
|
||||
[35]: https://www.eclipse.org/jetty/
|
||||
[36]: http://wildfly.org
|
||||
[37]: https://javaee.github.io/glassfish
|
||||
[38]: https://www.djangoproject.com/
|
||||
[39]: http://www.tornadoweb.org/en/stable
|
||||
[40]: https://gunicorn.org
|
||||
[41]: https://github.com/cdent/paste
|
||||
[42]: https://rubyonrails.org
|
||||
[43]: https://nodejs.org/en
|
||||
[44]: https://opensource.com/sites/default/files/uploads/5_applicationserver.jpg (Web application server)
|
||||
[45]: https://junit.org/junit5
|
||||
[46]: http://easymock.org
|
||||
[47]: https://site.mockito.org
|
||||
[48]: https://github.com/powermock/powermock
|
||||
[49]: https://docs.pytest.org
|
||||
[50]: https://hypothesis.works
|
||||
[51]: https://github.com/tox-dev/tox
|
||||
[52]: http://cobertura.github.io/cobertura
|
||||
[53]: http://codecover.org/
|
||||
[54]: https://github.com/nedbat/coveragepy
|
||||
[55]: http://emma.sourceforge.net
|
||||
[56]: https://github.com/jacoco/jacoco
|
||||
[57]: https://jasmine.github.io
|
||||
[58]: https://github.com/karma-runner/karma
|
||||
[59]: https://github.com/mochajs/mocha
|
||||
[60]: https://jestjs.io
|
||||
[61]: /resources/what-are-linux-containers
|
||||
[62]: https://www.docker.com
|
||||
[63]: https://kubernetes.io
|
||||
[64]: http://Opensource.com
|
||||
[65]: https://opensource.com/resources/what-docker
|
||||
[66]: https://opensource.com/business/15/1/introduction-docker
|
||||
[67]: https://opensource.com/resources/what-is-kubernetes
|
||||
[68]: https://opensource.com/article/17/11/kubernetes-lightning-talk
|
||||
[69]: https://www.ansible.com
|
||||
[70]: https://www.saltstack.com
|
||||
[71]: https://www.chef.io
|
||||
[72]: https://puppet.com
|
||||
[73]: https://opensource.com/article/19/2/quickstart-guide-ansible
|
||||
[74]: https://opensource.com/article/19/1/automating-deployment-strategies-ansible
|
||||
[75]: https://opensource.com/article/18/12/configuration-management-tools
|
||||
[76]: https://opensource.com/alternatives/slack
|
||||
[77]: https://opensource.com/resources/devops
|
||||
[78]: https://opensource.com/article/19/2/master-devops-engineer
|
||||
[79]: https://opensource.com/article/18/11/how-non-engineer-got-devops
|
||||
[80]: https://opensource.com/article/19/1/getting-started-predictive-analytics-devops
|
||||
[81]: https://opensource.com/article/18/10/what-agile
|
||||
[82]: https://opensource.com/article/19/2/steps-agile-developer
|
||||
@ -0,0 +1,68 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Bash vs. Python: Which language should you use?)
|
||||
[#]: via: (https://opensource.com/article/19/4/bash-vs-python)
|
||||
[#]: author: (Archit Modi (Red Hat) https://opensource.com/users/architmodi/users/greg-p/users/oz123)
|
||||
|
||||
Bash vs. Python: Which language should you use?
|
||||
======
|
||||
Both programming languages have pros and cons that make them better for
|
||||
some tasks than others.
|
||||
![][1]
|
||||
|
||||
[Bash][2] and [Python][3] are most automation engineers' favorite programming languages. Both have pros and cons, and sometimes it can be hard to choose which one you should use. The honest answer is: It depends on the task, the scope, the context, and the complexity of the task.
|
||||
|
||||
Let's compare these two languages to get a better understanding of where each one shines.
|
||||
|
||||
### Bash
|
||||
|
||||
* Is a Linux/Unix shell command language
|
||||
* Is great for writing shell scripts that use command line interface (CLI) utilities, utilizing output from one command to another (piping), and executing simple tasks (up to 100 lines of code)
|
||||
* Can utilize command-line commands and utilities as-is
|
||||
* Has better startup time than Python but poor execution time performance
|
||||
* Does not come preinstalled in Windows; your script might not be compatible with multiple operating systems, but Bash is the default shell on most Linux/Unix systems
|
||||
* Is _not_ fully compatible with other shells (e.g., csh, zsh, fish)
|
||||
* Piping ("|") CLI utilities like sed, awk, grep, etc. can slow its performance
|
||||
* Lacks many functions, objects, data structures, and multi-threading, which limits its use for complex scripting/programming
|
||||
* Lacks good debugging tools and utilities
|
||||
|
||||
|
||||
|
||||
### Python
|
||||
|
||||
* Is an object-oriented programming (OOP) language, so it's more general purpose than Bash
|
||||
* Can be used for almost any task
|
||||
* Works on most major operating systems and is also installed by default on most Unix/Linux systems
|
||||
* Is very similar to writing pseudo code
|
||||
* Has simple, clear, easy-to-learn, and easy-to-read syntax
|
||||
* Has lots of libraries, documentation, and an active community
|
||||
* Provides better error handling features than Bash
|
||||
* Has better debugging tools and utilities than Bash, which makes it a great language for developing complex software applications involving many lines of code
|
||||
* Applications (or scripts) can contain many third-party dependencies that must be installed before executing them
|
||||
* Requires writing more lines of code for simple tasks than Bash does
|
||||
|
||||
|
||||
|
||||
I hope these lists give you a better understanding of which language to use and when to use it.
|
||||
|
||||
Which language do you use more in your day-to-day work, Bash or Python? Please share in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/bash-vs-python
|
||||
|
||||
作者:[Archit Modi (Red Hat)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/architmodi/users/greg-p/users/oz123
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_happy_sad_developer_programming.png?itok=72nkfSQ_
|
||||
[2]: /article/18/7/admin-guide-bash
|
||||
[3]: /article/17/11/5-approaches-learning-python
|
||||
@ -0,0 +1,111 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Getting started with Python's cryptography library)
|
||||
[#]: via: (https://opensource.com/article/19/4/cryptography-python)
|
||||
[#]: author: (Moshe Zadka (Community Moderator) https://opensource.com/users/moshez)
|
||||
|
||||
Getting started with Python's cryptography library
|
||||
======
|
||||
Encrypt your data and keep it safe from attackers.
|
||||
![lock on world map][1]
|
||||
|
||||
The first rule of cryptography club is: never _invent_ a cryptography system yourself. The second rule of cryptography club is: never _implement_ a cryptography system yourself: many real-world holes are found in the _implementation_ phase of a cryptosystem as well as in the design.
|
||||
|
||||
One useful library for cryptographic primitives in Python is called simply [**cryptography**][2]. It has both "secure" primitives as well as a "hazmat" layer. The "hazmat" layer requires care and knowledge of cryptography and it is easy to implement security holes using it. We will not cover anything in the "hazmat" layer in this introductory article!
|
||||
|
||||
The most useful high-level secure primitive in **cryptography** is the Fernet implementation. Fernet is a standard for encrypting buffers in a way that follows best-practices cryptography. It is not suitable for very big files—anything in the gigabyte range and above—since it requires you to load the whole buffer that you want to encrypt or decrypt into memory at once.
|
||||
|
||||
Fernet supports _symmetric_ , or _secret key_ , cryptography: the same key is used for encryption and decryption, and therefore must be kept safe.
|
||||
|
||||
Generating a key is easy:
|
||||
|
||||
|
||||
```
|
||||
>>> k = fernet.Fernet.generate_key()
|
||||
>>> type(k)
|
||||
<class 'bytes'>
|
||||
```
|
||||
|
||||
Those bytes can be written to a file with appropriate permissions, ideally on a secure machine.
|
||||
|
||||
Once you have key material, encrypting is easy as well:
|
||||
|
||||
|
||||
```
|
||||
>>> frn = fernet.Fernet(k)
|
||||
>>> encrypted = frn.encrypt(b"x marks the spot")
|
||||
>>> encrypted[:10]
|
||||
b'gAAAAABb1'
|
||||
```
|
||||
|
||||
You will get slightly different values if you encrypt on your machine. Not only because (I hope) you generated a different key from me, but because Fernet concatenates the value to be encrypted with some randomly generated buffer. This is one of the "best practices" I alluded to earlier: it will prevent an adversary from being able to tell which encrypted values are identical, which is sometimes an important part of an attack.
|
||||
|
||||
Decryption is equally simple:
|
||||
|
||||
|
||||
```
|
||||
>>> frn = fernet.Fernet(k)
|
||||
>>> frn.decrypt(encrypted)
|
||||
b'x marks the spot'
|
||||
```
|
||||
|
||||
Note that this only encrypts and decrypts _byte strings_. In order to encrypt and decrypt _text strings_ , they will need to be encoded and decoded, usually with [UTF-8][3].
|
||||
|
||||
One of the most interesting advances in cryptography in the mid-20th century was _public key_ cryptography. It allows the encryption key to be published while the _decryption key_ is kept secret. It can, for example, be used to store API keys to be used by a server: the server is the only thing with access to the decryption key, but anyone can add to the store by using the public encryption key.
|
||||
|
||||
While **cryptography** does not have any public key cryptographic _secure_ primitives, the [**PyNaCl**][4] library does. PyNaCl wraps and offers some nice ways to use the [**NaCl**][5] encryption system invented by Daniel J. Bernstein.
|
||||
|
||||
NaCl always _encrypts_ and _signs_ or _decrypts_ and _verifies signatures_ simultaneously. This is a way to prevent malleability-based attacks, where an adversary modifies the encrypted value.
|
||||
|
||||
Encryption is done with a public key, while signing is done with a secret key:
|
||||
|
||||
|
||||
```
|
||||
>>> from nacl.public import PrivateKey, PublicKey, Box
|
||||
>>> source = PrivateKey.generate()
|
||||
>>> with open("target.pubkey", "rb") as fpin:
|
||||
... target_public_key = PublicKey(fpin.read())
|
||||
>>> enc_box = Box(source, target_public_key)
|
||||
>>> result = enc_box.encrypt(b"x marks the spot")
|
||||
>>> result[:4]
|
||||
b'\xe2\x1c0\xa4'
|
||||
```
|
||||
|
||||
Decryption reverses the roles: it needs the private key for decryption and the public key to verify the signature:
|
||||
|
||||
|
||||
```
|
||||
>>> from nacl.public import PrivateKey, PublicKey, Box
|
||||
>>> with open("source.pubkey", "rb") as fpin:
|
||||
... source_public_key = PublicKey(fpin.read())
|
||||
>>> with open("target.private_key", "rb") as fpin:
|
||||
... target = PrivateKey(fpin.read())
|
||||
>>> dec_box = Box(target, source_public_key)
|
||||
>>> dec_box.decrypt(result)
|
||||
b'x marks the spot'
|
||||
```
|
||||
|
||||
The [**PocketProtector**][6] library builds on top of PyNaCl and contains a complete secrets management solution.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/cryptography-python
|
||||
|
||||
作者:[Moshe Zadka (Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/security-lock-cloud-safe.png?itok=yj2TFPzq (lock on world map)
|
||||
[2]: https://cryptography.io/en/latest/
|
||||
[3]: https://en.wikipedia.org/wiki/UTF-8
|
||||
[4]: https://pynacl.readthedocs.io/en/stable/
|
||||
[5]: https://nacl.cr.yp.to/
|
||||
[6]: https://github.com/SimpleLegal/pocket_protector/blob/master/USER_GUIDE.md
|
||||
@ -0,0 +1,182 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Anbox – Easy Way To Run Android Apps On Linux)
|
||||
[#]: via: (https://www.2daygeek.com/anbox-best-android-emulator-for-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
Anbox – Easy Way To Run Android Apps On Linux
|
||||
======
|
||||
|
||||
Android emulator applications are allow us to run our favorite Android apps or games directly from Linux system.
|
||||
|
||||
There are many android emulators were available for Linux and we had covered few applications in the past.
|
||||
|
||||
You can review those by navigating to the following URLs.
|
||||
|
||||
* [How To Install Official Android Emulator (SDK) On Linux][1]
|
||||
* [How To Install GenyMotion (Android Emulator) On Linux][2]
|
||||
|
||||
|
||||
|
||||
Today we are going to discuss about the Anbox Android emulator.
|
||||
|
||||
### What Is Anbox?
|
||||
|
||||
Anbox stands for Android in a box. Anbox is a container-based approach to boot a full Android system on a regular GNU/Linux system.
|
||||
|
||||
It’s new and modern emulator among others.
|
||||
|
||||
Since Anbox places the core Android OS into a container using Linux namespaces (LXE) so, there is no slowness while accessing the installed applications.
|
||||
|
||||
Anbox will let you run Android on your Linux system without the slowness of virtualization because the core Android OS has placed into a container using Linux namespaces (LXE).
|
||||
|
||||
There is no direct access to any hardware from the Android container. All hardware access are going through the anbox daemon on the host.
|
||||
|
||||
Each applications will be open in a separate window, just like other native system applications, and it can be showing up in the launcher.
|
||||
|
||||
### How To Install Anbox In Linux?
|
||||
|
||||
Anbox application is available as snap package so, make sure you have enabled snap support on your system.
|
||||
|
||||
Anbox package is recently added to the Ubuntu (Cosmic) and Debian (Buster) repositories. If you are running these version then you can easily install with help of official distribution package manager. Other wise go with snap package installation.
|
||||
|
||||
Make sure the necessary kernel modules should be installed in your system in order to work Anbox. For Ubuntu based users, use the following PPA to install it.
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:morphis/anbox-support
|
||||
$ sudo apt update
|
||||
$ sudo apt install linux-headers-generic anbox-modules-dkms
|
||||
```
|
||||
|
||||
After you installed the `anbox-modules-dkms` package you have to manually reload the kernel modules or system reboot is required.
|
||||
|
||||
```
|
||||
$ sudo modprobe ashmem_linux
|
||||
$ sudo modprobe binder_linux
|
||||
```
|
||||
|
||||
For **`Debian/Ubuntu`** systems, use **[APT-GET Command][3]** or **[APT Command][4]** to install anbox.
|
||||
|
||||
```
|
||||
$ sudo apt install anbox
|
||||
```
|
||||
|
||||
We always used to get package for Arch Linux based systems from AUR repository. So, use any of the **[AUR helper][5]** to install it. I prefer to go with **[Yay utility][6]**.
|
||||
|
||||
```
|
||||
$ yuk -S anbox-git
|
||||
```
|
||||
|
||||
If no, you can **[install and configure snaps in Linux][7]** by navigating to the following article. Others can ignore if you have already installed snaps on your system.
|
||||
|
||||
```
|
||||
$ sudo snap install --devmode --beta anbox
|
||||
```
|
||||
|
||||
### Prerequisites For Anbox
|
||||
|
||||
By default, Anbox doesn’t ship with the Google Play Store.
|
||||
|
||||
Hence, we need to manually download each application (APK) and install it using Android Debug Bridge (ADB).
|
||||
|
||||
The ADB tool is readily available in most of the distributions repository so, we can easily install it.
|
||||
|
||||
For **`Debian/Ubuntu`** systems, use **[APT-GET Command][3]** or **[APT Command][4]** to install ADB.
|
||||
|
||||
```
|
||||
$ sudo apt install android-tools-adb
|
||||
```
|
||||
|
||||
For **`Fedora`** system, use **[DNF Command][8]** to install ADB.
|
||||
|
||||
```
|
||||
$ sudo dnf install android-tools
|
||||
```
|
||||
|
||||
For **`Arch Linux`** based systems, use **[Pacman Command][9]** to install ADB.
|
||||
|
||||
```
|
||||
$ sudo pacman -S android-tools
|
||||
```
|
||||
|
||||
For **`openSUSE Leap`** system, use **[Zypper Command][10]** to install ADB.
|
||||
|
||||
```
|
||||
$ sudo zypper install android-tools
|
||||
```
|
||||
|
||||
### Where To Download The Android Apps?
|
||||
|
||||
Since you can’t use the Play Store so, you have to download the APK packages from trusted sites like [APKMirror][11] then manually install it.
|
||||
|
||||
### How To Launch Anbox?
|
||||
|
||||
Anbox can be launched from the Dash. This is how the default Anbox looks.
|
||||
![][13]
|
||||
|
||||
### How To Push The Apps Into Anbox?
|
||||
|
||||
As i told previously, we need to manually install it. For testing purpose, we are going to install `YouTube` and `Firefox` apps.
|
||||
|
||||
First, you need to start ADB server. To do so, run the following command.
|
||||
|
||||
```
|
||||
$ adb devices
|
||||
```
|
||||
|
||||
We have already downloaded the `YouTube` and `Firefox` apps and the same we will install now.
|
||||
|
||||
**Common Syntax:**
|
||||
|
||||
```
|
||||
$ adb install Name-Of-Your-Application.apk
|
||||
```
|
||||
|
||||
Installing YouTube and Firefox app.
|
||||
|
||||
```
|
||||
$ adb install 'com.google.android.youtube_14.13.54-1413542800_minAPI19(x86_64)(nodpi)_apkmirror.com.apk'
|
||||
Success
|
||||
|
||||
$ adb install 'org.mozilla.focus_9.0-330191219_minAPI21(x86)(nodpi)_apkmirror.com.apk'
|
||||
Success
|
||||
```
|
||||
|
||||
I have installed `YouTube` and `Firefox` in my Anbox. See the screenshot below.
|
||||
![][14]
|
||||
|
||||
As we told in the beginning of the article, it will open any app as a new tab. Here, I’m going to open Firefox and accessing the **[2daygeek.com][15]** website.
|
||||
![][16]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/anbox-best-android-emulator-for-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/install-configure-sdk-android-emulator-on-linux/
|
||||
[2]: https://www.2daygeek.com/install-genymotion-android-emulator-on-ubuntu-debian-fedora-arch-linux/
|
||||
[3]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[5]: https://www.2daygeek.com/category/aur-helper/
|
||||
[6]: https://www.2daygeek.com/install-yay-yet-another-yogurt-aur-helper-on-arch-linux/
|
||||
[7]: https://www.2daygeek.com/linux-snap-package-manager-ubuntu/
|
||||
[8]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[9]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[10]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[11]: https://www.apkmirror.com/
|
||||
[12]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[13]: https://www.2daygeek.com/wp-content/uploads/2019/04/anbox-best-android-emulator-for-linux-1.jpg
|
||||
[14]: https://www.2daygeek.com/wp-content/uploads/2019/04/anbox-best-android-emulator-for-linux-2.jpg
|
||||
[15]: https://www.2daygeek.com/
|
||||
[16]: https://www.2daygeek.com/wp-content/uploads/2019/04/anbox-best-android-emulator-for-linux-3.jpg
|
||||
@ -0,0 +1,355 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Four Methods To Add A User To Group In Linux)
|
||||
[#]: via: (https://www.2daygeek.com/linux-add-user-to-group-primary-secondary-group-usermod-gpasswd/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
Four Methods To Add A User To Group In Linux
|
||||
======
|
||||
|
||||
Linux groups are organization units which are used to manage user accounts in Linux.
|
||||
|
||||
It has unique numerical identification number for each users and groups in the Linux system.
|
||||
|
||||
It’s called a userid (UID) and a groupid (GID). The main purpose of groups is to define a set of privileges to the member of the group.
|
||||
|
||||
They all can perform the particular operations but not others.
|
||||
|
||||
There are two types of default groups are available in Linux. Each user should have exactly one primary group and any number of secondary groups.
|
||||
|
||||
* **Primary Group:** Primary group has been added to the user when the user account creation. It’s typically the name of the user. The primary group is applied to the user when performing any actions such as creating new files (or directories), modifying files, or executing commands, etc,. The user primary group information is stored in the `/etc/passwd` file.
|
||||
* **Secondary Group:** It’s known as Supplementary Groups. It allows the group of users to perform the particular action in the same group members files.
|
||||
Say for example, if you would like to allow few users to run Apache (httpd) service command then it will perfectly suits.
|
||||
|
||||
|
||||
|
||||
You may have interested in the following articles which is related to user management.
|
||||
|
||||
* [Three Methods To Create An User Account In Linux?][1]
|
||||
* [How To Create The Bulk Users In Linux?][2]
|
||||
* [How to Update/Change Users Password in Linux Using Different Ways][3]
|
||||
|
||||
|
||||
|
||||
It can be done using the following four methods.
|
||||
|
||||
* **`usermod:`** The usermod command modifies the system account files to reflect the changes that are specified on the command line.
|
||||
* **`gpasswd:`** The gpasswd command is used to administer /etc/group, and /etc/gshadow. Every group can have administrators, members and a password.
|
||||
* **`Shell Script:`** Shell scripts are allow administrator to automate the required tasks.
|
||||
* **`Manual Method:`** We can manually add the users into any group by editing the `/etc/group` file.
|
||||
|
||||
|
||||
|
||||
I assume that you already have the necessary group and users for this activity. In this example, we are going to use following users and groups `user1`, `user2`, `user3` and group is `mygroup` and `mygroup1`.
|
||||
|
||||
Before making the changes, i would like to check the users and group information. See the details below.
|
||||
|
||||
I could see the below users were associate with their own group and not with others.
|
||||
|
||||
```
|
||||
# id user1
|
||||
uid=1008(user1) gid=1008(user1) groups=1008(user1)
|
||||
|
||||
# id user2
|
||||
uid=1009(user2) gid=1009(user2) groups=1009(user2)
|
||||
|
||||
# id user3
|
||||
uid=1010(user3) gid=1010(user3) groups=1010(user3)
|
||||
```
|
||||
|
||||
I could see there is no users are associated in this group.
|
||||
|
||||
```
|
||||
# getent group mygroup
|
||||
mygroup:x:1012:
|
||||
|
||||
# getent group mygroup1
|
||||
mygroup1:x:1013:
|
||||
```
|
||||
|
||||
### Method-1: What Is usermod Command?
|
||||
|
||||
The usermod command modifies the system account files to reflect the changes that are specified on the command line.
|
||||
|
||||
### How to Add an Existing User to Secondary or Supplementary Group Using usermod Command?
|
||||
|
||||
To add an existing user to a secondary group, use the usermod command with `-G` option and the name of the group.
|
||||
Syntax
|
||||
|
||||
```
|
||||
# usermod [-G] [GroupName] [UserName]
|
||||
```
|
||||
|
||||
You will be getting an error message if the given user or group doesn’t exist in your system. If you doesn’t get any error then the user has been added to the corresponding group.
|
||||
|
||||
```
|
||||
# usermod -a -G mygroup user1
|
||||
```
|
||||
|
||||
Let me see the output using id command. Yes, it’s added successfully.
|
||||
|
||||
```
|
||||
# id user1
|
||||
uid=1008(user1) gid=1008(user1) groups=1008(user1),1012(mygroup)
|
||||
```
|
||||
|
||||
### How to Add an Existing User to Multiple Secondary or Supplementary Groups Using usermod Command?
|
||||
|
||||
To add an existing user to multiple secondary groups, use the usermod command with `-G` option and the name of the groups with comma.
|
||||
|
||||
Syntax
|
||||
|
||||
```
|
||||
# usermod [-G] [GroupName1,GroupName2] [UserName]
|
||||
```
|
||||
|
||||
In this example, we are going to add the `user2` into `mygroup` and `mygroup1`.
|
||||
|
||||
```
|
||||
# usermod -a -G mygroup,mygroup1 user2
|
||||
```
|
||||
|
||||
Let me see the output using id command. Yes, `user2` is successfully added into `mygroup` and `mygroup1`.
|
||||
|
||||
```
|
||||
# id user2
|
||||
uid=1009(user2) gid=1009(user2) groups=1009(user2),1012(mygroup),1013(mygroup1)
|
||||
```
|
||||
|
||||
### How to Change a User’s Primary Group?
|
||||
|
||||
To change a user’s primary group, use the usermod command with `-g` option and the name of the group.
|
||||
|
||||
Syntax
|
||||
|
||||
```
|
||||
# usermod [-g] [GroupName] [UserName]
|
||||
```
|
||||
|
||||
We have to use `-g` to change user’s primary group.
|
||||
|
||||
```
|
||||
# usermod -g mygroup user3
|
||||
```
|
||||
|
||||
Let see the output. Yes, it has been successfully changed. Now, it’s showing `mygroup` as `user3` primary group instead of `user3`.
|
||||
|
||||
```
|
||||
# id user3
|
||||
uid=1010(user3) gid=1012(mygroup) groups=1012(mygroup)
|
||||
```
|
||||
|
||||
### Method-2: What Is gpasswd Command?
|
||||
|
||||
The gpasswd command is used to administer /etc/group, and /etc/gshadow. Every group can have administrators, members and a password.
|
||||
|
||||
### How to Add an Existing User to Secondary or Supplementary Group Using gpasswd Command?
|
||||
|
||||
To add an existing user to a secondary group, use the gpasswd command with `-M` option and the name of the group.
|
||||
|
||||
Syntax
|
||||
|
||||
```
|
||||
# gpasswd [-M] [UserName] [GroupName]
|
||||
```
|
||||
|
||||
In this example, we are going to add the `user1` into `mygroup`.
|
||||
|
||||
```
|
||||
# gpasswd -M user1 mygroup
|
||||
```
|
||||
|
||||
Let me see the output using id command. Yes, `user1` is successfully added into `mygroup`.
|
||||
|
||||
```
|
||||
# id user1
|
||||
uid=1008(user1) gid=1008(user1) groups=1008(user1),1012(mygroup)
|
||||
```
|
||||
|
||||
### How to Add The Multiple User’s to Secondary or Supplementary Group Using gpasswd Command?
|
||||
|
||||
To add the multiple users to a secondary group, use the gpasswd command with `-M` option and the name of the group.
|
||||
|
||||
Syntax
|
||||
|
||||
```
|
||||
# gpasswd [-M] [UserName1,UserName2] [GroupName]
|
||||
```
|
||||
|
||||
In this example, we are going to add the `user2` and `user3` into `mygroup1`.
|
||||
|
||||
```
|
||||
# gpasswd -M user2,user3 mygroup1
|
||||
```
|
||||
|
||||
Let me see the output using getent command. Yes, `user2` and `user3` are successfully added into `mygroup1`.
|
||||
|
||||
```
|
||||
# getent group mygroup1
|
||||
mygroup1:x:1013:user2,user3
|
||||
```
|
||||
|
||||
### How to Remove a User From a Group Using gpasswd Command?
|
||||
|
||||
To remove the user from the group, use the gpasswd command with `-d` option and the name of the user and group.
|
||||
|
||||
Syntax
|
||||
|
||||
```
|
||||
# gpasswd [-d] [UserName] [GroupName]
|
||||
```
|
||||
|
||||
In this example, we are going to remove the `user1` from `mygroup`.
|
||||
|
||||
```
|
||||
# gpasswd -d user1 mygroup
|
||||
Removing user user1 from group mygroup
|
||||
```
|
||||
|
||||
### Method-3: Using Shell Script?
|
||||
|
||||
Based on the above examples what i came to know is the `usermod` command doesn’t has capable to add multiple users into the group but it can be done through the `gpasswd` command.
|
||||
|
||||
However, it will overwrite the existing users which are currently associated on the group.
|
||||
|
||||
For example, `user1` has already associated with `mygroup`. If you would like to add `user2` and `user3` into the `mygroup` with `gpasswd` command, it doesn’t work as expected and it over right the group instead of modifying it.
|
||||
|
||||
What would be the solution if you would like to add multiple users to multiple groups?
|
||||
|
||||
There is no default option is available in both of the commands to achieve this.
|
||||
|
||||
Hence, we need to write a small shell script to achieve this.
|
||||
|
||||
### Method-3a: How to Add The Multiple Users to Secondary or Supplementary Group Using gpasswd Command?
|
||||
|
||||
Create the following small shell script if you would like to add the multiple users to secondary or supplementary group using gpasswd command.
|
||||
|
||||
Create The Users list. Each user should be in separate line.
|
||||
|
||||
```
|
||||
$ cat user-lists.txt
|
||||
user1
|
||||
user2
|
||||
user3
|
||||
```
|
||||
|
||||
Use the following shell script to add multiple users to single secondary group.
|
||||
|
||||
```
|
||||
vi group-update.sh
|
||||
|
||||
#!/bin/bash
|
||||
for user in `cat user-lists.txt`
|
||||
do
|
||||
usermod -a -G mygroup $user
|
||||
done
|
||||
```
|
||||
|
||||
Set an executable permission to `group-update.sh` file.
|
||||
|
||||
```
|
||||
# chmod + group-update.sh
|
||||
```
|
||||
|
||||
Finally run the script to achieve this.
|
||||
|
||||
```
|
||||
# sh group-update.sh
|
||||
```
|
||||
|
||||
Let me see the output using getent command. Yes, `user1`, `user2` and `user3` are successfully added into `mygroup`.
|
||||
|
||||
```
|
||||
# getent group mygroup
|
||||
mygroup:x:1012:user1,user2,user3
|
||||
```
|
||||
|
||||
### Method-3a: How to Add The Multiple Users Into Multiple Secondary or Supplementary Group Using gpasswd Command?
|
||||
|
||||
Create the following small shell script if you would like to add the multiple users into multiple secondary or supplementary group using gpasswd command.
|
||||
|
||||
Create The Users list. Each user should be in separate line.
|
||||
|
||||
```
|
||||
$ cat user-lists.txt
|
||||
user1
|
||||
user2
|
||||
user3
|
||||
```
|
||||
|
||||
Create The Groups list. Each group should be in separate line.
|
||||
|
||||
```
|
||||
$ cat group-lists.txt
|
||||
mygroup
|
||||
mygroup1
|
||||
```
|
||||
|
||||
Use the following shell script to add multiple users to multiple secondary groups.
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
for user in `more user-lists.txt`
|
||||
do
|
||||
for group in `more group-lists.txt`
|
||||
do
|
||||
usermod -a -G $group $user
|
||||
done
|
||||
done
|
||||
```
|
||||
|
||||
Set an executable permission to `group-update-1.sh` file.
|
||||
|
||||
```
|
||||
# chmod +x group-update-1.sh
|
||||
```
|
||||
|
||||
Finally run the script to achieve this.
|
||||
|
||||
```
|
||||
# sh group-update-1.sh
|
||||
```
|
||||
|
||||
Let me see the output using getent command. Yes, `user1`, `user2` and `user3` are successfully added into `mygroup`.
|
||||
|
||||
```
|
||||
# getent group mygroup
|
||||
mygroup:x:1012:user1,user2,user3
|
||||
```
|
||||
|
||||
Also, `user1`, `user2` and `user3` are successfully added into `mygroup1`.
|
||||
|
||||
```
|
||||
# getent group mygroup1
|
||||
mygroup1:x:1013:user1,user2,user3
|
||||
```
|
||||
|
||||
### Method-4: Manual Method To Add A User Into A Group In Linux?
|
||||
|
||||
We can manually add the users into any group by editing the `/etc/group` file.
|
||||
|
||||
Open the `/etc/group` file and search the group name where you want to update the users. Finally update the Users into the corresponding group.
|
||||
|
||||
```
|
||||
# vi /etc/group
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-add-user-to-group-primary-secondary-group-usermod-gpasswd/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/linux-user-account-creation-useradd-adduser-newusers/
|
||||
[2]: https://www.2daygeek.com/how-to-create-the-bulk-users-in-linux/
|
||||
[3]: https://www.2daygeek.com/linux-passwd-chpasswd-command-set-update-change-users-password-in-linux-using-shell-script/
|
||||
@ -0,0 +1,225 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Install And Configure Chrony As NTP Client?)
|
||||
[#]: via: (https://www.2daygeek.com/configure-ntp-client-using-chrony-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
How To Install And Configure Chrony As NTP Client?
|
||||
======
|
||||
|
||||
The NTP server and NTP client allow us to sync the clock across the network.
|
||||
|
||||
We had written an article about **[NTP server and NTP client installation and configuration][1]** in the past.
|
||||
|
||||
If you would like to check these, navigate to the above URL.
|
||||
|
||||
### What Is Chrony Client?
|
||||
|
||||
Chrony is replacement of NTP client.
|
||||
|
||||
It can synchronize the system clock faster with better time accuracy and it can be particularly useful for the systems which are not online all the time.
|
||||
|
||||
chronyd is smaller, it uses less memory and it wakes up the CPU only when necessary, which is better for power saving.
|
||||
|
||||
It can perform well even when the network is congested for longer periods of time.
|
||||
|
||||
It supports hardware timestamping on Linux, which allows extremely accurate synchronization on local networks.
|
||||
|
||||
It offers following two services.
|
||||
|
||||
* **`chronyc:`** Command line interface for chrony.
|
||||
* **`chronyd:`** Chrony daemon service.
|
||||
|
||||
|
||||
|
||||
### How To Install And Configure Chrony In Linux?
|
||||
|
||||
Since the package is available in most of the distributions official repository. So, use the package manager to install it.
|
||||
|
||||
For **`Fedora`** system, use **[DNF Command][2]** to install chrony.
|
||||
|
||||
```
|
||||
$ sudo dnf install chrony
|
||||
```
|
||||
|
||||
For **`Debian/Ubuntu`** systems, use **[APT-GET Command][3]** or **[APT Command][4]** to install chrony.
|
||||
|
||||
```
|
||||
$ sudo apt install chrony
|
||||
```
|
||||
|
||||
For **`Arch Linux`** based systems, use **[Pacman Command][5]** to install chrony.
|
||||
|
||||
```
|
||||
$ sudo pacman -S chrony
|
||||
```
|
||||
|
||||
For **`RHEL/CentOS`** systems, use **[YUM Command][6]** to install chrony.
|
||||
|
||||
```
|
||||
$ sudo yum install chrony
|
||||
```
|
||||
|
||||
For **`openSUSE Leap`** system, use **[Zypper Command][7]** to install chrony.
|
||||
|
||||
```
|
||||
$ sudo zypper install chrony
|
||||
```
|
||||
|
||||
In this article, we are going to use the following setup to test this.
|
||||
|
||||
* **`NTP Server:`** HostName: CentOS7.2daygeek.com, IP:192.168.1.5, OS:CentOS 7
|
||||
* **`Chrony Client:`** HostName: Ubuntu18.2daygeek.com, IP:192.168.1.3, OS:Ubuntu 18.04
|
||||
|
||||
|
||||
|
||||
Navigate to the following URL for **[NTP server installation and configuration in Linux][1]**.
|
||||
|
||||
I have installed and configured the NTP server on `CentOS7.2daygeek.com` so, append the same into all the client machines. Also, include the other required information on it.
|
||||
|
||||
The `chrony.conf` file will be placed in the different locations based on your distribution.
|
||||
|
||||
For RHEL based systems, it’s located at `/etc/chrony.conf`.
|
||||
|
||||
For Debian based systems, it’s located at `/etc/chrony/chrony.conf`.
|
||||
|
||||
```
|
||||
# vi /etc/chrony/chrony.conf
|
||||
|
||||
server CentOS7.2daygeek.com prefer iburst
|
||||
keyfile /etc/chrony/chrony.keys
|
||||
driftfile /var/lib/chrony/chrony.drift
|
||||
logdir /var/log/chrony
|
||||
maxupdateskew 100.0
|
||||
makestep 1 3
|
||||
cmdallow 192.168.1.0/24
|
||||
```
|
||||
|
||||
Bounce the Chrony service once you update the configuration.
|
||||
|
||||
For sysvinit systems. For RHEL based system we need to run `chronyd` instead of chrony.
|
||||
|
||||
```
|
||||
# service chrony restart
|
||||
|
||||
# chkconfig chrony on
|
||||
```
|
||||
|
||||
For systemctl systems. For RHEL based system we need to run `chronyd` instead of chrony.
|
||||
|
||||
```
|
||||
# systemctl restart chrony
|
||||
|
||||
# systemctl enable chrony
|
||||
```
|
||||
|
||||
Use the following commands like tacking, sources and sourcestats to check chrony synchronization details.
|
||||
|
||||
To check chrony tracking status.
|
||||
|
||||
```
|
||||
# chronyc tracking
|
||||
Reference ID : C0A80105 (CentOS7.2daygeek.com)
|
||||
Stratum : 3
|
||||
Ref time (UTC) : Thu Mar 28 05:57:27 2019
|
||||
System time : 0.000002545 seconds slow of NTP time
|
||||
Last offset : +0.001194361 seconds
|
||||
RMS offset : 0.001194361 seconds
|
||||
Frequency : 1.650 ppm fast
|
||||
Residual freq : +184.101 ppm
|
||||
Skew : 2.962 ppm
|
||||
Root delay : 0.107966967 seconds
|
||||
Root dispersion : 1.060455322 seconds
|
||||
Update interval : 2.0 seconds
|
||||
Leap status : Normal
|
||||
```
|
||||
|
||||
Run the sources command to displays information about the current time sources.
|
||||
|
||||
```
|
||||
# chronyc sources
|
||||
210 Number of sources = 1
|
||||
MS Name/IP address Stratum Poll Reach LastRx Last sample
|
||||
===============================================================================
|
||||
^* CentOS7.2daygeek.com 2 6 17 62 +36us[+1230us] +/- 1111ms
|
||||
```
|
||||
|
||||
The sourcestats command displays information about the drift rate and offset estimation process for each of the sources currently being examined by chronyd.
|
||||
|
||||
```
|
||||
# chronyc sourcestats
|
||||
210 Number of sources = 1
|
||||
Name/IP Address NP NR Span Frequency Freq Skew Offset Std Dev
|
||||
==============================================================================
|
||||
CentOS7.2daygeek.com 5 3 71 -97.314 78.754 -469us 441us
|
||||
```
|
||||
|
||||
When chronyd is configured as an NTP client or peer, you can have the transmit and receive timestamping modes and the interleaved mode reported for each NTP source by the chronyc ntpdata command.
|
||||
|
||||
```
|
||||
# chronyc ntpdata
|
||||
|
||||
Remote address : 192.168.1.5 (C0A80105)
|
||||
Remote port : 123
|
||||
Local address : 192.168.1.3 (C0A80103)
|
||||
Leap status : Normal
|
||||
Version : 4
|
||||
Mode : Server
|
||||
Stratum : 2
|
||||
Poll interval : 6 (64 seconds)
|
||||
Precision : -23 (0.000000119 seconds)
|
||||
Root delay : 0.108994 seconds
|
||||
Root dispersion : 0.076523 seconds
|
||||
Reference ID : 85F3EEF4 ()
|
||||
Reference time : Thu Mar 28 06:43:35 2019
|
||||
Offset : +0.000160221 seconds
|
||||
Peer delay : 0.000664478 seconds
|
||||
Peer dispersion : 0.000000178 seconds
|
||||
Response time : 0.000243252 seconds
|
||||
Jitter asymmetry: +0.00
|
||||
NTP tests : 111 111 1111
|
||||
Interleaved : No
|
||||
Authenticated : No
|
||||
TX timestamping : Kernel
|
||||
RX timestamping : Kernel
|
||||
Total TX : 46
|
||||
Total RX : 46
|
||||
Total valid RX : 46
|
||||
```
|
||||
|
||||
Finally run the `date` command.
|
||||
|
||||
```
|
||||
# date
|
||||
Thu Mar 28 03:08:11 CDT 2019
|
||||
```
|
||||
|
||||
To step the system clock immediately, bypassing any adjustments in progress by slewing, issue the following command as root (To adjust the system clock manually).
|
||||
|
||||
```
|
||||
# chronyc makestep
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/configure-ntp-client-using-chrony-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/install-configure-ntp-server-ntp-client-in-linux/
|
||||
[2]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[3]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[5]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[6]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[7]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
@ -0,0 +1,262 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Install And Configure NTP Server And NTP Client In Linux?)
|
||||
[#]: via: (https://www.2daygeek.com/install-configure-ntp-server-ntp-client-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
How To Install And Configure NTP Server And NTP Client In Linux?
|
||||
======
|
||||
|
||||
You might heard this word many times and also you might had worked on this.
|
||||
|
||||
However, i will tell you clearly in this article about NTP Server setup and NTP Client setup
|
||||
|
||||
We will see about **[Chrony NTP Client setup][1]** later.
|
||||
|
||||
### What Is NTP Server?
|
||||
|
||||
NTP stands for Network Time Protocol.
|
||||
|
||||
It is a networking protocol that synchronize the clock between computer systems over the network.
|
||||
|
||||
In other hand I can say. It will keep the same time (It keep an accurate time) to all the systems which are connected to NTP server through NTP or Chrony client.
|
||||
|
||||
NTP can usually maintain time to within tens of milliseconds over the public Internet, and can achieve better than one millisecond accuracy in local area networks under ideal conditions.
|
||||
|
||||
It uses User Datagram Protocol (UDP) on port number 123 for send and receive timestamps. It’s a client/server application.
|
||||
|
||||
It send and receive timestamps using the User Datagram Protocol (UDP) on port number 123.
|
||||
|
||||
### What Is NTP Client?
|
||||
|
||||
NTP client will synchronize its clock to the network time server.
|
||||
|
||||
### What Is Chrony Client?
|
||||
|
||||
Chrony is replacement of NTP client. It can synchronize the system clock faster with better time accuracy and it can be particularly useful for the systems which are not online all the time.
|
||||
|
||||
### Why We Need NTP Server?
|
||||
|
||||
To keep all the servers in your organization in-sync with an accurate time to perform time based jobs.
|
||||
|
||||
To clarify this, I will tell you a scenario. Say for example, we have two servers (Server1 and Server2). The server1 usually complete the batch jobs at 10:55 then the server2 needs to run another job at 11:00 based on the server1 job completion report.
|
||||
|
||||
If both the system is using in a different time (if one system is ahead of the others, the others are behind that particular one) then we can’t perform this. To achieve this, we should setup NTP. Hope it cleared your doubts about NTP.
|
||||
|
||||
In this article, we are going to use the following setup to test this.
|
||||
|
||||
* **`NTP Server:`** HostName: CentOS7.2daygeek.com, IP:192.168.1.8, OS:CentOS 7
|
||||
* **`NTP Client:`** HostName: Ubuntu18.2daygeek.com, IP:192.168.1.5, OS:Ubuntu 18.04
|
||||
|
||||
|
||||
|
||||
### NTP SERVER SIDE: How To Install NTP Server In Linux?
|
||||
|
||||
There is no different packages for NTP server and NTP client since it’s a client/server model. The NTP package is available in distribution official repository so, use the distribution package manger to install it.
|
||||
|
||||
For **`Fedora`** system, use **[DNF Command][2]** to install ntp.
|
||||
|
||||
```
|
||||
$ sudo dnf install ntp
|
||||
```
|
||||
|
||||
For **`Debian/Ubuntu`** systems, use **[APT-GET Command][3]** or **[APT Command][4]** to install ntp.
|
||||
|
||||
```
|
||||
$ sudo apt install ntp
|
||||
```
|
||||
|
||||
For **`Arch Linux`** based systems, use **[Pacman Command][5]** to install ntp.
|
||||
|
||||
```
|
||||
$ sudo pacman -S ntp
|
||||
```
|
||||
|
||||
For **`RHEL/CentOS`** systems, use **[YUM Command][6]** to install ntp.
|
||||
|
||||
```
|
||||
$ sudo yum install ntp
|
||||
```
|
||||
|
||||
For **`openSUSE Leap`** system, use **[Zypper Command][7]** to install ntp.
|
||||
|
||||
```
|
||||
$ sudo zypper install ntp
|
||||
```
|
||||
|
||||
### How To Configure The NTP Server In Linux?
|
||||
|
||||
Once you have installed the NTP package, make sure you have to uncomment the following configuration in the `/etc/ntp.conf` file on server side.
|
||||
|
||||
By default the NTP server configuration relies on `X.distribution_name.pool.ntp.org`. If you want you can use the default configuration or you can change it as per your location (country specific) by visiting <https://www.ntppool.org/zone/@> site.
|
||||
|
||||
Say for example. If you are in India then your NTP server will be `0.in.pool.ntp.org` and it will work for most of the countries.
|
||||
|
||||
```
|
||||
# vi /etc/ntp.conf
|
||||
|
||||
restrict default kod nomodify notrap nopeer noquery
|
||||
restrict -6 default kod nomodify notrap nopeer noquery
|
||||
restrict 127.0.0.1
|
||||
restrict -6 ::1
|
||||
server 0.asia.pool.ntp.org
|
||||
server 1.asia.pool.ntp.org
|
||||
server 2.asia.pool.ntp.org
|
||||
server 3.asia.pool.ntp.org
|
||||
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
|
||||
driftfile /var/lib/ntp/drift
|
||||
keys /etc/ntp/keys
|
||||
```
|
||||
|
||||
We have allowed only `192.168.1.0/24` subnet clients to access the NTP server.
|
||||
|
||||
Since firewall is enabled by default on RHEL 7 based distributions so, allow the ntp server/service.
|
||||
|
||||
```
|
||||
# firewall-cmd --add-service=ntp --permanent
|
||||
# firewall-cmd --reload
|
||||
```
|
||||
|
||||
Bounce the service once you update the configuration.
|
||||
|
||||
For sysvinit systems. For Debian based system we need to run `ntp` instead of ntpd.
|
||||
|
||||
```
|
||||
# service ntpd restart
|
||||
|
||||
# chkconfig ntpd on
|
||||
```
|
||||
|
||||
For systemctl systems. For Debian based system we need to run `ntp` instead of ntpd.
|
||||
|
||||
```
|
||||
# systemctl restart ntpd
|
||||
|
||||
# systemctl enable ntpd
|
||||
```
|
||||
|
||||
### NTP CLIENT SIDE: How To Install NTP Client On Linux?
|
||||
|
||||
As I mentioned earlier in this article. There is no specific package for NTP server and client. So, install the same package on client also.
|
||||
|
||||
For **`Fedora`** system, use **[DNF Command][2]** to install ntp.
|
||||
|
||||
```
|
||||
$ sudo dnf install ntp
|
||||
```
|
||||
|
||||
For **`Debian/Ubuntu`** systems, use **[APT-GET Command][3]** or **[APT Command][4]** to install ntp.
|
||||
|
||||
```
|
||||
$ sudo apt install ntp
|
||||
```
|
||||
|
||||
For **`Arch Linux`** based systems, use **[Pacman Command][5]** to install ntp.
|
||||
|
||||
```
|
||||
$ sudo pacman -S ntp
|
||||
```
|
||||
|
||||
For **`RHEL/CentOS`** systems, use **[YUM Command][6]** to install ntp.
|
||||
|
||||
```
|
||||
$ sudo yum install ntp
|
||||
```
|
||||
|
||||
For **`openSUSE Leap`** system, use **[Zypper Command][7]** to install ntp.
|
||||
|
||||
```
|
||||
$ sudo zypper install ntp
|
||||
```
|
||||
|
||||
I have installed and configured the NTP server on `CentOS7.2daygeek.com` so, append the same into all the client machines.
|
||||
|
||||
```
|
||||
# vi /etc/ntp.conf
|
||||
|
||||
restrict default kod nomodify notrap nopeer noquery
|
||||
restrict -6 default kod nomodify notrap nopeer noquery
|
||||
restrict 127.0.0.1
|
||||
restrict -6 ::1
|
||||
server CentOS7.2daygeek.com prefer iburst
|
||||
driftfile /var/lib/ntp/drift
|
||||
keys /etc/ntp/keys
|
||||
```
|
||||
|
||||
Bounce the service once you update the configuration.
|
||||
|
||||
For sysvinit systems. For Debian based system we need to run `ntp` instead of ntpd.
|
||||
|
||||
```
|
||||
# service ntpd restart
|
||||
|
||||
# chkconfig ntpd on
|
||||
```
|
||||
|
||||
For systemctl systems. For Debian based system we need to run `ntp` instead of ntpd.
|
||||
|
||||
```
|
||||
# systemctl restart ntpd
|
||||
|
||||
# systemctl enable ntpd
|
||||
```
|
||||
|
||||
Wait for few minutes post restart of the NTP service to get synchronize time from the NTP server.
|
||||
|
||||
Run the following commands to verify the NTP server synchronization status on Linux.
|
||||
|
||||
```
|
||||
# ntpq –p
|
||||
Or
|
||||
# ntpq -pn
|
||||
|
||||
remote refid st t when poll reach delay offset jitter
|
||||
==============================================================================
|
||||
*CentOS7.2daygee 133.243.238.163 2 u 14 64 37 0.686 0.151 16.432
|
||||
```
|
||||
|
||||
Run the following command to get the current status of ntpd.
|
||||
|
||||
```
|
||||
# ntpstat
|
||||
synchronised to NTP server (192.168.1.8) at stratum 3
|
||||
time correct to within 508 ms
|
||||
polling server every 64 s
|
||||
```
|
||||
|
||||
Finally run the `date` command.
|
||||
|
||||
```
|
||||
# date
|
||||
Tue Mar 26 23:17:05 CDT 2019
|
||||
```
|
||||
|
||||
If you are observing a significant offset in the NTP output. Run the following command to sync clock manually from the NTP server. Make sure that your NTP client should be inactive state when you perform the command.
|
||||
|
||||
```
|
||||
# ntpdate –uv CentOS7.2daygeek.com
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/install-configure-ntp-server-ntp-client-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/configure-ntp-client-using-chrony-in-linux/
|
||||
[2]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[3]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[5]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[6]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[7]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
@ -0,0 +1,304 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Install And Enable Flatpak Support On Linux?)
|
||||
[#]: via: (https://www.2daygeek.com/how-to-install-and-enable-flatpak-support-on-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
How To Install And Enable Flatpak Support On Linux?
|
||||
======
|
||||
|
||||
Currently we all are using distributions official package managers to install any required packages.
|
||||
|
||||
in Linux, it’s doing good without any issues. (It’s doing their job nicely without any compromise)
|
||||
|
||||
There was some limitation on this that will think about other alternative solutions to fix it.
|
||||
|
||||
Yes, by default we won’t get the latest version of packages from the distributions official package managers because as these were built while building a current OS version. And they offers only security updates until the next major release comes.
|
||||
|
||||
So, what will be the solution for this?
|
||||
|
||||
Yes, we have multiple solutions for this and most of us were already started using few of those.
|
||||
|
||||
What it is and what is the benefit of those?
|
||||
|
||||
* **For Ubuntu based systems:** PPAs
|
||||
* **For RHEL based systems:** [EPEL Repository][1], [ELRepo Repository][2], [nux-dextop Repository][3], [IUS Community Repo][4], [RPMfusion Repository][5] and [Remi Repository][6].
|
||||
|
||||
|
||||
|
||||
Using the above repos, we will be getting the latest packages for the distribution. And these are usually well maintained and suggested by most of the community. But these are advisable by the OS and may not always be safe.
|
||||
|
||||
In recent years, the following universal packaging formats were come out and gained a lot of popularity.
|
||||
|
||||
* **`Flatpak:`**`` It’s distribution independent package format and the main contributor is Fedora project team. The Flatpak framework is adopted by most of the major Linux distributions.
|
||||
* **`Snaps:`**`` Snappy is a universal packaging formats originally designed and built by Canonical for the Ubuntu phone and it’s operating system. Later most of the distributions are adapted.
|
||||
* **`AppImage:`**`` AppImage is a portable package format and it can run without installation or the need for root rights.
|
||||
|
||||
|
||||
|
||||
We had already covered about the **[Snap package manager& packaging format][7]** in the past. Today we are going to discuss about Flatpak packing format.
|
||||
|
||||
### What Is Flatpak?
|
||||
|
||||
Flatpak (formerly know as X Desktop Group or xdg-app) is a software utility. It’s offering a universal packaging formats which can be used in any Linux distributions.
|
||||
|
||||
It provides a sandbox (isolated) environment to run the app and it doesn’t impact either other apps and distribution core packages. Also we can install and run the different version of same package.
|
||||
|
||||
There is an disadvantage on flatpak is that doesn’t support server OS unlike Snap and AppImage. It’s working only on few desktops environment.
|
||||
|
||||
Say for example. If you would like to run two version of php on your system then you can easily install and run as your wish.
|
||||
|
||||
That’s where the universal packaging formats are become very famous nowadays.
|
||||
|
||||
### How To Install Flatpak On Linux?
|
||||
|
||||
Flatpak package is available in most of the Linux distribution official repository. Hence, it can be installed using those.
|
||||
|
||||
For **`Fedora`** system, use **[DNF Command][8]** to install flatpak.
|
||||
|
||||
```
|
||||
$ sudo dnf install flatpak
|
||||
```
|
||||
|
||||
For **`Debian/Ubuntu`** systems, use **[APT-GET Command][9]** or **[APT Command][10]** to install flatpak.
|
||||
|
||||
```
|
||||
$ sudo apt install flatpak
|
||||
```
|
||||
|
||||
For older Ubuntu versions.
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:alexlarsson/flatpak
|
||||
$ sudo apt update
|
||||
$ sudo apt install flatpak
|
||||
```
|
||||
|
||||
For **`Arch Linux`** based systems, use **[Pacman Command][11]** to install flatpak.
|
||||
|
||||
```
|
||||
$ sudo pacman -S flatpak
|
||||
```
|
||||
|
||||
For **`RHEL/CentOS`** systems, use **[YUM Command][12]** to install flatpak.
|
||||
|
||||
```
|
||||
$ sudo yum install flatpak
|
||||
```
|
||||
|
||||
For **`openSUSE Leap`** system, use **[Zypper Command][13]** to install flatpak.
|
||||
|
||||
```
|
||||
$ sudo zypper install flatpak
|
||||
```
|
||||
|
||||
### How To Enable Flathub Support On Linux?
|
||||
|
||||
Flatbub website is a app store for Flatpak packages where you can find them.
|
||||
|
||||
It’s a central repository where all the flatpak applications are available for users.
|
||||
|
||||
Run the following command to enable Flathub support on Linux.
|
||||
|
||||
```
|
||||
$ sudo flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
|
||||
```
|
||||
|
||||
Install the Software Flatpak plugin for GNOME Desktop Environment.
|
||||
|
||||
```
|
||||
$ sudo apt install gnome-software-plugin-flatpak
|
||||
```
|
||||
|
||||
Also, you can enable GNOME Repository if you are using GNOME Desktop Environment. It’s containing all GNOME core applications.
|
||||
|
||||
```
|
||||
$ wget https://sdk.gnome.org/keys/gnome-sdk.gpg
|
||||
$ sudo flatpak remote-add --gpg-import=gnome-sdk.gpg --if-not-exists gnome-apps https://sdk.gnome.org/repo-apps/
|
||||
```
|
||||
|
||||
### How To List configured flatpak repositories?
|
||||
|
||||
Run the following command, if you would like to view list of the configured flatpak repositories on your system.
|
||||
|
||||
```
|
||||
$ flatpak remotes
|
||||
Name Options
|
||||
flathub system
|
||||
gnome-apps system
|
||||
```
|
||||
|
||||
### How To List The Available Packages In The Configured Repositories?
|
||||
|
||||
Run the following command, if you would like to view list of the available packages (It will display all together like, applications and run times) in the configured repositories.
|
||||
|
||||
```
|
||||
$ flatpak remote-ls | head -10
|
||||
|
||||
org.freedesktop.GlxInfo gnome-apps
|
||||
org.gnome.Books gnome-apps
|
||||
org.gnome.Builder gnome-apps
|
||||
org.gnome.Calculator gnome-apps
|
||||
org.gnome.Calendar gnome-apps
|
||||
org.gnome.Characters gnome-apps
|
||||
org.gnome.Devhelp gnome-apps
|
||||
org.gnome.Dictionary gnome-apps
|
||||
org.gnome.Documents gnome-apps
|
||||
org.gnome.Epiphany gnome-apps
|
||||
```
|
||||
|
||||
To list only applications not runtimes.
|
||||
|
||||
```
|
||||
$ flatpak remote-ls --app
|
||||
```
|
||||
|
||||
To list specific repository applications.
|
||||
|
||||
```
|
||||
$ flatpak remote-ls gnome-apps
|
||||
```
|
||||
|
||||
### How To Install A Package From flatpak?
|
||||
|
||||
Run the following command to install a package from flatpak repository.
|
||||
|
||||
```
|
||||
$ sudo flatpak install flathub com.github.muriloventuroso.easyssh
|
||||
|
||||
Required runtime for com.github.muriloventuroso.easyssh/x86_64/stable (runtime/org.gnome.Platform/x86_64/3.30) found in remote flathub
|
||||
Do you want to install it? [y/n]: y
|
||||
Installing in system:
|
||||
org.gnome.Platform/x86_64/3.30 flathub 4e93789f42ac
|
||||
org.gnome.Platform.Locale/x86_64/3.30 flathub 6abf9c0e2b72
|
||||
org.freedesktop.Platform.html5-codecs/x86_64/18.08 flathub d6abde36c0be
|
||||
com.github.muriloventuroso.easyssh/x86_64/stable flathub 337db43043d2
|
||||
permissions: ipc, network, wayland, x11, dri
|
||||
file access: home, xdg-run/dconf, ~/.config/dconf:ro
|
||||
dbus access: ca.desrt.dconf
|
||||
com.github.muriloventuroso.easyssh.Locale/x86_64/stable flathub af837356b222
|
||||
Is this ok [y/n]: y
|
||||
Installing: org.gnome.Platform/x86_64/3.30 from flathub
|
||||
[####################] 1 metadata, 14908 content objects fetched; 228018 KiB transferred in 364 seconds
|
||||
Now at 4e93789f42ac.
|
||||
Installing: org.gnome.Platform.Locale/x86_64/3.30 from flathub
|
||||
[####################] 4 metadata, 1 content objects fetched; 16 KiB transferred in 2 seconds
|
||||
Now at 6abf9c0e2b72.
|
||||
Installing: org.freedesktop.Platform.html5-codecs/x86_64/18.08 from flathub
|
||||
[####################] 26 metadata, 131 content objects fetched; 2737 KiB transferred in 8 seconds
|
||||
Now at d6abde36c0be.
|
||||
Installing: com.github.muriloventuroso.easyssh/x86_64/stable from flathub
|
||||
[####################] 191 metadata, 3633 content objects fetched; 24857 KiB transferred in 117 seconds
|
||||
Now at 337db43043d2.
|
||||
Installing: com.github.muriloventuroso.easyssh.Locale/x86_64/stable from flathub
|
||||
[####################] 3 metadata, 1 content objects fetched; 14 KiB transferred in 2 seconds
|
||||
Now at af837356b222.
|
||||
```
|
||||
|
||||
All the installed application will be placed in the following location.
|
||||
|
||||
```
|
||||
$ ls /var/lib/flatpak/app/
|
||||
com.github.muriloventuroso.easyssh
|
||||
```
|
||||
|
||||
### How To Run The Installed Application?
|
||||
|
||||
Run the following command to launch the required application. Make sure, you have to replace with your application name instead.
|
||||
|
||||
```
|
||||
$ flatpak run com.github.muriloventuroso.easyssh
|
||||
```
|
||||
|
||||
### How To View The Installed Application?
|
||||
|
||||
Run the following command to view the installed application.
|
||||
|
||||
```
|
||||
$ flatpak list
|
||||
Ref Options
|
||||
com.github.muriloventuroso.easyssh/x86_64/stable system,current
|
||||
org.freedesktop.Platform.html5-codecs/x86_64/18.08 system,runtime
|
||||
org.gnome.Platform/x86_64/3.30 system,runtime
|
||||
```
|
||||
|
||||
### How To View The Detailed Information About The Installed Application?
|
||||
|
||||
Run the following command to view the detailed information about the installed application.
|
||||
|
||||
```
|
||||
$ flatpak info com.github.muriloventuroso.easyssh
|
||||
|
||||
Ref: app/com.github.muriloventuroso.easyssh/x86_64/stable
|
||||
ID: com.github.muriloventuroso.easyssh
|
||||
Arch: x86_64
|
||||
Branch: stable
|
||||
Origin: flathub
|
||||
Collection ID: org.flathub.Stable
|
||||
Date: 2019-01-08 13:36:32 +0000
|
||||
Subject: Update com.github.muriloventuroso.easyssh.json (cd35819c)
|
||||
Commit: 337db43043d282c74d14a9caecdc780464b5e526b4626215d534d38b0935049f
|
||||
Parent: 6e49096146f675db6ecc0ce7c5347b4b4f049b21d83a6cc4d01ff3f27c707cb6
|
||||
Location: /var/lib/flatpak/app/com.github.muriloventuroso.easyssh/x86_64/stable/337db43043d282c74d14a9caecdc780464b5e526b4626215d534d38b0935049f
|
||||
Installed size: 100.0 MB
|
||||
Runtime: org.gnome.Platform/x86_64/3.30
|
||||
Sdk: org.gnome.Sdk/x86_64/3.30
|
||||
```
|
||||
|
||||
### How To Update The Installed Application?
|
||||
|
||||
Run the following command to updated the installed application to latest version.
|
||||
|
||||
```
|
||||
$ flatpak update
|
||||
```
|
||||
|
||||
For specific application, use the following format.
|
||||
|
||||
```
|
||||
$ flatpak update com.github.muriloventuroso.easyssh
|
||||
```
|
||||
|
||||
### How To Remove The Installed Application?
|
||||
|
||||
Run the following command to remove the installed application.
|
||||
|
||||
```
|
||||
$ sudo flatpak uninstall com.github.muriloventuroso.easyssh
|
||||
```
|
||||
|
||||
Go to the man page for more details and options.
|
||||
|
||||
```
|
||||
$ flatpak --help
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-install-and-enable-flatpak-support-on-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-scientific-linux-oracle-linux/
|
||||
[2]: https://www.2daygeek.com/install-enable-elrepo-on-rhel-centos-scientific-linux/
|
||||
[3]: https://www.2daygeek.com/install-enable-nux-dextop-repository-on-centos-rhel-scientific-linux/
|
||||
[4]: https://www.2daygeek.com/install-enable-ius-community-repository-on-rhel-centos/
|
||||
[5]: https://www.2daygeek.com/install-enable-rpm-fusion-repository-on-centos-fedora-rhel/
|
||||
[6]: https://www.2daygeek.com/install-enable-remi-repository-on-centos-rhel-fedora/
|
||||
[7]: https://www.2daygeek.com/linux-snap-package-manager-ubuntu/
|
||||
[8]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[9]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[10]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[11]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[12]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[13]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
@ -0,0 +1,149 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (UP Shell Script – Quickly Navigate To A Specific Parent Directory In Linux)
|
||||
[#]: via: (https://www.2daygeek.com/up-shell-script-quickly-go-back-to-a-specific-parent-directory-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
UP Shell Script – Quickly Navigate To A Specific Parent Directory In Linux
|
||||
======
|
||||
|
||||
Recently we had written an article about **[bd command][1]** , which help us to **[quickly go back to the specific parent directory][1]**.
|
||||
|
||||
Even, the [up shell script][2] allow us to perform the same but has different approach so, we would like to explore it.
|
||||
|
||||
This will allow us to quickly navigate to a specific parent directory with mentioning the directory name.
|
||||
|
||||
Instead we can give the directory number. I mean to say that number of times you’d have to go back.
|
||||
|
||||
Stop typing `cd ../../..` endlessly and navigate easily to a specific parent directory by using up shell script.
|
||||
|
||||
It support tab completion so, it’s become more convenient.
|
||||
|
||||
The `up.sh` registers the up function and some completion functions via your `.bashrc` or `.zshrc` file.
|
||||
|
||||
It was completely written using shell script and it’s support zsh and fish shell as well.
|
||||
|
||||
We had written an article about **[autocd][3]**. It’s a builtin shell variable that helps us to **[navigate to inside a directory without cd command][3]**.
|
||||
|
||||
### How To Install up Linux?
|
||||
|
||||
It’s not based on the distribution and you have to install it based on your shell.
|
||||
|
||||
Simple run the following command to enable up script on `bash` shell.
|
||||
|
||||
```
|
||||
$ curl --create-dirs -o ~/.config/up/up.sh https://raw.githubusercontent.com/shannonmoeller/up/master/up.sh
|
||||
|
||||
$ echo 'source ~/.config/up/up.sh' >> ~/.bashrc
|
||||
```
|
||||
|
||||
Run the following command to take the changes to effect.
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
Simple run the following command to enable up script on `zsh` shell.
|
||||
|
||||
```
|
||||
$ curl --create-dirs -o ~/.config/up/up.sh https://raw.githubusercontent.com/shannonmoeller/up/master/up.sh
|
||||
|
||||
$ echo 'source ~/.config/up/up.sh' >> ~/.zshrc
|
||||
```
|
||||
|
||||
Run the following command to take the changes to effect.
|
||||
|
||||
```
|
||||
$ source ~/.zshrc
|
||||
```
|
||||
|
||||
Simple run the following command to enable up script on `fish` shell.
|
||||
|
||||
```
|
||||
$ curl --create-dirs -o ~/.config/up/up.fish https://raw.githubusercontent.com/shannonmoeller/up/master/up.fish
|
||||
|
||||
$ source ~/.config/up/up.fish
|
||||
```
|
||||
|
||||
### How To Use This In Linux?
|
||||
|
||||
We have successfully installed and configured the up script on system. It’s time to test it.
|
||||
|
||||
I’m going to take the below directory path for this testing.
|
||||
|
||||
Run the `pwd` command or `dirs` command to know your current location.
|
||||
|
||||
```
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ pwd
|
||||
or
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ dirs
|
||||
|
||||
/usr/share/icons/Adwaita/256x256/apps
|
||||
```
|
||||
|
||||
How to up one level? Quickly go back to one directory. I’m currently in `/usr/share/icons/Adwaita/256x256/apps` and if i want to go one directory up `256x256` directory quickly then simple type the following command.
|
||||
|
||||
```
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ up
|
||||
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256$ pwd
|
||||
/usr/share/icons/Adwaita/256x256
|
||||
```
|
||||
|
||||
How to up multiple levels? Quickly go back to multiple directory. I’m currently in `/usr/share/icons/Adwaita/256x256/apps` and if i want to go to `share` directory quickly then simple type the following command.
|
||||
|
||||
```
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ up 4
|
||||
|
||||
daygeek@Ubuntu18:/usr/share$ pwd
|
||||
/usr/share
|
||||
```
|
||||
|
||||
How to up by full name? Quickly go back to the given directory instead of number.
|
||||
|
||||
```
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ up icons
|
||||
|
||||
daygeek@Ubuntu18:/usr/share/icons$ pwd
|
||||
/usr/share/icons
|
||||
```
|
||||
|
||||
How to up by partial name? Quickly go back to the given directory instead of number.
|
||||
|
||||
```
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ up Ad
|
||||
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita$ pwd
|
||||
/usr/share/icons/Adwaita
|
||||
```
|
||||
|
||||
As i told in the beginning of the article, it supports tab completion.
|
||||
|
||||
```
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ up
|
||||
256x256/ Adwaita/ icons/ share/ usr/
|
||||
```
|
||||
|
||||
This tutorial allows you to quickly go back to a specific parent directory but there is no option to move forward quickly.
|
||||
|
||||
We have another solution for this, will come up with new solution shortly. Please stay tune with us.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/up-shell-script-quickly-go-back-to-a-specific-parent-directory-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/bd-quickly-go-back-to-a-specific-parent-directory-in-linux/
|
||||
[2]: https://github.com/shannonmoeller/up
|
||||
[3]: https://www.2daygeek.com/navigate-switch-directory-without-using-cd-command-in-linux/
|
||||
@ -0,0 +1,207 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (topgrade – Upgrade/Update Everything In Single Command On Linux?)
|
||||
[#]: via: (https://www.2daygeek.com/topgrade-upgrade-update-everything-in-single-command-on-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
topgrade – Upgrade/Update Everything In Single Command On Linux?
|
||||
======
|
||||
|
||||
As a Linux administrator, you have to keep your system up-to-date to get ride out from some unexpected issues.
|
||||
|
||||
We have to keep the system with latest patches as part of best practices.
|
||||
|
||||
To do so, you need to perform the patching activity at least once in a month.
|
||||
|
||||
Most of the time you have to reboot the server after patching to activate the latest kernel.
|
||||
|
||||
It’s good to reboot the server at least 90-120 days once that will fix some outstanding issue which we already having.
|
||||
|
||||
If you have a single system then we can directly login to the system and do perform the patching that is not a big deal.
|
||||
|
||||
Even, if you have few of servers with the same flavor then you can perform the patching with help of shell script.
|
||||
|
||||
If you have high number of servers then i would advise you to go with any of the parallel utility, which will help us to perform the patching in parallel.
|
||||
|
||||
It will save a lot’s of time compared with shell script as this go with sequential order.
|
||||
|
||||
how to patch all togeter if you have servers with multiple flavors? What will be the solution ?
|
||||
|
||||
I recently came to know the utility called `topgrade` that can fulfill your requirement.
|
||||
|
||||
Also, your distribution package manager doesn’t upgrade the packages which was installed with other package managers such as pip, npm, snap, etc,. but topgrade can fix this issue as well.
|
||||
|
||||
### What Is topgrade?
|
||||
|
||||
[topgrade][1] is a new tool that will upgrade all the installed packages on your system to latest available version by detecting and running the appropriate package managers.
|
||||
|
||||
### How To Install topgrade In Linux?
|
||||
|
||||
There is no separate package manager for distributions wise. Hence, you need to install topgrade with help of cargo package manager.
|
||||
|
||||
The topgrade is available in AUR. So, use one of the **[AUR helper][2]** to install it on Arch-based systems. I prefer to go with **[Yay helper][3]** program.
|
||||
|
||||
```
|
||||
$ yay -S topgrade
|
||||
```
|
||||
|
||||
Once you have installed the **[cargo package manager][4]** , use the following command to install it.
|
||||
|
||||
```
|
||||
$ cargo install topgrade
|
||||
```
|
||||
|
||||
Once topgrade is initiated, it will perform the following tasks one by one.
|
||||
|
||||
* Try to self-upgrade if any updated is available for topgrade.
|
||||
* Arch: Run yay or fall back to pacman
|
||||
* CentOS/RHEL: Run yum upgrade
|
||||
* Fedora: Run dnf upgrade
|
||||
* Debian/Ubuntu: Run apt update && apt dist-upgrade
|
||||
* openSUSE: Run zypper refresh && zypper dist-upgrade
|
||||
* Upgrade Vim/Neovim packages.
|
||||
* Run npm update -g if NPM is installed
|
||||
* Upgrade Atom packages
|
||||
* Linux: Update Flatpak packages
|
||||
* Linux: Update snap packages
|
||||
* Linux: Run fwupdmgr to show firmware upgrade.
|
||||
* Finally it will run needrestart to bounce all the services.
|
||||
|
||||
|
||||
|
||||
Now, we have successfully installed `topgrade` so, run the topgrade alone to upgrade everything on your system. I have tested the utility on Ubuntu 18.04 LTS and the results are below.
|
||||
|
||||
```
|
||||
$ topgrade
|
||||
|
||||
―― System update ――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――
|
||||
[sudo] password for daygeek:
|
||||
Hit:1 http://in.archive.ubuntu.com/ubuntu bionic InRelease
|
||||
Get:2 http://security.ubuntu.com/ubuntu bionic-security InRelease [88.7 kB]
|
||||
Get:3 http://in.archive.ubuntu.com/ubuntu bionic-updates InRelease [88.7 kB]
|
||||
Get:4 http://in.archive.ubuntu.com/ubuntu bionic-backports InRelease [74.6 kB]
|
||||
.
|
||||
Get:16 http://security.ubuntu.com/ubuntu bionic-security/universe DEP-11 64x64 Icons [45.2 kB]
|
||||
Get:17 http://security.ubuntu.com/ubuntu bionic-security/multiverse amd64 DEP-11 Metadata [2,460 B]
|
||||
Fetched 1,565 kB in 13s (117 kB/s)
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
119 packages can be upgraded. Run 'apt list --upgradable' to see them.
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
Calculating upgrade... Done
|
||||
The following packages were automatically installed and are no longer required:
|
||||
libopts25 linux-headers-4.15.0-45 linux-headers-4.15.0-45-generic linux-image-4.15.0-45-generic
|
||||
linux-modules-4.15.0-29-generic linux-modules-4.15.0-45-generic linux-modules-extra-4.15.0-45-generic sntp
|
||||
Use 'sudo apt autoremove' to remove them.
|
||||
The following packages will be upgraded:
|
||||
apport apport-gtk apt apt-utils cups cups-bsd cups-client cups-common cups-core-drivers cups-daemon cups-ipp-utils
|
||||
cups-ppdc cups-server-common distro-info-data fwupdate fwupdate-signed gir1.2-dbusmenu-glib-0.4 gir1.2-gtk-3.0
|
||||
gir1.2-packagekitglib-1.0 gir1.2-snapd-1 gnome-settings-daemon gnome-settings-daemon-schemas grub-common grub-pc
|
||||
python3-httplib2 python3-problem-report samba-libs systemd systemd-sysv ubuntu-drivers-common udev ufw
|
||||
unattended-upgrades xdg-desktop-portal xdg-desktop-portal-gtk
|
||||
119 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.
|
||||
Need to get 38.5 MB of archives.
|
||||
After this operation, 475 kB of additional disk space will be used.
|
||||
Do you want to continue? [Y/n]
|
||||
.
|
||||
.
|
||||
Setting up grub-pc (2.02-2ubuntu8.13) ...
|
||||
Installing for i386-pc platform.
|
||||
Installation finished. No error reported.
|
||||
Sourcing file `/etc/default/grub'
|
||||
Generating grub configuration file ...
|
||||
Found memtest86+ image: /boot/memtest86+.elf
|
||||
Found memtest86+ image: /boot/memtest86+.bin
|
||||
done
|
||||
Setting up mesa-vdpau-drivers:amd64 (18.2.8-0ubuntu0~18.04.2) ...
|
||||
Updating PPD files for cups ...
|
||||
Setting up apport-gtk (2.20.9-0ubuntu7.6) ...
|
||||
Setting up pulseaudio-module-bluetooth (1:11.1-1ubuntu7.2) ...
|
||||
Processing triggers for libc-bin (2.27-3ubuntu1) ...
|
||||
Processing triggers for initramfs-tools (0.130ubuntu3.7) ...
|
||||
update-initramfs: Generating /boot/initrd.img-4.15.0-47-generic
|
||||
```
|
||||
|
||||
It will run the self-updates once the distribution official packages update done.
|
||||
|
||||
```
|
||||
―― rustup ―――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――
|
||||
info: checking for self-updates
|
||||
info: syncing channel updates for 'stable-x86_64-unknown-linux-gnu'
|
||||
info: checking for self-updates
|
||||
|
||||
stable-x86_64-unknown-linux-gnu unchanged - rustc 1.33.0 (2aa4c46cf 2019-02-28)
|
||||
```
|
||||
|
||||
Then it will try to update the packages that has installed with other package managers.
|
||||
|
||||
```
|
||||
―― Flatpak User Packages ――――――――――――――――――――――――――――――――――――――――――――――――――――――――
|
||||
Looking for updates...
|
||||
Looking for updates...
|
||||
Updating in system:
|
||||
org.gnome.Platform/x86_64/3.30 flathub 862e6b8ec2b5
|
||||
org.gnome.Platform.Locale/x86_64/3.30 flathub 5e66e981ae00
|
||||
org.freedesktop.Platform.html5-codecs/x86_64/18.08 flathub 282fd2c4ef33
|
||||
com.github.muriloventuroso.easyssh/x86_64/stable flathub c6bc3a3e72fb
|
||||
new permissions: ssh-auth
|
||||
com.github.muriloventuroso.easyssh.Locale/x86_64/stable flathub b705864b8d78
|
||||
Updating: org.gnome.Platform/x86_64/3.30 from flathub
|
||||
[####################] 16 delta parts, 10 loose fetched; 65539 KiB transferred in 63 seconds
|
||||
Error: Failed to update org.gnome.Platform/x86_64/3.30: Flatpak system operation Deploy not allowed for user
|
||||
|
||||
Skipping org.gnome.Platform.Locale/x86_64/3.30 due to previous error
|
||||
|
||||
Skipping org.freedesktop.Platform.html5-codecs/x86_64/18.08 due to previous error
|
||||
Updating: com.github.muriloventuroso.easyssh/x86_64/stable from flathub
|
||||
[####################] 2 delta parts, 3 loose fetched; 1532 KiB transferred in 5 seconds
|
||||
Error: Failed to update com.github.muriloventuroso.easyssh/x86_64/stable: Flatpak system operation Deploy not allowed for user
|
||||
|
||||
Skipping com.github.muriloventuroso.easyssh.Locale/x86_64/stable due to previous error
|
||||
error: There were one or more errors
|
||||
|
||||
Retry? [y/N]
|
||||
```
|
||||
|
||||
Then it will run the firmwre upgrade.
|
||||
|
||||
```
|
||||
―― Firmware upgrades ――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――
|
||||
Fetching metadata https://cdn.fwupd.org/downloads/firmware.xml.gz
|
||||
Downloading… [***************************************]
|
||||
Fetching signature https://cdn.fwupd.org/downloads/firmware.xml.gz.asc
|
||||
```
|
||||
|
||||
Finally, it shows the summary about the patching has done.
|
||||
|
||||
```
|
||||
―― Summary ――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――
|
||||
System update: OK
|
||||
rustup: OK
|
||||
Flatpak User Packages: FAILED
|
||||
Firmware upgrade: OK
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/topgrade-upgrade-update-everything-in-single-command-on-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/r-darwish/topgrade
|
||||
[2]: https://www.2daygeek.com/category/aur-helper/
|
||||
[3]: https://www.2daygeek.com/install-yay-yet-another-yogurt-aur-helper-on-arch-linux/
|
||||
[4]: https://www.2daygeek.com/how-to-install-rust-programming-language-in-linux/
|
||||
@ -0,0 +1,118 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Moelf)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (A Look Back at the History of Firefox)
|
||||
[#]: via: (https://itsfoss.com/history-of-firefox)
|
||||
[#]: author: (John Paul https://itsfoss.com/author/john/)
|
||||
|
||||
回顾 Firefox 历史
|
||||
======
|
||||
|
||||
火狐浏览器从很久之前就一直是开源社区的一根顶梁柱。多年来它一直作为几乎所有 Linux 发行版的默认浏览器,并且曾是阻挡微软彻底争霸浏览器界的最后一块磐石。这款浏览器的根子可以一直最回溯到互联网创生的时代。这周标志着互联网成立30周年,趁这个机会回顾一下我们熟悉并爱戴的火狐浏览器实在是再好不过了。
|
||||
|
||||
### 发源
|
||||
|
||||
在90年代早期,一个叫 [Marc Andreessen][1] 的年轻人正在伊利诺伊大学(U of Illinois)就读本科计算机科学。他那时还为[国家超算应用中心][2]工作。Marc 在那时候[了解][4]到了一款叫[ViolaWWW][5]的化石级浏览器。Marc 和 Eric Bina 看到了这种技术的潜力,他们开发了一个易于安装的 Unix 浏览器取名 [NCSA Mosaic][6]。第一个 alpha 版本发布于 1993 年 6 月。到 9 月的时候,浏览器已经有 Windows 和 Macintosh 移植版本了。因为比当时其他任何浏览器软件都易于使用,Mosaic 很快变得相当流行。
|
||||
|
||||
1994 年,Marc 毕业并移居到加州。他被一个叫 Jim Clark 的人找上了,Clark 那时候通过卖电脑软硬件赚了点钱。Clark 也用过 Mosaic 浏览器并且在互联网上看到了发家的机会。Clark 创立了一家公司并且雇了 Marc 和 Eric 专做互联网软件。公司一开始叫 “Mosaic 通讯”,但是伊利诺伊大学不喜欢他们[名字里用 Mosaic][7]。所以公司转而改名大家后来熟悉的 “Netscape Communication 企业”。
|
||||
|
||||
公司的第一个企划是给任天堂 64 开发在线对战网络,然而不怎么成功。他们第一个以公司名义发布的产品是一款叫做 Mosaic Netscape 0.9 的浏览器,很快这款浏览器被改名叫 Netscape Navigator。在内部,浏览器的开发代号就是 mozilla,意味着”Mosaic 杀手“。一位员工还创作了一幅[类似哥斯拉的][8]卡通画。他们当时想在竞争中彻底胜出。
|
||||
|
||||
|
||||
![Early Firefox Mascot][9]早期 Mozilla 在 Netscape 的吉祥物
|
||||
|
||||
他们取得了辉煌的生理。那时,Netscape 最大的优势是他们的浏览器在各种操作系统上体验极为一致。Netscape 把这个情况宣传为给所有人公平的互联网体验。
|
||||
|
||||
随着越来越多的人使用 Netscape Navigator,NCSA Mosaic 的市场份额逐步下降。到了 1995 年,Netscape 公开上市了。[第一天][10],股价从开盘的 $28,直窜到 $78,收盘于 $58。Netscape 那时所向披靡。
|
||||
|
||||
但好景不长。在 1994 年的夏天,微软发布了 Internet Explorer 1.0,这款浏览器基于 Spyglass Mosaic,而后者又直接基于 NCSA Mosaic。[浏览器战争][11] 就此展开。
|
||||
|
||||
在接下来的几年里,Netscape 和微软就浏览器霸主地位展开斗争。他们各自加入了很多新特性以取得优势。不幸的是,IE 有和 Windows 操作系统捆绑的巨大优势。更甚于此,微软也有更多的程序员和资本可以调动。在接近 1997 年的尾声,Netscape 公司开始逐步有金融困难。
|
||||
|
||||
|
||||
### 迈向开源
|
||||
|
||||
![Mozilla Firefox][12]
|
||||
|
||||
1998 年 1 月,Netscape 开源了 Netscape Communicator 4.0 软件套装的代码。[旨在][13] ”集合互联网上万千程序员的才智,把最好的功能加入 Netscape 的软件。这一策略能加速开发并且让 Netscape 能自由的向个人和商业用户提供未来高质量的 Netscape Communicator“。
|
||||
|
||||
这个项目会由新创立的 Mozilla Orgnization 管理。然而,Netscape Communicator 4.0 的代码由于大小和复杂性,很难被社区上的程序员们独自开发。雪上加霜的是,浏览器的一些组件由于第三方证书问题并不能被开源。到头来,他们决定用新星的 [Gecko][14] 重写渲染引擎。
|
||||
|
||||
到了 1998 年的 11 月,Netscape 被美国在线(AOL)收购,[价格是价值 42 亿美元的股权][15]。
|
||||
|
||||
从头来过是一项艰巨的任务。Mozilla Firefox(一开始有昵称 Phoenix)直到 2002 年 6 月才面世,它同样支持多系统:Linux,Mac OS,微软 Windows,Solaris。
|
||||
|
||||
到了第二年,AOL 宣布他们会停止浏览器开发。紧接着 Mozilla 基金会成立了,用于管理 Mozilla 的商标和项目相关的金融情况。最早 Mozilla 基金会收到了一笔来自 AOL,IBM,Sun 微型操作系统和红帽(Red Hat)总计 2 百万美金的捐赠。
|
||||
|
||||
到了 2003 年 3月,Mozilla [宣布][16] 由于越来越沉重的软件包袱,计划把浏览器套件分割成单独的应用。这个单独的浏览器一开始起名 Phoenix。但是由于和 BIOS 制造企业凤凰科技的商标官司,浏览器改名 Firebird 火鸟——结果和火鸟数据库的开发者又起了冲突。浏览器只能再次被重命名,才有了现在家喻户晓的 Firefox 火狐。
|
||||
|
||||
那时,[Mozilla 说][17],”我们在过去一年里学到了很多关于起名的技巧(不是因为我们愿意才学的)。我们现在很小心地研究了名字,确保未来不会再有什么夭蛾子了。我们同时展开了在美国专利局和商标办注册我们新品牌的流程”。
|
||||
|
||||
|
||||
![Mozilla Firefox 1.0][18]Firefox 1.0 : [照片致谢][19]
|
||||
|
||||
第一个正式的 Firefox 版本是 [0.8][20],发布于 2004 年 2 月 8 日。紧接着 11 月 9 日他们发布了 1.0 版本。接着 2.0 和 3.0 分别在 06 年 10 月 和 08 年 6 月问世。每个大版本更新都带来了很多新的特性和提升。从很多角度上讲,Firefox 都领先 IE 不少,无论是功能还是技术先进性,即便如此 IE 还是有更多用户。
|
||||
|
||||
一切都在 Google 发布 Chrome 浏览器的时候改变了。在 Chrome 发布(2008 年 9 月)的前几个月,Firefox 占有 30% 的[浏览器份额][21] 而 IE 有超过 60%。而在 [2019 年 1 月][22] 的 StatCounter's 报告里,Firefox 有不到 10% 的份额,而 Chrome 有超过 70%。
|
||||
|
||||
趣味知识点
|
||||
|
||||
和大家以为的不一样,火狐的 logo 其实没有狐狸。那其实是个 [红的熊猫][23]。在中文里,“火狐狸”是红熊猫的一个昵称(译者:我真的从来没听说过)
|
||||
|
||||
### 展望未来
|
||||
|
||||
如上文所说的一样,Firefox 正在经历很长一段以来的份额低谷。曾经有那么一段时间,有很多浏览器都基于 Firefox 开发,比如早期的 [Flock 浏览器][24]。而现在大多数浏览器都基于谷歌的技术了,比如 Opera 和 Vivaldi。甚至连微软都放弃开发自己的浏览器而转而[加入 Chromium 帮派][25]。
|
||||
|
||||
这也许看起来和 Netscape 当年的辉煌形成鲜明的对比。但让我们不要忘记 Firefox 已经有的许多成就。一群来自世界各地的程序员,就这么开发除了星球上第二大份额的浏览器。他们在微软垄断如日中天的时候还占据这 30% 的份额,他们现在也在做一样的事。无论如何,他们都有我们,开源社区,坚定地站在他们身后。
|
||||
|
||||
抗争垄断是众多我使用 Firefox [的原因之一][26]。Mozilla 在改头换面的 [Firefox Quantum][27] 上赢回了一些份额,我相信他们还能一路向上攀爬。
|
||||
|
||||
你还想了解 Linux 和开源历史上的什么其他事件?欢迎在评论区告诉我们。
|
||||
|
||||
如果你觉得这篇文章不错,请大方在社交媒体上分享!比如 Hacker News 或者 [Reddit][28]。(译者:可惜 Reddit 已经是不存在的网站了)
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/history-of-firefox
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Marc_Andreessen
|
||||
[2]: https://en.wikipedia.org/wiki/National_Center_for_Supercomputing_Applications
|
||||
[3]: https://en.wikipedia.org/wiki/Tim_Berners-Lee
|
||||
[4]: https://www.w3.org/DesignIssues/TimBook-old/History.html
|
||||
[5]: http://viola.org/
|
||||
[6]: https://en.wikipedia.org/wiki/Mosaic_(web_browser
|
||||
[7]: http://www.computinghistory.org.uk/det/1789/Marc-Andreessen/
|
||||
[8]: http://www.davetitus.com/mozilla/
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/Mozilla_boxing.jpg?ssl=1
|
||||
[10]: https://www.marketwatch.com/story/netscape-ipo-ignited-the-boom-taught-some-hard-lessons-20058518550
|
||||
[11]: https://en.wikipedia.org/wiki/Browser_wars
|
||||
[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/mozilla-firefox.jpg?resize=800%2C450&ssl=1
|
||||
[13]: https://web.archive.org/web/20021001071727/wp.netscape.com/newsref/pr/newsrelease558.html
|
||||
[14]: https://en.wikipedia.org/wiki/Gecko_(software)
|
||||
[15]: http://news.cnet.com/2100-1023-218360.html
|
||||
[16]: https://web.archive.org/web/20050618000315/http://www.mozilla.org/roadmap/roadmap-02-Apr-2003.html
|
||||
[17]: https://www-archive.mozilla.org/projects/firefox/firefox-name-faq.html
|
||||
[18]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/firefox-1.jpg?ssl=1
|
||||
[19]: https://www.iceni.com/blog/firefox-1-0-introduced-2004/
|
||||
[20]: https://en.wikipedia.org/wiki/Firefox_version_history
|
||||
[21]: https://en.wikipedia.org/wiki/Usage_share_of_web_browsers
|
||||
[22]: http://gs.statcounter.com/browser-market-share/desktop/worldwide/#monthly-201901-201901-bar
|
||||
[23]: https://en.wikipedia.org/wiki/Red_panda
|
||||
[24]: https://en.wikipedia.org/wiki/Flock_(web_browser
|
||||
[25]: https://www.windowscentral.com/microsoft-building-chromium-powered-web-browser-windows-10
|
||||
[26]: https://itsfoss.com/why-firefox/
|
||||
[27]: https://itsfoss.com/firefox-quantum-ubuntu/
|
||||
[28]: http://reddit.com/r/linuxusersgroup
|
||||
[29]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/mozilla-firefox.jpg?fit=800%2C450&ssl=1
|
||||
@ -0,0 +1,93 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Take to the virtual skies with FlightGear)
|
||||
[#]: via: (https://opensource.com/article/19/1/flightgear)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
使用 FlightGear 进入虚拟天空
|
||||
======
|
||||
你梦想驾驶飞机么?试试开源飞行模拟器 FlightGear 吧。
|
||||

|
||||
|
||||
如果你曾梦想驾驶飞机,你会喜欢 [FlightGear][1] 的。它是一个功能齐全的[开源][2]飞行模拟器,可在 Linux、MacOS 和 Windows 中运行。
|
||||
|
||||
FlightGear 项目始于 1996 年,原因是对商业飞行模拟程序的不满,因为这些程序无法扩展。它的目标是创建一个复杂、强大、可扩展、开放的飞行模拟器框架,来用于学术界和飞行员培训,或者任何想要玩飞行模拟场景的人。
|
||||
|
||||
### 入门
|
||||
|
||||
FlightGear 的硬件要求适中,包括支持 OpenGL 以实现平滑帧速的加速 3D 显卡。它在我的配备 i5 处理器和仅 4GB 的内存的 Linux 笔记本上运行良好。它的文档包括[在线手册][3]、一个包含[用户][5]和[开发者][6]门户的 [wiki][4],还有大量的教程(例如它的默认飞机 [Cessna 172p][7])教你如何操作它。
|
||||
|
||||
在 [Fedora][8]和 [Ubuntu][9] Linux 中很容易安装。Fedora 用户可以参考 [Fedora 安装页面][10]来运行 FlightGear。
|
||||
|
||||
在 Ubuntu 18.04 中,我需要安装一个仓库:
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:saiarcot895/flightgear
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install flightgear
|
||||
```
|
||||
|
||||
安装完成后,我从 GUI 启动它,但你也可以通过输入以下命令从终端启动应用:
|
||||
|
||||
```
|
||||
$ fgfs
|
||||
```
|
||||
|
||||
### 配置 FlightGear
|
||||
|
||||
应用窗口左侧的菜单提供配置选项。
|
||||
|
||||

|
||||
|
||||
**Summary** 返回应用的主页面。
|
||||
|
||||
**Aircraft** 显示你已安装的飞机,并提供了 FlightGear 的默认“机库”中安装多达 539 种其他飞机的选项。我安装了 Cessna 150L、Piper J-3 Cub 和 Bombardier CRJ-700。一些飞机(包括 CRJ-700)有教你如何驾驶商用喷气式飞机的教程。我发现这些教程内容翔实且准确。
|
||||
|
||||

|
||||
|
||||
要选择驾驶的飞机,请将其高亮显示,然后单击菜单底部的 **Fly!**。我选择了默认的 Cessna 172p 并发现驾驶舱的刻画非常准确。
|
||||
|
||||

|
||||
|
||||
默认机场是檀香山,但你在 **Location** 菜单中提供你最喜欢机场的 [ICAO 机场代码] [11]进行修改。我找到了一些小型的本地无塔机场,如 Olean 和 Dunkirk,纽约,以及包括 Buffalo,O'Hare 和 Raleigh 在内的大型机场,甚至可以选择特定的跑道。
|
||||
|
||||
在 **Environment** 下,你可以调整一天中的时间、季节和天气。模拟包括高级天气建模和从 [NOAA][12] 下载当前天气的能力。
|
||||
|
||||
**Settings** 提供在暂停模式中开始模拟的选项。同样在设置中,你可以选择多人模式,这样你就可以与 FlightGear 支持者的全球服务器网络上的其他玩家一起“飞行”。你必须有比较快速的互联网连接来支持此功能。
|
||||
|
||||
**Add-ons** 菜单允许你下载飞机和其他场景。
|
||||
|
||||
### 开始飞行
|
||||
|
||||
为了“起飞”我的 Cessna,我使用了罗技操纵杆,它用起来不错。你可以使用顶部 **File** 菜单中的选项校准操纵杆。
|
||||
|
||||
总的来说,我发现模拟非常准确,图形界面也很棒。你自己试下 FlightGear - 我认为你会发现它是一个非常有趣和完整的模拟软件。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/flightgear
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://home.flightgear.org/
|
||||
[2]: http://wiki.flightgear.org/GNU_General_Public_License
|
||||
[3]: http://flightgear.sourceforge.net/getstart-en/getstart-en.html
|
||||
[4]: http://wiki.flightgear.org/FlightGear_Wiki
|
||||
[5]: http://wiki.flightgear.org/Portal:User
|
||||
[6]: http://wiki.flightgear.org/Portal:Developer
|
||||
[7]: http://wiki.flightgear.org/Cessna_172P
|
||||
[8]: http://rpmfind.net/linux/rpm2html/search.php?query=flightgear
|
||||
[9]: https://launchpad.net/~saiarcot895/+archive/ubuntu/flightgear
|
||||
[10]: https://apps.fedoraproject.org/packages/FlightGear/
|
||||
[11]: https://en.wikipedia.org/wiki/ICAO_airport_code
|
||||
[12]: https://www.noaa.gov/
|
||||
@ -5,23 +5,22 @@
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to create a filesystem on a Linux partition or logical volume)
|
||||
[#]: via: (https://opensource.com/article/19/4/create-filesystem-linux-partition)
|
||||
[#]: author: (Kedar Vijay Kulkarni (Red Hat) https://opensource.com/users/kkulkarn)
|
||||
[#]: 作者: (Kedar Vijay Kulkarni (Red Hat) https://opensource.com/users/kkulkarn)
|
||||
|
||||
How to create a filesystem on a Linux partition or logical volume
|
||||
如何在 Linux 分区或逻辑卷中创建文件系统
|
||||
======
|
||||
Learn to create a filesystem and mount it persistently or
|
||||
non-persistently in your system.
|
||||
学习在你的系统中创建一个文件系统,并且长期或者非长期地挂载它。
|
||||
![Filing papers and documents][1]
|
||||
|
||||
In computing, a filesystem controls how data is stored and retrieved and helps organize the files on the storage media. Without a filesystem, information in storage would be one large block of data, and you couldn't tell where one piece of information stopped and the next began. A filesystem helps manage all of this by providing names to files that store data and maintaining a table of files and directories—along with their start/end location, total size, etc.—on disks within the filesystem.
|
||||
在计算技术中,文件系统控制如何存储和检索数据,并且帮助组织存储媒介中的文件。如果没有文件系统,信息将被存储为一个大数据块,而且你无法知道一条信息在哪结束,下一条信息在哪开始。文件系统通过为存储数据的文件提供名称,并且在文件系统中的磁盘上维护文件和目录表以及它们的开始和结束位置,总的大小等来帮助管理所有的这些信息。
|
||||
|
||||
In Linux, when you create a hard disk partition or a logical volume, the next step is usually to create a filesystem by formatting the partition or logical volume. This how-to assumes you know how to create a partition or a logical volume, and you just want to format it to contain a filesystem and mount it.
|
||||
在 Linux 中,当你创建一个硬盘分区或者逻辑卷之后,接下来通常是通过格式化这个分区或逻辑卷来创建文件系统。这个操作方法假设你已经知道如何创建分区或逻辑卷,并且你希望将它格式化为包含有文件系统,并且挂载它。
|
||||
|
||||
### Create a filesystem
|
||||
### 创建文件系统
|
||||
|
||||
Imagine you just added a new disk to your system and created a partition named **/dev/sda1** on it.
|
||||
假设你为你的系统添加了一块新的硬盘并且在它上面创建了一个叫 **/dev/sda1** 的分区。
|
||||
|
||||
1. To verify that the Linux kernel can see the partition, you can **cat** out **/proc/partitions** like this:
|
||||
1. 为了验证 Linux 内核已经发现这个分区,你可以 **cat** 出 **/proc/partitions** 的内容,就像这样:
|
||||
|
||||
```
|
||||
[root@localhost ~]# cat /proc/partitions
|
||||
@ -40,7 +39,7 @@ major minor #blocks name
|
||||
```
|
||||
|
||||
|
||||
2. Decide what kind of filesystem you want to create, such as ext4, XFS, or anything else. Here are a few options:
|
||||
2. 决定你想要去创建的文件系统种类,比如 ext4, XFS,或者其他的一些。这里是一些选项:
|
||||
|
||||
```
|
||||
[root@localhost ~]# mkfs.<tab><tab>
|
||||
@ -48,7 +47,7 @@ mkfs.btrfs mkfs.cramfs mkfs.ext2 mkfs.ext3 mkfs.ext4 mkfs.minix mkfs.xfs
|
||||
```
|
||||
|
||||
|
||||
3. For the purposes of this exercise, choose ext4. (I like ext4 because it allows you to shrink the filesystem if you need to, a thing that isn't as straightforward with XFS.) Here's how it can be done (the output may differ based on device name/sizes):
|
||||
3. 为了这次练习的目的,选择 ext4。(我喜欢 ext4 因为如果你需要的话,它可以允许你去压缩文件系统,这对于 XFS 并不简单。)这里是完成它的方法(输出可能会因设备名称或者大小而不同):
|
||||
|
||||
```
|
||||
[root@localhost ~]# mkfs.ext4 /dev/sda1
|
||||
@ -74,15 +73,15 @@ Creating journal (16384 blocks): done
|
||||
Writing superblocks and filesystem accounting information: done
|
||||
```
|
||||
|
||||
4. In the previous step, if you want to create a different kind of filesystem, use a different **mkfs** command variation.
|
||||
4. 在上一步中,如果你想去创建不同的文件系统,请使用不同变种的 **mkfs** 命令。
|
||||
|
||||
|
||||
|
||||
### Mount a filesystem
|
||||
### 挂载文件系统
|
||||
|
||||
After you create your filesystem, you can mount it in your operating system.
|
||||
当你创建好文件系统后,你可以在你的操作系统中挂载它。
|
||||
|
||||
1. First, identify the UUID of your new filesystem. Issue the **blkid** command to list all known block storage devices and look for **sda1** in the output:
|
||||
1. 首先,识别出新文件系统的 UUID 号。使用 **blkid** 命令列出所有可识别的块存储设备并且在输出信息中查找 **sda1**:
|
||||
|
||||
```
|
||||
[root@localhost ~]# blkid
|
||||
@ -95,7 +94,7 @@ After you create your filesystem, you can mount it in your operating system.
|
||||
```
|
||||
|
||||
|
||||
2. Run the following command to mount the **/dev/sd1** device :
|
||||
2. 运行下面的命令挂载 **/dev/sd1** 设备:
|
||||
|
||||
```
|
||||
[root@localhost ~]# mkdir /mnt/mount_point_for_dev_sda1
|
||||
@ -113,11 +112,11 @@ tmpfs 93M 0 93M 0% /run/user/0
|
||||
/dev/sda1 2.9G 9.0M 2.7G 1% /mnt/mount_point_for_dev_sda1
|
||||
[root@localhost ~]#
|
||||
```
|
||||
The **df -h** command shows which filesystem is mounted on which mount point. Look for **/dev/sd1**. The mount command above used the device name **/dev/sda1**. Substitute it with the UUID identified in the **blkid** command. Also, note that a new directory was created to mount **/dev/sda1** under **/mnt**.
|
||||
命令 **df -h** 显示了每个文件系统被挂载的挂载点。查找 **/dev/sd1**。上面的挂载命令使用的设备名称是 **/dev/sda1**。用 **blkid** 命令中的 UUID 号替换它。注意,在 **/mnt** 下一个被新创建的目录挂载了 **/dev/sda1**。
|
||||
|
||||
|
||||
|
||||
3. A problem with using the mount command directly on the command line (as in the previous step) is that the mount won't persist across reboots. To mount the filesystem persistently, edit the **/etc/fstab** file to include your mount information:
|
||||
3. 直接在命令行下使用挂载命令(就像上一步一样)会有一个问题,那就是挂载不会在设备重启后存在。为使永久性地挂载文件系统,编辑 **/etc/fstab** 文件去包含你的挂载信息:
|
||||
|
||||
```
|
||||
UUID=ac96b366-0cdd-4e4c-9493-bb93531be644 /mnt/mount_point_for_dev_sda1/ ext4 defaults 0 0
|
||||
@ -125,7 +124,7 @@ UUID=ac96b366-0cdd-4e4c-9493-bb93531be644 /mnt/mount_point_for_dev_sda1/ ext4 de
|
||||
|
||||
|
||||
|
||||
4. After you edit **/etc/fstab** , you can **umount /mnt/mount_point_for_dev_sda1** and run the command **mount -a** to mount everything listed in **/etc/fstab**. If everything went right, you can still list **df -h** and see your filesystem mounted:
|
||||
4. 编辑完 **/etc/fstab** 文件后,你可以 **umount /mnt/mount_point_for_fev_sda1** 并且运行 **mount -a** 命令去挂载被列在 **/etc/fstab** 文件中的所有设备文件。如果一切顺利的话,你可以使用 **df -h** 列出并且查看你挂载的文件系统:
|
||||
|
||||
```
|
||||
root@localhost ~]# umount /mnt/mount_point_for_dev_sda1/
|
||||
@ -141,7 +140,7 @@ tmpfs 93M 0 93M 0% /run/user/0
|
||||
/dev/sda1 2.9G 9.0M 2.7G 1% /mnt/mount_point_for_dev_sda1
|
||||
```
|
||||
|
||||
5. You can also check whether the filesystem was mounted:
|
||||
5. 你也可以检测文件系统是否被挂载:
|
||||
|
||||
```
|
||||
[root@localhost ~]# mount | grep ^/dev/sd
|
||||
@ -150,7 +149,7 @@ tmpfs 93M 0 93M 0% /run/user/0
|
||||
|
||||
|
||||
|
||||
Now you know how to create a filesystem and mount it persistently or non-persistently within your system.
|
||||
现在你已经知道如何去创建文件系统并且长期或者非长期的挂载在你的系统中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
Loading…
Reference in New Issue
Block a user