mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-03 01:10:13 +08:00
commit
d660462f52
@ -0,0 +1,127 @@
|
||||
如何拯救一台GRUB 2启动失败的Linux电脑
|
||||
================================================================================
|
||||
|
||||
|
||||
旧版GRUB我们使用了一段时间了,这个重要的Linux通用引导器的版本已经到了0.97。尽管旧版GRUB有很多的优点,但是它已经有点陈旧了,并且它的开发者也希望添加更多的功能,于是,GRUB 2 时代就要来了。
|
||||
|
||||
GRUB 2 做了几个明显的改进。它可以从移动存储设备上启动,并且可以通过配置一个选项来进入系统BIOS。相对于将所有的配置都放到一个配置文件`/boot/grub/menu.lst`中 (现在默认是`/boot/grub/grub.cfg `),使用各种脚本来配置会更复杂。你不要直接编辑这个文件,那不是人干的事,太复杂了,我们需要使用其它的脚本来改变。我们卑微的人类可以编辑修改`/etc/default/grub`文件,它主要是控制Grub菜单的外观。我们还可以修改` /etc/grub.d/ `下的脚本,这些脚本用于启动操作系统、控制外部应用程序,如memtest 、os_prober和theming等等 。`./boot/grub/grub.cfg`是由`/etc/default/grub`和`/etc/grub.d/*`生成的。当你修改了某个地方,你必须要运行update-grub命令来生成它。
|
||||
|
||||
好消息是,update-grub脚本可以可靠的检测内核、启动文件,并添加所有的操作系统,自动生成你的启动菜单,所以你不必手动的修改他们。
|
||||
|
||||
我们还要学习如何解决两个常见的故障。当启动系统时,它会停在grub>提示上,这是一个完整的GRUB 2命令界面,所以不要惊慌。这意味着GRUB 2依旧可以正常启动和加载normal.mod模块(它和其他模块分别位于/boot/grub/[架构]/ 下),但没有找到你的grub.cfg文件。如果你看到grub rescue> 这意味着它无法找到normal.mod,因此它有可能找不到你的启动文件。
|
||||
|
||||
这是如何发生的?因为内核可能改变驱动器分区号码的分配,或者您移动了您的硬盘驱动器,或者你手动改变一些分区,也有可能是安装一个新的操作系统或者移动一些文件。在这些情况下你的启动文件仍然存在,但GRUB不能找到他们。所以你可以在GRUB提示符中找到启动文件,设置它们的位置,然后启动您的系统并修复GRUB配置。
|
||||
|
||||
### GRUB 2 命令行 ###
|
||||
|
||||
GRUB 2 的命令界面和上一代GRUB中的一样强大。你可以用它来找到引导镜像,内核和根文件系统。事实上,它可以让你避开权限和其它访问控制,完全访问本地计算机上的所有文件。有些人可能会认为这是一个安全漏洞,但是你知道古老的UNIX的名言:有物理访问机器权限的人,就是拥有它的人。
|
||||
|
||||
当你在` grub > `提示时,你有许多类似命令行界面的功能,如命令历史和tab补全。但是`grub rescue> `模式是受限的,没有命令历史,没有tab补全。
|
||||
|
||||
如果你是在一个正常运作的系统上练习,那就当GRUB菜单出现时,可以按下C来打开GRUB命令行界面。你可以通过向上和向下光标键滚动你的菜单条目来停止启动倒计时。在GRUB命令行下做实验是安全的,因为做不了永久的修改,一切都是暂时的。如果你已经看到`grub > `或`grub rescue> `提示符,那就说明你的表现时刻到了。
|
||||
|
||||
接下来的几个命令可以在`grub>`和`grub rescue`模式下运行。你应该运行的第一个命令是设置一个分页器,将长的命令分页。如下:
|
||||
|
||||
grub> set pager=1
|
||||
|
||||
等号两侧必须不能出现空格。现在让我们做一点探索。输入`ls`来列出的GRUB识别的所有分区:
|
||||
|
||||
grub> ls
|
||||
(hd0) (hd0,msdos2) (hd0,msdos1)
|
||||
|
||||
msdos是什么?这意味着该系统具有老式的MS-DOS分区表,而不是全新的全局唯一标识符的分区表(GPT)。参见“[在Linux下使用新的GUID分区表,和古老的MBR说再见!][1]”。如果你正在运行的GPT,它会出现(hd0,GPT1)。现在让我们看看,使用ls命令查看你的系统里面有什么文件:
|
||||
|
||||
grub> ls (hd0,1)/
|
||||
lost+found/ bin/ boot/ cdrom/ dev/ etc/ home/ lib/
|
||||
lib64/ media/ mnt/ opt/ proc/ root/ run/ sbin/
|
||||
srv/ sys/ tmp/ usr/ var/ vmlinuz vmlinuz.old
|
||||
initrd.img initrd.img.old
|
||||
|
||||
太好了,我们已经找到了根文件系统。你可以省略msdos和GPT的标签。如果没有加分区后面的斜杠/,则只会列出分区的信息。你可以用cat命令显示文件系统上的任何文件:
|
||||
|
||||
grub> cat (hd0,1)/etc/issue
|
||||
Ubuntu 14.04 LTS \n \l
|
||||
|
||||
在一个多引导系统上,通过/etc/issue文件可以知道这是哪个Linux系统。
|
||||
|
||||
### 从 grub> 中启动###
|
||||
|
||||
下面讲述如何设置启动文件并从`grub >`提示下启动系统。我们已经知道如何从Linux根文件系统(hd0,1)下运行ls命令,你可以一直寻找直到找到你的/boot/grub所在位置。然后运行以下命令,记得使用您自己的根分区,内核和initrd映像等参数:
|
||||
|
||||
grub> set root=(hd0,1)
|
||||
grub> linux /boot/vmlinuz-3.13.0-29-generic root=/dev/sda1
|
||||
grub> initrd /boot/initrd.img-3.13.0-29-generic
|
||||
grub> boot
|
||||
|
||||
第一行设置分区的根文件系统。第二行告诉GRUB您想要使用的内核位置。开始输入/boot/vmli,然后使用tab补完填写。输入`root= /dev/sdX`设置根文件系统位置。是的,这似乎是多余的,但如果你忘记了输入,你会得到一个kernel panic。你知道怎么找到正确的分区吗?hd0,1 即 /dev/sda1,hd1,1 即 /dev/sdb1,hd3,2 即 /dev/ sdd2。我想你可以自己推算剩下的了。
|
||||
|
||||
第三行设置initrd文件,必须是和内核相同的版本号。
|
||||
|
||||
最后一行启动系统。
|
||||
|
||||
在一些Linux系统上,内核和initrd是被符号链接到当前的根文件系统的根目录,就像:
|
||||
|
||||
$ ls -l /
|
||||
vmlinuz -> boot/vmlinuz-3.13.0-29-generic
|
||||
initrd.img -> boot/initrd.img-3.13.0-29-generic
|
||||
|
||||
所以,你也可以这样输入命令:
|
||||
|
||||
grub> set root=(hd0,1)
|
||||
grub> linux /vmlinuz root=/dev/sda1
|
||||
grub> initrd /initrd.img
|
||||
grub> boot
|
||||
|
||||
### 从grub rescue> 中启动 ###
|
||||
|
||||
如果你处在grub rescue> 命令界面下,命令有所不同,你必须要先加载两个模块normal.mod 和 linux.mod。
|
||||
|
||||
grub rescue> set prefix=(hd0,1)/boot/grub
|
||||
grub rescue> set root=(hd0,1)
|
||||
grub rescue> insmod normal
|
||||
grub rescue> normal
|
||||
grub rescue> insmod linux
|
||||
grub rescue> linux /boot/vmlinuz-3.13.0-29-generic root=/dev/sda1
|
||||
grub rescue> initrd /boot/initrd.img-3.13.0-29-generic
|
||||
grub rescue> boot
|
||||
|
||||
在你加载了这两个模块之后tab补完的功能就可以用了。
|
||||
|
||||
### 永久性的修复 ###
|
||||
|
||||
当你成功地启动你的系统,运行这些命令来永久修复GRUB:
|
||||
|
||||
# update-grub
|
||||
Generating grub configuration file ...
|
||||
Found background: /usr/share/images/grub/Apollo_17_The_Last_Moon_Shot_Edit1.tga
|
||||
Found background image: /usr/share/images/grub/Apollo_17_The_Last_Moon_Shot_Edit1.tga
|
||||
Found linux image: /boot/vmlinuz-3.13.0-29-generic
|
||||
Found initrd image: /boot/initrd.img-3.13.0-29-generic
|
||||
Found linux image: /boot/vmlinuz-3.13.0-27-generic
|
||||
Found initrd image: /boot/initrd.img-3.13.0-27-generic
|
||||
Found linux image: /boot/vmlinuz-3.13.0-24-generic
|
||||
Found initrd image: /boot/initrd.img-3.13.0-24-generic
|
||||
Found memtest86+ image: /boot/memtest86+.elf
|
||||
Found memtest86+ image: /boot/memtest86+.bin
|
||||
done
|
||||
# grub-install /dev/sda
|
||||
Installing for i386-pc platform.
|
||||
Installation finished. No error reported.
|
||||
|
||||
当你运行 `grub-install` 时,记得GRUB是安装到整个硬盘驱动器的主引导扇区而不是到一个具体分区,所以不要加上像/dev/sda1一样的分区号。
|
||||
|
||||
### 如果还是不能使用 ###
|
||||
|
||||
如果你的系统是如此的倒霉,而且这个方式没有能起作用,那就尝试[超级GRUB2现场救援磁盘][2]吧。[官方GNU GRUB手册][3]也应该有所帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/learn/tutorials/776643-how-to-rescue-a-non-booting-grub-2-on-linux
|
||||
|
||||
译者:[MikeCoder](https://github.com/MikeCoder) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.linux.com/learn/tutorials/730440-using-the-new-guid-partition-table-in-linux-good-bye-ancient-mbr-
|
||||
[2]:http://www.supergrubdisk.org/
|
||||
[3]:https://www.gnu.org/software/grub/manual/grub.html
|
||||
@ -1,11 +1,9 @@
|
||||
CNprober 翻译完成... 619913541
|
||||
|
||||
10招让你的Git技能提升一个台阶
|
||||
已经会用Git了?不会这十招怎么行
|
||||
================================================================================
|
||||
|
||||
之前我们发了一些教程让你熟悉[Git基础][1]和[在团队合作环境中使用Git][2].我们讨论的这些Git命令足够让一个开发者在Git的世界里生存下去。在这篇教程里,我们试着探索如何高效地管理你的时间以及如何充分利用Git提供的特性。
|
||||
|
||||
> 注意:这里介绍的命令中有的包含方括号(例如:`git add -p [file_name]`)。在这些例子中,你应该用你自己的数字,标识符等替代方括号里的内容,并且去掉方括号。
|
||||
> 注意:这里介绍的命令中有的包含方括号(例如:`git add -p [file_name]`)。在这些例子中,你应该用你自己的数字、标识符等替代方括号里的内容,并且去掉方括号。
|
||||
|
||||
### 1. Git自动补全 ###
|
||||
|
||||
@ -62,7 +60,7 @@ CNprober 翻译完成... 619913541
|
||||
|
||||
假设你提交了一些不需要的东西,然后你进行了hard重置回到之前的状态。后来,你发现在这个过程中你丢失了其他一些重要的信息,你想要把这些信息找回来,或者至少可以查看一下这些信息。这就需要`git reflog`帮忙。
|
||||
|
||||
简单的`git log`只能告诉你最近的提交,这个提交的父提交,父提交的父提交,等等。但是`git reflog`是一个HEAD指向的提交的列表。记住,这个列表依赖于你自己的操作环境,它不是库的一部分,也不包含在push或者merge中。
|
||||
简单的`git log`只能告诉你最近的提交,这个提交的父提交,父提交的父提交,等等。但是`git reflog`是一个HEAD指向的提交的列表。记住,这个列表依赖于你自己的本地操作环境,它不是库的一部分,也不包含在push或者merge中。
|
||||
|
||||
如果执行`git log`命令,可以看到提交历史,这是我的库的一部分:
|
||||
|
||||
@ -74,7 +72,7 @@ CNprober 翻译完成... 619913541
|
||||
|
||||
### 6. 暂存文件的一部分更改以便进行一次提交 ###
|
||||
|
||||
通常依据特性来提交是一个好的实践方法,意思是说,每一个提交都只添加一个特性或者修复一个bug。想一下如果你一次修复了两个bug或者添加了两个特性但是都还没有提交该怎么办。这种场景下,你可以将他们一起提交。但是有一个更好的办法:单独暂存这些文件,然后分开提交。
|
||||
通常依据特性来提交是一个好的实践方法,意思是说,每一个提交都只添加一个特性或者修复一个bug。想一下如果你一次修复了两个bug或者添加了两个特性但是都还没有逐个提交该怎么办。这种场景下,你可以将他们一起提交。但是有一个更好的办法:单独暂存这些文件,然后分开提交。
|
||||
|
||||
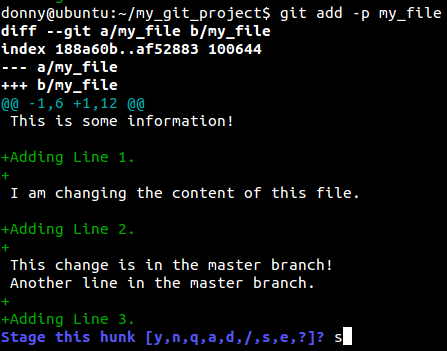
让我们假设你对一个文件做了多个更改,然后想让这些更改分开提交。这时,我们用带`-p`的添加命令。
|
||||
|
||||
@ -88,7 +86,7 @@ CNprober 翻译完成... 619913541
|
||||
|
||||
|
||||
|
||||
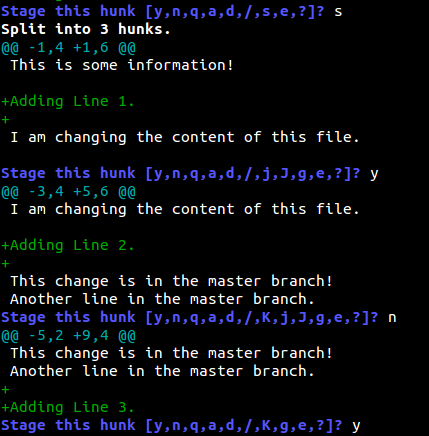
似乎Git认为所有的更改都是同一个目的的一部分,所以把他们分组到同一个块里。这时,你可以:
|
||||
看起来Git认为所有的更改都是同一个目的的一部分,所以把他们分组到同一个块里。这时,你可以:
|
||||
|
||||
- 输入 y 暂存块
|
||||
- 输入 n 不暂存块
|
||||
@ -100,13 +98,13 @@ CNprober 翻译完成... 619913541
|
||||
|
||||
|
||||
|
||||
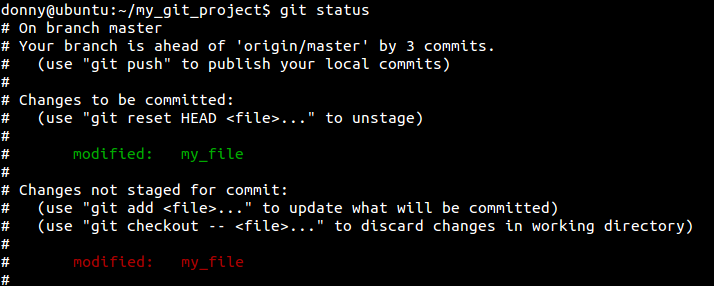
如你所见,我们已经添加了第1和第3行,忽略了第2行。你可以看到库的状态并且进行一次提交。
|
||||
如你所见,我们已经逐个添加了第1和第3行,忽略了第2行。你可以看到库的状态并且进行一次提交。
|
||||
|
||||
|
||||
|
||||
### 7. 合并多个提交 ###
|
||||
|
||||
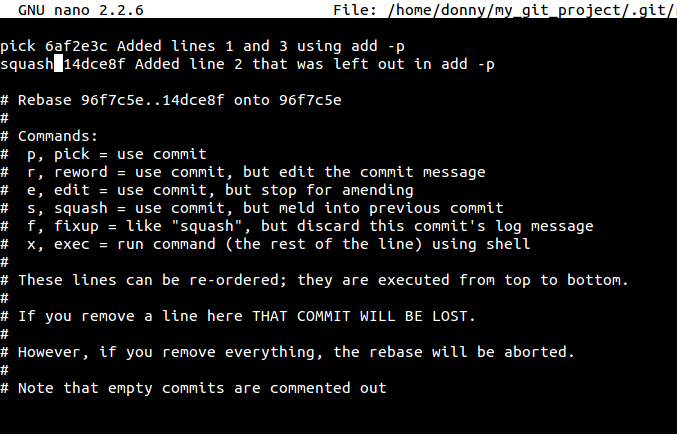
为了进行核查或者发起一个合并请求(这经常发生在开源项目里),对代码进行了修改提交。但在最后代码被接受之前,你也许会被要求修改你的代码。于是你修改代码,但是下一次核查的时候又一次被要求进行修改。不知不觉中,你就已经有了好几个提交。理论上你应该用rebase命令把他们合并起来。
|
||||
为了进行核查或者发起一个合并请求(这经常发生在开源项目里),对代码进行了修改提交。但在最后代码被接受之前,你也许会需要修改你的代码。于是你修改代码,但是下一次核查的时候又一次需要进行修改。不知不觉中,你就已经有了好几个提交。理论上你应该用rebase命令把他们合并起来。
|
||||
|
||||
git rebase -i HEAD~[number_of_commits]
|
||||
|
||||
@ -118,7 +116,7 @@ CNprober 翻译完成... 619913541
|
||||
|
||||
|
||||
|
||||
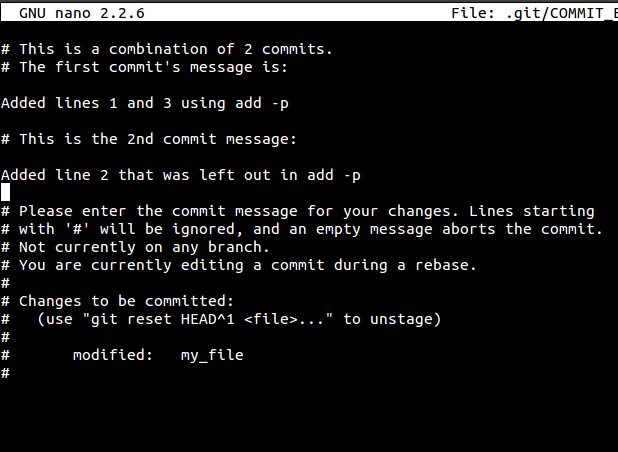
接着你被要求提供一个对新提交的说明。这个过程会重写你的提交历史。
|
||||
接着你应该提供一个对新提交的说明。这个过程会重写你的提交历史。
|
||||
|
||||
|
||||
|
||||
@ -182,7 +180,7 @@ CNprober 翻译完成... 619913541
|
||||
|
||||
via: http://www.sitepoint.com/10-tips-git-next-level/
|
||||
|
||||
译者:[love_daisy_love](https://github.com/CNprober) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[love\_daisy\_love](https://github.com/CNprober) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
如何在Linux上检查MySQL的存储引擎类型
|
||||
[小白技巧]如何在Linux上检查MySQL数据表的存储引擎类型
|
||||
================================================================================
|
||||
> **提问**: 我想要知道我的MySQL数据库是MyISAM还是Innodb类型。我该如何检查MySQL数据库表的类型?
|
||||
|
||||
MySQl主要使用两种存储引擎:**MyISAM and Innodb**。MyISAM是非事务的,因此拥有读取更快,然而InnoDB完全支持细颗粒的事务锁定(比如:commit/rollback)。当你创建一张新的MySQL表时,你要选择它的类型(也就是存储引擎)。如果没有选择,你就会使用与预设置的默认引擎。
|
||||
MySQl主要使用两种存储引擎:**MyISAM 和 Innodb**。MyISAM是非事务的,因此拥有读取更快,然而InnoDB完全支持细颗粒度的事务锁定(比如:commit/rollback)。当你创建一张新的MySQL表时,你要选择它的类型(也就是存储引擎)。如果没有选择,你就会使用与预设置的默认引擎。
|
||||
|
||||
如果你想要知道已经存在的MySQL数据表的类型,这里有几种方法达到。
|
||||
|
||||
@ -34,7 +34,7 @@ MySQl主要使用两种存储引擎:**MyISAM and Innodb**。MyISAM是非事务
|
||||
|
||||
via: http://ask.xmodulo.com/check-mysql-storage-engine-type-linux.html
|
||||
|
||||
译者:[geekpi](https://github.com/geekpi) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,57 @@
|
||||
Dropbox原生Linux客户端首次展示QT界面
|
||||
================================================================================
|
||||
**Dropbox原生Linux客户端的最新试验版首次展示了全新的QT界面。**
|
||||
|
||||
Dropbox表示这次的UI重写,将同时应用到Windows和Linux,将修复“大量”长期遗留下来的错误和问题。这个跨平台的工具也将整体提升性能。
|
||||
|
||||
在全新的设置向导和登录界面(见下面的图片)旁边是几个重新设计过的启动画面。
|
||||
|
||||

|
||||
登录界面
|
||||
|
||||

|
||||
设置界面
|
||||
|
||||

|
||||
欢迎界面
|
||||
|
||||
### 目前还不稳定 ###
|
||||
|
||||
Dropbox开发人员提醒参与测试的人,目前大部分新界面“还很粗糙”,在使用中可能会碰到大量的界面问题。新界面还不能配合一些辅助工具一起工作,例如屏幕阅读器。
|
||||
|
||||

|
||||
|
||||
新UI使用了(目前)系统自带的QT界面主题。它本身也不算很丑,不过在Ubuntu桌面上看起来不怎么合适,特别是和之前的版本比较。据说内存占用也变多了,在空闲情况下有时候会从60MB一下子跳到178MB。那些使用低端设备的人应该忍耐一下试用这个版本的诱惑-至少在这个特别的问题解决之后。
|
||||
|
||||
Dropbox 2.11.0 (试验版本) for Linux的完整改动日志:
|
||||
|
||||
- 用QT重写了Windows & Linux界面
|
||||
- 在移动和重命名文件后会尝试识别
|
||||
- 新的设置/登录体验
|
||||
- 更快上传小文件
|
||||
- 新的启动画面
|
||||
|
||||
### 下载Dropbox Linux Build 2.11.x ###
|
||||
|
||||
想尝鲜的话,可以通过下面的链接下载和你系统对应的安装包。
|
||||
|
||||
- [Dropbox Experimental (64bit) Offline Linux Installer][1]
|
||||
- [Dropbox Experimental (32bit) Offline Linux Installer][2]
|
||||
|
||||
下载完后,解压到主目录。它默认是隐藏的,所以打开终端,’`cd`‘到‘`.dropbox-dist/dropbox-lnx`‘目录下,然后运行‘`./dropbox start`‘。
|
||||
|
||||
演示Dropbox终端操作的gif动画:
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/07/dropbox-experimental-linux-build-qt-rewrite
|
||||
|
||||
原文作者:[Joey-Elijah Sneddon][a] 译者:[zpl1025](https://github.com/zpl1025) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://d1ilhw0800yew8.cloudfront.net/client/dropbox-lnx.x86_64-2.11.0.tar.gz
|
||||
[2]:https://d1ilhw0800yew8.cloudfront.net/client/dropbox-lnx.x86-2.11.0.tar.gz
|
||||
@ -0,0 +1,43 @@
|
||||
Oracle Linux 7.0发布!
|
||||
===
|
||||

|
||||
|
||||
**Oracle已经发布了Oracle Linux 7.0操作系统,新系统带来了大量的新特性,比如“第三代坚不可摧的内核 UEK”(Unbreakable Enterprise Kernel Release 3)和一个新的默认文件系统**
|
||||
|
||||
为了这次新的发行版的发布,Oracle的开发者们已经放出过两个预览版,现在最终版终于来了。果然,它有着大量的改进,其中包括使用新的XFS作为默认的文件系统**[注:原文为操作系统,应该是笔误]**,可选的Btrfs文件系统,Linux Containers (LXC), DTrace,Ksplice,加强版Xen和UEK R3。
|
||||
|
||||
作为广泛流行的文件系统EXT4的对抗者,XFS有一个显著优势。它所允许用户的文件系统的大小达到了500TB,这比你在EXT4文件系统中所能达到最大值的十倍还多。唯一的缺点是单个文件的大小最大仅为16TB。
|
||||
|
||||
这个发行版的一大特色是它支持两种内核。一个是红帽兼容性内核(RHCK),基于Linux内核版本3.10,第二个是Oracle自己的内核版本“第三代坚不可摧的内核”(UEK R3),版本号从3.8.13开始,因为它基于3.8的Linux内核。你或许还记得Linux内核3.8.x已经寿终正寝,但是看来Oracle一直在维护着自己的分支。
|
||||
|
||||
“已经能够从Oracle软件发布云上下载了,Oracle Linux 7可以免费下载和部署。所有的bug修复和安全勘误会被发布到Oracle的公共yum服务器上,不管有没有付费,用户都能安装同样的代码,并且从免费到付费的迁移十分简单,无需重新安装。”
|
||||
|
||||
“当发布最新的Linux更新,工具以及推送给客户和参与者新功能的时候,需要为现代化的数据中心提供企业级的解决方案。为此最新的发行版是构建在Oracle对OpenStack这样的新兴技术提供支持的基础上,”从官方声明可以看出。
|
||||
|
||||
通过变更记录来看,Ksplice已经为了实现零宕机的内核完成了安全更新和bug修复,systemd也成了新的系统管理工具,Grub2现在是默认的启动引导程序,并且支持新的固件类型(比如UEFI),还有一个加强版Anaconda安装器,一个新的Apache Web服务器,支持GPT,和大量的安全特性被添加进来。
|
||||
|
||||
更多关于最新的Oracle Linux发行版的详细内容可以参考官方[声明][1]。
|
||||
|
||||
立即下载Oracle Linux 7.0:
|
||||
|
||||
|
||||
- [Oracle Enterprise Linux 6.5 (ISO) 64-bit][2][iso] [3 GB]
|
||||
- [Oracle Enterprise Linux 6.5 (ISO) 32-bit][3][iso] [3.60 GB]
|
||||
- [Oracle Enterprise Linux 7.0 (ISO) 64-bit][4][iso] [4.50 GB]
|
||||
|
||||
|
||||
---------------------------------
|
||||
|
||||
原文: http://news.softpedia.com/news/Oracle-Linux-7-0-OS-Has-XFS-as-Default-File-System-and-Unbreakable-Enterprise-Kernel-Release-3-451894.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[guodongxiaren](https://github.com/guodongxiaren)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:http://www.oracle.com/us/corporate/press/2245947
|
||||
[2]:http://mirrors.dotsrc.org/oracle-linux/OL6/U5/i386/OracleLinux-R6-U5-Server-i386-dvd.iso
|
||||
[3]:http://mirrors.dotsrc.org/oracle-linux/OL6/U5/x86_64/OracleLinux-R6-U5-Server-x86_64-dvd.iso
|
||||
[4]:https://edelivery.oracle.com/linux/
|
||||
@ -1,59 +0,0 @@
|
||||
The Native Dropbox Linux Client Debuts New Qt Interface
|
||||
================================================================================
|
||||
**The latest experimental build of the native Dropbox Linux client has debuted with an all new Qt interface.**
|
||||
|
||||
Dropbox say that the UI rewrite, which will be used on both Windows and Linux, will fix a ‘large number’ of long-standing bugs, issues and glitches. The cross-platform toolkit is also set to improve general performance.
|
||||
|
||||
Alongside an all new setup wizard and login screen (see below) is a handful of redesigned splash screens.
|
||||
|
||||

|
||||
Login Screen
|
||||
|
||||

|
||||
Setup Screen
|
||||
|
||||

|
||||
Congratulations Screen
|
||||
|
||||
### Not Stable Yet ###
|
||||
|
||||
Dropbox developers caution that since much of the new interface “is still rough around the edges” testers should expect to encounter various visual bugs while using it. The new UI does not yet work with accessibility tools like screen readers.
|
||||
|
||||

|
||||
|
||||
The new UI uses (for now) the stock Qt theme. This isn’t ugly per se, but it does look a little out of place on the Ubuntu desktop, especially compared to previous builds. Memory usage is also reportedly higher, in some cases jumping from 60MB when idle to more than 178MB. Those on low-end devices should resist the temptation to try this build — at least until this particular bug has been addressed.
|
||||
|
||||
Full change log for Dropbox 2.11.0 (Experimental) for Linux:
|
||||
|
||||
- Rewrite of the Windows & Linux UI in Qt
|
||||
- File identifiers detect when files have been moved/renamed
|
||||
- New setup/login experience
|
||||
- Faster uploads for small files
|
||||
- New splash screens
|
||||
|
||||
### Download Dropbox Linux Build 2.11.x ###
|
||||
|
||||
To try the experimental builds just download the correct archive for your system using the links below.
|
||||
|
||||
- [Dropbox Experimental (64bit) Offline Linux Installer][1]
|
||||
- [Dropbox Experimental (32bit) Offline Linux Installer][2]
|
||||
|
||||
Once downloaded, extract the archive to your Home folder. It’s hidden by default, so using the Terminal, ‘`cd`‘ into the ‘`.dropbox-dist/dropbox-lnx`‘ folder and run ‘`./dropbox start`‘.
|
||||
|
||||
Dropbox terminal navigation gif:
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/07/dropbox-experimental-linux-build-qt-rewrite
|
||||
|
||||
原文作者:[Joey-Elijah Sneddon][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://d1ilhw0800yew8.cloudfront.net/client/dropbox-lnx.x86_64-2.11.0.tar.gz
|
||||
[2]:https://d1ilhw0800yew8.cloudfront.net/client/dropbox-lnx.x86-2.11.0.tar.gz
|
||||
145
sources/news/20140725 GOG.com Now Supports Linux.md
Normal file
145
sources/news/20140725 GOG.com Now Supports Linux.md
Normal file
@ -0,0 +1,145 @@
|
||||
GOG.com Now Supports Linux!
|
||||
================================================================================
|
||||
> 50 games for the free OS available right NOW!
|
||||
|
||||
[][1]
|
||||
|
||||
A while ago, [we've announced our plans][2] to add Linux support as one of the features of our digital platform, with 100 games on the launch day sometime this fall. We've put much time and effort into this project and now we've found ourselves with over 50 titles, classic and new, prepared for distribution, site infrastructure ready, support team trained and standing by, and absolutely no reason to wait until October or November. We're still aiming to have at least 100 Linux games in the coming months, but we've decided not to delay the launch just for the sake of having a nice-looking number to show off to the press. It's not about them, after all, it's about you. So, one of the most popular site feature requests on our [community wishlist][3] is granted today: Linux support has officially arrived on GOG.com!
|
||||
|
||||
The first 50+ titles we've have in store for you come from all the corners of our DRM-Free catalog. Note that we've got many classic titles coming officially to Linux for the very first time, thanks to the custom builds prepared by our dedicated team of penguin tamers. That's over twenty fan-favorite GOG.com classics, like [FlatOut][4]&[Flatout 2][5], , [Darklands][6], or [Realms of the Haunting][7] we've personally ushered one by one into the welcoming embrace of Linux gamers. That's already quite a nice chunk of our back-catalog, and you can expect more from our dedicated Linux team soon!
|
||||
|
||||
Now, for the recent titles. We've got some indie games with native Linux versions that finally find their well-deserved spot in our store. Among them, debuting on Linux, [CLARC][8] - a well received original comedic Sci-Fi puzzler. On top of that, be on the lookout for two new additions to the GOG.com catalog: [Gods Will Be Watching][9] (coming in a couple of hours) and [Unrest:Special Edition][10] (Linux build coming right up!), both of them very fresh and intriguing. This is the very first time we can provide you with all the PC versions of a premiere game, and we will continue to do so in the future. If there's a Linux version of a title we're releasing, our aim is to deliver it to you Day-1. But enough about us, let's talk about the games. Here's what you can be playing on Linux today:
|
||||
|
||||
- [**Anomaly Warzone Earth**][11]
|
||||
- [**Ascendant**][12]
|
||||
- [**Bionic Dues**][13]
|
||||
- [**Blake Stone: Aliens of Gold**][14] - first time on Linux!
|
||||
- [**Blake Stone: Planet Strike**][15] - first time on Linux!
|
||||
- [**Bloodnet**][16] - first time on Linux!
|
||||
- [**Braveland**][17]
|
||||
- [**CLARC**][18] - first time on Linux!
|
||||
- [**Darklands**][19] - first time on Linux!
|
||||
- [**Darwinia**][20]
|
||||
- [**Defcon**][21]
|
||||
- [**Don't Starve + DLC**][22]
|
||||
- [**Dragonsphere**][23] - first time on Linux!
|
||||
- [**Duke Nukem 3D: Atomic Edition**][24]
|
||||
- [**FlatOut**][25] - first time on Linux!
|
||||
- [**Flatout 2**][26] - first time on Linux!
|
||||
- [**Fragile Allegiance**][27] - first time on Linux!
|
||||
- [**Gemini Rue**][28]
|
||||
- [**Gods Will Be Watching**][29]
|
||||
- [**Hammerwatch**][30]
|
||||
- [**Hocus Pocus**][31] - first time on Linux!
|
||||
- [**Kentucky Route Zero**][32]
|
||||
- [**The Last Federation**][33]
|
||||
- [**Legend of Grimrock**][34]
|
||||
- [**Litil Divil**][35] - first time on Linux!
|
||||
- [**Long Live the Queen**][36]
|
||||
- [**MouseCraft**][37]
|
||||
- [**Multiwinia**][38]
|
||||
- [**Normality**][39] - first time on Linux!
|
||||
- [**Pinball Gold Pack**][40] - first time on Linux!
|
||||
- [**Pinball World**][41] - first time on Linux!
|
||||
- [**Pirates! Gold Plus**][42] - first time on Linux!
|
||||
- [**Realms of the Haunting**][43] - first time on Linux!
|
||||
- [**Rex Nebular and the Cosmic Gender Bender**][44] - first time on Linux!
|
||||
- [**Rise of the Triad: Dark War**][45] - first time on Linux!
|
||||
- [**Shattered Haven**][46]
|
||||
- [**The Shivah HD**][47]
|
||||
- [**Sid Meier's Colonization**][48] - first time on Linux!
|
||||
- [**Sid Meier's Covert Action**][49] - first time on Linux!
|
||||
- [**Sir, You Are Being Hunted**][50]
|
||||
- [**Slipstream 5000**][51] - first time on Linux!
|
||||
- [**Space Pirates and Zombies**][52]
|
||||
- [**Spacechem**][53]
|
||||
- [**Stargunner**][54] - first time on Linux!
|
||||
- [**SteamWorld Dig**][55]
|
||||
- [**Super Hexagon**][56]
|
||||
- [**Surgeon Simulator 2013**][57]
|
||||
- [**Sword of the Samurai**][58] - first time on Linux!
|
||||
- [**Teslagrad**][59]
|
||||
- [**Unrest:Special Edition**][60] (Linux build on the way!)
|
||||
- [**Uplink**][61]
|
||||
- [**VVVVVV**][62]
|
||||
|
||||
As if this wasn't exciting enough, we've put more than half of these titles on a [special promo][63]! Head out to the [promo page][64] and find out which of them you can get up to 75% off until Tuesday, 9:59AM GMT. Of course, all of the games from the list above that you already own will be updated with Linux versions with no additional cost for you, just as you might have expected from GOG.com.
|
||||
|
||||
"OK, but how will Linux support actually work on GOG.com" - you might ask. For both native Linux versions, as well as special builds prepared by our team, GOG.com will provide distro-independent tar.gz archives and support convenient DEB installers for the two most popular Linux distributions: Ubuntu and Mint, in their current and future LTS editions. Helpful and responsive customer support has always been an important part of the GOG.com gaming experience. We wouldn't have it any other way when it comes to Linux, and starting today our helpdesk offers support for our official Linux releases on Ubuntu and Mint systems.
|
||||
|
||||
Diversity and freedom of choice have always been an important part of the GOG.com way. We're very glad that we could improve our service with the addition of the free (and DRM-Free) alternative to the commercial operating systems. Talking with gamers is just as important, so we're counting on your feedback! If you've got any questions, suggestions, or run into any trouble, just tell us in the forum thread below this post. Just please be gentle, this is [our very first time][65] with Linux. Happy launch day, everyone!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.gog.com/news/gogcom_now_supports_linux
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.gog.com/promo/linux_launch_promo_240714
|
||||
[2]:http://www.gog.com/news/gogcom_soon_on_more_platforms
|
||||
[3]:http://www.gog.com/wishlist/site#search=linux
|
||||
[4]:http://www.gog.com/game/flatout
|
||||
[5]:http://www.gog.com/game/flatout_2
|
||||
[6]:http://www.gog.com/game/darklands
|
||||
[7]:http://www.gog.com/game/realms_of_the_haunting
|
||||
[8]:http://www.gog.com/game/clarc
|
||||
[9]:http://www.gog.com/game/gods_will_be_watching
|
||||
[10]:http://www.gog.com/game/unrest_special_edition
|
||||
[11]:http://www.gog.com/game/anomaly_warzone_earth
|
||||
[12]:http://www.gog.com/game/ascendant
|
||||
[13]:http://www.gog.com/game/bionic_dues
|
||||
[14]:http://www.gog.com/game/blake_stone_aliens_of_gold
|
||||
[15]:http://www.gog.com/game/blake_stone_planet_strike
|
||||
[16]:http://www.gog.com/game/bloodnet
|
||||
[17]:http://www.gog.com/game/braveland
|
||||
[18]:http://www.gog.com/game/clarc
|
||||
[19]:http://www.gog.com/game/darklands
|
||||
[20]:http://www.gog.com/game/darwinia
|
||||
[21]:http://www.gog.com/game/defcon
|
||||
[22]:http://www.gog.com/game/dont_starve
|
||||
[23]:http://www.gog.com/game/dragonsphere
|
||||
[24]:http://www.gog.com/game/duke_nukem_3d_atomic_edition
|
||||
[25]:http://www.gog.com/game/flatout
|
||||
[26]:http://www.gog.com/game/flatout_2
|
||||
[27]:http://www.gog.com/game/fragile_allegiance
|
||||
[28]:http://www.gog.com/game/gemini_rue
|
||||
[29]:http://www.gog.com/game/gods_will_be_watching
|
||||
[30]:http://www.gog.com/game/hammerwatch
|
||||
[31]:http://www.gog.com/game/hocus_pocus
|
||||
[32]:http://www.gog.com/game/kentucky_route_zero_season_pass
|
||||
[33]:http://www.gog.com/game/last_federation_the
|
||||
[34]:http://www.gog.com/game/legend_of_grimrock
|
||||
[35]:http://www.gog.com/game/litil_divil
|
||||
[36]:http://www.gog.com/game/long_live_the_queen
|
||||
[37]:http://www.gog.com/game/mousecraft
|
||||
[38]:http://www.gog.com/game/multiwinia
|
||||
[39]:http://www.gog.com/game/normality
|
||||
[40]:http://www.gog.com/game/pinball_gold_pack
|
||||
[41]:http://www.gog.com/game/pinball_world
|
||||
[42]:http://www.gog.com/game/pirates_gold_plus
|
||||
[43]:http://www.gog.com/game/realms_of_the_haunting
|
||||
[44]:http://www.gog.com/game/rex_nebular_and_the_cosmic_gender_bender
|
||||
[45]:http://www.gog.com/game/rise_of_the_triad__dark_war
|
||||
[46]:http://www.gog.com/game/shattered_haven
|
||||
[47]:http://www.gog.com/game/the_shivah
|
||||
[48]:http://www.gog.com/game/sid_meiers_colonization
|
||||
[49]:http://www.gog.com/game/sid_meiers_covert_action
|
||||
[50]:http://www.gog.com/game/sir_you_are_being_hunted
|
||||
[51]:http://www.gog.com/game/slipstream_5000
|
||||
[52]:http://www.gog.com/game/space_pirates_and_zombies
|
||||
[53]:http://www.gog.com/game/spacechem
|
||||
[54]:http://www.gog.com/game/stargunner
|
||||
[55]:http://www.gog.com/game/steamworld_dig
|
||||
[56]:http://www.gog.com/game/super_hexagon
|
||||
[57]:http://www.gog.com/game/surgeon_simulator_2013
|
||||
[58]:http://www.gog.com/game/sword_of_the_samurai
|
||||
[59]:http://www.gog.com/game/teslagrad
|
||||
[60]:http://www.gog.com/game/unrest_special_edition
|
||||
[61]:http://www.gog.com/game/uplink_hacker_elite
|
||||
[62]:http://www.gog.com/game/vvvvvv
|
||||
[63]:http://www.gog.com/promo/linux_launch_promo_240714
|
||||
[64]:http://www.gog.com/promo/linux_launch_promo_240714
|
||||
[65]:http://youtu.be/qBxbPts5tOk
|
||||
@ -0,0 +1,50 @@
|
||||
Linux System Administration Skills are Changing
|
||||
================================================================================
|
||||
When was the last time you compiled a kernel? For many of the latest generation of Linux admins, the answer is really simple: never. I am one of those, provided we don't count a few times I tried it just for fun, then couldn't see why I would need a custom kernel and went back to my out-of-the-box kernel.
|
||||
|
||||
For many of the longer-time Linux admins and engineers this may seem laughable, but it is a reality: As Linux adoption grows in the enterprise, a new generation of Linux admins is created that has extremely good technical skills, but lacks these 'simple' low level skills seen by many as fundamental to being a good Linux admin. We can build a high performance, highly available web infrastructure that uses the latest of the latest techniques, but don't ask us to fix a non-booting Linux machine: our advice will be to ditch it and set up a new vm.
|
||||
|
||||
Over the past decade or so, we have seen some interesting trends. Linux became a commodity in the enterprise, and as that happened the various distributions became powerful yet flexible enough to remove the need for the average admin to ever have to do low level things like compiling a kernel.
|
||||
|
||||
Next, we welcomed virtual machine technology as a commodity, which added another layer of abstraction. Users of clouds like amazon or VPS providers will possibly never have to deal with deploying Linux on bare metal. As hybrid and private clouds are becoming common as well, many enterprise admins will also not have to deal with this kind of thing anymore, they will just log into a web interface and spin up 5 more apache vm's.
|
||||
|
||||
The newest two trends add even more abstraction: configuration management and the seemingly brand new (yet not new at all) containerization with tools like docker. Whenever a client asks us at [OlinData][1] to configure a Linux machine, our first action will be to set up [Puppet][2]. With our trusted library of well-functioning Puppet modules, that is very easy and will cost me less time then doing this manually.
|
||||
|
||||
For example with Puppet, I can install Apache on a new machine as simple as this:
|
||||
|
||||
node 'web01.olindata.com' {
|
||||
include apache
|
||||
apache::vhost{ 'www.olindata.com':
|
||||
docroot => '/var/www/olindata'
|
||||
}
|
||||
}
|
||||
|
||||
Depending on the environment, I don't even have to log into the machine anymore. Deploying this code through Continuous Deployment tools like [Jenkins][3] will allow me to deploy my infrastructure code automatically as it passes the tests I set up.
|
||||
|
||||
### SysAdmin skills move up the stack ###
|
||||
|
||||
Even as we move toward higher levels of abstraction, ongoing Linux training is still highly valuable and desirable for admins today and will be well into the future. Knowing the fundamentals is key but as abstraction removes some of the old tasks, this requires sysadmins to move up further in the stack and enhance their skills in the higher level tools and practices. It is critical for a sysadmin to become familiar with the tools that enable these higher levels of abstraction. It pushes them to become more skilled in things like coding so that they can do more with these "new" tools.
|
||||
|
||||
Will the need for low(er) level linux skills ever go away completely? Of course not. We still have many other uses for Linux then just the commodity server deployments. Also, people will still benefit hugely from knowing how to do lower level operations in their everyday work. On top of that, with demonstrable Linux skills on your resume, I (and many other employers with me) will always prefer you over candidates that don't have them. You never know when you need those low-level skills!
|
||||
|
||||
|
||||
----------
|
||||

|
||||
|
||||
Walter Heck is CEO and Founder of OlinData, an authorized Linux Foundation training partner. Here's a list of [scheduled official Linux Foundation courses by OlinData][4].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/news/enterprise/systems-management/780956-linux-system-administration-skills-are-changing
|
||||
|
||||
原文作者:[Walter Heck][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.com/community/forums/person/59207
|
||||
[1]:http://olindata.com/
|
||||
[2]:http://puppetlabs.com/
|
||||
[3]:http://jenkins.org/
|
||||
[4]:http://www.olindata.com/training/upcoming?technology=295
|
||||
81
sources/talk/20140724 Best Linux Browsers.md
Normal file
81
sources/talk/20140724 Best Linux Browsers.md
Normal file
@ -0,0 +1,81 @@
|
||||
Best Linux Browsers
|
||||
================================================================================
|
||||
> Pros and cons of the best browsers for the Linux desktop, including Firefox, Chrome and other browsers.
|
||||
|
||||
Choosing the best Linux browser for your needs requires just a bit of homework: Web browsers for the Linux desktop have evolved over the years, just as they have for other popular desktop platforms. With this evolution, both good and bad revelations have been discovered. Revelations from new functionality, to broken extensions, and so forth. In this article, I'll serve as your guide through these murky waters to help you discover the best in Linux browsers.
|
||||
|
||||
### **Firefox** ###
|
||||
|
||||
– [Firefox][1] has long been a friendly browser for Linux users. Accessible on both 32bit and 64bit Linux installs, Firefox also offers extensive extensions to choose from. It's a fast loading, easy to navigate Web browser that has found itself in a popular place with Linux users.
|
||||
|
||||
**The good**: It's easily installed from most common Linux software repositories, if not already installed on the distro by default. Thousands of extensions to choose from to make your Firefox browser more fully featured. Nearly every website on the Web (including government and banking sites) render properly.
|
||||
|
||||
Also important: Firefox respects your privacy. In addition to a straight forward privacy policy, they're not in the "same business" as Google. Therefore, most users feel more comfortable allowing Firefox to see their daily browsing activities whereas other browsers, might have more profit-driven interests. Firefox is also great for web developers, thanks to its element inspection tool, built right into the browser.
|
||||
|
||||
**The bad**: Not too long ago, I was finding that Firefox's frequent updates were breaking my extensions. This meant I needed to verify that my favorite extensions were compatible with new Firefox updates BEFORE I updated my browser.
|
||||
|
||||
To be blunt, this caused me to rethink which browser would be my default tool to browse the Internet. In fairness, Mozilla does post a blog post with each browser update for extension developers. In these posts, developers are told what has changed and what needs to be done to keep things working smoothly.
|
||||
|
||||
### **Chrome/Chromium** ###
|
||||
|
||||
– Google promotes its browser named [Chrome][2], however I tend to put [Chromium][3] into the same group as Chrome since Chromium is used as its base for development. Unlike Firefox, Chrome/Chromium was late to the game for Linux. Linux users only considered it worth trying at the time due to the fact that Chrome/Chromium was perceived by many as being the fastest browser.
|
||||
|
||||
**The good**: Even today, Chrome/Chromium is considered pretty fast. Even with the recent updates made to other competing browsers, Chrome/Chromium hasn't lost its speed. Extensions for Chrome/Chromium are plentiful and even better, updates to the browser have no affect on said extensions. This means that, unlike Firefox, I haven't dealt with extension incompatibilities. Like Firefox, Chrome/Chromium also has an element inspection tool, built right into the browser. After trying syncing options with other browsers, only Chrome/Chromium has proven itself to be truly idiot-proof. Without question, Chrome/Chromium syncing is the best in the browser space, from my perspective.
|
||||
|
||||
**The bad**: Chrome/Chromium doesn't always render pages correctly. Be it rare, some sites like Ebay don't always render correctly. Case in point, if I create a new Ebay submission, I find there are buttons missing in some cases. I've also found that sometimes Chrome/Chromium can lockup completely if an open tab is rendering heavy script. Sites like Google Plus and Facebook are the most common offenders.
|
||||
|
||||
### **Qupzilla** ###
|
||||
|
||||
– When it comes to lightweight browsers, I've found [Qupzilla][4] to be among the most awesome. Based on Webkit, it provides decent rendering support while maintaining a very small resource footprint.
|
||||
|
||||
**The good**: Qupzilla is ideal for lightweight desktop environments where you need a modern browser capable of rendering pages correctly and generally providing a solid web browser experience. It's extremely lightweight and will run on older PCs without missing a beat. Access Keys and [GreaseMonkey][5] extensions are installed (but disabled) by default.
|
||||
|
||||
Like Firefox and Chrome/Chromium, Qupzilla provides access to an element inspection tool as well. And finally, having [Adblock][6] installed by default makes this a clear lightweight winner for me.
|
||||
|
||||
**The bad**: HTML5 video doesn't seem to work reliably. Also, in order to watch Flash videos, you must visit the preferences and uncheck Click to Flash in the Extensions, Webkit plugins area. This is a poorly thought out decision to essentially disable Flash out of the box, while HTML5 video remains completely broken.
|
||||
|
||||
### **Midori** ###
|
||||
|
||||
– I like to call [Midori][7] the lightweight Chrome alternative. Like Google's browser(s), Midori offers a minimalist experience with its "hamburger menu," which is nice as it takes up less browser space. Not only do you get a solid browsing experience without the usual browser politics found elsewhere, Midori is also quite fast.
|
||||
|
||||
**The good**: Midori is fast, lightweight and feels familiar out of the box. I'm also happy to report that it renders pages correctly and works great with sites like YouTube. The best part, in my opinion, is the built-in functionality for creating browser profiles and actual launchable links for Web apps. For example, you can easily create a web app on your desktop for Gmail or Facebook. You can also setup user specific browser profiles as well, without creating new Linux user accounts.
|
||||
|
||||
**The bad**: Despite mentioning user extensions for this browser, the selection available is less than impressive. Also, the browser layout takes a bit of getting used to. A trash can for previously visited websites – seriously?
|
||||
|
||||
### **Opera** ###
|
||||
|
||||
– [Opera][8] has long been one of the misunderstood browsers out there. Very early on, Opera provided Linux support despite being dismissed by the overall Linux community. In addition to being a compatible, fast web browser that has been nothing but good to Linux users, it's also a full of configurable options.
|
||||
|
||||
**The good**: It's fast and it's full of user controllable settings. You can import and export everything from RSS feeds to email, and skin Opera with easy access to breathtaking themes. Plus, Opera offers an extensive library of extensions to choose from. Not to mention the ability to read RSS feeds and email, from your browser! Relive the days of the Mozilla Suite by using Opera's extended suite functionality. And perhaps best of all, Opera Turbo – super-charge your browser speed with selective compression to provide a faster experience.
|
||||
|
||||
**The bad**: A nag for the Terms of Service on its first run. Also, Opera Turbo can slightly alter your browsing experience – YouTube for example, may not show a video's thumbnail. Opera also provides so many options that it can feel a bit overwhelming to the casual user. And lastly, it's a closed source browser that hasn't been well recognized for desktop use. Most folks think of Opera as a mobile browser only these days.
|
||||
|
||||
### Which browser is right for you? ###
|
||||
|
||||
With so many great choices, it can be a tough call to say which browser is right for you. Speaking for myself, I've found that I rely heavily on Firefox and Chromium due to specific extensions I put to work each day. For someone with a lower end system or netbook, my suggestion is to try Midori first and if that's not a fit, fallback to Qupzilla.
|
||||
|
||||
So what about other web browsers for Linux? Such as the [Epiphany][9] browser or [Konqueror][10]? Browsers like these are great, but I feel strongly about the browsers I've shared above specifically. Each of the options listed above are browsers I use often and have found to be something I feel good about recommending to friends and family.
|
||||
|
||||
That said, by all means, share any browsers you're passionate about in the Comments below so others can benefit from your preferred method of browsing the Web.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/best-linux-browsers-1.html
|
||||
|
||||
原文作者:[Matt Hartley][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]:https://www.mozilla.org/en-US/firefox/new/
|
||||
[2]:https://www.google.com/intl/en_us/chrome/browser/
|
||||
[3]:http://www.chromium.org/
|
||||
[4]:http://www.qupzilla.com/
|
||||
[5]:https://addons.mozilla.org/en-US/firefox/addon/greasemonkey/
|
||||
[6]:https://adblockplus.org/
|
||||
[7]:http://midori-browser.org/
|
||||
[8]:http://www.opera.com/
|
||||
[9]:https://wiki.gnome.org/Apps/Web
|
||||
[10]:http://www.konqueror.org/
|
||||
150
sources/talk/20140724 What are useful online tools for Linux.md
Normal file
150
sources/talk/20140724 What are useful online tools for Linux.md
Normal file
@ -0,0 +1,150 @@
|
||||
What are useful online tools for Linux
|
||||
================================================================================
|
||||
As you know, GNU Linux is much more than just an OS. There is literally a whole sphere on the Internet dedicated to the penguin OS. If you read this post, you are probably inclined towards reading about Linux online. Among all the pages that you can find on the subject, there are a couple of websites that every Linux adventurer should have in his bookmarks. These websites are more than just tutorials or reviews. They are real tools that you can access from anywhere and share with everyone. So today I shall propose you a non-exhaustive list of sixteen websites that should be in your bookmarks. Some of them can also be useful for Windows or Mac users: that's the extent of their reach.
|
||||
|
||||
### 1. [ExplainShell.com][1] ###
|
||||
|
||||
[][2]
|
||||
|
||||
If you are interested in Linux command line, you should use this website. If you are not interested in Linux command line, you should use it even more as it will explain in detail how a command works. This could prevent you from launching a command detrimental to your computer, and is a good way to learn with a great interface.
|
||||
|
||||
### 2. [BashrcGenerator.com][3] ###
|
||||
|
||||
[][4]
|
||||
|
||||
If you want to begin with Linux command line, or if you want to quickly get a customized shell prompt but not sure how, this website will generate for you PS1 prompt code to place your .bashrc file in your home directory. You can drag and drop the elements that you would like to see in your prompt, like your username and the current time, and the website will write the code for you. It's easy and very readable. Definitely a must for the lazy.
|
||||
|
||||
### 3. [Vim-adventures.com][5] ###
|
||||
|
||||
[][6]
|
||||
|
||||
I only recently discovered this website, but it already sucked in many hours of my life. In short: a RPG game with Vim commands. Move your character in the isometric levels with the 'h,j,k,l' keys, gain new commands/abilities, collect keys, and learn how to use Vim proficiently very quickly.
|
||||
|
||||
### 4. [Try Github][7] ###
|
||||
|
||||
[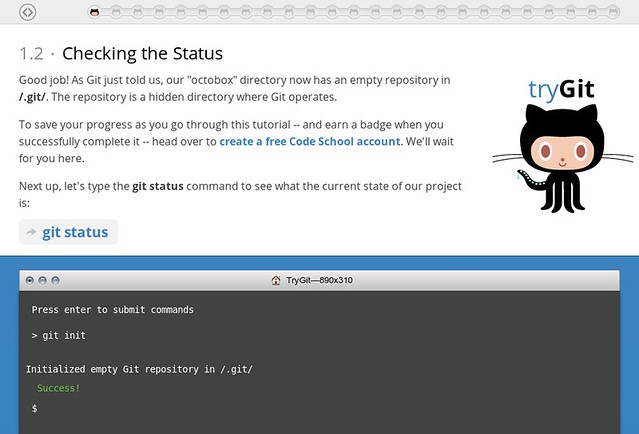][8]
|
||||
|
||||
The pitch is simple: learn Git in 15 minutes. This website simulates a console, and walks you though the steps of collaborative editing. The interface is very stylish and the intention is worthy. The only downside is for the Git allergic. But it is definitely a good skill to have, and a good place to learn it.
|
||||
|
||||
### 5. [Shortcutfoo.com][9] ###
|
||||
|
||||
[][10]
|
||||
|
||||
Another shortcut database, shortcutfoo is a bit more standard in its way to present its content to the user, but definitely more straight-forward than funny mini-games. The shortcuts of several programs are available and grouped by categories. As it might not be super complete for software like Vim, which is completely reliant on shortcuts, it is perfect for giving a quick tip or a general overview.
|
||||
|
||||
### 6. [GitHub Free Programming Books][11] ###
|
||||
|
||||
[][12]
|
||||
|
||||
As you might guess from the URL, this is a collection of free online books about programming, written collaboratively using Git. The content is awesome and the authors deserve to be praised for such work. It might not be the easiest read at first, but it is one of the most instructive for sure. We can only hope that the movement will keep growing.
|
||||
|
||||
### 7. [Collabedit.com][13] ###
|
||||
|
||||
[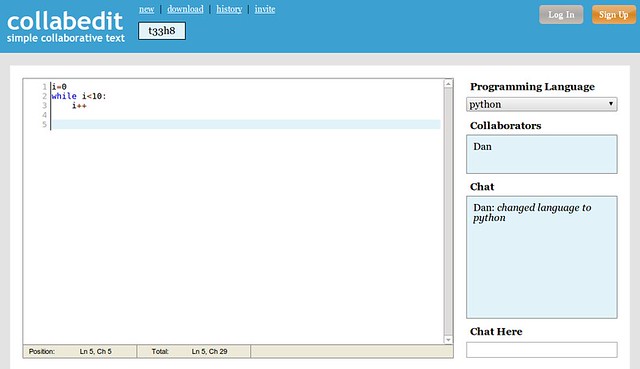][14]
|
||||
|
||||
If you ever plan on giving a phone interview, you should check out collabedit beforehand. It allows you to create a document, select the programming language that you want to write in, and then share that document via the URL. The people opening the link will be able to freely interact in real time with the text, allowing you to judge their programming skills or just exchange snippets. It even comes with the proper syntax highlighting and a chat widget. In other words, it is the instant-Google Document of programmers.
|
||||
|
||||
### 8. [Cpp.sh][15] ###
|
||||
|
||||
[][16]
|
||||
|
||||
This is one of those websites that extend beyond just Linux, but it is so useful that it deserves its place here. In short, an online development environment for C++. Just write your code in your navigator and run it. As a bonus, you get an auto-indentation feature, Ctrl+Z, and the possibility to share the URL with your buddy. This is just one of those crazy things that you can do from a simple browser.
|
||||
|
||||
### 9. [Copy.sh][17] ###
|
||||
|
||||
[][18]
|
||||
|
||||
In continuation with crazy things that you can do from your browser, copy.sh lets you run a virtual machine online. Just that. It gained fame relatively recently, but the idea is just insane. From the navigator you can select among the defaults virtual images to run, or upload your own iso file. The code for that feat has been shared on [GitHub][19]. Just amazing.
|
||||
|
||||
### 10. [Commandlinefu.com][20] ###
|
||||
|
||||
[][21]
|
||||
|
||||
We all keep a big snippet of command-line "gems" on our computer. commandlinefu's goal is to release those snippets to the world. As a collaborative database, it resembles the Wikipedia of the command line. Everyone is free to register and post their favorite command on the website for everyone else to see. You will then be able to access that knowledge from everywhere and share it with everyone. If you are interested in mastering the shell, commandlinefu also proposes great features like random commands and a news feed to learn something new every day.
|
||||
|
||||
### 11. [Alias.sh][22] ###
|
||||
|
||||
[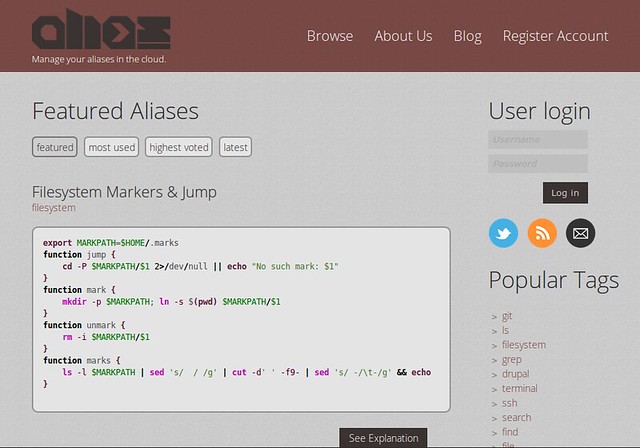][23]
|
||||
|
||||
Another collaborative database, alias.sh (I love the URL) is a bit like commandlinefu but for shell aliases. You can share and discover useful aliases which will make your CLI experience so much better. I personally like the alias to get the dimensions of a picture.
|
||||
|
||||
function dim(){ sips $1 -g pixelWidth -g pixelHeight }
|
||||
|
||||
All the seconds you save with alias.sh probably accumulate with time, and turn to years by the end of your life.
|
||||
|
||||
### 12. [Distrowatch.com][24] ###
|
||||
|
||||
[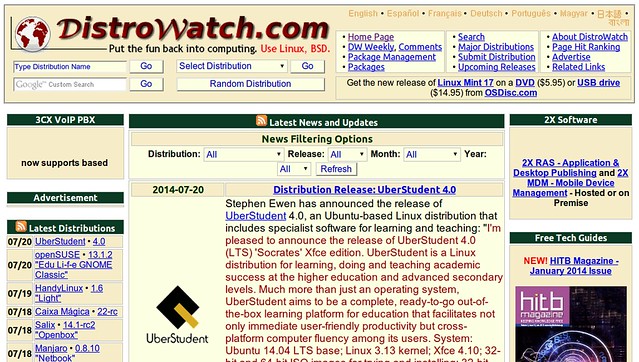][25]
|
||||
|
||||
Who does not know Distrowatch? Besides giving a precise ranking of Linux distributions based on their website popularity, Distrowatch is also a very useful database. Whether you are looking for a new distribution to try, or just curious, it presents an exhaustive account of every Linux you can find, with information like which default desktop environment it uses, or package system, or its default applications. And all the versions, and with easily accessible download links. In a word, the Linux database.
|
||||
|
||||
### 13. [Linuxmanpages.com][26] ###
|
||||
|
||||
[][27]
|
||||
|
||||
Everything is in the URL: access the manual pages for popular commands from anywhere. Not really sure if this would actually be useful for Linux users as you can access that from your actual terminal, but the intent is remarkable.
|
||||
|
||||
### 14. [AwesomeCow.com][28] ###
|
||||
|
||||
[][29]
|
||||
|
||||
This is maybe a bit less hardcore Linux, but definitely useful to some. Awesomecow is a search engine for finding alternatives to Windows software on Linux. It can be helpful for anyone migrating to the penguin, or nostalgic of a Windows program. I see this as a strength, showing that Linux can compete with the professional spheres when it comes sot software quality. Or at least try to.
|
||||
|
||||
### 15. [PenguSpy.com][30] ###
|
||||
|
||||
[][31]
|
||||
|
||||
Before Steam started to show up on Linux, gaming was probably one of the penguin's weakness. But the website penguspy made the effort of fighting that weakness by collecting all Linux compatible games in a database with a sexy interface. Games can be sorted by categories, release dates, ratings, etc. I really hope that websites like this are not going to disappear because of Steam as it remains one of my favorites of this list.
|
||||
|
||||
### 16. [Linux Cross Reference by Free Electrons][32] ###
|
||||
|
||||
[][33]
|
||||
|
||||
Finally, for all the experts and the curious, lxr is the anagram from Linux Cross Reference, and allows us to interactively view the Linux Kernel code online. The navigation is made easy via identifiers, and you can compare the different versions of the files with a standard diff markup. The interface is sober and straight-forward, and this is just a website that perfectly illustrates the concept of open source.
|
||||
|
||||
To conclude, there are a lot more websites which deserve to be listed, and this might be a topic for a part two to this post. But this is a good start. It serves as an appetizer to what can be found online as tools for Linux users. If you have any other pages that you would like to share, following this thematic, do so in the comments. And maybe contribute to a sequel to this list.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/07/useful-online-tools-linux.html
|
||||
|
||||
原文作者:[Adrien Brochard][a](I am a Linux aficionado from France. After trying multiple distributions, I finally settled for Archlinux. But I am always trying to improve my system by stacking up tips and tricks.)
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://explainshell.com/
|
||||
[2]:https://www.flickr.com/photos/xmodulo/14517716647/
|
||||
[3]:http://bashrcgenerator.com/
|
||||
[4]:https://www.flickr.com/photos/xmodulo/14703872782/
|
||||
[5]:http://vim-adventures.com/
|
||||
[6]:https://www.flickr.com/photos/xmodulo/14681149696/
|
||||
[7]:https://try.github.io/
|
||||
[8]:https://www.flickr.com/photos/xmodulo/14517499739/
|
||||
[9]:https://www.shortcutfoo.com/
|
||||
[10]:https://www.flickr.com/photos/xmodulo/14517499799/
|
||||
[11]:https://github.com/vhf/free-programming-books/blob/master/free-programming-books.md
|
||||
[12]:https://www.flickr.com/photos/xmodulo/14517499989/
|
||||
[13]:http://collabedit.com/
|
||||
[14]:https://www.flickr.com/photos/xmodulo/14681150086/
|
||||
[15]:http://cpp.sh/
|
||||
[16]:https://www.flickr.com/photos/xmodulo/14700981001/
|
||||
[17]:http://copy.sh/v24/
|
||||
[18]:https://www.flickr.com/photos/xmodulo/14517479870/
|
||||
[19]:https://github.com/copy/v86
|
||||
[20]:http://www.commandlinefu.com/
|
||||
[21]:https://www.flickr.com/photos/xmodulo/14517495938/
|
||||
[22]:http://alias.sh/
|
||||
[23]:https://www.flickr.com/photos/xmodulo/14701762124/
|
||||
[24]:http://distrowatch.com/
|
||||
[25]:https://www.flickr.com/photos/xmodulo/14681149996/
|
||||
[26]:http://www.linuxmanpages.com/
|
||||
[27]:https://www.flickr.com/photos/xmodulo/14704165765/
|
||||
[28]:http://awesomecow.com/
|
||||
[29]:https://www.flickr.com/photos/xmodulo/14704165965/
|
||||
[30]:http://www.penguspy.com/
|
||||
[31]:https://www.flickr.com/photos/xmodulo/14517495728/
|
||||
[32]:http://lxr.free-electrons.com/
|
||||
[33]:https://www.flickr.com/photos/xmodulo/14712049464/
|
||||
@ -0,0 +1,45 @@
|
||||
diff -u: What's New in Kernel Development
|
||||
================================================================================
|
||||
Once in a while someone points out a POSIX violation in Linux. Often the answer is to fix the violation, but sometimes Linus Torvalds decides that the POSIX behavior is broken, in which case they keep the Linux behavior, but they might build an additional POSIX compatibility layer, even if that layer is slower and less efficient.
|
||||
|
||||
This time, *Michael Kerrisk* reported a POSIX violation that affected file operations. Apparently, reading and writing to files during multithreaded operations could hit race conditions and overwrite each other's changes.
|
||||
|
||||
There was some discussion over whether this was really a violation of POSIX, but ultimately, who cares? Data clobbering is bad. After Michael posted some code to reproduce the problem, the conversation focused on what to do to fix it. But Michael did make an argument that "Linux isn't consistent with UNIX since early times. (E.g., page 191 of the 1992 edition of Stevens APUE discusses the sharing of the file offset between the parent and child after fork(). Although Stevens didn't explicitly spell out the atomicity guarantee, the discussion there would be a bit nonsensical without the presumption of that guarantee.)"
|
||||
|
||||
Al Viro joined Linus in trying to come up with a fix. Linus tried introducing a simple mutex to lock files so that write operations couldn't clobber each other, and Al offered his own refinements that improved on Linus' patch.
|
||||
|
||||
At one point, Linus explained the history of the bug itself. Apparently, once upon a time the file pointer, which told the system where to write into the file, had been locked in a semaphore so only one process could do anything to it at a time. But, they took it out of the semaphore in order to accommodate device files and other non-regular files that ran into race conditions when users were barred from writing to them whenever they pleased.
|
||||
|
||||
That was what introduced the bug. At the time, it slipped through undetected, because that actual reading and writing to regular files was still handled atomically by the kernel. It was only the file pointer itself that could get out of sync. And, because high-speed threaded file operations are a pretty rare need, it took a long time for anyone to run into the problem and report it.
|
||||
|
||||
An interesting little detail is that, while Linus and Al were hunting for a fix, Al at one point complained that the approach Linus was taking wouldn't support certain architectures, including *ARM* and *PowerPC*. Linus' response was, "I doubt it's worth caring about. [...] If the ARM/PPC people end up caring, they could add the struct-return support to gcc."
|
||||
|
||||
It's always interesting to see how corner cases crop up and get dealt with. In some cases, part of the fix has to happen in the kernel, part in GCC and part elsewhere. In this particular instance, Al felt the whole thing could be done in the kernel, and he was inspired to write his own version of the patch, which Linus accepted.
|
||||
|
||||
*Andi Kleen* wanted to add low-level CPU event support to *perf*. The problem was that there could be tons of low-level events, and it varied widely from CPU to CPU. Even storing the possible events in memory for all CPUs would significantly increase the kernel's running size. So, hard-coding this information into the kernel would be problematic.
|
||||
|
||||
He pointed out that the *OProfile* tool relied on publicly available lists of these events, though he said the OProfile developers didn't always keep their lists up to date with the latest available versions.
|
||||
|
||||
To solve these issues, Andi submitted a patch that allowed perf to identify which event-list was needed for the particular CPU on the given system, and automatically download the latest version of that list from its home location. Then perf could interpret the list and analyze the events, without overburdening the kernel.
|
||||
|
||||
There was various feedback to Andi's code, mostly to do with which directory should house the event-lists, and what the filenames should be called. The behavior of the code itself seemed to get a good reception. One detail that may turn out to be more controversial than the others was Andi's decision to download the lists to a subdirectory of the user's own home directory. Andi said that otherwise users might be encouraged to download the event-lists as the root user, which would be bad security practice.
|
||||
|
||||
Sasha Levin recently posted a script to translate the *hexadecimal offsets *from stack dumps into meaningful line numbers that pointed into the kernel's source files. So something like "ffffffff811f0ec8" might be translated into "fs/proc/generic.c:445".
|
||||
|
||||
However, it turned out that Linus Torvalds was planning to remove the hex offsets from the stack dumps for exactly the reason that they were unreadable. So Sasha's code was about to go out of date.
|
||||
|
||||
They went back and forth a bit on it. At first Sasha decided to rely on data stored in the System.map file to compensate, but Linus pointed out that some people, including him, didn't keep their System.map file around. Linus recommended using /usr/bin/nm to extract the symbols from the compiled kernel files.
|
||||
|
||||
So, it seems as though Sasha's script may actually provide meaningful file and line numbers for debugging stack dumps, assuming the stack dumps provide enough information to do the calculations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/diff-u-whats-new-kernel-development-0
|
||||
|
||||
原文作者:[Zack Brown][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/user/801501
|
||||
@ -1,204 +0,0 @@
|
||||
alim0x translating
|
||||
|
||||
The history of Android
|
||||
================================================================================
|
||||
> Follow the endless iterations from Android 0.5 to Android 4.4.
|
||||
|
||||
|
||||
Android's home screen over the years.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Android has been with us in one form or another for more than six years. During that time, we've seen an absolutely breathtaking rate of change unlike any other development cycle that has ever existed. When it came time for Google to dive in to the smartphone wars, the company took its rapid-iteration, Web-style update cycle and applied it to an operating system, and the result has been an onslaught of continual improvement. Lately, Android has even been running on a previously unheard of six-month development cycle, and that's slower than it used to be. For the first year of Android’s commercial existence, Google was putting out a new version every two-and-a-half months.
|
||||
|
||||
注:youtube视频地址开始
|
||||
<iframe width="640" height="480" frameborder="0" src="http://www.youtube-nocookie.com/embed/1FJHYqE0RDg?start=0&wmode=transparent" type="text/html" style="display:block"></iframe>
|
||||
|
||||
Google's original introduction of Android, from way back in November 2007.
|
||||
注:youtube视频地址结束
|
||||
|
||||
The rest of the industry, by comparison, moves at a snail's pace. Microsoft updates its desktop OS every three to five years, and Apple is on a yearly update cycle for OS X and iOS. Not every update is created equal, either. iOS has one major design revision in seven years, and the newest version of Windows Phone 8 looks very similar to Windows Phone 7. On Android, however, users are lucky if anything looks the same this year as it did last year. The Play Store, for instance, has had five major redesigns in five years. For Android, that's normal.
|
||||
|
||||
Looking back, Android's existence has been a blur. It's now a historically big operating system. Almost a billion total devices have been sold, and 1.5 million devices are activated per day—but how did Google get here? With this level of scale and success, you would think there would be tons of coverage of Android’s rise from zero to hero. However, there just isn’t. Android wasn’t very popular in the early days, and until Android 4.0, screenshots could only be taken with the developer kit. These two factors mean you aren’t going to find a lot of images or information out there about the early versions of Android.
|
||||
|
||||
The problem now with the lack of early coverage is that *early versions of Android are dying*. While something like Windows 1.0 will be around forever—just grab an old computer and install it—Android could be considered the first cloud-based operating system. Many features are heavily reliant on Google’s servers to function. With fewer and fewer people using old versions of Android, those servers are being shut down. And when a cloud-reliant app has its server support shut off, it will never work again—the app crashes and displays a blank screen, or it just refuses to start.
|
||||
|
||||
Thanks to this “[cloud rot][1]," an Android retrospective won’t be possible in a few years. Early versions of Android will be empty, broken husks that won't function without cloud support. While it’s easy to think of this as a ways off, it's happening right now. While writing this piece, we ran into tons of apps that no longer function because the server support has been turned off. Early clients for Google Maps and the Android Market, for instance, are no longer able to communicate with Google. They either throw an error message and crash or display blank screens. Some apps even worked one week and died the next, because Google was actively shutting down servers during our writing!
|
||||
|
||||
To prevent any more of Android's past from being lost to the annals of history, we did what needed to be done. This is 20+ versions of Android, seven devices, and lots and lots of screenshots cobbled together in one space. This is The History of Android, from the very first public builds to the newest version of KitKat.
|
||||
|
||||
注:下面一块为文章链接列表,发布后可以改为发布后的地址
|
||||
----------
|
||||
|
||||
### Table of Contents ###
|
||||
|
||||
- [Android 0.5 Milestone 3—the first public build][10]
|
||||
- [Android 0.5 Milestone 5—the land of scrapped interfaces][11]
|
||||
- [Android 0.9 Beta—hey, this looks familiar!][12]
|
||||
- [Android 1.0—introducing Google Apps and actual hardware][13]
|
||||
- [Android 1.1—the first truly incremental update][14]
|
||||
- [Android 1.5 Cupcake—a virtual keyboard opens up device design][15]
|
||||
- ----[Google Maps is the first built-in app to hit the Android Market][16]
|
||||
- [Android 1.6 Donut—CDMA support brings Android to any carrier][17]
|
||||
- [Android 2.0 Éclair—blowing up the GPS industry][18]
|
||||
- [The Nexus One—enter the Google Phone][19]
|
||||
- [Android 2.1—the discovery (and abuse) of animations][20]
|
||||
- ----[Android 2.1, update 1—the beginning of an endless war][21]
|
||||
- [Android 2.2 Froyo—faster and Flash-ier][22]
|
||||
- ----[Voice Actions—a supercomputer in your pocket][23]
|
||||
- [Android 2.3 Gingerbread—the first major UI overhaul][24]
|
||||
- [Android 3.0 Honeycomb—tablets and a design renaissance][25]
|
||||
- ----[Google Music Beta—cloud storage in lieu of a content store][26]
|
||||
- [Android 4.0 Ice Cream Sandwich—the modern era][27]
|
||||
- ----[Google Play and the return of direct-to-consumer device sales][28]
|
||||
- [Android 4.1 Jelly Bean—Google Now points toward the future][29]
|
||||
- ----[Google Play Services—fragmentation and making OS versions (nearly) obsolete][30]
|
||||
- [Android 4.2 Jelly Bean—new Nexus devices, new tablet interface][31]
|
||||
- ----[Out-of-cycle updates—who needs a new OS?][32]
|
||||
- [Android 4.3 Jelly Bean—getting wearable support out early][33]
|
||||
- [Android 4.4 KitKat—more polish; less memory usage][34]
|
||||
- [Today Android everywhere][35]
|
||||
|
||||
----------
|
||||
|
||||
### Android 0.5, Milestone 3—the first public build ###
|
||||
|
||||
Before we go diving into Android on real hardware, we're going to start with the early, early days of Android. While 1.0 was the first version to ship on hardware, there were several beta versions only released in emulator form with the SDK. The emulators were meant for development purposes only, so they don’t include any of the Google Apps, or even many core OS apps. Still, they’re our best look into the pre-release days of Android.
|
||||
|
||||
|
||||
The emulator’s default qwerty-bar layout running the Milestone 3 build.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Before whimsical candy code names and [cross-promotional deals with multinational food corporations][2], the first public release of Android was labeled "m3-rc20a"—"m3" standing for "Milestone 3." While Google may not have publicized the version number—and this build didn't even have a settings app to check—the browser user agent identifies this as "Android 0.5."
|
||||
|
||||
In November 2007, two years after Google acquired Android and five months after the launch of the iPhone, [Android was announced][3], and the first emulator was released. Back then, the OS was still getting its feet under it. It was easily dismissed as "just a BlackBerry clone." The emulator used a qwerty-bar skin with a 320x240 display, replicating an [actual prototype device][4]. The device was built by HTC, and it seems to be the device that was codenamed "Sooner" according to many early Android accounts. But the Sooner was never released to market.
|
||||
|
||||
[According to accounts][5] of the early development days of Android, when Apple finally showed off its revolutionary smartphone in January 2007, Google had to "start over" with Android—including scrapping the Sooner. Considering the Milestone 3 emulator came out almost a year after Apple's iPhone unveiling, it's surprising to see the device interface still closely mimicked the Blackberry model instead. While work had no doubt been done on the underlying system during that year of post-iPhone development, the emulator still launched with what was perceived as an "old school" interface. It didn't make a good first impression.
|
||||
|
||||
At this early stage, it seems like the Android button layout had not been finalized yet. While the first commercial Android devices would use “Home," “Back," “Menu," and “Search" as the standard set of buttons, the emulator had a blank space marked as an "X" where you would expect the search button to be. The “Sooner" hardware prototype was even stranger—it had a star symbol as the fourth button.
|
||||
|
||||
|
||||
From left to right: the home screen, an open notification, and the “apps" folder.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
There was no configurable home screen or widgets, just a simple dock of icons at the bottom that could be cycled through or tapped on. While touch screen support worked for some features, Milestone 3 was primarily controlled with a five-way d-pad—an anachronism that Android still supports to this day. Even this early version of Android could do animations. Icons would grow and shrink as they entered and exited the dock’s center window.
|
||||
|
||||
There was no notification panel yet, either. Notification icons showed up in the status bar (shown above as a smiley face), and the only way to open them was to press "up" on the d-pad while on the home screen. You couldn't tap on the icon to open it, nor could you access notifications from any screen other than home. When a notification was opened, the status bar expanded slightly, and the text of the notification appeared in a speech bubble. Once you had a notification, there was no manual way to clear it—apps were responsible for clearing their own notifications.
|
||||
|
||||
App drawer duties were handled by a simple "Applications" folder on the left of the dock. Despite having a significant amount of functions, the Milestone 3 emulator was not very forthcoming with app icons. "Browser," "Contacts," and "Maps" were the only real apps here. Oddly, "recent calls" was elevated to a standalone icon. Because this was just an emulator, icons for core smartphone functionality were missing, like alarm, calendar, dialer, calculator, camera, gallery, and settings. Hardware prototypes demoed to the press had [many of these][6], and there was a suite of Google Apps up and running by this point. Sadly, there’s no way for us to look at them. They’re so old they can't connect to Google’s servers now anyway.
|
||||
|
||||
|
||||
Milestone 3's menu system in the browser, the wallpaper interface, and the volume control.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
The now-deprecated menu system was up and running in Milestone 3. Hitting the hardware menu button brought up a gray list with a blue gradient highlight, complete with hardware keyboard shortcuts. In the screenshot above, you can see the menu open in the browser. Going to a second level, like the zoom menu, turned the first level of the menu oddly transparent.
|
||||
|
||||
Surprisingly, multitasking and background applications already worked in Milestone 3. Leaving an app didn't close it—apps would save state, even down to text left in a text box. This was a feature iOS wouldn’t get around to matching until the release of iOS 4 in 2010, and it really showed the difference between the two platforms. iOS was originally meant to be a closed platform with no third-party apps, so the platform robustness wasn’t a huge focus. Android was built from the ground up to be a powerful app platform, and ease of app development was one of the driving forces behind its creation.
|
||||
|
||||
Before Android, Google was already making moves into mobile with [WAP sites][7] and [J2ME flip phone apps][8], which made it acutely aware of how difficult mobile development was. According to [The Atlantic][9], Larry Page once said of the company’s mobile efforts “We had a closet full of over 100 phones, and we were building our software pretty much one device at a time.” Developers often complain about Android fragmentation now, but the problem was much, much worse before the OS came along.
|
||||
|
||||
Google’s platform strategy eventually won out, and iOS ended up slowly adding many of these app-centric features—multitasking, cross-app sharing, and an app switcher—later on.
|
||||
|
||||
|
||||
The dialer screen that pops up when you press numbers on the home screen, an incoming call, and the call conferencing interface.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Despite not having a dialer icon, Milestone 3 emulator was equipped with a way to make phone calls. Pressing anything on the keyboard would bring up the screen on the left, which was a hybrid dialer/contact search. Entering only numbers and hitting the green phone hardware button would start a phone call, and letters would search contacts. Contacts were not searchable by number, however. Even a direct hit on a phone number would not bring up a contact.
|
||||
|
||||
Incoming calls were displayed as an almost-full-screen popup with a sweet transparent background. Once inside a call, the background became dark gray, and Milestone 3 presented the user with a surprisingly advanced feature set: mute, speakerphone, hold, and call conferencing buttons. Multiple calls were presented as overlapping, semi-transparent cards, and users had options to swap or merge calls. Swapping calls triggered a nice little card shuffle animation.
|
||||
|
||||

|
||||
The contacts list, an individual contact, editing a contact, and the recent calls screen.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Contacts was a stark, black and blue list of names. Contact cards had a spot for a contact picture but couldn't assign one to the space (at least in the emulator). The only frill in this area was XMPP presence dots to the left of each name in Contacts. An always-on XMPP connection has traditionally been at the heart of Android, and that deep integration already started in Milestone 3. Android used XMPP to power a 24/7 connection to Google’s servers, powering Google Talk, cloud-to-device push messaging, and app install and uninstall messages.
|
||||
|
||||
|
||||
The browser’s fake Google homepage, the address bar, and the history interface.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
The browser ran Webkit 419.3, which put it in the same era as Mac OS X 10.4's Safari 2. The homepage was not Google.com, but a hard-coded home.html file included with Android. It looked like Google.com from a thousand years ago. The browser's OS X heritage was still visible, rendering browser buttons with a glossy, Aqua-style search button.
|
||||
|
||||
The tiny BlackBerry-style screen necessitated a separate address bar, which was brought up by a "go to" option in the browser's menu. While autocomplete didn't work, the address bar live searched your history as you typed. The picture on the right was the History display, which used thumbnails to display each site. The current thumbnail was in front of the other two, and scrolling through them triggered a swooping animation. But at this early stage, the browser didn’t support multiple tabs or windows—you had the current website, and that was it.
|
||||
|
||||
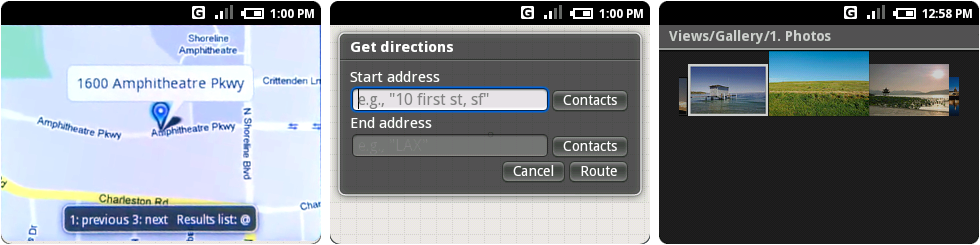
|
||||
A video-screengrab-derived Google Maps Photoshop, the directions interface, and the gallery test view.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
From the beginning, Google knew maps would be important on mobile, even shipping a Maps client on the Milestone 5 emulator. That version of Google Maps was the first thing we came across that died from cloud rot. The client can't load information from Google’s servers, so the map displayed as a blank, gray grid. Nothing works.
|
||||
|
||||
Luckily, for the first screenshot above, we were able to piece together an accurate representation from the Android launch video. Old Google Maps seemed fully prepared for a non-touch device, listing hardware key shortcuts along the bottom of the screen. It’s unclear if places worked, or if Maps only ran on addresses at this point.
|
||||
|
||||
Hidden behind the menu were options for search, directions, and satellite and traffic layers. The middle screenshot is of the directions UI, where you could even pick a contact address as a start or end address. Maps lacked any kind of GPS integration, however; you can't find a "my location" button anywhere.
|
||||
|
||||
While there was no proper gallery, on the right is a test view for a gallery, which was hidden in the "API Demos" app. The pictures scrolled left and right, but there was no way to open photos to a full screen view. There were no photo management options either. It was essentially a test of a scrolling picture view.
|
||||
|
||||
|
||||
The time picker and calendar, with ridiculous kerning issues, and the vertical list test, featuring Ars.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
There was also no settings app, but we can look at the original time and date pickers, thanks to the API Demos. This demonstrates how raw a lot of Android was: kerning issues all over the place, a huge gap in between the minute digits, and unevenly spaced days of the week on the calendar. While the time picker let you change each digit independently, there was no way to change months or years other than moving the day block out of the current month and on to the next or previous month.
|
||||
|
||||
Keep in mind that while this may seem like dinosaur remnants from some forgotten era, this was only released six years ago. We tend to get used to the pace of technology. It's easy to look back on stuff like this and think that it was from 20 years ago. Compare this late-2007 timeframe to desktop OSes, and Microsoft was trying to sell Windows Vista to the world for almost a year, and Apple just released OS X 10.5 Leopard.
|
||||
|
||||
One last Milestone 3 detail: Google gave Ars Technica a shoutout in the Milestone 3 emulator. Opening the “API Demos" app and going to "Views," "Focus," then "Vertical" revealed a test list headlined by *this very Website*.
|
||||
|
||||
|
||||
The new emulator skin that comes with Milestone 3, RC37a, which uses a more modern, all-touchscreen style.
|
||||
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Two months later, in December 2007, Google released an update for the Milestone 3 emulator that came with a much roomier 480×320 device configuration. This was tagged "m3-rc37a." The software was still identical to the BlackBerry build, just with much more screen real estate available.
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
|
||||
|
||||
[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://arstechnica.com/gadgets/2014/06/how-we-found-and-installed-every-version-of-android/
|
||||
[2]:http://arstechnica.com/gadgets/2013/09/official-the-next-edition-of-android-is-kitkat-version-4-4/
|
||||
[3]:http://arstechnica.com/gadgets/2007/11/its-official-google-announces-open-source-mobile-phone-os-android/
|
||||
[4]:http://www.zdnet.com/blog/mobile-gadgeteer/mwc08-hands-on-with-a-working-google-android-device/860
|
||||
[5]:http://www.theatlantic.com/technology/archive/2013/12/the-day-google-had-to-start-over-on-android/282479/
|
||||
[6]:http://www.letsgomobile.org/en/2974/google-android/
|
||||
[7]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/%E2%80%9D
|
||||
[8]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/%E2%80%9D
|
||||
[9]:http://www.theatlantic.com/technology/archive/2013/12/the-day-google-had-to-start-over-on-android/282479/
|
||||
[10]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/1/#milestone3
|
||||
[11]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/2/#milestone5
|
||||
[12]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/3/#0.9
|
||||
[13]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/6/#1.0
|
||||
[14]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/7/#1.1
|
||||
[15]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/8/#cupcake
|
||||
[16]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/9/#Mapsmarket
|
||||
[17]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/9/#donut
|
||||
[18]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/10/#2.0eclair
|
||||
[19]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/11/#nexusone
|
||||
[20]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/12/#2.1eclair
|
||||
[21]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/13/#alloutwar
|
||||
[22]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/13/#froyo
|
||||
[23]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/14/#voiceactions
|
||||
[24]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/14/#gingerbread
|
||||
[25]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/16/#honeycomb
|
||||
[26]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/19/#music
|
||||
[27]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/19/#ics
|
||||
[28]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/21/#googleplay
|
||||
[29]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/21/#4.1jellybean
|
||||
[30]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/21/#playservices
|
||||
[31]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/22/#4.2jellybean
|
||||
[32]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/23/#outofcycle
|
||||
[33]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/24/#4.3jellybean
|
||||
[34]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/25/#kitkat
|
||||
[35]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/26/#conclusion
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -1,71 +0,0 @@
|
||||
zpl1025
|
||||
Super Pi Brothers
|
||||
================================================================================
|
||||
I don't game as much as I used to. Although I've certainly spent countless hours of my life in front of a Nintendo, SNES, or after that, playing a first-person shooter on my computer (Linux only, thank you), these days, my free time tends to go toward one of the many nongaming hobbies I've accumulated. Recently though, I found myself dusting off my Wii console just so I could play an NES and SNES game I re-purchased for it. The thing is, those games require using a somewhat strange controller, and I already have a modified SNES controller that can connect over USB. That was enough to encourage me to search for a better solution. Of course, I simply could connect three or four consoles and stack up games in my living room, but I've grown accustomed to ripping my CDs and DVDs and picking what I want to listen to or watch from a central media center. It would be nice if I didn't have to get up and find a cartridge every time I wanted to switch games. This, of course, means going with emulation, but although in the past I'd had success with a modified classic Xbox, I didn't have that hardware anymore. I figured someone must have gotten this set up on the Raspberry Pi, and sure enough, after a brief search and a few commands, I had a perfect retro-gaming arcade set up on a spare Raspberry Pi.
|
||||
|
||||
One nice thing about the Raspberry Pi project is the large number of people out there with identical hardware. For me, that meant instead of having to go through someone else's instructions, knowing I'd likely have to tweak it to suit my setup, I basically could follow someone else's guide verbatim. In my case, I found the RetroPie project, which wrapped up all of the commands you would need to install everything on a Raspberry Pi into a single large script. At the end, you have the RetroArch project fully installed and configured, which includes all of the major emulators you'd want and a centralized method to configure them, plus an EmulationStation graphical front end the Pi can boot directly into that makes it simple to navigate to the game you want, all from a gamepad.
|
||||
|
||||
### Install RetroPie ###
|
||||
|
||||
Before you install RetroPie, you will want to make sure your Raspbian distribution (the default Linux distribution for a Raspberry Pi, and the one this project assumes you will use) is completely up to date, including any new firmware images. This just means a few common `apt` commands. Although you certainly could connect a keyboard to your Raspberry Pi for this step, I've found it more convenient to `ssh` in to the device so I could copy and paste commands:
|
||||
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get -y upgrade
|
||||
|
||||
Now that the Raspberry Pi is up to date, make sure the git and dialog packages are installed, and then use git to download RetroPie:
|
||||
|
||||
|
||||
$ sudo apt-get -y install git dialog
|
||||
$ cd
|
||||
$ git clone --depth=0
|
||||
↪git://github.com/petrockblog/RetroPie-Setup.git
|
||||
|
||||
This will create a RetroPie-Setup directory containing the main setup script. Now you just need to go inside that directory and execute it:
|
||||
|
||||
$ cd RetroPie-Setup
|
||||
$ chmod +x retropie_setup.sh
|
||||
$ sudo ./retropie_setup.sh
|
||||
|
||||
This script presents you with an in-terminal menu (Figure 1) where you can choose to perform a binary installation or source installation, set up RetroPie, or perform a series of updates for the RetroPie setup script and binaries. Choose either the binary or source installation. The binary installation won't take as much time, but you may risk running older versions of some of the software. The source installation requires you to compile software, so it takes longer, but at the end, you will have the latest possible versions of everything. Personally, I opted for the binary install, knowing I always could re-run the script and go with the source install if I found any problems.
|
||||
|
||||

|
||||
|
||||
#### Figure 1. RetroPie Setup Menu ####
|
||||
|
||||
This part of the process will take quite some time on a vanilla Raspbian image, as there are a lot of different packages to download and install. Once the installation completes, go back to the main RetroPie setup screen and select SETUP from the main menu. In this submenu, you can tweak settings, such as whether to start EmulationStation from boot (recommended) and whether to enable a splash screen. In my case, I enabled both settings as I intended my device to be a standalone emulation machine. Note that if you do allow EmulationStation to start up from boot, you still can always ssh in to the machine and run the original RetroPie configuration script to change the settings.
|
||||
|
||||
### Adding ROMs ###
|
||||
|
||||
You also can add ROMs within the RetroPie setup screen. If you choose the Samba method in the menu, you then can locate a local Samba mountpoint on your network, and you can copy ROMs from that. With the USB stick method, RetroPie will generate a directory structure on a USB stick that you plug in to your Raspberry Pi that represents the different emulators it supports. After this point, you can take that USB stick to another computer and copy ROMs over to the appropriate directory, and the next time you plug it in to the Raspberry Pi, it automatically will sync the files over. Finally (and this is what I did), you just can use scp or rsync to copy over ROMs to the appropriate directory under ~/RetroPie/roms/. So for instance, NES games would be copied to ~/RetroPie/roms/nes/.
|
||||
|
||||
Once you are done with the configuration and exit out of the RetroPie setup script, you will want to reboot back into EmulationStation, but before you do, you should reconfigure the memory split on the Raspberry Pi so that it is set to 192 or 128, so run:
|
||||
|
||||
|
||||
$ sudo raspi-config
|
||||
|
||||
and go to the Advanced Settings to change the memory split setting. Now you can reboot safely.
|
||||
|
||||
### EmulationStation ###
|
||||
|
||||
Once you reboot, you should be greeted with the initial EmulationStation screen, which will prompt you to set up your joystick, gamepad or keyboard buttons so it can work with the EmulationStation menu. Note that this doesn't affect how your controllers work within games, just within the EmulationStation menu. After your controller or controllers are set up, you should be able to press right and left on your controller to switch between the different emulator menus. In my case, all of the buttons on my gamepad were going to be used within games, so I made a point to bind a key on a separate keyboard to the menu function so I could exit out of games when I was done without having to reboot the Raspberry Pi.
|
||||
|
||||
EmulationStation will show you only menus that represent emulators for which it has detected ROMs, so if you haven't copied ROMs for a particular emulator yet, you will want to do that and potentially restart your Raspberry Pi before you can see them. Also, by default, your controller will not be configured for any games, but if you press the right arrow enough times within EmulationStation, you will get to an input configuration screen that allows you to map keys on your controller to keys inside a game. The nice thing about this setup is that after you configure the keys, it will apply appropriately within each emulator.
|
||||
|
||||
That's it. From this point, you can browse through your collection of games and press whatever button you bound to Accept to start playing. At first I was concerned the Raspberry Pi wouldn't have the horsepower to play my games, but so far, it has been able to play any games I tried without a problem.
|
||||
|
||||
### Resources ###
|
||||
|
||||
The RetroPie Project: [http://blog.petrockblock.com/retropie][1]
|
||||
|
||||
RetroPie Installation Docs: [https://github.com/petrockblog/RetroPie-Setup][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/super-pi-brothers
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://blog.petrockblock.com/retropie
|
||||
[2]:https://github.com/petrockblog/RetroPie-Setup
|
||||
@ -1,43 +0,0 @@
|
||||
nd0104 is translate
|
||||
Linux FAQs with Answers--How to define PATH environment variable for sudo commands
|
||||
================================================================================
|
||||
> **Question**: I built and installed a program in /usr/local/bin. The program requires root privilege to run. But when I try to run the program with sudo, I get "sudo: XXXXX: command not found" error. Somehow /usr/local/bin is not included in the PATH environment variable. How can I fix this problem?
|
||||
|
||||
When you run a program with sudo, the program is executed with a new, minimum environment for security reasons. That is, not all the environment variables you define are inherited to sudo commands. In case of PATH environment variable, it is reset to a new "default" PATH variable when sudo is used. So if the new default PATH variable does not include the folder where your program is, you will get "command not found" error with sudo.
|
||||
|
||||
To customize the default PATH variable for sudo session, open /etc/sudoers file with a text editor, and look for "secure_path". The value defined in "secure_path" will be used as the default PATH variable when you execute sudo commands.
|
||||
|
||||
So add any necessary path (e.g., /usr/local/bin) to "secure_path", and it will be passed to sudo commands.
|
||||
|
||||
Defaults secure_path = /sbin:/bin:/usr/sbin:/usr/bin:/usr/local/bin
|
||||
|
||||
This change will be effective immediately.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/define-path-environment-variable-sudo-commands.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:
|
||||
[2]:
|
||||
[3]:
|
||||
[4]:
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
@ -1,56 +0,0 @@
|
||||
Love-xuan 翻译中
|
||||
Display Song Lyrics On Desktop In Ubuntu 14.04
|
||||
================================================================================
|
||||

|
||||
|
||||
Apart from free streaming music, what I like the most in [Spotify][1] is its lyrics plugin. At times I don’t understand all of the words of the song, specially if it’s rap. [TuneWiki][2] plugin comes handy in this case. While TuneWiki has plugins for Windows Media Player and iTune, what options do we have on desktop Linux?
|
||||
|
||||
If you have been using desktop Linux for sometime, you might have heard of [OSD Lyrics][3]. It is a small application that **displays song lyrics on the desktop**. You can use it with several audio players such as Rythmbox, [Banshee][4], [Clementine][5] etc.
|
||||
|
||||
### Install OSD Lyrics in Ubuntu 14.04 and Linux Mint 17 ###
|
||||
|
||||
OSD Lyrics was actively maintained through its official PPA about 2 years back. There is no development anymore. While the PPA is no longer usable, the executables (.deb) can be downloaded from the website. Though these executables are originally for Ubuntu 12.04 Precise Pangolin, these files work very well in Ubuntu 14.04 also. Let’s see **how to install OSD Lyrics in Ubuntu 14.04 and Linux Mint 17**.
|
||||
|
||||
Go to the [download page of OSD Lyrics][6]. Get the .deb files depending upon [whether you are using 32 bit or 64 bit Ubuntu][7]. You will find the files on the top.
|
||||
|
||||

|
||||
|
||||
Once downloaded, just double click on it to install it via Ubuntu Software Center. Alternatively, you can [use Gdebi to quickly install .deb packages][8].
|
||||
|
||||
### How to display lyrics in Ubuntu and Linux Mint using OSD Lyrics ###
|
||||
|
||||
Once installed, you can run OSD Lyrics from the Unity Dash:
|
||||
|
||||

|
||||
|
||||
On the first run, it will detect the existing players which are compatible with OSD Lyrics. You can set a default player which will be opened automatically each time you start OSD Lyrics.
|
||||
|
||||

|
||||
|
||||
One thing to note is that unlike [Shazam][9] etc, OSD Lyrics doesn’t find the lyrics from the audio, rather it uses the information linked to the music files such as name, album, artist etc. So make sure that you have music files from “respectable sources” or keep the file information correct and updated.
|
||||
|
||||
If it recognizes the music files, it will display the lyrics on the desktop in Karaoke format:
|
||||
|
||||

|
||||
|
||||
There are plenty of configuration options available with OSD Lyrics. You can change the font, size behavior of the lyrics display among many other things.
|
||||
|
||||
How do you like OSD Lyrics? Do you use some other Lyrics plugin? Do share your views with rest of us.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/display-song-lyrics-desktop-ubuntu-1404/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://itsfoss.com/install-spotify-ubuntu-1404/
|
||||
[2]:http://www.tunewiki.com/
|
||||
[3]:https://code.google.com/p/osd-lyrics
|
||||
[4]:http://banshee.fm/
|
||||
[5]:https://www.clementine-player.org/
|
||||
[6]:https://code.google.com/p/osd-lyrics/downloads/list
|
||||
[7]:http://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
[8]:http://itsfoss.com/install-deb-files-easily-and-quickly-in-ubuntu-12-10-quick-tip/
|
||||
[9]:http://www.shazam.com/
|
||||
@ -1,108 +0,0 @@
|
||||
[bazz2 so handsome]
|
||||
Linux Kernel Testing and Debugging
|
||||
================================================================================
|
||||
### Compiling and Installing Stable Kernel ###
|
||||
|
||||
If you cloned the stable git:
|
||||
|
||||
cd linux-stable
|
||||
|
||||
git checkout linux-3.x.y
|
||||
|
||||
or if you are using the tar-ball:
|
||||
|
||||
cd linux-3.x.y
|
||||
|
||||
Starting out with the distribution configuration file is the safest approach for the very first kernel install on any system. You can do so by copying the configuration for your current kernel from /boot.
|
||||
|
||||
cp /boot/config-3.x.y-z-generic .config
|
||||
|
||||
Run the following command to generate kernel configuration file based on the current configuration. You will be prompted to tune the configuration to enable new features and drivers that have been added since the Ubuntu snapshot the kernel from the mainline.
|
||||
|
||||
make oldconfig
|
||||
|
||||
Once this step is complete, it is time to compile the kernel:
|
||||
|
||||
make all
|
||||
|
||||
Once the kernel compilation is complete, install the new kernel:
|
||||
|
||||
sudo "make modules_install install"
|
||||
|
||||
The above command will install the new kernel and run update-grub to add the new kernel to the grub menu. Now it is time to reboot the system to boot the newly installed kernel. Before we do that, let's save logs from the current kernel to compare and look for regressions and new errors, if any:
|
||||
|
||||
dmesg -t > dmesg_current
|
||||
|
||||
dmesg -t -k > dmesg_kernel
|
||||
|
||||
dmesg -t -l emerg > dmesg_current_emerg
|
||||
|
||||
dmesg -t -l alert > dmesg_current_alert
|
||||
|
||||
dmesg -t -l crit > dmesg_current_alert
|
||||
|
||||
dmesg -t -l err > dmesg_current_err
|
||||
|
||||
dmesg -t -l warn > dmesg_current_warn
|
||||
|
||||
In general, dmesg should be clean with no emerg, alert, crit, and err level messages. If you see any of these, it might indicate some hardware and/or kernel problem.
|
||||
|
||||
A couple more important steps before trying out the newly installed kernel. There is no guarantee that the new kernel will boot. As a safe guard, please ensure that there is at least one good kernel installed. Change the default grub configuration file /etc/default/grub:
|
||||
|
||||
Enable printing early boot messages to vga using earlyprink=vga kernel boot option:
|
||||
|
||||
GRUB_CMDLINE_LINUX="earlyprink=vga"
|
||||
|
||||
Increase the GRUB_TIMEOUT value to 10 - 15 seconds, so grub pauses in menu allowing time to choose kernel to be boot:
|
||||
|
||||
Uncomment GRUB_TIMEOUT and set it to 10: GRUB_TIMEOUT=10
|
||||
Comment out GRUB_HIDDEN_TIMEOUT and GRUB_HIDDEN_TIMEOUT_QUIET
|
||||
|
||||
Run update-grub to update the grun configuration in /boot
|
||||
|
||||
sudo update-grub
|
||||
|
||||
Now restart the system. Once the new kernel comes up, compare the saved dmesg from the old kernel with the new one and see if there are any regressions. If the newly installed kernel fails to boot, you will have to boot a good kernel and then investigate why the new kernel failed to boot.
|
||||
|
||||
### Living in The Fast Lane ###
|
||||
|
||||
If you like driving in the fast lane and have the need for speed, clone the mainline kernel git or better yet the linux-next git. Booting and testing mainline and linux-next helps find and fix problems before the kernel is released.
|
||||
|
||||
Mainline:
|
||||
|
||||
git clone git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git
|
||||
|
||||
linux-next:
|
||||
|
||||
git clone git://git.kernel.org/pub/scm/linux/kernel/git/next/linux-next.git
|
||||
|
||||
Compiling and installing mainline and linux-next kernels is exactly same as the stable kernel. Please follow the instructions from previous sections.
|
||||
|
||||
### Applying Patches ###
|
||||
|
||||
Linux kernel patch files are text files that contain the differences from the original source to the new. Each Linux patch is a self-contained change to the code that stands on its own, unless explicitly made part of a patch series. New patches are applied as follows:
|
||||
|
||||
patch -p1 < file.patch
|
||||
|
||||
git apply --index file.patch
|
||||
|
||||
Either one will work, however, when a patch adds a new file and if it is applied using the patch command, git doesn't know about the new files and they will be treated as untracked files. "git diff" will not show the files in its output and "git status" will show the files as untracked.
|
||||
|
||||
For the most part, there are no issues with building and installing kernels, however, "git reset --hard" will not remove the newly added files and a subsequent git pull will fail. A couple of ways to tell git about the new files and have it track them, there by avoiding the above issues:
|
||||
|
||||
|
||||
Option 1:
|
||||
|
||||
> When a patch that adds new files is applied using the patch command, run "git clean" to remove untracked files, before running "git reset --hard". For example, git clean -dfx will force remove untracked directories and files, ignoring any standard ignore rules specified in the .gitignore file. You could include -q option to run git clean in quiet mode, if you don't care to know which files are removed.
|
||||
|
||||
Option 2:
|
||||
|
||||
> An alternate approach is to tell git to track the newly added files by running "git apply --index file.patch". This will result in git applying the patch and adding the result to the index. Once this is done, git diff will show the newly added files in its output and git status will report the status correctly tagging these files as newly created files.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/linux-kernel-testing-and-debugging?page=0,1
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -1,125 +0,0 @@
|
||||
Linux Kernel Testing and Debugging
|
||||
================================================================================
|
||||
### Basic Testing ###
|
||||
|
||||
Once a new kernel is installed, the next step is try to boot it and see what happens. Once the new kernel is up and running, check dmesg for any regressions. Run a few usage tests:
|
||||
|
||||
- Is networking (wifi or wired) functional?
|
||||
- Does ssh work?
|
||||
- Run rsync of a large file over ssh
|
||||
- Run git clone and git pull
|
||||
- Start web browser
|
||||
- Read email
|
||||
- Download files: ftp, wget etc.
|
||||
- Play audio/video files
|
||||
- Connect new USB devices mouse, usb stick etc.
|
||||
|
||||
|
||||
### Examine Kernel Logs ###
|
||||
|
||||
Checking for regressions in dmesg is a good way to identify problems, if any, introduced by the new code. As a general rule, there should be no new crit, alert, and emerg level messages in dmesg. There should be no new err level messages. Pay close attention to any new warn level messages as well. lease note that new warn messages aren't as bad. New code at times adds new warning messages which are just warnings.
|
||||
|
||||
- dmesg -t -l emerg
|
||||
- dmesg -t -l crit
|
||||
- dmesg -t -l alert
|
||||
- dmesg -t -l err
|
||||
- dmesg -t -l warn
|
||||
- dmesg -t -k
|
||||
- dmesg -t
|
||||
|
||||
The following script runs the above dmesg commands and saves the output for comparing with older release dmesg files. It then runs diff commands against the older release dmesg files. Old release is a required input parameter. If one is not supplied, it will simply generate dmesg files and exit. Regressions indicate newly introduced bugs and/or bugs that escaped patch testing and integration testing in linux git trees prior to including the patch in a release. Are there any stack traces resulting from WARN_ON in the dmesg? These are serious problems that require further investigation.
|
||||
|
||||
- [**dmesg regression check script**][1]
|
||||
|
||||
### Stress Testing ###
|
||||
|
||||
Running 3 to 4 kernel compiles in parallel is a good overall stress test. Download a few Linux kernel gits, stable, linux-next etc.. Run timed compiles in parallel. Compare times with old runs of this test for regressions in performance. Longer compile times could be indicators of performance regression in one of the kernel modules. Performance problems are hard to debug. First step is to detect them. Running several compiles in parallel is a good overall stress test that could be used as a performance regression test and overall kernel regression test, as it exercises various kernel modules like memory, file-systems, dma, and drivers.
|
||||
|
||||
time make all
|
||||
|
||||
### Kernel Testing Tools ###
|
||||
|
||||
There are several tests under tools/testing that are included in the Linux kernel git. There is a good mix of automated and functional tests.
|
||||
ktest suite
|
||||
|
||||
ktest is an automated test suite that can test builds, installs, and kernel boots. It can also run cross-compile tests provided the system has cross-compilers installed. ktest depends on flex and bison tools. Please consult the ktest documentation in tools/testing/ktest for details on how to run ktest. It is left to the reader as a self-study. A few resources that go into detail on how to run ktest:
|
||||
|
||||
- [**ktest-eLinux.org**][2]
|
||||
|
||||
### tools/testing/selftests ###
|
||||
|
||||
Let's start with selftests. Kernel sources include a set of self-tests which test various sub-systems. As of this writing, breakpoints, cpu-hotplug, efivarfs, ipc, kcmp, memory-hotplug, mqueue, net, powerpc, ptrace, rcutorture, timers, and vm sub-systems have self-tests. In addition to these, user memory self-tests test user memory to kernel memory copies via test_user_copy module. The following is on how to run these self-tests:
|
||||
|
||||
Compile tests:
|
||||
|
||||
make -C tools/testing/selftests
|
||||
|
||||
Run all tests: (running some tests needs root access, login as root and run)
|
||||
|
||||
make -C tools/testing/selftests run_tests
|
||||
|
||||
Run only tests targeted for a single sub-system:
|
||||
|
||||
make -C tools/testing/selftests TARGETS=vm run_tests
|
||||
|
||||
### tools/testing/fault-injection ###
|
||||
|
||||
Another test suite under tools/testing is fault-injection. failcmd.sh script runs a command to inject slab and page allocation failures. This type of testing helps validate how well kernel can recover from faults. This test should be run as root. The following is a quick summary of currently implemented fault injection capabilities. The list keeps growing as new fault injection capabilities get added. Please refer to the Documentation/fault-injection/fault-injection.txt for the latest.
|
||||
|
||||
failslab (default option)
|
||||
|
||||
injects slab allocation failures. kmalloc(), kmem_cache_alloc(), ...
|
||||
|
||||
fail_page_alloc
|
||||
|
||||
injects page allocation failures. alloc_pages(), get_free_pages(), ...
|
||||
|
||||
fail_make_request
|
||||
|
||||
injects disk IO errors on devices permitted by setting, /sys/block//make-it-fail or /sys/block///make-it-fail. (generic_make_request())
|
||||
|
||||
fail_mmc_request
|
||||
|
||||
injects MMC data errors on devices permitted by setting debugfs entries under /sys/kernel/debug/mmc0/fail_mmc_request
|
||||
|
||||
The capabilities and behavior of fault-injection can be configured. fault-inject-debugfs kernel module provides some debugfs entries for runtime. Ability to specify the error probability rate for faults, the interval between fault injection are just a couple of examples of the configuration choices fault-injection test supports. Please refer to the Documentation/fault-injection/fault-injection.txt for details. Boot options can be used to inject faults during early boot before debugfs becomes available. The following boot options are supported:
|
||||
|
||||
- failslab=
|
||||
- fail_page_alloc=
|
||||
- fail_make_request=
|
||||
- mmc_core.fail_request=[interval],[probability],[space],[times]
|
||||
|
||||
The fault-injection infrastructure provides interfaces to add new fault-injection capabilities. The following is a brief outline of the steps involved in adding a new capability. Please refer to the above mentioned document for details:
|
||||
|
||||
define the fault attributes using DECLARE_FAULT_INJECTION(name);
|
||||
|
||||
> Please see the definition of struct fault_attr in fault-inject.h for details.
|
||||
|
||||
add a boot option to configure fault attributes
|
||||
|
||||
> This can be done using helper function setup_fault_attr(attr, str); Adding a boot option is necessary to enable the fault injection capability during early boot time.
|
||||
|
||||
add debugfs entries
|
||||
|
||||
> Use the helper function fault_create_debugfs_attr(name, parent, attr); to add new debugfs entries for this new capability.
|
||||
|
||||
add module parameters
|
||||
|
||||
> Adding module parameters to configure the fault attributes is a good option, when the scope of the new fault capability is limited to a single kernel module.
|
||||
|
||||
add a hook to insert failures
|
||||
|
||||
> should_fail(attr, size); Upon should_fail() returning true, client code should inject a failure.
|
||||
|
||||
Applications using this fault-injection infrastructure can target a specific kernel module to inject slab and page allocation failures to limit the testing scope if need be.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/linux-kernel-testing-and-debugging?page=0,2
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://linuxdriverproject.org/mediawiki/index.php/Dmesg_regression_check_script
|
||||
[2]:http://elinux.org/Ktest#Git_Bisect_type
|
||||
@ -1,3 +1,4 @@
|
||||
[bazz2 keep moving]
|
||||
Linux Kernel Testing and Debugging
|
||||
================================================================================
|
||||
### Auto Testing Tools ###
|
||||
@ -140,4 +141,4 @@ via:http://www.linuxjournal.com/content/linux-kernel-testing-and-debugging?page=
|
||||
[1]:http://autotest.github.io/
|
||||
[2]:https://github.com/autotest/autotest/wiki/WhitePaper
|
||||
[3]:http://events.linuxfoundation.org/sites/events/files/slides/Shuah_Khan_dma_map_error.pdf
|
||||
[4]:http://www.linuxjournal.com/content/july-2013-linux-kernel-news
|
||||
[4]:http://www.linuxjournal.com/content/july-2013-linux-kernel-news
|
||||
|
||||
@ -0,0 +1,36 @@
|
||||
Fix Missing Speaker Icon From Moka Icon Theme [Quick Tip]
|
||||
================================================================================
|
||||
[Moka][1] is a beautiful icon theme. It has been constantly featured among the [best icon themes available for Ubuntu][2]. But there is little issue with Moka in Ubuntu 14.04. If you use Moka icons in Ubuntu 14.04 with Unity, you’ll find that speaker icon used for sound is missing:
|
||||
|
||||

|
||||
|
||||
### Fix missing sound icon while using Moka icon theme ###
|
||||
|
||||
Though you might have already added official Moka PPA but for the sake of checking, add it again:
|
||||
|
||||
sudo add-apt-repository ppa:moka/stable
|
||||
sudo apt-get update
|
||||
|
||||
Now, next step is to install monochrome panel icons. Use the following command to install it:
|
||||
|
||||
sudo apt-get install faba-mono-icons
|
||||
|
||||
Once you have installed the Faba monochrome icons, change your icon theme from Moka to Faba. This will give you Moka icon theme along with beautiful monochrome icons in the top panel in Unity:
|
||||
|
||||

|
||||
|
||||
I hope this helped you to fix the missing sound icon. Enjoy every bit and every sip of the Moka.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/fix-missing-speaker-icon-from-moka/
|
||||
|
||||
原文作者:[Abhishek][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://mokaproject.com/
|
||||
[2]:http://itsfoss.com/best-icon-themes-ubuntu-1404/
|
||||
@ -0,0 +1,89 @@
|
||||
How to access SoundCloud from the command line in Linux
|
||||
================================================================================
|
||||
If you enjoy music streaming and originally-created sounds, you cannot have missed [SoundCloud][1]. Based in Germany, this cloud streaming service is now famous and well-established for any music adventurer. And naturally, as a Linux enthusiast, you might wonder how to join your passion for Linux with your love for music. As a solution, I advise you to check out Soundcloud2000, **a command line client for SoundCloud** born out of the [Music Hack Day Stockholm '13][2].
|
||||
|
||||
### Installation ###
|
||||
|
||||
For Debian or Ubuntu users, install via:
|
||||
|
||||
$ sudo apt-get install portaudio19-dev libmpg123-dev libncurses-dev ruby1.9.1-dev
|
||||
$ sudo gem install soundcloud2000
|
||||
|
||||
For Archlinux users, the package is available in [AUR][3].
|
||||
|
||||
For Fedora users, install via:
|
||||
|
||||
$ sudo yum install portaudio-devel libmpg123-devel ncurses-devel ruby-devel
|
||||
$ sudo gem install soundcloud2000
|
||||
|
||||
For CentOS users, install or upgrade to the [latest Ruby/RubyGems][4] (1.9 and higher), enable [Repoforge repo][5], and install via:
|
||||
|
||||
$ sudo yum install portaudio-devel mpg123-devel
|
||||
$ sudo gem install curses soundcloud2000
|
||||
|
||||
And finally, go to the official github page for the sources.
|
||||
|
||||
### Usage ###
|
||||
|
||||
Soundcloud2000 is very easy to pick up. Some might even say simplistic. I like it for that sobriety and the effort of the three authors and contributors. Launch it via:
|
||||
|
||||
$ soundcloud2000
|
||||
|
||||
From there, you will be welcomed with a splash screen:
|
||||
|
||||

|
||||
|
||||
and then a list of songs:
|
||||
|
||||
|
||||
|
||||
You can scroll through the list via the up and down keys, play a song with enter, pause/resume with the space bar, and fast forward/rewind with the right and left arrow keys. As you can see, nothing groundbreaking but definitely ergonomic.
|
||||
|
||||
If the random list is too long to scroll through, you have an option to see all the tracks for a particular user by hitting the 'u' key and then typing his name.
|
||||
|
||||

|
||||
|
||||
That is probably one of the major defaults of Soundcloud2000. While the navigation is not optimized, I have high hopes for improvements and support as the software is still very young.
|
||||
|
||||
### Bonus ###
|
||||
|
||||
Another alternative as a bonus: if you like the idea of using SoundCloud from a terminal, but do not want to install any additional software (or maybe you cannot), I advise you to go to [cmd.fm][6]. The website is a kind of camouflage for SoundCloud, as it hides it behind a shell interface.
|
||||
|
||||
[][7]
|
||||
|
||||
Type "help" for a list of commands, which is a lot longer than for Soundcloud2000. As examples, I noticed:
|
||||
|
||||
- _genres to list all genres
|
||||
- _play random to play a random track
|
||||
- _pause to pause the current track
|
||||
- _playlist new to make a new playlist
|
||||
- _loop to loop current track
|
||||
- _cinema to watch and ASCII version of Star Wars which completely blew my mind.
|
||||
|
||||
And it even supports auto-completion via the tabulation key for genres.
|
||||
|
||||
To conclude, Soundcloud2000 is a neat program that does exactly what it is supposed to. We can forgive its current flaws as they are surely tied to its youth. I really hope that it will grow and include more features (and potentially get inspiration from cmd.fm).
|
||||
|
||||
If you like the idea, I invite you to support the programmers, and if you like these kinds of initiatives, support [Music Hack Day][8] which mixes software development and music.
|
||||
|
||||
What do you think of using SoundCloud from the command line? Please let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/07/access-soundcloud-command-line-linux.html
|
||||
|
||||
原文作者:[Adrien Brochard][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:https://soundcloud.com/
|
||||
[2]:https://www.hackerleague.org/hackathons/music-hack-day-stockholm-13/
|
||||
[3]:https://aur.archlinux.org/packages/ruby-soundcloud2000/
|
||||
[4]:http://ask.xmodulo.com/upgrade-ruby-centos.html
|
||||
[5]:http://xmodulo.com/2013/01/how-to-set-up-rpmforge-repoforge-repository-on-centos.html
|
||||
[6]:https://cmd.fm/
|
||||
[7]:https://www.flickr.com/photos/xmodulo/14494448218/
|
||||
[8]:http://new.musichackday.org/
|
||||
@ -0,0 +1,89 @@
|
||||
How to configure chroot SFTP in Linux
|
||||
================================================================================
|
||||
There are **some scenario** where system admin wants only few users should be allowed to transfer files to Linux boxes not ssh. We can achieve this by setting up **SFTP** in chroot environment.
|
||||
|
||||
### Background of SFTP & chroot : ###
|
||||
|
||||
**SFTP** stands for **SSH File Transfer protocol or Secure File Transfer Protocol**. SFTP provides file access, file transfer, and file management functionalities over any reliable data stream. When we configure SFTP in chroot environment , then only allowed users will be limited to their **home directory** , or we can say allowed users will be in jail like environment where they can’t even change their directory.
|
||||
|
||||
In article we will configure **Chroot SFTP in RHEL 6.X** & **CentOS 6.X**. We have one user ‘**Jack**’ , this users will be allowed to transfer files on linux box but no ssh access.
|
||||
|
||||
### Step:1 Create a group ###
|
||||
|
||||
[root@localhost ~]# groupadd sftp_users
|
||||
|
||||
### Step:2 Assign the secondary group(sftp_users) to the user. ###
|
||||
|
||||
If the users doesn’t exist on system , use below command :
|
||||
|
||||
[root@localhost ~]# useradd -G sftp_users -s /sbin/nologin jack
|
||||
[root@localhost ~]# passwd jack
|
||||
|
||||
For **already existing users** , use below usermod command :
|
||||
|
||||
[root@localhost ~]# usermod –G sftp_users -s /sbin/nologin jack
|
||||
|
||||
**Note** : if you want to change the **default home directory** of users , then use ‘**-d**’ option in useradd and usermod command and set the **correct permissions**.
|
||||
|
||||
### Step:3 Now edit the config file “/etc/ssh/sshd_config” ###
|
||||
|
||||
# vi /etc/ssh/sshd_config
|
||||
#comment out the below line and add a line like below
|
||||
#Subsystem sftp /usr/libexec/openssh/sftp-server
|
||||
Subsystem sftp internal-sftp
|
||||
|
||||
# add Below lines at the end of file
|
||||
Match Group sftp_users
|
||||
X11Forwarding no
|
||||
AllowTcpForwarding no
|
||||
ChrootDirectory %h
|
||||
ForceCommand internal-sftp
|
||||
|
||||
#### Where : ####
|
||||
|
||||
- **Match Group sftp_users** – This indicates that the following lines will be matched only for users who belong to group sftp_users
|
||||
- **ChrootDirectory %h** – This is the path(default user's home directory) that will be used for chroot after the user is authenticated. So, for Jack, this will be /home/jack.
|
||||
- **ForceCommand internal-sftp** – This forces the execution of the internal-sftp and ignores any command that are mentioned in the ~/.ssh/rc file.
|
||||
|
||||
Restart the ssh service
|
||||
|
||||
# service sshd restart
|
||||
|
||||
### Step:4 Set the Permissions : ###
|
||||
|
||||
[root@localhost ~]# chmod 755 /home/jack
|
||||
[root@localhost ~]# chown root /home/jack
|
||||
[root@localhost ~]# chgrp -R sftp_users /home/jack
|
||||
|
||||
If You want that jack user should be allowed to upload files , then create a upload folder with the below permissions ,
|
||||
|
||||
[root@localhost jack]# mkdir /home/jack/upload
|
||||
[root@localhost jack]# chown jack. /home/jack upload/
|
||||
|
||||
### Step:5 Now try to access the system & do testing ###
|
||||
|
||||
Try to access the system via ssh
|
||||
|
||||

|
||||
|
||||
As You can see below jack user is logged in via SFTP and can't change the directory becuase of chroot environment.
|
||||
|
||||
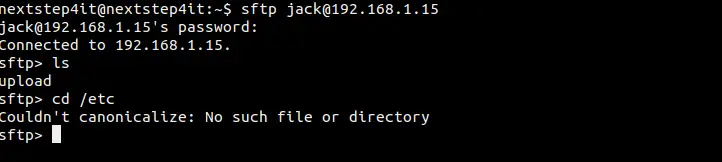
|
||||
|
||||
Now do the **uploading and downloading** testing as shown below:
|
||||
|
||||
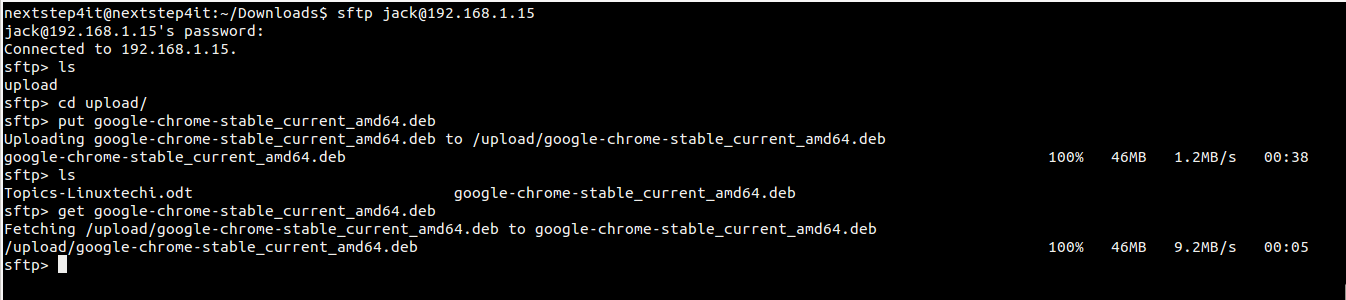
|
||||
|
||||
As we can see above , both uploading & downloading working fine for jack user.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/configure-chroot-sftp-in-linux/
|
||||
|
||||
原文作者:[Pradeep Kumar][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
116
sources/tech/20140723 Top 10 Fun On The Command Line.md
Normal file
116
sources/tech/20140723 Top 10 Fun On The Command Line.md
Normal file
@ -0,0 +1,116 @@
|
||||
Top 10! Fun On The Command Line
|
||||
================================================================================
|
||||
**If you just love making 'top 10'-type lists but are a little embarrassed to say so, tell people you're passionate about data exploration. To impress them even more, explain that you do your data exploration on the command line. But don't ruin the impression by telling them how easy that is!**
|
||||
|
||||
In this article I'll do some data exploration with basic GNU/Linux tools and 'one-column tables', by which I mean simple lists. For more information on the commands used here, see their Linux 'man' pages, or ask for an explanation in the 'Comments' section.
|
||||
|
||||
### Passwords ###
|
||||
|
||||
The first list to explore is Mark Burnett's 2011 compilation of the [10000 most commonly used passwords][1]. The list is ordered most-frequent-first, and is one source of the widely known factoid that 'password' is the most commonly used password, with '123456' in second place. Here I've put the list in a file called passwords, and used the head command to show the first 10 lines:
|
||||
|
||||

|
||||
|
||||
(Burnett explains how he collects his passwords [here][2]. Note that he converted all uppercase letters to lowercase in his list.)
|
||||
|
||||
OK, so 'password' is top of the Burnett list. What about individual digits?
|
||||
|
||||

|
||||
|
||||
Interesting. The digit '1' appears in the password list more than twice as often as the next most-used digit, '2', and the 10 digits are in numerical as well as popularity order, except for 0 and 9. And the top 10 letters?
|
||||
|
||||

|
||||
|
||||
The most frequent letters in the passwords file are EARONISTLC. That's not too far off EAIRTONSLC, which is the frequency pattern in at least [one published table][3] of letter usage in common English words. Does this mean that most passwords are actually common English words, maybe with a few digits thrown in?
|
||||
|
||||
To find out, I'll first convert passwords to a list of letters-only strings, then see how many of those strings are in an English dictionary.
|
||||
|
||||
First I'll delete all the digits in passwords with a **sed** command, then delete all the punctuation marks, then all the blank lines. This creates a list of letters-only passwords. Then I'll prune that list with **sort** and **uniq** to get rid of any duplicates. (For example, 'abc1234def' and 'abc1!2!3!def!' both reduce to 'abcdef'.) According to the wc command, my pruning reduces the 10000 passwords to 8583 letters-only strings:
|
||||
|
||||

|
||||
|
||||
For a handy English dictionary I'll use the file `usr/share/dict/american-english`, which came with my Debian Linux distribution. It contains 99171 words. I'll first convert this wordlist to lowercase-only with the **tr** command, then delete any duplicate entries with **sort** and **uniq** (like 'A' and 'a' both becoming 'a'). That reduces the wordlist to 97723 entries:
|
||||
|
||||

|
||||
|
||||
I can now ask the comm command with the '-23' option to compare the two lists and report just the words in the letters-only file that are not found in the dictionary:
|
||||
|
||||

|
||||
|
||||
The total is 3137, so at least 8583 - 3137 = 5446 'core' passwords in Burnett's lowercase-only list (about 63%) are either plain English words, or plain English words with some digits or punctuation marks added. I wrote at least because a big proportion of the 3137 strings are only slight modifications of plain English words or names, or words or names missing from the /usr/share dictionary. Among the LA's, for example, are 'labtec', 'ladyboy', 'lakeside', 'lalakers', 'lalala', 'laserjet', 'lasvegas', 'lavalamp' and 'lawman'.
|
||||
|
||||
### Placenames ###
|
||||
|
||||
In a previous [Linux Rain article][4], I described how I built a table of Australian placenames with more than 370 000 entries. Using it, I can now answer vital questions like 'Is Round Hill the most popular name for hills in Australia?' and 'Is Sandy Beach tops for beaches, and Rocky Creek for creeks?'
|
||||
|
||||
The placename field in the gazetteer table is number 2, so here goes:
|
||||
|
||||

|
||||
|
||||
Wow. I wasn't even close. (But note how I saved typing by using the **^string1^string2** command. It repeats the last command, but substitutes string2 for string1. Wonderful BASH trick!)
|
||||
|
||||
Another burning question is how many placenames there are with 'Mile' in them, like 'Six Mile Creek', and how they rank:
|
||||
|
||||

|
||||
|
||||
I've noticed a lot of Dead Horse Creeks in my Australian travels, and so has the gazetteer:
|
||||
|
||||

|
||||
|
||||
### Species ###
|
||||
|
||||
The third list to explore comes from a table I published this year of new Australian insect species named in the period 1961-2010. From the table I've pulled out all the 'species epithets', which are the second parts of genus-species combinations like Homo sapiens (you and me) and Apis mellifera (European honeybee).
|
||||
|
||||
(Tech note: The insects table, which is available from the open data Zenodo repository at [https://zenodo.org/record/10481][5], includes subspecies. For my 'top 10' exercise I first isolated all the unique genus-species combinations, to avoid duplication from subspecies like Apis mellifera iberica, Apis mellifera intermissa, etc. The final species file has 18155 species epithets.)
|
||||
|
||||
Most people who make jokes about scientific names use the '-us' ending, as in 'Biggus buggus'. What about entomologists? There are a couple of good, command-line ways to get the last 2 letters of a string, and here I've used both:
|
||||
|
||||

|
||||
|
||||
Yep, entomologists prefer '-us', too. Next, I wonder how many species are named for my home State of Tasmania? (Below I ask head for the first 100 lines to make sure I get all the 'tasman' combinations.)
|
||||
|
||||

|
||||
|
||||
How about Queensland?
|
||||
|
||||

|
||||
|
||||
And generally speaking, what are the top 10 names in that insect species list?
|
||||
|
||||

|
||||
|
||||
Hmm. Apart from the obvious 'australis' and 'australiensis', and the geographical 'occidentalis' (of the west), the other 7 epithets in the 10-most-popular list have been created by entomologists to honour other entomologists. (The epithet 'commoni' honors the Australian butterfly and moth specialist Ian F.B. Common, 1917-2006.)
|
||||
|
||||
### Speechifying ###
|
||||
|
||||
The commands used above work on simple lists. To make a simple list out a block of text, the command line is again your friend. For example, I've saved a rather filibustery [speech][6] in the Australian Senate on 16 July 2014 as the text file hansard. To split hansard into a list of words:
|
||||
|
||||

|
||||
|
||||
And to look at word frequency in the speech:
|
||||
|
||||

|
||||
|
||||
### Coming soon... ###
|
||||
|
||||
Doing 'top 10' and other rankings from multi-column tables requires a few more command-line tools. I'll demonstrate their use in a future article.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thelinuxrain.com/articles/top-10-fun-on-the-command-line
|
||||
|
||||
原文作者:Bob Mesibov(Bob Mesibov is Tasmanian, retired and a keen Linux tinkerer.)
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://xato.net/passwords/more-top-worst-passwords/#.U8eD13AvDy0
|
||||
[2]:https://xato.net/passwords/how-i-collect-passwords/#.U8eEdnAvDy0
|
||||
[3]:http://www.rinkworks.com/words/letterfreq.shtml
|
||||
[4]:http://www.thelinuxrain.com/articles/building-a-gazetteer-table-from-kml-files
|
||||
[5]:https://zenodo.org/record/10481
|
||||
[6]:http://parlinfo.aph.gov.au/parlInfo/search/display/display.w3p;db=CHAMBER;id=chamber%2Fhansards%2F232fa1a8-d7e8-4b22-9018-1a99b5a96812%2F0025;query=Id%3A%22chamber%2Fhansards%2F232fa1a8-d7e8-4b22-9018-1a99b5a96812%2F0000%22
|
||||
@ -0,0 +1,191 @@
|
||||
7 ‘dmesg’ Commands for Troubleshooting and Collecting Information of Linux Systems
|
||||
================================================================================
|
||||
The ‘dmesg‘ command displays the messages from the kernel ring buffer. A system passes multiple runlevel from where we can get lot of information like system architecture, cpu, attached device, RAM etc. When computer boots up, a kernel (core of an operating system) is loaded into memory. During that period number of messages are being displayed where we can see hardware devices detected by kernel.
|
||||
|
||||

|
||||
dmesg Command Examples
|
||||
|
||||
The messages are very important in terms of diagnosing purpose in case of device failure. When we connect or disconnect hardware device on the system, with the help of dmesg command we come to know detected or disconnected information on the fly. The **dmesg** command is available on most **Linux and Unix** based Operating System.
|
||||
|
||||
Let’s throw some light on most famous tool called ‘dmesg’ command with their practical examples as discussed below. The exact syntax of dmesg as follows.
|
||||
|
||||
# dmseg [options...]
|
||||
|
||||
### 1. List all loaded Drivers in Kernel ###
|
||||
|
||||
We can use text-manipulation tools i.e. ‘**more**‘, ‘**tail**‘, ‘**less**‘ or ‘**grep**‘ with dmesg command. As output of dmesg log won’t fit on a single page, using dmesg with pipe more or less command will display logs in a single page.
|
||||
|
||||
[root@tecmint.com ~]# dmesg | more
|
||||
[root@tecmint.com ~]# dmesg | less
|
||||
|
||||
#### Sample Output ####
|
||||
|
||||
[ 0.000000] Initializing cgroup subsys cpuset
|
||||
[ 0.000000] Initializing cgroup subsys cpu
|
||||
[ 0.000000] Initializing cgroup subsys cpuacct
|
||||
[ 0.000000] Linux version 3.11.0-13-generic (buildd@aatxe) (gcc version 4.8.1 (Ubuntu/Linaro 4.8.1-10ubuntu8) ) #20-Ubuntu SMP Wed Oct 23 17:26:33 UTC 2013
|
||||
(Ubuntu 3.11.0-13.20-generic 3.11.6)
|
||||
[ 0.000000] KERNEL supported cpus:
|
||||
[ 0.000000] Intel GenuineIntel
|
||||
[ 0.000000] AMD AuthenticAMD
|
||||
[ 0.000000] NSC Geode by NSC
|
||||
[ 0.000000] Cyrix CyrixInstead
|
||||
[ 0.000000] Centaur CentaurHauls
|
||||
[ 0.000000] Transmeta GenuineTMx86
|
||||
[ 0.000000] Transmeta TransmetaCPU
|
||||
[ 0.000000] UMC UMC UMC UMC
|
||||
[ 0.000000] e820: BIOS-provided physical RAM map:
|
||||
[ 0.000000] BIOS-e820: [mem 0x0000000000000000-0x000000000009fbff] usable
|
||||
[ 0.000000] BIOS-e820: [mem 0x00000000000f0000-0x00000000000fffff] reserved
|
||||
[ 0.000000] BIOS-e820: [mem 0x0000000000100000-0x000000007dc08bff] usable
|
||||
[ 0.000000] BIOS-e820: [mem 0x000000007dc08c00-0x000000007dc5cbff] ACPI NVS
|
||||
[ 0.000000] BIOS-e820: [mem 0x000000007dc5cc00-0x000000007dc5ebff] ACPI data
|
||||
[ 0.000000] BIOS-e820: [mem 0x000000007dc5ec00-0x000000007fffffff] reserved
|
||||
[ 0.000000] BIOS-e820: [mem 0x00000000e0000000-0x00000000efffffff] reserved
|
||||
[ 0.000000] BIOS-e820: [mem 0x00000000fec00000-0x00000000fed003ff] reserved
|
||||
[ 0.000000] BIOS-e820: [mem 0x00000000fed20000-0x00000000fed9ffff] reserved
|
||||
[ 0.000000] BIOS-e820: [mem 0x00000000fee00000-0x00000000feefffff] reserved
|
||||
[ 0.000000] BIOS-e820: [mem 0x00000000ffb00000-0x00000000ffffffff] reserved
|
||||
[ 0.000000] NX (Execute Disable) protection: active
|
||||
.....
|
||||
|
||||
### 2. List all Detected Devices ###
|
||||
|
||||
To discover which hard disks has been detected by kernel, you can search for the keyword “**sda**” along with “**grep**” like shown below.
|
||||
|
||||
[root@tecmint.com ~]# dmesg | grep sda
|
||||
|
||||
[ 1.280971] sd 2:0:0:0: [sda] 488281250 512-byte logical blocks: (250 GB/232 GiB)
|
||||
[ 1.281014] sd 2:0:0:0: [sda] Write Protect is off
|
||||
[ 1.281016] sd 2:0:0:0: [sda] Mode Sense: 00 3a 00 00
|
||||
[ 1.281039] sd 2:0:0:0: [sda] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA
|
||||
[ 1.359585] sda: sda1 sda2 < sda5 sda6 sda7 sda8 >
|
||||
[ 1.360052] sd 2:0:0:0: [sda] Attached SCSI disk
|
||||
[ 2.347887] EXT4-fs (sda1): mounted filesystem with ordered data mode. Opts: (null)
|
||||
[ 22.928440] Adding 3905532k swap on /dev/sda6. Priority:-1 extents:1 across:3905532k FS
|
||||
[ 23.950543] EXT4-fs (sda1): re-mounted. Opts: errors=remount-ro
|
||||
[ 24.134016] EXT4-fs (sda5): mounted filesystem with ordered data mode. Opts: (null)
|
||||
[ 24.330762] EXT4-fs (sda7): mounted filesystem with ordered data mode. Opts: (null)
|
||||
[ 24.561015] EXT4-fs (sda8): mounted filesystem with ordered data mode. Opts: (null)
|
||||
|
||||
**NOTE**: The ‘sda’ first SATA hard drive, ‘sdb’ is the second SATA hard drive and so on. Search with ‘hda’ or ‘hdb’ in the case of IDE hard drive.
|
||||
|
||||
### 3. Print Only First 20 Lines of Output ###
|
||||
|
||||
The ‘head’ along with dmesg will show starting lines i.e. ‘dmesg | head -20′ will print only 20 lines from the starting point.
|
||||
|
||||
[root@tecmint.com ~]# dmesg | head -20
|
||||
|
||||
[ 0.000000] Initializing cgroup subsys cpuset
|
||||
[ 0.000000] Initializing cgroup subsys cpu
|
||||
[ 0.000000] Initializing cgroup subsys cpuacct
|
||||
[ 0.000000] Linux version 3.11.0-13-generic (buildd@aatxe) (gcc version 4.8.1 (Ubuntu/Linaro 4.8.1-10ubuntu8) ) #20-Ubuntu SMP Wed Oct 23 17:26:33 UTC 2013 (Ubuntu 3.11.0-13.20-generic 3.11.6)
|
||||
[ 0.000000] KERNEL supported cpus:
|
||||
[ 0.000000] Intel GenuineIntel
|
||||
[ 0.000000] AMD AuthenticAMD
|
||||
[ 0.000000] NSC Geode by NSC
|
||||
[ 0.000000] Cyrix CyrixInstead
|
||||
[ 0.000000] Centaur CentaurHauls
|
||||
[ 0.000000] Transmeta GenuineTMx86
|
||||
[ 0.000000] Transmeta TransmetaCPU
|
||||
[ 0.000000] UMC UMC UMC UMC
|
||||
[ 0.000000] e820: BIOS-provided physical RAM map:
|
||||
[ 0.000000] BIOS-e820: [mem 0x0000000000000000-0x000000000009fbff] usable
|
||||
[ 0.000000] BIOS-e820: [mem 0x00000000000f0000-0x00000000000fffff] reserved
|
||||
[ 0.000000] BIOS-e820: [mem 0x0000000000100000-0x000000007dc08bff] usable
|
||||
[ 0.000000] BIOS-e820: [mem 0x000000007dc08c00-0x000000007dc5cbff] ACPI NVS
|
||||
[ 0.000000] BIOS-e820: [mem 0x000000007dc5cc00-0x000000007dc5ebff] ACPI data
|
||||
[ 0.000000] BIOS-e820: [mem 0x000000007dc5ec00-0x000000007fffffff] reserved
|
||||
|
||||
### 4. Print Only Last 20 Lines of Output ###
|
||||
|
||||
### 4. Print Only Last 20 Lines of Output ###
|
||||
|
||||
The ‘tail’ along with dmesg command will print only 20 last lines, this is useful in case we insert removable device.
|
||||
|
||||
[root@tecmint.com ~]# dmesg | tail -20
|
||||
|
||||
parport0: PC-style at 0x378, irq 7 [PCSPP,TRISTATE]
|
||||
ppdev: user-space parallel port driver
|
||||
EXT4-fs (sda1): mounted filesystem with ordered data mode
|
||||
Adding 2097144k swap on /dev/sda2. Priority:-1 extents:1 across:2097144k
|
||||
readahead-disable-service: delaying service auditd
|
||||
ip_tables: (C) 2000-2006 Netfilter Core Team
|
||||
nf_conntrack version 0.5.0 (16384 buckets, 65536 max)
|
||||
NET: Registered protocol family 10
|
||||
lo: Disabled Privacy Extensions
|
||||
e1000: eth0 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: None
|
||||
Slow work thread pool: Starting up
|
||||
Slow work thread pool: Ready
|
||||
FS-Cache: Loaded
|
||||
CacheFiles: Loaded
|
||||
CacheFiles: Security denies permission to nominate security context: error -95
|
||||
eth0: no IPv6 routers present
|
||||
type=1305 audit(1398268784.593:18630): audit_enabled=0 old=1 auid=4294967295 ses=4294967295 res=1
|
||||
readahead-collector: starting delayed service auditd
|
||||
readahead-collector: sorting
|
||||
readahead-collector: finished
|
||||
|
||||
### 5. Search Detected Device or Particular String ###
|
||||
|
||||
It’s difficult to search particular string due to length of dmesg output. So, filter the lines with are having string like ‘**usb**‘ ‘**dma**‘ ‘**tty**‘ and ‘**memory**‘ etc. The ‘-i’ option instruct to [grep command][1] to ignore the case (upper or lower case letters).
|
||||
|
||||
[root@tecmint.com log]# dmesg | grep -i usb
|
||||
[root@tecmint.com log]# dmesg | grep -i dma
|
||||
[root@tecmint.com log]# dmesg | grep -i tty
|
||||
[root@tecmint.com log]# dmesg | grep -i memory
|
||||
|
||||
#### Sample Output ####
|
||||
|
||||
[ 0.000000] Scanning 1 areas for low memory corruption
|
||||
[ 0.000000] initial memory mapped: [mem 0x00000000-0x01ffffff]
|
||||
[ 0.000000] Base memory trampoline at [c009b000] 9b000 size 16384
|
||||
[ 0.000000] init_memory_mapping: [mem 0x00000000-0x000fffff]
|
||||
[ 0.000000] init_memory_mapping: [mem 0x37800000-0x379fffff]
|
||||
[ 0.000000] init_memory_mapping: [mem 0x34000000-0x377fffff]
|
||||
[ 0.000000] init_memory_mapping: [mem 0x00100000-0x33ffffff]
|
||||
[ 0.000000] init_memory_mapping: [mem 0x37a00000-0x37bfdfff]
|
||||
[ 0.000000] Early memory node ranges
|
||||
[ 0.000000] PM: Registered nosave memory: [mem 0x0009f000-0x000effff]
|
||||
[ 0.000000] PM: Registered nosave memory: [mem 0x000f0000-0x000fffff]
|
||||
[ 0.000000] please try 'cgroup_disable=memory' option if you don't want memory cgroups
|
||||
[ 0.000000] Memory: 2003288K/2059928K available (6352K kernel code, 607K rwdata, 2640K rodata, 880K init, 908K bss, 56640K reserved, 1146920K highmem)
|
||||
[ 0.000000] virtual kernel memory layout:
|
||||
[ 0.004291] Initializing cgroup subsys memory
|
||||
[ 0.004609] Freeing SMP alternatives memory: 28K (c1a3e000 - c1a45000)
|
||||
[ 0.899622] Freeing initrd memory: 23616K (f51d0000 - f68e0000)
|
||||
[ 0.899813] Scanning for low memory corruption every 60 seconds
|
||||
[ 0.946323] agpgart-intel 0000:00:00.0: detected 32768K stolen memory
|
||||
[ 1.360318] Freeing unused kernel memory: 880K (c1962000 - c1a3e000)
|
||||
[ 1.429066] [drm] Memory usable by graphics device = 2048M
|
||||
|
||||
### 6. Clear dmesg Buffer Logs ###
|
||||
|
||||
Yes, we can clear dmesg logs if required with below command. It will clear dmesg ring buffer message logs till you executed the command below. Still you can view logs stored in ‘**/var/log/dmesg**‘ files. If you connect any device will generate dmesg output.
|
||||
|
||||
[root@tecmint.com log]# dmesg -c
|
||||
|
||||
### 7. Monitoring dmesg in Real Time ###
|
||||
|
||||
Some distro allows command ‘tail -f /var/log/dmesg’ as well for real time dmesg monitoring.
|
||||
|
||||
[root@tecmint.com log]# watch "dmesg | tail -20"
|
||||
|
||||
Conclusion: The dmesg command is useful as dmesg records all the system changes done or occur in real time. As always you can man dmesg to get more information.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/dmesg-commands/
|
||||
|
||||
原文作者:
|
||||
|
||||

|
||||
|
||||
[Narad Shrestha][a](He has over 10 years of rich IT experience which includes various Linux Distros, FOSS and Networking. Narad always believes sharing IT knowledge with others and adopts new technology with ease.)
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/navin/
|
||||
[1]:http://www.tecmint.com/12-practical-examples-of-linux-grep-command/
|
||||
@ -0,0 +1,167 @@
|
||||
Camicri Cube: An Offline And Portable Package Management System
|
||||
================================================================================
|
||||

|
||||
|
||||
As we all know, we must have an Internet connection in our System for downloading and installing applications using synaptic manager or software center. But, what if you don’t have an Internet connection, or the Internet connection is dead slow? This will be definitely a headache when installing packages using software center in your Linux desktop. Instead, you can manually download the applications from their official site, and install them. But, most of the Linux users doesn’t aware about the required dependencies for the applications that they wanted to install. What could you do if you have such situation? Leave all the worries now. Today, we introduce an awesome offline package manager called **Camicri Cube**.
|
||||
|
||||
You can use this package manager on any Internet connected system, download the list of packages you want to install, bring them back to your offline computer, and Install them. Sounds good? Yes, It is! Cube is a package manager like Synaptic and Ubuntu Software Center, but a portable one. It can be used and run in any platform (Windows, Apt-Based Linux Distributions), online and offline, in flashdrive or any removable devices. The main goal of this project is to enable the offline Linux users to download and install Linux applications easily.
|
||||
|
||||
Cube will gather complete details of your offline computer such as OS details, installed applications and more. Then, just the copy the cube application using any USB thumb drive, and use it on the other Internet connected system, and download the list of applications you want. After downloading all required packages, head back to your original computer and start installing them. Cube is developed and maintained by **Jake Capangpangan**. It is written using C++, and bundled with all necessary packages. So, you don’t have to install any extra software to use it.
|
||||
|
||||
### Installation ###
|
||||
|
||||
Now, let us download and install Cube on the Offline system which doesn’t have the Internet connection. Download Cube latest version either from the [official Launchpad Page][1] or [Sourceforge site][2]. Make sure you have downloaded the correct version depending upon your offline computer architecture. As I use 64 bit system, I downloaded the 64bit version.
|
||||
|
||||
wget http://sourceforge.net/projects/camicricube/files/Camicri%20Cube%201.0.9/cube-1.0.9.2_64bit.zip/
|
||||
|
||||
Extract the zip file and move it to your home directory or anywhere you want:
|
||||
|
||||
unzip cube-1.0.9.2_64bit.zip
|
||||
|
||||
That’s it. Now it’s time to know how to use it.
|
||||
|
||||
### Usage ###
|
||||
|
||||
Here, I will be using Two Ubuntu systems. The original (Offline – no Internet) is running with **Ubuntu 14.04**, and the Internet connected system is running with **Lubuntu 14.04** Desktop.
|
||||
|
||||
#### Steps to do On Offline system: ####
|
||||
|
||||
From the offline system, Go to the extracted Cube folder. You’ll find an executable called “cube-linux”. Double click it, and Click Execute. If it not executable, set the executable permission as shown below.
|
||||
|
||||
sudo chmod -R +x cube/
|
||||
|
||||
Then, go to the cube directory,
|
||||
|
||||
cd cube/
|
||||
|
||||
And run the following command to run it.
|
||||
|
||||
./cube-linux
|
||||
|
||||
Enter the Project name (Ex.sk) and click **Create**. As I mentioned above, this will create a new project with complete details of your system such as OS details, list of installed applications, list of repositories etc.
|
||||
|
||||

|
||||
|
||||
As you know, our system is an offline computer that means I don’t have Internet connection. So I skipped the Update Repositories process by clicking on the **Cancel** button. We will update the repositories later on an Internet connected system.
|
||||
|
||||

|
||||
|
||||
Again, I clicked **No** to skip updating the offline computer, because we don’t have Internet connection.
|
||||
|
||||

|
||||
|
||||
That’s it. Now the new project has been created. The new project will be saved on your main cube folder. Go to the Cube folder, and you’ll find a folder called Projects. This folder will hold all the essential details of your offline system.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Now, close the cube application, and copy the entire main **cube** folder to any flash drive, and go to the Internet connected system.
|
||||
|
||||
#### Steps to do on an Internet connected system: ####
|
||||
|
||||
The following steps needs to be done on the Internet connected system. In our case, Its **Lubuntu 14.04**.
|
||||
|
||||
Make the cube folder executable as we did in the original computer.
|
||||
|
||||
sudo chmod -R +x cube/
|
||||
|
||||
Now, double click the file cube-linux to open it or you can launch it from the Terminal as shown below.
|
||||
|
||||
cd cube/
|
||||
./cube-linux
|
||||
|
||||
You will see that your project is now listed in the “Open Existing Projects” part of the window. Select your project
|
||||
|
||||

|
||||
|
||||
Then, the cube will ask if this is your project’s original computer. It’s not my original (Offline) computer, so I clicked **No**.
|
||||
|
||||

|
||||
|
||||
You’ll be asked if you want to update your repositories. Click **Ok** to update the repositories.
|
||||
|
||||

|
||||
|
||||
Next, we have to update all outdated packages/applications. Click on the “**Mark All updates**” button from the Cube’s tool bar. After that, click “**Download all marked**” button to update all updated packages/applications. As you see in the below screenshot, there are 302 packages needs to be updated in my case. Then, Click **Ok** to continue to download marked packages.
|
||||
|
||||

|
||||
|
||||
Now, Cube will start to download all marked packages.
|
||||
|
||||

|
||||
|
||||
We have completed updating repositories and packages. Now, you can download a new package if you want to install it on your offline system.
|
||||
|
||||
#### Downloading New Applications ####
|
||||
|
||||
For example, here I am going to download the **apache2** Package. Enter the name of the package in the **search** box, and hit Search button. The Cube will fetch the details of the application that you are looking for. Hit the “**Download this package now**” button, and click **Ok** to start download.
|
||||
|
||||

|
||||
|
||||
Cube will start downloading the apache2 package with all its dependencies.
|
||||
|
||||

|
||||
|
||||
If you want to search and download more packages, simply Click the button “**Mark this package**”, and do search the required packages. You can mark as many as packages you want to install on your original computer. Once you marked all packages, hit the “**Download all marked**” button on the top tool bar to start downloading them.
|
||||
|
||||
After you completed updating repositories, outdated packages, and downloading new applications, close the Cube application. Then, copy the entire Cube folder to any flash drive or external hdd, and go back to your Offline system.
|
||||
|
||||
#### Steps to do on Offline computer: ####
|
||||
|
||||
Copy the Cube folder back to your Offline system on any place you want. Go to the cube folder and double click **cube-linux** file to launch Cube application.
|
||||
|
||||
Or, you can launch it from Terminal as shown below.
|
||||
|
||||
cd cube/
|
||||
./cube-linux
|
||||
|
||||
Select your project and click Open.
|
||||
|
||||

|
||||
|
||||
Then a dialog will ask you to update your system, please click “Yes” especially when you download new repositories, because this will transfer all new repositories to your computer.
|
||||
|
||||

|
||||
|
||||
You’ll see that the repositories will be updated on your offline computer without Internet connection. Because, we already have updated the repositories on the Internet connected system. Seems cool, isn’t it?
|
||||
|
||||
After updating the repositories, let us install all downloaded packages. Click the “Mark All Downloaded” button to select all downloaded packages, and click “Install All Marked” to install all of them from the Cube main Tool bar. The Cube application will automatically open a new Terminal, and install all packages.
|
||||
|
||||

|
||||
|
||||
If you encountered with dependency problems, go to **Cube Menu -> Packages -> Install packages with complete dependencies** to install all packages.
|
||||
|
||||
If you want to install a specific package, Navigate to the List Packages, click the “Downloaded” button, and all downloaded packages will be listed.
|
||||
|
||||

|
||||
|
||||
Then, double click the desired package, and click “Install this”, or “Mark this” if you want to install it later.
|
||||
|
||||

|
||||
|
||||
By this way, you can download the required packages from any Internet connected system, and then you can install them in your offline computer without Internet connection.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
This is one of the best and useful tool ever I have used. But during testing this tool in my Ubuntu 14.04 testbox, I faced many dependency problems, and the Cube application is suddenly closed often. Also, I could use this tool only on a fresh Ubuntu 14.04 offline system without any issues. Hope all these issues wouldn’t happen on previous versions of Ubuntu. Apart from these minor issues, this tool does this job as advertised and worked like a charm.
|
||||
|
||||
Cheers!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/camicri-cube-offline-portable-package-management-system/
|
||||
|
||||
原文作者:
|
||||
|
||||

|
||||
|
||||
[SK][a](Senthilkumar, aka SK, is a Linux enthusiast, FOSS Supporter & Linux Consultant from Tamilnadu, India. A passionate and dynamic person, aims to deliver quality content to IT professionals and loves very much to write and explore new things about Linux, Open Source, Computers and Internet.)
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:https://launchpad.net/camicricube
|
||||
[2]:http://sourceforge.net/projects/camicricube/
|
||||
@ -0,0 +1,75 @@
|
||||
How to Merge Directory Trees in Linux using cp Command
|
||||
================================================================================
|
||||
How to merge two directory trees with similar layout into a third directory? Let us consider the following example to understand the problem.
|
||||
|
||||
Suppose two directories dir1 and dir2 have 3 sub-directories a, b and c in each of them. The directory layout is like below:
|
||||
|
||||

|
||||
Layout of input directories
|
||||
|
||||
These directories a, b and c have some files in them. The output of tree command will illustrate better:
|
||||
|
||||

|
||||
Layout of files
|
||||
|
||||
### 1. Using cp to create merge: ###
|
||||
|
||||
Now we want to merge these two directories into a third directory, say “merged”.
|
||||
The simplest thing that you can do to achieve this is to copy recursively the directories like below:
|
||||
|
||||

|
||||
Copy directories recursively to create new merge
|
||||
|
||||
#### 1.1 Problem with cp command and alternative: ####
|
||||
|
||||
The problem with this approach is that the files created inside merged directory are copy of original files, and not the original files themselves. But wait, (you might be asking yourself) what is the problem if the files are not original? So to answer your question, consider the situation where you have large number of bulky files. In that case, copying all the files might take hours.
|
||||
|
||||
Now let’s get back and try the same with mv command instead of cp.
|
||||
|
||||

|
||||
Attempt to merge with mv command
|
||||
|
||||
The directories are not merged. So we cannot use mv command to merge directories like this.
|
||||
Now how can you keep the original files inside “merged” directory?
|
||||
|
||||
### 2. The solution: ###
|
||||
|
||||
The cp command has a very useful option to draw us out of this situation.
|
||||
The -l or --link option to cp aommand creates the hard links instead of copying the files themselves. Let us try with that.
|
||||
|
||||
Before trying out the hard link option to cp command, let us print the inode number of the original files.
|
||||
The tree command has option to print the inodes with --inodes option:
|
||||
|
||||

|
||||
Display inodes of original files
|
||||
|
||||
Now we have the inodes listed here, we can proceed to creating the hard links with --link option to cp command:
|
||||
|
||||

|
||||
Merge directories with hard links
|
||||
|
||||
#### 2.1 Verify the files: ####
|
||||
|
||||
Now the files are copied, let us verify if the inodes match with original files:
|
||||
|
||||

|
||||
Verify Inodes
|
||||
|
||||
#### 2.2 Cleanup: ####
|
||||
|
||||
As you can see that the files have same inodes as original files. Now the problem is solved and we have the original files inside merged directory. We can now cleanup by removing the directories dir1 and dir2.
|
||||
|
||||

|
||||
Remove original directories
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-command/merge-directory-trees-linux/
|
||||
|
||||
原文作者:[Raghu][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/raghu/
|
||||
@ -0,0 +1,141 @@
|
||||
Install Google Docs on Linux with Grive Tools
|
||||
================================================================================
|
||||
Google Drive is two years old now and Google’s cloud storage solution seems to be still going strong thanks to its integration with Google Docs and Gmail. There’s one thing still missing though: a lack of an official Linux client. Apparently Google has had one floating around their offices for a while now, however it’s not seen the light of day on any Linux system.
|
||||
|
||||
Thankfully, there is an alternative solution using Grive Tools. We’ve covered Grive once before when it was in its infancy, but it’s received a fair few upgrades since then thanks to Grive Tools and is now compatible with Fedora and OpenSUSE to cover a better selection of distros. Over the course of this tutorial, we’ll show you how to set up Grive Tools and get it syncing files to and from Google Drive on a regular basis, so your work is always perfectly backed up. With the death of Ubuntu One, it’s a great alternative to Canonical’s own cloud storage solution.
|
||||
|
||||

|
||||
Accesss your backed up Linux files from anywhere with an internet connection by making use of the Drive connection
|
||||
|
||||
### Resources ###
|
||||
|
||||
A Google account
|
||||
|
||||
- [Grive Tools][1]
|
||||
|
||||
### Step-by-step ###
|
||||
|
||||
#### Step 01 Ubuntu repository ####
|
||||
|
||||
Grive Tools is not included in Ubuntu or Ubuntu-based distros yet, so you’ll need to add a third-party repository to access it. Add this with:
|
||||
|
||||
$ sudo add-apt-repository ppa:thefanclub/grive-tools
|
||||
|
||||
Follow this up with the usual sudo apt-get update before we continue.
|
||||
|
||||
#### Step 02 Ubuntu install ####
|
||||
|
||||
After the apt-get update, Grive Tools will appear in the software centre. If you want to go there and install it you can, however as we already have a terminal open we might as well use:
|
||||
|
||||
$ sudo apt-get install grive-tools
|
||||
|
||||
#### Step 03 Fedora dependencies ####
|
||||
|
||||
You’ll need to install some specific dependencies for OpenSUSE, Fedora and other RHEL-based distros. In Fedora specifically, open a terminal and install them with:
|
||||
|
||||
$ sudo yum install json-c json-c-devel qt-devel boost-devel openssl-devel libxslt libcurl libcurl-devel
|
||||
|
||||
The same packages will need to be installed on the other distros.
|
||||
|
||||
#### Step 04 Grive package ####
|
||||
|
||||
Grive is not in the repositories of any of
|
||||
these distros, however binaries exist if you won’t want to build it from source. Go to RPMSEEK.com and search for Grive; look out for the version for your distro and download it.
|
||||
|
||||
#### Step 05 Install the download ####
|
||||
|
||||
Once downloaded, install the package; you can either do it graphical or install with:
|
||||
|
||||
$ sudo yum install grive-tools-1.9.noarch.rpm
|
||||
|
||||
After that, go to the Resources link for Grive Tools and locate the Fedora package on the website: download this binary and install it alongside Grive.
|
||||
|
||||
#### Step 06 Start the setup ####
|
||||
|
||||
The method to actually get Grive and Grive Tools working on both systems is basically the same, so we’ll cover both at once while mentioning any extras that need to be done for a specific distro. The first thing you’ll need to do is look for Grive Setup in your list of programs.
|
||||
|
||||
#### Step 07 Log into your account ####
|
||||
|
||||
If you haven’t already created a Google account, you’ll need to get one sorted now before continuing. Otherwise, click Next to bring up a browser that will point you towards Google and ask you to log in. Make sure you’re logged in to the correct email address before continuing.
|
||||
|
||||
#### Step 08 Connect your account ####
|
||||
|
||||
You’ll be asked if the specific info it can look at is okay – you’ll need to confirm to continue, otherwise it can’t download or sync your Drive data. It will then give you a code to paste into a pop-up that launched when the browser opened.
|
||||
|
||||
#### Step 09 Code input ####
|
||||
|
||||
Press Next for Grive to accept the code. It will automatically open up a new Google Drive window and show your files being synced straight to your PC. This may take a while depending on how much you have stored on your account.
|
||||
|
||||
#### Step 10 Desktop notifications ####
|
||||
|
||||
Once the sync is complete, search again for Grive in your programs and look for Google Drive Indicator. Click on this and it will automatically launch a Dropbox-style toolbar notifier for Google Drive. This is also similar to the kind of notifier on desktops with an official client.
|
||||
|
||||
#### Step 11 Access Google Drive ####
|
||||
|
||||
You can quick access the contents of your Google Drive by finding the app of the same name in your program list. It links straight to your folder for ease of access, so you can add it to favourites or quick bar if you wish. There’s also an option to open it from the notifier.
|
||||
|
||||
#### Step 12 Drive options ####
|
||||
|
||||
You can access syncing options from the indicator to make sure Grive works as you want it to. Access them by clicking on the toolbar icon and select preferences. A couple of options you’d probably want checked are ‘Start Drive when computer turns on’, and ‘On screen notifications’.
|
||||
|
||||
#### Step 13 Auto-syncing ####
|
||||
|
||||
Unlike the official clients, you cannot select which folders do and do not get synced on your client. Depending on how you plan to use it, you can turn on Auto-sync so that everything is synced up and down at all times, or you can turn it off and sync manually when everything is ready.
|
||||
|
||||
#### Step 14 Large file tip ####
|
||||
|
||||
Google Drive – not just Grive – always seems to have issues with uploading larger files. We suggest splitting them up into smaller files using split on a compressed file to make them all a specific size. You can do it in a terminal with:
|
||||
|
||||
split -b 500m file.mp4 newfilename
|
||||
|
||||
#### Step 15 File types ####
|
||||
|
||||
One of the major things you may have noticed is which documents have and have not been downloaded by Grive. On the official clients, links will be added that can let you jump straight to pure Google Docs files, while files that are actually DOC, ODF or PDF will be downloaded outright to the system. Only the latter files are downloaded with Grive as they’re purely stored in the cloud on Drive. The upside is they’re properly stored locally and will still sync between the cloud and other systems.
|
||||
|
||||
#### Step 16 Location ####
|
||||
|
||||
Very simply, the Google Drive folder is kept in the home folder under Google Drive. If you’re using standard GNOME it’s actually opening the files in the GNOME file manager; for some reason it also does that in Unity and any non-GNOME desktop environment.
|
||||
|
||||
#### Step 17 Backup to Grive ####
|
||||
|
||||
One of the benefits of cloud storage for files is that the storage itself is off-site and difficult to lose. This makes it ideal for backing up other important documents and settings. The simplest and quickest way to do this is to periodically copy a file over to the Drive folder and watch it upload.
|
||||
|
||||
#### Step 18 Better backup ####
|
||||
|
||||
This is not the most efficient way to backup such files though; fortunately Linux comes with many tools to back up data that also includes backup scheduling thanks to cron. We’ll be using luckyBackup for this: find it in your package manager and install it.
|
||||
|
||||
#### Step 19 Set up the backup ####
|
||||
|
||||
Click Add to create a new task and name it however you wish. Keep the Type setting to ‘Backup Source inside Destination’, choose your Source and finally set the Destination as the Google Drive folder. Click OK to save it, followed by the checkbox next to the task to activate it.
|
||||
|
||||
#### Step 20 First backup ####
|
||||
|
||||
Click Run at the top to do the first backup operation. It will print out a verbose list of the files and operations and will inform you once it’s finished, along with any errors that occurred along the way. If you have automatic sync on, it will start uploading the backed up files to Drive.
|
||||
|
||||
#### Step 21 Timed backup ####
|
||||
|
||||
Click Done to return to the main menu. Click Profile followed by Schedule to bring up the scheduling dialog. The schedules are done by profiles, which can all contain a number of different backup tasks. Click Add to start creating a schedule for our Drive backup.
|
||||
|
||||
#### Step 22 To schedule ####
|
||||
|
||||
The schedule creates a cron job, so you can set it to occur on specific days of the week or specific months of the year and at what time the backup should occur. You can have it do so every hour at a specific minute past the hour if you need it to back up so frequently.
|
||||
|
||||
#### Step 23 Reverse backup ####
|
||||
|
||||
Google Drive helpfully keeps a record of past versions of files on its servers; however they do not extend forever. If you’re backing up or saving to the cloud you may want to consider creating a backup of the Drive files to your PC or network as well.
|
||||
|
||||
#### Step 24 Driven ####
|
||||
|
||||
While there are no official tools for Linux just yet, Grive and Grive Tools at least enable you to emulate what they should be relatively well. Look out for updates to Drive and Grive Tools to see if any new functions would work well for you.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxuser.co.uk/tutorials/install-google-docs-on-linux-with-grive-tools
|
||||
|
||||
原文作者:Rob Zwetsloot
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.thefanclub.co.za/
|
||||
@ -0,0 +1,201 @@
|
||||
安卓编年史
|
||||
================================================================================
|
||||
> 让我们跟着安卓从0.5版本到4.4的无尽迭代来看看它的发展历史。
|
||||
|
||||

|
||||
这些年来历代安卓的主屏幕。
|
||||
图片提供:Ron Amadeo
|
||||
|
||||
安卓已经以不止一种形式陪伴了我们六年以上。在这段时间内,我们已经看到了不同于任何已有开发周期的,绝对惊人变化速度。当Google卷入智能手机的战场中时,它拿出了它的快速迭代,Web风格的更新周期,把它们应用到了开发的这个操作系统之中,而结果就是突击式的持续改进。近来,安卓项目甚至以前所未闻的六个月开发周期在运行,这可比它之前的开发周期慢。在安卓的第一年商业运作时,Google每两个半月就会发布一个新版本。
|
||||
|
||||
注:youtube视频地址开始
|
||||
<iframe width="640" height="480" frameborder="0" src="http://www.youtube-nocookie.com/embed/1FJHYqE0RDg?start=0&wmode=transparent" type="text/html" style="display:block"></iframe>
|
||||
|
||||
Google在2007年11月时对安卓最初的介绍。
|
||||
注:youtube视频地址结束
|
||||
|
||||
同行业的其它公司和其相比,只能是以蜗牛的步伐在缓慢前进。微软每三到五年升级它的桌面操作系统,苹果对OS X和iOS以一年为一个更新周期。另外不是每个更新都是同等地位的。iOS在七年内有一个主要的设计上的大变动,而最新的Windows Phone 8看起来和Windows Phone 7十分相似。但在安卓上,如果用户能看到今年的任何东西看起来和去年一样,那简直是中彩票了一样。比如Play商店,五年内有五次的重新设计。对安卓来说那更是家常便饭。
|
||||
|
||||
回头看看,安卓的存在是很模糊的。从其历史来看,现在它是个使用量巨大的操作系统。近十亿的设备销量,以及每天一百五十万左右的激活量——但Google是如何达到这种地步的?安卓现在如此水平的规模和成功,可能会让你觉得安卓从零开始到万众瞩目的英雄中覆盖到了方方面面。但事实上不是这样的。安卓在早期并不流行,以及直到安卓4.0屏幕截图还只能通过开发者工具实现。这两个因素意味着你无法轻易找到许多安卓早期版本的图片或信息。
|
||||
|
||||
对于早期版本的缺乏覆盖问题现在称作*安卓早期版本正在消亡*。尽管像Windows 1.0这样的系统可以永远在你身边——只要找台旧电脑把它装上去就好了——安卓可以被认为是第一个基于云的操作系统。许多功能严重依赖Google的服务来实现。随着越来越少的人使用老版本的安卓,那些服务被逐渐关闭。当一个依赖云的应用其服务支持停止之后,它再也不能正常运作——应用崩溃并显示空白的屏幕,或直接无法启动。
|
||||
|
||||
正是由于这种“[云腐烂][1]”现象,安卓回顾展在几年内不可能出现。早期版本的安卓没有了云的支持会是一个不能正常工作的破碎的空壳。尽管可以简单地认为这是早期版本安卓渐渐消失的一种方法,但这正是正在发生的。就在写到这里的时候,正有无数的应用因为服务器支持被关闭而失去作用。例如早期的谷歌地图和安卓市场客户端,已经不能和Google服务器交互。它们会弹出错误消息并崩溃或者是显示一个空白的界面。有些应用甚至在一个星期正常运行然后下个星期就宣告死亡,因为就在我们写下这篇文章的时候谷歌正在积极地关闭服务器!
|
||||
|
||||
为了防止在滚滚历史里丢失掉更多关于安卓的过去,我们做了需要完成的工作。这里有20+个版本的安卓,七台设备,以及无数的屏幕截图被集合到一起。这就是安卓编年史,从最早的公开版本到罪行的KitKat。
|
||||
|
||||
注:下面一块为文章链接列表,发布后可以改为发布后的地址
|
||||
----------
|
||||
|
||||
### 目录 ###
|
||||
|
||||
- [Android 0.5 Milestone 3——第一个公开版本][10]
|
||||
- [Android 0.5 Milestone 5——报废接口的领地][11]
|
||||
- [Android 0.9 Beta——嘿,这看起来很眼熟!][12]
|
||||
- [Android 1.0——谷歌应用的引入和实体硬件][13]
|
||||
- [Android 1.1——第一个真正的增量更新][14]
|
||||
- [Android 1.5 Cupcake——虚拟键盘打开设备设计的大门][15]
|
||||
- ----[谷歌地图———登陆安卓市场的第一个内置应用][16]
|
||||
- [Android 1.6 Donut——CDMA支持将安卓带给了各个运营商][17]
|
||||
- [Android 2.0 Éclair——带动GPS产业][18]
|
||||
- [The Nexus One——迎来Google Phone][19]
|
||||
- [Android 2.1——动画的大发现(以及滥用)时代][20]
|
||||
- ----[Android 2.1, update 1——无尽战争的开端][21]
|
||||
- [Android 2.2 Froyo——更快更华丽][22]
|
||||
- ----[语音操作——口袋里的超级电脑][23]
|
||||
- [Android 2.3 Gingerbread——第一个UI大变][24]
|
||||
- [Android 3.0 Honeycomb——平板和设计的新生][25]
|
||||
- ----[Google Music Beta——云存储的内容库][26]
|
||||
- [Android 4.0 Ice Cream Sandwich——摩登时代][27]
|
||||
- ----[Google Play以及直接面向消费者销售设备的回归][28]
|
||||
- [Android 4.1 Jelly Bean——Google Now指明未来][29]
|
||||
- ----[Google Play服务——碎片化以及让系统版本(几乎)过时][30]
|
||||
- [Android 4.2 Jelly Bean——新Nexus设备,新平板界面][31]
|
||||
- ----[周期外更新——谁需要一个新系统?][32]
|
||||
- [Android 4.3 Jelly Bean——为可穿戴设备做好准备][33]
|
||||
- [Android 4.4 KitKat——更完美;更少的内存占用][34]
|
||||
- [今日安卓无处不在][35]
|
||||
|
||||
----------
|
||||
|
||||
### Android 0.5, Milestone 3——第一个公开版本 ###
|
||||
|
||||
在我们开始在实体硬件上研究安卓之前,我们要从很早,很早以前的安卓时光开始说起。尽管1.0是第一个运行在实体硬件上的版本,但在那之前其实还有若干个只随SDK发布的模拟器beta版本。这些模拟器只用于开发的目的,所以它们不含任何谷歌应用,甚至是一些核心系统应用。但它们仍然是回顾安卓的发布前时光的最好渠道。
|
||||
|
||||

|
||||
模拟器默认的qwerty布局并运行Milestone 3。
|
||||
Ron Amadeo供图
|
||||
|
||||
在异想天开的糖果版本代号和[与跨国食品公司跨界合作][2]之前,第一个安卓的公开发布版本的标签是“m3-rc20a”——“m3”代表“Milestone 3(里程碑3)”。尽管谷歌可能不会公布版本号——这个版本甚至没有一个设置应用来查看——浏览器用户标识识别为“Android 0.5”。
|
||||
|
||||
在2007年11月,谷歌获得安卓两年,iPhone发布五个月之后,[安卓正式发布][3],第一个模拟器正式释出。回到那时候看,这个系统才刚处于起步阶段。它很容易就被认为“只是个黑莓的山寨而已”。模拟器使用了一个qwerty布局的皮肤以及320×240的显示屏,是一台[原型设备][4]的复制品。这台设备由HTC制造,通过一些早期的安卓账户可以得知这台设备的代号似乎是“Sooner”。但是Sooner从未正式上市。
|
||||
|
||||
通过安卓早期[开发账号][5]得知,当苹果在2007年1月最终发布它革命性的智能手机后,谷歌不得不对安卓“从头来过”——包括放弃Sooner。考虑到Milestone 3模拟器在苹果的iPhone后近一年才推出,设备界面看起来还是那么像黑莓的模型是在是令人惊奇的事情。尽管在iPhone发布后的开发里任务毫无疑问地在优先保障下完成了,但模拟器仍然以被认为是“旧学院风”的界面发布。这使得它没能给人留下一个好的第一印象。
|
||||
|
||||
在早期阶段,安卓按键布局看起来并没有最终确定下来。尽管第一台商业安卓设备使用了“主屏幕”,“后退”,“菜单”以及“搜索”作为标准的按键套件,模拟器上有一个空白的标记为“X”的键,你可能会认为是那是搜索键应该在的地方。“Sooner”原型机看起来更奇怪——它在第四个键上有个星形标记。
|
||||
|
||||

|
||||
从左到右:主屏幕,一个打开的通知,以及“应用”文件夹。
|
||||
Ron Amadeo供图
|
||||
|
||||
在这里没有可以配置的主屏幕或小插件,仅仅只是简单的在底部有聚合图标的dock,可以循环或是点击。尽管已经有一些特性支持触摸屏,Milestone 3主要还是使用五向十字键——一个时至今日安卓仍然支持的不合时宜的设计。甚至早期的安卓都能够实现动画效果。图标在进入dock的中心窗口时会变大或缩小。
|
||||
|
||||
在这时候一样也还没有通知栏。通知图标显示在顶部状态栏(上面图片中的微笑标志),打开它的唯一方法是在主屏幕按下十字键的上键。你无法通过点击微笑的图标来打开它,也无法从除主屏幕以外的地方打开通知。当通知被打开的时候,状态栏些许地扩展开,通知文本会显示在一个聊天气泡中。一旦你阅读完通知,你无法手动清除它——应用本身负责清除它的通知消息。
|
||||
|
||||
应用抽屉的职责由一个dock左侧简单的“应用程序”文件夹负责。尽管有着不少标志性的功能,Milestone 3模拟器应用图标还不是十分完善。只有“浏览器”,“联系人” ,以及“地图”是这里面真正的应用。奇怪的是,“最近通话”被提升为一个独立的图标。因为这仅仅只是个模拟器,像闹钟,日历,拨号,计算器,照相机,相册,以及设置这样的智能手机核心功能的图标统统没有。硬件原型倒是有[其中的大部分][6],它还有一套谷歌应用出现并运行着。不幸的是我们没办法看到它们了。它们已经老到无论如何都连不上谷歌的服务器了。
|
||||
|
||||

|
||||
Milestone 3的浏览器菜单系统,壁纸界面,以及音量控制。
|
||||
Ron Amadeo供图
|
||||
|
||||
这套现在已经过时的菜单系统出现并运行在Milestone 3上。点击实体菜单键会打开一个灰色带有蓝色梯度高亮的列表,通过实体键盘完成操作。在上面的截图中,你可以看到在浏览器中打开的菜单。进入二级菜单,像缩放菜单,一级菜单变成有些奇怪的透明状态。
|
||||
|
||||
令人惊喜的是,多任务及后台应用在Milestone 3上已经可以运作了。离开应用而不关闭它——应用会保存状态,甚至写入文本保存。这个特性iOS直到2010年推出iOS 4才能与其相比,这就真正显示出了这两个平台的不同。iOS最初是作为一个封闭的平台而没有第三方应用,所以平台的鲁棒性并没有得到很大的关注。安卓是从头开始被构建成一个强大的应用软件平台,轻松开发应用是它创造出来背后的推动力之一。
|
||||
|
||||
在安卓之前,谷歌已经通过[WAP网站][7]和[J2ME手机应用][8]向移动端开始迁移,这使得它们强烈地意识到移动开发的难度。据[The Atlantic][9],拉里佩奇曾这么描述公司在移动端的努力“我们有一系列超过100台手机,我们在每一台设备上都要构建一次我们的应用”。开发者们现在经常抱怨安卓的碎片化,但在安卓出现之前,问题要比现在糟糕很多。
|
||||
|
||||
谷歌的平台战略实际上胜出了,iOS最终在不久后开始慢慢加入这些围绕应用的特性——多任务,跨应用分享,以及应用切换。
|
||||
|
||||

|
||||
当你在主屏幕按数字键弹出的拨号界面,来电,以及电话会议界面。
|
||||
Ron Amadeo供图
|
||||
|
||||
尽管没有拨号图标,Milestone 3模拟器还是有办法拨号。按键盘上的任意键会打开左侧界面,这是拨号/联系人搜索混合界面。仅输入数字并点击绿色的实体拨号键来开始通话,输入字母会搜索联系人。但是联系人无法通过数字搜索。甚至直接点击一个号码也不会打开联系人。
|
||||
|
||||
来电被显示成一个几乎全屏的令人愉快的透明背景弹窗。一旦进入通话,背景会变成深灰色,Milestone 3展现给用户一些令人惊奇的高级特性:静音,扬声器,保持,以及电话会议按钮。多方通话会显示成重叠,半透明的卡片状,用户有切换或者合并通话的选项可以选择。切换通话会触发一个漂亮的小卡片洗牌动画。
|
||||
|
||||

|
||||
联系人列表,打开一个联系人,编缉联系人,以及最近通话界面。
|
||||
Ron Amadeo供图
|
||||
|
||||
联系人是一个质朴的,黑色和蓝色的姓名列表。联系人卡片中有个联系人头像的位置但是没办法设置一张图像上去(至少在模拟器中不行)。这里唯一的装饰是每个联系人名字左侧的XMPP状态点。传统来说一个保持在线的XMPP连接是安卓的核心,它的深度集成从Milestone 3就已经开始了。安卓使用XMPP来驱动一个24/7在线的与谷歌服务器之间的连接,驱动Google Talk,云到端消息推送,以及应用的安装和卸载信息。
|
||||
|
||||

|
||||
浏览器的假Google首页,地址栏,浏览历史界面。
|
||||
Ron Amadeo供图
|
||||
|
||||
浏览器运行Webkit 419.3,它也被用在相同时代的像Mac OS X 10.4的Safari 2上。浏览器主页并不是Google.com,而是一个包含在安卓里的硬编码的home.html文件。它看起来就像是千年之前的Google.com。浏览器的OS X遗留还可以辨认出来,用了光滑的,Aqua风格的搜索按钮来渲染浏览器按钮。
|
||||
|
||||
这个小小的黑莓风格的屏幕需要一个分离的地址栏,可以通过浏览器菜单里的“前往”选项打开。尽管自动补全不起作用,地址栏会在你输入的时候实时搜索你的浏览历史。右侧图片显示的是历史界面,它使用了略缩图来显示各个站点。当前的略缩图在其它两个之前,滑动它们会触发一个猛扑的动画效果。但在早期阶段,浏览器不支持多标签或窗口——你可以看到当前站点,那就是全部了。
|
||||
|
||||

|
||||
一个视频屏幕抓取导出的谷歌地图界面,方向界面,相册测试界面。
|
||||
Ron Amadeo供图
|
||||
|
||||
在开始的时候,谷歌认识到在移动端地图将会非常重要,甚至在Milestone 5模拟器中内置了地图客户端。那个版本的谷歌地图是我们遇到的第一个死于云腐烂的。这个客户端无法从谷歌的服务器上载入信息,所以地图显示为一片空白,灰色的网格。没有什么能够运转。
|
||||
|
||||
幸运的是,因为上面的第一张截图,我们能够从安卓启动视频中拼凑出准确的界面。旧的谷歌地图看起来完全是为非触摸设备准备的,实体键快捷方式列表排列在屏幕底部。这样在看地图时,或是在如果仅仅显示该点的地址的时候就不大清楚。
|
||||
|
||||
隐藏在菜单之后的是搜索选项,方向,以及卫星和交通图层。中间的截图是方向的UI之一,你可以选择一个联系人的地址作为起点或者终点。但地图缺乏任何种类的集成GPS,你在哪都找不到“我的位置”这个按钮。
|
||||
|
||||
尽管没有合适的相册,在右边是相册的测试界面,隐藏在“API Demos”应用里。图片可以向左向右滚动,但无法以全屏的方式打开一张照片。同样它也没有照片管理选项。它本质上就是个图片滚动界面的测试视图。
|
||||
|
||||

|
||||
时间设置和日历,有点字间距问题,以及以Ars为特色的垂直列表测试。
|
||||
Ron Amadeo供图
|
||||
|
||||
同样模拟器中也没有设置应用,但是通过API Demos我们可以看到最初的日期时间设置界面。这个示例暴露出很多安卓没来得及处理的问题:到处都有的字间距问题,分钟数字间巨大的间隔,以及日历中星期日间不均等的间隔。尽管时间设置允许你单独更改每个数字,但除非你将当前日期移出本月到前一个或下一个月,否则你无法改变月份或年份。
|
||||
|
||||
别忘了尽管这看起来像是一些被遗忘时代的恐龙级别遗留物,但这仅仅是六年前发布的。我们总趋向与适应科技的脚步。我们很容易将这样的东西看作是20年前的东西。比较一下2007年晚些时候这个时间段的桌面操作系统,微软尝试将Windows Vista售往全世界快要一年了,而苹果刚刚发布OS X 10.5 Leopard。
|
||||
|
||||
最后一个关于Milestone 3的细节:谷歌在Milestone 3模拟器中给了Ars Technica一个快捷方式。打开“API Demos”应用并打开"Views," "Focus,"然后"Vertical"显示一个*this very Website*的头条测试列表。
|
||||
|
||||

|
||||
随Milestone 3,RC37a发布的更加现代,全触控风格的模拟器。
|
||||
Ron Amadeo供图
|
||||
|
||||
两个月后,2007年12月,谷歌放出了一个Milestone 3的更新,带来了更大的480×320设备设置。这个更新的标签是“m3-rc37a”。软件看起来还是像黑莓一样,仅仅是带来了更多的屏幕分辨率支持。
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
|
||||
|
||||
[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/
|
||||
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://arstechnica.com/gadgets/2014/06/how-we-found-and-installed-every-version-of-android/
|
||||
[2]:http://arstechnica.com/gadgets/2013/09/official-the-next-edition-of-android-is-kitkat-version-4-4/
|
||||
[3]:http://arstechnica.com/gadgets/2007/11/its-official-google-announces-open-source-mobile-phone-os-android/
|
||||
[4]:http://www.zdnet.com/blog/mobile-gadgeteer/mwc08-hands-on-with-a-working-google-android-device/860
|
||||
[5]:http://www.theatlantic.com/technology/archive/2013/12/the-day-google-had-to-start-over-on-android/282479/
|
||||
[6]:http://www.letsgomobile.org/en/2974/google-android/
|
||||
[7]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/%E2%80%9D
|
||||
[8]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/%E2%80%9D
|
||||
[9]:http://www.theatlantic.com/technology/archive/2013/12/the-day-google-had-to-start-over-on-android/282479/
|
||||
[10]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/1/#milestone3
|
||||
[11]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/2/#milestone5
|
||||
[12]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/3/#0.9
|
||||
[13]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/6/#1.0
|
||||
[14]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/7/#1.1
|
||||
[15]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/8/#cupcake
|
||||
[16]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/9/#Mapsmarket
|
||||
[17]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/9/#donut
|
||||
[18]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/10/#2.0eclair
|
||||
[19]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/11/#nexusone
|
||||
[20]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/12/#2.1eclair
|
||||
[21]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/13/#alloutwar
|
||||
[22]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/13/#froyo
|
||||
[23]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/14/#voiceactions
|
||||
[24]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/14/#gingerbread
|
||||
[25]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/16/#honeycomb
|
||||
[26]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/19/#music
|
||||
[27]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/19/#ics
|
||||
[28]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/21/#googleplay
|
||||
[29]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/21/#4.1jellybean
|
||||
[30]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/21/#playservices
|
||||
[31]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/22/#4.2jellybean
|
||||
[32]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/23/#outofcycle
|
||||
[33]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/24/#4.3jellybean
|
||||
[34]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/25/#kitkat
|
||||
[35]:http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/26/#conclusion
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -1,128 +0,0 @@
|
||||
如何拯救一台没有成功通过Grub启动的Linux电脑
|
||||
================================================================================
|
||||

|
||||
Figure 1: GRUB 2 menu with cool Apollo 17 background.
|
||||
|
||||
自从我们拥有GRUB以来,Linux Bootloader 0.97就开始了传奇的一生。尽管传统的GRUB有很多的有点,但是他开始陈旧了,并且他的开发者也开始添加更多的功能,于是,Grub2.0时代就要来了。
|
||||
|
||||
GRUB 2 做了几个明显的改进。它可以从移动存储设备上启动,并且可以有进入BIOS配置的选项。尽管它有着更复杂的脚本配置,但是一个简单的`/boot/grub/menu.lst`文件却一个地方集中了所有配置选项,默认的是存放在`/boot/grub/grub.cfg `。你不能直接编辑,这不是人做的事,太复杂,我们需要用简单的脚本实现。我们卑微的人类可以编辑`/etc/default/grub`文件来修改,它主要是控制Grub菜单。我们还可以修改` /etc/grub.d/ `。这些脚本可以启动操作系统,控制外部应用程序,如memtest 和 os_prober,还有theming `./boot/grub/grub.cfg`是建立在`/etc/default/grub`和`/etc/grub.d/*`的基础上的。当你修改了一个地方,你必须要运行更新GRUB的命令。
|
||||
|
||||
好消息是,update-grub脚本是可以可靠的检测内核,启动文件,并添加所有的操作系统的,自动生成你的启动菜单,所以你不必手动的修改他们。
|
||||
|
||||
我们还要学习如何解决两个常见的故障。当启动系统时,它会停在GRUB >提示上,这是完整的GRUB 2命令界面,所以不要惊慌。这意味着GRUB 2依旧可以正常启动和加载normal.mod模块(和其他模块分别位于/boot/grub/[arch]/),但没有找到你的grub.cfg文件。如果你看到grub rescue> 这意味着它无法找到normal.mod,因此它有可能找不到你的启动文件。
|
||||
|
||||
这是如何发生的?因为内核可能改变驱动器分配或您移动您的硬盘驱动器,或者你手动改变一些分区,或安装一个新的操作系统或者移动一些文件。在这些情况下你的启动文件仍然存在,但GRUB不能找到他们。所以你可以看看在GRUB提示符中启动文件,设置它们的位置,然后启动您的系统和修复您的grub配置。
|
||||
|
||||
### GRUB 2 命令行 ###
|
||||
|
||||
GRUB 2 命令是一个伟大的财富。你不仅可以用它来发现引导镜像,内核,和根文件系统。事实上,它给你完全访问本地计算机上的所有文件的系统权限。其中有些人可能会认为一个安全漏洞,但是你知道古老的UNIX的名言:有物理访问机器权限的人,就是拥有它的人。
|
||||
|
||||
当你在` GRUB > `提示时,你有许多类似的功能,如命令如历史和tab补全。但是`grub rescue> `模式是有限的,没有历史,没有tab补全。
|
||||
|
||||
如果你是在一个正常运作的系统上练习,那就当GRUB菜单打开GRUB命令行时,按C。你可以通过向上和向下滚动你的菜单条目箭头键停止启动倒计时。它是安全的,在此GRUB命令行下,你不会进行永久的修改,一切都是暂时的。如果你已经看到`grub > `或`grub rescue> `提示符,那就说明你的表现时刻到了。
|
||||
|
||||
接下来的几个命令可以在`grub>`和`grub rescue`模式下运行。同时,你应该第一个运行的命令如下:
|
||||
|
||||
grub> set pager=1
|
||||
|
||||
等号两侧必须不能出现空格。现在让我们做一点探讨。ls列出的所有分区:
|
||||
|
||||
grub> ls
|
||||
(hd0) (hd0,msdos2) (hd0,msdos1)
|
||||
|
||||
MSDOS是什么?这意味着该系统具有老式的MS-DOS分区表,而不是全新的全局唯一标识符的分区表(GPT)。(见[Using the New GUID Partition Table in Linux (Goodbye Ancient MBR)][1]。如果你正在运行的GPT,它会出现(hd0,GPT1)。使用ls命令查看你的系统文件是什么:
|
||||
|
||||
grub> ls (hd0,1)/
|
||||
lost+found/ bin/ boot/ cdrom/ dev/ etc/ home/ lib/
|
||||
lib64/ media/ mnt/ opt/ proc/ root/ run/ sbin/
|
||||
srv/ sys/ tmp/ usr/ var/ vmlinuz vmlinuz.old
|
||||
initrd.img initrd.img.old
|
||||
|
||||
好的,我们已经找到了根文件系统。你可以省略MSDOS和GPT的标签。如果你无视打印的分区信息。你可以用cat命令读取文件系统上的文件:
|
||||
|
||||
grub> cat (hd0,1)/etc/issue
|
||||
Ubuntu 14.04 LTS \n \l
|
||||
|
||||
从/etc/issue文件中,可以看到你的不同的Linux系统
|
||||
|
||||
### 从 grub> 中启动###
|
||||
|
||||
这是如何设置启动文件和启动从`GRUB>`提示中进入系统。我们知道,从运行ls命令有一个Linux根文件系统(hd0,1),你可以继续寻找直到你找到你的/boot/grub所在位置。然后运行这些命令,使用您自己的根分区,内核和initrd映像:
|
||||
|
||||
grub> set root=(hd0,1)
|
||||
grub> linux /boot/vmlinuz-3.13.0-29-generic root=/dev/sda1
|
||||
grub> initrd /boot/initrd.img-3.13.0-29-generic
|
||||
grub> boot
|
||||
|
||||
第一行设置分区的根文件系统是。第二行告诉grub您想要使用的内核位置。开始输入/boot/vmli,然后使用tab完成填写。输入`root= /dev/sdX`设置根文件系统位置。是的,这似乎是多余的,但如果你忘记了输入你会得到一个kernel panic。你知道怎么正确的分区?hd0,1 = /dev/sda1。hd1,1 = /dev/sdb1。hd3,2 = /开发/ sdd2。我想你可以推出自己的。
|
||||
|
||||
第三行设置initrd文件,必须是和内核相同的版本号。
|
||||
|
||||
最后一行启动系统。
|
||||
|
||||
在一些Linux系统上,内核和initrds是被符号链接到当前的根文件系统的根目录,就像:
|
||||
|
||||
$ ls -l /
|
||||
vmlinuz -> boot/vmlinuz-3.13.0-29-generic
|
||||
initrd.img -> boot/initrd.img-3.13.0-29-generic
|
||||
|
||||
所以,你也可以这样输入命令:
|
||||
|
||||
grub> set root=(hd0,1)
|
||||
grub> linux /vmlinuz root=/dev/sda1
|
||||
grub> initrd /initrd.img
|
||||
grub> boot
|
||||
|
||||
### 从grub-rescue> 中启动 ###
|
||||
|
||||
你必须要加载两个模块normal.mod 和 linux.mod,如果你的GRUB命令不同于大众。
|
||||
|
||||
grub rescue> set prefix=(hd0,1)/boot/grub
|
||||
grub rescue> set root=(hd0,1)
|
||||
grub rescue> insmod normal
|
||||
grub rescue> normal
|
||||
grub rescue> insmod linux
|
||||
grub rescue> linux /boot/vmlinuz-3.13.0-29-generic root=/dev/sda1
|
||||
grub rescue> initrd /boot/initrd.img-3.13.0-29-generic
|
||||
grub rescue> boot
|
||||
|
||||
tab补全应该在你加载了这几个模块之后开始工作。
|
||||
|
||||
### 永久性的修复 ###
|
||||
|
||||
当你成功地启动你的系统,运行这些命令来永久修复GRUB:
|
||||
|
||||
# update-grub
|
||||
Generating grub configuration file ...
|
||||
Found background: /usr/share/images/grub/Apollo_17_The_Last_Moon_Shot_Edit1.tga
|
||||
Found background image: /usr/share/images/grub/Apollo_17_The_Last_Moon_Shot_Edit1.tga
|
||||
Found linux image: /boot/vmlinuz-3.13.0-29-generic
|
||||
Found initrd image: /boot/initrd.img-3.13.0-29-generic
|
||||
Found linux image: /boot/vmlinuz-3.13.0-27-generic
|
||||
Found initrd image: /boot/initrd.img-3.13.0-27-generic
|
||||
Found linux image: /boot/vmlinuz-3.13.0-24-generic
|
||||
Found initrd image: /boot/initrd.img-3.13.0-24-generic
|
||||
Found memtest86+ image: /boot/memtest86+.elf
|
||||
Found memtest86+ image: /boot/memtest86+.bin
|
||||
done
|
||||
# grub-install /dev/sda
|
||||
Installing for i386-pc platform.
|
||||
Installation finished. No error reported.
|
||||
|
||||
当你运行 `grub-install` 时,记得grub是安装到硬盘驱动器的引导扇区而不是到一个具体分区,所以不要加上像/dev/sda1的分区号。
|
||||
|
||||
### 如果还是不能使用 ###
|
||||
|
||||
如果你的系统是如此的倒霉,而且这个方式没有能起作用,那就尝试[超级GRUB2现场救援磁盘][2]。[官方GNU GRUB手册][3]也应该是有帮助的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/learn/tutorials/776643-how-to-rescue-a-non-booting-grub-2-on-linux
|
||||
|
||||
译者:[MikeCoder](https://github.com/MikeCoder) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.linux.com/learn/tutorials/730440-using-the-new-guid-partition-table-in-linux-good-bye-ancient-mbr-
|
||||
[2]:http://www.supergrubdisk.org/
|
||||
[3]:https://www.gnu.org/software/grub/manual/grub.html
|
||||
70
translated/tech/20140624 Super Pi Brothers.md
Normal file
70
translated/tech/20140624 Super Pi Brothers.md
Normal file
@ -0,0 +1,70 @@
|
||||
超级树莓派兄弟
|
||||
================================================================================
|
||||
我已经不象以前那样玩那么多游戏了。虽然之前我当然花费了生命里的无数时间在任天堂,SNES,或是之后在我电脑上的第一人称射击游戏(只在Linux下,谢谢),如今,我更愿意把空余时间花在我累积起来的许多其他非游戏爱好上。但是最近,我发现自己又抹掉了Wii手柄上的灰尘,这样就可以玩一玩我重新购买的NES和SNES游戏了。不过问题是,这些游戏需要用到一些特别的控制器,而且我已经有一个修改过的SNES控制器可以通过USB连接。这已经有足够的理由让我去寻找一个更合适的方案。当然,我也可以简单地接上三个甚至四个手柄,然后在客厅里面堆满游戏。但是我已经习惯于把我的CD和DVD都提取成文件,然后在中心媒体服务器上挑选着听或是看。所以如果每次我想换游戏的时候,不用起身去翻游戏卡带,那就完美了。当然,这意味着得使用模拟器。尽管之前我在一个改动过的Xbox上成功过,不过可惜它已经不在我手上了。然后我觉得一定有什么人已经在树莓派上实现过这种平台,结果是肯定的,在简单地搜索和一些命令之后,我在一个剩下的树莓派上搭起来一个完美的怀旧游戏中心。
|
||||
|
||||
树莓派项目的一个优点是,有大量的用户在使用相同的硬件。对我来说,这意味着我不用完整地参考别人的指引再根据自己的需求做出必要的改动,而只需要简单地完全按照别人的指导做就行了。在我这件事情上,我找到了RetroPie项目,它把你安装时需要用到的所有命令都包到了一个单一的大脚本中。在执行完后,你就完整地安装并配置好了RetroArch,它集成了所有的主流模拟器以及一个统一的配置方式,再加上一个在树莓派上开机启动的EmulationStation图形界面,通过它可以只用手柄就能方便地定位到你想玩的游戏。
|
||||
|
||||
### 安装RetroPie ###
|
||||
|
||||
在安装RetroPie之前,你可能需要确认一下你的Raspbian版本(树莓派默认的Linux发行版,这也是这个项目假设你在用的)是不是最新的,包括有没有新的固件。这只需要几个通用的`apt`命令。虽然,在这一步里你当然可以接个键盘到树莓派上,不过我觉得用`ssh`登录到树莓派上更方便。之后直接复制和粘贴下面的命令:
|
||||
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get -y upgrade
|
||||
|
||||
现在树莓派已经更新到最新了,再确认一下是否安装了git和dialog,然后可以通过git来下载RetroPie:
|
||||
|
||||
|
||||
$ sudo apt-get -y install git dialog
|
||||
$ cd
|
||||
$ git clone --depth=0
|
||||
↪git://github.com/petrockblog/RetroPie-Setup.git
|
||||
|
||||
执行完上边的命令后会创建一个RetroPie-Setup目录,里面有主要的安装脚本。之后你只需要进去这个目录,并运行安装脚本:
|
||||
|
||||
$ cd RetroPie-Setup
|
||||
$ chmod +x retropie_setup.sh
|
||||
$ sudo ./retropie_setup.sh
|
||||
|
||||
这个脚本会在终端里显示一个菜单(图1),在里面你可以选择二进制安装或是源码安装,配置RetroPie,或是更新RetroPie安装脚本和执行文件。之后选择二进制安装或是源码安装,任选一个。二进制安装会快一些,不过有些软件版本可能不是最新的。源码安装需要编译软件,所以用的时间会比较长,但是完成之后,所有的一切都是最新版的。我个人会选择二进制安装,因为我知道在碰到任何问题之后,随时都可以重新执行这个脚本再选择源码安装。
|
||||
|
||||

|
||||
|
||||
#### 图1. RetroPie安装菜单 ####
|
||||
|
||||
在vanilla Raspbian固件版本中,这一步会需要很长时间,因为有大量不同的包需要下载和安装。在安装完成之后,返回在RetroPie安装主界面中,在主菜单里选择SETUP,在之后的二级菜单里,你可以调整设置,例如是否开机启动EmulationStation(推荐打开)以及是否允许欢迎界面。在我这里,我两个都允许了,因为我希望这个设备是一个独立的模拟游戏机。不过你需要了解的是,如果你确实允许了EmulationStation开机自动启动,你仍然可以ssh登录到机器上然后执行原始的RetroPie安装配置脚本来改变这个设置。
|
||||
|
||||
### 添加ROM ###
|
||||
|
||||
你也可以在RetroPie设置界面添加ROM。如果你在菜单里选择了Samba方式,就可以在网络上找一个Samba共享目录,然后从里面拷贝ROM。如果通过U盘的方式,RetroPie会在插到树莓派的U盘上创建一个目录结构,分别对应不同的模拟器。在这之后,你就可以把U盘插到其他电脑上,然后把ROM拷贝到合适的目录里,当再插回树莓派的时候,它会自动同步文件。最后(我就是这么做的),你还可以使用scp或者rsync来拷贝ROM到~/RetroPie/roms/的合适目录下。举个例子,NES游戏需要拷贝到~/RetroPie/roms/nes/目录里。
|
||||
|
||||
当你完成了配置并退出了RetroPie的设置脚本后,应该会想重启并进入EmulationStation,但是在那之前,你应该重新配置树莓派的内存空间,设为192或者128,运行命令:
|
||||
|
||||
|
||||
$ sudo raspi-config
|
||||
|
||||
然后选择高级设置,调整内存空间设定。之后就可以安全地重启了。
|
||||
|
||||
### EmulationStation ###
|
||||
|
||||
重启完之后,当看到EmulationStation界面时应该会很高兴,之后它会提示你设定控制杆,游戏手柄,或键盘按键,这样就可以控制EmulationStation菜单了。不过注意一下,这并不会影响手柄在游戏里的按键定义,只是用于控制EmulationStation菜单的。在设定完手柄后,你应该可以按下向右或向左方向键来切换不同的模拟器菜单了。在我这里,我将会在游戏里用到手柄上的所有按钮,所以我特别将另一个键盘上的键映射到菜单功能,这样在我玩完一个游戏后,不用重启树莓派就可以退出来。
|
||||
|
||||
EmulationStation只会显示已经侦测到ROM的模拟器,所以,如果你还没有拷贝ROM的话,得先做这件事情,然后可能还得重启一下才会有效果。而且,默认情况下,你的手柄没有为任何游戏做配置,但是,如果你在EmulationStation里一直按向右键足够多次以后,会弹出输入设定界面,你可以在里面映射手柄按键。有一个亮点是,当你设定好按键后,它会相应地应用到其他模拟器中。
|
||||
|
||||
就是这些了。在这之后,你可以浏览你收藏的各种游戏,然后按下绑定到确定的那个按键开始游戏。一开始我还担心树莓派可能不够强劲来玩我的游戏,但是直到现在,我试过地所有游戏都可以完美地运行。
|
||||
|
||||
### 资源 ###
|
||||
|
||||
RetroPie项目主页:[http://blog.petrockblock.com/retropie][1]
|
||||
|
||||
RetroPie安装文档:[https://github.com/petrockblog/RetroPie-Setup][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/super-pi-brothers
|
||||
|
||||
译者:[zpl1025](https://github.com/zpl1025) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://blog.petrockblock.com/retropie
|
||||
[2]:https://github.com/petrockblog/RetroPie-Setup
|
||||
@ -0,0 +1,57 @@
|
||||
怎样在ubuntu 14.04上安装轻量级的Budgie桌面
|
||||
================================================================================
|
||||
**如果你在推特上关注了我们,你可能看见了我们最近分享的一张截图,和这张截图一起的还有对它所展示的桌面进行命名的邀请。 **
|
||||
|
||||
你猜对了吗? 答案就是budgie —— 一种为基于openSUSE 的linux发行版Evolve OS所设计,但不仅仅只能用于 Evolve OS的简易桌面环境。
|
||||
|
||||
|
||||
|
||||
我们第一次描写Budgie是在三月份,当时我们被它的整洁,小巧的美感,灵活的架构,还有重复使用在当今大多数发行版中所使用的GNOME 3.10 成熟技术中的公共部分和标堆栈的决定所折服。
|
||||
|
||||
我对此项目的领导者LKey Doherty所作出的开发选择非常佩服。无可否认另起炉灶有它的优点,但决定从上游的项目获取帮助将可以整个项目进展得更快,无论是在发展方面(更轻的技术负担)还是在用户可使用方面(更容易在其它发行版上运行)。
|
||||
|
||||
政治因素选择除外,这款桌面以干净,小巧向谷歌Chrome OS的Ash桌面表示敬意。如果你不介意有些许粗糙的边缘,那它值得你玩玩。那么怎样在Ubuntu安装Budgie呢?
|
||||
|
||||
###非官方的PPA是不正式的 ###
|
||||
|
||||
开源意味着如果你有一点终端使用知识的话,你就可以在获得Budgie桌面的源代码后进行编译,然后运行。
|
||||
|
||||
但如果你很懒,想不费周折就在Ubuntu 14.04 LTS(或者一个基于它的发行版)运行Budgie,那么你可以通过比较容易的途径来实现。
|
||||
|
||||
添加一个非官方的Unofficial PPA,刷新你的软件源然后进行安装。几分钟后在这个家庭中你将有一位名叫Bob的新叔叔,并且有一个新的桌面可以玩耍。
|
||||
|
||||
###添加Budgie PPA ###
|
||||
|
||||
将以下命令复制进一个打开的终端窗口,在提示过后输入你的密码(如果需要的话)
|
||||
|
||||
sudo add-apt-repository ppa:sukso96100/budgie-desktop
|
||||
sudo apt-get update && sudo apt-get install budgie-desktop
|
||||
|
||||
### 登入Budgie会话 ###
|
||||
|
||||
安装完成后你就可以在Unity欢迎界面的会话选择器中选择Budgie会话了。(别忘了以后要把选择项改回到稳定的桌面环境)
|
||||
|
||||
### 注意 ###
|
||||
|
||||
**budgie是不稳定,不完善的,它在Ubuntu上也没有被正式支持。它正在积极开发中,缺少一些特性,包括(但不仅仅只有这些):不支持网络管理,没有音量控制小程序(键盘工作良好),没有通知系统,无法将应用程序“固定”在任务栏。**
|
||||
|
||||
它对UBUNTU的叠加滚动条和一些GTK主题的支持也不是很好,而且在使用upstart的发行版(例如ubuntu,即使它正在改变之中)中会话管理器(例如,注销,重启等等)将无法工作。
|
||||
|
||||
一个应变方法是:禁用叠加滚动条,设置一个默认主题,通过在终端中使用以下命名来退出会话。
|
||||
|
||||
gnome-session-quit
|
||||
|
||||
想着脑海中所有的这些警告,我建议想使用稳定的,可靠的系统的人现在暂时不要使用它。
|
||||
|
||||
而作为狂热一族的业余体验呢?请在下面评论,让我们了解你的想法。我将退出而让Bob来接手。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/07/install-budgie-evolve-os-desktop-ubuntu-14-04
|
||||
|
||||
译者:[Love-xuan](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.omgubuntu.co.uk/2014/03/budgie-desktop-chrome-os-like
|
||||
[2]:http://en.wikipedia.org/wiki/Bob
|
||||
[3]:http://www.omgubuntu.co.uk/2014/02/ubuntu-debian-switching-systemd
|
||||
@ -1,12 +1,13 @@
|
||||
Ubuntu 14.04中修复默认启用HDMI后没有声音问题
|
||||
Ubuntu 14.04中修复默认启用HDMI后没有声音的问题
|
||||
================================================================================
|
||||
声音问题在Ubuntu中是老生常谈了。先前我已经在[修复Ubuntu中的“无声”问题][1]一文中写到了多种方法,但是我在此正要谈及的声音问题跟在另外一篇文章中提到的不同。
|
||||
|
||||
因此,我安装了Ubuntu 14.04,实际上是重新安装了一遍。一如既往,我将[全新安装Ubuntu 14.04后要做的事][2]全部又重新做了一遍。然后,我意识到系统突然失声了。当我正侦查问题所在之时,我发现了一件奇怪的事情。我检查了[alsamixer][3],发现它的状况有点离奇:
|
||||
声音问题在Ubuntu中是老生常谈了。先前我已经在[修复Ubuntu中的“无声”问题][1]一文中写到了多种方法,但是我在此正要谈及的声音问题跟在另外一篇文章中提到的有所不同。
|
||||
|
||||
因此,我安装了Ubuntu 14.04,实际上是重新安装了一遍。一如既往,我将[全新安装Ubuntu 14.04后要做的事][2]全部又重新做了一遍。然后,我意识到系统突然失声了。当我正侦查问题所在之时,我发现了一件奇怪的事情。我检查了[alsamixer][3],发现它的状况有点离奇。
|
||||
|
||||

|
||||
|
||||
正如你能看到的,**alsamixer中默认设置了HDMI**。这意味着默认情况下将使用HDMI输出,而不是内建扬声器。这就是我从系统上内建扬声器无法获得声音的原因。
|
||||
正如你能看到的,**alsamixer中默认设置了HDMI**。这意味着默认情况下将使用HDMI输出,而不是内置扬声器。这就是我从系统上内置扬声器无法获得声音的原因。
|
||||
|
||||
使用下面的命令来检查alsamixer的状态:
|
||||
|
||||
@ -20,7 +21,7 @@ Ubuntu 14.04中修复默认启用HDMI后没有声音问题
|
||||
|
||||
aplay -l
|
||||
|
||||
这会列出设备,卡号之类的东西。注意,向下检查模拟输出使用的卡和设备编号。对于我而言,输出看上去像这样:
|
||||
这会列出设备,卡号之类的东西。注意,向下检查模拟输出使用的卡和设备编号。我的输出如下所示:
|
||||
|
||||

|
||||
|
||||
@ -28,14 +29,14 @@ Ubuntu 14.04中修复默认启用HDMI后没有声音问题
|
||||
|
||||
sudo gedit /etc/asound.conf
|
||||
|
||||
上面的命令也会打开文件,将下面的行添加进去,当然将卡和设备编号替换成你自己的:
|
||||
上面的命令也会打开文件,将下面两行添加进去,当然将卡和设备编号替换成你自己的:
|
||||
|
||||
defaults.pcm.card 1
|
||||
defaults.pcm.device 0
|
||||
|
||||
保存文件,并重启计算机。现在,你应该听到了声音了吧。需要提一下的是,这对所有的Linux发行版都有效,像Linux Mint,Elementary OS,Fedora,Arch Linux等等都行。正如我先前说的,该“失声疗法”仅针对HDMI被设置为默认设备的情况。对于其它情况,你可以阅读[关于在Ubuntu和Linux Mint中修复失声问题这篇文章][4]。
|
||||
保存文件,并重启计算机。现在,你应该听到声音了吧。需要提一下的是,这对所有的Linux发行版都有效,如Linux Mint,Elementary OS,Fedora,Arch Linux等等都可以。正如我之前所说,该“失声疗法”仅针对HDMI被设置为默认设备的情况。对于其它情况,你可以阅读[关于在Ubuntu和Linux Mint中修复失声问题这篇文章][4]。
|
||||
|
||||
你可以尽情使用评论部分来告诉我这个方法是否有疗效,或者你有更好的方法来处理该问题,你也可以告诉我。再见了!
|
||||
您可以尽情发表评论来告诉我这个方法是否有疗效,或者您有更好的方法来处理该问题,也可以告诉我。再见了!
|
||||
|
||||

|
||||
|
||||
@ -44,14 +45,14 @@ Ubuntu 14.04中修复默认启用HDMI后没有声音问题
|
||||

|
||||
|
||||
关于Abhishek
|
||||
|
||||
|
||||
我是Abhishek Prakash,It's F.O.S.S.的“创立者”,我有一个通信系统工程的硕士学位。我酷爱Linux和开源。我使用Ubuntu,信奉知识分享。除了Linux之外,我也喜爱经典的侦探推理小说,是Agatha Christie作品的超级粉丝。大家尽可以在[Google+][g]上将我圈进去,并追随[@abhishek_pc][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/fix-sound-ubuntu-1404/
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[GOLinux](https://github.com/GOLinux) 校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,26 +1,29 @@
|
||||
利用终端(Terminal)在Debian/Ubuntu中设置默认浏览器
|
||||
[快速技巧]利用终端在 Debian/Ubuntu 中设置默认浏览器
|
||||
================================================================================
|
||||
嘿,伙计们
|
||||
|
||||
在这篇文章中,我们将使用终端设置默认浏览器
|
||||

|
||||
|
||||
嘿,伙计们!
|
||||
|
||||
虽然,可以很方便地使用浏览器主界面来设置为默认浏览器,但是有时,你需要远程做到这一点
|
||||
在这篇文章中,我们将使用终端设置默认浏览器。
|
||||
|
||||
要做到这一点,你只需简简单单的打开终端,然后执行下述的命令:
|
||||
虽然,使用浏览器主界面来设置默认浏览器很方便,但是有时,你需要远程来操作。
|
||||
|
||||
要做到这一点,你只需打开终端,然后执行下述命令:
|
||||
```
|
||||
sudo update-alternatives --config x-www-browser
|
||||
```
|
||||
之后输入你想设置为默认的浏览器的号码,你就完成了!
|
||||
之后输入你想设置为默认浏览器的号码,这样就搞定了!
|
||||
|
||||
真个过程截图如下:
|
||||
截图如下:
|
||||
|
||||

|
||||
|
||||
你成功了吗?
|
||||
成功了吗?
|
||||
|
||||
---
|
||||
via: http://www.unixmen.com/quick-tip-set-default-browser-debianubuntu-using-terminal/
|
||||
|
||||
译者:译者ID 校对:校对者ID
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao) 校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 LCTT 原创翻译,Linux中国 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,23 @@
|
||||
|
||||
Linux 常见问题(有答案的哦)-- 如何为sudo命令定义PATH环境变量
|
||||
================================================================================
|
||||
>**问题**:我安装了一个程序到/usr/local/bin目录下,这个程序需要root权限才能执行,当我用sudo去执行它时,收到"sudo: XXXXX: command not found"的错误提示,不知道为什么/usr/local/bin没有被包含到PATH环境变量下面来,我该如何解决这个问题?
|
||||
|
||||
当你使用sudo去执行一个程序时,处于安全的考虑,这个程序将在一个新的、最小化的环境中执行,也就是说,诸如PATH这样的环境变量,在sudo命令下已经被重置成默认状态了。
|
||||
所以当一个刚初始化的PATH变量中不包含你所要运行的程序所在的目录,你就会得到"command not found"的错误提示。
|
||||
|
||||
为了改变PATH在sudo会话中的初始值,打开/etc/sudoers文件并编辑,找到"secure_path"一行,"secure_path"中包含的路径就将在sudo会话中的PATH变量中生效。
|
||||
|
||||
添加所需要的路径(如 /usr/local/bin)到"secure_path"下,在开篇所遇见的问题就将迎刃而解。
|
||||
Defaults secure_path = /sbin:/bin:/usr/sbin:/usr/bin:/usr/local/bin
|
||||
|
||||
|
||||
这个修改会即刻生效。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/define-path-environment-variable-sudo-commands.html
|
||||
|
||||
译者:[nd0104](https://github.com/nd0104) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,54 @@
|
||||
在Ubuntu上显示桌面歌词
|
||||
================================================================================
|
||||

|
||||
|
||||
除了免费的流媒体音乐外,我最喜欢[Spotify][1]的地方就是它的歌词插件了。有时候我听不懂一首歌里面的所有歌词,尤其是rap。[TuneWiki][2]插件在这种情况下就派得上用场了。但TuneWiki仅有支持Windows和iTune的插件,那我们在linux桌面上有什么选择呢?
|
||||
|
||||
如果你使用过Linux桌面一段时间,你也许听过[OSD Lyrics][3]。它是一个显示桌面歌词的小程序。你可以借助一些音乐播放器来使用它,比如Rythmbox,[Banshee][4],[Clementine][5]等等。
|
||||
|
||||
### 在Ubuntu 14.04和Linux mint 17上安装OSD Lyrics ###
|
||||
|
||||
两年以前OSD Lyrics在它的官方仓库中被积极地维护,但现在对它的开发已经停止了。尽管这个PPA已经不可用,但可以通过网络下载OSD Lyrics的安装包。虽然这些安装执行文件最初是为Ubuntu 12.02设计的,但这些文件也能在Ubuntu 14.04上很良好地工作。我们一起看看怎么在UUUUbuntu 14.04和 Linux mint 17上安装OSD Lyrics。
|
||||
|
||||
[前往下载页下载OSDLyrics][6],根据你是使用[32位还是64位的ubuntu][7]来下载相应的.deb 文件。你会在网页的上方找到这些文件。
|
||||
|
||||

|
||||
|
||||
下载完成后,通过双击它来使用Ubuntu软件中心来安装。另外,你也可以使用[Gdebi ][8]来快速地安装.deb安装包。
|
||||
|
||||
### 怎样在Ububtu和linux mnit 上使用OSD Lyrics使用歌词 ###
|
||||
|
||||
安装完成后,你可以从Unity Dash运行OSD Lyrics :
|
||||
|
||||

|
||||
|
||||
首次运行时,OSD Lyrics会检测你的系统中能被它支持的播放器。你可以设定一个默认播放器,以后当你运行OSD Lyrics时它就会自动启动 。
|
||||
|
||||

|
||||
|
||||
有一件事值得注意,那就是OSD Lyrics不像[Shazam][9]等一样,它不是通过音频来寻找歌词,而是通过比如名称,专辑,艺术家等信息来关联音乐文件。所以你得确保你的音乐文件的来源正当,或者是你得保持你的音乐文件的信息是正确和已经更新了的。
|
||||
|
||||
如果OSD Lyrics辨认出了音乐文件,它就会用卡拉OK格式在桌面上显示歌词了:(译者注:OSD Lyrics可以自动在千千静听和虾米歌词站点在线下载歌词,这对我们中文用户来说是个福音)
|
||||
|
||||

|
||||
|
||||
OSD Lyrics有大量设置选项,你可以改变歌词字体的种类,大小等等其它许多设置。
|
||||
|
||||
你认为OSD Lyrics怎么样?你使用其它的一些歌词插件吗?闲余时间请和我们分享你的看法。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/display-song-lyrics-desktop-ubuntu-1404/
|
||||
|
||||
译者:[Love-xuan](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://itsfoss.com/install-spotify-ubuntu-1404/
|
||||
[2]:http://www.tunewiki.com/
|
||||
[3]:https://code.google.com/p/osd-lyrics
|
||||
[4]:http://banshee.fm/
|
||||
[5]:https://www.clementine-player.org/
|
||||
[6]:https://code.google.com/p/osd-lyrics/downloads/list
|
||||
[7]:http://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
[8]:http://itsfoss.com/install-deb-files-easily-and-quickly-in-ubuntu-12-10-quick-tip/
|
||||
[9]:http://www.shazam.com/
|
||||
106
translated/tech/20140718 Linux Kernel Testing and Debugging 2.md
Normal file
106
translated/tech/20140718 Linux Kernel Testing and Debugging 2.md
Normal file
@ -0,0 +1,106 @@
|
||||
Linux 内核测试与调试 - 2
|
||||
================================================================================
|
||||
### 编译安装稳定版内核 ###
|
||||
|
||||
如果你用 git 下载源码,就执行以下命令:
|
||||
|
||||
cd linux-stable
|
||||
|
||||
git checkout linux-3.x.y
|
||||
|
||||
如果是直接下载压缩文件,用以下命令进入源码目录:
|
||||
|
||||
cd linux-3.x.y
|
||||
|
||||
如果你想把内核安装到自己的系统上,最安全的方法是使用你安装好的发行版拥有的配置文件。你可以在 /boot 目录找到当前发行版的内核配置文件:
|
||||
|
||||
cp /boot/config-3.x.y-z-generic .config
|
||||
|
||||
运行下面的命令,可以在当前内核配置的基础上修改一些小地方,然后产生新的内核配置文件。比如说新的内核比你的 Ubuntu 发行版自带的内核多了些新功能,而你正好需要用到它们,这个时候你就要修改配置了。
|
||||
|
||||
make oldconfig
|
||||
|
||||
完成配置后,就可以编译了:
|
||||
|
||||
make all
|
||||
|
||||
完成编译后,安装这个新的内核:
|
||||
|
||||
sudo "make modules_install install"
|
||||
|
||||
上面的命令安装新内核,并把新内核作为启动项添加到 grub 文件(LCTT:就是你下次开机时会多出一个开机选项)。好了你可以重启电脑,然后选择新的内核启动系统。等等!先别冲动,在重启电脑之前,我们保存下编译内核产生的日志,用于比较和查找错误(如果有错误发生的话):
|
||||
|
||||
dmesg -t > dmesg_current
|
||||
|
||||
dmesg -t -k > dmesg_kernel
|
||||
|
||||
dmesg -t -l emerg > dmesg_current_emerg
|
||||
|
||||
dmesg -t -l alert > dmesg_current_alert
|
||||
|
||||
dmesg -t -l crit > dmesg_current_alert
|
||||
|
||||
dmesg -t -l err > dmesg_current_err
|
||||
|
||||
dmesg -t -l warn > dmesg_current_warn
|
||||
|
||||
正常的话,dmesg 不会输出 emerg, alert, crit 和 err 级别的信息。如果你不幸看到这些输出了,说明内核或者你的硬件环境有问题。
|
||||
|
||||
再介绍一些重启前的需要执行的操作。谁也不能保证新内核能够正常启动,所以请不要潇洒地把老内核删除,至少保留一个稳定可用的内核在系统上。修改一下 /etc/default/grub 文件:
|
||||
|
||||
使用 earlyprink=vga 作为内核启动选项,把系统早期启动的信息打印到显示屏上:
|
||||
|
||||
GRUB_CMDLINE_LINUX="earlyprink=vga"
|
||||
|
||||
将 GRUB_TIMEOUT 的值设置成10秒到15秒之间的值,保证在开机启动的时候你有足够的时间来选择启动哪个内核:
|
||||
|
||||
取消对 GRUB_TIMEOUT 的注释,并把它设置为10:GRUB_TIMEOUT=10
|
||||
注释掉 GRUB_HIDDEN_TIMEOUT 和 GRUB_HIDDEN_TIMEOUT_QUIET
|
||||
|
||||
运行 update-grub 命令,更新 /boot 目录下的 grub 配置文件:
|
||||
|
||||
sudo update-grub
|
||||
|
||||
现在可以重启系统了。新内核起来后,比较新老内核的 dmesg 信息,看看新的内核有没有编译错误。如果新内核启动失败,你需要通过老内核启动系统,然后分析下为什么失败。
|
||||
|
||||
### 跟上节奏,永不落后(编译最新版内核) ###
|
||||
|
||||
如果你想开上内核快车道,追求与时俱进,那就去下载 mainline 状态的内核或 linux-next 状态的内核(LCTT:读者可进入 kernel.org 获取代码,linux 代码被分为4种状态:mainline, stable, longterm, linux-next)。安装测试 mainline 状态或 linux-next 状态的内核,你就可以在正式发布之前帮助内核找到并修复里面的 bug。
|
||||
|
||||
mainline 状态的内核源码:
|
||||
|
||||
git clone git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git
|
||||
|
||||
linux-next 状态的内核源码:
|
||||
|
||||
git clone git://git.kernel.org/pub/scm/linux/kernel/git/next/linux-next.git
|
||||
|
||||
编译安装这两种内核的步骤与编译安装稳定版内核一样。按之前讲过的步骤来就行了。
|
||||
|
||||
### 打补丁 ###
|
||||
|
||||
Linux 内核的补丁是一个文本文件,包含新源码与老源码之间的改变量。每个补丁只包含自己依赖的源码的增量,除非它被特意包含进一系列补丁之中。打补丁方法如下:
|
||||
|
||||
patch -p1 < file.patch
|
||||
|
||||
git apply --index file.patch
|
||||
|
||||
两种方法都可以打补丁。但是,如果你要打的补丁包含一个新文件,git 命令不能识别这个新增的文件,也就是说这个新文件在 git 里面属于 untracked 文件(LCTT:玩 git 的人对这个会比较熟悉,就是文件处于未被跟踪的状态,你需要使用 git add <file> 命令将文件放入暂存区)。git diff 命令不会将这个文件的增量显示出来,并且 git status 命令会显示这个文件处于 untracked 状态。
|
||||
|
||||
大多数情况下,有个没被跟踪的文件,对于编译安装内核来说没什么问题,但是 git 操作就会出现一些问题了: git reset --hard 命令不会删除这个新加的文件,并且接下来的 git pull 操作也会失败。你有多种选择来避免上面所说的状况:
|
||||
|
||||
选项1,不跟踪这个新文件:
|
||||
|
||||
> 如果打补丁后新添加了文件,在 git reset --hard 前使用 git clean 命令来删除没有被跟踪的文件。举个例子,git clean -dfx 命令会强制删除未被跟踪的目录和文件,忽略在 .gitigniore 文件内规定的文件。如果你不在乎哪些文件会被删除,你可以使用 -q 选项让 git clean 命令进入安静模式,不输出任何处理过程。
|
||||
|
||||
选项2,跟踪新文件:
|
||||
|
||||
> 你可以在使用 git apply --index file.patch 命令后让 git 跟踪打完补丁后新产生的文件(LCTT:使用 git add <new file> 命令),就是让 git 把文件放入 index 区域。做完这个后,git diff 命令会将新文件的增量打印出来,git status 也会显示者这是一个正常的新增文件。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/linux-kernel-testing-and-debugging?page=0,1
|
||||
|
||||
译者:[bazz2](https://github.com/bazz2) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
124
translated/tech/20140718 Linux Kernel Testing and Debugging 3.md
Normal file
124
translated/tech/20140718 Linux Kernel Testing and Debugging 3.md
Normal file
@ -0,0 +1,124 @@
|
||||
Linux 内核测试与调试 - 3
|
||||
================================================================================
|
||||
### 基本测试 ###
|
||||
|
||||
安装好内核后,试试能不能启动它。能启动的话,检查 dmesg 看看有没有隐藏的错误。试试下面的功能:
|
||||
|
||||
- 网络(Wifi 或者网线)是否可用?
|
||||
- ssh 是否可用?
|
||||
- 使用 ssh 远程传输文件。
|
||||
- 使用 git clone 和 git pull 命令。
|
||||
- 用用网络浏览器。
|
||||
- 查看 email。
|
||||
- 使用 ftp, wget 等软件下载文件。
|
||||
- 播放音频视频文件。
|
||||
- 连上 USB 鼠标等设备。
|
||||
|
||||
|
||||
### 检查内核日志 ###
|
||||
|
||||
使用 dmesg 查看隐藏的问题,对于定位新代码带来的 bug 是一个好方法。一般来说,dmesg 不会输出新的 crit, alert, emerg 级别的错误信息,也不应该出现新的 err 级别的信息。你要注意的是那些 warn 级别的日志信息。请注意 warn 这个级别的信息并不是坏消息,新代码带来新的警告信息,不会给内核带去严重的影响。
|
||||
|
||||
- dmesg -t -l emerg
|
||||
- dmesg -t -l crit
|
||||
- dmesg -t -l alert
|
||||
- dmesg -t -l err
|
||||
- dmesg -t -l warn
|
||||
- dmesg -t -k
|
||||
- dmesg -t
|
||||
|
||||
下面的脚本运行了上面的命令,并且将输出保存起来,以便与老的内核的 dmesg 输出作比较(LCTT:老内核的 dmesg 输出在本系列的第一篇文章中有介绍)。然后运行 diff 命令,查看新老内核 dmesg 日志之间的不同。脚本需要输入老内核版本号,如果不输入参数,它只会生成新内核的 dmesg 日志文件后直接退出,不再作比较(LCTT:话是这么说没错,但点开脚本一看,没输参数的话,这货会直接退出,连新内核的 dmesg 日志也不会保存的)。如果 dmesg 日志有新的警告信息,表示新发布的内核有漏网之鱼(LCTT:嗯,漏网之 bug 会更好理解些么?),这些 bug 逃过了自测和系统测试。你要看看,那些警告信息后面有没有栈跟踪信息?也许这里有很多问题需要你进一步调查分析。
|
||||
|
||||
- [**dmesg 测试脚本**][1]
|
||||
|
||||
### 压力测试 ###
|
||||
|
||||
执行压力测试的一个好办法是同时跑三四个内核编译任务。下载各种版本的内核,同时编译它们,并记录时间。比较新内核跑压力测试和老内核跑压力测试所花的时间,然后可以定位新内核的性能。如果新内核跑压力测试的时间比老内核的更长,说明新内核的部分模块性能退步了。性能问题很难调试出来。第一步是找出哪里导致的性能退步。同时跑多个内核编译任务对检测内核整体性能来说是个好方法,但是这种方法涵盖了多个内核模块,比如内存管理、文件系统、DMA、驱动等(LCTT:也就是说,这种压力测试没办法定位到是哪个模块造成了性能的下降)。
|
||||
|
||||
time make all
|
||||
|
||||
### 内核测试工具 ###
|
||||
|
||||
我们可以在 Linux 内核本身找到多种测试方法。下面介绍一个很好用的功能测试工具集: ktest 套件
|
||||
|
||||
ktest 是一个自动测试套件,它可以提供编译安装启动内核一条龙测试服务,也可以跑交叉编译测试,前提是你的系统有安装交叉编译所需要的软件。ktest 依赖于 flex 和 bison。详细信息请参考放在 tools/testing/ktest 目录下的文档,你可以自学成材。另外还有一些参考资料教你怎么使用 ktest:
|
||||
|
||||
- [**ktest-eLinux.org**][2]
|
||||
|
||||
### tools/testing/selftests 套件 ###
|
||||
|
||||
我们来玩玩自测吧。内核源码的多个子系统都有自己的自测工具,到目前为止,断点、cpu热插拔、efivarfs、IPC、KCMP、内存热插拔、mqueue、网络、powerpc、ptrace、rcutorture、定时器和虚拟机子系统都有自测工具。另外,用户态内存的自测工具可以利用 test_user_copy 模块来测试用户态内存到内核态的拷贝过程。下面的命令演示了如何使用这些测试工具:
|
||||
|
||||
编译测试:
|
||||
|
||||
make -C tools/testing/selftests
|
||||
|
||||
测试全部:(有些测试需要 root 权限,你需要以 root 用户登入系统然后运行命令)
|
||||
|
||||
make -C tools/testing/selftests run_tests
|
||||
|
||||
只测试单个子系统:
|
||||
|
||||
make -C tools/testing/selftests TARGETS=vm run_tests
|
||||
|
||||
### tools/testing/fault-injection 套件 ###
|
||||
|
||||
在 tools/testing 目录下的另一个测试套件是 fault-injection。failcmd.sh 脚本用于检测 slab 和内存页分配器的错误。这些工具可以测试内核能否很好地从错误状态中恢复回来。这些测试需要用到 root 权限。下面简单介绍了一些当前能提供的错误检测方法。随着错误检测方法的增加,这份名单也会不断增长。最新的名单请参考 Documentation/fault-injection/fault-injection.txt 文档。
|
||||
|
||||
failslab (默认选项)
|
||||
|
||||
产生 slab 分配错误。作用于 kmalloc(), kmem_cache_alloc() 等函数(LCTT:产生的结果是调用这些函数就会返回失败,可以模拟程序分不到内存时是否还能稳定运行下去)。
|
||||
|
||||
fail_page_alloc
|
||||
|
||||
产生内存页分配的错误。作用于 alloc_pages(), get_free_pages() 等函数(LCTT:同上,调用这些函数,返回错误)。
|
||||
|
||||
fail_make_request
|
||||
|
||||
对满足条件(可以设置 /sys/block//make-it-fail 或 /sys/block///make-it-fail 文件)的磁盘产生 IO 错误,作用于 generic_make_request() 函数(LCTT:所有针对这块磁盘的读或写请求都会出错)。
|
||||
|
||||
fail_mmc_request
|
||||
|
||||
对满足条件(可以设置 /sys/kernel/debug/mmc0/fail_mmc_request 这个 debugfs 属性)的磁盘产生 MMC 数据错误。
|
||||
|
||||
你可以自己配置 fault-injection 套件的功能。fault-inject-debugfs 内核模块在系统运行时会在 debugfs 文件系统下面提供一些属性文件。你可以指定出错的概率,指定两个错误之间的时间间隔,当然本套件还能提供更多其他功能,具体请查看 Documentation/fault-injection/fault-injection.txt。 Boot 选项可以让你的系统在 debugfs 文件系统起来之前就可以产生错误,下面列出几个 boot 选项:
|
||||
|
||||
- failslab=
|
||||
- fail_page_alloc=
|
||||
- fail_make_request=
|
||||
- mmc_core.fail_request=[interval],[probability],[space],[times]
|
||||
|
||||
fault-injection 套件提供接口,以便增加新的功能。下面简单介绍下增加新功能的步骤,详细信息请参考上面提到过的文档:
|
||||
|
||||
使用 DECLARE_FAULT_INJECTION(name) 定义默认属性;
|
||||
|
||||
> 详细信息可查看 fault-inject.h 中定义的 struct fault_attr 结构体。
|
||||
|
||||
配置 fault 属性,新建一个 boot 选项;
|
||||
|
||||
> 这步可以使用 setup_fault_attr(attr, str) 函数完成,为了能在系统启动的早期产生错误,添加一个 boot 选项这一步是必须要有的。
|
||||
|
||||
添加 debugfs 属性;
|
||||
|
||||
> 使用 fault_create_debugfs_attr(name, parent, attr) 函数,为新功能添加新的 debugfs 属性。
|
||||
|
||||
为模块设置参数;
|
||||
|
||||
> 为模块添加一些参数,对于配置错误属性来说是一个好主意,特别是当新功能的应用范围受限于单个内核模块的时候(LCTT:不同内核,你的新功能可能需要不同的测试参数,通过设置参数,你的功能可以不必为了迎合不同内核而每次都重新编译一遍)。
|
||||
|
||||
添加一个钩子函数到错误测试的代码中。
|
||||
|
||||
> should_fail(attr, size) —— 当这个钩子函数返回 true 时,用户的代码就应该产生一个错误。
|
||||
|
||||
应用程序使用这个 fault-injection 套件可以指定某个具体的内核模块产生 slab 和内存页分配的错误,这样就可以缩小性能测试的范围。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/linux-kernel-testing-and-debugging?page=0,2
|
||||
|
||||
译者:[bazz2](https://github.com/bazz2) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://linuxdriverproject.org/mediawiki/index.php/Dmesg_regression_check_script
|
||||
[2]:http://elinux.org/Ktest#Git_Bisect_type
|
||||
Loading…
Reference in New Issue
Block a user