mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-30 02:40:11 +08:00
commit
d63db399c9
@ -1,53 +1,54 @@
|
||||
Autojump – 一个高级的‘cd’命令用以快速浏览 Linux 文件系统
|
||||
Autojump:一个可以在 Linux 文件系统快速导航的高级 cd 命令
|
||||
================================================================================
|
||||
对于那些主要通过控制台或终端使用 Linux 命令行来工作的 Linux 用户来说,他们真切地感受到了 Linux 的强大。 然而在 Linux 的分层文件系统中进行浏览有时或许是一件头疼的事,尤其是对于那些新手来说。
|
||||
|
||||
对于那些主要通过控制台或终端使用 Linux 命令行来工作的 Linux 用户来说,他们真切地感受到了 Linux 的强大。 然而在 Linux 的分层文件系统中进行导航有时或许是一件头疼的事,尤其是对于那些新手来说。
|
||||
|
||||
现在,有一个用 Python 写的名为 `autojump` 的 Linux 命令行实用程序,它是 Linux ‘[cd][1]’命令的高级版本。
|
||||
|
||||

|
||||
|
||||
Autojump – 浏览 Linux 文件系统的最快方式
|
||||
*Autojump – Linux 文件系统导航的最快方式*
|
||||
|
||||
这个应用原本由 Joël Schaerer 编写,现在由 +William Ting 维护。
|
||||
|
||||
Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行更轻松的目录浏览。与传统的 `cd` 命令相比,autojump 能够更加快速地浏览至目的目录。
|
||||
Autojump 应用可以从用户那里学习并帮助用户在 Linux 命令行中进行更轻松的目录导航。与传统的 `cd` 命令相比,autojump 能够更加快速地导航至目的目录。
|
||||
|
||||
#### autojump 的特色 ####
|
||||
|
||||
- 免费且开源的应用,在 GPL V3 协议下发布。
|
||||
- 自主学习的应用,从用户的浏览习惯中学习。
|
||||
- 更快速地浏览。不必包含子目录的名称。
|
||||
- 对于大多数的标准 Linux 发行版本,能够在软件仓库中下载得到,它们包括 Debian (testing/unstable), Ubuntu, Mint, Arch, Gentoo, Slackware, CentOS, RedHat and Fedora。
|
||||
- 自由开源的应用,在 GPL V3 协议下发布。
|
||||
- 自主学习的应用,从用户的导航习惯中学习。
|
||||
- 更快速地导航。不必包含子目录的名称。
|
||||
- 对于大多数的标准 Linux 发行版本,能够在软件仓库中下载得到,它们包括 Debian (testing/unstable), Ubuntu, Mint, Arch, Gentoo, Slackware, CentOS, RedHat 和 Fedora。
|
||||
- 也能在其他平台中使用,例如 OS X(使用 Homebrew) 和 Windows (通过 Clink 来实现)
|
||||
- 使用 autojump 你可以跳至任何特定的目录或一个子目录。你还可以打开文件管理器来到达某个目录,并查看你在某个目录中所待时间的统计数据。
|
||||
- 使用 autojump 你可以跳至任何特定的目录或一个子目录。你还可以用文件管理器打开某个目录,并查看你在某个目录中所待时间的统计数据。
|
||||
|
||||
#### 前提 ####
|
||||
|
||||
- 版本号不低于 2.6 的 Python
|
||||
|
||||
### 第 1 步: 做一次全局系统升级 ###
|
||||
### 第 1 步: 做一次完整的系统升级 ###
|
||||
|
||||
1. 以 **root** 用户的身份,做一次系统更新或升级,以此保证你安装有最新版本的 Python。
|
||||
1、 以 **root** 用户的身份,做一次系统更新或升级,以此保证你安装有最新版本的 Python。
|
||||
|
||||
# apt-get update && apt-get upgrade && apt-get dist-upgrade [APT based systems]
|
||||
# yum update && yum upgrade [YUM based systems]
|
||||
# dnf update && dnf upgrade [DNF based systems]
|
||||
# apt-get update && apt-get upgrade && apt-get dist-upgrade [基于 APT 的系统]
|
||||
# yum update && yum upgrade [基于 YUM 的系统]
|
||||
# dnf update && dnf upgrade [基于 DNF 的系统]
|
||||
|
||||
**注** : 这里特别提醒,在基于 YUM 或 DNF 的系统中,更新和升级执行相同的行动,大多数时间里它们是通用的,这点与基于 APT 的系统不同。
|
||||
|
||||
### 第 2 步: 下载和安装 Autojump ###
|
||||
|
||||
2. 正如前面所言,在大多数的 Linux 发行版本的软件仓库中, autojump 都可获取到。通过包管理器你就可以安装它。但若你想从源代码开始来安装它,你需要克隆源代码并执行 python 脚本,如下面所示:
|
||||
2、 正如前面所言,在大多数的 Linux 发行版本的软件仓库中, autojump 都可获取到。通过包管理器你就可以安装它。但若你想从源代码开始来安装它,你需要克隆源代码并执行 python 脚本,如下面所示:
|
||||
|
||||
#### 从源代码安装 ####
|
||||
|
||||
若没有安装 git,请安装它。我们需要使用它来克隆 git 仓库。
|
||||
|
||||
# apt-get install git [APT based systems]
|
||||
# yum install git [YUM based systems]
|
||||
# dnf install git [DNF based systems]
|
||||
# apt-get install git [基于 APT 的系统]
|
||||
# yum install git [基于 YUM 的系统]
|
||||
# dnf install git [基于 DNF 的系统]
|
||||
|
||||
一旦安装完 git,以常规用户身份登录,然后像下面那样来克隆 autojump:
|
||||
一旦安装完 git,以普通用户身份登录,然后像下面那样来克隆 autojump:
|
||||
|
||||
$ git clone git://github.com/joelthelion/autojump.git
|
||||
|
||||
@ -55,29 +56,29 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||
$ cd autojump
|
||||
|
||||
下载,赋予脚本文件可执行权限,并以 root 用户身份来运行安装脚本。
|
||||
下载,赋予安装脚本文件可执行权限,并以 root 用户身份来运行安装脚本。
|
||||
|
||||
# chmod 755 install.py
|
||||
# ./install.py
|
||||
|
||||
#### 从软件仓库中安装 ####
|
||||
|
||||
3. 假如你不想麻烦,你可以以 **root** 用户身份从软件仓库中直接安装它:
|
||||
3、 假如你不想麻烦,你可以以 **root** 用户身份从软件仓库中直接安装它:
|
||||
|
||||
在 Debian, Ubuntu, Mint 及类似系统中安装 autojump :
|
||||
|
||||
# apt-get install autojump (注: 这里原文为 autojumo, 应该为 autojump)
|
||||
# apt-get install autojump
|
||||
|
||||
为了在 Fedora, CentOS, RedHat 及类似系统中安装 autojump, 你需要启用 [EPEL 软件仓库][2]。
|
||||
|
||||
# yum install epel-release
|
||||
# yum install autojump
|
||||
OR
|
||||
或
|
||||
# dnf install autojump
|
||||
|
||||
### 第 3 步: 安装后的配置 ###
|
||||
|
||||
4. 在 Debian 及其衍生系统 (Ubuntu, Mint,…) 中, 激活 autojump 应用是非常重要的。
|
||||
4、 在 Debian 及其衍生系统 (Ubuntu, Mint,…) 中, 激活 autojump 应用是非常重要的。
|
||||
|
||||
为了暂时激活 autojump 应用,即直到你关闭当前会话或打开一个新的会话之前让 autojump 均有效,你需要以常规用户身份运行下面的命令:
|
||||
|
||||
@ -89,7 +90,7 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||
### 第 4 步: Autojump 的预测试和使用 ###
|
||||
|
||||
5. 如先前所言, autojump 将只跳到先前 `cd` 命令到过的目录。所以在我们开始测试之前,我们要使用 `cd` 切换到一些目录中去,并创建一些目录。下面是我所执行的命令。
|
||||
5、 如先前所言, autojump 将只跳到先前 `cd` 命令到过的目录。所以在我们开始测试之前,我们要使用 `cd` 切换到一些目录中去,并创建一些目录。下面是我所执行的命令。
|
||||
|
||||
$ cd
|
||||
$ cd
|
||||
@ -120,45 +121,45 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||
现在,我们已经切换到过上面所列的目录,并为了测试创建了一些目录,一切准备就绪,让我们开始吧。
|
||||
|
||||
**需要记住的一点** : `j` 是 autojump 的一个包装,你可以使用 j 来代替 autojump, 相反亦可。
|
||||
**需要记住的一点** : `j` 是 autojump 的一个封装,你可以使用 j 来代替 autojump, 相反亦可。
|
||||
|
||||
6. 使用 -v 选项查看安装的 autojump 的版本。
|
||||
6、 使用 -v 选项查看安装的 autojump 的版本。
|
||||
|
||||
$ j -v
|
||||
or
|
||||
或
|
||||
$ autojump -v
|
||||
|
||||

|
||||
|
||||
查看 Autojump 的版本
|
||||
*查看 Autojump 的版本*
|
||||
|
||||
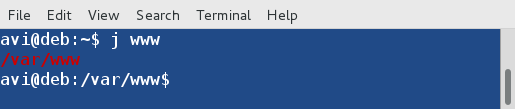
7. 跳到先前到过的目录 ‘/var/www‘。
|
||||
7、 跳到先前到过的目录 ‘/var/www‘。
|
||||
|
||||
$ j www
|
||||
|
||||
|
||||
|
||||
跳到目录
|
||||
*跳到目录*
|
||||
|
||||
8. 跳到先前到过的子目录‘/home/avi/autojump-test/b‘ 而不键入子目录的全名。
|
||||
8、 跳到先前到过的子目录‘/home/avi/autojump-test/b‘ 而不键入子目录的全名。
|
||||
|
||||
$ jc b
|
||||
|
||||

|
||||
|
||||
跳到子目录
|
||||
*跳到子目录*
|
||||
|
||||
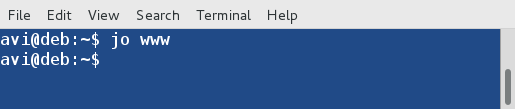
9. 使用下面的命令,你就可以从命令行打开一个文件管理器,例如 GNOME Nautilus ,而不是跳到一个目录。
|
||||
9、 使用下面的命令,你就可以从命令行打开一个文件管理器,例如 GNOME Nautilus ,而不是跳到一个目录。
|
||||
|
||||
$ jo www
|
||||
|
||||
|
||||

|
||||
|
||||
跳到目录
|
||||
*打开目录*
|
||||
|
||||

|
||||
|
||||
在文件管理器中打开目录
|
||||
*在文件管理器中打开目录*
|
||||
|
||||
你也可以在一个文件管理器中打开一个子目录。
|
||||
|
||||
@ -166,19 +167,19 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||

|
||||
|
||||
打开子目录
|
||||
*打开子目录*
|
||||
|
||||

|
||||
|
||||
在文件管理器中打开子目录
|
||||
*在文件管理器中打开子目录*
|
||||
|
||||
10. 查看每个文件夹的关键权重和在所有目录权重中的总关键权重的相关统计数据。文件夹的关键权重代表在这个文件夹中所花的总时间。 目录权重是列表中目录的数目。(注: 在这一句中,我觉得原文中的 if 应该为 is)
|
||||
10、 查看每个文件夹的权重和全部文件夹计算得出的总权重的统计数据。文件夹的权重代表在这个文件夹中所花的总时间。 文件夹权重是该列表中目录的数字。(LCTT 译注: 在这一句中,我觉得原文中的 if 应该为 is)
|
||||
|
||||
$ j --stat
|
||||
|
||||

|
||||

|
||||
|
||||
查看目录统计数据
|
||||
*查看文件夹统计数据*
|
||||
|
||||
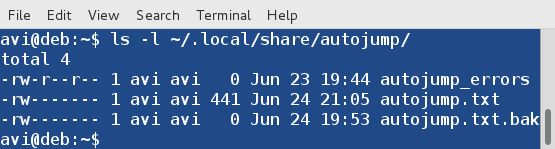
**提醒** : autojump 存储其运行日志和错误日志的地方是文件夹 `~/.local/share/autojump/`。千万不要重写这些文件,否则你将失去你所有的统计状态结果。
|
||||
|
||||
@ -186,15 +187,15 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||
|
||||
|
||||
Autojump 的日志
|
||||
*Autojump 的日志*
|
||||
|
||||
11. 假如需要,你只需运行下面的命令就可以查看帮助 :
|
||||
11、 假如需要,你只需运行下面的命令就可以查看帮助 :
|
||||
|
||||
$ j --help
|
||||
|
||||

|
||||
|
||||
Autojump 的帮助和选项
|
||||
*Autojump 的帮助和选项*
|
||||
|
||||
### 功能需求和已知的冲突 ###
|
||||
|
||||
@ -204,18 +205,19 @@ Autojump 的帮助和选项
|
||||
|
||||
### 结论: ###
|
||||
|
||||
假如你是一个命令行用户, autojump 是你必备的实用程序。它可以简化许多事情。它是一个在命令行中浏览 Linux 目录的绝佳的程序。请自行尝试它,并在下面的评论框中让我知晓你宝贵的反馈。保持联系,保持分享。喜爱并分享,帮助我们更好地传播。
|
||||
假如你是一个命令行用户, autojump 是你必备的实用程序。它可以简化许多事情。它是一个在命令行中导航 Linux 目录的绝佳的程序。请自行尝试它,并在下面的评论框中让我知晓你宝贵的反馈。保持联系,保持分享。喜爱并分享,帮助我们更好地传播。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/autojump-a-quickest-way-to-navigate-linux-filesystem/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/cd-command-in-linux/
|
||||
[2]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[2]:https://linux.cn/article-2324-1.html
|
||||
[3]:http://www.tecmint.com/manage-linux-filenames-with-special-characters/
|
||||
@ -1,6 +1,6 @@
|
||||
如何在Ubuntu 14.04/15.04上配置Chef(服务端/客户端)
|
||||
如何在 Ubuntu 上安装配置管理系统 Chef (大厨)
|
||||
================================================================================
|
||||
Chef是对于信息技术专业人员的一款配置管理和自动化工具,它可以配置和管理你的设备无论它在本地还是在云上。它可以用于加速应用部署并协调多个系统管理员和开发人员的工作,涉及到成百甚至上千的服务器和程序来支持大量的客户群。chef最有用的是让设备变成代码。一旦你掌握了Chef,你可以获得一流的网络IT支持来自动化管理你的云端设备或者终端用户。
|
||||
Chef是面对IT专业人员的一款配置管理和自动化工具,它可以配置和管理你的基础设施,无论它在本地还是在云上。它可以用于加速应用部署并协调多个系统管理员和开发人员的工作,这涉及到可支持大量的客户群的成百上千的服务器和程序。chef最有用的是让基础设施变成代码。一旦你掌握了Chef,你可以获得一流的网络IT支持来自动化管理你的云端基础设施或者终端用户。
|
||||
|
||||
下面是我们将要在本篇中要设置和配置Chef的主要组件。
|
||||
|
||||
@ -10,34 +10,13 @@ Chef是对于信息技术专业人员的一款配置管理和自动化工具,
|
||||
|
||||
我们将在下面的基础环境下设置Chef配置管理系统。
|
||||
|
||||
注:表格
|
||||
<table width="701" style="height: 284px;">
|
||||
<tbody>
|
||||
<tr>
|
||||
<td width="660" colspan="2"><strong>管理和配置工具:Chef</strong></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="220"><strong>基础操作系统</strong></td>
|
||||
<td width="492">Ubuntu 14.04.1 LTS (x86_64)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="220"><strong>Chef Server</strong></td>
|
||||
<td width="492">Version 12.1.0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="220"><strong>Chef Manage</strong></td>
|
||||
<td width="492">Version 1.17.0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="220"><strong>Chef Development Kit</strong></td>
|
||||
<td width="492">Version 0.6.2</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="220"><strong>内存和CPU</strong></td>
|
||||
<td width="492">4 GB , 2.0+2.0 GHZ</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|管理和配置工具:Chef||
|
||||
|-------------------------------|---|
|
||||
|基础操作系统|Ubuntu 14.04.1 LTS (x86_64)|
|
||||
|Chef Server|Version 12.1.0|
|
||||
|Chef Manage|Version 1.17.0|
|
||||
|Chef Development Kit|Version 0.6.2|
|
||||
|内存和CPU|4 GB , 2.0+2.0 GHz|
|
||||
|
||||
### Chef服务端的安装和配置 ###
|
||||
|
||||
@ -45,15 +24,15 @@ Chef服务端是核心组件,它存储配置以及其他和工作站交互的
|
||||
|
||||
我使用下面的命令来下载和安装它。
|
||||
|
||||
**1) 下载Chef服务端**
|
||||
####1) 下载Chef服务端
|
||||
|
||||
root@ubuntu-14-chef:/tmp# wget https://web-dl.packagecloud.io/chef/stable/packages/ubuntu/trusty/chef-server-core_12.1.0-1_amd64.deb
|
||||
|
||||
**2) 安装Chef服务端**
|
||||
####2) 安装Chef服务端
|
||||
|
||||
root@ubuntu-14-chef:/tmp# dpkg -i chef-server-core_12.1.0-1_amd64.deb
|
||||
|
||||
**3) 重新配置Chef服务端**
|
||||
####3) 重新配置Chef服务端
|
||||
|
||||
现在运行下面的命令来启动所有的chef服务端服务,这步也许会花费一些时间,因为它有许多不同一起工作的服务组成来创建一个正常运作的系统。
|
||||
|
||||
@ -64,35 +43,35 @@ chef服务端启动命令'chef-server-ctl reconfigure'需要运行两次,这
|
||||
Chef Client finished, 342/350 resources updated in 113.71139964 seconds
|
||||
opscode Reconfigured!
|
||||
|
||||
**4) 重启系统 **
|
||||
####4) 重启系统
|
||||
|
||||
安装完成后重启系统使系统能最好的工作,不然我们或许会在创建用户的时候看到下面的SSL连接错误。
|
||||
|
||||
ERROR: Errno::ECONNRESET: Connection reset by peer - SSL_connect
|
||||
|
||||
**5) 创建心的管理员**
|
||||
####5) 创建新的管理员
|
||||
|
||||
运行下面的命令来创建一个新的用它自己的配置的管理员账户。创建过程中,用户的RSA私钥会自动生成并需要被保存到一个安全的地方。--file选项会保存RSA私钥到指定的路径下。
|
||||
运行下面的命令来创建一个新的管理员账户及其配置。创建过程中,用户的RSA私钥会自动生成,它需要保存到一个安全的地方。--file选项会保存RSA私钥到指定的路径下。
|
||||
|
||||
root@ubuntu-14-chef:/tmp# chef-server-ctl user-create kashi kashi kashi kashif.fareedi@gmail.com kashi123 --filename /root/kashi.pem
|
||||
|
||||
### Chef服务端的管理设置 ###
|
||||
|
||||
Chef Manage是一个针对企业Chef用户的管理控制台,它启用了可视化的web用户界面并可以管理节点、数据包、规则、环境、配置和基于角色的访问控制(RBAC)
|
||||
Chef Manage是一个针对企业Chef用户的管理控制台,它提供了可视化的web用户界面,可以管理节点、数据包、规则、环境、Cookbook 和基于角色的访问控制(RBAC)
|
||||
|
||||
**1) 下载Chef Manage**
|
||||
####1) 下载Chef Manage
|
||||
|
||||
从官网复制链接病下载chef manage的安装包。
|
||||
从官网复制链接并下载chef manage的安装包。
|
||||
|
||||
root@ubuntu-14-chef:~# wget https://web-dl.packagecloud.io/chef/stable/packages/ubuntu/trusty/opscode-manage_1.17.0-1_amd64.deb
|
||||
|
||||
**2) 安装Chef Manage**
|
||||
####2) 安装Chef Manage
|
||||
|
||||
使用下面的命令在root的家目录下安装它。
|
||||
|
||||
root@ubuntu-14-chef:~# chef-server-ctl install opscode-manage --path /root
|
||||
|
||||
**3) 重启Chef Manage和服务端**
|
||||
####3) 重启Chef Manage和服务端
|
||||
|
||||
安装完成后我们需要运行下面的命令来重启chef manage和服务端。
|
||||
|
||||
@ -101,28 +80,27 @@ Chef Manage是一个针对企业Chef用户的管理控制台,它启用了可
|
||||
|
||||
### Chef Manage网页控制台 ###
|
||||
|
||||
我们可以使用localhost访问网页控制台以及fqdn,并用已经创建的管理员登录
|
||||
我们可以使用localhost或它的全称域名来访问网页控制台,并用已经创建的管理员登录
|
||||
|
||||

|
||||
|
||||
**1) Chef Manage创建新的组织 **
|
||||
####1) Chef Manage创建新的组织
|
||||
|
||||
你或许被要求创建新的组织或者接受其他阻止的邀请。如下所示,使用缩写和全名来创建一个新的组织。
|
||||
你或许被要求创建新的组织,或者也可以接受其他组织的邀请。如下所示,使用缩写和全名来创建一个新的组织。
|
||||
|
||||

|
||||
|
||||
**2) 用命令行创建心的组织 **
|
||||
####2) 用命令行创建新的组织
|
||||
|
||||
We can also create new Organization from the command line by executing the following command.
|
||||
我们同样也可以运行下面的命令来创建新的组织。
|
||||
|
||||
root@ubuntu-14-chef:~# chef-server-ctl org-create linux Linoxide Linux Org. --association_user kashi --filename linux.pem
|
||||
|
||||
### 设置工作站 ###
|
||||
|
||||
我们已经完成安装chef服务端,现在我们可以开始创建任何recipes、cookbooks、属性和其他任何的我们想要对Chef的修改。
|
||||
我们已经完成安装chef服务端,现在我们可以开始创建任何recipes([基础配置元素](https://docs.chef.io/recipes.html))、cookbooks([基础配置集](https://docs.chef.io/cookbooks.html))、attributes([节点属性](https://docs.chef.io/attributes.html))和其他任何的我们想要对Chef做的修改。
|
||||
|
||||
**1) 在Chef服务端上创建新的用户和组织 **
|
||||
####1) 在Chef服务端上创建新的用户和组织
|
||||
|
||||
为了设置工作站,我们用命令行创建一个新的用户和组织。
|
||||
|
||||
@ -130,25 +108,23 @@ We can also create new Organization from the command line by executing the follo
|
||||
|
||||
root@ubuntu-14-chef:~# chef-server-ctl org-create blogs Linoxide Blogs Inc. --association_user bloger --filename blogs.pem
|
||||
|
||||
**2) 下载工作站入门套件 **
|
||||
####2) 下载工作站入门套件
|
||||
|
||||
Now Download and Save starter-kit from the chef manage web console on a workstation and use it to work with Chef server.
|
||||
在工作站的网页控制台中下面并保存入门套件用于与服务端协同工作
|
||||
在工作站的网页控制台中下载保存入门套件,它用于与服务端协同工作
|
||||
|
||||

|
||||
|
||||
**3) 点击"Proceed"下载套件 **
|
||||
####3) 下载套件后,点击"Proceed"
|
||||
|
||||

|
||||
|
||||
### 对于工作站的Chef开发套件设置 ###
|
||||
### 用于工作站的Chef开发套件设置 ###
|
||||
|
||||
Chef开发套件是一款包含所有开发chef所需工具的软件包。它捆绑了由Chef开发的带Chef客户端的工具。
|
||||
Chef开发套件是一款包含开发chef所需的所有工具的软件包。它捆绑了由Chef开发的带Chef客户端的工具。
|
||||
|
||||
**1) 下载 Chef DK**
|
||||
####1) 下载 Chef DK
|
||||
|
||||
We can Download chef development kit from its official web link and choose the required operating system to get its chef development tool kit.
|
||||
我们可以从它的官网链接中下载开发包,并选择操作系统来得到chef开发包。
|
||||
我们可以从它的官网链接中下载开发包,并选择操作系统来下载chef开发包。
|
||||
|
||||

|
||||
|
||||
@ -156,13 +132,13 @@ We can Download chef development kit from its official web link and choose the r
|
||||
|
||||
root@ubuntu-15-WKS:~# wget https://opscode-omnibus-packages.s3.amazonaws.com/ubuntu/12.04/x86_64/chefdk_0.6.2-1_amd64.deb
|
||||
|
||||
**1) Chef开发套件安装**
|
||||
####2) Chef开发套件安装
|
||||
|
||||
使用dpkg命令安装开发套件
|
||||
|
||||
root@ubuntu-15-WKS:~# dpkg -i chefdk_0.6.2-1_amd64.deb
|
||||
|
||||
**3) Chef DK 验证**
|
||||
####3) Chef DK 验证
|
||||
|
||||
使用下面的命令验证客户端是否已经正确安装。
|
||||
|
||||
@ -195,7 +171,7 @@ We can Download chef development kit from its official web link and choose the r
|
||||
Verification of component 'chefspec' succeeded.
|
||||
Verification of component 'package installation' succeeded.
|
||||
|
||||
**连接Chef服务端**
|
||||
####4) 连接Chef服务端
|
||||
|
||||
我们将创建 ~/.chef并从chef服务端复制两个用户和组织的pem文件到chef的文件到这个目录下。
|
||||
|
||||
@ -209,7 +185,7 @@ We can Download chef development kit from its official web link and choose the r
|
||||
kashi.pem 100% 1678 1.6KB/s 00:00
|
||||
linux.pem 100% 1678 1.6KB/s 00:00
|
||||
|
||||
** 编辑配置来管理chef环境 **
|
||||
####5) 编辑配置来管理chef环境
|
||||
|
||||
现在使用下面的内容创建"~/.chef/knife.rb"。
|
||||
|
||||
@ -231,13 +207,13 @@ We can Download chef development kit from its official web link and choose the r
|
||||
|
||||
root@ubuntu-15-WKS:/# mkdir cookbooks
|
||||
|
||||
**测试Knife配置**
|
||||
####6) 测试Knife配置
|
||||
|
||||
运行“knife user list”和“knife client list”来验证knife是否在工作。
|
||||
|
||||
root@ubuntu-15-WKS:/.chef# knife user list
|
||||
|
||||
第一次运行的时候可能会得到下面的错误,这是因为工作站上还没有chef服务端的SSL证书。
|
||||
第一次运行的时候可能会看到下面的错误,这是因为工作站上还没有chef服务端的SSL证书。
|
||||
|
||||
ERROR: SSL Validation failure connecting to host: 172.25.10.173 - SSL_connect returned=1 errno=0 state=SSLv3 read server certificate B: certificate verify failed
|
||||
ERROR: Could not establish a secure connection to the server.
|
||||
@ -245,24 +221,24 @@ We can Download chef development kit from its official web link and choose the r
|
||||
If your Chef Server uses a self-signed certificate, you can use
|
||||
`knife ssl fetch` to make knife trust the server's certificates.
|
||||
|
||||
要从上面的命令中恢复,运行下面的命令来获取ssl整数并重新运行knife user和client list,这时候应该就可以了。
|
||||
要从上面的命令中恢复,运行下面的命令来获取ssl证书,并重新运行knife user和client list,这时候应该就可以了。
|
||||
|
||||
root@ubuntu-15-WKS:/.chef# knife ssl fetch
|
||||
WARNING: Certificates from 172.25.10.173 will be fetched and placed in your trusted_cert
|
||||
directory (/.chef/trusted_certs).
|
||||
|
||||
knife没有办法验证这些是有效的证书。你应该在下载时候验证这些证书的真实性。
|
||||
knife没有办法验证这些是有效的证书。你应该在下载时候验证这些证书的真实性。
|
||||
|
||||
在/.chef/trusted_certs/ubuntu-14-chef_test_com.crt下面添加ubuntu-14-chef.test.com的证书。
|
||||
在/.chef/trusted_certs/ubuntu-14-chef_test_com.crt下面添加ubuntu-14-chef.test.com的证书。
|
||||
|
||||
在上面的命令取得ssl证书后,接着运行下面的命令。
|
||||
|
||||
root@ubuntu-15-WKS:/.chef#knife client list
|
||||
kashi-linux
|
||||
|
||||
### 与chef服务端交互的新的节点 ###
|
||||
### 配置与chef服务端交互的新节点 ###
|
||||
|
||||
节点是执行所有设备自动化的chef客户端。因此是时侯添加新的服务端到我们的chef环境下,在配置完chef-server和knife工作站后配置新的节点与chef-server交互。
|
||||
节点是执行所有基础设施自动化的chef客户端。因此,在配置完chef-server和knife工作站后,通过配置新的与chef-server交互的节点,来添加新的服务端到我们的chef环境下。
|
||||
|
||||
我们使用下面的命令来添加新的节点与chef服务端工作。
|
||||
|
||||
@ -291,16 +267,16 @@ We can Download chef development kit from its official web link and choose the r
|
||||
172.25.10.170 to file /tmp/install.sh.26024/metadata.txt
|
||||
172.25.10.170 trying wget...
|
||||
|
||||
之后我们可以在knife节点列表下看到新创建的节点,也会新节点列表下创建新的客户端。
|
||||
之后我们可以在knife节点列表下看到新创建的节点,它也会在新节点创建新的客户端。
|
||||
|
||||
root@ubuntu-15-WKS:~# knife node list
|
||||
mydns
|
||||
|
||||
相似地我们只要提供ssh证书通过上面的knife命令来创建多个节点到chef设备上。
|
||||
相似地我们只要提供ssh证书通过上面的knife命令,就可以在chef设施上创建多个节点。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
本篇我们学习了chef管理工具并通过安装和配置设置浏览了它的组件。我希望你在学习安装和配置Chef服务端以及它的工作站和客户端节点中获得乐趣。
|
||||
本篇我们学习了chef管理工具并通过安装和配置设置基本了解了它的组件。我希望你在学习安装和配置Chef服务端以及它的工作站和客户端节点中获得乐趣。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -308,7 +284,7 @@ via: http://linoxide.com/ubuntu-how-to/install-configure-chef-ubuntu-14-04-15-04
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
178
published/20150717 How to collect NGINX metrics - Part 2.md
Normal file
178
published/20150717 How to collect NGINX metrics - Part 2.md
Normal file
@ -0,0 +1,178 @@
|
||||
|
||||
如何收集 NGINX 指标(第二篇)
|
||||
================================================================================
|
||||

|
||||
|
||||
### 如何获取你所需要的 NGINX 指标 ###
|
||||
|
||||
如何获取需要的指标取决于你正在使用的 NGINX 版本以及你希望看到哪些指标。(参见 [如何监控 NGINX(第一篇)][1] 来深入了解NGINX指标。)自由开源的 NGINX 和商业版的 NGINX Plus 都有可以报告指标度量的状态模块,NGINX 也可以在其日志中配置输出特定指标:
|
||||
|
||||
**指标可用性**
|
||||
|
||||
| 指标 | [NGINX (开源)](https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source) | [NGINX Plus](https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#plus) | [NGINX 日志](https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#logs)|
|
||||
|-----|------|-------|-----|
|
||||
|accepts(接受) / accepted(已接受)|x|x| |
|
||||
|handled(已处理)|x|x| |
|
||||
|dropped(已丢弃)|x|x| |
|
||||
|active(活跃)|x|x| |
|
||||
|requests (请求数)/ total(全部请求数)|x|x| |
|
||||
|4xx 代码||x|x|
|
||||
|5xx 代码||x|x|
|
||||
|request time(请求处理时间)|||x|
|
||||
|
||||
#### 指标收集:NGINX(开源版) ####
|
||||
|
||||
开源版的 NGINX 会在一个简单的状态页面上显示几个与服务器状态有关的基本指标,它们由你启用的 HTTP [stub status module][2] 所提供。要检查该模块是否已启用,运行以下命令:
|
||||
|
||||
nginx -V 2>&1 | grep -o with-http_stub_status_module
|
||||
|
||||
如果你看到终端输出了 **http_stub_status_module**,说明该状态模块已启用。
|
||||
|
||||
如果该命令没有输出,你需要启用该状态模块。你可以在[从源代码构建 NGINX ][3]时使用 `--with-http_stub_status_module` 配置参数:
|
||||
|
||||
./configure \
|
||||
… \
|
||||
--with-http_stub_status_module
|
||||
make
|
||||
sudo make install
|
||||
|
||||
在验证该模块已经启用或你自己启用它后,你还需要修改 NGINX 配置文件,来给状态页面设置一个本地可访问的 URL(例如: /nginx_status):
|
||||
|
||||
server {
|
||||
location /nginx_status {
|
||||
stub_status on;
|
||||
|
||||
access_log off;
|
||||
allow 127.0.0.1;
|
||||
deny all;
|
||||
}
|
||||
}
|
||||
|
||||
注:nginx 配置中的 server 块通常并不放在主配置文件中(例如:/etc/nginx/nginx.conf),而是放在主配置会加载的辅助配置文件中。要找到主配置文件,首先运行以下命令:
|
||||
|
||||
nginx -t
|
||||
|
||||
打开列出的主配置文件,在以 http 块结尾的附近查找以 include 开头的行,如:
|
||||
|
||||
include /etc/nginx/conf.d/*.conf;
|
||||
|
||||
在其中一个包含的配置文件中,你应该会找到主 **server** 块,你可以如上所示配置 NGINX 的指标输出。更改任何配置后,通过执行以下命令重新加载配置文件:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
现在,你可以浏览状态页看到你的指标:
|
||||
|
||||
Active connections: 24
|
||||
server accepts handled requests
|
||||
1156958 1156958 4491319
|
||||
Reading: 0 Writing: 18 Waiting : 6
|
||||
|
||||
请注意,如果你希望从远程计算机访问该状态页面,则需要将远程计算机的 IP 地址添加到你的状态配置文件的白名单中,在上面的配置文件中的白名单仅有 127.0.0.1。
|
||||
|
||||
NGINX 的状态页面是一种快速查看指标状况的简单方法,但当连续监测时,你需要按照标准间隔自动记录该数据。监控工具箱 [Nagios][4] 或者 [Datadog][5],以及收集统计信息的服务 [collectD][6] 已经可以解析 NGINX 的状态信息了。
|
||||
|
||||
#### 指标收集: NGINX Plus ####
|
||||
|
||||
商业版的 NGINX Plus 通过它的 ngx_http_status_module 提供了比开源版 NGINX [更多的指标][7]。NGINX Plus 以字节流的方式提供这些额外的指标,提供了关于上游系统和高速缓存的信息。NGINX Plus 也会报告所有的 HTTP 状态码类型(1XX,2XX,3XX,4XX,5XX)的计数。一个 NGINX Plus 状态报告例子[可在此查看][8]:
|
||||
|
||||

|
||||
|
||||
注:NGINX Plus 在状态仪表盘中的“Active”连接的定义和开源 NGINX 通过 stub_status_module 收集的“Active”连接指标略有不同。在 NGINX Plus 指标中,“Active”连接不包括Waiting状态的连接(即“Idle”连接)。
|
||||
|
||||
NGINX Plus 也可以输出 [JSON 格式的指标][9],可以用于集成到其他监控系统。在 NGINX Plus 中,你可以看到 [给定的上游服务器组][10]的指标和健康状况,或者简单地从上游服务器的[单个服务器][11]得到响应代码的计数:
|
||||
|
||||
{"1xx":0,"2xx":3483032,"3xx":0,"4xx":23,"5xx":0,"total":3483055}
|
||||
|
||||
要启动 NGINX Plus 指标仪表盘,你可以在 NGINX 配置文件的 http 块内添加状态 server 块。 (参见上一节,为收集开源版 NGINX 指标而如何查找相关的配置文件的说明。)例如,要设置一个状态仪表盘 (http://your.ip.address:8080/status.html)和一个 JSON 接口(http://your.ip.address:8080/status),可以添加以下 server 块来设定:
|
||||
|
||||
server {
|
||||
listen 8080;
|
||||
root /usr/share/nginx/html;
|
||||
|
||||
location /status {
|
||||
status;
|
||||
}
|
||||
|
||||
location = /status.html {
|
||||
}
|
||||
}
|
||||
|
||||
当你重新加载 NGINX 配置后,状态页就可以用了:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
关于如何配置扩展状态模块,官方 NGINX Plus 文档有 [详细介绍][13] 。
|
||||
|
||||
#### 指标收集:NGINX 日志 ####
|
||||
|
||||
NGINX 的 [日志模块][14] 会把可自定义的访问日志写到你配置的指定位置。你可以通过[添加或移除变量][15]来自定义日志的格式和包含的数据。要存储详细的日志,最简单的方法是添加下面一行在你配置文件的 server 块中(参见上上节,为收集开源版 NGINX 指标而如何查找相关的配置文件的说明。):
|
||||
|
||||
access_log logs/host.access.log combined;
|
||||
|
||||
更改 NGINX 配置文件后,执行如下命令重新加载配置文件:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
默认包含的 “combined” 的日志格式,会包括[一系列关键的数据][17],如实际的 HTTP 请求和相应的响应代码。在下面的示例日志中,NGINX 记录了请求 /index.html 时的 200(成功)状态码和访问不存在的请求文件 /fail 的 404(未找到)错误。
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:12:10:46 -0500] "GET /index.html HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari 537.36"
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:12:11:05 -0500] "GET /fail HTTP/1.1" 404 570 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36"
|
||||
|
||||
你可以通过在 NGINX 配置文件中的 http 块添加一个新的日志格式来记录请求处理时间:
|
||||
|
||||
log_format nginx '$remote_addr - $remote_user [$time_local] '
|
||||
'"$request" $status $body_bytes_sent $request_time '
|
||||
'"$http_referer" "$http_user_agent"';
|
||||
|
||||
并修改配置文件中 **server** 块的 access_log 行:
|
||||
|
||||
access_log logs/host.access.log nginx;
|
||||
|
||||
重新加载配置文件后(运行 `nginx -s reload`),你的访问日志将包括响应时间,如下所示。单位为秒,精度到毫秒。在这个例子中,服务器接收到一个对 /big.pdf 的请求时,发送 33973115 字节后返回 206(成功)状态码。处理请求用时 0.202 秒(202毫秒):
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:15:50:36 -0500] "GET /big.pdf HTTP/1.1" 206 33973115 0.202 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36"
|
||||
|
||||
你可以使用各种工具和服务来解析和分析 NGINX 日志。例如,[rsyslog][18] 可以监视你的日志,并将其传递给多个日志分析服务;你也可以使用自由开源工具,比如 [logstash][19] 来收集和分析日志;或者你可以使用一个统一日志记录层,如 [Fluentd][20] 来收集和解析你的 NGINX 日志。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
监视 NGINX 的哪一项指标将取决于你可用的工具,以及监控指标所提供的信息是否满足你们的需要。举例来说,错误率的收集是否足够重要到需要你们购买 NGINX Plus ,还是架设一个可以捕获和分析日志的系统就够了?
|
||||
|
||||
在 Datadog 中,我们已经集成了 NGINX 和 NGINX Plus,这样你就可以以最小的设置来收集和监控所有 Web 服务器的指标。[在本文中][21]了解如何用 NGINX Datadog 来监控 ,并开始 [Datadog 的免费试用][22]吧。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
|
||||
作者:K Young
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.datadoghq.com/blog/how-to-monitor-nginx/
|
||||
[2]:http://nginx.org/en/docs/http/ngx_http_stub_status_module.html
|
||||
[3]:http://wiki.nginx.org/InstallOptions
|
||||
[4]:https://exchange.nagios.org/directory/Plugins/Web-Servers/nginx
|
||||
[5]:http://docs.datadoghq.com/integrations/nginx/
|
||||
[6]:https://collectd.org/wiki/index.php/Plugin:nginx
|
||||
[7]:http://nginx.org/en/docs/http/ngx_http_status_module.html#data
|
||||
[8]:http://demo.nginx.com/status.html
|
||||
[9]:http://demo.nginx.com/status
|
||||
[10]:http://demo.nginx.com/status/upstreams/demoupstreams
|
||||
[11]:http://demo.nginx.com/status/upstreams/demoupstreams/0/responses
|
||||
[12]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source
|
||||
[13]:http://nginx.org/en/docs/http/ngx_http_status_module.html#example
|
||||
[14]:http://nginx.org/en/docs/http/ngx_http_log_module.html
|
||||
[15]:http://nginx.org/en/docs/http/ngx_http_log_module.html#log_format
|
||||
[16]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source
|
||||
[17]:http://nginx.org/en/docs/http/ngx_http_log_module.html#log_format
|
||||
[18]:http://www.rsyslog.com/
|
||||
[19]:https://www.elastic.co/products/logstash
|
||||
[20]:http://www.fluentd.org/
|
||||
[21]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
[22]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#sign-up
|
||||
[23]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_collect_nginx_metrics.md
|
||||
[24]:https://github.com/DataDog/the-monitor/issues
|
||||
@ -1,11 +1,12 @@
|
||||
新手应知应会的Linux命令
|
||||
================================================================================
|
||||
|
||||
在Fedora上通过命令行使用dnf来管理系统更新
|
||||
|
||||
基于Linux的系统的优点之一,就是你可以通过终端中使用命令该ing来管理整个系统。使用命令行的优势在于,你可以使用相同的知识和技能来管理随便哪个Linux发行版。
|
||||
*在Fedora上通过命令行使用dnf来管理系统更新*
|
||||
|
||||
对于各个发行版以及桌面环境(DE)而言,要一致地使用图形化用户界面(GUI)却几乎是不可能的,因为它们都提供了各自的用户界面。要明确的是,有那么些情况,你需要在不同的发行版上使用不同的命令来部署某些特定的任务,但是,或多或少它们的概念和意图却仍然是一致的。
|
||||
基于Linux的系统最美妙的一点,就是你可以在终端中使用命令行来管理整个系统。使用命令行的优势在于,你可以使用相同的知识和技能来管理随便哪个Linux发行版。
|
||||
|
||||
对于各个发行版以及桌面环境(DE)而言,要一致地使用图形化用户界面(GUI)却几乎是不可能的,因为它们都提供了各自的用户界面。要明确的是,有些情况下在不同的发行版上需要使用不同的命令来执行某些特定的任务,但是,基本来说它们的思路和目的是一致的。
|
||||
|
||||
在本文中,我们打算讨论Linux用户应当掌握的一些基本命令。我将给大家演示怎样使用命令行来更新系统、管理软件、操作文件以及切换到root,这些操作将在三个主要发行版上进行:Ubuntu(也包括其定制版和衍生版,还有Debian),openSUSE,以及Fedora。
|
||||
|
||||
@ -15,7 +16,7 @@
|
||||
|
||||
Linux是基于安全设计的,但事实上是,任何软件都有缺陷,会导致安全漏洞。所以,保持你的系统更新到最新是十分重要的。这么想吧:运行过时的操作系统,就像是你坐在全副武装的坦克里头,而门却没有锁。武器会保护你吗?任何人都可以进入开放的大门,对你造成伤害。同样,在你的系统中也有没有打补丁的漏洞,这些漏洞会危害到你的系统。开源社区,不像专利世界,在漏洞补丁方面反应是相当快的,所以,如果你保持系统最新,你也获得了安全保证。
|
||||
|
||||
留意新闻站点,了解安全漏洞。如果发现了一个漏洞,请阅读之,然后在补丁出来的第一时间更新。不管怎样,在生产机器上,你每星期必须至少运行一次更新命令。如果你运行这一台复杂的服务器,那么就要额外当心了。仔细阅读变更日志,以确保更新不会搞坏你的自定义服务。
|
||||
留意新闻站点,了解安全漏洞。如果发现了一个漏洞,了解它,然后在补丁出来的第一时间更新。不管怎样,在生产环境上,你每星期必须至少运行一次更新命令。如果你运行着一台复杂的服务器,那么就要额外当心了。仔细阅读变更日志,以确保更新不会搞坏你的自定义服务。
|
||||
|
||||
**Ubuntu**:牢记一点:你在升级系统或安装不管什么软件之前,都必须要刷新仓库(也就是repos)。在Ubuntu上,你可以使用下面的命令来更新系统,第一个命令用于刷新仓库:
|
||||
|
||||
@ -29,7 +30,7 @@ Linux是基于安全设计的,但事实上是,任何软件都有缺陷,会
|
||||
|
||||
sudo apt-get dist-upgrade
|
||||
|
||||
**openSUSE**:如果你是在openSUSE上,你可以使用以下命令来更新系统(照例,第一个命令的意思是更新仓库)
|
||||
**openSUSE**:如果你是在openSUSE上,你可以使用以下命令来更新系统(照例,第一个命令的意思是更新仓库):
|
||||
|
||||
sudo zypper refresh
|
||||
sudo zypper up
|
||||
@ -42,7 +43,7 @@ Linux是基于安全设计的,但事实上是,任何软件都有缺陷,会
|
||||
### 软件安装与移除 ###
|
||||
|
||||
你只可以安装那些你系统上启用的仓库中可用的包,各个发行版默认都附带有并启用了一些官方或者第三方仓库。
|
||||
**Ubuntu**: To install any package on Ubuntu, first update the repo and then use this syntax:
|
||||
|
||||
**Ubuntu**:要在Ubuntu上安装包,首先更新仓库,然后使用下面的语句:
|
||||
|
||||
sudo apt-get install [package_name]
|
||||
@ -75,9 +76,9 @@ Linux是基于安全设计的,但事实上是,任何软件都有缺陷,会
|
||||
|
||||
### 如何管理第三方软件? ###
|
||||
|
||||
在一个庞大的开发者社区中,这些开发者们为用户提供了许多的软件。不同的发行版有不同的机制来使用这些第三方软件,将它们提供给用户。同时也取决于开发者怎样将这些软件提供给用户,有些开发者会提供二进制包,而另外一些开发者则将软件发布到仓库中。
|
||||
在一个庞大的开发者社区中,这些开发者们为用户提供了许多的软件。不同的发行版有不同的机制来将这些第三方软件提供给用户。当然,同时也取决于开发者怎样将这些软件提供给用户,有些开发者会提供二进制包,而另外一些开发者则将软件发布到仓库中。
|
||||
|
||||
Ubuntu严重依赖于PPA(个人包归档),但是,不幸的是,它却没有提供一个内建工具来帮助用于搜索这些PPA仓库。在安装软件前,你将需要通过Google搜索PPA,然后手工添加该仓库。下面就是添加PPA到系统的方法:
|
||||
Ubuntu很多地方都用到PPA(个人包归档),但是,不幸的是,它却没有提供一个内建工具来帮助用于搜索这些PPA仓库。在安装软件前,你将需要通过Google搜索PPA,然后手工添加该仓库。下面就是添加PPA到系统的方法:
|
||||
|
||||
sudo add-apt-repository ppa:<repository-name>
|
||||
|
||||
@ -85,7 +86,7 @@ Ubuntu严重依赖于PPA(个人包归档),但是,不幸的是,它却
|
||||
|
||||
sudo add-apt-repository ppa:libreoffice/ppa
|
||||
|
||||
它会要你按下回车键来导入秘钥。完成后,使用'update'命令来刷新仓库,然后安装该包。
|
||||
它会要你按下回车键来导入密钥。完成后,使用'update'命令来刷新仓库,然后安装该包。
|
||||
|
||||
openSUSE拥有一个针对第三方应用的优雅的解决方案。你可以访问software.opensuse.org,一键点击搜索并安装相应包,它会自动将对应的仓库添加到你的系统中。如果你想要手工添加仓库,可以使用该命令:
|
||||
|
||||
@ -97,13 +98,13 @@ openSUSE拥有一个针对第三方应用的优雅的解决方案。你可以访
|
||||
sudo zypper refresh
|
||||
sudo zypper install libreoffice
|
||||
|
||||
Fedora用户只需要添加RPMFusion(free和non-free仓库一起),该仓库包含了大量的应用。如果你需要添加仓库,命令如下:
|
||||
Fedora用户只需要添加RPMFusion(包括自由软件和非自由软件仓库),该仓库包含了大量的应用。如果你需要添加该仓库,命令如下:
|
||||
|
||||
dnf config-manager --add-repo http://www.example.com/example.repo
|
||||
dnf config-manager --add-repo http://www.example.com/example.repo
|
||||
|
||||
### 一些基本命令 ###
|
||||
|
||||
我已经写了一些关于使用CLI来管理你系统上的文件的[文章][1],下面介绍一些基本米ing令,这些命令在所有发行版上都经常会用到。
|
||||
我已经写了一些关于使用CLI来管理你系统上的文件的[文章][1],下面介绍一些基本命令,这些命令在所有发行版上都经常会用到。
|
||||
|
||||
拷贝文件或目录到一个新的位置:
|
||||
|
||||
@ -113,13 +114,13 @@ dnf config-manager --add-repo http://www.example.com/example.repo
|
||||
|
||||
cp path_of_files/* path_of_the_directory_where_you_want_to_copy/
|
||||
|
||||
将一个文件从某个位置移动到另一个位置(尾斜杠是说在该目录中):
|
||||
将一个文件从某个位置移动到另一个位置(尾斜杠是说放在该目录中):
|
||||
|
||||
mv path_of_file_1 path_of_the_directory_where_you_want_to_move/
|
||||
mv path_of_file_1 path_of_the_directory_where_you_want_to_move/
|
||||
|
||||
将所有文件从一个位置移动到另一个位置:
|
||||
|
||||
mv path_of_directory_where_files_are/* path_of_the_directory_where_you_want_to_move/
|
||||
mv path_of_directory_where_files_are/* path_of_the_directory_where_you_want_to_move/
|
||||
|
||||
删除一个文件:
|
||||
|
||||
@ -135,11 +136,11 @@ dnf config-manager --add-repo http://www.example.com/example.repo
|
||||
|
||||
### 创建新目录 ###
|
||||
|
||||
要创建一个新目录,首先输入你要创建的目录的位置。比如说,你想要在你的Documents目录中创建一个名为'foundation'的文件夹。让我们使用 cd (即change directory,改变目录)命令来改变目录:
|
||||
要创建一个新目录,首先进入到你要创建该目录的位置。比如说,你想要在你的Documents目录中创建一个名为'foundation'的文件夹。让我们使用 cd (即change directory,改变目录)命令来改变目录:
|
||||
|
||||
cd /home/swapnil/Documents
|
||||
|
||||
(替换'swapnil'为你系统中的用户)
|
||||
(替换'swapnil'为你系统中的用户名)
|
||||
|
||||
然后,使用 mkdir 命令来创建该目录:
|
||||
|
||||
@ -149,13 +150,13 @@ dnf config-manager --add-repo http://www.example.com/example.repo
|
||||
|
||||
mdkir /home/swapnil/Documents/foundation
|
||||
|
||||
如果你想要创建父-子目录,那是指目录中的目录,那么可以使用 -p 选项。它会在指定路径中创建所有目录:
|
||||
如果你想要连父目录一起创建,那么可以使用 -p 选项。它会在指定路径中创建所有目录:
|
||||
|
||||
mdkir -p /home/swapnil/Documents/linux/foundation
|
||||
|
||||
### 成为root ###
|
||||
|
||||
你或许需要成为root,或者具有sudo权力的用户,来实施一些管理任务,如管理软件包或者对根目录或其下的文件进行一些修改。其中一个例子就是编辑'fstab'文件,该文件记录了挂载的硬件驱动器。它在'etc'目录中,而该目录又在根目录中,你只能作为超级用户来修改该文件。在大多数的发行版中,你可以通过'切换用户'来成为root。比如说,在openSUSE上,我想要成为root,因为我要在根目录中工作,你可以使用下面的命令之一:
|
||||
你或许需要成为root,或者具有sudo权力的用户,来实施一些管理任务,如管理软件包或者对根目录或其下的文件进行一些修改。其中一个例子就是编辑'fstab'文件,该文件记录了挂载的硬盘驱动器。它在'etc'目录中,而该目录又在根目录中,你只能作为超级用户来修改该文件。在大多数的发行版中,你可以通过'su'来成为root。比如说,在openSUSE上,我想要成为root,因为我要在根目录中工作,你可以使用下面的命令之一:
|
||||
|
||||
sudo su -
|
||||
|
||||
@ -165,7 +166,7 @@ dnf config-manager --add-repo http://www.example.com/example.repo
|
||||
|
||||
该命令会要求输入密码,然后你就具有root特权了。记住一点:千万不要以root用户来运行系统,除非你知道你正在做什么。另外重要的一点需要注意的是,你以root什么对目录或文件进行修改后,会将它们的拥有关系从该用户或特定的服务改变为root。你必须恢复这些文件的拥有关系,否则该服务或用户就不能访问或写入到那些文件。要改变用户,命令如下:
|
||||
|
||||
sudo chown -R user:user /path_of_file_or_directory
|
||||
sudo chown -R 用户:组 文件或目录名
|
||||
|
||||
当你将其它发行版上的分区挂载到系统中时,你可能经常需要该操作。当你试着访问这些分区上的文件时,你可能会碰到权限拒绝错误,你只需要改变这些分区的拥有关系就可以访问它们了。需要额外当心的是,不要改变根目录的权限或者拥有关系。
|
||||
|
||||
@ -177,7 +178,7 @@ via: http://www.linux.com/learn/tutorials/842251-must-know-linux-commands-for-ne
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
59
sources/talk/20150810 For Linux, Supercomputers R Us.md
Normal file
59
sources/talk/20150810 For Linux, Supercomputers R Us.md
Normal file
@ -0,0 +1,59 @@
|
||||
For Linux, Supercomputers R Us
|
||||
================================================================================
|
||||

|
||||
Credit: Michel Ngilen, CC BY 2.0, via Wikimedia Commons
|
||||
|
||||
> Almost all supercomputers run Linux, including the ones built from Raspberry Pi boards and PlayStation 3 game consoles
|
||||
|
||||
Supercomputers are serious things, called on to do serious computing. They tend to be engaged in serious pursuits like atomic bomb simulations, climate modeling and high-level physics. Naturally, they cost serious money. At the very top of the latest [Top500][1] supercomputer ranking is the Tianhe-2 supercomputer at China’s National University of Defense Technology. It cost about $390 million to build.
|
||||
|
||||
But then there’s the supercomputer that Joshua Kiepert, a doctoral student at Boise State’s Electrical and Computer Engineering department, [created with Raspberry Pi computers][2].It cost less than $2,000.
|
||||
|
||||
No, I’m not making that up. It’s an honest-to-goodness supercomputer made from overclocked 1-GHz [Model B Raspberry Pi][3] ARM11 processors with Videocore IV GPUs. Each one comes with 512MB of RAM, a pair of USB ports and a 10/100 BaseT Ethernet port.
|
||||
|
||||
And what do the Tianhe-2 and the Boise State supercomputer have in common? They both run Linux. As do [486 out of the world’s fastest 500 supercomputers][4]. It’s part of a domination of the category that began over 20 years ago. And now it’s trickling down to built-on-the-cheap supercomputers. Because Kiepert’s machine isn’t the only budget number cruncher out there.
|
||||
|
||||
Gaurav Khanna, an associate professor of physics at the University of Massachusetts Dartmouth, created a [supercomputer with something shy of 200 PlayStation 3 video game consoles][5].
|
||||
|
||||
The PlayStations are powered by a 3.2-GHz PowerPC-based Power Processing Element. Each comes with 512MB of RAM. You can still buy one, although Sony will be phasing them out by year’s end, for just over $200. Khanna started with only 16 PlayStation 3s for his first supercomputer, so you too could put a supercomputer on your credit card for less than four grand.
|
||||
|
||||
These machines may be built from toys, but they’re not playthings. Khanna has done serious astrophysics on his rig. A white-hat hacking group used a similar [PlayStation 3 supercomputer in 2008 to crack the SSL MD5 hashing algorithm][6] in 2008.
|
||||
|
||||
Two years later, the Air Force Research Laboratory [Condor Cluster was using 1,760 Sony PlayStation 3 processors][7] and 168 general-purpose graphical processing units. This bargain-basement supercomputer runs at about 500TFLOPs, or 500 trillion floating point operations per second.
|
||||
|
||||
Other cheap options for home supercomputers include specialist parallel-processing boards such as the [$99 credit-card-sized Parallella board][8], and high-end graphics boards such as [Nvidia’s Titan Z][9] and [AMD’s FirePro W9100][10]. Those high-end boards, coveted by gamers with visions of a dream machine or even a chance at winning the first-place prize of over $100,000 in the [Intel Extreme Masters World Championship League of][11] [Legends][12], cost considerably more, retailing for about $3,000. On the other hand, a single one can deliver over 2.5TFLOPS all by itself, and for scientists and researchers, they offer an affordable way to get a supercomputer they can call their own.
|
||||
|
||||
As for the Linux connection, that all started in 1994 at the Goddard Space Flight Center with the first [Beowulf supercomputer][13].
|
||||
|
||||
By our standards, there wasn’t much that was super about the first Beowulf. But in its day, the first homemade supercomputer, with its 16 Intel 486DX processors and 10Mbps Ethernet for the bus, was great. [Beowulf, designed by NASA contractors Don Becker and Thomas Sterling][14], was the first “maker” supercomputer. Its “compute components,” 486DX PCs, cost only a few thousand dollars. While its speed was only in single-digit gigaflops, [Beowulf][15] showed you could build supercomputers from commercial off-the-shelf (COTS) hardware and Linux.
|
||||
|
||||
I wish I’d had a part in its creation, but I’d already left Goddard by 1994 for a career as a full-time technology journalist. Darn it!
|
||||
|
||||
But even from this side of my reporter’s notebook, I can still appreciate how COTS and open-source software changed supercomputing forever. I hope you can too. Because, whether it’s a cluster of Raspberry Pis or a monster with over 3 million Intel Ivy Bridge and Xeon Phi chips, almost all of today’s supercomputers trace their ancestry to Beowulf.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[1]:http://www.top500.org/
|
||||
[2]:http://www.zdnet.com/article/build-your-own-supercomputer-out-of-raspberry-pi-boards/
|
||||
[3]:https://www.raspberrypi.org/products/model-b/
|
||||
[4]:http://www.zdnet.com/article/linux-still-rules-supercomputing/
|
||||
[5]:http://www.nytimes.com/2014/12/23/science/an-economical-way-to-save-progress.html?smid=fb-nytimes&smtyp=cur&bicmp=AD&bicmlukp=WT.mc_id&bicmst=1409232722000&bicmet=1419773522000&_r=4
|
||||
[6]:http://www.computerworld.com/article/2529932/cybercrime-hacking/researchers-hack-verisign-s-ssl-scheme-for-securing-web-sites.html
|
||||
[7]:http://phys.org/news/2010-12-air-playstation-3s-supercomputer.html
|
||||
[8]:http://www.zdnet.com/article/parallella-the-99-linux-supercomputer/
|
||||
[9]:http://blogs.nvidia.com/blog/2014/03/25/titan-z/
|
||||
[10]:http://www.amd.com/en-us/press-releases/Pages/amd-flagship-professional-2014apr7.aspx
|
||||
[11]:http://en.intelextrememasters.com/news/check-out-the-intel-extreme-masters-katowice-prize-money-distribution/
|
||||
[12]:http://www.google.com/url?q=http%3A%2F%2Fen.intelextrememasters.com%2Fnews%2Fcheck-out-the-intel-extreme-masters-katowice-prize-money-distribution%2F&sa=D&sntz=1&usg=AFQjCNE6yoAGGz-Hpi2tPF4gdhuPBEckhQ
|
||||
[13]:http://www.beowulf.org/overview/history.html
|
||||
[14]:http://yclept.ucdavis.edu/Beowulf/aboutbeowulf.html
|
||||
[15]:http://www.beowulf.org/
|
||||
@ -1,3 +1,5 @@
|
||||
FSSlc translating
|
||||
|
||||
Install OpenQRM Cloud Computing Platform In Debian
|
||||
================================================================================
|
||||
### Introduction ###
|
||||
@ -146,4 +148,4 @@ via: http://www.unixmen.com/install-openqrm-cloud-computing-platform-debian/
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:http://www.openqrm-enterprise.com/products/edition-comparison.html
|
||||
[2]:http://sourceforge.net/projects/openqrm/files/?source=navbar
|
||||
[3]:http://www.openqrm-enterprise.com/fileadmin/Documents/Whitepaper/openQRM-Enterprise-Administrator-Guide-5.2.pdf
|
||||
[3]:http://www.openqrm-enterprise.com/fileadmin/Documents/Whitepaper/openQRM-Enterprise-Administrator-Guide-5.2.pdf
|
||||
|
||||
@ -1,237 +0,0 @@
|
||||
|
||||
如何收集NGINX指标 - 第2部分
|
||||
================================================================================
|
||||

|
||||
|
||||
### 如何获取你所需要的NGINX指标 ###
|
||||
|
||||
如何获取需要的指标取决于你正在使用的 NGINX 版本。(参见 [the companion article][1] 将深入探索NGINX指标。)免费,开源版的 NGINX 和商业版的 NGINX 都有指标度量的状态模块,NGINX 也可以在其日志中配置指标模块:
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: center;">
|
||||
<col style="text-align: center;">
|
||||
<col style="text-align: center;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th rowspan="2" style="text-align: left;">Metric</th>
|
||||
<th colspan="3" style="text-align: center;">Availability</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<th style="text-align: center;"><a href="https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source">NGINX (open-source)</a></th>
|
||||
<th style="text-align: center;"><a href="https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#plus">NGINX Plus</a></th>
|
||||
<th style="text-align: center;"><a href="https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#logs">NGINX logs</a></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">accepts / accepted</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">handled</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">dropped</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">active</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">requests / total</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">4xx codes</td>
|
||||
<td style="text-align: center;"></td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">5xx codes</td>
|
||||
<td style="text-align: center;"></td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">request time</td>
|
||||
<td style="text-align: center;"></td>
|
||||
<td style="text-align: center;"></td>
|
||||
<td style="text-align: center;">x</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
#### 指标收集:NGINX(开源版) ####
|
||||
|
||||
开源版的 NGINX 会显示几个与服务器状态有关的指标在状态页面上,只要你启用了 HTTP [stub status module][2] 。要检查模块是否被加载,运行以下命令:
|
||||
|
||||
nginx -V 2>&1 | grep -o with-http_stub_status_module
|
||||
|
||||
如果你看到 http_stub_status_module 被输出在终端,说明状态模块已启用。
|
||||
|
||||
如果该命令没有输出,你需要启用状态模块。你可以使用 --with-http_stub_status_module 参数去配置 [building NGINX from source][3]:
|
||||
|
||||
./configure \
|
||||
… \
|
||||
--with-http_stub_status_module
|
||||
make
|
||||
sudo make install
|
||||
|
||||
验证模块已经启用或你自己启用它后,你还需要修改 NGINX 配置文件为状态页面设置本地访问的 URL(例如,/ nginx_status):
|
||||
|
||||
server {
|
||||
location /nginx_status {
|
||||
stub_status on;
|
||||
|
||||
access_log off;
|
||||
allow 127.0.0.1;
|
||||
deny all;
|
||||
}
|
||||
}
|
||||
|
||||
注:nginx 配置中的 server 块通常并不在主配置文件中(例如,/etc/nginx/nginx.conf),但主配置中会加载补充的配置文件。要找到主配置文件,首先运行以下命令:
|
||||
|
||||
nginx -t
|
||||
|
||||
打开主配置文件,在以 http 模块结尾的附近查找以 include 开头的行包,如:
|
||||
|
||||
include /etc/nginx/conf.d/*.conf;
|
||||
|
||||
在所包含的配置文件中,你应该会找到主服务器模块,你可以如上所示修改 NGINX 的指标报告。更改任何配置后,通过执行以下命令重新加载配置文件:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
现在,你可以查看指标的状态页:
|
||||
|
||||
Active connections: 24
|
||||
server accepts handled requests
|
||||
1156958 1156958 4491319
|
||||
Reading: 0 Writing: 18 Waiting : 6
|
||||
|
||||
请注意,如果你正试图从远程计算机访问状态页面,则需要将远程计算机的 IP 地址添加到你的状态配置文件的白名单中,在上面的配置文件中 127.0.0.1 仅在白名单中。
|
||||
|
||||
nginx 的状态页面是一中查看指标快速又简单的方法,但当连续监测时,你需要每隔一段时间自动记录该数据。然后通过监控工具箱 [Nagios][4] 或者 [Datadog][5],以及收集统计信息的服务 [collectD][6] 来分析已保存的 NGINX 状态信息。
|
||||
|
||||
#### 指标收集: NGINX Plus ####
|
||||
|
||||
商业版的 NGINX Plus 通过 ngx_http_status_module 提供的可用指标比开源版 NGINX 更多 [many more metrics][7] 。NGINX Plus 附加了更多的字节流指标,以及负载均衡系统和高速缓存的信息。NGINX Plus 还报告所有的 HTTP 状态码类型(1XX,2XX,3XX,4XX,5XX)的计数。一个简单的 NGINX Plus 状态报告 [here][8]。
|
||||
|
||||

|
||||
|
||||
*注: NGINX Plus 在状态仪表盘"Active”连接定义的收集指标的状态模块和开源 NGINX 的略有不同。在 NGINX Plus 指标中,活动连接不包括等待状态(又叫空闲连接)连接。*
|
||||
|
||||
NGINX Plus 也集成了其他监控系统的报告 [JSON格式指标][9] 。用 NGINX Plus 时,你可以看到 [负载均衡服务器组的][10]指标和健康状况,或着再向下能取得的仅是响应代码计数[从单个服务器][11]在负载均衡服务器中:
|
||||
{"1xx":0,"2xx":3483032,"3xx":0,"4xx":23,"5xx":0,"total":3483055}
|
||||
|
||||
启动 NGINX Plus 指标仪表盘,你可以在 NGINX 配置文件的 http 块内添加状态 server 块。 ([参见上一页][12]查找相关的配置文件,收集开源 NGINX 版指标的说明。)例如,设立以下一个状态仪表盘在http://your.ip.address:8080/status.html 和一个 JSON 接口 http://your.ip.address:8080/status,可以添加以下 server block 来设定:
|
||||
|
||||
server {
|
||||
listen 8080;
|
||||
root /usr/share/nginx/html;
|
||||
|
||||
location /status {
|
||||
status;
|
||||
}
|
||||
|
||||
location = /status.html {
|
||||
}
|
||||
}
|
||||
|
||||
一旦你重新加载 NGINX 配置,状态页就会被加载:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
关于如何配置扩展状态模块,官方 NGINX Plus 文档有 [详细介绍][13] 。
|
||||
|
||||
#### 指标收集:NGINX日志 ####
|
||||
|
||||
NGINX 的 [日志模块][14] 写到配置可以自定义访问日志到指定文件。你可以自定义日志的格式和时间通过 [添加或移除变量][15]。捕获日志的详细信息,最简单的方法是添加下面一行在你配置文件的server 块中(参见[此节][16] 通过加载配置文件的信息来收集开源 NGINX 的指标):
|
||||
|
||||
access_log logs/host.access.log combined;
|
||||
|
||||
更改 NGINX 配置文件后,必须要重新加载配置文件:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
“combined” 的日志格式,只包含默认参数,包括[一些关键数据][17],如实际的 HTTP 请求和相应的响应代码。在下面的示例日志中,NGINX 记录了200(成功)状态码当请求 /index.html 时和404(未找到)错误不存在的请求文件 /fail。
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:12:10:46 -0500] "GET /index.html HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari 537.36"
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:12:11:05 -0500] "GET /fail HTTP/1.1" 404 570 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36"
|
||||
|
||||
你可以记录请求处理的时间通过添加一个新的日志格式在 NGINX 配置文件中的 http 块:
|
||||
|
||||
log_format nginx '$remote_addr - $remote_user [$time_local] '
|
||||
'"$request" $status $body_bytes_sent $request_time '
|
||||
'"$http_referer" "$http_user_agent"';
|
||||
|
||||
通过修改配置文件中 server 块的 access_log 行:
|
||||
|
||||
access_log logs/host.access.log nginx;
|
||||
|
||||
重新加载配置文件(运行 nginx -s reload)后,你的访问日志将包括响应时间,如下图所示。单位为秒,毫秒。在这种情况下,服务器接收 /big.pdf 的请求时,发送33973115字节后返回206(成功)状态码。处理请求用时0.202秒(202毫秒):
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:15:50:36 -0500] "GET /big.pdf HTTP/1.1" 206 33973115 0.202 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36"
|
||||
|
||||
你可以使用各种工具和服务来收集和分析 NGINX 日志。例如,[rsyslog][18] 可以监视你的日志,并将其传递给多个日志分析服务;你也可以使用免费的开源工具,如[logstash][19]来收集和分析日志;或者你可以使用一个统一日志记录层,如[Fluentd][20]来收集和分析你的 NGINX 日志。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
监视 NGINX 的哪一项指标将取决于你提供的工具,以及是否由给定指标证明监控指标的开销。例如,通过收集和分析日志来定位问题是非常重要的在 NGINX Plus 或者 运行的系统中。
|
||||
|
||||
在 Datadog 中,我们已经集成了 NGINX 和 NGINX Plus,这样你就可以以最小的设置来收集和监控所有 Web 服务器的指标。了解如何用 NGINX Datadog来监控 [在本文中][21],并开始使用 [免费的Datadog][22]。
|
||||
|
||||
----------
|
||||
|
||||
原文在这 [on GitHub][23]。问题,更正,补充等?请[让我们知道][24]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
|
||||
作者:K Young
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.datadoghq.com/blog/how-to-monitor-nginx/
|
||||
[2]:http://nginx.org/en/docs/http/ngx_http_stub_status_module.html
|
||||
[3]:http://wiki.nginx.org/InstallOptions
|
||||
[4]:https://exchange.nagios.org/directory/Plugins/Web-Servers/nginx
|
||||
[5]:http://docs.datadoghq.com/integrations/nginx/
|
||||
[6]:https://collectd.org/wiki/index.php/Plugin:nginx
|
||||
[7]:http://nginx.org/en/docs/http/ngx_http_status_module.html#data
|
||||
[8]:http://demo.nginx.com/status.html
|
||||
[9]:http://demo.nginx.com/status
|
||||
[10]:http://demo.nginx.com/status/upstreams/demoupstreams
|
||||
[11]:http://demo.nginx.com/status/upstreams/demoupstreams/0/responses
|
||||
[12]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source
|
||||
[13]:http://nginx.org/en/docs/http/ngx_http_status_module.html#example
|
||||
[14]:http://nginx.org/en/docs/http/ngx_http_log_module.html
|
||||
[15]:http://nginx.org/en/docs/http/ngx_http_log_module.html#log_format
|
||||
[16]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source
|
||||
[17]:http://nginx.org/en/docs/http/ngx_http_log_module.html#log_format
|
||||
[18]:http://www.rsyslog.com/
|
||||
[19]:https://www.elastic.co/products/logstash
|
||||
[20]:http://www.fluentd.org/
|
||||
[21]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
[22]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#sign-up
|
||||
[23]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_collect_nginx_metrics.md
|
||||
[24]:https://github.com/DataDog/the-monitor/issues
|
||||
@ -1,320 +0,0 @@
|
||||
[translating by xiqingongzi]
|
||||
|
||||
RHCSA系列: 复习基础命令及系统文档 – 第一部分
|
||||
================================================================================
|
||||
RHCSA (红帽认证系统工程师) 是由给商业公司提供开源操作系统和软件的RedHat公司举行的认证考试, 除此之外,红帽公司还为这些企业和机构提供支持、训练以及咨询服务
|
||||
|
||||

|
||||
|
||||
RHCSA 考试准备指南
|
||||
|
||||
RHCSA 考试(考试编号 EX200)通过后可以获取由Red Hat 公司颁发的证书. RHCSA 考试是RHCT(红帽认证技师)的升级版,而且RHCSA必须在新的Red Hat Enterprise Linux(红帽企业版)下完成.RHCT和RHCSA的主要变化就是RHCT基于 RHEL5 , 而RHCSA基于RHEL6或者7, 这两个认证的等级也有所不同.
|
||||
|
||||
红帽认证管理员所会的最基础的是在红帽企业版的环境下执行如下系统管理任务:
|
||||
|
||||
- 理解并会使用命令管理文件、目录、命令行以及系统/软件包的文档
|
||||
- 使用不同的启动等级启动系统,认证和控制进程,启动或停止虚拟机
|
||||
- 使用分区和逻辑卷管理本地存储
|
||||
- 创建并且配置本地文件系统和网络文件系统,设置他们的属性(许可、加密、访问控制表)
|
||||
- 部署、配置、并且控制系统,包括安装、升级和卸载软件
|
||||
- 管理系统用户和组,独立使用集中制的LDAP目录权限控制
|
||||
- 确保系统安全,包括基础的防火墙规则和SELinux配置
|
||||
|
||||
|
||||
关于你所在国家的考试注册费用参考 [RHCSA Certification page][1].
|
||||
|
||||
关于你所在国家的考试注册费用参考RHCSA 认证页面
|
||||
|
||||
|
||||
在这个有15章的RHCSA(红帽认证管理员)备考系列,我们将覆盖以下的关于红帽企业Linux第七版的最新的信息
|
||||
|
||||
- Part 1: 回顾必会的命令和系统文档
|
||||
- Part 2: 在RHEL7如何展示文件和管理目录
|
||||
- Part 3: 在RHEL7中如何管理用户和组
|
||||
- Part 4: 使用nano和vim管理命令/ 使用grep和正则表达式分析文本
|
||||
- Part 5: RHEL7的进程管理:启动,关机,以及其他介于二者之间的.
|
||||
- Part 6: 使用 'Parted'和'SSM'来管理和加密系统存储
|
||||
- Part 7: 使用ACLs(访问控制表)并挂载 Samba /NFS 文件分享
|
||||
- Part 8: 加固SSH,设置主机名并开启网络服务
|
||||
- Part 9: 安装、配置和加固一个Web,FTP服务器
|
||||
- Part 10: Yum 包管理方式,使用Cron进行自动任务管理以及监控系统日志
|
||||
- Part 11: 使用FirewallD和Iptables设置防火墙,控制网络流量
|
||||
- Part 12: 使用Kickstart 自动安装RHEL 7
|
||||
- Part 13: RHEL7:什么是SeLinux?他的原理是什么?
|
||||
- Part 14: 在RHEL7 中使用基于LDAP的权限控制
|
||||
- Part 15: RHEL7的虚拟化:KVM 和虚拟机管理
|
||||
|
||||
在第一章,我们讲解如何输入和运行正确的命令在终端或者Shell窗口,并且讲解如何找到、插入,以及使用系统文档
|
||||
|
||||

|
||||
|
||||
RHCSA:回顾必会的Linux命令 - 第一部分
|
||||
|
||||
#### 前提: ####
|
||||
|
||||
至少你要熟悉如下命令
|
||||
|
||||
- [cd command][2] (改变目录)
|
||||
- [ls command][3] (列举文件)
|
||||
- [cp command][4] (复制文件)
|
||||
- [mv command][5] (移动或重命名文件)
|
||||
- [touch command][6] (创建一个新的文件或更新已存在文件的时间表)
|
||||
- rm command (删除文件)
|
||||
- mkdir command (创建目录)
|
||||
|
||||
在这篇文章中你将会找到更多的关于如何更好的使用他们的正确用法和特殊用法.
|
||||
|
||||
虽然没有严格的要求,但是作为讨论常用的Linux命令和方法,你应该安装RHEL7 来尝试使用文章中提到的命令.这将会使你学习起来更省力.
|
||||
|
||||
- [红帽企业版Linux(RHEL)7 安装指南][7]
|
||||
|
||||
### 使用Shell进行交互 ###
|
||||
如果我们使用文本模式登陆Linux,我们就无法使用鼠标在默认的shell。另一方面,如果我们使用图形化界面登陆,我们将会通过启动一个终端来开启shell,无论那种方式,我们都会看到用户提示,并且我们可以开始输入并且执行命令(当按下Enter时,命令就会被执行)
|
||||
|
||||
|
||||
当我们使用文本模式登陆Linux时,
|
||||
命令是由两个部分组成的:
|
||||
|
||||
- 命令本身
|
||||
- 参数
|
||||
|
||||
某些参数,称为选项(通常使用一个连字符区分),改变了由其他参数定义的命令操作.
|
||||
|
||||
命令的类型可以帮助我们识别某一个特定的命令是由shell内建的还是由一个单独的包提供。这样的区别在于我们能够找到更多关于该信息的命令,对shell内置的命令,我们需要看shell的ManPage,如果是其他提供的,我们需要看它自己的ManPage.
|
||||
|
||||
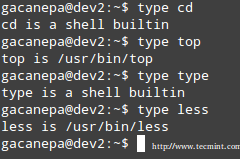
|
||||
|
||||
检查Shell的内建命令
|
||||
|
||||
在上面的例子中, cd 和 type 是shell内建的命令,top和 less 是由其他的二进制文件提供的(在这种情况下,type将返回命令的位置)
|
||||
其他的内建命令
|
||||
|
||||
- [echo command][8]: 展示字符串
|
||||
- [pwd command][9]: 输出当前的工作目录
|
||||
|
||||

|
||||
|
||||
更多内建函数
|
||||
|
||||
**exec 命令**
|
||||
|
||||
运行我们指定的外部程序。请注意,最好是只输入我们想要运行的程序的名字,不过exec命令有一个特殊的特性:使用旧的shell运行,而不是创建新的进程,可以作为子请求的验证.
|
||||
|
||||
# ps -ef | grep [shell 进程的PID]
|
||||
|
||||
当新的进程注销,Shell也随之注销,运行 exec top 然后按下 q键来退出top,你会注意到shell 会话会结束,如下面的屏幕录像展示的那样:
|
||||
|
||||
注:youtube视频
|
||||
<iframe width="640" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="https://www.youtube.com/embed/f02w4WT73LE"></iframe>
|
||||
|
||||
**export 命令**
|
||||
|
||||
输出之后执行的命令的环境的变量
|
||||
|
||||
**history 命令**
|
||||
|
||||
展示数行之前的历史命令.在感叹号前输入命令编号可以再次执行这个命令.如果我们需要编辑历史列表中的命令,我们可以按下 Ctrl + r 并输入与命令相关的第一个字符.
|
||||
当我们看到的命令自动补全,我们可以根据我们目前的需要来编辑它:
|
||||
|
||||
注:youtube视频
|
||||
<iframe width="640" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="https://www.youtube.com/embed/69vafdSMfU4"></iframe>
|
||||
|
||||
命令列表会保存在一个叫 .bash_history的文件里.history命令是一个非常有用的用于减少输入次数的工具,特别是进行命令行编辑的时候.默认情况下,bash保留最后输入的500个命令,不过可以通过修改 HISTSIZE 环境变量来增加:
|
||||
|
||||
|
||||

|
||||
|
||||
Linux history 命令
|
||||
|
||||
但上述变化,在我们的下一次启动不会保留。为了保持HISTSIZE变量的变化,我们需要通过手工修改文件编辑:
|
||||
|
||||
# 设置history请看 HISTSIZE 和 HISTFILESIZE 在 bash(1)的文档
|
||||
HISTSIZE=1000
|
||||
|
||||
**重要**: 我们的更改不会生效,除非我们重启了系统
|
||||
|
||||
**alias 命令**
|
||||
没有参数或使用-p参数将会以 名称=值的标准形式输出alias 列表.当提供了参数时,一个alias 将被定义给给定的命令和值
|
||||
|
||||
使用alias ,我们可以创建我们自己的命令,或修改现有的命令,包括需要的参数.举个例子,假设我们想别名 ls 到 ls –color=auto ,这样就可以使用不同颜色输出文件、目录、链接
|
||||
|
||||
|
||||
# alias ls='ls --color=auto'
|
||||
|
||||
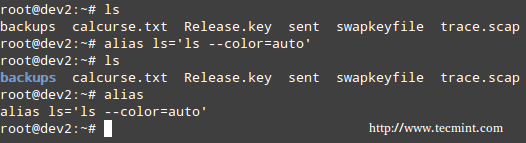
|
||||
|
||||
Linux 别名命令
|
||||
|
||||
**Note**: 你可以给你的新命令起任何的名字,并且附上足够多的使用单引号分割的参数,但是这样的情况下你要用分号区分开他们.
|
||||
|
||||
# alias myNewCommand='cd /usr/bin; ls; cd; clear'
|
||||
|
||||
**exit 命令**
|
||||
|
||||
Exit和logout命令都是退出shell.exit命令退出所有的shell,logout命令只注销登陆的shell,其他的自动以文本模式启动的shell不算.
|
||||
|
||||
如果我们对某个程序由疑问,我们可以看他的man Page,可以使用man命令调出它,额外的,还有一些重要的文件的手册页(inittab,fstab,hosts等等),库函数,shells,设备及其他功能
|
||||
|
||||
#### 举例: ####
|
||||
|
||||
- man uname (输出系统信息,如内核名称、处理器、操作系统类型、架构等).
|
||||
- man inittab (初始化守护设置).
|
||||
|
||||
另外一个重要的信息的来源就是info命令提供的,info命令常常被用来读取信息文件.这些文件往往比manpage 提供更多信息.通过info 关键词调用某个命令的信息
|
||||
|
||||
# info ls
|
||||
# info cut
|
||||
|
||||
|
||||
另外,在/usr/share/doc 文件夹包含了大量的子目录,里面可以找到大量的文档.他们包含文本文件或其他友好的格式.
|
||||
确保你使用这三种方法去查找命令的信息。重点关注每个命令文档中介绍的详细的语法
|
||||
|
||||
**使用expand命令把tabs转换为空格**
|
||||
|
||||
有时候文本文档包含了tabs但是程序无法很好的处理的tabs.或者我们只是简单的希望将tabs转换成空格.这就是为什么expand (GNU核心组件提供)工具出现,
|
||||
|
||||
举个例子,给我们一个文件 NumberList.txt,让我们使用expand处理它,将tabs转换为一个空格.并且以标准形式输出.
|
||||
|
||||
# expand --tabs=1 NumbersList.txt
|
||||
|
||||

|
||||
|
||||
Linux expand 命令
|
||||
|
||||
unexpand命令可以实现相反的功能(将空格转为tab)
|
||||
|
||||
**使用head输出文件首行及使用tail输出文件尾行**
|
||||
|
||||
通常情况下,head命令后跟着文件名时,将会输出该文件的前十行,我们可以通过 -n 参数来自定义具体的行数。
|
||||
|
||||
# head -n3 /etc/passwd
|
||||
# tail -n3 /etc/passwd
|
||||
|
||||

|
||||
|
||||
Linux 的 head 和 tail 命令
|
||||
|
||||
tail 最有意思的一个特性就是能够展现信息(最后一行)就像我们输入文件(tail -f my.log,一行一行的,就像我们在观察它一样。)这在我们监控一个持续增加的日志文件时非常有用
|
||||
|
||||
更多: [Manage Files Effectively using head and tail Commands][10]
|
||||
|
||||
**使用paste合并文本文件**
|
||||
paste命令一行一行的合并文件,默认会以tab来区分每一行,或者其他你自定义的分行方式.(下面的例子就是输出使用等号划分行的文件).
|
||||
# paste -d= file1 file2
|
||||
|
||||
|
||||
|
||||
Merge Files in Linux
|
||||
|
||||
**使用split命令将文件分块**
|
||||
|
||||
split 命令常常用于把一个文件切割成两个或多个文由我们自定义的前缀命名的件文件.这些文件可以通过大小、区块、行数,生成的文件会有一个数字或字母的后缀.在下面的例子中,我们将切割bash.pdf ,每个文件50KB (-b 50KB) ,使用命名后缀 (-d):
|
||||
|
||||
# split -b 50KB -d bash.pdf bash_
|
||||
|
||||

|
||||
|
||||
在Linux下划分文件
|
||||
|
||||
你可以使用如下命令来合并这些文件,生成源文件:
|
||||
|
||||
# cat bash_00 bash_01 bash_02 bash_03 bash_04 bash_05 > bash.pdf
|
||||
|
||||
**使用tr命令改变字符**
|
||||
|
||||
tr 命令多用于变化(改变)一个一个的字符活使用字符范围.和之前一样,下面的实例我们江使用同样的文件file2,我们将实习:
|
||||
|
||||
- 小写字母 o 变成大写
|
||||
- 所有的小写字母都变成大写字母
|
||||
|
||||
# cat file2 | tr o O
|
||||
# cat file2 | tr [a-z] [A-Z]
|
||||
|
||||
|
||||
|
||||
在Linux中替换文字
|
||||
|
||||
**使用uniq和sort检查或删除重复的文字**
|
||||
|
||||
uniq命令可以帮我们查出或删除文件中的重复的行,默认会写出到stdout.我们应当注意, uniq 只能查出相邻的两个相同的单纯,所以, uniq 往往和sort 一起使用(sort一般用于对文本文件的内容进行排序)
|
||||
|
||||
|
||||
默认的,sort 以第一个参数(使用空格区分)为关键字.想要定义特殊的关键字,我们需要使用 -k参数,请注意如何使用sort 和uniq输出我们想要的字段,具体可以看下面的例子
|
||||
|
||||
# cat file3
|
||||
# sort file3 | uniq
|
||||
# sort -k2 file3 | uniq
|
||||
# sort -k3 file3 | uniq
|
||||
|
||||

|
||||
|
||||
删除文件中重复的行
|
||||
|
||||
**从文件中提取文本的命令**
|
||||
|
||||
Cut命令基于字节(-b),字符(-c),或者区块(-f)从stdin活文件中提取到的部分将会以标准的形式展现在屏幕上
|
||||
|
||||
当我们使用区块切割时,默认的分隔符是一个tab,不过你可以通过 -d 参数来自定义分隔符.
|
||||
|
||||
# cut -d: -f1,3 /etc/passwd # 这个例子提取了第一块和第三块的文本
|
||||
# cut -d: -f2-4 /etc/passwd # 这个例子提取了第一块到第三块的文本
|
||||
|
||||

|
||||
|
||||
从文件中提取文本
|
||||
|
||||
|
||||
注意,上方的两个输出的结果是十分简洁的。
|
||||
|
||||
**使用fmt命令重新格式化文件**
|
||||
|
||||
fmt 被用于去“清理”有大量内容或行的文件,或者有很多缩进的文件.新的锻炼格式每行不会超过75个字符款,你能改变这个设定通过 -w(width 宽度)参数,它可以设置行宽为一个特定的数值
|
||||
|
||||
举个例子,让我们看看当我们用fmt显示定宽为100个字符的时候的文件/etc/passwd 时会发生什么.再来一次,输出值变得更加简洁.
|
||||
|
||||
# fmt -w100 /etc/passwd
|
||||
|
||||

|
||||
|
||||
Linux文件重新格式化
|
||||
|
||||
**使用pr命令格式化打印内容**
|
||||
|
||||
pr 分页并且在列中展示一个或多个用于打印的文件. 换句话说,使用pr格式化一个文件使他打印出来时看起来更好.举个例子,下面这个命令
|
||||
|
||||
# ls -a /etc | pr -n --columns=3 -h "Files in /etc"
|
||||
|
||||
以一个友好的排版方式(3列)输出/etc下的文件,自定义了页眉(通过 -h 选项实现),行号(-n)
|
||||
|
||||

|
||||
|
||||
Linux的文件格式
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇文章中,我们已经讨论了如何在Shell或终端以正确的语法输入和执行命令,并解释如何找到,检查和使用系统文档。正如你看到的一样简单,这就是你成为RHCSA的第一大步
|
||||
|
||||
如果你想添加一些其他的你经常使用的能够有效帮你完成你的日常工作的基础命令,并为分享他们而感到自豪,请在下方留言.也欢迎提出问题.我们期待您的回复.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://www.redhat.com/en/services/certification/rhcsa
|
||||
[2]:http://www.tecmint.com/cd-command-in-linux/
|
||||
[3]:http://www.tecmint.com/ls-command-interview-questions/
|
||||
[4]:http://www.tecmint.com/advanced-copy-command-shows-progress-bar-while-copying-files/
|
||||
[5]:http://www.tecmint.com/rename-multiple-files-in-linux/
|
||||
[6]:http://www.tecmint.com/8-pratical-examples-of-linux-touch-command/
|
||||
[7]:http://www.tecmint.com/redhat-enterprise-linux-7-installation/
|
||||
[8]:http://www.tecmint.com/echo-command-in-linux/
|
||||
[9]:http://www.tecmint.com/pwd-command-examples/
|
||||
[10]:http://www.tecmint.com/view-contents-of-file-in-linux/
|
||||
Loading…
Reference in New Issue
Block a user