mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-18 02:00:18 +08:00
commit
d545c74aa5
@ -0,0 +1,56 @@
|
||||
一周 GNOME 之旅:品味它和 KDE 的是是非非(第一节 介绍)
|
||||
================================================================================
|
||||
|
||||
*作者声明: 如果你是因为某种神迹而在没看标题的情况下点开了这篇文章,那么我想再重申一些东西……这是一篇评论文章,文中的观点都是我自己的,不代表 Phoronix 网站和 Michael 的观点。它们完全是我自己的想法。*
|
||||
|
||||
另外,没错……这可能是一篇引战的文章。我希望 KDE 和 Gnome 社团变得更好一些,因为我想发起一个讨论并反馈给他们。为此,当我想指出(我所看到的)一个瑕疵时,我会尽量地做到具体而直接。这样,相关的讨论也能做到同样的具体和直接。再次声明:本文另一可选标题为“死于成千上万的[纸割][1]”(LCTT 译注:paper cuts——纸割,被纸片割伤——指易修复但烦人的缺陷。Ubuntu 从 9.10 开始,发起了 [One Hundred Papercuts][1] 项目,用于修复那些小而烦人的易用性问题)。
|
||||
|
||||
现在,重申完毕……文章开始。
|
||||
|
||||
|
||||
|
||||
当我把[《评价 Fedora 22 KDE 》][2]一文发给 Michael 时,感觉很不是滋味。不是因为我不喜欢 KDE,或者不待见 Fedora,远非如此。事实上,我刚开始想把我的 T450s 的系统换为 Arch Linux 时,马上又决定放弃了,因为我很享受 fedora 在很多方面所带来的便捷性。
|
||||
|
||||
我感觉很不是滋味的原因是 Fedora 的开发者花费了大量的时间和精力在他们的“工作站”产品上,但是我却一点也没看到。在使用 Fedora 时,我并没用采用那些主要开发者希望用户采用的那种使用方式,因此我也就体验不到所谓的“ Fedora 体验”。它感觉就像一个人评价 Ubuntu 时用的却是 Kubuntu,评价 OS X 时用的却是 Hackintosh,或者评价 Gentoo 时用的却是 Sabayon。根据论坛里大量读者对 Michael 的说法,他们在评价各种发行版时都是使用的默认设置——我也不例外。但是我还是认为这些评价应该在“真实”配置下完成,当然我也知道在给定的情况下评论某些东西也的确是有价值的——无论是好是坏。
|
||||
|
||||
正是在怀着这种态度的情况下,我决定跳到 Gnome 这个水坑里来泡泡澡。
|
||||
|
||||
但是,我还要在此多加一个声明……我在这里所看到的 KDE 和 Gnome 都是打包在 Fedora 中的。OpenSUSE、 Kubuntu、 Arch等发行版的各个桌面可能有不同的实现方法,使得我这里所说的具体的“痛点”跟你所用的发行版有所不同。还有,虽然用了这个标题,但这篇文章将会是一篇“很 KDE”的重量级文章。之所以这样称呼,是因为我在“使用” Gnome 之后,才知道 KDE 的“纸割”到底有多么的多。
|
||||
|
||||
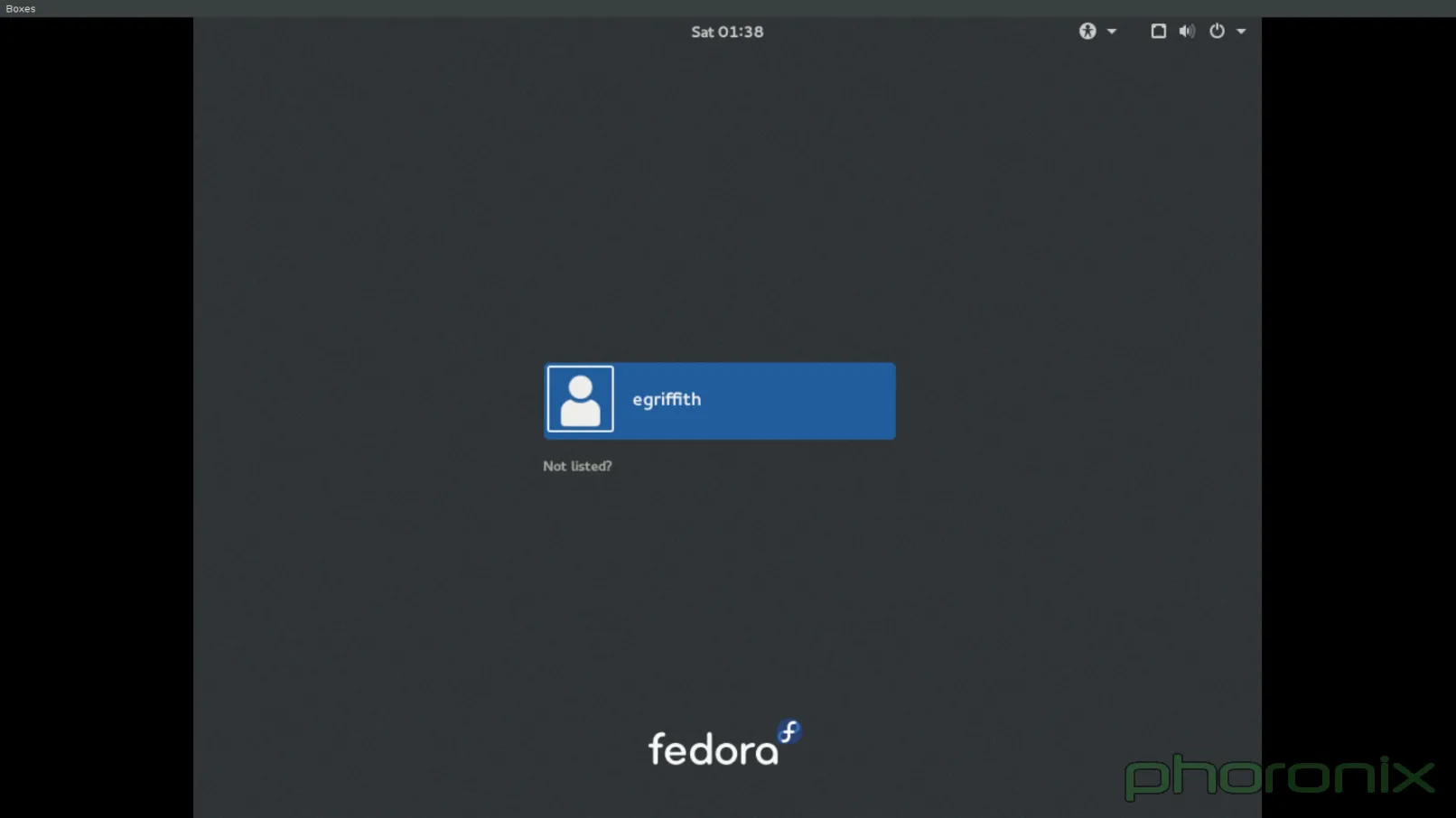
### 登录界面 ###
|
||||
|
||||
|
||||
|
||||
我一般情况下都不会介意发行版带着它们自己的特别主题,因为一般情况下桌面看起来会更好看。可我今天可算是找到了一个例外。
|
||||
|
||||
第一印象很重要,对吧?那么,GDM(LCTT 译注: Gnome Display Manage:Gnome 显示管理器。)绝对干得漂亮。它的登录界面看起来极度简洁,每一部分都应用了一致的设计风格。使用通用图标而不是文本框为它的简洁加了分。
|
||||
|
||||

|
||||
|
||||
这并不是说 Fedora 22 KDE ——现在已经是 SDDM 而不是 KDM 了——的登录界面不好看,但是看起来绝对没有它这样和谐。
|
||||
|
||||
问题到底出来在哪?顶部栏。看看 Gnome 的截图——你选择一个用户,然后用一个很小的齿轮简单地选择想登入哪个会话。设计很简洁,一点都不碍事,实话讲,如果你没注意的话可能完全会看不到它。现在看看那蓝色( LCTT 译注:blue,有忧郁之意,一语双关)的 KDE 截图,顶部栏看起来甚至不像是用同一个工具渲染出来的,它的整个位置的安排好像是某人想着:“哎哟妈呀,我们需要把这个选项扔在哪个地方……”之后决定下来的。
|
||||
|
||||
对于右上角的重启和关机选项也一样。为什么不单单用一个电源按钮,点击后会下拉出一个菜单,里面包括重启,关机,挂起的功能?按钮的颜色跟背景色不同肯定会让它更加突兀和显眼……但我可不觉得这样子有多好。同样,这看起来可真像“苦思”后的决定。
|
||||
|
||||
从实用观点来看,GDM 还要远远实用的多,再看看顶部一栏。时间被列了出来,还有一个音量控制按钮,如果你想保持周围安静,你甚至可以在登录前设置静音,还有一个可用性按钮来实现高对比度、缩放、语音转文字等功能,所有可用的功能通过简单的一个开关按钮就能得到。
|
||||
|
||||
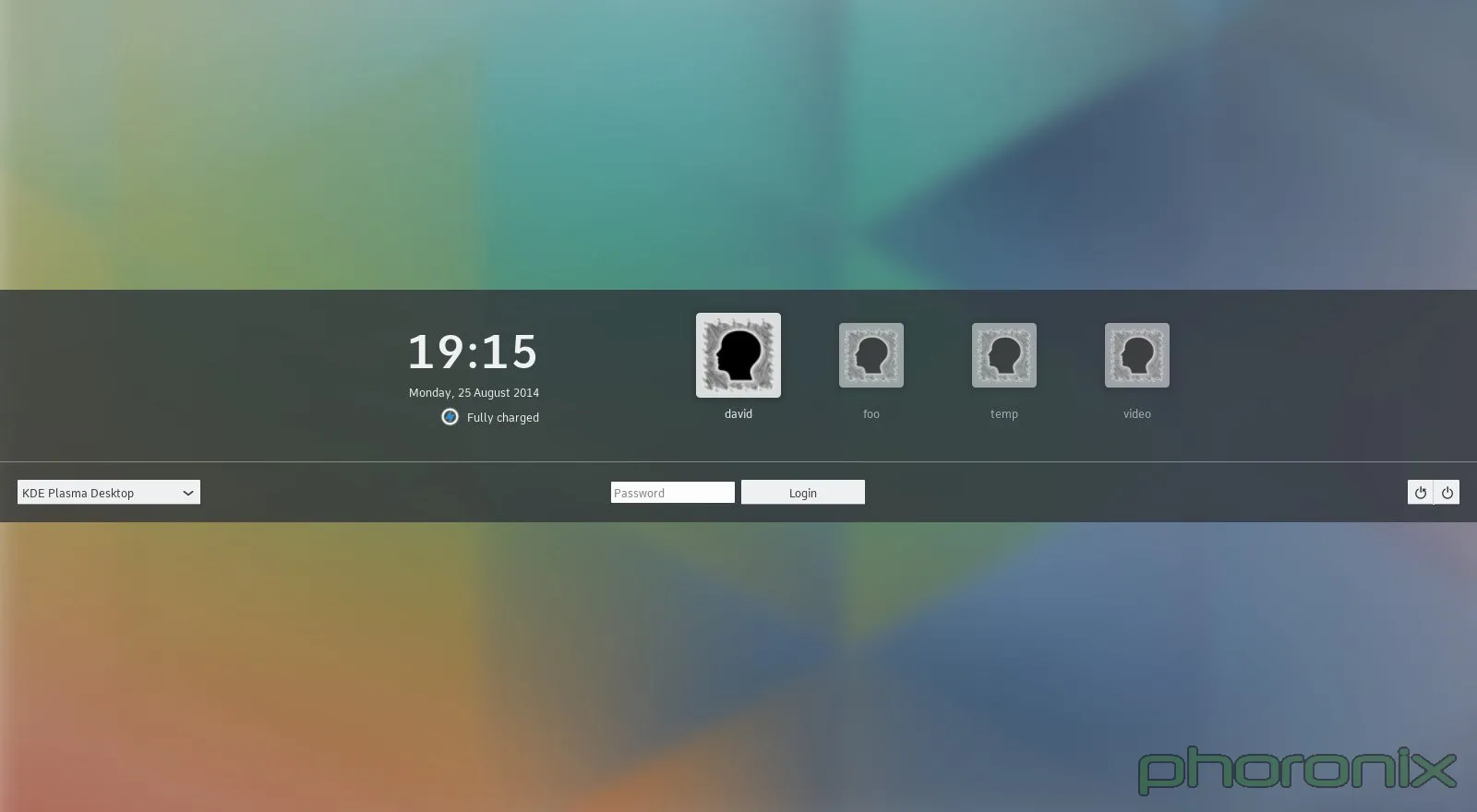
|
||||
|
||||
切换到上游(KDE 自带)的 Breeve 主题……突然间,我抱怨的大部分问题都被解决了。通用图标,所有东西都放在了屏幕中央,但不是那么重要的被放到了一边。因为屏幕顶部和底部都是同样的空白,在中间也就酝酿出了一种美好的和谐。还是有一个文本框来切换会话,但既然电源按钮被做成了通用图标,那么这点还算可以原谅。当前时间以一种漂亮的感觉呈现,旁边还有电量指示器。当然 gnome 还是有一些很好的附加物,例如音量小程序和可用性按钮,但 Breeze 总归要比 Fedora 的 KDE 主题进步。
|
||||
|
||||
到 Windows(Windows 8和10之前)或者 OS X 中去,你会看到类似的东西——非常简洁的,“不碍事”的锁屏与登录界面,它们都没有文本框或者其它分散视觉的小工具。这是一种有效的不分散人注意力的设计。Fedora……默认带有 Breeze 主题。VDG 在 Breeze 主题设计上干得不错。可别糟蹋了它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=1
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://wiki.ubuntu.com/One%20Hundred%20Papercuts
|
||||
[2]:http://www.phoronix.com/scan.php?page=article&item=fedora-22-kde&num=1
|
||||
[3]:https://launchpad.net/hundredpapercuts
|
||||
@ -0,0 +1,32 @@
|
||||
一周 GNOME 之旅:品味它和 KDE 的是是非非(第二节 GNOME桌面)
|
||||
================================================================================
|
||||
|
||||
### 桌面 ###
|
||||
|
||||
|
||||
|
||||
在我这一周的前五天中,我都是直接手动登录进 Gnome 的——没有打开自动登录功能。在第五天的晚上,每一次都要手动登录让我觉得很厌烦,所以我就到用户管理器中打开了自动登录功能。下一次我登录的时候收到了一个提示:“你的密钥链(keychain)未解锁,请输入你的密码解锁”。在这时我才意识到了什么……Gnome 以前一直都在自动解锁我的密钥链(KDE 中叫做我的钱包),每当我通过 GDM 登录时 !当我绕开 GDM 的登录程序时,Gnome 才不得不介入让我手动解锁。
|
||||
|
||||
现在,鄙人的陋见是如果你打开了自动登录功能,那么你的密钥链也应当自动解锁——否则,这功能还有何用?无论如何,你还是需要输入你的密码,况且在 GDM 登录界面你还有机会选择要登录的会话,如果你想换的话。
|
||||
|
||||
但是,这点且不提,也就是在那一刻,我意识到要让这桌面感觉就像它在**和我**一起工作一样是多么简单的一件事。当我通过 SDDM 登录 KDE 时?甚至连启动界面都还没加载完成,就有一个窗口弹出来遮挡了启动动画(因此启动动画也就被破坏了),它提示我解锁我的 KDE 钱包或 GPG 钥匙环。
|
||||
|
||||
如果当前还没有钱包,你就会收到一个创建钱包的提醒——就不能在创建用户的时候同时为我创建一个吗?接着它又让你在两种加密模式中选择一种,甚至还暗示我们其中一种(Blowfish)是不安全的,既然是为了安全,为什么还要我选择一个不安全的东西?作者声明:如果你安装了真正的 KDE spin 版本而不是仅仅安装了被 KDE 搞过的版本,那么在创建用户时,它就会为你创建一个钱包。但很不幸的是,它不会帮你自动解锁,并且它似乎还使用了更老的 Blowfish 加密模式,而不是更新而且更安全的 GPG 模式。
|
||||
|
||||
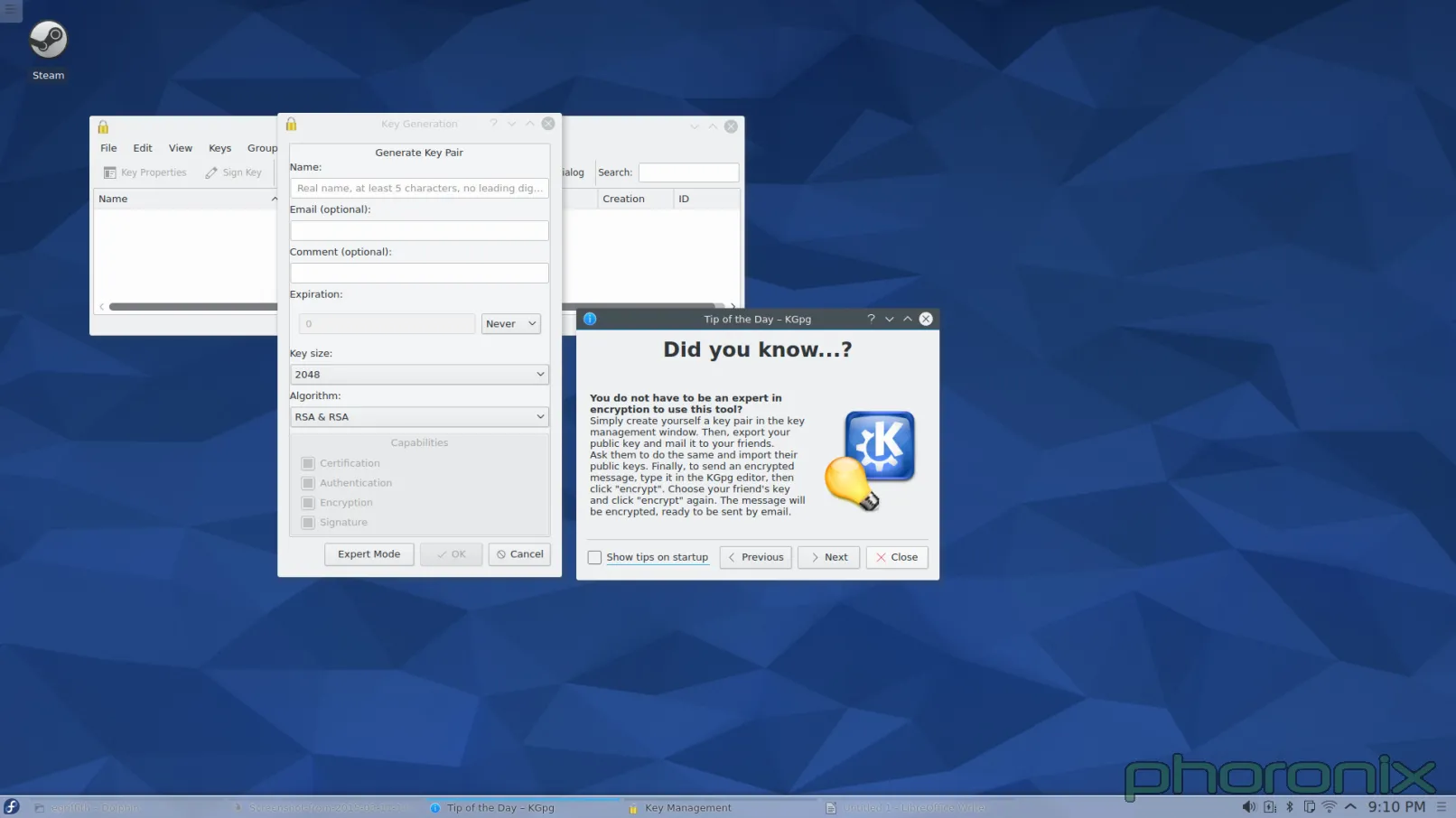
|
||||
|
||||
如果你选择了那个安全的加密模式(GPG),那么它会尝试加载 GPG 密钥……我希望你已经创建过一个了,因为如果你没有,那么你可又要被指责一番了。怎么样才能创建一个?额……它不帮你创建一个……也不告诉你怎么创建……假如你真的搞明白了你应该使用 KGpg 来创建一个密钥,接着在你就会遇到一层层的菜单和一个个的提示,而这些菜单和提示只能让新手感到困惑。为什么你要问我 GPG 的二进制文件在哪?天知道在哪!如果不止一个,你就不能为我选择一个最新的吗?如果只有一个,我再问一次,为什么你还要问我?
|
||||
|
||||
为什么你要问我要使用多大的密钥大小和加密算法?你既然默认选择了 2048 和 RSA/RSA,为什么不直接使用?如果你想让这些选项能够被修改,那就把它们扔在下面的“Expert mode(专家模式)” 按钮里去。这里不仅仅是说让配置可被用户修改的问题,而是说根本不需要默认把多余的东西扔在了用户面前。这种问题将会成为这篇文章剩下的主要内容之一……KDE 需要更理智的默认配置。配置是好的,我很喜欢在使用 KDE 时的配置,但它还需要知道什么时候应该,什么时候不应该去提示用户。而且它还需要知道“嗯,它是可配置的”不能做为默认配置做得不好的借口。用户最先接触到的就是默认配置,不好的默认配置注定要失去用户。
|
||||
|
||||
让我们抛开密钥链的问题,因为我想我已经表达出了我的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=2
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,120 @@
|
||||
如何更新 Linux 内核来提升系统性能
|
||||
================================================================================
|
||||

|
||||
|
||||
目前的 [Linux 内核][1]的开发速度是前所未有的,大概每2到3个月就会有一个主要的版本发布。每个发布都带来几个的新的功能和改进,可以让很多人的处理体验更快、更有效率、或者其它的方面更好。
|
||||
|
||||
问题是,你不能在这些内核发布的时候就用它们,你要等到你的发行版带来新内核的发布。我们先前讲到[定期更新内核的好处][2],所以你不必等到那时。让我们来告诉你该怎么做。
|
||||
|
||||
> 免责声明: 我们先前的一些文章已经提到过,升级内核有(很小)的风险可能会破坏你系统。如果发生这种情况,通常可以通过使用旧内核来使系统保持工作,但是有时还是不行。因此我们对系统的任何损坏都不负责,你得自己承担风险!
|
||||
|
||||
### 预备工作 ###
|
||||
|
||||
要更新你的内核,你首先要确定你使用的是32位还是64位的系统。打开终端并运行:
|
||||
|
||||
uname -a
|
||||
|
||||
检查一下输出的是 x86\_64 还是 i686。如果是 x86\_64,你就运行64位的版本,否则就运行32位的版本。千万记住这个,这很重要。
|
||||
|
||||

|
||||
|
||||
接下来,访问[官方的 Linux 内核网站][3],它会告诉你目前稳定内核的版本。愿意的话,你可以尝试下发布预选版(RC),但是这比稳定版少了很多测试。除非你确定想要需要发布预选版,否则就用稳定内核。
|
||||
|
||||

|
||||
|
||||
### Ubuntu 指导 ###
|
||||
|
||||
对 Ubuntu 及其衍生版的用户而言升级内核非常简单,这要感谢 Ubuntu 主线内核 PPA。虽然,官方把它叫做 PPA,但是你不能像其他 PPA 一样将它添加到你软件源列表中,并指望它自动升级你的内核。实际上,它只是一个简单的网页,你应该浏览并下载到你想要的内核。
|
||||
|
||||

|
||||
|
||||
现在,访问这个[内核 PPA 网页][4],并滚到底部。列表的最下面会含有最新发布的预选版本(你可以在名字中看到“rc”字样),但是这上面就可以看到最新的稳定版(说的更清楚些,本文写作时最新的稳定版是4.1.2。LCTT 译注:这里虽然 4.1.2 是当时的稳定版,但是由于尚未进入 Ubuntu 发行版中,所以文件夹名称为“-unstable”)。点击文件夹名称,你会看到几个选择。你需要下载 3 个文件并保存到它们自己的文件夹中(如果你喜欢的话可以放在下载文件夹中),以便它们与其它文件相隔离:
|
||||
|
||||
1. 针对架构的含“generic”(通用)的头文件(我这里是64位,即“amd64”)
|
||||
2. 放在列表中间,在文件名末尾有“all”的头文件
|
||||
3. 针对架构的含“generic”内核文件(再说一次,我会用“amd64”,但是你如果用32位的,你需要使用“i686”)
|
||||
|
||||
你还可以在下面看到含有“lowlatency”(低延时)的文件。但最好忽略它们。这些文件相对不稳定,并且只为那些通用文件不能满足像音频录制这类任务想要低延迟的人准备的。再说一次,首选通用版,除非你有特定的任务需求不能很好地满足。一般的游戏和网络浏览不是使用低延时版的借口。
|
||||
|
||||
你把它们放在各自的文件夹下,对么?现在打开终端,使用`cd`命令切换到新创建的文件夹下,如
|
||||
|
||||
cd /home/user/Downloads/Kernel
|
||||
|
||||
接着运行:
|
||||
|
||||
sudo dpkg -i *.deb
|
||||
|
||||
这个命令会标记文件夹中所有的“.deb”文件为“待安装”,接着执行安装。这是推荐的安装方法,因为不可以很简单地选择一个文件安装,它总会报出依赖问题。这这样一起安装就可以避免这个问题。如果你不清楚`cd`和`sudo`是什么。快速地看一下 [Linux 基本命令][5]这篇文章。
|
||||
|
||||

|
||||
|
||||
安装完成后,**重启**你的系统,这时应该就会运行刚安装的内核了!你可以在命令行中使用`uname -a`来检查输出。
|
||||
|
||||
### Fedora 指导 ###
|
||||
|
||||
如果你使用的是 Fedora 或者它的衍生版,过程跟 Ubuntu 很类似。不同的是文件获取的位置不同,安装的命令也不同。
|
||||
|
||||

|
||||
|
||||
查看 [最新 Fedora 内核构建][6]列表。选取列表中最新的稳定版并翻页到下面选择 i686 或者 x86_64 版。这取决于你的系统架构。这时你需要下载下面这些文件并保存到它们对应的目录下(比如“Kernel”到下载目录下):
|
||||
|
||||
- kernel
|
||||
- kernel-core
|
||||
- kernel-headers
|
||||
- kernel-modules
|
||||
- kernel-modules-extra
|
||||
- kernel-tools
|
||||
- perf 和 python-perf (可选)
|
||||
|
||||
如果你的系统是 i686(32位)同时你有 4GB 或者更大的内存,你需要下载所有这些文件的 PAE 版本。PAE 是用于32位系统上的地址扩展技术,它允许你使用超过 3GB 的内存。
|
||||
|
||||
现在使用`cd`命令进入文件夹,像这样
|
||||
|
||||
cd /home/user/Downloads/Kernel
|
||||
|
||||
接着运行下面的命令来安装所有的文件
|
||||
|
||||
yum --nogpgcheck localinstall *.rpm
|
||||
|
||||
最后**重启**你的系统,这样你就可以运行新的内核了!
|
||||
|
||||
#### 使用 Rawhide ####
|
||||
|
||||
另外一个方案是,Fedora 用户也可以[切换到 Rawhide][7],它会自动更新所有的包到最新版本,包括内核。然而,Rawhide 经常会破坏系统(尤其是在早期的开发阶段中),它**不应该**在你日常使用的系统中用。
|
||||
|
||||
### Arch 指导 ###
|
||||
|
||||
[Arch 用户][8]应该总是使用的是最新和最棒的稳定版(或者相当接近的版本)。如果你想要更接近最新发布的稳定版,你可以启用测试库提前2到3周获取到主要的更新。
|
||||
|
||||
要这么做,用[你喜欢的编辑器][9]以`sudo`权限打开下面的文件
|
||||
|
||||
/etc/pacman.conf
|
||||
|
||||
接着取消注释带有 testing 的三行(删除行前面的#号)。如果你启用了 multilib 仓库,就把 multilib-testing 也做相同的事情。如果想要了解更多参考[这个 Arch 的 wiki 界面][10]。
|
||||
|
||||
升级内核并不简单(有意这么做的),但是这会给你带来很多好处。只要你的新内核不会破坏任何东西,你可以享受它带来的性能提升,更好的效率,更多的硬件支持和潜在的新特性。尤其是你正在使用相对较新的硬件时,升级内核可以帮助到你。
|
||||
|
||||
|
||||
**怎么升级内核这篇文章帮助到你了么?你认为你所喜欢的发行版对内核的发布策略应该是怎样的?**。在评论栏让我们知道!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.makeuseof.com/tag/update-linux-kernel-improved-system-performance/
|
||||
|
||||
作者:[Danny Stieben][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.makeuseof.com/tag/author/danny/
|
||||
[1]:http://www.makeuseof.com/tag/linux-kernel-explanation-laymans-terms/
|
||||
[2]:http://www.makeuseof.com/tag/5-reasons-update-kernel-linux/
|
||||
[3]:http://www.kernel.org/
|
||||
[4]:http://kernel.ubuntu.com/~kernel-ppa/mainline/
|
||||
[5]:http://www.makeuseof.com/tag/an-a-z-of-linux-40-essential-commands-you-should-know/
|
||||
[6]:http://koji.fedoraproject.org/koji/packageinfo?packageID=8
|
||||
[7]:http://www.makeuseof.com/tag/bleeding-edge-linux-fedora-rawhide/
|
||||
[8]:http://www.makeuseof.com/tag/arch-linux-letting-you-build-your-linux-system-from-scratch/
|
||||
[9]:http://www.makeuseof.com/tag/nano-vs-vim-terminal-text-editors-compared/
|
||||
[10]:https://wiki.archlinux.org/index.php/Pacman#Repositories
|
||||
@ -1,6 +1,7 @@
|
||||
Darkstat一个基于网络的流量分析器 - 在Linux中安装
|
||||
在 Linux 中安装 Darkstat:基于网页的流量分析器
|
||||
================================================================================
|
||||
Darkstat是一个简易的,基于网络的流量分析程序。它可以在主流的操作系统如Linux、Solaris、MAC、AIX上工作。它以守护进程的形式持续工作在后台并不断地嗅探网络数据并以简单易懂的形式展现在网页上。它可以为主机生成流量报告,鉴别特定主机上哪些端口打开并且兼容IPv6。让我们看下如何在Linux中安装和配置它。
|
||||
|
||||
Darkstat是一个简易的,基于网页的流量分析程序。它可以在主流的操作系统如Linux、Solaris、MAC、AIX上工作。它以守护进程的形式持续工作在后台,不断地嗅探网络数据,以简单易懂的形式展现在它的网页上。它可以为主机生成流量报告,识别特定的主机上哪些端口是打开的,它兼容IPv6。让我们看下如何在Linux中安装和配置它。
|
||||
|
||||
### 在Linux中安装配置Darkstat ###
|
||||
|
||||
@ -20,14 +21,15 @@ Darkstat是一个简易的,基于网络的流量分析程序。它可以在主
|
||||
|
||||
### 配置 Darkstat ###
|
||||
|
||||
为了正确运行这个程序,我恩需要执行一些基本的配置。运行下面的命令用gedit编辑器打开/etc/darkstat/init.cfg文件。
|
||||
为了正确运行这个程序,我们需要执行一些基本的配置。运行下面的命令用gedit编辑器打开/etc/darkstat/init.cfg文件。
|
||||
|
||||
sudo gedit /etc/darkstat/init.cfg
|
||||
|
||||

|
||||
编辑 Darkstat
|
||||
|
||||
修改START_DARKSTAT这个参数为yes,并在“INTERFACE”中提供你的网络接口。确保取消了DIR、PORT、BINDIP和LOCAL这些参数的注释。如果你希望绑定Darkstat到特定的IP,在BINDIP中提供它
|
||||
*编辑 Darkstat*
|
||||
|
||||
修改START_DARKSTAT这个参数为yes,并在“INTERFACE”中提供你的网络接口。确保取消了DIR、PORT、BINDIP和LOCAL这些参数的注释。如果你希望绑定Darkstat到特定的IP,在BINDIP参数中提供它。
|
||||
|
||||
### 启动Darkstat守护进程 ###
|
||||
|
||||
@ -47,7 +49,7 @@ Darkstat是一个简易的,基于网络的流量分析程序。它可以在主
|
||||
|
||||
### 总结 ###
|
||||
|
||||
它是一个占用很少内存的轻量级工具。这个工具流行的原因是简易、易于配置和使用。这是一个对系统管理员而言必须拥有的程序
|
||||
它是一个占用很少内存的轻量级工具。这个工具流行的原因是简易、易于配置使用。这是一个对系统管理员而言必须拥有的程序。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -55,7 +57,7 @@ via: http://linuxpitstop.com/install-darkstat-on-ubuntu-linux/
|
||||
|
||||
作者:[Aun][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,14 +1,15 @@
|
||||
如何在 Linux 中从 Google Play 商店里下载 apk 文件
|
||||
如何在 Linux 上从 Google Play 商店里下载 apk 文件
|
||||
================================================================================
|
||||
假设你想在你的 Android 设备中安装一个 Android 应用,然而由于某些原因,你不能在 Andor 设备上访问 Google Play 商店。接着你该怎么做呢?在不访问 Google Play 商店的前提下安装应用的一种可能的方法是使用其他的手段下载该应用的 APK 文件,然后手动地在 Android 设备上 [安装 APK 文件][1]。
|
||||
|
||||
在非 Android 设备如常规的电脑和笔记本电脑上,有着几种方式来从 Google Play 商店下载到官方的 APK 文件。例如,使用浏览器插件(例如, 针对 [Chrome][2] 或针对 [Firefox][3] 的插件) 或利用允许你使用浏览器下载 APK 文件的在线的 APK 存档等。假如你不信任这些闭源的插件或第三方的 APK 仓库,这里有另一种手动下载官方 APK 文件的方法,它使用一个名为 [GooglePlayDownloader][4] 的开源 Linux 应用。
|
||||
假设你想在你的 Android 设备中安装一个 Android 应用,然而由于某些原因,你不能在 Andord 设备上访问 Google Play 商店(LCTT 译注:显然这对于我们来说是常态)。接着你该怎么做呢?在不访问 Google Play 商店的前提下安装应用的一种可能的方法是,使用其他的手段下载该应用的 APK 文件,然后手动地在 Android 设备上 [安装 APK 文件][1]。
|
||||
|
||||
GooglePlayDownloader 是一个基于 Python 的 GUI 应用,使得你可以从 Google Play 商店上搜索和下载 APK 文件。由于它是完全开源的,你可以放心地使用它。在本篇教程中,我将展示如何在 Linux 环境下,使用 GooglePlayDownloader 来从 Google Play 商店下载 APK 文件。
|
||||
在非 Android 设备如常规的电脑和笔记本电脑上,有着几种方式来从 Google Play 商店下载到官方的 APK 文件。例如,使用浏览器插件(例如,针对 [Chrome][2] 或针对 [Firefox][3] 的插件) 或利用允许你使用浏览器下载 APK 文件的在线的 APK 存档等。假如你不信任这些闭源的插件或第三方的 APK 仓库,这里有另一种手动下载官方 APK 文件的方法,它使用一个名为 [GooglePlayDownloader][4] 的开源 Linux 应用。
|
||||
|
||||
GooglePlayDownloader 是一个基于 Python 的 GUI 应用,它可以让你从 Google Play 商店上搜索和下载 APK 文件。由于它是完全开源的,你可以放心地使用它。在本篇教程中,我将展示如何在 Linux 环境下,使用 GooglePlayDownloader 来从 Google Play 商店下载 APK 文件。
|
||||
|
||||
### Python 需求 ###
|
||||
|
||||
GooglePlayDownloader 需要使用 Python 中 SSL 模块的扩展 SNI(服务器名称指示) 来支持 SSL/TLS 通信,该功能由 Python 2.7.9 或更高版本带来。这使得一些旧的发行版本如 Debian 7 Wheezy 及早期版本,Ubuntu 14.04 及早期版本或 CentOS/RHEL 7 及早期版本均不能满足该要求。假设你已经有了一个带有 Python 2.7.9 或更高版本的发行版本,可以像下面这样接着安装 GooglePlayDownloader。
|
||||
GooglePlayDownloader 需要使用带有 SNI(Server Name Indication 服务器名称指示)的 Python 来支持 SSL/TLS 通信,该功能由 Python 2.7.9 或更高版本引入。这使得一些旧的发行版本如 Debian 7 Wheezy 及早期版本,Ubuntu 14.04 及早期版本或 CentOS/RHEL 7 及早期版本均不能满足该要求。这里假设你已经有了一个带有 Python 2.7.9 或更高版本的发行版本,可以像下面这样接着安装 GooglePlayDownloader。
|
||||
|
||||
### 在 Ubuntu 上安装 GooglePlayDownloader ###
|
||||
|
||||
@ -16,7 +17,7 @@ GooglePlayDownloader 需要使用 Python 中 SSL 模块的扩展 SNI(服务器
|
||||
|
||||
#### 在 Ubuntu 14.10 上 ####
|
||||
|
||||
下载 [python-ndg-httpsclient][5] deb 软件包,这在旧一点的 Ubuntu 发行版本中是一个缺失的依赖。同时还要下载 GooglePlayDownloader 的官方 deb 软件包。
|
||||
下载 [python-ndg-httpsclient][5] deb 软件包,这是一个较旧的 Ubuntu 发行版本中缺失的依赖。同时还要下载 GooglePlayDownloader 的官方 deb 软件包。
|
||||
|
||||
$ wget http://mirrors.kernel.org/ubuntu/pool/main/n/ndg-httpsclient/python-ndg-httpsclient_0.3.2-1ubuntu4_all.deb
|
||||
$ wget http://codingteam.net/project/googleplaydownloader/download/file/googleplaydownloader_1.7-1_all.deb
|
||||
@ -64,7 +65,7 @@ GooglePlayDownloader 需要使用 Python 中 SSL 模块的扩展 SNI(服务器
|
||||
|
||||
### 使用 GooglePlayDownloader 从 Google Play 商店下载 APK 文件 ###
|
||||
|
||||
一旦你安装好 GooglePlayDownloader 后,你就可以像下面那样从 Google Play 商店下载 APK 文件。
|
||||
一旦你安装好 GooglePlayDownloader 后,你就可以像下面那样从 Google Play 商店下载 APK 文件。(LCTT 译注:显然你需要让你的 Linux 能爬梯子)
|
||||
|
||||
首先通过输入下面的命令来启动该应用:
|
||||
|
||||
@ -76,7 +77,7 @@ GooglePlayDownloader 需要使用 Python 中 SSL 模块的扩展 SNI(服务器
|
||||
|
||||
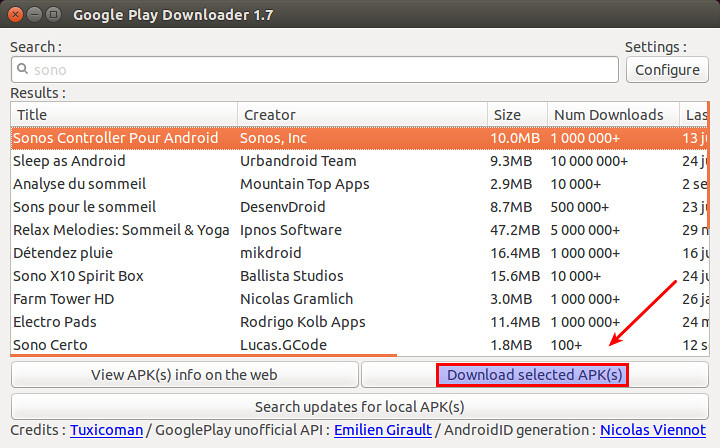
|
||||
|
||||
一旦你从搜索列表中找到了该应用,就选择该应用,接着点击 "下载选定的 APK 文件" 按钮。最后你将在你的家目录中找到下载的 APK 文件。现在,你就可以将下载到的 APK 文件转移到你所选择的 Android 设备上,然后手动安装它。
|
||||
一旦你从搜索列表中找到了该应用,就选择该应用,接着点击 “下载选定的 APK 文件” 按钮。最后你将在你的家目录中找到下载的 APK 文件。现在,你就可以将下载到的 APK 文件转移到你所选择的 Android 设备上,然后手动安装它。
|
||||
|
||||
希望这篇教程对你有所帮助。
|
||||
|
||||
@ -86,7 +87,7 @@ via: http://xmodulo.com/download-apk-files-google-play-store.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,63 @@
|
||||
Ubuntu 有望让你安装最新 Nvidia Linux 驱动更简单
|
||||
================================================================================
|
||||

|
||||
|
||||
*Ubuntu 上的游戏玩家在增长——因而需要最新版驱动*
|
||||
|
||||
**在 Ubuntu 上安装上游的 NVIDIA 图形驱动即将变得更加容易。**
|
||||
|
||||
Ubuntu 开发者正在考虑构建一个全新的'官方' PPA,以便为桌面用户分发最新的闭源 NVIDIA 二进制驱动。
|
||||
|
||||
该项改变会让 Ubuntu 游戏玩家收益,并且*不会*给其它人造成 OS 稳定性方面的风险。
|
||||
|
||||
**仅**当用户明确选择它时,新的上游驱动将通过这个新 PPA 安装并更新。其他人将继续得到并使用更近的包含在 Ubuntu 归档中的稳定版 NVIDIA Linux 驱动快照。
|
||||
|
||||
### 为什么需要该项目? ###
|
||||
|
||||
|
||||
|
||||
*Ubuntu 提供了驱动——但是它们不是最新的*
|
||||
|
||||
可以从归档中(使用命令行、synaptic,或者通过额外驱动工具)安装到 Ubuntu 上的闭源 NVIDIA 图形驱动在大多数情况下都能工作得很好,并且可以轻松地处理 Unity 桌面外壳的混染。
|
||||
|
||||
但对于游戏需求而言,那完全是另外一码事儿。
|
||||
|
||||
如果你想要将最高帧率和 HD 纹理从最新流行的 Steam 游戏中压榨出来,你需要最新的二进制驱动文件。
|
||||
|
||||
驱动越新,越可能支持最新的特性和技术,或者带有预先打包的游戏专门的优化和漏洞修复。
|
||||
|
||||
问题在于,在 Ubuntu 上安装最新 Nvidia Linux 驱动不是件容易的事儿,而且也不具安全保证。
|
||||
|
||||
要填补这个空白,许多由热心人维护的第三方 PPA 就出现了。由于许多这些 PPA 也发布了其它实验性的或者前沿软件,它们的使用**并不是毫无风险的**。添加一个前沿的 PPA 通常是搞崩整个系统的最快的方式!
|
||||
|
||||
一个解决方法是,让 Ubuntu 用户安装最新的专有图形驱动以满足对第三方 PPA 的需要,**但是**提供一个安全机制,如果有需要,你可以回滚到稳定版本。
|
||||
|
||||
### ‘对全新驱动的需求难以忽视’ ###
|
||||
|
||||
> '一个让Ubuntu用户安全地获得最新硬件驱动的解决方案出现了。'
|
||||
|
||||
‘在快速发展的市场中,对全新驱动的需求正变得难以忽视,用户将想要最新的上游软件,’卡斯特罗在一封给 Ubuntu 桌面邮件列表的电子邮件中解释道。
|
||||
|
||||
‘[NVIDIA] 可以毫不费力为 [Windows 10] 用户带来了不起的体验。直到我们可以说服 NVIDIA 在 Ubuntu 中做了同样的工作,这样我们就可以搞定这一切了。’
|
||||
|
||||
卡斯特罗的“官方的” NVIDIA PPA 方案就是最实现这一目的的最容易的方式。
|
||||
|
||||
游戏玩家将可以在 Ubuntu 的默认专有软件驱动工具中选择接收来自该 PPA 的新驱动,再也不需要它们从网站或维基页面拷贝并粘贴终端命令了。
|
||||
|
||||
该 PPA 内的驱动将由一个选定的社区成员组成的团队打包并维护,并受惠于一个名为**自动化测试**的半官方方式。
|
||||
|
||||
就像卡斯特罗自己说的那样:'人们想要最新的闪光的东西,而不管他们想要做什么。我们也许也要在其周围放置一个框架,因此人们可以获得他们所想要的,而不必破坏他们的计算机。'
|
||||
|
||||
**你想要使用这个 PPA 吗?你怎样来评估 Ubuntu 上默认 Nvidia 驱动的性能呢?在评论中分享你的想法吧,伙计们!**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/08/ubuntu-easy-install-latest-nvidia-linux-drivers
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
@ -0,0 +1,66 @@
|
||||
Ubuntu NVIDIA 显卡驱动 PPA 已经做好准备
|
||||
================================================================================
|
||||

|
||||
|
||||
加速你的帧率!
|
||||
|
||||
**嘿,各位,稍安勿躁,很快就好。**
|
||||
|
||||
就在提议开发一个[新的 PPA][1] 来给 Ubuntu 用户们提供最新的 NVIDIA 显卡驱动后不久,ubuntu 社区的人们又集结起来了,就是为了这件事。
|
||||
|
||||
顾名思义,‘**Graphics Drivers PPA**’ 包含了最新的 NVIDIA Linux 显卡驱动发布,已经打包好可供用户升级使用,没有让人头疼的二进制运行时文件!
|
||||
|
||||
这个 PPA 被设计用来让玩家们尽可能方便地在 Ubuntu 上运行最新款的游戏。
|
||||
|
||||
#### 万事俱备,只欠东风 ####
|
||||
|
||||
Jorge Castro 开发一个包含 NVIDIA 最新显卡驱动的 PPA 神器的想法得到了 Ubuntu 用户和广大游戏开发者的热烈响应。
|
||||
|
||||
就连那些致力于将“Steam平台”上的知名大作移植到 Linux 上的人们,也给了不少建议。
|
||||
|
||||
Edwin Smith,Feral Interactive 公司(‘Shadow of Mordor’) 的产品总监,对于“让用户更方便地更新驱动”的倡议表示非常欣慰。
|
||||
|
||||
### 如何使用最新的 Nvidia Drivers PPA###
|
||||
|
||||
虽然新的“显卡PPA”已经开发出来,但是现在还远远达不到成熟。开发者们提醒到:
|
||||
|
||||
> “这个 PPA 还处于测试阶段,在你使用它之前最好有一些打包的经验。请大家稍安勿躁,再等几天。”
|
||||
|
||||
将 PPA 试发布给 Ubuntu desktop 邮件列表的 Jorge,也强调说,使用现行的一些 PPA(比如 xorg-edgers)的玩家可能发现不了什么区别(因为现在的驱动只不过是把内容从其他那些现存驱动拷贝过来了)
|
||||
|
||||
“新驱动发布的时候,好戏才会上演呢,”他说。
|
||||
|
||||
截至写作本文时为止,这个 PPA 囊括了从 Ubuntu 12.04.1 到 15.10 各个版本的 Nvidia 驱动。注意这些驱动对所有的发行版都适用。
|
||||
|
||||
> **毫无疑问,除非你清楚自己在干些什么,并且知道如果出了问题应该怎么撤销,否则就不要进行下面的操作。**
|
||||
|
||||
新打开一个终端窗口,运行下面的命令加入 PPA:
|
||||
|
||||
sudo add-apt-repository ppa:graphics-drivers/ppa
|
||||
|
||||
安装或更新到最新的 Nvidia 显卡驱动:
|
||||
|
||||
sudo apt-get update && sudo apt-get install nvidia-355
|
||||
|
||||
记住:如果PPA把你的系统弄崩了,你可得自己去想办法,我们提醒过了哦。(译者注:切记!)
|
||||
|
||||
如果想要撤销对PPA的改变,使用 `ppa-purge` 命令。
|
||||
|
||||
有什么意见,想法,或者指正,就在下面的评论栏里写下来吧。(我没有 NVIDIA 的硬件来为我自己验证上面的这些东西,如果你可以验证的话,那就太感谢了。)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/08/ubuntu-nvidia-graphics-drivers-ppa-is-ready-for-action
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://linux.cn/article-6030-1.html
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,97 +0,0 @@
|
||||
translating by xiaoyu33
|
||||
|
||||
Tickr Is An Open-Source RSS News Ticker for Linux Desktops
|
||||
================================================================================
|
||||

|
||||
|
||||
**Latest! Latest! Read all about it!**
|
||||
|
||||
Alright, so the app we’re highlighting today isn’t quite the binary version of an old newspaper seller — but it is a great way to have the latest news brought to you, on your desktop.
|
||||
|
||||
Tick is a GTK-based news ticker for the Linux desktop that scrolls the latest headlines and article titles from your favourite RSS feeds in horizontal strip that you can place anywhere on your desktop.
|
||||
|
||||
Call me Joey Calamezzo; I put mine on the bottom TV news station style.
|
||||
|
||||
“Over to you, sub-heading.”
|
||||
|
||||
### RSS — Remember That? ###
|
||||
|
||||
“Thanks paragraph ending.”
|
||||
|
||||
In an era of push notifications, social media, and clickbait, cajoling us into reading the latest mind-blowing, humanity saving listicle ASAP, RSS can seem a bit old hat.
|
||||
|
||||
For me? Well, RSS lives up to its name of Really Simple Syndication. It’s the easiest, most manageable way to have news come to me. I can manage and read stuff when I want; there’s no urgency to view lest the tweet vanish into the stream or the push notification vanish.
|
||||
|
||||
The beauty of Tickr is in its utility. You can have a constant stream of news trundling along the bottom of your screen, which you can passively glance at from time to time.
|
||||
|
||||

|
||||
|
||||
There’s no pressure to ‘read’ or ‘mark all read’ or any of that. When you see something you want to read you just click it to open it in a web browser.
|
||||
|
||||
### Setting it Up ###
|
||||
|
||||

|
||||
|
||||
Although Tickr is available to install from the Ubuntu Software Centre it hasn’t been updated for a long time. Nowhere is this sense of abandonment more keenly felt than when opening the unwieldy and unintuitive configuration panel.
|
||||
|
||||
To open it:
|
||||
|
||||
1. Right click on the Tickr bar
|
||||
1. Go to Edit > Preferences
|
||||
1. Adjust the various settings
|
||||
|
||||
Row after row of options and settings, few of which seem to make sense at first. But poke and prod around and you’ll controls for pretty much everything, including:
|
||||
|
||||
- Set scrolling speed
|
||||
- Choose behaviour when mousing over
|
||||
- Feed update frequency
|
||||
- Font, including font sizes and color
|
||||
- Separator character (‘delineator’)
|
||||
- Position of Tickr on screen
|
||||
- Color and opacity of Tickr bar
|
||||
- Choose how many articles each feed displays
|
||||
|
||||
One ‘quirk’ worth mentioning is that pressing the ‘Apply’ only updates the on-screen Tickr to preview changes. For changes to take effect when you exit the Preferences window you need to click ‘OK’.
|
||||
|
||||
Getting the bar to sit flush on your display can also take a fair bit of tweaking, especially on Unity.
|
||||
|
||||
Press the “full width button” to have the app auto-detect your screen width. By default when placed at the top or bottom it leaves a 25px gap (the app was created back in the days of GNOME 2.x desktops). After hitting the top or bottom buttons just add an extra 25 pixels to the input box compensate for this.
|
||||
|
||||
Other options available include: choose which browser articles open in; whether Tickr appears within a regular window frame; whether a clock is shown; and how often the app checks feed for articles.
|
||||
|
||||
#### Adding Feeds ####
|
||||
|
||||
Tickr comes with a built-in list of over 30 different feeds, ranging from technology blogs to mainstream news services.
|
||||
|
||||

|
||||
|
||||
You can select as many of these as you like to show headlines in the on screen ticker. If you want to add your own feeds you can: –
|
||||
|
||||
1. Right click on the Tickr bar
|
||||
1. Go to File > Open Feed
|
||||
1. Enter Feed URL
|
||||
1. Click ‘Add/Upd’ button
|
||||
1. Click ‘OK (select)’
|
||||
|
||||
To set how many items from each feed shows in the ticker change the “Read N items max per feed” in the other preferences window.
|
||||
|
||||
### Install Tickr in Ubuntu 14.04 LTS and Up ###
|
||||
|
||||
So that’s Tickr. It’s not going to change the world but it will keep you abreast of what’s happening in it.
|
||||
|
||||
To install it in Ubuntu 14.04 LTS or later head to the Ubuntu Software Centre but clicking the button below.
|
||||
|
||||
- [Click to install Tickr form the Ubuntu Software Center][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/06/tickr-open-source-desktop-rss-news-ticker
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:apt://tickr
|
||||
@ -0,0 +1,159 @@
|
||||
translating by xiaoyu33
|
||||
|
||||
shellinabox – A Web based AJAX Terminal Emulator
|
||||
================================================================================
|
||||
### About shellinabox ###
|
||||
|
||||
Greetings Unixmen readers!
|
||||
|
||||
We, usually, access any remote servers using well known communication tools like OpenSSH, and Putty etc. But, one important thing is we can’t access the remote systems using those tools behind a Firewall or the firewalls that allow only HTTPS traffic. No worries! We, still, have some options to access your remote systems even if you’re behind a firewall. And also, you don’t need to install any communications tools like OpenSSH or Putty. All you need is only a modern JavaScript and CSS enabled browser. And you don’t need to install any plugins or third party softwares either.
|
||||
|
||||
Meet **Shell In A Box**, pronounced as **shellinabox**, a free, open source, web based AJAX Terminal emulator developed by **Markus Gutschke**. It uses AJAX technology to provide the look and feel of a native shell via a web browser. The **shellinaboxd** daemon implements a webserver that listens on the specified port. The web server publishes one or more services that will be displayed in a VT100 emulator implemented as an AJAX web application. By default, the port is 4200. You can change the default port to any random port number of your choice. After installing shellinabox on all your remote servers that you want to access them from your local system, open up the web browser and navigate to: **http://IP-Address:4200/**. Enter your user name and password and start using your remote system’s shell. Seems interesting, isn’t it? Indeed!
|
||||
|
||||
**Disclaimer**:
|
||||
|
||||
Shellinabox is not a ssh client or any sort of security software. It is just a application that emulates a remote system’s shell via a web browser. Also, It has nothing to do with SSH in anyway. It’s not a bullet proof security way to remote your systems. It is just one of the easiest methods so far. You should not run it on any public network for any reason.
|
||||
|
||||
### Install shellinabox ###
|
||||
|
||||
#### In Debian/Ubuntu based systems: ####
|
||||
|
||||
shellinabox is available in the default repositories. So, you can install it using command:
|
||||
|
||||
$ sudo apt-get install shellinabox
|
||||
|
||||
#### In RHEL/CentOS systems: ####
|
||||
|
||||
First, install EPEL repository using command:
|
||||
|
||||
# yum install epel-release
|
||||
|
||||
Then, install shellinabox using command:
|
||||
|
||||
# yum install shellinabox
|
||||
|
||||
Done!
|
||||
|
||||
### Configure shellinabox ###
|
||||
|
||||
As I mentioned before, shellinabox listens on port **4200** by default. You can change this port to any random number of your choice to make it difficult to guess by anyone.
|
||||
|
||||
The shellinabox config file is located in **/etc/default/shellinabox** file by default in Debian/Ubuntu systems. In RHEL/CentOS/Fedora, the default location of config file is **/etc/sysconfig/shellinaboxd**.
|
||||
|
||||
If you want to change the default port,
|
||||
|
||||
In Debian/Ubuntu:
|
||||
|
||||
$ sudo vi /etc/default/shellinabox
|
||||
|
||||
In RHEL/CentOS/Fedora:
|
||||
|
||||
# vi /etc/sysconfig/shellinaboxd
|
||||
|
||||
Change your port to any random number. Since I am testing it on my local network, I use the default values.
|
||||
|
||||
# Shell in a box daemon configuration
|
||||
# For details see shellinaboxd man page
|
||||
|
||||
# Basic options
|
||||
USER=shellinabox
|
||||
GROUP=shellinabox
|
||||
CERTDIR=/var/lib/shellinabox
|
||||
PORT=4200
|
||||
OPTS="--disable-ssl-menu -s /:LOGIN"
|
||||
|
||||
# Additional examples with custom options:
|
||||
|
||||
# Fancy configuration with right-click menu choice for black-on-white:
|
||||
# OPTS="--user-css Normal:+black-on-white.css,Reverse:-white-on-black.css --disable-ssl-menu -s /:LOGIN"
|
||||
|
||||
# Simple configuration for running it as an SSH console with SSL disabled:
|
||||
# OPTS="-t -s /:SSH:host.example.com"
|
||||
|
||||
Restart shelinabox service.
|
||||
|
||||
**In Debian/Ubuntu:**
|
||||
|
||||
$ sudo systemctl restart shellinabox
|
||||
|
||||
Or
|
||||
|
||||
$ sudo service shellinabox restart
|
||||
|
||||
In RHEL/CentOS systems run the following command to start shellinaboxd service automatically on every reboot.
|
||||
|
||||
# systemctl enable shellinaboxd
|
||||
|
||||
Or
|
||||
|
||||
# chkconfig shellinaboxd on
|
||||
|
||||
Remember to open up port **4200** or any port that you assign if you are running a firewall.
|
||||
|
||||
For example, in RHEL/CentOS systems, you can allow the port as shown below.
|
||||
|
||||
# firewall-cmd --permanent --add-port=4200/tcp
|
||||
|
||||
----------
|
||||
|
||||
# firewall-cmd --reload
|
||||
|
||||
### Usage ###
|
||||
|
||||
Now, go to your client systems, open up the web browser and navigate to: **https://ip-address-of-remote-servers:4200**.
|
||||
|
||||
**Note**: Mention the correct port if you have changed it.
|
||||
|
||||
You’ll get a warning message of certificate issue. Accept the certificate and go on.
|
||||
|
||||

|
||||
|
||||
Enter your remote system’s username and password. Now, you’ll be able to access the remote system’s shell right from the browser itself.
|
||||
|
||||

|
||||
|
||||
You can get some additional menu options which might be useful by right clicking on the empty space of your browser.
|
||||
|
||||

|
||||
|
||||
From now on, you can do whatever you want to do in your remote server from the local system’s web browser.
|
||||
|
||||
Once you done, type **exit** in the shell.
|
||||
|
||||
To connect again to the remote system, click the **Connect** button and then type the user name and password of your remote server.
|
||||
|
||||

|
||||
|
||||
For more details about shellinabox, type the following command in your Terminal:
|
||||
|
||||
# man shellinabox
|
||||
|
||||
Or
|
||||
|
||||
# shellinaboxd -help
|
||||
|
||||
Also, refer the [shellinabox wiki page][1] for comprehensive usage details.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Like I mentioned before, web-based SSH tools are very useful if you’re running servers behind a Firewall. There are many web-based ssh tools, but Shellinabox is pretty simple and useful tool to emulate a remote system’s shell from anywhere in your network. Since, it is browser based, you can access your remote server from any device as long as you have a JavaScript and CSS enabled browser.
|
||||
|
||||
That’s all for now. Have a good day!
|
||||
|
||||
#### Reference link: ####
|
||||
|
||||
- [shellinabox website][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/shellinabox-a-web-based-ajax-terminal-emulator/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:https://code.google.com/p/shellinabox/wiki/shellinaboxd_man
|
||||
[2]:https://code.google.com/p/shellinabox/
|
||||
@ -1,129 +0,0 @@
|
||||
|
||||
Translating by dingdongnigetou
|
||||
|
||||
Howto Configure Nginx as Rreverse Proxy / Load Balancer with Weave and Docker
|
||||
================================================================================
|
||||
Hi everyone today we'll learnHowto configure Nginx as Rreverse Proxy / Load balancer with Weave and Docker Weave creates a virtual network that connects Docker containers with each other, deploys across multiple hosts and enables their automatic discovery. It allows us to focus on developing our application, rather than our infrastructure. It provides such an awesome environment that the applications uses the network as if its containers were all plugged into the same network without need to configure ports, mappings, link, etc. The services of the application containers on the network can be easily accessible to the external world with no matter where its running. Here, in this tutorial we'll be using weave to quickly and easily deploy nginx web server as a load balancer for a simple php application running in docker containers on multiple nodes in Amazon Web Services. Here, we will be introduced to WeaveDNS, which provides a simple way for containers to find each other using hostname with no changes in codes and tells other containers to connect to those names.
|
||||
|
||||
Here, in this tutorial, we will use Nginx to load balance requests to a set of containers running Apache. Here are the simple and easy to do steps on using Weave to configure nginx as a load balancer running in ubuntu docker container.
|
||||
|
||||
### 1. Settting up AWS Instances ###
|
||||
|
||||
First of all, we'll need to setup Amazon Web Service Instances so that we can run docker containers with Weave and Ubuntu as Operating System. We will use the [AWS CLI][1] to setup and configure two AWS EC2 instances. Here, in this tutorial, we'll use the smallest available instances, t1.micro. We will need to have a valid **Amazon Web Services account** with AWS CLI setup and configured. We'll first gonna clone the repository of weave from the github by running the following command in AWS CLI.
|
||||
|
||||
$ git clone http://github.com/fintanr/weave-gs
|
||||
$ cd weave-gs/aws-nginx-ubuntu-simple
|
||||
|
||||
After cloning the repository, we wanna run the script that will deploy two instances of t1.micro instance running Weave and Docker in Ubuntu Operating System.
|
||||
|
||||
$ sudo ./demo-aws-setup.sh
|
||||
|
||||
Here, for this tutorial we'll need the IP addresses of these instances further in future. These are stored in an environment file weavedemo.env which is created during the execution of the demo-aws-setup.sh. To get those ip addresses, we need to run the following command which will give the output similar to the output below.
|
||||
|
||||
$ cat weavedemo.env
|
||||
|
||||
export WEAVE_AWS_DEMO_HOST1=52.26.175.175
|
||||
export WEAVE_AWS_DEMO_HOST2=52.26.83.141
|
||||
export WEAVE_AWS_DEMO_HOSTCOUNT=2
|
||||
export WEAVE_AWS_DEMO_HOSTS=(52.26.175.175 52.26.83.141)
|
||||
|
||||
Please note these are not the IP addresses for our tutorial, AWS dynamically allocate IP addresses to our instances.
|
||||
|
||||
As were are using a bash, we will just source this file and execute it using the command below.
|
||||
|
||||
. ./weavedemo.env
|
||||
|
||||
### 2. Launching Weave and WeaveDNS ###
|
||||
|
||||
After deploying the instances, we'll want to launch weave and weavedns on each hosts. Weave and weavedns allows us to easily deploy our containers to a new infrastructure and configuration without the need of changing the codes and without the need to understand concepts such as ambassador containers and links. Here are the commands to launch them in the first host.
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave launch
|
||||
$ sudo weave launch-dns 10.2.1.1/24
|
||||
|
||||
Next, we'll also wanna launch them in our second host.
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST2
|
||||
$ sudo weave launch $WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave launch-dns 10.2.1.2/24
|
||||
|
||||
### 3. Launching Application Containers ###
|
||||
|
||||
Now, we wanna launch six containers across our two hosts running an Apache2 Web Server instance with our simple php site. So, we'll be running the following commands which will run 3 containers running Apache2 Web Server on our 1st instance.
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave run --with-dns 10.3.1.1/24 -h ws1.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.2/24 -h ws2.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.3/24 -h ws3.weave.local fintanr/weave-gs-nginx-apache
|
||||
|
||||
After that, we'll again launch 3 containers running apache2 web server in our 2nd instance as shown below.
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST2
|
||||
$ sudo weave run --with-dns 10.3.1.4/24 -h ws4.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.5/24 -h ws5.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.6/24 -h ws6.weave.local fintanr/weave-gs-nginx-apache
|
||||
|
||||
Note: Here, --with-dns option tells the container to use weavedns to resolve names and -h x.weave.local allows the host to be resolvable with WeaveDNS.
|
||||
|
||||
### 4. Launching Nginx Container ###
|
||||
|
||||
After our application containers are running well as expected, we'll wanna launch an nginx container which contains the nginx configuration which will round-robin across the severs for the reverse proxy or load balancing. To run the nginx container, we'll need to run the following command.
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave run --with-dns 10.3.1.7/24 -ti -h nginx.weave.local -d -p 80:80 fintanr/weave-gs-nginx-simple
|
||||
|
||||
Hence, our Nginx container is publicly exposed as a http server on $WEAVE_AWS_DEMO_HOST1.
|
||||
|
||||
### 5. Testing the Load Balancer ###
|
||||
|
||||
To test our load balancer is working or not, we'll run a script that will make http requests to our nginx container. We'll make six requests so that we can see nginx moving through each of the webservers in round-robin turn.
|
||||
|
||||
$ ./access-aws-hosts.sh
|
||||
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws1.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws2.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws3.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws4.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws5.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws6.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Finally, we've successfully configured nginx as a reverse proxy or load balancer with weave and docker running ubuntu server in AWS (Amazon Web Service) EC2 . From the above output in above step, it is clear that we have configured it correctly. We can see that the request is being sent to 6 application containers in round-robin turn which is running a PHP app hosted in apache web server. Here, weave and weavedns did great work to deploy a containerised PHP application using nginx across multiple hosts on AWS EC2 without need to change in codes and connected the containers to eachother with the hostname using weavedns. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you ! Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/nginx-load-balancer-weave-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://console.aws.amazon.com/
|
||||
@ -1,419 +0,0 @@
|
||||
wyangsun translating
|
||||
Managing Linux Logs
|
||||
================================================================================
|
||||
A key best practice for logging is to centralize or aggregate your logs in one place, especially if you have multiple servers or tiers in your architecture. We’ll tell you why this is a good idea and give tips on how to do it easily.
|
||||
|
||||
### Benefits of Centralizing Logs ###
|
||||
|
||||
It can be cumbersome to look at individual log files if you have many servers. Modern web sites and services often include multiple tiers of servers, distributed with load balancers, and more. It’d take a long time to hunt down the right file, and even longer to correlate problems across servers. There’s nothing more frustrating than finding the information you are looking for hasn’t been captured, or the log file that could have held the answer has just been lost after a restart.
|
||||
|
||||
Centralizing your logs makes them faster to search, which can help you solve production issues faster. You don’t have to guess which server had the issue because all the logs are in one place. Additionally, you can use more powerful tools to analyze them, including log management solutions. These solutions can [transform plain text logs][1] into fields that can be easily searched and analyzed.
|
||||
|
||||
Centralizing your logs also makes them easier to manage:
|
||||
|
||||
- They are safer from accidental or intentional loss when they are backed up and archived in a separate location. If your servers go down or are unresponsive, you can use the centralized logs to debug the problem.
|
||||
- You don’t have to worry about ssh or inefficient grep commands requiring more resources on troubled systems.
|
||||
- You don’t have to worry about full disks, which can crash your servers.
|
||||
- You can keep your production servers secure without giving your entire team access just to look at logs. It’s much safer to give your team access to logs from the central location.
|
||||
|
||||
With centralized log management, you still must deal with the risk of being unable to transfer logs to the centralized location due to poor network connectivity or of using up a lot of network bandwidth. We’ll discuss how to intelligently address these issues in the sections below.
|
||||
|
||||
### Popular Tools for Centralizing Logs ###
|
||||
|
||||
The most common way of centralizing logs on Linux is by using syslog daemons or agents. The syslog daemon supports local log collection, then transports logs through the syslog protocol to a central server. There are several popular daemons that you can use to centralize your log files:
|
||||
|
||||
- [rsyslog][2] is a light-weight daemon installed on most common Linux distributions.
|
||||
- [syslog-ng][3] is the second most popular syslog daemon for Linux.
|
||||
- [logstash][4] is a heavier-weight agent that can do more advanced processing and parsing.
|
||||
- [fluentd][5] is another agent with advanced processing capabilities.
|
||||
|
||||
Rsyslog is the most popular daemon for centralizing your log data because it’s installed by default in most common distributions of Linux. You don’t need to download it or install it, and it’s lightweight so it won’t take up much of your system resources.
|
||||
|
||||
If you need more advanced filtering or custom parsing capabilities, Logstash is the next most popular choice if you don’t mind the extra system footprint.
|
||||
|
||||
### Configure Rsyslog.conf ###
|
||||
|
||||
Since rsyslog is the most widely used syslog daemon, we’ll show how to configure it to centralize logs. The global configuration file is located at /etc/rsyslog.conf. It loads modules, sets global directives, and has an include for application-specific files located in the directory /etc/rsyslog.d/. This directory contains /etc/rsyslog.d/50-default.conf which instructs rsyslog to write the system logs to file. You can read more about the configuration files in the [rsyslog documentation][6].
|
||||
|
||||
The configuration language for rsyslog is [RainerScript][7]. You set up specific inputs for logs as well as actions to output them to another destination. Rsyslog already configures standard defaults for syslog input, so you usually just need to add an output to your log server. Here is an example configuration for rsyslog to output logs to an external server. In this example, **BEBOP** is the hostname of the server, so you should replace it with your own server name.
|
||||
|
||||
action(type="omfwd" protocol="tcp" target="BEBOP" port="514")
|
||||
|
||||
You could send your logs to a log server with ample storage to keep a copy for search, backup, and analysis. If you’re storing logs in the file system, then you should set up [log rotation][8] to keep your disk from getting full.
|
||||
|
||||
Alternatively, you can send these logs to a log management solution. If your solution is installed locally you can send it to your local host and port as specified in your system documentation. If you use a cloud-based provider, you will send them to the hostname and port specified by your provider.
|
||||
|
||||
### Log Directories ###
|
||||
|
||||
You can centralize all the files in a directory or matching a wildcard pattern. The nxlog and syslog-ng daemons support both directories and wildcards (*).
|
||||
|
||||
Common versions of rsyslog can’t monitor directories directly. As a workaround, you can setup a cron job to monitor the directory for new files, then configure rsyslog to send those files to a destination, such as your log management system. As an example, the log management vendor Loggly has an open source version of a [script to monitor directories][9].
|
||||
|
||||
### Which Protocol: UDP, TCP, or RELP? ###
|
||||
|
||||
There are three main protocols that you can choose from when you transmit data over the Internet. The most common is UDP for your local network and TCP for the Internet. If you cannot lose logs, then use the more advanced RELP protocol.
|
||||
|
||||
[UDP][10] sends a datagram packet, which is a single packet of information. It’s an outbound-only protocol, so it doesn’t send you an acknowledgement of receipt (ACK). It makes only one attempt to send the packet. UDP can be used to smartly degrade or drop logs when the network gets congested. It’s most commonly used on reliable networks like localhost.
|
||||
|
||||
[TCP][11] sends streaming information in multiple packets and returns an ACK. TCP makes multiple attempts to send the packet, but is limited by the size of the [TCP buffer][12]. This is the most common protocol for sending logs over the Internet.
|
||||
|
||||
[RELP][13] is the most reliable of these three protocols but was created for rsyslog and has less industry adoption. It acknowledges receipt of data in the application layer and will resend if there is an error. Make sure your destination also supports this protocol.
|
||||
|
||||
### Reliably Send with Disk Assisted Queues ###
|
||||
|
||||
If rsyslog encounters a problem when storing logs, such as an unavailable network connection, it can queue the logs until the connection is restored. The queued logs are stored in memory by default. However, memory is limited and if the problem persists, the logs can exceed memory capacity.
|
||||
|
||||
**Warning: You can lose data if you store logs only in memory.**
|
||||
|
||||
Rsyslog can queue your logs to disk when memory is full. [Disk-assisted queues][14] make transport of logs more reliable. Here is an example of how to configure rsyslog with a disk-assisted queue:
|
||||
|
||||
$WorkDirectory /var/spool/rsyslog # where to place spool files
|
||||
$ActionQueueFileName fwdRule1 # unique name prefix for spool files
|
||||
$ActionQueueMaxDiskSpace 1g # 1gb space limit (use as much as possible)
|
||||
$ActionQueueSaveOnShutdown on # save messages to disk on shutdown
|
||||
$ActionQueueType LinkedList # run asynchronously
|
||||
$ActionResumeRetryCount -1 # infinite retries if host is down
|
||||
|
||||
### Encrypt Logs Using TLS ###
|
||||
|
||||
When the security and privacy of your data is a concern, you should consider encrypting your logs. Sniffers and middlemen could read your log data if you transmit it over the Internet in clear text. You should encrypt your logs if they contain private information, sensitive identification data, or government-regulated data. The rsyslog daemon can encrypt your logs using the TLS protocol and keep your data safer.
|
||||
|
||||
To set up TLS encryption, you need to do the following tasks:
|
||||
|
||||
1. Generate a [certificate authority][15] (CA). There are sample certificates in /contrib/gnutls, which are good only for testing, but you need to create your own for production. If you’re using a log management service, it will have one ready for you.
|
||||
1. Generate a [digital certificate][16] for your server to enable SSL operation, or use one from your log management service provider.
|
||||
1. Configure your rsyslog daemon to send TLS-encrypted data to your log management system.
|
||||
|
||||
Here’s an example rsyslog configuration with TLS encryption. Replace CERT and DOMAIN_NAME with your own server setting.
|
||||
|
||||
$DefaultNetstreamDriverCAFile /etc/rsyslog.d/keys/ca.d/CERT.crt
|
||||
$ActionSendStreamDriver gtls
|
||||
$ActionSendStreamDriverMode 1
|
||||
$ActionSendStreamDriverAuthMode x509/name
|
||||
$ActionSendStreamDriverPermittedPeer *.DOMAIN_NAME.com
|
||||
|
||||
### Best Practices for Application Logging ###
|
||||
|
||||
In addition to the logs that Linux creates by default, it’s also a good idea to centralize logs from important applications. Almost all Linux-based server class applications write their status information in separate, dedicated log files. This includes database products like PostgreSQL or MySQL, web servers like Nginx or Apache, firewalls, print and file sharing services, directory and DNS servers and so on.
|
||||
|
||||
The first thing administrators do after installing an application is to configure it. Linux applications typically have a .conf file somewhere within the /etc directory. It can be somewhere else too, but that’s the first place where people look for configuration files.
|
||||
|
||||
Depending on how complex or large the application is, the number of settable parameters can be few or in hundreds. As mentioned before, most applications would write their status in some sort of log file: configuration file is where log settings are defined among other things.
|
||||
|
||||
If you’re not sure where it is, you can use the locate command to find it:
|
||||
|
||||
[root@localhost ~]# locate postgresql.conf
|
||||
/usr/pgsql-9.4/share/postgresql.conf.sample
|
||||
/var/lib/pgsql/9.4/data/postgresql.conf
|
||||
|
||||
#### Set a Standard Location for Log Files ####
|
||||
|
||||
Linux systems typically save their log files under /var/log directory. This works fine, but check if the application saves under a specific directory under /var/log. If it does, great, if not, you may want to create a dedicated directory for the app under /var/log. Why? That’s because other applications save their log files under /var/log too and if your app saves more than one log file – perhaps once every day or after each service restart – it may be a bit difficult to trawl through a large directory to find the file you want.
|
||||
|
||||
If you have the more than one instance of the application running in your network, this approach also comes handy. Think about a situation where you may have a dozen web servers running in your network. When troubleshooting any one of the boxes, you would know exactly where to go.
|
||||
|
||||
#### Use A Standard Filename ####
|
||||
|
||||
Use a standard filename for the latest logs from your application. This makes it easy because you can monitor and tail a single file. Many applications add some sort of date time stamp in them. This makes it much more difficult to find the latest file and to setup file monitoring by rsyslog. A better approach is to add timestamps to older log files using logrotate. This makes them easier to archive and search historically.
|
||||
|
||||
#### Append the Log File ####
|
||||
|
||||
Is the log file going to be overwritten after each application restart? If so, we recommend turning that off. After each restart the app should append to the log file. That way, you can always go back to the last log line before the restart.
|
||||
|
||||
#### Appending vs. Rotation of Log File ####
|
||||
|
||||
Even if the application writes a new log file after each restart, how is it saving in the current log? Is it appending to one single, massive file? Linux systems are not known for frequent reboots or crashes: applications can run for very long periods without even blinking, but that can also make the log file very large. If you are trying to analyze the root cause of a connection failure that happened last week, you could easily be searching through tens of thousands of lines.
|
||||
|
||||
We recommend you configure the application to rotate its log file once every day, say at mid-night.
|
||||
|
||||
Why? Well it becomes manageable for a starter. It’s much easier to find a file name with a specific date time pattern than to search through one file for that date’s entries. Files are also much smaller: you don’t think vi has frozen when you open a log file. Secondly, if you are sending the log file over the wire to a different location – perhaps a nightly backup job copying to a centralized log server – it doesn’t chew up your network’s bandwidth. Third and final, it helps with your log retention. If you want to cull old log entries, it’s easier to delete files older than a particular date than to have an application parsing one single large file.
|
||||
|
||||
#### Retention of Log File ####
|
||||
|
||||
How long do you keep a log file? That definitely comes down to business requirement. You could be asked to keep one week’s worth of logging information, or it may be a regulatory requirement to keep ten years’ worth of data. Whatever it is, logs need to go from the server at one time or other.
|
||||
|
||||
In our opinion, unless otherwise required, keep at least a month’s worth of log files online, plus copy them to a secondary location like a logging server. Anything older than that can be offloaded to a separate media. For example, if you are on AWS, your older logs can be copied to Glacier.
|
||||
|
||||
#### Separate Disk Location for Log Files ####
|
||||
|
||||
Linux best practice usually suggests mounting the /var directory to a separate file system. This is because of the high number of I/Os associated with this directory. We would recommend mounting /var/log directory under a separate disk system. This can save I/O contention with the main application’s data. Also, if the number of log files becomes too large or the single log file becomes too big, it doesn’t fill up the entire disk.
|
||||
|
||||
#### Log Entries ####
|
||||
|
||||
What information should be captured in each log entry?
|
||||
|
||||
That depends on what you want to use the log for. Do you want to use it only for troubleshooting purposes, or do you want to capture everything that’s happening? Is it a legal requirement to capture what each user is running or viewing?
|
||||
|
||||
If you are using logs for troubleshooting purposes, save only errors, warnings or fatal messages. There’s no reason to capture debug messages, for example. The app may log debug messages by default or another administrator might have turned this on for another troubleshooting exercise, but you need to turn this off because it can definitely fill up the space quickly. At a minimum, capture the date, time, client application name, source IP or client host name, action performed and the message itself.
|
||||
|
||||
#### A Practical Example for PostgreSQL ####
|
||||
|
||||
As an example, let’s look at the main configuration file for a vanilla PostgreSQL 9.4 installation. It’s called postgresql.conf and contrary to other config files in Linux systems, it’s not saved under /etc directory. In the code snippet below, we can see it’s in /var/lib/pgsql directory of our CentOS 7 server:
|
||||
|
||||
root@localhost ~]# vi /var/lib/pgsql/9.4/data/postgresql.conf
|
||||
...
|
||||
#------------------------------------------------------------------------------
|
||||
# ERROR REPORTING AND LOGGING
|
||||
#------------------------------------------------------------------------------
|
||||
# - Where to Log -
|
||||
log_destination = 'stderr'
|
||||
# Valid values are combinations of
|
||||
# stderr, csvlog, syslog, and eventlog,
|
||||
# depending on platform. csvlog
|
||||
# requires logging_collector to be on.
|
||||
# This is used when logging to stderr:
|
||||
logging_collector = on
|
||||
# Enable capturing of stderr and csvlog
|
||||
# into log files. Required to be on for
|
||||
# csvlogs.
|
||||
# (change requires restart)
|
||||
# These are only used if logging_collector is on:
|
||||
log_directory = 'pg_log'
|
||||
# directory where log files are written,
|
||||
# can be absolute or relative to PGDATA
|
||||
log_filename = 'postgresql-%a.log' # log file name pattern,
|
||||
# can include strftime() escapes
|
||||
# log_file_mode = 0600 .
|
||||
# creation mode for log files,
|
||||
# begin with 0 to use octal notation
|
||||
log_truncate_on_rotation = on # If on, an existing log file with the
|
||||
# same name as the new log file will be
|
||||
# truncated rather than appended to.
|
||||
# But such truncation only occurs on
|
||||
# time-driven rotation, not on restarts
|
||||
# or size-driven rotation. Default is
|
||||
# off, meaning append to existing files
|
||||
# in all cases.
|
||||
log_rotation_age = 1d
|
||||
# Automatic rotation of logfiles will happen after that time. 0 disables.
|
||||
log_rotation_size = 0 # Automatic rotation of logfiles will happen after that much log output. 0 disables.
|
||||
# These are relevant when logging to syslog:
|
||||
#syslog_facility = 'LOCAL0'
|
||||
#syslog_ident = 'postgres'
|
||||
# This is only relevant when logging to eventlog (win32):
|
||||
#event_source = 'PostgreSQL'
|
||||
# - When to Log -
|
||||
#client_min_messages = notice # values in order of decreasing detail:
|
||||
# debug5
|
||||
# debug4
|
||||
# debug3
|
||||
# debug2
|
||||
# debug1
|
||||
# log
|
||||
# notice
|
||||
# warning
|
||||
# error
|
||||
#log_min_messages = warning # values in order of decreasing detail:
|
||||
# debug5
|
||||
# debug4
|
||||
# debug3
|
||||
# debug2
|
||||
# debug1
|
||||
# info
|
||||
# notice
|
||||
# warning
|
||||
# error
|
||||
# log
|
||||
# fatal
|
||||
# panic
|
||||
#log_min_error_statement = error # values in order of decreasing detail:
|
||||
# debug5
|
||||
# debug4
|
||||
# debug3
|
||||
# debug2
|
||||
# debug1
|
||||
# info
|
||||
# notice
|
||||
# warning
|
||||
# error
|
||||
# log
|
||||
# fatal
|
||||
# panic (effectively off)
|
||||
#log_min_duration_statement = -1 # -1 is disabled, 0 logs all statements
|
||||
# and their durations, > 0 logs only
|
||||
# statements running at least this number
|
||||
# of milliseconds
|
||||
# - What to Log
|
||||
#debug_print_parse = off
|
||||
#debug_print_rewritten = off
|
||||
#debug_print_plan = off
|
||||
#debug_pretty_print = on
|
||||
#log_checkpoints = off
|
||||
#log_connections = off
|
||||
#log_disconnections = off
|
||||
#log_duration = off
|
||||
#log_error_verbosity = default
|
||||
# terse, default, or verbose messages
|
||||
#log_hostname = off
|
||||
log_line_prefix = '< %m >' # special values:
|
||||
# %a = application name
|
||||
# %u = user name
|
||||
# %d = database name
|
||||
# %r = remote host and port
|
||||
# %h = remote host
|
||||
# %p = process ID
|
||||
# %t = timestamp without milliseconds
|
||||
# %m = timestamp with milliseconds
|
||||
# %i = command tag
|
||||
# %e = SQL state
|
||||
# %c = session ID
|
||||
# %l = session line number
|
||||
# %s = session start timestamp
|
||||
# %v = virtual transaction ID
|
||||
# %x = transaction ID (0 if none)
|
||||
# %q = stop here in non-session
|
||||
# processes
|
||||
# %% = '%'
|
||||
# e.g. '<%u%%%d> '
|
||||
#log_lock_waits = off # log lock waits >= deadlock_timeout
|
||||
#log_statement = 'none' # none, ddl, mod, all
|
||||
#log_temp_files = -1 # log temporary files equal or larger
|
||||
# than the specified size in kilobytes;5# -1 disables, 0 logs all temp files5
|
||||
log_timezone = 'Australia/ACT'
|
||||
|
||||
Although most parameters are commented out, they assume default values. We can see the log file directory is pg_log (log_directory parameter), the file names should start with postgresql (log_filename parameter), the files are rotated once every day (log_rotation_age parameter) and the log entries start with a timestamp (log_line_prefix parameter). Of particular interest is the log_line_prefix parameter: there is a whole gamut of information you can include there.
|
||||
|
||||
Looking under /var/lib/pgsql/9.4/data/pg_log directory shows us these files:
|
||||
|
||||
[root@localhost ~]# ls -l /var/lib/pgsql/9.4/data/pg_log
|
||||
total 20
|
||||
-rw-------. 1 postgres postgres 1212 May 1 20:11 postgresql-Fri.log
|
||||
-rw-------. 1 postgres postgres 243 Feb 9 21:49 postgresql-Mon.log
|
||||
-rw-------. 1 postgres postgres 1138 Feb 7 11:08 postgresql-Sat.log
|
||||
-rw-------. 1 postgres postgres 1203 Feb 26 21:32 postgresql-Thu.log
|
||||
-rw-------. 1 postgres postgres 326 Feb 10 01:20 postgresql-Tue.log
|
||||
|
||||
So the log files only have the name of the weekday stamped in the file name. We can change it. How? Configure the log_filename parameter in postgresql.conf.
|
||||
|
||||
Looking inside one log file shows its entries start with date time only:
|
||||
|
||||
[root@localhost ~]# cat /var/lib/pgsql/9.4/data/pg_log/postgresql-Fri.log
|
||||
...
|
||||
< 2015-02-27 01:21:27.020 EST >LOG: received fast shutdown request
|
||||
< 2015-02-27 01:21:27.025 EST >LOG: aborting any active transactions
|
||||
< 2015-02-27 01:21:27.026 EST >LOG: autovacuum launcher shutting down
|
||||
< 2015-02-27 01:21:27.036 EST >LOG: shutting down
|
||||
< 2015-02-27 01:21:27.211 EST >LOG: database system is shut down
|
||||
|
||||
### Centralizing Application Logs ###
|
||||
|
||||
#### Log File Monitoring with Imfile ####
|
||||
|
||||
Traditionally, the most common way for applications to log their data is with files. Files are easy to search on a single machine but don’t scale well with more servers. You can set up log file monitoring and send the events to a centralized server when new logs are appended to the bottom. Create a new configuration file in /etc/rsyslog.d/ then add a file input like this:
|
||||
|
||||
$ModLoad imfile
|
||||
$InputFilePollInterval 10
|
||||
$PrivDropToGroup adm
|
||||
|
||||
----------
|
||||
|
||||
# Input for FILE1
|
||||
$InputFileName /FILE1
|
||||
$InputFileTag APPNAME1
|
||||
$InputFileStateFile stat-APPNAME1 #this must be unique for each file being polled
|
||||
$InputFileSeverity info
|
||||
$InputFilePersistStateInterval 20000
|
||||
$InputRunFileMonitor
|
||||
|
||||
Replace FILE1 and APPNAME1 with your own file and application names. Rsyslog will send it to the outputs you have configured.
|
||||
|
||||
#### Local Socket Logs with Imuxsock ####
|
||||
|
||||
A socket is similar to a UNIX file handle except that the socket is read into memory by your syslog daemon and then sent to the destination. No file needs to be written. As an example, the logger command sends its logs to this UNIX socket.
|
||||
|
||||
This approach makes efficient use of system resources if your server is constrained by disk I/O or you have no need for local file logs. The disadvantage of this approach is that the socket has a limited queue size. If your syslog daemon goes down or can’t keep up, then you could lose log data.
|
||||
|
||||
The rsyslog daemon will read from the /dev/log socket by default, but you can specifically enable it with the [imuxsock input module][17] using the following command:
|
||||
|
||||
$ModLoad imuxsock
|
||||
|
||||
#### UDP Logs with Imupd ####
|
||||
|
||||
Some applications output log data in UDP format, which is the standard syslog protocol when transferring log files over a network or your localhost. Your syslog daemon receives these logs and can process them or transmit them in a different format. Alternately, you can send the logs to your log server or to a log management solution.
|
||||
|
||||
Use the following command to configure rsyslog to accept syslog data over UDP on the standard port 514:
|
||||
|
||||
$ModLoad imudp
|
||||
|
||||
----------
|
||||
|
||||
$UDPServerRun 514
|
||||
|
||||
### Manage Logs with Logrotate ###
|
||||
|
||||
Log rotation is a process that archives log files automatically when they reach a specified age. Without intervention, log files keep growing, using up disk space. Eventually they will crash your machine.
|
||||
|
||||
The logrotate utility can truncate your logs as they age, freeing up space. Your new log file retains the filename. Your old log file is renamed with a number appended to the end of it. Each time the logrotate utility runs, a new file is created and the existing file is renamed in sequence. You determine the threshold when old files are deleted or archived.
|
||||
|
||||
When logrotate copies a file, the new file has a new inode, which can interfere with rsyslog’s ability to monitor the new file. You can alleviate this issue by adding the copytruncate parameter to your logrotate cron job. This parameter copies existing log file contents to a new file and truncates these contents from the existing file. The inode never changes because the log file itself remains the same; its contents are in a new file.
|
||||
|
||||
The logrotate utility uses the main configuration file at /etc/logrotate.conf and application-specific settings in the directory /etc/logrotate.d/. DigitalOcean has a detailed [tutorial on logrotate][18].
|
||||
|
||||
### Manage Configuration on Many Servers ###
|
||||
|
||||
When you have just a few servers, you can manually configure logging on them. Once you have a few dozen or more servers, you can take advantage of tools that make this easier and more scalable. At a basic level, all of these copy your rsyslog configuration to each server, and then restart rsyslog so the changes take effect.
|
||||
|
||||
#### Pssh ####
|
||||
|
||||
This tool lets you run an ssh command on several servers in parallel. Use a pssh deployment for only a small number of servers. If one of your servers fails, then you have to ssh into the failed server and do the deployment manually. If you have several failed servers, then the manual deployment on them can take a long time.
|
||||
|
||||
#### Puppet/Chef ####
|
||||
|
||||
Puppet and Chef are two different tools that can automatically configure all of the servers in your network to a specified standard. Their reporting tools let you know about failures and can resync periodically. Both Puppet and Chef have enthusiastic supporters. If you aren’t sure which one is more suitable for your deployment configuration management, you might appreciate [InfoWorld’s comparison of the two tools][19].
|
||||
|
||||
Some vendors also offer modules or recipes for configuring rsyslog. Here is an example from Loggly’s Puppet module. It offers a class for rsyslog to which you can add an identifying token:
|
||||
|
||||
node 'my_server_node.example.net' {
|
||||
# Send syslog events to Loggly
|
||||
class { 'loggly::rsyslog':
|
||||
customer_token => 'de7b5ccd-04de-4dc4-fbc9-501393600000',
|
||||
}
|
||||
}
|
||||
|
||||
#### Docker ####
|
||||
|
||||
Docker uses containers to run applications independent of the underlying server. Everything runs from inside a container, which you can think of as a unit of functionality. ZDNet has an in-depth article about [using Docker][20] in your data center.
|
||||
|
||||
There are several ways to log from Docker containers including linking to a logging container, logging to a shared volume, or adding a syslog agent directly inside the container. One of the most popular logging containers is called [logspout][21].
|
||||
|
||||
#### Vendor Scripts or Agents ####
|
||||
|
||||
Most log management solutions offer scripts or agents to make sending data from one or more servers relatively easy. Heavyweight agents can use up extra system resources. Some vendors like Loggly offer configuration scripts to make using existing syslog daemons easier. Here is an example [script][22] from Loggly which can run on any number of servers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.loggly.com/ultimate-guide/logging/managing-linux-logs/
|
||||
|
||||
作者:[Jason Skowronski][a1]
|
||||
作者:[Amy Echeverri][a2]
|
||||
作者:[Sadequl Hussain][a3]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a1]:https://www.linkedin.com/in/jasonskowronski
|
||||
[a2]:https://www.linkedin.com/in/amyecheverri
|
||||
[a3]:https://www.linkedin.com/pub/sadequl-hussain/14/711/1a7
|
||||
[1]:https://docs.google.com/document/d/11LXZxWlkNSHkcrCWTUdnLRf_CiZz9kK0cr3yGM_BU_0/edit#heading=h.esrreycnpnbl
|
||||
[2]:http://www.rsyslog.com/
|
||||
[3]:http://www.balabit.com/network-security/syslog-ng/opensource-logging-system
|
||||
[4]:http://logstash.net/
|
||||
[5]:http://www.fluentd.org/
|
||||
[6]:http://www.rsyslog.com/doc/rsyslog_conf.html
|
||||
[7]:http://www.rsyslog.com/doc/master/rainerscript/index.html
|
||||
[8]:https://docs.google.com/document/d/11LXZxWlkNSHkcrCWTUdnLRf_CiZz9kK0cr3yGM_BU_0/edit#heading=h.eck7acdxin87
|
||||
[9]:https://www.loggly.com/docs/file-monitoring/
|
||||
[10]:http://www.networksorcery.com/enp/protocol/udp.htm
|
||||
[11]:http://www.networksorcery.com/enp/protocol/tcp.htm
|
||||
[12]:http://blog.gerhards.net/2008/04/on-unreliability-of-plain-tcp-syslog.html
|
||||
[13]:http://www.rsyslog.com/doc/relp.html
|
||||
[14]:http://www.rsyslog.com/doc/queues.html
|
||||
[15]:http://www.rsyslog.com/doc/tls_cert_ca.html
|
||||
[16]:http://www.rsyslog.com/doc/tls_cert_machine.html
|
||||
[17]:http://www.rsyslog.com/doc/v8-stable/configuration/modules/imuxsock.html
|
||||
[18]:https://www.digitalocean.com/community/tutorials/how-to-manage-log-files-with-logrotate-on-ubuntu-12-10
|
||||
[19]:http://www.infoworld.com/article/2614204/data-center/puppet-or-chef--the-configuration-management-dilemma.html
|
||||
[20]:http://www.zdnet.com/article/what-is-docker-and-why-is-it-so-darn-popular/
|
||||
[21]:https://github.com/progrium/logspout
|
||||
[22]:https://www.loggly.com/docs/sending-logs-unixlinux-system-setup/
|
||||
@ -1,3 +1,5 @@
|
||||
Vic020
|
||||
|
||||
Linux Tricks: Play Game in Chrome, Text-to-Speech, Schedule a Job and Watch Commands in Linux
|
||||
================================================================================
|
||||
Here again, I have compiled a list of four things under [Linux Tips and Tricks][1] series you may do to remain more productive and entertained with Linux Environment.
|
||||
@ -140,4 +142,4 @@ via: http://www.tecmint.com/text-to-speech-in-terminal-schedule-a-job-and-watch-
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/tag/linux-tricks/
|
||||
[2]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
[2]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
translating wi-cuckoo
|
||||
Howto Run JBoss Data Virtualization GA with OData in Docker Container
|
||||
================================================================================
|
||||
Hi everyone, today we'll learn how to run JBoss Data Virtualization 6.0.0.GA with OData in a Docker Container. JBoss Data Virtualization is a data supply and integration solution platform that transforms various scatered multiple sources data, treats them as single source and delivers the required data into actionable information at business speed to any applications or users. JBoss Data Virtualization can help us easily combine and transform data into reusable business friendly data models and make unified data easily consumable through open standard interfaces. It offers comprehensive data abstraction, federation, integration, transformation, and delivery capabilities to combine data from one or multiple sources into reusable for agile data utilization and sharing.For more information about JBoss Data Virtualization, we can check out [its official page][1]. Docker is an open source platform that provides an open platform to pack, ship and run any application as a lightweight container. Running JBoss Data Virtualization with OData in Docker Container makes us easy to handle and launch.
|
||||
@ -99,4 +100,4 @@ via: http://linoxide.com/linux-how-to/run-jboss-data-virtualization-ga-odata-doc
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.redhat.com/en/technologies/jboss-middleware/data-virtualization
|
||||
[2]:https://github.com/jbossdemocentral/dv-odata-docker-integration-demo
|
||||
[3]:http://www.jboss.org/products/datavirt/download/
|
||||
[3]:http://www.jboss.org/products/datavirt/download/
|
||||
|
||||
@ -1,164 +0,0 @@
|
||||
DongShuaike is translating.
|
||||
|
||||
Linux and Unix Test Disk I/O Performance With dd Command
|
||||
================================================================================
|
||||
How can I use dd command on a Linux to test I/O performance of my hard disk drive? How do I check the performance of a hard drive including the read and write speed on a Linux operating systems?
|
||||
|
||||
You can use the following commands on a Linux or Unix-like systems for simple I/O performance test:
|
||||
|
||||
- **dd command** : It is used to monitor the writing performance of a disk device on a Linux and Unix-like system
|
||||
- **hdparm command** : It is used to get/set hard disk parameters including test the reading and caching performance of a disk device on a Linux based system.
|
||||
|
||||
In this tutorial you will learn how to use the dd command to test disk I/O performance.
|
||||
|
||||
### Use dd command to monitor the reading and writing performance of a disk device: ###
|
||||
|
||||
- Open a shell prompt.
|
||||
- Or login to a remote server via ssh.
|
||||
- Use the dd command to measure server throughput (write speed) `dd if=/dev/zero of=/tmp/test1.img bs=1G count=1 oflag=dsync`
|
||||
- Use the dd command to measure server latency `dd if=/dev/zero of=/tmp/test2.img bs=512 count=1000 oflag=dsync`
|
||||
|
||||
#### Understanding dd command options ####
|
||||
|
||||
In this example, I'm using RAID-10 (Adaptec 5405Z with SAS SSD) array running on a Ubuntu Linux 14.04 LTS server. The basic syntax is
|
||||
|
||||
dd if=/dev/input.file of=/path/to/output.file bs=block-size count=number-of-blocks oflag=dsync
|
||||
## GNU dd syntax ##
|
||||
dd if=/dev/zero of=/tmp/test1.img bs=1G count=1 oflag=dsync
|
||||
## OR alternate syntax for GNU/dd ##
|
||||
dd if=/dev/zero of=/tmp/testALT.img bs=1G count=1 conv=fdatasync
|
||||
|
||||
Sample outputs:
|
||||
|
||||

|
||||
Fig.01: Ubuntu Linux Server with RAID10 and testing server throughput with dd
|
||||
|
||||
Please note that one gigabyte was written for the test and 135 MB/s was server throughput for this test. Where,
|
||||
|
||||
- `if=/dev/zero (if=/dev/input.file)` : The name of the input file you want dd the read from.
|
||||
- `of=/tmp/test1.img (of=/path/to/output.file)` : The name of the output file you want dd write the input.file to.
|
||||
- `bs=1G (bs=block-size)` : Set the size of the block you want dd to use. 1 gigabyte was written for the test.
|
||||
- `count=1 (count=number-of-blocks)`: The number of blocks you want dd to read.
|
||||
- `oflag=dsync (oflag=dsync)` : Use synchronized I/O for data. Do not skip this option. This option get rid of caching and gives you good and accurate results
|
||||
- `conv=fdatasyn`: Again, this tells dd to require a complete "sync" once, right before it exits. This option is equivalent to oflag=dsync.
|
||||
|
||||
In this example, 512 bytes were written one thousand times to get RAID10 server latency time:
|
||||
|
||||
dd if=/dev/zero of=/tmp/test2.img bs=512 count=1000 oflag=dsync
|
||||
|
||||
Sample outputs:
|
||||
|
||||
1000+0 records in
|
||||
1000+0 records out
|
||||
512000 bytes (512 kB) copied, 0.60362 s, 848 kB/s
|
||||
|
||||
Please note that server throughput and latency time depends upon server/application load too. So I recommend that you run these tests on a newly rebooted server as well as peak time to get better idea about your workload. You can now compare these numbers with all your devices.
|
||||
|
||||
#### But why the server throughput and latency time are so low? ####
|
||||
|
||||
Low values does not mean you are using slow hardware. The value can be low because of the HARDWARE RAID10 controller's cache.
|
||||
|
||||
Use hdparm command to see buffered and cached disk read speed
|
||||
|
||||
I suggest you run the following commands 2 or 3 times Perform timings of device reads for benchmark and comparison purposes:
|
||||
|
||||
### Buffered disk read test for /dev/sda ##
|
||||
hdparm -t /dev/sda1
|
||||
## OR ##
|
||||
hdparm -t /dev/sda
|
||||
|
||||
To perform timings of cache reads for benchmark and comparison purposes again run the following command 2-3 times (note the -T option):
|
||||
|
||||
## Cache read benchmark for /dev/sda ###
|
||||
hdparm -T /dev/sda1
|
||||
## OR ##
|
||||
hdparm -T /dev/sda
|
||||
|
||||
OR combine both tests:
|
||||
|
||||
hdparm -Tt /dev/sda
|
||||
|
||||
Sample outputs:
|
||||
|
||||
|
||||
Fig.02: Linux hdparm command to test reading and caching disk performance
|
||||
|
||||
Again note that due to filesystems caching on file operations, you will always see high read rates.
|
||||
|
||||
**Use dd command on Linux to test read speed**
|
||||
|
||||
To get accurate read test data, first discard caches before testing by running the following commands:
|
||||
|
||||
flush
|
||||
echo 3 | sudo tee /proc/sys/vm/drop_caches
|
||||
time time dd if=/path/to/bigfile of=/dev/null bs=8k
|
||||
|
||||
**Linux Laptop example**
|
||||
|
||||
Run the following command:
|
||||
|
||||
### Debian Laptop Throughput With Cache ##
|
||||
dd if=/dev/zero of=/tmp/laptop.bin bs=1G count=1 oflag=direct
|
||||
|
||||
### Deactivate the cache ###
|
||||
hdparm -W0 /dev/sda
|
||||
|
||||
### Debian Laptop Throughput Without Cache ##
|
||||
dd if=/dev/zero of=/tmp/laptop.bin bs=1G count=1 oflag=direct
|
||||
|
||||
**Apple OS X Unix (Macbook pro) example**
|
||||
|
||||
GNU dd has many more options but OS X/BSD and Unix-like dd command need to run as follows to test real disk I/O and not memory add sync option as follows:
|
||||
|
||||
## Run command 2-3 times to get good results ###
|
||||
time sh -c "dd if=/dev/zero of=/tmp/testfile bs=100k count=1k && sync"
|
||||
|
||||
Sample outputs:
|
||||
|
||||
1024+0 records in
|
||||
1024+0 records out
|
||||
104857600 bytes transferred in 0.165040 secs (635346520 bytes/sec)
|
||||
|
||||
real 0m0.241s
|
||||
user 0m0.004s
|
||||
sys 0m0.113s
|
||||
|
||||
So I'm getting 635346520 bytes (635.347 MB/s) write speed on my MBP.
|
||||
|
||||
**Not a fan of command line...?**
|
||||
|
||||
You can use disk utility (gnome-disk-utility) on a Linux or Unix based system to get the same information. The following screenshot is taken from my Fedora Linux v22 VM.
|
||||
|
||||
**Graphical method**
|
||||
|
||||
Click on the "Activities" or press the "Super" key to switch between the Activities overview and desktop. Type "Disks"
|
||||
|
||||
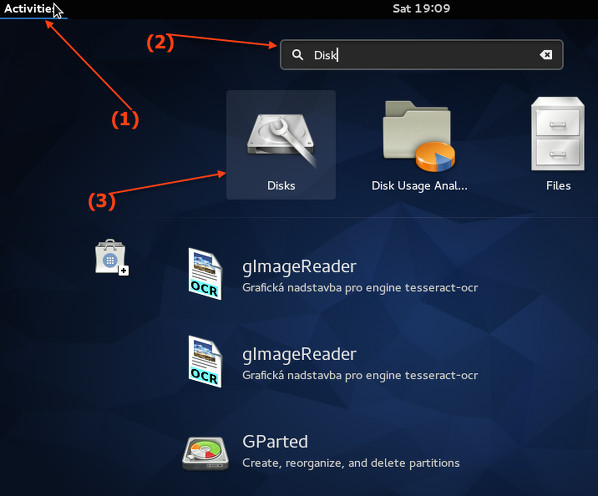
|
||||
Fig.03: Start the Gnome disk utility
|
||||
|
||||
Select your hard disk at left pane and click on configure button and click on "Benchmark partition":
|
||||
|
||||
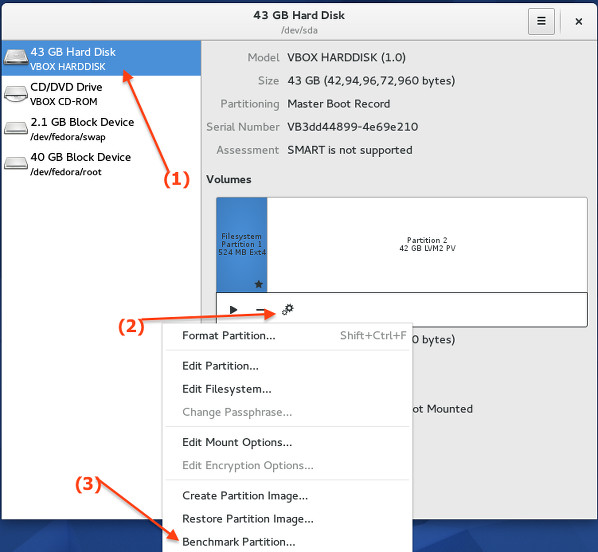
|
||||
Fig.04: Benchmark disk/partition
|
||||
|
||||
Finally, click on the "Start Benchmark..." button (you may be promoted for the admin username and password):
|
||||
|
||||
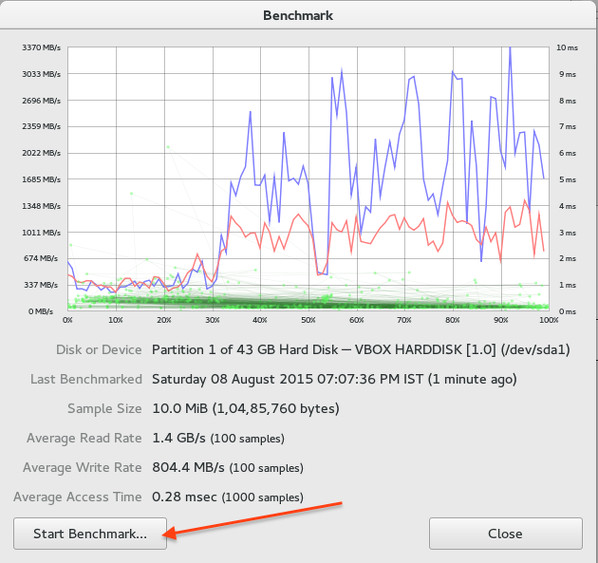
|
||||
Fig.05: Final benchmark result
|
||||
|
||||
Which method and command do you recommend to use?
|
||||
|
||||
- I recommend dd command on all Unix-like systems (`time sh -c "dd if=/dev/zero of=/tmp/testfile bs=100k count=1k && sync`"
|
||||
- If you are using GNU/Linux use the dd command (`dd if=/dev/zero of=/tmp/testALT.img bs=1G count=1 conv=fdatasync`)
|
||||
- Make sure you adjust count and bs arguments as per your setup to get a good set of result.
|
||||
- The GUI method is recommended only for Linux/Unix laptop users running Gnome2 or 3 desktop.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/howto-linux-unix-test-disk-performance-with-dd-command/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,187 @@
|
||||
translation by strugglingyouth
|
||||
How to migrate MySQL to MariaDB on Linux
|
||||
================================================================================
|
||||
Since the Oracle's acquisition of MySQL, a lot of MySQL developers and users moved away from MySQL due to Oracle's more closed-door stance on MySQL development and maintenance. The community-driven outcome of such movement is a fork of MySQL, called MariaDB. Led by original MySQL developers, the development of MariaDB follows the open-source philosophy and makes sure of [its binary compatibility with MySQL][1]. The Linux distributions such as Red Hat families (Fedora, CentOS, RHEL), Ubuntu and Mint, openSUSE and Debian already started to use and support MariaDB as a drop-in replacement of MySQL.
|
||||
|
||||
If you want to migrate your database from MySQL to MariaDB, this article is what you are looking for. Fortunately, due to their binary compatibility, MySQL-to-MariaDB migration process is pretty much straightforward. If you follow the steps below, the migration from MySQL to MariaDB will most likely be painless.
|
||||
|
||||
### Prepare a MySQL Database and a Table ###
|
||||
|
||||
For demonstration purpose, let's create a test MySQL database and one table in the database before doing the migration. Skip this step if you already have existing MySQL database(s) to migrate to MariaDB. Otherwise proceed as follows.
|
||||
|
||||
Log in into MySQL from a terminal by typing your MySQL root user password.
|
||||
|
||||
$ mysql -u root -p
|
||||
|
||||
Create a database and a table.
|
||||
|
||||
mysql> create database test01;
|
||||
mysql> use test01;
|
||||
mysql> create table pet(name varchar(30), owner varchar(30), species varchar(20), sex char(1));
|
||||
|
||||
Add some records to the table.
|
||||
|
||||
mysql> insert into pet values('brandon','Jack','puddle','m'),('dixie','Danny','chihuahua','f');
|
||||
|
||||
Then quit the MySQL database.
|
||||
|
||||
### Backup the MySQL Database ###
|
||||
|
||||
The next step is to back up existing MySQL database(s). Use the following mysqldump command to export all existing databases to a file. Before running this command, make sure that binary logging is enabled in your MySQL server. If you don't know how to enable binary logging, see the instructions toward the end of the tutorial.
|
||||
|
||||
$ mysqldump --all-databases --user=root --password --master-data > backupdb.sql
|
||||
|
||||
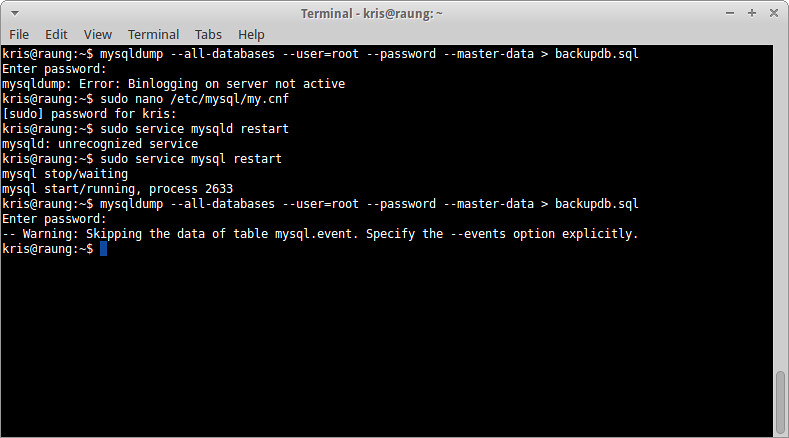
|
||||
|
||||
Now create a backup of my.cnf file somewhere in your system before uninstalling MySQL. This step is optional.
|
||||
|
||||
$ sudo cp /etc/mysql/my.cnf /opt/my.cnf.bak
|
||||
|
||||
### Uninstall MySQL Package ###
|
||||
|
||||
First, you need to stop the MySQL service.
|
||||
|
||||
$ sudo service mysql stop
|
||||
|
||||
or:
|
||||
|
||||
$ sudo systemctl stop mysql
|
||||
|
||||
or:
|
||||
|
||||
$ sudo /etc/init.d/mysql stop
|
||||
|
||||
Then go ahead and remove MySQL packages and configurations as follows.
|
||||
|
||||
On RPM based system (e.g., CentOS, Fedora or RHEL):
|
||||
|
||||
$ sudo yum remove mysql* mysql-server mysql-devel mysql-libs
|
||||
$ sudo rm -rf /var/lib/mysql
|
||||
|
||||
On Debian based system (e.g., Debian, Ubuntu or Mint):
|
||||
|
||||
$ sudo apt-get remove mysql-server mysql-client mysql-common
|
||||
$ sudo apt-get autoremove
|
||||
$ sudo apt-get autoclean
|
||||
$ sudo deluser mysql
|
||||
$ sudo rm -rf /var/lib/mysql
|
||||
|
||||
### Install MariaDB Package ###
|
||||
|
||||
The latest CentOS/RHEL 7 and Ubuntu (14.04 or later) contain MariaDB packages in their official repositories. In Fedora, MariaDB has become a replacement of MySQL since version 19. If you are using an old version or LTS type like Ubuntu 13.10 or earlier, you still can install MariaDB by adding its official repository.
|
||||
|
||||
[MariaDB website][2] provide an online tool to help you add MariaDB's official repository according to your Linux distribution. This tool provides steps to add the MariaDB repository for openSUSE, Arch Linux, Mageia, Fedora, CentOS, RedHat, Mint, Ubuntu, and Debian.
|
||||
|
||||

|
||||
|
||||
As an example, let's use the Ubuntu 14.04 distribution and CentOS 7 to configure the MariaDB repository.
|
||||
|
||||
**Ubuntu 14.04**
|
||||
|
||||
$ sudo apt-get install software-properties-common
|
||||
$ sudo apt-key adv --recv-keys --keyserver hkp://keyserver.ubuntu.com:80 0xcbcb082a1bb943db
|
||||
$ sudo add-apt-repository 'deb http://mirror.mephi.ru/mariadb/repo/5.5/ubuntu trusty main'
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install mariadb-server
|
||||
|
||||
**CentOS 7**
|
||||
|
||||
Create a custom yum repository file for MariaDB as follows.
|
||||
|
||||
$ sudo vi /etc/yum.repos.d/MariaDB.repo
|
||||
|
||||
----------
|
||||
|
||||
[mariadb]
|
||||
name = MariaDB
|
||||
baseurl = http://yum.mariadb.org/5.5/centos7-amd64
|
||||
gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
|
||||
gpgcheck=1
|
||||
|
||||
----------
|
||||
|
||||
$ sudo yum install MariaDB-server MariaDB-client
|
||||
|
||||
After all necessary packages are installed, you may be asked to type a new password for root user account. After setting the root password, don't forget to recover my.cnf backup file.
|
||||
|
||||
$ sudo cp /opt/my.cnf /etc/mysql/
|
||||
|
||||
Now start MariaDB service as follows.
|
||||
|
||||
$ sudo service mariadb start
|
||||
|
||||
or:
|
||||
|
||||
$ sudo systemctl start mariadb
|
||||
|
||||
or:
|
||||
|
||||
$ sudo /etc/init.d/mariadb start
|
||||
|
||||
### Importing MySQL Database(s) ###
|
||||
|
||||
Finally, we have to import the previously exported database(s) back to MariaDB server as follows.
|
||||
|
||||
$ mysql -u root -p < backupdb.sql
|
||||
|
||||
Enter your MariaDB's root password, and the database import process will start. When the import process is finished, it will return to a command prompt.
|
||||
|
||||
To check whether or not the import process is completed successfully, log in into MariaDB server and perform some sample queries.
|
||||
|
||||
$ mysql -u root -p
|
||||
|
||||
----------
|
||||
|
||||
MariaDB [(none)]> show databases;
|
||||
MariaDB [(none)]> use test01;
|
||||
MariaDB [test01]> select * from pet;
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
As you can see in this tutorial, MySQL-to-MariaDB migration is not difficult. MariaDB has a lot of new features than MySQL, that you should know about. As far as configuration is concerned, in my test case, I simply used my old MySQL configuration file (my.cnf) as a MariaDB configuration file, and the import process was completed fine without any issue. My suggestion for the configuration is that you read the documentation on MariaDB configuration options carefully before the migration, especially if you are using specific MySQL configurations.
|
||||
|
||||
If you are running more complex setup with tons of tables and databases including clustering or master-slave replication, take a look at the [more detailed guide][3] by the Mozilla IT and Operations team, or the [official MariaDB documentation][4].
|
||||
|
||||
### Troubleshooting ###
|
||||
|
||||
1. While running mysqldump command to back up databases, you are getting the following error.
|
||||
|
||||
$ mysqldump --all-databases --user=root --password --master-data > backupdb.sql
|
||||
|
||||
----------
|
||||
|
||||
mysqldump: Error: Binlogging on server not active
|
||||
|
||||
By using "--master-data", you are trying to include binary log information in the exported output, which is useful for database replication and recovery. However, binary logging is not enabled in MySQL server. To fix this error, modify your my.cnf file, and add the following option under [mysqld] section.
|
||||
|
||||
log-bin=mysql-bin
|
||||
|
||||
Save my.cnf file, and restart the MySQL service:
|
||||
|
||||
$ sudo service mysql restart
|
||||
|
||||
or:
|
||||
|
||||
$ sudo systemctl restart mysql
|
||||
|
||||
or:
|
||||
|
||||
$ sudo /etc/init.d/mysql restart
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/migrate-mysql-to-mariadb-linux.html
|
||||
|
||||
作者:[Kristophorus Hadiono][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/kristophorus
|
||||
[1]:https://mariadb.com/kb/en/mariadb/mariadb-vs-mysql-compatibility/
|
||||
[2]:https://downloads.mariadb.org/mariadb/repositories/#mirror=aasaam
|
||||
[3]:https://blog.mozilla.org/it/2013/12/16/upgrading-from-mysql-5-1-to-mariadb-5-5/
|
||||
[4]:https://mariadb.com/kb/en/mariadb/documentation/
|
||||
@ -1,228 +0,0 @@
|
||||
Translating by ictlyh
|
||||
Part 1 - RHCE Series: How to Setup and Test Static Network Routing
|
||||
================================================================================
|
||||
RHCE (Red Hat Certified Engineer) is a certification from Red Hat company, which gives an open source operating system and software to the enterprise community, It also gives training, support and consulting services for the companies.
|
||||
|
||||

|
||||
|
||||
RHCE Exam Preparation Guide
|
||||
|
||||
This RHCE (Red Hat Certified Engineer) is a performance-based exam (codename EX300), who possesses the additional skills, knowledge, and abilities required of a senior system administrator responsible for Red Hat Enterprise Linux (RHEL) systems.
|
||||
|
||||
**Important**: [Red Hat Certified System Administrator][1] (RHCSA) certification is required to earn RHCE certification.
|
||||
|
||||
Following are the exam objectives based on the Red Hat Enterprise Linux 7 version of the exam, which will going to cover in this RHCE series:
|
||||
|
||||
- Part 1: How to Setup and Test Static Routing in RHEL 7
|
||||
- Part 2: How to Perform Packet Filtering, Network Address Translation and Set Kernel Runtime Parameters
|
||||
- Part 3: How to Produce and Deliver System Activity Reports Using Linux Toolsets
|
||||
- Part 4: Automate System Maintenance Tasks Using Shell Scripts
|
||||
- Part 5: How to Configure Local and Remote System Logging
|
||||
- Part 6: How to Configure a Samba Server and a NFS Server
|
||||
- Part 7: Setting Up Complete SMTP Server for Mailing
|
||||
- Part 8: Setting Up HTTPS and TLS on RHEL 7
|
||||
- Part 9: Setting Up Network Time Protocol
|
||||
- Part 10: How to Configure a Cache-Only DNS Server
|
||||
|
||||
To view fees and register for an exam in your country, check the [RHCE Certification][2] page.
|
||||
|
||||
In this Part 1 of the RHCE series and the next, we will present basic, yet typical, cases where the principles of static routing, packet filtering, and network address translation come into play.
|
||||
|
||||

|
||||
|
||||
RHCE: Setup and Test Network Static Routing – Part 1
|
||||
|
||||
Please note that we will not cover them in depth, but rather organize these contents in such a way that will be helpful to take the first steps and build from there.
|
||||
|
||||
### Static Routing in Red Hat Enterprise Linux 7 ###
|
||||
|
||||
One of the wonders of modern networking is the vast availability of devices that can connect groups of computers, whether in relatively small numbers and confined to a single room or several machines in the same building, city, country, or across continents.
|
||||
|
||||
However, in order to effectively accomplish this in any situation, network packets need to be routed, or in other words, the path they follow from source to destination must be ruled somehow.
|
||||
|
||||
Static routing is the process of specifying a route for network packets other than the default, which is provided by a network device known as the default gateway. Unless specified otherwise through static routing, network packets are directed to the default gateway; with static routing, other paths are defined based on predefined criteria, such as the packet destination.
|
||||
|
||||
Let us define the following scenario for this tutorial. We have a Red Hat Enterprise Linux 7 box connecting to router #1 [192.168.0.1] to access the Internet and machines in 192.168.0.0/24.
|
||||
|
||||
A second router (router #2) has two network interface cards: enp0s3 is also connected to router #1 to access the Internet and to communicate with the RHEL 7 box and other machines in the same network, whereas the other (enp0s8) is used to grant access to the 10.0.0.0/24 network where internal services reside, such as a web and / or database server.
|
||||
|
||||
This scenario is illustrated in the diagram below:
|
||||
|
||||

|
||||
|
||||
Static Routing Network Diagram
|
||||
|
||||
In this article we will focus exclusively on setting up the routing table on our RHEL 7 box to make sure that it can both access the Internet through router #1 and the internal network via router #2.
|
||||
|
||||
In RHEL 7, you will use the [ip command][3] to configure and show devices and routing using the command line. These changes can take effect immediately on a running system but since they are not persistent across reboots, we will use ifcfg-enp0sX and route-enp0sX files inside /etc/sysconfig/network-scripts to save our configuration permanently.
|
||||
|
||||
To begin, let’s print our current routing table:
|
||||
|
||||
# ip route show
|
||||
|
||||

|
||||
|
||||
Check Current Routing Table
|
||||
|
||||
From the output above, we can see the following facts:
|
||||
|
||||
- The default gateway’s IP address is 192.168.0.1 and can be accessed via the enp0s3 NIC.
|
||||
- When the system booted up, it enabled the zeroconf route to 169.254.0.0/16 (just in case). In few words, if a machine is set to obtain an IP address through DHCP but fails to do so for some reason, it is automatically assigned an address in this network. Bottom line is, this route will allow us to communicate, also via enp0s3, with other machines who have failed to obtain an IP address from a DHCP server.
|
||||
- Last, but not least, we can communicate with other boxes inside the 192.168.0.0/24 network through enp0s3, whose IP address is 192.168.0.18.
|
||||
|
||||
These are the typical tasks that you would have to perform in such a setting. Unless specified otherwise, the following tasks should be performed in router #2:
|
||||
|
||||
Make sure all NICs have been properly installed:
|
||||
|
||||
# ip link show
|
||||
|
||||
If one of them is down, bring it up:
|
||||
|
||||
# ip link set dev enp0s8 up
|
||||
|
||||
and assign an IP address in the 10.0.0.0/24 network to it:
|
||||
|
||||
# ip addr add 10.0.0.17 dev enp0s8
|
||||
|
||||
Oops! We made a mistake in the IP address. We will have to remove the one we assigned earlier and then add the right one (10.0.0.18):
|
||||
|
||||
# ip addr del 10.0.0.17 dev enp0s8
|
||||
# ip addr add 10.0.0.18 dev enp0s8
|
||||
|
||||
Now, please note that you can only add a route to a destination network through a gateway that is itself already reachable. For that reason, we need to assign an IP address within the 192.168.0.0/24 range to enp0s3 so that our RHEL 7 box can communicate with it:
|
||||
|
||||
# ip addr add 192.168.0.19 dev enp0s3
|
||||
|
||||
Finally, we will need to enable packet forwarding:
|
||||
|
||||
# echo "1" > /proc/sys/net/ipv4/ip_forward
|
||||
|
||||
and stop / disable (just for the time being – until we cover packet filtering in the next article) the firewall:
|
||||
|
||||
# systemctl stop firewalld
|
||||
# systemctl disable firewalld
|
||||
|
||||
Back in our RHEL 7 box (192.168.0.18), let’s configure a route to 10.0.0.0/24 through 192.168.0.19 (enp0s3 in router #2):
|
||||
|
||||
# ip route add 10.0.0.0/24 via 192.168.0.19
|
||||
|
||||
After that, the routing table looks as follows:
|
||||
|
||||
# ip route show
|
||||
|
||||

|
||||
|
||||
Confirm Network Routing Table
|
||||
|
||||
Likewise, add the corresponding route in the machine(s) you’re trying to reach in 10.0.0.0/24:
|
||||
|
||||
# ip route add 192.168.0.0/24 via 10.0.0.18
|
||||
|
||||
You can test for basic connectivity using ping:
|
||||
|
||||
In the RHEL 7 box, run
|
||||
|
||||
# ping -c 4 10.0.0.20
|
||||
|
||||
where 10.0.0.20 is the IP address of a web server in the 10.0.0.0/24 network.
|
||||
|
||||
In the web server (10.0.0.20), run
|
||||
|
||||
# ping -c 192.168.0.18
|
||||
|
||||
where 192.168.0.18 is, as you will recall, the IP address of our RHEL 7 machine.
|
||||
|
||||
Alternatively, we can use [tcpdump][4] (you may need to install it with yum install tcpdump) to check the 2-way communication over TCP between our RHEL 7 box and the web server at 10.0.0.20.
|
||||
|
||||
To do so, let’s start the logging in the first machine with:
|
||||
|
||||
# tcpdump -qnnvvv -i enp0s3 host 10.0.0.20
|
||||
|
||||
and from another terminal in the same system let’s telnet to port 80 in the web server (assuming Apache is listening on that port; otherwise, indicate the right port in the following command):
|
||||
|
||||
# telnet 10.0.0.20 80
|
||||
|
||||
The tcpdump log should look as follows:
|
||||
|
||||

|
||||
|
||||
Check Network Communication between Servers
|
||||
|
||||
Where the connection has been properly initialized, as we can tell by looking at the 2-way communication between our RHEL 7 box (192.168.0.18) and the web server (10.0.0.20).
|
||||
|
||||
Please remember that these changes will go away when you restart the system. If you want to make them persistent, you will need to edit (or create, if they don’t already exist) the following files, in the same systems where we performed the above commands.
|
||||
|
||||
Though not strictly necessary for our test case, you should know that /etc/sysconfig/network contains system-wide network parameters. A typical /etc/sysconfig/network looks as follows:
|
||||
|
||||
# Enable networking on this system?
|
||||
NETWORKING=yes
|
||||
# Hostname. Should match the value in /etc/hostname
|
||||
HOSTNAME=yourhostnamehere
|
||||
# Default gateway
|
||||
GATEWAY=XXX.XXX.XXX.XXX
|
||||
# Device used to connect to default gateway. Replace X with the appropriate number.
|
||||
GATEWAYDEV=enp0sX
|
||||
|
||||
When it comes to setting specific variables and values for each NIC (as we did for router #2), you will have to edit /etc/sysconfig/network-scripts/ifcfg-enp0s3 and /etc/sysconfig/network-scripts/ifcfg-enp0s8.
|
||||
|
||||
Following our case,
|
||||
|
||||
TYPE=Ethernet
|
||||
BOOTPROTO=static
|
||||
IPADDR=192.168.0.19
|
||||
NETMASK=255.255.255.0
|
||||
GATEWAY=192.168.0.1
|
||||
NAME=enp0s3
|
||||
ONBOOT=yes
|
||||
|
||||
and
|
||||
|
||||
TYPE=Ethernet
|
||||
BOOTPROTO=static
|
||||
IPADDR=10.0.0.18
|
||||
NETMASK=255.255.255.0
|
||||
GATEWAY=10.0.0.1
|
||||
NAME=enp0s8
|
||||
ONBOOT=yes
|
||||
|
||||
for enp0s3 and enp0s8, respectively.
|
||||
|
||||
As for routing in our client machine (192.168.0.18), we will need to edit /etc/sysconfig/network-scripts/route-enp0s3:
|
||||
|
||||
10.0.0.0/24 via 192.168.0.19 dev enp0s3
|
||||
|
||||
Now reboot your system and you should see that route in your table.
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this article we have covered the essentials of static routing in Red Hat Enterprise Linux 7. Although scenarios may vary, the case presented here illustrates the required principles and the procedures to perform this task. Before wrapping up, I would like to suggest you to take a look at [Chapter 4][5] of the Securing and Optimizing Linux section in The Linux Documentation Project site for further details on the topics covered here.
|
||||
|
||||
Free ebook on Securing & Optimizing Linux: The Hacking Solution (v.3.0) – This 800+ eBook contains comprehensive collection of Linux security tips and how to use them safely and easily to configure Linux-based applications and services.
|
||||
|
||||

|
||||
|
||||
Linux Security and Optimization Book
|
||||
|
||||
[Download Now][6]
|
||||
|
||||
In the next article we will talk about packet filtering and network address translation to sum up the networking basic skills needed for the RHCE certification.
|
||||
|
||||
As always, we look forward to hearing from you, so feel free to leave your questions, comments, and suggestions using the form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/how-to-setup-and-configure-static-network-routing-in-rhel/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
[2]:https://www.redhat.com/en/services/certification/rhce
|
||||
[3]:http://www.tecmint.com/ip-command-examples/
|
||||
[4]:http://www.tecmint.com/12-tcpdump-commands-a-network-sniffer-tool/
|
||||
[5]:http://www.tldp.org/LDP/solrhe/Securing-Optimizing-Linux-RH-Edition-v1.3/net-manage.html
|
||||
[6]:http://tecmint.tradepub.com/free/w_opeb01/prgm.cgi
|
||||
@ -1,178 +0,0 @@
|
||||
Translating by ictlyh
|
||||
Part 2 - How to Perform Packet Filtering, Network Address Translation and Set Kernel Runtime Parameters
|
||||
================================================================================
|
||||
As promised in Part 1 (“[Setup Static Network Routing][1]”), in this article (Part 2 of RHCE series) we will begin by introducing the principles of packet filtering and network address translation (NAT) in Red Hat Enterprise Linux 7, before diving into setting runtime kernel parameters to modify the behavior of a running kernel if certain conditions change or needs arise.
|
||||
|
||||

|
||||
|
||||
RHCE: Network Packet Filtering – Part 2
|
||||
|
||||
### Network Packet Filtering in RHEL 7 ###
|
||||
|
||||
When we talk about packet filtering, we refer to a process performed by a firewall in which it reads the header of each data packet that attempts to pass through it. Then, it filters the packet by taking the required action based on rules that have been previously defined by the system administrator.
|
||||
|
||||
As you probably know, beginning with RHEL 7, the default service that manages firewall rules is [firewalld][2]. Like iptables, it talks to the netfilter module in the Linux kernel in order to examine and manipulate network packets. Unlike iptables, updates can take effect immediately without interrupting active connections – you don’t even have to restart the service.
|
||||
|
||||
Another advantage of firewalld is that it allows us to define rules based on pre-configured service names (more on that in a minute).
|
||||
|
||||
In Part 1, we used the following scenario:
|
||||
|
||||

|
||||
|
||||
Static Routing Network Diagram
|
||||
|
||||
However, you will recall that we disabled the firewall on router #2 to simplify the example since we had not covered packet filtering yet. Let’s see now how we can enable incoming packets destined for a specific service or port in the destination.
|
||||
|
||||
First, let’s add a permanent rule to allow inbound traffic in enp0s3 (192.168.0.19) to enp0s8 (10.0.0.18):
|
||||
|
||||
# firewall-cmd --permanent --direct --add-rule ipv4 filter FORWARD 0 -i enp0s3 -o enp0s8 -j ACCEPT
|
||||
|
||||
The above command will save the rule to /etc/firewalld/direct.xml:
|
||||
|
||||
# cat /etc/firewalld/direct.xml
|
||||
|
||||

|
||||
|
||||
Check Firewalld Saved Rules
|
||||
|
||||
Then enable the rule for it to take effect immediately:
|
||||
|
||||
# firewall-cmd --direct --add-rule ipv4 filter FORWARD 0 -i enp0s3 -o enp0s8 -j ACCEPT
|
||||
|
||||
Now you can telnet to the web server from the RHEL 7 box and run [tcpdump][3] again to monitor the TCP traffic between the two machines, this time with the firewall in router #2 enabled.
|
||||
|
||||
# telnet 10.0.0.20 80
|
||||
# tcpdump -qnnvvv -i enp0s3 host 10.0.0.20
|
||||
|
||||
What if you want to only allow incoming connections to the web server (port 80) from 192.168.0.18 and block connections from other sources in the 192.168.0.0/24 network?
|
||||
|
||||
In the web server’s firewall, add the following rules:
|
||||
|
||||
# firewall-cmd --add-rich-rule 'rule family="ipv4" source address="192.168.0.18/24" service name="http" accept'
|
||||
# firewall-cmd --add-rich-rule 'rule family="ipv4" source address="192.168.0.18/24" service name="http" accept' --permanent
|
||||
# firewall-cmd --add-rich-rule 'rule family="ipv4" source address="192.168.0.0/24" service name="http" drop'
|
||||
# firewall-cmd --add-rich-rule 'rule family="ipv4" source address="192.168.0.0/24" service name="http" drop' --permanent
|
||||
|
||||
Now you can make HTTP requests to the web server, from 192.168.0.18 and from some other machine in 192.168.0.0/24. In the first case the connection should complete successfully, whereas in the second it will eventually timeout.
|
||||
|
||||
To do so, any of the following commands will do the trick:
|
||||
|
||||
# telnet 10.0.0.20 80
|
||||
# wget 10.0.0.20
|
||||
|
||||
I strongly advise you to check out the [Firewalld Rich Language][4] documentation in the Fedora Project Wiki for further details on rich rules.
|
||||
|
||||
### Network Address Translation in RHEL 7 ###
|
||||
|
||||
Network Address Translation (NAT) is the process where a group of computers (it can also be just one of them) in a private network are assigned an unique public IP address. As result, they are still uniquely identified by their own private IP address inside the network but to the outside they all “seem” the same.
|
||||
|
||||
In addition, NAT makes it possible that computers inside a network sends requests to outside resources (like the Internet) and have the corresponding responses be sent back to the source system only.
|
||||
|
||||
Let’s now consider the following scenario:
|
||||
|
||||

|
||||
|
||||
Network Address Translation
|
||||
|
||||
In router #2, we will move the enp0s3 interface to the external zone, and enp0s8 to the internal zone, where masquerading, or NAT, is enabled by default:
|
||||
|
||||
# firewall-cmd --list-all --zone=external
|
||||
# firewall-cmd --change-interface=enp0s3 --zone=external
|
||||
# firewall-cmd --change-interface=enp0s3 --zone=external --permanent
|
||||
# firewall-cmd --change-interface=enp0s8 --zone=internal
|
||||
# firewall-cmd --change-interface=enp0s8 --zone=internal --permanent
|
||||
|
||||
For our current setup, the internal zone – along with everything that is enabled in it will be the default zone:
|
||||
|
||||
# firewall-cmd --set-default-zone=internal
|
||||
|
||||
Next, let’s reload firewall rules and keep state information:
|
||||
|
||||
# firewall-cmd --reload
|
||||
|
||||
Finally, let’s add router #2 as default gateway in the web server:
|
||||
|
||||
# ip route add default via 10.0.0.18
|
||||
|
||||
You can now verify that you can ping router #1 and an external site (tecmint.com, for example) from the web server:
|
||||
|
||||
# ping -c 2 192.168.0.1
|
||||
# ping -c 2 tecmint.com
|
||||
|
||||

|
||||
|
||||
Verify Network Routing
|
||||
|
||||
### Setting Kernel Runtime Parameters in RHEL 7 ###
|
||||
|
||||
In Linux, you are allowed to change, enable, and disable the kernel runtime parameters, and RHEL is no exception. The /proc/sys interface (sysctl) lets you set runtime parameters on-the-fly to modify the system’s behavior without much hassle when operating conditions change.
|
||||
|
||||
To do so, the echo shell built-in is used to write to files inside /proc/sys/<category>, where <category> is most likely one of the following directories:
|
||||
|
||||
- dev: parameters for specific devices connected to the machine.
|
||||
- fs: filesystem configuration (quotas and inodes, for example).
|
||||
- kernel: kernel-specific configuration.
|
||||
- net: network configuration.
|
||||
- vm: use of the kernel’s virtual memory.
|
||||
|
||||
To display the list of all the currently available values, run
|
||||
|
||||
# sysctl -a | less
|
||||
|
||||
In Part 1, we changed the value of the net.ipv4.ip_forward parameter by doing
|
||||
|
||||
# echo 1 > /proc/sys/net/ipv4/ip_forward
|
||||
|
||||
in order to allow a Linux machine to act as router.
|
||||
|
||||
Another runtime parameter that you may want to set is kernel.sysrq, which enables the Sysrq key in your keyboard to instruct the system to perform gracefully some low-level functions, such as rebooting the system if it has frozen for some reason:
|
||||
|
||||
# echo 1 > /proc/sys/kernel/sysrq
|
||||
|
||||
To display the value of a specific parameter, use sysctl as follows:
|
||||
|
||||
# sysctl <parameter.name>
|
||||
|
||||
For example,
|
||||
|
||||
# sysctl net.ipv4.ip_forward
|
||||
# sysctl kernel.sysrq
|
||||
|
||||
Some parameters, such as the ones mentioned above, require only one value, whereas others (for example, fs.inode-state) require multiple values:
|
||||
|
||||

|
||||
|
||||
Check Kernel Parameters
|
||||
|
||||
In either case, you need to read the kernel’s documentation before making any changes.
|
||||
|
||||
Please note that these settings will go away when the system is rebooted. To make these changes permanent, we will need to add .conf files inside the /etc/sysctl.d as follows:
|
||||
|
||||
# echo "net.ipv4.ip_forward = 1" > /etc/sysctl.d/10-forward.conf
|
||||
|
||||
(where the number 10 indicates the order of processing relative to other files in the same directory).
|
||||
|
||||
and enable the changes with
|
||||
|
||||
# sysctl -p /etc/sysctl.d/10-forward.conf
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this tutorial we have explained the basics of packet filtering, network address translation, and setting kernel runtime parameters on a running system and persistently across reboots. I hope you have found this information useful, and as always, we look forward to hearing from you!
|
||||
Don’t hesitate to share with us your questions, comments, or suggestions using the form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/perform-packet-filtering-network-address-translation-and-set-kernel-runtime-parameters-in-rhel/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/how-to-setup-and-configure-static-network-routing-in-rhel/
|
||||
[2]:http://www.tecmint.com/firewalld-rules-for-centos-7/
|
||||
[3]:http://www.tecmint.com/12-tcpdump-commands-a-network-sniffer-tool/
|
||||
[4]:https://fedoraproject.org/wiki/Features/FirewalldRichLanguage
|
||||
@ -1,183 +0,0 @@
|
||||
Translating by ictlyh
|
||||
Part 3 - How to Produce and Deliver System Activity Reports Using Linux Toolsets
|
||||
================================================================================
|
||||
As a system engineer, you will often need to produce reports that show the utilization of your system’s resources in order to make sure that: 1) they are being utilized optimally, 2) prevent bottlenecks, and 3) ensure scalability, among other reasons.
|
||||
|
||||

|
||||
|
||||
RHCE: Monitor Linux Performance Activity Reports – Part 3
|
||||
|
||||
Besides the well-known native Linux tools that are used to check disk, memory, and CPU usage – to name a few examples, Red Hat Enterprise Linux 7 provides two additional toolsets to enhance the data you can collect for your reports: sysstat and dstat.
|
||||
|
||||
In this article we will describe both, but let’s first start by reviewing the usage of the classic tools.
|
||||
|
||||
### Native Linux Tools ###
|
||||
|
||||
With df, you will be able to report disk space and inode usage of by filesystem. You need to monitor both because a lack of space will prevent you from being able to save further files (and may even cause the system to crash), just like running out of inodes will mean you can’t link further files with their corresponding data structures, thus producing the same effect: you won’t be able to save those files to disk.
|
||||
|
||||
# df -h [Display output in human-readable form]
|
||||
# df -h --total [Produce a grand total]
|
||||
|
||||
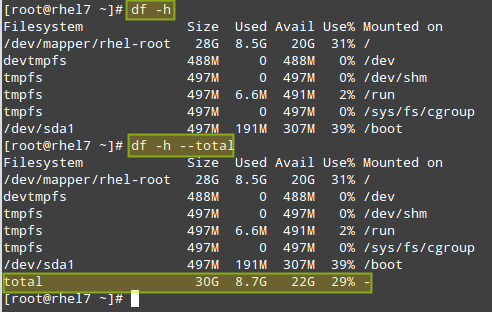
|
||||
|
||||
Check Linux Total Disk Usage
|
||||
|
||||
# df -i [Show inode count by filesystem]
|
||||
# df -i --total [Produce a grand total]
|
||||
|
||||

|
||||
|
||||
Check Linux Total inode Numbers
|
||||
|
||||
With du, you can estimate file space usage by either file, directory, or filesystem.
|
||||
|
||||
For example, let’s see how much space is used by the /home directory, which includes all of the user’s personal files. The first command will return the overall space currently used by the entire /home directory, whereas the second will also display a disaggregated list by sub-directory as well:
|
||||
|
||||
# du -sch /home
|
||||
# du -sch /home/*
|
||||
|
||||

|
||||
|
||||
Check Linux Directory Disk Size
|
||||
|
||||
Don’t Miss:
|
||||
|
||||
- [12 ‘df’ Command Examples to Check Linux Disk Space Usage][1]
|
||||
- [10 ‘du’ Command Examples to Find Disk Usage of Files/Directories][2]
|
||||
|
||||
Another utility that can’t be missing from your toolset is vmstat. It will allow you to see at a quick glance information about processes, CPU and memory usage, disk activity, and more.
|
||||
|
||||
If run without arguments, vmstat will return averages since the last reboot. While you may use this form of the command once in a while, it will be more helpful to take a certain amount of system utilization samples, one after another, with a defined time separation between samples.
|
||||
|
||||
For example,
|
||||
|
||||
# vmstat 5 10
|
||||
|
||||
will return 10 samples taken every 5 seconds:
|
||||
|
||||

|
||||
|
||||
Check Linux System Performance
|
||||
|
||||
As you can see in the above picture, the output of vmstat is divided by columns: procs (processes), memory, swap, io, system, and cpu. The meaning of each field can be found in the FIELD DESCRIPTION sections in the man page of vmstat.
|
||||
|
||||
Where can vmstat come in handy? Let’s examine the behavior of the system before and during a yum update:
|
||||
|
||||
# vmstat -a 1 5
|
||||
|
||||

|
||||
|
||||
Vmstat Linux Performance Monitoring
|
||||
|
||||
Please note that as files are being modified on disk, the amount of active memory increases and so does the number of blocks written to disk (bo) and the CPU time that is dedicated to user processes (us).
|
||||
|
||||
Or during the saving process of a large file directly to disk (caused by dsync):
|
||||
|
||||
# vmstat -a 1 5
|
||||
# dd if=/dev/zero of=dummy.out bs=1M count=1000 oflag=dsync
|
||||
|
||||

|
||||
|
||||
VmStat Linux Disk Performance Monitoring
|
||||
|
||||
In this case, we can see a yet larger number of blocks being written to disk (bo), which was to be expected, but also an increase of the amount of CPU time that it has to wait for I/O operations to complete before processing tasks (wa).
|
||||
|
||||
**Don’t Miss**: [Vmstat – Linux Performance Monitoring][3]
|
||||
|
||||
### Other Linux Tools ###
|
||||
|
||||
As mentioned in the introduction of this chapter, there are other tools that you can use to check the system status and utilization (they are not only provided by Red Hat but also by other major distributions from their officially supported repositories).
|
||||
|
||||
The sysstat package contains the following utilities:
|
||||
|
||||
- sar (collect, report, or save system activity information).
|
||||
- sadf (display data collected by sar in multiple formats).
|
||||
- mpstat (report processors related statistics).
|
||||
- iostat (report CPU statistics and I/O statistics for devices and partitions).
|
||||
- pidstat (report statistics for Linux tasks).
|
||||
- nfsiostat (report input/output statistics for NFS).
|
||||
- cifsiostat (report CIFS statistics) and
|
||||
- sa1 (collect and store binary data in the system activity daily data file.
|
||||
- sa2 (write a daily report in the /var/log/sa directory) tools.
|
||||
|
||||
whereas dstat adds some extra features to the functionality provided by those tools, along with more counters and flexibility. You can find an overall description of each tool by running yum info sysstat or yum info dstat, respectively, or checking the individual man pages after installation.
|
||||
|
||||
To install both packages:
|
||||
|
||||
# yum update && yum install sysstat dstat
|
||||
|
||||
The main configuration file for sysstat is /etc/sysconfig/sysstat. You will find the following parameters in that file:
|
||||
|
||||
# How long to keep log files (in days).
|
||||
# If value is greater than 28, then log files are kept in
|
||||
# multiple directories, one for each month.
|
||||
HISTORY=28
|
||||
# Compress (using gzip or bzip2) sa and sar files older than (in days):
|
||||
COMPRESSAFTER=31
|
||||
# Parameters for the system activity data collector (see sadc manual page)
|
||||
# which are used for the generation of log files.
|
||||
SADC_OPTIONS="-S DISK"
|
||||
# Compression program to use.
|
||||
ZIP="bzip2"
|
||||
|
||||
When sysstat is installed, two cron jobs are added and enabled in /etc/cron.d/sysstat. The first job runs the system activity accounting tool every 10 minutes and stores the reports in /var/log/sa/saXX where XX is the day of the month.
|
||||
|
||||
Thus, /var/log/sa/sa05 will contain all the system activity reports from the 5th of the month. This assumes that we are using the default value in the HISTORY variable in the configuration file above:
|
||||
|
||||
*/10 * * * * root /usr/lib64/sa/sa1 1 1
|
||||
|
||||
The second job generates a daily summary of process accounting at 11:53 pm every day and stores it in /var/log/sa/sarXX files, where XX has the same meaning as in the previous example:
|
||||
|
||||
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||
|
||||
For example, you may want to output system statistics from 9:30 am through 5:30 pm of the sixth of the month to a .csv file that can easily be viewed using LibreOffice Calc or Microsoft Excel (this approach will also allow you to create charts or graphs):
|
||||
|
||||
# sadf -s 09:30:00 -e 17:30:00 -dh /var/log/sa/sa06 -- | sed 's/;/,/g' > system_stats20150806.csv
|
||||
|
||||
You could alternatively use the -j flag instead of -d in the sadf command above to output the system stats in JSON format, which could be useful if you need to consume the data in a web application, for example.
|
||||
|
||||

|
||||
|
||||
Linux System Statistics
|
||||
|
||||
Finally, let’s see what dstat has to offer. Please note that if run without arguments, dstat assumes -cdngy by default (short for CPU, disk, network, memory pages, and system stats, respectively), and adds one line every second (execution can be interrupted anytime with Ctrl + C):
|
||||
|
||||
# dstat
|
||||
|
||||

|
||||
|
||||
Linux Disk Statistics Monitoring
|
||||
|
||||
To output the stats to a .csv file, use the –output flag followed by a file name. Let’s see how this looks on LibreOffice Calc:
|
||||
|
||||

|
||||
|
||||
Monitor Linux Statistics Output
|
||||
|
||||
I strongly advise you to check out the man page of dstat, included with this article along with the man page of sysstat in PDF format for your reading convenience. You will find several other options that will help you create custom and detailed system activity reports.
|
||||
|
||||
**Don’t Miss**: [Sysstat – Linux Usage Activity Monitoring Tool][4]
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this guide we have explained how to use both native Linux tools and specific utilities provided with RHEL 7 in order to produce reports on system utilization. At one point or another, you will come to rely on these reports as best friends.
|
||||
|
||||
You will probably have used other tools that we have not covered in this tutorial. If so, feel free to share them with the rest of the community along with any other suggestions / questions / comments that you may have- using the form below.
|
||||
|
||||
We look forward to hearing from you.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-performance-monitoring-and-file-system-statistics-reports/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/how-to-check-disk-space-in-linux/
|
||||
[2]:http://www.tecmint.com/check-linux-disk-usage-of-files-and-directories/
|
||||
[3]:http://www.tecmint.com/linux-performance-monitoring-with-vmstat-and-iostat-commands/
|
||||
[4]:http://www.tecmint.com/install-sysstat-in-linux/
|
||||
@ -0,0 +1,207 @@
|
||||
Part 4 - Using Shell Scripting to Automate Linux System Maintenance Tasks
|
||||
================================================================================
|
||||
Some time ago I read that one of the distinguishing characteristics of an effective system administrator / engineer is laziness. It seemed a little contradictory at first but the author then proceeded to explain why:
|
||||
|
||||

|
||||
|
||||
RHCE Series: Automate Linux System Maintenance Tasks – Part 4
|
||||
|
||||
if a sysadmin spends most of his time solving issues and doing repetitive tasks, you can suspect he or she is not doing things quite right. In other words, an effective system administrator / engineer should develop a plan to perform repetitive tasks with as less action on his / her part as possible, and should foresee problems by using,
|
||||
|
||||
for example, the tools reviewed in Part 3 – [Monitor System Activity Reports Using Linux Toolsets][1] of this series. Thus, although he or she may not seem to be doing much, it’s because most of his / her responsibilities have been taken care of with the help of shell scripting, which is what we’re going to talk about in this tutorial.
|
||||
|
||||
### What is a shell script? ###
|
||||
|
||||
In few words, a shell script is nothing more and nothing less than a program that is executed step by step by a shell, which is another program that provides an interface layer between the Linux kernel and the end user.
|
||||
|
||||
By default, the shell used for user accounts in RHEL 7 is bash (/bin/bash). If you want a detailed description and some historical background, you can refer to [this Wikipedia article][2].
|
||||
|
||||
To find out more about the enormous set of features provided by this shell, you may want to check out its **man page**, which is downloaded in in PDF format at ([Bash Commands][3]). Other than that, it is assumed that you are familiar with Linux commands (if not, I strongly advise you to go through [A Guide from Newbies to SysAdmin][4] article in **Tecmint.com** before proceeding). Now let’s get started.
|
||||
|
||||
### Writing a script to display system information ###
|
||||
|
||||
For our convenience, let’s create a directory to store our shell scripts:
|
||||
|
||||
# mkdir scripts
|
||||
# cd scripts
|
||||
|
||||
And open a new text file named `system_info.sh` with your preferred text editor. We will begin by inserting a few comments at the top and some commands afterwards:
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
# Sample script written for Part 4 of the RHCE series
|
||||
# This script will return the following set of system information:
|
||||
# -Hostname information:
|
||||
echo -e "\e[31;43m***** HOSTNAME INFORMATION *****\e[0m"
|
||||
hostnamectl
|
||||
echo ""
|
||||
# -File system disk space usage:
|
||||
echo -e "\e[31;43m***** FILE SYSTEM DISK SPACE USAGE *****\e[0m"
|
||||
df -h
|
||||
echo ""
|
||||
# -Free and used memory in the system:
|
||||
echo -e "\e[31;43m ***** FREE AND USED MEMORY *****\e[0m"
|
||||
free
|
||||
echo ""
|
||||
# -System uptime and load:
|
||||
echo -e "\e[31;43m***** SYSTEM UPTIME AND LOAD *****\e[0m"
|
||||
uptime
|
||||
echo ""
|
||||
# -Logged-in users:
|
||||
echo -e "\e[31;43m***** CURRENTLY LOGGED-IN USERS *****\e[0m"
|
||||
who
|
||||
echo ""
|
||||
# -Top 5 processes as far as memory usage is concerned
|
||||
echo -e "\e[31;43m***** TOP 5 MEMORY-CONSUMING PROCESSES *****\e[0m"
|
||||
ps -eo %mem,%cpu,comm --sort=-%mem | head -n 6
|
||||
echo ""
|
||||
echo -e "\e[1;32mDone.\e[0m"
|
||||
|
||||
Next, give the script execute permissions:
|
||||
|
||||
# chmod +x system_info.sh
|
||||
|
||||
and run it:
|
||||
|
||||
./system_info.sh
|
||||
|
||||
Note that the headers of each section are shown in color for better visualization:
|
||||
|
||||
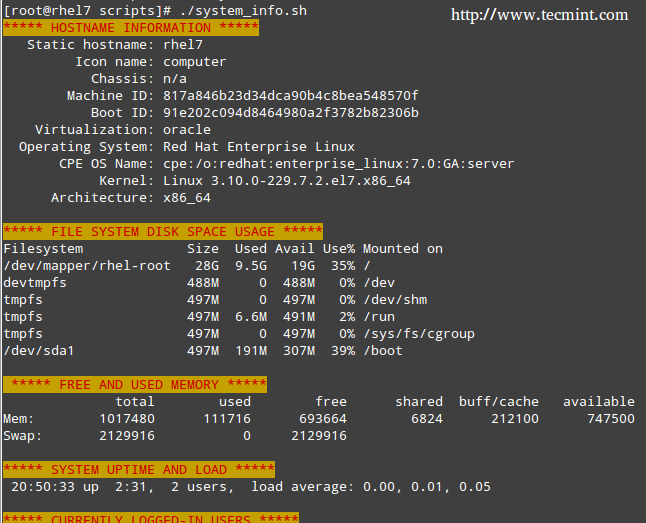
|
||||
|
||||
Server Monitoring Shell Script
|
||||
|
||||
That functionality is provided by this command:
|
||||
|
||||
echo -e "\e[COLOR1;COLOR2m<YOUR TEXT HERE>\e[0m"
|
||||
|
||||
Where COLOR1 and COLOR2 are the foreground and background colors, respectively (more info and options are explained in this entry from the [Arch Linux Wiki][5]) and <YOUR TEXT HERE> is the string that you want to show in color.
|
||||
|
||||
### Automating Tasks ###
|
||||
|
||||
The tasks that you may need to automate may vary from case to case. Thus, we cannot possibly cover all of the possible scenarios in a single article, but we will present three classic tasks that can be automated using shell scripting:
|
||||
|
||||
**1)** update the local file database, 2) find (and alternatively delete) files with 777 permissions, and 3) alert when filesystem usage surpasses a defined limit.
|
||||
|
||||
Let’s create a file named `auto_tasks.sh` in our scripts directory with the following content:
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
# Sample script to automate tasks:
|
||||
# -Update local file database:
|
||||
echo -e "\e[4;32mUPDATING LOCAL FILE DATABASE\e[0m"
|
||||
updatedb
|
||||
if [ $? == 0 ]; then
|
||||
echo "The local file database was updated correctly."
|
||||
else
|
||||
echo "The local file database was not updated correctly."
|
||||
fi
|
||||
echo ""
|
||||
|
||||
# -Find and / or delete files with 777 permissions.
|
||||
echo -e "\e[4;32mLOOKING FOR FILES WITH 777 PERMISSIONS\e[0m"
|
||||
# Enable either option (comment out the other line), but not both.
|
||||
# Option 1: Delete files without prompting for confirmation. Assumes GNU version of find.
|
||||
#find -type f -perm 0777 -delete
|
||||
# Option 2: Ask for confirmation before deleting files. More portable across systems.
|
||||
find -type f -perm 0777 -exec rm -i {} +;
|
||||
echo ""
|
||||
# -Alert when file system usage surpasses a defined limit
|
||||
echo -e "\e[4;32mCHECKING FILE SYSTEM USAGE\e[0m"
|
||||
THRESHOLD=30
|
||||
while read line; do
|
||||
# This variable stores the file system path as a string
|
||||
FILESYSTEM=$(echo $line | awk '{print $1}')
|
||||
# This variable stores the use percentage (XX%)
|
||||
PERCENTAGE=$(echo $line | awk '{print $5}')
|
||||
# Use percentage without the % sign.
|
||||
USAGE=${PERCENTAGE%?}
|
||||
if [ $USAGE -gt $THRESHOLD ]; then
|
||||
echo "The remaining available space in $FILESYSTEM is critically low. Used: $PERCENTAGE"
|
||||
fi
|
||||
done < <(df -h --total | grep -vi filesystem)
|
||||
|
||||
Please note that there is a space between the two `<` signs in the last line of the script.
|
||||
|
||||

|
||||
|
||||
Shell Script to Find 777 Permissions
|
||||
|
||||
### Using Cron ###
|
||||
|
||||
To take efficiency one step further, you will not want to sit in front of your computer and run those scripts manually. Rather, you will use cron to schedule those tasks to run on a periodic basis and sends the results to a predefined list of recipients via email or save them to a file that can be viewed using a web browser.
|
||||
|
||||
The following script (filesystem_usage.sh) will run the well-known **df -h** command, format the output into a HTML table and save it in the **report.html** file:
|
||||
|
||||
#!/bin/bash
|
||||
# Sample script to demonstrate the creation of an HTML report using shell scripting
|
||||
# Web directory
|
||||
WEB_DIR=/var/www/html
|
||||
# A little CSS and table layout to make the report look a little nicer
|
||||
echo "<HTML>
|
||||
<HEAD>
|
||||
<style>
|
||||
.titulo{font-size: 1em; color: white; background:#0863CE; padding: 0.1em 0.2em;}
|
||||
table
|
||||
{
|
||||
border-collapse:collapse;
|
||||
}
|
||||
table, td, th
|
||||
{
|
||||
border:1px solid black;
|
||||
}
|
||||
</style>
|
||||
<meta http-equiv='Content-Type' content='text/html; charset=UTF-8' />
|
||||
</HEAD>
|
||||
<BODY>" > $WEB_DIR/report.html
|
||||
# View hostname and insert it at the top of the html body
|
||||
HOST=$(hostname)
|
||||
echo "Filesystem usage for host <strong>$HOST</strong><br>
|
||||
Last updated: <strong>$(date)</strong><br><br>
|
||||
<table border='1'>
|
||||
<tr><th class='titulo'>Filesystem</td>
|
||||
<th class='titulo'>Size</td>
|
||||
<th class='titulo'>Use %</td>
|
||||
</tr>" >> $WEB_DIR/report.html
|
||||
# Read the output of df -h line by line
|
||||
while read line; do
|
||||
echo "<tr><td align='center'>" >> $WEB_DIR/report.html
|
||||
echo $line | awk '{print $1}' >> $WEB_DIR/report.html
|
||||
echo "</td><td align='center'>" >> $WEB_DIR/report.html
|
||||
echo $line | awk '{print $2}' >> $WEB_DIR/report.html
|
||||
echo "</td><td align='center'>" >> $WEB_DIR/report.html
|
||||
echo $line | awk '{print $5}' >> $WEB_DIR/report.html
|
||||
echo "</td></tr>" >> $WEB_DIR/report.html
|
||||
done < <(df -h | grep -vi filesystem)
|
||||
echo "</table></BODY></HTML>" >> $WEB_DIR/report.html
|
||||
|
||||
In our **RHEL 7** server (**192.168.0.18**), this looks as follows:
|
||||
|
||||
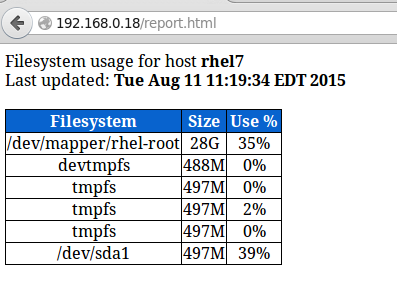
|
||||
|
||||
Server Monitoring Report
|
||||
|
||||
You can add to that report as much information as you want. To run the script every day at 1:30 pm, add the following crontab entry:
|
||||
|
||||
30 13 * * * /root/scripts/filesystem_usage.sh
|
||||
|
||||
### Summary ###
|
||||
|
||||
You will most likely think of several other tasks that you want or need to automate; as you can see, using shell scripting will greatly simplify this effort. Feel free to let us know if you find this article helpful and don't hesitate to add your own ideas or comments via the form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/using-shell-script-to-automate-linux-system-maintenance-tasks/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/linux-performance-monitoring-and-file-system-statistics-reports/
|
||||
[2]:https://en.wikipedia.org/wiki/Bash_%28Unix_shell%29
|
||||
[3]:http://www.tecmint.com/wp-content/pdf/bash.pdf
|
||||
[4]:http://www.tecmint.com/60-commands-of-linux-a-guide-from-newbies-to-system-administrator/
|
||||
[5]:https://wiki.archlinux.org/index.php/Color_Bash_Prompt
|
||||
@ -1,218 +0,0 @@
|
||||
FSSlc translating
|
||||
|
||||
RHCSA Series: Process Management in RHEL 7: Boot, Shutdown, and Everything in Between – Part 5
|
||||
================================================================================
|
||||
We will start this article with an overall and brief revision of what happens since the moment you press the Power button to turn on your RHEL 7 server until you are presented with the login screen in a command line interface.
|
||||
|
||||

|
||||
|
||||
Linux Boot Process
|
||||
|
||||
**Please note that:**
|
||||
|
||||
1. the same basic principles apply, with perhaps minor modifications, to other Linux distributions as well, and
|
||||
2. the following description is not intended to represent an exhaustive explanation of the boot process, but only the fundamentals.
|
||||
|
||||
### Linux Boot Process ###
|
||||
|
||||
1. The POST (Power On Self Test) initializes and performs hardware checks.
|
||||
|
||||
2. When the POST finishes, the system control is passed to the first stage boot loader, which is stored on either the boot sector of one of the hard disks (for older systems using BIOS and MBR), or a dedicated (U)EFI partition.
|
||||
|
||||
3. The first stage boot loader then loads the second stage boot loader, most usually GRUB (GRand Unified Boot Loader), which resides inside /boot, which in turn loads the kernel and the initial RAM–based file system (also known as initramfs, which contains programs and binary files that perform the necessary actions needed to ultimately mount the actual root filesystem).
|
||||
|
||||
4. We are presented with a splash screen that allows us to choose an operating system and kernel to boot:
|
||||
|
||||

|
||||
|
||||
Boot Menu Screen
|
||||
|
||||
5. The kernel sets up the hardware attached to the system and once the root filesystem has been mounted, launches process with PID 1, which in turn will initialize other processes and present us with a login prompt.
|
||||
|
||||
Note: That if we wish to do so at a later time, we can examine the specifics of this process using the [dmesg command][1] and filtering its output using the tools that we have explained in previous articles of this series.
|
||||
|
||||

|
||||
|
||||
Login Screen and Process PID
|
||||
|
||||
In the example above, we used the well-known ps command to display a list of current processes whose parent process (or in other words, the process that started them) is systemd (the system and service manager that most modern Linux distributions have switched to) during system startup:
|
||||
|
||||
# ps -o ppid,pid,uname,comm --ppid=1
|
||||
|
||||
Remember that the -o flag (short for –format) allows you to present the output of ps in a customized format to suit your needs using the keywords specified in the STANDARD FORMAT SPECIFIERS section in man ps.
|
||||
|
||||
Another case in which you will want to define the output of ps instead of going with the default is when you need to find processes that are causing a significant CPU and / or memory load, and sort them accordingly:
|
||||
|
||||
# ps aux --sort=+pcpu # Sort by %CPU (ascending)
|
||||
# ps aux --sort=-pcpu # Sort by %CPU (descending)
|
||||
# ps aux --sort=+pmem # Sort by %MEM (ascending)
|
||||
# ps aux --sort=-pmem # Sort by %MEM (descending)
|
||||
# ps aux --sort=+pcpu,-pmem # Combine sort by %CPU (ascending) and %MEM (descending)
|
||||
|
||||

|
||||
|
||||
Customize ps Command Output
|
||||
|
||||
### An Introduction to SystemD ###
|
||||
|
||||
Few decisions in the Linux world have caused more controversies than the adoption of systemd by major Linux distributions. Systemd’s advocates name as its main advantages the following facts:
|
||||
|
||||
Read Also: [The Story Behind ‘init’ and ‘systemd’][2]
|
||||
|
||||
1. Systemd allows more processing to be done in parallel during system startup (as opposed to older SysVinit, which always tends to be slower because it starts processes one by one, checks if one depends on another, and then waits for daemons to launch so more services can start), and
|
||||
|
||||
2. It works as a dynamic resource management in a running system. Thus, services are started when needed (to avoid consuming system resources if they are not being used) instead of being launched without a valid reason during boot.
|
||||
|
||||
3. Backwards compatibility with SysVinit scripts.
|
||||
|
||||
Systemd is controlled by the systemctl utility. If you come from a SysVinit background, chances are you will be familiar with:
|
||||
|
||||
- the service tool, which -in those older systems- was used to manage SysVinit scripts, and
|
||||
- the chkconfig utility, which served the purpose of updating and querying runlevel information for system services.
|
||||
- shutdown, which you must have used several times to either restart or halt a running system.
|
||||
|
||||
The following table shows the similarities between the use of these legacy tools and systemctl:
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="237"></colgroup>
|
||||
<colgroup width="256"></colgroup>
|
||||
<colgroup width="1945"></colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="left" height="25" bgcolor="#B7B7B7" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial; font-size: small;">Legacy tool</span></b></td>
|
||||
<td align="left" bgcolor="#B7B7B7" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial; font-size: small;">Systemctl equivalent</span></b></td>
|
||||
<td align="left" bgcolor="#B7B7B7" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial; font-size: small;">Description</span></b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name start</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl start name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Start name (where name is a service)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name stop</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl stop name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Stop name</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name condrestart</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl try-restart name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Restarts name (if it’s already running)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name restart</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl restart name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Restarts name</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name reload</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl reload name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Reloads the configuration for name</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name status</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl status name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Displays the current status of name</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service –status-all</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Displays the status of all current services</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig name on</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl enable name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Enable name to run on startup as specified in the unit file (the file to which the symlink points). The process of enabling or disabling a service to start automatically on boot consists in adding or removing symbolic links inside the /etc/systemd/system directory.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig name off</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl disable name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Disables name to run on startup as specified in the unit file (the file to which the symlink points)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig –list name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl is-enabled name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Verify whether name (a specific service) is currently enabled</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig –list</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl –type=service</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Displays all services and tells whether they are enabled or disabled</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">shutdown -h now</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl poweroff</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Power-off the machine (halt)</span></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">shutdown -r now</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl reboot</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Reboot the system</span></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
Systemd also introduced the concepts of units (which can be either a service, a mount point, a device, or a network socket) and targets (which is how systemd manages to start several related process at the same time, and can be considered -though not equal- as the equivalent of runlevels in SysVinit-based systems.
|
||||
|
||||
### Summing Up ###
|
||||
|
||||
Other tasks related with process management include, but may not be limited to, the ability to:
|
||||
|
||||
**1. Adjust the execution priority as far as the use of system resources is concerned of a process:**
|
||||
|
||||
This is accomplished through the renice utility, which alters the scheduling priority of one or more running processes. In simple terms, the scheduling priority is a feature that allows the kernel (present in versions => 2.6) to allocate system resources as per the assigned execution priority (aka niceness, in a range from -20 through 19) of a given process.
|
||||
|
||||
The basic syntax of renice is as follows:
|
||||
|
||||
# renice [-n] priority [-gpu] identifier
|
||||
|
||||
In the generic command above, the first argument is the priority value to be used, whereas the other argument can be interpreted as process IDs (which is the default setting), process group IDs, user IDs, or user names. A normal user (other than root) can only modify the scheduling priority of a process he or she owns, and only increase the niceness level (which means taking up less system resources).
|
||||
|
||||

|
||||
|
||||
Process Scheduling Priority
|
||||
|
||||
**2. Kill (or interrupt the normal execution) of a process as needed:**
|
||||
|
||||
In more precise terms, killing a process entitles sending it a signal to either finish its execution gracefully (SIGTERM=15) or immediately (SIGKILL=9) through the [kill or pkill commands][3].
|
||||
|
||||
The difference between these two tools is that the former is used to terminate a specific process or a process group altogether, while the latter allows you to do the same based on name and other attributes.
|
||||
|
||||
In addition, pkill comes bundled with pgrep, which shows you the PIDs that will be affected should pkill be used. For example, before running:
|
||||
|
||||
# pkill -u gacanepa
|
||||
|
||||
It may be useful to view at a glance which are the PIDs owned by gacanepa:
|
||||
|
||||
# pgrep -l -u gacanepa
|
||||
|
||||
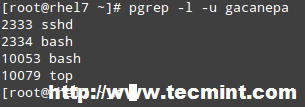
|
||||
|
||||
Find PIDs of User
|
||||
|
||||
By default, both kill and pkill send the SIGTERM signal to the process. As we mentioned above, this signal can be ignored (while the process finishes its execution or for good), so when you seriously need to stop a running process with a valid reason, you will need to specify the SIGKILL signal on the command line:
|
||||
|
||||
# kill -9 identifier # Kill a process or a process group
|
||||
# kill -s SIGNAL identifier # Idem
|
||||
# pkill -s SIGNAL identifier # Kill a process by name or other attributes
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article we have explained the basics of the boot process in a RHEL 7 system, and analyzed some of the tools that are available to help you with managing processes using common utilities and systemd-specific commands.
|
||||
|
||||
Note that this list is not intended to cover all the bells and whistles of this topic, so feel free to add your own preferred tools and commands to this article using the comment form below. Questions and other comments are also welcome.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-boot-process-and-process-management/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/dmesg-commands/
|
||||
[2]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
[3]:http://www.tecmint.com/how-to-kill-a-process-in-linux/
|
||||
@ -1,3 +1,5 @@
|
||||
FSSlc translating
|
||||
|
||||
RHCSA Series: Using ‘Parted’ and ‘SSM’ to Configure and Encrypt System Storage – Part 6
|
||||
================================================================================
|
||||
In this article we will discuss how to set up and configure local system storage in Red Hat Enterprise Linux 7 using classic tools and introducing the System Storage Manager (also known as SSM), which greatly simplifies this task.
|
||||
@ -266,4 +268,4 @@ via: http://www.tecmint.com/rhcsa-exam-create-format-resize-delete-and-encrypt-p
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/create-lvm-storage-in-linux/
|
||||
[1]:http://www.tecmint.com/create-lvm-storage-in-linux/
|
||||
|
||||
@ -0,0 +1,96 @@
|
||||
Trickr:一个开源的Linux桌面RSS新闻速递
|
||||
================================================================================
|
||||

|
||||
|
||||
**最新的!最新的!阅读关于它的一切!**
|
||||
|
||||
好了,所以我们今天要强调的应用程序不是相当于旧报纸的二进制版本—而是它会以一个伟大的方式,将最新的新闻推送到你的桌面上。
|
||||
|
||||
Tick是一个基于GTK的Linux桌面新闻速递,能够在水平带滚动显示最新头条新闻,以及你最爱的RSS资讯文章标题,当然你可以放置在你桌面的任何地方。
|
||||
|
||||
请叫我Joey Calamezzo;我把我的放在底部,有电视新闻台的风格。
|
||||
|
||||
“到你了,子标题”
|
||||
|
||||
### RSS -还记得吗? ###
|
||||
|
||||
“谢谢段落结尾。”
|
||||
|
||||
在一个推送通知,社交媒体,以及点击诱饵的时代,哄骗我们阅读最新的令人惊奇的,人人都爱读的清单,RSS看起来有一点过时了。
|
||||
|
||||
对我来说?恩,RSS是名副其实的真正简单的聚合。这是将消息通知给我的最简单,最易于管理的方式。我可以在我愿意的时候,管理和阅读一些东西;没必要匆忙的去看,以防这条微博消失在信息流中,或者推送通知消失。
|
||||
|
||||
tickr的美在于它的实用性。你可以不断地有新闻滚动在屏幕的底部,然后不时地瞥一眼。
|
||||
|
||||

|
||||
|
||||
你不会有“阅读”或“标记所有为已读”的压力。当你看到一些你想读的东西,你只需点击它,将它在Web浏览器中打开。
|
||||
|
||||
### 开始设置 ###
|
||||
|
||||

|
||||
|
||||
尽管虽然tickr可以从Ubuntu软件中心安装,然而它已经很久没有更新了。当你打开笨拙的不直观的控制面板的时候,没有什么能够比这更让人感觉被遗弃的了。
|
||||
|
||||
打开它:
|
||||
|
||||
1. 右键单击tickr条
|
||||
1. 转至编辑>首选项
|
||||
1. 调整各种设置
|
||||
|
||||
选项和设置行的后面,有些似乎是容易理解的。但是知己知彼你能够几乎掌控一切,包括:
|
||||
|
||||
- 设置滚动速度
|
||||
- 选择鼠标经过时的行为
|
||||
- 资讯更新频率
|
||||
- 字体,包括字体大小和颜色
|
||||
- 分隔符(“delineator”)
|
||||
- tickr在屏幕上的位置
|
||||
- tickr条的颜色和不透明度
|
||||
- 选择每种资讯显示多少文章
|
||||
|
||||
有个值得一提的“怪癖”是,当你点击“应用”按钮,只会更新tickr的屏幕预览。当您退出“首选项”窗口时,请单击“确定”。
|
||||
|
||||
想要滚动条在你的显示屏上水平显示,也需要公平一点的调整,特别是统一显示。
|
||||
|
||||
按下“全宽按钮”,能够让应用程序自动检测你的屏幕宽度。默认情况下,当放置在顶部或底部时,会留下25像素的间距(应用程序被创建在过去的GNOME2.x桌面)。只需添加额外的25像素到输入框,来弥补这个问题。
|
||||
|
||||
其他可供选择的选项包括:选择文章在哪个浏览器打开;tickr是否以一个常规的窗口出现;
|
||||
是否显示一个时钟;以及应用程序多久检查一次文章资讯。
|
||||
|
||||
#### 添加资讯 ####
|
||||
|
||||
tickr自带的有超过30种不同的资讯列表,从技术博客到主流新闻服务。
|
||||
|
||||

|
||||
|
||||
你可以选择很多你想在屏幕上显示的新闻提要。如果你想添加自己的资讯,你可以:—
|
||||
|
||||
1. 右键单击tickr条
|
||||
1. 转至文件>打开资讯
|
||||
1. 输入资讯网址
|
||||
1. 点击“添加/更新”按钮
|
||||
1. 单击“确定”(选择)
|
||||
|
||||
如果想设置每个资讯在ticker中显示多少条文章,可以去另一个首选项窗口修改“每个资讯最大读取N条文章”
|
||||
|
||||
### 在Ubuntu 14.04 LTS或更高版本上安装Tickr ###
|
||||
|
||||
在Ubuntu 14.04 LTS或更高版本上安装Tickr
|
||||
|
||||
在Ubuntu 14.04 LTS或更高版本中安装,转到Ubuntu软件中心,但要点击下面的按钮。
|
||||
|
||||
- [点击此处进入Ubuntu软件中心安装tickr][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/06/tickr-open-source-desktop-rss-news-ticker
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[xiaoyu33](https://github.com/xiaoyu33)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:apt://tickr
|
||||
@ -1,55 +0,0 @@
|
||||
将GNOME作为我的Linux桌面的一周: 他们做对的与做错的 - 第一节 - 简介
|
||||
================================================================================
|
||||
*作者声明: 如果你是因为某种神迹而在没看标题的情况下点开了这篇文章,那么我想再重申一些东西...这是一篇评论文章。文中的观点都是我自己的,不代表Phoronix和Michael的观点。它们完全是我自己的想法。
|
||||
|
||||
另外,没错……这可能是一篇引战的文章。我希望社团成员们更沉稳一些,因为我确实想在KDE和Gnome的社团上发起讨论,反馈。因此当我想指出——我所看到的——一个瑕疵时,我会尽量地做到具体而直接。这样,相关的讨论也能做到同样的具体和直接。再次声明:本文另一可选标题为“被[细纸片][1]千刀万剐”(原文含paper cuts一词,指易修复但烦人的缺陷,译者注)。
|
||||
|
||||
现在,重申完毕……文章开始。
|
||||
|
||||

|
||||
|
||||
当我把[《评价Fedora 22 KDE》][2]一文发给Michael时,感觉很不是滋味。不是因为我不喜欢KDE,或者不享受Fedora,远非如此。事实上,我刚开始想把我的T450s的系统换为Arch Linux时,马上又决定放弃了,因为我很享受fedora在很多方面所带来的便捷性。
|
||||
|
||||
我感觉很不是滋味的原因是Fedora的开发者花费了大量的时间和精力在他们的“工作站”产品上,但是我却一点也没看到。在使用Fedora时,我采用的并非那些主要开发者希望用户采用的那种使用方式,因此我也就体验不到所谓的“Fedora体验”。它感觉就像一个人评价Ubuntu时用的却是Kubuntu,评价OS X时用的却是Hackintosh,或者评价Gentoo时用的却是Sabayon。根据大量Michael论坛的读者的说法,它们在评价各种发行版时使用的都是默认设置的发行版——我也不例外。但是我还是认为这些评价应该在“真实”配置下完成,当然我也知道在给定的情况下评论某些东西也的确是有价值的——无论是好是坏。
|
||||
|
||||
正是在怀着这种态度的情况下,我决定到Gnome这个水坑里来泡泡澡。
|
||||
|
||||
但是,我还要在此多加一个声明……我在这里所看到的KDE和Gnome都是打包在Fedora中的。OpenSUSE, Kubuntu, Arch等发行版的各个桌面可能有不同的实现方法,使得我这里所说的具体的“痛处”跟你所用的发行版有所不同。还有,虽然用了这个标题,但这篇文章将会是一篇很沉重的非常“KDE”的文章。之所以这样称呼这篇文章,是因为我在使用了Gnome之后,才知道KDE的“剪纸”到底有多多。
|
||||
|
||||
### 登录界面 ###
|
||||
|
||||

|
||||
|
||||
我一般情况下都不会介意发行版装载它们自己的特别主题,因为一般情况下桌面看起来会更好看。可我今天可算是找到了一个例外。
|
||||
|
||||
第一印象很重要,对吧?那么,GDM(Gnome Display Manage:Gnome显示管理器,译者注,下同。)决对干得漂亮。它的登录界面看起来极度简洁,每一部分都应用了一致的设计风格。使用通用图标而不是输入框为它的简洁加了分。
|
||||
|
||||

|
||||
|
||||
这并不是说Fedora 22 KDE——现在已经是SDDM而不是KDM了——的登录界面不好看,但是看起来决对没有它这样和谐。
|
||||
|
||||
问题到底出来在哪?顶部栏。看看Gnome的截图——你选择一个用户,然后用一个很小的齿轮简单地选择想登入哪个会话。设计很简洁,它不挡着你的道儿,实话讲,如果你没注意的话可能完全会看不到它。现在看看那蓝色( blue,有忧郁之意,一语双关,译者注)的KDE截图,顶部栏看起来甚至不像是用同一个工具渲染出来的,它的整个位置的安排好像是某人想着:“哎哟妈呀,我们需要把这个选项扔在哪个地方……”之后决定下来的。
|
||||
|
||||
对于右上角的重启和关机选项也一样。为什么不单单用一个电源按钮,点击后会下拉出一个菜单,里面包括重启,关机,挂起的功能?按钮的颜色跟背景色不同肯定会让它更加突兀和显眼……但我可不觉得这样子有多好。同样,这看起来可真像“苦思”后的决定。
|
||||
|
||||
从实用观点来看,GDM还要远远实用的多,再看看顶部一栏。时间被列了出来,还有一个音量控制按钮,如果你想保持周围安静,你甚至可以在登录前设置静音,还有一个可用的按钮来实现高对比度,缩放,语音转文字等功能,所有可用的功能通过简单的一个开关按钮就能得到。
|
||||
|
||||

|
||||
|
||||
切换到upstream的Breeve主题……突然间,我抱怨的大部分问题都被完善了。通用图标,所有东西都放在了屏幕中央,但不是那么重要的被放到了一边。因为屏幕顶部和底部都是同样的空白,在中间也就酝酿出了一种美好的和谐。还是有一个输入框来切换会话,但既然电源按钮被做成了通用图标,那么这点还算可以原谅。当然gnome还是有一些很好的附加物,例如音量小程序和可访问按钮,但Breeze总归是Fedora的KDE主题的一个进步。
|
||||
|
||||
到Windows(Windows 8和10之前)或者OS X中去,你会看到类似的东西——非常简洁的,“不挡你道”的锁屏与登录界面,它们都没有输入框或者其它分散视觉的小工具。这是一种有效的不分散人注意力的设计。Fedora……默认装有Breeze。VDG在Breeze主题设计上干得不错。可别糟蹋了它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=1
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://wiki.ubuntu.com/One%20Hundred%20Papercuts
|
||||
[2]:http://www.phoronix.com/scan.php?page=article&item=fedora-22-kde&num=1
|
||||
[3]:https://launchpad.net/hundredpapercuts
|
||||
@ -1,31 +0,0 @@
|
||||
将GNOME作为我的Linux桌面的一周:他们做对的与做错的 - 第二节 - GNOME桌面
|
||||
================================================================================
|
||||
### 桌面 ###
|
||||
|
||||

|
||||
|
||||
在我这一周的前五天中,我都是直接手动登录进Gnome的——没有打开自动登录功能。在第五天的晚上,每一次都要手动登录让我觉得很厌烦,所以我就到用户管理器中打开了自动登录功能。下一次我登录的时候收到了一个提示:“你的密钥链(keychain)未解锁,请输入你的密码解锁”。在这时我才意识到了什么……每一次我通过GDM登录时——我的KDB钱包提示——Gnome以前一直都在自动解锁我的密钥链!当我绕开GDM的登录程序时,Gnome才不得不介入让我手动解锁。
|
||||
|
||||
现在,鄙人的陋见是如果你打开了自动登录功能,那么你的密钥链也应当自动解锁——否则,这功能还有何用?无论如何,你还是要输入你的密码,况且在GDM登录界面你还能有机会选择要登录的会话。
|
||||
|
||||
但是,这点且不提,也就是在那一刻,我意识到要让这桌面感觉是它在**和我**一起工作是多么简单的一件事。当我通过SDDM登录KDE时?甚至连启动界面都还没加载完成,就有一个窗口弹出来遮挡了启动动画——因此启动动画也就被破坏了——提示我解锁我的KDE钱包或GPG钥匙环。
|
||||
|
||||
如果当前不存在钱包,你就会收到一个创建钱包的提醒——就不能在创建用户的时候同时为我创建一个吗?——接着它又让你在两种加密模式中选择一种,甚至还暗示我们其中一种是不安全的(Blowfish),既然是为了安全,为什么还要我选择一个不安全的东西?作者声明:如果你安装了真正的KDE spin版本而不是仅仅安装了KDE的事后版本,那么在创建用户时,它就会为你创建一个钱包。但很不幸的是,它不会帮你解锁,并且它似乎还使用了更老的Blowfish加密模式,而不是更新而且更安全的GPG模式。
|
||||
|
||||

|
||||
|
||||
如果你选择了那个安全的加密模式(GPG),那么它会尝试加载GPG密钥……我希望你已经创建过一个了,因为如果你没有,那么你可又要被批一顿了。怎么样才能创建一个?额……它不帮你创建一个……也不告诉你怎么创建……假如你真的搞明白了你应该使用KGpg来创建一个密钥,接着在你就会遇到一层层的菜单和一个个的提示,而这些菜单和提示只能让新手感到困惑。为什么你要问我GPG的二进制文件在哪?天知道在哪!如果不止一个,你就不能为我选择一个最新的吗?如果只有一个,我再问一次,为什么你还要问我?
|
||||
|
||||
为什么你要问我要使用多大的密钥大小和加密算法?你既然默认选择了2048和RSA/RSA,为什么不直接使用?如果你想让这些选项能够被改变,那就把它们扔在下面的"Expert mode(专家模式)"按钮里去。这不仅仅关于使配置可被用户改变,而是关于默认地把多余的东西扔在了用户面前。这种问题将会成为剩下文章的主题之一……KDE需要更好更理智的默认配置。配置是好的,我很喜欢在使用KDE时的配置,但它还需要知道什么时候应该,什么时候不应该去提示用户。而且它还需要知道“嗯,它是可配置的”不能做为默认配置做得不好的借口。用户最先接触到的就是默认配置,不好的默认配置注定要失去用户。
|
||||
|
||||
让我们抛开密钥链的问题,因为我想我已经表达出了我的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=2
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,129 +0,0 @@
|
||||
如何更新Linux内核提升系统性能
|
||||
================================================================================
|
||||

|
||||
|
||||
[Linux内核][1]内核的开发速度目前是空前,大概每2到3个月就会有一个主要的版本发布。每个发布都带来让很多人的计算更加快、更加有效率、或者更好的功能和提升。
|
||||
|
||||
问题是你不能在这些内核发布的时候就用它们-你要等到你的发行版带来新内核的发布。我们先前发布了[定期更新内核的好处][2],你不必等到那时。我们会向你展示该怎么做。
|
||||
|
||||
> 免责声明: 我们先前的一些文章已经提到过,升级内核会带来(很小的)破坏你系统的风险。在这种情况下,通常可以通过旧内核来使系统工作,但是有时还是不行。因此我们对系统的任何损坏都不负责-你自己承担风险!
|
||||
|
||||
### 预备工作 ###
|
||||
|
||||

|
||||
|
||||
要更新你的内核,你首先要确定你使用的是32位还是64位的系统。打开终端并运行:
|
||||
|
||||
uname -a
|
||||
|
||||
检查一下输出的是x86_64还是i686。如果是x86_64,你就运行64位的版本,否则就运行32位的版本。记住这个因为这个很重要。
|
||||
|
||||

|
||||
|
||||
接下来,访问[官方Linux内核网站][3],它会告诉你目前稳定内核的版本。如果你喜欢你可以尝试发布预选版,但是这比稳定版少了很多测试。除非你确定想要用发布预选版否则就用稳定内核。
|
||||
|
||||
### Ubuntu指导 ###
|
||||
|
||||
对Ubuntu及其衍生版的用户而言升级内核非常简单,这要感谢Ubuntu主线内核PPA。虽然,官方称为一个PPA。但是你不能像其他PPA一样用来添加它到你软件源列表中,并指望它自动升级你的内核。而它只是一个简单的网页,你可以下载到你想要的内核。
|
||||
|
||||

|
||||
|
||||
现在,访问[内核PPA网页][4],并滚到底部。列表的最下面会含有最新发布的预选版本(你可以在名字中看到“rc”字样),但是这上面就可以看到最新的稳定版(为了更容易地解释这个,这时最新的稳定版是4.1.2)。点击它,你会看到几个选项。你需要下载3个文件并保存到各自的文件夹中(如果你喜欢的话可以在下载文件夹中),这样就可以将它们相互隔离了:
|
||||
|
||||
- 针对架构的含“generic”的头文件(我这里是64位或者“amd64”)
|
||||
- 中间的头文件在文件名末尾有“all”
|
||||
- 针对架构的含“generic”内核文件(再说一次,我会用“amd64”,但是你如果用32位的,你需要使用“i686”)
|
||||
|
||||
你会看到还有含有“lowlatency”的文件可以下面。但最好忽略它们。这些文件相对不稳定,并且只为那些通用文件不能满足像录音这类任务想要低延迟的人准备的。再说一次,首选通用版除非你特定的任务需求不能很好地满足。一般的游戏和网络浏览不是使用低延时版的借口。
|
||||
|
||||

|
||||
|
||||
你把它们放在各自的文件夹下,对么?现在打开终端,使用
|
||||
|
||||
cd
|
||||
|
||||
命令到新创建的文件夹下,像
|
||||
|
||||
cd /home/user/Downloads/Kernel
|
||||
|
||||
接着运行:
|
||||
|
||||
sudo dpkg -i *.deb
|
||||
|
||||
这个命令会标记所有文件夹的“.deb”文件为“待安装”,接着执行安装。这是推荐的安装放大,因为除非可以很简单地选择一个文件安装,它总会报出依赖问题。这个方法可以避免这个问题。如果你不清楚cd和sudo是什么。快速地看一下[Linux基本命令][5]这篇文章。
|
||||
|
||||
安装完成后,**重启**你的系统,这时应该就会运行刚安装的内核了!你可以在命令行中使用uname -a来检查输出。
|
||||
|
||||
### Fedora指导 ###
|
||||
|
||||
如果你使用的是Fedora或者它的衍生版,过程跟Ubuntu很类似。不同的是文件获取的位置不同,安装的命令也不同。
|
||||
|
||||

|
||||
|
||||
查看[Fedora最新内核编译][6]列表。选取列表中最新的稳定版并滚到下面选择i686或者x86_64版。这依赖于你的系统架构。这时你需要下载下面这些文件并保存到它们对应的目录下(比如“Kernel”到下载目录下):
|
||||
|
||||
- kernel
|
||||
- kernel-core
|
||||
- kernel-headers
|
||||
- kernel-modules
|
||||
- kernel-modules-extra
|
||||
- kernel-tools
|
||||
- perf and python-perf (optional)
|
||||
|
||||
如果你的系统是i686(32位)同时你有4GB或者更大的内存,你需要下载所有这些文件的PAE版本。PAE是用于32位的地址扩展技术上,它允许你使用3GB的内存。
|
||||
|
||||
现在使用
|
||||
|
||||
cd
|
||||
|
||||
命令进入文件夹,像这样
|
||||
|
||||
cd /home/user/Downloads/Kernel
|
||||
|
||||
and then run the following command to install all the files:
|
||||
接着运行下面的命令来安装所有的文件
|
||||
|
||||
yum --nogpgcheck localinstall *.rpm
|
||||
|
||||
最后**重启**你的系统,这样你就可以运行新的内核了!
|
||||
|
||||
### 使用 Rawhide ###
|
||||
|
||||
另外一个方案是,Fedora用户也可以[切换到Rawhide][7],它会自动更新所有的包到最新版本,包括内核。然而,Rawhide经常会破坏系统(尤其是在早期的开发版中),它**不应该**在你日常使用的系统中用。
|
||||
|
||||
### Arch指导 ###
|
||||
|
||||
[Arch][8]应该总是使用的是最新和最棒的稳定版(或者相当接近的版本)。如果你想要更接近最新发布的稳定版,你可以启用测试库提前2到3周获取到主要的更新。
|
||||
|
||||
要这么做,用[你喜欢的编辑器][9]以sudo权限打开下面的文件
|
||||
|
||||
/etc/pacman.conf
|
||||
|
||||
接着取消注释带有testing的三行(删除行前面的井号)。如果你想要启用multilib仓库,就把multilib-testing也做相同的事情。如果想要了解更多参考[这个Arch的wiki界面][10]。
|
||||
|
||||
升级内核并不简单(有意这么做),但是这会给你带来很多好处。只要你的新内核不会破坏任何东西,你可以享受它带来的性能提升,更好的效率,支持更多的硬件和潜在的新特性。尤其是你正在使用相对更新的硬件,升级内核可以帮助到它。
|
||||
|
||||
|
||||
**怎么升级内核这篇文章帮助到你了么?你认为你所喜欢的发行版对内核的发布策略应该是怎样的?**。在评论栏让我们知道!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.makeuseof.com/tag/update-linux-kernel-improved-system-performance/
|
||||
|
||||
作者:[Danny Stieben][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.makeuseof.com/tag/author/danny/
|
||||
[1]:http://www.makeuseof.com/tag/linux-kernel-explanation-laymans-terms/
|
||||
[2]:http://www.makeuseof.com/tag/5-reasons-update-kernel-linux/
|
||||
[3]:http://www.kernel.org/
|
||||
[4]:http://kernel.ubuntu.com/~kernel-ppa/mainline/
|
||||
[5]:http://www.makeuseof.com/tag/an-a-z-of-linux-40-essential-commands-you-should-know/
|
||||
[6]:http://koji.fedoraproject.org/koji/packageinfo?packageID=8
|
||||
[7]:http://www.makeuseof.com/tag/bleeding-edge-linux-fedora-rawhide/
|
||||
[8]:http://www.makeuseof.com/tag/arch-linux-letting-you-build-your-linux-system-from-scratch/
|
||||
[9]:http://www.makeuseof.com/tag/nano-vs-vim-terminal-text-editors-compared/
|
||||
[10]:https://wiki.archlinux.org/index.php/Pacman#Repositories
|
||||
@ -0,0 +1,126 @@
|
||||
如何使用Weave以及Docker搭建Nginx反向代理/负载均衡服务器
|
||||
================================================================================
|
||||
Hi, 今天我们将会学习如何使用如何使用Weave和Docker搭建Nginx反向代理/负载均衡服务器。Weave创建一个虚拟网络将跨主机部署的Docker容器连接在一起并使它们自动暴露给外部世界。它让我们更加专注于应用的开发,而不是基础架构。Weave提供了一个如此棒的环境,仿佛它的所有容器都属于同个网络,不需要端口/映射/连接等的配置。容器中的应用提供的服务在weave网络中可以轻易地被外部世界访问,不论你的容器运行在哪里。在这个教程里我们将会使用weave快速并且轻易地将nginx web服务器部署为一个负载均衡器,反向代理一个运行在Amazon Web Services里面多个节点上的docker容器中的简单php应用。这里我们将会介绍WeaveDNS,它提供一个简单的方式让容器利用主机名找到彼此,不需要改变代码,并且能够告诉其他容器连接到这些主机名。
|
||||
|
||||
在这篇教程里,我们需要一个运行的容器集合来配置nginx负载均衡服务器。最简单轻松的方法就是使用Weave在ubuntu的docker容器中搭建nginx负载均衡服务器。
|
||||
|
||||
### 1. 搭建AWS实例 ###
|
||||
|
||||
首先,我们需要搭建Amzaon Web Service实例,这样才能在ubuntu下用weave跑docker容器。我们将会使用[AWS CLI][1]来搭建和配置两个AWS EC2实例。在这里,我们使用最小的有效实例,t1.micro。我们需要一个有效的**Amazon Web Services账户**用以AWS命令行界面的搭建和配置。我们先在AWS命令行界面下使用下面的命令将github上的weave仓库克隆下来。
|
||||
|
||||
$ git clone http://github.com/fintanr/weave-gs
|
||||
$ cd weave-gs/aws-nginx-ubuntu-simple
|
||||
|
||||
在克隆完仓库之后,我们执行下面的脚本,这个脚本将会部署两个t1.micro实例,每个实例中都是ubuntu作为操作系统并用weave跑着docker容器。
|
||||
|
||||
$ sudo ./demo-aws-setup.sh
|
||||
|
||||
在这里,我们将会在以后用到这些实例的IP地址。这些地址储存在一个weavedemo.env文件中,这个文件在执行demo-aws-setup.sh脚本的期间被创建。为了获取这些IP地址,我们需要执行下面的命令,命令输出类似下面的信息。
|
||||
|
||||
$ cat weavedemo.env
|
||||
|
||||
export WEAVE_AWS_DEMO_HOST1=52.26.175.175
|
||||
export WEAVE_AWS_DEMO_HOST2=52.26.83.141
|
||||
export WEAVE_AWS_DEMO_HOSTCOUNT=2
|
||||
export WEAVE_AWS_DEMO_HOSTS=(52.26.175.175 52.26.83.141)
|
||||
|
||||
请注意这些不是固定的IP地址,AWS会为我们的实例动态地分配IP地址。
|
||||
|
||||
我们在bash下执行下面的命令使环境变量生效。
|
||||
|
||||
. ./weavedemo.env
|
||||
|
||||
### 2. 启动Weave and WeaveDNS ###
|
||||
|
||||
在安装完实例之后,我们将会在每台主机上启动weave以及weavedns。Weave以及weavedns使得我们能够轻易地将容器部署到一个全新的基础架构以及配置中, 不需要改变代码,也不需要去理解像Ambassador容器以及Link机制之类的概念。下面是在第一台主机上启动weave以及weavedns的命令。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave launch
|
||||
$ sudo weave launch-dns 10.2.1.1/24
|
||||
|
||||
下一步,我也准备在第二台主机上启动weave以及weavedns。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST2
|
||||
$ sudo weave launch $WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave launch-dns 10.2.1.2/24
|
||||
|
||||
### 3. 启动应用容器 ###
|
||||
|
||||
现在,我们准备跨两台主机启动六个容器,这两台主机都用Apache2 Web服务实例跑着简单的php网站。为了在第一个Apache2 Web服务器实例跑三个容器, 我们将会使用下面的命令。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave run --with-dns 10.3.1.1/24 -h ws1.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.2/24 -h ws2.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.3/24 -h ws3.weave.local fintanr/weave-gs-nginx-apache
|
||||
|
||||
在那之后,我们将会在第二个实例上启动另外三个容器,请使用下面的命令。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST2
|
||||
$ sudo weave run --with-dns 10.3.1.4/24 -h ws4.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.5/24 -h ws5.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.6/24 -h ws6.weave.local fintanr/weave-gs-nginx-apache
|
||||
|
||||
注意: 在这里,--with-dns选项告诉容器使用weavedns来解析主机名,-h x.weave.local则使得weavedns能够解析指定主机。
|
||||
|
||||
### 4. 启动Nginx容器 ###
|
||||
|
||||
在应用容器运行得有如意料中的稳定之后,我们将会启动nginx容器,它将会在六个应用容器服务之间轮询并提供反向代理或者负载均衡。 为了启动nginx容器,请使用下面的命令。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave run --with-dns 10.3.1.7/24 -ti -h nginx.weave.local -d -p 80:80 fintanr/weave-gs-nginx-simple
|
||||
|
||||
因此,我们的nginx容器在$WEAVE_AWS_DEMO_HOST1上公开地暴露成为一个http服务器。
|
||||
|
||||
### 5. 测试负载均衡服务器 ###
|
||||
|
||||
为了测试我们的负载均衡服务器是否可以工作,我们执行一段可以发送http请求给nginx容器的脚本。我们将会发送6个请求,这样我们就能看到nginx在一次的轮询中服务于每台web服务器之间。
|
||||
|
||||
$ ./access-aws-hosts.sh
|
||||
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws1.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws2.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws3.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws4.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws5.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws6.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
|
||||
### 结束语 ###
|
||||
|
||||
我们最终成功地将nginx配置成一个反向代理/负载均衡服务器,通过使用weave以及运行在AWS(Amazon Web Service)EC2之中的ubuntu服务器里面的docker。从上面的步骤输出可以清楚的看到我们已经成功地配置了nginx。我们可以看到请求在一次循环中被发送到6个应用容器,这些容器在Apache2 Web服务器中跑着PHP应用。在这里,我们部署了一个容器化的PHP应用,使用nginx横跨多台在AWS EC2上的主机而不需要改变代码,利用weavedns使得每个容器连接在一起,只需要主机名就够了,眼前的这些便捷, 都要归功于weave以及weavedns。 如果你有任何的问题、建议、反馈,请在评论中注明,这样我们才能够做得更好,谢谢:-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/nginx-load-balancer-weave-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[dingdongnigetou](https://github.com/dingdongnigetou)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://console.aws.amazon.com/
|
||||
418
translated/tech/20150803 Managing Linux Logs.md
Normal file
418
translated/tech/20150803 Managing Linux Logs.md
Normal file
@ -0,0 +1,418 @@
|
||||
Linux日志管理
|
||||
================================================================================
|
||||
管理日志的一个关键典型做法是集中或整合你的日志到一个地方,特别是如果你有许多服务器或多层级架构。我们将告诉你为什么这是一个好主意然后给出如何更容易的做这件事的一些小技巧。
|
||||
|
||||
### 集中管理日志的好处 ###
|
||||
|
||||
如果你有很多服务器,查看单独的一个日志文件可能会很麻烦。现代的网站和服务经常包括许多服务器层级,分布式的负载均衡器,还有更多。这将花费很长时间去获取正确的日志,甚至花更长时间在登录服务器的相关问题上。没什么比发现你找的信息没有被捕获更沮丧的了,或者本能保留答案时正好在重启后丢失了日志文件。
|
||||
|
||||
集中你的日志使他们查找更快速,可以帮助你更快速的解决产品问题。你不用猜测那个服务器存在问题,因为所有的日志在同一个地方。此外,你可以使用更强大的工具去分析他们,包括日志管理解决方案。一些解决方案能[转换纯文本日志][1]为一些字段,更容易查找和分析。
|
||||
|
||||
集中你的日志也可以是他们更易于管理:
|
||||
|
||||
- 他们更安全,当他们备份归档一个单独区域时意外或者有意的丢失。如果你的服务器宕机或者无响应,你可以使用集中的日志去调试问题。
|
||||
- 你不用担心ssh或者低效的grep命令需要更多的资源在陷入困境的系统。
|
||||
- 你不用担心磁盘占满,这个能让你的服务器死机。
|
||||
- 你能保持你的产品服务安全性,只是为了查看日志无需给你所有团队登录权限。给你的团队从中心区域访问日志权限更安全。
|
||||
|
||||
随着集中日志管理,你仍需处理由于网络联通性不好或者用尽大量网络带宽导致不能传输日志到中心区域的风险。在下面的章节我们将要讨论如何聪明的解决这些问题。
|
||||
|
||||
### 流行的日志归集工具 ###
|
||||
|
||||
在Linux上最常见的日志归集是通过使用系统日志守护进程或者代理。系统日志守护进程支持本地日志的采集,然后通过系统日志协议传输日志到中心服务器。你可以使用很多流行的守护进程来归集你的日志文件:
|
||||
|
||||
- [rsyslog][2]是一个轻量后台程序在大多数Linux分支上已经安装。
|
||||
- [syslog-ng][3]是第二流行的Linux系统日志后台程序。
|
||||
- [logstash][4]是一个重量级的代理,他可以做更多高级加工和分析。
|
||||
- [fluentd][5]是另一个有高级处理能力的代理。
|
||||
|
||||
Rsyslog是集中日志数据最流行的后台程序因为他在大多数Linux分支上是被默认安装的。你不用下载或安装它,并且它是轻量的,所以不需要占用你太多的系统资源。
|
||||
|
||||
如果你需要更多先进的过滤或者自定义分析功能,如果你不在乎额外的系统封装Logstash是下一个最流行的选择。
|
||||
|
||||
### 配置Rsyslog.conf ###
|
||||
|
||||
既然rsyslog成为最广泛使用的系统日志程序,我们将展示如何配置它为日志中心。全局配置文件位于/etc/rsyslog.conf。它加载模块,设置全局指令,和包含应用特有文件位于目录/etc/rsyslog.d中。这些目录包含/etc/rsyslog.d/50-default.conf命令rsyslog写系统日志到文件。在[rsyslog文档][6]你可以阅读更多相关配置。
|
||||
|
||||
rsyslog配置语言是是[RainerScript][7]。你建立特定的日志输入就像输出他们到另一个目标。Rsyslog已经配置为系统日志输入的默认标准,所以你通常只需增加一个输出到你的日志服务器。这里有一个rsyslog输出到一个外部服务器的配置例子。在举例中,**BEBOP**是一个服务器的主机名,所以你应该替换为你的自己的服务器名。
|
||||
|
||||
action(type="omfwd" protocol="tcp" target="BEBOP" port="514")
|
||||
|
||||
你可以发送你的日志到一个有丰富存储的日志服务器来存储,提供查询,备份和分析。如果你正存储日志在文件系统,然后你应该建立[日志转储][8]来防止你的磁盘报满。
|
||||
|
||||
作为一种选择,你可以发送这些日志到一个日志管理方案。如果你的解决方案是安装在本地你可以发送到您的本地系统文档中指定主机和端口。如果你使用基于云提供商,你将发送他们到你的提供商特定的主机名和端口。
|
||||
|
||||
### 日志目录 ###
|
||||
|
||||
你可以归集一个目录或者匹配一个通配符模式的所有文件。nxlog和syslog-ng程序支持目录和通配符(*)。
|
||||
|
||||
rsyslog的通用形式不支持直接的监控目录。一种解决方案,你可以设置一个定时任务去监控这个目录的新文件,然后配置rsyslog来发送这些文件到目的地,比如你的日志管理系统。作为一个例子,日志管理提供商Loggly有一个开源版本的[目录监控脚本][9]。
|
||||
|
||||
### 哪个协议: UDP, TCP, or RELP? ###
|
||||
|
||||
当你使用网络传输数据时,你可以选择三个主流的协议。UDP在你自己的局域网是最常用的,TCP是用在互联网。如果你不能失去日志,就要使用更高级的RELP协议。
|
||||
|
||||
[UDP][10]发送一个数据包,那只是一个简单的包信息。它是一个只外传的协议,所以他不发送给你回执(ACK)。它只尝试发送包。当网络拥堵时,UDP通常会巧妙的降级或者丢弃日志。它通常使用在类似局域网的可靠网络。
|
||||
|
||||
[TCP][11]通过多个包和返回确认发送流信息。TCP会多次尝试发送数据包,但是受限于[TCP缓存][12]大小。这是在互联网上发送送日志最常用的协议。
|
||||
|
||||
[RELP][13]是这三个协议中最可靠的,但是它是为rsyslog创建而且很少有行业应用。它在应用层接收数据然后再发出是否有错误。确认你的目标也支持这个协议。
|
||||
|
||||
### 用磁盘辅助队列可靠的传送 ###
|
||||
|
||||
如果rsyslog在存储日志时遭遇错误,例如一个不可用网络连接,他能将日志排队直到连接还原。队列日志默认被存储在内存里。无论如何,内存是有限的并且如果问题仍然存在,日志会超出内存容量。
|
||||
|
||||
**警告:如果你只存储日志到内存,你可能会失去数据。**
|
||||
|
||||
Rsyslog能在内存被占满时将日志队列放到磁盘。[磁盘辅助队列][14]使日志的传输更可靠。这里有一个例子如何配置rsyslog的磁盘辅助队列:
|
||||
|
||||
$WorkDirectory /var/spool/rsyslog # where to place spool files
|
||||
$ActionQueueFileName fwdRule1 # unique name prefix for spool files
|
||||
$ActionQueueMaxDiskSpace 1g # 1gb space limit (use as much as possible)
|
||||
$ActionQueueSaveOnShutdown on # save messages to disk on shutdown
|
||||
$ActionQueueType LinkedList # run asynchronously
|
||||
$ActionResumeRetryCount -1 # infinite retries if host is down
|
||||
|
||||
### 使用TLS加密日志 ###
|
||||
|
||||
当你的安全隐私数据是一个关心的事,你应该考虑加密你的日志。如果你使用纯文本在互联网传输日志,嗅探器和中间人可以读到你的日志。如果日志包含私人信息、敏感的身份数据或者政府管制数据,你应该加密你的日志。rsyslog程序能使用TLS协议加密你的日志保证你的数据更安全。
|
||||
|
||||
建立TLS加密,你应该做如下任务:
|
||||
|
||||
1. 生成一个[证书授权][15](CA)。在/contrib/gnutls有一些简单的证书,只是有助于测试,但是你需要创建自己的产品证书。如果你正在使用一个日志管理服务,它将有一个证书给你。
|
||||
1. 为你的服务器生成一个[数字证书][16]使它能SSL运算,或者使用你自己的日志管理服务提供商的一个数字证书。
|
||||
1. 配置你的rsyslog程序来发送TLS加密数据到你的日志管理系统。
|
||||
|
||||
这有一个rsyslog配置TLS加密的例子。替换CERT和DOMAIN_NAME为你自己的服务器配置。
|
||||
|
||||
$DefaultNetstreamDriverCAFile /etc/rsyslog.d/keys/ca.d/CERT.crt
|
||||
$ActionSendStreamDriver gtls
|
||||
$ActionSendStreamDriverMode 1
|
||||
$ActionSendStreamDriverAuthMode x509/name
|
||||
$ActionSendStreamDriverPermittedPeer *.DOMAIN_NAME.com
|
||||
|
||||
### 应用日志的最佳管理方法 ###
|
||||
|
||||
除Linux默认创建的日志之外,归集重要的应用日志也是一个好主意。几乎所有基于Linux的服务器的应用把他们的状态信息写入到独立专门的日志文件。这包括数据库产品,像PostgreSQL或者MySQL,网站服务器像Nginx或者Apache,防火墙,打印和文件共享服务还有DNS服务等等。
|
||||
|
||||
管理员要做的第一件事是安装一个应用后配置它。Linux应用程序典型的有一个.conf文件在/etc目录里。它也可能在其他地方,但是那是大家找配置文件首先会看的地方。
|
||||
|
||||
根据应用程序有多复杂多庞大,可配置参数的数量可能会很少或者上百行。如前所述,大多数应用程序可能会在某种日志文件写他们的状态:配置文件是日志设置的地方定义了其他的东西。
|
||||
|
||||
如果你不确定它在哪,你可以使用locate命令去找到它:
|
||||
|
||||
[root@localhost ~]# locate postgresql.conf
|
||||
/usr/pgsql-9.4/share/postgresql.conf.sample
|
||||
/var/lib/pgsql/9.4/data/postgresql.conf
|
||||
|
||||
#### 设置一个日志文件的标准位置 ####
|
||||
|
||||
Linux系统一般保存他们的日志文件在/var/log目录下。如果是,很好,如果不是,你也许想在/var/log下创建一个专用目录?为什么?因为其他程序也在/var/log下保存他们的日志文件,如果你的应用报错多于一个日志文件 - 也许每天一个或者每次重启一个 - 通过这么大的目录也许有点难于搜索找到你想要的文件。
|
||||
|
||||
如果你有多于一个的应用实例在你网络运行,这个方法依然便利。想想这样的情景,你也许有一打web服务器在你的网络运行。当排查任何一个盒子的问题,你将知道确切的位置。
|
||||
|
||||
#### 使用一个标准的文件名 ####
|
||||
|
||||
给你的应用最新的日志使用一个标准的文件名。这使一些事变得容易,因为你可以监控和追踪一个单独的文件。很多应用程序在他们的日志上追加一种时间戳。他让rsyslog更难于找到最新的文件和设置文件监控。一个更好的方法是使用日志转储增加时间戳到老的日志文件。这样更易去归档和历史查询。
|
||||
|
||||
#### 追加日志文件 ####
|
||||
|
||||
日志文件会在每个应用程序重启后被覆盖?如果这样,我们建议关掉它。每次重启app后应该去追加日志文件。这样,你就可以追溯重启前最后的日志。
|
||||
|
||||
#### 日志文件追加 vs. 转储 ####
|
||||
|
||||
虽然应用程序每次重启后写一个新日志文件,如何保存当前日志?追加到一个单独文件,巨大的文件?Linux系统不是因频繁重启或者崩溃出名的:应用程序可以运行很长时间甚至不间歇,但是也会使日志文件非常大。如果你查询分析上周发生连接错误的原因,你可能无疑的要在成千上万行里搜索。
|
||||
|
||||
我们建议你配置应用每天半晚转储它的日志文件。
|
||||
|
||||
为什么?首先它将变得可管理。找一个有特定日期部分的文件名比遍历一个文件指定日期的条目更容易。文件也小的多:你不用考虑当你打开一个日志文件时vi僵住。第二,如果你正发送日志到另一个位置 - 也许每晚备份任务拷贝到归集日志服务器 - 这样不会消耗你的网络带宽。最后第三点,这样帮助你做日志保持。如果你想剔除旧的日志记录,这样删除超过指定日期的文件比一个应用解析一个大文件更容易。
|
||||
|
||||
#### 日志文件的保持 ####
|
||||
|
||||
你保留你的日志文件多长时间?这绝对可以归结为业务需求。你可能被要求保持一个星期的日志信息,或者管理要求保持一年的数据。无论如何,日志需要在一个时刻或其他从服务器删除。
|
||||
|
||||
在我们看来,除非必要,只在线保持最近一个月的日志文件,加上拷贝他们到第二个地方如日志服务器。任何比这更旧的日志可以被转到一个单独的介质上。例如,如果你在AWS上,你的旧日志可以被拷贝到Glacier。
|
||||
|
||||
#### 给日志单独的磁盘分区 ####
|
||||
|
||||
Linux最典型的方式通常建议挂载到/var目录到一个单独度的文件系统。这是因为这个目录的高I/Os。我们推荐挂在/var/log目录到一个单独的磁盘系统下。这样可以节省与主应用的数据I/O竞争。另外,如果一些日志文件变的太多,或者一个文件变的太大,不会占满整个磁盘。
|
||||
|
||||
#### 日志条目 ####
|
||||
|
||||
每个日志条目什么信息应该被捕获?
|
||||
|
||||
这依赖于你想用日志来做什么。你只想用它来排除故障,或者你想捕获所有发生的事?这是一个规则条件去捕获每个用户在运行什么或查看什么?
|
||||
|
||||
如果你正用日志做错误排查的目的,只保存错误,报警或者致命信息。没有理由去捕获调试信息,例如,应用也许默认记录了调试信息或者另一个管理员也许为了故障排查使用打开了调试信息,但是你应该关闭它,因为它肯定会很快的填满空间。在最低限度上,捕获日期,时间,客户端应用名,原ip或者客户端主机名,执行动作和它自身信息。
|
||||
|
||||
#### 一个PostgreSQL的实例 ####
|
||||
|
||||
作为一个例子,让我们看看vanilla(这是一个开源论坛)PostgreSQL 9.4安装主配置文件。它叫做postgresql.conf与其他Linux系统中的配置文件不同,他不保存在/etc目录下。在代码段下,我们可以在我们的Centos 7服务器的/var/lib/pgsql目录下看见:
|
||||
|
||||
root@localhost ~]# vi /var/lib/pgsql/9.4/data/postgresql.conf
|
||||
...
|
||||
#------------------------------------------------------------------------------
|
||||
# ERROR REPORTING AND LOGGING
|
||||
#------------------------------------------------------------------------------
|
||||
# - Where to Log -
|
||||
log_destination = 'stderr'
|
||||
# Valid values are combinations of
|
||||
# stderr, csvlog, syslog, and eventlog,
|
||||
# depending on platform. csvlog
|
||||
# requires logging_collector to be on.
|
||||
# This is used when logging to stderr:
|
||||
logging_collector = on
|
||||
# Enable capturing of stderr and csvlog
|
||||
# into log files. Required to be on for
|
||||
# csvlogs.
|
||||
# (change requires restart)
|
||||
# These are only used if logging_collector is on:
|
||||
log_directory = 'pg_log'
|
||||
# directory where log files are written,
|
||||
# can be absolute or relative to PGDATA
|
||||
log_filename = 'postgresql-%a.log' # log file name pattern,
|
||||
# can include strftime() escapes
|
||||
# log_file_mode = 0600 .
|
||||
# creation mode for log files,
|
||||
# begin with 0 to use octal notation
|
||||
log_truncate_on_rotation = on # If on, an existing log file with the
|
||||
# same name as the new log file will be
|
||||
# truncated rather than appended to.
|
||||
# But such truncation only occurs on
|
||||
# time-driven rotation, not on restarts
|
||||
# or size-driven rotation. Default is
|
||||
# off, meaning append to existing files
|
||||
# in all cases.
|
||||
log_rotation_age = 1d
|
||||
# Automatic rotation of logfiles will happen after that time. 0 disables.
|
||||
log_rotation_size = 0 # Automatic rotation of logfiles will happen after that much log output. 0 disables.
|
||||
# These are relevant when logging to syslog:
|
||||
#syslog_facility = 'LOCAL0'
|
||||
#syslog_ident = 'postgres'
|
||||
# This is only relevant when logging to eventlog (win32):
|
||||
#event_source = 'PostgreSQL'
|
||||
# - When to Log -
|
||||
#client_min_messages = notice # values in order of decreasing detail:
|
||||
# debug5
|
||||
# debug4
|
||||
# debug3
|
||||
# debug2
|
||||
# debug1
|
||||
# log
|
||||
# notice
|
||||
# warning
|
||||
# error
|
||||
#log_min_messages = warning # values in order of decreasing detail:
|
||||
# debug5
|
||||
# debug4
|
||||
# debug3
|
||||
# debug2
|
||||
# debug1
|
||||
# info
|
||||
# notice
|
||||
# warning
|
||||
# error
|
||||
# log
|
||||
# fatal
|
||||
# panic
|
||||
#log_min_error_statement = error # values in order of decreasing detail:
|
||||
# debug5
|
||||
# debug4
|
||||
# debug3
|
||||
# debug2
|
||||
# debug1
|
||||
# info
|
||||
# notice
|
||||
# warning
|
||||
# error
|
||||
# log
|
||||
# fatal
|
||||
# panic (effectively off)
|
||||
#log_min_duration_statement = -1 # -1 is disabled, 0 logs all statements
|
||||
# and their durations, > 0 logs only
|
||||
# statements running at least this number
|
||||
# of milliseconds
|
||||
# - What to Log
|
||||
#debug_print_parse = off
|
||||
#debug_print_rewritten = off
|
||||
#debug_print_plan = off
|
||||
#debug_pretty_print = on
|
||||
#log_checkpoints = off
|
||||
#log_connections = off
|
||||
#log_disconnections = off
|
||||
#log_duration = off
|
||||
#log_error_verbosity = default
|
||||
# terse, default, or verbose messages
|
||||
#log_hostname = off
|
||||
log_line_prefix = '< %m >' # special values:
|
||||
# %a = application name
|
||||
# %u = user name
|
||||
# %d = database name
|
||||
# %r = remote host and port
|
||||
# %h = remote host
|
||||
# %p = process ID
|
||||
# %t = timestamp without milliseconds
|
||||
# %m = timestamp with milliseconds
|
||||
# %i = command tag
|
||||
# %e = SQL state
|
||||
# %c = session ID
|
||||
# %l = session line number
|
||||
# %s = session start timestamp
|
||||
# %v = virtual transaction ID
|
||||
# %x = transaction ID (0 if none)
|
||||
# %q = stop here in non-session
|
||||
# processes
|
||||
# %% = '%'
|
||||
# e.g. '<%u%%%d> '
|
||||
#log_lock_waits = off # log lock waits >= deadlock_timeout
|
||||
#log_statement = 'none' # none, ddl, mod, all
|
||||
#log_temp_files = -1 # log temporary files equal or larger
|
||||
# than the specified size in kilobytes;5# -1 disables, 0 logs all temp files5
|
||||
log_timezone = 'Australia/ACT'
|
||||
|
||||
虽然大多数参数被加上了注释,他们呈现了默认数值。我们可以看见日志文件目录是pg_log(log_directory参数),文件名应该以postgresql开头(log_filename参数),文件每天转储一次(log_rotation_age参数)然后日志记录以时间戳开头(log_line_prefix参数)。特别说明有趣的是log_line_prefix参数:你可以包含很多整体丰富的信息在这。
|
||||
|
||||
看/var/lib/pgsql/9.4/data/pg_log目录下展现给我们这些文件:
|
||||
|
||||
[root@localhost ~]# ls -l /var/lib/pgsql/9.4/data/pg_log
|
||||
total 20
|
||||
-rw-------. 1 postgres postgres 1212 May 1 20:11 postgresql-Fri.log
|
||||
-rw-------. 1 postgres postgres 243 Feb 9 21:49 postgresql-Mon.log
|
||||
-rw-------. 1 postgres postgres 1138 Feb 7 11:08 postgresql-Sat.log
|
||||
-rw-------. 1 postgres postgres 1203 Feb 26 21:32 postgresql-Thu.log
|
||||
-rw-------. 1 postgres postgres 326 Feb 10 01:20 postgresql-Tue.log
|
||||
|
||||
所以日志文件命只有工作日命名的标签。我们可以改变他。如何做?在postgresql.conf配置log_filename参数。
|
||||
|
||||
查看一个日志内容,它的条目仅以日期时间开头:
|
||||
|
||||
[root@localhost ~]# cat /var/lib/pgsql/9.4/data/pg_log/postgresql-Fri.log
|
||||
...
|
||||
< 2015-02-27 01:21:27.020 EST >LOG: received fast shutdown request
|
||||
< 2015-02-27 01:21:27.025 EST >LOG: aborting any active transactions
|
||||
< 2015-02-27 01:21:27.026 EST >LOG: autovacuum launcher shutting down
|
||||
< 2015-02-27 01:21:27.036 EST >LOG: shutting down
|
||||
< 2015-02-27 01:21:27.211 EST >LOG: database system is shut down
|
||||
|
||||
### 集中应用日志 ###
|
||||
|
||||
#### 使用Imfile监控日志 ####
|
||||
|
||||
习惯上,应用通常记录他们数据在文件里。文件容易在一个机器上寻找但是多台服务器上就不是很恰当了。你可以设置日志文件监控然后当新的日志被添加到底部就发送事件到一个集中服务器。在/etc/rsyslog.d/里创建一个新的配置文件然后增加一个文件输入,像这样:
|
||||
|
||||
$ModLoad imfile
|
||||
$InputFilePollInterval 10
|
||||
$PrivDropToGroup adm
|
||||
|
||||
----------
|
||||
|
||||
# Input for FILE1
|
||||
$InputFileName /FILE1
|
||||
$InputFileTag APPNAME1
|
||||
$InputFileStateFile stat-APPNAME1 #this must be unique for each file being polled
|
||||
$InputFileSeverity info
|
||||
$InputFilePersistStateInterval 20000
|
||||
$InputRunFileMonitor
|
||||
|
||||
替换FILE1和APPNAME1位你自己的文件和应用名称。Rsyslog将发送它到你配置的输出中。
|
||||
|
||||
#### 本地套接字日志与Imuxsock ####
|
||||
|
||||
套接字类似UNIX文件句柄,所不同的是套接字内容是由系统日志程序读取到内存中,然后发送到目的地。没有文件需要被写入。例如,logger命令发送他的日志到这个UNIX套接字。
|
||||
|
||||
如果你的服务器I/O有限或者你不需要本地文件日志,这个方法使系统资源有效利用。这个方法缺点是套接字有队列大小的限制。如果你的系统日志程序宕掉或者不能保持运行,然后你可能会丢失日志数据。
|
||||
|
||||
rsyslog程序将默认从/dev/log套接字中种读取,但是你要用[imuxsock输入模块][17]如下命令使它生效:
|
||||
|
||||
$ModLoad imuxsock
|
||||
|
||||
#### UDP日志与Imupd ####
|
||||
|
||||
一些应用程序使用UDP格式输出日志数据,这是在网络上或者本地传输日志文件的标准系统日志协议。你的系统日志程序收集这些日志然后处理他们或者用不同的格式传输他们。交替地,你可以发送日志到你的日志服务器或者到一个日志管理方案中。
|
||||
|
||||
使用如下命令配置rsyslog来接收标准端口514的UDP系统日志数据:
|
||||
|
||||
$ModLoad imudp
|
||||
|
||||
----------
|
||||
|
||||
$UDPServerRun 514
|
||||
|
||||
### 用Logrotate管理日志 ###
|
||||
|
||||
日志转储是当日志到达指定的时期时自动归档日志文件的方法。如果不介入,日志文件一直增长,会用尽磁盘空间。最后他们将破坏你的机器。
|
||||
|
||||
logrotate实例能随着日志的日期截取你的日志,腾出空间。你的新日志文件保持文件名。你的旧日志文件被重命名为后缀加上数字。每次logrotate实例运行,一个新文件被建立然后现存的文件被逐一重命名。你来决定何时旧文件被删除或归档的阈值。
|
||||
|
||||
当logrotate拷贝一个文件,新的文件已经有一个新的索引节点,这会妨碍rsyslog监控新文件。你可以通过增加copytruncate参数到你的logrotate定时任务来缓解这个问题。这个参数拷贝现有的日志文件内容到新文件然后从现有文件截短这些内容。这个索引节点从不改变,因为日志文件自己保持不变;它的内容是一个新文件。
|
||||
|
||||
logrotate实例使用的主配置文件是/etc/logrotate.conf,应用特有设置在/etc/logrotate.d/目录下。DigitalOcean有一个详细的[logrotate教程][18]
|
||||
|
||||
### 管理很多服务器的配置 ###
|
||||
|
||||
当你只有很少的服务器,你可以登陆上去手动配置。一旦你有几打或者更多服务器,你可以用高级工具使这变得更容易和更可扩展。基本上,所有的事情就是拷贝你的rsyslog配置到每个服务器,然后重启rsyslog使更改生效。
|
||||
|
||||
#### Pssh ####
|
||||
|
||||
这个工具可以让你在很多服务器上并行的运行一个ssh命令。使用pssh部署只有一小部分的服务器。如果你其中一个服务器失败,然后你必须ssh到失败的服务器,然后手动部署。如果你有很多服务器失败,那么手动部署他们会话费很长时间。
|
||||
|
||||
#### Puppet/Chef ####
|
||||
|
||||
Puppet和Chef是两个不同的工具,他们能在你的网络按你规定的标准自动的配置所有服务器。他们的报表工具使你知道关于错误然后定期重新同步。Puppet和Chef有一些狂热的支持者。如果你不确定那个更适合你的部署配置管理,你可以领会一下[InfoWorld上这两个工具的对比][19]
|
||||
|
||||
一些厂商也提供一些配置rsyslog的模块或者方法。这有一个Loggly上Puppet模块的例子。它提供给rsyslog一个类,你可以添加一个标识令牌:
|
||||
|
||||
node 'my_server_node.example.net' {
|
||||
# Send syslog events to Loggly
|
||||
class { 'loggly::rsyslog':
|
||||
customer_token => 'de7b5ccd-04de-4dc4-fbc9-501393600000',
|
||||
}
|
||||
}
|
||||
|
||||
#### Docker ####
|
||||
|
||||
Docker使用容器去运行应用不依赖底层服务。所有东西都从内部的容器运行,你可以想象为一个单元功能。ZDNet有一个深入文章关于在你的数据中心[使用Docker][20]。
|
||||
|
||||
这有很多方式从Docker容器记录日志,包括链接到一个日志容器,记录到一个共享卷,或者直接在容器里添加一个系统日志代理。其中最流行的日志容器叫做[logspout][21]。
|
||||
|
||||
#### 供应商的脚本或代理 ####
|
||||
|
||||
大多数日志管理方案提供一些脚本或者代理,从一个或更多服务器比较简单的发送数据。重量级代理会耗尽额外的系统资源。一些供应商像Loggly提供配置脚本,来使用现存的系统日志程序更轻松。这有一个Loggly上的例子[脚本][22],它能运行在任意数量的服务器上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.loggly.com/ultimate-guide/logging/managing-linux-logs/
|
||||
|
||||
作者:[Jason Skowronski][a1]
|
||||
作者:[Amy Echeverri][a2]
|
||||
作者:[Sadequl Hussain][a3]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a1]:https://www.linkedin.com/in/jasonskowronski
|
||||
[a2]:https://www.linkedin.com/in/amyecheverri
|
||||
[a3]:https://www.linkedin.com/pub/sadequl-hussain/14/711/1a7
|
||||
[1]:https://docs.google.com/document/d/11LXZxWlkNSHkcrCWTUdnLRf_CiZz9kK0cr3yGM_BU_0/edit#heading=h.esrreycnpnbl
|
||||
[2]:http://www.rsyslog.com/
|
||||
[3]:http://www.balabit.com/network-security/syslog-ng/opensource-logging-system
|
||||
[4]:http://logstash.net/
|
||||
[5]:http://www.fluentd.org/
|
||||
[6]:http://www.rsyslog.com/doc/rsyslog_conf.html
|
||||
[7]:http://www.rsyslog.com/doc/master/rainerscript/index.html
|
||||
[8]:https://docs.google.com/document/d/11LXZxWlkNSHkcrCWTUdnLRf_CiZz9kK0cr3yGM_BU_0/edit#heading=h.eck7acdxin87
|
||||
[9]:https://www.loggly.com/docs/file-monitoring/
|
||||
[10]:http://www.networksorcery.com/enp/protocol/udp.htm
|
||||
[11]:http://www.networksorcery.com/enp/protocol/tcp.htm
|
||||
[12]:http://blog.gerhards.net/2008/04/on-unreliability-of-plain-tcp-syslog.html
|
||||
[13]:http://www.rsyslog.com/doc/relp.html
|
||||
[14]:http://www.rsyslog.com/doc/queues.html
|
||||
[15]:http://www.rsyslog.com/doc/tls_cert_ca.html
|
||||
[16]:http://www.rsyslog.com/doc/tls_cert_machine.html
|
||||
[17]:http://www.rsyslog.com/doc/v8-stable/configuration/modules/imuxsock.html
|
||||
[18]:https://www.digitalocean.com/community/tutorials/how-to-manage-log-files-with-logrotate-on-ubuntu-12-10
|
||||
[19]:http://www.infoworld.com/article/2614204/data-center/puppet-or-chef--the-configuration-management-dilemma.html
|
||||
[20]:http://www.zdnet.com/article/what-is-docker-and-why-is-it-so-darn-popular/
|
||||
[21]:https://github.com/progrium/logspout
|
||||
[22]:https://www.loggly.com/docs/sending-logs-unixlinux-system-setup/
|
||||
@ -1,54 +1,54 @@
|
||||
How to Install Snort and Usage in Ubuntu 15.04
|
||||
在Ubuntu 15.04中如何安装和使用Snort
|
||||
================================================================================
|
||||
Intrusion detection in a network is important for IT security. Intrusion Detection System used for the detection of illegal and malicious attempts in the network. Snort is well-known open source intrusion detection system. Web interface (Snorby) can be used for better analysis of alerts. Snort can be used as an intrusion prevention system with iptables/pf firewall. In this article, we will install and configure an open source IDS system snort.
|
||||
对于IT安全而言入侵检测是一件非常重要的事。入侵检测系统用于检测网络中非法与恶意的请求。Snort是一款知名的开源入侵检测系统。Web界面(Snorby)可以用于更好地分析警告。Snort使用iptables/pf防火墙来作为入侵检测系统。本篇中,我们会安装并配置一个开源的IDS系统snort。
|
||||
|
||||
### Snort Installation ###
|
||||
### Snort 安装 ###
|
||||
|
||||
#### Prerequisite ####
|
||||
#### 要求 ####
|
||||
|
||||
Data Acquisition library (DAQ) is used by the snort for abstract calls to packet capture libraries. It is available on snort website. Downloading process is shown in the following screenshot.
|
||||
snort所使用的数据采集库(DAQ)用于抽象地调用采集库。这个在snort上就有。下载过程如下截图所示。
|
||||
|
||||

|
||||
|
||||
Extract it and run ./configure, make and make install commands for DAQ installation. However, DAQ required other tools therefore ./configure script will generate following errors .
|
||||
解压并运行./configure、make、make install来安装DAQ。然而,DAQ要求其他的工具,因此,./configure脚本会生成下面的错误。
|
||||
|
||||
flex and bison error
|
||||
flex和bison错误
|
||||
|
||||

|
||||
|
||||
libpcap error.
|
||||
libpcap错误
|
||||
|
||||

|
||||
|
||||
Therefore first install flex/bison and libcap before DAQ installation which is shown in the figure.
|
||||
因此在安装DAQ之前先安装flex/bison和libcap。
|
||||
|
||||

|
||||
|
||||
Installation of libpcap development library is shown below
|
||||
如下所示安装libpcap开发库
|
||||
|
||||

|
||||
|
||||
After installation of necessary tools, again run ./configure script which will show following output.
|
||||
安装完必要的工具后,再次运行./configure脚本,将会显示下面的输出。
|
||||
|
||||

|
||||
|
||||
make and make install commands result is shown in the following screens.
|
||||
make和make install 命令的结果如下所示。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
After successful installation of DAQ, now we will install snort. Downloading using wget is shown in the below figure.
|
||||
成功安装DAQ之后,我们现在安装snort。如下图使用wget下载它。
|
||||
|
||||

|
||||
|
||||
Extract compressed package using below given command.
|
||||
使用下面的命令解压安装包。
|
||||
|
||||
#tar -xvzf snort-2.9.7.3.tar.gz
|
||||
|
||||

|
||||
|
||||
Create installation directory and set prefix parameter in the configure script. It is also recommended to enable sourcefire flag for Packet Performance Monitoring (PPM).
|
||||
创建安装目录并在脚本中设置prefix参数。同样也建议启用包性能监控(PPM)标志。
|
||||
|
||||
#mkdir /usr/local/snort
|
||||
|
||||
@ -56,21 +56,21 @@ Create installation directory and set prefix parameter in the configure script.
|
||||
|
||||

|
||||
|
||||
Configure script generates error due to missing libpcre-dev , libdumbnet-dev and zlib development libraries.
|
||||
配置脚本由于缺少libpcre-dev、libdumbnet-dev 和zlib开发库而报错。
|
||||
|
||||
error due to missing libpcre library.
|
||||
配置脚本由于缺少libpcre库报错。
|
||||
|
||||

|
||||
|
||||
error due to missing dnet (libdumbnet) library.
|
||||
配置脚本由于缺少dnet(libdumbnet)库而报错。
|
||||
|
||||

|
||||
|
||||
configure script generate error due to missing zlib library.
|
||||
配置脚本由于缺少zlib库而报错
|
||||
|
||||

|
||||
|
||||
Installation of all required development libraries is shown in the next screenshots.
|
||||
如下所示,安装所有需要的开发库。
|
||||
|
||||
# aptitude install libpcre3-dev
|
||||
|
||||
@ -84,9 +84,9 @@ Installation of all required development libraries is shown in the next screensh
|
||||
|
||||

|
||||
|
||||
After installation of above required libraries for snort, again run the configure scripts without any error.
|
||||
安装完snort需要的库之后,再次运行配置脚本就不会报错了。
|
||||
|
||||
Run make & make install commands for the compilation and installations of snort in /usr/local/snort directory.
|
||||
运行make和make install命令在/usr/local/snort目录下完成安装。
|
||||
|
||||
#make
|
||||
|
||||
@ -96,22 +96,22 @@ Run make & make install commands for the compilation and installations of snort
|
||||
|
||||

|
||||
|
||||
Finally snort running from /usr/local/snort/bin directory. Currently it is in promisc mode (packet dump mode) of all traffic on eth0 interface.
|
||||
最终snort在/usr/local/snort/bin中运行。现在它对eth0的所有流量都处在promisc模式(包转储模式)。
|
||||
|
||||

|
||||
|
||||
Traffic dump by the snort interface is shown in following figure.
|
||||
如下图所示snort转储流量。
|
||||
|
||||

|
||||
|
||||
#### Rules and Configuration of Snort ####
|
||||
#### Snort的规则和配置 ####
|
||||
|
||||
Snort installation from source code required rules and configuration setting therefore now we will copy rules and configuration under /etc/snort directory. We have created single bash scripts for rules and configuration setting. It is used for following snort setting.
|
||||
从源码安装的snort需要规则和安装配置,因此我们会从/etc/snort下面复制规则和配置。我们已经创建了单独的bash脚本来用于规则和配置。它会设置下面这些snort设置。
|
||||
|
||||
- Creation of snort user for snort IDS service on linux.
|
||||
- Creation of directories and files under /etc directory for snort configuration.
|
||||
- Permission setting and copying data from etc directory of snort source code.
|
||||
- Remove # (comment sign) from rules path in snort.conf file.
|
||||
- 在linux中创建snort用户用于snort IDS服务。
|
||||
- 在/etc下面创建snort的配置文件和文件夹。
|
||||
- 权限设置并从etc中复制snortsnort源代码
|
||||
- 从snort文件中移除规则中的#(注释符号)。
|
||||
|
||||
#!/bin/bash##PATH of source code of snort
|
||||
snort_src="/home/test/Downloads/snort-2.9.7.3"
|
||||
@ -141,15 +141,15 @@ Snort installation from source code required rules and configuration setting the
|
||||
sed -i 's/include \$RULE\_PATH/#include \$RULE\_PATH/' /etc/snort/snort.conf
|
||||
echo "---DONE---"
|
||||
|
||||
Change the snort source directory in the script and run it. Following output appear in case of success.
|
||||
改变脚本中的snort源目录并运行。下面是成功的输出。
|
||||
|
||||

|
||||
|
||||
Above script copied following files/directories from snort source into /etc/snort configuration file.
|
||||
上面的脚本从snort源中复制下面的文件/文件夹到/etc/snort配置文件中
|
||||
|
||||

|
||||
|
||||
Snort configuration file is very complex however following necessary changes are required in snort.conf for IDS proper working.
|
||||
、snort的配置非常复杂,然而为了IDS能正常工作需要进行下面必要的修改。
|
||||
|
||||
ipvar HOME_NET 192.168.1.0/24 # LAN side
|
||||
|
||||
@ -169,35 +169,35 @@ Snort configuration file is very complex however following necessary changes are
|
||||
|
||||
include $RULE_PATH/local.rules # file for custom rules
|
||||
|
||||
remove comment sign (#) from other rules such as ftp.rules,exploit.rules etc.
|
||||
移除ftp.rules、exploit.rules前面的注释符号(#)。
|
||||
|
||||

|
||||
|
||||
Now [Download community][1] rules and extract under /etc/snort/rules directory. Enable community and emerging threats rules in snort.conf file.
|
||||
下载[下载社区][1]规则并解压到/etc/snort/rules。启用snort.conf中的社区及紧急威胁规则。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Run following command to test the configuration file after above mentioned changes.
|
||||
进行了上面的更改后,运行下面的命令来检验配置文件。
|
||||
|
||||
#snort -T -c /etc/snort/snort.conf
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
### 总结 ###
|
||||
|
||||
In this article our focus was on the installation and configuration of an open source IDPS system snort on Ubuntu distribution. By default it is used for the monitoring of events however it can con configured inline mode for the protection of network. Snort rules can be tested and analysed in offline mode using pcap capture file.
|
||||
本篇中,我们致力于开源IDPS系统snort在Ubuntu上的安装和配置。默认它用于监控时间,然而它可以被配置成用于网络保护的内联模式。snort规则可以在离线模式中可以使用pcap文件测试和分析
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/security/install-snort-usage-ubuntu-15-04/
|
||||
|
||||
作者:[nido][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/naveeda/
|
||||
[1]:https://www.snort.org/downloads/community/community-rules.tar.gz
|
||||
[1]:https://www.snort.org/downloads/community/community-rules.tar.gz
|
||||
@ -1,63 +0,0 @@
|
||||
Ubuntu想要让你安装最新版Nvidia Linux驱动更简单
|
||||
================================================================================
|
||||

|
||||
Ubuntu游戏在增长——因而需要最新版驱动
|
||||
|
||||
**Ubuntu上安装上游NVIDIA图形驱动即将变得更加容易。**
|
||||
|
||||
Ubuntu开发者正在考虑构建一个全新的'官方'PPA,以便为桌面用户分发最新的闭源NVIDIA二进制驱动。
|
||||
|
||||
该项运动将使得Ubuntu游戏玩家收益,并且**不会**给其它人造成OS稳定性方面的风险。
|
||||
|
||||
新的上游驱动将通过该新PPA安装并更新,**只有**在用户明确选择它。其他人将继续接收并使用更近的包含在Ubuntu归档中的稳定版NVIDIA Linux驱动快照。
|
||||
|
||||
### 为什么需要该项目? ###
|
||||
|
||||

|
||||
Ubuntu提供了驱动——但是它们不是最新的
|
||||
|
||||
可以从归档中(使用命令行、synaptic,或者通过额外驱动工具)安装到Ubuntu上的闭源NVIDIA图形驱动在大多数情况下都能工作得很好,并且可以轻松地处理混合Unity桌面shell。
|
||||
|
||||
对于游戏需求而言,那完全是另外一码事儿。
|
||||
|
||||
如果你想要将所有最后帧和HD纹理从最新的大游戏Steam游戏中挤压出来,你需要最新的二进制驱动对象。
|
||||
|
||||
> '安装最新Nvidia Linux驱动到Ubuntu不是件容易的事儿,而且也不具安全保证。'
|
||||
|
||||
驱动越新,越可能支持最新的特性和技术,或者预先打包好了游戏专门优化和漏洞修复。
|
||||
|
||||
问题在于安装最新的Nvidia Linux驱动到Ubuntu上不是件容易的事儿,也没有安全保证。
|
||||
|
||||
要填补空白,许多由热心人维护的第三方PPA就出现了。由于许多这些PPA也发布了其它实验性的或者前沿软件,它们的使用**没有风险**。添加一个前沿的PPA通常是最快的方式,以完全满足系统需要!
|
||||
|
||||
一个让Ubuntu用户安装作为第三方PPA提供最新专有图形驱动解决方案就十分需要了,**但是**提供了一个安全机制,如果有需要,你可以回滚到稳定版本。
|
||||
|
||||
### ‘对全新驱动的需求难以忽视’ ###
|
||||
|
||||
> '一个让Ubuntu用户安全地获得最新硬件驱动的解决方案出现了。'
|
||||
|
||||
'在快速开发市场中,对全新驱动的需求正变得难以忽视,用户将想要最新的上游软件,'卡斯特罗在一封给Ubuntu桌面邮件列表的电子邮件中解释道。
|
||||
|
||||
'[NVIDIA]可以分发一个了不起的体验,几乎像[Windows 10]用户那样毫不费力。直到我们可以证实NVIDIA在Ubuntu中做了同样的工作,我们就可以收拾残局了。'
|
||||
|
||||
卡斯特罗关于一个“神圣的”NVIDIA PPA命题就是最实现这一目的的最容易的方式。
|
||||
|
||||
游戏玩家将可以在Ubuntu的默认专有软件驱动工具中选择接收来自该PPA的新驱动——不需要它们从网站或维基页面拷贝并粘贴终端命令了。
|
||||
|
||||
该PPA内的驱动将由一个选定的社区成员组成的团队打包并维护,并从一个名为**自动化测试**的半官方选项受惠。
|
||||
|
||||
就像卡斯特罗自己说的那样:'人们想要最新的闪光的东西,不管他们想要做什么。我们也许也要在其周围放置一个框架,因此人们可以获得他们所想要的,而不必破坏他们的计算机。'
|
||||
|
||||
**你想要使用这个PPA吗?你怎样来评估Ubuntu上默认Nvidia驱动的性能呢?在评论中分享你的想法吧,伙计们!**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/08/ubuntu-easy-install-latest-nvidia-linux-drivers
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
@ -0,0 +1,167 @@
|
||||
使用dd命令在Linux和Unix环境下进行硬盘I/O性能检测
|
||||
================================================================================
|
||||
如何使用dd命令测试硬盘的性能?如何在linux操作系统下检测硬盘的读写能力?
|
||||
|
||||
你可以使用以下命令在一个Linux或类Unix操作系统上进行简单的I/O性能测试。
|
||||
|
||||
- **dd命令** :它被用来在Linux和类Unix系统下对硬盘设备进行写性能的检测。
|
||||
- **hparm命令**:它被用来获取或设置硬盘参数,包括测试读性能以及缓存性能等。
|
||||
|
||||
在这篇指南中,你将会学到如何使用dd命令来测试硬盘性能。
|
||||
|
||||
### 使用dd命令来监控硬盘的读写性能:###
|
||||
|
||||
- 打开shell终端(这里貌似不能翻译为终端提示符)。
|
||||
- 通过ssh登录到远程服务器。
|
||||
- 使用dd命令来测量服务器的吞吐率(写速度) `dd if=/dev/zero of=/tmp/test1.img bs=1G count=1 oflag=dsync`
|
||||
- 使用dd命令测量服务器延迟 `dd if=/dev/zero of=/tmp/test2.img bs=512 count=1000 oflag=dsync`
|
||||
|
||||
####理解dd命令的选项###
|
||||
|
||||
在这个例子当中,我将使用搭载Ubuntu Linux 14.04 LTS系统的RAID-10(配有SAS SSD的Adaptec 5405Z)服务器阵列来运行。基本语法为:
|
||||
|
||||
dd if=/dev/input.file of=/path/to/output.file bs=block-size count=number-of-blocks oflag=dsync
|
||||
## GNU dd语法 ##
|
||||
dd if=/dev/zero of=/tmp/test1.img bs=1G count=1 oflag=dsync
|
||||
##另外一种GNU dd的语法 ##
|
||||
dd if=/dev/zero of=/tmp/testALT.img bs=1G count=1 conv=fdatasync
|
||||
|
||||
输出样例:
|
||||
|
||||

|
||||
Fig.01: 使用dd命令获取的服务器吞吐率
|
||||
|
||||
请各位注意在这个实验中,我们写入一个G的数据,可以发现,服务器的吞吐率是135 MB/s,这其中
|
||||
|
||||
- `if=/dev/zero (if=/dev/input.file)` :用来设置dd命令读取的输入文件名。
|
||||
- `of=/tmp/test1.img (of=/path/to/output.file)` :dd命令将input.file写入的输出文件的名字。
|
||||
- `bs=1G (bs=block-size)` :设置dd命令读取的块的大小。例子中为1个G。
|
||||
- `count=1 (count=number-of-blocks)`: dd命令读取的块的个数。
|
||||
- `oflag=dsync (oflag=dsync)` :使用同步I/O。不要省略这个选项。这个选项能够帮助你去除caching的影响,以便呈现给你精准的结果。
|
||||
- `conv=fdatasyn`: 这个选项和`oflag=dsync`含义一样。
|
||||
|
||||
在这个例子中,一共写了1000次,每次写入512字节来获得RAID10服务器的延迟时间:
|
||||
|
||||
dd if=/dev/zero of=/tmp/test2.img bs=512 count=1000 oflag=dsync
|
||||
|
||||
输出样例:
|
||||
|
||||
1000+0 records in
|
||||
1000+0 records out
|
||||
512000 bytes (512 kB) copied, 0.60362 s, 848 kB/s
|
||||
|
||||
请注意服务器的吞吐率以及延迟时间也取决于服务器/应用的加载。所以我推荐你在一个刚刚重启过并且处于峰值时间的服务器上来运行测试,以便得到更加准确的度量。现在你可以在你的所有设备上互相比较这些测试结果了。
|
||||
|
||||
####为什么服务器的吞吐率和延迟时间都这么差?###
|
||||
|
||||
低的数值并不意味着你在使用差劲的硬件。可能是HARDWARE RAID10的控制器缓存导致的。
|
||||
|
||||
使用hdparm命令来查看硬盘缓存的读速度。
|
||||
|
||||
我建议你运行下面的命令2-3次来对设备读性能进行检测,以作为参照和相互比较:
|
||||
|
||||
### 有缓存的硬盘读性能测试——/dev/sda ###
|
||||
hdparm -t /dev/sda1
|
||||
## 或者 ##
|
||||
hdparm -t /dev/sda
|
||||
|
||||
然后运行下面这个命令2-3次来对缓存的读性能进行对照性检测:
|
||||
|
||||
## Cache读基准——/dev/sda ###
|
||||
hdparm -T /dev/sda1
|
||||
## 或者 ##
|
||||
hdparm -T /dev/sda
|
||||
|
||||
或者干脆把两个测试结合起来:
|
||||
|
||||
hdparm -Tt /dev/sda
|
||||
|
||||
输出样例:
|
||||
|
||||

|
||||
Fig.02: 检测硬盘读入以及缓存性能的Linux hdparm命令
|
||||
|
||||
请再一次注意由于文件文件操作的缓存属性,你将总是会看到很高的读速度。
|
||||
|
||||
**使用dd命令来测试读入速度**
|
||||
|
||||
为了获得精确的读测试数据,首先在测试前运行下列命令,来将缓存设置为无效:
|
||||
|
||||
flush
|
||||
echo 3 | sudo tee /proc/sys/vm/drop_caches
|
||||
time time dd if=/path/to/bigfile of=/dev/null bs=8k
|
||||
|
||||
**笔记本上的示例**
|
||||
|
||||
运行下列命令:
|
||||
|
||||
### Cache存在的Debian系统笔记本吞吐率###
|
||||
dd if=/dev/zero of=/tmp/laptop.bin bs=1G count=1 oflag=direct
|
||||
|
||||
###使cache失效###
|
||||
hdparm -W0 /dev/sda
|
||||
|
||||
###没有Cache的Debian系统笔记本吞吐率###
|
||||
dd if=/dev/zero of=/tmp/laptop.bin bs=1G count=1 oflag=direct
|
||||
|
||||
**苹果OS X Unix(Macbook pro)的例子**
|
||||
|
||||
GNU dd has many more options but OS X/BSD and Unix-like dd command need to run as follows to test real disk I/O and not memory add sync option as follows:
|
||||
GNU dd命令有其他许多选项但是在 OS X/BSD 以及类Unix中, dd命令需要像下面那样执行来检测去除掉内存地址同步的硬盘真实I/O性能:
|
||||
|
||||
## 运行这个命令2-3次来获得更好地结果 ###
|
||||
time sh -c "dd if=/dev/zero of=/tmp/testfile bs=100k count=1k && sync"
|
||||
|
||||
输出样例:
|
||||
|
||||
1024+0 records in
|
||||
1024+0 records out
|
||||
104857600 bytes transferred in 0.165040 secs (635346520 bytes/sec)
|
||||
|
||||
real 0m0.241s
|
||||
user 0m0.004s
|
||||
sys 0m0.113s
|
||||
|
||||
本人Macbook Pro的写速度是635346520字节(635.347MB/s)。
|
||||
|
||||
**不喜欢用命令行?^_^**
|
||||
|
||||
你可以在Linux或基于Unix的系统上使用disk utility(gnome-disk-utility)这款工具来得到同样的信息。下面的那个图就是在我的Fedora Linux v22 VM上截取的。
|
||||
|
||||
**图形化方法**
|
||||
|
||||
点击“Activites”或者“Super”按键来在桌面和Activites视图间切换。输入“Disks”
|
||||
|
||||

|
||||
Fig.03: 打开Gnome硬盘工具
|
||||
|
||||
在左边的面板上选择你的硬盘,点击configure按钮,然后点击“Benchmark partition”:
|
||||
|
||||

|
||||
Fig.04: 评测硬盘/分区
|
||||
|
||||
最后,点击“Start Benchmark...”按钮(你可能被要求输入管理员用户名和密码):
|
||||
|
||||

|
||||
Fig.05: 最终的评测结果
|
||||
|
||||
如果你要问,我推荐使用哪种命令和方法?
|
||||
|
||||
- 我推荐在所有的类Unix系统上使用dd命令(`time sh -c "dd if=/dev/zero of=/tmp/testfile bs=100k count=1k && sync`)
|
||||
- 如果你在使用GNU/Linux,使用dd命令 (`dd if=/dev/zero of=/tmp/testALT.img bs=1G count=1 conv=fdatasync`)
|
||||
- 确保你每次使用时,都调整了count以及bs参数以获得更好的结果。
|
||||
- GUI方法只适合桌面系统为Gnome2或Gnome3的Linux/Unix笔记本用户。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/howto-linux-unix-test-disk-performance-with-dd-command/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,227 @@
|
||||
RHCE 系列第一部分:如何设置和测试静态网络路由
|
||||
================================================================================
|
||||
RHCE(Red Hat Certified Engineer,红帽认证工程师)是红帽公司的一个认证,红帽向企业社区贡献开源操作系统和软件,同时它还给公司提供训练、支持和咨询服务。
|
||||
|
||||

|
||||
|
||||
RHCE 考试准备指南
|
||||
|
||||
这个 RHCE 是基于性能的考试(代号 EX300),面向那些拥有更多的技能、知识和能力的红帽企业版 Linux(RHEL)系统高级系统管理员。
|
||||
|
||||
**重要**: [红帽认证系统管理员][1] (Red Hat Certified System Administrator,RHCSA)认证要求先有 RHCE 认证。
|
||||
|
||||
以下是基于红帽企业版 Linux 7 考试的考试目标,我们会在该 RHCE 系列中分别介绍:
|
||||
|
||||
- 第一部分:如何在 RHEL 7 中设置和测试静态路由
|
||||
- 第二部分:如果进行包过滤、网络地址转换和设置内核运行时参数
|
||||
- 第三部分:如果使用 Linux 工具集产生和发送系统活动报告
|
||||
- 第四部分:使用 Shell 脚本进行自动化系统维护
|
||||
- 第五部分:如果配置本地和远程系统日志
|
||||
- 第六部分:如果配置一个 Samba 服务器或 NFS 服务器(译者注:Samba 是在 Linux 和 UNI X系统上实现 SMB 协议的一个免费软件,由服务器及客户端程序构成。SMB,Server Messages Block,信息服务块,是一种在局域网上共享文件和打印机的一种通信协议,它为局域网内的不同计算机之间提供文件及打印机等资源的共享服务。)
|
||||
- 第七部分:为收发邮件配置完整的 SMTP 服务器
|
||||
- 第八部分:在 RHEL 7 上设置 HTTPS 和 TLS
|
||||
- 第九部分:设置网络时间协议
|
||||
- 第十部分:如何配置一个 Cache-Only DNS 服务器
|
||||
|
||||
在你的国家查看考试费用和注册考试,可以到 [RHCE 认证][2] 网页。
|
||||
|
||||
在 RHCE 的第一和第二部分,我们会介绍一些基本的但典型的情形,也就是静态路由原理、包过滤和网络地址转换。
|
||||
|
||||

|
||||
|
||||
RHCE 系列第一部分:设置和测试网络静态路由
|
||||
|
||||
请注意我们不会作深入的介绍,但以这种方式组织内容能帮助你开始第一步并继续后面的内容。
|
||||
|
||||
### 红帽企业版 Linux 7 中的静态路由 ###
|
||||
|
||||
现代网络的一个奇迹就是有很多可用的设备能将一组计算机连接起来,不管是在一个房间里少量的机器还是在一栋建筑物、城市、国家或者大洲之间的多台机器。
|
||||
|
||||
然而,为了能在任意情形下有效的实现这些,需要对网络包进行路由,或者换句话说,它们从源到目的地的路径需要按照某种规则。
|
||||
|
||||
静态路由是为网络包指定一个路由的过程,而不是使用网络设备提供的默认网关。除非另有指定,否则通过路由,网络包会被导向默认网关;基于预定义的标准,例如数据包目的地,使用静态路由可以定义其它路径。
|
||||
|
||||
我们在该篇指南中会考虑以下场景。我们有一台红帽企业版 Linux 7,连接到路由器 1号 [192.168.0.1] 以访问因特网以及 192.168.0.0/24 中的其它机器。
|
||||
|
||||
第二个路由器(路由器 2号)有两个网卡:enp0s3 同样通过网络连接到路由器 1号,以便连接RHEL 7 以及相同网络中的其它机器,另外一个网卡(enp0s8)用于授权访问内部服务所在的 10.0.0.0/24 网络,例如 web 或数据库服务器。
|
||||
|
||||
该场景可以用下面的示意图表示:
|
||||
|
||||

|
||||
|
||||
静态路由网络示意图
|
||||
|
||||
在这篇文章中我们会集中介绍在 RHEL 7 中设置路由表,确保它能通过路由器 1号访问因特网以及通过路由器 2号访问内部网络。
|
||||
|
||||
在 RHEL 7 中,你会通过命令行用 [命令 ip][3] 配置和显示设备和路由。这些更改能在运行的系统中及时生效,但由于重启后不会保存,我们会使用 /etc/sysconfig/network-scripts 目录下的 ifcfg-enp0sX 和 route-enp0sX 文件永久保存我们的配置。
|
||||
|
||||
首先,让我们打印出当前的路由表:
|
||||
|
||||
# ip route show
|
||||
|
||||

|
||||
|
||||
检查当前路由表
|
||||
|
||||
从上面的输出中,我们可以得出以下结论:
|
||||
|
||||
- 默认网关的 IP 是 192.168.0.1,可以通过网卡 enp0s3 访问。
|
||||
- 系统启动的时候,它启用了到 169.254.0.0/16 的 zeroconf 路由(只是在本例中)。也就是说,如果机器设置为通过 DHCP 获取一个 IP 地址,但是由于某些原因失败了,它就会在该网络中自动分配到一个地址。这一行的意思是,该路由会允许我们通过 enp0s3 和其它没有从 DHCP 服务器中成功获得 IP 地址的机器机器连接。
|
||||
- 最后,但同样重要的是,我们也可以通过 IP 地址是 192.168.0.18 的 enp0s3 和 192.168.0.0/24 网络中的其它机器连接。
|
||||
|
||||
下面是这样的配置中你需要做的一些典型任务。除非另有说明,下面的任务都在路由器 2号上进行。
|
||||
|
||||
确保正确安装了所有网卡:
|
||||
|
||||
# ip link show
|
||||
|
||||
如果有某块网卡停用了,启动它:
|
||||
|
||||
# ip link set dev enp0s8 up
|
||||
|
||||
分配 10.0.0.0/24 网络中的一个 IP 地址给它:
|
||||
|
||||
# ip addr add 10.0.0.17 dev enp0s8
|
||||
|
||||
噢!我们分配了一个错误的 IP 地址。我们需要删除之前分配的那个并添加正确的地址(10.0.0.18):
|
||||
|
||||
# ip addr del 10.0.0.17 dev enp0s8
|
||||
# ip addr add 10.0.0.18 dev enp0s8
|
||||
|
||||
现在,请注意你只能添加一个通过已经能访问的网关到目标网络的路由。因为这个原因,我们需要在 192.168.0.0/24 范围中给 enp0s3 分配一个 IP 地址,这样我们的 RHEL 7 才能连接到它:
|
||||
|
||||
# ip addr add 192.168.0.19 dev enp0s3
|
||||
|
||||
最后,我们需要启用包转发:
|
||||
|
||||
# echo "1" > /proc/sys/net/ipv4/ip_forward
|
||||
|
||||
并停用/取消防火墙(从现在开始,直到下一篇文章中我们介绍了包过滤):
|
||||
|
||||
# systemctl stop firewalld
|
||||
# systemctl disable firewalld
|
||||
|
||||
回到我们的 RHEL 7(192.168.0.18),让我们配置一个通过 192.168.0.19(路由器 2号的 enp0s3)到 10.0.0.0/24 的路由:
|
||||
|
||||
# ip route add 10.0.0.0/24 via 192.168.0.19
|
||||
|
||||
之后,路由表看起来像下面这样:
|
||||
|
||||
# ip route show
|
||||
|
||||

|
||||
|
||||
确认网络路由表
|
||||
|
||||
同样,在你尝试连接的 10.0.0.0/24 网络的机器中添加对应的路由:
|
||||
|
||||
# ip route add 192.168.0.0/24 via 10.0.0.18
|
||||
|
||||
你可以使用 ping 测试基本连接:
|
||||
|
||||
在 RHEL 7 中运行:
|
||||
|
||||
# ping -c 4 10.0.0.20
|
||||
|
||||
10.0.0.20 是 10.0.0.0/24 网络中一个 web 服务器的 IP 地址。
|
||||
|
||||
在 web 服务器(10.0.0.20)中运行
|
||||
|
||||
# ping -c 192.168.0.18
|
||||
|
||||
192.168.0.18 也就是我们的 RHEL 7 机器的 IP 地址。
|
||||
|
||||
另外,我们还可以使用 [tcpdump][4](需要通过 yum install tcpdump 安装)来检查我们 RHEL 7 和 10.0.0.20 中 web 服务器之间的 TCP 双向通信。
|
||||
|
||||
首先在第一台机器中启用日志:
|
||||
|
||||
# tcpdump -qnnvvv -i enp0s3 host 10.0.0.20
|
||||
|
||||
在同一个系统上的另一个终端,让我们通过 telnet 连接到 web 服务器的 80 号端口(假设 Apache 正在监听该端口;否则在下面命令中使用正确的端口):
|
||||
|
||||
# telnet 10.0.0.20 80
|
||||
|
||||
tcpdump 日志看起来像下面这样:
|
||||
|
||||

|
||||
|
||||
检查服务器之间的网络连接
|
||||
|
||||
通过查看我们 RHEL 7(192.168.0.18)和 web 服务器(10.0.0.20)之间的双向通信,可以看出已经正确地初始化了连接。
|
||||
|
||||
请注意你重启系统后会丢失这些更改。如果你想把它们永久保存下来,你需要在我们运行上面的命令的相同系统中编辑(如果不存在的话就创建)以下的文件。
|
||||
|
||||
尽管对于我们的测试例子不是严格要求,你需要知道 /etc/sysconfig/network 包含了一些系统范围的网络参数。一个典型的 /etc/sysconfig/network 看起来类似下面这样:
|
||||
|
||||
# Enable networking on this system?
|
||||
NETWORKING=yes
|
||||
# Hostname. Should match the value in /etc/hostname
|
||||
HOSTNAME=yourhostnamehere
|
||||
# Default gateway
|
||||
GATEWAY=XXX.XXX.XXX.XXX
|
||||
# Device used to connect to default gateway. Replace X with the appropriate number.
|
||||
GATEWAYDEV=enp0sX
|
||||
|
||||
当需要为每个网卡设置特定的变量和值时(正如我们在路由器 2号上面做的),你需要编辑 /etc/sysconfig/network-scripts/ifcfg-enp0s3 和 /etc/sysconfig/network-scripts/ifcfg-enp0s8 文件。
|
||||
|
||||
下面是我们的例子,
|
||||
|
||||
TYPE=Ethernet
|
||||
BOOTPROTO=static
|
||||
IPADDR=192.168.0.19
|
||||
NETMASK=255.255.255.0
|
||||
GATEWAY=192.168.0.1
|
||||
NAME=enp0s3
|
||||
ONBOOT=yes
|
||||
|
||||
以及
|
||||
|
||||
TYPE=Ethernet
|
||||
BOOTPROTO=static
|
||||
IPADDR=10.0.0.18
|
||||
NETMASK=255.255.255.0
|
||||
GATEWAY=10.0.0.1
|
||||
NAME=enp0s8
|
||||
ONBOOT=yes
|
||||
|
||||
分别对应 enp0s3 和 enp0s8。
|
||||
|
||||
由于要为我们的客户端机器(192.168.0.18)进行路由,我们需要编辑 /etc/sysconfig/network-scripts/route-enp0s3:
|
||||
|
||||
10.0.0.0/24 via 192.168.0.19 dev enp0s3
|
||||
|
||||
现在重启系统你可以在路由表中看到该路由规则。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇文章中我们介绍了红帽企业版 Linux 7 的静态路由。尽管场景可能不同,这里介绍的例子说明了所需的原理以及进行该任务的步骤。结束之前,我还建议你看一下 Linux 文档项目中 [第四章 4][5] 保护和优化 Linux 部分,以了解这里介绍主题的更详细内容。
|
||||
|
||||
免费电子书 Securing & Optimizing Linux: The Hacking Solution (v.3.0) - 这本 800 多页的电子书全面收集了 Linux 安全的小技巧以及如果安全和简便的使用它们去配置基于 Linux 的应用和服务。
|
||||
|
||||

|
||||
|
||||
Linux 安全和优化
|
||||
|
||||
[马上下载][6]
|
||||
|
||||
在下篇文章中我们会介绍数据包过滤和网络地址转换,结束 RHCE 验证需要的网络基本技巧。
|
||||
|
||||
如往常一样,我们期望听到你的回复,用下面的表格留下你的疑问、评论和建议吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/how-to-setup-and-configure-static-network-routing-in-rhel/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
[2]:https://www.redhat.com/en/services/certification/rhce
|
||||
[3]:http://www.tecmint.com/ip-command-examples/
|
||||
[4]:http://www.tecmint.com/12-tcpdump-commands-a-network-sniffer-tool/
|
||||
[5]:http://www.tldp.org/LDP/solrhe/Securing-Optimizing-Linux-RH-Edition-v1.3/net-manage.html
|
||||
[6]:http://tecmint.tradepub.com/free/w_opeb01/prgm.cgi
|
||||
@ -0,0 +1,175 @@
|
||||
RHCE 第二部分 - 如何进行包过滤、网络地址转换和设置内核运行时参数
|
||||
================================================================================
|
||||
正如第一部分(“[设置静态网络路由][1]”)承诺的,在这篇文章(RHCE 系列第二部分),我们首先介绍红帽企业版 Linux 7中包过滤和网络地址转换原理,然后再介绍某些条件发送变化或者需要激活时设置运行时内核参数以改变运行时内核行为。
|
||||
|
||||

|
||||
|
||||
RHCE 第二部分:网络包过滤
|
||||
|
||||
### RHEL 7 中的网络包过滤 ###
|
||||
|
||||
当我们讨论数据包过滤的时候,我们指防火墙读取每个尝试通过它的数据包的包头所进行的处理。然后,根据系统管理员之前定义的规则,通过采取所要求的动作过滤数据包。
|
||||
|
||||
正如你可能知道的,从 RHEL 7 开始,管理防火墙的默认服务是 [firewalld][2]。类似 iptables,它和 Linux 内核的 netfilter 模块交互以便检查和操作网络数据包。不像 iptables,Firewalld 的更新可以立即生效,而不用中断活跃的连接 - 你甚至不需要重启服务。
|
||||
|
||||
Firewalld 的另一个优势是它允许我们定义基于预配置服务名称的规则(之后会详细介绍)。
|
||||
|
||||
在第一部分,我们用了下面的场景:
|
||||
|
||||

|
||||
|
||||
静态路由网络示意图
|
||||
|
||||
然而,你应该记得,由于还没有介绍包过滤,为了简化例子,我们停用了路由器 2号 的防火墙。现在让我们来看看如何可以使接收的数据包发送到目的地的特定服务或端口。
|
||||
|
||||
首先,让我们添加一条永久规则允许从 enp0s3 (192.168.0.19) 到 enp0s8 (10.0.0.18) 的绑定流量:
|
||||
|
||||
# firewall-cmd --permanent --direct --add-rule ipv4 filter FORWARD 0 -i enp0s3 -o enp0s8 -j ACCEPT
|
||||
|
||||
上面的命令会把规则保存到 /etc/firewalld/direct.xml:
|
||||
|
||||
# cat /etc/firewalld/direct.xml
|
||||
|
||||

|
||||
|
||||
检查 Firewalld 保存的规则
|
||||
|
||||
然后启用规则使其立即生效:
|
||||
|
||||
# firewall-cmd --direct --add-rule ipv4 filter FORWARD 0 -i enp0s3 -o enp0s8 -j ACCEPT
|
||||
|
||||
现在你可以从 RHEL 7 中通过 telnet 登录到 web 服务器并再次运行 [tcpdump][3] 监视两台机器之间的 TCP 流量,这次路由器 2号已经启用了防火墙。
|
||||
|
||||
# telnet 10.0.0.20 80
|
||||
# tcpdump -qnnvvv -i enp0s3 host 10.0.0.20
|
||||
|
||||
如果你想只允许从 192.168.0.18 到 web 服务器(80 号端口)的连接而阻塞 192.168.0.0/24 网络中的其它来源呢?
|
||||
|
||||
在 web 服务器的防火墙中添加以下规则:
|
||||
|
||||
# firewall-cmd --add-rich-rule 'rule family="ipv4" source address="192.168.0.18/24" service name="http" accept'
|
||||
# firewall-cmd --add-rich-rule 'rule family="ipv4" source address="192.168.0.18/24" service name="http" accept' --permanent
|
||||
# firewall-cmd --add-rich-rule 'rule family="ipv4" source address="192.168.0.0/24" service name="http" drop'
|
||||
# firewall-cmd --add-rich-rule 'rule family="ipv4" source address="192.168.0.0/24" service name="http" drop' --permanent
|
||||
|
||||
现在你可以从 192.168.0.18 和 192.168.0.0/24 中的其它机器发送到 web 服务器的 HTTP 请求。第一种情况连接会成功完成,但第二种情况最终会超时。
|
||||
|
||||
任何下面的命令可以验证这个结果:
|
||||
|
||||
# telnet 10.0.0.20 80
|
||||
# wget 10.0.0.20
|
||||
|
||||
我强烈建议你看看 Fedora Project Wiki 中的 [Firewalld Rich Language][4] 文档更详细地了解关于富规则的内容。
|
||||
|
||||
### RHEL 7 中的网络地址转换 ###
|
||||
|
||||
网络地址转换(NAT)是为专用网络中的一组计算机(也可能是其中的一台)分配一个独立的公共 IP 地址的过程。结果,在内部网络中仍然可以用它们自己的私有 IP 地址区别,但外部“看来”它们是一样的。
|
||||
|
||||
另外,网络地址转换使得内部网络中的计算机发送请求到外部资源(例如因特网)然后只有源系统能接收到对应的响应成为可能。
|
||||
|
||||
现在让我们考虑下面的场景:
|
||||
|
||||

|
||||
|
||||
网络地址转换
|
||||
|
||||
在路由器 2 中,我们会把 enp0s3 接口移动到外部区域,enp0s8 到内部区域,伪装或者说 NAT 默认是启用的:
|
||||
|
||||
# firewall-cmd --list-all --zone=external
|
||||
# firewall-cmd --change-interface=enp0s3 --zone=external
|
||||
# firewall-cmd --change-interface=enp0s3 --zone=external --permanent
|
||||
# firewall-cmd --change-interface=enp0s8 --zone=internal
|
||||
# firewall-cmd --change-interface=enp0s8 --zone=internal --permanent
|
||||
|
||||
对于我们当前的设置,内部区域 - 以及和它一起启用的任何东西都是默认区域:
|
||||
|
||||
# firewall-cmd --set-default-zone=internal
|
||||
|
||||
下一步,让我们重载防火墙规则并保持状态信息:
|
||||
|
||||
# firewall-cmd --reload
|
||||
|
||||
最后,在 web 服务器中添加路由器 2 为默认网关:
|
||||
|
||||
# ip route add default via 10.0.0.18
|
||||
|
||||
现在你会发现在 web 服务器中你可以 ping 路由器 1 和外部网站(例如 tecmint.com):
|
||||
|
||||
# ping -c 2 192.168.0.1
|
||||
# ping -c 2 tecmint.com
|
||||
|
||||

|
||||
|
||||
验证网络路由
|
||||
|
||||
### 在 RHEL 7 中设置内核运行时参数 ###
|
||||
|
||||
在 Linux 中,允许你更改、启用以及停用内核运行时参数,RHEL 也不例外。/proc/sys 接口允许你当操作条件发生变化时实时设置运行时参数以改变系统行为而不需太多麻烦。
|
||||
|
||||
为了实现这个目的,会用内建的 echo shell 写 /proc/sys/<category\> 中的文件,其中 <category\> 很可能是以下目录中的一个:
|
||||
|
||||
- dev: 连接到机器中的特定设备的参数。
|
||||
- fs: 文件系统配置(例如 quotas 和 inodes)。
|
||||
- kernel: 内核配置。
|
||||
- net: 网络配置。
|
||||
- vm: 内核虚拟内存的使用。
|
||||
|
||||
要显示所有当前可用值的列表,运行
|
||||
|
||||
# sysctl -a | less
|
||||
|
||||
在第一部分中,我们通过以下命令改变了 net.ipv4.ip_forward 参数的值以允许 Linux 机器作为一个路由器。
|
||||
|
||||
# echo 1 > /proc/sys/net/ipv4/ip_forward
|
||||
|
||||
另一个你可能想要设置的运行时参数是 kernel.sysrq,它会启用你键盘上的 Sysrq 键,以使系统更好的运行一些底层函数,例如如果由于某些原因冻结了后重启系统:
|
||||
|
||||
# echo 1 > /proc/sys/kernel/sysrq
|
||||
|
||||
要显示特定参数的值,可以按照下面方式使用 sysctl:
|
||||
|
||||
# sysctl <parameter.name>
|
||||
|
||||
例如,
|
||||
|
||||
# sysctl net.ipv4.ip_forward
|
||||
# sysctl kernel.sysrq
|
||||
|
||||
一些参数,例如上面提到的一个,只需要一个值,而其它一些(例如 fs.inode-state)要求多个值:
|
||||
|
||||

|
||||
|
||||
查看内核参数
|
||||
|
||||
不管什么情况下,做任何更改之前你都需要阅读内核文档。
|
||||
|
||||
请注意系统重启后这些设置会丢失。要使这些更改永久生效,我们需要添加内容到 /etc/sysctl.d 目录的 .conf 文件,像下面这样:
|
||||
|
||||
# echo "net.ipv4.ip_forward = 1" > /etc/sysctl.d/10-forward.conf
|
||||
|
||||
(其中数字 10 表示相对同一个目录中其它文件的处理顺序)。
|
||||
|
||||
并用下面命令启用更改
|
||||
|
||||
# sysctl -p /etc/sysctl.d/10-forward.conf
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇指南中我们解释了基本的包过滤、网络地址变换和在运行的系统中设置内核运行时参数并使重启后能持久化。我希望这些信息能对你有用,如往常一样,我们期望收到你的回复!
|
||||
别犹豫,在下面的表格中和我们分享你的疑问、评论和建议吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/perform-packet-filtering-network-address-translation-and-set-kernel-runtime-parameters-in-rhel/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/how-to-setup-and-configure-static-network-routing-in-rhel/
|
||||
[2]:http://www.tecmint.com/firewalld-rules-for-centos-7/
|
||||
[3]:http://www.tecmint.com/12-tcpdump-commands-a-network-sniffer-tool/
|
||||
[4]:https://fedoraproject.org/wiki/Features/FirewalldRichLanguage
|
||||
@ -0,0 +1,182 @@
|
||||
RHCE 第三部分 - 如何使用 Linux 工具集产生和发送系统活动报告
|
||||
================================================================================
|
||||
作为一个系统工程师,你经常需要生成一些显示系统资源利用率的报告,以便确保:1)正最佳利用它们,2)防止出现瓶颈,3)确保可扩展性,以及其它原因。
|
||||
|
||||

|
||||
|
||||
RHCE 第三部分:监视 Linux 性能活动报告
|
||||
|
||||
除了著名的用于检测磁盘、内存和 CPU 使用率的原生 Linux 工具 - 可以给出很多例子,红帽企业版 Linux 7 还提供了两个额外的工具集用于为你的报告增加可以收集的数据:sysstat 和 dstat。
|
||||
|
||||
在这篇文章中,我们会介绍两者,但首先让我们来回顾一下传统工具的使用。
|
||||
|
||||
### 原生 Linux 工具 ###
|
||||
|
||||
使用 df,你可以报告磁盘空间以及文件系统的 inode 使用情况。你需要监视两者,因为缺少磁盘空间会阻止你保存更多文件(甚至会导致系统崩溃),就像耗尽 inode 意味着你不能将文件链接到对应的数据结构,从而导致同样的结果:你不能将那些文件保存到磁盘中。
|
||||
|
||||
# df -h [以人类可读形式显示输出]
|
||||
# df -h --total [生成总计]
|
||||
|
||||

|
||||
|
||||
检查 Linux 总的磁盘使用
|
||||
|
||||
# df -i [显示文件系统的 inode 数目]
|
||||
# df -i --total [生成总计]
|
||||
|
||||

|
||||
|
||||
检查 Linux 总的 inode 数目
|
||||
|
||||
用 du,你可以估计文件、目录或文件系统的文件空间使用。
|
||||
|
||||
举个例子,让我们来看看 /home 目录使用了多少空间,它包括了所有用户的个人文件。第一条命令会返回整个 /home 目录当前使用的所有空间,第二条命令会显示子目录的分类列表:
|
||||
|
||||
# du -sch /home
|
||||
# du -sch /home/*
|
||||
|
||||

|
||||
|
||||
检查 Linux 目录磁盘大小
|
||||
|
||||
别错过了:
|
||||
|
||||
- [检查 Linux 磁盘空间使用的 12 个 ‘df’ 命令例子][1]
|
||||
- [查看文件/目录磁盘使用的 10 个 ‘du’ 命令例子][2]
|
||||
|
||||
另一个你工具集中不容忽视的工具就是 vmstat。它允许你查看进程、CPU 和 内存使用、磁盘活动以及其它的大概信息。
|
||||
|
||||
如果不带参数运行,vmstat 会返回自从上一次启动后的平均信息。尽管你可能以这种方式使用该命令有一段时间了,再看一些系统使用率的例子会有更多帮助,例如在例子中定义了时间间隔。
|
||||
|
||||
例如
|
||||
|
||||
# vmstat 5 10
|
||||
|
||||
会每个 5 秒返回 10 个事例:
|
||||
|
||||

|
||||
|
||||
检查 Linux 系统性能
|
||||
|
||||
正如你从上面图片看到的,vmstat 的输出分为很多列:proc(process)、memory、swap、io、system、和 CPU。每个字段的意义可以在 vmstat man 手册的 FIELD DESCRIPTION 部分找到。
|
||||
|
||||
在哪里 vmstat 可以派上用场呢?让我们在 yum 升级之前和升级时检查系统行为:
|
||||
|
||||
# vmstat -a 1 5
|
||||
|
||||

|
||||
|
||||
Vmstat Linux 性能监视
|
||||
|
||||
请注意当磁盘上的文件被更改时,活跃内存的数量增加,写到磁盘的块数目(bo)和属于用户进程的 CPU 时间(us)也是这样。
|
||||
|
||||
或者一个保存大文件到磁盘时(dsync 引发):
|
||||
|
||||
# vmstat -a 1 5
|
||||
# dd if=/dev/zero of=dummy.out bs=1M count=1000 oflag=dsync
|
||||
|
||||

|
||||
|
||||
Vmstat Linux 磁盘性能监视
|
||||
|
||||
在这个例子中,我们可以看到很大数目的块被写入到磁盘(bo),这正如预期的那样,同时 CPU 处理任务之前等待 IO 操作完成的时间(wa)也增加了。
|
||||
|
||||
**别错过**: [Vmstat – Linux 性能监视][3]
|
||||
|
||||
### 其它 Linux 工具 ###
|
||||
|
||||
正如本文介绍部分提到的,这里有其它的工具你可以用来检测系统状态和利用率(不仅红帽,其它主流发行版的官方支持库中也提供了这些工具)。
|
||||
|
||||
sysstat 软件包包含以下工具:
|
||||
|
||||
- sar (收集、报告、或者保存系统活动信息)。
|
||||
- sadf (以多种方式显式 sar 收集的数据)。
|
||||
- mpstat (报告处理器相关的统计信息)。
|
||||
- iostat (报告 CPU 统计信息和设备以及分区的 IO统计信息)。
|
||||
- pidstat (报告 Linux 任务统计信息)。
|
||||
- nfsiostat (报告 NFS 的输出/输出统计信息)。
|
||||
- cifsiostat (报告 CIFS 统计信息)
|
||||
- sa1 (收集并保存系统活动日常文件的二进制数据)。
|
||||
- sa2 (在 /var/log/sa 目录写每日报告)。
|
||||
|
||||
dstat 为这些工具提供的功能添加了一些额外的特性,以及更多的计数器和更大的灵活性。你可以通过运行 yum info sysstat 或者 yum info dstat 找到每个工具完整的介绍,或者安装完成后分别查看每个工具的 man 手册。
|
||||
|
||||
安装两个软件包:
|
||||
|
||||
# yum update && yum install sysstat dstat
|
||||
|
||||
sysstat 主要的配置文件是 /etc/sysconfig/sysstat。你可以在该文件中找到下面的参数:
|
||||
|
||||
# How long to keep log files (in days).
|
||||
# If value is greater than 28, then log files are kept in
|
||||
# multiple directories, one for each month.
|
||||
HISTORY=28
|
||||
# Compress (using gzip or bzip2) sa and sar files older than (in days):
|
||||
COMPRESSAFTER=31
|
||||
# Parameters for the system activity data collector (see sadc manual page)
|
||||
# which are used for the generation of log files.
|
||||
SADC_OPTIONS="-S DISK"
|
||||
# Compression program to use.
|
||||
ZIP="bzip2"
|
||||
|
||||
sysstat 安装完成后,/etc/cron.d/sysstat 中会添加和启用两个 cron 作业。第一个作业每 10 分钟运行系统活动计数工具并在 /var/log/sa/saXX 中保存报告,其中 XX 是该月的一天。
|
||||
|
||||
因此,/var/log/sa/sa05 会包括该月份第 5 天所有的系统活动报告。这里假设我们在上面的配置文件中对 HISTORY 变量使用默认的值:
|
||||
|
||||
*/10 * * * * root /usr/lib64/sa/sa1 1 1
|
||||
|
||||
第二个作业在每天夜间 11:53 生成每日进程计数总结并把它保存到 /var/log/sa/sarXX 文件,其中 XX 和之前例子中的含义相同:
|
||||
|
||||
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||
|
||||
例如,你可能想要输出该月份第 6 天从上午 9:30 到晚上 5:30 的系统统计信息到一个 LibreOffice Calc 或 Microsoft Excel 可以查看的 .csv 文件(它也允许你创建表格和图片):
|
||||
|
||||
# sadf -s 09:30:00 -e 17:30:00 -dh /var/log/sa/sa06 -- | sed 's/;/,/g' > system_stats20150806.csv
|
||||
|
||||
你可以在上面的 sadf 命令中用 -j 标记代替 -d 以 JSON 格式输出系统统计信息,这当你在 web 应用中使用这些数据的时候非常有用。
|
||||
|
||||

|
||||
|
||||
Linux 系统统计信息
|
||||
|
||||
最后,让我们看看 dstat 提供什么功能。请注意如果不带参数运行,dstat 默认使用 -cdngy(表示 CPU、磁盘、网络、内存页、和系统统计信息),并每秒添加一行(可以在任何时候用 Ctrl + C 中断执行):
|
||||
|
||||
# dstat
|
||||
|
||||

|
||||
|
||||
Linux 磁盘统计检测
|
||||
|
||||
要输出统计信息到 .csv 文件,可以用 -output 标记后面跟一个文件名称。让我们来看看在 LibreOffice Calc 中该文件看起来是怎样的:
|
||||
|
||||

|
||||
|
||||
检测 Linux 统计信息输出
|
||||
|
||||
我强烈建议你查看 dstat 的 man 手册,为了方便你的阅读用 PDF 格式包括本文以及 sysstat 的 man 手册。你会找到其它能帮助你创建自定义的详细系统活动报告的选项。
|
||||
|
||||
**别错过**: [Sysstat – Linux 的使用活动检测工具][4]
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在该指南中我们解释了如何使用 Linux 原生工具以及 RHEL 7 提供的特定工具来生成系统使用报告。在某种情况下,你可能像依赖最好的朋友那样依赖这些报告。
|
||||
|
||||
你很可能使用过这篇指南中我们没有介绍到的其它工具。如果真是这样的话,用下面的表格和社区中的其他成员一起分享吧,也可以是任何其它的建议/疑问/或者评论。
|
||||
|
||||
我们期待你的回复。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-performance-monitoring-and-file-system-statistics-reports/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/how-to-check-disk-space-in-linux/
|
||||
[2]:http://www.tecmint.com/check-linux-disk-usage-of-files-and-directories/
|
||||
[3]:http://www.tecmint.com/linux-performance-monitoring-with-vmstat-and-iostat-commands/
|
||||
[4]:http://www.tecmint.com/install-sysstat-in-linux/
|
||||
@ -0,0 +1,214 @@
|
||||
RHECSA 系列:RHEL7 中的进程管理:开机,关机,以及两者之间的所有其他事项 – Part 5
|
||||
================================================================================
|
||||
我们将概括和简要地复习从你按开机按钮来打开你的 RHEL 7 服务器到呈现出命令行界面的登录屏幕之间所发生的所有事情,以此来作为这篇文章的开始。
|
||||
|
||||

|
||||
|
||||
Linux 开机过程
|
||||
|
||||
**请注意:**
|
||||
|
||||
1. 相同的基本原则也可以应用到其他的 Linux 发行版本中,但可能需要较小的更改,并且
|
||||
2. 下面的描述并不是旨在给出开机过程的一个详尽的解释,而只是介绍一些基础的东西
|
||||
|
||||
### Linux 开机过程 ###
|
||||
|
||||
1.初始化 POST(加电自检)并执行硬件检查;
|
||||
|
||||
2.当 POST 完成后,系统的控制权将移交给启动管理器的第一阶段,它存储在一个硬盘的引导扇区(对于使用 BIOS 和 MBR 的旧式的系统)或存储在一个专门的 (U)EFI 分区上。
|
||||
|
||||
3.启动管理器的第一阶段完成后,接着进入启动管理器的第二阶段,通常大多数使用的是 GRUB(GRand Unified Boot Loader 的简称),它驻留在 `/boot` 中,反过来加载内核和驻留在 RAM 中的初始化文件系统(被称为 initramfs,它包含执行必要操作所需要的程序和二进制文件,以此来最终挂载真实的根文件系统)。
|
||||
|
||||
4.接着经历了闪屏过后,呈现在我们眼前的是类似下图的画面,它允许我们选择一个操作系统和内核来启动:
|
||||
|
||||

|
||||
|
||||
启动菜单屏幕
|
||||
|
||||
5.然后内核对挂载到系统的硬件进行设置,一旦根文件系统被挂载,接着便启动 PID 为 1 的进程,反过来这个进程将初始化其他的进程并最终呈现给我们一个登录提示符界面。
|
||||
|
||||
注意:假如我们想在后面这样做(注:这句话我总感觉不通顺,不明白它的意思,希望改一下),我们可以使用 [dmesg 命令][1](注:这篇文章已经翻译并发表了,链接是 https://linux.cn/article-3587-1.html )并使用这个系列里的上一篇文章中解释过的工具(注:即 grep)来过滤它的输出。
|
||||
|
||||

|
||||
|
||||
登录屏幕和进程的 PID
|
||||
|
||||
在上面的例子中,我们使用了众所周知的 `ps` 命令来显示在系统启动过程中的一系列当前进程的信息,它们的父进程(或者换句话说,就是那个开启这些进程的进程) 为 systemd(大多数现代的 Linux 发行版本已经切换到的系统和服务管理器):
|
||||
|
||||
# ps -o ppid,pid,uname,comm --ppid=1
|
||||
|
||||
记住 `-o`(为 -format 的简写)选项允许你以一个自定义的格式来显示 ps 的输出,以此来满足你的需求;这个自定义格式使用 man ps 里 STANDARD FORMAT SPECIFIERS 一节中的特定关键词。
|
||||
|
||||
另一个你想自定义 ps 的输出而不是使用其默认输出的情形是:当你需要找到引起 CPU 或内存消耗过多的那些进程,并按照下列方式来对它们进行排序时:
|
||||
|
||||
# ps aux --sort=+pcpu # 以 %CPU 来排序(增序)
|
||||
# ps aux --sort=-pcpu # 以 %CPU 来排序(降序)
|
||||
# ps aux --sort=+pmem # 以 %MEM 来排序(增序)
|
||||
# ps aux --sort=-pmem # 以 %MEM 来排序(降序)
|
||||
# ps aux --sort=+pcpu,-pmem # 结合 %CPU (增序) 和 %MEM (降序)来排列
|
||||
|
||||

|
||||
|
||||
自定义 ps 命令的输出
|
||||
|
||||
### systemd 的一个介绍 ###
|
||||
|
||||
在 Linux 世界中,很少有决定能够比在主流的 Linux 发行版本中采用 systemd 引起更多的争论。systemd 的倡导者根据以下事实命名其主要的优势:
|
||||
|
||||
另外请阅读: ['init' 和 'systemd' 背后的故事][2]
|
||||
|
||||
1. 在系统启动期间,systemd 允许并发地启动更多的进程(相比于先前的 SysVinit,SysVinit 似乎总是表现得更慢,因为它一个接一个地启动进程,检查一个进程是否依赖于另一个进程,然后等待守护进程去开启可以开始的更多的服务),并且
|
||||
2. 在一个运行着的系统中,它作为一个动态的资源管理器来工作。这样在开机期间,当一个服务被需要时,才启动它(以此来避免消耗系统资源)而不是在没有一个合理的原因的情况下启动额外的服务。
|
||||
3. 向后兼容 sysvinit 的脚本。
|
||||
|
||||
systemd 由 systemctl 工具控制,假如你带有 SysVinit 背景,你将会对以下的内容感到熟悉:
|
||||
|
||||
- service 工具, 在旧一点的系统中,它被用来管理 SysVinit 脚本,以及
|
||||
- chkconfig 工具, 为系统服务升级和查询运行级别信息
|
||||
- shutdown, 你一定使用过几次来重启或关闭一个运行的系统。
|
||||
|
||||
下面的表格展示了使用传统的工具和 systemctl 之间的相似之处:
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="237"></colgroup>
|
||||
<colgroup width="256"></colgroup>
|
||||
<colgroup width="1945"></colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="left" height="25" bgcolor="#B7B7B7" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial; font-size: small;">Legacy tool</span></b></td>
|
||||
<td align="left" bgcolor="#B7B7B7" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial; font-size: small;">Systemctl equivalent</span></b></td>
|
||||
<td align="left" bgcolor="#B7B7B7" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial; font-size: small;">Description</span></b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name start</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl start name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Start name (where name is a service)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name stop</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl stop name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Stop name</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name condrestart</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl try-restart name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Restarts name (if it’s already running)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name restart</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl restart name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Restarts name</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name reload</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl reload name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Reloads the configuration for name</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name status</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl status name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Displays the current status of name</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service –status-all</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Displays the status of all current services</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig name on</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl enable name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Enable name to run on startup as specified in the unit file (the file to which the symlink points). The process of enabling or disabling a service to start automatically on boot consists in adding or removing symbolic links inside the /etc/systemd/system directory.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig name off</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl disable name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Disables name to run on startup as specified in the unit file (the file to which the symlink points)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig –list name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl is-enabled name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Verify whether name (a specific service) is currently enabled</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig –list</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl –type=service</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Displays all services and tells whether they are enabled or disabled</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">shutdown -h now</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl poweroff</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Power-off the machine (halt)</span></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">shutdown -r now</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl reboot</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Reboot the system</span></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
systemd 也引进了单元(它可能是一个服务,一个挂载点,一个设备或者一个网络套接字)和目标(它们定义了 systemd 如何去管理和同时开启几个相关的进程,并可认为它们与在基于 SysVinit 的系统中的运行级别等价,尽管事实上它们并不等价)。
|
||||
|
||||
### 总结归纳 ###
|
||||
|
||||
其他与进程管理相关,但并不仅限于下面所列的功能的任务有:
|
||||
|
||||
**1. 在考虑到系统资源的使用上,调整一个进程的执行优先级:**
|
||||
|
||||
这是通过 `renice` 工具来完成的,它可以改变一个或多个正在运行着的进程的调度优先级。简单来说,调度优先级是一个允许内核(当前只支持 >= 2.6 的版本)根据某个给定进程被分配的执行优先级(即优先级,从 -20 到 19)来为其分配系统资源的功能。
|
||||
|
||||
`renice` 的基本语法如下:
|
||||
|
||||
# renice [-n] priority [-gpu] identifier
|
||||
|
||||
在上面的通用命令中,第一个参数是将要使用的优先级数值,而另一个参数可以解释为进程 ID(这是默认的设定),进程组 ID,用户 ID 或者用户名。一个常规的用户(即除 root 以外的用户)只可以更改他或她所拥有的进程的调度优先级,并且只能增加优先级的层次(这意味着占用更少的系统资源)。
|
||||
|
||||

|
||||
|
||||
进程调度优先级
|
||||
|
||||
**2. 按照需要杀死一个进程(或终止其正常执行):**
|
||||
|
||||
更精确地说,杀死一个进程指的是通过 [kill 或 pkill][3]命令给该进程发送一个信号,让它优雅地(SIGTERM=15)或立即(SIGKILL=9)结束它的执行。
|
||||
|
||||
这两个工具的不同之处在于前一个被用来终止一个特定的进程或一个进程组,而后一个则允许你在进程的名称和其他属性的基础上,执行相同的动作。
|
||||
|
||||
另外, pkill 与 pgrep 相捆绑,pgrep 提供将受影响的进程的 PID 给 pkill 来使用。例如,在运行下面的命令之前:
|
||||
|
||||
# pkill -u gacanepa
|
||||
|
||||
查看一眼由 gacanepa 所拥有的 PID 或许会带来点帮助:
|
||||
|
||||
# pgrep -l -u gacanepa
|
||||
|
||||

|
||||
|
||||
找到用户拥有的 PID
|
||||
|
||||
默认情况下,kill 和 pkiill 都发送 SIGTERM 信号给进程,如我们上面提到的那样,这个信号可以被忽略(即该进程可能会终止其自身的执行或者不终止),所以当你因一个合理的理由要真正地停止一个运行着的进程,则你将需要在命令行中带上特定的 SIGKILL 信号:
|
||||
|
||||
# kill -9 identifier # 杀死一个进程或一个进程组
|
||||
# kill -s SIGNAL identifier # 同上
|
||||
# pkill -s SIGNAL identifier # 通过名称或其他属性来杀死一个进程
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们解释了在 RHEL 7 系统中,有关开机启动过程的基本知识,并分析了一些可用的工具来帮助你通过使用一般的程序和 systemd 特有的命令来管理进程。
|
||||
|
||||
请注意,这个列表并不旨在涵盖有关这个话题的所有花哨的工具,请随意使用下面的评论栏来添加你自已钟爱的工具和命令。同时欢迎你的提问和其他的评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-boot-process-and-process-management/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/dmesg-commands/
|
||||
[2]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
[3]:http://www.tecmint.com/how-to-kill-a-process-in-linux/
|
||||
Loading…
Reference in New Issue
Block a user