mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-03 01:10:13 +08:00
commit
d50de2ff6d
@ -0,0 +1,67 @@
|
||||
Linux下优秀的音频编辑软件
|
||||
================================================================================
|
||||
|
||||
不论您是一个音乐爱好者或只是一个要记录您导师的讲话的学生,您都需要录制音频和编辑音频。长久以来这样的工作都要靠Macintosh,如今那个时代已经过去,现在Linux也可以胜任这些工作了。简而言之,这里有一份不完全的音频编辑器软件列表,适用于不同的任务和需求。
|
||||
|
||||
### 1. Audacity ###
|
||||
|
||||
|
||||
|
||||
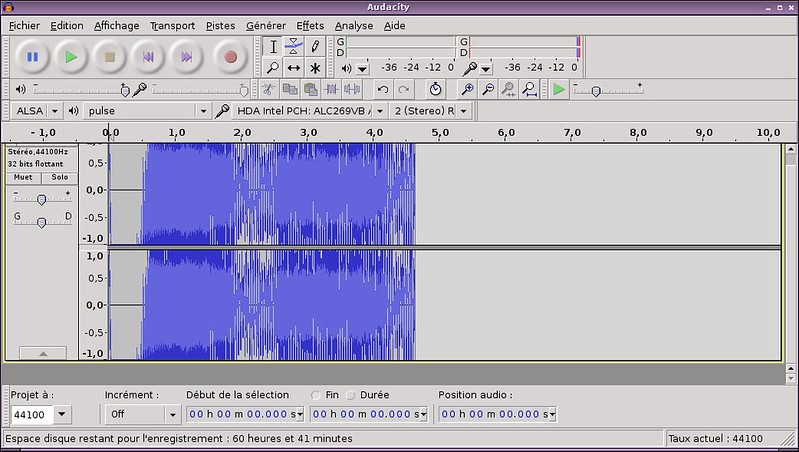
让我们从我个人最喜欢的软件开始。[Audacity][1]可以运行在Windows、Mac和Linux上。它是开源的,且易于使用。你会觉得:Audacity几乎是完美的。它可以让您在干净的界面上操作音频波形。简单地说,您可以覆盖音轨、剪切和修改音轨、增加特效、执行高级的声音分析,然后将它们导出到一大堆可用的格式。我喜欢它的原因是它将基本的功能和复杂的功能结合在一起并且保持一个简单的学习曲线。然而,它并不是一个完全最优化的软件,尤其是对于音乐家和专业人员。
|
||||
|
||||
### 2. Jokosher ###
|
||||
|
||||
|
||||
|
||||
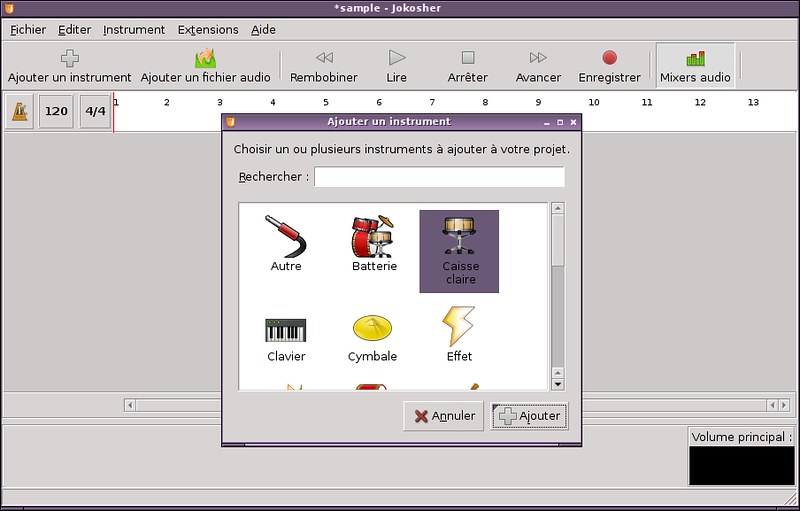
在不同的层次上,[Jokosher][2]更多的聚焦在多音轨方面。它使用Python和GTK+作为前端界面,并使用GStreamer作为音频后端。Jokosher那易用的界面和它的扩展性给我留下了深刻的印象。也许编辑的功能并不是最先进的,但它的提示十分清晰,适合音乐家。例如,我十分喜欢音轨和乐器的组合。简而言之,如果您是一个音乐家,那么它是在您转移到下一个软件前进行实践的好机会。
|
||||
|
||||
### 3. Ardour ###
|
||||
|
||||
|
||||
|
||||
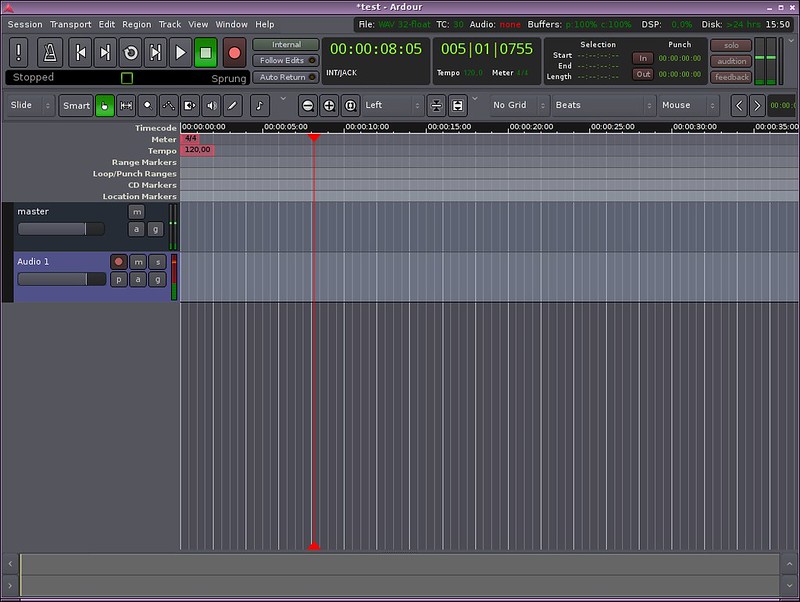
接下来谈论一些复杂的工具,[Ardour][3]是一套完整的可以录制、编辑和混音的软件。这个设计吸引了所有的专业人员,Ardour在声音和插件方面超出我的想象。如果您在寻找一头野兽并且不惧怕驯服它,那么Ardour或许是一个不错的选择。再次,它的界面和丰富的文档,尤其是它首次启动时的配置工具都是它迷人魅力的一部分。
|
||||
|
||||
### 4. Kwave ###
|
||||
|
||||

|
||||
|
||||
对于所有KDE的热爱者,[KWave][4]绝对符合您对于设计和功能的想象。它有丰富的快捷键以及很多有趣的选项,例如内存管理。尽管很多特效很不错,但我们更应该关注那些用于音频剪切/粘贴的工具。可惜的是它无法与Audacity相比,而更重要的是,它的界面并没有那么吸引我。
|
||||
|
||||
### 5. Qtractor ###
|
||||
|
||||

|
||||
|
||||
如果Kwave对您来说过于简单,但基于Qt的程序却有些吸引力,那么对您来说,也许[Qtractor][5]是一个选项。它致力于做一个“对于家庭用户来说足够简单,并且对专业人员来说足够强大的软件。”实际上它功能和选项的数量几乎是压倒性的。我最喜欢的当然是可定制的快捷键。除此之外,Qtractor可能是我最喜欢的一个处理MIDI文件的工具。
|
||||
|
||||
### 6. LMMS ###
|
||||
|
||||
|
||||
|
||||
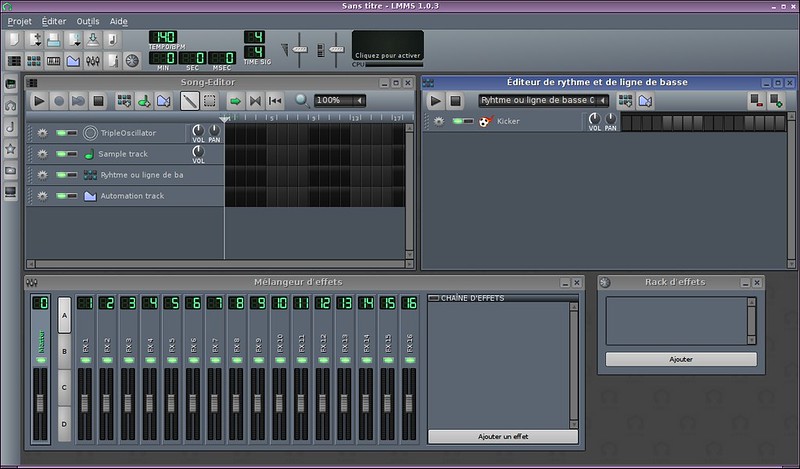
作为Linux多媒体工作室,LMMS的直接目标是音乐制作。如果您之前没有什么经验并且不想浪费太多的时间,那么请去别处吧。LMMS是其中一个复杂但强大的软件,只有少数的人真正的掌握了它。它有太多的功能和特效以至于无法一一列出,但如果我必须找一个,我会说用来模拟Game Boy声音系统的Freeboy插件简直像魔术一样。然后,去看看它那惊人的文档吧。
|
||||
|
||||
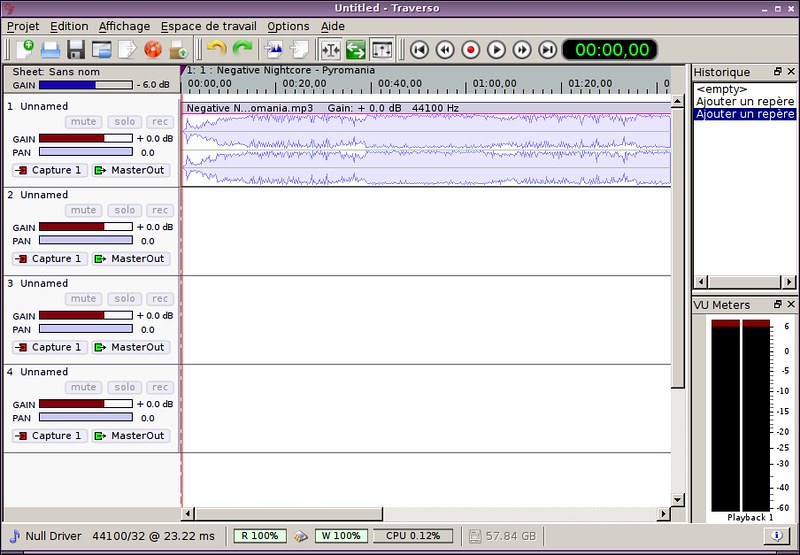
### 7. Traverso ###
|
||||
|
||||
|
||||
|
||||
最后站在我面前的是Traverso,它支持无限制的音轨计数,并直接整合了CD烧录的功能。另外,它对我来说是介于简单的软件和专业的软件之间的程序。它的界面是KDE样式的,其键盘配置很简单。更有趣的是,Traverso会监视您的系统资源以确定不会超过您的CPU或者硬件的能力。
|
||||
|
||||
总而言之,能在Linux系统上看到这么多不同的应用程序是一件开心的事。它使得您永远可以找到最适合自己的那一款。虽然我最喜欢的应用是Audacity,但我非常震惊于LMMS和Jokosher的设计。
|
||||
|
||||
我们有漏掉什么么?您在Linux下使用哪一款软件呢?原因是什么呢?请留言让我们知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/good-audio-editing-software-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://audacity.sourceforge.net/
|
||||
[2]:https://launchpad.net/jokosher/
|
||||
[3]:http://ardour.org/
|
||||
[4]:http://kwave.sourceforge.net/
|
||||
[5]:http://qtractor.sourceforge.net/qtractor-index.html
|
||||
154
published/20150128 The top 10 rookie open source projects.md
Normal file
154
published/20150128 The top 10 rookie open source projects.md
Normal file
@ -0,0 +1,154 @@
|
||||
2015 年度开源项目新秀榜
|
||||
================================================================================
|
||||
黑鸭(Black Duck)软件公布了一份名叫“年度开源项目新秀”的报告,介绍了由全球开源协会发起的10个最有趣、最活跃的新项目。
|
||||
|
||||

|
||||
|
||||
### 年度开源项目新秀 ###
|
||||
|
||||
每年都有上千新的开源项目问世,但只有少数能够真正的吸引我们的关注。一些项目因为利用了当前比较流行的技术而发展壮大,有一些则真正地开启了一个新的领域。很多开源项目建立的初衷是为了解决一些生产上的问题,还有一些项目则是世界各地志同道合的开发者们共同发起的一个宏伟项目。
|
||||
|
||||
从2009年起,开源软件管理公司黑鸭便发起了[年度开源项目新秀][1]这一活动,它的评选根据[Open Hub][2]网站(即以前的Ohloh)上的活跃度。今年,我们很荣幸能够报道2015年10大开源项目新秀的得主和2名荣誉奖得主,它们是从上千个开源项目中脱颖而出的。评选采用了加权评分系统,得分标准基于项目的活跃度,交付速度和几个其它因数。
|
||||
|
||||
开源俨然成为了产业创新的引擎,就拿今年来说,和Docker容器相关的开源项目在全球各地兴起,这也不恰巧反映了企业最感兴趣的技术领域吗?最后,我们接下来介绍的项目,将会让你了解到全球开源项目的开发者们的在思考什么,这很快将会成为一个指引我们发展的领头羊。
|
||||
|
||||
### 2015年度开源项目新秀: DebOps ###
|
||||
|
||||

|
||||
|
||||
[DebOps][3]收集打包了一套[Ansible][4]方案和规则(Ansible是一种自动化运维工具),可以从1个容器扩展到一个完整的数据中心。它的创始人Maciej Delmanowski将DebOps开源来保证项目长久进行,从而更好的通过外部贡献者的帮助发展下去。
|
||||
|
||||
DebOps始创于波兰的一个不起眼大学校园里,他们运营自己的数据中心,一切工作都采用手工配置。有时系统崩溃而导致几天的宕机,这时Delmanowski意识到一个配置管理系统是很有必要的。以Debian作为基础开始,DebOps是一组配置一整个数据基础设施的Ansible方案。此项目已经在许多不同的工作环境下实现,而创始者们则打算继续支持和改进这个项目。
|
||||
|
||||
###2015年度开源项目新秀: Code Combat ###
|
||||
|
||||

|
||||
|
||||
传统的纸笔学习方法已近不能满足技术学科了。然而游戏却有很多人都爱玩,这也就是为什么[CodeCombat][5]的创始人会去开发一款多人协同编程游戏来教人们如何编码。
|
||||
|
||||
刚开始CodeCombat是一个创业想法,但其创始人决定取而代之创建一个开源项目。此想法在社区传播开来,很快不少贡献者加入到项目中来。项目发起仅仅两个月后,这款游戏就被接纳到Google’s Summer of Code活动中。这款游戏吸引了大量玩家,并被翻译成45种语言。CodeCombat希望成为那些想要一边学习代码同时获得乐趣的同学的风向标。
|
||||
|
||||
### 2015年度开源项目新秀: Storj ###
|
||||
|
||||

|
||||
|
||||
[Storj][6]是一个点对点的云存储网络,可实现端到端加密,保证用户不用依赖第三方即可传输和共享数据。基于比特币block chain技术和点对点协议,Storj提供安全、私密、加密的云存储。
|
||||
|
||||
云数据存储的反对者担心成本开销和漏洞攻击。针对这两个担忧,Storj提供了一个私有云存储市场,用户可以通过Storjcoin X(SJCX) 购买交易存储空间。上传到Storj的文件会被粉碎、加密和存储到整个社区。只有文件所有者拥有密钥加密的信息。
|
||||
|
||||
在2014年举办的Texas Bitcoin Conference Hackathon会议上,去中心化的云存储市场概念首次被提出并证明可行。在第一次赢得黑客马拉松活动后,项目创始人们和领导团队利用开放论坛、Reddit、比特币论坛和社交媒体增长成了一个活跃的社区,如今,它们已成为影响Storj发展方向的一个重要组成部分。
|
||||
|
||||
### 2015年度开源项目新秀: Neovim ###
|
||||
|
||||

|
||||
|
||||
自1991年出现以来,Vim已经成为数以百万计软件开发人员所钟爱的文本编辑器。 而[Neovim][6]就是它的下一个版本。
|
||||
|
||||
在过去的23年里,软件开发生态系统经历了无数增长和创新。Neovim创始人Thiago de Arruda认为Vim缺乏当代元素,跟不上时代的发展。在保留Vim的招牌功能的前提下,Neovim团队同样在寻求改进和发展这个最受欢迎的文本编辑器的技术。早期众筹让Thiago de Arruda可以连续6个月时间投入到此项目。他相信Neovim社区会支持这个项目,激励他继续开发Neovim。
|
||||
|
||||
### 2015年度开源项目新秀: CockroachDB ###
|
||||
|
||||

|
||||
|
||||
前谷歌员工开发了一个开源的大型企业数据存储项目[CockroachDB][8],它是一个可扩展的、跨地域复制且支持事务的数据存储的解决方案。
|
||||
|
||||
为了保证在线的百万兆字节流量业务的质量,Google开发了Spanner系统,这是一个可扩展的,稳定的,支持事务的系统。许多参与开发CockroachDB的团队现在都服务于开源社区。就像真正的蟑螂(cockroach)一样,CockroachDB可以在没有数据头、任意节点失效的情况下正常运行。这个开源项目有很多富有经验的贡献者,创始人们通过社交媒体、Github、网络、会议和聚会结识他们并鼓励他们参与其中。
|
||||
|
||||
### 2015年度开源项目新秀: Kubernetes ###
|
||||
|
||||

|
||||
|
||||
在将容器化软件到引入开源社区发展时,[Docker][9]是一匹黑马,它创新了一套技术和工具。去年6月谷歌推出了[Kubernetes][10],这是一款开源的容器管理工具,用来加快开发和简化操作。
|
||||
|
||||
谷歌在它的内部运营上使用容器技术多年了。在2014年夏天的DockerCon上大会上,谷歌这个互联网巨头开源了Kubernetes,Kubernetes的开发是为了满足迅速增长的Docker生态系统的需要。通过和其它的组织、项目合作,比如Red Hat和CoreOS,Kubernetes项目的管理者们推动它登上了Docker Hub的工具下载榜榜首。Kubernetes的开发团队希望扩大这个项目,发展它的社区,这样的话软件开发者就能花更少的时间在管理基础设施上,而更多的去开发他们自己的APP。
|
||||
|
||||
### 2015年度开源项目新秀: Open Bazaar ###
|
||||
|
||||

|
||||
|
||||
OpenBazaar是一个使用比特币与其他人交易的去中心化的市场。OpenBazaar这一概念最早在编程马拉松(hackathon)活动中被提出,它的创始人结合了BitTorent、比特币和传统的金融服务方式,创造了一个不受审查的交易平台。OpenBazaar的开发团队在寻求新的成员,而且不久以后他们将极度扩大Open Bazaar社区。Open Bazaar的核心是透明度,其创始人和贡献者的共同目标是在商务交易中掀起一场革命,让他们向着一个真实的、一个无控制的,去中心化的市场奋进。
|
||||
|
||||
### 2015年度开源项目新秀: IPFS ###
|
||||
|
||||

|
||||
|
||||
IPFS 是一个面向全球的、点对点的分布式版本文件系统。它综合了Git,BitTorrent,HTTP的思想,开启了一个新的数据和数据结构传输协议。
|
||||
|
||||
人们所知的开源,它的本意用简单的方法解决复杂的问题,这样产生许多新颖的想法,但是那些强大的项目仅仅是开源社区的冰山一角。IFPS有一个非常激进的团队,这个概念的提出是大胆的,令人惊讶的,有点甚至高不可攀。看起来,一个点对点的分布式文件系统是在寻求将所有的计算设备连在一起。这个可能的 HTTP 替换品通过多种渠道维护着一个社区,包括Git社区和超过100名贡献者的IRC。这个疯狂的想法将在2015年进行软件内部测试。
|
||||
|
||||
### 2015年度开源项目新秀: cAdvisor ###
|
||||
|
||||

|
||||
|
||||
[cAdvisor (Container Advisor)][13] 是一个针对在运行中的容器进行收集,统计,处理和输出信息的工具,它可以给容器的使用者提供资源的使用情况和工作特性。对于每一个容器,cAdvisor记录着资源的隔离参数,资源使用历史,资源使用历史对比框图,网络状态。这些从容器输出的数据跨越主机传递。
|
||||
|
||||
cAdvisor可以在绝大多数的Linux发行版上运行,并且支持包括Docker在内的多种容器类型。事实上它成为了一种容器的代理,并被集成在了很多系统中。cAdvisor在DockerHub下载量也是位居前茅。cAdvisor的开发团队希望把cAdvisor改进到能够更深入地理解应用性能,并且集成到集群系统。
|
||||
|
||||
### 2015年度开源项目新秀: Terraform ###
|
||||
|
||||

|
||||
|
||||
[Terraform][14]提供了一些常见设置来创建一个基础设施,从物理机到虚拟机,以及email服务器、DNS服务器等。这个想法包括从家庭个人机解决方案到公共云平台提供的服务。一旦建立好了以后,Terraform可以让运维人员安全又高效地改变你的基础设施,就如同配置一样。
|
||||
|
||||
Terraform.io的创始者工作在一个Devops模式的公司,他找到了一个窍门把建立一个完整的数据中心所需的知识结合在一起,可以从添加服务器到支持网络服务的功能齐备的数据中心。基础设施的描述采用高级的配置语法,允许你把数据中心的蓝图按版本管理,并且转换成多种代码。著名开源公司HashiCorp赞助开发这个项目。
|
||||
|
||||
### 荣誉奖: Docker Fig ###
|
||||
|
||||

|
||||
|
||||
[Fig][15]为[Docker][16]的使用提供了一个快速的,分离的开发环境。Docker的移植只需要将配置信息放到一个简单的 fig.yml文件里。它会处理所有工作,包括构建、运行,端口转发,分享磁盘和容器链接。
|
||||
|
||||
Orchard去年发起了Fig,来创造一个使Docker工作起来的系统工具。它的开发像是为Docker设置开发环境,为了确保用户能够为他们的APP准确定义环境,在Docker中会运行数据库和缓存。Fig解决了开发者的一个难题。Docker全面支持这个开源项目,最近[将买下][17]Orchard来扩张这个项目。
|
||||
|
||||
### 荣誉奖: Drone ###
|
||||
|
||||

|
||||
|
||||
[Drone][18]是一个基于Docker的持续集成平台,而且它是用Go语言写的。Drone项目不满于现存的设置开发环境的技术和流程。
|
||||
|
||||
Drone提供了一个简单的自动测试和持续交付的方法:简单选择一个Docker镜像来满足你的需求,连接并提交至GitHub即可。Drone使用Docker容器来提供隔离的测试环境,让每个项目完全自主控制它的环境,没有传统的服务器管理的负担。Drone背后的100位社区贡献者强烈希望把这个项目带到企业和移动应用程序开发中。
|
||||
|
||||
### 开源新秀 ###
|
||||
|
||||

|
||||
|
||||
参见:
|
||||
|
||||
- [InfoWorld2015年年度技术奖][21]
|
||||
- [Bossies: 开源软件最高荣誉][22]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2875439/open-source-software/the-top-10-rookie-open-source-projects.html
|
||||
|
||||
作者:[Black Duck Software][a]
|
||||
译者:[sevenot](https://github.com/sevenot)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Black-Duck-Software/
|
||||
[1]:https://www.blackducksoftware.com/open-source-rookies
|
||||
[2]:https://www.openhub.net/
|
||||
[3]:https://github.com/debops/debops
|
||||
[4]:http://www.infoworld.com/article/2612397/data-center/review--ansible-orchestration-is-a-veteran-unix-admin-s-dream.html
|
||||
[5]:https://codecombat.com/
|
||||
[6]:http://storj.io/
|
||||
[7]:http://neovim.org/
|
||||
[8]:https://github.com/cockroachdb/cockroach
|
||||
[9]:http://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker
|
||||
[10]:http://kubernetes.io/
|
||||
[11]:https://openbazaar.org/
|
||||
[12]:http://ipfs.io/
|
||||
[13]:https://github.com/google/cadvisor
|
||||
[14]:https://www.terraform.io/
|
||||
[15]:http://www.fig.sh/
|
||||
[16]:http://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker
|
||||
[17]:http://www.infoworld.com/article/2608546/application-virtualization/docker-acquires-orchard-in-a-sign-of-rising-ambitions.html
|
||||
[18]:https://drone.io/
|
||||
[19]:http://www.infoworld.com/article/2683845/google-go/164121-Fast-guide-to-Go-programming.html
|
||||
[20]:https://www.blackducksoftware.com/open-source-rookies
|
||||
[21]:http://www.infoworld.com/article/2871935/application-development/infoworlds-2015-technology-of-the-year-award-winners.html
|
||||
[22]:http://www.infoworld.com/article/2688104/open-source-software/article.html
|
||||
[23]:http://www.infoworld.com/article/2854954/microsoft-windows/15-essential-open-source-tools-for-windows-admins.html
|
||||
|
||||
@ -0,0 +1,138 @@
|
||||
如何在 Linux 上使用 x2go 设置远程桌面
|
||||
================================================================================
|
||||
由于一切都迁移到了云上,作为提高职员生产力的一种方式,虚拟远程桌面在工业中越来越流行。尤其对于那些需要在多个地方和设备之间不停漫游的人,远程桌面可以让他们和工作环境保持无缝连接。远程桌面对于雇主同样有吸引力,可以在工作环境中提高敏捷性和灵活性,由于硬件整合、桌面安全加固等原因降低 IT 花费。
|
||||
|
||||
在 Linux 世界中,理所当然设置远程桌面有很多选择,支持许多协议(例如 RDP、RFB、NX) 和服务器/客户端实现(例如 [TigerVNC][1]、RealVNC、FreeNX、x2go、X11vnc、TeamViewer 等等)。
|
||||
|
||||
这当中有个出色的产品叫做 [X2Go][2],它是一个基于 NX(译者注:通过计算机网络显示远程桌面环境的一种技术,可参考 [Wiki][9])的远程桌面服务器和客户端的开源(GPLv2)实现。在这个教程中,我会介绍 **如何为 Linux VPS 使用 X2Go 设置远程桌面环境**。
|
||||
|
||||
### X2Go 是什么? ###
|
||||
|
||||
X2Go 的历史要追溯到 NoMachine 的 NX 技术。NX 远程桌面协议的设计目的是通过利用主动压缩和缓存解决低带宽和高延迟的网络连接问题。后来,NX 转为闭源,但 NX 库还是采用 GPL 协议。这导致出现了多种基于 NX 的远程桌面解决方案开源实现,X2Go 就是其中之一。
|
||||
|
||||
和其它解决方案例如 VNC 相比,X2Go 有哪些好处呢? X2Go 继承了 NX 技术的所有高级功能,很自然能在慢速网络连接上良好工作。另外,由于它内置的基于 SSH 的加密技术,X2Go 保持了确保安全的良好业绩记录。不再需要[手动设置 SSH 隧道][4] 。X2Go 默认支持音频,这意味着远程桌面的音乐播放可以通过网络传送,并进入本地扬声器。在易用性方面,远程桌面上运行的应用程序可以在你的本地桌面中以一个独立窗口无缝呈现,会给你造成一种应用程序实际上在你本地桌面运行的错觉。正如你看到的,这些都是一些基于 VNC 的解决方案所缺少的[强大功能][5]。
|
||||
|
||||
### X2GO 的桌面环境兼容性 ###
|
||||
|
||||
和其它远程桌面服务器一样,X2Go 服务器也有一些[已知的兼容性问题][6]。像 KDE 3/4、Xfce、MATE 和 LXDE 是对 X2Go 服务器最友好的桌面环境。但是,用其它桌面管理器效果可能有所不同。例如,已知 GNOME 3 之后的版本、KDE 5、Unity 和 X2Go 并不兼容。如果你的远程主机的桌面管理器和 X2Go 兼容,你可以继续以下的教程。
|
||||
|
||||
### 在 Linux 上安装 X2Go 服务器 ###
|
||||
|
||||
X2Go 由远程桌面服务器和客户端组件组成。让我们首先安装 X2Go 服务器。我假设你已经有一个和 X2Go 兼容的桌面管理器并且在远程主机上运行,我们会安装 X2Go 服务器到该远程主机。
|
||||
|
||||
注意系统启动后 X2Go 服务器组件没有需要单独启动的服务。你只需要保证开启了 SSH 服务并在正常运行。
|
||||
|
||||
#### Ubuntu 或 Linux Mint: ####
|
||||
|
||||
配置 X2Go PPA 库。对于 Ubuntu 14.04 以及更高版本,有可用的 X2Go PPA。
|
||||
|
||||
$ sudo add-apt-repository ppa:x2go/stable
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install x2goserver x2goserver-xsession
|
||||
|
||||
#### Debian (Wheezy): ####
|
||||
|
||||
$ sudo apt-key adv --recv-keys --keyserver keys.gnupg.net E1F958385BFE2B6E
|
||||
$ sudo sh -c "echo deb http://packages.x2go.org/debian wheezy main > /etc/apt/sources.list.d/x2go.list"
|
||||
$ sudo sh -c "echo deb-src http://packages.x2go.org/debian wheezy main >> /etc/apt/sources.list.d/x2go.list"
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install x2goserver x2goserver-xsession
|
||||
|
||||
#### Fedora: ####
|
||||
|
||||
$ sudo yum install x2goserver x2goserver-xsession
|
||||
|
||||
#### CentOS/RHEL: ####
|
||||
|
||||
首先启用 [EPEL 库][7] 然后运行:
|
||||
|
||||
$ sudo yum install x2goserver x2goserver-xsession
|
||||
|
||||
### 在 Linux 上安装 X2Go 客户端 ###
|
||||
|
||||
在将会连接到远程桌面的本地主机上,安装以下命令安装 X2Go 客户端。
|
||||
|
||||
#### Ubuntu 或 Linux Mint: ####
|
||||
|
||||
配置 X2Go PPA 库。对于 Ubuntu 14.04 以及更高版本,有可用的 X2Go PPA。
|
||||
|
||||
$ sudo add-apt-repository ppa:x2go/stable
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install x2goclient
|
||||
|
||||
Debian (Wheezy):
|
||||
|
||||
$ sudo apt-key adv --recv-keys --keyserver keys.gnupg.net E1F958385BFE2B6E
|
||||
$ sudo sh -c "echo deb http://packages.x2go.org/debian wheezy main > /etc/apt/sources.list.d/x2go.list"
|
||||
$ sudo sh -c "echo deb-src http://packages.x2go.org/debian wheezy main >> /etc/apt/sources.list.d/x2go.list"
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install x2goclient
|
||||
|
||||
#### Fedora: ####
|
||||
|
||||
$ sudo yum install x2goclient
|
||||
|
||||
CentOS/RHEL:
|
||||
|
||||
首先启用 [EPEL 库][7] ,然后运行:
|
||||
|
||||
$ sudo yum install x2goclient
|
||||
|
||||
### 用 X2Go 客户端连接到远程桌面 ###
|
||||
|
||||
现在可以连接到远程桌面了。在本地主机上,只需运行以下命令或者使用桌面启动器启动 X2Go 客户端。
|
||||
|
||||
$ x2goclient
|
||||
|
||||
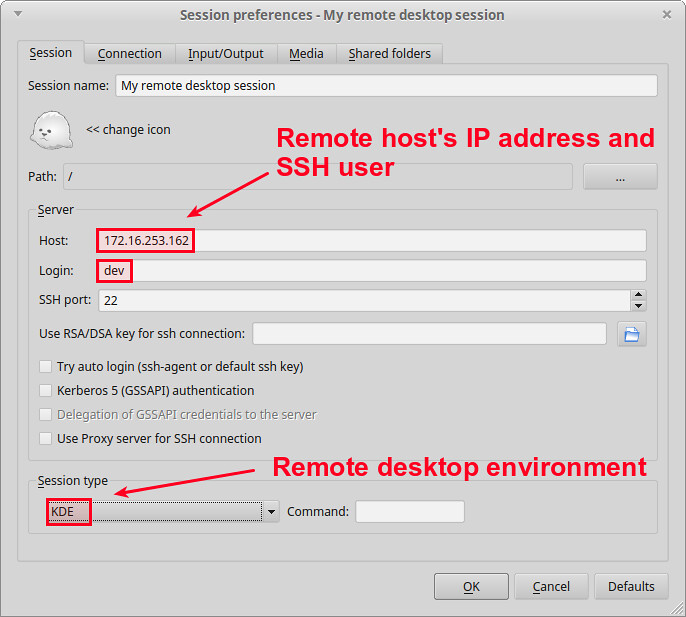
输入远程主机的 IP 地址和 SSH 用户名称。同时,指定会话类型(例如,远程主机的桌面管理器)。
|
||||
|
||||
|
||||
|
||||
如果需要的话,你可以自定义其它东西(通过点击其它的标签),例如连接速度、压缩、屏幕分辨率等等。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
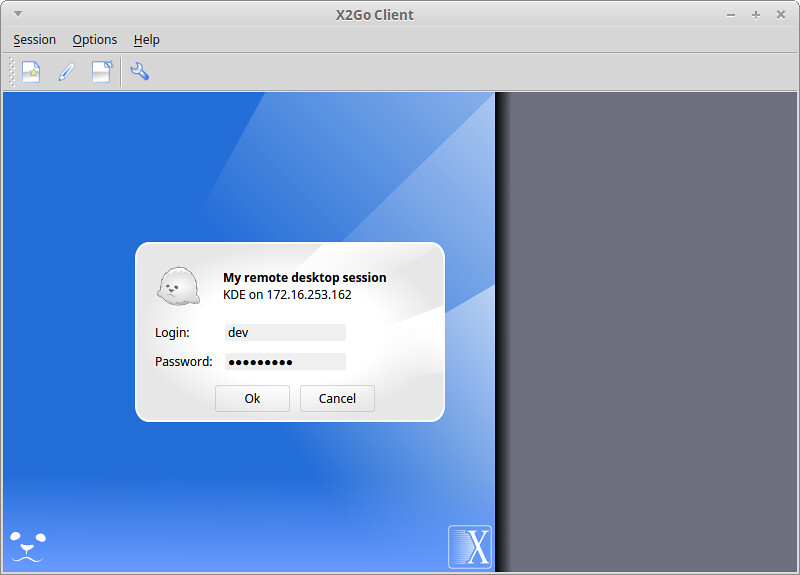
当你初始化一个远程桌面连接的时候,会要求你登录。输入你的 SSH 登录名和密码。
|
||||
|
||||
|
||||
|
||||
成功登陆后,你会看到远程桌面屏幕。
|
||||
|
||||

|
||||
|
||||
如果你想测试 X2Go 的无缝窗口功能,选择 "Single application" 会话类型,然后指定远处主机上可执行文件的路径。在该例子中,我选择远程 KDE 主机上的 Dolphin 文件管理器。
|
||||
|
||||

|
||||
|
||||
你成功连接后,你会在本地桌面上看到一个远程应用窗口,而不是完整的远程桌面屏幕。
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇教程中,我介绍了如何在 [Linux VPS][8] 实例上设置 X2Go 远程桌面。正如你所看到的,整个设置过程都非常简单(如果你使用一个合适的桌面环境的话)。尽管对于特定桌面仍有问题,X2Go 是一个安全、功能丰富、快速并且免费的远程桌面解决方案。
|
||||
|
||||
X2Go 的什么功能最吸引你?欢迎分享你的观点。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/x2go-remote-desktop-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://ask.xmodulo.com/centos-remote-desktop-vps.html
|
||||
[2]:http://wiki.x2go.org/
|
||||
[3]:http://xmodulo.com/go/digitalocean
|
||||
[4]:http://xmodulo.com/how-to-set-up-vnc-over-ssh.html
|
||||
[5]:http://wiki.x2go.org/doku.php/doc:newtox2go
|
||||
[6]:http://wiki.x2go.org/doku.php/doc:de-compat
|
||||
[7]:https://linux.cn/article-2324-1.html
|
||||
[8]:http://xmodulo.com/go/digitalocean
|
||||
[9]:https://en.wikipedia.org/wiki/NX_technology
|
||||
111
published/20150429 What are good command line HTTP clients.md
Normal file
111
published/20150429 What are good command line HTTP clients.md
Normal file
@ -0,0 +1,111 @@
|
||||
有哪些不错的命令行HTTP客户端?
|
||||
==============================================================================
|
||||
|
||||
“整体大于它的各部分之和”,这是引自希腊哲学家和科学家的亚里士多德的名言。这句话特别切中Linux。在我看来,Linux最强大的地方之一就是它的协作性。Linux的实用性并不仅仅源自大量的开源程序(命令行)。相反,其协作性来自于这些程序的综合利用,有时是结合成更大型的应用。
|
||||
|
||||
Unix哲学引发了一场“软件工具”的运动,关注开发简洁,基础,干净,模块化和扩展性好的代码,并可以运用于其他的项目。这种哲学成为了许多的Linux项目的一个重要的元素。
|
||||
|
||||
好的开源开发者写程序为了确保该程序尽可能运行得好,并且同时能与其他程序很好地协作。目标就是使用者拥有一堆方便的工具,每一个力求干好一件事。许多程序能独立工作得很好。
|
||||
|
||||
这篇文章讨论3个开源命令行HTTP客户端。这些客户端可以让你使用命令行从互联网上下载文件。但同时,他们也可以用于许多有意思的地方,如测试,调式和与HTTP服务器或web应用交互。对于HTTP架构师和API设计人员来说,使用命令行操作HTTP是一个值得花时间学习的技能。如果你需要经常使用API,HTTPie和cURL就非常有价值。
|
||||
|
||||
###HTTPie###
|
||||
|
||||

|
||||
|
||||
HTTPie(发音 aych-tee-tee-pie)是一款开源的命令行HTTP客户端。它是一个命令行界面,便于手工操作的类cURL工具。
|
||||
|
||||
该软件的目标是使得与Web服务器的交互尽可能的人性化。其提供了一个简单的http命令,允许使用简单且自然的语句发送任意的HTTP请求,并显示不同颜色的输出。HTTPie可以用于测试,调试,以及与HTTP服务器的常规交互。
|
||||
|
||||
#### 功能包括:####
|
||||
|
||||
- 生动而直观的语法格式
|
||||
- 经过格式化的彩色终端输出
|
||||
- 内建JSON支持
|
||||
- 支持表单和文件上传
|
||||
- 支持HTTPS,代理和认证
|
||||
- 任意数据请求
|
||||
- 自定义请求头
|
||||
- 持久会话
|
||||
- 类Wget的下载
|
||||
- 支持Python 2.6,2.7和3.x
|
||||
- 支持Linux,Mac OS X 和 Windows
|
||||
- 支持插件
|
||||
- 文档
|
||||
- 单元测试覆盖
|
||||
|
||||
---
|
||||
|
||||
- 网站:[httpie.org][1]
|
||||
- 开发者: Jakub Roztočil
|
||||
- 证书: 开源
|
||||
- 版本号: 0.9.2
|
||||
|
||||
###cURL###
|
||||
|
||||

|
||||
|
||||
cURL是一个开源的命令行工具,用于使用URL语句传输数据,支持DICT, FILE, FTP, FTPS, GOPHER, HTTP, HTTPS,IMAP, IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMTP, SMTPS, TELNET和TFTP等协议。
|
||||
|
||||
cURL支持SSL证书,HTTP POST,HTTP PUT,FTP上传,基于表单的HTTP上传,代理,缓存,用户名+密码的认证方式(Basic, Digest, NTLM, Negotiate, kerberos...),文件续传,代理通道和一些其他的有用功能。
|
||||
|
||||
#### 功能包括:####
|
||||
|
||||
- 支持配置文件
|
||||
- 一个单独命令行请求多个URL
|
||||
- 支持匹配: [0-13],{one, two, three}
|
||||
- 一个命令上传多个文件
|
||||
- 自定义最大传输速度
|
||||
- 重定向了标准错误输出
|
||||
- 支持Metalink
|
||||
|
||||
---
|
||||
|
||||
- 网站: [curl.haxx.se][2]
|
||||
- 开发者: Daniel Stenberg
|
||||
- 证书: MIT/X derivate license
|
||||
- 版本号: 7.42.0
|
||||
|
||||
###Wget###
|
||||
|
||||

|
||||
|
||||
Wget是一个从网络服务器获取信息的开源软件。其名字源于World Wide Web 和 get。Wget支持HTTP,HTTPS和FTP协议,同时也可以通过HTTP代理获取信息。
|
||||
|
||||
Wget可以根据HTML页面的链接,创建远程网络站点的本地副本,完全重造源站点的目录结构。这种方式被称作“递归下载”。
|
||||
|
||||
Wget设计上增强了低速或者不稳定的网络连接。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 使用REST和RANGE恢复中断的下载
|
||||
- 使用文件名通配符,支持递归地对目录镜像
|
||||
- 基于NLS的消息文件支持多语言
|
||||
- 可选的转换下载文档里地绝对链接为相对链接,使得下载文档可以在本地相互链接
|
||||
- 可以在大多数类UNIX操作系统和微软Windows上运行
|
||||
- 支持HTTP代理
|
||||
- 支持HTTP cookie
|
||||
- 支持HTTP持久连接
|
||||
- 无人照管/后台操作
|
||||
- 当对远程镜像时,使用本地文件时间戳来决定是否需要重新下载文档
|
||||
|
||||
---
|
||||
|
||||
- 站点: [www.gnu.org/software/wget/][3]
|
||||
- 开发者: Hrvoje Niksic, Gordon Matzigkeit, Junio Hamano, Dan Harkless, and many others
|
||||
- 证书: GNU GPL v3
|
||||
- 版本号: 1.16.3
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20150425174537249/HTTPclients.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://httpie.org/
|
||||
[2]:http://curl.haxx.se/
|
||||
[3]:https://www.gnu.org/software/wget/
|
||||
@ -1,133 +1,99 @@
|
||||
|
||||
如何在CentOS 7上安装Percona Server
|
||||
|
||||
如何在 CentOS 7 上安装 Percona服务器
|
||||
================================================================================
|
||||
在这篇文章中我们将了解关于Percona Server,一个开源简易的MySQL,MariaDB的替代。InnoDB的数据库引擎使得Percona Server非常有吸引力,如果你需要的高性能,高可靠性和高性价比的解决方案,它将是一个很好的选择。
|
||||
|
||||
在下文中将介绍在CentOS 7上Percona的服务器的安装,以及备份当前数据,配置的步骤和如何恢复备份。
|
||||
|
||||
|
||||
###目录###
|
||||
|
||||
|
||||
1.什么是Percona,为什么使用它
|
||||
2.备份你的数据库
|
||||
3.删除之前的SQL服务器
|
||||
4.使用二进制包安装Percona
|
||||
5.配置Percona
|
||||
6.保护你的数据
|
||||
7.恢复你的备份
|
||||
在这篇文章中我们将了解关于 Percona 服务器,一个开源的MySQL,MariaDB的替代品。InnoDB的数据库引擎使得Percona 服务器非常有吸引力,如果你需要的高性能,高可靠性和高性价比的解决方案,它将是一个很好的选择。
|
||||
|
||||
在下文中将介绍在CentOS 7上Percona 服务器的安装,以及备份当前数据,配置的步骤和如何恢复备份。
|
||||
|
||||
### 1.什么是Percona,为什么使用它 ###
|
||||
|
||||
|
||||
Percona是一个开源简易的MySQL,MariaDB数据库的替代,它是MYSQL的一个分支,相当多的改进和独特的功能使得它比MYSQL更可靠,性能更强,速度更快,它与MYSQL完全兼容,你甚至可以在Oracle的MYSQL与Percona之间使用复制命令。
|
||||
Percona是一个MySQL,MariaDB数据库的开源替代品,它是MySQL的一个分支,相当多的改进和独特的功能使得它比MYSQL更可靠,性能更强,速度更快,它与MYSQL完全兼容,你甚至可以在Oracle的MySQL与Percona之间使用复制。
|
||||
|
||||
#### 在Percona中独具特色的功能 ####
|
||||
|
||||
- 分区适应哈希搜索
|
||||
- 快速校验算法
|
||||
- 缓冲池预加载
|
||||
- 支持FlashCache
|
||||
|
||||
-分段自适应哈希搜索
|
||||
-快速校验算法
|
||||
-缓冲池预加载
|
||||
-支持FlashCache
|
||||
#### MySQL企业版和Percona中的特有功能 ####
|
||||
|
||||
#### MySQL企业版和Percona的特定功能 ####
|
||||
- 从不同的服务器导入表
|
||||
- PAM认证
|
||||
- 审计日志
|
||||
- 线程池
|
||||
|
||||
-从不同的服务器导入表
|
||||
-PAM认证
|
||||
-审计日志
|
||||
-线程池
|
||||
|
||||
|
||||
现在,你肯定很兴奋地看到这些好的东西整理在一起,我们将告诉你如何安装和做些的Percona Server的基本配置。
|
||||
现在,你肯定很兴奋地看到这些好的东西整合在一起,我们将告诉你如何安装和对Percona Server做基本配置。
|
||||
|
||||
### 2. 备份你的数据库 ###
|
||||
|
||||
|
||||
接下来,在命令行下使用SQL命令创建一个mydatabases.sql文件来重建/恢复salesdb和employeedb数据库,重命名数据库以便反映你的设置,如果没有安装MYSQL跳过此步
|
||||
接下来,在命令行下使用SQL命令创建一个mydatabases.sql文件,来重建或恢复salesdb和employeedb数据库,根据你的设置替换数据库名称,如果没有安装MySQL则跳过此步:
|
||||
|
||||
mysqldump -u root -p --databases employeedb salesdb > mydatabases.sql
|
||||
|
||||
复制当前的配置文件,如果你没有安装MYSQL也可跳过
|
||||
|
||||
复制当前的配置文件,如果你没有安装MYSQL也可跳过:
|
||||
|
||||
cp my.cnf my.cnf.bkp
|
||||
|
||||
### 3.删除之前的SQL服务器 ###
|
||||
|
||||
|
||||
停止MYSQL/MariaDB如果它们还在运行
|
||||
|
||||
停止MYSQL/MariaDB,如果它们还在运行:
|
||||
|
||||
systemctl stop mysql.service
|
||||
|
||||
卸载MariaDB和MYSQL
|
||||
|
||||
卸载MariaDB和MYSQL:
|
||||
|
||||
yum remove MariaDB-server MariaDB-client MariaDB-shared mysql mysql-server
|
||||
|
||||
移动重命名在/var/lib/mysql当中的MariaDB文件,这比仅仅只是移除更为安全快速,这就像2级即时备份。:)
|
||||
|
||||
移动重命名放在/var/lib/mysql当中的MariaDB文件。这比仅仅只是移除更为安全快速,这就像2级即时备份。:)
|
||||
|
||||
mv /var/lib/mysql /var/lib/mysql_mariadb
|
||||
|
||||
### 4.使用二进制包安装Percona ###
|
||||
|
||||
|
||||
你可以在众多Percona安装方法中选择,在CentOS中使用Yum或者RPM包安装通常是更好的主意,所以这些是本文介绍的方式,下载源文件编译后安装在本文中并没有介绍。
|
||||
|
||||
从Yum仓库中安装:
|
||||
|
||||
从Yum仓库中安装:
|
||||
|
||||
|
||||
首先,你需要设置的Percona的Yum库:
|
||||
|
||||
首先,你需要设置Percona的Yum库:
|
||||
|
||||
yum install http://www.percona.com/downloads/percona-release/redhat/0.1-3/percona-release-0.1-3.noarch.rpm
|
||||
|
||||
接下来安装Percona:
|
||||
|
||||
|
||||
yum install Percona-Server-client-56 Percona-Server-server-56
|
||||
|
||||
上面的命令安装Percona的服务器和客户端,共享库,可能需要Perl和Perl模块,以及其他依赖的需要。如DBI::MySQL的,如果这些尚未安装,
|
||||
|
||||
使用RPM包安装:
|
||||
上面的命令安装Percona的服务器和客户端、共享库,可能需要Perl和Perl模块,以及其他依赖的需要,如DBI::MySQL。如果这些尚未安装,可能需要安装更多的依赖包。
|
||||
|
||||
使用RPM包安装:
|
||||
|
||||
我们可以使用wget命令下载所有的rpm包:
|
||||
|
||||
|
||||
wget -r -l 1 -nd -A rpm -R "*devel*,*debuginfo*" \ http://www.percona.com/downloads/Percona-Server-5.5/Percona-Server-5.5.42-37.1/binary/redhat/7/x86_64/
|
||||
wget -r -l 1 -nd -A rpm -R "*devel*,*debuginfo*" \
|
||||
http://www.percona.com/downloads/Percona-Server-5.5/Percona-Server-5.5.42-37.1/binary/redhat/7/x86_64/
|
||||
|
||||
使用rpm工具,一次性安装所有的rpm包:
|
||||
|
||||
rpm -ivh Percona-Server-server-55-5.5.42-rel37.1.el7.x86_64.rpm \
|
||||
Percona-Server-client-55-5.5.42-rel37.1.el7.x86_64.rpm \
|
||||
Percona-Server-shared-55-5.5.42-rel37.1.el7.x86_64.rpm
|
||||
|
||||
rpm -ivh Percona-Server-server-55-5.5.42-rel37.1.el7.x86_64.rpm \ Percona-Server-client-55-5.5.42-rel37.1.el7.x86_64.rpm \ Percona-Server-shared-55-5.5.42-rel37.1.el7.x86_64.rpm
|
||||
|
||||
注意在上面命令语句中最后的反斜杠'\',如果您安装单独的软件包,记住要解决依赖关系,在安装客户端之前要先安装共享包,在安装服务器之前请先安装客户端。
|
||||
注意在上面命令语句中最后的反斜杠'\'(只是为了换行方便)。如果您安装单独的软件包,记住要解决依赖关系,在安装客户端之前要先安装共享包,在安装服务器之前请先安装客户端。
|
||||
|
||||
### 5.配置Percona服务器 ###
|
||||
|
||||
|
||||
|
||||
#### 恢复之前的配置 ####
|
||||
|
||||
|
||||
当我们从MariaDB迁移过来时,你可以将之前的my.cnf的备份文件恢复回来。
|
||||
|
||||
|
||||
cp /etc/my.cnf.bkp /etc/my.cnf
|
||||
|
||||
#### 创建一个新的my.cnf文件 ####
|
||||
|
||||
|
||||
如果你需要一个适合你需求的新的配置文件或者你并没有备份配置文件,你可以使用以下方法,通过简单的几步生成新的配置文件。
|
||||
|
||||
下面是Percona-server软件包自带的my.cnf文件
|
||||
|
||||
|
||||
# Percona Server template configuration
|
||||
|
||||
[mysqld]
|
||||
@ -158,33 +124,29 @@ Percona是一个开源简易的MySQL,MariaDB数据库的替代,它是MYSQL
|
||||
|
||||
根据你的需要配置好my.cnf后,就可以启动该服务了:
|
||||
|
||||
|
||||
systemctl restart mysql.service
|
||||
|
||||
如果一切顺利的话,它已经准备好执行SQL命令了,你可以用以下命令检查它是否已经正常启动:
|
||||
|
||||
|
||||
mysql -u root -p -e 'SHOW VARIABLES LIKE "version_comment"'
|
||||
|
||||
如果你不能够正常启动它,你可以在**/var/log/mysql/mysqld.log**中查找原因,该文件可在my.cnf的[mysql_safe]的log-error中设置。
|
||||
|
||||
tail /var/log/mysql/mysqld.log
|
||||
|
||||
你也可以在/var/lib/mysql/文件夹下查找格式为[hostname].err的文件,就像下面这个例子样:
|
||||
|
||||
你也可以在/var/lib/mysql/文件夹下查找格式为[主机名].err的文件,就像下面这个例子:
|
||||
|
||||
tail /var/lib/mysql/centos7.err
|
||||
|
||||
如果还是没找出原因,你可以试试strace:
|
||||
|
||||
|
||||
yum install strace && systemctl stop mysql.service && strace -f -f mysqld_safe
|
||||
|
||||
上面的命令挺长的,输出的结果也相对简单,但绝大多数时候你都能找到无法启动的原因。
|
||||
|
||||
### 6.保护你的数据 ###
|
||||
|
||||
好了,你的关系数据库管理系统已经准备好接收SQL查询,但是把你宝贵的数据放在没有最起码安全保护的服务器上并不可取,为了更为安全最好使用mysql_secure_instalation,这个工具可以帮助删除未使用的默认功能,还设置root的密码,并限制使用此用户进行访问。
|
||||
只需要在shell中执行,并参照屏幕上的说明。
|
||||
好了,你的关系数据库管理系统已经准备好接收SQL查询,但是把你宝贵的数据放在没有最起码安全保护的服务器上并不可取,为了更为安全最好使用mysql_secure_install来安装,这个工具可以帮助你删除未使用的默认功能,并设置root的密码,限制使用此用户进行访问。只需要在shell中执行该命令,并参照屏幕上的说明操作。
|
||||
|
||||
mysql_secure_install
|
||||
|
||||
@ -192,28 +154,27 @@ Percona是一个开源简易的MySQL,MariaDB数据库的替代,它是MYSQL
|
||||
|
||||
如果您参照之前的设置,现在你可以恢复数据库,只需再用mysqldump一次。
|
||||
|
||||
|
||||
mysqldump -u root -p < mydatabases.sql
|
||||
恭喜你,你刚刚已经在你的CentOS上成功安装了Percona,你的服务器已经可以正式投入使用;你可以像使用MYSQL一样使用它,你的服务器与他完全兼容。
|
||||
|
||||
恭喜你,你刚刚已经在你的CentOS上成功安装了Percona,你的服务器已经可以正式投入使用;你可以像使用MySQL一样使用它,你的服务器与它完全兼容。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
为了获得更强的性能你需要对配置文件做大量的修改,但这里也有一些简单的选项来提高机器的性能。当使用InnoDB引擎时,将innodb_file_per_table设置为on,它将在一个文件中为每个表创建索引表,这意味着每个表都有它自己的索引文件,它使系统更强大和更容易维修。
|
||||
为了获得更强的性能你需要对配置文件做大量的修改,但这里也有一些简单的选项来提高机器的性能。当使用InnoDB引擎时,将innodb_file_per_table设置为on,它将在一个文件中为每个表创建索引表,这意味着每个表都有它自己的索引文件,它使系统更强大和更容易维修。
|
||||
|
||||
可以修改innodb_buffer_pool_size选项,InnoDB应该有足够的缓存池来应对你的数据集,大小应该为当前可用内存的70%到80%。
|
||||
|
||||
过将innodb-flush-method设置为O_DIRECT,关闭写入高速缓存,如果你使用了RAID,这可以提升性能因为在底层已经完成了缓存操作。
|
||||
将innodb-flush-method设置为O_DIRECT,关闭写入高速缓存,如果你使用了RAID,这可以提升性能,因为在底层已经完成了缓存操作。
|
||||
|
||||
如果你的数据并不是十分关键并且并不需要对数据库事务正确执行的四个基本要素完全兼容,可以将innodb_flush_log_at_trx_commit设置为2,这也能提升系统的性能。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/percona-server-centos-7/
|
||||
|
||||
作者:[Carlos Alberto][a]
|
||||
译者:[FatJoe123](https://github.com/FatJoe123)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
如何在云服务提供商的机器使用Docker Machine
|
||||
如何在云服务提供商的平台上使用Docker Machine
|
||||
================================================================================
|
||||
大家好,今天我们来学习如何使用Docker Machine在各种云服务提供商的平台部署Docker。Docker Machine是一个可以帮助我们在自己的电脑、云服务提供商的机器以及我们数据中心的机器上创建Docker机器的应用程序。它为创建服务器、在服务器中安装Docker、根据用户需求配置Docker客户端提供了简单的解决方案。驱动API对本地机器、数据中心的虚拟机或者公用云机器都适用。Docker Machine支持Windows、OSX和Linux,并且提供一个独立的二进制文件,可以直接使用。它让我们可以充分利用支持Docker的基础设施的生态环境合作伙伴,并且使用相同的接口进行访问。它让人们可以使用一个命令来简单而迅速地在不同的云平台部署Docker容器。
|
||||
|
||||
|
||||
大家好,今天我们来了解如何使用Docker Machine在各种云服务提供商的平台上部署Docker。Docker Machine是一个可以帮助我们在自己的电脑、云服务提供商的平台以及我们数据中心的机器上创建Docker机器的应用程序。它为创建服务器、在服务器中安装Docker、根据用户需求配置Docker客户端提供了简单的解决方案。驱动API对本地机器、数据中心的虚拟机或者公用云机器都适用。Docker Machine支持Windows、OSX和Linux,并且提供一个独立的二进制文件,可以直接使用。它让我们可以充分利用支持Docker的基础设施的生态环境合作伙伴,并且使用相同的接口进行访问。它让人们可以使用一个命令来简单而迅速地在不同的云平台部署Docker容器。
|
||||
|
||||
### 1. 安装Docker Machine ###
|
||||
|
||||
@ -25,14 +25,14 @@ Docker Machine可以很好地支持每一种Linux发行版。首先,我们需
|
||||
|
||||

|
||||
|
||||
另外机器上需要有docker命令,可以使用如下命令安装:
|
||||
要在我们的机器上启用docker命令,需要使用如下命令安装Docker客户端:
|
||||
|
||||
# curl -L https://get.docker.com/builds/linux/x86_64/docker-latest > /usr/local/bin/docker
|
||||
# chmod +x /usr/local/bin/docker
|
||||
|
||||
### 2. 创建机器 ###
|
||||
|
||||
在自己的Linux机器上安装好了Docker Machine之后,我们想要将一个docker虚拟机部署到云服务器上。Docker Machine支持几个流行的云平台,如igital Ocean、Amazon Web Services(AWS)、Microsoft Azure、Google Cloud Computing等等,所以我们可以在不同的平台使用相同的接口来部署Docker。本文中我们会使用digitalocean驱动在Digital Ocean的服务器上部署Docker,--driver选项指定digitalocean驱动,--digitalocean-access-token选项指定[Digital Ocean Control Panel][1]提供的API Token,命令最后的是我们创建的Docker虚拟机的机器名。运行如下命令:
|
||||
在自己的Linux机器上安装好了Docker Machine之后,我们想要将一个docker虚拟机部署到云服务器上。Docker Machine支持几个流行的云平台,如igital Ocean、Amazon Web Services(AWS)、Microsoft Azure、Google Cloud Computing及其它等等,所以我们可以在不同的平台使用相同的接口来部署Docker。本文中我们会使用digitalocean驱动在Digital Ocean的服务器上部署Docker,--driver选项指定digitalocean驱动,--digitalocean-access-token选项指定[Digital Ocean Control Panel][1]提供的API Token,命令最后的是我们创建的Docker虚拟机的机器名。运行如下命令:
|
||||
|
||||
# docker-machine create --driver digitalocean --digitalocean-access-token <API-Token> linux-dev
|
||||
|
||||
@ -40,7 +40,7 @@ Docker Machine可以很好地支持每一种Linux发行版。首先,我们需
|
||||
|
||||

|
||||
|
||||
**注意**: 这里linux-dev是我们将要创建的机器的名称。`<API-Token>`是一个安全key,可以在Digtal Ocean Control Panel生成。要找到这个key,我们只需要登录到我们的Digital Ocean Control Panel,然后点击API,再点击Generate New Token,填写一个名称,选上Read和Write。然后我们就会得到一串十六进制的key,那就是`<API-Token>`,简单地替换到上边的命令中即可。
|
||||
**注意**: 这里linux-dev是我们将要创建的机器的名称。`<API-Token>`是一个安全key,可以在Digtal Ocean Control Panel生成。要找到这个key,我们只需要登录到我们的Digital Ocean Control Panel,然后点击API,再点击 Generate New Token,填写一个名称,选上Read和Write。然后我们就会得到一串十六进制的key,那就是`<API-Token>`,简单地替换到上边的命令中即可。
|
||||
|
||||
运行如上命令后,我们可以在Digital Ocean Droplet Panel中看到一个具有默认配置的droplet已经被创建出来了。
|
||||
|
||||
@ -48,35 +48,35 @@ Docker Machine可以很好地支持每一种Linux发行版。首先,我们需
|
||||
|
||||
简便起见,docker-machine会使用默认配置来部署Droplet。我们可以通过增加选项来定制我们的Droplet。这里是一些digitalocean相关的选项,我们可以使用它们来覆盖Docker Machine所使用的默认配置。
|
||||
|
||||
--digitalocean-image "ubuntu-14-04-x64" 是选择Droplet的镜像
|
||||
--digitalocean-ipv6 enable 是启用IPv6网络支持
|
||||
--digitalocean-private-networking enable 是启用专用网络
|
||||
--digitalocean-region "nyc3" 是选择部署Droplet的区域
|
||||
--digitalocean-size "512mb" 是选择内存大小和部署的类型
|
||||
- --digitalocean-image "ubuntu-14-04-x64" 用于选择Droplet的镜像
|
||||
- --digitalocean-ipv6 enable 启用IPv6网络支持
|
||||
- --digitalocean-private-networking enable 启用专用网络
|
||||
- --digitalocean-region "nyc3" 选择部署Droplet的区域
|
||||
- --digitalocean-size "512mb" 选择内存大小和部署的类型
|
||||
|
||||
如果你想在其他云服务使用docker-machine,并且想覆盖默认的配置,可以运行如下命令来获取Docker Mackine默认支持的对每种平台适用的参数。
|
||||
|
||||
# docker-machine create -h
|
||||
|
||||
### 3. 选择活跃机器 ###
|
||||
### 3. 选择活跃主机 ###
|
||||
|
||||
部署Droplet后,我们想马上运行一个Docker容器,但在那之前,我们需要检查下活跃机器是否是我们需要的机器。可以运行如下命令查看。
|
||||
部署Droplet后,我们想马上运行一个Docker容器,但在那之前,我们需要检查下活跃主机是否是我们需要的机器。可以运行如下命令查看。
|
||||
|
||||
# docker-machine ls
|
||||
|
||||

|
||||
|
||||
ACTIVE一列有“*”标记的是活跃机器。
|
||||
ACTIVE一列有“*”标记的是活跃主机。
|
||||
|
||||
现在,如果我们想将活跃机器切换到需要的机器,运行如下命令:
|
||||
现在,如果我们想将活跃主机切换到需要的主机,运行如下命令:
|
||||
|
||||
# docker-machine active linux-dev
|
||||
|
||||
**注意**:这里,linux-dev是机器名,我们打算激活这个机器,并且在其中运行Docker容器。
|
||||
**注意**:这里,linux-dev是机器名,我们打算激活这个机器,并且在其上运行Docker容器。
|
||||
|
||||
### 4. 运行一个Docker容器 ###
|
||||
|
||||
现在,我们已经选择了活跃机器,就可以运行Docker容器了。可以测试一下,运行一个busybox容器来执行`echo hello word`命令,这样就可以得到输出:
|
||||
现在,我们已经选择了活跃主机,就可以运行Docker容器了。可以测试一下,运行一个busybox容器来执行`echo hello word`命令,这样就可以得到输出:
|
||||
|
||||
# docker run busybox echo hello world
|
||||
|
||||
@ -98,9 +98,9 @@ SSH到机器上之后,我们可以在上边运行任何Docker容器。这里
|
||||
|
||||
# exit
|
||||
|
||||
### 5. 删除机器 ###
|
||||
### 5. 删除主机 ###
|
||||
|
||||
删除在运行的机器以及它的所有镜像和容器,我们可以使用docker-machine rm命令:
|
||||
删除在运行的主机以及它的所有镜像和容器,我们可以使用docker-machine rm命令:
|
||||
|
||||
# docker-machine rm linux-dev
|
||||
|
||||
@ -112,15 +112,15 @@ SSH到机器上之后,我们可以在上边运行任何Docker容器。这里
|
||||
|
||||

|
||||
|
||||
### 6. 在不使用驱动的情况新增一个机器 ###
|
||||
### 6. 在不使用驱动的情况新增一个主机 ###
|
||||
|
||||
我们可以在不使用驱动的情况往Docker增加一台机器,只需要一个URL。它可以使用一个已有机器的别名,所以我们就不需要每次在运行docker命令时输入完整的URL了。
|
||||
我们可以在不使用驱动的情况往Docker增加一台主机,只需要一个URL。它可以使用一个已有机器的别名,所以我们就不需要每次在运行docker命令时输入完整的URL了。
|
||||
|
||||
$ docker-machine create --url=tcp://104.131.50.36:2376 custombox
|
||||
|
||||
### 7. 管理机器 ###
|
||||
### 7. 管理主机 ###
|
||||
|
||||
如果你已经让Docker运行起来了,可以使用简单的**docker-machine stop**命令来停止所有正在运行的机器,如果需要再启动的话可以运行**docker-machine start**:
|
||||
如果你已经让Docker运行起来了,可以使用简单的**docker-machine stop**命令来停止所有正在运行的主机,如果需要再启动的话可以运行**docker-machine start**:
|
||||
|
||||
# docker-machine stop
|
||||
# docker-machine start
|
||||
@ -140,7 +140,7 @@ via: http://linoxide.com/linux-how-to/use-docker-machine-cloud-provider/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[goreliu](https://github.com/goreliu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
Shell脚本:使用rsync备份文件/目录
|
||||
================================================================================
|
||||
本文,我们带来了shell脚本,用来使用rsync命令将你本地Linux机器上的文件/目录备份到远程Linux服务器上。使用该脚本实施备份会是一个交互的方式,你需要提供远程备份服务器的主机名/ip地址和文件夹位置。我们保留了一个独立文件,在这个文件中你需要提供需要备份的文件/目录。我们添加了两个脚本,**第一个脚本**在每次拷贝完一个文件后询问密码(如果你启用了ssh验证密钥,那么就不会询问密码),而第二个脚本中,则只会提示一次输入密码。
|
||||
本文我们介绍一个shell脚本,用来使用rsync命令将你本地Linux机器上的文件/目录备份到远程Linux服务器上。使用该脚本会以交互的方式实施备份,你需要提供远程备份服务器的主机名/ip地址和文件夹位置。我们使用一个单独的列表文件,在这个文件中你需要列出要备份的文件/目录。我们添加了两个脚本,**第一个脚本**在每次拷贝完一个文件后询问密码(如果你启用了ssh密钥验证,那么就不会询问密码),而第二个脚本中,则只会提示一次输入密码。
|
||||
|
||||
我们打算备份bckup.txt,dataconfig.txt,docs和orcledb。
|
||||
|
||||
@ -12,7 +12,7 @@ Shell脚本:使用rsync备份文件/目录
|
||||
drwxr-xr-x. 2 root root 4096 May 15 10:45 docs
|
||||
drwxr-xr-x. 2 root root 4096 May 15 10:44 oracledb
|
||||
|
||||
该文件包含了备份文件/目录的详情
|
||||
bckup.txt文件包含了需要备份的文件/目录的详情
|
||||
|
||||
[root@Fedora21 tmp]# cat /tmp/bckup.txt
|
||||
/tmp/oracledb
|
||||
@ -24,46 +24,46 @@ Shell脚本:使用rsync备份文件/目录
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
#We will save path to backup file in variable
|
||||
# 将备份列表文件的路径保存到变量中
|
||||
backupf='/tmp/bckup.txt'
|
||||
|
||||
#Next line just prints message
|
||||
# 输入一个提示信息
|
||||
echo "Shell Script Backup Your Files / Directories Using rsync"
|
||||
|
||||
#next line check if entered value is not null, and if null it will reask user to enter Destination Server
|
||||
# 检查是否输入了目标服务器,如果为空就再次提示用户输入
|
||||
while [ x$desthost = "x" ]; do
|
||||
|
||||
#next line prints what userd should enter, and stores entered value to variable with name desthost
|
||||
# 提示用户输入目标服务器地址并保存到变量
|
||||
read -p "Destination backup Server : " desthost
|
||||
|
||||
#next line finishes while loop
|
||||
# 结束循环
|
||||
done
|
||||
|
||||
#next line check if entered value is not null, and if null it will reask user to enter Destination Path
|
||||
# 检查是否输入了目标文件夹,如果为空就再次提示用户输入
|
||||
while [ x$destpath = "x" ]; do
|
||||
|
||||
#next line prints what userd should enter, and stores entered value to variable with name destpath
|
||||
# 提示用户输入目标文件夹并保存到变量
|
||||
read -p "Destination Folder : " destpath
|
||||
|
||||
#next line finishes while loop
|
||||
# 结束循环
|
||||
done
|
||||
|
||||
#Next line will start reading backup file line by line
|
||||
# 逐行读取备份列表文件
|
||||
for line in `cat $backupf`
|
||||
|
||||
#and on each line will execute next
|
||||
# 对每一行都进行处理
|
||||
do
|
||||
|
||||
#print message that file/dir will be copied
|
||||
# 显示要被复制的文件/文件夹名称
|
||||
echo "Copying $line ... "
|
||||
#copy via rsync file/dir to destination
|
||||
# 通过 rsync 复制文件/文件夹到目标位置
|
||||
|
||||
rsync -ar "$line" "$desthost":"$destpath"
|
||||
|
||||
#this line just print done
|
||||
# 显示完成
|
||||
echo "DONE"
|
||||
|
||||
#end of reading backup file
|
||||
# 结束
|
||||
done
|
||||
|
||||
#### 运行带有输出结果的脚本 ####
|
||||
@ -91,64 +91,65 @@ Shell脚本:使用rsync备份文件/目录
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
#We will save path to backup file in variable
|
||||
# 将备份列表文件的路径保存到变量中
|
||||
backupf='/tmp/bckup.txt'
|
||||
|
||||
#Next line just prints message
|
||||
# 输入一个提示信息
|
||||
echo "Shell Script Backup Your Files / Directories Using rsync"
|
||||
|
||||
#next line check if entered value is not null, and if null it will reask user to enter Destination Server
|
||||
# 检查是否输入了目标服务器,如果为空就再次提示用户输入
|
||||
while [ x$desthost = "x" ]; do
|
||||
|
||||
#next line prints what userd should enter, and stores entered value to variable with name desthost
|
||||
# 提示用户输入目标服务器地址并保存到变量
|
||||
read -p "Destination backup Server : " desthost
|
||||
|
||||
#next line finishes while loop
|
||||
# 结束循环
|
||||
done
|
||||
|
||||
#next line check if entered value is not null, and if null it will reask user to enter Destination Path
|
||||
# 检查是否输入了目标文件夹,如果为空就再次提示用户输入
|
||||
while [ x$destpath = "x" ]; do
|
||||
|
||||
#next line prints what userd should enter, and stores entered value to variable with name destpath
|
||||
# 提示用户输入目标文件夹并保存到变量
|
||||
read -p "Destination Folder : " destpath
|
||||
|
||||
#next line finishes while loop
|
||||
# 结束循环
|
||||
done
|
||||
|
||||
#next line check if entered value is not null, and if null it will reask user to enter password
|
||||
# 检查是否输入了目标服务器密码,如果为空就再次提示用户输入
|
||||
while [ x$password = "x" ]; do
|
||||
#next line prints what userd should enter, and stores entered value to variable with name password. #To hide password we are using -s key
|
||||
# 提示用户输入密码并保存到变量
|
||||
# 使用 -s 选项不回显输入的密码
|
||||
read -sp "Password : " password
|
||||
#next line finishes while loop
|
||||
# 结束循环
|
||||
done
|
||||
|
||||
#Next line will start reading backup file line by line
|
||||
# 逐行读取备份列表文件
|
||||
for line in `cat $backupf`
|
||||
|
||||
#and on each line will execute next
|
||||
# 对每一行都进行处理
|
||||
do
|
||||
|
||||
#print message that file/dir will be copied
|
||||
# 显示要被复制的文件/文件夹名称
|
||||
echo "Copying $line ... "
|
||||
#we will use expect tool to enter password inside script
|
||||
# 使用 expect 来在脚本中输入密码
|
||||
/usr/bin/expect << EOD
|
||||
#next line set timeout to -1, recommended to use
|
||||
# 推荐设置超时为 -1
|
||||
set timeout -1
|
||||
#copy via rsync file/dir to destination, using part of expect — spawn command
|
||||
# 通过 rsync 复制文件/文件夹到目标位置,使用 expect 的组成部分 spawn 命令
|
||||
|
||||
spawn rsync -ar ${line} ${desthost}:${destpath}
|
||||
#as result of previous command we expect “password” promtp
|
||||
# 上一行命令会等待 “password” 提示
|
||||
expect "*?assword:*"
|
||||
#next command enters password from script
|
||||
# 在脚本中提供密码
|
||||
send "${password}\r"
|
||||
#next command tells that we expect end of file (everything finished on remote server)
|
||||
# 等待文件结束符(远程服务器处理完了所有事情)
|
||||
expect eof
|
||||
#end of expect pard
|
||||
# 结束 expect 脚本
|
||||
EOD
|
||||
#this line just print done
|
||||
# 显示结束
|
||||
echo "DONE"
|
||||
|
||||
#end of reading backup file
|
||||
# 完成
|
||||
done
|
||||
|
||||
#### 运行第二个带有输出结果的脚本的屏幕截图 ####
|
||||
@ -163,7 +164,7 @@ via: http://linoxide.com/linux-shell-script/shell-script-backup-files-directorie
|
||||
|
||||
作者:[Yevhen Duma][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,14 +1,14 @@
|
||||
Linux 有问必答--如何在桌面版 Ubuntu 中用命令行更改系统代理设置
|
||||
Linux 有问必答:如何在桌面版 Ubuntu 中用命令行更改系统代理设置
|
||||
================================================================================
|
||||
> **问题**: 我经常需要在桌面版 Ubuntu 中更改系统代理设置,但我不想通过繁琐的 GUI 菜单链:"系统设置" -> "网络" -> "网络代理"。在命令行中有更方便的方法更改桌面版的代理设置吗?
|
||||
> **问题**: 我经常需要在桌面版 Ubuntu 中更改系统代理设置,但我不想通过繁琐的 GUI 菜单点击:"系统设置" -> "网络" -> "网络代理"。在命令行中有更方便的方法更改桌面版的代理设置吗?
|
||||
|
||||
在桌面版 Ubuntu 中,它的桌面环境设置,包括系统代理设置,都存储在 DConf 数据库,这是简单的键值对存储。如果你想通过系统设置菜单修改桌面属性,更改会持久保存在后端的 DConf 数据库。在 Ubuntu 中更改 DConf 数据库有基于图像用户界面和非图形用户界面的两种方式。系统设置或者 dconf-editor 是访问 DConf 数据库的图形方法,而 gsettings 或 dconf 就是能更改数据库的命令行工具。
|
||||
在桌面版 Ubuntu 中,它的桌面环境设置,包括系统代理设置,都存储在 DConf 数据库,这是简单的键值对存储。如果你想通过系统设置菜单修改桌面属性,更改会持久保存在后端的 DConf 数据库。在 Ubuntu 中更改 DConf 数据库有基于图像用户界面和非图形用户界面的两种方式。系统设置或者 `dconf-editor` 是访问 DConf 数据库的图形方法,而 `gsettings` 或 `dconf` 就是能更改数据库的命令行工具。
|
||||
|
||||
下面介绍如何用 gsettings 从命令行更改系统代理设置。
|
||||
下面介绍如何用 `gsettings` 从命令行更改系统代理设置。
|
||||
|
||||
|
||||
|
||||
gsetting 读写特定 Dconf 设置的基本用法如下:
|
||||
`gsettings` 读写特定 Dconf 设置的基本用法如下:
|
||||
|
||||
更改 DConf 设置:
|
||||
|
||||
@ -53,7 +53,7 @@ gsetting 读写特定 Dconf 设置的基本用法如下:
|
||||
|
||||
### 在命令行中清除系统代理设置 ###
|
||||
|
||||
最后,清除所有 手动/自动 代理设置,还原为无代理设置:
|
||||
最后,清除所有“手动/自动”代理设置,还原为无代理设置:
|
||||
|
||||
$ gsettings set org.gnome.system.proxy mode 'none'
|
||||
|
||||
@ -63,7 +63,7 @@ via: http://ask.xmodulo.com/change-system-proxy-settings-command-line-ubuntu-des
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -2,9 +2,9 @@
|
||||
================================================================================
|
||||

|
||||
|
||||
笔记本过热是最近一个常见的问题。监控硬件温度或许可以帮助你诊断笔记本为什么会过热。本篇中,我们会**了解如何在Ubuntu中检查CPU的温度**。
|
||||
夏天到了,笔记本过热是最近一个常见的问题。监控硬件温度或许可以帮助你诊断笔记本为什么会过热。本篇中,我们会**了解如何在Ubuntu中检查CPU的温度**。
|
||||
|
||||
我们将使用一个GUI工具[Psensor][1],它允许你在Linux中监控硬件温度。用Psensor你可以:
|
||||
我们将使用一个GUI工具[Psensor][1],它允许你在Linux中监控硬件温度。用Psensor你可以:
|
||||
|
||||
- 监控cpu和主板的温度
|
||||
- 监控NVidia GPU的文档
|
||||
@ -17,7 +17,7 @@ Psensor最新的版本同样提供了Ubuntu中的指示小程序,这样使得
|
||||
|
||||
### 如何在Ubuntu 15.04 和 14.04中安装Psensor ###
|
||||
|
||||
在安装Psensor前,你需要安装和配置[lm-sensors][2],一个用于硬件监控的命令行工具。如果你想要测量磁盘温度,你还需要安装[hddtemp][3]。要安装这些工具,运行下面的这些命令:
|
||||
在安装Psensor前,你需要安装和配置[lm-sensors][2],这是一个用于硬件监控的命令行工具。如果你想要测量磁盘温度,你还需要安装[hddtemp][3]。要安装这些工具,运行下面的这些命令:
|
||||
|
||||
sudo apt-get install lm-sensors hddtemp
|
||||
|
||||
@ -45,7 +45,7 @@ Psensor最新的版本同样提供了Ubuntu中的指示小程序,这样使得
|
||||
|
||||
sudo apt-get install psensor
|
||||
|
||||
安装完成后,在Unity Dash中运行程序。第一次运行时,你应该配置Psensor该监控什么状态。
|
||||
安装完成后,在Unity Dash中运行程序。第一次运行时,你应该配置Psensor该监控什么状态。
|
||||
|
||||

|
||||
|
||||
@ -73,7 +73,7 @@ via: http://itsfoss.com/check-laptop-cpu-temperature-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,10 @@
|
||||
Linux有问必答 -- 如何在Linux中挂载LVM分区
|
||||
Linux有问必答:如何在Linux中直接挂载LVM分区
|
||||
================================================================================
|
||||
> **提问**: 我有一个USB盘包含了LVM分区。 我想要在Linux中访问这些LVM分区。我该如何在Linux中挂载LVM分区?
|
||||
|
||||
】LVM是逻辑卷管理工具,它允许你使用逻辑卷和卷组的概念来管理磁盘空间。使用LVM相比传统分区最大的好处是弹性地位用户和程序分配空间而不用考虑每个物理磁盘的大小。
|
||||
LVM是逻辑卷管理工具,它允许你使用逻辑卷和卷组的概念来管理磁盘空间。使用LVM相比传统分区最大的好处是弹性地为用户和程序分配空间而不用考虑每个物理磁盘的大小。
|
||||
|
||||
在LVM中,那些创建了逻辑分区的物理存储是传统的分区(比如:/dev/sda2,/dev/sdb1)。这些分区必须被初始化位“物理卷”并被标签(如,“Linux LVM”)来使它们可以在LVM中使用。一旦分区被标记被LVM分区,你不能直接用mount命令挂载。
|
||||
在LVM中,那些创建了逻辑分区的物理存储是传统的分区(比如:/dev/sda2,/dev/sdb1)。这些分区必须被初始化为“物理卷 PV”并加上卷标(如,“Linux LVM”)来使它们可以在LVM中使用。一旦分区被标记被LVM分区,你不能直接用mount命令挂载。
|
||||
|
||||
如果你尝试挂载一个LVM分区(比如/dev/sdb2), 你会得到下面的错误。
|
||||
|
||||
@ -16,9 +16,9 @@ Linux有问必答 -- 如何在Linux中挂载LVM分区
|
||||
|
||||
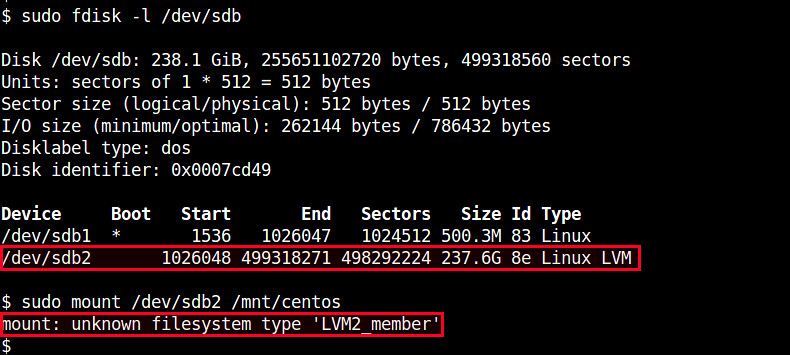
|
||||
|
||||
要正确地挂载LVM分区,你必须挂载分区创建的“逻辑分区”。下面就是如何做的。
|
||||
要正确地挂载LVM分区,你必须挂载分区中创建的“逻辑卷”。下面就是如何做的。
|
||||
|
||||
=首先,用下面的命令检查可用的卷组:
|
||||
首先,用下面的命令检查可用的卷组:
|
||||
|
||||
$ sudo pvs
|
||||
|
||||
@ -60,7 +60,9 @@ Linux有问必答 -- 如何在Linux中挂载LVM分区
|
||||
|
||||
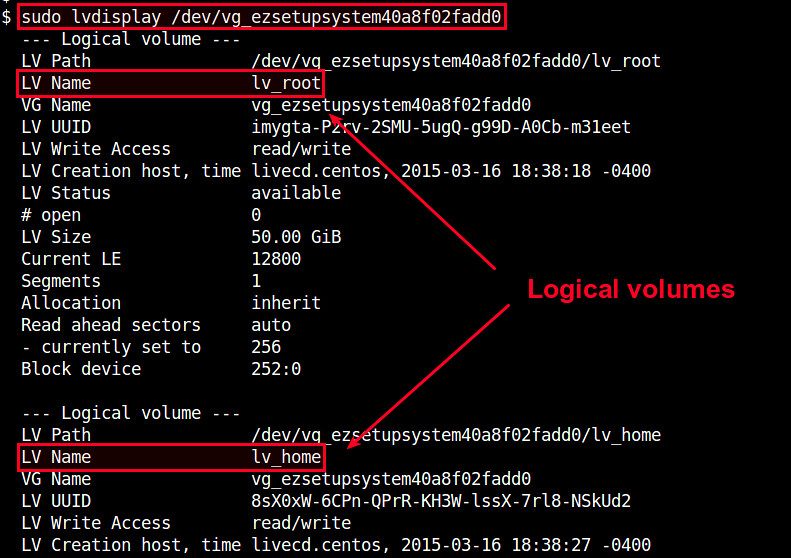
|
||||
|
||||
如果你想要挂载一个特定的逻辑卷,使用“LV Path”下面的设备名(如:/dev/vg_ezsetupsystem40a8f02fadd0/lv_home)。
|
||||
*上图可以看到两个逻辑卷的名字:lv_root和lv_home*
|
||||
|
||||
如果你想要挂载一个特定的逻辑卷,使用如下的“LV Path”的设备名(如:/dev/vg_ezsetupsystem40a8f02fadd0/lv_home)。
|
||||
|
||||
$ sudo mount /dev/vg_ezsetupsystem40a8f02fadd0/lv_home /mnt
|
||||
|
||||
@ -82,7 +84,7 @@ via: http://ask.xmodulo.com/mount-lvm-partition-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
11个让人惊叹的Linux终端彩蛋
|
||||
11个无用而有趣的Linux终端彩蛋
|
||||
================================================================================
|
||||
这里有一些很酷的Linux终端彩蛋,其中的每一个看上去并没有实际用途,但很精彩。
|
||||
这里有一些很酷的Linux终端彩蛋,其中的每一个看上去并没有实际用途,但很有趣。
|
||||
|
||||

|
||||
|
||||
@ -8,7 +8,7 @@
|
||||
|
||||
当我们使用命令行工作时,Linux是功能和实用性最好的操作系统之一。想要执行一个特殊任务?可能一个程序或者脚本就可以帮你搞定。但就像一本书中说到的,只工作不玩耍聪明的孩子也会变傻。下边是我最喜欢的可以在终端做的没有实际用途的、傻傻的、恼人的、可笑的事情。
|
||||
|
||||
### 给终端一个态度 ###
|
||||
### 让终端成为一个有态度的人 ###
|
||||
|
||||
* 第一步)敲入`sudo visudo`
|
||||
* 第二步)在“Defaults”末尾(文件的前半部分)添加一行“Defaults insults”。
|
||||
@ -20,13 +20,13 @@
|
||||
|
||||
### apt-get moo ###
|
||||
|
||||
你看过这张截图?那就是运行`apt-get moo`(在基于Debian的系统)的结果。对,就是它了。不要对它抱太多幻想,你会失望的,我不骗你。但是这是Linux世界最被人熟知的彩蛋之一。所以我把它包含进来,并且放在前排,然后我也就不会收到5千封邮件,指责我把它遗漏了。
|
||||
|
||||
|
||||
|
||||
你看过这张截图?那就是运行`apt-get moo`(在基于Debian的系统)的结果。对,就是它了。不要对它抱太多幻想,你会失望的,我不骗你。但是这是Linux世界最被人熟知的彩蛋之一。所以我把它包含进来,并且放在前排,然后我也就不会收到5千封邮件,指责我把它遗漏了。
|
||||
|
||||
### aptitude moo ###
|
||||
|
||||
更有趣的是将moo应用到aptitude上。敲入`aptitude moo`(在Ubuntu及其衍生版),你对`moo`可以做什么事情的看法会有所变化。你还还会知道更多事情,尝试重新输入这条命令,但这次添加一个`-v`参数。这还没有结束,试着添加更多`v`,一次添加一个,直到aptitude给了你想要的东西。
|
||||
更有趣的是将moo应用到aptitude上。敲入`aptitude moo`(在Ubuntu及其衍生版),你对`moo`可以做什么事情的看法会有所变化。你还还会知道更多事情,尝试重新输入这条命令,但这次添加一个`-v`参数。这还没有结束,试着添加更多`v`,一次添加一个,直到抓狂的aptitude给了你想要的东西。
|
||||
|
||||
|
||||
|
||||
@ -38,25 +38,25 @@
|
||||
* 第二步)在“# Misc options”部分,去掉“Color”前的“#”。
|
||||
* 第三步)添加“ILoveCandy”。
|
||||
|
||||
现在我们使用pacman安装新软件包时,进度条里会出现一个小吃豆人。真应该默认就是这样的。
|
||||
现在我们使用pacman安装新软件包时,进度条里会出现一个小吃豆人。真应该默认就这样的。
|
||||
|
||||
|
||||
|
||||
### Cowsay! ###
|
||||
|
||||
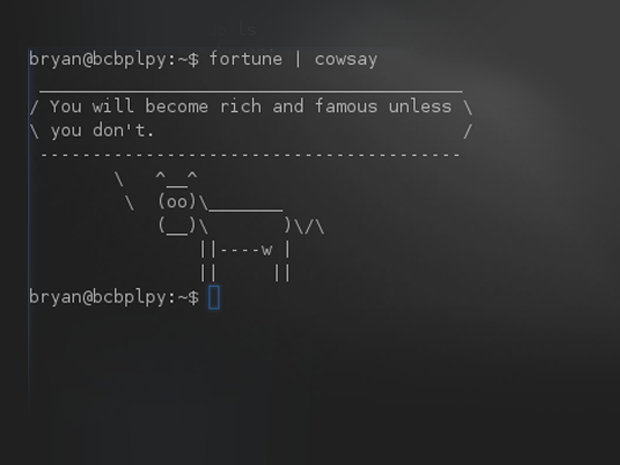
`aptitude moo`的输出格式很漂亮,但我想你苦于不能自由自在地使用。输入`cowsay`,它会做到你想做的事情。你可以让牛说任何你喜欢的东西。而且不只可以用牛,还可以用Calvin、Beavis和Ghostbusters的ASCII logo——输入`cowsay -l`可以得到所有可用的logo。它是Linux世界的强大工具。像很多其他命令一样,你可以使用管道把其他程序的输出输送给它,比如`fortune | cowsay`。
|
||||
`aptitude moo`的输出格式很漂亮,但我想你苦于不能自由自在地使用。输入`cowsay`,它会做到你想做的事情。你可以让牛说任何你喜欢的东西。而且不只可以用牛,还可以用Calvin、Beavis和Ghostbusters logo的ASCII的艺术,输入`cowsay -l`可以得到所有可用的参数。它是Linux世界的强大工具。像很多其他命令一样,你可以使用管道把其他程序的输出输送给它,比如`fortune | cowsay`,让这头牛变成哲学家。
|
||||
|
||||
|
||||
|
||||
### 变成3l33t h@x0r ###
|
||||
|
||||
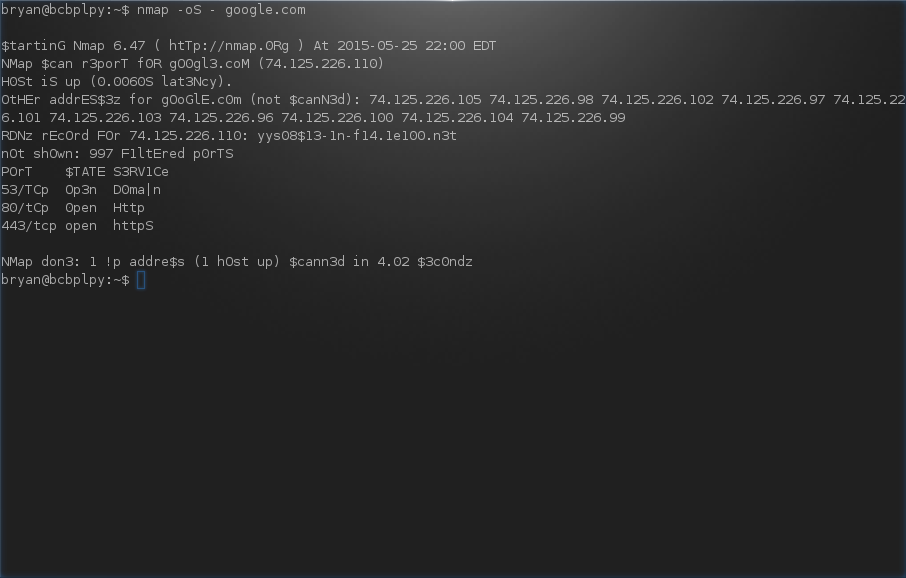
`nmap`并不是我们平时经常使用的基本命令。但如果你想蹂躏`nmap`的话,可能想在它的输出中看到l33t。在任何`nmap`命令(比如`nmap -oS - google.com`)后添加`-oS`。现在你的`nmap`已经处于官方名称是“[Script Kiddie Mode][1]”的模式了。Angelina Jolie和Keanu Reeves会为此骄傲的。
|
||||
`nmap`并不是我们平时经常使用的基本命令。但如果你想蹂躏`nmap`的话,比如像人一样看起来像l33t。在任何`nmap`命令后添加`-oS`(比如`nmap -oS - google.com`)。现在你的`nmap`已经处于标准叫法是“[脚本玩具模式][1]”的模式了。Angelina Jolie和Keanu Reeves会为此骄傲的。
|
||||
|
||||
|
||||
|
||||
### 获得所有的Discordian日期 ###
|
||||
|
||||
如果你们曾经坐在一起思考,“嗨!我想使用无用但异想天开的方式来书写今天的日期……”试试运行`ddate`。结果类似于“Today is Setting Orange, the 72nd day of Discord in the YOLD 3181”,这会让你的服务树日志平添不少香料。
|
||||
如果你们曾经坐在一起思考,“嗨!我想使用无用但异想天开的方式来书写今天的日期……”试试运行`ddate`。结果类似于“Today is Setting Orange, the 72nd day of Discord in the YOLD 3181”,这会让你的服务树日志平添不少趣味。
|
||||
|
||||
注意:在技术层面,确实有一个[Discordian Calendar][2],理论上被[Discordianism][3]追随者所使用。这意味着我可能得罪某些人。或者不会,我不确定。不管怎样,`ddate`是一个方便的工具。
|
||||
|
||||
@ -76,7 +76,7 @@
|
||||
|
||||
### 将任何文本逆序输出 ###
|
||||
|
||||
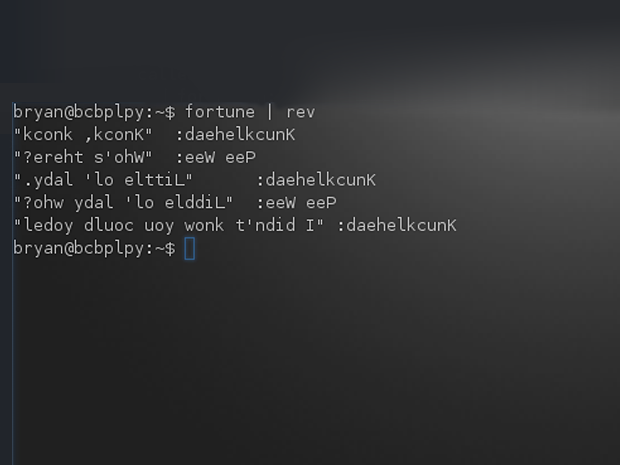
将任何文本使用管道输送给`rev`命令,它就会将文本内容逆序输出。`fortune | rev`会给你好运。当然,这不意味着rev会将幸运转换成不幸。
|
||||
将任何文本使用管道输送给`rev`命令,它就会将文本内容逆序输出。`fortune | rev`会给你好运。当然,这不意味着rev会将幸运(fortune)转换成不幸。
|
||||
|
||||
|
||||
|
||||
@ -94,7 +94,7 @@ via: http://www.networkworld.com/article/2926630/linux/11-pointless-but-awesome-
|
||||
|
||||
作者:[Bryan Lunduke][a]
|
||||
译者:[goreliu](https://github.com/goreliu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,15 @@
|
||||
如何在Linux中安装漂亮的扁平化Arc GTK+主题
|
||||
如何在 Linux 中安装漂亮的 GTK+ 扁平化主题 Arc
|
||||
================================================================================
|
||||
> 易于理解的分步教程
|
||||
|
||||
**今天我们将向你介绍最新发布的GTK+主题,它拥有透明和扁平元素,并且与多个桌面环境和Linux发行版兼容。[这个主题叫Arc][1]。**
|
||||
|
||||
开始讲细节之前,我建议你快速浏览一下下面的图,这样你有会对这个主题就会有一个基本的概念了。同样你应该知道它目前可以工作在GTK+ 2.x、GTK+ 3.x、GNOME-Shell、 Budgie、 Unity和Pantheon用户界面,它们都使用了GNOME栈。
|
||||
开始讲细节之前,我建议你快速浏览一下下面的图,这样你有会对这个主题就会有一个基本的概念了。同样你应该知道它目前可以工作在GTK+ 2.x、GTK+ 3.x、GNOME-Shell、 Budgie、 Unity和Pantheon用户界面,它们都使用了GNOME 体系。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
同样、Arc主题的开发者告诉我们它已经成功地在Ubuntu 15.04(Vivid Vervet)、 Arch Linux、 elementary OS 0.3 Freya、 Fedora 21、 Fedora 22、 Debian GNU/Linux 8.0 (Jessie)、 Debian Testing、 Debian Unstable、 openSUSE 13.2、 openSUSE Tumbleweed和Gentoo测试过了。
|
||||
|
||||
@ -12,7 +17,7 @@
|
||||
|
||||
要构建Arc主题,你需要先安装一些包,比如autoconf、 automake、 pkg-config (对于Fedora则是pkgconfig)、基于Debian/Ubuntu-based发行版的libgtk-3-dev或者基于RPM的gtk3-devel、 git、 gtk2-engines-pixbuf和gtk-engine-murrine (对于Fedora则是gtk-murrine-engine)。
|
||||
|
||||
Arc主题还没有二进制包,因此你需要从git仓库中取下最新的源码并编译。这样,打开终端并运行下面的命令,一行行地,并在每行的末尾按下回车键并等待上一步完成来继续下一步。
|
||||
Arc主题还没有二进制包,因此你需要从git仓库中取下最新的源码并编译。这样,打开终端并运行下面的命令,一行行地输入,并在每行的末尾按下回车键并等待上一步完成来继续下一步。
|
||||
|
||||
git clone https://github.com/horst3180/arc-theme --depth 1 && cd arc-theme
|
||||
git fetch --tags
|
||||
@ -22,11 +27,7 @@ Arc主题还没有二进制包,因此你需要从git仓库中取下最新的
|
||||
|
||||
就是这样!此时你已经在你的GNU/Linux发行版中安装了Arc主题,如果你使用GNOME可以使用GONME Tweak工具,如果你使用Ubuntu的Unity可以使用Unity Tweak工具来激活主题。玩得开心但不要忘了在下面的评论栏里留下你的截图。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -1,37 +1,36 @@
|
||||
如何在Ubuntu 15.04(Vivid Vervet)中安装nginx和google pagespeed
|
||||
如何在 Ubuntu 15.04 中安装 nginx 和 google pagespeed
|
||||
================================================================================
|
||||
Nginx (engine-x)是一个开源高性能http、反向代理和IMAP/POP3代理服务器。nginx杰出的功能有:稳定、丰富的功能集、简单的配置和低资源消耗。nginx被用于一些高性能网站并在站长之间变得越来越流行。本教程会从源码构建一个带有google paespeed模块用于Ubuntu 15.04中的.deb包。
|
||||
Nginx (engine-x)是一个开源的高性能 HTTP 服务器、反向代理和 IMAP/POP3 代理服务器。nginx 杰出的功能有:稳定、丰富的功能集、简单的配置和低资源消耗。nginx 被用于一些高性能网站并在站长之间变得越来越流行。本教程会从源码构建一个带有 google paespeed 模块的用于 Ubuntu 15.04 的 nginx .deb 安装包。
|
||||
|
||||
pagespeed 是一个由 google 开发的 web 服务器模块来加速网站响应时间、优化 html 和减少页面加载时间。ngx_pagespeed 的功能如下:
|
||||
|
||||
pagespeed是一个由google开发的web服务器模块来加速网站响应时间、优化html和减少页面加载时间。ngx_pagespeed的功能如下:
|
||||
|
||||
- 图像优化:去除meta数据、动态剪裁、重压缩。
|
||||
- CSS与JavaScript 放大、串联、内联、外联。
|
||||
- 图像优化:去除元数据、动态缩放、重压缩。
|
||||
- CSS 与 JavaScript 压缩、串联、内联、外联。
|
||||
- 小资源内联
|
||||
- 延迟图像与JavaScript加载
|
||||
- HTML重写。
|
||||
- 图像与 JavaScript 延迟加载
|
||||
- HTML 重写
|
||||
- 缓存生命期插件
|
||||
|
||||
更多请见 [https://developers.google.com/speed/pagespeed/module/][1].
|
||||
更多请见 [https://developers.google.com/speed/pagespeed/module/][1]。
|
||||
|
||||
### 预备要求 ###
|
||||
### 前置要求 ###
|
||||
|
||||
Ubuntu Server 15.04 64位
|
||||
root 权限
|
||||
- Ubuntu Server 15.04 64位
|
||||
- root 权限
|
||||
|
||||
本篇我们将要:
|
||||
|
||||
- 安装必备包
|
||||
- 安装带ngx_pagespeed的nginx
|
||||
- 安装必备软件包
|
||||
- 安装带 ngx_pagespeed 的 nginx
|
||||
- 测试
|
||||
|
||||
#### 安装必备包 ####
|
||||
|
||||
sudo apt-get install dpkg-dev build-essential zlib1g-dev libpcre3 libpcre3-dev
|
||||
sudo apt-get install dpkg-dev build-essential zlib1g-dev libpcre3 libpcre3-dev
|
||||
|
||||
#### 安装带ngx_pagespeed的nginx ####
|
||||
### 安装带 ngx_pagespeed 的 nginx ###
|
||||
|
||||
**第一步 - 添加nginx仓库**
|
||||
#### 第一步 - 添加nginx仓库####
|
||||
|
||||
vim /etc/apt/sources.list.d/nginx.list
|
||||
|
||||
@ -51,7 +50,7 @@ sudo apt-get install dpkg-dev build-essential zlib1g-dev libpcre3 libpcre3-dev
|
||||
sudo sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys KEYNUMBER
|
||||
sudo apt-get update
|
||||
|
||||
**第二步 - 从仓库下载nginx 1.8**
|
||||
####第二步 - 从仓库下载 nginx 1.8####
|
||||
|
||||
sudo su
|
||||
cd ~
|
||||
@ -60,7 +59,7 @@ sudo apt-get install dpkg-dev build-essential zlib1g-dev libpcre3 libpcre3-dev
|
||||
apt-get source nginx
|
||||
apt-get build-dep nginx
|
||||
|
||||
**第三步 - 下载Pagespeed**
|
||||
#### 第三步 - 下载 Pagespeed####
|
||||
|
||||
cd ~
|
||||
mkdir -p ~/new/ngx_pagespeed/
|
||||
@ -73,12 +72,12 @@ sudo apt-get install dpkg-dev build-essential zlib1g-dev libpcre3 libpcre3-dev
|
||||
wget https://dl.google.com/dl/page-speed/psol/${ngx_version}.tar.gz
|
||||
tar -xzf 1.9.32.3.tar.gz
|
||||
|
||||
**第三步 - 配置nginx来编译Pagespeed**
|
||||
####第四步 - 配置 nginx 来编译 Pagespeed####
|
||||
|
||||
cd ~/new/nginx_source/nginx-1.8.0/debin/
|
||||
vim rules
|
||||
|
||||
在CFLAGS `.configure`下添加模块:
|
||||
在两处 CFLAGS `.configure` 下添加模块:
|
||||
|
||||
--add-module=../../ngx_pagespeed/ngx_pagespeed-release-1.9.32.3-beta \
|
||||
|
||||
@ -86,27 +85,27 @@ sudo apt-get install dpkg-dev build-essential zlib1g-dev libpcre3 libpcre3-dev
|
||||
|
||||

|
||||
|
||||
**第五步 - 打包nginx包并安装**
|
||||
####第五步 - 打包 nginx 软件包并安装####
|
||||
|
||||
cd ~/new/nginx_source/nginx-1.8.0/
|
||||
dpkg-buildpackage -b
|
||||
|
||||
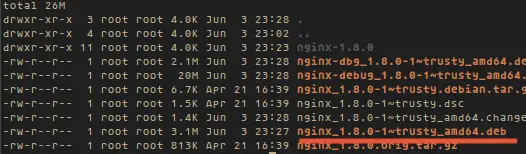
dpkg-buildpackage会编译 ~/new/ngix_source/成nginx.deb。打包完成后,看一下目录:
|
||||
dpkg-buildpackage 会编译 ~/new/ngix_source/ 为 nginx.deb。打包完成后,看一下目录:
|
||||
|
||||
cd ~/new/ngix_source/
|
||||
ls
|
||||
|
||||
|
||||
|
||||
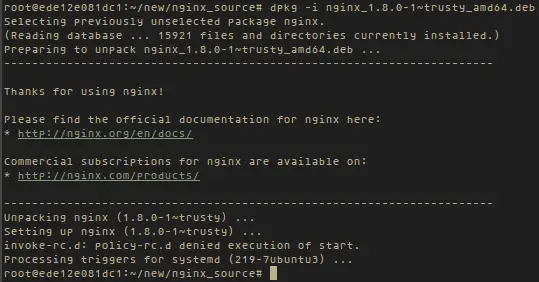
接着安装nginx。
|
||||
接着安装 nginx。
|
||||
|
||||
dpkg -i nginx_1.8.0-1~trusty_amd64.deb
|
||||
|
||||
|
||||
|
||||
#### 测试 ####
|
||||
### 测试 ###
|
||||
|
||||
运行nginx -V测试nginx是否已经自带ngx_pagespeed。
|
||||
运行 nginx -V 测试 nginx 是否已经自带 ngx_pagespeed。
|
||||
|
||||
nginx -V
|
||||
|
||||
@ -114,15 +113,15 @@ dpkg-buildpackage会编译 ~/new/ngix_source/成nginx.deb。打包完成后,
|
||||
|
||||
### 总结 ###
|
||||
|
||||
稳定、快速、开源的nginx支持许多不同的优化模块。这其中之一是google开发的‘pagespeed’。不像apache,nginx模块不是动态加载的,因此你必须在编译之前就选择完需要的模块。
|
||||
稳定、快速、开源的 nginx 支持许多不同的优化模块。这其中之一是 google 开发的‘pagespeed’。不像 apache,nginx 模块不是动态加载的,因此你必须在编译之前就选择好需要的模块。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-nginx-and-google-pagespeed-on-ubuntu-15-04/#step-build-nginx-package-and-install
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-nginx-and-google-pagespeed-on-ubuntu-15-04/
|
||||
|
||||
作者:Muhammad Arul
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,29 +1,27 @@
|
||||
|
||||
在Ubuntu 15.04下安装Android Studio
|
||||
PS 原MD文件有大段重复并且排版错误,译者已修复
|
||||
================================================================================
|
||||
|
||||
Android Studio是官方为了Android应用开发者而发布的IDE,它基于IntelliJ的IDEA。
|
||||

|
||||
|
||||
Android Studio是官方为了Android应用开发者而发布的IDE,它基于IntelliJ的IDEA。
|
||||
|
||||
### Android Studio的功能 ###
|
||||
|
||||
灵活的基于Gradle的建构系统
|
||||
- 灵活的基于Gradle的建构系统
|
||||
|
||||
针对不同手机编译多个版本的apk
|
||||
- 针对不同手机编译多个版本的apk
|
||||
|
||||
代码模板功能构建出各种常用的应用
|
||||
- 代码模板功能构建出各种常用的应用
|
||||
|
||||
支持拖动编辑主题的富布局编辑器
|
||||
- 支持拖动编辑主题的富布局编辑器
|
||||
|
||||
lint工具可以捕捉到应用的性能、可用性、版本冲突或者其他问题
|
||||
- lint工具可以捕捉到应用的性能、可用性、版本冲突或者其他问题
|
||||
|
||||
代码混淆和应用签名功能
|
||||
|
||||
内置 Google Cloud Platform 的支持,可以轻易的融入Google Cloud Messaging 和 App Engine支持
|
||||
|
||||
还有更多
|
||||
- 代码混淆和应用签名功能
|
||||
|
||||
- 内置 Google Cloud Platform 的支持,可以轻易的融入Google Cloud Messaging 和 App Engine支持
|
||||
|
||||
- 还有更多
|
||||
|
||||
### 在 Ubuntu 15.04 上安装 Android Studio ###
|
||||
|
||||
@ -33,7 +31,6 @@ lint工具可以捕捉到应用的性能、可用性、版本冲突或者其他
|
||||
sudo apt-get update
|
||||
sudo apt-get install android-studio
|
||||
|
||||
|
||||
如果要把Android Studio添加到启动栏,你需要如下操作
|
||||
|
||||
打开Android Studio,点击Configure选择Create Desktop Entry,这样Android Studio应该在dash中创建快捷方式了。
|
||||
@ -42,8 +39,6 @@ lint工具可以捕捉到应用的性能、可用性、版本冲突或者其他
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
@ -60,7 +55,7 @@ via: http://www.ubuntugeek.com/install-android-studio-on-ubuntu-15-04.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[NearTan](https://github.com/NearTan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,175 @@
|
||||
深入 NGINX: 我们如何设计性能和扩展
|
||||
================================================================================
|
||||
|
||||
NGINX 能在 web 性能中取得领先地位,这是由于其软件设计所决定的。许多 web 服务器和应用程序服务器使用一个简单的线程或基于流程的架构,NGINX 立足于一个复杂的事件驱动的体系结构,使它能够在现代硬件上扩展到成千上万的并发连接。
|
||||
|
||||
这张[深入 NGINX][1] 的信息图从高层次的流程架构深度挖掘说明了 NGINX 如何在单一进程里保持多个连接。这篇博客进一步详细地解释了这一切是如何工作的。
|
||||
|
||||
### 知识 – NGINX进程模型 ###
|
||||
|
||||
|
||||
|
||||
为了更好的理解这个设计,你需要理解 NGINX 如何运行的。NGINX 有一个主进程(它执行特权操作,如读取配置和绑定端口)和一些工作进程与辅助进程。
|
||||
|
||||
# service nginx restart
|
||||
* Restarting nginx
|
||||
# ps -ef --forest | grep nginx
|
||||
root 32475 1 0 13:36 ? 00:00:00 nginx: master process /usr/sbin/nginx \
|
||||
-c /etc/nginx/nginx.conf
|
||||
nginx 32476 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
|
||||
nginx 32477 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
|
||||
nginx 32479 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
|
||||
nginx 32480 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
|
||||
nginx 32481 32475 0 13:36 ? 00:00:00 \_ nginx: cache manager process
|
||||
nginx 32482 32475 0 13:36 ? 00:00:00 \_ nginx: cache loader process
|
||||
|
||||
在四核服务器,NGINX 主进程创建了4个工作进程和两个管理磁盘内容缓存的缓存辅助进程。
|
||||
|
||||
### 为什么架构很重要? ###
|
||||
|
||||
任何 Unix 应用程序的根本基础是线程或进程。(从 Linux 操作系统的角度来看,线程和进程大多是相同的,主要的区别是他们共享内存的程度。)一个线程或进程是一个自包含的指令集,操作系统可以在一个 CPU 核心上调度运行它们。大多数复杂的应用程序并行运行多个线程或进程有两个原因:
|
||||
|
||||
- 它们可以同时使用更多的计算核心。
|
||||
- 线程或进程可以轻松实现并行操作。(例如,在同一时刻保持多连接)。
|
||||
|
||||
进程和线程消耗资源。他们每个都使用内存和其他系统资源,他们会在 CPU 核心中换入和换出(一个操作可以叫做上下文切换)。大多数现代服务器可以并行保持上百个小型的、活动的线程或进程,但是一旦内存耗尽或高 I/O 压力引起大量的上下文切换会导致性能严重下降。
|
||||
|
||||
网络应用程序设计的常用方法是为每个连接分配一个线程或进程。此体系结构简单、容易实现,但是当应用程序需要处理成千上万的并发连接时这种结构就不具备扩展性。
|
||||
|
||||
### NGINX 如何工作? ###
|
||||
|
||||
NGINX 使用一种可预测的进程模式来分配可使用的硬件资源:
|
||||
|
||||
- 主进程(master)执行特权操作,如读取配置和绑定端口,然后创建少量的子进程(如下的三种类型)。
|
||||
- 缓存加载器进程(cache loader)在加载磁盘缓存到内存中时开始运行,然后退出。适当的调度,所以其资源需求很低。
|
||||
- 缓存管理器进程(cache manager)定期裁剪磁盘缓存中的记录来保持他们在配置的大小之内。
|
||||
- 工作进程(worker)做所有的工作!他们保持网络连接、读写内容到磁盘,与上游服务器通信。
|
||||
|
||||
在大多数情况下 NGINX 的配置建议:每个 CPU 核心运行一个工作进程,这样最有效地利用硬件资源。你可以在配置中包含 [worker_processes auto][2]指令配置:
|
||||
|
||||
worker_processes auto;
|
||||
|
||||
当一个 NGINX 服务处于活动状态,只有工作进程在忙碌。每个工作进程以非阻塞方式保持多连接,以减少上下文交换。
|
||||
|
||||
每个工作进程是一个单一线程并且独立运行,它们会获取新连接并处理之。这些进程可以使用共享内存通信来共享缓存数据、会话持久性数据及其它共享资源。(在 NGINX 1.7.11 及其以后版本,还有一个可选的线程池,工作进程可以转让阻塞的操作给它。更多的细节,参见“[NGINX 线程池可以爆增9倍性能!][16]”。对于 NGINX Plus 用户,该功能计划在今年晚些时候加入到 R7 版本中。)
|
||||
|
||||
### NGINX 工作进程内部 ###
|
||||
|
||||
|
||||
|
||||
每个 NGINX 工作进程按照 NGINX 配置初始化,并由主进程提供一组监听端口。
|
||||
|
||||
NGINX 工作进程首先在监听套接字上等待事件([accept_mutex][3] 和[内核套接字分片][4])。事件被新进来的连接初始化。这些连接被分配到一个状态机 – HTTP 状态机是最常用的,但 NGINX 也实现了流式(原始 TCP )状态机和几种邮件协议(SMTP、IMAP和POP3)的状态机。
|
||||
|
||||
|
||||
|
||||
状态机本质上是一组指令,告诉 NGINX 如何处理一个请求。大多数 web 服务器像 NGINX 一样使用类似的状态机来实现相同的功能 - 区别在于实现。
|
||||
|
||||
### 调度状态机 ###
|
||||
|
||||
把状态机想象成国际象棋的规则。每个 HTTP 事务是一个象棋游戏。一方面棋盘是 web 服务器 —— 一位大师可以非常迅速地做出决定。另一方面是远程客户端 —— 在一个相对较慢的网络下 web 浏览器访问网站或应用程序。
|
||||
|
||||
不管怎样,这个游戏规则很复杂。例如,web 服务器可能需要与各方沟通(代理一个上游的应用程序)或与身份验证服务器对话。web 服务器的第三方模块甚至可以扩展游戏规则。
|
||||
|
||||
#### 一个阻塞状态机 ####
|
||||
|
||||
回忆我们之前的描述,一个进程或线程就像一套独立的指令集,操作系统可以在一个 CPU 核心上调度运行它。大多数 web 服务器和 web 应用使用每个连接一个进程或者每个连接一个线程的模式来玩这个“象棋游戏”。每个进程或线程都包含玩完“一个游戏”的指令。在服务器运行该进程的期间,其大部分的时间都是“阻塞的” —— 等待客户端完成它的下一步行动。
|
||||
|
||||

|
||||
|
||||
1. web 服务器进程在监听套接字上监听新连接(客户端发起新“游戏”)
|
||||
1. 当它获得一个新游戏,就玩这个游戏,每走一步去等待客户端响应时就阻塞了。
|
||||
1. 游戏完成后,web 服务器进程可能会等待是否有客户机想要开始一个新游戏(这里指的是一个“保持的”连接)。如果这个连接关闭了(客户端断开或者发生超时),web 服务器进程会返回并监听一个新“游戏”。
|
||||
|
||||
要记住最重要的一点是每个活动的 HTTP 连接(每局棋)需要一个专用的进程或线程(象棋高手)。这个结构简单容并且易扩展第三方模块(“新规则”)。然而,还是有巨大的不平衡:尤其是轻量级 HTTP 连接其实就是一个文件描述符和小块内存,映射到一个单独的线程或进程,这是一个非常重量级的系统对象。这种方式易于编程,但太过浪费。
|
||||
|
||||
#### NGINX是一个真正的象棋大师 ####
|
||||
|
||||
也许你听过[同时表演赛][5]游戏,有一个象棋大师同时对战许多对手?
|
||||
|
||||

|
||||
|
||||
*[列夫·吉奥吉夫在保加利亚的索非亚同时对阵360人][6]。他的最终成绩是284胜70平6负。*
|
||||
|
||||
这就是 NGINX 工作进程如何“下棋”的。每个工作进程(记住 - 通常每个CPU核心上有一个工作进程)是一个可同时对战上百人(事实是,成百上千)的象棋大师。
|
||||
|
||||
|
||||
|
||||
1. 工作进程在监听和连接套接字上等待事件。
|
||||
1. 事件发生在套接字上,并且由工作进程处理它们:
|
||||
- 在监听套接字的事件意味着一个客户端已经开始了一局新棋局。工作进程创建了一个新连接套接字。
|
||||
- 在连接套接字的事件意味着客户端已经下了一步棋。工作进程及时响应。
|
||||
|
||||
一个工作进程在网络流量上从不阻塞,等待它的“对手”(客户端)做出反应。当它下了一步,工作进程立即继续其他的游戏,在那里工作进程正在处理下一步,或者在门口欢迎一个新玩家。
|
||||
|
||||
#### 为什么这个比阻塞式多进程架构更快? ####
|
||||
|
||||
NGINX 每个工作进程很好的扩展支撑了成百上千的连接。每个连接在工作进程中创建另外一个文件描述符和消耗一小部分额外内存。每个连接有很少的额外开销。NGINX 进程可以固定在某个 CPU 上。上下文交换非常罕见,一般只发生在没有工作要做时。
|
||||
|
||||
在阻塞方式,每个进程一个连接的方法中,每个连接需要大量额外的资源和开销,并且上下文切换(从一个进程切换到另一个)非常频繁。
|
||||
|
||||
更详细的解释,看看这篇关于 NGINX 架构的[文章][7],它由NGINX公司开发副总裁及共同创始人 Andrew Alexeev 写的。
|
||||
|
||||
通过适当的[系统优化][8],NGINX 的每个工作进程可以扩展来处理成千上万的并发 HTTP 连接,并能脸不红心不跳的承受峰值流量(大量涌入的新“游戏”)。
|
||||
|
||||
### 更新配置和升级 NGINX ###
|
||||
|
||||
NGINX 的进程体系架构使用少量的工作进程,有助于有效的更新配置文件甚至 NGINX 程序本身。
|
||||
|
||||
|
||||
|
||||
更新 NGINX 配置文件是非常简单、轻量、可靠的操作。典型的就是运行命令 `nginx –s reload`,所做的就是检查磁盘上的配置并发送 SIGHUP 信号给主进程。
|
||||
|
||||
当主进程接收到一个 SIGHUP 信号,它会做两件事:
|
||||
|
||||
- 重载配置文件和分支出一组新的工作进程。这些新的工作进程立即开始接受连接和处理流量(使用新的配置设置)
|
||||
- 通知旧的工作进程优雅的退出。工作进程停止接受新的连接。当前的 http 请求一旦完成,工作进程就彻底关闭这个连接(那就是,没有残存的“保持”连接)。一旦所有连接关闭,这个工作进程就退出。
|
||||
|
||||
这个重载过程能引发一个 CPU 和内存使用的小峰值,但是跟活动连接加载的资源相比它一般不易察觉。每秒钟你可以多次重载配置(很多 NGINX 用户都这么做)。非常罕见的情况下,有很多世代的工作进程等待关闭连接时会发生问题,但即使是那样也很快被解决了。
|
||||
|
||||
NGINX 的程序升级过程中拿到了高可用性圣杯 —— 你可以随随时更新这个软件,不会丢失连接,停机,或者中断服务。
|
||||
|
||||
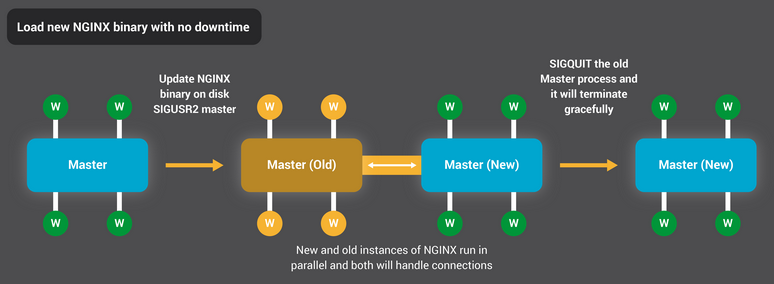
|
||||
|
||||
程序升级过程类似于平滑重载配置的方法。一个新的 NGINX 主进程与原主进程并行运行,然后他们共享监听套接字。两个进程都是活动的,并且各自的工作进程处理流量。然后你可以通知旧的主进程和它的工作进程优雅的退出。
|
||||
|
||||
整个过程的详细描述在 [NGINX 管理][9]。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
[深入 NGINX 信息图][10] 提供一个 NGINX 功能实现的高层面概览,但在这简单的解释的背后是超过十年的创新和优化,使得 NGINX 在广泛的硬件上提供尽可能最好的性能同时保持了现代 Web 应用程序所需要的安全性和可靠性。
|
||||
|
||||
如果你想阅读更多关于NGINX的优化,查看这些优秀的资源:
|
||||
|
||||
- [安装和 NGINX 性能调优][11] (webinar; Speaker Deck 上的[讲义][12])
|
||||
- [NGINX 性能调优][13]
|
||||
- [开源应用架构: NGINX 篇][14]
|
||||
- [NGINX 1.9.1 中的套接字分片][15] (使用 SO_REUSEPORT 套接字选项)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://nginx.com/blog/inside-nginx-how-we-designed-for-performance-scale/
|
||||
|
||||
作者:[Owen Garrett][a]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://nginx.com/author/owen/
|
||||
[1]:http://nginx.com/resources/library/infographic-inside-nginx/
|
||||
[2]:http://nginx.org/en/docs/ngx_core_module.html#worker_processes
|
||||
[3]:http://nginx.org/en/docs/ngx_core_module.html#accept_mutex
|
||||
[4]:http://nginx.com/blog/socket-sharding-nginx-release-1-9-1/
|
||||
[5]:http://en.wikipedia.org/wiki/Simultaneous_exhibition
|
||||
[6]:http://gambit.blogs.nytimes.com/2009/03/03/in-chess-records-were-made-to-be-broken/
|
||||
[7]:http://www.aosabook.org/en/nginx.html
|
||||
[8]:http://nginx.com/blog/tuning-nginx/
|
||||
[9]:http://nginx.org/en/docs/control.html
|
||||
[10]:http://nginx.com/resources/library/infographic-inside-nginx/
|
||||
[11]:http://nginx.com/resources/webinars/installing-tuning-nginx/
|
||||
[12]:https://speakerdeck.com/nginx/nginx-installation-and-tuning
|
||||
[13]:http://nginx.com/blog/tuning-nginx/
|
||||
[14]:http://www.aosabook.org/en/nginx.html
|
||||
[15]:http://nginx.com/blog/socket-sharding-nginx-release-1-9-1/
|
||||
[16]:http://nginx.com/blog/thread-pools-boost-performance-9x/
|
||||
@ -0,0 +1,84 @@
|
||||
PHP 20岁了:从玩具到巨头
|
||||
=============================================================================
|
||||
|
||||
> 曾经的‘丑小鸭工程’已经转变为一个互联网巨头,感谢灵活、务实和充满活力的开发者社区。
|
||||
|
||||
当Rasmus Lerdorf发布“[一个用C写的小型紧凑的CGI可执行程序集合][2]”时, 他没有想到他的创造会对网络发展产生多大的影响。今年在Miami举行的SunshinePHP大会上,Lerdorf做了开场演讲,他自嘲到,“在1995年的时候,我以为我已经在 Web 上解除了C API的束缚。显然,事情并非那样,我们全成了C程序员了。”
|
||||
|
||||

|
||||
|
||||
题图来自: [Steve Jurvetson via Flickr][1]
|
||||
|
||||
实际上,当Lerdorf发布个人主页工具(Personal Home Page Tools,即 PHP 名字的来源)的1.0版本时,那时的网络还是如此的年轻。直到那年的十一月份HTML 2.0还没有公布,而且HTTP/1.0也是次年的五月份才出现。那时,NCSA HTTPd是使用最广泛的网络服务器,而网景的Navigator则是最流行的网络浏览器,八月份的时候,IE1.0才刚刚出现。换句话说,PHP的开端刚好撞上了浏览器战争的前夜。
|
||||
|
||||
早些时候,我们谈论了一大堆关于PHP对网络发展的影响。回到那时候,当说到用于网络应用的服务器端处理,我们的选择是有限的。PHP满足了我们对于一种工具的需求,这就是可以使得我们在网络上做一些动态的事情。它的实用的灵活性只受限于我们的想像力,PHP从那时起便与网络共同成长。现在,PHP占据了网络语言的超过80%的份额,已经是成熟的脚本语言,特别适合解决网络问题。她独一无二的血统讲述了一个故事,实用高于理论,解决问题高于纯正。
|
||||
|
||||
### 把我们钩住的网络魔力 ###
|
||||
|
||||
PHP一开始并不是一门编程语言,从她的设计就很明显不是 -- 或者她本来就缺乏相关特性,正如那些贬低者指出的那样。最初,她是作为一种API帮助网络开发者能够接入底层的C语言封装库。第一个版本是一组小的CGI可执行程序,提供表单处理功能,可以访问查询参数和mSQL数据库。而且她可以如此容易地处理一个网络应用的数据库,证明了其在激发我们对于PHP的兴趣和PHP后来的支配地位的关键作用。
|
||||
|
||||
到了第二版 -- 即 PHP/FI -- 数据库的支持已经扩展到包括PostgreSQL、MySQL、Oracle、Sybase等等。她通过封装他们的C语言库来支持各种数据库,将他们作为PHP库的一部分。PHP/FI也封装了GD库,可以创建并管理GIF图像。她可以作为一个Apache模块运行,或者编译进FastCGI支持,并且她引入的 PHP 编程语言支持变量、数组、语言结构和函数。对于那个时候大多数在网络这块工作的人来说,PHP是我们一直在寻求的那款“胶水”。
|
||||
|
||||
当PHP吸纳越来越多的编程语言功能,演变为第三版和之后的版本时,她从来没有失去这种黏合的特性。通过仓库如PECL(PHP Extension Community Library),PHP可以把各种库都连在一起,将他们的函数引入到PHP层面。这种将组件结合在一起的能力,成为PHP之美的一个重要方面,使之不会受限于其源代码上。
|
||||
|
||||
### 网络,一个码农们的社区 ###
|
||||
|
||||
PHP在网络发展上的持续影响并不局限于能用这种语言干什么。PHP如何完成工作,谁参与进来 -- 这些都是PHP传奇中很重要的部分。
|
||||
|
||||
早在1997年,PHP的用户群体开始形成。其中最早的是美国中西部PHP用户组(后来叫做 Chiago PHP),并[1997年二月份的时候举行了第一次聚会][4]。这是一个充满生气、饱含激情的开发者社区形成的开端,聚合成一种吸引力 -- 在网络上的一个小工具就可以帮助他们解决问题。PHP这种普遍存在的特性使得她成为网络开发一个很自然的选择。在分享主导的世界里,她开始盛行,而且低入的门槛对于许多早期的网络开发者来说是十分有吸引力的。
|
||||
|
||||
伴随着社区的成长,为开发者带来了一堆工具和资源。这一年是2000年,出现了PHP的一个转折点,它见证了第一次PHP开发者大会,聚集了编程语言的核心开发者,他们在Tel Aviv见面,讨论即将到来的4.0版本的发布。PHP扩展和应用仓库(PEAR)也于2000年发起,它提供了高质量的用户代码包,依据标准和最佳操作。第一届PHP大会PHP Kongress不久之后在德国举行。[PHPDeveloper.org][5]也随后上线,直到今天,这都是PHP社区里最权威的新闻资源。
|
||||
|
||||
这个社区的势头表明了接下来几年里PHP成长的关键所在。随着网络开发产业的爆发,PHP也获得发展。PHP开始为更多、更大的网站提供动力。越来越多的用户群在世界各地开花。邮件列表、在线论坛、IRC、大会,以及如php[architect]、德国PHP杂志、国际PHP杂志等商业杂志 -- PHP社区的活力在完成网络工作的方式上有极其重要的影响:共同地,开放地,倡导代码共享。
|
||||
|
||||
然后,在10年前,PHP 5发布后不久,在网络发展史上一个有趣地事情发生了,它导致了PHP社区如何构建库和应用的转变:Ruby on Rails发布了。
|
||||
|
||||
### 框架的异军突起 ###
|
||||
|
||||
用于Ruby编程语言的Ruby on Rails框架在MVC(模型-视图-控制)架构模型上获得了不断增长的焦点与关注。Mojavi PHP框架几年前已经使用MVC模型了,但是Ruby on Rails的高明之处在于巩固了MVC。框架引爆了PHP社区,并且框架已经改变了开发者构建PHP应用程序的方式。
|
||||
|
||||
许多重要的项目和发展已经发端,这归功于PHP社区框架的生长。[PHP框架互用性组织][6]成立于2009年,致力于在框架间建立编码标准,命名约定与最佳操作。编纂这些标准和操作帮助为开发者在使用成员项目的代码时提供了越来越多的互用性软件。互用性意味着每个框架可以拆分为组块和独立的库,也可以作为整体的框架在一起使用。互用性带来了另一个重要的里程碑:Composer项目于2011年诞生了。
|
||||
|
||||
从Node.js的NPM和Ruby的Bundler获得灵感,Composer开辟了PHP应用开发的新纪元,创造了一次PHP“文艺复兴”。它激发了包互用性、标准命名约定、编码标准的采用、覆盖测试的提升。它是任何现代PHP应用中的一个基本工具。
|
||||
|
||||
### 加速和创新的需要 ###
|
||||
|
||||
如今,PHP社区有一个生机勃勃应用和库的生态系统,有一些被广泛安装的PHP应用包括WordPress,Drupal,Joomla和MediaWiki。从小型的夫妻店站点到whitehouse.gov和Wikipeida,这些应用支撑了各种不同规模的业务的网站。在Alexa前十的站点中,有6个使用PHP,在一天内为数十亿的页面访问提供服务。因此,PHP应用已成为需要加速的首选,并且许多创新也加入到PHP的核心来提升性能。
|
||||
|
||||
在2010年,Facebook公开了其用作PHP源对源的编译器的HipHop,可以翻译PHP代码为C++代码,并且编译为一个单独的可执行二进制应用。Facebook的规模和成长需要从标准互用的PHP代码迁移到更快、最佳的可执行的代码。尽管如此,由于PHP的易用和快速开发周期,Facebook还想继续使用PHP。HipHop后来进化为HHVM,这是一个针对PHP的JIT(just-in-time)编译基础的执行引擎,其包含一个基于PHP的新的语言:[Hack][7]。
|
||||
|
||||
Facebook的创新以及其他的VM项目是在引擎水平上的比较,其引起了关于Zend引擎未来的讨论。Zend引擎依然是PHP的内核和语言规范。在2014年,它创建了一个语言规范项目,“提供一个完整的,简明的语句定义,和PHP语言的语义学”,使得对编译器项目来说,创建互用的PHP实现成为可能。
|
||||
|
||||
下一个PHP的主要版本成为了激烈争论的话题,他们提出了一个叫做phpng(下一代)的项目,来清理,重构,优化和改进PHP代码基础,这也展示了对实际应用的性能的实质提升。由于之前有一个未发布的PHP 6.0版本,因此在决定命名下一个主要版本叫做“PHP 7”后,就合并了phpng分支,并制定了开发PHP 7的计划,以增加很多语言中拥有的功能,如scalar和返回类型提示。
|
||||
|
||||
随着[今天第一版PHP 7 alpha发布][8],基准检测程序显示她在许多方面[与HHVM的一样好或者拥有更好的性能][9],PHP正与现代网络开发需求保持一致的步伐。同样地,PHP-FIG继续创新和推动框架与库的协作 -- 最近由于[PSR-7][10]的采纳,这将会改变PHP项目处理HTTP的方式。用户组、会议、公众和如[PHPMentoring.org][11]这样的布道者继续在PHP开发者社区提倡最好的操作、编码标准和测试。
|
||||
|
||||
PHP从各个方面见证了网络的成熟,而且PHP自己也成熟了。曾经一个简单的低级C语言库的API封装,PHP以她自己的方式,已经成为一个羽翼丰满的编程语言。她的开发者社区是一个充满生气、乐于助人、在实用方面引以为傲,并且欢迎新人的地方。PHP已经经受了20年的考验,而且目前在语言与社区里的活跃性,会保证她在接下来的几年里将会是一个密切相关的、积极有用的的语言。
|
||||
|
||||
在Rasmus Lerdorf的SunshinePHP的演讲中,他回忆到,“我会想到我会在20年之后讨论当初做的这个愚蠢的小项目吗?没有。”
|
||||
|
||||
这里向Lerdorf和PHP社区的其他人致敬,感谢他们把这个“愚蠢的小项目”变成了一个如今网络上持久、强大的组件。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2933858/php/php-at-20-from-pet-project-to-powerhouse.html
|
||||
|
||||
作者:[Ben Ramsey][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Ben-Ramsey/
|
||||
[1]:https://www.flickr.com/photos/jurvetson/13049862325
|
||||
[2]:https://groups.google.com/d/msg/comp.infosystems.www.authoring.cgi/PyJ25gZ6z7A/M9FkTUVDfcwJ
|
||||
[3]:http://w3techs.com/technologies/overview/programming_language/all
|
||||
[4]:http://web.archive.org/web/20061215165756/http://chiphpug.php.net/mpug.htm
|
||||
[5]:http://www.phpdeveloper.org/
|
||||
[6]:http://www.php-fig.org/
|
||||
[7]:http://www.infoworld.com/article/2610885/facebook-q-a--hack-brings-static-typing-to-php-world.html
|
||||
[8]:https://wiki.php.net/todo/php70#timetable
|
||||
[9]:http://talks.php.net/velocity15
|
||||
[10]:http://www.php-fig.org/psr/psr-7/
|
||||
[11]:http://phpmentoring.org/
|
||||
|
||||
433
published/20150617 The Art of Command Line.md
Normal file
433
published/20150617 The Art of Command Line.md
Normal file
@ -0,0 +1,433 @@
|
||||
命令行艺术
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
|
||||
流畅地使用命令行是一个常被忽略的技能,或被认为是神秘的奥义。但是,它会以明显而微妙的方式改善你作为工程师的灵活度和生产力。这是我在 Linux 上工作时发现的有用的命令行使用小窍门和笔记的精粹。有些小窍门是很基础的,而有些是相当地特别、复杂、或者晦涩难懂。这篇文章不长,但是如果你可以使用并记得这里的所有内容,那么你就懂得很多了。
|
||||
|
||||
其中大部分[最初](http://www.quora.com/What-are-some-lesser-known-but-useful-Unix-commands)[出现](http://www.quora.com/What-are-the-most-useful-Swiss-army-knife-one-liners-on-Unix)在[Quora](http://www.quora.com/What-are-some-time-saving-tips-that-every-Linux-user-should-know)上,但是考虑到兴趣所在,似乎更应该放到 Github 上,这里的人比我更能提出改进建议。如果你看到一个错误,或者更好的某种东西,请提交问题或 PR!(当然,提交前请看看必读小节和已有的 PR/Issue。)
|
||||
|
||||
## 必读
|
||||
|
||||
范围:
|
||||
|
||||
- 本文是针对初学者和专业人员的,选题目标是覆盖面广(全都很重要)、有针对性(大多数情况下都给出具体实例)而简洁(避免不必要内容以及你能在其它地方轻松找到的离题的内容)。每个小窍门在某种情形下都很必需的,或者能比替代品大大节省时间。
|
||||
- 这是为 Linux 写的。绝大部分条目都可以同样应用到 MacOS(或者甚至 Cygwin)。
|
||||
- 主要针对交互式 Bash,尽管大多数小窍门也可以应用到其它 shell,以及常规 Bash 脚本。
|
||||
- 包括了“标准的”UNIX 命令以及那些需要安装的软件包(它们很重要,值得安装)。
|
||||
|
||||
注意:
|
||||
|
||||
- 为了能在一篇文章内展示尽量多的东西,一些具体的信息会被放到引用页里。你可以使用 Google 来获得进一步的内容。(如果需要的话,)你可以使用 `apt-get`/`yum`/`dnf`/`pacman`/`pip`/`brew` 来安装这些新的程序。
|
||||
- 使用 [Explainshell][1] 来获取命令、参数、管道等内容的解释。
|
||||
|
||||
## 基础
|
||||
|
||||
- 学习基本 Bash 技能。实际上,键入`man bash`,然后至少浏览一遍所有内容;它很容易理解,没那么长。其它 shell 也不错,但是 Bash 很强大,而且到处都可以找到(如果在你自己的笔记本上*只*学习 zsh、fish 之类,会在很多情形下受到限制,比如使用现存的服务器时)。
|
||||
|
||||
- 至少学好一种基于文本的编辑器。理想的一个是 Vim(`vi`),因为在终端中编辑时随时都能找到它(即使大多数时候你在使用 Emacs、一个大型的 IDE、或一个现代的时髦编辑器)。
|
||||
|
||||
- 学习怎样使用 `man` 来阅读文档(好奇的话,用 `man man` 来列出分区号,比如 1 是常规命令,5 是文件描述,8 用于管理员)。用 `apropos` 找到帮助页。了解哪些命令不是可执行程序,而是 Bash 内置的,你可以用 `help` 和 `help -d` 得到帮助。
|
||||
|
||||
- 学习使用 `>` 和 `<` 来进行输出和输入重定向,以及使用 `|` 来管道重定向,学习关于 stdout 和 stderr 的东西。
|
||||
|
||||
- 学习 `*`(也许还有 `?` 和 `{`...`}` )文件通配扩展和应用,以及双引号 `"` 和单引号 `'` 之间的区别。(更多内容请参看下面关于变量扩展部分)。
|
||||
|
||||
- 熟悉 Bash 作业管理:`&`, **ctrl-z**, **ctrl-c**, `jobs`, `fg`, `bg`, `kill` 等等。
|
||||
|
||||
- 掌握`ssh`,以及通过 `ssh-agent`,`ssh-add` 等进行无密码验证的基础技能。
|
||||
|
||||
- 基本的文件管理:`ls` 和 `ls -l`(特别是,知道`ls -l`各个列的意义),`less`, `head`, `tail` 和 `tail -f`(或者更好的`less +F`),`ln` 和 `ln -s`(知道硬链接和软链接的区别,以及硬链接相对于软链接的优势),`chown`,`chmod`,`du`(用于查看磁盘使用率的快速摘要:`du -sk *`)。文件系统管理:`df`, `mount`,`fdisk`,`mkfs`,`lsblk`。
|
||||
|
||||
- 基本的网络管理: `ip` 或 `ifconfig`,`dig`。
|
||||
|
||||
- 熟知正则表达式,以及各种使用`grep`/`egrep`的选项。`-i`,`-o`,`-A` 和 `-B` 选项值得掌握。
|
||||
|
||||
- 学会使用 `apt-get`,`yum` ,`dnf` 或 `pacman`(这取决于你的发行版)来查找并安装软件包。确保你可以用 `pip` 来安装基于 Python 的命令行工具(下面的一些东西可以很容易地通过 `pip` 安装)。
|
||||
|
||||
|
||||
## 日常使用
|
||||
|
||||
- 在Bash中,使用 **tab** 补完参数,使用 **ctrl-r** 来搜索命令历史。
|
||||
|
||||
- 在Bash中,使用 **ctrl-w** 来删除最后的单词,使用 **ctrl-u** 来删除整行,返回行首。使用 **alt-b** 和 **alt-f** 来逐词移动,使用 **ctrl-k** 来清除到行尾的内容,以及使用 **ctrl-l** 清屏。参见 `man readline` 来查看 Bash 中所有默认的键盘绑定,有很多。例如,**alt-.** 可以循环显示先前的参数,而**alt-** 扩展通配。(LCTT 译注:关于 Bash 下的快捷键,可以参阅: https://linux.cn/article-5660-1.html )
|
||||
|
||||
- 另外,如果你喜欢 vi 风格的键盘绑定,可以使用 `set -o vi`。
|
||||
|
||||
- 要查看最近用过的命令,请使用 `history` 。 有许多缩写形式,比如 `!$`(上次的参数)和`!!`(上次的命令),虽然使用 `ctrl-r` 和 `alt-.` 更容易些。(LCTT 译注:关于历史扩展功能,可以参阅: https://linux.cn/article-5658-1.html )
|
||||
|
||||
- 返回先前的工作目录: `cd -`
|
||||
|
||||
- 如果你命令输入到一半,但是改变主意了,可以敲 **alt-#** 来添加一个 `#` 到开头,然后将该命令作为注释输入(或者使用快捷键 **ctrl-a**, **#**,**enter** 输入)。然后,你可以在后面通过命令历史来回到该命令。
|
||||
|
||||
- 使用 `xargs`(或 `parallel`),它很强大。注意,你可以控制每行(`-L`)执行多少个项目,以及并行执行(`-P`)。如果你不确定它是否会做正确的事情,可以首先使用 `xargs echo`。同时,使用 `-I{}` 也很方便。样例:
|
||||
```bash
|
||||
find . -name '*.py' | xargs grep some_function
|
||||
cat hosts | xargs -I{} ssh root@{} hostname
|
||||
```
|
||||
|
||||
- `pstree -p` 对于显示进程树很有帮助。
|
||||
|
||||
- 使用 `pgrep` 和 `pkill` 来按名称查找进程或给指定名称的进程发送信号(`-f` 很有帮助)。
|
||||
|
||||
- 掌握各种可以发送给进程的信号。例如,要挂起进程,可以使用 `kill -STOP [pid]`。完整的列表可以查阅 `man 7 signal`。
|
||||
|
||||
- 如果你想要一个后台进程一直保持运行,使用 `nohup` 或 `disown`。
|
||||
|
||||
- 通过 `netstat -lntp` 或 `ss -plat` 检查哪些进程在监听(用于 TCP,对 UDP 使用 `-u` 替代 `-t`)。
|
||||
|
||||
- `lsof`来查看打开的套接字和文件。
|
||||
|
||||
- 在 Bash 脚本中,使用 `set -x` 调试脚本输出。尽可能使用严格模式。使用 `set -e` 在遇到错误时退出。也可以使用 `set -o pipefail`,对错误进行严格处理(虽然该话题有点微妙)。对于更复杂的脚本,也可以使用 `trap`。
|
||||
|
||||
- 在 Bash 脚本中,子 shell(写在括号中的)是组合命令的便利的方式。一个常见的例子是临时移动到一个不同的工作目录,如:
|
||||
```bash
|
||||
# 在当前目录做些事
|
||||
(cd /some/other/dir; other-command)
|
||||
# 继续回到原目录
|
||||
```
|
||||
|
||||
- 注意,在 Bash 中有大量的各种各样的变量扩展。检查一个变量是否存在:`${name:?error message}`。例如,如果一个Bash脚本要求一个单一参数,只需写 `input_file=${1:?usage: $0 input_file}`。算术扩展:`i=$(( (i + 1) % 5 ))`。序列: `{1..10}`。修剪字符串:`${var%suffix}` 和 `${var#prefix}`。例如,if `var=foo.pdf` ,那么 `echo ${var%.pdf}.txt` 会输出 `foo.txt`。
|
||||
|
||||
- 命令的输出可以通过 `<(some command)` 作为一个文件来处理。例如,将本地的 `/etc/hosts` 和远程的比较:
|
||||
```sh
|
||||
diff /etc/hosts <(ssh somehost cat /etc/hosts)
|
||||
```
|
||||
|
||||
- 了解 Bash 中的“嵌入文档”,就像在 `cat <<EOF ...` 中。
|
||||
|
||||
- 在 Bash 中,通过:`some-command >logfile 2>&1` 同时重定向标准输出和标准错误。通常,要确保某个命令不再为标准输入打开文件句柄,而是将它捆绑到你所在的终端,添加 `</dev/null` 是个不错的做法。
|
||||
|
||||
- `man ascii` 可以得到一个不错的ASCII表,带有十六进制和十进制值两种格式。对于常规编码信息,`man unicode`,`man utf-8` 和 `man latin1` 将很有帮助。
|
||||
|
||||
- 使用 `screen` 或 `tmux` 来复用屏幕,这对于远程 ssh 会话尤为有用,使用它们来分离并重连到会话。另一个只用于保持会话的最小可选方案是 `dtach`。
|
||||
|
||||
- 在 ssh 中,知道如何使用 `-L` 或 `-D`(偶尔也用`-R`)来打开端口通道是很有用的,如从一台远程服务器访问网站时。
|
||||
|
||||
- 为你的 ssh 配置进行优化很有用;例如,这个 `~/.ssh/config` 包含了可以避免在特定网络环境中连接被断掉的情况的设置、使用压缩(这对于通过低带宽连接使用 scp 很有用),以及使用一个本地控制文件来开启到同一台服务器的多通道:
|
||||
```
|
||||
TCPKeepAlive=yes
|
||||
ServerAliveInterval=15
|
||||
ServerAliveCountMax=6
|
||||
Compression=yes
|
||||
ControlMaster auto
|
||||
ControlPath /tmp/%r@%h:%p
|
||||
ControlPersist yes
|
||||
```
|
||||
|
||||
- 其它一些与 ssh 相关的选项对会影响到安全,请小心开启,如各个子网或主机,或者在信任的网络中:`StrictHostKeyChecking=no`, `ForwardAgent=yes`
|
||||
|
||||
- 要获得八进制格式的文件的权限,这对于系统配置很有用而用 `ls` 又没法查看,而且也很容易搞得一团糟,可以使用像这样的东西:
|
||||
```sh
|
||||
stat -c '%A %a %n' /etc/timezone
|
||||
```
|
||||
|
||||
- 对于从另一个命令的输出结果中交互选择值,可以使用[`percol`](https://github.com/mooz/percol)。
|
||||
|
||||
- 对于基于另一个命令(如`git`)输出的文件交互,可以使用`fpp` ([路径选择器](https://github.com/facebook/PathPicker))。
|
||||
|
||||
- 要为当前目录(及子目录)中的所有文件构建一个简单的 Web 服务器,让网络中的任何人都可以获取,可以使用:
|
||||
`python -m SimpleHTTPServer 7777` (使用端口 7777 和 Python 2)。
|
||||
|
||||
|
||||
## 处理文件和数据
|
||||
|
||||
- 要在当前目录中按名称定位文件,`find . -iname '*something*'`(或者相类似的)。要按名称查找任何地方的文件,使用 `locate something`(但请记住,`updatedb` 可能还没有索引最近创建的文件)。
|
||||
|
||||
- 对于源代码或数据文件进行的常规搜索(要比 `grep -r` 更高级),使用 [`ag`](https://github.com/ggreer/the_silver_searcher)。
|
||||
|
||||
- 要将 HTML 转成文本:`lynx -dump -stdin`。
|
||||
|
||||
- 对于 Markdown、HTML,以及各种类型的文档转换,可以试试 [`pandoc`](http://pandoc.org/)。
|
||||
|
||||
- 如果你必须处理 XML,`xmlstarlet` 虽然有点老旧,但是很好用。
|
||||
|
||||
- 对于 JSON,使用`jq`。
|
||||
|
||||
- 对于 Excel 或 CSV 文件,[csvkit](https://github.com/onyxfish/csvkit) 提供了 `in2csv`,`csvcut`,`csvjoin`,`csvgrep` 等工具。
|
||||
|
||||
- 对于亚马逊 S3 ,[`s3cmd`](https://github.com/s3tools/s3cmd) 会很方便,而 [`s4cmd`](https://github.com/bloomreach/s4cmd) 则更快速。亚马逊的 [`aws`](https://github.com/aws/aws-cli) 则是其它 AWS 相关任务的必备。
|
||||
|
||||
- 掌握 `sort` 和 `uniq`,包括 uniq 的 `-u` 和 `-d` 选项——参见下面的单行程序。
|
||||
|
||||
- 掌握 `cut`,`paste` 和 `join`,它们用于处理文本文件。很多人会使用 `cut`,但常常忘了 `join`。
|
||||
|
||||
- 了解 `tee`,它会将 stdin 同时复制到一个文件和 stdout,如 `ls -al | tee file.txt`。
|
||||
|
||||
- 知道 locale 会以微妙的方式对命令行工具产生大量的影响,包括排序的顺序(整理)以及性能。大多数安装好的 Linux 会设置 `LANG` 或其它 locale 环境变量为本地设置,比如像 US English。但是,你要明白,如果改变了本地环境,那么排序也将改变。而且 i18n 过程会让排序或其它命令的运行慢*好多倍*。在某些情形中(如像下面那样的设置操作或唯一性操作),你可以安全地整个忽略缓慢的 i18n 过程,然后使用传统的基于字节的排序顺序 `export LC_ALL=C`。
|
||||
|
||||
- 了解基本的改动数据的 `awk` 和 `sed` 技能。例如,计算某个文本文件第三列所有数字的和:`awk '{ x += $3 } END { print x }'`。这可能比 Python 的同等操作要快3倍,而且要短3倍。
|
||||
|
||||
- 在一个或多个文件中,替换所有出现在特定地方的某个字符串:
|
||||
```sh
|
||||
perl -pi.bak -e 's/old-string/new-string/g' my-files-*.txt
|
||||
```
|
||||
|
||||
- 要立即根据某个模式对大量文件重命名,使用 `rename`。对于复杂的重命名,[`repren`](https://github.com/jlevy/repren) 可以帮助你达成。
|
||||
```sh
|
||||
# 恢复备份的文件名 foo.bak -> foo:
|
||||
rename 's/\.bak$//' *.bak
|
||||
# 文件和目录的全名 foo -> bar:
|
||||
repren --full --preserve-case --from foo --to bar .
|
||||
```
|
||||
|
||||
- 使用 `shuf` 来从某个文件中打乱或随机选择行。
|
||||
|
||||
- 了解 `sort` 的选项。知道这些键是怎么工作的(`-t`和`-k`)。特别是,注意你需要写`-k1,1`来只通过第一个字段排序;`-k1`意味着根据整行排序。
|
||||
|
||||
- 稳定排序(`sort -s`)会很有用。例如,要首先按字段2排序,然后再按字段1排序,你可以使用 `sort -k1,1 | sort -s -k2,2`
|
||||
|
||||
- 如果你曾经需要在 Bash 命令行中写一个水平制表符(如,用于 -t 参数的排序),按**ctrl-v** **[Tab]**,或者写`$'\t'`(后面的更好,因为你可以复制/粘贴)。
|
||||
|
||||
- 对源代码进行补丁的标准工具是 `diff` 和 `patch`。 用 `diffstat` 来统计 diff 情况。注意 `diff -r` 可以用于整个目录,所以可以用 `diff -r tree1 tree2 | diffstat` 来统计(两个目录的)差异。
|
||||
|
||||
- 对于二进制文件,使用 `hd` 进行简单十六进制转储,以及 `bvi` 用于二进制编辑。
|
||||
|
||||
- 还是用于二进制文件,`strings`(加上 `grep` 等)可以让你找出一点文本。
|
||||
|
||||
- 对于二进制文件的差异(delta 压缩),可以使用 `xdelta3`。
|
||||
|
||||
- 要转换文本编码,试试 `iconv` 吧,或者对于更高级的用途使用 `uconv`;它支持一些高级的 Unicode 的东西。例如,这个命令可以转换为小写并移除所有重音符号(通过扩展和丢弃):
|
||||
```sh
|
||||
uconv -f utf-8 -t utf-8 -x '::Any-Lower; ::Any-NFD; [:Nonspacing Mark:] >; ::Any-NFC; ' < input.txt > output.txt
|
||||
```
|
||||
|
||||
- 要将文件分割成几个部分,来看看 `split`(按大小分割)和 `csplit`(按格式分割)吧。
|
||||
|
||||
- 使用 `zless`,`zmore`,`zcat` 和 `zgrep` 来操作压缩文件。
|
||||
|
||||
## 系统调试
|
||||
|
||||
- 对于 Web 调试,`curl` 和 `curl -I` 很方便灵活,或者也可以使用它们的同行 `wget`,或者更现代的 [`httpie`](https://github.com/jakubroztocil/httpie)。
|
||||
|
||||
- 要了解磁盘、CPU、网络的状态,使用 `iostat`,`netstat`,`top`(或更好的 `htop`)和(特别是)`dstat`。它们对于快速获知系统中发生的状况很好用。
|
||||
|
||||
- 对于更深层次的系统总览,可以使用 [`glances`](https://github.com/nicolargo/glances)。它会在一个终端窗口中为你呈现几个系统层次的统计数据,对于快速检查各个子系统很有帮助。
|
||||
|
||||
- 要了解内存状态,可以运行 `free` 和 `vmstat`,看懂它们的输出结果吧。特别是,要知道“cached”值是Linux内核为文件缓存所占有的内存,因此,要有效地统计“free”值。
|
||||
|
||||
- Java 系统调试是一件截然不同的事,但是对于 Oracle 系统以及其它一些 JVM 而言,不过是一个简单的小把戏,你可以运行 `kill -3 <pid>`,然后一个完整的堆栈追踪和内存堆的摘要(包括常规的垃圾收集细节,这很有用)将被转储到stderr/logs。
|
||||
|
||||
- 使用 `mtr` 作路由追踪更好,可以识别网络问题。
|
||||
|
||||
- 对于查看磁盘满载的原因,`ncdu` 会比常规命令如 `du -sh *` 更节省时间。
|
||||
|
||||
- 要查找占用带宽的套接字和进程,试试 `iftop` 或 `nethogs` 吧。
|
||||
|
||||
- (Apache附带的)`ab`工具对于临时应急检查网络服务器性能很有帮助。对于更复杂的负载测试,可以试试 `siege`。
|
||||
|
||||
- 对于更仔细的网络调试,可以用 `wireshark`,`tshark` 或 `ngrep`。
|
||||
|
||||
- 掌握 `strace` 和 `ltrace`。如果某个程序失败、挂起或崩溃,而你又不知道原因,或者如果你想要获得性能的大概信息,这些工具会很有帮助。注意,分析选项(`-c`)和使用 `-p` 关联运行进程。
|
||||
|
||||
- 掌握 `ldd` 来查看共享库等。
|
||||
|
||||
- 知道如何使用 `gdb` 来连接到一个运行着的进程并获取其堆栈追踪信息。
|
||||
|
||||
- 使用 `/proc`。当调试当前的问题时,它有时候出奇地有帮助。样例:`/proc/cpuinfo`,`/proc/xxx/cwd`,`/proc/xxx/exe`,`/proc/xxx/fd/`,`/proc/xxx/smaps`。
|
||||
|
||||
- 当调试过去某个东西为何出错时,`sar` 会非常有帮助。它显示了 CPU、内存、网络等的历史统计数据。
|
||||
|
||||
- 对于更深层的系统和性能分析,看看 `stap` ([SystemTap](https://sourceware.org/systemtap/wiki)),[`perf`](http://en.wikipedia.org/wiki/Perf_(Linux)) 和 [`sysdig`](https://github.com/draios/sysdig) 吧。
|
||||
|
||||
- 确认是正在使用的 Linux 发行版版本(支持大多数发行版):`lsb_release -a`。
|
||||
|
||||
- 每当某个东西的行为异常时(可能是硬件或者驱动器问题),使用`dmesg`。
|
||||
|
||||
## 单行程序
|
||||
|
||||
这是将命令连成一行的一些样例:
|
||||
|
||||
- 有时候通过 `sort`/`uniq` 对文本文件做交集、并集和差集运算时,这个例子会相当有帮助。假定 `a` 和 `b` 是已经进行了唯一性处理的文本文件。这会很快,而且可以处理任意大小的文件,总计可达数千兆字节。(Sort不受内存限制,不过如果 `/tmp` 放在一个很小的根分区的话,你可能需要使用 `-T` 选项。)也可参见上面关于`LC_ALL`的注解和 `-u` 选项(参见下面例子更清晰)。
|
||||
|
||||
```bash
|
||||
cat a b | sort | uniq > c # c 是 a 和 b 的并集
|
||||
cat a b | sort | uniq -d > c # c 是 a 和 b 的交集
|
||||
cat a b b | sort | uniq -u > c # c 是 a 减去 b 的差集
|
||||
```
|
||||
- 使用 `grep . *` 来可视化查看一个目录中的所有文件的所有内容,例如,对于放满配置文件的目录: `/sys`, `/proc`, `/etc`。
|
||||
|
||||
- 对某个文本文件的第三列中所有数据进行求和(该例子可能比同等功能的Python要快3倍,而且代码也少于其3倍):
|
||||
```sh
|
||||
awk '{ x += $3 } END { print x }' myfile
|
||||
```
|
||||
|
||||
- 如果想要查看某个文件树的大小/日期,该例子就像一个递归`ls -l`,但是比`ls -lR`要更容易读懂:
|
||||
```sh
|
||||
find . -type f -ls
|
||||
```
|
||||
|
||||
- 只要可以,请使用 `xargs` 或 `parallel`。注意,你可以控制每行(`-L`)执行多少个项目,以及并行执行(`-P`)。如果你不确定它是否会做正确的事情,可以首先使用 `xargs echo`。同时,使用 `-I{}` 也很方便。样例:
|
||||
```sh
|
||||
find . -name '*.py' | xargs grep some_function
|
||||
cat hosts | xargs -I{} ssh root@{} hostname
|
||||
```
|
||||
|
||||
- 比如说,你有一个文本文件,如 Web 服务器的日志,在某些行中出现了某个特定的值,如 URL 中出现的 `acct_id` 参数。如果你想要统计有多少个 `acct_id` 的请求:
|
||||
```sh
|
||||
cat access.log | egrep -o 'acct_id=[0-9]+' | cut -d= -f2 | sort | uniq -c | sort -rn
|
||||
```
|
||||
|
||||
- 运行该函数来获得来自本文的随机提示(解析Markdown并从中提取某个项目):
|
||||
```sh
|
||||
function taocl() {
|
||||
curl -s https://raw.githubusercontent.com/jlevy/the-art-of-command-line/master/README.md |
|
||||
pandoc -f markdown -t html |
|
||||
xmlstarlet fo --html --dropdtd |
|
||||
xmlstarlet sel -t -v "(html/body/ul/li[count(p)>0])[$RANDOM mod last()+1]" |
|
||||
xmlstarlet unesc | fmt -80
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## 晦涩难懂,但却有用
|
||||
|
||||
- `expr`:实施算术或布林操作,或者求正则表达式的值
|
||||
|
||||
- `m4`:简单的宏处理器
|
||||
|
||||
- `yes`:大量打印一个字符串
|
||||
|
||||
- `cal`:漂亮的日历
|
||||
|
||||
- `env`:(以特定的环境变量设置)运行一个命令(脚本中很有用)
|
||||
|
||||
- `look`:查找以某个字符串开头的英文单词(或文件中的行)
|
||||
|
||||
- `cut ` 和 `paste` 以及 `join`:数据处理
|
||||
|
||||
- `fmt`:格式化文本段落
|
||||
|
||||
- `pr`:格式化文本为页/列
|
||||
|
||||
- `fold`:文本折行
|
||||
|
||||
- `column`:格式化文本为列或表
|
||||
|
||||
- `expand` 和 `unexpand`:在制表符和空格间转换
|
||||
|
||||
- `nl`:添加行号
|
||||
|
||||
- `seq`:打印数字
|
||||
|
||||
- `bc`:计算器
|
||||
|
||||
- `factor`:分解质因子
|
||||
|
||||
- `gpg`:加密并为文件签名
|
||||
|
||||
- `toe`:terminfo 条目表
|
||||
|
||||
- `nc`:网络调试和数据传输
|
||||
|
||||
- `socat`:套接字中继和 tcp 端口转发(类似 `netcat`)
|
||||
|
||||
- `slurm`:网络流量可视化
|
||||
|
||||
- `dd`:在文件或设备间移动数据
|
||||
|
||||
- `file`:识别文件类型
|
||||
|
||||
- `tree`:以树形显示目录及子目录;类似 `ls`,但是是递归的。
|
||||
|
||||
- `stat`:文件信息
|
||||
|
||||
- `tac`:逆序打印文件
|
||||
|
||||
- `shuf`:从文件中随机选择行
|
||||
|
||||
- `comm`:逐行对比分类排序的文件
|
||||
|
||||
- `hd`和`bvi`:转储或编辑二进制文件
|
||||
|
||||
- `strings`:从二进制文件提取文本
|
||||
|
||||
- `tr`:字符转译或处理
|
||||
|
||||
- `iconv `或`uconv`:文本编码转换
|
||||
|
||||
- `split `和`csplit`:分割文件
|
||||
|
||||
- `units`:单位转换和计算;将每双周(fortnigh)一浪(浪,furlong,长度单位,约201米)转换为每瞬(blink)一缇(缇,twip,一种和屏幕无关的长度单位)(参见: /usr/share/units/definitions.units)(LCTT 译注:这都是神马单位啊!)
|
||||
|
||||
- `7z`:高比率文件压缩
|
||||
|
||||
- `ldd`:动态库信息
|
||||
|
||||
- `nm`:目标文件的符号
|
||||
|
||||
- `ab`:Web 服务器基准测试
|
||||
|
||||
- `strace`:系统调用调试
|
||||
|
||||
- `mtr`:用于网络调试的更好的路由追踪软件
|
||||
|
||||
- `cssh`:可视化并发 shell
|
||||
|
||||
- `rsync`:通过 SSH 同步文件和文件夹
|
||||
|
||||
- `wireshark` 和 `tshark`:抓包和网络调试
|
||||
|
||||
- `ngrep`:从网络层摘取信息
|
||||
|
||||
- `host` 和 `dig`:DNS查询
|
||||
|
||||
- `lsof`:处理文件描述符和套接字信息
|
||||
|
||||
- `dstat`:有用的系统统计数据
|
||||
|
||||
- [`glances`](https://github.com/nicolargo/glances):高级,多个子系统概览
|
||||
|
||||
- `iostat`:CPU和磁盘使用率统计
|
||||
|
||||
- `htop`:top的改进版
|
||||
|
||||
- `last`:登录历史
|
||||
|
||||
- `w`:谁登录进来了
|
||||
|
||||
- `id`:用户/组身份信息
|
||||
|
||||
- `sar`:历史系统统计数据
|
||||
|
||||
- `iftop`或`nethogs`:按套接口或进程的网络使用率
|
||||
|
||||
- `ss`:套接口统计数据
|
||||
|
||||
- `dmesg`:启动和系统错误信息
|
||||
|
||||
- `hdparm`:SATA/ATA 磁盘操作/改善性能
|
||||
|
||||
- `lsb_release`:Linux 发行版信息
|
||||
|
||||
- `lsblk`:列出块设备,以树形展示你的磁盘和分区
|
||||
|
||||
- `lshw`:硬件信息
|
||||
|
||||
- `fortune`,`ddate` 和 `sl`:嗯,好吧,它取决于你是否认为蒸汽机车和 Zippy 引用“有用”
|
||||
|
||||
|
||||
## 更多资源
|
||||
|
||||
- [超棒的shell](https://github.com/alebcay/awesome-shell): 一个shell工具和资源一览表。
|
||||
- [严格模式](http://redsymbol.net/articles/unofficial-bash-strict-mode/) 用于写出更佳的shell脚本。
|
||||
|
||||
|
||||
## 免责声明
|
||||
|
||||
除了非常小的任务外,其它都写出了代码供大家阅读。伴随力量而来的是责任。事实是,你*能*在Bash中做的,并不意味着是你所应该做的!;)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/jlevy/the-art-of-command-line
|
||||
|
||||
作者:[jlevy][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/jlevy
|
||||
[1]:http://explainshell.com/
|
||||
|
||||
@ -0,0 +1,62 @@
|
||||
Linux Kernel 4.1 Released, This Is What’s New
|
||||
================================================================================
|
||||
**TuxlogoA brand new version of the Linux Kernel — the heartbeat of the modern world (if we you want us to be poetic about it) — has been released.**
|
||||
|
||||

|
||||
|
||||
The arrival [has been announced][1] by Linus Torvalds (who else?) on the Linux Kernel Mailing List (where else?) and comes almost two months after the [first entry in the new 4.x series][2].
|
||||
|
||||
Levity aside, and like every release before it, Linux Kernel 4.1 features a big set of changes. These touch everything from hardware compatibility to power management to file-system performance and technical fixes for obscure processors you’ve never heard of.
|
||||
|
||||
Linux 4.1 is already being tracked in Ubuntu 15.10, due for release in October.
|
||||
|
||||
### What’s New In Linux 4.1? ###
|
||||
|
||||

|
||||
Tux got mail
|
||||
|
||||
The sub-heading is on your lips and we’re not here simply to serve up an announcement of an announcement.
|
||||
|
||||
We’ve gone through the (vast, long, lengthy and at times technically unintelligible) change-log to pick out some highlights that may not feed hyperbole but may impact on you, a desktop users.
|
||||
|
||||
#### Power Improvements ####
|
||||
|
||||
The big headline user-facing feature you’ll find in Linux 4.1 are the wealth of performance and power efficiency improvements committed for Intel’s Cherry Trail and Bay Trail chips. SoCs and devices, such as the Intel Compute Stick.
|
||||
|
||||
Anecdotal suggestions are that Linux Kernel 4.1 gives select combinations of newer Intel hardware as much as an extra hour of battery life. Such high gains are not likely to apply to anything but a very specific sub-set of chips and systems (and high-end ones at that) but it’s still exciting to hear of.
|
||||
|
||||
**Highlights of Linux 4.1 include:**
|
||||
|
||||
- EXT4 gains file-system level encryption (thanks to Google)
|
||||
- Logitech lg4ff driver improves ‘force feedback’ for gaming wheels
|
||||
- Toshiba laptop driver gains USB sleep charging and backlight improvements
|
||||
- Rumble support for Xbox One controller
|
||||
- Better battery reporting in Wacom tablet driver
|
||||
- Various misc. power improvements for both ARM and x86 devices
|
||||
- Samsung Exynos 3250 power management improvements
|
||||
- Support for the Bamboo Pad
|
||||
- Lenovo OneLink Pro Dock gains USB support
|
||||
- Support for Realtek 8723A, 8723B, 8761A, 8821 Wi-Fi cards
|
||||
|
||||
### Install Linux Kernel 4.1 on Ubuntu ###
|
||||
|
||||
Although this release of the kernel is classed as stable there is no pressing need for Ubuntu desktop users to go out of their way to install it.
|
||||
|
||||
Not that you can’t; if you’re impatient and skilled enough to do so you can take a crack at installing Linux 4.1 on Ubuntu by grabbing the appropriate set of packages from [Canonical’s mainline kernel archive][3] (or by risking a third-party PPA).
|
||||
|
||||
Ubuntu 15.10 Wily Werewolf, due for release in October, is to be based on the Ubuntu Kernel 4.1.x (the Ubuntu kernel is the Linux Kernel plus Ubuntu-specific patches that have not been accepted upstream).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/06/linux-4-1-kernel-new-features
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://lkml.org/lkml/2015/6/22/8
|
||||
[2]:http://www.omgubuntu.co.uk/2015/04/linux-kernel-4-0-new-features
|
||||
[3]:http://kernel.ubuntu.com/~kernel-ppa/mainline/?C=N;O=D
|
||||
@ -1,3 +1,5 @@
|
||||
translating by wwy-hust
|
||||
|
||||
Linux Humor on the Command-line
|
||||
================================================================================
|
||||
The desktop is full of eye candy. It enhances the visual experience and, in some cases, can also increase functionality of software. But it also makes software fun. Working on the command-line does not have to be always serious. If you want some fun on the command-line, there are lots of commands to raise a smile.
|
||||
@ -124,4 +126,4 @@ via: http://www.linuxlinks.com/article/20150614112018846/Humor.html
|
||||
[4]:http://www.robobunny.com/projects/asciiquarium/html/
|
||||
[5]:https://github.com/mtoyoda/sl
|
||||
[6]:http://aa-project.sourceforge.net/aalib/
|
||||
[7]:http://www.asty.org/cmatrix/
|
||||
[7]:http://www.asty.org/cmatrix/
|
||||
|
||||
@ -0,0 +1,152 @@
|
||||
Screen Capture Made Easy with these Dedicated Tools
|
||||
================================================================================
|
||||
"A picture is worth a thousand words", a phrase which emerged in the USA in the early part of the 20th century, refers to the notion that a single still image can present as much information as a large amount of descriptive text. Essentially, pictures convey information more effectively and efficiently than words can.
|
||||
|
||||
A screenshot (or screengrab) is a snapshot or picture captured by a computer to record the output of a visual device. Screen capture software enable screenshots to be taken on a computer. This type of software has lots of uses. As an image can illustrate the operation of computer software well, screenshots play an important role in software development and documentation. Alternatively, if you have a technical problem with your computer, a screenshot allows a technical support department to understand the problems you are facing. Writing computer-related articles, documentation and tutorials is nigh on impossible without a good tool for creating screenshots. Screenshots are also useful to save snippets of anything you have on your screen, particularly when it can not be easily printed.
|
||||
|
||||
Linux has a good selection of open source dedicated screenshot programs, both graphical and console based. For a feature-rich dedicated screenshot utility, look no further than Shutter. This tool is a superb example of a small open source tool. But there are some great alternatives too.
|
||||
|
||||
Screen capture functionality is not only provided by dedicated applications. GIMP and ImageMagick, two programs which are primarily image manipulation tools, also offer competent screen capturing functionality.
|
||||
|
||||
----------
|
||||
|
||||
### Shutter ###
|
||||
|
||||

|
||||
|
||||
Shutter is a feature-rich screenshot application. You can take a screenshot of a specific area, window, your whole screen, or even of a website - apply different effects to it, draw on it to highlight points, and then upload to an image hosting site, all within one window.
|
||||
|
||||
Features include:
|
||||
|
||||
|
||||
- Take a screenshot of:
|
||||
- a specific area
|
||||
- window
|
||||
- the complete desktop
|
||||
- web pages from a script
|
||||
- Apply different effects to the screenshot
|
||||
- Hotkeys
|
||||
- Print
|
||||
- Take screenshot directly or with a specified delay time
|
||||
- Save the screenshots to a specified directory and name them in a convenient way (using special wild-cards)
|
||||
- Fully integrated into the GNOME Desktop (TrayIcon etc)
|
||||
- Generate thumbnails directly when you are taking a screenshot and set a size level in %
|
||||
- Shutter session collection:
|
||||
- Keep track of all screenshots during session
|
||||
- Copy screeners to clipboard
|
||||
- Print screenshots
|
||||
- Delete screenshots
|
||||
- Rename your file
|
||||
- Upload your files directly to Image-Hosters (e.g. http://ubuntu-pics.de), retrieve all the needed links and share them with others
|
||||
- Edit screenshots directly using the embedded drawing tool
|
||||
|
||||
- Website: [shutter-project.org][1]
|
||||
- Developer: Mario Kemper and Shutter Team
|
||||
- License: GNU GPL v3
|
||||
- Version Number: 0.93.1
|
||||
|
||||
----------
|
||||
|
||||
### HotShots ###
|
||||
|
||||

|
||||
|
||||
HotShots is an application for capturing screens and saving them in a variety of image formats as well as adding annotations and graphical data (arrows, lines, texts, ...).
|
||||
|
||||
You can also upload your creations to the web (FTP/some web services). HotShots is written with Qt.
|
||||
|
||||
HotShots is not available in Ubuntu's Software Center. But it's easy to install by typing at the command line:
|
||||
|
||||
sudo add-apt-repository ppa:ubuntuhandbook1/apps
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install hotshots
|
||||
|
||||
Features include:
|
||||
|
||||
- Simple to use
|
||||
- Full featured
|
||||
- Built-in editor
|
||||
- Hotkeys
|
||||
- Built-in magnification
|
||||
- Freehand and multi-screen capture
|
||||
- Supported Output Formats: Black & Whte (bw), Encapsulated PostScript (eps, epsf), Encapsulated PostScript Interchange (epsi), OpenEXR (exr), PC Paintbrush Exchange (pcx), Photoshop Document (psd), ras, rgb, rgba, Irix RGB (sgi), Truevision Targa (tga), eXperimental Computing Facility (xcf), Windows Bitmap (bmp), DirectDraw Surface (dds), Graphic Interchange Format (gif), Icon Image (ico), Joint Photographic Experts Group 2000 (jp2), Joint Photographic Experts Group (jpeg, jpg), Multiple-image Network Graphics (mng), Portable Pixmap (ppm), Scalable Vector Graphics (svg), svgz, Tagged Image File Format (tif, tiff), webp, X11 Bitmap (xbm), X11 Pixmap (xpm), and Khoros Visualization (xv)
|
||||
- Internationalization support: Basque, Chinese, Czech, French, Galician, German, Greek, Italian, Japanese, Lithuanian, Polish, Portuguese, Romanian, Russian, Serbian, Singhalese, Slovak, Spanish, Turkish, Ukrainian, and Vietnamese
|
||||
|
||||
- Website: [thehive.xbee.net][2]
|
||||
- Developer: xbee
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 2.2.0
|
||||
|
||||
----------
|
||||
|
||||
### ScreenCloud ###
|
||||
|
||||

|
||||
|
||||
ScreenCloud is an easy to use open source screenshot tool.
|
||||
|
||||
With this software, users can take a screenshot using one of the 3 hotkeys or simply click the ScreenCloud tray icon. Users can choose where you want to save the screenshot.
|
||||
|
||||
If you choose to upload your screenshot to the screencloud website, a link will automatically be copied to your clipboard. This can be shared with friends or colleagues via email or in an IM conversation. All they have to do is click the link and look at your screenshot.
|
||||
|
||||
Features include:
|
||||
|
||||
- Capture full screen, window or selection
|
||||
- Fast and easy: Snap a photo, paste the link, done
|
||||
- Free hosting of your screenshots
|
||||
- Hotkeys
|
||||
- Set timer delay
|
||||
- Enable 'Capture window borders'
|
||||
- Enable/Disable Notifications
|
||||
- Set app to run on start up
|
||||
- Adjust account/upload/filename/shortcut settings
|
||||
- Cross platform tool
|
||||
- Plugin support, save to Dropbox, Imgur, and more
|
||||
- Supports uploading to FTP and SFTP servers
|
||||
|
||||
- Website: [screencloud.net][3]
|
||||
- Developer: Olav S Thoresen
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 1.2.1
|
||||
|
||||
----------
|
||||
|
||||
### KSnapshot ###
|
||||
|
||||

|
||||
|
||||
KSnapshot is a simple utility for taking screenshots. It can capture images of the whole desktop, a single window, a section of a window or a selected region. Images can then be saved in a variety of different formats.
|
||||
|
||||
KSnapshot also allows users to use hotkeys to take a screenshot. Besides saving the screenshot, it can be copied to the clipboard or opened with any program that is associated with image files.
|
||||
|
||||
KSnapshot is part of the KDE 4 graphics module.
|
||||
|
||||
Features include:
|
||||
|
||||
- Save snapshot in multiple formats
|
||||
- Snapshot delay
|
||||
- Exclude window decorations
|
||||
- Copy the snapshot to the clipboard
|
||||
- Hotkeys
|
||||
- Can be scripted using its D-Bus interface
|
||||
|
||||
- Website: [www.kde.org][4]
|
||||
- Developer: KDE, Richard J. Moore, Aaron J. Seigo, Matthias Ettrich
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 0.8.2
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/2015062316235249/ScreenCapture.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://shutter-project.org/
|
||||
[2]:http://thehive.xbee.net/
|
||||
[3]:https://screencloud.net/
|
||||
[4]:https://www.kde.org/applications/graphics/ksnapshot/
|
||||
@ -1,422 +0,0 @@
|
||||
25 Useful Apache ‘.htaccess’ Tricks to Secure and Customize Websites
|
||||
================================================================================
|
||||
Websites are important parts of our lives. They serve the means to expand businesses, share knowledge and lots more. Earlier restricted to providing only static contents, with introduction of dynamic client and server side scripting languages and continued advancement of existing static language like html to html5, adding every bit of dynamicity is possible to the websites and what left is expected to follow soon in near future.
|
||||
|
||||
With websites, comes the need of a unit that can display these websites to a huge set of audience all over the globe. This need is fulfilled by the servers that provide means to host a website. This includes a list of servers like: Apache HTTP Server, Joomla, and WordPress that allow one to host their websites.
|
||||
|
||||

|
||||
25 htaccess Tricks
|
||||
|
||||
One who wants to host a website can create a local server of his own or can contact any of above mentioned or any another server administrator to host his website. But the actual issue starts from this point. Performance of a website depends mainly on following factors:
|
||||
|
||||
- Bandwidth consumed by the website.
|
||||
- How secure is the website against hackers.
|
||||
- Optimism when it comes to data search through the database
|
||||
- User-friendliness when it comes to displaying navigation menus and providing more UI features.
|
||||
|
||||
Alongside this, various factors that govern success of servers in hosting websites are:
|
||||
|
||||
- Amount of data compression achieved for a particular website.
|
||||
- Ability to simultaneously serve multiple clients asking for a same or different website.
|
||||
- Securing the confidential data entered on the websites like: emails, credit card details and so on.
|
||||
- Allowing more and more options to enhance dynamicity to a website.
|
||||
|
||||
This article deals with one such feature provided by the servers that help enhance performance of websites along with securing them from bad bots, hotlinks etc. i.e. ‘.htaccess‘ file.
|
||||
|
||||
### What is .htaccess? ###
|
||||
|
||||
htaccess (or hypertext access) are the files that provide options for website owners to control the server environment variables and other parameters to enhance functionality of their websites. These files can reside in any and every directory in the directory tree of the website and provide features to the directory and the files and folders inside it.
|
||||
|
||||
What are these features? Well these are the server directives i.e. the lines that instruct server to perform a specific task, and these directives apply only to the files and folders inside the folder in which this file is placed. These files are hidden by default as all Operating System and the web servers are configured to ignore them by default but making the hidden files visible can make you see this very special file. What type of parameters can be controlled is the topic of discussion of subsequent sections.
|
||||
|
||||
Note: If .htaccess file is placed in /apache/home/www/Gunjit/ directory then it will provide directives for all the files and folders in that directory, but if this directory contains another folder namely: /Gunjit/images/ which again has another .htaccess file then the directives in this folder will override those provided by the master .htaccess file (or file in the folder up in hierarchy).
|
||||
|
||||
### Apache Server and .htaccess files ###
|
||||
|
||||
Apache HTTP Server colloquially called Apache was named after a Native American Tribe Apache to respect its superior skills in warfare strategy. Build on C/C++ and XML it is cross-platform web server which is based on NCSA HTTPd server and has a key role in growth and advancement of World Wide Web.
|
||||
|
||||
Most commonly used on UNIX, Apache is available for wide variety of platforms including FreeBSD, Linux, Windows, Mac OS, Novel Netware etc. In 2009, Apache became the first server to serve more than 100 million websites.
|
||||
|
||||
Apache server has one .htaccess file per user in www/ directory. Although these files are hidden but can be made visible if required. In www/ directory there are a number of folders each pertaining to a website named on user’s or owner’s name. Apart from this you can have one .htaccess file in each folder which configured files in that folder as stated above.
|
||||
|
||||
How to configure htaccess file on Apache server is as follows…
|
||||
|
||||
### Configuration on Apache Server ###
|
||||
|
||||
There can be two cases:
|
||||
|
||||
#### Hosting website on own server ####
|
||||
|
||||
In this case, if .htaccess files are not enabled, you can enable .htaccess files by simply going to httpd.conf (Default configuration file for Apache HTTP Daemon) and finding the <Directories> section.
|
||||
|
||||
<Directory "/var/www/htdocs">
|
||||
|
||||
And locate the line that says…
|
||||
|
||||
AllowOverride None
|
||||
|
||||
And correct it to.
|
||||
|
||||
AllowOverride All
|
||||
|
||||
Now, on restarting Apache, .htaccess will work.
|
||||
|
||||
#### Hosting website on different hosting provider server ####
|
||||
|
||||
In this case it is better to consult the hosting admin, if they allow access to .htaccess files.
|
||||
|
||||
### 25 ‘.htaccess’ Tricks of Apache Web Server for Websites ###
|
||||
|
||||
#### 1. How to enable mod_rewrite in .htaccess file ####
|
||||
|
||||
mod_rewrite option allows you to use redirections and hiding your true URL with redirecting to some other URL. This option can prove very useful allowing you to replace the lengthy and long URL’s to short and easy to remember ones.
|
||||
|
||||
To allow mod_rewrite just have a practice to add the following line as the first line of your .htaccess file.
|
||||
|
||||
Options +FollowSymLinks
|
||||
|
||||
This option allows you to follow symbolic links and thus enable the mod_rewrite option on the website. Replacing the URL with short and crispy one is presented later on.
|
||||
|
||||
#### 2. How to Allow or Deny Access to Websites ####
|
||||
|
||||
htaccess file can allow or deny access of website or a folder or files in the directory in which it is placed by using order, allow and deny keywords.
|
||||
|
||||
**Allowing access to only 192.168.3.1 IP**
|
||||
|
||||
Order Allow, Deny
|
||||
Deny from All
|
||||
Allow from 192.168.3.1
|
||||
|
||||
OR
|
||||
|
||||
Order Allow, Deny
|
||||
Allow from 192.168.3.1
|
||||
|
||||
Order keyword here specifies the order in which allow, deny access would be processed. For the above ‘Order’ statement, the Allow statements would be processed first and then the deny statements would be processed.
|
||||
|
||||
**Denying access to only one IP Address**
|
||||
|
||||
The below lines provide the means to allow access of the website to all the users accept one with IP Address: 192.168.3.1.
|
||||
|
||||
rder Allow, Deny
|
||||
Deny from 192.168.3.1
|
||||
Allow from All
|
||||
|
||||
OR
|
||||
|
||||
|
||||
Order Deny, Allow
|
||||
Deny from 192.168.3.1
|
||||
|
||||
#### 3. Generate Apache Error documents for different error codes. ####
|
||||
|
||||
Using some simple lines, we can fix the error document that run on different error codes generated by the server when user/client requests a page not available on the website like most of us would have seen the ‘404 Page not found’ page in their web browser. ‘.htaccess’ files specify what action to take in case of such error conditions.
|
||||
|
||||
To do this, the following lines are needed to be added to the ‘.htaccess’ files:
|
||||
|
||||
ErrorDocument <error-code> <path-of-document/string-representing-html-file-content>
|
||||
|
||||
‘ErrorDocument’ is a keyword, error-code can be any of 401, 403, 404, 500 or any valid error representing code and lastly, ‘path-of-document’ represents the path on the local machine (in case you are using your own local server) or on the server (in case you are using any other’s server to host your website).
|
||||
|
||||
**Example:**
|
||||
|
||||
ErrorDocument 404 /error-docs/error-404.html
|
||||
|
||||
The above line sets the document ‘error-404.html’ placed in error-docs folder to be displayed in case the 404 error is reported by the server for any invalid request for a page by the client.
|
||||
|
||||
rrorDocument 404 "<html><head><title>404 Page not found</title></head><body><p>The page you request is not present. Check the URL you have typed</p></body></html>"
|
||||
|
||||
The above representation is also correct which places the string representing a usual html file.
|
||||
|
||||
#### 4. Setting/Unsetting Apache server environment variables ####
|
||||
|
||||
In .htaccess file you can set or unset the global environment variables that server allow to be modified by the hosters of the websites. For setting or unsetting the environment variables you need to add the following lines to your .htaccess files.
|
||||
|
||||
**Setting the Environment variables**
|
||||
|
||||
SetEnv OWNER “Gunjit Khera”
|
||||
|
||||
Unsetting the Environment variables
|
||||
|
||||
UnsetEnv OWNER
|
||||
|
||||
#### 5. Defining different MIME types for files ####
|
||||
|
||||
MIME (Multipurpose Internet Multimedia Extensions) are the types that are recognized by the browser by default when running any web page. You can define MIME types for your website in .htaccess files, so that different types of files as defined by you can be recognized and run by the server.
|
||||
|
||||
<IfModule mod_mime.c>
|
||||
AddType application/javascript js
|
||||
AddType application/x-font-ttf ttf ttc
|
||||
</IfModule>
|
||||
|
||||
Here, mod_mime.c is the module for controlling definitions of different MIME types and if you have this module installed on your system then you can use this module to define different MIME types for different extensions used in your website so that server can understand them.
|
||||
|
||||
#### 6. How to Limit the size of Uploads and Downloads in Apache ####
|
||||
|
||||
.htaccess files allow you the feature to control the amount of data being uploaded or downloaded by a particular client from your website. For this you just need to append the following lines to your .htaccess file:
|
||||
|
||||
php_value upload_max_filesize 20M
|
||||
php_value post_max_size 20M
|
||||
php_value max_execution_time 200
|
||||
php_value max_input_time 200
|
||||
|
||||
The above lines set maximum upload size, maximum size of data being posted, maximum execution time i.e. the maximum time the a user is allowed to execute a website on his local machine, maximum time constrain within on the input time.
|
||||
|
||||
#### 7. Making Users to download .mp3 and other files before playing on your website. ####
|
||||
|
||||
Mostly, people play songs on websites before downloading them to check the song quality etc. Being a smart seller you can add a feature that can come in very handy for you which will not let any user play songs or videos online and users have to download them for playing. This is very useful as online playing of songs and videos consumes a lot of bandwidth.
|
||||
|
||||
Following lines are needed to be added to be added to your .htaccess file:
|
||||
|
||||
AddType application/octet-stream .mp3 .zip
|
||||
|
||||
#### 8. Setting Directory Index for Website ####
|
||||
|
||||
Most of website developers would already know that the first page that is displayed i.e. the home page of a website is named as ‘index.html’ .Many of us would have seen this also. But how is this set?
|
||||
|
||||
.htaccess file provides a way to list a set of pages which would be scanned in order when a client requests to visit home page of the website and accordingly any one of the listed set of pages if found would be listed as the home page of the website and displayed to the user.
|
||||
|
||||
Following line is needed to be added to produce the desired effect.
|
||||
|
||||
DirectoryIndex index.html index.php yourpage.php
|
||||
|
||||
The above line specifies that if any request for visiting the home page comes by any visitor then the above listed pages will be searched in order in the directory firstly: index.html which if found will be displayed as the sites home page, otherwise list will proceed to the next page i.e. index.php and so on till the last page you have entered in the list.
|
||||
|
||||
#### 9. How to enable GZip compression for Files to save site’s bandwidth. ####
|
||||
|
||||
This is a common observation that heavy sites generally run bit slowly than light weight sites that take less amount of space. This is just because for a heavy site it takes time to load the huge script files and images before displaying them on the client’s web browser.
|
||||
|
||||
This is a common mechanism that when a browser requests a web page, server provides the browser with that webpage and now to locally display that web page, the browser has to download that page and then run the script inside that page.
|
||||
|
||||
What GZip compression does here is saving the time required to serve a single customer thus increasing the bandwidth. The source files of the website on the server are kept in compressed form and when the request comes from a user then these files are transferred in compressed form which are then uncompressed and executed on the server. This improves the bandwidth constrain.
|
||||
|
||||
Following lines can allow you to compress the source files of your website but this requires mod_deflate.c module to be installed on your server.
|
||||
|
||||
<IfModule mod_deflate.c>
|
||||
AddOutputFilterByType DEFLATE text/plain
|
||||
AddOutputFilterByType DEFLATE text/html
|
||||
AddOutputFilterByType DEFLATE text/xml
|
||||
AddOutputFilterByType DEFLATE application/html
|
||||
AddOutputFilterByType DEFLATE application/javascript
|
||||
AddOutputFilterByType DEFLATE application/x-javascript
|
||||
</IfModule>
|
||||
|
||||
#### 10. Playing with the File types. ####
|
||||
|
||||
There are certain conditions that the server assumes by default. Like: .php files are run on the server, similarly .txt files say for example are meant to be displayed. Like this we can make some executable cgi-scripts or files to be simply displayed as the source code on our website instead of being executed.
|
||||
|
||||
To do this observe the following lines from a .htaccess file.
|
||||
|
||||
RemoveHandler cgi-script .php .pl .py
|
||||
AddType text/plain .php .pl .py
|
||||
|
||||
These lines tell the server that .pl (perl script), .php (PHP file) and .py (Python file) are meant to just be displayed and not executed as cgi-scripts.
|
||||
|
||||
#### 11. Setting the Time Zone for Apache server ####
|
||||
|
||||
The power and importance of .htaccess files can be seen by the fact that this can be used to set the Time Zone of the server accordingly. This can be done by setting a global Environment variable ‘TZ’ of the list of global environment variables that are provided by the server to each of the hosted website for modification.
|
||||
|
||||
Due to this reason only, we can see time on the websites (that display it) according to our time zone. May be some other person hosting his website on the server would have the timezone set according to the location where he lives.
|
||||
|
||||
Following lines set the Time Zone of the Server.
|
||||
|
||||
SetEnv TZ India/Kolkata
|
||||
|
||||
#### 12. How to enable Cache Control on Website ####
|
||||
|
||||
A very interesting feature of browser, most have observed is that on opening one website simultaneously more than one time, the latter one opens fast as compared to the first time. But how is this possible? Well in this case, the browser stores some frequently visited pages in its cache for faster access later on.
|
||||
|
||||
But for how long? Well this answer depends on you i.e. on the time you set in your .htaccess file for Cache control. The .htaccess file can specify the amount of time for which the pages of website can stay in the browser’s cache and after expiration of time, it must revalidate i.e. pages would be deleted from the Cache and recreated the next time user visits the site.
|
||||
|
||||
Following lines implement Cache Control for your website.
|
||||
|
||||
<FilesMatch "\.(ico|png|jpeg|svg|ttf)$">
|
||||
Header Set Cache-Control "max-age=3600, public"
|
||||
</FilesMatch>
|
||||
<FilesMatch "\.(js|css)$">
|
||||
Header Set Cache-Control "public"
|
||||
Header Set Expires "Sat, 24 Jan 2015 16:00:00 GMT"
|
||||
</FilesMatch>
|
||||
|
||||
The above lines allow caching of the pages which are inside the directory in which .htaccess files are placed for 1 hour.
|
||||
|
||||
#### 13. Configuring a single file, the <files> option. ####
|
||||
|
||||
Usually the content in .htaccess files apply to all the files and folders inside the directory in which the file is placed, but you can also provide some special permissions to a special file, like denying access to that file only or so on.
|
||||
|
||||
For this you need to add <File> tag to your file in a way like this:
|
||||
|
||||
<files conf.html="">
|
||||
Order allow, deny
|
||||
Deny from 188.100.100.0
|
||||
</files>
|
||||
|
||||
This is a simple case of denying a file ‘conf.html’ from access by IP 188.100.100.0, but you can add any or every feature described for .htaccess file till now including the features yet to be described to the file like: Cache-control, GZip compression.
|
||||
|
||||
This feature is used by most of the servers to secure .htaccess files which is the reason why we are not able to see the .htaccess files on the browsers. How the files are authenticated is demonstrated in subsequent heading.
|
||||
|
||||
#### 14. Enabling CGI scripts to run outside of cgi-bin folder. ####
|
||||
|
||||
Usually servers run CGI scripts that are located inside the cgi-bin folder but, you can enable running of CGI scripts located in your desired folder but just adding following lines to .htaccess file located in the desired folder and if not, then creating one, appending following lines:
|
||||
|
||||
AddHandler cgi-script .cgi
|
||||
Options +ExecCGI
|
||||
|
||||
#### 15. How to enable SSI on Website with .htaccess ####
|
||||
|
||||
Server side includes as the name suggests would be related to something included at the server side. But what? Generally when we have many pages in our website and we have a navigation menu on our home page that displays links to other pages then, we can enable SSI (Server Size Includes) option that allows all the pages displayed in the navigation menu to be included with the home page completely.
|
||||
|
||||
The SSI allows inclusion of multiple pages as if content they contain is a part of a single page so that any editing needed to be done is done in one file only which saves a lot of disk space. This option is by default enabled on servers but for .shtml files.
|
||||
|
||||
In case you want to enable it for .html files you need to add following lines:
|
||||
|
||||
AddHandler server-parsed .html
|
||||
|
||||
After this following in the html file would lead to SSI.
|
||||
|
||||
<!--#inlcude virtual= “gk/document.html”-->
|
||||
|
||||
#### 16. How to Prevent website Directory Listing ####
|
||||
|
||||
To prevent any client being able to list the directories of the website on the server at his local machine add following lines to the file inside the directory you don’t want to get listed.
|
||||
|
||||
Options -Indexes
|
||||
|
||||
#### 17. Changing Default charset and language headers. ####
|
||||
|
||||
.htaccess files allow you to modify the character set used i.e. ASCII or UNICODE, UTF-8 etc. for your website along with the default language used for the display of content.
|
||||
|
||||
Following server’s global environment variables allow you to achieve above feature.
|
||||
|
||||
AddDefaultCharset UTF-8
|
||||
DefaultLanguage en-US
|
||||
|
||||
**Re-writing URL’s: Redirection Rules**
|
||||
|
||||
Re-writing feature simply means replacing the long and un-rememberable URL’s with short and easy to remember ones. But, before going into this topic there are some rules and some conventions for special symbols used later on in this article.
|
||||
|
||||
**Special Symbols:**
|
||||
|
||||
Symbol Meaning
|
||||
^ - Start of the string
|
||||
$ - End of the String
|
||||
| - Or [a|b] – a or b
|
||||
[a-z] - Any of the letter between a to z
|
||||
+ - One or more occurrence of previous letter
|
||||
* - Zero or more occurrence of previous letter
|
||||
? - Zero or one occurrence of previous letter
|
||||
|
||||
**Constants and their meaning:**
|
||||
|
||||
Constant Meaning
|
||||
NC - No-case or case sensitive
|
||||
L - Last rule – stop processing further rules
|
||||
R - Temporary redirect to new URL
|
||||
R=301 - Permanent redirect to new URL
|
||||
F - Forbidden, send 403 header to the user
|
||||
P - Proxy – grab remote content in substitution section and return it
|
||||
G - Gone, no longer exists
|
||||
S=x - Skip next x rules
|
||||
T=mime-type - Force specified MIME type
|
||||
E=var:value - Set environment variable var to value
|
||||
H=handler - Set handler
|
||||
PT - Pass through – in case of URL’s with additional headers.
|
||||
QSA - Append query string from requested to substituted URL
|
||||
|
||||
#### 18. Redirecting a non-www URL to a www URL. ####
|
||||
|
||||
Before starting with the explanation, lets first see the lines that are needed to be added to .htaccess file to enable this feature.
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteCond %{HTTP_HOST} ^abc\.net$
|
||||
RewriteRule (.*) http://www.abc.net/$1 [R=301,L]
|
||||
|
||||
The above lines enable the Rewrite Engine and then in second line check all those URL’s that pertain to host abc.net or have the HTTP_HOST environment variable set to “abc.net”.
|
||||
|
||||
For all such URL’s the code permanently redirects them (as R=301 rule is enabled) to the new URL http://www.abc.net/$1 where $1 is the non-www URL having host as abc.net. The non-www URL is the one in bracket and is referred by $1.
|
||||
|
||||
#### 19. Redirecting entire website to https. ####
|
||||
|
||||
Following lines will help you transfer entire website to https:
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteCond %{HTTPS} !on
|
||||
RewriteRule (.*) https://%{HTTP_HOST}%{REQUEST_URI}
|
||||
|
||||
The above lines enable the re-write engine and then check the value of HTTPS environment variable. If it is on then re-write the entire pages of the website to https.
|
||||
|
||||
#### 20. A custom redirection example ####
|
||||
|
||||
For example, redirect url ‘http://www.abc.net?p=100&q=20 ‘ to ‘http://www.abc.net/10020pq’.
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteRule ^http://www.abc.net/([0-9]+)([0-9]+)pq$ ^http://www.abc.net?p=$1&q=$2
|
||||
|
||||
In above lines, $1 represents the first bracket and $2 represents the second bracket.
|
||||
|
||||
#### 21. Renaming the htaccess file ####
|
||||
|
||||
For preventing the .htaccess file from the intruders and other people from viewing those files you can rename that file so that it is not accessed by client’s browser. The line that does this is:
|
||||
|
||||
AccessFileName htac.cess
|
||||
|
||||
#### 22. How to Prevent Image Hotlinking for your Website ####
|
||||
|
||||
Another problem that is major factor of large bandwidth consumption by the websites is the problem of hot links which are links to your websites by other websites for display of images mostly of your website which consumes your bandwidth. This problem is also called as ‘bandwidth theft’.
|
||||
|
||||
A common observation is when a site displays the image contained in some other site due to this hot-linking your site needs to be loaded and at the stake of your site’s bandwidth, the other site’s images are displayed. To prevent this for like: images such as: .gif, .jpeg etc. following lines of code would help:
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteCond %{HTTP_REFERER} !^$
|
||||
RewriteCond %{HTTP_REFERERER} !^http://(www\.)?mydomain.com/.*$ [NC]
|
||||
RewriteRule \.(gif|jpeg|png)$ - [F].
|
||||
|
||||
The above lines check if the HTTP_REFERER is not set to blank or not set to any of the links in your websites. If this is happening then all the images in your page are replaced by 403 forbidden.
|
||||
|
||||
#### 23. How to Redirect Users to Maintenance Page. ####
|
||||
|
||||
In case your website is down for maintenance and you want to notify all your clients that need to access your websites about this then for such cases you can add following lines to your .htaccess websites that allow only admin access and replace the site pages having links to any .jpg, .css, .gif, .js etc.
|
||||
|
||||
RewriteCond %{REQUEST_URI} !^/admin/ [NC]
|
||||
RewriteCond %{REQUEST_URI} !^((.*).css|(.*).js|(.*).png|(.*).jpg) [NC]
|
||||
RewriteRule ^(.*)$ /ErrorDocs/Maintainence_Page.html
|
||||
[NC,L,U,QSA]
|
||||
|
||||
These lines check if the Requested URL contains any request for any admin page i.e. one starting with ‘/admin/’ or any request to ‘.png, .jpg, .js, .css’ pages and for any such requests it replaces that page to ‘ErrorDocs/Maintainence_Page.html’.
|
||||
|
||||
#### 24. Mapping IP Address to Domain Name ####
|
||||
|
||||
Name servers are the servers that convert a specific IP Address to a domain name. This mapping can also be specified in the .htaccess files in the following manner.
|
||||
|
||||
For Mapping L.M.N.O address to a domain name www.hellovisit.com
|
||||
RewriteCond %{HTTP_HOST} ^L\.M\.N\.O$ [NC]
|
||||
RewriteRule ^(.*)$ http://www.hellovisit.com/$1 [L,R=301]
|
||||
|
||||
The above lines check if the host for any page is having the IP Address as: L.M.N.O and if so the page is mapped to the domain name http://www.hellovisit.com by the third line by permanent redirection.
|
||||
|
||||
#### 25. FilesMatch Tag ####
|
||||
|
||||
Like <files> tag that is used to apply conditions to a single file, <FilesMatch> can be used to match to a group of files and apply some conditions to the group of files as below:
|
||||
|
||||
<FilesMatch “\.(png|jpg)$”>
|
||||
Order Allow, Deny
|
||||
Deny from All
|
||||
</FilesMatch>
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
The list of tricks that can be done with .htaccess files is much more. Thus, this gives us an idea how powerful this file is and how much security and dynamicity and other features it can give to your website.
|
||||
|
||||
We’ve tried our best to cover as much as htaccess tricks in this article, but incase if we’ve missed any important trick, or you most welcome to post your htaccess ideas and tricks that you know via comments section below – we will include those in our article too…
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/apache-htaccess-tricks/
|
||||
|
||||
作者:[Gunjit Khera][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gunjitk94/
|
||||
@ -1,268 +0,0 @@
|
||||
How to Manage and Use LVM (Logical Volume Management) in Ubuntu
|
||||
================================================================================
|
||||

|
||||
|
||||
In our [previous article we told you what LVM is and what you may want to use it for][1], and today we are going to walk you through some of the key management tools of LVM so you will be confident when setting up or expanding your installation.
|
||||
|
||||
As stated before, LVM is a abstraction layer between your operating system and physical hard drives. What that means is your physical hard drives and partitions are no longer tied to the hard drives and partitions they reside on. Rather, the hard drives and partitions that your operating system sees can be any number of separate hard drives pooled together or in a software RAID.
|
||||
|
||||
To manage LVM there are GUI tools available but to really understand what is happening with your LVM configuration it is probably best to know what the command line tools are. This will be especially useful if you are managing LVM on a server or distribution that does not offer GUI tools.
|
||||
|
||||
Most of the commands in LVM are very similar to each other. Each valid command is preceded by one of the following:
|
||||
|
||||
- Physical Volume = pv
|
||||
- Volume Group = vg
|
||||
- Logical Volume = lv
|
||||
|
||||
The physical volume commands are for adding or removing hard drives in volume groups. Volume group commands are for changing what abstracted set of physical partitions are presented to your operating in logical volumes. Logical volume commands will present the volume groups as partitions so that your operating system can use the designated space.
|
||||
|
||||
### Downloadable LVM Cheat Sheet ###
|
||||
|
||||
To help you understand what commands are available for each prefix we made a LVM cheat sheet. We will cover some of the commands in this article, but there is still a lot you can do that won’t be covered here.
|
||||
|
||||
All commands on this list will need to be run as root because you are changing system wide settings that will affect the entire machine.
|
||||
|
||||

|
||||
|
||||
### How to View Current LVM Information ###
|
||||
|
||||
The first thing you may need to do is check how your LVM is set up. The s and display commands work with physical volumes (pv), volume groups (vg), and logical volumes (lv) so it is a good place to start when trying to figure out the current settings.
|
||||
|
||||
The display command will format the information so it’s easier to understand than the s command. For each command you will see the name and path of the pv/vg and it should also give information about free and used space.
|
||||
|
||||

|
||||
|
||||
The most important information will be the PV name and VG name. With those two pieces of information we can continue working on the LVM setup.
|
||||
|
||||
### Creating a Logical Volume ###
|
||||
|
||||
Logical volumes are the partitions that your operating system uses in LVM. To create a logical volume we first need to have a physical volume and volume group. Here are all of the steps necessary to create a new logical volume.
|
||||
|
||||
#### Create physical volume ####
|
||||
|
||||
We will start from scratch with a brand new hard drive with no partitions or information on it. Start by finding which disk you will be working with. (/dev/sda, sdb, etc.)
|
||||
|
||||
> Note: Remember all of the commands will need to be run as root or by adding ‘sudo’ to the beginning of the command.
|
||||
|
||||
fdisk -l
|
||||
|
||||
If your hard drive has never been formatted or partitioned before you will probably see something like this in the fdisk output. This is completely fine because we are going to create the needed partitions in the next steps.
|
||||
|
||||

|
||||
|
||||
Our new disk is located at /dev/sdb so lets use fdisk to create a new partition on the drive.
|
||||
|
||||
There are a plethora of tools that can create a new partition with a GUI, [including Gparted][2], but since we have the terminal open already, we will use fdisk to create the needed partition.
|
||||
|
||||
From a terminal type the following commands:
|
||||
|
||||
fdisk /dev/sdb
|
||||
|
||||
This will put you in a special fdisk prompt.
|
||||
|
||||

|
||||
|
||||
Enter the commands in the order given to create a new primary partition that uses 100% of the new hard drive and is ready for LVM. If you need to change the partition size or want multiple partions I suggest using GParted or reading about fdisk on your own.
|
||||
|
||||
**Warning: The following steps will format your hard drive. Make sure you don’t have any information on this hard drive before following these steps.**
|
||||
|
||||
- n = create new partition
|
||||
- p = creates primary partition
|
||||
- 1 = makes partition the first on the disk
|
||||
|
||||
Push enter twice to accept the default first cylinder and last cylinder.
|
||||
|
||||

|
||||
|
||||
To prepare the partition to be used by LVM use the following two commands.
|
||||
|
||||
- t = change partition type
|
||||
- 8e = changes to LVM partition type
|
||||
|
||||
Verify and write the information to the hard drive.
|
||||
|
||||
- p = view partition setup so we can review before writing changes to disk
|
||||
- w = write changes to disk
|
||||
|
||||

|
||||
|
||||
After those commands, the fdisk prompt should exit and you will be back to the bash prompt of your terminal.
|
||||
|
||||
Enter pvcreate /dev/sdb1 to create a LVM physical volume on the partition we just created.
|
||||
|
||||
You may be asking why we didn’t format the partition with a file system but don’t worry, that step comes later.
|
||||
|
||||

|
||||
|
||||
#### Create volume Group ####
|
||||
|
||||
Now that we have a partition designated and physical volume created we need to create the volume group. Luckily this only takes one command.
|
||||
|
||||
vgcreate vgpool /dev/sdb1
|
||||
|
||||

|
||||
|
||||
Vgpool is the name of the new volume group we created. You can name it whatever you’d like but it is recommended to put vg at the front of the label so if you reference it later you will know it is a volume group.
|
||||
|
||||
#### Create logical volume ####
|
||||
|
||||
To create the logical volume that LVM will use:
|
||||
|
||||
lvcreate -L 3G -n lvstuff vgpool
|
||||
|
||||

|
||||
|
||||
The -L command designates the size of the logical volume, in this case 3 GB, and the -n command names the volume. Vgpool is referenced so that the lvcreate command knows what volume to get the space from.
|
||||
|
||||
#### Format and Mount the Logical Volume ####
|
||||
|
||||
One final step is to format the new logical volume with a file system. If you want help choosing a Linux file system, read our [how to that can help you choose the best file system for your needs][3].
|
||||
|
||||
mkfs -t ext3 /dev/vgpool/lvstuff
|
||||
|
||||

|
||||
|
||||
Create a mount point and then mount the volume somewhere you can use it.
|
||||
|
||||
mkdir /mnt/stuff
|
||||
mount -t ext3 /dev/vgpool/lvstuff /mnt/stuff
|
||||
|
||||

|
||||
|
||||
#### Resizing a Logical Volume ####
|
||||
|
||||
One of the benefits of logical volumes is you can make your shares physically bigger or smaller without having to move everything to a bigger hard drive. Instead, you can add a new hard drive and extend your volume group on the fly. Or if you have a hard drive that isn’t used you can remove it from the volume group to shrink your logical volume.
|
||||
|
||||
There are three basic tools for making physical volumes, volume groups, and logical volumes bigger or smaller.
|
||||
|
||||
Note: Each of these commands will need to be preceded by pv, vg, or lv depending on what you are working with.
|
||||
|
||||
- resize – can shrink or expand physical volumes and logical volumes but not volume groups
|
||||
- extend – can make volume groups and logical volumes bigger but not smaller
|
||||
- reduce – can make volume groups and logical volumes smaller but not bigger
|
||||
|
||||
Let’s walk through an example of how to add a new hard drive to the logical volume “lvstuff” we just created.
|
||||
|
||||
#### Install and Format new Hard Drive ####
|
||||
|
||||
To install a new hard drive follow the steps above to create a new partition and add change it’s partition type to LVM (8e). Then use pvcreate to create a physical volume that LVM can recognize.
|
||||
|
||||
#### Add New Hard Drive to Volume Group ####
|
||||
|
||||
To add the new hard drive to a volume group you just need to know what your new partition is, /dev/sdc1 in our case, and the name of the volume group you want to add it to.
|
||||
|
||||
This will add the new physical volume to the existing volume group.
|
||||
|
||||
vgextend vgpool /dev/sdc1
|
||||
|
||||

|
||||
|
||||
#### Extend Logical Volume ####
|
||||
|
||||
To resize the logical volume we need to say how much we want to extend by size instead of by device. In our example we just added a 8 GB hard drive to our 3 GB vgpool. To make that space usable we can use lvextend or lvresize.
|
||||
|
||||
lvextend -L8G /dev/vgpool/lvstuff
|
||||
|
||||

|
||||
|
||||
While this command will work you will see that it will actually resize our logical volume to 8 GB instead of adding 8 GB to the existing volume like we wanted. To add the last 3 available gigabytes you need to use the following command.
|
||||
|
||||
lvextend -L+3G /dev/vgpool/lvstuff
|
||||
|
||||

|
||||
|
||||
Now our logical volume is 11 GB in size.
|
||||
|
||||
#### Extend File System ####
|
||||
|
||||
The logical volume is 11 GB but the file system on that volume is still only 3 GB. To make the file system use the entire 11 GB available you have to use the command resize2fs. Just point resize2fs to the 11 GB logical volume and it will do the magic for you.
|
||||
|
||||
resize2fs /dev/vgpool/lvstuff
|
||||
|
||||

|
||||
|
||||
**Note: If you are using a different file system besides ext3/4 please see your file systems resize tools.**
|
||||
|
||||
#### Shrink Logical Volume ####
|
||||
|
||||
If you wanted to remove a hard drive from a volume group you would need to follow the above steps in reverse order and use lvreduce and vgreduce instead.
|
||||
|
||||
1. resize file system (make sure to move files to a safe area of the hard drive before resizing)
|
||||
1. reduce logical volume (instead of + to extend you can also use – to reduce by size)
|
||||
1. remove hard drive from volume group with vgreduce
|
||||
|
||||
#### Backing up a Logical Volume ####
|
||||
|
||||
Snapshots is a feature that some newer advanced file systems come with but ext3/4 lacks the ability to do snapshots on the fly. One of the coolest things about LVM snapshots is your file system is never taken offline and you can have as many as you want without taking up extra hard drive space.
|
||||
|
||||

|
||||
|
||||
When LVM takes a snapshot, a picture is taken of exactly how the logical volume looks and that picture can be used to make a copy on a different hard drive. While a copy is being made, any new information that needs to be added to the logical volume is written to the disk just like normal, but changes are tracked so that the original picture never gets destroyed.
|
||||
|
||||
To create a snapshot we need to create a new logical volume with enough free space to hold any new information that will be written to the logical volume while we make a backup. If the drive is not actively being written to you can use a very small amount of storage. Once we are done with our backup we just remove the temporary logical volume and the original logical volume will continue on as normal.
|
||||
|
||||
#### Create New Snapshot ####
|
||||
|
||||
To create a snapshot of lvstuff use the lvcreate command like before but use the -s flag.
|
||||
|
||||
lvcreate -L512M -s -n lvstuffbackup /dev/vgpool/lvstuff
|
||||
|
||||

|
||||
|
||||
Here we created a logical volume with only 512 MB because the drive isn’t being actively used. The 512 MB will store any new writes while we make our backup.
|
||||
|
||||
#### Mount New Snapshot ####
|
||||
|
||||
Just like before we need to create a mount point and mount the new snapshot so we can copy files from it.
|
||||
|
||||
mkdir /mnt/lvstuffbackup
|
||||
mount /dev/vgpool/lvstuffbackup /mnt/lvstuffbackup
|
||||
|
||||

|
||||
|
||||
#### Copy Snapshot and Delete Logical Volume ####
|
||||
|
||||
All you have left to do is copy all of the files from /mnt/lvstuffbackup/ to an external hard drive or tar it up so it is all in one file.
|
||||
|
||||
**Note: tar -c will create an archive and -f will say the location and file name of the archive. For help with the tar command use man tar in the terminal.**
|
||||
|
||||
tar -cf /home/rothgar/Backup/lvstuff-ss /mnt/lvstuffbackup/
|
||||
|
||||

|
||||
|
||||
Remember that while the backup is taking place all of the files that would be written to lvstuff are being tracked in the temporary logical volume we created earlier. Make sure you have enough free space while the backup is happening.
|
||||
|
||||
Once the backup finishes, unmount the volume and remove the temporary snapshot.
|
||||
|
||||
umount /mnt/lvstuffbackup
|
||||
lvremove /dev/vgpool/lvstuffbackup/
|
||||
|
||||

|
||||
|
||||
#### Deleting a Logical Volume ####
|
||||
|
||||
To delete a logical volume you need to first make sure the volume is unmounted, and then you can use lvremove to delete it. You can also remove a volume group once the logical volumes have been deleted and a physical volume after the volume group is deleted.
|
||||
|
||||
Here are all the commands using the volumes and groups we’ve created.
|
||||
|
||||
umount /mnt/lvstuff
|
||||
lvremove /dev/vgpool/lvstuff
|
||||
vgremove vgpool
|
||||
pvremove /dev/sdb1 /dev/sdc1
|
||||
|
||||

|
||||
|
||||
That should cover most of what you need to know to use LVM. If you’ve got some experience on the topic, be sure to share your wisdom in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.howtogeek.com/howto/40702/how-to-manage-and-use-lvm-logical-volume-management-in-ubuntu/
|
||||
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.howtogeek.com/howto/36568/what-is-logical-volume-management-and-how-do-you-enable-it-in-ubuntu/
|
||||
[2]:http://www.howtogeek.com/howto/17001/how-to-format-a-usb-drive-in-ubuntu-using-gparted/
|
||||
[3]:http://www.howtogeek.com/howto/33552/htg-explains-which-linux-file-system-should-you-choose/
|
||||
@ -1,137 +0,0 @@
|
||||
How to set up remote desktop on Linux VPS using x2go
|
||||
================================================================================
|
||||
As everything is moved to the cloud, virtualized remote desktop becomes increasingly popular in the industry as a way to enhance employee's productivity. Especially for those who need to roam constantly across multiple locations and devices, remote desktop allows them to stay connected seamlessly to their work environment. Remote desktop is attractive for employers as well, achieving increased agility and flexibility in work environments, lower IT cost due to hardware consolidation, desktop security hardening, and so on.
|
||||
|
||||
In the world of Linux, of course there is no shortage of choices for settings up remote desktop environment, with many protocols (e.g., RDP, RFB, NX) and server/client implementations (e.g., [TigerVNC][1], RealVNC, FreeNX, x2go, X11vnc, TeamViewer) available.
|
||||
|
||||
Standing out from the pack is [X2Go][2], an open-source (GPLv2) implementation of NX-based remote desktop server and client. In this tutorial, I am going to demonstrate **how to set up remote desktop environment for [Linux VPS][3] using X2Go**.
|
||||
|
||||
### What is X2Go? ###
|
||||
|
||||
The history of X2Go goes back to NoMachine's NX technology. The NX remote desktop protocol was designed to deal with low bandwidth and high latency network connections by leveraging aggressive compression and caching. Later, NX was turned into closed-source while NX libraries were made GPL-ed. This has led to open-source implementation of several NX-based remote desktop solutions, and one of them is X2Go.
|
||||
|
||||
What benefits does X2Go bring to the table, compared to other solutions such as VNC? X2Go inherits all the advanced features of NX technology, so naturally it works well over slow network connections. Besides, X2Go boasts of an excellent track record of ensuring security with its built-in SSH-based encryption. No longer need to set up an SSH tunnel [manually][4]. X2Go comes with audio support out of box, which means that music playback at the remote desktop is delivered (via PulseAudio) over network, and fed into local speakers. On usability front, an application that you run on remote desktop can be seamlessly rendered as a separate window on your local desktop, giving you an illusion that the application is actually running on the local desktop. As you can see, these are some of [its powerful features][5] lacking in VNC based solutions.
|
||||
|
||||
### X2GO's Desktop Environment Compatibility ###
|
||||
|
||||
As with other remote desktop servers, there are [known compatibility issues][6] for X2Go server. Desktop environments like KDE3/4, Xfce, MATE and LXDE are the most friendly to X2Go server. However, your mileage may vary with other desktop managers. For example, the later versions of GNOME 3, KDE5, Unity are known to be not compatible with X2Go. If the desktop manager of your remote host is compatible with X2Go, you can follow the rest of the tutorial.
|
||||
|
||||
### Install X2Go Server on Linux ###
|
||||
|
||||
X2Go consists of remote desktop server and client components. Let's start with X2Go server installation. I assume that you already have an X2Go-compatible desktop manager up and running on a remote host, where we will be installing X2Go server.
|
||||
|
||||
Note that X2Go server component does not have a separate service that needs to be started upon boot. You just need to make sure that SSH service is up and running.
|
||||
|
||||
#### Ubuntu or Linux Mint: ####
|
||||
|
||||
Configure X2Go PPA repository. X2Go PPA is available for Ubuntu 14.04 and higher.
|
||||
|
||||
$ sudo add-apt-repository ppa:x2go/stable
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install x2goserver x2goserver-xsession
|
||||
|
||||
#### Debian (Wheezy): ####
|
||||
|
||||
$ sudo apt-key adv --recv-keys --keyserver keys.gnupg.net E1F958385BFE2B6E
|
||||
$ sudo sh -c "echo deb http://packages.x2go.org/debian wheezy main > /etc/apt/sources.list.d/x2go.list"
|
||||
$ sudo sh -c "echo deb-src http://packages.x2go.org/debian wheezy main >> /etc/apt/sources.list.d/x2go.list"
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install x2goserver x2goserver-xsession
|
||||
|
||||
#### Fedora: ####
|
||||
|
||||
$ sudo yum install x2goserver x2goserver-xsession
|
||||
|
||||
#### CentOS/RHEL: ####
|
||||
|
||||
Enable [EPEL respository][7] first, and then run:
|
||||
|
||||
$ sudo yum install x2goserver x2goserver-xsession
|
||||
|
||||
### Install X2Go Client on Linux ###
|
||||
|
||||
On a local host where you will be connecting to remote desktop, install X2GO client as follows.
|
||||
|
||||
#### Ubuntu or Linux Mint: ####
|
||||
|
||||
Configure X2Go PPA repository. X2Go PPA is available for Ubuntu 14.04 and higher.
|
||||
|
||||
$ sudo add-apt-repository ppa:x2go/stable
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install x2goclient
|
||||
|
||||
Debian (Wheezy):
|
||||
|
||||
$ sudo apt-key adv --recv-keys --keyserver keys.gnupg.net E1F958385BFE2B6E
|
||||
$ sudo sh -c "echo deb http://packages.x2go.org/debian wheezy main > /etc/apt/sources.list.d/x2go.list"
|
||||
$ sudo sh -c "echo deb-src http://packages.x2go.org/debian wheezy main >> /etc/apt/sources.list.d/x2go.list"
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install x2goclient
|
||||
|
||||
#### Fedora: ####
|
||||
|
||||
$ sudo yum install x2goclient
|
||||
|
||||
CentOS/RHEL:
|
||||
|
||||
Enable EPEL respository first, and then run:
|
||||
|
||||
$ sudo yum install x2goclient
|
||||
|
||||
### Connect to Remote Desktop with X2Go Client ###
|
||||
|
||||
Now it's time to connect to your remote desktop. On the local host, simply run the following command or use desktop launcher to start X2Go client.
|
||||
|
||||
$ x2goclient
|
||||
|
||||
Enter the remote host's IP address and SSH user name. Also, specify session type (i.e., desktop manager of a remote host).
|
||||
|
||||

|
||||
|
||||
If you want, you can customize other things (by pressing other tabs), like connection speed, compression, screen resolution, and so on.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
When you initiate a remote desktop connection, you will be asked to log in. Type your SSH login and password.
|
||||
|
||||

|
||||
|
||||
Upon successful login, you will see the remote desktop screen.
|
||||
|
||||

|
||||
|
||||
If you want to test X2Go's seamless window feature, choose "Single application" as session type, and specify the path to an executable on the remote host. In this example, I choose Dolphin file manager on a remote KDE host.
|
||||
|
||||

|
||||
|
||||
Once you are successfully connected, you will see a remote application window open on your local desktop, not the entire remote desktop screen.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this tutorial, I demonstrated how to set up X2Go remote desktop on [Linux VPS][8] instance. As you can see, the whole setup process is pretty much painless (if you are using a right desktop environment). While there are some desktop-specific quirkiness, X2Go is a solid remote desktop solution which is secure, feature-rich, fast, and free.
|
||||
|
||||
What feature is the most appealing to you in X2Go? Please share your thought.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/x2go-remote-desktop-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://ask.xmodulo.com/centos-remote-desktop-vps.html
|
||||
[2]:http://wiki.x2go.org/
|
||||
[3]:http://xmodulo.com/go/digitalocean
|
||||
[4]:http://xmodulo.com/how-to-set-up-vnc-over-ssh.html
|
||||
[5]:http://wiki.x2go.org/doku.php/doc:newtox2go
|
||||
[6]:http://wiki.x2go.org/doku.php/doc:de-compat
|
||||
[7]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[8]:http://xmodulo.com/go/digitalocean
|
||||
@ -1,91 +0,0 @@
|
||||
How to combine two graphs on Cacti
|
||||
================================================================================
|
||||
[Cacti][1] a fantastic open source network monitoring system that is widely used to graph network elements like bandwidth, storage, processor and memory utilization. Using its web based interface, you can create and organize graphs easily. However, some advanced features like merging graphs, creating aggregate graphs using multiple sources, migration of Cacti to another server are not provided by default. You might need some experience with Cacti to pull these off. In this tutorial, we will see how we can merge two Cacti graphs into one.
|
||||
|
||||
Consider this example. Client-A has been connected to port 5 of switch-A for the last six months. Port 5 becomes faulty, and so the client is migrated to Port 6. As Cacti uses different graphs for each interface/element, the bandwidth history of the client would be split into port 5 and port 6. So we end up with two graphs for one client - one with six months' worth of old data, and the other that contains ongoing data.
|
||||
|
||||
In such cases, we can actually combine the two graphs so the old data is appended to the new graph, and we get to keep a single graph containing historic and new data for one customer. This tutorial will explain exactly how we can achieve that.
|
||||
|
||||
Cacti stores the data of each graph in its own RRD (round robin database) file. When a graph is requested, the values stored in a corresponding RRD file are used to generate the graph. RRD files are stored in `/var/lib/cacti/rra` in Ubuntu/Debian systems and in `/var/www/cacti/rra` in CentOS/RHEL systems.
|
||||
|
||||
The idea behind merging graphs is to alter these RRD files so the values from the old RRD file are appended to the new RRD file.
|
||||
|
||||
### Scenario ###
|
||||
|
||||
The services for a client is running on eth0 for over a year. Because of hardware failure, the client has been migrated to eth1 interface of another server. We want to graph the bandwidth of the new interface, while retaining the historic data for over a year. The client would see only one graph.
|
||||
|
||||
### Identifying the RRD for the Graph ###
|
||||
|
||||
The first step during graph merging is to identify the RRD file associated with a graph. We can check the file by opening the graph in debug mode. To do this, go to Cacti's menu: Console > Graph Management > Select Graph > Turn On Graph Debug Mode.
|
||||
|
||||
#### Old graph: ####
|
||||
|
||||
|
||||
|
||||
#### New graph: ####
|
||||
|
||||
|
||||
|
||||
From the example output (which is based on a Debian system), we can identify the RRD files for two graphs:
|
||||
|
||||
- **Old graph**: /var/lib/cacti/rra/old_graph_traffic_in_8.rrd
|
||||
- **New graph**: /var/lib/cacti/rra/new_graph_traffic_in_10.rrd
|
||||
|
||||
### Preparing a Script ###
|
||||
|
||||
We will merge two RRD files using a [RRD splice script][2]. Download this PHP script, and install it as /var/lib/cacti/rra/rrdsplice.php (for Debian/Ubuntu) or /var/www/cacti/rra/rrdsplice.php (for CentOS/RHEL).
|
||||
|
||||
Next, make sure that the file is owned by Apache user.
|
||||
|
||||
On Debian or Ubuntu, run the following command:
|
||||
|
||||
# chown www-data:www-data rrdsplice.php
|
||||
|
||||
and update rrdsplice.php accordingly. Look for the following line:
|
||||
|
||||
chown($finrrd, "apache");
|
||||
|
||||
and replace it with:
|
||||
|
||||
chown($finrrd, "www-data");
|
||||
|
||||
On CentOS or RHEL, run the following command:
|
||||
|
||||
# chown apache:apache rrdsplice.php
|
||||
|
||||
### Merging Two Graphs ###
|
||||
|
||||
The syntax usage of the script can easily be found by running it without any parameters.
|
||||
|
||||
# cd /path/to/rrdsplice.php
|
||||
# php rrdsplice.php
|
||||
|
||||
----------
|
||||
|
||||
USAGE: rrdsplice.php --oldrrd=file --newrrd=file --finrrd=file
|
||||
|
||||
Now we are ready to merge two RRD files. Simply supply the names of an old RRD file and a new RRD file. We will overwrite the merged result back to the new RRD file.
|
||||
|
||||
# php rrdsplice.php --oldrrd=old_graph_traffic_in_8.rrd --newrrd=new_graph_traffic_in_10.rrd --finrrd=new_graph_traffic_in_10.rrd
|
||||
|
||||
Now the data from the old RRD file should be appended to the new RRD. Any new data will continue to be written by Cacti to the new RRD file. If we click on the graph, we should be able to verify that the weekly, monthly and yearly records have also been added from the old graph. The second graph in the following diagram shows weekly records from the old graph.
|
||||
|
||||
|
||||
|
||||
To sum up, this tutorial showed how we can easily merge two Cacti graphs into one. This trick is useful when a service is migrated to another device/interface and we want to deal with only one graph instead of two. The script is very handy as it can join graphs regardless of the source device e.g., Cisco 1800 router and Cisco 2960 switch.
|
||||
|
||||
Hope this helps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/combine-two-graphs-cacti.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/install-configure-cacti-linux.html
|
||||
[2]:http://svn.cacti.net/viewvc/developers/thewitness/rrdsplice/rrdsplice.php
|
||||
@ -1,436 +0,0 @@
|
||||
Translating by GOLinux!
|
||||
The Art of Command Line
|
||||
================================================================================
|
||||
- [Basics](#basics)
|
||||
- [Everyday use](#everyday-use)
|
||||
- [Processing files and data](#processing-files-and-data)
|
||||
- [System debugging](#system-debugging)
|
||||
- [One-liners](#one-liners)
|
||||
- [Obscure but useful](#obscure-but-useful)
|
||||
- [More resources](#more-resources)
|
||||
- [Disclaimer](#disclaimer)
|
||||
|
||||
|
||||

|
||||
|
||||
Fluency on the command line is a skill often neglected or considered arcane, but it improves your flexibility and productivity as an engineer in both obvious and subtle ways. This is a selection of notes and tips on using the command-line that I've found useful when working on Linux. Some tips are elementary, and some are fairly specific, sophisticated, or obscure. This page is not long, but if you can use and recall all the items here, you know a lot.
|
||||
|
||||
Much of this
|
||||
[originally](http://www.quora.com/What-are-some-lesser-known-but-useful-Unix-commands)
|
||||
[appeared](http://www.quora.com/What-are-the-most-useful-Swiss-army-knife-one-liners-on-Unix)
|
||||
on [Quora](http://www.quora.com/What-are-some-time-saving-tips-that-every-Linux-user-should-know),
|
||||
but given the interest there, it seems it's worth using Github, where people more talented than I can readily suggest improvements. If you see an error or something that could be better, please submit an issue or PR!
|
||||
|
||||
Scope:
|
||||
|
||||
- The goals are breadth and brevity. Every tip is essential in some situation or significantly saves time over alternatives.
|
||||
- This is written for Linux. Many but not all items apply equally to MacOS (or even Cygwin).
|
||||
- The focus is on interactive Bash, though many tips apply to other shells and to general Bash scripting.
|
||||
- Descriptions are intentionally minimal, with the expectation you'll use `man`, `apt-get`/`yum`/`dnf` to install, and Google for more background.
|
||||
|
||||
|
||||
## Basics
|
||||
|
||||
- Learn basic Bash. Actually, type `man bash` and at least skim the whole thing; it's pretty easy to follow and not that long. Alternate shells can be nice, but Bash is powerful and always available (learning *only* zsh, fish, etc., while tempting on your own laptop, restricts you in many situations, such as using existing servers).
|
||||
|
||||
- Learn at least one text-based editor well. Ideally Vim (`vi`), as there's really no competition for random editing in a terminal (even if you use Emacs, a big IDE, or a modern hipster editor most of the time).
|
||||
|
||||
- Learn about redirection of output and input using `>` and `<` and pipes using `|`. Learn about stdout and stderr.
|
||||
|
||||
- Learn about file glob expansion with `*` (and perhaps `?` and `{`...`}`) and quoting and the difference between double `"` and single `'` quotes. (See more on variable expansion below.)
|
||||
|
||||
- Be familiar with Bash job management: `&`, **ctrl-z**, **ctrl-c**, `jobs`, `fg`, `bg`, `kill`, etc.
|
||||
|
||||
- Know `ssh`, and the basics of passwordless authentication, via `ssh-agent`, `ssh-add`, etc.
|
||||
|
||||
- Basic file management: `ls` and `ls -l` (in particular, learn what every column in `ls -l` means), `less`, `head`, `tail` and `tail -f` (or even better, `less +F`), `ln` and `ln -s` (learn the differences and advantages of hard versus soft links), `chown`, `chmod`, `du` (for a quick summary of disk usage: `du -sk *`), `df`, `mount`.
|
||||
|
||||
- Basic network management: `ip` or `ifconfig`, `dig`.
|
||||
|
||||
- Know regular expressions well, and the various flags to `grep`/`egrep`. The `-i`, `-o`, `-A`, and `-B` options are worth knowing.
|
||||
|
||||
- Learn to use `apt-get`, `yum`, or `dnf` (depending on distro) to find and install packages. And make sure you have `pip` to install Python-based command-line tools (a few below are easiest to install via `pip`).
|
||||
|
||||
|
||||
## Everyday use
|
||||
|
||||
- In Bash, use **ctrl-r** to search through command history.
|
||||
|
||||
- In Bash, use **ctrl-w** to delete the last word, and **ctrl-u** to delete the whole line. Use **alt-b** and **alt-f** to move by word, and **ctrl-k** to kill to the end of the line. See `man readline` for all the default keybindings in Bash. There are a lot. For example **alt-.** cycles through previous arguments, and **alt-*** expands a glob.
|
||||
|
||||
- To go back to the previous working directory: `cd -`
|
||||
|
||||
- If you are halfway through typing a command but change your mind, hit **alt-#** to add a `#` at the beginning and enter it as a comment (or use **ctrl-a**, **#**, **enter**). You can then return to it later via command history.
|
||||
|
||||
- Use `xargs` (or `parallel`). It's very powerful. Note you can control how many items execute per line (`-L`) as well as parallelism (`-P`). If you're not sure if it'll do the right thing, use `xargs echo` first. Also, `-I{}` is handy. Examples:
|
||||
```bash
|
||||
find . -name '*.py' | xargs grep some_function
|
||||
cat hosts | xargs -I{} ssh root@{} hostname
|
||||
```
|
||||
|
||||
- `pstree -p` is a helpful display of the process tree.
|
||||
|
||||
- Use `pgrep` and `pkill` to find or signal processes by name (`-f` is helpful).
|
||||
|
||||
- Know the various signals you can send processes. For example, to suspend a process, use `kill -STOP [pid]`. For the full list, see `man 7 signal`
|
||||
|
||||
- Use `nohup` or `disown` if you want a background process to keep running forever.
|
||||
|
||||
- Check what processes are listening via `netstat -lntp`.
|
||||
|
||||
- See also `lsof` for open sockets and files.
|
||||
|
||||
- In Bash scripts, use `set -x` for debugging output. Use strict modes whenever possible. Use `set -e` to abort on errors. Use `set -o pipefail` as well, to be strict about errors (though this topic is a bit subtle). For more involved scripts, also use `trap`.
|
||||
|
||||
- In Bash scripts, subshells (written with parentheses) are convenient ways to group commands. A common example is to temporarily move to a different working directory, e.g.
|
||||
```bash
|
||||
# do something in current dir
|
||||
(cd /some/other/dir; other-command)
|
||||
# continue in original dir
|
||||
```
|
||||
|
||||
- In Bash, note there are lots of kinds of variable expansion. Checking a variable exists: `${name:?error message}`. For example, if a Bash script requires a single argument, just write `input_file=${1:?usage: $0 input_file}`. Arithmetic expansion: `i=$(( (i + 1) % 5 ))`. Sequences: `{1..10}`. Trimming of strings: `${var%suffix}` and `${var#prefix}`. For example if `var=foo.pdf`, then `echo ${var%.pdf}.txt` prints `foo.txt`.
|
||||
|
||||
- The output of a command can be treated like a file via `<(some command)`. For example, compare local `/etc/hosts` with a remote one:
|
||||
```sh
|
||||
diff /etc/hosts <(ssh somehost cat /etc/hosts)
|
||||
```
|
||||
|
||||
- Know about "here documents" in Bash, as in `cat <<EOF ...`.
|
||||
|
||||
- In Bash, redirect both standard output and standard error via: `some-command >logfile 2>&1`. Often, to ensure a command does not leave an open file handle to standard input, tying it to the terminal you are in, it is also good practice to add `</dev/null`.
|
||||
|
||||
- Use `man ascii` for a good ASCII table, with hex and decimal values. For general encoding info, `man unicode`, `man utf-8`, and `man latin1` are helpful.
|
||||
|
||||
- Use `screen` or `tmux` to multiplex the screen, especially useful on remote ssh sessions and to detach and re-attach to a session. A more minimal alternative for session persistence only is `dtach`.
|
||||
|
||||
- In ssh, knowing how to port tunnel with `-L` or `-D` (and occasionally `-R`) is useful, e.g. to access web sites from a remote server.
|
||||
|
||||
- It can be useful to make a few optimizations to your ssh configuration; for example, this `~/.ssh/config` contains settings to avoid dropped connections in certain network environments, use compression (which is helpful with scp over low-bandwidth connections), and multiplex channels to the same server with a local control file:
|
||||
```
|
||||
TCPKeepAlive=yes
|
||||
ServerAliveInterval=15
|
||||
ServerAliveCountMax=6
|
||||
Compression=yes
|
||||
ControlMaster auto
|
||||
ControlPath /tmp/%r@%h:%p
|
||||
ControlPersist yes
|
||||
```
|
||||
|
||||
- A few other options relevant to ssh are security sensitive and should be enabled with care, e.g. per subnet or host or in trusted networks: `StrictHostKeyChecking=no`, `ForwardAgent=yes`
|
||||
|
||||
- To get the permissions on a file in octal form, which is useful for system configuration but not available in `ls` and easy to bungle, use something like
|
||||
```sh
|
||||
stat -c '%A %a %n' /etc/timezone
|
||||
```
|
||||
|
||||
- For interactive selection of values from the output of another command, use [`percol`](https://github.com/mooz/percol).
|
||||
|
||||
- For interaction with files based on the output of another command (like `git`), use `fpp` ([PathPicker](https://github.com/facebook/PathPicker)).
|
||||
|
||||
- For a simple web server for all files in the current directory (and subdirs), available to anyone on your network, use:
|
||||
`python -m SimpleHTTPServer 7777` (for port 7777 and Python 2).
|
||||
|
||||
|
||||
## Processing files and data
|
||||
|
||||
- To locate a file by name in the current directory, `find . -iname '*something*'` (or similar). To find a file anywhere by name, use `locate something` (but bear in mind `updatedb` may not have indexed recently created files).
|
||||
|
||||
- For general searching through source or data files (more advanced than `grep -r`), use [`ag`](https://github.com/ggreer/the_silver_searcher).
|
||||
|
||||
- To convert HTML to text: `lynx -dump -stdin`
|
||||
|
||||
- For Markdown, HTML, and all kinds of document conversion, try [`pandoc`](http://pandoc.org/).
|
||||
|
||||
- If you must handle XML, `xmlstarlet` is old but good.
|
||||
|
||||
- For JSON, use `jq`.
|
||||
|
||||
- For Excel or CSV files, [csvkit](https://github.com/onyxfish/csvkit) provides `in2csv`, `csvcut`, `csvjoin`, `csvgrep`, etc.
|
||||
|
||||
- For Amazon S3, [`s3cmd`](https://github.com/s3tools/s3cmd) is convenient and [`s4cmd`](https://github.com/bloomreach/s4cmd) is faster. Amazon's [`aws`](https://github.com/aws/aws-cli) is essential for other AWS-related tasks.
|
||||
|
||||
- Know about `sort` and `uniq`, including uniq's `-u` and `-d` options -- see one-liners below.
|
||||
|
||||
- Know about `cut`, `paste`, and `join` to manipulate text files. Many people use `cut` but forget about `join`.
|
||||
|
||||
- Know that locale affects a lot of command line tools in subtle ways, including sorting order (collation) and performance. Most Linux installations will set `LANG` or other locale variables to a local setting like US English. But be aware sorting will change if you change locale. And know i18n routines can make sort or other commands run *many times* slower. In some situations (such as the set operations or uniqueness operations below) you can safely ignore slow i18n routines entirely and use traditional byte-based sort order, using `export LC_ALL=C`.
|
||||
|
||||
- Know basic `awk` and `sed` for simple data munging. For example, summing all numbers in the third column of a text file: `awk '{ x += $3 } END { print x }'`. This is probably 3X faster and 3X shorter than equivalent Python.
|
||||
|
||||
- To replace all occurrences of a string in place, in one or more files:
|
||||
```sh
|
||||
perl -pi.bak -e 's/old-string/new-string/g' my-files-*.txt
|
||||
```
|
||||
|
||||
- To rename many files at once according to a pattern, use `rename`. For complex renames, [`repren`](https://github.com/jlevy/repren) may help.
|
||||
```sh
|
||||
# Recover backup files foo.bak -> foo:
|
||||
rename 's/\.bak$//' *.bak
|
||||
# Full rename of filenames, directories, and contents foo -> bar:
|
||||
repren --full --preserve-case --from foo --to bar .
|
||||
```
|
||||
|
||||
- Use `shuf` to shuffle or select random lines from a file.
|
||||
|
||||
- Know `sort`'s options. Know how keys work (`-t` and `-k`). In particular, watch out that you need to write `-k1,1` to sort by only the first field; `-k1` means sort according to the whole line.
|
||||
|
||||
- Stable sort (`sort -s`) can be useful. For example, to sort first by field 2, then secondarily by field 1, you can use `sort -k1,1 | sort -s -k2,2`
|
||||
|
||||
- If you ever need to write a tab literal in a command line in Bash (e.g. for the -t argument to sort), press **ctrl-v** **[Tab]** or write `$'\t'` (the latter is better as you can copy/paste it).
|
||||
|
||||
- For binary files, use `hd` for simple hex dumps and `bvi` for binary editing.
|
||||
|
||||
- Also for binary files, `strings` (plus `grep`, etc.) lets you find bits of text.
|
||||
|
||||
- To convert text encodings, try `iconv`. Or `uconv` for more advanced use; it supports some advanced Unicode things. For example, this command lowercases and removes all accents (by expanding and dropping them):
|
||||
```sh
|
||||
uconv -f utf-8 -t utf-8 -x '::Any-Lower; ::Any-NFD; [:Nonspacing Mark:] >; ::Any-NFC; ' < input.txt > output.txt
|
||||
```
|
||||
|
||||
- To split files into pieces, see `split` (to split by size) and `csplit` (to split by a pattern).
|
||||
|
||||
- Use `zless`, `zmore`, `zcat`, and `zgrep` to operate on compressed files.
|
||||
|
||||
|
||||
## System debugging
|
||||
|
||||
- For web debugging, `curl` and `curl -I` are handy, or their `wget` equivalents, or the more modern [`httpie`](https://github.com/jakubroztocil/httpie).
|
||||
|
||||
- To know disk/cpu/network status, use `iostat`, `netstat`, `top` (or the better `htop`), and (especially) `dstat`. Good for getting a quick idea of what's happening on a system.
|
||||
|
||||
- For a more in-depth system overview, use [`glances`](https://github.com/nicolargo/glances). It presents you with several system level statistics in one terminal window. Very helpful for quickly checking on various subsystems.
|
||||
|
||||
- To know memory status, run and understand the output of `free` and `vmstat`. In particular, be aware the "cached" value is memory held by the Linux kernel as file cache, so effectively counts toward the "free" value.
|
||||
|
||||
- Java system debugging is a different kettle of fish, but a simple trick on Oracle's and some other JVMs is that you can run `kill -3 <pid>` and a full stack trace and heap summary (including generational garbage collection details, which can be highly informative) will be dumped to stderr/logs.
|
||||
|
||||
- Use `mtr` as a better traceroute, to identify network issues.
|
||||
|
||||
- For looking at why a disk is full, `ncdu` saves time over the usual commands like `du -sh *`.
|
||||
|
||||
- To find which socket or process is using bandwidth, try `iftop` or `nethogs`.
|
||||
|
||||
- The `ab` tool (comes with Apache) is helpful for quick-and-dirty checking of web server performance. For more complex load testing, try `siege`.
|
||||
|
||||
- For more serious network debugging, `wireshark`, `tshark`, or `ngrep`.
|
||||
|
||||
- Know about `strace` and `ltrace`. These can be helpful if a program is failing, hanging, or crashing, and you don't know why, or if you want to get a general idea of performance. Note the profiling option (`-c`), and the ability to attach to a running process (`-p`).
|
||||
|
||||
- Know about `ldd` to check shared libraries etc.
|
||||
|
||||
- Know how to connect to a running process with `gdb` and get its stack traces.
|
||||
|
||||
- Use `/proc`. It's amazingly helpful sometimes when debugging live problems. Examples: `/proc/cpuinfo`, `/proc/xxx/cwd`, `/proc/xxx/exe`, `/proc/xxx/fd/`, `/proc/xxx/smaps`.
|
||||
|
||||
- When debugging why something went wrong in the past, `sar` can be very helpful. It shows historic statistics on CPU, memory, network, etc.
|
||||
|
||||
- For deeper systems and performance analyses, look at `stap` ([SystemTap](https://sourceware.org/systemtap/wiki)), [`perf`](http://en.wikipedia.org/wiki/Perf_(Linux)), and [`sysdig`](https://github.com/draios/sysdig).
|
||||
|
||||
- Confirm what Linux distribution you're using (works on most distros): `lsb_release -a`
|
||||
|
||||
- Use `dmesg` whenever something's acting really funny (it could be hardware or driver issues).
|
||||
|
||||
|
||||
## One-liners
|
||||
|
||||
A few examples of piecing together commands:
|
||||
|
||||
- It is remarkably helpful sometimes that you can do set intersection, union, and difference of text files via `sort`/`uniq`. Suppose `a` and `b` are text files that are already uniqued. This is fast, and works on files of arbitrary size, up to many gigabytes. (Sort is not limited by memory, though you may need to use the `-T` option if `/tmp` is on a small root partition.) See also the note about `LC_ALL` above.
|
||||
```sh
|
||||
cat a b | sort | uniq > c # c is a union b
|
||||
cat a b | sort | uniq -d > c # c is a intersect b
|
||||
cat a b b | sort | uniq -u > c # c is set difference a - b
|
||||
```
|
||||
|
||||
- Summing all numbers in the third column of a text file (this is probably 3X faster and 3X less code than equivalent Python):
|
||||
```sh
|
||||
awk '{ x += $3 } END { print x }' myfile
|
||||
```
|
||||
|
||||
- If want to see sizes/dates on a tree of files, this is like a recursive `ls -l` but is easier to read than `ls -lR`:
|
||||
```sh
|
||||
find . -type f -ls
|
||||
```
|
||||
|
||||
- Use `xargs` or `parallel` whenever you can. Note you can control how many items execute per line (`-L`) as well as parallelism (`-P`). If you're not sure if it'll do the right thing, use xargs echo first. Also, `-I{}` is handy. Examples:
|
||||
```sh
|
||||
find . -name '*.py' | xargs grep some_function
|
||||
cat hosts | xargs -I{} ssh root@{} hostname
|
||||
```
|
||||
|
||||
- Say you have a text file, like a web server log, and a certain value that appears on some lines, such as an `acct_id` parameter that is present in the URL. If you want a tally of how many requests for each `acct_id`:
|
||||
```sh
|
||||
cat access.log | egrep -o 'acct_id=[0-9]+' | cut -d= -f2 | sort | uniq -c | sort -rn
|
||||
```
|
||||
|
||||
- Run this function to get a random tip from this document (parses Markdown and extracts an item):
|
||||
```sh
|
||||
function taocl() {
|
||||
curl -s https://raw.githubusercontent.com/jlevy/the-art-of-command-line/master/README.md |
|
||||
pandoc -f markdown -t html |
|
||||
xmlstarlet fo --html --dropdtd |
|
||||
xmlstarlet sel -t -v "(html/body/ul/li[count(p)>0])[$RANDOM mod last()+1]" |
|
||||
xmlstarlet unesc | fmt -80
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## Obscure but useful
|
||||
|
||||
- `expr`: perform arithmetic or boolean operations or evaluate regular expressions
|
||||
|
||||
- `m4`: simple macro processor
|
||||
|
||||
- `screen`: powerful terminal multiplexing and session persistence
|
||||
|
||||
- `yes`: print a string a lot
|
||||
|
||||
- `cal`: nice calendar
|
||||
|
||||
- `env`: run a command (useful in scripts)
|
||||
|
||||
- `look`: find English words (or lines in a file) beginning with a string
|
||||
|
||||
- `cut `and `paste` and `join`: data manipulation
|
||||
|
||||
- `fmt`: format text paragraphs
|
||||
|
||||
- `pr`: format text into pages/columns
|
||||
|
||||
- `fold`: wrap lines of text
|
||||
|
||||
- `column`: format text into columns or tables
|
||||
|
||||
- `expand` and `unexpand`: convert between tabs and spaces
|
||||
|
||||
- `nl`: add line numbers
|
||||
|
||||
- `seq`: print numbers
|
||||
|
||||
- `bc`: calculator
|
||||
|
||||
- `factor`: factor integers
|
||||
|
||||
- `gpg`: encrypt and sign files
|
||||
|
||||
- `toe`: table of terminfo entries
|
||||
|
||||
- `nc`: network debugging and data transfer
|
||||
|
||||
- `ngrep`: grep for the network layer
|
||||
|
||||
- `dd`: moving data between files or devices
|
||||
|
||||
- `file`: identify type of a file
|
||||
|
||||
- `stat`: file info
|
||||
|
||||
- `tac`: print files in reverse
|
||||
|
||||
- `shuf`: random selection of lines from a file
|
||||
|
||||
- `comm`: compare sorted files line by line
|
||||
|
||||
- `hd` and `bvi`: dump or edit binary files
|
||||
|
||||
- `strings`: extract text from binary files
|
||||
|
||||
- `tr`: character translation or manipulation
|
||||
|
||||
- `iconv `or uconv: conversion for text encodings
|
||||
|
||||
- `split `and `csplit`: splitting files
|
||||
|
||||
- `7z`: high-ratio file compression
|
||||
|
||||
- `ldd`: dynamic library info
|
||||
|
||||
- `nm`: symbols from object files
|
||||
|
||||
- `ab`: benchmarking web servers
|
||||
|
||||
- `strace`: system call debugging
|
||||
|
||||
- `mtr`: better traceroute for network debugging
|
||||
|
||||
- `cssh`: visual concurrent shell
|
||||
|
||||
- `wireshark` and `tshark`: packet capture and network debugging
|
||||
|
||||
- `host` and `dig`: DNS lookups
|
||||
|
||||
- `lsof`: process file descriptor and socket info
|
||||
|
||||
- `dstat`: useful system stats
|
||||
|
||||
- [`glances`](https://github.com/nicolargo/glances): high level, multi-subsystem overview
|
||||
|
||||
- `iostat`: CPU and disk usage stats
|
||||
|
||||
- `htop`: improved version of top
|
||||
|
||||
- `last`: login history
|
||||
|
||||
- `w`: who's logged on
|
||||
|
||||
- `id`: user/group identity info
|
||||
|
||||
- `sar`: historic system stats
|
||||
|
||||
- `iftop` or `nethogs`: network utilization by socket or process
|
||||
|
||||
- `ss`: socket statistics
|
||||
|
||||
- `dmesg`: boot and system error messages
|
||||
|
||||
- `hdparm`: SATA/ATA disk manipulation/performance
|
||||
|
||||
- `lsb_release`: Linux distribution info
|
||||
|
||||
- `lshw`: hardware information
|
||||
|
||||
- `fortune`, `ddate`, and `sl`: um, well, it depends on whether you consider steam locomotives and Zippy quotations "useful"
|
||||
|
||||
|
||||
## More resources
|
||||
|
||||
- [awesome-shell](https://github.com/alebcay/awesome-shell): A curated list of shell tools and resources.
|
||||
- [Strict mode](http://redsymbol.net/articles/unofficial-bash-strict-mode/) for writing better shell scripts.
|
||||
|
||||
|
||||
## Disclaimer
|
||||
|
||||
With the exception of very small tasks, code is written so others can read it. With power comes responsibility. The fact you *can* do something in Bash doesn't necessarily mean you should! ;)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/jlevy/the-art-of-command-line
|
||||
|
||||
作者:[jlevy][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/jlevy
|
||||
[1]:
|
||||
[2]:
|
||||
[3]:
|
||||
[4]:
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
@ -1,208 +0,0 @@
|
||||
translating by wwy-hust
|
||||
|
||||
Tor Browser: An Ultimate Web Browser for Anonymous Web Browsing in Linux
|
||||
================================================================================
|
||||
Most of us give a considerable time of ours to Internet. The primary Application we require to perform our internet activity is a browser, a web browser to be more perfect. Over Internet most of our’s activity is logged to Server/Client machine which includes IP address, Geographical Location, search/activity trends and a whole lots of Information which can potentially be very harmful, if used intentionally the other way.
|
||||
|
||||

|
||||
|
||||
Tor Browser: Anonymous Browsing
|
||||
|
||||
Moreover the National Security Agency (NSA) aka International Spying Agency keeps tracks of ours digital footprints. Not to mention a restricted proxy server which again can be used as data ripping server is not the answer. And most of the corporates and companies wont allow you to access a proxy server.
|
||||
|
||||
So, what we need here is an application, preferably small in size and let it be standalone, portable and which servers the purpose. Here comes an application – the Tor Browser, which has all the above discussed features and even beyond that.
|
||||
|
||||
In this article we will be discussing Tor browser, its features, its usages and Area of Application, Installation and other important aspects of The Tor Browser Application.
|
||||
|
||||
#### What is Tor Browser? ####
|
||||
|
||||
Tor is a Freely distributed Application Software, released under BSD style Licensing which allows to surf Internet anonymously, through its safe and reliable onion like structure. Tor previously was called as ‘The Onion Router‘ because of its structure and functioning mechanism. This Application is written in C programming Language.
|
||||
|
||||
#### Features of Tor Browser ####
|
||||
|
||||
- Cross Platform Availability. i.e., this application is available for Linux, Windows as well as Mac.
|
||||
- Complex Data encryption before it it sent over Internet.
|
||||
- Automatic data decryption at client side.
|
||||
- It is a combination of Firefox Browser + Tor Project.
|
||||
- Provides anonymity to servers and websites.
|
||||
- Makes it possible to visit locked websites.
|
||||
- Performs task without revealing IP of Source.
|
||||
- Capable of routing data to/from hidden services and application behind firewall.
|
||||
- Portable – Run a preconfigured web browser directly from the USB storage Device. No need to install it locally.
|
||||
- Available for architectures x86 and x86_64.
|
||||
- Easy to set FTP with Tor using configuration as “socks4a” proxy on “localhost” port “9050”
|
||||
- Tor is capable of handling thousands of relay and millions of users.
|
||||
|
||||
#### How Tor Browser Works? ####
|
||||
|
||||
Tor works on the concept of Onion routing. Onion routing resemble to onion in structure. In onion routing the layers are nested one over the other similar to the layers of onion. This nested layer is responsible for encrypting data several times and sends it through virtual circuits. On the client side each layer decrypt the data before passing it to the next level. The last layer decrypts the innermost layer of encrypted data before passing the original data to the destination.
|
||||
|
||||
In this process of decryption all the layers function so intelligently that there is no need to reveal IP and Geographical location of User thus limiting any chance of anybody watching your internet connection or the sites you are visiting.
|
||||
|
||||
All these working seems a bit complex, but the end user execution and working of Tor browser is nothing to worry about. In-fact Tor browser resembles any other browser (Especially Mozilla Firefox) in functioning.
|
||||
|
||||
### Installation of Tor Browser in Linux ###
|
||||
|
||||
As discussed above, Tor browser is available for Linux, Windows and Mac. The user need to download the latest version (i.e. Tor Browser 4.0.4) application from the link below as per their system and architecture.
|
||||
|
||||
- [https://www.torproject.org/download/download-easy.html.en][1]
|
||||
|
||||
After downloading the Tor browser, we need to install it. But the good thing with ‘Tor’ is that we don’t need to install it. It can run directly from a Pen Drive and the browser can be preconfigured. That means plug and Run Feature in perfect sense of Portability.
|
||||
|
||||
After downloading the Tar-ball (*.tar.xz) we need to Extract it.
|
||||
|
||||
**On 32-Bit System**
|
||||
|
||||
$ wget https://www.torproject.org/dist/torbrowser/4.0.4/tor-browser-linux32-4.0.4_en-US.tar.xz
|
||||
$ tar xpvf tor-browser-linux32-4.0.4_en-US.tar.xz
|
||||
|
||||
**On 64-Bit System**
|
||||
|
||||
$ wget https://www.torproject.org/dist/torbrowser/4.0.4/tor-browser-linux64-4.0.4_en-US.tar.xz
|
||||
$ tar -xpvf tor-browser-linux64-4.0.4_en-US.tar.xz
|
||||
|
||||
**Note** : In the above command we used ‘$‘ which means that the package is extracted as user and not root. It is strictly suggested to extract and run tor browser not as root.
|
||||
|
||||
After successful extraction, we can move the extracted browser to anywhere/USB Mass Storage device. And run the application from the extracted folder and run ‘start-tor-browser’ strictly not as root.
|
||||
|
||||
$ cd tor-browser_en-US
|
||||
$ ./start-tor-browser
|
||||
|
||||
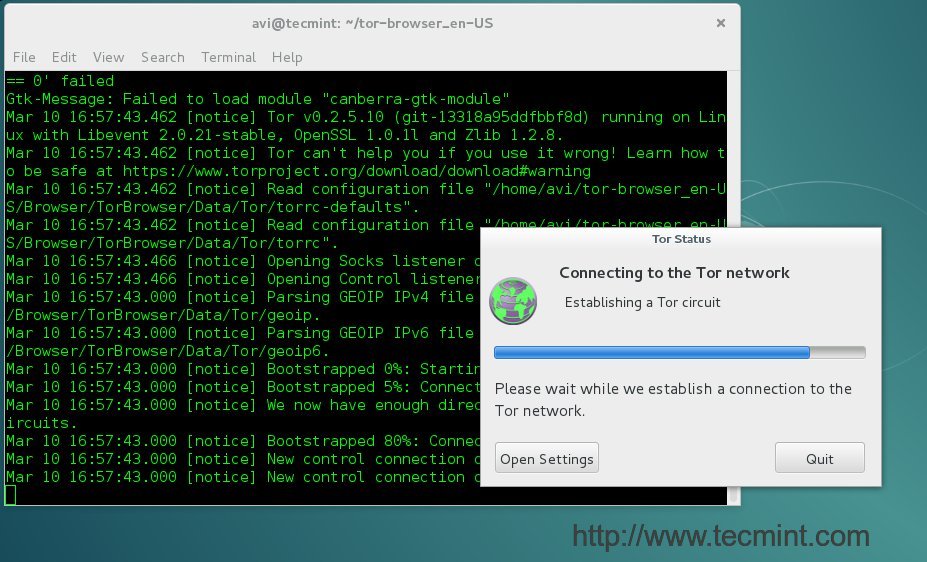
|
||||
|
||||
Starting Tor Browser
|
||||
|
||||
**1. Trying to connect to the Tor Network. Click “Connect” and Tor will do rest of the settings for you.**
|
||||
|
||||

|
||||
|
||||
Connecting to Tor Network
|
||||
|
||||
**2. The welcome Window/Tab.**
|
||||
|
||||
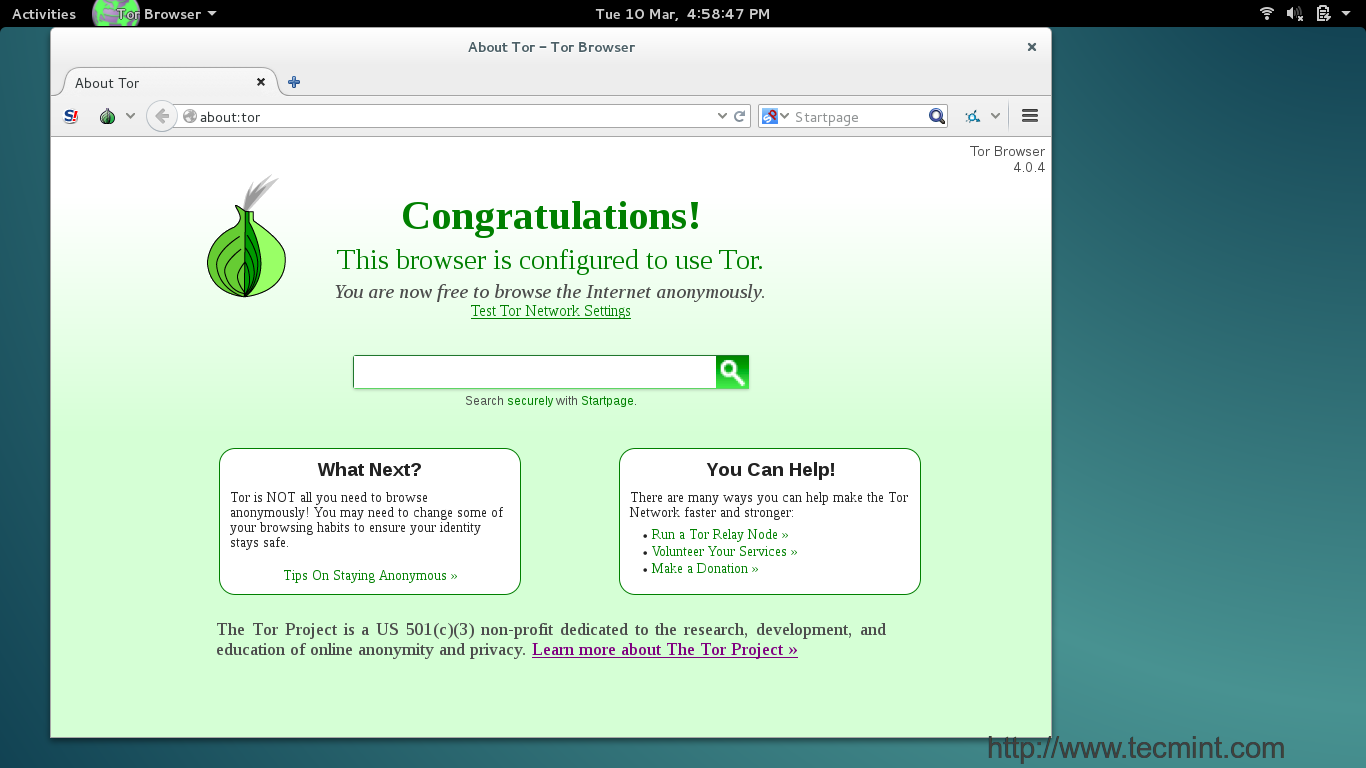
|
||||
|
||||
Tor Welcome Screen
|
||||
|
||||
**3. Tor Browser Running a Video from Youtube.**
|
||||
|
||||

|
||||
|
||||
Watching Video on Youtube
|
||||
|
||||
**4. Opening a banking site for online Purchasing/Transaction.**
|
||||
|
||||

|
||||
|
||||
Browsing a Banking Site
|
||||
|
||||
**5. The browser showing my current proxy IP. Note that the text that reads “Proxy Server detected”.**
|
||||
|
||||
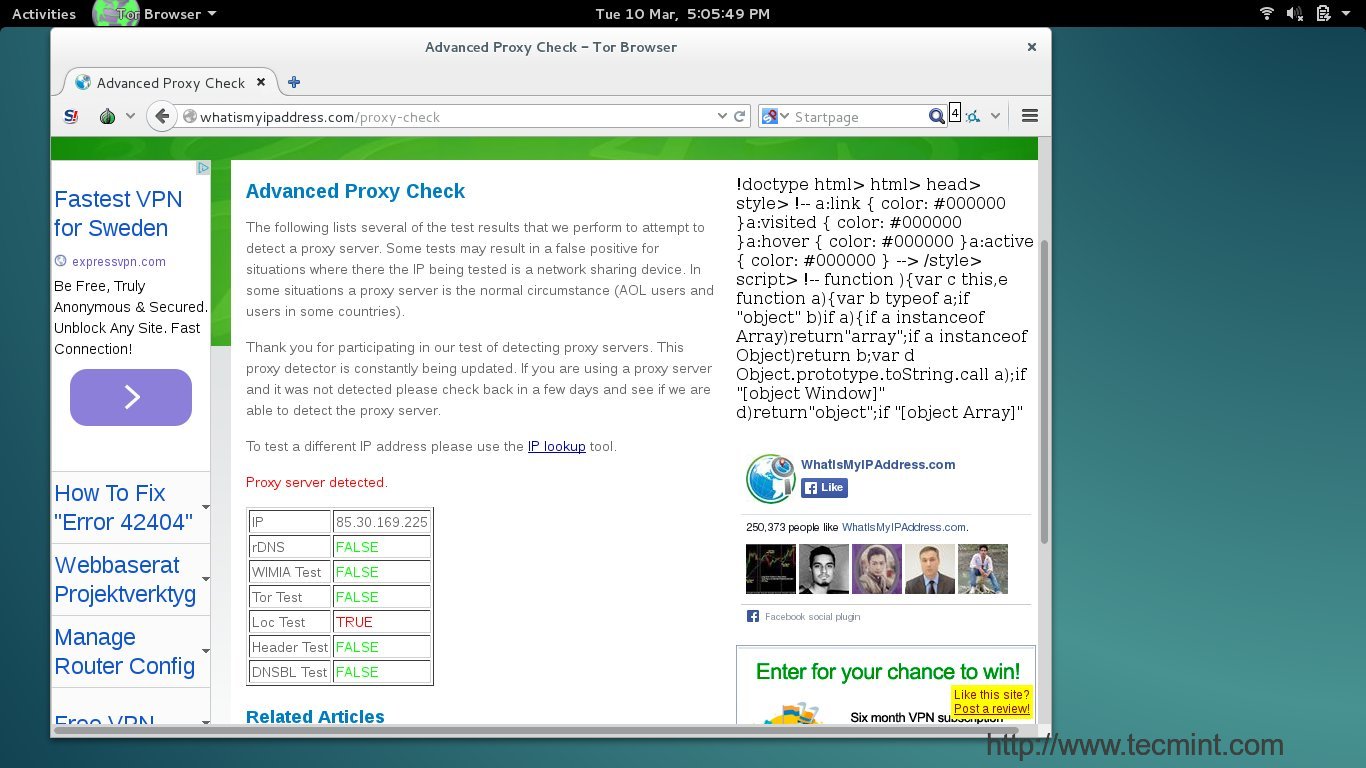
|
||||
|
||||
Checking IP Address
|
||||
|
||||
**Note**: That you need to point to the Tor startup script using text session, everytime you want to run Tor. Moreover a terminal will be busy all the time till you are running tor. How to overcome this and create a desktop/dock-bar Icon?
|
||||
|
||||
6. We need to create `tor.desktop` file inside the directory where extracted files resides.
|
||||
|
||||
$ touch tor.desktop
|
||||
|
||||
Now edit the file using your favourite editor with the text below. Save and exit. I used nano.
|
||||
|
||||
$ nano tor.desktop
|
||||
|
||||
----------
|
||||
|
||||
#!/usr/bin/env xdg-open
|
||||
[Desktop Entry]
|
||||
Encoding=UTF-8
|
||||
Name=Tor
|
||||
Comment=Anonymous Browse
|
||||
Type=Application
|
||||
Terminal=false
|
||||
Exec=/home/avi/Downloads/tor-browser_en-US/start-tor-browser
|
||||
Icon=/home/avi/Downloads/tor-browser_en-US/Browser/browser/icons/mozicon128.png
|
||||
StartupNotify=true
|
||||
Categories=Network;WebBrowser;
|
||||
|
||||
**Note**: Make sure to replace the path with the location of your tor browser in the above.
|
||||
|
||||
**7. Once done! Double click the file `tor.desktop` to fire Tor browser. You may need to trust it for the first time.**
|
||||
|
||||

|
||||
|
||||
Tor Application Launcher
|
||||
|
||||
**8. Once you trust you might note that the icon of `tor.desktop` changed.**
|
||||
|
||||

|
||||
|
||||
Tor icon Changed
|
||||
|
||||
9. You may drag and drop the `tor.desktop` icon to create shortcut on Desktop and Dock Bar.
|
||||
|
||||

|
||||
|
||||
Add Tor Shortcut on Desktop
|
||||
|
||||
**10. About Tor Browser.**
|
||||
|
||||

|
||||
|
||||
About Tor Browser
|
||||
|
||||
**Note**: If you are using older version of Tor, you may update it from the above window.
|
||||
|
||||
#### Usability/Area of Application ####
|
||||
|
||||
- Anonymous communication over web.
|
||||
- Surf to Blocked web Pages.
|
||||
- Link other Application Viz (FTP) to this secure Internet Browsing Application.
|
||||
|
||||
#### Controversies of Tor-browser ####
|
||||
|
||||
- No security at the boundary of Tor Application i.e., Data Entry and Exit Points.
|
||||
- A study in 2011 reveals that a specific way of attacking Tor will reveal IP address of BitTorrent Users.
|
||||
- Some protocols shows the tendency of leaking IP address, revealed in a study.
|
||||
- Earlier version of Tor bundled with older versions of Firefox browser were found to be JavaScript Attack Vulnerable.
|
||||
- Tor Browser Seems to Work slow.
|
||||
|
||||
#### Real world Implementation of Tor-browser ####
|
||||
|
||||
- Vuze BitTorrent Client
|
||||
- Anonymous Os
|
||||
- Os’es from Scratch
|
||||
- whonix, etc.
|
||||
|
||||
#### Future of Tor Browser ####
|
||||
|
||||
Tor browser is promising. Perhaps the first application of its kind is implemented very brilliantly. Tor browser must invest for Support, Scalability and research for securing the data from latest attacks. This application is need of the future.
|
||||
|
||||
#### Download Free eBook ####
|
||||
|
||||
Unofficial Guide to Tor Private Browsing
|
||||
|
||||
[][2]
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Tor bowser is a must tool in the present time where the organization you are working for don’t allow you to access certain websites or if you don’t want others to look into your private business or you don’t want to provide your digital footprints to NSA.
|
||||
|
||||
**Note**: Tor Browser don’t provide any safety from Viruses, Trojans or other threats of this kind. Moreover by writing an article of this we never mean to indulge into illegal activity by hiding our identity over Internet. This Post is totally for educational Purpose and for any illegal use of it neither the author of the post nor Tecmint will be responsible. It is the sole responsibility of user.
|
||||
|
||||
Tor-browser is a wonderful application and you must give it a try. That’s all for now. I’ll be here again with another interesting article you people will love to read. Till then stay tuned and connected to Tecmint. Don’t forget to provide us with your value-able feedback in our comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/tor-browser-for-anonymous-web-browsing/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:https://www.torproject.org/download/download-easy.html.en
|
||||
[2]:http://tecmint.tradepub.com/free/w_make129/prgm.cgi
|
||||
@ -0,0 +1,348 @@
|
||||
Shilpa Nair Shares Her Interview Experience on RedHat Linux Package Management
|
||||
================================================================================
|
||||
**Shilpa Nair has just graduated in the year 2015. She went to apply for Trainee position in a National News Television located in Noida, Delhi. When she was in the last year of graduation and searching for help on her assignments she came across Tecmint. Since then she has been visiting Tecmint regularly.**
|
||||
|
||||

|
||||
|
||||
Linux Interview Questions on RPM
|
||||
|
||||
All the questions and answers are rewritten based upon the memory of Shilpa Nair.
|
||||
|
||||
> “Hi friends! I am Shilpa Nair from Delhi. I have completed my graduation very recently and was hunting for a Trainee role soon after my degree. I have developed a passion for UNIX since my early days in the collage and I was looking for a role that suits me and satisfies my soul. I was asked a lots of questions and most of them were basic questions related to RedHat Package Management.”
|
||||
|
||||
Here are the questions, that I was asked and their corresponding answers. I am posting only those questions that are related to RedHat GNU/Linux Package Management, as they were mainly asked.
|
||||
|
||||
### 1. How will you find if a package is installed or not? Say you have to find if ‘nano’ is installed or not, what will you do? ###
|
||||
|
||||
> **Answer** : To find the package nano, weather installed or not, we can use rpm command with the option -q is for query and -a stands for all the installed packages.
|
||||
>
|
||||
> # rpm -qa nano
|
||||
> OR
|
||||
> # rpm -qa | grep -i nano
|
||||
>
|
||||
> nano-2.3.1-10.el7.x86_64
|
||||
>
|
||||
> Also the package name must be complete, an incomplete package name will return the prompt without printing anything which means that package (incomplete package name) is not installed. It can be understood easily by the example below:
|
||||
>
|
||||
> We generally substitute vim command with vi. But if we find package vi/vim we will get no result on the standard output.
|
||||
>
|
||||
> # vi
|
||||
> # vim
|
||||
>
|
||||
> However we can clearly see that the package is installed by firing vi/vim command. Here is culprit is incomplete file name. If we are not sure of the exact file-name we can use wildcard as:
|
||||
>
|
||||
> # rpm -qa vim*
|
||||
>
|
||||
> vim-minimal-7.4.160-1.el7.x86_64
|
||||
>
|
||||
> This way we can find information about any package, if installed or not.
|
||||
|
||||
### 2. How will you install a package XYZ using rpm? ###
|
||||
|
||||
> **Answer** : We can install any package (*.rpm) using rpm command a shown below, here options -i (install), -v (verbose or display additional information) and -h (print hash mark during package installation).
|
||||
>
|
||||
> # rpm -ivh peazip-1.11-1.el6.rf.x86_64.rpm
|
||||
>
|
||||
> Preparing... ################################# [100%]
|
||||
> Updating / installing...
|
||||
> 1:peazip-1.11-1.el6.rf ################################# [100%]
|
||||
>
|
||||
> If upgrading a package from earlier version -U switch should be used, option -v and -h follows to make sure we get a verbose output along with hash Mark, that makes it readable.
|
||||
|
||||
### 3. You have installed a package (say httpd) and now you want to see all the files and directories installed and created by the above package. What will you do? ###
|
||||
|
||||
> **Answer** : We can list all the files (Linux treat everything as file including directories) installed by the package httpd using options -l (List all the files) and -q (is for query).
|
||||
>
|
||||
> # rpm -ql httpd
|
||||
>
|
||||
> /etc/httpd
|
||||
> /etc/httpd/conf
|
||||
> /etc/httpd/conf.d
|
||||
> ...
|
||||
|
||||
### 4. You are supposed to remove a package say postfix. What will you do? ###
|
||||
|
||||
> **Answer** : First we need to know postfix was installed by what package. Find the package name that installed postfix using options -e erase/uninstall a package) and –v (verbose output).
|
||||
>
|
||||
> # rpm -qa postfix*
|
||||
>
|
||||
> postfix-2.10.1-6.el7.x86_64
|
||||
>
|
||||
> and then remove postfix as:
|
||||
>
|
||||
> # rpm -ev postfix-2.10.1-6.el7.x86_64
|
||||
>
|
||||
> Preparing packages...
|
||||
> postfix-2:3.0.1-2.fc22.x86_64
|
||||
|
||||
### 5. Get detailed information about an installed package, means information like Version, Release, Install Date, Size, Summary and a brief description. ###
|
||||
|
||||
> **Answer** : We can get detailed information about an installed package by using option -qa with rpm followed by package name.
|
||||
>
|
||||
> For example to find details of package openssh, all I need to do is:
|
||||
>
|
||||
> # rpm -qi openssh
|
||||
>
|
||||
> [root@tecmint tecmint]# rpm -qi openssh
|
||||
> Name : openssh
|
||||
> Version : 6.8p1
|
||||
> Release : 5.fc22
|
||||
> Architecture: x86_64
|
||||
> Install Date: Thursday 28 May 2015 12:34:50 PM IST
|
||||
> Group : Applications/Internet
|
||||
> Size : 1542057
|
||||
> License : BSD
|
||||
> ....
|
||||
|
||||
### 6. You are not sure about what are the configuration files provided by a specific package say httpd. How will you find list of all the configuration files provided by httpd and their location. ###
|
||||
|
||||
> **Answer** : We need to run option -c followed by package name with rpm command and it will list the name of all the configuration file and their location.
|
||||
>
|
||||
> # rpm -qc httpd
|
||||
>
|
||||
> /etc/httpd/conf.d/autoindex.conf
|
||||
> /etc/httpd/conf.d/userdir.conf
|
||||
> /etc/httpd/conf.d/welcome.conf
|
||||
> /etc/httpd/conf.modules.d/00-base.conf
|
||||
> /etc/httpd/conf/httpd.conf
|
||||
> /etc/sysconfig/httpd
|
||||
>
|
||||
> Similarly we can list all the associated document files as:
|
||||
>
|
||||
> # rpm -qd httpd
|
||||
>
|
||||
> /usr/share/doc/httpd/ABOUT_APACHE
|
||||
> /usr/share/doc/httpd/CHANGES
|
||||
> /usr/share/doc/httpd/LICENSE
|
||||
> ...
|
||||
>
|
||||
> also, we can list the associated License file as:
|
||||
>
|
||||
> # rpm -qL openssh
|
||||
>
|
||||
> /usr/share/licenses/openssh/LICENCE
|
||||
>
|
||||
> Not to mention that the option -d and option -L in the above command stands for ‘documents‘ and ‘License‘, respectively.
|
||||
|
||||
### 7. You came across a configuration file located at ‘/usr/share/alsa/cards/AACI.conf’ and you are not sure this configuration file is associated with what package. How will you find out the parent package name? ###
|
||||
|
||||
> **Answer** : When a package is installed, the relevant information gets stored in the database. So it is easy to trace what provides the above package using option -qf (-f query packages owning files).
|
||||
>
|
||||
> # rpm -qf /usr/share/alsa/cards/AACI.conf
|
||||
> alsa-lib-1.0.28-2.el7.x86_64
|
||||
>
|
||||
> Similarly we can find (what provides) information about any sub-packge, document files and License files.
|
||||
|
||||
### 8. How will you find list of recently installed software’s using rpm? ###
|
||||
|
||||
> **Answer** : As said earlier, everything being installed is logged in database. So it is not difficult to query the rpm database and find the list of recently installed software’s.
|
||||
>
|
||||
> We can do this by running the below commands using option –last (prints the most recent installed software’s).
|
||||
>
|
||||
> # rpm -qa --last
|
||||
>
|
||||
> The above command will print all the packages installed in a order such that, the last installed software appears at the top.
|
||||
>
|
||||
> If our concern is to find out specific package, we can grep that package (say sqlite) from the list, simply as:
|
||||
>
|
||||
> # rpm -qa --last | grep -i sqlite
|
||||
>
|
||||
> sqlite-3.8.10.2-1.fc22.x86_64 Thursday 18 June 2015 05:05:43 PM IST
|
||||
>
|
||||
> We can also get a list of 10 most recently installed software simply as:
|
||||
>
|
||||
> # rpm -qa --last | head
|
||||
>
|
||||
> We can refine the result to output a more custom result simply as:
|
||||
>
|
||||
> # rpm -qa --last | head -n 2
|
||||
>
|
||||
> In the above command -n represents number followed by a numeric value. The above command prints a list of 2 most recent installed software.
|
||||
|
||||
### 9. Before installing a package, you are supposed to check its dependencies. What will you do? ###
|
||||
|
||||
> **Answer** : To check the dependencies of a rpm package (XYZ.rpm), we can use switches -q (query package), -p (query a package file) and -R (Requires / List packages on which this package depends i.e., dependencies).
|
||||
>
|
||||
> # rpm -qpR gedit-3.16.1-1.fc22.i686.rpm
|
||||
>
|
||||
> /bin/sh
|
||||
> /usr/bin/env
|
||||
> glib2(x86-32) >= 2.40.0
|
||||
> gsettings-desktop-schemas
|
||||
> gtk3(x86-32) >= 3.16
|
||||
> gtksourceview3(x86-32) >= 3.16
|
||||
> gvfs
|
||||
> libX11.so.6
|
||||
> ...
|
||||
|
||||
### 10. Is rpm a front-end Package Management Tool? ###
|
||||
|
||||
> **Answer** : No! rpm is a back-end package management for RPM based Linux Distribution.
|
||||
>
|
||||
> [YUM][1] which stands for Yellowdog Updater Modified is the front-end for rpm. YUM automates the overall process of resolving dependencies and everything else.
|
||||
>
|
||||
> Very recently [DNF][2] (Dandified YUM) replaced YUM in Fedora 22. Though YUM is still available to be used in RHEL and CentOS, we can install dnf and use it alongside of YUM. DNF is said to have a lots of improvement over YUM.
|
||||
>
|
||||
> Good to know, you keep yourself updated. Lets move to the front-end part.
|
||||
|
||||
### 11. How will you list all the enabled repolist on a system. ###
|
||||
|
||||
> **Answer** : We can list all the enabled repos on a system simply using following commands.
|
||||
>
|
||||
> # yum repolist
|
||||
> or
|
||||
> # dnf repolist
|
||||
>
|
||||
> Last metadata expiration check performed 0:30:03 ago on Mon Jun 22 16:50:00 2015.
|
||||
> repo id repo name status
|
||||
> *fedora Fedora 22 - x86_64 44,762
|
||||
> ozonos Repository for Ozon OS 61
|
||||
> *updates Fedora 22 - x86_64 - Updates
|
||||
>
|
||||
> The above command will only list those repos that are enabled. If we need to list all the repos, enabled or not, we can do.
|
||||
>
|
||||
> # yum repolist all
|
||||
> or
|
||||
> # dnf repolist all
|
||||
>
|
||||
> Last metadata expiration check performed 0:29:45 ago on Mon Jun 22 16:50:00 2015.
|
||||
> repo id repo name status
|
||||
> *fedora Fedora 22 - x86_64 enabled: 44,762
|
||||
> fedora-debuginfo Fedora 22 - x86_64 - Debug disabled
|
||||
> fedora-source Fedora 22 - Source disabled
|
||||
> ozonos Repository for Ozon OS enabled: 61
|
||||
> *updates Fedora 22 - x86_64 - Updates enabled: 5,018
|
||||
> updates-debuginfo Fedora 22 - x86_64 - Updates - Debug
|
||||
|
||||
### 12. How will you list all the available and installed packages on a system? ###
|
||||
|
||||
> **Answer** : To list all the available packages on a system, we can do:
|
||||
>
|
||||
> # yum list available
|
||||
> or
|
||||
> # dnf list available
|
||||
>
|
||||
> ast metadata expiration check performed 0:34:09 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Available Packages
|
||||
> 0ad.x86_64 0.0.18-1.fc22 fedora
|
||||
> 0ad-data.noarch 0.0.18-1.fc22 fedora
|
||||
> 0install.x86_64 2.6.1-2.fc21 fedora
|
||||
> 0xFFFF.x86_64 0.3.9-11.fc22 fedora
|
||||
> 2048-cli.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
> 2048-cli-nocurses.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
> ....
|
||||
>
|
||||
> To list all the installed Packages on a system, we can do.
|
||||
>
|
||||
> # yum list installed
|
||||
> or
|
||||
> # dnf list installed
|
||||
>
|
||||
> Last metadata expiration check performed 0:34:30 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Installed Packages
|
||||
> GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
> GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
> NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
> NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
> aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
> ....
|
||||
>
|
||||
> To list all the available and installed packages on a system, we can do.
|
||||
>
|
||||
> # yum list
|
||||
> or
|
||||
> # dnf list
|
||||
>
|
||||
> Last metadata expiration check performed 0:32:56 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Installed Packages
|
||||
> GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
> GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
> NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
> NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
> aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
> acl.x86_64 2.2.52-7.fc22 @System
|
||||
> ....
|
||||
|
||||
### 13. How will you install and update a package and a group of packages separately on a system using YUM/DNF? ###
|
||||
|
||||
> Answer : To Install a package (say nano), we can do,
|
||||
>
|
||||
> # yum install nano
|
||||
>
|
||||
> To Install a Group of Package (say Haskell), we can do.
|
||||
>
|
||||
> # yum groupinstall 'haskell'
|
||||
>
|
||||
> To update a package (say nano), we can do.
|
||||
>
|
||||
> # yum update nano
|
||||
>
|
||||
> To update a Group of Package (say Haskell), we can do.
|
||||
>
|
||||
> # yum groupupdate 'haskell'
|
||||
|
||||
### 14. How will you SYNC all the installed packages on a system to stable release? ###
|
||||
|
||||
> **Answer** : We can sync all the packages on a system (say CentOS or Fedora) to stable release as,
|
||||
>
|
||||
> # yum distro-sync [On CentOS/RHEL]
|
||||
> or
|
||||
> # dnf distro-sync [On Fedora 20 Onwards]
|
||||
|
||||
Seems you have done a good homework before coming for the interview,Good!. Before proceeding further I just want to ask one more question.
|
||||
|
||||
### 15. Are you familiar with YUM local repository? Have you tried making a Local YUM repository? Let me know in brief what you will do to create a local YUM repo. ###
|
||||
|
||||
> **Answer** : First I would like to Thank you Sir for appreciation. Coming to question, I must admit that I am quiet familiar with Local YUM repositories and I have already implemented it for testing purpose in my local machine.
|
||||
>
|
||||
> 1. To set up Local YUM repository, we need to install the below three packages as:
|
||||
>
|
||||
> # yum install deltarpm python-deltarpm createrepo
|
||||
>
|
||||
> 2. Create a directory (say /home/$USER/rpm) and copy all the RPMs from RedHat/CentOS DVD to that folder.
|
||||
>
|
||||
> # mkdir /home/$USER/rpm
|
||||
> # cp /path/to/rpm/on/DVD/*.rpm /home/$USER/rpm
|
||||
>
|
||||
> 3. Create base repository headers as.
|
||||
>
|
||||
> # createrepo -v /home/$USER/rpm
|
||||
>
|
||||
> 4. Create the .repo file (say abc.repo) at the location /etc/yum.repos.d simply as:
|
||||
>
|
||||
> cd /etc/yum.repos.d && cat << EOF > abc.repo
|
||||
> [local-installation]name=yum-local
|
||||
> baseurl=file:///home/$USER/rpm
|
||||
> enabled=1
|
||||
> gpgcheck=0
|
||||
> EOF
|
||||
|
||||
**Important**: Make sure to remove $USER with user_name.
|
||||
|
||||
That’s all we need to do to create a Local YUM repository. We can now install applications from here, that is relatively fast, secure and most important don’t need an Internet connection.
|
||||
|
||||
Okay! It was nice interviewing you. I am done. I am going to suggest your name to HR. You are a young and brilliant candidate we would like to have in our organization. If you have any question you may ask me.
|
||||
|
||||
**Me**: Sir, it was really a very nice interview and I feel very lucky today, to have cracked the interview..
|
||||
|
||||
Obviously it didn’t end here. I asked a lots of questions like the project they are handling. What would be my role and responsibility and blah..blah..blah
|
||||
|
||||
Friends, by the time all these were documented I have been called for HR round which is 3 days from now. Hope I do my best there as well. All your blessings will count.
|
||||
|
||||
Thankyou friends and Tecmint for taking time and documenting my experience. Mates I believe Tecmint is doing some really extra-ordinary which must be praised. When we share ours experience with other, other get to know many things from us and we get to know our mistakes.
|
||||
|
||||
It enhances our confidence level. If you have given any such interview recently, don’t keep it to yourself. Spread it! Let all of us know that. You may use the below form to share your experience with us.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-rpm-package-management-interview-questions/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
@ -0,0 +1,125 @@
|
||||
How to Provision Swarm Clusters using Docker Machine
|
||||
================================================================================
|
||||
Hi all, today we'll learn how we can deploy Swarm Clusters using Docker Machine. It serves the standard Docker API, so any tool which can communicate with a Docker daemon can use Swarm to transparently scale to multiple hosts. Docker Machine is an application that helps to create Docker hosts on our computer, on cloud providers and inside our own data center. It provides easy solution for creating servers, installing Docker on them and then configuring the Docker client according the users configuration and requirements. We can provision swarm clusters with any driver we need and is highly secured with TLS Encryption.
|
||||
|
||||
Here are some quick and easy steps on how to provision swarm clusters with Docker Machine.
|
||||
|
||||
### 1. Installing Docker Machine ###
|
||||
|
||||
Docker Machine supports awesome on every Linux Operating System. First of all, we'll need to download the latest version of Docker Machine from the Github site . Here, we'll use curl to download the latest version of Docker Machine ie 0.2.0 .
|
||||
|
||||
For 64 Bit Operating System
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-amd64 > /usr/local/bin/docker-machine
|
||||
|
||||
For 32 Bit Operating System
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-i386 > /usr/local/bin/docker-machine
|
||||
|
||||
After downloading the latest release of Docker Machine, we'll make the file named docker-machine under /usr/local/bin/ executable using the command below.
|
||||
|
||||
# chmod +x /usr/local/bin/docker-machine
|
||||
|
||||
After doing the above, we'll wanna ensure that we have successfully installed docker-machine. To check it, we can run the docker-machine -v which will give output of the version of docker-machine installed in our system.
|
||||
|
||||
# docker-machine -v
|
||||
|
||||

|
||||
|
||||
To enable Docker commands on our machines, make sure to install the Docker client as well by running the command below.
|
||||
|
||||
# curl -L https://get.docker.com/builds/linux/x86_64/docker-latest > /usr/local/bin/docker
|
||||
# chmod +x /usr/local/bin/docker
|
||||
|
||||
### 2. Creating Machine ###
|
||||
|
||||
After installing Machine into our working PC or device, we'll wanna go forward to create a machine using Docker Machine. Here, in this tutorial we'll gonna deploy a machine in the Digital Ocean Platform so we'll gonna use "digitalocean" as its Driver API then, docker swarm will be running into that Droplet which will be further configured as Swarm Master and another droplet will be created which will be configured as Swarm Node Agent.
|
||||
|
||||
So, to create the machine, we'll need to run the following command.
|
||||
|
||||
# docker-machine create --driver digitalocean --digitalocean-access-token <API-Token> linux-dev
|
||||
|
||||
**Note**: Here, linux-dev is the name of the machine we are wanting to create. <API-Token> is a security key which can be generated from the Digital Ocean Control Panel of the account holder of Digital Ocean Cloud Platform. To retrieve that key, we simply need to login to our Digital Ocean Control Panel then click on API, then click on Generate New Token and give it a name tick on both Read and Write. Then we'll get a long hex key, thats the <API-Token> now, simply replace it into the command above.
|
||||
|
||||
Now, to load the Machine configuration into the shell we are running the comamands, run the following command.
|
||||
|
||||
# eval "$(docker-machine env linux-dev)"
|
||||
|
||||

|
||||
|
||||
Then, we'll mark our machine as ACTIVE by running the below command.
|
||||
|
||||
# docker-machine active linux-dev
|
||||
|
||||
Now, we'll check whether its been marked as ACTIVE "*" or not.
|
||||
|
||||
# docker-machine ls
|
||||
|
||||

|
||||
|
||||
### 3. Running Swarm Docker Image ###
|
||||
|
||||
Now, after we finish creating the required machine. We'll gonna deploy swarm docker image in our active machine. This machine will run the docker image and will control over the Swarm master and node. To run the image, we can simply run the below command.
|
||||
|
||||
# docker run swarm create
|
||||
|
||||

|
||||
|
||||
If you are trying to run swarm docker image using **32 bit Operating System** in the computer where Docker Machine is running, we'll need to SSH into the Droplet.
|
||||
|
||||
# docker-machine ssh
|
||||
#docker run swarm create
|
||||
#exit
|
||||
|
||||
### 4. Creating Swarm Master ###
|
||||
|
||||
Now, after our machine and swarm image is running into the machine, we'll now create a Swarm Master. This will also add the master as a node. To do so, here's the command below.
|
||||
|
||||
# docker-machine create \
|
||||
-d digitalocean \
|
||||
--digitalocean-access-token <DIGITALOCEAN-TOKEN>
|
||||
--swarm \
|
||||
--swarm-master \
|
||||
--swarm-discovery token://<CLUSTER-ID> \
|
||||
swarm-master
|
||||
|
||||

|
||||
|
||||
### 5. Creating Swarm Nodes ###
|
||||
|
||||
Now, we'll create a swarm node which will get connected with the Swarm Master. The command below will create a new droplet which will be named as swarm-node and will get connected with the Swarm Master as node. This will create a Swarm cluster across the two nodes.
|
||||
|
||||
# docker-machine create \
|
||||
-d digitalocean \
|
||||
--digitalocean-access-token <DIGITALOCEAN-TOKEN>
|
||||
--swarm \
|
||||
--swarm-discovery token://<TOKEN-FROM-ABOVE> \
|
||||
swarm-node
|
||||
|
||||

|
||||
|
||||
### 6. Connecting to the Swarm Master ###
|
||||
|
||||
We, now connect to the Swarm Master so that we can deploy Docker containers across the nodes as per the requirement and configuration. To load the Swarm Master's Machine configuration into our environment, we can run the below command.
|
||||
|
||||
# eval "$(docker-machine env --swarm swarm-master)"
|
||||
|
||||
After that, we can run the required containers of our choice across the nodes. Here, we'll check if everything went fine or not. So, we'll run **docker info** to check the information about the Swarm Clusters.
|
||||
|
||||
# docker info
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
We can pretty easily create Swarm Cluster with Docker Machine. This method is a lot productive because it reduces a lot of time of a system admin or users. In this article, we successfully provisioned clusters by creating a master and a node using a machine with Digital Ocean as driver. It can be created using any driver like VirtualBox, Google Cloud Computing, Amazon Web Service, Microsoft Azure and more according to the need and requirement of the user and the connection is highly secured with TLS Encryption. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you ! Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/provision-swarm-clusters-using-docker-machine/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -0,0 +1,307 @@
|
||||
translation by strugglingyouth
|
||||
|
||||
15 Useful MySQL/MariaDB Performance Tuning and Optimization Tips
|
||||
================================================================================
|
||||
MySQL is a powerful open source Relational Database Management System or in short RDBMS. It was released back in 1995 (20 years old). It uses Structured Query Language which is probably the most popular choice for managing content within a database. The latest MySQL version is 5.6.25 and was released on 29 May 2015.
|
||||
|
||||
An interesting fact about MySQL is the fact that the name comes from Michael Widenius’s (MySQL’s creator) daughter My. Even though there are plenty of interesting facts about MySQL, this article is meant to show you some useful practices to help you manage your MySQL server.
|
||||
|
||||

|
||||
|
||||
MySQL Performance Tuning
|
||||
|
||||
In April 2009 the MySQL project was bought by Oracle. As a result a MySQL community fork called MariaDB was created. The main reason for creating the fork was to keep the project free under the General Public License.
|
||||
|
||||
Today MySQL and MariaDB are one of the most (if not the most) frequently used RDBMS used for web applications such as WordPress, Joomla, Magento and others.
|
||||
|
||||
This article will show you some basic, yet useful tips how to optimize the fine tune the performance of MySQL/MariaDB. Please keep in mind that this article assumes that you already have MySQL or MariaDB installed. If you are still wondering how to install them on your system, you can follow our extensive guides here:
|
||||
|
||||
- [Installing LAMP on RHEL/CentOS 7][1]
|
||||
- [Installing LAMP on Fedora 22][2]
|
||||
- [Setting Up LAMP on Ubuntu 15.04][3]
|
||||
- [Installing MariaDB on Debian 8][4]
|
||||
- [Install MariaDB on Gentoo Linux][5]
|
||||
- [Install MariaDB on Arch Linux][6]
|
||||
|
||||
**Important**: Before we start – do not accept this suggestions blindly. Each MySQL setup is unique and requires additional thought, before making any changes.
|
||||
|
||||
Things you need to know:
|
||||
|
||||
- MySQL/MariaDB configuration file is located in `/etc/my.cnf`. Every time you modify this file you will need to restart the MySQL service so the new changes can take effect.
|
||||
- For writing this article MySQL version 5.6 has been used as template.
|
||||
|
||||
### 1. Enable InnoDB file-per-table ###
|
||||
|
||||
First it is important to explain that InnoDB is a storage engine. MySQL and MariaDB use InnoDB as default storage engine. In the past MySQL used to keep database tables and indexes in a system tablespace. This approach was meant for servers which sole purpose is database processing and their storage disk is not used for any other purposes.
|
||||
|
||||
The InnoDB provides more flexible approach and each database information is kept in a `.ibd` data file. Each .ibd file represents a tablespace of its own. That way database operations such as “TRUNCATE” can be completed faster and you may also reclaim unused space when dropping or truncating a database table.
|
||||
|
||||
Another benefit of this configuration is the fact that you can keep some of the database tables in a separate storage device. This can greatly improve the I/O load on your disks.
|
||||
|
||||
The innodb_file_per_table is enabled by default in MySQL 5.6 and above. You can see that in /etc/my.cnf file. The directive looks like this:
|
||||
|
||||
innodb_file_per_table=1
|
||||
|
||||
### 2. Store MySQL Database Data on Separate Partition ###
|
||||
|
||||
**Note**: This setup only works with MySQL, but not with MariaDB.
|
||||
|
||||
Sometimes OS read/writes can slow down the performance of your MySQL server, especially if located on same hard drive. Instead, I would recommend using separate hard drive (preferably SSD) for the MySQL service.
|
||||
|
||||
To complete, this you will need to attach the new drive to your computer/server. For the purpose of this article, I will assume that the drive will be under /dev/sdb.
|
||||
|
||||
The next step is to prepare the new drive:
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
Now press “n” to create new partition. Next press “p” to make the new partition primary. After that, set the partition number from 1-4. After that you will select the partition size. Press enter here. On the next step you will need to configure the size of the partition.
|
||||
|
||||
If you wish to use the entire disk press enter once more. Otherwise you can manually set the size of the new partition. When ready press “w” to write the changes. Now we will need to create a filesystem for our new partition. This can be easily done with:
|
||||
|
||||
# mkfs.ext4 /dev/sdb1
|
||||
|
||||
Now we will mount our new partition in a folder. I have named my folder “ssd” and created in the root directory:
|
||||
|
||||
# mkdir /ssd/
|
||||
|
||||
We are ready to mount the new partition we just made in the new folder:
|
||||
|
||||
# mount /dev/sdb1 /ssd/
|
||||
|
||||
You can perform the mount at startup by adding the following line in /etc/fstab file.
|
||||
|
||||
/dev/sdb1 /ssd ext3 defaults 0 0
|
||||
|
||||
Now you are ready to move MySQL to the new disk. First stop the MySQL service with:
|
||||
|
||||
# service mysqld stop
|
||||
|
||||
I would recommend you stopping Apache/nginx as well to prevent any attempts to write in the databases:
|
||||
|
||||
# service httpd stop
|
||||
# service nginx stop
|
||||
|
||||
Now copy the entire MySQL directory in the new drive:
|
||||
|
||||
# cp /var/lib/mysql /ssd/ -Rp
|
||||
|
||||
This may take a while depending on the site of your MySQL databases. Once this process is complete rename the MySQL directory:
|
||||
|
||||
# mv /var/lib/mysql /var/lib/mysql-backup
|
||||
|
||||
Next we will create a symlink.
|
||||
|
||||
# ln -s /ssd/mysql /var/lib/mysql
|
||||
|
||||
Now you are ready to start your MySQL and web service:
|
||||
|
||||
# service mysqld start
|
||||
# service httpd start
|
||||
# service nginx start
|
||||
|
||||
At this point your MySQL databases will be accessed from the new drive.
|
||||
|
||||
### 3. Optimizing InnoDB buffer pool Usage ###
|
||||
|
||||
The InnoDB engine has a buffer pool used for caching data and indexes in memory. This of course will help your MySQL/MariaDB queries be executed significantly faster. Choosing the proper size here requires some very important decisions and good knowledge on your system’s memory consumption.
|
||||
|
||||
Here is what you need to consider:
|
||||
|
||||
- How much memory you need for other processes. This includes your system processes, page tables, socket buffers.
|
||||
- Is your server dedicated for MySQL or you will be running other memory hungry services.
|
||||
|
||||
On a dedicated box, you would probably want to give about 60-70% of the memory to the innodb_buffer_pool_size. If you plan on running more services on a single box, you should re-consider the amount of memory you dedicate for your innodb_buffer_pool_size.
|
||||
|
||||
The value that you should edit in my.cnf is:
|
||||
|
||||
innodb_buffer_pool_size
|
||||
|
||||
### 4. Avoid Swappiness in MySQL ###
|
||||
|
||||
Swapping is process that occurs when system moves part of memory to a special disk space called “swap”. The event usually appears when your system runs out of physical memory and instead of freeing up some RAM, the system pushed the information into disk. As you might have guess the disk is much slower than your RAM.
|
||||
|
||||
By default the option is enabled:
|
||||
|
||||
# sysctl vm.swappiness
|
||||
|
||||
vm.swappiness = 60
|
||||
|
||||
To disable swappiness, run the following command:
|
||||
|
||||
# sysctl -w vm.swappiness=0
|
||||
|
||||
### 5. Set MySQL Max Connections ###
|
||||
|
||||
The max_connections directive tells your server how many concurrent connections are permitted. The MySQL/MariaDB server allows the value given in max_connections + 1 for user with SUPER privileges. The connection is opened only for the time MySQL query is executed – after that it is closed and new connection can take its place.
|
||||
|
||||
Keep in mind that too many connections can cause high RAM usage and lock up your MySQL server. Usually small websites will require between 100-200 connections while larger may require 500-800 or even more. The value you apply here strongly depends on your particular MySQL/MariaDB usage.
|
||||
|
||||
You can dynamically change the value of `max_connections`, without having to restart the MySQL service by running:
|
||||
|
||||
# mysql -u root -p
|
||||
mysql> set global max_connections := 300;
|
||||
|
||||
### 6. Configure MySQL thread_cache_size ###
|
||||
|
||||
The `thread_cache_size` directive sets the amount of threads that your server should cache. As the client disconnects, his threads are put in the cache if they are less than the thread_cache_size. Further requests are completed by using the threads stored in the cache.
|
||||
|
||||
To improve your performance you can set the thread_cache_size to a relatively high number. To find the thread cache hit rate, you can use the following technique:
|
||||
|
||||
mysql> show status like 'Threads_created';
|
||||
mysql> show status like 'Connections';
|
||||
|
||||
Now use the following formula to calculate the thread cache hit rate percentage:
|
||||
|
||||
100 - ((Threads_created / Connections) * 100)
|
||||
|
||||
If you get a low number, it means that most of the new mysql connections are starting new thread instead of loading from cache. You will surely want to increase the thread_cache_size in such cases.
|
||||
|
||||
The good thing here is that the thread_cache_size can be dynamically changed without having to restart the MySQL service. You can achieve this by running:
|
||||
|
||||
mysql> set global thread_cache_size = 16;
|
||||
|
||||
### 7. Disable MySQL Reverse DNS Lookups ###
|
||||
|
||||
By default MySQL/MariaDB perform a DNS lookup of the user’s IP address/Hostname from which the connection is coming. For each client connection, the IP address is checked by resolving it to a host name. After that the host name is resolved back to an IP to verify that both match.
|
||||
|
||||
This unfortunately may cause delays in case of badly configured DNS or problems with DNS server. This is why you can disable the reverse DNS lookup by adding the following in your configuration file:
|
||||
|
||||
[mysqld]
|
||||
# Skip reverse DNS lookup of clients
|
||||
skip-name-resolve
|
||||
|
||||
You will have to restart the MySQL service after applying these changes.
|
||||
|
||||
### 8. Configure MySQL query_cache_size ###
|
||||
|
||||
If you have many repetitive queries and your data does not change often – use query cache. People often do not understand the concept behind the `query_cache_size` and set this value to gigabytes, which can actually cause degradation in the performance.
|
||||
|
||||
The reason behind that is the fact that threads need to lock the cache during updates. Usually value of 200-300 MB should be more than enough. If your website is relatively small, you can try giving the value of 64M and increase in time.
|
||||
|
||||
You will have to add the following settings in the MySQL configuration file:
|
||||
|
||||
query_cache_type = 1
|
||||
query_cache_limit = 256K
|
||||
query_cache_min_res_unit = 2k
|
||||
query_cache_size = 80M
|
||||
|
||||
### 9. Configure tmp_table_size and max_heap_table_size ###
|
||||
|
||||
Both directives should have the same size and will help you prevent disk writes. The `tmp_table_size` is the maximum amount of size of internal in-memory tables. In case the limit in question is exceeded the table will be converted to on-disk MyISAM table.
|
||||
|
||||
This will affect the database performance. Administrators usually recommend giving 64M for both values for every GB of RAM on the server.
|
||||
|
||||
[mysqld]
|
||||
tmp_table_size= 64M
|
||||
max_heap_table_size= 64M
|
||||
|
||||
### 10. Enable MySQL Slow query Logs ###
|
||||
|
||||
Logging slow queries can help you determine issues with your database and help you debug them. This can be easily enabled by adding the following values in your MySQL configuration file:
|
||||
|
||||
slow-query-log = 1
|
||||
slow-query-log-file = /var/lib/mysql/mysql-slow.log
|
||||
long_query_time = 1
|
||||
|
||||
The first directive enables the logging of slow queries, while the second one tells MySQL where to store the actual log file. Use `long_query_time` to define the amount of time that is considered long for MySQL query to be completed.
|
||||
|
||||
### 11. Check for MySQL idle Connections ###
|
||||
|
||||
Idle connections consume resources and should be interrupted or refreshed when possible. Such connections are in “sleep” state and usually stay that way for long period of time. To look for idled connections you can run the following command:
|
||||
|
||||
# mysqladmin processlist -u root -p | grep “Sleep”
|
||||
|
||||
This will show you list of processes that are in sleep state. The event appears when the code is using persistent connection to the database. When using PHP this event can appear when using mysql_pconnect which opens the connection, after that executes queries, removes the authentication and leaves the connection open. This will cause any per-thread buffers to be kept in memory until the thread dies.
|
||||
|
||||
The first thing you would do here is to check the code and fix it. If you don’t have access to the code that is being ran, you can change the `wait_timeout` directive. The default value is 28800 seconds, while you can safely decrease it to something like 60:
|
||||
|
||||
wait_timeout=60
|
||||
|
||||
### 12. Choosing Right MySQL Filesystem ###
|
||||
|
||||
Choosing the right filesystem is vital for your databases. Most important things you need to consider here are – data integrity, performance and ease of administration.
|
||||
|
||||
As per MariaDB’s recommendations, the best file systems are XFS, Ext4 and Btrfs. All of them are enterprise journaling filesystems that can be used with very large files and large storage volumes.
|
||||
|
||||
Below you can find some useful information about the three filesystems:
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="179"></colgroup>
|
||||
<colgroup width="85" span="3"></colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="center" height="18" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial;">Filesystems</span></b></td>
|
||||
<td align="center" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial;">XFS</span></b></td>
|
||||
<td align="center" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial;">Ext4</span></b></td>
|
||||
<td align="center" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial;">Btrfs</span></b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="center" height="18" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Maximum filesystem size</span></td>
|
||||
<td align="center" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">8EB</span></td>
|
||||
<td align="center" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">1EB</span></td>
|
||||
<td align="center" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">16EB</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center" height="18" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Maximum file size</span></td>
|
||||
<td align="center" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">8EB</span></td>
|
||||
<td align="center" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">16TB</span></td>
|
||||
<td align="center" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">16EB</span></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
The pros and cons of the Linux filesystems have been extensively covered in our article:
|
||||
|
||||
- [Linux Filesystem Explained][7]
|
||||
|
||||
### 13. Set MySQL max_allowed_packet ###
|
||||
|
||||
MySQL splits data into packets. Usually a single packet is considered a row that is sent to a client. The `max_allowed_packet` directive defines the maximum size of packet that can be sent.
|
||||
|
||||
Setting this value too low can cause a query to stall and you will receive an error in your MySQL error log. It is recommended to set the value to the size of your largest packet.
|
||||
|
||||
### 14. Check MySQL Performance Tuning ###
|
||||
|
||||
Measuring your MySQL/MariaDB performance is something that you should do on regular basis. This will help you see if something in the resource usage changes or needs to be improved.
|
||||
|
||||
There are plenty of tools available for benchmarking, but I would like to suggest you one that is simple and easy to use. The tool is called mysqltuner.
|
||||
|
||||
To download and run it, use the following set of commands:
|
||||
|
||||
# wget https://github.com/major/MySQLTuner-perl/tarball/master
|
||||
# tar xf master
|
||||
# cd major-MySQLTuner-perl-993bc18/
|
||||
# ./mysqltuner.pl
|
||||
|
||||
You will receive a detailed report about your MySQL usage and recommendation tips. Here is a sample output of default MariaDB installation:
|
||||
|
||||

|
||||
|
||||
### 15. Optimize and Repair MySQL Databases ###
|
||||
|
||||
Sometimes MySQL/MariaDB database tables get crashed quite easily, especially when unexpected server shut down, sudden file system corruption or during copy operation, when database is still accessed. Surprisingly, there is a free open source tool called ‘mysqlcheck‘, which automatically check, repair and optimize databases of all tables in Linux.
|
||||
|
||||
# mysqlcheck -u root -p --auto-repair --check --optimize --all-databases
|
||||
# mysqlcheck -u root -p --auto-repair --check --optimize databasename
|
||||
|
||||
That’s it! I hope you have found the above article useful and help you tune up your MySQL server. As always if you have any further questions or comments, please submit them in the comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/mysql-mariadb-performance-tuning-and-optimization/
|
||||
|
||||
作者:[Marin Todorov][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/marintodorov89/
|
||||
[1]:http://www.tecmint.com/install-lamp-in-centos-7/
|
||||
[2]:http://www.tecmint.com/install-lamp-linux-apache-mysql-php-on-fedora-22/
|
||||
[3]:http://www.tecmint.com/install-lamp-on-ubuntu-15-04/
|
||||
[4]:http://www.tecmint.com/install-mariadb-in-debian/
|
||||
[5]:http://www.tecmint.com/install-lemp-in-gentoo-linux/
|
||||
[6]:http://www.tecmint.com/install-lamp-in-arch-linux/
|
||||
[7]:http://www.tecmint.com/linux-file-system-explained/
|
||||
@ -0,0 +1,188 @@
|
||||
RHCSA Series: Essentials of Virtualization and Guest Administration with KVM – Part 15
|
||||
================================================================================
|
||||
If you look up the word virtualize in a dictionary, you will find that it means “to create a virtual (rather than actual) version of something”. In computing, the term virtualization refers to the possibility of running multiple operating systems simultaneously and isolated one from another, on top of the same physical (hardware) system, known in the virtualization schema as host.
|
||||
|
||||

|
||||
|
||||
RHCSA Series: Essentials of Virtualization and Guest Administration with KVM – Part 15
|
||||
|
||||
Through the use of the virtual machine monitor (also known as hypervisor), virtual machines (referred to as guests) are provided virtual resources (i.e. CPU, RAM, storage, network interfaces, to name a few) from the underlying hardware.
|
||||
|
||||
With that in mind, it is plain to see that one of the main advantages of virtualization is cost savings (in equipment and network infrastructure and in terms of maintenance effort) and a substantial reduction in the physical space required to accommodate all the necessary hardware.
|
||||
|
||||
Since this brief how-to cannot cover all virtualization methods, I encourage you to refer to the documentation listed in the summary for further details on the subject.
|
||||
|
||||
Please keep in mind that the present article is intended to be a starting point to learn the basics of virtualization in RHEL 7 using [KVM][1] (Kernel-based Virtual Machine) with command-line utilities, and not an in-depth discussion of the topic.
|
||||
|
||||
### Verifying Hardware Requirements and Installing Packages ###
|
||||
|
||||
In order to set up virtualization, your CPU must support it. You can verify whether your system meets the requirements with the following command:
|
||||
|
||||
# grep -E 'svm|vmx' /proc/cpuinfo
|
||||
|
||||
In the following screenshot we can see that the current system (with an AMD microprocessor) supports virtualization, as indicated by svm. If we had an Intel-based processor, we would see vmx instead in the results of the above command.
|
||||
|
||||

|
||||
|
||||
Check KVM Support
|
||||
|
||||
In addition, you will need to have virtualization capabilities enabled in the firmware of your host (BIOS or UEFI).
|
||||
|
||||
Now install the necessary packages:
|
||||
|
||||
- qemu-kvm is an open source virtualizer that provides hardware emulation for the KVM hypervisor whereas qemu-img provides a command line tool for manipulating disk images.
|
||||
- libvirt includes the tools to interact with the virtualization capabilities of the operating system.
|
||||
- libvirt-python contains a module that permits applications written in Python to use the interface supplied by libvirt.
|
||||
- libguestfs-tools: miscellaneous system administrator command line tools for virtual machines.
|
||||
- virt-install: other command-line utilities for virtual machine administration.
|
||||
|
||||
# yum update && yum install qemu-kvm qemu-img libvirt libvirt-python libguestfs-tools virt-install
|
||||
|
||||
Once the installation completes, make sure you start and enable the libvirtd service:
|
||||
|
||||
# systemctl start libvirtd.service
|
||||
# systemctl enable libvirtd.service
|
||||
|
||||
By default, each virtual machine will only be able to communicate with the rest in the same physical server and with the host itself. To allow the guests to reach other machines inside our LAN and also the Internet, we need to set up a bridge interface in our host (say br0, for example) by,
|
||||
|
||||
1. adding the following line to our main NIC configuration (most likely `/etc/sysconfig/network-scripts/ifcfg-enp0s3`):
|
||||
|
||||
BRIDGE=br0
|
||||
|
||||
2. creating the configuration file for br0 (/etc/sysconfig/network-scripts/ifcfg-br0) with these contents (note that you may have to change the IP address, gateway address, and DNS information):
|
||||
|
||||
DEVICE=br0
|
||||
TYPE=Bridge
|
||||
BOOTPROTO=static
|
||||
IPADDR=192.168.0.18
|
||||
NETMASK=255.255.255.0
|
||||
GATEWAY=192.168.0.1
|
||||
NM_CONTROLLED=no
|
||||
DEFROUTE=yes
|
||||
PEERDNS=yes
|
||||
PEERROUTES=yes
|
||||
IPV4_FAILURE_FATAL=no
|
||||
IPV6INIT=yes
|
||||
IPV6_AUTOCONF=yes
|
||||
IPV6_DEFROUTE=yes
|
||||
IPV6_PEERDNS=yes
|
||||
IPV6_PEERROUTES=yes
|
||||
IPV6_FAILURE_FATAL=no
|
||||
NAME=br0
|
||||
ONBOOT=yes
|
||||
DNS1=8.8.8.8
|
||||
DNS2=8.8.4.4
|
||||
|
||||
3. finally, enabling packet forwarding by making, in `/etc/sysctl.conf`,
|
||||
|
||||
net.ipv4.ip_forward = 1
|
||||
|
||||
and loading the changes to the current kernel configuration:
|
||||
|
||||
# sysctl -p
|
||||
|
||||
Note that you may also need to tell firewalld that this kind of traffic should be allowed. Remember that you can refer to the article on that topic in this same series ([Part 11: Network Traffic Control Using FirewallD and Iptables][2]) if you need help to do that.
|
||||
|
||||
### Creating VM Images ###
|
||||
|
||||
By default, VM images will be created to `/var/lib/libvirt/images` and you are strongly advised to not change this unless you really need to, know what you’re doing, and want to handle SELinux settings yourself (such topic is out of the scope of this tutorial but you can refer to Part 13 of the RHCSA series: [Mandatory Access Control Essentials with SELinux][3] if you want to refresh your memory).
|
||||
|
||||
This means that you need to make sure that you have allocated the necessary space in that filesystem to accommodate your virtual machines.
|
||||
|
||||
The following command will create a virtual machine named `tecmint-virt01` with 1 virtual CPU, 1 GB (=1024 MB) of RAM, and 20 GB of disk space (represented by `/var/lib/libvirt/images/tecmint-virt01.img`) using the rhel-server-7.0-x86_64-dvd.iso image located inside /home/gacanepa/ISOs as installation media and the br0 as network bridge:
|
||||
|
||||
# virt-install \
|
||||
--network bridge=br0
|
||||
--name tecmint-virt01 \
|
||||
--ram=1024 \
|
||||
--vcpus=1 \
|
||||
--disk path=/var/lib/libvirt/images/tecmint-virt01.img,size=20 \
|
||||
--graphics none \
|
||||
--cdrom /home/gacanepa/ISOs/rhel-server-7.0-x86_64-dvd.iso
|
||||
--extra-args="console=tty0 console=ttyS0,115200"
|
||||
|
||||
If the installation file was located in a HTTP server instead of an image stored in your disk, you will have to replace the –cdrom flag with –location and indicate the address of the online repository.
|
||||
|
||||
As for the –graphics none option, it tells the installer to perform the installation in text-mode exclusively. You can omit that flag if you are using a GUI interface and a VNC window to access the main VM console. Finally, with –extra-args we are passing kernel boot parameters to the installer that set up a serial VM console.
|
||||
|
||||
The installation should now proceed as a regular (real) server now. If not, please review the steps listed above.
|
||||
|
||||
### Managing Virtual Machines ###
|
||||
|
||||
These are some typical administration tasks that you, as a system administrator, will need to perform on your virtual machines. Note that all of the following commands need to be run from your host:
|
||||
|
||||
**1. List all VMs:**
|
||||
|
||||
# virsh list --all
|
||||
|
||||
From the output of the above command you will have to note the Id for the virtual machine (although it will also return its name and current status) because you will need it for most administration tasks related to a particular VM.
|
||||
|
||||
**2. Display information about a guest:**
|
||||
|
||||
# virsh dominfo [VM Id]
|
||||
|
||||
**3. Start, restart, or stop a guest operating system:**
|
||||
|
||||
# virsh start | reboot | shutdown [VM Id]
|
||||
|
||||
**4. Access a VM’s serial console if networking is not available and no X server is running on the host:**
|
||||
|
||||
# virsh console [VM Id]
|
||||
|
||||
**Note** that this will require that you add the serial console configuration information to the `/etc/grub.conf` file (refer to the argument passed to the –extra-args option when the VM was created).
|
||||
|
||||
**5. Modify assigned memory or virtual CPUs:**
|
||||
|
||||
First, shutdown the guest:
|
||||
|
||||
# virsh shutdown [VM Id]
|
||||
|
||||
Edit the VM configuration for RAM:
|
||||
|
||||
# virsh edit [VM Id]
|
||||
|
||||
Then modify
|
||||
|
||||
<memory>[Memory size here without brackets]</memory>
|
||||
|
||||
Restart the VM with the new settings:
|
||||
|
||||
# virsh create /etc/libvirt/qemu/tecmint-virt01.xml
|
||||
|
||||
Finally, change the memory dynamically:
|
||||
|
||||
# virsh setmem [VM Id] [Memory size here without brackets]
|
||||
|
||||
For CPU:
|
||||
|
||||
# virsh edit [VM Id]
|
||||
|
||||
Then modify
|
||||
|
||||
<cpu>[Number of CPUs here without brackets]</cpu>
|
||||
|
||||
For further commands and details, please refer to table 26.1 in Chapter 26 of the RHEL 5 Virtualization guide (that guide, though a bit old, includes an exhaustive list of virsh commands used for guest administration).
|
||||
|
||||
### SUMMARY ###
|
||||
|
||||
In this article we have covered some basic aspects of virtualization with KVM in RHEL 7, which is both a vast and a fascinating topic, and I hope it will be helpful as a starting guide for you to later explore more advanced subjects found in the official [RHEL virtualization][4] getting started and [deployment / administration guides][5].
|
||||
|
||||
In addition, you can refer to the preceding articles in [this KVM series][6] in order to clarify or expand some of the concepts explained here.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/kvm-virtualization-basics-and-guest-administration/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.linux-kvm.org/page/Main_Page
|
||||
[2]:http://www.tecmint.com/firewalld-vs-iptables-and-control-network-traffic-in-firewall/
|
||||
[3]:http://www.tecmint.com/selinux-essentials-and-control-filesystem-access/
|
||||
[4]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Virtualization_Getting_Started_Guide/index.html
|
||||
[5]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Virtualization_Deployment_and_Administration_Guide/index.html
|
||||
[6]:http://www.tecmint.com/install-and-configure-kvm-in-linux/
|
||||
@ -1,110 +0,0 @@
|
||||
什么是好的命令行HTTP客户端?
|
||||
==============================================================================
|
||||
整体大于各部分之和,这是引自希腊哲学家和科学家的亚里士多德的名言。这句话特别切中Linux。在我看来,Linux最强大的地方之一就是它的协作性。Linux的实用性并不仅仅源自大量的开源程序(命令行)。相反,其协作性来自于这些程序的综合利用,有时是结合更大型的应用。
|
||||
|
||||
Unix哲学引发了一场“软件工具”的运动,关注开发简洁,基础,干净,模块化和扩展性好的代码,并可以运用于其他的项目。这种哲学为许多的Linux项目留下了一个重要的元素。
|
||||
|
||||
好的开源开发者写程序为了确保该程序尽可能运行正确,同时能与其他程序很好地协作。目标就是使用者拥有一堆方便的工具,每一个力求干不止一件事。许多程序能独立工作得很好。
|
||||
|
||||
这篇文章讨论3个开源命令行HTTP客户端。这些客户端可以让你使用命令行从互联网上下载文件。但同时,他们也可以用于许多有意思的地方,如测试,调式和与HTTP服务器或网络应用互动。对于HTTP架构师和API设计人员来说,使用命令行操作HTTP是一个值得花时间学习的技能。如果你需要来回使用API,HTTPie和cURL,这没什么价值。
|
||||
|
||||
-------------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
HTTPie(发音 aych-tee-tee-pie)是一款开源命令行HTTP客户端。它是一个命令行界面,类cURL的工具。
|
||||
|
||||
该软件的目标是使得与网络服务器的交互尽可能的人性化。其提供了一个简单的http命令,允许使用简单且自然的语句发送任意的HTTP请求,并显示不同颜色的输出。HTTPie可以用于测试,调式和与HTTP服务器的一般交互。
|
||||
|
||||
#### 功能包括:####
|
||||
|
||||
- 可表达,直观的语句
|
||||
- 格式化,颜色区分的终端输出
|
||||
- 内建JSON支持
|
||||
- 表单和文件上传
|
||||
- HTTPS,代理和认证
|
||||
- 任意数据请求
|
||||
- 自定义标题 (此处header不确定是否特别意义)
|
||||
- 持久会话
|
||||
- 类Wget下载
|
||||
- Python 2.6,2.7和3.x支持
|
||||
- Linux,Mac OS X 和 Windows支持
|
||||
- 支持插件
|
||||
- 帮助文档
|
||||
- 测试覆盖 (直译有点别扭)
|
||||
|
||||
- 网站:[httpie.org][1]
|
||||
- 开发者: Jakub Roztočil
|
||||
- 证书: 开源
|
||||
- 版本号: 0.9.2
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
cURL是一个开源命令行工具,用于使用URL语句传输数据,支持DICT, FILE, FTP, FTPS, GOPHER, HTTP, HTTPS,IMAP, IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMTP, SMTPS, TELNET和TFTP。
|
||||
|
||||
cURL支持SSL证书,HTTP POST,HTTP PUT,FTP上传,HTTP基于表单上传,代理,缓存,用户名+密码认证(Basic, Digest, NTLM, Negotiate, kerberos...),文件传输恢复, 代理通道和一些其他实用窍门的总线负载。(这里的名词我不明白其专业意思)
|
||||
|
||||
#### 功能包括:####
|
||||
|
||||
- 配置文件支持
|
||||
- 一个单独命令行多个URL
|
||||
- “globbing”漫游支持: [0-13],{one, two, three}
|
||||
- 一个命令上传多个文件
|
||||
- 自定义最大传输速度
|
||||
- 重定向标准错误输出
|
||||
- Metalink支持
|
||||
|
||||
- 网站: [curl.haxx.se][2]
|
||||
- 开发者: Daniel Stenberg
|
||||
- 证书: MIT/X derivate license
|
||||
- 版本号: 7.42.0
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Wget是一个从网络服务器获取信息的开源软件。其名字源于World Wide Web 和 get。Wget支持HTTP,HTTPS和FTP协议,同时也通过HTTP代理获取信息。
|
||||
|
||||
Wget可以根据HTML页面的链接,创建远程网络站点的本地版本,是完全重造源站点的目录结构。这种方式被冠名“recursive downloading。”
|
||||
|
||||
Wget已经设计可以加快低速或者不稳定的网络连接。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 使用REST和RANGE恢复中断的下载
|
||||
- 使用文件名
|
||||
- 多语言的基于NLS的消息文件
|
||||
- 选择性地转换下载文档里地绝对链接为相对链接,使得下载文档可以本地相互链接
|
||||
- 在大多数类UNIX操作系统和微软Windows上运行
|
||||
- 支持HTTP代理
|
||||
- 支持HTTP数据缓存
|
||||
- 支持持续地HTTP连接
|
||||
- 无人照管/后台操作
|
||||
- 当远程对比时,使用本地文件时间戳来决定是否需要重新下载文档 (mirroring没想出合适的表达)
|
||||
|
||||
- 站点: [www.gnu.org/software/wget/][3]
|
||||
- 开发者: Hrvoje Niksic, Gordon Matzigkeit, Junio Hamano, Dan Harkless, and many others
|
||||
- 证书: GNU GPL v3
|
||||
- 版本号: 1.16.3
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20150425174537249/HTTPclients.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://httpie.org/
|
||||
[2]:http://curl.haxx.se/
|
||||
[3]:https://www.gnu.org/software/wget/
|
||||
@ -1,153 +0,0 @@
|
||||
sevenot translated
|
||||
排名前十的年度开源项目新秀
|
||||
================================================================================
|
||||
黑鸭(Black Duck)软件公布了一份名叫“年度开源项目新秀”的报告,介绍了由全球开源协会发起的10个最有趣、最活跃的新项目。
|
||||
|
||||

|
||||
|
||||
### 年度开源项目新秀 ###
|
||||
|
||||
每年都有上千新的开源项目问世,但只有少数能够真正的吸引我们的关注。一些项目因为利用了当前比较流行的技术而发展壮大,有一些则真正地开启了一个新的邻域。很多开源项目建立的初衷是为了解决一些生产上的问题,还有一些项目则是世界各地志同道合的开发者们共同发起的一个宏伟项目。
|
||||
|
||||
从2009年起,开源软件公司黑鸭便发起了[年度开源项目新秀][1]这一活动,它的评选根据[Open Hub][2] 网站(即以前的Ohloh)。今年,我们很荣幸能够报道2015年10大开源项目新秀的得主和2名荣誉奖得主,它们是从上千个开源项目中脱颖而出的。评选采用了加权评分系统,得分标准基于项目的活跃度,交付速度,和几个其它因数。
|
||||
|
||||
开源俨然成为了产业创新的引擎,就拿今年来说,和Docker容器相关的开源项目在全球各地新起,这也不恰巧反映了企业最感兴趣的技术邻域吗?最后,我们接下来介绍的项目,将会让你了解到全球开源项目的开发者们的在思考什么,这很快将会成为一个指引我们发展的领头羊。
|
||||
|
||||
### 2015年度开源项目新秀: DebOps ###
|
||||
|
||||

|
||||
|
||||
[DebOps][3]收集打包了一套[Ansible][4] (Ansible是一种自动化运维工具)方案和规则,可以从1个容器扩展到一个完整的数据中心。它的创始人Maciej Delmanowski将DebOps开源来保证项目长久进行,从而更好的利用外部贡献者来发展下去
|
||||
|
||||
DebOps始创于波兰的一个不起眼大学校园里,在自己的数据中心上运行,一切都是手工配置的。有时系统崩溃而导致几天的宕机,这时Delmanowski意识到一个配置管理系统是很有必要的。从Debian的基础做起,DebOps是一组配置一整个数据基础设施Ansible方案。此项目已经在许多不同的工作环境下实现,而创始者们则打算继续支持和开发这个项目。
|
||||
|
||||
###2015年度开源项目新秀: Code Combat ###
|
||||
|
||||

|
||||
|
||||
传统的纸笔学习方法已近不能满足技术学科了。然而游戏都是关于参与者,这也就是为什么[CodeCombat][5] 的创始人会去开发一款多人协同编程游戏来教人们如何编码。
|
||||
|
||||
刚开始CodeCombat是一个创业想法,但其创始人决定创建一个开源项目将其取代。此想法在社区传播开来,很快不少贡献者加入到项目中来。项目发起仅仅两个月后,这款游戏就被收入Google’s Summer of Code。这款游戏吸引了大量玩家,并被翻译成45种语言。CodeCombat希望成为那些想要一边学习代码同时获得乐趣的同学的风向标。
|
||||
|
||||
### 2015年度开源项目新秀: Storj ###
|
||||
|
||||

|
||||
|
||||
[Storj][6]是一个点对点的云存储网络,可实现端到端加密,保证用户不用依赖第三方即可传输、共享数据。基于比特币block chain技术和点对点协议,Storj提供安全、私密、加密的云存储。
|
||||
|
||||
云数据存储的反对者担心成本开销和漏洞攻击。为了做到没有死角,Storj是一个私有云存储市场,用户可以通过Storjcoin X(SJCX) 购买交易存储空间。上传到Storj的文件会被粉碎、加密和存储到整个社区。只有文件所有者拥有密钥加密的信息
|
||||
|
||||
在2014年举办的Texas Bitcoin Conference Hackathon会议上,云存储市场概念首次被提出并证明可行。在第一次赢得黑客马拉松活动后,项目创始人们和领导团队利用开源论坛Reddit、比特币论坛和社交媒体推广此项目。如今,它们已成为Storj决策过程的一个重要组成部分。
|
||||
|
||||
### 2015年度开源项目新秀: Neovim ###
|
||||
|
||||

|
||||
|
||||
自1991年提出概念以来,Vim已经成为数以百万计软件开发人员所钟爱的文本编辑器。 [Neovim][6] 是它的下一个版本。
|
||||
|
||||
在过去的23年里,软件开发生态系统经历了无数增长和创新。Neovim创始人Thiago de Arruda知道Vim缺少当代元素,跟不上时代的发展。在保留Vim的签名功能的前提下,Neovim团队同样在寻求最受欢迎的文本编辑器改善和发展技术。集资初期,Thiago de Arruda连续6个月时间关注推出此项目。他相信他的团队和支持他激励他继续发展Neovim。
|
||||
|
||||
### 2015年度开源项目新秀: CockroachDB ###
|
||||
|
||||

|
||||
|
||||
前谷歌员工开发了一个开源的企业数据存储项目[CockroachDB][8],它是一个可扩展的、跨地域复制且支持事务的数据存储的解决方案。
|
||||
|
||||
为了保证在线百万兆字节流量业务的质量,Google公开了他们的Spanner系统,这是一个可扩展的,稳定的,支持事务的系统。许多参与开发CockroachDB的团队现在都服务与开源社区。就像真正的蟑螂一样,CockroachDB可以在没有数据头、没有任何节点的情况下正常运行。这个开源项目有很多富有经验的贡献者,创始人们通过社会媒体、Github、网络、会议和聚会结识他们并鼓励他们参与其中。
|
||||
|
||||
### 2015年度开源项目新秀: Kubernetes ###
|
||||
|
||||

|
||||
|
||||
在介绍集装箱化的软件对开源社区的发展时,[Docker][9]是一匹黑马,它在技术和工具的设置上做了创新。去年6月谷歌推出了[Kubernetes][10],这是一款开源的容器管理工具,用来加快开发和简化操作。
|
||||
|
||||
谷歌在它的网络系统上使用容器技术多年了。在2014年夏天的DockerCon上大会上,谷歌这个互联网巨头开源了Kubernetes,Kubernetes的开发是为了满足迅速增长的Docker生态系统的需要。通过和其它的组织、项目合作,比如 Red Hat和CoreOS,Kubernetes的管理者们促使它登上了Docker Hub的工具下载榜榜首。Kubernetes的开发团队希望扩大这个项目,发展它的社区,这样的话软件开发者就能花更少的时间在管理基础设施上,而更多的去开发他们自己的APP。
|
||||
|
||||
### 2015年度开源项目新秀: Open Bazaar ###
|
||||
|
||||

|
||||
|
||||
OpenBazaar是一个使用比特币和其他人交易的市场。OpenBazaar这一概念最早在编程马拉松(hackathon)活动中被提出,它的创始人结合了BitTorent,比特币和传统的金融服务方式,创造了一个不受审查的交易平台。OpenBazaar的开发团队在寻求新的成员,而且不久以后他们将无限扩大Open Bazaar的社区。Open Bazaar旨在透明度和同一个目标去在商务交易中掀起一场革命,这会帮助创始人和贡献者向着一个真实的世界奋斗,一个没有控制,分散的市场。
|
||||
|
||||
### 2015年度开源项目新秀: IPFS ###
|
||||
|
||||

|
||||
|
||||
IPFS 是一个全球的点对点式的分布式版本文件系统。它综合了Git,BitTorrent,HTTP的思想,开启了一个新的数据和数据结构传输协议。
|
||||
|
||||
开源被人们所知晓的原因,是它本意用简单的方法解决复杂的问题,这样产生许多新颖的想法,但是着些强大的项目仅仅是开源社区的冰山一角。IFPS有一个积极的团队,这个概念的提出是大胆的,令人惊讶的,有点甚至高不可攀。这样来看,一个点对点的分布是文件系统是在寻找所有连在一起的计算设备。也许HTTP的更换可以靠着通过多种手段继续保持一个社区,包括Git社区和超过100名贡献者的IRC。这个疯狂的想法将在2015年进行软件内部测试。
|
||||
|
||||
### 2015年度开源项目新秀: cAdvisor ###
|
||||
|
||||

|
||||
|
||||
[cAdvisor (Container Advisor)][13] 是一个针对在运行中的容器进行收集,合计,处理和输出信息的工具,它可以给容器的使用者提供资源的使用情况和工作特性。对于每一个容器,cAdvisor记录着资源的分离参数,资源使用历史,资源使用历史对比框图,网络状态。这些从容器输出的数据在机器中传递。
|
||||
|
||||
cAdvisor可以在绝大多数的Linux上运行,并且支持包括Docker在内的多种容器类型。事实上它成为了一种容器的代理,并被集成在了很多系统中。cAdvisor在DockerHub下载量也是位居前茅。cAdvisor的开发团队希望把cAdvisor发展到能够更深入地理解应用并且集成到集群系统。
|
||||
|
||||
### 2015年度开源项目新秀: Terraform ###
|
||||
|
||||

|
||||
|
||||
[Terraform][14]提供了一些列的设置来创建一个基础设施,从物理机到虚拟机再到email服务器、DNS服务器。这个概念包括从家庭个人机解决方案到公共云平台提供的服务。一旦建立好了以后,Terraform便进行一系列的操作来改变你的基础设施,安全又高效,就如同配置一样。
|
||||
|
||||
如果你在Devops模式下的公司里工作,Terraform.io的创始者找到了一个窍门把建立一个完整的数据中心所需的知识结合在一起,从插入服务器到整个网络和功能齐备的数据中心。基础设施的描述采用高级的配置语法,允许你把数据中心的蓝图做成多版本并且可以使用多种代码。著名开源公司HashiCorp赞助开发这个项目。
|
||||
|
||||
### 荣誉奖: Docker Fig ###
|
||||
|
||||

|
||||
|
||||
[Fig][15] 为[Docker][16]的使用提供了一个快速的,分离的开发环境。Docker的移植只需要将配置信息放到一个简单的 fig.yml文件里。它会处理所有工作,包括建立、运行,端口转发,分享磁盘和容器链接。
|
||||
Fig solved a major pain point for developers. Docker fully supports this open source project and [recently purchased Orchard][17] to expand the reach of Fig.
|
||||
Orchard去年发起了Fig,来创造一个使Docker工作的系统工具。它的开发像是为Docker设置开发环境,为了确保用户能够为他们的APP准确定义环境,在Docker中会运行数据库和缓存。Fig解决了开发者的一个难题。Docker全面支持这个开源项目,最近将买下Orchard来扩张这个项目。
|
||||
|
||||
### 荣誉奖: Drone ###
|
||||
|
||||

|
||||
|
||||
[Drone][18]是一个基于Docker的持续集成平台,而且它是用Go语言写的。Drone项目不满于现存的技术和流程,它旨在开发环境。
|
||||
|
||||
Drone提供了一个简单的自动测试和持续交付的方法:简单选择一个Docker形象来满足你的需求,连接并提交至GitHub即可。Drone使用Docker容器来提供隔离的测试环境,让每个项目完全自主控制堆栈,没有传统的服务器管理的负担。Drone背后的100位社区贡献者强烈希望把这个项目带到企业和移动应用程序开发中
|
||||
### 开源新秀 ###
|
||||
|
||||

|
||||
|
||||
- [2014年度开源项目新秀][20]
|
||||
- [InfoWorld2015年年度技术奖][21]
|
||||
- [Bossies: 开源软件最高荣誉][22]
|
||||
- [ Windows管理员15个必不可少的开源工具][23]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2875439/open-source-software/the-top-10-rookie-open-source-projects.html
|
||||
|
||||
作者:[Black Duck Software][a]
|
||||
译者:[sevenot](https://github.com/sevenot)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Black-Duck-Software/
|
||||
[1]:https://www.blackducksoftware.com/open-source-rookies
|
||||
[2]:https://www.openhub.net/
|
||||
[3]:https://github.com/debops/debops
|
||||
[4]:http://www.infoworld.com/article/2612397/data-center/review--ansible-orchestration-is-a-veteran-unix-admin-s-dream.html
|
||||
[5]:https://codecombat.com/
|
||||
[6]:http://storj.io/
|
||||
[7]:http://neovim.org/
|
||||
[8]:https://github.com/cockroachdb/cockroach
|
||||
[9]:http://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker
|
||||
[10]:http://kubernetes.io/
|
||||
[11]:https://openbazaar.org/
|
||||
[12]:http://ipfs.io/
|
||||
[13]:https://github.com/google/cadvisor
|
||||
[14]:https://www.terraform.io/
|
||||
[15]:http://www.fig.sh/
|
||||
[16]:http://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker
|
||||
[17]:http://www.infoworld.com/article/2608546/application-virtualization/docker-acquires-orchard-in-a-sign-of-rising-ambitions.html
|
||||
[18]:https://drone.io/
|
||||
[19]:http://www.infoworld.com/article/2683845/google-go/164121-Fast-guide-to-Go-programming.html
|
||||
[20]:https://www.blackducksoftware.com/open-source-rookies
|
||||
[21]:http://www.infoworld.com/article/2871935/application-development/infoworlds-2015-technology-of-the-year-award-winners.html
|
||||
[22]:http://www.infoworld.com/article/2688104/open-source-software/article.html
|
||||
[23]:http://www.infoworld.com/article/2854954/microsoft-windows/15-essential-open-source-tools-for-windows-admins.html
|
||||
@ -1,81 +0,0 @@
|
||||
PHP 20岁了:从兴趣工程到强大的组织
|
||||
=============================================================================
|
||||

|
||||
|
||||
信任: [Steve Jurvetson via Flickr][1]
|
||||
|
||||
> 曾经的‘丑小鸭工程’已经转变为一个网络世界的强大组织,感谢网络世界的灵活,实用与充满生气的社区
|
||||
|
||||
当Rasmus Lerdorf发布“[一个用C写的紧凑的CGI可执行程序集合][2],” 他没有想到他的创造会对网络发展产生多大的影响。今年在Miami举行的SunshinePHP大会上,Lerdorf做了开场演讲,他自嘲到,“在1995年的时候,我以为我已经解除了C API的束缚,在网络之上。显然,事情并非那样,或者我们都已经是C程序员了。”
|
||||
|
||||
实际上,当Lerdorf发布个人主页工具 -- 后来以PHP闻名的1.0版本时 -- 那时的网络还是如此的年轻。HTML 2.0还没有公布,直到那年的十一月份,而且HTTP/1.0也是次年的五月份才出现。NCSA HTTPd是使用最广泛的网络浏览器,而网景的Navigator则是最流行的网络浏览器,八月份的时候,IE1.0才到来。换句话说,PHP的开端刚好撞上了浏览器战争的前夜。
|
||||
|
||||
早些时候,说了大堆关于PHP对网络发展的影响。回到那时候,我们的选择是有限的,当说到服务器方面对于网络软件的进展。PHP满足了我们对于一个工具的需求,就是可以使得我们在网络上做一些动态的事情。实用的灵活性束缚了我们的想像,PHP从那时起便与网络共同成长。现在,PHP占据了网络语言超过80%的份额,已经是成熟的脚本语言,特别适合解决网络问题。她独一无二的血统讲述一个故事,实用高于理论,解决问题高于纯粹。
|
||||
|
||||
### 把我们钩住的网络魔力 ###
|
||||
|
||||
PHP一开始并不是一门编程语言,从她的设计就很明星 -- 或者她本来就缺,正如那些贬低者指出的那样。最初,她是作为一种API帮助网络开发者能够接入底层的C语言封装库。第一个版本是一组小的CGI可执行程序,提供表单处理功能,通过接入需要的参数和mSQL数据库。而且她如此容易地处理一个网络应用的数据库,证明了其在激发我们对于PHP的兴趣和PHP后来的支配地位的关键作用。
|
||||
|
||||
到了第二版 -- aka PHP/FI -- 数据库的支持已经扩展到包括PostgreSQL、MySQL、Oracle、Sybase等等。她通过包括他们的C语言库来支持其数据库,将他们作为PHP库的一部分。PHP/FI也可以包括GD库,创建并管理GIF镜像。她可以作为一个Apache模块运行,或者有FastCGI支持的时候被编译,并且她展示了支持变量,数组,语言结构和函数的PHP脚本语言。对于那个时候大多数在网络这块工作的人来说,PHP是我们一直在寻求的那款“胶水”。
|
||||
|
||||
当PHP吸纳越来越多的编程语言分支,演变为第三版和之后的版本,她从来没有失去连接的特性。通过仓库如PECL(PHP Extension Community Library),PHP可以把库都连在一起,暴露他们的函数给PHP层。这种将组件结合在一起的能力,成为PHP之美的一个重要方面,尽管她没有被限制在其资源代码上。
|
||||
|
||||
### 网络,一个码农们的社区 ###
|
||||
|
||||
PHP在网络发展上的持续影响并不局限于能用这种语言干什么。PHP如何完成工作,谁参与近进来 -- 这些都是PHP传奇很重要的部分。
|
||||
|
||||
早在1997年,PHP的用户群体开始形成。其中最早的是中东的PHP用户群(后来以Chiago PHP闻名),并[1997年二月份的时候举行了第一次聚会][4]。这是一个充满生气,饱含激情的开发者社区形成的开端,聚合成一种吸引力 -- 在网络上很少的工具就可以帮助他们解决问题。PHP这种普遍存在的特性使得她成为网络开发一个很自然的选择。在分享主导的世界里,她开始盛行,而且低入的门槛对于许多早期的网络开发者来说是十分有吸引力的。
|
||||
|
||||
伴随着社区的成长,为开发者带来了一堆工具和资源。这一年2000年 -- PHP的一个转折点 -- 见证了第一次PHP开发者大会,编程语言的核心开发者的一次聚集,在Tel Aviv见面,讨论即将到来的4.0版本的发布。PHP扩展和应用仓库(PEAR)也于2000发起,提供高质量的用户代码包,根据标准且最好的操作。第一届PHP大会,PHP Kongress,不久之后在德国举行。[PHPDeveloper.org][5]随后上线,直到今天。这是在PHP社区里最权威的新闻资源。
|
||||
|
||||
这种公社的势头(有待校正)证明了接下来几年里PHP成长的关键所在,且随着网络开发产业的爆发,PHP也获得发展。PHP开始占领更多,更大的网站。越来越多的用户群在世界范围内形成。邮件列表;在线论坛;IRC;大会;交易日记如php[架构],德国PHP杂志,国际PHP杂志 -- PHP社区的活力在完成网络工作的方式上有极其重要的影响:共同地,开放地,倡导代码共享。
|
||||
|
||||
然后,10年前,PHP 5发布后不久,在网络发展史上一个有趣地事情发生了,导致了PHP社区如何构建库和应用的转变:Ruby on Rails发布了。
|
||||
|
||||
### 框架的异军突起 ###
|
||||
|
||||
针对Ruby编程语言的Ruby on Rails,在MVC(模型-视图-控制)架构模型上获得了不断增长的焦点与关注。Mojavi PHP框架几年前已经使用该模型了,但是Ruby on Rails的高明之处在于巩固了MVC。框架在PHP社区炸开了,并且框架已经改变了开发者构建PHP应用程序的方式。
|
||||
|
||||
许多重要的项目和发展已经起势,这归功于PHP社区框架的生长。PHP[框架互用性组织][6]成立于2009年,致力于在框架间建立编码标准,命名约定与最佳操作。编纂这些标准和操作帮助为开发者提供了越来越多的互动性软件,使用成员项目的代码。互用性意味着每个框架可以拆分为组块和独立的库,可以被一起使用作为整体的框架。互用性带来了另一个重要的里程碑:Composer项目于2011年诞生了。
|
||||
|
||||
从Node.js的NPM和Ruby的Bundler获得灵感,Composer开辟了PHP应用开发的新纪元,创造了一次PHP“文艺复兴”。它激起了包,标准命名约定,编码标准的采用与成长中的覆盖测试间的互用性。它是任何现代PHP应用中的一个基本工具。
|
||||
|
||||
### 加速和创新的需要 ###
|
||||
|
||||
如今,PHP社区有一个生机勃勃应用和库的生态系统,一些被广泛安装的PHP应用包括WordPress,Drupal,Joomla和MediaWiki。这些应用占据了所有规模的商业的网络形式,从小型的夫妻店到站点如whitehouse.gov和Wikipeida。Alexa前十的站点中,6个使用PHP在一天内服务数十亿的页面。结果,PHP应用已成加速需要的首选 -- 并且许多创新也加入到PHP的核心来提升表现。
|
||||
|
||||
在2010年,Facebook公开了其用作PHP源对源的编译器的HipHop,翻译PHP代码为C++代码,并且编译为一个单独的可执行二进制应用。Facebook的规模和成长需要从标准互用的PHP代码迁移到更快,最佳的可执行的代码。尽管如此,Facebook想继续使用PHP,由于PHP的易用和快速开发周期。HipHop进化为HHVM,一个针对PHP的JIT(just-in-time)编译基础的执行引擎,其包含一个基于PHP的新的语言:[Hack][7]。
|
||||
|
||||
Facebook的创新,和其他的VM项目,创建了在引擎水平上的比较,引起了关于Zend引擎未来的讨论。Zend引擎依然占据PHP和一种语言表述的问题的核心。在2004年,一个语言表述项目被创建,“为提供一个完整的,简明的语句定义,和PHP语言的语义学,”使得对编译器项目来说,创建共用的PHP实现成为可能。
|
||||
|
||||
下一个PHP的主要版本成为了激烈争论的话题,一个著名的pgpng项目(下一代)作为一个能清理,重构,优化和提升PHP代码基础的选项被提出来,这也展示了对真实世界应用的性能的实质上的提升。由于之前未发布的PHP 6.0版本,在决定命名下一个主要版本为“PHP 7”后,phpng分支被合并了,并制定了计划开发PHP 7,Hack提供了很多语言中拥有的功能,如scalar和返回键入提示。
|
||||
|
||||
随着[今天第一版PHP 7 alpha发布][8],标准检测程序显示在许多方面[与HHVM的一样或者更好的性能][9],PHP正与现代网络开发需求保持一致的步伐。同样地,PHP-FIG继续创新和推送框架与库用于协作 -- 最近由于[PSR-7][10]的采纳,这将会改变PHP项目处理HTTP的方式。用户组,会议,公众和积极性如[PHPMentoring.org][11]继续在PHP开发者社区提倡最好的操作,编码标准和测试
|
||||
|
||||
PHP从各个方面见证了网络的成熟,而且PHP自己也成熟了。曾经一个单一的低层次的C语言库的API包装,PHP以她自己的方式,已经成为一个羽翼丰满的编程语言。她的开发者社区是一个充满生气,乐于帮助,在实用方面以自己为傲,并且欢迎新入者的地方。PHP已经经受了20年的考验,而且目前在语言与社区里活跃性,会保证她将会是一个中肯的,有用的的语言,在接下来的几年里。
|
||||
|
||||
他的SunshinePHP的关键发言中,Rasmus Lerdorf回忆到,“我曾想过我会在20年之后与我当初做的这个愚蠢的小项目交流吗?没有。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2933858/php/php-at-20-from-pet-project-to-powerhouse.html
|
||||
|
||||
作者:[Ben Ramsey][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Ben-Ramsey/
|
||||
[1]:https://www.flickr.com/photos/jurvetson/13049862325
|
||||
[2]:https://groups.google.com/d/msg/comp.infosystems.www.authoring.cgi/PyJ25gZ6z7A/M9FkTUVDfcwJ
|
||||
[3]:http://w3techs.com/technologies/overview/programming_language/all
|
||||
[4]:http://web.archive.org/web/20061215165756/http://chiphpug.php.net/mpug.htm
|
||||
[5]:http://www.phpdeveloper.org/
|
||||
[6]:http://www.php-fig.org/
|
||||
[7]:http://www.infoworld.com/article/2610885/facebook-q-a--hack-brings-static-typing-to-php-world.html
|
||||
[8]:https://wiki.php.net/todo/php70#timetable
|
||||
[9]:http://talks.php.net/velocity15
|
||||
[10]:http://www.php-fig.org/psr/psr-7/
|
||||
[11]:http://phpmentoring.org/
|
||||
这里向Lerdorf和PHP社区的其他人致敬,感谢他们把这个“愚蠢的小项目”变成了一个如今网络上持久的,强大的组块。
|
||||
@ -1,67 +0,0 @@
|
||||
Linux下优秀的音频编辑软件
|
||||
================================================================================
|
||||
|
||||
不论您是一个音乐爱好者或只是一个要记录您导师声音的学生,您都需要录制音频和编辑音频。长久以来这样的工作都要靠Macintosh,如今那个时代已经过去,现在Linux也可以胜任这些工作了。简而言之,这里有一份不完全的音频编辑器软件列表,适用于不同的任务和需求。
|
||||
|
||||
### 1. Audacity ###
|
||||
|
||||

|
||||
|
||||
让我们从我个人最喜欢的软件开始。[Audacity][1]可以运行在Windows、Mac和Linux上。它是开源的,且易于使用。你会觉得:Audacity几乎是完美的。它可以让您在干净的界面上操作音频波形。简单地说,您可以覆盖音轨、剪切和修改音轨、增加特效、执行高级的声音分析,然后将它们导出到一大堆可用的格式。我喜欢它的原因是它将基本的功能和复杂的功能结合在一起并且保持一个简单的学习曲线。然而,它并不是一个完全最优化的软件,尤其是对于音乐家和有着专业知识的人。
|
||||
|
||||
### 2. Jokosher ###
|
||||
|
||||

|
||||
|
||||
在不同的层次上,[Jokosher][2]更多的聚焦在多音轨方面。它使用Python和GTK+作为前端借口,并使用GStreamer作为音频后端。Jokosher那平滑的界面和它的扩展性给我留下了深刻的印象。也许编辑的功能并不是最先进的,但它的语言十分清晰,适合音乐家。例如,我十分喜欢音轨和乐器的组合。简而言之,如果您是一个音乐家,那么它是在您转移到下一个软件前进行实践的好机会。
|
||||
|
||||
### 3. Ardour ###
|
||||
|
||||

|
||||
|
||||
接下来谈论一些复杂的工具,[Ardour][3]是一套完整的可以录制、编辑和混音的软件。这个设计吸引所有的专业人员,Ardour在声音和插件方面超出我的想象。如果您在寻找一头野兽并且不惧怕驯服他,那么Ardour获取是一个不错的选择。再次,它的接口和它丰富的文档,尤其是它首次启动时的配置工具都是他迷人魅力的一部分。
|
||||
|
||||
### 4. Kwave ###
|
||||
|
||||

|
||||
|
||||
对于所有KDE的热爱者,[KWave][4]绝对符合您对于设计和功能的想象。它有丰富的快捷键以及很多有趣的选项,例如内存管理。尽管很多特效很不错,但我们更应该关注那些用于音频剪切/粘贴的工具。可惜的是它无法与Audacity相比,而更重要的是,该接口并没有那么吸引我。
|
||||
|
||||
### 5. Qtractor ###
|
||||
|
||||

|
||||
|
||||
如果Kwave对您来说过于简单,但基于Qt的程序却有些吸引力,那么对您来说,也许[Qtractor][5]是一个选项。它致力于做一个“对于家庭用户来说足够简单,并且对专业人员来说足够强大的软件。”实际上它功能和选项的数量几乎是压倒性的。我最喜欢的当然是可定制的快捷键。除此之外,Qtractor可能是我最喜欢的一个处理MIDI文件的工具。
|
||||
|
||||
### 6. LMMS ###
|
||||
|
||||

|
||||
|
||||
作为Linux多媒体工作室,LMMS的直接目标是音乐制作。如果您之前没有什么经验并且不想浪费太多的时间,那么请去别处吧。LMMS是其中一个复杂但强大的软件,只有少数的人真正的掌握了它。它有太多的功能和特效以至于无法一一列出,但如果我必须找一个,我会说用来模拟Game Boy声音系统的Freeboy插件简直像魔术一样。然后,去看看它那惊人的文档吧。
|
||||
|
||||
### 7. Traverso ###
|
||||
|
||||

|
||||
|
||||
最后站在我面前的是Traverso,它支持无限制的音轨计数,并直接整合了CD烧录的功能。另外,它对我来说是介于简单的软件和专业的软件之间的程序。它的界面是KDE样式的,其键盘配置很简单。更有趣的是,Traverso会监视您的系统资源以确定不会超过您的CPU或者硬件的能力。
|
||||
|
||||
总而言之,能在Linux系统上看到这么多不同的应用程序是一件开心的事。它使得您永远可以找到最适合自己的那一款。虽然我最喜欢的应用是Audacity,但我非常震惊于LMMS和Jokosher的设计。
|
||||
|
||||
我们有漏掉什么么?您在Linux下使用哪一款软件呢?原因是什么呢?请在留言处留言让我们知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/good-audio-editing-software-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://audacity.sourceforge.net/
|
||||
[2]:https://launchpad.net/jokosher/
|
||||
[3]:http://ardour.org/
|
||||
[4]:http://kwave.sourceforge.net/
|
||||
[5]:http://qtractor.sourceforge.net/qtractor-index.html
|
||||
@ -0,0 +1,422 @@
|
||||
用于提高网站安全性和自定义网站的 25 个有用 Apache ‘.htaccess’ 小技巧
|
||||
================================================================================
|
||||
网站是我们生活中重要的一部分。它们是实现扩大业务、分享知识以及其它更多功能的方式。之前受制于只能提供静态内容,随着动态客户端和服务器端脚本语言的引入和现有静态语言的持续改进,例如从 html 到 html5,动态网站成为可能,剩下的也许在不久的将来也会实现。
|
||||
|
||||
有了网站,随之而来的是对能向全球大规模用户显示站点的单元的需求。这个需求通过托管网站的服务器实现。这包括一系列的服务器,例如:Apache HTTP Server、Joomla 以及 允许个人拥有自己网站的 WordPress。
|
||||
|
||||

|
||||
25 个 htaccess 小技巧
|
||||
|
||||
想要拥有一个网站,可以创建一个自己的本地服务器,或者联系任何上面提到的或其它服务器管理员来托管他的网站。但实际问题也从这点开始。网站的性能主要取决于以下因素:
|
||||
|
||||
- 网站消耗的带宽。
|
||||
- 针对黑客网站有多安全。
|
||||
- 对数据库进行数据检索时的优化。
|
||||
- 显示导航菜单和提供更多 UI 功能时的用户友好性。
|
||||
|
||||
除此之外,保证托管网站服务器成功的多种因素还包括:
|
||||
|
||||
- 对于一个流行站点的数据压缩量。
|
||||
- 同时为多个请求同一或不同站点的用户服务的能力。
|
||||
- 保证网站上输入的机密数据安全,例如:Email、信用卡信息等等。
|
||||
- 允许更多的选项用于增强站点的动态性。
|
||||
|
||||
这篇文章讨论一个服务器提供的用于增强网站性能和提高针对坏机器人、热链接等的安全性的功能。例如 ‘.htaccess’ 文件。
|
||||
|
||||
### .htaccess 是什么? ###
|
||||
|
||||
htaccess (hypertext access,超文本访问) 是为网站所有者提供用于控制服务器环境变量以及其它参数的选项,从而增强他们网站的功能的文件。这些文件可以在网站目录树的任何一个目录中,并向该目录以及目录中的文件和子目录提供功能。
|
||||
|
||||
这些功能是什么呢?其实这些是服务器的指令,例如命令服务器执行特定任务的行,这些命令只对该文件所在目录中的文件和子目录有效。这些文件默认是隐藏的,因为所有操作系统和网站服务器默认配置为忽略。但让隐藏文件可见可以让你看到这些特殊文件。后续章节的话题将讨论能控制什么类型的参数。
|
||||
|
||||
注意:如果 .htaccess 文件保存在 /apache/home/www/Gunjit/ 目录,那么它会向该目录中的所有文件和子目录提供命令,但如果该目录包含一个名为 /Gunjit/images/ 子目录,且该子目录中也有一个 .htaccess 文件,那么这个子目录中的命令会覆盖父目录中 .htaccess 文件(或者层次结构中更上层文件)提供的命令。
|
||||
|
||||
### Apache Server 和 .htaccess 文件 ###
|
||||
|
||||
Apache HTTP Server 俗称为 Apache,是为了表示对一个有卓越战争策略技能的美洲土著部落的尊敬而命名。它是用 C/C++ 和 XML 建立的基于 [NCSA HTTPd 服务器][1] 的跨平台 Web 服务器,它在万维网的成长和发展中起到了关键作用。
|
||||
|
||||
最常用于 UNIX,Apache 也能用于多种平台,包括 FreeBSD、Linux、Windows、Mac OS、Novel Netware 等。在 2009 年,Apache 成为第一个为超过一亿站点提供服务的服务器。
|
||||
|
||||
Apache 服务器对于 www/ 目录中的每个用户有一个单独的 .htaccess 文件。尽管这些文件是隐藏的,但如果需要的话可以使它们可见。在 www/ 目录中有很多子目录,每个子目录通过用户名或所有者名称命名,包含了一个站点。除此之外你可以在每个子目录中有一个 .htaccess 文件,像之前所述用于配置子目录中的文件。
|
||||
|
||||
下面介绍如果配置 Apache 服务器上的 htaccess 文件。
|
||||
|
||||
### Apache 服务器上的配置 ###
|
||||
|
||||
这里有两种情况:
|
||||
|
||||
#### 在自己的服务器上托管网站 ####
|
||||
|
||||
在这种情况下,如果没有启用 .htaccess 文件,你可以通过在 http.conf(Apache HTTP 守护进程的默认配置文件) 中找到 <Directories> 部分启用。
|
||||
|
||||
<Directory "/var/www/htdocs">
|
||||
|
||||
定位如下行
|
||||
|
||||
AllowOverride None
|
||||
|
||||
更改为
|
||||
|
||||
AllowOverride All
|
||||
|
||||
现在,重启 Apache 后就启用了 .htaccess。
|
||||
|
||||
#### 在不同的托管服务提供商的服务器上托管网站 ####
|
||||
|
||||
在这种情况下最好咨询托管管理员,如果他们允许访问 .htaccess 文件的话。
|
||||
|
||||
### 用于站点的 25 个 Apache Web 服务器 ‘.htaccess’ 小技巧 ###
|
||||
|
||||
#### 1. 如何在 .htaccess 文件中启用 mod_rewrite ####
|
||||
|
||||
mod_rewrite 选项允许你使用重定向并通过重定向到其它 URL 隐藏你真实的 URL。这个选项非常有用,允许你用短的容易记忆的 URL 替换长 URL。
|
||||
|
||||
要允许 mod_rewrite,只需要在你的 .htaccess 文件的第一行添加如下一行。
|
||||
|
||||
Options +FollowSymLinks
|
||||
|
||||
该选项允许你跟踪符号链接从而在站点中启用 mod_rewrite。后面会介绍用短 URL 替换。
|
||||
|
||||
#### 2. 如果允许或禁止对站点的访问 ####
|
||||
|
||||
通过使用 order、allow 和 deny 关键字,htaccess 文件可以允许或者禁止对站点或目录中子目录或文件的访问。
|
||||
|
||||
**只允许 IP 192.168.3.1 的访问**
|
||||
|
||||
Order Allow, Deny
|
||||
Deny from All
|
||||
Allow from 192.168.3.1
|
||||
|
||||
或
|
||||
|
||||
Order Allow, Deny
|
||||
Allow from 192.168.3.1
|
||||
|
||||
这里的 Order 关键字指定处理 allow 和 deny 访问的顺序。对于上面的 ‘Order’ 语句,首先会处理 Allow 语句,然后是 deny 语句。
|
||||
|
||||
**只禁止某个 IP 的访问**
|
||||
|
||||
下面一行的意思是除了 IP 地址 192.168.3.1,允许所有用户访问网站。
|
||||
|
||||
Order Allow, Deny
|
||||
Deny from 192.168.3.1
|
||||
Allow from All
|
||||
|
||||
或
|
||||
|
||||
Order Deny, Allow
|
||||
Deny from 192.168.3.1
|
||||
|
||||
#### 3. 为不同错误码生成 Apache 错误文档 ####
|
||||
|
||||
用一些简单行,我们可以解决当用户/客户端请求一个站点上不可用的网页时服务器产生的错误码的错误文档,例如我们大部分人见过的浏览器中显示的 ‘404 Page not found’。‘.htaccess’ 文件指定了发生这些错误情况时采取何种操作。
|
||||
|
||||
要做到这点,需要添加下面的行到 ‘.htaccess’ 文件:
|
||||
|
||||
ErrorDocument <error-code> <path-of-document/string-representing-html-file-content>
|
||||
|
||||
‘ErrorDocument’ 是一个关键字,error-code 可以是 401、403、404、500 或任何有效的表示错误的代码,最后 ‘path-of-document’ 表示本地机器上的路径(如果你使用的是你自己的本地服务器) 或 服务器上的路径(如果你使用任何其它服务器来托管网站)。
|
||||
|
||||
**例子:**
|
||||
|
||||
ErrorDocument 404 /error-docs/error-404.html
|
||||
|
||||
上面一行设置客户请求任何无效页面,服务器报告 404 错误时显示 error-docs 目录下的 ‘error-404.html’ 文档。
|
||||
|
||||
ErrorDocument 404 "<html><head><title>404 Page not found</title></head><body><p>The page you request is not present. Check the URL you have typed</p></body></html>"
|
||||
|
||||
上面的表示也正确,其中字符串表示一个普通的 html 文件。
|
||||
|
||||
#### 4. 设置/取消 Apache 服务器环境变量 ####
|
||||
|
||||
在 .htaccess 文件中你可以设置或者取消站点所有者用来更改服务器设置的全局环境变量。要设置或取消环境变量,你需要在你的 .htaccess 文件中添加下面的行。
|
||||
|
||||
**设置环境变量**
|
||||
|
||||
SetEnv OWNER “Gunjit Khera”
|
||||
|
||||
**取消环境变量**
|
||||
|
||||
UnsetEnv OWNER
|
||||
|
||||
#### 5. 为文件定义不同 MIME 类型 ####
|
||||
|
||||
MIME(Multipurpose Internet Multimedia Extensions,,多用途 Internet 多媒体扩展) 是浏览器运行任何页面默认能识别的类型。你可以在 .htaccess 文件中为你的站点定义 MIME 类型,然后服务器就可以识别你定义的类型的文件并运行。
|
||||
|
||||
<IfModule mod_mime.c>
|
||||
AddType application/javascript js
|
||||
AddType application/x-font-ttf ttf ttc
|
||||
</IfModule>
|
||||
|
||||
这里,mod_mime.c 是用于控制定义不同 MIME 类型的模块,如果在你的系统中已经安装了这个模块,那么你就可以用该模块去为你站点中不同的扩展定义不同的 MIME 类型,从而服务器可以理解这些文件。
|
||||
|
||||
#### 6. 如何在 Apache 中限制上传和下载的大小 ####
|
||||
|
||||
.htaccess 文件允许你拥有控制一个特定用户从你的站点上传或下载数据量大小的功能。要做到这点你只需要添加下面的行到你的 .htaccess 文件:
|
||||
|
||||
php_value upload_max_filesize 20M
|
||||
php_value post_max_size 20M
|
||||
php_value max_execution_time 200
|
||||
php_value max_input_time 200
|
||||
|
||||
上面的行设置最大上传大小、最大推送数据大小、最大执行时间,例如允许用户在本地机器运行站点的最大时间、限制的最大输入时间。
|
||||
|
||||
#### 7. 让用户在站点上播放 .mp3 和其它文件之前预先下载 ####
|
||||
|
||||
大部分情况下,人们在下载检查音乐质量之前会在网站上播放等等。作为一个聪明的销售者,你可以添加一个简单的功能,不允许任何用户在线播放音乐或视频,而是必须下载后才能播放。这非常有用,因为在线播放音乐和视频会消耗很多带宽。
|
||||
|
||||
要添加下面的行到你的 .htaccess 文件:
|
||||
|
||||
AddType application/octet-stream .mp3 .zip
|
||||
|
||||
#### 8. 为站点设置目录索引 ####
|
||||
|
||||
大部分网站开发者都知道第一个显示的页面,例如一个站点的主页面,被命名为 ‘index.html’。我们大部分也见过这个。但是如何设置呢?
|
||||
|
||||
.htaccess 文件提供了一种方式用于列出一个客户端请求访问网站的主页面时会顺序扫描的一些网页集,相应地如果找到了列出的页面中的任何一个就会作为站点的主页面并显示给用户。
|
||||
|
||||
需要添加下面的行产生所需的效果。
|
||||
|
||||
DirectoryIndex index.html index.php yourpage.php
|
||||
|
||||
上面一行指定如果有任何访问主页面的请求到来,首先会在目录中顺序搜索上面列出的网页:如果发现了 index.html 则显示为主页面,否则会处理下一个页面,例如 index.php,如此直到你在列表中输入的最后一个页面。
|
||||
|
||||
#### 9. 如何为文件启用 GZip 压缩以节省网站带宽 ####
|
||||
|
||||
繁重站点通常比只占少量空间的轻量级站点运行更慢是常见的现象。这是因为对于繁重站点需要时间加载大量的脚本文件和图片用于在客户端的 Web 浏览器上显示。
|
||||
|
||||
当浏览器请求一个 web 页面时,服务器提供给浏览器该页面并局部显示该 web 页面,浏览器需要下载该页面然后在页面内部运行脚本,这是一种常见机制。
|
||||
|
||||
这里 GZip 压缩所做的就是节省单个用户的服务时间从而提高带宽。服务器上站点的源文件以压缩形式保存,当用户请求到来的时候,这些文件以压缩形式传送,然后在服务器上解压并执行。这改进了带宽限制。
|
||||
|
||||
下面的行允许你压缩站点的源文件,但要求在你的服务器上安装 mod_deflate.c 模块。
|
||||
|
||||
<IfModule mod_deflate.c>
|
||||
AddOutputFilterByType DEFLATE text/plain
|
||||
AddOutputFilterByType DEFLATE text/html
|
||||
AddOutputFilterByType DEFLATE text/xml
|
||||
AddOutputFilterByType DEFLATE application/html
|
||||
AddOutputFilterByType DEFLATE application/javascript
|
||||
AddOutputFilterByType DEFLATE application/x-javascript
|
||||
</IfModule>
|
||||
|
||||
#### 10. 处理文件类型 ####
|
||||
|
||||
服务器默认的有一些特定情况。例如:在服务器上运行 .php 文件,显示 .txt 文件。像这些我们可以以源代码形式只显示一些可执行 cgi 脚本或文件而不是执行它们。
|
||||
|
||||
要做到这点在 .htaccess 文件中有如下行。
|
||||
|
||||
RemoveHandler cgi-script .php .pl .py
|
||||
AddType text/plain .php .pl .py
|
||||
|
||||
这些行告诉服务器只显示而不执行 .pl (perl 脚本)、.php (PHP 文件) 和 .py (Python 文件) 。
|
||||
|
||||
#### 11. 为 Apache 服务器设置时区 ####
|
||||
|
||||
.htaccess 文件可用于为服务器设置时区可以看出它的能力和重要性。这可以通过设置一个服务器为每个托管站点提供的一系列全局环境变量中的 ‘TZ’ 完成。
|
||||
|
||||
由于这个原因,我们可以在网站上看到根据我们的时区显示的时间。也许服务器上其他拥有网站的人会根据他居住地点的位置设置时区。
|
||||
|
||||
下面的一行为服务器设置时区。
|
||||
|
||||
SetEnv TZ India/Kolkata
|
||||
|
||||
#### 12. 如果在站点上启用缓存控制 ####
|
||||
|
||||
浏览器很有趣的一个功能是,已经观察到多次同时打开一个网站,和第一次打开相比之后会更快。但为什么会这样呢?事实上,浏览器在它的缓存中保存了一些通常访问的页面用于加快后面的访问。
|
||||
|
||||
但保存多长时间呢?这取决于你自己。例如,你的 .htaccess 文件中设置的缓存控制时间。.htaccess 文件指定了站点的网页可以在浏览器缓存中保存的时间,时间到期后需要重新验证,例如页面会从缓存中删除然后在下次用户访问站点的时候重建。
|
||||
|
||||
下面的行为你的站点实现缓存控制。
|
||||
|
||||
<FilesMatch "\.(ico|png|jpeg|svg|ttf)$">
|
||||
Header Set Cache-Control "max-age=3600, public"
|
||||
</FilesMatch>
|
||||
<FilesMatch "\.(js|css)$">
|
||||
Header Set Cache-Control "public"
|
||||
Header Set Expires "Sat, 24 Jan 2015 16:00:00 GMT"
|
||||
</FilesMatch>
|
||||
|
||||
上面的行允许缓存 .htaccess 文件所在目录中的页面一小时。
|
||||
|
||||
#### 13. <files> 配置单个文件 ####
|
||||
|
||||
通常 .htaccess 文件中的内容会对该文件所在目录中的所有文件和子目录起作用,但是你也可以对特殊文件设置一些特殊权限,例如只禁止对某个文件的访问等等。
|
||||
|
||||
要做到这点,你需要在文件中以类似方式添加 <File> 标记:
|
||||
|
||||
<files conf.html="">
|
||||
Order allow, deny
|
||||
Deny from 188.100.100.0
|
||||
</files>
|
||||
|
||||
这是一个禁止 IP 188.100.100.0 访问 ‘conf.html’ 的简单例子,但是你也可以添加介绍过的 .htaccess 文件的任何功能,包括将要介绍的功能,例如:缓存控制、GZip 压缩。
|
||||
|
||||
大部分服务器会用这个功能增强 .htaccess 文件的安全,这也是我们在浏览器上看不到 .htaccess 文件的原因。在后面的章节中会介绍如何给文件授权。
|
||||
|
||||
#### 14. 启用在 cgi-bin 目录以外运行 CGI 脚本 ####
|
||||
|
||||
通常服务器运行的 CGI 脚本都保存在 cgi-bin 目录中,但是你可以启用在你需要的目录运行 CGI 脚本,只需要在所需的目录中添加下面的行到 .htaccess 文件,如果没有改文件就创建一个,并添加下面的行:
|
||||
|
||||
AddHandler cgi-script .cgi
|
||||
Options +ExecCGI
|
||||
|
||||
#### 15.如何用 .htaccess 在站点上启用 SSI ####
|
||||
|
||||
服务器端包括顾名思义的和服务器部分相关的东西。但是什么呢?通常当我们在站点上有很多页面的时候,我们在主页面上会有一个显示到其它页面链接的导航菜单,我们可以启用 SSI(Server Size Includes) 选项允许导航菜单中显示的所有页面完全包含在主页面中。
|
||||
|
||||
SSI 允许包含多个页面,好像他们包含的内容就是一个单一页面的一部分,因此任何需要的编辑都只有一个文件,从而可以节省很多磁盘空间。除了 .shtml 文件,服务器默认启用了该选项。
|
||||
|
||||
如果你想要对 .html 启用该选项,你需要添加下面的行:
|
||||
|
||||
AddHandler server-parsed .html
|
||||
|
||||
这之后 html 文件会导向 SSI。
|
||||
|
||||
<!--#inlcude virtual= “gk/document.html”-->
|
||||
|
||||
#### 16. 如何防止网站目录列表 ####
|
||||
|
||||
为防止任何客户端在本地机器罗列服务器上的网站目录列表,添加下面的行到你不想列出的目录的文件中。
|
||||
|
||||
Options -Indexes
|
||||
|
||||
#### 17. 更改默认字符集和语言头 ####
|
||||
|
||||
.htaccess 文件允许你更改网站使用的字符集,例如 ASCII 或 UNICODE,UTF-8 等,以及用于显示内容的默认语言。
|
||||
|
||||
在服务器的全局环境变量之后添加下面语句可以实现上述功能。
|
||||
|
||||
AddDefaultCharset UTF-8
|
||||
DefaultLanguage en-US
|
||||
|
||||
**重写 URL 的重定向规则**
|
||||
|
||||
重写功能仅意味着用短而易记的 URL 替换长而难以记忆的 URL。但是,在开始这个话题之前,这里有一些本文后面会使用的特殊字符的规则和约定。
|
||||
|
||||
**特殊符号:**
|
||||
|
||||
符号 含义
|
||||
^ - 字符串开头
|
||||
$ - 字符串结尾
|
||||
| - 或 [a|b] – a 或 b
|
||||
[a-z] - a 到 z 的任意字母
|
||||
+ - 之前字母的一次或多次出现
|
||||
* - 之前字母的零次或多次出现
|
||||
? - 之前字母的零次或一次出现
|
||||
|
||||
**常量和它们的含义:**
|
||||
|
||||
常量 含义
|
||||
NC - 区分大小写
|
||||
L - 最后的规则 – 停止处理更多规则
|
||||
R - 临时重定向到新 URL
|
||||
R=301 - 永久重定向到新 URL
|
||||
F - 禁止发送 403 头给用户
|
||||
P - 代理 – 获取远程内容代替部分并返回
|
||||
G - Gone, 不再存在
|
||||
S=x - 跳过后面的 x 条规则
|
||||
T=mime-type - 强制指定 MIME 类型
|
||||
E=var:value - 设置环境变量 var 的值为 value
|
||||
H=handler - 设置处理器
|
||||
PT - Pass through – 如果 URL 有额外的头
|
||||
QSA - 从到替换 URL 的请求追加查询字符串
|
||||
|
||||
#### 18. 重定向一个非 www URL 到 www URL ####
|
||||
|
||||
在开始解释之前,首先看看启用该功能需要添加到 .htaccess 文件的行。
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteCond %{HTTP_HOST} ^abc\.net$
|
||||
RewriteRule (.*) http://www.abc.net/$1 [R=301,L]
|
||||
|
||||
上面的行启用 Rewrite Engine 然后在第二行检查所有涉及到主机 abc.net 或 环境变量 HTTP_HOST 为 “abc.net” 的 URL。
|
||||
|
||||
对于所有这样的 URL,代码永久重定向它们(如果启用了 R=301 规则)到新 URL http://www.abc.net/$1,其中 $1 是主机为 abc.net 的非 www URL。非 www URL 是大括号内的内容,并通过 $1 引用。
|
||||
|
||||
#### 19. 重定向整个站点到 https ####
|
||||
|
||||
下面的行会帮助你转换整个网站到 https:
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteCond %{HTTPS} !on
|
||||
RewriteRule (.*) https://%{HTTP_HOST}%{REQUEST_URI}
|
||||
|
||||
上面的行启用 re-write engine 然后检查环境变量 HTTPS 的值。如果设置了那么重写所有网站页面到 https。
|
||||
|
||||
#### 20.一个自定义重写例子 ####
|
||||
|
||||
例如,重定向 url ‘http://www.abc.net?p=100&q=20’ 到 ‘http://www.abc.net/10020pq’。
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteRule ^http://www.abc.net/([0-9]+)([0-9]+)pq$ ^http://www.abc.net?p=$1&q=$2
|
||||
|
||||
在上面的行中,$1 表示第一个括号,$2 表示第二个括号。
|
||||
|
||||
#### 21. 重命名 htaccess 文件 ####
|
||||
|
||||
为了防止入侵者和其他人查看 .htaccess 文件,你可以重命名该文件,这样就不能通过客户端浏览器访问。实现该目标的语句是:
|
||||
|
||||
AccessFileName htac.cess
|
||||
|
||||
#### 22. 如何为你的网站禁用图片链接 ####
|
||||
|
||||
网站大的带宽消耗的另外一个重要问题是热链接问题,这是其它站点用于显示你网站的图片而链接到你的网站的链接,这会消耗你的带宽。这问题也被成为 ‘带宽盗窃’。
|
||||
|
||||
一个常见现象是当一个网站要显示其它网站所包含的图片时,由于该链接你的网站需要被加载,消耗你站点的带宽而显示其它站点的图片。为了防止出现这种情况,例如 .gif、.jpeg 图片等,下面的代码行会有所帮助:
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteCond %{HTTP_REFERER} !^$
|
||||
RewriteCond %{HTTP_REFERERER} !^http://(www\.)?mydomain.com/.*$ [NC]
|
||||
RewriteRule \.(gif|jpeg|png)$ - [F].
|
||||
|
||||
上面的行检查 HTTP_REFERER 是否没有设为空或没有设为你站点上的任何链接。如果是这样的话,你网页上的所有图片会用 403 禁止访问代替。
|
||||
|
||||
#### 23. 如何将用户重定向到维护页面 ####
|
||||
|
||||
如果你的网站需要进行维护并且你想向所有需要访问该网站的你的所有客户通知这个消息,对于这种情况,你可以添加下面的行到你的 .htaccess 文件,从而只允许管理员访问并替换所有有 .jpg、.css、.gif、.js 等的页面。
|
||||
|
||||
RewriteCond %{REQUEST_URI} !^/admin/ [NC]
|
||||
RewriteCond %{REQUEST_URI} !^((.*).css|(.*).js|(.*).png|(.*).jpg) [NC]
|
||||
RewriteRule ^(.*)$ /ErrorDocs/Maintainence_Page.html
|
||||
[NC,L,U,QSA]
|
||||
|
||||
这些行检查请求 URL 是否包含任何例如以 ‘/admin/’ 开头的管理页面的请求,或任何到 ‘.png, .jpg, .js, .css’ 页面的请求,对于任何这样的请求,用 ‘ErrorDocs/Maintainence_Page.html’ 替换那个页面。
|
||||
|
||||
#### 24. 映射 IP 地址到域名 ####
|
||||
|
||||
名称服务器是将特定 IP 地址转换为域名的服务器。该映射也可以在 .htaccess 文件中用以下形式指定。
|
||||
|
||||
为了将地址 L.M.N.O 映射到域名 www.hellovisit.com
|
||||
RewriteCond %{HTTP_HOST} ^L\.M\.N\.O$ [NC]
|
||||
RewriteRule ^(.*)$ http://www.hellovisit.com/$1 [L,R=301]
|
||||
|
||||
上面的行检查任何页面的主机是否包含类似 L.M.N.O 的 IP 地址,如果是的话第三行会通过永久重定向将页面映射到域名 http://www.hellovisit.com。
|
||||
|
||||
#### 25. FilesMatch 标签 ####
|
||||
|
||||
类似用于应用条件到单个文件的 <files> 标签,<FilesMatch> 能用于匹配一组文件并对该组文件应用一些条件,如下:
|
||||
|
||||
<FilesMatch “\.(png|jpg)$”>
|
||||
Order Allow, Deny
|
||||
Deny from All
|
||||
</FilesMatch>
|
||||
|
||||
### 结论 ###
|
||||
|
||||
.htaccess 文件能实现的小技巧还有很多。这告诉了我们这个文件有多么强大,通过该文件能给你的站点添加多少安全性、动态性以及其它功能。
|
||||
|
||||
我们已经在这篇文章中尽最大努力覆盖尽可能多的 htaccess 小技巧,但如果我们缺少了任何重要的技巧,或者你愿意告诉我们你的 htaccess 想法和技巧,你可以在下面的评论框中提交,我们也会在文章中进行介绍。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/apache-htaccess-tricks/
|
||||
|
||||
作者:[Gunjit Khera][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gunjitk94/
|
||||
[1]:https://en.wikipedia.org/wiki/NCSA_HTTPd
|
||||
@ -0,0 +1,268 @@
|
||||
如何在 Ubuntu 中管理和使用 LVM(Logical Volume Management,逻辑卷管理)
|
||||
================================================================================
|
||||

|
||||
|
||||
在我们之前的文章中,我们介绍了[什么是 LVM 以及能用 LVM 做什么][1],今天我们会给你介绍一些 LVM 的主要管理工具,使得你在设置和扩展安装时更游刃有余。
|
||||
|
||||
正如之前所述,LVM 是介于你的操作系统和物理硬盘驱动器之间的抽象层。这意味着你的物理硬盘驱动器和分区不再依赖于他们所在的硬盘驱动和分区。而是,你的操作系统所见的硬盘驱动和分区可以是由任意数目的独立硬盘驱动汇集而成或是一个软件磁盘阵列。
|
||||
|
||||
要管理 LVM,这里有很多可用的 GUI 工具,但要真正理解 LVM 配置发生的事情,最好要知道一些命令行工具。这当你在一个服务器或不提供 GUI 工具的发行版上管理 LVM 时尤为有用。
|
||||
|
||||
LVM 的大部分命令和彼此都非常相似。每个可用的命令都由以下其中之一开头:
|
||||
|
||||
- Physical Volume = pv
|
||||
- Volume Group = vg
|
||||
- Logical Volume = lv
|
||||
|
||||
物理卷命令用于在卷组中添加或删除硬盘驱动。卷组命令用于为你的逻辑卷操作更改显示的物理分区抽象集。逻辑卷命令会以分区形式显示卷组使得你的操作系统能使用指定的空间。
|
||||
|
||||
### 可下载的 LVM 备忘单 ###
|
||||
|
||||
为了帮助你理解每个前缀可用的命令,我们制作了一个备忘单。我们会在该文章中介绍一些命令,但仍有很多你可用但没有介绍到的命令。
|
||||
|
||||
该列表中的所有命令都要以 root 身份运行,因为你更改的是会影响整个机器系统级设置。
|
||||
|
||||

|
||||
|
||||
### 如何查看当前 LVM 信息 ###
|
||||
|
||||
你首先需要做的事情是检查你的 LVM 设置。s 和 display 命令和物理卷(pv)、卷组(vg)以及逻辑卷(lv)一起使用,是一个找出当前设置好的开始点。
|
||||
|
||||
display 命令会格式化输出信息,因此比 s 命令更易于理解。对每个命令你会看到名称和 pv/vg 的路径,它还会给出空闲和已使用空间的信息。
|
||||
|
||||

|
||||
|
||||
最重要的信息是 PV 名称和 VG 名称。用这两部分信息我们可以继续进行 LVM 设置。
|
||||
|
||||
### 创建一个逻辑卷 ###
|
||||
|
||||
逻辑卷是你的操作系统在 LVM 中使用的分区。创建一个逻辑卷,首先需要拥有一个物理卷和卷组。下面是创建一个新的逻辑卷所需要的全部命令。
|
||||
|
||||
#### 创建物理卷 ####
|
||||
|
||||
我们会从一个完全新的没有任何分区和信息的硬盘驱动开始。首先找出你将要使用的磁盘。(/dev/sda, sdb, 等)
|
||||
|
||||
> 注意:记住所有的命令都要以 root 身份运行或者在命令前面添加 'sudo' 。
|
||||
|
||||
fdisk -l
|
||||
|
||||
如果之前你的硬盘驱动从没有格式化或分区,在 fdisk 的输出中你很可能看到类似下面的信息。这完全正常,因为我们会在下面的步骤中创建需要的分区。
|
||||
|
||||

|
||||
|
||||
我们的新磁盘位置是 /dev/sdb,让我们用 fdisk 命令在驱动上创建一个新的分区。
|
||||
|
||||
这里有大量能创建新分区的 GUI 工具,包括 [Gparted][2],但由于我们已经打开了终端,我们将使用 fdisk 命令创建需要的分区。
|
||||
|
||||
在终端中输入以下命令:
|
||||
|
||||
fdisk /dev/sdb
|
||||
|
||||
这会使你进入到一个特殊的 fdisk 提示符中。
|
||||
|
||||

|
||||
|
||||
以指定的顺序输入命令创建一个使用新硬盘驱动 100% 空间的主分区并为 LVM 做好了准备。如果你需要更改分区的大小或相应多个分区,我建议使用 GParted 或自己了解关于 fdisk 命令的使用。
|
||||
|
||||
**警告:下面的步骤会格式化你的硬盘驱动。确保在进行下面步骤之前你的硬盘驱动中没有任何信息。**
|
||||
|
||||
- n = 创建新分区
|
||||
- p = 创建主分区
|
||||
- 1 = 成为磁盘上的首个分区
|
||||
|
||||
输入 enter 键两次以接受默认的第一个和最后一个柱面。
|
||||
|
||||

|
||||
|
||||
用下面的命令准备 LVM 所使用的分区。
|
||||
|
||||
- t = 更改分区类型
|
||||
- 8e = 更改为 LVM 分区类型
|
||||
|
||||
核实并将信息写入硬盘驱动器。
|
||||
|
||||
- p = 查看分区设置使得写入更改到磁盘之前可以回看
|
||||
- w = 写入更改到磁盘
|
||||
|
||||

|
||||
|
||||
运行这些命令之后,会退出 fdisk 提示符并返回到终端的 bash 提示符中。
|
||||
|
||||
输入 pvcreate /dev/sdb1 在刚创建的分区上新建一个 LVM 物理卷。
|
||||
|
||||
你也许会问为什么我们不用一个文件系统格式化分区,不用担心,该步骤在后面。
|
||||
|
||||

|
||||
|
||||
#### 创建卷组 ####
|
||||
|
||||
现在我们有了一个指定的分区和创建好的物理卷,我们需要创建一个卷组。很幸运这只需要一个命令。
|
||||
|
||||
vgcreate vgpool /dev/sdb1
|
||||
|
||||

|
||||
|
||||
Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称,但建议标签以 vg 开头,以便后面你使用它时能意识到这是一个卷组。
|
||||
|
||||
#### 创建逻辑卷 ####
|
||||
|
||||
创建 LVM 将使用的逻辑卷:
|
||||
|
||||
lvcreate -L 3G -n lvstuff vgpool
|
||||
|
||||

|
||||
|
||||
-L 命令指定逻辑卷的大小,在该情况中是 3 GB,-n 命令指定卷的名称。 指定 vgpool 所以 lvcreate 命令知道从什么卷获取空间。
|
||||
|
||||
#### 格式化并挂载逻辑卷 ####
|
||||
|
||||
最后一步是用一个文件系统格式化新的逻辑卷。如果你需要选择一个 Linux 文件系统的帮助,请阅读 [如果根据需要选取最合适的文件系统][3]。
|
||||
|
||||
mkfs -t ext3 /dev/vgpool/lvstuff
|
||||
|
||||

|
||||
|
||||
创建挂载点并将卷挂载到你可以使用的地方。
|
||||
|
||||
mkdir /mnt/stuff
|
||||
mount -t ext3 /dev/vgpool/lvstuff /mnt/stuff
|
||||
|
||||

|
||||
|
||||
#### 重新设置逻辑卷大小 ####
|
||||
|
||||
逻辑卷的一个好处是你能使你的共享物理变大或变小而不需要移动所有东西到一个更大的硬盘驱动。另外,你可以添加新的硬盘驱动并同时扩展你的卷组。或者如果你有一个不使用的硬盘驱动,你可以从卷组中移除它使得逻辑卷变小。
|
||||
|
||||
这里有三个用于使物理卷、卷组和逻辑卷变大或变小的基础工具。
|
||||
|
||||
注意:这些命令中的每个都要以 pv、vg 或 lv 开头,取决于你的工作对象。
|
||||
|
||||
- resize – 能压缩或扩展物理卷和逻辑卷,但卷组不能
|
||||
- extend – 能使卷组和逻辑卷变大但不能变小
|
||||
- reduce – 能使卷组和逻辑卷变小但不能变大
|
||||
|
||||
让我们来看一个如何向刚创建的逻辑卷 "lvstuff" 添加新硬盘驱动的例子。
|
||||
|
||||
#### 安装并格式化新硬盘驱动 ####
|
||||
|
||||
按照上面创建新分区并更改分区类型为 LVM(8e) 的步骤安装一个新硬盘驱动。然后用 pvcreate 命令创建一个 LVM 能识别的物理卷。
|
||||
|
||||
#### 添加新硬盘驱动到卷组 ####
|
||||
|
||||
要添加新的硬盘驱动到一个卷组,你只需要知道你的新分区,在我们的例子中是 /dev/sdc1,以及想要添加到的卷组的名称。
|
||||
|
||||
这会添加新物理卷到已存在的卷组中。
|
||||
|
||||
vgextend vgpool /dev/sdc1
|
||||
|
||||

|
||||
|
||||
#### 扩展逻辑卷 ####
|
||||
|
||||
调整逻辑卷的大小,我们需要指出的是通过大小而不是设备来扩展。在我们的例子中,我们会添加一个 8GB 的硬盘驱动到我们的 3GB vgpool。我们可以用 lvextend 或 lvresize 命令使该空间可用。
|
||||
|
||||
lvextend -L8G /dev/vgpool/lvstuff
|
||||
|
||||

|
||||
|
||||
当这个命令工作的时候你会发现它实际上重新设置逻辑卷大小为 8GB 而不是我们期望的将 8GB 添加到已存在的卷上。要添加剩余的可用 3GB 你需要用下面的命令。
|
||||
|
||||
lvextend -L+3G /dev/vgpool/lvstuff
|
||||
|
||||

|
||||
|
||||
现在我们的逻辑卷已经是 11GB 大小了。
|
||||
|
||||
#### 扩展文件系统 ####
|
||||
|
||||
逻辑卷是 11GB 大小但是上面的文件系统仍然只有 3GB。要使文件系统使用整个的 11GB 可用空间你需要用 resize2fs 命令。你只需要指定 resize2fs 到 11GB 逻辑卷它就会帮你完成其余的工作。
|
||||
|
||||
resize2fs /dev/vgpool/lvstuff
|
||||
|
||||

|
||||
|
||||
**注意:如果你使用除 ext3/4 之外的文件系统,请查看调整你的文件系统大小的工具。**
|
||||
|
||||
#### 压缩逻辑卷 ####
|
||||
|
||||
如果你想从卷组中移除一个硬盘驱动你可以按照上面的步骤反向操作,并用 lvreduce 或 vgreduce 命令代替。
|
||||
|
||||
1. 调整文件系统大小 (调整之前确保已经移动文件到硬盘驱动安全的地方)
|
||||
1. 减小逻辑卷 (除了 + 可以扩展大小,你也可以用 - 压缩大小)
|
||||
1. 用 vgreduce 从卷组中移除硬盘驱动
|
||||
|
||||
#### 备份逻辑卷 ####
|
||||
|
||||
快照是一些新的高级文件系统提供的功能,但是 ext3/4 文件系统并没有快照的功能。LVM 快照最棒的是你的文件系统永不掉线,你可以拥有你想要的任何大小而不需要额外的硬盘空间。
|
||||
|
||||

|
||||
|
||||
LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该照片可以用于在不同的硬盘驱动上进行备份。生成一个备份的时候,任何需要添加到逻辑卷的新信息会如往常一样写入磁盘,但会跟踪更改使得原始快照永远不会损毁。
|
||||
|
||||
要创建一个快照,我们需要创建拥有足够空闲空间的逻辑卷,用于保存我们备份的时候会写入该逻辑卷的任何新信息。如果驱动并不是经常写入,你可以使用很小的一个存储空间。备份完成的时候我们只需要移除临时逻辑卷,原始逻辑卷会和往常一样。
|
||||
|
||||
#### 创建新快照 ####
|
||||
|
||||
创建 lvstuff 的快照,用带 -s 标记的 lvcreate 命令。
|
||||
|
||||
lvcreate -L512M -s -n lvstuffbackup /dev/vgpool/lvstuff
|
||||
|
||||

|
||||
|
||||
这里我们创建了一个只有 512MB 的逻辑卷,因为驱动实际上并不会使用。512MB 的空间会保存备份时产生的任何新数据。
|
||||
|
||||
#### 挂载新快照 ####
|
||||
|
||||
和之前一样,我们需要创建一个挂载点并挂载新快照,然后才能从中复制文件。
|
||||
|
||||
mkdir /mnt/lvstuffbackup
|
||||
mount /dev/vgpool/lvstuffbackup /mnt/lvstuffbackup
|
||||
|
||||

|
||||
|
||||
#### 复制快照和删除逻辑卷 ####
|
||||
|
||||
你剩下需要做的是从 /mnt/lvstuffbackup/ 中复制所有文件到一个外部的硬盘驱动或者打包所有文件到一个文件。
|
||||
|
||||
**注意:tar -c 会创建一个归档文件,-f 要指出归档文件的名称和路径。要获取 tar 命令的帮助信息,可以在终端中输入 man tar。**
|
||||
|
||||
tar -cf /home/rothgar/Backup/lvstuff-ss /mnt/lvstuffbackup/
|
||||
|
||||

|
||||
|
||||
记住备份发生的时候写到 lvstuff 的所有文件都会在我们之前创建的临时逻辑卷中被跟踪。确保备份的时候你有足够的空闲空间。
|
||||
|
||||
备份完成后,卸载卷并移除临时快照。
|
||||
|
||||
umount /mnt/lvstuffbackup
|
||||
lvremove /dev/vgpool/lvstuffbackup/
|
||||
|
||||

|
||||
|
||||
#### 删除逻辑卷 ####
|
||||
|
||||
要删除一个逻辑卷,你首先需要确保卷已经卸载,然后你可以用 lvremove 命令删除它。逻辑卷删除后你可以移除卷组,卷组删除后你可以删除物理卷。
|
||||
|
||||
这是所有移除我们创建的卷和组的命令。
|
||||
|
||||
umount /mnt/lvstuff
|
||||
lvremove /dev/vgpool/lvstuff
|
||||
vgremove vgpool
|
||||
pvremove /dev/sdb1 /dev/sdc1
|
||||
|
||||

|
||||
|
||||
这些已经囊括了关于 LVM 你需要了解的大部分知识。如果你有任何关于这些讨论的经验,请在下面的评论框中和大家分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.howtogeek.com/howto/40702/how-to-manage-and-use-lvm-logical-volume-management-in-ubuntu/
|
||||
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.howtogeek.com/howto/36568/what-is-logical-volume-management-and-how-do-you-enable-it-in-ubuntu/
|
||||
[2]:http://www.howtogeek.com/howto/17001/how-to-format-a-usb-drive-in-ubuntu-using-gparted/
|
||||
[3]:http://www.howtogeek.com/howto/33552/htg-explains-which-linux-file-system-should-you-choose/
|
||||
@ -1,77 +0,0 @@
|
||||
Ubuntu中安装Unity 8桌面预览版
|
||||
================================================================================
|
||||

|
||||
|
||||
如果你一直关注新闻,那么Ubuntu将会切换到[Mir显示服务器][1],并随同发布[Unity 8][2]桌面。然而,在尚未确定Unity 8是否会在[Ubuntu 15.10 Willy Werewolf][3]中部署到Mir上之前,提供了一个Unity 8的预览版本供你体验和测试。通过官方PPA,可以很容地**安装Unity 8到Ubuntu 14.04,14.10和15.04中**。
|
||||
|
||||
到目前为止,开发者已经可以通过[ISO][4]获得该Unity 8预览来进行测试。但是Canonical已经通过[LXC容器][5]发布了。通过该方法,你可以获取Unity 8桌面会话,让它作为任何一个桌面环境运行在Mir显示服务器上。就像你[在Ubuntu中安装Mate桌面][6],然后从LightDm登录屏幕选择桌面会话一样。
|
||||
|
||||
好奇?想要试试Unity 8?让我们来看怎样安装它吧。
|
||||
|
||||
**注意: 它是一个实验性预览,可能不是所有人都可以让它正确工作的。**
|
||||
|
||||
### 安装Unity 8桌面到Ubuntu ###
|
||||
|
||||
下面是安装并使用Unity 8的步骤:
|
||||
|
||||
#### 步骤 1: 安装Unity 8到Ubuntu 12.04和14.04 ####
|
||||
|
||||
如果你真运行着Ubuntu 12.04和14.04,那么你必须使用官方PPA来安装Unity 8。使用以下命令进行安装:
|
||||
|
||||
sudo apt-add-repository ppa:unity8-desktop-session-team/unity8-preview-lxc
|
||||
sudo apt-get update
|
||||
sudo apt-get upgrade
|
||||
sudo apt-get install unity8-lxc
|
||||
|
||||
#### 步骤 1: 安装Unity 8到Ubuntu 14.10和15.04 ####
|
||||
|
||||
如果你真运行着Ubuntu 14.10或15.04,那么Unity 8 LXC已经在源中准备好。你只需要运行以下命令:
|
||||
|
||||
sudo apt-get update
|
||||
sudo apt-get install unity8-lxc
|
||||
|
||||
#### 步骤 2: 设置Unity 8桌面预览LXC ####
|
||||
|
||||
安装Unity 8 LXC后,该对它进行设置,下面的命令就可达到目的:
|
||||
|
||||
sudo unity8-lxc-setup
|
||||
|
||||
它将花费一些时间来设置,所以,给点耐心吧。它会下载ISO,然后解压缩,接着完整最后一些必要的设置来让它工作。它也会安装一个LightDM的轻度修改版本。这一切都搞定后,需要重启。
|
||||
|
||||
#### 步骤 3: 选择Unity 8 ####
|
||||
|
||||
重启后,在登录屏幕,点击你的登录旁边的Ubuntu图标:
|
||||
|
||||

|
||||
|
||||
你应该可以在这看到Unity 8的选项,选择它:
|
||||
|
||||

|
||||
|
||||
### 卸载Unity 8 LXC ###
|
||||
|
||||
如果你发现Unity 8毛病太多,或者你不喜欢它,那么你可以以相同的方式切换会默认Unity版本。此外,你也可以通过下面的命令移除Unity 8:
|
||||
|
||||
sudo apt-get remove unity8-lxc
|
||||
|
||||
该命令会将Unity 8选项从LightDM屏幕移除,但是配置仍然保留着。
|
||||
|
||||
以上就是你在Ubuntu中安装嗲有Mir的Unity 8的全部过程,试玩后请分享你关于Unity 8的想法哦!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/install-unity-8-desktop-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://en.wikipedia.org/wiki/Mir_%28software%29
|
||||
[2]:https://wiki.ubuntu.com/Unity8Desktop
|
||||
[3]:http://itsfoss.com/ubuntu-15-10-codename/
|
||||
[4]:https://wiki.ubuntu.com/Unity8DesktopIso
|
||||
[5]:https://wiki.ubuntu.com/Unity8inLXC
|
||||
[6]:http://itsfoss.com/install-mate-desktop-ubuntu-14-04/
|
||||
@ -1,174 +0,0 @@
|
||||
NGINX内部: 我们如何设计性能和扩展
|
||||
================================================================================
|
||||
NGINX是web应用中性能最好的一个,这一切都是由于软件设计。而许多web服务器和应用程序服务器使用一个简单的线程或基于流程的架构,NGINX立足于一个复杂的事件驱动的体系结构,使它能够在现代硬件上扩展到成千上万的并发连接。
|
||||
|
||||
[NGINX内部][1]信息图从高级流程架构深度挖掘说明了NGINX如何在单进程里保持多连接。这个博客进一步详细地解释了这一切是如何工作的。
|
||||
|
||||
### 知识 – NGINX进程模型 ###
|
||||
|
||||

|
||||
|
||||
为了更好的理解这个设计,你需要理解NGINX如何运行的。NGINX有一个主进程(它执行特权操作如读取配置和绑定端口)和一些工作进程与辅助进程。
|
||||
|
||||
# service nginx restart
|
||||
* Restarting nginx
|
||||
# ps -ef --forest | grep nginx
|
||||
root 32475 1 0 13:36 ? 00:00:00 nginx: master process /usr/sbin/nginx \
|
||||
-c /etc/nginx/nginx.conf
|
||||
nginx 32476 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
|
||||
nginx 32477 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
|
||||
nginx 32479 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
|
||||
nginx 32480 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
|
||||
nginx 32481 32475 0 13:36 ? 00:00:00 \_ nginx: cache manager process
|
||||
nginx 32482 32475 0 13:36 ? 00:00:00 \_ nginx: cache loader process
|
||||
|
||||
在四核服务器,NGINX主进程创建4工作进程和两个管理磁盘内容缓存的缓存辅助进程。
|
||||
|
||||
### 为什么架构很重要? ###
|
||||
|
||||
任何Unix应用程序的根本基础是线程或进程。(从Linux操作系统的角度来看,线程和进程大多是相同的,主要的区别是他们共享内存的程度。)一个线程或进程是一个独立的指令,操作系统可以运行在一个CPU核心。大多数复杂的应用程序并行运行多个线程或进程有两个原因:
|
||||
|
||||
- 他们可以同时使用更多的计算核心。
|
||||
- 线程或进程可以轻松实现并行操作。(例如,在同一时刻保持多连接)。
|
||||
|
||||
进程和线程消耗资源。他们每个都使用内存和其他系统资源,他们需要被交换进出核心(一个操作可以叫做上下文切换)。大多数现代服务器可以保持上百小型、活动的并发连接,一旦内存耗尽或高I/O压力引起大量的上下文切换性能会严重下降。
|
||||
|
||||
网络应用程序设计的常用方法是为每个连接分配一个线程或进程。此体系结构简单、容易实现,但是当应用程序需要处理成千上万的并发连接时这种结构不具规模。
|
||||
|
||||
### NGINX如何工作? ###
|
||||
|
||||
NGINX使用一种可预测进程模式,被调到了可使用的硬件资源上:
|
||||
|
||||
- 主进程执行特权操作,如读取配置和绑定端口,然后创建一个小数量的子进程(接下来的三种类型)。
|
||||
- 缓存加载程序进程在加载磁盘缓存到内存中时开始运行,然后退出。它被适当的安排,所以其资源需求很低。
|
||||
- 缓存管理器进程定期修剪磁盘缓存中的记录来保持他们在配置的大小之内。
|
||||
- 工作进程做所有的工作!他们保持网络连接、读写内容到磁盘,与上游服务器通信。
|
||||
|
||||
在大多数情况下建议NGINX的配置 – 每个CPU核心运行一个工作进程 – 最有效地利用硬件资源。你的配置包含了[worker_processes auto][2]指令配置:
|
||||
|
||||
worker_processes auto;
|
||||
|
||||
当一个NGINX服务处于活动状态,只有工作进程是忙碌的。每个工作进程以非阻塞方式保持多连接,减少上下文交换。
|
||||
|
||||
每个工作进程是一个单线程并且独立运行,获取新链接并处理他们。这些进程可以使用共享内存通信来共享缓存数据,会话持久性数据,和其他共享资源。
|
||||
|
||||
### NGINX工作进程内部 ###
|
||||
|
||||

|
||||
|
||||
NGINX主进程通过NGINX配置初始化每个工作进程并提供一组监听端口。
|
||||
|
||||
NGINX工作进程首先在监听套接字上等待事件([accept_mutex][3]和[内核套接字分片][4])。事件被新进来的链接初始化。这些连接被分配到一个状态机 – HTTP状态机是最常用的,但NGINX也具备流式(原始的TCP)状态机和大量的邮件协议(SMTP、IMAP和POP3)。
|
||||
|
||||

|
||||
|
||||
状态机本质上是一组指令,告诉NGINX如何处理一个请求。大多数web服务器执行相同的函数作为NGINX使用类似的状态机 - 区别在于实现。
|
||||
|
||||
### 调度状态机 ###
|
||||
|
||||
把状态机想象成国际象棋的规则。每个HTTP事务是一个象棋游戏。一方面棋盘是web服务器 – 一位大师可以非常迅速地做出决定。另一方面是远程客户端 – 在一个相对较慢的网络下web浏览器访问网站或应用程序。
|
||||
|
||||
不管咋地,这个游戏规则很复杂。例如,web服务器可能需要与各方沟通(代理一个上游的应用程序)或与身份验证服务器对话。web服务器的第三方模块甚至可以扩展游戏规则。
|
||||
|
||||
#### 一个阻塞状态机 ####
|
||||
|
||||
回忆我们描述一个进程或线程就像一个独立的指令集,操作系统可以调度运行它在一个CPU核心。大多数web服务器和web应用使用一个进程一个链接或者一个线程一个链接的模式来运行这个“象棋游戏”。每个进程或线程都包含指令来玩“一个游戏”直到结束。一次进程在服务器运行,它花费大部分的时间“阻塞” - 等待客户端完成它的下一步行动。
|
||||
|
||||

|
||||
|
||||
1. web服务器进程在监听套接字监听新连接(客户端发起新“游戏”)
|
||||
1. 当它获得一个新游戏,就玩这个游戏,每走一步去等待客户端响应时就阻塞了。
|
||||
1. 游戏完成后,web服务器进程可能会等待是否有客户机想要开始一个新游戏(这对应于一个保持连接)。如果这个链接关闭了(客户端离开或者发生超时),web服务器进程返回监听一个新“游戏”。
|
||||
|
||||
要记住最重要的一点是每个活动的HTTP链接(每局棋)需要一个专用的进程或线程(象棋高手)。这个结构简单容并且易扩展第三方模块(“新规则”)。无论如何,还是有巨大的不平衡:尤其是轻量的HTTP链接,作为代表是一个文件描述符和小量的内存,映射到一个单独的线程或进程,一个非常重量的系统对象。这种方式易于编程,但太过浪费。
|
||||
|
||||
#### NGINX是一个真正的象棋大师 ####
|
||||
|
||||
也许你听过[同时表演赛][5]游戏,有一个象棋大师同时对战许多对手?
|
||||
|
||||

|
||||
|
||||
[列夫·吉奥吉夫在保加利亚的索非亚同时对阵360人][6]。他的最终成绩是284胜70平6负。
|
||||
|
||||
这就是NGINX工作进程如何“下棋”的。每个工作进程(记住 - 通常每个CPU核心上有一个工作进程)是一个可同时对战上百人(事实是,成百上千)的象棋大师。
|
||||
|
||||

|
||||
|
||||
1. 工作进程在监听和链接套接字上等待事件。
|
||||
1. 事件发生在套接字并且由工作进程处理它们:
|
||||
|
||||
- 在监听套接字的事件意味着一个客户端已经开始了一局新棋局。工作进程创建了一个新链接套接字。
|
||||
- 在链接套接字的事件意味着客户端已经下了一步棋。工作进程快速的响应。
|
||||
|
||||
一个工作进程在网络流量上从不阻塞,等待它的“对手”(客户端)做出反应。当它下了一步,工作进程立即继续其他的游戏,在那里工作进程正在处理下一步,或者在门口欢迎一个新玩家。
|
||||
|
||||
### 为什么这个比阻塞式多进程架构更快? ###
|
||||
|
||||
NGINX每个工作进程很好的扩展支撑了成百上千的链接。每个链接在工作进程中创建另一个文件描述符和消耗一小部分额外内存。每个链接很少有额外的开销。NGINX进程可以固定在一些CPU上。上下文交换非常罕见,只发生在没有工作要做。
|
||||
|
||||
阻塞方式,一个链接一个进程的方法中,每个连接需要大量额外的资源和开销,和上下文切换(从一个进程切换到另一个)非常频繁
|
||||
|
||||
更详细的解释,看看这个[文章][7]关于NGINX架构,由NGINX公司发展副总裁和创始人之一 Andrew Alexeev 著。
|
||||
|
||||
适当的[系统优化][8],NGINX的每个工作进程可以扩展来处理成千上万的并发HTTP连接,并能脸不红心不跳的承受峰值流量(大量涌入的新“游戏”)。
|
||||
|
||||
### 更新配置和升级NGINX ###
|
||||
|
||||
NGINX是过程体系架构,有一小部分工作进程,有助于有效的更新配置文件甚至NGINX程序本身。
|
||||
|
||||

|
||||
|
||||
更新NGINX配置文件是非常简单、轻量、可靠的操作。它通常意味着运行命令`nginx –s reload`,所做的就是检查磁盘上的配置并发送SIGHUP信号给主进程。
|
||||
|
||||
当主进程接收到一个SIGHUP信号,它会做两件事:
|
||||
|
||||
- 重载配置文件和分出一组新的工作进程。这些新的工作进程立即开始接受连接和处理流量(使用新的配置设置)
|
||||
- 通知旧的工作进程优雅的退出。工作进程停止接受新的链接。当前的http请求一完成,工作进程就彻底关闭这个链接(那就是,没有残存的保持链接)。一旦所有链接关闭,这个工作进程就退出。
|
||||
|
||||
这个重载过程能引发一个CPU和内存使用的小峰值,但是跟活动链接加载的支援比它一般不易察觉。你可以每秒多次重载配置(很多NGINX用户都这么做)。很少情况下,问题发生在很多代的工作进程等待关闭连接时,但即使是那样也很快被解决了。
|
||||
|
||||
NGINX的程序升级过程中实现了高可用的圣杯 - 你可以随随时更新这个软件,不会丢失连接,停机,或者中断服务。
|
||||
|
||||

|
||||
|
||||
程序升级过程很像优雅的重载配置的方法。一个新的NGINX主进程与原主进程并行运行,然后他们共享监听套接字。两个进程都是活动的,并且各自的工作进程处理流量。然后你可以通知旧主进程和他的工作进程优雅的退出。
|
||||
|
||||
整个进程的详细描述在[NGINX管理][9].
|
||||
|
||||
### 结论 ###
|
||||
|
||||
[NGINX内部信息图][10] 提供一个NGINX功能实现的高级的概况,但在这简单的解释是超过十年的创新和优化,使Nginx在一个范围广泛的硬件上提供尽可能最好的性能同时保持现代Web应用程序需要的安全性和可靠性。
|
||||
|
||||
如果你想阅读更多关于NGINX的优化,查看这些优秀的资源:
|
||||
|
||||
- [Installing and Tuning NGINX for Performance][11] (webinar; [slides][12] at Speaker Deck)
|
||||
- [Tuning NGINX for Performance][13]
|
||||
- [The Architecture of Open Source Applications – NGINX][14]
|
||||
- [Socket Sharding in NGINX Release 1.9.1][15] (using the SO_REUSEPORT socket option)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://nginx.com/blog/inside-nginx-how-we-designed-for-performance-scale/
|
||||
|
||||
作者:[Owen Garrett][a]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://nginx.com/author/owen/
|
||||
[1]:http://nginx.com/resources/library/infographic-inside-nginx/
|
||||
[2]:http://nginx.org/en/docs/ngx_core_module.html#worker_processes
|
||||
[3]:http://nginx.org/en/docs/ngx_core_module.html#accept_mutex
|
||||
[4]:http://nginx.com/blog/socket-sharding-nginx-release-1-9-1/
|
||||
[5]:http://en.wikipedia.org/wiki/Simultaneous_exhibition
|
||||
[6]:http://gambit.blogs.nytimes.com/2009/03/03/in-chess-records-were-made-to-be-broken/
|
||||
[7]:http://www.aosabook.org/en/nginx.html
|
||||
[8]:http://nginx.com/blog/tuning-nginx/
|
||||
[9]:http://nginx.org/en/docs/control.html
|
||||
[10]:http://nginx.com/resources/library/infographic-inside-nginx/
|
||||
[11]:http://nginx.com/resources/webinars/installing-tuning-nginx/
|
||||
[12]:https://speakerdeck.com/nginx/nginx-installation-and-tuning
|
||||
[13]:http://nginx.com/blog/tuning-nginx/
|
||||
[14]:http://www.aosabook.org/en/nginx.html
|
||||
[15]:http://nginx.com/blog/socket-sharding-nginx-release-1-9-1/
|
||||
@ -0,0 +1,91 @@
|
||||
如何在 Cacti 中合并两幅图片
|
||||
================================================================================
|
||||
[Cacti][1] 是一个很棒的开源网络监视系统,它广泛使用于图示网络元素,例如带宽、存储、处理器和内存使用。使用它的基于网络的接口,你可以轻松地创建和组织图。然而,默认并没有提供一些高级功能,例如合并图片、使用多个来源创建聚合图、迁移 Cacti 到另一台服务器。使用 Cacti 的这些功能你还需要一些经验。在该教程中,我们会看到如何在将两幅 Cacti 图片合并为一幅。
|
||||
|
||||
考虑这个例子。在过去的 6 个月中,客户端 A 连接到了交换机 A 的端口 5。端口 5 发生了错误,因此客户端迁移到了端口 6。由于 Cacti 为每个接口/元素使用不同的图,客户端的带宽历史会分成端口 5 和端口 6。结果是对于一个客户端我们有两幅图片 - 一幅是 6 个月的旧数据,另一幅保存了后续的数据。
|
||||
|
||||
在这种情况下,我们实际上可以合并两幅图片将旧数据加到新的图中,使得用一个单独的图为一个用户保存历史的和新数据。该教程将会解释如何做到这一点。
|
||||
|
||||
Cacti 将每幅图片的数据保存在它自己的 RRD(round robin database,循环数据库) 文件中。当请求一幅图片时,根据保存在对应 RRD 文件中的值生成图。在 Ubuntu/Debian 系统中,RRD 文件保存在 `/var/lib/cacti/rra`,在 CentOS/RHEL 系统中则是 `/var/www/cacti/rra`。
|
||||
|
||||
合并图片背后的思想是更改这些 RRD 文件使得旧 RRD 文件中的值能追加到新的 RRD 文件中。
|
||||
|
||||
### 情景 ###
|
||||
|
||||
一个客户端的服务在 eth0 上运行了超过一年。由于硬件损坏,客户端迁移到了另一台服务器的 eth1 接口。我们想图示新接口的带宽,同时保留超过一年的历史数据。只在一幅图中显示客户端。
|
||||
|
||||
### 确定图的 RRD 文件 ###
|
||||
|
||||
图合并的首个步骤是确定和图关联的 RRD 文件。我们可以通过以调试模式打开图检查文件。要做到这点,在 Cacti 的菜单中: 控制台 > 管理图 > 选择图 > 打开图调试模式。
|
||||
|
||||
#### 旧图: ####
|
||||
|
||||

|
||||
|
||||
#### 新图: ####
|
||||
|
||||

|
||||
|
||||
从样例输出(基于 Debian 系统)中,我们可以确定两幅图片的 RRD 文件:
|
||||
|
||||
- **旧图**: /var/lib/cacti/rra/old_graph_traffic_in_8.rrd
|
||||
- **新图**: /var/lib/cacti/rra/new_graph_traffic_in_10.rrd
|
||||
|
||||
### 准备脚本 ###
|
||||
|
||||
我们会用一个 [RRD 剪接脚本][2] 合并两个 RRD 文件。下载该 PHP 脚本,并安装为 /var/lib/cacti/rra/rrdsplice.php (Debian/Ubuntu 系统) 或 /var/www/cacti/rra/rrdsplice.php (CentOS/RHEL 系统)。
|
||||
|
||||
下一步,确认 Apache 用户拥有该文件。
|
||||
|
||||
在 Debian 或 Ubuntu 系统中,运行下面的命令:
|
||||
|
||||
# chown www-data:www-data rrdsplice.php
|
||||
|
||||
并更新 rrdsplice.php。查找下面的行:
|
||||
|
||||
chown($finrrd, "apache");
|
||||
|
||||
用下面的语句替换:
|
||||
|
||||
chown($finrrd, "www-data");
|
||||
|
||||
在 CentOS 或 RHEL 系统中,运行下面的命令:
|
||||
|
||||
# chown apache:apache rrdsplice.php
|
||||
|
||||
### 合并两幅图 ###
|
||||
|
||||
通过不带任何参数运行该脚本可以获得脚本的使用语法。
|
||||
|
||||
# cd /path/to/rrdsplice.php
|
||||
# php rrdsplice.php
|
||||
|
||||
----------
|
||||
|
||||
USAGE: rrdsplice.php --oldrrd=file --newrrd=file --finrrd=file
|
||||
|
||||
现在我们准备好合并两个 RRD 文件了。只需要指定旧 RRD 文件和新 RRD 文件的名称。我们会将合并后的结果重写到新 RRD 文件中。
|
||||
|
||||
# php rrdsplice.php --oldrrd=old_graph_traffic_in_8.rrd --newrrd=new_graph_traffic_in_10.rrd --finrrd=new_graph_traffic_in_10.rrd
|
||||
|
||||
现在旧 RRD 文件中的数据已经追加到了新 RRD 文件中。Cacti 会将任何新数据写到新 RRD 文件中。如果我们点击图,我们可以发现也已经添加了旧图的周、月、年记录。下面图表中的第二幅图显示了旧图的周记录。
|
||||
|
||||

|
||||
|
||||
总之,该教程显示了如何简单地将两幅 Cacti 图片合并为一幅。当服务迁移到另一个设备/接口,我们希望只处理一幅图片而不是两幅时,这个小技巧非常有用。该脚本非常方便,因为它可以不管源设备合并图片,例如 Cisco 1800 路由器和 Cisco 2960 交换机。
|
||||
|
||||
希望这些能对你有所帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/combine-two-graphs-cacti.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/install-configure-cacti-linux.html
|
||||
[2]:http://svn.cacti.net/viewvc/developers/thewitness/rrdsplice/rrdsplice.php
|
||||
@ -1,64 +1,64 @@
|
||||
Installing LAMP (Linux, Apache, MariaDB, PHP/PhpMyAdmin) in RHEL/CentOS 7.0
|
||||
在RHEL/CentOS 7.0中安装LAMP(Linux、 Apache、 MariaDB、 PHP/PhpMyAdmin)
|
||||
================================================================================
|
||||
Skipping the LAMP introduction, as I’m sure that most of you know what is all about. This tutorial will concentrate on how to install and configure famous LAMP stack – Linux Apache, MariaDB, PHP, PhpMyAdmin – on the last release of Red Hat Enterprise Linux 7.0 and CentOS 7.0, with the mention that both distributions have upgraded httpd daemon to Apache HTTP 2.4.
|
||||
跳过LAMP的介绍因为我认为你们大多数已经知道了。这个教程会集中在如何在升级到Apache 2.4的 Red Hat Enterprise Linux 7.0 和 CentOS 7.0中安装和配置LAMP-Linux Apache、 MariaDB、 PHP、PhpMyAdmin。
|
||||
|
||||

|
||||
|
||||
Install LAMP in RHEL/CentOS 7.0
|
||||
在RHEL/CentOS 7.0中安装LAMP
|
||||
|
||||
#### Requirements ####
|
||||
#### 要求 ####
|
||||
|
||||
Depending on the used distribution, RHEL or CentOS 7.0, use the following links to perform a minimal system installation, using a static IP Address for network configuration.
|
||||
根据使用的发行版,RHEL 或者 CentOS 7.0使用下面的链接来执行最小的系统安装,网络使用静态ip
|
||||
|
||||
**For RHEL 7.0**
|
||||
**对于RHEL 7.0**
|
||||
|
||||
- [RHEL 7.0 Installation Procedure][1]
|
||||
- [Register and Enable Subscriptions/Repositories on RHEL 7.0][2]
|
||||
- [RHEL 7.0安装过程][1]
|
||||
- [在RHEL 7.0中注册和启用订阅仓库][2]
|
||||
|
||||
**For CentOS 7.0**
|
||||
**对于 CentOS 7.0**
|
||||
|
||||
- [CentOS 7.0 Installation Procedure][3]
|
||||
- [CentOS 7.0 安装过程][3]
|
||||
|
||||
### Step 1: Install Apache Server with Basic Configurations ###
|
||||
### 第一步: 使用基本配置安装apache ###
|
||||
|
||||
**1. After performing a minimal system installation and configure your server network interface with a [Static IP Address on RHEL/CentOS 7.0][4], go ahead and install Apache 2.4 httpd service binary package provided form official repositories using the following command.**
|
||||
**1. 在执行最小系统安装并配置[在RHEL/CentOS 7.0中配置静态ip][4]**就可以从使用下面的命令从官方仓库安装最新的Apache 2.4 httpd服务。
|
||||
|
||||
# yum install httpd
|
||||
|
||||
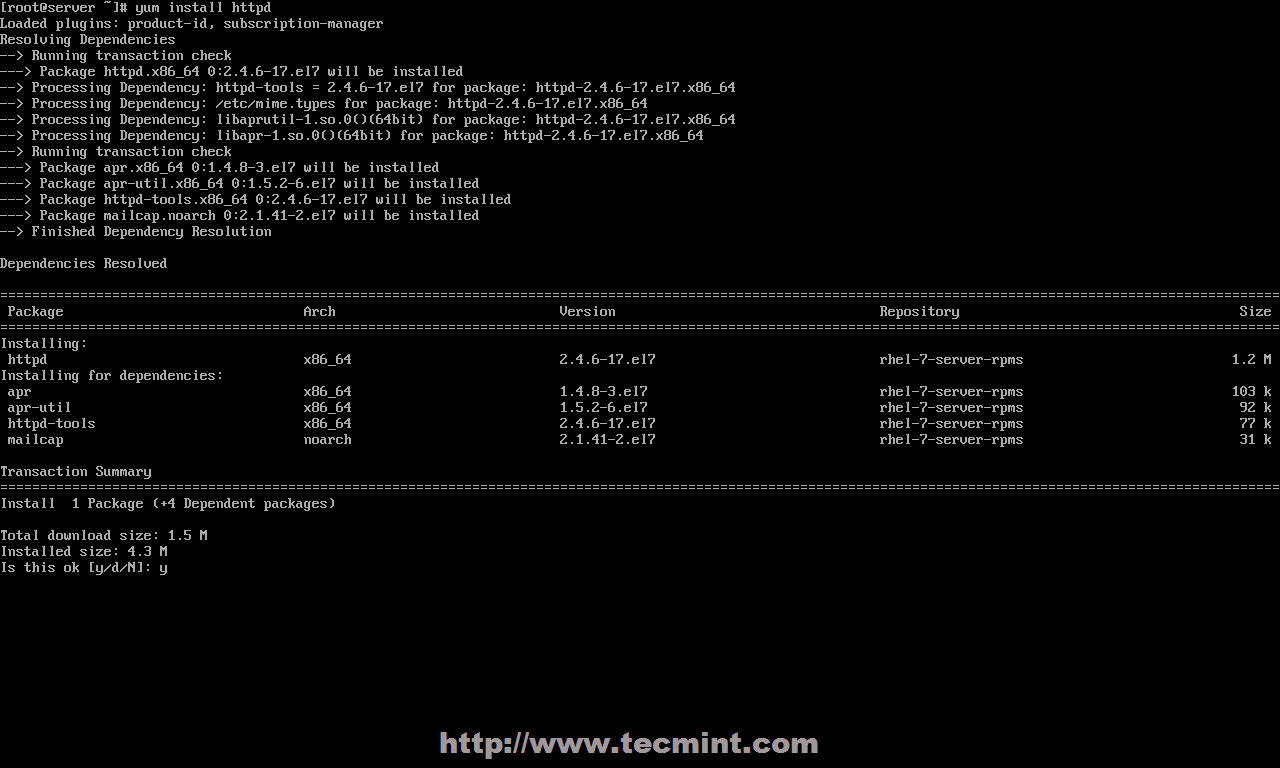
|
||||
|
||||
Install Apache Web Server
|
||||
安装apache服务
|
||||
|
||||
**2. After yum manager finish installation, use the following commands to manage Apache daemon, since RHEL and CentOS 7.0 both migrated their init scripts from SysV to systemd – you can also use SysV and Apache scripts the same time to manage the service.**
|
||||
**2. 安装安城后,使用下面的命令来管理apache守护进程,因为RHEL and CentOS 7.0都将init脚本从SysV升级到了systemd - 你也可以同事使用SysV和Apache脚本来管理服务。**
|
||||
|
||||
# systemctl status|start|stop|restart|reload httpd
|
||||
|
||||
OR
|
||||
或者
|
||||
|
||||
# service httpd status|start|stop|restart|reload
|
||||
|
||||
OR
|
||||
或者
|
||||
|
||||
# apachectl configtest| graceful
|
||||
|
||||

|
||||
|
||||
Start Apache Web Server
|
||||
启动apache服务
|
||||
|
||||
**3. On the next step start Apache service using systemd init script and open RHEL/CentOS 7.0 Firewall rules using firewall-cmd, which is the default command to manage iptables through firewalld daemon.**
|
||||
**3. 下一步使用systemd初始化脚本来启动apache服务并用firewall-cmd打开RHEL/CentOS 7.0防火墙规则, 这是通过firewalld守护进程管理iptables的默认命令。**
|
||||
|
||||
# firewall-cmd --add-service=http
|
||||
|
||||
**NOTE**: Make notice that using this rule will lose its effect after a system reboot or firewalld service restart, because it opens on-fly rules, which are not applied permanently. To apply consistency iptables rules on firewall use –permanent option and restart firewalld service to take effect.
|
||||
**注意**:上面的命令会在系统重启或者firewalld服务重启后失效,因为它是即时的规则,它不会永久生效。要使iptables规则在fiewwall中持久化,使用-permanent选项并重启firewalld服务来生效。
|
||||
|
||||
# firewall-cmd --permanent --add-service=http
|
||||
# systemctl restart firewalld
|
||||
|
||||

|
||||
|
||||
Enable Firewall in CentOS 7
|
||||
在CentOS 7中启用Firewall
|
||||
|
||||
Other important Firewalld options are presented below:
|
||||
下面是firewalld其他的重要选项:
|
||||
|
||||
# firewall-cmd --state
|
||||
# firewall-cmd --list-all
|
||||
@ -67,37 +67,38 @@ Other important Firewalld options are presented below:
|
||||
# firewall-cmd --query-service service_name
|
||||
# firewall-cmd --add-port=8080/tcp
|
||||
|
||||
**4. To verify Apache functionality open a remote browser and type your server IP Address using HTTP protocol on URL (http://server_IP), and a default page should appear like in the screenshot below.**
|
||||
**4. 要验证apache的功能,打开一个远程浏览器并使用http协议输入你服务器的ip地址(http://server_IP), 应该会显示下图中的默认页面。**
|
||||
|
||||

|
||||
|
||||
Apache Default Page
|
||||
Apache默认页
|
||||
|
||||
**5. For now, Apache DocumentRoot path it’s set to /var/www/html system path, which by default doesn’t provide any index file. If you want to see a directory list of your DocumentRoot path open Apache welcome configuration file and set Indexes statement from – to + on <LocationMach> directive, using the below screenshot as an example.**
|
||||
**5. 现在apache的根地址在/var/www/html,该目录中没有提供任何index文件。如果你想要看见根目录下的文件夹列表,打开apache欢迎配置文件并设置 <LocationMach>下Indexes前的状态从-到+,下面的截图就是一个例子。**
|
||||
|
||||
# nano /etc/httpd/conf.d/welcome.conf
|
||||
|
||||

|
||||
|
||||
Apache Directory Listing
|
||||
Apache目录列出
|
||||
|
||||
**6. Close the file, restart Apache service to reflect changes and reload your browser page to see the final result.**
|
||||
**6. 关闭文件,重启apache服务来使设置生效,重载页面来看最终效果。**
|
||||
|
||||
# systemctl restart httpd
|
||||
|
||||

|
||||
|
||||
Apache Index File
|
||||
Apache Index 文件
|
||||
|
||||
### Step 2: Install PHP5 Support for Apache ###
|
||||
### 第二步: 为Apache安装php5支持 ###
|
||||
|
||||
**7. Before installing PHP5 dynamic language support for Apache, get a full list of available PHP modules and extensions using the following command.**
|
||||
|
||||
**7. 在为apache安装php支持之前,使用下面的命令的得到所有可用的php模块和扩展。**
|
||||
|
||||
# yum search php
|
||||
|
||||

|
||||
|
||||
Install PHP in CentOS 7
|
||||
在
|
||||
|
||||
**8. Depending on what type of applications you want to use, install the required PHP modules from the above list, but for a basic MariaDB support in PHP and PhpMyAdmin you need to install the following modules.**
|
||||
|
||||
@ -140,22 +141,22 @@ Set Timezone in PHP
|
||||
|
||||

|
||||
|
||||
Install MariaDB in CentOS 7
|
||||
在CentOS 7中安装PHP
|
||||
|
||||
**12. After MariaDB package is installed, start database daemon and use mysql_secure_installation script to secure database (set root password, disable remotely logon from root, remove test database and remove anonymous users).**
|
||||
***12. 安装MariaDB后,开启数据库守护进程并使用mysql_secure_installation脚本来保护数据库(设置root密码、禁止远程root登录、移除测试数据库、移除匿名用户)**
|
||||
|
||||
# systemctl start mariadb
|
||||
# mysql_secure_installation
|
||||
|
||||

|
||||
|
||||
Start MariaDB Database
|
||||
启动MariaDB数据库
|
||||
|
||||

|
||||
|
||||
Secure MySQL Installation
|
||||
MySQL安全设置
|
||||
|
||||
**13. To test database functionality login to MariaDB using its root account and exit using quit statement.**
|
||||
**13. 要测试数据库功能,使用root账户登录MariaDB并用quit退出。**
|
||||
|
||||
mysql -u root -p
|
||||
MariaDB > SHOW VARIABLES;
|
||||
@ -163,27 +164,27 @@ Secure MySQL Installation
|
||||
|
||||

|
||||
|
||||
Connect MySQL Database
|
||||
连接MySQL数据库
|
||||
|
||||
### Step 4: Install PhpMyAdmin ###
|
||||
### 第四步: 安装PhpMyAdmin ###
|
||||
|
||||
**14. By default official RHEL 7.0 or CentOS 7.0 repositories doesn’t provide any binary package for PhpMyAdmin Web Interface. If you are uncomfortable using MySQL command line to manage your database you can install PhpMyAdmin package by enabling CentOS 7.0 rpmforge repositories using the following command.**
|
||||
**14. RHEL 7.0 或者 CentOS 7.0仓库默认没有提供PhpMyAdmin二进制安装包。如果你不适应使用MySQL命令行来管理你的数据库,你可以通过下面的命令启用CentOS 7.0 rpmforge仓库来安装PhpMyAdmin。**
|
||||
|
||||
# yum install http://pkgs.repoforge.org/rpmforge-release/rpmforge-release-0.5.3-1.el7.rf.x86_64.rpm
|
||||
|
||||
After enabling rpmforge repository, next install PhpMyAdmin.
|
||||
启用rpmforge仓库后,下面安装PhpMyAdmin。
|
||||
|
||||
# yum install phpmyadmin
|
||||
|
||||

|
||||
|
||||
Enable RPMForge Repository
|
||||
启用RPMForge仓库
|
||||
|
||||
**15. Next configure PhpMyAdmin to allow connections from remote hosts by editing phpmyadmin.conf file, located on Apache conf.d directory, commenting the following lines.**
|
||||
**15. 下面配置PhpMyAdmin的phpmyadmin.conf来允许远程连接,它位于Apache conf.d目录下,并注释掉下面的行。**
|
||||
|
||||
# nano /etc/httpd/conf.d/phpmyadmin.conf
|
||||
|
||||
Use a # and comment this lines.
|
||||
使用#来注释掉行。
|
||||
|
||||
# Order Deny,Allow
|
||||
# Deny from all
|
||||
@ -191,40 +192,40 @@ Use a # and comment this lines.
|
||||
|
||||

|
||||
|
||||
Allow Remote PhpMyAdmin Access
|
||||
允许远程PhpMyAdmin访问
|
||||
|
||||
**16. To be able to login to PhpMyAdmin Web interface using cookie authentication method add a blowfish string to phpmyadmin config.inc.php file like in the screenshot below using the [generate a secret string][6], restart Apache Web service and direct your browser to the URL address http://server_IP/phpmyadmin/.**
|
||||
**16. 要使用cookie验证来登录PhpMyAdmin,像下面的截图那样使用[生成字符串][6]添加一个blowfish字符串到config.inc.php文件下,重启apache服务并打开URL:http://server_IP/phpmyadmin/。**
|
||||
|
||||
# nano /etc/httpd/conf.d/phpmyadmin.conf
|
||||
# systemctl restart httpd
|
||||
|
||||

|
||||
|
||||
Add Blowfish in PhpMyAdmin
|
||||
在PhpMyAdmin中添加Blowfish
|
||||
|
||||

|
||||
|
||||
PhpMyAdmin Dashboard
|
||||
PhpMyAdmin面板
|
||||
|
||||
### Step 5: Enable LAMP System-wide ###
|
||||
### 第五步: 系统范围启用LAMP ###
|
||||
|
||||
**17. If you need MariaDB and Apache services to be automatically started after reboot issue the following commands to enable them system-wide.**
|
||||
**17. 如果你需要在重启后自动运行MariaDB和Apache服务,你需要系统级地启用它们。**
|
||||
|
||||
# systemctl enable mariadb
|
||||
# systemctl enable httpd
|
||||
|
||||

|
||||
|
||||
Enable Services System Wide
|
||||
系统级启用服务
|
||||
|
||||
That’s all it takes for a basic LAMP installation on Red Hat Enterprise 7.0 or CentOS 7.0. The next series of articles related to LAMP stack on CentOS/RHEL 7.0 will discuss how to create Virtual Hosts, generate SSL Certificates and Keys and add SSL transaction support for Apache HTTP Server.
|
||||
这就是在Red Hat Enterprise 7.0或者CentOS 7.0中安装LAMP的过程。CentOS/RHEL 7.0上关于LAMP洗系列文章将会讨论在Apache中创建虚拟主机,生成SSL证书、密钥和添加SSL事物支持。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-lamp-in-centos-7/
|
||||
|
||||
作者:[Matei Cezar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -235,4 +236,4 @@ via: http://www.tecmint.com/install-lamp-in-centos-7/
|
||||
[3]:http://www.tecmint.com/centos-7-installation/
|
||||
[4]:http://www.tecmint.com/configure-network-interface-in-rhel-centos-7-0/
|
||||
[5]:http://php.net/manual/en/timezones.php
|
||||
[6]:http://www.question-defense.com/tools/phpmyadmin-blowfish-secret-generator
|
||||
[6]:http://www.question-defense.com/tools/phpmyadmin-blowfish-secret-generator
|
||||
@ -0,0 +1,206 @@
|
||||
Tor浏览器:Linux下用于匿名Web浏览的终极浏览器
|
||||
================================================================================
|
||||
我们大多数人都在上网方面花费很多时间。上网使用的应用程序主要是浏览器,一个Web浏览器则更加完美。我们网络的活动要以客户端/服务器的方式登录,这个过程会包括IP地址、地理信息、搜索、活动以及许多潜在的信息,这些信息如果以其他方式被故意使用,会存在潜在的危险性。
|
||||
|
||||

|
||||
|
||||
Tor浏览器:匿名浏览器
|
||||
|
||||
此外,美国国家安全局(NSA)即国际间谍机构会记录我们的数字足迹。更不必说某个受限的代理服务器也会被用来做为数据搜集服务器。并且大多数企业和公司不会允许您访问代理服务器(使您能保障自己的隐私)。
|
||||
|
||||
因此,我们需要的最好是一个小型、独立、可携带的应用程序,它能达到匿名的效果。Tor浏览器便是这样的一个应用,它拥有上面提到的所有功能,甚至不止于此。
|
||||
|
||||
这篇文章里我们会讨论Tor浏览器,它的功能、使用方式、领域、安装以及其他关于Tor浏览器的重要方面。
|
||||
|
||||
#### 什么是Tor浏览器? ####
|
||||
|
||||
Tor是一个自由分发的应用软件,以BSD式的许可证发布,通过其安全可靠的洋葱式的结构,允许用户匿名的进行网络浏览。从前,由于它的结构和运作机制,Tor被称为‘洋葱路由器’。这个应用是由C语言写成的。
|
||||
|
||||
#### Tor浏览器的功能 ####
|
||||
|
||||
- 跨平台可用。例如,这个应用程序在Linux、Windows和Mac下都可用。
|
||||
- 在发送数据到因特网前进行复杂的数据加密。
|
||||
- 在客户端进行的数据自动解密。
|
||||
- 它是火狐浏览器和Tor工程的结合。
|
||||
- 对服务器和网站提供匿名性。
|
||||
- 可以访问被锁定的网站。
|
||||
- 无需暴露源IP便可以执行任务。
|
||||
- 可以在防火墙后将数据路由至/从隐藏的服务和应用程序。
|
||||
- 便携性 - 可以直接从USB存储器运行一个预配置的web浏览器。无需本地安装。
|
||||
- 在x86和x86_64平台均可用
|
||||
- 可以通过使用Tor以“socks4a”的方式在“localhost”的“9050”端口上配置代理以设置FTP。
|
||||
- Tor拥有处理上千的转播和上百万用户的能力。
|
||||
|
||||
#### Tor浏览器如何工作? ####
|
||||
|
||||
Tor的工作方式基于洋葱路由的概念。洋葱路由的结构类似洋葱,它的每一层都嵌套在另一层里面,就像洋葱一样。这种嵌套的结构负责多次加密数据并将其通过虚拟电路进行发送。在客户端一边每一层都在将他传递到下一层之前解密数据。最后一层在将原始数据传递到目的地前解密最里面一层的加密数据。
|
||||
|
||||
在这个过程里,这种解密整个层的功能设计的如此高明以至于无法追踪IP以及用户的地理位置,因此可以限制任何人观察您访问站点的网络连接。
|
||||
|
||||
所有这些过程看起来有些复杂,但用户使用Tor浏览器时没有必要担心。实际上,Tor浏览器的功能像其他浏览器一样(尤其是Mozilla的Firefox)。
|
||||
|
||||
### 在Linux中安装Tor浏览器 ###
|
||||
|
||||
就像上面讨论的一样,Tor浏览器在Linux和Windows以及Mac下都可用。用户需要根据系统和架构的不同在下面的链接处下载最新的版本(例如,Tor浏览器4.0.4)。
|
||||
|
||||
- [https://www.torproject.org/download/download-easy.html.en][1]
|
||||
|
||||
在下载Tor浏览器后,我们需要安装它。但好的是我们不需要安装‘Tor’。它能直接从随身设备中运行,并且该浏览器可以被预配置。这意味着插件和运行的特性可以完美的移植。
|
||||
|
||||
下载打包文件(*.tar.xz)后我们需要解压它。
|
||||
|
||||
**32位系统**
|
||||
|
||||
$ wget https://www.torproject.org/dist/torbrowser/4.0.4/tor-browser-linux32-4.0.4_en-US.tar.xz
|
||||
$ tar xpvf tor-browser-linux32-4.0.4_en-US.tar.xz
|
||||
|
||||
**64位系统**
|
||||
|
||||
$ wget https://www.torproject.org/dist/torbrowser/4.0.4/tor-browser-linux64-4.0.4_en-US.tar.xz
|
||||
$ tar -xpvf tor-browser-linux64-4.0.4_en-US.tar.xz
|
||||
|
||||
**注意** : 在上面的命令中,我们使用‘$‘意味着这个压缩包应以普通用户而不是root用户来解压。我们强烈建议您不要以root用户解压和运行Tor浏览器。
|
||||
|
||||
在成功的解压后,我们便可以将解压后的浏览器移动到任何地方/USB存储设备中。并从解压的文件夹以非root用户直接运行‘start-tor-browser’。
|
||||
|
||||
$ cd tor-browser_en-US
|
||||
$ ./start-tor-browser
|
||||
|
||||

|
||||
|
||||
开始使用Tor浏览器
|
||||
|
||||
**1. 尝试连接到Tor网络。点击“连接”之后Tor将按照设置帮您做剩下的事情。**
|
||||
|
||||

|
||||
|
||||
连接到Tor网络
|
||||
|
||||
**2. 欢迎窗口/标签。**
|
||||
|
||||

|
||||
|
||||
Tor欢迎界面
|
||||
|
||||
**3. Tor浏览器从Youtube处加载视频。**
|
||||
|
||||

|
||||
|
||||
在Youtube上看视频
|
||||
|
||||
**4. 打开银行网址以进行在线购物和交易。**
|
||||
|
||||

|
||||
|
||||
浏览银行站点
|
||||
|
||||
**5. 浏览器显示我当前的代理IP。注意文本为“Proxy Server detected”。**
|
||||
|
||||

|
||||
|
||||
检查IP地址
|
||||
|
||||
**注意**: 每次您想运行Tor时,您需要使用文本模式来指向Tor启动脚本。并且该终端在您运行Tor时会持续保持忙碌状态。如何克服这些,并创建一个桌面/Dock栏图标呢?
|
||||
|
||||
**6. 我们需要在解压的文件夹中创建`tor.desktop`。**
|
||||
|
||||
$ touch tor.desktop
|
||||
|
||||
接着使用您喜欢的编辑器编辑这个文件,加入下面的文本,这里我使用nano。
|
||||
|
||||
$ nano tor.desktop
|
||||
|
||||
----------
|
||||
|
||||
#!/usr/bin/env xdg-open
|
||||
[Desktop Entry]
|
||||
Encoding=UTF-8
|
||||
Name=Tor
|
||||
Comment=Anonymous Browse
|
||||
Type=Application
|
||||
Terminal=false
|
||||
Exec=/home/avi/Downloads/tor-browser_en-US/start-tor-browser
|
||||
Icon=/home/avi/Downloads/tor-browser_en-US/Browser/browser/icons/mozicon128.png
|
||||
StartupNotify=true
|
||||
Categories=Network;WebBrowser;
|
||||
|
||||
**注意**: 确保将上面的tor浏览器的路径替换为您的环境中的路径。
|
||||
|
||||
**7. 一旦搞定后,您就可以双击`tor.desktop`文件来运行Tor浏览器了,您可能需要在第一次运行时信任该文件。**
|
||||
|
||||

|
||||
|
||||
Tor应用启动器
|
||||
|
||||
**8. 一旦您选择了信任,请注意`tor.desktop`文件的图标则会改变。**
|
||||
|
||||

|
||||
|
||||
Tor图标已改变
|
||||
|
||||
**9. 您可以通过拖拽`tor.desktop`的图标在桌面和Dock栏中创建快捷方式。**
|
||||
|
||||

|
||||
|
||||
在桌面添加Tor快捷方式
|
||||
|
||||
**10. 关于Tor浏览器。**
|
||||
|
||||

|
||||
|
||||
关于Tor浏览器
|
||||
|
||||
**注意**: 如果您在使用旧版本的Tor,您可以从上面的窗口更新它。
|
||||
|
||||
#### 应用的可用性和领域 ####
|
||||
|
||||
- 匿名使用网络。
|
||||
- 浏览被阻挡的页面。
|
||||
- 连接其他应用,即(FTP)来保证网络安全的访问。
|
||||
|
||||
#### 关于Tor浏览器的争论 ####
|
||||
|
||||
- 在Tor浏览器的周边并没有什么安全措施。比如,数据入口点和出口点。
|
||||
- 一项2011年的研究发现一种特殊的针对Tor浏览器的攻击可以得到BitTorrent用户的IP地址。
|
||||
- 在一些研究中发现某些特定的协议有泄漏IP地址的倾向。
|
||||
- Tor早些的版本绑定了旧版本的Firefox浏览器,这被证明较易受JavaScript攻击。
|
||||
- Tor浏览器工作的比较缓慢。
|
||||
|
||||
#### 真实世界中Tor浏览器的实现 ####
|
||||
|
||||
- Vuze BitTorrent Client
|
||||
- Anonymous Os
|
||||
- Os’es from Scratch
|
||||
- whonix 等
|
||||
|
||||
#### Tor浏览器的未来 ####
|
||||
|
||||
Tor浏览器是前途无量的。也许它实现的第一个应用程序非常出色,但Tor浏览器必须加大对伸缩性的支持以及对近期的攻击进行研究以保证数据安全。这个应用程序是未来的需要。
|
||||
|
||||
#### 下载免费的电子书 ####
|
||||
|
||||
非官方的Tor私密浏览指南
|
||||
|
||||
[][2]
|
||||
|
||||
### 结论 ###
|
||||
|
||||
如果您工作的部门不允许您访问某网站或者如果您不希望别人知道您的私人事务或您不想向NSA提供您的个人数字足迹,那么Tor浏览器在目前是必须的。
|
||||
|
||||
**注意**: Tor浏览器提供的安全性不能抵御病毒、木马或其他类似这样的安全威胁。写这篇文章的目的也不是希望通过在互联网上隐藏我们的身份来放纵非法活动。这篇文章纯粹是为了教学的目的,作者和Tecmint均不会为任何非法的使用负责。这是用户的唯一责任。
|
||||
|
||||
Tor浏览器是一个非常不错的应用,您值得尝试!这就是我要说的全部了,我还会在这里写一些您感兴趣的文章,所以请继续关注Tecmint。别忘了在留言区提供给我们您有价值的反馈。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/tor-browser-for-anonymous-web-browsing/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:https://www.torproject.org/download/download-easy.html.en
|
||||
[2]:http://tecmint.tradepub.com/free/w_make129/prgm.cgi
|
||||
Loading…
Reference in New Issue
Block a user