mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
d4f6e3056c
@ -0,0 +1,155 @@
|
||||
用 Hugo 30 分钟搭建静态博客
|
||||
======
|
||||
> 了解 Hugo 如何使构建网站变得有趣。
|
||||
|
||||

|
||||
|
||||
你是不是强烈地想搭建博客来将自己对软件框架等的探索学习成果分享呢?你是不是面对缺乏指导文档而一团糟的项目就有一种想去改变它的冲动呢?或者换个角度,你是不是十分期待能创建一个属于自己的个人博客网站呢?
|
||||
|
||||
很多人在想搭建博客之前都有一些严重的迟疑顾虑:感觉自己缺乏内容管理系统(CMS)的相关知识,更缺乏时间去学习这些知识。现在,如果我说不用花费大把的时间去学习 CMS 系统、学习如何创建一个静态网站、更不用操心如何去强化网站以防止它受到黑客攻击的问题,你就可以在 30 分钟之内创建一个博客?你信不信?利用 Hugo 工具,就可以实现这一切。
|
||||
|
||||
|
||||
|
||||
Hugo 是一个基于 Go 语言开发的静态站点生成工具。也许你会问,为什么选择它?
|
||||
|
||||
* 无需数据库、无需需要各种权限的插件、无需跑在服务器上的底层平台,更没有额外的安全问题。
|
||||
* 都是静态站点,因此拥有轻量级、快速响应的服务性能。此外,所有的网页都是在部署的时候生成,所以服务器负载很小。
|
||||
* 极易操作的版本控制。一些 CMS 平台使用它们自己的版本控制软件(VCS)或者在网页上集成 Git 工具。而 Hugo,所有的源文件都可以用你所选的 VCS 软件来管理。
|
||||
|
||||
### 0-5 分钟:下载 Hugo,生成一个网站
|
||||
|
||||
直白的说,Hugo 使得写一个网站又一次变得有趣起来。让我们来个 30 分钟计时,搭建一个网站。
|
||||
|
||||
为了简化 Hugo 安装流程,这里直接使用 Hugo 可执行安装文件。
|
||||
|
||||
1. 下载和你操作系统匹配的 Hugo [版本][2];
|
||||
2. 压缩包解压到指定路径,例如 windows 系统的 `C:\hugo_dir` 或者 Linux 系统的 `~/hugo_dir` 目录;下文中的变量 `${HUGO_HOME}` 所指的路径就是这个安装目录;
|
||||
3. 打开命令行终端,进入安装目录:`cd ${HUGO_HOME}`;
|
||||
4. 确认 Hugo 已经启动:
|
||||
* Unix 系统:`${HUGO_HOME}/[hugo version]`;
|
||||
* Windows 系统:`${HUGO_HOME}\[hugo.exe version]`,例如:cmd 命令行中输入:`c:\hugo_dir\hugo version`。
|
||||
|
||||
为了书写上的简化,下文中的 `hugo` 就是指 hugo 可执行文件所在的路径(包括可执行文件),例如命令 `hugo version` 就是指命令 `c:\hugo_dir\hugo version` 。(LCTT 译注:可以把 hugo 可执行文件所在的路径添加到系统环境变量下,这样就可以直接在终端中输入 `hugo version`)
|
||||
|
||||
如果命令 `hugo version` 报错,你可能下载了错误的版本。当然,有很多种方法安装 Hugo,更多详细信息请查阅 [官方文档][3]。最稳妥的方法就是把 Hugo 可执行文件放在某个路径下,然后执行的时候带上路径名
|
||||
5. 创建一个新的站点来作为你的博客,输入命令:`hugo new site awesome-blog`;
|
||||
6. 进入新创建的路径下: `cd awesome-blog`;
|
||||
|
||||
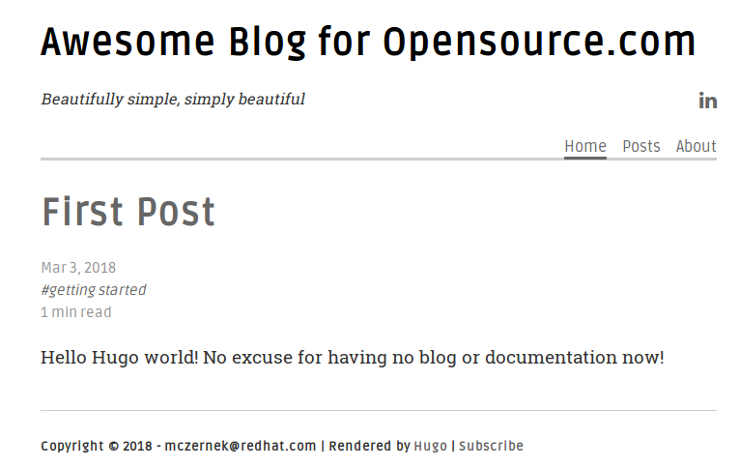
恭喜你!你已经创建了自己的新博客。
|
||||
|
||||
### 5-10 分钟:为博客设置主题
|
||||
|
||||
Hugo 中你可以自己构建博客的主题或者使用网上已经有的一些主题。这里选择 [Kiera][4] 主题,因为它简洁漂亮。按以下步骤来安装该主题:
|
||||
|
||||
1. 进入主题所在目录:`cd themes`;
|
||||
2. 克隆主题:`git clone https://github.com/avianto/hugo-kiera kiera`。如果你没有安装 Git 工具:
|
||||
* 从 [Github][5] 上下载 hugo 的 .zip 格式的文件;
|
||||
* 解压该 .zip 文件到你的博客主题 `theme` 路径;
|
||||
* 重命名 `hugo-kiera-master` 为 `kiera`;
|
||||
3. 返回博客主路径:`cd awesome-blog`;
|
||||
4. 激活主题;通常来说,主题(包括 Kiera)都自带文件夹 `exampleSite`,里面存放了内容配置的示例文件。激活 Kiera 主题需要拷贝它提供的 `config.toml` 到你的博客下:
|
||||
* Unix 系统:`cp themes/kiera/exampleSite/config.toml .`;
|
||||
* Windows 系统:`copy themes\kiera\exampleSite\config.toml .`;
|
||||
* 选择 `Yes` 来覆盖原有的 `config.toml`;
|
||||
|
||||
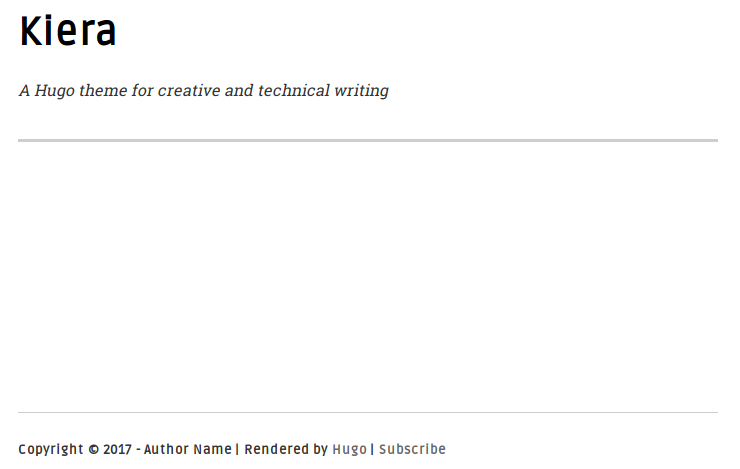
5. ( 可选操作 )你可以选择可视化的方式启动服务器来验证主题是否生效:`hugo server -D` 然后在浏览器中输入 `http://localhost:1313`。可用通过在终端中输入 `Crtl+C` 来停止服务器运行。现在你的博客还是空的,但这也给你留了写作的空间。它看起来如下所示:
|
||||
|
||||
|
||||
|
||||
你已经成功的给博客设置了主题!你可以在官方 [Hugo 主题][4] 网站上找到上百种漂亮的主题供你使用。
|
||||
|
||||
### 10-20 分钟:给博客添加内容
|
||||
|
||||
对于碗来说,它是空的时候用处最大,可以用来盛放东西;但对于博客来说不是这样,空博客几乎毫无用处。在这一步,你将会给博客添加内容。Hugo 和 Kiera 主题都为这个工作提供了方便性。按以下步骤来进行你的第一次提交:
|
||||
|
||||
1. archetypes 将会是你的内容模板。
|
||||
2. 添加主题中的 archtypes 至你的博客:
|
||||
* Unix 系统: `cp themes/kiera/archetypes/* archetypes/`
|
||||
* Windows 系统:`copy themes\kiera\archetypes\* archetypes\`
|
||||
* 选择 `Yes` 来覆盖原来的 `default.md` 内容架构类型
|
||||
|
||||
3. 创建博客 posts 目录:
|
||||
* Unix 系统: `mkdir content/posts`
|
||||
* Windows 系统: `mkdir content\posts`
|
||||
|
||||
4. 利用 Hugo 生成你的 post:
|
||||
* Unix 系统:`hugo nes posts/first-post.md`;
|
||||
* Windows 系统:`hugo new posts\first-post.md`;
|
||||
|
||||
5. 在文本编辑器中打开这个新建的 post 文件:
|
||||
* Unix 系统:`gedit content/posts/first-post.md`;
|
||||
* Windows 系统:`notepadd content\posts\first-post.md`;
|
||||
|
||||
此刻,你可以疯狂起来了。注意到你的提交文件中包括两个部分。第一部分是以 `+++` 符号分隔开的。它包括了提交文档的主要数据,例如名称、时间等。在 Hugo 中,这叫做前缀。在前缀之后,才是正文。下面编辑第一个提交文件内容:
|
||||
|
||||
```
|
||||
+++
|
||||
title = "First Post"
|
||||
date = 2018-03-03T13:23:10+01:00
|
||||
draft = false
|
||||
tags = ["Getting started"]
|
||||
categories = []
|
||||
+++
|
||||
|
||||
Hello Hugo world! No more excuses for having no blog or documentation now!
|
||||
```
|
||||
|
||||
现在你要做的就是启动你的服务器:`hugo server -D`;然后打开浏览器,输入 `http://localhost:1313/`。
|
||||
|
||||

|
||||
|
||||
### 20-30 分钟:调整网站
|
||||
|
||||
前面的工作很完美,但还有一些问题需要解决。例如,简单地命名你的站点:
|
||||
|
||||
1. 终端中按下 `Ctrl+C` 以停止服务器。
|
||||
2. 打开 `config.toml`,编辑博客的名称,版权,你的姓名,社交网站等等。
|
||||
|
||||
当你再次启动服务器后,你会发现博客私人订制味道更浓了。不过,还少一个重要的基础内容:主菜单。快速的解决这个问题。返回 `config.toml` 文件,在末尾插入如下一段:
|
||||
|
||||
```
|
||||
[[menu.main]]
|
||||
name = "Home" #Name in the navigation bar
|
||||
weight = 10 #The larger the weight, the more on the right this item will be
|
||||
url = "/" #URL address
|
||||
[[menu.main]]
|
||||
name = "Posts"
|
||||
weight = 20
|
||||
url = "/posts/"
|
||||
```
|
||||
|
||||
上面这段代码添加了 `Home` 和 `Posts` 到主菜单中。你还需要一个 `About` 页面。这次是创建一个 `.md` 文件,而不是编辑 `config.toml` 文件:
|
||||
|
||||
1. 创建 `about.md` 文件:`hugo new about.md` 。注意它是 `about.md`,不是 `posts/about.md`。该页面不是博客提交内容,所以你不想它显示到博客内容提交当中吧。
|
||||
2. 用文本编辑器打开该文件,输入如下一段:
|
||||
|
||||
```
|
||||
+++
|
||||
title = "About"
|
||||
date = 2018-03-03T13:50:49+01:00
|
||||
menu = "main" #Display this page on the nav menu
|
||||
weight = "30" #Right-most nav item
|
||||
meta = "false" #Do not display tags or categories
|
||||
+++
|
||||
|
||||
> Waves are the practice of the water. Shunryu Suzuki
|
||||
```
|
||||
|
||||
当你启动你的服务器并输入:`http://localhost:1313/`,你将会看到你的博客。(访问我 Gihub 主页上的 [例子][6] )如果你想让文章的菜单栏和 Github 相似,给 `themes/kiera/static/css/styles.css` 打上这个 [补丁][7]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/start-blog-30-minutes-hugo
|
||||
|
||||
作者:[Marek Czernek][a]
译者:[jrg](https://github.com/jrglinux)
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mczernek
|
||||
[1]:https://gohugo.io/
|
||||
[2]:https://github.com/gohugoio/hugo/releases
|
||||
[3]:https://gohugo.io/getting-started/installing/
|
||||
[4]:https://themes.gohugo.io/
|
||||
[5]:https://github.com/avianto/hugo-kiera
|
||||
[6]:https://m-czernek.github.io/awesome-blog/
|
||||
[7]:https://github.com/avianto/hugo-kiera/pull/18/files
|
||||
@ -1,223 +0,0 @@
|
||||
[翻译中]translating by jrg!
|
||||
|
||||
Automating backups on a Raspberry Pi NAS
|
||||
======
|
||||

|
||||
|
||||
In the [first part][1] of this three-part series using a Raspberry Pi for network-attached storage (NAS), we covered the fundamentals of the NAS setup, attached two 1TB hard drives (one for data and one for backups), and mounted the data drive on a remote device via the network filesystem (NFS). In part two, we will look at automating backups. Automated backups allow you to continually secure your data and recover from a hardware defect or accidental file removal.
|
||||
|
||||
|
||||
|
||||
### Backup strategy
|
||||
|
||||
Let's get started by coming up with with a backup strategy for our small NAS. I recommend creating daily backups of your data and scheduling them for a time they won't interfere with other NAS activities, including when you need to access or store your files. For example, you could trigger the backup activities each day at 2am.
|
||||
|
||||
You also need to decide how long you'll keep each backup, since you would quickly run out of storage if you kept each daily backup indefinitely. Keeping your daily backups for one week allows you to travel back into your recent history if you realize something went wrong over the previous seven days. But what if you need something from further in the past? Keeping each Monday backup for a month and one monthly backup for a longer period of time should be sufficient. Let's keep the monthly backups for a year and one backup every year for long-distance time travels, e.g., for the last five years.
|
||||
|
||||
This results in a bunch of backups on your backup drive over a five-year period:
|
||||
|
||||
* 7 daily backups
|
||||
* 4 (approx.) weekly backups
|
||||
* 12 monthly backups
|
||||
* 5 annual backups
|
||||
|
||||
|
||||
|
||||
You may recall that your backup drive and your data drive are of equal size (1TB each). How will more than 10 backups of 1TB from your data drive fit onto a 1TB backup disk? If you create full backups, they won't. Instead, you will create incremental backups, reusing the data from the last backup if it didn't change and creating replicas of new or changed files. That way, the backup doesn't double every night, but only grows a little bit depending on the changes that happen to your data over a day.
|
||||
|
||||
Here is my situation: My NAS has been running since August 2016, and 20 backups are on the backup drive. Currently, I store 406GB of files on the data drive. The backups take up 726GB on my backup drive. Of course, this depends heavily on your data's change frequency, but as you can see, the incremental backups don't consume as much space as 20 full backups would. Nevertheless, over time the 1TB disk will probably become insufficient for your backups. Once your data grows close to the 1TB limit (or whatever your backup drive capacity), you should choose a bigger backup drive and move your data there.
|
||||
|
||||
### Creating backups with rsync
|
||||
|
||||
To create a full backup, you can use the rsync command line tool. Here is an example command to create the initial full backup.
|
||||
```
|
||||
pi@raspberrypi:~ $ rsync -a /nas/data/ /nas/backup/2018-08-01
|
||||
|
||||
```
|
||||
|
||||
This command creates a full replica of all data stored on the data drive, mounted on `/nas/data`, on the backup drive. There, it will create the folder `2018-08-01` and create the backup inside it. The `-a` flag starts rsync in archive-mode, which means it preserves all kinds of metadata, like modification dates, permissions, and owners, and copies soft links as soft links.
|
||||
|
||||
Now that you have created your full, initial backup as of August 1, on August 2, you will create your first daily incremental backup.
|
||||
```
|
||||
pi@raspberrypi:~ $ rsync -a --link-dest /nas/backup/2018-08-01/ /nas/data/ /nas/backup/2018-08-02
|
||||
|
||||
```
|
||||
|
||||
This command tells rsync to again create a backup of `/nas/data`. The target directory this time is `/nas/backup/2018-08-02`. The script also specified the `--link-dest` option and passed the location of the last backup as an argument. With this option specified, rsync looks at the folder `/nas/backup/2018-08-01` and checks what data files changed compared to that folder's content. Unchanged files will not be copied, rather they will be hard-linked to their counterparts in yesterday's backup folder.
|
||||
|
||||
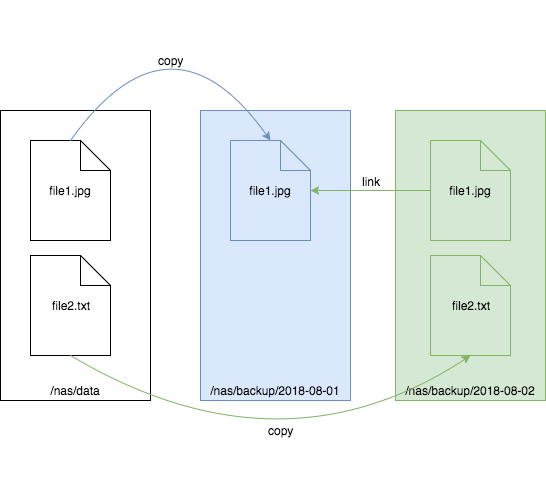
When using a hard-linked file from a backup, you won't notice any difference between the initial copy and the link. They behave exactly the same, and if you delete either the link or the initial file, the other will still exist. You can imagine them as two equal entry points to the same file. Here is an example:
|
||||
|
||||
|
||||
|
||||
The left box reflects the state shortly after the second backup. The box in the middle is yesterday's replica. The `file2.txt` didn't exist yesterday, but the image `file1.jpg` did and was copied to the backup drive. The box on the right reflects today's incremental backup. The incremental backup command created `file2.txt`, which didn't exist yesterday. Since `file1.jpg` didn't change since yesterday, today a hard link is created so it doesn't take much additional space on the disk.
|
||||
|
||||
### Automate your backups
|
||||
|
||||
You probably don't want to execute your daily backup command by hand at 2am each day. Instead, you can automate your backup by using a script like the following, which you may want to start with a cron job.
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
|
||||
|
||||
TODAY=$(date +%Y-%m-%d)
|
||||
|
||||
DATADIR=/nas/data/
|
||||
|
||||
BACKUPDIR=/nas/backup/
|
||||
|
||||
SCRIPTDIR=/nas/data/backup_scripts
|
||||
|
||||
LASTDAYPATH=${BACKUPDIR}/$(ls ${BACKUPDIR} | tail -n 1)
|
||||
|
||||
TODAYPATH=${BACKUPDIR}/${TODAY}
|
||||
|
||||
if [[ ! -e ${TODAYPATH} ]]; then
|
||||
|
||||
mkdir -p ${TODAYPATH}
|
||||
|
||||
fi
|
||||
|
||||
|
||||
|
||||
rsync -a --link-dest ${LASTDAYPATH} ${DATADIR} ${TODAYPATH} $@
|
||||
|
||||
|
||||
|
||||
${SCRIPTDIR}/deleteOldBackups.sh
|
||||
|
||||
```
|
||||
|
||||
The first block calculates the last backup's folder name to use for links and the name of today's backup folder. The second block has the rsync command (as described above). The last block executes a `deleteOldBackups.sh` script. It will clean up the old, unnecessary backups based on the backup strategy outlined above. You could also execute the cleanup script independently from the backup script if you want it to run less frequently.
|
||||
|
||||
The following script is an example implementation of the backup strategy in this how-to article.
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
BACKUPDIR=/nas/backup/
|
||||
|
||||
|
||||
|
||||
function listYearlyBackups() {
|
||||
|
||||
for i in 0 1 2 3 4 5
|
||||
|
||||
do ls ${BACKUPDIR} | egrep "$(date +%Y -d "${i} year ago")-[0-9]{2}-[0-9]{2}" | sort -u | head -n 1
|
||||
|
||||
done
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function listMonthlyBackups() {
|
||||
|
||||
for i in 0 1 2 3 4 5 6 7 8 9 10 11 12
|
||||
|
||||
do ls ${BACKUPDIR} | egrep "$(date +%Y-%m -d "${i} month ago")-[0-9]{2}" | sort -u | head -n 1
|
||||
|
||||
done
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function listWeeklyBackups() {
|
||||
|
||||
for i in 0 1 2 3 4
|
||||
|
||||
do ls ${BACKUPDIR} | grep "$(date +%Y-%m-%d -d "last monday -${i} weeks")"
|
||||
|
||||
done
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function listDailyBackups() {
|
||||
|
||||
for i in 0 1 2 3 4 5 6
|
||||
|
||||
do ls ${BACKUPDIR} | grep "$(date +%Y-%m-%d -d "-${i} day")"
|
||||
|
||||
done
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function getAllBackups() {
|
||||
|
||||
listYearlyBackups
|
||||
|
||||
listMonthlyBackups
|
||||
|
||||
listWeeklyBackups
|
||||
|
||||
listDailyBackups
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function listUniqueBackups() {
|
||||
|
||||
getAllBackups | sort -u
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function listBackupsToDelete() {
|
||||
|
||||
ls ${BACKUPDIR} | grep -v -e "$(echo -n $(listUniqueBackups) |sed "s/ /\\\|/g")"
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
cd ${BACKUPDIR}
|
||||
|
||||
listBackupsToDelete | while read file_to_delete; do
|
||||
|
||||
rm -rf ${file_to_delete}
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
This script will first list all the backups to keep (according to our backup strategy), then it will delete all the backup folders that are not necessary anymore.
|
||||
|
||||
To execute the scripts every night to create daily backups, schedule the backup script by running `crontab -e` as the root user. (You need to be in root to make sure it has permission to read all the files on the data drive, no matter who created them.) Add a line like the following, which starts the script every night at 2am.
|
||||
```
|
||||
0 2 * * * /nas/data/backup_scripts/daily.sh
|
||||
|
||||
```
|
||||
|
||||
For more information, read about [scheduling tasks with cron][2].
|
||||
|
||||
* Unmount your backup drive or mount it as read-only when no backups are running
|
||||
* Attach the backup drive to a remote server and sync the files over the internet
|
||||
|
||||
|
||||
|
||||
There are additional things you can do to fortify your backups against accidental removal or damage, including the following:
|
||||
|
||||
This example backup strategy enables you to back up your valuable data to make sure it won't get lost. You can also easily adjust this technique for your personal needs and preferences.
|
||||
|
||||
In part three of this series, we will talk about [Nextcloud][3], a convenient way to store and access data on your NAS system that also provides offline access as it synchronizes your data to the client devices.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/automate-backups-raspberry-pi
|
||||
|
||||
作者:[Manuel Dewald][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ntlx
|
||||
[1]:https://opensource.com/article/18/7/network-attached-storage-Raspberry-Pi
|
||||
[2]:https://opensource.com/article/17/11/how-use-cron-linux
|
||||
[3]:https://nextcloud.com/
|
||||
@ -1,113 +0,0 @@
|
||||
[翻译中]translating by jrg!
|
||||
|
||||
Host your own cloud with Raspberry Pi NAS
|
||||
======
|
||||
|
||||
Protect and secure your data with a self-hosted cloud powered by your Raspberry Pi.
|
||||
|
||||
In the first two parts of this series, we discussed the [hardware and software fundamentals][1] for building network-attached storage (NAS) on a Raspberry Pi. We also put a proper [backup strategy][2] in place to secure the data on the NAS. In this third part, we will talk about a convenient way to store, access, and share your data with [Nextcloud][3].
|
||||
|
||||
### Prerequisites
|
||||
|
||||
To use Nextcloud conveniently, you have to meet a few prerequisites. First, you should have a domain you can use for the Nextcloud instance. For the sake of simplicity in this how-to, we'll use **nextcloud.pi-nas.com**. This domain should be directed to your Raspberry Pi. If you want to run it on your home network, you probably need to set up dynamic DNS for this domain and enable port forwarding of ports 80 and 443 (if you go for an SSL setup, which is highly recommended; otherwise port 80 should be sufficient) from your router to the Raspberry Pi.
|
||||
|
||||
You can automate dynamic DNS updates from the Raspberry Pi using [ddclient][4].
|
||||
|
||||
### Install Nextcloud
|
||||
|
||||
To run Nextcloud on your Raspberry Pi (using the setup described in the [first part][1] of this series), install the following packages as dependencies to Nextcloud using **apt**.
|
||||
|
||||
```
|
||||
sudo apt install unzip wget php apache2 mysql-server php-zip php-mysql php-dom php-mbstring php-gd php-curl
|
||||
```
|
||||
|
||||
The next step is to download Nextcloud. [Get the latest release's URL][5] and copy it to download via **wget** on the Raspberry Pi. In the first article in this series, we attached two disk drives to the Raspberry Pi, one for current data and one for backups. Install Nextcloud on the data drive to make sure data is backed up automatically every night.
|
||||
|
||||
```
|
||||
sudo mkdir -p /nas/data/nextcloud
|
||||
sudo chown pi /nas/data/nextcloud
|
||||
cd /nas/data/
|
||||
wget https://download.nextcloud.com/server/releases/nextcloud-14.0.0.zip -O /nas/data/nextcloud.zip
|
||||
unzip nextcloud.zip
|
||||
sudo ln -s /nas/data/nextcloud /var/www/nextcloud
|
||||
sudo chown -R www-data:www-data /nas/data/nextcloud
|
||||
```
|
||||
|
||||
When I wrote this, the latest release (as you see in the code above) was 14. Nextcloud is under heavy development, so you may find a newer version when installing your copy of Nextcloud onto your Raspberry Pi.
|
||||
|
||||
### Database setup
|
||||
|
||||
When we installed Nextcloud above, we also installed MySQL as a dependency to use it for all the metadata Nextcloud generates (for example, the users you create to access Nextcloud). If you would rather use a Postgres database, you'll need to adjust some of the modules installed above.
|
||||
|
||||
To access the MySQL database as root, start the MySQL client as root:
|
||||
|
||||
```
|
||||
sudo mysql
|
||||
```
|
||||
|
||||
This will open a SQL prompt where you can insert the following commands—substituting the placeholder with the password you want to use for the database connection—to create a database for Nextcloud.
|
||||
|
||||
```
|
||||
CREATE USER nextcloud IDENTIFIED BY '<insert-password-here>';
|
||||
CREATE DATABASE nextcloud;
|
||||
GRANT ALL ON nextcloud.* TO nextcloud;
|
||||
```
|
||||
|
||||
You can exit the SQL prompt by pressing **Ctrl+D** or entering **quit**.
|
||||
|
||||
### Web server configuration
|
||||
|
||||
Nextcloud can be configured to run using Nginx or other web servers, but for this how-to, I decided to go with the Apache web server on my Raspberry Pi NAS. (Feel free to try out another alternative and let me know if you think it performs better.)
|
||||
|
||||
To set it up, configure a virtual host for the domain you created for your Nextcloud instance **nextcloud.pi-nas.com**. To create a virtual host, create the file **/etc/apache2/sites-available/001-nextcloud.conf** with content similar to the following. Make sure to adjust the ServerName to your domain and paths, if you didn't use the ones suggested earlier in this series.
|
||||
|
||||
```
|
||||
<VirtualHost *:80>
|
||||
ServerName nextcloud.pi-nas.com
|
||||
ServerAdmin admin@pi-nas.com
|
||||
DocumentRoot /var/www/nextcloud/
|
||||
|
||||
<Directory /var/www/nextcloud/>
|
||||
AllowOverride None
|
||||
</Directory>
|
||||
</VirtualHost>
|
||||
```
|
||||
|
||||
To enable this virtual host, run the following two commands.
|
||||
|
||||
```
|
||||
a2ensite 001-nextcloud
|
||||
sudo systemctl reload apache2
|
||||
```
|
||||
|
||||
With this configuration, you should now be able to reach the web server with your domain via the web browser. To secure your data, I recommend using HTTPS instead of HTTP to access Nextcloud. A very easy (and free) way is to obtain a [Let's Encrypt][6] certificate with [Certbot][7] and have a cron job automatically refresh it. That way you don't have to mess around with self-signed or expiring certificates. Follow Certbot's simple how-to [instructions to install it on your Raspberry Pi][8]. During Certbot configuration, you can even decide to automatically forward HTTP to HTTPS, so visitors to **<http://nextcloud.pi-nas.com>** will be redirected to **<https://nextcloud.pi-nas.com>**. Please note, if your Raspberry Pi is running behind your home router, you must have port forwarding enabled for ports 443 and 80 to obtain Let's Encrypt certificates.
|
||||
|
||||
### Configure Nextcloud
|
||||
|
||||
The final step is to visit your fresh Nextcloud instance in a web browser to finish the configuration. To do so, open your domain in a browser and insert the database details from above. You can also set up your first Nextcloud user here, the one you can use for admin tasks. By default, the data directory should be inside the Nextcloud folder, so you don't need to change anything for the backup mechanisms from the [second part of this series][2] to pick up the data stored by users in Nextcloud.
|
||||
|
||||
Afterward, you will be directed to your Nextcloud and can log in with the admin user you created previously. To see a list of recommended steps to ensure a performant and secure Nextcloud installation, visit the Basic Settings tab in the Settings page (in our example: <https://nextcloud.pi-nas.com/>settings/admin) and see the Security & Setup Warnings section.
|
||||
|
||||
Congratulations! You've set up your own Nextcloud powered by a Raspberry Pi. Go ahead and [download a Nextcloud client][9] from the Nextcloud page to sync data with your client devices and access it offline. Mobile clients even provide features like instant upload of pictures you take, so they'll automatically sync to your desktop PC without wondering how to get them there.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/host-cloud-nas-raspberry-pi
|
||||
|
||||
作者:[Manuel Dewald][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ntlx
|
||||
[1]: https://opensource.com/article/18/7/network-attached-storage-Raspberry-Pi
|
||||
[2]: https://opensource.com/article/18/8/automate-backups-raspberry-pi
|
||||
[3]: https://nextcloud.com/
|
||||
[4]: https://sourceforge.net/p/ddclient/wiki/Home/
|
||||
[5]: https://nextcloud.com/install/#instructions-server
|
||||
[6]: https://letsencrypt.org/
|
||||
[7]: https://certbot.eff.org/
|
||||
[8]: https://certbot.eff.org/lets-encrypt/debianother-apache
|
||||
[9]: https://nextcloud.com/install/#install-clients
|
||||
@ -1,179 +0,0 @@
|
||||
Hugo,30分钟搭建博客,一个Go语言开发的静态站点生成工具
|
||||
======
|
||||

|
||||
|
||||
你是不是强烈的想搭建博客来将自己对软件框架等的探索学习成果分享呢?
|
||||
|
||||
你是不是面对缺乏指导文档而一团糟的项目就有一种想去改变它的冲动呢?
|
||||
|
||||
或者换个角度,你是不是十分期待能创建一个属于自己的个人博客网站呢?
|
||||
|
||||
很多人在想搭建博客之前都有一些严重的迟疑顾虑:感觉自己缺乏内容管理系统(CMS)的相关知识,更缺乏时间去学习这些知识。现在,如果我说不用花费大把的时间去学习 CMS 系统、学习如何创建一个静态网站、更不用操心如何去强化网站以防止它受到黑客攻击的问题,你就可以在 30 分钟之内创建一个博客?你信不信?利用 Hugo 工具,就可以实现这一切。
|
||||
|
||||

|
||||
|
||||
Hugo 是一个基于 Go 语言开发的静态站点生成工具。也许你会问,为什么选择它?
|
||||
* 无需数据库、无需需要各种权限的插件、无需跑在服务器上的底层平台,更没有额外的安全问题。
|
||||
* 都是静态站点,因此拥有轻量级、快速响应的服务性能。此外,所有的网页都是在部署的时候呈现,所以服务器负载很小。
|
||||
* 极易操作的版本控制。一些 CMS 平台使用它们自己的版本控制软件(VCS)或者在网页上集成 Git 工具。而 Hugo,所有的源文件都可以用你所选的 VCS 软件来管理。
|
||||
|
||||
### 0-5 分钟:下载 Hugo,生成一个网站
|
||||
|
||||
直白的说,Hugo 使得写一个网站又一次变得有趣起来。让我们来个 30 分钟计时,搭建一个网站。
|
||||
|
||||
为了简化 Hugo 安装流程,这里直接使用 Hugo 可执行安装文件。
|
||||
|
||||
1. 下载和你操作系统匹配的 Hugo [版本][2];
|
||||
|
||||
2. 压缩包解压到指定路径,例如 windows 系统的 `C:\hugo_dir` 或者 Linux 系统的 `~/hugo_dir` 目录;下文中的变量 `${HUGO_HOME}` 所指的路径就是这个安装目录;
|
||||
|
||||
3. 打开命令行终端,进入安装目录:`cd ${HUGO_HOME}`;
|
||||
|
||||
4. 确认 Hugo 已经启动:
|
||||
* Unix 系统:`${HUGO_HOME}/[hugo version]`;
|
||||
* Windows 系统:`${HUGO_HOME}\[hugo.exe version]`;
|
||||
|
||||
例如:Windows 系统下,cmd 命令行中输入:`c:\hugo_dir\hugo version`。
|
||||
|
||||
为了书写上的简化,下文中的 `hugo` 就是指 hugo 可执行文件所在的路径(包括可执行文件),例如命令 `hugo version` 就是指命令 `c:\hugo_dir\hugo version` 。(译者注:可以把 hugo 可执行文件所在的路径添加到系统环境变量下,这样就可以直接在终端中输入 `hugo version`)
|
||||
如果命令 `hugo version` 报错,你可能下载了错误的版本。当然,有很多种方法安装 Hugo,更多详细信息请查阅 [官方文档][3]。最稳妥的方法就是把 Hugo 可执行文件放在某个路径下,然后执行的时候带上路径名
|
||||
|
||||
5. 创建一个新的站点来作为你的博客,输入命令:`hugo new site awesome-blog`;
|
||||
|
||||
6. 进入新创建的路径下: `cd awesome-blog`;
|
||||
|
||||
恭喜你!你已经创建了自己的新博客。
|
||||
|
||||
### 5-10 分钟:为博客设置主题
|
||||
|
||||
Hugo 中你可以自己构建博客的主题或者使用网上已经有的一些主题。这里选择 [Kiera][4] 主题,因为它简洁漂亮。按以下步骤来安装该主题:
|
||||
|
||||
1. 进入主题所在目录:`cd themes`;
|
||||
|
||||
2. 克隆主题:`git clone https://github.com/avianto/hugo-kiera kiera`。如果你没有安装 Git 工具:
|
||||
* 从 [Github][5] 上下载 hugo 的 .zip 格式的文件;
|
||||
* 解压该 .zip 文件到你的博客主题 `theme` 路径;
|
||||
* 重命名 `hugo-kiera-master` 为 `kiera`;
|
||||
|
||||
3. 返回博客主路径:`cd awesome-blog`;
|
||||
|
||||
4. 激活主题;通常来说,主题(包括 Kiera )都自带文件夹 `exampleSite`,里面存放了内容配置的示例文件。激活 Kiera 主题需要拷贝它提供的 `config.toml` 到你的博客下:
|
||||
* Unix 系统:`cp themes/kiera/exampleSite/config.toml .`;
|
||||
* Windows 系统:`copy themes\kiera\exampleSite\config.toml .`;
|
||||
* 选择 `Yes` 来覆盖原有的 `config.toml`;
|
||||
|
||||
5. ( 可选操作 )你可以选择可视化的方式启动服务器来验证主题是否生效:`hugo server -D` 然后在浏览器中输入 `http://localhost:1313`。可用通过在终端中输入 `Crtl+C` 来停止服务器运行。现在你的博客还是空的,但这也给你留了写作的空间。它看起来如下所示:
|
||||
|
||||

|
||||
|
||||
你已经成功的给博客设置了主题!你可以在官方 [Hugo 主题][4] 网站上找到上百种漂亮的主题供你使用。
|
||||
|
||||
### 10-20 分钟:给博客添加内容
|
||||
|
||||
对于碗来说,它是空的时候用处最大,可以用来盛放东西;但对于博客来说不是这样,空博客几乎毫无用处。在这一步,你将会给博客添加内容。Hugo 和 Kiera 主题都为这个工作提供了方便性。按以下步骤来进行你的第一次提交:
|
||||
|
||||
1. archetypes 将会是你的内容模板。
|
||||
|
||||
2. 添加主题中的 archtypes 至你的博客:
|
||||
* Unix 系统: `cp themes/kiera/archetypes/* archetypes/`
|
||||
* Windows 系统:`copy themes\kiera\archetypes\* archetypes\`
|
||||
* 选择 `Yes` 来覆盖原来的 `default.md` 内容架构类型
|
||||
|
||||
3. 创建博客 posts 目录:
|
||||
* Unix 系统: `mkdir content/posts`
|
||||
* Windows 系统: `mkdir content\posts`
|
||||
|
||||
4. 利用 Hugo 生成你的 post:
|
||||
* Unix 系统:`hugo nes posts/first-post.md`;
|
||||
* Windows 系统:`hugo new posts\first-post.md`;
|
||||
|
||||
5. 在文本编辑器中打开这个新建的 post 文件:
|
||||
* Unix 系统:`gedit content/posts/first-post.md`;
|
||||
* Windows 系统:`notepadd content\posts\first-post.md`;
|
||||
|
||||
此刻,你可以疯狂起来了。注意到你的提交文件中包括两个部分。第一部分是以 `+++` 符号分隔开的。它包括了提交文档的主要数据,例如名称、时间等。在 Hugo 中,这叫做前缀。在前缀之后,才是正文。下面编辑第一个提交文件内容:
|
||||
|
||||
```
|
||||
+++
|
||||
title = "First Post"
|
||||
date = 2018-03-03T13:23:10+01:00
|
||||
draft = false
|
||||
tags = ["Getting started"]
|
||||
categories = []
|
||||
+++
|
||||
Hello Hugo world! No more excuses for having no blog or documentation now!
|
||||
```
|
||||
|
||||
现在你要做的就是启动你的服务器:`hugo server -D`;然后打开浏览器,输入 `http://localhost:1313/`。
|
||||
|
||||

|
||||
|
||||
### 20-30 分钟:调整网站
|
||||
|
||||
前面的工作很完美,但还有一些问题需要解决。例如,简单地命名你的站点:
|
||||
|
||||
1. 终端中按下 `Ctrl+C` 以停止服务器。
|
||||
|
||||
2. 打开 `config.toml`,编辑博客的名称,版权,你的姓名,社交网站等等。
|
||||
|
||||
当你再次启动服务器后,你会发现博客私人订制味道更浓了。不过,还少一个重要的基础内容:主菜单。快速的解决这个问题。返回 `config.toml` 文件,在末尾插入如下一段:
|
||||
|
||||
```
|
||||
[[menu.main]]
|
||||
name = "Home" #Name in the navigation bar
|
||||
weight = 10 #The larger the weight, the more on the right this item will be
|
||||
url = "/" #URL address
|
||||
[[menu.main]]
|
||||
name = "Posts"
|
||||
weight = 20
|
||||
url = "/posts/"
|
||||
```
|
||||
|
||||
上面这段代码添加了 `Home` 和 `Posts` 到主菜单中。你还需要一个 `About` 页面。这次是创建一个 `.md` 文件,而不是编辑 `config.toml` 文件:
|
||||
|
||||
1. 创建 `about.md` 文件:`hugo new about.md` 。注意它是 `about.md`,不是 `posts/about.md`。该页面不是博客提交内容,所以你不想它显示到博客内容提交当中吧。
|
||||
|
||||
2. 用文本编辑器打开该文件,输入如下一段:
|
||||
|
||||
```
|
||||
+++
|
||||
title = "About"
|
||||
date = 2018-03-03T13:50:49+01:00
|
||||
menu = "main" #Display this page on the nav menu
|
||||
weight = "30" #Right-most nav item
|
||||
meta = "false" #Do not display tags or categories
|
||||
+++
|
||||
> Waves are the practice of the water. Shunryu Suzuki
|
||||
|
||||
```
|
||||
|
||||
当你启动你的服务器并输入:`http://localhost:1313/`,你将会看到你的博客。(访问我 Gihub 主页上的 [例子][6] )如果你想让文章的菜单栏和 Github 相似,给 `themes/kiera/static/css/styles.css` 打上这个 [补丁][7]。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/start-blog-30-minutes-hugo
|
||||
|
||||
作者:[Marek Czernek][a]
|
||||
|
||||
译者:[jrg](https://github.com/jrglinux)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mczernek
|
||||
|
||||
[1]:https://gohugo.io/
|
||||
|
||||
[2]:https://github.com/gohugoio/hugo/releases
|
||||
|
||||
[3]:https://gohugo.io/getting-started/installing/
|
||||
|
||||
[4]:https://themes.gohugo.io/
|
||||
|
||||
[5]:https://github.com/avianto/hugo-kiera
|
||||
|
||||
[6]:https://m-czernek.github.io/awesome-blog/
|
||||
|
||||
[7]:https://github.com/avianto/hugo-kiera/pull/18/files
|
||||
@ -0,0 +1,229 @@
|
||||
Part-II 树莓派自建 NAS 云盘之数据自动备份
|
||||
======
|
||||
|
||||

|
||||
|
||||
在《树莓派自建 NAS 云盘》系列的 [第一篇][1] 文章中,我们讨论了建立 NAS 的一些基本步骤,添加了两块 1TB 的存储硬盘驱动(一个用于数据存储,一个用于数据备份),并且通过 网络文件系统(NFS)将数据存储盘挂载到远程终端上。本文是此系列的第二篇文章,我们将探讨数据自动备份。数据自动备份保证了数据的安全,为硬件损坏后的数据恢复提供便利以及减少了文件误操作带来的不必要的麻烦。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
### 备份策略
|
||||
|
||||
我们就从为小型 NAS 构想一个备份策略着手开始吧。我建议每天有时间节点有计划的去备份数据,以防止干扰到我们正常的访问 NAS,比如备份时间点避开正在访问 NAS 并写入文件的时间点。举个例子,你可以每天凌晨 2 点去进行数据备份。
|
||||
|
||||
另外,你还得决定每天的备份需要被保留的时间长短,因为如果没有时间限制,存储空间很快就会被用完。一般每天的备份保留一周便可以,如果数据出了问题,你便可以很方便的从备份中恢复出来原数据。但是如果需要恢复数据到更久之前怎么办?可以将每周一的备份文件保留一个月、每个月的备份保留更长时间。让我们把每月的备份保留一年时间,每一年的备份保留更长时间、例如五年。
|
||||
|
||||
这样,五年内在备份盘上产生大量备份:
|
||||
|
||||
* 每周 7 个日备份
|
||||
* 每月 4 个周备份
|
||||
* 每年 12 个月备份
|
||||
* 每五年 5 个年备份
|
||||
|
||||
|
||||
你应该还记得,我们搭建的备份盘和数据盘大小相同(每个 1 TB)。如何将不止 10 个 1TB 数据的备份从数据盘存放到只有 1TB 大小的备份盘呢?如果你创建的是完整备份,这显然不可能。因此,你需要创建增量备份,它是每一份备份都基于上一份备份数据而创建的。增量备份方式不会每隔一天就成倍的去占用存储空间,它每天只会增加一点占用空间。
|
||||
|
||||
以下是我的情况:我的 NAS 自 2016 年 8 月开始运行,备份盘上有 20 个备份。目前,我在数据盘上存储了 406GB 的文件。我的备份盘用了 726GB。当然,备份盘空间使用率在很大程度上取决于数据的更改频率,但正如你所看到的,增量备份不会占用 20 个完整备份所需的空间。然而,随着时间的推移,1TB 空间也可能不足以进行备份。一旦数据增长接近 1TB 限制(或任何备份盘容量),应该选择更大的备份盘空间并将数据移动转移过去。
|
||||
|
||||
### 利用 rsync 进行数据备份
|
||||
|
||||
利用 rsync 命令行工具可以生成完整备份。
|
||||
|
||||
```
|
||||
pi@raspberrypi:~ $ rsync -a /nas/data/ /nas/backup/2018-08-01
|
||||
|
||||
```
|
||||
|
||||
这段命令将挂载在 /nas/data/ 目录下的数据盘中的数据进行了完整的复制备份。备份文件保存在 /nas/backup/2018-08-01 目录下。`-a` 参数是以归档模式进行备份,这将会备份所有的元数据,例如文件的修改日期、权限、拥有者以及软连接文件。
|
||||
|
||||
现在,你已经在 8 月 1 日创建了完整的初始备份,你将在 8 月 2 日创建第一个增量备份。
|
||||
|
||||
```
|
||||
pi@raspberrypi:~ $ rsync -a --link-dest /nas/backup/2018-08-01/ /nas/data/ /nas/backup/2018-08-02
|
||||
|
||||
```
|
||||
|
||||
上面这行代码又创建了一个关于 `/nas/data` 目录中数据的备份。备份路径是 `/nas/backup/2018-08-02`。这里的参数 `--link-dest` 指定了一个备份文件所在的路径。这样,这次备份会与 `/nas/backup/2018-08-01` 的备份进行比对,只备份已经修改过的文件,未做修改的文件将不会被复制,而是创建一个到上一个备份文件中它们的硬链接。
|
||||
|
||||
使用备份文件中的硬链接文件时,你一般不会注意到硬链接和初始拷贝之间的差别。它们表现的完全一样,如果删除其中一个硬链接或者文件,其他的依旧存在。你可以把它们看做是同一个文件的两个不同入口。下面就是一个例子:
|
||||
|
||||

|
||||
|
||||
左侧框是在进行了第二次备份后的原数据状态。中间的盒子是昨天的备份。昨天的备份中只有图片 `file1.jpg` 并没有 `file2.txt` 。右侧的框反映了今天的增量备份。增量备份命令创建昨天不存在的 `file2.txt`。由于 `file1.jpg` 自昨天以来没有被修改,所以今天创建了一个硬链接,它不会额外占用磁盘上的空间。
|
||||
|
||||
### 自动化备份
|
||||
|
||||
你肯定也不想每天凌晨去输入命令进行数据备份吧。你可以创建一个任务定时去调用下面的脚本让它自动化备份
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
|
||||
|
||||
TODAY=$(date +%Y-%m-%d)
|
||||
|
||||
DATADIR=/nas/data/
|
||||
|
||||
BACKUPDIR=/nas/backup/
|
||||
|
||||
SCRIPTDIR=/nas/data/backup_scripts
|
||||
|
||||
LASTDAYPATH=${BACKUPDIR}/$(ls ${BACKUPDIR} | tail -n 1)
|
||||
|
||||
TODAYPATH=${BACKUPDIR}/${TODAY}
|
||||
|
||||
if [[ ! -e ${TODAYPATH} ]]; then
|
||||
|
||||
mkdir -p ${TODAYPATH}
|
||||
|
||||
fi
|
||||
|
||||
|
||||
|
||||
rsync -a --link-dest ${LASTDAYPATH} ${DATADIR} ${TODAYPATH} $@
|
||||
|
||||
|
||||
|
||||
${SCRIPTDIR}/deleteOldBackups.sh
|
||||
|
||||
```
|
||||
|
||||
第一段代码指定了数据路径、备份路劲、脚本路径以及昨天和今天的备份路径。第二段代码调用 rsync 命令。最后一段代码执行 `deleteOldBackups.sh` 脚本,它会清除一些过期的没有必要的备份数据。如果不想频繁的调用 `deleteOldBackups.sh`,你也可以手动去执行它。
|
||||
|
||||
下面是今天讨论的备份策略的一个简单完整的示例脚本。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
BACKUPDIR=/nas/backup/
|
||||
|
||||
|
||||
|
||||
function listYearlyBackups() {
|
||||
|
||||
for i in 0 1 2 3 4 5
|
||||
|
||||
do ls ${BACKUPDIR} | egrep "$(date +%Y -d "${i} year ago")-[0-9]{2}-[0-9]{2}" | sort -u | head -n 1
|
||||
|
||||
done
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function listMonthlyBackups() {
|
||||
|
||||
for i in 0 1 2 3 4 5 6 7 8 9 10 11 12
|
||||
|
||||
do ls ${BACKUPDIR} | egrep "$(date +%Y-%m -d "${i} month ago")-[0-9]{2}" | sort -u | head -n 1
|
||||
|
||||
done
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function listWeeklyBackups() {
|
||||
|
||||
for i in 0 1 2 3 4
|
||||
|
||||
do ls ${BACKUPDIR} | grep "$(date +%Y-%m-%d -d "last monday -${i} weeks")"
|
||||
|
||||
done
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function listDailyBackups() {
|
||||
|
||||
for i in 0 1 2 3 4 5 6
|
||||
|
||||
do ls ${BACKUPDIR} | grep "$(date +%Y-%m-%d -d "-${i} day")"
|
||||
|
||||
done
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function getAllBackups() {
|
||||
|
||||
listYearlyBackups
|
||||
|
||||
listMonthlyBackups
|
||||
|
||||
listWeeklyBackups
|
||||
|
||||
listDailyBackups
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function listUniqueBackups() {
|
||||
|
||||
getAllBackups | sort -u
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function listBackupsToDelete() {
|
||||
|
||||
ls ${BACKUPDIR} | grep -v -e "$(echo -n $(listUniqueBackups) |sed "s/ /\\\|/g")"
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
cd ${BACKUPDIR}
|
||||
|
||||
listBackupsToDelete | while read file_to_delete; do
|
||||
|
||||
rm -rf ${file_to_delete}
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
这段脚本会首先根据你的备份策略列出所有需要保存的备份文件,然后它会删除那些再也不需要了的备份目录。
|
||||
|
||||
下面创建一个定时任务去执行上面这段代码。以 root 用户权限打开 `crontab -e`,输入以下这段命令,它将会创建一个每天凌晨 2 点去执行 `/nas/data/backup_scripts/daily.sh` 的定时任务。
|
||||
|
||||
```
|
||||
0 2 * * * /nas/data/backup_scripts/daily.sh
|
||||
|
||||
```
|
||||
|
||||
有关创建定时任务请参考 [cron 创建定时任务][2]。
|
||||
|
||||
* 当没有备份任务时,卸载你的备份盘或者将它挂载为只读盘;
|
||||
* 利用远程服务器作为你的备份盘,这样就可以通过互联网同步数据
|
||||
|
||||
你也可用下面的方法来加强你的备份策略,以防止备份数据的误删除或者被破坏:
|
||||
|
||||
本文中备份策略示例是备份一些我觉得有价值的数据,你也可以根据个人需求去修改这些策略。
|
||||
|
||||
我将会在 《树莓派自建 NAS 云盘》 系列的第三篇文章中讨论 [Nextcloud][3]。Nextcloud 提供了更方便的方式去访问 NAS 云盘上的数据并且它还提供了离线操作,你还可以在客户端中同步你的数据。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/automate-backups-raspberry-pi
|
||||
|
||||
作者:[Manuel Dewald][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jrg](https://github.com/jrglinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ntlx
|
||||
[1]: https://opensource.com/article/18/7/network-attached-storage-Raspberry-Pi
|
||||
[2]: https://opensource.com/article/17/11/how-use-cron-linux
|
||||
[3]: https://nextcloud.com/
|
||||
|
||||
@ -0,0 +1,112 @@
|
||||
Part-III 树莓派自建 NAS 云盘之云盘构建
|
||||
======
|
||||
|
||||
用树莓派 NAS 云盘来保护数据的安全!
|
||||
|
||||
在前面两篇文章中(译注:文章链接 [Part-I][1],[Part-II][2]),我们讨论了用树莓派搭建一个 NAS(network-attached storage) 所需要的一些 [软硬件环境及其操作步骤][1]。我们还制定了适当的 [备份策略][2] 来保护NAS上的数据。本文中,我们将介绍讨论利用 [Nestcloud][3] 来方便快捷的存储、获取以及分享你的数据。
|
||||
|
||||
### 必要的准备工作
|
||||
|
||||
想要方便的使用 Nextcloud,需要一些必要的准备工作。首先,你需要一个指向 Nextcloud 的域名。方便起见,本文将使用 **nextcloud.pi-nas.com** 。如果你是在家庭网络里运行,你需要为该域名配置 DNS 服务(动态域名解析服务)并在路由器中开启 80 端口和 443 端口转发功能(如果需要使用 https,则需要开启 443 端口转发,如果只用 http,80 端口足以)。
|
||||
|
||||
你可以使用 [ddclient][4] 在树莓派中自动更新 DNS。
|
||||
|
||||
### 安装 Nextcloud
|
||||
|
||||
为了在树莓派(参考 [Part-I][1] 中步骤设置)中运行 Nextcloud,首先用命令 **apt** 安装 以下的一些依赖软件包。
|
||||
|
||||
```
|
||||
sudo apt install unzip wget php apache2 mysql-server php-zip php-mysql php-dom php-mbstring php-gd php-curl
|
||||
```
|
||||
|
||||
其次,下载 Nextcloud。在树莓派中利用 **wget** 下载其 [最新的版本][5]。在 [Part-I] 文章中,我们将两个磁盘驱动器连接到树莓派,一个用于存储当前数据,另一个用于备份。这里在数据存储盘上安装 Nextcloud,以确保每晚自动备份数据。
|
||||
|
||||
```
|
||||
sudo mkdir -p /nas/data/nextcloud
|
||||
sudo chown pi /nas/data/nextcloud
|
||||
cd /nas/data/
|
||||
wget https://download.nextcloud.com/server/releases/nextcloud-14.0.0.zip -O /nas/data/nextcloud.zip
|
||||
unzip nextcloud.zip
|
||||
sudo ln -s /nas/data/nextcloud /var/www/nextcloud
|
||||
sudo chown -R www-data:www-data /nas/data/nextcloud
|
||||
```
|
||||
|
||||
截止到写作本文时,Nextcloud 最新版更新到如上述代码中所示的 14.0.0 版本。Nextcloud 正在快速的迭代更新中,所以你可以在你的树莓派中安装更新一点的版本。
|
||||
|
||||
### 配置数据库
|
||||
|
||||
如上所述,Nextcloud 安装完毕。之前安装依赖软件包时就已经安装了 MySQL 数据库来存储 Nextcloud 的一些重要数据(例如,那些你创建的可以访问 Nextcloud 的用户的信息)。如果你更愿意使用 Pstgres 数据库,则上面的依赖软件包需要做一些调整。
|
||||
|
||||
以 root 权限启动 MySQL:
|
||||
|
||||
```
|
||||
sudo mysql
|
||||
```
|
||||
|
||||
这将会打开 SQL 提示符界面,在那里可以插入如下指令--使用数据库连接密码替换其中的占位符--为 Nextcloud 创建一个数据库。
|
||||
|
||||
```
|
||||
CREATE USER nextcloud IDENTIFIED BY '<insert-password-here>';
|
||||
CREATE DATABASE nextcloud;
|
||||
GRANT ALL ON nextcloud.* TO nextcloud;
|
||||
```
|
||||
|
||||
按 **Ctrl+D** 或输入 **quit** 退出 SQL 提示符界面。
|
||||
|
||||
### Web 服务器配置
|
||||
|
||||
Nextcloud 可以配置以适配于 Nginx 服务器或者其他 Web 服务器运行的环境。但本文中,我决定在我的树莓派 NAS 中运行 Apache 服务器(如果你有其他效果更好的服务器选择方案,不妨也跟我分享一下)。
|
||||
|
||||
首先为你的 Nextcloud 域名创建一个虚拟主机,创建配置文件 **/etc/apache2/sites-available/001-netxcloud.conf**,在其中输入下面的参数内容。修改其中 ServerName 为你的域名。
|
||||
|
||||
```
|
||||
<VirtualHost *:80>
|
||||
ServerName nextcloud.pi-nas.com
|
||||
ServerAdmin admin@pi-nas.com
|
||||
DocumentRoot /var/www/nextcloud/
|
||||
|
||||
<Directory /var/www/nextcloud/>
|
||||
AllowOverride None
|
||||
</Directory>
|
||||
</VirtualHost>
|
||||
```
|
||||
|
||||
使用下面的命令来启动该虚拟主机。
|
||||
|
||||
```
|
||||
a2ensite 001-nextcloud
|
||||
sudo systemctl reload apache2
|
||||
```
|
||||
|
||||
现在,你应该可以通过浏览器中输入域名访问到 web 服务器了。这里我推荐使用 HTTPS 协议而不是 HTTP 协议来访问 Nextcloud。一个简单而且免费的方法就是利用 [Certbot][7] 下载 [Let's Encrypt][6] 证书,然后设置定时任务自动刷新。这样就避免了自签证书等的麻烦。参考 [如何在树莓派中安装][8] Certbot 。在配置 Certbot 的时候,你甚至可以配置将 HTTP 自动转到 HTTPS ,例如访问 **<http://nextcloud.pi-nas.com>** 自动跳转到 **<https://nextcloud.pi-nas.com>**。注意,如果你的树莓派 NAS 运行在家庭路由器的下面,别忘了设置路由器的 443 端口和 80 端口转发。
|
||||
|
||||
### 配置 Nextcloud
|
||||
|
||||
最后一步,通过浏览器访问 Nextcloud 来配置它。在浏览器中输入域名地址,插入上文中的数据库设置信息。这里,你可以创建 Nextcloud 管理员用户。默认情况下,数据保存目录在在 Nextcloud 目录下,所以你也无需修改我们在 [Part-II][2] 一文中设置的备份策略。
|
||||
|
||||
然后,页面会跳转到 Nextcloud 登陆界面,用刚才创建的管理员用户登陆。在设置页面中会有基础操作教程和安全安装教程(这里是访问 <https://nextcloud.pi-nas.com/>settings/admin)。
|
||||
|
||||
恭喜你,到此为止,你已经成功在树莓派中安装了你自己的云 Nextcloud。去 Nextcloud 主页 [下载 Nextcloud 客户端][9],客户端可以同步数据并且离线访问服务器。移动端甚至可以上传图片等资源,然后电脑桌面都可以去访问它们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/host-cloud-nas-raspberry-pi
|
||||
|
||||
作者:[Manuel Dewald][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jrg](https://github.com/jrglinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ntlx
|
||||
[1]: https://opensource.com/article/18/7/network-attached-storage-Raspberry-Pi
|
||||
[2]: https://opensource.com/article/18/8/automate-backups-raspberry-pi
|
||||
[3]: https://nextcloud.com/
|
||||
[4]: https://sourceforge.net/p/ddclient/wiki/Home/
|
||||
[5]: https://nextcloud.com/install/#instructions-server
|
||||
[6]: https://letsencrypt.org/
|
||||
[7]: https://certbot.eff.org/
|
||||
[8]: https://certbot.eff.org/lets-encrypt/debianother-apache
|
||||
[9]: https://nextcloud.com/install/#install-clients
|
||||
|
||||
Loading…
Reference in New Issue
Block a user