mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-28 23:20:10 +08:00
commit
d4033cb682
4
LCTT翻译规范.md
Normal file
4
LCTT翻译规范.md
Normal file
@ -0,0 +1,4 @@
|
||||
# Linux中国翻译规范
|
||||
1. 翻译中出现的专有名词,可参见Dict.md中的翻译。
|
||||
2. 英文人名,如无中文对应译名,一般不译。
|
||||
2. 缩写词,一般不须翻译,可考虑旁注中文全名。
|
||||
132
published/20150716 Interview--Larry Wall.md
Normal file
132
published/20150716 Interview--Larry Wall.md
Normal file
@ -0,0 +1,132 @@
|
||||
Larry Wall 专访——语言学、Perl 6 的设计和发布
|
||||
================================================================================
|
||||
|
||||
> 经历了15年的打造,Perl 6 终将在年底与大家见面。我们预先采访了它的作者了解一下新特性。
|
||||
|
||||
Larry Wall 是个相当有趣的人。他是编程语言 Perl 的创造者,这种语言被广泛的誉为将互联网粘在一起的胶水,也由于大量地在各种地方使用非字母的符号被嘲笑为‘只写’语言——以难以阅读著称。Larry 本人具有语言学背景,以其介绍 Perl 未来发展的演讲“[洋葱的状态][1](State of the Onion)”而闻名。(LCTT 译注:“洋葱的状态”是 Larry Wall 的年度演讲的主题,洋葱也是 Perl 基金会的标志。)
|
||||
|
||||
在2015年布鲁塞尔的 FOSDEM 上,我们赶上了 Larry,问了问他为什么 Perl 6 花了如此长的时间(Perl 5 的发布时间是1994年),了解当项目中的每个人都各执己见时是多么的难以管理,以及他的语言学背景自始至终究竟给 Perl 带来了怎样的影响。做好准备,让我们来领略其中的奥妙……
|
||||
|
||||

|
||||
|
||||
**Linux Voice:你曾经有过计划去寻找世界上某个地方的某种不见经传的语言,然后为它创造书写的文字,但你从未有机会去实现它。如果你能回到过去,你会去做么?**
|
||||
|
||||
Larry Wall:你首先得是个年轻人才能搞得定!做这些事需要投入很大的努力和人力,以至于已经不适合那些上了年纪的人了。健康、活力是其中的一部分,同样也因为人们在年轻的时候更容易学习一门新的语言,只有在你学会了语言之后你才能写呀。
|
||||
|
||||
我自学了日语十年,由于我的音系学和语音学的训练我能说的比较流利——但要理解别人的意思对我来说还十分困难。所以到了日本我会问路,但我听不懂他们的回答!
|
||||
|
||||
通常需要一门语言学习得足够好才能开发一个文字体系,并可以使用这种语言进行少量的交流。在你能够实际推广它和用本土人自己的文化教育他们前,那还需要一些年。最后才可以教授本土人如何以他们的文明书写。
|
||||
|
||||
当然如果在语言方面你有帮手 —— 经过别人的提醒我们不再使用“语言线人”来称呼他们了,那样显得我们像是在 CIA 工作的一样!—— 你可以通过他们的帮助来学习外语。他们不是老师,但他们会以另一种方式来启发你学习 —— 当然他们也能教你如何说。他们会拿着一根棍子,指着它说“这是一根棍子”,然后丢掉同时说“棒子掉下去了”。然后,你就可以记下一些东西并将其系统化。
|
||||
|
||||
大多数让人们有这样做的动力是翻译圣经。但是这只是其中的一方面;另一方面也是为了文化保护。传教士在这方面臭名昭著,因为人类学家认为人们应该基于自己的文明来做这件事。但有些人注定会改变他们的文化——他们可能是军队、或是商业侵入,如可口可乐或者缝纫机,或传教士。在这三者之间,传教士相对来讲伤害最小的了,如果他们恪守本职的话。
|
||||
|
||||
**LV:许多文字系统有本可依,相较而言你的发明就像是格林兰语…**
|
||||
|
||||
印第安人照搬字母就发明了他们自己的语言,而且没有在这些字母上施加太多我们给这些字母赋予的涵义,这种做法相当随性。它们只要能够表达出人们的所思所想,使交流顺畅就行。经常是有些声调语言(Tonal language)使用的是西方文字拼写,并尽可能的使用拉丁文的字符变化,然后用重音符或数字标注出音调。
|
||||
|
||||
在你开始学习如何使用语音和语调表示之后,你也开始变得迷糊——或者你的书写就不如从前准确。或者你对话的时候像在讲英文,但发音开始无法匹配拼写。
|
||||
|
||||
**LV:当你在开发 Perl 的时候,你的语言学背景会不会使你认为:“这对程序设计语言真的非常重要”?**
|
||||
|
||||
LW:我在人们是如何使用语言上想了很多。在现实的语言中,你有一套名词、动词和形容词的体系,并且你知道这些单词的词性。在现实的自然语言中,你时常将一个单词放到不同的位置。我所学的语言学理论也被称为法位学(phoenetic),它解释了这些在自然语言中工作的原理 —— 也就是有些你当做名词的东西,有时候你可以将它用作动词,并且人们总是这样做。
|
||||
|
||||
你能很好的将任何单词放在任何位置而进行沟通。我比较喜欢的例子是将一个整句用作为一个形容词。这句话会是这样的:“我不喜欢你的[我可以用任何东西来取代这个形容词的]态度”!
|
||||
|
||||
所以自然语言非常灵活,因为聆听者非常聪明 —— 至少,相对于电脑而言 —— 你相信他们会理解你最想表达的意思,即使存在歧义。当然对电脑而言,你必须保证歧义不大。
|
||||
|
||||
> “在 Perl 6 中,我们试图让电脑更准确的了解我们。”
|
||||
|
||||
可以说在 Perl 1到5上,我们针对歧义方面处理做得还不够。有时电脑会在不应该的时候迷惑。在 Perl 6上,我们找了许多方法,使得电脑对你所说的话能更准确的理解,就算用户并不清楚这底是字符串还是数字,电脑也能准确的知道它的类型。我们找到了内部以强类型存储,而仍然可以无视类型的“以此即彼”的方法。
|
||||
|
||||

|
||||
|
||||
**LV:Perl 被视作互联网上的“胶水(glue)”语言已久,能将点点滴滴组合在一起。在你看来 Perl 6 的发布是否符合当前用户的需要,或者旨在招揽更多新用户,能使它重获新生吗?**
|
||||
|
||||
LW:最初的设想是为 Perl 程序员带来更好的 Perl。但在看到了 Perl 5 上的不足后,很明显改掉这些不足会使 Perl 6更易用,就像我在讨论中提到过 —— 类似于 [托尔金(J. R. R. Tolkien) 在《指环王》前言中谈到的适用性一样][2]。
|
||||
|
||||
重点是“简单的东西应该简单,而困难的东西应该可以实现”。让我们回顾一下,在 Perl 2和3之间的那段时间。在 Perl 2上我们不能处理二进制数据或嵌入的 null 值 —— 只支持 C 语言风格的字符串。我曾说过“Perl 只是文本处理语言 —— 在文本处理语言里你并不需要这些功能”。
|
||||
|
||||
但当时发生了一大堆的问题,因为大多数的文本中会包含少量的二进制数据 —— 如网络地址(network addresses)及类似的东西。你使用二进制数据打开套接字,然后处理文本。所以通过支持二进制数据,语言的适用性(applicability)翻了一倍。
|
||||
|
||||
这让我们开始探讨在语言中什么应该简单。现在的 Perl 中有一条原则,是我们偷师了哈夫曼编码(Huffman coding)的做法,它在位编码系统中为字符采取了不同的尺寸,常用的字符占用的位数较少,不常用的字符占用的位数更多。
|
||||
|
||||
我们偷师了这种想法并将它作为 Perl 的一般原则,针对常用的或者说常输入的 —— 这些常用的东西必须简单或简洁。不过,另一方面,也显得更加的不规则(irregular)。在自然语言中也是这样的,最常用的动词实际上往往是最不规则的。
|
||||
|
||||
所以在这样的情况下需要更多的差异存在。我很喜欢一本书是 Umberto Eco 写的的《探寻完美的语言(The Search for the Perfect Language)》,说的并不是计算机语言;而是哲学语言,大体的意思是古代的语言也许是完美的,我们应该将它们带回来。
|
||||
|
||||
所有的这类语言错误的认为类似的事物其编码也应该总是类似的。但这并不是我们沟通的方式。如果你的农场中有许多动物,他们都有相近的名字,当你想杀一只鸡的时候说“走,去把 Blerfoo 宰了”,你的真实想法是宰了 Blerfee,但有可能最后死的是一头牛(LCTT 译注:这是杀鸡用牛刀的意思吗?哈哈)。
|
||||
|
||||
所以在这种时候我们其实更需要好好的将单词区分开,使沟通信道的冗余增加。常用的单词应该有更多的差异。为了达到更有效的通讯,还有一种自足(LCTT 译注:self-clocking ,自同步,[概念][3]来自电信和电子行业,此处译为“自足”更能体现涵义)编码。如果你在一个货物上看到过 UPC 标签(条形码),它就是一个自足编码,每对“条”和“空”总是以七个列宽为单位,据此你就知道“条”的宽度加起来总是这么宽。这就是自足。
|
||||
|
||||
在电子产品中还有另一种自足编码。在老式的串行传输协议中有停止和启动位,来保持同步。自然语言中也会包含这些。比如说,在写日语时,不用使用空格。由于书写方式的原因,他们会在每个词组的开头使用中文中的汉字字符,然后用音节表(syllabary)中的字符来结尾。
|
||||
|
||||
**LV:是平假名,对吗?**
|
||||
|
||||
LW: 是的,平假名。所以在这一系统,每个词组的开头就自然就很重要了。同样的,在古希腊,大多数的动词都是搭配好的(declined 或 conjugated),所以它们的标准结尾是一种自足机制。在他们的书写体系中空格也是可有可无的 —— 引入空格是更近代的发明。
|
||||
|
||||
所以在计算机语言上也要如此,有的值也可以自足编码。在 Perl 上我们重度依赖这种方法,而且在 Perl 6 上相较于前几代这种依赖更重。当你使用表达式时,你要么得到的是一个词,要么得到的是插值(infix)操作符。当你想要得到一个词,你有可能得到的是一个前缀操作符,它也在相同的位置;同样当你想要得到一个插值操作符,你也可能得到的是前一个词的后缀。
|
||||
|
||||
但是反过来。如果编译器准确的知道它想要什么,你可以稍微重载(overload)它们,其它的让 Perl 来完成。所以在斜线“/”后面是单词时它会当成正则表达式,而斜线“/”在字串中时视作除法。而我们并不会重载所有东西,因为那只会使你失去自足冗余。
|
||||
|
||||
多数情况下我们提示的比较好的语法错误消息,是出于发现了一行中出现了两个关键词,然后我们尝试找出为什么一行会出现两个关键字 —— “哦,你一定漏掉了上一行的分号”,所以我们相较于很多其他的按步照班的解析器可以生成更好的错误消息。
|
||||
|
||||

|
||||
|
||||
**LV:为什么 Perl 6 花了15年?当每个人对事物有不同看法时一定十分难于管理,而且正确和错误并不是绝对的。**
|
||||
|
||||
LW:这必须要非常小心地平衡。刚开始会有许多的好的想法 —— 好吧,我并不是说那些全是好的想法。也有很多令人烦恼的地方,就像有361条 RFC [功能建议文件],而我也许只想要20条。我们需要坐下来,将它们全部看完,并忽略其中的解决方案,因为它们通常流于表象、视野狭隘。几乎每一条只针对一样事物,如若我们将它们全部拼凑起来,那简直是一堆垃圾。
|
||||
|
||||
> “掌握平衡时需要格外小心。毕竟在刚开始的时候总会有许多的好主意。”
|
||||
|
||||
所以我们必须基于人们在使用 Perl 5 时的真实感受重新整理,寻找统一、深层的解决方案。这些 RFC 文档许多都提到了一个事实,就是类型系统的不足。通过引入更条理分明的类型系统,我们可以解决很多问题并且即聪明又紧凑。
|
||||
|
||||
同时我们开始关注其他方面:如何统一特征集并开始重用不同领域的想法,这并不需要它们在下层相同。我们有一种标准的书写配对(pair)的方式——好吧,在 Perl 里面有两种!但使用冒号书写配对的方法同样可以用于基数计数法或是任何进制的文本编号。同样也可以用于其他形式的引用(quoting)。在 Perl 里我们称它为“奇妙的一致”。
|
||||
|
||||
> “做了 Perl 6 的早期实现的朋友们,握着我的手说:“我们真的很需要一位语言的设计者。””
|
||||
|
||||
同样的想法涌现出来,你说“我已经熟悉了语法如何运作,但是我看见它也被用在别处”,所以说视角相同才能找出这种一致。那些提出各种想法和做了 Perl 6 的早期实现的人们回来看我,握着我的手说:“我们真的需要一位语言的设计者。您能作为我们的[仁慈独裁者][4](benevolent dictator)吗?”(LCTT 译注:Benevolent Dictator For Life,或 BDFL,指开源领袖,通常指对社区争议拥有最终裁决权的领袖,典故来自 Python 创始人 Guido van Rossum, 具体参考维基条目[解释][4])
|
||||
|
||||
所以我是语言的设计者,但总是听到:“不要管具体实现(implementation)!我们目睹了你对 Perl 5 做的那些,我们不想历史重演!”真是让我忍俊不禁,因为他们作为起步的核心和原先 Perl 5 的内部结构上几乎别无二致,也许这就是为什么一些早期的实现做的并不好的原因。
|
||||
|
||||
因为我们仍然在摸索我们的整个设计,其实现在做了许多 VM (虚拟机)该做什么和不该做什么的假设,所以最终这个东西就像面向对象的汇编语言一样。类似的问题在伊始阶段无处不在。然后 Pugs 这家伙走过来说:“用用看 Haskell 吧,它能让你们清醒的认识自己正在干什么,让我们用它来弄清楚下层的语义模型(semantic model)。”
|
||||
|
||||
因此,我们明确了其中的一些语义模型,但更重要的是,我们开始建立符合那些语义模型的测试套件。在这之后,Parrot VM 继续进行开发,并且出现了另一个实现 Niecza ,它基于 .Net,是由一个年轻的家伙搞出来的。他很聪明,实现了 Perl 6 的一个很大的子集。不过他还是一个人干,并没有找到什么好方法让别人介入他的项目。
|
||||
|
||||
同时 Parrot 项目变得过于庞大,以至于任何人都不能真正的深入掌控它,并且很难重构。同时,开发 Rakudo 的人们觉得我们可能需要在更多平台上运行它,而不只是在 Parrot VM 上。 于是他们发明了所谓的可移植层 NQP ,即 “Not Quite Perl”。他们一开始将它移植到 JVM(Java虚拟机)上运行,与此同时,他们还秘密的开发了一个叫做 MoarVM 的 VM ,它去年才刚刚为人知晓。
|
||||
|
||||
无论 MoarVM 还是 JVM 在回归测试(regression test)中表现得十分接近 —— 在许多方面 Parrot 算是尾随其后。这样不挑剔 VM 真的很棒,我们也能开始考虑将 NQP 发扬光大。谷歌夏季编码大赛(Google Summer of Code project)的目标就是针对 JavaScript 的 NQP,这应该靠谱,因为 MoarVM 也同样使用 Node.js 作为日常处理。
|
||||
|
||||
我们可能要将今年余下的时光投在 MoarVM 上,直到 6.0 发布,方可休息片刻。
|
||||
|
||||
**LV:去年英国,政府开展编程年活动(Year of Code),来激发年轻人对编程的兴趣。针对活动的建议五花八门——类似为了让人们准确的认识到内存的使用你是否应该从低阶语言开始讲授,或是一门高阶语言。你对此作何看法?**
|
||||
|
||||
LW:到现在为止,Python 社区在低阶方面的教学工作做得比我们要好。我们也很想在这一方面做点什么,这也是我们有蝴蝶 logo 的部分原因,以此来吸引七岁大小的女孩子!
|
||||
|
||||

|
||||
|
||||
> “到现在为止,Python 社区在低阶方面的教学工作做得比我们要好。”
|
||||
|
||||
我们认为将 Perl 6 作为第一门语言来学习是可行的。一大堆的将 Perl 5 作为第一门语言学习的人让我们吃惊。你知道,在 Perl 5 中有许多相当大的概念,如闭包,词法范围,和一些你通常在函数式编程中见到的特性。甚至在 Perl 6 中更是如此。
|
||||
|
||||
Perl 6 花了这么长时间的部分原因是我们尝试去坚持将近 50 种互不相同的原则,在设计语言的最后对于“哪点是最重要的规则”这个问题还是悬而未决。有太多的问题需要讨论。有时我们做出了决定,并已经工作了一段时间,才发现这个决定并不很正确。
|
||||
|
||||
之前我们并未针对并发程序设计或指定很多东西,直到 Jonathan Worthington 的出现,他非常巧妙的权衡了各个方面。他结合了一些其他语言诸如 Go 和 C# 的想法,将并发原语写的非常好。可组合性(Composability)是一个语言至关重要的一部分。
|
||||
|
||||
有很多的程序设计系统的并发和并行写的并不好 —— 比如线程和锁,不良的操作方式有很多。所以在我看来,额外花点时间看一下 Go 或者 C# 这种高阶原语的开发是很值得的 —— 那是一种关键字上的矛盾 —— 写的相当棒。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxvoice.com/interview-larry-wall/
|
||||
|
||||
作者:[Mike Saunders][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxvoice.com/author/mike/
|
||||
[1]:https://en.wikipedia.org/wiki/Perl#State_of_the_Onion
|
||||
[2]:http://tinyurl.com/nhpr8g2
|
||||
[3]:http://en.wikipedia.org/wiki/Self-clocking_signal
|
||||
[4]:https://en.wikipedia.org/wiki/Benevolent_dictator_for_life
|
||||
@ -0,0 +1,28 @@
|
||||
Linux 4.3 内核增加了 MOST 驱动子系统
|
||||
================================================================================
|
||||
当 4.2 内核还没有正式发布的时候,Greg Kroah-Hartman 就为他维护的各种子系统模块打开了4.3 的合并窗口。
|
||||
|
||||
之前 Greg KH 发起的拉取请求(pull request)里包含了 linux 4.3 的合并窗口更新,内容涉及驱动核心、TTY/串口、USB 驱动、字符/杂项以及暂存区内容。这些拉取申请没有提供任何震撼性的改变,大部分都是改进/附加/修改bug。暂存区内容又是大量的修正和清理,但是还是有一个新的驱动子系统。
|
||||
|
||||
Greg 提到了[4.3 的暂存区改变][2],“这里的很多东西,几乎全部都是细小的修改和改变。通常的 IIO 更新和新驱动,以及我们已经添加了的 MOST 驱动子系统,已经在源码树里整理了。ozwpan 驱动最终还是被删掉,因为它很明显被废弃了而且也没有人关心它。”
|
||||
|
||||
MOST 驱动子系统是面向媒体的系统传输(Media Oriented Systems Transport)的简称。在 linux 4.3 新增的文档里面解释道,“MOST 驱动支持 LInux 应用程序访问 MOST 网络:汽车信息骨干网(Automotive Information Backbone),高速汽车多媒体网络的事实上的标准。MOST 定义了必要的协议、硬件和软件层,提供高效且低消耗的传输控制,实时的数据包传输,而只需要使用一个媒介(物理层)。目前使用的媒介是光线、非屏蔽双绞线(UTP)和同轴电缆。MOST 也支持多种传输速度,最高支持150Mbps。”如文档解释的,MOST 主要是关于 Linux 在汽车上的应用。
|
||||
|
||||
当 Greg KH 发出了他为 Linux 4.3 多个子系统做出的更新,但是他还没有打算提交 [KDBUS][5] 的内核代码。他之前已经放出了 [linux 4.3 的 KDBUS] 的开发计划,所以我们将需要等待官方的4.3 合并窗口,看看会发生什么。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=news_item&px=Linux-4.3-Staging-Pull
|
||||
|
||||
作者:[Michael Larabel][a]
|
||||
译者:[oska874](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.michaellarabel.com/
|
||||
[1]:http://www.phoronix.com/scan.php?page=search&q=Linux+4.2
|
||||
[2]:http://lkml.iu.edu/hypermail/linux/kernel/1508.2/02604.html
|
||||
[3]:http://www.phoronix.com/scan.php?page=news_item&px=KDBUS-Not-In-Linux-4.2
|
||||
[4]:http://www.phoronix.com/scan.php?page=news_item&px=Linux-4.2-rc7-Released
|
||||
[5]:http://www.phoronix.com/scan.php?page=search&q=KDBUS
|
||||
@ -1,14 +1,12 @@
|
||||
translation by strugglingyouth
|
||||
nstalling NGINX and NGINX Plus With Ansible
|
||||
使用 ansible 安装 NGINX 和 NGINX Plus
|
||||
================================================================================
|
||||
在生产环境中,我会更喜欢做与自动化相关的所有事情。如果计算机能完成你的任务,何必需要你亲自动手呢?但是,在不断变化并存在多种技术的环境中,创建和实施自动化是一项艰巨的任务。这就是为什么我喜欢[Ansible][1]。Ansible是免费的,开源的,对于 IT 配置管理,部署和业务流程,使用起来非常方便。
|
||||
在生产环境中,我会更喜欢做与自动化相关的所有事情。如果计算机能完成你的任务,何必需要你亲自动手呢?但是,在不断变化并存在多种技术的环境中,创建和实施自动化是一项艰巨的任务。这就是为什么我喜欢 [Ansible][1] 的原因。Ansible 是一个用于 IT 配置管理,部署和业务流程的开源工具,使用起来非常方便。
|
||||
|
||||
我最喜欢 Ansible 的一个特点是,它是完全无客户端的。要管理一个系统,通过 SSH 建立连接,它使用[Paramiko][2](一个 Python 库)或本地的 [OpenSSH][3]。Ansible 另一个吸引人的地方是它有许多可扩展的模块。这些模块可被系统管理员用于执行一些的常见任务。特别是,它们使用 Ansible 这个强有力的工具可以跨多个服务器、环境或操作系统安装和配置任何程序,只需要一个控制节点。
|
||||
|
||||
我最喜欢 Ansible 的一个特点是,它是完全无客户端。要管理一个系统,通过 SSH 建立连接,也使用了[Paramiko][2](一个 Python 库)或本地的 [OpenSSH][3]。Ansible 另一个吸引人的地方是它有许多可扩展的模块。这些模块可被系统管理员用于执行一些的相同任务。特别是,它们使用 Ansible 这个强有力的工具可以安装和配置任何程序在多个服务器上,环境或操作系统,只需要一个控制节点。
|
||||
在本教程中,我将带你使用 Ansible 完成安装和部署开源 [NGINX][4] 和我们的商业产品 [NGINX Plus][5]。我将在 [CentOS][6] 服务器上演示,但我也在下面的“在 Ubuntu 上创建 Ansible Playbook 来安装 NGINX 和 NGINX Plus”小节中包含了在 Ubuntu 服务器上部署的细节。
|
||||
|
||||
在本教程中,我将带你使用 Ansible 完成安装和部署开源[NGINX][4] 和 [NGINX Plus][5],我们的商业产品。我将在 [CentOS][6] 服务器上演示,但我也写了一个详细的教程关于在 Ubuntu 服务器上部署[在 Ubuntu 上创建一个 Ansible Playbook 来安装 NGINX 和 NGINX Plus][7] 。
|
||||
|
||||
在本教程中我将使用 Ansible 1.9.2 版本的,并在 CentOS 7.1 服务器上部署运行。
|
||||
在本教程中我将使用 Ansible 1.9.2 版本,并在 CentOS 7.1 服务器上部署运行。
|
||||
|
||||
$ ansible --version
|
||||
ansible 1.9.2
|
||||
@ -20,14 +18,13 @@ nstalling NGINX and NGINX Plus With Ansible
|
||||
|
||||
如果你使用的是 CentOS,安装 Ansible 十分简单,只要输入以下命令。如果你想使用源码编译安装或使用其他发行版,请参阅上面 Ansible 链接中的说明。
|
||||
|
||||
|
||||
$ sudo yum install -y epel-release && sudo yum install -y ansible
|
||||
|
||||
根据环境的不同,在本教程中的命令有的可能需要 sudo 权限。文件路径,用户名,目标服务器的值取决于你的环境中。
|
||||
根据环境的不同,在本教程中的命令有的可能需要 sudo 权限。文件路径,用户名和目标服务器取决于你的环境的情况。
|
||||
|
||||
### 创建一个 Ansible Playbook 来安装 NGINX (CentOS) ###
|
||||
|
||||
首先,我们为 NGINX 的部署创建一个工作目录,以及子目录和部署配置文件目录。我通常建议在主目录中创建目录,在文章的所有例子中都会有说明。
|
||||
首先,我们要为 NGINX 的部署创建一个工作目录,包括子目录和部署配置文件。我通常建议在你的主目录中创建该目录,在文章的所有例子中都会有说明。
|
||||
|
||||
$ cd $HOME
|
||||
$ mkdir -p ansible-nginx/tasks/
|
||||
@ -54,11 +51,11 @@ nstalling NGINX and NGINX Plus With Ansible
|
||||
|
||||
$ vim $HOME/ansible-nginx/deploy.yml
|
||||
|
||||
**deploy.yml** 文件是 Ansible 部署的主要文件,[ 在使用 Ansible 部署 NGINX][9] 时,我们将运行 ansible‑playbook 命令执行此文件。在这个文件中,我们指定运行时 Ansible 使用的库以及其它配置文件。
|
||||
**deploy.yml** 文件是 Ansible 部署的主要文件,在“使用 Ansible 部署 NGINX”小节中,我们运行 ansible‑playbook 命令时会使用此文件。在这个文件中,我们指定 Ansible 运行时使用的库以及其它配置文件。
|
||||
|
||||
在这个例子中,我使用 [include][10] 模块来指定配置文件一步一步来安装NGINX。虽然可以创建一个非常大的 playbook 文件,我建议你将其分割为小文件,以保证其可靠性。示例中的包括复制静态内容,复制配置文件,为更高级的部署使用逻辑配置设定变量。
|
||||
在这个例子中,我使用 [include][10] 模块来指定配置文件一步一步来安装NGINX。虽然可以创建一个非常大的 playbook 文件,我建议你将其分割为小文件,让它们更有条理。include 的示例中可以复制静态内容,复制配置文件,为更高级的部署使用逻辑配置设定变量。
|
||||
|
||||
在文件中输入以下行。包括顶部参考注释中的文件名。
|
||||
在文件中输入以下行。我在顶部的注释包含了文件名用于参考。
|
||||
|
||||
# ./ansible-nginx/deploy.yml
|
||||
|
||||
@ -66,21 +63,21 @@ nstalling NGINX and NGINX Plus With Ansible
|
||||
tasks:
|
||||
- include: 'tasks/install_nginx.yml'
|
||||
|
||||
hosts 语句说明 Ansible 部署 **nginx** 组的所有服务器,服务器在 **/etc/ansible/hosts** 中指定。我们将编辑此文件来 [创建 NGINX 服务器的列表][11]。
|
||||
hosts 语句说明 Ansible 部署 **nginx** 组的所有服务器,服务器在 **/etc/ansible/hosts** 中指定。我们会在下面的“创建 NGINX 服务器列表”小节编辑此文件。
|
||||
|
||||
include 语句说明 Ansible 在部署过程中从 **tasks** 目录下读取并执行 **install_nginx.yml** 文件中的内容。该文件包括以下几步:下载,安装,并启动 NGINX。我们将创建此文件在下一节。
|
||||
include 语句说明 Ansible 在部署过程中从 **tasks** 目录下读取并执行 **install\_nginx.yml** 文件中的内容。该文件包括以下几步:下载,安装,并启动 NGINX。我们将在下一节创建此文件。
|
||||
|
||||
#### 为 NGINX 创建部署文件 ####
|
||||
|
||||
现在,先保存 **deploy.yml** 文件,并在编辑器中打开 **install_nginx.yml** 。
|
||||
现在,先保存 **deploy.yml** 文件,并在编辑器中打开 **install\_nginx.yml** 。
|
||||
|
||||
$ vim $HOME/ansible-nginx/tasks/install_nginx.yml
|
||||
|
||||
该文件包含的说明有 - 以 [YAML][12] 格式写入 - 使用 Ansible 安装和配置 NGINX。每个部分(步骤中的过程)起始于一个 name 声明(前面连字符)描述此步骤。下面的 name 字符串:是 Ansible 部署过程中写到标准输出的,可以根据你的意愿来改变。YAML 文件中的下一个部分是在部署过程中将使用的模块。在下面的配置中,[yum][13] 和 [service][14] 模块使将被用。yum 模块用于在 CentOS 上安装软件包。service 模块用于管理 UNIX 的服务。在这部分的最后一行或几行指定了几个模块的参数(在本例中,这些行以 name 和 state 开始)。
|
||||
该文件包含有指令(使用 [YAML][12] 格式写的), Ansible 会按照指令安装和配置我们的 NGINX 部署过程。每个节(过程中的步骤)起始于一个描述此步骤的 `name` 语句(前面有连字符)。 `name` 后的字符串是 Ansible 部署过程中输出到标准输出的,可以根据你的意愿来修改。YAML 文件中的节的下一行是在部署过程中将使用的模块。在下面的配置中,使用了 [`yum`][13] 和 [`service`][14] 模块。`yum` 模块用于在 CentOS 上安装软件包。`service` 模块用于管理 UNIX 的服务。在这个节的最后一行或几行指定了几个模块的参数(在本例中,这些行以 `name` 和 `state` 开始)。
|
||||
|
||||
在文件中输入以下行。对于 **deploy.yml**,在我们文件的第一行是关于文件名的注释。第一部分说明 Ansible 从 NGINX 仓库安装 **.rpm** 文件在CentOS 7 上。这说明软件包管理器直接从 NGINX 仓库安装最新最稳定的版本。需要在你的 CentOS 版本上修改路径。可使用包的列表可以在 [开源 NGINX 网站][15] 上找到。接下来的两节说明 Ansible 使用 yum 模块安装最新的 NGINX 版本,然后使用 service 模块启动 NGINX。
|
||||
在文件中输入以下行。就像 **deploy.yml**,在我们文件的第一行是用于参考的文件名的注释。第一个节告诉 Ansible 在CentOS 7 上从 NGINX 仓库安装该 **.rpm** 文件。这让软件包管理器直接从 NGINX 仓库安装最新最稳定的版本。根据你的 CentOS 版本修改路径。所有可用的包的列表可以在 [开源 NGINX 网站][15] 上找到。接下来的两节告诉 Ansible 使用 `yum` 模块安装最新的 NGINX 版本,然后使用 `service` 模块启动 NGINX。
|
||||
|
||||
**注意:** 在第一部分中,CentOS 包中的路径名是连着的两行。在一行上输入其完整路径。
|
||||
**注意:** 在第一个节中,CentOS 包中的路径名可能由于宽度显示为连着的两行。请在一行上输入其完整路径。
|
||||
|
||||
# ./ansible-nginx/tasks/install_nginx.yml
|
||||
|
||||
@ -100,12 +97,12 @@ include 语句说明 Ansible 在部署过程中从 **tasks** 目录下读取并
|
||||
|
||||
#### 创建 NGINX 服务器列表 ####
|
||||
|
||||
现在,我们有 Ansible 部署所有配置的文件,我们需要告诉 Ansible 部署哪个服务器。我们需要在 Ansible 中指定 **hosts** 文件。先备份现有的文件,并新建一个新文件来部署。
|
||||
现在,我们设置好了 Ansible 部署的所有配置文件,我们需要告诉 Ansible 部署哪个服务器。我们需要在 Ansible 中指定 **hosts** 文件。先备份现有的文件,并新建一个新文件来部署。
|
||||
|
||||
$ sudo mv /etc/ansible/hosts /etc/ansible/hosts.backup
|
||||
$ sudo vim /etc/ansible/hosts
|
||||
|
||||
在文件中输入以下行来创建一个名为 **nginx** 的组并列出安装 NGINX 的服务器。你可以指定服务器通过主机名,IP 地址,或者在一个区域,例如 **server[1-3].domain.com**。在这里,我指定一台服务器通过 IP 地址。
|
||||
在文件中输入(或编辑)以下行来创建一个名为 **nginx** 的组并列出安装 NGINX 的服务器。你可以通过主机名、IP 地址、或者在一个范围,例如 **server[1-3].domain.com** 来指定服务器。在这里,我通过 IP 地址指定一台服务器。
|
||||
|
||||
# /etc/ansible/hosts
|
||||
|
||||
@ -114,20 +111,20 @@ include 语句说明 Ansible 在部署过程中从 **tasks** 目录下读取并
|
||||
|
||||
#### 设置安全性 ####
|
||||
|
||||
在部署之前,我们需要确保 Ansible 已通过 SSH 授权能访问我们的目标服务器。
|
||||
接近完成了,但在部署之前,我们需要确保 Ansible 已被授权通过 SSH 访问我们的目标服务器。
|
||||
|
||||
首选并且最安全的方法是添加 Ansible 所要部署服务器的 RSA SSH 密钥到目标服务器的 **authorized_keys** 文件中,这给 Ansible 在目标服务器上的 SSH 权限不受限制。要了解更多关于此配置,请参阅 [安全的 OpenSSH][16] 在 wiki.centos.org。这样,你就可以自动部署而无需用户交互。
|
||||
首选并且最安全的方法是添加 Ansible 所要部署服务器的 RSA SSH 密钥到目标服务器的 **authorized\_keys** 文件中,这给予 Ansible 在目标服务器上的不受限制 SSH 权限。要了解更多关于此配置,请参阅 wiki.centos.org 上 [安全加固 OpenSSH][16]。这样,你就可以自动部署而无需用户交互。
|
||||
|
||||
另外,你也可以在部署过程中需要输入密码。我强烈建议你只在测试过程中使用这种方法,因为它是不安全的,没有办法判断目标主机的身份。如果你想这样做,将每个目标主机 **/etc/ssh/ssh_config** 文件中 StrictHostKeyChecking 的默认值 yes 改为 no。然后在 ansible-playbook 命令中添加 --ask-pass参数来表示 Ansible 会提示输入 SSH 密码。
|
||||
另外,你也可以在部署过程中要求输入密码。我强烈建议你只在测试过程中使用这种方法,因为它是不安全的,没有办法跟踪目标主机的身份(fingerprint)变化。如果你想这样做,将每个目标主机 **/etc/ssh/ssh\_config** 文件中 StrictHostKeyChecking 的默认值 yes 改为 no。然后在 ansible-playbook 命令中添加 --ask-pass 参数来让 Ansible 提示输入 SSH 密码。
|
||||
|
||||
在这里,我将举例说明如何编辑 **ssh_config** 文件来禁用在目标服务器上严格的主机密钥检查。我们手动 SSH 到我们将部署 NGINX 的服务器并将StrictHostKeyChecking 的值更改为 no。
|
||||
在这里,我将举例说明如何编辑 **ssh\_config** 文件来禁用在目标服务器上严格的主机密钥检查。我们手动连接 SSH 到我们将部署 NGINX 的服务器,并将 StrictHostKeyChecking 的值更改为 no。
|
||||
|
||||
$ ssh kjones@172.16.239.140
|
||||
kjones@172.16.239.140's password:***********
|
||||
|
||||
[kjones@nginx ]$ sudo vim /etc/ssh/ssh_config
|
||||
|
||||
当你更改后,保存 **ssh_config**,并通过 SSH 连接到你的 Ansible 服务器。保存后的设置应该如下图所示。
|
||||
当你更改后,保存 **ssh\_config**,并通过 SSH 连接到你的 Ansible 服务器。保存后的设置应该如下所示。
|
||||
|
||||
# /etc/ssh/ssh_config
|
||||
|
||||
@ -135,7 +132,7 @@ include 语句说明 Ansible 在部署过程中从 **tasks** 目录下读取并
|
||||
|
||||
#### 运行 Ansible 部署 NGINX ####
|
||||
|
||||
如果你一直照本教程的步骤来做,你可以运行下面的命令来使用 Ansible 部署NGINX。(同样,如果你设置了 RSA SSH 密钥认证,那么--ask-pass 参数是不需要的。)在 Ansible 服务器运行命令,并使用我们上面创建的配置文件。
|
||||
如果你一直照本教程的步骤来做,你可以运行下面的命令来使用 Ansible 部署 NGINX。(再次提示,如果你设置了 RSA SSH 密钥认证,那么 --ask-pass 参数是不需要的。)在 Ansible 服务器运行命令,并使用我们上面创建的配置文件。
|
||||
|
||||
$ sudo ansible-playbook --ask-pass $HOME/ansible-nginx/deploy.yml
|
||||
|
||||
@ -163,7 +160,7 @@ Ansible 提示输入 SSH 密码,输出如下。recap 中显示 failed=0 这条
|
||||
|
||||
如果你没有得到一个成功的 play recap,你可以尝试用 -vvvv 参数(带连接调试的详细信息)再次运行 ansible-playbook 命令来解决部署过程的问题。
|
||||
|
||||
当部署成功(因为我们不是第一次部署)后,你可以验证 NGINX 在远程服务器上运行基本的 [cURL][17] 命令。在这里,它会返回 200 OK。Yes!我们使用Ansible 成功安装了 NGINX。
|
||||
当部署成功(假如我们是第一次部署)后,你可以在远程服务器上运行基本的 [cURL][17] 命令验证 NGINX 。在这里,它会返回 200 OK。Yes!我们使用 Ansible 成功安装了 NGINX。
|
||||
|
||||
$ curl -Is 172.16.239.140 | grep HTTP
|
||||
HTTP/1.1 200 OK
|
||||
@ -174,11 +171,11 @@ Ansible 提示输入 SSH 密码,输出如下。recap 中显示 failed=0 这条
|
||||
|
||||
#### 复制 NGINX Plus 上的证书和密钥到 Ansible 服务器 ####
|
||||
|
||||
使用 Ansible 安装和配置 NGINX Plus 时,首先我们需要将 [NGINX Plus Customer Portal][18] 的密钥和证书复制到部署 Ansible 服务器上的标准位置。
|
||||
使用 Ansible 安装和配置 NGINX Plus 时,首先我们需要将 [NGINX Plus Customer Portal][18] NGINX Plus 订阅的密钥和证书复制到 Ansible 部署服务器上的标准位置。
|
||||
|
||||
购买了 NGINX Plus 或正在试用的客户也可以访问 NGINX Plus Customer Portal。如果你有兴趣测试 NGINX Plus,你可以申请免费试用30天[点击这里][19]。在你注册后不久你将收到一个试用证书和密钥的链接。
|
||||
购买了 NGINX Plus 或正在试用的客户也可以访问 NGINX Plus Customer Portal。如果你有兴趣测试 NGINX Plus,你可以申请免费试用30天,[点击这里][19]。在你注册后不久你将收到一个试用证书和密钥的链接。
|
||||
|
||||
在 Mac 或 Linux 主机上,我在这里演示使用 [scp][20] 工具。在 Microsoft Windows 主机,可以使用 [WinSCP][21]。在本教程中,先下载文件到我的 Mac 笔记本电脑上,然后使用 scp 将其复制到 Ansible 服务器。密钥和证书的位置都在我的家目录下。
|
||||
在 Mac 或 Linux 主机上,我在这里使用 [scp][20] 工具演示。在 Microsoft Windows 主机,可以使用 [WinSCP][21]。在本教程中,先下载文件到我的 Mac 笔记本电脑上,然后使用 scp 将其复制到 Ansible 服务器。密钥和证书的位置都在我的家目录下。
|
||||
|
||||
$ cd /path/to/nginx-repo-files/
|
||||
$ scp nginx-repo.* user@destination-server:.
|
||||
@ -189,7 +186,7 @@ Ansible 提示输入 SSH 密码,输出如下。recap 中显示 failed=0 这条
|
||||
$ sudo mkdir -p /etc/ssl/nginx/
|
||||
$ sudo mv nginx-repo.* /etc/ssl/nginx/
|
||||
|
||||
验证你的 **/etc/ssl/nginx** 目录包含证书(**.crt**)和密钥(**.key**)文件。你可以使用 tree 命令检查。
|
||||
验证你的 **/etc/ssl/nginx** 目录包含了证书(**.crt**)和密钥(**.key**)文件。你可以使用 tree 命令检查。
|
||||
|
||||
$ tree /etc/ssl/nginx
|
||||
/etc/ssl/nginx
|
||||
@ -204,7 +201,7 @@ Ansible 提示输入 SSH 密码,输出如下。recap 中显示 failed=0 这条
|
||||
|
||||
#### 创建 Ansible 目录结构 ####
|
||||
|
||||
以下执行的步骤将和开源 NGINX 的非常相似在[创建安装 NGINX 的 Ansible Playbook 中(CentOS)][22]。首先,我们建一个工作目录为部署 NGINX Plus 使用。我喜欢将它创建为我主目录的子目录。
|
||||
以下执行的步骤和我们的“创建 Ansible Playbook 来安装 NGINX(CentOS)”小节中部署开源 NGINX 的非常相似。首先,我们建一个工作目录用于部署 NGINX Plus 使用。我喜欢将它创建为我主目录的子目录。
|
||||
|
||||
$ cd $HOME
|
||||
$ mkdir -p ansible-nginx-plus/tasks/
|
||||
@ -223,11 +220,11 @@ Ansible 提示输入 SSH 密码,输出如下。recap 中显示 failed=0 这条
|
||||
|
||||
#### 创建主部署文件 ####
|
||||
|
||||
接下来,我们使用 vim 为开源的 NGINX 创建 **deploy.yml** 文件。
|
||||
接下来,像开源的 NGINX 一样,我们使用 vim 创建 **deploy.yml** 文件。
|
||||
|
||||
$ vim ansible-nginx-plus/deploy.yml
|
||||
|
||||
和开源 NGINX 的部署唯一的区别是,我们将包含文件的名称修改为**install_nginx_plus.yml**。该文件告诉 Ansible 在 **nginx** 组中的所有服务器(**/etc/ansible/hosts** 中定义的)上部署 NGINX Plus ,然后在部署过程中从 **tasks** 目录读取并执行 **install_nginx_plus.yml** 的内容。
|
||||
和开源 NGINX 的部署唯一的区别是,我们将包含文件的名称修改为 **install\_nginx\_plus.yml**。该文件告诉 Ansible 在 **nginx** 组中的所有服务器(**/etc/ansible/hosts** 中定义的)上部署 NGINX Plus ,然后在部署过程中从 **tasks** 目录读取并执行 **install\_nginx\_plus.yml** 的内容。
|
||||
|
||||
# ./ansible-nginx-plus/deploy.yml
|
||||
|
||||
@ -235,22 +232,22 @@ Ansible 提示输入 SSH 密码,输出如下。recap 中显示 failed=0 这条
|
||||
tasks:
|
||||
- include: 'tasks/install_nginx_plus.yml'
|
||||
|
||||
如果你还没有这样做的话,你需要创建 hosts 文件,详细说明在上面的 [创建 NGINX 服务器的列表][23]。
|
||||
如果你之前没有安装过的话,你需要创建 hosts 文件,详细说明在上面的“创建 NGINX 服务器的列表”小节。
|
||||
|
||||
#### 为 NGINX Plus 创建部署文件 ####
|
||||
|
||||
在文本编辑器中打开 **install_nginx_plus.yml**。该文件在部署过程中使用 Ansible 来安装和配置 NGINX Plus。这些命令和模块仅针对 CentOS,有些是 NGINX Plus 独有的。
|
||||
在文本编辑器中打开 **install\_nginx\_plus.yml**。该文件包含了使用 Ansible 来安装和配置 NGINX Plus 部署过程中的指令。这些命令和模块仅针对 CentOS,有些是 NGINX Plus 独有的。
|
||||
|
||||
$ vim ansible-nginx-plus/tasks/install_nginx_plus.yml
|
||||
|
||||
第一部分使用 [文件][24] 模块,告诉 Ansible 使用指定的路径和状态参数为 NGINX Plus 创建特定的 SSL 目录,设置根目录的权限,将权限更改为0700。
|
||||
第一节使用 [`file`][24] 模块,告诉 Ansible 使用指定的`path`和`state`参数为 NGINX Plus 创建特定的 SSL 目录,设置属主为 root,将权限 `mode` 更改为0700。
|
||||
|
||||
# ./ansible-nginx-plus/tasks/install_nginx_plus.yml
|
||||
|
||||
- name: NGINX Plus | 创建 NGINX Plus ssl 证书目录
|
||||
file: path=/etc/ssl/nginx state=directory group=root mode=0700
|
||||
|
||||
接下来的两节使用 [copy][25] 模块从部署 Ansible 的服务器上将 NGINX Plus 的证书和密钥复制到 NGINX Plus 服务器上,再修改权根,将权限设置为0700。
|
||||
接下来的两节使用 [copy][25] 模块从 Ansible 部署服务器上将 NGINX Plus 的证书和密钥复制到 NGINX Plus 服务器上,再修改属主为 root,权限 `mode` 为0700。
|
||||
|
||||
- name: NGINX Plus | 复制 NGINX Plus repo 证书
|
||||
copy: src=/etc/ssl/nginx/nginx-repo.crt dest=/etc/ssl/nginx/nginx-repo.crt owner=root group=root mode=0700
|
||||
@ -258,17 +255,17 @@ Ansible 提示输入 SSH 密码,输出如下。recap 中显示 failed=0 这条
|
||||
- name: NGINX Plus | 复制 NGINX Plus 密钥
|
||||
copy: src=/etc/ssl/nginx/nginx-repo.key dest=/etc/ssl/nginx/nginx-repo.key owner=root group=root mode=0700
|
||||
|
||||
接下来,我们告诉 Ansible 使用 [get_url][26] 模块从 NGINX Plus 仓库下载 CA 证书在 url 参数指定的远程位置,通过 dest 参数把它放在指定的目录,并设置权限为 0700。
|
||||
接下来,我们告诉 Ansible 使用 [`get_url`][26] 模块在 url 参数指定的远程位置从 NGINX Plus 仓库下载 CA 证书,通过 `dest` 参数把它放在指定的目录 `dest` ,并设置权限 `mode` 为 0700。
|
||||
|
||||
- name: NGINX Plus | 下载 NGINX Plus CA 证书
|
||||
get_url: url=https://cs.nginx.com/static/files/CA.crt dest=/etc/ssl/nginx/CA.crt mode=0700
|
||||
|
||||
同样,我们告诉 Ansible 使用 get_url 模块下载 NGINX Plus repo 文件,并将其复制到 **/etc/yum.repos.d** 目录下在 NGINX Plus 服务器上。
|
||||
同样,我们告诉 Ansible 使用 `get_url` 模块下载 NGINX Plus repo 文件,并将其复制到 NGINX Plus 服务器上的 **/etc/yum.repos.d** 目录下。
|
||||
|
||||
- name: NGINX Plus | 下载 yum NGINX Plus 仓库
|
||||
get_url: url=https://cs.nginx.com/static/files/nginx-plus-7.repo dest=/etc/yum.repos.d/nginx-plus-7.repo mode=0700
|
||||
|
||||
最后两节的 name 告诉 Ansible 使用 yum 和 service 模块下载并启动 NGINX Plus。
|
||||
最后两节的 `name` 告诉 Ansible 使用 `yum` 和 `service` 模块下载并启动 NGINX Plus。
|
||||
|
||||
- name: NGINX Plus | 安装 NGINX Plus
|
||||
yum:
|
||||
@ -282,7 +279,7 @@ Ansible 提示输入 SSH 密码,输出如下。recap 中显示 failed=0 这条
|
||||
|
||||
#### 运行 Ansible 来部署 NGINX Plus ####
|
||||
|
||||
在保存 **install_nginx_plus.yml** 文件后,然后运行 ansible-playbook 命令来部署 NGINX Plus。同样在这里,我们使用 --ask-pass 参数使用 Ansible 提示输入 SSH 密码并把它传递给每个 NGINX Plus 服务器,指定路径在 **deploy.yml** 文件中。
|
||||
在保存 **install\_nginx\_plus.yml** 文件后,运行 ansible-playbook 命令来部署 NGINX Plus。同样在这里,我们使用 --ask-pass 参数使用 Ansible 提示输入 SSH 密码并把它传递给每个 NGINX Plus 服务器,并指定主配置文件路径 **deploy.yml** 文件。
|
||||
|
||||
$ sudo ansible-playbook --ask-pass $HOME/ansible-nginx-plus/deploy.yml
|
||||
|
||||
@ -315,18 +312,18 @@ Ansible 提示输入 SSH 密码,输出如下。recap 中显示 failed=0 这条
|
||||
PLAY RECAP ********************************************************************
|
||||
172.16.239.140 : ok=8 changed=7 unreachable=0 failed=0
|
||||
|
||||
playbook 的 recap 是成功的。现在,使用 curl 命令来验证 NGINX Plus 是否在运行。太好了,我们得到的是 200 OK!成功了!我们使用 Ansible 成功地安装了 NGINX Plus。
|
||||
playbook 的 recap 成功完成。现在,使用 curl 命令来验证 NGINX Plus 是否在运行。太好了,我们得到的是 200 OK!成功了!我们使用 Ansible 成功地安装了 NGINX Plus。
|
||||
|
||||
$ curl -Is http://172.16.239.140 | grep HTTP
|
||||
HTTP/1.1 200 OK
|
||||
|
||||
### 在 Ubuntu 上创建一个 Ansible Playbook 来安装 NGINX 和 NGINX Plus ###
|
||||
### 在 Ubuntu 上创建 Ansible Playbook 来安装 NGINX 和 NGINX Plus ###
|
||||
|
||||
此过程在 [Ubuntu 服务器][27] 上部署 NGINX 和 NGINX Plus 与 CentOS 很相似,我将一步一步的指导来完成整个部署文件,并指出和 CentOS 的细微差异。
|
||||
在 [Ubuntu 服务器][27] 上部署 NGINX 和 NGINX Plus 的过程与 CentOS 很相似,我将一步一步的指导来完成整个部署文件,并指出和 CentOS 的细微差异。
|
||||
|
||||
首先和 CentOS 一样,创建 Ansible 目录结构和主要的 Ansible 部署文件。也创建 **/etc/ansible/hosts** 文件来描述 [创建 NGINX 服务器的列表][28]。对于 NGINX Plus,你也需要复制证书和密钥在此步中 [复制 NGINX Plus 证书和密钥到 Ansible 服务器][29]。
|
||||
首先和 CentOS 一样,创建 Ansible 目录结构和 Ansible 主部署文件。也按“创建 NGINX 服务器的列表”小节的描述创建 **/etc/ansible/hosts** 文件。对于 NGINX Plus,你也需要安装“复制 NGINX Plus 证书和密钥到 Ansible 服务器”小节的描述复制证书和密钥。
|
||||
|
||||
下面是开源 NGINX 的 **install_nginx.yml** 部署文件。在第一部分,我们使用 [apt_key][30] 模块导入 Nginx 的签名密钥。接下来的两节使用[lineinfile][31] 模块来添加 URLs 到 **sources.list** 文件中。最后,我们使用 [apt][32] 模块来更新缓存并安装 NGINX(apt 取代了我们在 CentOS 中部署时的 yum 模块)。
|
||||
下面是开源 NGINX 的 **install\_nginx.yml** 部署文件。在第一节,我们使用 [`apt_key`][30] 模块导入 NGINX 的签名密钥。接下来的两节使用 [`lineinfile`][31] 模块来添加 Ubuntu 14.04 的软件包 URL 到 **sources.list** 文件中。最后,我们使用 [`apt`][32] 模块来更新缓存并安装 NGINX(`apt` 取代了我们在 CentOS 中部署时的 `yum` 模块)。
|
||||
|
||||
# ./ansible-nginx/tasks/install_nginx.yml
|
||||
|
||||
@ -352,7 +349,8 @@ playbook 的 recap 是成功的。现在,使用 curl 命令来验证 NGINX Plu
|
||||
service:
|
||||
name: nginx
|
||||
state: started
|
||||
下面是 NGINX Plus 的部署文件 **install_nginx.yml**。前四节设置了 NGINX Plus 密钥和证书。然后,我们用 apt_key 模块为开源的 NGINX 导入签名密钥,get_url 模块为 NGINX Plus 下载 apt 配置文件。[shell][33] 模块使用 printf 命令写下输出到 **nginx-plus.list** 文件中在**sources.list.d** 目录。最终的 name 模块是为开源 NGINX 的。
|
||||
|
||||
下面是 NGINX Plus 的部署文件 **install\_nginx.yml**。前四节设置了 NGINX Plus 密钥和证书。然后,我们像开源的 NGINX 一样用 `apt_key` 模块导入签名密钥,`get_url` 模块为 NGINX Plus 下载 `apt` 配置文件。[`shell`][33] 模块使用 `printf` 命令写下输出到 **sources.list.d** 目录中的 **nginx-plus.list** 文件。最终的 `name` 模块和开源 NGINX 一样。
|
||||
|
||||
# ./ansible-nginx-plus/tasks/install_nginx_plus.yml
|
||||
|
||||
@ -395,13 +393,12 @@ playbook 的 recap 是成功的。现在,使用 curl 命令来验证 NGINX Plu
|
||||
|
||||
$ sudo ansible-playbook --ask-pass $HOME/ansible-nginx-plus/deploy.yml
|
||||
|
||||
你应该得到一个成功的 play recap。如果你没有成功,你可以使用 verbose 参数,以帮助你解决在 [运行 Ansible 来部署 NGINX][34] 中出现的问题。
|
||||
你应该得到一个成功的 play recap。如果你没有成功,你可以使用冗余参数,以帮助你解决出现的问题。
|
||||
|
||||
### 小结 ###
|
||||
|
||||
我在这个教程中演示是什么是 Ansible,可以做些什么来帮助你自动部署 NGINX 或 NGINX Plus,这仅仅是个开始。还有许多有用的模块,用户账号管理,自定义配置模板等。如果你有兴趣了解更多关于这些,请访问 [Ansible 官方文档][35]。
|
||||
我在这个教程中演示是什么是 Ansible,可以做些什么来帮助你自动部署 NGINX 或 NGINX Plus,这仅仅是个开始。还有许多有用的模块,包括从用户账号管理到自定义配置模板等。如果你有兴趣了解关于这些的更多信息,请访问 [Ansible 官方文档][35]。
|
||||
|
||||
要了解更多关于 Ansible,来听我讲用 Ansible 部署 NGINX Plus 在[NGINX.conf 2015][36],9月22-24日在旧金山。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -409,7 +406,7 @@ via: https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/
|
||||
|
||||
作者:[Kevin Jones][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,92 @@
|
||||
如何使用 GRUB 2 直接从硬盘运行 ISO 文件
|
||||
================================================================================
|
||||

|
||||
|
||||
大多数 Linux 发行版都会提供一个可以从 USB 启动的 live 环境,以便用户无需安装即可测试系统。我们可以用它来评测这个发行版或仅仅是当成一个一次性系统,并且很容易将这些文件复制到一个 U 盘上,在某些情况下,我们可能需要经常运行同一个或不同的 ISO 镜像。GRUB 2 可以配置成直接从启动菜单运行一个 live 环境,而不需要烧录这些 ISO 到硬盘或 USB 设备。
|
||||
|
||||
### 获取和检查可启动的 ISO 镜像 ###
|
||||
|
||||
为了获取 ISO 镜像,我们通常应该访问所需的发行版的网站下载与我们架构兼容的镜像文件。如果这个镜像可以从 U 盘启动,那它也应该可以从 GRUB 菜单启动。
|
||||
|
||||
当镜像下载完后,我们应该通过 MD5 校验检查它的完整性。这会输出一大串数字与字母合成的序列。
|
||||
|
||||

|
||||
|
||||
将这个序列与下载页提供的 MD5 校验码进行比较,两者应该完全相同。
|
||||
|
||||
### 配置 GRUB 2 ###
|
||||
|
||||
ISO 镜像文件包含了整个系统。我们要做的仅仅是告诉 GRUB 2 哪里可以找到 kernel 和 initramdisk 或 initram 文件系统(这取决于我们所使用的发行版)。
|
||||
|
||||
在下面的例子中,一个 Kubuntu 15.04 live 环境将被配置到 Ubuntu 14.04 机器的 Grub 启动菜单项。这应该能在大多数新的以 Ubuntu 为基础的系统上运行。如果你是其它系统并且想实现一些其它的东西,你可以从[这些文件][1]了解更多细节,但这会要求你拥有一点 GRUB 使用经验。
|
||||
|
||||
这个例子的文件 `kubuntu-15.04-desktop-amd64.iso` 放在位于 `/dev/sda1` 的 `/home/maketecheasier/TempISOs/` 上。
|
||||
|
||||
为了使 GRUB 2 能正确找到它,我们应该编辑
|
||||
|
||||
/etc/grub.d40-custom
|
||||
|
||||

|
||||
|
||||
menuentry "Kubuntu 15.04 ISO" {
|
||||
set isofile="/home/maketecheasier/TempISOs/kubuntu-15.04-desktop-amd64.iso"
|
||||
loopback loop (hd0,1)$isofile
|
||||
echo "Starting $isofile..."
|
||||
linux (loop)/casper/vmlinuz.efi boot=casper iso-scan/filename=${isofile} quiet splash
|
||||
initrd (loop)/casper/initrd.lz
|
||||
}
|
||||
|
||||

|
||||
|
||||
### 分析上述代码 ###
|
||||
|
||||
首先设置了一个变量名 `$menuentry` ,这是 ISO 文件的所在位置 。如果你想换一个 ISO ,你应该修改 `isofile="/path/to/file/name-of-iso-file-.iso"`.
|
||||
|
||||
下一行是指定回环设备,且必须给出正确的分区号码。
|
||||
|
||||
loopback loop (hd0,1)$isofile
|
||||
|
||||
注意 hd0,1 这里非常重要,它的意思是第一硬盘,第一分区 (`/dev/sda1`)。
|
||||
|
||||
GRUB 的命名在这里稍微有点困惑,对于硬盘来说,它从 “0” 开始计数,第一块硬盘为 #0 ,第二块为 #1 ,第三块为 #2 ,依此类推。但是对于分区来说,它从 “1” 开始计数,第一个分区为 #1 ,第二个分区为 #2 ,依此类推。也许这里有一个很好的原因,但肯定不是明智的(明显用户体验很糟糕)..
|
||||
|
||||
在 Linux 中第一块硬盘,第一个分区是 `/dev/sda1` ,但在 GRUB2 中则是 `hd0,1` 。第二块硬盘,第三个分区则是 `hd1,3`, 依此类推.
|
||||
|
||||
下一个重要的行是:
|
||||
|
||||
linux (loop)/casper/vmlinuz.efi boot=casper iso-scan/filename=${isofile} quiet splash
|
||||
|
||||
这会载入内核镜像,在新的 Ubuntu Live CD 中,内核被存放在 `/casper` 目录,并且命名为 `vmlinuz.efi` 。如果你使用的是其它系统,可能会没有 `.efi` 扩展名或内核被存放在其它地方 (可以使用归档管理器打开 ISO 文件在 `/casper` 中查找确认)。最后一个选项, `quiet splash` ,是一个常规的 GRUB 选项,改不改无所谓。
|
||||
|
||||
最后
|
||||
|
||||
initrd (loop)/casper/initrd.lz
|
||||
|
||||
这会载入 `initrd` ,它负责载入 RAMDisk 到内存用于启动。
|
||||
|
||||
### 启动 live 系统 ###
|
||||
|
||||
做完上面所有的步骤后,需要更新 GRUB2:
|
||||
|
||||
sudo update-grub
|
||||
|
||||

|
||||
|
||||
当重启系统后,应该可以看见一个新的、并且允许我们启动刚刚配置的 ISO 镜像的 GRUB 条目:
|
||||
|
||||

|
||||
|
||||
选择这个新条目就允许我们像从 DVD 或 U 盘中启动一个 live 环境一样。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/run-iso-files-hdd-grub2/
|
||||
|
||||
作者:[Attila Orosz][a]
|
||||
译者:[Locez](https://github.com/locez)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/attilaorosz/
|
||||
[1]:http://git.marmotte.net/git/glim/tree/grub2
|
||||
@ -1,17 +1,17 @@
|
||||
Linux 中管理文件类型和系统时间的 5 个有用命令 - 第三部分
|
||||
5 个在 Linux 中管理文件类型和系统时间的有用命令
|
||||
================================================================================
|
||||
对于想学习 Linux 的初学者来说要适应使用命令行或者终端可能非常困难。由于终端比图形用户界面程序更能帮助用户控制 Linux 系统,我们必须习惯在终端中运行命令。因此为了有效记忆 Linux 不同的命令,你应该每天使用终端并明白怎样将命令和不同选项以及参数一同使用。
|
||||
|
||||

|
||||
|
||||
在 Linux 中管理文件类型并设置时间 - 第三部分
|
||||
*在 Linux 中管理文件类型并设置时间*
|
||||
|
||||
请先查看我们 [Linux 小技巧][1]系列之前的文章。
|
||||
请先查看我们 Linux 小技巧系列之前的文章:
|
||||
|
||||
- [Linux 中 5 个有趣的命令行提示和技巧 - 第一部分][2]
|
||||
- [给新手的有用命令行技巧 - 第二部分][3]
|
||||
- [5 个有趣的 Linux 命令行技巧][2]
|
||||
- [给新手的 10 个有用 Linux 命令行技巧][3]
|
||||
|
||||
在这篇文章中,我们打算看看终端中 10 个和文件以及时间相关的提示和技巧。
|
||||
在这篇文章中,我们打算看看终端中 5 个和文件以及时间相关的提示和技巧。
|
||||
|
||||
### Linux 中的文件类型 ###
|
||||
|
||||
@ -22,10 +22,10 @@ Linux 系统中文件有不同的类型:
|
||||
- 普通文件:可能包含命令、文档、音频文件、视频、图像,归档文件等。
|
||||
- 设备文件:系统用于访问你硬件组件。
|
||||
|
||||
这里有两种表示存储设备的设备文件块文件,例如硬盘,它们以快读取数据,字符文件,以逐个字符读取数据。
|
||||
这里有两种表示存储设备的设备文件:块文件,例如硬盘,它们以块读取数据;字符文件,以逐个字符读取数据。
|
||||
|
||||
- 硬链接和软链接:用于在 Linux 文件系统的任意地方访问文件。
|
||||
- 命名管道和套接字:允许不同的进程彼此之间交互。
|
||||
- 命名管道和套接字:允许不同的进程之间进行交互。
|
||||
|
||||
#### 1. 用 ‘file’ 命令确定文件类型 ####
|
||||
|
||||
@ -219,7 +219,7 @@ which 命令用于定位文件系统中的命令。
|
||||
20 21 22 23 24 25 26
|
||||
27 28 29 30
|
||||
|
||||
使用 hwclock 命令查看硬件始终时间。
|
||||
使用 hwclock 命令查看硬件时钟时间。
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ sudo hwclock
|
||||
Wednesday 09 September 2015 06:02:58 PM IST -0.200081 seconds
|
||||
@ -231,7 +231,7 @@ which 命令用于定位文件系统中的命令。
|
||||
tecmint@tecmint ~/Linux-Tricks $ sudo hwclock
|
||||
Wednesday 09 September 2015 12:33:11 PM IST -0.891163 seconds
|
||||
|
||||
系统时间是由硬件始终时间在启动时设置的,系统关闭时,硬件时间被重置为系统时间。
|
||||
系统时间是由硬件时钟时间在启动时设置的,系统关闭时,硬件时间被重置为系统时间。
|
||||
|
||||
因此你查看系统时间和硬件时间时,它们是一样的,除非你更改了系统时间。当你的 CMOS 电量不足时,硬件时间可能不正确。
|
||||
|
||||
@ -256,7 +256,7 @@ which 命令用于定位文件系统中的命令。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
对于初学者来说理解 Linux 中的文件类型是一个好的尝试,同时时间管理也非常重要,尤其是在需要可靠有效地管理服务的服务器上。希望这篇指南能对你有所帮助。如果你有任何反馈,别忘了给我们写评论。和 Tecmint 保持联系。
|
||||
对于初学者来说理解 Linux 中的文件类型是一个好的尝试,同时时间管理也非常重要,尤其是在需要可靠有效地管理服务的服务器上。希望这篇指南能对你有所帮助。如果你有任何反馈,别忘了给我们写评论。和我们保持联系。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -264,16 +264,16 @@ via: http://www.tecmint.com/manage-file-types-and-set-system-time-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/tag/linux-tricks/
|
||||
[2]:http://www.tecmint.com/free-online-linux-learning-guide-for-beginners/
|
||||
[3]:http://www.tecmint.com/10-useful-linux-command-line-tricks-for-newbies/
|
||||
[2]:https://linux.cn/article-5485-1.html
|
||||
[3]:https://linux.cn/article-6314-1.html
|
||||
[4]:http://www.tecmint.com/linux-dir-command-usage-with-examples/
|
||||
[5]:http://www.tecmint.com/12-practical-examples-of-linux-grep-command/
|
||||
[5]:https://linux.cn/article-2250-1.html
|
||||
[6]:http://www.tecmint.com/wc-command-examples/
|
||||
[7]:http://www.tecmint.com/setup-samba-file-sharing-for-linux-windows-clients/
|
||||
[8]:http://www.tecmint.com/35-practical-examples-of-linux-find-command/
|
||||
@ -0,0 +1,102 @@
|
||||
在 Ubuntu 14.04/15.04 上配置 Node JS v4.0.0
|
||||
================================================================================
|
||||
大家好,Node.JS 4.0 发布了,这个流行的服务器端 JS 平台合并了 Node.js 和 io.js 的代码,4.0 版就是这两个项目结合的产物——现在合并为一个代码库。这次最主要的变化是 Node.js 封装了4.5 版本的 Google V8 JS 引擎,与当前的 Chrome 所带的一致。所以,紧跟 V8 的发布可以让 Node.js 运行的更快、更安全,同时更好的利用 ES6 的很多语言特性。
|
||||
|
||||

|
||||
|
||||
Node.js 4.0 发布的主要目标是为 io.js 用户提供一个简单的升级途径,所以这次并没有太多重要的 API 变更。下面的内容让我们来看看如何轻松的在 ubuntu server 上安装、配置 Node.js。
|
||||
|
||||
### 基础系统安装 ###
|
||||
|
||||
Node 在 Linux,Macintosh,Solaris 这几个系统上都可以完美的运行,linux 的发行版本当中使用 Ubuntu 相当适合。这也是我们为什么要尝试在 ubuntu 15.04 上安装 Node.js,当然了在 14.04 上也可以使用相同的步骤安装。
|
||||
|
||||
#### 1) 系统资源 ####
|
||||
|
||||
Node.js 所需的基本的系统资源取决于你的架构需要。本教程我们会在一台 1GB 内存、 1GHz 处理器和 10GB 磁盘空间的服务器上进行,最小安装即可,不需要安装 Web 服务器或数据库服务器。
|
||||
|
||||
#### 2) 系统更新 ####
|
||||
|
||||
在我们安装 Node.js 之前,推荐你将系统更新到最新的补丁和升级包,所以请登录到系统中使用超级用户运行如下命令:
|
||||
|
||||
# apt-get update
|
||||
|
||||
#### 3) 安装依赖 ####
|
||||
|
||||
Node.js 仅需要你的服务器上有一些基本系统和软件功能,比如 'make'、'gcc'和'wget' 之类的。如果你还没有安装它们,运行如下命令安装:
|
||||
|
||||
# apt-get install python gcc make g++ wget
|
||||
|
||||
### 下载最新版的Node JS v4.0.0 ###
|
||||
|
||||
访问链接 [Node JS Download Page][1] 下载源代码.
|
||||
|
||||

|
||||
|
||||
复制其中的最新的源代码的链接,然后用`wget` 下载,命令如下:
|
||||
|
||||
# wget https://nodejs.org/download/rc/v4.0.0-rc.1/node-v4.0.0-rc.1.tar.gz
|
||||
|
||||
下载完成后使用命令`tar` 解压缩:
|
||||
|
||||
# tar -zxvf node-v4.0.0-rc.1.tar.gz
|
||||
|
||||

|
||||
|
||||
### 安装 Node JS v4.0.0 ###
|
||||
|
||||
现在可以开始使用下载好的源代码编译 Node.js。在开始编译前,你需要在 ubuntu server 上切换到源代码解压缩后的目录,运行 configure 脚本来配置源代码。
|
||||
|
||||
root@ubuntu-15:~/node-v4.0.0-rc.1# ./configure
|
||||
|
||||

|
||||
|
||||
现在运行命令 'make install' 编译安装 Node.js:
|
||||
|
||||
root@ubuntu-15:~/node-v4.0.0-rc.1# make install
|
||||
|
||||
make 命令会花费几分钟完成编译,安静的等待一会。
|
||||
|
||||
### 验证 Node.js 安装 ###
|
||||
|
||||
一旦编译任务完成,我们就可以开始验证安装工作是否 OK。我们运行下列命令来确认 Node.js 的版本。
|
||||
|
||||
root@ubuntu-15:~# node -v
|
||||
v4.0.0-pre
|
||||
|
||||
在命令行下不带参数的运行`node` 就会进入 REPL(Read-Eval-Print-Loop,读-执行-输出-循环)模式,它有一个简化版的emacs 行编辑器,通过它你可以交互式的运行JS和查看运行结果。
|
||||
|
||||

|
||||
|
||||
### 编写测试程序 ###
|
||||
|
||||
我们也可以写一个很简单的终端程序来测试安装是否成功,并且工作正常。要做这个,我们将会创建一个“test.js” 文件,包含以下代码,操作如下:
|
||||
|
||||
root@ubuntu-15:~# vim test.js
|
||||
var util = require("util");
|
||||
console.log("Hello! This is a Node Test Program");
|
||||
:wq!
|
||||
|
||||
现在为了运行上面的程序,在命令行运行下面的命令。
|
||||
|
||||
root@ubuntu-15:~# node test.js
|
||||
|
||||

|
||||
|
||||
在一个成功安装了 Node JS 的环境下运行上面的程序就会在屏幕上得到上图所示的输出,这个程序加载类 “util” 到变量 “util” 中,接着用对象 “util” 运行终端任务,console.log 这个命令作用类似 C++ 里的cout
|
||||
|
||||
### 结论 ###
|
||||
|
||||
就是这些了。如果你刚刚开始使用 Node.js 开发应用程序,希望本文能够通过在 ubuntu 上安装、运行 Node.js 让你了解一下Node.js 的大概。最后,我们可以认为我们可以期待 Node JS v4.0.0 能够取得显著性能提升。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/setup-node-js-4-0-ubuntu-14-04-15-04/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[osk874](https://github.com/osk874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
[1]:https://nodejs.org/download/rc/v4.0.0-rc.1/
|
||||
@ -0,0 +1,72 @@
|
||||
Linux 有问必答:如何在 Linux 命令行下浏览天气预报
|
||||
================================================================================
|
||||
> **Q**: 我经常在 Linux 桌面查看天气预报。然而,是否有一种在终端环境下,不通过桌面小插件或者浏览器查询天气预报的方法?
|
||||
|
||||
对于 Linux 桌面用户来说,有很多办法获取天气预报,比如使用专门的天气应用、桌面小插件,或者面板小程序。但是如果你的工作环境是基于终端的,这里也有一些在命令行下获取天气的手段。
|
||||
|
||||
其中有一个就是 [wego][1],**一个终端下的小巧程序**。使用基于 ncurses 的接口,这个命令行程序允许你查看当前的天气情况和之后的预报。它也会通过一个天气预报的 API 收集接下来 5 天的天气预报。
|
||||
|
||||
### 在 Linux 下安装 wego ###
|
||||
|
||||
安装 wego 相当简单。wego 是用 Go 编写的,引起第一个步骤就是安装 [Go 语言][2]。然后再安装 wego。
|
||||
|
||||
$ go get github.com/schachmat/wego
|
||||
|
||||
wego 会被安装到 $GOPATH/bin,所以要将 $GOPATH/bin 添加到 $PATH 环境变量。
|
||||
|
||||
$ echo 'export PATH="$PATH:$GOPATH/bin"' >> ~/.bashrc
|
||||
$ source ~/.bashrc
|
||||
|
||||
现在就可与直接从命令行启动 wego 了。
|
||||
|
||||
$ wego
|
||||
|
||||
第一次运行 weg 会生成一个配置文件(`~/.wegorc`),你需要指定一个天气 API key。
|
||||
你可以从 [worldweatheronline.com][3] 获取一个免费的 API key。免费注册和使用。你只需要提供一个有效的邮箱地址。
|
||||
|
||||

|
||||
|
||||
你的 .wegorc 配置文件看起来会这样:
|
||||
|
||||

|
||||
|
||||
除了 API key,你还可以把你想要查询天气的地方、使用的城市/国家名称、语言配置在 `~/.wegorc` 中。
|
||||
注意,这个天气 API 的使用有限制:每秒最多 5 次查询,每天最多 250 次查询。
|
||||
当你重新执行 wego 命令,你将会看到最新的天气预报(当然是你的指定地方),如下显示。
|
||||
|
||||

|
||||
|
||||
显示出来的天气信息包括:(1)温度,(2)风速和风向,(3)可视距离,(4)降水量和降水概率
|
||||
默认情况下会显示3 天的天气预报。如果要进行修改,可以通过参数改变天气范围(最多5天),比如要查看 5 天的天气预报:
|
||||
|
||||
$ wego 5
|
||||
|
||||
如果你想检查另一个地方的天气,只需要提供城市名即可:
|
||||
|
||||
$ wego Seattle
|
||||
|
||||
### 问题解决 ###
|
||||
|
||||
1. 可能会遇到下面的错误:
|
||||
|
||||
user: Current not implemented on linux/amd64
|
||||
|
||||
当你在一个不支持原生 Go 编译器的环境下运行 wego 时就会出现这个错误。在这种情况下你只需要使用 gccgo ——一个 Go 的编译器前端来编译程序即可。这一步可以通过下面的命令完成。
|
||||
|
||||
$ sudo yum install gcc-go
|
||||
$ go get -compiler=gccgo github.com/schachmat/wego
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/weather-forecasts-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[oska874](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:https://github.com/schachmat/wego
|
||||
[2]:http://ask.xmodulo.com/install-go-language-linux.html
|
||||
[3]:https://developer.worldweatheronline.com/auth/register
|
||||
@ -1,27 +1,28 @@
|
||||
在 Ubuntu 和 Linux Mint 上安装 Terminator 0.98
|
||||
================================================================================
|
||||
[Terminator][1],在一个窗口中有多个终端。该项目的目标之一是为管理终端提供一个有用的工具。它的灵感来自于类似 gnome-multi-term,quankonsole 等程序,这些程序关注于在窗格中管理终端。 Terminator 0.98 带来了更完美的标签功能,更好的布局保存/恢复,改进了偏好用户界面和多出 bug 修复。
|
||||
[Terminator][1],它可以在一个窗口内打开多个终端。该项目的目标之一是为摆放终端提供一个有用的工具。它的灵感来自于类似 gnome-multi-term,quankonsole 等程序,这些程序关注于按网格摆放终端。 Terminator 0.98 带来了更完美的标签功能,更好的布局保存/恢复,改进了偏好用户界面和多处 bug 修复。
|
||||
|
||||

|
||||
|
||||
###TERMINATOR 0.98 的更改和新特性
|
||||
|
||||
- 添加了一个布局启动器,允许在不用布局之间简单切换(用 Alt + L 打开一个新的布局切换器);
|
||||
- 添加了一个新的手册(使用 F1 打开);
|
||||
- 保存的时候,布局现在会记住:
|
||||
- * 最大化和全屏状态
|
||||
- * 窗口标题
|
||||
- * 激活的标签
|
||||
- * 激活的终端
|
||||
- * 每个终端的工作目录
|
||||
- 添加选项用于启用/停用非同质标签和滚动箭头;
|
||||
- 最大化和全屏状态
|
||||
- 窗口标题
|
||||
- 激活的标签
|
||||
- 激活的终端
|
||||
- 每个终端的工作目录
|
||||
- 添加选项用于启用/停用非同类(non-homogenous)标签和滚动箭头;
|
||||
- 添加快捷键用于按行/半页/一页向上/下滚动;
|
||||
- 添加使用 Ctrl+鼠标滚轮放大/缩小,Shift+鼠标滚轮向上/下滚动页面;
|
||||
- 为下一个/上一个 profile 添加快捷键
|
||||
- 添加使用 Ctrl+鼠标滚轮来放大/缩小,Shift+鼠标滚轮向上/下滚动页面;
|
||||
- 为下一个/上一个配置文件(profile)添加快捷键
|
||||
- 改进自定义命令菜单的一致性
|
||||
- 新增快捷方式/代码来切换所有/标签分组;
|
||||
- 改进监视插件
|
||||
- 增加搜索栏切换;
|
||||
- 清理和重新组织窗口偏好,包括一个完整的全局便签更新
|
||||
- 清理和重新组织偏好(preferences)窗口,包括一个完整的全局便签更新
|
||||
- 添加选项用于设置 ActivityWatcher 插件静默时间
|
||||
- 其它一些改进和 bug 修复
|
||||
- [点击此处查看完整更新日志][2]
|
||||
@ -37,10 +38,6 @@ Terminator 0.98 有可用的 PPA,首先我们需要在 Ubuntu/Linux Mint 上
|
||||
如果你想要移除 Terminator,只需要在终端中运行下面的命令(可选)
|
||||
|
||||
$ sudo apt-get remove terminator
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -48,7 +45,7 @@ via: http://www.ewikitech.com/articles/linux/terminator-install-ubuntu-linux-min
|
||||
|
||||
作者:[admin][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,26 +1,26 @@
|
||||
如何在Ubuntu中添加和删除书签[新手技巧]
|
||||
[新手技巧] 如何在Ubuntu中添加和删除书签
|
||||
================================================================================
|
||||

|
||||
|
||||
这是一篇对完全是新手的一篇技巧,我将向你展示如何在Ubuntu文件管理器中添加书签。
|
||||
|
||||
现在如果你想知道为什么要这么做,答案很简单。它可以让你可以快速地在左边栏中访问。比如。我[在Ubuntu中安装了Copy][1]。现在它创建了/Home/Copy。先进入Home目录再进入Copy目录并不是一件大事,但是我想要更快地访问它。因此我添加了一个书签这样我就可以直接从侧边栏访问了。
|
||||
现在如果你想知道为什么要这么做,答案很简单。它可以让你可以快速地在左边栏中访问。比如,我[在Ubuntu中安装了Copy 云服务][1]。它创建在/Home/Copy。先进入Home目录再进入Copy目录并不是很麻烦,但是我想要更快地访问它。因此我添加了一个书签这样我就可以直接从侧边栏访问了。
|
||||
|
||||
### 在Ubuntu中添加书签 ###
|
||||
|
||||
打开Files。进入你想要保存快速访问的目录。你需要在标记书签的目录里面。
|
||||
|
||||
现在,你有两种方法。
|
||||
现在,你有两种方法:
|
||||
|
||||
#### 方法1: ####
|
||||
|
||||
当你在Files中时(Ubuntu中的文件管理器),查看顶部菜单。你会看到书签按钮。点击它你会看到将当前路径保存为书签的选项。
|
||||
当你在Files(Ubuntu中的文件管理器)中时,查看顶部菜单。你会看到书签按钮。点击它你会看到将当前路径保存为书签的选项。
|
||||
|
||||

|
||||
|
||||
#### 方法 2: ####
|
||||
|
||||
你可以直接按下Ctrl+D就可以将当前位置保存位书签。
|
||||
你可以直接按下Ctrl+D就可以将当前位置保存为书签。
|
||||
|
||||
如你所见,这里左边栏就有一个新添加的Copy目录:
|
||||
|
||||
@ -32,7 +32,7 @@
|
||||
|
||||

|
||||
|
||||
这就是在Ubuntu中管理书签需要做的。我知道这对于大多数用户而言很贱,但是这也许多Ubuntu的新手而言或许还有用。
|
||||
这就是在Ubuntu中管理书签需要做的。我知道这对于大多数用户而言很简单,但是这也许多Ubuntu的新手而言或许还有用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -40,7 +40,7 @@ via: http://itsfoss.com/add-remove-bookmarks-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,28 +1,29 @@
|
||||
在 Ubuntu 15.04 上安装 Justniffer
|
||||
================================================================================
|
||||
### 简介 ###
|
||||

|
||||
|
||||
[Justniffer][1] 是一个可用于替换 Snort 的网络协议分析器。它非常流行,可交互式地跟踪/探测一个网络连接。它能从实时环境中抓取流量,支持 “lipcap” 和 “tcpdump” 文件格式。它可以帮助用户分析一个用 wireshark 难以抓包的复杂网络。尤其是它可以有效的帮助分析应用层流量,能提取类似图像、脚本、HTML 等 http 内容。Justniffer 有助于理解不同组件之间是如何通信的。
|
||||
[Justniffer][1] 是一个可用于替代 Snort 的网络协议分析器。它非常流行,可交互式地跟踪/探测一个网络连接。它能从实时环境中抓取流量,支持 “lipcap” 和 “tcpdump” 文件格式。它可以帮助用户分析一个用 wireshark 难以抓包的复杂网络。尤其是它可以有效的帮助你分析应用层流量,能提取类似图像、脚本、HTML 等 http 内容。Justniffer 有助于理解不同组件之间是如何通信的。
|
||||
|
||||
### 功能 ###
|
||||
|
||||
Justniffer 收集一个复杂网络的所有流量而不影响系统性能,这是 Justniffer 的一个优势,它还可以保存日志用于之后的分析,Justniffer 其它一些重要功能包括:
|
||||
Justniffer 可以收集一个复杂网络的所有流量而不影响系统性能,这是 Justniffer 的一个优势,它还可以保存日志用于之后的分析,Justniffer 其它一些重要功能包括:
|
||||
|
||||
#### 1. 可靠的 TCP 流重建 ####
|
||||
1. 可靠的 TCP 流重建
|
||||
|
||||
它可以使用主机 Linux 内核的一部分用于记录并重现 TCP 片段和 IP 片段。
|
||||
它可以使用主机 Linux 内核的一部分用于记录并重现 TCP 片段和 IP 片段。
|
||||
|
||||
#### 2. 日志 ####
|
||||
2. 日志
|
||||
|
||||
保存日志用于之后的分析,并能自定义保存内容和时间。
|
||||
保存日志用于之后的分析,并能自定义保存内容和时间。
|
||||
|
||||
#### 3. 可扩展 ####
|
||||
3. 可扩展
|
||||
|
||||
可以通过外部 python、 perl 和 bash 脚本扩展来从分析报告中获取一些额外的结果。
|
||||
可以通过外部的 python、 perl 和 bash 脚本扩展来从分析报告中获取一些额外的结果。
|
||||
|
||||
#### 4. 性能管理 ####
|
||||
4. 性能管理
|
||||
|
||||
基于连接时间、关闭时间、响应时间或请求时间等提取信息。
|
||||
基于连接时间、关闭时间、响应时间或请求时间等提取信息。
|
||||
|
||||
### 安装 ###
|
||||
|
||||
@ -44,41 +45,41 @@ make 的时候失败了,然后我运行下面的命令并尝试重新安装服
|
||||
|
||||
$ sudo apt-get -f install
|
||||
|
||||
### 事例 ###
|
||||
### 示例 ###
|
||||
|
||||
首先用 -v 选项验证安装的 Justniffer 版本,你需要用超级用户权限来使用这个工具。
|
||||
|
||||
$ sudo justniffer -V
|
||||
|
||||
事例输出:
|
||||
示例输出:
|
||||
|
||||

|
||||
|
||||
**1. 为 eth1 接口导出 apache 中的流量到终端**
|
||||
**1、 以类似 apache 的格式导出 eth1 接口流量,显示到终端**
|
||||
|
||||
$ sudo justniffer -i eth1
|
||||
|
||||
事例输出:
|
||||
示例输出:
|
||||
|
||||

|
||||
|
||||
**2. 可以永恒下面的选项跟踪正在运行的 tcp 流**
|
||||
**2、 可以用下面的选项跟踪正在运行的 tcp 流**
|
||||
|
||||
$ sudo justniffer -i eth1 -r
|
||||
|
||||
事例输出:
|
||||
示例输出:
|
||||
|
||||

|
||||
|
||||
**3. 获取 web 服务器的响应时间**
|
||||
**3、 获取 web 服务器的响应时长**
|
||||
|
||||
$ sudo justniffer -i eth1 -a " %response.time"
|
||||
|
||||
事例输出:
|
||||
示例输出:
|
||||
|
||||

|
||||
|
||||
**4. 使用 Justniffer 读取一个 tcpdump 抓取的文件**
|
||||
**4、 使用 Justniffer 读取一个 tcpdump 抓取的文件**
|
||||
|
||||
首先,用 tcpdump 抓取流量。
|
||||
|
||||
@ -88,33 +89,33 @@ make 的时候失败了,然后我运行下面的命令并尝试重新安装服
|
||||
|
||||
$ justniffer -f file.cap
|
||||
|
||||
事例输出:
|
||||
示例输出:
|
||||
|
||||

|
||||
|
||||
**5. 只抓取 http 数据**
|
||||
**5、 只抓取 http 数据**
|
||||
|
||||
$ sudo justniffer -i eth1 -r -p "port 80 or port 8080"
|
||||
|
||||
事例输出:
|
||||
示例输出:
|
||||
|
||||

|
||||
|
||||
**6. 从一个指定主机获取 http 数据**
|
||||
**6、 获取一个指定主机 http 数据**
|
||||
|
||||
$ justniffer -i eth1 -r -p "host 192.168.1.250 and tcp port 80"
|
||||
|
||||
事例输出:
|
||||
示例输出:
|
||||
|
||||

|
||||
|
||||
**7. 以更精确的格式抓取数据**
|
||||
**7、 以更精确的格式抓取数据**
|
||||
|
||||
当你输入 **justniffer -h** 的时候你可以看到很多用于以更精确的方式获取数据的格式关键字
|
||||
|
||||
$ justniffer -h
|
||||
|
||||
事例输出:
|
||||
示例输出:
|
||||
|
||||

|
||||
|
||||
@ -122,15 +123,15 @@ make 的时候失败了,然后我运行下面的命令并尝试重新安装服
|
||||
|
||||
$ justniffer -i eth1 -l "%request.timestamp %request.header.host %request.url %response.time"
|
||||
|
||||
事例输出:
|
||||
示例输出:
|
||||
|
||||

|
||||
|
||||
其中还有很多你可以探索的选项
|
||||
其中还有很多你可以探索的选项。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
Justniffer 是用于网络测试一个很好的工具。在我看来对于那些用 Snort 来进行网络探测的用户来说,Justniffer 是一个更简单的工具。它提供了很多 **格式关键字** 用于按照你的需要精确地提取数据。你可以用 .cap 文件格式记录网络信息,之后用于分析监视网络服务性能。
|
||||
Justniffer 是一个很好的用于网络测试的工具。在我看来对于那些用 Snort 来进行网络探测的用户来说,Justniffer 是一个更简单的工具。它提供了很多 **格式关键字** 用于按照你的需要精确地提取数据。你可以用 .cap 文件格式记录网络信息,之后用于分析监视网络服务性能。
|
||||
|
||||
**参考资料:**
|
||||
|
||||
@ -142,7 +143,7 @@ via: http://www.unixmen.com/install-justniffer-ubuntu-15-04/
|
||||
|
||||
作者:[Rajneesh Upadhyay][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,10 @@
|
||||
如何在Ubuntu 14.04 / 15.04中设置IonCube Loaders
|
||||
================================================================================
|
||||
IonCube Loaders是PHP中用于辅助加速页面的加解密工具。它保护你的PHP代码不会被在未授权的计算机上查看。使用ionCube编码并加密PHP需要一个叫ionCube Loader的文件安装在web服务器上并提供给需要大量访问的PHP用。它在运行时处理并执行编码。PHP只需在‘php.ini’中添加一行就可以使用这个loader。
|
||||
IonCube Loaders是一个PHP中用于加解密的工具,并带有加速页面运行的功能。它也可以保护你的PHP代码不会查看和运行在未授权的计算机上。要使用ionCube编码、加密的PHP文件,需要在web服务器上安装一个叫ionCube Loader的文件,并需要让 PHP 可以访问到,很多 PHP 应用都在用它。它可以在运行时读取并执行编码过后的代码。PHP只需在‘php.ini’中添加一行就可以使用这个loader。
|
||||
|
||||
### 前提条件 ###
|
||||
|
||||
在这篇文章中,我们将在Ubuntu14.04/15.04安装Ioncube Loader ,以便它可以在所有PHP模式中使用。本教程的唯一要求就是你系统安装了LEMP,并有“的php.ini”文件。
|
||||
在这篇文章中,我们将在Ubuntu14.04/15.04安装Ioncube Loader ,以便它可以在所有PHP模式中使用。本教程的唯一要求就是你系统安装了LEMP,并有“php.ini”文件。
|
||||
|
||||
### 下载 IonCube Loader ###
|
||||
|
||||
@ -14,15 +14,15 @@ IonCube Loaders是PHP中用于辅助加速页面的加解密工具。它保护
|
||||
|
||||

|
||||
|
||||
下载完成后用下面的命令解压到"/usr/local/src/"。
|
||||
下载完成后用下面的命令解压到“/usr/local/src/"。
|
||||
|
||||
# tar -zxvf ioncube_loaders_lin_x86-64.tar.gz -C /usr/local/src/
|
||||
|
||||

|
||||
|
||||
解压完成后我们就可以看到所有的存在的模块。但是我们只需要我们安装的PHP版本的相关模块。
|
||||
解压完成后我们就可以看到所有提供的模块。但是我们只需要我们所安装的PHP版本的对应模块。
|
||||
|
||||
要检查PHP版本,你可以运行下面的命令来找出相关的模块。
|
||||
要检查PHP版本,你可以运行下面的命令来找出相应的模块。
|
||||
|
||||
# php -v
|
||||
|
||||
@ -30,14 +30,14 @@ IonCube Loaders是PHP中用于辅助加速页面的加解密工具。它保护
|
||||
|
||||
根据上面的命令我们知道我们安装的是PHP 5.6.4,因此我们需要拷贝合适的模块到PHP模块目录下。
|
||||
|
||||
首先我们在“/usr/local/”创建一个叫“ioncube”的目录并复制需要的ioncube loader到这里。
|
||||
首先我们在“/usr/local/”创建一个叫“ioncube”的目录并复制所需的ioncube loader到这里。
|
||||
|
||||
root@ubuntu-15:/usr/local/src/ioncube# mkdir /usr/local/ioncube
|
||||
root@ubuntu-15:/usr/local/src/ioncube# cp ioncube_loader_lin_5.6.so ioncube_loader_lin_5.6_ts.so /usr/local/ioncube/
|
||||
|
||||
### PHP 配置 ###
|
||||
|
||||
我们要在位于"/etc/php5/cli/"文件夹下的"php.ini"中加入下面的配置行并重启web服务和php模块。
|
||||
我们要在位于"/etc/php5/cli/"文件夹下的"php.ini"中加入如下的配置行并重启web服务和php模块。
|
||||
|
||||
# vim /etc/php5/cli/php.ini
|
||||
|
||||
@ -54,7 +54,6 @@ IonCube Loaders是PHP中用于辅助加速页面的加解密工具。它保护
|
||||
|
||||
要为我们的网站测试ioncube loader。用下面的内容创建一个"info.php"文件并放在网站的web目录下。
|
||||
|
||||
|
||||
# vim /usr/share/nginx/html/info.php
|
||||
|
||||
加入phpinfo的脚本后重启web服务后用域名或者ip地址访问“info.php”。
|
||||
@ -63,7 +62,6 @@ IonCube Loaders是PHP中用于辅助加速页面的加解密工具。它保护
|
||||
|
||||

|
||||
|
||||
From the terminal issue the following command to verify the php version that shows the ionCube PHP Loader is Enabled.
|
||||
在终端中运行下面的命令来验证php版本并显示PHP Loader已经启用了。
|
||||
|
||||
# php -v
|
||||
@ -74,7 +72,7 @@ From the terminal issue the following command to verify the php version that sho
|
||||
|
||||
### 总结 ###
|
||||
|
||||
教程的最后你已经了解了在安装有nginx的Ubuntu中安装和配置ionCube Loader,如果你正在使用其他的web服务,这与其他服务没有明显的差别。因此做完这些安装Loader是很简单的,并且在大多数服务器上的安装都不会有问题。然而并没有一个所谓的“标准PHP安装”,服务可以通过许多方式安装,并启用或者禁用功能。
|
||||
教程的最后你已经了解了如何在安装有nginx的Ubuntu中安装和配置ionCube Loader,如果你正在使用其他的web服务,这与其他服务没有明显的差别。因此安装Loader是很简单的,并且在大多数服务器上的安装都不会有问题。然而并没有一个所谓的“标准PHP安装”,服务可以通过许多方式安装,并启用或者禁用功能。
|
||||
|
||||
如果你是在共享服务器上,那么确保运行了ioncube-loader-helper.php脚本,并点击链接来测试运行时安装。如果安装时你仍然遇到了问题,欢迎联系我们及给我们留下评论。
|
||||
|
||||
@ -84,7 +82,7 @@ via: http://linoxide.com/ubuntu-how-to/setup-ioncube-loaders-ubuntu-14-04-15-04/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
与新的Ubuntu 15.10默认壁纸相遇
|
||||
看看新的 Ubuntu 15.10 默认壁纸
|
||||
================================================================================
|
||||
**全新的Ubuntu 15.10 Wily Werewolf默认壁纸已经亮相 **
|
||||
**全新的Ubuntu 15.10 Wily Werewolf默认壁纸已经亮相**
|
||||
|
||||
乍一看你几乎无法发现与今天4月发布的Ubuntu 15.04中收到折纸启发的‘Suru’设计有什么差别。但是仔细看你就会发现默认背景有一些细微差别。
|
||||
乍一看你几乎无法发现与今天4月发布的Ubuntu 15.04中受到折纸启发的‘Suru’设计有什么差别。但是仔细看你就会发现默认背景有一些细微差别。
|
||||
|
||||
其中一点是更淡,受到由左上角图片发出的橘黄色光的帮助。保持了角褶皱和色块,但是增加了块和矩形部分。
|
||||
|
||||
@ -10,25 +10,25 @@
|
||||
|
||||

|
||||
|
||||
Ubuntu 15.10 默认桌面背景
|
||||
*Ubuntu 15.10 默认桌面背景*
|
||||
|
||||
只是为了显示改变,这个是Ubuntu 15.04的默认壁纸作为比较:
|
||||
为了凸显变化,这个是Ubuntu 15.04的默认壁纸作为比较:
|
||||
|
||||

|
||||
|
||||
Ubuntu 15.04 默认壁纸
|
||||
*Ubuntu 15.04 默认壁纸*
|
||||
|
||||
### 下载Ubuntu 15.10 壁纸 ###
|
||||
|
||||
如果你正运行的是Ubuntu 15.10 Wily Werewolf每日编译版本,那么你无法看到这个默认壁纸:设计已经亮相但是还没有打包到Wily中。
|
||||
如果你正运行的是Ubuntu 15.10 Wily Werewolf每日构建版本,那么你无法看到这个默认壁纸:设计已经亮相但是还没有打包到Wily中。
|
||||
|
||||
你不必等到10月份来使用新的设计来作为你的桌面背景。你可以点击下面的按钮下载4096×2304高清壁纸。
|
||||
|
||||
- [下载Ubuntu 15.10新的默认壁纸][1]
|
||||
|
||||
最后,如我们每次在有新壁纸时说的,你不必在意发布版品牌和设计细节。如果壁纸不和你的口味或者不想永远用它,轻易地就换掉毕竟这不是Ubuntu Phone!
|
||||
最后,如我们每次在有新壁纸时说的,你不必在意发布版品牌和设计细节。如果壁纸不合你的口味或者不想永远用它,轻易地就换掉,毕竟这不是Ubuntu Phone!
|
||||
|
||||
**你是你版本的粉丝么?在评论中让我们知道 **
|
||||
**你是新版本的粉丝么?在评论中让我们知道**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -36,7 +36,7 @@ via: http://www.omgubuntu.co.uk/2015/09/ubuntu-15-10-wily-werewolf-default-wallp
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,12 @@
|
||||
Xenlism WildFire: 一个精美的 Linux 桌面版主题
|
||||
Xenlism WildFire: Linux 桌面的极简风格图标主题
|
||||
================================================================================
|
||||

|
||||
|
||||
有那么一段时间,我一直使用一个主题,没有更换过。可能是在最近的一段时间都没有一款主题能满足我的需求。有那么一些我认为是[Ubuntu 上最好的图标主题][1],比如 Numix 和 Moka,并且,我一直也对 Numix 比较满意。
|
||||
有那么一段时间我没更换主题了,可能最近的一段时间没有一款主题能让我眼前一亮了。我考虑过更换 [Ubuntu 上最好的图标主题][1],但是它们和 Numix 和 Moka 差不多,而且我觉得 Numix 也不错。
|
||||
|
||||
但是,一段时间后,我使用了[Xenslim WildFire][2],并且我必须承认,他看起来太好了。Minimail 是当前比较流行的设计趋势。并且 Xenlism 完美的表现了它。平滑和美观。Xenlism 收到了诺基亚的 Meego 和苹果图标的影响。
|
||||
但是前几天我试了试 [Xenslim WildFire][2],我必须承认,它看起来太棒了。极简风格是设计界当前的流行趋势,而 Xenlism 完美的表现了这种风格。平滑而美观,Xenlism 显然受到了诺基亚的 Meego 和苹果图标的影响。
|
||||
|
||||
让我们来看一下他的几个不同应用的图标:
|
||||
让我们来看一下它的几个不同应用的图标:
|
||||
|
||||

|
||||
|
||||
@ -14,15 +14,15 @@ Xenlism WildFire: 一个精美的 Linux 桌面版主题
|
||||
|
||||

|
||||
|
||||
主题开发者,[Nattapong Pullkhow][3], 说,这个图标主题最适合 GNOME,但是在 Unity 和 KDE,Mate 上也表现良好。
|
||||
主题开发者 [Nattapong Pullkhow][3] 说,这个图标主题最适合 GNOME,但是在 Unity 和 KDE,Mate 上也表现良好。
|
||||
|
||||
### 安装 Xenlism Wildfire ###
|
||||
|
||||
Xenlism Theme 大约有 230 MB, 对于一个主题来说确实很大,但是考虑到它支持的庞大的软件数量,这个大小,确实也不是那么令人吃惊。
|
||||
Xenlism Theme 大约有 230 MB, 对于一个主题来说确实很大,但是考虑到它所支持的庞大的软件数量,这个大小,确实也不是那么令人吃惊。
|
||||
|
||||
#### 在 Ubuntu/Debian 上安装 Xenlism ####
|
||||
|
||||
在 Ubuntu 的变种中安装前,用以下的命令添加 GPG 秘钥:
|
||||
在 Ubuntu 系列中安装之前,用以下的命令添加 GPG 秘钥:
|
||||
|
||||
sudo apt-key adv --keyserver keys.gnupg.net --recv-keys 90127F5B
|
||||
|
||||
@ -42,7 +42,7 @@ Xenlism Theme 大约有 230 MB, 对于一个主题来说确实很大,但是考
|
||||
|
||||
sudo nano /etc/pacman.conf
|
||||
|
||||
添加如下的代码块,在配置文件中:
|
||||
添加如下的代码块,在配置文件中:
|
||||
|
||||
[xenlism-arch]
|
||||
SigLevel = Never
|
||||
@ -55,17 +55,17 @@ Xenlism Theme 大约有 230 MB, 对于一个主题来说确实很大,但是考
|
||||
|
||||
#### 使用 Xenlism 主题 ####
|
||||
|
||||
在 Ubuntu Unity, [可以使用 Unity Tweak Tool 来改变主题][4]. In GNOME, [使用 Gnome Tweak Tool 改变主题][5]. 我确信你会接下来的步骤,如果你不会,请来信通知我,我会继续完善这篇文章。
|
||||
在 Ubuntu Unity, [可以使用 Unity Tweak Tool 来改变主题][4]。 在 GNOME 中,[使用 Gnome Tweak Tool 改变主题][5]。 我确信你会接下来的步骤,如果你不会,请来信通知我,我会继续完善这篇文章。
|
||||
|
||||
这就是 Xenlism 在 Ubuntu 15.04 Unity 中的截图。同时也使用了 Xenlism 桌面背景。
|
||||
|
||||

|
||||
|
||||
这看来真棒,不是吗?如果你试用了,并且喜欢他,你可以感谢他的开发者:
|
||||
这看来真棒,不是吗?如果你试用了,并且喜欢它,你可以感谢它的开发者:
|
||||
|
||||
> [Xenlism is a stunning minimal icon theme for Linux. Thanks @xenatt for this beautiful theme.][6]
|
||||
> [Xenlism 是一个用于 Linux 的、令人兴奋的极简风格的图标主题,感谢 @xenatt 做出这么漂亮的主题。][6]
|
||||
|
||||
我希望你喜欢他。同时也希望你分享你对这个主题的看法,或者你喜欢的主题。Xenlism 真的很棒,可能会替换掉你最喜欢的主题。
|
||||
我希望你喜欢它。同时也希望你分享你对这个主题的看法,或者你喜欢的主题。Xenlism 真的很棒,可能会替换掉你最喜欢的主题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -73,7 +73,7 @@ via: http://itsfoss.com/xenlism-wildfire-theme/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
127
published/20150925 HTTP 2 Now Fully Supported in NGINX Plus.md
Normal file
127
published/20150925 HTTP 2 Now Fully Supported in NGINX Plus.md
Normal file
@ -0,0 +1,127 @@
|
||||
NGINX Plus 现在完全支持 HTTP/2
|
||||
================================================================================
|
||||
早些时候,我们发布了支持 HTTP/2 协议的 [NGINX Plus R7][1]。作为 HTTP 协议的最新标准,HTTP/2 的设计为现在的 web 应用程序带来了更高的性能和安全性。(LCTT 译注: [开源版本的 NGINX 1.95 也支持 HTTP/2 了][18]。)
|
||||
|
||||
NGINX Plus 所实现的 HTTP/2 协议可与现有的网站和应用程序进行无缝衔接。只需要一点改变,不管用户选择什么样的浏览器,NGINX Plus 都能为用户同时提供 HTTP/1.x 与HTTP/2 的最佳体验。
|
||||
|
||||
要支持 HTTP/2 仅需通过可选的 **nginx‑plus‑http2** 软件包。**nginx‑plus** 和 **nginx‑plus‑extras** 软件包支持 SPDY 协议,目前推荐用于生产站点,因为其被大多数浏览器所支持并且代码也是相当成熟了。
|
||||
|
||||
### 为什么要使用 HTTP/2? ###
|
||||
|
||||
HTTP/2 使数据传输更高效,对你的应用程序更安全。 HTTP/2 相比于 HTTP/1.x 有五个提高性能特点:
|
||||
|
||||
- **完全复用** – 在一个保持激活(keepalive)的连接上,HTTP/1.1 强制按严格的顺序来处理请求。一个请求必须在下一个请求开始前结束。 HTTP/2 消除了这一要求,允许并行和乱序来处理请求。
|
||||
|
||||
- **单一,持久连接** – 由于 HTTP/2 允许请求完全复用,所以可以通过单一连接并行下载网页上的所有对象。在 HTTP/1.x 中,使用多个连接来并行下载资源,从而导致使用底层 TCP 协议效率很低。
|
||||
|
||||
- **二进制编码** – Header 信息使用紧凑的二进制格式发送,而不是纯文本格式,节省了传输字节。
|
||||
|
||||
- **Header 压缩** – Headers 使用专用的 HPACK 压缩算法来进行压缩,这进一步降低数据通过网络传输的字节。
|
||||
|
||||
- **SSL/TLS 加密** – 在 HTTP/2 中,强制使用 SSL/TLS。在 [RFC][2] 中并没有强制,其允许纯文本的 HTTP/2,但是当前所有实现 HTTP/2的 Web 浏览器都只支持加密。 SSL/TLS 可以使你的网站更安全,并且使用 HTTP/2 各项性能会有提升,加密和解密过程的性能损失就减少了。
|
||||
|
||||
要了解更多关于 HTTP/2:
|
||||
|
||||
- 请阅读我们的 [白皮书][3],它涵盖了你需要了解HTTP/2 的一切。
|
||||
- 下载由 Google 的 Ilya Grigorik 编写的 [特别版的高性能浏览器网络电子书][4] 。
|
||||
|
||||
### NGINX Plus 如何实现 HTTP/2 ###
|
||||
|
||||
我们的 HTTP/2 实现是基于 SPDY 支持的,它已经被广泛部署(使用了 NGINX 或 NGINX Plus 的网站近 75% 都使用了 SPDY)。使用 NGINX Plus 部署 HTTP/2 时,几乎不会改变你应用程序的配置。本节将讨论 NGINX Plus如何实现对 HTTP/2 的支持。
|
||||
|
||||
#### 一个 HTTP/2 网关 ####
|
||||
|
||||

|
||||
|
||||
NGINX Plus 作为一个 HTTP/2 网关。它与支持 HTTP/2 的客户端 Web 浏览器用 HTTP/2 通讯,而转换 HTTP/2 请求给后端服务器通信时使用 HTTP/1.x(或者 FastCGI, SCGI, uWSGI, 等等. – 取决于你目前正在使用的协议)。
|
||||
|
||||
#### 向后兼容性 ####
|
||||
|
||||

|
||||
|
||||
在一段时间内,你需要同时支持 HTTP/2 和 HTTP/1.x。在撰写本文时,超过50%的用户使用的 Web 浏览器已经[支持 HTTP/2][5],但这也意味着近50%的人还没有使用。
|
||||
|
||||
为了同时支持 HTTP/1.x 和 HTTP/2,NGINX Plus 实现了 TLS 上的 Next Protocol Negotiation (NPN)扩展。当 Web 浏览器连接到服务器时,其将所支持的协议列表发送到服务器端。如果浏览器支持的协议列表中包括 h2 - 即 HTTP/2,NGINX Plus 将使用 HTTP/2 连接到浏览器。如果浏览器不支持 NPN 或在发送支持的协议列表中没有 h2,NGINX Plus 将继续回落到 HTTP/1.x。
|
||||
|
||||
### 转向 HTTP/2 ###
|
||||
|
||||
NGINX 公司会尽可能帮助大家无缝过渡到使用 HTTP/2。本节介绍了通过对你应用进行改变来启用对 HTTP/2 支持,其中只需对 NGINX Plus 配置进行几个变化。
|
||||
|
||||
#### 前提条件 ####
|
||||
|
||||
使用 **nginx‑plus‑http2** 软件包升级到 NGINX Plus R7。注意现在还没有支持 HTTP/2 版本的 **nginx‑plus‑extras** 软件包。
|
||||
|
||||
#### 重定向所有流量到 SSL/TLS ####
|
||||
|
||||
如果你的应用尚未使用 SSL/TLS 加密,现在启用它正是一个好的时机。加密你的应用程序可以保护你免受间谍以及来自其他中间人的攻击。一些搜索引擎甚至在搜索结果中对加密站点[提高排名][6]。下面的配置块重定向所有的普通 HTTP 请求到该网站的加密版本。
|
||||
|
||||
server {
|
||||
listen 80;
|
||||
location / {
|
||||
return 301 https://$host$request_uri;
|
||||
}
|
||||
}
|
||||
|
||||
#### 启用 HTTP/2 ####
|
||||
|
||||
要启用对 HTTP/2 的支持,只需将 http2 参数添加到所有的 [listen][7] 指令中,也要包括 SSL 参数,因为浏览器不支持不加密的 HTTP/2 请求。
|
||||
|
||||
server {
|
||||
listen 443 ssl http2 default_server;
|
||||
|
||||
ssl_certificate server.crt;
|
||||
ssl_certificate_key server.key;
|
||||
…
|
||||
}
|
||||
|
||||
如果有必要,重启 NGINX Plus,例如通过运行 `nginx -s reload` 命令。要验证 HTTP/2 是否正常工作,你可以在 [Google Chrome][8] 和 [Firefox][9] 中使用 “HTTP/2 and SPDY indicator” 插件来检查。
|
||||
|
||||
### 注意事项 ###
|
||||
|
||||
- 在安装 **nginx‑plus‑http2** 包之前, 你必须删除配置文件中所有 listen 指令后的 SPDY 参数(使用 http2 和 ssl 参数来替换它以启用对 HTTP/2 的支持)。使用这个包后,如果 listen 指令后有 spdy 参数,NGINX Plus 将无法启动。
|
||||
|
||||
- 如果你在 NGINX Plus 前端使用了 Web 应用防火墙(WAF),请确保它能够解析 HTTP/2,或者把它移到 NGINX Plus 后面。
|
||||
|
||||
- 此版本不支持在 HTTP/2 RFC 中定义的 “Server Push” 特性。 NGINX Plus 以后的版本可能会支持它。
|
||||
|
||||
- NGINX Plus R7 同时支持 SPDY 和 HTTP/2(LCTT 译注:但是你只能同时使用其中一种)。在以后的版本中,我们将弃用对 SPDY 的支持。谷歌在2016年初将 [弃用 SPDY][10],因此同时支持这两种协议也非必要。
|
||||
|
||||
- 如果 [ssl_prefer_server_ciphers][11] 设置为 on 或者使用了定义在 [Appendix A: TLS 1.2 Ciper Suite Black List][13] 中的 [ssl_ciphers][12] 列表时,浏览器会出现 handshake-errors 而无法正常工作。详细内容请参阅 [section 9.2.2 of the HTTP/2 RFC][14]。
|
||||
|
||||
### 特别感谢 ###
|
||||
|
||||
NGINX 公司要感谢 [Dropbox][15] 和 [Automattic][16],他们是我们软件的重度使用者,并帮助我们实现 HTTP/2。他们的贡献帮助我们加速完成这个软件,我们希望你也能支持他们。
|
||||
|
||||

|
||||
|
||||
[O'REILLY'S BOOK ABOUT HTTP/2 & PERFORMANCE TUNING][17]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.nginx.com/blog/http2-r7/
|
||||
|
||||
作者:[Faisal Memon][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.nginx.com/blog/author/fmemon/
|
||||
[1]:https://www.nginx.com/blog/nginx-plus-r7-released/
|
||||
[2]:https://tools.ietf.org/html/rfc7540
|
||||
[3]:https://www.nginx.com/wp-content/uploads/2015/09/NGINX_HTTP2_White_Paper_v4.pdf
|
||||
[4]:https://www.nginx.com/http2-ebook/
|
||||
[5]:http://caniuse.com/#feat=http2
|
||||
[6]:http://googlewebmastercentral.blogspot.co.uk/2014/08/https-as-ranking-signal.html
|
||||
[7]:http://nginx.org/en/docs/http/ngx_http_core_module.html#listen
|
||||
[8]:https://chrome.google.com/webstore/detail/http2-and-spdy-indicator/mpbpobfflnpcgagjijhmgnchggcjblin?hl=en
|
||||
[9]:https://addons.mozilla.org/en-us/firefox/addon/spdy-indicator/
|
||||
[10]:http://blog.chromium.org/2015/02/hello-http2-goodbye-spdy-http-is_9.html
|
||||
[11]:http://nginx.org/en/docs/http/ngx_http_ssl_module.html#ssl_prefer_server_ciphers
|
||||
[12]:http://nginx.org/en/docs/http/ngx_http_ssl_module.html#ssl_ciphers
|
||||
[13]:https://tools.ietf.org/html/rfc7540#appendix-A
|
||||
[14]:https://tools.ietf.org/html/rfc7540#section-9.2.2
|
||||
[15]:http://dropbox.com/
|
||||
[16]:http://automattic.com/
|
||||
[17]:https://www.nginx.com/http2-ebook/
|
||||
[18]:http://mailman.nginx.org/pipermail/nginx-announce/2015/000162.html
|
||||
@ -0,0 +1,65 @@
|
||||
Debian 拋弃 Linux 标准规范(LSB)
|
||||
=======================
|
||||
|
||||
Linux 标准规范(LSB)是一个意图定义 Linux 发行版为第三方程序所提供的服务和应用层 ABI(Application Binary Interfaces,程序二进制界面) 的[规范][1]。但 Debian 项目内的某些人正在质疑是否值得维持兼容 LSB,他们认为,该项工作的工作量巨大,但好处有限。
|
||||
|
||||
LSB 于2001年首次公布,其模型建立在 [POSIX][2] 和[单一 UNIX 规范(Single UNIX Specification)][3]的基础之上。目前,LSB 由 Linux 基金会的一个[工作小组][4]维护。最新的版本是于2015年6月发布的 [LSB 5.0][5]。它定义了五个 LSB 模块(核芯(core)、桌面、语言、成像(imaging)和试用)。
|
||||
|
||||
每个模块都包含了一系列所需的库及其强制性版本,外加对每个库的公共函数和数据定义的描述。这些模块还包括命名和组织规范,如[文件系统层次标准(FHS,Filesystem Hierarchy Standard)][6]中的文件系统布局或象 Freedesktop 的[XDG 基础目录(XDG Base Directory)][7]规范这样的目录规范。
|
||||
|
||||
似乎只是一个巧合,就在 LSB 5.0 发布的同一周,Debian 项目内部针对其是否值得保持兼容 LSB 进行了一次讨论。在另一个贴子中,在提及兼容 LSB 后,Didier Raboud 顺势[提议][8]将 Debian 的兼容工作维持在最低水平。他说,目前的情况是,Debian 的“lsb-*” 元包( meta-packages)试图规定该标准中提及的库的正确版本,但事实上却没有人去检查所有的符号和数据定义是否满足要求。
|
||||
|
||||
另外,LSB 还不断在膨胀;他说, LSB 4.1 版(接近 Debian “jessie” 发布时的最新版本)包含“*1493个组件、1672个库、38491条命令、30176个类和716202个接口*”。似乎没有人有兴趣检查 Debian 包中的这些细节,他解释道,又补充说,“*去年在 DebConf 上我举行过一次 LSB BoF,后来又与很多人讨论过 src:lsb,我收回自己的‘几乎没有人在意’的说法*”。但,重要的是,Debian 似乎并不仅局限于兴趣的缺乏:
|
||||
|
||||
我认为,这个问题的关键在于是否值得去玩这整个游戏:我还没听说有哪个软件通过 LSB 包来发行。LSB 认证的应用清单上只有 6个公司的_8_个应用,其中仅有一个是针对不低于 LSB 4 的。
|
||||
|
||||
Raboud 提议 Debian 摈弃除了 [lsb-base][9] 包(目前包括一个用于启动系统所需的小的 shell 函数集合)和 [lsb-release][10] 包(提供一个简单工具,用户可用它查询发行版的身份以及该发行版宣称的与哪个 LSB 级别兼容)之外的所有内容。
|
||||
|
||||
[后来][11],他又称,将 LSB 基本上改变为“*Debian 和 FLOSS 世界中的所有的其它人所_实际_做的任何事*”可能会使得该标准(以及在 Debian 为支持它所做的工作)更有价值。但此时他再次质疑是否有人会对推动这个目标有兴趣。
|
||||
|
||||
如果说他最初称 LSB 中缺乏兴趣没有足够的证据,随后整整三个月之内没有任何人对维持 LSB 兼容的包提供支持,并进行了两次拋弃它们的投票。最后,9月17日,Raboud [宣布][12]他已经抽掉 `src:lsb` 包(如前所述,保留了`lsb-base` 和 `lsb-release`),将将其上载到 “unstable” 归档中。这个最小的工具集可以让感兴趣的用户在启动了下一个 Debian 版本后查询它是否兼容 LSB:结果将为“否”。
|
||||
|
||||
Raboud 补充说,即便摈弃了兼容 LSB,Debian 仍计划继续兼容 FHS:
|
||||
|
||||
但 Debian 并没有放弃所有的 LSB:我们仍将严格遵守 FHS(直到 Debian Policy 版本 2.3;虽然今年8月已经发布了3.0),而且我们的 SysV 启动脚本几乎全部遵循 VIII.22.{2-8}。但请不要误解,此次 src:lsb 上载明确说明我们将离开 LSB。
|
||||
|
||||
在该宣告之后,Nikolaus Rath [回应][13]称某些私有应用依赖`/lib`和`/lib64`中的符号链接`ld-lsb.so*`,而这些符号链接由`lsb-*`包提供。Raboud 则[建议][14]应改由`libc6`包提供;该包维护人员Aurelien Jarno [称][15],如果提供这样一个补丁,他将会接受它。
|
||||
|
||||
似乎唯一的遗留问题只是某些打印机驱动包会依赖 LSB 兼容。Raboud 称,在其首个贴子中已经说明,据他所知,实际发布的唯一一个依赖 LSB 兼容的包为 [OpenPrinting][16] 驱动程序。Michael Biebl [称][17],主归档中有这样一个驱动包;Raboud 则[回应][18]说,他认为这个有问题的包应该被移到非自由仓库,因其包括了一个二进制驱动。
|
||||
|
||||
于是,这个问题看上去已经尘埃落定,至于对于目前的 Debian 开发周期来说是如此的状况。很自然的是,未来让人更感觉兴趣的是,如果该决定存在一些影响的话,那么人们将会看到它对更广泛的 LSB 接受度有何影响。正如 Raboud 所说的那样,被认证为 LSB 兼容的发行版数量很[少][19]。人们很难不会注意到这些发行版很大程度上是“企业”的变种。
|
||||
|
||||
也许,对某些商业领域来说,LSB 仍很重要,但很难知道有多少那些企业发行版的客户真正关心 LSB 认证标签。然而,如果 Debian 的经验靠得住的话,对这种认证的一般兴趣可能会急剧下降。
|
||||
|
||||
----
|
||||
|
||||
via:https://lwn.net/Articles/658809/
|
||||
|
||||
作者:Nathan Willis
|
||||
译者:[Yuking](https://github.com/Yuking-net)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,
|
||||
[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[1]:http://refspecs.linuxfoundation.org/lsb.shtml
|
||||
[2]:https://en.wikipedia.org/wiki/POSIX
|
||||
[3]:https://en.wikipedia.org/wiki/Single_UNIX_Specification
|
||||
[4]:http://www.linuxfoundation.org/collaborate/workgroups/lsb
|
||||
[5]:http://www.linuxfoundation.org/collaborate/workgroups/lsb/lsb-50
|
||||
[6]:http://www.linuxfoundation.org/collaborate/workgroups/lsb/fhs
|
||||
[7]:http://standards.freedesktop.org/basedir-spec/basedir-spec-0.6.html
|
||||
[8]:https://lwn.net/Articles/658838/
|
||||
[9]:https://packages.debian.org/sid/lsb-base
|
||||
[10]:https://packages.debian.org/sid/lsb-release
|
||||
[11]:https://lwn.net/Articles/658842/
|
||||
[12]:https://lwn.net/Articles/658843/
|
||||
[13]:https://lwn.net/Articles/658846/
|
||||
[14]:https://lwn.net/Articles/658847/
|
||||
[15]:https://lwn.net/Articles/658848/
|
||||
[16]:http://www.linuxfoundation.org/collaborate/workgroups/openprinting/
|
||||
[17]:https://lwn.net/Articles/658844/
|
||||
[18]:https://lwn.net/Articles/658845/
|
||||
[19]:https://www.linuxbase.org/lsb-cert/productdir.php?by_lsb
|
||||
|
||||
@ -0,0 +1,42 @@
|
||||
pyinfo():一个像 phpinfo 一样的 Python 脚本
|
||||
================================================================================
|
||||
作为一个热衷于 php 的家伙,我已经习惯了使用 `phpinfo()` 函数来让我轻松访问 php.ini 里的配置和加载的模块等信息。当然我也想要使用一个不存在的 `pyinfo()` 函数,但没有成功。按下 CTRL-E,google 一下是否有人实现了它?
|
||||
|
||||
是的,有人已经实现了。但是,对我来说它非常难看。荒谬!因为我无法忍受丑陋的布局,*咳咳*,我不得不亲自动手来改改。我用找到的代码,并重新进行布局使之更好看点。Python 官方网站的布局看起来不错,那么何不借用他们的颜色和背景图片呢?是的,这听起来像一个计划。
|
||||
|
||||
- [Gist 代码地址][1]
|
||||
- [下载地址][2]
|
||||
- [例子][3]
|
||||
|
||||
提醒你下,我仅仅在 Python 2.6.4 上运行过它,所以在别的版本上可能有风险(将它移植到任何其他版本它应该是没有问题的)。要使用它,只需要导入该文件, 并调用`pyinfo()`函数得到它的返回值打印到屏幕上。好嘞!
|
||||
|
||||
如果你在使用 [mod_wsgi][4] 时没有得到正确的返回结果,你可以如下运行它(当然得替换路径):
|
||||
|
||||
```
|
||||
def application(environ, start_response):
|
||||
import sys
|
||||
path = 'YOUR_WWW_ROOT_DIRECTORY'
|
||||
if path not in sys.path:
|
||||
sys.path.append(path)
|
||||
from pyinfo import pyinfo
|
||||
output = pyinfo()
|
||||
start_response('200 OK', [('Content-type', 'text/html')])
|
||||
return [output]
|
||||
```
|
||||
---
|
||||
|
||||
via:http://bran.name/articles/pyinfo-a-good-looking-phpinfo-like-python-script/
|
||||
|
||||
作者:[Bran van der Meer][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,
|
||||
[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]:http://bran.name/resume/
|
||||
[1]:https://gist.github.com/951825#file_pyinfo.py
|
||||
[2]:http://bran.name/dump/pyinfo.zip
|
||||
[3]:http://bran.name/dump/pyinfo/index.py
|
||||
[4]:http://code.google.com/p/modwsgi/
|
||||
@ -0,0 +1,57 @@
|
||||
开源媒体播放器 MPlayer 1.2 发布
|
||||
================================================================================
|
||||

|
||||
|
||||
在 [MPlayer][1] 1.1 发布将近3年后,新版 MPlayer 终于在上周发布了。在新版本 MPlayer 1.2 中带来了对许多新编码的解码支持。
|
||||
|
||||
MPlayer 是一款跨平台的开源媒体播放器。它的名字是“Movie Player”的缩写。MPlayer 是 Linux 上最老牌的媒体播放器之一,在过去的15年里,它还带动出现了许多其他媒体播放器。著名的基于 MPlayer 的媒体播放器有:
|
||||
|
||||
- [MPV][2]
|
||||
- SMPlayer
|
||||
- KPlayer
|
||||
- GNOME MPlayer
|
||||
- Deepin Player(深度影音)
|
||||
|
||||
#### MPlayer 1.2 更新了些什么? ####
|
||||
|
||||
- 兼容 FFmpeg 2.8
|
||||
- 对 H.265/HEVC 的 VDPAU 硬件加速
|
||||
- 通过 FFmpeg 支持一些新的编码解码
|
||||
- 改善电视与数字视频广播支持
|
||||
- 界面优化
|
||||
- libdvdcss/libdvdnav 包外部依赖
|
||||
|
||||
#### 在 Linux 安装 MPlayer 1.2 ####
|
||||
|
||||
大多数 Linux 发行版仓库中还是 MPlayer 1.1 版本。如果你想使用新的 MPlayer 1.2 版本,你需要从源码手动编译,这对新手来说可能有点棘手。
|
||||
|
||||
我是在 Ubuntu 15.04 上安装的 MPlayer 1.2。除了需要安装 yasm 的地方以外,对所有 Linux 发行版来说安装说明都是一样的。
|
||||
|
||||
打开一个终端,运行下列命令:
|
||||
|
||||
wget http://www.mplayerhq.hu/MPlayer/releases/MPlayer-1.2.tar.xz
|
||||
tar xvf MPlayer-1.1.1.tar.xz
|
||||
cd MPlayer-1.2
|
||||
sudo apt-get install yasm
|
||||
./configure
|
||||
|
||||
在你运行 make 的时候,在你的终端屏幕上会显示一些东西,并且你需要一些时间来编译它。保持耐心。
|
||||
|
||||
make
|
||||
sudo make install
|
||||
|
||||
如果你觉得从源码编译不大习惯的话,我建议你等待 MPlayer 1.2 提交到你的 Linux 发行版仓库中,或者用其它的播放器替代,比如 MPV。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/mplayer-1-2-released/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:https://www.mplayerhq.hu/
|
||||
[2]:http://mpv.io/
|
||||
77
published/20151007 Productivity Tools And Tips For Linux.md
Normal file
77
published/20151007 Productivity Tools And Tips For Linux.md
Normal file
@ -0,0 +1,77 @@
|
||||
Linux 产能工具及其使用技巧
|
||||
================================================================================
|
||||

|
||||
|
||||
由于生产力本身是一个主观术语,我不打算详细解释我这里要讲到的“生产力”是什么。我打算给你们展示一些工具及其使用技巧,希望这会帮助你在Linux中工作时能更专注、更高效,并且能节省时间。
|
||||
|
||||
### Linux产能工具及其使用技巧 ###
|
||||
|
||||
再次说明,我在写下本文时正在使用的是Ubuntu。但是,我将要在这里展示给大家产能工具及其使用技巧却适用于市面上的大多数Linux发行版。
|
||||
|
||||
#### 外界的音乐 ####
|
||||
|
||||
[音乐影响生产力][1],这已经是一个公开的秘密了。从心理学家到管理大师,他们都一直在建议使用外界的杂音来让自己放松并专注于工作。我不打算就此进行辩论,因为这对于我确实有效。我戴上耳机,然后倾听着鸟叫声和风声,这确实让我很放松。
|
||||
|
||||
在Linux中,我使用ANoise播放器来播放外界的杂音。多亏了官方提供的PPA,你可以很容易地[安装Ambient Noise播放器到Ubuntu中][2],以及其它基于Ubuntu的Linux发行版中。安装它,也可以让它离线播放外界的音乐。
|
||||
|
||||
另外,你也总可以在线听外界杂音。我最喜欢的在线外界音乐站点是[Noisli][3]。强烈推荐你试试这个。
|
||||
|
||||
#### 任务管理应用 ####
|
||||
|
||||
一个良好的生产习惯,就是制订一个任务列表。如果你将它和[番茄工作法][4]组合使用,那就可能创造奇迹了。这里我所说的是,创建一个任务列表,如果可能,将这些任务分配到特定的某个时间。这将会帮助你跟踪一天中计划好的任务。
|
||||
|
||||
对于此,我推荐[Go For It!][5]应用。你可以将它安装到所有主流Linux发行版中,由于它基于[ToDo.txt][6],你也可以很容易地同步到你的智能手机中。我已经为此写了一个详尽的指南[如何使用Go For It!][7]。
|
||||
|
||||
此外,你可以使用[Sticky Notes][8]或者[Google Keep][9]。如果你需要某些更类似[Evernote][10]的功能,你可以使用这些[Evernote的开源替代品][11]。
|
||||
|
||||
#### 剪贴板管理器 ####
|
||||
|
||||
Ctrl+ C和Ctrl+V是我们日常计算机生活中不可缺少的一部分,它们唯一的不足之处在于,这些重要的活动不会被记住(默认情况下)。假如你拷贝了一些重要的东西,然后你意外地又拷贝了一些其它东西,你将丢失先前拷贝的东西。
|
||||
|
||||
剪贴板管理器在这种情况下会派上用场,它可以显示你最近拷贝(到剪贴板的)内容的历史记录,你可以从它这里将文本拷贝回到剪贴板中。
|
||||
|
||||
对于该目的,我更偏好[Diodon剪贴板管理器][12]。它处于活跃开发中,并且在Ubuntu的仓库中可以得到它。
|
||||
|
||||
#### 最近通知 ####
|
||||
|
||||
如果你正忙着处理其它事情,而此时一个桌面通知闪了出来又逐渐消失了,你会怎么做?你会想要看看通知都说了什么,不是吗?最近通知指示器就是用于处理此项工作,它会保留一个最近所有通知的历史记录。这样,你就永远不会错过桌面通知了。
|
||||
|
||||
你可以在此阅读[最近通知指示器][13]。
|
||||
|
||||
#### 终端技巧 ####
|
||||
|
||||
不,我不打算给你们展示所有那些Linux命令技巧和快捷方法,那会写满整个博客了。我打算给你们展示一些终端黑技巧,你可以用它们来提高你的生产力。
|
||||
|
||||
- **修改**sudo**密码超时**:默认情况下,sudo命令要求你在15分钟后再次输入密码,这真是让人讨厌。实际上,你可以修改默认的sudo密码超时。[此教程][14]会给你展示如何来实现。
|
||||
- **获取命令完成的桌面通知**:这是IT朋友们之间的一个常见的玩笑——开发者们花费大量时间来等待程序编译完成——然而这不完全是正确的。但是,它确实影响到了生产力,因为在你等待程序编译完成时,你可以做其它事情,并忘了你在终端中运行的命令。一个更好的途径,就是在一个命令完成时,让它显示桌面通知。这样,你就不会长时间被打断,并且可以回到之前想要做的事情上。请阅读[如何获取命令完成的桌面通知][15]。
|
||||
|
||||
我知道,这不是一篇全面涵盖了**提升生产力**的文章。但是,这些小应用和小技巧可以在实际生活中帮助你在你宝贵的时间中做得更多。
|
||||
|
||||
现在,该轮到你们了。在Linux中,你使用了什么程序或者技巧来提高生产力呢?有哪些东西你想要和社区分享呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/productivity-tips-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://www.helpscout.net/blog/music-productivity/
|
||||
[2]:https://linux.cn/article-5233-1.html
|
||||
[3]:http://www.noisli.com/
|
||||
[4]:https://en.wikipedia.org/wiki/Pomodoro_Technique
|
||||
[5]:http://manuel-kehl.de/projects/go-for-it/
|
||||
[6]:http://todotxt.com/
|
||||
[7]:https://linux.cn/article-5337-1.html
|
||||
[8]:http://itsfoss.com/indicator-stickynotes-windows-like-sticky-note-app-for-ubuntu/
|
||||
[9]:https://linux.cn/article-2634-1.html
|
||||
[10]:https://evernote.com/
|
||||
[11]:http://itsfoss.com/5-evernote-alternatives-linux/
|
||||
[12]:https://esite.ch/tag/diodon/
|
||||
[13]:http://itsfoss.com/7-best-indicator-applets-for-ubuntu-13-10/
|
||||
[14]:http://itsfoss.com/change-sudo-password-timeout-ubuntu/
|
||||
[15]:http://itsfoss.com/notification-terminal-command-completion-ubuntu/
|
||||
@ -0,0 +1,53 @@
|
||||
Linux 有问必答:如何在 Linux 中永久修改 USB 设备权限
|
||||
================================================================================
|
||||
> **提问**:当我尝试在 Linux 中运行 USB GPS 接收器时我遇到了下面来自 gpsd 的错误。
|
||||
>
|
||||
> gpsd[377]: gpsd:ERROR: read-only device open failed: Permission denied
|
||||
> gpsd[377]: gpsd:ERROR: /dev/ttyUSB0: device activation failed.
|
||||
> gpsd[377]: gpsd:ERROR: device open failed: Permission denied - retrying read-only
|
||||
>
|
||||
> 看上去 gpsd 没有权限访问 USB 设备(/dev/ttyUSB0)。我该如何永久修改它在Linux上的权限?
|
||||
|
||||
当你在运行一个会读取或者写入USB设备的进程时,进程的用户/组必须有权限这么做才行。当然你可以手动用`chmod`命令改变 USB 设备的权限,但是手动的权限改变只是暂时的。USB 设备会在下次重启时恢复它的默认权限。
|
||||
|
||||

|
||||
|
||||
作为一个永久的方式,你可以创建一个基于 udev 的 USB 权限规则,它可以根据你的选择分配任何权限模式。下面是该如何做。
|
||||
|
||||
首先,你需要找出 USB 设备的 vendorID 和 productID。使用`lsusb`命令。
|
||||
|
||||
$ lsusb -vvv
|
||||
|
||||
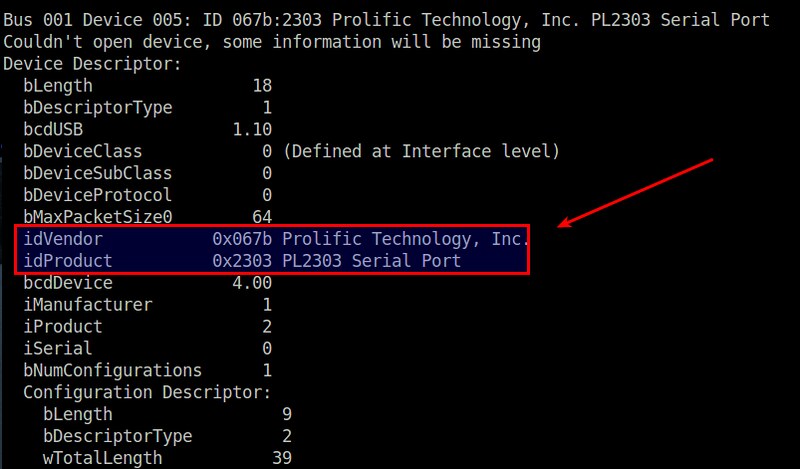
|
||||
|
||||
上面`lsusb`的输出中,找出你的 USB 设备,并找出"idVendor"和"idProduct"字段。本例中,我们的结果是`idVendor (0x067b)`和 `idProduct (0x2303)`
|
||||
|
||||
下面创建一个新的udev规则。
|
||||
|
||||
$ sudo vi /etc/udev/rules.d/50-myusb.rules
|
||||
|
||||
----------
|
||||
|
||||
SUBSYSTEMS=="usb", ATTRS{idVendor}=="067b", ATTRS{idProduct}=="2303", GROUP="users", MODE="0666"
|
||||
|
||||
用你自己的"idVendor"和"idProduct"来替换。**MODE="0666"**表示USB设备的权限。
|
||||
|
||||
现在重启电脑并重新加载 udev 规则:
|
||||
|
||||
$ sudo udevadm control --reload
|
||||
|
||||
接着验证下 USB 设备的权限。
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/change-usb-device-permission-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -0,0 +1,55 @@
|
||||
Mytodo:为 DIY 爱好者准备的待办事项管理软件
|
||||
================================================================================
|
||||

|
||||
|
||||
通常我关注的软件都是那些不用折腾并且易用的(对图形界面而言)。这就是我把 [Go For It][1] 待办事项程序归到 [Linux 产能工具][2] 列表的原因。今天,我要向你们展示另一款待办事项列表应用,和其它的待办事项软件有点不一样。
|
||||
|
||||
[Mytodo][3] 是个开源的待办事项列表程序,让你能够掌管一切。与其它类似的程序不同的是,Mytodo 更加面向 DIY 爱好者,因为它允许你配置服务器(如果你想在多台电脑上使用的话),除了主要的功能外还提供一个命令行界面。
|
||||
|
||||
它是用 Python 编写的,因此可以在所有 Linux 发行版以及其它操作系统,比如 Windows 上使用。
|
||||
|
||||
Mytodo 的一些主要特性:
|
||||
|
||||
- 同时拥有图形界面和命令行界面
|
||||
- 配置你自己的服务器
|
||||
- 添加用户/密码
|
||||
- Python 编写
|
||||
- 可根据标签搜索
|
||||
- 待办事项可以在 [Conky][4] 显示
|
||||
|
||||

|
||||
|
||||
*图形界面*
|
||||
|
||||

|
||||
|
||||
*命令行*
|
||||
|
||||

|
||||
|
||||
*Conky 显示着待办事项*
|
||||
|
||||
你可以在下面的 Github 链接里找到源码和配置介绍:
|
||||
|
||||
- [下载和配置 Mytodo ][5]
|
||||
|
||||
尽管有些人可能不大喜欢命令行和配置部分的内容,但它自然有它的乐趣所在。我建议你自己尝试一下,看看 Mytodo 是否符合我们的需求和口味。
|
||||
|
||||
图片致谢: https://pixabay.com/en/to-do-list-task-list-notes-written-734587
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/mytodo-list-manager/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/go-for-it-to-do-app-in-linux/
|
||||
[2]:https://linux.cn/article-6425-1.html
|
||||
[3]:https://github.com/mohamed-aziz/mytodo
|
||||
[4]:http://itsfoss.com/conky-gui-ubuntu-1304/
|
||||
[5]:https://github.com/mohamed-aziz/mytodo
|
||||
@ -0,0 +1,167 @@
|
||||
在 Linux 下使用 RAID(八):当软件 RAID 故障时如何恢复和重建数据
|
||||
================================================================================
|
||||
|
||||
在阅读过 [RAID 系列][1] 前面的文章后你已经对 RAID 比较熟悉了。回顾前面几个软件 RAID 的配置,我们对每一个都做了详细的解释,使用哪一个取决与你的具体情况。
|
||||
|
||||

|
||||
|
||||
*恢复并重建故障的软件 RAID - 第8部分*
|
||||
|
||||
在本文中,我们将讨论当一个磁盘发生故障时如何重建软件 RAID 阵列并且不会丢失数据。为方便起见,我们仅考虑RAID 1 的配置 - 但其方法和概念适用于所有情况。
|
||||
|
||||
#### RAID 测试方案 ####
|
||||
|
||||
在进一步讨论之前,请确保你已经配置好了 RAID 1 阵列,可以按照本系列第3部分提供的方法:[在 Linux 中如何创建 RAID 1(镜像)][2]。
|
||||
|
||||
在目前的情况下,仅有的变化是:
|
||||
|
||||
1. 使用不同版本 CentOS(v7),而不是前面文章中的(v6.5)。
|
||||
2. 磁盘容量发生改变, /dev/sdb 和 /dev/sdc(各8GB)。
|
||||
|
||||
此外,如果 SELinux 设置为 enforcing 模式,你需要将相应的标签添加到挂载 RAID 设备的目录中。否则,当你试图挂载时,你会碰到这样的警告信息:
|
||||
|
||||
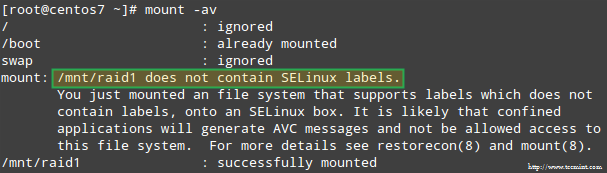
|
||||
|
||||
*启用 SELinux 时 RAID 挂载错误*
|
||||
|
||||
通过以下命令来解决:
|
||||
|
||||
# restorecon -R /mnt/raid1
|
||||
|
||||
### 配置 RAID 监控 ###
|
||||
|
||||
存储设备损坏的原因很多(尽管固态硬盘大大减少了这种情况发生的可能性),但不管是什么原因,可以肯定问题随时可能发生,你需要准备好替换发生故障的部分,并确保数据的可用性和完整性。
|
||||
|
||||
首先建议是。虽然你可以查看 `/proc/mdstat` 来检查 RAID 的状态,但有一个更好的和节省时间的方法,使用监控 + 扫描模式运行 mdadm,它将警报通过电子邮件发送到一个预定义的收件人。
|
||||
|
||||
要这样设置,在 `/etc/mdadm.conf` 添加以下行:
|
||||
|
||||
MAILADDR user@<domain or localhost>
|
||||
|
||||
我自己的设置如下:
|
||||
|
||||
MAILADDR gacanepa@localhost
|
||||
|
||||

|
||||
|
||||
*监控 RAID 并使用电子邮件进行报警*
|
||||
|
||||
要让 mdadm 运行在监控 + 扫描模式中,以 root 用户添加以下 crontab 条目:
|
||||
|
||||
@reboot /sbin/mdadm --monitor --scan --oneshot
|
||||
|
||||
默认情况下,mdadm 每隔60秒会检查 RAID 阵列,如果发现问题将发出警报。你可以通过添加 `--delay` 选项到crontab 条目上面,后面跟上秒数,来修改默认行为(例如,`--delay` 1800意味着30分钟)。
|
||||
|
||||
最后,确保你已经安装了一个邮件用户代理(MUA),如[mutt 或 mailx][3]。否则,你将不会收到任何警报。
|
||||
|
||||
在一分钟内,我们就会看到 mdadm 发送的警报。
|
||||
|
||||
### 模拟和更换发生故障的 RAID 存储设备 ###
|
||||
|
||||
为了给 RAID 阵列中的存储设备模拟一个故障,我们将使用 `--manage` 和 `--set-faulty` 选项,如下所示:
|
||||
|
||||
# mdadm --manage --set-faulty /dev/md0 /dev/sdc1
|
||||
|
||||
这将导致 /dev/sdc1 被标记为 faulty,我们可以在 /proc/mdstat 看到:
|
||||
|
||||
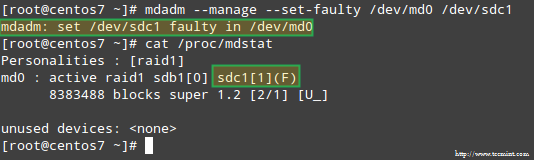
|
||||
|
||||
*在 RAID 存储设备上模拟问题*
|
||||
|
||||
更重要的是,让我们看看是不是收到了同样的警报邮件:
|
||||
|
||||

|
||||
|
||||
*RAID 设备故障时发送邮件警报*
|
||||
|
||||
在这种情况下,你需要从软件 RAID 阵列中删除该设备:
|
||||
|
||||
# mdadm /dev/md0 --remove /dev/sdc1
|
||||
|
||||
然后,你可以直接从机器中取出,并将其使用备用设备来取代(/dev/sdd 中类型为 fd 的分区是以前创建的):
|
||||
|
||||
# mdadm --manage /dev/md0 --add /dev/sdd1
|
||||
|
||||
幸运的是,该系统会使用我们刚才添加的磁盘自动重建阵列。我们可以通过标记 /dev/sdb1 为 faulty 来进行测试,从阵列中取出后,并确认 tecmint.txt 文件仍然在 /mnt/raid1 是可访问的:
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
# mount | grep raid1
|
||||
# ls -l /mnt/raid1 | grep tecmint
|
||||
# cat /mnt/raid1/tecmint.txt
|
||||
|
||||

|
||||
|
||||
*确认 RAID 重建*
|
||||
|
||||
上面图片清楚的显示,添加 /dev/sdd1 到阵列中来替代 /dev/sdc1,数据的重建是系统自动完成的,不需要干预。
|
||||
|
||||
虽然要求不是很严格,有一个备用设备是个好主意,这样更换故障的设备就可以在瞬间完成了。要做到这一点,先让我们重新添加 /dev/sdb1 和 /dev/sdc1:
|
||||
|
||||
# mdadm --manage /dev/md0 --add /dev/sdb1
|
||||
# mdadm --manage /dev/md0 --add /dev/sdc1
|
||||
|
||||

|
||||
|
||||
*取代故障的 Raid 设备*
|
||||
|
||||
### 从冗余丢失中恢复数据 ###
|
||||
|
||||
如前所述,当一个磁盘发生故障时, mdadm 将自动重建数据。但是,如果阵列中的2个磁盘都故障时会发生什么?让我们来模拟这种情况,通过标记 /dev/sdb1 和 /dev/sdd1 为 faulty:
|
||||
|
||||
# umount /mnt/raid1
|
||||
# mdadm --manage --set-faulty /dev/md0 /dev/sdb1
|
||||
# mdadm --stop /dev/md0
|
||||
# mdadm --manage --set-faulty /dev/md0 /dev/sdd1
|
||||
|
||||
此时尝试以同样的方式重新创建阵列就(或使用 `--assume-clean` 选项)可能会导致数据丢失,因此不到万不得已不要使用。
|
||||
|
||||
让我们试着从 /dev/sdb1 恢复数据,例如,在一个类似的磁盘分区(/dev/sde1 - 注意,这需要你执行前在/dev/sde 上创建一个 fd 类型的分区)上使用 `ddrescue`:
|
||||
|
||||
# ddrescue -r 2 /dev/sdb1 /dev/sde1
|
||||
|
||||
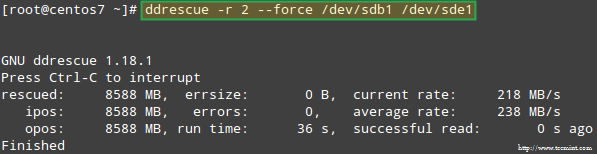
|
||||
|
||||
*恢复 Raid 阵列*
|
||||
|
||||
请注意,到现在为止,我们还没有触及 /dev/sdb 和 /dev/sdd,这是 RAID 阵列的一部分分区。
|
||||
|
||||
现在,让我们使用 /dev/sde1 和 /dev/sdf1 来重建阵列:
|
||||
|
||||
# mdadm --create /dev/md0 --level=mirror --raid-devices=2 /dev/sd[e-f]1
|
||||
|
||||
请注意,在真实的情况下,你需要使用与原来的阵列中相同的设备名称,即设备失效后替换的磁盘的名称应该是 /dev/sdb1 和 /dev/sdc1。
|
||||
|
||||
在本文中,我选择了使用额外的设备来重新创建全新的磁盘阵列,是为了避免与原来的故障磁盘混淆。
|
||||
|
||||
当被问及是否继续写入阵列时,键入 Y,然后按 Enter。阵列被启动,你也可以查看它的进展:
|
||||
|
||||
# watch -n 1 cat /proc/mdstat
|
||||
|
||||
当这个过程完成后,你就应该能够访问 RAID 的数据:
|
||||
|
||||
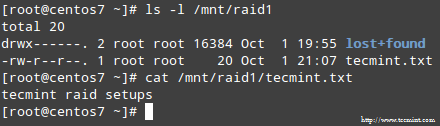
|
||||
|
||||
*确认 Raid 数据*
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在本文中,我们回顾了从 RAID 故障和冗余丢失中恢复数据。但是,你要记住,这种技术是一种存储解决方案,不能取代备份。
|
||||
|
||||
本文中介绍的方法适用于所有 RAID 中,其中的概念我将在本系列的最后一篇(RAID 管理)中涵盖它。
|
||||
|
||||
如果你对本文有任何疑问,随时给我们以评论的形式说明。我们期待倾听阁下的心声!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/recover-data-and-rebuild-failed-software-raid/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://linux.cn/article-6085-1.html
|
||||
[2]:https://linux.cn/article-6093-1.html
|
||||
[3]:http://www.tecmint.com/send-mail-from-command-line-using-mutt-command/
|
||||
@ -0,0 +1,162 @@
|
||||
在 Linux 下使用 RAID(九):如何使用 ‘Mdadm’ 工具管理软件 RAID
|
||||
================================================================================
|
||||
|
||||
无论你以前有没有使用 RAID 阵列的经验,以及是否完成了 [此 RAID 系列][1] 的所有教程,一旦你在 Linux 中熟悉了 `mdadm --manage` 命令的使用,管理软件 RAID 将不是很复杂的任务。
|
||||
|
||||

|
||||
|
||||
*在 Linux 中使用 mdadm 管理 RAID 设备 - 第9部分*
|
||||
|
||||
在本教程中,我们会再介绍此工具提供的功能,这样当你需要它,就可以派上用场。
|
||||
|
||||
#### RAID 测试方案 ####
|
||||
|
||||
在本系列的最后一篇文章中,我们将使用一个简单的 RAID 1(镜像)阵列,它由两个 8GB 的磁盘(/dev/sdb 和 /dev/sdc)和一个备用设备(/dev/sdd)来演示,但在此使用的方法也适用于其他类型的配置。也就是说,放心去用吧,把这个页面添加到浏览器的书签,然后让我们开始吧。
|
||||
|
||||
### 了解 mdadm 的选项和使用方法 ###
|
||||
|
||||
幸运的是,mdadm 有一个内建的 `--help` 参数来对每个主要的选项提供说明文档。
|
||||
|
||||
因此,让我们开始输入:
|
||||
|
||||
# mdadm --manage --help
|
||||
|
||||
就会使我们看到 `mdadm --manage` 能够执行哪些任务:
|
||||
|
||||
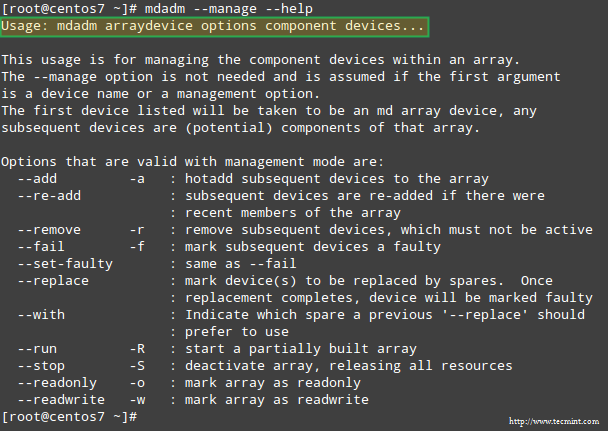
|
||||
|
||||
*使用 mdadm 工具来管理 RAID*
|
||||
|
||||
正如我们在上面的图片看到,管理一个 RAID 阵列可以在任意时间执行以下任务:
|
||||
|
||||
- (重新)将设备添加到阵列中
|
||||
- 把设备标记为故障
|
||||
- 从阵列中删除故障设备
|
||||
- 使用备用设备更换故障设备
|
||||
- 先创建部分阵列
|
||||
- 停止阵列
|
||||
- 标记阵列为 ro(只读)或 rw(读写)
|
||||
|
||||
### 使用 mdadm 工具管理 RAID 设备 ###
|
||||
|
||||
需要注意的是,如果用户忽略 `--manage` 选项,mdadm 默认使用管理模式。请记住这一点,以避免出现最坏的情况。
|
||||
|
||||
上图中的高亮文本显示了管理 RAID 的基本语法:
|
||||
|
||||
# mdadm --manage RAID options devices
|
||||
|
||||
让我们来演示几个例子。
|
||||
|
||||
#### 例1:为 RAID 阵列添加设备 ####
|
||||
|
||||
你通常会添加新设备来更换故障的设备,或者使用空闲的分区以便在出现故障时能及时替换:
|
||||
|
||||
# mdadm --manage /dev/md0 --add /dev/sdd1
|
||||
|
||||

|
||||
|
||||
*添加设备到 Raid 阵列*
|
||||
|
||||
#### 例2:把一个 RAID 设备标记为故障并从阵列中移除 ####
|
||||
|
||||
在从逻辑阵列中删除该设备前,这是强制性的步骤,然后才能从机器中取出它 - 注意顺序(如果弄错了这些步骤,最终可能会造成实际设备的损害):
|
||||
|
||||
# mdadm --manage /dev/md0 --fail /dev/sdb1
|
||||
|
||||
请注意在前面的例子中,知道如何添加备用设备来自动更换出现故障的磁盘。在此之后,[恢复和重建 raid 数据][2] 就开始了:
|
||||
|
||||

|
||||
|
||||
*恢复和重建 raid 数据*
|
||||
|
||||
一旦设备已被手动标记为故障,你就可以安全地从阵列中删除它:
|
||||
|
||||
# mdadm --manage /dev/md0 --remove /dev/sdb1
|
||||
|
||||
#### 例3:重新添加设备,来替代阵列中已经移除的设备 ####
|
||||
|
||||
到现在为止,我们有一个工作的 RAID 1 阵列,它包含了2个活动的设备:/dev/sdc1 和 /dev/sdd1。现在让我们试试重新添加 /dev/sdb1 到/dev/md0:
|
||||
|
||||
# mdadm --manage /dev/md0 --re-add /dev/sdb1
|
||||
|
||||
我们会碰到一个错误:
|
||||
|
||||
# mdadm: --re-add for /dev/sdb1 to /dev/md0 is not possible
|
||||
|
||||
因为阵列中的磁盘已经达到了最大的数量。因此,我们有两个选择:a)将 /dev/sdb1 添加为备用的,如例1;或 b)从阵列中删除 /dev/sdd1 然后重新添加 /dev/sdb1。
|
||||
|
||||
我们选择选项 b),先停止阵列然后重新启动:
|
||||
|
||||
# mdadm --stop /dev/md0
|
||||
# mdadm --assemble /dev/md0 /dev/sdb1 /dev/sdc1
|
||||
|
||||
如果上面的命令不能成功添加 /dev/sdb1 到阵列中,使用例1中的命令来完成。
|
||||
|
||||
mdadm 能检测到新添加的设备并将其作为备用设备,当添加完成后它会开始重建数据,它也被认为是 RAID 中的活动设备:
|
||||
|
||||
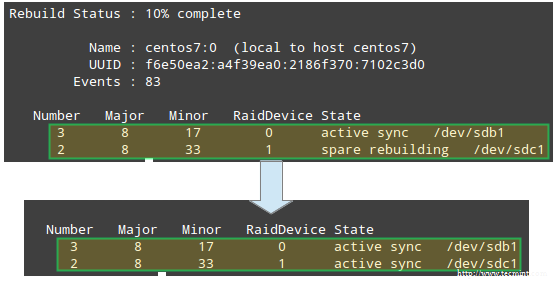
|
||||
|
||||
*重建 Raid 的状态*
|
||||
|
||||
#### 例4:使用特定磁盘更换 RAID 设备 ####
|
||||
|
||||
在阵列中使用备用磁盘更换磁盘很简单:
|
||||
|
||||
# mdadm --manage /dev/md0 --replace /dev/sdb1 --with /dev/sdd1
|
||||
|
||||

|
||||
|
||||
*更换 Raid 设备*
|
||||
|
||||
这会导致 `--replace` 指定的设备被标记为故障,而 `--with`指定的设备添加到 RAID 中来替代它:
|
||||
|
||||
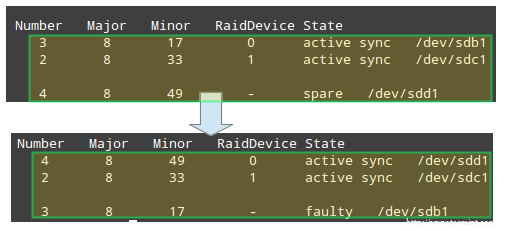
|
||||
|
||||
*检查 Raid 重建状态*
|
||||
|
||||
#### 例5:标记 RAID 阵列为 ro 或 rw ####
|
||||
|
||||
创建阵列后,你必须在它上面创建一个文件系统并将其挂载到一个目录下才能使用它。你可能不知道,RAID 也可以被设置为 ro,使其只读;或者设置为 rw,就可以同时写入了。
|
||||
|
||||
要标记该设备为 ro,首先需要将其卸载:
|
||||
|
||||
# umount /mnt/raid1
|
||||
# mdadm --manage /dev/md0 --readonly
|
||||
# mount /mnt/raid1
|
||||
# touch /mnt/raid1/test1
|
||||
|
||||

|
||||
|
||||
*在 RAID 阵列上设置权限*
|
||||
|
||||
要配置阵列允许写入操作需要使用 `--readwrite` 选项。请注意,在设置 rw 标志前,你需要先卸载设备并停止它:
|
||||
|
||||
# umount /mnt/raid1
|
||||
# mdadm --manage /dev/md0 --stop
|
||||
# mdadm --assemble /dev/md0 /dev/sdc1 /dev/sdd1
|
||||
# mdadm --manage /dev/md0 --readwrite
|
||||
# touch /mnt/raid1/test2
|
||||
|
||||
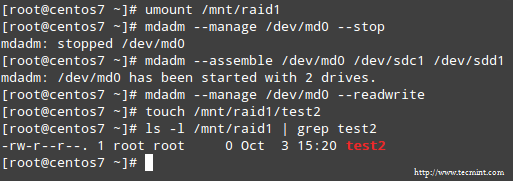
|
||||
|
||||
*配置 Raid 允许读写操作*
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在本系列中,我们已经解释了如何建立一个在企业环境中使用的软件 RAID 阵列。如果你按照这些文章所提供的例子进行配置,在 Linux 中你会充分领会到软件 RAID 的价值。
|
||||
|
||||
如果你碰巧任何问题或有建议,请随时使用下面的方式与我们联系。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-software-raid-devices-in-linux-with-mdadm/
|
||||
|
||||
作者:[GABRIEL CÁNEPA][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://linux.cn/article-6085-1.html
|
||||
[2]:https://linux.cn/article-6448-1.html
|
||||
@ -1,27 +1,28 @@
|
||||
RHCE 系列第一部分:如何设置和测试静态网络路由
|
||||
RHCE 系列(一):如何设置和测试静态网络路由
|
||||
================================================================================
|
||||
RHCE(Red Hat Certified Engineer,红帽认证工程师)是红帽公司的一个认证,红帽向企业社区贡献开源操作系统和软件,同时它还给公司提供训练、支持和咨询服务。
|
||||
|
||||

|
||||
|
||||
RHCE 考试准备指南
|
||||
*RHCE 考试准备指南*
|
||||
|
||||
这个 RHCE 是基于性能的考试(代号 EX300),面向那些拥有更多的技能、知识和能力的红帽企业版 Linux(RHEL)系统高级系统管理员。
|
||||
这个 RHCE 是一个绩效考试(代号 EX300),面向那些拥有更多的技能、知识和能力的红帽企业版 Linux(RHEL)系统高级系统管理员。
|
||||
|
||||
**重要**: [红帽认证系统管理员][1] (Red Hat Certified System Administrator,RHCSA)认证要求先有 RHCE 认证。
|
||||
|
||||
以下是基于红帽企业版 Linux 7 考试的考试目标,我们会在该 RHCE 系列中分别介绍:
|
||||
|
||||
- 第一部分:如何在 RHEL 7 中设置和测试静态路由
|
||||
- 第二部分:如果进行包过滤、网络地址转换和设置内核运行时参数
|
||||
- 第三部分:如果使用 Linux 工具集产生和发送系统活动报告
|
||||
- 第二部分:如何进行包过滤、网络地址转换和设置内核运行时参数
|
||||
- 第三部分:如何使用 Linux 工具集产生和发送系统活动报告
|
||||
- 第四部分:使用 Shell 脚本进行自动化系统维护
|
||||
- 第五部分:如果配置本地和远程系统日志
|
||||
- 第六部分:如果配置一个 Samba 服务器或 NFS 服务器(译者注:Samba 是在 Linux 和 UNI X系统上实现 SMB 协议的一个免费软件,由服务器及客户端程序构成。SMB,Server Messages Block,信息服务块,是一种在局域网上共享文件和打印机的一种通信协议,它为局域网内的不同计算机之间提供文件及打印机等资源的共享服务。)
|
||||
- 第七部分:为收发邮件配置完整的 SMTP 服务器
|
||||
- 第八部分:在 RHEL 7 上设置 HTTPS 和 TLS
|
||||
- 第九部分:设置网络时间协议
|
||||
- 第十部分:如何配置一个 Cache-Only DNS 服务器
|
||||
- 第五部分:如何在 RHEL 7 中管理系统日志(配置、轮换和导入到数据库)
|
||||
- 第六部分:设置 Samba 服务器并配置 FirewallD 和 SELinux 支持客户端文件共享
|
||||
- 第七部分:设置 NFS 服务器及基于 Kerberos 认证的客户端
|
||||
- 第八部分:在 Apache 上使用网络安全服务(NSS)通过 TLS 提供 HTTPS 服务
|
||||
- 第九部分:如何使用无客户端配置来设置 Postfix 邮件服务器(SMTP)
|
||||
- 第十部分:在 RHEL/CentOS 7 中设置网络时间协议(NTP)服务器
|
||||
- 第十一部分:如何配置一个只缓存的 DNS 服务器
|
||||
|
||||
在你的国家查看考试费用和注册考试,可以到 [RHCE 认证][2] 网页。
|
||||
|
||||
@ -29,31 +30,31 @@ RHCE 考试准备指南
|
||||
|
||||

|
||||
|
||||
RHCE 系列第一部分:设置和测试网络静态路由
|
||||
*RHCE 系列第一部分:设置和测试网络静态路由*
|
||||
|
||||
请注意我们不会作深入的介绍,但以这种方式组织内容能帮助你开始第一步并继续后面的内容。
|
||||
|
||||
### 红帽企业版 Linux 7 中的静态路由 ###
|
||||
|
||||
现代网络的一个奇迹就是有很多可用的设备能将一组计算机连接起来,不管是在一个房间里少量的机器还是在一栋建筑物、城市、国家或者大洲之间的多台机器。
|
||||
现代网络的一个奇迹就是有很多可用设备能将一组计算机连接起来,不管是在一个房间里少量的机器还是在一栋建筑物、城市、国家或者大洲之间的多台机器。
|
||||
|
||||
然而,为了能在任意情形下有效的实现这些,需要对网络包进行路由,或者换句话说,它们从源到目的地的路径需要按照某种规则。
|
||||
|
||||
静态路由是为网络包指定一个路由的过程,而不是使用网络设备提供的默认网关。除非另有指定,否则通过路由,网络包会被导向默认网关;基于预定义的标准,例如数据包目的地,使用静态路由可以定义其它路径。
|
||||
静态路由是为网络包指定一个路由的过程,而不是使用网络设备提供的默认网关。除非另有指定静态路由,网络包会被导向默认网关;而静态路由则基于预定义标准所定义的其它路径,例如数据包目的地。
|
||||
|
||||
我们在该篇指南中会考虑以下场景。我们有一台红帽企业版 Linux 7,连接到路由器 1号 [192.168.0.1] 以访问因特网以及 192.168.0.0/24 中的其它机器。
|
||||
我们在该篇指南中会考虑以下场景。我们有一台 RHEL 7,连接到 1号路由器 [192.168.0.1] 以访问因特网以及 192.168.0.0/24 中的其它机器。
|
||||
|
||||
第二个路由器(路由器 2号)有两个网卡:enp0s3 同样通过网络连接到路由器 1号,以便连接RHEL 7 以及相同网络中的其它机器,另外一个网卡(enp0s8)用于授权访问内部服务所在的 10.0.0.0/24 网络,例如 web 或数据库服务器。
|
||||
第二个路由器(2号路由器)有两个网卡:enp0s3 同样连接到路由器1号以访问互联网,及与 RHEL 7 和同一网络中的其它机器通讯,另外一个网卡(enp0s8)用于授权访问内部服务所在的 10.0.0.0/24 网络,例如 web 或数据库服务器。
|
||||
|
||||
该场景可以用下面的示意图表示:
|
||||
|
||||

|
||||
|
||||
静态路由网络示意图
|
||||
*静态路由网络示意图*
|
||||
|
||||
在这篇文章中我们会集中介绍在 RHEL 7 中设置路由表,确保它能通过路由器 1号访问因特网以及通过路由器 2号访问内部网络。
|
||||
在这篇文章中我们会集中介绍在 RHEL 7 中设置路由表,确保它能通过1号路由器访问因特网以及通过2号路由器访问内部网络。
|
||||
|
||||
在 RHEL 7 中,你会通过命令行用 [命令 ip][3] 配置和显示设备和路由。这些更改能在运行的系统中及时生效,但由于重启后不会保存,我们会使用 /etc/sysconfig/network-scripts 目录下的 ifcfg-enp0sX 和 route-enp0sX 文件永久保存我们的配置。
|
||||
在 RHEL 7 中,你可以通过命令行用 [ip 命令][3] 配置和显示设备和路由。这些更改能在运行的系统中及时生效,但由于重启后不会保存,我们会使用 `/etc/sysconfig/network-scripts` 目录下的 `ifcfg-enp0sX` 和 `route-enp0sX` 文件永久保存我们的配置。
|
||||
|
||||
首先,让我们打印出当前的路由表:
|
||||
|
||||
@ -61,15 +62,15 @@ RHCE 系列第一部分:设置和测试网络静态路由
|
||||
|
||||

|
||||
|
||||
检查当前路由表
|
||||
*检查当前路由表*
|
||||
|
||||
从上面的输出中,我们可以得出以下结论:
|
||||
|
||||
- 默认网关的 IP 是 192.168.0.1,可以通过网卡 enp0s3 访问。
|
||||
- 系统启动的时候,它启用了到 169.254.0.0/16 的 zeroconf 路由(只是在本例中)。也就是说,如果机器设置为通过 DHCP 获取一个 IP 地址,但是由于某些原因失败了,它就会在该网络中自动分配到一个地址。这一行的意思是,该路由会允许我们通过 enp0s3 和其它没有从 DHCP 服务器中成功获得 IP 地址的机器机器连接。
|
||||
- 最后,但同样重要的是,我们也可以通过 IP 地址是 192.168.0.18 的 enp0s3 和 192.168.0.0/24 网络中的其它机器连接。
|
||||
- 系统启动的时候,它启用了到 169.254.0.0/16 的 zeroconf 路由(只是在本例中)。也就是说,如果机器设置通过 DHCP 获取 IP 地址,但是由于某些原因失败了,它就会在上述网段中自动分配到一个地址。这一行的意思是,该路由会允许我们通过 enp0s3 和其它没有从 DHCP 服务器中成功获得 IP 地址的机器机器相连接。
|
||||
- 最后,但同样重要的是,我们也可以通过 IP 地址是 192.168.0.18 的 enp0s3 与 192.168.0.0/24 网络中的其它机器连接。
|
||||
|
||||
下面是这样的配置中你需要做的一些典型任务。除非另有说明,下面的任务都在路由器 2号上进行。
|
||||
下面是这样的配置中你需要做的一些典型任务。除非另有说明,下面的任务都在2号路由器上进行。
|
||||
|
||||
确保正确安装了所有网卡:
|
||||
|
||||
@ -88,7 +89,7 @@ RHCE 系列第一部分:设置和测试网络静态路由
|
||||
# ip addr del 10.0.0.17 dev enp0s8
|
||||
# ip addr add 10.0.0.18 dev enp0s8
|
||||
|
||||
现在,请注意你只能添加一个通过已经能访问的网关到目标网络的路由。因为这个原因,我们需要在 192.168.0.0/24 范围中给 enp0s3 分配一个 IP 地址,这样我们的 RHEL 7 才能连接到它:
|
||||
现在,请注意你只能添加一个通过网关到目标网络的路由,网关需要可以访问到。因为这个原因,我们需要在 192.168.0.0/24 范围中给 enp0s3 分配一个 IP 地址,这样我们的 RHEL 7 才能连接到它:
|
||||
|
||||
# ip addr add 192.168.0.19 dev enp0s3
|
||||
|
||||
@ -101,7 +102,7 @@ RHCE 系列第一部分:设置和测试网络静态路由
|
||||
# systemctl stop firewalld
|
||||
# systemctl disable firewalld
|
||||
|
||||
回到我们的 RHEL 7(192.168.0.18),让我们配置一个通过 192.168.0.19(路由器 2号的 enp0s3)到 10.0.0.0/24 的路由:
|
||||
回到我们的 RHEL 7(192.168.0.18),让我们配置一个通过 192.168.0.19(2号路由器的 enp0s3)到 10.0.0.0/24 的路由:
|
||||
|
||||
# ip route add 10.0.0.0/24 via 192.168.0.19
|
||||
|
||||
@ -111,7 +112,7 @@ RHCE 系列第一部分:设置和测试网络静态路由
|
||||
|
||||

|
||||
|
||||
确认网络路由表
|
||||
*确认网络路由表*
|
||||
|
||||
同样,在你尝试连接的 10.0.0.0/24 网络的机器中添加对应的路由:
|
||||
|
||||
@ -131,13 +132,13 @@ RHCE 系列第一部分:设置和测试网络静态路由
|
||||
|
||||
192.168.0.18 也就是我们的 RHEL 7 机器的 IP 地址。
|
||||
|
||||
另外,我们还可以使用 [tcpdump][4](需要通过 yum install tcpdump 安装)来检查我们 RHEL 7 和 10.0.0.20 中 web 服务器之间的 TCP 双向通信。
|
||||
另外,我们还可以使用 [tcpdump][4](需要通过 `yum install tcpdump` 安装)来检查我们 RHEL 7 和 10.0.0.20 中 web 服务器之间的 TCP 双向通信。
|
||||
|
||||
首先在第一台机器中启用日志:
|
||||
|
||||
# tcpdump -qnnvvv -i enp0s3 host 10.0.0.20
|
||||
|
||||
在同一个系统上的另一个终端,让我们通过 telnet 连接到 web 服务器的 80 号端口(假设 Apache 正在监听该端口;否则在下面命令中使用正确的端口):
|
||||
在同一个系统上的另一个终端,让我们通过 telnet 连接到 web 服务器的 80 号端口(假设 Apache 正在监听该端口;否则应在下面命令中使用正确的监听端口):
|
||||
|
||||
# telnet 10.0.0.20 80
|
||||
|
||||
@ -145,7 +146,7 @@ tcpdump 日志看起来像下面这样:
|
||||
|
||||

|
||||
|
||||
检查服务器之间的网络连接
|
||||
*检查服务器之间的网络连接*
|
||||
|
||||
通过查看我们 RHEL 7(192.168.0.18)和 web 服务器(10.0.0.20)之间的双向通信,可以看出已经正确地初始化了连接。
|
||||
|
||||
@ -162,7 +163,7 @@ tcpdump 日志看起来像下面这样:
|
||||
# Device used to connect to default gateway. Replace X with the appropriate number.
|
||||
GATEWAYDEV=enp0sX
|
||||
|
||||
当需要为每个网卡设置特定的变量和值时(正如我们在路由器 2号上面做的),你需要编辑 /etc/sysconfig/network-scripts/ifcfg-enp0s3 和 /etc/sysconfig/network-scripts/ifcfg-enp0s8 文件。
|
||||
当需要为每个网卡设置特定的变量和值时(正如我们在2号路由器上面做的),你需要编辑 `/etc/sysconfig/network-scripts/ifcfg-enp0s3` 和 `/etc/sysconfig/network-scripts/ifcfg-enp0s8` 文件。
|
||||
|
||||
下面是我们的例子,
|
||||
|
||||
@ -184,23 +185,23 @@ tcpdump 日志看起来像下面这样:
|
||||
NAME=enp0s8
|
||||
ONBOOT=yes
|
||||
|
||||
分别对应 enp0s3 和 enp0s8。
|
||||
其分别对应 enp0s3 和 enp0s8。
|
||||
|
||||
由于要为我们的客户端机器(192.168.0.18)进行路由,我们需要编辑 /etc/sysconfig/network-scripts/route-enp0s3:
|
||||
由于要为我们的客户端机器(192.168.0.18)进行路由,我们需要编辑 `/etc/sysconfig/network-scripts/route-enp0s3`:
|
||||
|
||||
10.0.0.0/24 via 192.168.0.19 dev enp0s3
|
||||
|
||||
现在重启系统你可以在路由表中看到该路由规则。
|
||||
现在`reboot`你的系统,就可以在路由表中看到该路由规则。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇文章中我们介绍了红帽企业版 Linux 7 的静态路由。尽管场景可能不同,这里介绍的例子说明了所需的原理以及进行该任务的步骤。结束之前,我还建议你看一下 Linux 文档项目中 [第四章 4][5] 保护和优化 Linux 部分,以了解这里介绍主题的更详细内容。
|
||||
在这篇文章中我们介绍了红帽企业版 Linux 7 的静态路由。尽管场景可能不同,这里介绍的例子说明了所需的原理以及进行该任务的步骤。结束之前,我还建议你看一下 Linux 文档项目(The Linux Documentation Project)网站上的《安全加固和优化 Linux(Securing and Optimizing Linux)》的[第四章][5],以了解这里介绍主题的更详细内容。
|
||||
|
||||
免费电子书 Securing & Optimizing Linux: The Hacking Solution (v.3.0) - 这本 800 多页的电子书全面收集了 Linux 安全的小技巧以及如果安全和简便的使用它们去配置基于 Linux 的应用和服务。
|
||||
免费电子书《Securing and Optimizing Linux: The Hacking Solution (v.3.0)》 - 这本 800 多页的电子书全面收集了 Linux 安全的小技巧以及如果安全和简便的使用它们去配置基于 Linux 的应用和服务。
|
||||
|
||||

|
||||
|
||||
Linux 安全和优化
|
||||
*Linux 安全和优化*
|
||||
|
||||
[马上下载][6]
|
||||
|
||||
@ -214,12 +215,12 @@ via: http://www.tecmint.com/how-to-setup-and-configure-static-network-routing-in
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
[1]:https://linux.cn/article-6133-1.html
|
||||
[2]:https://www.redhat.com/en/services/certification/rhce
|
||||
[3]:http://www.tecmint.com/ip-command-examples/
|
||||
[4]:http://www.tecmint.com/12-tcpdump-commands-a-network-sniffer-tool/
|
||||
@ -1,16 +1,17 @@
|
||||
RHCE 第二部分 - 如何进行包过滤、网络地址转换和设置内核运行时参数
|
||||
RHCE 系列(二):如何进行包过滤、网络地址转换和设置内核运行时参数
|
||||
================================================================================
|
||||
正如第一部分(“[设置静态网络路由][1]”)承诺的,在这篇文章(RHCE 系列第二部分),我们首先介绍红帽企业版 Linux 7中包过滤和网络地址转换原理,然后再介绍某些条件发送变化或者需要激活时设置运行时内核参数以改变运行时内核行为。
|
||||
|
||||
正如第一部分(“[设置静态网络路由][1]”)提到的,在这篇文章(RHCE 系列第二部分),我们首先介绍红帽企业版 Linux 7(RHEL)中包过滤和网络地址转换(NAT)的原理,然后再介绍在某些条件发生变化或者需要变动时设置运行时内核参数以改变运行时内核行为。
|
||||
|
||||

|
||||
|
||||
RHCE 第二部分:网络包过滤
|
||||
*RHCE 第二部分:网络包过滤*
|
||||
|
||||
### RHEL 7 中的网络包过滤 ###
|
||||
|
||||
当我们讨论数据包过滤的时候,我们指防火墙读取每个尝试通过它的数据包的包头所进行的处理。然后,根据系统管理员之前定义的规则,通过采取所要求的动作过滤数据包。
|
||||
当我们讨论数据包过滤的时候,我们指防火墙读取每个试图通过它的数据包的包头所进行的处理。然后,根据系统管理员之前定义的规则,通过采取所要求的动作过滤数据包。
|
||||
|
||||
正如你可能知道的,从 RHEL 7 开始,管理防火墙的默认服务是 [firewalld][2]。类似 iptables,它和 Linux 内核的 netfilter 模块交互以便检查和操作网络数据包。不像 iptables,Firewalld 的更新可以立即生效,而不用中断活跃的连接 - 你甚至不需要重启服务。
|
||||
正如你可能知道的,从 RHEL 7 开始,管理防火墙的默认服务是 [firewalld][2]。类似 iptables,它和 Linux 内核的 netfilter 模块交互以便检查和操作网络数据包。但不像 iptables,Firewalld 的更新可以立即生效,而不用中断活跃的连接 - 你甚至不需要重启服务。
|
||||
|
||||
Firewalld 的另一个优势是它允许我们定义基于预配置服务名称的规则(之后会详细介绍)。
|
||||
|
||||
@ -18,27 +19,27 @@ Firewalld 的另一个优势是它允许我们定义基于预配置服务名称
|
||||
|
||||

|
||||
|
||||
静态路由网络示意图
|
||||
*静态路由网络示意图*
|
||||
|
||||
然而,你应该记得,由于还没有介绍包过滤,为了简化例子,我们停用了路由器 2号 的防火墙。现在让我们来看看如何可以使接收的数据包发送到目的地的特定服务或端口。
|
||||
然而,你应该记得,由于还没有介绍包过滤,为了简化例子,我们停用了2号路由器的防火墙。现在让我们来看看如何使接收的数据包发送到目的地的特定服务或端口。
|
||||
|
||||
首先,让我们添加一条永久规则允许从 enp0s3 (192.168.0.19) 到 enp0s8 (10.0.0.18) 的绑定流量:
|
||||
首先,让我们添加一条永久规则允许从 enp0s3 (192.168.0.19) 到 enp0s8 (10.0.0.18) 的入站流量:
|
||||
|
||||
# firewall-cmd --permanent --direct --add-rule ipv4 filter FORWARD 0 -i enp0s3 -o enp0s8 -j ACCEPT
|
||||
|
||||
上面的命令会把规则保存到 /etc/firewalld/direct.xml:
|
||||
上面的命令会把规则保存到 `/etc/firewalld/direct.xml` 中:
|
||||
|
||||
# cat /etc/firewalld/direct.xml
|
||||
|
||||

|
||||
|
||||
检查 Firewalld 保存的规则
|
||||
*检查 Firewalld 保存的规则*
|
||||
|
||||
然后启用规则使其立即生效:
|
||||
|
||||
# firewall-cmd --direct --add-rule ipv4 filter FORWARD 0 -i enp0s3 -o enp0s8 -j ACCEPT
|
||||
|
||||
现在你可以从 RHEL 7 中通过 telnet 登录到 web 服务器并再次运行 [tcpdump][3] 监视两台机器之间的 TCP 流量,这次路由器 2号已经启用了防火墙。
|
||||
现在你可以从 RHEL 7 中通过 telnet 到 web 服务器并再次运行 [tcpdump][3] 监视两台机器之间的 TCP 流量,这次2号路由器已经启用了防火墙。
|
||||
|
||||
# telnet 10.0.0.20 80
|
||||
# tcpdump -qnnvvv -i enp0s3 host 10.0.0.20
|
||||
@ -61,19 +62,19 @@ Firewalld 的另一个优势是它允许我们定义基于预配置服务名称
|
||||
|
||||
我强烈建议你看看 Fedora Project Wiki 中的 [Firewalld Rich Language][4] 文档更详细地了解关于富规则的内容。
|
||||
|
||||
### RHEL 7 中的网络地址转换 ###
|
||||
### RHEL 7 中的网络地址转换(NAT) ###
|
||||
|
||||
网络地址转换(NAT)是为专用网络中的一组计算机(也可能是其中的一台)分配一个独立的公共 IP 地址的过程。结果,在内部网络中仍然可以用它们自己的私有 IP 地址区别,但外部“看来”它们是一样的。
|
||||
网络地址转换(NAT)是为专用网络中的一组计算机(也可能是其中的一台)分配一个独立的公共 IP 地址的过程。这样,在内部网络中仍然可以用它们自己的私有 IP 地址来区别,但外部“看来”它们是一样的。
|
||||
|
||||
另外,网络地址转换使得内部网络中的计算机发送请求到外部资源(例如因特网)然后只有源系统能接收到对应的响应成为可能。
|
||||
另外,网络地址转换使得内部网络中的计算机发送请求到外部资源(例如因特网),然后只有源系统能接收到对应的响应成为可能。
|
||||
|
||||
现在让我们考虑下面的场景:
|
||||
|
||||

|
||||
|
||||
网络地址转换
|
||||
*网络地址转换*
|
||||
|
||||
在路由器 2 中,我们会把 enp0s3 接口移动到外部区域,enp0s8 到内部区域,伪装或者说 NAT 默认是启用的:
|
||||
在2号路由器中,我们会把 enp0s3 接口移动到外部区域(external),enp0s8 到内部区域(external),伪装(masquerading)或者说 NAT 默认是启用的:
|
||||
|
||||
# firewall-cmd --list-all --zone=external
|
||||
# firewall-cmd --change-interface=enp0s3 --zone=external
|
||||
@ -81,7 +82,7 @@ Firewalld 的另一个优势是它允许我们定义基于预配置服务名称
|
||||
# firewall-cmd --change-interface=enp0s8 --zone=internal
|
||||
# firewall-cmd --change-interface=enp0s8 --zone=internal --permanent
|
||||
|
||||
对于我们当前的设置,内部区域 - 以及和它一起启用的任何东西都是默认区域:
|
||||
对于我们当前的设置,内部区域(internal) - 以及和它一起启用的任何东西都是默认区域:
|
||||
|
||||
# firewall-cmd --set-default-zone=internal
|
||||
|
||||
@ -89,44 +90,44 @@ Firewalld 的另一个优势是它允许我们定义基于预配置服务名称
|
||||
|
||||
# firewall-cmd --reload
|
||||
|
||||
最后,在 web 服务器中添加路由器 2 为默认网关:
|
||||
最后,在 web 服务器中添加2号路由器为默认网关:
|
||||
|
||||
# ip route add default via 10.0.0.18
|
||||
|
||||
现在你会发现在 web 服务器中你可以 ping 路由器 1 和外部网站(例如 tecmint.com):
|
||||
现在你会发现在 web 服务器中你可以 ping 1号路由器和外部网站(例如 tecmint.com):
|
||||
|
||||
# ping -c 2 192.168.0.1
|
||||
# ping -c 2 tecmint.com
|
||||
|
||||

|
||||
|
||||
验证网络路由
|
||||
*验证网络路由*
|
||||
|
||||
### 在 RHEL 7 中设置内核运行时参数 ###
|
||||
|
||||
在 Linux 中,允许你更改、启用以及停用内核运行时参数,RHEL 也不例外。/proc/sys 接口允许你当操作条件发生变化时实时设置运行时参数以改变系统行为而不需太多麻烦。
|
||||
在 Linux 中,允许你更改、启用以及停用内核运行时参数,RHEL 也不例外。当操作条件发生变化时,`/proc/sys` 接口(sysctl)允许你实时设置运行时参数改变系统行为,而不需太多麻烦。
|
||||
|
||||
为了实现这个目的,会用内建的 echo shell 写 /proc/sys/<category\> 中的文件,其中 <category\> 很可能是以下目录中的一个:
|
||||
为了实现这个目的,会用 shell 内建的 echo 写 `/proc/sys/<category>` 中的文件,其中 `<category>` 一般是以下目录中的一个:
|
||||
|
||||
- dev: 连接到机器中的特定设备的参数。
|
||||
- fs: 文件系统配置(例如 quotas 和 inodes)。
|
||||
- kernel: 内核配置。
|
||||
- net: 网络配置。
|
||||
- vm: 内核虚拟内存的使用。
|
||||
- vm: 内核的虚拟内存的使用。
|
||||
|
||||
要显示所有当前可用值的列表,运行
|
||||
|
||||
# sysctl -a | less
|
||||
|
||||
在第一部分中,我们通过以下命令改变了 net.ipv4.ip_forward 参数的值以允许 Linux 机器作为一个路由器。
|
||||
在第一部分中,我们通过以下命令改变了 `net.ipv4.ip_forward` 参数的值以允许 Linux 机器作为一个路由器。
|
||||
|
||||
# echo 1 > /proc/sys/net/ipv4/ip_forward
|
||||
|
||||
另一个你可能想要设置的运行时参数是 kernel.sysrq,它会启用你键盘上的 Sysrq 键,以使系统更好的运行一些底层函数,例如如果由于某些原因冻结了后重启系统:
|
||||
另一个你可能想要设置的运行时参数是 `kernel.sysrq`,它会启用你键盘上的 `Sysrq` 键,以使系统更好的运行一些底层功能,例如如果由于某些原因冻结了后重启系统:
|
||||
|
||||
# echo 1 > /proc/sys/kernel/sysrq
|
||||
|
||||
要显示特定参数的值,可以按照下面方式使用 sysctl:
|
||||
要显示特定参数的值,可以按照下面方式使用 `sysctl`:
|
||||
|
||||
# sysctl <parameter.name>
|
||||
|
||||
@ -135,28 +136,29 @@ Firewalld 的另一个优势是它允许我们定义基于预配置服务名称
|
||||
# sysctl net.ipv4.ip_forward
|
||||
# sysctl kernel.sysrq
|
||||
|
||||
一些参数,例如上面提到的一个,只需要一个值,而其它一些(例如 fs.inode-state)要求多个值:
|
||||
有些参数,例如上面提到的某个,只需要一个值,而其它一些(例如 `fs.inode-state`)要求多个值:
|
||||
|
||||

|
||||
|
||||
查看内核参数
|
||||
*查看内核参数*
|
||||
|
||||
不管什么情况下,做任何更改之前你都需要阅读内核文档。
|
||||
|
||||
请注意系统重启后这些设置会丢失。要使这些更改永久生效,我们需要添加内容到 /etc/sysctl.d 目录的 .conf 文件,像下面这样:
|
||||
请注意系统重启后这些设置会丢失。要使这些更改永久生效,我们需要添加内容到 `/etc/sysctl.d` 目录的 .conf 文件,像下面这样:
|
||||
|
||||
# echo "net.ipv4.ip_forward = 1" > /etc/sysctl.d/10-forward.conf
|
||||
|
||||
(其中数字 10 表示相对同一个目录中其它文件的处理顺序)。
|
||||
|
||||
并用下面命令启用更改
|
||||
并用下面命令启用更改:
|
||||
|
||||
# sysctl -p /etc/sysctl.d/10-forward.conf
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇指南中我们解释了基本的包过滤、网络地址变换和在运行的系统中设置内核运行时参数并使重启后能持久化。我希望这些信息能对你有用,如往常一样,我们期望收到你的回复!
|
||||
别犹豫,在下面的表格中和我们分享你的疑问、评论和建议吧。
|
||||
|
||||
别犹豫,在下面的表单中和我们分享你的疑问、评论和建议吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -164,12 +166,12 @@ via: http://www.tecmint.com/perform-packet-filtering-network-address-translation
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/how-to-setup-and-configure-static-network-routing-in-rhel/
|
||||
[1]:https://linux.cn/article-6451-1.html
|
||||
[2]:http://www.tecmint.com/firewalld-rules-for-centos-7/
|
||||
[3]:http://www.tecmint.com/12-tcpdump-commands-a-network-sniffer-tool/
|
||||
[4]:https://fedoraproject.org/wiki/Features/FirewalldRichLanguage
|
||||
@ -1,18 +1,19 @@
|
||||
RHCSA 系列: 虚拟化基础和使用 KVM 进行虚拟机管理 – Part 15
|
||||
RHCSA 系列(十五): 虚拟化基础和使用 KVM 进行虚拟机管理
|
||||
================================================================================
|
||||
假如你在词典中查一下单词 “virtualize”,你将会发现它的意思是 “创造某些事物的一个虚拟物(而非真实的)”。在计算机行业中,术语虚拟化指的是:在相同的物理(硬件)系统上,同时运行多个操作系统,且这几个系统相互隔离的可能性,而那个硬件在虚拟化架构中被称作宿主机(host)。
|
||||
|
||||
假如你在词典中查一下单词 “虚拟化(virtualize)”,你将会发现它的意思是 “创造某些事物的一个虚拟物(而非真实的)”。在计算机行业中,术语虚拟化(virtualization)指的是:在相同的物理(硬件)系统上,同时运行多个操作系统,且这几个系统相互隔离的**可能性**,而那个硬件在虚拟化架构中被称作宿主机(host)。
|
||||
|
||||

|
||||
|
||||
RHCSA 系类: 虚拟化基础和使用 KVM 进行虚拟机管理 – Part 15
|
||||
*RHCSA 系列: 虚拟化基础和使用 KVM 进行虚拟机管理 – Part 15*
|
||||
|
||||
通过使用虚拟机监视器(也被称为虚拟机管理程序 hypervisor),虚拟机(被称为 guest)由底层的硬件来提供虚拟资源(举几个例来说如 CPU,RAM,存储介质,网络接口等)。
|
||||
通过使用虚拟机监视器(也被称为虚拟机管理程序(hypervisor)),虚拟机(被称为 guest)由底层的硬件来供给虚拟资源(举几个例子来说,如 CPU,RAM,存储介质,网络接口等)。
|
||||
|
||||
考虑到这一点就可以清楚地看出,虚拟化的主要优点是节约成本(在设备和网络基础设施,及维护工作等方面)和显著地减少容纳所有必要硬件所需的物理空间。
|
||||
|
||||
由于这个简单的指南不能涵盖所有的虚拟化方法,我鼓励你参考在总结部分中列出的文档,以此对这个话题做更深入的了解。
|
||||
|
||||
请记住当前文章只是用于在 RHEL 7 中用命令行工具使用 [KVM][1] (Kernel-based Virtual Machine) 学习虚拟化基础知识的一个起点,而并不是对这个话题的深入探讨。
|
||||
请记住当前文章只是用于在 RHEL 7 中用命令行工具使用 [KVM][1] (Kernel-based Virtual Machine(基于内核的虚拟机)) 学习虚拟化基础知识的一个起点,而并不是对这个话题的深入探讨。
|
||||
|
||||
### 检查硬件要求并安装软件包 ###
|
||||
|
||||
@ -24,7 +25,7 @@ RHCSA 系类: 虚拟化基础和使用 KVM 进行虚拟机管理 – Part 15
|
||||
|
||||

|
||||
|
||||
检查 KVM 支持
|
||||
*检查 KVM 支持*
|
||||
|
||||
另外,你需要在你宿主机的硬件(BIOS 或 UEFI)中开启虚拟化。
|
||||
|
||||
@ -36,21 +37,22 @@ RHCSA 系类: 虚拟化基础和使用 KVM 进行虚拟机管理 – Part 15
|
||||
- libguestfs-tools 包含各式各样的针对虚拟机的系统管理员命令行工具。
|
||||
- virt-install 包含针对虚拟机管理的其他命令行工具。
|
||||
|
||||
命令如下:
|
||||
|
||||
# yum update && yum install qemu-kvm qemu-img libvirt libvirt-python libguestfs-tools virt-install
|
||||
|
||||
一旦安装完全,请确保你启动并开启了 libvirtd 服务:
|
||||
一旦安装完成,请确保你启动并开启了 libvirtd 服务:
|
||||
|
||||
# systemctl start libvirtd.service
|
||||
# systemctl enable libvirtd.service
|
||||
|
||||
默认情况下,每个虚拟机将只能够与相同的物理服务器和宿主机自身通信。要使得虚拟机能够访问位于局域网或因特网中的其他机器,我们需要像下面这样在我们的宿主机上设置一个桥接接口(比如说 br0):
|
||||
默认情况下,每个虚拟机将只能够与放在相同的物理服务器上的虚拟机以及宿主机自身通信。要使得虚拟机能够访问位于局域网或因特网中的其他机器,我们需要像下面这样在我们的宿主机上设置一个桥接接口(比如说 br0):
|
||||
|
||||
1. 添加下面的一行到我们的 NIC 主配置中(一般是 `/etc/sysconfig/network-scripts/ifcfg-enp0s3` 这个文件):
|
||||
1、 添加下面的一行到我们的 NIC 主配置中(类似 `/etc/sysconfig/network-scripts/ifcfg-enp0s3` 这样的文件):
|
||||
|
||||
BRIDGE=br0
|
||||
|
||||
2. 使用下面的内容(注意,你可能必须更改 IP 地址,网关地址和 DNS 信息)为 br0 创建一个配置文件(`/etc/sysconfig/network-scripts/ifcfg-br0`):
|
||||
2、 使用下面的内容(注意,你可能需要更改 IP 地址,网关地址和 DNS 信息)为 br0 创建一个配置文件(`/etc/sysconfig/network-scripts/ifcfg-br0`):
|
||||
|
||||
|
||||
DEVICE=br0
|
||||
@ -75,7 +77,7 @@ RHCSA 系类: 虚拟化基础和使用 KVM 进行虚拟机管理 – Part 15
|
||||
DNS1=8.8.8.8
|
||||
DNS2=8.8.4.4
|
||||
|
||||
3. 最后通过使得文件`/etc/sysctl.conf` 中的
|
||||
3、 最后在文件`/etc/sysctl.conf` 中设置:
|
||||
|
||||
net.ipv4.ip_forward = 1
|
||||
|
||||
@ -83,11 +85,11 @@ RHCSA 系类: 虚拟化基础和使用 KVM 进行虚拟机管理 – Part 15
|
||||
|
||||
# sysctl -p
|
||||
|
||||
注意,你可能还需要告诉 firewalld 这类的流量应当被允许通过防火墙。假如你需要这样做,记住你可以参考这个系列的 [Part 11: 使用 firewalld 和 iptables 来进行网络流量控制][2]。
|
||||
注意,你可能还需要告诉 firewalld 让这类的流量应当被允许通过防火墙。假如你需要这样做,记住你可以参考这个系列的 [使用 firewalld 和 iptables 来控制网络流量][2]。
|
||||
|
||||
### 创建虚拟机镜像 ###
|
||||
|
||||
默认情况下,虚拟机镜像将会被创建到 `/var/lib/libvirt/images` 中,且强烈建议你不要更改这个设定,除非你真的需要那么做且知道你在做什么,并能自己处理有关 SELinux 的设定(这个话题已经超出了本教程的讨论范畴,但你可以参考这个系列的第 13 部分[使用 SELinux 来进行强制访问控制][3],假如你想更新你的知识的话)。
|
||||
默认情况下,虚拟机镜像将会被创建到 `/var/lib/libvirt/images` 中,且强烈建议你不要更改这个设定,除非你真的需要那么做且知道你在做什么,并能自己处理有关 SELinux 的设定(这个话题已经超出了本教程的讨论范畴,但你可以参考这个系列的第 13 部分 [使用 SELinux 来进行强制访问控制][3],假如你想更新你的知识的话)。
|
||||
|
||||
这意味着你需要确保你在文件系统中分配了必要的空间来容纳你的虚拟机。
|
||||
|
||||
@ -104,11 +106,11 @@ RHCSA 系类: 虚拟化基础和使用 KVM 进行虚拟机管理 – Part 15
|
||||
--cdrom /home/gacanepa/ISOs/rhel-server-7.0-x86_64-dvd.iso
|
||||
--extra-args="console=tty0 console=ttyS0,115200"
|
||||
|
||||
假如安装文件位于一个 HTTP 服务器上,而不是存储在你磁盘中的镜像中,你必须将上面的 `-cdrom` 替换为 `-location`,并明显地指出在线存储仓库的地址。
|
||||
假如安装文件位于一个 HTTP 服务器上,而不是存储在你磁盘中的镜像中,你必须将上面的 `-cdrom` 替换为 `-location`,并明确地指出在线存储仓库的地址。
|
||||
|
||||
至于上面的 `–graphics none` 选项,它告诉安装程序只以文本模式执行安装过程。假如你使用一个 GUI 界面和一个 VNC 窗口来访问主虚拟机控制台,则可以省略这个选项。最后,使用 `–extra-args`参数,我们将传递内核启动参数给安装程序,以此来设置一个串行的虚拟机控制台。
|
||||
至于上面的 `–graphics none` 选项,它告诉安装程序只以文本模式执行安装过程。假如你使用一个 GUI 界面和一个 VNC 窗口来访问主虚拟机控制台,则可以省略这个选项。最后,使用 `–extra-args` 参数,我们将传递内核启动参数给安装程序,以此来设置一个串行的虚拟机控制台。
|
||||
|
||||
现在,安装应当作为一个正常的(真实的)服务来执行了。假如没有,请查看上面列出的步骤。
|
||||
现在,所安装的虚拟机应当可以作为一个正常的(真实的)服务来运行了。假如没有,请查看上面列出的步骤。
|
||||
|
||||
### 管理虚拟机 ###
|
||||
|
||||
@ -128,11 +130,11 @@ RHCSA 系类: 虚拟化基础和使用 KVM 进行虚拟机管理 – Part 15
|
||||
|
||||
# virsh start | reboot | shutdown [VM Id]
|
||||
|
||||
**4. 假如网络无法连接且在宿主机上没有运行 X 服务器,可以使用下面的目录来访问虚拟机的串行控制台:**
|
||||
**4. 假如网络无法连接且在宿主机上没有运行 X 服务器,可以使用下面的命令来访问虚拟机的串行控制台:**
|
||||
|
||||
# virsh console [VM Id]
|
||||
|
||||
**注** 这需要你添加一个串行控制台配置信息到 `/etc/grub.conf` 文件中(参考刚才创建虚拟机时传递给`–extra-args`选项的参数)。
|
||||
**注**:这需要你添加一个串行控制台配置信息到 `/etc/grub.conf` 文件中(参考刚才创建虚拟机时传递给`-extra-args`选项的参数)。
|
||||
|
||||
**5. 修改分配的内存或虚拟 CPU:**
|
||||
|
||||
@ -146,7 +148,7 @@ RHCSA 系类: 虚拟化基础和使用 KVM 进行虚拟机管理 – Part 15
|
||||
|
||||
然后更改
|
||||
|
||||
<memory>[内存大小,这里没有括号]</memory>
|
||||
<memory>[内存大小,注意不要加上方括号]</memory>
|
||||
|
||||
使用新的设定重启虚拟机:
|
||||
|
||||
@ -178,14 +180,14 @@ via: http://www.tecmint.com/kvm-virtualization-basics-and-guest-administration/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.linux-kvm.org/page/Main_Page
|
||||
[2]:http://www.tecmint.com/firewalld-vs-iptables-and-control-network-traffic-in-firewall/
|
||||
[3]:http://www.tecmint.com/selinux-essentials-and-control-filesystem-access/
|
||||
[2]:https://linux.cn/article-6315-1.html
|
||||
[3]:https://linux.cn/article-6339-1.html
|
||||
[4]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Virtualization_Getting_Started_Guide/index.html
|
||||
[5]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Virtualization_Deployment_and_Administration_Guide/index.html
|
||||
[6]:http://www.tecmint.com/install-and-configure-kvm-in-linux/
|
||||
@ -0,0 +1,44 @@
|
||||
Curious about Linux? Try Linux Desktop on the Cloud
|
||||
================================================================================
|
||||
Linux maintains a very small market share as a desktop operating system. Current surveys estimate its share to be a mere 2%; contrast that with the various strains (no pun intended) of Windows which total nearly 90% of the desktop market. For Linux to challenge Microsoft's monopoly on the desktop, there needs to be a simple way of learning about this different operating system. And it would be naive to believe a typical Windows user is going to buy a second machine, tinker with partitioning a hard disk to set up a multi-boot system, or just jump ship to Linux without an easy way back.
|
||||
|
||||

|
||||
|
||||
We have examined a number of risk-free ways users can experiment with Linux without dabbling with partition management. Various options include Live CD/DVDs, USB keys and desktop virtualization software. For the latter, I can strongly recommend VMWare (VMWare Player) or Oracle VirtualBox, two relatively easy and free ways of installing and running multiple operating systems on a desktop or laptop computer. Each virtual machine has its own share of CPU, memory, network interfaces etc which is isolated from other virtual machines. But virtual machines still require some effort to get Linux up and running, and a reasonably powerful machine. Too much effort for a mere inquisitive mind.
|
||||
|
||||
It can be difficult to break down preconceptions. Many Windows users will have experimented with free software that is available on Linux. But there are many facets to learn on Linux. And it takes time to become accustomed to the way things work in Linux.
|
||||
|
||||
Surely there should be an effortless way for a beginner to experiment with Linux for the first time? Indeed there is; step forward the online cloud lab.
|
||||
|
||||
### LabxNow ###
|
||||
|
||||

|
||||
|
||||
LabxNow provides a free service for general users offering Linux remote desktop over the browser. The developers promote the service as having a personal remote lab (to play around, develop, whatever!) that will be accessible from anywhere, with the internet of course.
|
||||
|
||||
The service currently offers a free virtual private server with 2 cores, 4GB RAM and 10GB SSD space. The service runs on a 4 AMD 6272 CPU with 128GB RAM.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
- Machine images: Ubuntu 14.04 with Xfce 4.10, RHEL 6.5, CentOS with Gnome, and Oracle
|
||||
- Hardware: CPU - 1 or 2 cores; RAM: 512MB, 1GB, 2GB or 4GB
|
||||
- Fast network for data transfers
|
||||
- Works with all popular browsers
|
||||
- Install anything, run anything - an excellent way to experiment and learn all about Linux without any risk
|
||||
- Easily add, delete, manage and customize VMs
|
||||
- Share VMs, Remote desktop support
|
||||
|
||||
All you need is a reasonable Internet connected device. Forget about high cost VPS, domain space or hardware support. LabxNow offers a great way of experimenting with Ubuntu, RHEL and CentOS. It gives Windows users an excellent environment to dip their toes into the wonderful world of Linux. Further, it allows users to do (programming) work from anywhere in the word without having the stress of installing Linux on each machine. Point your web browser at [www.labxnow.org/labxweb/][1].
|
||||
|
||||
There are other services (mostly paid services) that allow users to experiment with Linux. These include Cloudsigma which offers a free 7 day trial, and Icebergs.io (full root access via HTML5). But for now, LabxNow gets my recommendation.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20151003095334682/LinuxCloud.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.labxnow.org/labxweb/
|
||||
63
sources/share/20151012 What is a good IDE for R on Linux.md
Normal file
63
sources/share/20151012 What is a good IDE for R on Linux.md
Normal file
@ -0,0 +1,63 @@
|
||||
FSSlc translating
|
||||
|
||||
What is a good IDE for R on Linux
|
||||
================================================================================
|
||||
Some time ago, I covered some of the [best IDEs for C/C++][1] on Linux. Obviously C and C++ are not the only programming languages out there, and it is time to turn to something a bit more specific.
|
||||
|
||||
If you have ever done some statistics, it is possible that you have encountered the [language R][2]. If you have not, I really recommend this open source programming language which is tailored for statistics and data mining. Coming from a coding background, you might be thrown off a bit by the syntax, but hopefully you will get seduced by the speed of its vector operations. In short, try it. And to do so, what better way to start with an IDE? R being a cross platform language, there are a bunch of good IDEs which make data analysis in R far more pleasurable. If you are very attached to a particular editor, there are also some very good plugins to turn that editor into a fully-fledged R IDE.
|
||||
|
||||
Here is a list of five good IDEs for R language in Linux environment.
|
||||
|
||||
### 1. RStudio ###
|
||||
|
||||
|
||||
|
||||
Let’s start hard with maybe one of the most popular R IDEs out there: [RStudio][3]. In addition to common IDE features like syntax highlighting and code completion, RStudio stands out for its integration of R documentation, its powerful debugger and its multiple views system. If you start with R, I can only recommend RStudio as the R console on the side is perfect for testing your code in real time, and the object explorer will help you understand what kind of data you are dealing with. Finally, what really conquered me was the integration of the plots visualiser, making it easy to export your graphs as images. On the downside, RStudio lacks the shortcuts and the advanced settings to make it a perfect IDE. Still, with a free version under AGPL license, Linux users have no excuses not to give this IDE a try.
|
||||
|
||||
### 2. Emacs with ESS ###
|
||||
|
||||
|
||||
|
||||
In my last post about IDEs, some people were disappointed by the absence of Emacs in my list. My main reason for that is that Emacs is kind of the wild card of IDE: you could place it on any list for any languages. But things are different for [R with the ESS plugin][4]. Emacs Speaks Statistics (ESS) is an amazing plugin which completely changes the way you use the Emacs editor and really fits the needs of R coders. A bit like RStudio which has multiple views, Emacs with ESS displays presents two panels: one with the code and one with an R console, making it easy to test your code in real time and explore the objects. But ESS's real strength is its seamless integration with other Emacs plugins you might have installed and its advanced configuration options. In short, if you like your Emacs shortcuts, you will like to be able to use them in an environment that makes sense for R development. For full disclosure, however, I have heard of and experienced some efficiency issues when dealing with a lot of data in ESS. Nothing too major to be a problem, but just enough have me prefer RStudio.
|
||||
|
||||
### 3. Vim with Vim-R-plugin ###
|
||||
|
||||
|
||||
|
||||
Because I do not want to discriminate after talking about Emacs, I also tried the equivalent for Vim: the [Vim-R-plugin][5]. Using the terminal tool called tmux, this plugin makes it possible to have an R console open and code at the same time. But most importantly, it brings syntax highlighting and omni-completion for R objects to Vim. You can also easily access R documentation and browse objects. But once again, the strength comes from its extensive customization capacities and the speed of Vim. If you are tempted by this option, I direct you to the extremely thorough [documentation][6] on installing and setting up your environment.
|
||||
|
||||
### 4. Gedit with RGedit ###
|
||||
|
||||
|
||||
|
||||
If neither Emacs or Vim is your cup of tea, and what you like is your default Gnome editor, then [RGedit][7] is made for you: a plugin to code in R from Gedit. Gedit is known to be more powerful than what it looks. With a very large library of plugins, it is possible to do a lot with it. And RGedit is precisely the plugin you need to code in R from Gedit. It comes with the classic syntax highlighting and integration of the R console at the bottom of the screen, but also a bunch of unique features like multiple profiles, code folding, file explorer, and even a GUI wizard to generate code from snippets. Despite my indifference towards Gedit, I have to admit that these features go beyond the basic plugin functionality and really make a difference when you spend a lot of time analyzing data. The only shadow is that the last update is from 2013. I really hope that this project can pick up again.
|
||||
|
||||
### 5. RKWard ###
|
||||
|
||||
|
||||
|
||||
Finally, last but not least, [RKWard][8] is an R IDE made for KDE environments. What I love the most about it is its name. But honestly, its package management system and spreadsheet-like data editor come in close second. In addition to that, it includes an easy system for plotting and importing data, and can be extended by plugins. If you are not a fan of the KDE feel, you might be a bit uncomfortable, but if you are, I would really recommend checking it out.
|
||||
|
||||
To conclude, whether you are new to R or not, these IDEs might be useful to you. It does not matter if you prefer something that stands for itself, or a plugin for your favorite editor, I am sure that you will appreciate one of the features these software provide. I am also sure I missed a lot of good IDEs for R, which deserve to be on this list. So since you wrote a lot of very good comments for the post on the IDEs for C/C++, I invite you to do the same here and share your knowledge.
|
||||
|
||||
What do you feel is a good IDE for R on Linux? Please let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/good-ide-for-r-on-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://xmodulo.com/good-ide-for-c-cpp-linux.html
|
||||
[2]:https://www.r-project.org/
|
||||
[3]:https://www.rstudio.com/
|
||||
[4]:http://ess.r-project.org/
|
||||
[5]:http://www.vim.org/scripts/script.php?script_id=2628
|
||||
[6]:http://www.lepem.ufc.br/jaa/r-plugin.html
|
||||
[7]:http://rgedit.sourceforge.net/
|
||||
[8]:https://rkward.kde.org/
|
||||
220
sources/talk/20101020 19 Years of KDE History--Step by Step.md
Normal file
220
sources/talk/20101020 19 Years of KDE History--Step by Step.md
Normal file
@ -0,0 +1,220 @@
|
||||
19 Years of KDE History: Step by Step
|
||||
================================================================================
|
||||
注:youtube 视频
|
||||
<iframe width="660" height="371" src="https://www.youtube.com/embed/1UG4lQOMBC4?feature=oembed" frameborder="0" allowfullscreen></iframe>
|
||||
|
||||
### Introduction ###
|
||||
|
||||
KDE – one of most functional desktop environment ever. It’s open source and free for use. 19 years ago, 14 october 1996 german programmer Matthias Ettrich has started a development of this beautiful environment. KDE provides the shell and many applications for everyday using. Today KDE uses the hundred thousand peoples over the world on Unix and Windows operating system. 19 years – serious age for software projects. Time to return and see how it begin.
|
||||
|
||||
K Desktop Environment has some new aspects: new design, good look & feel, consistency, easy to use, powerful applications for typical desktop work and special use cases. Name “KDE” is an easy word hack with “Common Desktop Environment”, “K” – “Cool”. The first KDE version used proprietary Trolltech’s Qt framework (parent of Qt) with dual licensing: open source QPL(Q public license) and proprietary commercial license. In 2000 Trolltech released some Qt libraries under GPL; Qt 4.5 was released in LGPL 2.1. Since 2009 KDE is compiled for three products: Plasma Workspaces (Shell), KDE Applications, KDE Platform as KDE Software compilation.
|
||||
|
||||
### Releases ###
|
||||
|
||||
#### Pre-Release – 14 October 1996 ####
|
||||
|
||||

|
||||
|
||||
Kool Desktop Environment. Word “Kool” will be dropped in future. In the beginning, all components were released to the developer community separately without any coordinated timeframe throughout the overall project. First communication of KDE via mailing list, that was called kde@fiwi02.wiwi.uni-Tubingen.de.
|
||||
|
||||
#### KDE 1.0 – July 12, 1998 ####
|
||||
|
||||

|
||||
|
||||
This version received mixed reception. Many criticized the use of the Qt software framework – back then under the FreeQt license which was claimed to not be compatible with free software – and advised the use of Motif or LessTif instead. Despite that criticism, KDE was well received by many users and made its way into the first Linux distributions.
|
||||
|
||||

|
||||
|
||||
28 January 1999
|
||||
|
||||
An update, **K Desktop Environment 1.1**, was faster, more stable and included many small improvements. It also included a new set of icons, backgrounds and textures. Among this overhauled artwork was a new KDE logo by Torsten Rahn consisting of the letter K in front of a gear which is used in revised form to this day.
|
||||
|
||||
#### KDE 2.0 – October 23, 2000 ####
|
||||
|
||||

|
||||
|
||||
Major updates: * DCOP (Desktop COmmunication Protocol), a client-to-client communications protocol * KIO, an application I/O library. * KParts, a component object model * KHTML, an HTML 4.0 compliant rendering and drawing engine
|
||||
|
||||

|
||||
|
||||
26 February 2001
|
||||
|
||||
**K Desktop Environment 2.1** release inaugurated the media player noatun, which used a modular, plugin design. For development, K Desktop Environment 2.1 was bundled with KDevelop.
|
||||
|
||||

|
||||
|
||||
15 August 2001
|
||||
|
||||
The **KDE 2.2** release featured up to a 50% improvement in application startup time on GNU/Linux systems and increased stability and capabilities for HTML rendering and JavaScript; some new features in KMail.
|
||||
|
||||
#### KDE 3.0 – April 3, 2002 ####
|
||||
|
||||

|
||||
|
||||
K Desktop Environment 3.0 introduced better support for restricted usage, a feature demanded by certain environments such as kiosks, Internet cafes and enterprise deployments, which disallows the user from having full access to all capabilities of a piece of software.
|
||||
|
||||

|
||||
|
||||
28 January 2003
|
||||
|
||||
**K Desktop Environment 3.1** introduced new default window (Keramik) and icon (Crystal) styles as well as several feature enhancements.
|
||||
|
||||

|
||||
|
||||
3 February 2004
|
||||
|
||||
**K Desktop Environment 3.2** included new features, such as inline spell checking for web forms and emails, improved e-mail and calendaring support, tabs in Konqueror and support for Microsoft Windows desktop sharing protocol (RDP).
|
||||
|
||||

|
||||
|
||||
19 August 2004
|
||||
|
||||
**K Desktop Environment 3.3** focused on integrating different desktop components. Kontact was integrated with Kolab, a groupware application, and Kpilot. Konqueror was given better support for instant messaging contacts, with the capability to send files to IM contacts and support for IM protocols (e.g., IRC).
|
||||
|
||||

|
||||
|
||||
16 March 2005
|
||||
|
||||
**K Desktop Environment 3.4** focused on improving accessibility. The update added a text-to-speech system with support for Konqueror, Kate, KPDF, the standalone application KSayIt and text-to-speech synthesis on the desktop.
|
||||
|
||||

|
||||
|
||||
29 November 2005
|
||||
|
||||
**The K Desktop Environment 3.5** release added SuperKaramba, which provides integrated and simple-to-install widgets to the desktop. Konqueror was given an ad-block feature and became the second web browser to pass the Acid2 CSS test.
|
||||
|
||||
#### KDE SC 4.0 – January 11, 2008 ####
|
||||
|
||||

|
||||
|
||||
The majority of development went into implementing most of the new technologies and frameworks of KDE 4. Plasma and the Oxygen style were two of the biggest user-facing changes. Dolphin replaces Konqueror as file manager, Okular – default document viewer.
|
||||
|
||||

|
||||
|
||||
29 July 2008
|
||||
|
||||
**KDE 4.1** includes a shared emoticon theming system which is used in PIM and Kopete, and DXS, a service that lets applications download and install data from the Internet with one click. Also introduced are GStreamer, QuickTime 7, and DirectShow 9 Phonon backends. New applications: * Dragon Player * Kontact * Skanlite – software for scanners * Step – physics simulator * New games: Kdiamond, Kollision, KBreakout and others
|
||||
|
||||

|
||||
|
||||
27 January 2009
|
||||
|
||||
**KDE 4.2** is considered a significant improvement beyond KDE 4.1 in nearly all aspects, and a suitable replacement for KDE 3.5 for most users.
|
||||
|
||||

|
||||
|
||||
4 August 2009
|
||||
|
||||
**KDE 4.3** fixed over 10,000 bugs and implemented almost 2,000 feature requests. Integration with other technologies, such as PolicyKit, NetworkManager & Geolocation services, was another focus of this release.
|
||||
|
||||

|
||||
|
||||
9 February 2010
|
||||
|
||||
**KDE SC 4.4** is based on version 4.6 of the Qt 4 toolkit. New application – KAddressBook, first release of Kopete.
|
||||
|
||||

|
||||
|
||||
10 August 2010
|
||||
|
||||
**KDE SC 4.5** has some new features: integration of the WebKit library, an open-source web browser engine, which is used in major browsers such as Apple Safari and Google Chrome. KPackageKit replaced Kpackage.
|
||||
|
||||

|
||||
|
||||
26 January 2011
|
||||
|
||||
**KDE SC 4.6** has better OpenGL compositing along with the usual myriad of fixes and features.
|
||||
|
||||

|
||||
|
||||
27 July 2011
|
||||
|
||||
**KDE SC 4.7** has updated KWin with OpenGL ES 2.0 compatible, Qt Quick, Plasma Desktop with many enhancements and a lot of new functions in general applications. 12k bugs if fixed.
|
||||
|
||||

|
||||
|
||||
25 January 2012
|
||||
|
||||
**KDE SC 4.8**: better KWin performance and Wayland support, new design of Doplhin.
|
||||
|
||||

|
||||
|
||||
1 August 2012
|
||||
|
||||
**KDE SC 4.9**: several improvements to the Dolphin file manager, including the reintroduction of in-line file renaming, back and forward mouse buttons, improvement of the places panel and better usage of file metadata.
|
||||
|
||||

|
||||
|
||||
6 February 2013
|
||||
|
||||
**KDE SC 4.10**: many of the default Plasma widgets were rewritten in QML, and Nepomuk, Kontact and Okular received significant speed improvements.
|
||||
|
||||

|
||||
|
||||
14 August 2013
|
||||
|
||||
**KDE SC 4.11**: Kontact and Nepomuk received many optimizations. The first generation Plasma Workspaces entered maintenance-only development mode.
|
||||
|
||||

|
||||
|
||||
18 December 2013
|
||||
|
||||
**KDE SC 4.12**: Kontact received substantial improvements, many small improvements.
|
||||
|
||||

|
||||
|
||||
18 December 2013
|
||||
|
||||
**KDE SC 4.13**: Nepomuk semantic desktop search was replaced with KDE’s in house Baloo. KDE SC 4.13 was released in 53 different translations.
|
||||
|
||||

|
||||
|
||||
18 December 2013
|
||||
|
||||
**KDE SC 4.14**: he release primarily focused on stability, with numerous bugs fixed and few new features added. This was the final KDE SC 4 release.
|
||||
|
||||
#### KDE Plasma 5.0 – July 15, 2014 ####
|
||||
|
||||

|
||||
|
||||
KDE Plasma 5 – 5th generation of KDE. Massive impovements in design and system, new default theme – Breeze, complete migration to QML, better performance with OpenGL, better HiDPI displays support.
|
||||
|
||||

|
||||
|
||||
11 November 2014
|
||||
|
||||
**KDE Plasma 5.1**: Ported missing features from Plasma 4.
|
||||
|
||||

|
||||
|
||||
27 January 2015
|
||||
|
||||
**KDE Plasma 5.2**: New components: BlueDevil, KSSHAskPass, Muon, SDDM theme configuration, KScreen, GTK+ style configuration and KDecoration.
|
||||
|
||||

|
||||
|
||||
28 April 2015
|
||||
|
||||
**KDE Plasma 5.3**: Tech preview of Plasma Media Center. New Bluetooth and touchpad applets. Enhanced power management.
|
||||
|
||||

|
||||
|
||||
25 August 2015
|
||||
|
||||
**KDE Plasma 5.4**: Initial Wayland session, new QML-based audio volume applet, and alternative full-screen application launcher.
|
||||
|
||||
Big thanks to the [KDE][1] developers and community, Wikipedia for [descriptions][2] and all my readers. Be free and use the open source software like a KDE.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://tlhp.cf/kde-history/
|
||||
|
||||
作者:[Pavlo RudyiCategories][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://tlhp.cf/author/paul/
|
||||
[1]:https://www.kde.org/
|
||||
[2]:https://en.wikipedia.org/wiki/KDE_Plasma_5
|
||||
@ -1,127 +0,0 @@
|
||||
translating...
|
||||
|
||||
Interview: Larry Wall
|
||||
================================================================================
|
||||
> Perl 6 has been 15 years in the making, and is now due to be released at the end of this year. We speak to its creator to find out what’s going on.
|
||||
|
||||
Larry Wall is a fascinating man. He’s the creator of Perl, a programming language that’s widely regarded as the glue holding the internet together, and mocked by some as being a “write-only” language due to its density and liberal use of non-alphanumeric characters. Larry also has a background in linguistics, and is well known for delivering entertaining “State of the Onion” presentations about the future of Perl.
|
||||
|
||||
At FOSDEM 2015 in Brussels, we caught up with Larry to ask him why Perl 6 has taken so long (Perl 5 was released in 1994), how difficult it is to manage a project when everyone has strong opinions and pulling in different directions, and how his background in linguistics influenced the design of Perl from the start. Get ready for some intriguing diversions…
|
||||
|
||||

|
||||
|
||||
**Linux Voice: You once had a plan to go and find an undocumented language somewhere in the world and create a written script for it, but you never had the opportunity to fulfil this plan. Is that something you’d like to go back and do now?**
|
||||
|
||||
Larry Wall: You have to be kind of young to be able to carry that off! It’s actually a lot of hard work, and organisations that do these things don’t tend to take people in when they’re over a certain age. Partly this is down to health and vigour, but also because people are much better at picking up new languages when they’re younger, and you have to learn the language before making a script for it.
|
||||
|
||||
I started trying to teach myself Japanese about 10 years ago, and I could speak it quite well, because of my phonology and phonetics training – but it’s very hard for me to understand what anybody says. So I can go to Japan and ask for directions, but I can’t really understand the answers!
|
||||
|
||||
> “With Perl 6, we found some ways to make the computer more sure about what the user is talking about.”
|
||||
|
||||
So usually learning a language well enough to develop a writing system, and to at least be conversational in the language, takes some period of years before you can get to the point where you can actually do literacy and start educating people on their own culture, as it were. And then you teach them to write about their own culture as well.
|
||||
|
||||
Of course, if you have language helpers – and we were told not to call them “language informants”, or everyone would think we were working for the CIA! – if you have these people, you can get them to come in and help you learn the foreign language. They are not teachers but there are ways of eliciting things from someone who’s not a language teacher – they can still teach you how to speak. They can take a stick and point to it and say “that’s a stick”, and drop it and say “the stick falls”. Then you start writing things down and systematising things.
|
||||
|
||||
The motivation that most people have, going out to these groups, is to translate the Bible into their languages. But that’s only one part of it; the other is also culture preservation. Missionaries get kind of a bad rep on that, because anthropologists think they should be left to sit their in their own culture. But somebody is probably going to change their culture anyway – it’s usually the army, or businesses coming in, like Coca Cola or the sewing machine people, or missionaries. And of those three, the missionaries are the least damaging, if they’re doing their job right.
|
||||
|
||||
**LV: Many writing systems are based on existing scripts, and then you have invented ones like Greenlandic…**
|
||||
|
||||
LW: The Cherokee invented their own just by copying letters, and they have no mapping much to what we think of letters, and it’s fairly arbitrary in that sense. It just has to represent how the people themselves think of the language, and sufficiently well to communicate. Often there will be variations on Western orthography, using characters from Latin where possible. Tonal languages have to mark the tones somehow, by accents or by numbers.
|
||||
|
||||
As soon as you start leaning towards a phoenetic or phonological representation, then you also start to lose dialectical differences – or you have to write the dialectal differences. Or you have conventional spelling like we have in English, but pronunciation that doesn’t really match it.
|
||||
|
||||
**LV: When you started working on Perl, what did you take from your background in linguistics that made you think: “this is really important in a programming language”?**
|
||||
|
||||
LW: I thought a lot about how people use languages. In real languages, you have a system of nouns and verbs and adjectives, and you kind of know which words are which type. And in real natural languages, you have a lot of instances of shoving one word into a different slot. The linguistic theory I studied was called tagmemics, and it accounts for how this works in a natural language – that you could have something that you think of as a noun, but you can verb it, and people do that all time.
|
||||
|
||||
You can pretty much shove anything in any slot, and you can communicate. One of my favourite examples is shoving an entire sentence in as an adjective. The sentence goes like this: “I don’t like your I-can-use-anything-as-an-adjective attitude”!
|
||||
|
||||
So natural language is very flexible this way because you have a very intelligent listener – or at least, compared with a computer – who you can rely on to figure out what you must have meant, in case of ambiguity. Of course, in a computer language you have to manage the ambiguity much more closely.
|
||||
|
||||
Arguably in Perl 1 through to 5 we didn’t manage it quite adequately enough. Sometimes the computer was confused when it really shouldn’t be. With Perl 6, we discovered some ways to make the computer more sure about what the user is talking about, even if the user is confused about whether something is really a string or a number. The computer knows the exact type of it. We figured out ways of having stronger typing internally but still have the allomorphic “you can use this as that” idea.
|
||||
|
||||

|
||||
|
||||
**LV: For a long time Perl was seen as the “glue” language of the internet, for fitting bits and pieces together. Do you see Perl 6 as a release to satisfy the needs of existing users, or as a way to bring in new people, and bring about a resurgence in the language?**
|
||||
|
||||
LW: The initial intent was to make a better Perl for Perl programmers. But as we looked at the some of the inadequacies of Perl 5, it became apparent that if we fixed these inadequacies, Perl 6 would be more applicable, as I mentioned in my talk – like how J. R. R. Tolkien talked about applicability [see http://tinyurl.com/nhpr8g2].
|
||||
|
||||
The idea that “easy things should be easy and hard things should be possible” goes way back, to the boundary between Perl 2 and Perl 3. In Perl 2, we couldn’t handle binary data or embedded nulls – it was just C-style strings. I said then that “Perl is just a text processing language – you don’t need those things in a text processing language”.
|
||||
|
||||
But it occurred to me at the time that there were a large number of problems that were mostly text, and had a little bit of binary data in them – network addresses and things like that. You use binary data to open the socket but then text to process it. So the applicability of the language more than doubled by making it possible to handle binary data.
|
||||
|
||||
That began a trade-off about what things should be easy in a language. Nowadays we have a principle in Perl, and we stole the phrase Huffman coding for it, from the bit encoding system where you have different sizes for characters. Common characters are encoded in a fewer number of bits, and rarer characters are encoded in more bits.
|
||||
|
||||
> “There had to be a very careful balancing act. There were just so many good ideas at the beginning.”
|
||||
|
||||
We stole that idea as a general principle for Perl, for things that are commonly used, or when you have to type them very often – the common things need to be shorter or more succinct. Another bit of that, however, is that they’re allowed to be more irregular. In natural language, it’s actually the most commonly used verbs that tend to be the most irregular.
|
||||
|
||||
And there’s a reason for that, because you need more differentiation of them. One of my favourite books is called The Search for the Perfect Language by Umberto Eco, and it’s not about computer languages; it’s about philosophical languages, and the whole idea that maybe some ancient language was the perfect language and we should get back to it.
|
||||
|
||||
All of those languages make the mistake of thinking that similar things should always be encoded similarly. But that’s not how you communicate. If you have a bunch of barnyard animals, and they all have related names, and you say “Go out and kill the Blerfoo”, but you really wanted them to kill the Blerfee, you might get a cow killed when you want a chicken killed.
|
||||
|
||||
So in realms like that it’s actually better to differentiate the words, for more redundancy in the communication channel. The common words need to have more of that differentiation. It’s all about communicating efficiently, and then there’s also this idea of self-clocking codes. If you look at a UPC label on a product – a barcode – that’s actually a self-clocking code where each pair of bars and spaces is always in a unit of seven columns wide. You rely on that – you know the width of the bars will always add up to that. So it’s self-clocking.
|
||||
|
||||
There are other self-clocking codes used in electronics. In the old transmission serial protocols there were stop and start bits so you could keep things synced up. Natural languages also do this. For instance, in the writing of Japanese, they don’t use spaces. Because the way they write it, they will have a Kanji character from Chinese at the head of each phrase, and then the endings are written in the a syllabary.
|
||||
|
||||
**LV: Hiragana, right?**
|
||||
|
||||
LW: Yes, Hiragana. So naturally the head of each phrase really stands out with this system. Similarly, in ancient Greek, most of the verbs were declined or conjugated. So they had standard endings were sort-of a clocking mechanism. Spaces were optional in their writing system as well – it was a more modern invention to put the spaces in.
|
||||
|
||||
So similarly in computer languages, there’s value in having a self-clocking code. We rely on this heavily in Perl, and even more heavily in Perl 6 than in previous releases. The idea that when you’re parsing an expression, you’re either expecting a term or an infix operator. When you’re expecting a term you might also get a prefix operator – that’s kind-of in the same expectation slot – and when you’re expecting an infix you might also get a postfix for the previous term.
|
||||
|
||||
But it flips back and forth. And if the compiler actually knows which it is expecting, you can overload those a little bit, and Perl does this. So a slash when it’s expecting a term will introduce a regular expression, whereas a slash when you’re expecting an infix will be division. On the other hand, we don’t want to overload everything, because then you lose the self-clocking redundancy.
|
||||
|
||||
Most of our best error messages, for syntax errors, actually come out of noticing that you have two terms in a row. And then we try to figure out why there are two terms in a row – “oh, you must have left a semicolon out on the previous line”. So we can produce much better error messages than the more ad-hoc parsers.
|
||||
|
||||

|
||||
|
||||
**LV: Why has Perl 6 taken fifteen years? It must be hard overseeing a language when everyone has different opinions about things, and there’s not always the right way to do things, and the wrong way.**
|
||||
|
||||
LW: There had to be a very careful balancing act. There were just so many good ideas at the beginning – well, I don’t want to say they were all good ideas. There were so many pain points, like there were 361 RFCs [feature proposal documents] when I expected maybe 20. We had to sit back and actually look at them all, and ignore the proposed solutions, because they were all over the map and all had tunnel vision. Each one many have just changed one thing, but if we had done them all, it would’ve been a complete mess.
|
||||
|
||||
So we had to re-rationalise based on how people were actually hurting when they tried to use Perl 5. We started to look at the unifying, underlying ideas. Many of these RFCs were based on the fact that we had an inadequate type system. By introducing a more coherent type system we could fix many problems in a sane fashion and a cohesive fashion.
|
||||
|
||||
And we started noticing other ways how we could unify the featuresets and start reusing ideas in different areas. Not necessarily that they were the same thing underneath. We have a standard way of writing pairs – well, two ways in Perl! But the way of writing pairs with a colon could also be reused for radix notation, or for literal numbers in any base. It could also be used for various alternative forms of quoting. We say in Perl that it’s “strangely consistent”.
|
||||
|
||||
> “People who made early implementations of Perl 6 came back to me, cap in hand, and said “We really need a language designer.””
|
||||
|
||||
Similar ideas pop up, and you say “I’m already familiar with how that syntax works, but I see it’s being used for something else”. So it took some unity of vision to find these unifications. People who had the various ideas and made early implementations of Perl 6 came back to me, cap-in-hand, and said “We really need a language designer. Could you be our benevolent dictator?”
|
||||
|
||||
So I was the language designer, but I was almost explicitly told: “Stay out of the implementation! We saw what you did made out of Perl 5, and we don’t like it!” It was really funny because the innards of the new implementation started looking a whole lot like Perl 5 inside, and maybe that’s why some of the early implementations didn’t work well.
|
||||
|
||||
Because we were still feeling our way into the whole design, the implementations made a lot of assumptions about what VM should do and shouldn’t do, so we ended up with something like an object oriented assembly language. That sort of problem was fairly pervasive at the beginning. Then the Pugs guys came along and said “Let’s use Haskell, because it makes you think very clearly about what you’re doing. Let’s use it to clarify our semantic model underneath.”
|
||||
|
||||
So we nailed down some of those semantic models, but more importantly, we started building the test suite at that point, to be consistent with those semantic models. Then after that, the Parrot VM continued developing, and then another implementation, Niecza, came along and it was based on .NET. It was by a young fellow who was very smart and implemented a large subset of Perl 6, but he was kind of a loner, didn’t really figure out a way to get other people involved in his project.
|
||||
|
||||
At the same time the Parrot project was getting too big for anyone to really manage it inside, and very difficult to refactor. At that point the fellows working on Rakudo decided that we probably needed to be on more platforms than just the Parrot VM. So they invented a portability layer called NQP which stands for “Not Quite Perl”. They ported it to first of all run on the JVM (Java Virtual Machine), and while they were doing that they were also secretly working on a new VM called MoarVM. That became public a little over a year ago.
|
||||
|
||||
Both MoarVM and JVM run a pretty much equivalent set of regression tests – Parrot is kind-of trailing back in some areas. So that has been very good to flush out VM-specific assumptions, and we’re starting to think about NQP targeting other things. There was a Google Summer of Code project year to target NQP to JavaScript, and that might fit right in, because MoarVM also uses Node.js for much of its more mundane processing.
|
||||
|
||||
We probably need to concentrate on MoarVM for the rest of this year, until we actually define 6.0, and then the rest will catch up.
|
||||
|
||||
**LV: Last year in the UK, the government kicked off the Year of Code, an attempt to get young people interested in programming. There are lots of opinions about how this should be done – like whether you should teach low-level languages at the start, so that people really understand memory usage, or a high-level language. What’s your take on that?**
|
||||
|
||||
LW: Up until now, the Python community has done a much better job of getting into the lower levels of education than we have. We’d like to do something in that space too, and that’s partly why we have the butterfly logo, because it’s going to be appealing to seven year old girls!
|
||||
|
||||
But we do think that Perl 6 will be learnable as a first language. A number of people have surprised us by learning Perl 5 as their first language. And you know, there are a number of fairly powerful concepts even in Perl 5, like closures, lexical scoping, and features you generally get from functional programming. Even more so in Perl 6.
|
||||
|
||||
> “Until now, the Python community has done a much better job of getting into the lower levels of education.”
|
||||
|
||||
Part of the reason the Perl 6 has taken so long is that we have around 50 different principles we try to stick to, and in language design you’re end up juggling everything and saying “what’s really the most important principle here”? There has been a lot of discussion about a lot of different things. Sometimes we commit to a decision, work with it for a while, and then realise it wasn’t quite the right decision.
|
||||
|
||||
We didn’t design or specify pretty much anything about concurrent programming until someone came along who was smart enough about it and knew what the different trade-offs were, and that’s Jonathan Worthington. He has blended together ideas from other languages like Go and C#, with concurrent primitives that compose well. Composability is important in the rest of the language.
|
||||
|
||||
There are an awful lot of concurrent and parallel programming systems that don’t compose well – like threads and locks, and there have been lots of ways to do it poorly. So in one sense, it’s been worth waiting this extra time to see some of these languages like Go and C# develop really good high-level primitives – that’s sort of a contradiction in terms – that compose well.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxvoice.com/interview-larry-wall/
|
||||
|
||||
作者:[Mike Saunders][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxvoice.com/author/mike/
|
||||
@ -1,30 +0,0 @@
|
||||
- translating by Ezio
|
||||
|
||||
Linux 4.3 Kernel To Add The MOST Driver Subsystem
|
||||
================================================================================
|
||||
While the [Linux 4.2][1] kernel hasn't been officially released yet, Greg Kroah-Hartman sent in early his pull requests for the various subsystems he maintains for the Linux 4.3 merge window.
|
||||
|
||||
The pull requests sent in by Greg KH on Thursday include the Linux 4.3 merge window updates for the driver core, TTY/serial, USB driver, char/misc, and the staging area. These pull requests don't offer any really shocking changes but mostly routine work on improvements / additions / bug-fixes. The staging area once again is heavy with various fixes and clean-ups but there's also a new driver subsystem.
|
||||
|
||||
Greg mentioned of the [4.3 staging changes][2], "Lots of things all over the place, almost all of them trivial fixups and changes. The usual IIO updates and new drivers and we have added the MOST driver subsystem which is getting cleaned up in the tree. The ozwpan driver is finally being deleted as it is obviously abandoned and no one cares about it."
|
||||
|
||||
The MOST driver subsystem is short for the Media Oriented Systems Transport. The documentation to be added in the Linux 4.3 kernel explains, "The Media Oriented Systems Transport (MOST) driver gives Linux applications access a MOST network: The Automotive Information Backbone and the de-facto standard for high-bandwidth automotive multimedia networking. MOST defines the protocol, hardware and software layers necessary to allow for the efficient and low-cost transport of control, real-time and packet data using a single medium (physical layer). Media currently in use are fiber optics, unshielded twisted pair cables (UTP) and coax cables. MOST also supports various speed grades up to 150 Mbps." As explained, MOST is mostly about Linux in automotive applications.
|
||||
|
||||
While Greg KH sent in his various subsystem updates for Linux 4.3, he didn't yet propose the [KDBUS][5] kernel code be pulled. He's previously expressed plans for [KDBUS in Linux 4.3][3] so we'll wait until the 4.3 merge window officially gets going to see what happens. Stay tuned to Phoronix for more Linux 4.3 kernel coverage next week when the merge window will begin, [assuming Linus releases 4.2][4] this weekend.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=news_item&px=Linux-4.3-Staging-Pull
|
||||
|
||||
作者:[Michael Larabel][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.michaellarabel.com/
|
||||
[1]:http://www.phoronix.com/scan.php?page=search&q=Linux+4.2
|
||||
[2]:http://lkml.iu.edu/hypermail/linux/kernel/1508.2/02604.html
|
||||
[3]:http://www.phoronix.com/scan.php?page=news_item&px=KDBUS-Not-In-Linux-4.2
|
||||
[4]:http://www.phoronix.com/scan.php?page=news_item&px=Linux-4.2-rc7-Released
|
||||
[5]:http://www.phoronix.com/scan.php?page=search&q=KDBUS
|
||||
@ -1,3 +1,5 @@
|
||||
martin translating...
|
||||
|
||||
Superclass: 15 of the world’s best living programmers
|
||||
================================================================================
|
||||
When developers discuss who the world’s top programmer is, these names tend to come up a lot.
|
||||
@ -386,4 +388,4 @@ via: http://www.itworld.com/article/2823547/enterprise-software/158256-superclas
|
||||
[131]:http://community.topcoder.com/tc?module=AlgoRank
|
||||
[132]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi
|
||||
[133]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi/comment/4720779
|
||||
[134]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi/comment/4880549
|
||||
[134]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi/comment/4880549
|
||||
|
||||
@ -1,37 +0,0 @@
|
||||
Red Hat CEO Optimistic on OpenStack Revenue Opportunity
|
||||
================================================================================
|
||||
Red Hat continues to accelerate its growth thanks to an evolving mix of platform and infrastructure technology revolving around Linux and the cloud. Red Hat announced its second quarter fiscal 2016 financial results on September 21, once again exceeding expectations.
|
||||
|
||||

|
||||
|
||||
For the quarter, Red Hat reported revenue of $504 million for a 13 percent year-over-year gain. Net Income was reported at $51 million, up from $47 Red Hatmillion in the second quarter of fiscal 2015. Looking forward, Red Hat provided some aggressive guidance for the coming quarter and the full year. For the third quarter, Red Hat provided guidance for revenue to be in the range of $519 million to $523 million, which is a 15 percent year-over-year gain.
|
||||
|
||||
On a full year basis, Red Hat's full year guidance is for fiscal 2016 revenue of $2.044 billion, for a 14 percent year-over-year gain.
|
||||
|
||||
Red Hat CFO Frank Calderoni commented during the earnings call that all of Red Hat's top 30 largest deals were approximately $1 million or more. He noted that Red Hat had four deals that were in excess of $5 million and one deal that was well over $10 million. As has been the case in recent years, cross selling across Red Hat products is strong with 65 percent of all deals including one or more components from Red Hat's group of application development and emerging technologies offerings.
|
||||
|
||||
"We expect the growing adoption of these technologies, like Middleware, the RHEL OpenStack platform, OpenShift, cloud management and storage, to continue to drive revenue growth," Calderoni said.
|
||||
|
||||
### OpenStack ###
|
||||
|
||||
During the earnings call, Red Hat CEO Jim Whitehurst was repeatedly asked about the revenue prospects for OpenStack. Whitehurst said that the recently released Red Hat OpenStack Platform 7.0 is a big jump forward thanks to the improved installer.
|
||||
|
||||
"It does a really good job of kind of identifying hardware and lighting it up," Whitehurst said. "Of course, that means there's a lot of work to do around certifying that hardware, making sure it lights up appropriately."
|
||||
|
||||
Whitehurst said that he's starting to see a lot more production application start to move to the OpenStack cloud. He cautioned however that it's still largely the early adopters moving to OpenStack in production and it isn't quite mainstream, yet.
|
||||
|
||||
From a competitive perspective, Whitehurst talked specifically about Microsoft, HP and Mirantis. In Whitehurst's view many organizations will continue to use multiple operating systems and if they choose Microsoft for one part, they are more likely to choose an open-source option,as the alternative option. Whitehurst said he doesn't see a lot of head-to-head competition against HP in cloud, but he does see Mirantis.
|
||||
|
||||
"We've had several wins or people who were moving away from Mirantis to RHEL," Whitehurst said.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.serverwatch.com/server-news/red-hat-ceo-optimistic-on-openstack-revenue-opportunity.html
|
||||
|
||||
作者:[Sean Michael Kerner][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.serverwatch.com/author/Sean-Michael-Kerner-101580.htm
|
||||
@ -0,0 +1,101 @@
|
||||
The Brief History Of Aix, HP-UX, Solaris, BSD, And LINUX
|
||||
================================================================================
|
||||

|
||||
|
||||
Always remember that when doors close on you, other doors open. [Ken Thompson][1] and [Dennis Richie][2] are a great example for such saying. They were two of the best information technology specialists in the **20th** century as they created the **UNIX** system which is considered one the most influential and inspirational software that ever written.
|
||||
|
||||
### The UNIX systems beginning at Bell Labs ###
|
||||
|
||||
**UNIX** which was originally called **UNICS** (**UN**iplexed **I**nformation and **C**omputing **S**ervice) has a great family and was never born by itself. The grandfather of UNIX was **CTSS** (**C**ompatible **T**ime **S**haring **S**ystem) and the father was the **Multics** (**MULT**iplexed **I**nformation and **C**omputing **S**ervice) project which supports interactive timesharing for mainframe computers by huge communities of users.
|
||||
|
||||
UNIX was born at **Bell Labs** in **1969** by **Ken Thompson** and later **Dennis Richie**. These two great researchers and scientists worked on a collaborative project with **General Electric** and the **Massachusetts Institute of Technology** to create an interactive timesharing system called the Multics.
|
||||
|
||||
Multics was created to combine timesharing with other technological advances, allowing the users to phone the computer from remote terminals, then edit documents, read e-mail, run calculations, and so on.
|
||||
|
||||
Over the next five years, AT&T corporate invested millions of dollars in the Multics project. They purchased mainframe computer called GE-645 and they dedicated to the effort of the top researchers at Bell Labs such as Ken Thompson, Stuart Feldman, Dennis Ritchie, M. Douglas McIlroy, Joseph F. Ossanna, and Robert Morris. The project was too ambitious, but it fell troublingly behind the schedule. And at the end, AT&T leaders decided to leave the project.
|
||||
|
||||
Bell Labs managers decided to stop any further work on operating systems which made many researchers frustrated and upset. But thanks to Thompson, Richie, and some researchers who ignored their bosses’ instructions and continued working with love on their labs, UNIX was created as one the greatest operating systems of all times.
|
||||
|
||||
UNIX started its life on a PDP-7 minicomputer which was a testing machine for Thompson’s ideas about the operating systems design and a platform for Thompsons and Richie’s game simulation that was called Space and Travel.
|
||||
|
||||
> “What we wanted to preserve was not just a good environment in which to do programming, but a system around which a fellowship could form. We knew from experience that the essence of communal computing, as supplied by remote-access, time-shared machines, is not just to type programs into a terminal instead of a keypunch, but to encourage close communication”. Dennis Richie Said.
|
||||
|
||||
UNIX was so close to be the first system under which the programmer could directly sit down at a machine and start composing programs on the fly, explore possibilities and also test while composing. All through UNIX lifetime, it has had a growing more capabilities pattern by attracting skilled volunteer effort from different programmers impatient with the other operating systems limitations.
|
||||
|
||||
UNIX has received its first funding for a PDP-11/20 in 1970, the UNIX operating system was then officially named and could run on the PDP-11/20. The first real job from UNIX was in 1971, it was to support word processing for the patent department at Bell Labs.
|
||||
|
||||
### The C revolution on UNIX systems ###
|
||||
|
||||
Dennis Richie invented a higher level programming language called “**C**” in **1972**, later he decided with Ken Thompson to rewrite the UNIX in “C” to give the system more portability options. They wrote and debugged almost 100,000 code lines that year. The migration to the “C” language resulted in highly portable software that require only a relatively small machine-dependent code to be then replaced when porting UNIX to another computing platform.
|
||||
|
||||
The UNIX was first formally presented to the outside world in 1973 on Operating Systems Principles, where Dennis Ritchie and Ken Thompson delivered a paper, then AT&T released Version 5 of the UNIX system and licensed it to the educational institutions, and then in 1975 they licensed Version 6 of UNIX to companies for the first time with a cost **$20.000**. The most widely used version of UNIX was Version 7 in 1980 where anybody could purchase a license but it was very restrictive terms in this license. The license included the source code, the machine dependents kernel which was written in PDP-11 assembly language. At all, versions of UNIX systems were determined by its user manuals editions.
|
||||
|
||||
### The AIX System ###
|
||||
|
||||
In **1983**, **Microsoft** had a plan to make a **Xenix** MS-DOS’s multiuser successor, and they created Xenix-based Altos 586 with **512 KB** RAM and **10 MB** hard drive by this year with cost $8,000. By 1984, 100,000 UNIX installations around the world for the System V Release 2. In 1986, 4.3BSD was released that included internet name server and the **AIX system** was announced by **IBM** with Installation base over 250,000. AIX is based on Unix System V, this system has BSD roots and is a hybrid of both.
|
||||
|
||||
AIX was the first operating system that introduced a **journaled file system (JFS)** and an integrated Logical Volume Manager (LVM). IBM ported AIX to its RS/6000 platform by 1989. The Version 5L was a breakthrough release that was introduced in 2001 to provide Linux affinity and logical partitioning with the Power4 servers.
|
||||
|
||||
AIX introduced virtualization by 2004 in AIX 5.3 with Advanced Power Virtualization (APV) which offered Symmetric multi-threading, micro-partitioning, and shared processor pools.
|
||||
|
||||
In 2007, IBM started to enhance its virtualization product, by coinciding with the AIX 6.1 release and the architecture of Power6. They also rebranded Advanced Power Virtualization to PowerVM.
|
||||
|
||||
The enhancements included form of workload partitioning that was called WPARs, that are similar to Solaris zones/Containers, but with much better functionality.
|
||||
|
||||
### The HP-UX System ###
|
||||
|
||||
The **Hewlett-Packard’s UNIX (HP-UX)** was based originally on System V release 3. The system initially ran exclusively on the PA-RISC HP 9000 platform. The Version 1 of HP-UX was released in 1984.
|
||||
|
||||
The Version 9, introduced SAM, its character-based graphical user interface (GUI), from which one can administrate the system. The Version 10, was introduced in 1995, and brought some changes in the layout of the system file and directory structure, which made it similar to AT&T SVR4.
|
||||
|
||||
The Version 11 was introduced in 1997. It was HP’s first release to support 64-bit addressing. But in 2000, this release was rebranded to 11i, as HP introduced operating environments and bundled groups of layered applications for specific Information Technology purposes.
|
||||
|
||||
In 2001, The Version 11.20 was introduced with support for Itanium systems. The HP-UX was the first UNIX that used ACLs (Access Control Lists) for file permissions and it was also one of the first that introduced built-in support for Logical Volume Manager.
|
||||
|
||||
Nowadays, HP-UX uses Veritas as primary file system due to partnership between Veritas and HP.
|
||||
|
||||
The HP-UX is up to release 11iv3, update 4.
|
||||
|
||||
### The Solaris System ###
|
||||
|
||||
The Sun’s UNIX version, **Solaris**, was the successor of **SunOS**, which was founded in 1992. SunOS was originally based on the BSD (Berkeley Software Distribution) flavor of UNIX but SunOS versions 5.0 and later were based on Unix System V Release 4 which was rebranded as Solaris.
|
||||
|
||||
SunOS version 1.0 was introduced with support for Sun-1 and Sun-2 systems in 1983. Version 2.0 was introduced later in 1985. In 1987, Sun and AT&T announced that they would collaborate on a project to merge System V and BSD into only one release, based on SVR4.
|
||||
|
||||
The Solaris 2.4 was first Sparc/x86 release by Sun. The last release of the SunOS was version 4.1.4 announced in November 1994. The Solaris 7 was the first 64-bit Ultra Sparc release and it added native support for file system metadata logging.
|
||||
|
||||
Solaris 9 was introduced in 2002, with support for Linux capabilities and Solaris Volume Manager. Then, Solaris 10 was introduced in 2005, and has number of innovations, such as support for its Solaris Containers, new ZFS file system, and Logical Domains.
|
||||
|
||||
The Solaris system is presently up to version 10 as the latest update was released in 2008.
|
||||
|
||||
### Linux ###
|
||||
|
||||
By 1991 there were growing requirements for a free commercial alternative. Therefore **Linus Torvalds** set out to create new free operating system kernel that eventually became **Linux**. Linux started with a small number of “C” files and under a license which prohibited commercial distribution. Linux is a UNIX-like system and is different than UNIX.
|
||||
|
||||
Version 3.18 was introduced in 2015 under a GNU Public License. IBM said that more than 18 million lines of code are Open Source and available to developers.
|
||||
|
||||
The GNU Public License becomes the most widely available free software license which you can find nowadays. In accordance with the Open Source principles, this license permits individuals and organizations the freedom to distribute, run, share by copying, study, and also modify the code of the software.
|
||||
|
||||
### UNIX vs. Linux: Technical Overview ###
|
||||
|
||||
- Linux can encourage more diversity, and Linux developers come from wider range of backgrounds with different experiences and opinions.
|
||||
- Linux can run on wider range of platforms and also types of architecture than UNIX.
|
||||
- Developers of UNIX commercial editions have a specific target platform and audience in mind for their operating system.
|
||||
- **Linux is more secure than UNIX** as it is less affected by virus threats or malware attacks. Linux has had about 60-100 viruses to date, but at the same time none of them are currently spreading. On the other hand, UNIX has had 85-120 viruses but some of them are still spreading.
|
||||
- With commands of UNIX, tools and elements are rarely changed, and even some interfaces and command lines arguments still remain in later versions of UNIX.
|
||||
- Some Linux development projects get funded on a voluntary basis such as Debian. The other projects maintain a community version of commercial Linux distributions such as SUSE with openSUSE and Red Hat with Fedora.
|
||||
- Traditional UNIX is about scale up, but on the other hand Linux is about scale out.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/brief-history-aix-hp-ux-solaris-bsd-linux/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/pirat9/
|
||||
[1]:http://www.unixmen.com/ken-thompson-unix-systems-father/
|
||||
[2]:http://www.unixmen.com/dennis-m-ritchie-father-c-programming-language/
|
||||
203
sources/talk/20151019 Gaming On Linux--All You Need To Know.md
Normal file
203
sources/talk/20151019 Gaming On Linux--All You Need To Know.md
Normal file
@ -0,0 +1,203 @@
|
||||
Gaming On Linux: All You Need To Know
|
||||
================================================================================
|
||||

|
||||
|
||||
**Can I play games on Linux?**
|
||||
|
||||
This is one of the most frequently asked questions by people who are thinking about [switching to Linux][1]. After all, gaming on Linux often termed as a distant possibility. In fact, some people even wonder if they can listen to music or watch movies on Linux. Considering that, question about native Linux games seem genuine.
|
||||
|
||||
In this article, I am going to answer most of the Linux gaming questions a Linux beginner may have. For example, if it is possible to play games on Linux, if yes, what are the Linux games available, where can you **download Linux games** from or how do you get more information of gaming on Linux.
|
||||
|
||||
But before I do that, let me make a confession. I am not a PC gamer or rather I should say, I am not desktop Linux gamer. I prefer to play games on my PS4 and I don’t care about PC games or even mobile games (no candy crush request sent to anyone in my friend list). This is the reason you see only a few articles in [Linux games][2] section of It’s FOSS.
|
||||
|
||||
So why am I covering this topic then?
|
||||
|
||||
Because I have been asked questions about playing games on Linux several times and I wanted to come up with a Linux gaming guide that could answer all those question. And remember, it’s not just gaming on Ubuntu I am talking about here. I am talking about Linux in general.
|
||||
|
||||
### Can you play games on Linux? ###
|
||||
|
||||
Yes and no!
|
||||
|
||||
Yes, you can play games on Linux and no, you cannot play ‘all the games’ in Linux.
|
||||
|
||||
Confused? Don’t be. What I meant here is that you can get plenty of popular games on Linux such as [Counter Strike, Metro Last Night][3] etc. But you might not get all the latest and popular Windows games on Linux, for e.g., [PES 2015][4].
|
||||
|
||||
The reason, in my opinion, is that Linux has less than 2% of desktop market share and these numbers are demotivating enough for most game developers to avoid working on the Linux version of their games.
|
||||
|
||||
Which means that there is huge possibility that the most talked about games of the year may not be playable in Linux. Don’t despair, there are ‘other means’ to get these games on Linux and we shall see it in coming sections, but before that let’s talk about what kind of games are available for Linux.
|
||||
|
||||
If I have to categorize, I’ll divide them in four categories:
|
||||
|
||||
1. Native Linux Games
|
||||
1. Windows games in Linux
|
||||
1. Browser Games
|
||||
1. Terminal Games
|
||||
|
||||
Let’s start with the most important one, native Linux games, first.
|
||||
|
||||
----------
|
||||
|
||||
### 1. Where to find native Linux games? ###
|
||||
|
||||
Native Linux games mean those games which are officially supported in Linux. These games have native Linux client and can be installed like most other applications in Linux without requiring any additional effort (we’ll see about these in next section).
|
||||
|
||||
So, as you see, there are games developed for Linux. Next question that arises is where can you find these Linux games and how can you play them. I am going to list some of the resources where you can get Linux games.
|
||||
|
||||
#### Steam ####
|
||||
|
||||

|
||||
|
||||
“[Steam][5] is a digital distribution platform for video games. As Amazon Kindle is digital distribution platform for e-Books, iTunes for music, similarly Steam is for games. It provides you the option to buy and install games, play multiplayer and stay in touch with other games via social networking on its platform. The games are protected with [DRM][6].”
|
||||
|
||||
A couple of years ago, when gaming platform Steam announced support for Linux, it was a big news. It was an indication that gaming on Linux is being taken seriously. Though Steam’s decision was more influenced with its own Linux-based gaming console and a separate [Linux distribution called Steam OS][7], it still was a reassuring move that has brought a number of games on Linux.
|
||||
|
||||
I have written a detailed article about installing and using Steam. If you are getting started with Steam, do read it.
|
||||
|
||||
- [Install and use Steam for gaming on Linux][8]
|
||||
|
||||
#### GOG.com ####
|
||||
|
||||
[GOG.com][9] is another platform similar to Steam. Like Steam, you can browse and find hundreds of native Linux games on GOG.com, purchase the games and install them. If the games support several platforms, you can download and use them across various operating systems. Your purchased games are available for you all the time in your account. You can download them anytime you wish.
|
||||
|
||||
One main difference between the two is that GOG.com offers only DRM free games and movies. Also, GOG.com is entirely web based. So you don’t need to install a client like Steam. You can simply download the games from browser and install them in your system.
|
||||
|
||||
#### Portable Linux Games ####
|
||||
|
||||
[Portable Linux Games][10] is a website that has a collection of a number of Linux games. The unique and best thing about Portable Linux Games is that you can download and store the games for offline installation.
|
||||
|
||||
The downloaded files have all the dependencies (at times Wine and Perl installation) and these are also platform independent. All you need to do is to download the files and double click to install them. Store the downloadable file on external hard disk and use them in future. Highly recommend if you don’t have continuous access to high speed internet.
|
||||
|
||||
#### Game Drift Game Store ####
|
||||
|
||||
[Game Drift][11] is actually a Linux distribution based on Ubuntu with sole focus on gaming. While you might not want to start using this Linux distribution for the sole purpose of gaming, you can always visit its game store online and see what games are available for Linux and install them.
|
||||
|
||||
#### Linux Game Database ####
|
||||
|
||||
As the name suggests, [Linux Game Database][12] is a website with a huge collection of Linux games. You can browse through various category of games and download/install them from the game developer’s website. As a member of Linux Game Database, you can even rate the games. LGDB, kind of, aims to be the IGN or IMDB for Linux games.
|
||||
|
||||
#### Penguspy ####
|
||||
|
||||
Created by a gamer who refused to use Windows for playing games, [Penguspy][13] showcases a collection of some of the best Linux games. You can browse games based on category and if you like the game, you’ll have to go to the respective game developer’s website.
|
||||
|
||||
#### Software Repositories ####
|
||||
|
||||
Look into the software repositories of your own Linux distribution. There always will be some games in it. If you are using Ubuntu, Ubuntu Software Center itself has an entire section for games. Same is true for other Linux distributions such as Linux Mint etc.
|
||||
|
||||
----------
|
||||
|
||||
### 2. How to play Windows games in Linux? ###
|
||||
|
||||

|
||||
|
||||
So far we talked about native Linux games. But there are not many Linux games, or to be more precise, most popular Linux games are not available for Linux but they are available for Windows PC. So the questions arises, how to play Windows games in Linux?
|
||||
|
||||
Good thing is that with the help of tools like Wine, PlayOnLinux and CrossOver, you can play a number of popular Windows games in Linux.
|
||||
|
||||
#### Wine ####
|
||||
|
||||
Wine is a compatibility layer which is capable of running Windows applications in systems like Linux, BSD and OS X. With the help of Wine, you can install and use a number of Windows applications in Linux.
|
||||
|
||||
[Installing Wine in Ubuntu][14] or any other Linux is easy as it is available in most Linux distributions’ repository. There is a huge [database of applications and games supported by Wine][15] that you can browse.
|
||||
|
||||
#### CrossOver ####
|
||||
|
||||
[CrossOver][16] is an improved version of Wine that brings professional and technical support to Wine. But unlike Wine, CrossOver is not free. You’ll have to purchase the yearly license for it. Good thing about CrossOver is that every purchase contributes to Wine developers and that in fact boosts the development of Wine to support more Windows games and applications. If you can afford $48 a year, you should buy CrossOver for the support they provide.
|
||||
|
||||
### PlayOnLinux ###
|
||||
|
||||
PlayOnLinux too is based on Wine but implemented differently. It has different interface and slightly easier to use than Wine. Like Wine, PlayOnLinux too is free to use. You can browse the [applications and games supported by PlayOnLinux on its database][17].
|
||||
|
||||
----------
|
||||
|
||||
### 3. Browser Games ###
|
||||
|
||||

|
||||
|
||||
Needless to say that there are tons of browser based games that are available to play in any operating system, be it Windows or Linux or Mac OS X. Most of the addictive mobile games, such as [GoodGame Empire][18], also have their web browser counterparts.
|
||||
|
||||
Apart from that, thanks to [Google Chrome Web Store][19], you can play some more games in Linux. These Chrome games are installed like a standalone app and they can be accessed from the application menu of your Linux OS. Some of these Chrome games are playable offline as well.
|
||||
|
||||
----------
|
||||
|
||||
### 4. Terminal Games ###
|
||||
|
||||

|
||||
|
||||
Added advantage of using Linux is that you can use the command line terminal to play games. I know that it’s not the best way to play games but at times, it’s fun to play games like [Snake][20] or [2048][21] in terminal. There is a good collection of Linux terminal games at [this blog][22]. You can browse through it and play the ones you want.
|
||||
|
||||
----------
|
||||
|
||||
### How to stay updated about Linux games? ###
|
||||
|
||||
When you have learned a lot about what kind of games are available on Linux and how could you use them, next question is how to stay updated about new games on Linux? And for that, I advise you to follow these blogs that provide you with the latest happenings of the Linux gaming world:
|
||||
|
||||
- [Gaming on Linux][23]: I won’t be wrong if I call it the nest Linux gaming news portal. You get all the latest rumblings and news about Linux games. Frequently updated, Gaming on Linux has dedicated fan following which makes it a nice community of Linux game lovers.
|
||||
- [Free Gamer][24]: A blog focusing on free and open source games.
|
||||
- [Linux Game News][25]: A Tumbler blog that updates on various Linux games.
|
||||
|
||||
#### What else? ####
|
||||
|
||||
I think that’s pretty much what you need to know to get started with gaming on Linux. If you are still not convinced, I would advise you to [dual boot Linux with Windows][26]. Use Linux as your main desktop and if you want to play games, boot into Windows. This could be a compromised solution.
|
||||
|
||||
I think that’s pretty much what you need to know to get started with gaming on Linux. If you are still not convinced, I would advise you to [dual boot Linux with Windows][27]. Use Linux as your main desktop and if you want to play games, boot into Windows. This could be a compromised solution.
|
||||
|
||||
It’s time for you to add your inputs. Do you play games on your Linux desktop? What are your favorites? What blogs you follow to stay updated on latest Linux games?
|
||||
|
||||
|
||||
投票项目:
|
||||
How do you play games on Linux?
|
||||
|
||||
- I use Wine and PlayOnLinux along with native Linux Games
|
||||
- I am happy with Browser Games
|
||||
- I prefer the Terminal Games
|
||||
- I use native Linux games only
|
||||
- I play it on Steam
|
||||
- I dual boot and go in to Windows to play games
|
||||
- I don't play games at all
|
||||
|
||||
注:投票代码
|
||||
<div class="PDS_Poll" id="PDI_container9132962" style="display:inline-block;"></div>
|
||||
<div id="PD_superContainer"></div>
|
||||
<script type="text/javascript" charset="UTF-8" src="http://static.polldaddy.com/p/9132962.js"></script>
|
||||
<noscript><a href="http://polldaddy.com/poll/9132962">Take Our Poll</a></noscript>
|
||||
|
||||
注,发布时根据情况看怎么处理
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/linux-gaming-guide/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/reasons-switch-linux-windows-xp/
|
||||
[2]:http://itsfoss.com/category/games/
|
||||
[3]:http://blog.counter-strike.net/
|
||||
[4]:https://pes.konami.com/tag/pes-2015/
|
||||
[5]:http://store.steampowered.com/
|
||||
[6]:https://en.wikipedia.org/wiki/Digital_rights_management
|
||||
[7]:http://itsfoss.com/valve-annouces-linux-based-gaming-operating-system-steamos/
|
||||
[8]:http://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[9]:http://www.gog.com/
|
||||
[10]:http://www.portablelinuxgames.org/
|
||||
[11]:http://gamedrift.org/GameStore.html
|
||||
[12]:http://www.lgdb.org/
|
||||
[13]:http://www.penguspy.com/
|
||||
[14]:http://itsfoss.com/wine-1-5-11-released-ppa-available-to-download/
|
||||
[15]:https://appdb.winehq.org/
|
||||
[16]:https://www.codeweavers.com/products/
|
||||
[17]:https://www.playonlinux.com/en/supported_apps.html
|
||||
[18]:http://empire.goodgamestudios.com/
|
||||
[19]:https://chrome.google.com/webstore/category/apps
|
||||
[20]:http://itsfoss.com/nsnake-play-classic-snake-game-linux-terminal/
|
||||
[21]:http://itsfoss.com/play-2048-linux-terminal/
|
||||
[22]:https://ttygames.wordpress.com/
|
||||
[23]:https://www.gamingonlinux.com/
|
||||
[24]:http://freegamer.blogspot.fr/
|
||||
[25]:http://linuxgamenews.com/
|
||||
[26]:http://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
|
||||
[27]:http://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
|
||||
@ -0,0 +1,38 @@
|
||||
Nautilus File Search Is About To Get A Big Power Up
|
||||
================================================================================
|
||||

|
||||
|
||||
**Finding stray files and folders in Nautilus is about to get a whole lot easier. **
|
||||
|
||||
A new **search filter** for the default [GNOME file manager][1] is in development. It makes heavy use of GNOME’s spiffy pop-over menus in an effort to offer a simpler way to narrow in on search results and find exactly what you’re after.
|
||||
|
||||
Developer Georges Stavracas is working on the new UI and [describes][2] the new editor as “cleaner, saner and more intuitive”.
|
||||
|
||||
Based on a video he’s [uploaded to YouTube][3] demoing the new approach – which he hasn’t made available for embedding – he’s not wrong.
|
||||
|
||||
> “Nautilus has very complex but powerful internals, which allows us to do many things. And indeed, there is code for the many options in there. So, why did it used to look so poorly implemented/broken?”, he writes on his blog.
|
||||
|
||||
The question is part rhetorical; the new search filter interface surfaces many of these ‘powerful internals’ to yhe user. Searches can be filtered ad **hoc** based on content type, name or by date range.
|
||||
|
||||
Changing anything in an app like Nautilus is likely to upset some users, so as helpful and straightforward as the new UI seems it could come in for some heat.
|
||||
|
||||
Not that worry of discontent seems to hamper progress (though the outcry at the [removal of ‘type ahead’ search][4] in 2014 still rings loud in many ears, no doubt). GNOME 3.18, [released last month][5], introduced a new file progress dialog to Nautilus and better integration for remote shares, including Google Drive.
|
||||
|
||||
Stavracas’ search filter are not yet merged in to Files’ trunk, but the reworked search UI is tentatively targeted for inclusion in GNOME 3.20, due spring next year.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/10/new-nautilus-search-filter-ui
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://wiki.gnome.org/Apps/Nautilus
|
||||
[2]:http://feaneron.com/2015/10/12/the-new-search-for-gnome-files-aka-nautilus/
|
||||
[3]:https://www.youtube.com/watch?v=X2sPRXDzmUw
|
||||
[4]:http://www.omgubuntu.co.uk/2014/01/ubuntu-14-04-nautilus-type-ahead-patch
|
||||
[5]:http://www.omgubuntu.co.uk/2015/09/gnome-3-18-release-new-features
|
||||
@ -0,0 +1,199 @@
|
||||
18 Years of GNOME Design and Software Evolution: Step by Step
|
||||
================================================================================
|
||||
注:youtube 视频
|
||||
<iframe width="660" height="371" src="https://www.youtube.com/embed/MtmcO5vRNFQ?feature=oembed" frameborder="0" allowfullscreen></iframe>
|
||||
|
||||
[GNOME][1] (GNU Object Model Environment) was started on August 15th 1997 by two Mexican programmers – Miguel de Icaza and Federico Mena. GNOME – Free Software project to develop a desktop environment and applications by volunteers and paid full-time developers. All of GNOME Desktop Environment is the open source software and support Linux, FreeBSD, OpenBSD and others.
|
||||
|
||||
Now we move to 1997 and see the first version of GNOME:
|
||||
|
||||
### GNOME 1 ###
|
||||
|
||||

|
||||
|
||||
**GNOME 1.0** (1997) – First major GNOME release
|
||||
|
||||

|
||||
|
||||
**GNOME 1.2** “Bongo”, 2000
|
||||
|
||||

|
||||
|
||||
**GNOME 1.4** “Tranquility”, 2001
|
||||
|
||||
### GNOME 2 ###
|
||||
|
||||

|
||||
|
||||
**GNOME 2.0**, 2002
|
||||
|
||||
Major upgrade based on GTK+2. Introduction of the Human Interface Guidelines.
|
||||
|
||||

|
||||
|
||||
**GNOME 2.2**, 2003
|
||||
|
||||
Multimedia and file manager improvements.
|
||||
|
||||

|
||||
|
||||
**GNOME 2.4** “Temujin”, 2003
|
||||
|
||||
First release of Epiphany Browser, accessibility support.
|
||||
|
||||

|
||||
|
||||
**GNOME 2.6**, 2004
|
||||
|
||||
Nautilus changes to a spatial file manager, and a new GTK+ file dialog is introduced. A short-lived fork of GNOME, GoneME, is created as a response to the changes in this version.
|
||||
|
||||

|
||||
|
||||
**GNOME 2.8**, 2004
|
||||
|
||||
Improved removable device support, adds Evolution
|
||||
|
||||

|
||||
|
||||
**GNOME 2.10**, 2005
|
||||
|
||||
Lower memory requirements and performance improvements. Adds: new panel applets (modem control, drive mounter and trashcan); and the Totem and Sound Juicer applications.
|
||||
|
||||

|
||||
|
||||
**GNOME 2.12**, 2005
|
||||
|
||||
Nautilus improvements; improvements in cut/paste between applications and freedesktop.org integration. Adds: Evince PDF viewer; New default theme: Clearlooks; menu editor; keyring manager and admin tools. Based on GTK+ 2.8 with cairo support
|
||||
|
||||

|
||||
|
||||
**GNOME 2.14**, 2006
|
||||
|
||||
Performance improvements (over 100% in some cases); usability improvements in user preferences; GStreamer 0.10 multimedia framework. Adds: Ekiga video conferencing application; Deskbar search tool; Pessulus lockdown editor; Fast user switching; Sabayon system administration tool.
|
||||
|
||||

|
||||
|
||||
**GNOME 2.16**, 2006
|
||||
|
||||
Performance improvements. Adds: Tomboy notetaking application; Baobab disk usage analyser; Orca screen reader; GNOME Power Manager (improving laptop battery life); improvements to Totem, Nautilus; compositing support for Metacity; new icon theme. Based on GTK+ 2.10 with new print dialog
|
||||
|
||||

|
||||
|
||||
**GNOME 2.18**, 2007
|
||||
|
||||
Performance improvements. Adds: Seahorse GPG security application, allowing encryption of emails and local files; Baobab disk usage analyser improved to support ring chart view; Orca screen reader; improvements to Evince, Epiphany and GNOME Power Manager, Volume control; two new games, GNOME Sudoku and glChess. MP3 and AAC audio encoding.
|
||||
|
||||

|
||||
|
||||
**GNOME 2.20**, 2007
|
||||
|
||||
Tenth anniversary release. Evolution backup functionality; improvements in Epiphany, EOG, GNOME Power Manager; password keyring management in Seahorse. Adds: PDF forms editing in Evince; integrated search in the file manager dialogs; automatic multimedia codec installer.
|
||||
|
||||

|
||||
|
||||
**GNOME 2.22**, 2008
|
||||
|
||||
Addition of Cheese, a tool for taking photos from webcams and Remote Desktop Viewer; basic window compositing support in Metacity; introduction of GVFS; improved playback support for DVDs and YouTube, MythTV support in Totem; internationalised clock applet; Google Calendar support and message tagging in Evolution; improvements in Evince, Tomboy, Sound Juicer and Calculator.
|
||||
|
||||

|
||||
|
||||
**GNOME 2.24**, 2008
|
||||
|
||||
Addition of the Empathy instant messenger client, Ekiga 3.0, tabbed browsing in Nautilus, better multiple screens support and improved digital TV support.
|
||||
|
||||

|
||||
|
||||
**GNOME 2.26**, 2009
|
||||
|
||||
New optical disc recording application Brasero, simpler file sharing, media player improvements, support for multiple monitors and fingerprint reader support.
|
||||
|
||||

|
||||
|
||||
**GNOME 2.28**, 2009
|
||||
|
||||
Addition of GNOME Bluetooth module. Improvements to Epiphany web browser, Empathy instant messenger client, Time Tracker, and accessibility. Upgrade to GTK+ version 2.18.
|
||||
|
||||

|
||||
|
||||
**GNOME 2.30**, 2010
|
||||
|
||||
Improvements to Nautilus file manager, Empathy instant messenger client, Tomboy, Evince, Time Tracker, Epiphany, and Vinagre. iPod and iPod Touch devices are now partially supported via GVFS through libimobiledevice. Uses GTK+ 2.20.
|
||||
|
||||

|
||||
|
||||
**GNOME 2.32**, 2010
|
||||
|
||||
Addition of Rygel and GNOME Color Manager. Improvements to Empathy instant messenger client, Evince, Nautilus file manager and others. 3.0 was intended to be released in September 2010, so a large part of the development effort since 2.30 went towards 3.0.
|
||||
|
||||
### GNOME 3 ###
|
||||
|
||||

|
||||
|
||||
**GNOME 3.0**, 2011
|
||||
|
||||
Introduction of GNOME Shell. A redesigned settings framework with fewer, more focused options. Topic-oriented help based on the Mallard markup language. Side-by-side window tiling. A new visual theme and default font. Adoption of GTK+ 3.0 with its improved language bindings, themes, touch, and multiplatform support. Removal of long-deprecated development APIs.[73]
|
||||
|
||||

|
||||
|
||||
**GNOME 3.2**, 2011
|
||||
|
||||
Online accounts support; Web applications support; contacts manager; documents and files manager; quick preview of files in the File Manager; greater integration; better documentation; enhanced looks and various performance improvements.
|
||||
|
||||

|
||||
|
||||
**GNOME 3.4**, 2012
|
||||
|
||||
New Look for GNOME 3 Applications: Documents, Epiphany (now called Web), and GNOME Contacts. Search for documents from the Activities overview. Application menus support. Refreshed interface components: New color picker, redesigned scrollbars, easier to use spin buttons, and hideable title bars. Smooth scrolling support. New animated backgrounds. Improved system settings with new Wacom panel. Easier extensions management. Better hardware support. Topic-oriented documentation. Video calling and Live Messenger support in Empathy. Better accessibility: Improved Orca integration, better high contrast mode, and new zoom settings. Plus many other application enhancements and smaller details.
|
||||
|
||||

|
||||
|
||||
**GNOME 3.6**, 2012
|
||||
|
||||
Refreshed Core components: New applications button and improved layout in the Activities Overview. A new login and lock screen. Redesigned Message Tray. Notifications are now smarter, more noticeable, easier to dismiss. Improved interface and settings for System Settings. The user menu now shows Power Off by default. Integrated Input Methods. Accessibility is always on. New applications: Boxes, that was introduced as a preview version in GNOME 3.4, and Clocks, an application to handle world times. Updated looks for Disk Usage Analyzer, Empathy and Font Viewer. Improved braille support in Orca. In Web, the previously blank start page was replaced by a grid that holds your most visited pages, plus better full screen mode and a beta of WebKit2. Evolution renders email using WebKit. Major improvements to Disks. Revamped Files application (also known as Nautilus), with new features like Recent files and search.
|
||||
|
||||

|
||||
|
||||
**GNOME 3.8**, 2013
|
||||
|
||||
Refreshed Core components: A new applications view with frequently used and all apps. An overhauled window layout. New input methods OSD switcher. The Notifications & Messaging tray now react to the force with which the pointer is pressed against the screen edge. Added Classic mode for those who prefer a more traditional desktop experience. The GNOME Settings application features an updated toolbar design. New Initial Setup assistant. GNOME Online Accounts integrates with more services. Web has been upgraded to use the WebKit2 engine. Web has a new private browsing mode. Documents has gained a new dual page mode & Google Documents integration. Improved user interface of Contacts. GNOME Files, GNOME Boxes and GNOME Disks have received a number of improvements. Integration of ownCloud. New GNOME Core Applications: GNOME Clocks and GNOME Weather.
|
||||
|
||||

|
||||
|
||||
**GNOME 3.10**, 2013
|
||||
|
||||
A reworked system status area, which gives a more focused overview of the system. A collection of new applications, including GNOME Maps, GNOME Notes, GNOME Music and GNOME Photos. New geolocation features, such as automatic time zones and world clocks. HiDPI support[75] and smart card support. D-Bus activation made possible with GLib 2.38
|
||||
|
||||

|
||||
|
||||
**GNOME 3.12**, 2014
|
||||
|
||||
Improved keyboard navigation and window selection in the Overview. Revamped first set-up utility based on usability tests. Wired networking re-added to the system status area. Customizable application folders in the Applications view. Introduction of new GTK+ widgets such as popovers in many applications. New tab style in GTK+. GNOME Videos GNOME Terminal and gedit were given a fresh look, more consistent with the HIG. A search provider for the terminal emulator is included in GNOME Shell. Improvements to GNOME Software and high-density display support. A new sound recorder application. New desktop notifications API. Progress in the Wayland port has reached a usable state that can be optionally previewed.
|
||||
|
||||

|
||||
|
||||
**GNOME 3.14**, 2014
|
||||
|
||||
Improved desktop environment animations. Improved touchscreen support. GNOME Software supports managing installed add-ons. GNOME Photos adds support for Google. Redesigned UI for Evince, Sudoku, Mines and Weather. Hitori is added as part of GNOME Games.
|
||||
|
||||

|
||||
|
||||
**GNOME 3.16**, 2015
|
||||
|
||||
33,000 changes. Major changes include UI color scheme goes from black to charcoal. Overlay scroll bars added. Improvements to notifications including integration with Calendar applet. Tweaks to various apps including Files, Image Viewer, and Maps. Access to Preview Apps. Continued porting from X11 to Wayland.
|
||||
|
||||
Thanks to [Wikipedia][2] for short changelogs review and another big thanks for GNOME Project! Stay tuned!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://tlhp.cf/18-years-of-gnome-evolution/
|
||||
|
||||
作者:[Pavlo Rudyi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://tlhp.cf/author/paul/
|
||||
[1]:https://www.gnome.org/
|
||||
[2]:https://en.wikipedia.org/wiki/GNOME
|
||||
@ -0,0 +1,170 @@
|
||||
30 Years of Free Software Foundation: Best Quotes of Richard Stallman
|
||||
================================================================================
|
||||
注:youtube 视频
|
||||
<iframe width="660" height="495" src="https://www.youtube.com/embed/aIL594DTzH4?feature=oembed" frameborder="0" allowfullscreen></iframe>
|
||||
|
||||
**Richard Matthew Stallman** (rms) – one of biggest figure in Information Technology. He is a computer programmer and architect (GNU Compiler Collection (GCC)), GNU Debugger, Emacs), software freedom evangelist, [GNU Project][1] and [FSF][2] founder.
|
||||
|
||||
**GNU** is a recursive acronym “GNU’s Not Unix!”. GNU – collection of free computer software for Unix-based operation system. Can be used with GNU/Hurd and Linux kernels. Announced on September 27, 1983. General components:
|
||||
|
||||
- GNU Compiler Collection (GCC)
|
||||
- GNU C library (glibc)
|
||||
- GNU Core Utilities (coreutils)
|
||||
- GNU Debugger (GDB)
|
||||
- GNU Binary Utilities (binutils)
|
||||
- GNU Bash shell
|
||||
- NOME desktop environment
|
||||
|
||||
注:视频
|
||||
<video src="//static.fsf.org/nosvn/FSF30-video/FSF_30_720p.webm" controls="controls" width="640" height="390"></video>
|
||||
|
||||
**Free Software Foundation** (FSF) – non-profit organization for free software and computer user freedom promotion and defend their rights. Read more information here. Founded on 4 October 1985.
|
||||
|
||||
- The freedom to run the program as you wish, for any purpose (freedom 0).
|
||||
- The freedom to study how the program works, and change it so it does your computing as you wish (freedom 1). Access to the source code is a precondition for this.
|
||||
- The freedom to redistribute copies so you can help your neighbor (freedom 2).
|
||||
- The freedom to distribute copies of your modified versions to others (freedom 3). By doing this you can give the whole community a chance to benefit from your changes. Access to the source code is a precondition for this.
|
||||
|
||||
This is the Four Freedoms of free software.
|
||||
|
||||
Here is quotes of Richard Stallman about freedom, software, social, philosophy and others things.
|
||||
|
||||
**About Facebook:**
|
||||
|
||||
> Facebook is not your friend, it is a surveillance engine.
|
||||
|
||||
**About Android:**
|
||||
|
||||
> Android is very different from the GNU/Linux operating system because it contains very little of GNU. Indeed, just about the only component in common between Android and GNU/Linux is Linux, the kernel.
|
||||
|
||||
**About computer industry:**
|
||||
|
||||
> The computer industry is the only industry that is more fashion-driven than women's fashion.
|
||||
|
||||
**About cloud computing:**
|
||||
|
||||
> The interesting thing about cloud computing is that we've redefined cloud computing to include everything that we already do.
|
||||
|
||||
**About ethics:**
|
||||
|
||||
> Whether gods exist or not, there is no way to get absolute certainty about ethics. Without absolute certainty, what do we do? We do the best we can.
|
||||
|
||||
**About freedom:**
|
||||
|
||||
> Free software is software that respects your freedom and the social solidarity of your community. So it's free as in freedom.
|
||||
|
||||
**About goal and idealism:**
|
||||
|
||||
> If you want to accomplish something in the world, idealism is not enough - you need to choose a method that works to achieve the goal.
|
||||
|
||||
**About sharing:**
|
||||
|
||||
> Sharing is good, and with digital technology, sharing is easy.
|
||||
|
||||
**About facebook (extended version):**
|
||||
|
||||
> Facebook mistreats its users. Facebook is not your friend; it is a surveillance engine. For instance, if you browse the Web and you see a 'like' button in some page or some other site that has been displayed from Facebook. Therefore, Facebook knows that your machine visited that page.
|
||||
|
||||
**About web application:**
|
||||
|
||||
> One reason you should not use web applications to do your computing is that you lose control.
|
||||
>
|
||||
> If you use a proprietary program or somebody else's web server, you're defenceless. You're putty in the hands of whoever developed that software.
|
||||
|
||||
**About books:**
|
||||
|
||||
> With paper printed books, you have certain freedoms. You can acquire the book anonymously by paying cash, which is the way I always buy books. I never use a credit card. I don't identify to any database when I buy books. Amazon takes away that freedom.
|
||||
|
||||
**About MPAA:**
|
||||
|
||||
> Officially, MPAA stands for Motion Picture Association of America, but I suggest that MPAA stands for Malicious Power Attacking All.
|
||||
|
||||
**About money and career:**
|
||||
|
||||
> I could have made money this way, and perhaps amused myself writing code. But I knew that at the end of my career, I would look back on years of building walls to divide people, and feel I had spent my life making the world a worse place.
|
||||
|
||||
**About proprietary software:**
|
||||
|
||||
> Proprietary software keeps users divided and helpless. Divided because each user is forbidden to redistribute it to others, and helpless because the users can't change it since they don't have the source code. They can't study what it really does. So the proprietary program is a system of unjust power.
|
||||
|
||||
**About smartphone:**
|
||||
|
||||
> A smartphone is a computer - it's not built using a computer - the job it does is the job of being a computer. So, everything we say about computers, that the software you run should be free - you should insist on that - applies to smart phones just the same. And likewise to those tablets.
|
||||
|
||||
**About CD and digital content:**
|
||||
|
||||
> CD stores have the disadvantage of an expensive inventory, but digital bookshops would need no such thing: they could write copies at the time of sale on to memory sticks, and sell you one if you forgot your own.
|
||||
|
||||
**About paradigm of competition:**
|
||||
|
||||
> The paradigm of competition is a race: by rewarding the winner, we encourage everyone to run faster. When capitalism really works this way, it does a good job; but its defenders are wrong in assuming it always works this way.
|
||||
|
||||
**About vi and emacs:**
|
||||
|
||||
> People sometimes ask me if it is a sin in the Church of Emacs to use vi. Using a free version of vi is not a sin; it is a penance. So happy hacking.
|
||||
|
||||
**About freedom and history:**
|
||||
|
||||
> Value your freedom or you will lose it, teaches history. 'Don't bother us with politics', respond those who don't want to learn.
|
||||
|
||||
**About patents:**
|
||||
|
||||
> Fighting patents one by one will never eliminate the danger of software patents, any more than swatting mosquitoes will eliminate malaria.
|
||||
>
|
||||
> Software patents are dangerous to software developers because they impose monopolies on software ideas.
|
||||
|
||||
**About copyrights:**
|
||||
|
||||
> In practice, the copyright system does a bad job of supporting authors, aside from the most popular ones. Other authors' principal interest is to be better known, so sharing their work benefits them as well as readers.
|
||||
|
||||
**About pay for work:**
|
||||
|
||||
> There is nothing wrong with wanting pay for work, or seeking to maximize one's income, as long as one does not use means that are destructive.
|
||||
|
||||
**About Chrome OS:**
|
||||
|
||||
> In essence, Chrome OS is the GNU/Linux operating system. However, it is delivered without the usual applications, and rigged up to impede and discourage installing applications.
|
||||
|
||||
**About Linux users:**
|
||||
|
||||
> Many users of the GNU/Linux system will not have heard the ideas of free software. They will not be aware that we have ideas, that a system exists because of ethical ideals, which were omitted from ideas associated with the term 'open source.'
|
||||
|
||||
**About privacy in facebook:**
|
||||
|
||||
> If there is a Like button in a page, Facebook knows who visited that page. And it can get IP address of the computer visiting the page even if the person is not a Facebook user.
|
||||
|
||||
**About programming:**
|
||||
|
||||
> Programming is not a science. Programming is a craft.
|
||||
>
|
||||
> My favorite programming languages are Lisp and C. However, since around 1992 I have worked mainly on free software activism, which means I am too busy to do much programming. Around 2008 I stopped doing programming projects.
|
||||
>
|
||||
> C++ is a badly designed and ugly language. It would be a shame to use it in Emacs.
|
||||
|
||||
**About hacking and learn programming:**
|
||||
|
||||
> People could no longer learn hacking the way I did, by starting to work on a real operating system, making real improvements. In fact, in the 1980s I often came across newly graduated computer science majors who had never seen a real program in their lives. They had only seen toy exercises, school exercises, because every real program was a trade secret. They never had the experience of writing features for users to really use, and fixing the bugs that real users came across. The things you need to know to do real work.
|
||||
>
|
||||
> It is hard to write a simple definition of something as varied as hacking, but I think what these activities have in common is playfulness, cleverness, and exploration. Thus, hacking means exploring the limits of what is possible, in a spirit of playful cleverness. Activities that display playful cleverness have "hack value".
|
||||
|
||||
**About web browsing:**
|
||||
|
||||
> For personal reasons, I do not browse the web from my computer. (I also have no net connection much of the time.) To look at page I send mail to a daemon which runs wget and mails the page back to me. It is very efficient use of my time, but it is slow in real time.
|
||||
|
||||
**About music sharing:**
|
||||
|
||||
> Friends share music with each other, they don't allow themselves to be divided by a system that says that nobody is supposed to have copies.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://tlhp.cf/fsf-richard-stallman/
|
||||
|
||||
作者:[Pavlo Rudyi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://tlhp.cf/author/paul/
|
||||
[1]:http://www.gnu.org/
|
||||
[2]:http://www.fsf.org/
|
||||
@ -0,0 +1,83 @@
|
||||
Five Years of LibreOffice Evolution (2010-2015)
|
||||
================================================================================
|
||||
注:youtube 视频
|
||||
<iframe width="660" height="371" src="https://www.youtube.com/embed/plo8kP_ts-8?feature=oembed" frameborder="0" allowfullscreen></iframe>
|
||||
|
||||
[LibreOffice][1] – amazing free and open source office suite from The Document Foundation. LO was forked from [OpenOffice.org][2] in September 28, 2010 and OOo is an open-source version of the earlier [StarOffice][3]. The LibreOffice support word processing, the creation and editing of spreadsheets, slideshows, diagrams and drawings, databases, mathematical formulae.
|
||||
|
||||
### Core applications: ###
|
||||
|
||||
- **Writer** – word processor
|
||||
- **Calc** – spreadsheet app, similar to Excel
|
||||
- **Impress** – application for presentations, support Microsoft PowerPoint’s format
|
||||
- **Draw** – vector graphics editor
|
||||
- **Math** – special application for writing and editing mathematical formulae
|
||||
- **Base** – database management
|
||||
|
||||

|
||||
|
||||
LibreOffice 3.3, 2011
|
||||
|
||||
First version of LibreOffice – fork of OpenOffice.org
|
||||
|
||||

|
||||
|
||||
LibreOffice 3.4
|
||||
|
||||

|
||||
|
||||
LibreOffice 3.5
|
||||
|
||||

|
||||
|
||||
LibreOffice 3.6
|
||||
|
||||

|
||||
|
||||
LibreOffice 4.0
|
||||
|
||||

|
||||
|
||||
LibreOffice 4.1
|
||||
|
||||

|
||||
|
||||
Libre Office 4.2
|
||||
|
||||

|
||||
|
||||
LibreOffice 4.3
|
||||
|
||||

|
||||
|
||||
LibreOffice 4.4
|
||||
|
||||

|
||||
|
||||
LibreOffice 5.0
|
||||
|
||||
### History of Libre Office from Wikipedia ###
|
||||
|
||||

|
||||
|
||||
|
||||
### LibreOffice 5.0 Review ###
|
||||
|
||||
注:youtube 视频
|
||||
|
||||
<iframe width="660" height="371" src="https://www.youtube.com/embed/BVdofVqarAc?feature=oembed" frameborder="0" allowfullscreen></iframe>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://tlhp.cf/libreoffice-5years-evolution/
|
||||
|
||||
作者:[Pavlo Rudyi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://tlhp.cf/author/paul/
|
||||
[1]:http://www.libreoffice.org/
|
||||
[2]:https://www.openoffice.org/
|
||||
[3]:http://www.staroffice.org/
|
||||
@ -0,0 +1,119 @@
|
||||
Mark Shuttleworth – The Man Behind Ubuntu Operating System
|
||||
================================================================================
|
||||

|
||||
|
||||
**Mark Richard Shuttleworth** is the founder of **Ubuntu** or the man behind the Debian as they call him. He was born in 1973 in Welkom, South Africa. He’s an entrepreneur and also space tourist who became later **1st citizen of independent African country who could travel to the space**.
|
||||
|
||||
Mark also founded **Thawte** in 1996, the Internet commerce security company, while he was studying finance and IT at University of Cape Town.
|
||||
|
||||
In 2000, Mark founded the HBD, as an investment company, and also he created the Shuttleworth Foundation in order to fund the innovative leaders in the society with combination of fellowships and some investments.
|
||||
|
||||
> “The mobile world is crucial to the future of the PC. This month, for example, it became clear that the traditional PC is shrinking in favor of tablets. So if we want to be relevant on the PC, we have to figure out how to be relevant in the mobile world first. Mobile is also interesting because there’s no pirated Windows market. So if you win a device to your OS, it stays on your OS. In the PC world, we are constantly competing with “free Windows”, which presents somewhat unique challenges. So our focus now is to establish a great story around Ubuntu and mobile form factors – the tablet and the phone – on which we can build deeper relationships with everyday consumers.”
|
||||
>
|
||||
> — Mark Shuttleworth
|
||||
|
||||
In 2002, he flew to International Space Station as member of their crew of Soyuz mission TM-34, after 1 year of training in the Star City, Russia. And after running campaign to promote the science, code, and mathematics to the aspiring astronauts and the other ambitious types at schools in SA, Mark founded the **Canonical Ltd**. and in 2013, he provided leadership for Ubuntu operating system for software development purposes.
|
||||
|
||||
Today, Shuttleworth holds dual citizenship of United Kingdom and South Africa currently lives on lovely Mallards botanical garden in Isle of Man, with 18 precocious ducks, equally his lovely girlfriend Claire, 2 black bitches and occasional itinerant sheep.
|
||||
|
||||
> “Computer is not a device anymore. It is an extension of your mind and your gateway to other people.”
|
||||
>
|
||||
> — Mark Shuttleworth
|
||||
|
||||
### Mark Shuttleworth’s Early life ###
|
||||
|
||||
As we mentioned above, Mark was born in Welkom, South Africa’s Orange Free State as son of surgeon and nursery-school teacher, Mark attended the school at Western Province Preparatory School where he became eventually the Head Boy in 1986, followed by 1 term at Rondebosch Boys’ High School, and later at Bishops/Diocesan College where he was again Head Boy in 1991.
|
||||
|
||||
Mark obtained the Bachelor of Business Science degree in the Finance and Information Systems at University of Cape Town, where he lived there in Smuts Hall. He became, as a student, involved in installations of the 1st residential Internet connections at his university.
|
||||
|
||||
> “There are many examples of companies and countries that have improved their competitiveness and efficiency by adopting open source strategies. The creation of skills through all levels is of fundamental importance to both companies and countries.”
|
||||
>
|
||||
> — Mark Shuttleworth
|
||||
|
||||
### Mark Shuttleworth’s Career ###
|
||||
|
||||
Mark founded Thawte in 1995, which was specialized in the digital certificates and Internet security, then he sold it to VeriSign in 1999, earning about $575 million at the time.
|
||||
|
||||
In 2000, Mark formed the HBD Venture Capital (Here be Dragons), the business incubator and venture capital provider. In 2004, he formed the Canonical Ltd., for promotion and commercial support of the free software development projects, especially Ubuntu operating system. In 2009, Mark stepped down as CEO of Canonical, Ltd.
|
||||
|
||||
> “In the early days of the DCC I preferred to let the proponents do their thing and then see how it all worked out in the end. Now we are pretty close to the end.”
|
||||
>
|
||||
> — Mark Shuttleworth
|
||||
|
||||
### Linux and FOSS with Mark Shuttleworth ###
|
||||
|
||||
In the late 1990s, Mark participated as one of developers of Debian operating system.
|
||||
|
||||
In 2001, Mark formed the Shuttleworth Foundation, It is non-profit organization dedicated to the social innovation that also funds free, educational, and open source software projects in South Africa, including Freedom Toaster.
|
||||
|
||||
In 2004, Mark returned to free software world by funding software development of Ubuntu, as it was Linux distribution based on Debian, throughout his company Canonical Ltd.
|
||||
|
||||
In 2005, Mark founded Ubuntu Foundation and made initial investment of 10 million dollars. In Ubuntu project, Mark is often referred to with tongue-in-cheek title “**SABDFL (Self-Appointed Benevolent Dictator for Life)**”. To come up with list of names of people in order to hire for the entire project, Mark took about six months of Debian mailing list archives with him during his travelling to Antarctica aboard icebreaker Kapitan Khlebnikov in 2004. In 2005, Mark purchased 65% stake of Impi Linux.
|
||||
|
||||
> “I urge telecommunications regulators to develop a commercial strategy for delivering effective access to the continent.”
|
||||
>
|
||||
> — Mark Shuttleworth
|
||||
|
||||
In 2006, it was announced that Shuttleworth became **first patron of KDE**, which was highest level of sponsorship available at the time. This patronship ended in 2012, with financial support together for Kubuntu, which was Ubuntu variant with KDE as a main desktop.
|
||||
|
||||

|
||||
|
||||
In 2009, Shuttleworth announced that, he would step down as the CEO of Canonical in order to focus more energy on partnership, product design, and the customers. Jane Silber, took on this job as the CEO at Canonical after he was the COO at Canonical since 2004.
|
||||
|
||||
In 2010, Mark received the honorary degree from Open University for that work.
|
||||
|
||||
In 2012, Mark and Kenneth Rogoff took part together in debate opposite Peter Thiel and Garry Kasparov at Oxford Union, this debate was entitled “**The Innovation Enigma**”.
|
||||
|
||||
In 2013, Mark and Ubuntu were awarded **Austrian anti-privacy Big Brother Award** for sending the local Ubuntu Unity Dash searches to the Canonical servers by default. One year earlier in 2012, Mark had defended the anonymization method that was used.
|
||||
|
||||
> “All the major PC companies now ship PC’s with Ubuntu pre-installed. So we have a very solid set of working engagements in the industry. But those PC companies are nervous to promote something new to PC buyers. If we can get PC buyers familiar with Ubuntu as a phone and tablet experience, then they may be more willing buy it on the PC too. Because no OS ever succeeded by emulating another OS. Android is great, but if we want to succeed we need to bring something new and better to market. We are all at risk of stagnating if we don’t pursue the future, vigorously. But if you pursue the future, you have to accept that not everybody will agree with your vision.”
|
||||
>
|
||||
> — Mark Shuttleworth
|
||||
|
||||
### Mark Shuttleworth’s Spaceflight ###
|
||||
|
||||
Mark gained worldwide fame in 2002 as a second self-funded space tourist and the first South African who could travel to the space. Flying through Space Adventures, Mark launched aboard Russian Soyuz TM-34 mission as spaceflight participant, and he paid approximately $20 million for that voyage. 2 days later, Soyuz spacecraft arrived at International Space Station, where Mark spent 8 days participating in the experiments related to the AIDS and the GENOME research. Later in 2002, Mark returned to the Earth on the Soyuz TM-33. To participate in that flight, Mark had to undergo 1 year of preparation and training, including 7 months spent in the Star City, Russia.
|
||||
|
||||

|
||||
|
||||
While in space, Mark had radio conversation with Nelson Mandela and another 14 year old South African girl, called Michelle Foster, who asked Mark to marry her. Of course Mark politely dodged that question, stating that he was much honored to this question before cunningly change the subject. The terminally ill Foster was also provided the opportunity to have conversation with Mark and Nelson Mandela by Reach for Dream foundation.
|
||||
|
||||
Upon returning, Mark traveled widely and also spoke about that spaceflight to schoolchildren around the world.
|
||||
|
||||
> “The raw numbers suggest that Ubuntu continues to grow in terms of actual users. And our partnerships – Dell, HP, Lenovo on the hardware front, and gaming companies like EA, Valve joining up on the software front – make me feel like we continue to lead where it matters.”
|
||||
>
|
||||
> — Mark Shuttleworth
|
||||
|
||||
### Mark Shuttleworth’s Transport ###
|
||||
|
||||
Mark has his private jet, Bombardier Global Express that is often referred to as Canonical One but it’s in fact owned through the HBD Venture Capital Company. The dragon depicted on side of the plane is Norman, HBD Venture Capital mascot.
|
||||
|
||||
### The Legal Clash with South African Reserve Bank ###
|
||||
|
||||
Upon the moving R2.5 billion in the capital from South Africa to Isle of Man, South African Reserve Bank imposed R250 million levy to release Mark’s assets. Mark appealed, and then after lengthy legal battle, Reserve Bank was ordered to repay Mark his R250 million, plus the interest. Mark announced that he would be donating that entire amount to trust that will be established in order to help others take cases to Constitutional Court.
|
||||
|
||||
> “The exit charge was not inconsistent with the Constitution. The dominant purpose of the exit charge was not to raise revenue but rather to regulate conduct by discouraging the export of capital to protect the domestic economy.”
|
||||
>
|
||||
> — Judge Dikgang Moseneke
|
||||
|
||||
In 2015, Constitutional Court of South Africa reversed and set-aside findings of lower courts, ruling that dominant purpose of the exit charge was in order to regulate conduct rather than for raising the revenue.
|
||||
|
||||
### Mark Shuttleworth’s likes ###
|
||||
|
||||
Cesária Évora, mp3s,Spring, Chelsea, finally seeing something obvious for first time, coming home, Sinatra, daydreaming, sundowners, flirting, d’Urberville, string theory, Linux, particle physics, Python, reincarnation, mig-29s, snow, travel, Mozilla, lime marmalade, body shots, the African bush, leopards, Rajasthan, Russian saunas, snowboarding, weightlessness, Iain m banks, broadband, Alastair Reynolds, fancy dress, skinny-dipping, flashes of insight, post-adrenaline euphoria, the inexplicable, convertibles, Clifton, country roads, international space station, machine learning, artificial intelligence, Wikipedia, Slashdot, kitesurfing, and Manx lanes.
|
||||
|
||||
### Shuttleworth’s dislikes ###
|
||||
|
||||
Admin, salary negotiations, legalese, and public speaking.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/mark-shuttleworth-man-behind-ubuntu-operating-system/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/pirat9/
|
||||
@ -0,0 +1,68 @@
|
||||
Ubuntu 15.10, Codenamed Wily Werewolf, Review
|
||||
================================================================================
|
||||

|
||||
|
||||
The problem we have with reviewing Ubuntu on any occasion, is readers consistently expect to read of a revolutionary new release, every 6 months. If you’re expecting Ubuntu 15.10 to be just that, then you may want to click out of this review right now. It’s important to clarify that this is nothing negative towards 15.10 as a release, but it is a maintenance release and not a release which purports to introduce a great deal of new software.
|
||||
|
||||
With that opening disclaimer out of the way, let’s take a look at what 15.10 does offer.
|
||||
|
||||
### Linux kernel 4.2 ###
|
||||
|
||||
The biggest change you will find with Ubuntu 15.10 is the kernel branch has been upgraded to **Linux 4.2**.
|
||||
|
||||
This is long overdue for Ubuntu. It feels like it has been lagging behind other distributions by sticking with the 3.x branch of Linux for the entirety of the 15.04 cycle.
|
||||
|
||||
If you’re going to be installing Ubuntu 15.10 on new hardware, then you will benefit greatly from the Linux kernel upgrade to 4.x branch as there is loads of updates which directly improve performance on new hardware. Support for AMDGPU kernel DRM is included, which is a boon for owners of recent Radeon graphics cards. The latest iteration of the driver will reside alongside the current Radeon DRM drivers, which was already in the kernel in addition to the usual open-source driver offerings.
|
||||
|
||||
Support for Intel Broxton is also included in Linux 4.2, albeit Ubuntu 15.10 users are probably going to get nothing out of this update, yet it’s still worthy of a mention we think. There are also some erroneous updates for Skylake CPU’s. Finally, there is a host of code updates and fixes for Ext4 filesystems.
|
||||
|
||||
That pretty much rounds out the Linux kernel 4.2 updates. So what else is new? Let’s take a closer look at the software that you may be more familiar with and get more excited about.
|
||||
|
||||
### Software ###
|
||||
|
||||
LibreOffice has been upgraded to 5.0.1.2, a major update for LibreOffice users. Firefox on the version that we tested is sitting at 41.0.2. By the time you read this, it will most-likely be updated again and you may see a newer version be pushed out through the Ubuntu Repositories.
|
||||
|
||||
On the desktop front, a vanilla Ubuntu installation will see you running Unity 7.3.2 while GNOME sits at 3.8. On the KDE end, a Plasma 5 desktop will see you running version 5.4.2. For the alternative desktop-environments, XFCE has been upgraded to the latest revision, 4.12 while the version of MATE includes 1.10.
|
||||
|
||||
### User Experience/Screenshots ###
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Ubuntu 15.10 as a operating system for Review is pretty lackluster. There’s nothing new as such and there’s nothing we can really say that is going to change your opinion from its predecessor, 15.04. Therefore, we recommend you to upgrade either out of habit and according to your regular upgrade schedule rather than out of a specific necessity for a specific feature of this release. Because there is really nothing that could possibly differentiate it from the older, yet still very stable 15.04 release. But if you’re going to stick with 15.04 for a little longer, we do recommend that you look at [upgrading the kernel to the latest 4.2 branch][2]. It is worth it.
|
||||
|
||||
If you really want a reason to upgrade? Linux kernel 4.2 would be our sole reason for taking Ubuntu 15.10 into consideration.
|
||||
|
||||
### Looking Ahead ###
|
||||
|
||||
What we really look forward to is the release of Ubuntu 16.04. We have been promised over and over again for several releases that Mir will be the default display server included in Ubuntu. We still see releases pushed out that rely on X.org. It has resulted in us adopting a “yeah right” attitude as we have become accustomed to the usual delay announcements.
|
||||
|
||||
We are hopeful that Mir Developers can push out a working version in time for the release of 16.04 next year. As precaution though, we urge you to not get too excited because it may very well not happen.
|
||||
|
||||
It remains much the same with Unity 8. It’s most certainly a possibility, but we can’t guarantee that it will be included in 16.04, yet we remain hopeful.
|
||||
|
||||
As we’ve mentioned for this release, there’s nothing really ground-breaking with this release. In fact, it has been much the same story for the last couple of releases of Ubuntu Linux. It is in dire need of a distribution-wide reboot. Developers and Ubuntu users alike are positive that Mir and Unity 8 will be the two primary packages that may just provide the popular, yet ailing, distribution the reboot that it needs.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/ubuntu-15-10-codenamed-wily-werewolf-review/
|
||||
|
||||
作者:[Chris Jones][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/chris/
|
||||
[1]:http://www.unixmen.com/how-to-install-linux-kernel-4-2-3/
|
||||
@ -1,202 +0,0 @@
|
||||
[bazz222]
|
||||
How to filter BGP routes in Quagga BGP router
|
||||
================================================================================
|
||||
In the [previous tutorial][1], we demonstrated how to turn a CentOS box into a BGP router using Quagga. We also covered basic BGP peering and prefix exchange setup. In this tutorial, we will focus on how we can control incoming and outgoing BGP prefixes by using **prefix-list** and **route-map**.
|
||||
|
||||
As described in earlier tutorials, BGP routing decisions are made based on the prefixes received/advertised. To ensure error-free routing, it is recommended that you use some sort of filtering mechanism to control these incoming and outgoing prefixes. For example, if one of your BGP neighbors starts advertising prefixes which do not belong to them, and you accept such bogus prefixes by mistake, your traffic can be sent to that wrong neighbor, and end up going nowhere (so-called "getting blackholed"). To make sure that such prefixes are not received or advertised to any neighbor, you can use prefix-list and route-map. The former is a prefix-based filtering mechanism, while the latter is a more general prefix-based policy mechanism used to fine-tune actions.
|
||||
|
||||
We will show you how to use prefix-list and route-map in Quagga.
|
||||
|
||||
### Topology and Requirement ###
|
||||
|
||||
In this tutorial, we assume the following topology.
|
||||
|
||||

|
||||
|
||||
Service provider A has already established an eBGP peering with service provider B, and they are exchanging routing information between them. The AS and prefix details are as stated below.
|
||||
|
||||
- **Peering block**: 192.168.1.0/24
|
||||
- **Service provider A**: AS 100, prefix 10.10.0.0/16
|
||||
- **Service provider B**: AS 200, prefix 10.20.0.0/16
|
||||
|
||||
In this scenario, service provider B wants to receive only prefixes 10.10.10.0/23, 10.10.10.0/24 and 10.10.11.0/24 from provider A.
|
||||
|
||||
### Quagga Installation and BGP Peering ###
|
||||
|
||||
In the [previous tutorial][1], we have already covered the method of installing Quagga and setting up BGP peering. So we will not go through the details here. Nonetheless, I am providing a summary of BGP configuration and prefix advertisements:
|
||||
|
||||

|
||||
|
||||
The above output indicates that the BGP peering is up. Router-A is advertising multiple prefixes towards router-B. Router-B, on the other hand, is advertising a single prefix 10.20.0.0/16 to router-A. Both routers are receiving the prefixes without any problems.
|
||||
|
||||
### Creating Prefix-List ###
|
||||
|
||||
In a router, a prefix can be blocked with either an ACL or prefix-list. Using prefix-list is often preferred to ACLs since prefix-list is less processor intensive than ACLs. Also, prefix-list is easier to create and maintain.
|
||||
|
||||
ip prefix-list DEMO-PRFX permit 192.168.0.0/23
|
||||
|
||||
The above command creates prefix-list called 'DEMO-FRFX' that allows only 192.168.0.0/23.
|
||||
|
||||
Another great feature of prefix-list is that we can specify a range of subnet mask(s). Take a look at the following example:
|
||||
|
||||
ip prefix-list DEMO-PRFX permit 192.168.0.0/23 le 24
|
||||
|
||||
The above command creates prefix-list called 'DEMO-PRFX' that permits prefixes between 192.168.0.0/23 and /24, which are 192.168.0.0/23, 192.168.0.0/24 and 192.168.1.0/24. The 'le' operator means less than or equal to. You can also use 'ge' operator for greater than or equal to.
|
||||
|
||||
A single prefix-list statement can have multiple permit/deny actions. Each statement is assigned a sequence number which can be determined automatically or specified manually.
|
||||
|
||||
Multiple prefix-list statements are parsed one by one in the increasing order of sequence numbers. When configuring prefix-list, we should keep in mind that there is always an **implicit deny** at the end of all prefix-list statements. This means that anything that is not explicitly allowed will be denied.
|
||||
|
||||
To allow everything, we can use the following prefix-list statement which allows any prefix starting from 0.0.0.0/0 up to anything with subnet mask /32.
|
||||
|
||||
ip prefix-list DEMO-PRFX permit 0.0.0.0/0 le 32
|
||||
|
||||
Now that we know how to create prefix-list statements, we will create prefix-list called 'PRFX-LST' that will allow prefixes required in our scenario.
|
||||
|
||||
router-b# conf t
|
||||
router-b(config)# ip prefix-list PRFX-LST permit 10.10.10.0/23 le 24
|
||||
|
||||
### Creating Route-Map ###
|
||||
|
||||
Besides prefix-list and ACLs, there is yet another mechanism called route-map, which can control prefixes in a BGP router. In fact, route-map can fine-tune possible actions more flexibly on the prefixes matched with an ACL or prefix-list.
|
||||
|
||||
Similar to prefix-list, a route-map statement specifies permit or deny action, followed by a sequence number. Each route-map statement can have multiple permit/deny actions with it. For example:
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
|
||||
The above statement creates route-map called 'DEMO-RMAP', and adds permit action with sequence 10. Now we will use match command under sequence 10.
|
||||
|
||||
router-a(config-route-map)# match (press ? in the keyboard)
|
||||
|
||||
----------
|
||||
|
||||
as-path Match BGP AS path list
|
||||
community Match BGP community list
|
||||
extcommunity Match BGP/VPN extended community list
|
||||
interface match first hop interface of route
|
||||
ip IP information
|
||||
ipv6 IPv6 information
|
||||
metric Match metric of route
|
||||
origin BGP origin code
|
||||
peer Match peer address
|
||||
probability Match portion of routes defined by percentage value
|
||||
tag Match tag of route
|
||||
|
||||
As we can see, route-map can match many attributes. We will match a prefix in this tutorial.
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
match ip address prefix-list DEMO-PRFX
|
||||
|
||||
The match command will match the IP addresses permitted by the prefix-list 'DEMO-PRFX' created earlier (i.e., prefixes 192.168.0.0/23, 192.168.0.0/24 and 192.168.1.0/24).
|
||||
|
||||
Next, we can modify the attributes by using the set command. The following example shows possible use cases of set.
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
match ip address prefix-list DEMO-PRFX
|
||||
set (press ? in keyboard)
|
||||
|
||||
----------
|
||||
|
||||
aggregator BGP aggregator attribute
|
||||
as-path Transform BGP AS-path attribute
|
||||
atomic-aggregate BGP atomic aggregate attribute
|
||||
comm-list set BGP community list (for deletion)
|
||||
community BGP community attribute
|
||||
extcommunity BGP extended community attribute
|
||||
forwarding-address Forwarding Address
|
||||
ip IP information
|
||||
ipv6 IPv6 information
|
||||
local-preference BGP local preference path attribute
|
||||
metric Metric value for destination routing protocol
|
||||
metric-type Type of metric
|
||||
origin BGP origin code
|
||||
originator-id BGP originator ID attribute
|
||||
src src address for route
|
||||
tag Tag value for routing protocol
|
||||
vpnv4 VPNv4 information
|
||||
weight BGP weight for routing table
|
||||
|
||||
As we can see, the set command can be used to change many attributes. For a demonstration purpose, we will set BGP local preference.
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
match ip address prefix-list DEMO-PRFX
|
||||
set local-preference 500
|
||||
|
||||
Just like prefix-list, there is an implicit deny at the end of all route-map statements. So we will add another permit statement in sequence number 20 to permit everything.
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
match ip address prefix-list DEMO-PRFX
|
||||
set local-preference 500
|
||||
!
|
||||
route-map DEMO-RMAP permit 20
|
||||
|
||||
The sequence number 20 does not have a specific match command, so it will, by default, match everything. Since the decision is permit, everything will be permitted by this route-map statement.
|
||||
|
||||
If you recall, our requirement is to only allow/deny some prefixes. So in our scenario, the set command is not necessary. We will just use one permit statement as follows.
|
||||
|
||||
router-b# conf t
|
||||
router-b(config)# route-map RMAP permit 10
|
||||
router-b(config-route-map)# match ip address prefix-list PRFX-LST
|
||||
|
||||
This route-map statement should do the trick.
|
||||
|
||||
### Applying Route-Map ###
|
||||
|
||||
Keep in mind that ACLs, prefix-list and route-map are not effective unless they are applied to an interface or a BGP neighbor. Just like ACLs or prefix-list, a single route-map statement can be used with any number of interfaces or neighbors. However, any one interface or a neighbor can support only one route-map statement for inbound, and one for outbound traffic.
|
||||
|
||||
We will apply the created route-map to the BGP configuration of router-B for neighbor 192.168.1.1 with incoming prefix advertisement.
|
||||
|
||||
router-b# conf terminal
|
||||
router-b(config)# router bgp 200
|
||||
router-b(config-router)# neighbor 192.168.1.1 route-map RMAP in
|
||||
|
||||
Now, we check the routes advertised and received by using the following commands.
|
||||
|
||||
For advertised routes:
|
||||
|
||||
show ip bgp neighbor-IP advertised-routes
|
||||
|
||||
For received routes:
|
||||
|
||||
show ip bgp neighbor-IP routes
|
||||
|
||||

|
||||
|
||||
You can see that while router-A is advertising four prefixes towards router-B, router-B is accepting only three prefixes. If we check the range, we can see that only the prefixes that are allowed by route-map are visible on router-B. All other prefixes are discarded.
|
||||
|
||||
**Tip**: If there is no change in the received prefixes, try resetting the BGP session using the command: "clear ip bgp neighbor-IP". In our case:
|
||||
|
||||
clear ip bgp 192.168.1.1
|
||||
|
||||
As we can see, the requirement has been met. We can create similar prefix-list and route-map statements in routers A and B to further control inbound and outbound prefixes.
|
||||
|
||||
I am summarizing the configuration in one place so you can see it all at a glance.
|
||||
|
||||
router bgp 200
|
||||
network 10.20.0.0/16
|
||||
neighbor 192.168.1.1 remote-as 100
|
||||
neighbor 192.168.1.1 route-map RMAP in
|
||||
!
|
||||
ip prefix-list PRFX-LST seq 5 permit 10.10.10.0/23 le 24
|
||||
!
|
||||
route-map RMAP permit 10
|
||||
match ip address prefix-list PRFX-LST
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this tutorial, we showed how we can filter BGP routes in Quagga by defining prefix-list and route-map. We also demonstrated how we can combine prefix-list with route-map to fine-control incoming prefixes. You can create your own prefix-list and route-map in a similar way to match your network requirements. These tools are one of the most effective ways to protect the production network from route poisoning and advertisement of bogon routes.
|
||||
|
||||
Hope this helps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/filter-bgp-routes-quagga-bgp-router.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/centos-bgp-router-quagga.html
|
||||
@ -1,96 +0,0 @@
|
||||
How to Run ISO Files Directly From the HDD with GRUB2
|
||||
================================================================================
|
||||

|
||||
|
||||
Most Linux distros offer a live environment, which you can boot up from a USB drive, for you to test the system without installing. You can either use it to evaluate the distro or as a disposable OS. While it is easy to copy these onto a USB disk, in certain cases one might want to run the same ISO image often or run different ones regularly. GRUB 2 can be configured so that you do not need to burn the ISOs to disk or use a USB drive, but need to run a live environment directly form the boot menu.
|
||||
|
||||
### Obtaining and checking bootable ISO images ###
|
||||
|
||||
To obtain an ISO image, you should usually visit the website of the desired distribution and download any image that is compatible with your setup. If the image can be started from a USB, it should be able to start from the GRUB menu as well.
|
||||
|
||||
Once the image has finished downloading, you should check its integrity by running a simple md5 check on it. This will output a long combination of numbers and alphanumeric characters
|
||||
|
||||

|
||||
|
||||
which you can compare against the MD5 checksum provided on the download page. The two should be identical.
|
||||
|
||||
### Setting up GRUB 2 ###
|
||||
|
||||
ISO images contain full systems. All you need to do is direct GRUB2 to the appropriate file, and tell it where it can find the kernel and the initramdisk or initram filesystem (depending on which one your distribution uses).
|
||||
|
||||
In this example, a Kubuntu 15.04 live environment will be set up to run on an Ubuntu 14.04 box as a Grub menu item. It should work for most newer Ubuntu-based systems and derivatives. If you have a different system or want to achieve something else, you can get some ideas on how to do this from one of [these files][1], although it will require a little experience with GRUB.
|
||||
|
||||
In this example the file `kubuntu-15.04-desktop-amd64.iso`
|
||||
|
||||
lives in `/home/maketecheasier/TempISOs/` on `/dev/sda1`.
|
||||
|
||||
To make GRUB2 look for it in the right place, you need to edit the
|
||||
|
||||
/etc/grub.d40-custom
|
||||
|
||||

|
||||
|
||||
To start Kubuntu from the above location, add the following code (after adjusting it to your needs) below the commented section, without modifying the original content.
|
||||
|
||||
menuentry "Kubuntu 15.04 ISO" {
|
||||
set isofile="/home/maketecheasier/TempISOs/kubuntu-15.04-desktop-amd64.iso"
|
||||
loopback loop (hd0,1)$isofile
|
||||
echo "Starting $isofile..."
|
||||
linux (loop)/casper/vmlinuz.efi boot=casper iso-scan/filename=${isofile} quiet splash
|
||||
initrd (loop)/casper/initrd.lz
|
||||
}
|
||||
|
||||

|
||||
|
||||
### Breaking down the above code ###
|
||||
|
||||
First set up a variable named `$menuentry`. This is where the ISO file is located. If you want to change to a different ISO, you need to change the bit where it says set `isofile="/path/to/file/name-of-iso-file-.iso"`.
|
||||
|
||||
The next line is where you specify the loopback device; you also need to give it the right partition number. This is the bit where it says
|
||||
|
||||
loopback loop (hd0,1)$isofile
|
||||
|
||||
Note the hd0,1 bit; it is important. This means first HDD, first partition (`/dev/sda1`).
|
||||
|
||||
GRUB’s naming here is slightly confusing. For HDDs, it starts counting from “0”, making the first HDD #0, the second one #1, the third one #2, etc. However, for partitions, it will start counting from 1. First partition is #1, second is #2, etc. There might be a good reason for this but not necessarily a sane one (UX-wise it is a disaster, to be sure)..
|
||||
|
||||
This makes fist disk, first partition, which in Linux would usually look something like `/dev/sda1` become `hd0,1` in GRUB2. The second disk, third partition would be `hd1,3`, and so on.
|
||||
|
||||
The next important line is
|
||||
|
||||
linux (loop)/casper/vmlinuz.efi boot=casper iso-scan/filename=${isofile} quiet splash
|
||||
|
||||
It will load the kernel image. On newer Ubuntu Live CDs, this would be in the `/casper` directory and called `vmlinuz.efi`. If you use a different system, your kernel might be missing the `.efi` extension or be located somewhere else entirely (You can easily check this by opening the ISO file with an archive manager and looking inside `/casper.`). The last options, `quiet splash`, would be your regular GRUB options, if you care to change them.
|
||||
|
||||
Finally
|
||||
|
||||
initrd (loop)/casper/initrd.lz
|
||||
|
||||
will load `initrd`, which is responsible to load a RAMDisk into memory for bootup.
|
||||
|
||||
### Booting into your live system ###
|
||||
|
||||
To make it all work, you will only need to update GRUB2
|
||||
|
||||
sudo update-grub
|
||||
|
||||

|
||||
|
||||
When you reboot your system, you should be presented with a new GRUB entry which will allow you to load into the ISO image you’ve just set up.
|
||||
|
||||

|
||||
|
||||
Selecting the new entry should boot you into the live environment, just like booting from a DVD or USB would.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/run-iso-files-hdd-grub2/
|
||||
|
||||
作者:[Attila Orosz][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/attilaorosz/
|
||||
[1]:http://git.marmotte.net/git/glim/tree/grub2
|
||||
@ -0,0 +1,322 @@
|
||||
Getting Started to Calico Virtual Private Networking on Docker
|
||||
================================================================================
|
||||
Calico is a free and open source software for virtual networking in data centers. It is a pure Layer 3 approach to highly scalable datacenter for cloud virtual networking. It seamlessly integrates with cloud orchestration system such as openstack, docker clusters in order to enable secure IP communication between virtual machines and containers. It implements a highly productive vRouter in each node that takes advantage of the existing Linux kernel forwarding engine. Calico works in such an awesome technology that it has the ability to peer directly with the data center’s physical fabric whether L2 or L3, without the NAT, tunnels on/off ramps, or overlays. Calico makes full utilization of docker to run its containers in the nodes which makes it multi-platform and very easy to ship, pack and deploy. Calico has the following salient features out of the box.
|
||||
|
||||
- It can scale tens of thousands of servers and millions of workloads.
|
||||
- Calico is easy to deploy, operate and diagnose.
|
||||
- It is open source software licensed under Apache License version 2 and uses open standards.
|
||||
- It supports container, virtual machines and bare metal workloads.
|
||||
- It supports both IPv4 and IPv6 internet protocols.
|
||||
- It is designed internally to support rich, flexible and secure network policy.
|
||||
|
||||
In this tutorial, we'll perform a virtual private networking between two nodes running Calico in them with Docker Technology. Here are some easy steps on how we can do that.
|
||||
|
||||
### 1. Installing etcd ###
|
||||
|
||||
To get started with the calico virtual private networking, we'll need to have a linux machine running etcd. As CoreOS comes preinstalled and preconfigured with etcd, we can use CoreOS but if we want to configure Calico in other linux distributions, then we'll need to setup it in our machine. As we are running Ubuntu 14.04 LTS, we'll need to first install and configure etcd in our machine. To install etcd in our Ubuntu box, we'll need to add the official ppa repository of Calico by running the following command in the machine which we want to run etcd server. Here, we'll be installing etcd in our 1st node.
|
||||
|
||||
# apt-add-repository ppa:project-calico/icehouse
|
||||
|
||||
The primary source of Ubuntu packages for Project Calico based on OpenStack Icehouse, an open source solution for virtual networking in cloud data centers. Find out more at http://www.projectcalico.org/
|
||||
More info: https://launchpad.net/~project-calico/+archive/ubuntu/icehouse
|
||||
Press [ENTER] to continue or ctrl-c to cancel adding it
|
||||
gpg: keyring `/tmp/tmpi9zcmls1/secring.gpg' created
|
||||
gpg: keyring `/tmp/tmpi9zcmls1/pubring.gpg' created
|
||||
gpg: requesting key 3D40A6A7 from hkp server keyserver.ubuntu.com
|
||||
gpg: /tmp/tmpi9zcmls1/trustdb.gpg: trustdb created
|
||||
gpg: key 3D40A6A7: public key "Launchpad PPA for Project Calico" imported
|
||||
gpg: Total number processed: 1
|
||||
gpg: imported: 1 (RSA: 1)
|
||||
OK
|
||||
|
||||
Then, we'll need to edit /etc/apt/preferences and make changes to prefer Calico-provided packages for Nova and Neutron.
|
||||
|
||||
# nano /etc/apt/preferences
|
||||
|
||||
We'll need to add the following lines into it.
|
||||
|
||||
Package: *
|
||||
Pin: release o=LP-PPA-project-calico-*
|
||||
Pin-Priority: 100
|
||||
|
||||

|
||||
|
||||
Next, we'll also need to add the official BIRD PPA for Ubuntu 14.04 LTS so that bugs fixes are installed before its available on the Ubuntu repo.
|
||||
|
||||
# add-apt-repository ppa:cz.nic-labs/bird
|
||||
|
||||
The BIRD Internet Routing Daemon PPA (by upstream & .deb maintainer)
|
||||
More info: https://launchpad.net/~cz.nic-labs/+archive/ubuntu/bird
|
||||
Press [ENTER] to continue or ctrl-c to cancel adding it
|
||||
gpg: keyring `/tmp/tmphxqr5hjf/secring.gpg' created
|
||||
gpg: keyring `/tmp/tmphxqr5hjf/pubring.gpg' created
|
||||
gpg: requesting key F9C59A45 from hkp server keyserver.ubuntu.com
|
||||
apt-ggpg: /tmp/tmphxqr5hjf/trustdb.gpg: trustdb created
|
||||
gpg: key F9C59A45: public key "Launchpad Datov<6F> schr<68>nky" imported
|
||||
gpg: Total number processed: 1
|
||||
gpg: imported: 1 (RSA: 1)
|
||||
OK
|
||||
|
||||
Now, after the PPA jobs are done, we'll now gonna update the local repository index and then install etcd in our machine.
|
||||
|
||||
# apt-get update
|
||||
|
||||
To install etcd in our ubuntu machine, we'll gonna run the following apt command.
|
||||
|
||||
# apt-get install etcd python-etcd
|
||||
|
||||
### 2. Starting Etcd ###
|
||||
|
||||
After the installation is complete, we'll now configure the etcd configuration file. Here, we'll edit **/etc/init/etcd.conf** using a text editor and append the line exec **/usr/bin/etcd** and make it look like below configuration.
|
||||
|
||||
# nano /etc/init/etcd.conf
|
||||
exec /usr/bin/etcd --name="node1" \
|
||||
--advertise-client-urls="http://10.130.65.71:2379,http://10.130.65.71:4001" \
|
||||
--listen-client-urls="http://0.0.0.0:2379,http://0.0.0.0:4001" \
|
||||
--listen-peer-urls "http://0.0.0.0:2380" \
|
||||
--initial-advertise-peer-urls "http://10.130.65.71:2380" \
|
||||
--initial-cluster-token $(uuidgen) \
|
||||
--initial-cluster "node1=http://10.130.65.71:2380" \
|
||||
--initial-cluster-state "new"
|
||||
|
||||

|
||||
|
||||
**Note**: In the above configuration, we'll need to replace 10.130.65.71 and node-1 with the private ip address and hostname of your etcd server box. After done with editing, we'll need to save and exit the file.
|
||||
|
||||
We can get the private ip address of our etcd server by running the following command.
|
||||
|
||||
# ifconfig
|
||||
|
||||

|
||||
|
||||
As our etcd configuration is done, we'll now gonna start our etcd service in our Ubuntu node. To start etcd daemon, we'll gonna run the following command.
|
||||
|
||||
# service etcd start
|
||||
|
||||
After done, we'll have a check if etcd is really running or not. To ensure that, we'll need to run the following command.
|
||||
|
||||
# service etcd status
|
||||
|
||||
### 3. Installing Docker ###
|
||||
|
||||
Next, we'll gonna install Docker in both of our nodes running Ubuntu. To install the latest release of docker, we'll simply need to run the following command.
|
||||
|
||||
# curl -sSL https://get.docker.com/ | sh
|
||||
|
||||

|
||||
|
||||
After the installation is completed, we'll gonna start the docker daemon in-order to make sure that its running before we move towards Calico.
|
||||
|
||||
# service docker restart
|
||||
|
||||
docker stop/waiting
|
||||
docker start/running, process 3056
|
||||
|
||||
### 3. Installing Calico ###
|
||||
|
||||
We'll now install calico in our linux machine in-order to run the calico containers. We'll need to install Calico in every node which we're wanting to connect into the Calico network. To install Calico, we'll need to run the following command under root or sudo permission.
|
||||
|
||||
#### On 1st Node ####
|
||||
|
||||
# wget https://github.com/projectcalico/calico-docker/releases/download/v0.6.0/calicoctl
|
||||
|
||||
--2015-09-28 12:08:59-- https://github.com/projectcalico/calico-docker/releases/download/v0.6.0/calicoctl
|
||||
Resolving github.com (github.com)... 192.30.252.129
|
||||
Connecting to github.com (github.com)|192.30.252.129|:443... connected.
|
||||
...
|
||||
Resolving github-cloud.s3.amazonaws.com (github-cloud.s3.amazonaws.com)... 54.231.9.9
|
||||
Connecting to github-cloud.s3.amazonaws.com (github-cloud.s3.amazonaws.com)|54.231.9.9|:443... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 6166661 (5.9M) [application/octet-stream]
|
||||
Saving to: 'calicoctl'
|
||||
100%[=========================================>] 6,166,661 1.47MB/s in 6.7s
|
||||
2015-09-28 12:09:08 (898 KB/s) - 'calicoctl' saved [6166661/6166661]
|
||||
|
||||
# chmod +x calicoctl
|
||||
|
||||
After done with making it executable, we'll gonna make the binary calicoctl available as the command in any directory. To do so, we'll need to run the following command.
|
||||
|
||||
# mv calicoctl /usr/bin/
|
||||
|
||||
#### On 2nd Node ####
|
||||
|
||||
# wget https://github.com/projectcalico/calico-docker/releases/download/v0.6.0/calicoctl
|
||||
|
||||
--2015-09-28 12:09:03-- https://github.com/projectcalico/calico-docker/releases/download/v0.6.0/calicoctl
|
||||
Resolving github.com (github.com)... 192.30.252.131
|
||||
Connecting to github.com (github.com)|192.30.252.131|:443... connected.
|
||||
...
|
||||
Resolving github-cloud.s3.amazonaws.com (github-cloud.s3.amazonaws.com)... 54.231.8.113
|
||||
Connecting to github-cloud.s3.amazonaws.com (github-cloud.s3.amazonaws.com)|54.231.8.113|:443... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 6166661 (5.9M) [application/octet-stream]
|
||||
Saving to: 'calicoctl'
|
||||
100%[=========================================>] 6,166,661 1.47MB/s in 5.9s
|
||||
2015-09-28 12:09:11 (1022 KB/s) - 'calicoctl' saved [6166661/6166661]
|
||||
|
||||
# chmod +x calicoctl
|
||||
|
||||
After done with making it executable, we'll gonna make the binary calicoctl available as the command in any directory. To do so, we'll need to run the following command.
|
||||
|
||||
# mv calicoctl /usr/bin/
|
||||
|
||||
Likewise, we'll need to execute the above commands to install in every other nodes.
|
||||
|
||||
### 4. Starting Calico services ###
|
||||
|
||||
After we have installed calico on each of our nodes, we'll gonna start our Calico services. To start the calico services, we'll need to run the following commands.
|
||||
|
||||
#### On 1st Node ####
|
||||
|
||||
# calicoctl node
|
||||
|
||||
WARNING: Unable to detect the xt_set module. Load with `modprobe xt_set`
|
||||
WARNING: Unable to detect the ipip module. Load with `modprobe ipip`
|
||||
No IP provided. Using detected IP: 10.130.61.244
|
||||
Pulling Docker image calico/node:v0.6.0
|
||||
Calico node is running with id: fa0ca1f26683563fa71d2ccc81d62706e02fac4bbb08f562d45009c720c24a43
|
||||
|
||||
#### On 2nd Node ####
|
||||
|
||||
Next, we'll gonna export a global variable in order to connect our calico nodes to the same etcd server which is hosted in node1 in our case. To do so, we'll need to run the following command in each of our nodes.
|
||||
|
||||
# export ETCD_AUTHORITY=10.130.61.244:2379
|
||||
|
||||
Then, we'll gonna run calicoctl container in our every our second node.
|
||||
|
||||
# calicoctl node
|
||||
|
||||
WARNING: Unable to detect the xt_set module. Load with `modprobe xt_set`
|
||||
WARNING: Unable to detect the ipip module. Load with `modprobe ipip`
|
||||
No IP provided. Using detected IP: 10.130.61.245
|
||||
Pulling Docker image calico/node:v0.6.0
|
||||
Calico node is running with id: 70f79c746b28491277e28a8d002db4ab49f76a3e7d42e0aca8287a7178668de4
|
||||
|
||||
This command should be executed in every nodes in which we want to start our Calico services. The above command start a container in the respective node. To check if the container is running or not, we'll gonna run the following docker command.
|
||||
|
||||
# docker ps
|
||||
|
||||

|
||||
|
||||
If we see the output something similar to the output shown below then we can confirm that Calico containers are up and running.
|
||||
|
||||
### 5. Starting Containers ###
|
||||
|
||||
Next, we'll need to start few containers in each of our nodes running Calico services. We'll assign a different name to each of the containers running ubuntu. Here, workload-A, workload-B, etc has been assigned as the unique name for each of the containers. To do so, we'll need to run the following command.
|
||||
|
||||
#### On 1st Node ####
|
||||
|
||||
# docker run --net=none --name workload-A -tid ubuntu
|
||||
|
||||
Unable to find image 'ubuntu:latest' locally
|
||||
latest: Pulling from library/ubuntu
|
||||
...
|
||||
91e54dfb1179: Already exists
|
||||
library/ubuntu:latest: The image you are pulling has been verified. Important: image verification is a tech preview feature and should not be relied on to provide security.
|
||||
Digest: sha256:73fbe2308f5f5cb6e343425831b8ab44f10bbd77070ecdfbe4081daa4dbe3ed1
|
||||
Status: Downloaded newer image for ubuntu:latest
|
||||
a1ba9105955e9f5b32cbdad531cf6ecd9cab0647d5d3d8b33eca0093605b7a18
|
||||
|
||||
# docker run --net=none --name workload-B -tid ubuntu
|
||||
|
||||
89dd3d00f72ac681bddee4b31835c395f14eeb1467300f2b1b9fd3e704c28b7d
|
||||
|
||||
#### On 2nd Node ####
|
||||
|
||||
# docker run --net=none --name workload-C -tid ubuntu
|
||||
|
||||
Unable to find image 'ubuntu:latest' locally
|
||||
latest: Pulling from library/ubuntu
|
||||
...
|
||||
91e54dfb1179: Already exists
|
||||
library/ubuntu:latest: The image you are pulling has been verified. Important: image verification is a tech preview feature and should not be relied on to provide security.
|
||||
Digest: sha256:73fbe2308f5f5cb6e343425831b8ab44f10bbd77070ecdfbe4081daa4dbe3ed1
|
||||
Status: Downloaded newer image for ubuntu:latest
|
||||
24e2d5d7d6f3990b534b5643c0e483da5b4620a1ac2a5b921b2ba08ebf754746
|
||||
|
||||
# docker run --net=none --name workload-D -tid ubuntu
|
||||
|
||||
c6f28d1ab8f7ac1d9ccc48e6e4234972ed790205c9ca4538b506bec4dc533555
|
||||
|
||||
Similarly, if we have more nodes, we can run ubuntu docker container into it by running the above command with assigning a different container name.
|
||||
|
||||
### 6. Assigning IP addresses ###
|
||||
|
||||
After we have got our docker containers running in each of our hosts, we'll go for adding a networking support to the containers. Now, we'll gonna assign a new ip address to each of the containers using calicoctl. This will add a new network interface to the containers with the assigned ip addresses. To do so, we'll need to run the following commands in the hosts running the containers.
|
||||
|
||||
#### On 1st Node ####
|
||||
|
||||
# calicoctl container add workload-A 192.168.0.1
|
||||
# calicoctl container add workload-B 192.168.0.2
|
||||
|
||||
#### On 2nd Node ####
|
||||
|
||||
# calicoctl container add workload-C 192.168.0.3
|
||||
# calicoctl container add workload-D 192.168.0.4
|
||||
|
||||
### 7. Adding Policy Profiles ###
|
||||
|
||||
After our containers have got networking interfaces and ip address assigned, we'll now need to add policy profiles to enable networking between the containers each other. After adding the profiles, the containers will be able to communicate to each other only if they have the common profiles assigned. That means, if they have different profiles assigned, they won't be able to communicate to eachother. So, before being able to assign. we'll need to first create some new profiles. That can be done in either of the hosts. Here, we'll run the following command in 1st Node.
|
||||
|
||||
# calicoctl profile add A_C
|
||||
|
||||
Created profile A_C
|
||||
|
||||
# calicoctl profile add B_D
|
||||
|
||||
Created profile B_D
|
||||
|
||||
After the profile has been created, we'll simply add our workload to the required profile. Here, in this tutorial, we'll place workload A and workload C in a common profile A_C and workload B and D in a common profile B_D. To do so, we'll run the following command in our hosts.
|
||||
|
||||
#### On 1st Node ####
|
||||
|
||||
# calicoctl container workload-A profile append A_C
|
||||
# calicoctl container workload-B profile append B_D
|
||||
|
||||
#### On 2nd Node ####
|
||||
|
||||
# calicoctl container workload-C profile append A_C
|
||||
# calicoctl container workload-D profile append B_D
|
||||
|
||||
### 8. Testing the Network ###
|
||||
|
||||
After we've added a policy profile to each of our containers using Calicoctl, we'll now test whether our networking is working as expected or not. We'll take a node and a workload and try to communicate with the other containers running in same or different nodes. And due to the profile, we should be able to communicate only with the containers having a common profile. So, in this case, workload A should be able to communicate with only C and vice versa whereas workload A shouldn't be able to communicate with B or D. To test the network, we'll gonna ping the containers having common profiles from the 1st host running workload A and B.
|
||||
|
||||
We'll first ping workload-C having ip 192.168.0.3 using workload-A as shown below.
|
||||
|
||||
# docker exec workload-A ping -c 4 192.168.0.3
|
||||
|
||||
Then, we'll ping workload-D having ip 192.168.0.4 using workload-B as shown below.
|
||||
|
||||
# docker exec workload-B ping -c 4 192.168.0.4
|
||||
|
||||

|
||||
|
||||
Now, we'll check if we're able to ping the containers having different profiles. We'll now ping workload-D having ip address 192.168.0.4 using workload-A.
|
||||
|
||||
# docker exec workload-A ping -c 4 192.168.0.4
|
||||
|
||||
After done, we'll try to ping workload-C having ip address 192.168.0.3 using workload-B.
|
||||
|
||||
# docker exec workload-B ping -c 4 192.168.0.3
|
||||
|
||||

|
||||
|
||||
Hence, the workloads having same profiles could ping each other whereas having different profiles couldn't ping to each other.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Calico is an awesome project providing an easy way to configure a virtual network using the latest docker technology. It is considered as a great open source solution for virtual networking in cloud data centers. Calico is being experimented by people in different cloud platforms like AWS, DigitalOcean, GCE and more these days. As Calico is currently under experiment, its stable version hasn't been released yet and is still in pre-release. The project consists a well documented documentations, tutorials and manuals in their [official documentation site][2].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/calico-virtual-private-networking-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://docs.projectcalico.org/
|
||||
81
sources/tech/20151012 How To Use iPhone In Antergos Linux.md
Normal file
81
sources/tech/20151012 How To Use iPhone In Antergos Linux.md
Normal file
@ -0,0 +1,81 @@
|
||||
How To Use iPhone In Antergos Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
Troubles with iPhone and Arch Linux? iPhone and Linux never really go along very well. In this tutorial, I am going to show you how can you use iPhone in Antergos Linux. Since Antergos is based on Arch Linux, the same steps should be applicable to other Arch based Linux distros such as Manjaro Linux.
|
||||
|
||||
So, recently I bought me a brand new iPhone 6S and when I connected it to Antergos Linux to copy some pictures, it was not detected at all. I could see that iPhone was being charged and I had allowed iPhone to ‘trust the computer’ but there was nothing at all detected. I tried to run dmseg but there was no trace of iPhone or Apple there. What is funny that [libimobiledevice][1] was installed as well, which always fixes [iPhone mount issue in Ubuntu][2].
|
||||
|
||||
I am going to show you how I am using iPhone 6S, running on iOS 9 in Antergos. It goes more in command line way, but I presume since you are in Arch Linux zone, you are not scared of terminal (and you should not be as well).
|
||||
|
||||
### Mount iPhone in Arch Linux ###
|
||||
|
||||
**Step 1**: Unplug your iPhone, if it is already plugged in.
|
||||
|
||||
**Step 2**: Now, open a terminal and use the following command to install some necessary packages. Don’t worry if they are already installed.
|
||||
|
||||
sudo pacman -Sy ifuse usbmuxd libplist libimobiledevice
|
||||
|
||||
**Step 3**: Once these programs and libraries are installed, reboot your system.
|
||||
|
||||
sudo reboot
|
||||
|
||||
**Step 4**: Make a directory where you want the iPhone to be mounted. I would suggest making a directory named iPhone in your home directory.
|
||||
|
||||
mkdir ~/iPhone
|
||||
|
||||
**Step 5**: Unlock your phone and plug it in. If asked to trust the computer, allow it.
|
||||
|
||||

|
||||
|
||||
**Step 6**: Verify that iPhone is recognized by the system this time.
|
||||
|
||||
dmesg | grep -i iphone
|
||||
|
||||
This should show you some result with iPhone and Apple in it. Something like this:
|
||||
|
||||
[ 31.003392] ipheth 2-1:4.2: Apple iPhone USB Ethernet device attached
|
||||
[ 40.950883] ipheth 2-1:4.2: Apple iPhone USB Ethernet now disconnected
|
||||
[ 47.471897] ipheth 2-1:4.2: Apple iPhone USB Ethernet device attached
|
||||
[ 82.967116] ipheth 2-1:4.2: Apple iPhone USB Ethernet now disconnected
|
||||
[ 106.735932] ipheth 2-1:4.2: Apple iPhone USB Ethernet device attached
|
||||
|
||||
This means that iPhone has been successfully recognized by Antergos/Arch Linux.
|
||||
|
||||
**Step 7**: When everything is set, it’s time to mount the iPhone. Use the command below:
|
||||
|
||||
ifuse ~/iPhone
|
||||
|
||||
Since we created the mount directory in home, it won’t need root access and you should also be able to see it easily in your home directory. If the command is successful, you won’t see any output.
|
||||
|
||||
Go back to Files and see if the iPhone is recognized or not. For me, it looks like this in Antergos:
|
||||
|
||||

|
||||
|
||||
You can access the files in this directory. Copy files from it or to it.
|
||||
|
||||

|
||||
|
||||
**Step 8**: When you want to unmount it, you should use this command:
|
||||
|
||||
sudo umount ~/iPhone
|
||||
|
||||
### Worked for you? ###
|
||||
|
||||
I know that it is not very convenient and ideally, iPhone should be recognized as any other USB storage device but things don’t always behave as they are expected to. Good thing is that a little DIY hack can always fix the issue and it gives a sense of achievement (at least to me). That being said, I must say Antergos should work to fix this issue so that iPhone can be mounted by default.
|
||||
|
||||
Did this trick work for you? If you have questions or suggestions, feel free to drop a comment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/iphone-antergos-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://www.libimobiledevice.org/
|
||||
[2]:http://itsfoss.com/mount-iphone-ipad-ios-7-ubuntu-13-10/
|
||||
@ -0,0 +1,114 @@
|
||||
translating by Ezio
|
||||
|
||||
|
||||
How to Setup DockerUI - a Web Interface for Docker
|
||||
================================================================================
|
||||
Docker is getting more popularity day by day. The idea of running a complete Operating System inside a container rather than running inside a virtual machine is an awesome technology. Docker has made lives of millions of system administrators and developers pretty easy for getting their work done in no time. It is an open source technology that provides an open platform to pack, ship, share and run any application as a lightweight container without caring on which operating system we are running on the host. It has no boundaries of Language support, Frameworks or packaging system and can be run anywhere, anytime from a small home computers to high-end servers. Running docker containers and managing them may come a bit difficult and time consuming, so there is a web based application named DockerUI which is make managing and running container pretty simple. DockerUI is highly beneficial to people who are not much aware of linux command lines and want to run containerized applications. DockerUI is an open source web based application best known for its beautiful design and ease simple interface for running and managing docker containers.
|
||||
|
||||
Here are some easy steps on how we can setup Docker Engine with DockerUI in our linux machine.
|
||||
|
||||
### 1. Installing Docker Engine ###
|
||||
|
||||
First of all, we'll gonna install docker engine in our linux machine. Thanks to its developers, docker is very easy to install in any major linux distribution. To install docker engine, we'll need to run the following command with respect to which distribution we are running.
|
||||
|
||||
#### On Ubuntu/Fedora/CentOS/RHEL/Debian ####
|
||||
|
||||
Docker maintainers have written an awesome script that can be used to install docker engine in Ubuntu 15.04/14.10/14.04, CentOS 6.x/7, Fedora 22, RHEL 7 and Debian 8.x distributions of linux. This script recognizes the distribution of linux installed in our machine, then adds the required repository to the filesystem, updates the local repository index and finally installs docker engine and required dependencies from it. To install docker engine using that script, we'll need to run the following command under root or sudo mode.
|
||||
|
||||
# curl -sSL https://get.docker.com/ | sh
|
||||
|
||||
#### On OpenSuse/SUSE Linux Enterprise ####
|
||||
|
||||
To install docker engine in the machine running OpenSuse 13.1/13.2 or SUSE Linux Enterprise Server 12, we'll simply need to execute the zypper command. We'll gonna install docker using zypper command as the latest docker engine is available on the official repository. To do so, we'll run the following command under root/sudo mode.
|
||||
|
||||
# zypper in docker
|
||||
|
||||
#### On ArchLinux ####
|
||||
|
||||
Docker is available in the official repository of Archlinux as well as in the AUR packages maintained by the community. So, we have two options to install docker in archlinux. To install docker using the official arch repository, we'll need to run the following pacman command.
|
||||
|
||||
# pacman -S docker
|
||||
|
||||
But if we want to install docker from the Archlinux User Repository ie AUR, then we'll need to execute the following command.
|
||||
|
||||
# yaourt -S docker-git
|
||||
|
||||
### 2. Starting Docker Daemon ###
|
||||
|
||||
After docker is installed, we'll now gonna start our docker daemon so that we can run docker containers and manage them. We'll run the following command to make sure that docker daemon is installed and to start the docker daemon.
|
||||
|
||||
#### On SysVinit ####
|
||||
|
||||
# service docker start
|
||||
|
||||
#### On Systemd ####
|
||||
|
||||
# systemctl start docker
|
||||
|
||||
### 3. Installing DockerUI ###
|
||||
|
||||
Installing DockerUI is pretty easy than installing docker engine. We just need to pull the dockerui from the Docker Registry Hub and run it inside a container. To do so, we'll simply need to run the following command.
|
||||
|
||||
# docker run -d -p 9000:9000 --privileged -v /var/run/docker.sock:/var/run/docker.sock dockerui/dockerui
|
||||
|
||||

|
||||
|
||||
Here, in the above command, as the default port of the dockerui web application server 9000, we'll simply map the default port of it with -p flag. With -v flag, we specify the docker socket. The --privileged flag is required for hosts using SELinux.
|
||||
|
||||
After executing the above command, we'll now check if the dockerui container is running or not by running the following command.
|
||||
|
||||
# docker ps
|
||||
|
||||

|
||||
|
||||
### 4. Pulling an Image ###
|
||||
|
||||
Currently, we cannot pull an image directly from DockerUI so, we'll need to pull a docker image from the linux console/terminal. To do so, we'll need to run the following command.
|
||||
|
||||
# docker pull ubuntu
|
||||
|
||||

|
||||
|
||||
The above command will pull an image tagged as ubuntu from the official [Docker Hub][1]. Similarly, we can pull more images that we require and are available in the hub.
|
||||
|
||||
### 4. Managing with DockerUI ###
|
||||
|
||||
After we have started the dockerui container, we'll now have fun with it to start, pause, stop, remove and perform many possible activities featured by dockerui with docker containers and images. First of all, we'll need to open the web application using our web browser. To do so, we'll need to point our browser to http://ip-address:9000 or http://mydomain.com:9000 according to the configuration of our system. By default, there is no login authentication needed for the user access but we can configure our web server for adding authentication. To start a container, first we'll need to have images of the required application we want to run a container with.
|
||||
|
||||
#### Create a Container ####
|
||||
|
||||
To create a container, we'll need to go to the section named Images then, we'll need to click on the image id which we want to create a container of. After clicking on the required image id, we'll need to click on Create button then we'll be asked to enter the required properties for our container. And after everything is set and done. We'll need to click on Create button to finally create a container.
|
||||
|
||||

|
||||
|
||||
#### Stop a Container ####
|
||||
|
||||
To stop a container, we'll need to move towards the Containers page and then select the required container we want to stop. Now, we'll want to click on Stop option which we can see under Actions drop-down menu.
|
||||
|
||||

|
||||
|
||||
#### Pause and Resume ####
|
||||
|
||||
To pause a container, we simply select the required container we want to pause by keeping a check mark on the container and then click the Pause option under Actions . This is will pause the running container and then, we can simply resume the container by selecting Unpause option from the Actions drop down menu.
|
||||
|
||||
#### Kill and Remove ####
|
||||
|
||||
Like we had performed the above tasks, its pretty easy to kill and remove a container or an image. We just need to check/select the required container or image and then select the Kill or Remove button from the application according to our need.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
DockerUI is a beautiful utilization of Docker Remote API to develop an awesome web interface for managing docker containers. The developers have designed and developed this application in pure HTML and JS language. It is currently incomplete and is under heavy development so we don't recommend it for the use in production currently. It makes users pretty easy to manage their containers and images with simple clicks without needing to execute lines of commands to do small jobs. If we want to contribute DockerUI, we can simply visit its [Github Repository][2]. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you !
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/setup-dockerui-web-interface-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[oska874](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://hub.docker.com/
|
||||
[2]:https://github.com/crosbymichael/dockerui/
|
||||
@ -0,0 +1,62 @@
|
||||
translating by Ezio
|
||||
|
||||
Remember sed and awk? All Linux admins should
|
||||
================================================================================
|
||||

|
||||
|
||||
Credit: Shutterstock
|
||||
|
||||
**We aren’t doing the next generation of Linux and Unix admins any favors by forgetting init scripts and fundamental tools**
|
||||
|
||||
I happened across a post on Reddit by chance, [asking about textfile manipulation][1]. It was a fairly simple request, similar to those that folks in Unix see nearly every day. In this case, it was how to remove all duplicate lines in a file, keeping one instance of each. This sounds relatively easy, but can get a bit complicated if the source file is sufficiently large and random.
|
||||
|
||||
There are countless answers to this problem. You could write a script in nearly any language to do this, with varying levels of complexity and time investment, which I suspect is what most would do. It might take 20 or 60 minutes depending on skill level, but armed with Perl, Python, or Ruby, you could make quick work of it.
|
||||
|
||||
Or you could use the answer stated in that thread, which warmed my heart: Just use awk.
|
||||
|
||||
That answer is the most concise and simplest solution to the problem by far. It’s one line:
|
||||
|
||||
awk '!seen[$0]++' <filename>.
|
||||
|
||||
Let’s take a look at this.
|
||||
|
||||
In this command, there’s a lot of hidden code. Awk is a text processing language, and as such it makes a lot of assumptions. For starters, what you see here is actually the meat of a for loop. Awk assumes you want to loop through every line of the input file, so you don’t need to explicitly state it. Awk also assumes you want to print the postprocessed output, so you don’t need to state that either. Finally, Awk then assumes the loop ends when the last statement finishes, so no need to state it.
|
||||
|
||||
The string seen in this example is the name given to an associative array. $0 is a variable that represents the entirety of the current line of the file. Thus, this command translates to “Evaluate every line in this file, and if you haven’t seen this line before, print it.” Awk does this by adding $0 to the seen array if it doesn’t already exist and incrementing the value so that it will not match the pattern the next time around and, thus, not print.
|
||||
|
||||
Some will see this as elegant, while others may see this as obfuscation. Anyone who uses awk on a daily basis will be in the first group. Awk is designed to do this. You can write multiline programs in awk. You can even write [disturbingly complex functions in awk][2]. But at the end of the day, awk is designed to do text processing, generally within a pipe. Eliminating the extraneous cruft of loop definition is simply a shortcut for a very common use case. If you like, you could write the same thing as the following:
|
||||
|
||||
awk '{ if (!seen[$0]) print $0; seen[$0]++ }’
|
||||
|
||||
It would lead to the same result.
|
||||
|
||||
Awk is the perfect tool for this job. Nevertheless, I believe many admins -- especially newer admins -- would jump into [Bash][3] or Python to try to accomplish this task, because knowledge of awk and what it can do seems to be fading as time goes on. I think it may be an indicator of things to come, where problems that have been solved for decades suddenly emerge again, based on lack of exposure to the previous solutions.
|
||||
|
||||
The shell, grep, sed, and awk are fundaments of Unix computing. If you’re not completely comfortable with their use, you’re artificially hamstrung because they form the basis of interaction with Unix systems via the CLI and shell scripting. One of the best ways to learn how these tools work is by observing and working with live examples, which every Unix flavor has in spades with their init systems -- or had, in the case of Linux distros that have adopted [systemd][4].
|
||||
|
||||
Millions of Unix admins learned how shell scripting and Unix tools worked by reading, writing, modifying, and working with init scripts. Init scripts differ greatly from OS to OS, even from distribution to distribution in the case of Linux, but they are all rooted in sh, and they all use core CLI tools like sed, awk, and grep.
|
||||
|
||||
I’ve heard many complaints that init scripts are “ancient” and “difficult,” but in fact, init scripts use the same tools that Unix admins work with every day, and thus provide an excellent way to become more familiar and comfortable with those tools. Saying that init scripts are hard to read or difficult to work with is to admit that you lack fundamental familiarity with the Unix toolset.
|
||||
|
||||
Speaking of things found on Reddit, I also came across this question from a budding Linux sys admin, [asking whether he should bother to learn sysvinit][5]. Most of the answers in the thread are good -- yes, definitely learn sysvinit and systemd. One commenter even notes that init scripts are a great way to learn Bash, and another states that the Fortune 50 company he works for has no plans to move to a systemd-based release.
|
||||
|
||||
But it concerns me that this is a question at all. If we continue down the path of eliminating scripts and roping off core system elements within our operating systems, we will inadvertently make it harder for new admins to learn the fundamental Unix toolset due to the lack of exposure.
|
||||
|
||||
I’m not sure why some want to cover up Unix internals with abstraction after abstraction, but such a path may reduce a generation of Unix admins to hapless button pushers dependent on support contracts. I’m pretty sure that would not be a good development.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2985804/linux/remember-sed-awk-linux-admins-should.html
|
||||
|
||||
作者:[Paul Venezia][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Paul-Venezia/
|
||||
[1]:https://www.reddit.com/r/linuxadmin/comments/3lwyko/how_do_i_remove_every_occurence_of_duplicate_line/
|
||||
[2]:http://intro-to-awk.blogspot.com/2008/08/awk-more-complex-examples.html
|
||||
[3]:http://www.infoworld.com/article/2613338/linux/linux-how-to-script-a-bash-crash-course.html
|
||||
[4]:http://www.infoworld.com/article/2608798/data-center/systemd--harbinger-of-the-linux-apocalypse.html
|
||||
[5]:https://www.reddit.com/r/linuxadmin/comments/3ltq2y/when_i_start_learning_about_linux_administration/
|
||||
@ -0,0 +1,63 @@
|
||||
DFileManager: Cover Flow File Manager
|
||||
================================================================================
|
||||
A real gem of a file manager absent from the standard Ubuntu repositories but sporting a unique feature. That’s DFileManager in a twitterish statement.
|
||||
|
||||
A tricky question to answer is just how many open source Linux applications are available. Just out of curiosity, you can type at the shell:
|
||||
|
||||
~$ for f in /var/lib/apt/lists/*Packages; do printf ’%5d %s\n’ $(grep ’^Package: ’ “$f” | wc -l) ${f##*/} done | sort -rn
|
||||
|
||||
On my Ubuntu 15.04 system, it produces the following results:
|
||||
|
||||

|
||||
|
||||
As the screenshot above illustrates, there are approximately 39,000 packages in the Universe repository, and around 8,500 packages in the main repository. These numbers sound a lot. But there is a smorgasbord of open source applications, utilities, and libraries that don’t have an Ubuntu team generating a package. And more importantly, there are some real treasures missing from the repositories which can only be discovered by compiling source code. DFileManager is one such utility. It is a Qt based cross-platform file manager which is in an early stage of development. Qt provides single-source portability across all major desktop operating systems.
|
||||
|
||||
In the absence of a binary package, the user needs to compile the code. For some tools, this can be problematic, particularly if the application depends on any obscure libraries, or specific versions which may be incompatible with other software installed on a system.
|
||||
|
||||
### Installation ###
|
||||
|
||||
Fortunately, DFileManager is simple to compile. The installation instructions on the developer’s website provide most of the steps necessary for my creaking Ubuntu box, but a few essential packages were missing (why is it always that way however many libraries clutter up your filesystem?) To prepare my system, download the source code from GitHub and then compile the software, I entered the following commands at the shell:
|
||||
|
||||
~$ sudo apt-get install qt5-default qt5-qmake libqt5x11extras5-dev
|
||||
~$ git clone git://git.code.sf.net/p/dfilemanager/code dfilemanager-code
|
||||
~$ cd dfilemananger-code
|
||||
~$ mkdir build
|
||||
~$ cd build
|
||||
~$ cmake ../ -DCMAKE_INSTALL_PREFIX=/usr
|
||||
~$ make
|
||||
~$ sudo make install
|
||||
|
||||
You can then start the application by typing at the shell:
|
||||
|
||||
~$ dfm
|
||||
|
||||
Here is a screenshot of DFileManager in action, with the main attraction in full view; the Cover Flow view. This offers the ability to slide through items in the current folder with an attractive feel. It’s ideal for viewing photos. The file manager bears a resemblance to Finder (the default file manager and graphical user interface shell used on all Macintosh operating systems), which may appeal to you.
|
||||
|
||||

|
||||
|
||||
### Features: ###
|
||||
|
||||
- 4 views: Icons, Details, Columns, and Cover Flow
|
||||
- Categorised bookmarks with Places and Devices
|
||||
- Tabs
|
||||
- Simple searching and filtering
|
||||
- Customizable thumbnails for filetypes including multimedia files
|
||||
- Information bar which can be undocked
|
||||
- Open folders and files with one click
|
||||
- Option to queue IO operations
|
||||
- Remembers some view properties for each folder
|
||||
- Show hidden files
|
||||
|
||||
DFileManager is not a replacement for KDE’s Dolphin, but do give it a go. It’s a file manager that really helps the user browse files. And don’t forget to give feedback to the developer; that’s a contribution anyone can offer.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://gofk.tumblr.com/post/131014089537/dfilemanager-cover-flow-file-manager-a-real-gem
|
||||
|
||||
作者:[gofk][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://gofk.tumblr.com/
|
||||
376
sources/tech/20151020 how to h2 in apache.md
Normal file
376
sources/tech/20151020 how to h2 in apache.md
Normal file
@ -0,0 +1,376 @@
|
||||
ictlyh Translating
|
||||
how to h2 in apache
|
||||
================================================================================
|
||||
Copyright (C) 2015 greenbytes GmbH
|
||||
|
||||
Support for HTTP/2 is finally being released with Apache httpd 2.4.17! This pages gives advice on how to build/deploy/configure it. The plan is to update this as people find out new things (read: bugs) or give recommendations on what works best for them.
|
||||
|
||||
Ultimately, this will then flow back into the official Apache documentation and this page will only contain a single link to it. But we are not quite there yet...
|
||||
|
||||
### Sources ###
|
||||
|
||||
You can get the Apache release from [here][1]. HTTP/2 support is included in Apache 2.4.17 and upwards. I will not repeat instructions on how to build the server in general. There is excellent material available in several places, for example [here][2].
|
||||
|
||||
(Any links to experimental packages? Drop me a note on twitter @icing.)
|
||||
|
||||
#### Building with HTTP/2 Support ####
|
||||
|
||||
Should you build from a release, you will need to **configure** first. There are tons of options. The ones specific for HTTP/2 are:
|
||||
|
||||
- **--enable-http2**
|
||||
|
||||
This enables the module 'http2' which does implement the protocol inside the Apache server.
|
||||
|
||||
- **--with-nghttp2=<dir>**
|
||||
|
||||
This specifies a non-standard location for the library libnghttp2 which is necessary for the http2 module. If nghttp2 is in a standard place, the configure process will pick it up automatically.
|
||||
|
||||
- **--enable-nghttp2-staticlib-deps**
|
||||
|
||||
Ultra-rarely needed option that you may use to static link the nghttp2 library to the server. On most platforms, this only has an effect when there is no shared nghttp2 library to be found.
|
||||
|
||||
In case you want to build nghttp2 for yourself, you find documentation at [nghttp2.org][3]. The library is also being shipped in the latest Fedora and other distros will follow.
|
||||
|
||||
#### TLS Support ####
|
||||
|
||||
Most people will want to use HTTP/2 with browsers and browser only support it on TLS connections (**https://** urls). You'll need proper configuration for that which I cover below. But foremost what you will need is an TLS library that supports the ALPN extension.
|
||||
|
||||
ALPN is neccessary to negotiate the protocol to use between server and client. If it is not implemented by the TLS lib on your server, the client will only ever talk HTTP/1.1. So, who does link with Apache and support it?
|
||||
|
||||
- **OpenSSL 1.0.2** and onward.
|
||||
- ???
|
||||
|
||||
If you get your OpenSSL library from your Linux distro, the version number used there might be different from the official OpenSSL releases. Check with your distro in case of doubt.
|
||||
|
||||
### Configuration ###
|
||||
|
||||
One useful addition to your server is to set a good logging level for the http2 module. Add this:
|
||||
|
||||
# this needs to be somewhere
|
||||
LoadModule http2_module modules/mod_http2.so
|
||||
|
||||
<IfModule http2_module>
|
||||
LogLevel http2:info
|
||||
</IfModule>
|
||||
|
||||
When you start your server and look in the error log, you should see one line like:
|
||||
|
||||
[timestamp] [http2:info] [pid XXXXX:tid numbers]
|
||||
mod_http2 (v1.0.0, nghttp2 1.3.4), initializing...
|
||||
|
||||
#### Protocols ####
|
||||
|
||||
So, assume you have the server built and deployed, the TLS library is bleeding edge (sorry), your server starts, you open your browser and...how do you know it is working?
|
||||
|
||||
If you have not added more to your server config, it probably isn't.
|
||||
|
||||
You need to tell the server where to use the protocol. By default, the HTTP/2 protocol is not enabled anywhere in your server. Because that is the safe route and you might have an existing deployment should continue to work.
|
||||
|
||||
You enable the HTTP/2 protocol with the new **Protocols** directive:
|
||||
|
||||
# for a https server
|
||||
Protocols h2 http/1.1
|
||||
...
|
||||
|
||||
# for a http server
|
||||
Protocols h2c http/1.1
|
||||
|
||||
You can add this for the server in general or for specific **vhosts**.
|
||||
|
||||
#### SSL Parameter ####
|
||||
|
||||
HTTP/2 has some special requirements regarding TLS (SSL). See the chapter about [https:// connections][4] for more information.
|
||||
|
||||
### http:// Connections (h2c) ###
|
||||
|
||||
Although no browser currently supports it, the HTTP/2 protocol also works for http:// urls and mod_h[ttp]2 supports this. The only thing you need to do in order to enable it is the Protocols configuration:
|
||||
|
||||
# for a http server
|
||||
Protocols h2c http/1.1
|
||||
|
||||
inside your **httpd.conf**.
|
||||
|
||||
There are several client (and client libraries) that support **h2c**. I'll dicusss some specifics below:
|
||||
|
||||
#### curl ####
|
||||
|
||||
Of course, the command line client for network resources, maintained by Daniel Stenberg. If you have curl on your system, there is an easy way to check its http/2 support:
|
||||
|
||||
sh> curl -V
|
||||
curl 7.43.0 (x86_64-apple-darwin15.0) libcurl/7.43.0 SecureTransport zlib/1.2.5
|
||||
Protocols: dict file ftp ftps gopher http https imap imaps ldap ldaps pop3 pop3s rtsp smb smbs smtp smtps telnet tftp
|
||||
Features: AsynchDNS IPv6 Largefile GSS-API Kerberos SPNEGO NTLM NTLM_WB SSL libz UnixSockets
|
||||
|
||||
which is no good. There is no 'HTTP2' among the features. You'd want something like this:
|
||||
|
||||
sh> curl -V
|
||||
url 7.45.0 (x86_64-apple-darwin15.0.0) libcurl/7.45.0 OpenSSL/1.0.2d zlib/1.2.8 nghttp2/1.3.4
|
||||
Protocols: dict file ftp ftps gopher http https imap imaps ldap ldaps pop3 pop3s rtsp smb smbs smtp smtps telnet tftp
|
||||
Features: IPv6 Largefile NTLM NTLM_WB SSL libz TLS-SRP HTTP2 UnixSockets
|
||||
|
||||
If you have a curl with the HTTP2 feature, you may check your server with some simple commands:
|
||||
|
||||
sh> curl -v --http2 http://<yourserver>/
|
||||
...
|
||||
> Connection: Upgrade, HTTP2-Settings
|
||||
> Upgrade: h2c
|
||||
> HTTP2-Settings: AAMAAABkAAQAAP__
|
||||
>
|
||||
< HTTP/1.1 101 Switching Protocols
|
||||
< Upgrade: h2c
|
||||
< Connection: Upgrade
|
||||
* Received 101
|
||||
* Using HTTP2, server supports multi-use
|
||||
* Connection state changed (HTTP/2 confirmed)
|
||||
...
|
||||
<the resource>
|
||||
|
||||
Congratulations, id you see the line with **...101 Switching...**, it's working!
|
||||
|
||||
There are cases, where the upgrade to HTTP/2 will not happen. When your first request does have content, for example you do a file upload, the Upgrade will not trigger. For a detailed explanation, see the section [h2c restrictions][5].
|
||||
|
||||
#### nghttp ####
|
||||
|
||||
nghttp2 has its own client and servers that can be build with it. If you have the client on your system, you can verify your installation by simply retrieving a resource:
|
||||
|
||||
sh> nghttp -uv http://<yourserver>/
|
||||
[ 0.001] Connected
|
||||
[ 0.001] HTTP Upgrade request
|
||||
...
|
||||
Connection: Upgrade, HTTP2-Settings
|
||||
Upgrade: h2c
|
||||
HTTP2-Settings: AAMAAABkAAQAAP__
|
||||
...
|
||||
[ 0.005] HTTP Upgrade response
|
||||
HTTP/1.1 101 Switching Protocols
|
||||
Upgrade: h2c
|
||||
Connection: Upgrade
|
||||
|
||||
[ 0.006] HTTP Upgrade success
|
||||
...
|
||||
|
||||
which is very similar to the Upgrade dance we see in the **curl** example above.
|
||||
|
||||
There is another way to use **h2c** hidden in the command line arguments: **-u**. This instructs **nghttp** to perform the HTTP/1 Upgrade dance. But what if we leave this out?
|
||||
|
||||
sh> nghttp -v http://<yourserver>/
|
||||
[ 0.002] Connected
|
||||
[ 0.002] send SETTINGS frame
|
||||
...
|
||||
[ 0.002] send HEADERS frame
|
||||
; END_STREAM | END_HEADERS | PRIORITY
|
||||
(padlen=0, dep_stream_id=11, weight=16, exclusive=0)
|
||||
; Open new stream
|
||||
:method: GET
|
||||
:path: /
|
||||
:scheme: http
|
||||
...
|
||||
|
||||
The connection immediately speaks HTTP/2! This is what the protocol calls the direct mode and it works by some magic 24 bytes that the client sends to the server right away:
|
||||
|
||||
0x505249202a20485454502f322e300d0a0d0a534d0d0a0d0a
|
||||
or in ASCII: PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n
|
||||
|
||||
A **h2c** capable server sees this on a new connection and can immediately switch its HTTP/2 processing on. A HTTP/1.1 server will see a funny request, answer it and close the connection.
|
||||
|
||||
Therefore **direct** mode is only good for clients if they can be resonably sure that the server supports this. For example, because a previous Upgrade dance was successful.
|
||||
|
||||
The charme of **direct** is the zero overhead and that it works for all requests, even those that carry a body (see [h2c restrictions][6]). The direct mode is enabled by default on any server that allows the h2c protocol. If you want to disable it, add the configuration directive:
|
||||
|
||||
注:下面这行打删除线
|
||||
|
||||
H2Direct off
|
||||
|
||||
注:下面这行打删除线
|
||||
to your server.
|
||||
|
||||
For the 2.4.17 release, **H2Direct** is enabled by default on cleartext connection. However there are some modules with whom this is incompatible with. Therefore, in the next release, the default will change to **off** and if you want your server to support it, you need to set it to
|
||||
|
||||
H2Direct on
|
||||
|
||||
### https:// Connections (h2) ###
|
||||
|
||||
Once you get mod_h[ttp]2 working for h2c connections, it's time to get the **h2** sibling going, as browsers only do it with **https:** nowadays.
|
||||
|
||||
The HTTP/2 standard imposes some extra requirements on https: (TLS) connections. The ALPN extension has already been mentioned above. An additional requirement is that no cipher from a specified [black list][7] may be used.
|
||||
|
||||
While the current version of **mod_h[ttp]2** does not enforce these ciphers (but some day will), most clients will do so. If you point your browser at a **h2** server with inappropriate ciphers, you will get the obscure warning **INADEQUATE_SECURITY** and the browser will simply refuse to continue.
|
||||
|
||||
An acceptable Apache SSL configuration regarding this is:
|
||||
|
||||
SSLCipherSuite ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!3DES:!MD5:!PSK
|
||||
SSLProtocol All -SSLv2 -SSLv3
|
||||
...
|
||||
|
||||
(Yes, it's that long.)
|
||||
|
||||
There are other SSL configuration parameters that should be tweaked, but do not have to: **SSLSessionCache**, **SSLUseStapling**, etc. but those are covered elsewhere. See the excellent [High Performance Browser Networking][8] by Ilya Grigorik, for example.
|
||||
|
||||
#### curl ####
|
||||
|
||||
Time to fire up a shell and use curl again (see the [h2c section about curl][9] for requirements). Using curl, you may check your server with some simple commands:
|
||||
|
||||
sh> curl -v --http2 https://<yourserver>/
|
||||
...
|
||||
* ALPN, offering h2
|
||||
* ALPN, offering http/1.1
|
||||
...
|
||||
* ALPN, server accepted to use h2
|
||||
...
|
||||
<the resource>
|
||||
|
||||
Congratulations, it's working! If not, the reason might be:
|
||||
|
||||
- Your curl does not support HTTP/2, see [this check][10].
|
||||
- Your openssl is old and does not support ALPN.
|
||||
- Your certificate could not be verified or your cipher configuration is not accepted. Try adding the command line option -k to disable those checks in curl. If that works, review yor SSL configuration and certificate.
|
||||
|
||||
#### nghttp ####
|
||||
|
||||
**nghttp** we discussed already for **h2c**. If you use it for a **https:** connection, you will either see the resource or an error like this:
|
||||
|
||||
sh> nghttp https://<yourserver>/
|
||||
[ERROR] HTTP/2 protocol was not selected. (nghttp2 expects h2)
|
||||
|
||||
There are two possiblities for this which you can check by adding -v. Either your get this:
|
||||
|
||||
sh> nghttp -v https://<yourserver>/
|
||||
[ 0.034] Connected
|
||||
[ERROR] HTTP/2 protocol was not selected. (nghttp2 expects h2)
|
||||
|
||||
This means that the TLS library your server uses does not implement ALPN. Getting this installtion correct is sometimes tricky. Use stackoverflow.
|
||||
|
||||
Or you get this:
|
||||
|
||||
sh> nghttp -v https://<yourserver>/
|
||||
[ 0.034] Connected
|
||||
The negotiated protocol: http/1.1
|
||||
[ERROR] HTTP/2 protocol was not selected. (nghttp2 expects h2)
|
||||
|
||||
which means ALPN is working, only the h2 protocol was not selected. You need to check that Protocols is set as described above for yourserver. Try setting it in the general section, in case you do not get it working in a vhost at first.
|
||||
|
||||
#### Firefox ####
|
||||
|
||||
Update: Steffen Land from [Apache Lounge][11] pointed me to the [HTTP/2 indicator Add-on for Firefox][12]. Nice if you want to see in how many places you already talk h2 (Hint: Apache Lounge talks h2 for some time now...).
|
||||
|
||||
In Firefox you can to open the Developer Tools and there the Network tab to check for HTTP/2 connections. When you have those open and reload your html page, you see something like the following:
|
||||
|
||||
|
||||
|
||||
Among the response headers, you see this strange **X-Firefox-Spdy** entry listing "h2". That is the indication that HTTP/2 is used on this **https:** connection.
|
||||
|
||||
#### Google Chrome ####
|
||||
|
||||
In Google Chrome, you will not see a HTTP/2 indicator in the developer tools. Instead, Chrome uses the special location **chrome://net-internals/#http2** to give information.
|
||||
|
||||
If you have opened a page on your server and look at that net-internals page, you will see something like this:
|
||||
|
||||
|
||||
|
||||
If your server is among the ones listed here, it is working.
|
||||
|
||||
#### Microsoft Edge ####
|
||||
|
||||
HTTP/2 is supported in the Windows 10 successor to Internet Explorer: Edge. Here you can also see the protocol used in the Developer Tools in the Network tab:
|
||||
|
||||
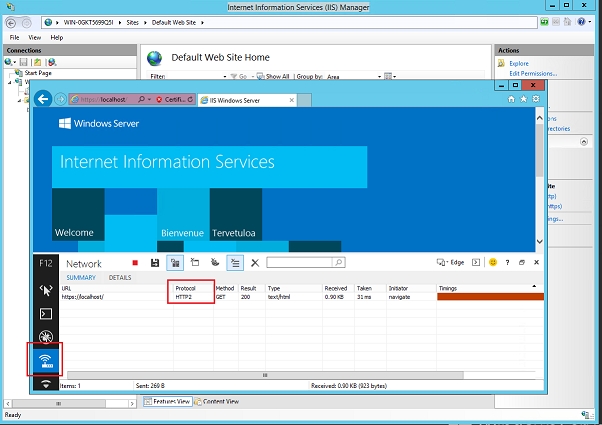
|
||||
|
||||
#### Safari ####
|
||||
|
||||
In Apple's Safari, you open the Developer Tools and there the Network tab. Reload your server page and select the row in the Developer Tools that shows the load. If you enable the right side details view, look at the **Status**. It should show **HTTP/2.0 200** like here:
|
||||
|
||||
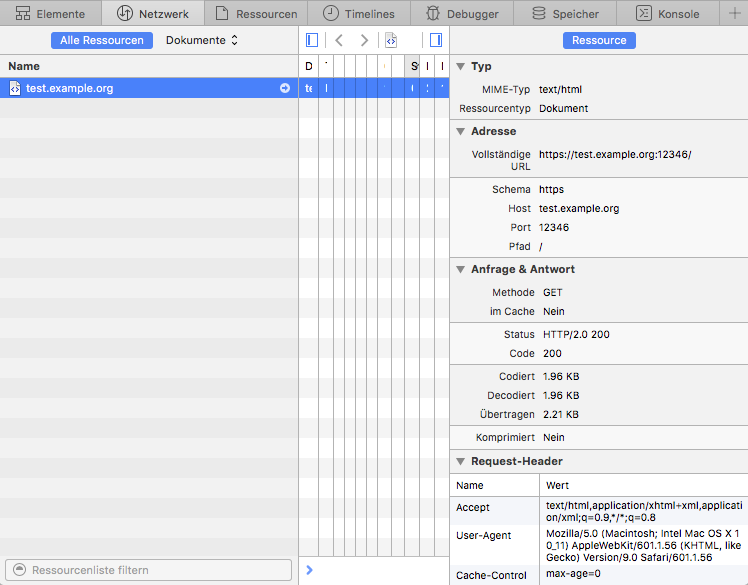
|
||||
|
||||
#### Renegotiations ####
|
||||
|
||||
Renegotiations on a https: connection means that certain TLS parameters are changed on the running connection. In Apache httpd you can change TLS parameters in directory configurations. If a request arrives for a resource in a certain location, configured TLS parameter are compared to the current TLS parameters. If they differ, renegotiation is triggered.
|
||||
|
||||
Most common use cases for this are cipher changes and client certificates. You can require clients to meet authentication only for special locations, or you might enable more secure, but CPU intensive ciphers for specific resources.
|
||||
|
||||
Whatever your good use cases are, renegotiation are a **MUST NOT** in HTTP/2. With 100s of requests ongoing on the same connection, which renegotiation would otherwise occur when?
|
||||
|
||||
The current **mod_h[ttp]2** does not protect you from such configuration. If you have a site which uses TLS renegotiation, DO NOT enable h2 on it!
|
||||
|
||||
Again, we will address that in future releases so that you can enable it safely.
|
||||
|
||||
### Restrictions ###
|
||||
|
||||
#### Non-HTTP Protocols ####
|
||||
|
||||
Modules implementing protocols other than HTTP may be incompatible with **mod_http2**. This will most certainly be the case when this other protocol requires the server to send data first.
|
||||
|
||||
**NNTP** is one example of such a protocol. If you have a **mod_nntp_like_ssl** configured in your server, do not even load mod_http2. Wait for the next release.
|
||||
|
||||
#### h2c Restrictions ####
|
||||
|
||||
There are some restrictions on the **h2c** implementation, you should be aware of:
|
||||
|
||||
#### Deny h2c on virtual host ####
|
||||
|
||||
You cannot deny **h2c direct** on specific virtual hosts. **direct** gets triggered at connection setup when there is not request to be seen yet. Which makes it impossible to foresee which virtual host Apache needs to look at.
|
||||
|
||||
#### Upgrade on request body ####
|
||||
|
||||
The **h2c** Upgrade dance will not work on requests that have a body. Those are PUT and POST requests (form submits and uploads). If you write a client, you may precede those requests with a simple GET or an OPTIONS * to trigger the upgrade.
|
||||
|
||||
The reason is quite technical in nature, but in case you want to know: during Upgrade, the connection is in a half insane state. The request is coming in HTTP/1.1 format and the response is being written in HTTP/2 frames. If the request carries a body, the server needs to read the whole body before it sends a response back. Because the response might need answers from the client for flow control among other things. But if the HTTP/1.1 request is still being sent, the client is unable to talk HTTP/2 yet.
|
||||
|
||||
In order to make behaviour predictable, several server implementors decided to not do an Upgrade in the presence of any request bodies, even small ones.
|
||||
|
||||
#### Upgrade on 302s ####
|
||||
|
||||
The h2c Upgrade dance also does currently not work when there is a general redirect in place. Seems that rewrite happens before the mod_http2 has a chance to act. Certainly not a deal breaker, but might be confusing when you test a site that has it.
|
||||
|
||||
#### h2 Restrictions ####
|
||||
|
||||
There are some restrictions on the h2 implementation you should be aware of:
|
||||
|
||||
#### Connection Reuse ####
|
||||
|
||||
The HTTP/2 protocol allows reuse of TLS connections under certain conditions: if you have a certiface with wildcards or several altSubject names, browsers will reuse any existing connection they might have. Example:
|
||||
|
||||
You have a certificate for **a.example.org** that has as additional name **b.example.org**. You open in your browser the url **https://a.example.org/**, open another tab and load **https://b.example.org/**.
|
||||
|
||||
Before opening a new connection, the browser sees that it still has the one to **a.example.org** open and that the certificate is also valid for **b.example.org**. So, it sends the request for second tab over the connection of the first one.
|
||||
|
||||
This connection reuse is intentional and makes it easier for sites that have invested in sharding for efficiency in HTTP/1 to also benefit from HTTP/2 without much change.
|
||||
|
||||
In Apache **mod_h[ttp]2** this is not fully implemented, yet. When **a.example.org** and **b.example.org** are separate virtual hosts, Apache will not allow such connection reuse and inform the browser with status code **421 Misdirected Request** about it. The browser will understand that it has to open a new connection to **b.example.org**. All will work, however some efficiency gets lost.
|
||||
|
||||
We expect to have the proper checks in place for the next release.
|
||||
|
||||
Münster, 12.10.2015,
|
||||
|
||||
Stefan Eissing, greenbytes GmbH
|
||||
|
||||
Copying and distribution of this file, with or without modification, are permitted in any medium without royalty provided the copyright notice and this notice are preserved. This file is offered as-is, without warranty of any kind. See LICENSE for details.
|
||||
|
||||
|
||||
----------
|
||||
|
||||
This project is maintained by [icing][13]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://icing.github.io/mod_h2/howto.html
|
||||
|
||||
作者:[icing][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/icing
|
||||
[1]:https://httpd.apache.org/download.cgi
|
||||
[2]:https://httpd.apache.org/docs/2.4/install.html
|
||||
[3]:https://nghttp2.org/
|
||||
[4]:https://icing.github.io/mod_h2/howto.html#https
|
||||
[5]:https://icing.github.io/mod_h2/howto.html#h2c-restrictions
|
||||
[6]:https://icing.github.io/mod_h2/howto.html#h2c-restrictions
|
||||
[7]:https://httpwg.github.io/specs/rfc7540.html#BadCipherSuites
|
||||
[8]:http://chimera.labs.oreilly.com/books/1230000000545
|
||||
[9]:https://icing.github.io/mod_h2/howto.html#curl
|
||||
[10]:https://icing.github.io/mod_h2/howto.html#curl
|
||||
[11]:https://www.apachelounge.com/
|
||||
[12]:https://addons.mozilla.org/en-US/firefox/addon/spdy-indicator/
|
||||
[13]:https://github.com/icing
|
||||
@ -0,0 +1,513 @@
|
||||
struggling 翻译中...
|
||||
9 Tips for Improving WordPress Performance
|
||||
================================================================================
|
||||
WordPress is the single largest platform for website creation and web application delivery worldwide. About [a quarter][1] of all sites are now built on open-source WordPress software, including sites for eBay, Mozilla, RackSpace, TechCrunch, CNN, MTV, the New York Times, the Wall Street Journal.
|
||||
|
||||
WordPress.com, the most popular site for user-created blogs, also runs on WordPress open source software. [NGINX powers WordPress.com][2]. Among WordPress customers, many sites start on WordPress.com and then move to hosted WordPress open-source software; more and more of these sites use NGINX software as well.
|
||||
|
||||
WordPress’ appeal is its simplicity, both for end users and for implementation. However, the architecture of a WordPress site presents problems when usage ramps upward – and several steps, including caching and combining WordPress and NGINX, can solve these problems.
|
||||
|
||||
In this blog post, we provide nine performance tips to help overcome typical WordPress performance challenges:
|
||||
|
||||
- [Cache static resources][3]
|
||||
- [Cache dynamic files][4]
|
||||
- [Move to NGINX][5]
|
||||
- [Add permalink support to NGINX][6]
|
||||
- [Configure NGINX for FastCGI][7]
|
||||
- [Configure NGINX for W3_Total_Cache][8]
|
||||
- [Configure NGINX for WP-Super-Cache][9]
|
||||
- [Add security precautions to your NGINX configuration][10]
|
||||
- [Configure NGINX to support WordPress Multisite][11]
|
||||
|
||||
### WordPress Performance on LAMP Sites ###
|
||||
|
||||
Most WordPress sites are run on a traditional LAMP software stack: the Linux OS, Apache web server software, MySQL database software – often on a separate database server – and the PHP programming language. Each of these is a very well-known, widely used, open source tool. Most people in the WordPress world “speak” LAMP, so it’s easy to get help and support.
|
||||
|
||||
When a user visits a WordPress site, a browser running the Linux/Apache combination creates six to eight connections per user. As the user moves around the site, PHP assembles each page on the fly, grabbing resources from the MySQL database to answer requests.
|
||||
|
||||
LAMP stacks work well for anywhere from a few to, perhaps, hundreds of simultaneous users. However, sudden increases in traffic are common online and – usually – a good thing.
|
||||
|
||||
But when a LAMP-stack site gets busy, with the number of simultaneous users climbing into the many hundreds or thousands, it can develop serious bottlenecks. Two main causes of bottlenecks are:
|
||||
|
||||
1. The Apache web server – Apache consumes substantial resources for each and every connection. If Apache accepts too many simultaneous connections, memory can be exhausted and performance slows because data has to be paged back and forth to disk. If connections are limited to protect response time, new connections have to wait, which also leads to a poor user experience.
|
||||
1. The PHP/MySQL interaction – Together, an application server running PHP and a MySQL database server can serve a maximum number of requests per second. When the number of requests exceeds the maximum, users have to wait. Exceeding the maximum by a relatively small amount can cause a large slowdown in responsiveness for all users. Exceeding it by two or more times can cause significant performance problems.
|
||||
|
||||
The performance bottlenecks in a LAMP site are particularly resistant to the usual instinctive response, which is to upgrade to more powerful hardware – more CPUs, more disk space, and so on. Incremental increases in hardware performance can’t keep up with the exponential increases in demand for system resources that Apache and the PHP/MySQL combination experience when they get overloaded.
|
||||
|
||||
The leading alternative to a LAMP stack is a LEMP stack – Linux, NGINX, MySQL, and PHP. (In the LEMP acronym, the E stands for the sound at the start of “engine-x.”) We describe a LEMP stack in [Tip 3][12].
|
||||
|
||||
### Tip 1. Cache Static Resources ###
|
||||
|
||||
Static resources are unchanging files such as CSS files, JavaScript files, and image files. These files often make up half or more of the data on a web page. The remainder of the page is dynamically generated content like comments in a forum, a performance dashboard, or personalized content (think Amazon.com product recommendations).
|
||||
|
||||
Caching static resources has two big benefits:
|
||||
|
||||
- Faster delivery to the user – The user gets the static file from their browser cache or a caching server closer to them on the Internet. These are sometimes big files, so reducing latency for them helps a lot.
|
||||
- Reduced load on the application server – Every file that’s retrieved from a cache is one less request the web server has to process. The more you cache, the more you avoid thrashing because resources have run out.
|
||||
|
||||
To support browser caching, set the correct HTTP headers for static files. Look into the HTTP Cache-Control header, specifically the max-age setting, the Expires header, and Entity tags. You can find a good introduction [here][13].
|
||||
|
||||
When local caching is enabled and a user requests a previously accessed file, the browser first checks whether the file is in the cache. If so, it asks the web server if the file has changed. If the file hasn’t changed, the web server can respond immediately with code 304 (Not Modified) meaning that the file is unchanged, instead of returning code 200 OK and then retrieving and delivering the changed file.
|
||||
|
||||
To support caching beyond the browser, consider the Tips below, and consider a content delivery network (CDN).CDNs are a popular and powerful tool for caching, but we don’t describe them in detail here. Consider a CDN after you implement the other techniques mentioned here. Also, CDNs may be less useful as you transition your site from HTTP/1.x to the new HTTP/2 standard; investigate and test as needed to find the right answer for your site.
|
||||
|
||||
If you move to NGINX Plus or the open source NGINX software as part of your software stack, as suggested in [Tip 3][14], then configure NGINX to cache static resources. Use the following configuration, replacing www.example.com with the URL of your web server.
|
||||
|
||||
server {
|
||||
# substitute your web server's URL for www.example.com
|
||||
server_name www.example.com;
|
||||
root /var/www/example.com/htdocs;
|
||||
index index.php;
|
||||
|
||||
access_log /var/log/nginx/example.com.access.log;
|
||||
error_log /var/log/nginx/example.com.error.log;
|
||||
|
||||
location / {
|
||||
try_files $uri $uri/ /index.php?$args;
|
||||
}
|
||||
|
||||
location ~ \.php$ {
|
||||
try_files $uri =404;
|
||||
include fastcgi_params;
|
||||
# substitute the socket, or address and port, of your WordPress server
|
||||
fastcgi_pass unix:/var/run/php5-fpm.sock;
|
||||
#fastcgi_pass 127.0.0.1:9000;
|
||||
}
|
||||
|
||||
location ~* .(ogg|ogv|svg|svgz|eot|otf|woff|mp4|ttf|css|rss|atom|js|jpg|jpeg|gif|png|ico|zip|tgz|gz|rar|bz2|doc|xls|exe|ppt|tar|mid|midi|wav|bmp|rtf)$ {
|
||||
expires max;
|
||||
log_not_found off;
|
||||
access_log off;
|
||||
}
|
||||
}
|
||||
|
||||
### Tip 2. Cache Dynamic Files ###
|
||||
|
||||
WordPress generates web pages dynamically, meaning that it generates a given web page every time it is requested (even if the result is the same as the time before). This means that users always get the freshest content.
|
||||
|
||||
Think of a user visiting a blog post that has comments enabled at the bottom of the post. You want the user to see all comments – even a comment that just came in a moment ago. Dynamic content makes this happen.
|
||||
|
||||
But now let’s say that the blog post is getting ten or twenty requests per second. The application server might start to thrash under the pressure of trying to regenerate the page so often, causing big delays. The goal of delivering the latest content to new visitors becomes relevant only in theory, because they’re have to wait so long to get the page in the first place.
|
||||
|
||||
To prevent page delivery from slowing down due to increasing load, cache the dynamic file. This makes the file less dynamic, but makes the whole system more responsive.
|
||||
|
||||
To enable caching in WordPress, use one of several popular plug-ins – described below. A WordPress caching plug-in asks for a fresh page, then caches it for a brief period of time – perhaps just a few seconds. So, if the site is getting several requests a second, most users get their copy of the page from the cache. This helps the retrieval time for all users:
|
||||
|
||||
- Most users get a cached copy of the page. The application server does no work at all.
|
||||
- Users who do get a fresh copy get it fast. The application server only has to generate a fresh page every so often. When the server does generate a fresh page (for the first user to come along after the cached page expires), it does this much faster because it’s not overloaded with requests.
|
||||
|
||||
You can cache dynamic files for WordPress running on a LAMP stack or on a [LEMP stack][15] (described in [Tip 3][16]). There are several caching plug-ins you can use with WordPress. Here are the most popular caching plug-ins and caching techniques, listed from the simplest to the most powerful:
|
||||
|
||||
- [Hyper-Cache][17] and [Quick-Cache][18] – These two plug-ins create a single PHP file for each WordPress page or post. This supports some dynamic functionality while bypassing much WordPress core processing and the database connection, creating a faster user experience. They don’t bypass all PHP processing, so they don’t give the same performance boost as the following options. They also don’t require changes to the NGINX configuration.
|
||||
- [WP Super Cache][19] – The most popular caching plug-in for WordPress. It has many settings, which are presented through an easy-to-use interface, shown below. We show a sample NGINX configuration in [Tip 7][20].
|
||||
- [W3 Total Cache][21] – This is the second most popular cache plug-in for WordPress. It has even more option settings than WP Super Cache, making it a powerful but somewhat complex option. For a sample NGINX configuration, see [Tip 6][22].
|
||||
- [FastCGI][23] – CGI stands for Common Gateway Interface, a language-neutral way to request and receive files on the Internet. FastCGI is not a plug-in but a way to interact with a cache. FastCGI can be used in Apache as well as in NGINX, where it’s the most popular dynamic caching approach; we describe how to configure NGINX to use it in [Tip 5][24].
|
||||
|
||||
The documentation for these plug-ins and techniques explains how to configure them in a typical LAMP stack. Configuration options include database and object caching; minification for HTML, CSS, and JavaScript files; and integration options for popular CDNs. For NGINX configuration, see the Tips referenced in the list.
|
||||
|
||||
**Note**: Caches do not work for users who are logged into WordPress, because their view of WordPress pages is personalized. (For most sites, only a small minority of users are likely to be logged in.) Also, most caches do not show a cached page to users who have recently left a comment, as that user will want to see their comment appear when they refresh the page. To cache the non-personalized content of a page, you can use a technique called [fragment caching][25], if it’s important to overall performance.
|
||||
|
||||
### Tip 3. Move to NGINX ###
|
||||
|
||||
As mentioned above, Apache can cause performance problems when the number of simultaneous users rises above a certain point – perhaps hundreds of simultaneous users. Apache allocates substantial resources to each connection, and therefore tends to run out of memory. Apache can be configured to limit connections to avoid exhausting memory, but that means, when the limit is exceeded, new connection requests have to wait.
|
||||
|
||||
In addition, Apache loads another copy of the mod_php module into memory for every connection, even if it’s only serving static files (images, CSS, JavaScript, etc.). This consumes even more resources for each connection and limits the capacity of the server further.
|
||||
|
||||
To start solving these problems, move from a LAMP stack to a LEMP stack – replace Apache with (e)NGINX. NGINX handles many thousands of simultaneous connections in a fixed memory footprint, so you don’t have to experience thrashing, nor limit simultaneous connections to a small number.
|
||||
|
||||
NGINX also deals with static files better, with built-in, easily tuned [caching][26] controls. The load on the application server is reduced, and your site can serve far more traffic with a faster, more enjoyable experience for your users.
|
||||
|
||||
You can use NGINX on all the web servers in your deployment, or you can put an NGINX server “in front” of Apache as a reverse proxy – the NGINX server receives client requests, serves static files, and sends PHP requests to Apache, which processes them.
|
||||
|
||||
For dynamically generated pages – the core use case for WordPress experience – choose a caching tool, as described in [Tip 2][27]. In the Tips below, you can find NGINX configuration suggestions for FastCGI, W3_Total_Cache, and WP-Super-Cache. (Hyper-Cache and Quick-Cache don’t require changes to NGINX configuration.)
|
||||
|
||||
**Tip.** Caches are typically saved to disk, but you can use [tmpfs][28] to store the cache in memory and increase performance.
|
||||
|
||||
Setting up NGINX for WordPress is easy. Just follow these four steps, which are described in further detail in the indicated Tips:
|
||||
|
||||
1. Add permalink support – Add permalink support to NGINX. This eliminates dependence on the **.htaccess** configuration file, which is Apache-specific. See [Tip 4][29].
|
||||
1. Configure for caching – Choose a caching tool and implement it. Choices include FastCGI cache, W3 Total Cache, WP Super Cache, Hyper Cache, and Quick Cache. See Tips [5][30], [6][31], and [7][32].
|
||||
1. Implement security precautions – Adopt best practices for WordPress security on NGINX. See [Tip 8][33].
|
||||
1. Configure WordPress Multisite – If you use WordPress Multisite, configure NGINX for a subdirectory, subdomain, or multiple-domain architecture. See [Tip 9][34].
|
||||
|
||||
### Tip 4. Add Permalink Support to NGINX ###
|
||||
|
||||
Many WordPress sites depend on **.htaccess** files, which are required for several WordPress features, including permalink support, plug-ins, and file caching. NGINX does not support **.htaccess** files. Fortunately, you can use NGINX’s simple, yet comprehensive, configuration language to achieve most of the same functionality.
|
||||
|
||||
You can enable [Permalinks][35] in WordPress with NGINX by including the following location block in your main [server][36] block. (This location block is also included in other code samples below.)
|
||||
|
||||
The **try_files** directive tells NGINX to check whether the requested URL exists as a file ( **$uri**) or directory (**$uri/**) in the document root, **/var/www/example.com/htdocs**. If not, NGINX does a redirect to **/index.php**, passing the query string arguments as parameters.
|
||||
|
||||
server {
|
||||
server_name example.com www.example.com;
|
||||
root /var/www/example.com/htdocs;
|
||||
index index.php;
|
||||
|
||||
access_log /var/log/nginx/example.com.access.log;
|
||||
error_log /var/log/nginx/example.com.error.log;
|
||||
|
||||
location / {
|
||||
try_files $uri $uri/ /index.php?$args;
|
||||
}
|
||||
}
|
||||
|
||||
### Tip 5. Configure NGINX for FastCGI ###
|
||||
|
||||
NGINX can cache responses from FastCGI applications like PHP. This method offers the best performance.
|
||||
|
||||
For NGINX open source, compile in the third-party module [ngx_cache_purge][37], which provides cache purging capability, and use the configuration code below. NGINX Plus includes its own implementation of this code.
|
||||
|
||||
When using FastCGI, we recommend you install the [Nginx Helper plug-in][38] and use a configuration such as the one below, especially the use of **fastcgi_cache_key** and the location block including **fastcgi_cache_purge**. The plug-in automatically purges your cache when a page or a post is published or modified, a new comment is published, or the cache is manually purged from the WordPress Admin Dashboard.
|
||||
|
||||
The Nginx Helper plug-in can also add a short HTML snippet to the bottom of your pages, confirming the cache is working and displaying some statistics. (You can also confirm the cache is functioning properly using the [$upstream_cache_status][39] variable.)
|
||||
|
||||
fastcgi_cache_path /var/run/nginx-cache levels=1:2
|
||||
keys_zone=WORDPRESS:100m inactive=60m;
|
||||
fastcgi_cache_key "$scheme$request_method$host$request_uri";
|
||||
|
||||
server {
|
||||
server_name example.com www.example.com;
|
||||
root /var/www/example.com/htdocs;
|
||||
index index.php;
|
||||
|
||||
access_log /var/log/nginx/example.com.access.log;
|
||||
error_log /var/log/nginx/example.com.error.log;
|
||||
|
||||
set $skip_cache 0;
|
||||
|
||||
# POST requests and urls with a query string should always go to PHP
|
||||
if ($request_method = POST) {
|
||||
set $skip_cache 1;
|
||||
}
|
||||
|
||||
if ($query_string != "") {
|
||||
set $skip_cache 1;
|
||||
}
|
||||
|
||||
# Don't cache uris containing the following segments
|
||||
if ($request_uri ~* "/wp-admin/|/xmlrpc.php|wp-.*.php|/feed/|index.php
|
||||
|sitemap(_index)?.xml") {
|
||||
set $skip_cache 1;
|
||||
}
|
||||
|
||||
# Don't use the cache for logged in users or recent commenters
|
||||
if ($http_cookie ~* "comment_author|wordpress_[a-f0-9]+|wp-postpass
|
||||
|wordpress_no_cache|wordpress_logged_in") {
|
||||
set $skip_cache 1;
|
||||
}
|
||||
|
||||
location / {
|
||||
try_files $uri $uri/ /index.php?$args;
|
||||
}
|
||||
|
||||
location ~ \.php$ {
|
||||
try_files $uri /index.php;
|
||||
include fastcgi_params;
|
||||
fastcgi_pass unix:/var/run/php5-fpm.sock;
|
||||
fastcgi_cache_bypass $skip_cache;
|
||||
fastcgi_no_cache $skip_cache;
|
||||
fastcgi_cache WORDPRESS;
|
||||
fastcgi_cache_valid 60m;
|
||||
}
|
||||
|
||||
location ~ /purge(/.*) {
|
||||
fastcgi_cache_purge WORDPRESS "$scheme$request_method$host$1";
|
||||
}
|
||||
|
||||
location ~* ^.+\.(ogg|ogv|svg|svgz|eot|otf|woff|mp4|ttf|css|rss|atom|js|jpg|jpeg|gif|png
|
||||
|ico|zip|tgz|gz|rar|bz2|doc|xls|exe|ppt|tar|mid|midi|wav|bmp|rtf)$ {
|
||||
|
||||
access_log off;
|
||||
log_not_found off;
|
||||
expires max;
|
||||
}
|
||||
|
||||
location = /robots.txt {
|
||||
access_log off;
|
||||
log_not_found off;
|
||||
}
|
||||
|
||||
location ~ /\. {
|
||||
deny all;
|
||||
access_log off;
|
||||
log_not_found off;
|
||||
}
|
||||
}
|
||||
|
||||
### Tip 6. Configure NGINX for W3_Total_Cache ###
|
||||
|
||||
[W3 Total Cache][40], by Frederick Townes of [W3-Edge][41], is a WordPress caching framework that supports NGINX. It’s an alternative to FastCGI cache with a wide range of option settings.
|
||||
|
||||
The caching plug-in offers a variety of caching configurations and also includes options for database and object caching, minification of HTML, CSS, and JavaScript, as well as options to integrate with popular CDNs.
|
||||
|
||||
The plug-in handles NGINX configuration by writing to an NGINX configuration file located in the root directory of your domain.
|
||||
|
||||
server {
|
||||
server_name example.com www.example.com;
|
||||
|
||||
root /var/www/example.com/htdocs;
|
||||
index index.php;
|
||||
access_log /var/log/nginx/example.com.access.log;
|
||||
error_log /var/log/nginx/example.com.error.log;
|
||||
|
||||
include /path/to/wordpress/installation/nginx.conf;
|
||||
|
||||
location / {
|
||||
try_files $uri $uri/ /index.php?$args;
|
||||
}
|
||||
|
||||
location ~ \.php$ {
|
||||
try_files $uri =404;
|
||||
include fastcgi_params;
|
||||
fastcgi_pass unix:/var/run/php5-fpm.sock;
|
||||
}
|
||||
}
|
||||
|
||||
### Tip 7. Configure NGINX for WP Super Cache ###
|
||||
|
||||
[WP Super Cache][42] by Donncha O Caoimh, a WordPress developer at [Automattic][43], is a WordPress caching engine that turns dynamic WordPress pages into static HTML files that NGINX can serve very quickly. It was one of the first caching plug-ins for WordPress and has a smaller, more focused range of options than others.
|
||||
|
||||
NGINX configurations for WP-Super-Cache can vary depending on your preference. One possible configuration follows.
|
||||
|
||||
In the configuration below, the location block with supercache named in it is the WP Super Cache-specific part, and is needed for the configuration to work. The rest of the code is made up of WordPress rules for not caching users who are logged into WordPress, not caching POST requests, and setting expires headers for static assets, plus standard PHP implementation; these parts can be customized to fit your needs.
|
||||
|
||||
server {
|
||||
server_name example.com www.example.com;
|
||||
root /var/www/example.com/htdocs;
|
||||
index index.php;
|
||||
|
||||
access_log /var/log/nginx/example.com.access.log;
|
||||
error_log /var/log/nginx/example.com.error.log debug;
|
||||
|
||||
set $cache_uri $request_uri;
|
||||
|
||||
# POST requests and urls with a query string should always go to PHP
|
||||
if ($request_method = POST) {
|
||||
set $cache_uri 'null cache';
|
||||
}
|
||||
if ($query_string != "") {
|
||||
set $cache_uri 'null cache';
|
||||
}
|
||||
|
||||
# Don't cache uris containing the following segments
|
||||
if ($request_uri ~* "(/wp-admin/|/xmlrpc.php|/wp-(app|cron|login|register|mail).php
|
||||
|wp-.*.php|/feed/|index.php|wp-comments-popup.php
|
||||
|wp-links-opml.php|wp-locations.php |sitemap(_index)?.xml
|
||||
|[a-z0-9_-]+-sitemap([0-9]+)?.xml)") {
|
||||
|
||||
set $cache_uri 'null cache';
|
||||
}
|
||||
|
||||
# Don't use the cache for logged-in users or recent commenters
|
||||
if ($http_cookie ~* "comment_author|wordpress_[a-f0-9]+
|
||||
|wp-postpass|wordpress_logged_in") {
|
||||
set $cache_uri 'null cache';
|
||||
}
|
||||
|
||||
# Use cached or actual file if it exists, otherwise pass request to WordPress
|
||||
location / {
|
||||
try_files /wp-content/cache/supercache/$http_host/$cache_uri/index.html
|
||||
$uri $uri/ /index.php;
|
||||
}
|
||||
|
||||
location = /favicon.ico {
|
||||
log_not_found off;
|
||||
access_log off;
|
||||
}
|
||||
|
||||
location = /robots.txt {
|
||||
log_not_found off
|
||||
access_log off;
|
||||
}
|
||||
|
||||
location ~ .php$ {
|
||||
try_files $uri /index.php;
|
||||
include fastcgi_params;
|
||||
fastcgi_pass unix:/var/run/php5-fpm.sock;
|
||||
#fastcgi_pass 127.0.0.1:9000;
|
||||
}
|
||||
|
||||
# Cache static files for as long as possible
|
||||
location ~*.(ogg|ogv|svg|svgz|eot|otf|woff|mp4|ttf|css
|
||||
|rss|atom|js|jpg|jpeg|gif|png|ico|zip|tgz|gz|rar|bz2
|
||||
|doc|xls|exe|ppt|tar|mid|midi|wav|bmp|rtf)$ {
|
||||
expires max;
|
||||
log_not_found off;
|
||||
access_log off;
|
||||
}
|
||||
}
|
||||
|
||||
### Tip 8. Add Security Precautions to Your NGINX Configuration ###
|
||||
|
||||
To protect against attacks, you can control access to key resources and limit the ability of bots to overload the login utility.
|
||||
|
||||
Allow only specific IP addresses to access the WordPress Dashboard.
|
||||
|
||||
# Restrict access to WordPress Dashboard
|
||||
location /wp-admin {
|
||||
deny 192.192.9.9;
|
||||
allow 192.192.1.0/24;
|
||||
allow 10.1.1.0/16;
|
||||
deny all;
|
||||
}
|
||||
|
||||
Only allow uploading of specific types of files to prevent programs with malicious intent from being uploaded and running.
|
||||
|
||||
# Deny access to uploads which aren’t images, videos, music, etc.
|
||||
location ~* ^/wp-content/uploads/.*.(html|htm|shtml|php|js|swf)$ {
|
||||
deny all;
|
||||
}
|
||||
|
||||
Deny access to **wp-config.php**, the WordPress configuration file. Another way to deny access is to move the file one directory level above the domain root.
|
||||
|
||||
# Deny public access to wp-config.php
|
||||
location ~* wp-config.php {
|
||||
deny all;
|
||||
}
|
||||
|
||||
Rate limit **wp-login.php** to block against brute force attacks.
|
||||
|
||||
# Deny access to wp-login.php
|
||||
location = /wp-login.php {
|
||||
limit_req zone=one burst=1 nodelay;
|
||||
fastcgi_pass unix:/var/run/php5-fpm.sock;
|
||||
#fastcgi_pass 127.0.0.1:9000;
|
||||
}
|
||||
|
||||
### Tip 9. Use NGINX with WordPress Multisite ###
|
||||
|
||||
WordPress Multisite, as its name implies, is a version of WordPress software that allows you to manage two or more sites from a single WordPress instance. The [WordPress.com][44] service, which hosts thousands of user blogs, is run from WordPress Multisite.
|
||||
|
||||
You can run separate sites from either subdirectories of a single domain or from separate subdomains.
|
||||
|
||||
Use this code block to add support for a subdirectory structure.
|
||||
|
||||
# Add support for subdirectory structure in WordPress Multisite
|
||||
if (!-e $request_filename) {
|
||||
rewrite /wp-admin$ $scheme://$host$uri/ permanent;
|
||||
rewrite ^(/[^/]+)?(/wp-.*) $2 last;
|
||||
rewrite ^(/[^/]+)?(/.*\.php) $2 last;
|
||||
}
|
||||
|
||||
Use this code block instead of the code block above to add support for a subdirectory structure, substituting your own subdirectory names.
|
||||
|
||||
# Add support for subdomains
|
||||
server_name example.com *.example.com;
|
||||
|
||||
Older versions of WordPress Multisite (3.4 and earlier) use readfile() to serve static content. However, readfile() is PHP code, which causes a significant performance hit when it executes. We can use NGINX to bypass this unnecessary PHP processing. The code snippets below are separated by separator lines (==============).
|
||||
|
||||
# Avoid PHP readfile() for /blogs.dir/structure in the subdirectory path.
|
||||
location ^~ /blogs.dir {
|
||||
internal;
|
||||
alias /var/www/example.com/htdocs/wp-content/blogs.dir;
|
||||
access_log off;
|
||||
log_not_found off;
|
||||
expires max;
|
||||
}
|
||||
|
||||
============================================================
|
||||
|
||||
# Avoid php readfile() for /files/structure in the subdirectory path
|
||||
location ~ ^(/[^/]+/)?files/(?.+) {
|
||||
try_files /wp-content/blogs.dir/$blogid/files/$rt_file /wp-includes/ms-files.php?file=$rt_file;
|
||||
access_log off;
|
||||
log_not_found off;
|
||||
expires max;
|
||||
}
|
||||
|
||||
============================================================
|
||||
|
||||
# WPMU files structure for the subdomain path
|
||||
location ~ ^/files/(.*)$ {
|
||||
try_files /wp-includes/ms-files.php?file=$1 =404;
|
||||
access_log off;
|
||||
log_not_found off;
|
||||
expires max;
|
||||
}
|
||||
|
||||
============================================================
|
||||
|
||||
# Map blog ID to specific directory
|
||||
map $http_host $blogid {
|
||||
default 0;
|
||||
example.com 1;
|
||||
site1.example.com 2;
|
||||
site1.com 2;
|
||||
}
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Scalability is a challenge for more and more site developers as they achieve success with their WordPress sites. (And for new sites that want to head WordPress performance problems off at the pass.) Adding WordPress caching, and combining WordPress and NGINX, are solid answers.
|
||||
|
||||
NGINX is not only useful with WordPress sites. NGINX is the [leading web server][45] among the busiest 1,000, 10,000, and 100,000 sites in the world.
|
||||
|
||||
For more on NGINX performance, see our recent blog post, [10 Tips for 10x Application Performance][46].
|
||||
|
||||
NGINX software comes in two versions:
|
||||
|
||||
- NGINX open source software – Like WordPress, this is software you download, configure, and compile yourself.
|
||||
- NGINX Plus – NGINX Plus includes a pre-built reference version of the software, as well as service and technical support.
|
||||
|
||||
To get started, go to [nginx.org][47] for the open source software or check out [NGINX Plus][48].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/
|
||||
|
||||
作者:[Floyd Smith][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.nginx.com/blog/author/floyd/
|
||||
[1]:http://w3techs.com/technologies/overview/content_management/all
|
||||
[2]:https://www.nginx.com/press/choosing-nginx-growth-wordpresscom/
|
||||
[3]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#cache-static
|
||||
[4]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#cache-dynamic
|
||||
[5]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#adopt-nginx
|
||||
[6]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#permalink
|
||||
[7]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#fastcgi
|
||||
[8]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#w3-total-cache
|
||||
[9]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#wp-super-cache
|
||||
[10]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#security
|
||||
[11]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#multisite
|
||||
[12]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#adopt-nginx
|
||||
[13]:http://www.mobify.com/blog/beginners-guide-to-http-cache-headers/
|
||||
[14]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#adopt-nginx
|
||||
[15]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#lamp
|
||||
[16]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#adopt-nginx
|
||||
[17]:https://wordpress.org/plugins/hyper-cache/
|
||||
[18]:https://wordpress.org/plugins/quick-cache/
|
||||
[19]:https://wordpress.org/plugins/wp-super-cache/
|
||||
[20]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#wp-super-cache
|
||||
[21]:https://wordpress.org/plugins/w3-total-cache/
|
||||
[22]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#w3-total-cache
|
||||
[23]:http://www.fastcgi.com/
|
||||
[24]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#fastcgi
|
||||
[25]:https://css-tricks.com/wordpress-fragment-caching-revisited/
|
||||
[26]:https://www.nginx.com/resources/admin-guide/content-caching/
|
||||
[27]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#cache-dynamic
|
||||
[28]:https://www.kernel.org/doc/Documentation/filesystems/tmpfs.txt
|
||||
[29]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#permalink
|
||||
[30]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#fastcgi
|
||||
[31]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#w3-total-cache
|
||||
[32]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#wp-super-cache
|
||||
[33]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#security
|
||||
[34]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#multisite
|
||||
[35]:http://codex.wordpress.org/Using_Permalinks
|
||||
[36]:http://nginx.org/en/docs/http/ngx_http_core_module.html#server
|
||||
[37]:https://github.com/FRiCKLE/ngx_cache_purge
|
||||
[38]:https://wordpress.org/plugins/nginx-helper/
|
||||
[39]:http://nginx.org/en/docs/http/ngx_http_upstream_module.html#variables
|
||||
[40]:https://wordpress.org/plugins/w3-total-cache/
|
||||
[41]:http://www.w3-edge.com/
|
||||
[42]:https://wordpress.org/plugins/wp-super-cache/
|
||||
[43]:http://automattic.com/
|
||||
[44]:https://wordpress.com/
|
||||
[45]:http://w3techs.com/technologies/cross/web_server/ranking
|
||||
[46]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/
|
||||
[47]:http://www.nginx.org/en
|
||||
[48]:https://www.nginx.com/products/
|
||||
[49]:
|
||||
[50]:
|
||||
@ -0,0 +1,37 @@
|
||||
红帽 CEO 对 OpenStack 收益表示乐观
|
||||
================================================================================
|
||||
得益于围绕 Linux 和云不断发展的平台和基础设施技术,红帽正在持续快速发展。红帽宣布在九月二十一日完成了 2016 财年第二季度的财务业绩,再次超过预期。
|
||||
|
||||

|
||||
|
||||
这一季度,红帽的收入为 5 亿 4 百万美元,和去年同比增长 13%。网络输入为 5 千 1 百万美元,超过 2015 年第二季度的 4 千 7 百万美元。展望未来,红帽为下一季度和全年提供了积极的目标。对于第三季度,红帽希望指导收益能在 5亿1千9百万美元和5亿2千3百万美元之间,和去年同期相比增长 15%。
|
||||
|
||||
对于 2016 财年,红帽的全年指导目标是 20亿4千4百万美元,和去年相比增长 14%。
|
||||
|
||||
红帽 CFO Frank Calderoni 在电话会议上指出,红帽最高的 30 个订单大概甚至超过 1 百万美元。其中有 4 个订单超过 5百万美元,还有一个超过1千万美元。从近几年的经验来看,红帽产品的交叉销售非常成功,全部订单中有超过 65% 的订单包括了一个或多个红帽应用和新兴技术产品组件。
|
||||
|
||||
Calderoni 说 “我们希望这些技术,例如中间件、RHEL OpenStack 平台、OpenShift、云管理和存储能持续推动收益增长。”
|
||||
|
||||
### OpenStack ###
|
||||
|
||||
在电话会议中,红帽 CEO Jim Whitehurst 多次问到 OpenStack 的收入前景。Whitehurst 说得益于安装程序的改进,最近发布的 Red Hat OpenStack Platform 7.0 向前垮了一大步。
|
||||
|
||||
Whitehurst 提到:“在识别硬件和使用方面它做的很好,当然,这也意味着在硬件识别并正确使用它们方便还有很多工作要做。”
|
||||
|
||||
Whitehurst 说他已经开始注意到很多的生产应用程序开始迁移到 OpenStack 云上来。他也警告说在产业化方面迁移到 OpenStack 大部分只是尝鲜,还并没有成为主流。
|
||||
|
||||
对于竞争对手, Whitehurst 尤其提到了微软、惠普和 Mirantis。在他看来,很多组织仍然会使用多种操作系统,如果他们其中一部分使用了微软,他们更倾向于开源方案作为替代选项。Whitehurst 说在云方面他还没有看到太多和惠普面对面的竞争,但和 Mirantis 则确实如此。
|
||||
|
||||
Whitehurst 说 “我们也有几次胜利,他们从 Mirantis 转到了 RHEL。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.serverwatch.com/server-news/red-hat-ceo-optimistic-on-openstack-revenue-opportunity.html
|
||||
|
||||
作者:[Sean Michael Kerner][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.serverwatch.com/author/Sean-Michael-Kerner-101580.htm
|
||||
@ -0,0 +1,79 @@
|
||||
新的合作组将加速实时Linux的发展
|
||||
================================================================================
|
||||

|
||||
|
||||
在本周的Linux大会活动(LinuxCon)上Linux基金会(Linux Foundation)[宣称][1],“Real-Time
|
||||
Linux”项目(译者注:实时Linux操作系统项目,简称RTL)得到了新的资金支持,并预期这将促进该项目,使其自成立15年来第一次有机会在实时操作性上和其他的实时操作系统(RTOS,译者注:Real Time Operation System)一较高下。Linux基金会将RTL项目重组为一个新的项目,并命名为“Real-Time Linux Collaborative Project”(译者注,下文将称其为“RTL协作组”),该项目将获得更有力的资金支持,更多的开发人员将投入其中,并在开发和集成上和Linux内核主线保持更紧密的联系。
|
||||
|
||||
根据Linux基金会的说法,RTL项目并入Linux基金会后“将为业界节省数百万美元的重复研发费用。”同时此举也将“通过基于稳定的主线内核版本开发而改善本项目的代码质量”。
|
||||
|
||||
在过去的十几年中,RTL项目的开发管理和经费资助主要由[开源自动化开发实验室(译者注:Open Source Automation Development Lab,以下简称OSADL)] [2]承担,OSDL将继续作为新合作项目的金牌成员之一,但其原来承担的资金资助工作将会在一月份移交给Linux基金。RTL项目和[OSADL][3]长久以来一直负责维护[内核的实时抢占(RT-Preempt)补丁][4],并定期将其更新到Linux内核的主线上。
|
||||
|
||||
据长期以来一直担任OSADL总经理的Carsten Emde博士介绍,支持内核实时特性的工作已经完成了将近90%。 “这就像盖房子,”他解释说。 “主要的部件,如墙壁,窗户和门都已经安装到位,就实时内核来说,类似的主要部件包括:高精度定时器(high-resolution timers),中断线程化机制(interrupt threads)和基于优先级可继承的互斥量(priority-inheritance mutexes)等。你所剩下的就是还需要一些边边角角的工作,就如同装修房子过程中还剩下铺设如地毯和墙纸等来完成最终的工程。”
|
||||
|
||||
以Emde观点来看,从技术的角度来说,实时Linux的性能已经可以媲美绝大多数其他的实时操作系统 - 但前提是你要不厌其烦地把所有的补丁都打上。 Emde的原话如下:“该项目(译者注,指RTL)的唯一目标就是提供一个满足实时性要求Linux系统,使其无论运行状况如何恶劣都可以保证在确定的可以预先定义的时间期限内对外界处理做出响应。这个目标已经实现,但需要你手动地将RTL提供的补丁添加到Linux内核主线的版本代码上,但新项目将在Linux内核主线版本上直接支持同样的的目标。唯一的,当然也是最重要的区别就是相应的维护工作将少得多,因为我们再也不用一次又一次移植那些独立于内核主线的补丁代码了。”
|
||||
|
||||
新的RTL协作组将继续在Thomas Gleixner的指导下工作,Thomas Gleixner在过去的十多年里一直是RTL的核心维护人员。本周,Gleixner被任命为Linux基金会成员,并加入了一个特别的小组,小组成员包括Linux稳定内核维护者Greg Kroah-Hartman,Yocto项目维护者Richard Purdie和Linus Torvalds本人。
|
||||
|
||||
据Emde介绍,RTL的第二维护人Steven Rostedt来自Red Hat公司,他负责维护旧的内核版本,他将和同样来自Red Hat的Ingo Molnàr继续参与该项目,Ingo是RTL的关键开发人员,但近年来更多地从事咨询方面的工作。有些令人惊讶的是,Red Hat竟然不是RTL协作组的成员之一。相反,谷歌作为唯一的白金会员占据了头把交椅,其他黄金会员包括国家仪器公司(National Instruments,简称NI),OSADL和德州仪器(TI)。银卡会员包括Altera公司,ARM,Intel和IBM。
|
||||
|
||||
###走向实时内核的漫长道路###
|
||||
|
||||
当15年前Linux第一次出现在嵌入式设备上的时候,它所面临的嵌入式计算市场已经被其他的实时操作系统,譬如风河公司(WindRiver)的VxWorks,所牢牢占据。VxWorks从那时起到现在,一直在为众多的工控设备,航空电子设备以及交通运输应用提供着工业级别的高确定性的,硬实时的内核。微软后来也提供了一个支持实时性的操作系统版本-Windows CE,当时的Linux所面临的是来自潜在工业客户的公开嘲讽和层层阻力。他们认为那些从桌面系统改进来的Linux发行版本顶多适合要求不高的轻量级消费类电子产品,而不适合那些对硬实时要求更高的设备。
|
||||
|
||||
对于嵌入式Linux的先行者如[MontaVista公司][6]来说,其[早期的目标][5]很明确就是要改进Linux的实时能力。多年以来,对Linux的实时性能开发发展迅速,得到各种组织的支持,如OSADL[成立于2006年][7],以及实时Linux基金会(Real-Time Linux Foundation,简称RTLF)。在2009年[OSADL与RTLF合并][8],OSADL及其RTL组承担了所有的抢占式实时内核(PREEMPT-RT)补丁的维护工作并始终保存跟踪最新的Linux内核主线版本。除此之外OSADL还负责监管其他自动化相关的项目,例如[高可靠性Linux][9](Safety Critical Linux,译者注:指研究如何在关键系统上可靠安全地运行Linux)。
|
||||
|
||||
OSADL对RTL的支持经历了三个阶段:拥护和推广,测试和质量评估,以及最后的资金支持。Emde表示,在早期,OSADL的角色仅限于写写推广的文章,制作专题报告,组织相关培训,以及“宣传”RTL的优点。他说:“要让一个相当保守的工控行业接受象Linux之类的新技术及其基于社区的那种开发模式,首先就需要建立其对新事物的信心。从使用专有的实时操作系统转向改用Linux对公司意味着必须引入新的战略和流程,才能与社区进行互动。”
|
||||
|
||||
后来,OSADL改而提供技术性能数据,建立[质量评估和测试中心][10],并在和开源相关的法律事务问题和安全认证方面向行业成员提供帮助。
|
||||
|
||||
当RTL在实时性上变得愈加成熟的同时,相反地Windows CE却是江河日下,[其市场份额正在快速地被RTL所蚕食][11],一些与RTL竞争的实时Linux项目,主要是[Xenomai][12]也已开始集成RTL。
|
||||
|
||||
“伴随RTL补丁的成功发展,以及明确的预期其最终会被集成到Linux内核主线代码中,导致Xenomai关注的重心发生了变化,”Emde说。 “Xenomai 3.0可与RT补丁结合起来使用,并提供了所谓的‘皮肤’,(译者注:一个封装层),使我们可以复用为其他系统编写的代码。不过,它们还没有完全统一起来,因为Xenomai使用了双内核方法,而RT补丁只适用于单一的Linux内核。“
|
||||
|
||||
近些年来,RTL项目的资助来源越来越少,所以最终OSADL接过了这个重任。Emde说:“当最近开发工作因缺少资金而陷入停滞时,OSADL对RTL的支持进入到第三个重大阶段:开始直接资助Thomas Gleixner的工作。”
|
||||
|
||||
正如Emde在其[10月5日的一篇博文][13]中所描述的那样,实时Linux的应用领域正在日益扩大,由其原来主要服务的工业控制扩大到了汽车行业和电信业等领域,这表明资助的来源也应该得到拓宽。Emde原文写道:“仅仅靠来自工控行业的资金来支撑全部的工作是不合理的,因为电信等其他行业也在享用实时Linux内核。”
|
||||
|
||||
当Linux基金会表明有兴趣提供资金支持时,OSADL认为“单一的资助和控制渠道要有效得多”(译者注:指最终由Linux基金会全盘接手了RTL项目),Emde如是说。不过,他补充说,作为黄金级成员,OSADL仍参与监管项目的工作,会继续从事其宣传和质量保证方面的活动。
|
||||
|
||||
###汽车行业期待RTL的崛起###
|
||||
|
||||
Emde表示,RTL会继续在工业应用领域飞速发展并逐渐取代其他实时操作系统。而且,他补充说,RTL在汽车行业发展也很迅猛,以后会扩大并应用到铁路和航空电子设备上。
|
||||
|
||||
的确,Linux在汽车行业将扮演越来越重要的角色,这也是Linux基金对RTL所寄予厚望的原因之所在。RTL工作组可能会与Linux基金会旗下的[车载Linux(Automotive Grade Linux,简称AGL)][14]工作组展开合作。Emde猜测,Google高调参与的主要动因可能也是希望将RTL用于汽车控制。此外,德州仪器(TI)也非常期望将其Jacinto处理器应用于汽车行业。
|
||||
|
||||
面向车载Linux的项目(比如AGL)的目标是要扩大Linux在车载设备上的应用范围,其应用不是仅限于车载信息娱乐(In-Vehicle Infotainment,简称IVI),而是要进入到譬如集群控制和车载通讯领域,而这些领域目前主要使用的是QNX之类的实时操作系统。无人驾驶汽车在实时性上对操作系统也有很高的要求。
|
||||
|
||||
Emde特别指出,OSADL的[SIL2LinuxMP][15]项目可能会在将RTL引入到汽车工业领域上扮演重要的角色。SIL2LinuxMP并不是专门针对汽车工业的项目,但随着BMW公司参与其中,汽车行业成为其很重要的应用领域之一。该项目的目标在于验证RTL在采用单核或多核CPU的标准化商用(Commercial Off-The-Shelf,简称COTS)板卡上运行所需的基本组件。它定义了引导程序、根文件系统、Linux内核以及对应支持RTL的C库。
|
||||
|
||||
无人机和机器人使用实时Linux的时机也已成熟,Xenomai系统早已用在许多机器人以及一些无人机中。不过,在更广泛的嵌入式Linux世界,包括了消费电子产品和物联网应用中,RTL可以扮演的角色很有限。主要的障碍在于,无线通信和互联网本身会带来延迟。
|
||||
|
||||
Emde说:“目前实时Linux主要还是应用于系统内部控制以及系统与周边外设之间的控制,在远程控制机器上作用不大。企图通过互联网实现实时控制恐怕不是一件可行的事情。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/news/software/applications/858828-new-collaborative-group-to-speed-real-time-linux
|
||||
|
||||
作者:[Eric Brown][a]
|
||||
译者:[unicornx](https://github.com/unicornx)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.com/community/forums/person/42808
|
||||
[1]:http://www.linuxfoundation.org/news-media/announcements/2015/10/linux-foundation-announces-project-advance-real-time-linux
|
||||
[2]:http://archive.linuxgizmos.com/celebrating-the-open-source-automation-development-labs-first-birthday/
|
||||
[3]:https://www.osadl.org/
|
||||
[4]:http://linuxgizmos.com/adding-real-time-to-linux-with-preempt-rt/
|
||||
[5]:http://archive.linuxgizmos.com/real-time-linux-what-is-it-why-do-you-want-it-how-do-you-do-it-a/
|
||||
[6]:http://www.linux.com/news/embedded-mobile/mobile-linux/841651-embedded-linux-pioneer-montavista-spins-iot-linux-distribution
|
||||
[7]:http://archive.linuxgizmos.com/industry-group-aims-linux-at-automation-apps/
|
||||
[8]:http://archive.linuxgizmos.com/industrial-linux-groups-merge/
|
||||
[9]:https://www.osadl.org/Safety-Critical-Linux.safety-critical-linux.0.html
|
||||
[10]:http://www.osadl.org/QA-Farm-Realtime.qa-farm-about.0.html
|
||||
[11]:http://www.linux.com/news/embedded-mobile/mobile-linux/818011-embedded-linux-keeps-growing-amid-iot-disruption-says-study
|
||||
[12]:http://xenomai.org/
|
||||
[13]:https://www.osadl.org/Single-View.111+M5dee6946dab.0.html
|
||||
[14]:http://www.linux.com/news/embedded-mobile/mobile-linux/833358-first-open-automotive-grade-linux-spec-released
|
||||
[15]:http://www.osadl.org/SIL2LinuxMP.sil2-linux-project.0.html
|
||||
301
translated/talk/20151020 Linux History--24 Years Step by Step.md
Normal file
301
translated/talk/20151020 Linux History--24 Years Step by Step.md
Normal file
@ -0,0 +1,301 @@
|
||||
Linux 的历史:24 年,一步一个脚印
|
||||
================================================================================
|
||||
注:youtube 视频
|
||||
|
||||
<iframe width="660" height="371" src="https://www.youtube.com/embed/84cHeoEebJM?feature=oembed" frameborder="0" allowfullscreen></iframe>
|
||||
|
||||
### 史前 ###
|
||||
|
||||
没有 [C 编程语言][1] and [GNU 项目][2] - Linux 环境,也就不可能有 Linux 的成功。
|
||||
|
||||

|
||||
|
||||
|
||||
Ken Thompson 和 Dennis Ritchie
|
||||
|
||||
[Ken Thompson][1] 和 [Dennis Ritchie][2] 在 1969-1970 创造了 Unix 操作系统。之后发布了新的 [C 编程语言][3] - 高级可移植编程语言。 Linux 内核用 C 和一些汇编代码写成。
|
||||
|
||||
|
||||

|
||||
|
||||
Richard Matthew Stallman
|
||||
|
||||
[Richard Matthew Stallman][4] 在 1984 年启动了 [GNU 项目][5]。最大的一个目标 - 完全自由的类-Unix 操作系统。
|
||||
|
||||
### 1991 – 元年 ###
|
||||
|
||||

|
||||
|
||||
Linus Torvalds, 1991
|
||||
|
||||
[Linus Torvalds][5] 在芬兰赫尔辛基开始了 Linux 内核开发 - 为他的硬件 - Intel 30386 CPU 编写程序。他也使用 Minix 和 GNU C 编译器。下面是 Linus Torvalds 给 Minix 新闻组的历史消息:
|
||||
|
||||
> From: torvalds@klaava.Helsinki.FI (Linus Benedict Torvalds)
|
||||
> Newsgroups: comp.os.minix
|
||||
> Subject: What would you like to see most in minix?
|
||||
> Summary: small poll for my new operating system
|
||||
> Message-ID:
|
||||
> Date: 25 Aug 91 20:57:08 GMT
|
||||
> Organization: University of Helsinki
|
||||
>
|
||||
>
|
||||
> Hello everybody out there using minix -
|
||||
>
|
||||
> I'm doing a (free) operating system (just a hobby, won't be big and
|
||||
> professional like gnu) for 386(486) AT clones. This has been brewing
|
||||
> since april, and is starting to get ready. I'd like any feedback on
|
||||
> things people like/dislike in minix, as my OS resembles it somewhat
|
||||
> (same physical layout of the file-system (due to practical reasons)
|
||||
> among other things).
|
||||
>
|
||||
> I've currently ported bash(1.08) and gcc(1.40), and things seem to work.
|
||||
> This implies that I'll get something practical within a few months, and
|
||||
> I'd like to know what features most people would want. Any suggestions
|
||||
> are welcome, but I won't promise I'll implement them :-)
|
||||
>
|
||||
> Linus (torvalds@kruuna.helsinki.fi)
|
||||
|
||||
从此之后,Linux 开始得到了世界范围志愿者和专业专家的支持。Linus 的合作者 Ari Lemmke 把它命名为 “Linux” - 大学服务器项目上的目录名称。
|
||||
|
||||
### 1992 ###
|
||||
|
||||

|
||||
|
||||
在 GPLv2 协议下发布了 0.12 版 Linux 内核。
|
||||
|
||||
### 1993 ###
|
||||
|
||||

|
||||
|
||||
第一次发布 Slackware(译者注:Slackware Linux 是一个高度技术性的,干净的发行版,只有少量非常有限的个人设置) – 相同主导者 Patrick Volkerding 最老的 Linux 发行版。Linux 内核有 100 多个开发者。
|
||||
|
||||

|
||||
|
||||
Debian
|
||||
|
||||
Debian – 1991 年创立了最大的 Linux 社区之一。
|
||||
|
||||
### 1994 ###
|
||||
|
||||
Linux 1.0 发布了,多亏了 XFree 86 项目,第一次有了 GUI。
|
||||
|
||||

|
||||
|
||||
Red Hat Linux
|
||||
|
||||
发布 Red Hat Linux 1.0
|
||||
|
||||

|
||||
|
||||
S.u.S.E Linux
|
||||
|
||||
和 [S.u.S.E. Linux][6] 1.0.
|
||||
|
||||
### 1995 ###
|
||||
|
||||

|
||||
|
||||
Red Hat Inc.
|
||||
|
||||
Bob Yound 和 Marc Ewing 合并他们的本地业务为 [Red Hat Software][7]。Linux 移植到了很多硬件平台。
|
||||
|
||||
### 1996 ###
|
||||
|
||||

|
||||
|
||||
### Tux ###
|
||||
|
||||
企鹅 Tux - Linux 官方吉祥物。Linus Torvalds 参观了堪培拉国家动物园和水族馆之后有了这个想法。发布了 Linux 2.0,支持对称多处理器。开始开发 KDE。
|
||||
|
||||
### 1997 ###
|
||||
|
||||

|
||||
|
||||
Miguel de Icaza
|
||||
|
||||
Miguel de Icaza 和 Federico Mena 开始开发 GNOME - 自由桌面环境和应用程序。Linus Torvalds 赢得了 Linux 商标冲突,Linux 成为了 Linus 的注册商标。
|
||||
|
||||
### 1998 ###
|
||||
|
||||

|
||||
|
||||
大教堂和集市
|
||||
|
||||
Eric S. Raymond 出版了文章 [The Cathedral and the Bazaar][8](大教堂和集市) - 非常推荐阅读。Linux 得到了大公司的支持: IBM、Oracle、康柏。
|
||||
|
||||

|
||||
|
||||
Mandrake Linux
|
||||
|
||||
首次发布 Mandrake Linux - 基于红帽 Linux 带 K 桌面环境的发行版。
|
||||
|
||||
### 1999 ###
|
||||
|
||||

|
||||
|
||||
第一个主要的 KDE 发行版。
|
||||
|
||||
### 2000 ###
|
||||
|
||||

|
||||
|
||||
Dell 支持 Linux - 第一个大的硬件供应商。
|
||||
|
||||
### 2001 ###
|
||||
|
||||

|
||||
|
||||
Revolution OS
|
||||
|
||||
纪录片 “Revolution OS”(译者注:操作系统革命) - GNU、Linux、开源、自由软件的 20 年历史,以及 Linux 和开源界最好骇客的采访。
|
||||
|
||||
### 2002 ###
|
||||
|
||||

|
||||
|
||||
BitKeeper
|
||||
|
||||
Linux 开始使用 BitKeeper - 分布式版本控制专用软件。
|
||||
|
||||
### 2003 ###
|
||||
|
||||

|
||||
|
||||
SUSE
|
||||
|
||||
Novell 用 210 美元购买了 SUSE Linux AG。2003 年也开始了 SCO 集团,IBM、以及 Linux 社区关于 Unix 版权的史诗般战役。
|
||||
|
||||

|
||||
|
||||
Fedora
|
||||
|
||||
红帽和 Linux 社区第一次发布了 Fedora Linux。
|
||||
|
||||
### 2004 ###
|
||||
|
||||

|
||||
|
||||
X.ORG 基金会
|
||||
|
||||
XFree86 解散了并加入到 [X.Org 基金会][9], X 的开发更快了。
|
||||
|
||||

|
||||
|
||||
Ubuntu 4.10 – 第一次发布
|
||||
|
||||
### 2005 ###
|
||||
|
||||

|
||||
|
||||
openSUSE
|
||||
|
||||
开始了 [openSUSE][10] - 企业版 Novell’s OS 的免费版本。OpenOffice.org 开始支持 OpenDocument 标准。
|
||||
|
||||
### 2006 ###
|
||||
|
||||

|
||||
|
||||
新的 Linux 发行版 - 基于红帽企业版 Linux 的 Oracle Linux。微软和 Novell 开始在 IT 和专利保护方面进行合作。
|
||||
|
||||
### 2007 ###
|
||||
|
||||

|
||||
|
||||
Dell Linux 笔记本
|
||||
|
||||
Dell 发布了预安装 Linux 的笔记本。
|
||||
|
||||
### 2008 ###
|
||||
|
||||

|
||||
|
||||
KDE 4.0
|
||||
|
||||
在不稳定的情况下发布了 KDE 4,很多用户开始迁移到 GNOME。
|
||||
|
||||
### 2009 ###
|
||||
|
||||

|
||||
|
||||
Red Hat
|
||||
|
||||
红帽 Linux 的成功 - 市值 2亿6千2百万美元。
|
||||
|
||||
2009 年微软第一次在 GPLv2 协议下向 Linux 内核提交了补丁。
|
||||
|
||||
### 2010 ###
|
||||
|
||||

|
||||
|
||||
Novell -> Attachmate
|
||||
|
||||
Novell 已 2亿2千万美元卖给了 Attachmate Group, Inc。在新公司 SUSE 和 Novell 成为了两款独立的产品。
|
||||
|
||||
第一次发布了 [systemd][11],开始了 Linux 系统的革命。
|
||||
|
||||
### 2011 ###
|
||||
|
||||

|
||||
|
||||
Unity Desktop in 2011
|
||||
|
||||
发布了 Ubuntu Unity - 遭到很多用户的批评。
|
||||
|
||||

|
||||
|
||||
GNOME 3.0, 2011
|
||||
|
||||
发布了 GNOME 3.0 - Linus Torvalds 评论为 “unholy mess” 以及很多负面评论。发布了 Linux 内核 3.0。
|
||||
|
||||
### 2012 ###
|
||||
|
||||

|
||||
|
||||
1500 万行代码
|
||||
|
||||
Linux 内核有 1500 万行代码。微软成为主要共享者之一。
|
||||
|
||||
### 2013 ###
|
||||
|
||||

|
||||
|
||||
发布了 Kali Linux 1.0 - 用户渗透测试和数字取证的基于 Debian 的 Linux 发行版。2014 年 CentOS 代码开发者加入到了红帽公司。
|
||||
|
||||
### 2014 ###
|
||||
|
||||

|
||||
|
||||
Lennart Poettering 和 Kay Sievers
|
||||
|
||||
systemd - Ubuntu 和所有主流 Linux 发行版的默认初始化程序。Ubuntu 有 2200 万用户。安卓的大进步 - 占了所有移动设备的 75%。
|
||||
|
||||
### 2015 ###
|
||||
|
||||

|
||||
|
||||
发布了 Linux 4.0。没有了 Mandriva(译者注:Mandriva 是目前全球最优秀的 Linux 发行版之一,稳居于 linux 排行榜第一梯队。2005年之前稳居 linux 排行榜 NO.1。它是目前最易用的 linux 发行版,也是众多国际级 linux 发行版中唯一一个默认即支持中文环境的 linux) - 但还有很多分支 - 其中最流行的一个是 Mageia。
|
||||
|
||||
写于对 Linux 的热爱。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://tlhp.cf/linux-history/
|
||||
|
||||
作者:[Pavlo Rudyi][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://tlhp.cf/author/paul/
|
||||
[1]:https://en.wikipedia.org/wiki/C_(programming_language)
|
||||
[2]:https://en.wikipedia.org/wiki/GNU_Project
|
||||
[3]:https://en.wikipedia.org/wiki/Ken_Thompson
|
||||
[4]:https://en.wikipedia.org/wiki/Dennis_Ritchie
|
||||
[5]:https://en.wikipedia.org/wiki/Linus_Torvalds
|
||||
[6]:https://en.wikipedia.org/wiki/SUSE_Linux_distributions
|
||||
[7]:https://en.wikipedia.org/wiki/Red_Hat
|
||||
[8]:https://en.wikipedia.org/wiki/The_Cathedral_and_the_Bazaar
|
||||
[9]:http://www.x.org/
|
||||
[10]:https://en.opensuse.org/Main_Page
|
||||
[11]:https://en.wikipedia.org/wiki/Systemd
|
||||
@ -0,0 +1,201 @@
|
||||
如何使用 Quagga BGP(边界网关协议)路由器来过滤 BGP 路由
|
||||
================================================================================
|
||||
在[之前的文章][1]中,我们介绍了如何使用 Quagga 将 CentOS 服务器变成一个 BGP 路由器,也介绍了 BGP 对等体和前缀交换设置。在本教程中,我们将重点放在如何使用**前缀列表**和**路由映射**来分别控制数据注入和数据输出。
|
||||
|
||||
之前的文章已经说过,BGP 的路由判定是基于前缀的收取和前缀的广播。为避免错误的路由,你需要使用一些过滤机制来控制这些前缀的收发。举个例子,如果你的一个 BGP 邻居开始广播一个本不属于它们的前缀,而你也将错就错地接收了这些不正常前缀,并且也将它转发到网络上,这个转发过程会不断进行下去,永不停止(所谓的“黑洞”就这样产生了)。所以确保这样的前缀不会被收到,或者不会转发到任何网络,要达到这个目的,你可以使用前缀列表和路由映射。前者是基于前缀的过滤机制,后者是更为常用的基于前缀的策略,可用于精调过滤机制。
|
||||
|
||||
本文会向你展示如何在 Quagga 中使用前缀列表和路由映射。
|
||||
|
||||
### 拓扑和需求 ###
|
||||
|
||||
本教程使用下面的拓扑结构。
|
||||
|
||||

|
||||
|
||||
服务供应商A和供应商B已经将对方设置成为 eBGP 对等体,实现互相通信。他们的自治系统号和前缀分别如下所示。
|
||||
|
||||
- **对等区段**: 192.168.1.0/24
|
||||
- **服务供应商A**: 自治系统号 100, 前缀 10.10.0.0/16
|
||||
- **服务供应商B**: 自治系统号 200, 前缀 10.20.0.0/16
|
||||
|
||||
在这个场景中,供应商B只想从A接收 10.10.10.0/23, 10.10.10.0/24 和 10.10.11.0/24 三个前缀。
|
||||
|
||||
### 安装 Quagga 和设置 BGP 对等体 ###
|
||||
|
||||
在[之前的教程][1]中,我们已经写了安装 Quagga 和设置 BGP 对等体的方法,所以这里就不再详细说明了,只简单介绍下 BGP 配置和前缀广播:
|
||||
|
||||

|
||||
|
||||
上图说明 BGP 对等体已经开启。Router-A 在向 router-B 广播多个前缀,而 Router-B 也在向 router-A 广播一个前缀 10.20.0.0/16。两个路由器都能正确无误地收发前缀。
|
||||
|
||||
### 创建前缀列表 ###
|
||||
|
||||
路由器可以使用 ACL 或前缀列表来过滤一个前缀。前缀列表比 ACL 更常用,因为前者处理步骤少,而且易于创建和维护。
|
||||
|
||||
ip prefix-list DEMO-PRFX permit 192.168.0.0/23
|
||||
|
||||
上面的命令创建了名为“DEMO-FRFX”的前缀列表,只允许存在 192.168.0.0/23 这个前缀。
|
||||
|
||||
前缀列表的另一个牛X功能是支持子网掩码区间,请看下面的例子:
|
||||
|
||||
ip prefix-list DEMO-PRFX permit 192.168.0.0/23 le 24
|
||||
|
||||
这个命令创建的前缀列表包含在 192.168.0.0/23 和 /24 之间的前缀,分别是 192.168.0.0/23, 192.168.0.0/24 and 192.168.1.0/24。运算符“le”表示小于等于,你也可以使用“ge”表示大于等于。
|
||||
|
||||
一个前缀列表语句可以有多个允许或拒绝操作。每个语句都自动或手动地分配有一个序列号。
|
||||
|
||||
如果存在多个前缀列表语句,则这些语句会按序列号顺序被依次执行。在配置前缀列表的时候,我们需要注意在所有前缀列表语句后面的**隐性拒绝**属性,就是说凡是不被明显允许的,都会被拒绝。
|
||||
|
||||
如果要设置成允许所有前缀,前缀列表语句设置如下:
|
||||
|
||||
ip prefix-list DEMO-PRFX permit 0.0.0.0/0 le 32
|
||||
|
||||
我们已经知道如何创建前缀列表语句了,现在我们要创建一个名为“PRFX-LST”的前缀列表,来满足我们实验场景的需求。
|
||||
|
||||
router-b# conf t
|
||||
router-b(config)# ip prefix-list PRFX-LST permit 10.10.10.0/23 le 24
|
||||
|
||||
### 创建路由映射 ###
|
||||
|
||||
除了前缀列表和 ACL,这里还有另一种机制,叫做路由映射,也可以在 BGP 路由器中控制前缀。事实上,路由映射针对前缀匹配的微调效果比前缀列表和 ACL 都强。
|
||||
|
||||
与前缀列表类似,路由映射语句也可以指定允许和拒绝操作,也需要分配一个序列号。每个路由匹配可以有多个允许或拒绝操作。例如:
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
|
||||
上面的语句创建了名为“DEMO-RMAP”的路由映射,添加序列号为10的允许操作。现在我们在这个序列号所对应的路由映射下使用 match 命令进行匹配。
|
||||
|
||||
router-a(config-route-map)# match (press ? in the keyboard)
|
||||
|
||||
----------
|
||||
|
||||
as-path Match BGP AS path list
|
||||
community Match BGP community list
|
||||
extcommunity Match BGP/VPN extended community list
|
||||
interface match first hop interface of route
|
||||
ip IP information
|
||||
ipv6 IPv6 information
|
||||
metric Match metric of route
|
||||
origin BGP origin code
|
||||
peer Match peer address
|
||||
probability Match portion of routes defined by percentage value
|
||||
tag Match tag of route
|
||||
|
||||
如你所见,路由映射可以匹配很多属性,本教程需要匹配一个前缀。
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
match ip address prefix-list DEMO-PRFX
|
||||
|
||||
这个 match 命令会匹配之前建好的前缀列表中允许的 IP 地址(也就是前缀 192.168.0.0/23, 192.168.0.0/24 和 192.168.1.0/24)。
|
||||
|
||||
接下来,我们可以使用 set 命令来修改这些属性。例子如下:
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
match ip address prefix-list DEMO-PRFX
|
||||
set (press ? in keyboard)
|
||||
|
||||
----------
|
||||
|
||||
aggregator BGP aggregator attribute
|
||||
as-path Transform BGP AS-path attribute
|
||||
atomic-aggregate BGP atomic aggregate attribute
|
||||
comm-list set BGP community list (for deletion)
|
||||
community BGP community attribute
|
||||
extcommunity BGP extended community attribute
|
||||
forwarding-address Forwarding Address
|
||||
ip IP information
|
||||
ipv6 IPv6 information
|
||||
local-preference BGP local preference path attribute
|
||||
metric Metric value for destination routing protocol
|
||||
metric-type Type of metric
|
||||
origin BGP origin code
|
||||
originator-id BGP originator ID attribute
|
||||
src src address for route
|
||||
tag Tag value for routing protocol
|
||||
vpnv4 VPNv4 information
|
||||
weight BGP weight for routing table
|
||||
|
||||
如你所见,set 命令也可以修改很多属性。为了作个示范,我们修改一下 BGP 的 local-preference 这个属性。
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
match ip address prefix-list DEMO-PRFX
|
||||
set local-preference 500
|
||||
|
||||
如同前缀列表,路由映射语句的末尾也有隐性拒绝操作。所以我们需要添加另外一个允许语句(使用序列号20)来允许所有前缀。
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
match ip address prefix-list DEMO-PRFX
|
||||
set local-preference 500
|
||||
!
|
||||
route-map DEMO-RMAP permit 20
|
||||
|
||||
序列号20未指定任何匹配命令,所以默认匹配所有前缀。在这个路由映射语句中,所有的前缀都被允许。
|
||||
|
||||
回想一下,我们的需求是只允许或只拒绝一些前缀,所以上面的 set 命令不应该存在于这个场景中。我们只需要一个允许语句,如下如示:
|
||||
|
||||
router-b# conf t
|
||||
router-b(config)# route-map RMAP permit 10
|
||||
router-b(config-route-map)# match ip address prefix-list PRFX-LST
|
||||
|
||||
这个路由映射才是我们需要的效果。
|
||||
|
||||
### 应用路由映射 ###
|
||||
|
||||
注意,在被应用于一个接口或一个 BGP 邻居之前,ACL、前缀列表和路由映射都不会生效。与 ACL 和前缀列表一样,一条路由映射语句也能被多个接口或邻居使用。然而,一个接口或一个邻居只能有一条路由映射语句应用于输入端,以及一条路由映射语句应用于输出端。
|
||||
|
||||
下面我们将这条路由映射语句应用于 router-B 的 BGP 配置,为 router-B 的邻居 192.168.1.1 设置输入前缀广播。
|
||||
|
||||
router-b# conf terminal
|
||||
router-b(config)# router bgp 200
|
||||
router-b(config-router)# neighbor 192.168.1.1 route-map RMAP in
|
||||
|
||||
现在检查下广播路由和收取路由。
|
||||
|
||||
显示广播路由的命令:
|
||||
|
||||
show ip bgp neighbor-IP advertised-routes
|
||||
|
||||
显示收取路由的命令:
|
||||
|
||||
show ip bgp neighbor-IP routes
|
||||
|
||||

|
||||
|
||||
可以看到,router-A 有4条路由前缀到达 router-B,而 router-B 只接收3条。查看一下范围,我们就能知道只有被路由映射允许的前缀才能在 router-B 上显示出来,其他的前缀一概丢弃。
|
||||
|
||||
**小提示**:如果接收前缀内容没有刷新,试试重置下 BGP 会话,使用这个命令:clear ip bgp neighbor-IP。本教程中命令如下:
|
||||
|
||||
clear ip bgp 192.168.1.1
|
||||
|
||||
我们能看到系统已经满足我们的要求了。接下来我们可以在 router-A 和 router-B 上创建相似的前缀列表和路由映射语句来更好地控制输入输出的前缀。
|
||||
|
||||
这里把配置过程总结一下,方便查看。
|
||||
|
||||
router bgp 200
|
||||
network 10.20.0.0/16
|
||||
neighbor 192.168.1.1 remote-as 100
|
||||
neighbor 192.168.1.1 route-map RMAP in
|
||||
!
|
||||
ip prefix-list PRFX-LST seq 5 permit 10.10.10.0/23 le 24
|
||||
!
|
||||
route-map RMAP permit 10
|
||||
match ip address prefix-list PRFX-LST
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在本教程中我们演示了如何在 Quagga 中设置前缀列表和路由映射来过滤 BGP 路由。我们也展示了如何将前缀列表结合进路由映射来进行输入前缀的微调功能。你可以参考这些方法来设置满足自己需求的前缀列表和路由映射。这些工具是保护网络免受路由毒化和来自 bogon 路由(LCTT 译注:指不该出现在internet路由表中的地址)的广播。
|
||||
|
||||
希望本文对你有帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/filter-bgp-routes-quagga-bgp-router.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/centos-bgp-router-quagga.html
|
||||
@ -1,88 +1,88 @@
|
||||
Display Awesome Linux Logo With Basic Hardware Info Using screenfetch and linux_logo Tools
|
||||
用 screenfetch 和 linux_logo 工具显示带有酷炫 Linux 标志的基本硬件信息
|
||||
================================================================================
|
||||
Do you want to display a super cool logo of your Linux distribution along with basic hardware information? Look no further try awesome screenfetch and linux_logo utilities.
|
||||
想在屏幕上显示出你的 Linux 发行版的酷炫标志和基本硬件信息吗?不用找了,来试试超赞的 screenfetch 和 linux_logo 工具。
|
||||
|
||||
### Say hello to screenfetch ###
|
||||
### 来见见 screenfetch 吧 ###
|
||||
|
||||
screenFetch is a CLI bash script to show system/theme info in screenshots. It runs on a Linux, OS X, FreeBSD and many other Unix-like system. From the man page:
|
||||
screenFetch 是一个能够在截屏中显示系统/主题信息的命令行脚本。它可以在 Linux,OS X,FreeBSD 以及其它的许多类Unix系统上使用。来自 man 手册的说明:
|
||||
|
||||
> This handy Bash script can be used to generate one of those nifty terminal theme information + ASCII distribution logos you see in everyone's screenshots nowadays. It will auto-detect your distribution and display an ASCII version of that distribution's logo and some valuable information to the right.
|
||||
> 这个方便的 Bash 脚本可以用来生成那些漂亮的终端主题信息和 ASCII 发行版标志,就像如今你在别人的截屏里看到的那样。它会自动检测你的发行版并显示 ASCII 版的发行版标志,并且在右边显示一些有价值的信息。
|
||||
|
||||
#### Installing screenfetch on Linux ####
|
||||
#### 在 Linux 上安装 screenfetch ####
|
||||
|
||||
Open the Terminal application. Simply type the following [apt-get command][1] on a Debian or Ubuntu or Mint Linux based system:
|
||||
打开终端应用。在基于 Debian 或 Ubuntu 或 Mint 的系统上只需要输入下列 [apt-get 命令][1]:
|
||||
|
||||
$ sudo apt-get install screenfetch
|
||||
|
||||
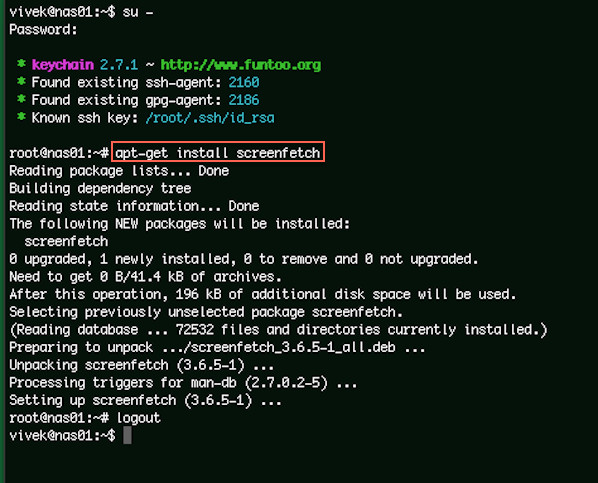
|
||||
|
||||
Fig.01: Installing screenfetch using apt-get
|
||||
图一:用 apt-get 安装 screenfetch
|
||||
|
||||
#### Installing screenfetch Mac OS X ####
|
||||
#### 在 Mac OS X 上安装 screenfetch ####
|
||||
|
||||
Type the following command:
|
||||
输入下列命令:
|
||||
|
||||
$ brew install screenfetch
|
||||
|
||||

|
||||
|
||||
Fig.02: Installing screenfetch using brew command
|
||||
图二:用 brew 命令安装 screenfetch
|
||||
|
||||
#### Installing screenfetch on FreeBSD ####
|
||||
#### 在 FreeBSD 上安装 screenfetch ####
|
||||
|
||||
Type the following pkg command:
|
||||
输入下列 pkg 命令:
|
||||
|
||||
$ sudo pkg install sysutils/screenfetch
|
||||
|
||||
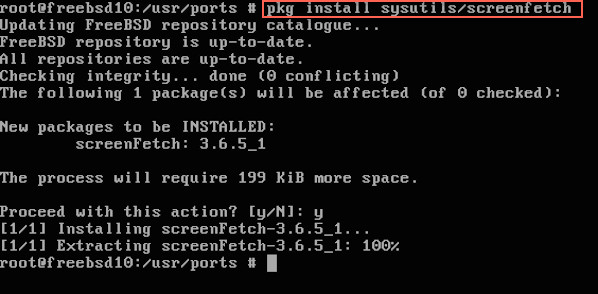
|
||||
|
||||
Fig.03: FreeBSD install screenfetch using pkg
|
||||
图三:在 FreeBSD 用 pkg 安装 screenfetch
|
||||
|
||||
#### Installing screenfetch on Fedora Linux ####
|
||||
#### 在 Fedora 上安装 screenfetch ####
|
||||
|
||||
Type the following dnf command:
|
||||
输入下列 dnf 命令:
|
||||
|
||||
$ sudo dnf install screenfetch
|
||||
|
||||
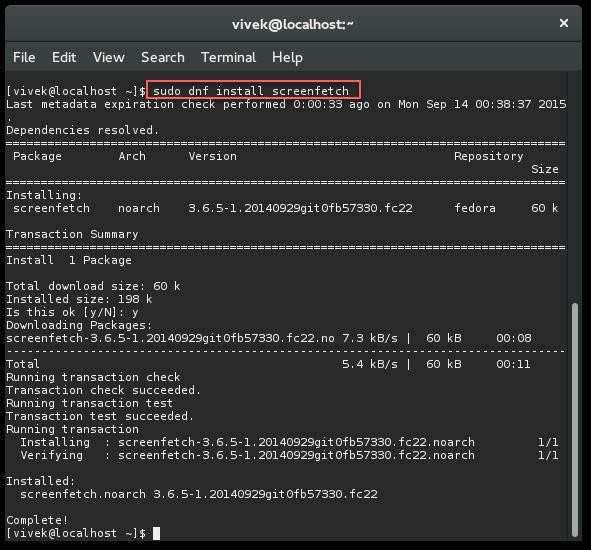
|
||||
|
||||
Fig.04: Fedora Linux 22 install screenfetch using dnf
|
||||
图四:在 Fedora 22 用 dnf 安装 screenfetch
|
||||
|
||||
#### How do I use screefetch utility? ####
|
||||
#### 我该怎么使用 screefetch 工具? ####
|
||||
|
||||
Simply type the following command:
|
||||
只需输入以下命令:
|
||||
|
||||
$ screenfetch
|
||||
|
||||
Here is the output from various operating system:
|
||||
这是不同系统的输出:
|
||||
|
||||
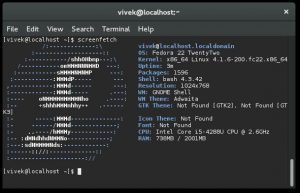
|
||||
|
||||
Screenfetch on Fedora
|
||||
Fedora 上的 Screenfetch
|
||||
|
||||
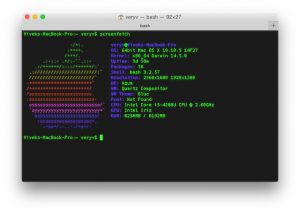
|
||||
|
||||
Screenfetch on OS X
|
||||
OS X 上的 Screenfetch
|
||||
|
||||
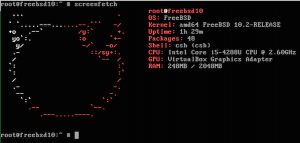
|
||||
|
||||
Screenfetch on FreeBSD
|
||||
FreeBSD 上的 Screenfetch
|
||||
|
||||
|
||||
|
||||
Screenfetch on Debian Linux
|
||||
Debian 上的 Screenfetch
|
||||
|
||||
#### Take screenshot ####
|
||||
#### 获取截屏 ####
|
||||
|
||||
To take a screenshot and to save a file, enter:
|
||||
要获取截屏并保存成文件,输入:
|
||||
|
||||
$ screenfetch -s
|
||||
|
||||
You will see a screenshot file at ~/Desktop/screenFetch-*.jpg. To take a screenshot and upload to imgur directly, enter:
|
||||
你会看到一个文件 ~/Desktop/screenFetch-*.jpg。获取截屏并直接上传到 imgur,输入:
|
||||
|
||||
$ screenfetch -su imgur
|
||||
$ screenfetch -su imgur
|
||||
|
||||
**Sample outputs:**
|
||||
**输出示例:**
|
||||
|
||||
-/+:. veryv@Viveks-MacBook-Pro
|
||||
:++++. OS: 64bit Mac OS X 10.10.5 14F27
|
||||
@ -100,49 +100,49 @@ You will see a screenshot file at ~/Desktop/screenFetch-*.jpg. To take a screens
|
||||
`ossssssssssssssssssssss/ RAM: 6405MB / 8192MB
|
||||
:ooooooooooooooooooo+.
|
||||
`:+oo+/:-..-:/+o+/-
|
||||
|
||||
|
||||
Taking shot in 3.. 2.. 1.. 0.
|
||||
==> Uploading your screenshot now...your screenshot can be viewed at http://imgur.com/HKIUznn
|
||||
|
||||
You can visit [http://imgur.com/HKIUznn][2] to see uploaded screenshot.
|
||||
你可以访问 [http://imgur.com/HKIUznn][2] 来查看上传的截屏。
|
||||
|
||||
### Say hello to linux_logo ###
|
||||
### 再来看看 linux_logo ###
|
||||
|
||||
The linux_logo program generates a color ANSI picture of a penguin which includes some system information obtained from the /proc filesystem.
|
||||
linux_logo 程序生成一个彩色的 ANSI 版企鹅图片,还包含一些来自 /proc 的系统信息。
|
||||
|
||||
#### Installation ####
|
||||
#### 安装 ####
|
||||
|
||||
Simply type the following command as per your Linux distro.
|
||||
只需按照你的 Linux 发行版输入对应的命令:
|
||||
|
||||
#### Debian/Ubutnu/Mint ####
|
||||
|
||||
# apt-get install linux_logo
|
||||
|
||||
#### CentOS/RHEL/Older Fedora ####
|
||||
#### CentOS/RHEL/旧版 Fedora ####
|
||||
|
||||
# yum install linux_logo
|
||||
|
||||
#### Fedora Linux v22+ or newer ####
|
||||
#### Fedora Linux v22+ 或更新版本 ####
|
||||
|
||||
# dnf install linux_logo
|
||||
|
||||
#### Run it ####
|
||||
#### 运行它 ####
|
||||
|
||||
Simply type the following command:
|
||||
只需输入下列命令:
|
||||
|
||||
$ linux_logo
|
||||
$ linux_logo
|
||||
|
||||
|
||||
|
||||
linux_logo in action
|
||||
运行 linux_logo
|
||||
|
||||
#### But wait, there's more! ####
|
||||
#### 等等,还有更多! ####
|
||||
|
||||
You can see a list of compiled in logos using:
|
||||
你可以用这个命令查看内置的标志列表:
|
||||
|
||||
$ linux_logo -f -L list
|
||||
|
||||
**Sample outputs:**
|
||||
**输出示例:**
|
||||
|
||||
Available Built-in Logos:
|
||||
Num Type Ascii Name Description
|
||||
@ -176,46 +176,46 @@ You can see a list of compiled in logos using:
|
||||
28 Banner Yes sourcemage Source Mage GNU/Linux large
|
||||
29 Banner Yes suse SUSE Logo
|
||||
30 Banner Yes ubuntu Ubuntu Logo
|
||||
|
||||
|
||||
Do "linux_logo -L num" where num is from above to get the appropriate logo.
|
||||
Remember to also use -a to get ascii version.
|
||||
|
||||
To see aix logo, enter:
|
||||
查看 aix 的标志,输入:
|
||||
|
||||
$ linux_logo -f -L aix
|
||||
|
||||
To see openbsd logo:
|
||||
查看 openbsd 的标志:
|
||||
|
||||
$ linux_logo -f -L openbsd
|
||||
|
||||
Or just see some random Linux logo:
|
||||
或者只是随机看看一些 Linux 标志:
|
||||
|
||||
$ linux_logo -f -L random_xy
|
||||
|
||||
You [can combine bash for loop as follows to display various logos][3], enter:
|
||||
你[可以像下面那样结合 bash 的循环来显示不同的标志][3],输入:
|
||||
|
||||

|
||||
|
||||
Gif 01: linux_logo and bash for loop for fun and profie
|
||||
动图1: linux_logo 和 bash 循环,既有趣又能发朋友圈耍酷
|
||||
|
||||
### Getting help ###
|
||||
### 获取帮助 ###
|
||||
|
||||
Simply type the following command:
|
||||
输入下列命令:
|
||||
|
||||
$ screefetch -h
|
||||
$ linux_logo -h
|
||||
|
||||
**References**
|
||||
**参考**
|
||||
|
||||
- [screenFetch home page][4]
|
||||
- [linux_logo home page][5]
|
||||
- [screenFetch 主页][4]
|
||||
- [linux_logo 主页][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/hardware/howto-display-linux-logo-in-bash-terminal-using-screenfetch-linux_logo/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -224,4 +224,4 @@ via: http://www.cyberciti.biz/hardware/howto-display-linux-logo-in-bash-terminal
|
||||
[2]:http://imgur.com/HKIUznn
|
||||
[3]:http://www.cyberciti.biz/faq/bash-for-loop/
|
||||
[4]:https://github.com/KittyKatt/screenFetch
|
||||
[5]:https://github.com/deater/linux_logo
|
||||
[5]:https://github.com/deater/linux_logo
|
||||
@ -1,102 +0,0 @@
|
||||
|
||||
在ubunt 14.04/15.04 上配置Node JS v4.0.0
|
||||
================================================================================
|
||||
大家好,Node.JS 4.0 发布了,主流的服务器端JS 平台已经将Node.js 和io.js 结合到一起。4.0 版就是两者结合的产物——共用一个代码库。这次最主要的变化是Node.js 封装了Google V8 4.5 JS 引擎,而这一版与当前的Chrome 一致。所以,紧跟V8 的版本号可以让Node.js 运行的更快、更安全,同时更好的利用ES6 的很多语言特性。
|
||||
|
||||

|
||||
|
||||
Node.js 4.0 的目标是为io.js 当前用户提供一个简单的升级途径,所以这次并没有太多重要的API 变更。剩下的内容会让我们看到如何轻松的在ubuntu server 上安装、配置Node.js。
|
||||
|
||||
### 基础系统安装 ###
|
||||
|
||||
Node 在Linux,Macintosh,Solaris 这几个系统上都可以完美的运行,同时linux 的发行版本当中Ubuntu 是最合适的。这也是我们为什么要尝试在ubuntu 15.04 上安装Node,当然了在14.04 上也可以使用相同的步骤安装。
|
||||
#### 1) 系统资源 ####
|
||||
|
||||
The basic system resources for Node depend upon the size of your infrastructure requirements. So, here in this tutorial we will setup Node with 1 GB RAM, 1 GHz Processor and 10 GB of available disk space with minimal installation packages installed on the server that is no web or database server packages are installed.
|
||||
|
||||
#### 2) 系统更新 ####
|
||||
|
||||
It always been recommended to keep your system upto date with latest patches and updates, so before we move to the installation on Node, let's login to your server with super user privileges and run update command.
|
||||
|
||||
# apt-get update
|
||||
|
||||
#### 3) 安装依赖 ####
|
||||
|
||||
Node JS only requires some basic system and software utilities to be present on your server, for its successful installation like 'make' 'gcc' and 'wget'. Let's run the below command to get them installed if they are not already present.
|
||||
|
||||
# apt-get install python gcc make g++ wget
|
||||
|
||||
### 下载最新版的Node JS v4.0.0 ###
|
||||
|
||||
使用链接 [Node JS Download Page][1] 下载源代码.
|
||||
|
||||

|
||||
|
||||
我们会复制最新源代码的链接,然后用`wget` 下载,命令如下:
|
||||
|
||||
# wget https://nodejs.org/download/rc/v4.0.0-rc.1/node-v4.0.0-rc.1.tar.gz
|
||||
|
||||
下载完成后使用命令`tar` 解压缩:
|
||||
|
||||
# tar -zxvf node-v4.0.0-rc.1.tar.gz
|
||||
|
||||

|
||||
|
||||
### 安装 Node JS v4.0.0 ###
|
||||
|
||||
现在可以开始使用下载好的源代码编译Nod JS。你需要在ubuntu serve 上开始编译前运行配置脚本来修改你要使用目录和配置参数。
|
||||
|
||||
root@ubuntu-15:~/node-v4.0.0-rc.1# ./configure
|
||||
|
||||

|
||||
|
||||
现在运行命令'make install' 编译安装Node JS:
|
||||
|
||||
root@ubuntu-15:~/node-v4.0.0-rc.1# make install
|
||||
|
||||
make 命令会花费几分钟完成编译,冷静的等待一会。
|
||||
|
||||
### 验证Node 安装 ###
|
||||
|
||||
一旦编译任务完成,我们就可以开始验证安装工作是否OK。我们运行下列命令来确认Node JS 的版本。
|
||||
|
||||
root@ubuntu-15:~# node -v
|
||||
v4.0.0-pre
|
||||
|
||||
在命令行下不带参数的运行`node` 就会进入REPL(Read-Eval-Print-Loop,读-执行-输出-循环)模式,它有一个简化版的emacs 行编辑器,通过它你可以交互式的运行JS和查看运行结果。
|
||||

|
||||
|
||||
### 写测试程序 ###
|
||||
|
||||
我们也可以写一个很简单的终端程序来测试安装是否成功,并且工作正常。要完成这一点,我们将会创建一个“tes.js” 文件,包含一下代码,操作如下:
|
||||
|
||||
root@ubuntu-15:~# vim test.js
|
||||
var util = require("util");
|
||||
console.log("Hello! This is a Node Test Program");
|
||||
:wq!
|
||||
|
||||
现在为了运行上面的程序,在命令行运行下面的命令。
|
||||
|
||||
root@ubuntu-15:~# node test.js
|
||||
|
||||

|
||||
|
||||
在一个成功安装了Node JS 的环境下运行上面的程序就会在屏幕上得到上图所示的输出,这个程序加载类 “util” 到变量“util” 中,接着用对象“util” 运行终端任务,console.log 这个命令作用类似C++ 里的cout
|
||||
|
||||
### 结论 ###
|
||||
|
||||
That’s it. Hope this gives you a good idea of Node.js going with Node.js on Ubuntu. If you are new to developing applications with Node.js. After all we can say that we can expect significant performance gains with Node JS Version 4.0.0.
|
||||
希望本文能够通过在ubuntu 上安装、运行Node.JS让你了解一下Node JS 的大概,如果你是刚刚开始使用Node.JS 开发应用程序。最后我们可以说我们能够通过Node JS v4.0.0 获取显著的性能。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/setup-node-js-4-0-ubuntu-14-04-15-04/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[译者ID](https://github.com/osk874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
[1]:https://nodejs.org/download/rc/v4.0.0-rc.1/
|
||||
@ -1,70 +0,0 @@
|
||||
Linux 问与答:如何在Linux 命令行下浏览天气预报
|
||||
================================================================================
|
||||
> **Q**: 我经常在Linux 桌面查看天气预报。然而,是否有一种在终端环境下,不通过桌面小插件或者网络查询天气预报的方法?
|
||||
|
||||
对于Linux 桌面用户来说,有很多办法获取天气预报,比如使用专门的天气应用,桌面小插件,或者面板小程序。但是如果你的工作环境实际与终端的,这里也有一些在命令行下获取天气的手段。
|
||||
|
||||
其中有一个就是 [wego][1],**一个终端下的小巧程序**。使用基于ncurses 的接口,这个命令行程序允许你查看当前的天气情况和之后的预报。它也会通过一个天气预报的API 收集接下来5 天的天气预报。
|
||||
|
||||
### 在Linux 下安装Wego ###
|
||||
安装wego 相当简单。wego 是用Go 编写的,引起第一个步骤就是安装[Go 语言][2]。然后再安装wego。
|
||||
|
||||
$ go get github.com/schachmat/wego
|
||||
|
||||
wego 会被安装到$GOPATH/bin,所以要将$GOPATH/bin 添加到$PATH 环境变量。
|
||||
|
||||
$ echo 'export PATH="$PATH:$GOPATH/bin"' >> ~/.bashrc
|
||||
$ source ~/.bashrc
|
||||
|
||||
现在就可与直接从命令行启动wego 了。
|
||||
|
||||
$ wego
|
||||
|
||||
第一次运行weg 会生成一个配置文件(~/.wegorc),你需要指定一个天气API key。
|
||||
你可以从[worldweatheronline.com][3] 获取一个免费的API key。免费注册和使用。你只需要提供一个有效的邮箱地址。
|
||||
|
||||

|
||||
|
||||
你的 .wegorc 配置文件看起来会这样:
|
||||
|
||||

|
||||
|
||||
除了API key,你还可以把你想要查询天气的地方、使用的城市/国家名称、语言配置在~/.wegorc 中。
|
||||
注意,这个天气API 的使用有限制:每秒最多5 次查询,每天最多250 次查询。
|
||||
当你重新执行wego 命令,你将会看到最新的天气预报(当然是你的指定地方),如下显示。
|
||||
|
||||

|
||||
|
||||
显示出来的天气信息包括:(1)温度,(2)风速和风向,(3)可视距离,(4)降水量和降水概率
|
||||
默认情况下会显示3 天的天气预报。如果要进行修改,可以通过参数改变天气范围(最多5天),比如要查看5 天的天气预报:
|
||||
|
||||
$ wego 5
|
||||
|
||||
如果你想检查另一个地方的天气,只需要提供城市名即可:
|
||||
|
||||
$ wego Seattle
|
||||
|
||||
### 问题解决 ###
|
||||
1. 可能会遇到下面的错误:
|
||||
|
||||
user: Current not implemented on linux/amd64
|
||||
|
||||
当你在一个不支持原生Go 编译器的环境下运行wego 时就会出现这个错误。在这种情况下你只需要使用gccgo ——一个Go 的编译器前端来编译程序即可。这一步可以通过下面的命令完成。
|
||||
|
||||
$ sudo yum install gcc-go
|
||||
$ go get -compiler=gccgo github.com/schachmat/wego
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/weather-forecasts-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:https://github.com/schachmat/wego
|
||||
[2]:http://ask.xmodulo.com/install-go-language-linux.html
|
||||
[3]:https://developer.worldweatheronline.com/auth/register
|
||||
@ -1,126 +0,0 @@
|
||||
|
||||
NGINX Plus 现在完全支持 HTTP/2
|
||||
================================================================================
|
||||
本周早些时候,我们发布了对 HTTP/2 支持的 [NGINX Plus R7][1]。作为 HTTP 协议的最新标准,HTTP/2 的设计对现在的 web 应用程序带来了更高的性能和安全性。
|
||||
|
||||
NGINX Plus 使用 HTTP/2 协议可与现有的网站和应用程序进行无缝衔接。最微小的变化就是不管用户选择什么样的浏览器,NGINX Plus 都能为用户提供 HTTP/1.x 与HTTP/2 并发运行带来的最佳体验。
|
||||
|
||||
要支持 HTTP/2 仅需提供 **nginx‑plus‑http2** 软件包。**nginx‑plus** 和 **nginx‑plus‑extras** 软件包支持 SPDY 协议,目前推荐用于生产站点,因为其被大多数浏览器所支持并且代码也是相当成熟了。
|
||||
|
||||
### 为什么要使用 HTTP/2? ###
|
||||
HTTP/2 使数据传输更高效,对你的应用程序更安全。 HTTP/2 相比于 HTTP/1.x 有五个提高性能特点:
|
||||
|
||||
- **完全复用** – HTTP/1.1 强制按严格的顺序来对一个请求建立连接。请求建立必须在下一个进程开始之前完成。 HTTP/2 消除了这一要求,允许并行和乱序来完成请求的建立。
|
||||
|
||||
- **单一,持久连接** – 由于 HTTP/2 允许请求真正的复用,现在通过单一连接可以并行下载网页上的所有对象。在 HTTP/1.x 中,使用多个连接来并行下载资源,从而导致使用底层 TCP 协议效率很低。
|
||||
|
||||
- **二进制编码** – Header 信息使用紧凑二进制格式发送,而不是纯文本格式,节省了传输字节。
|
||||
|
||||
- **Header 压缩** – Headers 使用专用的算法来进行压缩,HPACK 压缩,这进一步降低数据通过网络传输的字节。
|
||||
|
||||
- **SSL/TLS encryption** – 在 HTTP/2 中,强制使用 SSL/TLS。在 [RFC][2] 中并没有强制,其允许纯文本的 HTTP/2,它是由当前 Web 浏览器执行 HTTP/2 的。 SSL/TLS 使你的网站更安全,并且使用 HTTP/2 所有性能会有提升,加密和解密过程的性能也有所提升。
|
||||
|
||||
要了解更多关于 HTTP/2:
|
||||
|
||||
- 请阅读我们的 [白皮书][3],它涵盖了你需要了解HTTP/2 的一切。
|
||||
- 下载由 Google 的 Ilya Grigorik 编写的 [特别版的高性能浏览器网络电子书][4] 。
|
||||
|
||||
### NGINX Plus 如何实现 HTTP/2 ###
|
||||
|
||||
实现 HTTP/2 要基于对 SPDY 的支持,它已经被广泛部署(使用了 NGINX 或 NGINX Plus 的网站近 75% 都使用了 SPDY)。使用 NGINX Plus 部署 HTTP/2 时,几乎不会改变你应用程序的配置。本节将讨论 NGINX Plus如何实现对 HTTP/2 的支持。
|
||||
|
||||
#### 一个 HTTP/2 网关 ####
|
||||
|
||||

|
||||
|
||||
NGINX Plus 作为一个 HTTP/2 网关。它谈到 HTTP/2 对客户端 Web 浏览器支持,但传输 HTTP/2 请求返回给后端服务器通信时使用 HTTP/1.x(或者 FastCGI, SCGI, uWSGI, 等等. – 取决于你目前正在使用的协议)。
|
||||
|
||||
#### 向后兼容性 ####
|
||||
|
||||

|
||||
|
||||
在不久的未来,你需要同时支持 HTTP/2 和 HTTP/1.x。在撰写本文时,超过50%的用户使用的 Web 浏览器已经[支持 HTTP/2][5],但这也意味着近50%的人还没有使用。
|
||||
|
||||
为了同时支持 HTTP/1.x 和 HTTP/2,NGINX Plus 实现了将 Next Protocol Negotiation (NPN协议)扩展到 TLS 中。当 Web 浏览器连接到服务器时,其将所支持的协议列表发送到服务器端。如果浏览器支持的协议列表中包括 h2 - 即,HTTP/2,NGINX Plus 将使用 HTTP/2 连接到浏览器。如果浏览器不支持 NPN 或在发送支持的协议列表中没有 h2,NGINX Plus 将继续使用 HTTP/1.x。
|
||||
|
||||
### 转向 HTTP/2 ###
|
||||
|
||||
NGINX,公司尽可能无缝过渡到使用 HTTP/2。本节通过对你应用程序的改变来启用对 HTTP/2 的支持,其中只包括对 NGINX Plus 配置的几个变化。
|
||||
|
||||
#### 前提条件 ####
|
||||
|
||||
使用 **nginx‑plus‑http2** 软件包升级到 NGINX Plus R7 . 注意启用 HTTP/2 版本在此时不需要使用 **nginx‑plus‑extras** 软件包。
|
||||
|
||||
#### 重定向所有流量到 SSL/TLS ####
|
||||
|
||||
如果你的应用程序尚未使用 SSL/TLS 加密,现在启用它正是一个好的时机。加密你的应用程序可以保护你免受间谍以及来自其他中间人的攻击。一些搜索引擎甚至在搜索结果中对加密站点 [提高排名][6]。下面的配置块重定向所有的普通 HTTP 请求到该网站的加密版本。
|
||||
|
||||
server {
|
||||
listen 80;
|
||||
location / {
|
||||
return 301 https://$host$request_uri;
|
||||
}
|
||||
}
|
||||
|
||||
#### 启用 HTTP/2 ####
|
||||
|
||||
要启用对 HTTP/2 的支持,只需将 http2 参数添加到所有的 [listen][7] 指令中,包括 SSL 参数,因为浏览器不支持不加密的 HTTP/2 请求。
|
||||
|
||||
server {
|
||||
listen 443 ssl http2 default_server;
|
||||
|
||||
ssl_certificate server.crt;
|
||||
ssl_certificate_key server.key;
|
||||
…
|
||||
}
|
||||
|
||||
如果有必要,重启 NGINX Plus,例如通过运行 nginx -s reload 命令。要验证 HTTP/2 是否正常工作,你可以在 [Google Chrome][8] 和 [Firefox][9] 中使用 “HTTP/2 and SPDY indicator” 插件来检查。
|
||||
|
||||
### 注意事项 ###
|
||||
|
||||
- 在安装 **nginx‑plus‑http2** 包之前, 你必须删除配置文件中所有 listen 指令后的 SPDY 参数(使用 http2 和 ssl 参数来替换它以启用对 HTTP/2 的支持)。使用这个包后,如果 listen 指令后有 spdy 参数,NGINX Plus 将无法启动。
|
||||
|
||||
- 如果你在 NGINX Plus 前端使用了 Web 应用防火墙(WAF),请确保它能够解析 HTTP/2,或者把它移到 NGINX Plus 后面。
|
||||
|
||||
- 此版本在 HTTP/2 RFC 不支持 “Server Push” 特性。 NGINX Plus 以后的版本可能会支持它。
|
||||
|
||||
- NGINX Plus R7 同时支持 SPDY 和 HTTP/2。在以后的版本中,我们将弃用对 SPDY 的支持。谷歌在2016年初将 [弃用 SPDY][10],因此同时支持这两种协议也非必要。
|
||||
|
||||
- 如果 [ssl_prefer_server_ciphers][11] 设置为 on 或者 [ssl_ciphers][12] 列表被定义在 [Appendix A: TLS 1.2 Ciper Suite Black List][13] 使用时,浏览器会出现 handshake-errors 而无法正常工作。详细内容请参阅 [section 9.2.2 of the HTTP/2 RFC][14]。
|
||||
|
||||
### 特别感谢 ###
|
||||
|
||||
NGINX,公司要感谢 [Dropbox][15] 和 [Automattic][16],他们是我们软件的重度使用者,并帮助我们实现 HTTP/2。他们的贡献帮助我们加速完成这个软件,我们希望你也能支持他们。
|
||||
|
||||

|
||||
|
||||
[O'REILLY'S BOOK ABOUT HTTP/2 & PERFORMANCE TUNING][17]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.nginx.com/blog/http2-r7/
|
||||
|
||||
作者:[Faisal Memon][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.nginx.com/blog/author/fmemon/
|
||||
[1]:https://www.nginx.com/blog/nginx-plus-r7-released/
|
||||
[2]:https://tools.ietf.org/html/rfc7540
|
||||
[3]:https://www.nginx.com/wp-content/uploads/2015/09/NGINX_HTTP2_White_Paper_v4.pdf
|
||||
[4]:https://www.nginx.com/http2-ebook/
|
||||
[5]:http://caniuse.com/#feat=http2
|
||||
[6]:http://googlewebmastercentral.blogspot.co.uk/2014/08/https-as-ranking-signal.html
|
||||
[7]:http://nginx.org/en/docs/http/ngx_http_core_module.html#listen
|
||||
[8]:https://chrome.google.com/webstore/detail/http2-and-spdy-indicator/mpbpobfflnpcgagjijhmgnchggcjblin?hl=en
|
||||
[9]:https://addons.mozilla.org/en-us/firefox/addon/spdy-indicator/
|
||||
[10]:http://blog.chromium.org/2015/02/hello-http2-goodbye-spdy-http-is_9.html
|
||||
[11]:http://nginx.org/en/docs/http/ngx_http_ssl_module.html#ssl_prefer_server_ciphers
|
||||
[12]:http://nginx.org/en/docs/http/ngx_http_ssl_module.html#ssl_ciphers
|
||||
[13]:https://tools.ietf.org/html/rfc7540#appendix-A
|
||||
[14]:https://tools.ietf.org/html/rfc7540#section-9.2.2
|
||||
[15]:http://dropbox.com/
|
||||
[16]:http://automattic.com/
|
||||
[17]:https://www.nginx.com/http2-ebook/
|
||||
@ -0,0 +1,93 @@
|
||||
如何在 Linux 中使用 youtube-dl 下载视频
|
||||
================================================================================
|
||||

|
||||
|
||||
我知道你已经看过[如何下载 YouTube 视频][1]。但那些工具大部分都采用图形用户界面的方式。我会向你展示如何通过终端使用 youtube-dl 下载 YouTube 视频。
|
||||
|
||||
### [youtube-dl][2] ###
|
||||
|
||||
youtube-dl 是基于 Python 的命令行小工具,允许你从 YouTube.com、Dailymotion、Google Video、Photobucket、Facebook、Yahoo、Metacafe、Depositfiles 以及其它一些类似网站中下载视频。它是用 pygtk 编写的,需要 Python 解析器来运行,对平台要求并不严格。它能够在 Unix、Windows 或者 Mac OS X 系统上运行。
|
||||
|
||||
youtube-dl 支持断点续传。如果在下载的过程中 youtube-dl 被杀死了(例如通过 Ctrl-C 或者丢失网络连接),你只需要使用相同的 YouTube 视频 URL 再次运行它。只要当前目录中有下载的部分文件,它就会自动恢复没有完成的下载,也就是说,你不需要[下载][3]管理器来恢复下载。
|
||||
|
||||
#### 安装 youtube-dl ####
|
||||
|
||||
如果你运行的是基于 Ubuntu 的 Linux 发行版,你可以使用下面的命令安装:
|
||||
|
||||
sudo apt-get install youtube-dl
|
||||
|
||||
对于任何 Linux 发行版,你都可以通过下面的命令行接口在你的系统上快速安装 youtube-dl:
|
||||
|
||||
sudo wget https://yt-dl.org/downloads/latest/youtube-dl -O/usr/local/bin/youtube-dl
|
||||
|
||||
获取到该文件后,为了能正常执行你需要给脚本设置可执行权限。
|
||||
|
||||
sudo chmod a+rx /usr/local/bin/youtube-dl
|
||||
|
||||
#### 使用 youtube-dl 下载视频: ####
|
||||
|
||||
要下载一个视频文件,只需要运行下面的命令。其中 “VIDEO_URL” 是你想要下载视频的 url。
|
||||
|
||||
youtube-dl VIDEO_URL
|
||||
|
||||
#### 以多种格式下载 YouTube 视频: ####
|
||||
|
||||
现在 YouTube 视频有不同的分辨率,首先你需要检查指定的 YouTube 视频可用的视频格式。可以使用 “-F” 选项运行 youtube-dl。它会向你显示出可用的格式。
|
||||
|
||||
youtube-dl -F http://www.youtube.com/watch?v=BlXaGWbFVKY
|
||||
|
||||
它的输出类似于:
|
||||
|
||||
Setting language
|
||||
BlXaGWbFVKY: Downloading video webpage
|
||||
BlXaGWbFVKY: Downloading video info webpage
|
||||
BlXaGWbFVKY: Extracting video information
|
||||
Available formats:
|
||||
37 : mp4 [1080×1920]
|
||||
46 : webm [1080×1920]
|
||||
22 : mp4 [720×1280]
|
||||
45 : webm [720×1280]
|
||||
35 : flv [480×854]
|
||||
44 : webm [480×854]
|
||||
34 : flv [360×640]
|
||||
18 : mp4 [360×640]
|
||||
43 : webm [360×640]
|
||||
5 : flv [240×400]
|
||||
17 : mp4 [144×176]
|
||||
|
||||
在可用的视频格式中,选择你需要的一种。例如,如果你想下载 MP4 格式的,你可以:
|
||||
|
||||
youtube-dl -f 17 http://www.youtube.com/watch?v=BlXaGWbFVKY
|
||||
|
||||
#### 使用 youtube-dl 下载视频字幕 ####
|
||||
|
||||
首先检查是否有可用的视频字幕。使用下面的命令列出视频所有可用的字幕:
|
||||
|
||||
youtube-dl --list-subs https://www.youtube.com/watch?v=Ye8mB6VsUHw
|
||||
|
||||
下载所有字幕,但不包括视频:
|
||||
|
||||
youtube-dl --all-subs --skip-download https://www.youtube.com/watch?v=Ye8mB6VsUHw
|
||||
|
||||
#### 下载整个播放列表 ####
|
||||
|
||||
运行下面的命令下载整个播放列表。其中 “playlist_url” 是你希望下载的播放列表的 url。
|
||||
|
||||
youtube-dl -cit playlist_url
|
||||
|
||||
youtube-dl 是一个多功能的命令行工具,它提供了很多功能。难怪这个命令行工具这么流行。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/download-youtube-linux/
|
||||
|
||||
作者:[alimiracle][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/ali/
|
||||
[1]:http://itsfoss.com/download-youtube-videos-ubuntu/
|
||||
[2]:https://rg3.github.io/youtube-dl/
|
||||
[3]:http://itsfoss.com/xtreme-download-manager-install/
|
||||
@ -0,0 +1,39 @@
|
||||
修复Sheell脚本在Ubuntu中用文本编辑器打开的方式
|
||||
================================================================================
|
||||

|
||||
|
||||
当你双击一个脚本(.sh文件)的时候,你想要做的是什么?通常的想法是执行它。但是在Ubuntu下面却不是这样,或者我应该更确切地说是在Files(Nautilus)中。你可能会疯狂地大叫“运行文件,运行文件”,但是文件没有运行而是用Gedit打开了。
|
||||
|
||||
我知道你也许会说文件有可执行权限么?我会说是的。脚本有可执行权限但是当我双击它的时候,它还是用文本编辑器打开了。我不希望这样如果你遇到了同样的问题,我想你也许也不需要这样。
|
||||
|
||||
我知道你或许已经被建议在终端下面运行,我知道这个可行但是这不是一个在GUI下不能运行的借口是么?
|
||||
|
||||
这篇教程中,我们会看到**如何在双击后运行shell脚本。**
|
||||
|
||||
#### 修复在Ubuntu中shell脚本用文本编辑器打开的方式 ####
|
||||
|
||||
shell脚本用文件编辑器打开的原因是Files(Ubuntu中的文件管理器)中的默认行为设置。在更早的版本中,它或许会询问你是否运行文件或者用编辑器打开。默认的行位在新的版本中被修改了。
|
||||
|
||||
要修复这个,进入文件管理器,并在菜单中点击**选项**:
|
||||
|
||||

|
||||
|
||||
接下来在**文件选项**中进入**行为**标签中,你会看到**文本文件执行**选项。
|
||||
|
||||
默认情况下,它被设置成“在打开是显示文本文件”。我建议你把它改成“每次询问”,这样你可以选择是执行还是编辑了,当然了你也可以选择默认执行。你可以自行选择。
|
||||
|
||||

|
||||
|
||||
我希望这个贴士可以帮你修复这个小“问题”。欢迎提出问题和建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/shell-script-opens-text-editor/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
264
translated/tech/20151012 10 Useful Utilities For Linux Users.md
Normal file
264
translated/tech/20151012 10 Useful Utilities For Linux Users.md
Normal file
@ -0,0 +1,264 @@
|
||||
对 Linux 用户10个有用的工具
|
||||
================================================================================
|
||||

|
||||
|
||||
### 引言 ###
|
||||
|
||||
在本教程中,我已经收集了对 Linux 用户10个有用的工具,其中包括各种网络监控,系统审计和一些其它实用的命令,它可以帮助用户提高工作效率。我希望你会喜欢他们。
|
||||
|
||||
#### 1. w ####
|
||||
|
||||
显示谁登录了系统并执行了哪些程序。
|
||||
|
||||
$w
|
||||
|
||||

|
||||
|
||||
显示帮助信息
|
||||
|
||||
$w -h
|
||||
|
||||
(LCTT译注:-h为不显示头部信息)
|
||||
|
||||
显示当前用户信息
|
||||
|
||||
$w <username>
|
||||
|
||||

|
||||
|
||||
#### 2. nmon ####
|
||||
Nmon(nigel’s monitor 的简写)是一个显示系统性能信息的工具。
|
||||
|
||||
$ sudo apt-get install nmon
|
||||
|
||||
----------
|
||||
|
||||
$ nmon
|
||||
|
||||

|
||||
|
||||
nmon 可以转储与 netwrok,cpu, memory 和磁盘使用情况的信息。
|
||||
|
||||
**nmon 显示 cpu 信息 (按 c)**
|
||||
|
||||

|
||||
|
||||
**nmon 显示 network 信息 (按 n)**
|
||||
|
||||

|
||||
|
||||
**nman 显示 disk 信息 (按 d)**
|
||||
|
||||

|
||||
|
||||
#### 3. ncdu ####
|
||||
|
||||
是一个基于‘du’的光标版本的命令行程序,这个命令是用来分析各种目录占用的磁盘空间。
|
||||
|
||||
$apt-get install ncdu
|
||||
|
||||
----------
|
||||
|
||||
$ncdu /
|
||||
|
||||

|
||||
|
||||
最终的输出:
|
||||
|
||||

|
||||
|
||||
按 n 则通过文件名来排序,按 s 则按文件大小来排序(默认的)。
|
||||
|
||||
#### 4. slurm ####
|
||||
|
||||
一个基于网络接口的带宽监控命令行程序,它会基于图形来显示 ascii 文件。
|
||||
|
||||
$ apt-get install slurm
|
||||
|
||||
例如:
|
||||
|
||||
$ slurm -i <interface>
|
||||
|
||||
----------
|
||||
|
||||
$ slurm -i eth1
|
||||
|
||||

|
||||
|
||||
**选项**
|
||||
|
||||
- 按 **l** 显示 lx/tx 指示灯.
|
||||
- 按 **c** 切换到经典模式.
|
||||
- 按 **r** 刷新屏幕.
|
||||
- 按 **q** 退出.
|
||||
|
||||
#### 5.findmnt ####
|
||||
|
||||
Findmnt 命令用于查找挂载的文件系统。它是用来列出安装设备,当需要时也可以挂载或卸载设备,它也是 util-linux 的一部分。
|
||||
|
||||
例子:
|
||||
|
||||
$findmnt
|
||||
|
||||

|
||||
|
||||
以列表格式输出。
|
||||
|
||||
$ findmnt -l
|
||||
|
||||

|
||||
|
||||
列出在 fstab 中挂载的文件系统。
|
||||
|
||||
$ findmnt -s
|
||||
|
||||

|
||||
|
||||
按文件类型列出已挂载的文件系统。
|
||||
|
||||
$ findmnt -t ext4
|
||||
|
||||

|
||||
|
||||
#### 6. dstat ####
|
||||
|
||||
一种组合和灵活的工具,它可用于监控内存,进程,网络和磁盘的性能,它可以用来取代 ifstat, iostat, dmstat 等。
|
||||
|
||||
$apt-get install dstat
|
||||
|
||||
例如:
|
||||
|
||||
查看有关 cpu,硬盘和网络的详细信息。
|
||||
|
||||
$ dstat
|
||||
|
||||

|
||||
|
||||
- **-c** cpu
|
||||
|
||||
$ dstat -c
|
||||
|
||||

|
||||
|
||||
显示 cpu 的详细信息。
|
||||
|
||||
$ dstat -cdl -D sda1
|
||||
|
||||

|
||||
|
||||
- **-d** 磁盘
|
||||
|
||||
$ dstat -d
|
||||
|
||||

|
||||
|
||||
#### 7. saidar ####
|
||||
|
||||
另一种基于 CLI 的系统统计数据监控工具,提供了有关磁盘使用,网络,内存,交换等信息。
|
||||
|
||||
$ sudo apt-get install saidar
|
||||
|
||||
例如:
|
||||
|
||||
$ saidar
|
||||
|
||||

|
||||
|
||||
启用彩色输出
|
||||
|
||||
$ saider -c
|
||||
|
||||

|
||||
|
||||
#### 8. ss ####
|
||||
|
||||
ss(socket statistics)是一个很好的选择来替代 netstat,它从内核空间收集信息,比 netstat 的性能更好。
|
||||
|
||||
例如:
|
||||
|
||||
列出所有的连接
|
||||
|
||||
$ ss |less
|
||||
|
||||

|
||||
|
||||
列出 tcp 流量
|
||||
|
||||
$ ss -A tcp
|
||||
|
||||

|
||||
|
||||
列出进程名和 pid
|
||||
|
||||
$ ss -ltp
|
||||
|
||||

|
||||
|
||||
#### 9. ccze ####
|
||||
|
||||
一个自定义日志格式的工具 :).
|
||||
|
||||
$ apt-get install ccze
|
||||
|
||||
例如:
|
||||
|
||||
$ tailf /var/log/syslog | ccze
|
||||
|
||||

|
||||
|
||||
列出 ccze 模块:
|
||||
|
||||
$ ccze -l
|
||||
|
||||

|
||||
|
||||
将日志保存为 html 文件。
|
||||
|
||||
tailf /var/log/syslog | ccze -h > /home/tux/Desktop/rajneesh.html
|
||||
|
||||

|
||||
|
||||
#### 10. ranwhen.py ####
|
||||
|
||||
一种基于 Python 的终端工具,它可以用来以图形方式显示系统活动状态。详细信息以一个丰富多彩的柱状图来展示。
|
||||
|
||||
安装 python:
|
||||
|
||||
$ sudo apt-add-repository ppa:fkrull/deadsnakes
|
||||
|
||||
更新系统:
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
下载 python:
|
||||
|
||||
$ sudo apt-get install python3.2
|
||||
|
||||
- [下载 ranwhen.py][1]
|
||||
|
||||
$ unzip ranwhen-master.zip && cd ranwhen-master
|
||||
|
||||
运行工具。
|
||||
|
||||
$ python3.2 ranwhen.py
|
||||
|
||||

|
||||
|
||||
### 结论 ###
|
||||
|
||||
这都是些冷门但重要的 Linux 管理工具。他们可以在日常生活中帮助用户。在我们即将发表的文章中,我们会尽量多带来些管理员/用户工具。
|
||||
|
||||
玩得愉快!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/10-useful-utilities-linux-users/
|
||||
|
||||
作者:[Rajneesh Upadhyay][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/rajneesh/
|
||||
[1]:https://github.com/p-e-w/ranwhen/archive/master.zip
|
||||
@ -0,0 +1,87 @@
|
||||
命令行下使用Mop 监视股票价格
|
||||
================================================================================
|
||||
有一份隐性收入通常很不错,特别是当你可以轻松的协调业余和全职工作。如果你的日常工作使用了联网的电脑,交易股票是一个很流行的选项来获取额外收入。
|
||||
|
||||
但是目前只有很少的股票监视软件可以用在linux 上,其中大多数还是基于图形界面的。如果你是一个Linux 专家,并且大量的工作时间是在没有图形界面的电脑上呢?你是不是就没办法了?不,这里还有一个命令行下的股票追踪工具,包括Mop,也就是本文要聊一聊的工具。
|
||||
### Mop ###
|
||||
|
||||
Mop,如上所述,是一个命令行下连续显示和更新美股和独立股票信息的工具。使用GO 实现的,是Michael Dvorkin 大脑的产物。
|
||||
### 下载安装 ###
|
||||
|
||||
|
||||
因为这个工程使用GO 实现的,所以你要做的第一步是在你的计算机上安装这种编程语言,下面就是在Debian 系系统,比如Ubuntu上安装GO的步骤:
|
||||
|
||||
sudo apt-get install golang
|
||||
mkdir ~/workspace
|
||||
echo 'export GOPATH="$HOME/workspace"' >> ~/.bashrc
|
||||
source ~/.bashrc
|
||||
|
||||
GO 安装好后的下一步是安装Mop 工具和配置环境,你要做的是运行下面的命令:
|
||||
|
||||
sudo apt-get install git
|
||||
go get github.com/michaeldv/mop
|
||||
cd $GOPATH/src/github.com/michaeldv/mop
|
||||
make install
|
||||
export PATH="$PATH:$GOPATH/bin"
|
||||
|
||||
完成之后就可以运行下面的命令执行Mop:
|
||||
cmd
|
||||
|
||||
### 特性 ###
|
||||
|
||||
当你第一次运行Mop 时,你会看到类似下面的输出信息:
|
||||
|
||||

|
||||
|
||||
如你所见,这些输出信息—— 周期性自动刷新 ——包含了主要几个交易所和个股的信息。
|
||||
|
||||
### 添加删除股票 ###
|
||||
|
||||
Mop 允许你轻松的从输出列表上添加/删除个股信息。要添加,你全部要做的是按”+“和输入股票名称。举个例子,下图就是添加Facebook (FB) 到列表里。
|
||||
|
||||

|
||||
|
||||
因为我按下了”+“键,一列包含文本”Add tickers:“出现了,提示我添加股票名称—— 我添加了FB 然后按下回车。输出列表更新了,我添加的新股票也出现在列表了:
|
||||
|
||||

|
||||
|
||||
类似的,你可以使用”-“ 键和提供股票名称删除一个股票。
|
||||
|
||||
#### 根据价格分组 ####
|
||||
|
||||
还有一个把股票分组的办法:依据他们的股价升跌,你索要做的就是按下”g“ 键。接下来,股票会分组显示:升的在一起使用绿色字体显示,而下跌的股票会黑色字体显示。
|
||||
|
||||
如下所示:
|
||||
|
||||

|
||||
|
||||
#### 列排序 ####
|
||||
|
||||
Mop 同时也允许你根据不同的列类型改变排序规则。这种用法需要你按下”o“(这个命令默认使用第一列的值来排序),然后使用左右键来选择你要使用的列。完成之后按下回车对内容重新排序。
|
||||
|
||||
举个例子,下面的截图就是根据输出内容的第一列、按照字母表排序之后的结果。
|
||||
|
||||

|
||||
|
||||
**注意**: 为了更好的理解,和前面的截屏对比一下。
|
||||
|
||||
#### 其他选项 ####
|
||||
|
||||
其它的可用选项包括”p“:暂停市场和股票信息更新,”q“ 或者”esc“ 来退出命令行程序,”?“ 显示帮助页。
|
||||

|
||||
|
||||
### 结论 ###
|
||||
|
||||
Mop 是一个基础的股票监控工具,并没有提供太多的特性,只提供了他声称的功能。很明显,这个工具并不是为专业股票交易者提供的,而仅仅为你在只有命令行的机器上得体的提供了一个跟踪股票信息的选择。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/monitor-stock-prices-ubuntu-command-line/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[oska874](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/himanshu/
|
||||
@ -0,0 +1,250 @@
|
||||
如何在 CentOS 7.0 上配置 Ceph 存储
|
||||
How to Setup Red Hat Ceph Storage on CentOS 7.0
|
||||
================================================================================
|
||||
Ceph 是一个将数据存储在单一分布式计算机集群上的开源软件平台。当你计划构建一个云时,你首先需要决定如何实现你的存储。开源的 CEPH 是红帽原生技术之一,它基于称为 RADOS 的对象存储系统,用一组网关 API 表示块、文件、和对象模式中的数据。由于它自身开源的特性,这种便携存储平台能在公有和私有云上安装和使用。Ceph 集群的拓扑结构是按照备份和信息分布设计的,这内在设计能提供数据完整性。它的设计目标就是容错、通过正确配置能运行于商业硬件和一些更高级的系统。
|
||||
|
||||
Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要求最近的内核以及其它最新的库。在这篇指南中,我们会使用最小化安装的 CentOS-7.0。
|
||||
|
||||
### 系统资源 ###
|
||||
|
||||
**CEPH-STORAGE**
|
||||
OS: CentOS Linux 7 (Core)
|
||||
RAM:1 GB
|
||||
CPU:1 CPU
|
||||
DISK: 20
|
||||
Network: 45.79.136.163
|
||||
FQDN: ceph-storage.linoxide.com
|
||||
|
||||
**CEPH-NODE**
|
||||
OS: CentOS Linux 7 (Core)
|
||||
RAM:1 GB
|
||||
CPU:1 CPU
|
||||
DISK: 20
|
||||
Network: 45.79.171.138
|
||||
FQDN: ceph-node.linoxide.com
|
||||
|
||||
### 安装前的配置 ###
|
||||
|
||||
在安装 CEPH 存储之前,我们要在每个节点上完成一些步骤。第一件事情就是确保每个节点的网络已经配置好并且能相互访问。
|
||||
|
||||
**配置 Hosts**
|
||||
|
||||
要在每个节点上配置 hosts 条目,要像下面这样打开默认的 hosts 配置文件。
|
||||
|
||||
# vi /etc/hosts
|
||||
|
||||
----------
|
||||
|
||||
45.79.136.163 ceph-storage ceph-storage.linoxide.com
|
||||
45.79.171.138 ceph-node ceph-node.linoxide.com
|
||||
|
||||
**安装 VMware 工具**
|
||||
|
||||
工作环境是 VMWare 虚拟环境时,推荐你安装它的 open VM 工具。你可以使用下面的命令安装。
|
||||
|
||||
#yum install -y open-vm-tools
|
||||
|
||||
**配置防火墙**
|
||||
|
||||
如果你正在使用启用了防火墙的限制性环境,确保在你的 CEPH 存储管理节点和客户端节点中开放了以下的端口。
|
||||
|
||||
你必须在你的 Admin Calamari 节点开放 80、2003、以及4505-4506 端口,并且允许通过 80 号端口到 CEPH 或 Calamari 管理节点,以便你网络中的客户端能访问 Calamari web 用户界面。
|
||||
|
||||
你可以使用下面的命令在 CentOS 7 中启动并启用防火墙。
|
||||
|
||||
#systemctl start firewalld
|
||||
#systemctl enable firewalld
|
||||
|
||||
运行以下命令使 Admin Calamari 节点开放上面提到的端口。
|
||||
|
||||
#firewall-cmd --zone=public --add-port=80/tcp --permanent
|
||||
#firewall-cmd --zone=public --add-port=2003/tcp --permanent
|
||||
#firewall-cmd --zone=public --add-port=4505-4506/tcp --permanent
|
||||
#firewall-cmd --reload
|
||||
|
||||
在 CEPH Monitor 节点,你要在防火墙中允许通过以下端口。
|
||||
|
||||
#firewall-cmd --zone=public --add-port=6789/tcp --permanent
|
||||
|
||||
然后允许以下默认端口列表,以便能和客户端以及监控节点交互,并发送数据到其它 OSD。
|
||||
|
||||
#firewall-cmd --zone=public --add-port=6800-7300/tcp --permanent
|
||||
|
||||
如果你工作在非生产环境,建议你停用防火墙以及 SELinux 设置,在我们的测试环境中我们会停用防火墙以及 SELinux。
|
||||
|
||||
#systemctl stop firewalld
|
||||
#systemctl disable firewalld
|
||||
|
||||
**系统升级**
|
||||
|
||||
现在升级你的系统并重启使所需更改生效。
|
||||
|
||||
#yum update
|
||||
#shutdown -r 0
|
||||
|
||||
### 设置 CEPH 用户 ###
|
||||
|
||||
现在我们会新建一个单独的 sudo 用户用于在每个节点安装 ceph-deploy工具,并允许该用户无密码访问每个节点,因为它需要在 CEPH 节点上安装软件和配置文件而不会有输入密码提示。
|
||||
|
||||
运行下面的命令在 ceph-storage 主机上新建有独立 home 目录的新用户。
|
||||
|
||||
[root@ceph-storage ~]# useradd -d /home/ceph -m ceph
|
||||
[root@ceph-storage ~]# passwd ceph
|
||||
|
||||
节点中新建的每个用户都要有 sudo 权限,你可以使用下面展示的命令赋予 sudo 权限。
|
||||
|
||||
[root@ceph-storage ~]# echo "ceph ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/ceph
|
||||
ceph ALL = (root) NOPASSWD:ALL
|
||||
|
||||
[root@ceph-storage ~]# sudo chmod 0440 /etc/sudoers.d/ceph
|
||||
|
||||
### 设置 SSH 密钥 ###
|
||||
|
||||
现在我们会在 ceph 管理节点生成 SSH 密钥并把密钥复制到每个 Ceph 集群节点。
|
||||
|
||||
在 ceph-node 运行下面的命令复制它的 ssh 密钥到 ceph-storage。
|
||||
|
||||
[root@ceph-node ~]# ssh-keygen
|
||||
Generating public/private rsa key pair.
|
||||
Enter file in which to save the key (/root/.ssh/id_rsa):
|
||||
Created directory '/root/.ssh'.
|
||||
Enter passphrase (empty for no passphrase):
|
||||
Enter same passphrase again:
|
||||
Your identification has been saved in /root/.ssh/id_rsa.
|
||||
Your public key has been saved in /root/.ssh/id_rsa.pub.
|
||||
The key fingerprint is:
|
||||
5b:*:*:*:*:*:*:*:*:*:c9 root@ceph-node
|
||||
The key's randomart image is:
|
||||
+--[ RSA 2048]----+
|
||||
|
||||
----------
|
||||
|
||||
[root@ceph-node ~]# ssh-copy-id ceph@ceph-storage
|
||||
|
||||

|
||||
|
||||
### 配置 PID 数目 ###
|
||||
|
||||
要配置 PID 数目的值,我们会使用下面的命令检查默认的内核值。默认情况下,是一个小的最大线程数 32768.
|
||||
如下图所示通过编辑系统配置文件配置该值为一个更大的数。
|
||||
|
||||

|
||||
|
||||
### 配置管理节点服务器 ###
|
||||
|
||||
配置并验证了所有网络后,我们现在使用 ceph 用户安装 ceph-deploy。通过打开文件检查 hosts 条目。
|
||||
|
||||
#vim /etc/hosts
|
||||
ceph-storage 45.79.136.163
|
||||
ceph-node 45.79.171.138
|
||||
|
||||
运行下面的命令添加它的库。
|
||||
|
||||
#rpm -Uhv http://ceph.com/rpm-giant/el7/noarch/ceph-release-1-0.el7.noarch.rpm
|
||||
|
||||

|
||||
|
||||
或者创建一个新文件并更新 CEPH 库参数,别忘了替换你当前的 Release 和版本号。
|
||||
|
||||
[root@ceph-storage ~]# vi /etc/yum.repos.d/ceph.repo
|
||||
|
||||
----------
|
||||
|
||||
[ceph-noarch]
|
||||
name=Ceph noarch packages
|
||||
baseurl=http://ceph.com/rpm-{ceph-release}/{distro}/noarch
|
||||
enabled=1
|
||||
gpgcheck=1
|
||||
type=rpm-md
|
||||
gpgkey=https://ceph.com/git/?p=ceph.git;a=blob_plain;f=keys/release.asc
|
||||
|
||||
之后更新你的系统并安装 ceph-deploy 软件包。
|
||||
|
||||
### 安装 CEPH-Deploy 软件包 ###
|
||||
|
||||
我们运行下面的命令以及 ceph-deploy 安装命令来更新系统以及最新的 ceph 库和其它软件包。
|
||||
|
||||
#yum update -y && yum install ceph-deploy -y
|
||||
|
||||
|
||||
### 配置集群 ###
|
||||
|
||||
使用下面的命令在 ceph 管理节点新建一个目录并进入新目录,用于收集所有输出文件和日志。
|
||||
|
||||
#mkdir ~/ceph-cluster
|
||||
#cd ~/ceph-cluster
|
||||
|
||||
----------
|
||||
|
||||
#ceph-deploy new storage
|
||||
|
||||

|
||||
|
||||
如果成功执行了上面的命令,你会看到它新建了配置文件。
|
||||
现在配置 CEPH 默认的配置文件,用任意编辑器打开它并在会影响你公共网络的 global 参数下面添加以下两行。
|
||||
|
||||
#vim ceph.conf
|
||||
osd pool default size = 1
|
||||
public network = 45.79.0.0/16
|
||||
|
||||
### 安装 CEPH ###
|
||||
|
||||
现在我们准备在和 CEPH 集群相关的每个节点上安装 CEPH。我们使用下面的命令在 ceph-storage 和 ceph-node 上安装 CEPH。
|
||||
|
||||
#ceph-deploy install ceph-node ceph-storage
|
||||
|
||||

|
||||
|
||||
处理所有所需仓库和安装所需软件包会需要一些时间。
|
||||
|
||||
当两个节点上的 ceph 安装过程都完成后,我们下一步会通过在相同节点上运行以下命令创建监视器并收集密钥。
|
||||
|
||||
#ceph-deploy mon create-initial
|
||||
|
||||

|
||||
|
||||
### 设置 OSDs 和 OSD 守护进程 ###
|
||||
|
||||
现在我们会设置磁盘存储,首先运行下面的命令列出你所有可用的磁盘。
|
||||
|
||||
#ceph-deploy disk list ceph-storage
|
||||
|
||||
结果中会列出你存储节点中使用的磁盘,你会用它们来创建 OSD。让我们运行以下包括你磁盘名称的命令。
|
||||
|
||||
#ceph-deploy disk zap storage:sda
|
||||
#ceph-deploy disk zap storage:sdb
|
||||
|
||||
为了最后完成 OSD 配置,运行下面的命令配置日志磁盘以及数据磁盘。
|
||||
|
||||
#ceph-deploy osd prepare storage:sdb:/dev/sda
|
||||
#ceph-deploy osd activate storage:/dev/sdb1:/dev/sda1
|
||||
|
||||
你需要在所有节点上运行相同的命令,它会清除你磁盘上的所有东西。之后为了集群能运转起来,我们需要使用以下命令从 ceph 管理节点复制不同的密钥和配置文件到所有相关节点。
|
||||
|
||||
#ceph-deploy admin ceph-node ceph-storage
|
||||
|
||||
### 测试 CEPH ###
|
||||
|
||||
我们几乎完成了 CEPH 集群设置,让我们在 ceph 管理节点上运行下面的命令检查正在运行的 ceph 状态。
|
||||
|
||||
#ceph status
|
||||
#ceph health
|
||||
HEALTH_OK
|
||||
|
||||
如果你在 ceph status 中没有看到任何错误信息,就意味着你成功地在 CentOS 7 上安装了 ceph 存储集群。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇详细的文章中我们学习了如何使用两台安装了 CentOS 7 的虚拟机设置 CEPH 存储集群,这能用于备份或者作为用于处理其它虚拟机的本地存储。我们希望这篇文章能对你有所帮助。当你试着安装的时候记得分享你的经验。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/storage/setup-red-hat-ceph-storage-centos-7-0/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
@ -0,0 +1,53 @@
|
||||
Linux有问必答--如何找出Linux中内置模块的信息
|
||||
================================================================================
|
||||
> **提问**:我想要知道Linux系统中内核内置的模块,以及每个模块的参数。有什么方法可以得到内置模块和设备驱动的列表,以及它们的详细信息呢?
|
||||
|
||||
现代Linux内核正在随着时间迅速地增长来支持大量的硬件、文件系统和网络功能。在此期间,“可加载模块”的引入防止内核变得越来越臃肿,以及在不同的环境中灵活地扩展功能及硬件支持,而不必重新构建内核。
|
||||
|
||||
最新的Linux发型版的内核只带了相对较小的“内置模块”,其余的特定硬件驱动或者自定义功能作为“可加载模块”来让你选择地加载或卸载。
|
||||
|
||||
内置模块被静态地编译进了内核。不像可加载内核模块可以动态地使用modprobe、insmod、rmmod、modinfo或者lsmod等命令地加载、卸载、查询模块,内置的模块总是在启动是就加载进了内核,不会被这些命令管理。
|
||||
|
||||
### 找出内置模块列表 ###
|
||||
|
||||
要得到内置模块列表,运行下面的命令。
|
||||
|
||||
$ cat /lib/modules/$(uname -r)/modules.builtin
|
||||
|
||||
|
||||
|
||||
你也可以用下面的命令来查看有哪些内置模块:
|
||||
|
||||
|
||||
|
||||
### 找出内置模块参数 ###
|
||||
|
||||
每个内核模块无论是内置的还是可加载的都有一系列的参数。对于可加载模块,modinfo命令显示它们的参数信息。然而这个命令不对内置模块管用。你会得到下面的错误。
|
||||
|
||||
modinfo: ERROR: Module XXXXXX not found.
|
||||
|
||||
如果你想要查看内置模块的参数,以及它们的值,你可以在**/sys/module** 下检查它们的内容。
|
||||
|
||||
在 /sys/module目录下,你可以找到内核模块(包含内置和可加载的)命名的子目录。结合则进入每个模块目录,这里有个“parameters”目录,列出了这个模块所有的参数。
|
||||
|
||||
比如你要找出tcp_cubic(内核默认的TCP实现)模块的参数。你可以这么做:
|
||||
|
||||
$ ls /sys/module/tcp_cubic/parameters
|
||||
|
||||
接着阅读这个文件查看每个参数的值。
|
||||
|
||||
$ cat /sys/module/tcp_cubic/parameters/tcp_friendliness
|
||||
|
||||
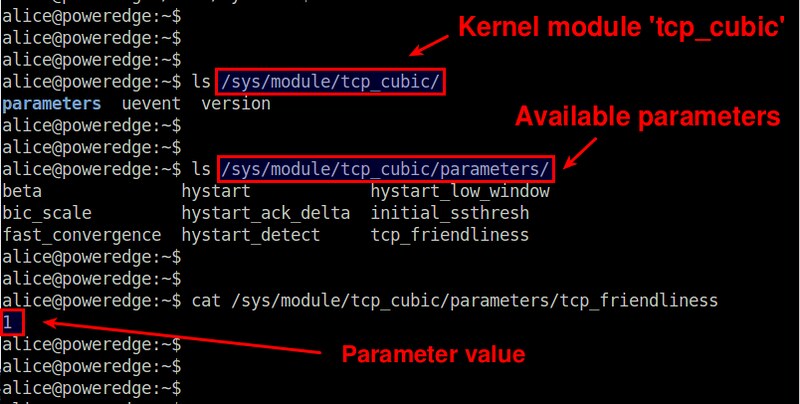
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/find-information-builtin-kernel-modules-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -0,0 +1,55 @@
|
||||
Linux有问必答--如何强制在下次登录Linux时更换密码
|
||||
================================================================================
|
||||
> **提问**:我管理着一台多人共享的Linux服务器。我刚使用默认密码创建了一个新用户,但是我想用户在第一次登录时更换密码。有没有什么方法可以让他/她在下次登录时修改密码呢?
|
||||
|
||||
在多用户Linux环境中,标准实践是使用一个默认的随机密码创建一个用户账户。成功登录后,新用户自己改变默认密码。出于安全里有,经常建议“强制”用户在第一次登录时修改密码来确保这个一次性使用的密码不会再被使用。
|
||||
|
||||
下面是**如何强制用户在下次登录时修改他/她的密码**。
|
||||
|
||||
changes, and when to expire the current password, etc.
|
||||
每个Linux用户都关联这不同的密码相关配置和信息。比如,记录着上次密码更改的日期、最小/最大的修改密码的天数、密码何时过期等等。
|
||||
|
||||
一个叫chage的命令行工具可以访问并调整密码过期相关配置。你可以使用这个工具来强制用户在下次登录修改密码、
|
||||
|
||||
要查看特定用户的过期信息(比如:alice),运行下面的命令。注意的是除了你自己之外查看其他任何用户的密码信息都需要root权限。
|
||||
|
||||
$ sudo chage -l alice
|
||||
|
||||
|
||||
|
||||
### 强制用户修改密码 ###
|
||||
|
||||
如果你想要强制用户去修改他/她的密码,使用下面的命令。
|
||||
|
||||
$ sudo chage -d0 <user-name>
|
||||
|
||||
原本“-d <N>”参数是用来设置密码的“年龄”(也就是上次修改密码起到1970 1.1起的天数)。因此“-d0”的意思是上次密码修改的时间是1970 1.1,这就让当前的密码过期了,也就强制让他在下次登录的时候修改密码了。
|
||||
|
||||
另外一个过期当前密码的方式是用passwd命令。
|
||||
|
||||
$ sudo passwd -e <user-name>
|
||||
|
||||
上面的命令和“chage -d0”作用一样,让当前用户的密码立即过期。
|
||||
|
||||
现在检查用户的信息,你会发现:
|
||||
|
||||
|
||||
|
||||
当你再次登录时候,你会被要求修改密码。你会在修改前被要求再验证一次当前密码。
|
||||
|
||||
|
||||
|
||||
要设置更全面的密码策略(如密码复杂性,防止重复使用),则可以使用PAM。参见[这篇文章][1]了解更多详情。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/force-password-change-next-login-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/set-password-policy-linux.html
|
||||
150
translated/tech/20151019 10 passwd command examples in Linux.md
Normal file
150
translated/tech/20151019 10 passwd command examples in Linux.md
Normal file
@ -0,0 +1,150 @@
|
||||
|
||||
在 Linux 中 passwd 命令的10个示例
|
||||
================================================================================
|
||||
|
||||
正如 **passwd** 命令的名称所示,其用于改变系统用户的密码。如果 passwd 命令由非 root 用户执行,那么它会询问当前用户的密码,然后设置调用命令用户的新密码。当此命令由超级用户 root 执行的话,就可以重新设置任何用户的密码,包括不知道当前密码的用户。
|
||||
|
||||
在这篇文章中,我们将讨论 passwd 命令实际的例子。
|
||||
|
||||
#### 语法 : ####
|
||||
|
||||
# passwd {options} {user_name}
|
||||
|
||||
可以在 passwd 命令使用不同的选项,列表如下:
|
||||
|
||||
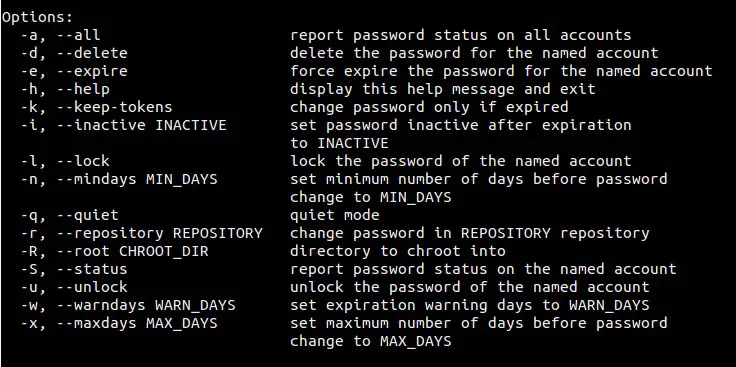
|
||||
|
||||
### 例1:更改系统用户的密码 ###
|
||||
|
||||
当你使用非 root 用户登录时,像我使用 ‘linuxtechi’ 登录的情况下,运行 passwd 命令它会重置当前登录用户的密码。
|
||||
|
||||
[linuxtechi@linuxworld ~]$ passwd
|
||||
Changing password for user linuxtechi.
|
||||
Changing password for linuxtechi.
|
||||
(current) UNIX password:
|
||||
New password:
|
||||
Retype new password:
|
||||
passwd: all authentication tokens updated successfully.
|
||||
[linuxtechi@linuxworld ~]$
|
||||
|
||||
当你作为 root 用户登录后并运行 **passwd** 命令时,它默认情况下会重新设置 root 的密码,如果你在 passwd 命令后指定了用户名,它会重置该用户的密码。
|
||||
|
||||
[root@linuxworld ~]# passwd
|
||||
[root@linuxworld ~]# passwd linuxtechi
|
||||
|
||||
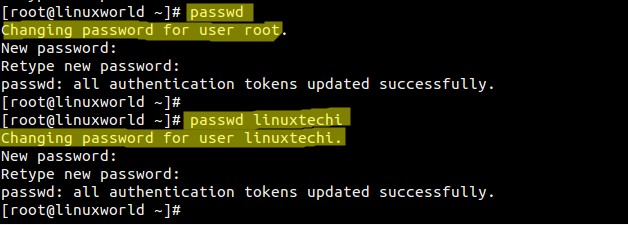
|
||||
|
||||
**注意** : 系统用户的密码以加密的形式保存在 /etc/shadow 文件中。
|
||||
|
||||
### 例2:显示密码状态信息 ###
|
||||
|
||||
要显示用户密码的状态信息,请在 passwd 命令后使用 **-S** 选项。
|
||||
|
||||
[root@linuxworld ~]# passwd -S linuxtechi
|
||||
linuxtechi PS 2015-09-20 0 99999 7 -1 (Password set, SHA512 crypt.)
|
||||
[root@linuxworld ~]#
|
||||
|
||||
在上面的输出中,第一个字段显示的用户名,第二个字段显示密码状态(**PS = 密码设置,LK = 密码锁定,NP = 无密码**),第三个字段显示了当密码被改变,后面的字段分别显示了密码能更改的最小期限和最大期限,超过更改期能使用的最大期限,最后的为过期禁用天数。
|
||||
|
||||
### 例3:显示所有账号的密码状态信息 ###
|
||||
|
||||
为了显示所有用户密码的状态信息需要使用 “**-aS**”选项在passwd 命令中,示例如下所示:
|
||||
|
||||
root@localhost:~# passwd -Sa
|
||||
|
||||
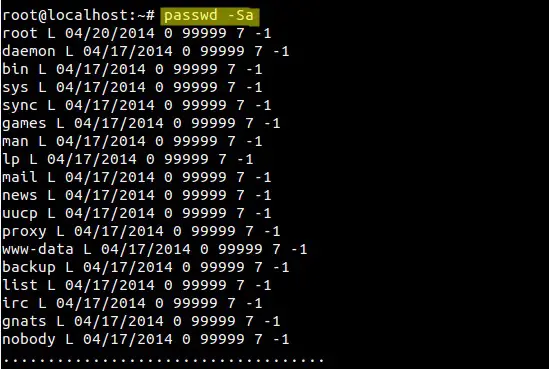
|
||||
|
||||
(LCTT译注:CentOS6.6 没有测试成功,但 Ubuntu 可以。)
|
||||
|
||||
### 例4:使用 -d 选项删除用户的密码 ###
|
||||
|
||||
就我而言,我删除 ‘**linuxtechi**‘ 用户的密码。
|
||||
|
||||
[root@linuxworld ~]# passwd -d linuxtechi
|
||||
Removing password for user linuxtechi.
|
||||
passwd: Success
|
||||
[root@linuxworld ~]#
|
||||
[root@linuxworld ~]# passwd -S linuxtechi
|
||||
linuxtechi NP 2015-09-20 0 99999 7 -1 (Empty password.)
|
||||
[root@linuxworld ~]#
|
||||
|
||||
“**-d**” 选项将使用户的密码为空,并禁用用户登录。
|
||||
|
||||
### 例5:设置密码立即过期 ###
|
||||
|
||||
在 passwd 命令中使用 '-e' 选项会立即使用户的密码过期,这将强制用户在下次登录时更改密码。
|
||||
|
||||
[root@linuxworld ~]# passwd -e linuxtechi
|
||||
Expiring password for user linuxtechi.
|
||||
passwd: Success
|
||||
[root@linuxworld ~]# passwd -S linuxtechi
|
||||
linuxtechi PS 1970-01-01 0 99999 7 -1 (Password set, SHA512 crypt.)
|
||||
[root@linuxworld ~]#
|
||||
|
||||
现在尝试用 linuxtechi 用户 SSH 到主机。
|
||||
|
||||
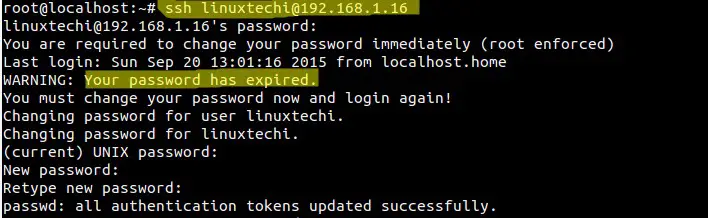
|
||||
|
||||
### 例6:锁定系统用户的密码 ###
|
||||
|
||||
在 passwd 命令中使用 ‘**-l**‘ 选项能锁定用户的密码,它会在密码的起始位置加上“!”。当他/她的密码被锁定时,用户将不能更改它的密码。
|
||||
|
||||
[root@linuxworld ~]# passwd -l linuxtechi
|
||||
Locking password for user linuxtechi.
|
||||
passwd: Success
|
||||
[root@linuxworld ~]# passwd -S linuxtechi
|
||||
linuxtechi LK 2015-09-20 0 99999 7 -1 (Password locked.)
|
||||
[root@linuxworld ~]#
|
||||
|
||||
### 例7:使用 -u 选项解锁用户密码 ###
|
||||
|
||||
[root@linuxworld ~]# passwd -u linuxtechi
|
||||
Unlocking password for user linuxtechi.
|
||||
passwd: Success
|
||||
[root@linuxworld ~]#
|
||||
|
||||
### 例8:使用 -i 选项设置非活动时间 ###
|
||||
|
||||
在 passwd 命令中使用 -i 选项用于设系统用户的非活动时间。当用户(我使用的是linuxtechi用户)密码过期后,用户再经过 ‘**n**‘ 天后(在我的情况下是10天)没有更改其密码,用户将不能登录。
|
||||
|
||||
[root@linuxworld ~]# passwd -i 10 linuxtechi
|
||||
Adjusting aging data for user linuxtechi.
|
||||
passwd: Success
|
||||
[root@linuxworld ~]#
|
||||
[root@linuxworld ~]# passwd -S linuxtechi
|
||||
linuxtechi PS 2015-09-20 0 99999 7 10 (Password set, SHA512 crypt.)
|
||||
[root@linuxworld ~]#
|
||||
|
||||
### 例9:使用 -n 选项设置密码更改的最短时间 ###
|
||||
|
||||
在下面的例子中,linuxtechi用户必须在90天内更改密码。0表示用户可以在任何时候更改它的密码。
|
||||
|
||||
[root@linuxworld ~]# passwd -n 90 linuxtechi
|
||||
Adjusting aging data for user linuxtechi.
|
||||
passwd: Success
|
||||
[root@linuxworld ~]# passwd -S linuxtechi
|
||||
linuxtechi PS 2015-09-20 90 99999 7 10 (Password set, SHA512 crypt.)
|
||||
[root@linuxworld ~]#
|
||||
|
||||
### 例10:使用 -w 选项设置密码过期前的警告期限 ###
|
||||
|
||||
‘**-w**’ 选项在 passwd 命令中用于设置用户的警告期限。这意味着,n天之后,他/她的密码将过期。
|
||||
|
||||
[root@linuxworld ~]# passwd -w 12 linuxtechi
|
||||
Adjusting aging data for user linuxtechi.
|
||||
passwd: Success
|
||||
[root@linuxworld ~]# passwd -S linuxtechi
|
||||
linuxtechi PS 2015-09-20 90 99999 12 10 (Password set, SHA512 crypt.)
|
||||
[root@linuxworld ~]#
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/10-passwd-command-examples-in-linux/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
259
translated/tech/20151019 11 df command examples in Linux.md
Normal file
259
translated/tech/20151019 11 df command examples in Linux.md
Normal file
@ -0,0 +1,259 @@
|
||||
Linux 中 df 命令的11个例子
|
||||
================================================================================
|
||||
|
||||
df(可用磁盘)命令用于显示文件系统的磁盘使用情况。默认情况下 df 命令将以 1KB 为单位进行显示所有当前已挂载的文件系统,如果你想以人类易读的格式显示 df 命令的输出,像这样“df -h”使用 -h 选项。
|
||||
|
||||
在这篇文章中,我们将讨论 ‘**df**‘ 命令在 Linux 下11种不同的实例
|
||||
|
||||
在 Linux 下 df 命令的基本格式为:
|
||||
|
||||
# df {options} {mount_point_of_filesystem}
|
||||
|
||||
在 df 命令中可用的选项有:
|
||||
|
||||
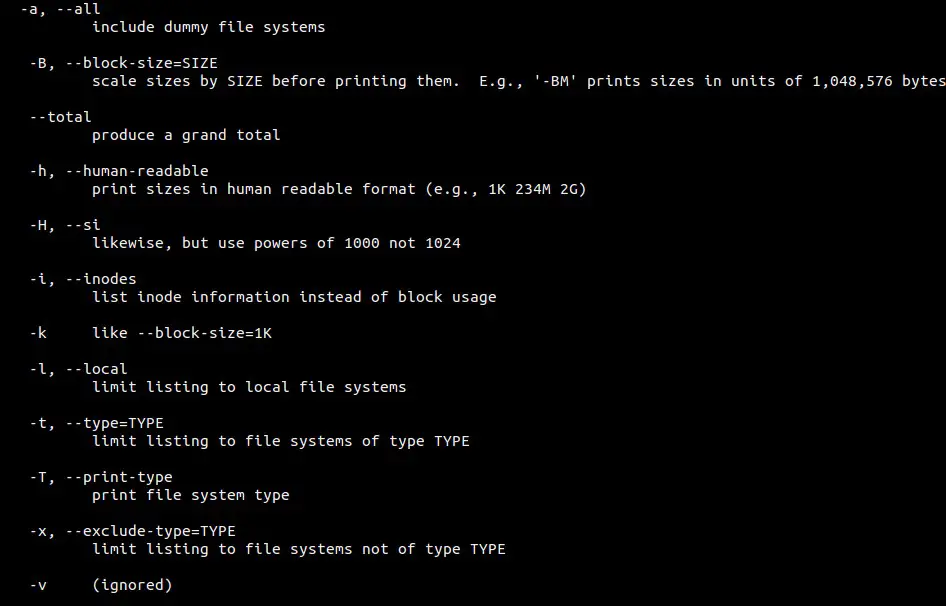
|
||||
|
||||
df 的原样输出 :
|
||||
|
||||
[root@linux-world ~]# df
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
/dev/mapper/vg00-root 17003304 804668 15311852 5% /
|
||||
devtmpfs 771876 0 771876 0% /dev
|
||||
tmpfs 777928 0 777928 0% /dev/shm
|
||||
tmpfs 777928 8532 769396 2% /run
|
||||
tmpfs 777928 0 777928 0% /sys/fs/cgroup
|
||||
/dev/mapper/vg00-home 14987616 41000 14162232 1% /home
|
||||
/dev/sda1 487652 62593 395363 14% /boot
|
||||
/dev/mapper/vg00-var 9948012 48692 9370936 1% /var
|
||||
/dev/mapper/vg00-sap 14987656 37636 14165636 1% /sap
|
||||
[root@linux-world ~]#
|
||||
|
||||
### 例1:使用 ‘-a’ 选项列出所有文件系统的磁盘使用量 ###
|
||||
|
||||
当我们在 df 命令中使用 ‘-a’ 选项时,它会显示所有文件系统的磁盘使用情况。
|
||||
|
||||
[root@linux-world ~]# df -a
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
rootfs 17003304 804668 15311852 5% /
|
||||
proc 0 0 0 - /proc
|
||||
sysfs 0 0 0 - /sys
|
||||
devtmpfs 771876 0 771876 0% /dev
|
||||
securityfs 0 0 0 - /sys/kernel/security
|
||||
tmpfs 777928 0 777928 0% /dev/shm
|
||||
devpts 0 0 0 - /dev/pts
|
||||
tmpfs 777928 8532 769396 2% /run
|
||||
tmpfs 777928 0 777928 0% /sys/fs/cgroup
|
||||
cgroup 0 0 0 - /sys/fs/cgroup/systemd
|
||||
pstore 0 0 0 - /sys/fs/pstore
|
||||
cgroup 0 0 0 - /sys/fs/cgroup/cpuset
|
||||
cgroup 0 0 0 - /sys/fs/cgroup/cpu,cpuacct
|
||||
cgroup 0 0 0 - /sys/fs/cgroup/memory
|
||||
cgroup 0 0 0 - /sys/fs/cgroup/devices
|
||||
cgroup 0 0 0 - /sys/fs/cgroup/freezer
|
||||
cgroup 0 0 0 - /sys/fs/cgroup/net_cls
|
||||
cgroup 0 0 0 - /sys/fs/cgroup/blkio
|
||||
cgroup 0 0 0 - /sys/fs/cgroup/perf_event
|
||||
cgroup 0 0 0 - /sys/fs/cgroup/hugetlb
|
||||
configfs 0 0 0 - /sys/kernel/config
|
||||
/dev/mapper/vg00-root 17003304 804668 15311852 5% /
|
||||
selinuxfs 0 0 0 - /sys/fs/selinux
|
||||
systemd-1 0 0 0 - /proc/sys/fs/binfmt_misc
|
||||
debugfs 0 0 0 - /sys/kernel/debug
|
||||
hugetlbfs 0 0 0 - /dev/hugepages
|
||||
mqueue 0 0 0 - /dev/mqueue
|
||||
/dev/mapper/vg00-home 14987616 41000 14162232 1% /home
|
||||
/dev/sda1 487652 62593 395363 14% /boot
|
||||
/dev/mapper/vg00-var 9948012 48692 9370936 1% /var
|
||||
/dev/mapper/vg00-sap 14987656 37636 14165636 1% /sap
|
||||
[root@linux-world ~]#
|
||||
|
||||
### 例2:以人类易读的格式显示 df 命令的输出 ###
|
||||
|
||||
在 df 命令中使用‘-h’选项,输出以人易读的格式输出(例如,5K,500M & 5G)
|
||||
|
||||
[root@linux-world ~]# df -h
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/mapper/vg00-root 17G 786M 15G 5% /
|
||||
devtmpfs 754M 0 754M 0% /dev
|
||||
tmpfs 760M 0 760M 0% /dev/shm
|
||||
tmpfs 760M 8.4M 752M 2% /run
|
||||
tmpfs 760M 0 760M 0% /sys/fs/cgroup
|
||||
/dev/mapper/vg00-home 15G 41M 14G 1% /home
|
||||
/dev/sda1 477M 62M 387M 14% /boot
|
||||
/dev/mapper/vg00-var 9.5G 48M 9.0G 1% /var
|
||||
/dev/mapper/vg00-sap 15G 37M 14G 1% /sap
|
||||
[root@linux-world ~]#
|
||||
|
||||
### 例3:显示特定文件系统已使用的空间 ###
|
||||
|
||||
假如我们想显示 /sap 文件系统空间的使用情况。
|
||||
|
||||
[root@linux-world ~]# df -h /sap/
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/mapper/vg00-sap 15G 37M 14G 1% /sap
|
||||
[root@linux-world ~]#
|
||||
|
||||
### 例4:输出所有已挂载文件系统的类型 ###
|
||||
|
||||
‘**-T**’ 选项用在 df 命令中用来显示文件系统的类型。
|
||||
|
||||
[root@linux-world ~]# df -T
|
||||
Filesystem Type 1K-blocks Used Available Use% Mounted on
|
||||
/dev/mapper/vg00-root ext4 17003304 804668 15311852 5% /
|
||||
devtmpfs devtmpfs 771876 0 771876 0% /dev
|
||||
tmpfs tmpfs 777928 0 777928 0% /dev/shm
|
||||
tmpfs tmpfs 777928 8532 769396 2% /run
|
||||
tmpfs tmpfs 777928 0 777928 0% /sys/fs/cgroup
|
||||
/dev/mapper/vg00-home ext4 14987616 41000 14162232 1% /home
|
||||
/dev/sda1 ext3 487652 62593 395363 14% /boot
|
||||
/dev/mapper/vg00-var ext3 9948012 48696 9370932 1% /var
|
||||
/dev/mapper/vg00-sap ext3 14987656 37636 14165636 1% /sap
|
||||
[root@linux-world ~]#
|
||||
|
||||
### 例5:输出文件系统磁盘使用的块大小 ###
|
||||
|
||||
[root@linux-world ~]# df -k
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
/dev/mapper/vg00-root 17003304 804668 15311852 5% /
|
||||
devtmpfs 771876 0 771876 0% /dev
|
||||
tmpfs 777928 0 777928 0% /dev/shm
|
||||
tmpfs 777928 8532 769396 2% /run
|
||||
tmpfs 777928 0 777928 0% /sys/fs/cgroup
|
||||
/dev/mapper/vg00-home 14987616 41000 14162232 1% /home
|
||||
/dev/sda1 487652 62593 395363 14% /boot
|
||||
/dev/mapper/vg00-var 9948012 48696 9370932 1% /var
|
||||
/dev/mapper/vg00-sap 14987656 37636 14165636 1% /sap
|
||||
[root@linux-world ~]#
|
||||
|
||||
### 例6:输出文件系统的 inode 信息 ###
|
||||
|
||||
‘**-i**’ 选项用在 df 命令用于显示文件系统的 inode 信息。
|
||||
|
||||
所有文件系统的 inode 信息:
|
||||
|
||||
[root@linux-world ~]# df -i
|
||||
Filesystem Inodes IUsed IFree IUse% Mounted on
|
||||
/dev/mapper/vg00-root 1089536 22031 1067505 3% /
|
||||
devtmpfs 192969 357 192612 1% /dev
|
||||
tmpfs 194482 1 194481 1% /dev/shm
|
||||
tmpfs 194482 420 194062 1% /run
|
||||
tmpfs 194482 13 194469 1% /sys/fs/cgroup
|
||||
/dev/mapper/vg00-home 960992 15 960977 1% /home
|
||||
/dev/sda1 128016 337 127679 1% /boot
|
||||
/dev/mapper/vg00-var 640848 1235 639613 1% /var
|
||||
/dev/mapper/vg00-sap 960992 11 960981 1% /sap
|
||||
[root@linux-world ~]#
|
||||
|
||||
特定文件系统的 inode 信息:
|
||||
|
||||
[root@linux-world ~]# df -i /sap/
|
||||
Filesystem Inodes IUsed IFree IUse% Mounted on
|
||||
/dev/mapper/vg00-sap 960992 11 960981 1% /sap
|
||||
[root@linux-world ~]#
|
||||
|
||||
### 例7:输出所有文件系统总的使用情况 ###
|
||||
|
||||
‘–total‘ 选项在 df 命令中用于显示所有文件系统的磁盘使用情况。
|
||||
|
||||
[root@linux-world ~]# df -h --total
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/mapper/vg00-root 17G 786M 15G 5% /
|
||||
devtmpfs 754M 0 754M 0% /dev
|
||||
tmpfs 760M 0 760M 0% /dev/shm
|
||||
tmpfs 760M 8.4M 752M 2% /run
|
||||
tmpfs 760M 0 760M 0% /sys/fs/cgroup
|
||||
/dev/mapper/vg00-home 15G 41M 14G 1% /home
|
||||
/dev/sda1 477M 62M 387M 14% /boot
|
||||
/dev/mapper/vg00-var 9.5G 48M 9.0G 1% /var
|
||||
/dev/mapper/vg00-sap 15G 37M 14G 1% /sap
|
||||
total 58G 980M 54G 2% -
|
||||
[root@linux-world ~]#
|
||||
|
||||
### 例8:只打印本地文件系统磁盘的使用情况 ###
|
||||
|
||||
假设网络文件系统也挂载在 Linux 上,但我们只想显示本地文件系统的信息,这可以通过使用 df 命令的 ‘-l‘ 选项来实现。
|
||||
|
||||
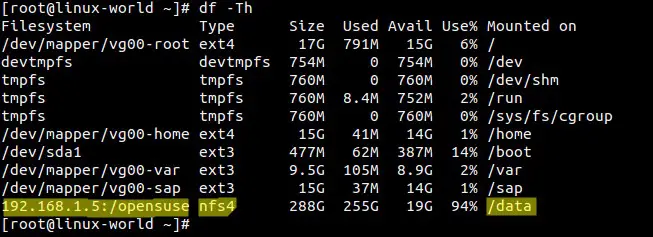
|
||||
|
||||
只打印本地文件系统:
|
||||
|
||||
[root@linux-world ~]# df -Thl
|
||||
Filesystem Type Size Used Avail Use% Mounted on
|
||||
/dev/mapper/vg00-root ext4 17G 791M 15G 6% /
|
||||
devtmpfs devtmpfs 754M 0 754M 0% /dev
|
||||
tmpfs tmpfs 760M 0 760M 0% /dev/shm
|
||||
tmpfs tmpfs 760M 8.4M 752M 2% /run
|
||||
tmpfs tmpfs 760M 0 760M 0% /sys/fs/cgroup
|
||||
/dev/mapper/vg00-home ext4 15G 41M 14G 1% /home
|
||||
/dev/sda1 ext3 477M 62M 387M 14% /boot
|
||||
/dev/mapper/vg00-var ext3 9.5G 105M 8.9G 2% /var
|
||||
/dev/mapper/vg00-sap ext3 15G 37M 14G 1% /sap
|
||||
[root@linux-world ~]#
|
||||
|
||||
### 例9:打印特定文件系统类型的磁盘使用情况 ###
|
||||
|
||||
‘**-t**’ 选项在 df 命令中用来打印特定文件系统类型的信息,‘-t’ 指定文件系统的类型,如下所示:
|
||||
|
||||
对于 ext4 :
|
||||
|
||||
[root@linux-world ~]# df -t ext4
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
/dev/mapper/vg00-root 17003304 809492 15307028 6% /
|
||||
/dev/mapper/vg00-home 14987616 41000 14162232 1% /home
|
||||
[root@linux-world ~]#
|
||||
|
||||
对于 nfs4 :
|
||||
|
||||
[root@linux-world ~]# df -t nfs4
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
192.168.1.5:/opensuse 301545472 266833920 19371008 94% /data
|
||||
[root@linux-world ~]#
|
||||
|
||||
### 例10:使用 ‘-x’ 选项排除特定的文件系统类型 ###
|
||||
|
||||
“**-x** 或 **–exclude-type**” 在 df 命令中用来在输出中排出某些文件系统类型。
|
||||
|
||||
假设我们想打印排出 ext3 外所有的文件系统。
|
||||
|
||||
[root@linux-world ~]# df -x ext3
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
/dev/mapper/vg00-root 17003304 809492 15307028 6% /
|
||||
devtmpfs 771876 0 771876 0% /dev
|
||||
tmpfs 777928 0 777928 0% /dev/shm
|
||||
tmpfs 777928 8540 769388 2% /run
|
||||
tmpfs 777928 0 777928 0% /sys/fs/cgroup
|
||||
/dev/mapper/vg00-home 14987616 41000 14162232 1% /home
|
||||
192.168.1.5:/opensuse 301545472 266834944 19369984 94% /data
|
||||
[root@linux-world ~]#
|
||||
|
||||
### 例11:在 df 命令的输出中只打印特定的字段 ###
|
||||
|
||||
‘**–output={field_name1,field_name2….}**‘ 选项用于显示 df 命令某些字段的输出。
|
||||
|
||||
可用的字段名有: ‘source’, ‘fstype’, ‘itotal’, ‘iused’, ‘iavail’, ‘ipcent’, ‘size’, ‘used’, ‘avail’, ‘pcent’ 和 ‘target’
|
||||
|
||||
[root@linux-world ~]# df --output=fstype,size,iused
|
||||
Type 1K-blocks IUsed
|
||||
ext4 17003304 22275
|
||||
devtmpfs 771876 357
|
||||
tmpfs 777928 1
|
||||
tmpfs 777928 423
|
||||
tmpfs 777928 13
|
||||
ext4 14987616 15
|
||||
ext3 487652 337
|
||||
ext3 9948012 1373
|
||||
ext3 14987656 11
|
||||
nfs4 301545472 451099
|
||||
[root@linux-world ~]#
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/11-df-command-examples-in-linux/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
@ -0,0 +1,39 @@
|
||||
如何在64位Ubuntu 15.10中编译最新版32位Wine
|
||||
================================================================================
|
||||
Wine发布了最新的1.7.53版本。此版本带来的大量性能提升,包括**XAudio**,**Direct3D**代码清理,改善**OLE对象嵌入**技术,更好的**Web服务dll**的实现,还有其他大量更新。
|
||||
|
||||
|
||||
|
||||
虽然官方PPA支持[Wine][1],但目前只提供1.7.44版本,所以安装最新版本可以从源码编译安装。
|
||||
|
||||
[下载源码包][2]([直接下载][3])并解压(**tar -xf wine-1.7.53**).然后,安装依赖。
|
||||
|
||||
sudo apt-get install build-essential gcc-multilib libx11-dev:i386 libfreetype6-dev:i386 libxcursor-dev:i386 libxi-dev:i386 libxshmfence-dev:i386 libxxf86vm-dev:i386 libxrandr-dev:i386 libxinerama-dev:i386 libxcomposite-dev:i386 libglu1-mesa-dev:i386 libosmesa6-dev:i386 libpcap0.8-dev:i386 libdbus-1-dev:i386 libncurses5-dev:i386 libsane-dev:i386 libv4l-dev:i386 libgphoto2-dev:i386 liblcms2-dev:i386 gstreamer0.10-plugins-base:i386 libcapi20-dev:i386 libcups2-dev:i386 libfontconfig1-dev:i386 libgsm1-dev:i386 libtiff5-dev:i386 libmpg123-dev:i386 libopenal-dev:i386 libldap2-dev:i386 libgnutls-dev:i386 libjpeg-dev:i386
|
||||
|
||||
现在切换到wine-1.7.53解压后的文件夹,并输入:
|
||||
|
||||
./configure
|
||||
make
|
||||
sudo make install
|
||||
|
||||
同样地,你也可以指定prefix配置脚本,以当前用户安装wine:
|
||||
|
||||
./configure --prefix=$HOME/usr/bin
|
||||
make
|
||||
make install
|
||||
|
||||
这种情况下,Wine将会安装在**$HOME/usr/bin/wine**,所以请检查$HOME/usr/bin在你的PATH变量中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tuxarena.com/2015/10/how-to-compile-latest-wine-32-bit-on-64-bit-ubuntu-15-10/
|
||||
|
||||
作者:Craciun Dan
|
||||
译者:[VicYu/Vic020](http://vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://launchpad.net/~ubuntu-wine/+archive/ubuntu/ppa
|
||||
[2]:https://www.winehq.org/announce/1.7.53
|
||||
[3]:http://prdownloads.sourceforge.net/wine/wine-1.7.53.tar.bz2
|
||||
@ -0,0 +1,61 @@
|
||||
Linux有问必答--如何在代理中安装Ubuntu
|
||||
================================================================================
|
||||
> **提问:** 我的电脑连接到的是使用HTTP代理的公司网络。当我想使用CD-ROM安装Ubuntu时,安装在尝试获取文件时被停滞了,可能是由于代理的原因。然而问题是Ubuntu的安装程序从来没有在安装过程中提示我配置代理。我该怎样在代理中安装Ubuntu桌面版?
|
||||
|
||||
不像Ubuntu服务器版,Ubuntu桌面版的安装非常自动化,没有留下太多的自定义空间,就像自定义磁盘分区,手动网络设置,包选择等等。虽然这种简单的,一键安装被认为是用户友好的,但却是那些寻找“高级安装模式”来定制自己的Ubuntu桌面安装的用户不希望的。
|
||||
|
||||
除此之外,默认的Ubuntu桌面版安装器的一个大问题是缺少代理设置。如果你电脑在代理后面,你会看到Ubuntu在准备下载文件的时候停滞了。
|
||||
|
||||

|
||||
|
||||
这篇文章描述了如何解除Ubuntu安装限制以及**如何在代理中安装Ubuntu桌面**。
|
||||
|
||||
基本的想打是这样的。首先启动到live Ubuntu桌面中而不是直接启动Ubuntu安装器,配置代理设置并且手动在live Ubuntu中启动Ubuntu安装器。下面是步骤。
|
||||
|
||||
从Ubuntu桌面版CD/DVD或者USB启动后,在欢迎页面点击“Try Ubuntu”。
|
||||
|
||||

|
||||
|
||||
当你进入live Ubuntu后,点击左边的设置图标。
|
||||
|
||||

|
||||
|
||||
进入网络菜单。
|
||||
|
||||

|
||||
|
||||
手动配置代理
|
||||
|
||||

|
||||
|
||||
接下来,打开终端。
|
||||
|
||||

|
||||
|
||||
输入下面的命令进入root会话。
|
||||
|
||||
$ sudo su
|
||||
|
||||
最后以root权限输入下面的命令。
|
||||
|
||||
# ubiquity gtk_ui
|
||||
|
||||
它会启动基于GUI的Ubuntu安装器。
|
||||
|
||||

|
||||
|
||||
接着完成剩余的安装。
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/install-ubuntu-desktop-behind-proxy.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -0,0 +1,130 @@
|
||||
第 10 部分:在 RHEL/CentOS 7 中设置 “NTP(网络时间协议) 服务器”
|
||||
================================================================================
|
||||
网络时间协议 - NTP - 是运行在传输层 123 号端口允许计算机通过网络同步准确时间的协议。随着时间的流逝,计算机内部时间会出现漂移,这会导致时间不一致问题,尤其是对于服务器和客户端日志文件,或者你想要备份服务器资源或数据库。
|
||||
|
||||

|
||||
|
||||
在 CentOS 和 RHEL 7 上安装 NTP 服务器
|
||||
|
||||
#### 要求: ####
|
||||
|
||||
- [CentOS 7 安装过程][1]
|
||||
- [RHEL 安装过程][2]
|
||||
|
||||
#### 额外要求: ####
|
||||
|
||||
- [注册并启用 RHEL 7 更新订阅][3]
|
||||
- [在 CentOS/RHCE 7 上配置静态 IP][4]
|
||||
- [在 CentOS/RHEL 7 上停用并移除不需要的服务][5]
|
||||
|
||||
这篇指南会告诉你如何在 CentOS/RHCE 7 上安装和配置 NTP 服务器,并使用 NTP 公共时间服务器池列表中和你服务器地理位置最近的可用节点中同步时间。
|
||||
|
||||
#### 步骤一:安装和配置 NTP 守护进程 ####
|
||||
|
||||
1. 官方 CentOS /RHEL 7 库默认提供 NTP 服务器安装包,可以通过使用下面的命令安装。
|
||||
|
||||
# yum install ntp
|
||||
|
||||
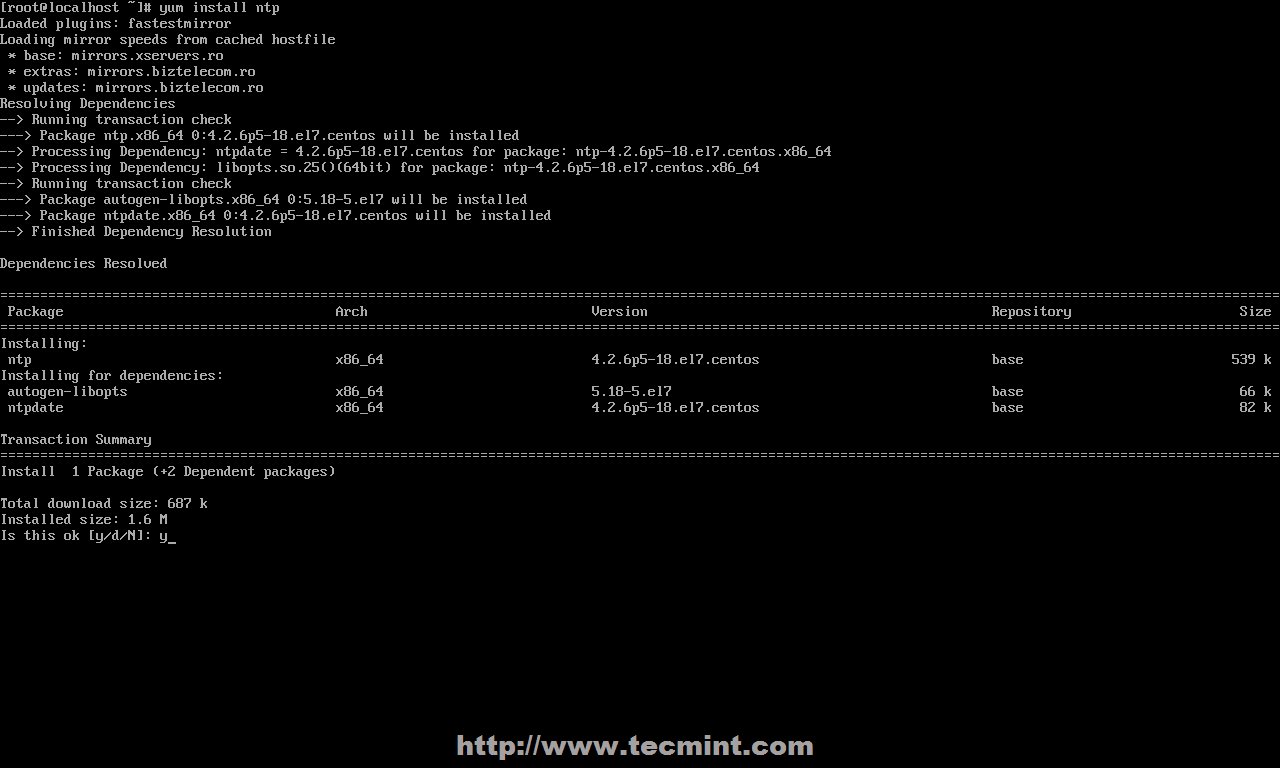
|
||||
|
||||
安装 NTP 服务器
|
||||
|
||||
2. 安装完服务器之后,首先到官方 [NTP 公共时间服务器池][6],选择你服务器物理位置所在的洲,然后搜索你的国家位置,然后会出现 NTP 服务器列表。
|
||||
|
||||

|
||||
|
||||
NTP 服务器池
|
||||
|
||||
3. 然后打开编辑 NTP 守护进程主要配置文件,从 pool.ntp.org 中注释掉默认的公共服务器列表并用类似下面截图提供给你国家的列表替换。
|
||||
|
||||

|
||||
|
||||
配置 NTP 服务器
|
||||
|
||||
4. 下一步,你需要允许客户端从你的网络中和这台服务器同步时间。为了做到这点,添加下面一行到 NTP 配置文件,其中限制语句控制允许哪些网络查询和同步时间 - 根据需要替换网络 IP。
|
||||
|
||||
restrict 192.168.1.0 netmask 255.255.255.0 nomodify notrap
|
||||
|
||||
nomodify notrap 语句意味着不允许你的客户端配置服务器或者作为同步时间的节点。
|
||||
|
||||
5. 如果你需要额外的信息用于错误处理,以防你的 NTP 守护进程出现问题,添加一个 logfile 语句,用于记录所有 NTP 服务器问题到一个指定的日志文件。
|
||||
|
||||
logfile /var/log/ntp.log
|
||||
|
||||

|
||||
|
||||
启用 NTP 日志
|
||||
|
||||
6. 你编辑完所有上面解释的配置并保存关闭 ntp.conf 文件后,你最终的配置看起来像下面的截图。
|
||||
|
||||

|
||||
|
||||
NTP 服务器配置
|
||||
|
||||
### 步骤二:添加防火墙规则并启动 NTP 守护进程 ###
|
||||
|
||||
7. NTP 服务在传输层(第四层)使用 123 号 UDP 端口。它是针对限制可变延迟的影响特别设计的。要在 RHEL/CentOS 7 中开放这个端口,可以对 Firewalld 服务使用下面的命令。
|
||||
|
||||
# firewall-cmd --add-service=ntp --permanent
|
||||
# firewall-cmd --reload
|
||||
|
||||

|
||||
|
||||
在 Firewall 中开放 NTP 端口
|
||||
|
||||
8. 你在防火墙中开放了 123 号端口之后,启动 NTP 服务器并确保系统范围内可用。用下面的命令管理服务。
|
||||
|
||||
# systemctl start ntpd
|
||||
# systemctl enable ntpd
|
||||
# systemctl status ntpd
|
||||
|
||||

|
||||
|
||||
启动 NTP 服务
|
||||
|
||||
### 步骤三:验证服务器时间同步 ###
|
||||
|
||||
9. 启动了 NTP 守护进程后,用几分钟等服务器和它的服务器池列表同步时间,然后运行下面的命令验证 NTP 节点同步状态和你的系统时间。
|
||||
|
||||
# ntpq -p
|
||||
# date -R
|
||||
|
||||

|
||||
|
||||
验证 NTP 时间同步
|
||||
|
||||
10. 如果你想查询或者和你选择的服务器池同步,你可以使用 ntpdate 命令,后面跟服务器名或服务器地址,类似下面建议的命令行事例。
|
||||
|
||||
# ntpdate -q 0.ro.pool.ntp.org 1.ro.pool.ntp.org
|
||||
|
||||

|
||||
|
||||
同步 NTP 时间
|
||||
|
||||
### 步骤四:设置 Windows NTP 客户端 ###
|
||||
|
||||
11. 如果你的 windows 机器不是域名控制器的一部分,你可以配置 Windows 和你的 NTP服务器同步时间。在任务栏右边 -> 时间 -> 更改日期和时间设置 -> 网络时间标签 -> 更改设置 -> 和一个网络时间服务器检查同步 -> 在 Server 空格输入服务器 IP 或 FQDN -> 马上更新 -> OK。
|
||||
|
||||

|
||||
|
||||
和 NTP 同步 Windows 时间
|
||||
|
||||
就是这些。在你的网络中配置一个本地 NTP 服务器能确保你所有的服务器和客户端有相同的时间设置,以防出现网络连接失败,并且它们彼此都相互同步。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-ntp-server-in-centos/
|
||||
|
||||
作者:[Matei Cezar][a]
|
||||
译者:[ictlyh](http://motouxiaogui.cn/blog)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/cezarmatei/
|
||||
[1]:http://www.tecmint.com/centos-7-installation/
|
||||
[2]:http://www.tecmint.com/redhat-enterprise-linux-7-installation/
|
||||
[3]:http://www.tecmint.com/enable-redhat-subscription-reposiories-and-updates-for-rhel-7/
|
||||
[4]:http://www.tecmint.com/configure-network-interface-in-rhel-centos-7-0/
|
||||
[5]:http://www.tecmint.com/remove-unwanted-services-in-centos-7/
|
||||
[6]:http://www.pool.ntp.org/en/
|
||||
Loading…
Reference in New Issue
Block a user